⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-13 更新
Think Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Authors:Wenqian Cui, Lei Zhu, Xiaohui Li, Zhihan Guo, Haoli Bai, Lu Hou, Irwin King
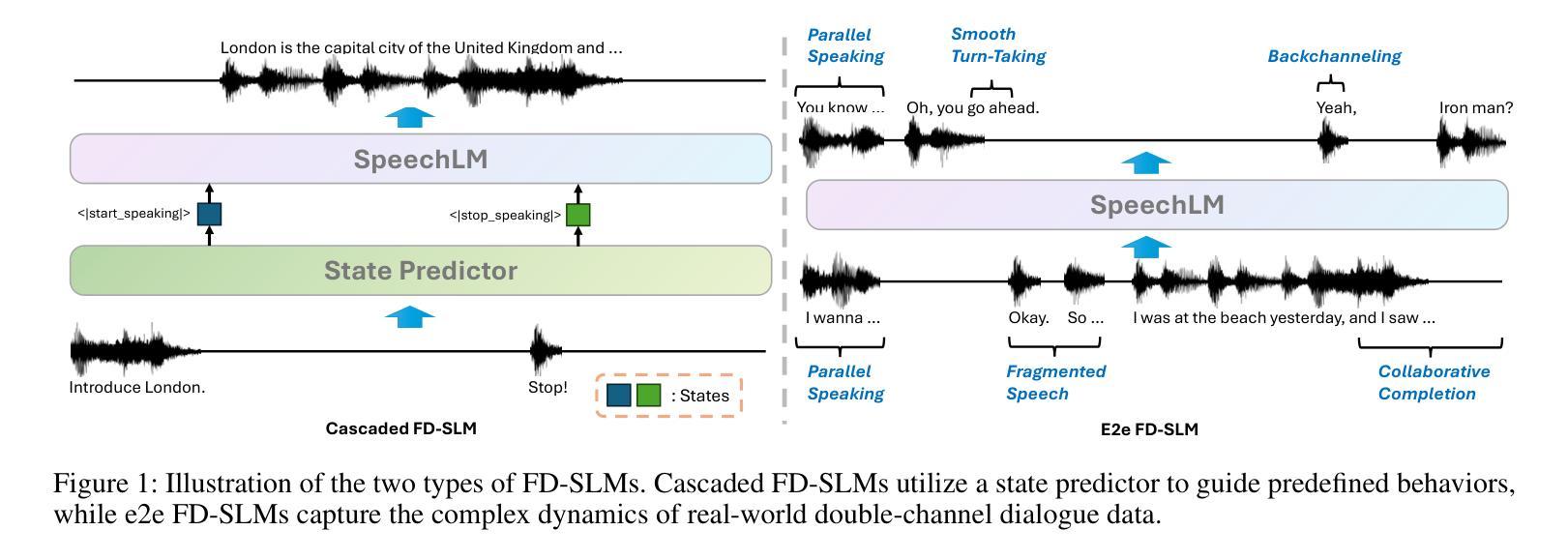
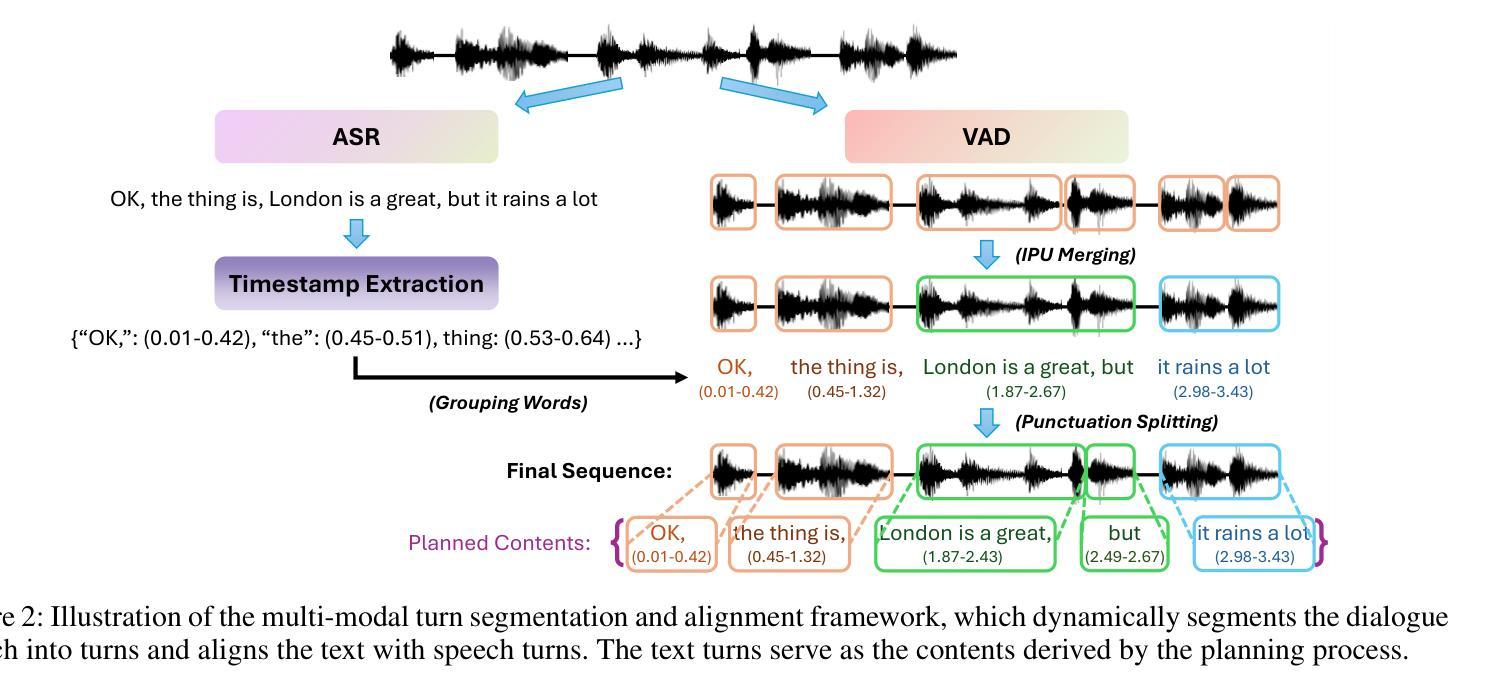
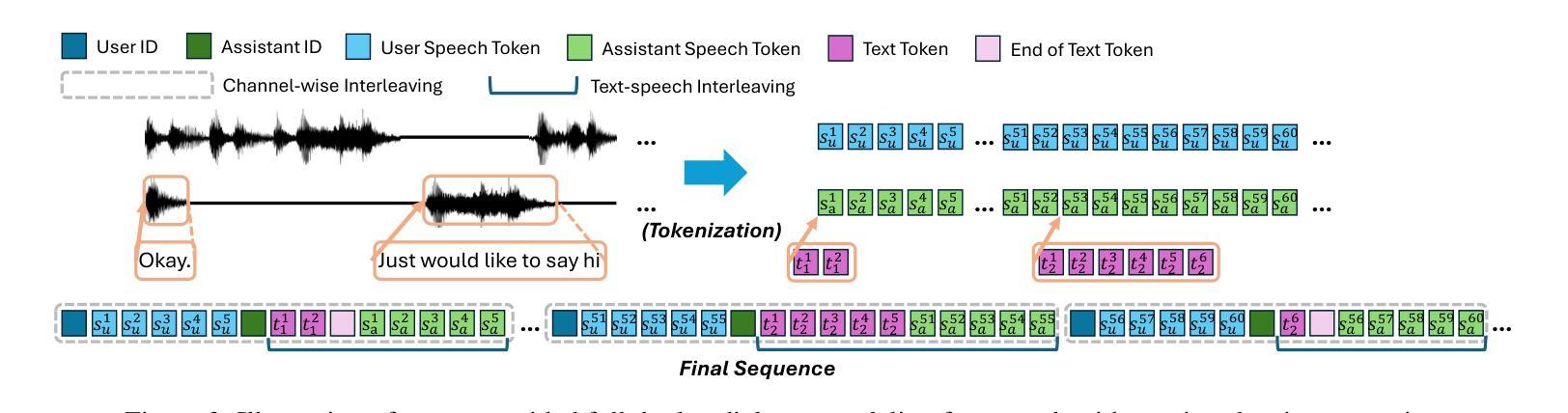
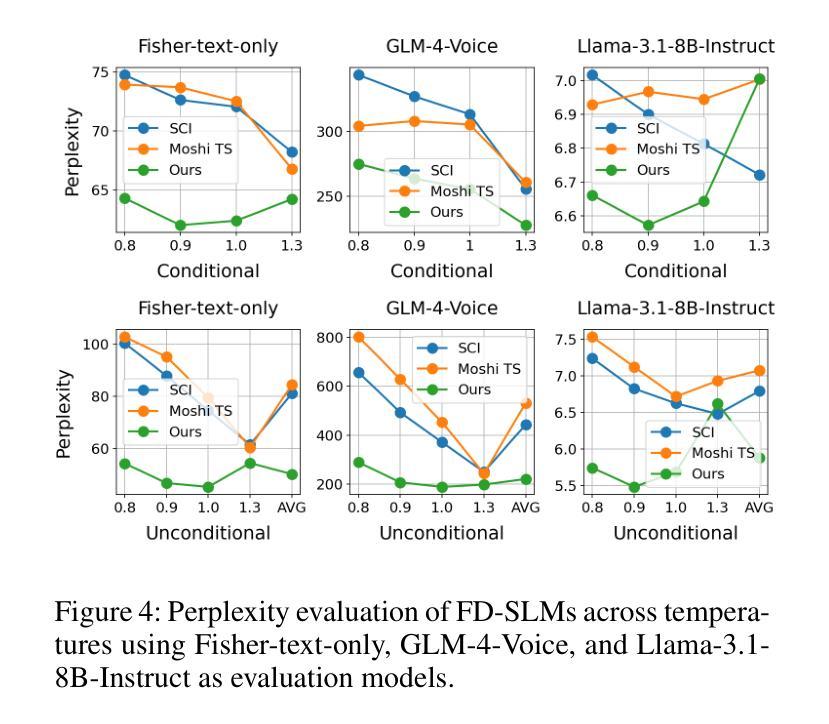
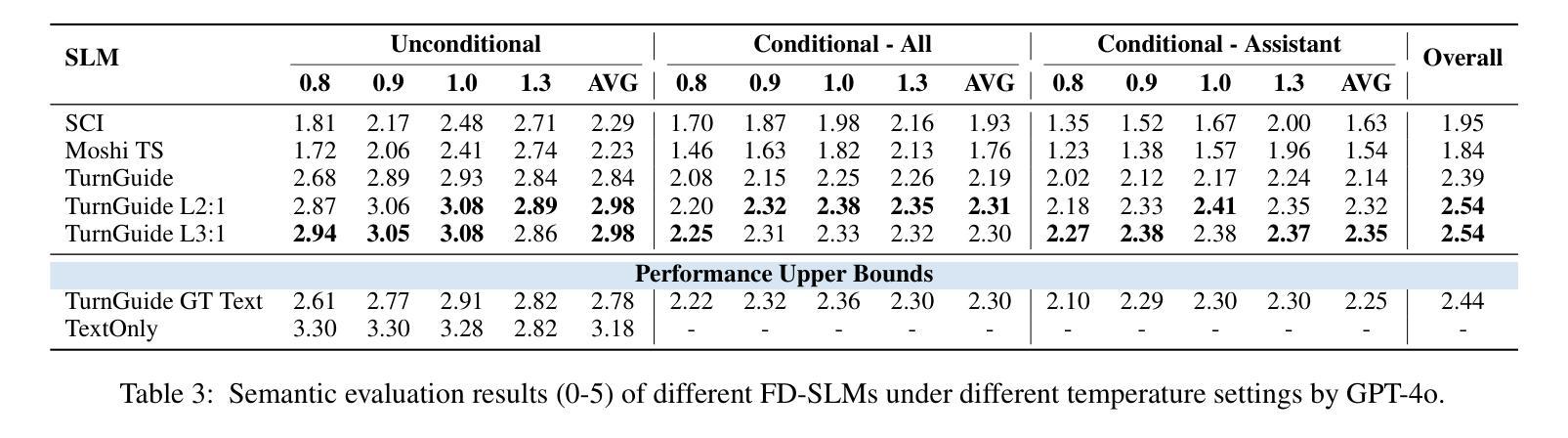
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge – their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs’ conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
全双工语音语言模型(FD-SLMs)是专门设计的基础模型,旨在通过模拟复杂对话动态(如中断、反馈通道和重叠语音)来支持自然、实时的语音交互。端到端(e2e)FD-SLMs则利用现实世界的双通道对话数据来捕捉微妙的双语者对话模式,以实现人性化的交互。然而,它们面临一个关键挑战——由于语音序列的延长和高质量口语对话数据的有限,它们的对话能力往往较纯文本对话有所下降。虽然文本引导的语音生成可以缓解这些问题,但在将文本引导集成到双通道音频流中时,它存在时间和长度问题,破坏了自然交互所必需的时间精确对齐。为了应对这些挑战,我们提出了TurnGuide,这是一种受规划启发的新方法,它通过动态地将助理语音分割成对话回合并生成回合级别的文本指导来进行语音输出,从而模仿人类的对话规划,有效地解决了插入时间和长度挑战。大量实验表明,我们的方法显著提高了端到端FD-SLMs的对话能力,使它们能够生成语义上有意义和连贯的语音,同时保持自然的对话流程。演示网站为:https://dreamtheater123.github.io/TurnGuide-Demo/。代码将在https://github.com/dreamtheater123/TurnGuide上提供。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了针对全双工语音语言模型(FD-SLMs)面临的挑战,提出一种名为TurnGuide的新方法。该方法通过动态地将助理语音分割成对话回合并生成回合级文本指导来解决插入时序和长度问题,从而改善端到端FD-SLMs的会话能力,使其在生成语义上有意义和连贯的语音时保持自然的对话流程。
Key Takeaways
- 全双工语音语言模型(FD-SLMs)是为了实现自然、实时的口语交互而设计的,并建模了复杂的对话动态,如中断、反馈和重叠的语音。
- 端到端(e2e)FD-SLMs利用现实世界双通道对话数据来捕捉微妙的双语音对话模式,以实现人性化的交互。
- FD-SLMs面临的关键挑战是由于语音序列延长和高质量口语对话数据有限而导致的对话能力下降。
- 虽然文本引导的语音生成可以缓解这些问题,但在将文本指导集成到双通道音频流中时存在时序和长度问题,破坏了自然交互所需的时间精确对齐。
- TurnGuide是一种新方法,它通过模仿人类对话规划来解决这些问题,动态地将助理语音分割成对话回合并生成回合级文本指导。
- 实验证明,TurnGuide显著提高了端到端FD-SLMs的会话能力,使其能够生成语义上有意义和连贯的语音,同时保持自然的对话流程。
点此查看论文截图


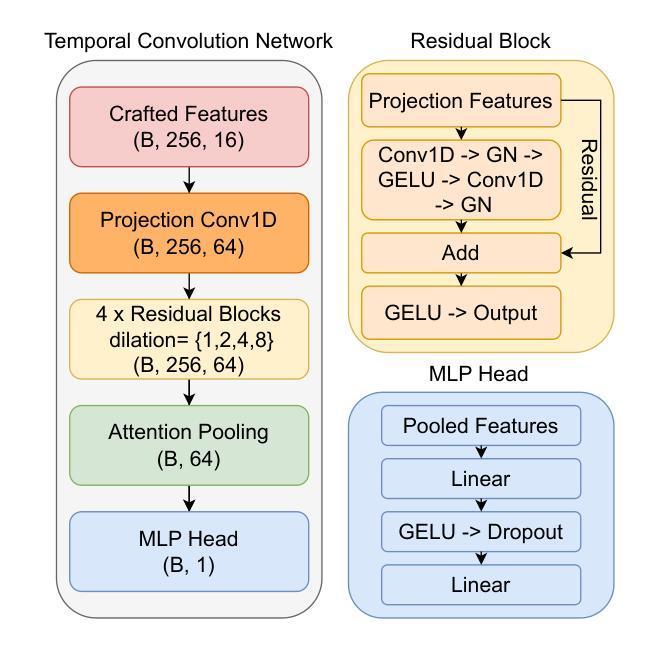
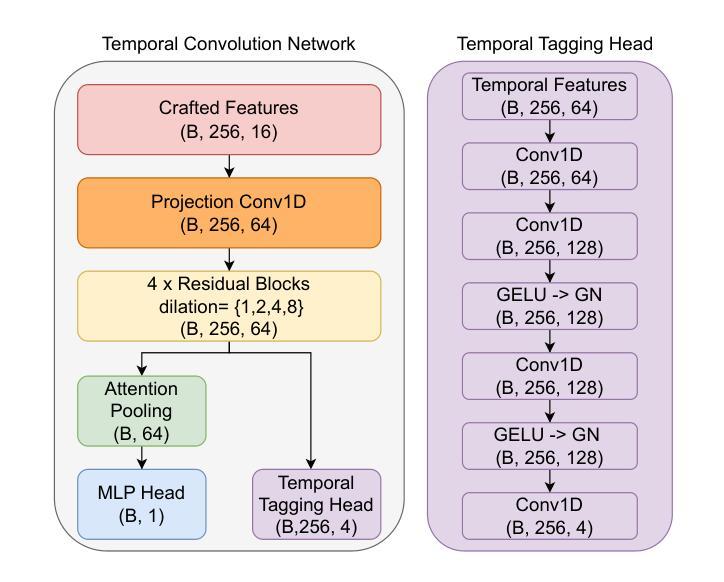
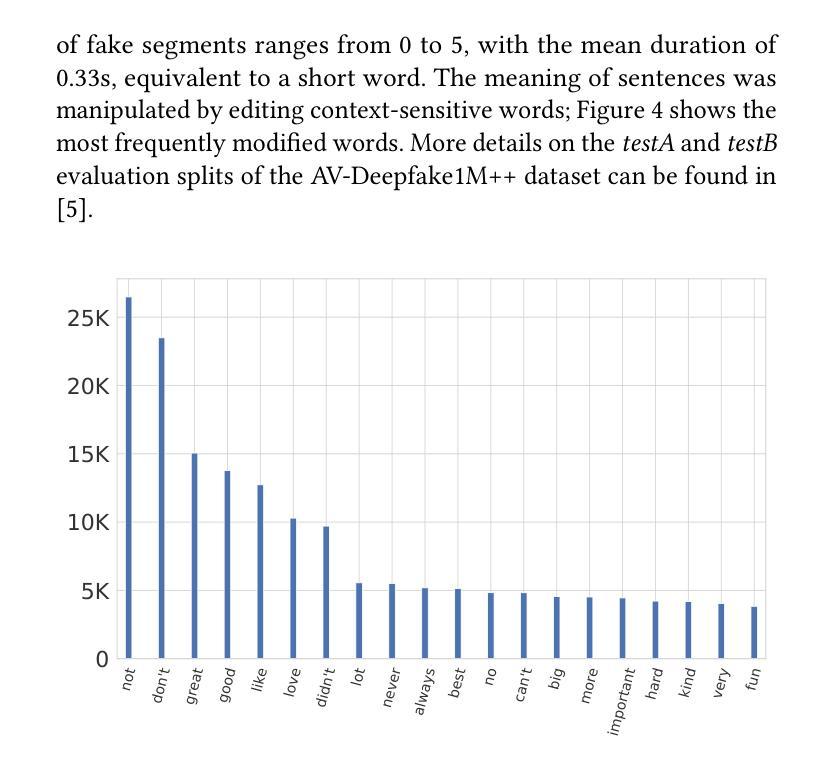
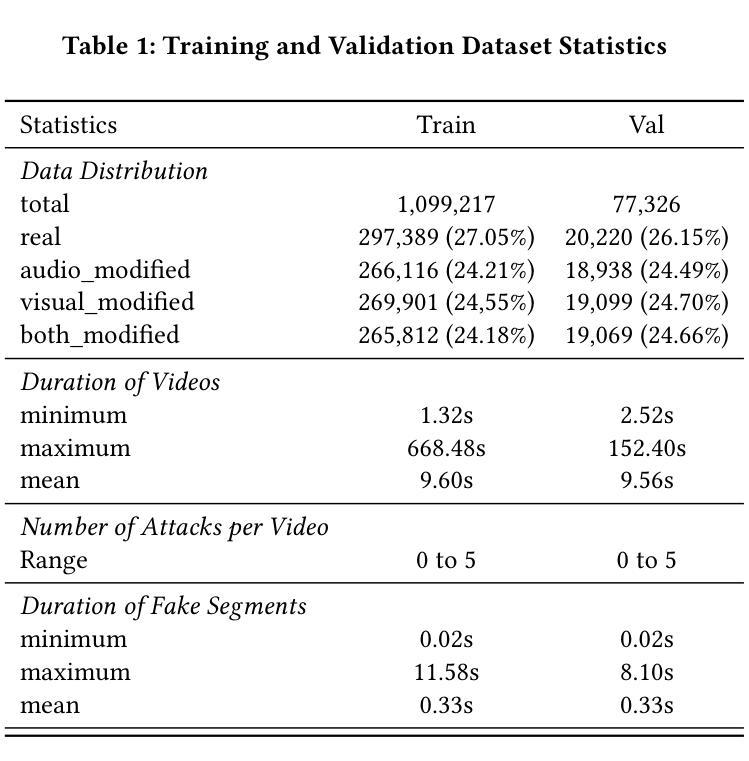
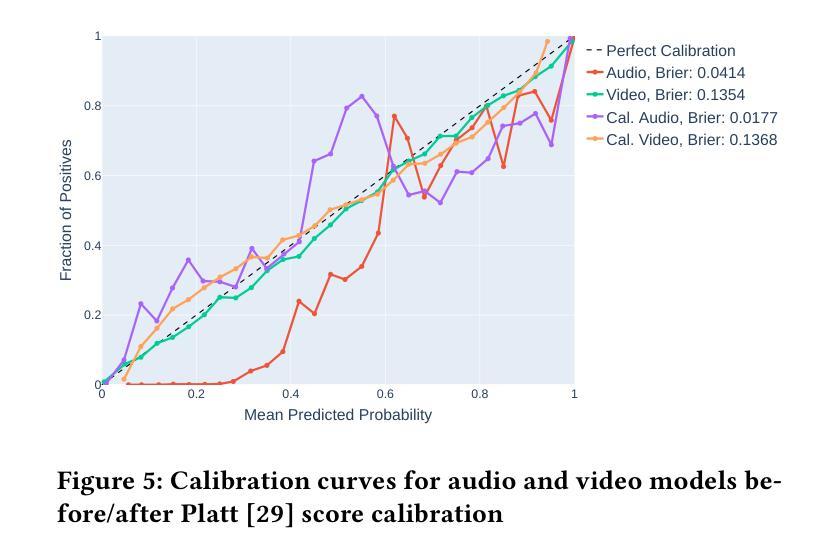
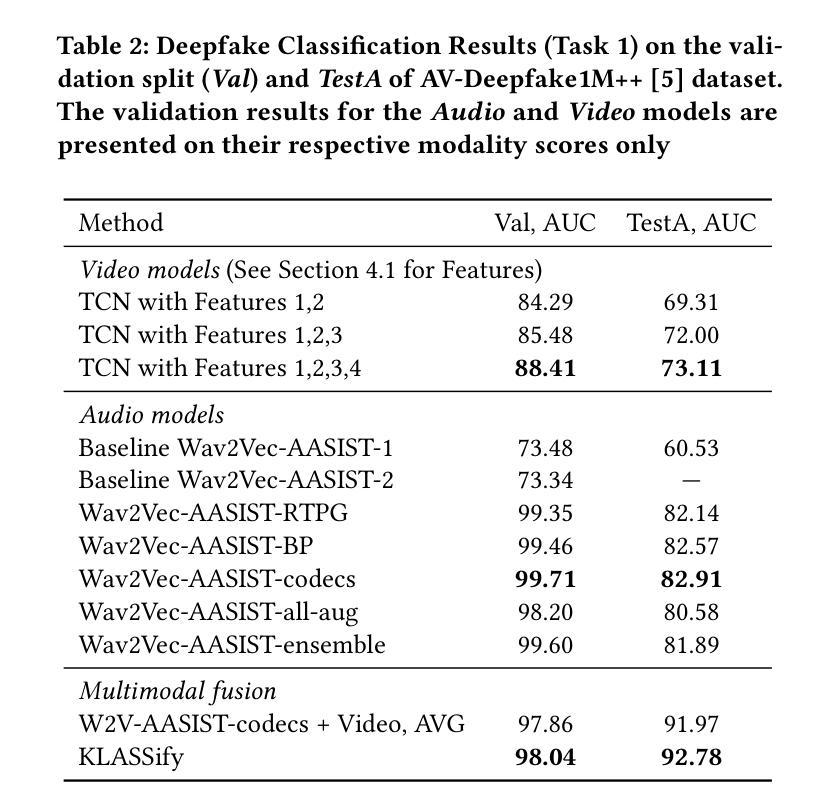
KLASSify to Verify: Audio-Visual Deepfake Detection Using SSL-based Audio and Handcrafted Visual Features
Authors:Ivan Kukanov, Jun Wah Ng
The rapid development of audio-driven talking head generators and advanced Text-To-Speech (TTS) models has led to more sophisticated temporal deepfakes. These advances highlight the need for robust methods capable of detecting and localizing deepfakes, even under novel, unseen attack scenarios. Current state-of-the-art deepfake detectors, while accurate, are often computationally expensive and struggle to generalize to novel manipulation techniques. To address these challenges, we propose multimodal approaches for the AV-Deepfake1M 2025 challenge. For the visual modality, we leverage handcrafted features to improve interpretability and adaptability. For the audio modality, we adapt a self-supervised learning (SSL) backbone coupled with graph attention networks to capture rich audio representations, improving detection robustness. Our approach strikes a balance between performance and real-world deployment, focusing on resilience and potential interpretability. On the AV-Deepfake1M++ dataset, our multimodal system achieves AUC of 92.78% for deepfake classification task and IoU of 0.3536 for temporal localization using only the audio modality.
音频驱动的说话人头像生成器和先进的文本到语音(TTS)模型的快速发展,导致了更复杂的时间深度伪造。这些进展强调了对鲁棒方法的需求,这些方法能够在新的、未见过的攻击场景下检测和定位深度伪造。虽然当前最先进的深度伪造检测器非常准确,但它们通常计算量大,难以推广到新的操作技术。为了解决这些挑战,我们为AV-Deepfake1M 2025挑战赛提出了多模式方法。对于视觉模式,我们利用手工特征来提高可解释性和适应性。对于音频模式,我们采用自我监督学习(SSL)骨干与图注意力网络相结合,以捕获丰富的音频表示,提高检测稳健性。我们的方法在性能和现实世界部署之间取得了平衡,侧重于弹性和潜在的可解释性。在AV-Deepfake1M++数据集上,我们的多模式系统仅使用音频模式就实现了深度伪造分类任务的AUC 92.78%,以及时间定位的IoU 0.3536。
论文及项目相关链接
PDF 7 pages, accepted to the 33rd ACM International Conference on Multimedia (MM’25)
Summary
先进的音频驱动说话人生成器和高级文本转语音(TTS)模型的发展导致了更复杂的时间深度伪造。这强调了需要鲁棒的方法,能够在新的、未见过的攻击场景下检测和定位深度伪造。针对当前先进的深度伪造检测器计算成本高、难以推广到新的操作技术的问题,我们提出了针对AV-Deepfake1M 2025挑战的跨模态方法。对于视觉模态,我们利用手工特征来提高可解释性和适应性。对于音频模态,我们采用自我监督学习(SSL)骨干网与图注意力网络相结合,捕捉丰富的音频表示,提高检测稳健性。我们的方法在性能和实际部署之间取得了平衡,注重恢复能力和潜在的可解释性。在AV-Deepfake1M++数据集上,我们的跨模态系统仅使用音频模态就实现了92.78%的AUC深度伪造分类任务和0.3536的IoU时间定位。
Key Takeaways
- 音频驱动说话头生成器和高级TTS模型的发展导致更复杂的时间深度伪造问题。
- 需要鲁棒的方法来检测和定位深度伪造,尤其在新和未见过的攻击场景下。
- 当前先进的深度伪造检测器面临计算成本高和难以推广的问题。
- 视觉模态和音频模态的双模态方法被提出以解决挑战。
- 对于视觉模态,手工特征用于提高可解释性和适应性。
- 对于音频模态,结合SSL骨干网和图注意力网络来提高检测稳健性。
点此查看论文截图


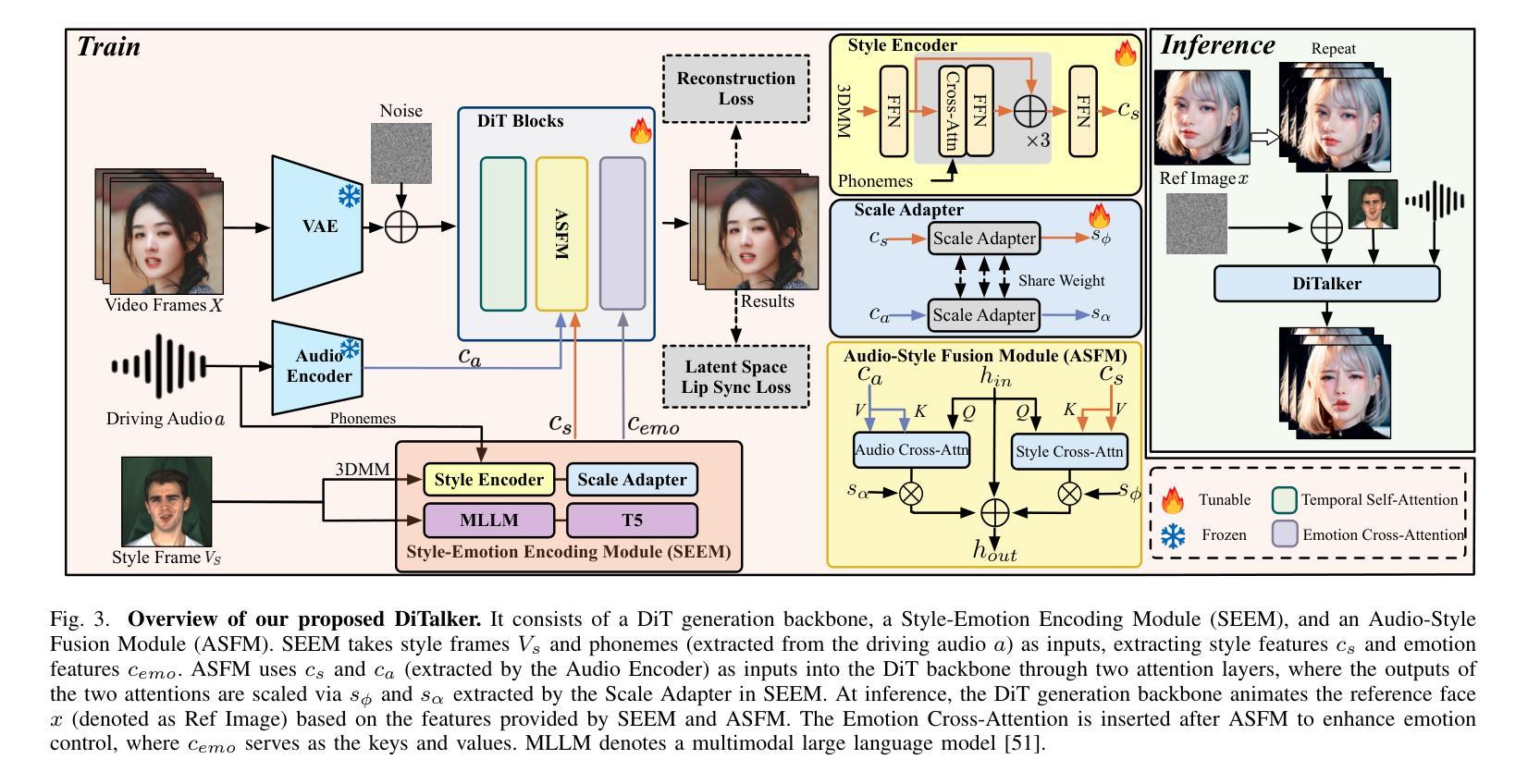
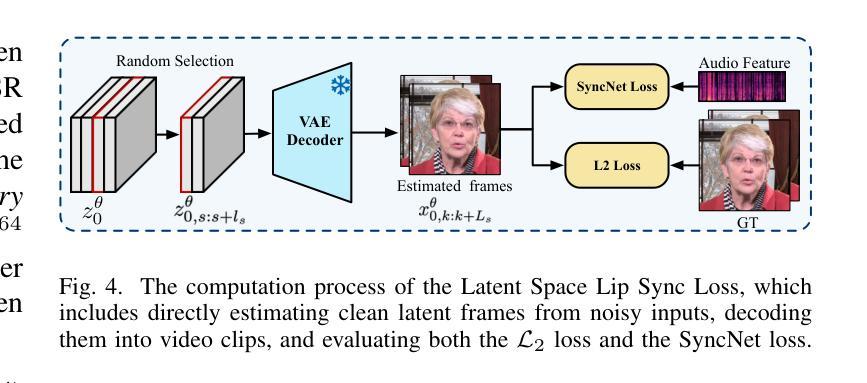
DiTalker: A Unified DiT-based Framework for High-Quality and Speaking Styles Controllable Portrait Animation
Authors:He Feng, Yongjia Ma, Donglin Di, Lei Fan, Tonghua Su, Xiangqian Wu
Portrait animation aims to synthesize talking videos from a static reference face, conditioned on audio and style frame cues (e.g., emotion and head poses), while ensuring precise lip synchronization and faithful reproduction of speaking styles. Existing diffusion-based portrait animation methods primarily focus on lip synchronization or static emotion transformation, often overlooking dynamic styles such as head movements. Moreover, most of these methods rely on a dual U-Net architecture, which preserves identity consistency but incurs additional computational overhead. To this end, we propose DiTalker, a unified DiT-based framework for speaking style-controllable portrait animation. We design a Style-Emotion Encoding Module that employs two separate branches: a style branch extracting identity-specific style information (e.g., head poses and movements), and an emotion branch extracting identity-agnostic emotion features. We further introduce an Audio-Style Fusion Module that decouples audio and speaking styles via two parallel cross-attention layers, using these features to guide the animation process. To enhance the quality of results, we adopt and modify two optimization constraints: one to improve lip synchronization and the other to preserve fine-grained identity and background details. Extensive experiments demonstrate the superiority of DiTalker in terms of lip synchronization and speaking style controllability. Project Page: https://thenameishope.github.io/DiTalker/
肖像动画的目标是根据音频和风格帧线索(如情感和头部姿势)合成静态参考脸的视频,同时确保精确的唇部同步和说话风格的忠实再现。现有的基于扩散的肖像动画方法主要关注唇部同步或静态情感转换,往往忽略了动态风格,如头部动作。此外,大多数这些方法依赖于双U-Net架构,这种架构保持了身份一致性,但造成了额外的计算开销。为此,我们提出了DiTalker,一个基于DiT的说话风格可控肖像动画的统一框架。我们设计了一个风格情感编码模块,它采用两个单独的分支:一个风格分支提取身份特定的风格信息(如头部姿势和动作),一个情感分支提取与身份无关的情感特征。我们还引入了一个音频风格融合模块,该模块通过两个并行交叉注意层将音频和说话风格解耦,使用这些特征来指导动画过程。为了提高结果的质量,我们采用并修改了两种优化约束:一种用于提高唇部同步,另一种用于保留精细的身份和背景细节。大量实验表明,DiTalker在唇部同步和说话风格可控性方面表现出优越性。项目页面:https://thenameishope.github.io/DiTalker/。
论文及项目相关链接
Summary
本文介绍了DiTalker,一个基于说话风格控制的肖像动画的统一框架。该框架设计了一个风格情感编码模块,包括提取身份特定风格信息(如头部姿势和动作)的风格分支和提取身份无关情感特征的情感分支。同时引入音频风格融合模块,通过两个并行交叉注意层将音频和说话风格解耦,以指导动画过程。为提高结果质量,采用并优化了两个优化约束,分别用于改进唇同步和保留精细身份和背景细节。实验证明DiTalker在唇同步和说话风格可控性方面具有优势。
Key Takeaways
- DiTalker是一个统一的框架,用于进行说话风格可控的肖像动画。
- 框架中包含风格情感编码模块,该模块有两个分支:风格分支提取身份特定信息(如头部姿势和动作),情感分支提取身份无关的情感特征。
- 引入音频风格融合模块,通过并行交叉注意层将音频和说话风格解耦。
- 采用并优化两个优化约束,以提高唇同步的质量和保留精细身份及背景细节。
- DiTalker在唇同步和说话风格可控性方面表现出优势。
- 该框架可用于合成与音频和风格帧提示相匹配的谈话视频。
点此查看论文截图


Learning Phonetic Context-Dependent Viseme for Enhancing Speech-Driven 3D Facial Animation
Authors:Hyung Kyu Kim, Hak Gu Kim
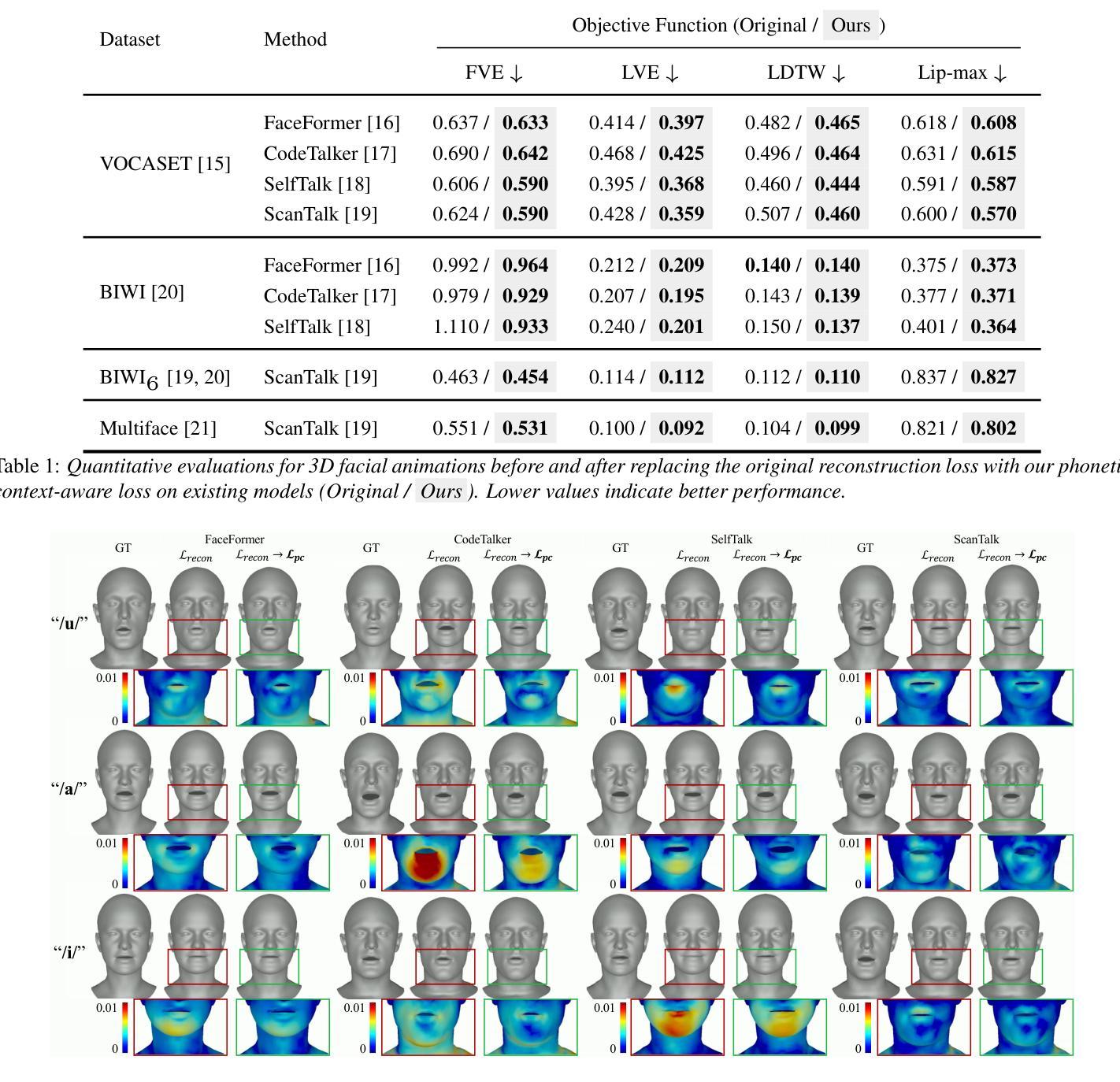
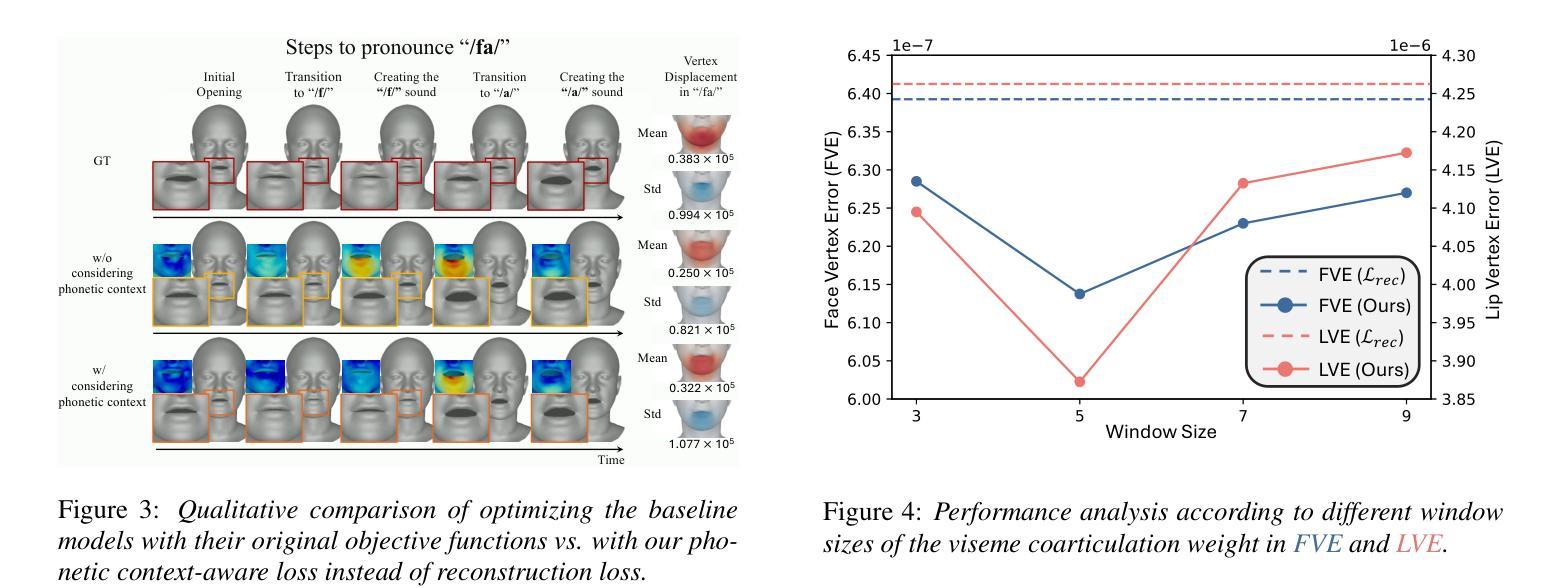
Speech-driven 3D facial animation aims to generate realistic facial movements synchronized with audio. Traditional methods primarily minimize reconstruction loss by aligning each frame with ground-truth. However, this frame-wise approach often fails to capture the continuity of facial motion, leading to jittery and unnatural outputs due to coarticulation. To address this, we propose a novel phonetic context-aware loss, which explicitly models the influence of phonetic context on viseme transitions. By incorporating a viseme coarticulation weight, we assign adaptive importance to facial movements based on their dynamic changes over time, ensuring smoother and perceptually consistent animations. Extensive experiments demonstrate that replacing the conventional reconstruction loss with ours improves both quantitative metrics and visual quality. It highlights the importance of explicitly modeling phonetic context-dependent visemes in synthesizing natural speech-driven 3D facial animation. Project page: https://cau-irislab.github.io/interspeech25/
语音驱动的3D面部动画旨在生成与音频同步的真实面部运动。传统方法主要通过将每一帧与地面真实数据进行比对来最小化重建损失。然而,这种逐帧的方法往往无法捕捉面部运动的连续性,由于协同发音导致输出产生抖动和不自然。为了解决这一问题,我们提出了一种新的语音语境感知损失,该损失能明确地建模语音语境对面部形状转变的影响。通过引入协同发音权重,我们根据面部动作随时间的变化动态地调整其重要性,确保更平滑和感知一致的动画效果。大量实验表明,用我们所提出的损失替换传统的重建损失,能提高定量指标和视觉质量。这强调了明确建模语音语境依赖型面部动作对于合成自然语音驱动3D面部动画的重要性。项目页面:链接。
论文及项目相关链接
PDF Interspeech 2025; Project Page: https://cau-irislab.github.io/interspeech25/
摘要
该文探讨了语音驱动的3D面部动画中的新问题。传统方法主要通过对每一帧与真实数据进行对齐来最小化重建损失,但这种方法无法捕捉面部运动的连续性,导致输出动画存在抖动和不自然的现象。为解决这一问题,本文提出了一种新颖的语音学语境感知损失模型,该模型明确模拟语音学语境对发音模式转换的影响。通过引入发音动作协同发音权重,根据时间动态变化对面部动作进行自适应重要性分配,确保动画更加流畅且感知一致。实验表明,用本文提出的模型替换传统重建损失可以提高定量指标和视觉质量,强调在合成自然语音驱动的3D面部动画中明确模拟语音学语境相关的发音模式的重要性。
要点瞭望
- 语音驱动的3D面部动画旨在生成与音频同步的真实面部运动。
- 传统方法主要通过对每一帧与真实数据进行对齐来最小化重建损失,但存在抖动和不自然的问题。
- 提出了新颖的语音学语境感知损失模型以捕捉面部运动的连续性。
- 通过引入发音动作协同发音权重,对面部动作进行自适应重要性分配。
- 模型替换传统重建损失能提高定量指标和视觉质量。
- 强调明确模拟语音学语境相关的发音模式在合成自然语音驱动的3D面部动画中的重要性。
点此查看论文截图