⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
Transfer Learning for Neutrino Scattering: Domain Adaptation with GANs
Authors:Jose L. Bonilla, Krzysztof M. Graczyk, Artur M. Ankowski, Rwik Dharmapal Banerjee, Beata E. Kowal, Hemant Prasad, Jan T. Sobczyk
We utilize transfer learning to extrapolate the physics knowledge encoded in a Generative Adversarial Network (GAN) model trained on synthetic charged-current (CC) neutrino-carbon inclusive scattering data. This base model is adapted to generate CC inclusive scattering events (lepton kinematics only) for neutrino-argon and antineutrino-carbon interactions. Furthermore, we assess the effectiveness of transfer learning in re-optimizing a custom model when new data comes from a different neutrino-nucleus interaction model. Our results demonstrate that transfer learning significantly outperforms training generative models from scratch. To study this, we consider two training data sets: one with 10,000 and another with 100,000 events. The models obtained via transfer learning perform well even with smaller training data. The proposed method provides a promising approach for constructing neutrino scattering event generators in scenarios where experimental data is sparse.
我们利用迁移学习来推断编码在生成对抗网络(GAN)模型中的物理知识,该模型经过合成带电电流(CC)中微子-碳包容散射数据的训练。这个基础模型被适应于为中微子-氩和中微子反粒子-碳的交互生成CC包容散射事件(仅涉及轻子运动学)。此外,我们评估了迁移学习在从新出现的不同中微子-核相互作用模型中获取新数据时重新优化自定义模型的有效性。我们的结果表明,迁移学习显著优于从头开始训练生成模型。为了研究这一点,我们考虑了两个训练数据集:一个包含10,000个事件,另一个包含100,000个事件。通过迁移学习获得的模型即使在较小的训练数据下也能表现良好。所提出的方法为在实验数据稀疏的情况下构建中微子散射事件生成器提供了一种有前途的方法。
论文及项目相关链接
PDF 17 pages, 17 figures
Summary
利用迁移学习技术,将经过合成带电粒子中微子与碳散射数据训练的生成对抗网络(GAN)模型中的物理知识知识迁移,并适应于生成中微子与氩及反中微子与碳的相互作用下的带电粒子散射事件。评估了迁移学习在新数据来自不同中微子核相互作用模型时的定制模型再优化效果。结果表明,迁移学习方法明显优于从头开始训练生成模型。通过使用包含10,000和100,000事件的两种训练数据集进行研究,证明了通过迁移学习得到的模型在训练数据量较小的情况下仍然表现良好。此方法为在中微子散射事件生成器构建中实验数据稀缺的场景提供了有效途径。
Key Takeaways
- 迁移学习技术被用来转移合成带电粒子中微子与碳散射数据中的GAN模型中的物理知识。
- 模型被适应于生成中微子与氩及反中微子与碳相互作用下的散射事件。
- 迁移学习在定制模型再优化方面表现出显著效果,尤其是在新数据来源于不同的中微子核相互作用模型时。
- 通过对比包含不同数量事件的训练数据集(分别为1万与十万),证明了迁移学习的优势。
- 即使训练数据量较小,通过迁移学习得到的模型也能表现良好。
- 该方法为中微子散射事件生成器的构建提供了一种有前途的解决方案,尤其在实验数据稀缺的场景中。
点此查看论文截图

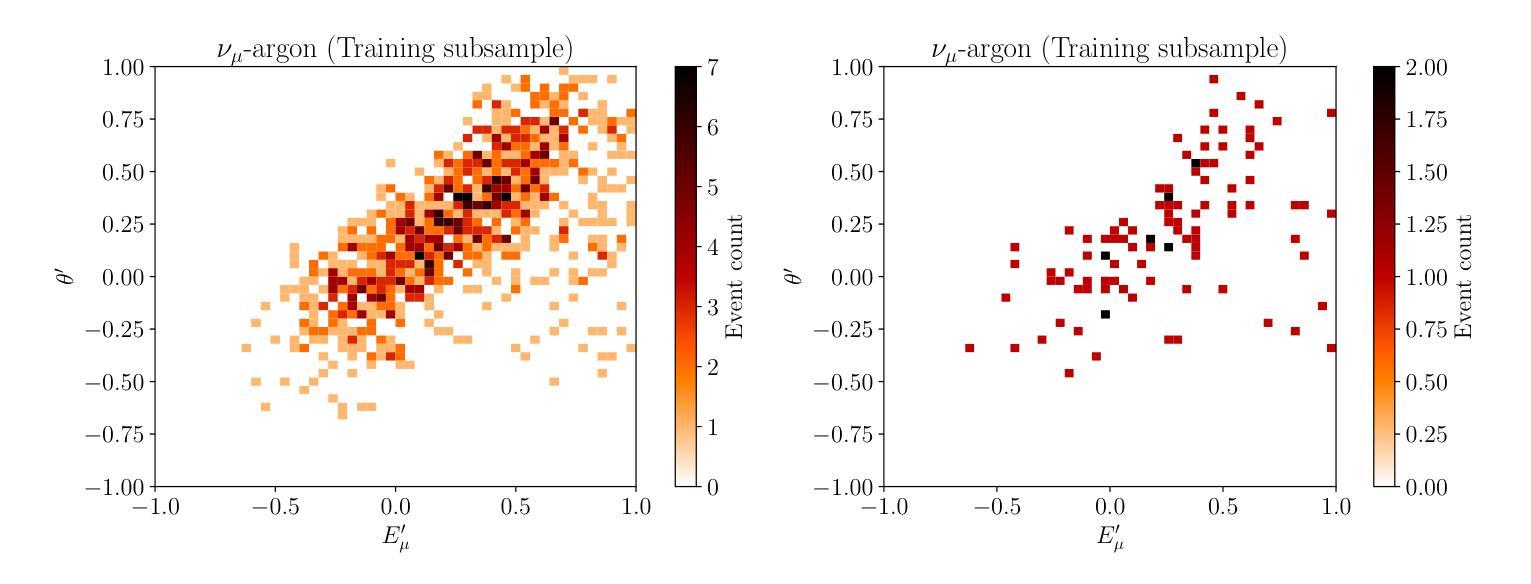
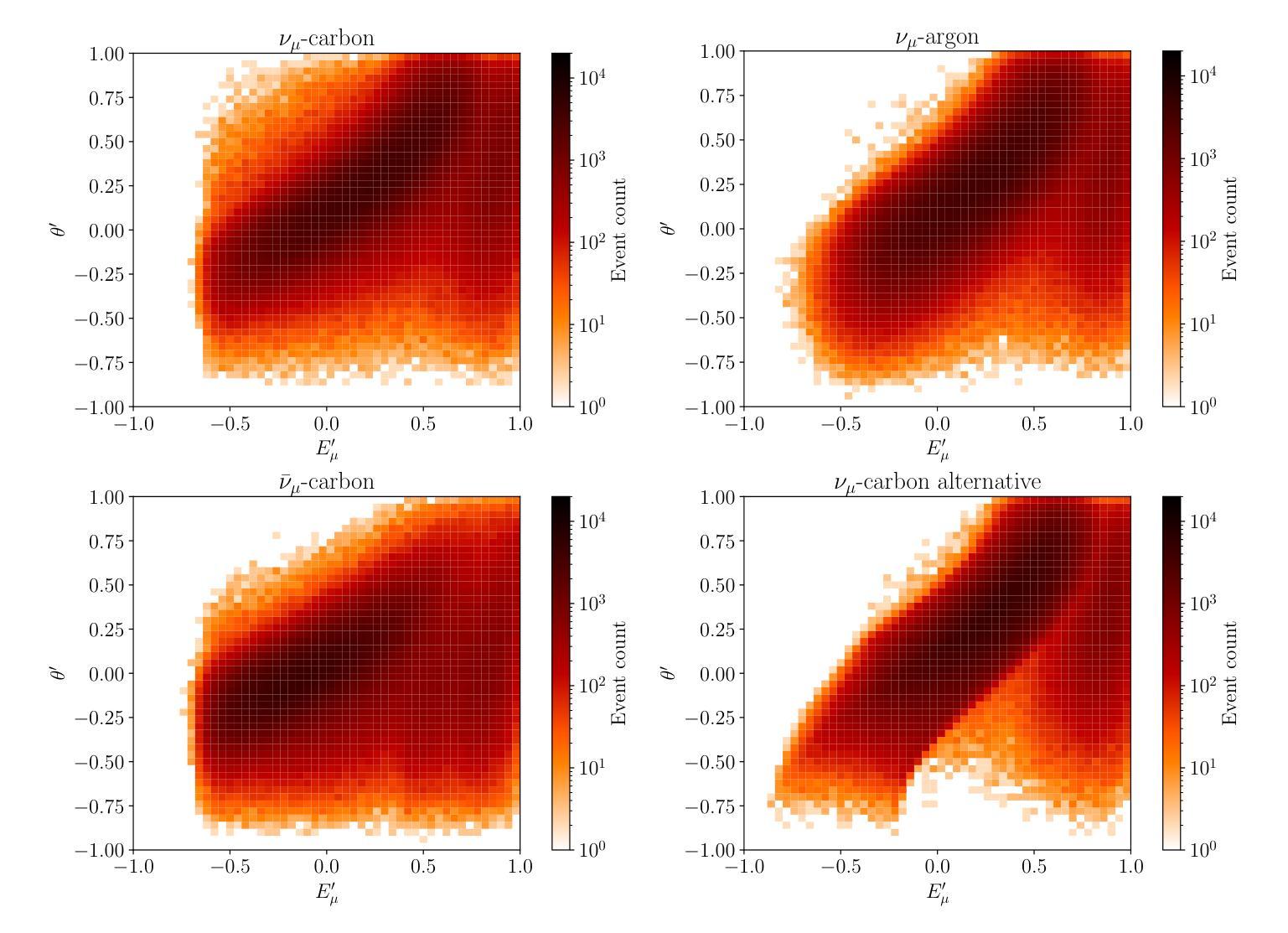
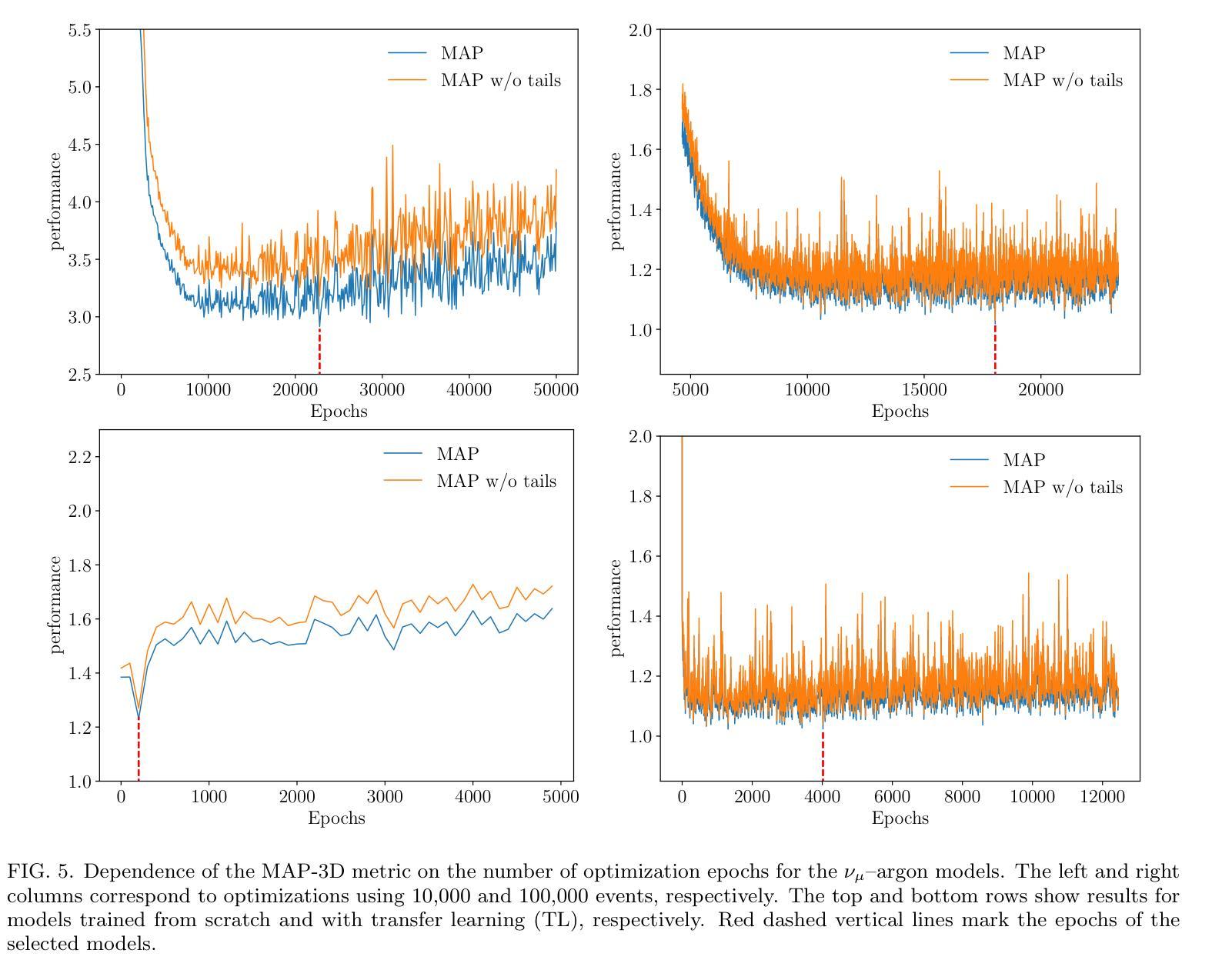
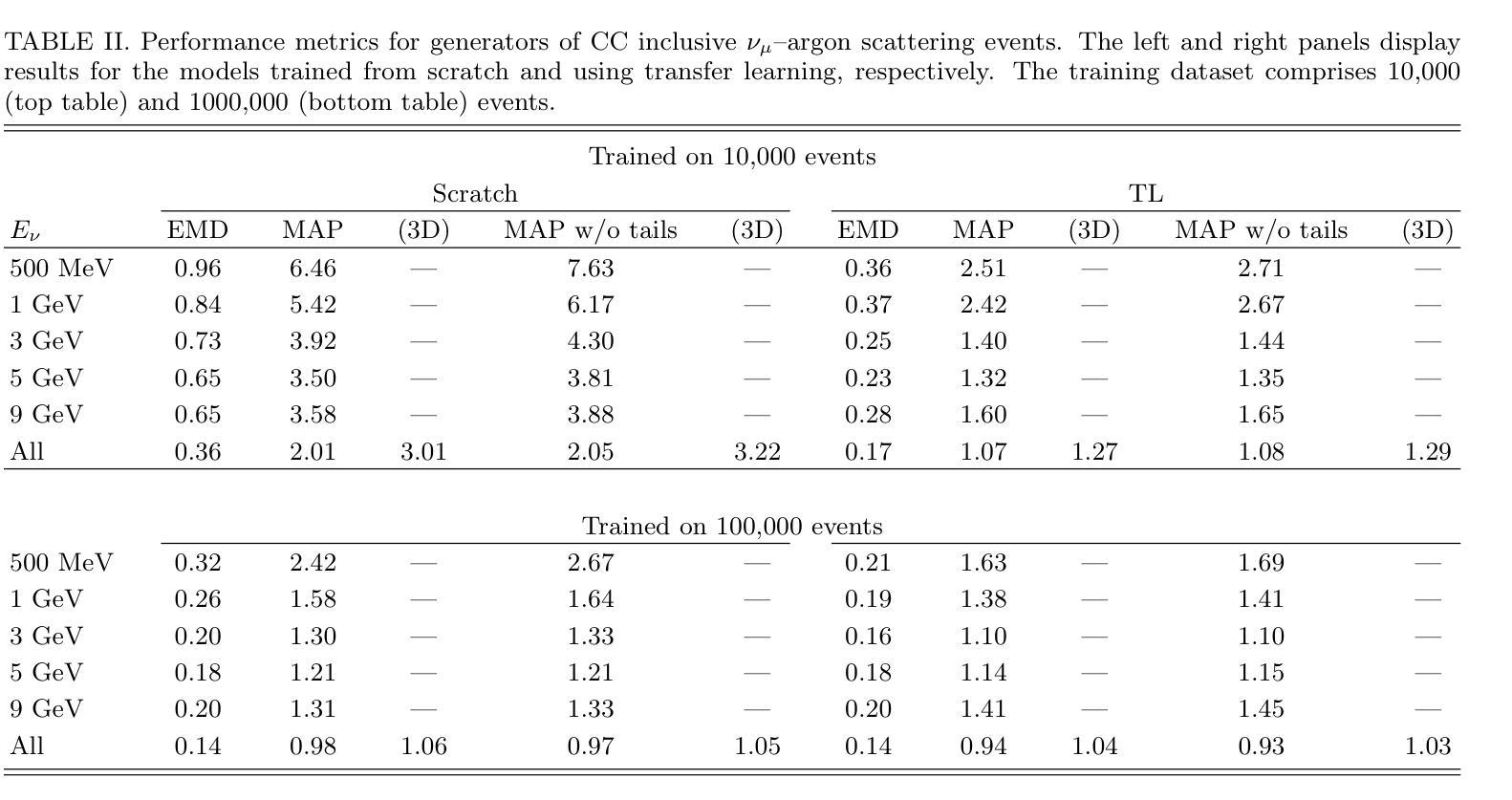
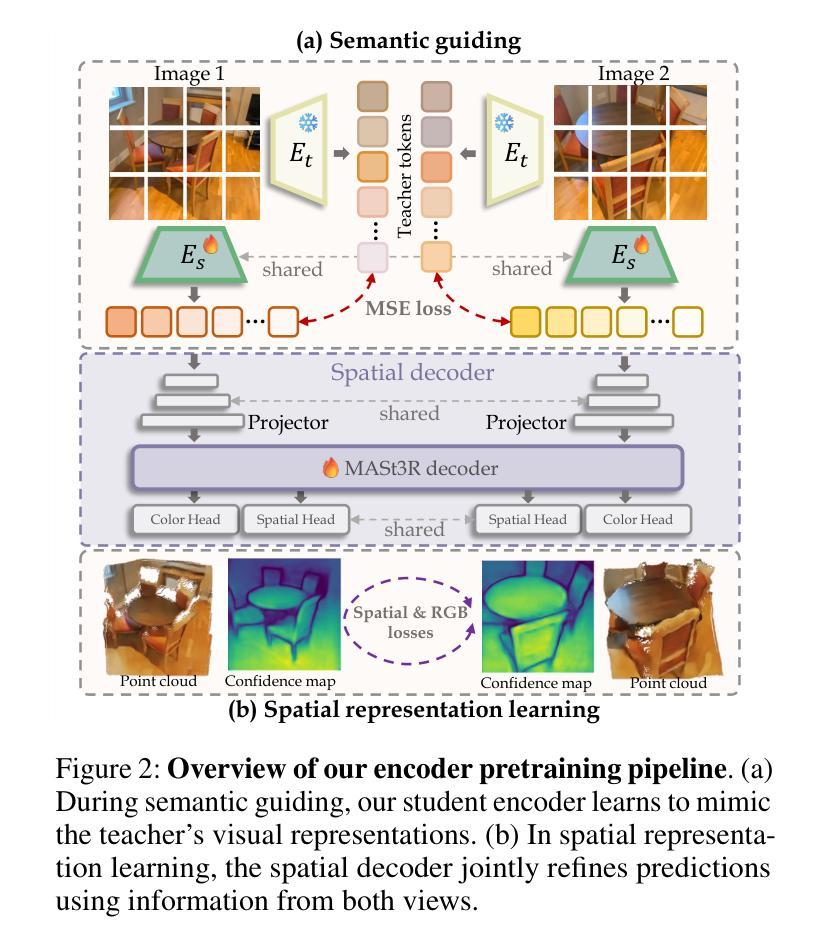
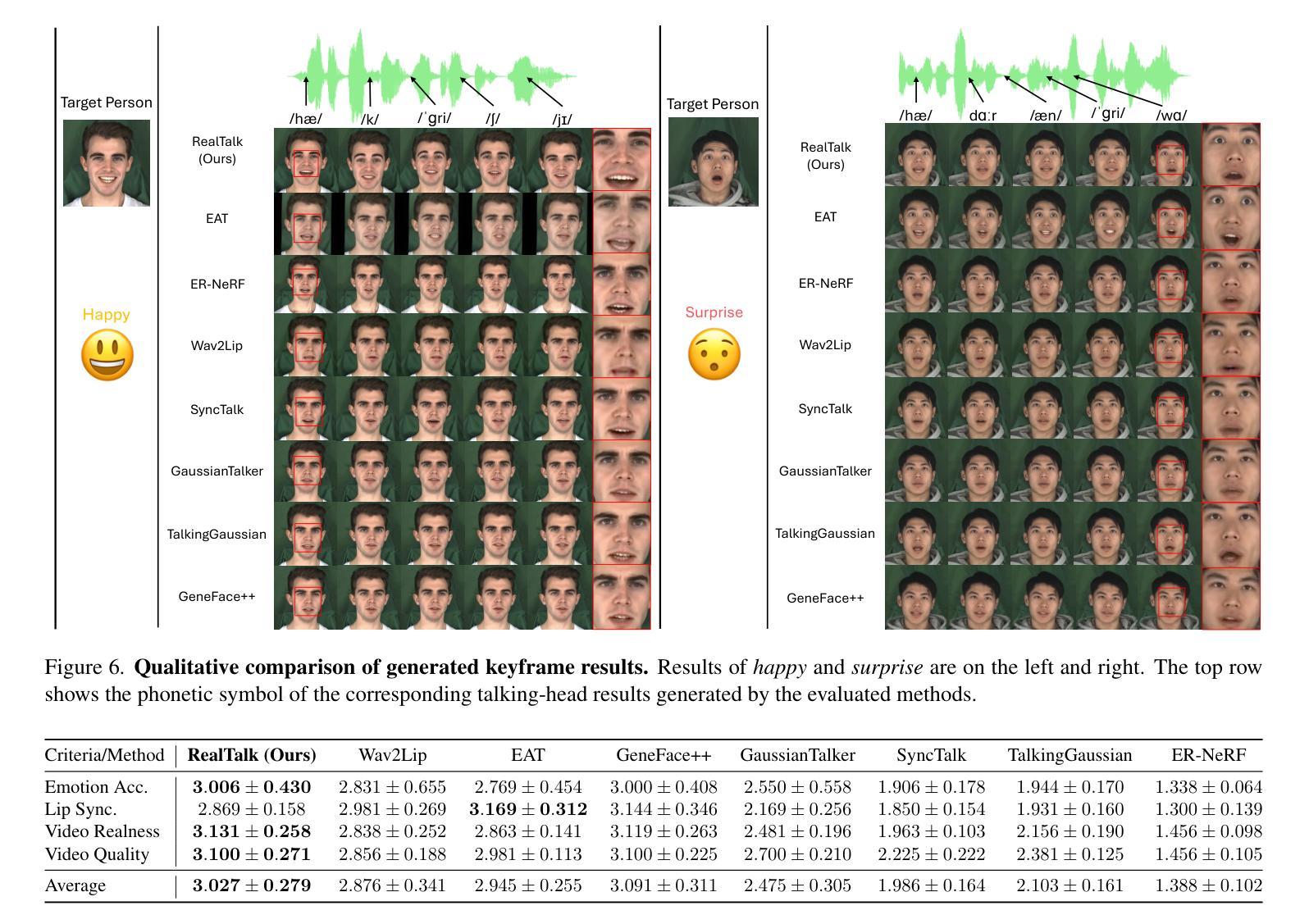
RealTalk: Realistic Emotion-Aware Lifelike Talking-Head Synthesis
Authors:Wenqing Wang, Yun Fu
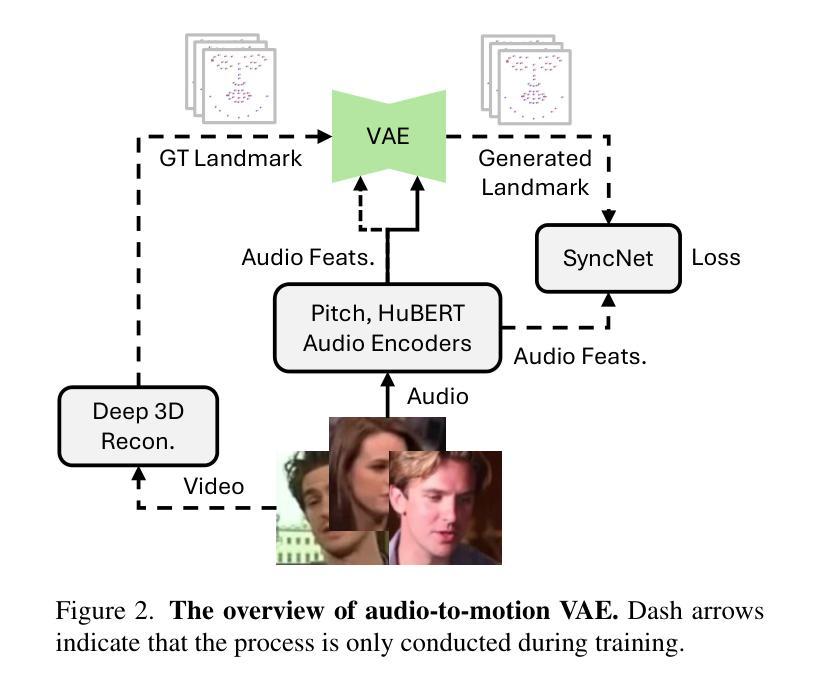
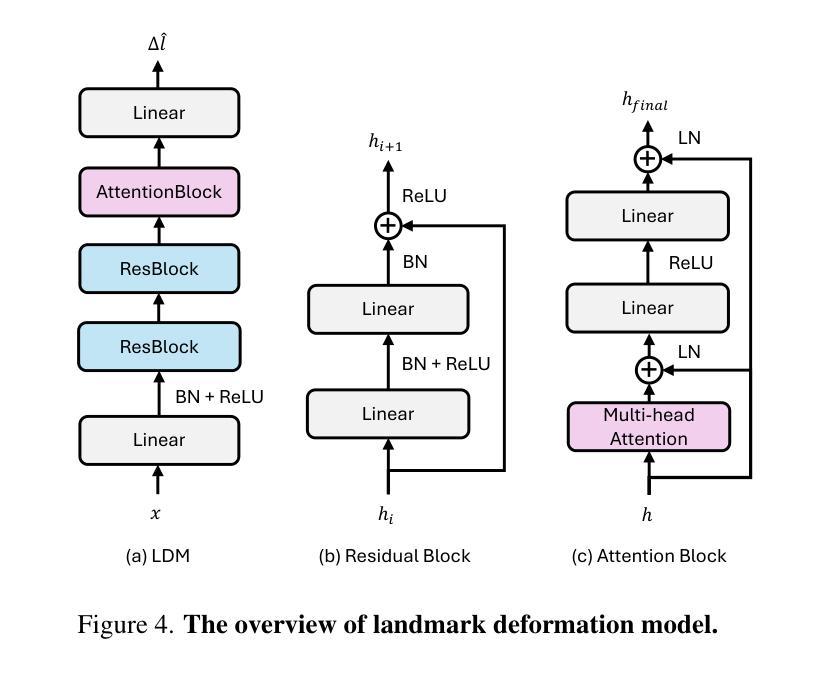
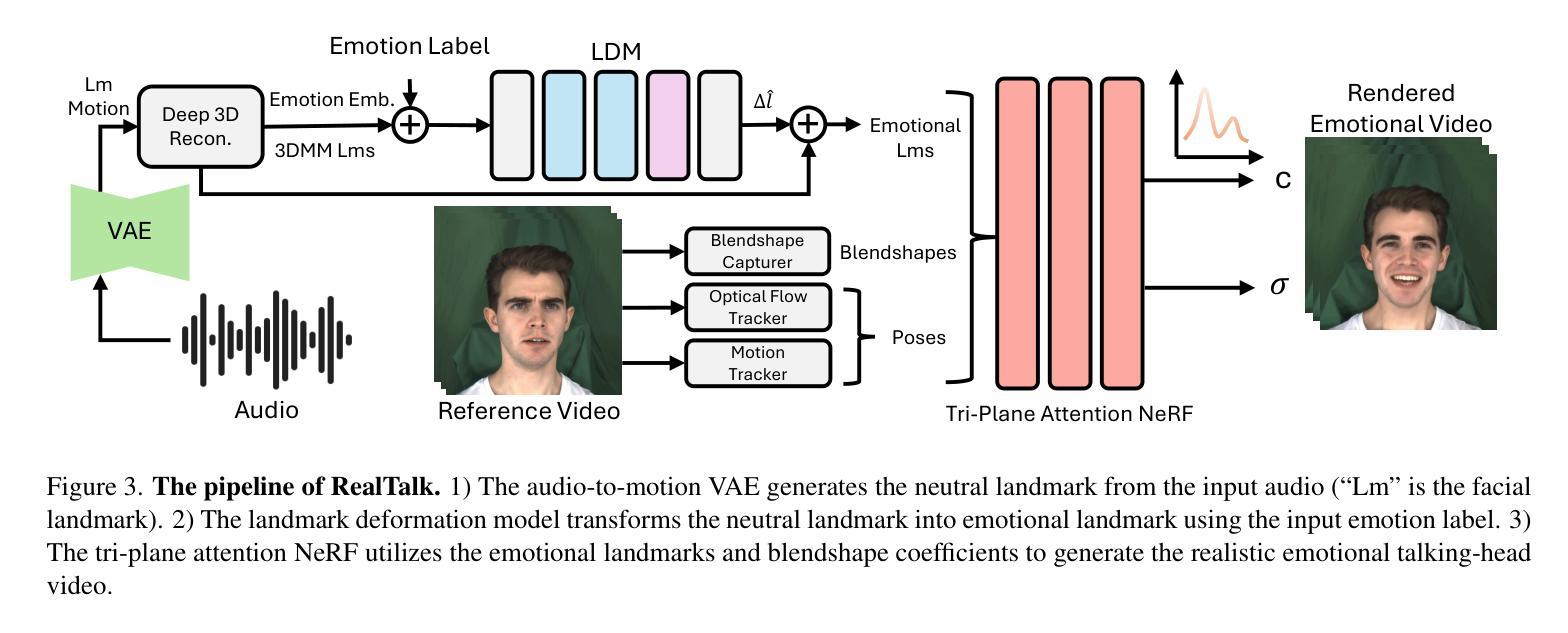
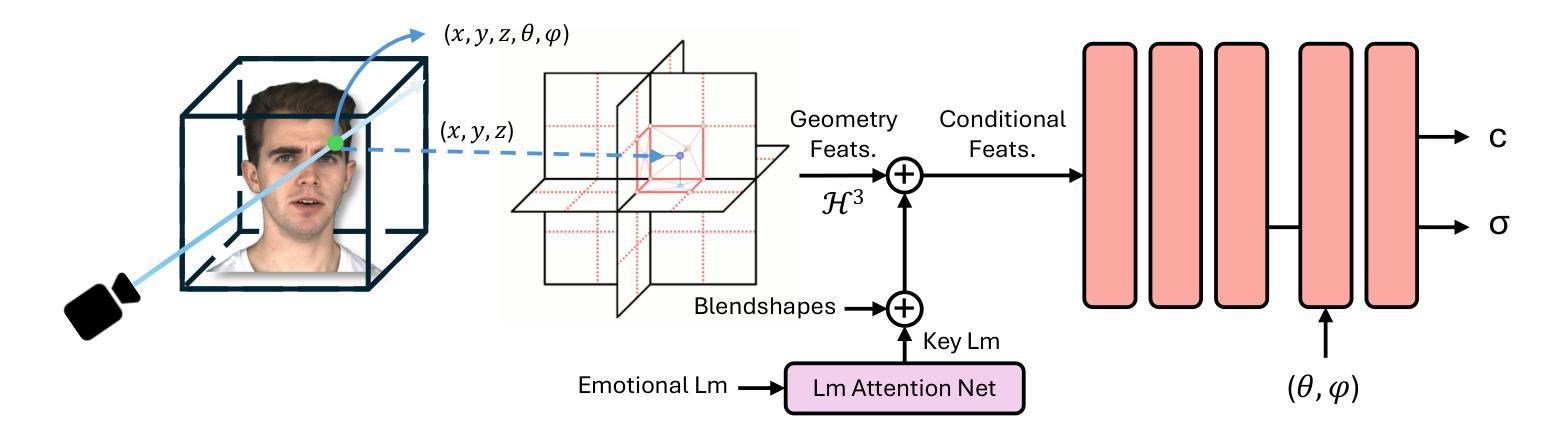
Emotion is a critical component of artificial social intelligence. However, while current methods excel in lip synchronization and image quality, they often fail to generate accurate and controllable emotional expressions while preserving the subject’s identity. To address this challenge, we introduce RealTalk, a novel framework for synthesizing emotional talking heads with high emotion accuracy, enhanced emotion controllability, and robust identity preservation. RealTalk employs a variational autoencoder (VAE) to generate 3D facial landmarks from driving audio, which are concatenated with emotion-label embeddings using a ResNet-based landmark deformation model (LDM) to produce emotional landmarks. These landmarks and facial blendshape coefficients jointly condition a novel tri-plane attention Neural Radiance Field (NeRF) to synthesize highly realistic emotional talking heads. Extensive experiments demonstrate that RealTalk outperforms existing methods in emotion accuracy, controllability, and identity preservation, advancing the development of socially intelligent AI systems.
情感是人工智能社会智能的关键组成部分。然而,虽然当前的方法在唇同步和图像质量方面表现出色,但它们往往难以在保持主体身份的同时生成准确且可控的情感表达。为了应对这一挑战,我们引入了RealTalk,这是一个合成情感说话人的新型框架,具有高度的情感准确性、增强的情感可控性和稳健的身份保留性。RealTalk使用变分自编码器(VAE)从驱动音频生成3D面部地标,这些地标与基于ResNet的地标变形模型(LDM)结合生成的情感标签嵌入相结合,以产生情感地标。这些地标和面部混合形状系数共同调节新型的三平面注意力神经辐射场(NeRF),以合成高度逼真的情感说话人。大量实验表明,RealTalk在情感准确性、可控性和身份保留方面优于现有方法,推动了社会智能AI系统的发展。
论文及项目相关链接
PDF Accepted to the ICCV 2025 Workshop on Artificial Social Intelligence
Summary
神经网络辐射场(NeRF)合成技术新进展,针对情感计算中的挑战提出RealTalk框架,利用变分自编码器生成三维面部地标并结合情感标签嵌入模型产生情绪化地标,以合成高度逼真的情感化虚拟头部动画,实现高情感准确度、可控性和身份保留。
Key Takeaways
- 情绪在人工智能社交智能中的重要性。
- 当前方法面临的挑战在于生成准确可控的情感表达同时保留身份特征。
- RealTalk框架采用变分自编码器(VAE)从驱动音频生成三维面部地标。
- 结合情感标签嵌入与ResNet-based LDM产生情绪化地标。
- 使用新型的三平面注意力NeRF合成高度逼真的情感化虚拟头部动画。
- RealTalk在情感准确度、可控性和身份保留方面超越现有方法。
点此查看论文截图

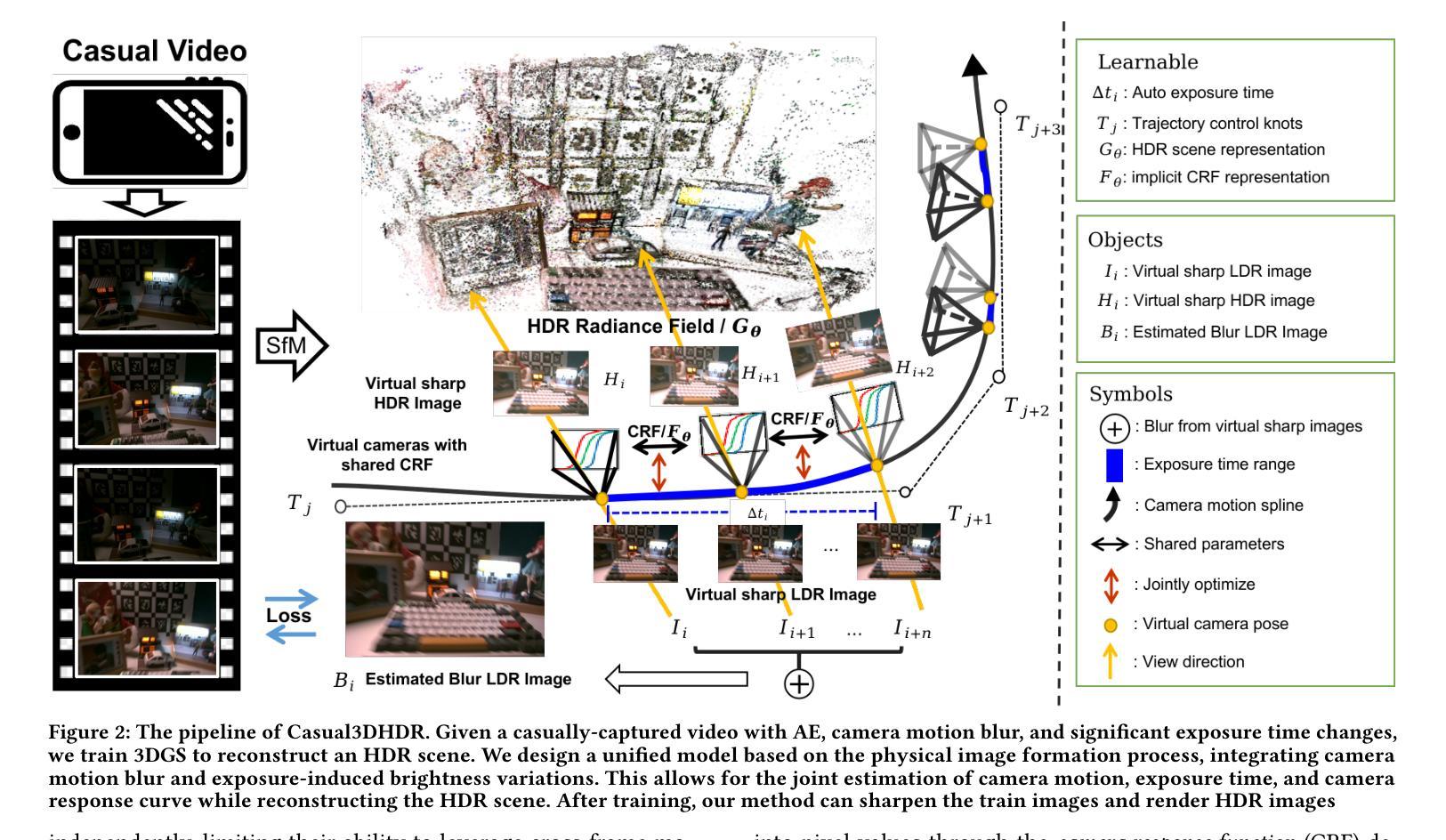
Casual3DHDR: Deblurring High Dynamic Range 3D Gaussian Splatting from Casually Captured Videos
Authors:Shucheng Gong, Lingzhe Zhao, Wenpu Li, Hong Xie, Yin Zhang, Shiyu Zhao, Peidong Liu
Photo-realistic novel view synthesis from multi-view images, such as neural radiance field (NeRF) and 3D Gaussian Splatting (3DGS), has gained significant attention for its superior performance. However, most existing methods rely on low dynamic range (LDR) images, limiting their ability to capture detailed scenes in high-contrast environments. While some prior works address high dynamic range (HDR) scene reconstruction, they typically require multi-view sharp images with varying exposure times captured at fixed camera positions, which is time-consuming and impractical. To make data acquisition more flexible, we propose \textbf{Casual3DHDR}, a robust one-stage method that reconstructs 3D HDR scenes from casually-captured auto-exposure (AE) videos, even under severe motion blur and unknown, varying exposure times. Our approach integrates a continuous-time camera trajectory into a unified physical imaging model, jointly optimizing exposure times, camera trajectory, and the camera response function (CRF). Extensive experiments on synthetic and real-world datasets demonstrate that \textbf{Casual3DHDR} outperforms existing methods in robustness and rendering quality. Our source code and dataset will be available at https://lingzhezhao.github.io/CasualHDRSplat/
从多视角图像进行逼真的新型视图合成,例如神经辐射场(NeRF)和3D高斯溅出(3DGS),因其卓越性能而受到广泛关注。然而,大多数现有方法依赖于低动态范围(LDR)图像,这限制了它们在高对比度环境中捕捉详细场景的能力。虽然一些早期的工作解决了高动态范围(HDR)场景重建的问题,但它们通常需要固定相机位置拍摄的多视角清晰图像,并具备不同的曝光时间,这在时间和实践上是不切实际的。为了使得数据采集更加灵活,我们提出了名为Casual3DHDR的稳健单阶段方法,该方法可以从偶然捕获的自动曝光(AE)视频中重建HDR 3D场景,即使在严重的运动模糊和未知变化的曝光时间下也可实现。我们的方法将连续时间的相机轨迹集成到一个统一的物理成像模型中,并联合优化曝光时间、相机轨迹和相机响应函数(CRF)。在合成和真实世界数据集上的大量实验表明,Casual3DHDR在稳健性和渲染质量方面优于现有方法。我们的源代码和数据集将在https://lingzhezhao.github.io/CasualHDRSplat/找到。
论文及项目相关链接
PDF Accepted to ACM Multimedia 2025. Project page: https://lingzhezhao.github.io/CasualHDRSplat/
Summary
神经辐射场(NeRF)和三维高斯溅射(3DGS)等从多视角图像合成真实感新视角的方法因其卓越性能而受到关注,但它们大多依赖于低动态范围(LDR)图像,难以在高对比度环境中捕捉详细场景。为解决这一问题,本文提出一种名为Casual3DHDR的稳健方法,可从随意拍摄的自动曝光(AE)视频中重建三维高动态范围(HDR)场景,即使面对严重的运动模糊和未知的、不同的曝光时间也是如此。它通过整合连续时间的相机轨迹到一个统一的物理成像模型,联合优化曝光时间、相机轨迹和相机响应函数(CRF)。在合成和真实世界数据集上的广泛实验表明,Casual3DHDR在鲁棒性和渲染质量上优于现有方法。
Key Takeaways
- 神经辐射场和三维高斯溅射方法虽然性能卓越,但在高对比度环境下捕捉详细场景的能力受限。
- 目前存在的方法大多依赖于低动态范围图像。
- 本文提出的Casual3DHDR方法能从随意拍摄的自动曝光视频中重建三维高动态范围场景。
- Casual3DHDR通过整合连续时间的相机轨迹到物理成像模型,适应不同的曝光时间并处理运动模糊。
- 该方法联合优化曝光时间、相机轨迹和相机响应函数,提高重建场景的鲁棒性和质量。
- 在合成和真实世界数据集上的实验表明,Casual3DHDR在性能和效果上超越现有方法。
点此查看论文截图