⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-19 更新
FantasyTalking2: Timestep-Layer Adaptive Preference Optimization for Audio-Driven Portrait Animation
Authors:MengChao Wang, Qiang Wang, Fan Jiang, Mu Xu
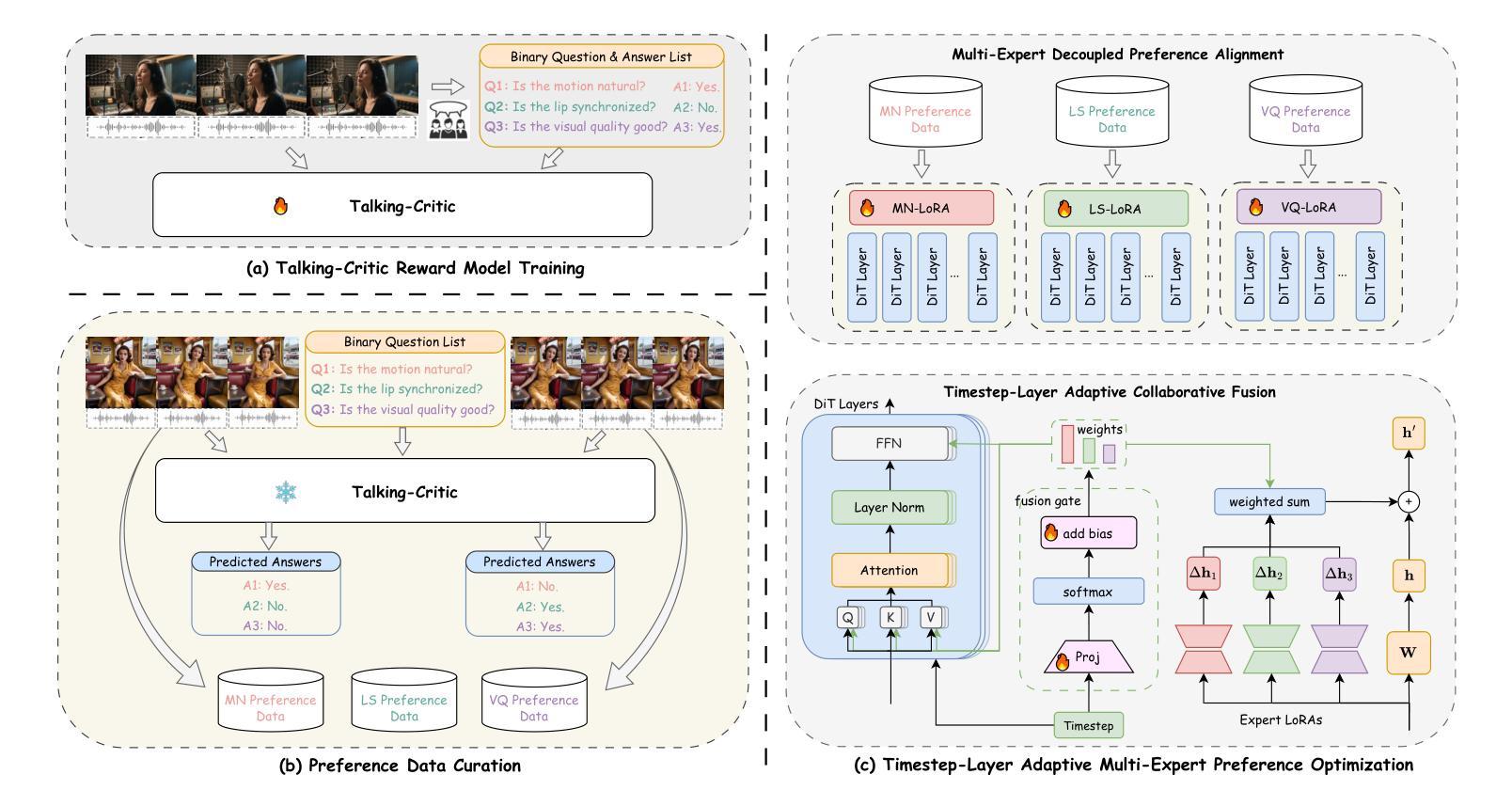
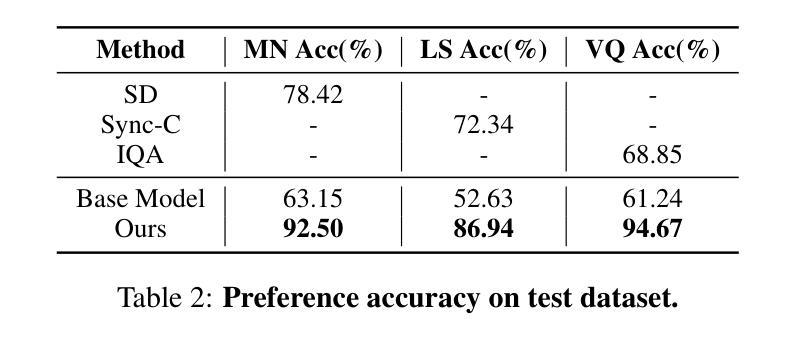
Recent advances in audio-driven portrait animation have demonstrated impressive capabilities. However, existing methods struggle to align with fine-grained human preferences across multiple dimensions, such as motion naturalness, lip-sync accuracy, and visual quality. This is due to the difficulty of optimizing among competing preference objectives, which often conflict with one another, and the scarcity of large-scale, high-quality datasets with multidimensional preference annotations. To address these, we first introduce Talking-Critic, a multimodal reward model that learns human-aligned reward functions to quantify how well generated videos satisfy multidimensional expectations. Leveraging this model, we curate Talking-NSQ, a large-scale multidimensional human preference dataset containing 410K preference pairs. Finally, we propose Timestep-Layer adaptive multi-expert Preference Optimization (TLPO), a novel framework for aligning diffusion-based portrait animation models with fine-grained, multidimensional preferences. TLPO decouples preferences into specialized expert modules, which are then fused across timesteps and network layers, enabling comprehensive, fine-grained enhancement across all dimensions without mutual interference. Experiments demonstrate that Talking-Critic significantly outperforms existing methods in aligning with human preference ratings. Meanwhile, TLPO achieves substantial improvements over baseline models in lip-sync accuracy, motion naturalness, and visual quality, exhibiting superior performance in both qualitative and quantitative evaluations. Ours project page: https://fantasy-amap.github.io/fantasy-talking2/
近期,音频驱动肖像动画方面的进展展示出了令人印象深刻的能力。然而,现有方法在多个维度上难以与精细的人类偏好对齐,如运动自然性、唇同步准确性和视觉质量。这是由于在优化竞争性的偏好目标时存在困难,这些目标经常相互冲突,以及缺乏大规模、高质量的多维度偏好注释数据集。
论文及项目相关链接
PDF https://fantasy-amap.github.io/fantasy-talking2/
Summary
近期音频驱动肖像动画技术的进展令人印象深刻,但现有方法在多个维度上难以符合人类精细偏好,如动作自然性、唇部同步准确性和视觉质量。为解决此问题,本文提出Talking-Critic模型,学习人类对齐奖励函数以量化生成视频满足多维度期望的程度。基于此模型,建立大规模多维度人类偏好数据集Talking-NSQ。最后,提出Timestep-Layer自适应多专家偏好优化(TLPO)框架,将扩散式肖像动画模型与精细多维度偏好对齐。实验表明,Talking-Critic在符合人类偏好评分上显著优于现有方法,而TLPO在唇部同步、动作自然性和视觉质量方面实现显著改进,并在定性和定量评估中展现卓越性能。
Key Takeaways
- 现有音频驱动肖像动画方法在多个维度上难以满足人类精细偏好。
- 推出Talking-Critic模型,能学习人类对齐奖励函数,量化生成视频满足多维度期望的程度。
- 基于Talking-Critic模型建立大规模多维度人类偏好数据集Talking-NSQ。
- 提出TLPO框架,通过解耦偏好到专业专家模块,实现在时间和网络层上的精细对齐。
- Talking-Critic在符合人类偏好评分上表现优越。
- TLPO在唇部同步、动作自然性和视觉质量方面显著改进。
点此查看论文截图



HM-Talker: Hybrid Motion Modeling for High-Fidelity Talking Head Synthesis
Authors:Shiyu Liu, Kui Jiang, Xianming Liu, Hongxun Yao, Xiaocheng Feng
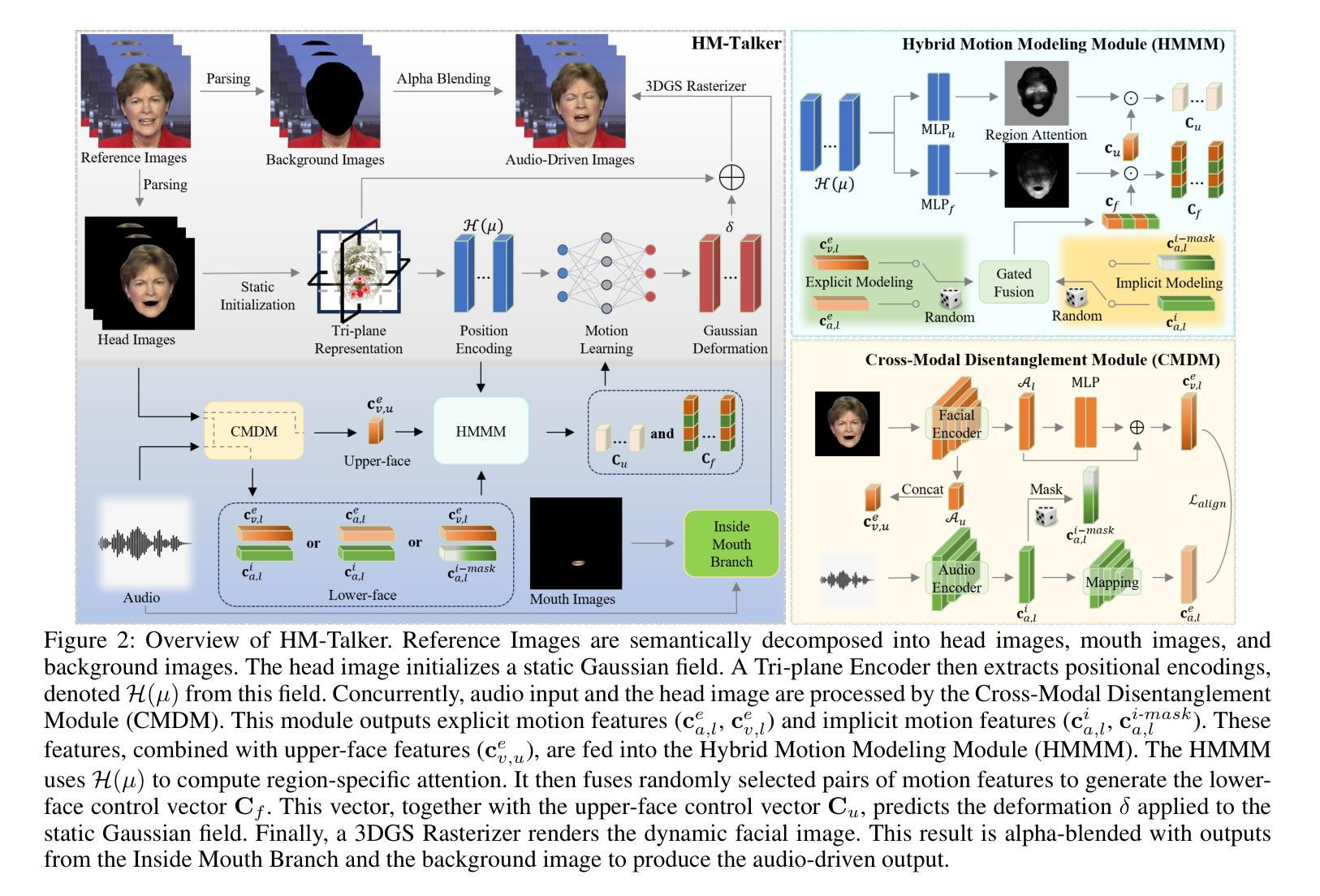
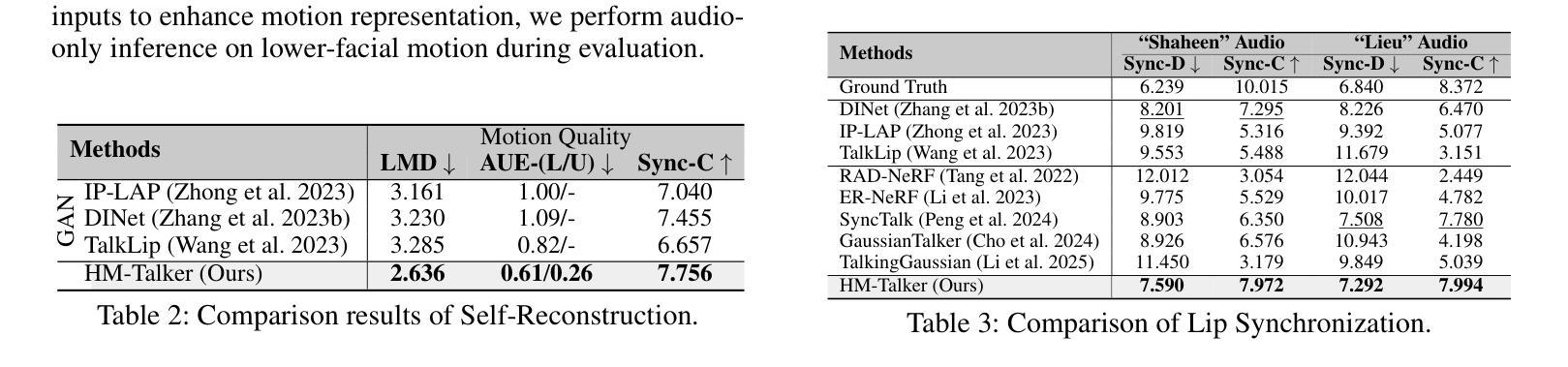
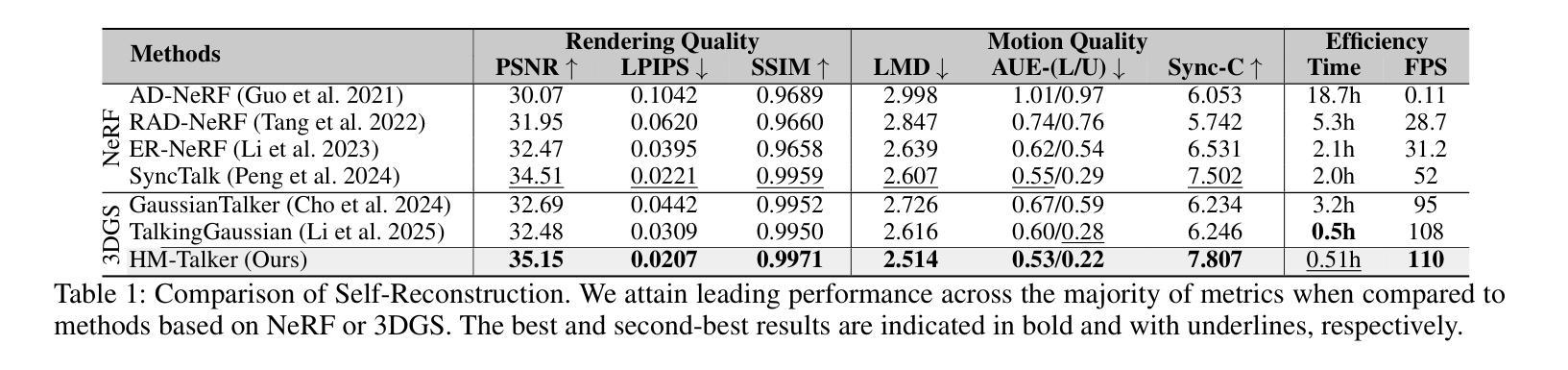
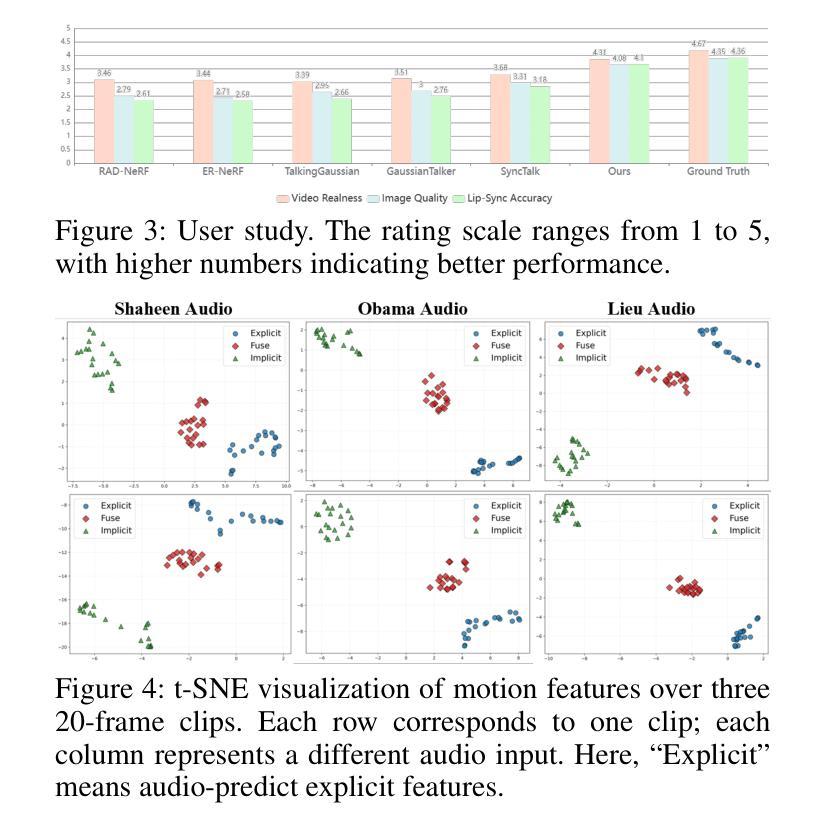
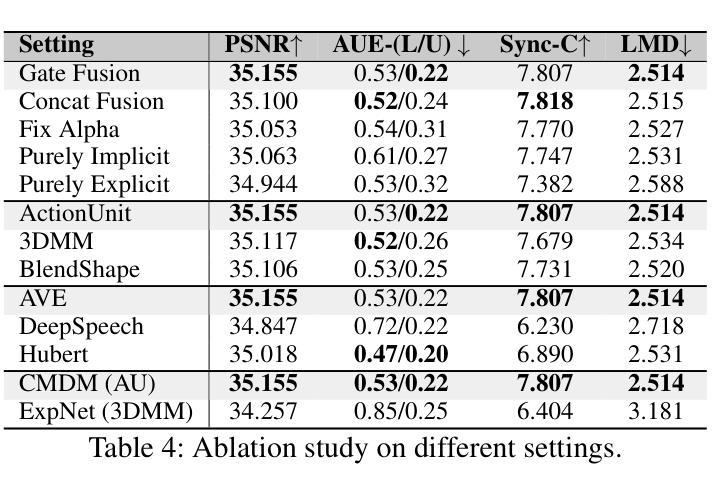
Audio-driven talking head video generation enhances user engagement in human-computer interaction. However, current methods frequently produce videos with motion blur and lip jitter, primarily due to their reliance on implicit modeling of audio-facial motion correlations–an approach lacking explicit articulatory priors (i.e., anatomical guidance for speech-related facial movements). To overcome this limitation, we propose HM-Talker, a novel framework for generating high-fidelity, temporally coherent talking heads. HM-Talker leverages a hybrid motion representation combining both implicit and explicit motion cues. Explicit cues use Action Units (AUs), anatomically defined facial muscle movements, alongside implicit features to minimize phoneme-viseme misalignment. Specifically, our Cross-Modal Disentanglement Module (CMDM) extracts complementary implicit/explicit motion features while predicting AUs directly from audio input aligned to visual cues. To mitigate identity-dependent biases in explicit features and enhance cross-subject generalization, we introduce the Hybrid Motion Modeling Module (HMMM). This module dynamically merges randomly paired implicit/explicit features, enforcing identity-agnostic learning. Together, these components enable robust lip synchronization across diverse identities, advancing personalized talking head synthesis. Extensive experiments demonstrate HM-Talker’s superiority over state-of-the-art methods in visual quality and lip-sync accuracy.
音频驱动的说话人头部视频生成提高了人机交互中的用户参与度。然而,当前的方法经常产生运动模糊和嘴唇抖动等问题的视频,这主要是因为它们依赖于音频面部运动之间的隐式建模关联——这种方法缺乏明确的发音先验知识(即与语音相关的面部运动的解剖指导)。为了克服这一局限性,我们提出了HM-Talker,这是一个用于生成高保真、时间连贯的说话人头部的全新框架。HM-Talker利用了一种混合运动表征,结合了隐式和显式的运动线索。显式线索使用行动单位(AUs),即面部解剖上定义的肌肉运动,以及隐式特征来最小化音素与可见语法的失配。具体来说,我们的跨模态分离模块(CMDM)在预测与视觉线索对齐的音频输入的直接AU时,提取了隐式/显式的互补运动特征。为了减轻显式特征中的身份相关偏见,并增强跨主体泛化,我们引入了混合运动建模模块(HMMM)。该模块动态地融合了随机配对的隐式/显式特征,强制实施身份无关的学习。这些组件共同作用,实现了跨不同身份的稳健嘴唇同步,推动了个性化说话人头部合成的进步。大量实验表明,HM-Talker在视觉质量和嘴唇同步精度方面优于最新技术的方法。
论文及项目相关链接
Summary
本文提出一种名为HM-Talker的新型框架,用于生成高保真、时间连贯的说话人头部视频。HM-Talker结合了隐式和显式运动线索的混合运动表示,利用面部肌肉动作单元(AUs)等显式线索和隐式特征,减少语音与面部动作的不对齐问题。通过跨模态解耦模块(CMDM)提取隐式和显式运动特征,并从音频输入预测与视觉线索对齐的AU。为解决身份相关偏差并增强跨主体泛化能力,引入混合运动建模模块(HMMM),动态合并随机配对的隐式和显式特征,实现身份无关的学习。HM-Talker显著提升了个性化说话人头部视频的合成效果,在视觉质量和唇同步准确性方面优于现有技术。
Key Takeaways
- HM-Talker框架结合了隐式和显式运动线索,提高了音频驱动说话人头部视频生成的质量。
- 显式运动线索利用面部肌肉动作单元(AUs)来减少语音与面部动作的不对齐问题。
- 跨模态解耦模块(CMDM)能够提取隐式和显式运动特征,并从音频预测与视觉对齐的AU。
- 混合运动建模模块(HMMM)解决了身份相关偏差问题,增强了跨主体泛化能力。
- HM-Talker通过动态合并隐式和显式特征,实现了身份无关的学习。
- HM-Talker在视觉质量和唇同步准确性方面优于现有技术。
点此查看论文截图

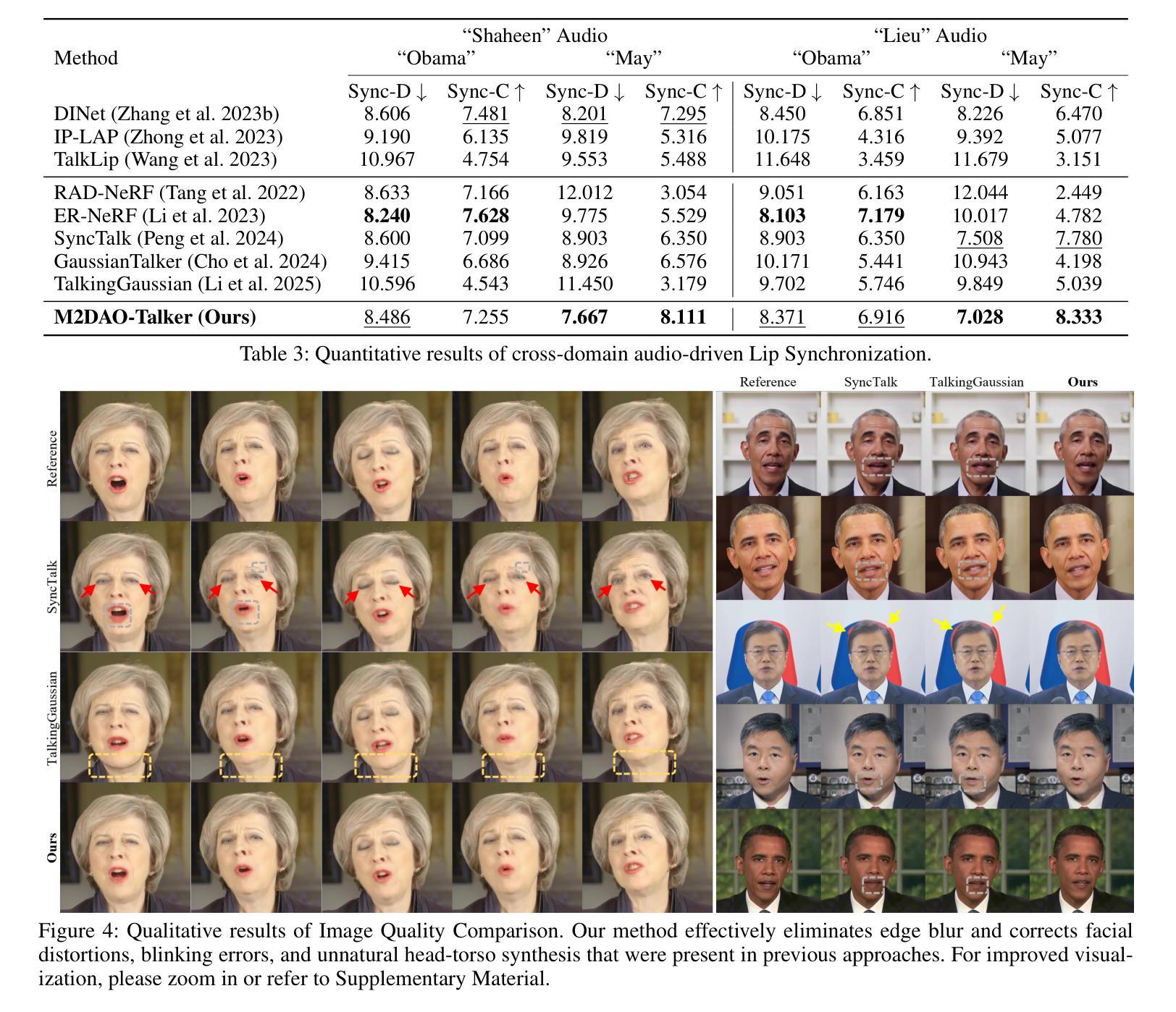
M2DAO-Talker: Harmonizing Multi-granular Motion Decoupling and Alternating Optimization for Talking-head Generation
Authors:Kui Jiang, Shiyu Liu, Junjun Jiang, Hongxun Yao, Xiaopeng Fan
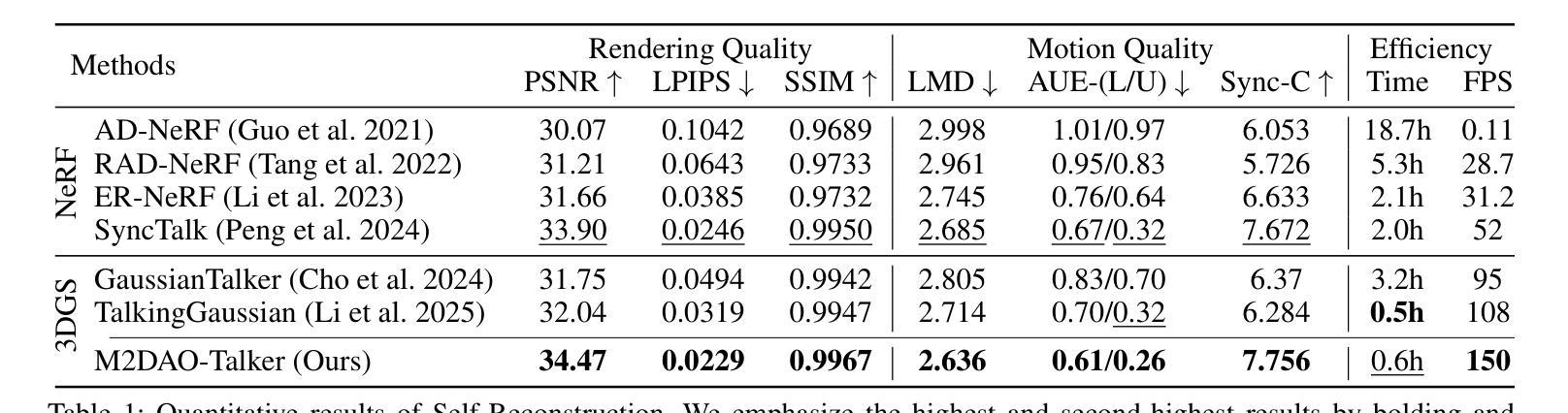
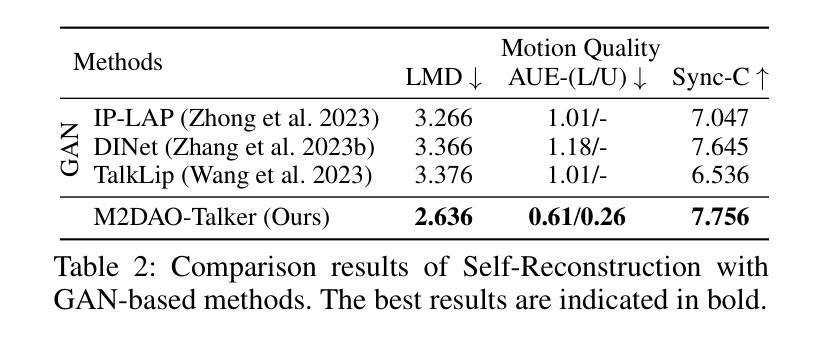
Audio-driven talking head generation holds significant potential for film production. While existing 3D methods have advanced motion modeling and content synthesis, they often produce rendering artifacts, such as motion blur, temporal jitter, and local penetration, due to limitations in representing stable, fine-grained motion fields. Through systematic analysis, we reformulate talking head generation into a unified framework comprising three steps: video preprocessing, motion representation, and rendering reconstruction. This framework underpins our proposed M2DAO-Talker, which addresses current limitations via multi-granular motion decoupling and alternating optimization. Specifically, we devise a novel 2D portrait preprocessing pipeline to extract frame-wise deformation control conditions (motion region segmentation masks, and camera parameters) to facilitate motion representation. To ameliorate motion modeling, we elaborate a multi-granular motion decoupling strategy, which independently models non-rigid (oral and facial) and rigid (head) motions for improved reconstruction accuracy. Meanwhile, a motion consistency constraint is developed to ensure head-torso kinematic consistency, thereby mitigating penetration artifacts caused by motion aliasing. In addition, an alternating optimization strategy is designed to iteratively refine facial and oral motion parameters, enabling more realistic video generation. Experiments across multiple datasets show that M2DAO-Talker achieves state-of-the-art performance, with the 2.43 dB PSNR improvement in generation quality and 0.64 gain in user-evaluated video realness versus TalkingGaussian while with 150 FPS inference speed. Our project homepage is https://m2dao-talker.github.io/M2DAO-Talk.github.io.
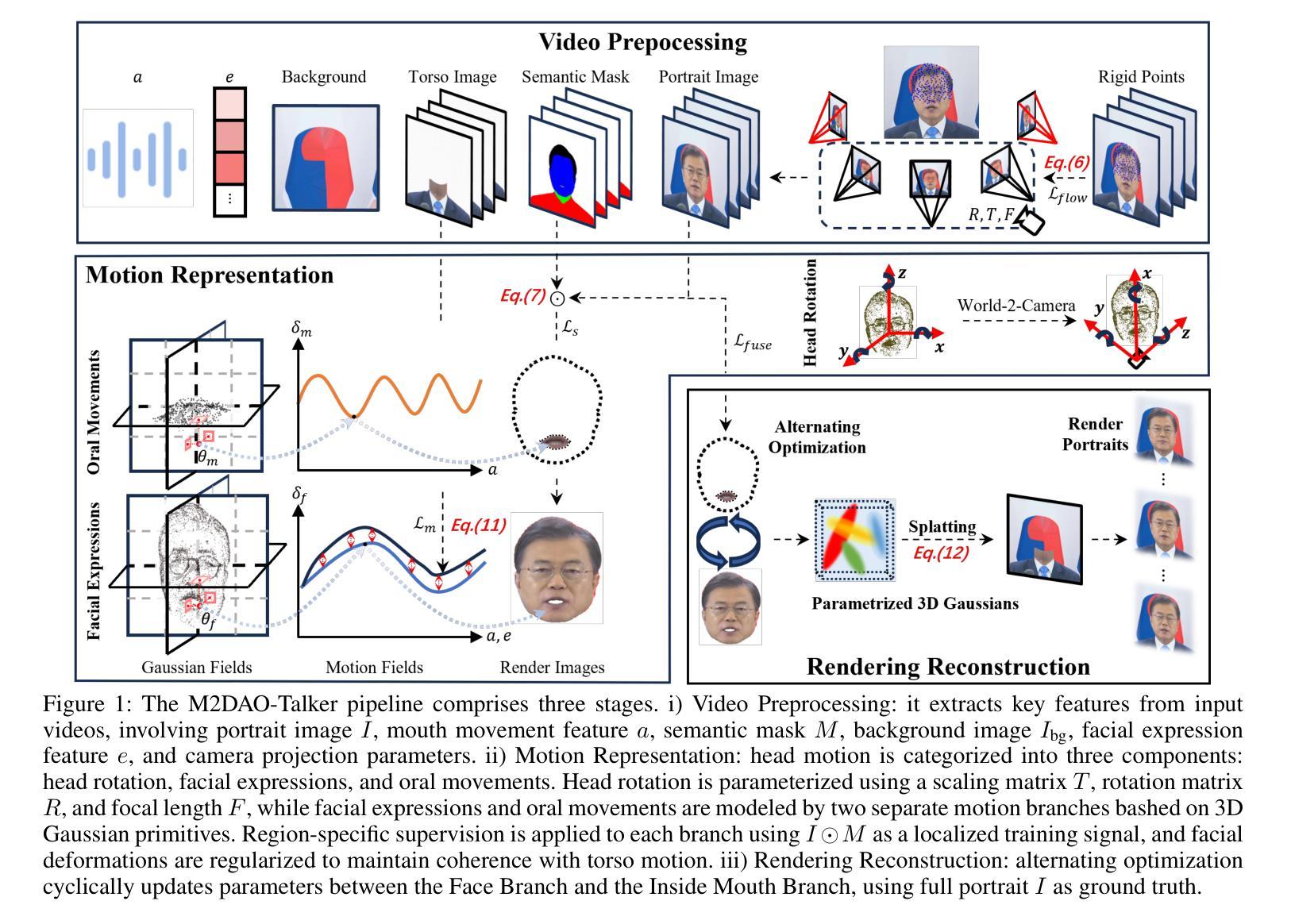
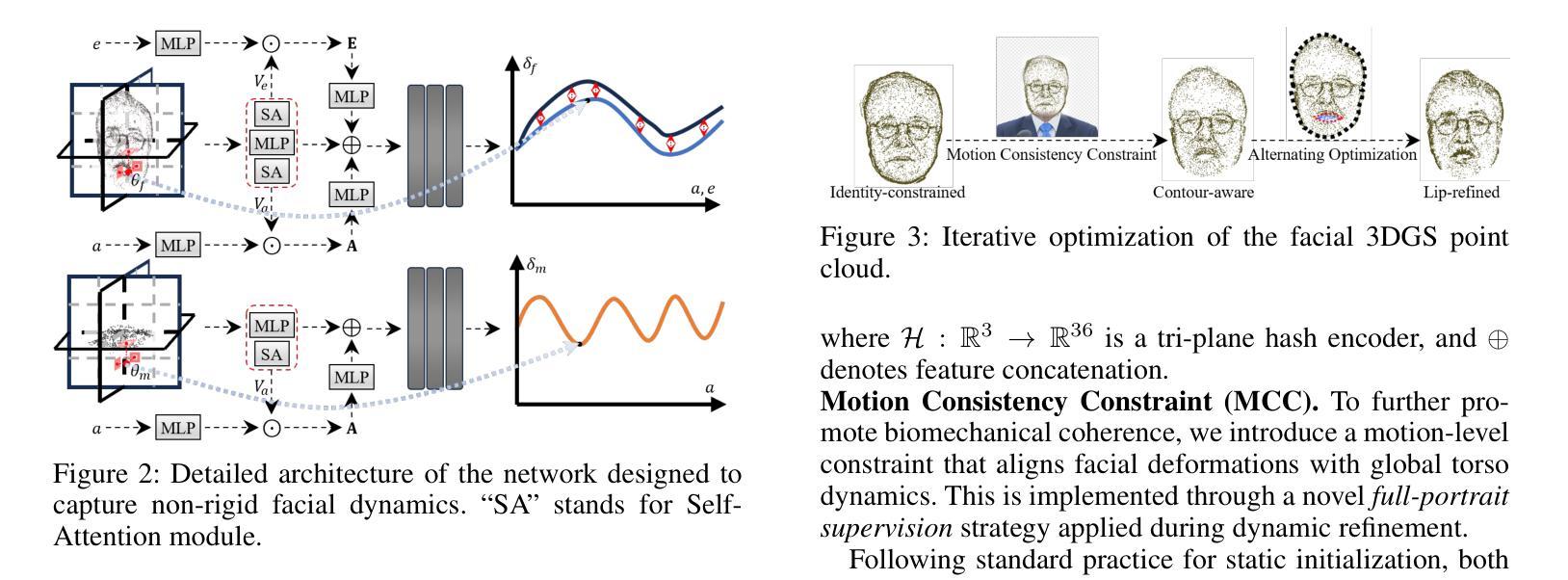
音频驱动的说话人头部生成对电影制作具有显著潜力。尽管现有的3D方法在动作建模和内容合成方面取得了进展,但由于在表示稳定、精细粒度的运动场方面的局限性,它们经常产生渲染伪影,如运动模糊、时间抖动和局部穿透。通过系统分析,我们将说话人头部生成重新制定为一个包含三个步骤的统一框架:视频预处理、运动表示和渲染重建。这一框架支撑了我们提出的M2DAO-Talker,它通过多粒度运动解耦和交替优化来解决当前限制。具体来说,我们设计了一种新型的2D肖像预处理管道,以提取帧级变形控制条件(运动区域分割掩膜和相机参数),以促进运动表示。为了改善运动建模,我们提出了一种多粒度运动解耦策略,该策略独立地对非刚性(口腔和面部)和刚性(头部)运动进行建模,以提高重建精度。同时,开发了一种运动一致性约束,以确保头部与躯干之间的运动学一致性,从而减轻由运动混淆引起的穿透伪影。此外,设计了一种交替优化策略,可以迭代地优化面部和口腔运动参数,以实现更逼真的视频生成。在多个数据集上的实验表明,M2DAO-Talker达到了领先水平,在生成质量上提高了2.43 dB PSNR,在用户评估的视频真实感方面获得了0.64的增益,同时推理速度为150 FPS。我们的项目主页是[https://m2dao-talker.github.io/M2DAO-Talk.github.io。]
论文及项目相关链接
Summary
本文探讨了音频驱动的说话人头部生成技术在电影制作中的潜力。针对现有3D方法的不足,如运动模糊、时间抖动和局部穿透等问题,提出了一种统一的框架M2DAO-Talker。该框架通过视频预处理、运动表示和渲染重建三个步骤,实现多粒度运动解耦和交替优化,提高了生成视频的质量和真实感。
Key Takeaways
- 音频驱动的说话人头部生成技术在电影制作中具有显著潜力。
- 现有3D方法在说话人头部生成中存在运动模糊、时间抖动和局部穿透等问题。
- 提出的M2DAO-Talker框架通过视频预处理、运动表示和渲染重建三个步骤解决这些问题。
- M2DAO-Talker通过多粒度运动解耦策略,独立建模非刚性(口腔和面部)和刚性(头部)运动,提高重建精度。
- 运动一致性约束确保头部与躯干运动学一致性,减少因运动别名导致的穿透伪影。
- 交替优化策略可迭代优化面部和口腔运动参数,生成更逼真的视频。
点此查看论文截图

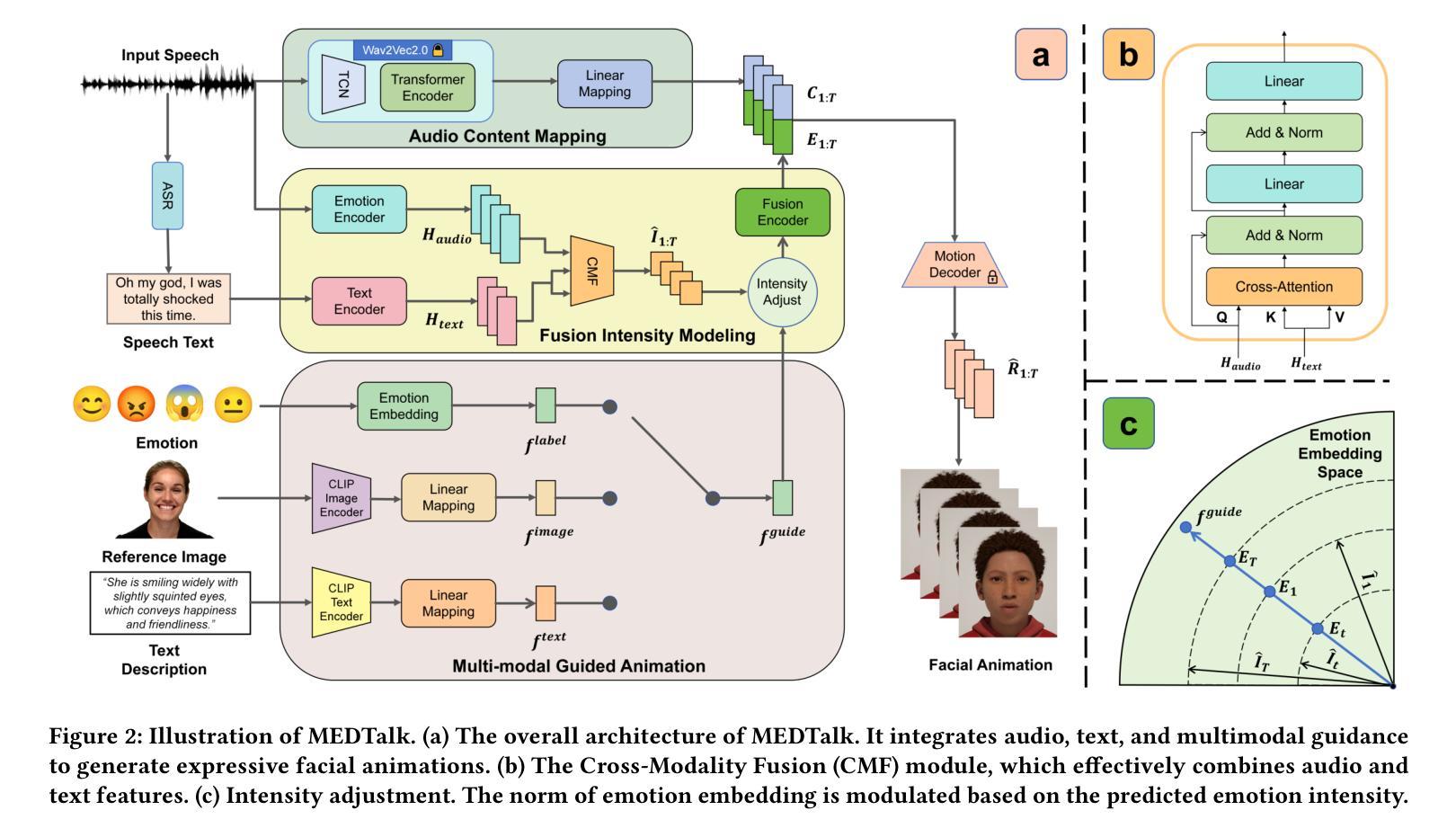
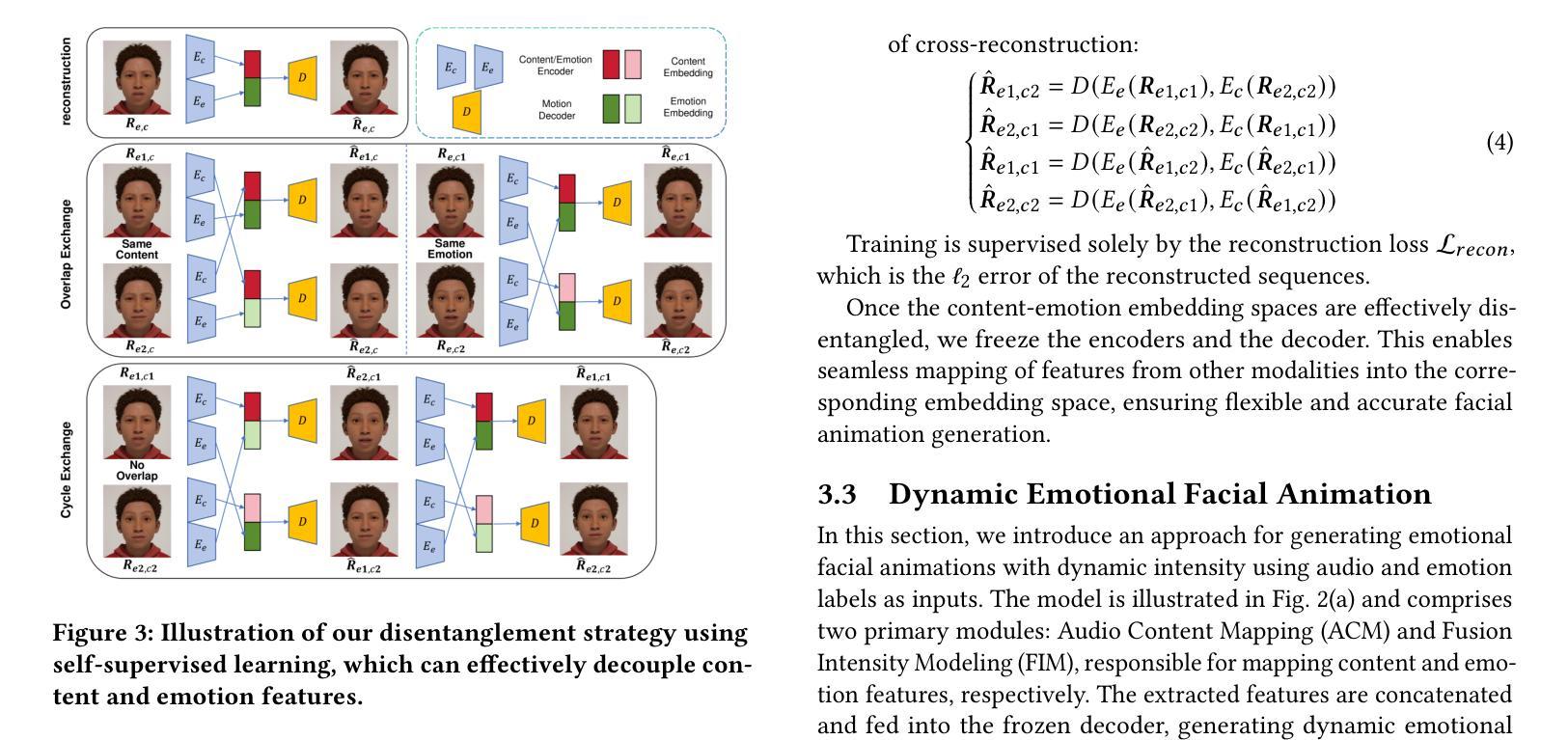
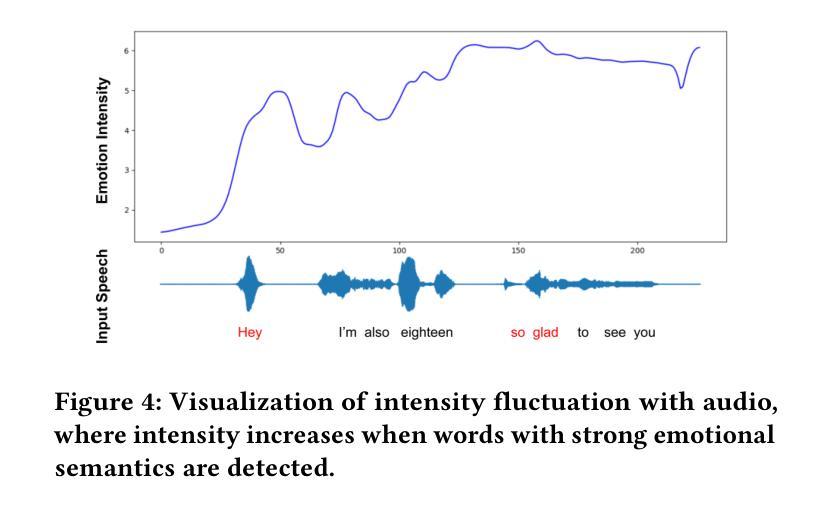
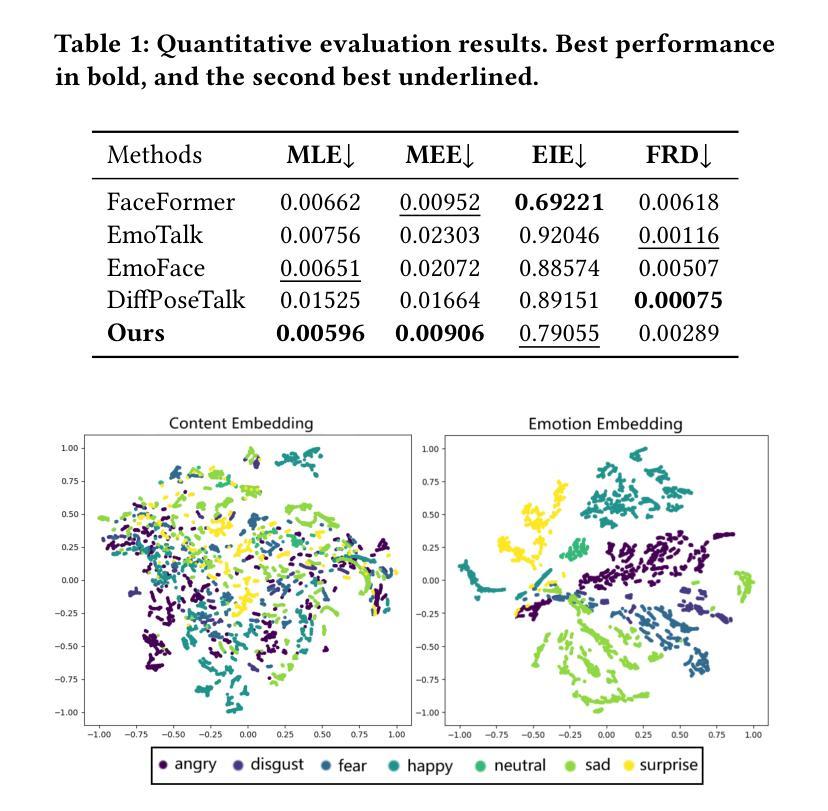
MEDTalk: Multimodal Controlled 3D Facial Animation with Dynamic Emotions by Disentangled Embedding
Authors:Chang Liu, Ye Pan, Chenyang Ding, Susanto Rahardja, Xiaokang Yang
Audio-driven emotional 3D facial animation aims to generate synchronized lip movements and vivid facial expressions. However, most existing approaches focus on static and predefined emotion labels, limiting their diversity and naturalness. To address these challenges, we propose MEDTalk, a novel framework for fine-grained and dynamic emotional talking head generation. Our approach first disentangles content and emotion embedding spaces from motion sequences using a carefully designed cross-reconstruction process, enabling independent control over lip movements and facial expressions. Beyond conventional audio-driven lip synchronization, we integrate audio and speech text, predicting frame-wise intensity variations and dynamically adjusting static emotion features to generate realistic emotional expressions. Furthermore, to enhance control and personalization, we incorporate multimodal inputs-including text descriptions and reference expression images-to guide the generation of user-specified facial expressions. With MetaHuman as the priority, our generated results can be conveniently integrated into the industrial production pipeline. The code is available at: https://github.com/SJTU-Lucy/MEDTalk.
音频驱动的情感3D面部动画旨在生成同步的唇部运动和生动的面部表情。然而,现有的大多数方法主要关注静态和预定义的情感标签,这限制了其多样性和自然性。为了应对这些挑战,我们提出了MEDTalk,这是一个用于精细粒度和动态情感对话头部生成的新型框架。我们的方法首先通过使用精心设计的跨重建过程,从运动序列中分离内容和情感嵌入空间,实现对唇部运动和面部表情的独立控制。除了传统的音频驱动唇同步外,我们还整合了音频和语音文本,预测帧强度变化并动态调整静态情感特征,以生成逼真的情感表达。此外,为了提高控制和个性化,我们引入了多模式输入,包括文本描述和参考表情图像,以指导用户指定的面部表情的生成。以MetaHuman为优先,我们生成的结果可以方便地集成到工业生产流程中。代码可在https://github.com/SJTU-Lucy/MEDTalk获得。
论文及项目相关链接
Summary
基于音频驱动的情感3D面部动画旨在生成同步的嘴唇动作和生动的面部表情。然而,大多数现有方法侧重于静态和预定义的情感标签,限制了其多样性和自然性。为了应对这些挑战,我们提出了MEDTalk框架,用于精细粒度和动态的情感说话头部生成。我们的方法通过精心设计交叉重建过程,从运动序列中分离内容和情感嵌入空间,实现对嘴唇动作和面部表情的独立控制。除了传统的音频驱动唇同步外,我们还整合了音频和语音文本,预测帧强度变化并动态调整静态情感特征,以生成逼真的情感表达。此外,为了提高控制和个性化,我们引入了多模式输入,包括文本描述和参考表情图像,以指导用户指定的面部表情的生成。我们的生成结果可轻松融入工业生产线,以MetaHuman为优先。
Key Takeaways
- MEDTalk是一个用于精细粒度和动态情感谈话头部生成的新框架。
- 它通过分离内容和情感嵌入空间,实现嘴唇动作和面部表情的独立控制。
- MEDTalk不仅同步音频和嘴唇动作,还整合音频和语音文本,生成更逼真的情感表达。
- 该框架支持多模式输入,包括文本描述和参考表情图像,以指导面部表情的生成。
- MEDTalk可以提高动画的多样性和自然性,克服现有方法的局限性。
- 该框架可轻松融入工业生产线,特别是以MetaHuman等数字人物模型为优先。
点此查看论文截图