⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
STORM: Token-Efficient Long Video Understanding for Multimodal LLMs
Authors:Jindong Jiang, Xiuyu Li, Zhijian Liu, Muyang Li, Guo Chen, Zhiqi Li, De-An Huang, Guilin Liu, Zhiding Yu, Kurt Keutzer, Sungjin Ahn, Jan Kautz, Hongxu Yin, Yao Lu, Song Han, Wonmin Byeon
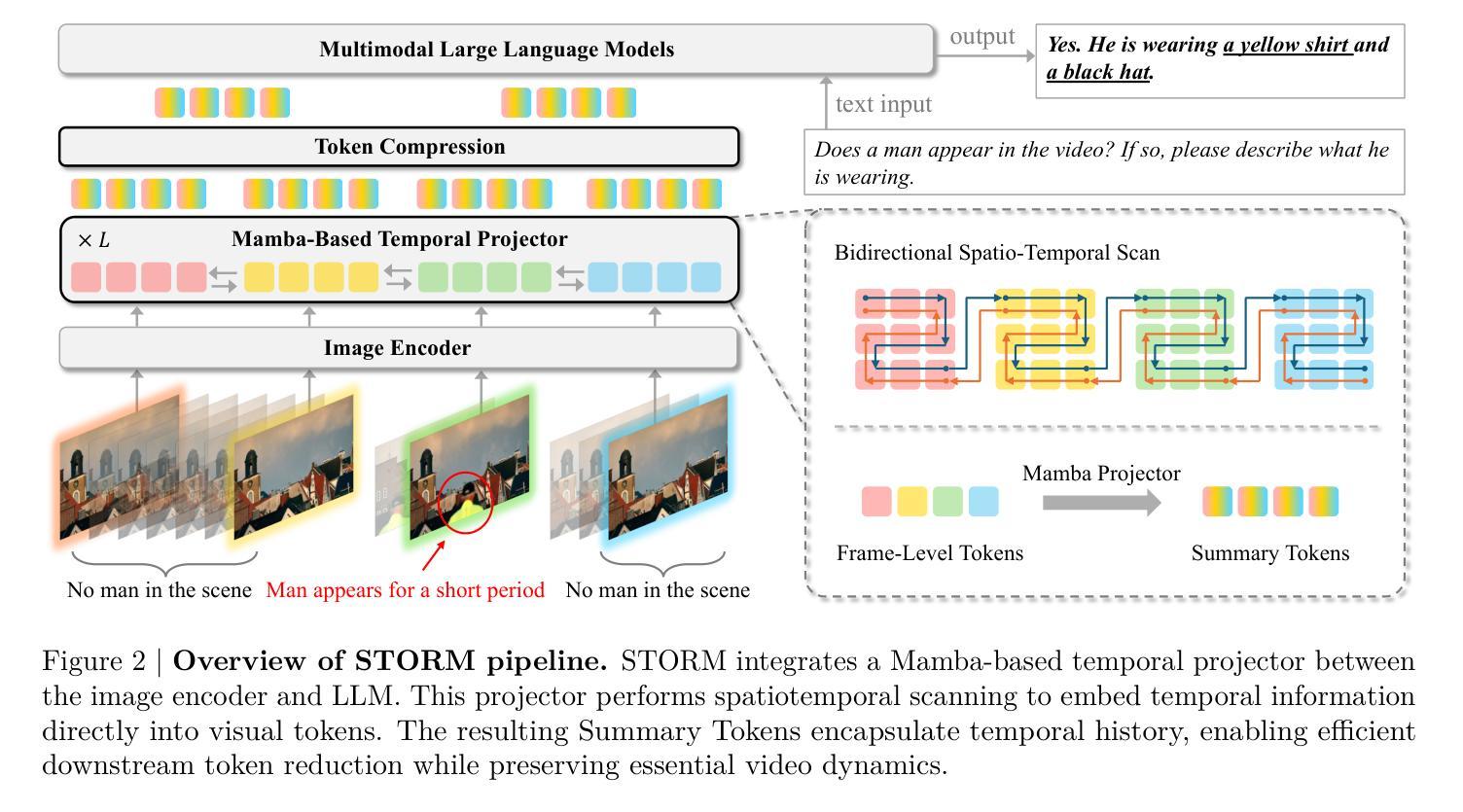
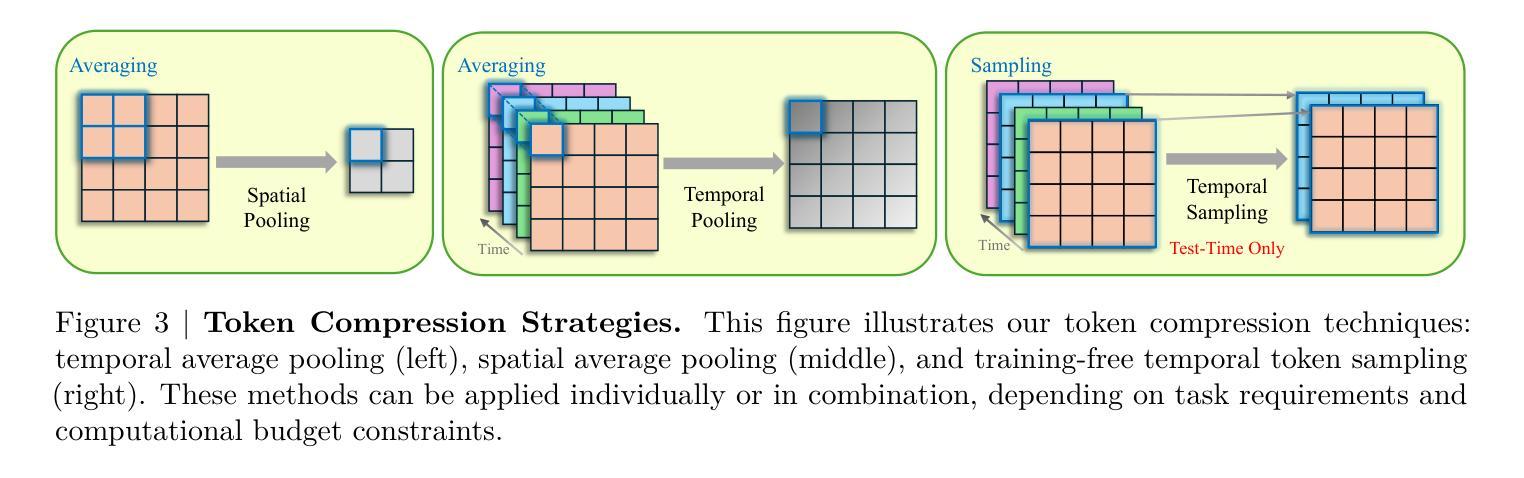
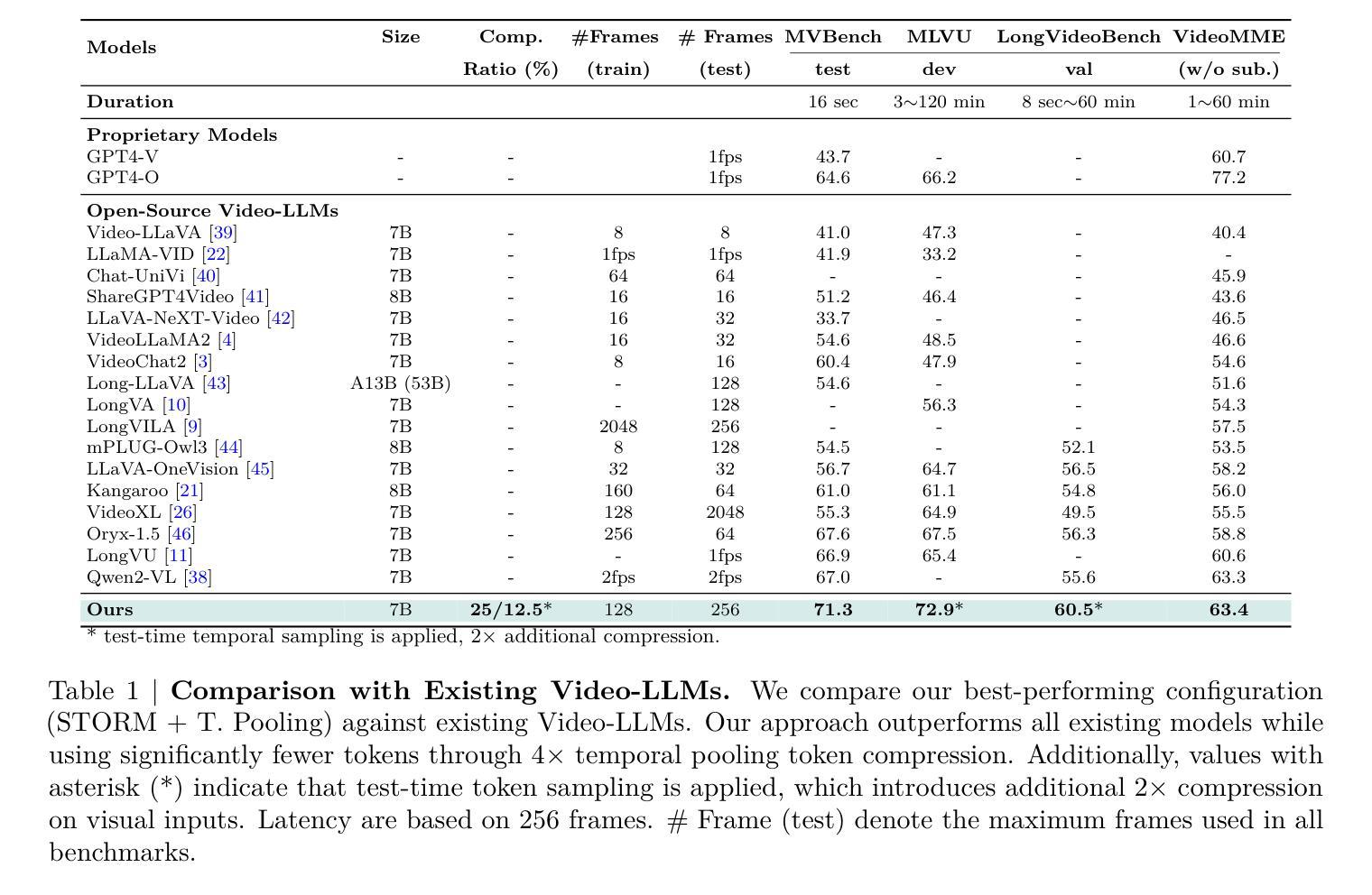
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (Spatiotemporal TOken Reduction for Multimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
基于视频的多媒体大型语言模型(Video-LLM)的最新进展通过将视频处理为图像帧序列来显著提高了视频理解能力。然而,许多现有方法在视觉主干网络中独立处理帧,缺乏明确的时序建模,这限制了它们捕捉动态模式和有效处理长视频的能力。为了解决这些局限性,我们引入了STORM(用于多媒体LLM的时空令牌缩减),这是一种新型架构,在图像编码器和LLM之间集成了一个专用的时序编码器。我们的时序编码器利用Mamba状态空间模型将时序信息集成到图像令牌中,生成丰富的表示形式,这些表示形式在整个视频序列中保留跨帧动态。这种丰富的编码不仅增强了视频推理能力,还实现了有效的令牌缩减策略,包括测试时采样和基于训练的时序和空间池化,在不影响关键时序信息的情况下,大大降低了LLM的计算需求。通过整合这些技术,我们的方法能够在提高性能的同时,同时减少训练和推理延迟,实现在扩展的时间上下文上进行高效且稳健的视频理解。广泛评估表明,STORM在多种长视频理解基准测试上达到了最新水平(在MLVU和LongVideoBench上的改进超过5%),同时计算成本降低了高达8倍,对于固定数量的输入帧,解码延迟减少了2.4-2.9倍。项目页面可在https://research.nvidia.com/labs/lpr/storm上查看。
论文及项目相关链接
Summary
本文介绍了针对视频理解领域的新技术——基于时空token缩减的多模态大型语言模型(STORM)。该技术通过引入专门的时空编码器,将视频帧序列中的时间信息融入图像token中,生成更丰富、保留跨帧动态的表示形式,从而提升视频理解的能力。这种方法结合了高效的token缩减策略,能在不影响关键时间信息的前提下,大大减少大型语言模型的计算需求和推断延迟,从而实现更高效的视频理解。目前该技术已在多个长视频理解基准测试中取得最佳结果。
Key Takeaways
1.STORM是一种新的视频理解技术,结合了时空信息来增强图像token的表示能力。
2.该技术通过引入Mamba状态空间模型作为时空编码器,生成包含跨帧动态的丰富表示形式。
3.丰富的编码不仅提高了视频推理能力,还使得有效的token缩减策略成为可能。
4.STORM采用了测试时的采样和基于训练的时空池化等token缩减策略。
5.这些策略能在不牺牲关键时间信息的前提下,大大减少大型语言模型的计算需求和推断延迟。
6.在多个长视频理解基准测试中,STORM实现了最佳性能,并显著降低了计算成本和解码延迟。
点此查看论文截图