⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
Single-Reference Text-to-Image Manipulation with Dual Contrastive Denoising Score
Authors:Syed Muhmmad Israr, Feng Zhao
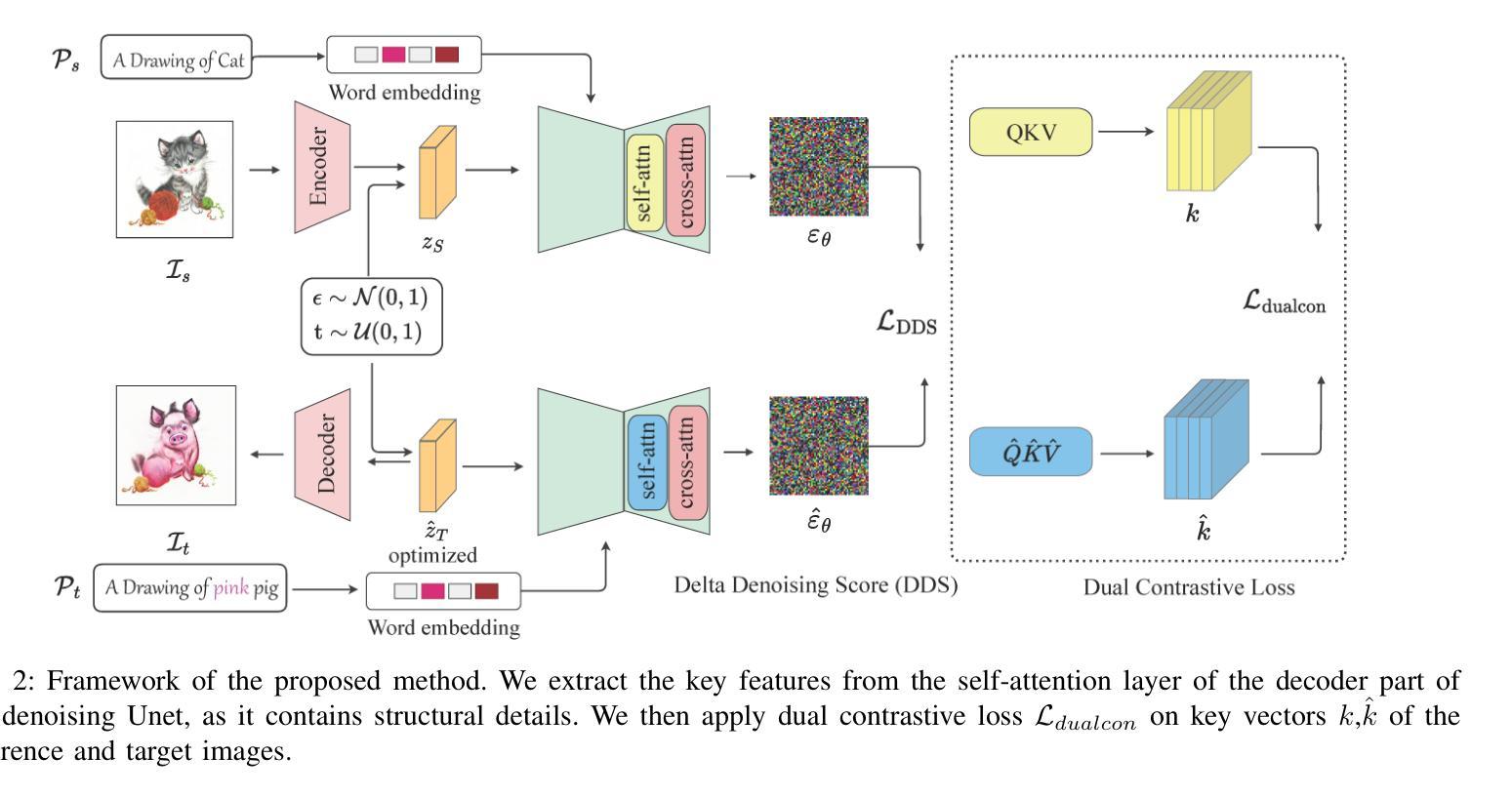
Large-scale text-to-image generative models have shown remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is difficult for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. To address these challenges, we present Dual Contrastive Denoising Score, a simple yet powerful framework that leverages the rich generative prior of text-to-image diffusion models. Inspired by contrastive learning approaches for unpaired image-to-image translation, we introduce a straightforward dual contrastive loss within the proposed framework. Our approach utilizes the extensive spatial information from the intermediate representations of the self-attention layers in latent diffusion models without depending on auxiliary networks. Our method achieves both flexible content modification and structure preservation between input and output images, as well as zero-shot image-to-image translation. Through extensive experiments, we show that our approach outperforms existing methods in real image editing while maintaining the capability to directly utilize pretrained text-to-image diffusion models without further training.
大规模文本到图像的生成模型已经显示出合成多样化和高质量图像的显著能力。然而,将这些模型直接应用于真实图像编辑仍然具有挑战性,原因有两点。首先,用户难以提出一个完美的文本提示,准确描述输入图像中的每个视觉细节。其次,虽然现有模型可以在某些区域引入理想的变化,但它们往往会剧烈改变输入内容,并在不需要的区域引入意外的变化。为了解决这些挑战,我们提出了双对比去噪评分(Dual Contrastive Denoising Score),这是一个简单而强大的框架,利用文本到图像扩散模型的丰富生成先验。受到无配对图像到图像转换的对比学习方法的启发,我们在所提出的框架中引入了一个简单的双对比损失。我们的方法利用潜在扩散模型中自注意力层中间表示的丰富空间信息,而不依赖于辅助网络。我们的方法实现了输入和输出图像之间的灵活内容修改和结构保留,以及零样本图像到图像的翻译。通过大量实验,我们证明我们的方法在真实图像编辑方面优于现有方法,同时保持直接使用预训练的文本到图像扩散模型的能力,无需进一步训练。
论文及项目相关链接
Summary
大规模文本到图像生成模型展现出合成多样化和高质量图像的能力。然而,将其直接应用于真实图像编辑仍面临挑战。本文提出一种名为Dual Contrastive Denoising Score的框架,利用文本到图像扩散模型的丰富生成先验。该框架借鉴了非配对图像到图像转换的对比学习方法,引入了一种简单的双重对比损失。该方法利用潜在扩散模型自注意力层中间表示的丰富空间信息,无需依赖辅助网络,实现了灵活的内容修改和结构保留,以及零样本图像到图像的翻译。实验表明,该方法在真实图像编辑方面优于现有方法,同时能够直接使用预训练的文本到图像扩散模型而无需进一步训练。
Key Takeaways
- 大规模文本到图像生成模型具备合成多样化和高质量图像的能力。
- 直接应用这些模型进行真实图像编辑面临挑战,包括用户难以制定完美文本提示和模型在引入期望更改时往往会对输入内容进行大幅改动。
- 提出了Dual Contrastive Denoising Score框架,利用文本到图像扩散模型的丰富生成先验。
- 该框架引入了一种简单的双重对比损失,借鉴了非配对图像到图像转换的对比学习方法。
- 方法利用潜在扩散模型自注意力层中间表示的丰富空间信息,实现了灵活的内容修改和结构保留。
- 该方法无需依赖辅助网络,能够实现零样本图像到图像的翻译。
点此查看论文截图



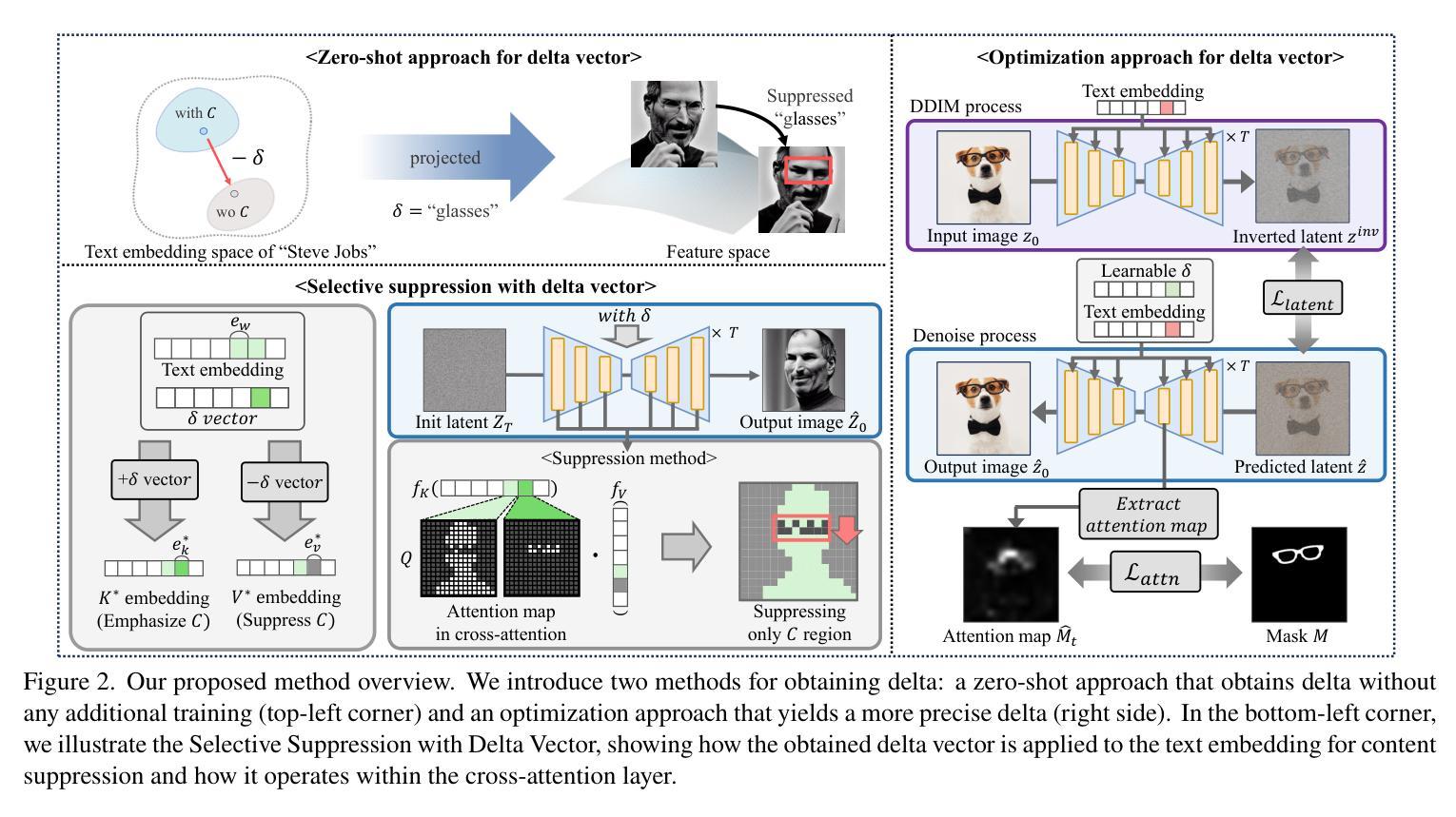
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Authors:Eunseo Koh, Seunghoo Hong, Tae-Young Kim, Simon S. Woo, Jae-Pil Heo
Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of “Charlie Chaplin”, a “mustache” consistently appears even if explicitly instructed not to include it, as the concept of “mustache” is strongly entangled with “Charlie Chaplin”. To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
文本到图像(T2I)扩散模型在根据文本提示生成多样化高质量图像方面取得了显著进展。然而,这些模型在抑制与特定单词强烈纠缠的内容方面仍面临挑战。例如,在生成“查理·卓别林”的图像时,即使明确指示不包括“胡子”,但“胡子”仍然会出现,因为“胡子”的概念与“查理·卓别林”紧密相连。为了解决这一问题,我们提出了一种新方法,直接在扩散模型的文本嵌入空间中抑制这种纠缠的内容。我们的方法引入了一个delta向量,该向量修改文本嵌入,以减弱生成图像中不需要内容的影响,我们进一步证明可以通过零样本方法轻松获得这个delta向量。此外,我们提出了一种带有Delta向量的选择性抑制(SSDV)方法,将delta向量适应到交叉注意机制中,从而更有效地抑制了不需要内容的区域。通过优化delta向量,我们还在个性化T2I模型中实现了更精确的抑制,这是以前基线无法达到的。大量的实验结果表明,我们的方法无论在定量还是定性指标上,都显著优于现有方法。
论文及项目相关链接
Summary
文本到图像(T2I)扩散模型根据文本提示生成多样化高质量图像方面已取得显著进展,但仍面临挑战,即在抑制与特定词语紧密相关的内容时存在困难。针对这一问题,本文提出了一种在扩散模型的文本嵌入空间中直接抑制纠缠内容的新方法。该方法通过引入一个修正文本嵌入的delta向量,减弱了生成图像中不需要内容的影响。此外,本文还提出了一种利用Delta向量的选择性抑制(SSDV)方法,将其融入交叉注意机制中,更有效地抑制了不需要的内容在生成区域的产生。实验结果表明,该方法在定量和定性指标上均显著优于现有方法。
Key Takeaways
- T2I扩散模型虽能生成高质量图像,但仍存在抑制与特定词语纠缠的内容的挑战。
- 提出了一种新方法,通过引入delta向量在文本嵌入空间中直接抑制纠缠内容。
- Delta向量可通过零样本方法轻松获得。
- SSDV方法将delta向量融入交叉注意机制,更有效地抑制了生成区域的不需要内容。
- 可在个性化T2I模型中实现更精确的内容抑制。
- 实验结果证明,该方法在定量和定性指标上均优于现有方法。
- 该方法为改进T2I扩散模型性能提供了新的思路。
点此查看论文截图

Categorical Schrödinger Bridge Matching
Authors:Grigoriy Ksenofontov, Alexander Korotin
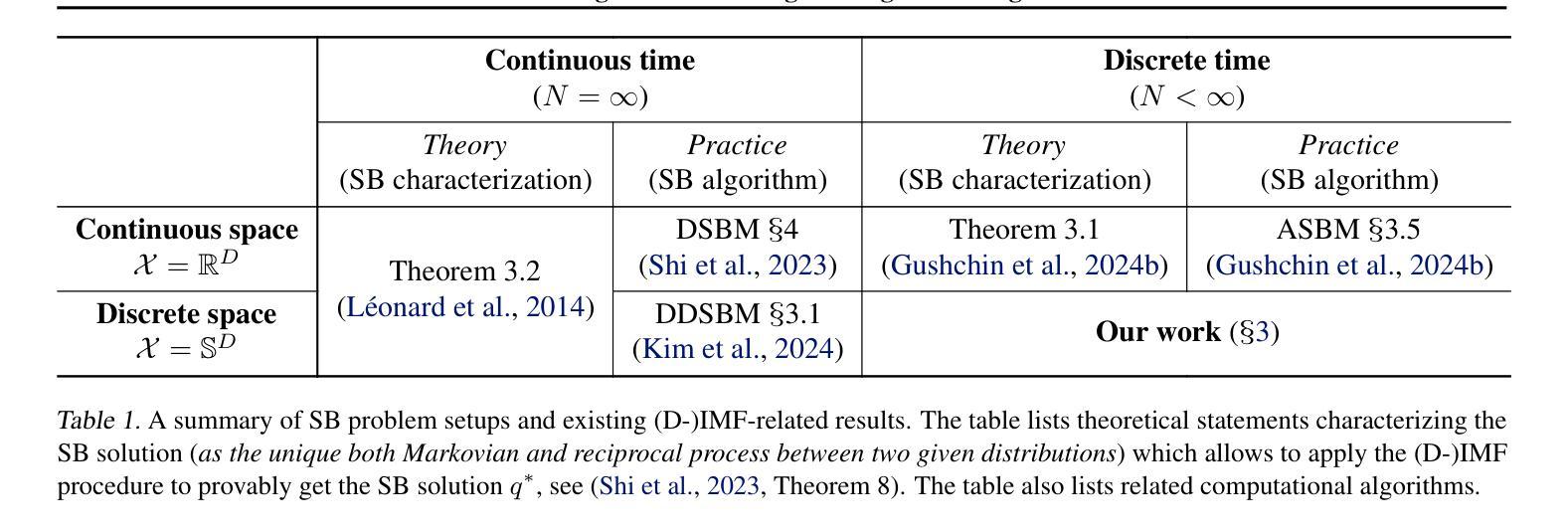
The Schr"odinger Bridge (SB) is a powerful framework for solving generative modeling tasks such as unpaired domain translation. Most SB-related research focuses on continuous data space $\mathbb{R}^{D}$ and leaves open theoretical and algorithmic questions about applying SB methods to discrete data, e.g, on finite spaces $\mathbb{S}^{D}$. Notable examples of such sets $\mathbb{S}$ are codebooks of vector-quantized (VQ) representations of modern autoencoders, tokens in texts, categories of atoms in molecules, etc. In this paper, we provide a theoretical and algorithmic foundation for solving SB in discrete spaces using the recently introduced Iterative Markovian Fitting (IMF) procedure. Specifically, we theoretically justify the convergence of discrete-time IMF (D-IMF) to SB in discrete spaces. This enables us to develop a practical computational algorithm for SB, which we call Categorical Schr"odinger Bridge Matching (CSBM). We show the performance of CSBM via a series of experiments with synthetic data and VQ representations of images. The code of CSBM is available at https://github.com/gregkseno/csbm.
薛定谔桥(SB)是一个强大的框架,用于解决如非配对域翻译等生成建模任务。大多数与SB相关的研究都集中在连续数据空间$\mathbb{R}^{D}$上,而将SB方法应用于离散数据(例如在有限空间$\mathbb{S}^{D}$上)的理论和算法问题留待解决。集合$\mathbb{S}$的显著例子包括现代自动编码器的向量量化(VQ)表示的代码本、文本中的标记、分子中的原子类别等。在本文中,我们利用最近提出的迭代马尔可夫拟合(IMF)程序,为解决离散空间中的SB提供了理论和算法基础。特别是,我们从理论上证明了离散时间IMF(D-IMF)收敛到离散空间中的SB。这使我们能够为SB开发一个实用的计算算法,我们称之为分类薛定谔桥匹配(CSBM)。我们通过合成数据和VQ图像表示的一系列实验展示了CSBM的性能。CSBM的代码可在https://github.com/gregkseno/csbm找到。
论文及项目相关链接
Summary
量子桥(Schrödinger Bridge,SB)是解决生成建模任务(如非配对域翻译)的强大框架。研究主要集中在连续数据空间上,而关于将SB方法应用于离散数据(如有限空间)的理论和算法问题仍然开放。本文利用最近引入的迭代马尔可夫拟合(IMF)程序,为解决离散空间中的SB提供了理论和算法基础。我们证明了离散时间IMF(D-IMF)收敛到SB的理论依据,并据此开发了一种实用的计算算法,称为分类量子桥匹配(CSBM)。通过合成数据和向量量化图像表示的实验,验证了CSBM的性能。
Key Takeaways
- 量子桥(SB)是解决生成建模任务的强大框架,尤其适用于解决非配对域翻译问题。
- 目前的研究主要集中在连续数据空间的SB应用上,而离散数据空间的SB应用仍存在理论和算法空白。
- 本文解决了在离散空间中使用量子桥的难题,利用迭代马尔可夫拟合(IMF)程序提供了理论和算法基础。
- 离散时间IMF(D-IMF)收敛到SB的理论依据被证明。
- 基于此理论,开发了一种实用的计算算法——分类量子桥匹配(CSBM)。
- 通过一系列实验验证了CSBM在合成数据和向量量化图像表示上的性能。
点此查看论文截图

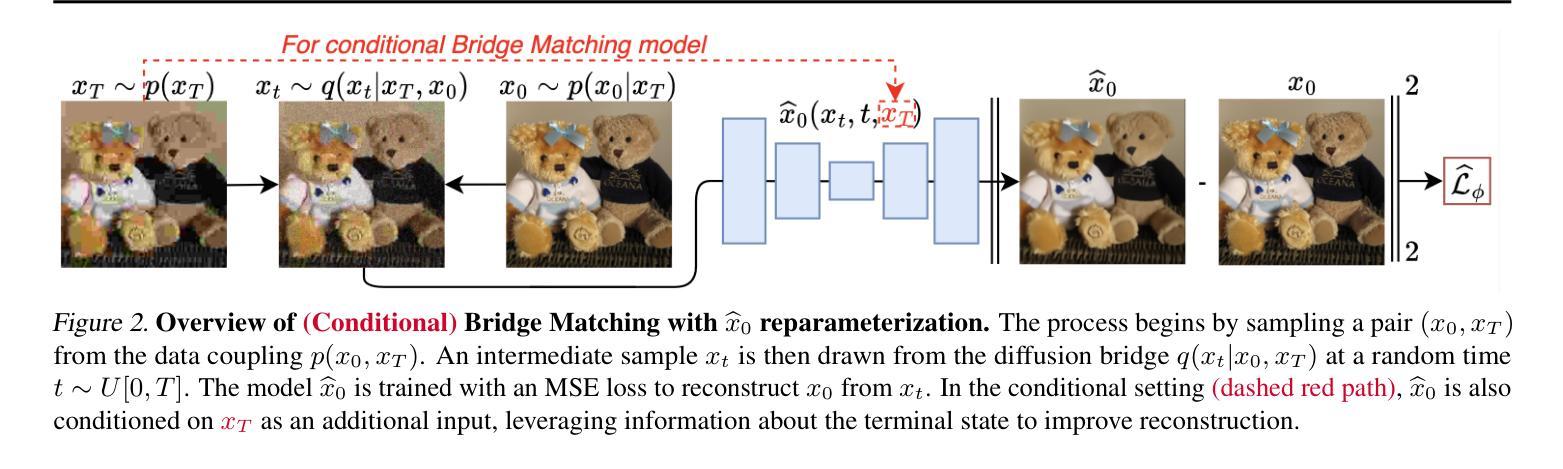
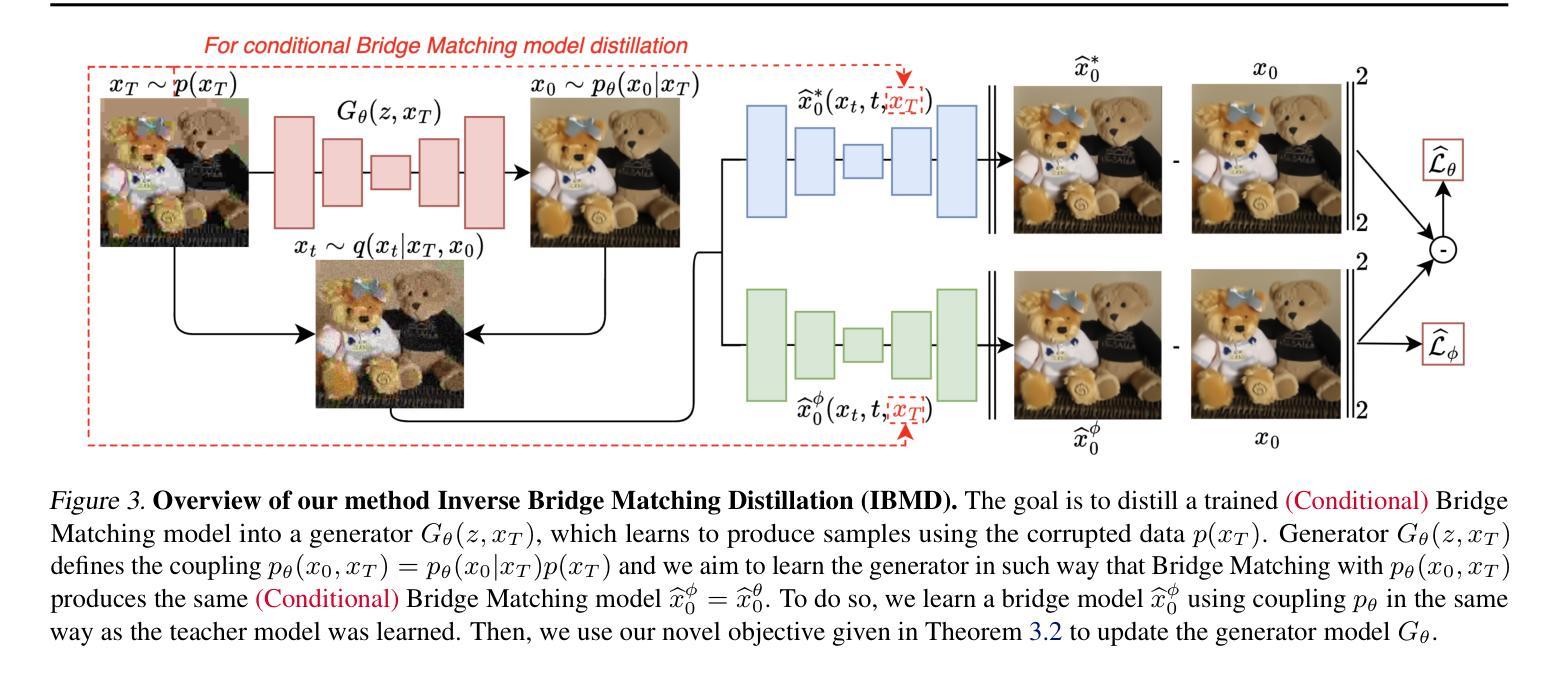
Inverse Bridge Matching Distillation
Authors:Nikita Gushchin, David Li, Daniil Selikhanovych, Evgeny Burnaev, Dmitry Baranchuk, Alexander Korotin
Learning diffusion bridge models is easy; making them fast and practical is an art. Diffusion bridge models (DBMs) are a promising extension of diffusion models for applications in image-to-image translation. However, like many modern diffusion and flow models, DBMs suffer from the problem of slow inference. To address it, we propose a novel distillation technique based on the inverse bridge matching formulation and derive the tractable objective to solve it in practice. Unlike previously developed DBM distillation techniques, the proposed method can distill both conditional and unconditional types of DBMs, distill models in a one-step generator, and use only the corrupted images for training. We evaluate our approach for both conditional and unconditional types of bridge matching on a wide set of setups, including super-resolution, JPEG restoration, sketch-to-image, and other tasks, and show that our distillation technique allows us to accelerate the inference of DBMs from 4x to 100x and even provide better generation quality than used teacher model depending on particular setup. We provide the code at https://github.com/ngushchin/IBMD
学习扩散桥模型很容易;使其快速实用是一种艺术。扩散桥模型(DBM)是扩散模型在图像到图像翻译应用中的一项有前途的扩展。然而,与许多现代扩散和流模型一样,DBM存在推理速度慢的问题。为了解决这一问题,我们提出了一种基于逆桥匹配公式的新型蒸馏技术,并推导出实用的目标来解决实际应用中的问题。与以前开发的DBM蒸馏技术不同,所提出的方法可以蒸馏条件性和非条件性的DBM、在一次生成器中蒸馏模型,并且只使用损坏的图像进行训练。我们在包括超分辨率、JPEG恢复、草图到图像等任务的一系列设置上,对条件性和非条件性的桥匹配进行了评估,结果表明我们的蒸馏技术能够将DBM的推理速度加速4倍至100倍,并且在特定设置下甚至提供了比所用教师模型更好的生成质量。我们在https://github.com/ngushchin/IBMD提供代码。
论文及项目相关链接
Summary
扩散桥模型(DBMs)是图像到图像翻译应用中有前景的扩散模型扩展。但其推理速度慢,为此提出了基于逆桥匹配公式的新型蒸馏技术来解决实践中的这个问题。该方法能蒸馏条件和无条件的DBMs,一步生成器中进行模型蒸馏,且仅使用损坏的图像进行训练。实验证明,该方法能加速DBMs的推理速度4至100倍,并根据特定设置提供比教师模型更好的生成质量。
Key Takeaways
- 扩散桥模型(DBMs)是一种面向图像到图像翻译应用的扩散模型扩展。
- DBMs面临推理速度慢的问题。
- 提出了一种基于逆桥匹配公式的蒸馏技术来解决这一问题。
- 该方法可以蒸馏条件和无条件的DBMs。
- 模型蒸馏可以在一步生成器中进行。
- 该方法仅使用损坏的图像进行训练。
点此查看论文截图