⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
KFFocus: Highlighting Keyframes for Enhanced Video Understanding
Authors:Ming Nie, Chunwei Wang, Hang Xu, Li Zhang
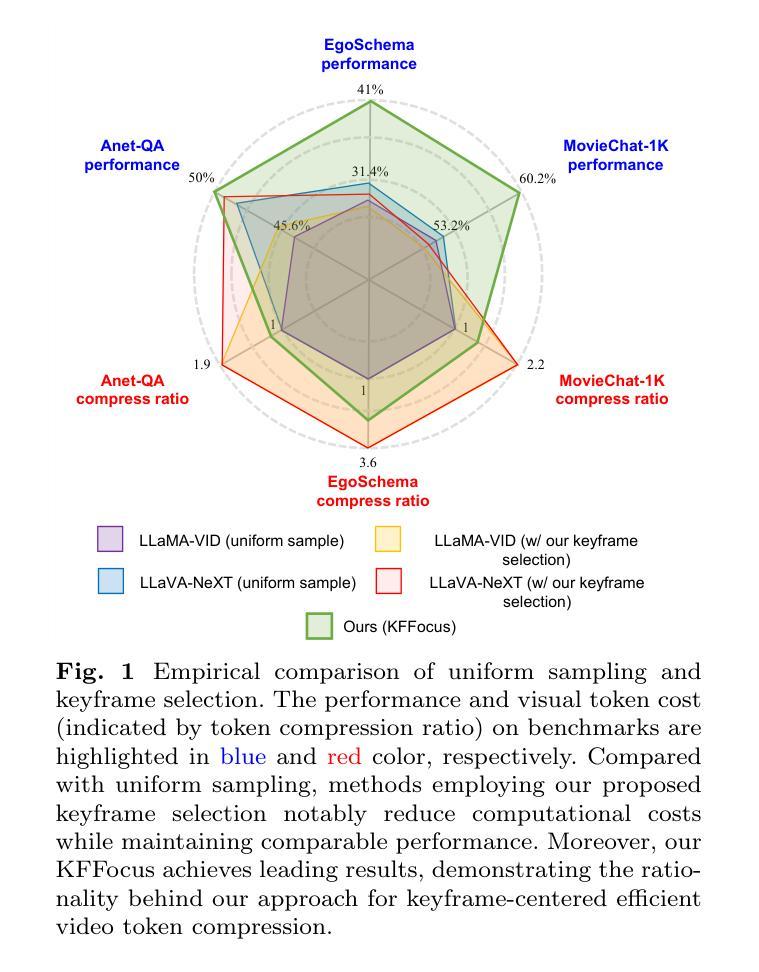
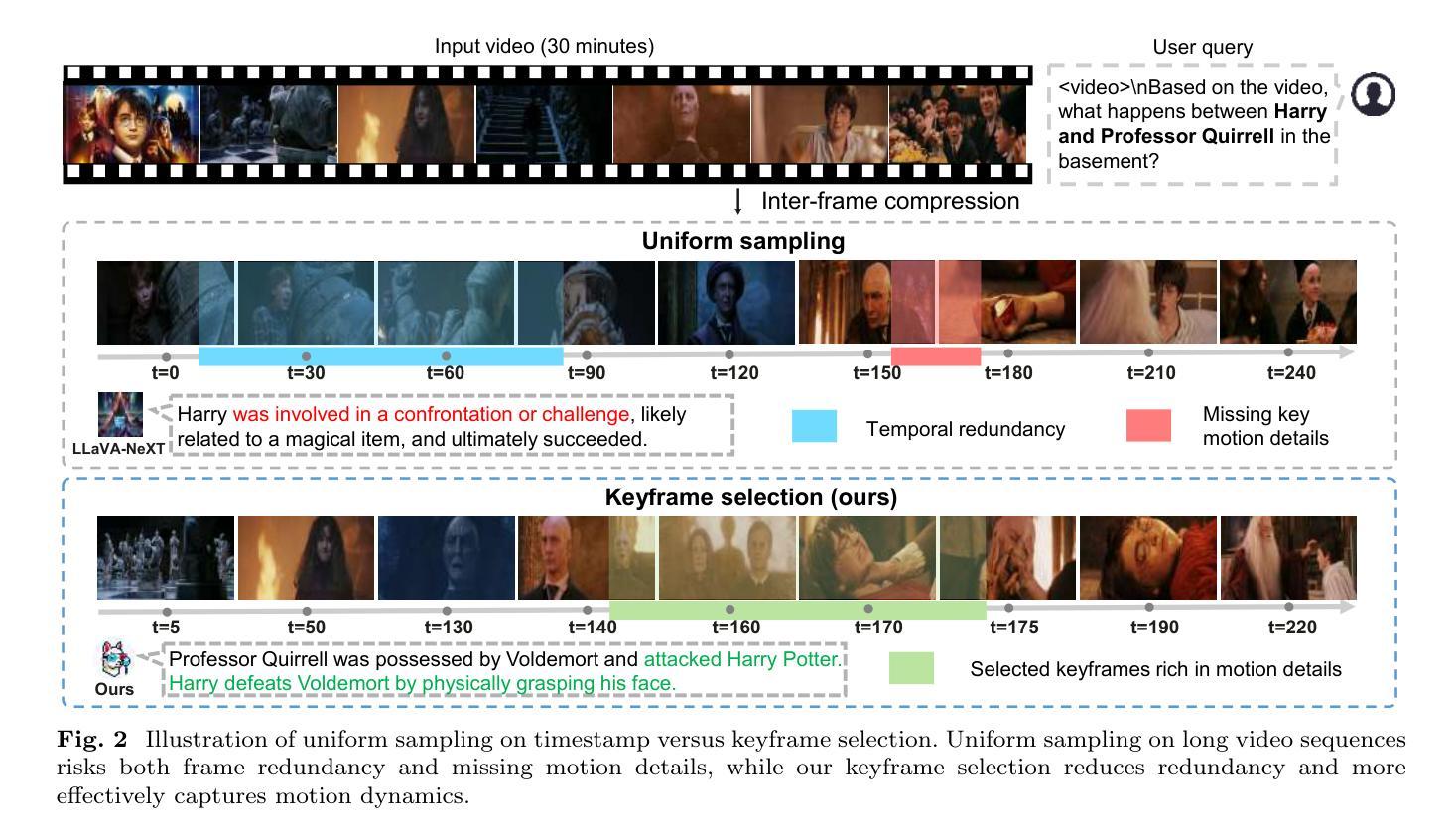
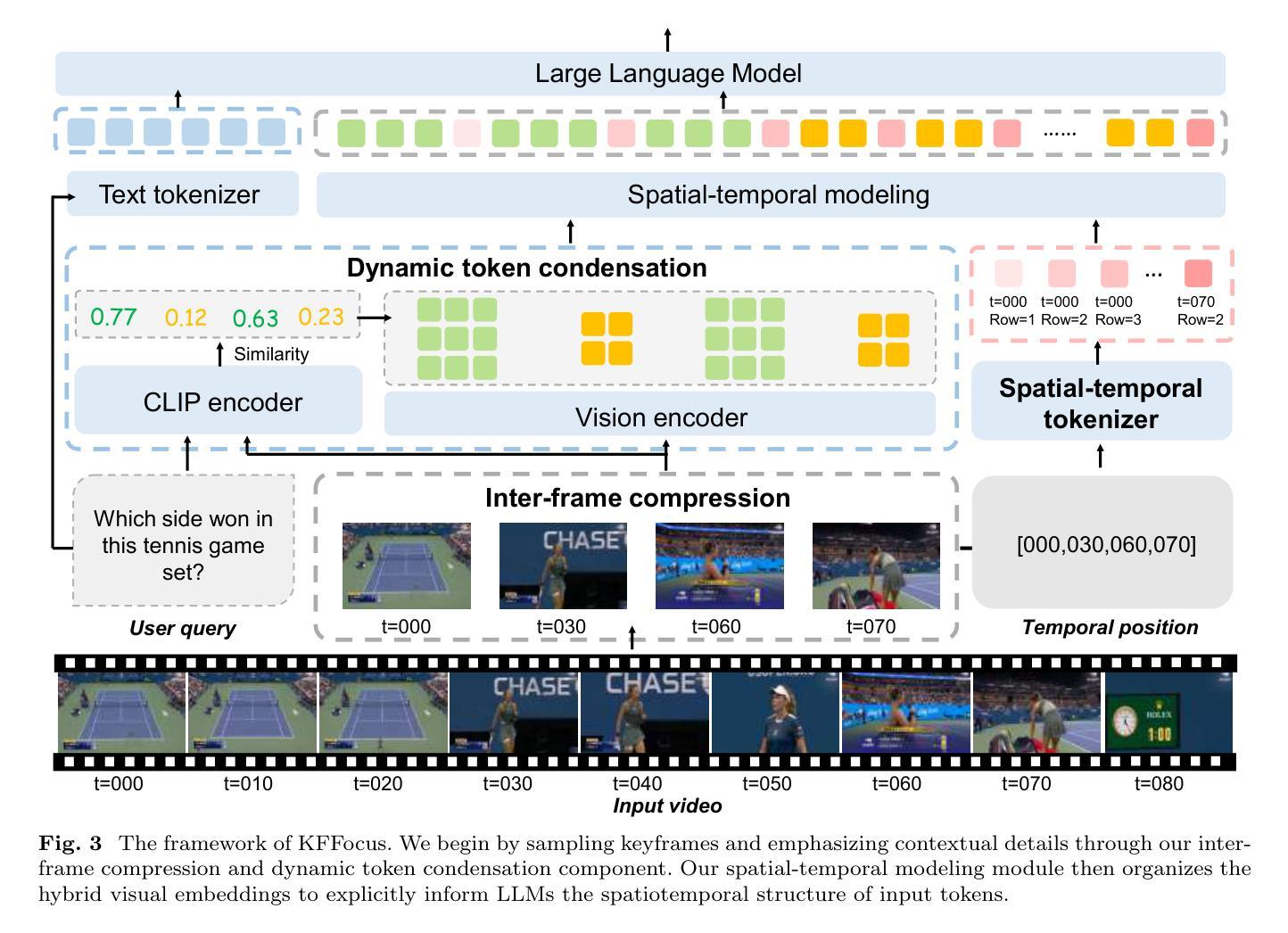
Recently, with the emergence of large language models, multimodal LLMs have demonstrated exceptional capabilities in image and video modalities. Despite advancements in video comprehension, the substantial computational demands of long video sequences lead current video LLMs (Vid-LLMs) to employ compression strategies at both the inter-frame level (e.g., uniform sampling of video frames) and intra-frame level (e.g., condensing all visual tokens of each frame into a limited number). However, this approach often neglects the uneven temporal distribution of critical information across frames, risking the omission of keyframes that contain essential temporal and semantic details. To tackle these challenges, we propose KFFocus, a method designed to efficiently compress video tokens and emphasize the informative context present within video frames. We substitute uniform sampling with a refined approach inspired by classic video compression principles to identify and capture keyframes based on their temporal redundancy. By assigning varying condensation ratios to frames based on their contextual relevance, KFFocus efficiently reduces token redundancy while preserving informative content details. Additionally, we introduce a spatiotemporal modeling module that encodes both the temporal relationships between video frames and the spatial structure within each frame, thus providing Vid-LLMs with a nuanced understanding of spatial-temporal dynamics. Extensive experiments on widely recognized video understanding benchmarks, especially long video scenarios, demonstrate that KFFocus significantly outperforms existing methods, achieving substantial computational efficiency and enhanced accuracy.
最近,随着大型语言模型的兴起,多模态LLM在图像和视频领域表现出了卓越的能力。尽管视频理解已经取得了进展,但长视频序列的巨大计算需求导致当前的视频LLM(Vid-LLM)在帧间和帧内级别采用压缩策略(例如,视频帧的统一采样,以及将每帧的所有视觉令牌浓缩成有限数量)。然而,这种方法常常忽略了跨帧的关键信息的不均匀时间分布,可能会遗漏包含重要时间和语义细节的帧。为了应对这些挑战,我们提出了KFFocus方法,它是一种设计用于有效压缩视频令牌并强调视频帧内信息上下文的方法。我们摒弃了统一采样,采用了一种受经典视频压缩原理启发的精细方法来根据时间冗余识别并捕获关键帧。通过根据帧的上下文相关性分配不同的压缩比率,KFFocus有效地减少了令牌的冗余,同时保留了信息内容的细节。此外,我们还引入了一个时空建模模块,该模块对视频帧之间的时间关系以及每帧内的空间结构进行编码,从而为Vid-LLM提供了对时空动态细微差别的理解。在广泛认可的视频理解基准测试上进行的广泛实验,尤其是在长视频场景中,表明KFFocus显著优于现有方法,实现了较高的计算效率和准确性。
论文及项目相关链接
Summary
近期随着大型语言模型的兴起,多模态LLM在图像和视频领域展现出卓越的能力。当前视频LLM在处理长视频序列时面临巨大的计算需求,通常采用帧间和帧内压缩策略。然而,这种方法忽视了关键信息在帧间的非均匀分布,可能遗漏包含重要时间和语义细节的帧。为应对这些挑战,本文提出KFFocus方法,旨在有效地压缩视频令牌并强调帧内的信息上下文。通过借鉴经典视频压缩原理的精炼方法取代均匀采样,根据上下文相关性为帧分配不同的压缩比,KFFocus能够减少令牌冗余并保留信息内容细节。此外,还引入了时空建模模块,编码视频帧之间的时间关系和帧内的空间结构,为视频LLM提供对时空动态的理解。在广泛认可的视频理解基准测试上,特别是在长视频场景下,KFFocus显著优于现有方法,实现了计算效率的提升和准确性的增强。
Key Takeaways
- 多模态LLM在图像和视频领域展现出卓越的能力,尤其在处理大型语言模型时。
- 当前视频LLM面临处理长视频序列时的计算需求挑战,采用帧间和帧内压缩策略。
- 均匀采样方法忽视了关键信息在帧间的非均匀分布,可能遗漏重要帧。
- KFFocus方法通过借鉴经典视频压缩原理的精炼方法,有效压缩视频令牌并强调信息上下文。
- KFFocus根据上下文相关性为帧分配不同的压缩比,减少令牌冗余并保留信息细节。
- 引入时空建模模块,编码视频帧之间的时间关系和帧内的空间结构。
点此查看论文截图