⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-13 更新
AD-AVSR: Asymmetric Dual-stream Enhancement for Robust Audio-Visual Speech Recognition
Authors:Junxiao Xue, Xiaozhen Liu, Xuecheng Wu, Xinyi Yin, Danlei Huang, Fei Yu
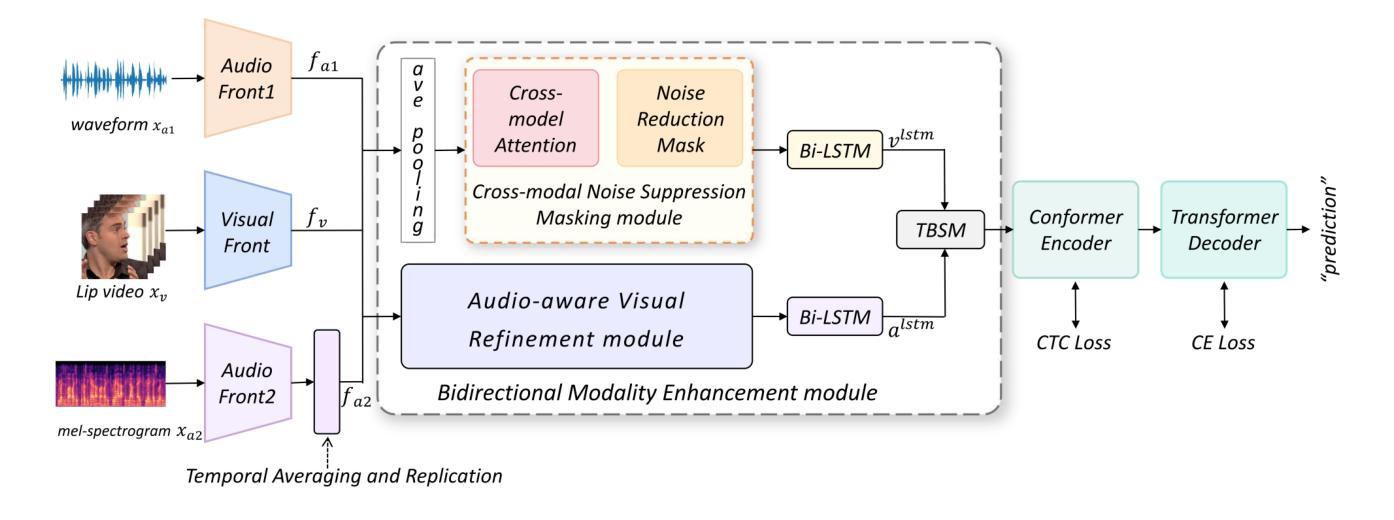
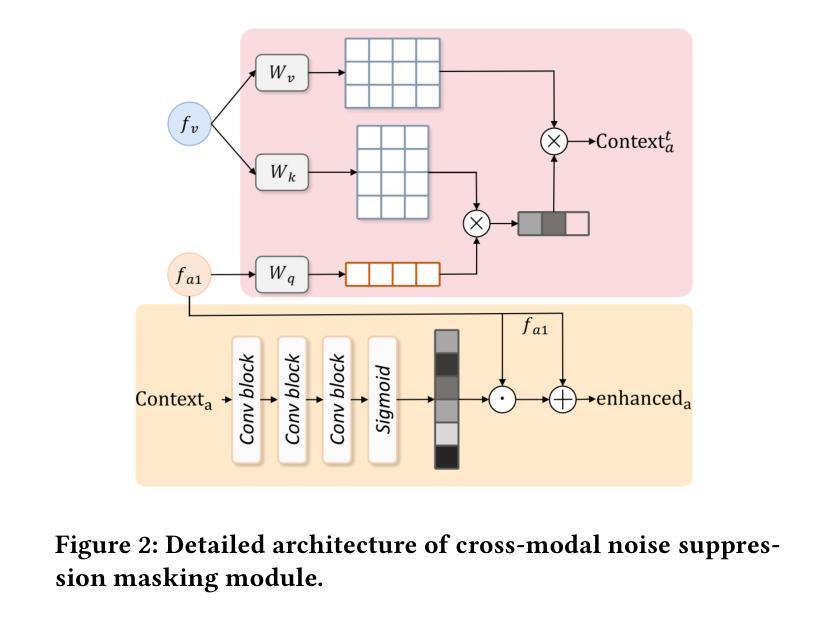
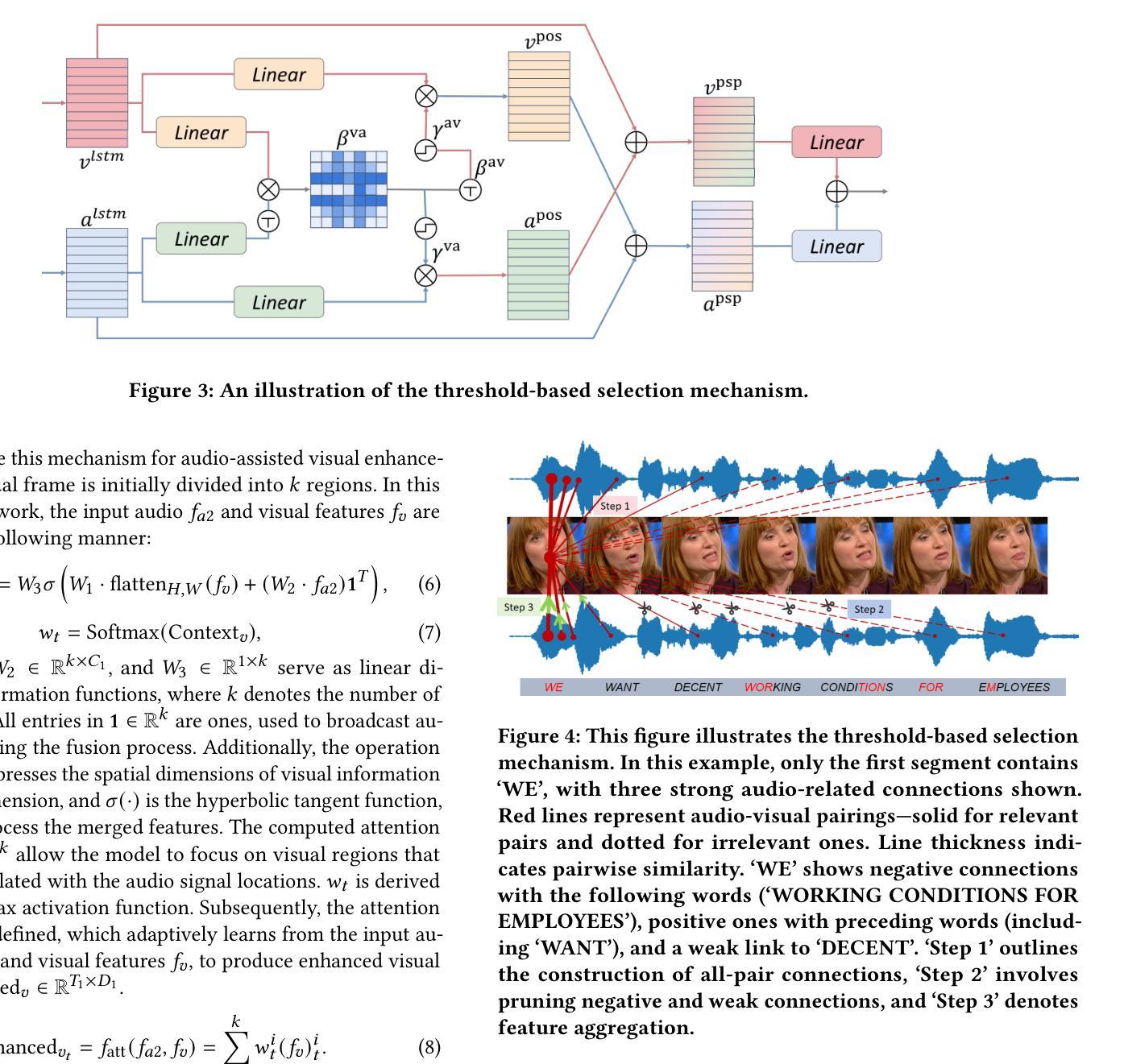
Audio-visual speech recognition (AVSR) combines audio-visual modalities to improve speech recognition, especially in noisy environments. However, most existing methods deploy the unidirectional enhancement or symmetric fusion manner, which limits their capability to capture heterogeneous and complementary correlations of audio-visual data-especially under asymmetric information conditions. To tackle these gaps, we introduce a new AVSR framework termed AD-AVSR based on bidirectional modality enhancement. Specifically, we first introduce the audio dual-stream encoding strategy to enrich audio representations from multiple perspectives and intentionally establish asymmetry to support subsequent cross-modal interactions. The enhancement process involves two key components, Audio-aware Visual Refinement Module for enhanced visual representations under audio guidance, and Cross-modal Noise Suppression Masking Module which refines audio representations using visual cues, collaboratively leading to the closed-loop and bidirectional information flow. To further enhance correlation robustness, we adopt a threshold-based selection mechanism to filter out irrelevant or weakly correlated audio-visual pairs. Extensive experimental results on the LRS2 and LRS3 datasets indicate that our AD-AVSR consistently surpasses SOTA methods in both performance and noise robustness, highlighting the effectiveness of our model design.
视听语音识别(AVSR)结合了视听模式来提高语音识别能力,特别是在嘈杂的环境中。然而,现有的大多数方法采用单向增强或对称融合的方式,这限制了它们捕捉视听数据的异构和互补关联的能力,尤其是在不对称信息条件下。为了弥补这些不足,我们引入了一种基于双向模式增强的新型AVSR框架,称为AD-AVSR。具体来说,我们首先采用音频双流编码策略,从多个角度丰富音频表示,并有意建立不对称性,以支持随后的跨模态交互。增强过程包括两个关键组件:音频感知视觉细化模块,用于在音频指导下增强视觉表示;跨模态噪声抑制掩模模块,使用视觉线索来完善音频表示,共同实现闭环和双向信息流。为了进一步增强关联鲁棒性,我们采用基于阈值的选择机制来过滤掉无关或弱相关的视听对。在LRS2和LRS3数据集上的大量实验结果表明,我们的AD-AVSR在性能和噪声稳健性方面始终超过最新方法,凸显了我们的模型设计的有效性。
论文及项目相关链接
PDF Accepted by the ACM MM 2025 Workshop on SVC
Summary
音频视觉语音识别(AVSR)结合视听模式以提高语音识别能力,尤其在噪声环境中。但现有方法大多采用单向增强或对称融合方式,难以捕捉视听数据的异质互补关联,尤其在不对称信息条件下。为解决这些问题,我们提出了基于双向模式增强的新型AVSR框架AD-AVSR。具体而言,我们引入音频双流编码策略,从多个角度丰富音频表征,并建立不对称性以支持后续跨模式交互。增强过程包括两个关键组件:受音频指导的视觉细化模块和跨模式噪声抑制掩模模块,共同实现闭环和双向信息流。为增强关联稳健性,我们采用阈值选择机制过滤掉无关或弱相关的视听对。在LRS2和LRS3数据集上的广泛实验表明,我们的AD-AVSR在性能和噪声稳健性方面均超越现有最佳方法,凸显了模型设计的有效性。
Key Takeaways
- AVSR结合了音频视觉模式以提高在噪声环境中的语音识别能力。
- 现有方法主要采取单向增强或对称融合,难以捕捉视听数据的异质互补性。
- 提出的AD-AVSR框架基于双向模式增强,引入音频双流编码策略丰富音频表征。
- AD-AVSR包括两个关键组件:受音频指导的视觉细化模块和跨模式噪声抑制掩模模块。
- 采用阈值选择机制以增强关联稳健性,过滤掉无关或弱相关的视听对。
- 在LRS2和LRS3数据集上的实验表明,AD-AVSR在性能和噪声稳健性方面超越现有最佳方法。
- 总体来说,AD-AVSR模型设计有效。
点此查看论文截图

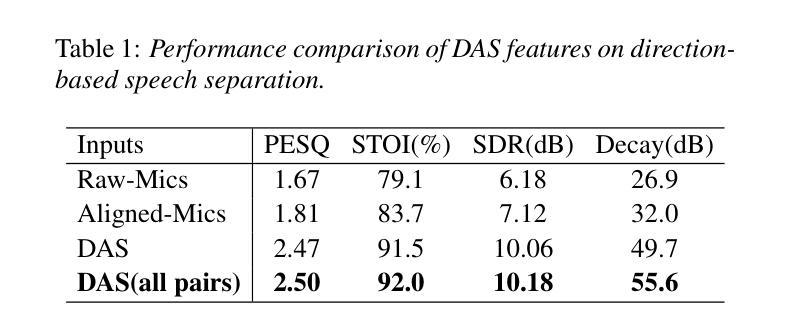
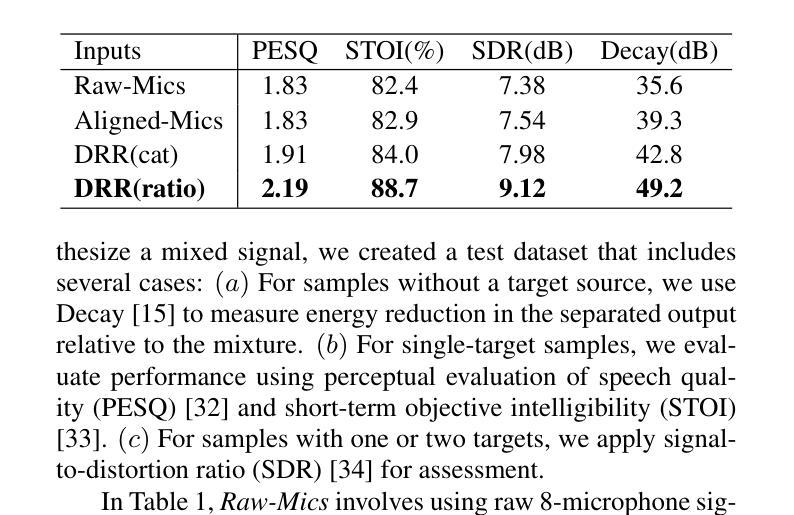
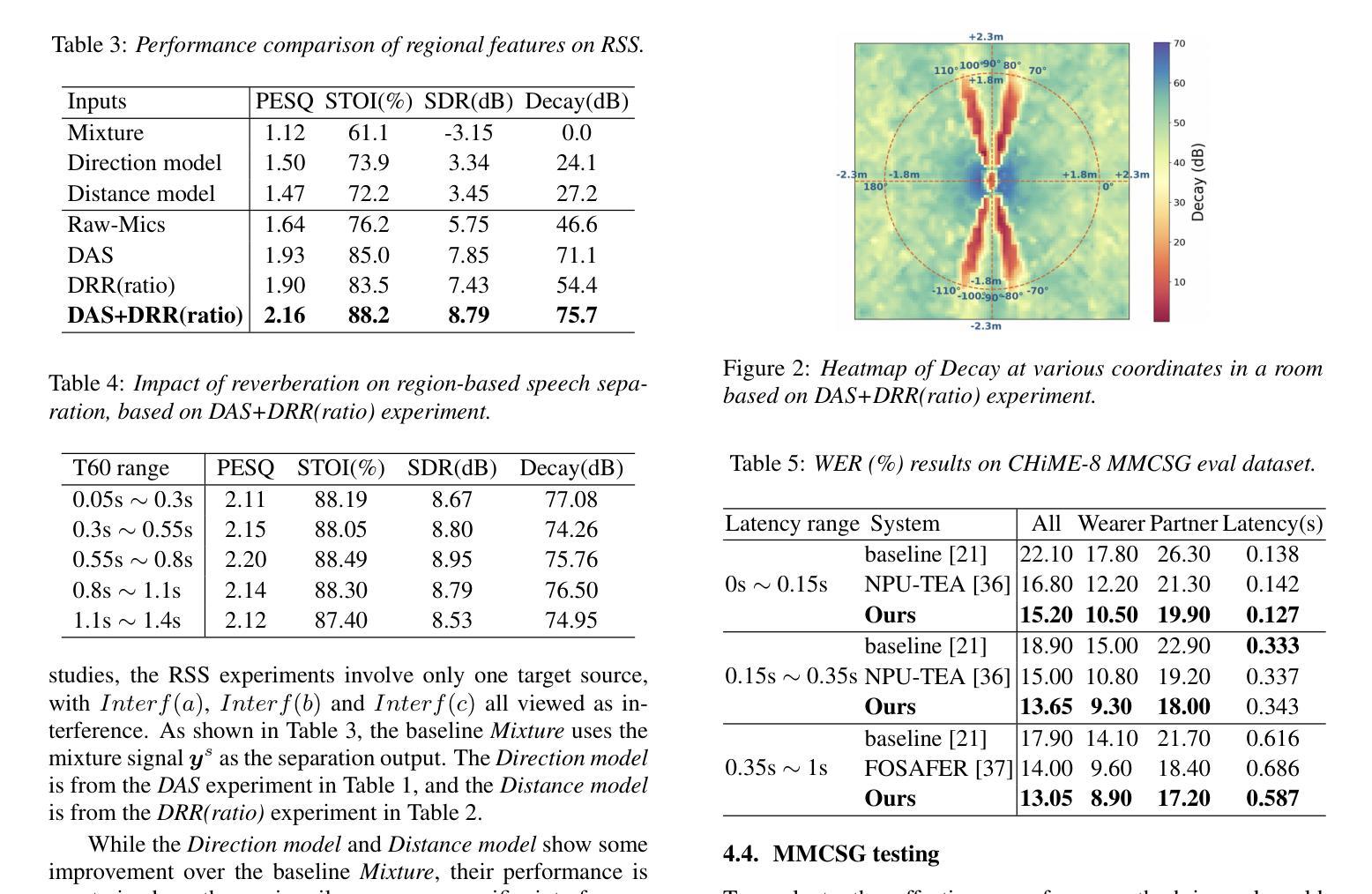
Exploring Efficient Directional and Distance Cues for Regional Speech Separation
Authors:Yiheng Jiang, Haoxu Wang, Yafeng Chen, Gang Qiao, Biao Tian
In this paper, we introduce a neural network-based method for regional speech separation using a microphone array. This approach leverages novel spatial cues to extract the sound source not only from specified direction but also within defined distance. Specifically, our method employs an improved delay-and-sum technique to obtain directional cues, substantially enhancing the signal from the target direction. We further enhance separation by incorporating the direct-to-reverberant ratio into the input features, enabling the model to better discriminate sources within and beyond a specified distance. Experimental results demonstrate that our proposed method leads to substantial gains across multiple objective metrics. Furthermore, our method achieves state-of-the-art performance on the CHiME-8 MMCSG dataset, which was recorded in real-world conversational scenarios, underscoring its effectiveness for speech separation in practical applications.
在这篇论文中,我们介绍了一种基于神经网络的方法,使用麦克风阵列进行区域语音分离。这种方法利用新型的空间线索来提取声源,不仅可以从指定方向,还可以从定义的范围内提取声音。具体来说,我们的方法采用改进的延迟求和技术来获得方向线索,从而极大地增强目标方向上的信号。我们通过将直达声与混响声比率纳入输入特征,进一步提高声音的分离效果,使模型能够更好地区分指定距离内和之外的声源。实验结果表明,我们提出的方法在多个客观指标上取得了显著的改进。此外,我们的方法在真实对话场景中录制的CHiME-8 MMCSG数据集上取得了最新性能,这凸显了其在语音分离的实用应用中的有效性。
论文及项目相关链接
PDF This paper has been accepted by Interspeech 2025
Summary
该论文提出了一种基于神经网络的区域语音分离方法,利用麦克风阵列进行声音采集。该方法通过提取空间线索,不仅可以从指定方向提取声源,还可以在特定距离内对声源进行定位。通过改进延时相加技术获得方向线索,提高了目标方向的信号质量。此外,通过将直达声与混响声比例纳入输入特征,提高了模型对内外声源的辨识能力。实验结果表明,该方法在多个客观评价指标上取得了显著的提升,并在真实对话场景的CHiME-8 MMCSG数据集上实现了卓越的性能,展示了其在实用场合语音分离的潜力。
Key Takeaways
- 该论文提出了一种基于神经网络的区域语音分离方法,使用麦克风阵列进行声音采集。
- 方法通过提取空间线索,可以在特定距离内定位声源。
- 通过改进延时相加技术提高目标方向的信号质量。
- 模型结合直达声与混响声比例,提高内外声源的辨识能力。
- 实验结果在多个客观评价指标上表现优异。
- 在真实对话场景的CHiME-8 MMCSG数据集上实现卓越性能。
点此查看论文截图

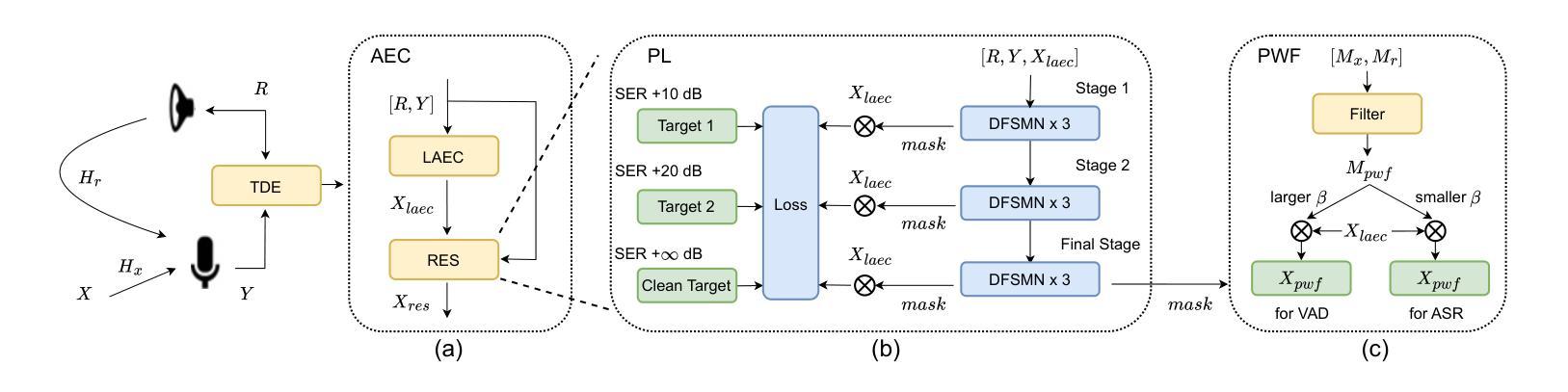
A Small-footprint Acoustic Echo Cancellation Solution for Mobile Full-Duplex Speech Interactions
Authors:Yiheng Jiang, Tian Biao
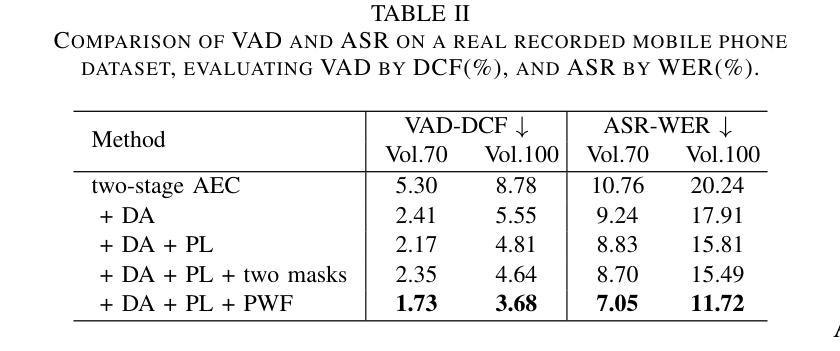
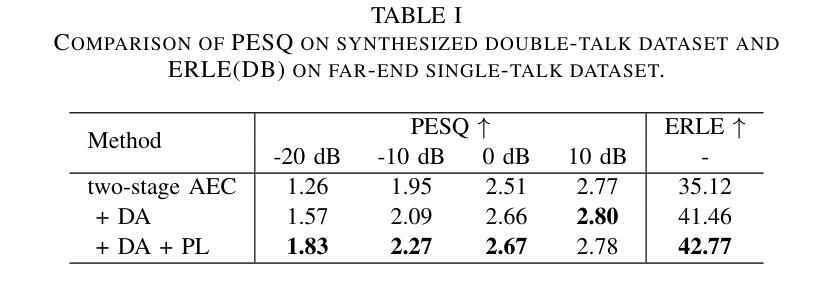
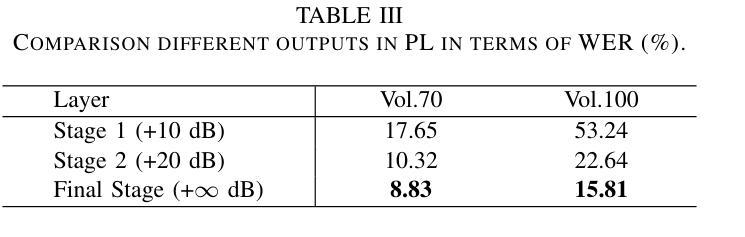
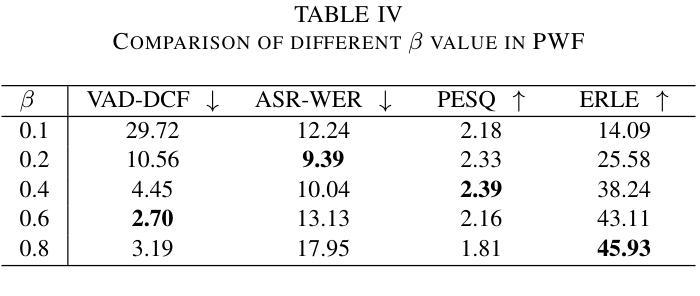
In full-duplex speech interaction systems, effective Acoustic Echo Cancellation (AEC) is crucial for recovering echo-contaminated speech. This paper presents a neural network-based AEC solution to address challenges in mobile scenarios with varying hardware, nonlinear distortions and long latency. We first incorporate diverse data augmentation strategies to enhance the model’s robustness across various environments. Moreover, progressive learning is employed to incrementally improve AEC effectiveness, resulting in a considerable improvement in speech quality. To further optimize AEC’s downstream applications, we introduce a novel post-processing strategy employing tailored parameters designed specifically for tasks such as Voice Activity Detection (VAD) and Automatic Speech Recognition (ASR), thus enhancing their overall efficacy. Finally, our method employs a small-footprint model with streaming inference, enabling seamless deployment on mobile devices. Empirical results demonstrate effectiveness of the proposed method in Echo Return Loss Enhancement and Perceptual Evaluation of Speech Quality, alongside significant improvements in both VAD and ASR results.
在双向语音交互系统中,有效的声学回声消除(AEC)对于恢复受回声污染的语音至关重要。本文针对移动场景中的硬件差异、非线性失真和长延迟等挑战,提出了一种基于神经网络的AEC解决方案。我们首先采用多种数据增强策略,提高模型在不同环境下的稳健性。此外,采用渐进学习方法来逐步改进AEC的有效性,从而显著提高语音质量。为了进一步优化AEC的下游应用,我们引入了一种新型后处理策略,采用针对任务设计的专用参数,如语音活动检测(VAD)和自动语音识别(ASR),从而提高其整体效率。最后,我们的方法使用一个小型模型进行流式推理,可在移动设备上无缝部署。经验结果表明,该方法在回声返回损耗增强和语音质量主观评价方面有效,同时显著提高了VAD和ASR的结果。
论文及项目相关链接
PDF This paper is accepted to ICASSP 2025
Summary
基于神经网络的全双工语音交互系统中,回声消除至关重要。本文通过多样的数据增强策略来提升模型在各种环境下的稳健性,并利用渐进学习逐步提升回声消除效果。此外,通过采用特定参数的后处理策略优化了下游应用如语音活动检测和语音识别。本文的方法在小模型足印和流式推断的支持下,可在移动设备上无缝部署。经验结果表明,该方法在回声损耗增强和语音质量感知评估上效果显著,并在语音活动和语音识别结果上有显著改善。
Key Takeaways
- 全双工语音交互系统中,声学回声消除(AEC)对于处理回声污染的语音至关重要。
- 通过多样的数据增强策略提升模型稳健性,适应各种环境。
- 渐进学习用于逐步提升AEC效果。
- 引入后处理策略,通过特定参数优化下游应用如语音活动检测(VAD)和语音识别(ASR)。
- 方法采用小模型足印和流式推断,支持在移动设备上无缝部署。
- 实证结果显示,该方法在回声损耗增强和语音质量评估上表现优秀。
点此查看论文截图

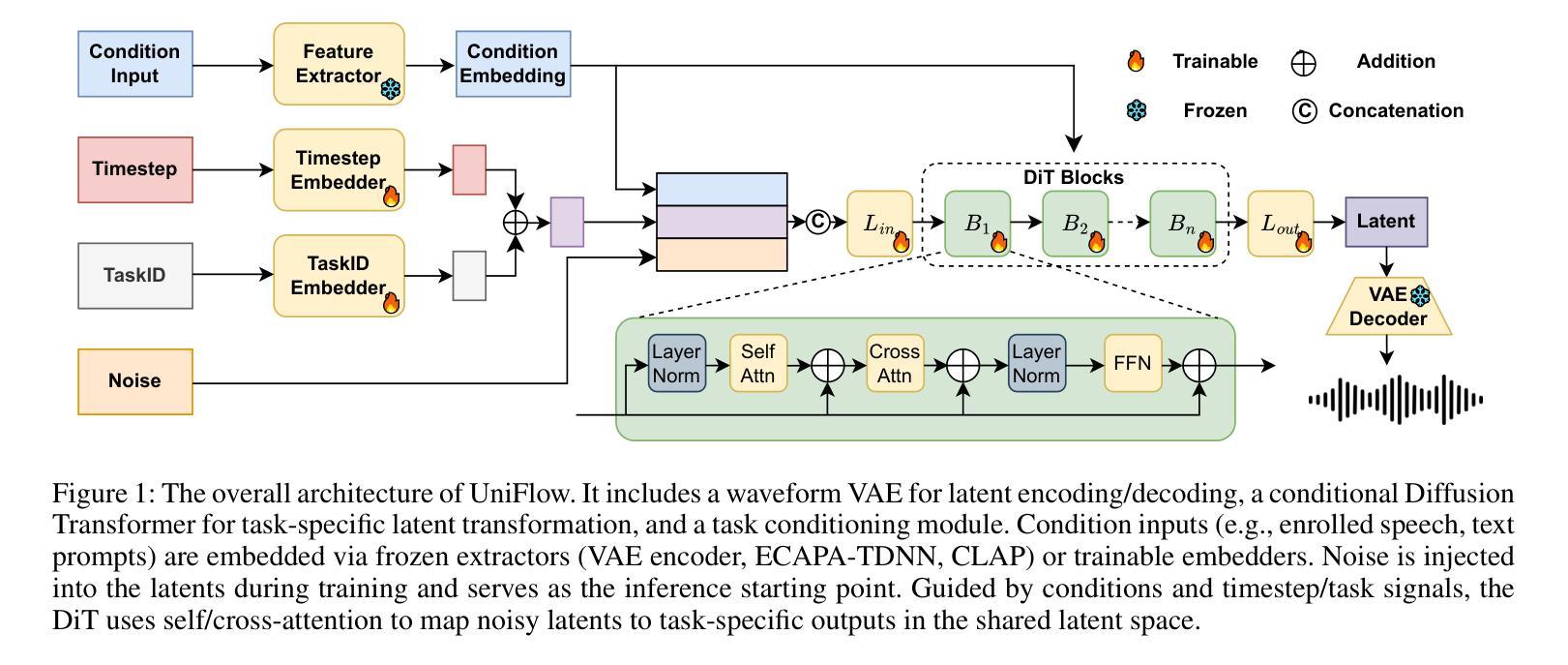
UniFlow: Unifying Speech Front-End Tasks via Continuous Generative Modeling
Authors:Ziqian Wang, Zikai Liu, Yike Zhu, Xingchen Li, Boyi Kang, Jixun Yao, Xianjun Xia, Chuanzeng Huang, Lei Xie
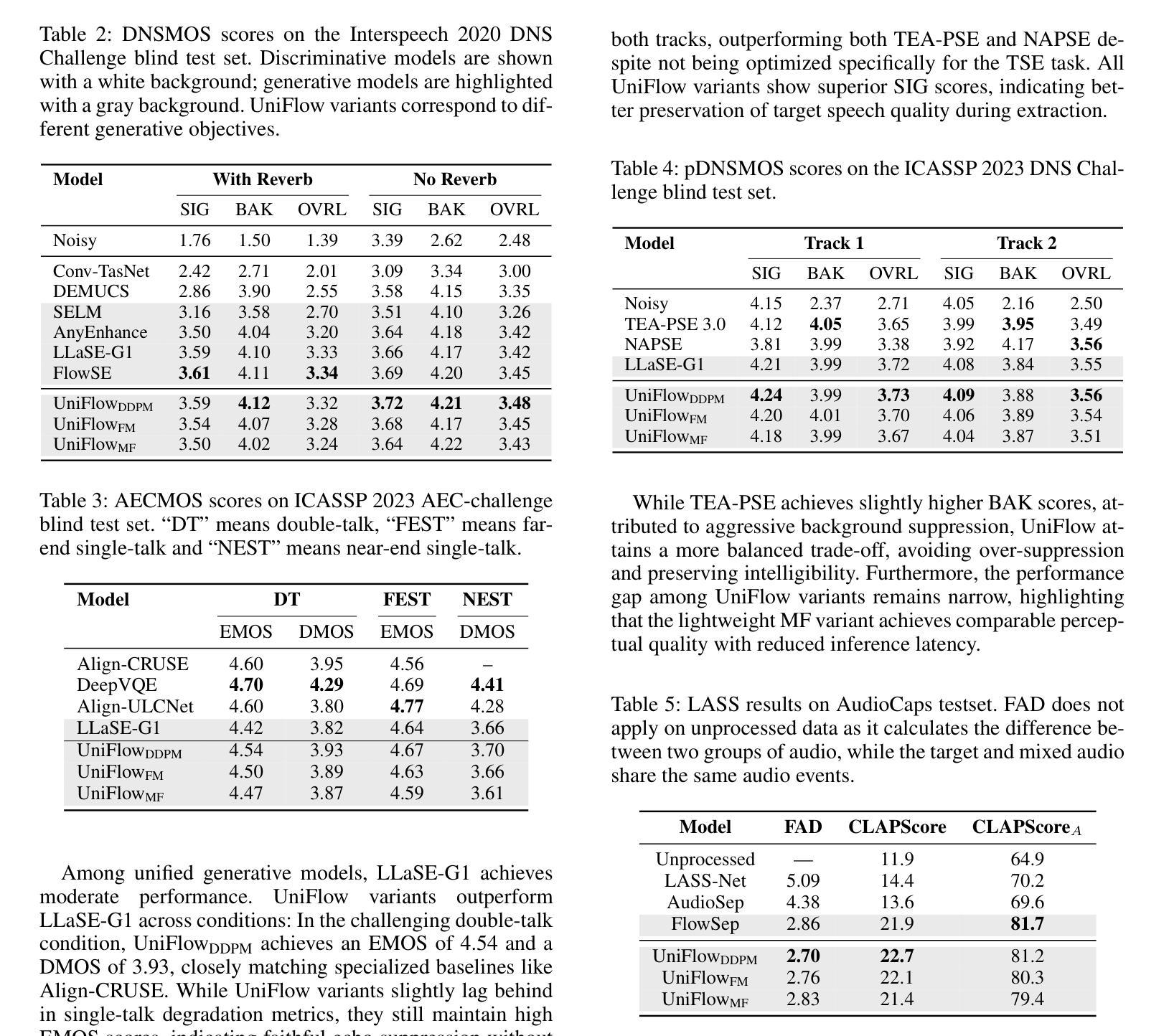
Generative modeling has recently achieved remarkable success across image, video, and audio domains, demonstrating powerful capabilities for unified representation learning. Yet speech front-end tasks such as speech enhancement (SE), target speaker extraction (TSE), acoustic echo cancellation (AEC), and language-queried source separation (LASS) remain largely tackled by disparate, task-specific solutions. This fragmentation leads to redundant engineering effort, inconsistent performance, and limited extensibility. To address this gap, we introduce UniFlow, a unified framework that employs continuous generative modeling to tackle diverse speech front-end tasks in a shared latent space. Specifically, UniFlow utilizes a waveform variational autoencoder (VAE) to learn a compact latent representation of raw audio, coupled with a Diffusion Transformer (DiT) that predicts latent updates. To differentiate the speech processing task during the training, learnable condition embeddings indexed by a task ID are employed to enable maximal parameter sharing while preserving task-specific adaptability. To balance model performance and computational efficiency, we investigate and compare three generative objectives: denoising diffusion, flow matching, and mean flow within the latent domain. We validate UniFlow on multiple public benchmarks, demonstrating consistent gains over state-of-the-art baselines. UniFlow’s unified latent formulation and conditional design make it readily extensible to new tasks, providing an integrated foundation for building and scaling generative speech processing pipelines. To foster future research, we will open-source our codebase.
生成式建模最近在图像、视频和音频领域取得了显著的成功,展示了统一表示学习的强大能力。然而,语音前端任务,如语音增强(SE)、目标说话人提取(TSE)、回声消除(AEC)和语言查询源分离(LASS),仍主要通过分散的、针对特定任务的解决方案来处理。这种碎片化导致了冗余的工程努力、性能不一致和扩展性有限。为了解决这一差距,我们引入了UniFlow,这是一个统一的框架,采用连续生成式建模,在共享潜在空间内解决多样化的语音前端任务。具体来说,UniFlow利用波形变分自编码器(VAE)学习原始音频的紧凑潜在表示,结合扩散变压器(DiT)来预测潜在更新。为了在训练过程中区分不同的语音处理任务,我们采用由任务ID索引的可学习条件嵌入,以实现最大参数共享,同时保留任务特定适应性。为了平衡模型性能和计算效率,我们研究和比较了三种生成目标:去噪扩散、流匹配和潜在域内的平均流。我们在多个公共基准测试集上验证了UniFlow,相较于最新基线技术,表现出了一致的优势。UniFlow的统一潜在公式和条件设计使其易于扩展到新任务,为构建和扩展生成式语音处理管道提供了集成基础。为了促进未来的研究,我们将开源我们的代码库。
论文及项目相关链接
PDF extended version
Summary
基于连续生成模型统一处理多种语音前端任务的框架UniFlow。该框架采用波形变分自编码器(VAE)学习原始音频的紧凑潜在表示,并结合扩散变压器(DiT)预测潜在更新。通过引入可学习的条件嵌入和索引任务ID,实现最大参数共享同时保留任务特定适应性。同时,探讨了三种生成目标,包括去噪扩散、流匹配和潜在域内的平均流,以实现模型性能和计算效率的平衡。在多个公共基准测试上的验证显示,UniFlow优于当前先进基线,易于扩展到新任务,为构建和扩展生成性语音处理管道提供了综合基础。
Key Takeaways
- UniFlow是一个利用连续生成模型处理多样化语音前端任务的统一框架。
- 该框架采用波形变分自编码器(VAE)学习音频的潜在表示,并结合扩散变压器进行预测。
- 通过引入可学习的条件嵌入和索引任务ID,实现参数共享和任务特定适应性的平衡。
- 探讨了三种生成目标以优化模型性能和计算效率。
- UniFlow在多个公共基准测试上表现优异,易于扩展到新任务。
- UniFlow为构建和扩展生成性语音处理管道提供了基础。
点此查看论文截图


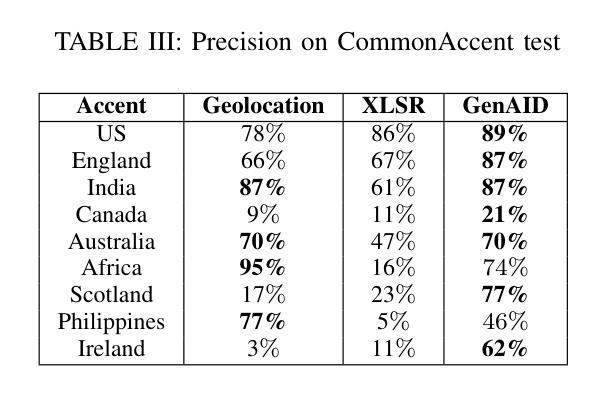
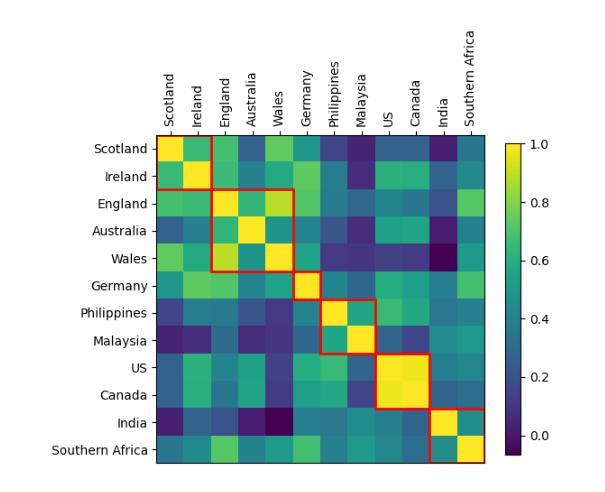
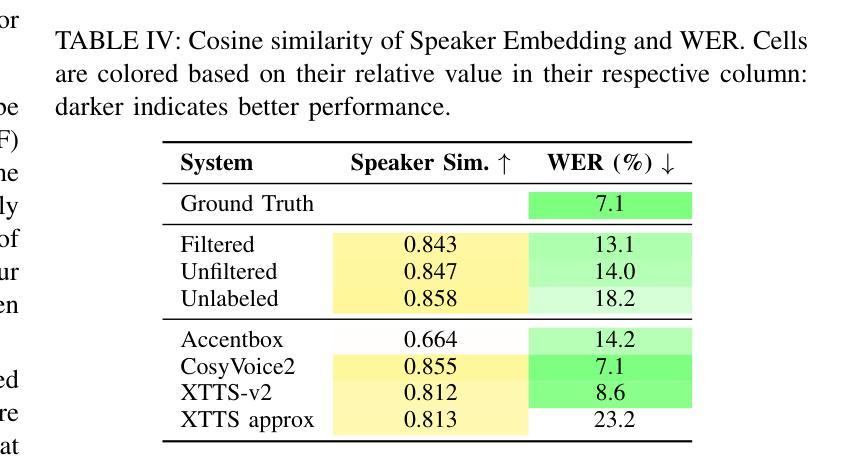
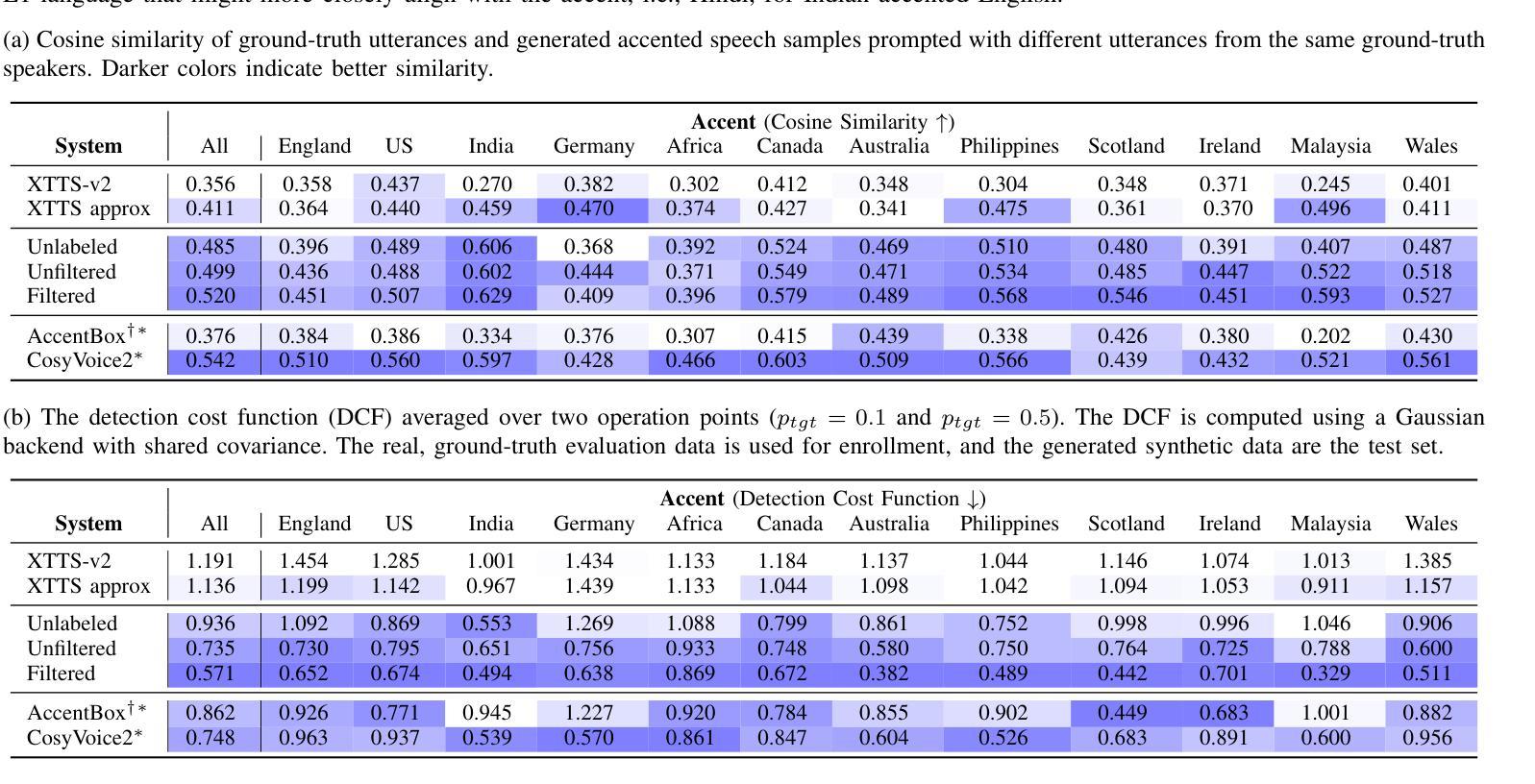
Scalable Controllable Accented TTS
Authors:Henry Li Xinyuan, Zexin Cai, Ashi Garg, Kevin Duh, Leibny Paola García-Perera, Sanjeev Khudanpur, Nicholas Andrews, Matthew Wiesner
We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.
我们面对了有口音的TTS系统所面临的扩展挑战,需要扩展它们的能力,以包含更大规模的训练数据和更多种类的口音标签,即使对于在传统TTS数据集中表示不佳或未标记的口音也是如此。为了实现这一点,我们采用了两种策略:1. 通过语音定位模型发现口音标签,该模型能够自动从原始语音数据中推断口音标签,而无需完全依赖于人工注释;2. 通过kNN语音转换增强音色,以增加数据多样性和模型稳健性。这些策略在CommonVoice上得到了验证,我们对XTTS-v2进行微调,以处理带有通过定位发现或增强的口音标签的口音TTS。我们证明,所得的带口音的TTS模型不仅优于在CommonVoice中自我报告的口音标签上调优的XTTS-v2,而且还优于现有的带口音TTS基准测试。
论文及项目相关链接
PDF Accepted at IEEE ASRU 2025
总结
本文介绍了如何通过采用两种策略来解决扩展带口音的文本转语音(TTS)系统的挑战。这两种策略分别是:一、利用语音地理位置模型进行口音标签发现,能够自动从原始语音数据中推断口音标签,无需完全依赖人工标注;二、通过kNN语音转换进行音色增强,以增加数据多样性和模型稳健性。文章在CommonVoice数据集上验证了这两种策略的有效性,使用地理位置发现的口音标签微调XTTS-v2模型后生成的带口音的TTS模型性能得到提升,不仅超越了使用CommonVoice自我报告的口音标签微调XTTS-v2模型的表现,而且相比现有的带口音的TTS基准测试也表现更出色。
关键见解
- 语音地理位置模型用于口音标签发现:能够自动从原始语音数据中推断口音标签,降低了对人工标注的依赖。
- 采用kNN语音转换进行音色增强:增加数据多样性和模型稳健性。
- 在CommonVoice数据集上验证了这两种策略的有效性。
- 提出的带口音的TTS模型表现超越了使用CommonVoice自我报告的口音标签微调XTTS-v2模型的表现。
- 与现有的带口音的TTS基准测试相比,该模型的性能更优越。
- 该方法对于扩展TTS系统的能力,包括处理更大量的训练数据和更广泛的口音标签具有重要意义。
- 此策略对于在传统TTS数据集中表示不足或无标签的口音特别重要。
点此查看论文截图




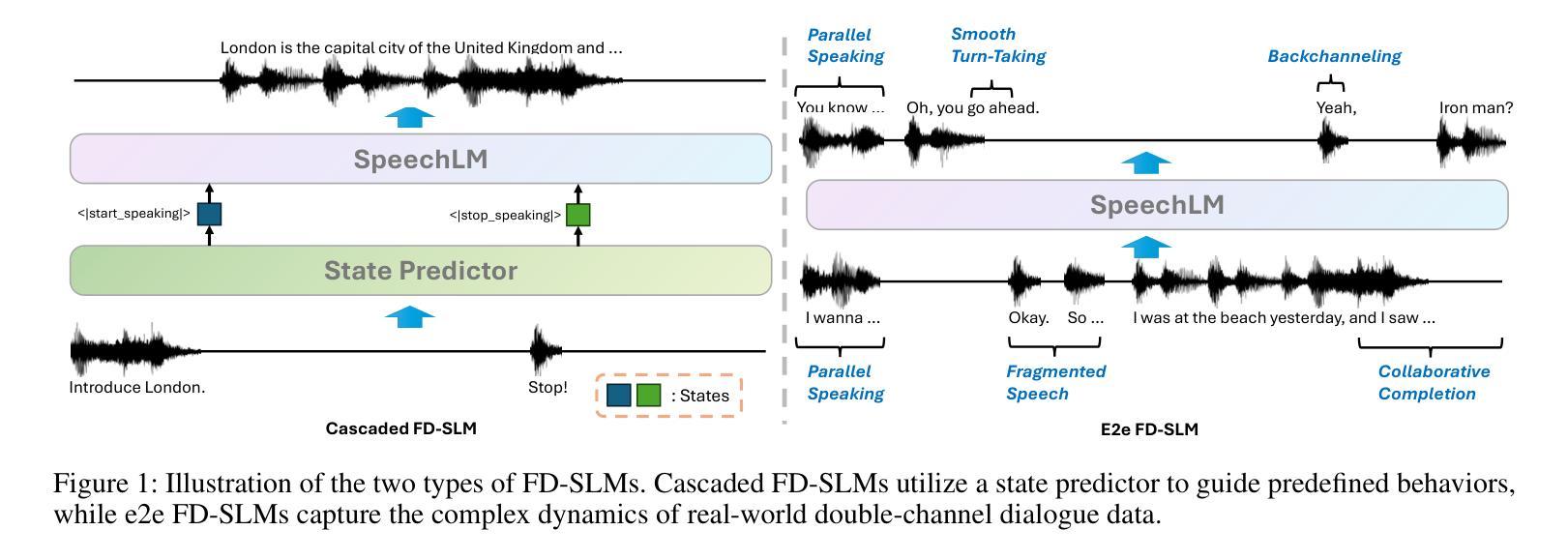
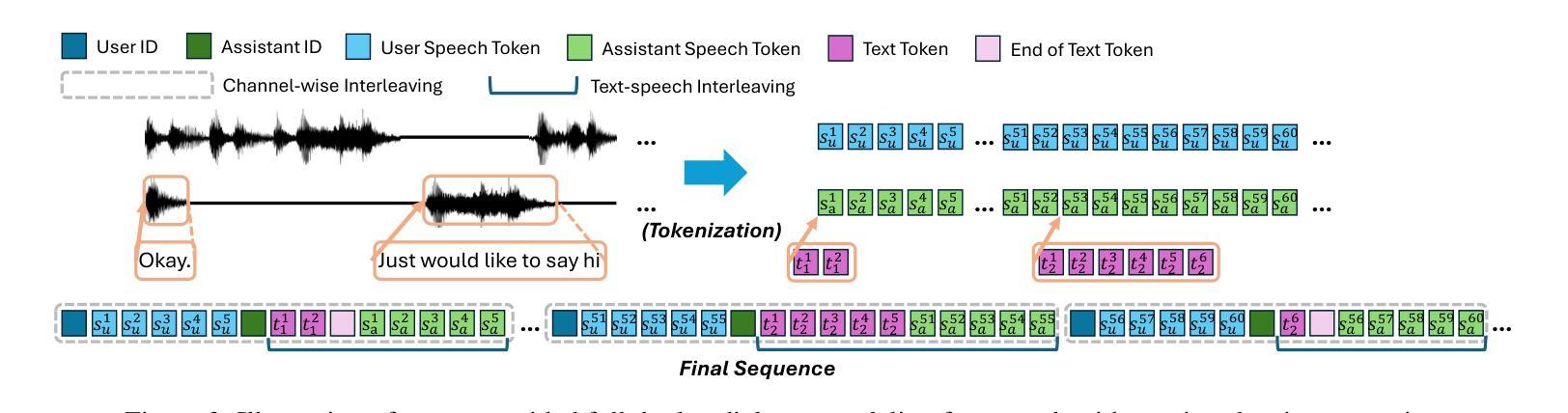
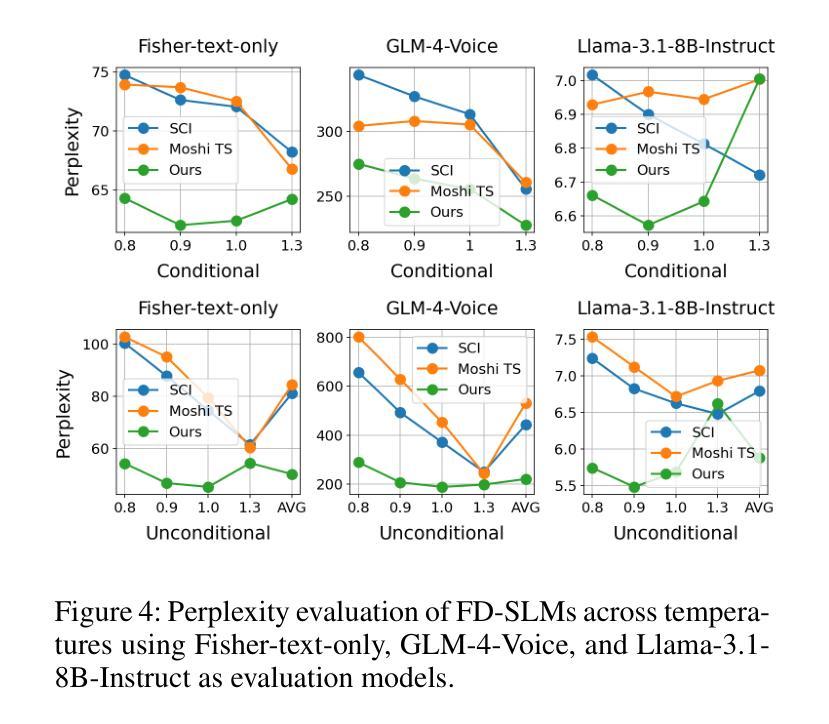
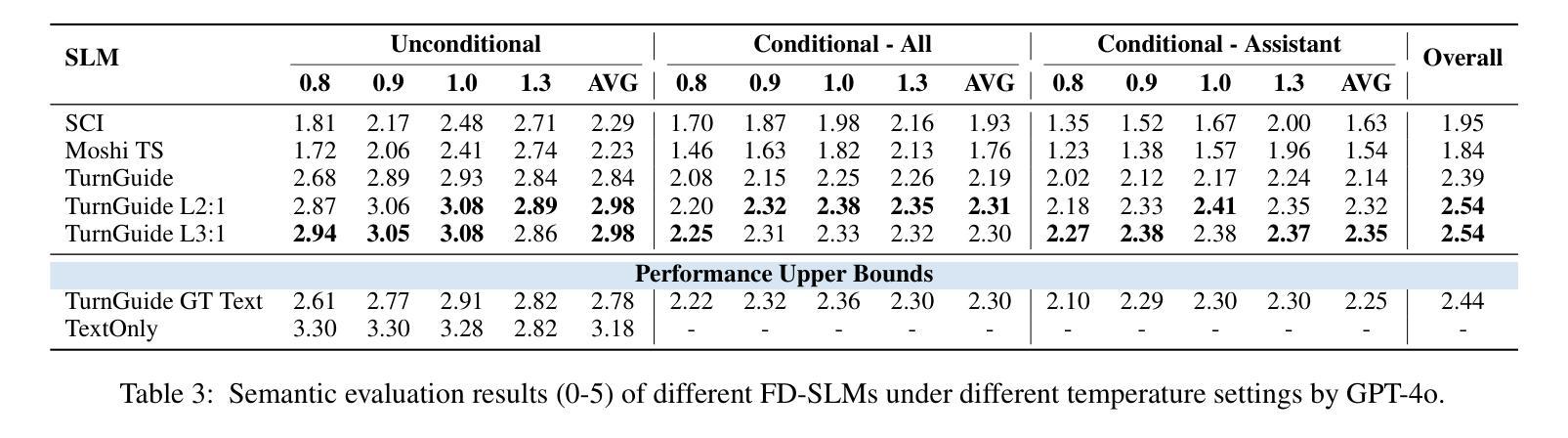
Think Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Authors:Wenqian Cui, Lei Zhu, Xiaohui Li, Zhihan Guo, Haoli Bai, Lu Hou, Irwin King
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge – their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs’ conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
全双工语音语言模型(FD-SLMs)是专门设计的基础模型,旨在通过模拟复杂对话动态(如中断、反馈通道和重叠语音)来实现自然、实时的口语交互。端到端(e2e)FD-SLMs则利用现实世界的双通道对话数据,捕捉微妙的两语者对话模式,用于人像交互。然而,它们面临一个关键挑战——由于长语音序列和有限的高质量口语对话数据,它们的对话能力通常与纯文本对话相比有所降低。虽然文本引导的语音生成可以缓解这些问题,但在将文本引导集成到双通道音频流中时,它存在时间和长度问题,破坏了自然交互所必需的时间精确对齐。为了解决这些挑战,我们提出了TurnGuide,这是一种受规划启发的新方法,通过动态地将助理语音分割成对话回合并生成回合级文本指导来模仿人类对话规划,在语音输出之前有效地解决了插入时间和长度挑战。大量实验表明,我们的方法显著提高了端到端FD-SLMs的对话能力,使它们能够生成语义上连贯的语音并保持自然的对话流程。演示网站为:https://dreamtheater123.github.io/TurnGuide-Demo/。代码将发布在:https://github.com/dreamtheater123/TurnGuide。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了全双工语音语言模型(FD-SLMs)面临的挑战,即对话能力在长时间语音序列和高质量语音对话数据有限的情况下会退化。为解决这一问题,提出了TurnGuide,一种模仿人类对话规划的方法,通过动态分割助理语音生成对话回合级别的文本指导,有效解决了插入时机和长度挑战。实验证明,该方法能显著提高端到端FD-SLMs的对话能力,使其在生成语义上有意义和连贯的语音的同时,保持自然的对话流程。
Key Takeaways
- FD-SLMs旨在实现自然、实时的口语交互,建模复杂的对话动态,如中断、反馈和重叠语音。
- 端到端FD-SLMs利用真实世界的双通道对话数据来捕捉微妙的两人对话模式,实现人性化的交互。
- FD-SLMs面临的关键挑战是:由于长时间的语音序列和高质量对话数据的限制,其对话能力退化。
- TurnGuide是一种模仿人类对话规划的方法,通过动态分割助理语音生成对话回合级别的文本指导来解决FD-SLMs的挑战。
- TurnGuide解决了插入时机和长度的问题,确保语音生成的精确时间对齐,保持自然的对话流程。
- 实验证明,TurnGuide能显著提高端到端FD-SLMs的对话能力,生成语义上有意义和连贯的语音。
点此查看论文截图

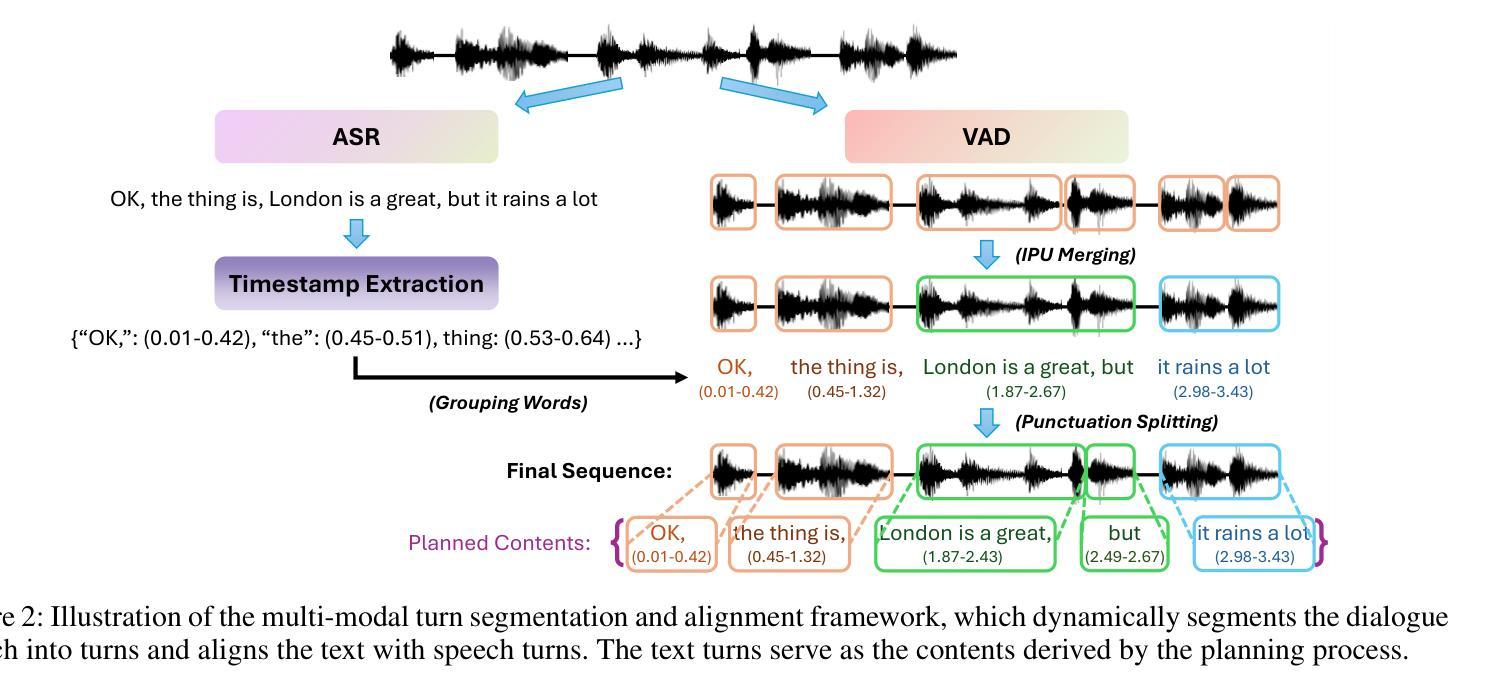

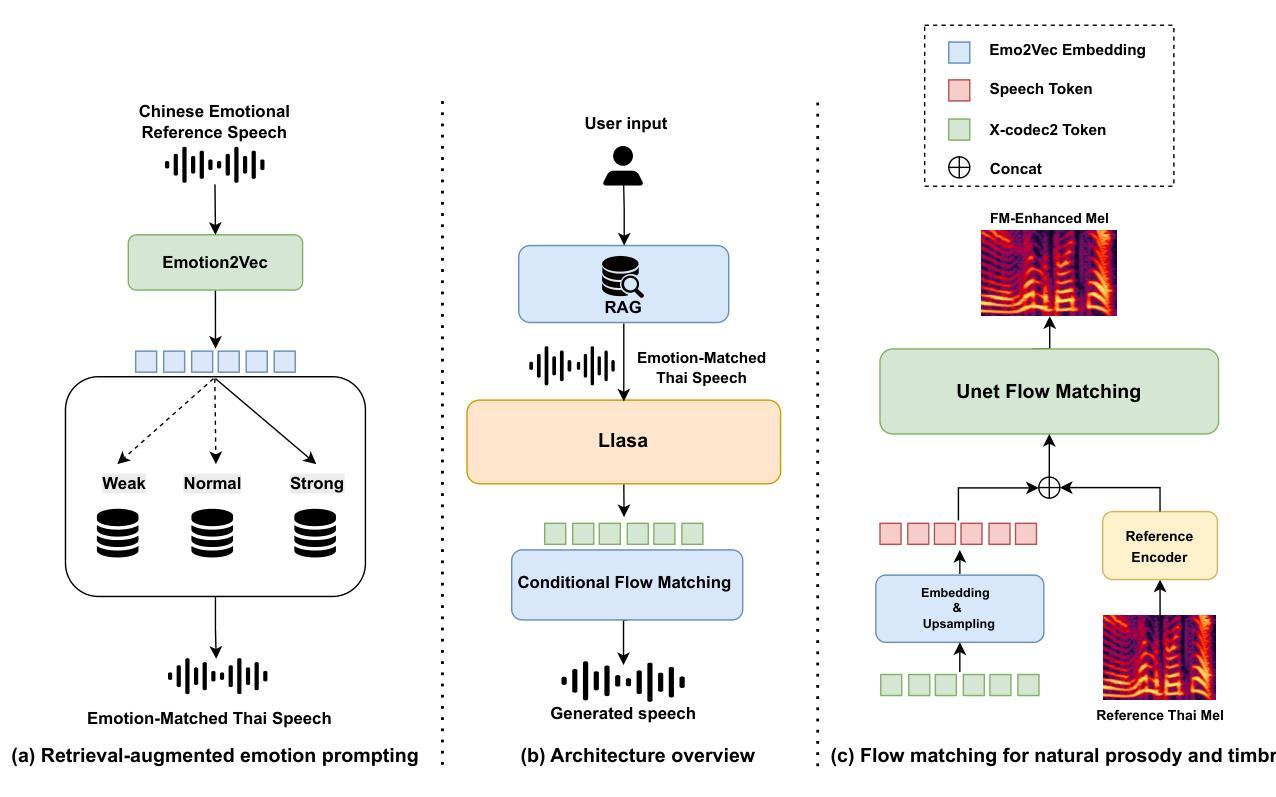
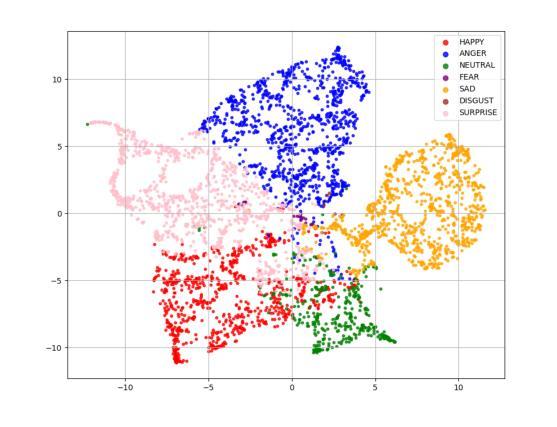
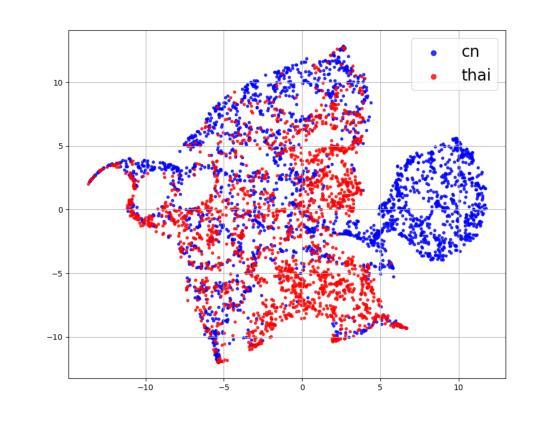
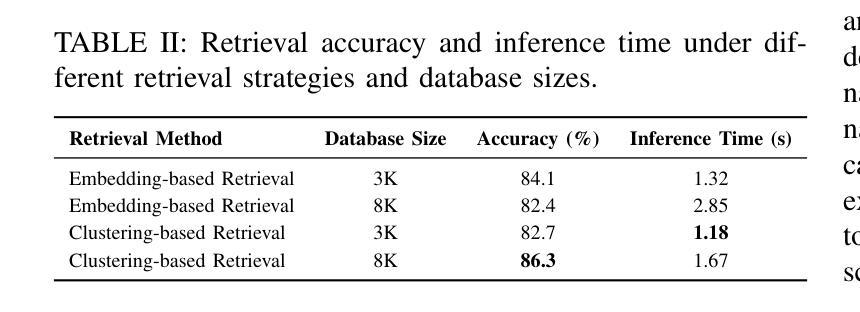
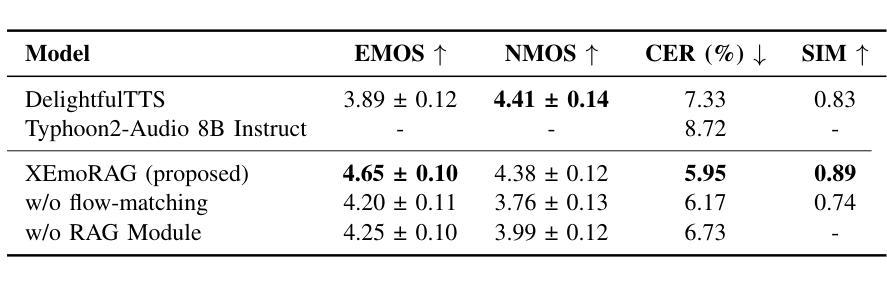
XEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Authors:Tianlun Zuo, Jingbin Hu, Yuke Li, Xinfa Zhu, Hai Li, Ying Yan, Junhui Liu, Danming Xie, Lei Xie
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language.However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features.In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data.XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency.Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels.These results highlight XEmoRAG’s capability to achieve flexible and low-resource emotional transfer across languages.Our demo is available at https://tlzuo-lesley.github.io/Demo-page/.
跨语言语音合成中的零样本情感迁移是指生成目标语言中的语音,情感的表达是基于源语言的参考语音。然而,由于缺乏平行多语言情感语料库、存在外来口音的伪迹以及从特定语言的韵律特征中分离情感的困难,这一任务仍然具有挑战性。在本文中,我们提出了XEmoRAG,这是一个无需依赖平行情感数据,能够实现从中文到泰语零样本情感迁移的新型框架,该框架基于大型语言模型(LLM)。XEmoRAG从中文语音中提取与语言无关的情感嵌入,并从精选的情感数据库中检索情感匹配的泰语话语,从而实现可控的情感迁移,无需明确的情感标签。此外,通过流匹配对齐模块最小化音高和持续时间的不匹配,确保自然的韵律。它还融合了中文音色到泰语合成中,提高了节奏准确性和情感表达,同时保持了说话人的特点和情感一致性。实验结果表明,XEmoRAG仅使用中文参考音频就能合成出富有表现力和自然感的泰语语音,无需明确的情感标签。这些结果突出了XEmoRAG在不同语言之间实现灵活和低资源情感迁移的能力。我们的演示可在https://tlzuo-lesley.github.io/Demo-page/上找到。
论文及项目相关链接
Summary
本论文提出了一种零样本情感转移框架XEmoRAG,可以实现从中文到泰语的跨语言语音合成中的情感转移。该框架基于大型语言模型,无需平行情感数据,通过提取语言无关的情感嵌入和检索情感匹配的泰语语音片段来实现可控的情感转移。同时,框架中的流匹配对齐模块可以最小化音高和持续时间的不匹配,确保自然的韵律。实验结果表明,XEmoRAG能够仅使用中文参考音频合成出表达力强、自然的泰语语音。
Key Takeaways
- 零样本情感转移在跨语言语音合成中是一项挑战,缺乏平行多语言情感语料库、存在外语口音问题以及从特定语言的韵律特征中分离情感难度大。
- 本论文提出了XEmoRAG框架,实现了从中文到泰语的零样本情感转移,基于大型语言模型,无需平行情感数据。
- XEmoRAG通过提取语言无关的情感嵌入和检索情感匹配的泰语语音片段,实现了可控的情感转移。
- 流匹配对齐模块最小化音高和持续时间的不匹配,确保自然的韵律。
- XEmoRAG将中文音色融入泰语合成中,提高了节奏准确性和情感表达,同时保持说话人的特征和情感一致性。
- 实验结果表明XEmoRAG能够仅使用中文参考音频合成出表达力强、自然的泰语语音。
点此查看论文截图

Lessons Learnt: Revisit Key Training Strategies for Effective Speech Emotion Recognition in the Wild
Authors:Jing-Tong Tzeng, Bo-Hao Su, Ya-Tse Wu, Hsing-Hang Chou, Chi-Chun Lee
In this study, we revisit key training strategies in machine learning often overlooked in favor of deeper architectures. Specifically, we explore balancing strategies, activation functions, and fine-tuning techniques to enhance speech emotion recognition (SER) in naturalistic conditions. Our findings show that simple modifications improve generalization with minimal architectural changes. Our multi-modal fusion model, integrating these optimizations, achieves a valence CCC of 0.6953, the best valence score in Task 2: Emotional Attribute Regression. Notably, fine-tuning RoBERTa and WavLM separately in a single-modality setting, followed by feature fusion without training the backbone extractor, yields the highest valence performance. Additionally, focal loss and activation functions significantly enhance performance without increasing complexity. These results suggest that refining core components, rather than deepening models, leads to more robust SER in-the-wild.
在这项研究中,我们重新审视了机器学习中的关键训练策略,这些策略通常会被更深的架构所忽视。具体来说,我们探索了平衡策略、激活函数和微调技术,以提高自然条件下的语音情感识别(SER)。我们的研究结果表明,简单的修改可以在极小的架构变化下提高泛化能力。我们融合了多种优化方式的多模态融合模型在任务2:情感属性回归中取得了0.6953的效价CCC值,成为最佳效价得分。值得注意的是,在单模态设置下分别对RoBERTa和WavLM进行微调,然后进行特征融合而不训练骨干提取器,可以获得最高的效价性能。此外,焦点损失和激活函数在不增加复杂性的情况下显著提高了性能。这些结果表明,改进核心组件而不是深化模型,能在野生环境下实现更稳健的SER。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本研究重新审视机器学习中的关键训练策略,包括平衡策略、激活函数和微调技术,以提升自然条件下的语音情感识别(SER)性能。研究结果表明,简单的修改可以大大提高泛化能力,且无需进行大规模架构更改。多模态融合模型在任务2:情感属性回归中取得了最佳效价分数0.6953。特别是,在单模态设置中分别微调RoBERTa和WavLM,然后进行特征融合,而无需训练骨干提取器,可获得最佳的效价性能。此外,焦点损失和激活函数显著提高性能且不增加复杂性。这些结果提示我们,优化核心组件而非深化模型能更稳健地在野外实现SER。
Key Takeaways
- 研究探索了平衡策略、激活函数和微调技术对语音情感识别的关键训练策略进行了重新审视。
- 简单修改可以在不改变架构的基础上提高模型的泛化能力。
- 多模态融合模型在情感属性回归任务中取得了最佳效价分数。
- 单独微调RoBERTa和WavLM,然后进行特征融合,可以获得最佳的效价性能。
- 焦点损失和激活函数的应用显著提高了模型的性能。
- 研究指出优化核心组件而不是深化模型是实现稳健语音情感识别的关键。
点此查看论文截图

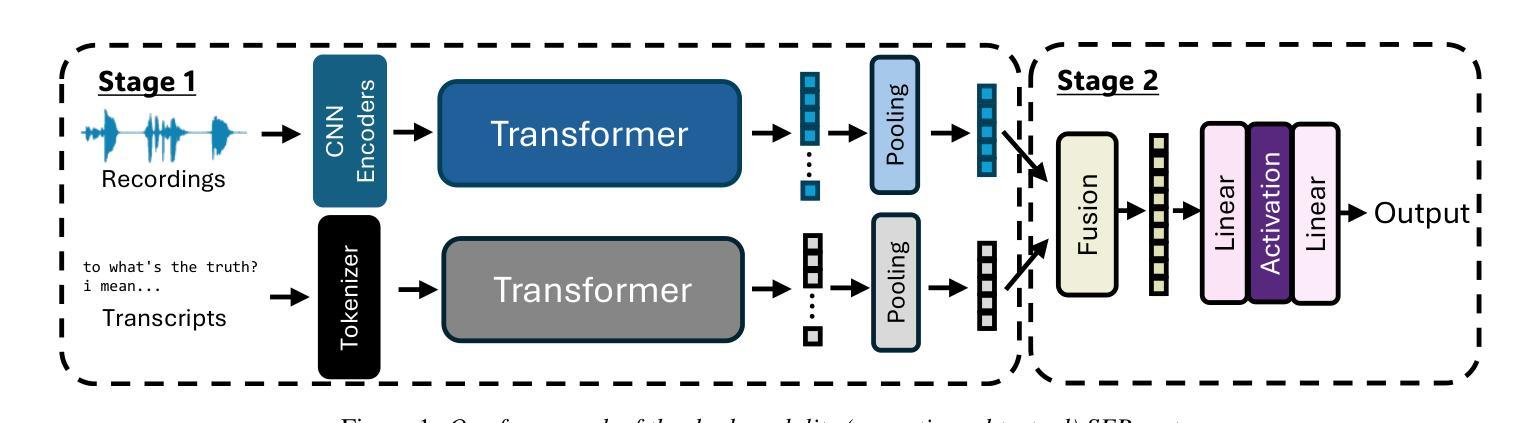



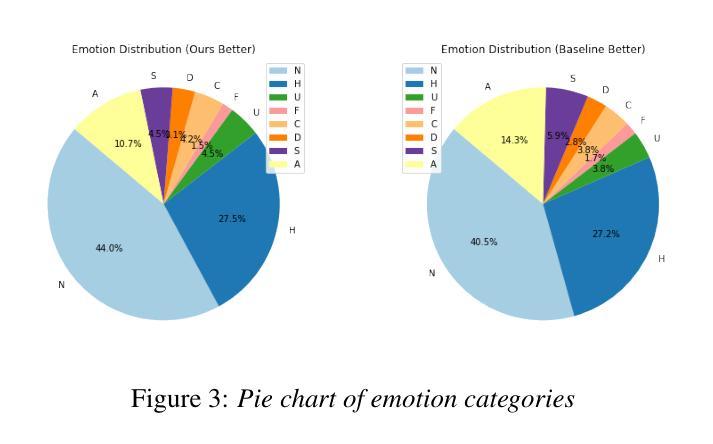
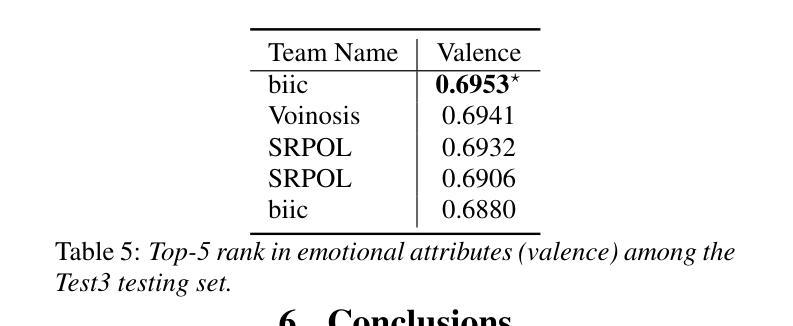
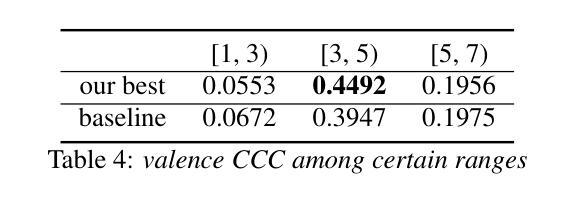
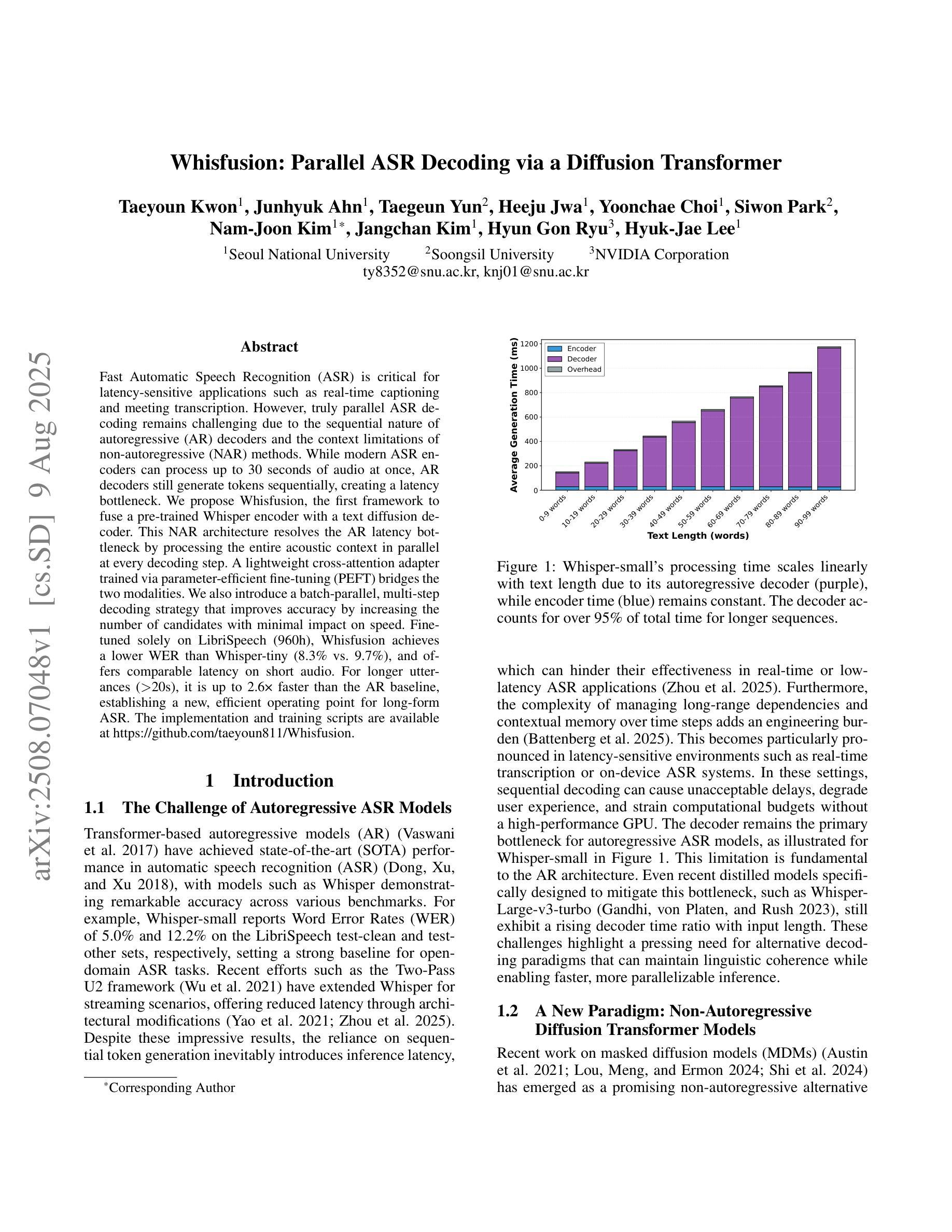
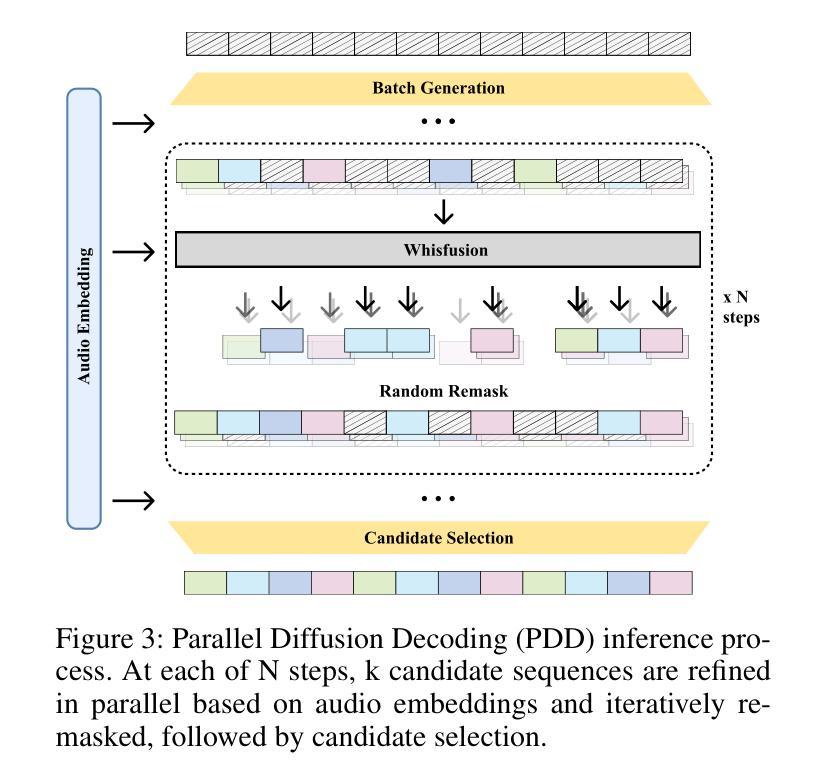
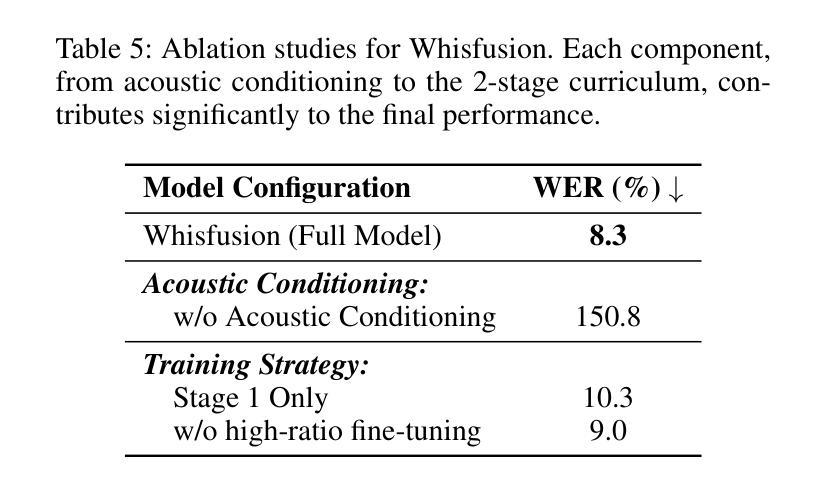
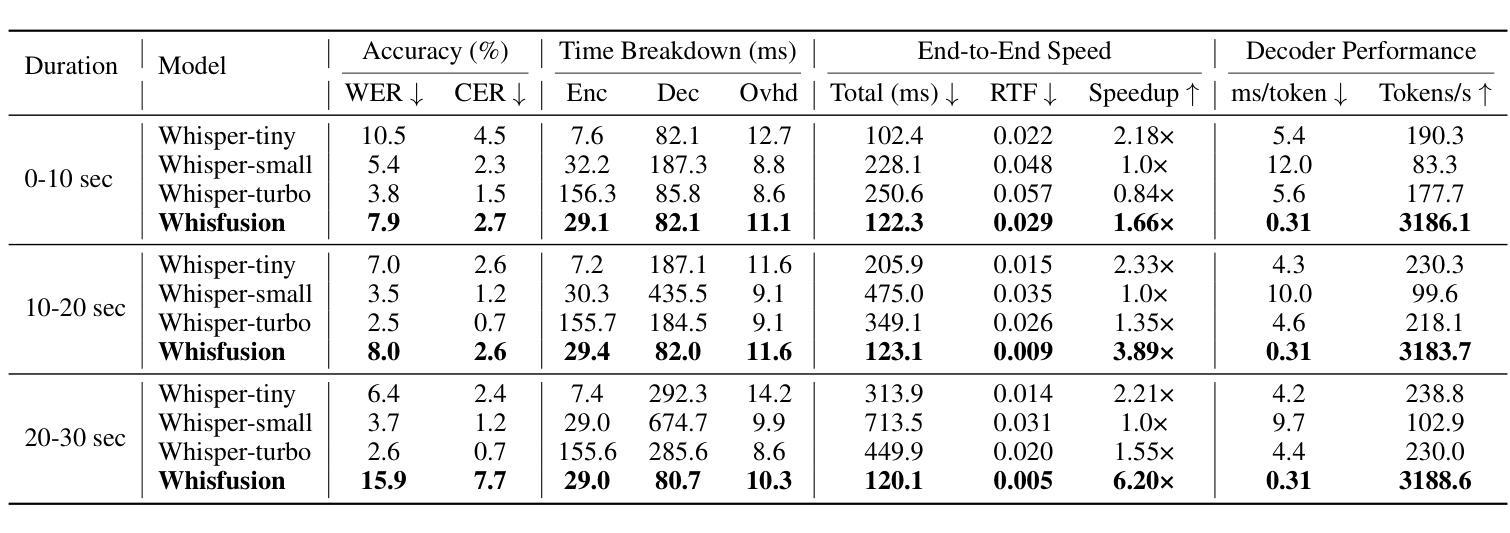
Whisfusion: Parallel ASR Decoding via a Diffusion Transformer
Authors:Taeyoun Kwon, Junhyuk Ahn, Taegeun Yun, Heeju Jwa, Yoonchae Choi, Siwon Park, Nam-Joon Kim, Jangchan Kim, Hyun Gon Ryu, Hyuk-Jae Lee
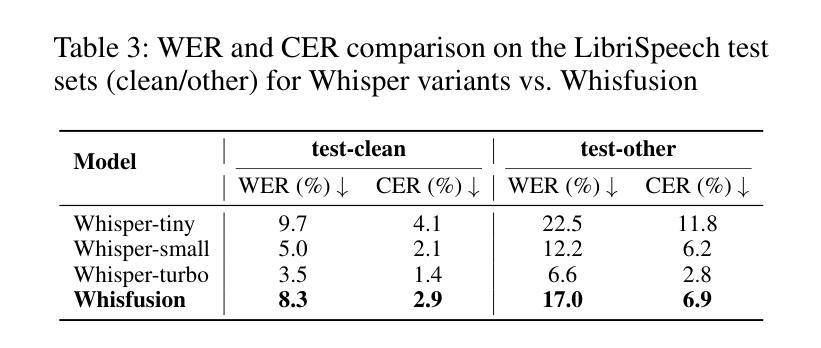
Fast Automatic Speech Recognition (ASR) is critical for latency-sensitive applications such as real-time captioning and meeting transcription. However, truly parallel ASR decoding remains challenging due to the sequential nature of autoregressive (AR) decoders and the context limitations of non-autoregressive (NAR) methods. While modern ASR encoders can process up to 30 seconds of audio at once, AR decoders still generate tokens sequentially, creating a latency bottleneck. We propose Whisfusion, the first framework to fuse a pre-trained Whisper encoder with a text diffusion decoder. This NAR architecture resolves the AR latency bottleneck by processing the entire acoustic context in parallel at every decoding step. A lightweight cross-attention adapter trained via parameter-efficient fine-tuning (PEFT) bridges the two modalities. We also introduce a batch-parallel, multi-step decoding strategy that improves accuracy by increasing the number of candidates with minimal impact on speed. Fine-tuned solely on LibriSpeech (960h), Whisfusion achieves a lower WER than Whisper-tiny (8.3% vs. 9.7%), and offers comparable latency on short audio. For longer utterances (>20s), it is up to 2.6x faster than the AR baseline, establishing a new, efficient operating point for long-form ASR. The implementation and training scripts are available at https://github.com/taeyoun811/Whisfusion.
快速自动语音识别(ASR)对于延迟敏感的应用(例如实时字幕和会议转录)至关重要。然而,由于自回归(AR)解码器的序列特性和非自回归(NAR)方法的上下文限制,真正的并行ASR解码仍然具有挑战性。尽管现代ASR编码器可以一次处理长达30秒的音频,但AR解码器仍然按顺序生成令牌,造成延迟瓶颈。我们提出了Whisfusion,这是第一个将预训练的Whisper编码器与文本扩散解码器融合的框架。这种NAR架构通过在每个解码步骤中并行处理整个声学上下文来解决AR延迟瓶颈问题。通过参数高效微调(PEFT)训练的轻量级跨注意适配器填补了两种模式的空白。我们还引入了一种批并行多步解码策略,通过增加候选人数量的方式提高准确性,对速度的影响微乎其微。仅在LibriSpeech(960小时)上进行微调,Whisfusion的单词错误率低于Whisper-tiny(8.3%对比9.7%),并且在短音频上提供相当的延迟。对于较长的语音片段(>20秒),它比AR基准测试快达2.6倍,为长形式ASR建立了新的高效操作点。实现和训练脚本可在https://github.com/taeyoun811/Whisfusion找到。
论文及项目相关链接
PDF 16 pages, 9 figures
Summary
本文介绍了针对自动语音识别(ASR)中的延迟问题,提出了一种新的解决方案——Whisfusion框架。该框架融合了预训练的Whisper编码器与文本扩散解码器,采用非自回归(NAR)架构,以并行处理整个声学上下文,解决自回归(AR)解码器的序列性质及上下文限制导致的延迟瓶颈。通过参数高效微调(PEFT)的跨注意力适配器,实现了两种模态之间的桥梁。同时,引入批量并行多步解码策略,通过增加候选数量来提高准确性,同时几乎不影响速度。在LibriSpeech上仅进行微调,Whisfusion的单词错误率低于Whisper-tiny,对短音频的延迟与Whisper相当,对长音频的处理速度则是自回归方法的2.6倍。
Key Takeaways
- Whisfusion框架融合了预训练的Whisper编码器与文本扩散解码器,解决了ASR中的延迟问题。
- 采用非自回归(NAR)架构,并行处理整个声学上下文,突破了自回归(AR)解码器的延迟瓶颈。
- 跨注意力适配器通过参数高效微调(PEFT)实现模态间的桥梁。
- 引入批量并行多步解码策略,提高准确性同时几乎不影响速度。
- Whisfusion在LibriSpeech上的单词错误率低于Whisper-tiny。
- 对于短音频,Whisfusion的延迟与Whisper相当。
- 对于长音频处理,Whisfusion的处理速度是自回归方法的2.6倍。
点此查看论文截图

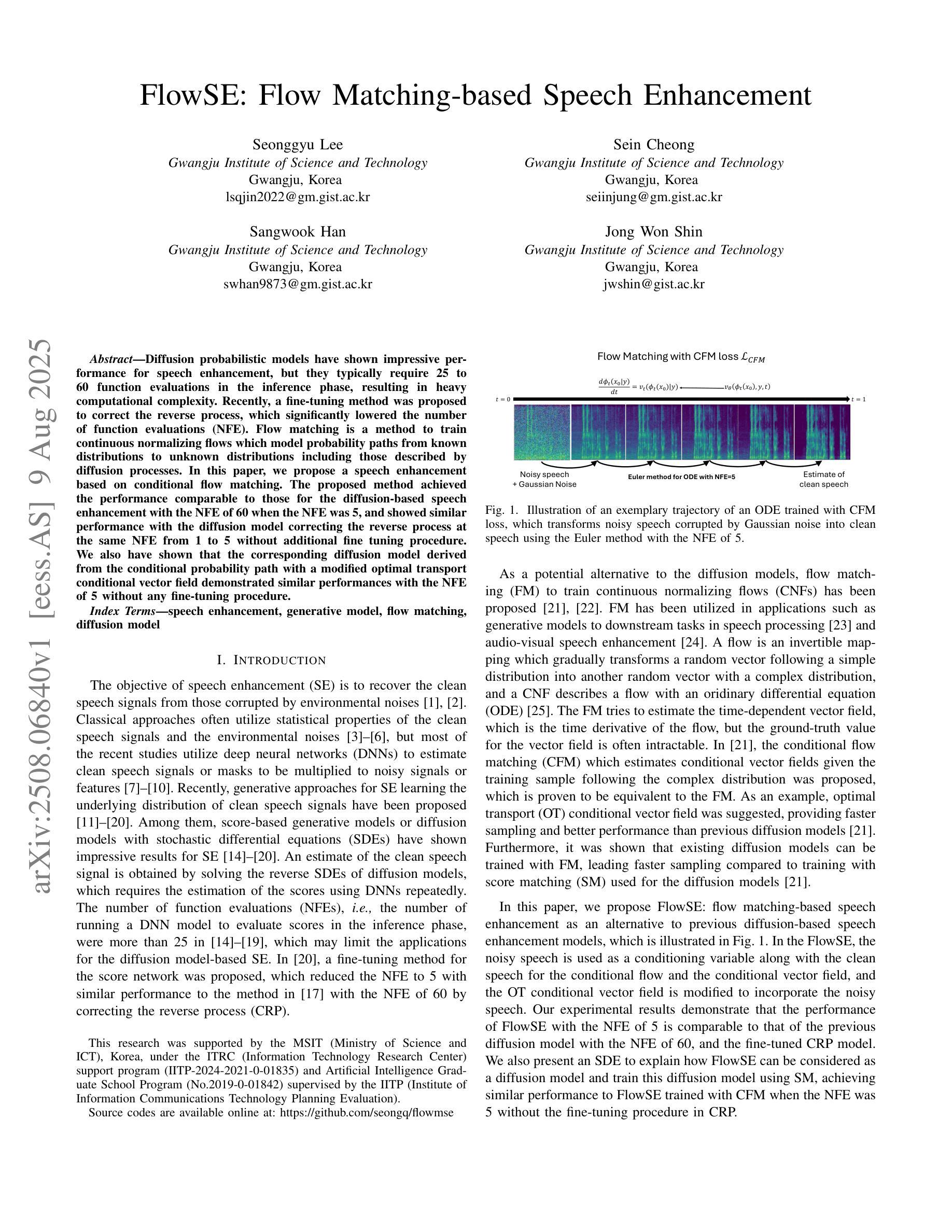
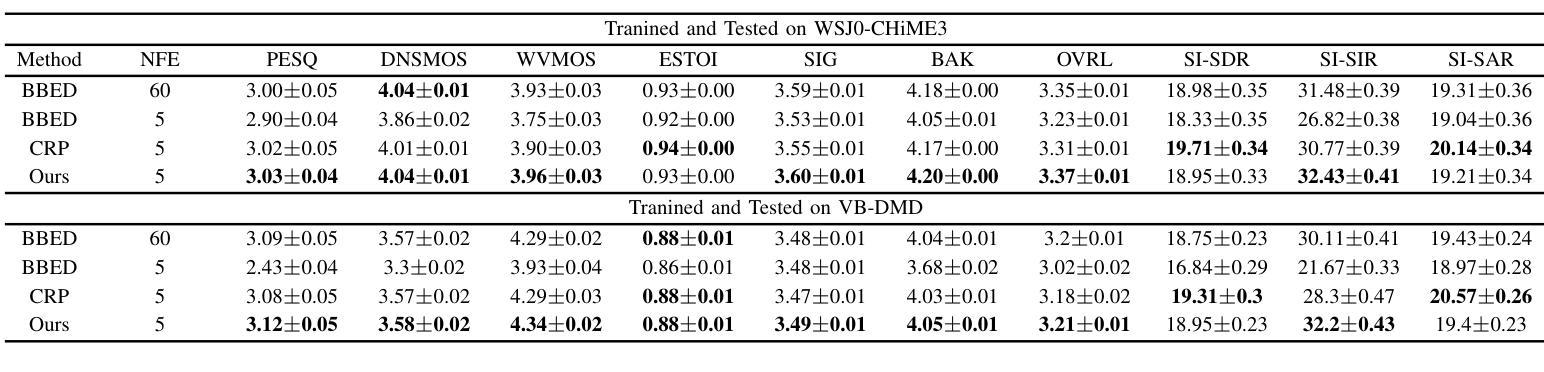
FlowSE: Flow Matching-based Speech Enhancement
Authors:Seonggyu Lee, Sein Cheong, Sangwook Han, Jong Won Shin
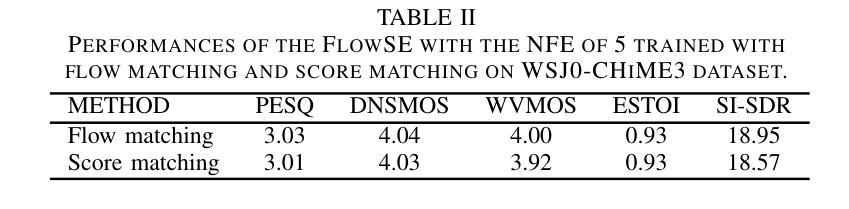
Diffusion probabilistic models have shown impressive performance for speech enhancement, but they typically require 25 to 60 function evaluations in the inference phase, resulting in heavy computational complexity. Recently, a fine-tuning method was proposed to correct the reverse process, which significantly lowered the number of function evaluations (NFE). Flow matching is a method to train continuous normalizing flows which model probability paths from known distributions to unknown distributions including those described by diffusion processes. In this paper, we propose a speech enhancement based on conditional flow matching. The proposed method achieved the performance comparable to those for the diffusion-based speech enhancement with the NFE of 60 when the NFE was 5, and showed similar performance with the diffusion model correcting the reverse process at the same NFE from 1 to 5 without additional fine tuning procedure. We also have shown that the corresponding diffusion model derived from the conditional probability path with a modified optimal transport conditional vector field demonstrated similar performances with the NFE of 5 without any fine-tuning procedure.
扩散概率模型在语音增强方面表现出令人印象深刻的性能,但它们通常在推理阶段需要25到60次函数评估,导致计算复杂度较高。最近,提出了一种微调方法来纠正反向过程,这大大降低了函数评估次数(NFE)。流匹配是一种训练连续归一化流的方法,该流从已知分布到未知分布建模概率路径,包括由扩散过程描述的那些分布。在本文中,我们提出了一种基于条件流匹配的语音增强方法。当NFE为5时,所提出的方法实现了与基于扩散的语音增强相当的性能(后者在NFE为60时表现),并且在相同的NFE从1到5范围内,无需额外的微调程序,其性能与纠正反向过程的扩散模型相似。我们还表明,对应于由带有修改后的最优传输条件向量场的条件概率路径派生的扩散模型,在无需任何微调程序的情况下,在NFE为5时表现出相似的性能。
论文及项目相关链接
PDF Published in ICASSP 2025
Summary
基于条件流匹配的语音增强方法被提出,该方法通过训练连续归一化流来建模从已知分布到未知分布的概率路径,包括由扩散过程描述的分布。该方法实现了与基于扩散的语音增强方法相当的性能,同时在函数评估次数(NFE)大幅降低的情况下表现出色。
Key Takeaways
- 扩散概率模型在语音增强方面表现出卓越性能,但推理阶段需要25至60次函数评估,计算复杂度较高。
- 最近提出的微调方法用于纠正反向过程,显著降低函数评估次数(NFE)。
- 流匹配是一种训练连续归一化流的方法,用于建模从已知分布到未知分布的概率路径,包括由扩散过程描述的分布。
- 本文提出了一种基于条件流匹配的语音增强方法,实现了与扩散模型相当的性能。
- 当NFE为5时,该方法达到了与NFE为60的扩散模型相当的性能。
- 在相同的NFE范围内(从1到5),该方法展示了无需额外微调程序即可与纠正反向过程的扩散模型相匹敌的性能。
点此查看论文截图
Learning Phonetic Context-Dependent Viseme for Enhancing Speech-Driven 3D Facial Animation
Authors:Hyung Kyu Kim, Hak Gu Kim
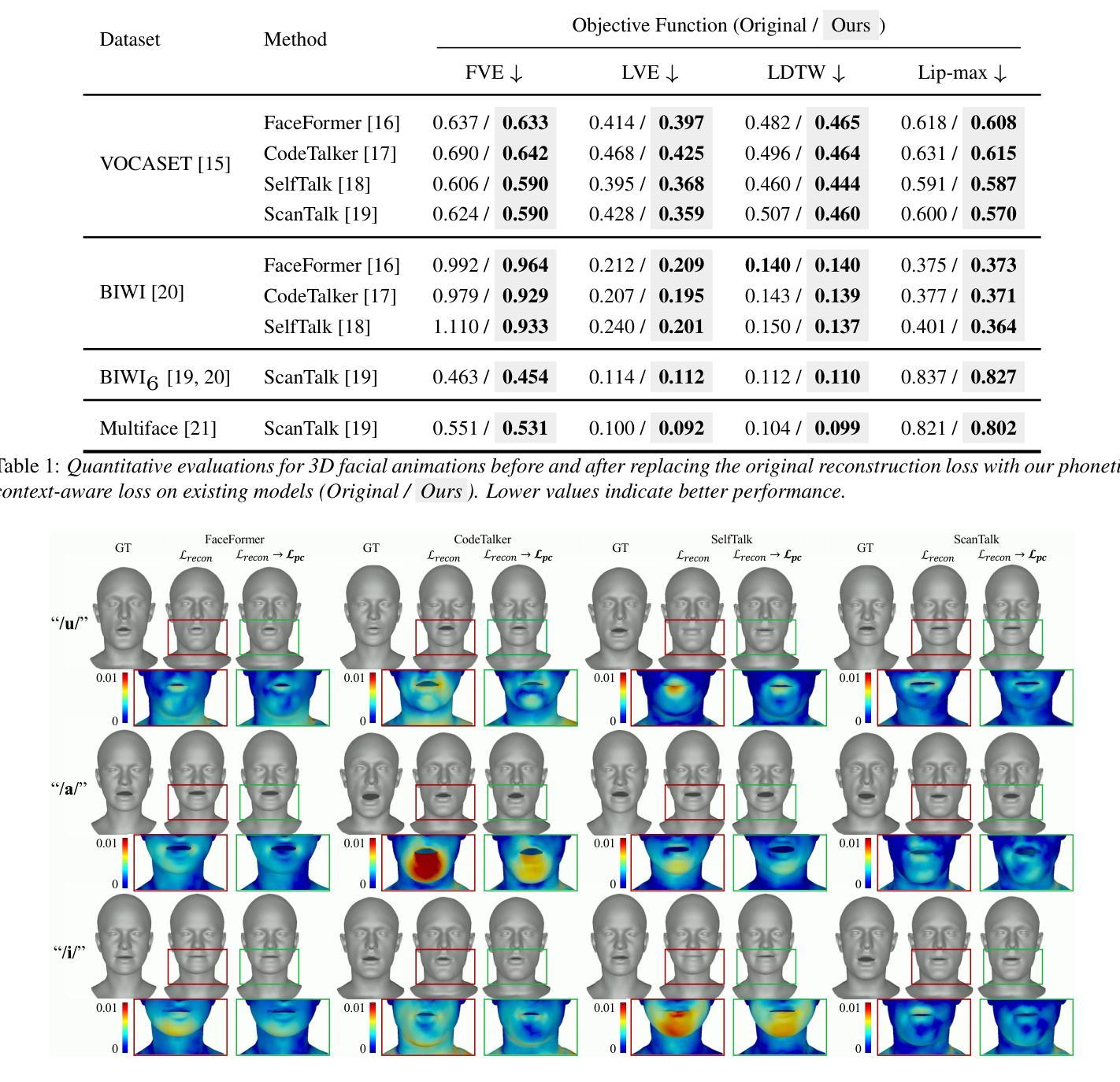
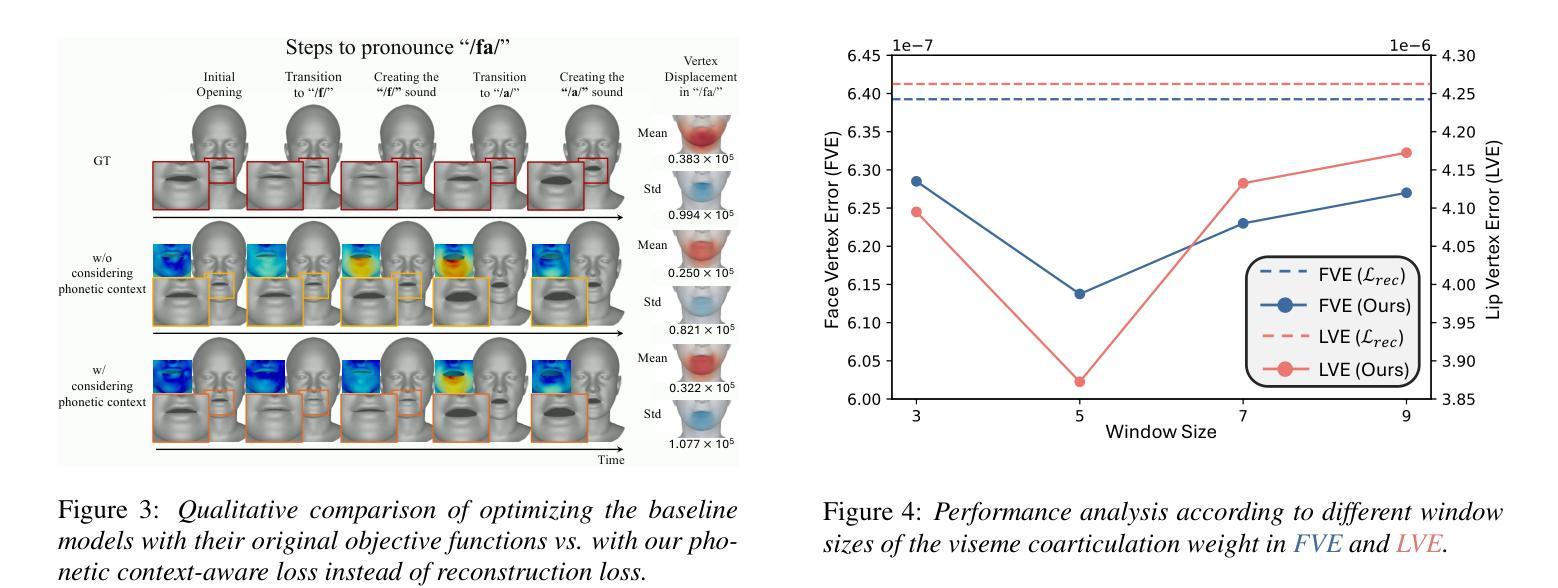
Speech-driven 3D facial animation aims to generate realistic facial movements synchronized with audio. Traditional methods primarily minimize reconstruction loss by aligning each frame with ground-truth. However, this frame-wise approach often fails to capture the continuity of facial motion, leading to jittery and unnatural outputs due to coarticulation. To address this, we propose a novel phonetic context-aware loss, which explicitly models the influence of phonetic context on viseme transitions. By incorporating a viseme coarticulation weight, we assign adaptive importance to facial movements based on their dynamic changes over time, ensuring smoother and perceptually consistent animations. Extensive experiments demonstrate that replacing the conventional reconstruction loss with ours improves both quantitative metrics and visual quality. It highlights the importance of explicitly modeling phonetic context-dependent visemes in synthesizing natural speech-driven 3D facial animation. Project page: https://cau-irislab.github.io/interspeech25/
语音驱动的3D面部动画旨在生成与音频同步的真实面部运动。传统方法主要通过将每一帧与地面真实数据进行比对来最小化重建损失。然而,这种基于帧的方法通常无法捕捉到面部运动的连续性,由于协同发音导致输出产生抖动和不自然的现象。为了解决这一问题,我们提出了一种新型语音上下文感知损失,该损失能够明确建模语音上下文对语音音素过渡的影响。通过引入语音协同发音权重,我们根据面部运动随时间的变化为其分配自适应重要性,确保动画更加流畅且视觉感知一致。大量实验表明,用我们的方法替换传统重建损失能提高定量指标和视觉质量。它强调了明确建模语音上下文相关音素在合成自然语音驱动的3D面部动画中的重要性。项目页面:https://cau-irislab.github.io/interspeech25/
论文及项目相关链接
PDF Interspeech 2025; Project Page: https://cau-irislab.github.io/interspeech25/
Summary
本文提出一种基于语音驱动的3D面部动画新方法,旨在生成与音频同步的真实面部运动。为解决传统方法因忽略语音上下文导致的面部运动不连续问题,本文提出一种新颖的语音上下文感知损失函数,通过建模语音上下文对颜面肌肉动作的影响,实现更平滑、感知一致的动画效果。实验证明,该方法在定量指标和视觉质量上均有所提升。
Key Takeaways
- 语音驱动的3D面部动画旨在生成与音频同步的真实面部运动。
- 传统方法主要通过最小化重建损失来实现帧与地面真实的对齐,但这种方法忽略了面部运动的连续性。
- 提出一种新颖的语音上下文感知损失函数,建模语音上下文对颜面肌肉动作的影响。
- 通过引入颜面肌肉动作协同发音权重,对面部运动进行自适应重要性分配,确保动画更平滑、感知一致。
- 实验证明,该方法在定量指标和视觉质量上均有所提升。
- 该方法强调了明确建模语音上下文相关的颜面肌肉动作在合成自然语音驱动3D面部动画中的重要性。
点此查看论文截图

TalkLess: Blending Extractive and Abstractive Speech Summarization for Editing Speech to Preserve Content and Style
Authors:Karim Benharrak, Puyuan Peng, Amy Pavel
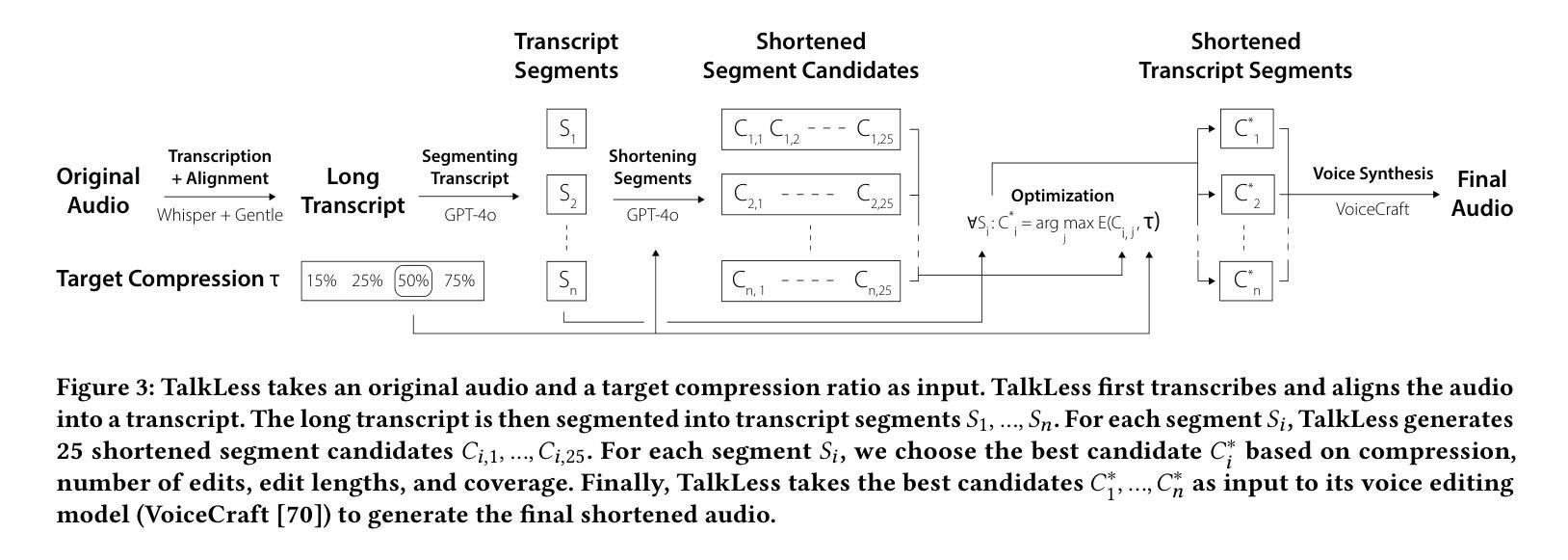
Millions of people listen to podcasts, audio stories, and lectures, but editing speech remains tedious and time-consuming. Creators remove unnecessary words, cut tangential discussions, and even re-record speech to make recordings concise and engaging. Prior work automatically summarized speech by removing full sentences (extraction), but rigid extraction limits expressivity. AI tools can summarize then re-synthesize speech (abstraction), but abstraction strips the speaker’s style. We present TalkLess, a system that flexibly combines extraction and abstraction to condense speech while preserving its content and style. To edit speech, TalkLess first generates possible transcript edits, selects edits to maximize compression, coverage, and audio quality, then uses a speech editing model to translate transcript edits into audio edits. TalkLess’s interface provides creators control over automated edits by separating low-level wording edits (via the compression pane) from major content edits (via the outline pane). TalkLess achieves higher coverage and removes more speech errors than a state-of-the-art extractive approach. A comparison study (N=12) showed that TalkLess significantly decreased cognitive load and editing effort in speech editing. We further demonstrate TalkLess’s potential in an exploratory study (N=3) where creators edited their own speech.
成千上万的人聆听播客、音频故事和讲座,但编辑语音仍然繁琐耗时。创作者会删除多余的词汇、剪辑离题的内容,甚至重新录制语音,以使录音更加简洁、引人入胜。之前的工作通过移除整个句子(提取)来自动总结语音,但僵化的提取方式限制了表达力。AI工具可以总结然后重新合成语音(抽象),但抽象会剥夺说话者的风格。我们推出了TalkLess系统,它灵活地结合了提取和抽象,浓缩语音的同时保留其内容风格。为了编辑语音,TalkLess首先生成可能的转录编辑,选择编辑以最大化压缩、覆盖范围和音频质量,然后使用语音编辑模型将转录编辑转化为音频编辑。TalkLess的界面通过区分低级别的措辞编辑(通过压缩面板)和主要的内容编辑(通过大纲面板),为创作者提供了对自动编辑的控制权。TalkLess的覆盖范围更广,去除的语音错误比最先进的提取方法更多。一项比较研究(N=12)显示,TalkLess显著降低了语音编辑的认知负荷和努力程度。在探索性研究(N=3)中,我们进一步展示了创作者使用TalkLess编辑自己的语音的潜力。
论文及项目相关链接
PDF Accepted to The 38th Annual ACM Symposium on User Interface Software and Technology (UIST ‘25), September 28-October 1, 2025, Busan, Republic of Korea. 19 pages
Summary
谈到一个名为TalkLess的系统,它将语音识别技术与人工智能技术结合,实现对演讲内容的精简和风格保留。该系统可以生成可能的转录编辑,选择能最大化压缩、覆盖和音频质量的编辑,并将转录编辑转化为音频编辑。TalkLess界面提供创作者对自动编辑的控制,分为低级别的措辞编辑(通过压缩面板)和主要的内容编辑(通过大纲面板)。与现有技术相比,TalkLess在覆盖率和去除语音错误方面表现更佳,同时能显著降低认知负荷和编辑工作量。
Key Takeaways
- TalkLess系统结合了语音识别与人工智能技术,旨在编辑语音内容。
- 它能够生成可能的转录编辑,并智能选择最大化压缩、覆盖和音频质量的编辑。
- TalkLess结合了提取和抽象技术,能在保持内容的同时调整语音。
- 系统界面提供两种编辑模式:针对措辞的低级别编辑和针对主要内容的编辑。
- 与现有技术相比,TalkLess在覆盖率和消除语音错误方面具有优势。
- TalkLess能显著降低认知负荷和编辑工作量。
点此查看论文截图


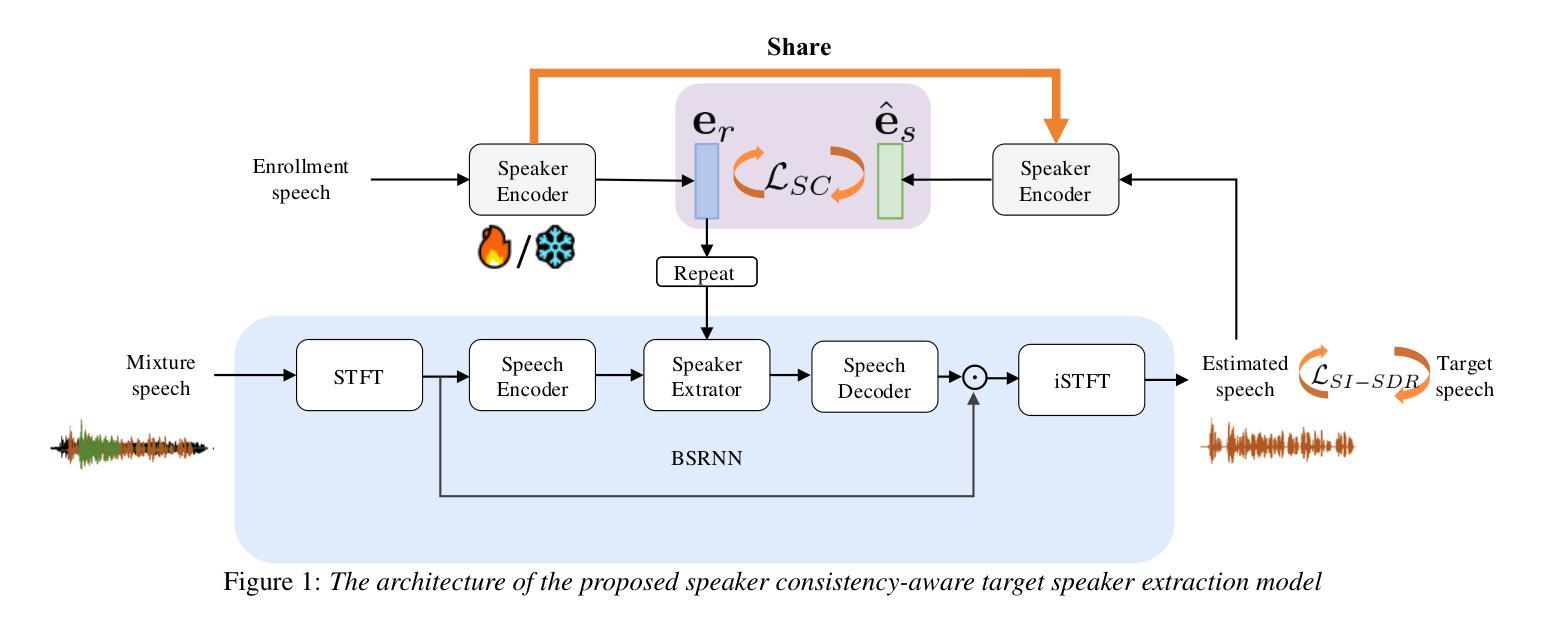
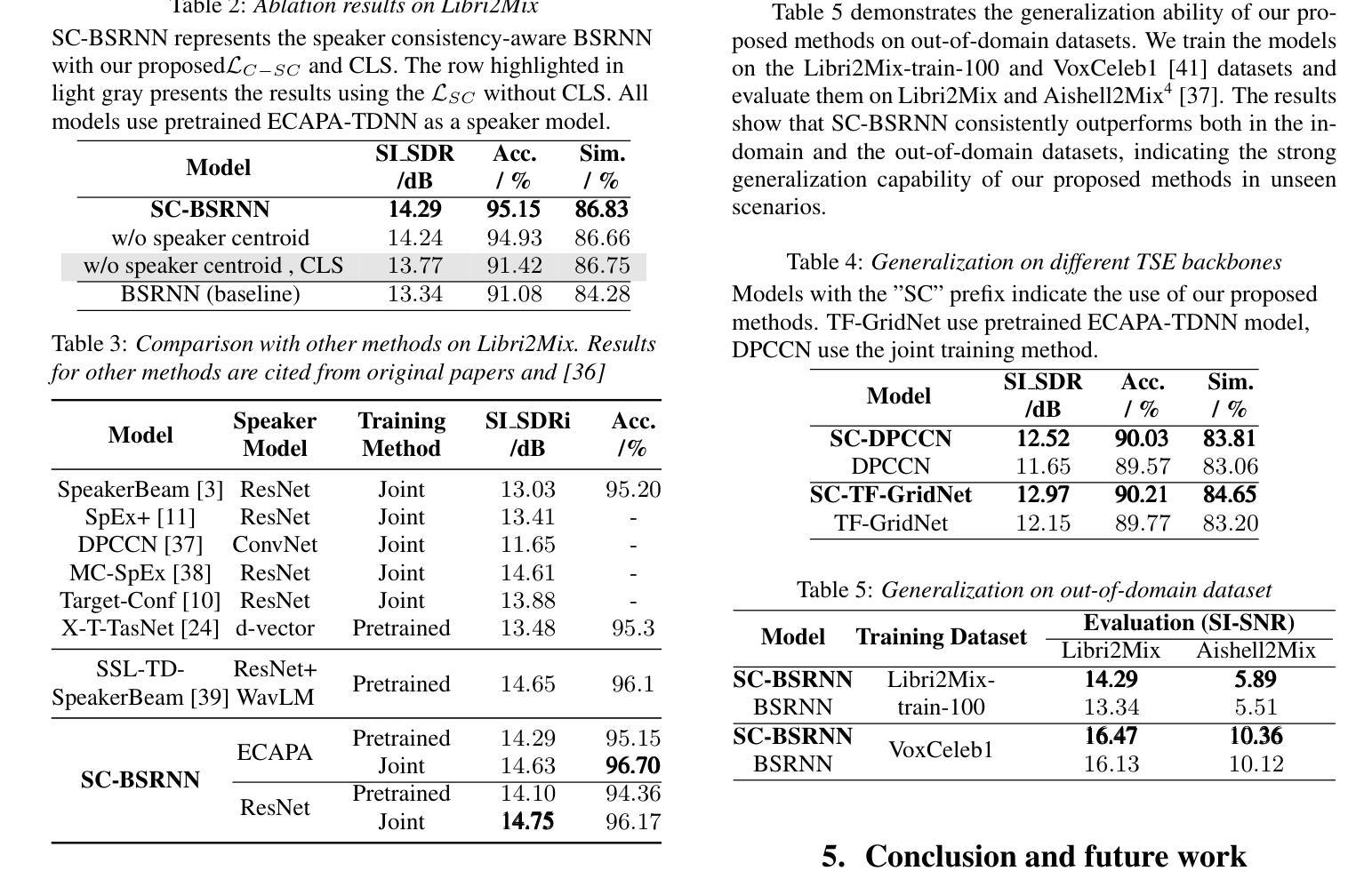
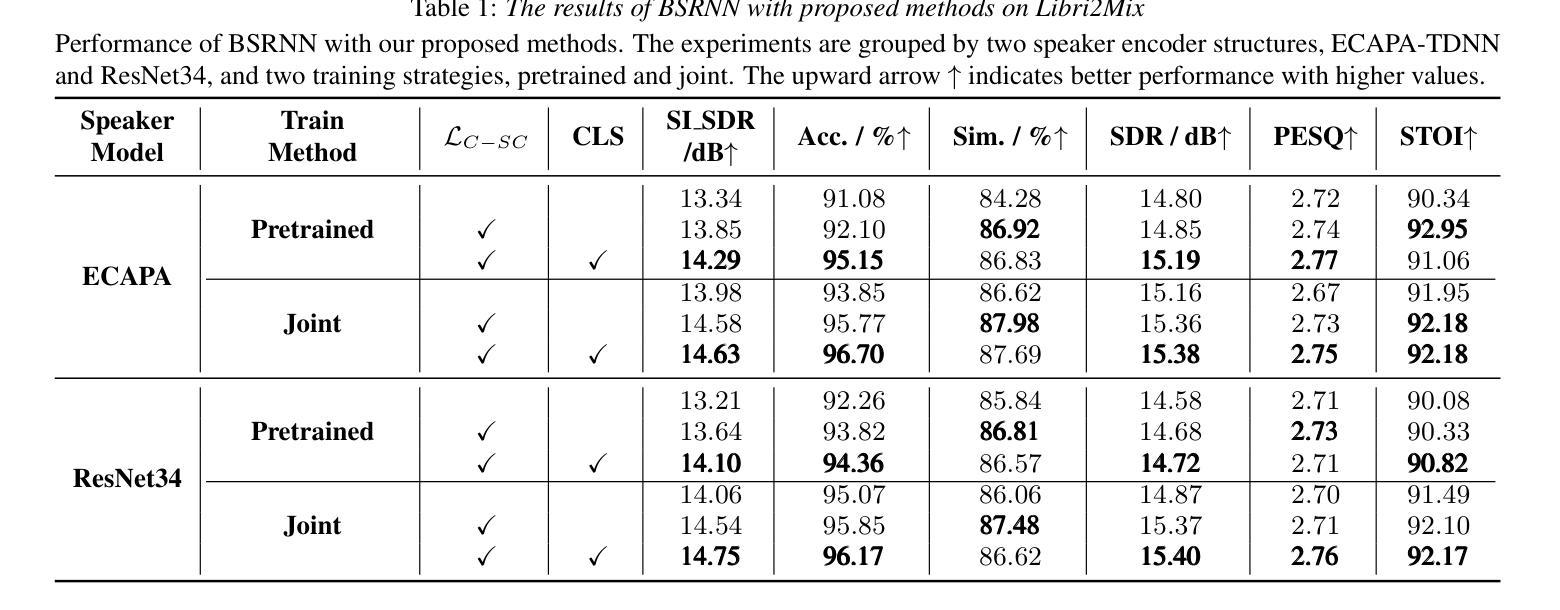
Enhancing Target Speaker Extraction with Explicit Speaker Consistency Modeling
Authors:Shu Wu, Anbin Qi, Yanzhang Xie, Xiang Xie
Target Speaker Extraction (TSE) uses a reference cue to extract the target speech from a mixture. In TSE systems relying on audio cues, the speaker embedding from the enrolled speech is crucial to performance. However, these embeddings may suffer from speaker identity confusion. Unlike previous studies that focus on improving speaker embedding extraction, we improve TSE performance from the perspective of speaker consistency. In this paper, we propose a speaker consistency-aware target speaker extraction method that incorporates a centroid-based speaker consistency loss. This approach enhances TSE performance by ensuring speaker consistency between the enrolled and extracted speech. In addition, we integrate conditional loss suppression into the training process. The experimental results validate the effectiveness of our proposed methods in advancing the TSE performance. A speech demo is available online:https://sc-tse.netlify.app/
目标说话人提取(TSE)使用参考线索从混合语音中提取目标语音。在依赖音频线索的TSE系统中,注册语音的说话人嵌入对性能至关重要。然而,这些嵌入可能会受到说话人身份混淆的影响。不同于之前专注于提高说话人嵌入提取的研究,我们从说话人一致性的角度提高TSE的性能。在本文中,我们提出了一种基于质心的说话人一致性感知目标说话人提取方法,该方法引入了基于质心的说话人一致性损失。这种方法通过确保注册语音和提取语音之间的说话人一致性,提高了TSE的性能。此外,我们将条件损失抑制融入训练过程。实验结果验证了我们提出的方法在提高TSE性能方面的有效性。在线演示链接:https://sc-tse.netlify.app/ 。
论文及项目相关链接
PDF preprint
Summary:目标说话人提取(TSE)利用参考线索从混合语音中提取目标语音。在依赖音频线索的TSE系统中,注册语音的说话人嵌入对性能至关重要,但这些嵌入可能会受到说话人身份混淆的影响。本文从说话人一致性的角度提高TSE性能,提出了一种基于质心的说话人一致性感知目标说话人提取方法,并引入了条件损失抑制到训练过程中。实验结果表明,该方法能有效提高TSE性能。
Key Takeaways:
- 目标说话人提取(TSE)依赖参考线索来从混合语音中提取目标语音。
- 说话人嵌入在TSE系统中对性能至关重要,但可能存在说话人身份混淆的问题。
- 本文从说话人一致性的角度提出改进TSE性能的方法。
- 引入了一种基于质心的说话人一致性损失来提高TSE性能,确保注册和提取的语音之间的说话人一致性。
- 将条件损失抑制集成到训练过程中,进一步提高TSE的性能。
- 实验结果验证了所提出方法的有效性。
点此查看论文截图

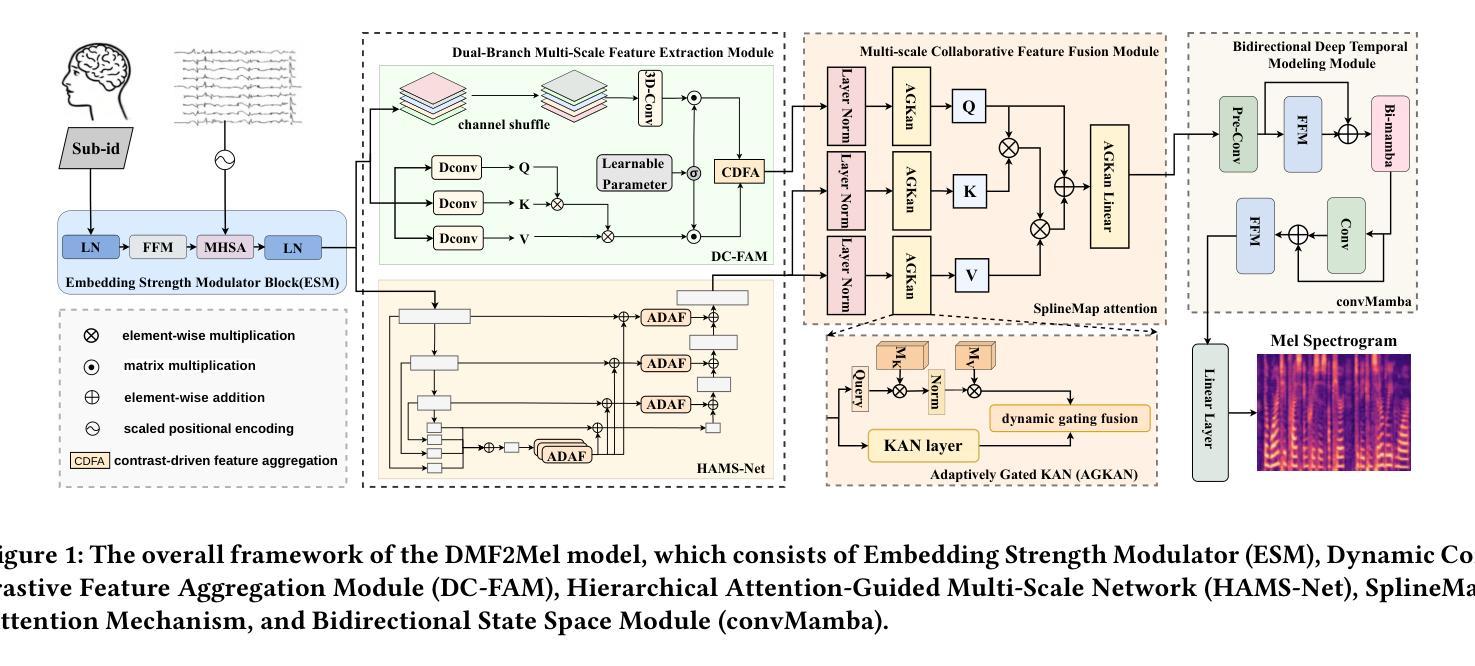
DMF2Mel: A Dynamic Multiscale Fusion Network for EEG-Driven Mel Spectrogram Reconstruction
Authors:Cunhang Fan, Sheng Zhang, Jingjing Zhang, Enrui Liu, Xinhui Li, Gangming Zhao, Zhao Lv
Decoding speech from brain signals is a challenging research problem. Although existing technologies have made progress in reconstructing the mel spectrograms of auditory stimuli at the word or letter level, there remain core challenges in the precise reconstruction of minute-level continuous imagined speech: traditional models struggle to balance the efficiency of temporal dependency modeling and information retention in long-sequence decoding. To address this issue, this paper proposes the Dynamic Multiscale Fusion Network (DMF2Mel), which consists of four core components: the Dynamic Contrastive Feature Aggregation Module (DC-FAM), the Hierarchical Attention-Guided Multi-Scale Network (HAMS-Net), the SplineMap attention mechanism, and the bidirectional state space module (convMamba). Specifically, the DC-FAM separates speech-related “foreground features” from noisy “background features” through local convolution and global attention mechanisms, effectively suppressing interference and enhancing the representation of transient signals. HAMS-Net, based on the U-Net framework,achieves cross-scale fusion of high-level semantics and low-level details. The SplineMap attention mechanism integrates the Adaptive Gated Kolmogorov-Arnold Network (AGKAN) to combine global context modeling with spline-based local fitting. The convMamba captures long-range temporal dependencies with linear complexity and enhances nonlinear dynamic modeling capabilities. Results on the SparrKULee dataset show that DMF2Mel achieves a Pearson correlation coefficient of 0.074 in mel spectrogram reconstruction for known subjects (a 48% improvement over the baseline) and 0.048 for unknown subjects (a 35% improvement over the baseline).Code is available at: https://github.com/fchest/DMF2Mel.
从脑电波解码语音是一个具有挑战性的研究课题。尽管现有技术已在重建听觉刺激的梅尔频谱图(在单词或字母层面)方面取得进展,但在精确重建分钟级连续想象中的语音方面仍存在核心挑战:传统模型在平衡时间依赖性建模的效率和长序列解码中的信息保留方面面临困难。针对这一问题,本文提出了动态多尺度融合网络(DMF2Mel),它包含四个核心组件:动态对比特征聚合模块(DC-FAM)、分层注意力引导多尺度网络(HAMS-Net)、SplineMap注意力机制和双向状态空间模块(convMamba)。具体来说,DC-FAM通过局部卷积和全局注意力机制,将语音相关的“前景特征”与噪声“背景特征”分离,有效地抑制了干扰并增强了瞬态信号的表示。HAMS-Net基于U-Net框架,实现了高级语义和低级细节的跨尺度融合。SplineMap注意力机制结合了自适应门控Kolmogorov-Arnold网络(AGKAN),将全局上下文建模与基于样条的局部拟合相结合。convMamba以线性复杂度捕捉长期时间依赖性,并增强了非线性动态建模能力。在SparrKULee数据集上的结果表明,DMF2Mel在已知主题的梅尔频谱图重建中实现了0.074的皮尔逊相关系数(比基线提高了48%),在未知主题上实现了0.048(比基线提高了35%)。代码可用:https://github.com/fchest/DMF2Mel。
论文及项目相关链接
PDF Accepted by ACM MM 2025
Summary
解码脑电波中的语音是一个挑战性的研究课题。现有技术虽已能在字词级别重建听觉刺激的梅尔频谱图,但在重建分钟级别的连续想象语音时仍存在核心挑战。传统模型难以在时序依赖建模的效率与长序列解码的信息保留之间取得平衡。为解决此问题,本文提出了动态多尺度融合网络(DMF2Mel),包含四大核心组件:动态对比特征聚合模块(DC-FAM)、分层注意力引导多尺度网络(HAMS-Net)、SplineMap注意力机制和双向状态空间模块(convMamba)。DMF2Mel在SparrKULee数据集上的重建结果表现出色,对已知主体和未知主体的梅尔频谱图重建的Pearson相关系数分别达到了0.074和0.048,相较于基线方法有显著改善。
Key Takeaways
- 解码脑电波中的语音是一个充满挑战的研究课题。
- 当前技术在重建连续想象语音时面临核心挑战。
- 传统模型在时序依赖建模和信息保留方面存在困难。
- DMF2Mel网络由四大核心组件构成,旨在解决上述问题。
- DC-FAM能有效分离语音相关的“前景特征”和干扰的“背景特征”。
- HAMS-Net基于U-Net框架,实现高层次语义与低层次细节的跨尺度融合。
- DMF2Mel在SparrKULee数据集上的重建结果优于基线方法,对已知和未知主体的重建均有显著改善。
点此查看论文截图

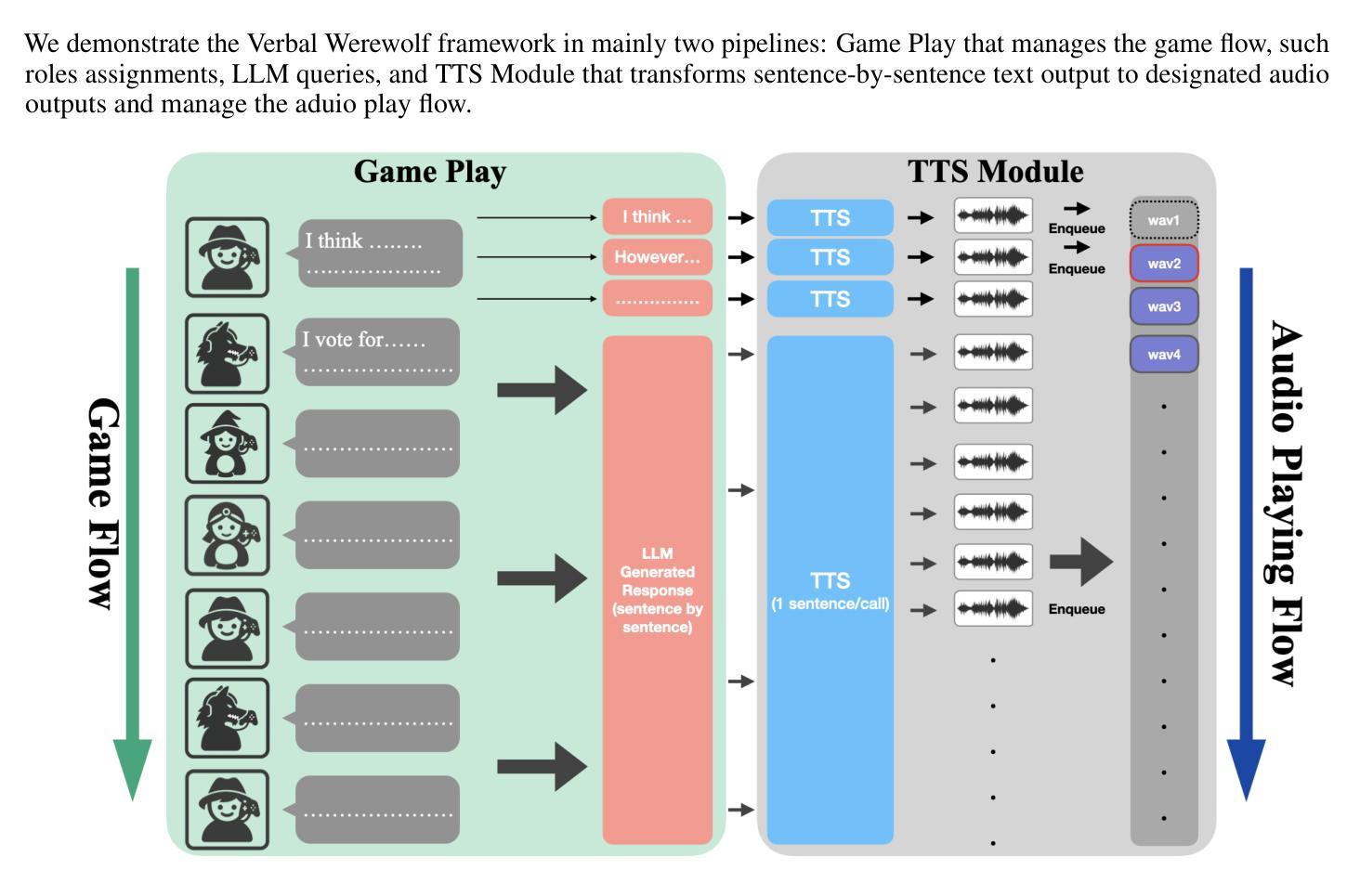
Verbal Werewolf: Engage Users with Verbalized Agentic Werewolf Game Framework
Authors:Qihui Fan, Wenbo Li, Enfu Nan, Yixiao Chen, Lei Lu, Pu Zhao, Yanzhi Wang
The growing popularity of social deduction games has created an increasing need for intelligent frameworks where humans can collaborate with AI agents, particularly in post-pandemic contexts with heightened psychological and social pressures. Social deduction games like Werewolf, traditionally played through verbal communication, present an ideal application for Large Language Models (LLMs) given their advanced reasoning and conversational capabilities. Prior studies have shown that LLMs can outperform humans in Werewolf games, but their reliance on external modules introduces latency that left their contribution in academic domain only, and omit such game should be user-facing. We propose \textbf{Verbal Werewolf}, a novel LLM-based Werewolf game system that optimizes two parallel pipelines: gameplay powered by state-of-the-art LLMs and a fine-tuned Text-to-Speech (TTS) module that brings text output to life. Our system operates in near real-time without external decision-making modules, leveraging the enhanced reasoning capabilities of modern LLMs like DeepSeek V3 to create a more engaging and anthropomorphic gaming experience that significantly improves user engagement compared to existing text-only frameworks.
随着社交推理游戏的日益普及,人类与AI代理协作的智能框架的需求也在不断增加,特别是在疫情后心理和社交压力加剧的背景下。狼人杀等社交推理游戏通过口头交流进行,鉴于大型语言模型(LLM)具备先进的推理和对话能力,是理想的适用对象。早期研究表明,LLM在狼人杀游戏中的表现可以超越人类,但它们对外部模块的依赖导致延迟,这使它们的贡献仅限于学术领域,并忽略了这样的游戏应该是面向用户的。我们提出了“Verbal Werewolf”,这是一种基于LLM的新型狼人杀游戏系统,优化了两个并行管道:由最新LLM驱动的游戏玩法和经过精细调整的文本到语音(TTS)模块,将文本输出转化为生动的声音。我们的系统在近实时状态下运行,无需外部决策模块,利用现代LLM(如DeepSeek V3)的增强推理能力,创建了一种更具参与感和拟人化的游戏体验,相较于现有的纯文本框架,极大地提高了用户参与度。
论文及项目相关链接
Summary
社交推理游戏的普及以及对智能框架的需求不断增长,特别是在疫情后心理和社交压力增加的背景下。文字版狼人杀作为一种社会推理游戏,因其逻辑推理和对话能力成为大型语言模型(LLM)的理想应用。尽管研究表明LLM在狼人杀游戏中表现优于人类,但由于对外部模块的依赖,导致反应时间延迟而局限于学术领域。本研究提出了一个名为“Verbal Werewolf”的新型系统,该系统优化了游戏流程并采用了先进的LLM和精细调整的文本到语音(TTS)模块。我们的系统在无外部决策模块的情况下几乎实时运行,利用现代LLM的推理能力创建一个更有趣的人型游戏体验,与用户参与现有纯文本框架相比显著提高用户参与度。
Key Takeaways
- 社会推理游戏受欢迎度增长需要人类与AI协作的智能框架。
- 文字版狼人杀成为大型语言模型(LLM)的理想应用,具备逻辑推理和对话能力。
- LLM在狼人杀游戏中表现优于人类,但对外部模块的依赖导致反应延迟限制了实际应用。
- “Verbal Werewolf”系统优化了两大模块:采用先进LLM的游戏流程和精细调整的文本到语音(TTS)模块。
- 系统实现了近实时运行,无需外部决策模块。
- 利用现代LLM的推理能力提高了游戏的趣味性和参与度。
点此查看论文截图



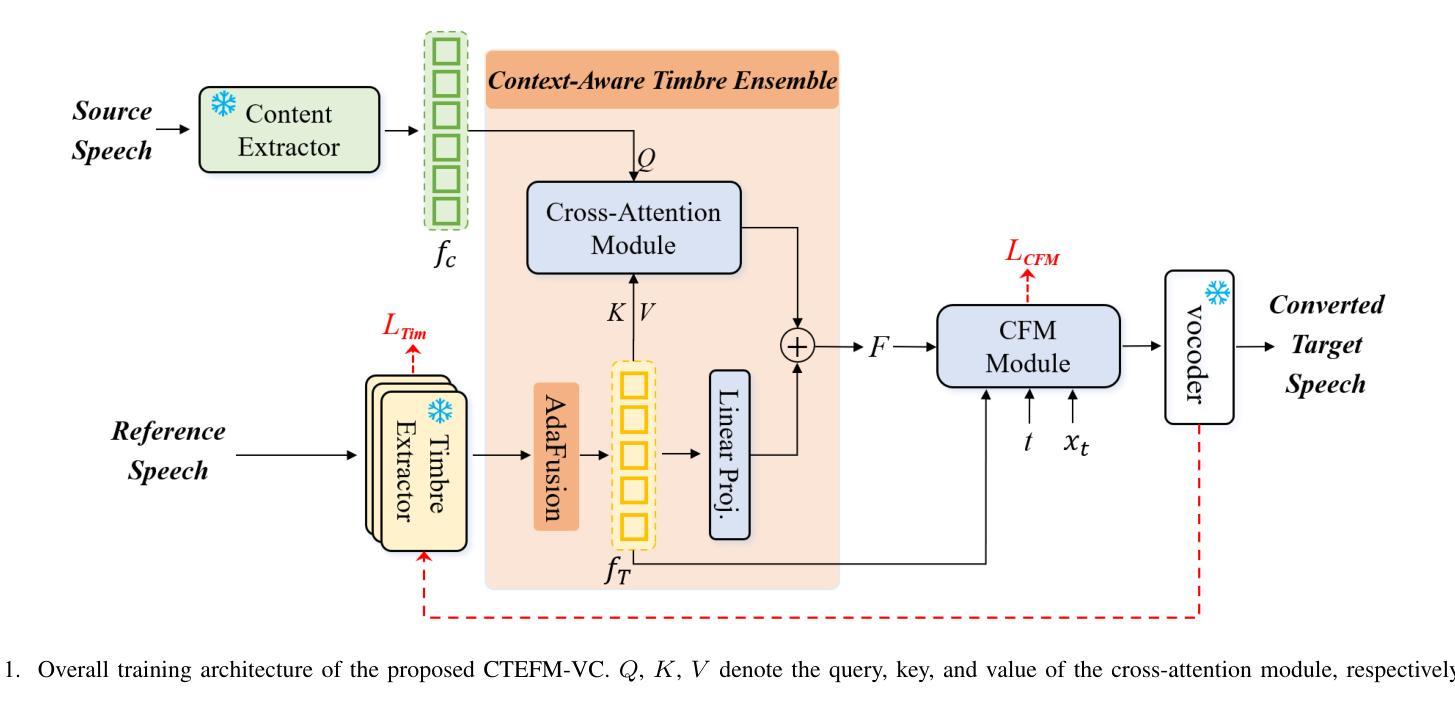
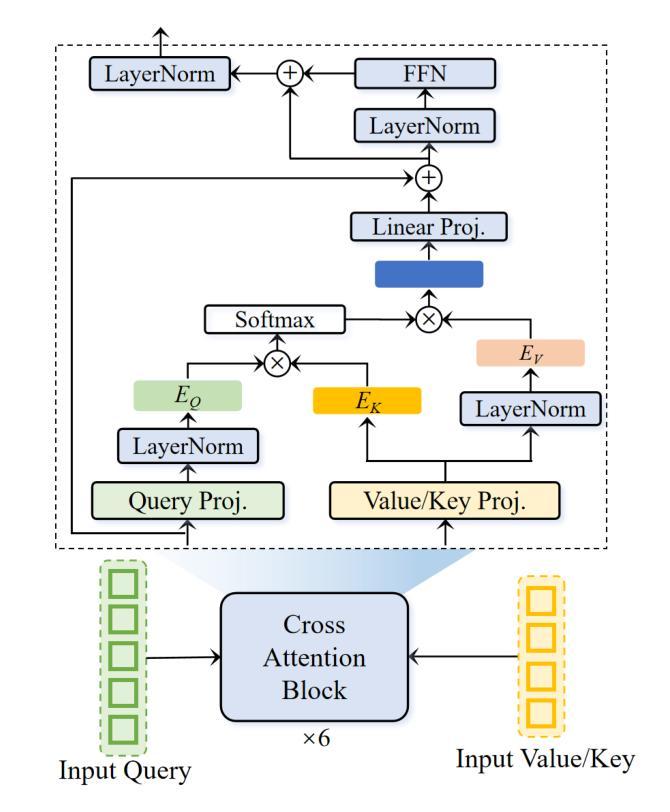
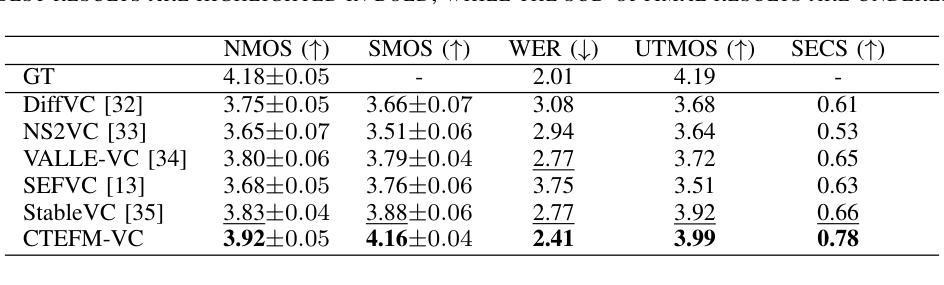
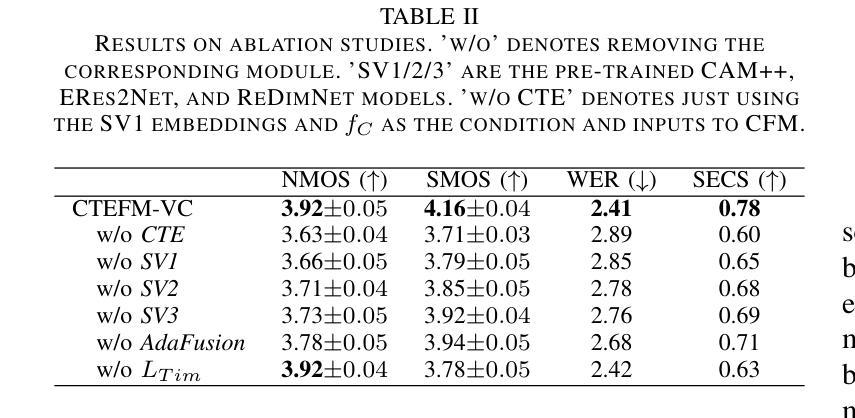
Zero-Shot Voice Conversion via Content-Aware Timbre Ensemble and Conditional Flow Matching
Authors:Yu Pan, Yuguang Yang, Jixun Yao, Lei Ma, Jianjun Zhao
Despite recent advances in zero-shot voice conversion (VC), achieving speaker similarity and naturalness comparable to ground-truth recordings remains a significant challenge. In this letter, we propose CTEFM-VC, a zero-shot VC framework that integrates content-aware timbre ensemble modeling with conditional flow matching. Specifically, CTEFM-VC decouples utterances into content and timbre representations and leverages a conditional flow matching model to reconstruct the Mel-spectrogram of the source speech. To enhance its timbre modeling capability and naturalness of generated speech, we first introduce a context-aware timbre ensemble modeling approach that adaptively integrates diverse speaker verification embeddings and enables the effective utilization of source content and target timbre elements through a cross-attention module. Furthermore, a structural similarity-based timbre loss is presented to jointly train CTEFM-VC end-to-end. Experiments show that CTEFM-VC consistently achieves the best performance in all metrics assessing speaker similarity, speech naturalness, and intelligibility, significantly outperforming state-of-the-art zero-shot VC systems.
尽管零样本语音转换(VC)领域近期取得了进展,但实现与真实录音相当的说话人相似性和自然性仍然是一个重大挑战。在这封信中,我们提出了CTEFM-VC,这是一个零样本VC框架,它结合了内容感知音色集合建模和条件流匹配。具体来说,CTEFM-VC将话语分解成内容和音色表示,并利用条件流匹配模型重建源语音的梅尔频谱图。为了增强其时域模型的能力和生成的语音的自然度,我们首先引入了一种上下文感知的音色集合建模方法,该方法自适应地集成了多种说话人验证嵌入,并通过交叉注意力模块实现了源内容和目标音色元素的有效利用。此外,还提出了一种基于结构相似性的音色损失,以端到端的方式联合训练CTEFM-VC。实验表明,CTEFM-VC在评估说话人相似性、语音自然性和清晰度的所有指标上均表现最佳,显著优于最先进的零样本VC系统。
论文及项目相关链接
PDF Work in progress; 5 pages;
Summary
文本提出了CTEFM-VC零射击语音转换框架,融合了内容感知音色集建模与条件流匹配技术。该框架通过对语音进行内容和音色分离,使用条件流匹配模型重建源语音的梅尔频谱图,增强了音色建模能力和生成语音的自然度。引入上下文感知音色集建模方法,自适应集成多种说话人验证嵌入,并通过交叉注意力模块实现源内容和目标音色元素的有效利用。此外,提出了一种基于结构相似性的音色损失,以端到端的方式联合训练CTEFM-VC。实验表明,CTEFM-VC在评估说话人相似性、语音自然度和清晰度的所有指标上均表现最佳,显著优于其他零射击语音转换系统。
Key Takeaways
以下是关于文本内容的七个关键见解:
- CTEFM-VC是零射击语音转换的新框架,结合了内容感知音色集建模与条件流匹配技术。
- 该框架通过分离语音内容和音色表示,使用条件流匹配模型重建源语音的梅尔频谱图。
- 引入上下文感知音色集建模方法,提高了音色建模能力和生成语音的自然度。
- 通过交叉注意力模块实现源内容和目标音色元素的有效结合。
- 提出了一种基于结构相似性的音色损失函数,用于联合训练CTEFM-VC。
- CTEFM-VC在说话人相似性、语音自然度和清晰度的评估指标上表现最佳。
点此查看论文截图