⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-15 更新
A Comprehensive Evaluation framework of Alignment Techniques for LLMs
Authors:Muneeza Azmat, Momin Abbas, Maysa Malfiza Garcia de Macedo, Marcelo Carpinette Grave, Luan Soares de Souza, Tiago Machado, Rogerio A de Paula, Raya Horesh, Yixin Chen, Heloisa Caroline de Souza Pereira Candello, Rebecka Nordenlow, Aminat Adebiyi
As Large Language Models (LLMs) become increasingly integrated into real-world applications, ensuring their outputs align with human values and safety standards has become critical. The field has developed diverse alignment approaches including traditional fine-tuning methods (RLHF, instruction tuning), post-hoc correction systems, and inference-time interventions, each with distinct advantages and limitations. However, the lack of unified evaluation frameworks makes it difficult to systematically compare these paradigms and guide deployment decisions. This paper introduces a multi-dimensional evaluation of alignment techniques for LLMs, a comprehensive evaluation framework that provides a systematic comparison across all major alignment paradigms. Our framework assesses methods along four key dimensions: alignment detection, alignment quality, computational efficiency, and robustness. Through experiments across diverse base models and alignment strategies, we demonstrate the utility of our framework in identifying strengths and limitations of current state-of-the-art models, providing valuable insights for future research directions.
随着大型语言模型(LLM)在现实世界应用中的集成度越来越高,确保其输出符合人类价值观和安全标准变得至关重要。该领域已经开发了多种对齐方法,包括传统的微调方法(RLHF、指令微调)、事后校正系统和推理时间干预,每种方法都有其独特的优势和局限性。然而,缺乏统一的评估框架使得难以系统地比较这些范式并做出部署决策。本文介绍了大型语言模型对齐技术的多维度评估,这是一个全面的评估框架,提供了所有主要对齐范式的系统比较。我们的框架沿着四个关键维度评估方法:对齐检测、对齐质量、计算效率和稳健性。通过对不同的基础模型和对齐策略进行实验,我们证明了该框架在识别当前最先进模型的优点和局限性方面的实用性,为未来研究方向提供了有价值的见解。
论文及项目相关链接
PDF In submission
Summary
大型语言模型(LLMs)在现实应用中的集成日益增多,确保其输出符合人类价值观和安全标准至关重要。本文引入了一个全面的评估框架,对LLM的对齐技术进行了多维评价,该框架提供了各主通过对齐方法沿着四个关键维度进行评估:对齐检测、对齐质量、计算效率和稳健性。通过跨不同基础模型和对齐策略的试验,该框架展示了当前最先进模型的优缺点,为未来研究方向提供了宝贵见解。
Key Takeaways
- 大型语言模型(LLMs)在现实应用中的集成引发了对确保其输出符合人类价值观和安全标准的关注。
- 存在多种LLM对齐方法,包括传统微调方法(如强化学习、指令调整)、事后校正系统和推理时间干预等,各有优势和局限。
- 缺乏统一的评估框架,难以系统地比较各种对齐范式并指导部署决策。
- 引入了一个全面的评估框架,从多个维度(如对齐检测、对齐质量、计算效率和稳健性)评估LLM的对齐技术。
- 实验表明,该框架有助于识别当前最先进模型的优缺点。
- 该框架为未来研究提供了方向,特别是在改进现有方法和开发新的对齐策略方面。
点此查看论文截图


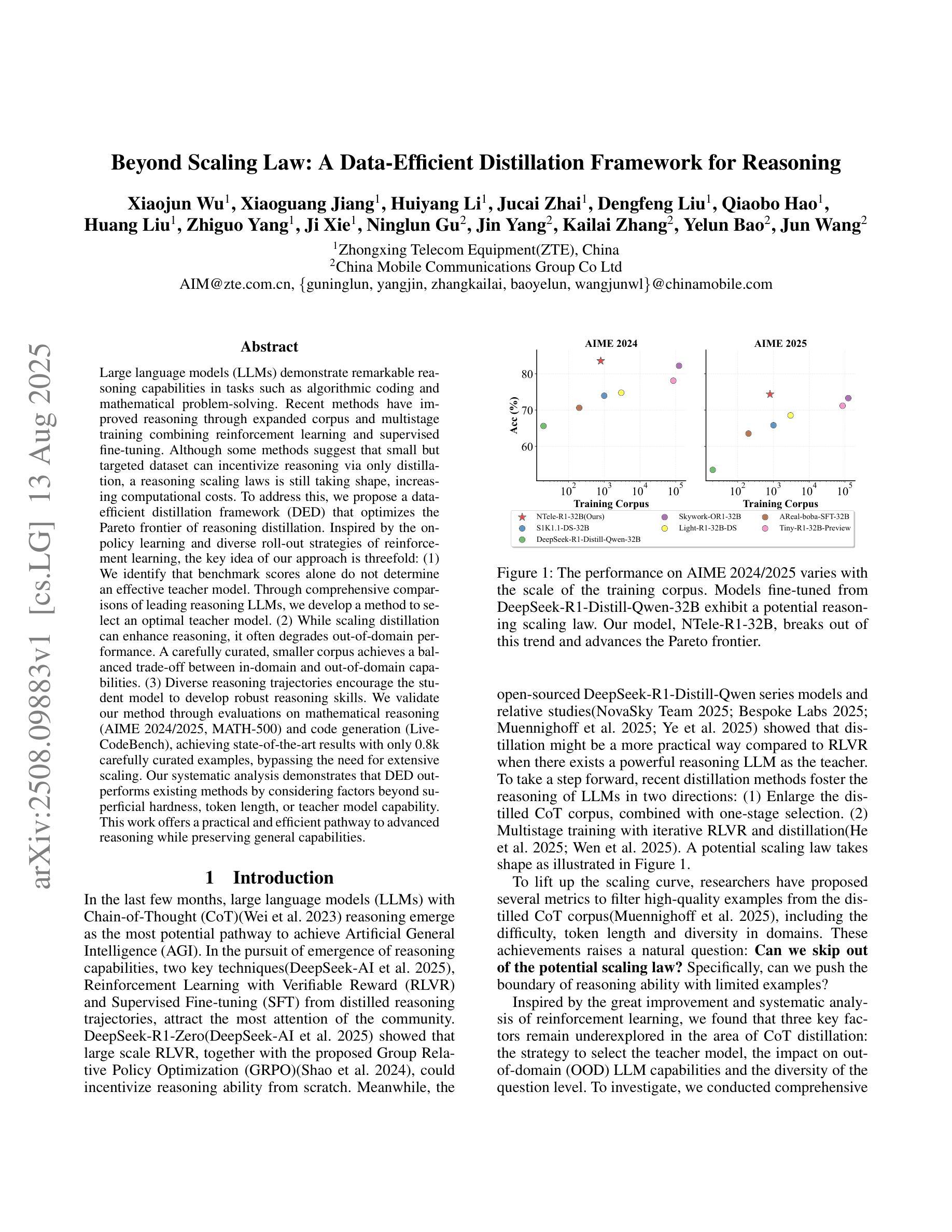
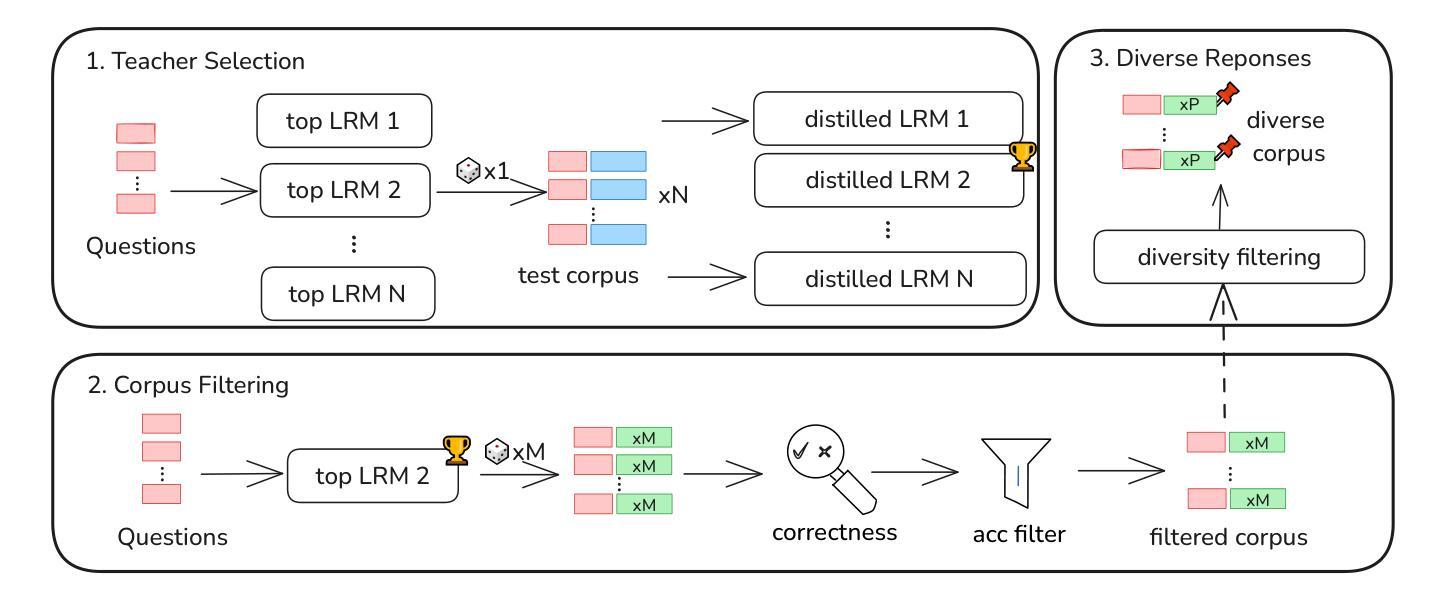
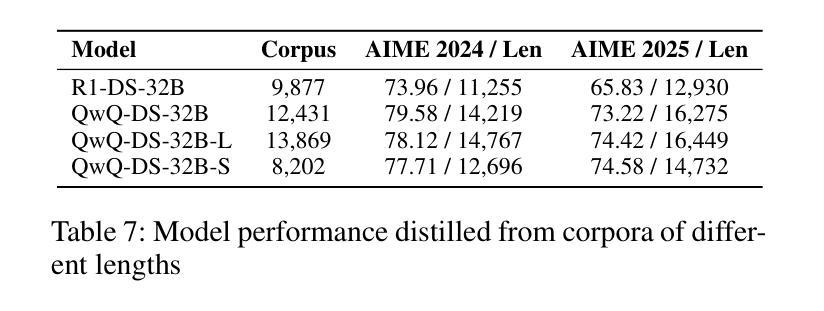
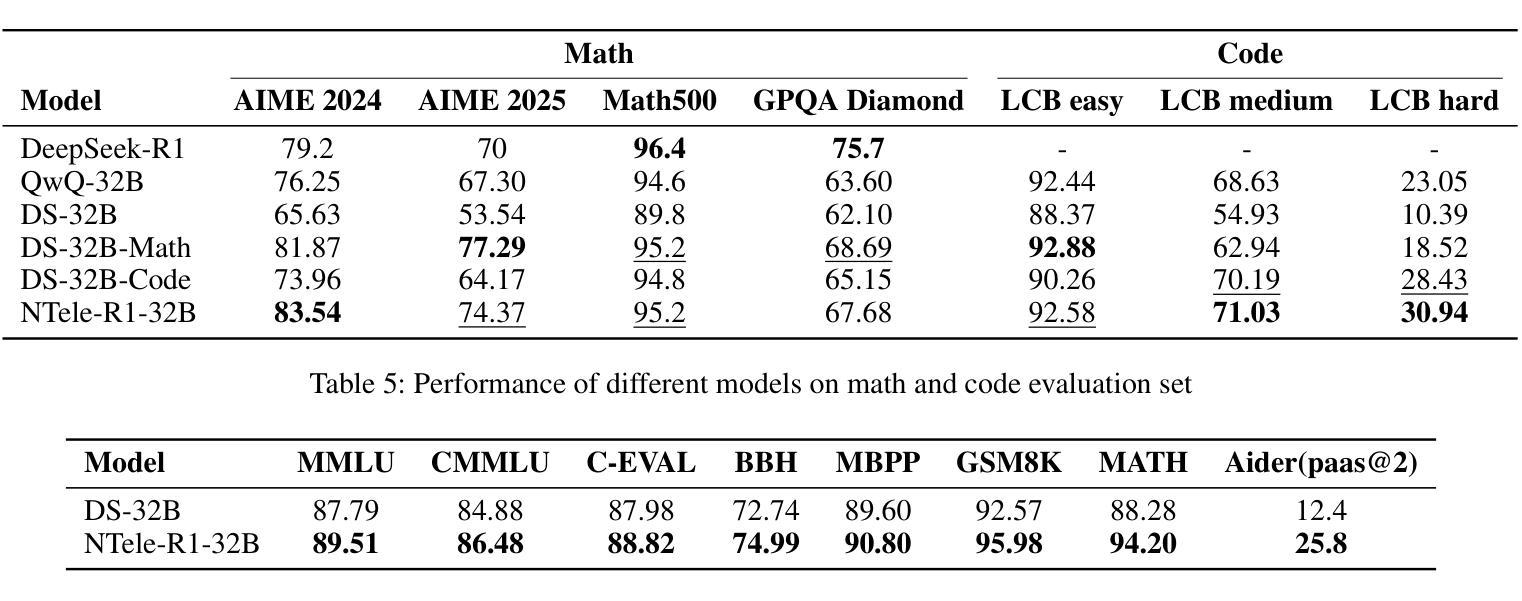
Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning
Authors:Xiaojun Wu, Xiaoguang Jiang, Huiyang Li, Jucai Zhai, Dengfeng Liu, Qiaobo Hao, Huang Liu, Zhiguo Yang, Ji Xie, Ninglun Gu, Jin Yang, Kailai Zhang, Yelun Bao, Jun Wang
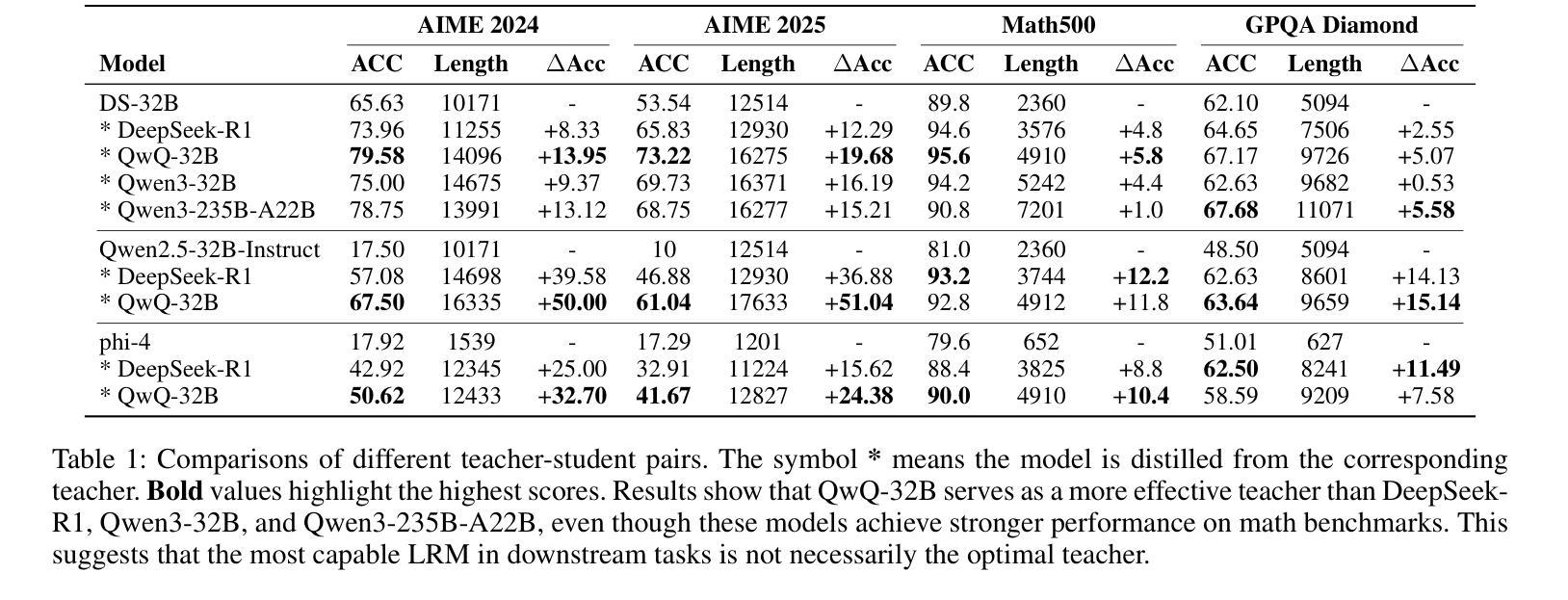
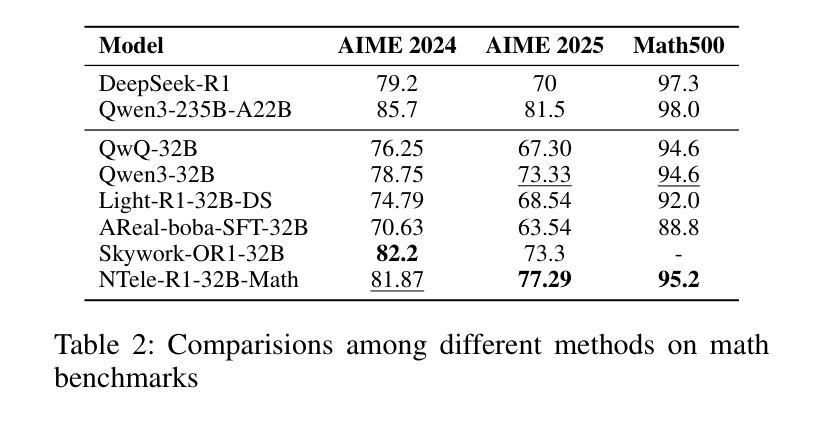
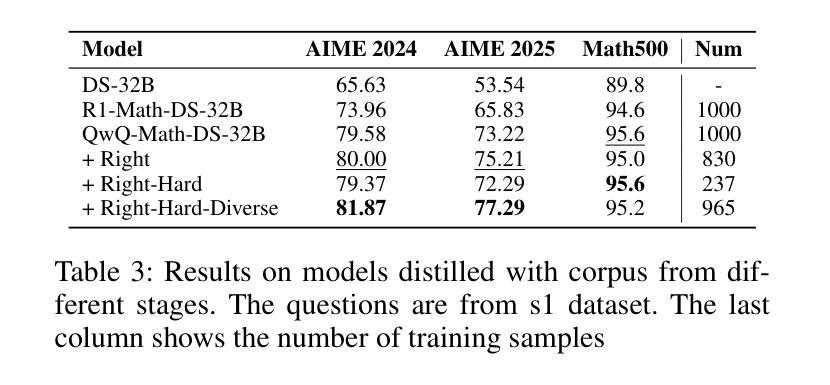
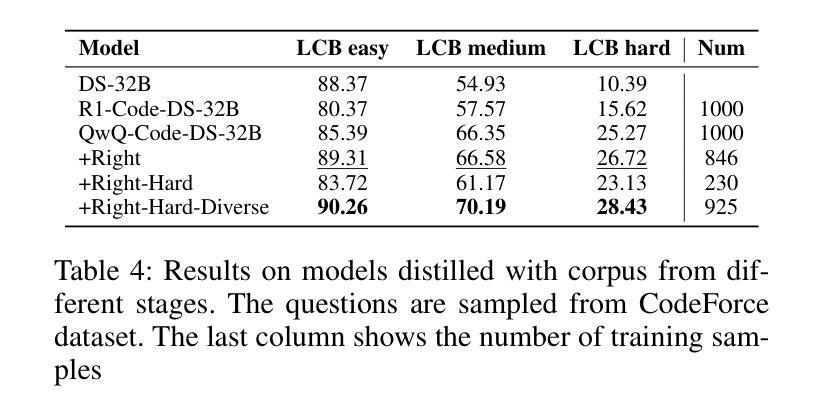
Large language models (LLMs) demonstrate remarkable reasoning capabilities in tasks such as algorithmic coding and mathematical problem-solving. Recent methods have improved reasoning through expanded corpus and multistage training combining reinforcement learning and supervised fine-tuning. Although some methods suggest that small but targeted dataset can incentivize reasoning via only distillation, a reasoning scaling laws is still taking shape, increasing computational costs. To address this, we propose a data-efficient distillation framework (DED) that optimizes the Pareto frontier of reasoning distillation. Inspired by the on-policy learning and diverse roll-out strategies of reinforcement learning, the key idea of our approach is threefold: (1) We identify that benchmark scores alone do not determine an effective teacher model. Through comprehensive comparisons of leading reasoning LLMs, we develop a method to select an optimal teacher model. (2) While scaling distillation can enhance reasoning, it often degrades out-of-domain performance. A carefully curated, smaller corpus achieves a balanced trade-off between in-domain and out-of-domain capabilities. (3) Diverse reasoning trajectories encourage the student model to develop robust reasoning skills. We validate our method through evaluations on mathematical reasoning (AIME 2024/2025, MATH-500) and code generation (LiveCodeBench), achieving state-of-the-art results with only 0.8k carefully curated examples, bypassing the need for extensive scaling. Our systematic analysis demonstrates that DED outperforms existing methods by considering factors beyond superficial hardness, token length, or teacher model capability. This work offers a practical and efficient pathway to advanced reasoning while preserving general capabilities.
大型语言模型(LLM)在算法编码和数学问题解决等任务中展现出卓越的推理能力。最近的方法通过扩大语料库和结合强化学习与监督微调的多阶段训练,提高了推理能力。虽然一些方法认为,只需通过蒸馏就可以激励推理能力,但推理规模法则仍在形成中,计算成本不断增加。为了解决这个问题,我们提出了一种数据高效蒸馏框架(DED),以优化推理蒸馏的帕累托前沿。我们的方法受到强化学习中的在线策略学习和多样化滚动策略启发,其关键思想有三点:(1)我们发现仅凭基准测试分数并不能确定有效的教师模型。通过对领先的推理LLM进行全面比较,我们开发了一种选择最佳教师模型的方法。(2)虽然规模蒸馏可以提高推理能力,但它往往会降低域外性能。一个精心挑选的小型语料库能够在域内和域外能力之间实现平衡。(3)多样化的推理轨迹鼓励学生模型发展稳健的推理技能。我们通过在数学推理(AIME 2024/2025,MATH-500)和代码生成(LiveCodeBench)上的评估验证了我们的方法,仅使用0.8k个精心挑选的示例即可实现最新结果,无需大规模扩展。我们的系统分析表明,DED在超越表面难度、令牌长度或教师模型能力等因素的情况下,优于现有方法。这项工作提供了一种实用且高效的途径来实现高级推理,同时保留了一般能力。
论文及项目相关链接
摘要
大型语言模型(LLM)在算法编码和数学问题解决等任务中展现出令人瞩目的推理能力。最近的方法通过扩大语料库和多阶段训练结合强化学习与监督微调来改进推理能力。尽管有些方法认为小而精准的数据集可以通过蒸馏激励推理,但推理规模法则仍在形成中,增加了计算成本。为解决这一问题,我们提出了一种数据高效蒸馏框架(DED),优化了推理蒸馏的帕累托前沿。我们的方法受到强化学习中的策略启发,关键思想有三点:一是我们确定了基准测试分数并不能单独决定一个有效的教师模型。通过对领先的推理LLM的全面比较,我们开发了一种选择最佳教师模型的方法。二是虽然规模化蒸馏可以增强推理能力,但它往往会降低非域内性能。精心挑选的小语料库可以在域内和域外能力之间实现平衡。三是多样化的推理轨迹鼓励学生模型发展稳健的推理技能。我们通过在数学推理(AIME 2024/2025、MATH-500)和代码生成(LiveCodeBench)上的评估验证了我们的方法,仅使用精心挑选的0.8k示例即可达到最新技术水平,无需大规模扩展。我们的系统分析表明,DED在超越表面难度、令牌长度或教师模型能力等因素的情况下,优于现有方法。这项工作提供了一个实用且高效的途径来实现高级推理能力的同时保持一般能力。
关键见解
- 大型语言模型展现出强大的推理能力,在算法和数学任务上表现突出。
- 现有方法试图通过扩大语料库和多阶段训练结合强化学习和监督微调来改善推理。
- 提出一种数据高效蒸馏框架(DED),旨在优化推理蒸馏的效率和效果。
- DED的关键思想包括选择最佳教师模型、平衡域内和域外能力,以及鼓励多样化的推理轨迹。
- 在数学推理和代码生成任务上的评估表明,DED在精心挑选的小数据集上实现了最新技术水平。
- 与现有方法相比,DED考虑了超越表面难度、令牌长度和教师模型能力的因素。
点此查看论文截图
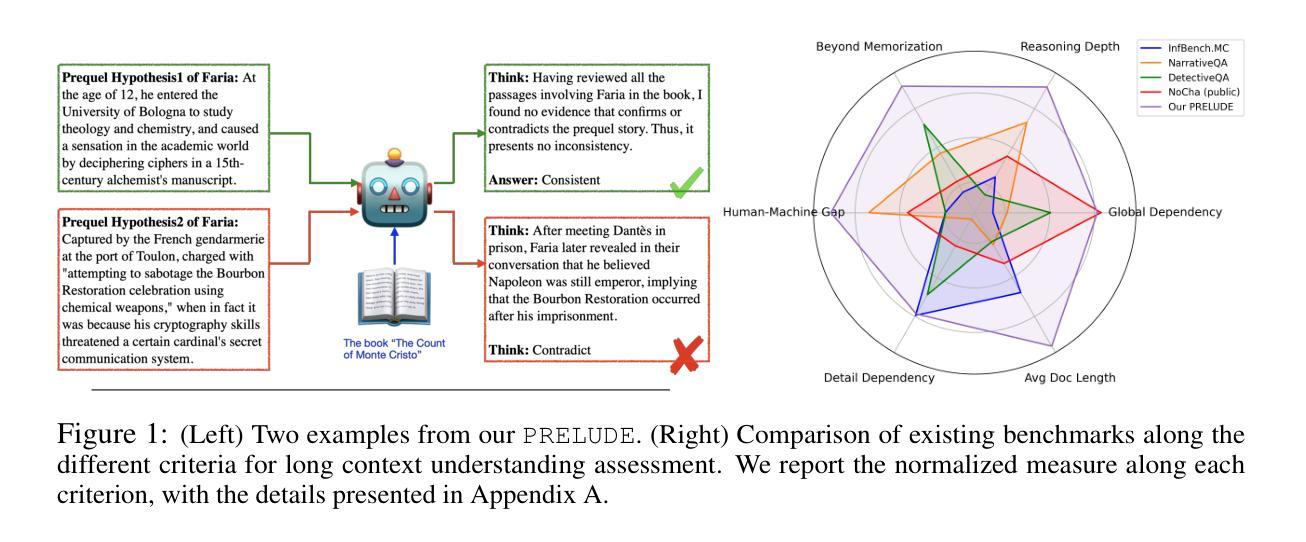
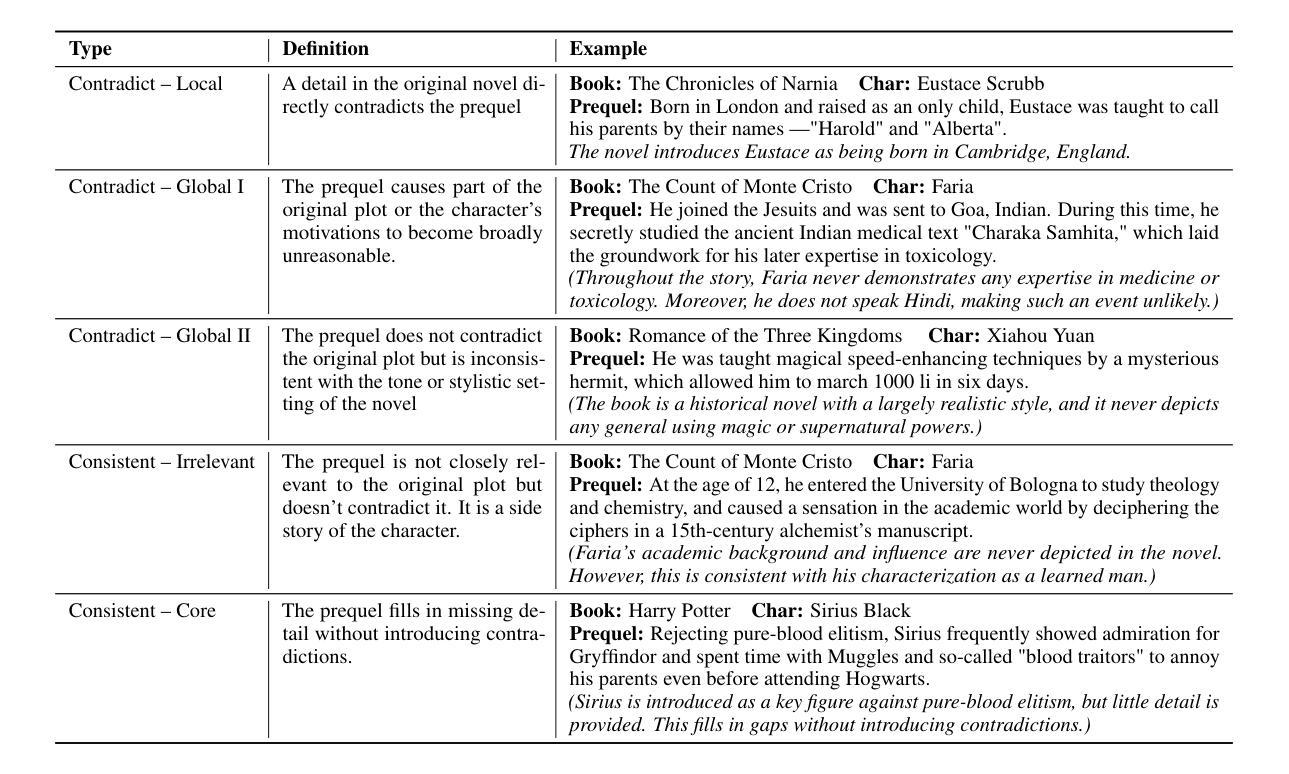
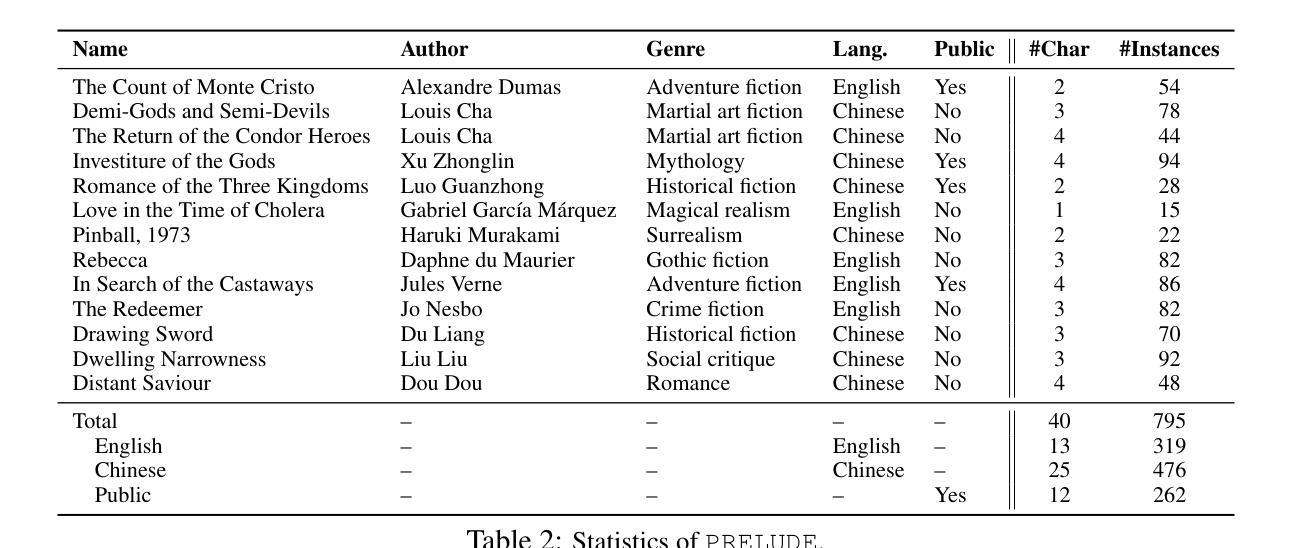
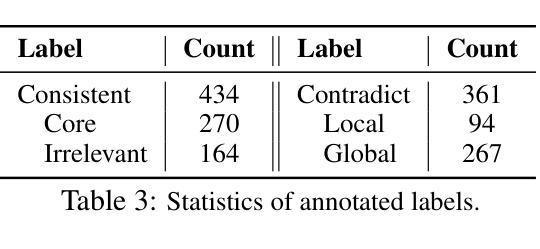
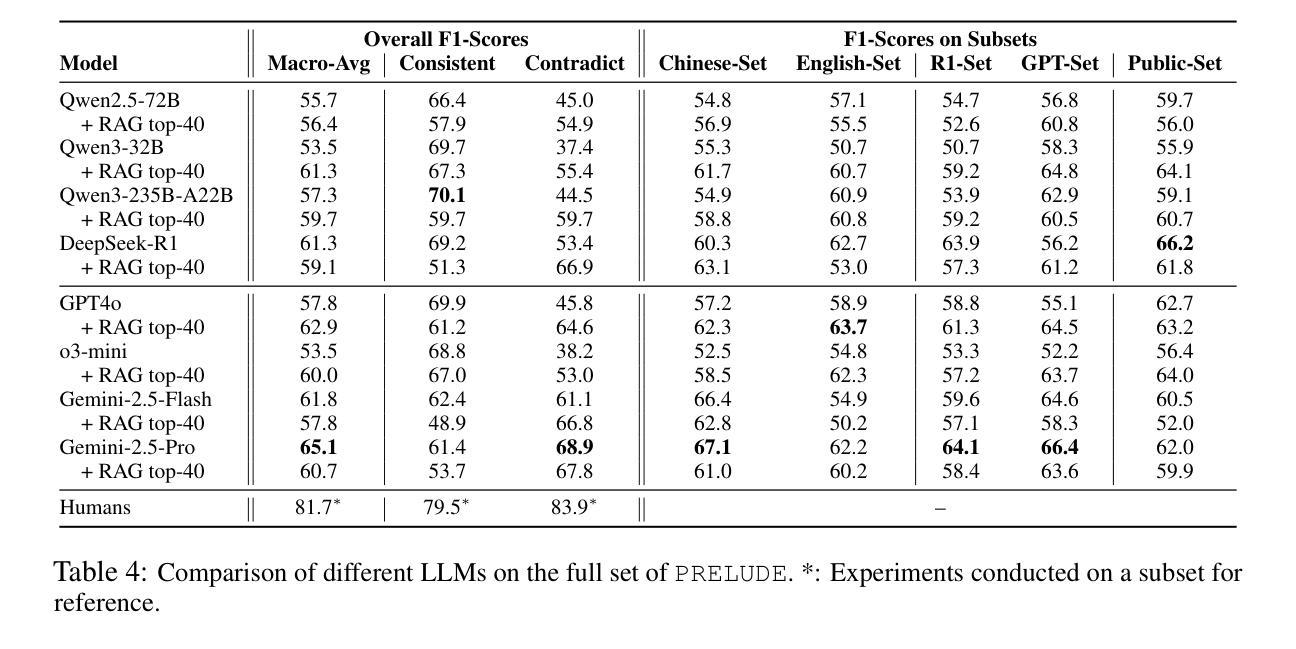
PRELUDE: A Benchmark Designed to Require Global Comprehension and Reasoning over Long Contexts
Authors:Mo Yu, Tsz Ting Chung, Chulun Zhou, Tong Li, Rui Lu, Jiangnan Li, Liyan Xu, Haoshu Lu, Ning Zhang, Jing Li, Jie Zhou
We introduce PRELUDE, a benchmark for evaluating long-context understanding through the task of determining whether a character’s prequel story is consistent with the canonical narrative of the original book. Our task poses a stronger demand for global comprehension and deep reasoning than existing benchmarks – as the prequels are not part of the original story, assessing their plausibility typically requires searching and integrating information that is only indirectly related. Empirically, 88% of instances require evidence from multiple parts of the narrative. Experimental results highlight the challenge of our task: in-context learning, RAG and in-domain training with state-of-the-art LLMs, and commercial DeepResearch services, lag behind humans by >15%. A further human study reveals that models often produce correct answers with flawed reasoning, leading to an over 30% gap in reasoning accuracy compared to humans. These findings underscore the substantial room for improvement in long-context understanding and reasoning.
我们介绍了PRELUDE基准测试,它是通过判断角色前传故事是否符合原著的规范叙事来评估对长文本上下文理解能力的基准测试。我们的任务对全局理解和深度推理的要求高于现有基准测试——由于前传不是原故事的一部分,因此评估其合理性通常需要搜索和整合间接相关的信息。实证结果显示,88%的实例需要来自叙事多个部分的证据。实验结果突出了我们任务的挑战性:在上下文学习、RAG和基于最新大型语言模型(LLMs)的领域内训练以及商业深度研究服务方面,与人类相比都有超过15%的差距。进一步的人类研究结果显示,模型常常在推理上有缺陷,即使答案正确,与人类相比推理准确性仍有超过30%的差距。这些发现突显了在长文本理解和推理方面仍有很大的提升空间。
论文及项目相关链接
PDF First 7 authors contributed equally. Project page: https://gorov.github.io/prelude
Summary:
我们提出了PRELUDE基准测试,用于评估通过判断角色前传故事是否与原著的规范叙事一致来评价对长文本内容的理解能力。我们的任务对全局理解和深度推理的要求高于现有基准测试,因为前传故事并非原著内容的一部分,评估其合理性通常需要搜索和整合间接相关的信息。实证结果显示,有百分之八十八的例子需要引用多个叙事部分的证据。实验结果显示我们的任务具有挑战性:即使在利用最先进的上下文学习、生成增强网络技术和深度领域训练的大型语言模型(LLMs)以及商业深度研究服务的情况下,与人类相比仍落后超过百分之十五。进一步的人类研究表明,模型虽然能产出正确答案,但推理过程往往存在缺陷,导致推理准确度与人类相差超过百分之三十。这些发现凸显出在长文本理解和推理方面仍有很大的提升空间。
Key Takeaways:
- PRELUDE是一个评估长文本理解能力的基准测试,通过判断角色前传故事是否与原著一致来评价理解程度。
- 该任务要求更高的全局理解和深度推理能力,因为前传故事的合理性需要整合间接相关的信息。
- 实证结果显示,大多数例子需要引用多个叙事部分的证据来判断前传故事的合理性。
- 最先进的LLMs和深度研究服务在进行此任务时仍面临挑战,与人类表现相差超过百分之十五。
- 进一步研究揭示模型虽然能产出正确答案,但推理过程存在缺陷,导致推理准确度较低。
- 模型与人类在推理准确度上存在的差距超过百分之三十,凸显出长文本理解和推理方面仍有很大的提升空间。
点此查看论文截图

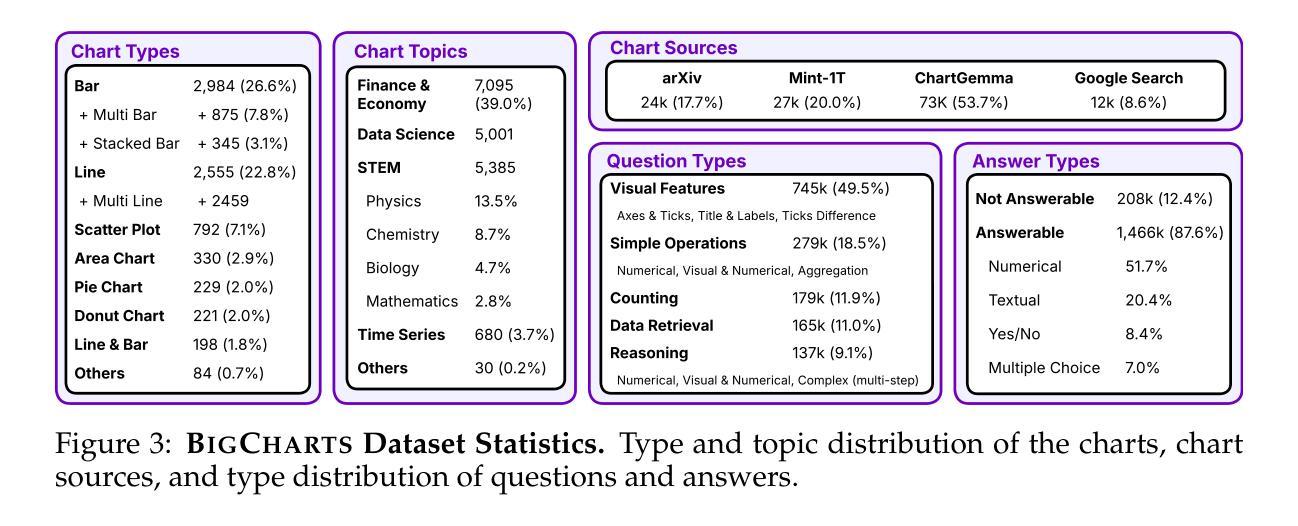
BigCharts-R1: Enhanced Chart Reasoning with Visual Reinforcement Finetuning
Authors:Ahmed Masry, Abhay Puri, Masoud Hashemi, Juan A. Rodriguez, Megh Thakkar, Khyati Mahajan, Vikas Yadav, Sathwik Tejaswi Madhusudhan, Alexandre Piché, Dzmitry Bahdanau, Christopher Pal, David Vazquez, Enamul Hoque, Perouz Taslakian, Sai Rajeswar, Spandana Gella
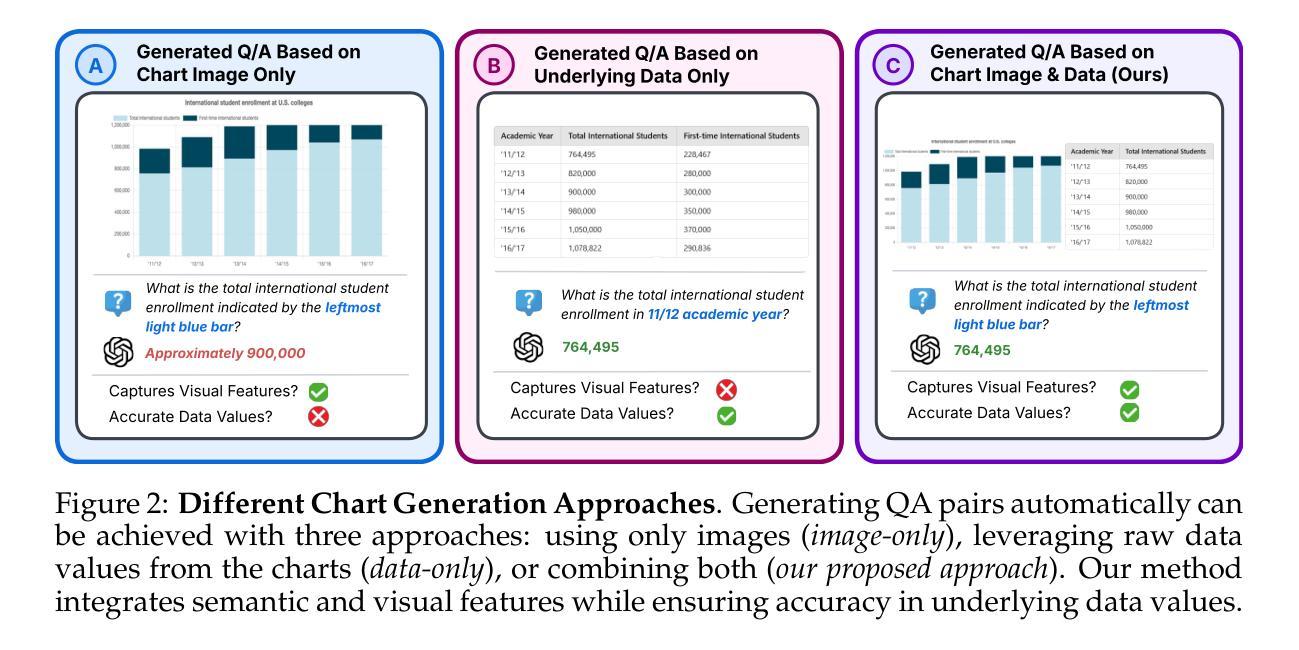
Charts are essential to data analysis, transforming raw data into clear visual representations that support human decision-making. Although current vision-language models (VLMs) have made significant progress, they continue to struggle with chart comprehension due to training on datasets that lack diversity and real-world authenticity, or on automatically extracted underlying data tables of charts, which can contain numerous estimation errors. Furthermore, existing models only rely on supervised fine-tuning using these low-quality datasets, severely limiting their effectiveness. To address these issues, we first propose BigCharts, a dataset creation pipeline that generates visually diverse chart images by conditioning the rendering process on real-world charts sourced from multiple online platforms. Unlike purely synthetic datasets, BigCharts incorporates real-world data, ensuring authenticity and visual diversity, while still retaining accurate underlying data due to our proposed replotting process. Additionally, we introduce a comprehensive training framework that integrates supervised fine-tuning with Group Relative Policy Optimization (GRPO)-based reinforcement learning. By introducing novel reward signals specifically designed for chart reasoning, our approach enhances model robustness and generalization across diverse chart styles and domains, resulting in a state-of-the-art chart reasoning model, BigCharts-R1. Extensive experiments demonstrate that our models surpass existing methods on multiple chart question-answering benchmarks compared to even larger open-source and closed-source models.
图表是数据分析的核心,将原始数据转化为清晰的视觉表现形式,以支持人类的决策制定。尽管当前的视觉语言模型(VLMs)已经取得了重大进展,但由于训练数据集缺乏多样性和真实世界的真实性,或者依赖于图表中自动提取的底层数据表(可能包含大量估算误差),它们仍在图表理解方面遇到困难。此外,现有模型仅依赖使用这些低质量数据集进行的有监督微调,这严重限制了其有效性。为了解决这些问题,我们首先提出BigCharts数据集创建管道,通过以从多个在线平台获取的真实世界图表为条件,生成视觉多样的图表图像。与纯合成数据集不同,BigCharts融入了真实世界数据,确保了真实性和视觉多样性,同时仍保留了底层数据的准确性,这是由于我们提出的重新绘图过程。此外,我们引入了一个全面的训练框架,将监督微调与基于群体相对策略优化(GRPO)的强化学习相结合。通过引入专门针对图表推理的新型奖励信号,我们的方法提高了模型在各种图表风格和领域中的稳健性和泛化能力,从而产生了最先进的图表推理模型——BigCharts-R1。大量实验表明,我们的模型在多个图表问答基准测试上超越了现有方法,与更大的开源和专有模型相比也是如此。
论文及项目相关链接
Summary:
数据可视化图表对数据分析至关重要,目前虽然已有一些视觉语言模型,但由于缺乏多样性和真实性的数据集,以及对图表数据自动提取的误差等问题,这些模型在图表理解方面仍存在困难。为此,研究者提出了BigCharts数据集创建流程,该流程基于真实世界图表生成视觉多样的图表图像,并引入了一种综合训练框架,包括监督微调与基于Group Relative Policy Optimization的强化学习。该框架为图表推理引入新型奖励信号,增强了模型的稳健性和跨不同图表风格和领域的泛化能力,形成当前最先进的图表推理模型BigCharts-R1。
Key Takeaways:
- 图表在数据分析中扮演重要角色,能够将原始数据转化为清晰的视觉表现形式以支持决策制定。
- 当前视觉语言模型在图表理解方面存在挑战,主要由于数据集缺乏多样性和真实性以及图表数据自动提取的误差。
- BigCharts数据集创建流程通过结合真实世界图表生成视觉多样的图表图像,保证真实性和视觉多样性的同时,保留了准确的底层数据。
- 综合训练框架结合了监督微调和强化学习,以提高模型在图表推理方面的稳健性和泛化能力。
- Group Relative Policy Optimization(GRPO)在训练过程中发挥了关键作用,通过引入新型奖励信号增强模型的性能。
- BigCharts-R1模型在多个图表问答基准测试中表现超越现有方法,相较于开源和闭源模型也表现出优势。
点此查看论文截图


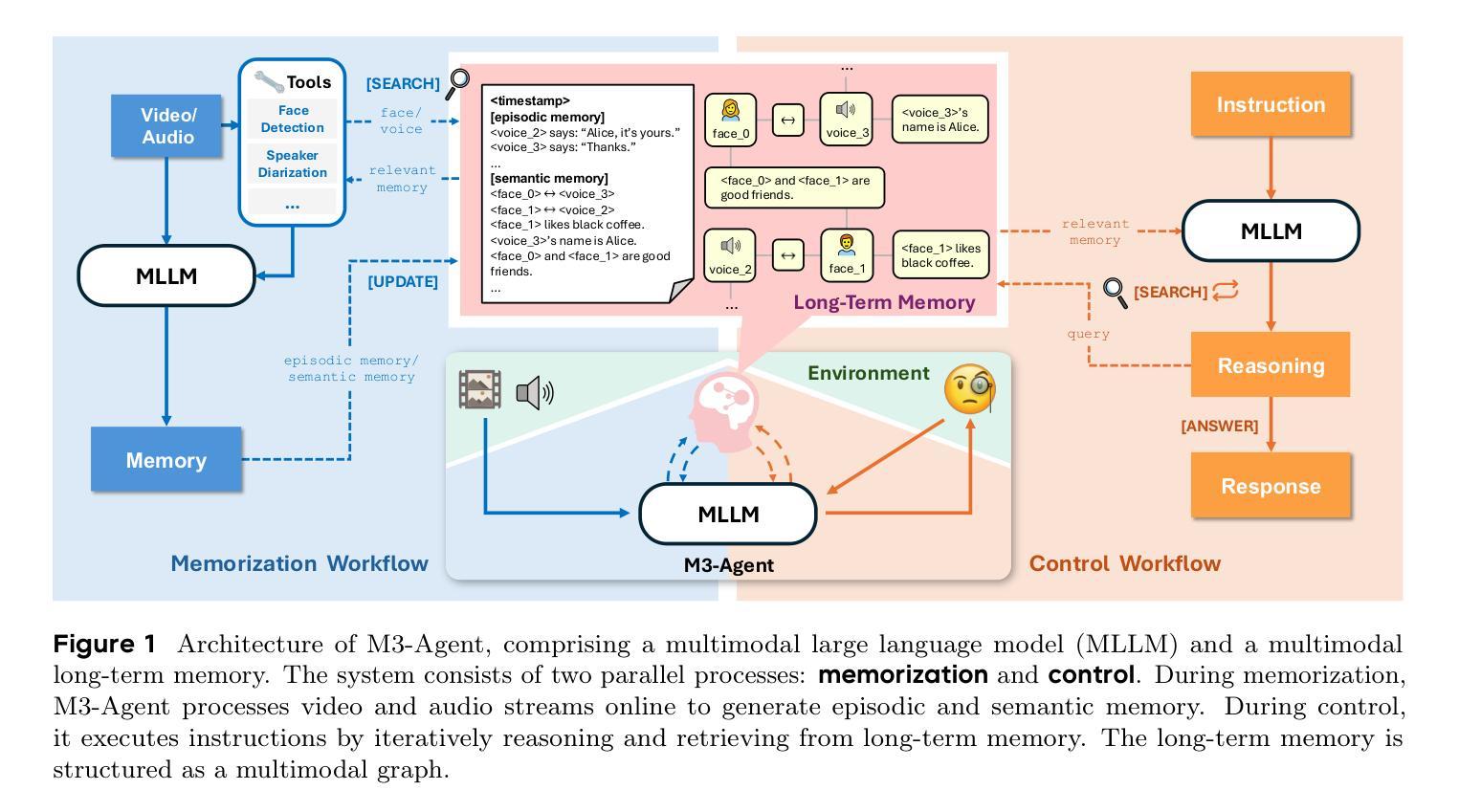
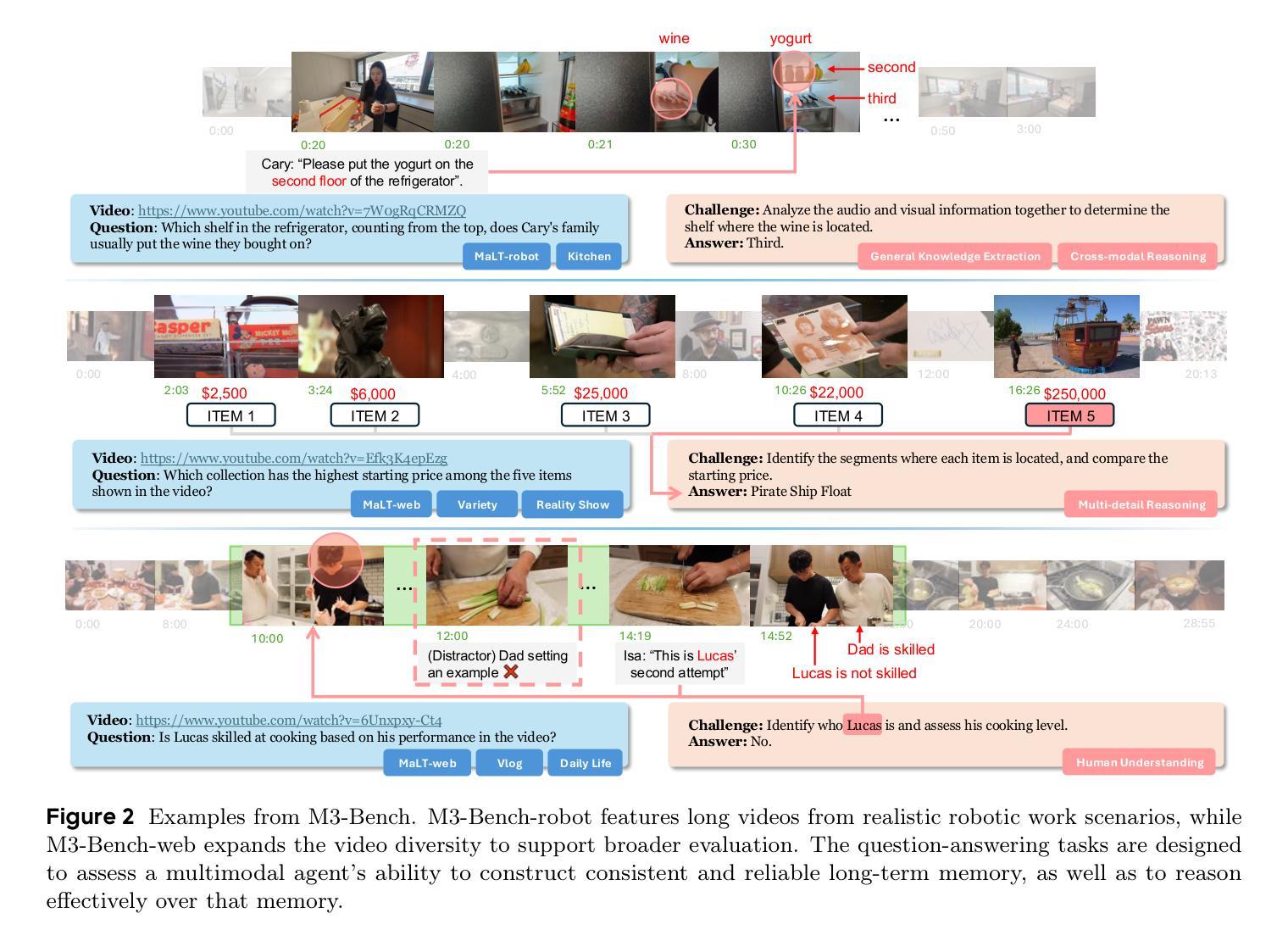
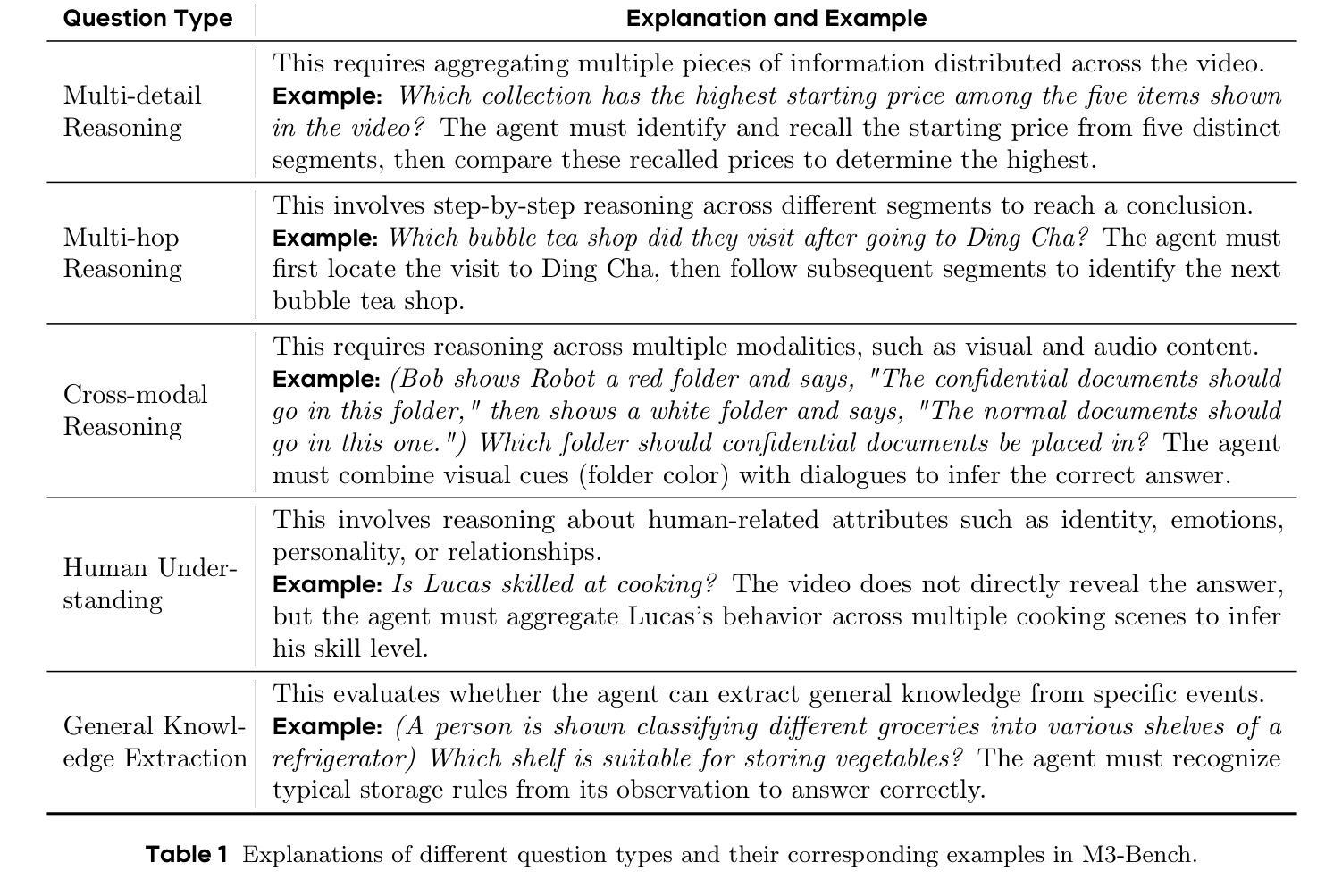
Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
Authors:Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, Wei Li
We introduce M3-Agent, a novel multimodal agent framework equipped with long-term memory. Like humans, M3-Agent can process real-time visual and auditory inputs to build and update its long-term memory. Beyond episodic memory, it also develops semantic memory, enabling it to accumulate world knowledge over time. Its memory is organized in an entity-centric, multimodal format, allowing deeper and more consistent understanding of the environment. Given an instruction, M3-Agent autonomously performs multi-turn, iterative reasoning and retrieves relevant information from memory to accomplish the task. To evaluate memory effectiveness and memory-based reasoning in multimodal agents, we develop M3-Bench, a new long-video question answering benchmark. M3-Bench comprises 100 newly recorded real-world videos captured from a robot’s perspective (M3-Bench-robot) and 929 web-sourced videos across diverse scenarios (M3-Bench-web). We annotate question-answer pairs designed to test key capabilities essential for agent applications, such as human understanding, general knowledge extraction, and cross-modal reasoning. Experimental results show that M3-Agent, trained via reinforcement learning, outperforms the strongest baseline, a prompting agent using Gemini-1.5-pro and GPT-4o, achieving 6.7%, 7.7%, and 5.3% higher accuracy on M3-Bench-robot, M3-Bench-web and VideoMME-long, respectively. Our work advances the multimodal agents toward more human-like long-term memory and provides insights into their practical design. Model, code and data are available at https://github.com/bytedance-seed/m3-agent
我们介绍了M3-Agent,这是一个配备长期记忆的新型多模态代理框架。像人类一样,M3-Agent可以处理实时视觉和听觉输入来构建和更新其长期记忆。除了情景记忆之外,它还发展出语义记忆,使其能够随着时间的推移积累世界知识。它的记忆以实体为中心的多模态格式组织,允许对环境的更深和更一致的理解。接收到指令后,M3-Agent会自主进行多轮迭代推理,从记忆中检索相关信息以完成任务。为了评估多模态代理中的记忆有效性和基于记忆推理的能力,我们开发了M3-Bench,这是一个新的长视频问答基准测试。M3-Bench包括100个新录制的世界视频(从机器人视角捕获)(M3-Bench-robot)和929个涵盖不同场景的网页视频(M3-Bench-web)。我们注释了问题和答案对,旨在测试代理应用程序必需的关键能力,例如人类理解、一般知识提取和跨模态推理。实验结果表明,通过强化学习训练的M3-Agent超越了最强基线——使用Gemini-1.5-pro和GPT-4o的提示代理,在M3-Bench-robot、M3-Bench-web和VideoMME-long上的准确率分别提高了6.7%、7.7%和5.3%。我们的工作推动了多模态代理朝着更类似于人类的长时记忆方向发展,并为其实践设计提供了见解。模型、代码和数据可在https://github.com/bytedance-seed/m3-agent找到。
论文及项目相关链接
Summary
M3-Agent是一个配备长期记忆的多模态代理框架,能处理实时视觉和听觉输入来构建和更新其长期记忆。除了情景记忆外,它还能发展语义记忆,能够随时间积累世界知识。其记忆以实体为中心、多模态的方式组织,能更深入地理解环境。为评估多模态代理的记忆效果和基于记忆推理的能力,开发了M3-Bench长视频问答基准测试。M3-Agent通过强化学习训练,在M3-Bench测试中表现出卓越性能,优于最强基线模型。
Key Takeaways
- M3-Agent是一个多模态代理框架,具备处理实时视觉和听觉输入的能力,以构建和更新其长期记忆。
- M3-Agent不仅能形成情景记忆,还能发展语义记忆,使其能够随时间积累世界知识。
- M3-Agent的记忆以实体为中心、多模态的方式组织,以提高对环境的理解。
- 为评估多模态代理的记忆效果和基于记忆推理的能力,引入了M3-Bench基准测试,包含真实世界和网页来源的视频。
- M3-Agent通过强化学习训练,在M3-Bench测试中实现了高准确率,优于现有最强基线模型。
- M3-Agent的设计推动了多模态代理向更类似人类长期记忆的方向发展。
点此查看论文截图

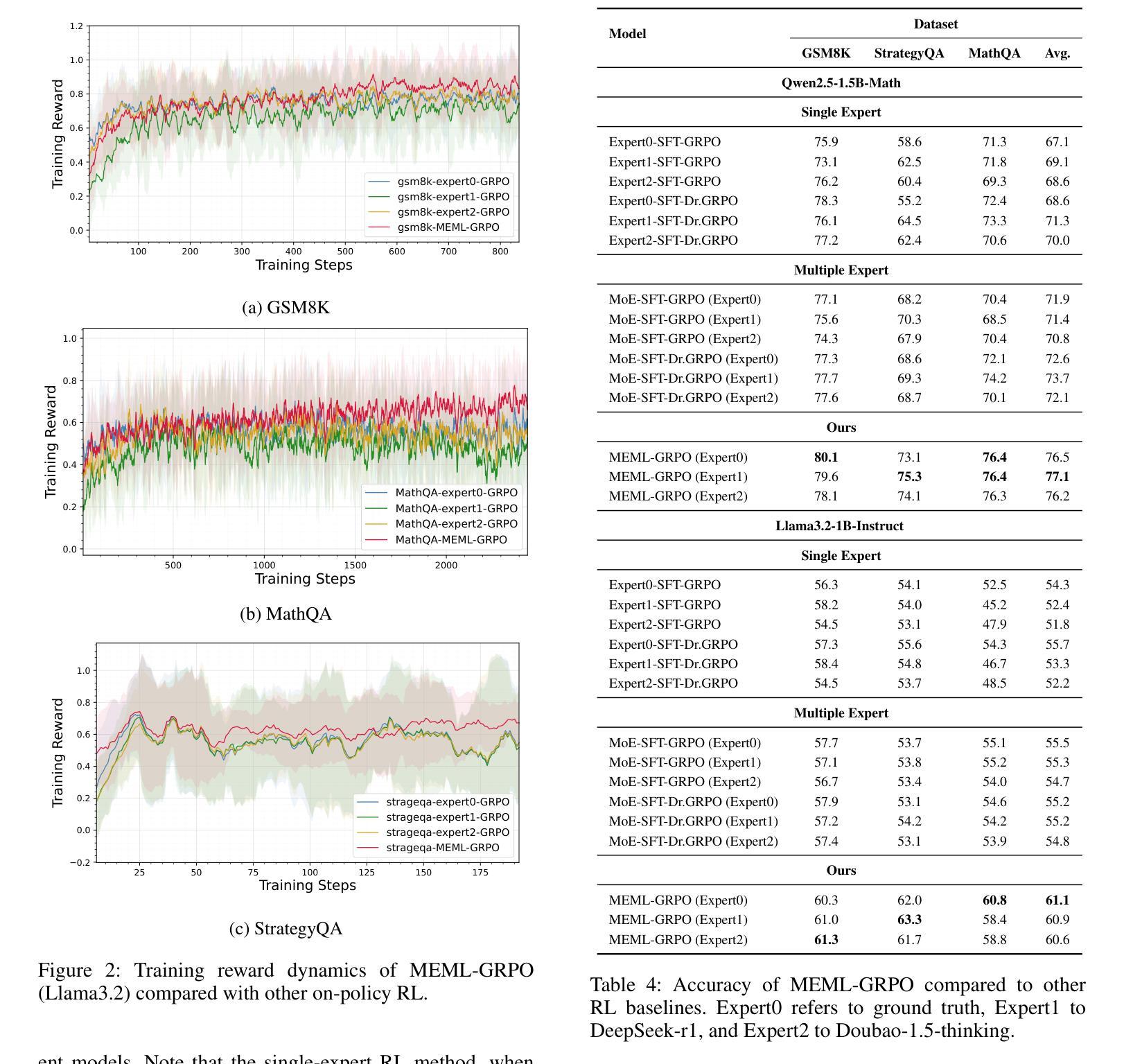
MEML-GRPO: Heterogeneous Multi-Expert Mutual Learning for RLVR Advancement
Authors:Weitao Jia, Jinghui Lu, Haiyang Yu, Siqi Wang, Guozhi Tang, An-Lan Wang, Weijie Yin, Dingkang Yang, Yuxiang Nie, Bin Shan, Hao Feng, Irene Li, Kun Yang, Han Wang, Jingqun Tang, Teng Fu, Changhong Jin, Chao Feng, Xiaohui Lv, Can Huang
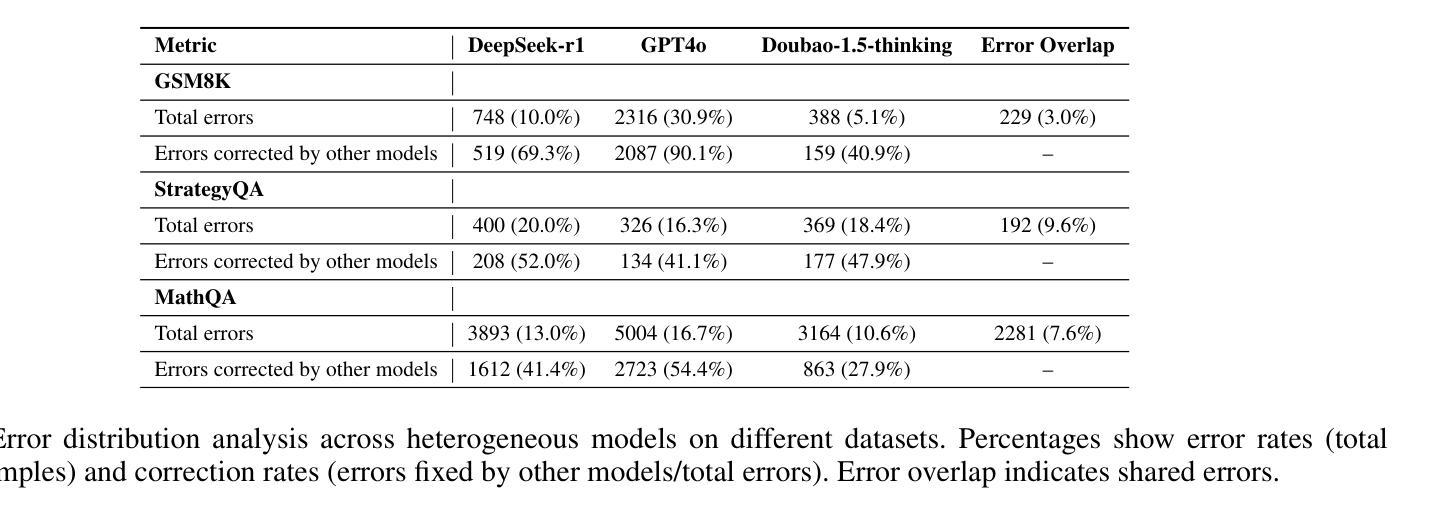
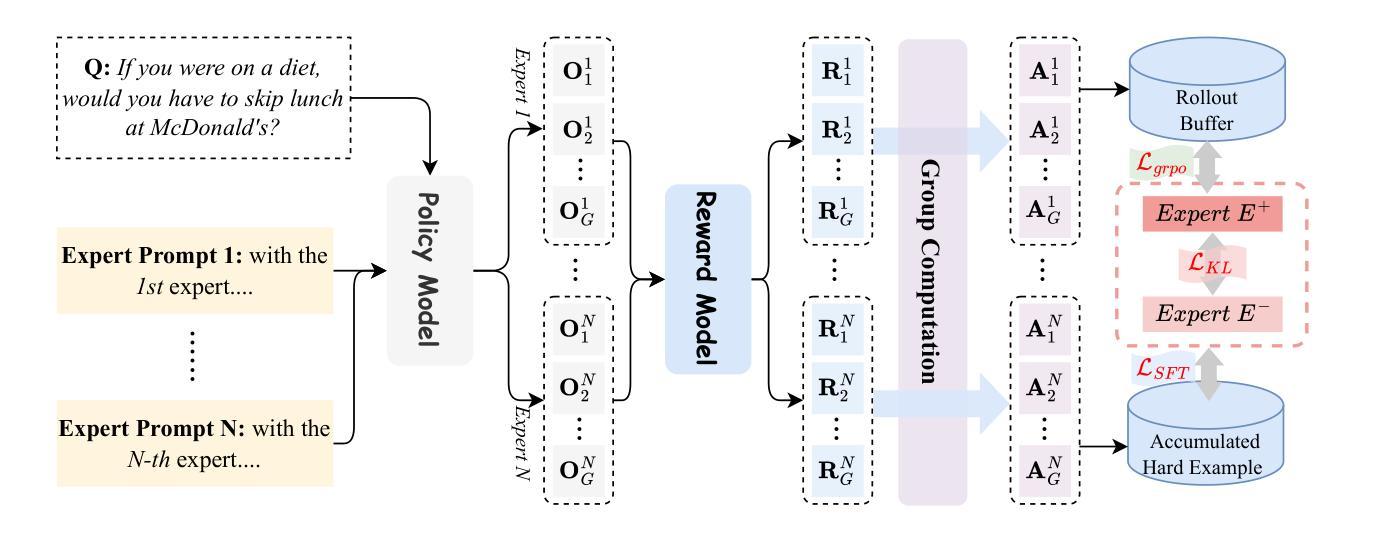
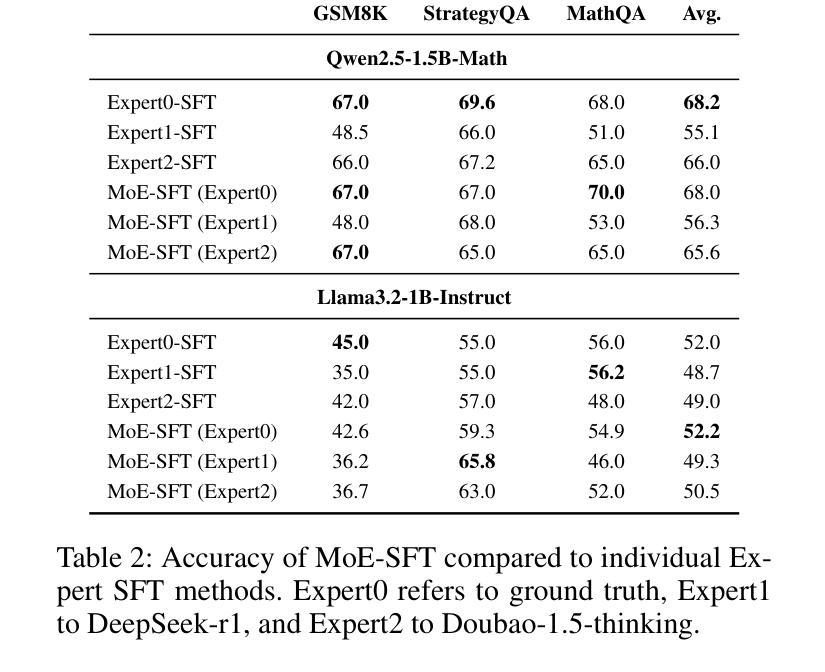
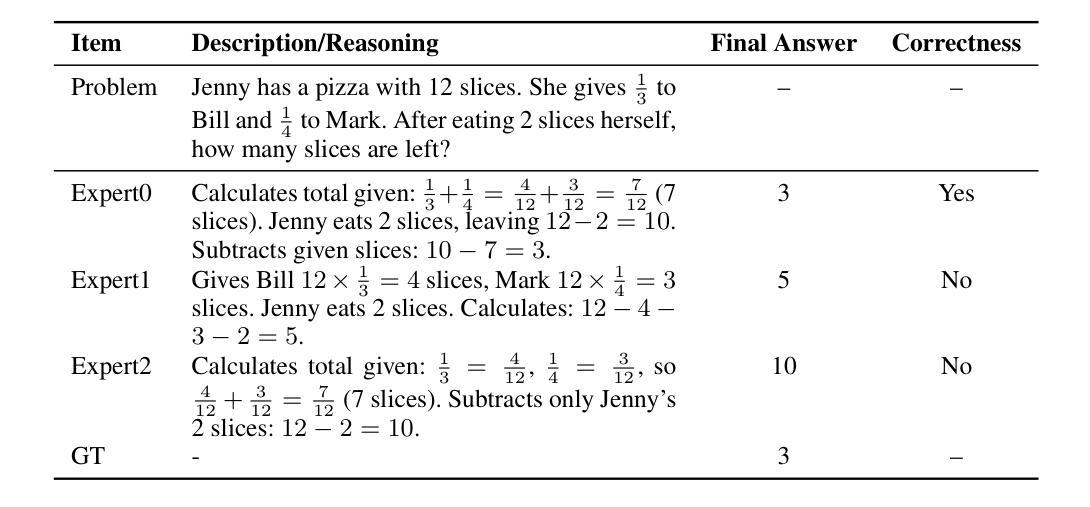
Recent advances demonstrate that reinforcement learning with verifiable rewards (RLVR) significantly enhances the reasoning capabilities of large language models (LLMs). However, standard RLVR faces challenges with reward sparsity, where zero rewards from consistently incorrect candidate answers provide no learning signal, particularly in challenging tasks. To address this, we propose Multi-Expert Mutual Learning GRPO (MEML-GRPO), an innovative framework that utilizes diverse expert prompts as system prompts to generate a broader range of responses, substantially increasing the likelihood of identifying correct solutions. Additionally, we introduce an inter-expert mutual learning mechanism that facilitates knowledge sharing and transfer among experts, further boosting the model’s performance through RLVR. Extensive experiments across multiple reasoning benchmarks show that MEML-GRPO delivers significant improvements, achieving an average performance gain of 4.89% with Qwen and 11.33% with Llama, effectively overcoming the core limitations of traditional RLVR methods.
最近的研究进展表明,使用可验证奖励的强化学习(RLVR)显著增强了大型语言模型(LLM)的推理能力。然而,标准RLVR面临奖励稀疏的挑战,其中不正确的候选答案提供的零奖励无法提供学习信号,特别是在具有挑战性的任务中。为了解决这一问题,我们提出了多专家相互学习GRPO(MEML-GRPO)这一创新框架,它利用不同的专家提示作为系统提示来生成更广泛的响应,大大提高了找到正确解决方案的可能性。此外,我们还引入了一种专家间相互学习机制,促进了专家之间的知识共享和转移,通过RLVR进一步提高了模型的性能。在多个推理基准测试上的广泛实验表明,MEML-GRPO取得了显著的改进,在Qwen上平均性能提升4.89%,在Llama上提升11.33%,有效地克服了传统RLVR方法的核心局限性。
论文及项目相关链接
Summary
强化学习与可验证奖励(RLVR)的结合显著提升了大型语言模型(LLM)的推理能力。然而,标准RLVR面临奖励稀疏的挑战,导致在困难任务中无法获得学习信号。为解决此问题,我们提出了多专家相互学习GRPO(MEML-GRPO)框架,通过利用多种专家提示作为系统提示生成更广泛的响应,提高正确解决方案的识别可能性。此外,我们还引入了专家间相互学习机制,促进知识共享和转移,进一步通过RLVR提升模型性能。在多个推理基准测试上的实验表明,MEML-GRPO取得了显著改进,在Qwen和Llama上分别实现了平均性能提升4.89%和11.33%,有效克服了传统RLVR方法的核心局限性。
Key Takeaways
- RLVR结合显著提升了LLM的推理能力。
- 标准RLVR面临奖励稀疏的挑战。
- MEML-GRPO框架利用多种专家提示生成更广泛的响应,提高正确解决方案的识别可能性。
- MEML-GRPO引入专家间相互学习机制,促进知识共享和转移。
- MEML-GRPO在多个推理基准测试上实现了显著的性能改进。
- 在Qwen和Llama上,MEML-GRPO分别实现了平均性能提升4.89%和11.33%。
点此查看论文截图

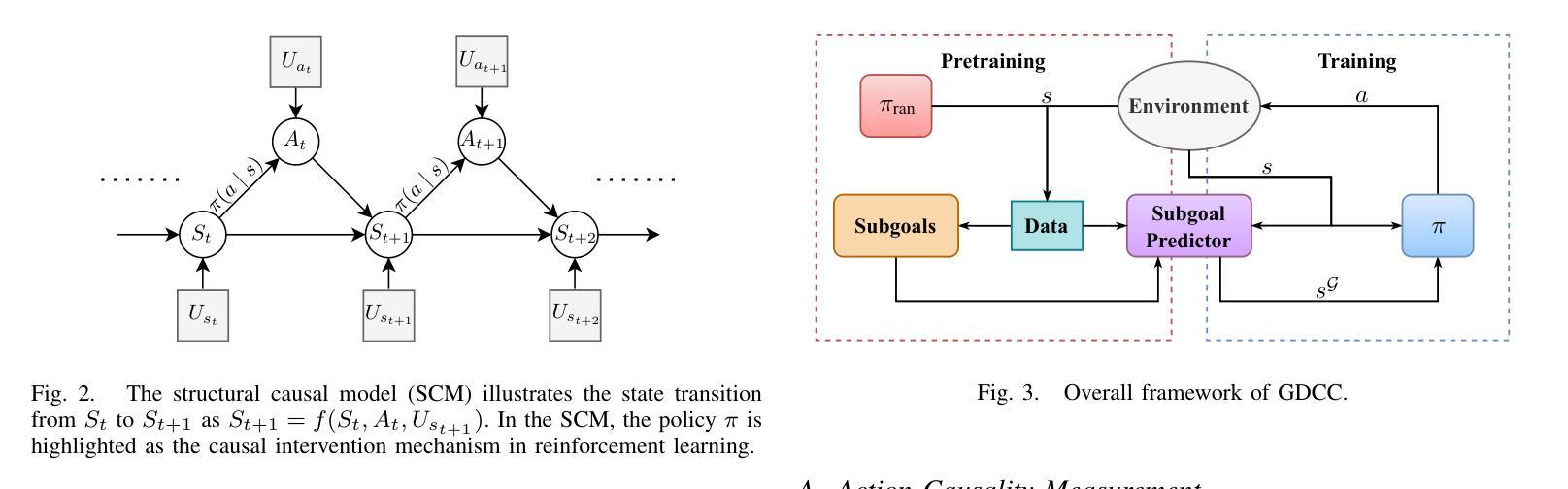
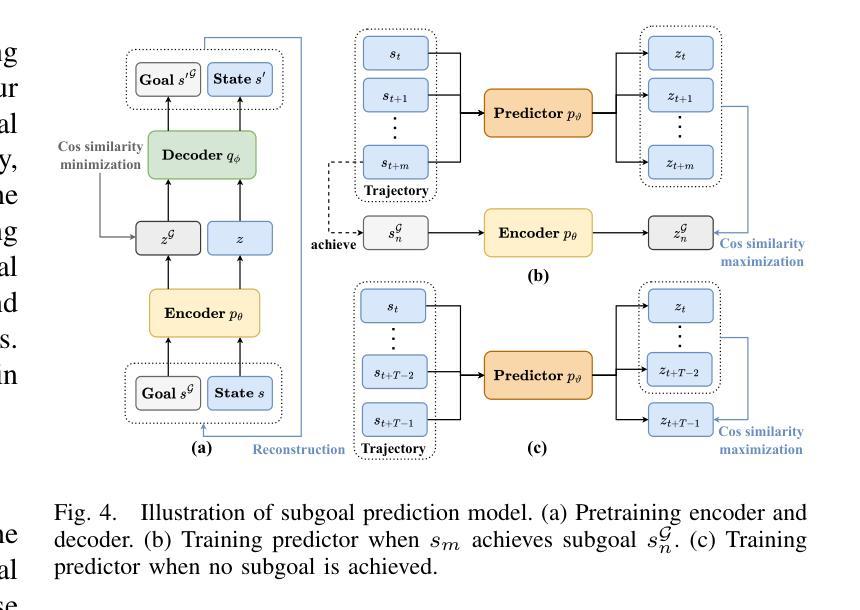
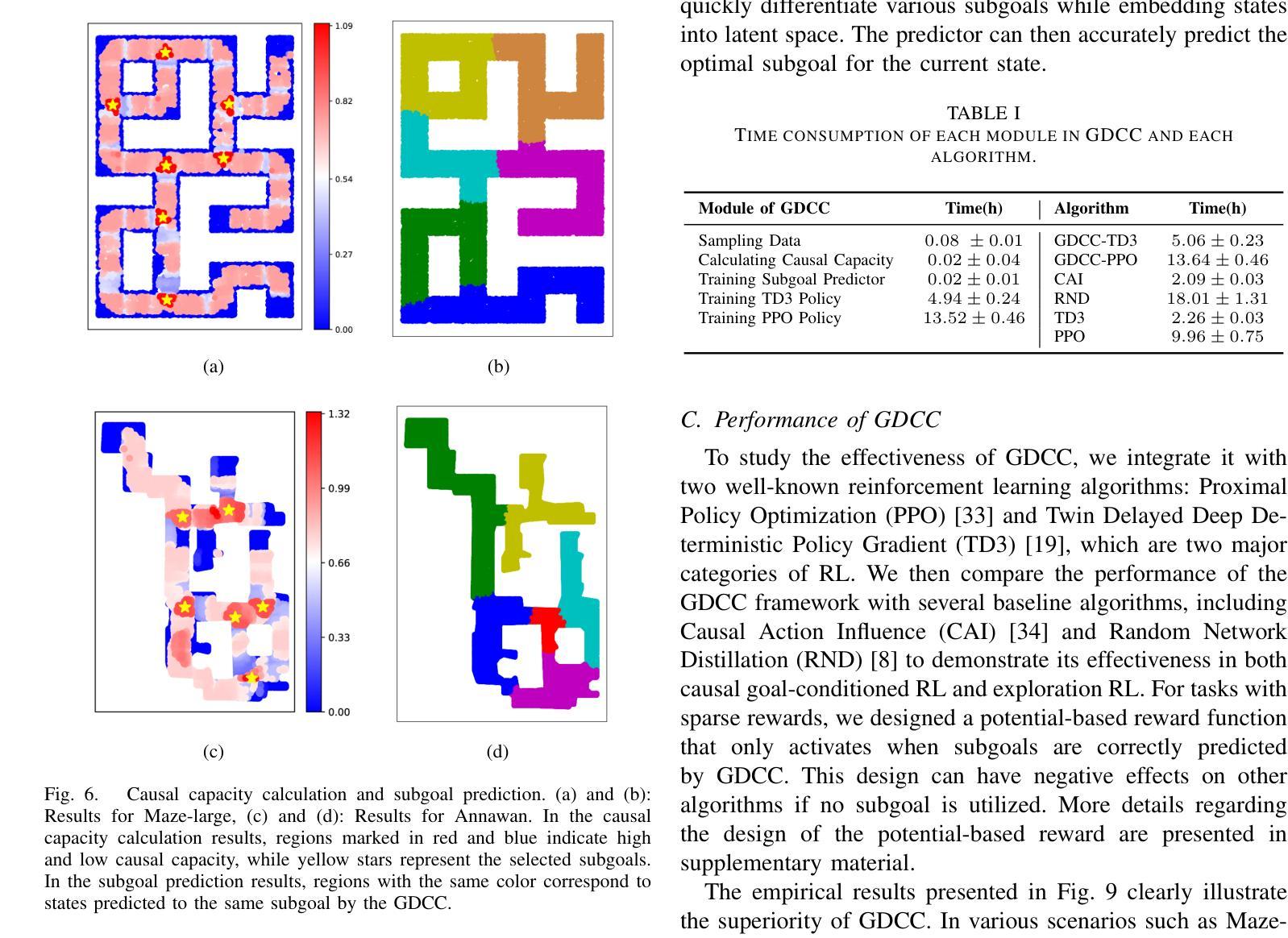
Goal Discovery with Causal Capacity for Efficient Reinforcement Learning
Authors:Yan Yu, Yaodong Yang, Zhengbo Lu, Chengdong Ma, Wengang Zhou, Houqiang Li
Causal inference is crucial for humans to explore the world, which can be modeled to enable an agent to efficiently explore the environment in reinforcement learning. Existing research indicates that establishing the causality between action and state transition will enhance an agent to reason how a policy affects its future trajectory, thereby promoting directed exploration. However, it is challenging to measure the causality due to its intractability in the vast state-action space of complex scenarios. In this paper, we propose a novel Goal Discovery with Causal Capacity (GDCC) framework for efficient environment exploration. Specifically, we first derive a measurement of causality in state space, \emph{i.e.,} causal capacity, which represents the highest influence of an agent’s behavior on future trajectories. After that, we present a Monte Carlo based method to identify critical points in discrete state space and further optimize this method for continuous high-dimensional environments. Those critical points are used to uncover where the agent makes important decisions in the environment, which are then regarded as our subgoals to guide the agent to make exploration more purposefully and efficiently. Empirical results from multi-objective tasks demonstrate that states with high causal capacity align with our expected subgoals, and our GDCC achieves significant success rate improvements compared to baselines.
因果推理对人类探索世界至关重要,可以被建模以使得智能体在强化学习中有效地探索环境。现有研究表明,建立动作和状态转移之间的因果关系将增强智能体推理政策如何影响其未来轨迹的能力,从而促进有方向性的探索。然而,由于复杂场景中的状态-动作空间庞大,测量因果关系具有挑战性。在本文中,我们提出了一个名为Goal Discovery with Causal Capacity(GDCC)的新型高效环境探索框架。具体而言,我们首先推导出状态空间中的因果关系度量,即因果容量,它代表智能体行为对未来轨迹的最高影响。之后,我们提出了一种基于蒙特卡洛的方法来确定离散状态空间中的关键点,并进一步为连续的高维环境优化此方法。这些关键点被用来发现智能体在环境中做出重要决策的地方,然后将其视为子目标,引导智能体进行更有目的和高效的探索。多目标任务的实证结果表明,具有高因果容量的状态与预期的子目标相符,我们的GDCC与基线相比实现了显著的成功率提升。
论文及项目相关链接
Summary
本文提出一种名为Goal Discovery with Causal Capacity(GDCC)的框架,用于强化学习中的有效环境探索。该框架通过衡量代理行为对未来轨迹的最高影响程度,即因果容量,来量化因果关系。此外,本文使用基于蒙特卡洛的方法在离散状态空间中找到关键点,并针对连续高维环境进行优化。这些关键点被用作环境中代理做出重要决策的依据,被视为子目标,以指导代理更有目的和有效地探索。在多目标任务上的实证结果表明,具有高因果容量的状态与预期的子目标相符,GDCC框架相较于基准方法实现了显著的成功率提升。
Key Takeaways
- 强化学习中,因果推理对于代理(agent)探索环境至关重要。
- 因果关系可建模以促使代理进行定向探索。
- 现有研究挑战在于在复杂场景的大规模状态动作空间中测量因果关系。
- 本文提出Goal Discovery with Causal Capacity(GDCC)框架来解决这一问题。
- GDCC框架通过衡量因果容量(即代理行为对未来轨迹的最高影响程度)来量化因果关系。
- 使用基于蒙特卡洛的方法在离散和连续状态空间中识别关键点作为子目标。
点此查看论文截图


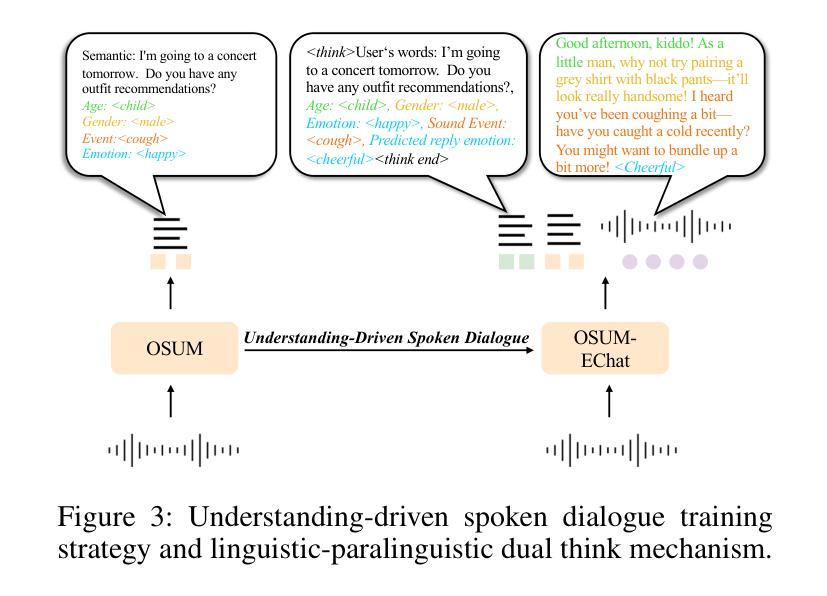
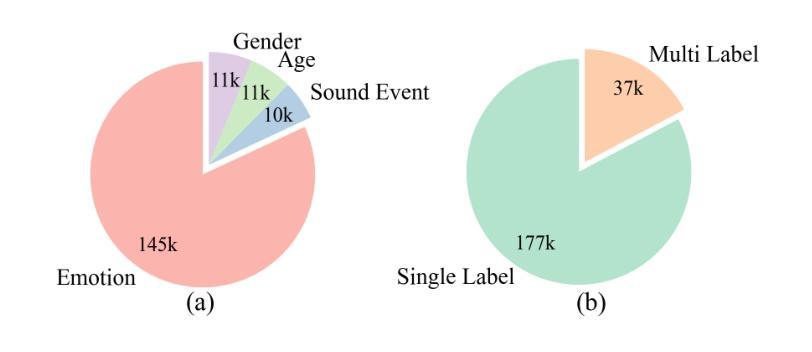
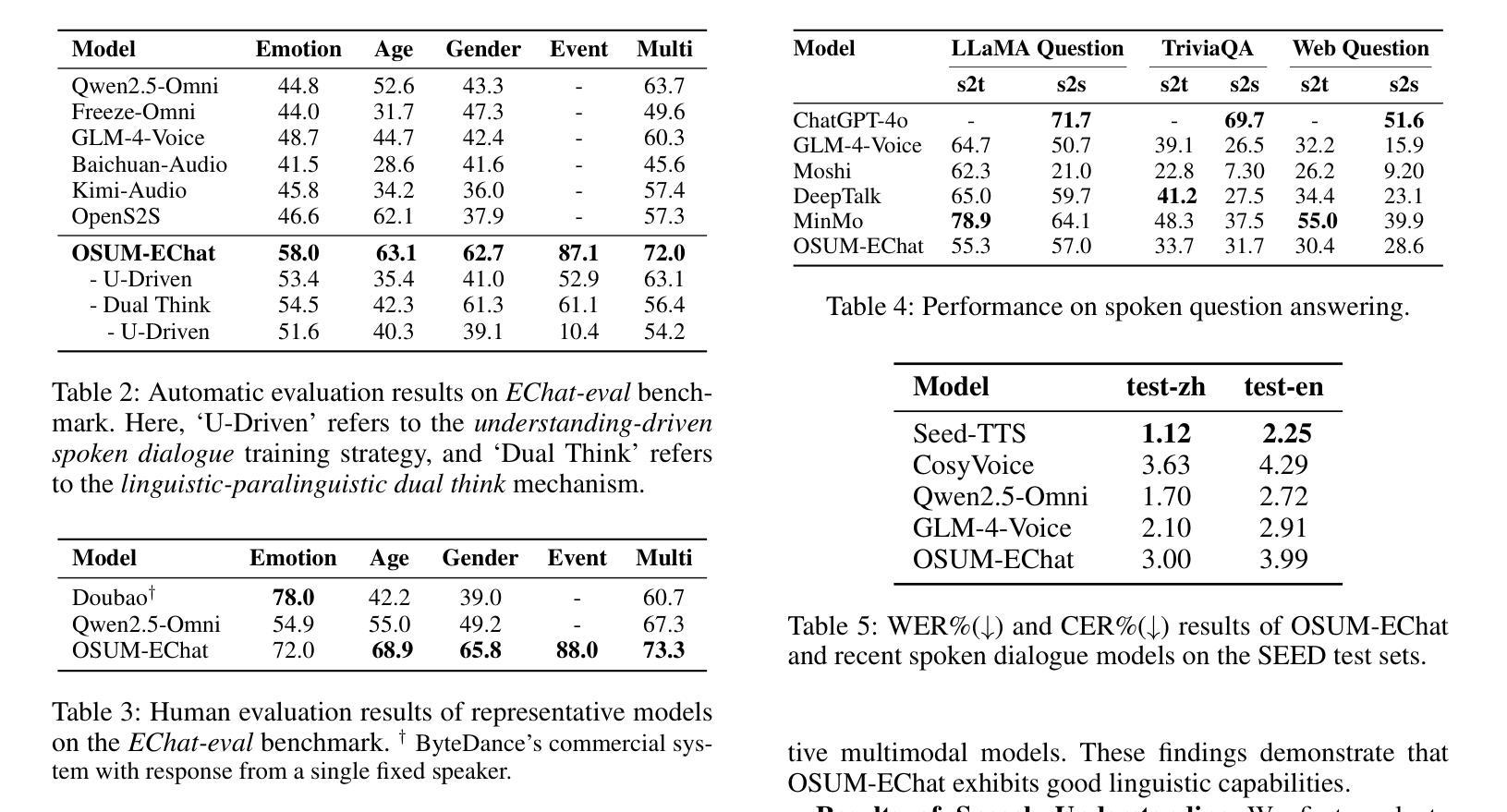
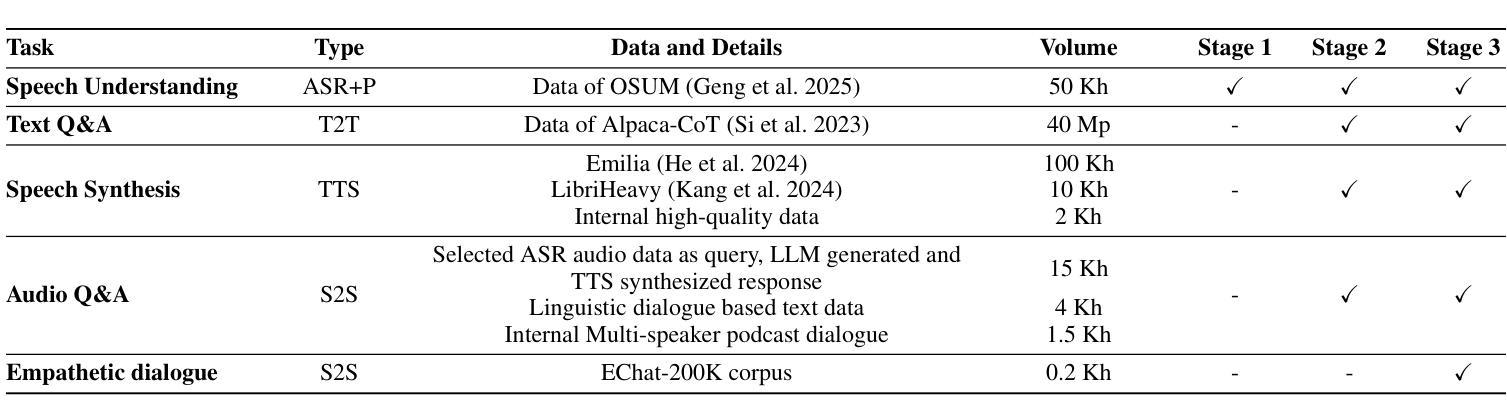
OSUM-EChat: Enhancing End-to-End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue
Authors:Xuelong Geng, Qijie Shao, Hongfei Xue, Shuiyuan Wang, Hanke Xie, Zhao Guo, Yi Zhao, Guojian Li, Wenjie Tian, Chengyou Wang, Zhixian Zhao, Kangxiang Xia, Ziyu Zhang, Zhennan Lin, Tianlun Zuo, Mingchen Shao, Yuang Cao, Guobin Ma, Longhao Li, Yuhang Dai, Dehui Gao, Dake Guo, Lei Xie
Empathy is crucial in enabling natural interactions within spoken dialogue systems, allowing machines to recognize and respond appropriately to paralinguistic cues such as age, gender, and emotion. Recent advancements in end-to-end speech language models, which unify speech understanding and generation, provide promising solutions. However, several challenges persist, including an over-reliance on large-scale dialogue datasets, insufficient extraction of paralinguistic cues vital for conveying empathy, and the lack of empathy-specific datasets and evaluation frameworks. To address these issues, we introduce OSUM-EChat, an open-source, end-to-end spoken dialogue system designed to enhance empathetic interactions, particularly in resource-limited settings. OSUM-EChat introduces two key innovations: (1) a three-stage understanding-driven spoken dialogue training strategy that extends the capabilities of a large speech understanding model to spoken dialogue tasks, and (2) a linguistic-paralinguistic dual thinking mechanism that integrates paralinguistic understanding through a chain of thought with dialogue generation, enabling the system to produce more empathetic responses. This approach reduces reliance on large-scale dialogue datasets while maintaining high-quality empathetic interactions. Additionally, we introduce the EChat-200K dataset, a rich corpus of empathetic speech-to-speech dialogues, and the EChat-eval benchmark, a comprehensive framework for evaluating the empathetic capabilities of dialogue systems. Experimental results demonstrate that OSUM-EChat outperforms end-to-end spoken dialogue models regarding empathetic responsiveness, validating its effectiveness.
共情在口语对话系统中实现自然交互至关重要,它让机器能够识别和适当回应诸如年龄、性别和情绪等副语言线索。端到端语音语言模型的最新进展,这些模型统一了语音理解和生成,提供了富有前景的解决方案。然而,仍然存在一些挑战,包括过度依赖大规模的对话数据集,未能充分提取用于表达共情的关键副语言线索,以及缺乏针对共情的特定数据集和评估框架。为了解决这些问题,我们推出了OSUM-EChat,这是一个旨在增强共情交互的开源端到端口语对话系统,特别是在资源有限的环境中。OSUM-EChat引入了两项关键创新:一是以理解为主导的口语对话三阶段训练策略,它扩展了大型语音理解模型在口语对话任务上的能力;二是语言-副语言双思机制,它通过思维链融入副语言理解,与对话生成相结合,使系统能够产生更具共情的回应。这种方法降低了对大规模对话数据集的依赖,同时保持了高质量的共情交互。此外,我们还推出了EChat-200K数据集,这是一份丰富的共情语音对话语料库,以及EChat-eval基准测试,这是一个全面评估对话系统共情能力的框架。实验结果表明,OSUM-EChat在共情响应方面优于端到端的口语对话模型,验证了其有效性。
论文及项目相关链接
Summary:
本文强调了在口语对话系统中,共情能力是进行自然交互的关键。近期的端到端语音语言模型的发展为该领域带来了希望,但仍然存在对大规模对话数据集的过度依赖、缺乏提取对表达共情至关重要的副语言线索以及缺乏针对共情的特定数据集和评估框架等问题。为解决这些问题,本文引入了OSUM-EChat这一开源的端到端口语对话系统,它旨在加强共情交互,特别是在资源受限的环境中。OSUM-EChat包含两项创新技术:一是理解驱动的三阶段口语对话训练策略,它将大规模的语音理解模型扩展到口语对话任务中;二是语言-副语言双重思考机制,它将副语言理解与对话生成相结合,使系统能够产生更具共情的响应。此外,本文还介绍了EChat-200K数据集和EChat-eval基准测试,用于评估对话系统的共情能力。实验结果表明,OSUM-EChat在共情响应方面优于其他端到端口语对话模型。
Key Takeaways:
- 共情在口语对话系统中是实现自然交互的关键。
- 近期端到端语音语言模型的发展为口语对话系统带来希望。
- 目前面临的挑战包括:对大规模对话数据集的依赖、缺乏提取副语言线索的能力以及缺乏针对共情的特定数据集和评估框架。
- OSUM-EChat是一个旨在增强共情交互的开源端到端口语对话系统。
- OSUM-EChat引入了两项创新技术:理解驱动的训练策略和语言-副语言双重思考机制。
- EChat-200K数据集和EChat-eval基准测试被用于评估对话系统的共情能力。
点此查看论文截图


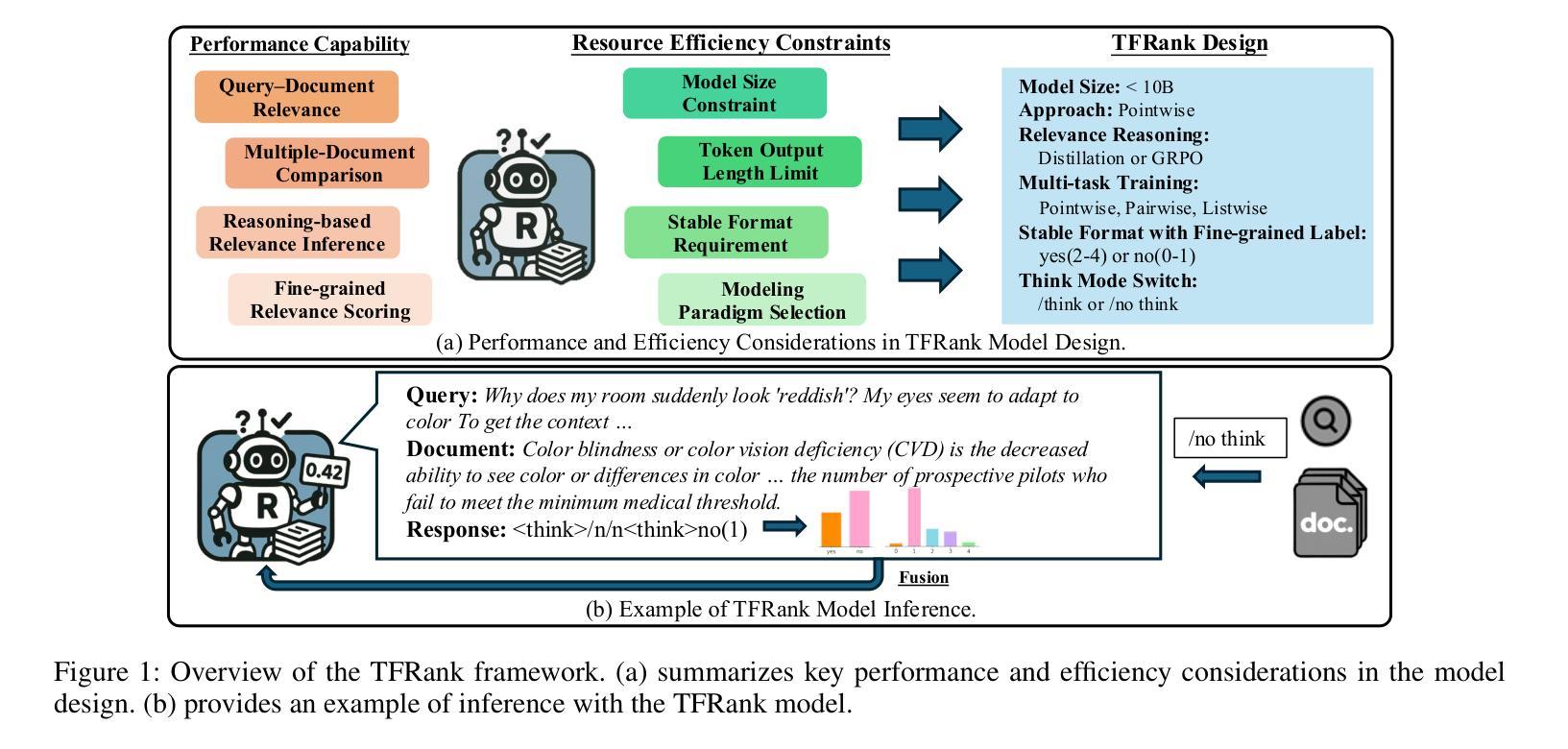
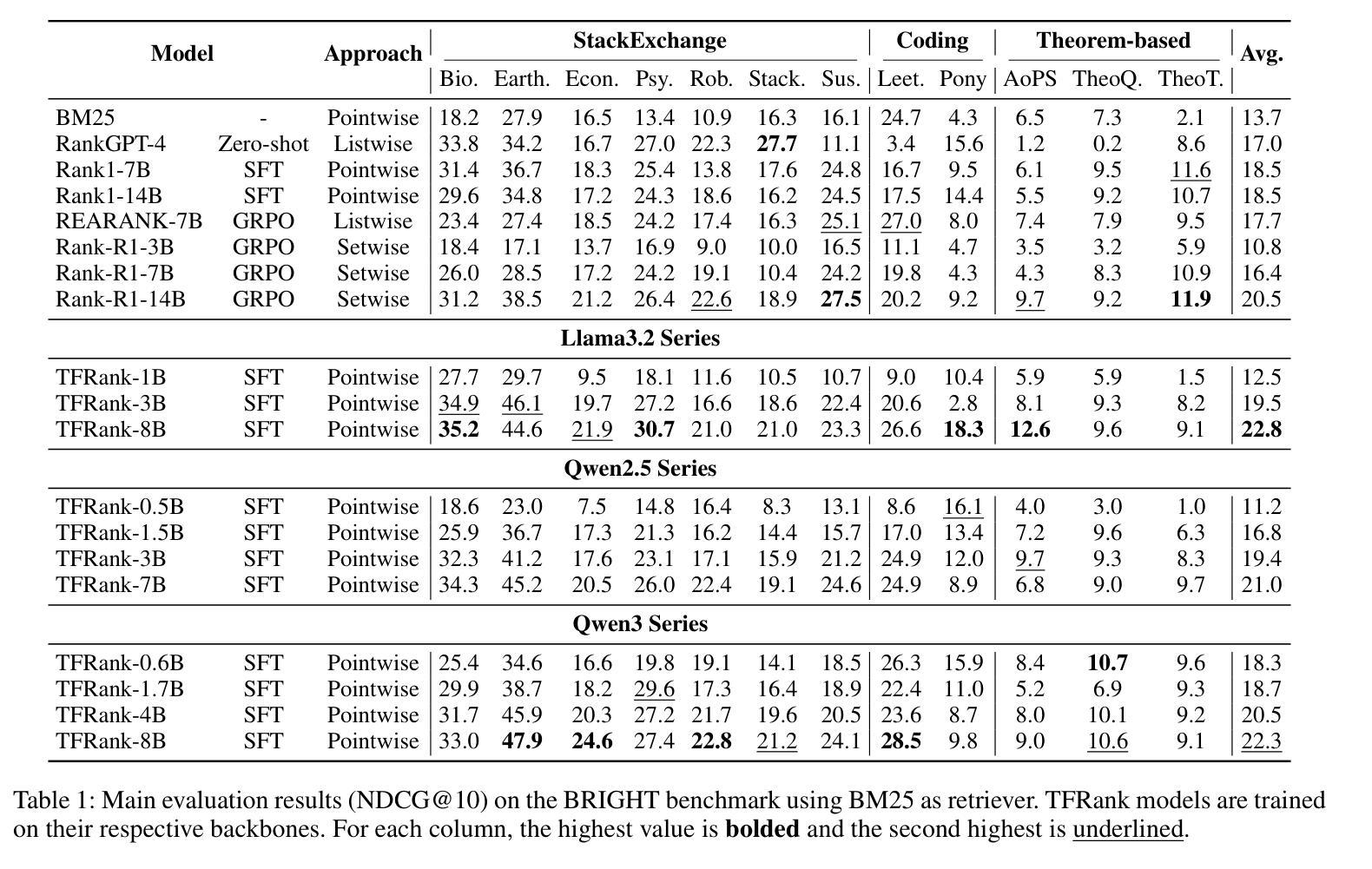
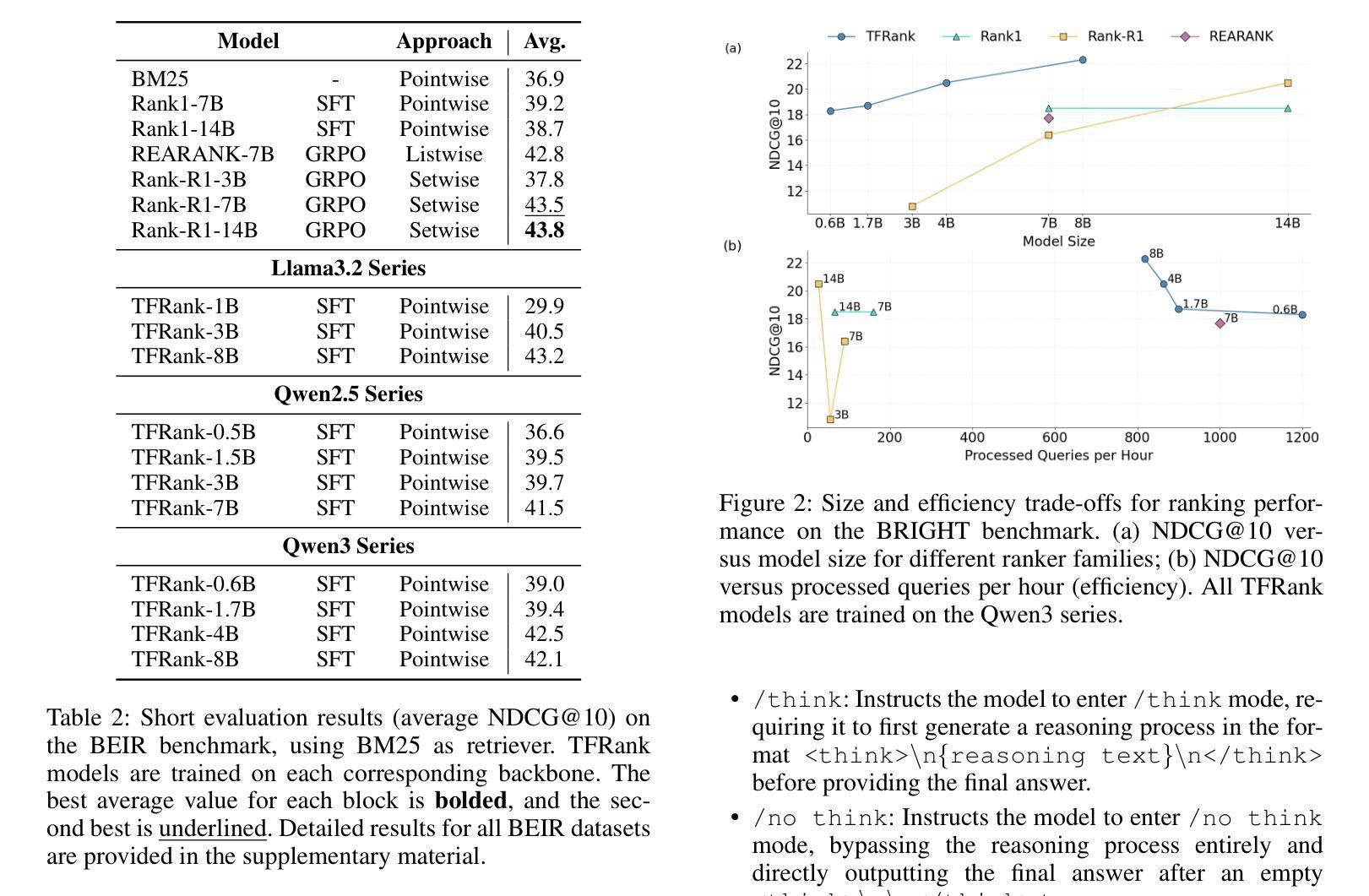
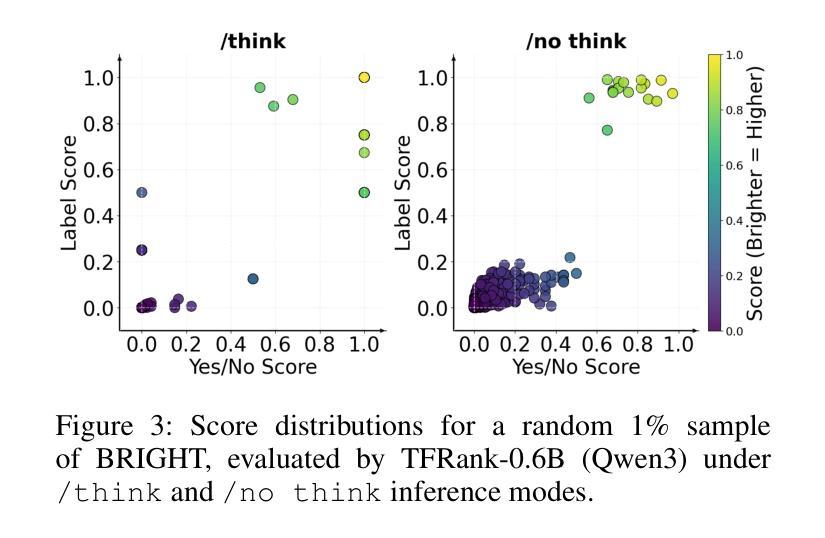
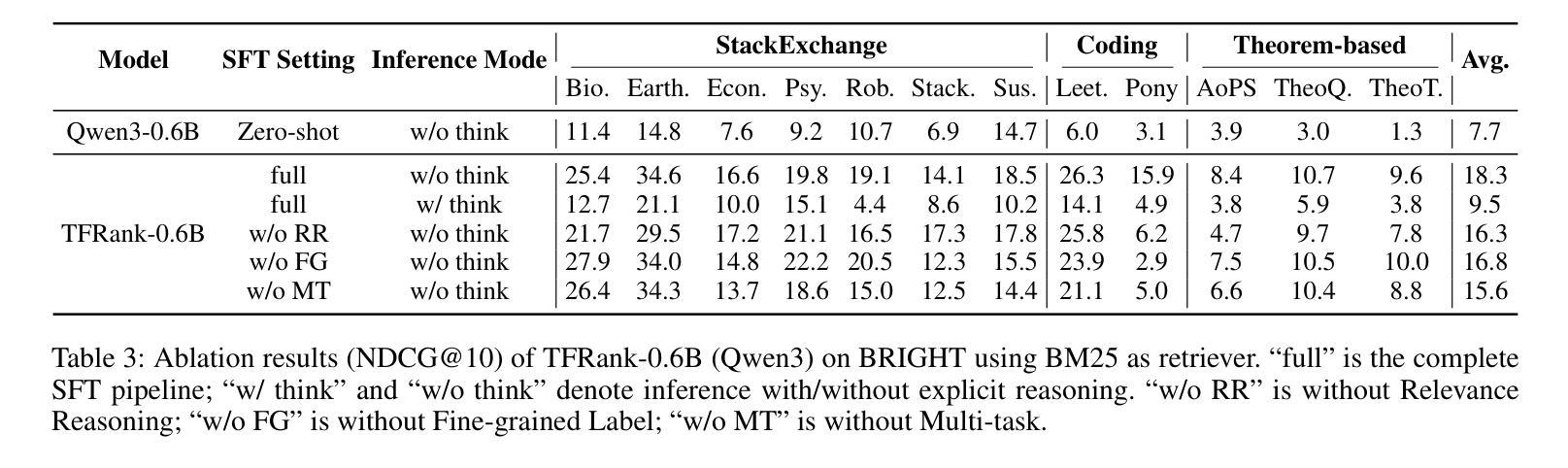
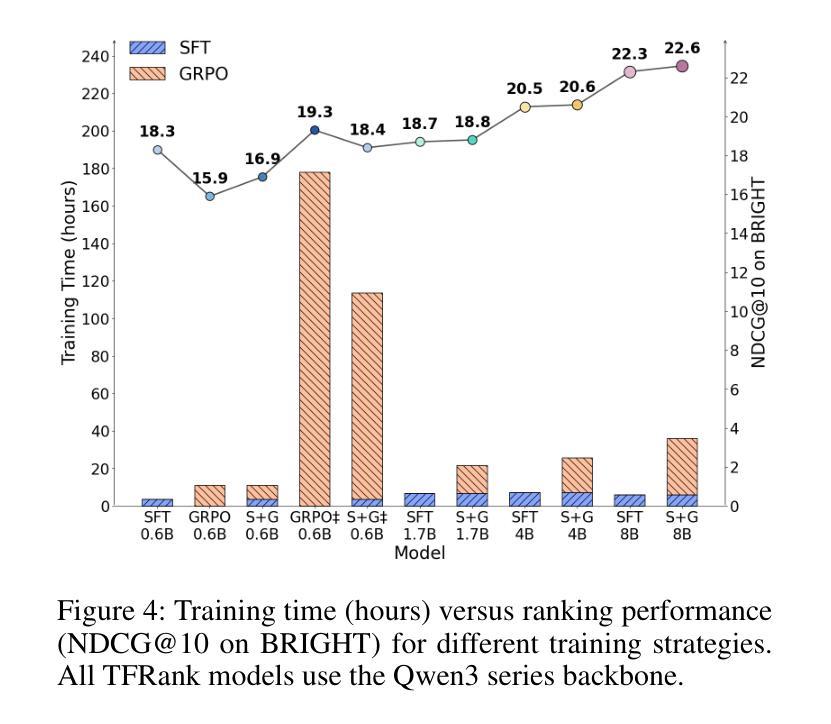
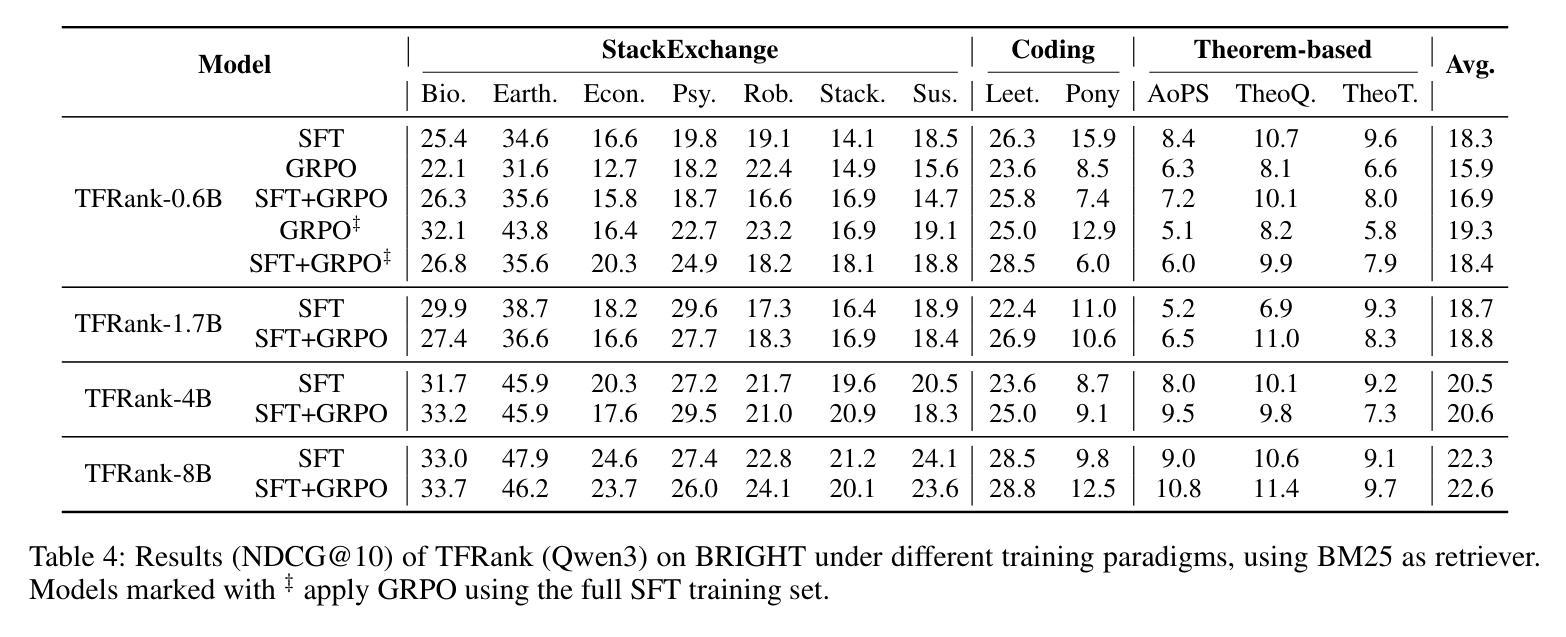
TFRank: Think-Free Reasoning Enables Practical Pointwise LLM Ranking
Authors:Yongqi Fan, Xiaoyang Chen, Dezhi Ye, Jie Liu, Haijin Liang, Jin Ma, Ben He, Yingfei Sun, Tong Ruan
Reasoning-intensive ranking models built on Large Language Models (LLMs) have made notable progress, but existing approaches often rely on large-scale LLMs and explicit Chain-of-Thought (CoT) reasoning, resulting in high computational cost and latency that limit real-world use. To address this, we propose \textbf{TFRank}, an efficient pointwise reasoning ranker based on small-scale LLMs. To improve ranking performance, TFRank effectively integrates CoT data, fine-grained score supervision, and multi-task training. Furthermore, it achieves an efficient \textbf{T}hink-\textbf{F}ree" reasoning capability by employing a think-mode switch’’ and pointwise format constraints. Specifically, this allows the model to leverage explicit reasoning during training while delivering precise relevance scores for complex queries at inference without generating any reasoning chains. Experiments show that TFRank (e.g., 1.7B) achieves performance comparable to models with four times more parameters on the BRIGHT benchmark, and demonstrates strong competitiveness on the BEIR benchmark. Further analysis shows that TFRank achieves an effective balance between performance and efficiency, providing a practical solution for integrating advanced reasoning into real-world systems. Our code and data are released in the repository: https://github.com/JOHNNY-fans/TFRank.
基于大型语言模型(LLM)的推理密集型排名模型已经取得了显著的进步,但现有方法往往依赖于大规模LLM和明确的思维链(CoT)推理,导致计算成本高和延迟,限制了其在现实世界中的应用。针对这一问题,我们提出了TFRank方案,这是一个基于小规模LLM的有效点推理排名器。为了提高排名性能,TFRank有效地整合了思维链数据、精细粒度的分数监督和多任务训练。此外,它通过采用“思考模式切换”和点格式约束,实现了高效的“无思考”推理能力。具体来说,这允许模型在训练过程中利用明确的推理,同时在推理时针对复杂查询提供精确的关联分数,无需生成任何推理链。实验表明,TFRank(例如,规模为1.7B)在BRIGHT基准测试中实现了与参数多四倍模型相当的性能,并在BEIR基准测试中表现出强大的竞争力。进一步的分析表明,TFRank在性能和效率之间实现了有效的平衡,为将高级推理集成到实际系统中提供了实用解决方案。我们的代码和数据已发布在存储库中:https://github.com/JOHNNY-fans/TFRank。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的推理密集型排名模型已取得显著进展,但现有方法通常依赖大规模LLM和显式链式思维(CoT)推理,导致计算成本高和延迟时间长,限制了其在现实世界中的应用。为解决此问题,我们提出TFRank,这是一种基于小规模LLM的高效点式推理排名器。TFRank通过整合CoT数据、精细分数监督和多任务训练,提高排名性能。此外,它通过使用“思维模式开关”和点格式约束,实现了高效的“无思考”推理能力。实验表明,TFRank(例如1.7B参数)在BRIGHT基准测试上的表现与参数多四倍的模型相当,并在BEIR基准测试上表现出强大的竞争力。进一步分析表明,TFRank在性能和效率之间实现了有效平衡,为将高级推理集成到现实系统中提供了实用解决方案。
Key Takeaways
- 现有推理密集型排名模型依赖大规模LLM和显式CoT推理,导致高计算成本和延迟。
- TFRank是一种基于小规模LLM的高效点式推理排名模型。
- TFRank通过整合CoT数据、精细分数监督和多任务训练来提高排名性能。
- TFRank实现了“无思考”推理能力,通过“思维模式开关”和点格式约束优化推理效率。
- 实验显示,TFRank在性能上表现优异,与较大的模型相当或在某些基准测试中更具竞争力。
- TFRank在性能和效率之间实现了平衡,为集成高级推理到现实系统中提供了实用解决方案。
点此查看论文截图

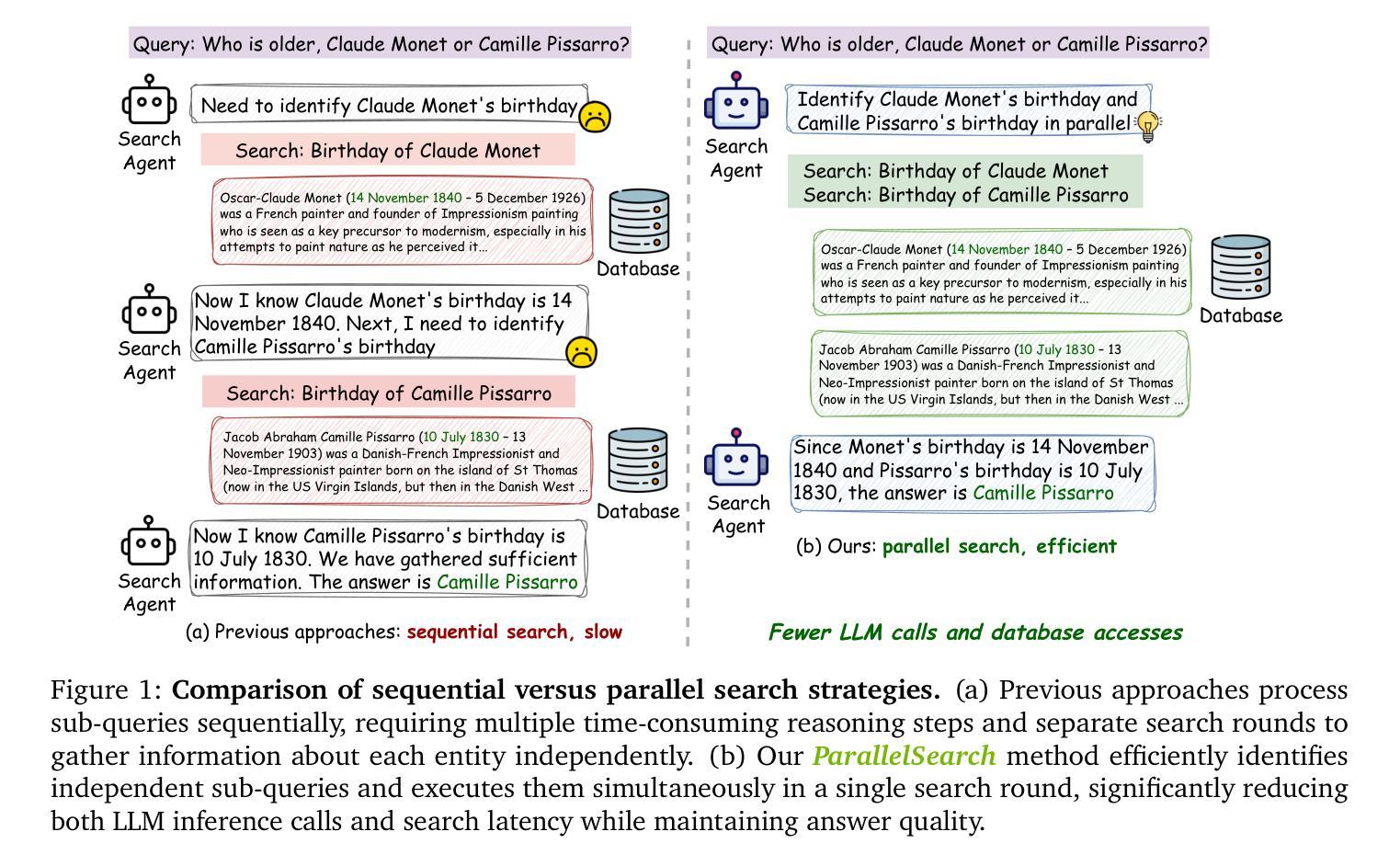
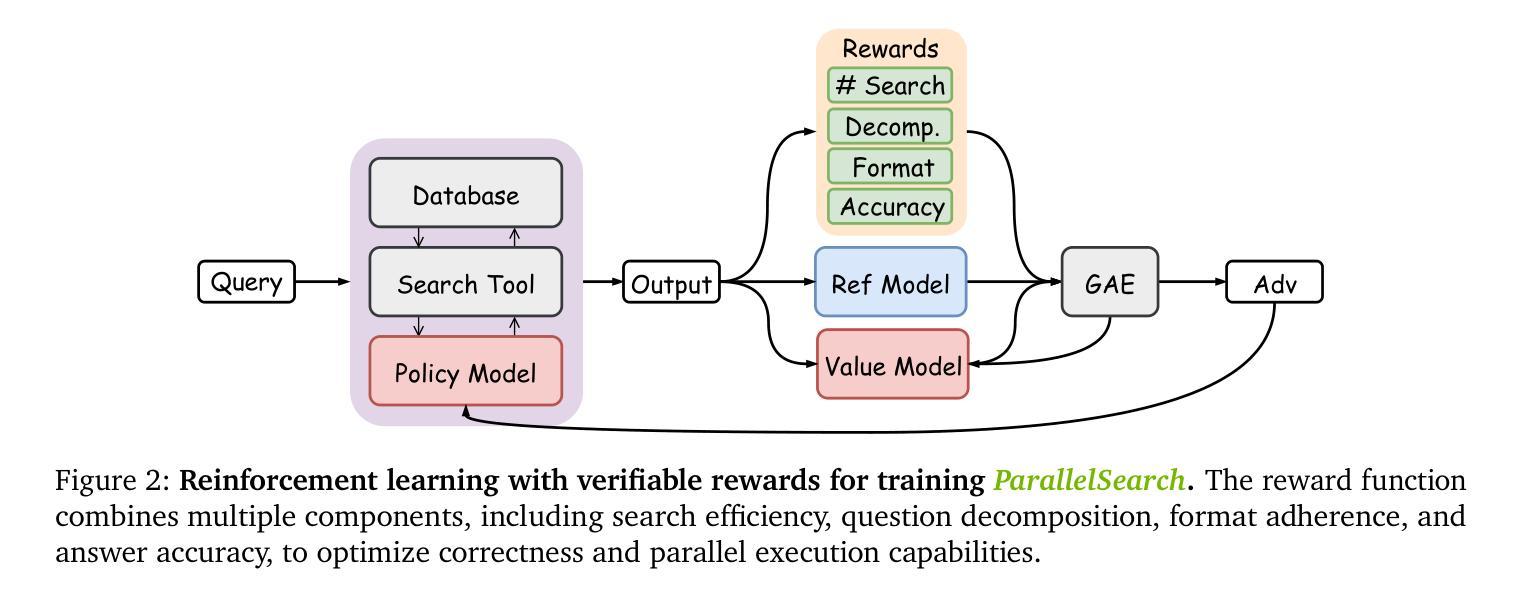
ParallelSearch: Train your LLMs to Decompose Query and Search Sub-queries in Parallel with Reinforcement Learning
Authors:Shu Zhao, Tan Yu, Anbang Xu, Japinder Singh, Aaditya Shukla, Rama Akkiraju
Reasoning-augmented search agents such as Search-R1, trained via reinforcement learning with verifiable rewards (RLVR), demonstrate remarkable capabilities in multi-step information retrieval from external knowledge sources. These agents address the limitations of their parametric memory by dynamically gathering relevant facts to address complex reasoning tasks. However, existing approaches suffer from a fundamental architectural limitation: they process search queries strictly sequentially, even when handling inherently parallelizable and logically independent comparisons. This sequential bottleneck significantly constrains computational efficiency, particularly for queries that require multiple entity comparisons. To address this critical limitation, we propose ParallelSearch, a novel reinforcement learning framework that empowers large language models (LLMs) to recognize parallelizable query structures and execute multiple search operations concurrently. Our approach introduces dedicated reward functions that incentivize the identification of independent query components while preserving answer accuracy through jointly considering correctness, query decomposition quality, and parallel execution benefits. Comprehensive experiments demonstrate that ParallelSearch outperforms state-of-the-art baselines by an average performance gain of 2.9% across seven question-answering benchmarks. Notably, on parallelizable questions, our method achieves a 12.7% performance improvement while requiring only 69.6% of the LLM calls compared to sequential approaches.
基于强化学习并使用可验证奖励(RLVR)训练的推理增强搜索代理,如Search-R1,在多步信息检索方面表现出从外部知识源获取显著的能力。这些代理通过动态收集相关事实来解决复杂的推理任务,从而克服了其参数内存的局限性。然而,现有方法存在基本架构上的局限性:它们严格地按顺序处理搜索查询,即使处理本质上可并行化和逻辑上独立的比较也是如此。这种顺序瓶颈显著地限制了计算效率,特别是对于需要多个实体比较查询。为了解决这一关键局限性,我们提出了ParallelSearch,这是一种新型强化学习框架,使大型语言模型(LLM)能够识别可并行化的查询结构并同时执行多个搜索操作。我们的方法引入了专用奖励功能,以激励独立查询组件的识别,同时联合考虑正确性、查询分解质量和并行执行效益来保持答案的准确性。综合实验表明,ParallelSearch在七个问答基准测试上的平均性能优于最新技术基线2.9%。值得注意的是,对于可并行化的问题,我们的方法在性能上提高了12.7%,同时与顺序方法相比,只需要LLM调用的69.6%。
论文及项目相关链接
Summary
基于强化学习与可验证奖励(RLVR)训练的Search-R1等推理增强搜索代理在多步信息检索中具有出色的能力,能从外部知识源获取相关事实以解决复杂的推理任务。然而,现有方法存在根本的架构限制:它们严格地按顺序处理搜索查询,即使处理本质上可并行化和逻辑独立的比较也是如此。为解决这一限制,我们提出了ParallelSearch,这是一个新的强化学习框架,能使大型语言模型(LLMs)识别可并行查询结构并同时执行多个搜索操作。通过引入专用奖励函数来激励独立查询组件的识别,同时联合考虑正确性、查询分解质量和并行执行效益来保持答案的准确性。实验表明,ParallelSearch在七个问答基准测试中平均性能提升2.9%,在可并行化问题上性能提升达12.7%,且相较于顺序方法仅需要69.6%的LLM调用次数。
Key Takeaways
- 推理增强搜索代理如Search-R1在解决复杂推理任务时,能够从外部知识源动态获取相关事实。
- 现有搜索方法存在顺序处理查询的瓶颈,限制了计算效率,特别是在需要多实体比较的问题中。
- ParallelSearch框架被提出以解决此问题,使大型语言模型能够识别并行查询结构并执行并行搜索操作。
- ParallelSearch通过专用奖励函数来平衡查询的独立组件识别和答案的准确性。
- 实验结果显示,ParallelSearch在多个问答基准测试中性能优越,平均提升2.9%。
- 在可并行化问题上,ParallelSearch的性能提升尤为显著,达到12.7%。
点此查看论文截图


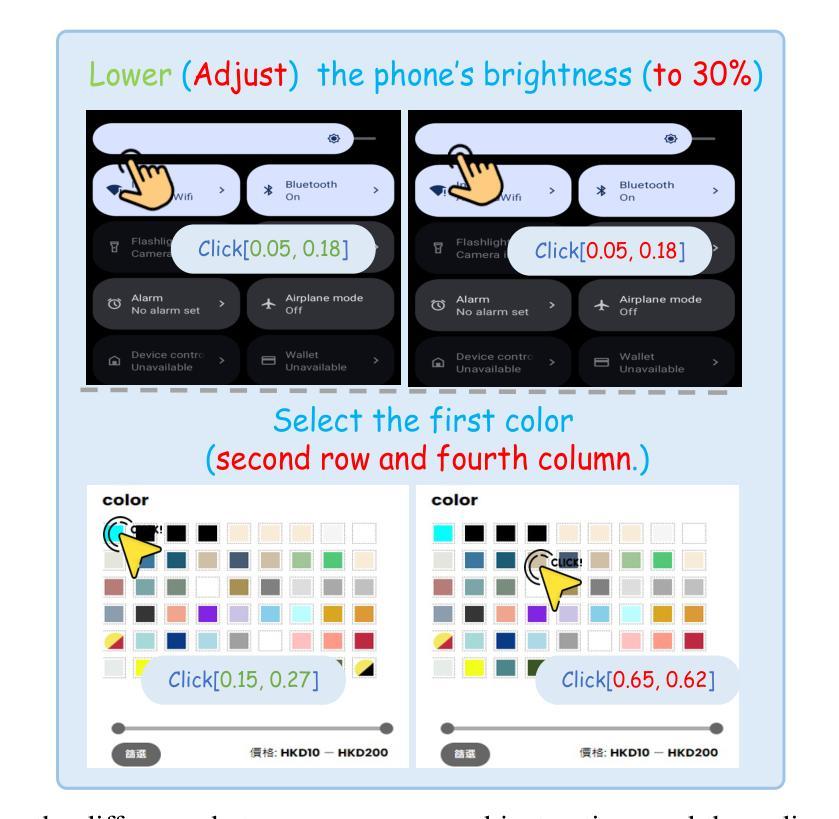
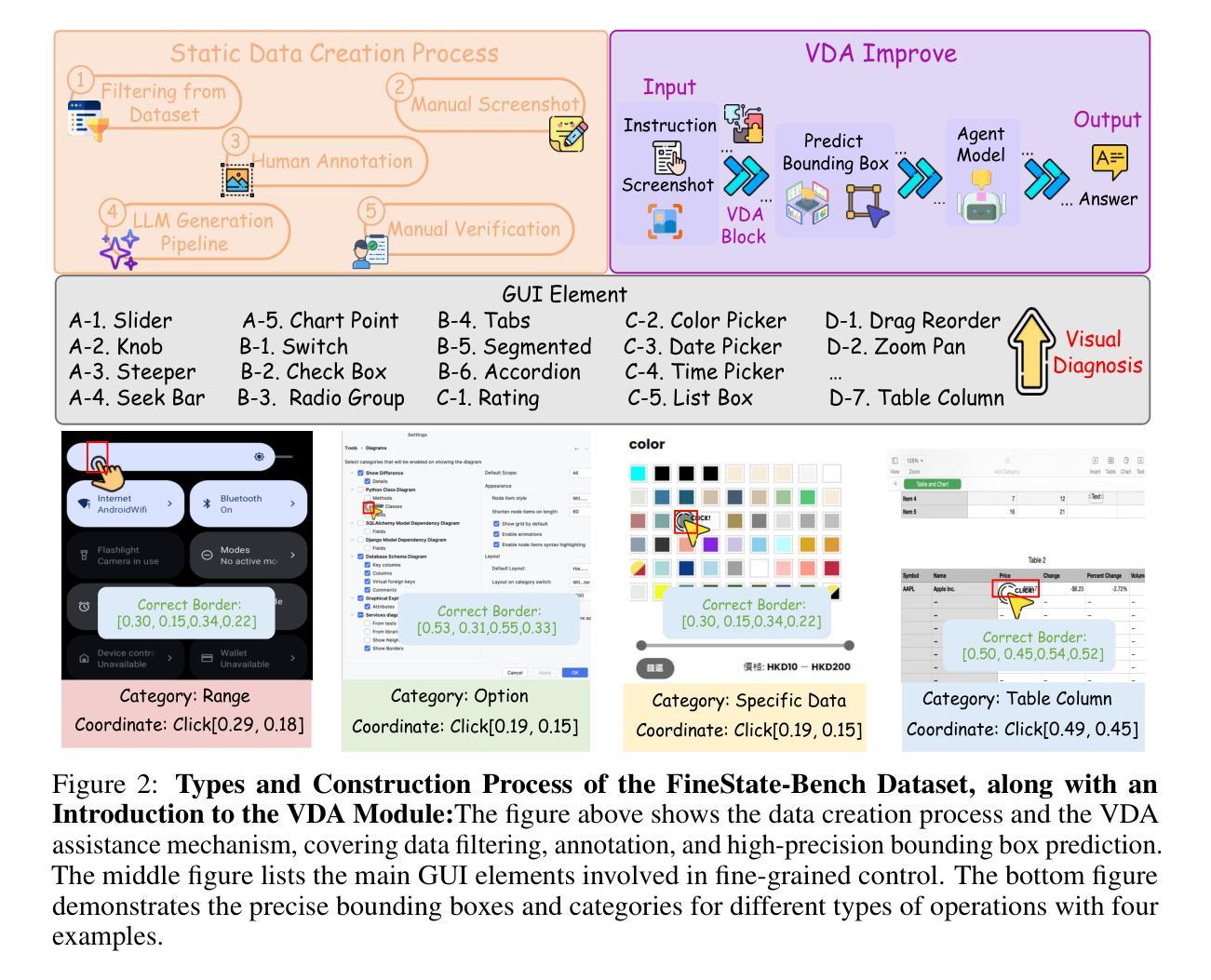
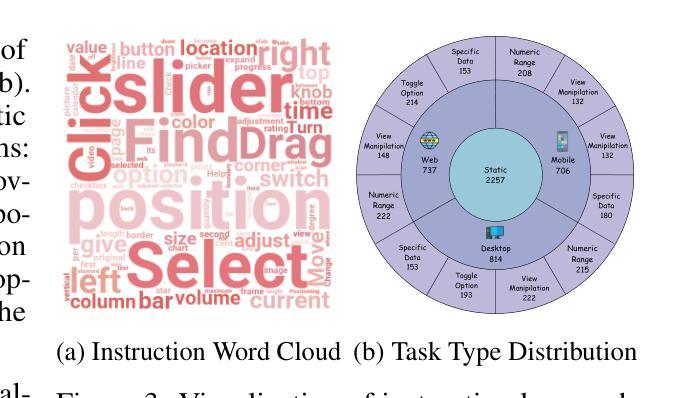
FineState-Bench: A Comprehensive Benchmark for Fine-Grained State Control in GUI Agents
Authors:Fengxian Ji, Jingpu Yang, Zirui Song, Yuanxi Wang, Zhexuan Cui, Yuke Li, Qian Jiang, Miao Fang, Xiuying Chen
With the rapid advancement of generative artificial intelligence technology, Graphical User Interface (GUI) agents have demonstrated tremendous potential for autonomously managing daily tasks through natural language instructions. However, current evaluation frameworks for GUI agents suffer from fundamental flaws: existing benchmarks overly focus on coarse-grained task completion while neglecting fine-grained control capabilities crucial for real-world applications. To address this, we introduce FineState-Bench, the first evaluation and diagnostic standard for fine-grained GUI proxy operations, designed to quantify fine-grained control. This multi-platform (desktop, Web, mobile) framework includes 2257 task benchmarks in four components and uses a four-phase indicator for comprehensive perception-to-control assessment. To analyze perception and positioning for refined operations, we developed the plug-and-play Visual Diagnostic Assistant (VDA), enabling the first quantitative decoupling analysis of these capabilities. Experimental results on our benchmark show that the most advanced models achieve only 32.8% fine-grained interaction accuracy. Using our VDA in controlled experiments, quantifying the impact of visual capabilities, we showed that ideal visual localization boosts Gemini-2.5-Flash’s success rate by 14.9%. Our diagnostic framework confirms for the first time that the primary bottleneck for current GUI proxies is basic visual positioning capability.All resources are fully open-source. github: https://github.com/AnonymousThewarehouse/FineState-Bench huggingface: https://huggingface.co/datasets/Willtime2006/Static-FineBench
随着生成式人工智能技术的快速发展,图形用户界面(GUI)代理通过自然语言指令自主管理日常任务方面展现出巨大的潜力。然而,现有的GUI代理评估框架存在根本缺陷:现有基准测试过于关注粗粒度的任务完成,而忽视对于现实世界应用至关重要的精细粒度控制功能。为了解决这一问题,我们推出了FineState-Bench,这是首个针对精细粒度GUI代理操作的评估与诊断标准,旨在量化精细粒度控制。这一多平台(桌面、网页、移动)框架包括四个组件中的2257项任务基准测试,并使用四阶段指标进行全方位的感知到控制的评估。为了对精细操作的感知和定位进行分析,我们开发了即插即用的视觉诊断助手(VDA),实现对这些能力的首次定量解耦分析。在我们的基准测试上的实验结果表明,最先进的模型仅实现了32.8%的精细交互准确率。在受控实验中,我们使用VDA量化视觉功能的影响,并显示理想的视觉定位可以将Gemini-2.5-Flash的成功率提高14.9%。我们的诊断框架首次证实,当前GUI代理的主要瓶颈在于基本的视觉定位能力。所有资源均完全开源。GitHub地址:https://github.com/AnonymousThewarehouse/FineState-Bench;Huggingface地址:https://huggingface.co/datasets/Willtime2006/Static-FineBench。
论文及项目相关链接
PDF submit/6682470 (Fengxian Ji)
Summary
随着生成式人工智能技术的快速发展,图形用户界面(GUI)代理在通过自然语言指令自主管理日常任务方面展现出巨大潜力。然而,现有的GUI代理评估框架存在根本性缺陷,过于关注粗粒度任务完成,忽视了现实世界应用中至关重要的精细控制功能。为解决这一问题,我们推出了FineState-Bench,这是首个用于精细粒度GUI代理操作的评估与诊断标准,旨在量化精细控制。此跨平台(桌面、网络、移动)框架包括四种成分的2257项任务基准测试,并使用四阶段指标进行全面感知到控制的评估。我们还开发了即插即用视觉诊断助手(VDA),用于分析精细操作的感知和定位能力,实现了这些能力的首次定量解耦分析。实验结果显示,最先进的模型精细交互准确率仅为32.8%。通过我们的VDA进行的受控实验表明,理想的视觉定位功能可以提升Gemini-2.5-Flash的成功率14.9%。我们的诊断框架首次证实,当前GUI代理的主要瓶颈在于基本的视觉定位能力。
Key Takeaways
- GUI代理在日常任务管理中展现潜力。
- 当前评估框架忽略精细控制功能的重要性。
- 推出FineState-Bench框架,用于精细粒度GUI操作的评估与诊断。
- 框架包含2257项任务基准测试,涵盖多种平台。
- 使用四阶段指标全面评估感知到控制的过程。
- 开发VDA进行感知和定位能力的定量解耦分析。
点此查看论文截图


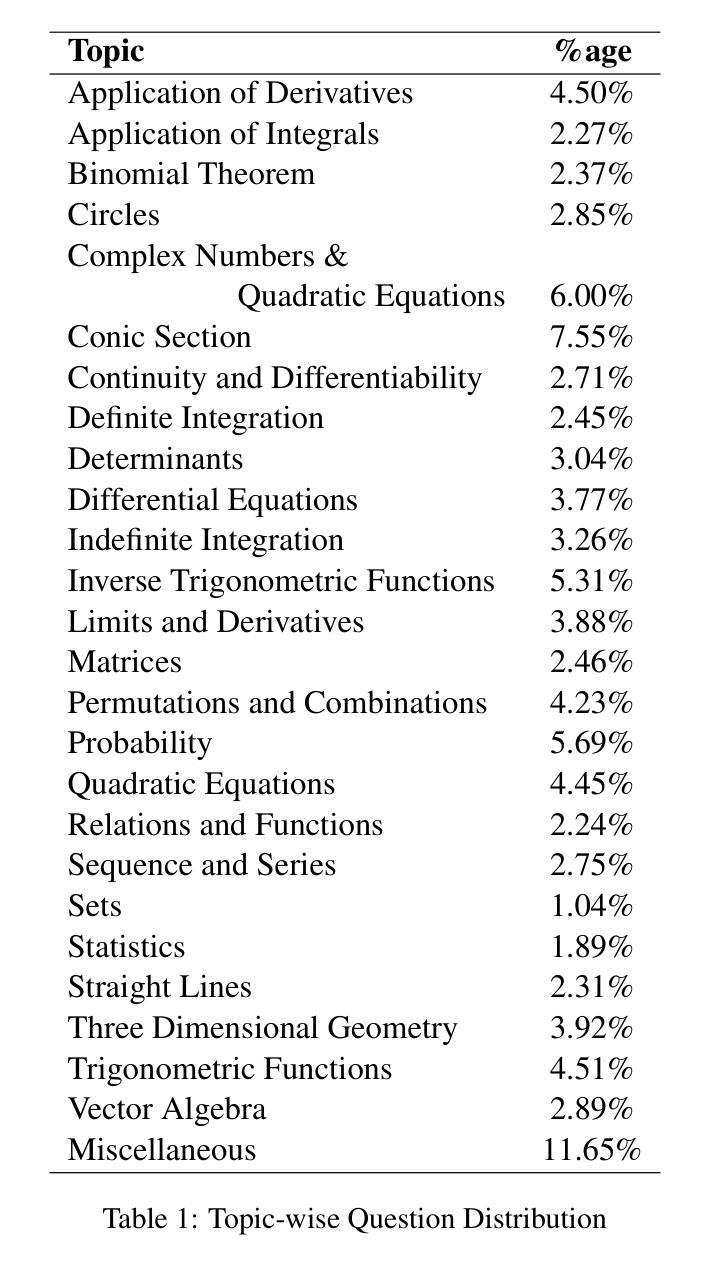
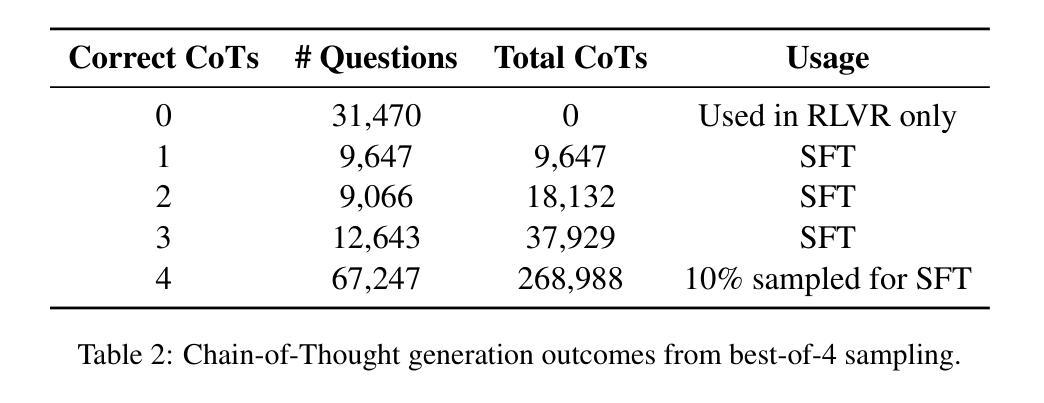
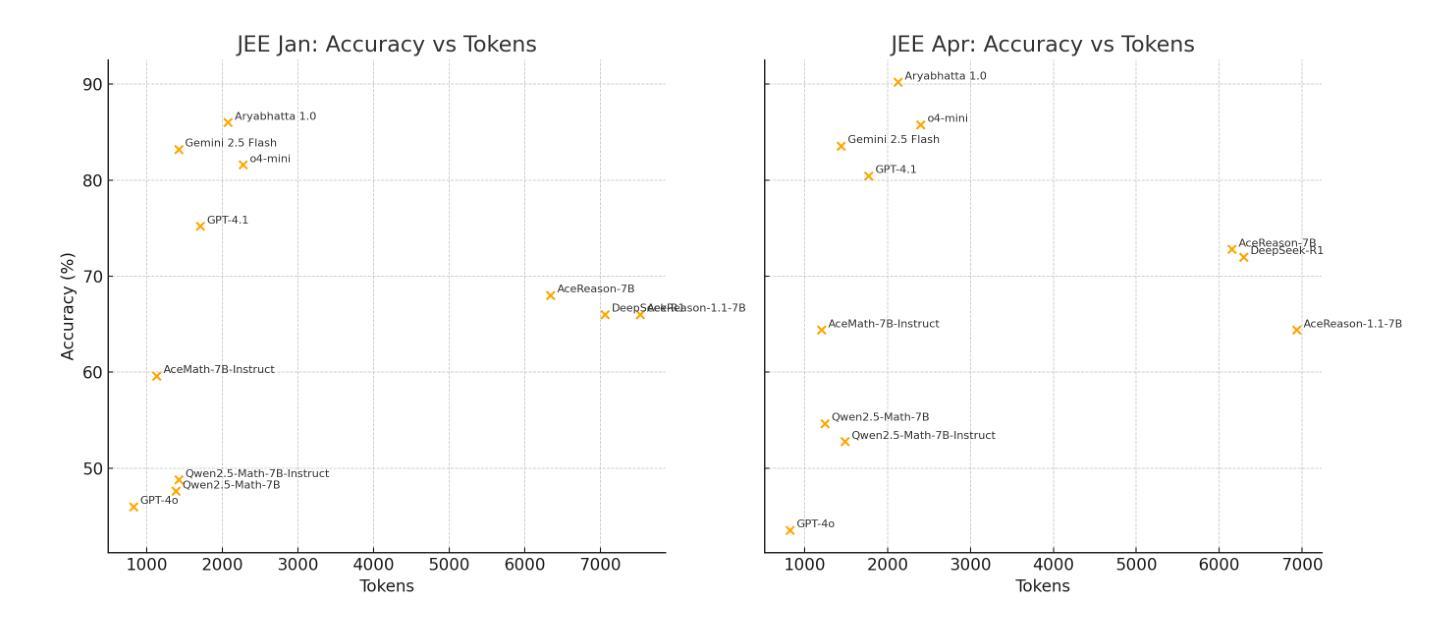
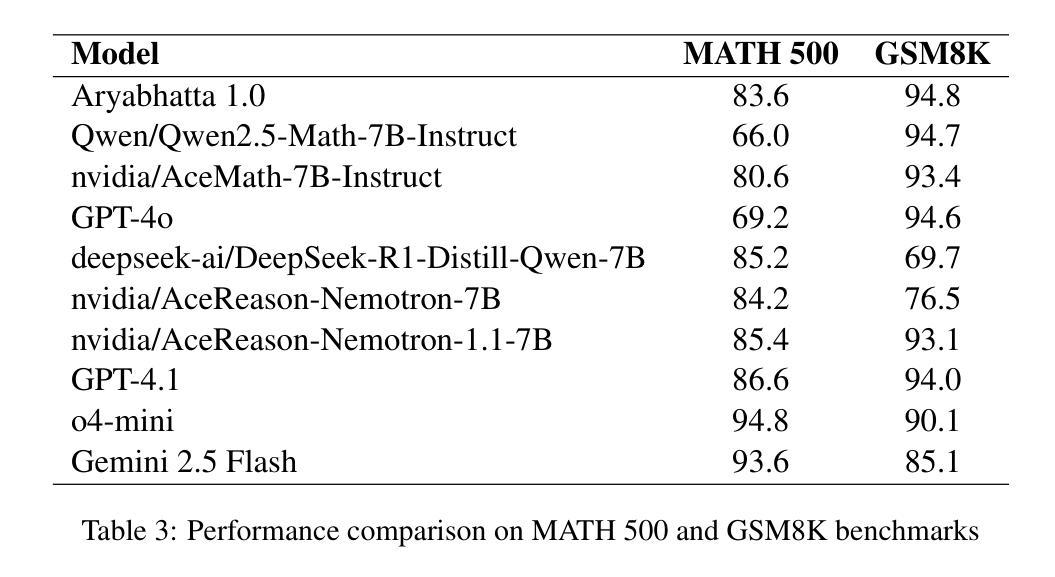
Aryabhata: An exam-focused language model for JEE Math
Authors:Ritvik Rastogi, Sachin Dharashivkar, Sandeep Varma
We present Aryabhata 1.0, a compact 7B parameter math reasoning model optimized for the Indian academic exam, the Joint Entrance Examination (JEE). Despite rapid progress in large language models (LLMs), current models often remain unsuitable for educational use. Aryabhata 1.0 is built by merging strong open-weight reasoning models, followed by supervised fine-tuning (SFT) with curriculum learning on verified chain-of-thought (CoT) traces curated through best-of-$n$ rejection sampling. To further boost performance, we apply reinforcement learning with verifiable rewards (RLVR) using A2C objective with group-relative advantage estimation along with novel exploration strategies such as Adaptive Group Resizing and Temperature Scaling. Evaluated on both in-distribution (JEE Main 2025) and out-of-distribution (MATH, GSM8K) benchmarks, Aryabhata outperforms existing models in accuracy and efficiency, while offering pedagogically useful step-by-step reasoning. We release Aryabhata as a foundation model to advance exam-centric, open-source small language models. This marks our first open release for community feedback (https://huggingface.co/PhysicsWallahAI/Aryabhata-1.0); PW is actively training future models to further improve learning outcomes for students.
我们推出了Aryabhata 1.0,这是一款针对印度学术考试——联合入学考试(JEE)优化的数学推理模型,具有紧凑的7亿参数。尽管大型语言模型(LLM)发展迅速,但当前模型在学术应用上仍有诸多不足。Aryabhata 1.0通过合并强大的开放权重推理模型,随后采用监督微调(SFT)与课程学习的方式,对通过最佳n拒绝采样筛选的验证思维链(CoT)轨迹进行训练。为了进一步提升性能,我们采用强化学习结合可验证奖励(RLVR),使用A2C目标进行群体相对优势评估,并辅以新型策略,如自适应小组调整和温度缩放。我们在内部数据集(JEE Main 2025)和外部数据集(MATH、GSM8K)上评估Aryabhata的表现,其在准确性和效率方面均优于现有模型,同时提供循序渐进的推理步骤,有助于教学。我们发布Aryabhata作为基础模型,推动以考试为中心的小型开源语言模型的发展。这是我们首次公开发布,以收集社区反馈;PhysicsWallah正在积极训练未来模型,以进一步改善学生的学习成果。[https://huggingface.co/PhysicsWallahAI/Aryabhata-1.0]
论文及项目相关链接
Summary:
Aryabhata 1.0是一款针对印度联考(JEE)优化的数学推理模型,具有7亿参数。它通过合并强大的开放权重推理模型,然后进行监督微调(SFT)和课程学习来增强性能。此外,使用可验证奖励的强化学习(RLVR)和自适应分组调整等技术来提高性能。Aryabhata在准确性和效率方面优于现有模型,并提供了逐步推理的教导功能。作为考试中心的小型语言模型的基石模型发布,用于收集社区反馈以改进未来的模型。
Key Takeaways:
- Aryabhata 1.0是一款针对印度联考(JEE)的数学推理模型。
- 该模型融合了多种技术优化手段:包括监督微调(SFT)、课程学习、强化学习等。
3.Aryabhata采用了经过验证的思维轨迹,采用最佳拒绝抽样来提高模型的推理准确性。 - 通过使用自适应分组调整和温度缩放等新颖策略提高了模型的性能。
- 在分布内和分布外的基准测试中,Aryabhata表现出优异的准确性和效率。
6.Aryabhata提供了逐步推理的教导功能,有助于学生理解和学习。
点此查看论文截图


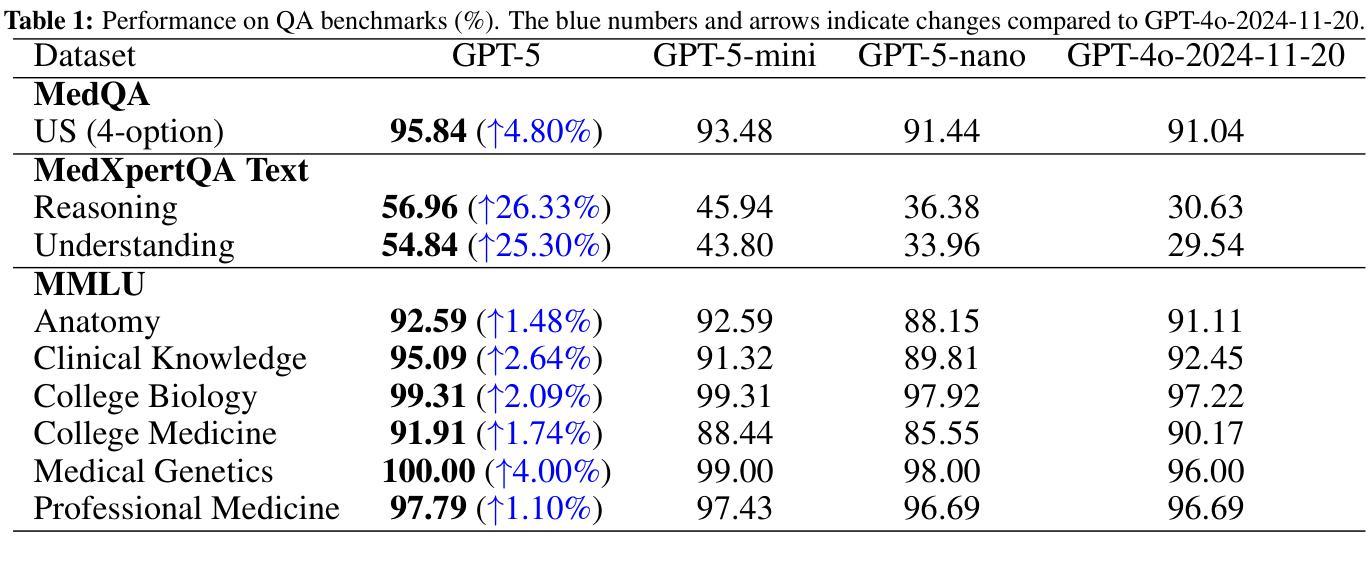
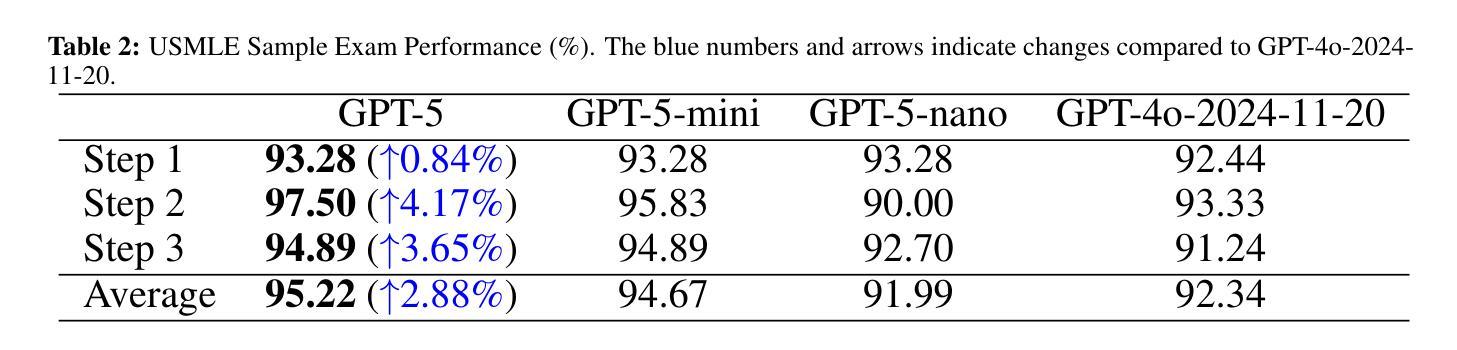
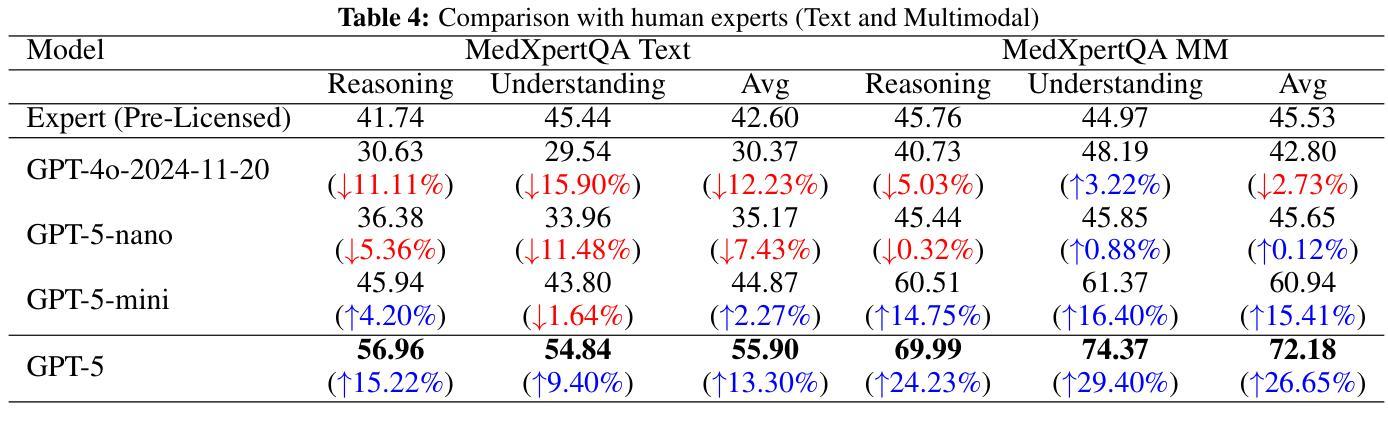
Capabilities of GPT-5 on Multimodal Medical Reasoning
Authors:Shansong Wang, Mingzhe Hu, Qiang Li, Mojtaba Safari, Xiaofeng Yang
Recent advances in large language models (LLMs) have enabled general-purpose systems to perform increasingly complex domain-specific reasoning without extensive fine-tuning. In the medical domain, decision-making often requires integrating heterogeneous information sources, including patient narratives, structured data, and medical images. This study positions GPT-5 as a generalist multimodal reasoner for medical decision support and systematically evaluates its zero-shot chain-of-thought reasoning performance on both text-based question answering and visual question answering tasks under a unified protocol. We benchmark GPT-5, GPT-5-mini, GPT-5-nano, and GPT-4o-2024-11-20 against standardized splits of MedQA, MedXpertQA (text and multimodal), MMLU medical subsets, USMLE self-assessment exams, and VQA-RAD. Results show that GPT-5 consistently outperforms all baselines, achieving state-of-the-art accuracy across all QA benchmarks and delivering substantial gains in multimodal reasoning. On MedXpertQA MM, GPT-5 improves reasoning and understanding scores by +29.26% and +26.18% over GPT-4o, respectively, and surpasses pre-licensed human experts by +24.23% in reasoning and +29.40% in understanding. In contrast, GPT-4o remains below human expert performance in most dimensions. A representative case study demonstrates GPT-5’s ability to integrate visual and textual cues into a coherent diagnostic reasoning chain, recommending appropriate high-stakes interventions. Our results show that, on these controlled multimodal reasoning benchmarks, GPT-5 moves from human-comparable to above human-expert performance. This improvement may substantially inform the design of future clinical decision-support systems.
近期大型语言模型(LLM)的进展使得通用系统能够在不需要广泛微调的情况下执行越来越复杂的特定领域推理。在医疗领域,决策制定通常需要整合多种异构信息源,包括患者叙述、结构化数据和医疗图像。本研究将GPT-5定位为医疗决策支持领域的通用多模态推理器,并在统一协议下系统地评估其在基于文本的问题回答和视觉问题回答任务上的零镜头思维链推理性能。我们用MedQA、MedXpertQA(文本和多模态)、MMLU医疗子集、USMLE自我评估考试和VQA-RAD的标准分割数据来评估GPT-5、GPT-5-mini、GPT-5-nano以及GPT-4o-2024-11-20的性能。结果表明,GPT-5持续超越所有基线,在所有问答基准测试中达到最先进的准确性,并在多模态推理方面取得实质性进展。在MedXpertQA MM上,GPT-5的推理和理解分数分别比GPT-4o高出+29.26%和+26.18%,并且在推理和理解方面超越预授权的人类专家+24.23%和+29.40%。相比之下,GPT-4o在大多数维度上仍低于人类专家的性能。一个典型的案例研究展示了GPT-5将视觉和文本线索整合到连贯的诊断推理链中的能力,并推荐适当的高风险干预措施。我们的结果表明,在这些受控的多模态推理基准测试中,GPT-5的性能已经从与人类相当提升到了超越人类专家的水平。这一进步可能会极大地影响未来临床决策支持系统的设计。
论文及项目相关链接
PDF Corrected some typos
Summary
大型语言模型(LLM)的最新进展使得通用系统能够在不需要广泛微调的情况下执行越来越复杂的领域特定推理。本研究将GPT-5定位为医疗决策支持的一般性多模式推理器,并系统地评估其在统一协议下基于文本和视觉的问题回答任务的零起点思维链推理性能。GPT-5在所有问答基准测试中均表现出卓越的性能,并在多模式推理方面取得了实质性的进步。在MedXpertQA MM上,GPT-5的推理和理解得分分别比GPT-4o高出+29.26%和+26.18%,并且在推理和理解方面分别超出预授权的人类专家+24.23%和+29.40%。相反,GPT-4o在大多数维度上仍低于人类专家的性能。一个典型的案例研究展示了GPT-5将视觉和文本线索整合到连贯的诊断推理链中的能力,并推荐了适当的高风险干预措施。我们的结果表明,在这些受控的多模式推理基准测试中,GPT-5的性能已经从人类相当的水平提升到了超越人类专家的水平。这一进步可以为未来的临床决策支持系统提供重要的参考。
Key Takeaways
- 大型语言模型(LLM)可以在不广泛微调的情况下执行复杂的领域特定推理。
- GPT-5被定位为医疗决策支持中的一般性多模式推理器。
- GPT-5在多种医疗问答基准测试中表现出卓越的性能,尤其是多模式推理方面。
- GPT-5在推理和理解方面的得分超出预授权的人类专家。
- GPT-5能将视觉和文本线索整合到连贯的诊断推理链中。
- GPT-5的性能超越了许多预训练模型,甚至在某些方面超越了人类专家。
点此查看论文截图




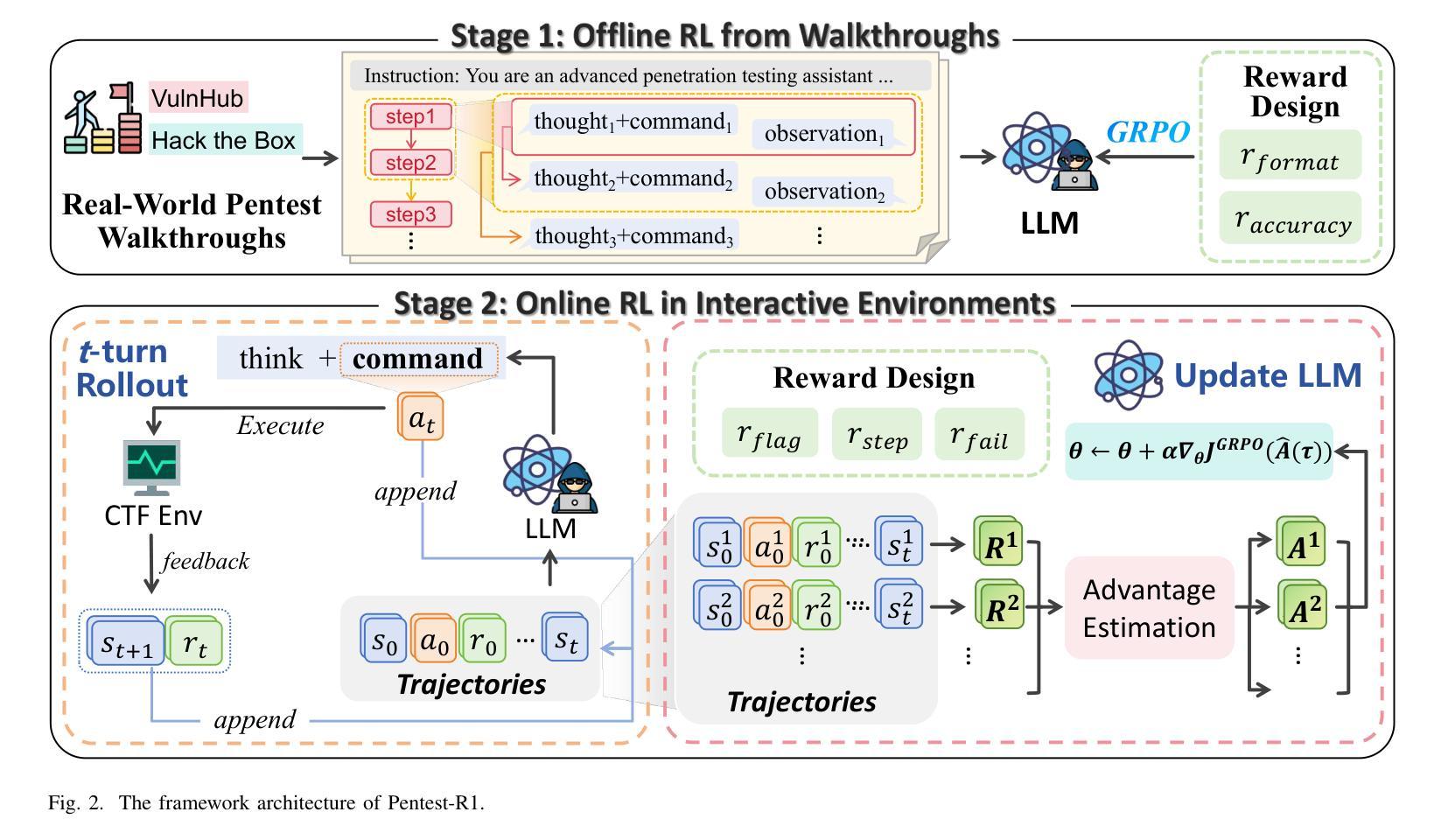
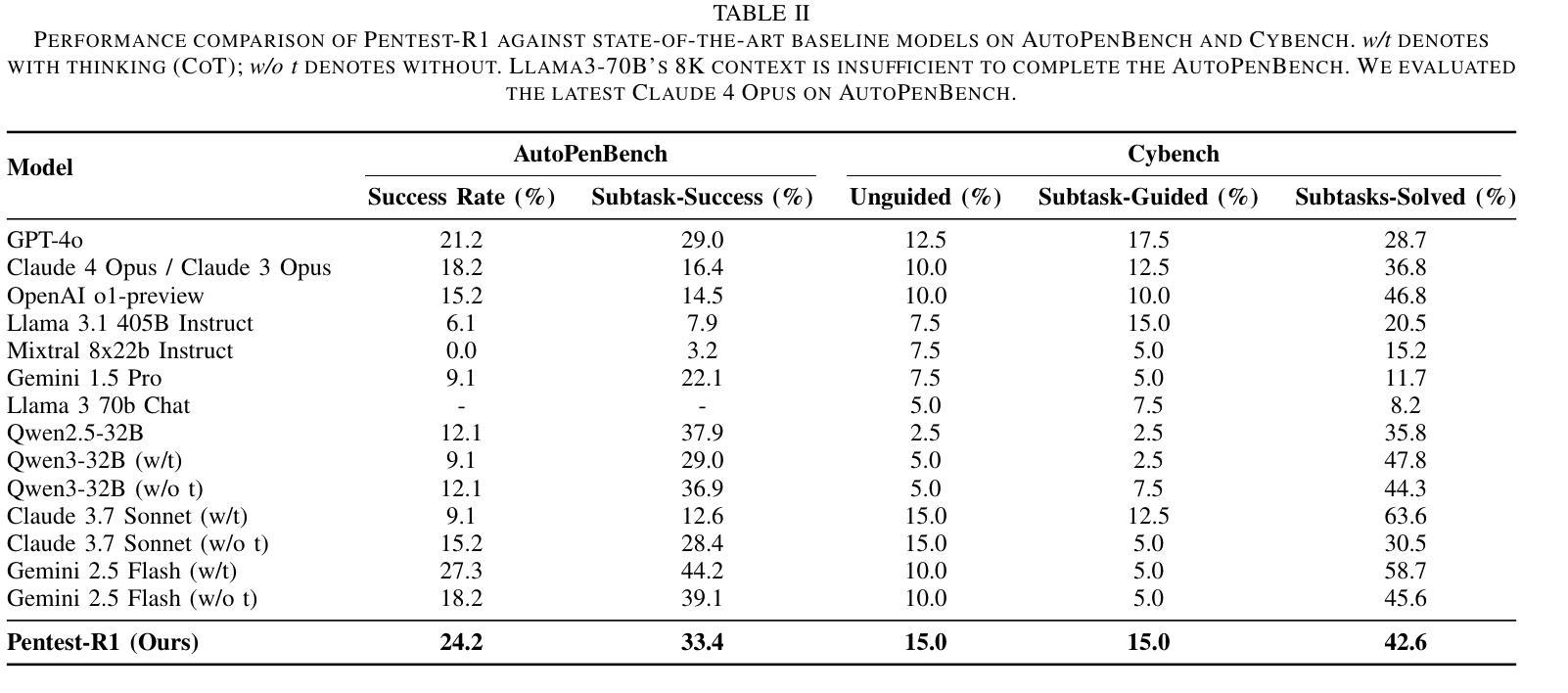
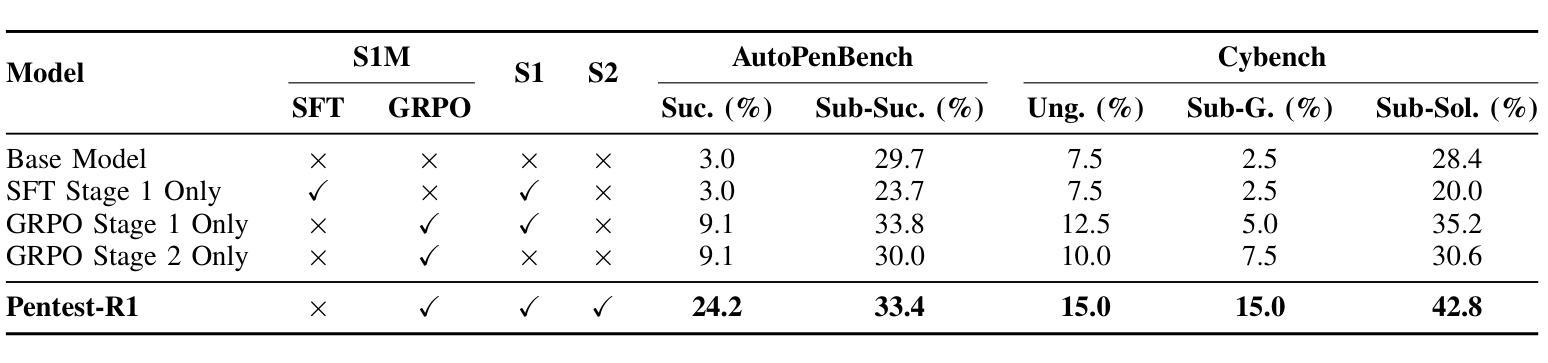
Pentest-R1: Towards Autonomous Penetration Testing Reasoning Optimized via Two-Stage Reinforcement Learning
Authors:He Kong, Die Hu, Jingguo Ge, Liangxiong Li, Hui Li, Tong Li
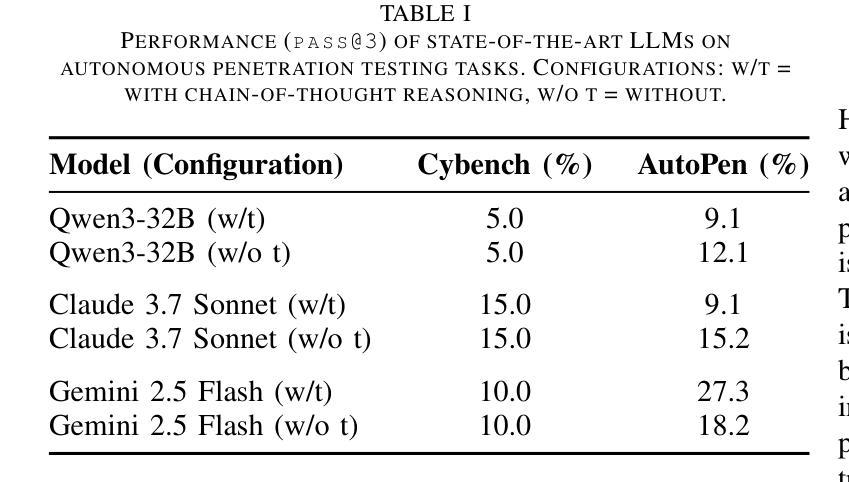
Automating penetration testing is crucial for enhancing cybersecurity, yet current Large Language Models (LLMs) face significant limitations in this domain, including poor error handling, inefficient reasoning, and an inability to perform complex end-to-end tasks autonomously. To address these challenges, we introduce Pentest-R1, a novel framework designed to optimize LLM reasoning capabilities for this task through a two-stage reinforcement learning pipeline. We first construct a dataset of over 500 real-world, multi-step walkthroughs, which Pentest-R1 leverages for offline reinforcement learning (RL) to instill foundational attack logic. Subsequently, the LLM is fine-tuned via online RL in an interactive Capture The Flag (CTF) environment, where it learns directly from environmental feedback to develop robust error self-correction and adaptive strategies. Our extensive experiments on the Cybench and AutoPenBench benchmarks demonstrate the framework’s effectiveness. On AutoPenBench, Pentest-R1 achieves a 24.2% success rate, surpassing most state-of-the-art models and ranking second only to Gemini 2.5 Flash. On Cybench, it attains a 15.0% success rate in unguided tasks, establishing a new state-of-the-art for open-source LLMs and matching the performance of top proprietary models. Ablation studies confirm that the synergy of both training stages is critical to its success.
自动化渗透测试对于增强网络安全至关重要,然而当前的大型语言模型(LLM)在这一领域面临重大挑战,包括错误处理不佳、推理效率低下以及无法自主完成复杂的端到端任务。为了应对这些挑战,我们推出了Pentest-R1,这是一个新型框架,旨在通过两阶段强化学习管道优化LLM的推理能力,以完成此任务。我们首先构建了包含超过500个真实世界、多步骤详解的数据集,Pentest-R1利用这些数据集进行离线强化学习(RL),以灌输基本的攻击逻辑。随后,LLM在一个交互式的Capture The Flag(CTF)环境中通过在线RL进行微调,它直接从环境反馈中学习,以发展稳健的错误自我修正和自适应策略。我们在Cybench和AutoPenBench基准测试上的大量实验证明了该框架的有效性。在AutoPenBench上,Pentest-R1的成功率达到24.2%,超越了大多数最先进的模型,仅次于Gemini 2.5 Flash。在Cybench上,它在无指导任务中的成功率达到15.0%,为开源LLM创造了新的最先进的性能,并与顶级专有模型的性能相匹配。消融研究证实,两个训练阶段的协同作用是成功的关键。
论文及项目相关链接
Summary:自动化渗透测试对提升网络安全至关重要,但大型语言模型(LLMs)在这一领域存在诸多挑战,如错误处理不佳、推理效率低下以及无法自主完成复杂端到端任务等。为应对这些挑战,我们提出了Pentest-R1框架,通过两阶段强化学习管道优化LLM的推理能力。首先,我们构建了一个包含超过500个真实世界多步骤流程的数据集,用于离线强化学习(RL),为Pentest-R1提供基础攻击逻辑。然后,通过在线RL在交互式Capture The Flag(CTF)环境中对LLM进行微调,使其直接从环境反馈中学习,发展出强大的错误自我修正和自适应策略。在Cybench和AutoPenBench基准测试上的实验证明了该框架的有效性。Pentest-R1在AutoPenBench上取得了24.2%的成功率,优于大多数最先进的模型,仅次于Gemini 2.5 Flash。在Cybench上,它在无指导任务中达到了15.0%的成功率,为开源LLMs创造了新的最佳水平,并匹配了顶级专有模型的性能。消融研究证实,两个阶段训练的协同作用是成功的关键。
Key Takeaways:
- 自动化渗透测试对增强网络安全至关重要,但当前大型语言模型(LLMs)在此领域存在挑战。
- Pentest-R1框架旨在通过两阶段强化学习解决LLM在渗透测试中的局限性。
- 第一阶段利用离线RL和真实世界数据集为LLM传授基础攻击逻辑。
- 第二阶段通过在线RL在CTF环境中对LLM进行微调,提升错误自我修正和自适应策略。
- Pentest-R1在AutoPenBench和Cybench基准测试上表现出优异性能。
- 在AutoPenBench上,Pentest-R1的成功率超过多数现有模型,并接近最佳表现。
点此查看论文截图



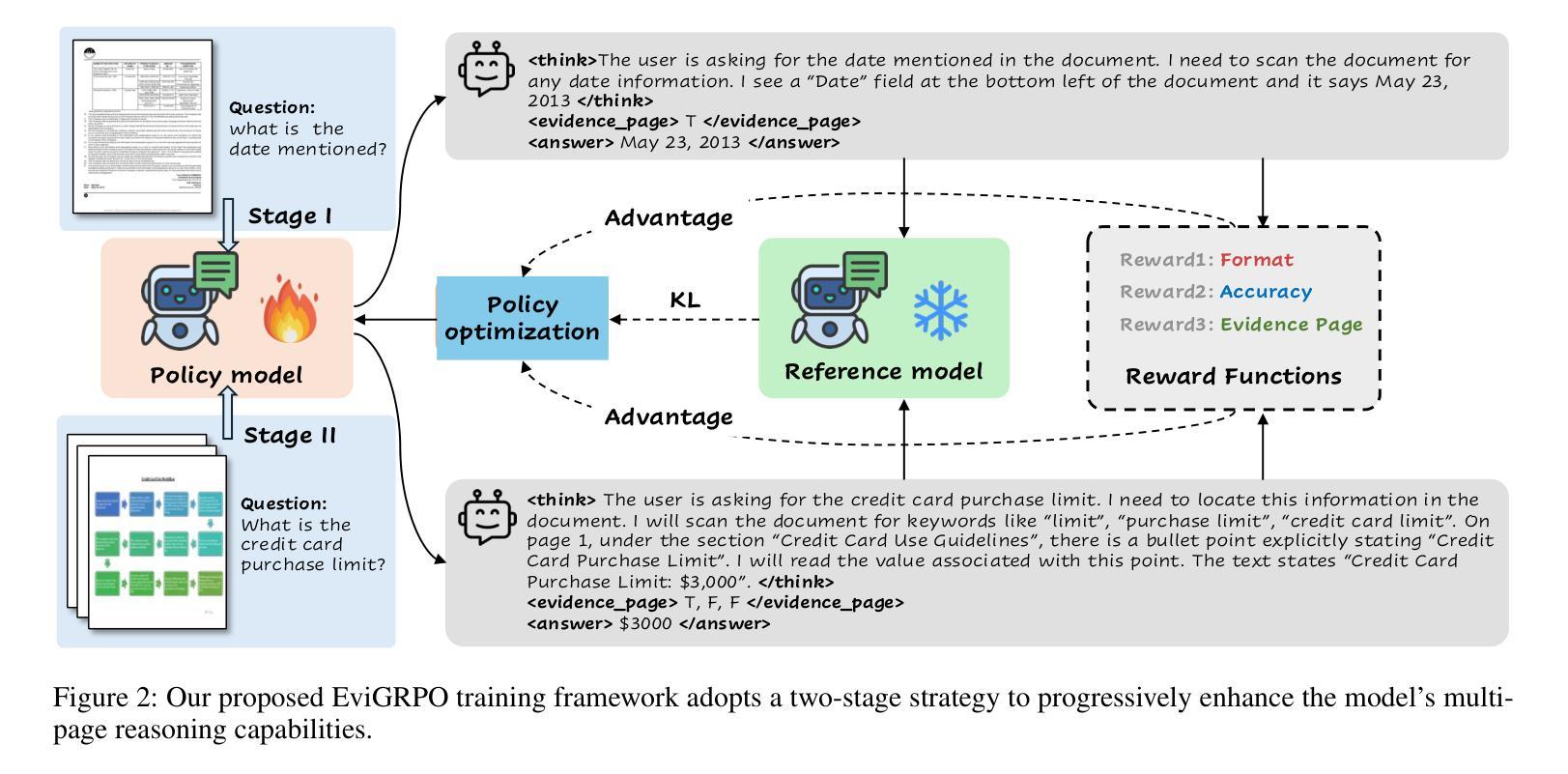
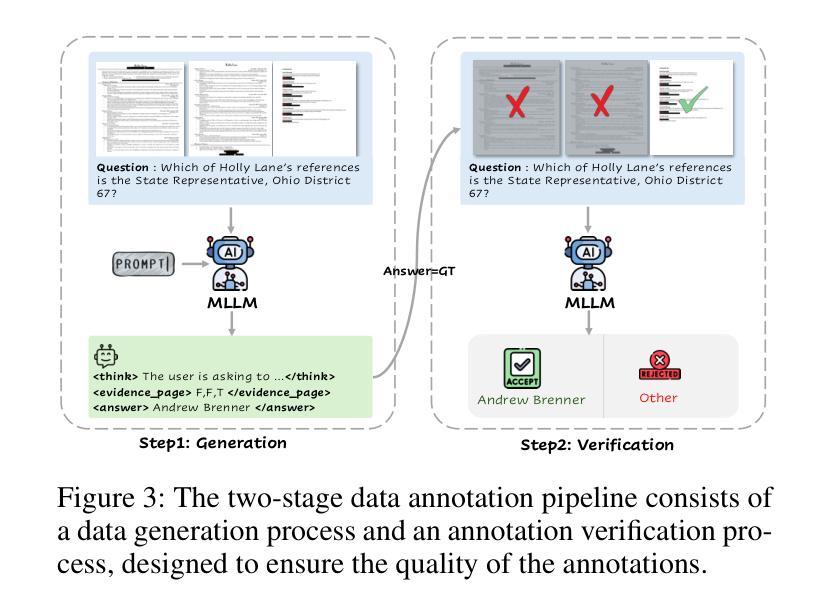
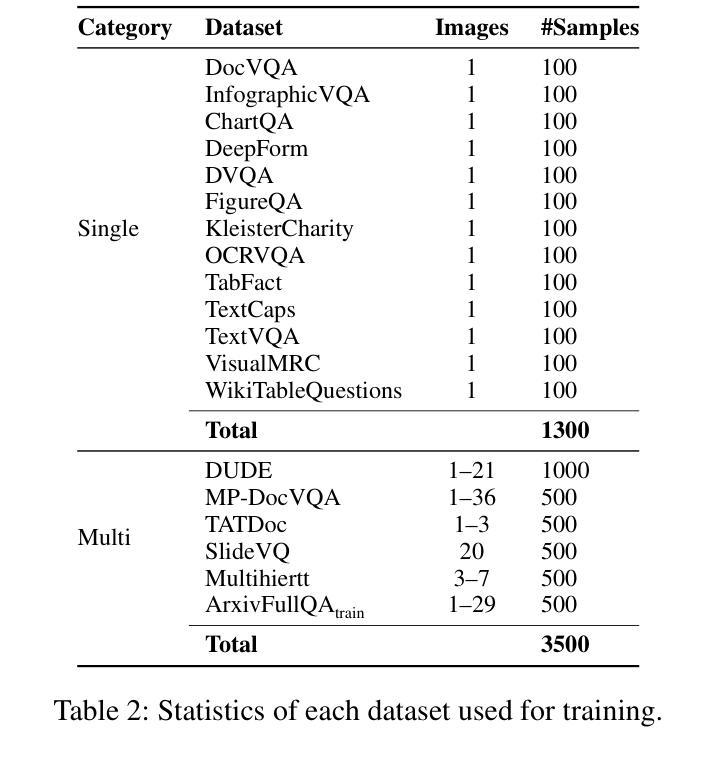
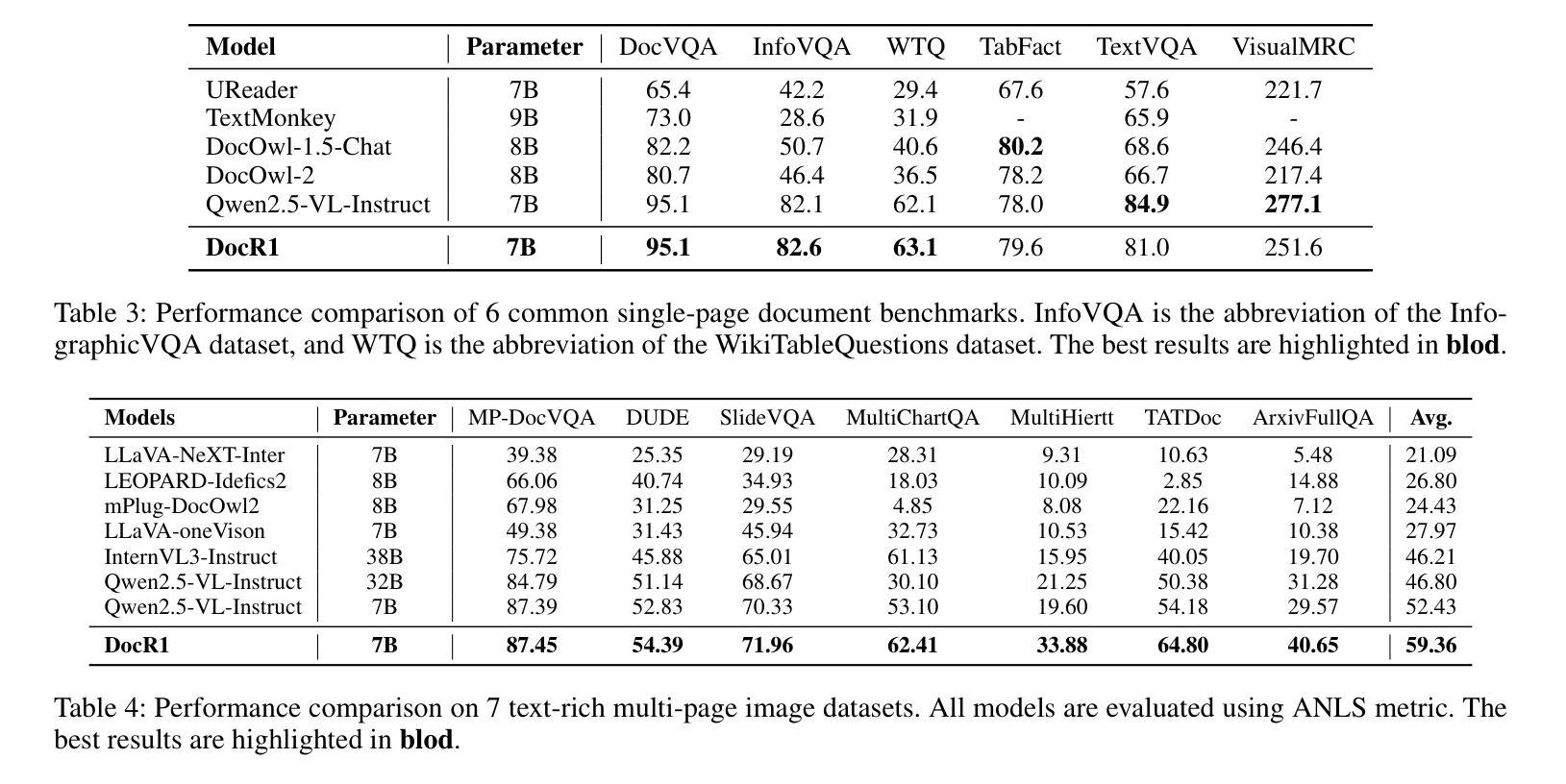
DocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Authors:Junyu Xiong, Yonghui Wang, Weichao Zhao, Chenyu Liu, Bing Yin, Wengang Zhou, Houqiang Li
Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.
理解多页文档对于多模态大型语言模型(MLLMs)来说是一个巨大的挑战,因为它需要精细的视觉理解和跨页的多步推理。尽管先前的工作已经探索了强化学习(RL)在增强MLLMs中的高级推理能力,但其在多页文档理解中的应用仍然被忽视。在本文中,我们介绍了DocR1,这是一个使用新型RL框架训练的多模态大型语言模型(MLLM)。EviGRPO是证据页面引导的证据GRPO(Evidence Page-Guided GRPO)。EviGRPO结合了证据感知奖励机制,该机制促进从粗到细的推理策略,引导模型在生成答案之前首先检索相关页面。这种训练模式使我们能够在有限的监督下构建高质量模型。为了支持这一点,我们设计了一个两阶段注释管道和一个基于课程的学习策略,基于此我们构建了两个数据集:EviBench是一个高质量的训练集,包含4.8k示例;ArxivFullQA是一个基于科学论文的评估基准,包含8.6k问答对。在多个基准测试上的大量实验表明,DocR1在多页任务上达到了最先进的性能,同时在单页基准测试上始终保持良好的结果。
论文及项目相关链接
Summary
该论文介绍了一种名为DocR1的多模态大型语言模型,该模型通过一种新型强化学习框架EviGRPO进行训练。EviGRPO结合了证据感知奖励机制,引导模型首先检索相关页面再生成答案,实现从粗到细的推理策略。这种训练模式在有限监督下构建高质量模型。为支持此,论文设计了两阶段注释管道和基于课程的学习策略,并构建了两个数据集:高质量训练集EviBench和基于科学论文的评估基准ArxivFullQA。实验表明,DocR1在多页任务上达到最新性能水平,同时在单页基准测试中保持强劲表现。
Key Takeaways
- DocR1是一种多模态大型语言模型(MLLM),能够处理多页文档理解任务。
- 引入新型强化学习框架EviGRPO,用于训练DocR1模型。
- EviGRPO结合证据感知奖励机制,采用从粗到细的推理策略。
- 构建了两个数据集:高质量训练集EviBench和评估基准ArxivFullQA。
- DocR1通过两阶段注释管道和基于课程的学习策略进行训练。
- DocR1在多页任务上实现最新性能水平。
点此查看论文截图



ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Authors:Wenhan Liu, Xinyu Ma, Weiwei Sun, Yutao Zhu, Yuchen Li, Dawei Yin, Zhicheng Dou
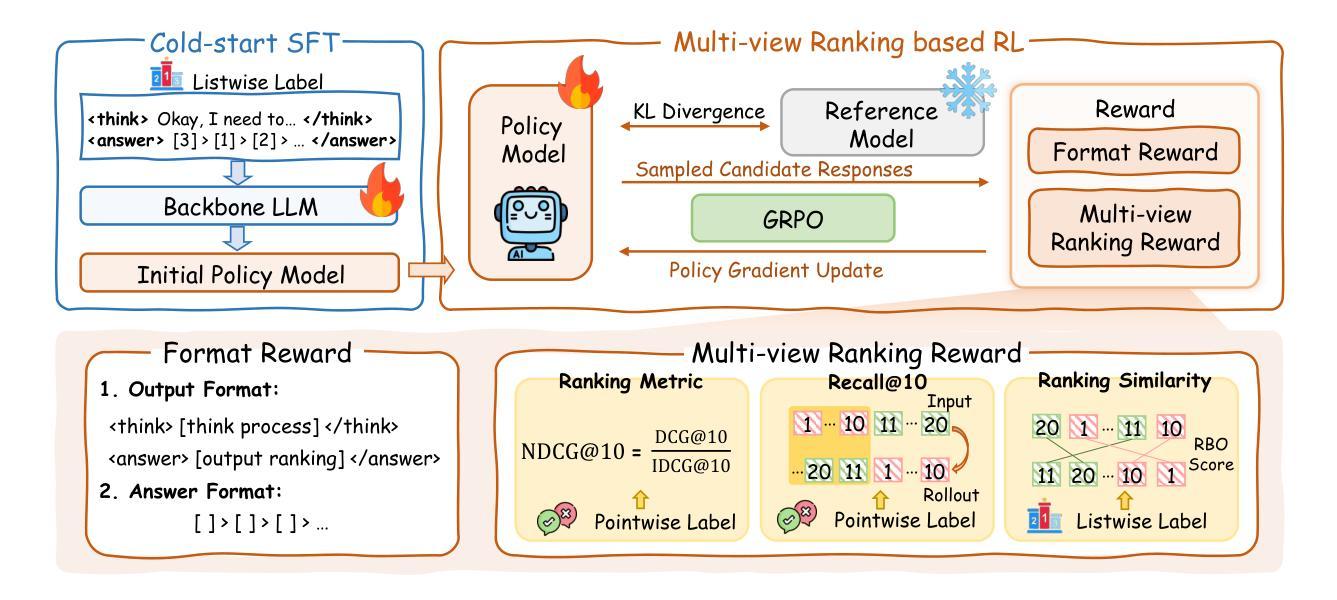
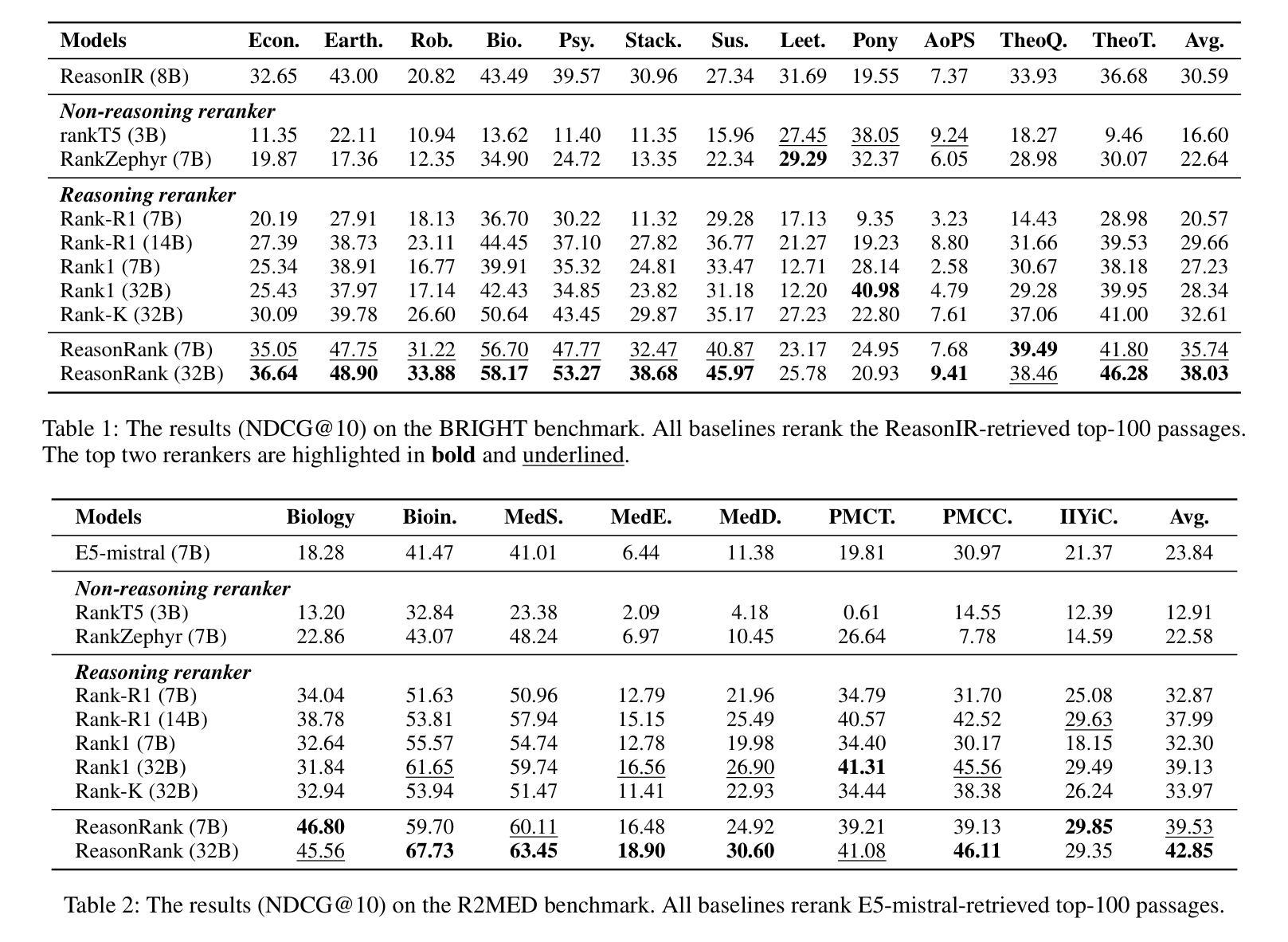
Large Language Model (LLM) based listwise ranking has shown superior performance in many passage ranking tasks. With the development of Large Reasoning Models, many studies have demonstrated that step-by-step reasoning during test-time helps improve listwise ranking performance. However, due to the scarcity of reasoning-intensive training data, existing rerankers perform poorly in many complex ranking scenarios and the ranking ability of reasoning-intensive rerankers remains largely underdeveloped. In this paper, we first propose an automated reasoning-intensive training data synthesis framework, which sources training queries and passages from diverse domains and applies DeepSeek-R1 to generate high-quality training labels. A self-consistency data filtering mechanism is designed to ensure the data quality. To empower the listwise reranker with strong reasoning ability, we further propose a two-stage post-training approach, which includes a cold-start supervised fine-tuning (SFT) stage for reasoning pattern learning and a reinforcement learning (RL) stage for further ranking ability enhancement. During the RL stage, based on the nature of listwise ranking, we design a multi-view ranking reward, which is more effective than a ranking metric-based reward. Extensive experiments demonstrate that our trained reasoning-intensive reranker \textbf{ReasonRank} outperforms existing baselines significantly and also achieves much lower latency than pointwise reranker Rank1. \textbf{Through further experiments, our ReasonRank has achieved state-of-the-art (SOTA) performance 40.6 on the BRIGHT leaderboard\footnote{https://brightbenchmark.github.io/}.} Our codes are available at https://github.com/8421BCD/ReasonRank.
基于大语言模型(LLM)的列表排序方法在许多段落排序任务中表现出卓越的性能。随着大型推理模型的发展,许多研究表明,测试时的逐步推理有助于提高列表排序性能。然而,由于推理密集型训练数据的稀缺,现有的重排器在许多复杂的排名场景中表现不佳,且推理密集型重排器的排名能力在很大程度上尚未开发。在本文中,我们首先提出了一个自动化的推理密集型训练数据合成框架,该框架从多个领域获取训练查询和段落,并应用DeepSeek-R1生成高质量的训练标签。设计了一种自我一致性数据过滤机制,以确保数据质量。为了赋予列表重排器强大的推理能力,我们进一步提出了一种两阶段的后训练方法,包括用于推理模式学习的冷启动监督微调(SFT)阶段和用于进一步增强排名能力的强化学习(RL)阶段。在RL阶段,基于列表排序的性质,我们设计了一个多视角排名奖励,它比基于排名指标的奖励更有效。大量实验表明,我们训练的推理密集型重排器ReasonRank显著优于现有基线,并且与逐点重排器Rank1相比,延迟时间更低。通过进一步的实验,我们的ReasonRank在BRIGHT排行榜上取得了最高性能,得分40.6分^[https://brightbenchmark.github.io/]。我们的代码可在[https://github.com/8421BCD/ReasonRank获取。](https://github.com/8421BCD/ReasonRank%E8%8E%B7%E5%8F%96%E3%80%82)
论文及项目相关链接
PDF 21 pages
Summary
在大型语言模型(LLM)基础上,本文提出了一种基于自动化推理密集训练数据合成框架的列表排名方法。通过DeepSeek-R1生成高质量训练标签,并设计自我一致性数据过滤机制以确保数据质量。此外,通过冷启动监督微调(SFT)和强化学习(RL)的两阶段后训练增强模型的推理排名能力。通过全面的实验验证了模型的有效性和高效性,实现低延迟并具有最新的高性能表现。该模型被称为ReasonRank,并已在官方排行榜上取得优异成绩。源代码已公开分享。
Key Takeaways
- 大型语言模型在段落排名任务中表现出卓越性能。
- 推理密集的训练数据稀缺导致现有重新排名器的性能不足。
- 提出一种自动化推理密集训练数据合成框架以改善这一状况。
- 使用DeepSeek-R1生成高质量训练标签并采用自我一致性数据过滤机制。
- 两阶段后训练以增强模型的推理排名能力。
- 设计了基于多视角排名的奖励机制以提高强化学习阶段的效率。
点此查看论文截图

AMFT: Aligning LLM Reasoners by Meta-Learning the Optimal Imitation-Exploration Balance
Authors:Lixuan He, Jie Feng, Yong Li
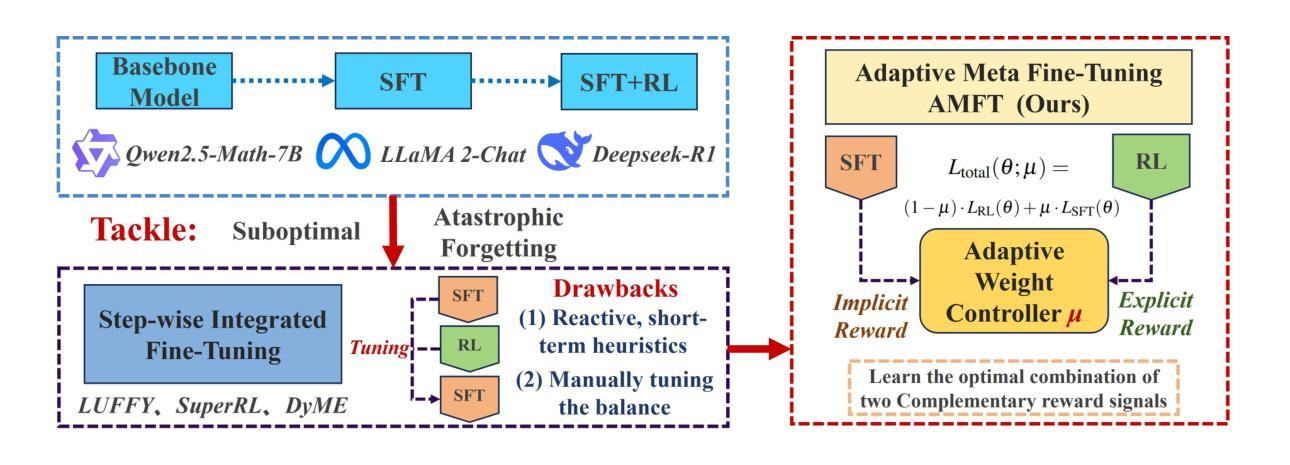
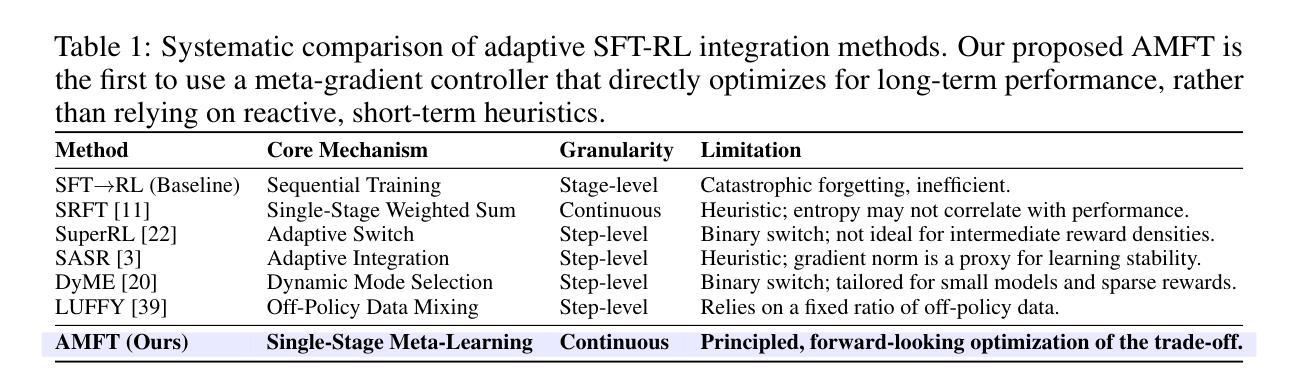
Large Language Models (LLMs) are typically fine-tuned for reasoning tasks through a two-stage pipeline of Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL), a process fraught with catastrophic forgetting and suboptimal trade-offs between imitation and exploration. Recent single-stage methods attempt to unify SFT and RL using heuristics, but lack a principled mechanism for dynamically balancing the two paradigms. In this paper, we reframe this challenge through the theoretical lens of \textbf{implicit rewards}, viewing SFT and RL not as distinct methods but as complementary reward signals. We introduce \textbf{Adaptive Meta Fine-Tuning (AMFT)}, a novel single-stage algorithm that learns the optimal balance between SFT’s implicit, path-level reward and RL’s explicit, outcome-based reward. The core of AMFT is a \textbf{meta-gradient adaptive weight controller} that treats the SFT-RL balance as a learnable parameter, dynamically optimizing it to maximize long-term task performance. This forward-looking approach, regularized by policy entropy for stability, autonomously discovers an effective training curriculum. We conduct a comprehensive evaluation on challenging benchmarks spanning mathematical reasoning, abstract visual reasoning (General Points), and vision-language navigation (V-IRL). AMFT consistently establishes a new state-of-the-art and demonstrats superior generalization on out-of-distribution (OOD) tasks. Ablation studies and training dynamic analysis confirm that the meta-learning controller is crucial for AMFT’s stability, sample efficiency, and performance, offering a more principled and effective paradigm for LLM alignment. Our codes are open-sourced via https://github.com/hlxtsyj/AMFT.
大型语言模型(LLM)通常通过监督微调(SFT)后的强化学习(RL)的两阶段管道进行微调,以完成推理任务。这一过程充满了灾难性遗忘和模仿与探索之间的次优权衡。最近的单阶段方法试图通过启发式方法统一SFT和RL,但缺乏一种动态平衡这两种范式的原则性机制。在本文中,我们通过隐式奖励的理论视角重新看待这一挑战,将SFT和RL视为互补的奖励信号,而不是截然不同的方法。我们引入了自适应元微调(AMFT)这一新颖的单阶段算法,它学习SFT的隐式路径级奖励和RL的显式结果级奖励之间的最佳平衡。AMFT的核心是一个元梯度自适应权重控制器,它将SFT-RL的平衡视为可学习的参数,通过动态优化以最大化长期任务性能。这种前瞻性的方法通过政策熵进行稳定性调节,能够自主地发现有效的训练课程。我们在涵盖数学推理、抽象视觉推理(通用点)和视觉语言导航(V-IRL)等具有挑战性的基准测试上对AMFT进行了全面评估。AMFT持续刷新了最新技术状态,并在离分布(OOD)任务上表现出卓越的外推能力。消融研究和训练动态分析证实,元学习控制器对于AMFT的稳定性、样本效率和性能至关重要,为LLM对齐提供了更具原则性和有效性的范式。我们的代码可通过https://github.com/hlxtsyj/AMFT公开获取。
中文翻译如下:
论文及项目相关链接
PDF https://github.com/hlxtsyj/AMFT
Summary
大型语言模型(LLM)通常在监督微调(SFT)和强化学习(RL)的两阶段管道中进行微调以执行推理任务。然而,这个过程面临着灾难性遗忘和模仿与探索之间次优权衡的问题。本文提出了一个名为自适应元微调(AMFT)的新型单阶段算法,它通过隐式奖励和显式奖励之间的最优平衡来解决这个问题。AMFT的核心是一个元梯度自适应权重控制器,它将SFT和RL之间的平衡视为可学习的参数,并对其进行动态优化,以最大化长期任务性能。我们在涵盖数学推理、抽象视觉推理(General Points)和视觉语言导航(V-IRL)等具有挑战性的基准测试上对AMFT进行了全面评估。AMFT表现优异,在超出分布范围的任务中展现出卓越泛化能力。消融研究和训练动态分析证实,元学习控制器对于AMFT的稳定性、样本效率和性能至关重要,为LLM对齐提供了更系统和有效的范式。
Key Takeaways
- 大型语言模型(LLM)在微调进行推理任务时面临灾难性遗忘和模仿与探索之间权衡的问题。
- 现有方法尝试通过启发式方法统一监督微调(SFT)和强化学习(RL),但缺乏动态平衡两种方法的机制。
- 本文提出了自适应元微调(AMFT)算法,通过隐式奖励和显式奖励之间的最优平衡来解决上述问题。
- AMFT使用一个元梯度自适应权重控制器来动态优化SFT和RL之间的平衡。
- AMFT在多个具有挑战性的基准测试上表现优异,并在超出分布范围的任务中展现出卓越泛化能力。
- 消融研究和训练动态分析证实,元学习控制器对AMFT的性能起到关键作用。
点此查看论文截图

AR-GRPO: Training Autoregressive Image Generation Models via Reinforcement Learning
Authors:Shihao Yuan, Yahui Liu, Yang Yue, Jingyuan Zhang, Wangmeng Zuo, Qi Wang, Fuzheng Zhang, Guorui Zhou
Inspired by the success of reinforcement learning (RL) in refining large language models (LLMs), we propose AR-GRPO, an approach to integrate online RL training into autoregressive (AR) image generation models. We adapt the Group Relative Policy Optimization (GRPO) algorithm to refine the vanilla autoregressive models’ outputs by carefully designed reward functions that evaluate generated images across multiple quality dimensions, including perceptual quality, realism, and semantic fidelity. We conduct comprehensive experiments on both class-conditional (i.e., class-to-image) and text-conditional (i.e., text-to-image) image generation tasks, demonstrating that our RL-enhanced framework significantly improves both the image quality and human preference of generated images compared to the standard AR baselines. Our results show consistent improvements across various evaluation metrics, establishing the viability of RL-based optimization for AR image generation and opening new avenues for controllable and high-quality image synthesis. The source codes and models are available at: https://github.com/Kwai-Klear/AR-GRPO.
受强化学习(RL)在大规模语言模型(LLM)中取得成功的启发,我们提出了AR-GRPO方法,这是一种将在线RL训练集成到自回归(AR)图像生成模型中的方法。我们采用Group Relative Policy Optimization (GRPO)算法,通过精心设计的奖励函数来优化基本的自回归模型的输出,这些奖励函数从多个质量维度评估生成的图像,包括感知质量、逼真度和语义保真度。我们对类别条件(即类到图像)和文本条件(即文本到图像)的图像生成任务进行了全面的实验,结果表明,我们的增强型RL框架与标准的自回归基线相比,显著提高了生成的图像的质量和人类偏好。我们的结果在各种评估指标上均表现出一致的提高,证明了基于RL的优化在AR图像生成中的可行性,并为可控和高质量的图像合成开辟了新途径。源代码和模型可在https://github.com/Kwai-Klear/AR-GRPO获取。
论文及项目相关链接
PDF 27 pages, 15 figures
Summary
本文介绍了将强化学习(RL)集成到自回归(AR)图像生成模型中的方法AR-GRPO。该方法通过精心设计的奖励函数来评估生成的图像在多个质量维度上的表现,包括感知质量、逼真度和语义保真度。实验表明,与标准AR基线相比,RL增强的框架显著提高了生成的图像的质量和人类偏好。
Key Takeaways
- AR-GRPO方法成功将强化学习应用于自回归图像生成模型,提高了图像生成质量。
- 通过精心设计的奖励函数,AR-GRPO评估了生成图像在感知质量、逼真度和语义保真度等多个维度上的表现。
- 实验证明,AR-GRPO在类条件(如类别到图像)和文本条件(如文本到图像)的图像生成任务中均表现优异。
- 与标准AR基线相比,AR-GRPO生成的图像质量和人类偏好均有显著提高。
- AR-GRPO方法在各种评估指标上表现一致,证明了其在自回归图像生成中的有效性。
- AR-GRPO的源代码和模型可在https://github.com/Kwai-Klear/AR-GRPO上获取。
点此查看论文截图

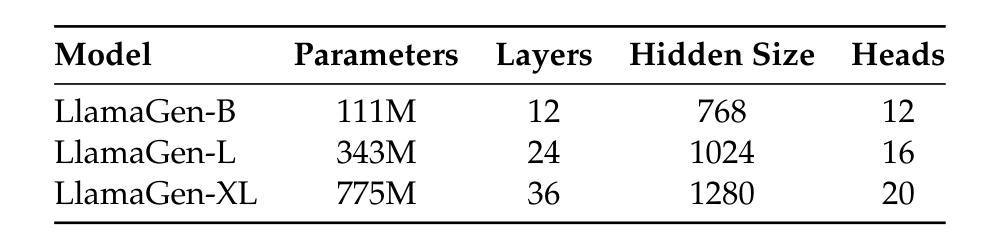
Technical Report: Full-Stack Fine-Tuning for the Q Programming Language
Authors:Brendan R. Hogan, Will Brown, Adel Boyarsky, Anderson Schneider, Yuriy Nevmyvaka
Even though large language models are becoming increasingly capable, it is still unreasonable to expect them to excel at tasks that are under-represented on the Internet. Leveraging LLMs for specialized applications, particularly in niche programming languages and private domains, remains challenging and largely unsolved. In this work, we address this gap by presenting a comprehensive, open-source approach for adapting LLMs to the Q programming language, a popular tool in quantitative finance that is much less present on the Internet compared to Python, C, Java, and other ``mainstream” languages and is therefore not a strong suit of general-purpose AI models. We introduce a new Leetcode style evaluation dataset for Q, benchmark major frontier models on the dataset, then do pretraining, supervised fine tuning, and reinforcement learning to train a suite of reasoning and non-reasoning models based on the Qwen-2.5 series, spanning five parameter sizes (1.5B, 3B, 7B, 14B, 32B). Our best model achieves a pass@1 accuracy of 59 percent on our Q benchmark, surpassing the best-performing frontier model, Claude Opus-4 by 29.5 percent. Additionally, all models, even our 1.5B model, outperform GPT-4.1 on this task. In addition to releasing models, code, and data, we provide a detailed blueprint for dataset construction, model pretraining, supervised fine-tuning, and reinforcement learning. Our methodology is broadly applicable, and we discuss how these techniques can be extended to other tasks, including those where evaluation may rely on soft or subjective signals.
尽管大型语言模型的能力越来越强,但期待它们在互联网上代表性不足的任务上表现出色仍然不合理。将大型语言模型应用于专业应用程序,特别是在小众编程语言和私有领域,仍然存在挑战且大部分尚未解决。在这项工作中,我们通过提出一种适应Q编程语言的全面开源方法来解决这一差距。Q是量化金融中流行的工具,与Python、C、Java等其他“主流”语言相比,其在互联网上的存在感要低得多,因此并不是通用AI模型的强项。我们为Q语言引入了新的Leetcode风格评估数据集,在该数据集上评估了主要的前沿模型,然后进行预训练、有监督的微调以及强化学习,基于Qwen-2.5系列训练了一套推理和非推理模型,涵盖五种参数大小(1.5B、3B、7B、14B、32B)。我们最好的模型在我们的Q基准测试上达到了59%的pass@1准确率,比最佳性能的前沿模型Claude Opus-4高出29.5%。此外,所有模型,即使是我们最小的1.5B模型,在此任务上也优于GPT-4.1。除了发布模型、代码和数据外,我们还提供了关于数据集构建、模型预训练、有监督的微调以及强化学习的详细蓝图。我们的方法是广泛适用的,我们讨论了如何将这些技术扩展到其他任务,包括那些可能依赖于软指标或主观信号的评估任务。
论文及项目相关链接
PDF 40 pages
摘要
针对大型语言模型在互联网较少代表领域面临的挑战,本文提出了一种适应于Q编程语言(金融量化中流行工具)的综合、开源方法。研究发布了针对Q编程语言的Leetcode风格评估数据集,对前沿模型进行基准测试,并通过预训练、监督微调及强化学习等方法训练模型。最佳模型在Q评估上达到59%的准确率,显著超越其他前沿模型并优于GPT-4.1。此外,研究还提供数据集构建、模型预训练等详细蓝图。此方法可广泛应用于其他任务。
关键见解
- 大型语言模型在代表性不足的任务领域(如金融量化编程语言Q)表现仍有挑战。
- 针对Q编程语言,提出了一种综合、开源的适应大型语言模型的方法。
- 发布了针对Q编程语言的Leetcode风格评估数据集,用于模型性能基准测试。
- 通过预训练、监督微调及强化学习等技术训练模型,提高了模型性能。
- 最佳模型在Q评估上实现较高准确率,优于当前前沿模型和GPT-4.1。
- 研究提供了详细的数据集构建、模型预训练等蓝图,为其他类似任务提供参考。
点此查看论文截图
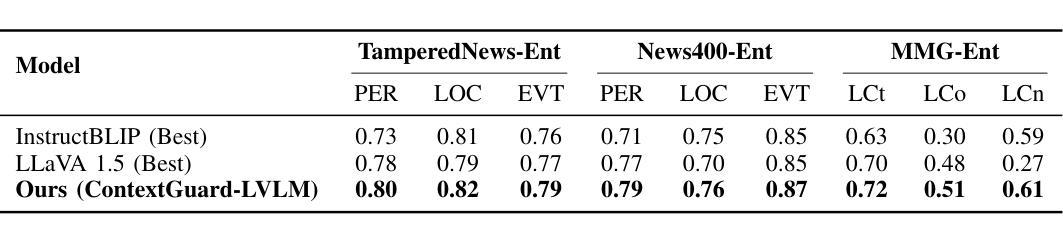
ContextGuard-LVLM: Enhancing News Veracity through Fine-grained Cross-modal Contextual Consistency Verification
Authors:Sihan Ma, Qiming Wu, Ruotong Jiang, Frank Burns
The proliferation of digital news media necessitates robust methods for verifying content veracity, particularly regarding the consistency between visual and textual information. Traditional approaches often fall short in addressing the fine-grained cross-modal contextual consistency (FCCC) problem, which encompasses deeper alignment of visual narrative, emotional tone, and background information with text, beyond mere entity matching. To address this, we propose ContextGuard-LVLM, a novel framework built upon advanced Vision-Language Large Models (LVLMs) and integrating a multi-stage contextual reasoning mechanism. Our model is uniquely enhanced through reinforced or adversarial learning paradigms, enabling it to detect subtle contextual misalignments that evade zero-shot baselines. We extend and augment three established datasets (TamperedNews-Ent, News400-Ent, MMG-Ent) with new fine-grained contextual annotations, including “contextual sentiment,” “visual narrative theme,” and “scene-event logical coherence,” and introduce a comprehensive CTXT (Contextual Coherence) entity type. Extensive experiments demonstrate that ContextGuard-LVLM consistently outperforms state-of-the-art zero-shot LVLM baselines (InstructBLIP and LLaVA 1.5) across nearly all fine-grained consistency tasks, showing significant improvements in complex logical reasoning and nuanced contextual understanding. Furthermore, our model exhibits superior robustness to subtle perturbations and a higher agreement rate with human expert judgments on challenging samples, affirming its efficacy in discerning sophisticated forms of context detachment.
数字新闻媒体的普及迫切需要验证内容真实性的稳健方法,特别是在视觉和文本信息之间的一致性方面。传统的方法往往难以解决精细的跨模态上下文一致性(FCCC)问题,该问题涉及视觉叙事、情感基调、背景信息与文本之间的更深层次对齐,而不仅仅是实体匹配。为了解决这一问题,我们提出了ContextGuard-LVLM框架,它是基于先进的视觉语言大模型(LVLMs)构建的,并融合了多阶段上下文推理机制。我们的模型通过强化或对抗性学习范式进行了独特增强,使其能够检测零样本基线所忽略的细微上下文不一致。我们对三个现有的数据集(TamperedNews-Ent、News400-Ent、MMG-Ent)进行了扩展和扩充,加入了新的精细上下文注释,包括“上下文情感”、“视觉叙事主题”和“场景事件逻辑连贯性”,并引入了全面的CTXT(上下文一致性)实体类型。大量实验表明,ContextGuard-LVLM在所有精细一致性任务上都超越了最新的零样本LVLM基线(InstructBLIP和LLaVA 1.5),在复杂的逻辑推理和微妙上下文理解方面取得了显著改进。此外,我们的模型对细微扰动具有更高的鲁棒性,并且在具有挑战性的样本上与人类专家判断有较高的符合率,证实了它在辨别复杂上下文脱离方面的有效性。
论文及项目相关链接
Summary
本文提出一种基于先进的视觉语言大模型(LVLMs)的ContextGuard-LVLM框架,用于验证数字新闻媒体的内容真实性。该框架通过多阶段上下文推理机制,解决了传统方法在处理跨模态上下文一致性(FCCC)问题时的不足,提高了模型在检测上下文细微不对齐方面的能力。实验表明,ContextGuard-LVLM在几乎所有精细的上下文一致性任务上都优于现有的零样本LVLM基线,表现出更出色的复杂逻辑推理和细微上下文理解能力。
Key Takeaways
- 数字新闻媒体的普及要求开发验证内容真实性的稳健方法,特别是视觉和文本信息之间的一致性问题。
- 传统方法在处理跨模态上下文一致性(FCCC)问题时常常不足,需要更深入的对视觉叙事、情感基调、背景信息与文本的匹配。
- ContextGuard-LVLM框架基于先进的视觉语言大模型(LVLMs),通过多阶段上下文推理机制解决这个问题。
- 强化或对抗性学习范式被用来增强ContextGuard-LVLM的检测能力,以识别逃避零样本基线的微妙上下文不一致。
- 对三个已建立的数据集进行了扩展和增强,引入了新的精细上下文注释,包括“上下文情感”、“视觉叙事主题”和“场景事件逻辑连贯性”。
- 实验表明,ContextGuard-LVLM在所有精细的上下文一致性任务上的表现均优于现有的零样本LVLM基线。
点此查看论文截图