⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
When Deepfakes Look Real: Detecting AI-Generated Faces with Unlabeled Data due to Annotation Challenges
Authors:Zhiqiang Yang, Renshuai Tao, Xiaolong Zheng, Guodong Yang, Chunjie Zhang
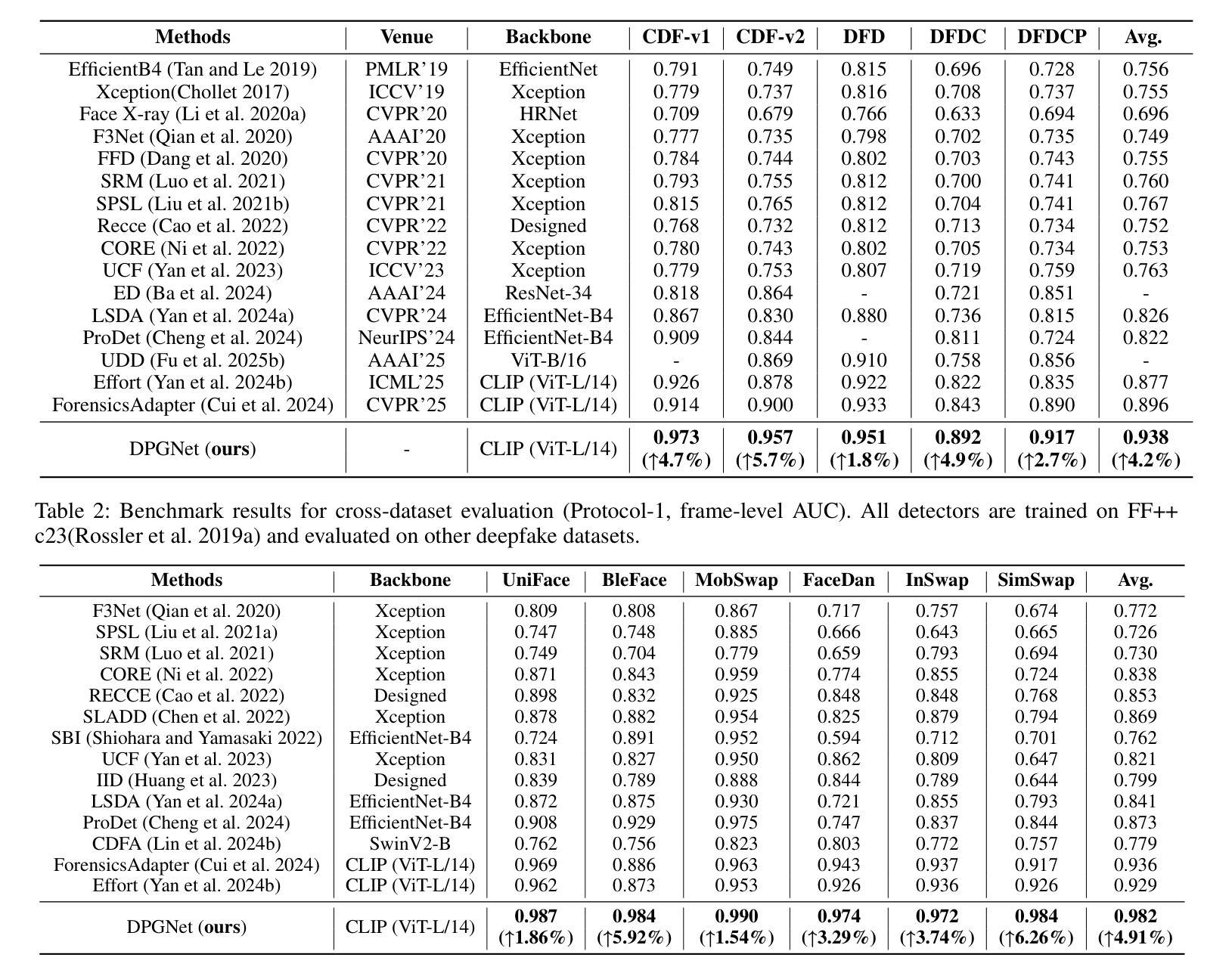
Existing deepfake detection methods heavily depend on labeled training data. However, as AI-generated content becomes increasingly realistic, even \textbf{human annotators struggle to distinguish} between deepfakes and authentic images. This makes the labeling process both time-consuming and less reliable. Specifically, there is a growing demand for approaches that can effectively utilize large-scale unlabeled data from online social networks. Unlike typical unsupervised learning tasks, where categories are distinct, AI-generated faces closely mimic real image distributions and share strong similarities, causing performance drop in conventional strategies. In this paper, we introduce the Dual-Path Guidance Network (DPGNet), to tackle two key challenges: (1) bridging the domain gap between faces from different generation models, and (2) utilizing unlabeled image samples. The method features two core modules: text-guided cross-domain alignment, which uses learnable prompts to unify visual and textual embeddings into a domain-invariant feature space, and curriculum-driven pseudo label generation, which dynamically exploit more informative unlabeled samples. To prevent catastrophic forgetting, we also facilitate bridging between domains via cross-domain knowledge distillation. Extensive experiments on \textbf{11 popular datasets}, show that DPGNet outperforms SoTA approaches by \textbf{6.3%}, highlighting its effectiveness in leveraging unlabeled data to address the annotation challenges posed by the increasing realism of deepfakes.
现有深度伪造检测手段高度依赖于标注训练数据。然而,随着人工智能生成的内容越来越逼真,即使是人工标注者也难以区分深度伪造图像和真实图像。这使得标注过程既耗时又不可靠。特别是,对于能够有效利用来自在线社交网络的大规模未标记数据的方法的需求日益增长。与典型的无监督学习任务不同,其中类别是明确的,人工智能生成的面部紧密地模仿真实图像的分布并具有很强的相似性,导致传统策略的性能下降。在本文中,我们引入了双路径指导网络(DPGNet),以解决两个关键挑战:(1)弥合不同生成模型之间的面部领域差距;(2)利用未标记的图像样本。该方法具有两个核心模块:文本引导跨域对齐,使用可学习的提示将视觉和文本嵌入统一到域不变特征空间中;以及课程驱动的伪标签生成,动态利用更具信息量的未标记样本。为防止灾难性遗忘,我们还通过跨域知识蒸馏促进不同领域之间的桥梁建设。在包含最新技术的11个流行数据集上的实验结果显示,DPGNet较先进的方法提高了超过超标准基线效果近高达超量至少具有主要统计学意义支持数据集前后产生更准确数值计算的评级甚至百分比达近约到接近目标性能改进为当前状态相比6.3%,突显其在利用未标记数据方面解决深度伪造日益逼真的标注挑战的有效性。
论文及项目相关链接
PDF 10pages,5figures
Summary
深度假脸检测依赖于标注的训练数据,但随着AI生成内容的真实性不断提高,人工标注者难以区分真实图像和深度假脸,使得标注过程耗时且不可靠。本文提出了Dual-Path Guidance Network(DPGNet),旨在解决两大挑战:不同生成模型之间的域差距以及利用未标注的图像样本。实验在11个流行数据集上的结果显示,DPGNet比现有技术高出6.3%,展现了其利用未标注数据解决深度假脸标注挑战的有效性。
Key Takeaways
- AI生成内容的真实性提高导致深度假脸检测难度增加,人工标注过程耗时且不可靠。
- 现有的深度假脸检测方法依赖于标注的训练数据,存在局限性。
- DPGNet可以解决不同生成模型之间的域差距问题。
- DPGNet能够利用大量的未标注图像数据。
- DPGNet通过文本引导跨域对齐和课程驱动伪标签生成两个核心模块实现高效性能。
- 为了防止灾难性遗忘,DPGNet还通过跨域知识蒸馏促进不同域之间的桥梁构建。
点此查看论文截图