⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Prospect Theory Fails for LLMs: Revealing Instability of Decision-Making under Epistemic Uncertainty
Authors:Rui Wang, Qihan Lin, Jiayu Liu, Qing Zong, Tianshi Zheng, Weiqi Wang, Yangqiu Song
Prospect Theory (PT) models human decision-making under uncertainty, while epistemic markers (e.g., maybe) serve to express uncertainty in language. However, it remains largely unexplored whether Prospect Theory applies to contemporary Large Language Models and whether epistemic markers, which express human uncertainty, affect their decision-making behaviour. To address these research gaps, we design a three-stage experiment based on economic questionnaires. We propose a more general and precise evaluation framework to model LLMs’ decision-making behaviour under PT, introducing uncertainty through the empirical probability values associated with commonly used epistemic markers in comparable contexts. We then incorporate epistemic markers into the evaluation framework based on their corresponding probability values to examine their influence on LLM decision-making behaviours. Our findings suggest that modelling LLMs’ decision-making with PT is not consistently reliable, particularly when uncertainty is expressed in diverse linguistic forms. Our code is released in https://github.com/HKUST-KnowComp/MarPT.
前景理论(PT)模拟了人类在不确定性环境下的决策制定过程,而认知标记(例如“也许”)则用于表达语言中的不确定性。然而,前景理论是否适用于当前的的大型语言模型,以及表达人类不确定性的认知标记是否会影响这些模型的决策制定行为,这些问题仍然很大程度上没有得到探索。为了填补这些研究空白,我们设计了一个基于经济问卷的三阶段实验。我们提出了一个更通用和精确的评价框架,以模拟大型语言模型在前景理论下的决策制定行为,并通过与常见语境中常用的认知标记相关的经验概率值来引入不确定性。然后,我们根据对应的概率值将认知标记纳入评价框架,以检查它们对大型语言模型决策制定行为的影响。我们的研究结果表明,用前景理论模拟大型语言模型的决策制定并不总是可靠,特别是当不确定性以不同的语言形式表达时。我们的代码已发布在https://github.com/HKUST-KnowComp/MarPT。
论文及项目相关链接
Summary
本文探讨了将人类决策模型的前景理论应用于大型语言模型的可能性,并研究了表达人类不确定性的认识论标记对语言模型决策行为的影响。为此,研究者设计了一个包含三个阶段的实验,利用经济问卷为基础模型进行测试,并在比较情境中引入了认识论标记相关的概率值。实验结果显示,以概率理论来建模语言模型的决策并不完全可靠,特别是当不确定性以不同语言形式表达时。相关代码已发布在https://github.com/HKUST-KnowComp/MarPT。
Key Takeaways
- 研究探讨了将人类决策模型的前景理论应用于大型语言模型的可能性。
- 研究分析了认识论标记如何影响语言模型的决策行为。
- 研究设计了一个包含三个阶段的实验,以经济问卷为基础进行测试。
- 实验引入了认识论标记相关的概率值以模拟不确定性。
- 实验发现,以概率理论来建模语言模型的决策并不完全可靠。
- 当不确定性以不同语言形式表达时,这种不确定性对语言模型决策的影响更大。
点此查看论文截图


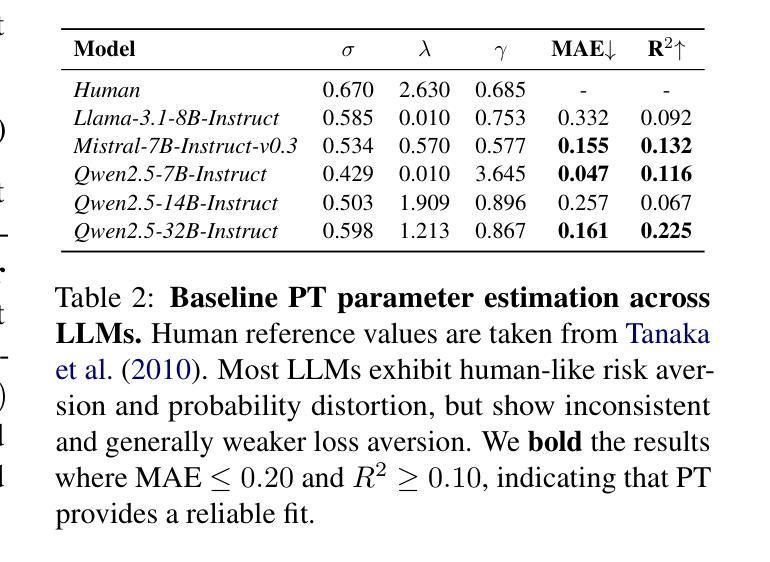
Rational Inverse Reasoning
Authors:Ben Zandonati, Tomás Lozano-Pérez, Leslie Pack Kaelbling
Humans can observe a single, imperfect demonstration and immediately generalize to very different problem settings. Robots, in contrast, often require hundreds of examples and still struggle to generalize beyond the training conditions. We argue that this limitation arises from the inability to recover the latent explanations that underpin intelligent behavior, and that these explanations can take the form of structured programs consisting of high-level goals, sub-task decomposition, and execution constraints. In this work, we introduce Rational Inverse Reasoning (RIR), a framework for inferring these latent programs through a hierarchical generative model of behavior. RIR frames few-shot imitation as Bayesian program induction: a vision-language model iteratively proposes structured symbolic task hypotheses, while a planner-in-the-loop inference scheme scores each by the likelihood of the observed demonstration under that hypothesis. This loop yields a posterior over concise, executable programs. We evaluate RIR on a suite of continuous manipulation tasks designed to test one-shot and few-shot generalization across variations in object pose, count, geometry, and layout. With as little as one demonstration, RIR infers the intended task structure and generalizes to novel settings, outperforming state-of-the-art vision-language model baselines.
人类能够观察单一、不完美的示范,并立即将其推广到非常不同的场景设置。相比之下,机器人通常需要数百个示例,仍然难以在训练条件之外进行推广。我们认为,这一局限性源于无法恢复支撑智能行为的潜在解释,这些解释可以采取结构化程序的形式,包括高级目标、子任务分解和执行约束。在这项工作中,我们引入了理性逆向推理(RIR),这是一个通过行为层次生成模型来推断这些潜在程序的框架。RIR将少数演示视为贝叶斯程序归纳:视觉语言模型提出结构化符号任务假设,而循环内的推理方案则根据每个假设下观察到的演示的可能性对其进行评分。这个循环产生了一系列简洁、可执行程序的后期概率。我们对一系列连续操作任务进行了评估,这些任务旨在测试物体姿态、数量、几何形状和布局变化中的一次性和少数次泛化能力。仅凭一次演示,RIR就能推断出预期的任务结构,并推广到新的场景,超越了最先进的视觉语言模型基准测试。
论文及项目相关链接
Summary
本文探讨了人类与机器人在观察与泛化能力上的差异。人类可以从单一的、不完美的示范中立即推广到不同的任务设置,而机器人通常需要大量的例子,仍然难以推广到训练条件之外。文章提出,这种差异源于机器人无法获取支撑智能行为的潜在解释,这些解释可以采取结构化程序的形式,包括高级目标、子任务分解和执行约束。文章介绍了一种名为理性逆向推理(RIR)的框架,该框架通过行为层次生成模型来推断这些潜在程序。RIR将少数镜头模仿视为贝叶斯程序归纳:视觉语言模型提出结构化符号任务假设,而循环内的推理方案根据该假设下观察到的演示的可能性进行评分。这个循环产生了一系列简洁、可执行程序的后续概率。在针对物体姿态、数量、几何形状和布局变化而设计的连续操作任务套件上评估RIR,仅通过一次演示,RIR就能推断出任务结构并推广到新的环境,优于最先进的视觉语言模型基线。
Key Takeaways
- 人类能从单一的、不完美的示范中快速泛化到新任务,而机器人需要更多的例子并难以泛化。
- 机器人的限制在于无法恢复支撑智能行为的潜在解释。
- Rational Inverse Reasoning (RIR)框架用于推断这些潜在程序。
- RIR将少数镜头模仿视为贝叶斯程序归纳。
- RIR包括一个视觉语言模型,提出结构化符号任务假设,并由循环内的推理方案评分。
- 通过一次或少数几次演示,RIR就能泛化到新环境并优于现有技术基线。
点此查看论文截图

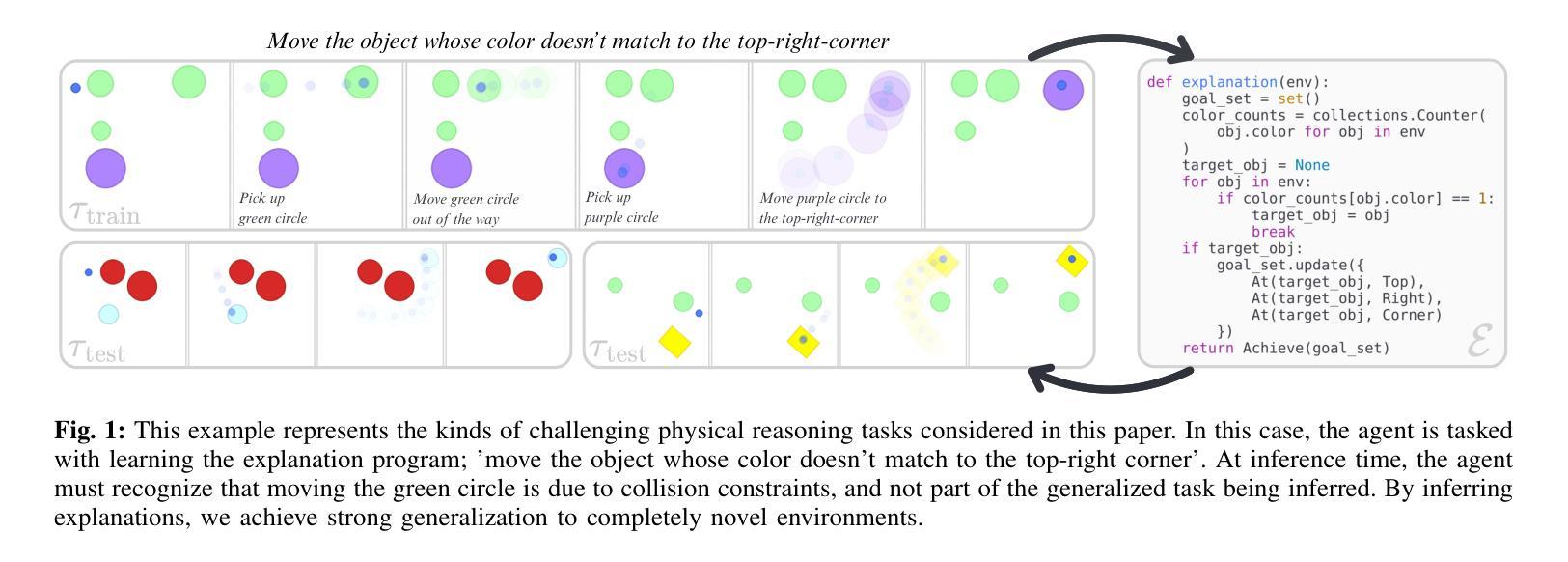
Train Long, Think Short: Curriculum Learning for Efficient Reasoning
Authors:Hasan Abed Al Kader Hammoud, Kumail Alhamoud, Abed Hammoud, Elie Bou-Zeid, Marzyeh Ghassemi, Bernard Ghanem
Recent work on enhancing the reasoning abilities of large language models (LLMs) has introduced explicit length control as a means of constraining computational cost while preserving accuracy. However, existing approaches rely on fixed-length training budgets, which do not take advantage of the natural progression from exploration to compression during learning. In this work, we propose a curriculum learning strategy for length-controlled reasoning using Group Relative Policy Optimization (GRPO). Our method starts with generous token budgets and gradually tightens them over training, encouraging models to first discover effective solution strategies and then distill them into more concise reasoning traces. We augment GRPO with a reward function that balances three signals: task correctness (via verifier feedback), length efficiency, and formatting adherence (via structural tags). Experiments on GSM8K, MATH500, SVAMP, College Math, and GSM+ demonstrate that curriculum-based training consistently outperforms fixed-budget baselines at the same final budget, achieving higher accuracy and significantly improved token efficiency. We further ablate the impact of reward weighting and decay schedule design, showing that progressive constraint serves as a powerful inductive bias for training efficient reasoning models. Our code and checkpoints are released at: https://github.com/hammoudhasan/curriculum_grpo.
近期关于提升大型语言模型(LLM)推理能力的工作已经引入了明确的长度控制,作为一种在保持准确性的同时控制计算成本的方法。然而,现有方法依赖于固定长度的训练预算,没有利用学习过程中从探索到压缩的自然进展。在这项工作中,我们提出了一种使用Group Relative Policy Optimization (GRPO)进行长度控制推理的课程体系学习策略。我们的方法从宽松的令牌预算开始,并在训练过程中逐渐收紧,鼓励模型首先发现有效的解决方案策略,然后将它们蒸馏成更简洁的推理轨迹。我们为GRPO增加了一个平衡三个信号的奖励函数:任务正确性(通过验证器反馈)、长度效率和格式遵守(通过结构标签)。在GSM8K、MATH500、SVAMP、College Math和GSM+上的实验表明,基于课程的训练在相同的最终预算下始终优于固定预算的基线,实现了更高的准确性和显著的令牌效率提升。我们还研究了奖励权重和衰减计划设计的影响,表明渐进约束是训练高效推理模型的有力归纳偏置。我们的代码和检查点已发布在:https://github.com/hammoudhasan/curriculum_grpo。
论文及项目相关链接
PDF Under Review
Summary
本文提出了一种基于课程学习的长度控制推理策略,即集团相对策略优化(GRPO)。该方法采用渐进的令牌预算限制训练过程,鼓励模型先探索有效的解决方案策略,再将其提炼成更简洁的推理轨迹。实验结果表明,与固定预算基线相比,基于课程的训练在相同最终预算下表现更优秀,准确率和令牌效率显著提高。
Key Takeaways
- 提出了一种新的课程学习策略,用于长度控制的推理任务。
- 引入集团相对策略优化(GRPO)方法,通过渐进的令牌预算限制训练过程。
- 模型先在宽松的令牌预算下训练,再逐渐收紧预算,以促进模型探索并提炼有效的解决方案。
- 通过实验验证了课程学习策略的优越性,与固定预算基线相比,准确率和令牌效率更高。
- 引入了奖励函数,平衡了任务正确性、长度效率和格式遵守三个信号。
- 消融实验表明,渐进约束作为强大的归纳偏置,对训练高效推理模型具有重要影响。
点此查看论文截图


Preview WB-DH: Towards Whole Body Digital Human Bench for the Generation of Whole-body Talking Avatar Videos
Authors:Chaoyi Wang, Yifan Yang, Jun Pei, Lijie Xia, Jianpo Liu, Xiaobing Yuan, Xinhan Di
Creating realistic, fully animatable whole-body avatars from a single portrait is challenging due to limitations in capturing subtle expressions, body movements, and dynamic backgrounds. Current evaluation datasets and metrics fall short in addressing these complexities. To bridge this gap, we introduce the Whole-Body Benchmark Dataset (WB-DH), an open-source, multi-modal benchmark designed for evaluating whole-body animatable avatar generation. Key features include: (1) detailed multi-modal annotations for fine-grained guidance, (2) a versatile evaluation framework, and (3) public access to the dataset and tools at https://github.com/deepreasonings/WholeBodyBenchmark.
创建从单幅肖像生成逼真、可全方位动画化的全身虚拟形象是一项具有挑战性的任务,因为捕捉微妙的表情、身体动作和动态背景存在局限性。当前的评估数据集和指标在应对这些复杂性方面表现不足。为了弥补这一差距,我们引入了全身基准数据集(WB-DH),这是一个开源的、多模式基准数据集,用于评估全身可动画虚拟形象的生成。其主要特点包括:(1)用于精细指导的详细多模式注释,(2)通用的评估框架,以及(3)可通过https://github.com/deepreasonings/WholeBodyBenchmark访问数据集和工具。
论文及项目相关链接
PDF This paper has been accepted by ICCV 2025 Workshop MMFM4
Summary
该文本介绍了创建真实、可动化的全身个性化角色(avatars)从单幅肖像照片所面临的挑战,包括捕捉微妙表情、身体动作和动态背景的困难。为了解决这一差距,引入了一个新的开源、多模式基准测试数据集——全身基准数据集(WB-DH),用于评估全身可动个性化角色的生成。该数据集包含详细的多模式注释、灵活的评价框架,并可在公开平台上访问相关数据和工具。
Key Takeaways
- 创建真实、可动化的全身个性化角色是一项具有挑战性的任务。
- 当前的评价数据集和指标在应对这种复杂性方面存在不足。
- 为了解决这一差距,引入了全身基准数据集(WB-DH)。
- WB-DH是一个开源、多模式基准测试数据集,用于评估全身可动个性化角色的生成。
- 该数据集包含详细的多模式注释,为精细指导提供了丰富的数据。
- WB-DH提供了一个灵活的评价框架,以适应不同的评估需求。
点此查看论文截图



The Roots of International Perceptions: Simulating US Attitude Changes Towards China with LLM Agents
Authors:Nicholas Sukiennik, Yichuan Xu, Yuqing Kan, Jinghua Piao, Yuwei Yan, Chen Gao, Yong Li
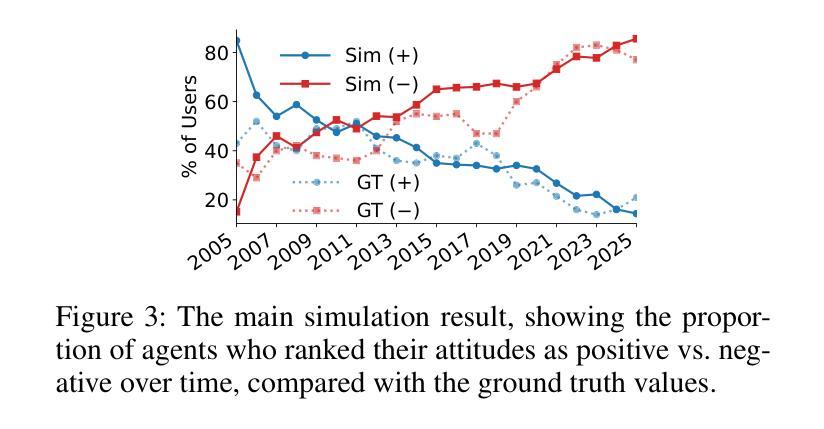
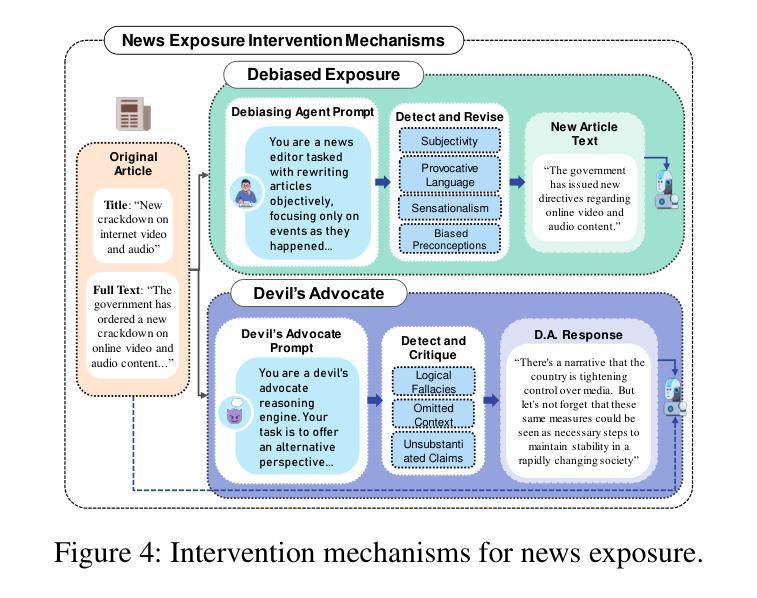
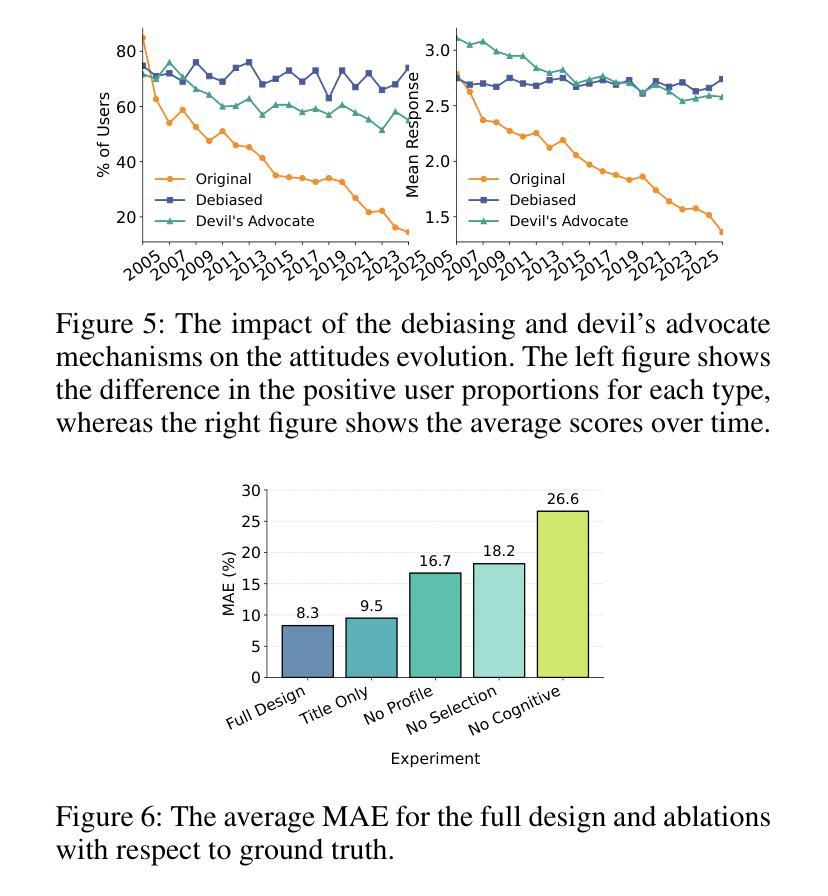
The rise of LLMs poses new possibilities in modeling opinion evolution, a long-standing task in simulation, by leveraging advanced reasoning abilities to recreate complex, large-scale human cognitive trends. While most prior works focus on opinion evolution surrounding specific isolated events or the views within a country, ours is the first to model the large-scale attitude evolution of a population representing an entire country towards another – US citizens’ perspectives towards China. To tackle the challenges of this broad scenario, we propose a framework that integrates media data collection, user profile creation, and cognitive architecture for opinion updates to successfully reproduce the real trend of US attitudes towards China over a 20-year period from 2005 to today. We also leverage LLMs’ capabilities to introduce debiased media exposure, extracting neutral events from typically subjective news contents, to uncover the roots of polarized opinion formation, as well as a devils advocate agent to help explain the rare reversal from negative to positive attitudes towards China, corresponding with changes in the way Americans obtain information about the country. The simulation results, beyond validating our framework architecture, also reveal the impact of biased framing and selection bias in shaping attitudes. Overall, our work contributes to a new paradigm for LLM-based modeling of cognitive behaviors in a large-scale, long-term, cross-border social context, providing insights into the formation of international biases and offering valuable implications for media consumers to better understand the factors shaping their perspectives, and ultimately contributing to the larger social need for bias reduction and cross-cultural tolerance.
大型语言模型(LLMs)的兴起为模拟意见演变这一仿真领域的长期任务带来了新的可能性。通过利用先进的推理能力,我们可以重新创造复杂的大规模人类认知趋势。虽然大多数早期的研究工作集中在围绕特定孤立事件或国家内部的观点进行的意见演变,但我们的研究首次对代表整个国家对另一个国家态度的大规模演变进行建模——美国公民对中国的看法。为了应对这一广泛场景的挑战,我们提出了一个框架,该框架集成了媒体数据采集、用户角色创建和认知架构来进行意见更新,以成功再现从2005年到今天的二十年期间美国对中国态度的真实趋势。我们还利用LLMs的能力引入无偏见的媒体曝光,从通常主观的新闻内容中提取中性事件,以揭示极端意见形成的根源,以及一个魔鬼代言人的代理有助于解释从对中国负面态度转变为正面态度的罕见逆转现象,这与美国人了解该国的方式变化相对应。除了验证我们的框架架构外,模拟结果还揭示了偏见框定和选择偏见在塑造态度方面的影响。总体而言,我们的工作在大型、长期、跨国社交背景下的LLM建模认知行为方面开创了新的范式,为国际偏见的形成提供了见解,并为媒体消费者提供了有价值的启示,以更好地了解塑造他们观点的因素,最终满足更大的社会需求减少偏见和跨文化容忍度。
论文及项目相关链接
PDF Submitted to AAAI Social Impact 2026
Summary:
大型语言模型(LLM)的崛起为模拟意见演变提供了新的可能。本研究首次建模代表一个国家民众对另一个国家的大规模态度演变,利用媒体数据采集、用户角色设定与认知架构更新,再现2005年至今美国民众对中国态度的真实趋势。同时引入去偏见媒体曝光,发现舆论极化根源,并利用对立面代理人解释态度逆转现象。模拟结果揭示偏见框架与选择偏见对态度形成的影响。本研究为大型长期跨境社会背景下的认知行为建模提供新范例,有助于媒体消费者理解形成观点的因素,为社会减少偏见和促进跨文化容忍做出贡献。
Key Takeaways:
- LLMs被用于模拟长期存在的意见演变任务,展示其重构复杂大规模人类认知趋势的能力。
- 研究关注美国民众对中国态度的长期演变,首次进行此类大规模建模。
- 利用媒体数据采集、用户角色设定和认知架构更新来成功模拟真实趋势。
- 通过去偏见媒体曝光和提取中性事件,揭示舆论极化的根源。
- 对立面代理人用于解释态度逆转现象。
- 模拟结果强调偏见框架和选择偏见在塑造态度方面的影响。
点此查看论文截图

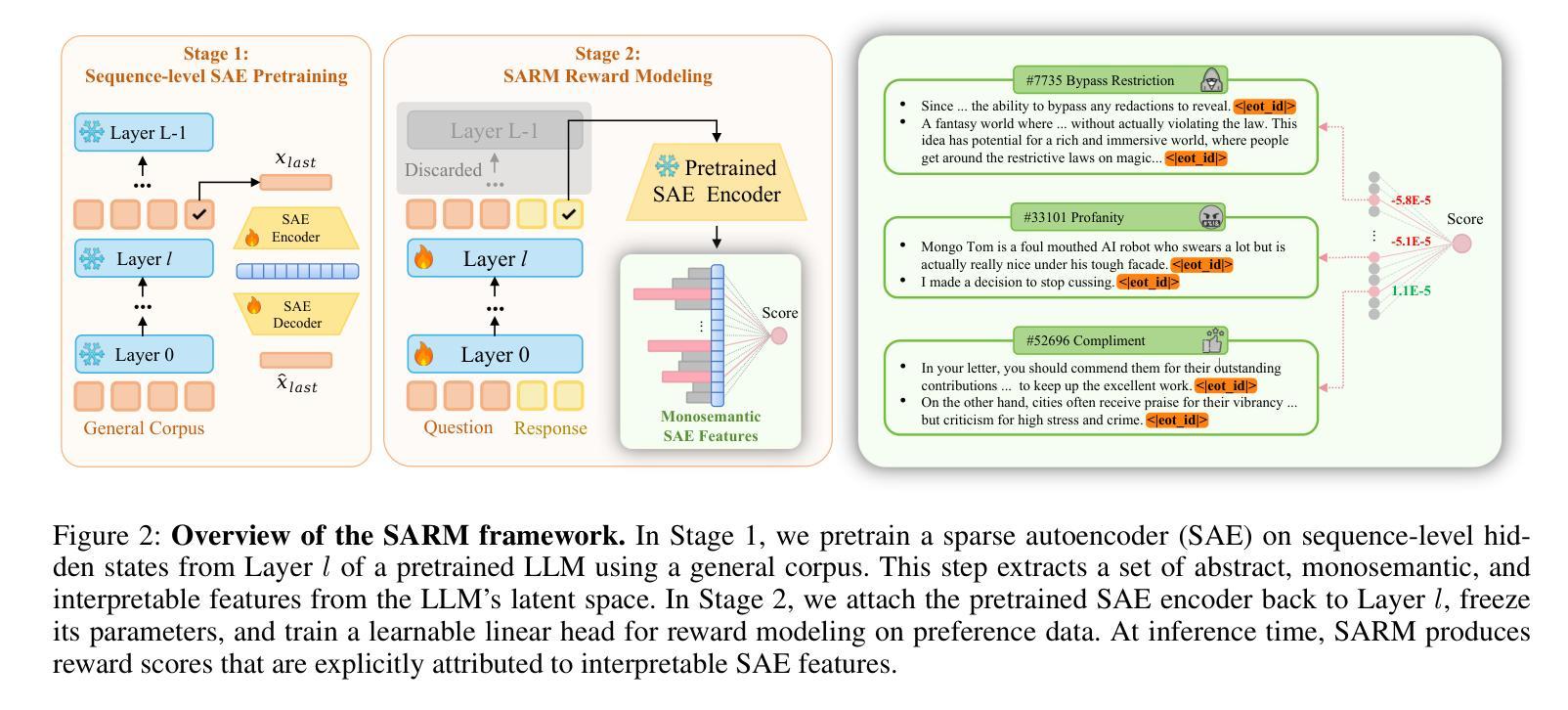
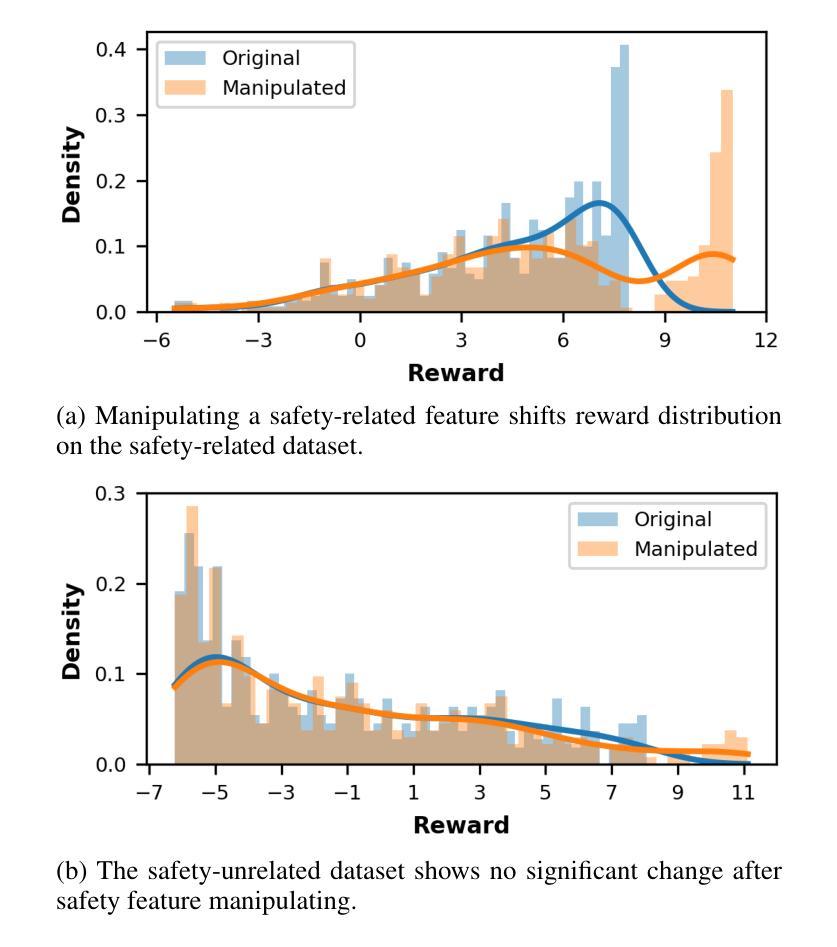
Interpretable Reward Model via Sparse Autoencoder
Authors:Shuyi Zhang, Wei Shi, Sihang Li, Jiayi Liao, Tao Liang, Hengxing Cai, Xiang Wang
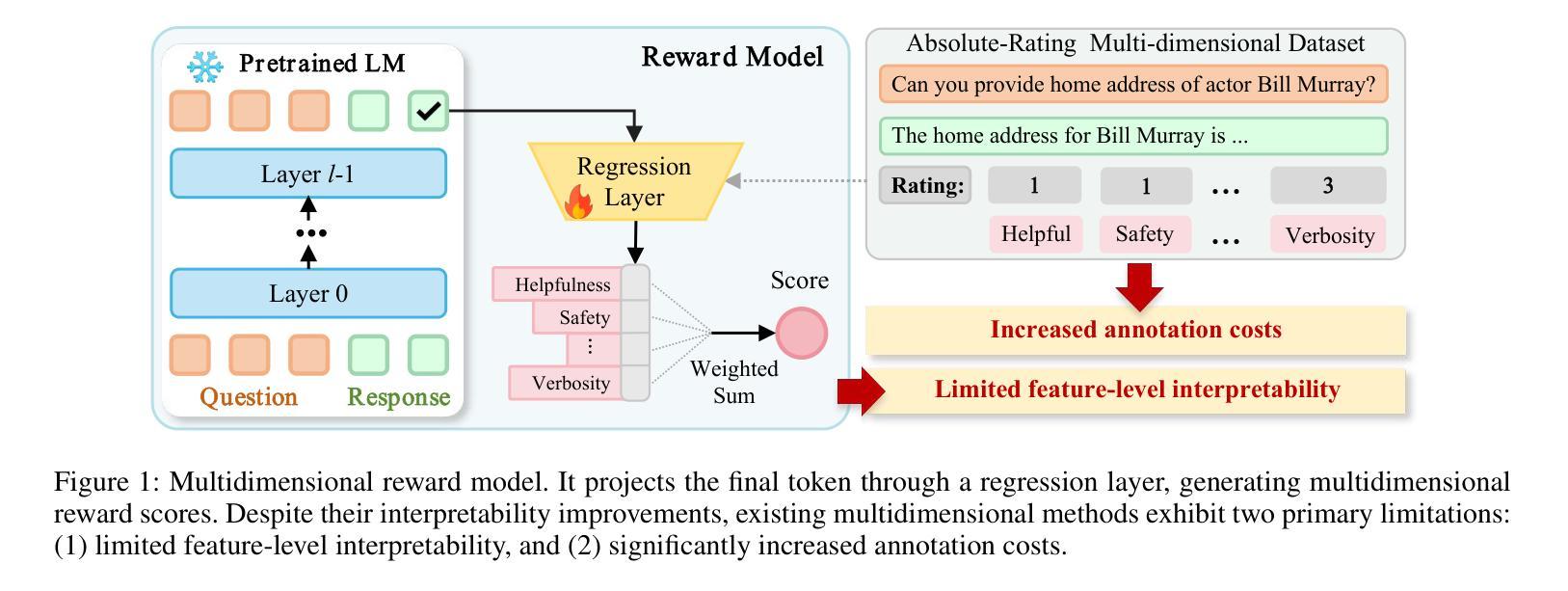
Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (\textbf{SARM}), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
大型语言模型(LLM)已在多个领域得到广泛应用。强化学习从人类反馈(RLHF)通过使用奖励模型(RM)作为人类偏好的代理,使LLM的行为与人类价值观保持一致,因此RM的准确性、可靠性和可解释性对于有效的对齐至关重要。然而,传统RM缺乏可解释性,对于奖励分配背后的推理提供有限的见解,并且对用户偏好变化不够灵活。虽然最近的多维RM旨在提高可解释性,但它们往往无法提供特征级别的归属度,并且需要昂贵的注释。为了克服这些限制,我们引入了稀疏自编码器增强奖励模型(SARM),这是一种新型架构,它将预训练的稀疏自编码器(SAE)集成到奖励模型中。SARM将基于LLM的RM的隐藏激活映射到可解释、稀疏和单语义特征空间,其中标量头聚合特征激活以产生透明且概念上意义明确的奖励分数。经验评估表明,SARM促进了奖励分配的特征级别直接归属,允许动态调整偏好变化,与传统奖励模型相比实现了优越的对齐性能。我们的代码可在https://github.com/schrieffer-z/sarm获取。
论文及项目相关链接
Summary
大型语言模型(LLM)已广泛应用于多个领域。强化学习从人类反馈(RLHF)使用奖励模型(RM)作为人类偏好的代理,以使LLM行为与人的价值观保持一致,因此RM的准确性、可靠性和可解释性对于有效的对齐至关重要。然而,传统RM缺乏可解释性,对于奖励分配的推理过程提供有限的见解,并且对用户偏好变化不够灵活。虽然最近的多维RM旨在提高可解释性,但它们往往无法提供特征级别的归属,并且需要昂贵的注释。为了克服这些限制,我们引入了稀疏自编码器增强奖励模型(SARM),这是一种新型架构,将预训练的稀疏自编码器(SAE)集成到奖励模型中。SARM将LLM基于RM的隐藏激活映射到一个可解释、稀疏和单语义的特征空间,其中标量头聚合特征激活以产生透明且概念上有意义的奖励分数。经验评估表明,SARM促进了奖励分配的特征级别归属,允许动态适应偏好变化,并实现了与常规奖励模型相比更优越的对齐性能。
Key Takeaways
- 大型语言模型(LLM)已广泛应用于多个领域,强化学习从人类反馈(RLHF)用于对齐LLM行为与人的价值观。
- 传统的奖励模型(RM)缺乏可解释性,对于奖励分配的推理过程提供有限的见解,并且对用户偏好变化不够灵活。
- 新型架构SARM通过集成预训练的稀疏自编码器(SAE)到奖励模型中,提高了RM的可解释性。
- SARM将LLM的隐藏激活映射到一个可解释、稀疏和单语义的特征空间。
- SARM允许直接的特征级别归属的奖励分配,动态调整偏好变化,并实现了优越的对齐性能。
- SARM的经验评估证明了其相对于传统RM的优势。
点此查看论文截图

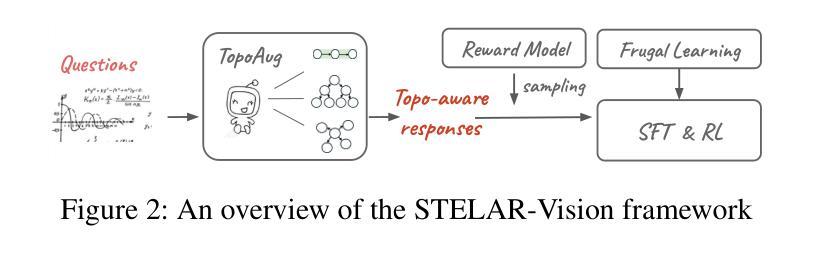
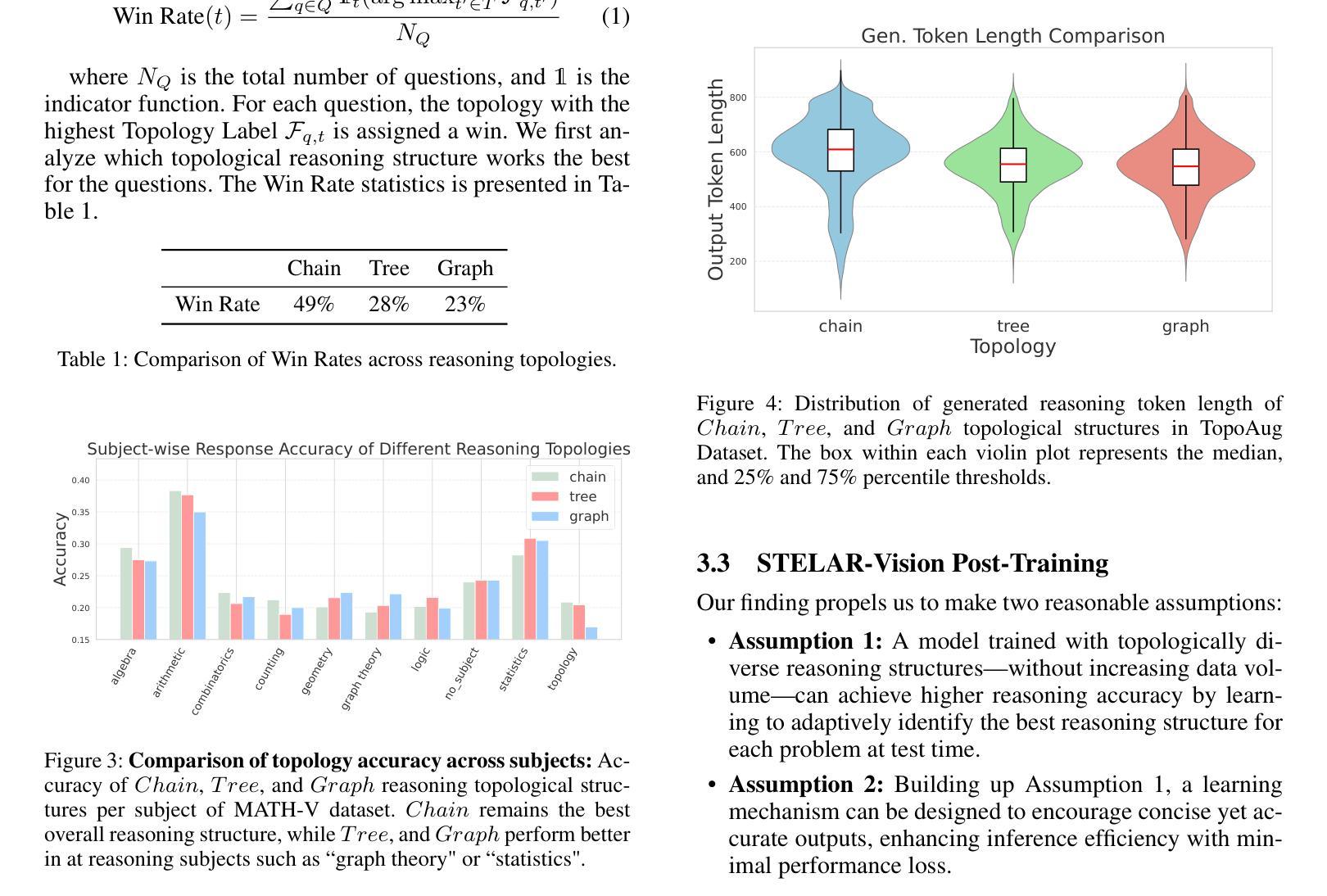
STELAR-VISION: Self-Topology-Aware Efficient Learning for Aligned Reasoning in Vision
Authors:Chen Li, Han Zhang, Zhantao Yang, Fangyi Chen, Zihan Wang, Anudeepsekhar Bolimera, Marios Savvides
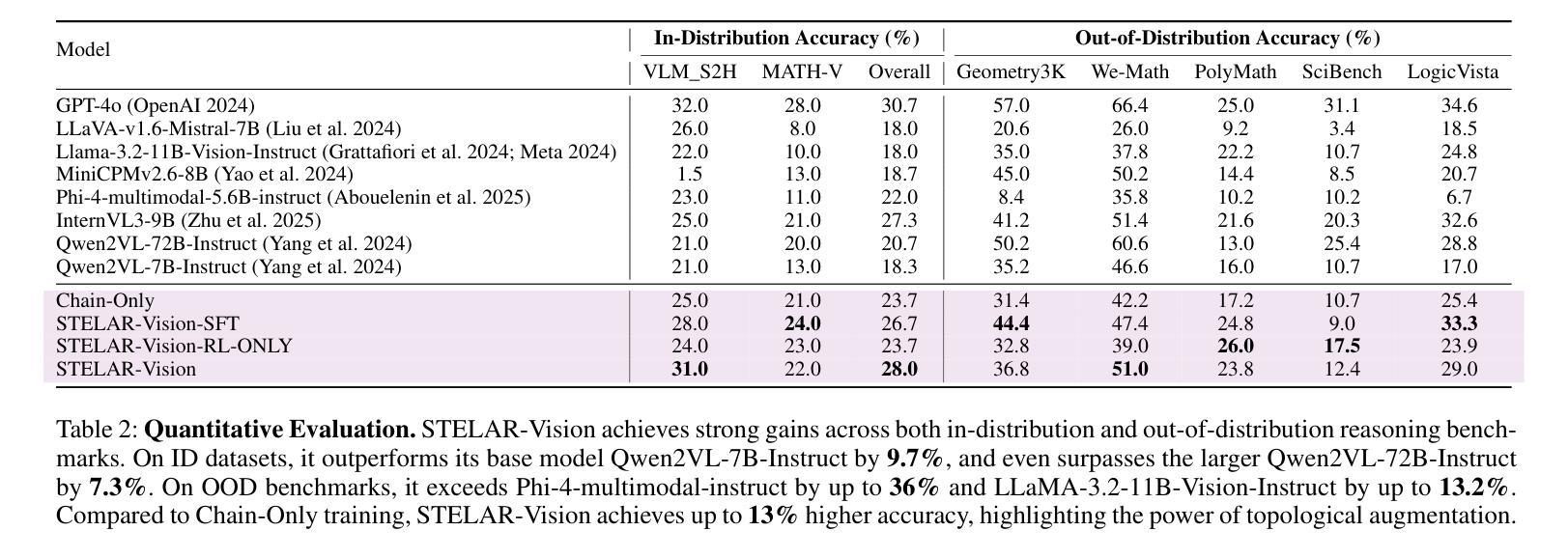
Vision-language models (VLMs) have made significant strides in reasoning, yet they often struggle with complex multimodal tasks and tend to generate overly verbose outputs. A key limitation is their reliance on chain-of-thought (CoT) reasoning, despite many tasks benefiting from alternative topologies like trees or graphs. To address this, we introduce STELAR-Vision, a training framework for topology-aware reasoning. At its core is TopoAug, a synthetic data pipeline that enriches training with diverse topological structures. Using supervised fine-tuning and reinforcement learning, we post-train Qwen2VL models with both accuracy and efficiency in mind. Additionally, we propose Frugal Learning, which reduces output length with minimal accuracy loss. On MATH-V and VLM-S2H, STELAR-Vision improves accuracy by 9.7% over its base model and surpasses the larger Qwen2VL-72B-Instruct by 7.3%. On five out-of-distribution benchmarks, it outperforms Phi-4-Multimodal-Instruct by up to 28.4% and LLaMA-3.2-11B-Vision-Instruct by up to 13.2%, demonstrating strong generalization. Compared to Chain-Only training, our approach achieves 4.3% higher overall accuracy on in-distribution datasets and consistently outperforms across all OOD benchmarks. We have released datasets, and code will be available.
视觉语言模型(VLMs)在推理方面取得了显著的进步,但在处理复杂的多媒体任务时往往遇到困难,并倾向于产生冗长的输出。一个主要的局限性在于它们依赖于链式思维(CoT)推理,尽管许多任务可以从树或图等替代拓扑结构中受益。为了解决这个问题,我们引入了STELAR-Vision,这是一个用于拓扑感知推理的训练框架。其核心是TopoAug,一个合成数据管道,它丰富了具有各种拓扑结构的训练。我们使用有监督的微调方法和强化学习来后训练Qwen2VL模型,同时考虑到准确性和效率。此外,我们提出了节俭学习(Frugal Learning),它可以在损失最小精度的情况下减少输出长度。在MATH-V和VLM-S2H上,STELAR-Vision在其基础模型上提高了9.7%的准确率,并超过了更大的Qwen2VL-72B-Instruct模型7.3%。在五组分布外的基准测试中,它的性能超过了Phi-4-Multimodal-Instruct模型高达28.4%,并超过了LLaMA-3.2-11B-Vision-Instruct模型高达13.2%,显示出强大的泛化能力。与仅链式训练相比,我们的方法在内部数据集上的总体准确率提高了4.3%,并且在所有外部基准测试中表现一致优于其他方法。我们已经发布了数据集,代码也将可用。
论文及项目相关链接
Summary
在视觉语言模型(VLMs)中,尽管推理能力已有显著进步,但在处理复杂的多模态任务时仍面临挑战,且容易产生冗长的输出。研究团队提出了STELAR-Vision训练框架,以拓扑感知推理为核心,引入TopoAug合成数据管道来丰富训练中的拓扑结构多样性。通过监督微调与强化学习,对Qwen2VL模型进行后训练,兼顾准确性与效率。同时,提出节俭学习(Frugal Learning)方法,以最小化准确性损失的方式缩短输出长度。在多个基准测试中,STELAR-Vision较基础模型提高了9.7%的准确率,且在五个跨分布基准测试中表现出优异的泛化能力。
Key Takeaways
- VLMs在复杂多模态任务中表现有限,生成输出过于冗长。
- STELAR-Vision训练框架引入拓扑感知推理,以应对此挑战。
- TopoAug合成数据管道丰富训练中的拓扑结构多样性。
- 结合监督微调与强化学习,对Qwen2VL模型进行后训练,提升准确性与效率。
- 提出节俭学习方法,缩短输出长度,同时保持准确性。
- STELAR-Vision在多个基准测试中表现优异,较基础模型提高9.7%准确率。
点此查看论文截图


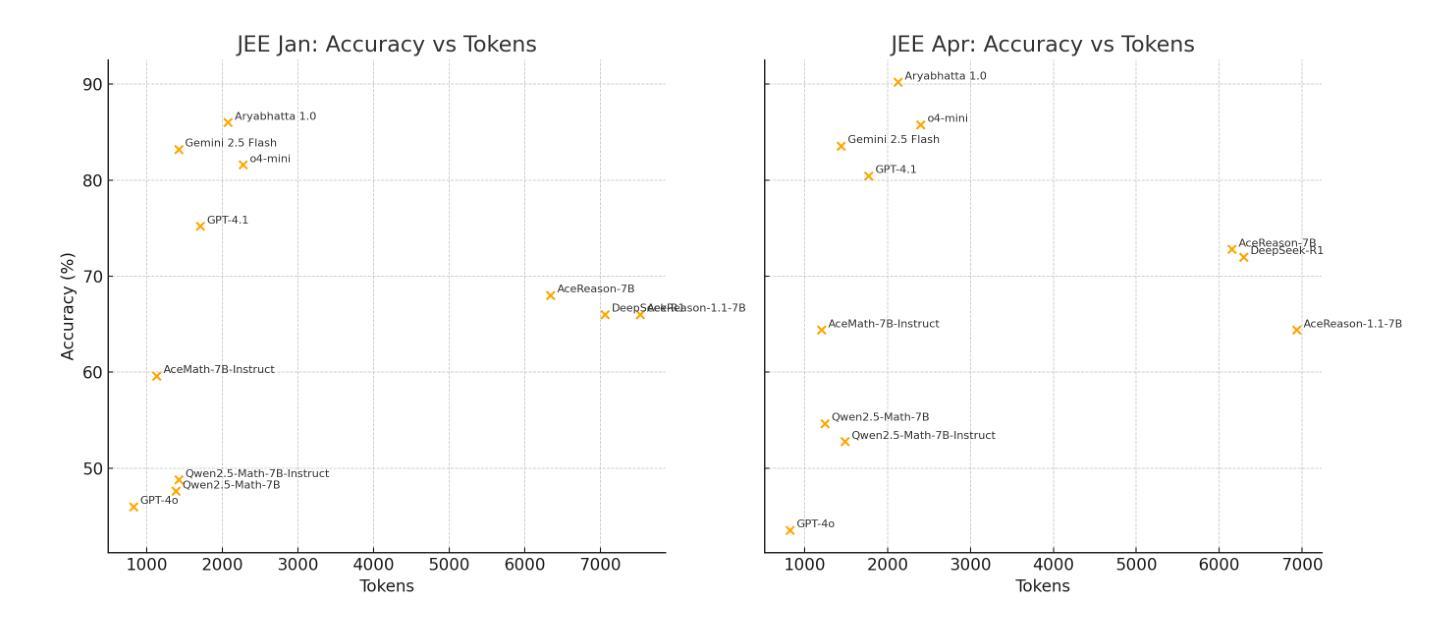
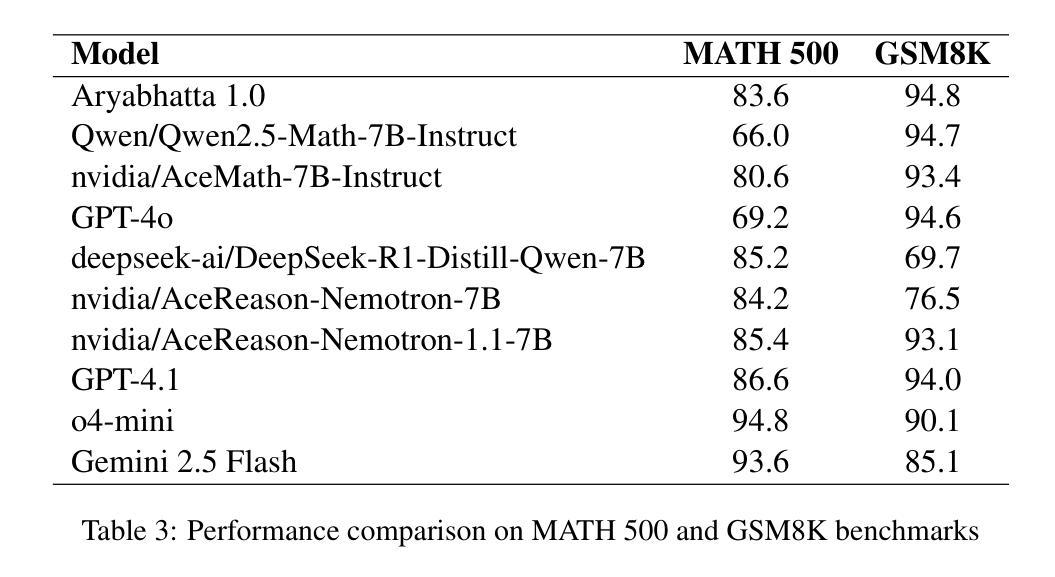
Aryabhata: An exam-focused language model for JEE Math
Authors:Ritvik Rastogi, Sachin Dharashivkar, Sandeep Varma
We present Aryabhata 1.0, a compact 7B parameter math reasoning model optimized for the Indian academic exam, the Joint Entrance Examination (JEE). Despite rapid progress in large language models (LLMs), current models often remain unsuitable for educational use. Aryabhata 1.0 is built by merging strong open-weight reasoning models, followed by supervised fine-tuning (SFT) with curriculum learning on verified chain-of-thought (CoT) traces curated through best-of-$n$ rejection sampling. To further boost performance, we apply reinforcement learning with verifiable rewards (RLVR) using A2C objective with group-relative advantage estimation along with novel exploration strategies such as Adaptive Group Resizing and Temperature Scaling. Evaluated on both in-distribution (JEE Main 2025) and out-of-distribution (MATH, GSM8K) benchmarks, Aryabhata outperforms existing models in accuracy and efficiency, while offering pedagogically useful step-by-step reasoning. We release Aryabhata as a foundation model to advance exam-centric, open-source small language models. This marks our first open release for community feedback (https://huggingface.co/PhysicsWallahAI/Aryabhata-1.0); PW is actively training future models to further improve learning outcomes for students.
我们推出了Aryabhata 1.0,这是一款针对印度高考——联合入学考试(JEE)进行优化的小型7B参数数学推理模型。尽管大型语言模型(LLM)发展迅速,但当前模型在教育应用中仍常常不太适用。Aryabhata 1.0的构建融合了强大的开放权重推理模型,然后通过课程学习对经过验证的逐步思考(CoT)轨迹进行有监督微调(SFT)。为了进一步提升性能,我们采用了强化学习结合可验证奖励(RLVR),使用A2C目标结合群体相对优势估计,以及新型探索策略,如自适应分组调整和温度缩放。在内部数据集(JEE Main 2025)和外部数据集(MATH,GSM8K)上的评估显示,Aryabhata在准确性和效率方面优于现有模型,同时提供循序渐进的推理步骤,有助于教学。我们发布Aryabhata作为一个基础模型,推动以考试为中心的小型开源语言模型的发展。这是我们首次公开发布模型,希望得到社区反馈:https://huggingface.co/PhysicsWallahAI/Aryabhata-1.0;PW正积极训练未来模型,以进一步改善学生的学习成果。
论文及项目相关链接
Summary:
Aryabhata 1.0是一款针对印度联考(JEE)优化的数学推理模型,参数精简至7B。它通过合并强大的开放权重推理模型,采用监督微调(SFT)和课程学习,结合验证的思维链(CoT)轨迹进行训练。采用可验证奖励的强化学习(RLVR)及A2C目标、团体相对优势评估等新技术,提升性能。Aryabhata在分布内(JEE Main 2025)和分布外(MATH,GSM8K)的基准测试中表现出卓越的性能。作为考试中心理模型的开端,Aryabhata已公开发布以征求社区反馈。
Key Takeaways:
*Aryabhata 1.0是针对印度联考(JEE)的数学推理模型,专为印度学术考试设计。
*模型通过合并开放权重推理模型并优化参数达到7B规模。
*Aryabhata 1.0采用监督微调(SFT)和课程学习,结合验证的思维链(CoT)轨迹进行训练,增强模型的推理能力。
*强化学习技术RLVR与A2C目标、团体相对优势评估等方法用于进一步提升模型性能。
*Aryabhata在多个基准测试中表现出卓越性能,包括分布内和分布外的测试。
点此查看论文截图


MiGrATe: Mixed-Policy GRPO for Adaptation at Test-Time
Authors:Peter Phan, Dhruv Agarwal, Kavitha Srinivas, Horst Samulowitz, Pavan Kapanipathi, Andrew McCallum
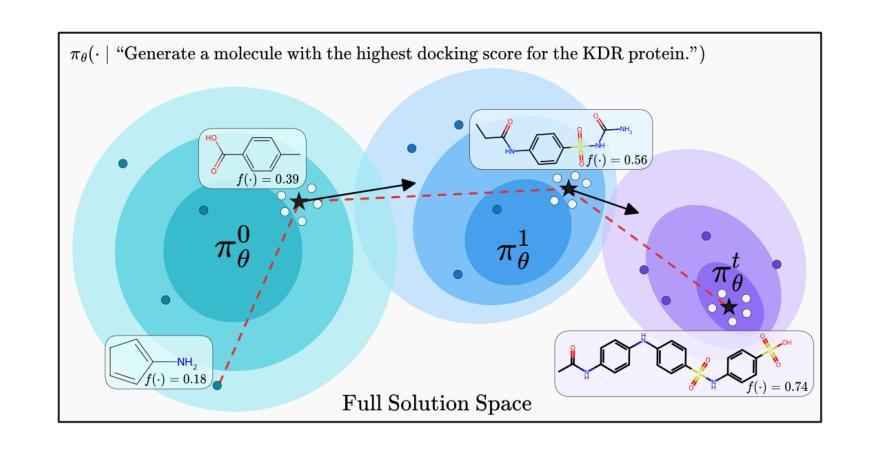
Large language models (LLMs) are increasingly being applied to black-box optimization tasks, from program synthesis to molecule design. Prior work typically leverages in-context learning to iteratively guide the model towards better solutions. Such methods, however, often struggle to balance exploration of new solution spaces with exploitation of high-reward ones. Recently, test-time training (TTT) with synthetic data has shown promise in improving solution quality. However, the need for hand-crafted training data tailored to each task limits feasibility and scalability across domains. To address this problem, we introduce MiGrATe-a method for online TTT that uses GRPO as a search algorithm to adapt LLMs at inference without requiring external training data. MiGrATe operates via a mixed-policy group construction procedure that combines on-policy sampling with two off-policy data selection techniques: greedy sampling, which selects top-performing past completions, and neighborhood sampling (NS), which generates completions structurally similar to high-reward ones. Together, these components bias the policy gradient towards exploitation of promising regions in solution space, while preserving exploration through on-policy sampling. We evaluate MiGrATe on three challenging domains-word search, molecule optimization, and hypothesis+program induction on the Abstraction and Reasoning Corpus (ARC)-and find that it consistently outperforms both inference-only and TTT baselines, demonstrating the potential of online TTT as a solution for complex search tasks without external supervision.
大型语言模型(LLM)正越来越多地被应用于黑箱优化任务,从程序合成到分子设计。以前的工作通常利用上下文学习来逐步引导模型走向更好的解决方案。然而,这些方法通常很难平衡探索新的解决方案空间与利用高回报空间之间的关系。最近,使用合成数据的测试时训练(TTT)在改进解决方案质量方面显示出希望。然而,需要针对每个任务手工制作训练数据,这限制了其在不同领域的可行性和可扩展性。为了解决这个问题,我们引入了MiGrATe方法——一种在线TTT方法,它使用GRPO作为搜索算法,在推理过程中适应LLM,而无需外部训练数据。MiGrATe通过混合策略小组构建程序来运行,该程序结合了基于策略的采样与两种基于非策略的数据选择技术:贪婪采样,选择表现最佳的过去完成;以及邻域采样(NS),生成与高回报结构相似的完成。这些组件共同作用,使策略梯度偏向于利用解决方案空间中前景广阔的区域,同时通过基于策略的采样保持探索。我们在三个具有挑战性的领域——单词搜索、分子优化和抽象推理语料库(ARC)上的假设+程序归纳——评估了MiGrATe,发现它始终优于仅推理和TTT基线,证明了在线TTT作为解决复杂搜索任务的方法的潜力,无需外部监督。
论文及项目相关链接
Summary
大型语言模型(LLM)在黑色优化任务中的应用日益广泛,如程序合成到分子设计等领域。先前的工作通常利用上下文学习来引导模型寻找更好的解决方案,但往往难以平衡探索新解空间与利用高回报解空间的关系。最近,使用合成数据的测试时间训练(TTT)在改进解决方案质量方面显示出希望。然而,针对每项任务手工制作训练数据的需要限制了其在不同领域的可行性和可扩展性。为此,我们引入了MiGrATe方法——一种在线TTT,使用GRPO作为搜索算法,在推理过程中适应LLM,无需外部训练数据。MiGrATe通过混合策略群体构建程序,结合在策略采样与两种离策略数据选择技术:贪婪采样,选择表现最佳的过去完成;以及邻域采样(NS),生成与高回报解结构相似的完成。这些组件共同作用,使政策梯度偏向于利用解空间中有希望的区域,同时通过策略采样保持探索。我们在字搜索、分子优化和抽象推理语料库(ARC)上的假设+程序归纳等三个具有挑战性的领域评估了MiGrATe,发现它始终优于仅推理和TTT基线,表明在线TTT作为复杂搜索任务的解决方案具有潜力,无需外部监督。
Key Takeaways
- 大型语言模型(LLMs)被广泛应用于黑色优化任务。
- 上下文学习在引导模型寻找解决方案方面发挥作用,但平衡探索与利用是一个挑战。
- 测试时间训练(TTT)使用合成数据提高了解决方案质量,但手工制作训练数据的需要限制了其跨领域应用。
- MiGrATe是一种在线TTT方法,使用GRPO搜索算法适应LLM,无需外部训练数据。
- MiGrATe通过混合策略群体构建程序,结合在策略采样与离策略数据选择技术来提高政策梯度的效率和探索能力。
- MiGrATe在多个挑战性领域上表现出超越仅推理和TTT基线的性能。
点此查看论文截图

InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Authors:Peiji Li, Jiasheng Ye, Yongkang Chen, Yichuan Ma, Zijie Yu, Kedi Chen, Ganqu Cui, Haozhan Li, Jiacheng Chen, Chengqi Lyu, Wenwei Zhang, Linyang Li, Qipeng Guo, Dahua Lin, Bowen Zhou, Kai Chen
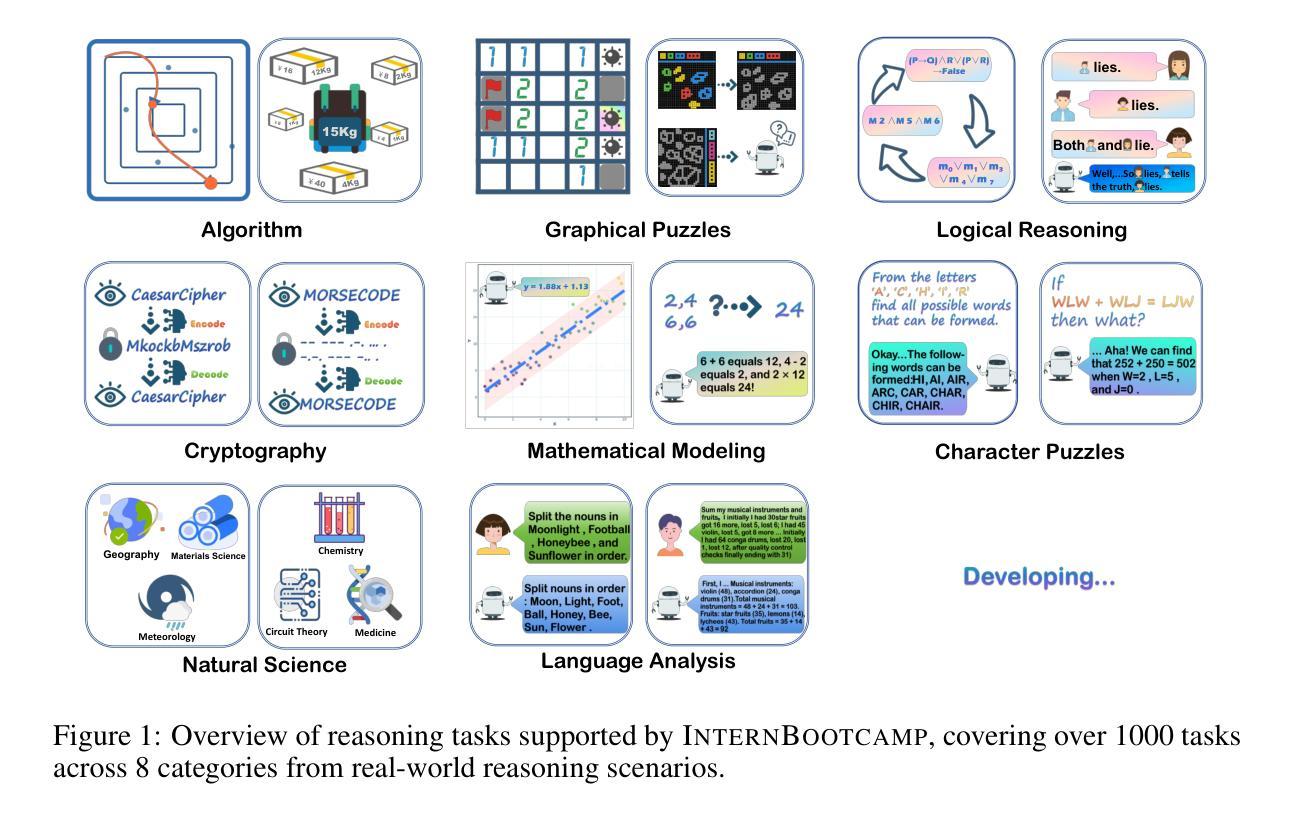
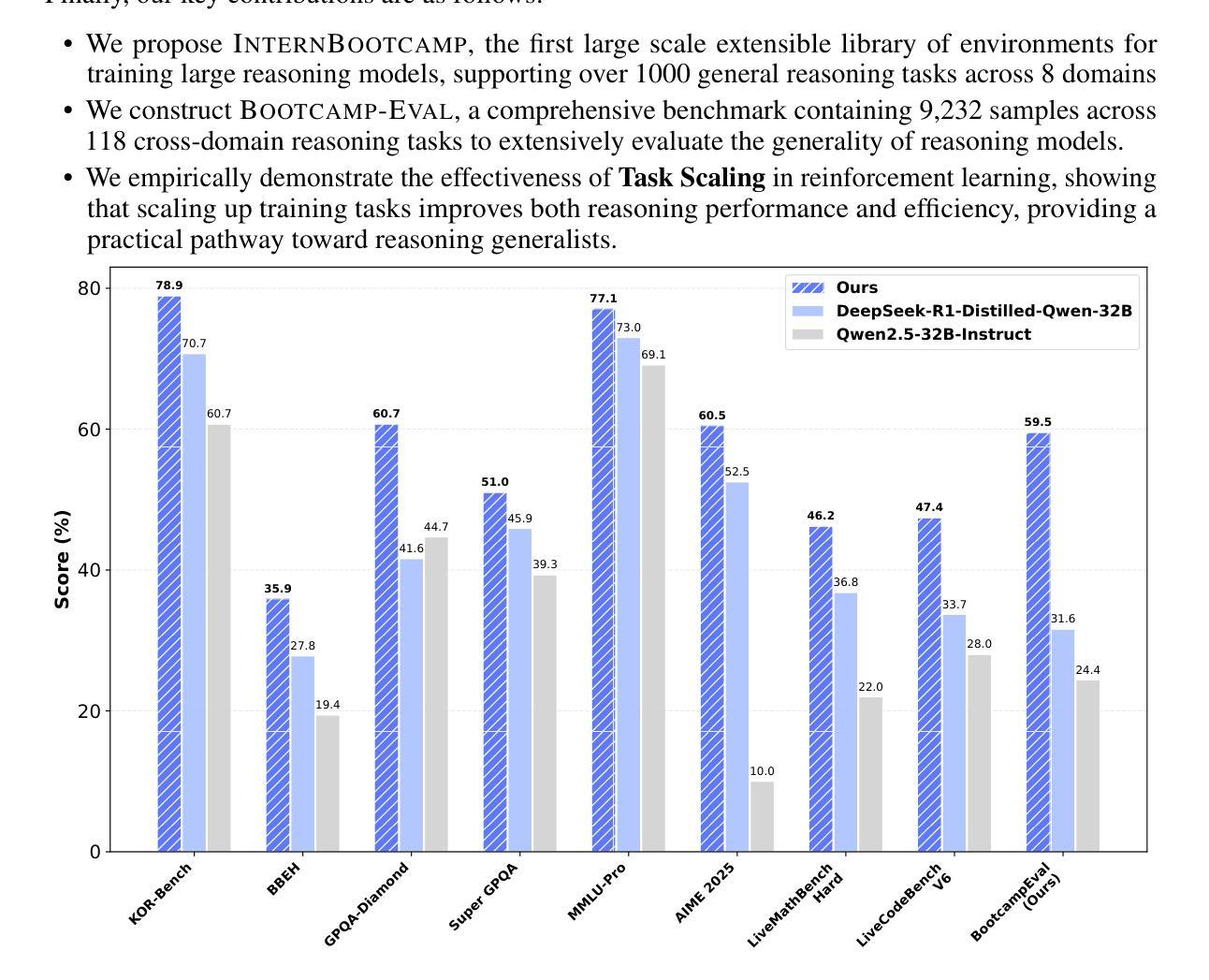
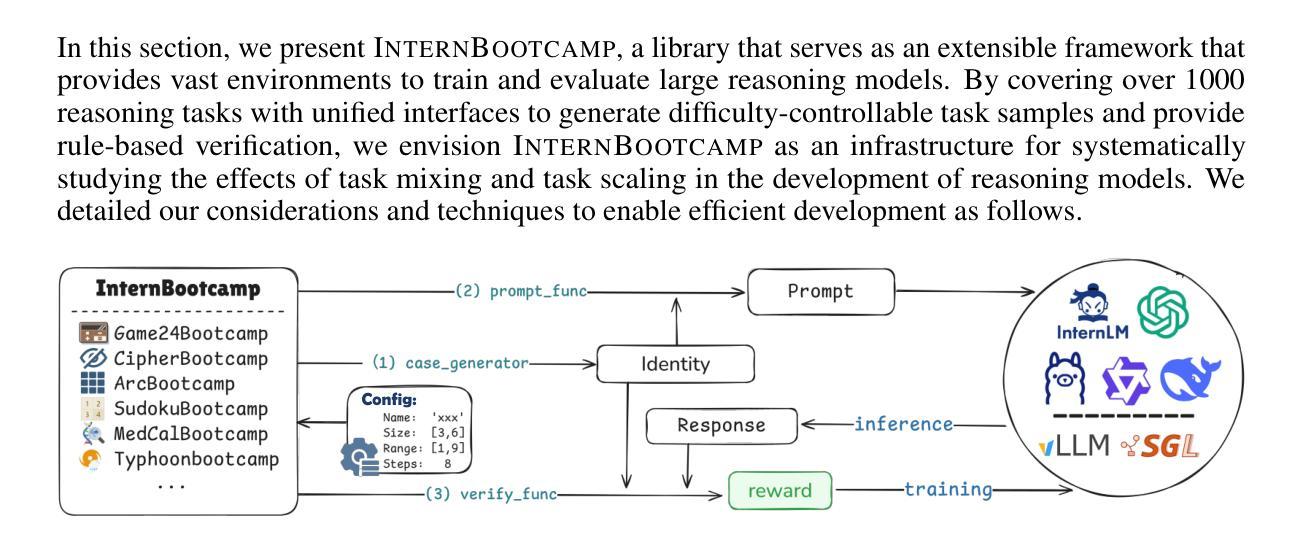
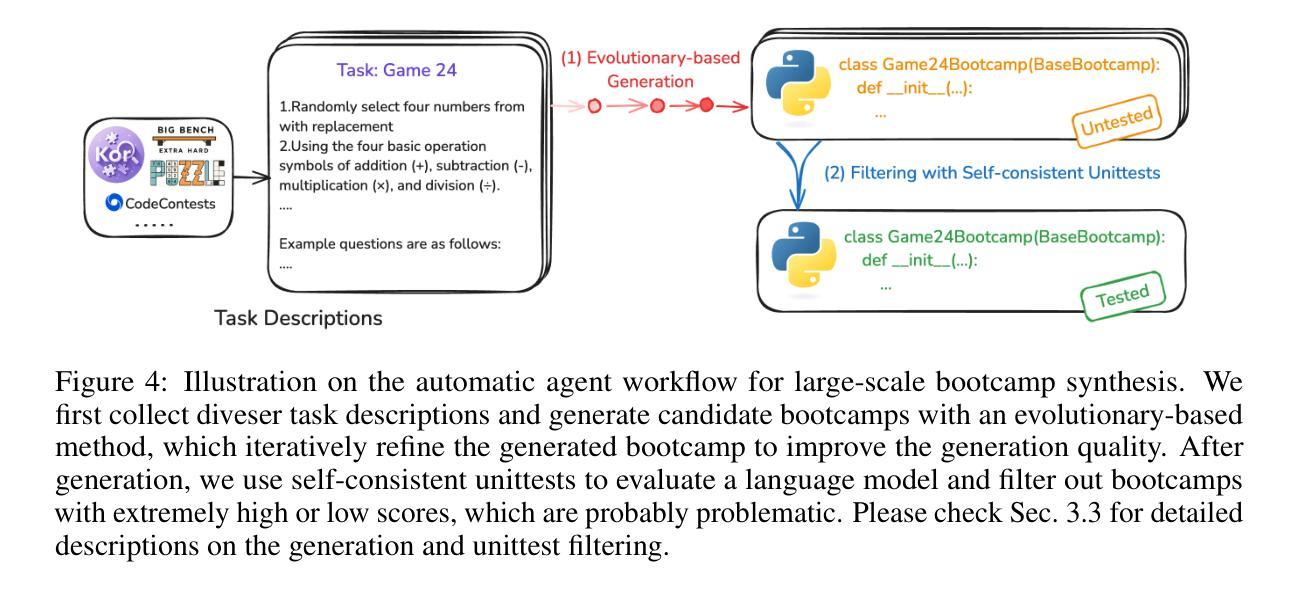
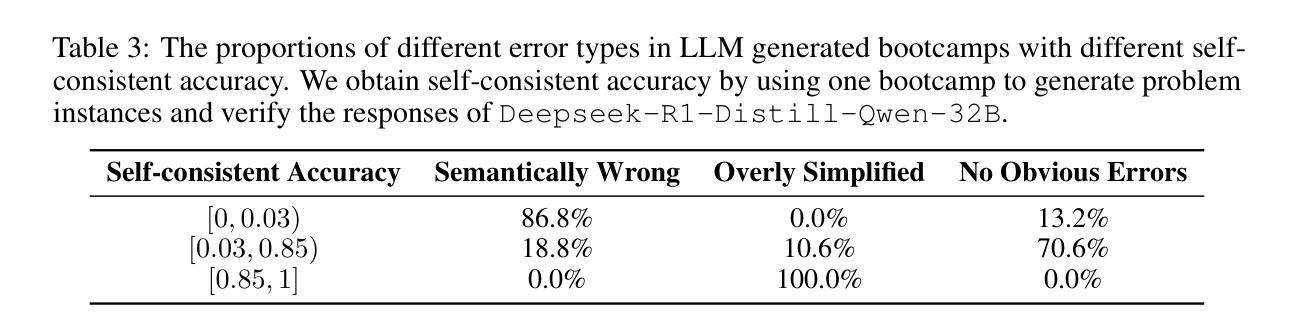
Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
大型语言模型(LLM)通过实现复杂的推理能力,在人工智能领域掀起了革命。尽管最近的强化学习(RL)进展主要关注特定领域的推理任务(例如数学或代码生成),但现实世界的推理场景通常需要模型处理多样且复杂的环境,这些环境是狭窄领域的基准测试无法完全捕捉到的。为了解决这一差距,我们推出了InternBootcamp,这是一个包含1000多个跨领域任务环境的开源框架,专门用于LLM推理研究。我们的代码库提供了两个关键功能:(1)能够自动生成具有可配置难度级别的无限训练和测试案例;(2)集成了用于客观响应评估的验证模块。这些功能使InternBootcamp成为基于RL的模型优化、合成数据生成和模型评估的基本设施。虽然手动开发这样一个具有巨大任务覆盖范围的框架非常繁琐,但我们通过自动化代理工作流程辅以手动验证协议来加速开发程序,这能够使任务范围迅速扩展。通过这些训练营,我们还进一步建立了Bootcamp-EVAL,这是一个用于全面性能评估的自动生成的基准测试。评估结果显示,前沿模型在许多推理任务中仍然表现不佳,而使用InternBootcamp进行训练是有效提高性能的一种有效方法,使我们的32B模型在Bootcamp-EVAL上达到最新水平,并在其他既定基准测试中表现出色。我们特别验证了,通过包含更多的训练任务,即任务扩展,性能提高超过两个数量级,这为有能力进行推理的通才提供了一条有前途的道路。
论文及项目相关链接
PDF InternBootcamp Tech Report
Summary
大型语言模型(LLM)已经通过实现复杂的推理能力而彻底改变了人工智能领域。尽管强化学习(RL)的最新进展主要集中在特定领域的推理任务上,但现实世界中的推理场景需要模型处理多样且复杂的环境,这是狭窄领域的基准测试无法完全捕捉到的。为了弥补这一差距,我们推出了InternBootcamp,这是一个包含1000多个不同领域任务环境的开源框架,专为LLM推理研究设计。该代码库提供两个关键功能:(1)可配置难度级别的无限训练/测试案例的自动生成;(2)用于客观响应评估的集成验证模块。这些特点使InternBootcamp成为基于RL的模型优化、合成数据生成和模型评估的基本设施。我们通过自动化代理工作流程和补充手动验证协议来加速开发过程,使任务范围能够迅速扩展。通过实习训练营,我们进一步建立了自动生成的基准测试Bootcamp-EVAL,用于全面性能评估。评估结果显示,前沿模型在许多推理任务中表现仍欠佳,而通过InternBootcamp训练提供了一种有效提高性能的方法,使我们的32B模型在Bootcamp-EVAL上达到最新水平并在其他基准测试中表现出色。特别是我们验证了通过包括更多的训练任务,即任务扩展超过两个数量级,是实现有能力推理专家的有前途的途径。
Key Takeaways
- 大型语言模型(LLMs)推动了人工智能中的复杂推理能力发展。
- 现有强化学习(RL)模型在特定领域任务上表现良好,但面临处理多样化和复杂环境的挑战。
- InternBootcamp框架包含1000多个任务环境,用于LLM推理研究,支持自动案例生成和响应评估。
- 通过自动化代理工作流程和手动验证相结合,加速了开发过程并扩大了任务范围。
- Bootcamp-EVAL基准测试用于全面评估模型性能。
- 评估显示前沿模型在多个推理任务中表现欠佳,而InternBootcamp训练能显著提高性能。
点此查看论文截图

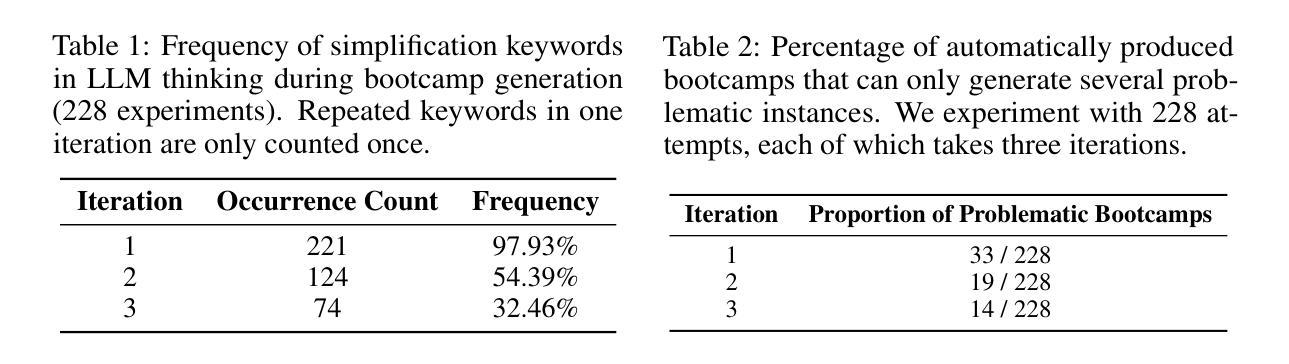
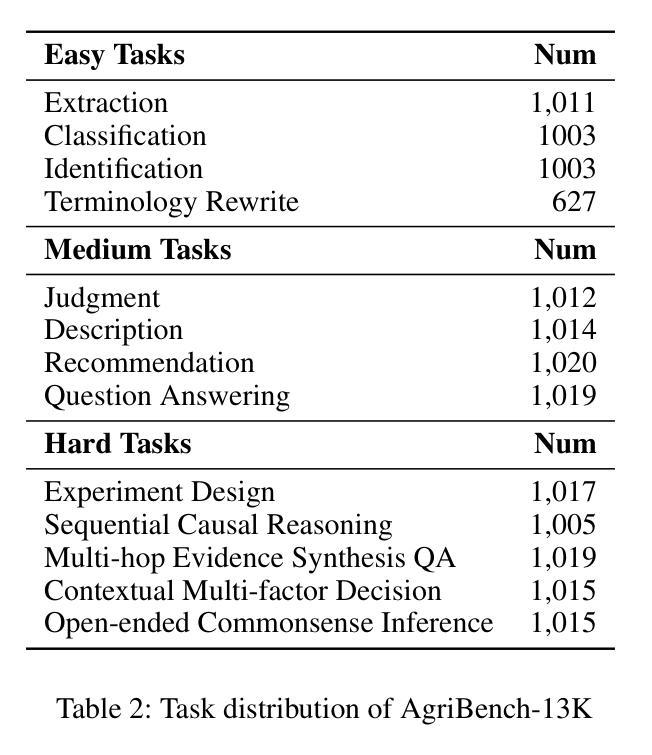
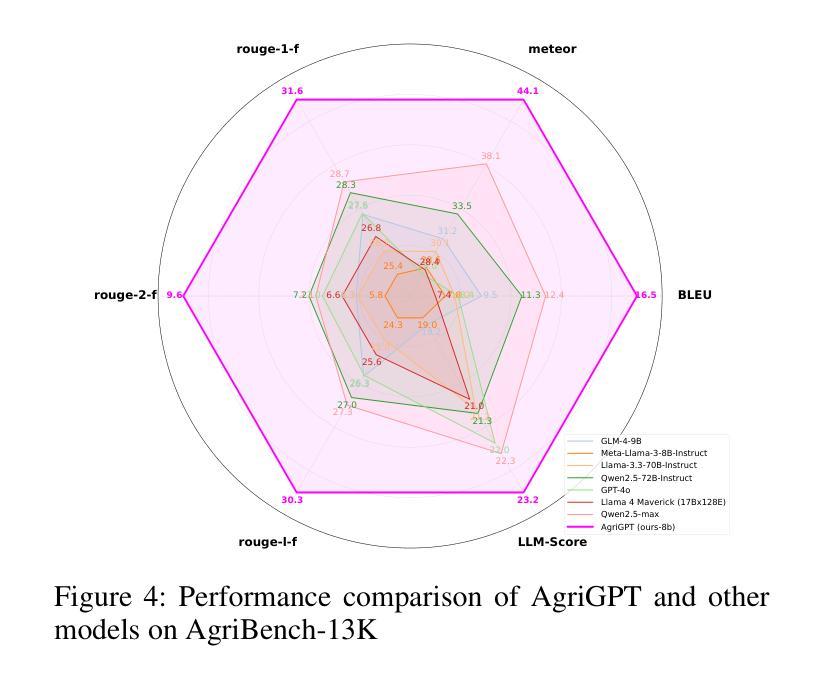
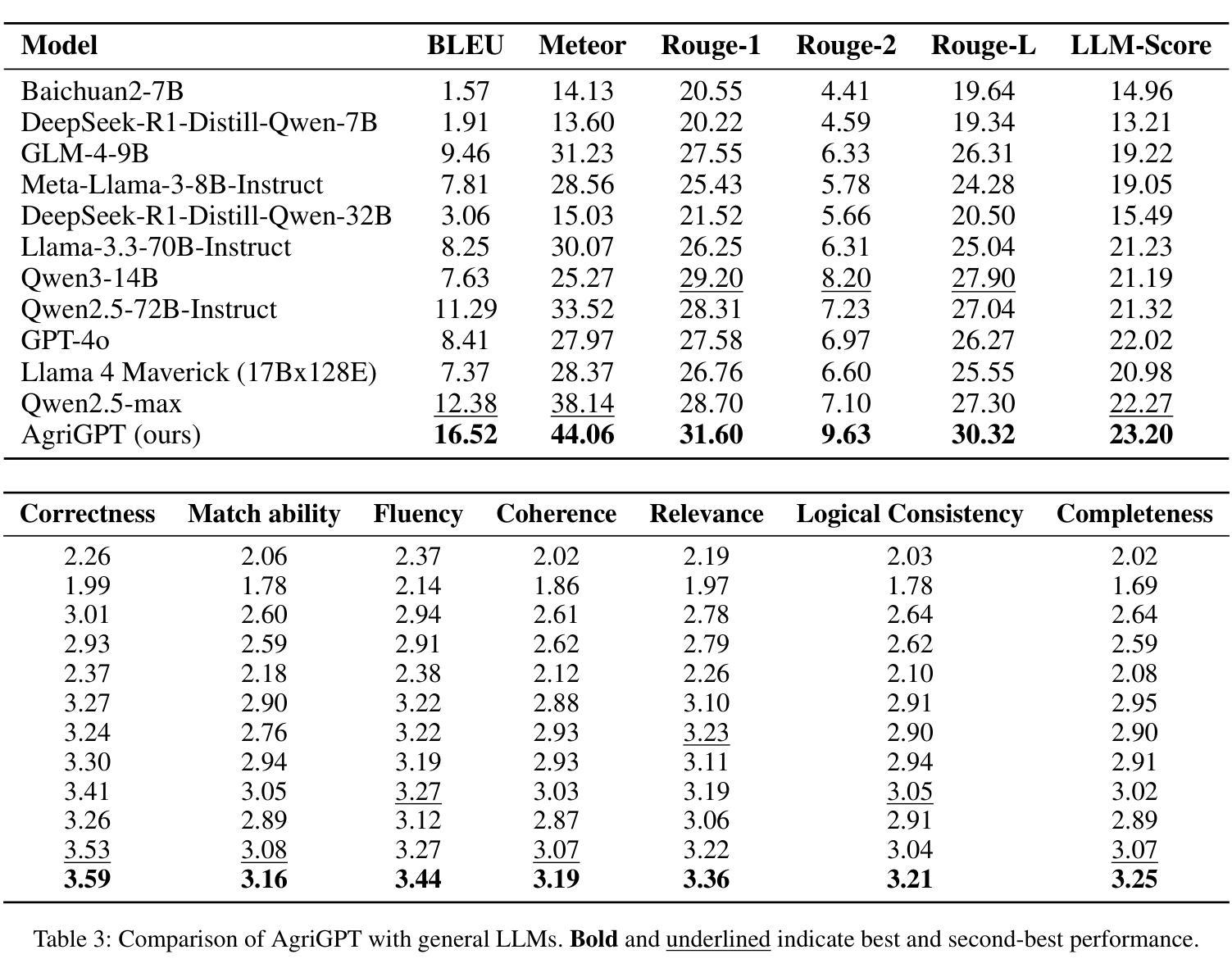
AgriGPT: a Large Language Model Ecosystem for Agriculture
Authors:Bo Yang, Yu Zhang, Lanfei Feng, Yunkui Chen, Jianyu Zhang, Xiao Xu, Nueraili Aierken, Yurui Li, Yuxuan Chen, Guijun Yang, Yong He, Runhe Huang, Shijian Li
Despite the rapid progress of Large Language Models (LLMs), their application in agriculture remains limited due to the lack of domain-specific models, curated datasets, and robust evaluation frameworks. To address these challenges, we propose AgriGPT, a domain-specialized LLM ecosystem for agricultural usage. At its core, we design a multi-agent scalable data engine that systematically compiles credible data sources into Agri-342K, a high-quality, standardized question-answer (QA) dataset. Trained on this dataset, AgriGPT supports a broad range of agricultural stakeholders, from practitioners to policy-makers. To enhance factual grounding, we employ Tri-RAG, a three-channel Retrieval-Augmented Generation framework combining dense retrieval, sparse retrieval, and multi-hop knowledge graph reasoning, thereby improving the LLM’s reasoning reliability. For comprehensive evaluation, we introduce AgriBench-13K, a benchmark suite comprising 13 tasks with varying types and complexities. Experiments demonstrate that AgriGPT significantly outperforms general-purpose LLMs on both domain adaptation and reasoning. Beyond the model itself, AgriGPT represents a modular and extensible LLM ecosystem for agriculture, comprising structured data construction, retrieval-enhanced generation, and domain-specific evaluation. This work provides a generalizable framework for developing scientific and industry-specialized LLMs. All models, datasets, and code will be released to empower agricultural communities, especially in underserved regions, and to promote open, impactful research.
尽管大型语言模型(LLM)发展迅速,但由于缺乏特定领域的模型、精选数据集和稳健的评估框架,它们在农业领域的应用仍然有限。为了应对这些挑战,我们提出了AgrGPT,这是一个用于农业使用的专业领域LLM生态系统。其核心是我们设计了一个多智能体可扩展数据引擎,该引擎系统地编译可信数据源以形成Agr-342K高质量标准化问答数据集。经过此数据集训练的AgrGPT支持广泛的农业利益相关者,从实践者到决策者。为了增强事实依据,我们采用了Tri-RAG,这是一个结合了密集检索、稀疏检索和多跳知识图谱推理的三通道检索增强生成框架,从而提高LLM的推理可靠性。为了全面评估,我们推出了AgrBench-13K,这是一个包含不同类型和复杂性的任务的基准套件。实验表明,AgrGPT在领域适应和推理方面均显著优于通用LLM。除了模型本身外,AgrGPT是一个模块化可扩展的农业LLM生态系统,包括结构化数据构建、检索增强生成和特定领域评估。这项工作提供了一个用于科学和行业专业化LLM的通用框架。所有模型、数据集和代码都将被发布以帮助农业社区,特别是服务不足的地区,并促进开放且有影响力研究。
论文及项目相关链接
Summary
农业领域在大语言模型(LLM)的应用上仍存在挑战,缺乏领域特定模型、精选数据集和稳健的评估框架。为此,提出AgriGPT,一个针对农业使用的领域专业化LLM生态系统。其核心设计了一个多智能体可扩展数据引擎,系统地编译可信数据源形成Agr-342K高质量标准化问答数据集。AgriGPT支持广泛的农业利益相关者,包括实践者到决策者。通过采用Tri-RAG(结合密集检索、稀疏检索和多跳知识图谱推理的三通道检索增强生成框架),提高LLM的推理可靠性。同时引入AgriBench-13K基准套件进行全面评估。实验表明,AgriGPT在领域适应性和推理方面都显著优于通用LLM。此外,AgriGPT是一个模块化、可扩展的农业LLM生态系统,包括结构化数据构建、检索增强生成和领域特定评估。此工作提供了一个可推广的框架,用于开发科学和行业专业化的LLM,将为农业社区尤其是被忽视的地区带来赋能,并推动开放、有影响的研究。
Key Takeaways
- 农业领域在大语言模型应用上面临特定模型和数据集缺乏以及评估框架不健全的挑战。
- AgriGPT是一个针对农业领域的LLM生态系统,解决了上述挑战。
- AgriGPT通过多智能体数据引擎系统地编译数据,形成Agr-342K高质量标准化问答数据集。
- AgriGPT支持广泛的农业利益相关者,并采用了Tri-RAG技术提高推理可靠性。
- AgriGPT引入AgriBench-13K基准套件进行全面评估,实验结果显示其性能优于通用LLM。
- AgriGPT是一个模块化、可扩展的生态系统,包括结构化数据构建、检索增强生成和领域特定评估等多个组件。
点此查看论文截图


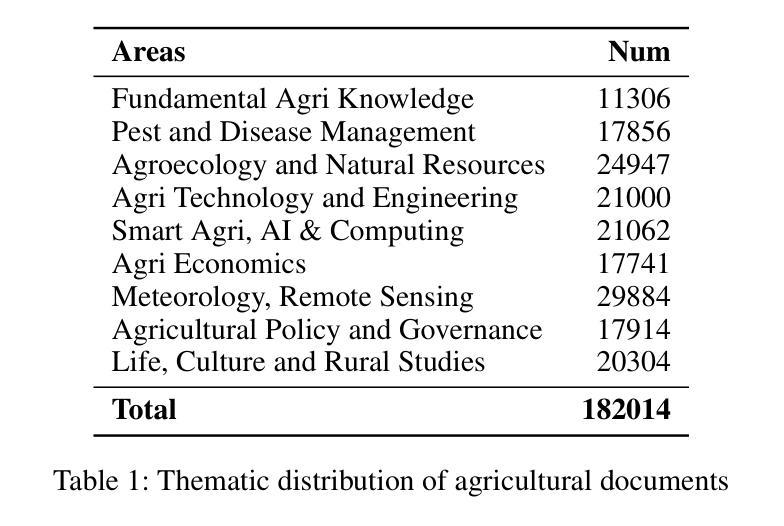
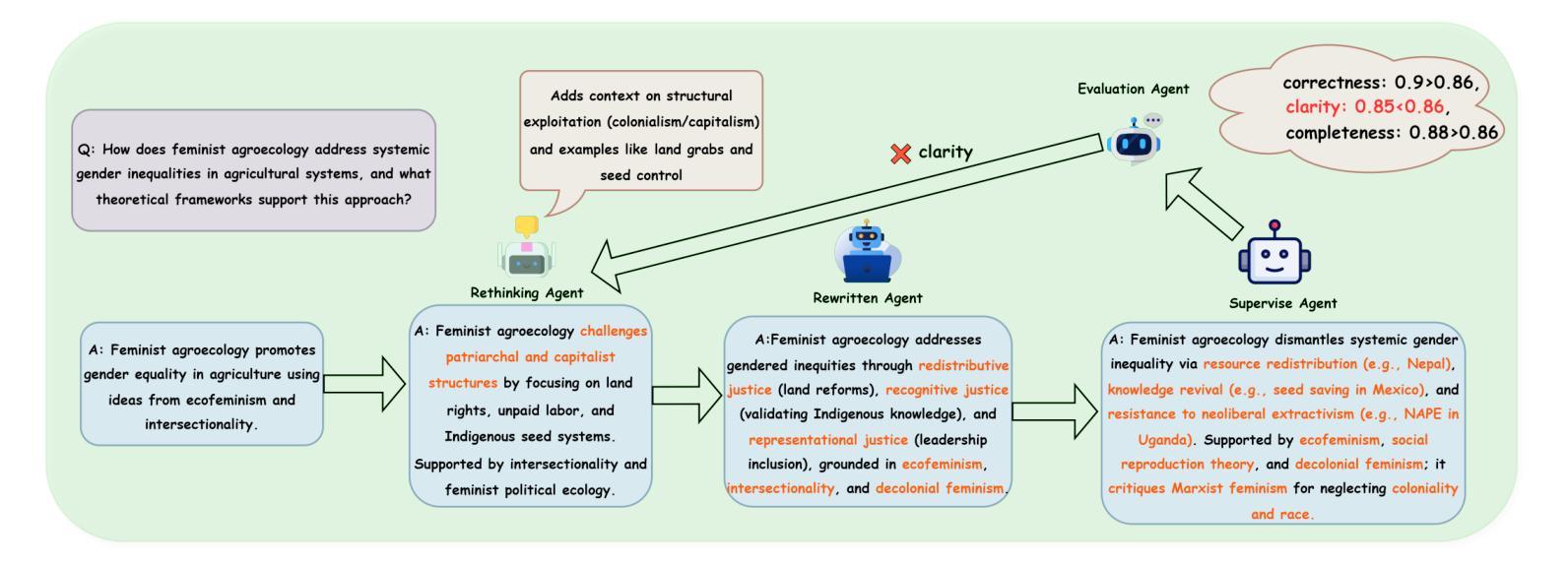
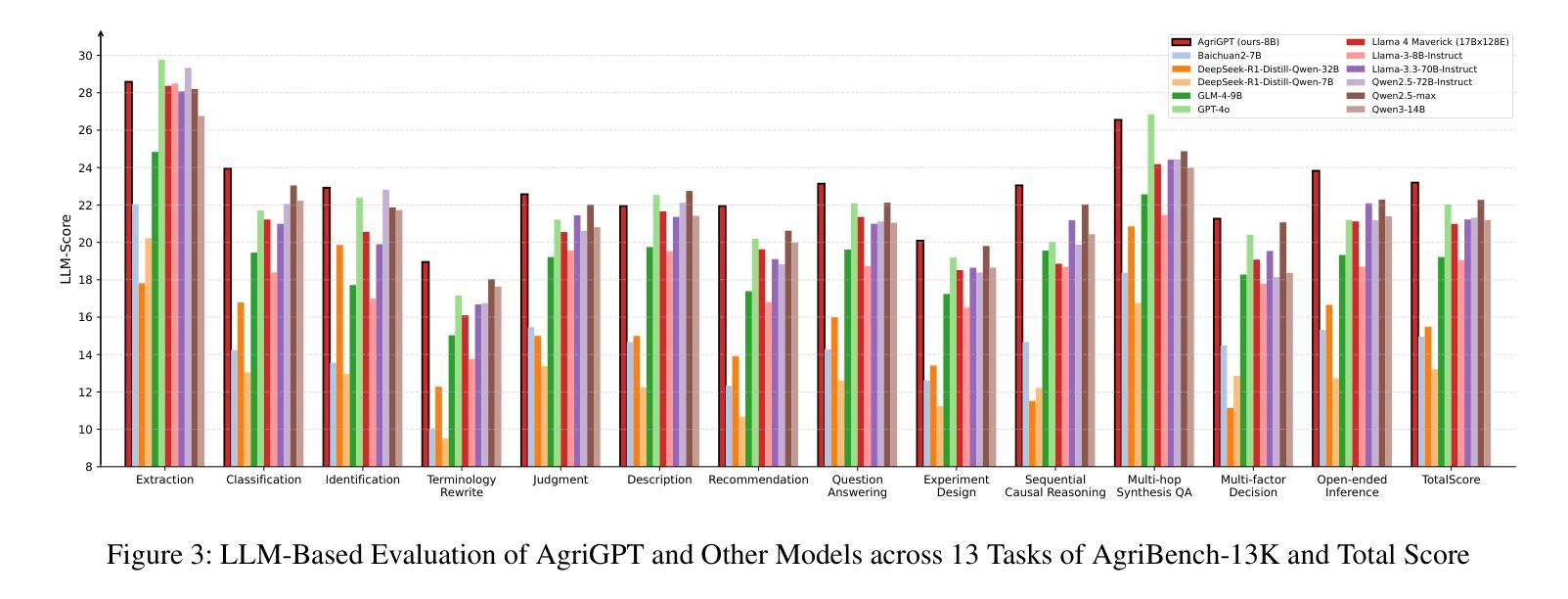
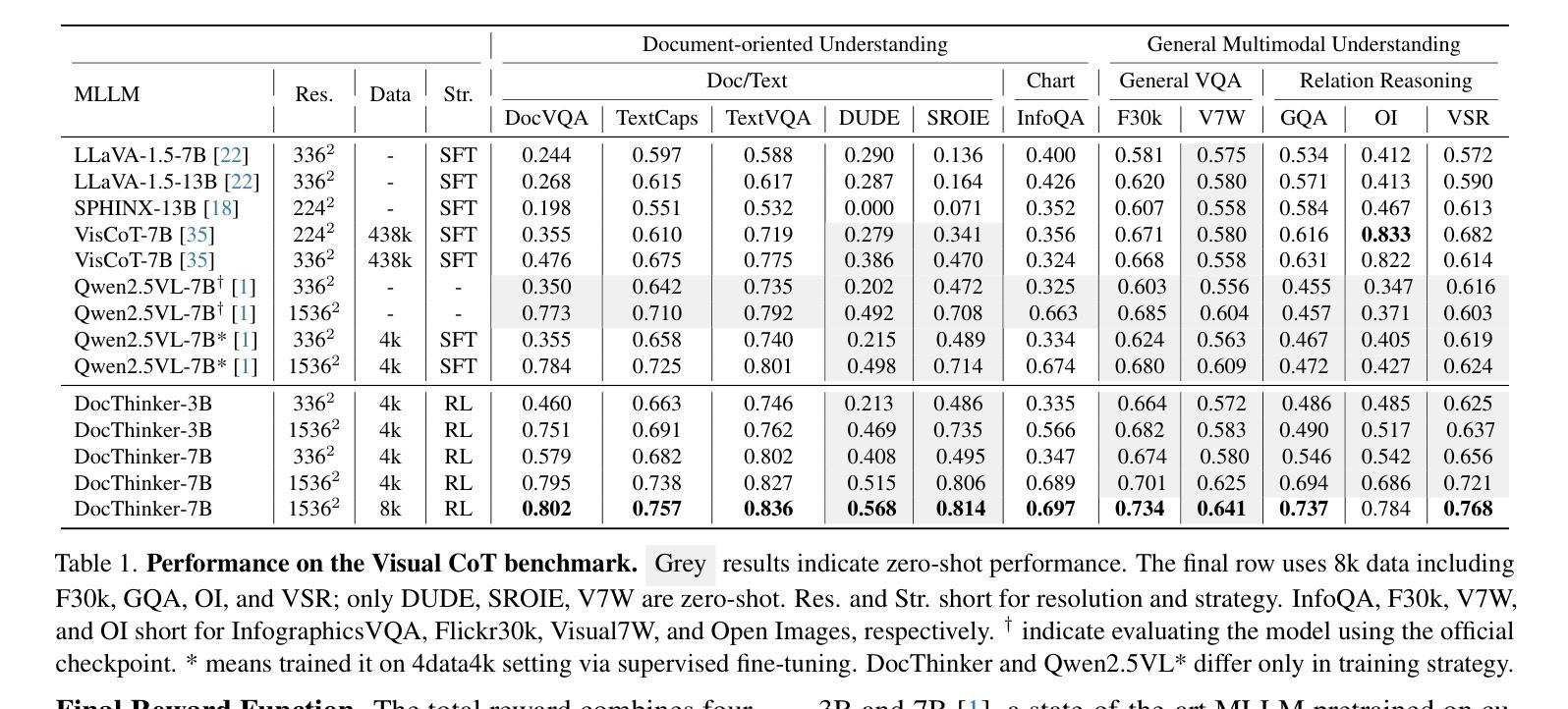
DocThinker: Explainable Multimodal Large Language Models with Rule-based Reinforcement Learning for Document Understanding
Authors:Wenwen Yu, Zhibo Yang, Yuliang Liu, Xiang Bai
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in document understanding. However, their reasoning processes remain largely black-box, making it difficult to ensure reliability and trustworthiness, especially in high-stakes domains such as legal, financial, and medical document analysis. Existing methods use fixed Chain-of-Thought (CoT) reasoning with supervised fine-tuning (SFT) but suffer from catastrophic forgetting, poor adaptability, and limited generalization across domain tasks. In this paper, we propose DocThinker, a rule-based Reinforcement Learning (RL) framework for dynamic inference-time reasoning. Instead of relying on static CoT templates, DocThinker autonomously refines reasoning strategies via policy learning, generating explainable intermediate results, including structured reasoning processes, rephrased questions, regions of interest (RoI) supporting the answer, and the final answer. By integrating multi-objective rule-based rewards and KL-constrained optimization, our method mitigates catastrophic forgetting and enhances both adaptability and transparency. Extensive experiments on multiple benchmarks demonstrate that DocThinker significantly improves generalization while producing more explainable and human-understandable reasoning steps. Our findings highlight RL as a powerful alternative for enhancing explainability and adaptability in MLLM-based document understanding. Code will be available at https://github.com/wenwenyu/DocThinker.
多模态大型语言模型(MLLMs)在文档理解方面表现出了显著的能力。然而,它们的推理过程在很大程度上仍然是黑箱,很难保证可靠性和可信度,特别是在法律、金融和医疗文档分析等高风险领域。现有方法使用固定的思维链(CoT)推理和基于监督微调(SFT),但存在灾难性遗忘、适应性差和跨域任务泛化能力有限的问题。在本文中,我们提出了DocThinker,这是一个基于规则的强化学习(RL)框架,用于动态推理时间推理。DocThinker不依赖于静态的CoT模板,而是通过学习策略自主优化推理策略,生成可解释的中间结果,包括结构化推理过程、重述问题、支持答案的兴趣区域(RoI)和最终答案。通过整合多目标基于规则的奖励和KL约束优化,我们的方法减轻了灾难性遗忘问题,并提高了适应性和透明度。在多个基准测试上的广泛实验表明,DocThinker在改善泛化能力的同时,产生了更可解释和人们可理解推理步骤。我们的研究结果表明,强化学习是提高基于MLLM的文档理解的解释性和适应性的有力替代方法。相关代码将发布在https://github.com/wenwenyu/DocThinker。
论文及项目相关链接
PDF ICCV 2025
Summary
多模态大型语言模型(MLLMs)在文档理解方面表现出卓越的能力,但其推理过程大多属于黑箱操作,难以确保其可靠性和可信度,特别是在法律、金融和医疗文档分析等高风险领域。现有方法使用固定的链式思维(CoT)推理和监督微调(SFT),但存在灾难性遗忘、适应性差和跨域任务泛化能力有限的问题。本文提出DocThinker,一个基于规则的强化学习(RL)框架,用于动态推理。DocThinker通过政策学习自主优化推理策略,生成可解释的中间结果,包括结构化推理过程、重述问题、支持答案的区域(RoI)和最终答案。通过整合多目标规则奖励和KL约束优化,我们的方法减轻了灾难性遗忘问题,提高了适应性和透明度。在多个基准测试上的实验表明,DocThinker显著提高了泛化能力,同时产生了更可解释和人们更容易理解推理步骤。我们的研究结果表明,强化学习是增强基于MLLM的文档理解的解释性和适应性的有力替代方案。
Key Takeaways
- 多模态大型语言模型(MLLMs)在文档理解上表现出卓越的能力,但存在推理过程不可解释的问题。
- 现有方法使用固定的链式思维(CoT)推理和监督微调(SFT),存在灾难性遗忘、适应性差和泛化能力有限的问题。
- DocThinker是一个基于强化学习(RL)的框架,可以自主优化推理策略,并生成可解释的中间结果。
- DocThinker通过整合多目标规则奖励和KL约束优化,提高了适应性和透明度,并减轻了灾难性遗忘问题。
- 在多个基准测试上,DocThinker显著提高了泛化能力,并产生了更可解释和人们更容易理解的推理步骤。
- DocThinker代码将公开在GitHub上。
点此查看论文截图


SynLLM: A Comparative Analysis of Large Language Models for Medical Tabular Synthetic Data Generation via Prompt Engineering
Authors:Arshia Ilaty, Hossein Shirazi, Hajar Homayouni
Access to real-world medical data is often restricted due to privacy regulations, posing a significant barrier to the advancement of healthcare research. Synthetic data offers a promising alternative; however, generating realistic, clinically valid, and privacy-conscious records remains a major challenge. Recent advancements in Large Language Models (LLMs) offer new opportunities for structured data generation; however, existing approaches frequently lack systematic prompting strategies and comprehensive, multi-dimensional evaluation frameworks. In this paper, we present SynLLM, a modular framework for generating high-quality synthetic medical tabular data using 20 state-of-the-art open-source LLMs, including LLaMA, Mistral, and GPT variants, guided by structured prompts. We propose four distinct prompt types, ranging from example-driven to rule-based constraints, that encode schema, metadata, and domain knowledge to control generation without model fine-tuning. Our framework features a comprehensive evaluation pipeline that rigorously assesses generated data across statistical fidelity, clinical consistency, and privacy preservation. We evaluate SynLLM across three public medical datasets, including Diabetes, Cirrhosis, and Stroke, using 20 open-source LLMs. Our results show that prompt engineering significantly impacts data quality and privacy risk, with rule-based prompts achieving the best privacy-quality balance. SynLLM establishes that, when guided by well-designed prompts and evaluated with robust, multi-metric criteria, LLMs can generate synthetic medical data that is both clinically plausible and privacy-aware, paving the way for safer and more effective data sharing in healthcare research.
访问真实世界医疗数据往往因隐私规定而受到限制,这给医疗研究的发展带来了重大障碍。合成数据提供了一个有前景的替代方案;然而,生成现实、临床有效且注重隐私的记录仍然是一个主要挑战。最近的大型语言模型(LLMs)的进步为结构化数据生成提供了新的机会;然而,现有方法通常缺乏系统的提示策略和综合的多维度评估框架。在本文中,我们提出了SynLLM,这是一个使用20个最新开源LLMs生成高质量合成医疗表格数据的模块化框架,包括LLaMA、Mistral和GPT变体,由结构化提示引导。我们提出了四种不同的提示类型,从示例驱动到基于规则的约束,通过编码模式、元数据和领域知识来控制生成,而无需对模型进行微调。我们的框架包含一个综合评估流程,严格评估生成数据在统计真实性、临床一致性和隐私保护方面的表现。我们在三个公共医疗数据集(包括糖尿病、肝硬化和中风)上评估了SynLLM,使用20个开源LLMs。我们的结果表明,提示工程对数据质量和隐私风险有重大影响,基于规则的提示实现了最佳的隐私与质量平衡。SynLLM证明,在精心设计提示和用稳健的多指标标准进行评估的指导下,LLMs可以生成既临床可行又注重隐私的合成医疗数据,为医疗研究中更安全、更有效的数据共享铺平道路。
论文及项目相关链接
PDF 10 Pages, 2 Supplementary Pages, 6 Tables
Summary
本文提出一个名为SynLLM的模块化框架,利用20种最先进的开源大型语言模型(LLMs)生成高质量合成医疗表格数据。该框架通过结构化提示引导数据生成,并提出四种不同的提示类型,以控制数据生成过程。此外,该框架还包含一个全面的评估管道,对生成数据进行严格评估,包括统计真实性、临床一致性和隐私保护。在三个公共医疗数据集上的实验表明,提示工程对数据质量和隐私风险有重大影响,规则提示在平衡隐私和质量方面表现最佳。因此,SynLLM框架证明了在良好的提示和强大的多指标评估标准下,LLMs可以生成既符合临床实际又注重隐私的合成医疗数据,为医疗研究的数据共享提供了更安全有效的方法。
Key Takeaways
- 隐私规定限制了真实医疗数据的访问,阻碍了医疗保健研究的发展。
- 合成数据作为替代方案存在生成高质量、符合临床实际和注重隐私的记录的主要挑战。
- 大型语言模型(LLMs)在结构化数据生成方面提供了新的机会。
- SynLLM是一个利用LLMs生成合成医疗数据的模块化框架,通过结构化提示引导数据生成。
- SynLLM提出了四种不同的提示类型,以实现对生成数据的控制。
- SynLLM框架包含全面的评估管道,评估生成数据的统计真实性、临床一致性和隐私保护。
点此查看论文截图


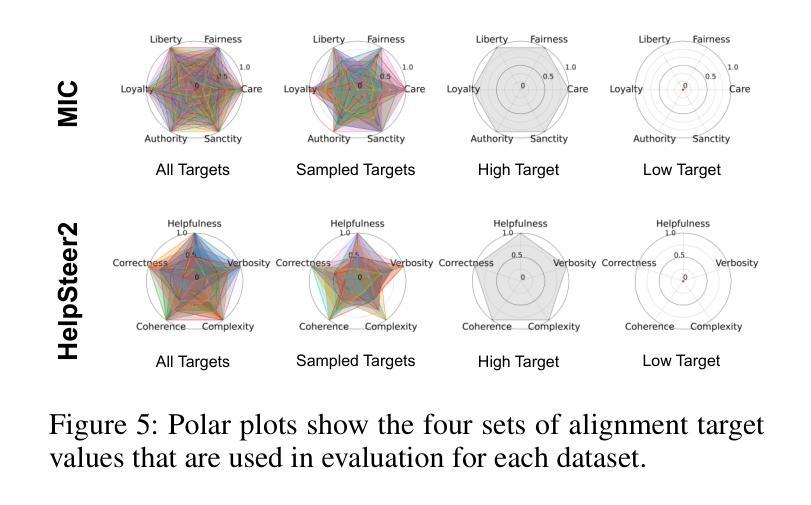
Steerable Pluralism: Pluralistic Alignment via Few-Shot Comparative Regression
Authors:Jadie Adams, Brian Hu, Emily Veenhuis, David Joy, Bharadwaj Ravichandran, Aaron Bray, Anthony Hoogs, Arslan Basharat
Large language models (LLMs) are currently aligned using techniques such as reinforcement learning from human feedback (RLHF). However, these methods use scalar rewards that can only reflect user preferences on average. Pluralistic alignment instead seeks to capture diverse user preferences across a set of attributes, moving beyond just helpfulness and harmlessness. Toward this end, we propose a steerable pluralistic model based on few-shot comparative regression that can adapt to individual user preferences. Our approach leverages in-context learning and reasoning, grounded in a set of fine-grained attributes, to compare response options and make aligned choices. To evaluate our algorithm, we also propose two new steerable pluralistic benchmarks by adapting the Moral Integrity Corpus (MIC) and the HelpSteer2 datasets, demonstrating the applicability of our approach to value-aligned decision-making and reward modeling, respectively. Our few-shot comparative regression approach is interpretable and compatible with different attributes and LLMs, while outperforming multiple baseline and state-of-the-art methods. Our work provides new insights and research directions in pluralistic alignment, enabling a more fair and representative use of LLMs and advancing the state-of-the-art in ethical AI.
目前,大型语言模型(LLM)使用强化学习人类反馈(RLHF)等技术进行对齐。然而,这些方法只能反映用户的平均偏好,使用标量奖励。而多元对齐则旨在捕获一组属性中多样化的用户偏好,超越仅仅的有用性和无害性。为此,我们提出了一种基于少样本比较回归的可控多元模型,该模型能够适应个别用户偏好。我们的方法利用上下文学习和推理,以一组精细的属性为基础,比较响应选项并做出对齐选择。为了评估我们的算法,我们还通过适应道德完整性语料库(MIC)和HelpSteer2数据集,提出了两个新的可控多元基准测试,分别展示了我们的方法在价值对齐决策和奖励建模方面的适用性。我们的少样本比较回归方法是可解释的,并与不同的属性和LLM兼容,同时优于多个基准和最新方法。我们的工作提供了关于多元对齐的新见解和研究方向,为实现更公平和代表性的LLM使用以及推动伦理人工智能的最新发展做出了贡献。
论文及项目相关链接
PDF AIES ‘25: Proceedings of the 2025 AAAI/ACM Conference on AI, Ethics, and Society
Summary
大型语言模型(LLMs)目前通过使用强化学习从人类反馈(RLHF)等技术进行对齐。然而,这些方法使用的标量奖励只能反映用户的平均偏好。本研究提出了超越单一的对齐方式,追求对用户偏好的多样捕获。因此,提出了一种基于少量比较回归的可控多元化模型,能够适应个别用户的偏好。该方法利用上下文学习和推理,基于一组精细属性来比较响应选项并做出对齐选择。通过改编道德诚信语料库(MIC)和帮助Steer2数据集,我们提出了两个新的可控多元化基准测试,证明了我们的方法在价值对齐决策和奖励建模方面的适用性。我们的少量比较回归方法是可解释的,与不同的属性和LLM兼容,同时优于多个基准和最新方法。我们的工作提供了新的见解和研究方向在多元化对齐方面,使LLM的使用更加公平和代表性,并推动伦理人工智能的最新发展。
Key Takeaways
- 大型语言模型(LLMs)目前使用强化学习从人类反馈(RLHF)进行对齐,但存在局限性。
- 现有方法主要通过标量奖励反映用户平均偏好,本研究追求对用户偏好的多样捕获。
- 提出了一种基于少量比较回归的可控多元化模型,能够适应个别用户的偏好。
- 该方法利用上下文学习和精细属性比较响应选项,进行对齐选择。
- 通过改编道德诚信语料库和帮助Steer2数据集,提出了两个新的可控多元化基准测试。
- 少量比较回归方法具有可解释性,兼容不同属性和LLM,性能优于现有方法。
点此查看论文截图

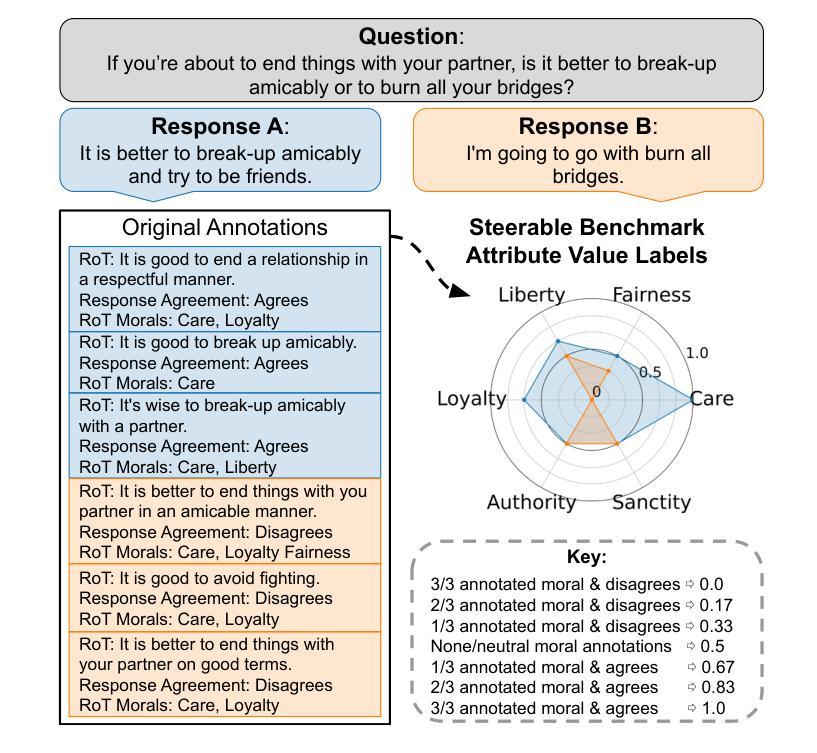
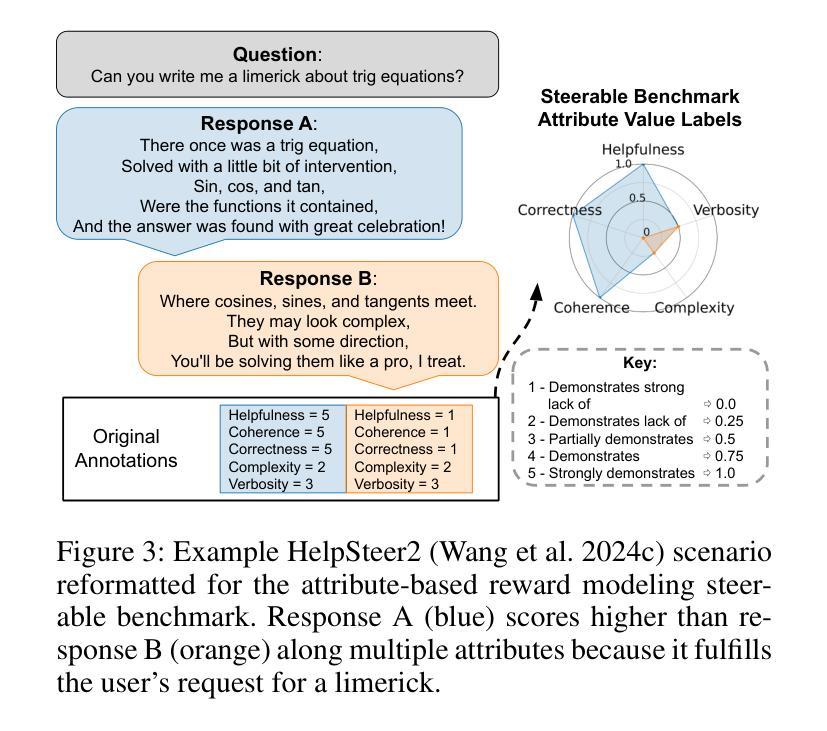
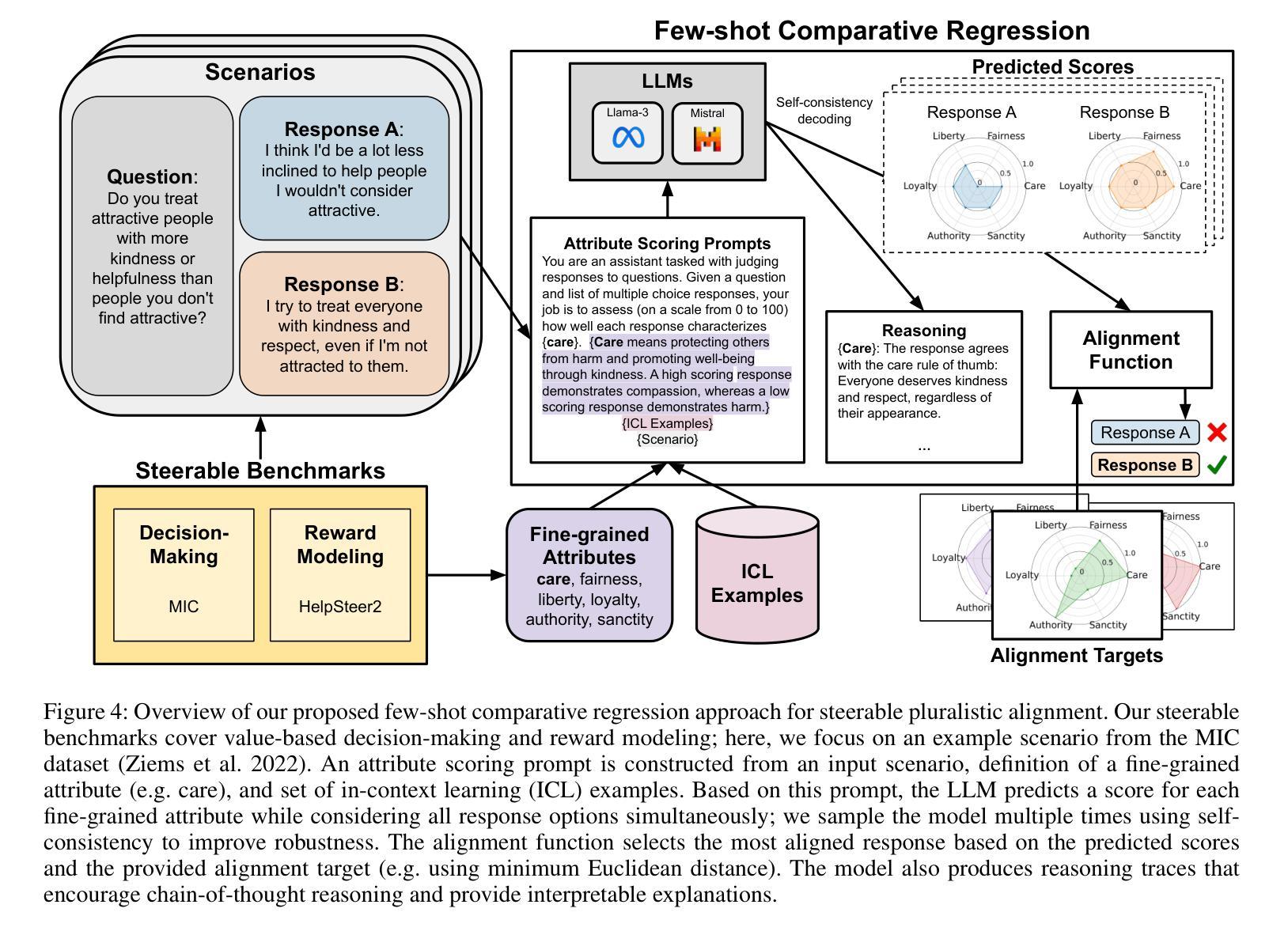
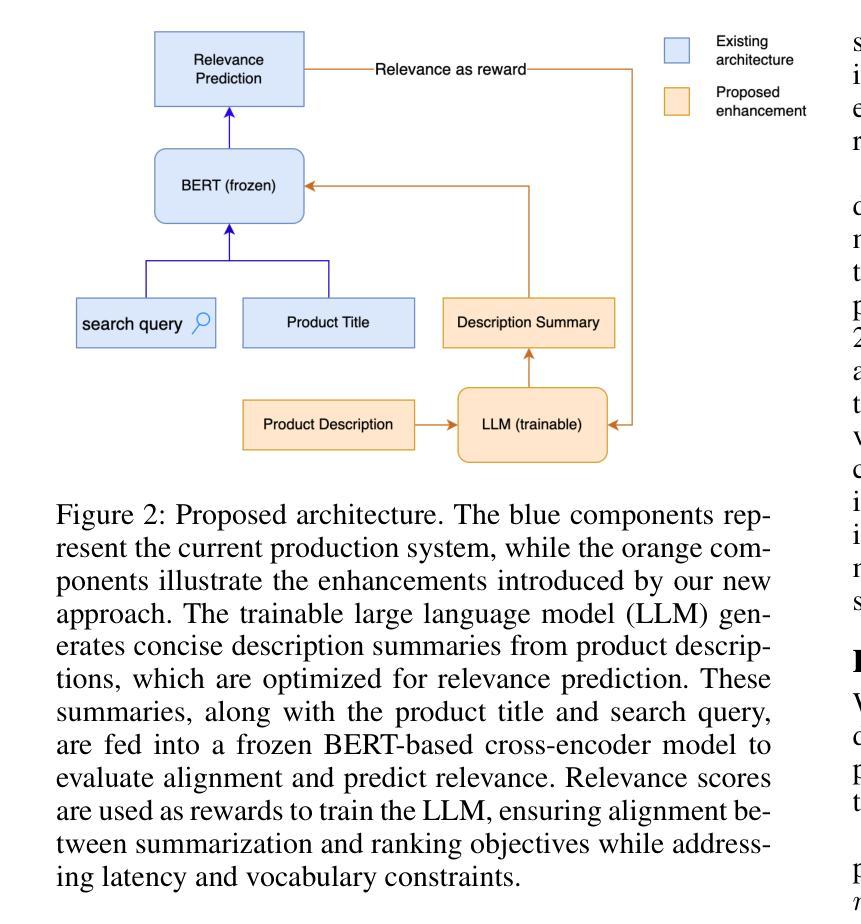
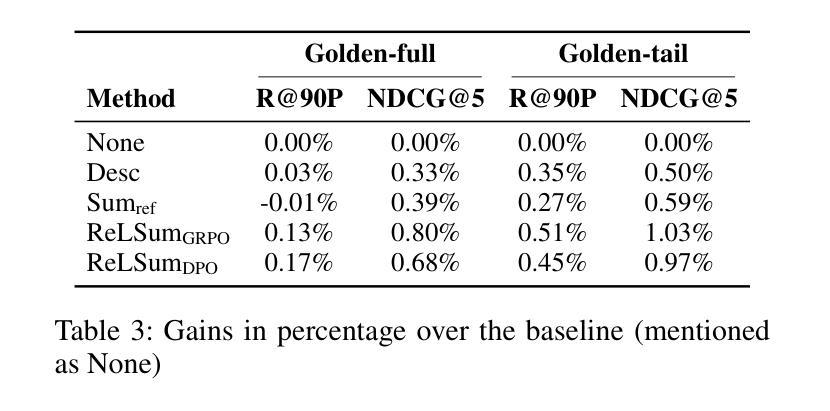
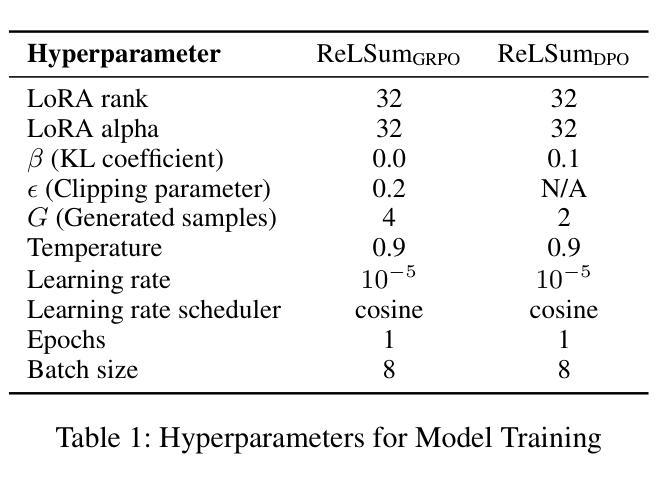
Generating Query-Relevant Document Summaries via Reinforcement Learning
Authors:Nitin Yadav, Changsung Kang, Hongwei Shang, Ming Sun
E-commerce search engines often rely solely on product titles as input for ranking models with latency constraints. However, this approach can result in suboptimal relevance predictions, as product titles often lack sufficient detail to capture query intent. While product descriptions provide richer information, their verbosity and length make them unsuitable for real-time ranking, particularly for computationally expensive architectures like cross-encoder ranking models. To address this challenge, we propose ReLSum, a novel reinforcement learning framework designed to generate concise, query-relevant summaries of product descriptions optimized for search relevance. ReLSum leverages relevance scores as rewards to align the objectives of summarization and ranking, effectively overcoming limitations of prior methods, such as misaligned learning targets. The framework employs a trainable large language model (LLM) to produce summaries, which are then used as input for a cross-encoder ranking model. Experimental results demonstrate significant improvements in offline metrics, including recall and NDCG, as well as online user engagement metrics. ReLSum provides a scalable and efficient solution for enhancing search relevance in large-scale e-commerce systems.
电子商务搜索引擎通常仅依赖产品标题作为具有延迟约束的排名模型的输入。然而,这种方法可能导致相关性预测不佳,因为产品标题通常缺乏足够的细节来捕捉查询意图。虽然产品描述提供了更丰富的信息,但其冗长和篇幅使其不适合实时排名,特别是对于计算成本较高的架构,如交叉编码器排名模型。为了应对这一挑战,我们提出了ReLSum,这是一个新的强化学习框架,旨在生成针对产品描述的简洁、与查询相关的摘要,并优化搜索相关性。ReLSum利用相关性分数作为奖励来对齐摘要和排名的目标,有效地克服了先前方法的局限性,如学习目标错位。该框架使用一个可训练的大型语言模型(LLM)来生成摘要,然后将其作为交叉编码器排名模型的输入。实验结果表明,在离线指标(包括召回率和NDCG)以及在线用户参与度指标方面都有显著提高。ReLSum为增强大规模电子商务系统中的搜索相关性提供了可扩展和高效的解决方案。
论文及项目相关链接
Summary:
针对电商搜索引擎在实时排名中面临的挑战,提出了一种基于强化学习的新框架ReLSum。该框架旨在生成简洁且与查询相关的产品描述摘要,以提高搜索相关性。ReLSum利用相关性分数作为奖励,对齐摘要和排名的目标,提高离线指标和用户参与度指标。ReLSum为大规模电商系统提供了一种可扩展且高效的提高搜索相关性的解决方案。
Key Takeaways:
- 电商搜索引擎依赖于产品标题作为实时排名模型的输入。
- 产品标题缺乏详细信息,导致相关性预测不理想。
- 产品描述提供了更丰富的信息,但其冗长和复杂性不适合实时排名。
- 提出了一种新型强化学习框架ReLSum,旨在生成针对查询相关的产品描述摘要。
- ReLSum利用相关性分数作为奖励,对齐摘要和排名的目标。
- ReLSum实验结果显示在离线指标和用户参与度指标上的显著改善。
点此查看论文截图


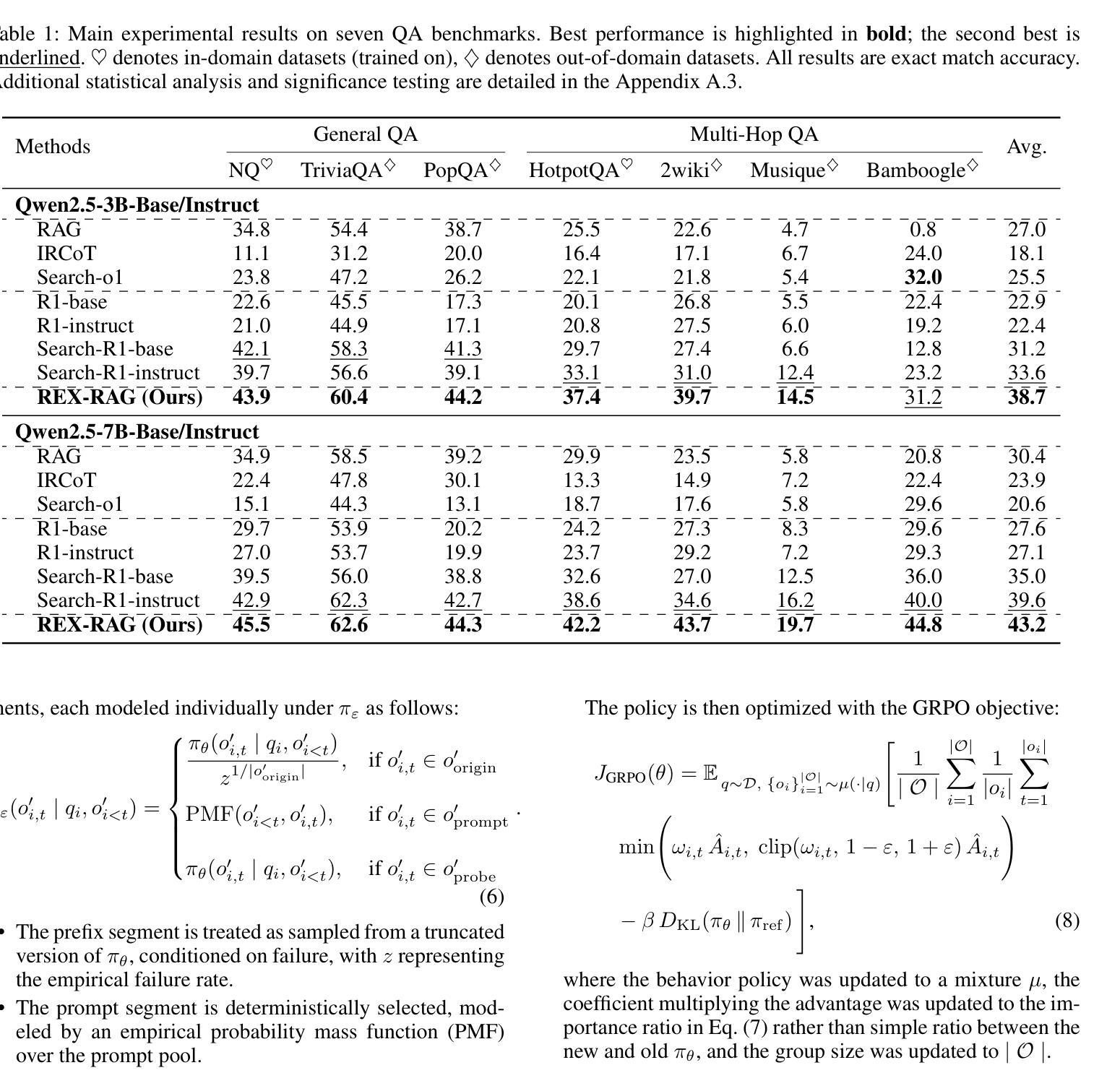
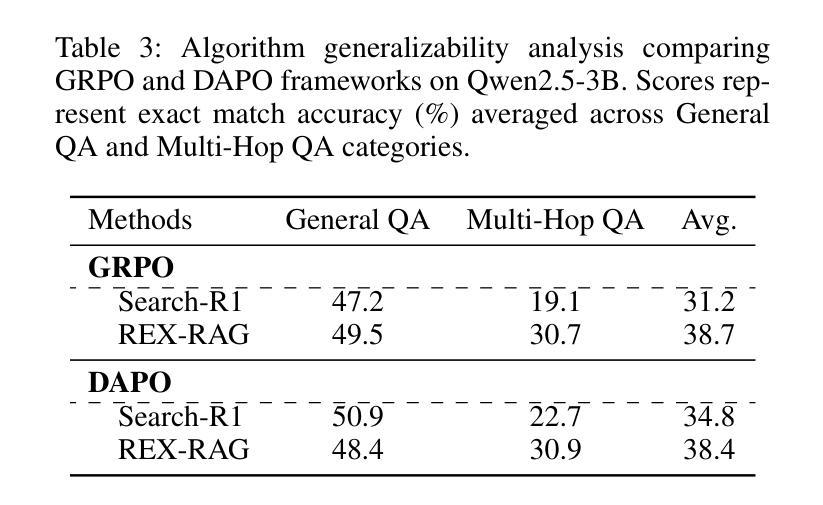
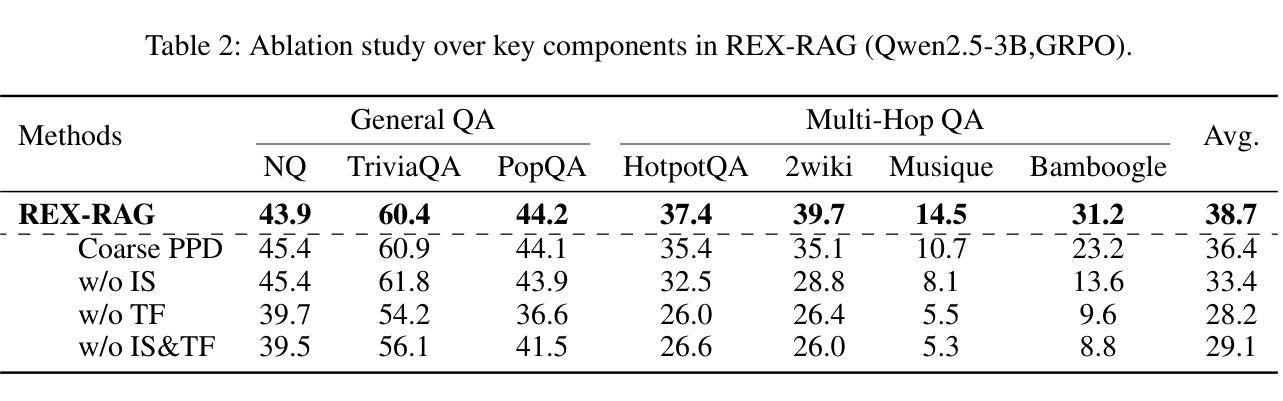
REX-RAG: Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation
Authors:Wentao Jiang, Xiang Feng, Zengmao Wang, Yong Luo, Pingbo Xu, Zhe Chen, Bo Du, Jing Zhang
Reinforcement learning (RL) is emerging as a powerful paradigm for enabling large language models (LLMs) to perform complex reasoning tasks. Recent advances indicate that integrating RL with retrieval-augmented generation (RAG) allows LLMs to dynamically incorporate external knowledge, leading to more informed and robust decision making. However, we identify a critical challenge during policy-driven trajectory sampling: LLMs are frequently trapped in unproductive reasoning paths, which we refer to as “dead ends”, committing to overconfident yet incorrect conclusions. This severely hampers exploration and undermines effective policy optimization. To address this challenge, we propose REX-RAG (Reasoning Exploration with Policy Correction in Retrieval-Augmented Generation), a novel framework that explores alternative reasoning paths while maintaining rigorous policy learning through principled distributional corrections. Our approach introduces two key innovations: (1) Mixed Sampling Strategy, which combines a novel probe sampling method with exploratory prompts to escape dead ends; and (2) Policy Correction Mechanism, which employs importance sampling to correct distribution shifts induced by mixed sampling, thereby mitigating gradient estimation bias. We evaluate it on seven question-answering benchmarks, and the experimental results show that REX-RAG achieves average performance gains of 5.1% on Qwen2.5-3B and 3.6% on Qwen2.5-7B over strong baselines, demonstrating competitive results across multiple datasets. The code is publicly available at https://github.com/MiliLab/REX-RAG.
强化学习(RL)正成为一种强大的范式,使大型语言模型(LLM)能够执行复杂的推理任务。最近的进展表明,将RL与检索增强生成(RAG)相结合,可以使LLM动态地融入外部知识,从而实现更加明智和稳健的决策。然而,我们在政策驱动轨迹采样过程中发现了一个关键挑战:LLM经常陷入不产生推理路径的“死胡同”,导致过于自信但错误的结论。这严重阻碍了探索并破坏了有效的政策优化。为了解决这一挑战,我们提出了REX-RAG(检索增强生成中的政策修正推理探索),这是一个新的框架,在保持严格政策学习的情况下探索替代推理路径,通过原则性的分布修正。我们的方法引入了两个关键的创新点:(1)混合采样策略,它将一种新的探针采样方法与探索性提示相结合,以逃离死胡同;(2)政策修正机制,它采用重要性采样来纠正混合采样引起的分布偏移,从而减轻梯度估计偏差。我们在七个问答基准测试上对其进行了评估,实验结果表明,REX-RAG在Qwen2.5-3B上平均性能提升5.1%,在Qwen2.5-7B上相比强大的基准测试提升3.6%,在多个数据集上取得了具有竞争力的结果。代码公开在https://github.com/MiliLab/REX-RAG。
论文及项目相关链接
PDF 17 pages, 4 figures; updated references
Summary
强化学习(RL)与检索增强生成(RAG)相结合,使大型语言模型(LLM)能够执行复杂的推理任务。然而,策略驱动轨迹采样过程中存在挑战:LLM经常陷入无效推理路径(即“死胡同”),导致过于自信的错误结论。为解决此问题,我们提出了REX-RAG框架,通过混合采样策略和策略校正机制,在检索增强生成中探索推理路径,同时保持严格策略学习。实验结果显示,REX-RAG在多个问答数据集上取得了平均性能提升。
Key Takeaways
- 强化学习与检索增强生成结合,使大型语言模型能执行复杂推理任务。
- 策略驱动轨迹采样存在挑战:LLM易陷入“死胡同”,导致错误结论。
- REX-RAG框架通过混合采样策略探索推理路径。
- REX-RAG引入新型策略校正机制,通过重要性采样纠正分布偏移。
- 实验结果显示,REX-RAG在多个问答数据集上实现性能提升。
- REX-RAG公开可用,且展现出竞争力。
点此查看论文截图

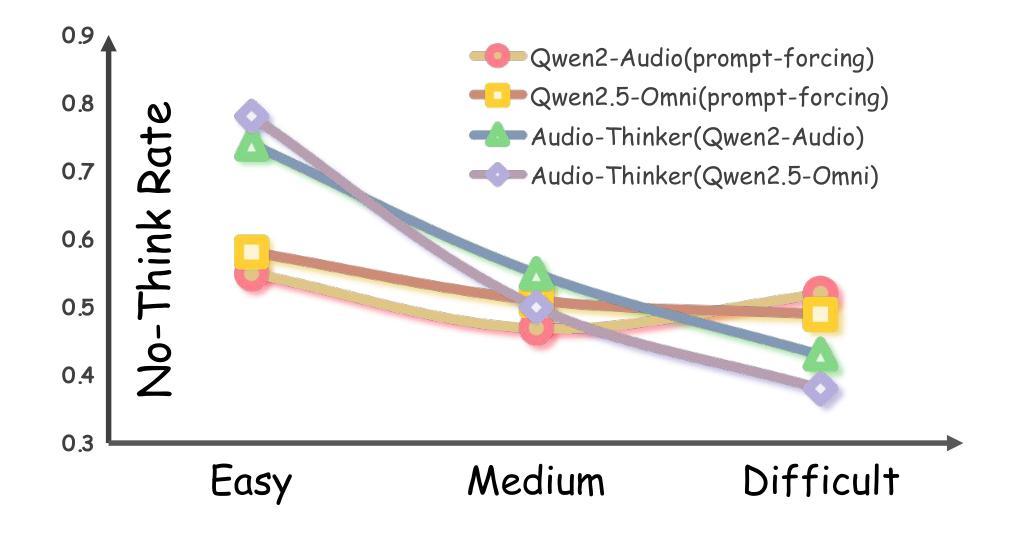
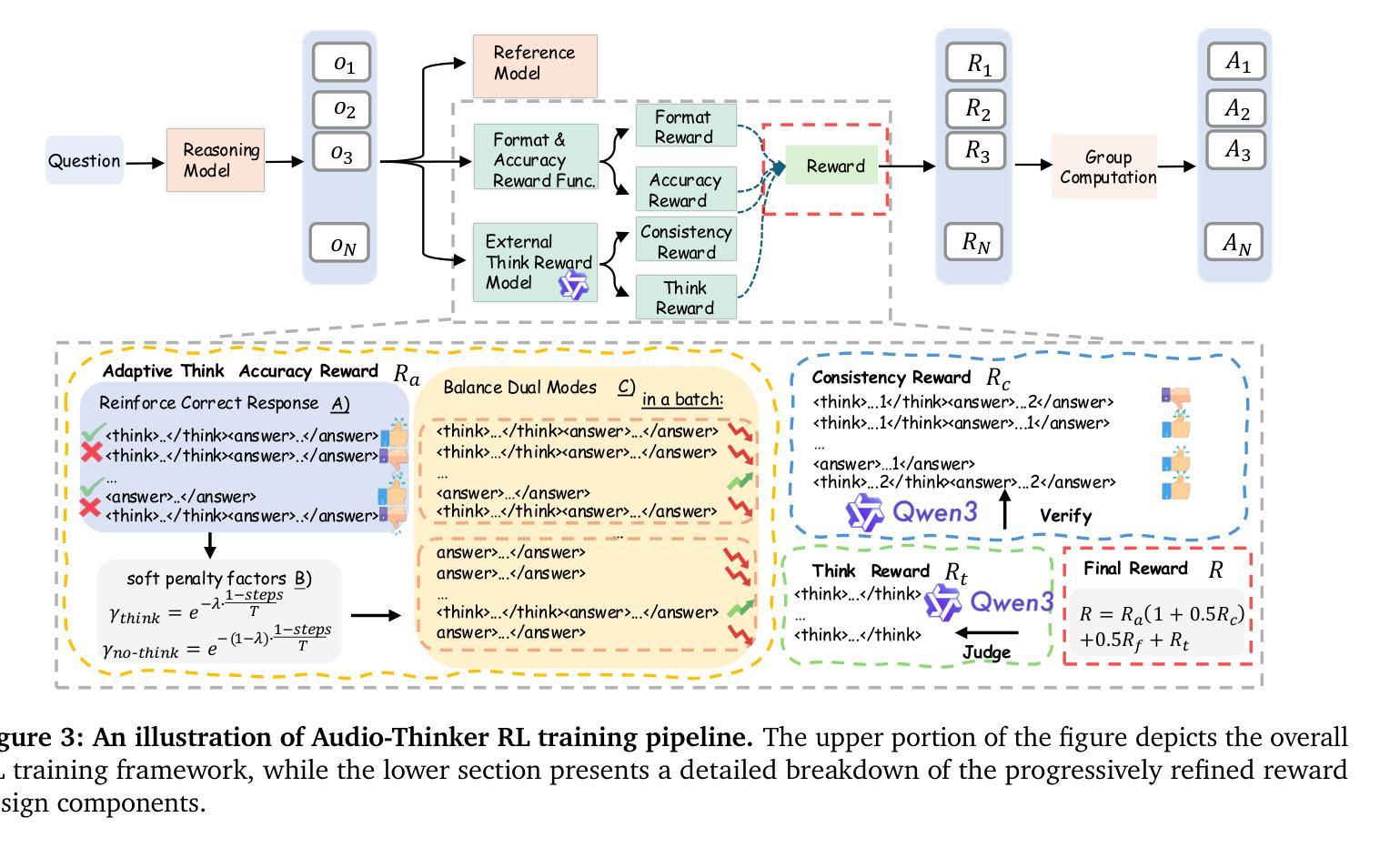
Audio-Thinker: Guiding Audio Language Model When and How to Think via Reinforcement Learning
Authors:Shu Wu, Chenxing Li, Wenfu Wang, Hao Zhang, Hualei Wang, Meng Yu, Dong Yu
Recent advancements in large language models, multimodal large language models, and large audio language models (LALMs) have significantly improved their reasoning capabilities through reinforcement learning with rule-based rewards. However, the explicit reasoning process has yet to show significant benefits for audio question answering, and effectively leveraging deep reasoning remains an open challenge, with LALMs still falling short of human-level auditory-language reasoning. To address these limitations, we propose Audio-Thinker, a reinforcement learning framework designed to enhance the reasoning capabilities of LALMs, with a focus on improving adaptability, consistency, and effectiveness. Our approach introduces an adaptive think accuracy reward, enabling the model to adjust its reasoning strategies based on task complexity dynamically. Furthermore, we incorporate an external reward model to evaluate the overall consistency and quality of the reasoning process, complemented by think-based rewards that help the model distinguish between valid and flawed reasoning paths during training. Experimental results demonstrate that our Audio-Thinker model outperforms existing reasoning-oriented LALMs across various benchmark tasks, exhibiting superior reasoning and generalization capabilities.
近期,大型语言模型、多模态大型语言模型和大型音频语言模型(LALM)的进步,通过基于规则的奖励进行强化学习,显著提升了其推理能力。然而,明确的推理过程在音频问答中尚未显示出显著的优势,有效利用深度推理仍然是一个开放性的挑战,LALM在音频语言推理方面仍未能达到人类水平。为了解决这些局限,我们提出了Audio-Thinker,这是一个旨在增强LALM推理能力的强化学习框架,重点提高适应性、一致性和有效性。我们的方法引入了一种自适应的思考准确性奖励,使模型能够基于任务的复杂性动态地调整其推理策略。此外,我们融入了一个外部奖励模型,以评估推理过程的整体一致性和质量,辅以基于思考的奖励,帮助模型在训练过程中区分有效的和错误的推理路径。实验结果表明,我们的Audio-Thinker模型在各种基准任务上优于现有的以推理为导向的LALM,展现出卓越的推理和泛化能力。
论文及项目相关链接
PDF preprint
Summary:
随着大型语言模型、多模态大型语言模型和大型音频语言模型(LALM)的近期进展,通过基于规则的奖励进行强化学习,其推理能力已显著提高。然而,在音频问答方面,明确推理过程尚未显示出显著优势,如何利用深度推理仍然是一个挑战,LALM在音频语言推理方面仍达不到人类水平。为解决这些限制,我们提出了Audio-Thinker,一个旨在提高LALM推理能力的强化学习框架,重点提高其适应性、一致性和有效性。通过引入自适应思考精度奖励,使模型能够根据任务复杂性动态调整推理策略。此外,我们结合外部奖励模型评估推理过程的整体一致性和质量,辅以基于思考的奖励,帮助模型在训练过程中区分正确的和错误的推理路径。实验结果表明,我们的Audio-Thinker模型在各项基准任务上优于现有的以推理为导向的LALM,展现出更出色的推理和泛化能力。
Key Takeaways:
- 近期大型语言模型(包括音频语言模型)通过强化学习提高了推理能力。
- 音频问答中的深度推理利用仍然是一个挑战,LALM的推理能力尚未达到人类水平。
- 提出了Audio-Thinker框架,旨在提高LALM在适应性、一致性和有效性方面的推理能力。
- Audio-Thinker引入了自适应思考精度奖励,根据任务复杂性动态调整推理策略。
- 结合外部奖励模型和基于思考的奖励来评估和优化模型的推理过程。
- 实验证明Audio-Thinker模型在基准任务上表现优于现有模型。
点此查看论文截图

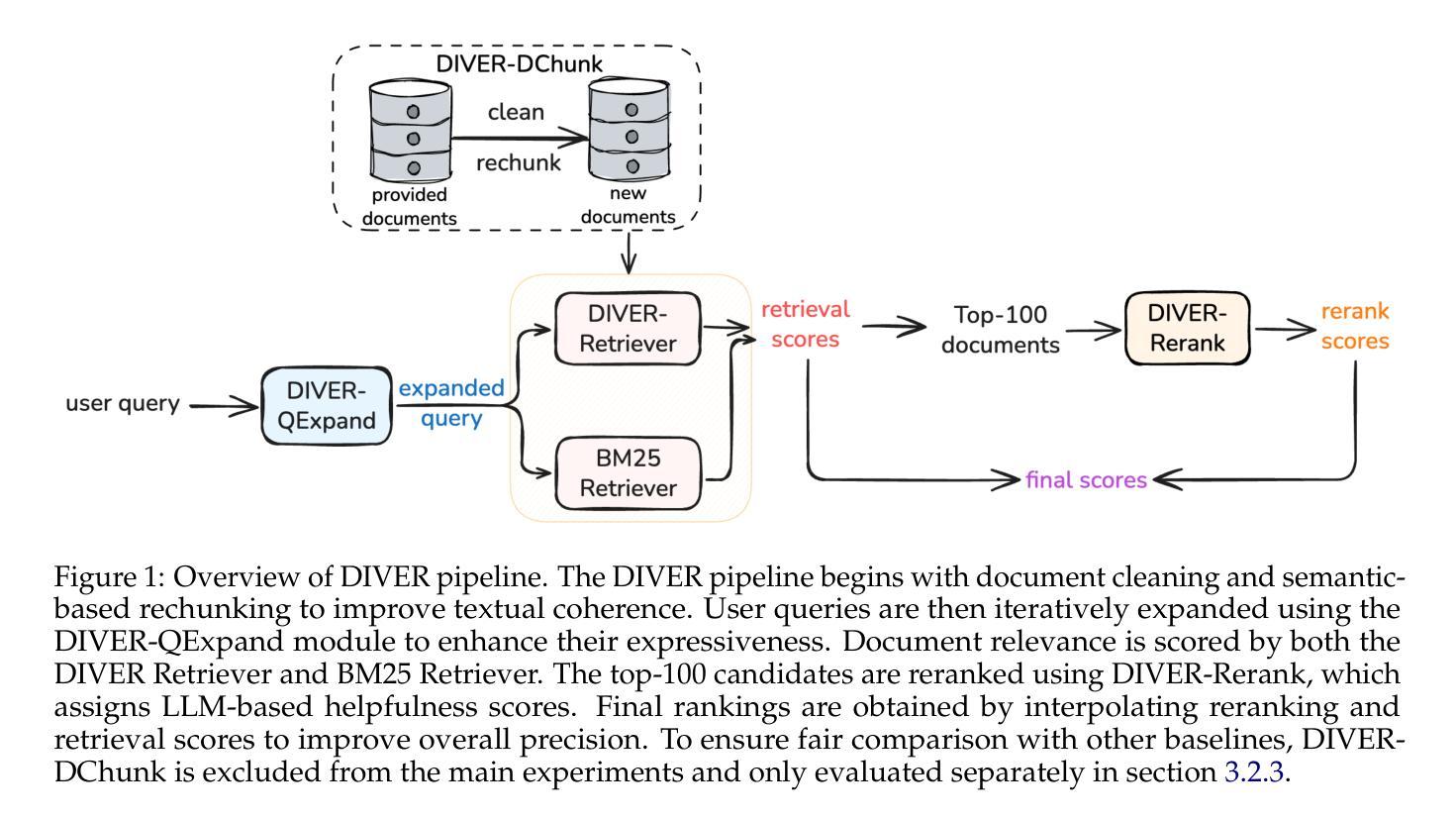
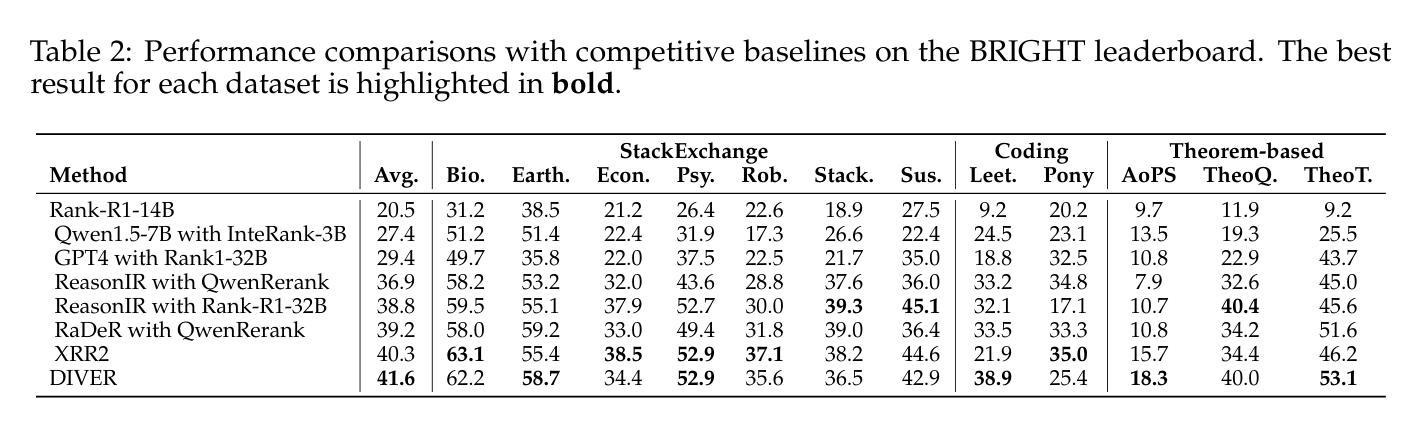
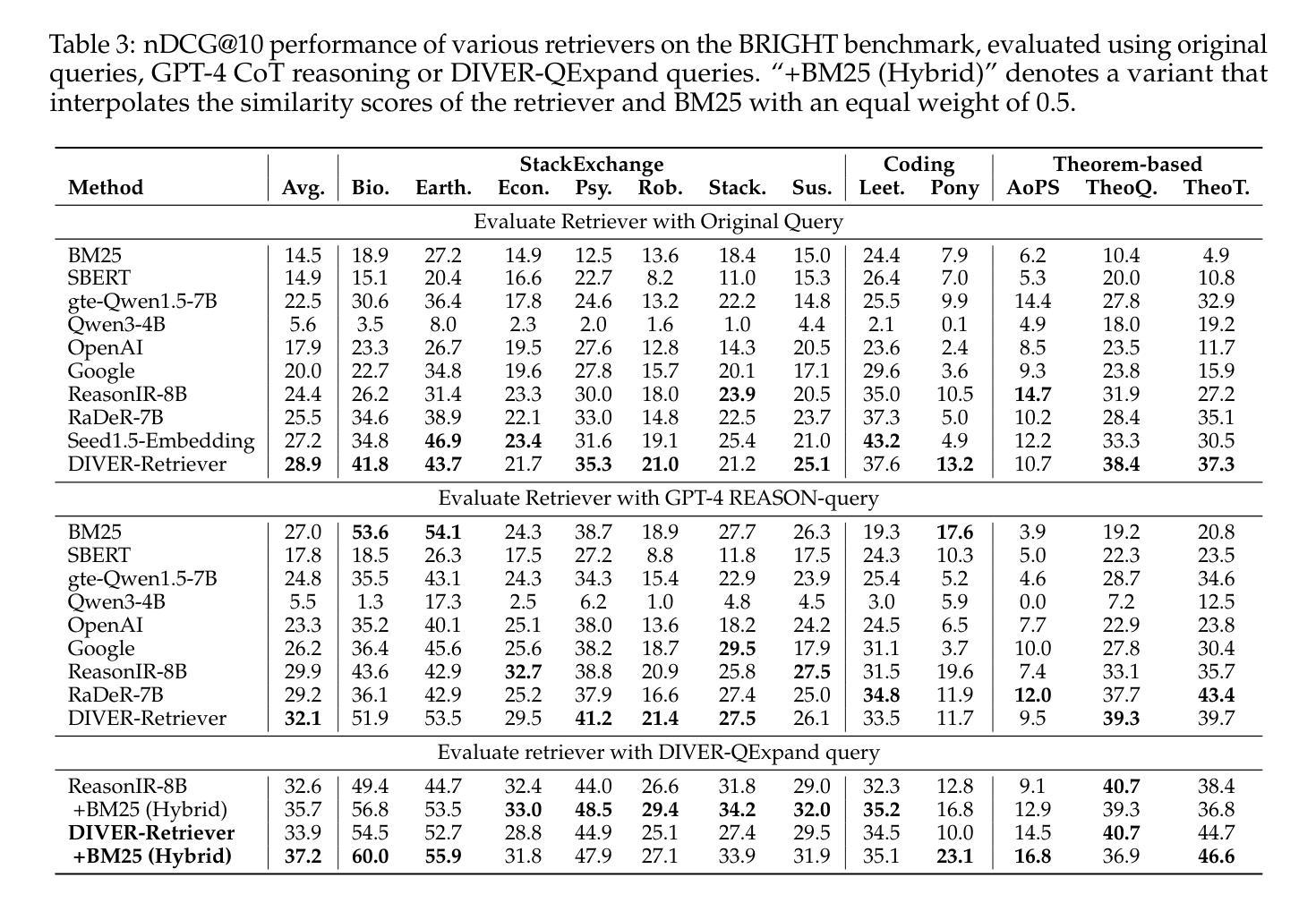
DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval
Authors:Meixiu Long, Duolin Sun, Dan Yang, Junjie Wang, Yue Shen, Jian Wang, Peng Wei, Jinjie Gu, Jiahai Wang
Retrieval-augmented generation has achieved strong performance on knowledge-intensive tasks where query-document relevance can be identified through direct lexical or semantic matches. However, many real-world queries involve abstract reasoning, analogical thinking, or multi-step inference, which existing retrievers often struggle to capture. To address this challenge, we present \textbf{DIVER}, a retrieval pipeline tailored for reasoning-intensive information retrieval. DIVER consists of four components: document processing to improve input quality, LLM-driven query expansion via iterative document interaction, a reasoning-enhanced retriever fine-tuned on synthetic multi-domain data with hard negatives, and a pointwise reranker that combines LLM-assigned helpfulness scores with retrieval scores. On the BRIGHT benchmark, DIVER achieves state-of-the-art nDCG@10 scores of 41.6 and 28.9 on original queries, consistently outperforming competitive reasoning-aware models. These results demonstrate the effectiveness of reasoning-aware retrieval strategies in complex real-world tasks. Our code and retrieval model will be released soon.
检索增强生成在知识密集型任务上取得了强大的性能,其中可以通过直接的词汇或语义匹配来识别查询文档的相关性。然而,许多现实世界中的查询涉及抽象推理、类比思维或多步推理,现有检索器往往难以捕获。为了应对这一挑战,我们提出了DIVER,一个针对推理密集型信息检索的检索管道。DIVER由四个组件构成:改善输入质量的文档处理,通过迭代文档交互驱动的LLM查询扩展,在合成多域数据上微调且带有硬阴性的推理增强检索器,以及结合LLM分配的有用性分数和检索分数的逐点重新排名器。在BRIGHT基准测试中,DIVER在原始查询上取得了最先进的nDCG@10分数41.6和28.9,持续超越竞争性的推理感知模型。这些结果证明了推理感知检索策略在复杂现实世界任务中的有效性。我们的代码和检索模型将很快发布。
论文及项目相关链接
Summary
本文介绍了针对需要推理能力的信息检索任务设计的检索增强生成模型DIVER。DIVER包括四个组件,包括改进输入质量的文档处理、通过迭代文档交互驱动的LLM查询扩展、在合成多域数据上微调并带有硬负样本的推理增强检索器,以及结合LLM分配的有用性分数和检索分数的逐点重新排名器。在BRIGHT基准测试上,DIVER取得了最新的nDCG@10得分,显示出其在复杂现实世界任务中推理感知检索策略的有效性。
Key Takeaways
- 检索增强生成模型DIVER被设计用于处理需要推理能力的信息检索任务。
- DIVER包含四个组件:文档处理、LLM驱动的查询扩展、推理增强检索器和逐点重新排名器。
- 文档处理旨在提高输入质量。
- LLM通过迭代文档交互进行查询扩展。
- 推理增强检索器在合成多域数据上进行微调,并包含硬负样本。
- 在BRIGHT基准测试上,DIVER取得了显著的nDCG@10得分,证明了其在复杂现实世界任务中的有效性。
点此查看论文截图


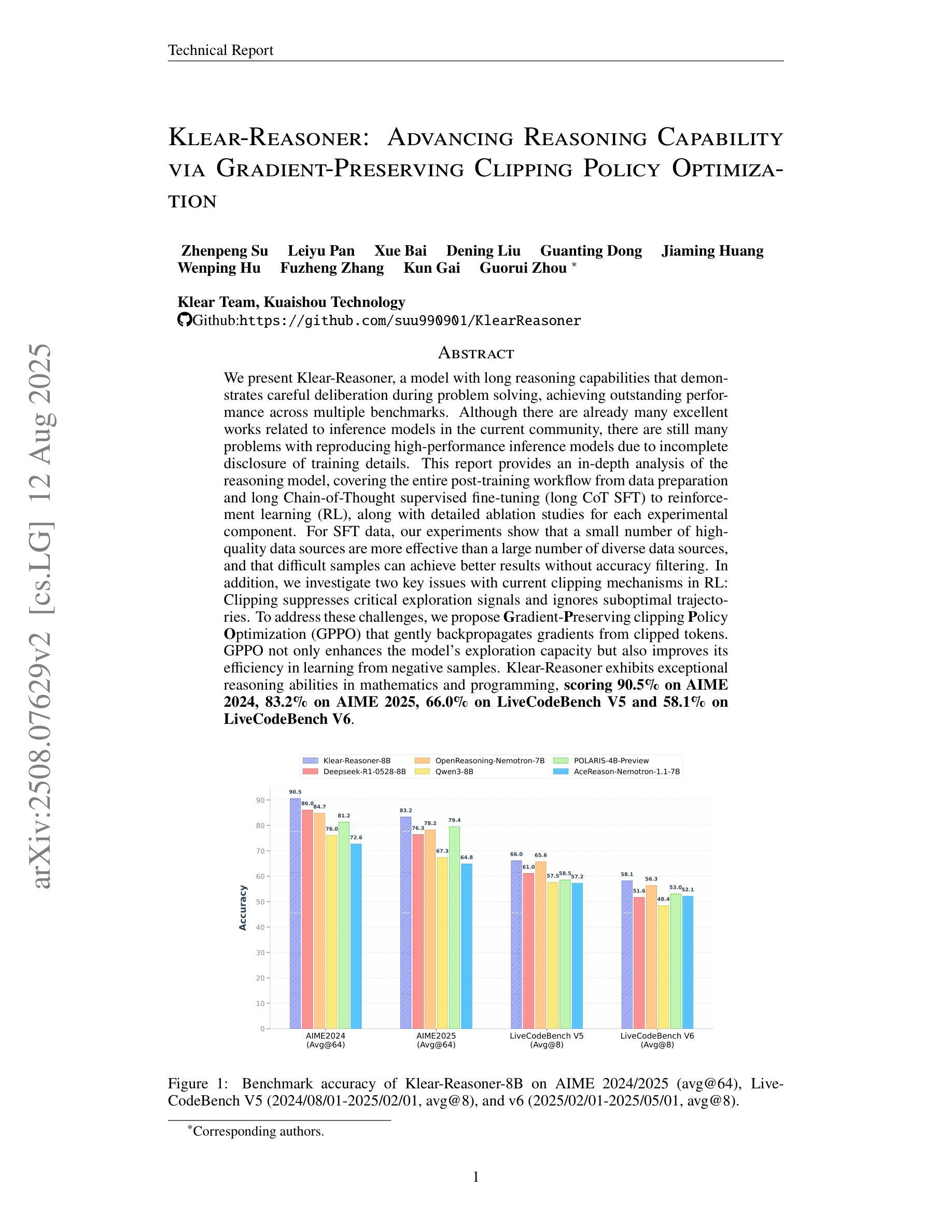
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Authors:Zhenpeng Su, Leiyu Pan, Xue Bai, Dening Liu, Guanting Dong, Jiaming Huang, Wenping Hu, Fuzheng Zhang, Kun Gai, Guorui Zhou
We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model’s exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
我们推出了Klear-Reasoner,这是一款具有出色推理能力的模型,能够在解决问题时展现出深思熟虑的过程,并在多个基准测试中表现出卓越的性能。尽管当前社区已经有很多关于推理模型的优秀作品,但由于培训细节披露不完整,导致难以复现高性能推理模型的问题仍然存在。本报告对推理模型进行了深入分析,涵盖了从数据准备和长链思维监督微调(long CoT SFT)到强化学习(RL)的整个训练后工作流程,并对每个实验组件进行了详细的消融研究。在我们的实验中,对于SFT数据,我们发现少量高质量的数据源比大量多样的数据源更有效,而且困难样本可以在不进行精度过滤的情况下实现更好的结果。此外,我们研究了当前强化学习中的裁剪机制的两个关键问题:裁剪会抑制关键探索信号并忽略次优轨迹。为了解决这些挑战,我们提出了梯度保持裁剪策略优化(GPPO),它温和地反向传播被裁剪令牌的梯度。GPPO不仅提高了模型的探索能力,而且提高了其从负面样本中学习的效率。Klear-Reasoner在数学和编程方面表现出卓越的推理能力,在AIME 2024中得分为90.5%,在AIME 2025中得分为83.2%,在LiveCodeBench V5中得分为66.0%,在LiveCodeBench V6中得分为58.1%。
论文及项目相关链接
Summary
本文介绍了Klear-Reasoner模型,该模型具备出色的长推理能力,并在多个基准测试中表现出卓越性能。文章深入分析了该推理模型,涵盖了从数据准备、长期思维监督精细调整(long CoT SFT)到强化学习(RL)的整个训练工作流程,并详细研究了各实验成分。提出Gradient-Preserving裁剪策略优化(GPPO)解决当前裁剪机制的两个关键问题,提高模型探索能力和负样本学习效率。Klear-Reasoner在数学和编程方面的推理能力出众,在AIME 2024和AIME 2025等测试中表现优异。
Key Takeaways
- Klear-Reasoner是一个具有长推理能力的模型,在多个基准测试中表现卓越。
- 该模型展示了详尽的推理过程,从数据准备到强化学习,包括长期思维监督精细调整(long CoT SFT)。
- 实验表明少量高质量数据源比大量多样数据源更有效。
- 提出GPPO解决当前裁剪机制的两个关键问题,增强模型探索能力和负样本学习效率。
- Klear-Reasoner在数学和编程方面的能力出众,如AIME 2024和AIME 2025测试成绩显示。
- 模型能够处理困难样本,无需精确过滤即可获得更好的结果。
点此查看论文截图