⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-15 更新
Data-Efficient Learning for Generalizable Surgical Video Understanding
Authors:Sahar Nasirihaghighi
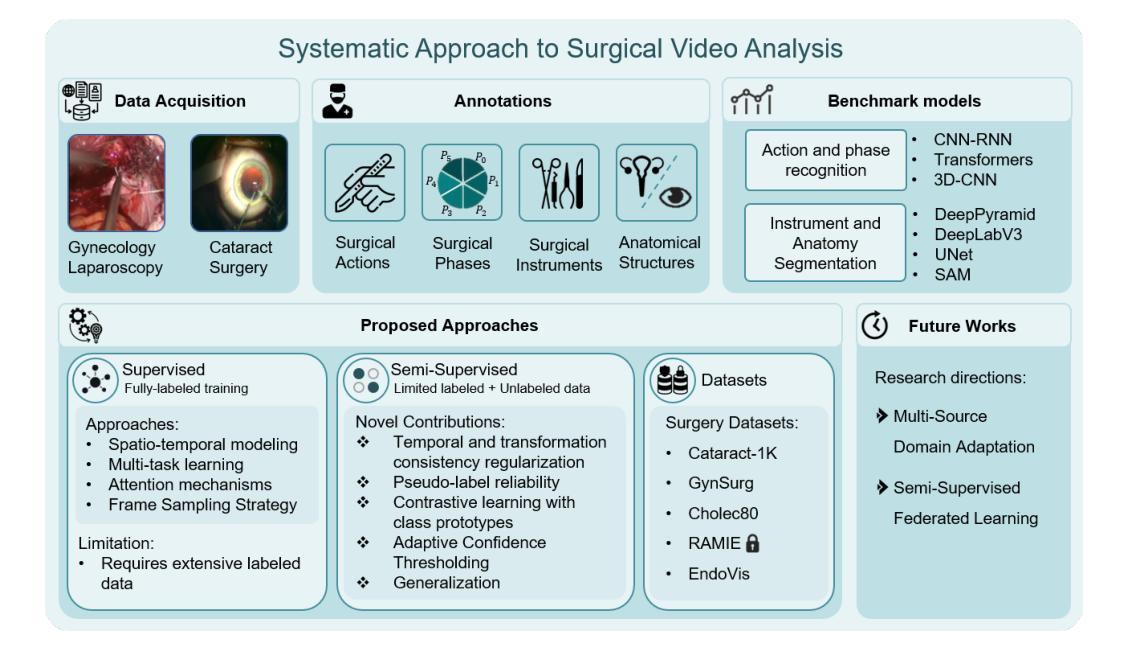
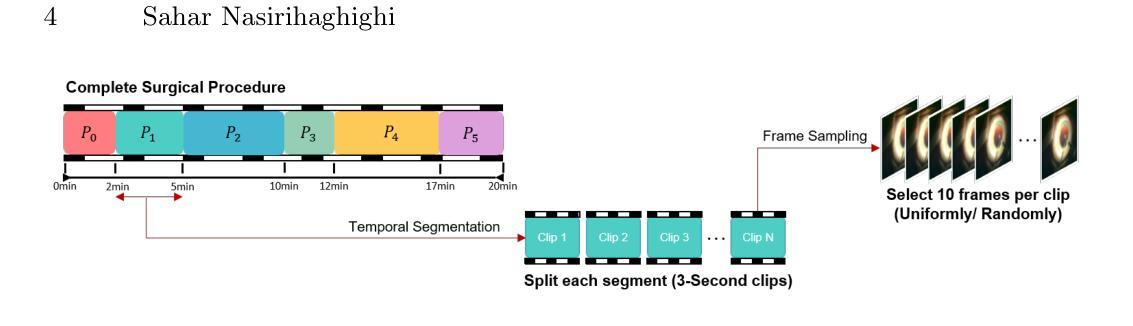
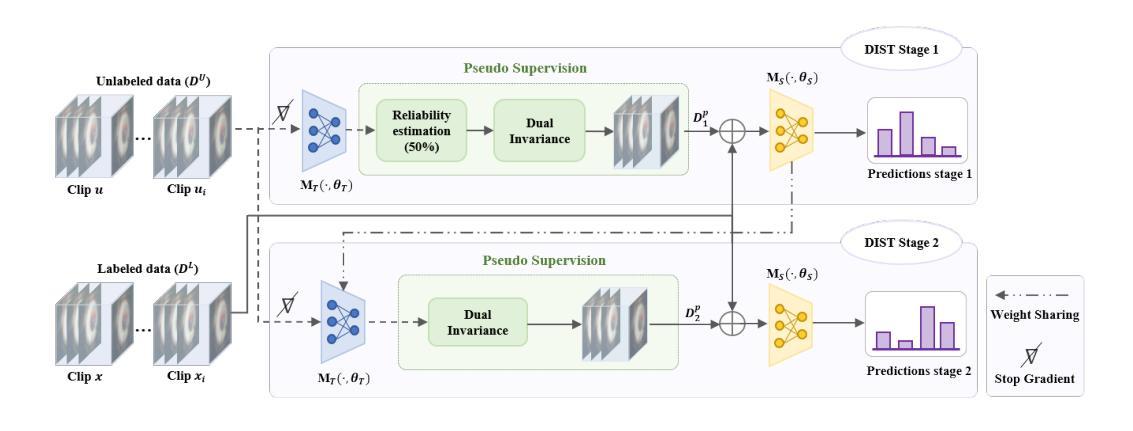
Advances in surgical video analysis are transforming operating rooms into intelligent, data-driven environments. Computer-assisted systems support full surgical workflow, from preoperative planning to intraoperative guidance and postoperative assessment. However, developing robust and generalizable models for surgical video understanding remains challenging due to (I) annotation scarcity, (II) spatiotemporal complexity, and (III) domain gap across procedures and institutions. This doctoral research aims to bridge the gap between deep learning-based surgical video analysis in research and its real-world clinical deployment. To address the core challenge of recognizing surgical phases, actions, and events, critical for analysis, I benchmarked state-of-the-art neural network architectures to identify the most effective designs for each task. I further improved performance by proposing novel architectures and integrating advanced modules. Given the high cost of expert annotations and the domain gap across surgical video sources, I focused on reducing reliance on labeled data. We developed semi-supervised frameworks that improve model performance across tasks by leveraging large amounts of unlabeled surgical video. We introduced novel semi-supervised frameworks, including DIST, SemiVT-Surge, and ENCORE, that achieved state-of-the-art results on challenging surgical datasets by leveraging minimal labeled data and enhancing model training through dynamic pseudo-labeling. To support reproducibility and advance the field, we released two multi-task datasets: GynSurg, the largest gynecologic laparoscopy dataset, and Cataract-1K, the largest cataract surgery video dataset. Together, this work contributes to robust, data-efficient, and clinically scalable solutions for surgical video analysis, laying the foundation for generalizable AI systems that can meaningfully impact surgical care and training.
手术视频分析技术的进步正在将手术室转变为智能、数据驱动的环境。计算机辅助系统支持从术前规划到术中指导和术后评估的完整手术工作流程。然而,由于(I)标注稀缺、(II)时空复杂性,以及(III)不同手术和机构之间的领域差距,开发用于手术视频理解的稳健且可推广的模型仍然具有挑战性。本博士研究旨在弥合深度学习方法在手术视频分析领域的研究与其在实际临床部署之间的差距。为了应对识别手术阶段、动作和事件的核心挑战,这些对于分析至关重要,我对最新神经网络架构进行了基准测试,以确定每项任务的最有效设计。我进一步提出了新型架构和集成高级模块来提高性能。考虑到专家标注的高成本和不同手术视频来源的域差距,我专注于减少对标注数据的依赖。我们开发了半监督框架,通过利用大量未标注的手术视频来提高各项任务的模型性能。我们引入了新型半监督框架,包括DIST、SemiVT-Surge和ENCORE,这些框架在具有挑战性的手术数据集上实现了最佳结果,通过利用少量标注数据并通过对动态伪标签增强模型训练。为了支持复现和推动该领域的发展,我们发布了两个多任务数据集:GynSurg(最大的妇科腹腔镜数据集)和Cataract-1K(最大的白内障手术视频数据集)。总体而言,这项工作为手术视频分析提供了稳健、数据高效且临床可扩展的解决方案,为可推广的人工智能系统奠定了基础,这些系统可以对手术护理和培训产生有意义的影响。
论文及项目相关链接
摘要
手术视频分析技术的进步正在将手术室转变为智能、数据驱动的环境。计算机辅助系统支持从术前规划到术中指导和术后评估的完整手术流程。然而,由于标注稀缺、时空复杂性和不同手术与机构间的领域差距,为手术视频理解开发稳健且通用的模型仍然具有挑战性。本研究旨在弥合深度学习在手术视频分析与临床实际部署之间的差距。解决手术阶段、动作和事件识别的核心挑战是分析的关键。对最先进的神经网络架构进行基准测试以确定每项任务的最有效设计。通过提出新型架构和集成先进模块进一步提高性能。鉴于专家标注的高成本和手术视频来源的域差距,重点降低对标注数据的依赖。开发了半监督框架,利用大量未标注手术视频提高模型跨任务的性能。引入了DIST、SemiVT-Surge和ENCORE等新型半监督框架,在具有挑战性的手术数据集上实现了最佳结果,通过最少的标注数据和动态伪标签增强模型训练。为支持可重复性和推动领域发展,发布两个多任务数据集:GynSurg(最大的妇科腹腔镜数据集)和Cataract-1K(最大的白内障手术视频数据集)。本研究为手术视频分析提供了稳健、数据高效和临床可扩展的解决方案,为能够有意义地影响手术护理和培训的通用AI系统奠定基础。
要点
- 手术视频分析技术的进展正在转变手术室环境,使其成为数据驱动和智能化的。
- 面临的挑战包括标注数据的稀缺性、手术视频的时空复杂性以及不同手术和机构间的领域差异。
- 研究旨在解决深度学习在手术视频分析中的实际应用问题,特别是在识别手术阶段、动作和事件方面。
- 通过基准测试选择最有效的神经网络架构,并开发新型架构和高级模块以提高性能。
- 为降低对标注数据的依赖,研究注重半监督学习方法的应用,成功引入几种新型框架以优化模型训练。
- 发布两个大型多任务数据集以支持研究可重复性和推动领域发展。
- 此研究为手术视频分析提供了实际应用的解决方案,为建立可影响手术护理和培训的通用AI系统奠定基础。
点此查看论文截图

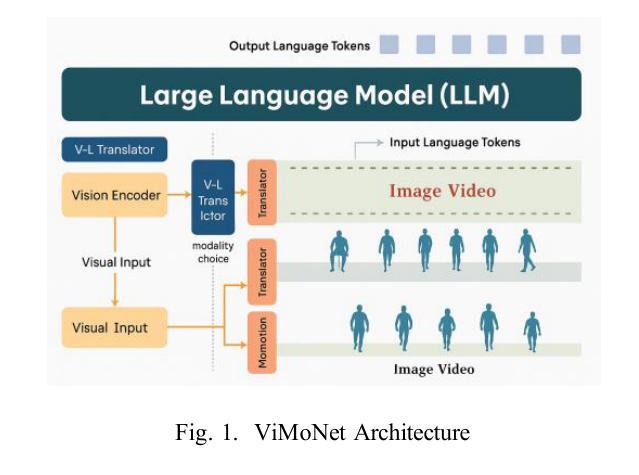
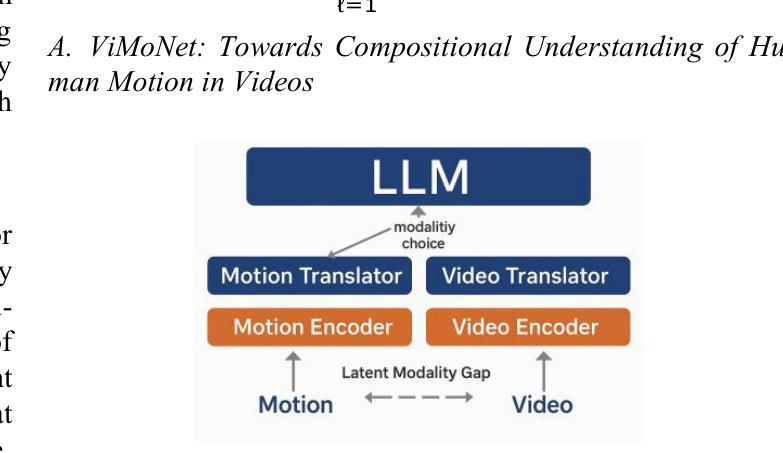
ViMoNet: A Multimodal Vision-Language Framework for Human Behavior Understanding from Motion and Video
Authors:Rajan Das Gupta, Md Yeasin Rahat, Nafiz Fahad, Abir Ahmed, Liew Tze Hui
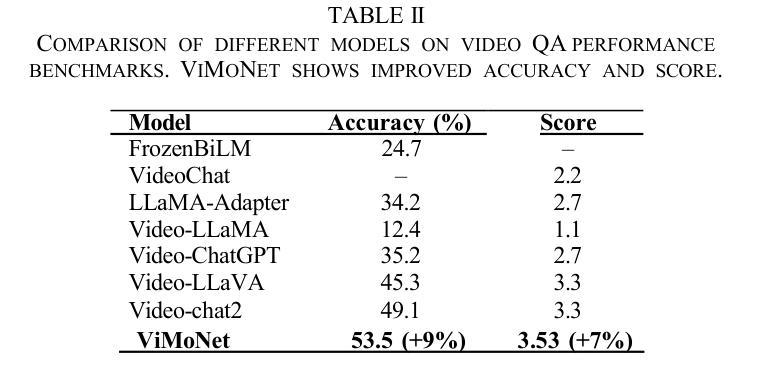
This study investigates how large language models (LLMs) can be used to understand human behavior using motion and video data. We think that mixing both types is essential to completely capture the nuanced movements and meanings of human actions, in contrast to recent models that simply concentrate on motion data or films. To address this, we provide ViMoNet, a straightforward yet effective framework for comprehending, characterizing, and deducing human action. ViMoNet employs a joint training strategy that leverages the advantages of two data types: detailed motion-text data, which is more exact, and generic video-text data, which is more comprehensive but less detailed. This aids in the model’s acquisition of rich data regarding time and space in human behavior. Additionally, we provide a brand new dataset named VIMOS that contains a variety of films, motion sequences, instructions, and subtitles. We developed ViMoNet-Bench, a standardized benchmark with carefully labeled samples, to evaluate how well models understand human behavior. Our tests show that ViMoNet outperforms existing methods in caption generation, motion understanding, and behavior interpretation.
本研究探讨了如何使用大型语言模型(LLM)通过动作和视频数据来理解人类行为。我们认为,混合两种类型的数据对于完全捕捉人类动作的细微动作和含义至关重要,与最近仅专注于运动数据或电影的模型形成对比。为了解决这一问题,我们提供了ViMoNet,这是一个简单有效的框架,用于理解、表征和推断人类行为。ViMoNet采用联合训练策略,利用两种数据类型的优势:详细的运动文本数据,更准确;通用的视频文本数据,更综合但不太详细。这有助于模型获得有关人类行为时间和空间的丰富数据。此外,我们提供了一个全新的数据集VIMOS,其中包含各种电影、运动序列、指令和字幕。我们还开发了ViMoNet-Bench,这是一个带有精心标注样本的标准基准测试,以评估模型对人类行为的了解程度。我们的测试表明,在字幕生成、动作理解和行为解释方面,ViMoNet的表现优于现有方法。
论文及项目相关链接
PDF Accepted in ICCVDM ‘25
Summary
大语言模型可以通过整合运动和视频数据来理解人类行为。本研究提出ViMoNet框架,采用联合训练策略,利用详细运动文本数据和通用视频文本数据的优势,旨在捕捉人类行为的细微动作和含义。同时,研究还推出了包含多种电影、动作序列、指令和字幕的新数据集VIMOS,以及用于评估模型对人类行为理解程度的标准化基准测试ViMoNet-Bench。实验表明,ViMoNet在生成字幕、理解运动和解释行为方面优于现有方法。
Key Takeaways
- 大语言模型通过整合运动和视频数据理解人类行为更加有效。
- ViMoNet框架通过联合训练策略利用两种数据类型:详细的运动文本数据和更全面的通用视频文本数据。
- 新推出的数据集VIMOS包含电影、动作序列、指令和字幕,用于丰富模型的训练数据。
- ViMoNet-Bench提供了一个标准化的基准测试,用于评估模型对人类行为的理解程度。
- 实验显示ViMoNet在生成字幕、理解和解释人类行为方面性能优异。
- 融合两种数据类型有助于捕捉人类行为的细微差别和含义。
点此查看论文截图

Episodic Memory Representation for Long-form Video Understanding
Authors:Yun Wang, Long Zhang, Jingren Liu, Jiaqi Yan, Zhanjie Zhang, Jiahao Zheng, Xun Yang, Dapeng Wu, Xiangyu Chen, Xuelong Li
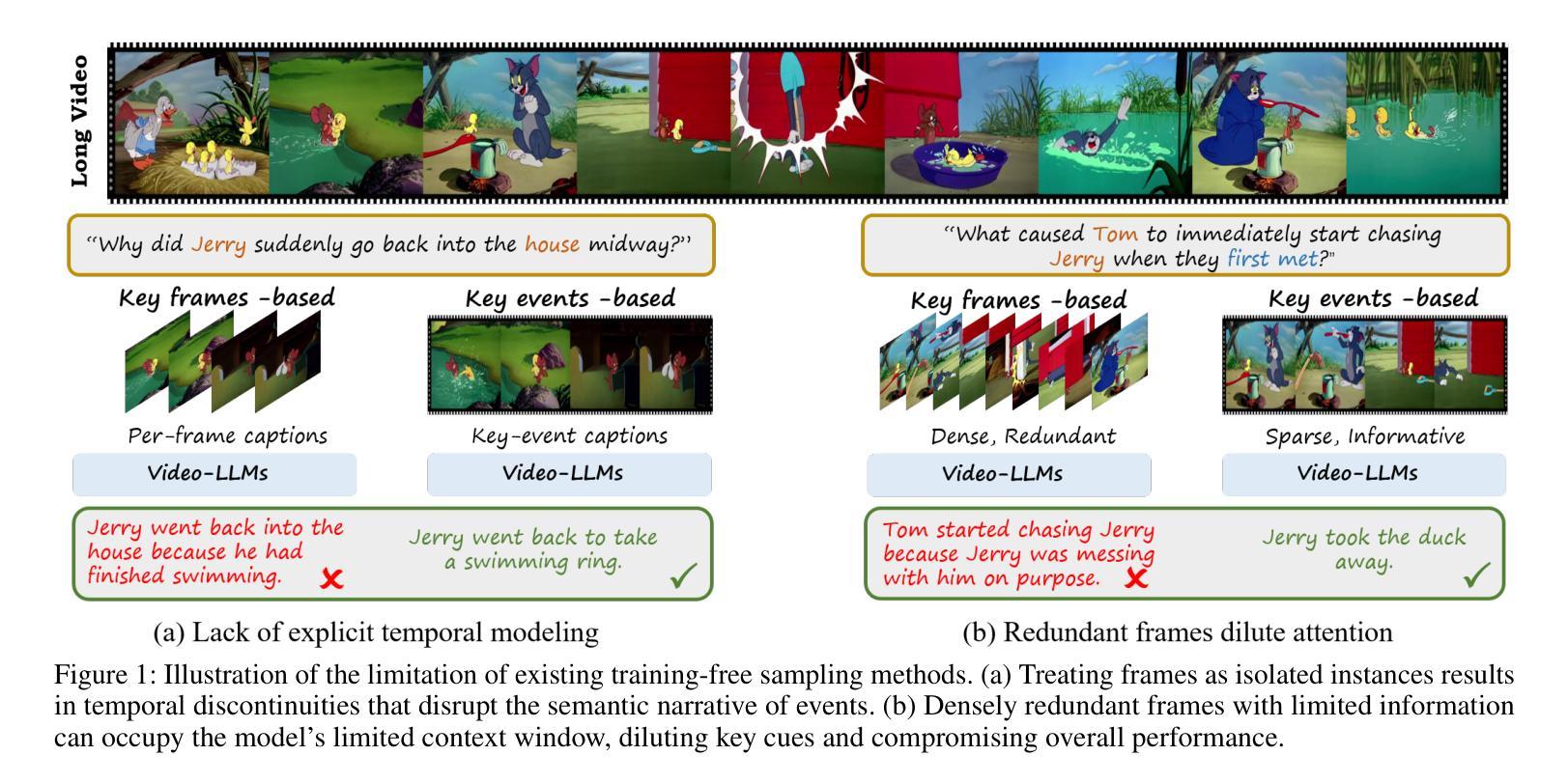
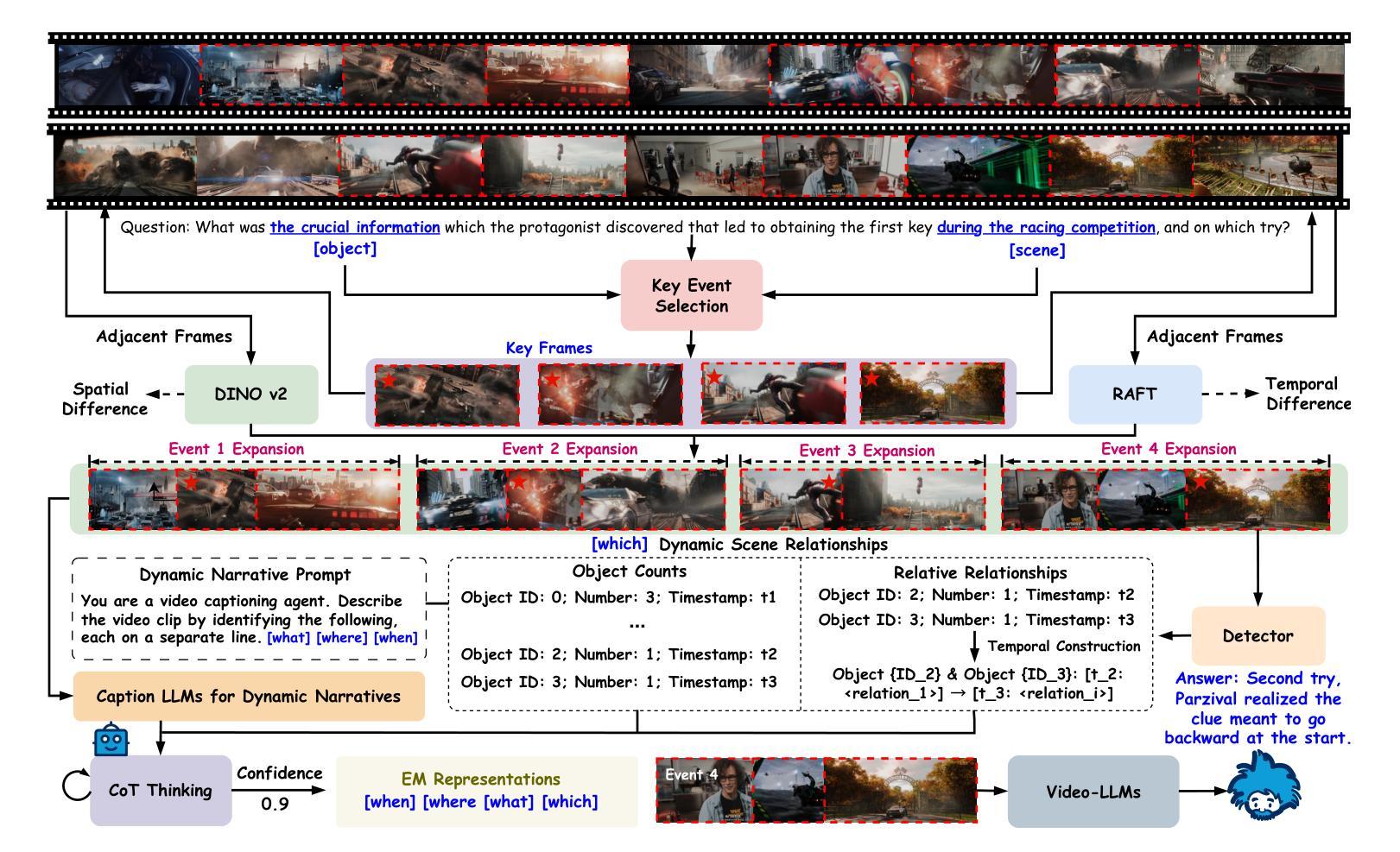
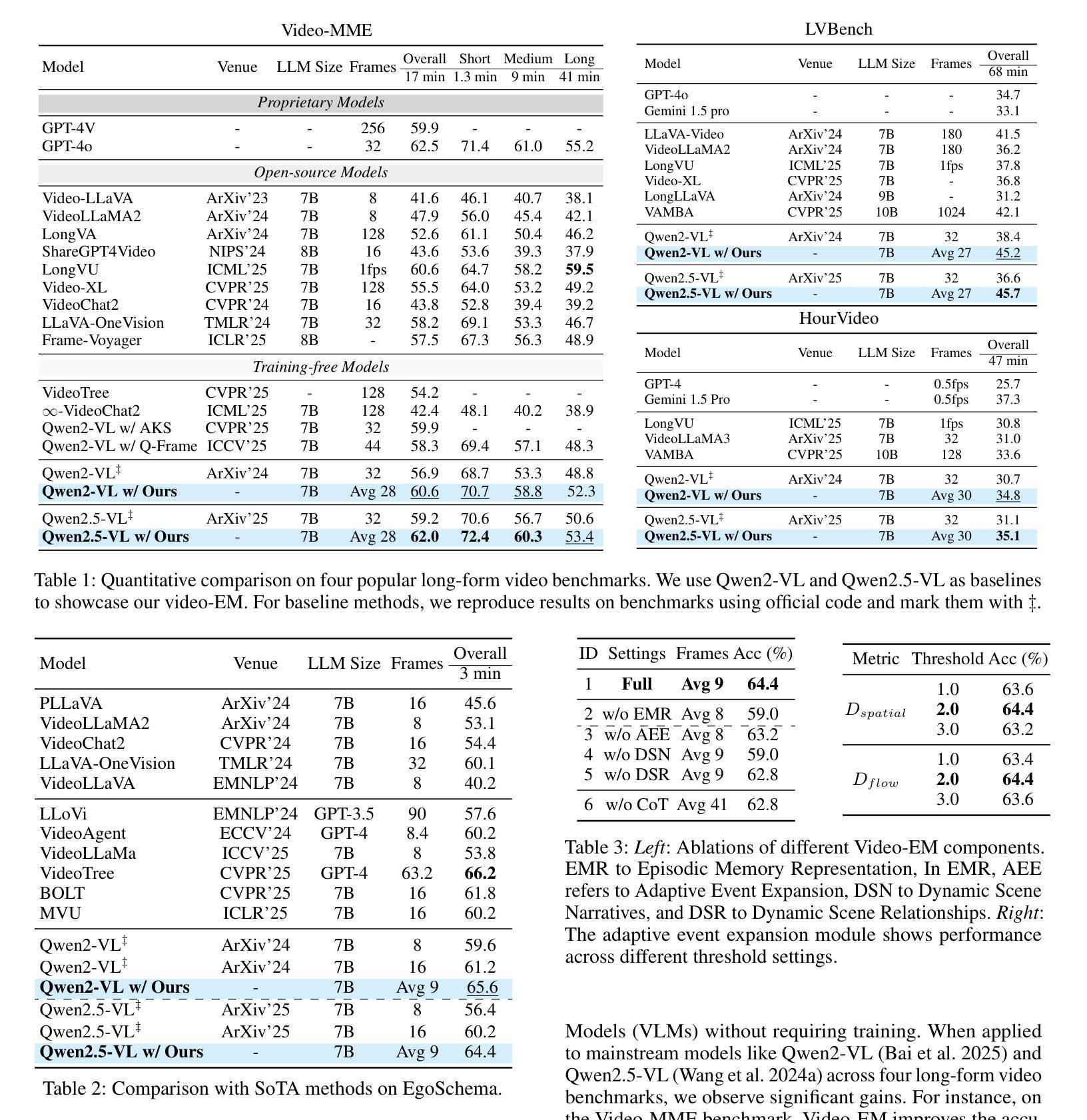
Video Large Language Models (Video-LLMs) excel at general video understanding but struggle with long-form videos due to context window limits. Consequently, recent approaches focus on keyframe retrieval, condensing lengthy videos into a small set of informative frames. Despite their practicality, these methods simplify the problem to static text image matching, overlooking spatio temporal relationships crucial for capturing scene transitions and contextual continuity, and may yield redundant keyframes with limited information, diluting salient cues essential for accurate video question answering. To address these limitations, we introduce Video-EM, a training free framework inspired by the principles of human episodic memory, designed to facilitate robust and contextually grounded reasoning. Rather than treating keyframes as isolated visual entities, Video-EM explicitly models them as temporally ordered episodic events, capturing both spatial relationships and temporal dynamics necessary for accurately reconstructing the underlying narrative. Furthermore, the framework leverages chain of thought (CoT) thinking with LLMs to iteratively identify a minimal yet highly informative subset of episodic memories, enabling efficient and accurate question answering by Video-LLMs. Extensive evaluations on the Video-MME, EgoSchema, HourVideo, and LVBench benchmarks confirm the superiority of Video-EM, which achieves highly competitive results with performance gains of 4-9 percent over respective baselines while utilizing fewer frames.
视频大型语言模型(Video-LLMs)在通用视频理解方面表现出色,但由于上下文窗口的限制,在处理长视频时面临困难。因此,最近的方法集中在关键帧检索上,将冗长的视频浓缩成一小部分信息丰富的帧。尽管这些方法在实际应用中很实用,但它们将问题简化为静态文本图像匹配,忽略了对于捕捉场景过渡和上下文连续性至关重要的时空关系,并且可能会产生信息有限的关键帧,从而稀释了对于准确视频问答至关重要的显著线索。为了解决这些局限性,我们引入了Video-EM,这是一个受人类情景记忆原理启发的无需训练的框架,旨在促进稳健和基于上下文推理。Video-EM不是将关键帧视为孤立的可视实体,而是明确地将其建模为按时间顺序排列的情景事件,捕捉重建底层叙事所必需的空间关系和时间动态。此外,该框架利用大型语言模型的链式思维(CoT),迭代地确定少量但高度信息丰富的情景记忆子集,使视频大型语言模型能够高效且准确地回答问题。在Video-MME、EgoSchema、HourVideo和LVBench基准测试上的广泛评估证实了Video-EM的优越性,其在各个基准测试上的性能均实现了与基线相比高达4-9%的提升,同时使用的帧数更少。
论文及项目相关链接
PDF 10 pages, 5 figures
摘要
视频大型语言模型(Video-LLMs)在一般视频理解方面表现出色,但在处理长视频时因上下文窗口限制而面临挑战。近期的方法主要关注关键帧检索,将长视频简化为少量信息帧。然而,这些方法将问题简化为静态文本图像匹配,忽略了场景转换和上下文连续性的时空关系,可能产生冗余的关键帧,并带有有限信息,淡化对于准确视频问答至关重要的显著线索。为解决这些局限性,我们推出Video-EM,一个基于人类情景记忆原理的免费训练框架,旨在实现稳健和基于上下文推理。Video-EM将关键帧明确地建模为按时间顺序排列的情景事件,捕捉用于准确重建底层叙事的空间关系和时态动态。此外,该框架利用链式思维(CoT)与LLMs相结合,迭代确定少量但高度信息性的情景记忆子集,使Video-LLMs能够实现高效且准确的问答。在Video-MME、EgoSchema、HourVideo和LVBench基准测试上的广泛评估证明Video-EM的优越性,其在实现高度竞争结果的同时,相较于各自基线具有4-9%的性能提升且使用较少的帧数。
关键见解
- Video-LLMs在长视频理解方面面临挑战,特别是在处理上下文信息时的限制。
- 当前的关键帧检索方法简化问题,忽视时空关系,可能导致冗余和不完全的信息收集。
- Video-EM框架借鉴人类情景记忆原理,将关键帧视为情景事件,捕捉空间与时间的动态关系。
- Video-EM利用链式思维(CoT)与LLMs结合,更有效地识别信息性高的关键帧子集。
- Video-EM框架在多个基准测试上表现优越,实现了对基线方法的高度竞争结果及显著性能提升。
- Video-EM使用的方法更加高效,使用较少的帧数即可完成准确问答。
点此查看论文截图