⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
Preview WB-DH: Towards Whole Body Digital Human Bench for the Generation of Whole-body Talking Avatar Videos
Authors:Chaoyi Wang, Yifan Yang, Jun Pei, Lijie Xia, Jianpo Liu, Xiaobing Yuan, Xinhan Di
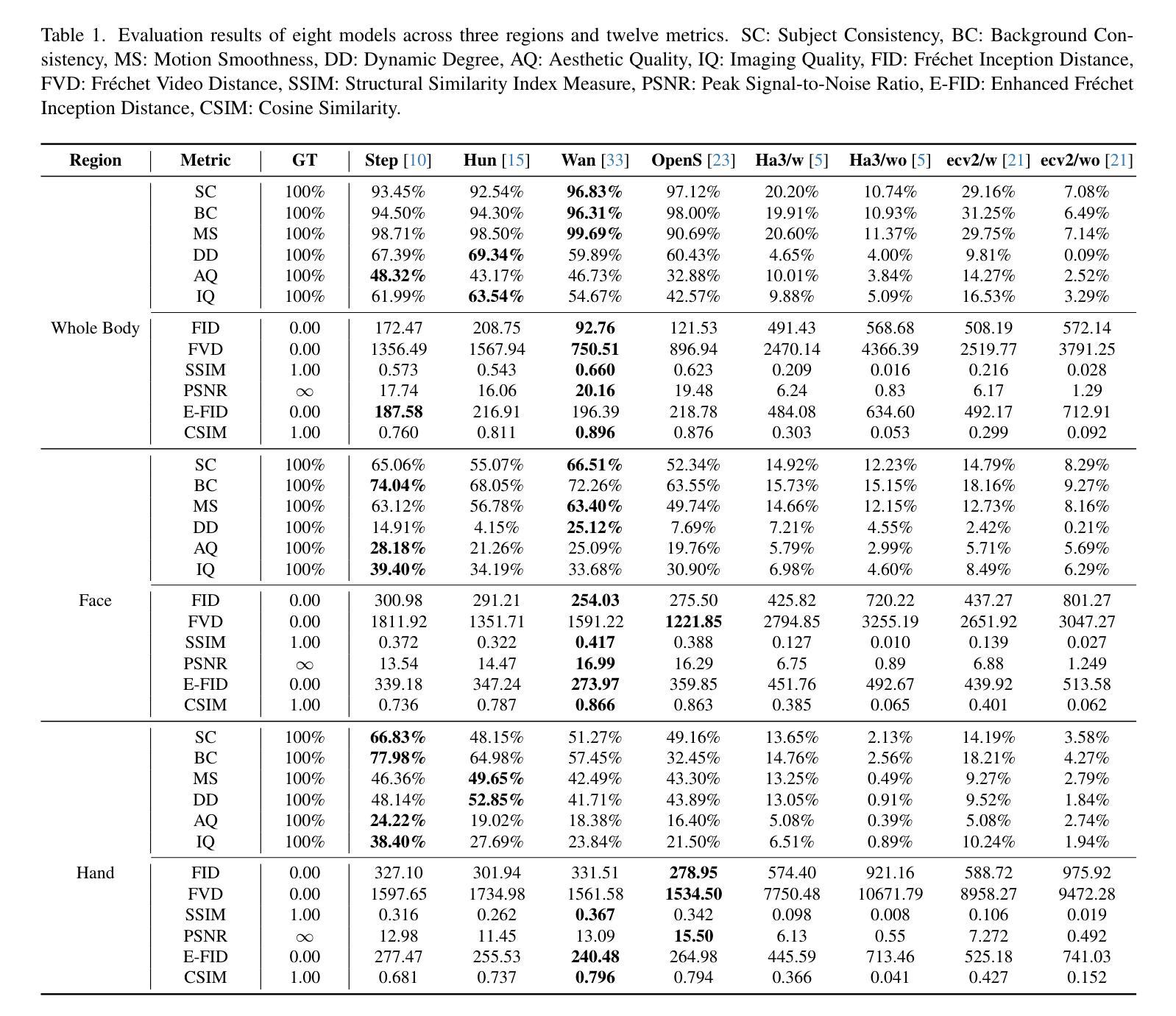
Creating realistic, fully animatable whole-body avatars from a single portrait is challenging due to limitations in capturing subtle expressions, body movements, and dynamic backgrounds. Current evaluation datasets and metrics fall short in addressing these complexities. To bridge this gap, we introduce the Whole-Body Benchmark Dataset (WB-DH), an open-source, multi-modal benchmark designed for evaluating whole-body animatable avatar generation. Key features include: (1) detailed multi-modal annotations for fine-grained guidance, (2) a versatile evaluation framework, and (3) public access to the dataset and tools at https://github.com/deepreasonings/WholeBodyBenchmark.
从单幅肖像创建逼真、可全动画化的全身虚拟形象是一个挑战,这主要是因为难以捕捉微妙的表情、身体动作和动态背景。当前的评估数据集和指标难以应对这些复杂性。为了弥补这一差距,我们推出了全身基准数据集(WB-DH),这是一个开源的、多模式基准测试,用于评估全身可动画虚拟形象生成。其主要特点包括:(1)用于精细指导的详细多模式注释,(2)通用的评估框架,以及(3)可通过https://github.com/deepreasonings/WholeBodyBenchmark访问数据集和工具。
论文及项目相关链接
PDF This paper has been accepted by ICCV 2025 Workshop MMFM4
Summary
本文介绍了创建一个能够全身动画的真实化身面临的技术挑战,并推出全新开源的多模态基准数据集——全身基准数据集(WB-DH),用于评估全身动画化身生成技术。该数据集包含详细的多模态注释、通用评估框架,并可在公开平台上访问和使用。
Key Takeaways
- 创建全身动画化身面临的技术挑战包括捕捉微妙的表情、身体动作和动态背景。
- 当前评估数据集和指标无法应对这些复杂性。
- 引入全新开源的多模态基准数据集——全身基准数据集(WB-DH),用于评估全身动画化身生成技术。
- 该数据集包含详细的多模态注释,提供精细指导。
- 提供通用的评估框架,方便技术评估。
- 数据集和工具可通过公开平台访问和使用。
点此查看论文截图



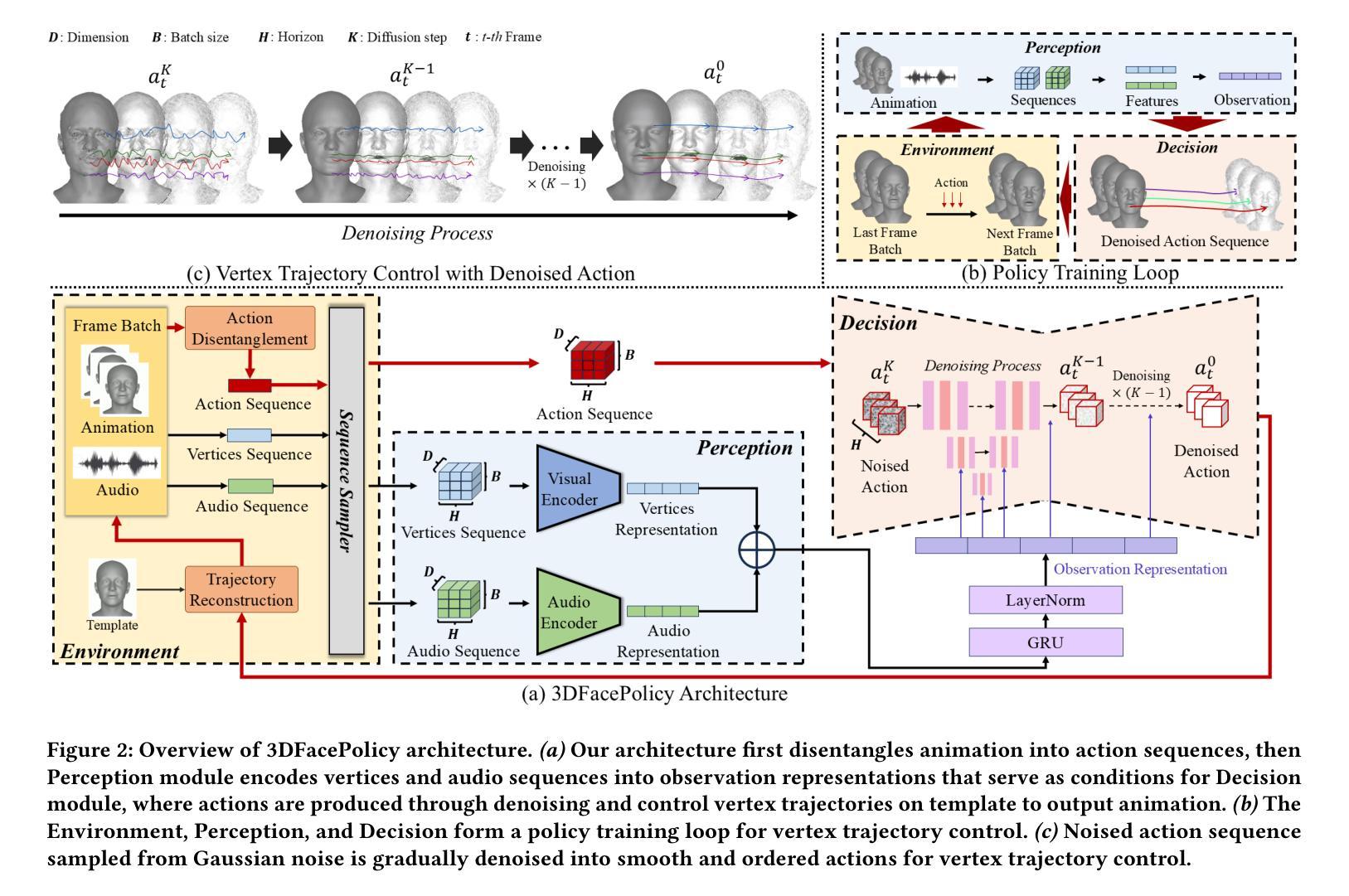
3DFacePolicy: Audio-Driven 3D Facial Animation Based on Action Control
Authors:Xuanmeng Sha, Liyun Zhang, Tomohiro Mashita, Naoya Chiba, Yuki Uranishi
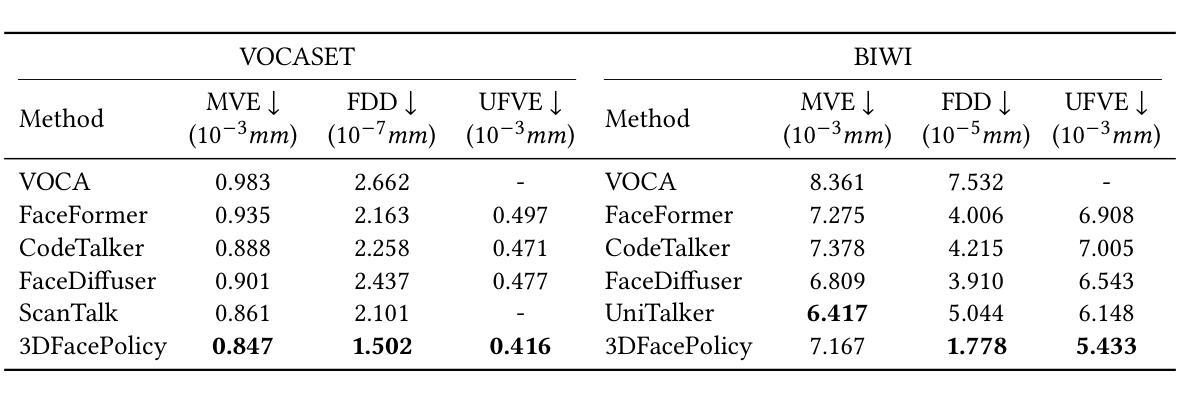
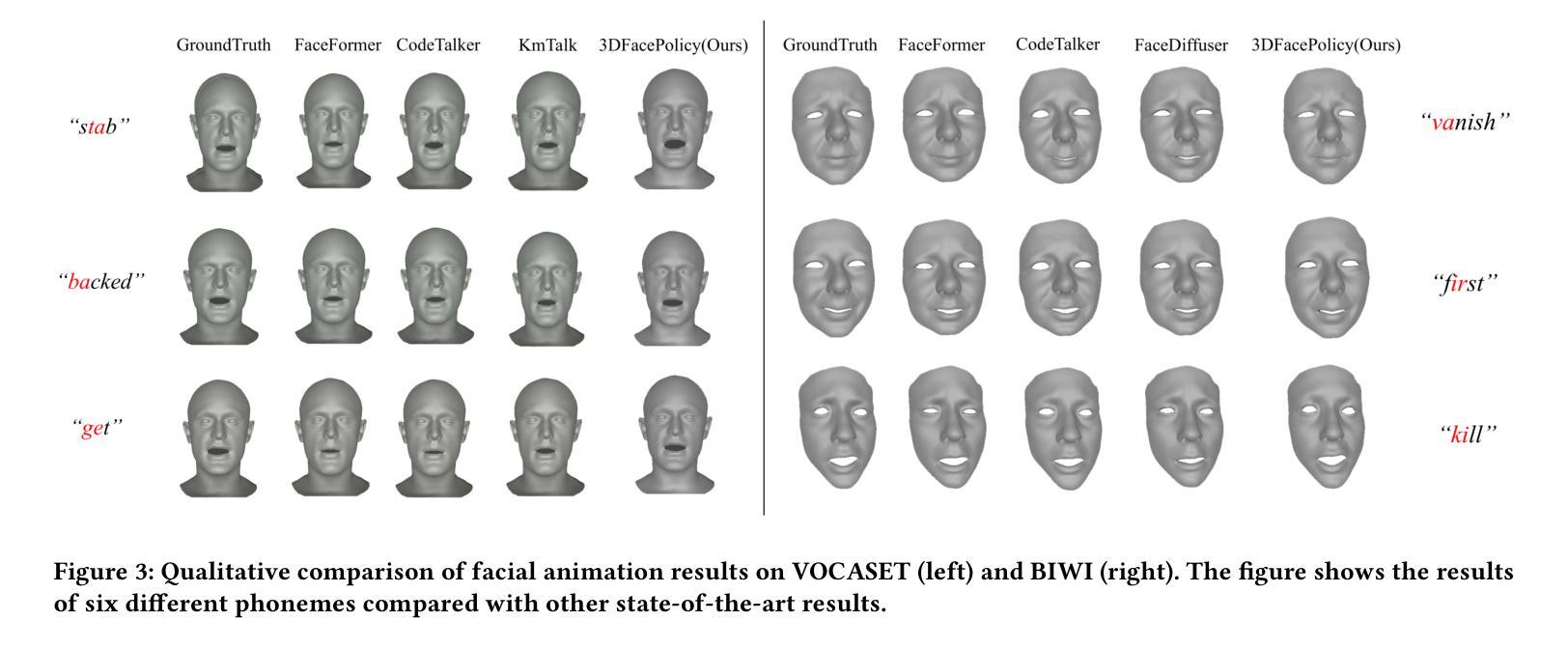
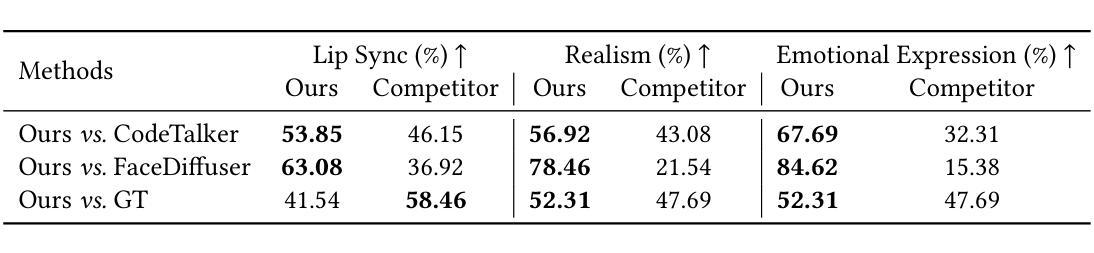
Audio-driven 3D facial animation has achieved significant progress in both research and applications. While recent baselines struggle to generate natural and continuous facial movements due to their frame-by-frame vertex generation approach, we propose 3DFacePolicy, a pioneer work that introduces a novel definition of vertex trajectory changes across consecutive frames through the concept of “action”. By predicting action sequences for each vertex that encode frame-to-frame movements, we reformulate vertex generation approach into an action-based control paradigm. Specifically, we leverage a robotic control mechanism, diffusion policy, to predict action sequences conditioned on both audio and vertex states. Extensive experiments on VOCASET and BIWI datasets demonstrate that our approach significantly outperforms state-of-the-art methods and is particularly expert in dynamic, expressive and naturally smooth facial animations.
音频驱动的3D面部动画在研究和应用方面都取得了显著的进展。尽管最近的基线方法由于其逐帧顶点生成方法而难以生成自然和连续的面部动作,但我们提出了3DFacePolicy,这是一项开创性的工作,通过“动作”的概念引入了顶点轨迹变化的新定义。我们通过预测每个顶点的动作序列来编码帧到帧的运动,将顶点生成方法重新制定为基于动作的控制范式。具体来说,我们利用机器人控制机制,即扩散策略,来预测基于音频和顶点状态的动作序列。在VOCASET和BIWI数据集上的大量实验表明,我们的方法显著优于最先进的方法,并且在动态、表达和自然平滑的面部动画方面特别擅长。
论文及项目相关链接
Summary
本文介绍了音频驱动的3D面部动画的最新进展,提出了一种基于动作序列的顶点生成方法,即3DFacePolicy。该方法通过预测每个顶点的动作序列来编码帧间移动,将顶点生成方法改革为基于动作的控制范式。实验证明,该方法在动态、表达和自然平滑的面部动画方面显著优于现有技术。
Key Takeaways
- 3DFacePolicy提出了基于动作序列的顶点生成方法,通过预测每个顶点的动作序列来实现面部动画的自然连续性。
- 动作序列编码了帧间移动,为音频驱动的3D面部动画提供了新的定义。
- 通过利用扩散策略这种机器人控制机制,动作序列的预测同时受到音频和顶点状态的影响。
- 相较于当前的技术基准,3DFacePolicy在动态、表达及自然平滑的面部动画方面表现更优秀。
- 该方法在VOCASET和BIWI数据集上的实验证明了其有效性。
- 该方法的创新之处在于将音频驱动的面部动画与机器人控制机制相结合,以实现对面部动作更精确的控制。
点此查看论文截图