⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
WP-CLIP: Leveraging CLIP to Predict Wölfflin’s Principles in Visual Art
Authors:Abhijay Ghildyal, Li-Yun Wang, Feng Liu
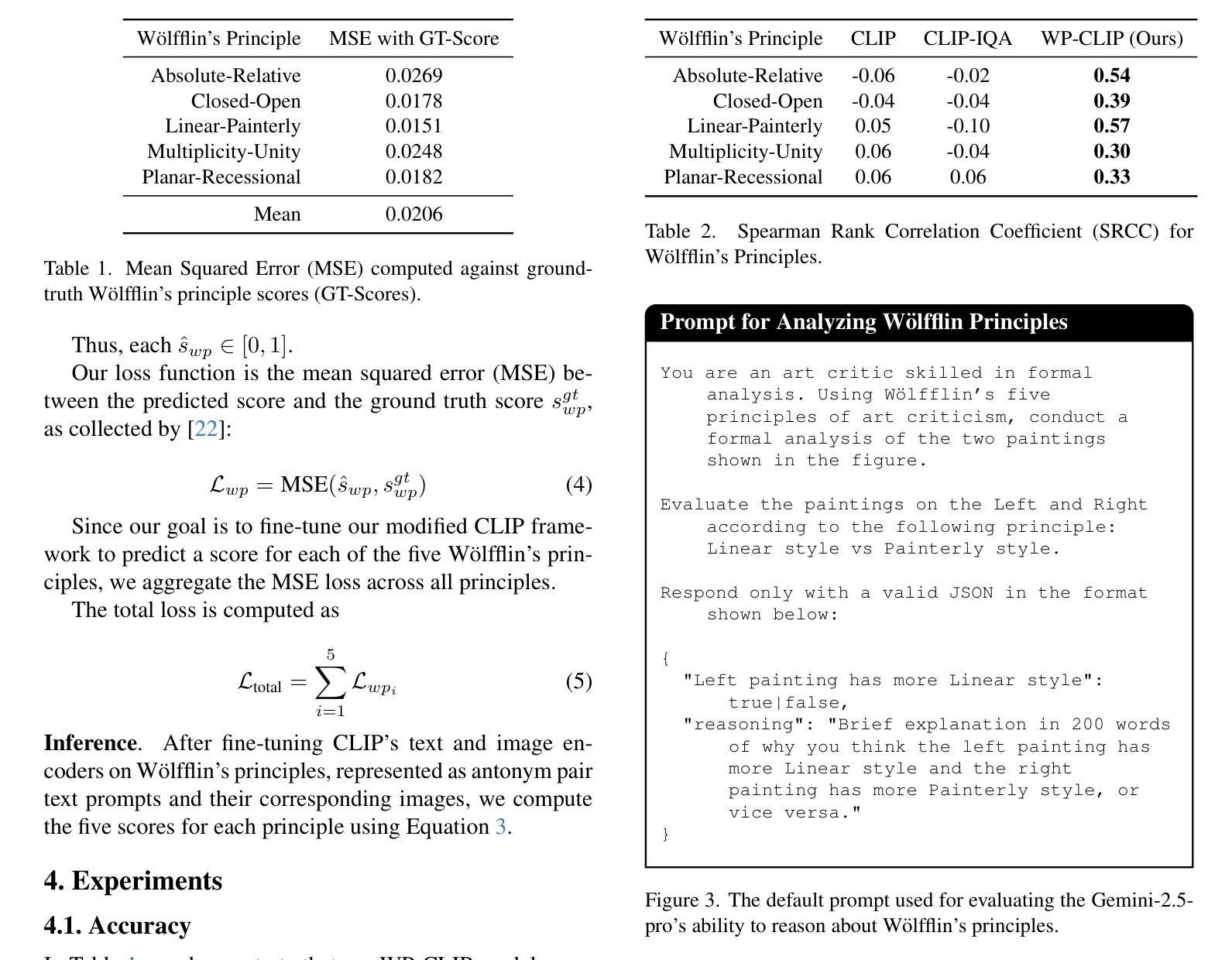
W"olfflin’s five principles offer a structured approach to analyzing stylistic variations for formal analysis. However, no existing metric effectively predicts all five principles in visual art. Computationally evaluating the visual aspects of a painting requires a metric that can interpret key elements such as color, composition, and thematic choices. Recent advancements in vision-language models (VLMs) have demonstrated their ability to evaluate abstract image attributes, making them promising candidates for this task. In this work, we investigate whether CLIP, pre-trained on large-scale data, can understand and predict W"olfflin’s principles. Our findings indicate that it does not inherently capture such nuanced stylistic elements. To address this, we fine-tune CLIP on annotated datasets of real art images to predict a score for each principle. We evaluate our model, WP-CLIP, on GAN-generated paintings and the Pandora-18K art dataset, demonstrating its ability to generalize across diverse artistic styles. Our results highlight the potential of VLMs for automated art analysis.
沃尔夫林提出的五项原则提供了一个分析风格变化的结构化方法,用于形式分析。然而,目前还没有任何现有指标能够有效地预测视觉艺术中的所有五项原则。从计算角度评估绘画的视觉方面需要一个能够解释颜色、构图和主题选择等关键元素的指标。最近视觉语言模型(VLM)的进步表明其能够评估抽象图像属性的能力,使其成为此任务最有希望的候选者。在这项工作中,我们调查了在大型数据上预训练的CLIP是否能够理解和预测沃尔夫林的原则。我们的研究结果表明,它并不自然地捕捉这些微妙的风格元素。为解决这一问题,我们对CLIP进行了微调,以适应真实艺术图像的注释数据集,并对每项原则进行评分预测。我们的模型WP-CLIP在GAN生成的画作和Pandora-18K艺术数据集上的评估结果表明,它在各种艺术风格中具有泛化能力。我们的结果突出了视觉语言模型在自动化艺术分析中的潜力。
论文及项目相关链接
PDF ICCV 2025 AI4VA workshop (oral), Code: https://github.com/abhijay9/wpclip
Summary
基于Wölfflin的五大原则,现有方法无法有效预测视觉艺术中的所有原则。研究利用计算机评估画作时,需要一个能解读色彩、构图和主题选择等关键元素的度量标准。本研究调查预训练于大规模数据的CLIP是否能理解和预测Wölfflin的原则。尽管CLIP未能内在地捕捉到这种风格细节,但通过微调于真实艺术图像注释数据集进行训练后,我们提出了能预测每项原则的模型WP-CLIP。在GAN生成的画作和Pandora-18K艺术数据集上的评估显示其能够跨越多种艺术风格进行泛化分析的能力。这一发现凸显了VLMs在自动化艺术分析方面的潜力。
Key Takeaways
- Wölfflin的五大原则用于分析风格变化,但缺乏有效度量指标预测视觉艺术中的原则。
- 视觉评估画作需要理解色彩、构图和主题等关键元素的度量标准。
- CLIP预训练模型未能内在理解Wölfflin的原则,无法直接应用于艺术风格分析。
- 通过微调CLIP模型于真实艺术图像注释数据集进行训练,形成新的模型WP-CLIP。
- WP-CLIP模型能在GAN生成的画作和Pandora-18K艺术数据集上预测Wölfflin原则,表现出泛化能力。
点此查看论文截图




Hybrid Generative Fusion for Efficient and Privacy-Preserving Face Recognition Dataset Generation
Authors:Feiran Li, Qianqian Xu, Shilong Bao, Boyu Han, Zhiyong Yang, Qingming Huang
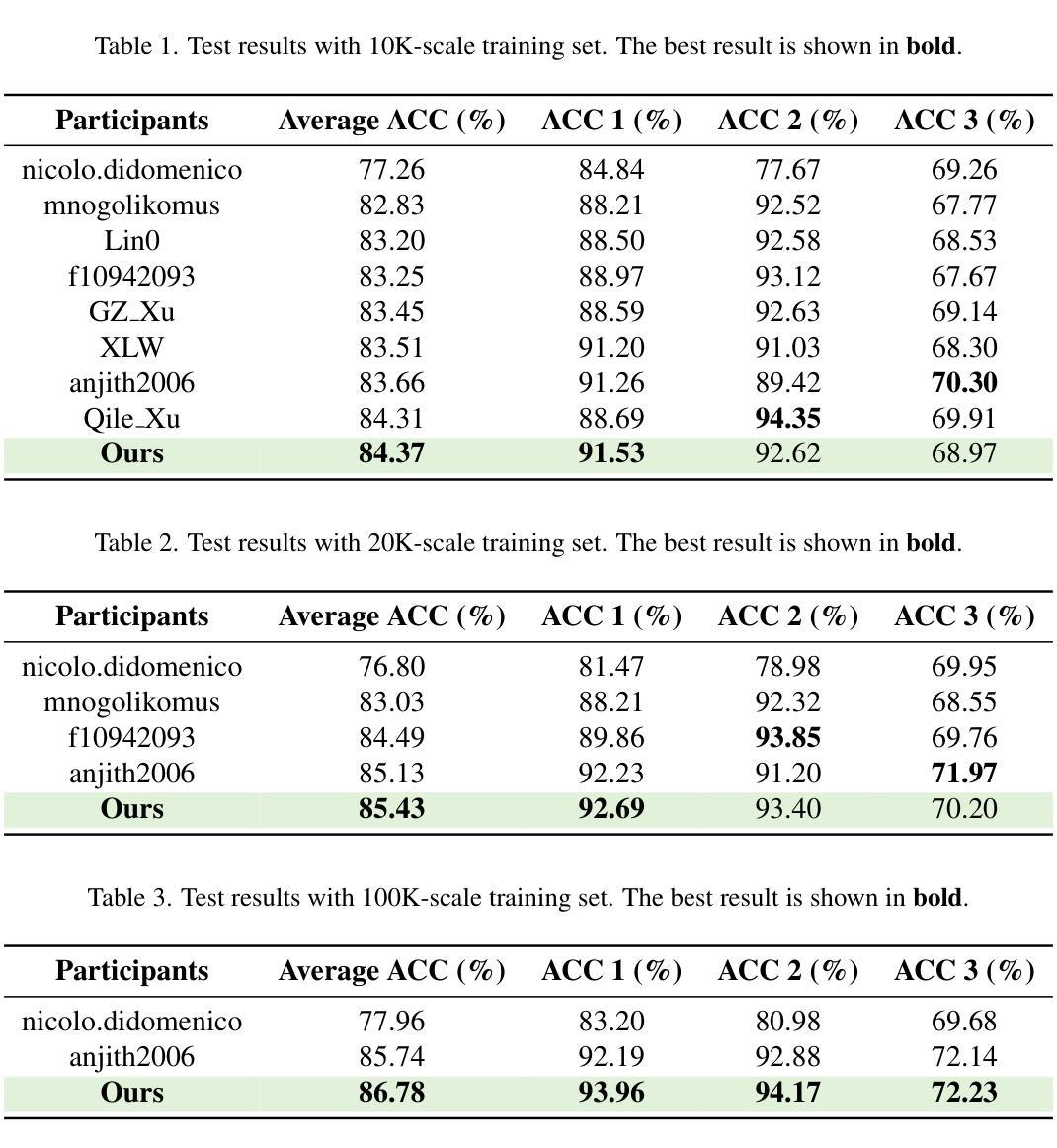
In this paper, we present our approach to the DataCV ICCV Challenge, which centers on building a high-quality face dataset to train a face recognition model. The constructed dataset must not contain identities overlapping with any existing public face datasets. To handle this challenge, we begin with a thorough cleaning of the baseline HSFace dataset, identifying and removing mislabeled or inconsistent identities through a Mixture-of-Experts (MoE) strategy combining face embedding clustering and GPT-4o-assisted verification. We retain the largest consistent identity cluster and apply data augmentation up to a fixed number of images per identity. To further diversify the dataset, we generate synthetic identities using Stable Diffusion with prompt engineering. As diffusion models are computationally intensive, we generate only one reference image per identity and efficiently expand it using Vec2Face, which rapidly produces 49 identity-consistent variants. This hybrid approach fuses GAN-based and diffusion-based samples, enabling efficient construction of a diverse and high-quality dataset. To address the high visual similarity among synthetic identities, we adopt a curriculum learning strategy by placing them early in the training schedule, allowing the model to progress from easier to harder samples. Our final dataset contains 50 images per identity, and all newly generated identities are checked with mainstream face datasets to ensure no identity leakage. Our method achieves \textbf{1st place} in the competition, and experimental results show that our dataset improves model performance across 10K, 20K, and 100K identity scales. Code is available at https://github.com/Ferry-Li/datacv_fr.
在这篇论文中,我们介绍了针对DataCV ICCV挑战的解决方案,该方案主要围绕构建高质量的人脸数据集来训练人脸识别模型。构建的数剧集不得与任何现有公开人脸数据集存在身份重叠。为应对这一挑战,我们对基线HSFace数据集进行了彻底清理,通过结合人脸嵌入聚类和GPT-4o辅助验证的混合专家(MoE)策略,识别和移除错误标记或不一致的身份。我们保留最大的连续身份集群,并对每个身份的图像进行增强,数量不超过固定数量。为了进一步丰富数据集,我们使用Stable Diffusion和提示工程生成合成身份。由于扩散模型计算量大,我们每个身份只生成一个参考图像,并使用Vec2Face有效地进行扩展,迅速生成49个身份一致的变体。这种混合方法融合了基于GAN和基于扩散的样本,能够高效构建多样且高质量的数据集。针对合成身份之间的高视觉相似性,我们采用课程学习策略,将它们放在训练安排的早期,允许模型从易到难逐步进行。我们的最终数据集每个身份包含50张图像,所有新生成的身份均经过主流人脸数据集检查,以确保无身份泄露。我们的方法在比赛中获得第一名,实验结果表明,我们的数据集在1万、2万和十万个身份规模上均提高了模型性能。代码可在https://github.com/Ferry-Li/datacv_fr获取。
论文及项目相关链接
PDF This paper has been accpeted to ICCV 2025 DataCV Workshop
Summary
本文介绍了一项针对DataCV ICCV挑战的研究,重点是如何构建一个高质量的人脸数据集来训练人脸识别模型。研究团队首先对基准HSFace数据集进行彻底清理,通过混合专家策略(MoE)结合人脸嵌入聚类和GPT-4o辅助验证来识别和移除误标记或身份不一致的数据。然后,研究团队保留最大的身份集群,对每个身份进行数据增强,并使用Stable Diffusion生成合成身份。为了高效构建多样化且高质量的数据集,研究团队融合了基于GAN和基于扩散的样本。为了解决合成身份之间的高视觉相似性,研究团队采用了一种课程学习策略,将合成身份放在训练初期,使模型从简单样本过渡到复杂样本。最终数据集包含每个身份50张图像,且新生成的身份均经过主流人脸数据集验证,确保无身份泄露。该方法在竞赛中荣获第一名,实验结果表明该数据集能提高模型在10K、20K和100K身份规模下的性能。
Key Takeaways
- 研究旨在构建高质量人脸数据集以训练人脸识别模型,应对DataCV ICCV挑战。
- 研究团队采用混合专家策略(MoE)对基准数据集进行清理,去除误标记和身份不一致数据。
- 利用Stable Diffusion生成合成身份,并采用课程学习策略解决合成身份高视觉相似性问题。
- 通过数据增强和Vec2Face技术,高效构建多样化且高质量的数据集。
- 融合GAN-基于和扩散-基于的样本,形成混合方法。
- 最终数据集包含每个身份50张图像,新生成身份经过主流数据集验证,无身份泄露。
- 该方法在竞赛中取得第一名,且实验表明数据集能提高模型性能。
点此查看论文截图



Degradation-Agnostic Statistical Facial Feature Transformation for Blind Face Restoration in Adverse Weather Conditions
Authors:Chang-Hwan Son
With the increasing deployment of intelligent CCTV systems in outdoor environments, there is a growing demand for face recognition systems optimized for challenging weather conditions. Adverse weather significantly degrades image quality, which in turn reduces recognition accuracy. Although recent face image restoration (FIR) models based on generative adversarial networks (GANs) and diffusion models have shown progress, their performance remains limited due to the lack of dedicated modules that explicitly address weather-induced degradations. This leads to distorted facial textures and structures. To address these limitations, we propose a novel GAN-based blind FIR framework that integrates two key components: local Statistical Facial Feature Transformation (SFFT) and Degradation-Agnostic Feature Embedding (DAFE). The local SFFT module enhances facial structure and color fidelity by aligning the local statistical distributions of low-quality (LQ) facial regions with those of high-quality (HQ) counterparts. Complementarily, the DAFE module enables robust statistical facial feature extraction under adverse weather conditions by aligning LQ and HQ encoder representations, thereby making the restoration process adaptive to severe weather-induced degradations. Experimental results demonstrate that the proposed degradation-agnostic SFFT model outperforms existing state-of-the-art FIR methods based on GAN and diffusion models, particularly in suppressing texture distortions and accurately reconstructing facial structures. Furthermore, both the SFFT and DAFE modules are empirically validated in enhancing structural fidelity and perceptual quality in face restoration under challenging weather scenarios.
随着智能CCTV系统在户外环境中的部署不断增加,对于适应恶劣天气条件的面部识别系统的需求也在日益增长。恶劣天气会显著降低图像质量,进而导致识别准确率下降。尽管基于生成对抗网络(GANs)和扩散模型的面部图像恢复(FIR)模型已经取得了进展,但由于缺乏专门处理天气引起的退化的模块,其性能仍然有限。这会导致面部纹理和结构失真。为了解决这些限制,我们提出了一种基于GAN的盲FIR新框架,该框架包含两个关键组件:局部统计面部特征变换(SFFT)和退化无关特征嵌入(DAFE)。局部SFFT模块通过对齐低质量(LQ)面部区域的局部统计分布与高质量(HQ)面部区域的统计分布,增强面部结构和颜色保真度。作为补充,DAFE模块通过对齐LQ和HQ编码器的表示形式,使面部特征提取在恶劣天气条件下更加稳健,从而使恢复过程适应由恶劣天气引起的退化。实验结果表明,所提出的退化无关SFFT模型在抑制纹理失真和准确重建面部结构方面优于现有的基于GAN和扩散模型的先进FIR方法。此外,SFFT和DAFE模块在挑战性的天气情况下提高面部恢复的结构保真度和感知质量方面也得到了实证验证。
论文及项目相关链接
Summary
针对户外环境中智能监控系统的广泛应用,对面部识别系统提出了在恶劣天气条件下的优化需求。虽然基于生成对抗网络(GAN)和扩散模型的面部图像恢复(FIR)模型已取得进展,但由于缺乏专门应对天气引起的降质的模块,其性能仍然有限。为此,提出一种新型的基于GAN的盲FIR框架,包括局部统计面部特征变换(SFFT)和降质无关特征嵌入(DAFE)两个关键组件。前者提高面部结构和色彩保真度,后者使面部特征提取在恶劣天气下更加稳健。实验证明,该模型在抑制纹理失真和准确重建面部结构方面优于现有技术。
Key Takeaways
- 智能监控系统在户外环境的广泛应用推动了面部识别系统在恶劣天气下的优化需求。
- 现有基于GAN和扩散模型的面部图像恢复模型虽有所进展,但性能受限于缺乏应对天气引起的降质的专门模块。
- 提出的盲FIR框架包含局部统计面部特征变换(SFFT)和降质无关特征嵌入(DAFE)两个关键组件。
- SFFT模块通过对齐低质量面部区域的局部统计分布与高质量区域,增强面部结构和色彩保真度。
- DAFE模块通过对齐低质量和高质量编码器表示,使面部特征提取在恶劣天气下更加稳健。
- 实验证明,该框架在抑制纹理失真和准确重建面部结构方面优于现有技术。
点此查看论文截图



