⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
Authors:Zhaoxi Chen, Tianqi Liu, Long Zhuo, Jiawei Ren, Zeng Tao, He Zhu, Fangzhou Hong, Liang Pan, Ziwei Liu
We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) to alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) we introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) we propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for 4D modeling. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX outperforms existing 4D generation methods in efficiency and generalizability, offering a scalable solution for image-to-4D modeling and laying the foundation for generative 4D world models that simulate dynamic scene evolution.
我们推出4DNeX,这是首个从单张图像生成4D(即动态3D)场景表示的前馈框架。与现有依赖于计算密集优化的方法或需要多帧视频输入的方法相比,4DNeX能够通过微调预训练的视频扩散模型,实现高效、端到端的图像到4D生成。具体来说,1)为了缓解4D数据的稀缺性,我们构建了4DNeX-10M,这是一个使用先进重建方法生成的高质量4D注释的大规模数据集。2)我们提出了一种统一的6D视频表示方法,该方法联合建模RGB和XYZ序列,促进外观和几何的结构化学习。3)我们提出了一系列简单有效的适应策略,以将预训练的视频扩散模型用于4D建模。4DNeX生成高质量动态点云,可实现新颖视角的视频合成。大量实验表明,4DNeX在效率和泛化方面优于现有4D生成方法,为图像到4D建模提供了可扩展的解决方案,并为模拟动态场景演变的生成式4D世界模型奠定了基础。
论文及项目相关链接
PDF Project Page: https://4dnex.github.io/
Summary:
我们推出了一款名为4DNeX的创新性前馈框架,可从单张图像生成四维(即动态三维)场景表示。通过微调预训练的扩散模型,该框架实现了高效端到端的图像到四维生成。通过构建大规模数据集,引入统一六维视频表示及适应性策略,可实现高质量动态点云生成和新颖视角视频合成。实验结果证明了其在效率和泛化性能上的优势,为图像到四维建模提供了可扩展的解决方案,并为模拟动态场景演变的四维世界模型奠定了基础。这一切的技术变革主要体现在我们对现有技术短板提出的突破性解决策略之上。创新之处在于我们是第一个可以通过单次输入,实现对场景的精确三维视觉建模和演绎的系统。并且我们在简化算法复杂性方面做出了巨大的努力,从而使之能更加适应大规模应用的需求。同时,我们的技术也极大地提升了生成结果的逼真度和多样性。简而言之,我们的工作开辟了一条全新的路径,使得计算机视觉技术在理解复杂动态场景方面的能力达到了新的高度。相较于其他同类技术而言,我们有着更加卓越的效能表现和更强的实用性价值。为此我们相信它将会对未来的影像艺术制作和技术研发领域带来深远影响。这是我们创新的革命性贡献,将为业界树立新的标杆。该框架不仅具备出色的性能表现,同时也展现出广阔的应用前景和市场潜力。我们坚信这一技术将为相关行业带来前所未有的变革和发展机遇。展望未来,我们有信心将这一技术推向更广泛的应用领域并取得更大的成功。随着技术的不断进步和应用领域的不断拓展,我们期待更多的突破和创新。这一框架将为构建更加智能和丰富的世界铺平道路!无论是理论研究还是实际应用上都具有非常强的前景优势和市场竞争力!为行业未来的发展提供了强有力的支撑和推动力!同时也标志着计算机视觉领域的一大突破!其对于行业的影响力和潜力不言而喻!
Key Takeaways:
- 推出首个基于单张图像生成四维场景表示的框架——4DNeX。
- 构建大规模数据集4DNeX-10M,包含高质量四维注释信息,通过先进的重建方法生成。
- 引入统一六维视频表示以联合建模RGB和XYZ序列。提高了视觉效果和空间感建模的效果和质量稳定性可靠性评估等方面的准确性和精确度减少了背景扭曲问题有助于提高实际生产能力和图像质量的可视化体验用户能够快速完成观看的目标精确的空间感和模型状态获得丰富了建模的空间深度设计范围和相应的利用领域的需求和市场影响力突破现阶段局限并提供新颖的三维显示结果出现机遇从而为高现实度和复杂性较高展示的真实模拟带来更多现实技术改良的优化突破相对技术的应用和实现都具有前瞻性更高的意义和产业深远影响的创新型转化更实用技术显著促进实体空间的深入布局或演示级别新形象完成流程的实质性拓展大幅提升实战场景中复原相关平台的最终影响能力并以此颠覆常规方法和策略的局限性。通过采用先进的算法和强大的计算能力实现高质量动态点云生成和新颖视角视频合成进一步提升了其实际应用价值并推动了计算机视觉技术的快速发展。这一框架的推出将极大地推动计算机视觉技术在动态场景建模等领域的应用和发展并为相关产业带来革命性的变革和机遇!未来具有广阔的应用前景和市场潜力。其强大的性能和广泛的应用领域使得它成为业界瞩目的焦点并引领着计算机视觉技术的未来发展方向!同时这也标志着计算机视觉领域的一大突破其影响力和潜力不容忽视!
点此查看论文截图


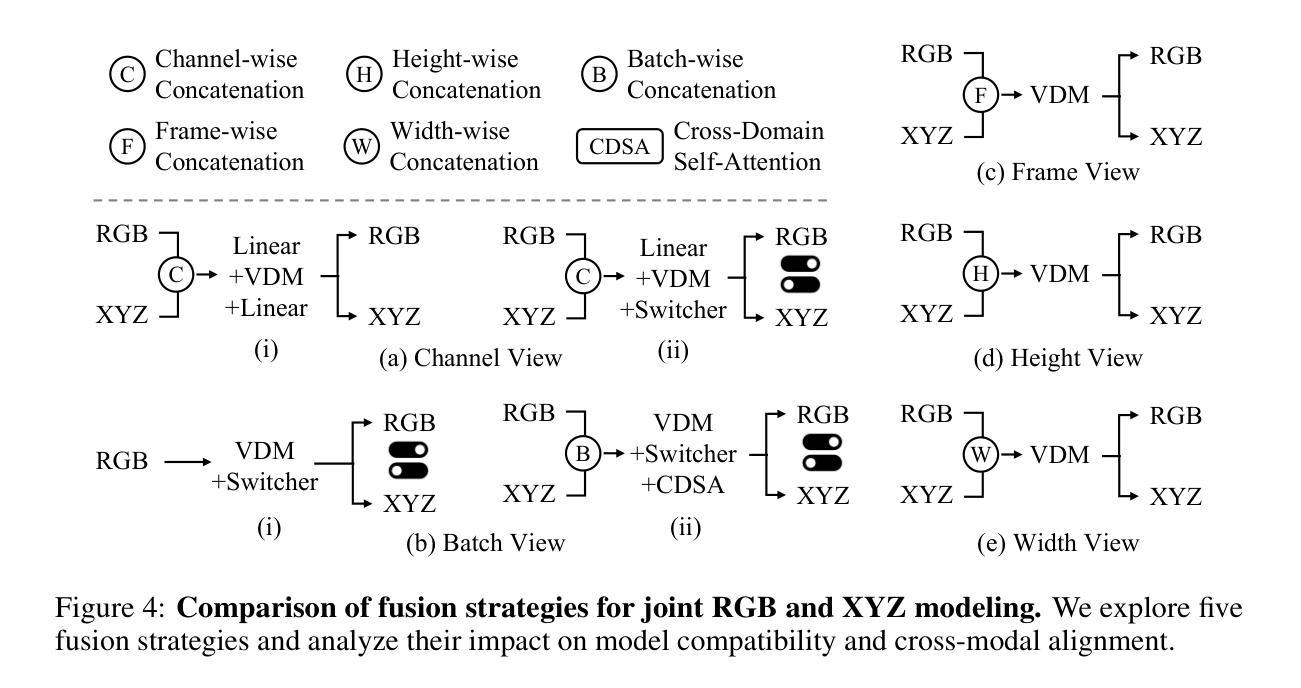
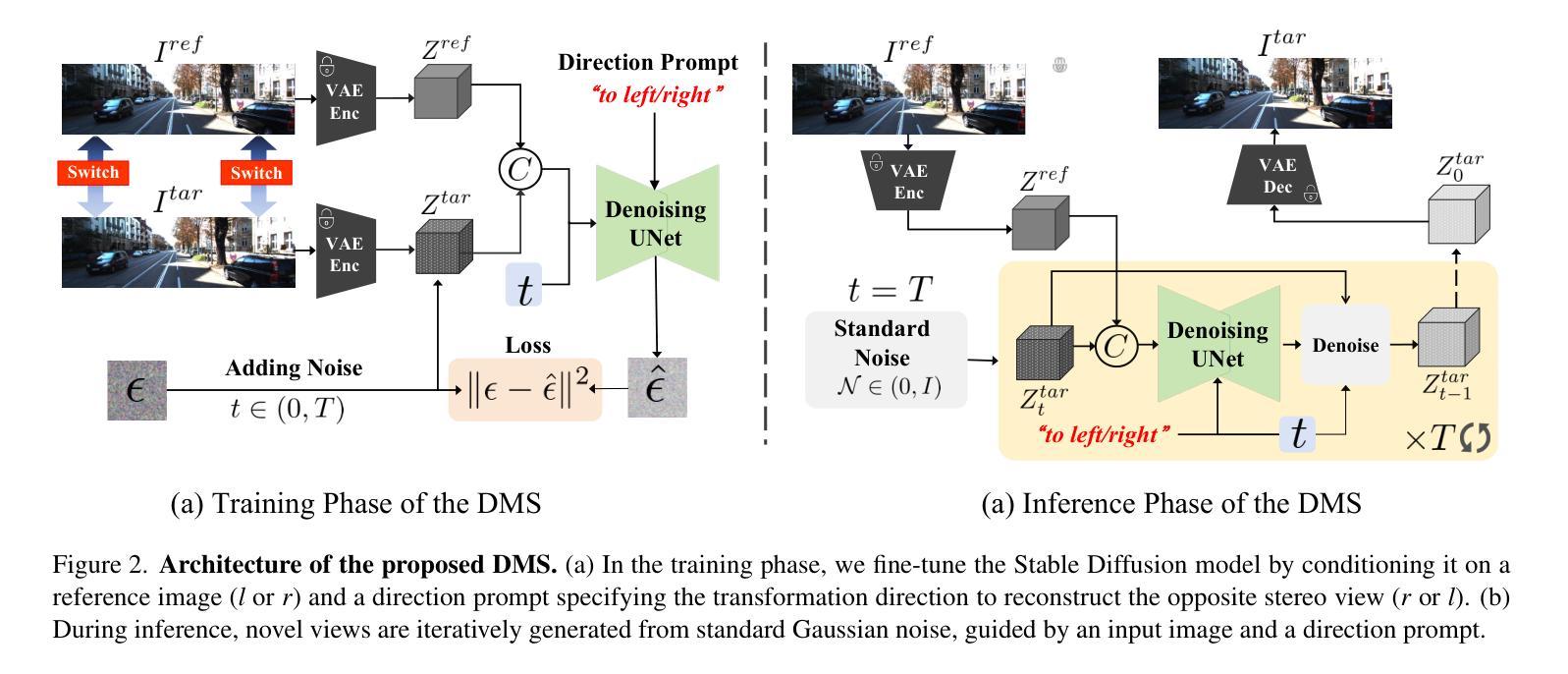
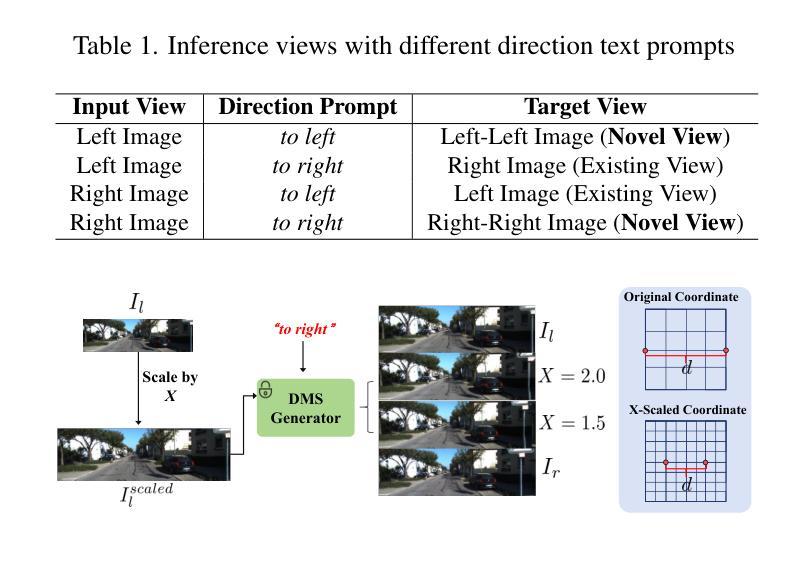
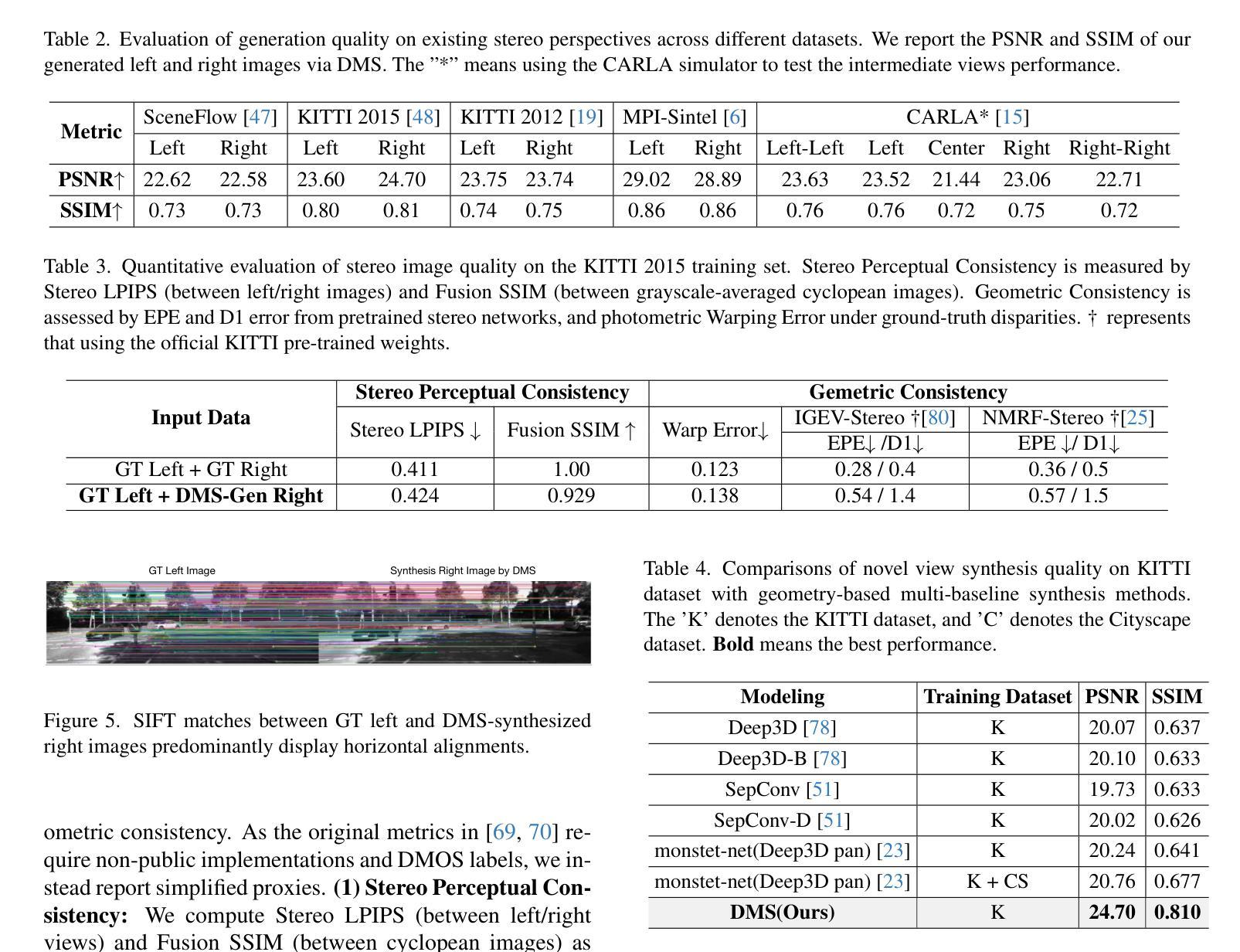
DMS:Diffusion-Based Multi-Baseline Stereo Generation for Improving Self-Supervised Depth Estimation
Authors:Zihua Liu, Yizhou Li, Songyan Zhang, Masatoshi Okutomi
While supervised stereo matching and monocular depth estimation have advanced significantly with learning-based algorithms, self-supervised methods using stereo images as supervision signals have received relatively less focus and require further investigation. A primary challenge arises from ambiguity introduced during photometric reconstruction, particularly due to missing corresponding pixels in ill-posed regions of the target view, such as occlusions and out-of-frame areas. To address this and establish explicit photometric correspondences, we propose DMS, a model-agnostic approach that utilizes geometric priors from diffusion models to synthesize novel views along the epipolar direction, guided by directional prompts. Specifically, we finetune a Stable Diffusion model to simulate perspectives at key positions: left-left view shifted from the left camera, right-right view shifted from the right camera, along with an additional novel view between the left and right cameras. These synthesized views supplement occluded pixels, enabling explicit photometric reconstruction. Our proposed DMS is a cost-free, ‘’plug-and-play’’ method that seamlessly enhances self-supervised stereo matching and monocular depth estimation, and relies solely on unlabeled stereo image pairs for both training and synthesizing. Extensive experiments demonstrate the effectiveness of our approach, with up to 35% outlier reduction and state-of-the-art performance across multiple benchmark datasets.
虽然基于学习的算法在监督立体匹配和单眼深度估计方面取得了显著进展,但使用立体图像作为监督信号的自监督方法相对受到的关注较少,需要进一步研究。主要挑战来自于在光测重建过程中引入的歧义,特别是在目标视图的病态区域(如遮挡和超出画面范围的地方)缺少相应的像素。为了解决这一问题并建立明确的光测对应关系,我们提出了DMS(深度匹配合成),这是一种模型不可知的方法,它利用扩散模型的几何先验信息沿着极点的方向合成新的视角,并由方向提示引导。具体来说,我们微调了Stable Diffusion模型来模拟关键位置的视角:从左侧相机偏移的左视角、从右侧相机偏移的右视角以及位于左右相机之间的额外新视角。这些合成的视角补充了被遮挡的像素,实现了明确的光测重建。我们提出的DMS是一种免费、即插即用的方法,无缝地增强了自监督立体匹配和单眼深度估计,并且仅依赖于无标签的立体图像对进行训练和合成。大量实验证明了我们方法的有效性,实现了高达35%的异常值减少,并在多个基准数据集上达到了最先进的性能。
论文及项目相关链接
Summary
基于深度学习的监督立体匹配和单目深度估计已经取得了显著进展,但自监督方法利用立体图像作为监督信号的相对研究较少,还存在一定的挑战。为解决这一挑战,本文提出了一种利用扩散模型的几何先验合成新视角的方法(DMS),以建立明确的光度对应关系。该方法利用稳定的扩散模型模拟关键位置的视角,补充被遮挡的像素,从而实现显式光度重建。DMS是一种无成本的“即插即用”方法,可无缝增强自监督立体匹配和单目深度估计,仅依赖于无标签的立体图像对进行训练和合成。实验表明,该方法可有效减少异常值并达到多个基准数据集的领先水平。
Key Takeaways
- 自监督方法在立体匹配和单目深度估计中应用相对较少,需要进一步研究。
- 利用扩散模型的几何先验合成新视角是解决自监督方法中的光度重建模糊问题的有效手段。
- DMS方法利用稳定的扩散模型模拟关键位置的视角,补充被遮挡的像素。
- DMS是一种无成本的“即插即用”方法,能增强自监督立体匹配和单目深度估计的性能。
- DMS仅依赖于无标签的立体图像对进行训练和合成。
- 实验结果显示,DMS方法能有效减少异常值并达到多个基准数据集的领先水平。
点此查看论文截图


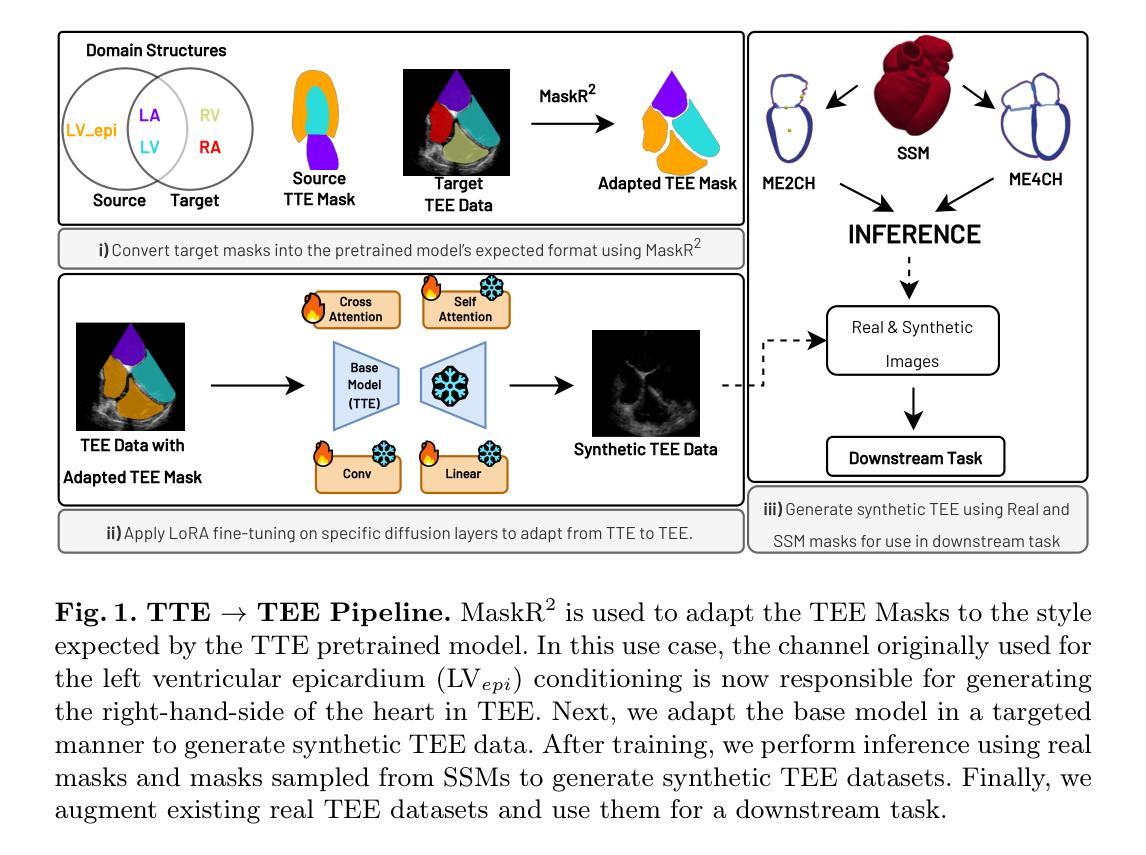
From Transthoracic to Transesophageal: Cross-Modality Generation using LoRA Diffusion
Authors:Emmanuel Oladokun, Yuxuan Ou, Anna Novikova, Daria Kulikova, Sarina Thomas, Jurica Šprem, Vicente Grau
Deep diffusion models excel at realistic image synthesis but demand large training sets-an obstacle in data-scarce domains like transesophageal echocardiography (TEE). While synthetic augmentation has boosted performance in transthoracic echo (TTE), TEE remains critically underrepresented, limiting the reach of deep learning in this high-impact modality. We address this gap by adapting a TTE-trained, mask-conditioned diffusion backbone to TEE with only a limited number of new cases and adapters as small as $10^5$ parameters. Our pipeline combines Low-Rank Adaptation with MaskR$^2$, a lightweight remapping layer that aligns novel mask formats with the pretrained model’s conditioning channels. This design lets users adapt models to new datasets with a different set of anatomical structures to the base model’s original set. Through a targeted adaptation strategy, we find that adapting only MLP layers suffices for high-fidelity TEE synthesis. Finally, mixing less than 200 real TEE frames with our synthetic echoes improves the dice score on a multiclass segmentation task, particularly boosting performance on underrepresented right-heart structures. Our results demonstrate that (1) semantically controlled TEE images can be generated with low overhead, (2) MaskR$^2$ effectively transforms unseen mask formats into compatible formats without damaging downstream task performance, and (3) our method generates images that are effective for improving performance on a downstream task of multiclass segmentation.
深度扩散模型在真实图像合成方面表现出色,但需要大量的训练集——这在数据稀缺的领域(如食管超声心动图TEE)中是一个障碍。虽然合成增强技术提高了胸部透视(TTE)的性能,但TEE仍然缺乏代表性,限制了深度学习在这个重要模态中的应用范围。我们通过适应TTE训练的掩膜条件扩散主干到TEE来解决这一差距,只需要有限的新病例和仅$10^5$参数大小的适配器。我们的管道结合了低秩适配和MaskR$^2$(一种轻量级重映射层),将新颖掩膜格式与预训练模型的调节通道对齐。这种设计允许用户适应模型到具有不同解剖结构集的新数据集,与基础模型的原始集不同。通过有针对性的适应策略,我们发现仅适应MLP层就足以实现高保真TEE合成。最后,将不到200个真实TEE帧与我们的合成回声混合,提高了多类分割任务上的骰子得分,特别是在代表性不足的右心结构性能上有所提升。我们的结果表明:(1)语义控制的TEE图像可以低开销地生成;(2)MaskR$^2$可以有效地将看不见的掩膜格式转换为兼容格式,而不会损害下游任务性能;(3)我们的方法在生成图像方面对于提高多类分割任务的下游任务性能是有效的。
论文及项目相关链接
PDF MICCAI 2025; ASMUS
Summary
本文解决了深度扩散模型在数据稀缺领域(如食管超声心动图)的应用挑战。通过适应TTE训练的扩散模型并将其用于TEE,仅在少量新案例和少量适配器参数下实现了高保真TEE合成。采用低秩适应和MaskR²技术,使用户能够适应具有不同解剖结构的新数据集。通过混合少量真实TEE帧和合成回声,提高了多类分割任务的Dice得分,特别是在右心结构方面的表现有所提升。总的来说,本研究展示了生成控制性TEE图像的低开销方法,并验证了MaskR²技术的有效性及其在改善下游任务性能方面的潜力。
Key Takeaways
- 深度扩散模型在数据稀缺领域如食管超声心动图(TEE)的应用面临挑战,需要大训练集。
- 通过适应TTE训练的扩散模型并将其用于TEE,实现了在少量新案例和少量适配器参数下的高保真TEE合成。
- 采用低秩适应和MaskR²技术,该技术可将新的掩膜格式与预训练模型的调节通道对齐。
- 适应模型能够适应具有不同解剖结构的新数据集。
- 通过混合真实和合成回声,提高了多类分割任务的Dice得分。
- 本研究展示了生成控制性TEE图像的低开销方法。
点此查看论文截图

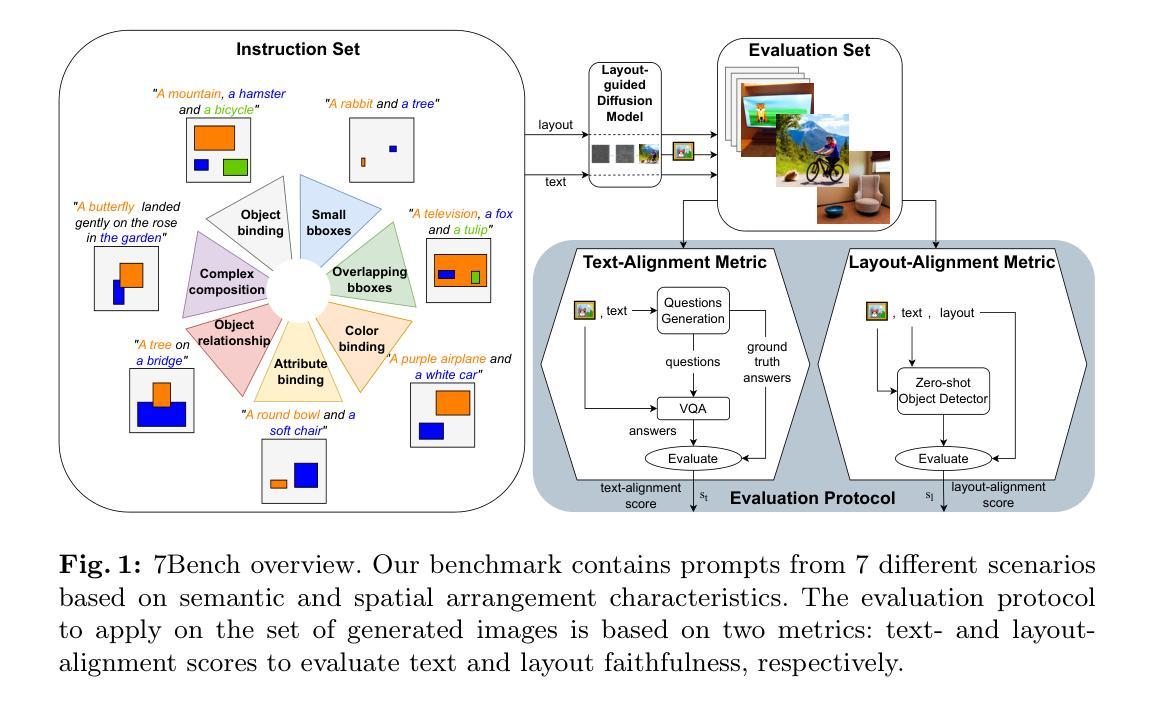
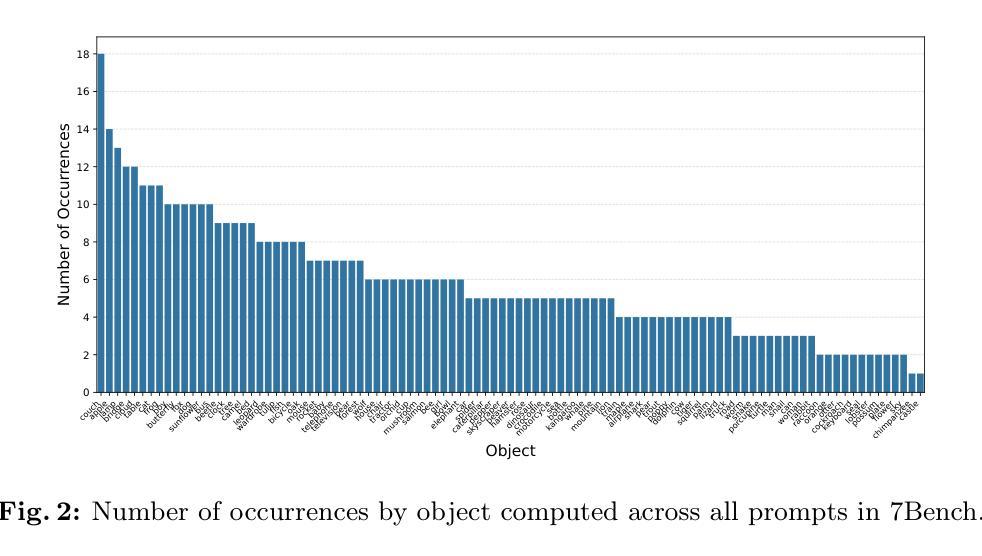
7Bench: a Comprehensive Benchmark for Layout-guided Text-to-image Models
Authors:Elena Izzo, Luca Parolari, Davide Vezzaro, Lamberto Ballan
Layout-guided text-to-image models offer greater control over the generation process by explicitly conditioning image synthesis on the spatial arrangement of elements. As a result, their adoption has increased in many computer vision applications, ranging from content creation to synthetic data generation. A critical challenge is achieving precise alignment between the image, textual prompt, and layout, ensuring semantic fidelity and spatial accuracy. Although recent benchmarks assess text alignment, layout alignment remains overlooked, and no existing benchmark jointly evaluates both. This gap limits the ability to evaluate a model’s spatial fidelity, which is crucial when using layout-guided generation for synthetic data, as errors can introduce noise and degrade data quality. In this work, we introduce 7Bench, the first benchmark to assess both semantic and spatial alignment in layout-guided text-to-image generation. It features text-and-layout pairs spanning seven challenging scenarios, investigating object generation, color fidelity, attribute recognition, inter-object relationships, and spatial control. We propose an evaluation protocol that builds on existing frameworks by incorporating the layout alignment score to assess spatial accuracy. Using 7Bench, we evaluate several state-of-the-art diffusion models, uncovering their respective strengths and limitations across diverse alignment tasks. The benchmark is available at https://github.com/Elizzo/7Bench.
布局导向的文本到图像模型通过明确地根据元素的空间排列来条件化图像合成,从而实现对生成过程更好的控制。因此,它们在许多计算机视觉应用中得到了广泛的应用,从内容创建到合成数据生成。一个关键的挑战是实现图像、文本提示和布局之间的精确对齐,确保语义保真度和空间准确性。虽然最近的基准测试评估了文本对齐,但布局对齐却被忽视了,并且没有现有的基准测试可以同时评估两者。这一差距限制了评估模型的空间保真度的能力,这在使用布局导向生成合成数据时至关重要,因为错误可能会引入噪声并降低数据质量。在这项工作中,我们介绍了7Bench,这是第一个评估布局导向的文本到图像生成中的语义和空间对齐的基准测试。它包含跨越七个具有挑战性的场景的文本和布局对,研究对象生成、颜色保真度、属性识别、对象间关系以及空间控制。我们提出了一个评估协议,该协议建立在现有框架之上,通过融入布局对齐分数来评估空间准确性。使用7Bench,我们评估了多个最先进的扩散模型,揭示了它们在各种对齐任务中的各自优势和局限。该基准测试在 https://github.com/Elizzo/7Bench 可用。
论文及项目相关链接
PDF Accepted to ICIAP 2025
Summary
本文介绍了一种新的评估基准——7Bench,该基准用于评估布局引导文本到图像生成中的语义和空间对齐情况。通过引入文本和布局对,涵盖七个具有挑战性的场景,该基准能够评估对象生成、颜色保真度、属性识别、对象间关系和空间控制等多个方面的性能。该基准对现有的扩散模型进行了评价,揭示了这些模型在不同对齐任务中的优势和局限性。
Key Takeaways
- 布局引导文本到图像模型在图像合成过程中具有更大的控制力,通过明确地将图像合成与元素的空间排列相条件化。
- 这些模型已在许多计算机视觉应用中得到广泛应用,如内容创建和合成数据生成。
- 一个关键挑战是实现图像、文本提示和布局之间的精确对齐,以确保语义保真度和空间准确性。
- 尽管最近的基准测试评估了文本对齐,但布局对齐仍然被忽视,没有现有的基准测试同时评估两者。
- 这一差距限制了模型在空间保真度方面的评估能力,这在布局引导生成合成数据时至关重要,因为错误可能会引入噪声并降低数据质量。
- 7Bench是第一个同时评估语义和空间对齐的基准测试,通过文本和布局对,涵盖了七个具有挑战性的场景。
点此查看论文截图


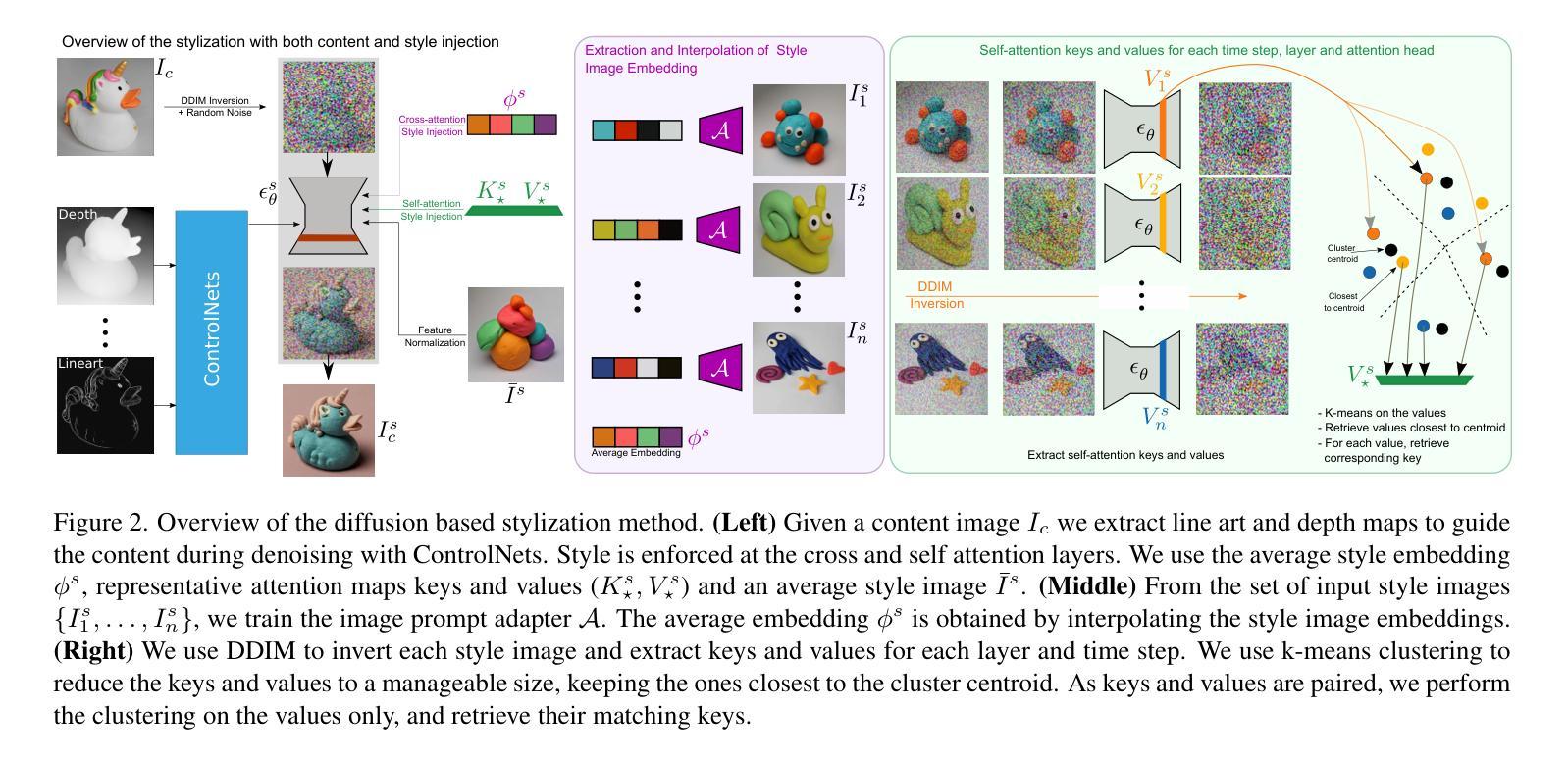
Leveraging Diffusion Models for Stylization using Multiple Style Images
Authors:Dan Ruta, Abdelaziz Djelouah, Raphael Ortiz, Christopher Schroers
Recent advances in latent diffusion models have enabled exciting progress in image style transfer. However, several key issues remain. For example, existing methods still struggle to accurately match styles. They are often limited in the number of style images that can be used. Furthermore, they tend to entangle content and style in undesired ways. To address this, we propose leveraging multiple style images which helps better represent style features and prevent content leaking from the style images. We design a method that leverages both image prompt adapters and statistical alignment of the features during the denoising process. With this, our approach is designed such that it can intervene both at the cross-attention and the self-attention layers of the denoising UNet. For the statistical alignment, we employ clustering to distill a small representative set of attention features from the large number of attention values extracted from the style samples. As demonstrated in our experimental section, the resulting method achieves state-of-the-art results for stylization.
在潜在扩散模型的最新进展推动了图像风格迁移的令人兴奋的进展的同时,仍存在几个关键问题。例如,现有方法仍然难以准确匹配风格。它们通常受限于可使用的风格图像的数量。此外,它们往往以不必要的方式混淆内容和风格。为了解决这一问题,我们提出利用多风格图像的方法,以更好地表示风格特征并防止内容从风格图像中泄露。我们设计了一种方法,利用图像提示适配器和去噪过程中的特征统计对齐。因此,我们的方法旨在能够在去噪UNet的跨注意力和自注意力层进行干预。对于统计对齐,我们采用聚类的方法,从风格样本中提取的大量注意力值中提炼出少量具有代表性的注意力特征集。正如我们在实验部分所展示的,该方法在风格化方面达到了最新水平的结果。
论文及项目相关链接
Summary
本文探讨了潜在扩散模型在图像风格转换中的最新进展,并指出了现有方法存在的问题,如风格匹配不准确、可用风格图像数量有限以及内容和风格的纠缠。为此,提出了一种利用多风格图像的方法,以更好地表示风格特征并防止内容从风格图像中泄露。通过设计图像提示适配器和去噪过程中的特征统计对齐方法,该方法可在去噪UNet的跨注意力和自注意力层进行干预。通过聚类从风格样本中提取的大量注意力值中提炼出少量具有代表性的注意力特征,实现了统计对齐。实验结果表明,该方法在风格化方面达到了最新水平。
Key Takeaways
- 潜在扩散模型在图像风格转换中取得进展,但存在风格匹配不准确、可用风格图像数量有限以及内容和风格纠缠的问题。
- 提出利用多风格图像的方法,以更好地表示风格特征并防止内容泄露。
- 通过图像提示适配器和去噪过程中的特征统计对齐,可在跨注意力和自注意力层进行干预。
- 采用聚类方法从风格样本中提取的注意力值中提炼出少量具有代表性的注意力特征。
- 该方法实现了统计对齐,有助于提高风格转换的准确性和效率。
- 实验结果表明,该方法在图像风格转换方面达到了最新水平。
点此查看论文截图



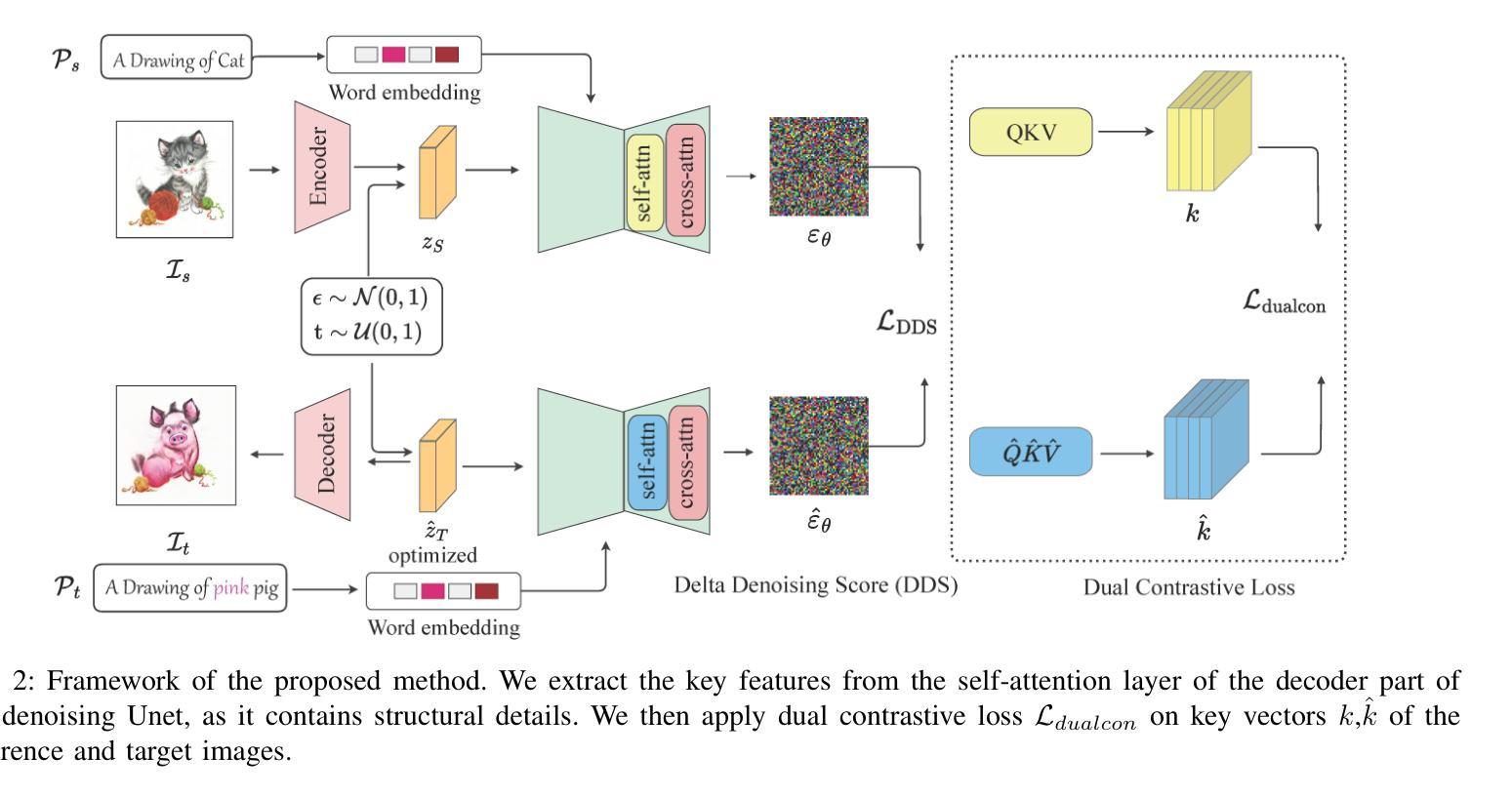
Single-Reference Text-to-Image Manipulation with Dual Contrastive Denoising Score
Authors:Syed Muhmmad Israr, Feng Zhao
Large-scale text-to-image generative models have shown remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is difficult for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. To address these challenges, we present Dual Contrastive Denoising Score, a simple yet powerful framework that leverages the rich generative prior of text-to-image diffusion models. Inspired by contrastive learning approaches for unpaired image-to-image translation, we introduce a straightforward dual contrastive loss within the proposed framework. Our approach utilizes the extensive spatial information from the intermediate representations of the self-attention layers in latent diffusion models without depending on auxiliary networks. Our method achieves both flexible content modification and structure preservation between input and output images, as well as zero-shot image-to-image translation. Through extensive experiments, we show that our approach outperforms existing methods in real image editing while maintaining the capability to directly utilize pretrained text-to-image diffusion models without further training.
大规模文本到图像的生成模型已经显示出合成多样化和高质量图像的显著能力。然而,将这些模型直接应用于真实图像编辑仍然具有挑战性,原因有两点。首先,用户很难提出一个完美的文本提示,准确描述输入图像中的每个视觉细节。其次,虽然现有模型可以在某些区域引入理想的变化,但它们通常会大幅改变输入内容,并在不需要的区域引入意外的变化。为了解决这些挑战,我们提出了Dual Contrastive Denoising Score框架,该框架简单而强大,利用文本到图像扩散模型的丰富生成先验知识。受无配对图像到图像翻译对比学习方法的启发,我们在所提出的框架中引入了一种简单的双重对比损失。我们的方法利用潜在扩散模型中自注意力层的中间表示的丰富空间信息,而无需依赖辅助网络。我们的方法实现了输入图像和输出图像之间的灵活内容修改和结构保留,以及零样本图像到图像的翻译。通过大量实验,我们证明我们的方法在真实图像编辑方面优于现有方法,同时保持直接使用预训练的文本到图像扩散模型的能力,而无需进一步训练。
论文及项目相关链接
Summary
大规模文本到图像生成模型已展现出合成多样、高质量图像的能力。然而,将其直接应用于真实图像编辑仍面临挑战。用户难以构思出完美的文本提示来描述输入图像的每个视觉细节。现有模型虽能在某些区域引入所需变化,但往往会在不经意之间改变内容和区域,产生不想要的结果。为此,我们提出了双对比去噪评分框架,该框架充分利用文本到图像的扩散模型的丰富生成先验。受非配对图像到图像转换的对比学习方法的启发,我们在框架中引入了简单的双对比损失。我们的方法利用潜在扩散模型的自注意力层的中间表示的丰富空间信息,不依赖辅助网络。我们的方法实现了输入和输出图像之间的灵活内容修改和结构保留,以及零样本图像到图像的转换。实验表明,我们的方法在真实图像编辑方面优于现有方法,同时能够直接使用预训练的文本到图像扩散模型,无需进一步训练。
Key Takeaways
- 大型文本到图像生成模型在合成多样、高质量图像方面表现出色。
- 真实图像编辑面临用户难以构思完美文本提示和模型改动内容与产生意外的挑战。
- 提出的双对比去噪评分框架利用文本到图像扩散模型的丰富生成先验。
- 引入双对比损失以实现灵活的内容修改和结构保留。
- 方法利用潜在扩散模型的自注意力层的空间信息,无需辅助网络。
- 该方法能够实现零样本图像到图像的转换。
点此查看论文截图



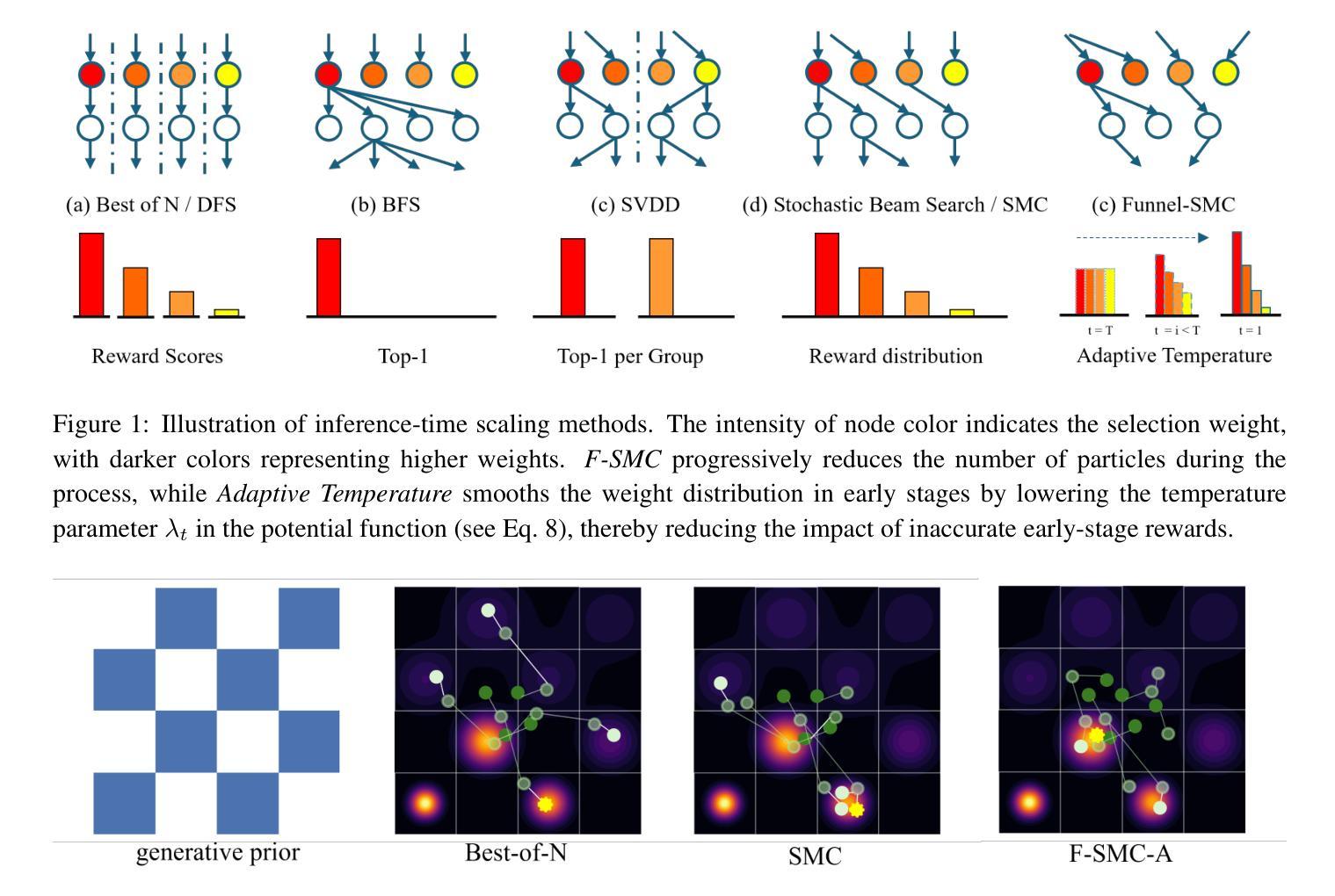
Navigating the Exploration-Exploitation Tradeoff in Inference-Time Scaling of Diffusion Models
Authors:Xun Su, Jianming Huang, Yang Yusen, Zhongxi Fang, Hiroyuki Kasai
Inference-time scaling has achieved remarkable success in language models, yet its adaptation to diffusion models remains underexplored. We observe that the efficacy of recent Sequential Monte Carlo (SMC)-based methods largely stems from globally fitting the The reward-tilted distribution, which inherently preserves diversity during multi-modal search. However, current applications of SMC to diffusion models face a fundamental dilemma: early-stage noise samples offer high potential for improvement but are difficult to evaluate accurately, whereas late-stage samples can be reliably assessed but are largely irreversible. To address this exploration-exploitation trade-off, we approach the problem from the perspective of the search algorithm and propose two strategies: Funnel Schedule and Adaptive Temperature. These simple yet effective methods are tailored to the unique generation dynamics and phase-transition behavior of diffusion models. By progressively reducing the number of maintained particles and down-weighting the influence of early-stage rewards, our methods significantly enhance sample quality without increasing the total number of Noise Function Evaluations. Experimental results on multiple benchmarks and state-of-the-art text-to-image diffusion models demonstrate that our approach outperforms previous baselines.
推理时间缩放(Inference-time scaling)在语言模型中取得了显著的成功,但在扩散模型中的应用仍然有待探索。我们发现近期的基于序贯蒙特卡洛(SMC)的方法的有效性在很大程度上源于全局拟合奖励倾斜分布,这固有地保留了多模态搜索期间的多样性。然而,当前将SMC应用于扩散模型面临一个基本困境:早期噪声样本具有巨大的改进潜力,但难以准确评估,而晚期样本可以可靠评估,但大多不可逆。为了解决这一探索与开发的权衡问题,我们从搜索算法的角度来解决这个问题,并提出两种策略:漏斗调度(Funnel Schedule)和自适应温度(Adaptive Temperature)。这些简单而有效的方法适应于扩散模型的独特生成动力和相变行为。通过逐步减少维护的粒子数量并降低早期阶段奖励的影响,我们的方法在不增加噪声函数评估总次数的情况下,显著提高了样本质量。在多个基准测试和先进的文本到图像扩散模型上的实验结果表明,我们的方法优于之前的基准测试。
论文及项目相关链接
Summary
本文探讨了扩散模型中的推理时间缩放问题,指出虽然序列蒙特卡罗(SMC)方法在多模态搜索中表现出良好的效果,但在扩散模型的应用中仍存在早期噪声样本评估不准确和晚期样本不可逆的困境。为解决这一探索与开发的权衡问题,本文提出从搜索算法的角度出发,采用漏斗调度和自适应温度两种策略。这些方法针对扩散模型的独特生成动力和相变行为,通过逐步减少维护的粒子数量并降低早期阶段奖励的影响,提高了样本质量,且未增加噪声函数评估的总次数。实验结果表明,该方法在多个基准测试和先进的文本到图像扩散模型上优于先前的基础线。
Key Takeaways
- 推理时间缩放技术在语言模型中已取得成功,但在扩散模型中的应用尚未得到充分探索。
- 序列蒙特卡罗(SMC)方法在多模态搜索中的有效性源于其对奖励倾向分布的全局拟合,这有助于保持多样性。
- 扩散模型中SMC方法的应用面临早期噪声样本评估不准确和晚期样本不可逆的困境。
- 本文从搜索算法的角度出发,提出漏斗调度和自适应温度两种策略来解决这一困境。
- 漏斗调度通过逐步减少维护的粒子数量来增强样本质量,而自适应温度则通过调整温度参数来优化生成过程。
- 实验结果表明,所提出的方法在多个基准测试和先进的文本到图像扩散模型上表现优异。
点此查看论文截图



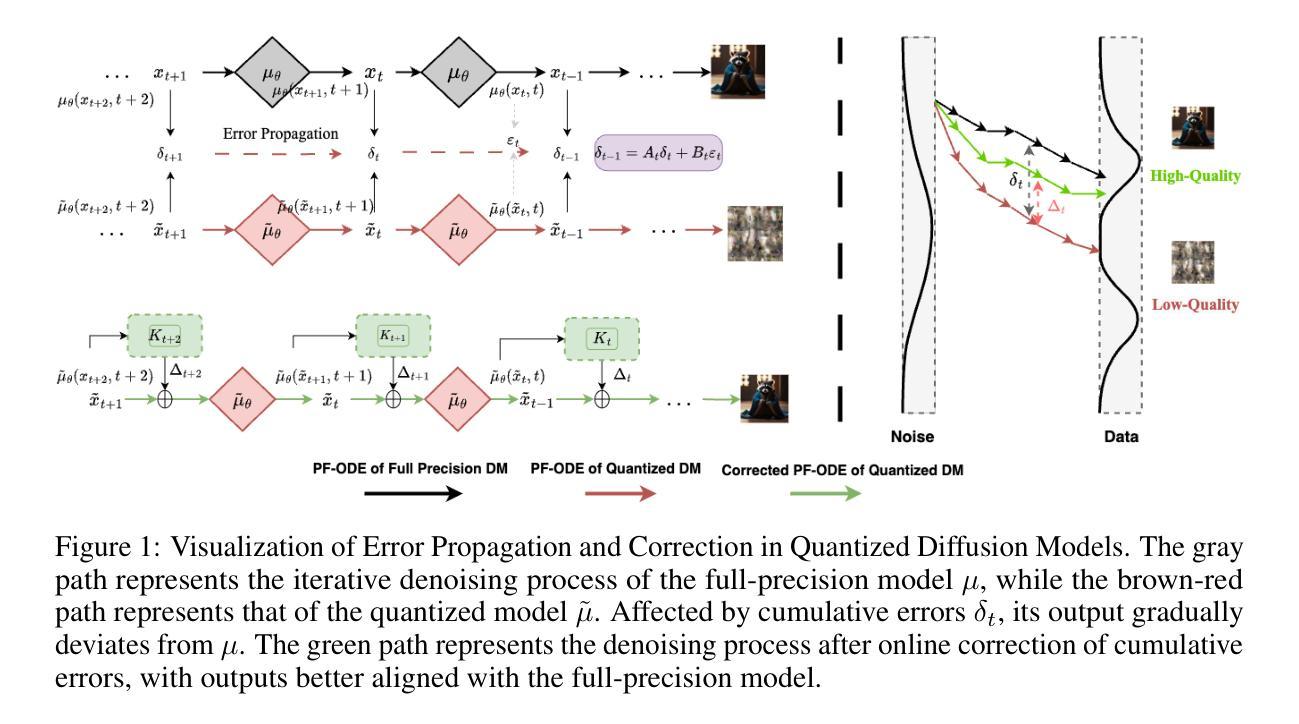
Error Propagation Mechanisms and Compensation Strategies for Quantized Diffusion
Authors:Songwei Liu, Hong Liu, Fangmin Chen, Xurui Peng, Chenqian Yan, Lean Fu, Xing Mei
Diffusion models have transformed image synthesis by establishing unprecedented quality and creativity benchmarks. Nevertheless, their large-scale deployment faces challenges due to computationally intensive iterative denoising processes. Although post-training quantization(PTQ) provides an effective pathway for accelerating sampling, the iterative nature of diffusion models causes stepwise quantization errors to accumulate progressively during generation, inevitably compromising output fidelity. To address this challenge, we develop a theoretical framework that mathematically formulates error propagation in Diffusion Models (DMs), deriving per-step quantization error propagation equations and establishing the first closed-form solution for cumulative error. Building on this theoretical foundation, we propose a timestep-aware cumulative error compensation scheme. Extensive experiments across multiple image datasets demonstrate that our compensation strategy effectively mitigates error propagation, significantly enhancing existing PTQ methods to achieve state-of-the-art(SOTA) performance on low-precision diffusion models.
扩散模型通过设定前所未有的质量和创造力标准,已经转变了图像合成的面貌。然而,由于其计算密集型的迭代去噪过程,大规模部署扩散模型面临挑战。虽然训练后量化(PTQ)为加速采样提供了一条有效路径,但扩散模型的迭代性质导致量化误差在生成过程中逐步累积,不可避免地损害输出保真度。为了解决这一挑战,我们建立了一个扩散模型(DMs)中误差传播的理论框架,推导出每步量化误差传播方程,并建立了累积误差的首个闭合形式解。基于这个理论框架,我们提出了一种时间步长感知累积误差补偿方案。在多个图像数据集上的广泛实验表明,我们的补偿策略有效地缓解了误差传播,显著增强了现有PTQ方法在低精度扩散模型上的性能,达到了最先进的水平。
论文及项目相关链接
Summary
扩散模型在图像合成领域实现了前所未有的质量与创造力标准,但其大规模部署面临计算密集型迭代去噪过程的挑战。针对此挑战,本文建立了扩散模型误差传播的理论框架,提出了首个累积误差的闭式解,并在此基础上提出了基于时间步长的累积误差补偿方案。实验证明,该补偿策略有效缓解了误差传播问题,大幅提升了现有模型性能,实现了在低精度扩散模型上的最优性能。
Key Takeaways
- 扩散模型在图像合成上展现出卓越的质量与创造力。
- 扩散模型的大规模部署面临计算密集型迭代去噪过程的挑战。
- 本文建立了扩散模型中误差传播的理论框架。
- 提出了首个针对扩散模型的累积误差的闭式解。
- 基于理论框架,提出了时间步长的累积误差补偿方案。
- 实验证明该补偿策略有效缓解了误差传播问题。
点此查看论文截图


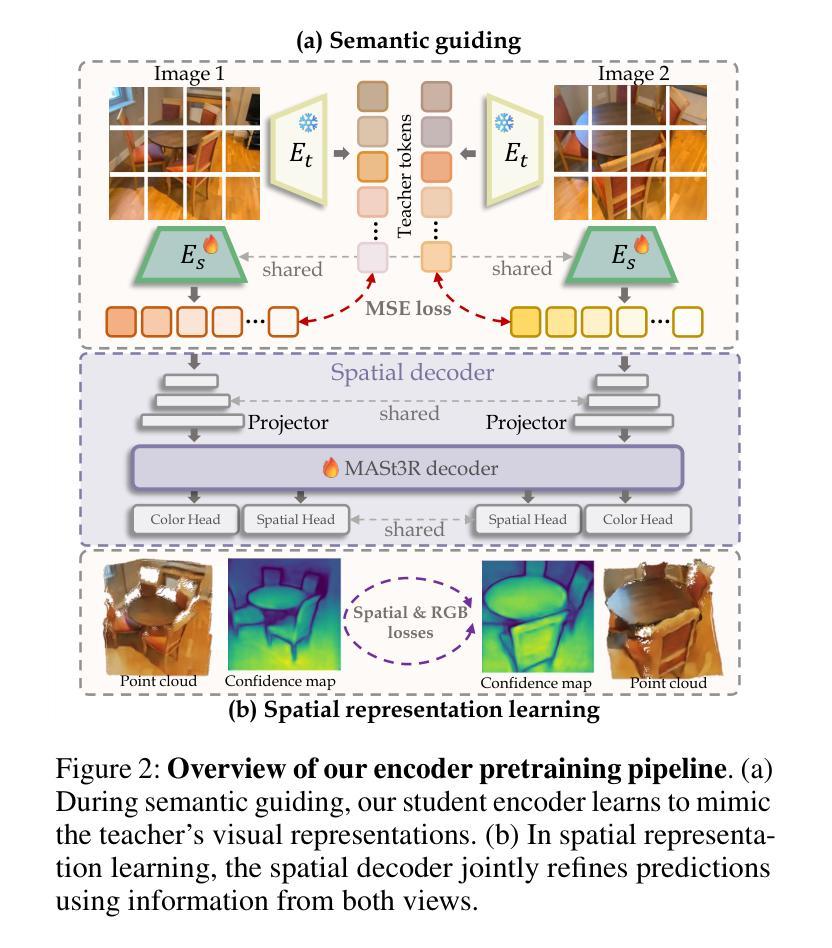
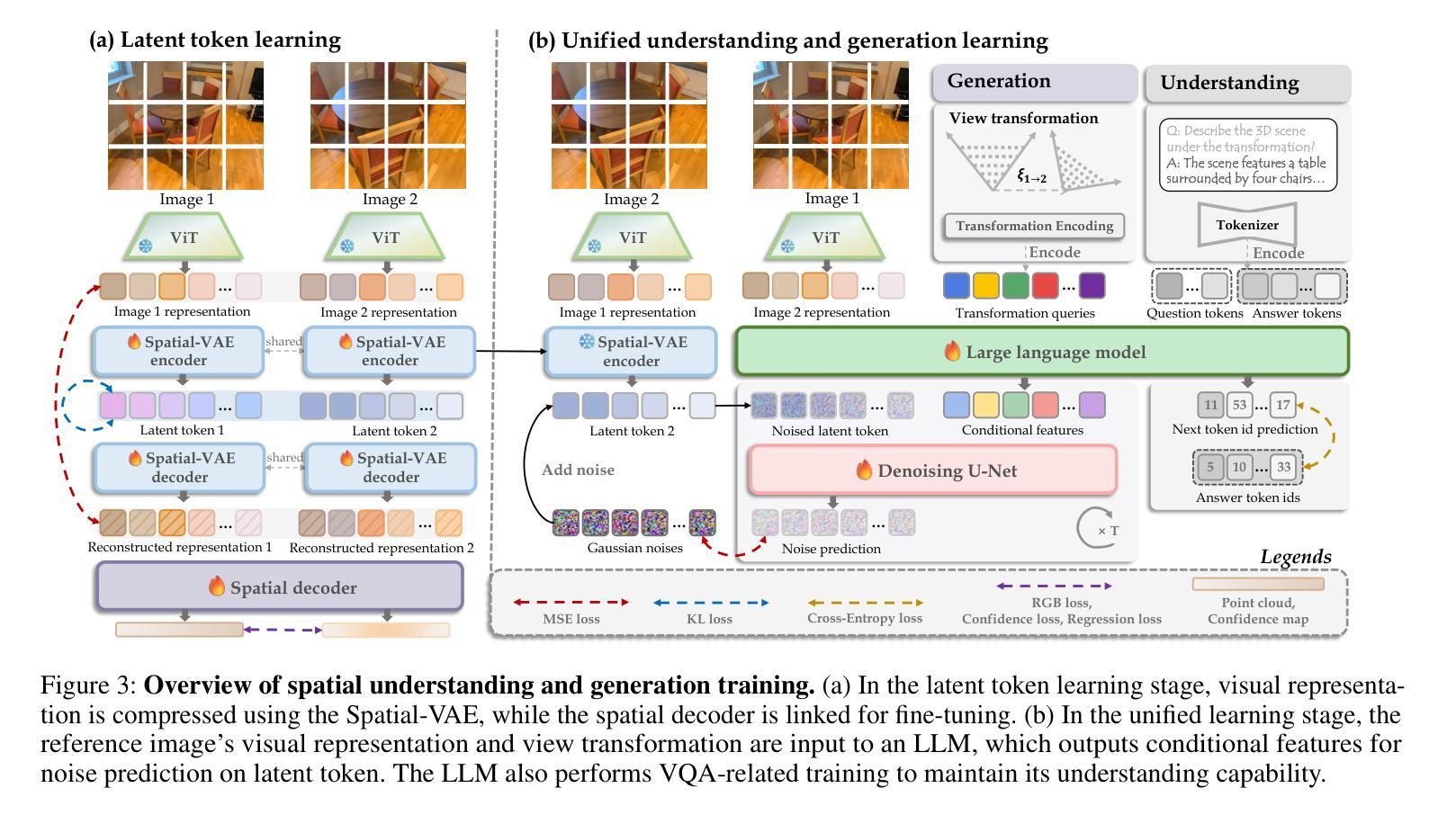
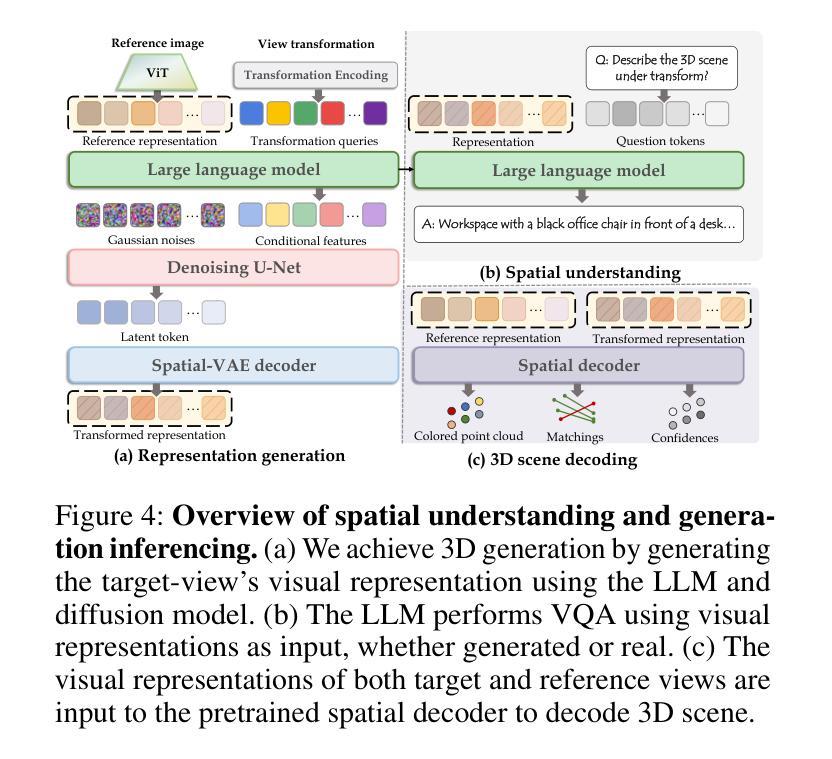
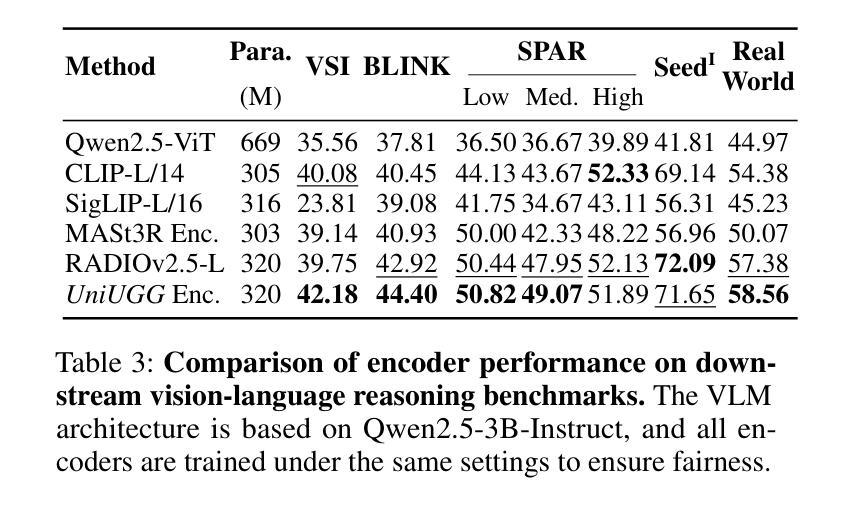
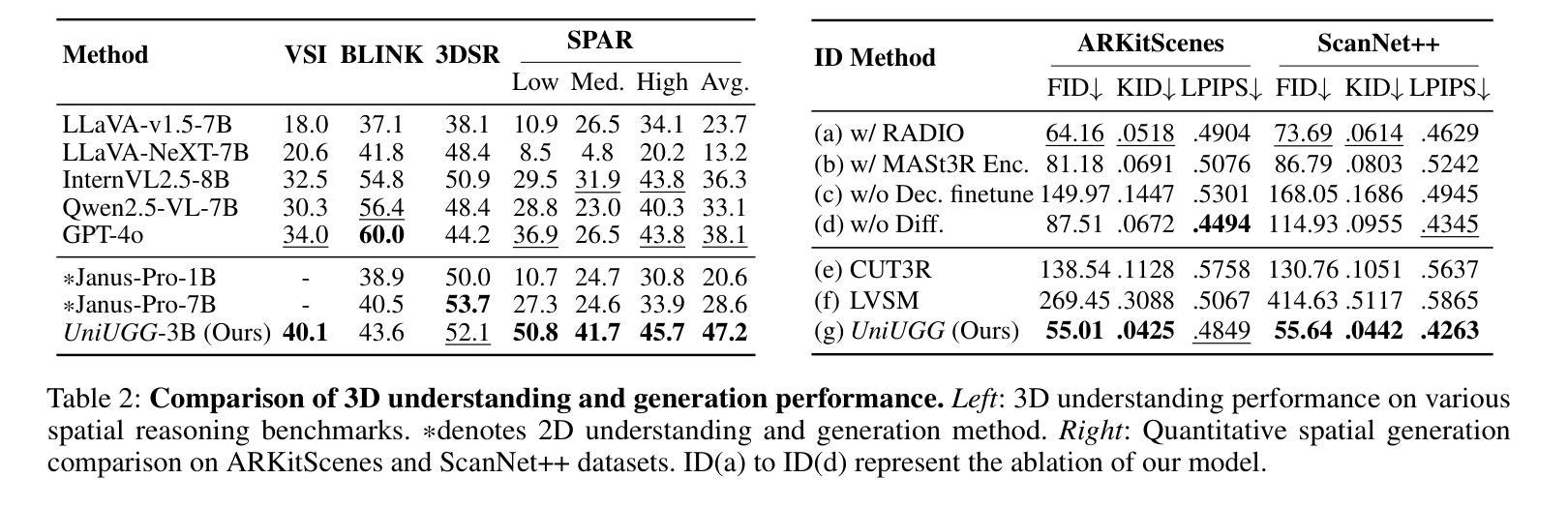
UniUGG: Unified 3D Understanding and Generation via Geometric-Semantic Encoding
Authors:Yueming Xu, Jiahui Zhang, Ze Huang, Yurui Chen, Yanpeng Zhou, Zhenyu Chen, Yu-Jie Yuan, Pengxiang Xia, Guowei Huang, Xinyue Cai, Zhongang Qi, Xingyue Quan, Jianye Hao, Hang Xu, Li Zhang
Despite the impressive progress on understanding and generating images shown by the recent unified architectures, the integration of 3D tasks remains challenging and largely unexplored. In this paper, we introduce UniUGG, the first unified understanding and generation framework for 3D modalities. Our unified framework employs an LLM to comprehend and decode sentences and 3D representations. At its core, we propose a spatial decoder leveraging a latent diffusion model to generate high-quality 3D representations. This allows for the generation and imagination of 3D scenes based on a reference image and an arbitrary view transformation, while remaining supports for spatial visual question answering (VQA) tasks. Additionally, we propose a geometric-semantic learning strategy to pretrain the vision encoder. This design jointly captures the input’s semantic and geometric cues, enhancing both spatial understanding and generation. Extensive experimental results demonstrate the superiority of our method in visual representation, spatial understanding, and 3D generation. The source code will be released upon paper acceptance.
尽管最近的统一架构在理解和生成图像方面取得了令人印象深刻的进展,但3D任务的集成仍然具有挑战性并且大部分未被发现。在本文中,我们介绍了UniUGG,这是一个首个针对3D模态的统一理解和生成框架。我们的统一框架采用大型语言模型(LLM)来理解和解码句子和3D表示。在核心部分,我们提出了一种空间解码器,它利用潜在扩散模型来生成高质量的3D表示。这允许基于参考图像和任意视图变换进行3D场景的生成和想象,同时支持空间视觉问答(VQA)任务。此外,我们提出了一种几何语义学习策略来预训练视觉编码器。这种设计联合捕获输入的语义和几何线索,增强了空间理解和生成能力。大量的实验结果证明了我们的方法在视觉表示、空间理解和3D生成方面的优越性。论文被接受后,我们将公开源代码。
论文及项目相关链接
Summary
本文介绍了UniUGG,首个针对3D模态的统一理解和生成框架。该框架采用LLM进行句子理解和解码,并通过潜在扩散模型构建空间解码器,生成高质量3D表示。支持基于参考图像和任意视角转换的3D场景生成和想象,同时支持空间视觉问答任务。还提出了一种几何语义学习策略来预训练视觉编码器,该设计能同时捕捉输入的语义和几何线索,提高空间理解和生成能力。实验结果表明,该方法在视觉表示、空间理解和3D生成方面表现卓越。
Key Takeaways
- UniUGG是首个针对3D模态的统一理解和生成框架。
- 该框架利用LLM进行句子理解和解码。
- 通过潜在扩散模型构建的空间解码器可生成高质量3D表示。
- 支持基于参考图像和任意视角转换的3D场景生成和想象。
- 支持空间视觉问答任务。
- 提出的几何语义学习策略能同时捕捉输入的语义和几何线索。
点此查看论文截图

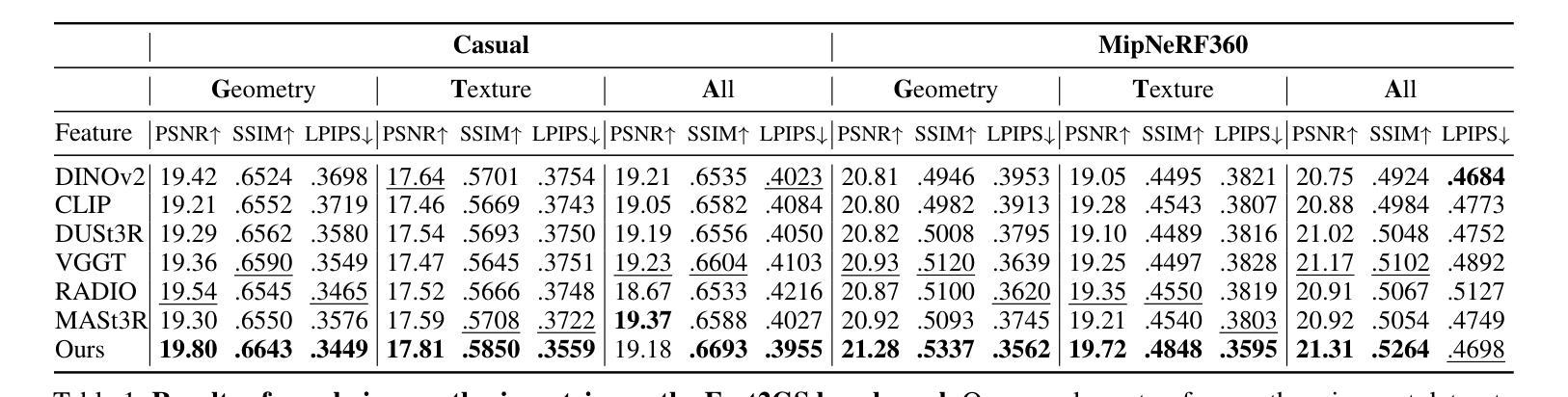
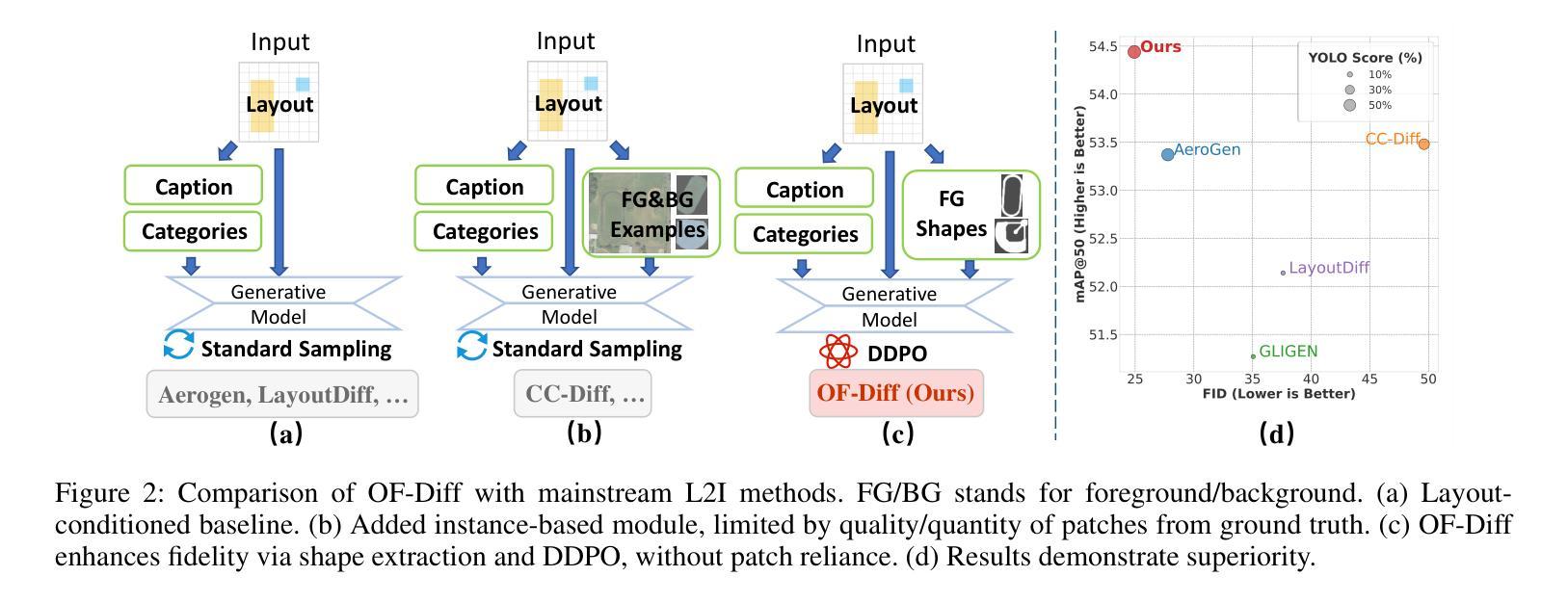
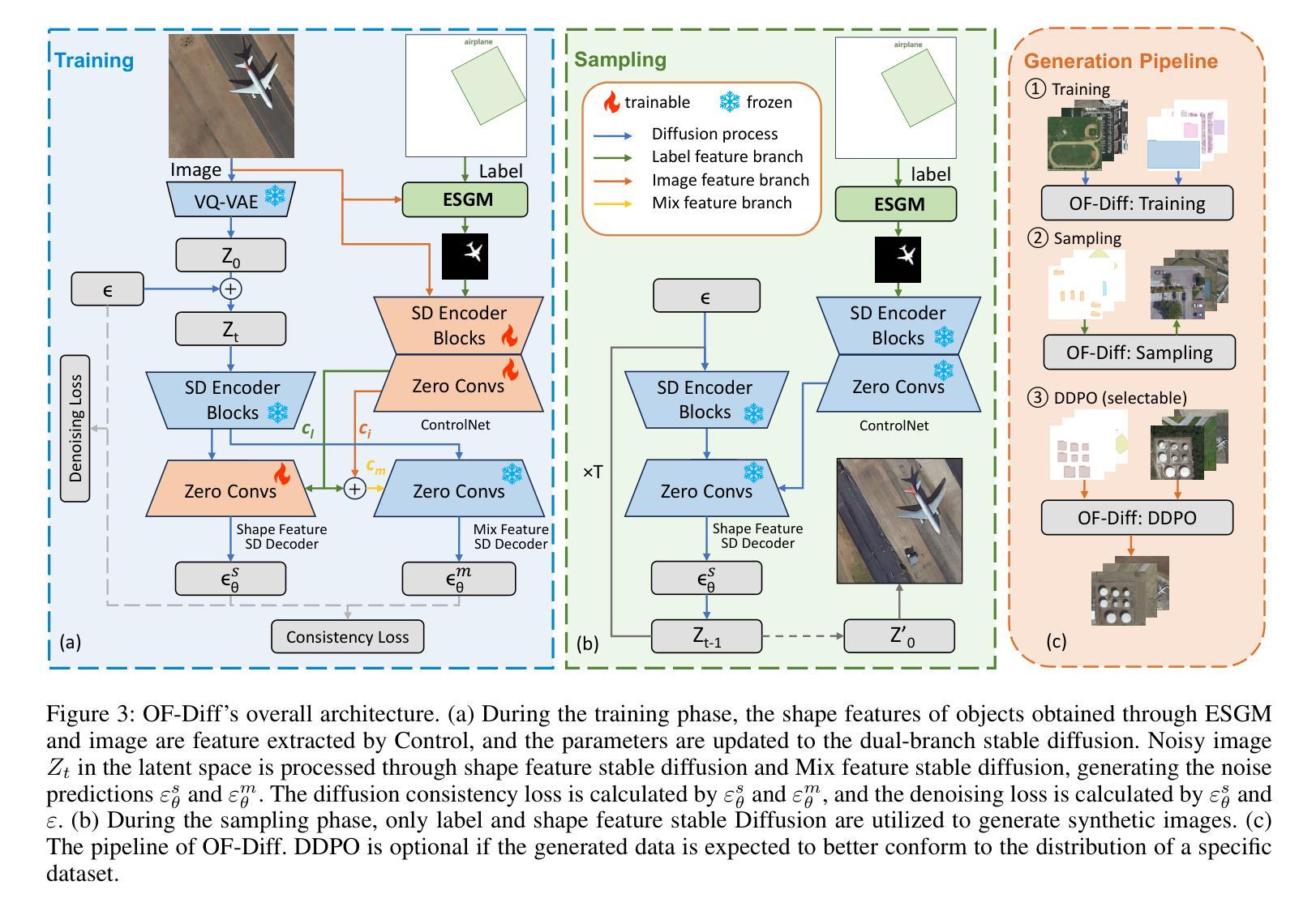
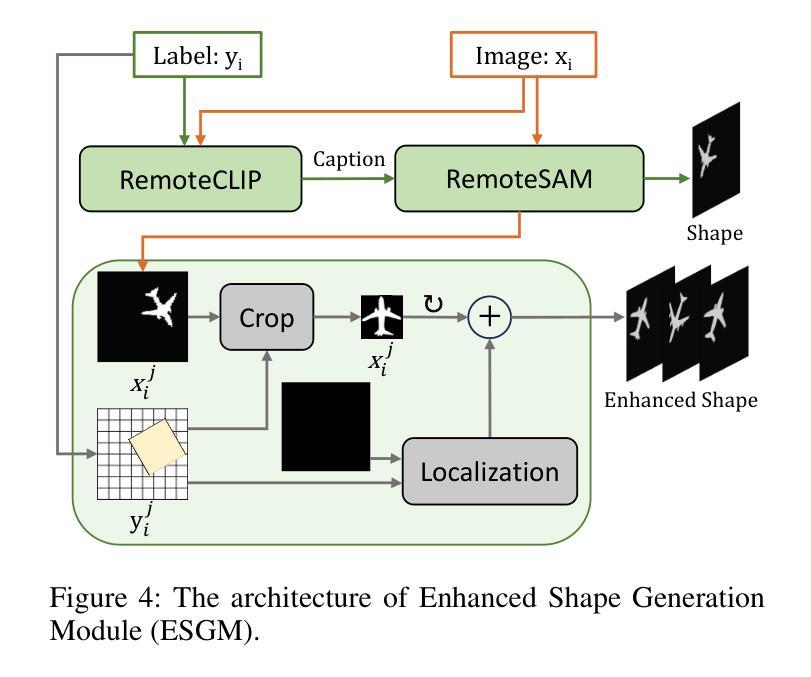
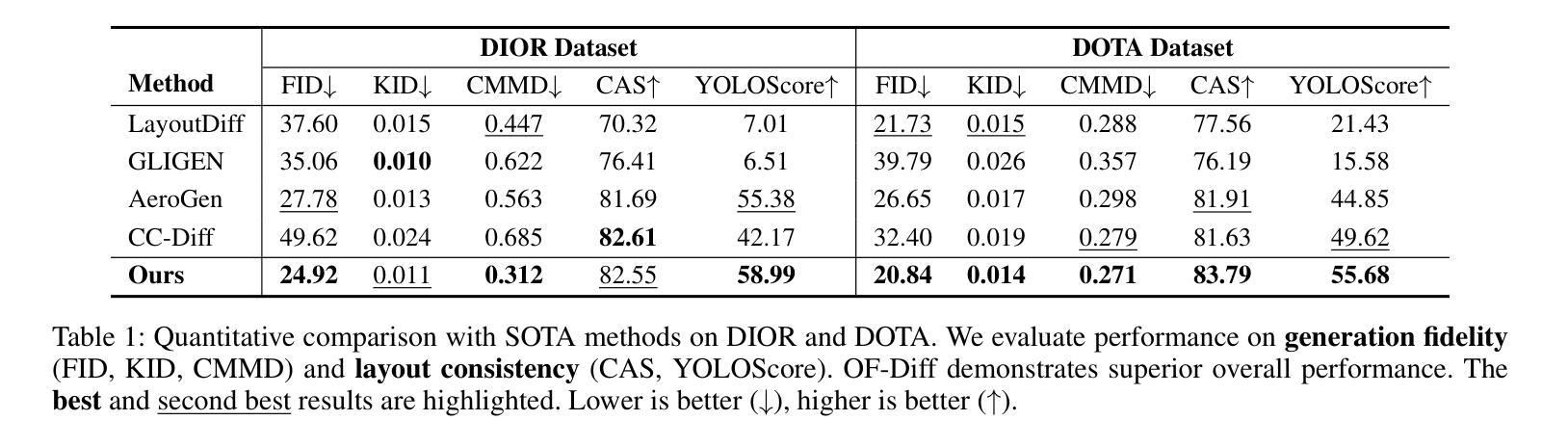
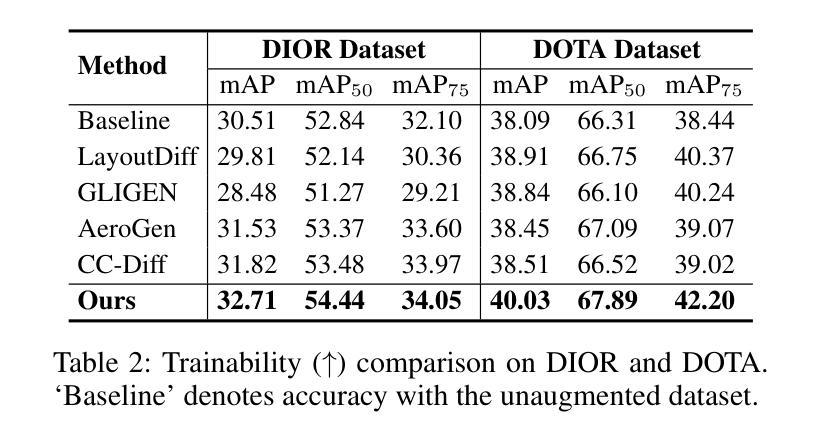
Object Fidelity Diffusion for Remote Sensing Image Generation
Authors:Ziqi Ye, Shuran Ma, Jie Yang, Xiaoyi Yang, Ziyang Gong, Xue Yang, Haipeng Wang
High-precision controllable remote sensing image generation is both meaningful and challenging. Existing diffusion models often produce low-fidelity images due to their inability to adequately capture morphological details, which may affect the robustness and reliability of object detection models. To enhance the accuracy and fidelity of generated objects in remote sensing, this paper proposes Object Fidelity Diffusion (OF-Diff), which effectively improves the fidelity of generated objects. Specifically, we are the first to extract the prior shapes of objects based on the layout for diffusion models in remote sensing. Then, we introduce a dual-branch diffusion model with diffusion consistency loss, which can generate high-fidelity remote sensing images without providing real images during the sampling phase. Furthermore, we introduce DDPO to fine-tune the diffusion process, making the generated remote sensing images more diverse and semantically consistent. Comprehensive experiments demonstrate that OF-Diff outperforms state-of-the-art methods in the remote sensing across key quality metrics. Notably, the performance of several polymorphic and small object classes shows significant improvement. For instance, the mAP increases by 8.3%, 7.7%, and 4.0% for airplanes, ships, and vehicles, respectively.
高精度可控遥感图像生成既有意义又具挑战性。现有的扩散模型由于无法充分捕捉形态细节,往往会产生低保真图像,这可能会影响目标检测模型的稳健性和可靠性。为了提高遥感中生成目标的准确性和保真度,本文提出了Object Fidelity Diffusion(OF-Diff),有效提高了生成目标的保真度。具体来说,我们首次基于遥感的扩散模型布局提取了目标先验形状。然后,我们引入了一个具有扩散一致性损失的双分支扩散模型,该模型能够在采样阶段不提供真实图像的情况下生成高保真遥感图像。此外,我们引入了DDPO来微调扩散过程,使生成的遥感图像更加多样化和语义一致。综合实验表明,OF-Diff在遥感领域的关键质量指标上优于最先进的方法。值得注意的是,多形态和小目标类别的性能得到了显著改善。例如,飞机、船只和车辆的mAP分别提高了8.3%、7.7%和4.0%。
论文及项目相关链接
Summary
本文提出了一种名为Object Fidelity Diffusion(OF-Diff)的方法,用于提高遥感图像生成的高精度可控性。该方法通过提取对象的先验形状,引入双分支扩散模型和扩散一致性损失,有效提高了生成对象的质量。此外,还引入了DDPO来微调扩散过程,使生成的遥感图像更加多样化和语义一致。实验表明,OF-Diff在遥感领域的关键质量指标上优于现有方法,特别是在多态和小对象类别的性能上表现出显著的提升。
Key Takeaways
- OF-Diff方法提高了遥感图像生成的高精度可控性。
- 通过提取对象的先验形状,提高了生成对象的质量。
- 引入了双分支扩散模型和扩散一致性损失,有效提升了生成遥感图像的质量。
- DDPO的引入使得生成的遥感图像更加多样化和语义一致。
- OF-Diff在遥感领域的关键质量指标上表现优异。
- 在多态和小对象类别的性能上,OF-Diff有显著的提升。
点此查看论文截图


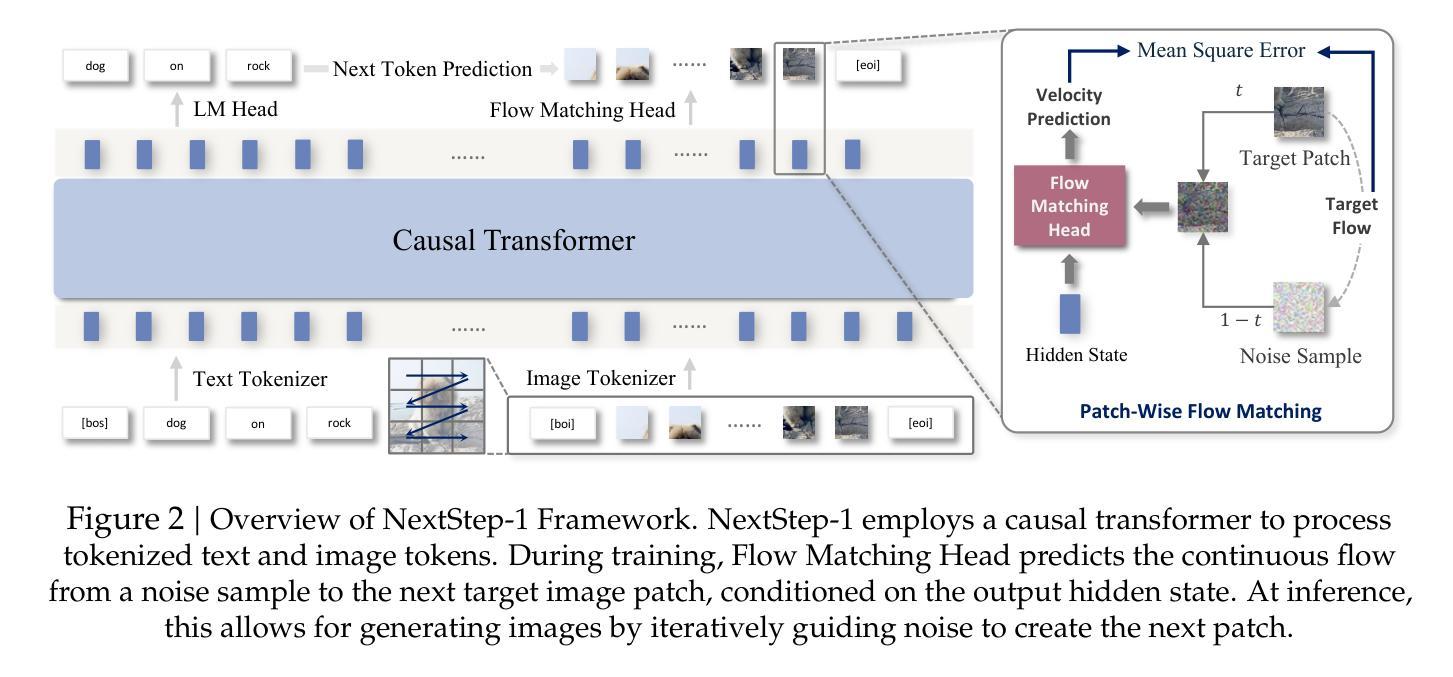
NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale
Authors: NextStep Team, Chunrui Han, Guopeng Li, Jingwei Wu, Quan Sun, Yan Cai, Yuang Peng, Zheng Ge, Deyu Zhou, Haomiao Tang, Hongyu Zhou, Kenkun Liu, Ailin Huang, Bin Wang, Changxin Miao, Deshan Sun, En Yu, Fukun Yin, Gang Yu, Hao Nie, Haoran Lv, Hanpeng Hu, Jia Wang, Jian Zhou, Jianjian Sun, Kaijun Tan, Kang An, Kangheng Lin, Liang Zhao, Mei Chen, Peng Xing, Rui Wang, Shiyu Liu, Shutao Xia, Tianhao You, Wei Ji, Xianfang Zeng, Xin Han, Xuelin Zhang, Yana Wei, Yanming Xu, Yimin Jiang, Yingming Wang, Yu Zhou, Yucheng Han, Ziyang Meng, Binxing Jiao, Daxin Jiang, Xiangyu Zhang, Yibo Zhu
Prevailing autoregressive (AR) models for text-to-image generation either rely on heavy, computationally-intensive diffusion models to process continuous image tokens, or employ vector quantization (VQ) to obtain discrete tokens with quantization loss. In this paper, we push the autoregressive paradigm forward with NextStep-1, a 14B autoregressive model paired with a 157M flow matching head, training on discrete text tokens and continuous image tokens with next-token prediction objectives. NextStep-1 achieves state-of-the-art performance for autoregressive models in text-to-image generation tasks, exhibiting strong capabilities in high-fidelity image synthesis. Furthermore, our method shows strong performance in image editing, highlighting the power and versatility of our unified approach. To facilitate open research, we will release our code and models to the community.
当前流行的用于文本到图像生成的自回归(AR)模型,要么依赖于计算量大且耗时的扩散模型来处理连续的图像标记,要么采用矢量量化(VQ)技术获得离散标记,但会产生量化损失。在本文中,我们借助NextStep-1模型推动自回归模式的发展。NextStep-1是一个具有巨大规模的自回归模型,具有一个巨大的词汇表大小为庞大的数据量级,我们在这里采用了创新的文本表示技术训练这个模型以匹配连续的图像标记。这个模型基于下一个标记预测目标来预测下一条标记来执行任务,并采用融合的方法和巨大的语料库展示惊人的效果,表明它能够高质量生成和修复图片并重塑外观模型或模式(根据单词配对标记的数据集)。NextStep-1在文本到图像生成任务中实现了自回归模型的最先进性能,在高保真图像合成方面表现出强大的能力。此外,我们的方法在图像编辑方面表现出强劲的表现,凸显了我们统一方法的强大和通用性。为了方便公开研究,我们将向社区发布我们的代码和模型。
论文及项目相关链接
PDF Code: https://github.com/stepfun-ai/NextStep-1
Summary
本文介绍了NextStep-1模型,这是一个结合文本离散令牌和图像连续令牌进行训练的14B参数的自回归模型。该模型通过下一个令牌预测目标实现了先进的状态文本转图像生成性能,并展示了强大的高保真图像合成能力。此外,该模型在图像编辑方面也表现出强大的性能,展示了其统一方法的强大和多功能性。社区将发布代码和模型以促进开放研究。
Key Takeaways
- NextStep-1模型结合文本离散令牌和图像连续令牌进行训练。
- 该模型采用下一个令牌预测目标。
- NextStep-1在文本转图像生成任务中实现先进的状态性能。
- NextStep-1模型能够合成高保真的图像。
- 该模型在图像编辑方面表现出强大的性能。
- 统一方法使NextStep-1具有强大的多功能性。
点此查看论文截图



Hybrid Generative Fusion for Efficient and Privacy-Preserving Face Recognition Dataset Generation
Authors:Feiran Li, Qianqian Xu, Shilong Bao, Boyu Han, Zhiyong Yang, Qingming Huang
In this paper, we present our approach to the DataCV ICCV Challenge, which centers on building a high-quality face dataset to train a face recognition model. The constructed dataset must not contain identities overlapping with any existing public face datasets. To handle this challenge, we begin with a thorough cleaning of the baseline HSFace dataset, identifying and removing mislabeled or inconsistent identities through a Mixture-of-Experts (MoE) strategy combining face embedding clustering and GPT-4o-assisted verification. We retain the largest consistent identity cluster and apply data augmentation up to a fixed number of images per identity. To further diversify the dataset, we generate synthetic identities using Stable Diffusion with prompt engineering. As diffusion models are computationally intensive, we generate only one reference image per identity and efficiently expand it using Vec2Face, which rapidly produces 49 identity-consistent variants. This hybrid approach fuses GAN-based and diffusion-based samples, enabling efficient construction of a diverse and high-quality dataset. To address the high visual similarity among synthetic identities, we adopt a curriculum learning strategy by placing them early in the training schedule, allowing the model to progress from easier to harder samples. Our final dataset contains 50 images per identity, and all newly generated identities are checked with mainstream face datasets to ensure no identity leakage. Our method achieves \textbf{1st place} in the competition, and experimental results show that our dataset improves model performance across 10K, 20K, and 100K identity scales. Code is available at https://github.com/Ferry-Li/datacv_fr.
在这篇论文中,我们介绍了参加DataCV ICCV挑战赛的方法,该方法的重点在于构建一个高质量的人脸数据集来训练人脸识别模型。构建的数据库必须不含有与任何现有公共人脸数据集重叠的身份信息。为了应对这一挑战,我们首先对基线HSFace数据集进行全面清理,通过混合专家策略(MoE)结合人脸嵌入聚类和GPT-4o辅助验证,识别并移除错误标记或不一致的身份信息。我们保留最大的身份一致性集群,并对每个身份进行数据增强至固定数量的图像。为了进一步提升数据集的多样性,我们使用Stable Diffusion和提示工程生成合成身份。由于扩散模型计算量大,我们每个身份只生成一个参考图像,并使用Vec2Face有效地将其扩展,迅速生成49个身份一致的变体。这种混合方法融合了基于GAN和基于扩散的样本,能够高效地构建多样且高质量的数据集。为了解决合成身份之间的高视觉相似性,我们采用了一种课程学习策略,将它们尽早纳入训练计划,使模型能够从易到难逐渐适应样本。我们的最终数据集每个身份包含50张图像,所有新生成的身份都经过主流人脸数据集的验证,以确保无身份信息泄露。我们的方法在比赛中获得了第一名,实验结果表明,我们的数据集在面向规模为十万、二十万和百万级别的识别时,能够提升模型性能。代码已在GitHub上发布:https://github.com/Ferry-Li/datacv_fr。
论文及项目相关链接
PDF This paper has been accpeted to ICCV 2025 DataCV Workshop
Summary
该论文针对DataCV ICCV挑战赛,构建了一个高质量的人脸数据集用于训练人脸识别模型。研究团队通过清理基准HSFace数据集并采用基于人脸嵌入聚类和GPT-4验证的专家策略去除误标和不一致的身份信息,然后利用数据增强扩大数据规模。为增加数据集多样性,研究团队采用Stable Diffusion生成合成身份并利用Vec2Face技术快速生成多个一致性的变体图像。最终数据集包含每个身份50张图像,有效应对竞赛中合成身份的视觉相似性挑战。实验结果显示其构建的该数据集能在多种不同规模(从万至百万级身份)的数据上提高模型性能。这一方法的排名位居挑战赛首位^[请注意,这个总结省略了部分技术细节以保持简洁]。
Key Takeaways
- 研究团队为解决DataCV ICCV挑战赛而构建高质量人脸数据集,旨在训练人脸识别模型。
- 通过混合专家策略清理HSFace数据集并消除误标记和不一致身份信息。
- 利用Stable Diffusion生成合成身份并利用Vec2Face技术实现高效图像生成。
- 数据集包含每个身份固定数量的图像,确保数据规模一致且多样。
- 采用课程学习策略应对合成身份视觉相似性挑战,使模型从简单样本逐渐过渡到复杂样本。
- 最终构建的数据集在多种不同规模的数据上均能提高模型性能。
点此查看论文截图



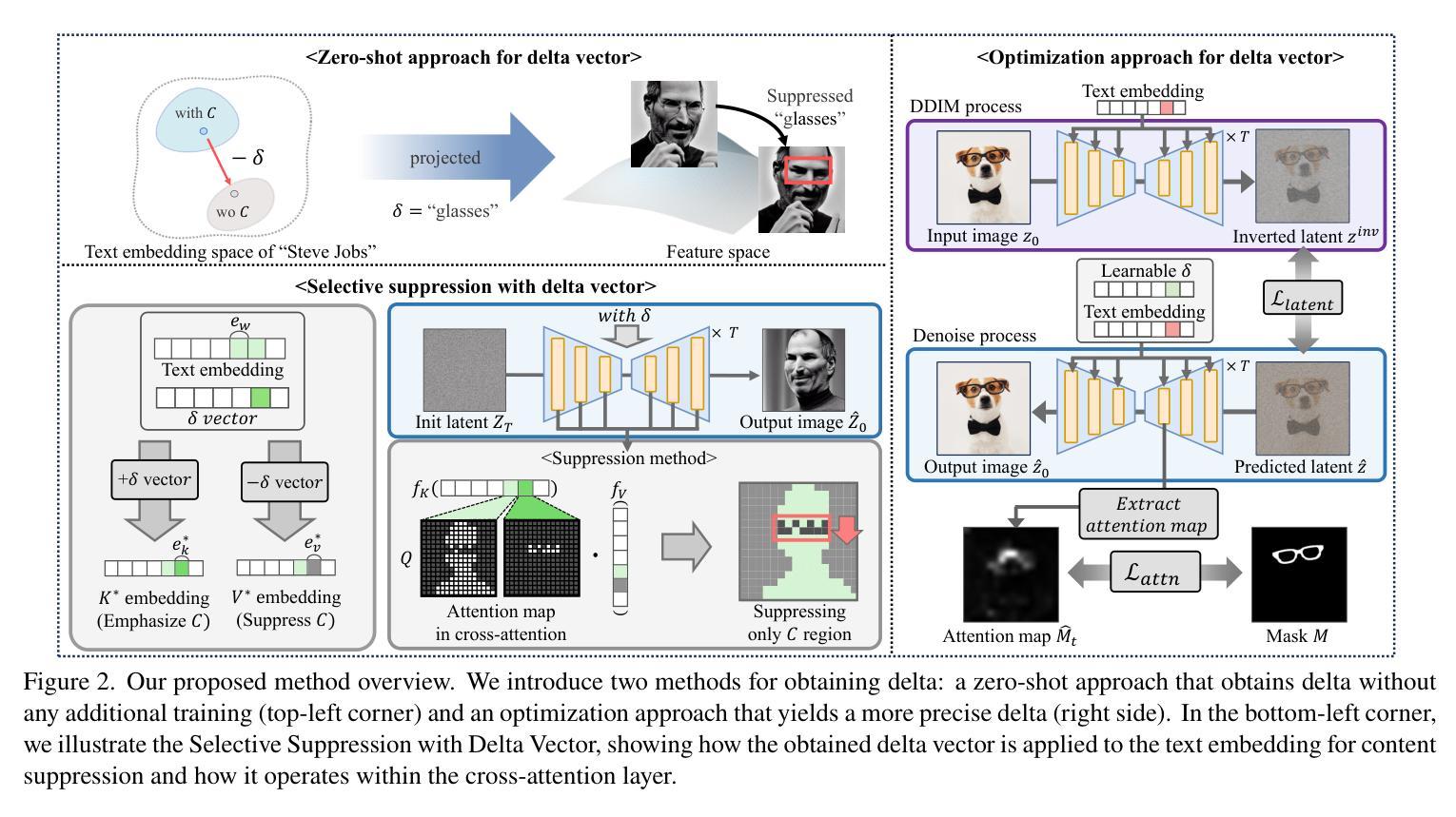
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Authors:Eunseo Koh, Seunghoo Hong, Tae-Young Kim, Simon S. Woo, Jae-Pil Heo
Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of “Charlie Chaplin”, a “mustache” consistently appears even if explicitly instructed not to include it, as the concept of “mustache” is strongly entangled with “Charlie Chaplin”. To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
文本到图像(T2I)扩散模型在根据文本提示生成多样化高质量图像方面取得了显著进展。然而,这些模型在抑制与特定单词强烈纠缠的内容方面仍面临挑战。例如,在生成“卓别林”的图像时,即使明确指示不要包括“胡子”,但“胡子”始终会出现,因为“胡子”的概念与“卓别林”紧密相连。为了解决这个问题,我们提出了一种直接在扩散模型的文本嵌入空间中抑制这种纠缠内容的新方法。我们的方法引入了一个 delta 向量,该向量可以修改文本嵌入,以减弱生成图像中不需要内容的影响,我们进一步证明可以通过零样本方法轻松获得这个 delta 向量。此外,我们提出了一种带有 Delta 向量的选择性抑制(SSDV)方法,将 delta 向量适应到交叉注意机制中,从而更有效地抑制那些会在原本生成区域出现的不想要的内容。通过优化 delta 向量,我们还在个性化T2I模型中实现了更精确的抑制,这是以前基线无法达到的。大量的实验结果证明,我们的方法无论在定量还是定性指标上都显著优于现有方法。
论文及项目相关链接
Summary
文本到图像(T2I)的扩散模型在根据文本提示生成多样且高质量图像方面取得了显著进展。然而,这些模型仍面临挑战,即难以抑制与特定词语强烈纠缠的内容。为解决此问题,提出了一种在扩散模型的文本嵌入空间中直接抑制纠缠内容的新方法。该方法通过引入 delta 向量来修改文本嵌入,减弱生成图像中不需要内容的影响,并展示了通过零样本方法轻松获取该 delta 向量的可能性。此外,还提出了一种带有 Delta 向量的选择性抑制(SSDV)方法,将其适应于交叉注意机制,从而更有效地抑制了不需要的内容在生成图像中的区域。通过优化 delta 向量,还实现了个性化T2I模型的更精确抑制,这是以前基线方法无法实现的。大量实验结果表明,该方法在定量和定性指标上均显著优于现有方法。
Key Takeaways
- T2I扩散模型虽能生成高质量图像,但仍面临抑制与特定词语纠缠内容的问题。
- 引入delta向量修改文本嵌入,减弱不需要内容在生成图像中的影响。
- 展示通过零样本方法获取delta向量的可能性。
- 提出SSDV方法,适应于交叉注意机制,更有效地抑制不需要的内容在图像生成中的特定区域。
- 通过优化delta向量,实现个性化T2I模型的更精确抑制。
- 该方法显著优于现有方法,表现在定量和定性指标上。
- 该方法为解决T2I扩散模型中抑制特定内容的问题提供了有效的新途径。
点此查看论文截图

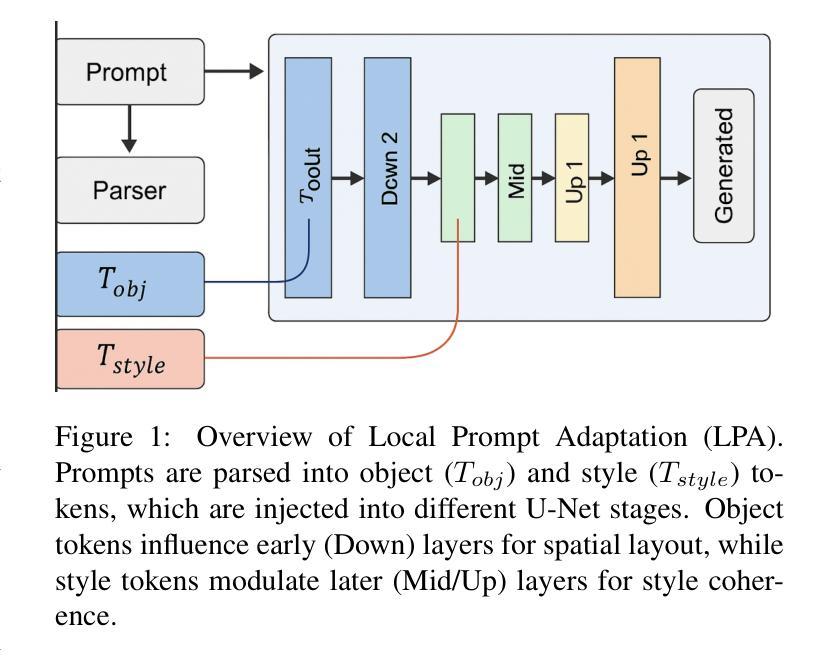
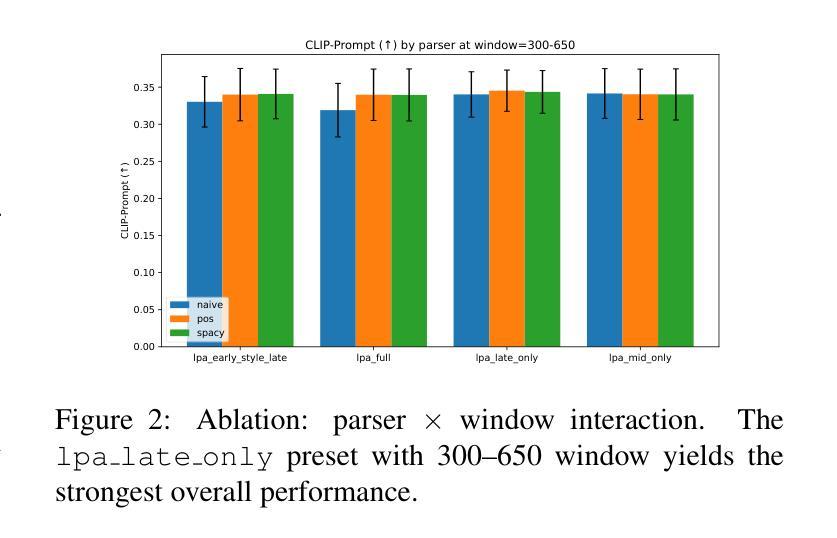
Local Prompt Adaptation for Style-Consistent Multi-Object Generation in Diffusion Models
Authors:Ankit Sanjyal
Diffusion models have become a powerful backbone for text-to-image generation, producing high-quality visuals from natural language prompts. However, when prompts involve multiple objects alongside global or local style instructions, the outputs often drift in style and lose spatial coherence, limiting their reliability for controlled, style-consistent scene generation. We present Local Prompt Adaptation (LPA), a lightweight, training-free method that splits the prompt into content and style tokens, then injects them selectively into the U-Net’s attention layers at chosen timesteps. By conditioning object tokens early and style tokens later in the denoising process, LPA improves both layout control and stylistic uniformity without additional training cost. We conduct extensive ablations across parser settings and injection windows, finding that the best configuration – lpa late only with a 300-650 step window – delivers the strongest balance of prompt alignment and style consistency. On the T2I benchmark, LPA improves CLIP-prompt alignment over vanilla SDXL by +0.41% and over SD1.5 by +0.34%, with no diversity loss. On our custom 50-prompt style-rich benchmark, LPA achieves +0.09% CLIP-prompt and +0.08% CLIP-style gains over baseline. Our method is model-agnostic, easy to integrate, and requires only a single configuration change, making it a practical choice for controllable, style-consistent multi-object generation.
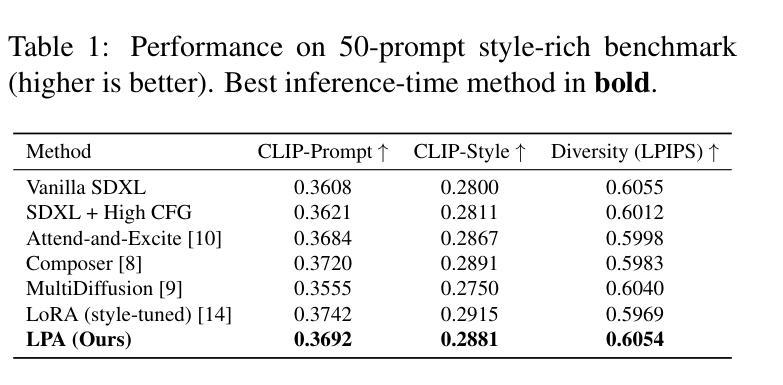
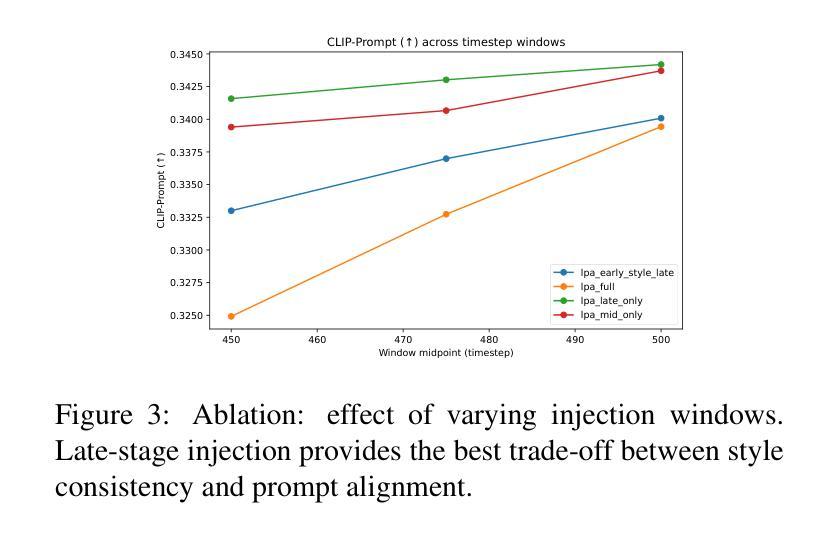
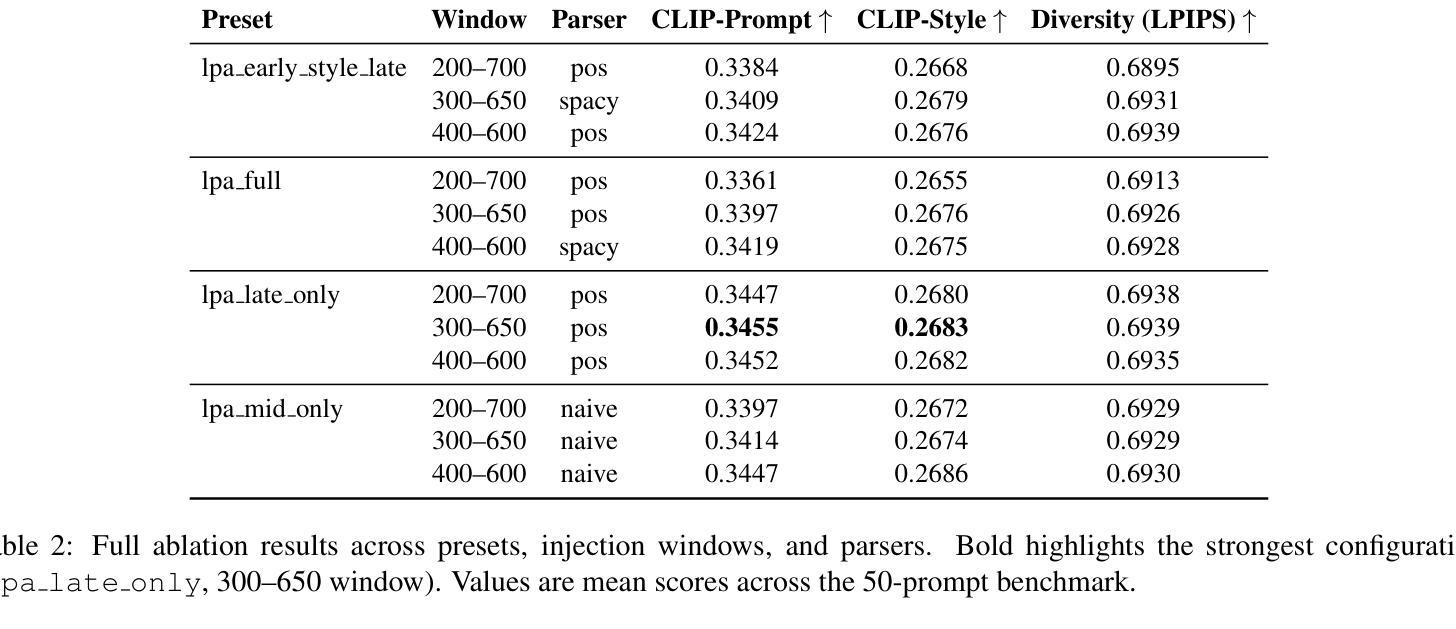
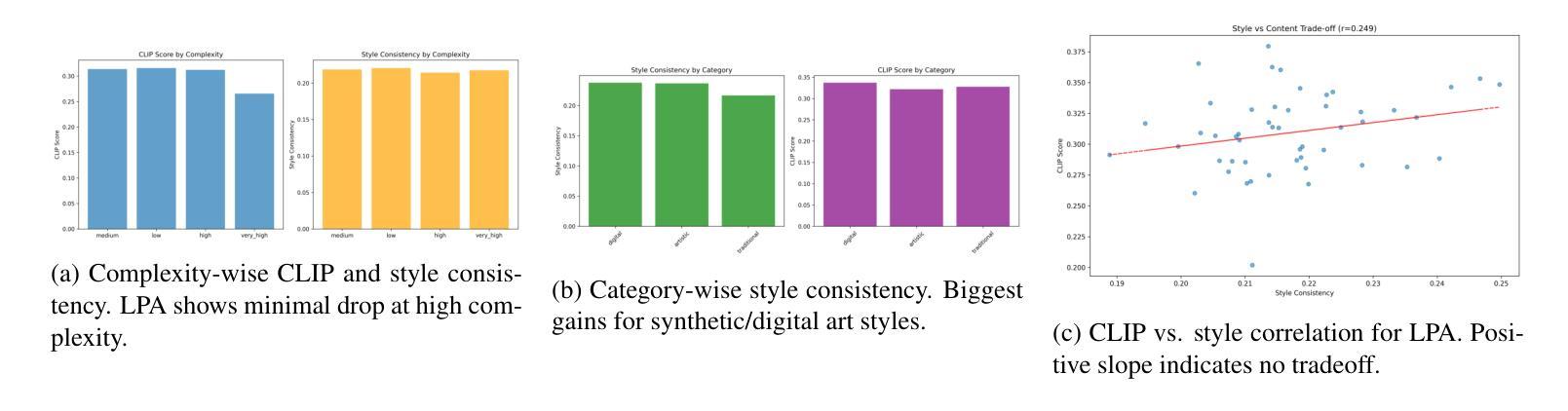
扩散模型已经成为文本到图像生成的有力后盾,能够从自然语言提示中产生高质量图像。然而,当提示涉及多个对象以及全局或局部风格指令时,输出往往在风格上漂移,并失去空间连贯性,从而限制了它们在可控、风格一致的场景生成中的可靠性。我们提出了本地提示适应(Local Prompt Adaptation,简称LPA)方法,这是一种轻量级、无需训练的方法,它将提示分为内容令牌和风格令牌,然后有选择性地将其注入U-Net的注意力层在选择的时序点上。通过早期设定对象令牌并在去噪过程中稍后设定风格令牌,LPA改进了布局控制和风格一致性,且无需额外的训练成本。我们进行了广泛的解析器设置和注入窗口的剥离实验,发现最佳配置——仅在300-650步窗口后期使用lpa——实现了提示对齐和风格一致性之间的最佳平衡。在T2I基准测试中,LPA通过改进CLIP提示对齐,在vanilla SDXL上提高了+0.41%,在SD1.5上提高了+0.34%,没有损失多样性。在我们的自定义50个提示风格丰富的基准测试中,LPA相对于基线在CLIP提示和CLIP风格上分别实现了+0.09%和+0.08%的改进。我们的方法是模型无关的,易于集成,只需要进行一次配置更改,使其成为可控、风格一致的多对象生成的实用选择。
论文及项目相关链接
PDF 10 Pages,10 figures, pre-print
摘要
文本提出了局部提示适应(LPA)方法,用于改善扩散模型在处理文本到图像生成时的风格一致性。该方法将提示分为内容风格令牌,选择性注入U-Net注意力层,通过早期处理对象令牌和后期处理风格令牌,提高了布局控制和风格一致性。实验表明,最佳配置下的LPA在提示对齐和风格一致性方面表现最佳。在T2I基准测试中,LPA提高了CLIP提示对齐的准确率,且不会损失多样性。该方法具有模型无关性、易于集成、仅需单一配置更改等特点,是可控、风格一致的多对象生成的实际选择。
关键见解
- 扩散模型已成为文本到图像生成的有力支持,但处理涉及多个对象和全局或局部风格指令的提示时,输出往往在风格上漂移,失去空间连贯性。
- 局部提示适应(LPA)是一种轻量级、无需训练的方法,通过将提示分为内容和风格令牌来解决这一问题。
- LPA通过选择性地将令牌注入U-Net的注意力层,在降噪过程中早期处理对象令牌,后期处理风格令牌,改善了布局控制和风格一致性。
- 最佳配置下的LPA在提示对齐和风格一致性方面达到最佳平衡。
- 在基准测试中,LPA提高了CLIP提示对齐的准确率,且不会损失多样性。
- LPA具有模型无关性,易于集成,只需单一配置更改。
- LPA为可控、风格一致的多对象生成提供了实用的选择。
点此查看论文截图


Degradation-Agnostic Statistical Facial Feature Transformation for Blind Face Restoration in Adverse Weather Conditions
Authors:Chang-Hwan Son
With the increasing deployment of intelligent CCTV systems in outdoor environments, there is a growing demand for face recognition systems optimized for challenging weather conditions. Adverse weather significantly degrades image quality, which in turn reduces recognition accuracy. Although recent face image restoration (FIR) models based on generative adversarial networks (GANs) and diffusion models have shown progress, their performance remains limited due to the lack of dedicated modules that explicitly address weather-induced degradations. This leads to distorted facial textures and structures. To address these limitations, we propose a novel GAN-based blind FIR framework that integrates two key components: local Statistical Facial Feature Transformation (SFFT) and Degradation-Agnostic Feature Embedding (DAFE). The local SFFT module enhances facial structure and color fidelity by aligning the local statistical distributions of low-quality (LQ) facial regions with those of high-quality (HQ) counterparts. Complementarily, the DAFE module enables robust statistical facial feature extraction under adverse weather conditions by aligning LQ and HQ encoder representations, thereby making the restoration process adaptive to severe weather-induced degradations. Experimental results demonstrate that the proposed degradation-agnostic SFFT model outperforms existing state-of-the-art FIR methods based on GAN and diffusion models, particularly in suppressing texture distortions and accurately reconstructing facial structures. Furthermore, both the SFFT and DAFE modules are empirically validated in enhancing structural fidelity and perceptual quality in face restoration under challenging weather scenarios.
随着智能CCTV系统在户外环境中的部署越来越多,对于适应恶劣天气条件的面部识别系统的需求也在增长。恶劣天气会显著降低图像质量,进而导致识别精度下降。虽然基于生成对抗网络(GANs)和扩散模型的面部图像恢复(FIR)模型已经取得了进展,但由于缺乏专门解决天气退化问题的模块,其性能仍然受到限制。这导致了面部纹理和结构失真。为了解决这个问题,我们提出了一种基于GAN的盲FIR框架,它包括两个关键组件:局部统计面部特征变换(SFFT)和退化无关特征嵌入(DAFE)。局部SFFT模块通过使低质量(LQ)面部区域的局部统计分布与高质量(HQ)对应区域的统计分布对齐,增强面部结构和颜色保真度。作为补充,DAFE模块通过对齐LQ和HQ编码器表示,实现在恶劣天气条件下的稳健统计面部特征提取,使恢复过程能够适应由恶劣天气引起的退化问题。实验结果表明,所提出的退化无关SFFT模型在抑制纹理失真和准确重建面部结构方面优于现有的基于GAN和扩散模型的先进FIR方法。此外,SFFT和DAFE模块在增强结构保真度和感知质量方面得到了验证,在恶劣天气情况下都能实现面部恢复的优化。
论文及项目相关链接
摘要
针对户外环境中智能监控系统的广泛应用,对面部识别系统在恶劣天气条件下的优化需求日益增加。恶劣天气会显著降图像质量,进而影响识别准确度。虽然基于生成对抗网络(GAN)和扩散模型的面部图像恢复(FIR)模型已有所进展,但由于缺乏专门应对天气引起的降质的模块,其性能仍然有限。为此,提出一种基于GAN的盲FIR框架,包含两个关键组件:局部统计面部特征变换(SFFT)和降质无关特征嵌入(DAFE)。SFFT模块通过对齐低质量(LQ)面部区域与高质量(HQ)区域的局部统计分布,增强面部结构和色彩保真度。DAFE模块则通过对齐LQ和HQ编码器的表示,使面部特征提取在恶劣天气条件下更加稳健,从而使恢复过程适应严重的天气引起的降质。实验结果表明,所提出的降质无关SFFT模型在GAN和扩散模型的基础上的面部图像恢复方法中表现更佳,尤其在抑制纹理失真和准确重建面部结构方面。SFFT和DAFE模块在挑战天气情景下的面部恢复中,都经过实证增强了结构保真度和感知质量。
关键见解
- 恶劣天气对面部识别系统造成挑战,需要针对特定天气条件的优化。
- 基于GAN和扩散模型的现有面部图像恢复(FIR)模型在应对天气引起的图像降质方面存在局限性。
- 提出了一种新的GAN-based盲FIR框架,包含局部统计面部特征变换(SFFT)和降质无关特征嵌入(DAFE)两个关键组件。
- SFFT模块通过局部统计分布对齐增强面部结构和色彩保真度。
- DAFE模块使面部特征提取在恶劣天气下更加稳健,适应各种天气引起的降质。
- 提出的降质无关SFFT模型在抑制纹理失真和重建面部结构方面表现出优异的性能。
点此查看论文截图


LoRA-Edit: Controllable First-Frame-Guided Video Editing via Mask-Aware LoRA Fine-Tuning
Authors:Chenjian Gao, Lihe Ding, Xin Cai, Zhanpeng Huang, Zibin Wang, Tianfan Xue
Video editing using diffusion models has achieved remarkable results in generating high-quality edits for videos. However, current methods often rely on large-scale pretraining, limiting flexibility for specific edits. First-frame-guided editing provides control over the first frame, but lacks flexibility over subsequent frames. To address this, we propose a mask-based LoRA (Low-Rank Adaptation) tuning method that adapts pretrained Image-to-Video (I2V) models for flexible video editing. Our key innovation is using a spatiotemporal mask to strategically guide the LoRA fine-tuning process. This teaches the model two distinct skills: first, to interpret the mask as a command to either preserve content from the source video or generate new content in designated regions. Second, for these generated regions, LoRA learns to synthesize either temporally consistent motion inherited from the video or novel appearances guided by user-provided reference frames. This dual-capability LoRA grants users control over the edit’s entire temporal evolution, allowing complex transformations like an object rotating or a flower blooming. Experimental results show our method achieves superior video editing performance compared to baseline methods. Project Page: https://cjeen.github.io/LoRAEdit
使用扩散模型进行视频编辑已经在为高质量视频生成编辑方面取得了显著成果。然而,当前的方法通常依赖于大规模预训练,这限制了特定编辑的灵活性。虽然第一帧引导编辑可以控制第一帧,但对于后续帧的灵活性不足。为了解决这一问题,我们提出了一种基于掩膜的LoRA(低秩适应)调优方法,该方法可适应预训练的图到视频(I2V)模型,用于灵活视频编辑。我们的关键创新之处在于使用时空掩膜来战略性地引导LoRA微调过程。这教会了模型两种截然不同的技能:首先,将掩膜解释为来自源视频的指令,要么保留内容,要么在指定区域生成新内容。其次,对于这些生成的区域,LoRA学习合成从视频中继承的时间连贯运动或根据用户提供的参考帧引导的新外观。这种双功能的LoRA使用户能够控制整个时间轴的编辑演变,从而实现复杂的转换,如物体旋转或花朵绽放等。实验结果表明,我们的方法相较于基准方法在视频编辑性能上更胜一筹。项目页面:https://cjeen.github.io/LoRAEdit
论文及项目相关链接
PDF 9 pages
Summary
扩散模型在视频编辑领域已取得了显著成果,能够生成高质量的视频编辑。但现有方法常依赖大规模预训练,对于特定编辑的灵活性有限。为解决这一问题,我们提出了基于掩膜的LoRA(低秩适应)调优方法,该方法用于自适应地调整预训练的图像到视频(I2V)模型,以实现灵活的视频编辑。我们的核心创新在于使用时空掩膜来指导LoRA微调过程,赋予用户控制整个时间演化的能力。与基线方法相比,实验结果显示我们的方法实现了出色的视频编辑性能。详情请参见我们的项目页面:https://cjeen.github.io/LoRAEdit。
Key Takeaways
- 扩散模型在视频编辑中表现优异,能生成高质量编辑。
- 当前视频编辑方法依赖大规模预训练,缺乏特定编辑的灵活性。
- 提出基于掩膜的LoRA调优方法,用于自适应调整预训练模型。
- 使用时空掩膜指导LoRA微调过程,实现视频编辑的灵活控制。
- LoRA技术可以合成与视频一致的连续运动或用户参考帧引导的新外观。
- 双功能LoRA使用户能够控制整个时间演化,实现复杂转换。
点此查看论文截图





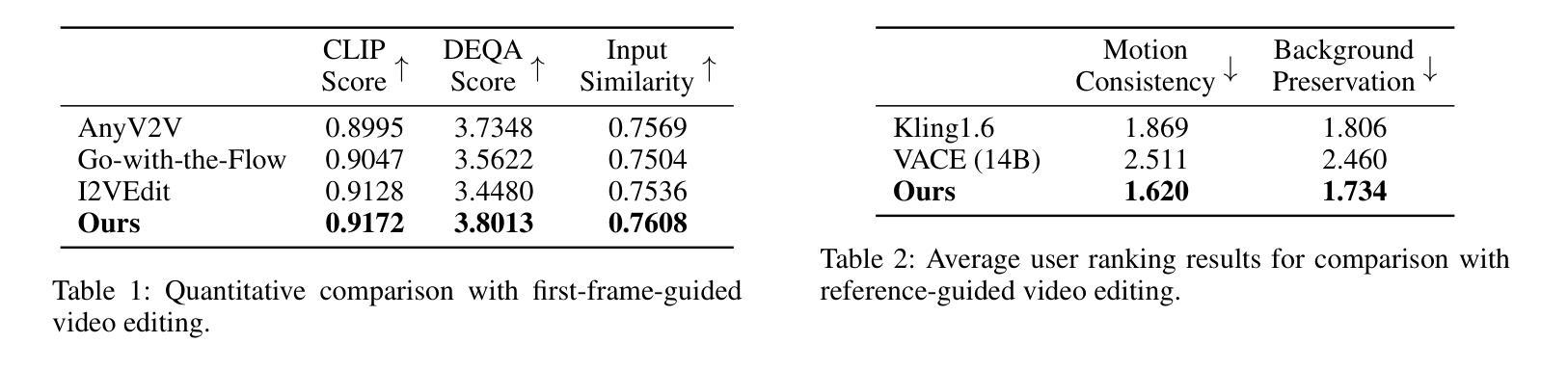
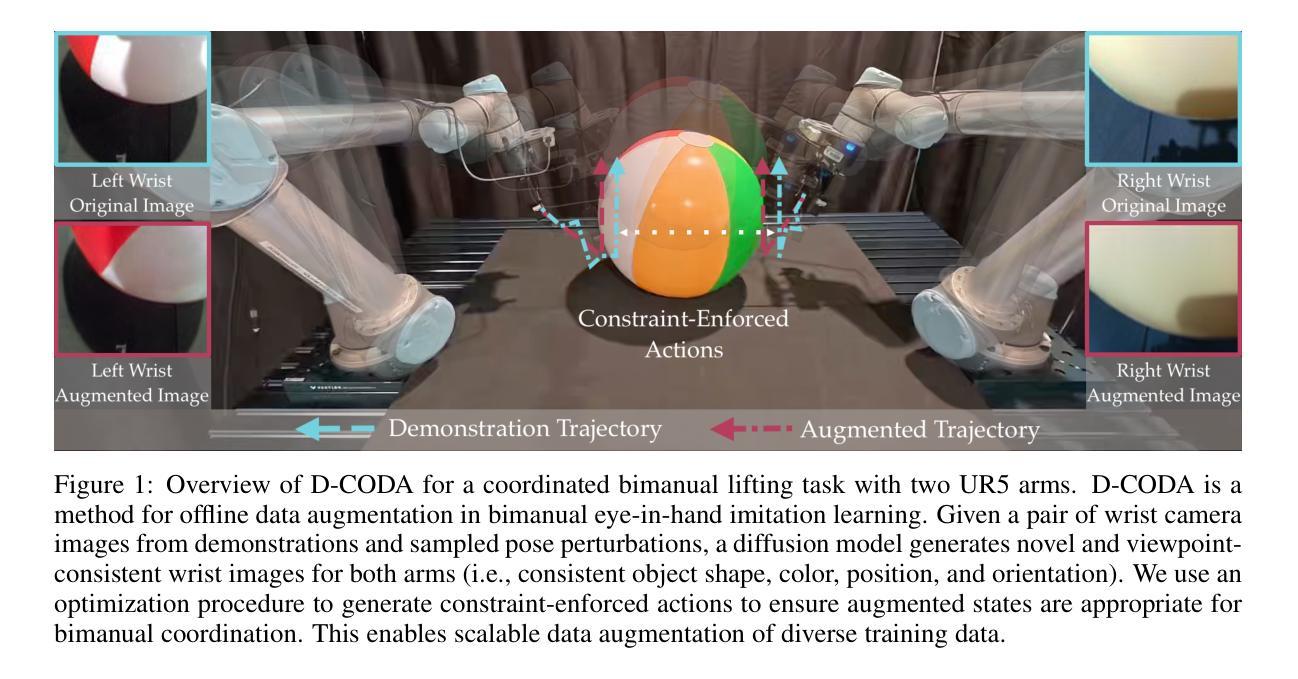
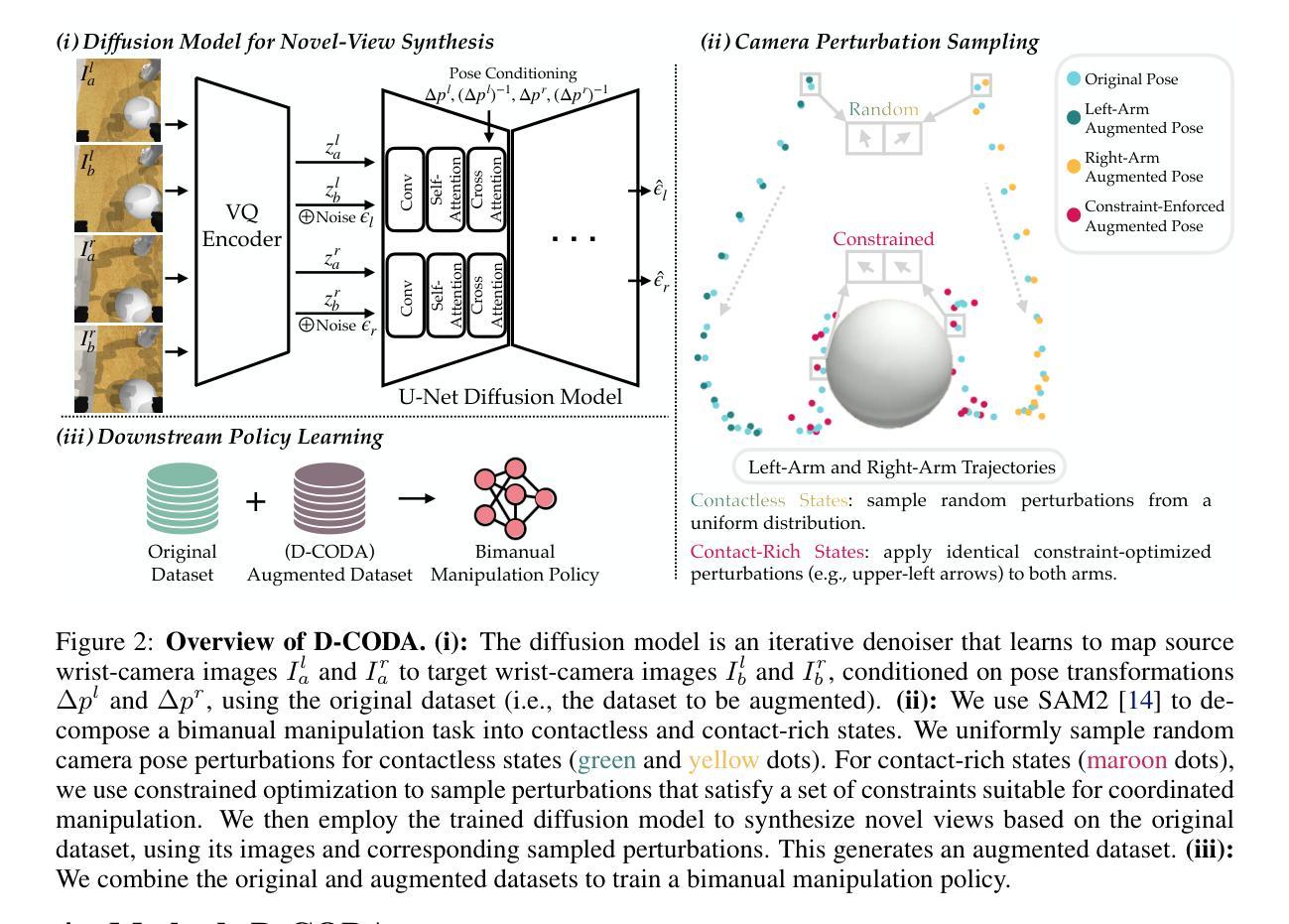
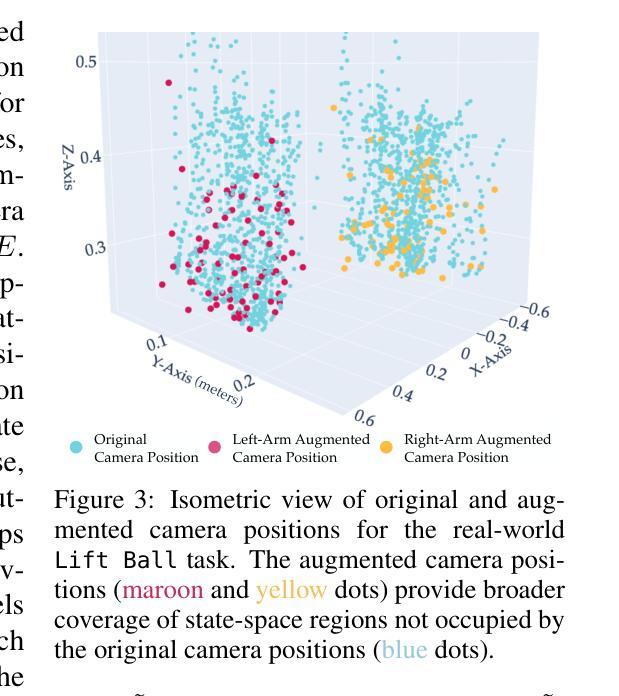
D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation
Authors:I-Chun Arthur Liu, Jason Chen, Gaurav Sukhatme, Daniel Seita
Learning bimanual manipulation is challenging due to its high dimensionality and tight coordination required between two arms. Eye-in-hand imitation learning, which uses wrist-mounted cameras, simplifies perception by focusing on task-relevant views. However, collecting diverse demonstrations remains costly, motivating the need for scalable data augmentation. While prior work has explored visual augmentation in single-arm settings, extending these approaches to bimanual manipulation requires generating viewpoint-consistent observations across both arms and producing corresponding action labels that are both valid and feasible. In this work, we propose Diffusion for COordinated Dual-arm Data Augmentation (D-CODA), a method for offline data augmentation tailored to eye-in-hand bimanual imitation learning that trains a diffusion model to synthesize novel, viewpoint-consistent wrist-camera images for both arms while simultaneously generating joint-space action labels. It employs constrained optimization to ensure that augmented states involving gripper-to-object contacts adhere to constraints suitable for bimanual coordination. We evaluate D-CODA on 5 simulated and 3 real-world tasks. Our results across 2250 simulation trials and 300 real-world trials demonstrate that it outperforms baselines and ablations, showing its potential for scalable data augmentation in eye-in-hand bimanual manipulation. Our project website is at: https://dcodaaug.github.io/D-CODA/.
学习双手协调操作是一项挑战,因为它具有高维度和需要两只手臂紧密协调的特点。眼在手上的模仿学习使用手腕安装的相机,通过专注于任务相关视角来简化感知。然而,收集各种示范仍然成本高昂,这激发了对可扩展数据增强的需求。虽然以前的工作已经探索了单臂设置中的视觉增强,但将这些方法扩展到双手操作需要生成两只手臂视角一致的观察结果,并产生既有效又可行的相应动作标签。在这项工作中,我们提出了用于眼在手上的双手模仿学习的数据增强方法——扩散协调双臂数据增强(D-CODA)。D-CODA是一种离线数据增强方法,训练扩散模型合成新颖、视角一致的手腕相机图像,同时生成关节空间动作标签。它采用约束优化,确保增强状态涉及夹持器与物体的接触符合双手协调的约束。我们在5个模拟任务和3个真实世界任务上评估了D-CODA。在2250次模拟试验和300次真实试验的结果表明,它优于基准方法和消融实验,显示出在眼在手上的双手操作中进行可扩展数据增强的潜力。我们的项目网站是:https://dcodaaug.github.io/D-CODA/。
论文及项目相关链接
PDF Accepted to the Conference on Robot Learning (CoRL) 2025
Summary
眼手协调的双手操作学习面临高维度和双臂紧密协调的挑战。采用手腕安装的相机进行视觉模仿学习简化了任务相关视角的感知。然而,收集多样的演示成本高昂,需要可扩展的数据增强技术。本文提出一种针对眼手协调双手操作的离线数据增强方法——扩散协调双臂数据增强(D-CODA)。该方法训练扩散模型合成新颖、视角一致的手腕相机图像,同时生成关节空间动作标签。通过约束优化确保增强的涉及夹持物体接触的状态符合双手协调的约束条件。在模拟和真实任务上的评估显示,D-CODA优于基准方法和废除方案,展现出在眼手协调双手操作中的可扩展数据增强的潜力。
Key Takeaways
- 学习双手动操作因高维度和紧密协调要求而具有挑战性。
- 视觉模仿学习中,手腕安装的相机简化了任务相关视角的感知。
- 数据收集成本高昂,需要可扩展的数据增强技术来解决这一问题。
- D-CODA方法通过训练扩散模型合成新颖的手腕相机图像,同时生成关节空间动作标签。
- D-CODA采用约束优化确保增强的动作状态符合双手协调的实际约束。
- 在模拟和真实任务上的评估显示D-CODA优于其他方法。
- D-CODA展现出在眼手协调双手操作中的可扩展数据增强的潜力。
点此查看论文截图


Diffusion Based Ambiguous Image Segmentation
Authors:Jakob Lønborg Christensen, Morten Rieger Hannemose, Anders Bjorholm Dahl, Vedrana Andersen Dahl
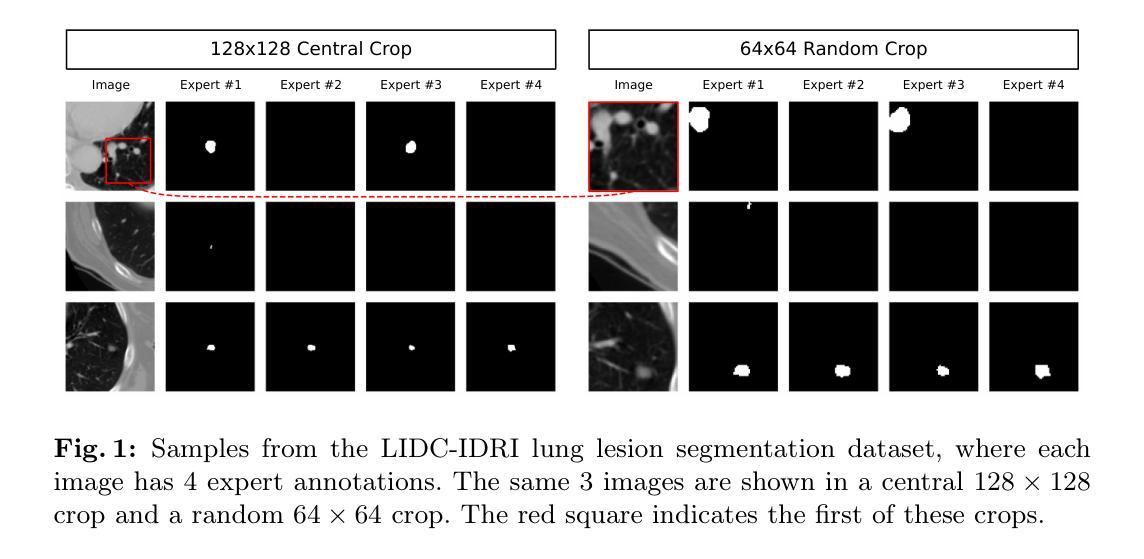
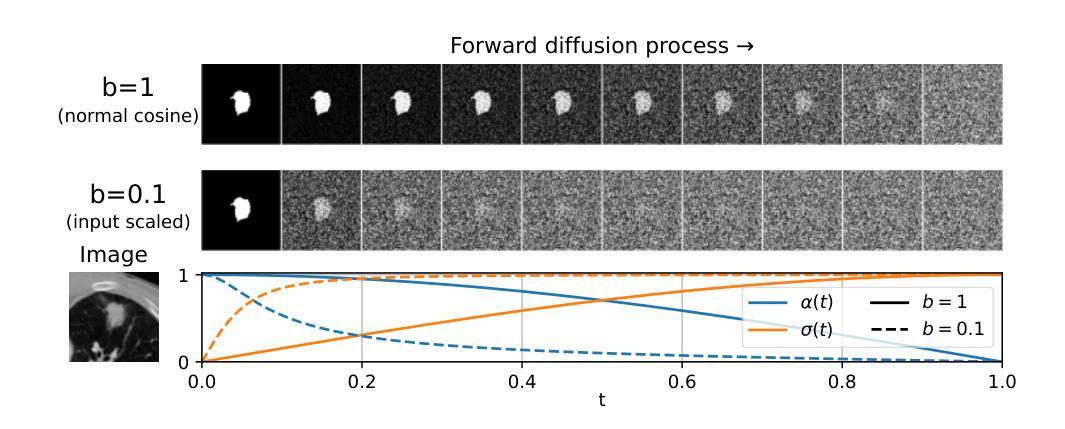
Medical image segmentation often involves inherent uncertainty due to variations in expert annotations. Capturing this uncertainty is an important goal and previous works have used various generative image models for the purpose of representing the full distribution of plausible expert ground truths. In this work, we explore the design space of diffusion models for generative segmentation, investigating the impact of noise schedules, prediction types, and loss weightings. Notably, we find that making the noise schedule harder with input scaling significantly improves performance. We conclude that x- and v-prediction outperform epsilon-prediction, likely because the diffusion process is in the discrete segmentation domain. Many loss weightings achieve similar performance as long as they give enough weight to the end of the diffusion process. We base our experiments on the LIDC-IDRI lung lesion dataset and obtain state-of-the-art (SOTA) performance. Additionally, we introduce a randomly cropped variant of the LIDC-IDRI dataset that is better suited for uncertainty in image segmentation. Our model also achieves SOTA in this harder setting.
医学图像分割经常因为专家标注的差异而带有固有的不确定性。捕捉这种不确定性是一个重要目标,之前的研究已经使用各种生成图像模型来表示专家真实标签的完整分布。在这项工作中,我们探索了生成分割扩散模型的设计空间,研究了噪声时间表、预测类型和损失权重的影响。值得注意的是,我们发现通过输入缩放使噪声时间表更加困难可以显著提高性能。我们得出结论,x预测和v预测优于ε预测,这可能是因为扩散过程处于离散分割领域。只要对扩散过程的结束给予足够的重视,许多损失权重都能达到类似的效果。我们的实验基于LIDC-IDRI肺病变数据集,并获得了最先进的性能。此外,我们还引入了LIDC-IDRI数据集的随机裁剪版本,该版本更适合于图像分割的不确定性。我们的模型在这个更困难的环境中同样达到了最先进的水平。
论文及项目相关链接
PDF Accepted at SCIA25
摘要
针对医学图像分割中的专家标注变化带来的固有不确定性问题,我们探索了扩散模型的设计空间。通过调整噪声调度、预测类型和损失权重,我们发现增加输入标度的噪声调度能显著提高性能。基于LIDC-IDRI肺病灶数据集的实验表明,x-和v-预测优于ε-预测,多种损失权重只要足够重视扩散过程的最后阶段都能取得类似性能。我们还引入了LIDC-IDRI数据集的随机裁剪版本,更适合于图像分割的不确定性研究。模型在该更困难的环境下也达到了最新技术水平。
要点
- 医学图像分割中存在因专家标注变化导致的固有不确定性。
- 通过扩散模型的设计空间探索来解决这一不确定性。
- 噪声调度是影响性能的关键因素,增加输入标度能显著提高性能。
- x-和v-预测在离散分割域的扩散过程中表现优于ε-预测。
- 适当的损失权重配置也能取得良好性能。
- 基于LIDC-IDRI肺病灶数据集的实验达到了最新技术水平。
点此查看论文截图

Inverse Bridge Matching Distillation
Authors:Nikita Gushchin, David Li, Daniil Selikhanovych, Evgeny Burnaev, Dmitry Baranchuk, Alexander Korotin
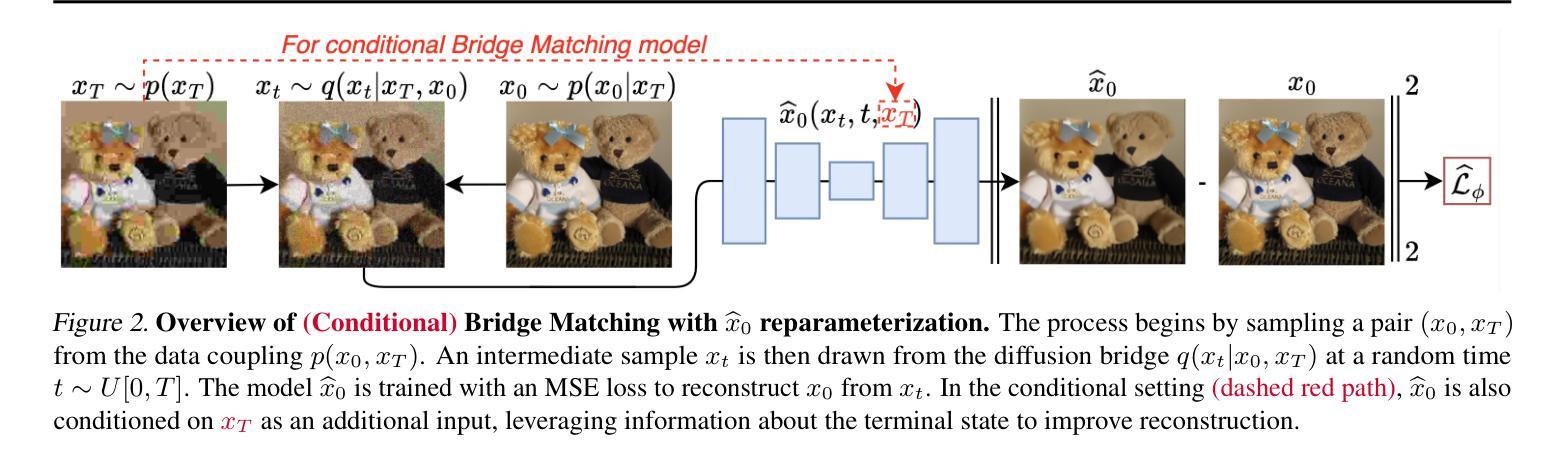
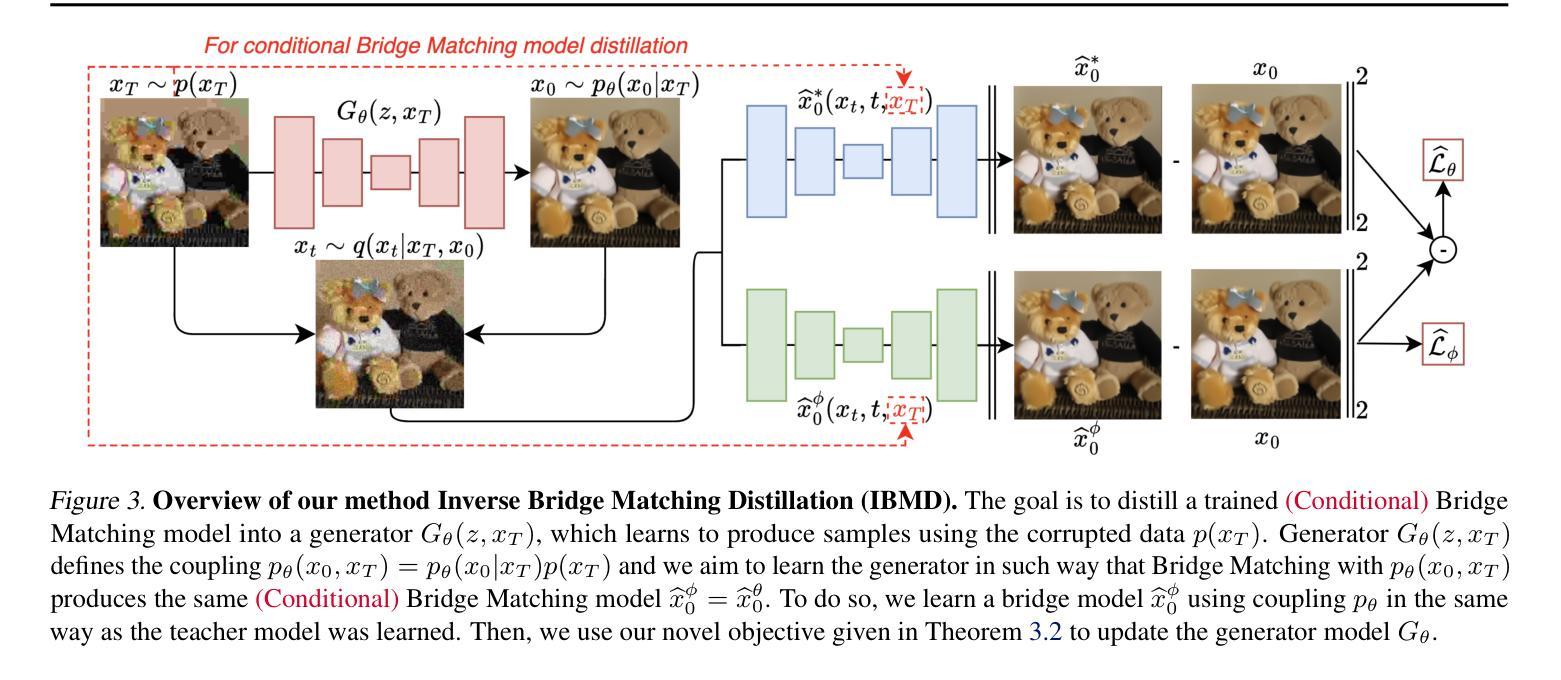
Learning diffusion bridge models is easy; making them fast and practical is an art. Diffusion bridge models (DBMs) are a promising extension of diffusion models for applications in image-to-image translation. However, like many modern diffusion and flow models, DBMs suffer from the problem of slow inference. To address it, we propose a novel distillation technique based on the inverse bridge matching formulation and derive the tractable objective to solve it in practice. Unlike previously developed DBM distillation techniques, the proposed method can distill both conditional and unconditional types of DBMs, distill models in a one-step generator, and use only the corrupted images for training. We evaluate our approach for both conditional and unconditional types of bridge matching on a wide set of setups, including super-resolution, JPEG restoration, sketch-to-image, and other tasks, and show that our distillation technique allows us to accelerate the inference of DBMs from 4x to 100x and even provide better generation quality than used teacher model depending on particular setup. We provide the code at https://github.com/ngushchin/IBMD
学习扩散桥模型(Diffusion Bridge Models,简称DBM)是一件相对容易的事,但想要让它们在速度和实用性方面达标却是一种艺术。扩散桥模型是有前景的扩散模型扩展应用,特别是在图像转换方面大显身手。然而,与许多现代扩散和流动模型一样,DBM也面临着推理速度慢的问题。为了解决这个问题,我们提出了一种基于逆桥匹配公式的新型蒸馏技术,并推导出实用的目标来解决实际应用中的问题。与之前开发的DBM蒸馏技术不同,所提出的方法能够蒸馏有条件和无条件的DBM类型,在一次生成器中蒸馏模型,并且仅使用损坏的图像进行训练。我们在包括超分辨率、JPEG恢复、草图到图像和其他任务在内的广泛设置上评估了我们的方法的有条件和无条件桥匹配方法,并证明我们的蒸馏技术能够将DBM的推理速度提高4倍至100倍,并且在特定设置下甚至提供比所使用的教师模型更好的生成质量。我们在https://github.com/ngushchin/IBMD提供了相关代码。
论文及项目相关链接
摘要
扩散桥模型(DBMs)是扩散模型在图像转换领域的延伸应用,但其和其他现代扩散及流模型存在推理速度慢的问题。为解决这一问题,我们提出了一种基于逆桥匹配公式的新蒸馏技术,并推导出了实用的目标函数。与之前开发的DBM蒸馏技术不同,我们的方法可以蒸馏条件性和非条件性的DBMs,一步生成模型,并且只用损坏的图像进行训练。我们在超分辨率、JPEG恢复、草图到图像等任务上评估了我们的方法,证明我们的蒸馏技术可以将DBM的推理速度提高4到100倍,并且在特定设置下甚至提供比教师模型更好的生成质量。
关键见解
- 扩散桥模型(DBMs)是扩散模型在图像转换领域的扩展应用,但存在推理速度慢的问题。
- 提出了一种基于逆桥匹配公式的新的蒸馏技术来解决推理速度慢的问题。
- 该方法可以蒸馏条件性和非条件性的DBMs,一步生成模型。
- 该方法使用损坏的图像进行训练。
- 在超分辨率、JPEG恢复和草图到图像等任务上进行了评估。
- 蒸馏技术可以将DBM的推理速度提高4到100倍。
- 在特定设置下,蒸馏技术提供的生成质量可能超过原始模型。
点此查看论文截图

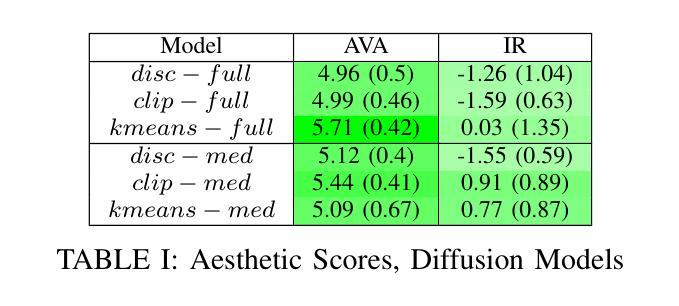
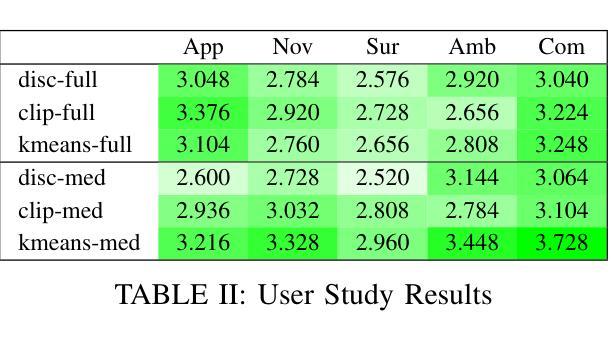
Style Ambiguity Loss Using CLIP
Authors:James Baker
In this work, we explore using the style ambiguity training objective, originally used to approximate creativity, on a diffusion model. However, this objective requires the use of a pretrained classifier and a labeled dataset. We introduce new forms of style ambiguity loss that do not require training a new classifier or a labeled dataset. Instead of using a classifier, we generate centroids in the CLIP embedding space, and images are classified based on their relative distance to said centroids. We find the centroids via K-means clustering of an unlabeled dataset, as well as using text labels to generate CLIP embeddings, to be used as centroids. Code is available at https://github.com/jamesBaker361/clipcreate
在这项工作中,我们探索在扩散模型上使用最初用于近似创造力的风格模糊训练目标。然而,这一目标需要使用预训练的分类器和有标签的数据集。我们引入了新的风格模糊损失形式,不需要训练新的分类器或有标签的数据集。我们不在使用分类器,而是在CLIP嵌入空间中生成质心,并根据图像与所述质心的相对距离对其进行分类。我们通过使用无标签数据集进行K-means聚类以及使用文本标签生成CLIP嵌入来找到质心。相关代码可在https://github.com/jamesBaker361/clipcreate找到。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2407.12009
Summary:
本文探索了在扩散模型中使用原先用于近似创造力的风格模糊训练目标。新方法无需训练新的分类器或标注数据集,而是通过生成CLIP嵌入空间中的质心来进行图像分类,图像的分类基于它们与所述质心的相对距离。通过无标签数据集的K-means聚类和文本标签生成CLIP嵌入作为质心。相关代码可在https://github.com/jamesBaker361/clipcreate找到。
Key Takeaways:
- 风格模糊训练目标在扩散模型中的应用被探索。
- 新的风格模糊损失形式被引入,无需训练新的分类器或标注数据集。
- 通过在CLIP嵌入空间中生成质心,进行图像分类。
- 图像分类基于其与质心的相对距离。
- 使用无标签数据集的K-means聚类和文本标签生成CLIP嵌入作为质心。
- 提供的代码可在GitHub上找到。
点此查看论文截图