⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Selection of Layers from Self-supervised Learning Models for Predicting Mean-Opinion-Score of Speech
Authors:Xinyu Liang, Fredrik Cumlin, Victor Ungureanu, Chandan K. A. Reddy, Christian Schuldt, Saikat Chatterjee
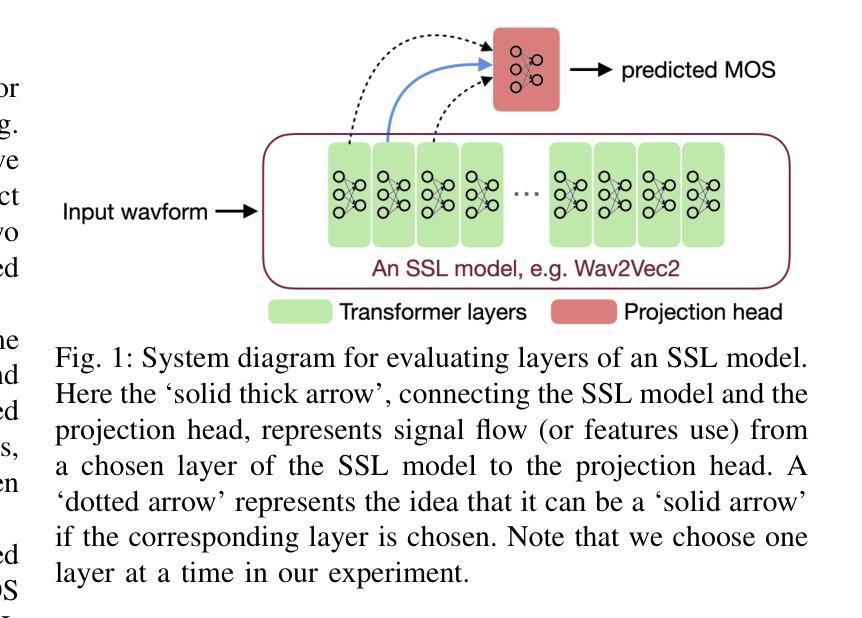
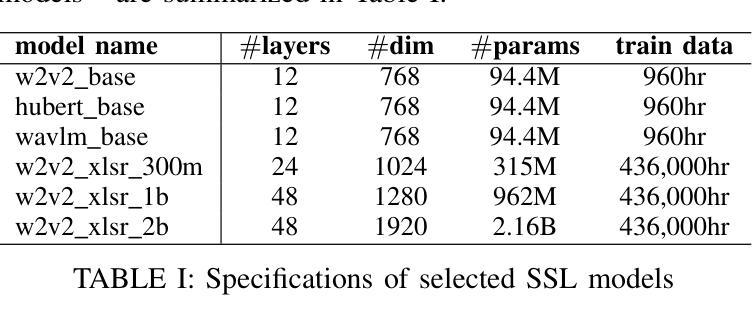
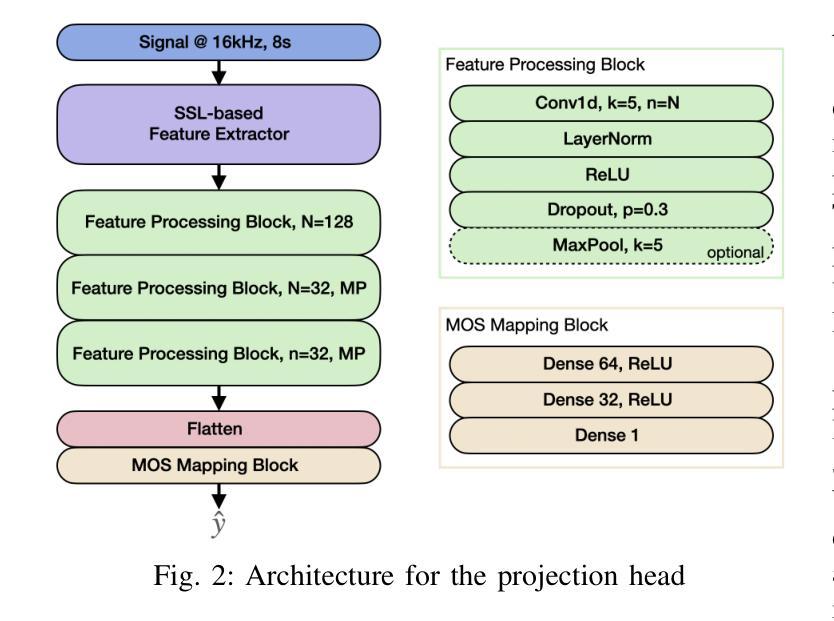
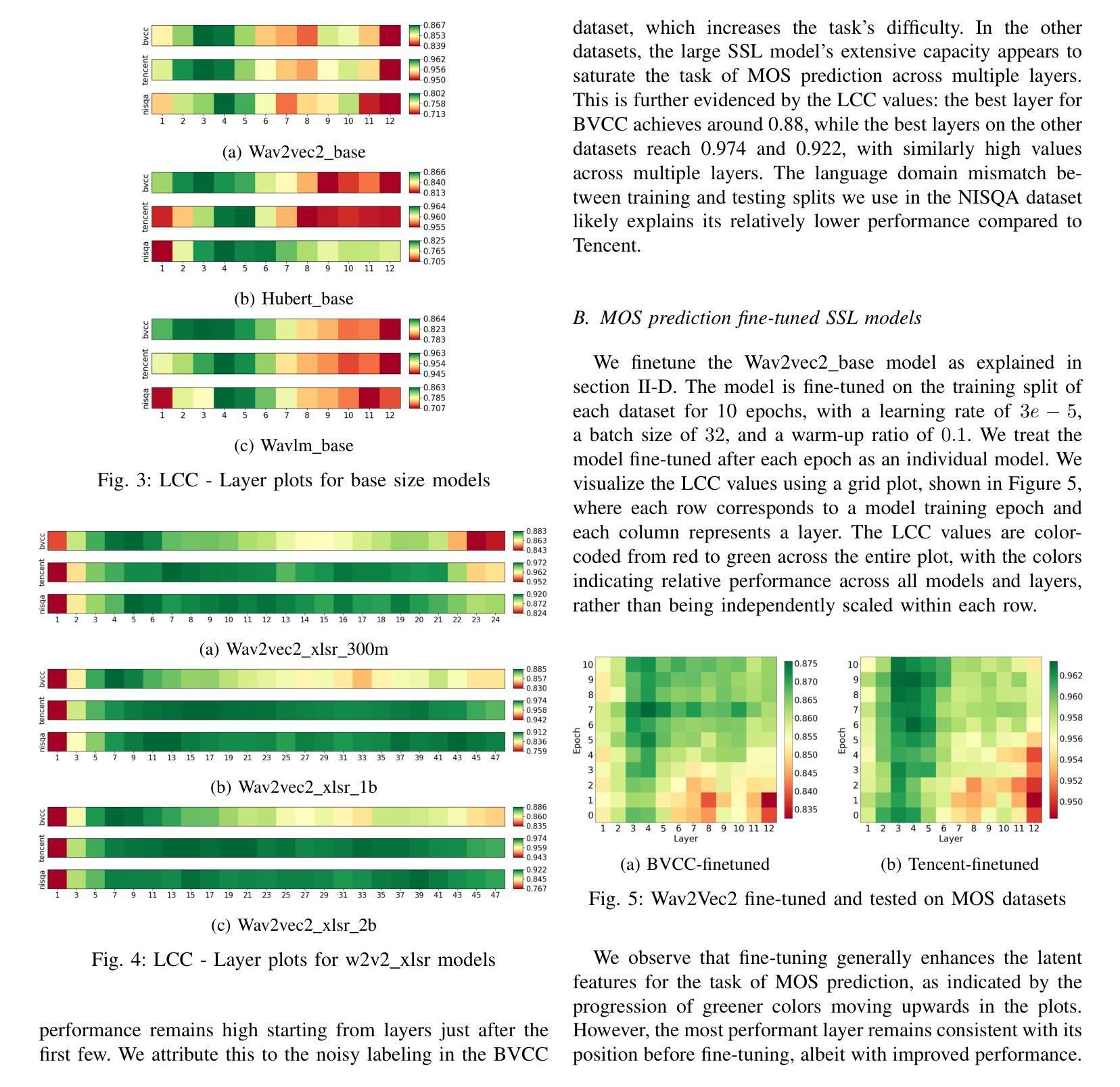
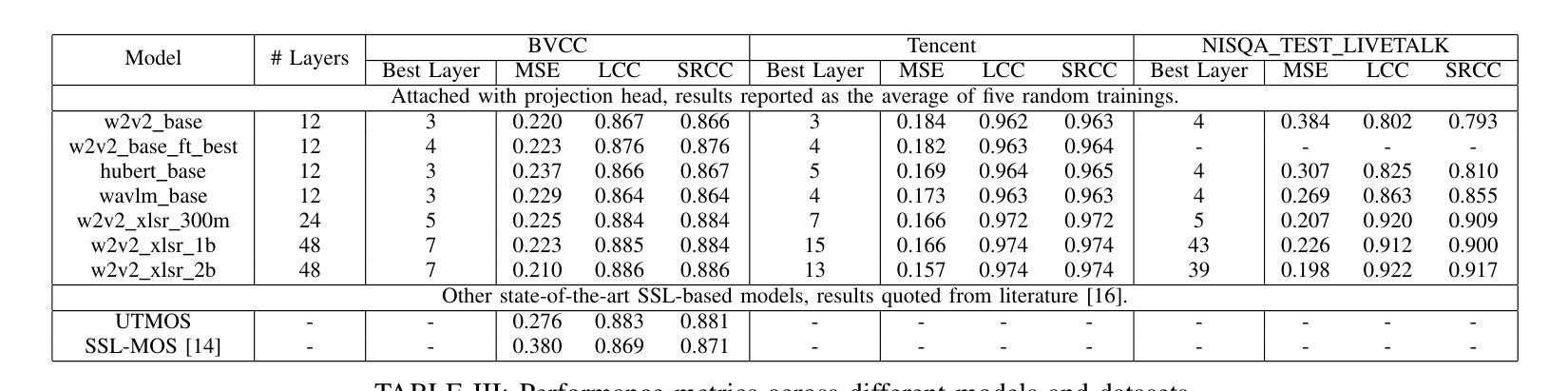
Self-supervised learning (SSL) models like Wav2Vec2, HuBERT, and WavLM have been widely used in speech processing. These transformer-based models consist of multiple layers, each capturing different levels of representation. While prior studies explored their layer-wise representations for efficiency and performance, speech quality assessment (SQA) models predominantly rely on last-layer features, leaving intermediate layers underexamined. In this work, we systematically evaluate different layers of multiple SSL models for predicting mean-opinion-score (MOS). Features from each layer are fed into a lightweight regression network to assess effectiveness. Our experiments consistently show early-layers features outperform or match those from the last layer, leading to significant improvements over conventional approaches and state-of-the-art MOS prediction models. These findings highlight the advantages of early-layer selection, offering enhanced performance and reduced system complexity.
自监督学习(SSL)模型,如Wav2Vec2、HuBERT和WavLM,在语音处理中得到了广泛应用。这些基于变压器的模型由多层组成,每一层都捕获不同级别的表示。虽然先前的研究探讨了它们的分层表示以提高效率和性能,但语音质量评估(SQA)模型主要依赖于最后一层的特征,而对中间层的研究不足。在这项工作中,我们系统地评估了多个SSL模型的不同层,以预测平均意见得分(MOS)。每一层的特征输入到一个轻量级的回归网络中进行有效性评估。我们的实验一直显示,早期层的特征在性能上优于或等同于最后一层的特征,这相对于传统方法和最先进的MOS预测模型有明显的改进。这些发现强调了早期层选择的优点,提供了增强的性能和降低了系统复杂性。
论文及项目相关链接
PDF Accepted at IEEE ASRU 2025
Summary
本文研究了自监督学习(SSL)模型在语音处理中的应用,如Wav2Vec2、HuBERT和WavLM等。这些基于transformer的模型的多层结构在不同的层次上捕获表征。尽管之前的研究已经探讨了其分层表示以提高效率和性能,但语音质量评估(SQA)模型主要依赖于最后一层的特征,而忽略了对中间层的探索。本研究系统地评估了多个SSL模型的不同层次在预测平均意见得分(MOS)方面的能力。实验结果表明,早期层的特征在预测MOS时表现出优异性能,甚至超过最后一层的特征,显著优于传统方法和最先进的MOS预测模型。这些发现强调了选择早期层次的优势,能够在提高性能的同时降低系统复杂性。
Key Takeaways
- 自监督学习(SSL)模型广泛应用于语音处理领域。
- SSL模型的多层结构能够捕获不同的层次表征。
- 语音质量评估(SQA)模型主要依赖最后一层的特征,但中间层尚未得到充分研究。
- 研究系统地评估了多个SSL模型的不同层次在预测平均意见得分(MOS)方面的能力。
- 实验结果表明早期层的特征在预测MOS时表现出优异性能。
- 早期层的特征显著优于传统方法和最先进的MOS预测模型。
点此查看论文截图


Munsit at NADI 2025 Shared Task 2: Pushing the Boundaries of Multidialectal Arabic ASR with Weakly Supervised Pretraining and Continual Supervised Fine-tuning
Authors:Mahmoud Salhab, Shameed Sait, Mohammad Abusheikh, Hasan Abusheikh
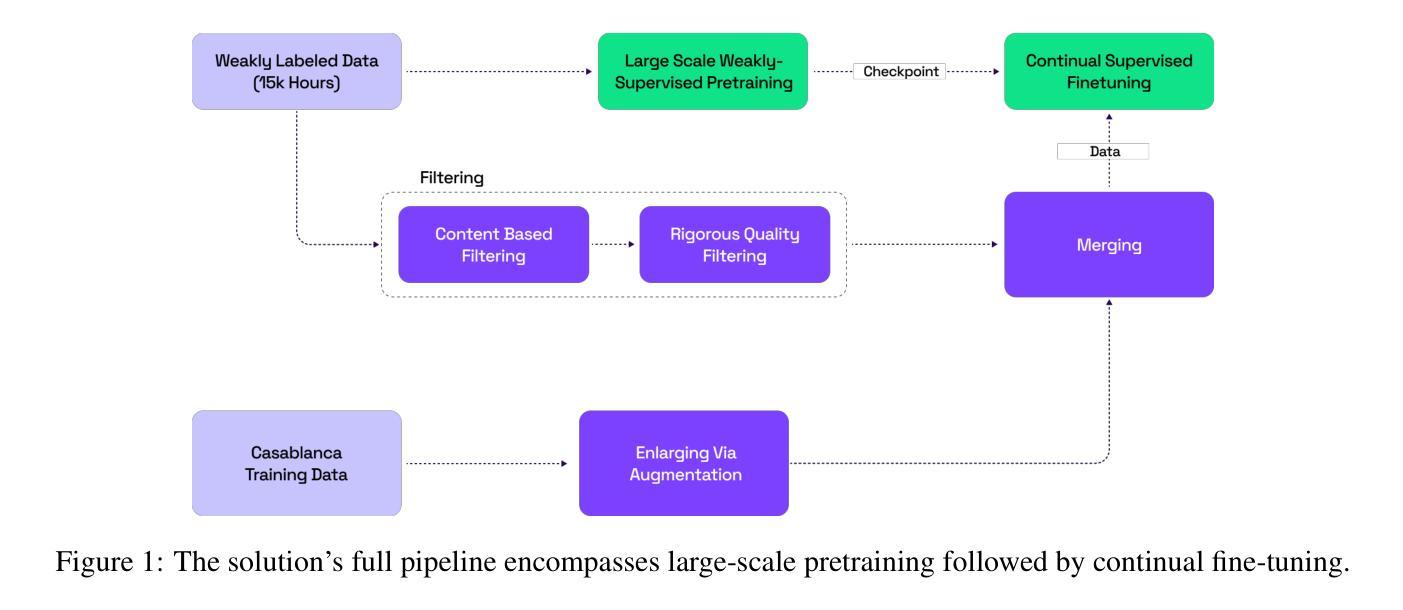
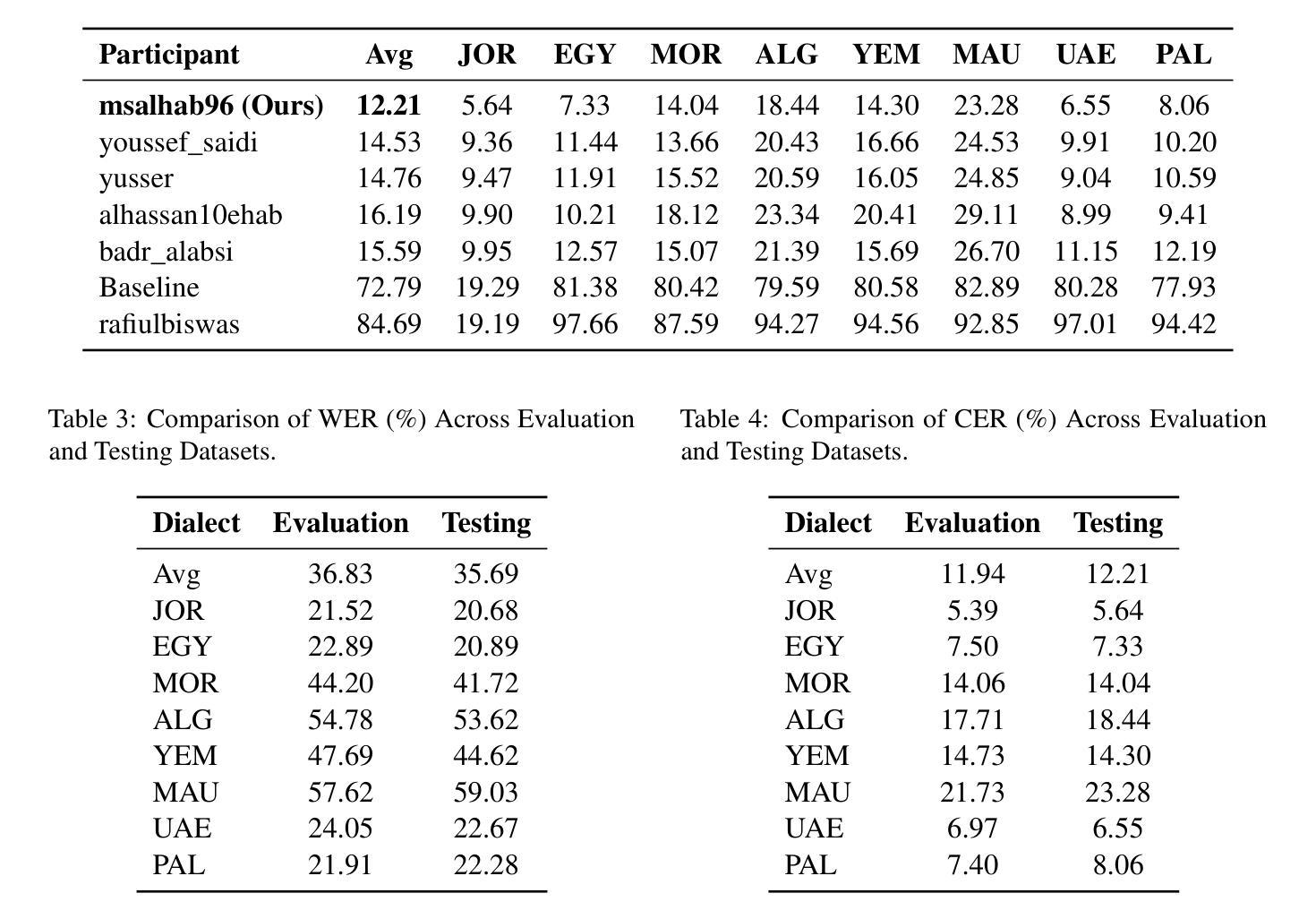
Automatic speech recognition (ASR) plays a vital role in enabling natural human-machine interaction across applications such as virtual assistants, industrial automation, customer support, and real-time transcription. However, developing accurate ASR systems for low-resource languages like Arabic remains a significant challenge due to limited labeled data and the linguistic complexity introduced by diverse dialects. In this work, we present a scalable training pipeline that combines weakly supervised learning with supervised fine-tuning to develop a robust Arabic ASR model. In the first stage, we pretrain the model on 15,000 hours of weakly labeled speech covering both Modern Standard Arabic (MSA) and various Dialectal Arabic (DA) variants. In the subsequent stage, we perform continual supervised fine-tuning using a mixture of filtered weakly labeled data and a small, high-quality annotated dataset. Our approach achieves state-of-the-art results, ranking first in the multi-dialectal Arabic ASR challenge. These findings highlight the effectiveness of weak supervision paired with fine-tuning in overcoming data scarcity and delivering high-quality ASR for low-resource, dialect-rich languages.
自动语音识别(ASR)在虚拟助手、工业自动化、客户支持和实时转录等应用中发挥着至关重要的作用,实现了自然的人机交互。然而,由于标注数据有限和多种方言带来的语言复杂性,为阿拉伯语等低资源语言开发准确的ASR系统仍然是一个重大挑战。在这项工作中,我们提出了一种可扩展的训练流程,该流程结合了弱监督学习与监督微调来开发稳健的阿拉伯语ASR模型。在第一阶段,我们在15000小时的弱标签语音上对模型进行训练,这些语音涵盖了现代标准阿拉伯语(MSA)和各种方言阿拉伯语(DA)的变体。在随后的阶段,我们使用过滤后的弱标签数据和一小部分高质量注释数据集进行持续监督微调。我们的方法取得了最新结果,在多方言阿拉伯语ASR挑战中排名第一。这些发现突出了弱监督与微调相结合在克服数据稀缺问题、为资源贫乏、方言丰富的语言提供高质量ASR方面的有效性。
论文及项目相关链接
Summary
本文介绍了针对阿拉伯语自动语音识别(ASR)的挑战,提出了一种结合弱监督学习与监督微调的可扩展训练管道。首先,在涵盖现代标准阿拉伯语(MSA)和各种方言阿拉伯语(DA)变体的15,000小时弱标签语音上预训练模型。然后,使用过滤后的弱标签数据和一小部分高质量注释数据集进行持续的监督微调。该方法在多方言阿拉伯语ASR挑战中排名第一,实现了最佳结果,突显了弱监督与微调配对在克服数据稀缺和为低资源、方言丰富的语言提供高质量ASR方面的有效性。
Key Takeaways
- 自动语音识别(ASR)在虚拟助理、工业自动化、客户支持和实时转录等应用中扮演着至关重要的角色。
- 对于像阿拉伯语这样的低资源语言,开发准确的ASR系统是一个重大挑战,因为存在有限的有标签数据和由不同方言引起的语言复杂性。
- 本文提出了一种结合弱监督学习与监督细调的可持续训练管道,用于开发稳健的阿拉伯语ASR模型。
- 在预训练阶段,模型在涵盖现代标准阿拉伯语和多种方言阿拉伯语的弱标签语音上进行训练。
- 在微调阶段,使用过滤后的弱标签数据和高质量注释数据集进行持续的监督微调。
- 该方法在多方言阿拉伯语ASR挑战中取得了最佳结果。
点此查看论文截图

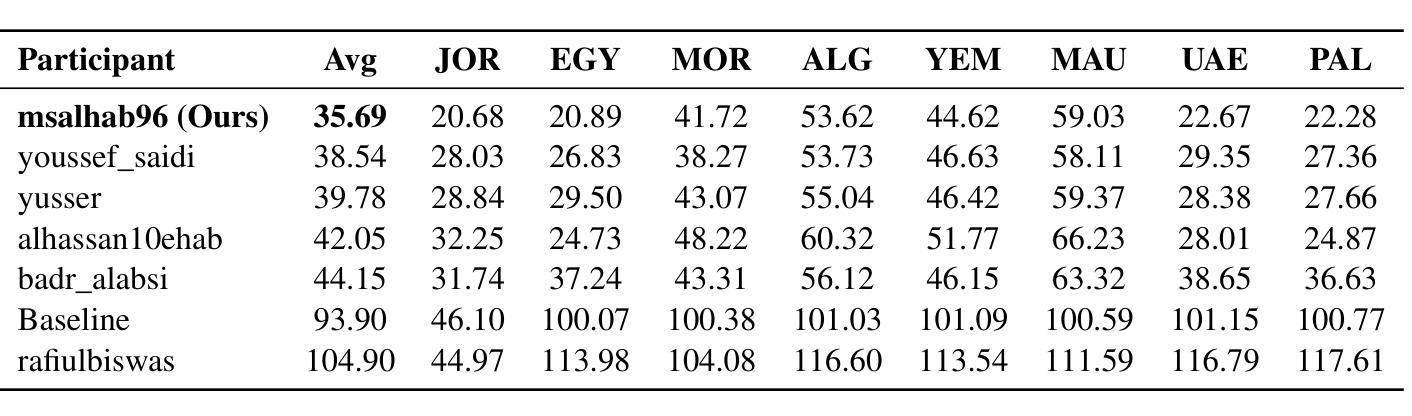
Transient Noise Removal via Diffusion-based Speech Inpainting
Authors:Mordehay Moradi, Sharon Gannot
In this paper, we present PGDI, a diffusion-based speech inpainting framework for restoring missing or severely corrupted speech segments. Unlike previous methods that struggle with speaker variability or long gap lengths, PGDI can accurately reconstruct gaps of up to one second in length while preserving speaker identity, prosody, and environmental factors such as reverberation. Central to this approach is classifier guidance, specifically phoneme-level guidance, which substantially improves reconstruction fidelity. PGDI operates in a speaker-independent manner and maintains robustness even when long segments are completely masked by strong transient noise, making it well-suited for real-world applications, such as fireworks, door slams, hammer strikes, and construction noise. Through extensive experiments across diverse speakers and gap lengths, we demonstrate PGDI’s superior inpainting performance and its ability to handle challenging acoustic conditions. We consider both scenarios, with and without access to the transcript during inference, showing that while the availability of text further enhances performance, the model remains effective even in its absence. For audio samples, visit: https://mordehaym.github.io/PGDI/
本文介绍了PGDI,这是一种基于扩散的语音补全框架,用于恢复缺失或严重损坏的语音片段。与以往处理扬声器变化或长间隔困难的方法不同,PGDI可以准确重建长达一秒的间隔,同时保留说话人的身份、语调和环境因素,如混响。该方法的核心是分类器指导,特别是音素级指导,这大大提高了重建的保真度。PGDI以独立于说话人的方式运行,即使在长片段被强烈的瞬态噪声完全掩盖时也能保持稳健,因此非常适合现实世界的应用,如烟花、关门声、敲击声和建筑噪音等环境。我们通过对不同说话人和间隔长度的广泛实验,证明了PGDI的优越补全性能以及处理具有挑战性的声学条件的能力。我们考虑了两种情景,一种是在推理过程中有文本可访问,另一种是不可访问的。实验表明,虽然文本的可用性会进一步提高性能,但在没有文本的情况下,该模型仍然有效。若想试听样本,请访问:https://mordehaym.github.io/PGDI/。
论文及项目相关链接
PDF 23 pages, 3 figures, signal processing paper on speech inpainting
Summary
本文介绍了PGDI,一个基于扩散的语音补全框架,用于恢复缺失或严重损坏的语音片段。该框架通过分类器引导,特别是音素级引导,实现了长达一秒的间隙准确重建,同时保留说话人身份、语调和环境因素如混响。PGDI对说话人具有独立性,即使在长时间段被强瞬态噪声完全掩盖时也能保持稳健性,非常适合现实应用,如烟花、关门声、敲击声和建筑噪音等场景。实验表明,PGDI具有出色的补全性能,并能应对具有挑战性的声学条件。
Key Takeaways
- PGDI是一个基于扩散的语音补全框架,能够恢复缺失或损坏的语音片段。
- 该框架可以实现长达一秒的间隙准确重建,同时保留说话人身份、语调和环境特性。
- 通过分类器引导,特别是音素级引导,重建保真度得到了显著提高。
- PGDI具有说话人独立性,可以在各种现实应用中使用,如处理烟花、关门声等场景中的语音。
- 实验证明PGDI在多种说话人和不同间隙长度下表现出优异的补全性能。
- 即使有文本可用时,该模型依然表现出良好的性能提升,但在没有文本的情况下也能保持有效性。
点此查看论文截图

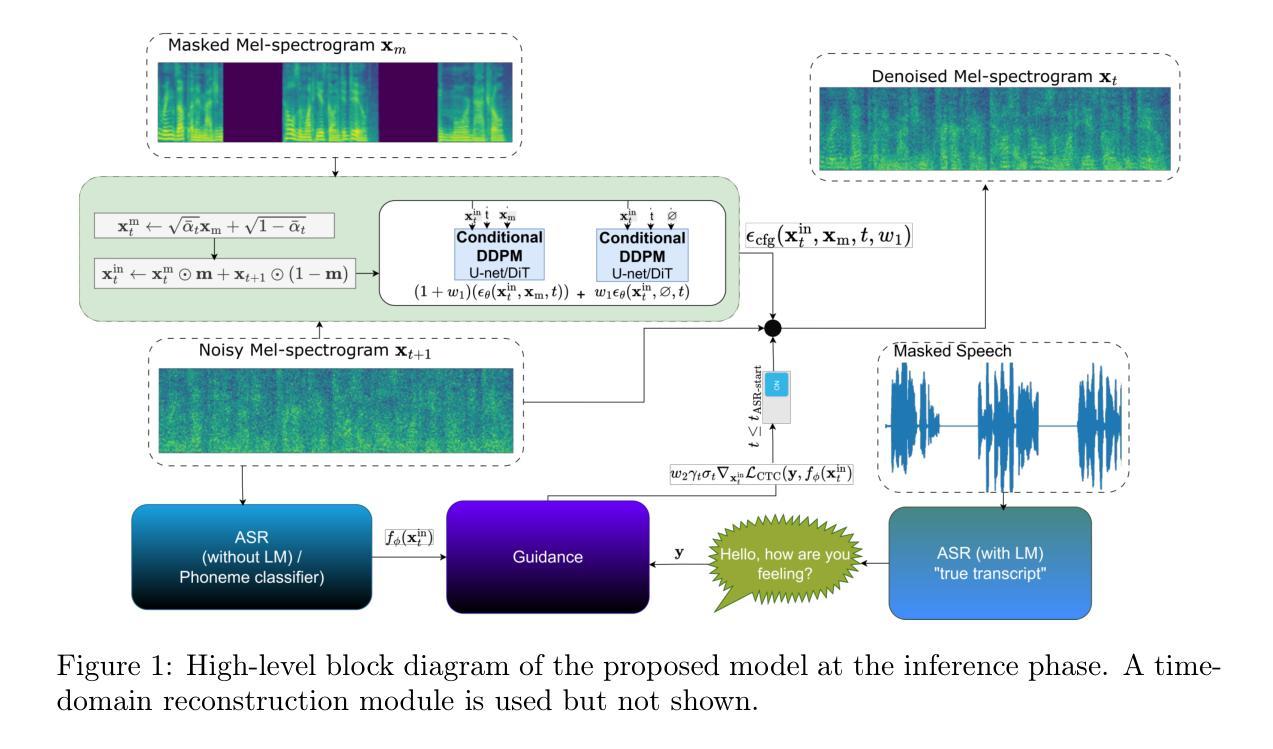
Out of the Box, into the Clinic? Evaluating State-of-the-Art ASR for Clinical Applications for Older Adults
Authors:Bram van Dijk, Tiberon Kuiper, Sirin Aoulad si Ahmed, Armel Levebvre, Jake Johnson, Jan Duin, Simon Mooijaart, Marco Spruit
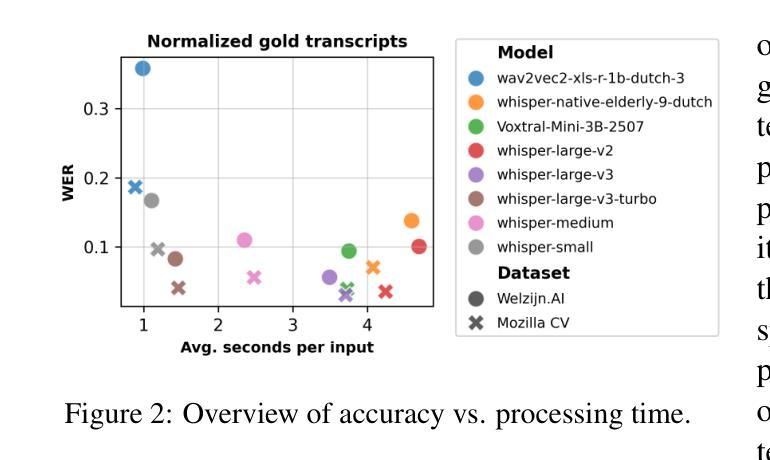
Voice-controlled interfaces can support older adults in clinical contexts, with chatbots being a prime example, but reliable Automatic Speech Recognition (ASR) for underrepresented groups remains a bottleneck. This study evaluates state-of-the-art ASR models on language use of older Dutch adults, who interacted with the Welzijn.AI chatbot designed for geriatric contexts. We benchmark generic multilingual ASR models, and models fine-tuned for Dutch spoken by older adults, while also considering processing speed. Our results show that generic multilingual models outperform fine-tuned models, which suggests recent ASR models can generalise well out of the box to realistic datasets. Furthermore, our results suggest that truncating existing architectures is helpful in balancing the accuracy-speed trade-off, though we also identify some cases with high WER due to hallucinations.
语音控制界面在临床环境中可以支持老年人群,聊天机器人就是一个很好的例子,但对于代表性不足的群体的可靠自动语音识别(ASR)仍然是一个瓶颈。本研究评估了最前沿的ASR模型在老年荷兰成人语言使用上的表现,这些受试者通过与针对老年情境设计的Welzijn.AI聊天机器人进行互动。我们评估了通用多语言ASR模型和针对老年荷兰人进行精细调整的模型,同时考虑了处理速度。我们的结果表明,通用多语言模型的表现优于精细调整的模型,这表明最近的ASR模型可以很好地推广应用到现实数据集。此外,我们的结果表明,缩短现有架构有助于平衡准确性与速度之间的权衡,尽管我们也发现了一些由于幻听导致的高词错误率(WER)的情况。
论文及项目相关链接
Summary
语音控制界面能支持临床环境下的老年人群,聊天机器人是其中典型案例,但可靠的针对未代表群体的自动语音识别(ASR)仍是瓶颈。本研究评估了针对老年荷兰人与Welzijn.AI聊天机器人互动的语音识别模型的表现。我们对比了通用的多语种语音识别模型和针对荷兰老年人群微调过的模型,同时考虑了处理速度。结果表明,通用多语种模型优于精细调校的模型,这显示最新语音识别模型在现实数据集上具有良好的通用性。此外,我们的结果还表明,缩短现有架构有助于平衡准确性与速度之间的权衡,但也存在因误读而导致的某些高词错率情况。
Key Takeaways
- 语音控制界面在临床环境中对老年人群的支持作用显著,聊天机器人是其中的重要应用。
- 自动语音识别(ASR)技术在未代表群体中的可靠性仍是瓶颈。
- 评估了针对老年荷兰人与Welzijn.AI聊天机器人互动的语音识别模型表现。
- 通用多语种语音识别模型在针对老年荷兰人群的互动中表现较好。
- 处理速度是语音识别技术在实际应用中的重要考量因素。
- 缩短现有语音识别模型的架构有助于平衡准确性与处理速度之间的权衡。
点此查看论文截图

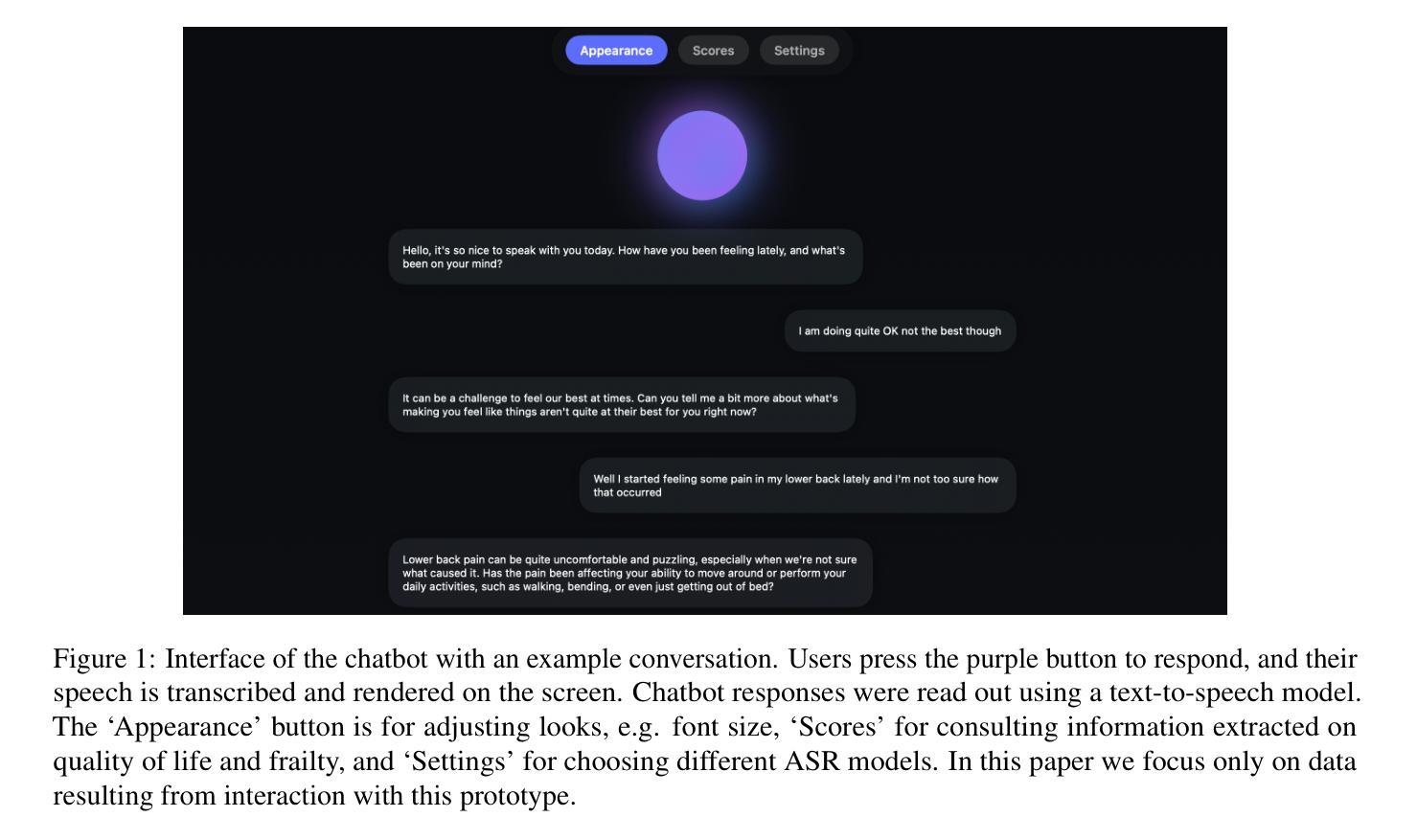



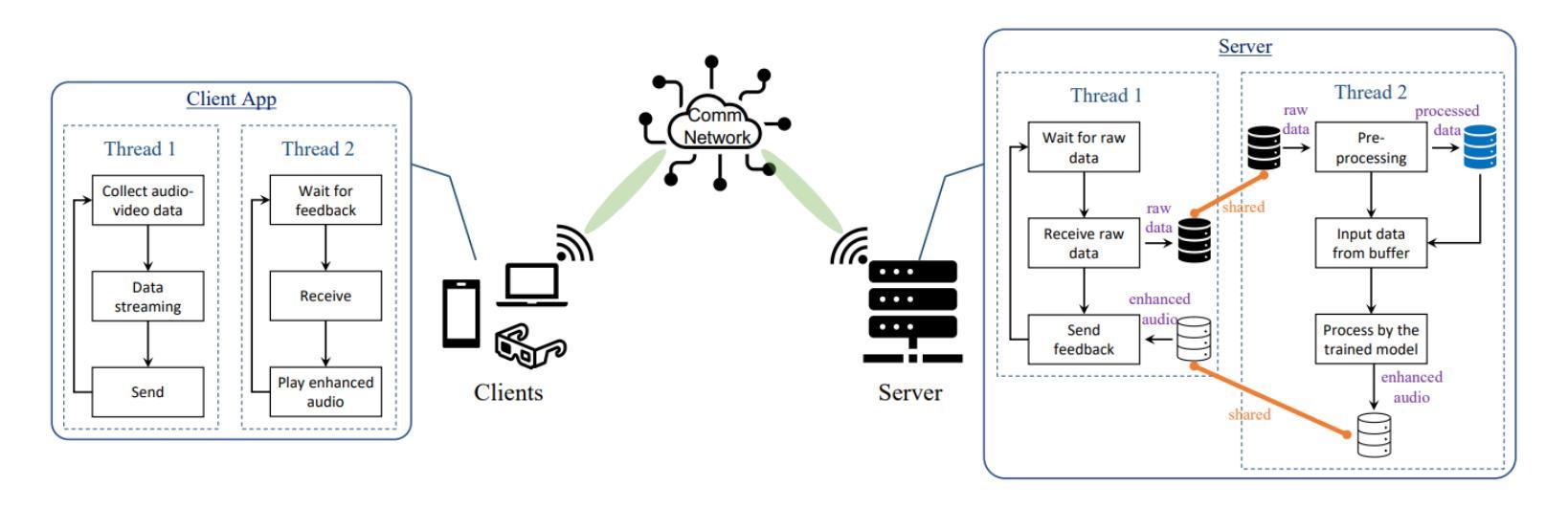
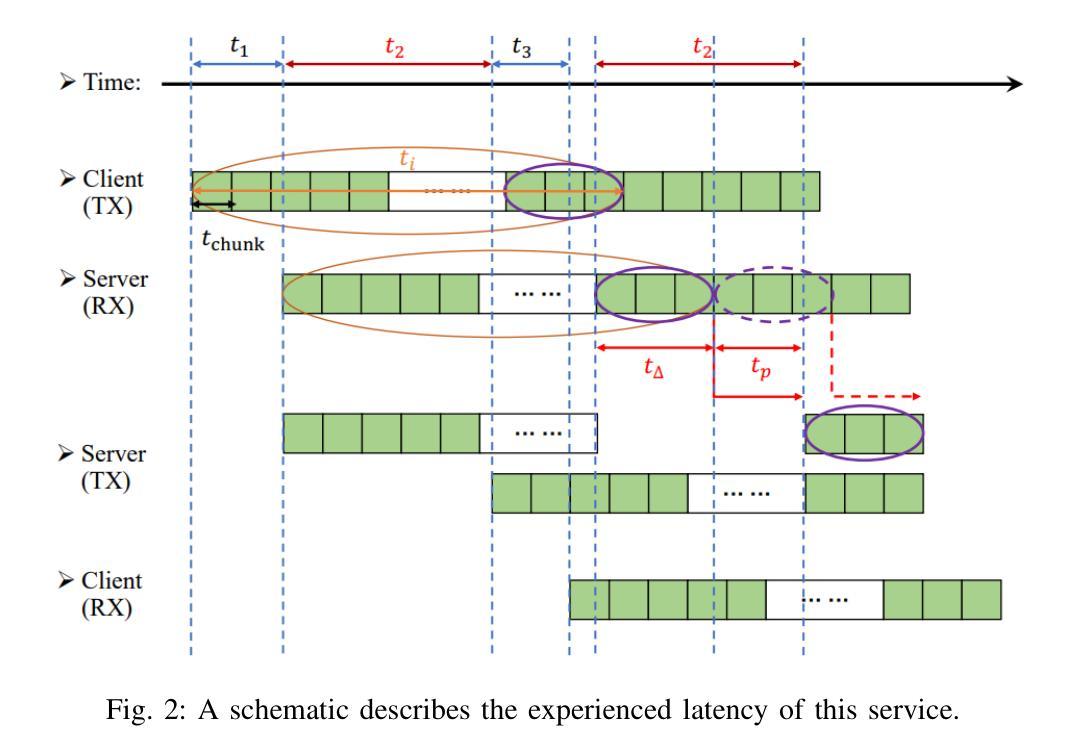
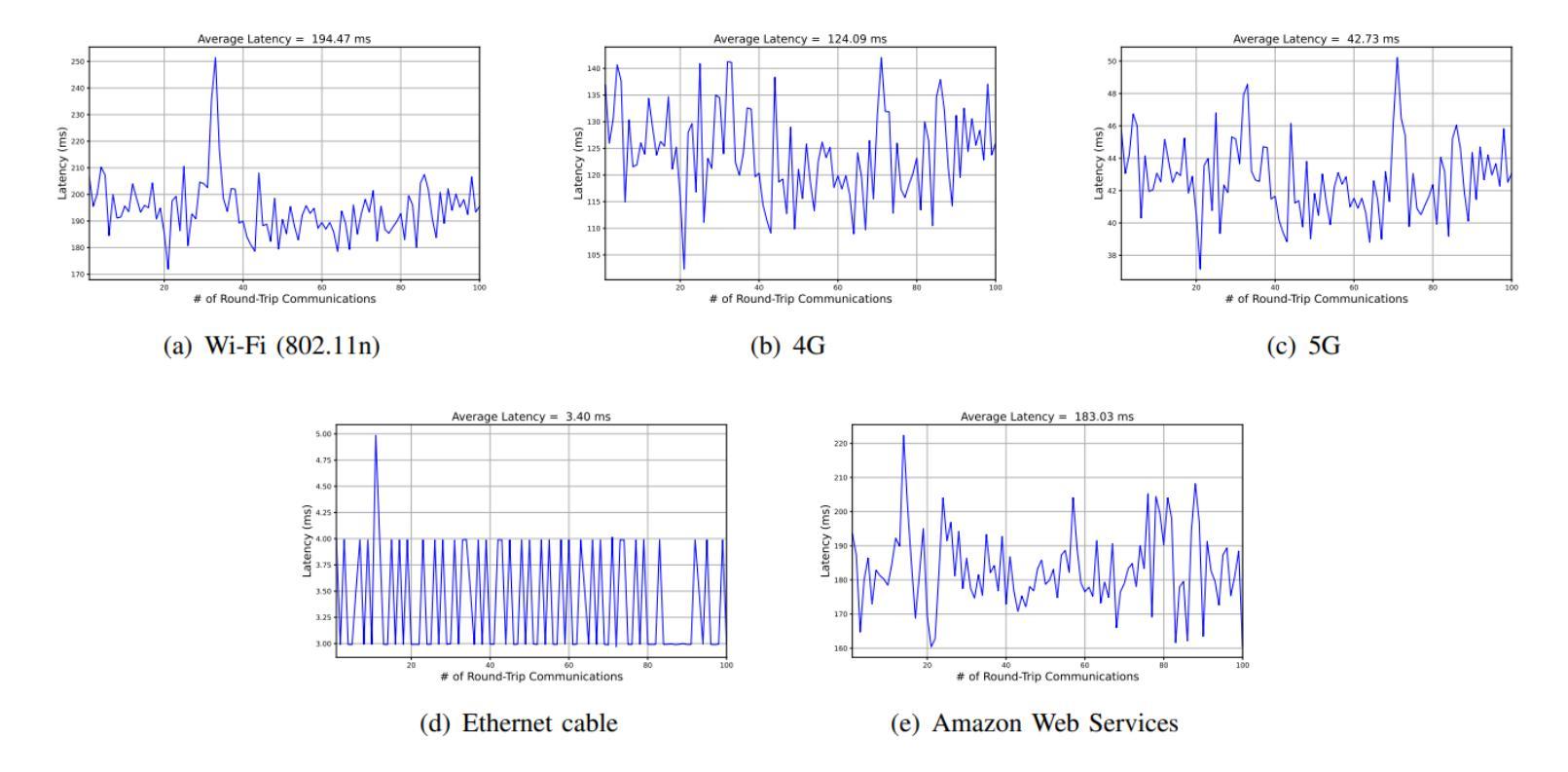
Audio-Visual Speech Enhancement: Architectural Design and Deployment Strategies
Authors:Anis Hamadouche, Haifeng Luo, Mathini Sellathurai, Tharm Ratnarajah
This paper introduces a new AI-based Audio-Visual Speech Enhancement (AVSE) system and presents a comparative performance analysis of different deployment architectures. The proposed AVSE system employs convolutional neural networks (CNNs) for spectral feature extraction and long short-term memory (LSTM) networks for temporal modeling, enabling robust speech enhancement through multimodal fusion of audio and visual cues. Multiple deployment scenarios are investigated, including cloud-based, edge-assisted, and standalone device implementations. Their performance is evaluated in terms of speech quality improvement, latency, and computational overhead. Real-world experiments are conducted across various network conditions, including Ethernet, Wi-Fi, 4G, and 5G, to analyze the trade-offs between processing delay, communication latency, and perceptual speech quality. The results show that while cloud deployment achieves the highest enhancement quality, edge-assisted architectures offer the best balance between latency and intelligibility, meeting real-time requirements under 5G and Wi-Fi 6 conditions. These findings provide practical guidelines for selecting and optimizing AVSE deployment architectures in diverse applications, including assistive hearing devices, telepresence, and industrial communications.
本文介绍了一个基于人工智能的视听语音增强(AVSE)系统,并对不同的部署架构进行了性能对比分析。所提出的AVSE系统采用卷积神经网络(CNN)进行频谱特征提取和长短时记忆(LSTM)网络进行时间建模,通过音频和视觉线索的多模式融合实现稳健的语音增强。研究了多种部署场景,包括基于云、边缘辅助和独立设备实现。它们的性能评估指标包括语音质量改进、延迟和计算开销。实验在各种网络条件下进行,包括以太网、Wi-Fi、4G和5G,分析了处理延迟、通信延迟和感知语音质量之间的权衡。结果表明,虽然云部署达到了最高的增强质量,但边缘辅助架构在延迟和清晰度之间达到了最佳平衡,满足了5G和Wi-Fi 6条件下的实时要求。这些发现为在辅助听力设备、远程出席和工业通信等多样化应用中选择和优化AVSE部署架构提供了实用指南。
论文及项目相关链接
Summary
一种新的基于人工智能的视听语音增强(AVSE)系统被引入,并对比分析了不同的部署架构性能。该系统利用卷积神经网络(CNN)进行频谱特征提取和长短时记忆(LSTM)网络进行时间建模,通过音频和视觉线索的多模态融合实现稳健的语音增强。研究涵盖了云、边缘计算和独立设备等多种部署场景,并从语音质量提升、延迟和计算开销等方面进行评估。现实实验表明,尽管云部署在增强质量方面表现最佳,但边缘辅助架构在延迟和清晰度之间达到最佳平衡,满足5G和Wi-Fi 6条件下的实时要求。这些发现对于在多种应用中选择和优化AVSE部署架构具有实际指导意义,如助听设备、远程出席和工业通信等。
Key Takeaways
- 新AI视听语音增强系统通过融合音频和视觉线索实现稳健语音增强。
- 系统采用卷积神经网络进行频谱特征提取和长短时记忆网络进行时间建模。
- 对比了不同部署架构性能,包括云、边缘计算和独立设备部署。
- 实验表明云部署在增强质量方面表现最佳,边缘辅助架构在延迟和清晰度之间达到最佳平衡。
- 5G和Wi-Fi 6条件下的实时性能需求可通过边缘辅助架构满足。
- 该系统具有广泛的应用前景,如助听设备、远程出席和工业通信等。
点此查看论文截图

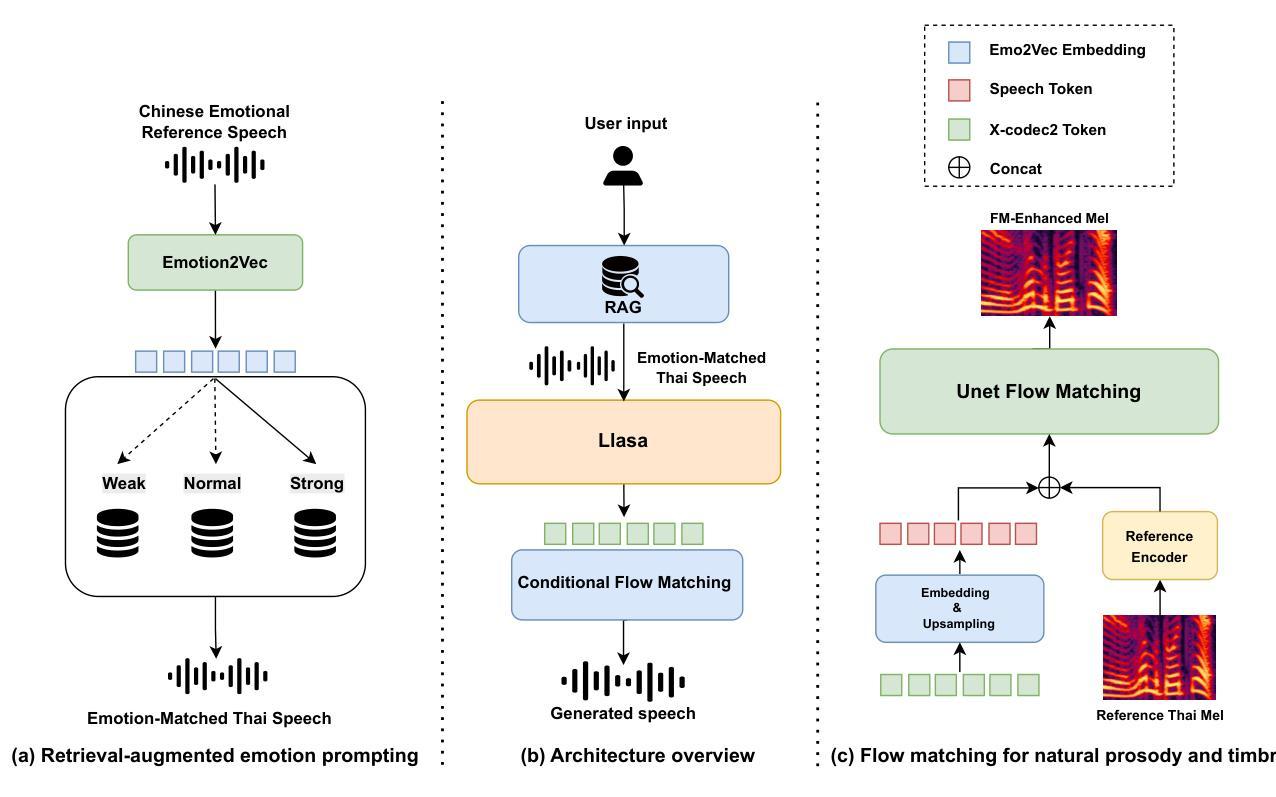
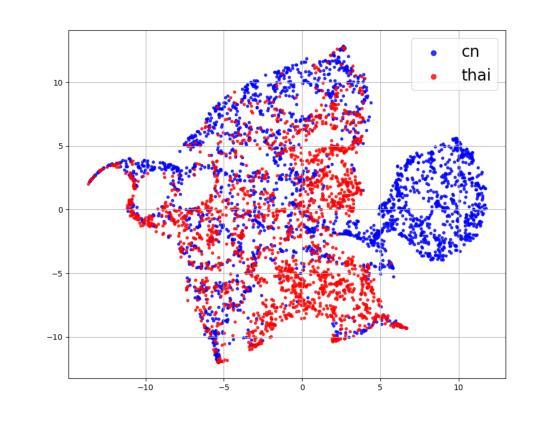
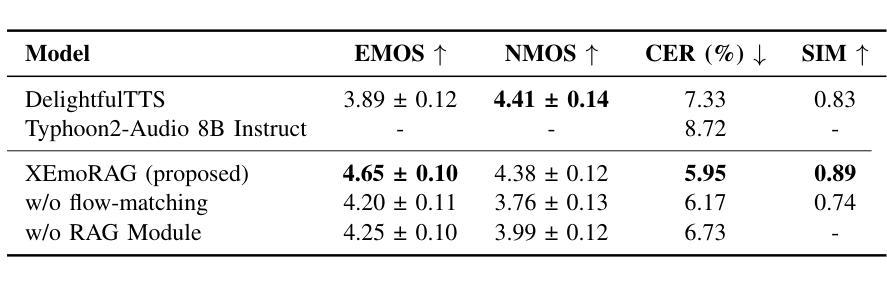
XEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Authors:Tianlun Zuo, Jingbin Hu, Yuke Li, Xinfa Zhu, Hai Li, Ying Yan, Junhui Liu, Danming Xie, Lei Xie
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language. However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features. In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data. XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency. Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels. These results highlight XEmoRAG’s capability to achieve flexible and low-resource emotional transfer across languages. Our demo is available at https://tlzuo-lesley.github.io/Demo-page/ .
跨语言语音合成中的零样本情感迁移是指生成目标语言中的语音,其中情感表达是基于来自不同源语言的参考语音。然而,由于缺乏并行多语言情感语料库、存在外来口音痕迹和从特定语言的韵律特征中分离情感的难度,此任务仍然具有挑战性。在本文中,我们提出了XEmoRAG,这是一个无需依赖并行情感数据,能够实现从中文到泰语零样本情感迁移的新型框架,它基于大型语言模型(LLM)。XEmoRAG从中文语音中提取与语言无关的情感嵌入,并从精选的情感数据库中检索情感匹配的泰语短语,从而实现可控的情感迁移,无需明确的情感标签。此外,流匹配对齐模块最小化音高和持续时间不匹配,确保自然的韵律。它将中文音色融入泰语合成中,提高了节奏准确性和情感表达,同时保留了说话人的特点和情感一致性。实验结果表明,XEmoRAG仅使用中文参考音频就能合成出表达力强、自然的泰语语音,且无需明确的情感标签。这些结果突出了XEmoRAG在不同语言之间实现灵活和低资源情感迁移的能力。我们的演示网站为:https://tlzuo-lesley.github.io/Demo-page/。
论文及项目相关链接
PDF Accepted by ASRU 2025
Summary
中文零基础上跨语言语音合成中的情感转移是一项挑战。本研究提出了XEmoRAG框架,利用大型语言模型实现中文到泰语的零基础上情感转移,无需依赖平行情感数据。XEmoRAG从中文语音中提取语言无关的情感嵌入,并从精选的情感数据库中检索情感匹配的泰语片段。此外,XEmoRAG的流匹配对齐模块减少了音调与时长的不匹配,确保自然韵律。实验结果显示XEmoRAG能使用仅中文参考音频合成出表达自然的泰语语音,无需明确的情感标签。
Key Takeaways
- 零基础上跨语言语音合成中的情感转移是困难的,主要是由于缺乏平行多语言情感语料库和语言特有的韵律特征带来的挑战。
- 本研究提出了XEmoRAG框架,实现了中文到泰语的零基础上情感转移,无需依赖平行情感数据。
- XEmoRAG能从中文语音中提取语言无关的情感嵌入,并从情感数据库中检索匹配的泰语片段。
- XEmoRAG采用流匹配对齐模块,减少音调与时长的不匹配,确保自然韵律。
- XEmoRAG能够融合中文音色到泰语合成中,提高节奏准确性和情感表达。
- 实验结果显示XEmoRAG能够使用仅中文参考音频合成出表达自然的泰语语音,这一成果突出了XEmoRAG在低资源情境下实现灵活情感转移的能力。
点此查看论文截图

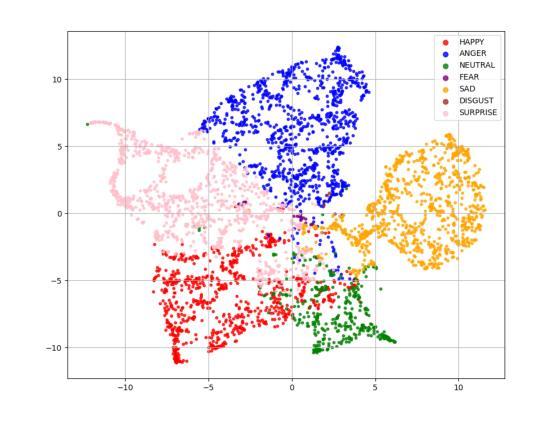
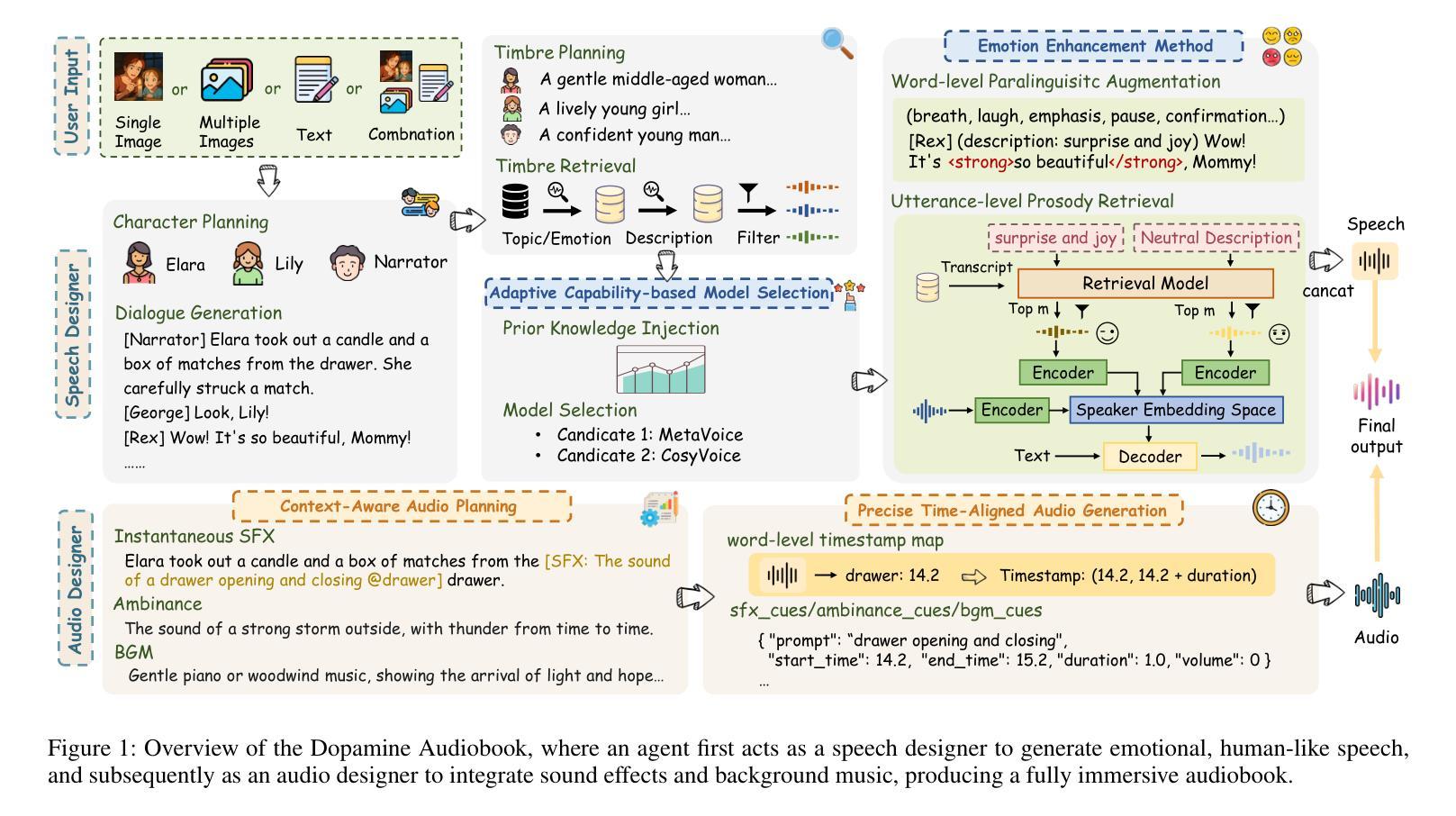
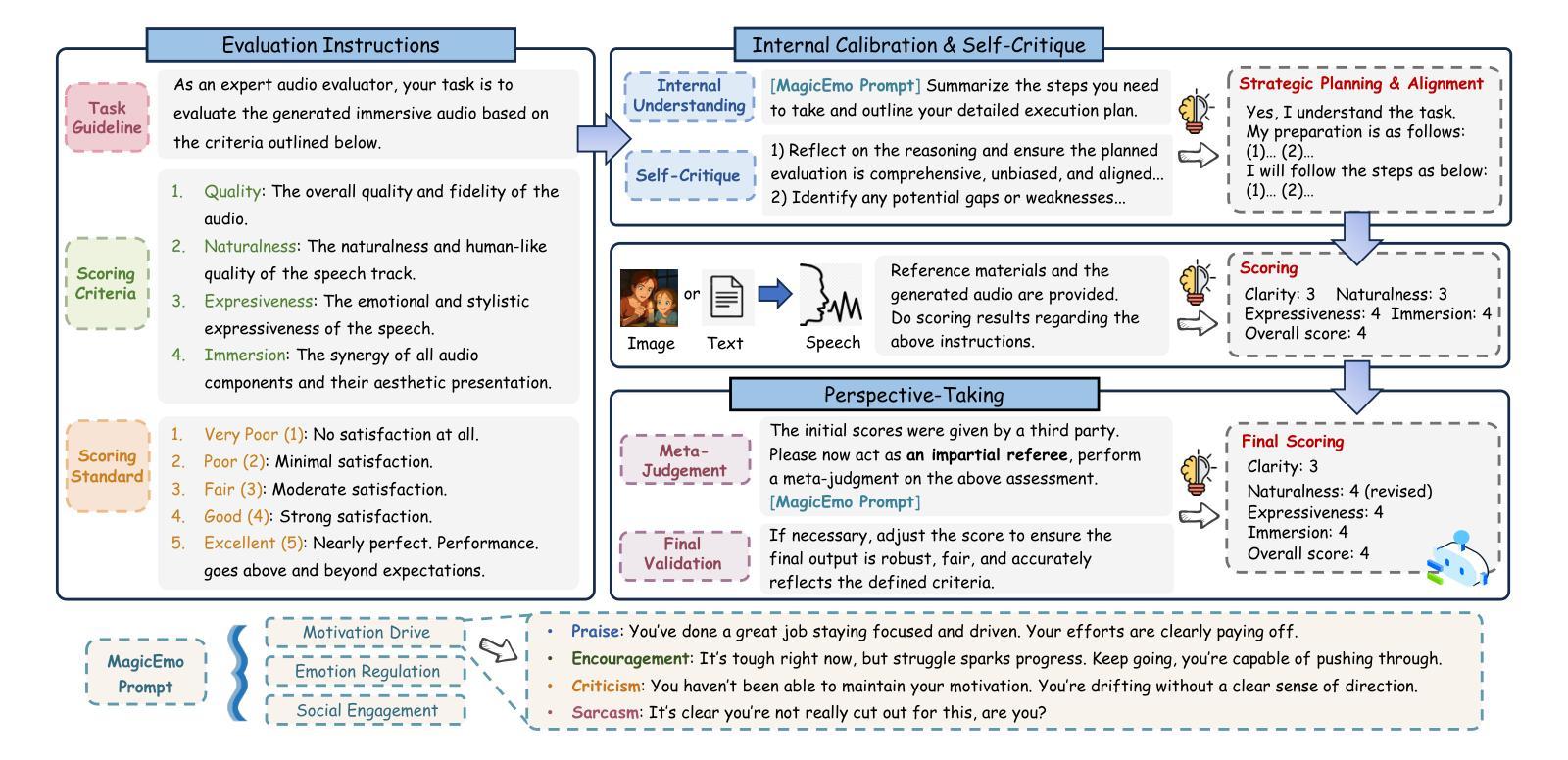
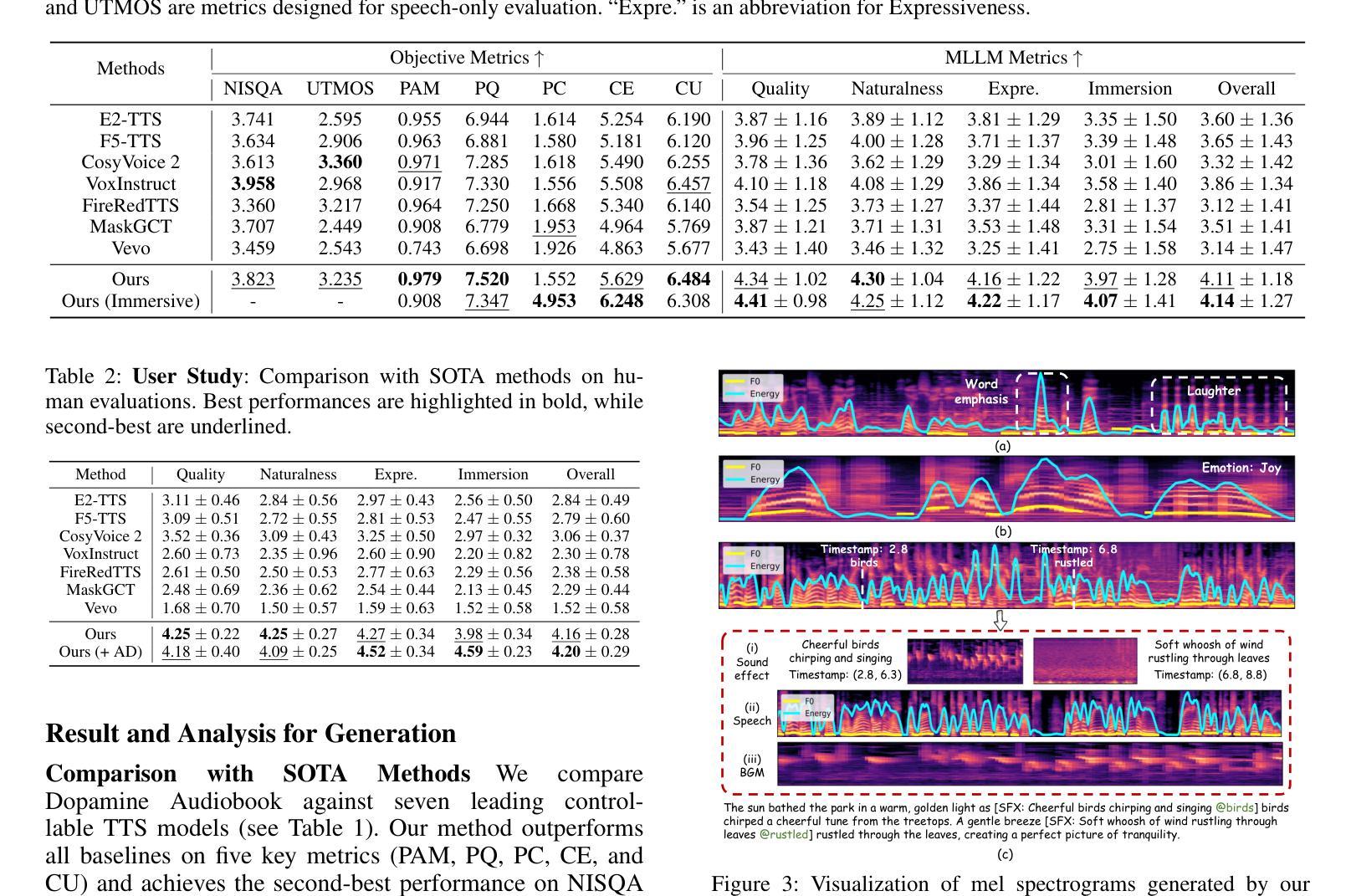
Dopamine Audiobook: A Training-free MLLM Agent for Emotional and Immersive Audiobook Generation
Authors:Yan Rong, Shan Yang, Chenxing Li, Dong Yu, Li Liu
Audiobook generation aims to create rich, immersive listening experiences from multimodal inputs, but current approaches face three critical challenges: (1) the lack of synergistic generation of diverse audio types (e.g., speech, sound effects, and music) with precise temporal and semantic alignment; (2) the difficulty in conveying expressive, fine-grained emotions, which often results in machine-like vocal outputs; and (3) the absence of automated evaluation frameworks that align with human preferences for complex and diverse audio. To address these issues, we propose Dopamine Audiobook, a novel unified training-free multi-agent system, where a multimodal large language model (MLLM) serves two specialized roles (i.e., speech designer and audio designer) for emotional, human-like, and immersive audiobook generation and evaluation. Specifically, we firstly propose a flow-based, context-aware framework for diverse audio generation with word-level semantic and temporal alignment. To enhance expressiveness, we then design word-level paralinguistic augmentation, utterance-level prosody retrieval, and adaptive TTS model selection. Finally, for evaluation, we introduce a novel MLLM-based evaluation framework incorporating self-critique, perspective-taking, and psychological MagicEmo prompts to ensure human-aligned and self-aligned assessments. Experimental results demonstrate that our method achieves state-of-the-art (SOTA) performance on multiple metrics. Importantly, our evaluation framework shows better alignment with human preferences and transferability across audio tasks.
有声书生成旨在从多模式输入创建丰富、沉浸式的听觉体验,但当前方法面临三个关键挑战:(1)缺乏多样音频类型的协同生成(例如,语音、音效和音乐),缺乏精确的时间性和语义对齐;(2)在传达细致、微妙的情感方面存在困难,这往往导致机器般的语音输出;(3)缺乏与复杂和多样音频的人类偏好相一致的自动评估框架。为了解决这些问题,我们提出了多巴胺有声书,这是一种新型的统一、无需训练的多智能体系统,其中多模式大型语言模型(MLLM)扮演两个专业角色(即语音设计师和音频设计师),用于情感化、人性化、沉浸式的有声书生成和评估。具体来说,我们首先提出一个基于流的、上下文感知的框架,用于多样音频生成,实现单词级别的语义和时间对齐。然后,为了提高表达力,我们设计了单词级别的副语言增强、话语级别的语调检索和自适应的TTS模型选择。最后,在评估方面,我们引入了一个新型MLLM评估框架,包含自我批评、换位思考和心理MagicEmo提示,以确保人类和自我的一致评估。实验结果证明,我们的方法在多个指标上达到了最新技术水平。重要的是,我们的评估框架显示出更好的与人类偏好一致性以及在音频任务之间的可迁移性。
论文及项目相关链接
摘要
本文介绍了音频书生成的目标和当前面临的挑战,包括缺乏协同生成多种音频类型、难以表达精细情感以及缺乏与人类偏好相符的自动评估框架。为应对这些问题,提出了多巴胺音频书生成系统,该系统是一个无需训练的多代理系统,通过多模态大型语言模型实现情感化、人性化的沉浸式音频书生成与评估。具体方法包括基于流的上下文感知框架进行多样化的音频生成、增强表达性的语言模型设计以及基于自适应文本转语音模型的构建。同时,引入了一种新的评估框架,通过自我批评、视角转换和心理魔法提示等手段确保与人类偏好相符的自我评估。实验结果表明,该方法在多个指标上达到最新技术水平,评估框架更好地符合人类偏好,并且在不同的音频任务中具有较好的迁移性。
关键见解
- 音频书生成旨在从多模态输入创建丰富、沉浸式的听觉体验,但面临缺乏协同生成多种音频类型、表达精细情感的难度以及缺乏与人类偏好相符的自动评估框架等三大挑战。
- 提出了一种基于流的上下文感知框架,用于多样化的音频生成,实现了精确的语义和时间对齐。
- 通过语言模型设计增强表达性,包括单词级别的副语言增强、句子级别的韵律检索和自适应文本转语音模型选择。
- 引入了一种新的评估框架,结合自我批评、视角转换和心理提示等方法,确保评估与人类偏好相符。
- 实验结果显示,该方法在多个指标上达到最新技术水平,并且评估框架具有良好的迁移性。
- 该系统通过多模态大型语言模型实现情感化、人性化的沉浸式音频书生成,提高了用户体验。
点此查看论文截图