⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-19 更新
Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
Authors:Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, Wei Li
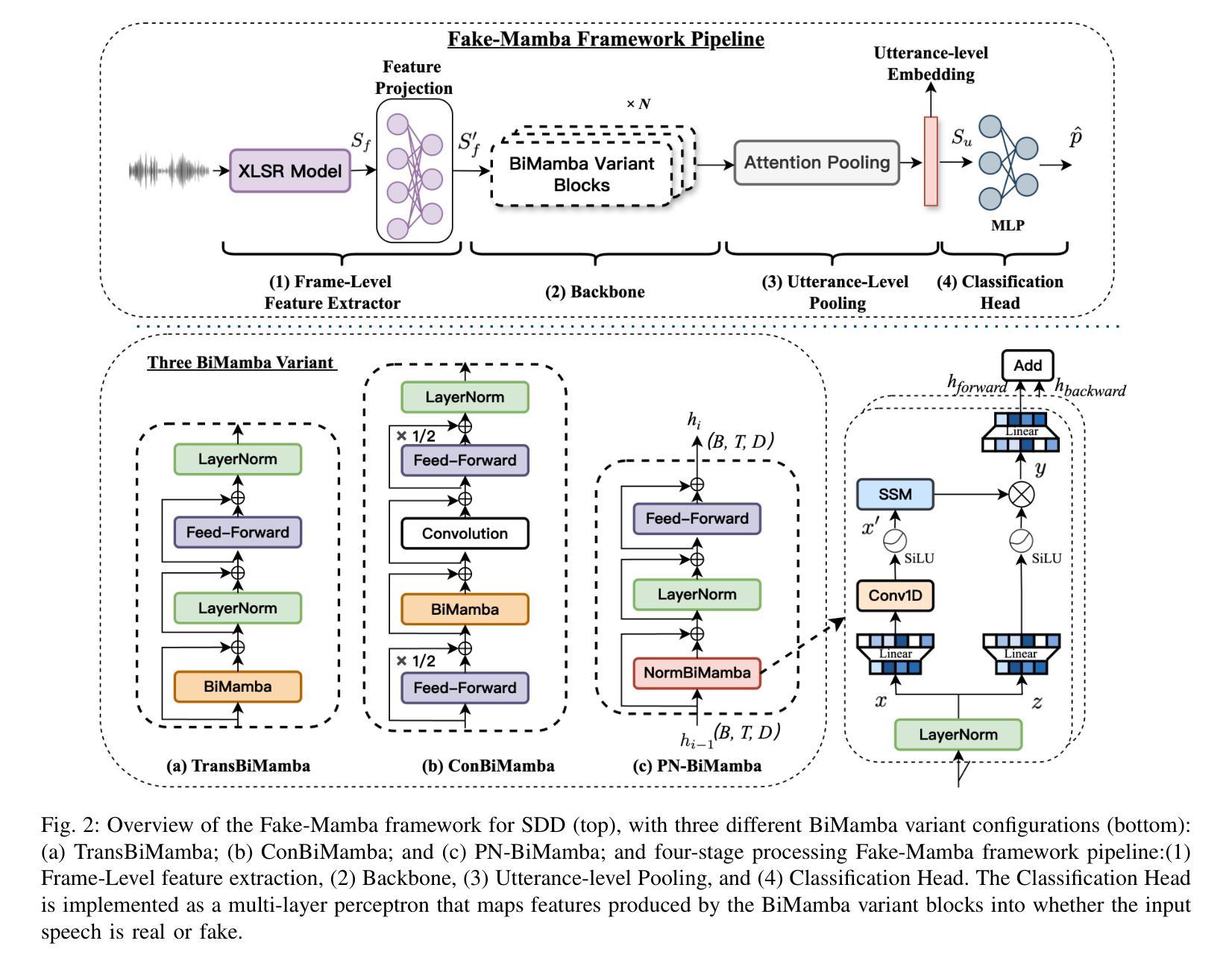
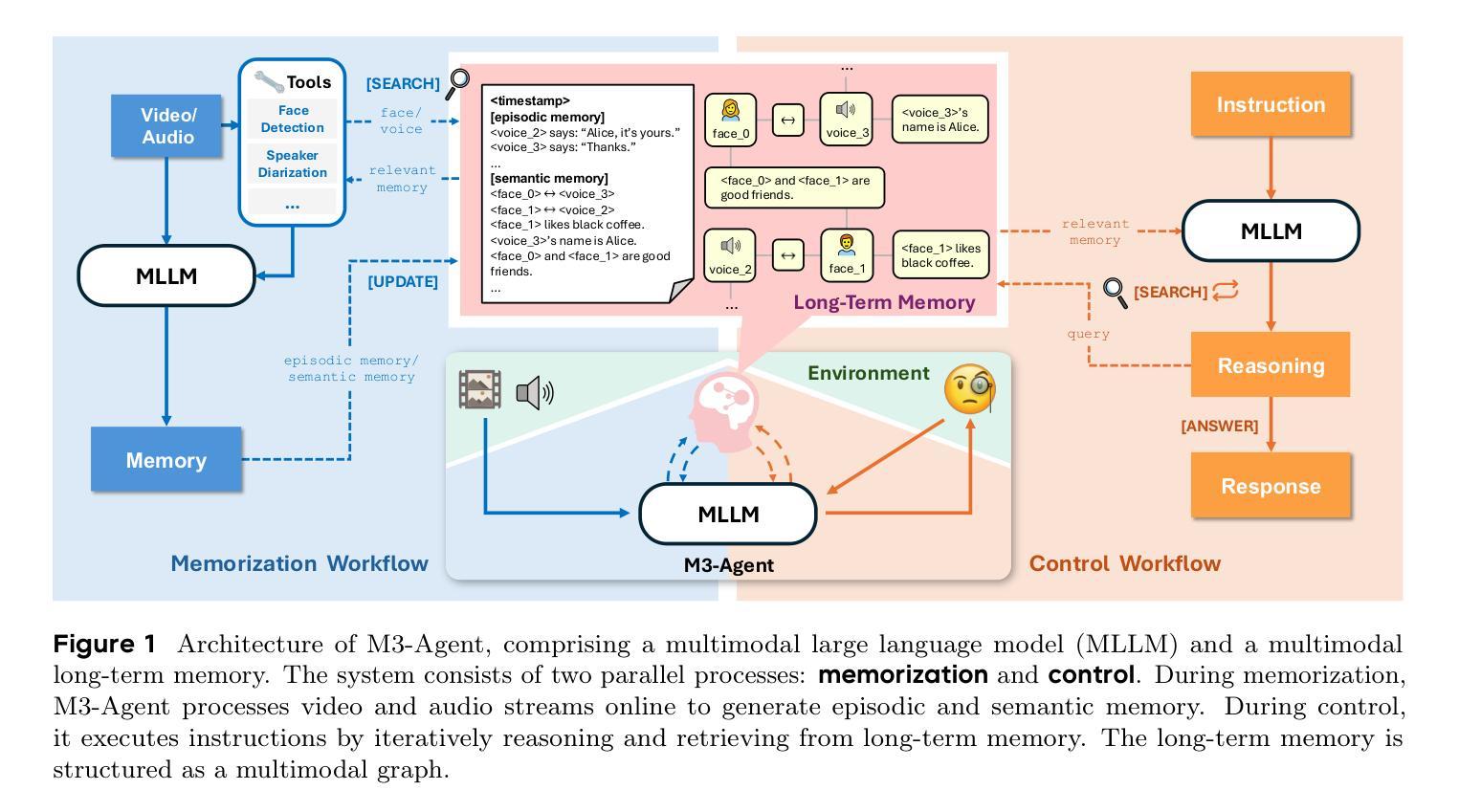
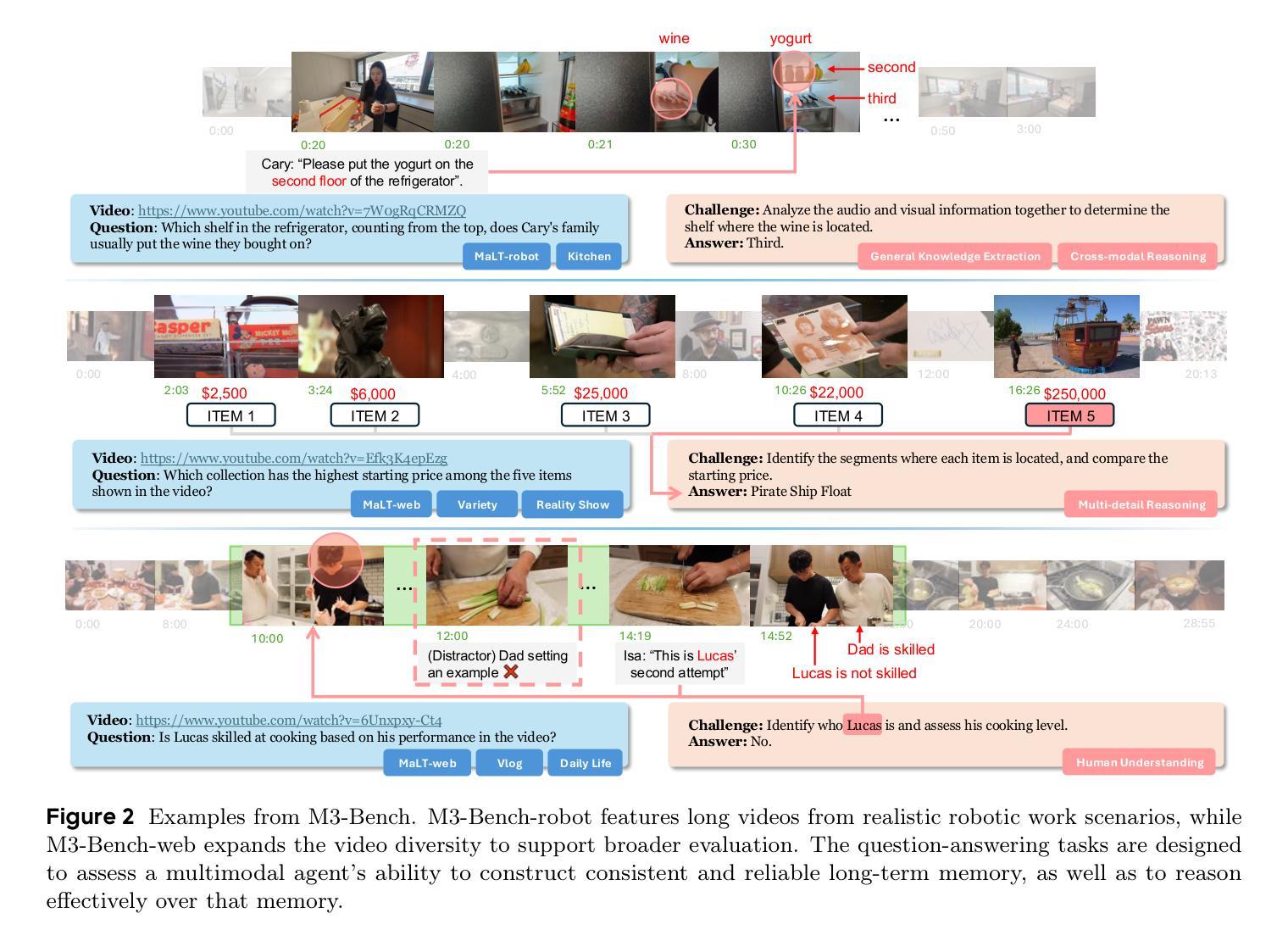
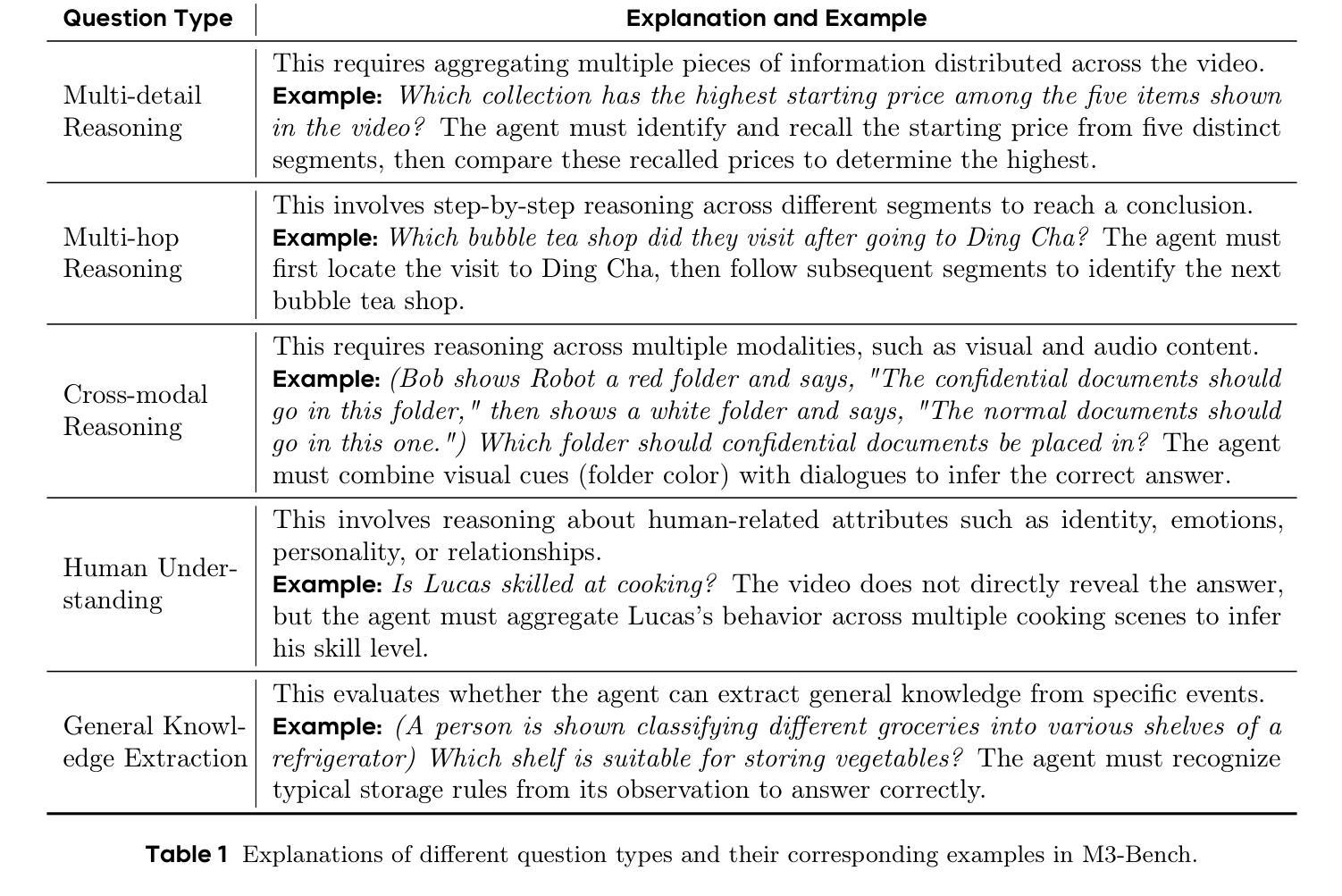
We introduce M3-Agent, a novel multimodal agent framework equipped with long-term memory. Like humans, M3-Agent can process real-time visual and auditory inputs to build and update its long-term memory. Beyond episodic memory, it also develops semantic memory, enabling it to accumulate world knowledge over time. Its memory is organized in an entity-centric, multimodal format, allowing deeper and more consistent understanding of the environment. Given an instruction, M3-Agent autonomously performs multi-turn, iterative reasoning and retrieves relevant information from memory to accomplish the task. To evaluate memory effectiveness and memory-based reasoning in multimodal agents, we develop M3-Bench, a new long-video question answering benchmark. M3-Bench comprises 100 newly recorded real-world videos captured from a robot’s perspective (M3-Bench-robot) and 920 web-sourced videos across diverse scenarios (M3-Bench-web). We annotate question-answer pairs designed to test key capabilities essential for agent applications, such as human understanding, general knowledge extraction, and cross-modal reasoning. Experimental results show that M3-Agent, trained via reinforcement learning, outperforms the strongest baseline, a prompting agent using Gemini-1.5-pro and GPT-4o, achieving 6.7%, 7.7%, and 5.3% higher accuracy on M3-Bench-robot, M3-Bench-web and VideoMME-long, respectively. Our work advances the multimodal agents toward more human-like long-term memory and provides insights into their practical design. Model, code and data are available at https://github.com/bytedance-seed/m3-agent
我们介绍了M3-Agent,这是一个配备长期记忆的新型多模式代理框架。与人类相似,M3-Agent可以处理实时视觉和听觉输入来构建和更新其长期记忆。除了情景记忆之外,它还发展出语义记忆,使其能够随着时间的推移积累世界知识。它的记忆以实体为中心的多模式形式组织,允许对环境的更深层次和更一致的理解。接受指令后,M3-Agent可以自主进行多轮迭代推理,从记忆中检索相关信息以完成任务。为了评估多模式代理中的记忆有效性和基于记忆推理,我们开发了M3-Bench,这是一个新的长视频问答基准测试。M3-Bench包括100个新录制的世界真实视频(从机器人视角捕获)(M3-Bench-robot)和920个来自不同场景的web视频(M3-Bench-web)。我们注释了问题答案对,旨在测试代理应用程序必需的关键能力,如人类理解、一般知识提取和跨模式推理。实验结果表明,通过强化学习训练的M3-Agent超越了最强的基线,使用Gemini-1.5-pro和GPT-4o的提示代理,在M3-Bench-robot、M3-Bench-web和VideoMME-long上的准确率分别提高了6.7%、7.7%和5.3%。我们的工作使多模式代理朝着更人性化长期记忆的方向发展,并为其实践设计提供了见解。模型、代码和数据可在https://github.com/bytedance-seed/m3-agent找到。
论文及项目相关链接
Summary
M3-Agent是一个配备长期记忆的多模态代理框架,能够处理实时视觉和听觉输入来构建和更新其长期记忆。它不仅拥有情景记忆,还发展出语义记忆,从而能够随时间积累世界知识。其记忆以实体为中心的多模态形式组织,使对环境有更深、更一致的理解。M3-Agent接受指令后,可自主进行多轮迭代推理,从记忆中检索相关信息完成任务。为评估多模态代理的记忆效果和基于记忆推理的能力,推出了M3-Bench长视频问答基准测试,包含真实世界视频和跨场景网络视频。实验结果显示,通过强化学习训练的M3-Agent在M3-Bench测试中表现优于最强基线模型,展现出更高准确性。
Key Takeaways
- M3-Agent是一个多模态代理框架,具备处理实时视觉和听觉输入的能力,以构建和更新其长期记忆。
- M3-Agent不仅具备情景记忆,还具备语义记忆,使其能够随时间积累世界知识。
- M3-Agent的记忆以实体为中心的多模态形式组织,增强了对环境的理解。
- M3-Agent可以自主进行多轮迭代推理,完成复杂任务。
- 为评估多模态代理的记忆和推理能力,推出了新的长视频问答基准测试M3-Bench。
- M3-Bench包含真实世界和网络视频,旨在测试关键能力,如人类理解、通用知识提取和跨模态推理。
点此查看论文截图

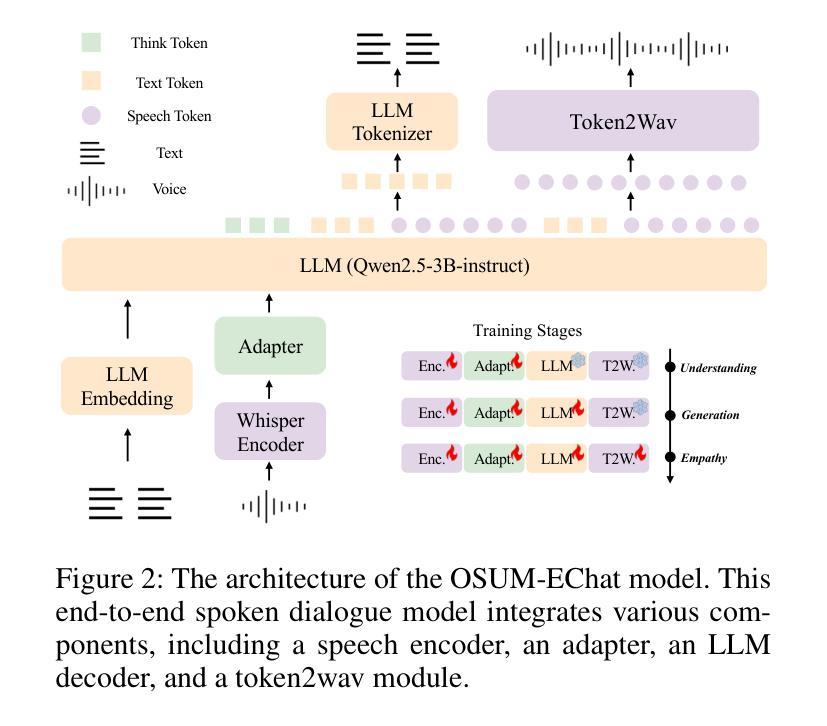
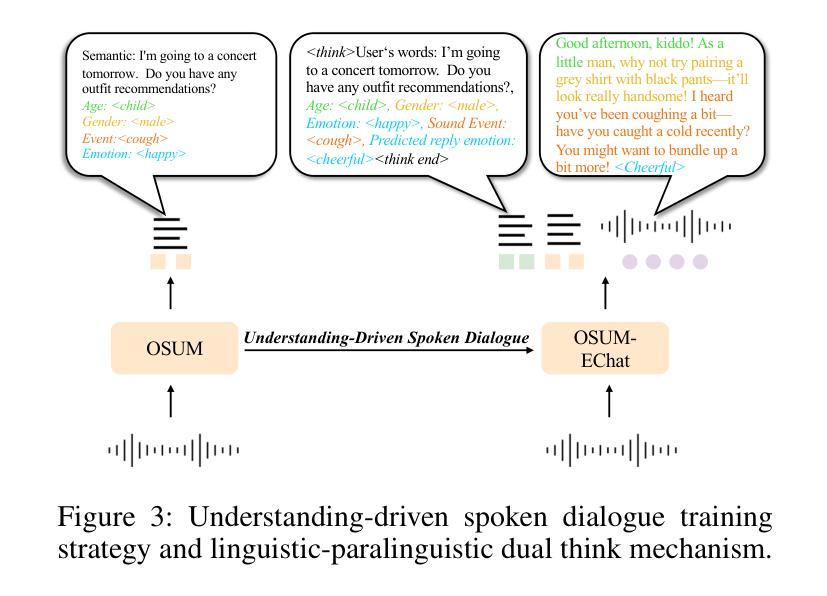
OSUM-EChat: Enhancing End-to-End Empathetic Spoken Chatbot via Understanding-Driven Spoken Dialogue
Authors:Xuelong Geng, Qijie Shao, Hongfei Xue, Shuiyuan Wang, Hanke Xie, Zhao Guo, Yi Zhao, Guojian Li, Wenjie Tian, Chengyou Wang, Zhixian Zhao, Kangxiang Xia, Ziyu Zhang, Zhennan Lin, Tianlun Zuo, Mingchen Shao, Yuang Cao, Guobin Ma, Longhao Li, Yuhang Dai, Dehui Gao, Dake Guo, Lei Xie
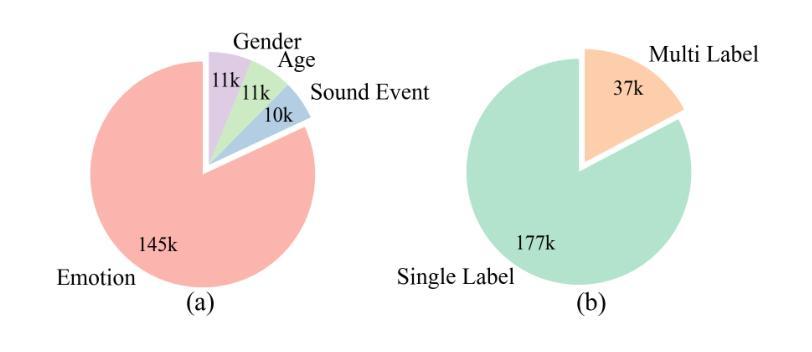
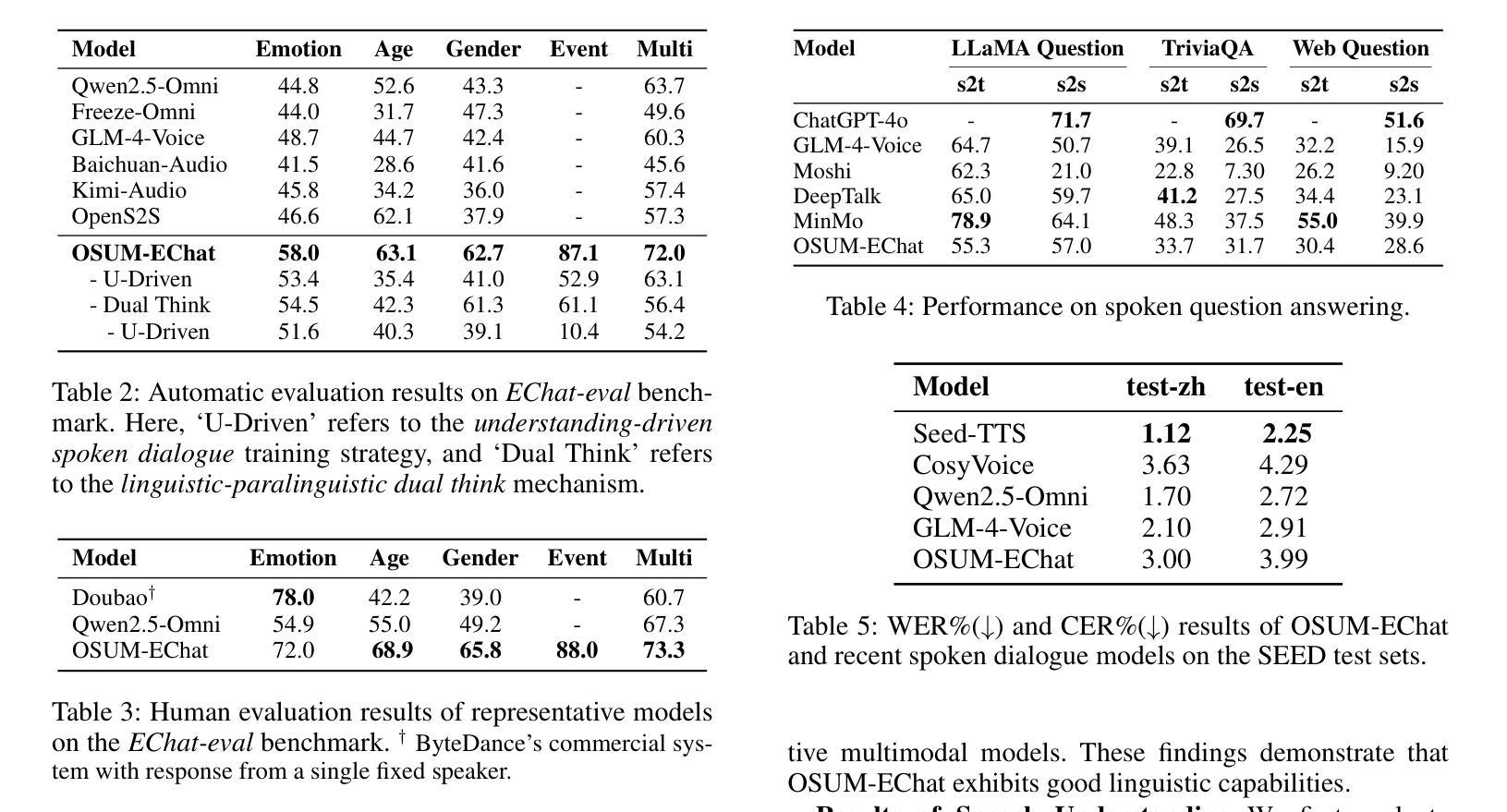
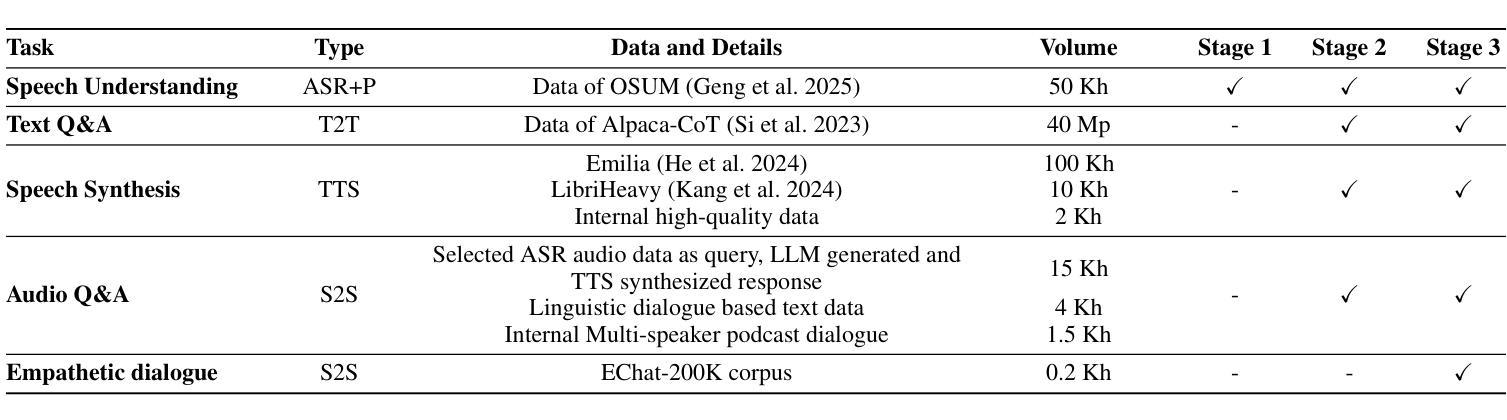
Empathy is crucial in enabling natural interactions within spoken dialogue systems, allowing machines to recognize and respond appropriately to paralinguistic cues such as age, gender, and emotion. Recent advancements in end-to-end speech language models, which unify speech understanding and generation, provide promising solutions. However, several challenges persist, including an over-reliance on large-scale dialogue datasets, insufficient extraction of paralinguistic cues vital for conveying empathy, and the lack of empathy-specific datasets and evaluation frameworks. To address these issues, we introduce OSUM-EChat, an open-source, end-to-end spoken dialogue system designed to enhance empathetic interactions, particularly in resource-limited settings. OSUM-EChat introduces two key innovations: (1) a three-stage understanding-driven spoken dialogue training strategy that extends the capabilities of a large speech understanding model to spoken dialogue tasks, and (2) a linguistic-paralinguistic dual thinking mechanism that integrates paralinguistic understanding through a chain of thought with dialogue generation, enabling the system to produce more empathetic responses. This approach reduces reliance on large-scale dialogue datasets while maintaining high-quality empathetic interactions. Additionally, we introduce the EChat-200K dataset, a rich corpus of empathetic speech-to-speech dialogues, and the EChat-eval benchmark, a comprehensive framework for evaluating the empathetic capabilities of dialogue systems. Experimental results demonstrate that OSUM-EChat outperforms end-to-end spoken dialogue models regarding empathetic responsiveness, validating its effectiveness.
共情在口语对话系统中实现自然交互中起着至关重要的作用,它使机器能够识别和响应年龄、性别和情感等副语言线索。最近的端到端自然语言模型取得了进展,这种模型能够统一语音理解和生成,为解决共情对话提供了前景。然而,仍然存在一些挑战,包括过于依赖大规模的对话数据集、未能充分提取对表达共情至关重要的副语言线索以及缺乏针对共情的特定数据集和评估框架。为了解决这些问题,我们推出了OSUM-EChat,这是一个旨在增强共情交互的开源端到端口语对话系统,特别是在资源受限的环境中。OSUM-EChat引入了两个关键的创新点:(1)一个三阶段的以理解为主导的口语对话训练策略,该策略扩展了大型语音理解模型在口语对话任务方面的能力;(2)一种语言副语言双重思考机制,它将副语言理解融入思维链中并与对话生成相结合,使系统能够产生更具共情的回应。这种方法减少了大规模对话数据集的依赖,同时保持了高质量的共情交互。此外,我们还推出了EChat-200K数据集,这是一份丰富的共情语音对话语料库,以及EChat-eval基准测试,这是一个全面评估对话系统共情能力的框架。实验结果表明,OSUM-EChat在共情响应方面优于端到端的口语对话模型,验证了其有效性。
论文及项目相关链接
摘要
共情在口语对话系统中实现自然交互至关重要,它让机器能够识别和响应诸如年龄、性别和情绪等副语言线索。虽然端到端的语音语言模型在统一语音理解和生成方面取得了进展,但仍存在诸多挑战,包括过于依赖大规模的对话数据集、未能充分提取对表达共情至关重要的副语言线索,以及缺乏针对共情的特定数据集和评估框架。为解决这些问题,我们推出了OSUM-EChat这一开源的端到端口语对话系统,旨在加强共情交互,特别是在资源有限的环境中。OSUM-EChat引入了两个关键的创新点:一是理解驱动的三阶段口语对话训练策略,它能扩展大型语音理解模型在口语对话任务上的能力;二是语言副语言双思考机制,通过思维链将副语言理解整合到对话生成中,使系统能够产生更具共情的回应。这种方法降低了对大规模对话数据集的依赖,同时保持了高质量的共情交互。此外,我们还推出了EChat-200K数据集,这是一个包含丰富共情言语对话的语料库,以及EChat-eval基准测试框架,用以全面评估对话系统的共情能力。实验结果表明,OSUM-EChat在共情响应方面优于端到端的口语对话模型,验证了其有效性。
要点速览
一、共情在口语对话系统中的重要性
二、现有技术挑战及解决方案
OSUM-EChat系统的两大创新点:理解驱动的训练策略和语言副语言双思考机制
三、OSUM-EChat对大规模对话数据集的依赖程度降低
四、引入EChat-200K数据集和EChat-eval基准测试框架
五、OSUM-EChat在共情响应方面的优越性
六、验证了OSUM-EChat系统的有效性
点此查看论文截图

ShoulderShot: Generating Over-the-Shoulder Dialogue Videos
Authors:Yuang Zhang, Junqi Cheng, Haoyu Zhao, Jiaxi Gu, Fangyuan Zou, Zenghui Lu, Peng Shu
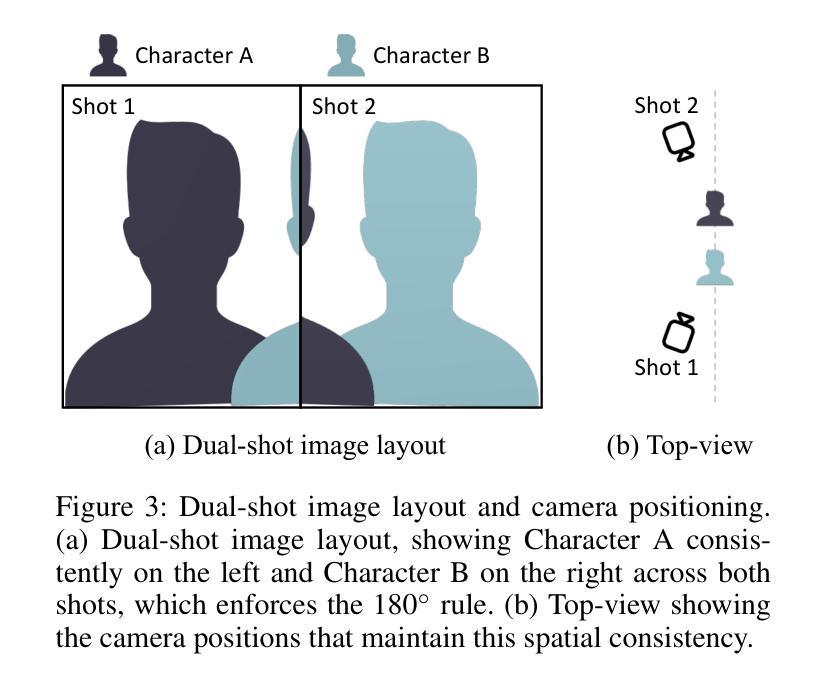
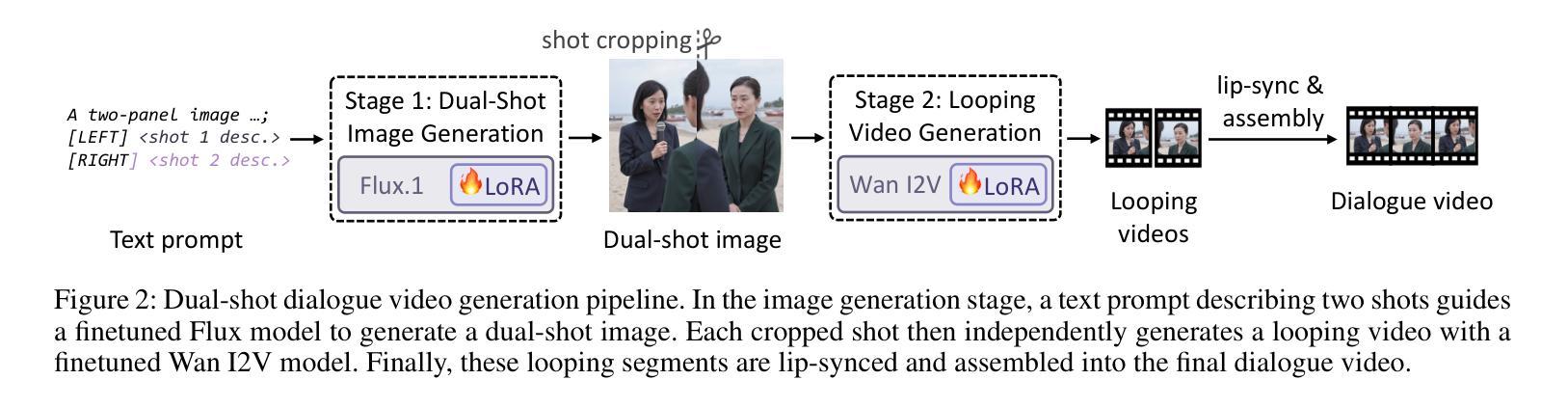
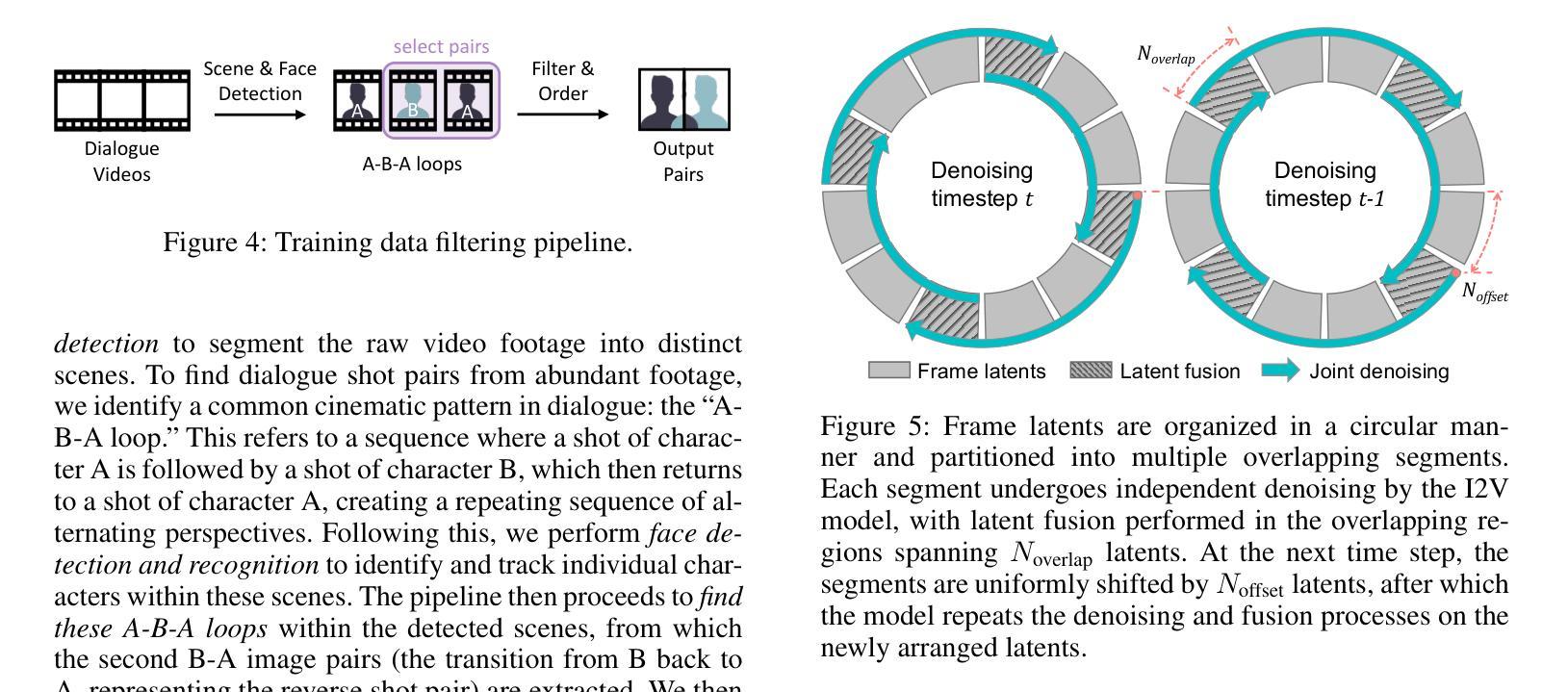
Over-the-shoulder dialogue videos are essential in films, short dramas, and advertisements, providing visual variety and enhancing viewers’ emotional connection. Despite their importance, such dialogue scenes remain largely underexplored in video generation research. The main challenges include maintaining character consistency across different shots, creating a sense of spatial continuity, and generating long, multi-turn dialogues within limited computational budgets. Here, we present ShoulderShot, a framework that combines dual-shot generation with looping video, enabling extended dialogues while preserving character consistency. Our results demonstrate capabilities that surpass existing methods in terms of shot-reverse-shot layout, spatial continuity, and flexibility in dialogue length, thereby opening up new possibilities for practical dialogue video generation. Videos and comparisons are available at https://shouldershot.github.io.
过肩对话视频在电影、短片和小品中占据重要地位,它提供了丰富的视觉多样性并增强了观众的情感联系。尽管它们在视频生成研究中十分重要,但这类对话场景仍受到较大程度的忽视。主要挑战包括在不同镜头中保持角色一致性、营造空间连续性和在有限的计算预算内生成长篇多轮对话。在这里,我们推出ShoulderShot框架,它将双镜头生成与循环视频相结合,能够在保持角色一致性的同时实现扩展对话。我们的结果表明,在镜头反转镜头布局、空间连续性和对话长度灵活性方面,我们的方法超越了现有方法,从而为实际对话视频生成提供了新的可能性。视频和对比视频可在https://shouldershot.github.io上观看。
论文及项目相关链接
Summary
对话场景在影片、短片及广告中不可或缺,能增加视觉多样性并加深观众的情感连接。尽管其重要性显著,对话场景在视频生成研究中的探索仍不足。主要挑战包括在不同镜头中保持角色一致性、创造空间连贯性以及在有限的计算预算内生成冗长、多回合的对话。本研究提出ShoulderShot框架,结合双镜头生成与循环视频技术,在延长对话的同时保持角色一致性。结果证明,该框架在镜头反转布局、空间连贯性及对话长度灵活性方面超越现有方法,为实用对话视频生成开启新的可能性。更多视频及对比信息请访问:https://shouldershot.github.io。
Key Takeaways
- 对话场景在影视、短片及广告中具有重要作用,能增强视觉多样性和观众情感连接。
- 对话场景在视频生成研究中受到忽视,存在保持角色一致性、空间连贯性和对话长度等方面的挑战。
- ShoulderShot框架结合双镜头生成与循环视频技术,实现了对话的延长并保持角色一致性。
- 该框架在镜头反转布局、空间连贯性和对话长度灵活性方面超越现有方法。
- ShouldersShot框架的推出为实用对话视频生成带来新可能性。
- 该研究提供了视频及对比信息访问链接:https://shouldershot.github.io。
- 该研究为电影、电视、广告等行业的对话场景制作提供了新的思路和方法。
点此查看论文截图