⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Gotta Hear Them All: Towards Sound Source Aware Audio Generation
Authors:Wei Guo, Heng Wang, Jianbo Ma, Weidong Cai
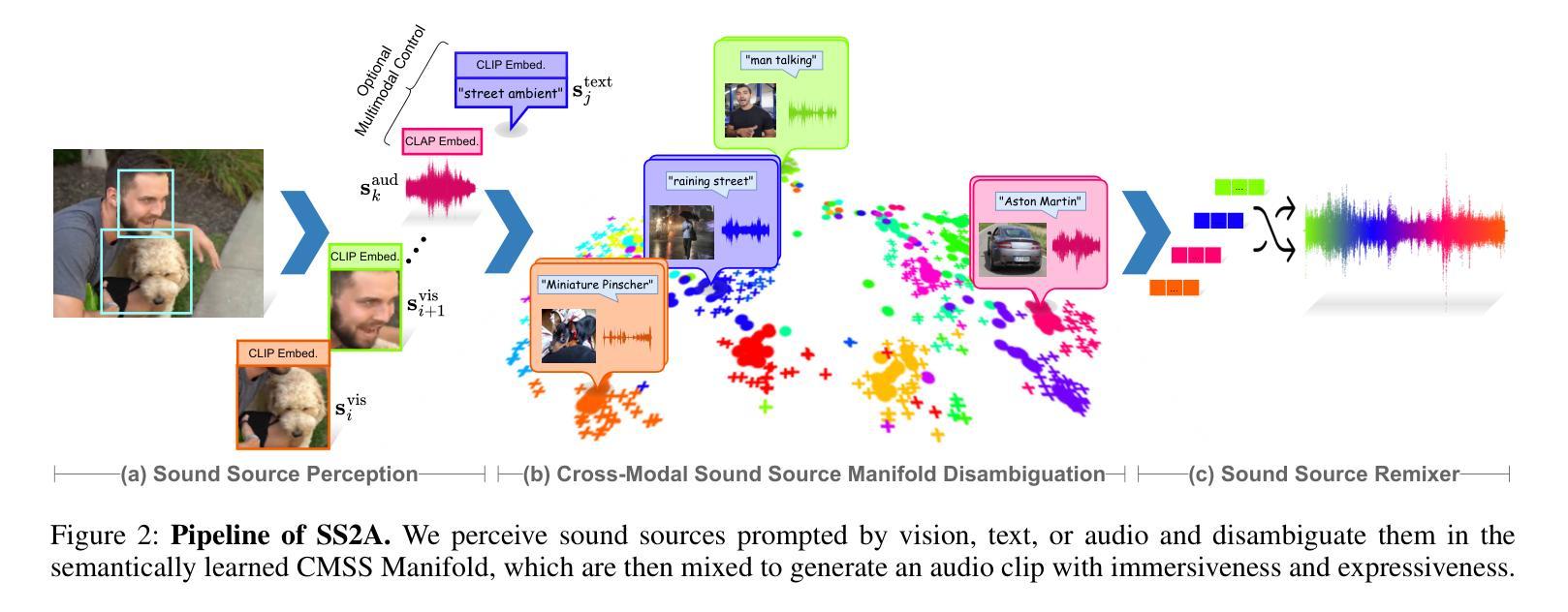
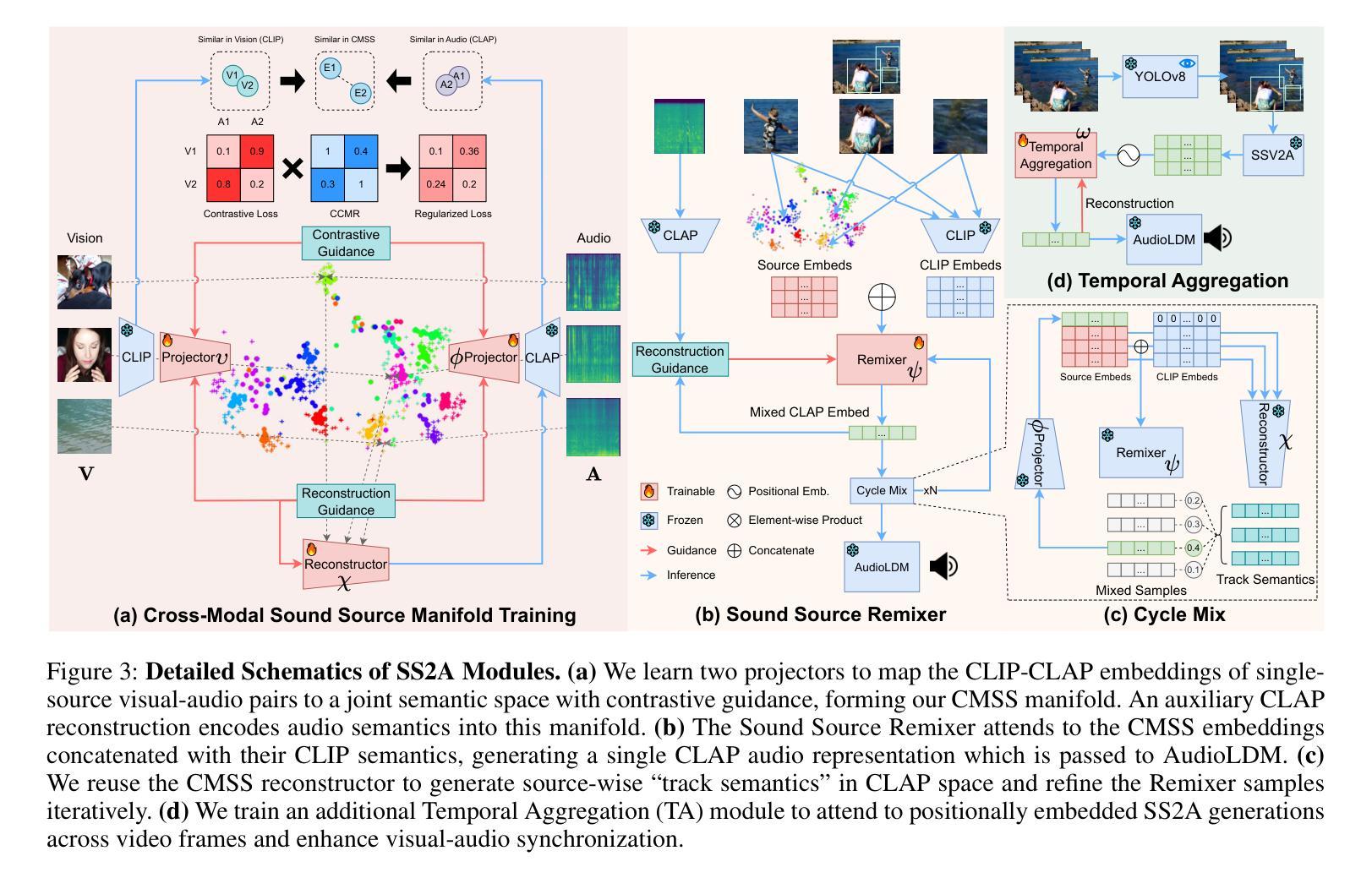
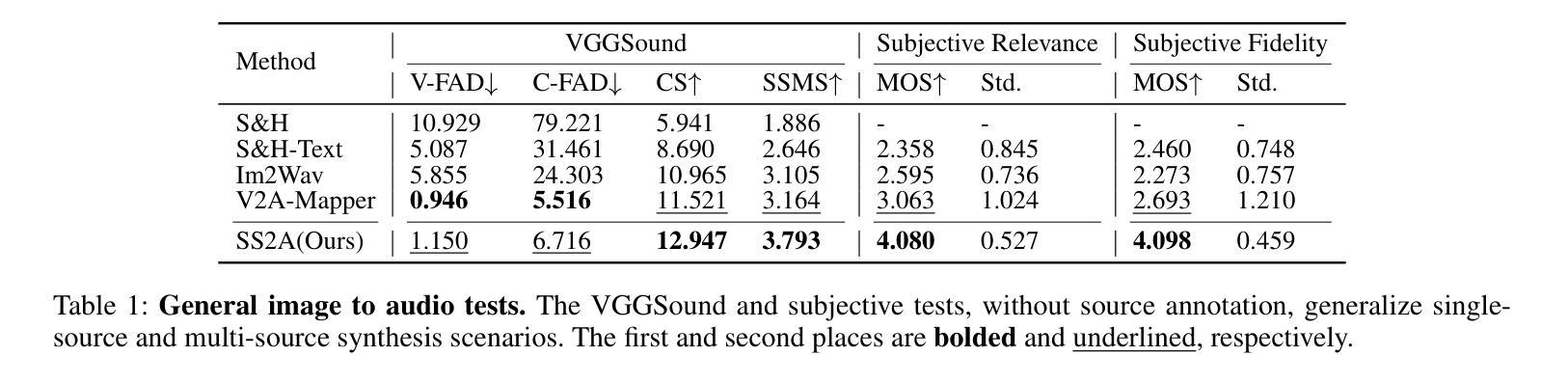
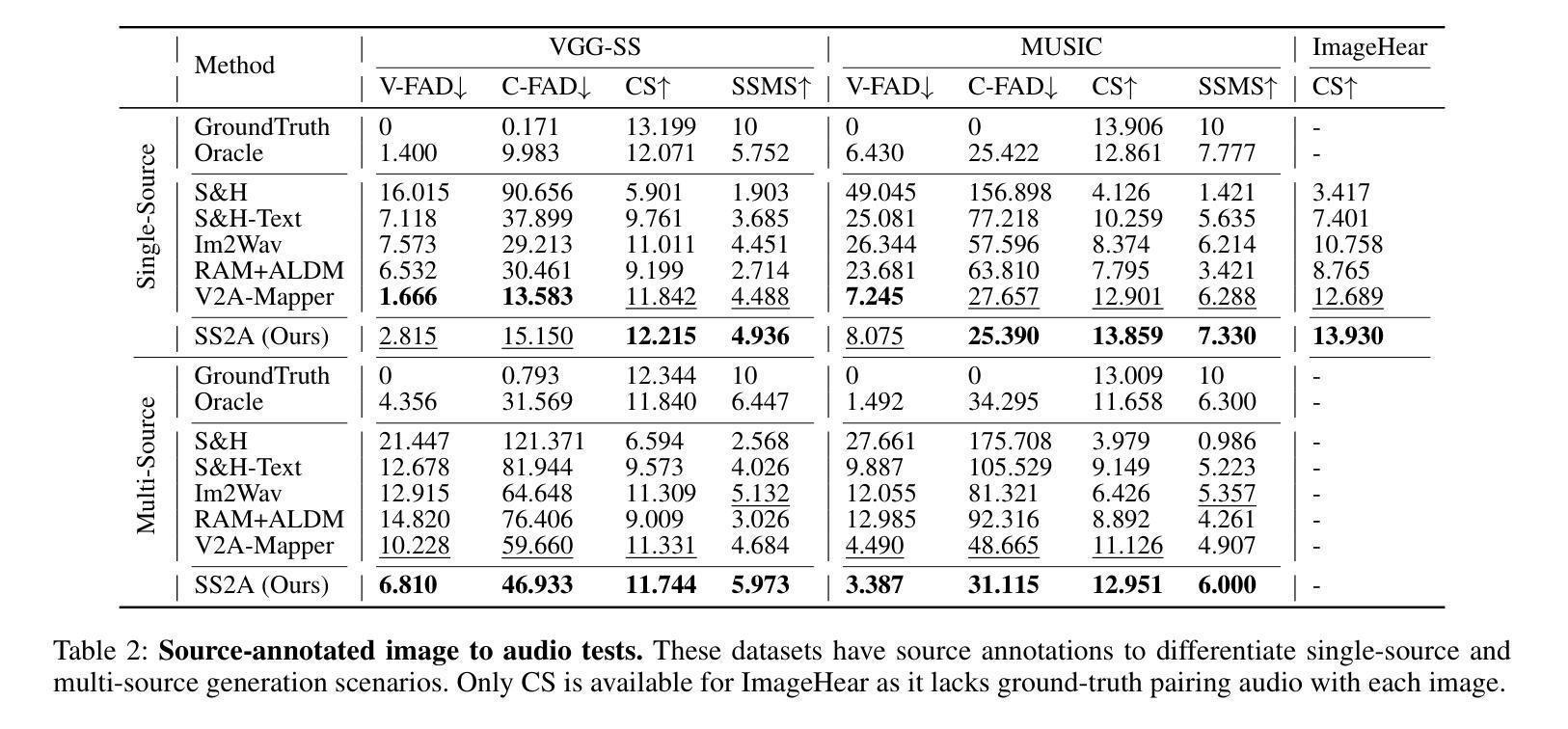
Audio synthesis has broad applications in multimedia. Recent advancements have made it possible to generate relevant audios from inputs describing an audio scene, such as images or texts. However, the immersiveness and expressiveness of the generation are limited. One possible problem is that existing methods solely rely on the global scene and overlook details of local sounding objects (i.e., sound sources). To address this issue, we propose a Sound Source-Aware Audio (SS2A) generator. SS2A is able to locally perceive multimodal sound sources from a scene with visual detection and cross-modality translation. It then contrastively learns a Cross-Modal Sound Source (CMSS) Manifold to semantically disambiguate each source. Finally, we attentively mix their CMSS semantics into a rich audio representation, from which a pretrained audio generator outputs the sound. To model the CMSS manifold, we curate a novel single-sound-source visual-audio dataset VGGS3 from VGGSound. We also design a Sound Source Matching Score to clearly measure localized audio relevance. With the effectiveness of explicit sound source modeling, SS2A achieves state-of-the-art performance in extensive image-to-audio tasks. We also qualitatively demonstrate SS2A’s ability to achieve intuitive synthesis control by compositing vision, text, and audio conditions. Furthermore, we show that our sound source modeling can achieve competitive video-to-audio performance with a straightforward temporal aggregation mechanism.
音频合成在多媒体领域有着广泛的应用。最近的进展使得从描述音频场景(如图像或文本)的输入生成相关音频成为可能。然而,生成的沉浸感和表现力有限。可能的问题之一是现有方法仅依赖于全局场景,而忽略了局部发声物体的细节(即声源)。为了解决这一问题,我们提出了一种声音源感知音频(SS2A)生成器。SS2A能够局部感知场景中的多模态声源,通过视觉检测和跨模态翻译来实现。然后,它对比学习跨模态声源(CMSS)流形,以语义方式区分每个声源。最后,我们将CMSS语义融合到丰富的音频表示中,预训练的音频生成器根据该表示输出声音。为了建模CMSS流形,我们从VGGSound中精选了新型的单声源视觉音频数据集VGGS3。我们还设计了一种声源匹配得分,以清晰测量局部音频相关性。通过有效的显式声源建模,SS2A在广泛的图像到音频任务中实现了最先进的性能。我们还通过组合视觉、文本和音频条件,定性展示了SS2A实现直观合成控制的能力。此外,我们证明了我们的声源建模可以通过简单的时间聚合机制实现具有竞争力的视频到音频性能。
论文及项目相关链接
PDF 17 pages, 12 figures, source code available at https://github.com/wguo86/SSV2A
Summary
本文介绍了音频合成在多媒体领域的广泛应用。针对现有方法忽视局部声源细节的问题,提出了一种声音源感知音频(SS2A)生成器。SS2A能够从场景中局部感知多模式声源,通过视觉检测和跨模态翻译来学习跨模态声源(CMSS)流形,以语义方式区分每个声源。最后,将CMSS语义与丰富的音频表示相结合,由预训练的音频生成器输出声音。为建模CMSS流形,从VGGSound中精选了新型单声源视觉音频数据集VGGS3,并设计了声音源匹配得分来清晰测量局部音频相关性。SS2A在广泛的图像到音频任务中取得了最先进的性能,并展示了直观的合成控制能力,同时实现视频到音频的竞争力表现。
Key Takeaways
- 音频合成在多媒体领域有广泛应用,近期技术进展使根据描述音频场景(如图像或文本)生成相关音频成为可能。
- 现有方法忽视局部声源细节,导致生成的音频沉浸感和表达力有限。
- SS2A生成器能局部感知多模式声源,结合视觉检测和跨模态翻译来学习跨模态声源(CMSS)流形。
- SS2A通过CMSS语义与丰富的音频表示结合,由预训练音频生成器输出声音。
- 为建模CMSS流形,从VGGSound中精选VGGS3数据集,并设计声音源匹配得分来测量局部音频相关性。
- SS2A在图像到音频任务中表现优秀,提供直观的合成控制能力。
点此查看论文截图

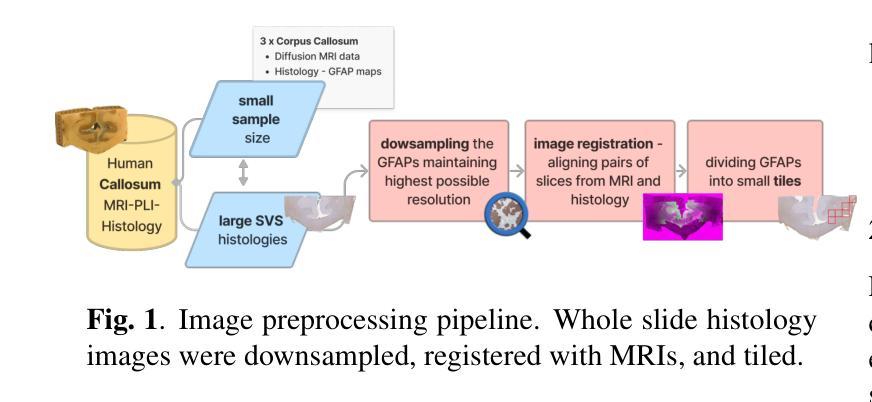
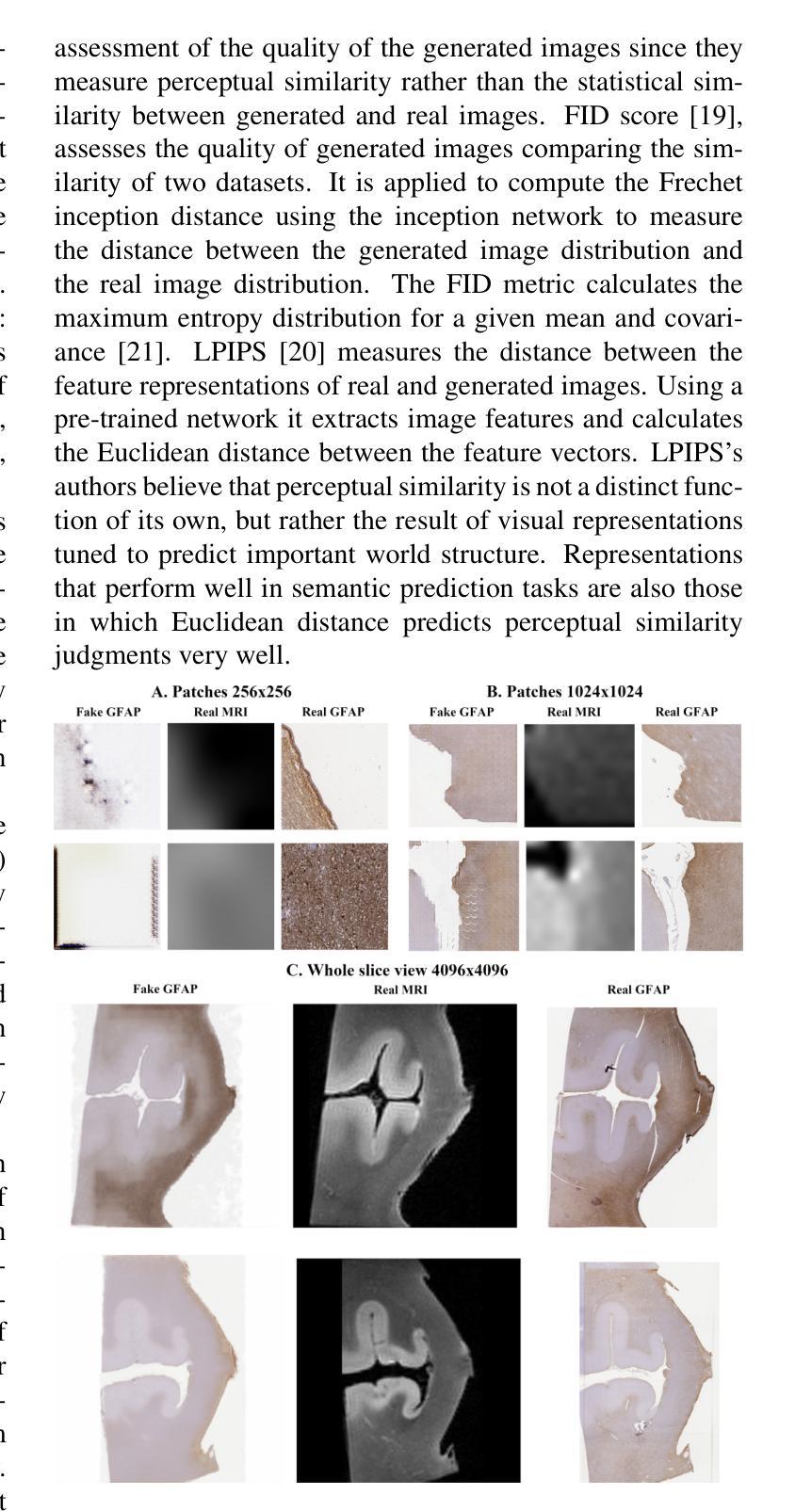
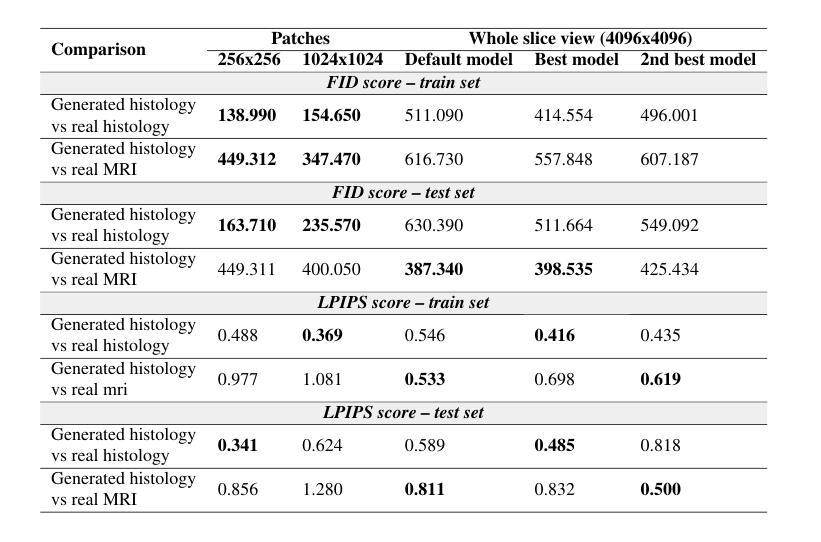
Style transfer between Microscopy and Magnetic Resonance Imaging via Generative Adversarial Network in small sample size settings
Authors:Monika Pytlarz, Adrian Onicas, Alessandro Crimi
Cross-modal augmentation of Magnetic Resonance Imaging (MRI) and microscopic imaging based on the same tissue samples is promising because it can allow histopathological analysis in the absence of an underlying invasive biopsy procedure. Here, we tested a method for generating microscopic histological images from MRI scans of the human corpus callosum using conditional generative adversarial network (cGAN) architecture. To our knowledge, this is the first multimodal translation of the brain MRI to histological volumetric representation of the same sample. The technique was assessed by training paired image translation models taking sets of images from MRI scans and microscopy. The use of cGAN for this purpose is challenging because microscopy images are large in size and typically have low sample availability. The current work demonstrates that the framework reliably synthesizes histology images from MRI scans of corpus callosum, emphasizing the network’s ability to train on high resolution histologies paired with relatively lower-resolution MRI scans. With the ultimate goal of avoiding biopsies, the proposed tool can be used for educational purposes.
基于同一组织样本的磁共振成像(MRI)和显微镜成像的跨模态增强很有前景,因为它可以在没有潜在的侵入性活检程序的情况下进行组织病理学分析。在这里,我们测试了一种方法,即使用条件生成对抗网络(cGAN)架构,根据人脑胼胝体的MRI扫描生成显微镜组织学图像。据我们所知,这是首次将脑MRI转化为同一样本的组织学体积表示的多模式翻译。该技术通过训练配对图像翻译模型来评估,这些模型采用MRI扫描和显微镜的图像集。使用cGAN进行此操作具有挑战性,因为显微镜图像尺寸较大,而且通常样本可用量较少。当前的工作证明,该框架能够可靠地合成胼胝体的MRI扫描的组织学图像,突出了网络在相对较低的分辨率MRI扫描上训练高分辨率组织学的能力。以最终避免活检为目标,所提出的工具可用于教学目的。
论文及项目相关链接
PDF 2023 IEEE International Conference on Image Processing (ICIP)
Summary
MRI与显微镜成像的跨模态增强技术,基于同一组织样本,可在无需侵入性活检程序的情况下进行病理分析。本研究通过条件生成对抗网络(cGAN)架构,测试了从MRI扫描生成微观组织图像的方法。此为首个将脑MRI转换为同一样本的组织学体积表示的多模式转换。通过训练配对图像翻译模型评估该技术,该模型采用MRI扫描和显微镜图像集。显微镜图像尺寸大且样本可用性低,使用cGAN进行此目的具有挑战性。当前工作证明该框架可靠地合成来自脑回状MRI扫描的组织学图像,突显网络在高分辨率组织学上训练的能力,与相对较低的分辨率MRI扫描配对。最终目标是为了避免活检,所提出的工具可用于教学目的。
Key Takeaways
- 跨模态增强MRI和显微镜成像技术对于避免侵入性活检程序下的病理分析具有潜力。
- 研究采用cGAN架构实现从MRI扫描到微观组织图像的生成。
- 这是首个将脑MRI转换为同一样本的组织学体积表示的多模式转换技术。
- 使用配对图像翻译模型评估技术,涉及MRI扫描和显微镜图像集。
- 使用cGAN处理大尺寸、低样本可用性的显微镜图像具有挑战性。
- 研究证明框架能从脑回状MRI扫描中可靠合成组织学图像。
点此查看论文截图