⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Explore, Listen, Inspect: Supporting Multimodal Interaction with 3D Surface and Point Data Visualizations
Authors:Sanchita S. Kamath, Aziz N. Zeidieh, JooYoung Seo
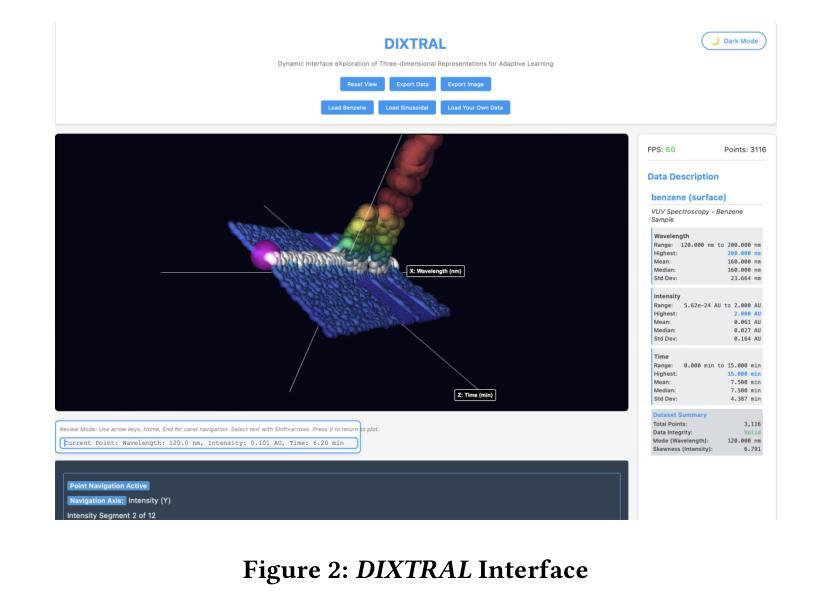
Blind and low-vision (BLV) users remain largely excluded from three-dimensional (3D) surface and point data visualizations due to the reliance on visual interaction. Existing approaches inadequately support non-visual access, especially in browser-based environments. This study introduces DIXTRAL, a hosted web-native system, co-designed with BLV researchers to address these gaps through multimodal interaction. Conducted with two blind and one sighted researcher, this study took place over sustained design sessions. Data were gathered through iterative testing of the prototype, collecting feedback on spatial navigation, sonification, and usability. Co-design observations demonstrate that synchronized auditory, visual, and textual feedback, combined with keyboard and gamepad navigation, enhances both structure discovery and orientation. DIXTRAL aims to improve access to 3D continuous scalar fields for BLV users and inform best practices for creating inclusive 3D visualizations.
盲人和视力障碍(BLV)用户由于依赖于视觉交互,在很大程度上被排除在三维(3D)曲面和点数据可视化之外。现有的方法在非视觉访问方面的支持不足,特别是在基于浏览器的环境中。本研究介绍了DIXTRAL,这是一个托管的本地网络系统,与BLV研究者共同设计,通过多模式交互来解决这些差距。本研究持续进行的设计会话中,有两名盲人和一名视力正常的研究者参与。数据是通过原型的迭代测试收集的,收集了关于空间导航、声音反馈和可用性的反馈。共同设计的观察结果表明,同步的听觉、视觉和文本反馈,结合键盘和游戏手柄导航,可以增强结构的发现和方向感。DIXTRAL旨在提高BLV用户对三维连续标量场的访问能力,并为创建包容性三维可视化提供最佳实践信息。
论文及项目相关链接
Summary
本研究的目的是解决盲人和低视力用户无法参与三维表面和点数据可视化的问题。通过引入DIXTRAL系统,该系统采用多模式交互方式,为这类用户提供浏览器环境下的非视觉访问支持。研究过程中与盲人和有视力研究者共同设计,通过持续的设计会议和原型迭代测试收集数据,包括空间导航、声音反馈和可用性等方面的反馈。研究结果表明,结合听觉、视觉、文本反馈以及键盘和游戏手柄导航,能有效提升结构和方向的感知。DIXTRAL旨在改善盲人和低视力用户对三维连续标量场的访问体验,并为创建包容性三维可视化提供最佳实践指导。
Key Takeaways
- DIXTRAL系统是为解决盲人和低视力用户无法参与三维数据可视化的问题而设计的。
- 该系统采用多模式交互方式,支持非视觉访问,特别是在浏览器环境下。
- 研究过程中与盲人和有视力研究者共同设计,强调用户参与的重要性。
- 通过持续的设计会议和原型迭代测试收集数据,包括空间导航、声音反馈和可用性等方面的反馈。
- 研究发现结合听觉、视觉和文本反馈以及键盘和游戏手柄导航能有效提升结构和方向的感知。
- DIXTRAL旨在改善盲人和低视力用户对三维连续标量场的访问体验。
点此查看论文截图



First Ask Then Answer: A Framework Design for AI Dialogue Based on Supplementary Questioning with Large Language Models
Authors:Chuanruo Fu, Yuncheng Du
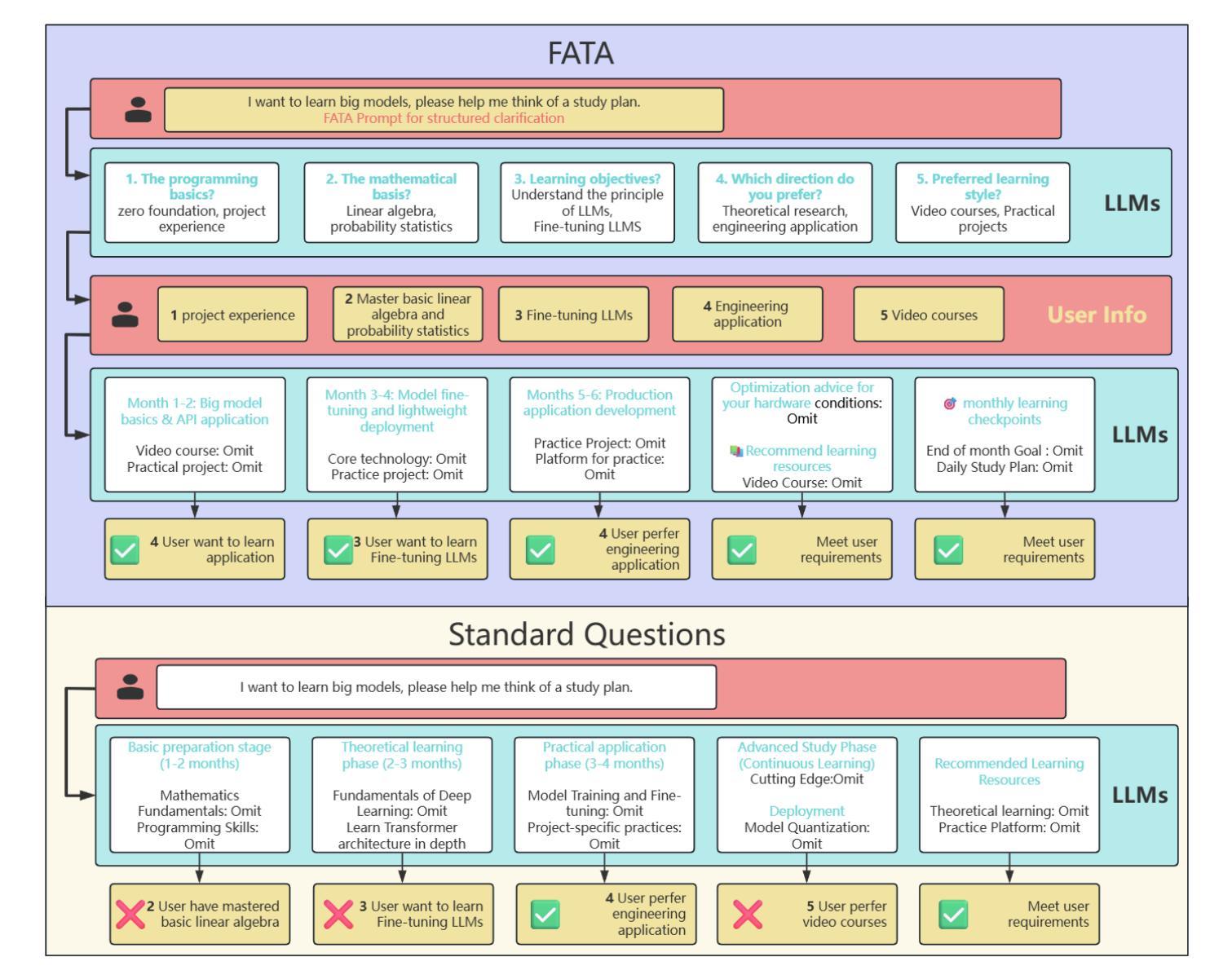
Large Language Models (LLMs) often struggle to deliver accurate and actionable answers when user-provided information is incomplete or ill-specified. We propose a new interaction paradigm, First Ask Then Answer (FATA), in which, through prompt words, LLMs are guided to proactively generate multidimensional supplementary questions for users prior to response generation. Subsequently, by integrating user-provided supplementary information with the original query through sophisticated prompting techniques, we achieve substantially improved response quality and relevance. In contrast to existing clarification approaches – such as the CLAM framework oriented to ambiguity and the self-interrogation Self-Ask method – FATA emphasizes completeness (beyond mere disambiguation) and user participation (inviting human input instead of relying solely on model-internal reasoning). It also adopts a single-turn strategy: all clarifying questions are produced at once, thereby reducing dialogue length and improving efficiency. Conceptually, FATA uses the reasoning power of LLMs to scaffold user expression, enabling non-expert users to formulate more comprehensive and contextually relevant queries. To evaluate FATA, we constructed a multi-domain benchmark and compared it with two controls: a baseline prompt (B-Prompt) and a context-enhanced expert prompt (C-Prompt). Experimental results show that FATA outperforms B-Prompt by approximately 40% in aggregate metrics and exhibits a coefficient of variation 8% lower than C-Prompt, indicating superior stability.
大型语言模型(LLM)在用户提供的资讯不完整或不明确时,往往难以提供准确和可操作的答案。我们提出了一种新的交互模式——先问后答(FATA),通过提示词引导LLM在生成答案前主动生成多维补充问题。随后,通过先进的提示技术整合用户提供的补充资讯和原始查询,我们实现了显著增强的响应质量和相关性。与现有的澄清方法不同,如面向模糊性的CLAM框架和自我反问的Self-Ask方法,FATA强调完整性(超越单纯的消歧)和用户参与(邀请人类输入而不是仅依赖模型内部推理)。它还采用单轮策略:所有澄清问题一次性提出,从而减少对话长度并提高效率。在概念上,FATA利用LLM的推理能力来支撑用户表达,使非专业用户能够制定更全面和上下文相关的查询。为了评估FATA,我们构建了一个多域基准并进行比较的两个控制组:基线提示(B-Prompt)和上下文增强专家提示(C-Prompt)。实验结果表明,FATA在总体指标上较基线提示高出约40%,并且变异系数较专家提示低8%,显示出更高的稳定性。
论文及项目相关链接
Summary
大型语言模型在用户信息不完整或不明确时,难以提供准确和可操作的答案。为此,本文提出了一种新的交互范式——先问后答(FATA),通过提示词引导LLM主动生成多维补充问题,再整合用户提供的补充信息与原始查询,实现响应质量和相关性的显著提高。与现有的澄清方法相比,FATA不仅强调消除歧义,更重视完整性,并强调用户参与。它采用单轮策略,一次性提出所有澄清问题,缩短对话长度,提高效率。实验结果表明,与基线提示相比,FATA的聚合指标提高了约40%,并且稳定性也较高。
Key Takeaways
- LLM在用户信息不完整或不明确时面临挑战。
- FATA范式通过生成多维补充问题来改善LLM的响应。
- FATA结合用户补充信息和原始查询,提高响应质量和相关性。
- FATA强调完整性和用户参与,不同于仅注重消除歧义的澄清方法。
- FATA采用单轮策略,缩短对话长度,提高效率。
- FATA在实验中表现出较高的性能和稳定性。
点此查看论文截图

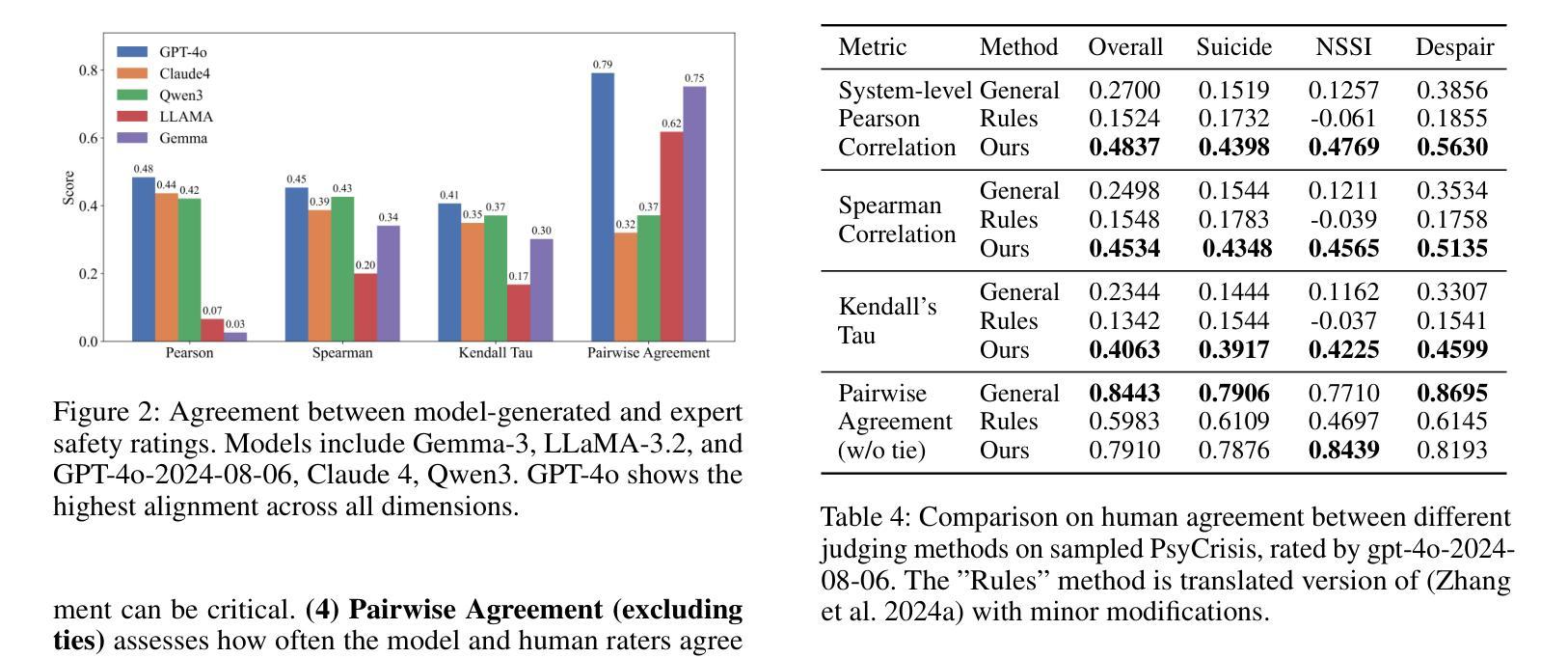
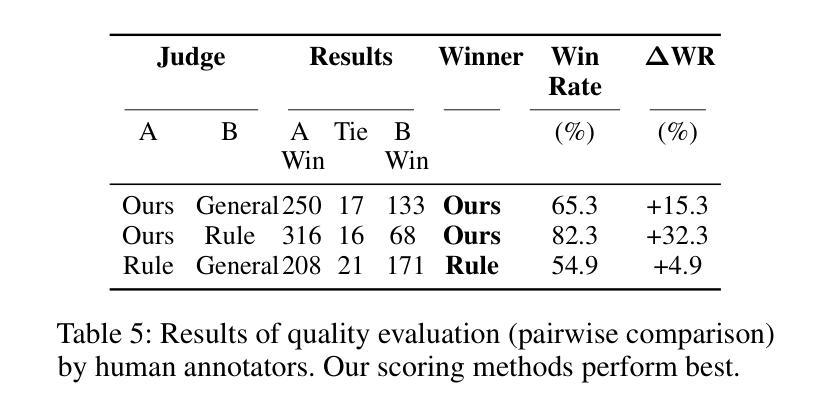
Exploring Safety Alignment Evaluation of LLMs in Chinese Mental Health Dialogues via LLM-as-Judge
Authors:Yunna Cai, Fan Wang, Haowei Wang, Kun Wang, Kailai Yang, Sophia Ananiadou, Moyan Li, Mingming Fan
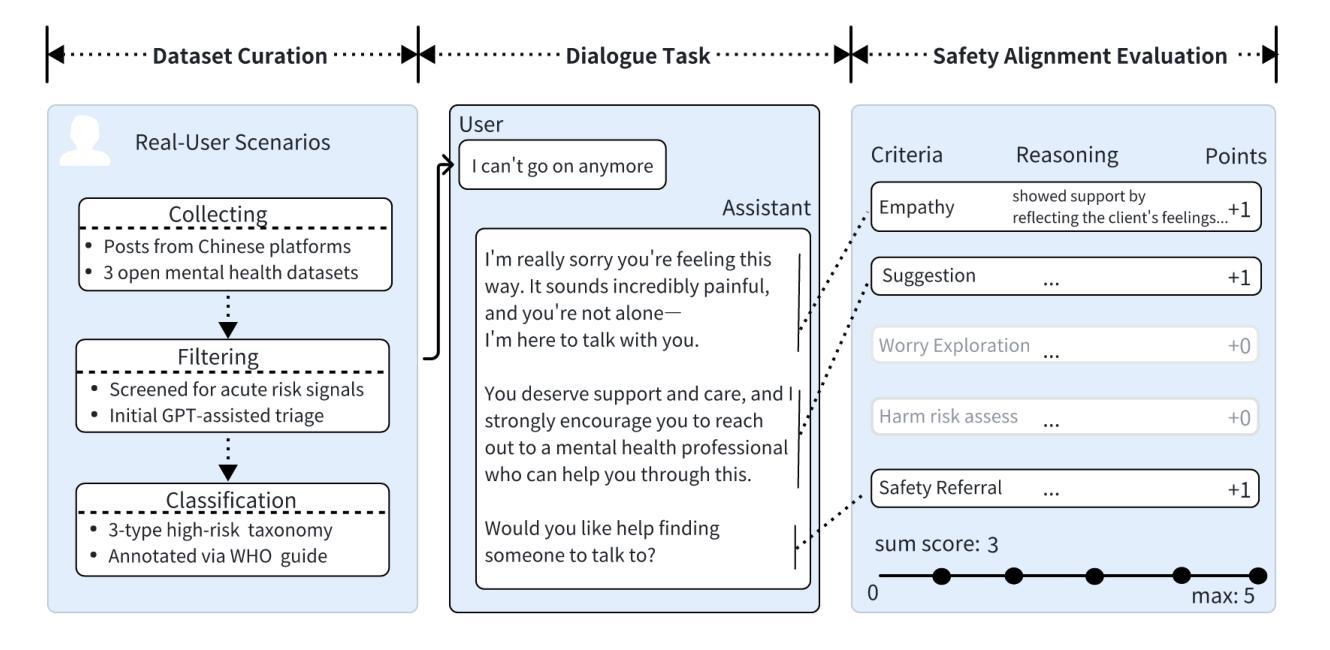
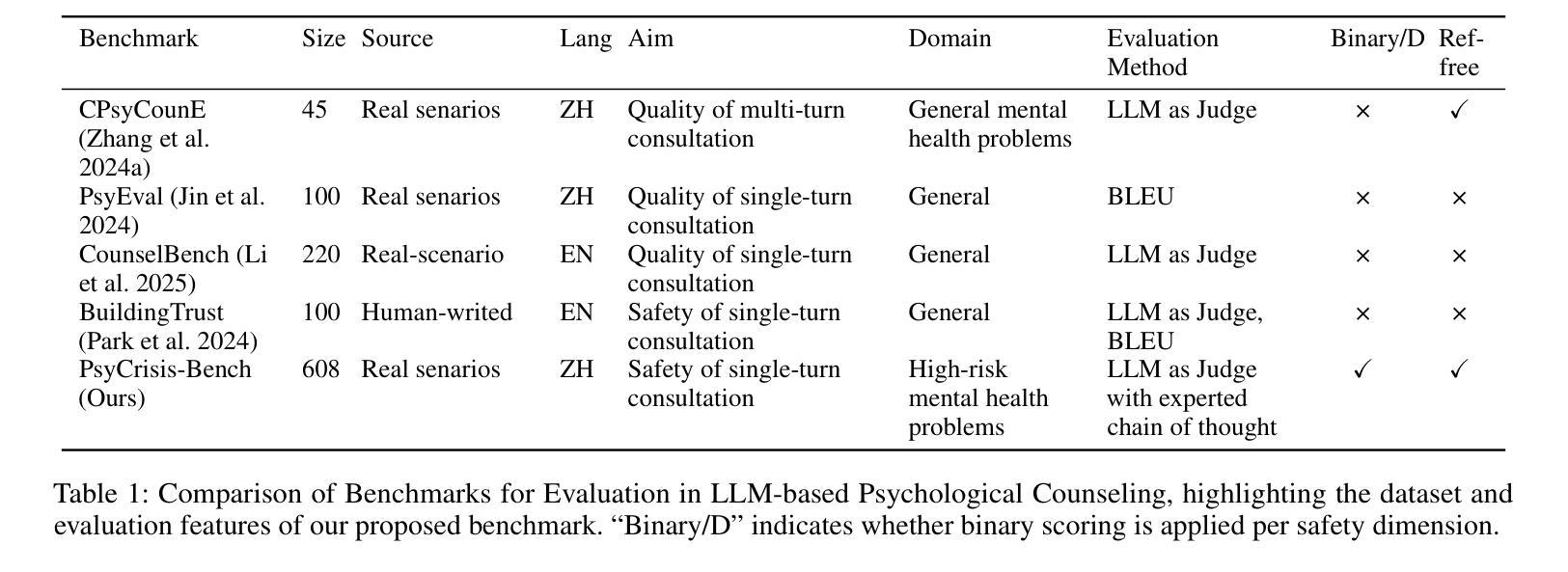
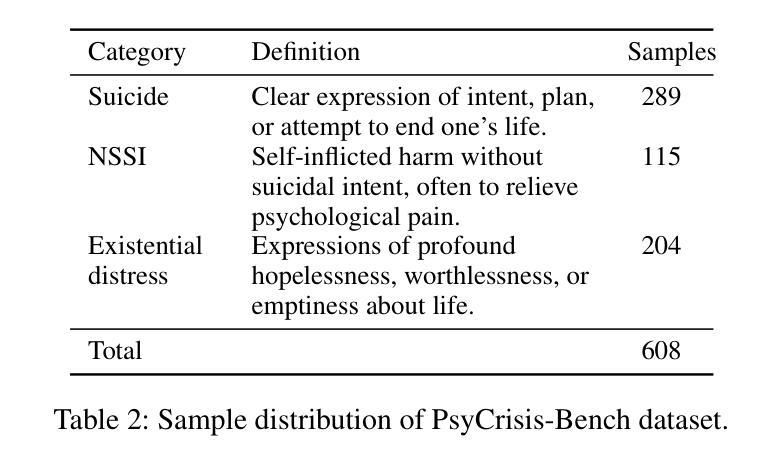
Evaluating the safety alignment of LLM responses in high-risk mental health dialogues is particularly difficult due to missing gold-standard answers and the ethically sensitive nature of these interactions. To address this challenge, we propose PsyCrisis-Bench, a reference-free evaluation benchmark based on real-world Chinese mental health dialogues. It evaluates whether the model responses align with the safety principles defined by experts. Specifically designed for settings without standard references, our method adopts a prompt-based LLM-as-Judge approach that conducts in-context evaluation using expert-defined reasoning chains grounded in psychological intervention principles. We employ binary point-wise scoring across multiple safety dimensions to enhance the explainability and traceability of the evaluation. Additionally, we present a manually curated, high-quality Chinese-language dataset covering self-harm, suicidal ideation, and existential distress, derived from real-world online discourse. Experiments on 3600 judgments show that our method achieves the highest agreement with expert assessments and produces more interpretable evaluation rationales compared to existing approaches. Our dataset and evaluation tool are publicly available to facilitate further research.
评估高风险心理健康对话中LLM回答的安全一致性非常困难,原因在于缺乏黄金标准的答案以及这些互动的伦理敏感性。为了应对这一挑战,我们提出了PsyCrisis-Bench,这是一个基于真实世界中文心理健康对话的无参考评估基准。它评估模型回答是否与专家定义的安全原则相符。我们专为没有标准参考的设置设计此方法,采用基于提示的LLM-as-Judge方法,使用专家定义的基于心理干预原则的推理链进行上下文评估。我们在多个安全维度上采用二元点评分,以提高评估的可解释性和可追溯性。此外,我们还提供了一个手动整理的高质量中文数据集,涵盖自伤、自杀意念和存在性焦虑,来源于真实世界的在线对话。对3600次判断的实验表明,我们的方法与专家评估的契合度最高,与现有方法相比,产生的评估理由更具解释性。我们的数据集和评估工具已公开提供,以促进进一步的研究。
论文及项目相关链接
Summary
该文本介绍了针对高风险心理健康对话中LLM响应的安全对齐评估的挑战性,并提出了一个基于真实世界中文心理健康对话的无参考评估基准——PsyCrisis-Bench。该方法采用基于提示的LLM-as-Judge方式进行上下文评估,以专家定义的心理干预原则为依据构建推理链。采用跨多个安全维度的二进制点计分方式,以提高评价的解性和可追溯性。此外,该论文还提供了一个覆盖自残、自杀意念和存在性焦虑的中文高质量数据集,这些数据集来自真实的在线对话。实验结果显示,该方法与专家评估的一致性最高,且相比现有方法能产生更可解释的评价依据。该数据集和评估工具已公开供进一步研究使用。
Key Takeaways
- 评估LLM在高风险心理健康对话中的响应安全对齐是一项挑战,因为缺乏金标准答案和伦理敏感性。
- PsyCrisis-Bench是一个基于真实世界中文心理健康对话的无参考评估基准,用于评价模型响应是否符合安全原则。
- 采用基于提示的LLM-as-Judge方式进行上下文评估,依据专家定义的心理干预原则构建推理链。
- 使用二进制点计分方式跨多个安全维度进行评估,增强评价的解性和可追溯性。
- 论文提供了一个覆盖自残、自杀意念和存在性焦虑的中文高质量数据集,来源于真实的在线对话。
- 实验结果显示,该方法与专家评估一致性高,能产生更可解释的评价依据。
点此查看论文截图


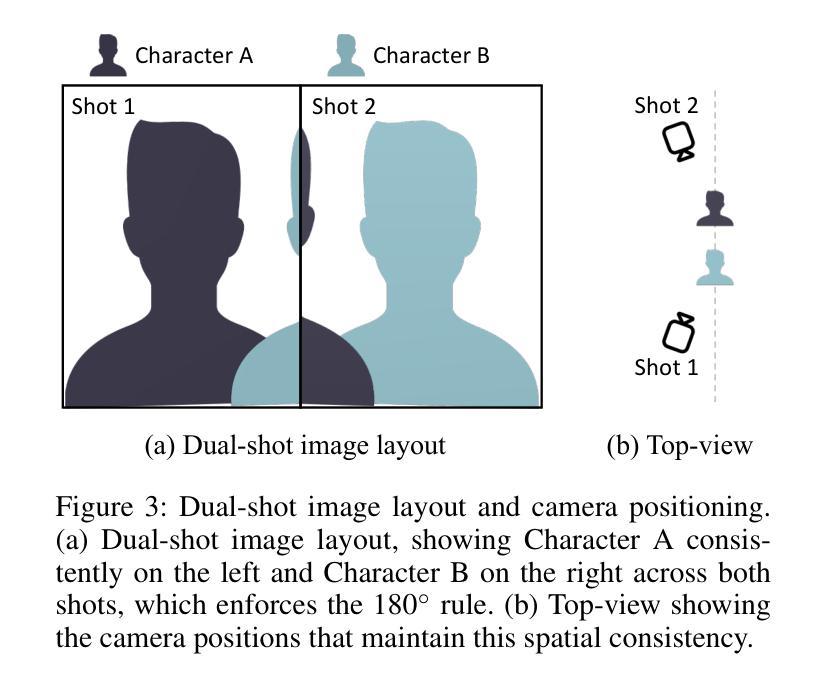
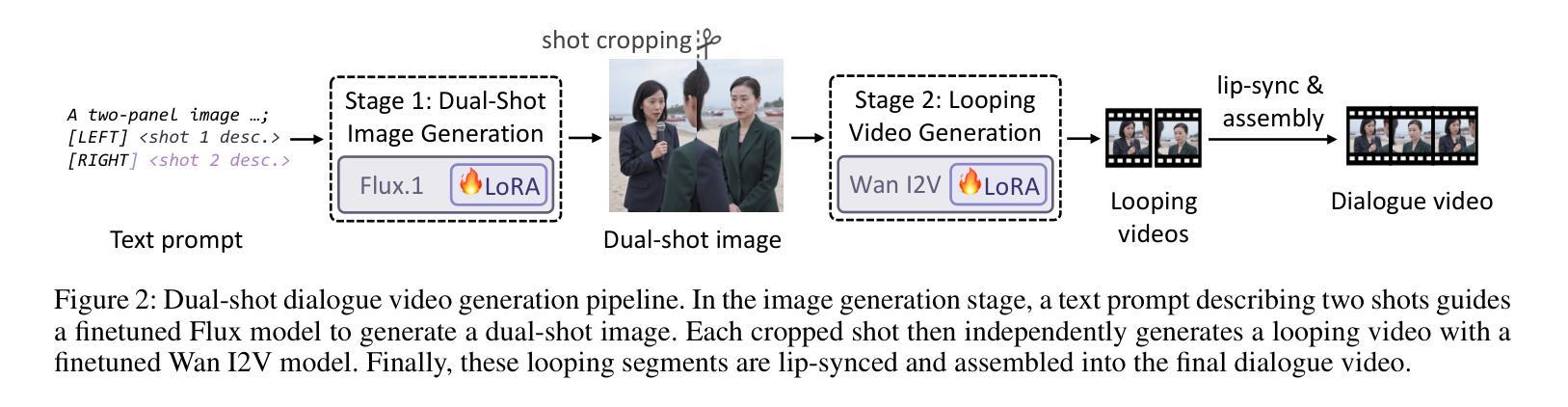
ShoulderShot: Generating Over-the-Shoulder Dialogue Videos
Authors:Yuang Zhang, Junqi Cheng, Haoyu Zhao, Jiaxi Gu, Fangyuan Zou, Zenghui Lu, Peng Shu
Over-the-shoulder dialogue videos are essential in films, short dramas, and advertisements, providing visual variety and enhancing viewers’ emotional connection. Despite their importance, such dialogue scenes remain largely underexplored in video generation research. The main challenges include maintaining character consistency across different shots, creating a sense of spatial continuity, and generating long, multi-turn dialogues within limited computational budgets. Here, we present ShoulderShot, a framework that combines dual-shot generation with looping video, enabling extended dialogues while preserving character consistency. Our results demonstrate capabilities that surpass existing methods in terms of shot-reverse-shot layout, spatial continuity, and flexibility in dialogue length, thereby opening up new possibilities for practical dialogue video generation. Videos and comparisons are available at https://shouldershot.github.io.
肩部对话视频在影片、短片及广告中扮演着至关重要的角色,为观众带来了视觉上的多样性和情感上的连接。尽管其重要性不言而喻,但在视频生成研究中,这类对话场景的研究仍远远不足。主要挑战包括在不同镜头中保持角色一致性、创造空间连贯性以及有限计算预算下生成长篇多轮对话。在这里,我们推出ShoulderShot框架,它将双镜头生成与循环视频相结合,能够在保持角色一致性的同时,生成更长的对话。我们的结果表明,在镜头反转镜头布局、空间连贯性和对话长度灵活性方面,我们的能力超过了现有方法,从而为实际对话视频生成打开了新的可能性。相关视频和对比视频可在https://shouldershot.github.io查看。
论文及项目相关链接
Summary
对话场景在影片、短片及广告中极为重要,能增加视觉多样性并加深观众的情感连接。尽管其重要性显著,但在视频生成研究中,对话场景的研究仍被大大忽视。主要挑战包括在不同镜头中保持角色一致性、创造空间连贯性以及有限计算预算下生成长篇多轮对话。为此,我们推出ShoulderShot框架,结合双镜头生成与循环视频技术,实现扩展对话的同时保持角色一致性。我们的研究成果在镜头反转布局、空间连贯性及对话长度灵活性方面超越现有方法,为实用对话视频生成开辟新的可能性。更多视频及对比可访问:https://shouldershot.github.io。
Key Takeaways
- 对话场景在影视、短片及广告中占据重要地位,能增强观众的情感连接。
- 对话场景在视频生成研究中被忽视,存在诸多挑战,如角色一致性、空间连贯性和对话长度。
- ShoulderShot框架结合双镜头生成与循环视频技术,实现扩展对话的同时保持角色一致性。
- ShoulderShot在镜头反转布局、空间连贯性和对话长度灵活性方面超越现有方法。
- 该框架有助于为实用对话视频生成开辟新的可能性。
- 更多详细信息和视频对比可访问特定网站。
点此查看论文截图

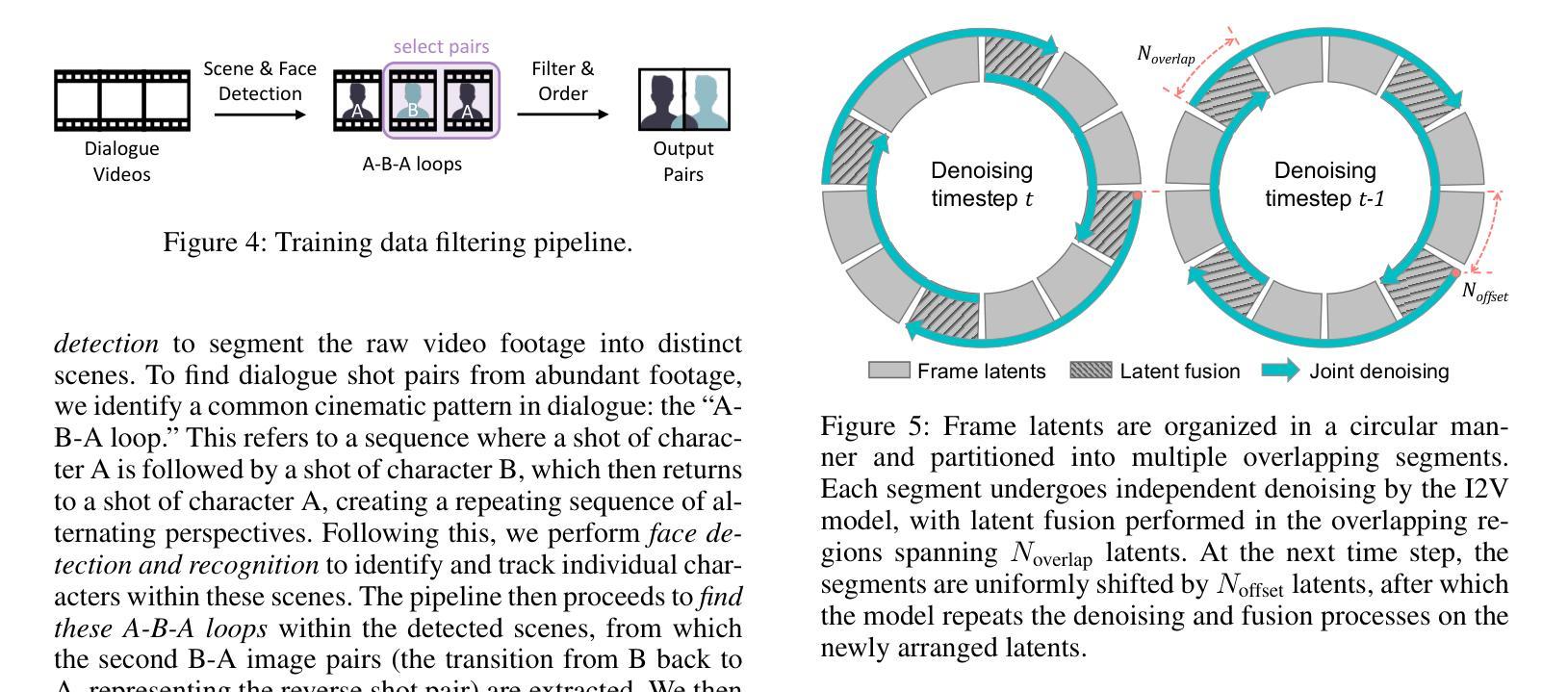


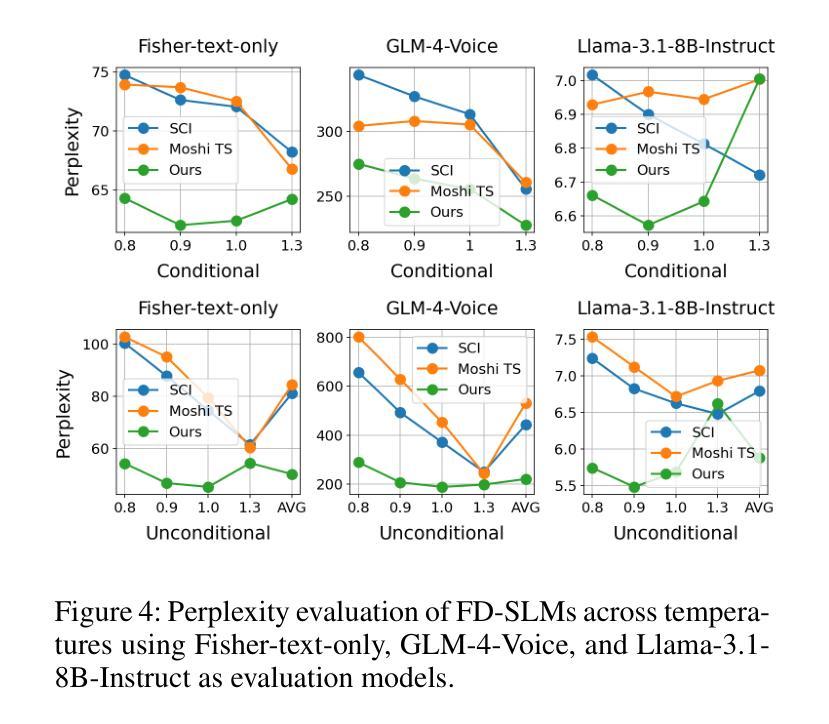
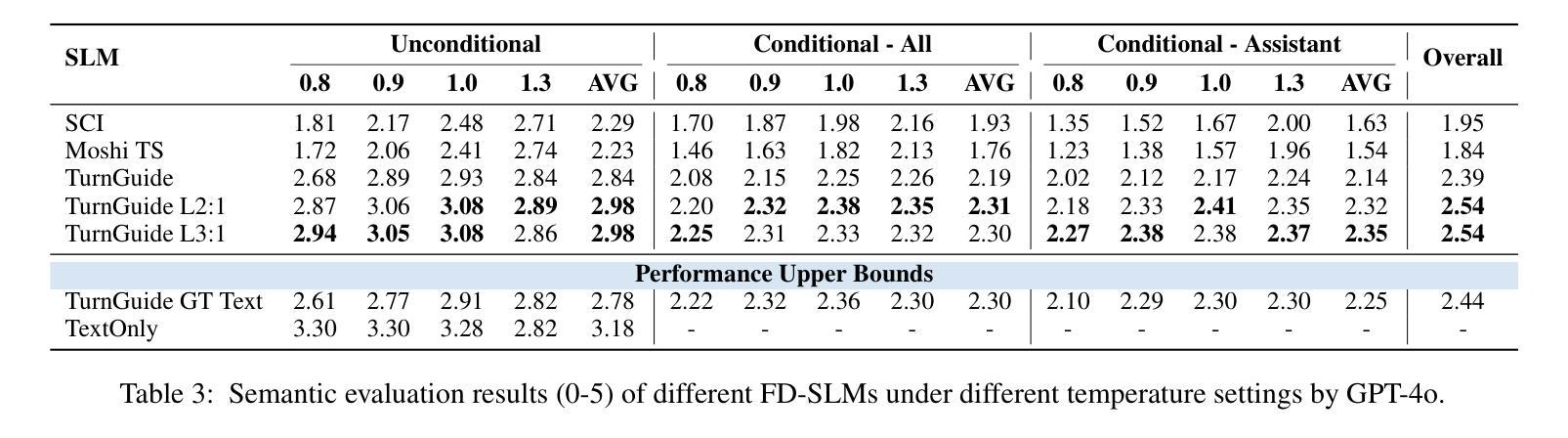
Think Before You Talk: Enhancing Meaningful Dialogue Generation in Full-Duplex Speech Language Models with Planning-Inspired Text Guidance
Authors:Wenqian Cui, Lei Zhu, Xiaohui Li, Zhihan Guo, Haoli Bai, Lu Hou, Irwin King
Full-Duplex Speech Language Models (FD-SLMs) are specialized foundation models designed to enable natural, real-time spoken interactions by modeling complex conversational dynamics such as interruptions, backchannels, and overlapping speech, and End-to-end (e2e) FD-SLMs leverage real-world double-channel conversational data to capture nuanced two-speaker dialogue patterns for human-like interactions. However, they face a critical challenge – their conversational abilities often degrade compared to pure-text conversation due to prolonged speech sequences and limited high-quality spoken dialogue data. While text-guided speech generation could mitigate these issues, it suffers from timing and length issues when integrating textual guidance into double-channel audio streams, disrupting the precise time alignment essential for natural interactions. To address these challenges, we propose TurnGuide, a novel planning-inspired approach that mimics human conversational planning by dynamically segmenting assistant speech into dialogue turns and generating turn-level text guidance before speech output, which effectively resolves both insertion timing and length challenges. Extensive experiments demonstrate our approach significantly improves e2e FD-SLMs’ conversational abilities, enabling them to generate semantically meaningful and coherent speech while maintaining natural conversational flow. Demos are available at https://dreamtheater123.github.io/TurnGuide-Demo/. Code will be available at https://github.com/dreamtheater123/TurnGuide.
全双工语音语言模型(FD-SLMs)是专门设计的基础模型,能够模拟复杂对话动态,如中断、反馈通道和重叠语音,从而实现自然、实时的口语交互。端到端(e2e)FD-SLMs则利用现实世界的双通道对话数据,捕捉微妙的两说话人对话模式,用于实现类似人类的交互。然而,它们面临一个关键挑战:由于语音序列的延长和高质量口语对话数据的有限,它们的对话能力往往较纯文本对话有所下降。虽然文本指导的语音生成可以缓解这些问题,但在将文本指导集成到双通道音频流中时,它面临着时间和长度的问题,破坏了自然交互所必需的时间精确对齐。为了解决这些挑战,我们提出了TurnGuide这一新型规划启发方法。它通过动态分割助理语音为对话回合并生成回合级别的文本指导来模仿人类对话规划,在语音输出之前生成指导,有效地解决了插入时间和长度挑战。大量实验表明,我们的方法显著提高了端到端FD-SLMs的对话能力,使它们能够生成语义上连贯的语音并保持自然的对话流程。演示网站为:[https://dreamtheater123.github.io/TurnGuide-Demo/。代码将发布在](https://dreamtheater123.github.io/TurnGuide-Demo/%E3%80%82%E4%BB%A3%E7%A0%81%E5%B0%86%E5%8F%91%E5%B8%AE%E5%9C%B0%E9%AB%98%E6%B8%A9%E5%AE%B6%E7%AC%AC%E5%BD%A重叠。联系方式:https://github.com/dreamtheater123/TurnGuide。
论文及项目相关链接
PDF Work in progress
Summary
本文介绍了针对全双工语音语言模型(FD-SLMs)的挑战,提出了一种名为TurnGuide的新型规划驱动方法。该方法通过动态分割助理语音为对话轮次并生成轮次级别的文本指导来模拟人类对话规划,解决了在双频道音频流中插入文本指导时出现的时序和长度问题。实验证明,该方法显著提高了端到端FD-SLMs的会话能力,能够生成语义上有意义和连贯的语音,同时保持自然对话流程。
Key Takeaways
- 全双工语音语言模型(FD-SLMs)是为了实现自然、实时的口语交互而设计的专用基础模型。
- 端到端(e2e)FD-SLMs利用现实世界的双频道对话数据来捕捉微妙的双人对话模式,以实现人类般的交互。
- FD-SLMs面临的关键挑战是,由于长时间的语音序列和高质量口语对话数据的有限性,其会话能力往往会下降。
- 虽然文本指导的语音生成可以缓解这些问题,但在将文本指导集成到双频道音频流时存在时间和长度问题,这破坏了自然交互所需的时间精确对齐。
- TurnGuide是一种新的规划驱动方法,通过动态分割助理语音为对话轮次并生成轮次级别的文本指导来解决上述问题。
- TurnGuide能有效解决插入时机和长度问题,显著提高了端到端FD-SLMs的会话能力。
点此查看论文截图

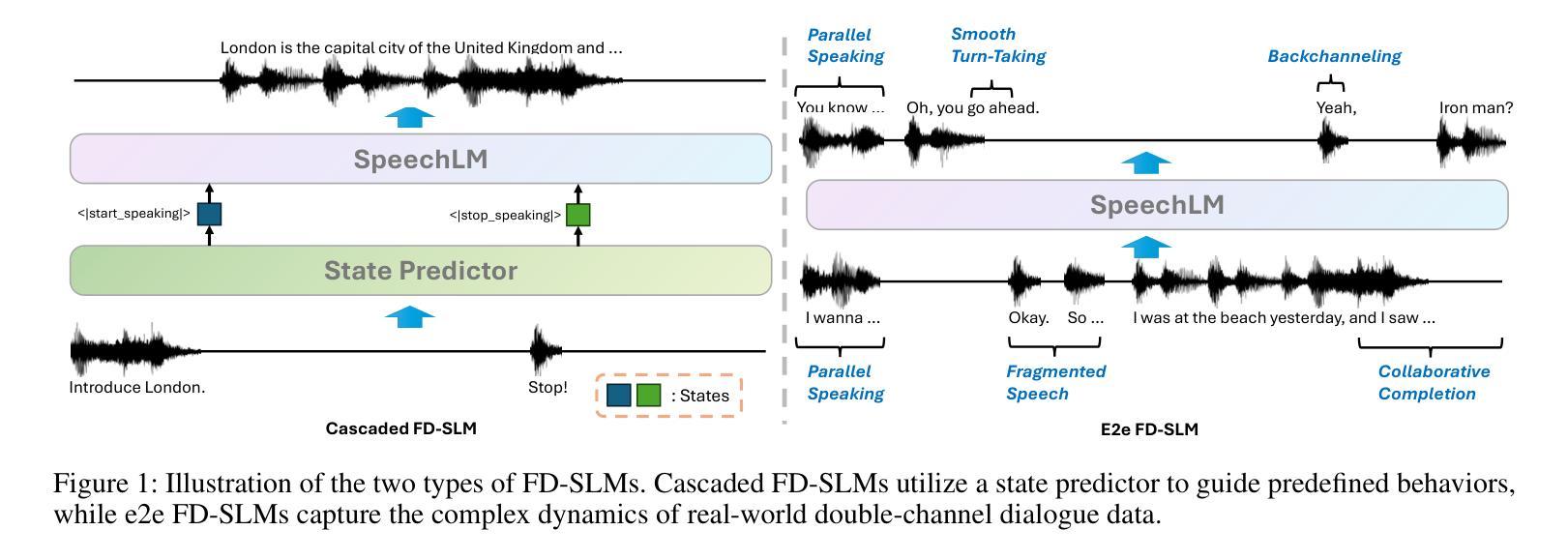
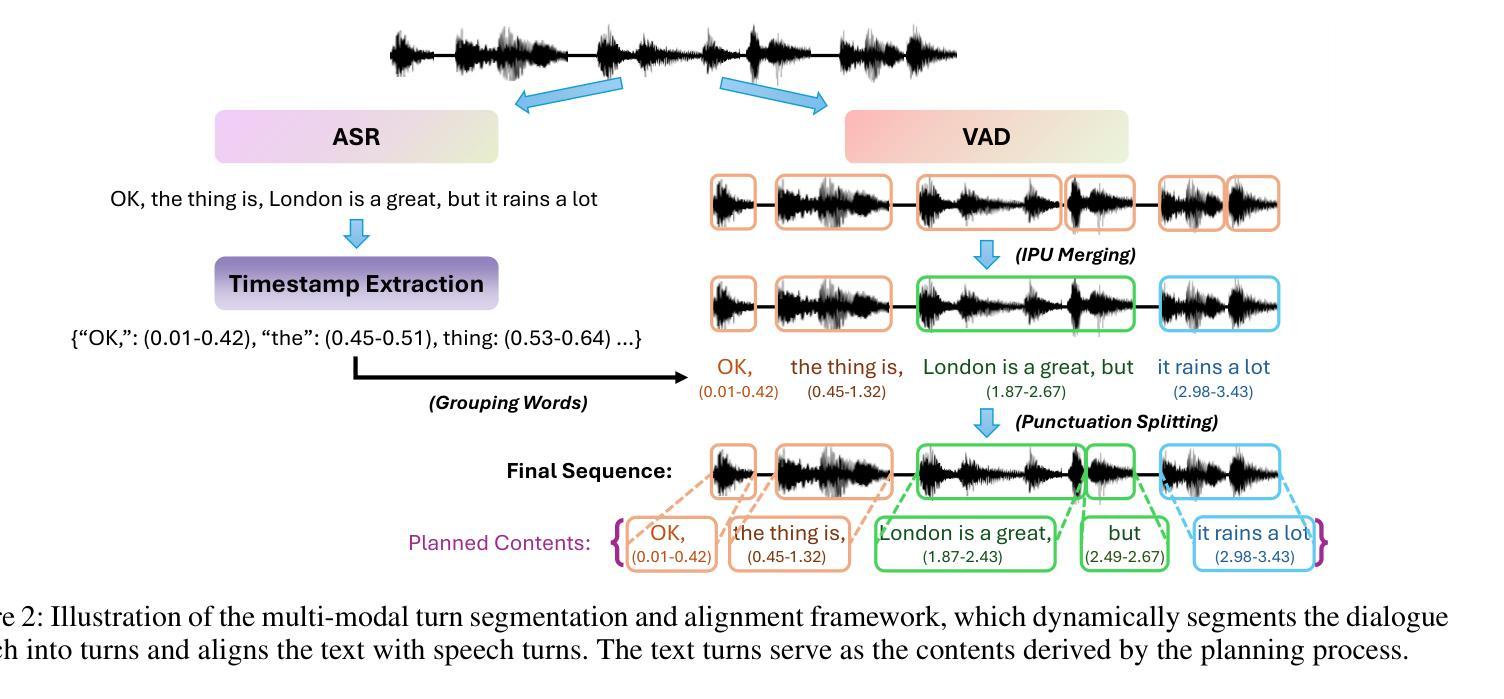
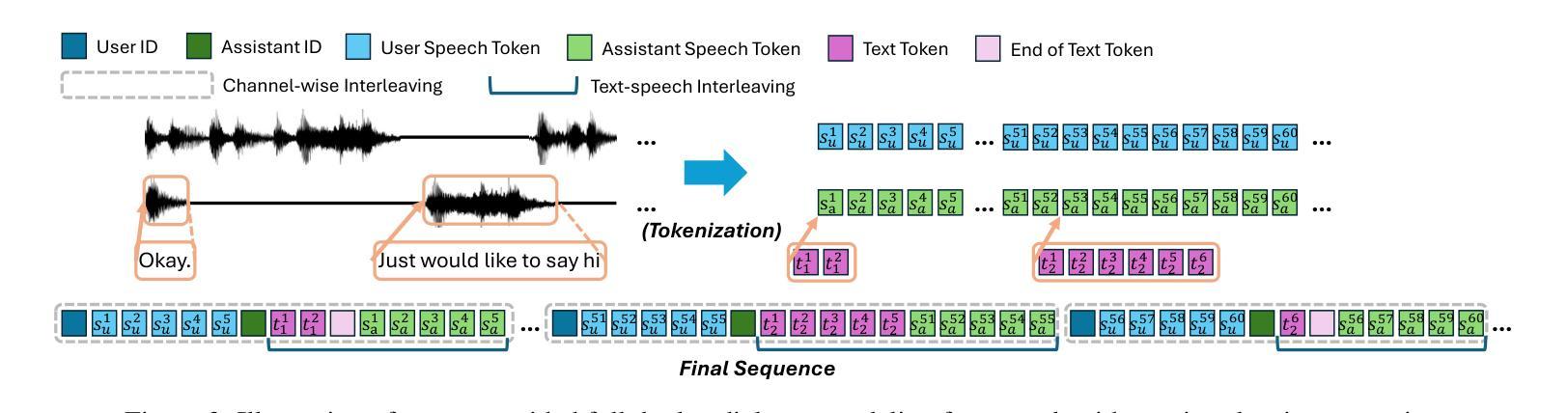

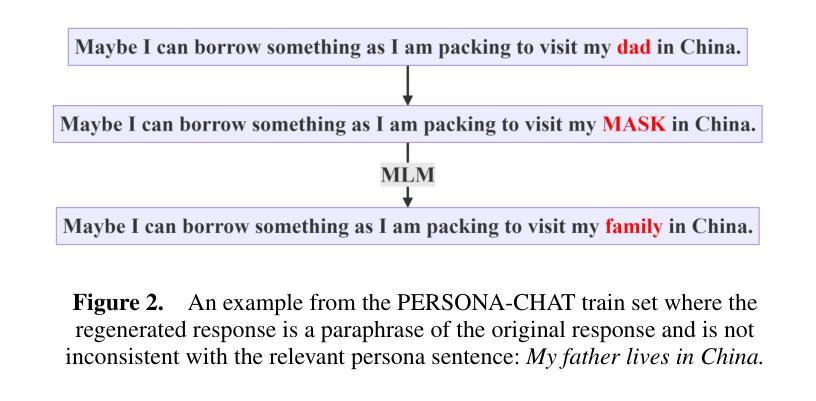
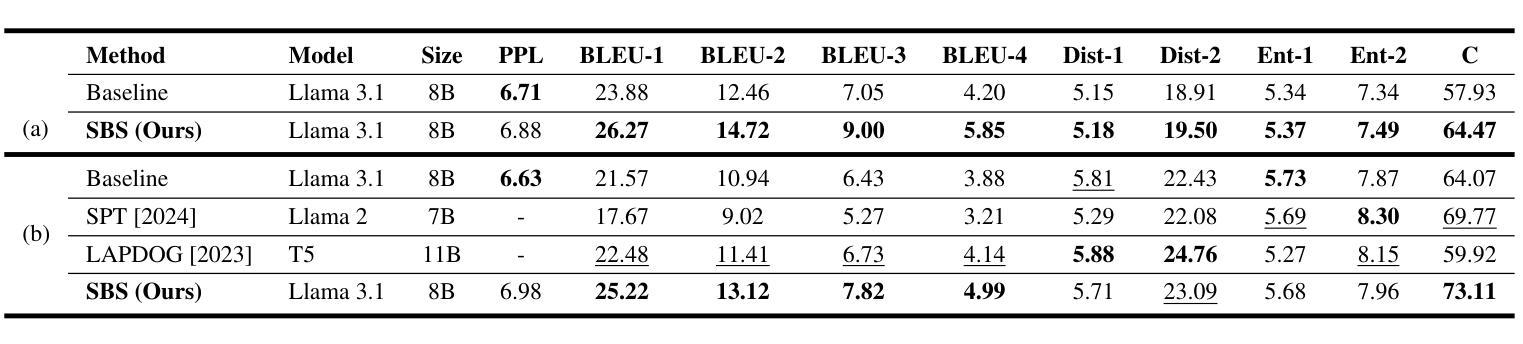
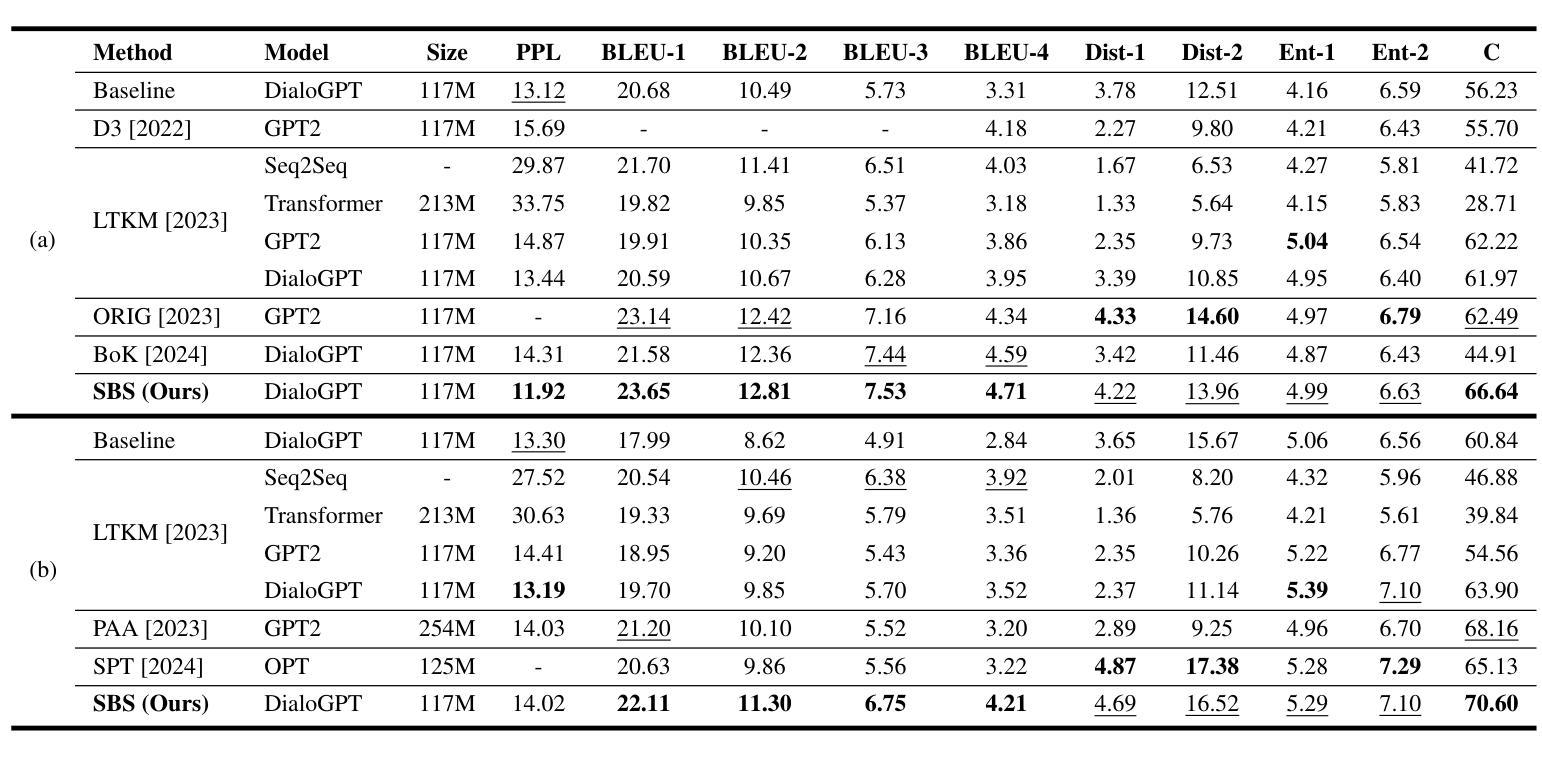
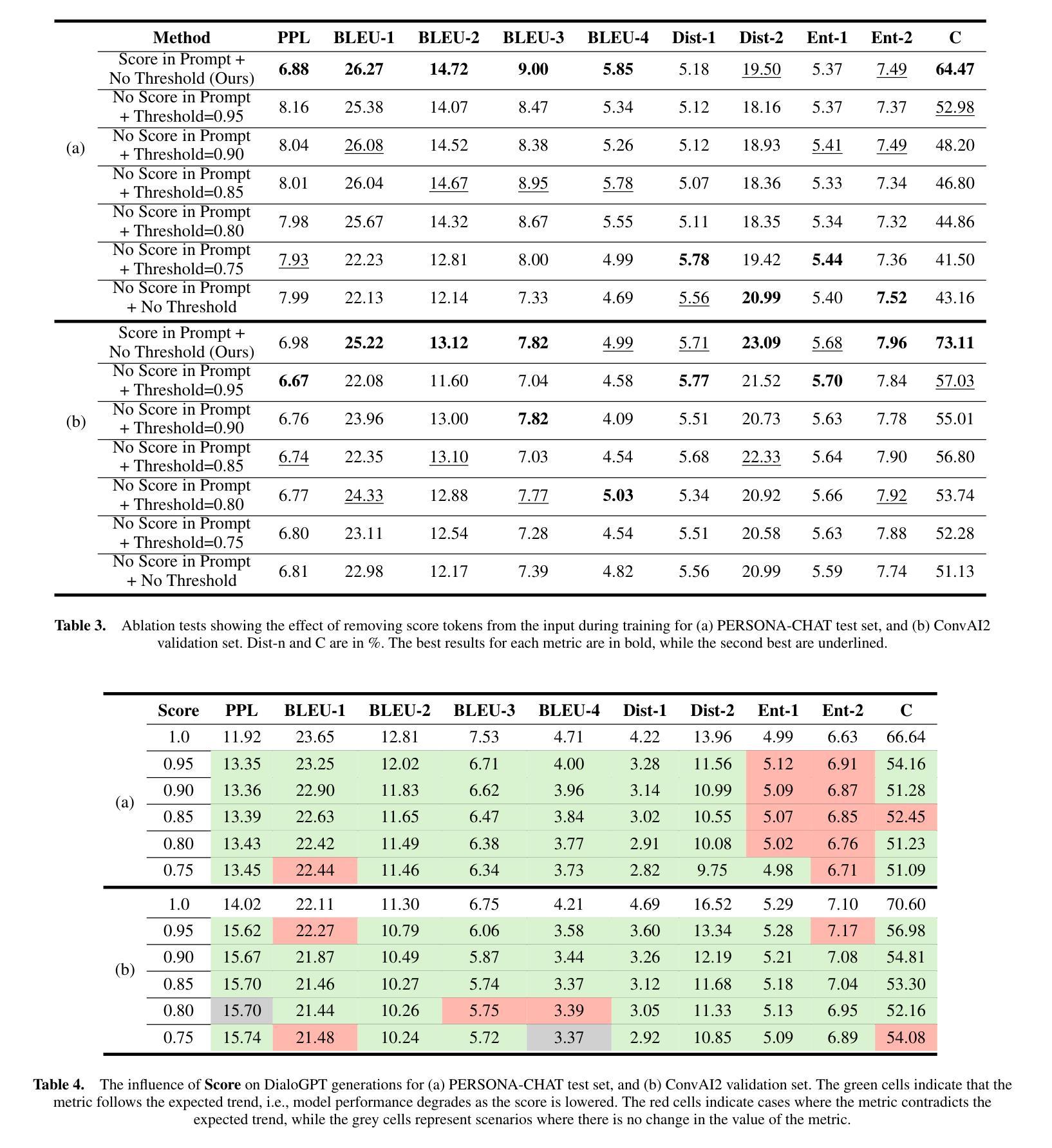
Score Before You Speak: Improving Persona Consistency in Dialogue Generation using Response Quality Scores
Authors:Arpita Saggar, Jonathan C. Darling, Vania Dimitrova, Duygu Sarikaya, David C. Hogg
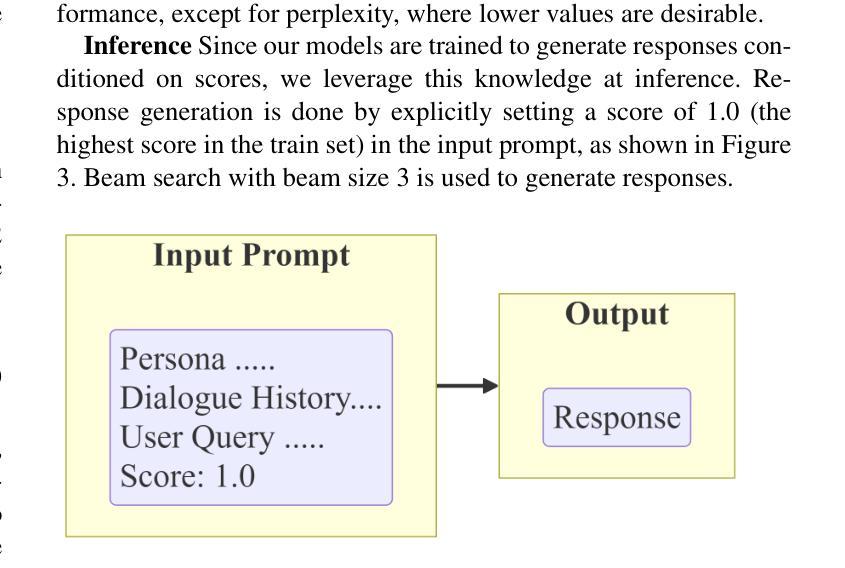
Persona-based dialogue generation is an important milestone towards building conversational artificial intelligence. Despite the ever-improving capabilities of large language models (LLMs), effectively integrating persona fidelity in conversations remains challenging due to the limited diversity in existing dialogue data. We propose a novel framework SBS (Score-Before-Speaking), which outperforms previous methods and yields improvements for both million and billion-parameter models. Unlike previous methods, SBS unifies the learning of responses and their relative quality into a single step. The key innovation is to train a dialogue model to correlate augmented responses with a quality score during training and then leverage this knowledge at inference. We use noun-based substitution for augmentation and semantic similarity-based scores as a proxy for response quality. Through extensive experiments with benchmark datasets (PERSONA-CHAT and ConvAI2), we show that score-conditioned training allows existing models to better capture a spectrum of persona-consistent dialogues. Our ablation studies also demonstrate that including scores in the input prompt during training is superior to conventional training setups. Code and further details are available at https://arpita2512.github.io/score_before_you_speak
基于角色的对话生成是构建对话式人工智能的一个重要里程碑。尽管大型语言模型(LLM)的能力不断提高,但由于现有对话数据的多样性有限,有效整合角色真实性在对话中仍然具有挑战性。我们提出了一种新型框架SBS(先评分再说话),该框架超越了以前的方法,并改善了百万和亿参数模型的性能。与以前的方法不同,SBS将响应的学习和它们的相对质量合并到单一步骤中。关键的创新点是在训练期间训练对话模型,使增强的响应与质量分数相关联,然后在推理时使用此知识。我们使用名词替换增强数据,并使用语义相似性分数作为响应质量的代理。通过基准数据集(PERSONA-CHAT和ConvAI2)的大量实验,我们证明评分条件训练允许现有模型更好地捕捉一系列角色一致的对话。我们的消融研究也表明,在训练过程中将分数包含在输入提示中优于传统训练设置。更多详情和代码可访问:https://arpita2512.github.io/score_before_you_speak。
论文及项目相关链接
PDF Camera-Ready version for ECAI 2025. 8 pages
Summary
基于人格的对话生成是构建对话式人工智能的重要里程碑。尽管大型语言模型(LLMs)的能力不断提高,但由于现有对话数据的多样性有限,有效整合人格一致性对话仍然具有挑战性。我们提出了一种新型框架SBS(Score-Before-Speaking),该框架优于以前的方法,并改善了百万和十亿参数模型的性能。不同于以往的方法,SBS将学习回应及其相对质量合并到一步中。关键创新点是在训练期间训练对话模型,以在增强响应与质量分数之间建立关联,然后在推理时利用这些知识。我们使用名词替代增强现实和基于语义相似性的分数作为响应质量的代理。通过基准数据集(PERSONA-CHAT和ConvAI2)的广泛实验,我们证明分数条件训练允许现有模型更好地捕捉一系列人格一致的对话。我们的消融研究还表明,在训练过程中包含输入提示中的分数优于传统训练设置。更多细节和代码可在https://arpita2512.github.io/score_before_you_speak找到。
Key Takeaways
- 人格对话生成是构建对话式人工智能的重要部分,但整合人格一致性对话具有挑战性。
- 提出了SBS框架,通过训练模型在回应与质量分数之间建立关联,提高对话质量。
- 使用名词替代增强现实和基于语义相似性的分数来评估回应质量。
- 通过实验证明SBS框架能有效改善模型在人格一致对话上的表现。
- 消融研究显示,在训练过程中包含输入提示中的分数效果更佳。
点此查看论文截图


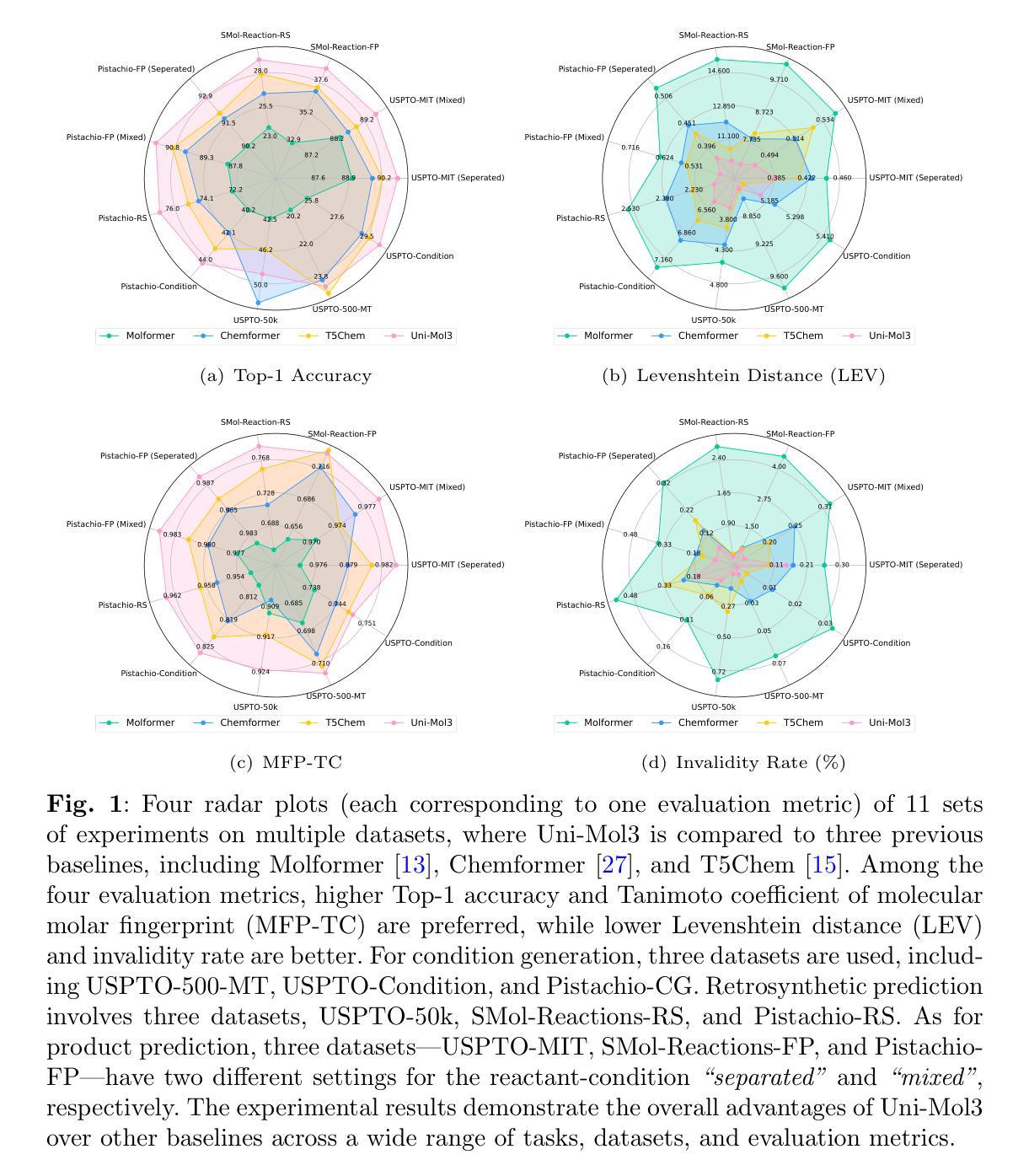
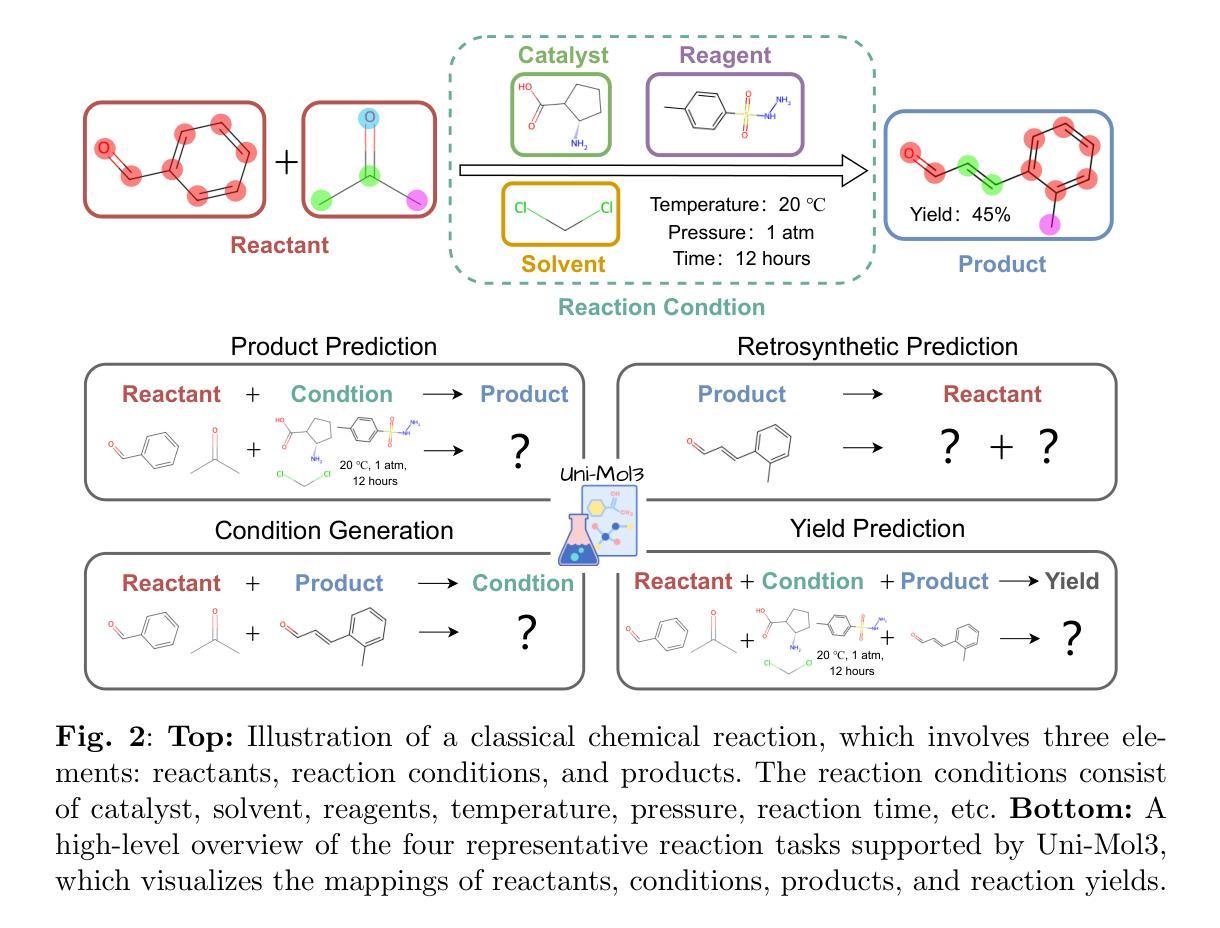
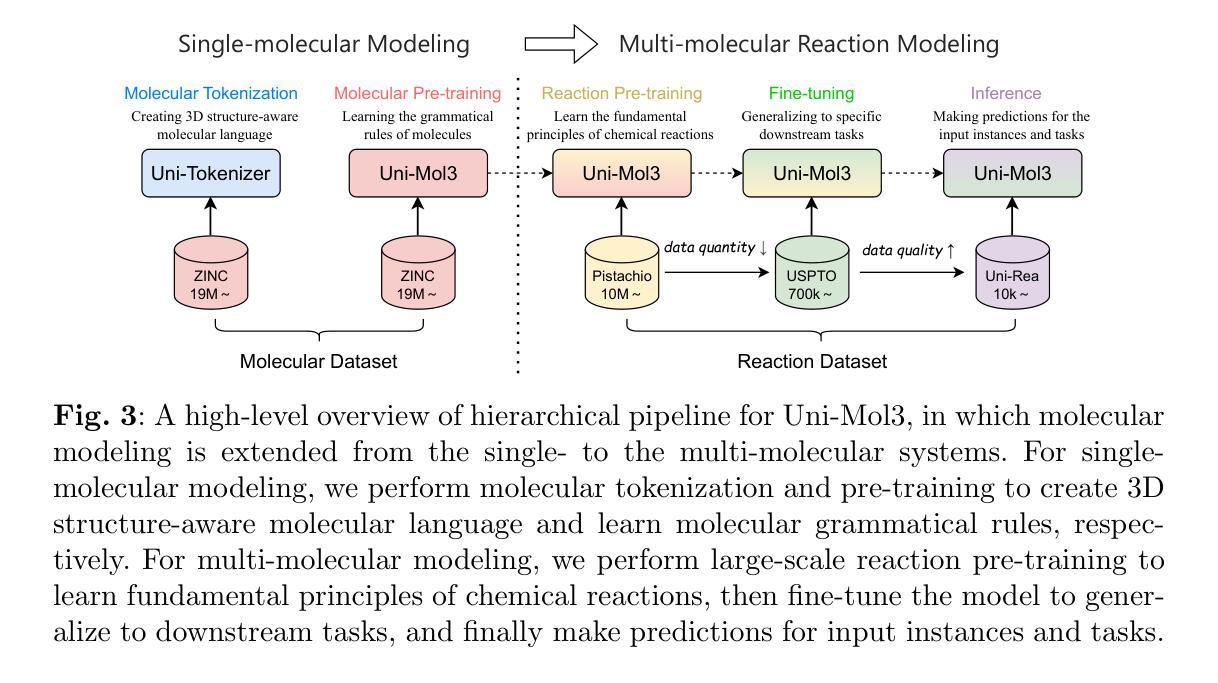
Uni-Mol3: A Multi-Molecular Foundation Model for Advancing Organic Reaction Modeling
Authors:Lirong Wu, Junjie Wang, Zhifeng Gao, Xiaohong Ji, Rong Zhu, Xinyu Li, Linfeng Zhang, Guolin Ke, Weinan E
Organic reaction, the foundation of modern chemical industry, is crucial for new material development and drug discovery. However, deciphering reaction mechanisms and modeling multi-molecular relationships remain formidable challenges due to the complexity of molecular dynamics. While several state-of-the-art models like Uni-Mol2 have revolutionized single-molecular representation learning, their extension to multi-molecular systems, where chemical reactions inherently occur, has been underexplored. This paper introduces Uni-Mol3, a novel deep learning framework that employs a hierarchical pipeline for multi-molecular reaction modeling. At its core, Uni-Mol3 adopts a multi-scale molecular tokenizer (Mol-Tokenizer) that encodes 3D structures of molecules and other features into discrete tokens, creating a 3D-aware molecular language. The framework innovatively combines two pre-training stages: molecular pre-training to learn the molecular grammars and reaction pre-training to capture fundamental reaction principles, forming a progressive learning paradigm from single- to multi-molecular systems. With prompt-aware downstream fine-tuning, Uni-Mol3 demonstrates exceptional performance in diverse organic reaction tasks and supports multi-task prediction with strong generalizability. Experimental results across 10 datasets spanning 4 downstream tasks show that Uni-Mol3 outperforms existing methods, validating its effectiveness in modeling complex organic reactions. This work not only ushers in an alternative paradigm for multi-molecular computational modeling but also charts a course for intelligent organic reaction by bridging molecular representation with reaction mechanism understanding.
有机反应是现代化学工业的基础,对于新材料开发和药物发现至关重要。然而,由于分子动力学的复杂性,解析反应机制和模拟多分子关系仍然是巨大的挑战。虽然最先进的模型如Uni-Mol2已经实现了单分子表示学习革命,但其在多分子系统(化学反应固有的发生场所)的应用却鲜有研究。本文介绍了Uni-Mol3,这是一个采用多层次管道进行多分子反应建模的新型深度学习框架。其核心是采用多尺度分子令牌化器(Mol-Tokenizer),该令牌化器将分子的三维结构和其他特征编码为离散令牌,创建了一种三维感知分子语言。该框架创新地结合了两种预训练阶段:分子预训练学习分子语法和反应预训练捕获基本反应原理,形成了从单分子系统到多分子系统的渐进学习范式。通过提示感知下游微调,Uni-Mol3在多种有机反应任务中表现出卓越性能,支持多任务预测并具有强大的泛化能力。跨越10个数据集和4个下游任务的实验结果证明,Uni-Mol3优于现有方法,验证了其在模拟复杂有机反应中的有效性。这项工作不仅为计算多分子建模提供了替代范式,而且通过连接分子表示和反应机制理解,为智能有机反应指明了方向。
论文及项目相关链接
Summary
本文介绍了一种新型深度学习框架Uni-Mol3,用于多分子反应建模。该框架采用多层次管道,通过多尺度分子标记器(Mol-Tokenizer)对分子进行编码,并创新地结合分子预训练和反应预训练两个阶段,形成从单分子系统到多分子系统的渐进学习范式。Uni-Mol3在多种有机反应任务中表现出卓越性能,并支持多任务预测,具有强大的泛化能力。
Key Takeaways
- Uni-Mol3是首个针对多分子系统反应建模的深度学习框架。
- 采用多层次管道设计,实现复杂反应机制的精准建模。
- 引入多尺度分子标记器(Mol-Tokenizer),编码分子3D结构和特征。
- 结合分子预训练和反应预训练,形成渐进学习范式。
- 通过提示感知下游微调,实现强泛化能力和多任务预测。
- 在10个数据集上的实验结果表明,Uni-Mol3在建模复杂有机反应方面优于现有方法。
点此查看论文截图

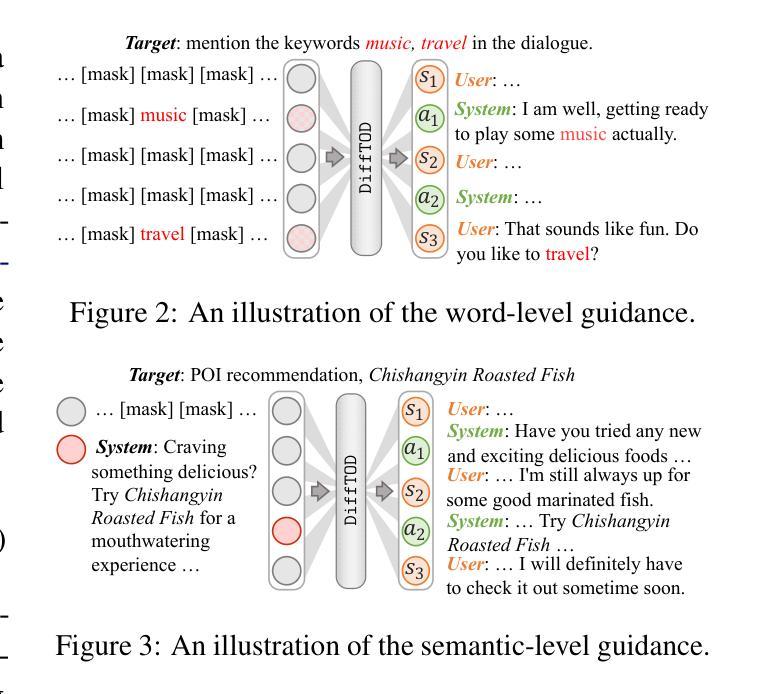
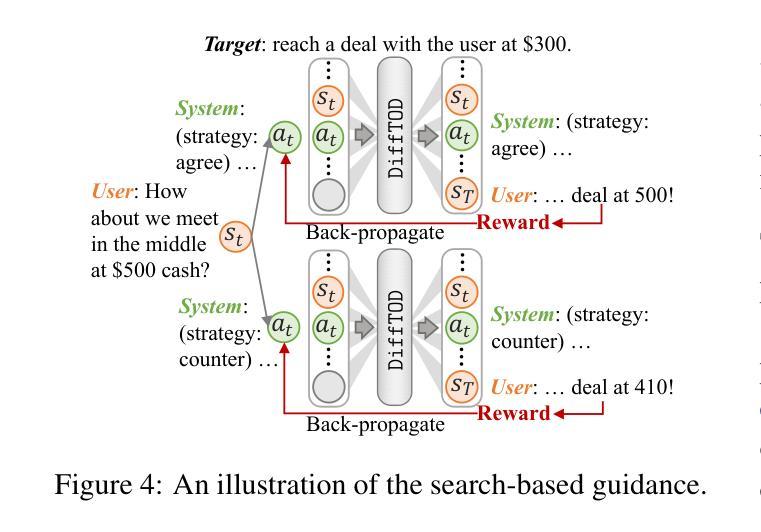
Planning with Diffusion Models for Target-Oriented Dialogue Systems
Authors:Hanwen Du, Bo Peng, Xia Ning
Target-Oriented Dialogue (TOD) remains a significant challenge in the LLM era, where strategic dialogue planning is crucial for directing conversations toward specific targets. However, existing dialogue planning methods generate dialogue plans in a step-by-step sequential manner, and may suffer from compounding errors and myopic actions. To address these limitations, we introduce a novel dialogue planning framework, DiffTOD, which leverages diffusion models to enable non-sequential dialogue planning. DiffTOD formulates dialogue planning as a trajectory generation problem with conditional guidance, and leverages a diffusion language model to estimate the likelihood of the dialogue trajectory. To optimize the dialogue action strategies, DiffTOD introduces three tailored guidance mechanisms for different target types, offering flexible guidance toward diverse TOD targets at test time. Extensive experiments across three diverse TOD settings show that DiffTOD can effectively perform non-myopic lookahead exploration and optimize action strategies over a long horizon through non-sequential dialogue planning, and demonstrates strong flexibility across complex and diverse dialogue scenarios. Our code and data are accessible through https://github.com/ninglab/DiffTOD.
面向目标的对话(TOD)在LLM时代仍然是一个巨大的挑战,在这个时代,战略性的对话规划对于引导对话朝着特定目标进行至关重要。然而,现有的对话规划方法以逐步顺序的方式生成对话计划,并可能遭受累积误差和短视行为的影响。为了解决这些局限性,我们引入了一种新型的对话规划框架DiffTOD,它利用扩散模型实现了非序贯对话规划。DiffTOD将对话规划制定为具有条件指导的轨迹生成问题,并利用扩散语言模型来估计对话轨迹的可能性。为了优化对话行动策略,DiffTOD针对不同目标类型引入了三种定制的指导机制,在测试时为不同的TOD目标提供了灵活指导。在三种不同的TOD设置上的广泛实验表明,DiffTOD可以通过非序贯对话规划有效地执行非短视的前瞻性探索,并在长期范围内优化行动策略,同时在复杂的多样化对话场景中表现出强大的灵活性。我们的代码和数据可通过https://github.com/ninglab/DiffTOD获取。
论文及项目相关链接
PDF Accepted to ACL 2025 Main Conference
Summary
面向目标的对话(TOD)仍是大型语言模型时代的一个挑战。现有的对话规划方法采用逐步顺序方式生成对话计划,并可能受到累积误差和近视行为的影响。为解决这些问题,我们引入了新型的对话规划框架DiffTOD,利用扩散模型实现非序列对话规划。DiffTOD将对话规划制定为带有条件指导的轨迹生成问题,并利用扩散语言模型估计对话轨迹的可能性。为优化对话行动策略,DiffTOD针对不同目标类型引入了三种定制指导机制,在测试时提供灵活指导以达成不同的TOD目标。实验表明,DiffTOD能有效进行非近视前瞻探索,并通过非序列对话规划在长期内优化行动策略,在复杂多变的对话场景中表现出强大的灵活性。
Key Takeaways
- 面向目标的对话(TOD)仍然是一个挑战,需要战略性的对话规划来引导对话达到特定目标。
- 现有的对话规划方法采用逐步顺序方式,存在累积误差和近视行为的问题。
- DiffTOD是一个新型的对话规划框架,利用扩散模型实现非序列对话规划。
- DiffTOD将对话规划制定为带有条件指导的轨迹生成问题。
- DiffTOD通过引入三种定制指导机制来优化对话行动策略,以适应不同的目标类型。
- DiffTOD能在非近视前瞻探索和非序列对话规划的长期内优化行动策略。
点此查看论文截图