⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-14 更新
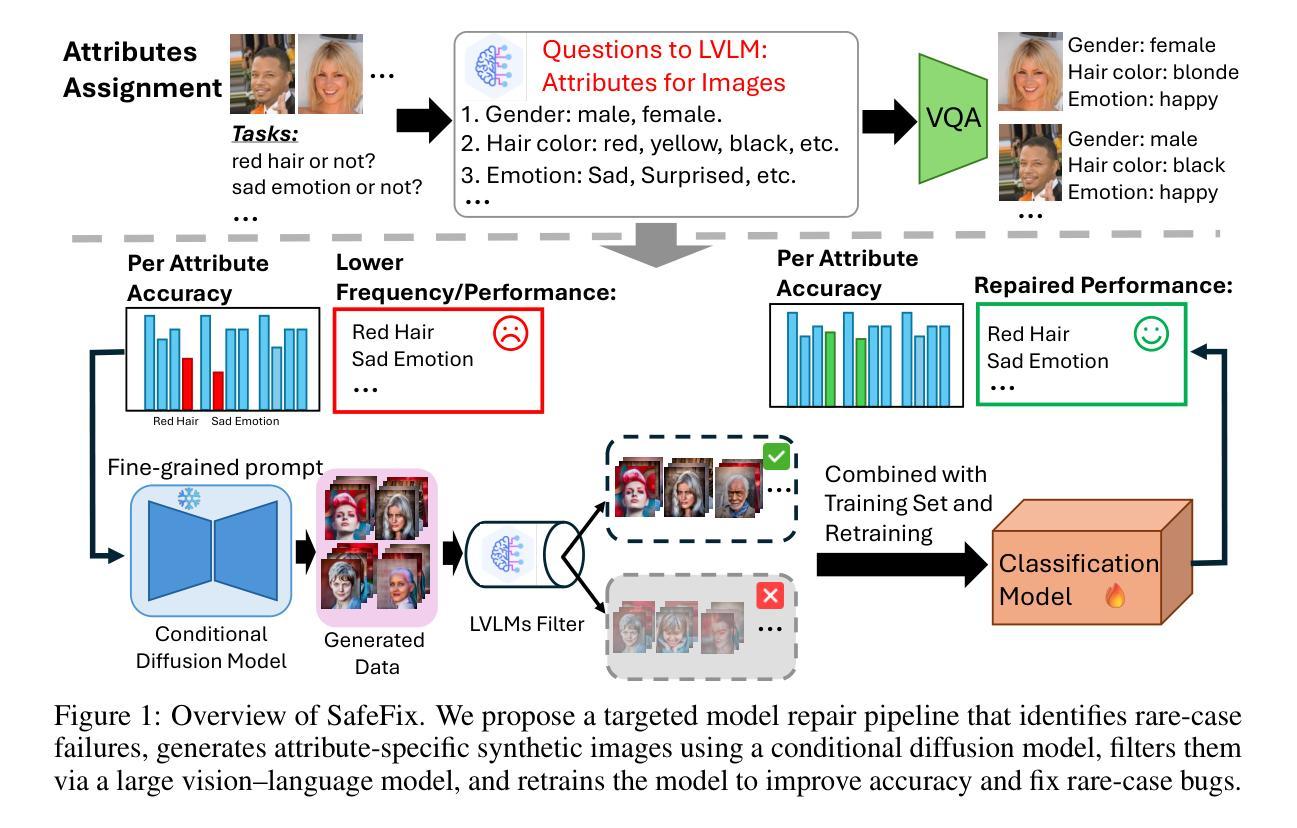
SafeFix: Targeted Model Repair via Controlled Image Generation
Authors:Ouyang Xu, Baoming Zhang, Ruiyu Mao, Yunhui Guo
Deep learning models for visual recognition often exhibit systematic errors due to underrepresented semantic subpopulations. Although existing debugging frameworks can pinpoint these failures by identifying key failure attributes, repairing the model effectively remains difficult. Current solutions often rely on manually designed prompts to generate synthetic training images – an approach prone to distribution shift and semantic errors. To overcome these challenges, we introduce a model repair module that builds on an interpretable failure attribution pipeline. Our approach uses a conditional text-to-image model to generate semantically faithful and targeted images for failure cases. To preserve the quality and relevance of the generated samples, we further employ a large vision-language model (LVLM) to filter the outputs, enforcing alignment with the original data distribution and maintaining semantic consistency. By retraining vision models with this rare-case-augmented synthetic dataset, we significantly reduce errors associated with rare cases. Our experiments demonstrate that this targeted repair strategy improves model robustness without introducing new bugs. Code is available at https://github.com/oxu2/SafeFix
深度学习模型在视觉识别方面经常由于语义子群体代表性不足而表现出系统性错误。尽管现有的调试框架可以通过识别关键失败属性来指出这些故障,但有效地修复模型仍然很困难。当前解决方案通常依赖于手动设计的提示来生成合成训练图像,这种方法容易受到分布偏移和语义错误的影响。为了克服这些挑战,我们引入了一个模型修复模块,该模块建立在可解释的失败归属管道之上。我们的方法使用条件文本到图像模型来生成针对失败案例的语义上忠实且定位准确的图像。为了保持生成样本的质量和相关性,我们进一步采用大型视觉语言模型(LVLM)来过滤输出,强制其与原始数据分布对齐并保持语义一致性。通过使用该罕见案例增强合成数据集重新训练视觉模型,我们显著减少了与罕见案例相关的错误。我们的实验表明,这种有针对性的修复策略提高了模型的稳健性,而没有引入新错误。代码可在https://github.com/oxu2/SafeFix找到。
论文及项目相关链接
Summary
文本介绍了一种针对视觉识别深度学习模型的系统性错误的修复方法。该方法通过构建一个可解释的失败归因管道,使用条件文本到图像模型生成针对失败案例的语义忠实图像。为提高生成样本的质量和相关性,采用大型视觉语言模型(LVLM)对输出进行过滤,确保与原始数据分布一致并维持语义一致性。通过用此罕见案例增强合成数据集重新训练视觉模型,显著减少与罕见案例相关的错误。实验表明,这种有针对性的修复策略提高了模型的稳健性,且未引入新错误。
Key Takeaways
- 深度学习模型在视觉识别中会因语义亚群体代表性不足而出现系统性错误。
- 现有调试框架能识别关键失败属性,但有效修复模型仍具挑战性。
- 现有解决方案倾向于通过手动设计提示生成合成训练图像,但这种方法易导致分布偏移和语义错误。
- 引入了一个模型修复模块,该模块建立在可解释的失败归因管道之上。
- 使用条件文本到图像模型生成针对失败案例的语义忠实图像。
- 采用大型视觉语言模型(LVLM)过滤输出,以确保与原始数据分布一致并维持语义一致性。
点此查看论文截图

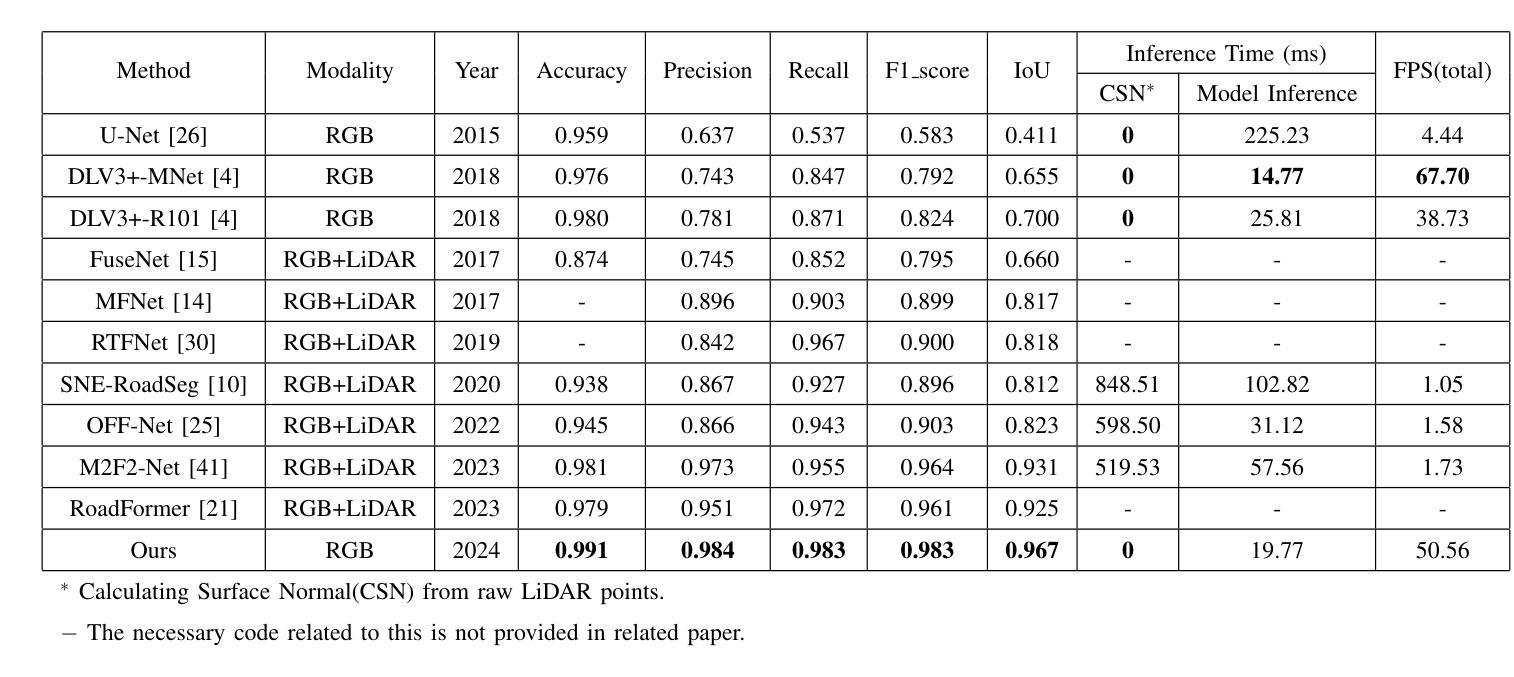
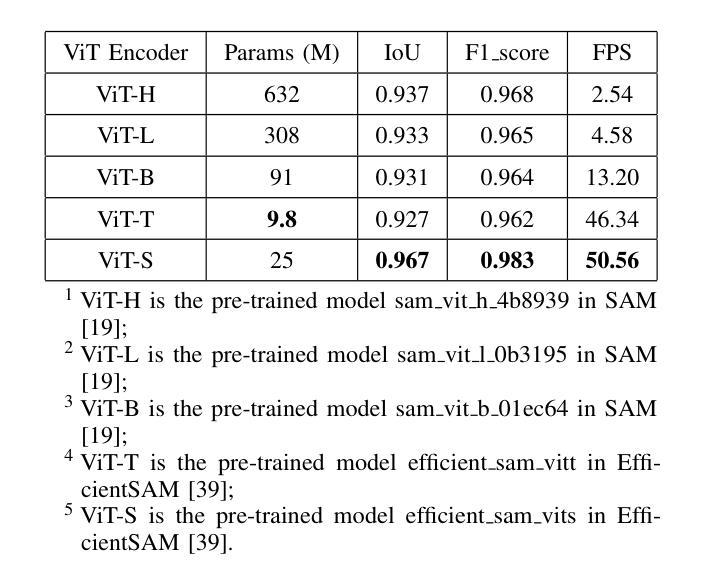
ROD: RGB-Only Fast and Efficient Off-road Freespace Detection
Authors:Tong Sun, Hongliang Ye, Jilin Mei, Liang Chen, Fangzhou Zhao, Leiqiang Zong, Yu Hu
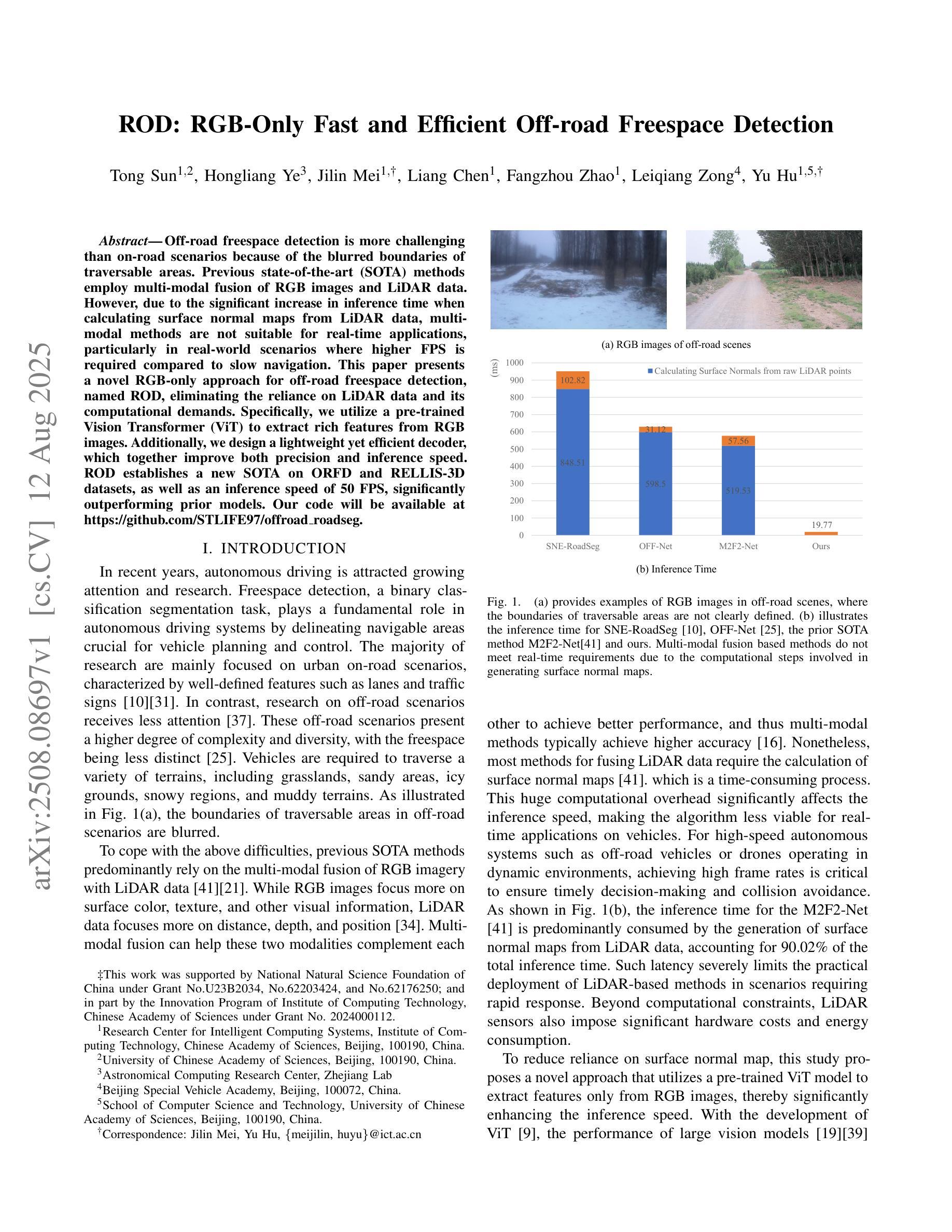
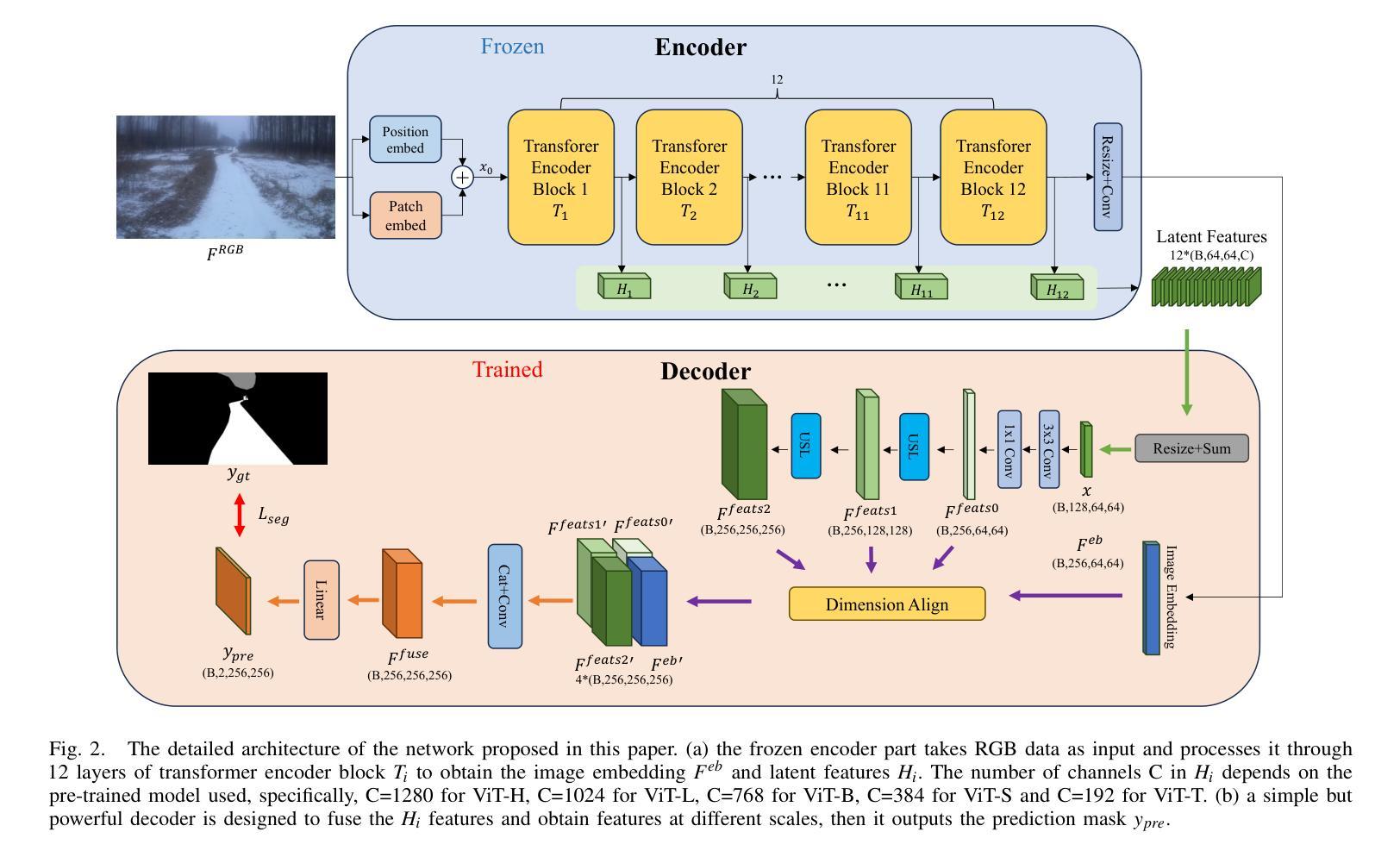
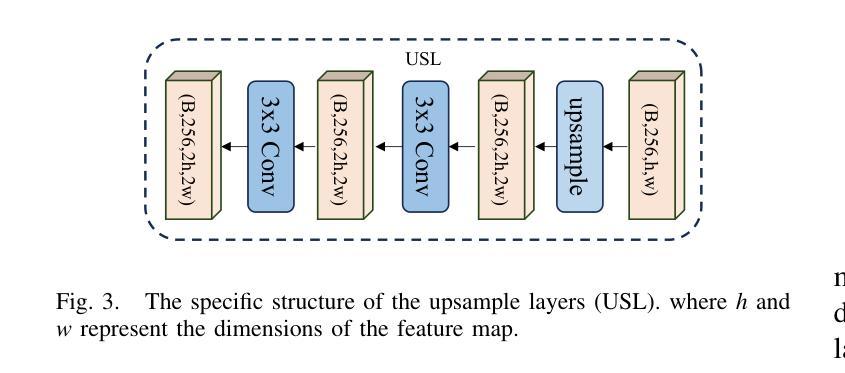
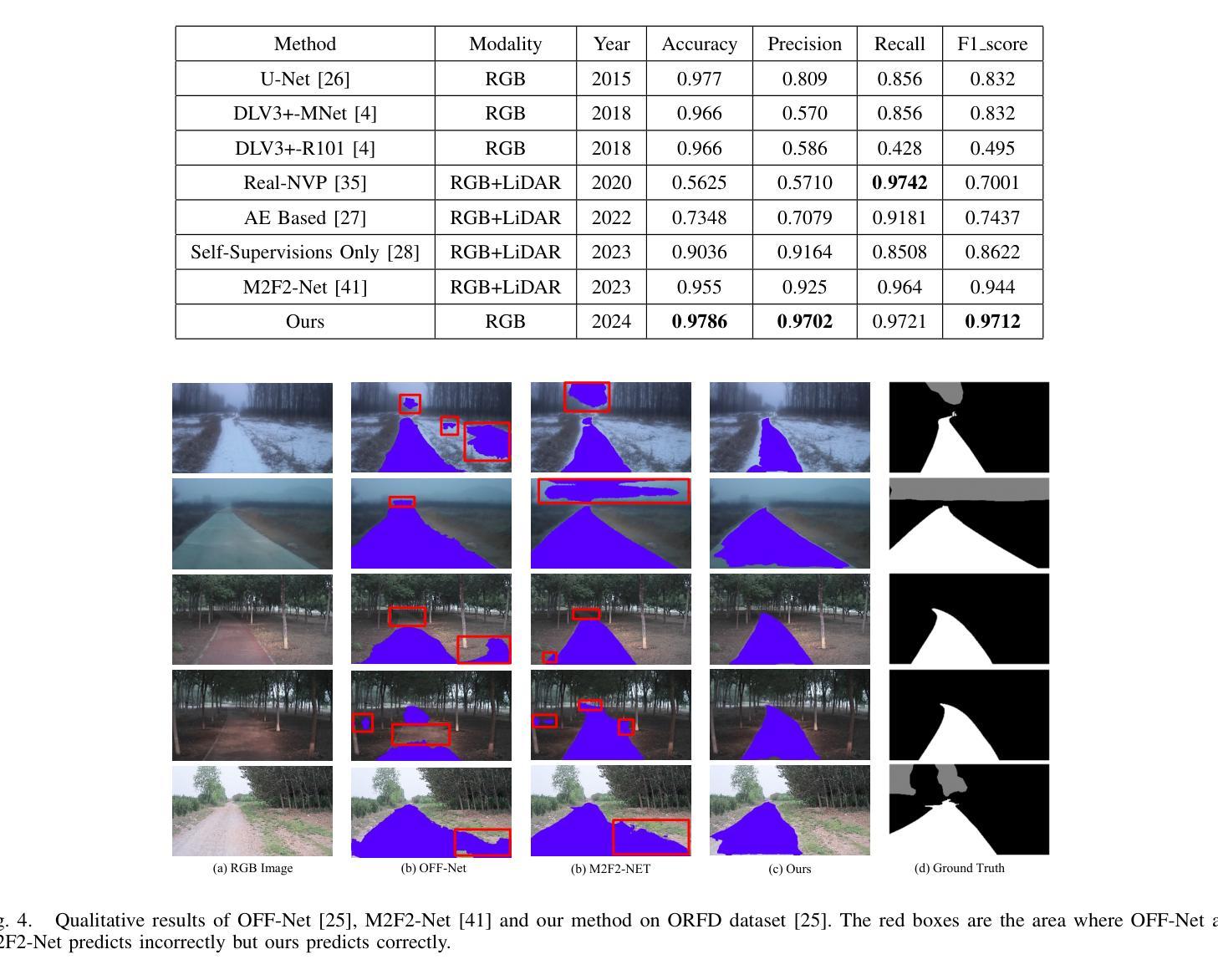
Off-road freespace detection is more challenging than on-road scenarios because of the blurred boundaries of traversable areas. Previous state-of-the-art (SOTA) methods employ multi-modal fusion of RGB images and LiDAR data. However, due to the significant increase in inference time when calculating surface normal maps from LiDAR data, multi-modal methods are not suitable for real-time applications, particularly in real-world scenarios where higher FPS is required compared to slow navigation. This paper presents a novel RGB-only approach for off-road freespace detection, named ROD, eliminating the reliance on LiDAR data and its computational demands. Specifically, we utilize a pre-trained Vision Transformer (ViT) to extract rich features from RGB images. Additionally, we design a lightweight yet efficient decoder, which together improve both precision and inference speed. ROD establishes a new SOTA on ORFD and RELLIS-3D datasets, as well as an inference speed of 50 FPS, significantly outperforming prior models.
越野空闲空间检测比公路场景更具挑战性,因为可行驶区域的边界模糊。之前的最先进方法采用RGB图像和激光雷达数据的多模式融合。然而,由于从激光雷达数据计算表面法线图时推理时间的显著增长,多模式方法不适用于实时应用,特别是在现实世界场景中,与缓慢导航相比,需要更高的帧率。本文提出了一种仅使用RGB的越野空闲空间检测新方法,名为ROD,消除了对激光雷达数据及其计算需求的依赖。具体来说,我们利用预训练的视觉转换器(ViT)从RGB图像中提取丰富的特征。此外,我们设计了一个轻便高效的解码器,这两者共同提高了精度和推理速度。ROD在ORFD和RELLIS-3D数据集上建立了新的最先进的水平,同时推理速度达到50 FPS,显著优于先前模型。
论文及项目相关链接
Summary
这篇论文提出了一种新型的仅使用RGB图像进行越野空闲空间检测的方法,名为ROD。该方法利用预训练的Vision Transformer(ViT)从RGB图像中提取丰富特征,并设计了一个轻便高效的解码器,提高了精度和推理速度。相较于之前依赖LiDAR数据和其计算需求的方法,ROD在不使用LiDAR数据的情况下建立了新的技术领先,并且在ORFD和RELLIS-3D数据集上的表现优异,推理速度达到每秒50帧。
Key Takeaways
- 该论文提出了一种新型的仅使用RGB图像的越野空闲空间检测方法,命名为ROD。
- ROD利用预训练的Vision Transformer(ViT)提取图像特征。
- ROD设计了一个高效轻便的解码器,提高了检测精度和推理速度。
- ROD方法不依赖LiDAR数据,避免了其计算需求和相关复杂性。
- ROD在ORFD和RELLIS-3D数据集上实现了卓越性能。
- ROD的推理速度达到了每秒50帧,显著优于先前的模型。
点此查看论文截图

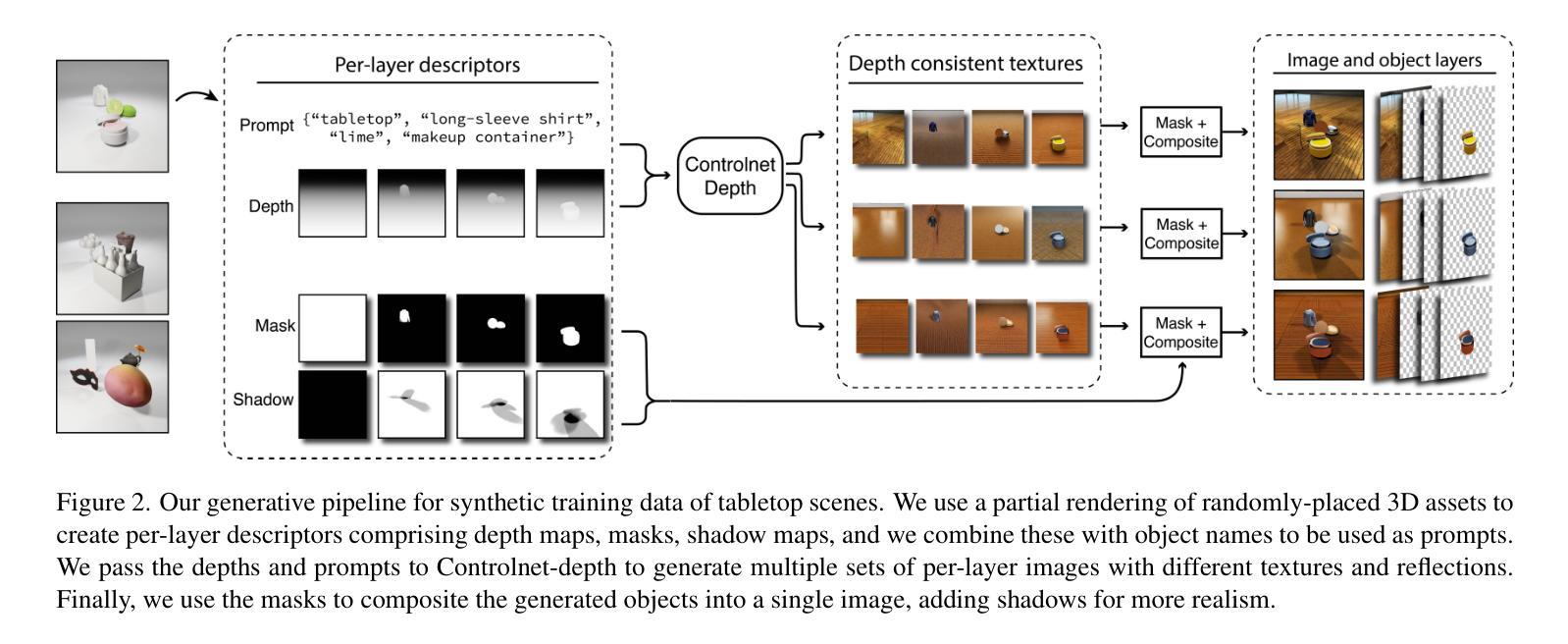
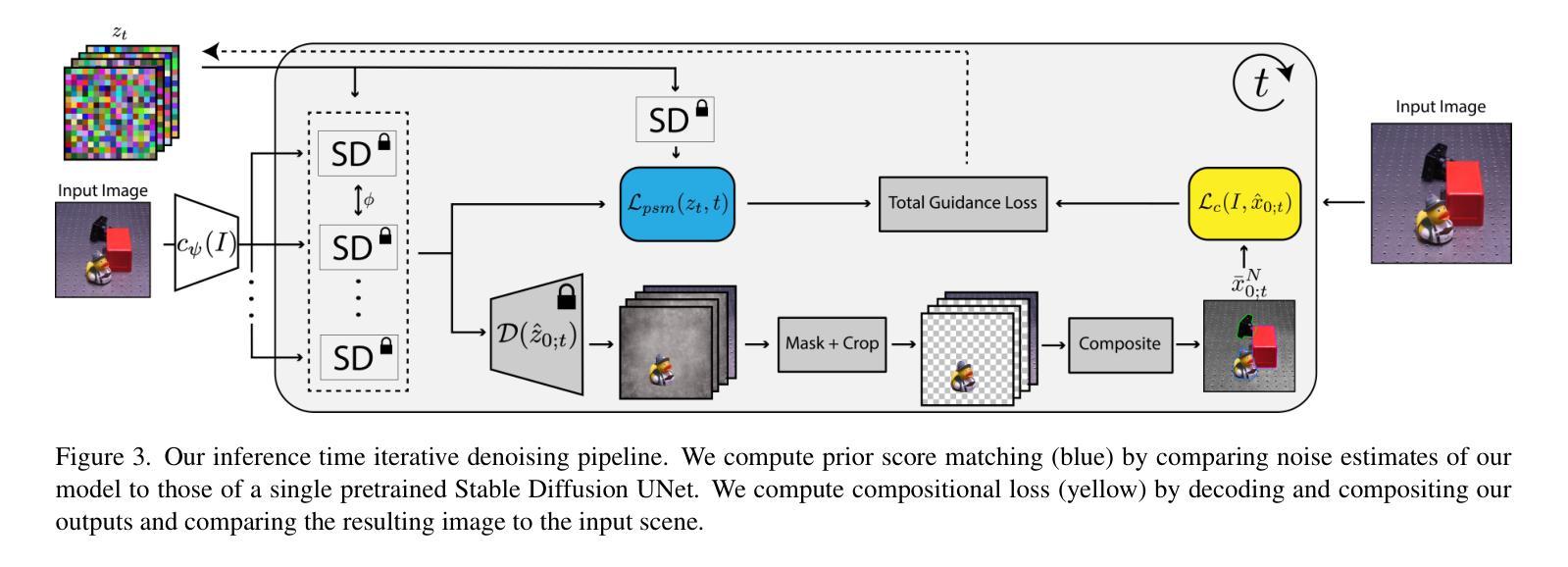
CObL: Toward Zero-Shot Ordinal Layering without User Prompting
Authors:Aneel Damaraju, Dean Hazineh, Todd Zickler
Vision benefits from grouping pixels into objects and understanding their spatial relationships, both laterally and in depth. We capture this with a scene representation comprising an occlusion-ordered stack of “object layers,” each containing an isolated and amodally-completed object. To infer this representation from an image, we introduce a diffusion-based architecture named Concurrent Object Layers (CObL). CObL generates a stack of object layers in parallel, using Stable Diffusion as a prior for natural objects and inference-time guidance to ensure the inferred layers composite back to the input image. We train CObL using a few thousand synthetically-generated images of multi-object tabletop scenes, and we find that it zero-shot generalizes to photographs of real-world tabletops with varying numbers of novel objects. In contrast to recent models for amodal object completion, CObL reconstructs multiple occluded objects without user prompting and without knowing the number of objects beforehand. Unlike previous models for unsupervised object-centric representation learning, CObL is not limited to the world it was trained in.
视觉受益于将像素分组为对象并理解它们的空间关系,包括横向和深度方向上的关系。我们通过构建一个包含“对象层”遮挡顺序堆叠的场景表示来捕捉这一点,每一层都包含一个孤立的、模态完成的对象。为了从图像中推断出这种表示,我们引入了一种基于扩散的架构,名为并发对象层(CObL)。CObL并行生成对象层堆栈,使用稳定扩散作为自然对象的先验和推理时间指导,以确保推断的层能够重新组合回输入图像。我们使用合成生成的包含多对象桌面场景的照片对CObL进行训练,发现它能够零样本泛化到具有不同数量新对象的真实桌面照片上。与最近的模态对象完成模型相比,CObL能够重建多个被遮挡的对象,无需用户提示且不知道事先存在的对象数量。与之前的无监督对象中心表示学习模型相比,CObL并不局限于其所受训练的世界背景。
论文及项目相关链接
PDF ICCV 2025: Project page with demo, datasets, and code: https://vision.seas.harvard.edu/cobl/
Summary
本文将像素分组为对象并理解它们之间的空间关系,提出一种名为Concurrent Object Layers(CObL)的扩散架构来捕获场景表示。CObL使用稳定扩散作为自然对象的先验知识,并通过推理时间指导确保推断出的图层能够合成输入图像。使用合成多目标桌面场景图像进行训练,并发现它能在真实世界桌面照片上零样本泛化,无需用户提示即可重建多个被遮挡对象,且无需事先知道对象数量。与先前的无监督对象中心表示学习模型相比,CObL并不局限于其训练的世界。
Key Takeaways
- 本文通过分组像素为对象并理解其空间关系来提升视觉理解。
- 提出一种名为Concurrent Object Layers(CObL)的扩散架构来捕获场景表示,包括遮挡顺序的对象层堆叠。
- CObL通过稳定扩散生成自然对象的先验知识,并使用推理时间指导确保图层合成效果。
- 使用合成多目标桌面场景图像对CObL进行训练。
- CObL能够在真实世界桌面照片上实现零样本泛化。
- CObL无需用户提示即可重建多个被遮挡对象,且无需事先知道对象数量。
点此查看论文截图


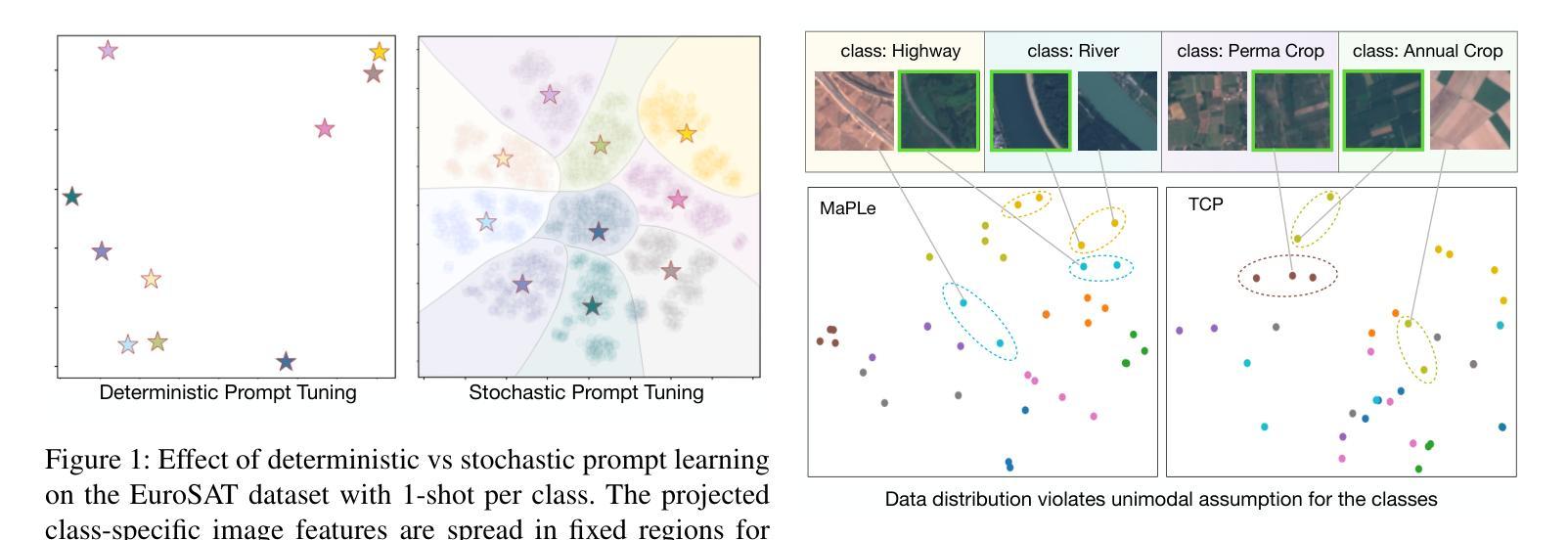
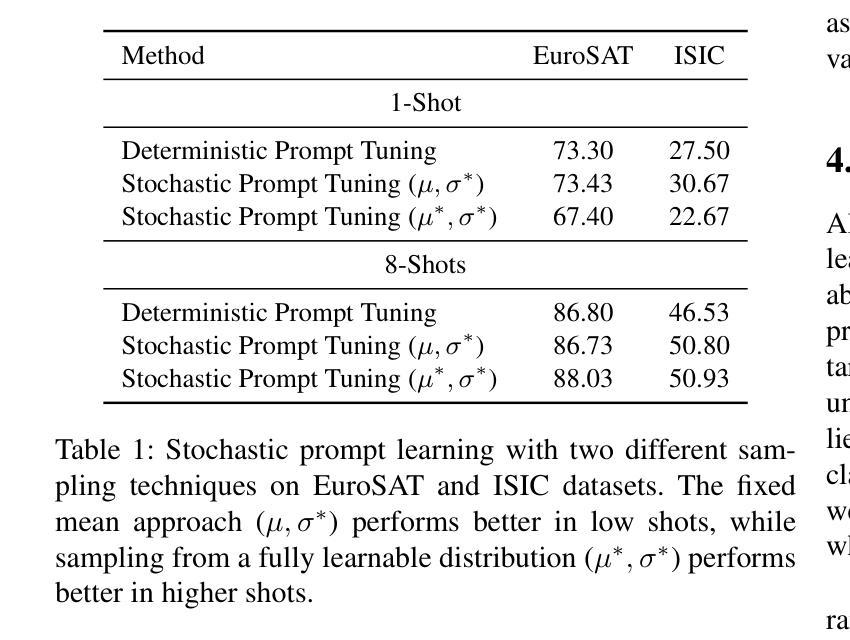
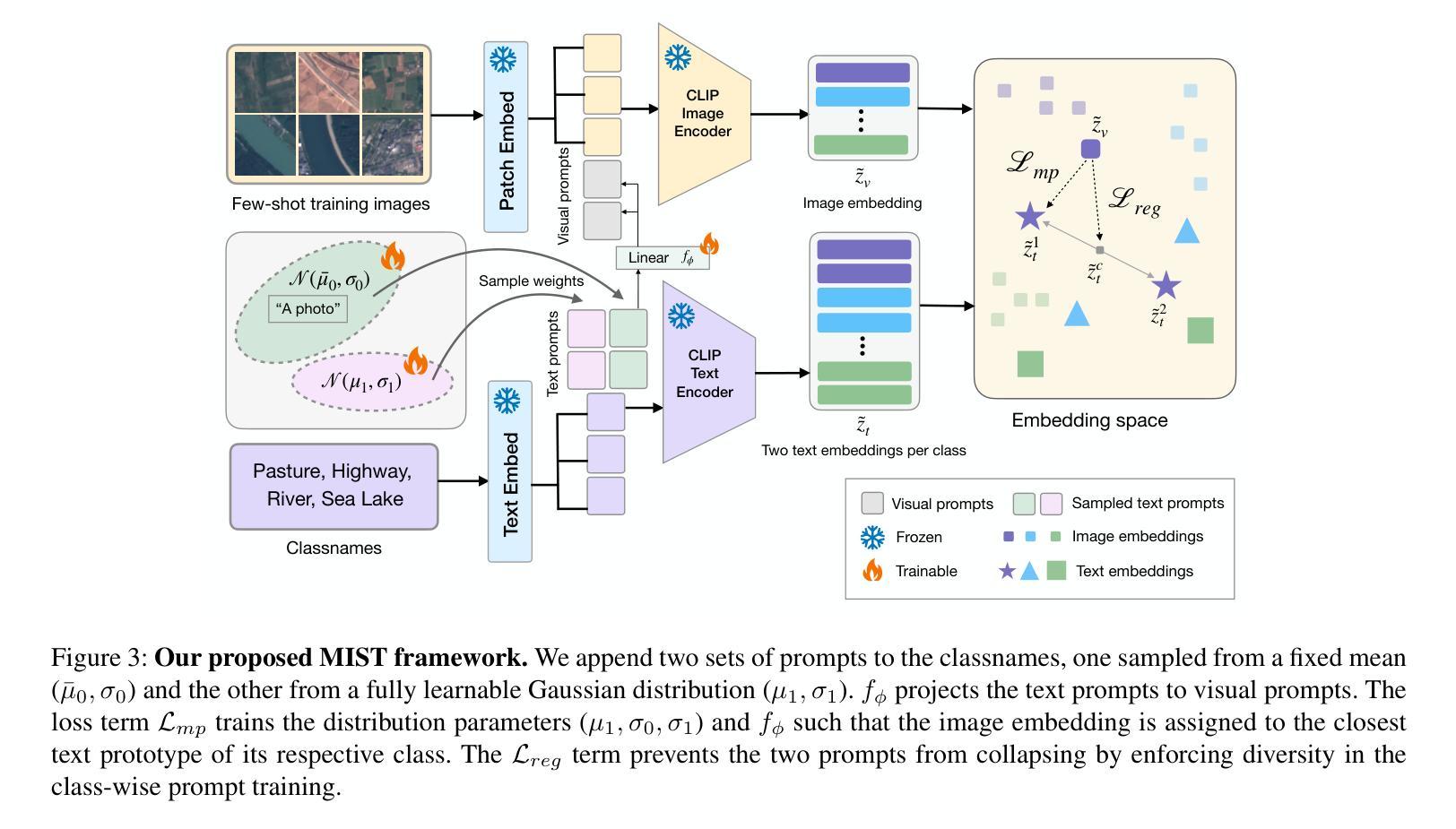
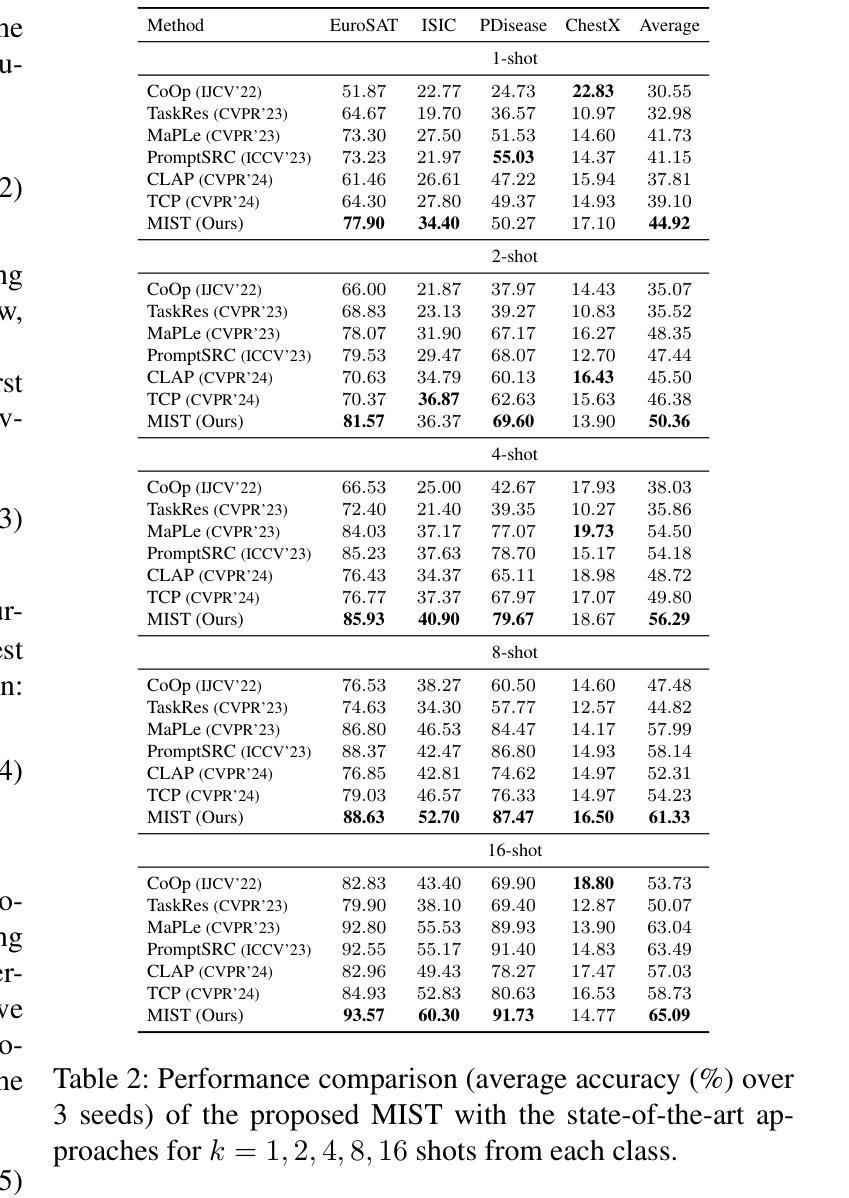
Multiple Stochastic Prompt Tuning for Few-shot Adaptation under Extreme Domain Shift
Authors:Debarshi Brahma, Soma Biswas
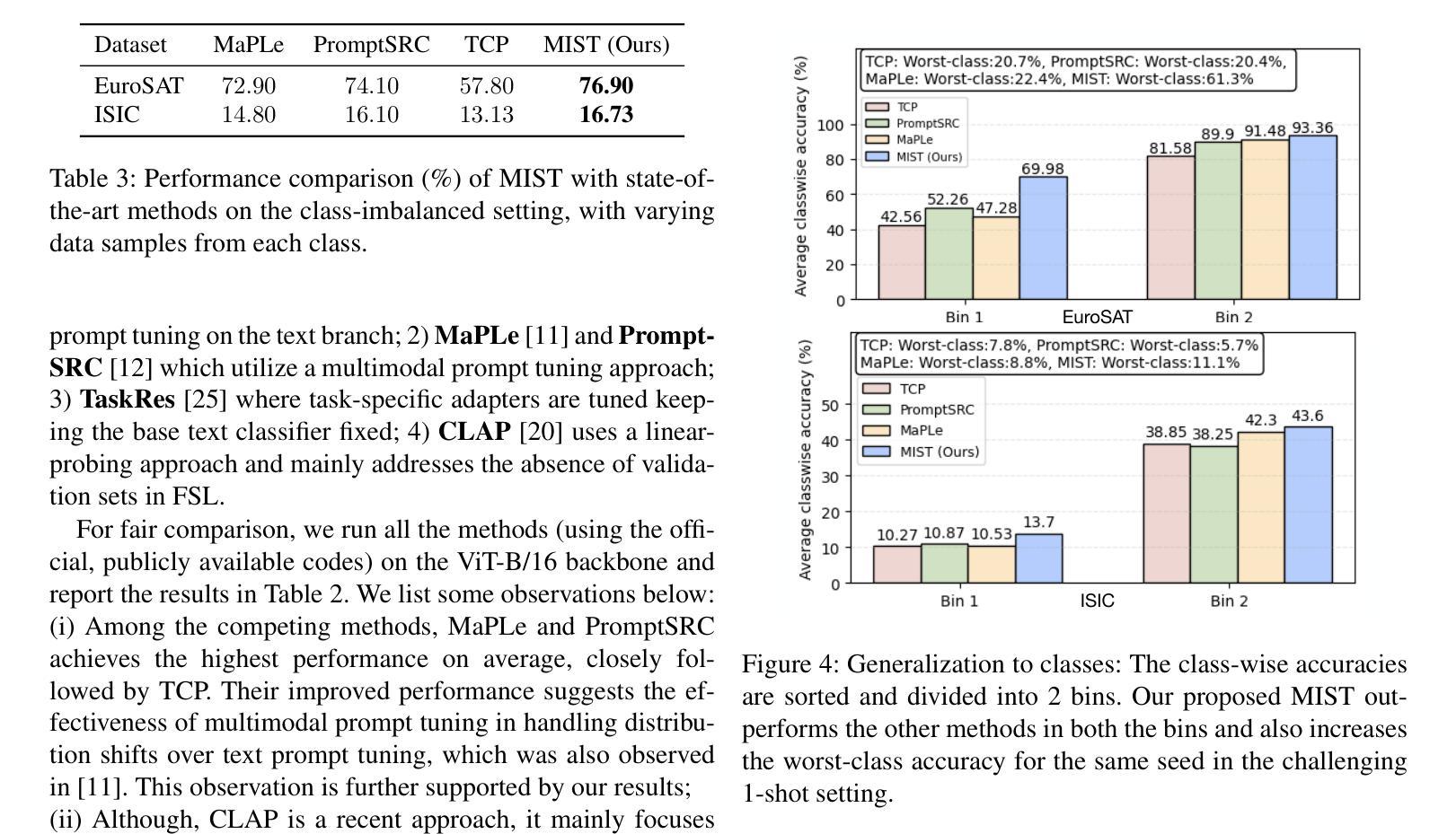
Foundation Vision-Language Models (VLMs) like CLIP exhibit strong generalization capabilities due to large-scale pretraining on diverse image-text pairs. However, their performance often degrades when applied to target datasets with significant distribution shifts in both visual appearance and class semantics. Recent few-shot learning approaches adapt CLIP to downstream tasks using limited labeled data via adapter or prompt tuning, but are not specifically designed to handle such extreme domain shifts. Conversely, some works addressing cross-domain few-shot learning consider such domain-shifted scenarios but operate in an episodic setting with only a few classes per episode, limiting their applicability to real-world deployment, where all classes must be handled simultaneously. To address this gap, we propose a novel framework, MIST (Multiple Stochastic Prompt Tuning), for efficiently adapting CLIP to datasets with extreme distribution shifts using only a few labeled examples, in scenarios involving all classes at once. Specifically, we introduce multiple learnable prompts per class to effectively capture diverse modes in visual representations arising from distribution shifts. To further enhance generalization, these prompts are modeled as learnable Gaussian distributions, enabling efficient exploration of the prompt parameter space and reducing overfitting caused by limited supervision. Extensive experiments and comparisons with state-of-the-art methods demonstrate the effectiveness of the proposed framework.
基于大规模预训练在多样化图像文本对上的能力,诸如CLIP之类的视觉语言模型(VLMs)展现出强大的泛化能力。然而,当应用于目标数据集时,如果在视觉外观和类别语义方面存在显著分布偏移,其性能往往会下降。最近的少量学习法通过适配器或提示调整使CLIP适应下游任务,使用有限的标记数据,但并未专门设计来处理这种极端的域偏移。相反,一些解决跨域少量学习的作品考虑了这种域偏移场景,但在每个片段中只有少数类别的情况下采用片段式设置,限制了其在现实世界部署中的应用,其中必须同时处理所有类别。为了解决这一空白,我们提出了一种新的框架MIST(多重随机提示调整),该框架旨在仅使用少量标记示例有效地适应具有极端分布偏移的数据集,涉及一次性处理所有类别的情况。具体来说,我们为每个类别引入了多个可学习的提示,以有效捕获由分布偏移引起的视觉表示中的不同模式。为了进一步提高泛化能力,这些提示被建模为可学习的高斯分布,能够高效探索提示参数空间并减少因有限监督而导致的过度拟合。大量实验与最先进方法的比较表明,该框架是有效的。
论文及项目相关链接
Summary
大型预训练的Vision-Language模型,如CLIP,在多样图像文本对上展现出强大的泛化能力,但当应用于目标数据集时,其性能在视觉外观和类别语义出现显著分布偏移时会下降。为了处理这种情况,我们提出MIST框架(Multiple Stochastic Prompt Tuning),仅使用少量标签样本即可快速适应极端分布偏移的数据集。我们使用可学习的提示来提高模型泛化能力,将提示建模为高斯分布以更有效地探索参数空间并减少因有限监督而导致的过拟合。
Key Takeaways
- Vision-Language模型如CLIP在多样图像文本对上具有强大的泛化能力。
- 在目标数据集上,CLIP性能在分布偏移时可能下降。
- MIST框架通过引入多个可学习提示来处理极端分布偏移问题。
- 提示建模为高斯分布有助于更有效地探索参数空间并减少过拟合。
- MIST框架能在少量标签样本的情况下实现高效适应。
- MIST框架适用于所有类别的同时处理,扩大了其在实际部署中的应用范围。
点此查看论文截图

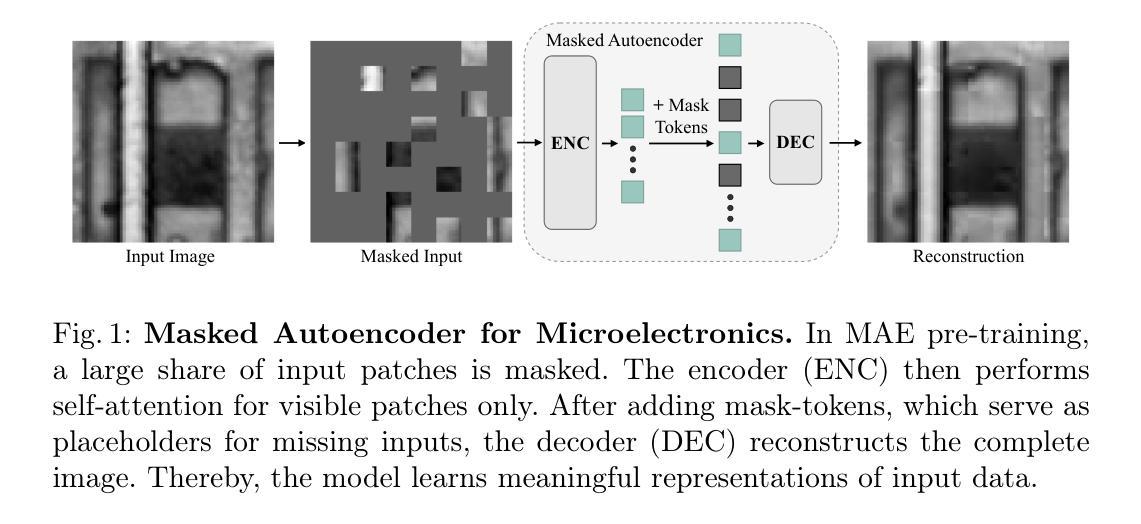
Masked Autoencoder Self Pre-Training for Defect Detection in Microelectronics
Authors:Nikolai Röhrich, Alwin Hoffmann, Richard Nordsieck, Emilio Zarbali, Alireza Javanmardi
While transformers have surpassed convolutional neural networks (CNNs) in various computer vision tasks, microelectronics defect detection still largely relies on CNNs. We hypothesize that this gap is due to the fact that a) transformers have an increased need for data and b) (labelled) image generation procedures for microelectronics are costly, and data is therefore sparse. Whereas in other domains, pre-training on large natural image datasets can mitigate this problem, in microelectronics transfer learning is hindered due to the dissimilarity of domain data and natural images. We address this challenge through self pre-training, where models are pre-trained directly on the target dataset, rather than another dataset. We propose a resource-efficient vision transformer (ViT) pre-training framework for defect detection in microelectronics based on masked autoencoders (MAE). We perform pre-training and defect detection using a dataset of less than 10,000 scanning acoustic microscopy (SAM) images. Our experimental results show that our approach leads to substantial performance gains compared to a) supervised ViT, b) ViT pre-trained on natural image datasets, and c) state-of-the-art CNN-based defect detection models used in microelectronics. Additionally, interpretability analysis reveals that our self pre-trained models attend to defect-relevant features such as cracks in the solder material, while baseline models often attend to spurious patterns. This shows that our approach yields defect-specific feature representations, resulting in more interpretable and generalizable transformer models for this data-sparse domain.
虽然变压器在各种计算机视觉任务上已经超越了卷积神经网络(CNN),但微电子缺陷检测仍然很大程度上依赖于CNN。我们假设这一差距是由于以下事实造成的:a)变压器对数据的需求增加;b)微电子(标记)图像生成程序成本高昂,因此数据稀疏。与其他领域不同,在大规模自然图像数据集上进行预训练可以缓解这个问题,但在微电子领域,由于领域数据与自然图像的差异性,迁移学习受到了阻碍。我们通过自我预训练来解决这一挑战,其中模型直接在目标数据集上进行预训练,而不是在其他数据集上。我们提出了一种基于掩码自动编码器(MAE)的资源高效型视觉变压器(ViT)预训练框架,用于微电子中的缺陷检测。我们使用少于10,000张扫描声学显微镜(SAM)图像的数据集进行预训练和缺陷检测。我们的实验结果表明,与a)监督型ViT、b)在自然图像数据集上预训练的ViT以及c)当前微电子缺陷检测中使用的最先进的CNN模型相比,我们的方法带来了巨大的性能提升。此外,可解释性分析表明,我们的自训练模型关注缺陷相关特征,如焊料中的裂缝,而基准模型通常关注于虚假模式。这表明我们的方法产生了特定的缺陷特征表示,从而为此数据稀疏领域产生了更可解释和更通用的变压器模型。
论文及项目相关链接
PDF 16 pages, 5 figures
Summary
针对微电子缺陷检测领域数据稀疏的问题,本文提出了一种资源高效的视觉转换器(ViT)预训练框架,基于掩码自编码器(MAE)进行预训练和缺陷检测。实验结果表明,该方法相较于其他方法具有显著的性能提升,且生成的模型更具备可解释性和泛化性。
Key Takeaways
- 虽然转换器在各种计算机视觉任务中已超越卷积神经网络(CNN),但微电子缺陷检测仍主要依赖CNN。
- 转换器对数据的需求更高,且微电子领域的图像标签生成成本高昂,导致数据稀疏。
- 直接在目标数据集上进行预训练是解决此挑战的方法。
- 提出了一种基于掩码自编码器(MAE)的资源高效视觉转换器(ViT)预训练框架,用于微电子缺陷检测。
- 实验结果显示,该方法相较于监督学习的ViT、在自然图像数据集上预训练的ViT以及当前先进的CNN基缺陷检测模型有明显性能提升。
- 解读性分析显示,自训练模型更关注缺陷相关特征,如焊料中的裂缝,而基线模型常关注于无关模式。
点此查看论文截图