⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-13 更新
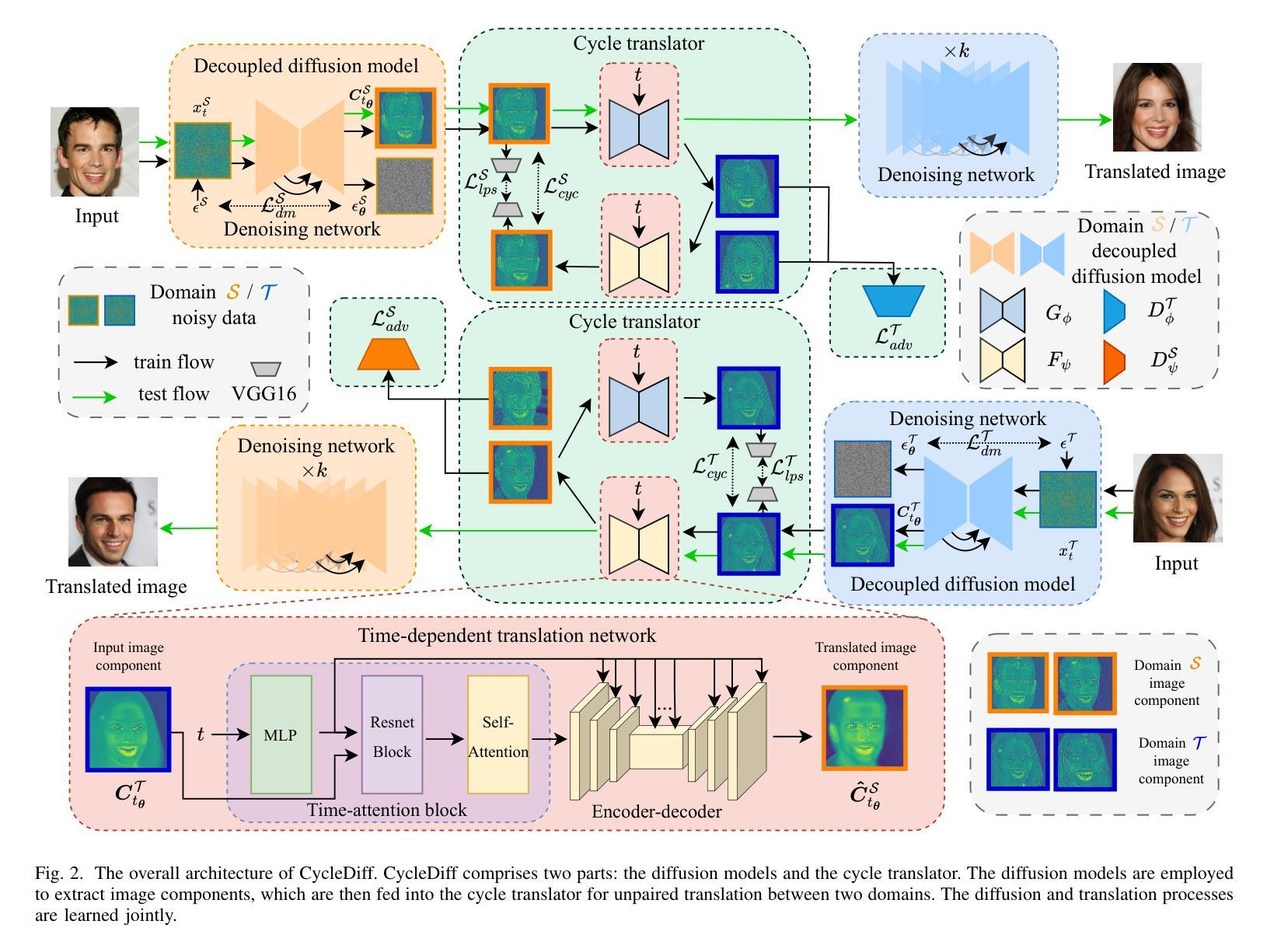
CycleDiff: Cycle Diffusion Models for Unpaired Image-to-image Translation
Authors:Shilong Zou, Yuhang Huang, Renjiao Yi, Chenyang Zhu, Kai Xu
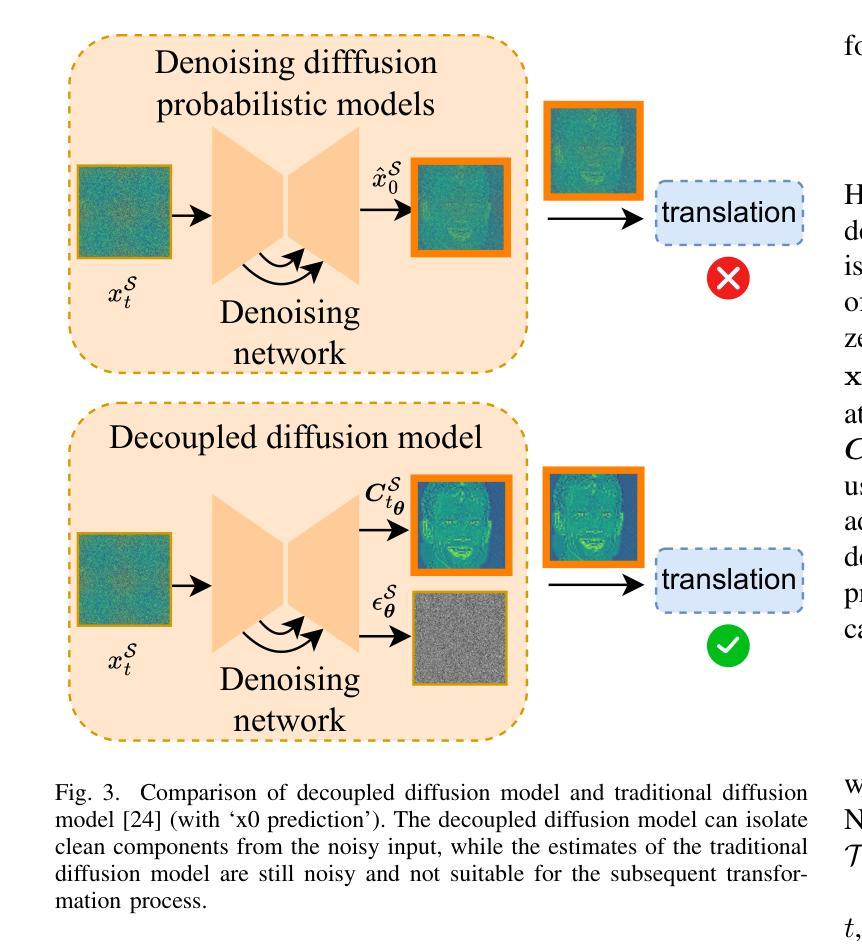
We introduce a diffusion-based cross-domain image translator in the absence of paired training data. Unlike GAN-based methods, our approach integrates diffusion models to learn the image translation process, allowing for more coverable modeling of the data distribution and performance improvement of the cross-domain translation. However, incorporating the translation process within the diffusion process is still challenging since the two processes are not aligned exactly, i.e., the diffusion process is applied to the noisy signal while the translation process is conducted on the clean signal. As a result, recent diffusion-based studies employ separate training or shallow integration to learn the two processes, yet this may cause the local minimal of the translation optimization, constraining the effectiveness of diffusion models. To address the problem, we propose a novel joint learning framework that aligns the diffusion and the translation process, thereby improving the global optimality. Specifically, we propose to extract the image components with diffusion models to represent the clean signal and employ the translation process with the image components, enabling an end-to-end joint learning manner. On the other hand, we introduce a time-dependent translation network to learn the complex translation mapping, resulting in effective translation learning and significant performance improvement. Benefiting from the design of joint learning, our method enables global optimization of both processes, enhancing the optimality and achieving improved fidelity and structural consistency. We have conducted extensive experiments on RGB$\leftrightarrow$RGB and diverse cross-modality translation tasks including RGB$\leftrightarrow$Edge, RGB$\leftrightarrow$Semantics and RGB$\leftrightarrow$Depth, showcasing better generative performances than the state of the arts.
我们引入了一种基于扩散的无配对训练数据跨域图像翻译器。不同于基于GAN的方法,我们的方法结合了扩散模型来学习图像翻译过程,实现对数据分布的更全面的建模和跨域翻译的性能提升。然而,在扩散过程中融入翻译过程仍然具有挑战性,因为这两个过程并不完全对齐,即扩散过程应用于噪声信号,而翻译过程则在清洁信号上进行。因此,最近的基于扩散的研究采用单独训练或浅层集成来学习这两个过程,但这可能会导致翻译优化的局部最小值,限制扩散模型的有效性。为了解决这一问题,我们提出了一种新的联合学习框架,该框架对齐了扩散和翻译过程,从而提高了全局最优性。具体来说,我们提议用扩散模型提取图像成分来表示清洁信号,并利用图像成分进行翻译过程,从而实现端到端的联合学习方式。另一方面,我们引入了一个时间依赖的翻译网络来学习复杂的翻译映射,从而实现有效的翻译学习和显著的性能提升。受益于联合学习设计,我们的方法能够实现两个过程的全局优化,提高最优性,实现更高的保真度和结构一致性。我们在RGB→RGB和各种跨模态翻译任务(包括RGB→边缘、RGB→语义和RGB→深度)上进行了大量实验,展示了比现有技术更好的生成性能。
论文及项目相关链接
Summary
本文介绍了一种无需配对训练数据的扩散基础跨域图像翻译器。通过整合扩散模型来学习图像翻译过程,实现了更全面的数据分布建模和跨域翻译性能的提升。为克服扩散过程和翻译过程不对齐的问题,提出了联合学习框架,通过提取图像组件并对其进行翻译过程处理,实现了端到端的联合学习方式。同时,引入时间依赖翻译网络,有效学习复杂翻译映射,显著提高翻译学习效果和性能。实验结果表明,该方法在RGB与RGB、RGB与边缘、RGB与语义以及RGB与深度等多种跨模态翻译任务上,生成性能优于现有技术。
Key Takeaways
- 引入扩散模型进行跨域图像翻译,无需配对训练数据。
- 通过整合扩散模型,实现更全面的数据分布建模和性能提升。
- 克服扩散和翻译过程不对齐的问题,提出联合学习框架。
- 通过提取图像组件并进行端到端翻译处理,提高全局优化性能。
- 引入时间依赖翻译网络,有效学习复杂翻译映射。
- 在多种跨模态翻译任务上实现优于现有技术的生成性能。
点此查看论文截图



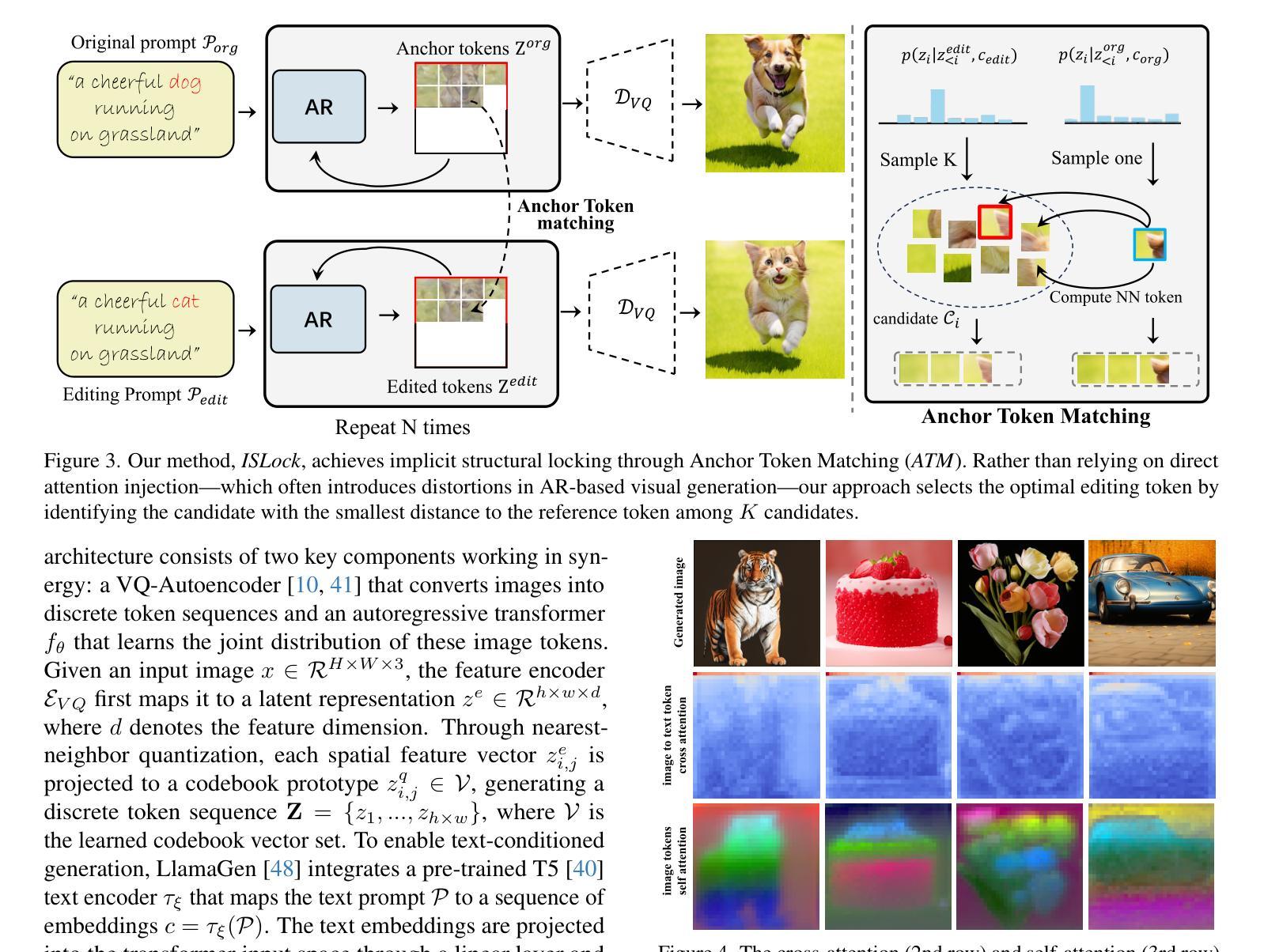
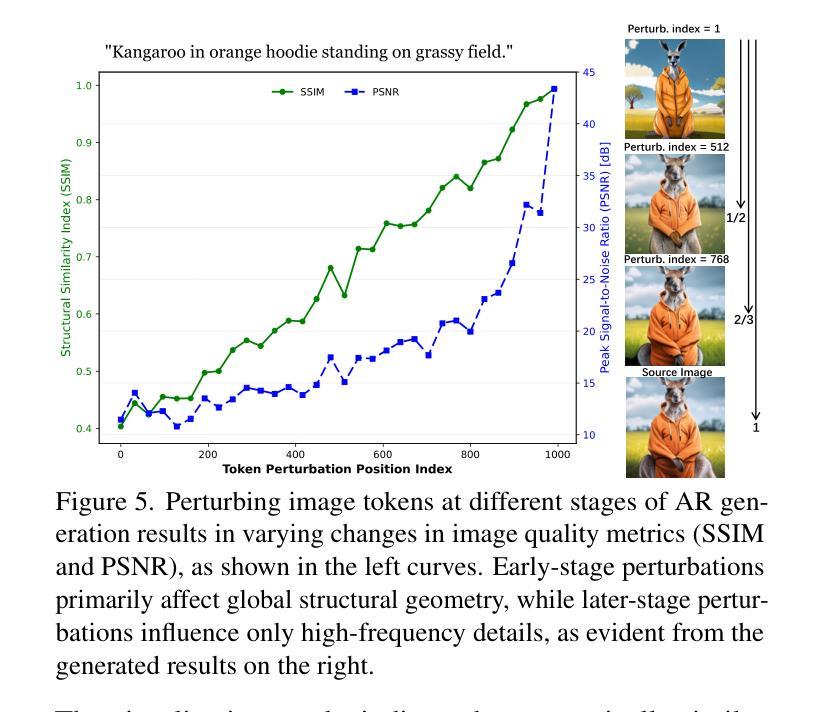
Anchor Token Matching: Implicit Structure Locking for Training-free AR Image Editing
Authors:Taihang Hu, Linxuan Li, Kai Wang, Yaxing Wang, Jian Yang, Ming-Ming Cheng
Text-to-image generation has seen groundbreaking advancements with diffusion models, enabling high-fidelity synthesis and precise image editing through cross-attention manipulation. Recently, autoregressive (AR) models have re-emerged as powerful alternatives, leveraging next-token generation to match diffusion models. However, existing editing techniques designed for diffusion models fail to translate directly to AR models due to fundamental differences in structural control. Specifically, AR models suffer from spatial poverty of attention maps and sequential accumulation of structural errors during image editing, which disrupt object layouts and global consistency. In this work, we introduce Implicit Structure Locking (ISLock), the first training-free editing strategy for AR visual models. Rather than relying on explicit attention manipulation or fine-tuning, ISLock preserves structural blueprints by dynamically aligning self-attention patterns with reference images through the Anchor Token Matching (ATM) protocol. By implicitly enforcing structural consistency in latent space, our method ISLock enables structure-aware editing while maintaining generative autonomy. Extensive experiments demonstrate that ISLock achieves high-quality, structure-consistent edits without additional training and is superior or comparable to conventional editing techniques. Our findings pioneer the way for efficient and flexible AR-based image editing, further bridging the performance gap between diffusion and autoregressive generative models. The code will be publicly available at https://github.com/hutaiHang/ATM
文本到图像生成领域已经因为扩散模型而取得了突破性进展,能够通过跨注意力操控实现高保真合成和精确图像编辑。近期,自回归(AR)模型作为强大的替代方案重新出现,利用下一代令牌与扩散模型相匹配。然而,为扩散模型设计的现有编辑技术无法直接应用到AR模型上,这是因为两者在结构控制上存在根本差异。具体来说,AR模型存在注意力图的空间贫困问题,以及在图像编辑过程中序列累积的结构错误,会破坏对象布局和全局一致性。在此工作中,我们引入了隐式结构锁定(ISLock),这是首个用于AR视觉模型的无需训练的培训编辑策略。ISLock不依赖于显式注意力操控或微调,而是通过锚定令牌匹配(ATM)协议,动态地将自我注意力模式与参考图像对齐,从而保留结构蓝图。通过在潜在空间中隐式强制执行结构一致性,我们的ISLock方法能够在保持生成自主性的同时进行结构感知编辑。大量实验表明,ISLock无需额外训练即可实现高质量、结构一致性的编辑,并且优于或相当于传统编辑技术。我们的研究结果为高效、灵活的AR基图像编辑开辟了道路,进一步缩小了扩散模型和自回归生成模型之间的性能差距。代码将在https://github.com/hutaiHang/ATM上公开提供。
论文及项目相关链接
PDF Accepted by ICCV2025. Code will be released in https://github.com/hutaiHang/ATM
Summary
文本介绍了一种针对自回归(AR)视觉模型的新型训练外编辑策略——Implicit Structure Locking(ISLock)。它通过动态对齐参考图像的自我关注模式,在潜在空间中实现结构一致性,从而进行结构感知编辑,同时保持生成自主性。该技术无需额外训练,即可实现高质量、结构一致性的编辑。
Key Takeaways
- 自回归(AR)模型在文本转图像生成领域展现出强大的替代能力。
- AR模型在图像编辑时面临空间注意力图的贫困和结构性错误顺序累积的问题。
- Implicit Structure Locking(ISLock)是首个针对AR视觉模型的训练外编辑策略。
- ISLock通过动态对齐参考图像的自我关注模式,在潜在空间中实现结构一致性。
- ISLock实现了高质量、结构一致性的编辑,无需额外训练。
- ISLock方法适用于结构感知编辑,可维持生成自主性。
点此查看论文截图