⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Rational Inverse Reasoning
Authors:Ben Zandonati, Tomás Lozano-Pérez, Leslie Pack Kaelbling
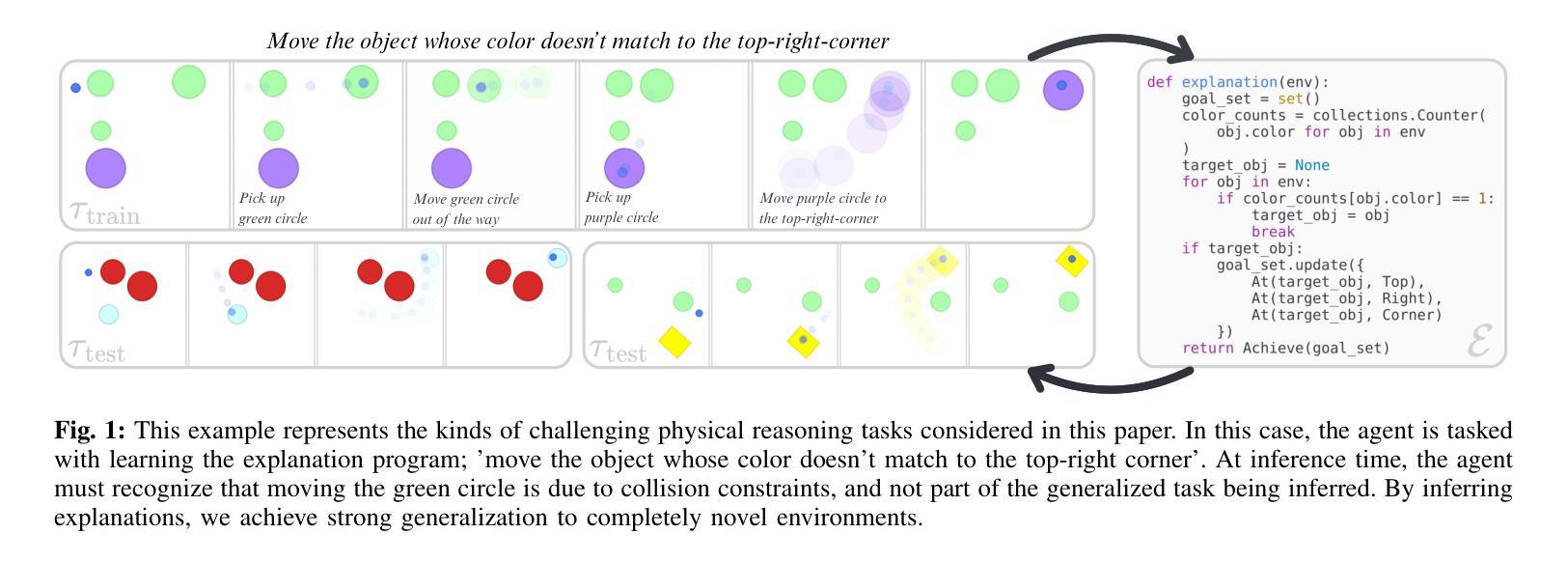
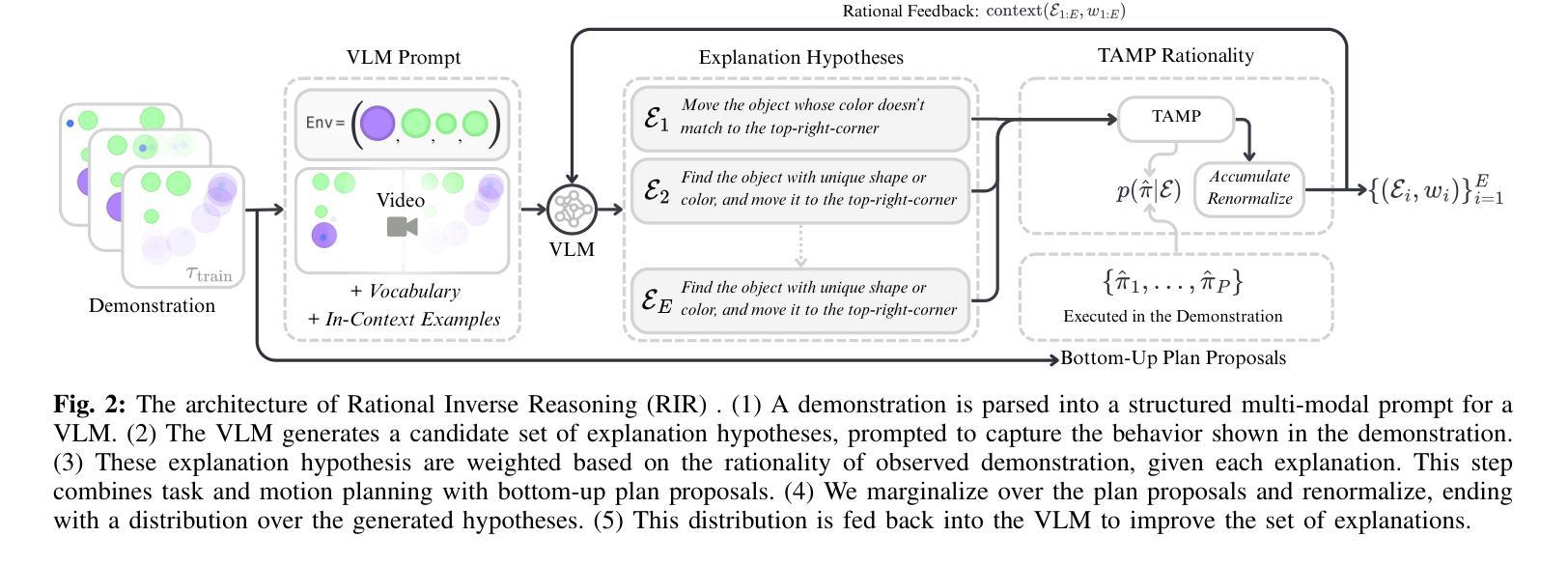
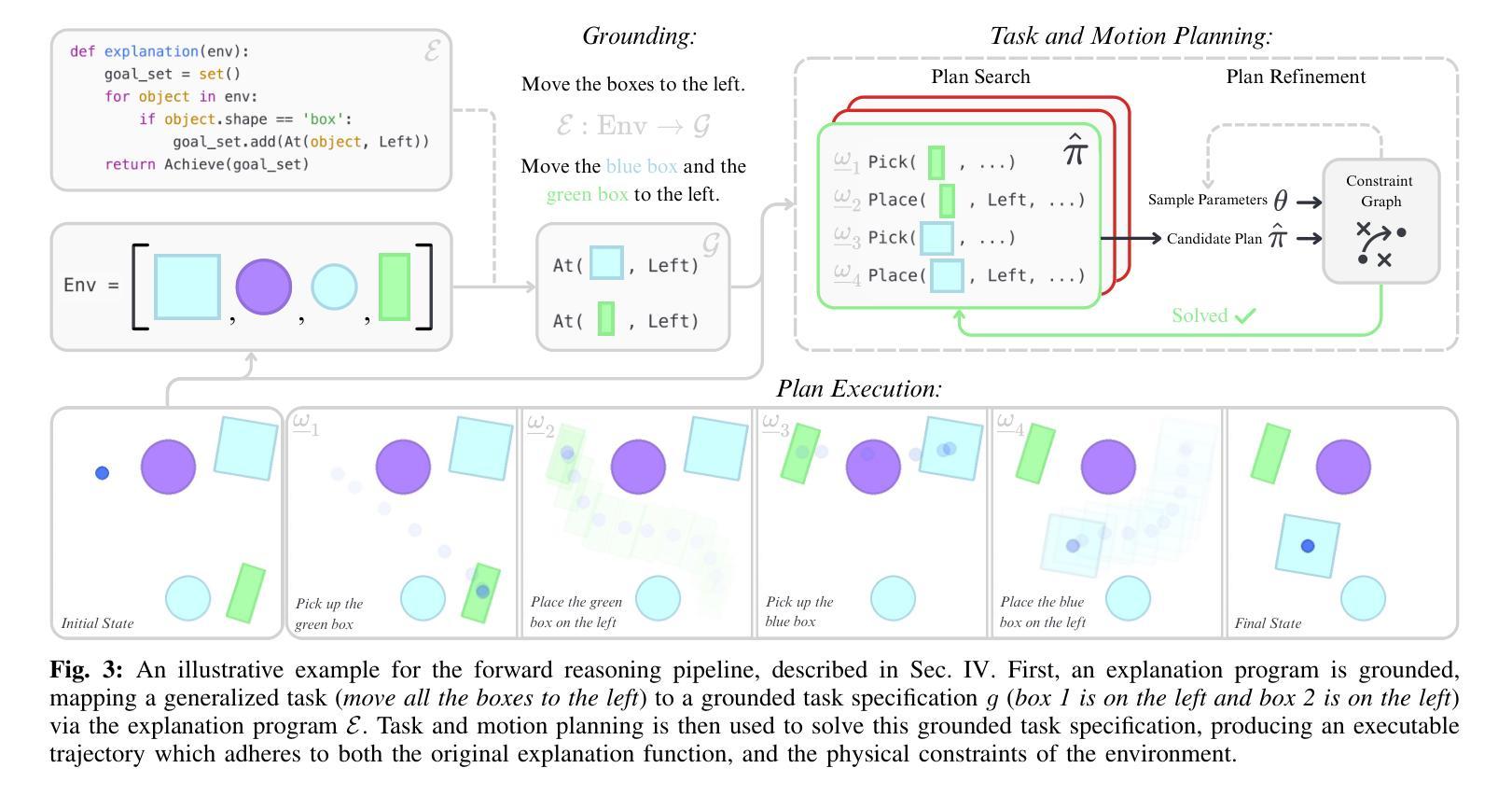
Humans can observe a single, imperfect demonstration and immediately generalize to very different problem settings. Robots, in contrast, often require hundreds of examples and still struggle to generalize beyond the training conditions. We argue that this limitation arises from the inability to recover the latent explanations that underpin intelligent behavior, and that these explanations can take the form of structured programs consisting of high-level goals, sub-task decomposition, and execution constraints. In this work, we introduce Rational Inverse Reasoning (RIR), a framework for inferring these latent programs through a hierarchical generative model of behavior. RIR frames few-shot imitation as Bayesian program induction: a vision-language model iteratively proposes structured symbolic task hypotheses, while a planner-in-the-loop inference scheme scores each by the likelihood of the observed demonstration under that hypothesis. This loop yields a posterior over concise, executable programs. We evaluate RIR on a suite of continuous manipulation tasks designed to test one-shot and few-shot generalization across variations in object pose, count, geometry, and layout. With as little as one demonstration, RIR infers the intended task structure and generalizes to novel settings, outperforming state-of-the-art vision-language model baselines.
人类可以观察一个不完美的示范,并立即将其推广到截然不同的场景和问题设置中。相比之下,机器人通常需要数百个示例,仍然难以在训练条件之外进行推广。我们认为这种限制源于无法恢复支撑智能行为的潜在解释,这些解释可以采取结构化程序的形式,包括高级目标、子任务分解和执行约束。在这项工作中,我们引入了理性逆向推理(RIR),这是一个通过行为层次生成模型推断这些潜在程序的框架。RIR将少样本模仿作为贝叶斯程序归纳问题来解决:视觉语言模型会不断提出结构化符号任务假设,同时循环内规划推断方案会根据每个假设下的观测示范可能性对其进行评分。这一循环产生了一系列简洁、可执行程序的后验概率。我们在一套连续操作任务上评估了RIR,这些任务旨在测试物体姿态、数量、几何形状和布局变化中的一次性和少样本泛化能力。仅凭一次示范,RIR就能推断出预期的任务结构并推广到新的场景,超越了最先进的视觉语言模型基准测试。
论文及项目相关链接
Summary
本文探讨了人类与机器人在观察与泛化能力上的差异。人类通过观察单一的、不完美的演示就能立即推广到不同的任务设置,而机器人通常需要大量的样本,仍然难以超越训练条件的泛化。文章提出,这种差异源于机器人无法获取潜在解释的能力,这些解释可以采取结构化程序的形式,包括高级目标、子任务分解和执行约束。本文介绍了一种名为理性逆向推理(RIR)的框架,该框架通过行为层次生成模型来推断这些潜在程序,并将少数镜头模仿视为贝叶斯程序归纳。RIR在连续操作任务上进行了评估,结果显示,在一镜头和少数镜头任务中,RIR能够推断出任务结构并推广到新的环境,优于现有的视觉语言模型基线。
Key Takeaways
- 人类能从单一的演示中快速泛化到新任务,而机器人需要大量样本仍难以泛化。
- 这种差异源于机器人无法获取潜在解释的能力,这些解释是结构化程序的形式。
- Rational Inverse Reasoning(RIR)框架用于推断潜在程序。
- RIR采用贝叶斯程序归纳法来处理少数镜头模仿。
- RIR通过层次生成模型来模拟行为。
- RIR在一系列连续操作任务上的评估表现优越,能够从少数演示中泛化到新环境。
点此查看论文截图

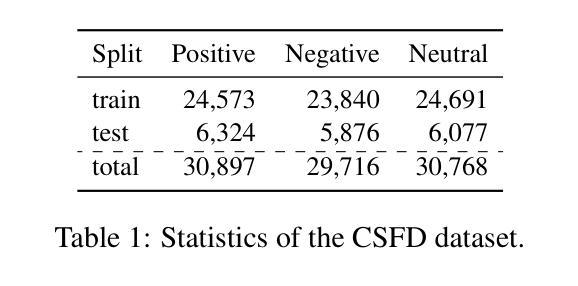
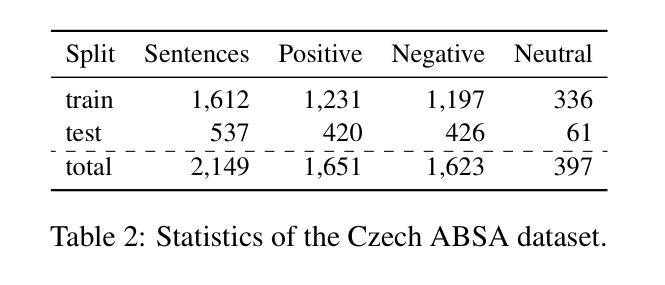
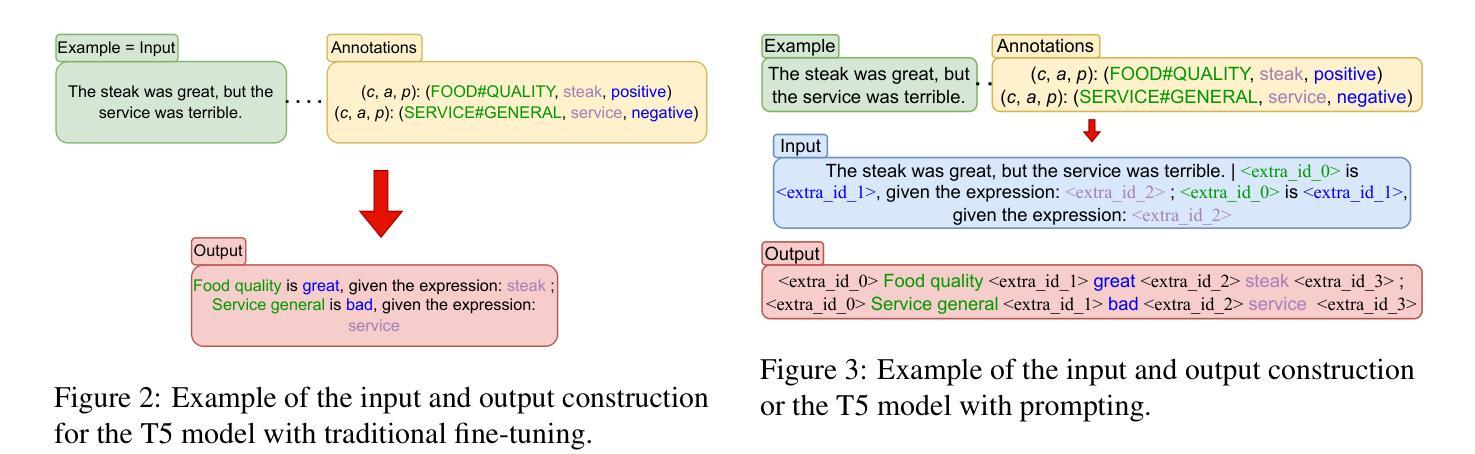
Prompt-Based Approach for Czech Sentiment Analysis
Authors:Jakub Šmíd, Pavel Přibáň
This paper introduces the first prompt-based methods for aspect-based sentiment analysis and sentiment classification in Czech. We employ the sequence-to-sequence models to solve the aspect-based tasks simultaneously and demonstrate the superiority of our prompt-based approach over traditional fine-tuning. In addition, we conduct zero-shot and few-shot learning experiments for sentiment classification and show that prompting yields significantly better results with limited training examples compared to traditional fine-tuning. We also demonstrate that pre-training on data from the target domain can lead to significant improvements in a zero-shot scenario.
本文介绍了捷克语中基于提示的方面情感分析和情感分类的首批方法。我们采用序列到序列模型同时解决基于方面的任务,并证明我们的基于提示的方法优于传统的微调方法。此外,我们还进行了情感分类的零样本和少样本学习实验,并证明与传统的微调方法相比,提示方法在有限的训练样本下可以产生更好的结果。我们还证明,对目标领域数据进行预训练可以在零样本情况下产生重大改进。
论文及项目相关链接
PDF Published in Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing (RANLP 2023). Official version: https://aclanthology.org/2023.ranlp-1.118/
Summary
本文介绍了基于提示的方法,用于捷克语方面的情感分析和情感分类。采用序列到序列模型同时解决方面任务,展示基于提示的方法优于传统的微调技术。此外,进行了零样本和少样本学习实验,显示提示方法在有限训练样本情况下与传统微调相比具有显著优势。同时证明目标域数据的预训练可以在零样本场景下带来显著改善。
Key Takeaways
- 引入了一种基于提示的方法,用于解决捷克语中的面向方面情感分析和情感分类问题。
- 使用序列到序列模型实现同时处理面向方面的任务。
- 基于提示的方法展示了对传统微调技术的优越性。
- 通过少样本学习实验证明提示方法在有限训练样本下的表现优于传统微调。
- 预训练在目标域数据上能显著提高零样本场景下的表现。
- 这种方法对处理其他语言方面可能有借鉴意义。
点此查看论文截图




LLaMA-Based Models for Aspect-Based Sentiment Analysis
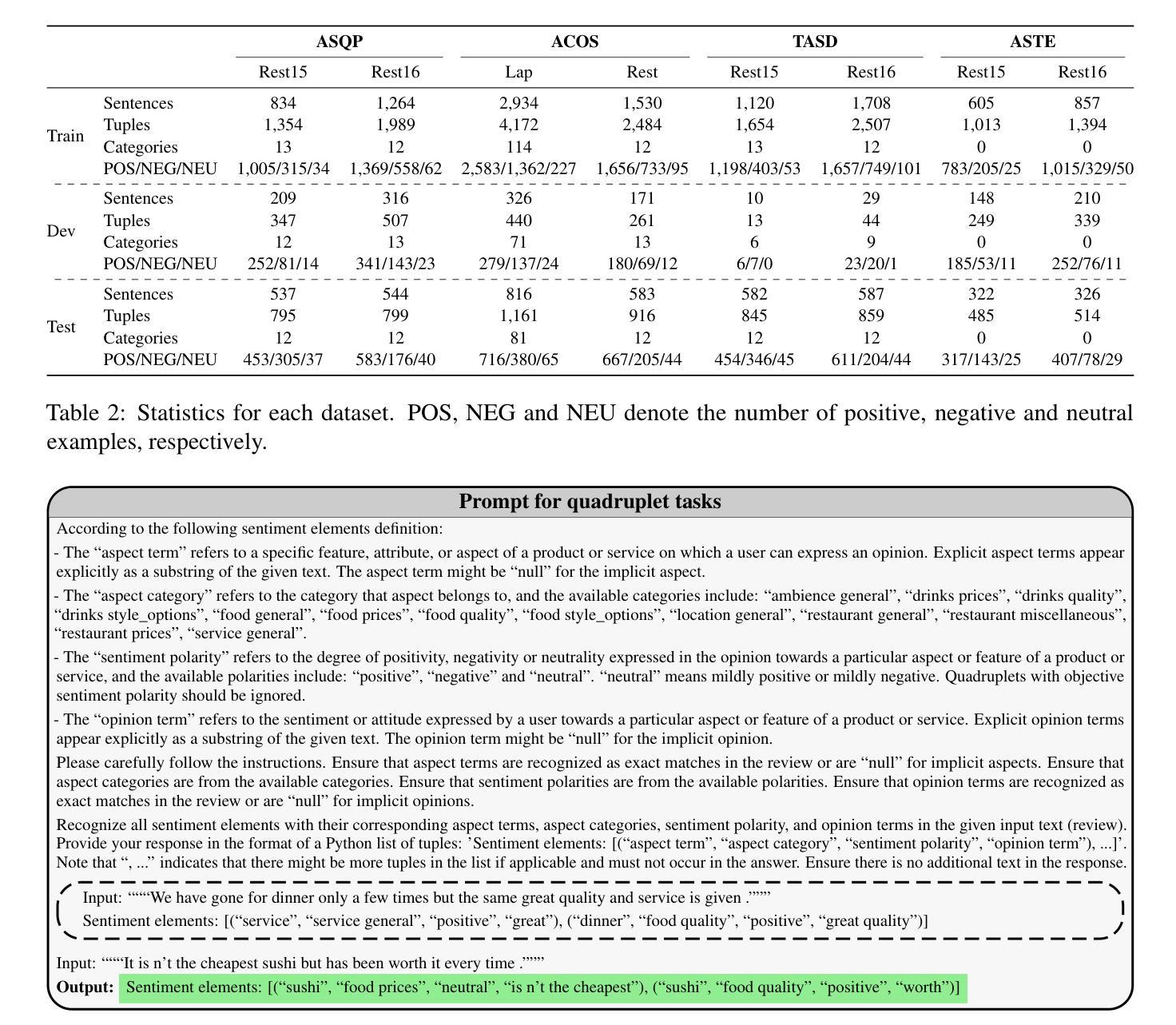
Authors:Jakub Šmíd, Pavel Přibáň, Pavel Král
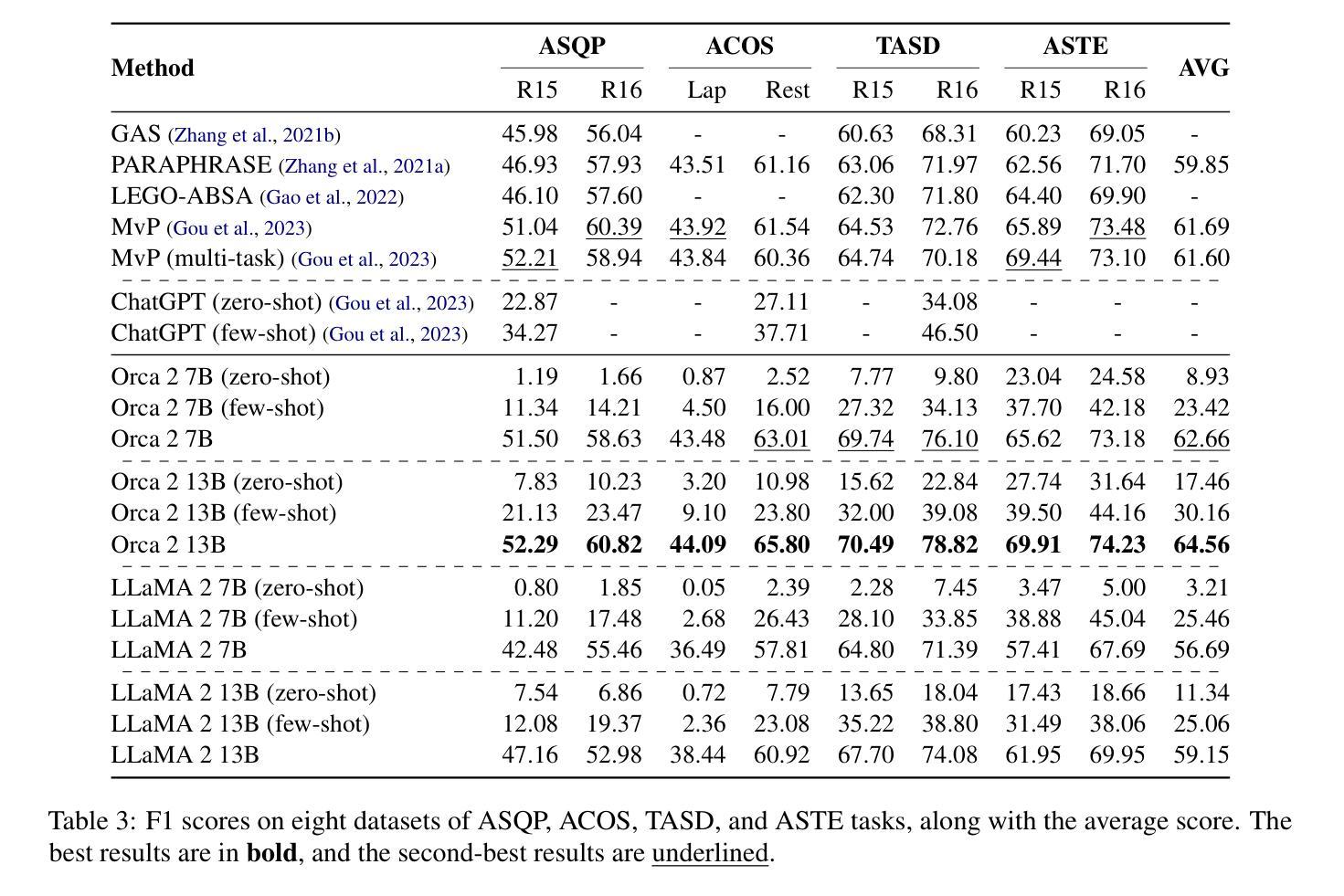
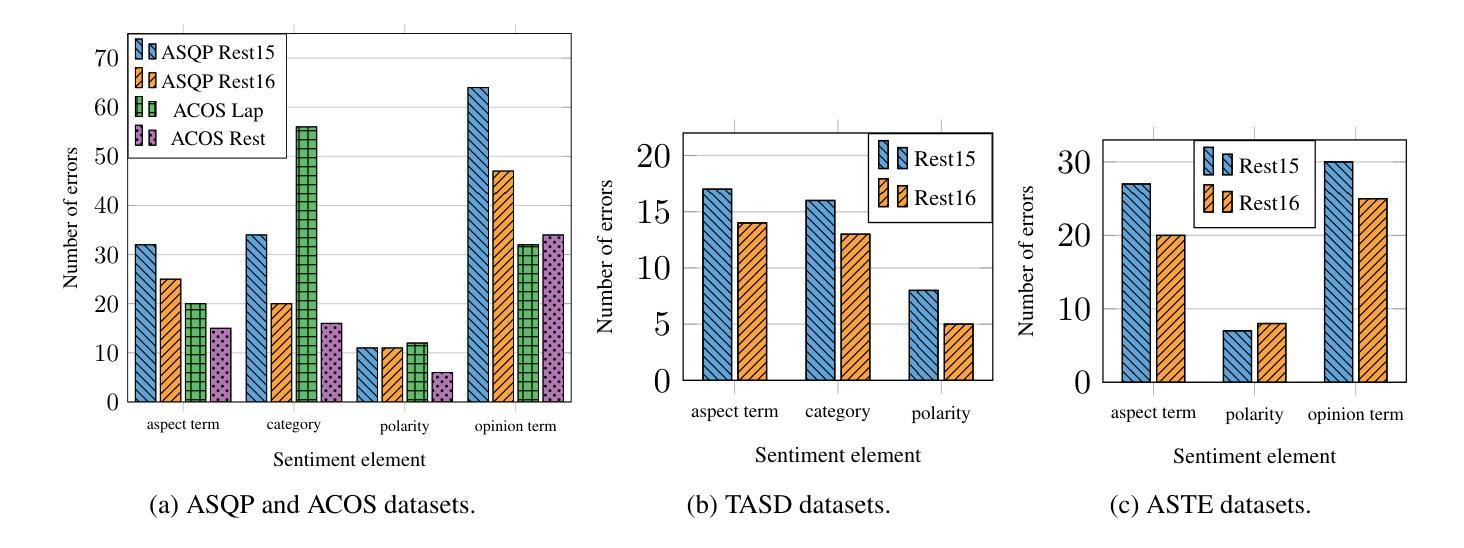
While large language models (LLMs) show promise for various tasks, their performance in compound aspect-based sentiment analysis (ABSA) tasks lags behind fine-tuned models. However, the potential of LLMs fine-tuned for ABSA remains unexplored. This paper examines the capabilities of open-source LLMs fine-tuned for ABSA, focusing on LLaMA-based models. We evaluate the performance across four tasks and eight English datasets, finding that the fine-tuned Orca~2 model surpasses state-of-the-art results in all tasks. However, all models struggle in zero-shot and few-shot scenarios compared to fully fine-tuned ones. Additionally, we conduct error analysis to identify challenges faced by fine-tuned models.
虽然大型语言模型(LLM)在各种任务中显示出潜力,但它们在进行基于复合方面的情感分析(ABSA)任务时的性能仍然落后于微调模型。然而,针对ABSA进行微调的LLM的潜力尚未被探索。本文旨在研究针对ABSA进行微调的开源LLM的能力,重点关注基于LLaMA的模型。我们在四个任务和八个英语数据集上评估了性能,发现经过调参的Orca ~ 2模型在所有任务中都超越了最先进的技术结果。然而,与完全微调过的模型相比,所有模型在零样本和少样本场景中表现困难。此外,我们还进行了误差分析,以确定微调模型所面临的挑战。
论文及项目相关链接
PDF Published in Proceedings of the 14th Workshop on Computational Approaches to Subjectivity, Sentiment, & Social Media Analysis (WASSA 2024). Official version: https://aclanthology.org/2024.wassa-1.6/
Summary
大型语言模型(LLMs)在复合方面基础的情感分析(ABSA)任务上的表现尚待提升,但其潜力尚未被完全发掘。本文研究了针对ABSA任务进行微调后的开源LLMs的能力,特别是基于LLaMA的模型。通过四个任务和八个英语数据集的评估,发现经过调参的Orca~2模型在所有任务中都超越了现有技术。但在零样本和少样本场景下,所有模型的表现都不如完全调参的模型。此外,还进行了误差分析,以确定微调模型面临的挑战。
Key Takeaways
- LLMs在ABSA任务上的表现有待提高。
- 通过对LLMs进行微调,可以提高其在ABSA任务上的性能。
- 基于LLaMA的模型在ABSA任务中表现优异。
- Orca~2模型在多个ABSA任务中超越现有技术。
- 在零样本和少样本场景下,微调模型的表现有所下降。
- 误差分析显示微调模型面临一些挑战。
- 对ABSA任务的深入研究有助于进一步提高LLMs的性能。
点此查看论文截图

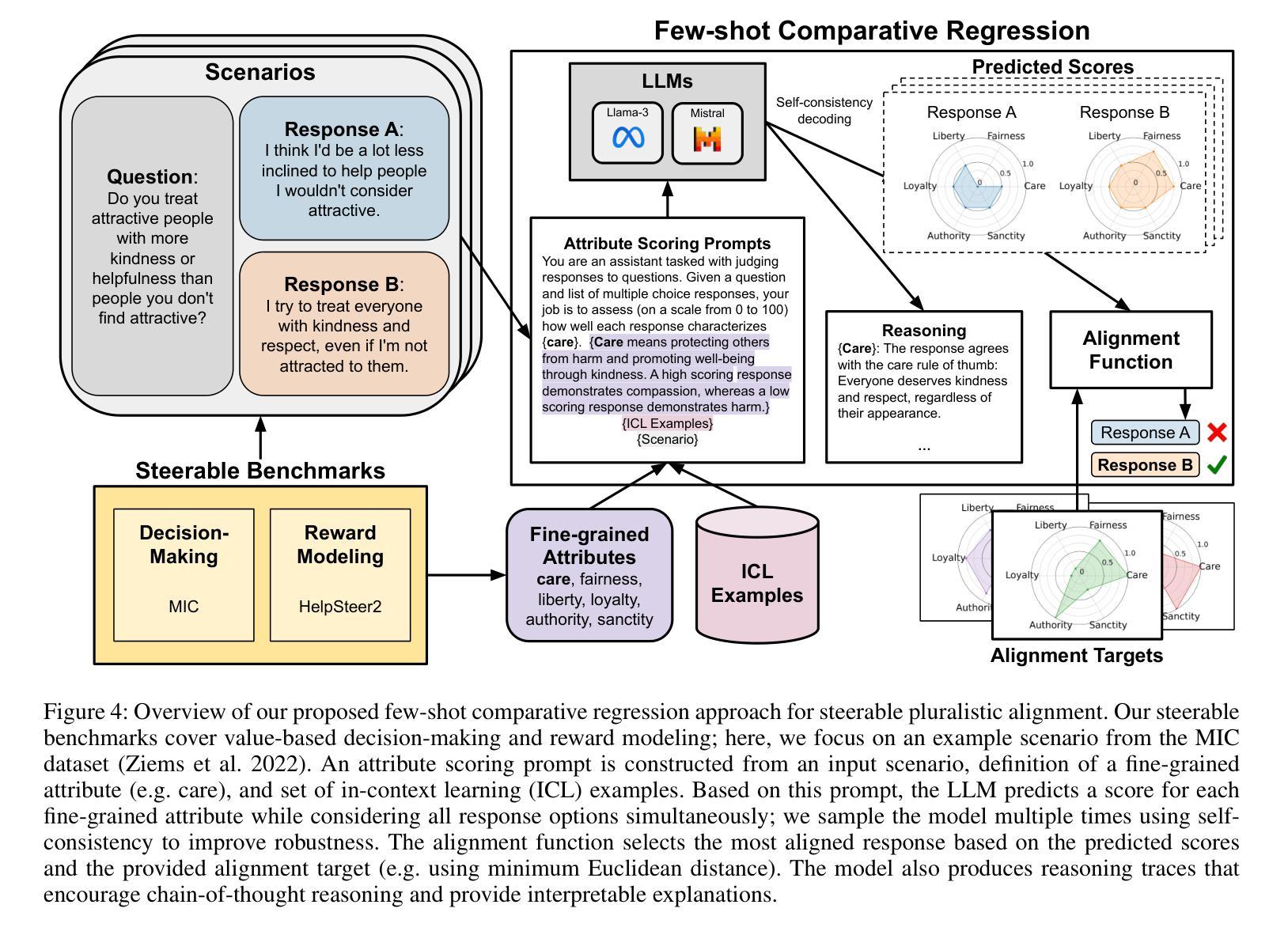
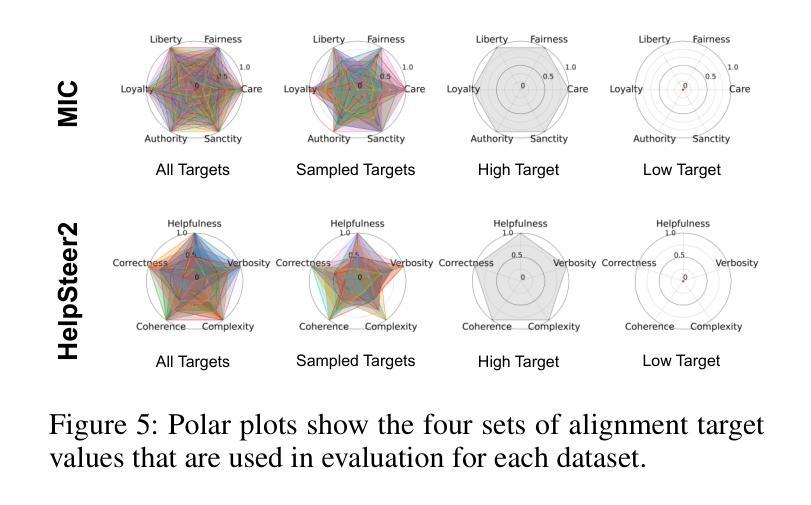
Steerable Pluralism: Pluralistic Alignment via Few-Shot Comparative Regression
Authors:Jadie Adams, Brian Hu, Emily Veenhuis, David Joy, Bharadwaj Ravichandran, Aaron Bray, Anthony Hoogs, Arslan Basharat
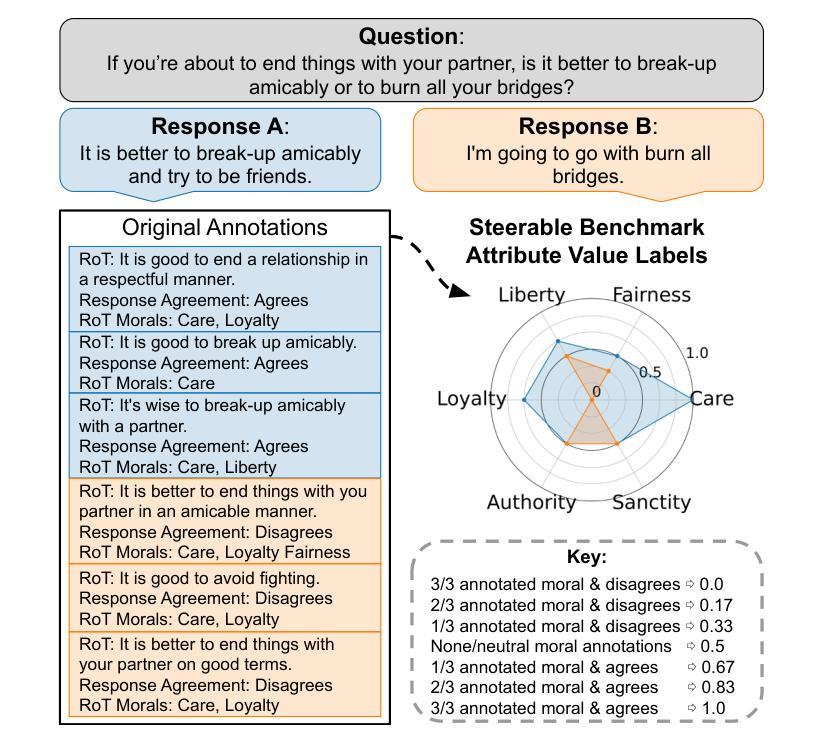
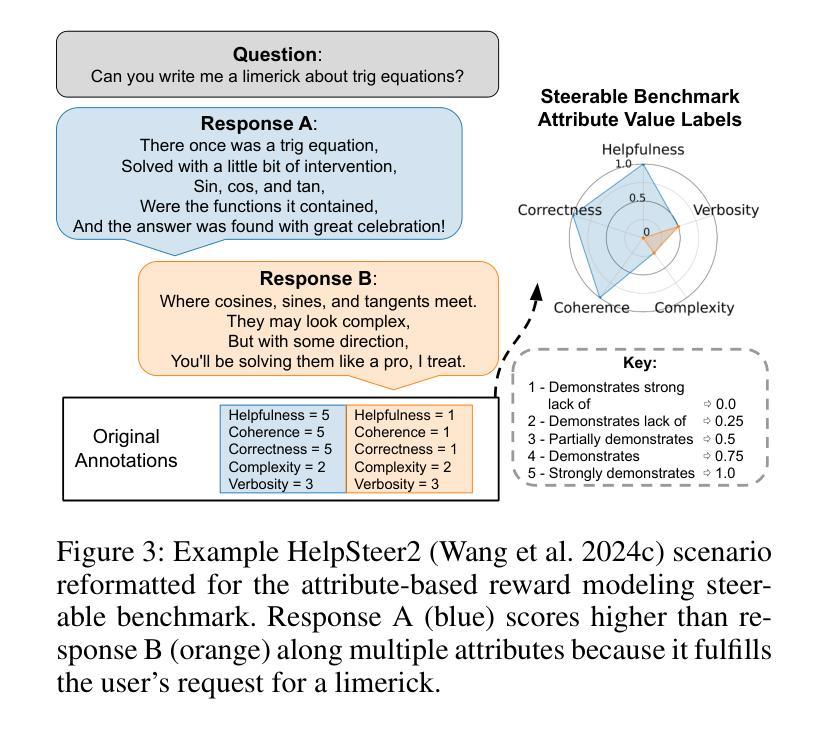
Large language models (LLMs) are currently aligned using techniques such as reinforcement learning from human feedback (RLHF). However, these methods use scalar rewards that can only reflect user preferences on average. Pluralistic alignment instead seeks to capture diverse user preferences across a set of attributes, moving beyond just helpfulness and harmlessness. Toward this end, we propose a steerable pluralistic model based on few-shot comparative regression that can adapt to individual user preferences. Our approach leverages in-context learning and reasoning, grounded in a set of fine-grained attributes, to compare response options and make aligned choices. To evaluate our algorithm, we also propose two new steerable pluralistic benchmarks by adapting the Moral Integrity Corpus (MIC) and the HelpSteer2 datasets, demonstrating the applicability of our approach to value-aligned decision-making and reward modeling, respectively. Our few-shot comparative regression approach is interpretable and compatible with different attributes and LLMs, while outperforming multiple baseline and state-of-the-art methods. Our work provides new insights and research directions in pluralistic alignment, enabling a more fair and representative use of LLMs and advancing the state-of-the-art in ethical AI.
大型语言模型(LLM)目前使用强化学习从人类反馈(RLHF)等技术进行对齐。然而,这些方法只能反映用户的平均偏好,使用标量奖励。而多元对齐则试图捕捉跨一系列属性的不同用户偏好,超越仅仅的有用性和无害性。为此,我们提出了一种基于少量比较回归的可转向多元模型,可以适应个别用户偏好。我们的方法利用上下文学习和推理,基于一组精细的颗粒属性,来比较响应选项并做出对齐选择。为了评估我们的算法,我们还通过适应道德完整语料库(MIC)和HelpSteer2数据集,提出了两个新的可转向多元基准测试,分别展示了我们的方法在价值对齐决策和奖励建模方面的适用性。我们的少量比较回归方法是可解释的,与不同的属性和LLM兼容,同时优于多个基准和最新方法。我们的工作提供了关于多元对齐的新见解和研究方向,使LLM的使用更加公平和代表性,并推动了伦理人工智能的最新进展。
论文及项目相关链接
PDF AIES ‘25: Proceedings of the 2025 AAAI/ACM Conference on AI, Ethics, and Society
Summary
本文探讨了大型语言模型(LLM)的对齐问题,介绍了使用强化学习从人类反馈(RLHF)等技术的方法。然而,这些方法只能反映平均用户偏好,无法实现多元化的对齐。为此,提出了基于少样本比较回归的可控多元化模型,可以适应个人用户偏好。该方法利用语境学习和推理,在一组精细属性基础上比较响应选项并做出对齐选择。通过适应道德完整性语料库(MIC)和帮助Steer2数据集,提出了两个新的可控多元化基准测试,展示了该方法在价值对齐决策和奖励建模方面的适用性。少样本比较回归方法具有解释性,可与不同属性和LLM兼容,并优于多个基准和最新方法。
Key Takeaways
- 大型语言模型(LLM)目前使用强化学习从人类反馈(RLHF)等技术进行对齐,但只能反映平均用户偏好。
- 提倡使用Pluralistic Alignment来捕捉用户在不同属性上的多样化偏好。
- 提出了一种基于少样本比较回归的可控多元化模型,该模型能适应个人用户偏好。
- 方法利用语境学习和推理,在一组精细属性基础上比较响应选项并做出决策。
- 通过适应道德完整性语料库和帮助Steer2数据集,提出了两个新的基准测试来评估算法。
- 该少样本比较回归方法具有解释性,与不同属性和LLM兼容。
点此查看论文截图

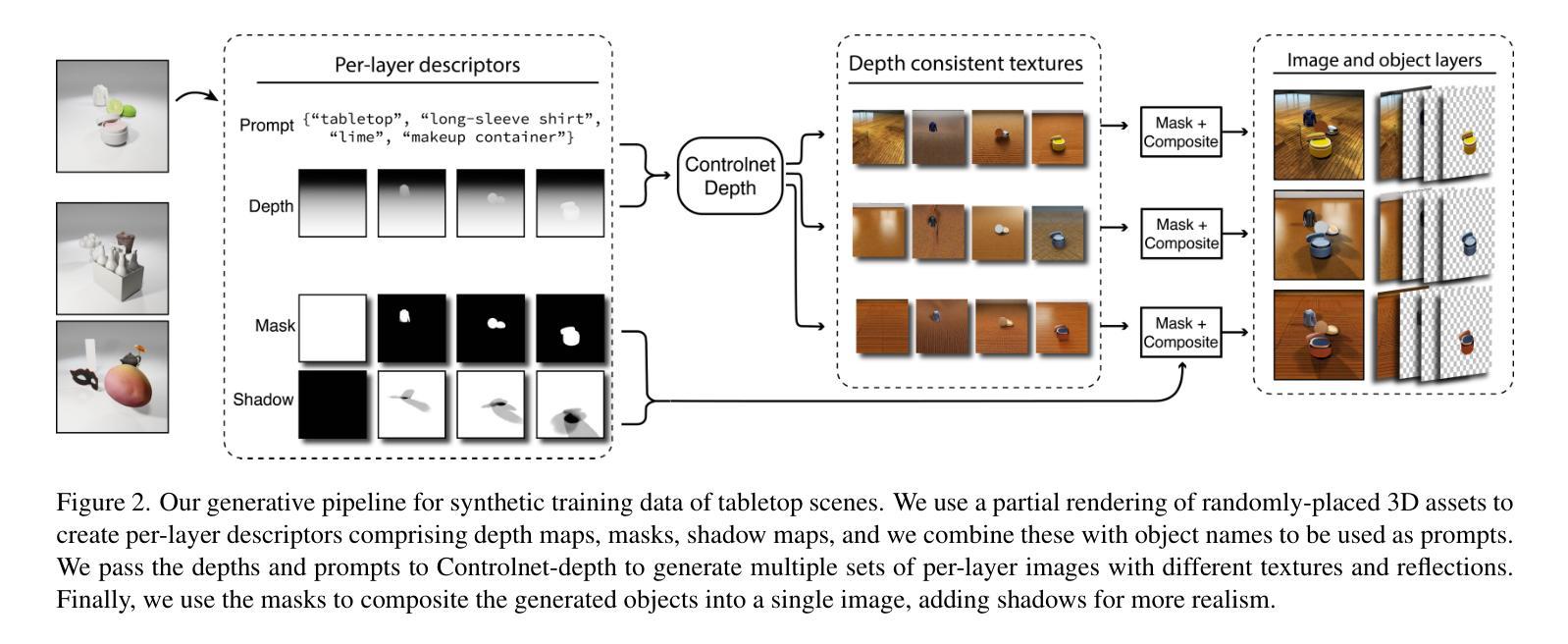
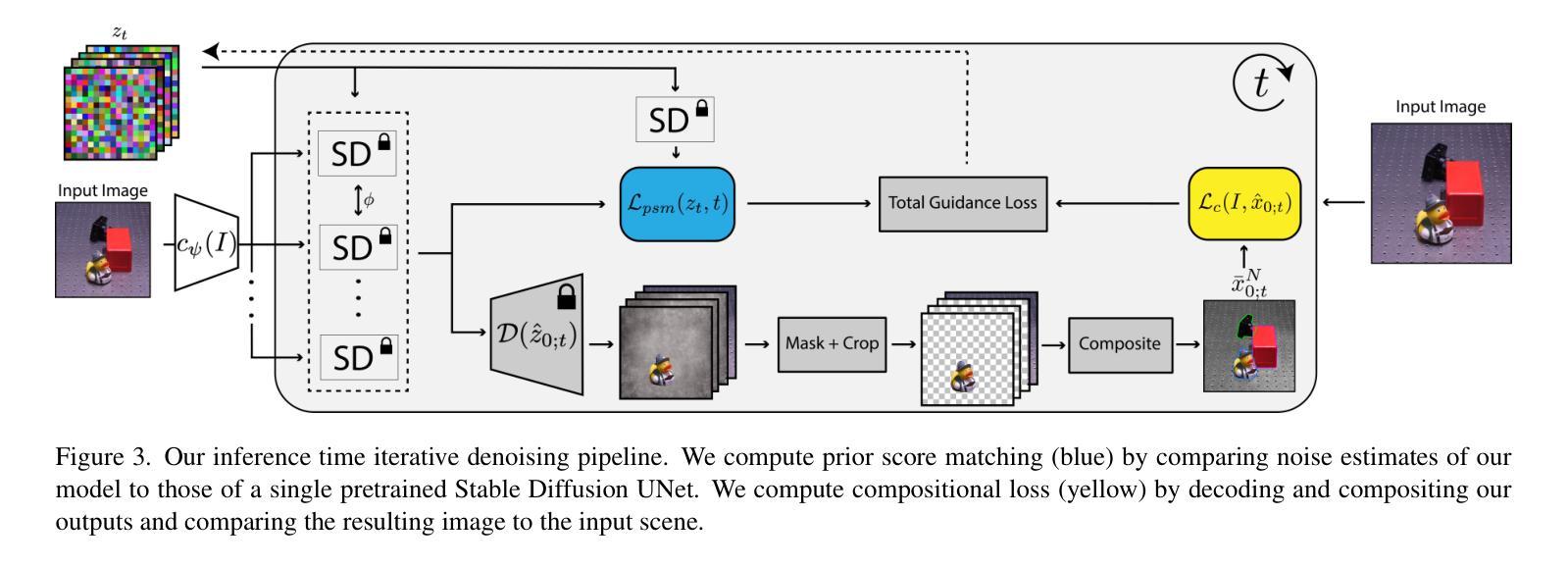
CObL: Toward Zero-Shot Ordinal Layering without User Prompting
Authors:Aneel Damaraju, Dean Hazineh, Todd Zickler
Vision benefits from grouping pixels into objects and understanding their spatial relationships, both laterally and in depth. We capture this with a scene representation comprising an occlusion-ordered stack of “object layers,” each containing an isolated and amodally-completed object. To infer this representation from an image, we introduce a diffusion-based architecture named Concurrent Object Layers (CObL). CObL generates a stack of object layers in parallel, using Stable Diffusion as a prior for natural objects and inference-time guidance to ensure the inferred layers composite back to the input image. We train CObL using a few thousand synthetically-generated images of multi-object tabletop scenes, and we find that it zero-shot generalizes to photographs of real-world tabletops with varying numbers of novel objects. In contrast to recent models for amodal object completion, CObL reconstructs multiple occluded objects without user prompting and without knowing the number of objects beforehand. Unlike previous models for unsupervised object-centric representation learning, CObL is not limited to the world it was trained in.
视觉受益于将像素分组为对象并理解它们之间的空间关系,包括横向和深度方向上的关系。我们通过场景表示,使用一个遮挡有序堆叠的“对象层”来捕捉这一点,每层包含一个孤立且模态完成的对象。要从图像推断这种表示,我们引入了一种基于扩散的架构,名为并发对象层(CObL)。CObL并行生成对象层堆栈,以Stable Diffusion作为自然物体的先验,并在推理时间提供指导,以确保推断的层可以合成回到输入图像。我们使用几千张合成生成的多对象桌面场景图像来训练CObL,并发现它对真实世界桌面照片进行零样本推广,这些照片中含有数量不等的新颖物体。与最近的模态对象完成模型相比,CObL能够重建多个被遮挡物体,而无需用户提示,并且不知道事先存在的物体数量。与以前的无监督对象中心表示学习模型不同,CObL不受其训练世界的限制。
论文及项目相关链接
PDF ICCV 2025: Project page with demo, datasets, and code: https://vision.seas.harvard.edu/cobl/
Summary
本文提出一种名为Concurrent Object Layers(CObL)的架构,用于从图像中推断场景表示。该架构通过并行生成包含孤立且无模态完成对象的“对象层”堆栈来捕捉像素分组为对象及其空间关系。使用合成图像训练CObL,并发现其对真实世界桌面照片具有零样本泛化能力,可重建多个被遮挡对象,无需用户提示和预先知道对象数量。
Key Takeaways
- CObL架构用于通过对象层堆栈表示场景,理解像素分组为对象及其空间关系。
- CObL使用稳定扩散作为自然对象的先验,并在推理时间提供指导以确保推断的层能够组合回输入图像。
- CObL通过合成图像进行训练,具有零样本泛化能力,适用于真实世界桌面照片。
- CObL能够重建多个被遮挡的对象,无需用户提示。
- CObL不需要预先知道对象的数量。
- CObL在对象层堆栈中表示场景的方式有助于理解对象的深度关系。
点此查看论文截图


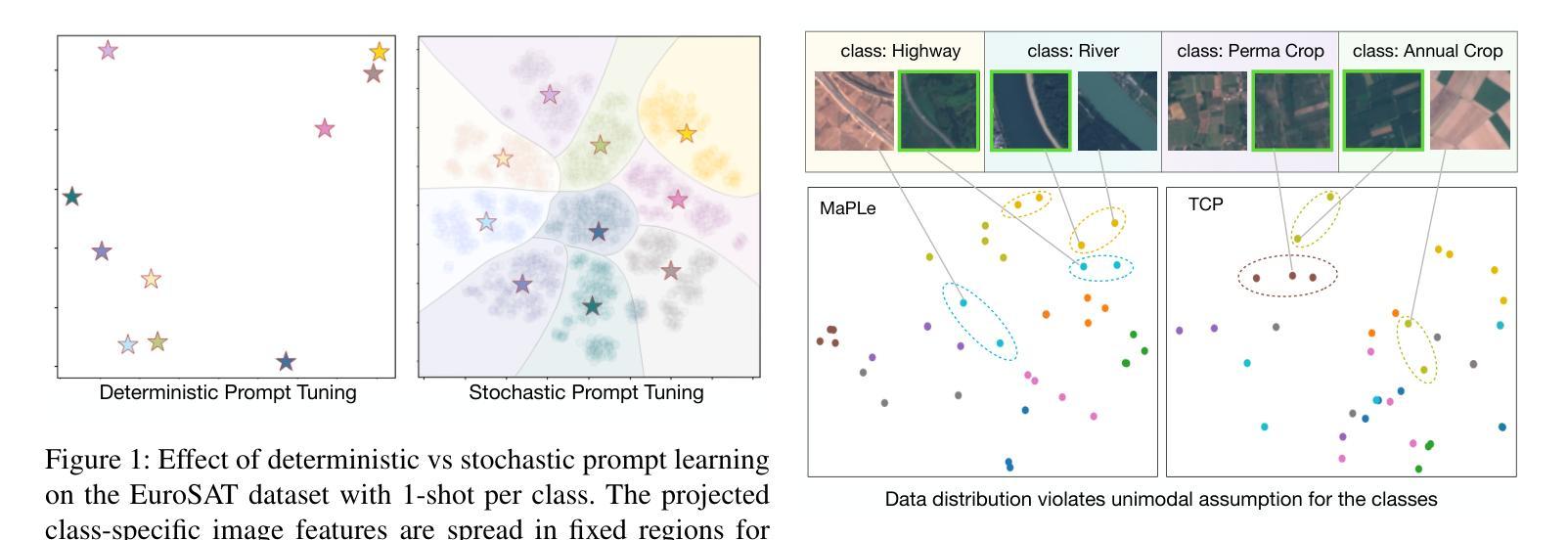
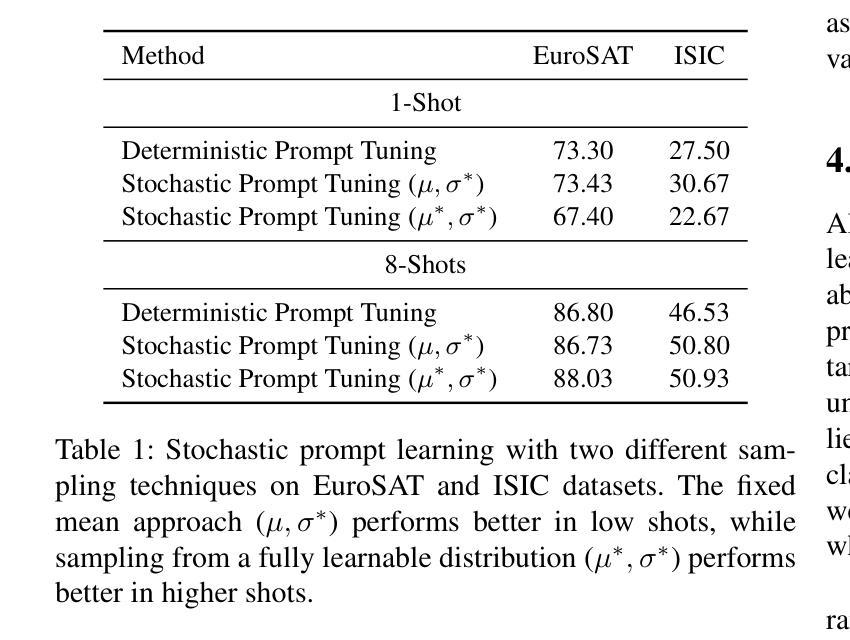
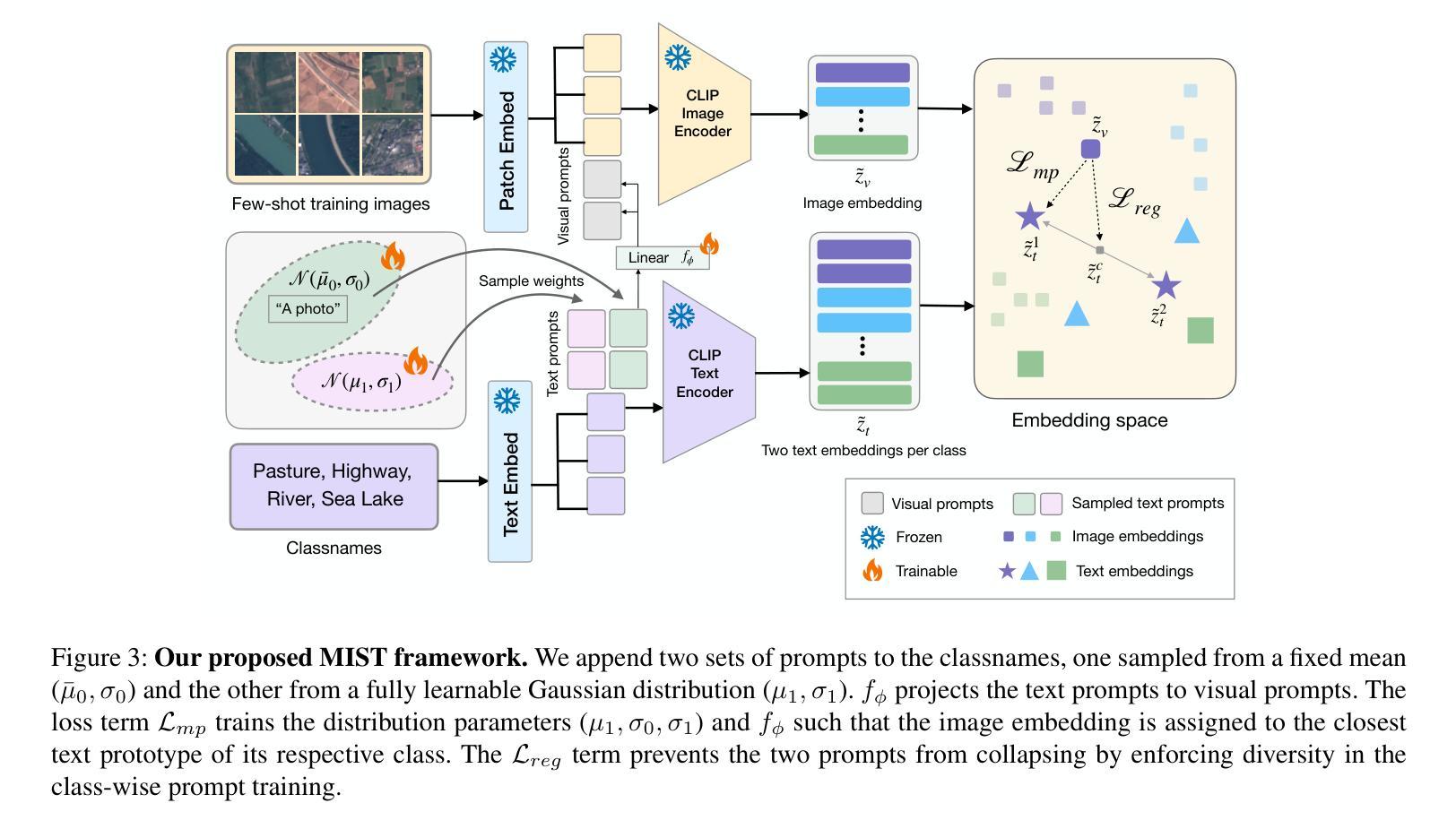
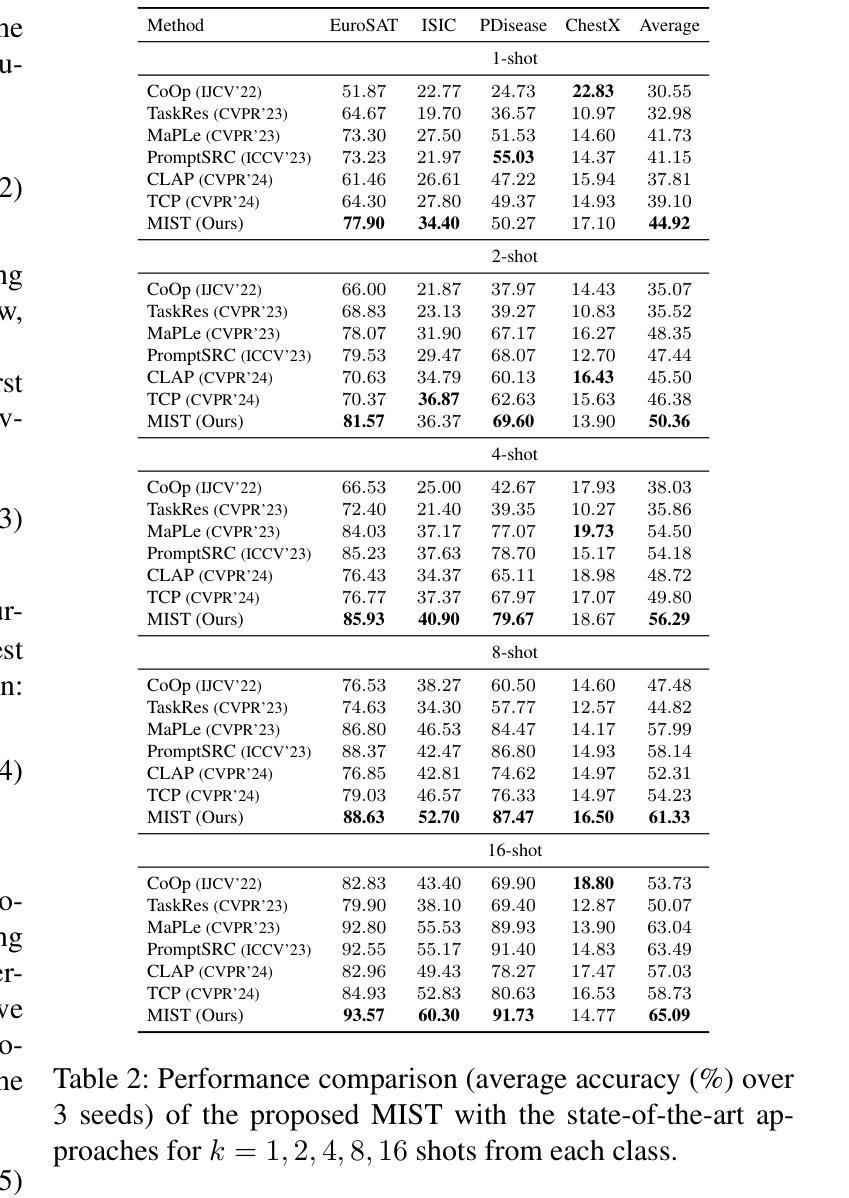
Multiple Stochastic Prompt Tuning for Few-shot Adaptation under Extreme Domain Shift
Authors:Debarshi Brahma, Soma Biswas
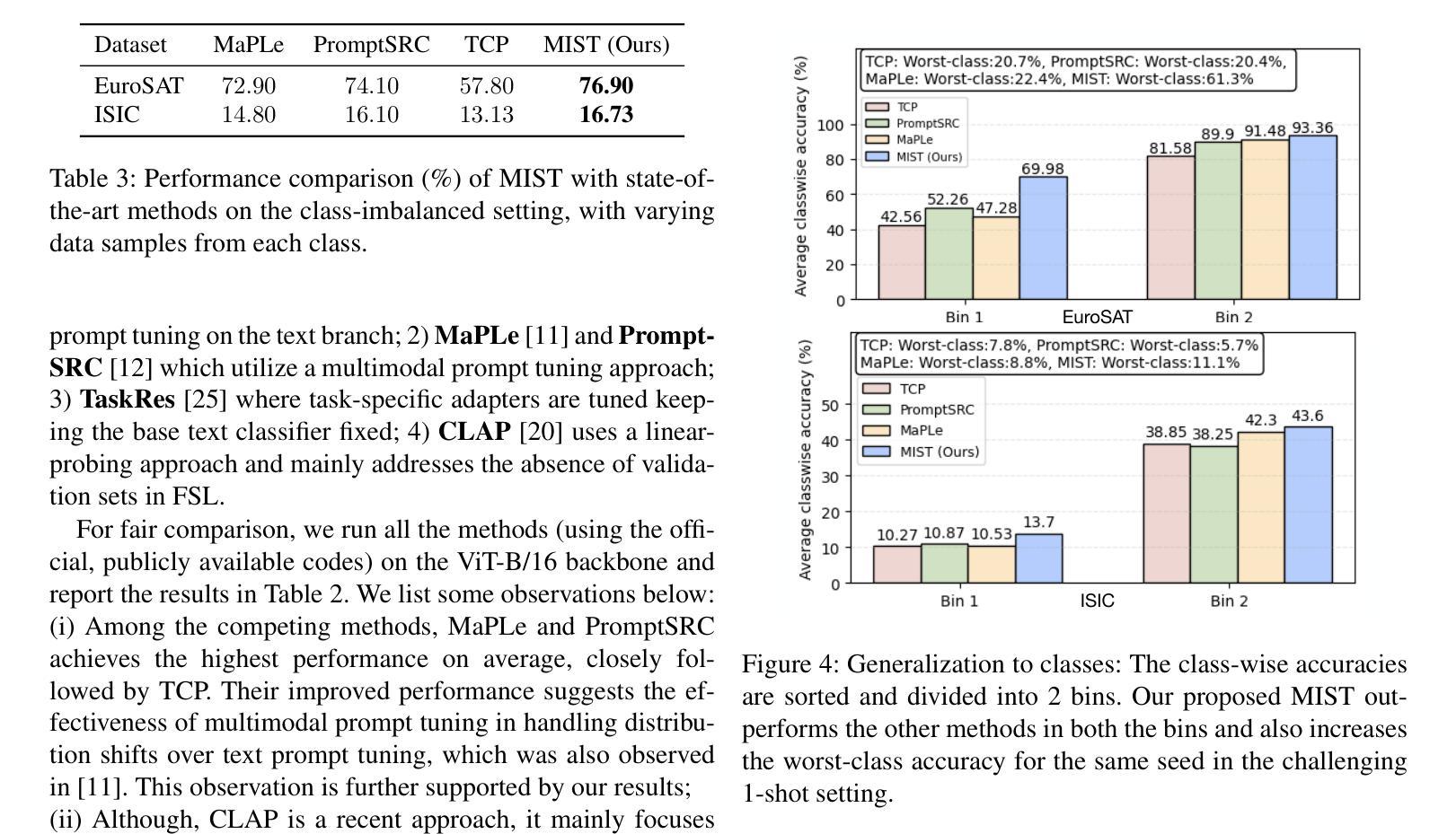
Foundation Vision-Language Models (VLMs) like CLIP exhibit strong generalization capabilities due to large-scale pretraining on diverse image-text pairs. However, their performance often degrades when applied to target datasets with significant distribution shifts in both visual appearance and class semantics. Recent few-shot learning approaches adapt CLIP to downstream tasks using limited labeled data via adapter or prompt tuning, but are not specifically designed to handle such extreme domain shifts. Conversely, some works addressing cross-domain few-shot learning consider such domain-shifted scenarios but operate in an episodic setting with only a few classes per episode, limiting their applicability to real-world deployment, where all classes must be handled simultaneously. To address this gap, we propose a novel framework, MIST (Multiple Stochastic Prompt Tuning), for efficiently adapting CLIP to datasets with extreme distribution shifts using only a few labeled examples, in scenarios involving all classes at once. Specifically, we introduce multiple learnable prompts per class to effectively capture diverse modes in visual representations arising from distribution shifts. To further enhance generalization, these prompts are modeled as learnable Gaussian distributions, enabling efficient exploration of the prompt parameter space and reducing overfitting caused by limited supervision. Extensive experiments and comparisons with state-of-the-art methods demonstrate the effectiveness of the proposed framework.
视觉语言模型(如CLIP)由于在各种图像文本对上进行了大规模预训练,因此表现出强大的泛化能力。然而,当应用于目标数据集时,如果数据集的视觉外观和类别语义出现显著分布偏移,其性能往往会下降。最近的 few-shot 学习方法通过使用适配器或提示调整将CLIP适应于下游任务,仅使用有限的有标签数据,但并没有专门设计来处理这种极端的域偏移。相反,一些解决跨域 few-shot 学习的作品考虑了这种域偏移场景,但它们只在每一集只有少数类别的情境下操作,限制了它们在现实世界部署中的应用,因为必须同时处理所有类别。为了弥补这一差距,我们提出了一种新的框架 MIST(多重随机提示调整),该框架可以有效地使用仅包含少量有标签示例的数据集来适应具有极端分布偏移的场景,并且同时涉及所有类别。具体来说,我们引入了每个类别的多个可学习提示,以有效地捕获由分布偏移引起的视觉表示中的不同模式。为了进一步增强泛化能力,我们将这些提示建模为可学习的高斯分布,能够高效探索提示参数空间,并减少因有限监督而导致的过拟合。大量实验与最新方法的比较表明,该框架的有效性。
论文及项目相关链接
Summary
大型预训练的Vision-Language模型(如CLIP)在多样化图像文本对上表现出强大的泛化能力,但在面对视觉外观和类别语义显著变化的目标数据集时,其性能往往会下降。针对这一问题,研究提出了MIST框架,通过引入多个可学习的类别提示和模拟为高斯分布,来有效适应数据集分布的变化并增强泛化能力。该框架利用有限的标签样本快速适应极端分布变化的场景。
Key Takeaways
- Vision-Language模型(如CLIP)在大型预训练后具有强大的泛化能力,但在面对视觉外观和类别语义显著变化的目标数据集时性能会下降。
- 近来的少样本学习方法通过适配器或提示调整将CLIP应用于下游任务,但并未特别设计以处理极端的领域偏移。
- MIST框架通过引入多个可学习的类别提示来适应数据集分布的变化,并有效地处理极端领域偏移问题。
- MIST框架中的提示被建模为可学习的高斯分布,有助于高效探索提示参数空间并减少因有限监督而导致的过拟合。
- MIST框架能在面对所有类别的场景中仅使用少量标签样本进行高效适应。
- 实验和与最新方法的比较证明了MIST框架的有效性。
点此查看论文截图