⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-15 更新
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Authors:Eunseo Koh, Seunghoo Hong, Tae-Young Kim, Simon S. Woo, Jae-Pil Heo
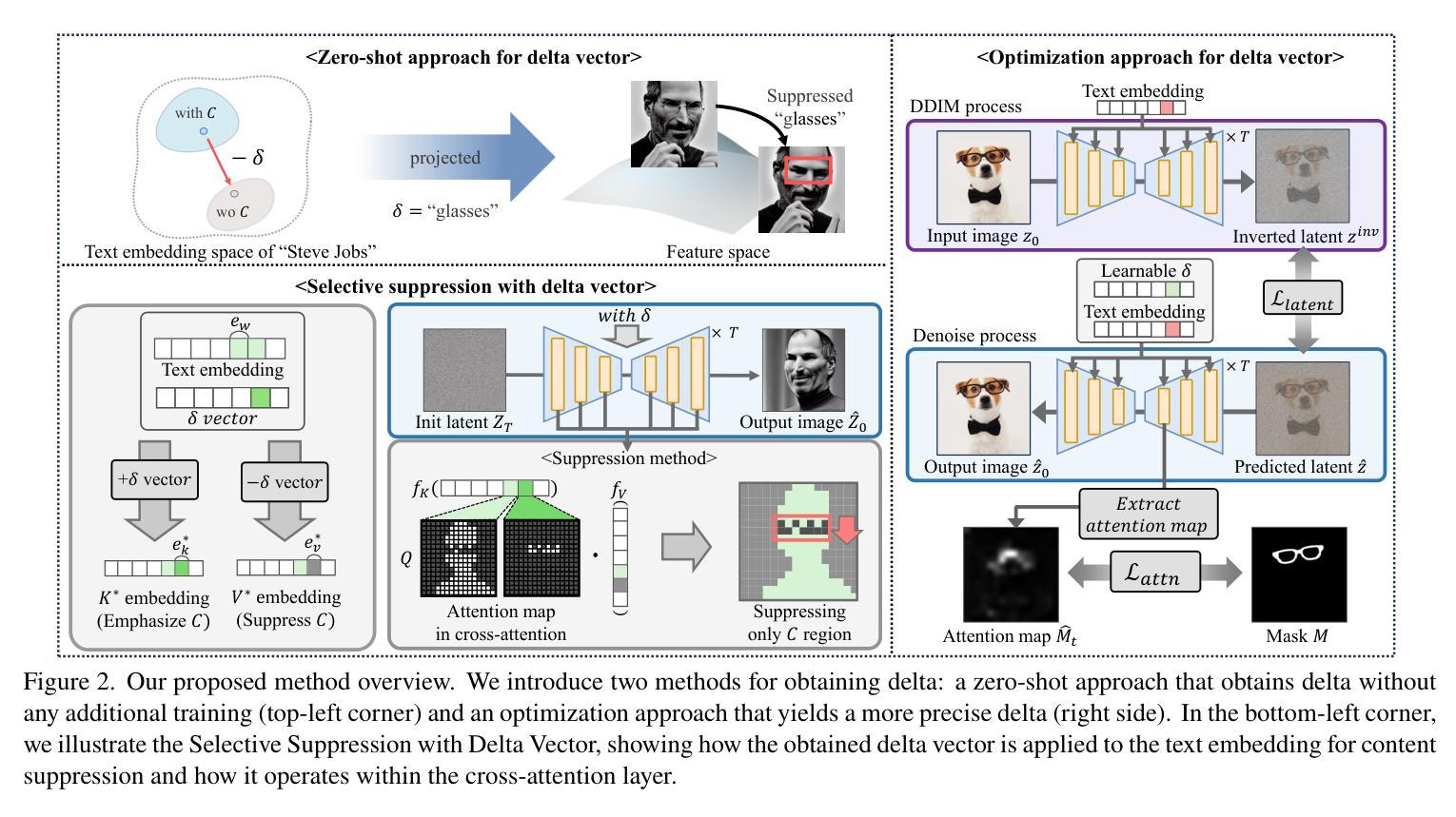
Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of Charlie Chaplin", a mustache” consistently appears even if explicitly instructed not to include it, as the concept of mustache" is strongly entangled with Charlie Chaplin”. To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
文本到图像(T2I)的扩散模型在根据文本提示生成多样化高质量图像方面取得了显著进展。然而,这些模型在抑制与特定词语强烈纠缠的内容方面仍面临挑战。例如,在生成“查理·卓别林”的图像时,即使明确指示不要包含“胡子”,但“胡子”仍然会一致出现,因为“胡子”的概念与“查理·卓别林”强烈相关。为了解决这个问题,我们提出了一种直接在扩散模型的文本嵌入空间中抑制这种纠缠内容的新方法。我们的方法引入了一个delta向量,该向量修改文本嵌入,以减弱生成图像中不需要内容的影响,我们进一步证明可以通过零样本方法轻松获得这个delta向量。此外,我们提出了一种带有Delta向量的选择性抑制(SSDV)方法,将delta向量适应到交叉注意机制中,从而更有效地抑制了原本会生成的区域中的不需要的内容。通过优化delta向量,我们能够在个性化T2I模型中实现更精确的抑制,这是以前基线无法达到的。大量的实验结果证明,我们的方法在定量和定性指标上都显著优于现有方法。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型在根据文本提示生成多样化高质量图像方面取得了显著进展。然而,这些模型在抑制与特定单词强烈纠缠的内容方面仍面临挑战。为解决这个问题,我们提出了一种在扩散模型的文本嵌入空间中直接抑制这种纠缠内容的新方法。我们通过引入一个修正文本嵌入的增量向量来减弱生成图像中不需要内容的影响,并展示了通过零样本方法可轻松获得这种增量向量。此外,我们提出了一种带有增量向量的选择性抑制(SSDV)方法,将其适应到交叉注意机制中,使对不需要内容的抑制更加有效,特别是在之前基线无法实现更精确抑制个性化T2I模型中。实验结果表明,我们的方法显著优于现有方法,在定量和定性指标上均表现优异。
Key Takeaways
- T2I扩散模型能够在生成高质量图像方面取得显著进展,但仍面临抑制与特定单词纠缠内容的挑战。
- 引入了一种新方法,通过修正文本嵌入的增量向量来抑制不需要的内容。
- 展示了通过零样本方法轻松获得增量向量的可能性。
- 提出了一种名为SSDV的方法,将增量向量适应到交叉注意机制中,更有效地抑制不需要的内容。
- 在个性化T2I模型中实现了更精确的抑制,这是之前基线无法达到的。
- 实验结果表明,新方法在定量和定性指标上均显著优于现有方法。
- 该方法为提高T2I模型的性能提供了新的思路。
点此查看论文截图