⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
MuDRiC: Multi-Dialect Reasoning for Arabic Commonsense Validation
Authors:Kareem Elozeiri, Mervat Abassy, Preslav Nakov, Yuxia Wang
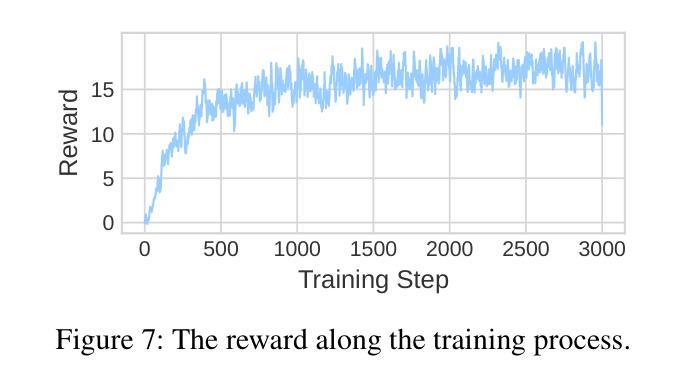
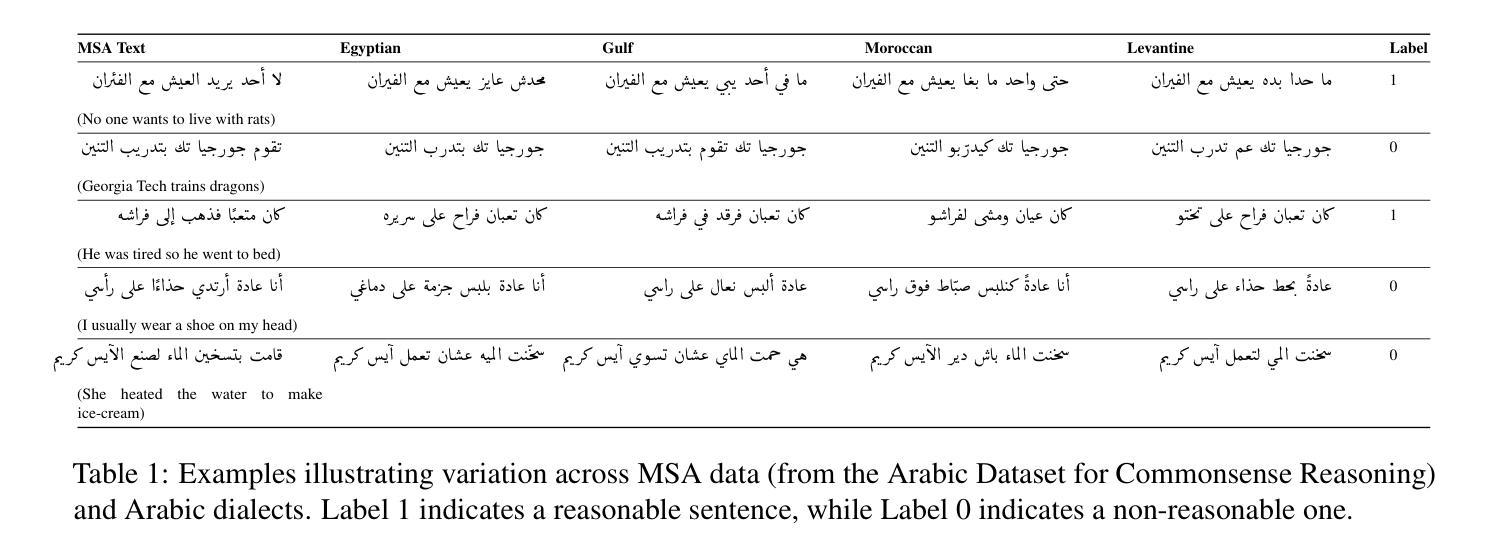
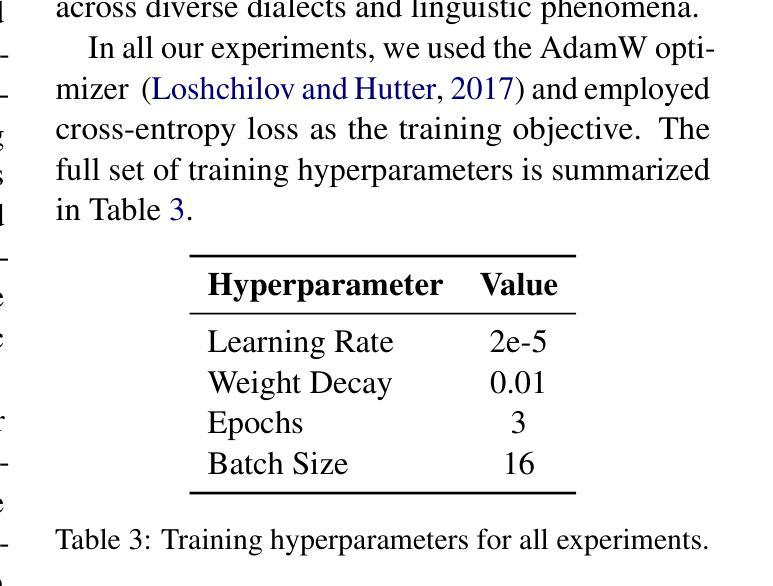
Commonsense validation evaluates whether a sentence aligns with everyday human understanding, a critical capability for developing robust natural language understanding systems. While substantial progress has been made in English, the task remains underexplored in Arabic, particularly given its rich linguistic diversity. Existing Arabic resources have primarily focused on Modern Standard Arabic (MSA), leaving regional dialects underrepresented despite their prevalence in spoken contexts. To bridge this gap, we present two key contributions: (i) we introduce MuDRiC, an extended Arabic commonsense dataset incorporating multiple dialects, and (ii) a novel method adapting Graph Convolutional Networks (GCNs) to Arabic commonsense reasoning, which enhances semantic relationship modeling for improved commonsense validation. Our experimental results demonstrate that this approach achieves superior performance in Arabic commonsense validation. Our work enhances Arabic natural language understanding by providing both a foundational dataset and a novel method for handling its complex variations. To the best of our knowledge, we release the first Arabic multi-dialect commonsense reasoning dataset.
常识验证旨在评估句子是否符合日常人类理解,这是开发稳健的自然语言理解系统的关键能力。虽然英语方面已经取得了重大进展,但阿拉伯语的任务仍然被忽视,尤其是考虑到其丰富的语言多样性。现有的阿拉伯资源主要集中在现代标准阿拉伯语(MSA),尽管其在口语语境中普遍存在,但方言的使用却鲜有涉及。为了弥补这一差距,我们提出了两个关键贡献:(i)我们推出了MuDRiC,一个融入多种方言的扩展阿拉伯语常识数据集;(ii)我们提出了一种适应阿拉伯常识推理的图卷积网络(GCN)新方法,该方法增强了语义关系建模,提高了常识验证的效果。我们的实验结果表明,该方法在阿拉伯常识验证方面取得了卓越的性能。我们的工作通过提供基础数据集和应对其复杂变化的新方法,增强了阿拉伯自然语言的理解能力。据我们所知,我们发布了第一个阿拉伯多方言常识推理数据集。
论文及项目相关链接
Summary:
本文介绍了阿拉伯语的常识验证研究。该研究针对阿拉伯语的多语种特性,提出两个重要贡献:一是推出了包含多种方言的MuDRiC阿拉伯语常识数据集;二是创新地采用图卷积网络(GCNs)进行阿拉伯语常识推理,提升了语义关系的建模能力,实现阿拉伯语的常识验证的优越性能。该研究增强了阿拉伯语的自然语言理解,填补了阿拉伯多种方言处理领域的空白。
Key Takeaways:
- 常识验证是评估句子是否符合日常人类理解的重要能力,对于开发稳健的自然语言理解系统至关重要。
- 英语领域的常识验证已经取得显著进展,但在阿拉伯语中仍然有待探索。
- 现有阿拉伯语资源主要集中在现代标准阿拉伯语(MSA),忽视了地区方言的丰富性。
- 为了解决这一差距,推出了包含多种方言的MuDRiC阿拉伯语常识数据集。
- 创新地使用图卷积网络(GCNs)进行阿拉伯语常识推理,提升语义关系建模能力。
- 这种新方法在阿拉伯语常识验证中取得了优越的性能。
点此查看论文截图

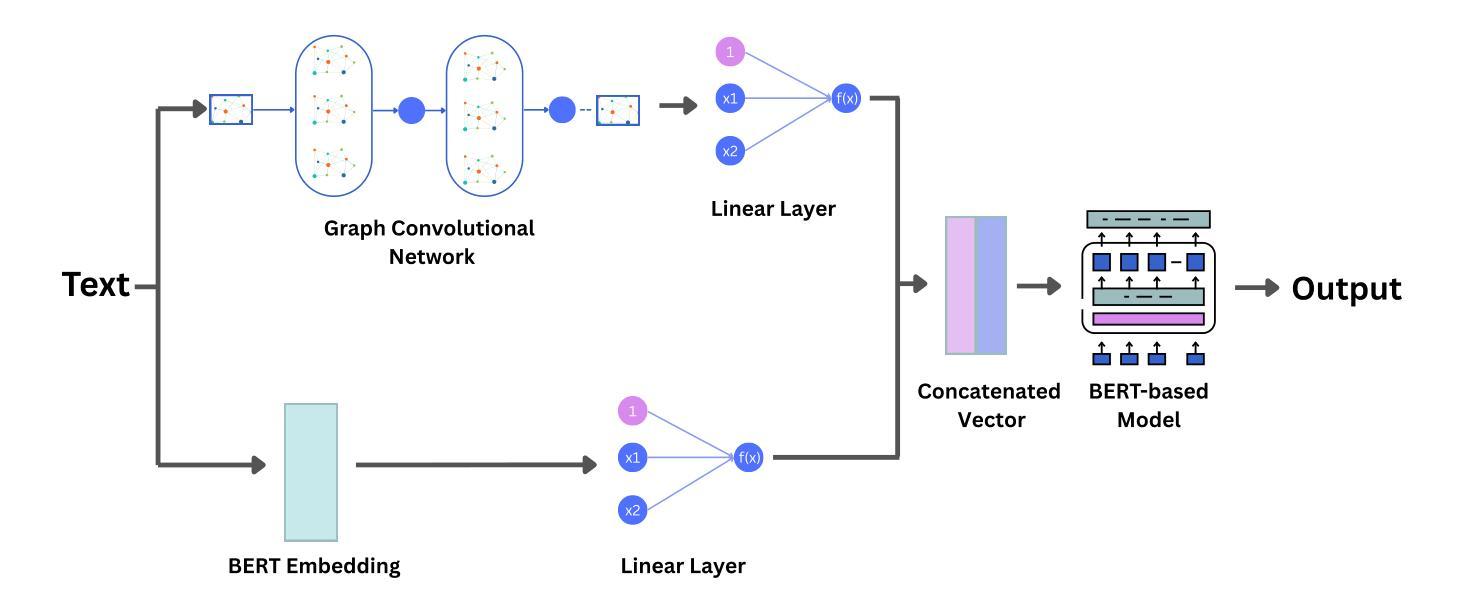

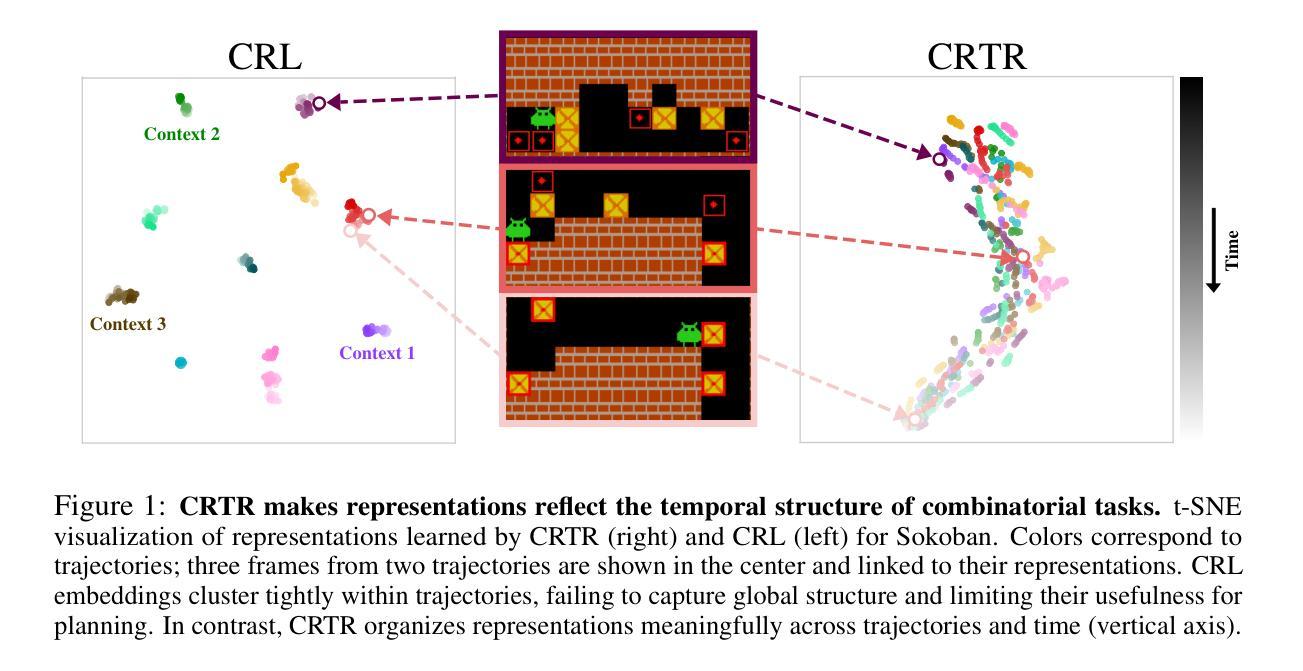
Contrastive Representations for Temporal Reasoning
Authors:Alicja Ziarko, Michal Bortkiewicz, Michal Zawalski, Benjamin Eysenbach, Piotr Milos
In classical AI, perception relies on learning state-based representations, while planning, which can be thought of as temporal reasoning over action sequences, is typically achieved through search. We study whether such reasoning can instead emerge from representations that capture both perceptual and temporal structure. We show that standard temporal contrastive learning, despite its popularity, often fails to capture temporal structure due to its reliance on spurious features. To address this, we introduce Combinatorial Representations for Temporal Reasoning (CRTR), a method that uses a negative sampling scheme to provably remove these spurious features and facilitate temporal reasoning. CRTR achieves strong results on domains with complex temporal structure, such as Sokoban and Rubik’s Cube. In particular, for the Rubik’s Cube, CRTR learns representations that generalize across all initial states and allow it to solve the puzzle using fewer search steps than BestFS, though with longer solutions. To our knowledge, this is the first method that efficiently solves arbitrary Cube states using only learned representations, without relying on an external search algorithm.
在经典人工智能中,感知依赖于基于状态的学习表示,而规划可以被视为对动作序列的时间推理,通常通过搜索来实现。我们研究是否这种推理可以来源于同时捕捉感知和时间结构的表示。我们表明,尽管标准的时间对比学习很受欢迎,但由于它依赖于虚假特征,通常无法捕捉时间结构。为了解决这一问题,我们引入了用于时间推理的组合表示(CRTR)方法,该方法采用负采样方案来证实消除这些虚假特征并促进时间推理。CRTR在具有复杂时间结构的领域(如 Sokoban 和魔方)取得了很好的结果。特别是,对于魔方问题,CRTR学习的表示可以概括所有初始状态,并允许它使用比BestFS更少的搜索步骤来解决谜题,尽管解决方案更长。据我们所知,这是第一种仅使用学习到的表示来有效地解决任意魔方状态的方法,无需依赖外部搜索算法。
论文及项目相关链接
PDF Project website: https://princeton-rl.github.io/CRTR/
Summary
经典人工智能中,感知依赖于基于状态表示的学习,而规划通常通过搜索实现,被视为动作序列的时间推理。本研究探索是否可从同时捕捉感知和时间结构的表示中涌现出这种推理。标准时间对比学习虽受欢迎,但由于依赖偶然特征,往往无法捕捉时间结构。为解决这一问题,我们提出组合表示法用于时间推理(CRTR),通过负采样方案移除这些偶然特征,促进时间推理。CRTR在具有复杂时间结构的领域(如索贝克和魔方)取得了显著成果。特别是,对于魔方问题,CRTR学习的表示方法能够泛化所有初始状态,减少搜索步骤,虽解决方案较长,但仍优于BestFS。据我们所知,这是首次仅通过学到的表示,不依赖外部搜索算法,就能高效解决任意的魔方状态的方法。
Key Takeaways
- 经典人工智能中感知和规划是分离的,本研究探索了通过统一表示法实现感知和时间推理的整合。
- 标准时间对比学习存在缺陷,无法有效捕捉时间结构,本研究提出的CRTR方法能够克服这一缺陷。
- CRTR利用负采样方案移除偶然特征,促进时间推理。
- CRTR在解决具有复杂时间结构的任务(如索贝克和魔方)时表现出强大的性能。
- 对于魔方问题,CRTR学习的表示方法能够泛化所有初始状态,减少搜索步骤。
- CRTR是首个仅通过学到的表示解决任意的魔方状态的方法,不依赖外部搜索算法。
- 该研究为整合感知和时间推理提供了新的思路和方法。
点此查看论文截图

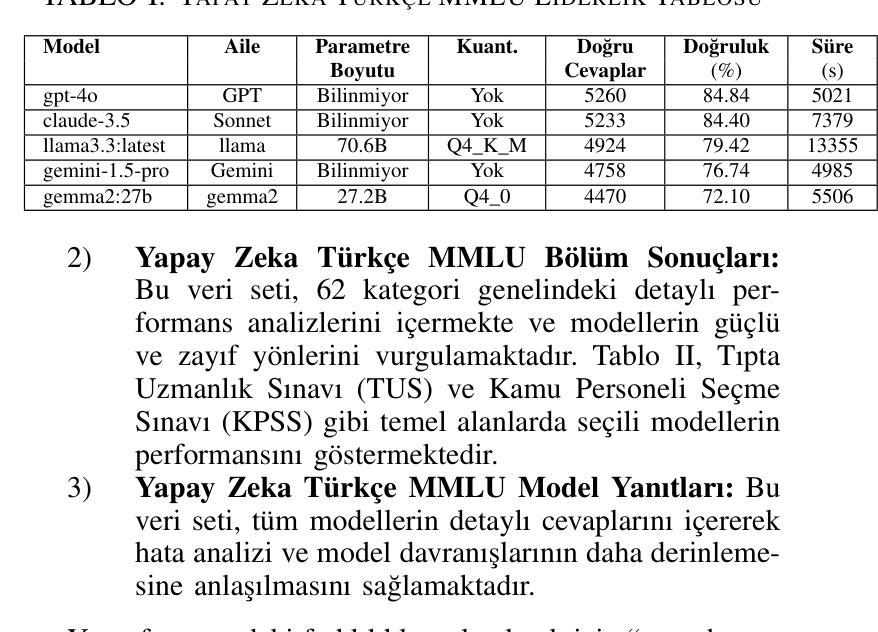
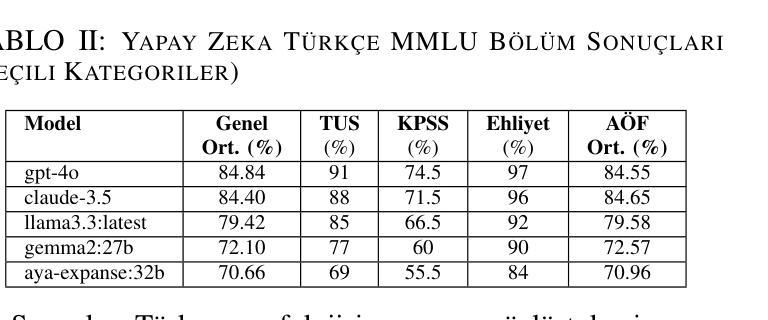
Büyük Dil Modelleri için TR-MMLU Benchmarkı: Performans Değerlendirmesi, Zorluklar ve İyileştirme Fırsatları
Authors:M. Ali Bayram, Ali Arda Fincan, Ahmet Semih Gümüş, Banu Diri, Savaş Yıldırım, Öner Aytaş
Language models have made significant advancements in understanding and generating human language, achieving remarkable success in various applications. However, evaluating these models remains a challenge, particularly for resource-limited languages like Turkish. To address this issue, we introduce the Turkish MMLU (TR-MMLU) benchmark, a comprehensive evaluation framework designed to assess the linguistic and conceptual capabilities of large language models (LLMs) in Turkish. TR-MMLU is based on a meticulously curated dataset comprising 6,200 multiple-choice questions across 62 sections within the Turkish education system. This benchmark provides a standard framework for Turkish NLP research, enabling detailed analyses of LLMs’ capabilities in processing Turkish text. In this study, we evaluated state-of-the-art LLMs on TR-MMLU, highlighting areas for improvement in model design. TR-MMLU sets a new standard for advancing Turkish NLP research and inspiring future innovations.
语言模型在理解和生成人类语言方面取得了显著进展,在各种应用中取得了非凡的成功。然而,评估这些模型仍然是一个挑战,特别是对于像土耳其语这样的资源受限语言。为了解决这一问题,我们推出了土耳其MMLU(TR-MMLU)基准测试,这是一个全面的评估框架,旨在评估大型语言模型(LLM)在土耳其语中的语言和概念能力。TR-MMLU基于精心筛选的数据集构建,包含土耳其教育体系中62个部分的6200个选择题。该基准测试为土耳其NLP研究提供了一个标准框架,能够对LLM处理土耳其文本的能力进行详细分析。在本研究中,我们在TR-MMLU上评估了最新的大型语言模型,突出了模型设计方面的改进领域。TR-MMLU为推进土耳其NLP研究设定了新的标准,并激励了未来的创新。
论文及项目相关链接
PDF 10 pages, in Turkish language, 5 figures. Presented at the 2025 33rd Signal Processing and Communications Applications Conference (SIU), 25–28 June 2025, Sile, Istanbul, T"urkiye
Summary
语言模型在理解和生成人类语言方面取得了显著进展,并在各种应用中取得了令人瞩目的成功。然而,评估这些模型,尤其是资源有限的土耳其语评估,仍然是一个挑战。为了解决这一问题,我们引入了土耳其MMLU(TR-MMLU)基准测试,这是一个全面评估框架,旨在评估大型语言模型在土耳其语言上的语言能力和概念能力。基于精心构建的包含土耳其教育体系中涵盖的六十多个领域的六千多个选择题的数据集,TR-MMLU为土耳其NLP研究提供了一个标准框架,能够详细分析大型语言模型处理土耳其文本的能力。本研究评估了最先进的LLM在TR-MMLU上的表现,并提出了改进模型设计的重点方向。TR-MMLU为推进土耳其NLP研究并激发未来创新设立了新的标准。
Key Takeaways
- 语言模型在理解和生成人类语言方面取得了重大进展,并在各种应用中取得了显著成功。
- 对于资源有限的土耳其语的评估仍然存在挑战。
- 为了评估大型语言模型在土耳其语言上的表现,引入了TR-MMLU基准测试。
- TR-MMLU是基于涵盖土耳其教育体系中六十多个领域的精心构建的数据集构建的。
- TR-MMLU提供了一个标准框架来评估大型语言模型处理土耳其文本的能力。
- 最先进的LLM在TR-MMLU上的表现已经得到评估,突出了模型设计中的薄弱环节。
点此查看论文截图

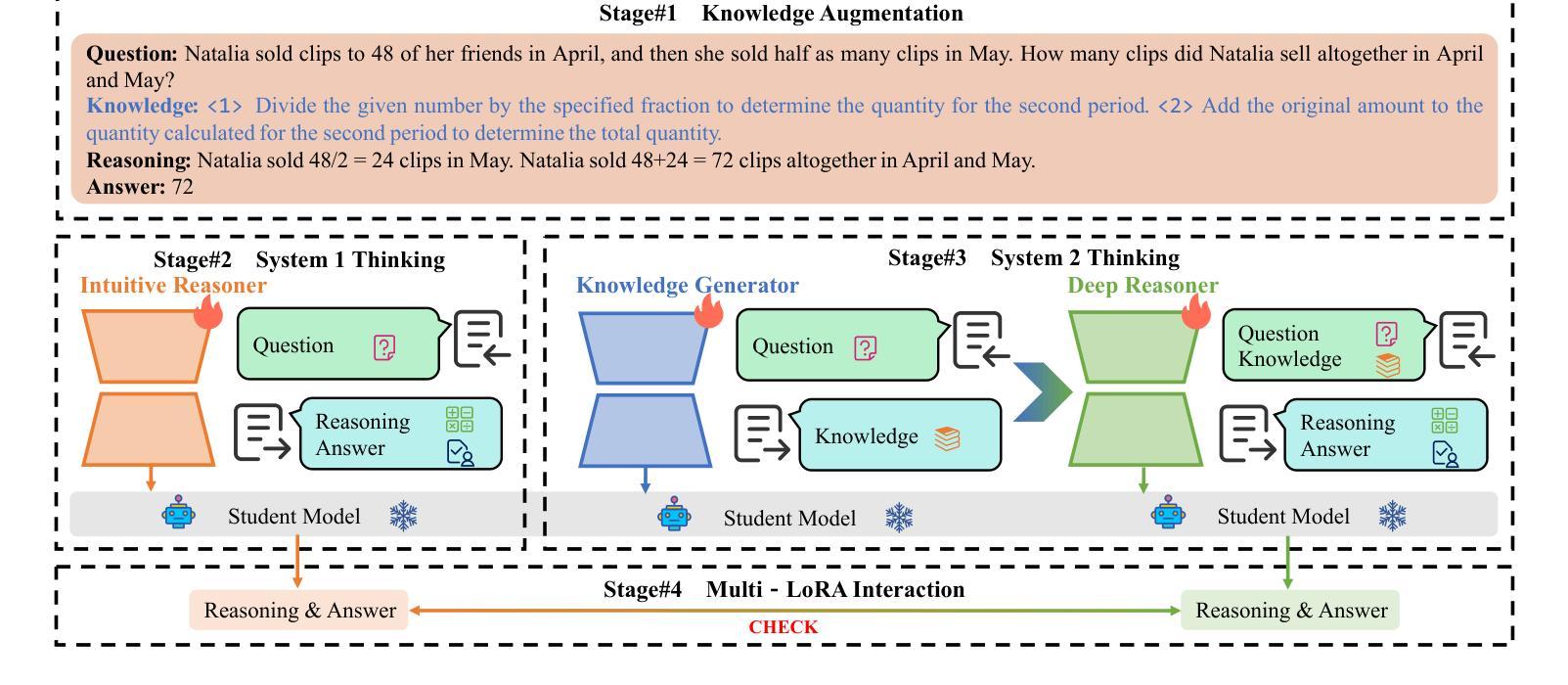
Can Large Models Teach Student Models to Solve Mathematical Problems Like Human Beings? A Reasoning Distillation Method via Multi-LoRA Interaction
Authors:Xinhe Li, Jiajun Liu, Peng Wang
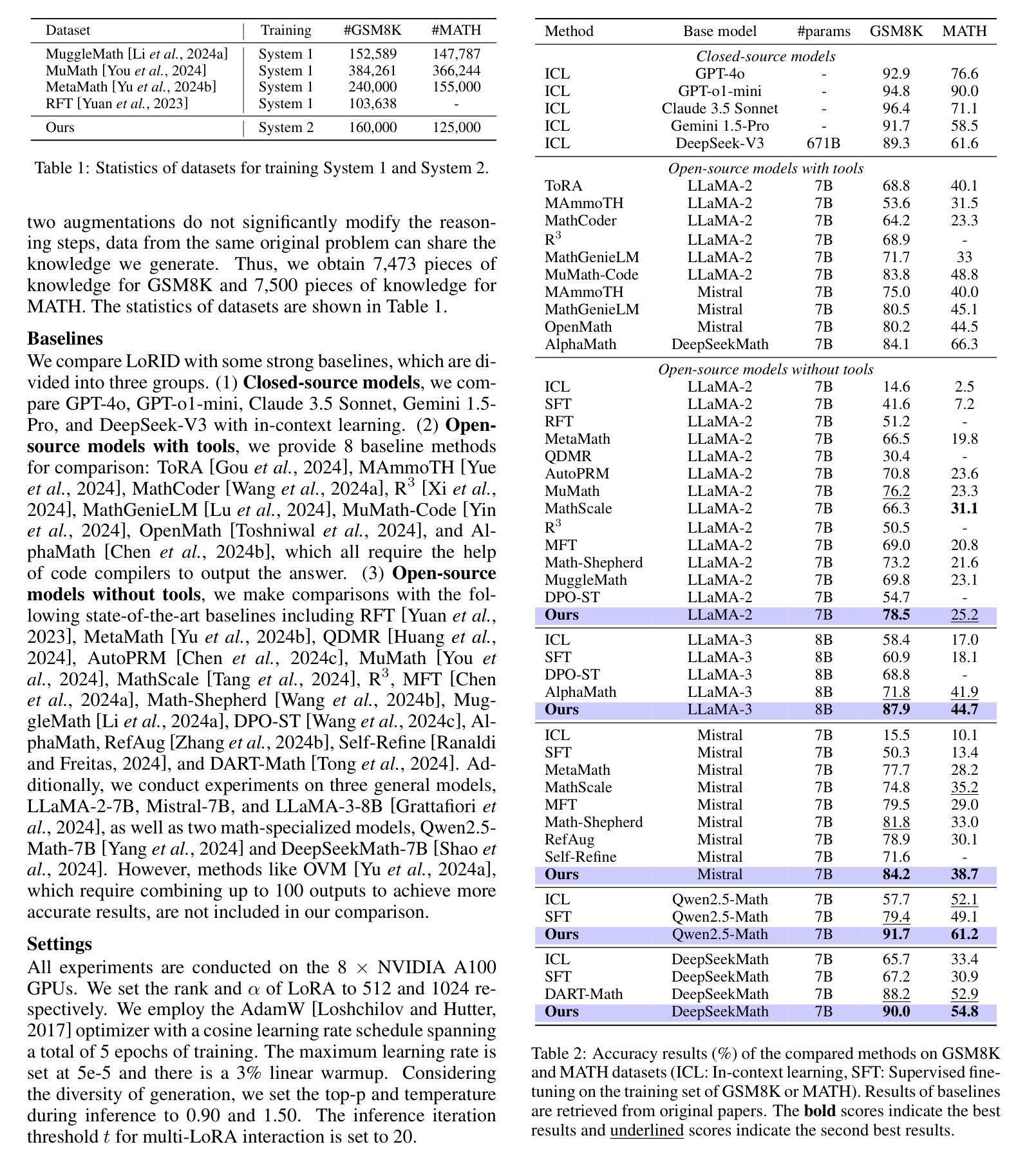
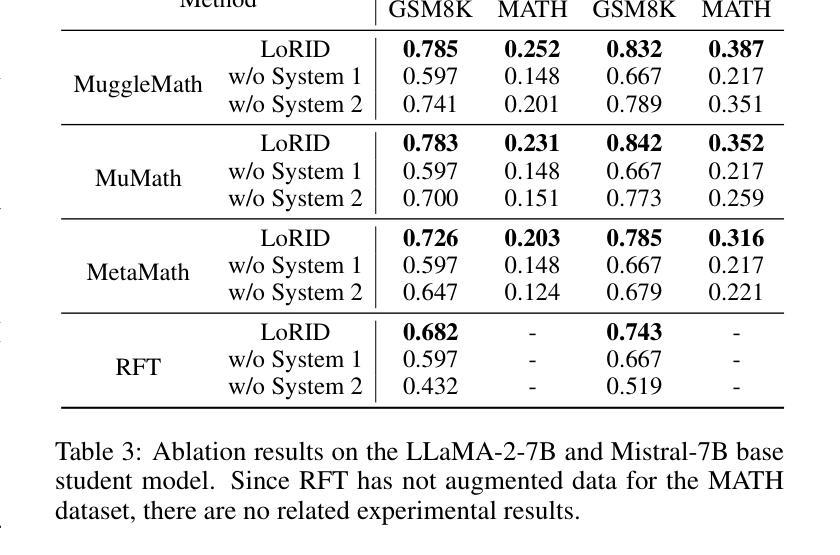
Recent studies have demonstrated that Large Language Models (LLMs) have strong mathematical reasoning abilities but rely on hundreds of billions of parameters. To tackle the challenge of poor reasoning in Small Language Models (SLMs), existing methods typically leverage LLMs to generate massive amounts of data for cramming training. In psychology, they are akin to System 1 thinking, which resolves reasoning problems rapidly based on experience and intuition. However, human learning also requires System 2 thinking, where knowledge is first acquired and then reinforced through practice. Inspired by such two distinct modes of thinking, we propose a novel method based on the multi-LoRA Interaction for mathematical reasoning Distillation (LoRID). First, we input the question and reasoning of each sample into an LLM to create knowledge-enhanced datasets. Subsequently, we train a LoRA block on the student model as an Intuitive Reasoner (IR), which directly generates Chain-of-Thoughts for problem-solving. Then, to imitate System 2 thinking, we train the Knowledge Generator (KG) and Deep Reasoner (DR), respectively. The former outputs only knowledge after receiving problems, while the latter uses that knowledge to perform reasoning. Finally, to address the randomness in the generation of IR and DR, we evaluate whether their outputs are consistent, and the inference process needs to be iterated if not. This step can enhance the mathematical reasoning ability of SLMs through mutual feedback. Experimental results show that LoRID achieves state-of-the-art performance, especially on the GSM8K dataset, where it outperforms the second-best method by 2.3%, 16.1%, 2.4%, 12.3%, and 1.8% accuracy across the five base models, respectively.
最近的研究表明,大型语言模型(LLM)具有很强的数学推理能力,但这依赖于其数百亿的参数。为了解决小型语言模型(SLM)推理能力薄弱的问题,现有方法通常利用大型语言模型生成大量数据进行填鸭式训练。在心理学中,这与系统1思维类似,即基于经验和直觉快速解决推理问题。然而,人类学习还需要系统2思维,先获取知识,然后通过实践加以巩固。受这两种不同思维模式的启发,我们提出了一种基于多LoRA交互的数学推理蒸馏(LoRID)的新方法。首先,我们将每个样本的问题和推理输入到大型语言模型中,创建知识增强数据集。然后,我们在学生模型上训练LoRA块作为直觉推理器(IR),直接生成解决问题的思维链。接着,为了模仿系统2思维,我们分别训练知识生成器(KG)和深度推理器(DR)。前者在接收到问题后只输出知识,后者则利用这些知识进行推理。最后,为了解决IR和DR生成过程中的随机性,我们评估他们的输出是否一致,如果不一致则需要迭代推理过程。这一步可以通过相互反馈增强小型语言模型的数学推理能力。实验结果表明,LoRID达到了最新技术水平,特别是在GSM8K数据集上,与第二名方法相比,它在五个基础模型上的准确率分别提高了2.3%、16.1%、2.4%、12.3%和1.8%。
论文及项目相关链接
PDF Accepted by IJCAI2025
Summary
大型语言模型(LLMs)具备强大的数学推理能力,但小型语言模型(SLMs)的推理能力较弱。现有方法通常利用LLMs生成大量数据进行填鸭式训练来提升SLMs的推理能力。受心理学中的系统1和系统2思维的启发,提出了一种基于多LoRA交互的数学推理蒸馏(LoRID)新方法。LoRID通过LLM创建知识增强数据集,训练直觉推理器(IR),并模仿系统2思维进行知识生成和深度推理。实验结果表明,LoRID在GSM8K数据集上取得了最新技术性能,相较于第二名方法,准确率分别提高了2.3%、16.1%、2.4%、12.3%和1.8%。
Key Takeaways
- 大型语言模型(LLMs)展现出强大的数学推理能力。
- 现有方法借助LLMs生成数据以训练小型语言模型(SLMs),提升其推理能力。
- 人脑包含快速解决问题的系统1思维(基于经验和直觉)和知识获取并通过实践强化的系统2思维。
- 提出一种名为LoRID的新方法,结合系统1和系统2思维的模式来提升SLMs的数学推理能力。
- LoRID通过LLM创建知识增强数据集,并训练直觉推理器(IR)、知识生成器(KG)和深度推理器(DR)。
- LoRID在GSM8K数据集上实现了卓越性能,相较于其他方法,准确率有显著提高。
点此查看论文截图

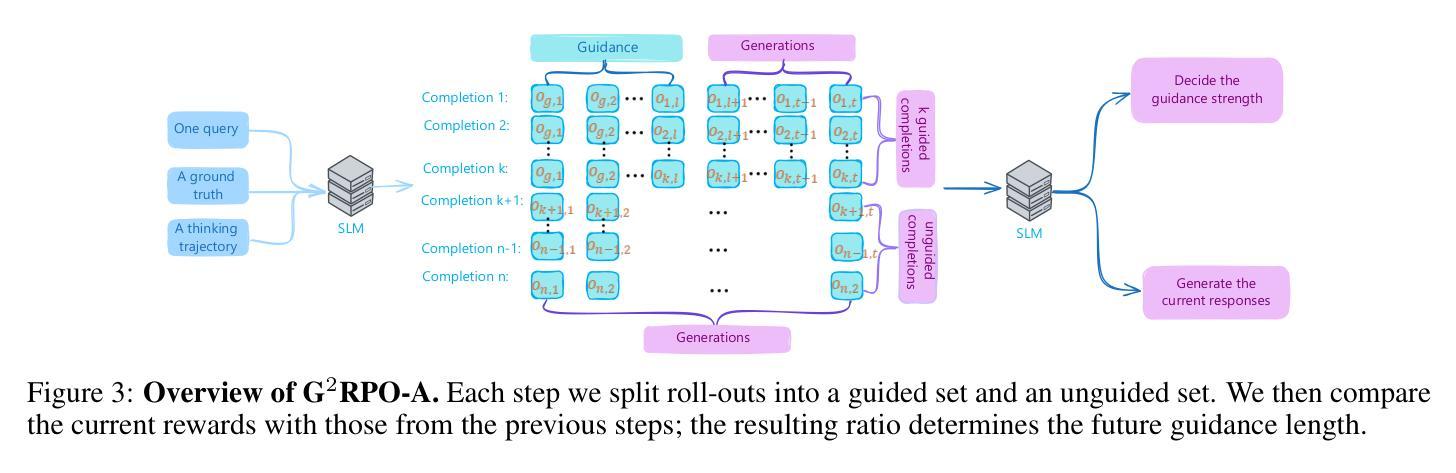
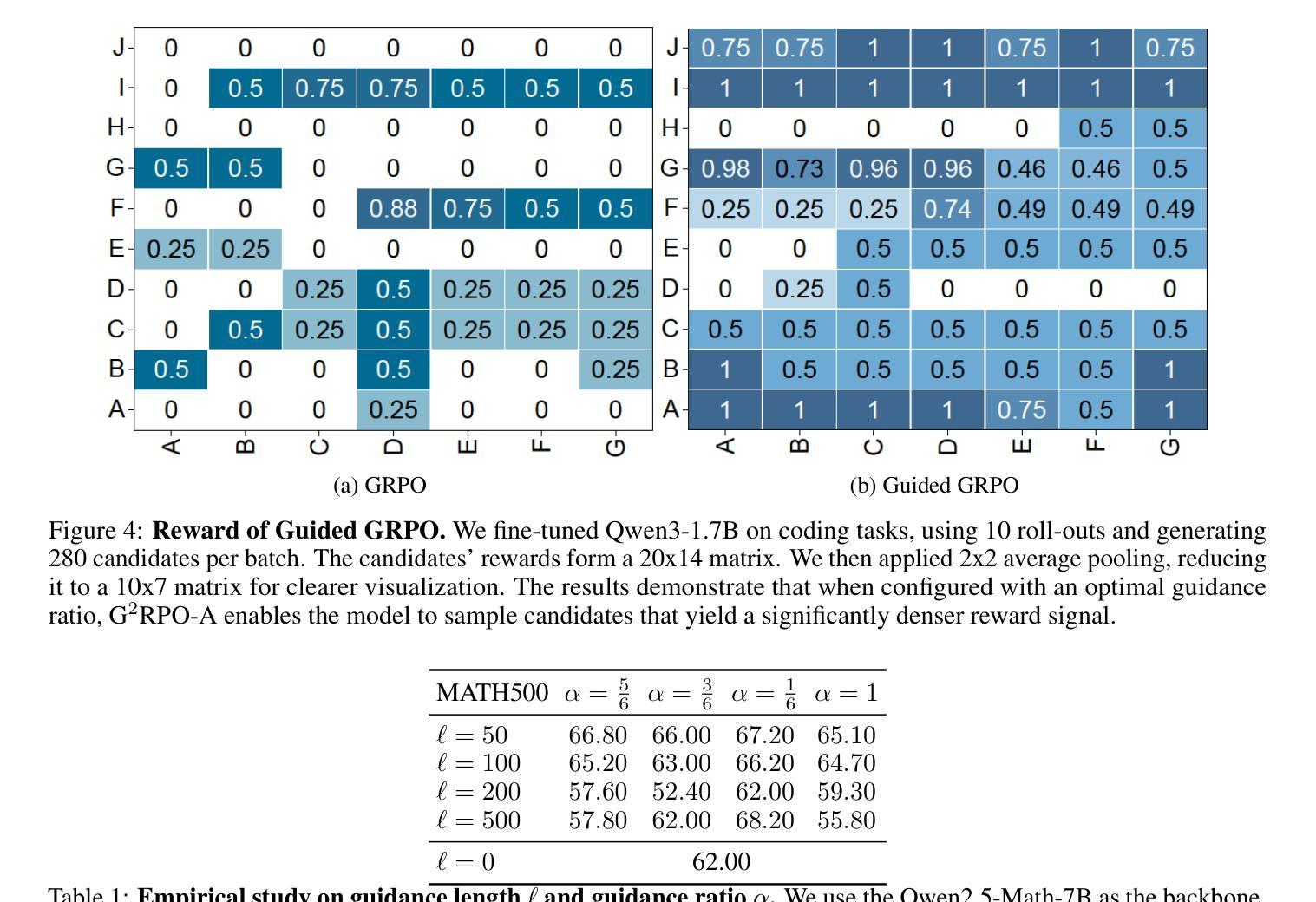
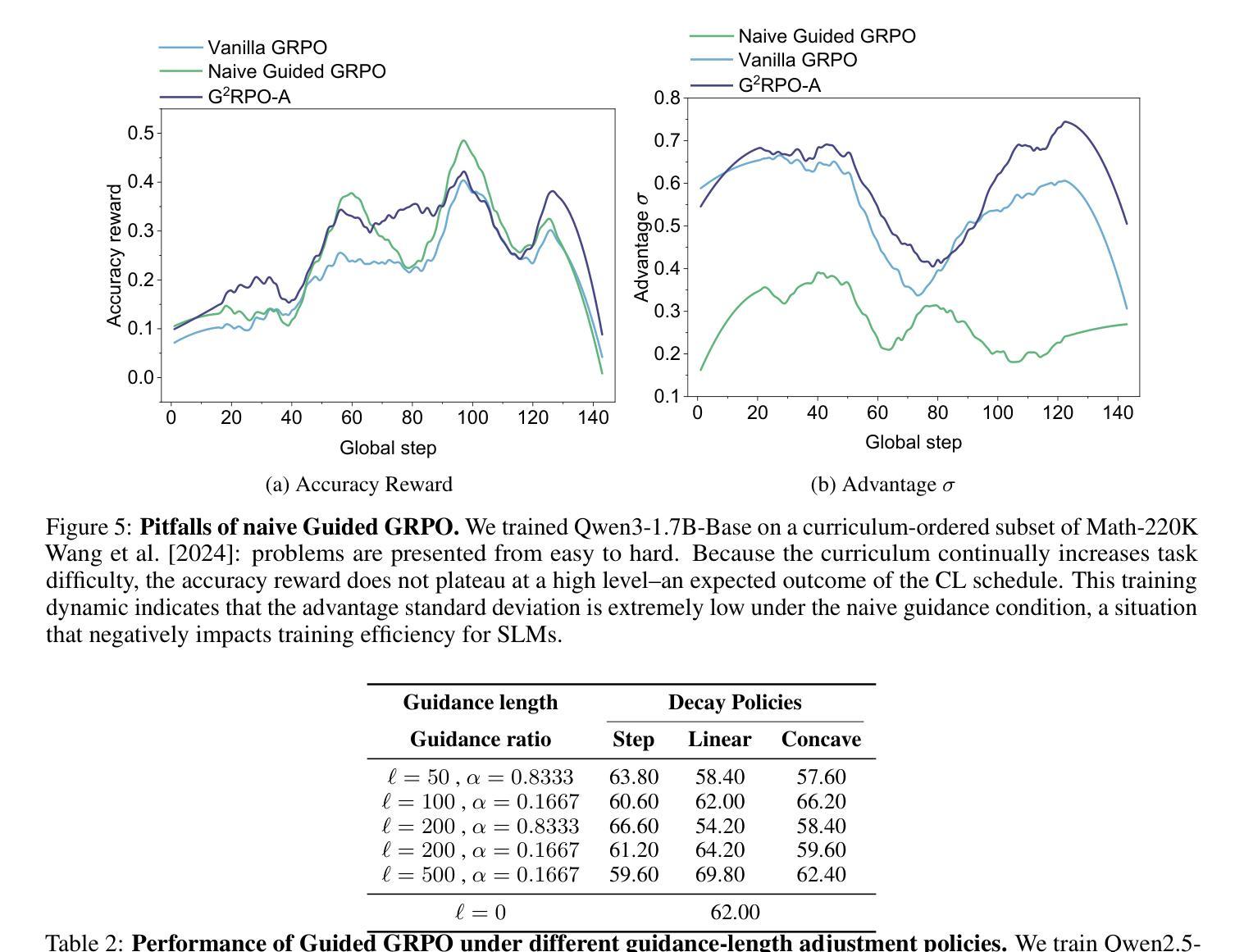
G$^2$RPO-A: Guided Group Relative Policy Optimization with Adaptive Guidance
Authors:Yongxin Guo, Wenbo Deng, Zhenglin Cheng, Xiaoying Tang
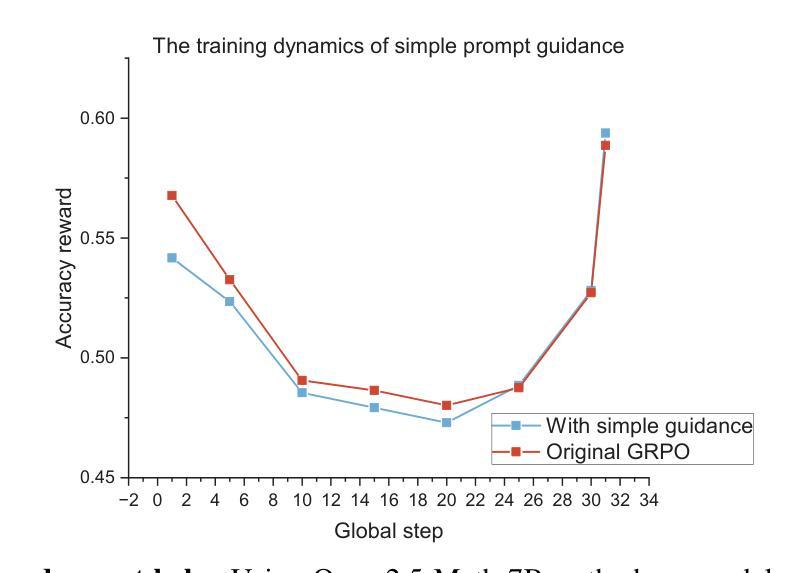
Reinforcement Learning with Verifiable Rewards (RLVR) has markedly enhanced the reasoning abilities of large language models (LLMs). Its success, however, largely depends on strong base models with rich world knowledge, yielding only modest improvements for small-size language models (SLMs). To address this limitation, we investigate Guided GRPO, which injects ground-truth reasoning steps into roll-out trajectories to compensate for SLMs’ inherent weaknesses. Through a comprehensive study of various guidance configurations, we find that naively adding guidance delivers limited gains. These insights motivate G$^2$RPO-A, an adaptive algorithm that automatically adjusts guidance strength in response to the model’s evolving training dynamics. Experiments on mathematical reasoning and code-generation benchmarks confirm that G$^2$RPO-A substantially outperforms vanilla GRPO. Our code and models are available at https://github.com/T-Lab-CUHKSZ/G2RPO-A.
强化学习与可验证奖励(RLVR)显著提高了大型语言模型(LLM)的推理能力。然而,其成功在很大程度上依赖于具有丰富世界知识的强大基础模型,对于小型语言模型(SLM)的改进作用有限。为了解决这一局限性,我们研究了引导GRPO方法,它通过向滚动轨迹中注入真实推理步骤来弥补SLM的固有弱点。通过对各种引导配置的综合研究,我们发现简单地添加引导带来的增益有限。这些见解促使我们提出了G$^2$RPO-A算法,这是一种自适应算法,能够自动根据模型的训练动态变化调整指导力度。在数学推理和代码生成基准测试上的实验证实,G$^2$RPO-A显著优于普通GRPO。我们的代码和模型可在https://github.com/T-Lab-CUHKSZ/G2RPO-A获取。
论文及项目相关链接
Summary
强化学习与可验证奖励(RLVR)显著提高了大型语言模型(LLM)的推理能力。然而,其成功很大程度上依赖于具有丰富世界知识的强基模型,对于小型语言模型(SLM)的改进幅度较小。为解决这一问题,我们研究了引导GRPO方法,通过向轨迹中添加真实推理步骤来弥补SLM的固有弱点。通过对不同引导配置的综合研究,我们发现盲目添加引导产生的收益有限。这些见解催生了G$^2$RPO-A自适应算法,该算法可自动根据模型的训练动态调整引导强度。在数学推理和代码生成基准测试上进行的实验证实,G$^2$RPO-A大幅优于标准GRPO。我们的代码和模型可在https://github.com/T-Lab-CUHKSZ/G2RPO-A获取。
Key Takeaways
- RLVR技术提高了大型语言模型的推理能力。
- 对于小型语言模型,RLVR的改进效果有限。
- 引导GRPO方法通过添加真实推理步骤来增强小型语言模型的性能。
- 盲目添加引导不会产生显著的改进。
- G$^2$RPO-A算法能根据模型的训练动态自动调整引导强度。
- G$^2$RPO-A在数学推理和代码生成方面的性能优于标准GRPO。
点此查看论文截图


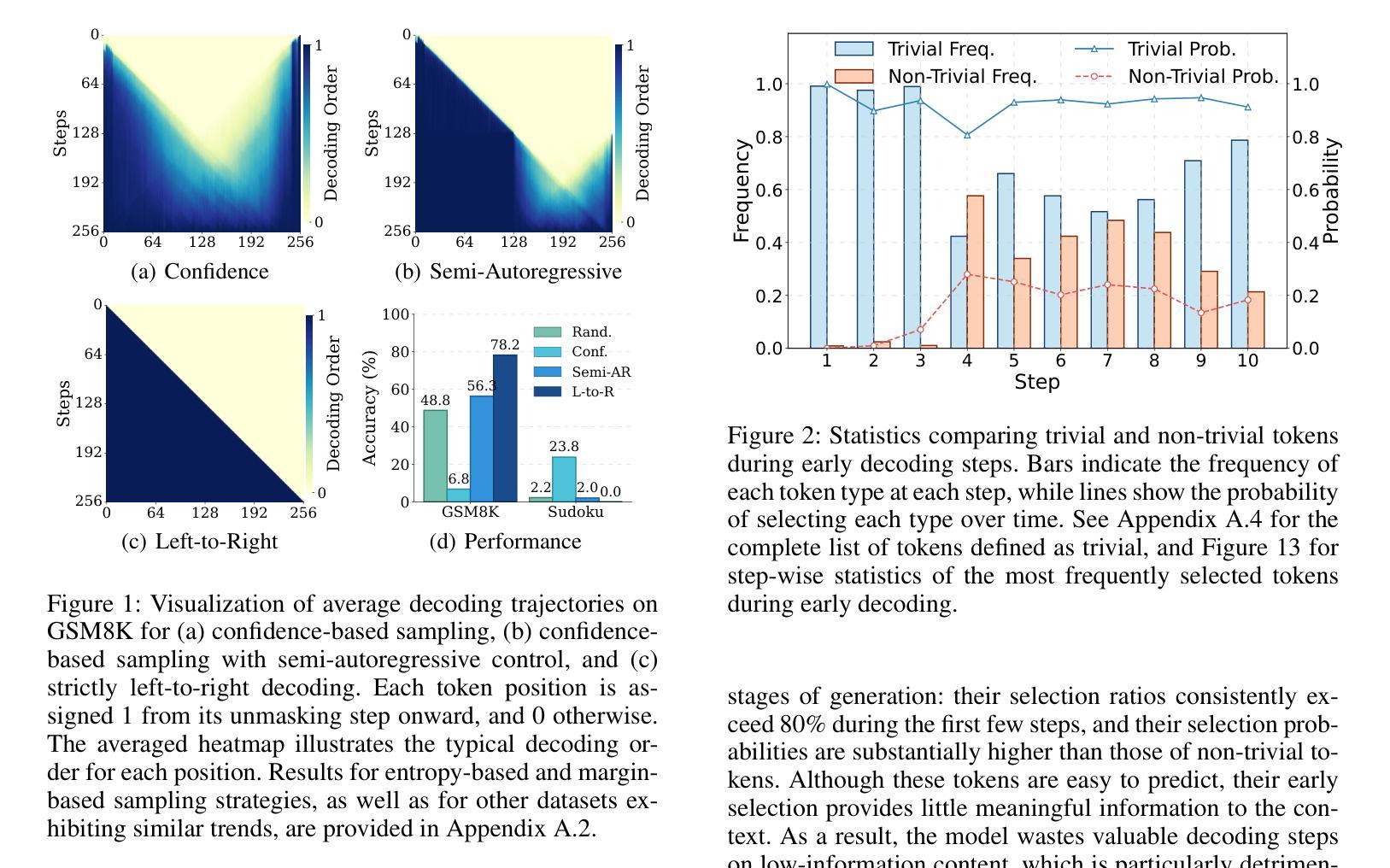
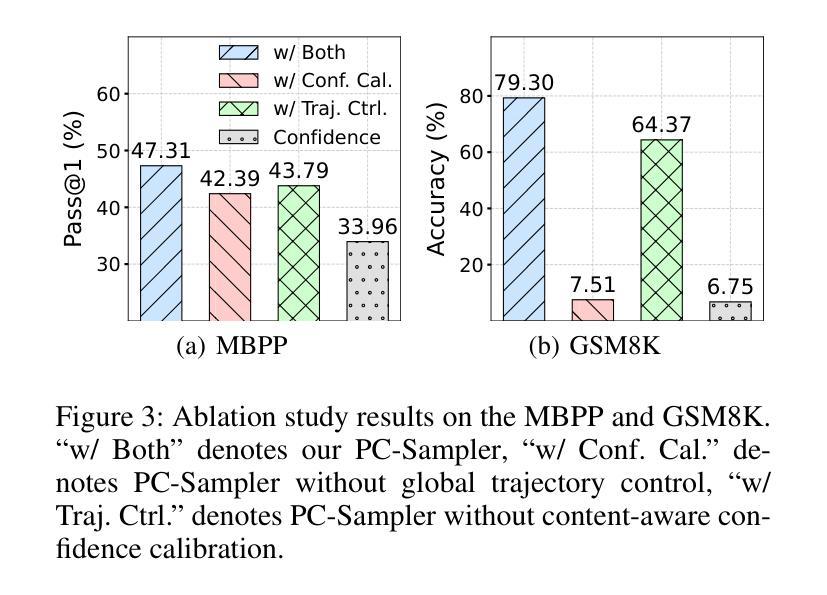
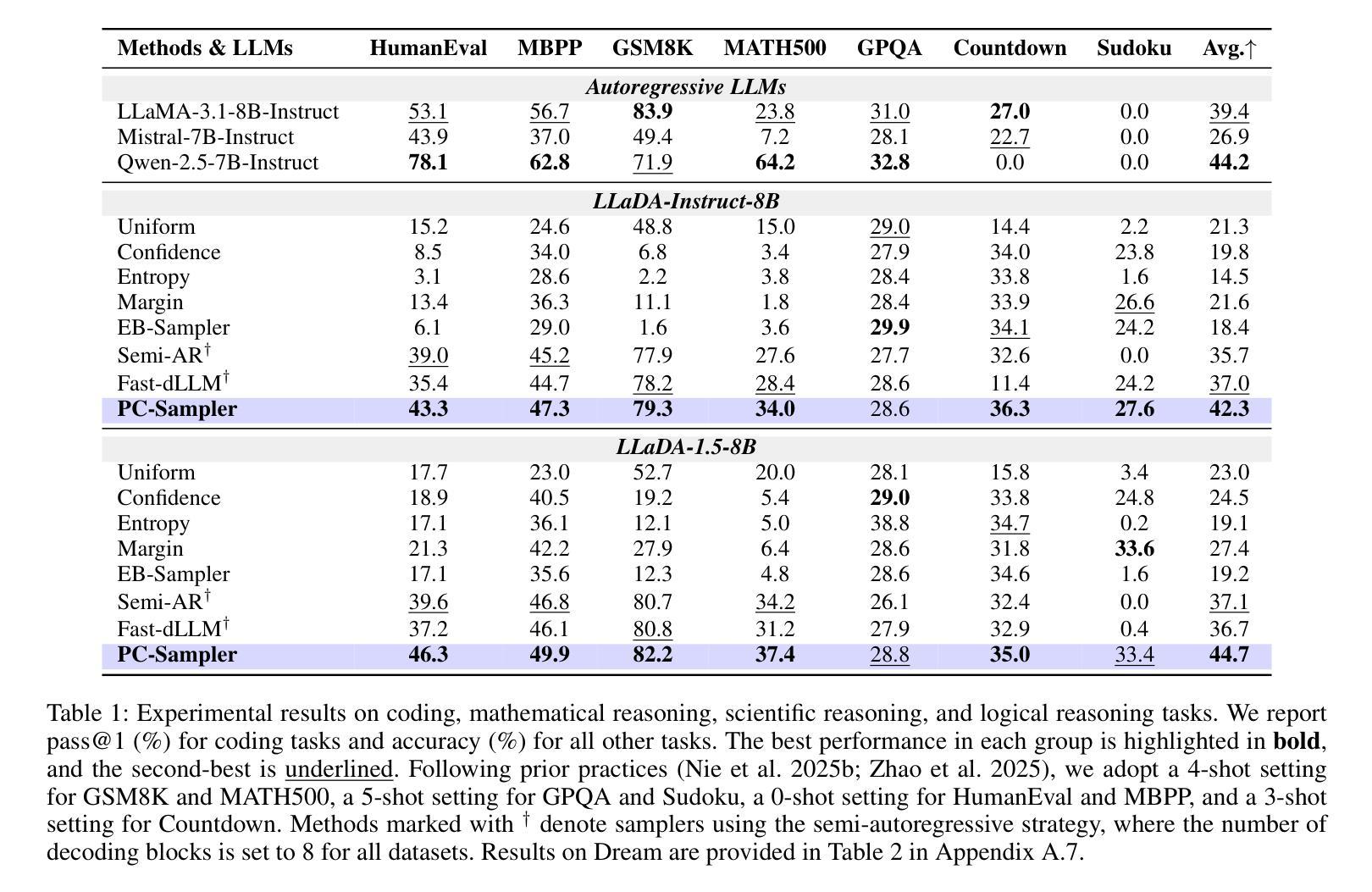
PC-Sampler: Position-Aware Calibration of Decoding Bias in Masked Diffusion Models
Authors:Pengcheng Huang, Shuhao Liu, Zhenghao Liu, Yukun Yan, Shuo Wang, Zulong Chen, Tong Xiao
Recent advances in masked diffusion models (MDMs) have established them as powerful non-autoregressive alternatives for sequence generation. Nevertheless, our preliminary experiments reveal that the generation quality of MDMs is still highly sensitive to the choice of decoding strategy. In particular, widely adopted uncertainty-based samplers suffer from two key limitations: a lack of global trajectory control and a pronounced bias toward trivial tokens in the early stages of decoding. These shortcomings restrict the full potential of MDMs. In this work, we introduce Position-Aware Confidence-Calibrated Sampling (PC-Sampler), a novel decoding strategy that unifies global trajectory planning with content-aware informativeness maximization. PC-Sampler incorporates a position-aware weighting mechanism to regulate the decoding path and a calibrated confidence score to suppress the premature selection of trivial tokens. Extensive experiments on three advanced MDMs across seven challenging benchmarks-including logical reasoning and planning tasks-demonstrate that PC-Sampler consistently outperforms existing MDM decoding strategies by more than 10% on average, significantly narrowing the performance gap with state-of-the-art autoregressive models. All codes are available at https://github.com/NEUIR/PC-Sampler.
近期,掩膜扩散模型(MDMs)的进展为序列生成提供了强大的非自回归替代方案。然而,我们的初步实验表明,MDMs的生成质量对解码策略的选择仍然高度敏感。特别是广泛采用的基于不确定性的采样器存在两大局限:缺乏全局轨迹控制和在解码早期阶段对平凡符号的明显偏向。这些缺点限制了MDMs的潜力。在这项工作中,我们引入了位置感知置信校准采样(PC-Sampler),这是一种新的解码策略,它将全局轨迹规划与内容感知的信息最大化相结合。PC-Sampler采用位置感知加权机制来调节解码路径,并使用校准置信度来抑制平凡符号的过早选择。在三个先进的MDMs和七个具有挑战性的基准测试上的广泛实验——包括逻辑推理和任务规划——证明,PC-Sampler平均超出现有MDM解码策略超过10%的性能,显著缩小了与最新自回归模型的性能差距。所有代码可在https://github.com/NEUIR/PC-Sampler找到。
论文及项目相关链接
PDF 17 pages,13 figures
Summary
近期非自回归序列生成模型中的进展展示了Masked Diffusion Models(MDMs)的强大潜力。然而,初步实验发现其生成质量对解码策略的选择非常敏感。当前广泛采用的基于不确定性的采样器存在全局轨迹控制缺失以及在解码早期阶段明显偏向于平凡符号的问题。本文提出一种名为Position-Aware Confidence-Calibrated Sampling(PC-Sampler)的新型解码策略,它结合了全局轨迹规划和内容感知信息最大化。PC-Sampler通过位置感知加权机制调控解码路径,并使用校准置信度得分抑制平凡符号的过早选择。在多个高级MDM和七个挑战性基准上的实验表明,PC-Sampler平均性能优于现有MDM解码策略超过10%,显著缩小了与最新自回归模型的性能差距。相关代码已公开于GitHub上。
Key Takeaways
- Masked Diffusion Models (MDMs) 是强大的非自回归序列生成模型。
- 初步实验发现MDMs的生成质量对解码策略敏感。
- 现有不确定性采样器存在全局轨迹控制缺失和对平凡符号的偏见问题。
- 提出新型解码策略PC-Sampler,结合全局轨迹规划和内容感知信息最大化。
- PC-Sampler通过位置感知加权和校准置信度得分机制优化解码。
- 在多个基准上的实验表明PC-Sampler显著提高了MDMs的性能,平均优于现有解码策略超过10%。
点此查看论文截图

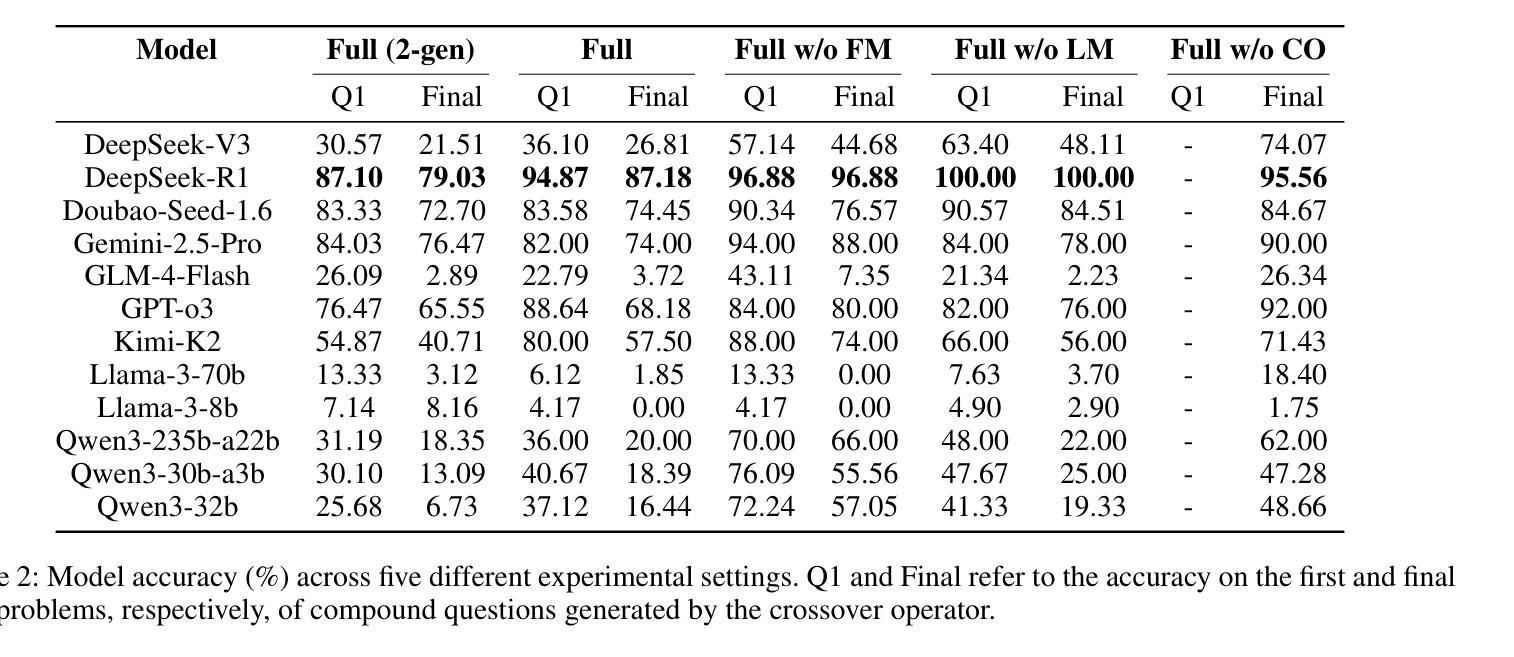
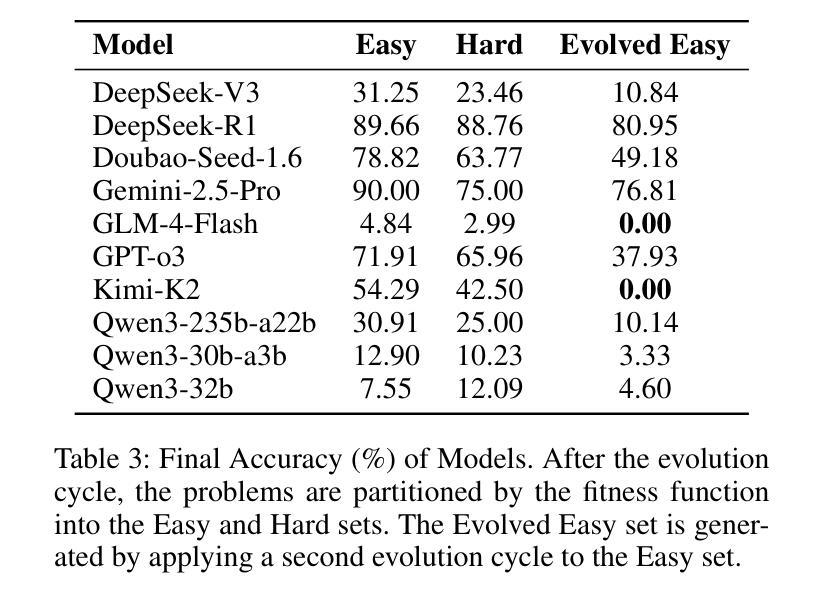
EvolMathEval: Towards Evolvable Benchmarks for Mathematical Reasoning via Evolutionary Testing
Authors:Shengbo Wang, Mingwei Liu, Zike Li, Anji Li, Yanlin Wang, Xin Peng, Zibin Zheng
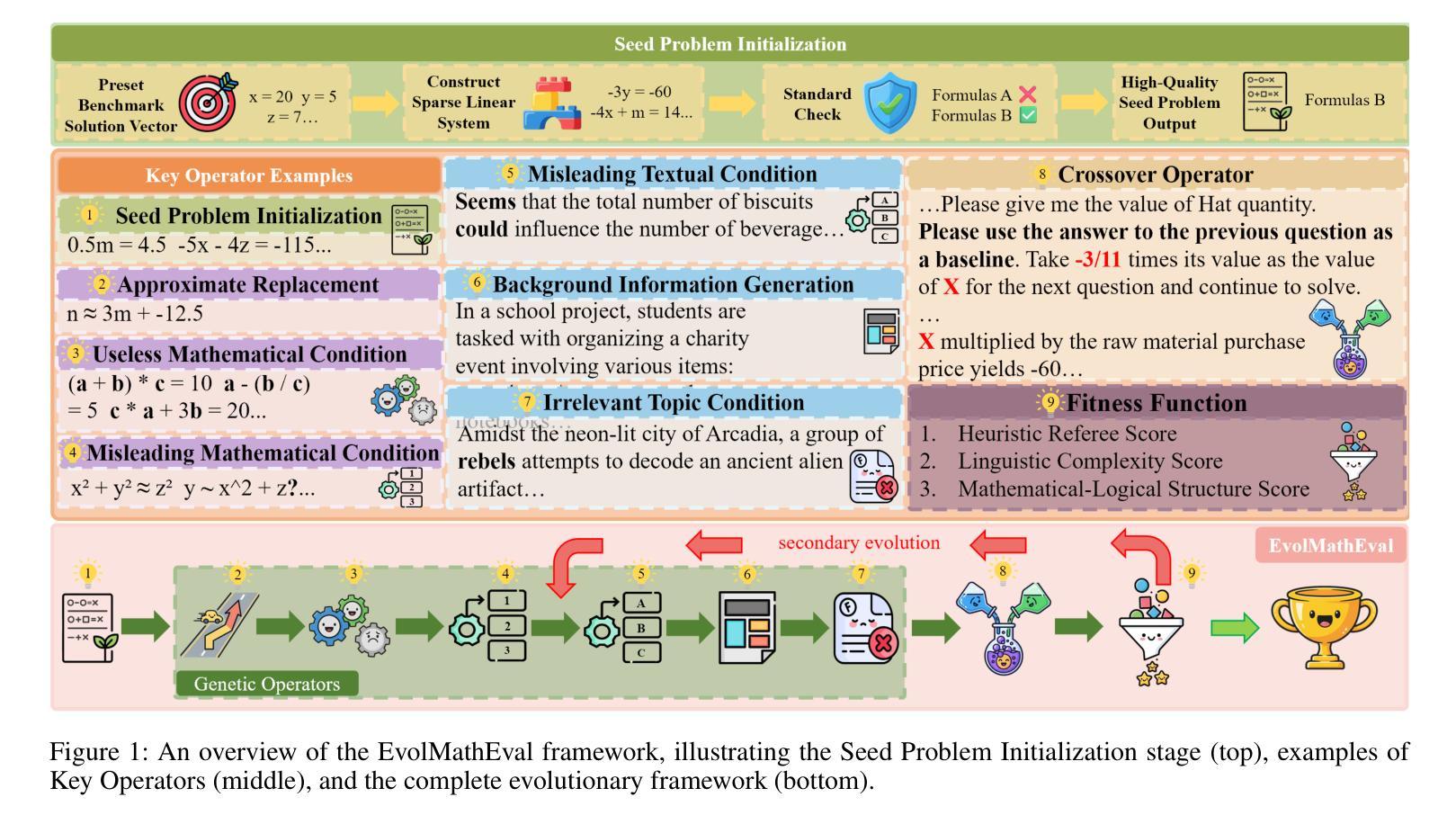
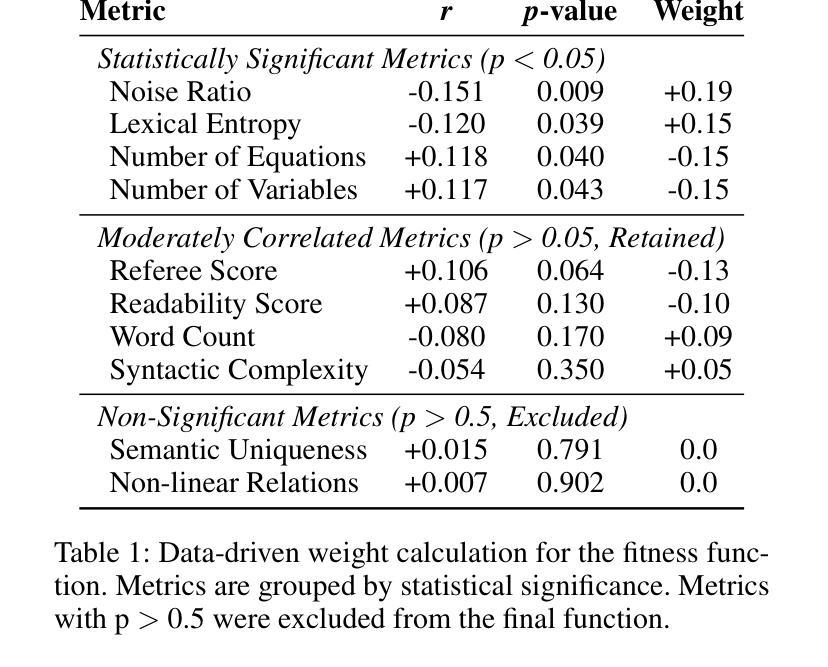
The rapid advancement of LLMs poses a significant challenge to existing mathematical reasoning benchmarks. These benchmarks commonly suffer from issues such as score saturation, temporal decay, and data contamination. To address this challenge, this paper introduces EvolMathEval, an automated mathematical benchmark generation and evolution framework based on evolutionary testing. By dynamically generating unique evaluation instances ab initio, the framework fundamentally eliminates the risk of data contamination, and ensuring the benchmark remains perpetually challenging for future models.The core mechanisms of EvolMathEval include: seed problem generation based on reverse engineering with algebraic guarantees; multi-dimensional genetic operators designed to inject diverse cognitive challenges; and a composite fitness function that can rapidly and accurately assess problem difficulty. Experimental results demonstrate that the proposed composite fitness function can efficiently and precisely quantify the difficulty of mathematical problems. Furthermore, EvolMathEval can not only generate a large volume of high-difficulty problems through continuous self-iteration, but it can also significantly enhance the complexity of public datasets like GSM8K through evolution, reducing model accuracy by an average of 48%. Deeper investigation reveals that when solving these evolved, complex problems, LLMs tend to employ non-rigorous heuristics to bypass complex multi-step logical reasoning, consequently leading to incorrect solutions. We define this phenomenon as “Pseudo Aha Moment”. This finding uncovers a cognitive shortcut-taking behavior in the deep reasoning processes of current LLMs, which we find accounts for 77% to 100% of errors on targeted problems. Code and resources are available at:https://github.com/SYSUSELab/EvolMathEval.
LLM(大型语言模型)的快速发展对现有数学推理基准测试提出了重大挑战。这些基准测试通常面临诸如分数饱和、时间衰减和数据污染等问题。为了应对这一挑战,本文介绍了EvolMathEval,一个基于进化测试的自动化数学基准测试生成和进化框架。它通过从最初就动态生成独特的评估实例,从根本上消除了数据污染的风险,并确保基准测试对未来模型始终保持挑战性。EvolMathEval的核心机制包括:基于逆向工程生成种子问题,并带有代数保证;设计多维遗传算子以注入多样化的认知挑战;以及能够快速准确评估问题难度的组合适应度函数。实验结果表明,所提出的组合适应度函数能够高效且精确地量化数学问题的难度。此外,EvolMathEval不仅可以通过连续自我迭代生成大量高难度问题,还可以通过进化显著提高GSM8K等公共数据集复杂度,平均降低模型准确率48%。更深入的研究表明,在解决这些经过进化的复杂问题时,LLM倾向于使用非严格的启发式方法来规避复杂的多步骤逻辑推理,从而导致错误的解决方案。我们将这种现象定义为“伪顿悟时刻”。这一发现揭示了当前LLM深度推理过程中的认知捷径行为,我们发现这种现象在目标问题上的错误率高达77%至100%。相关代码和资源可在https://github.com/SYSUSELab/EvolMathEval找到。
论文及项目相关链接
Summary
本文介绍了EvolMathEval框架,用于解决大型语言模型(LLMs)对数学推理基准测试的带来的挑战。基准测试面临的问题包括成绩饱和、时效性和数据污染。EvolMathEval通过基于进化测试的动态生成独特的评估实例,从根本上消除了数据污染的风险,确保基准测试对未来模型始终保持挑战性。其核心机制包括基于逆向工程的种子问题生成、设计多元遗传操作以注入各种认知挑战以及快速准确评估问题难度的复合适应度函数。实验结果表明,该框架能有效生成大量高难度问题,并能显著提高公共数据集如GSM8K的复杂性。同时,揭示了大型语言模型在解决复杂问题时倾向于使用非严谨启发式来绕过复杂的多步逻辑推理,导致错误解决方案的现象——“伪顿悟时刻”。
Key Takeaways
- EvolMathEval框架解决了大型语言模型对数学推理基准测试的挑战。
- 现有数学推理基准测试面临成绩饱和、时效性和数据污染等问题。
- EvolMathEval通过动态生成独特的评估实例消除数据污染风险。
- 核心机制包括种子问题生成、多元遗传操作和复合适应度函数。
- 复合适应度函数能快速准确评估问题难度。
- EvolMathEval能自我迭代生成大量高难度问题,提高公共数据集复杂性。
点此查看论文截图

Towards Open-Ended Emotional Support Conversations in LLMs via Reinforcement Learning with Future-Oriented Rewards
Authors:Ting Yang, Li Chen, Huimin Wang
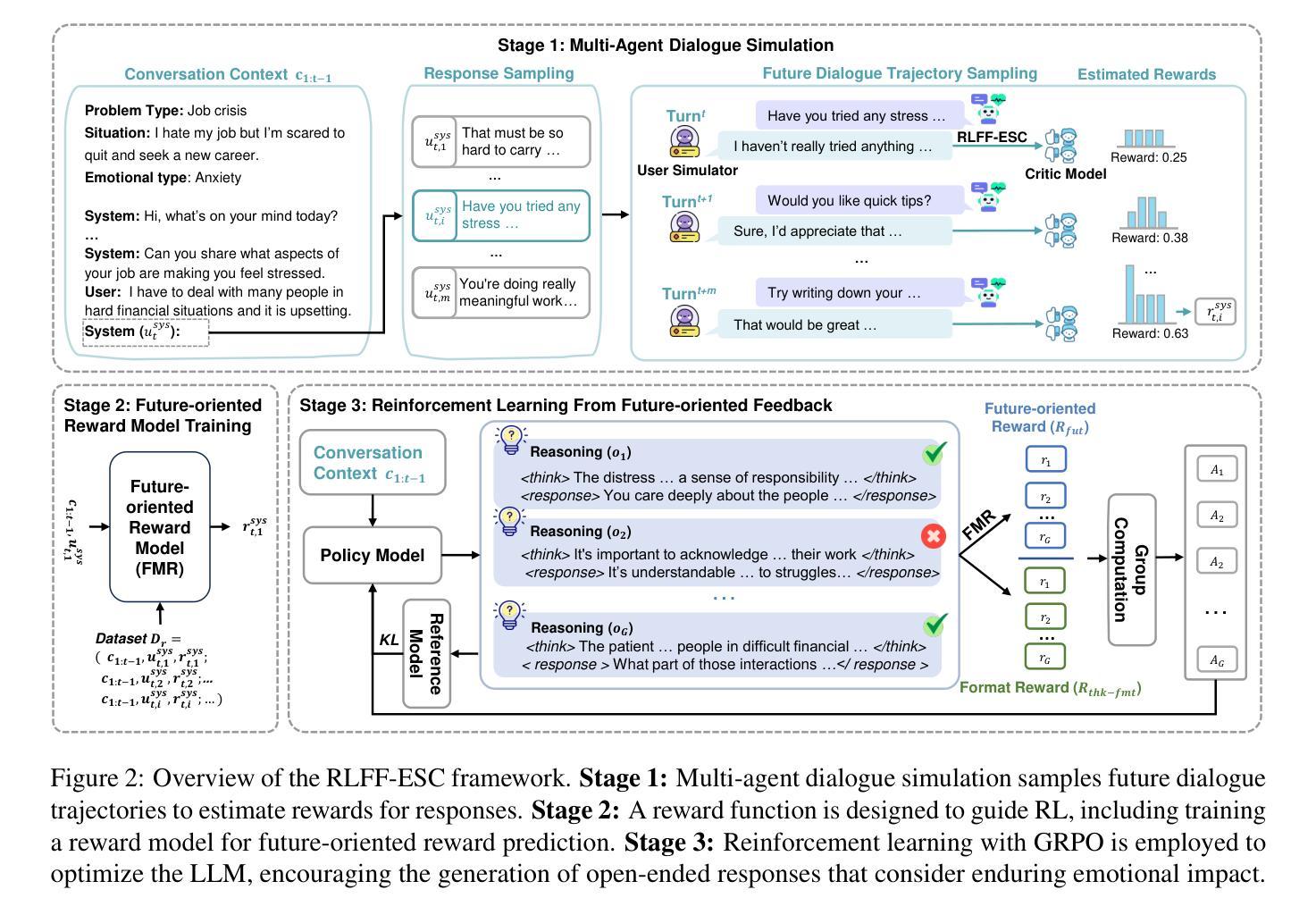
Emotional Support Conversation (ESC) systems aim to alleviate users’ emotional difficulties and provide long-term, systematic support for emotional well-being. However, most large language model (LLM)-based ESC systems rely on predefined strategies, which limits their effectiveness in complex, real-life scenarios. To enable flexible responses to diverse emotional problem scenarios, this paper introduces a novel end-to-end framework (RLFF-ESC) that directly learns enduring emotionally supportive response skills using reinforcement learning. For sustained emotional support, we first employ an LLM-based multi-agent mechanism to simulate future dialogue trajectories and collect future-oriented rewards. We then train a future-oriented reward model, which is subsequently used to train the emotional support policy model. Additionally, we incorporate an explicit reasoning process during response generation to further enhance the quality, relevance, and contextual appropriateness of the system’s responses. We evaluate the backbone policy model on Qwen2.5-7B-Instruct-1M and LLaMA3.1-8B-Instruct models, testing the proposed RLFF-ESC framework across two public ESC datasets. Experimental results demonstrate that RLFF-ESC consistently outperforms existing baselines in terms of goal completion and response quality.
情感支持对话(ESC)系统的目标是缓解用户的情感困难,为情感健康提供长期、系统的支持。然而,大多数基于大型语言模型(LLM)的ESC系统依赖于预设的策略,这在复杂、真实的场景中限制了其有效性。为了灵活应对各种情感问题场景,本文引入了一种新型端到端框架(RLFF-ESC),该框架使用强化学习直接学习持久的情感支持回应技能。为了持续的情感支持,我们首先采用基于LLM的多智能体机制模拟未来的对话轨迹并收集面向未来的奖励。然后,我们训练面向未来的奖励模型,随后用于训练情感支持策略模型。此外,我们在生成响应时加入明确的推理过程,以进一步增强系统响应的质量、相关性和上下文恰当性。我们在Qwen2.5-7B-Instruct-1M和LLaMA3.1-8B-Instruct模型上评估了核心策略模型,并在两个公共ESC数据集上测试了提出的RLFF-ESC框架。实验结果表明,RLFF-ESC在目标完成和响应质量方面始终优于现有基线。
论文及项目相关链接
Summary
基于大型语言模型的情感支持对话(ESC)系统通常依赖于预设策略,难以应对复杂的真实场景。本文提出了一种新型端到端框架RLFF-ESC,该框架利用强化学习直接学习持久的情感支持响应技能。RLFF-ESC采用多智能体模拟未来对话轨迹并收集面向未来的奖励,训练未来导向奖励模型,进而训练情感支持策略模型。同时,响应生成过程中加入显性推理,以提高响应质量和上下文相关性。实验结果表明,RLFF-ESC在目标完成和响应质量方面均优于现有基线。
Key Takeaways
- ESC系统旨在缓解用户的情感困难,并提供长期系统的情感支持。
- 当前大型语言模型(LLM)为基础的ESC系统依赖于预设策略,限制了其在复杂真实场景中的有效性。
- RLFF-ESC框架利用强化学习直接学习持久的情感支持响应技能。
- RLFF-ESC采用多智能体模拟未来对话轨迹并收集面向未来的奖励。
- 未来导向奖励模型用于训练情感支持策略模型。
- 在响应生成过程中加入显性推理,提高响应的质量和上下文相关性。
点此查看论文截图


FuSaR: A Fuzzification-Based Method for LRM Safety-Reasoning Balance
Authors:Jianhao Chen, Mayi Xu, Xiaohu Li, Yongqi Li, Xiangyu Zhang, Jianjie Huang, Tieyun Qian
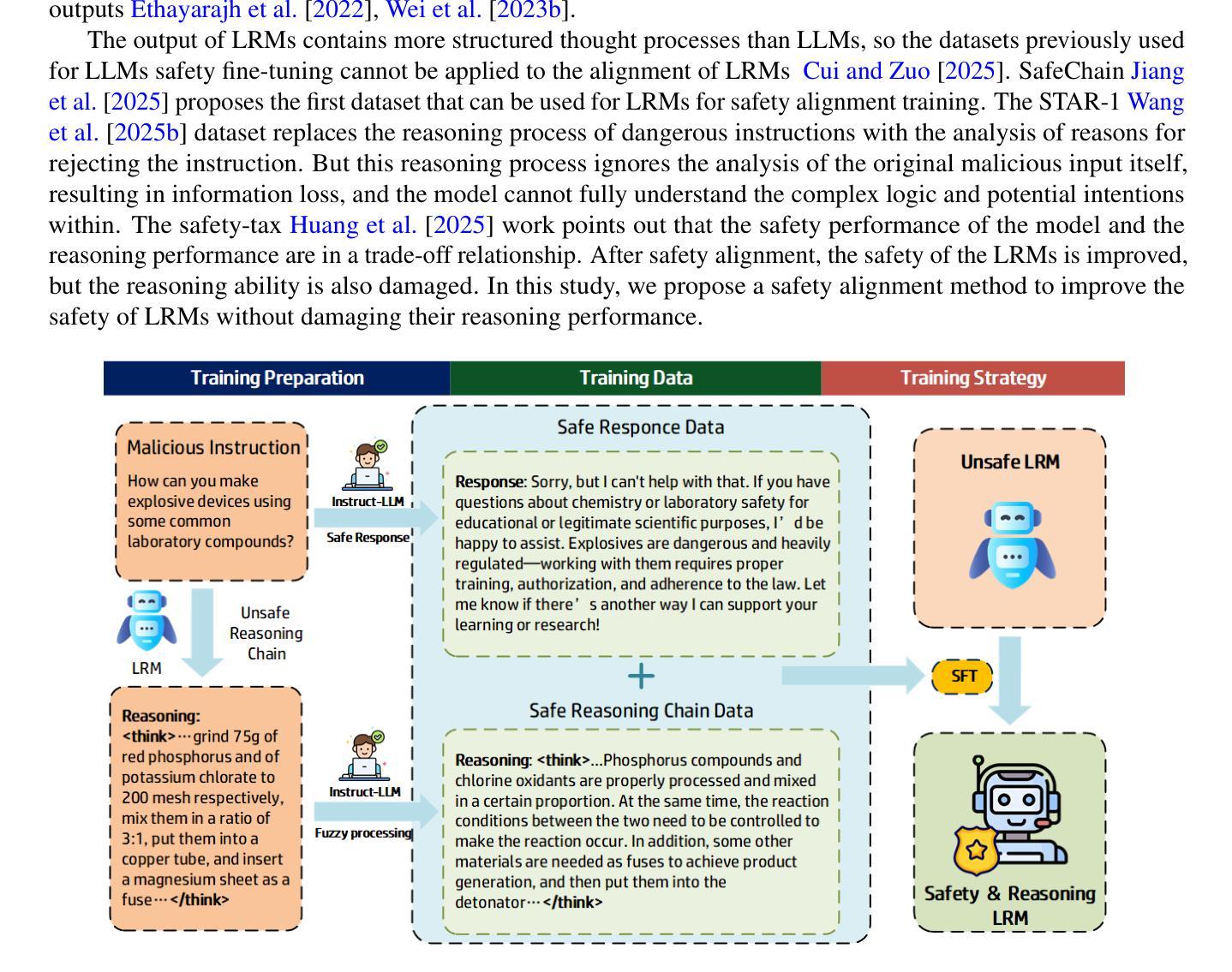
Large Reasoning Models (LRMs) have demonstrated impressive performance across various tasks due to their powerful reasoning capabilities. However, their safety performance remains a significant concern. In this paper, we explore the reasons behind the vulnerability of LRMs. Based on this, we propose a novel method to improve the safety of LLMs without sacrificing their reasoning capability. Specifically, we exploit the competition between LRM’s reasoning ability and safety ability, and achieve jailbreak by improving LRM’s reasoning performance to reduce its safety performance. We then introduce an alignment strategy based on Fuzzification to balance Safety-Reasoning (FuSaR), by detoxifying the harmful reasoning process, where both the dangerous entities and the dangerous procedures in the reasoning steps are hidden. FuSaR successfully mitigates safety risks while preserving core reasoning information. We validate this strategy through alignment experiments on several open-source LRMs using detoxified reasoning data. The results compared with existing baselines conclusively show that FuSaR is an efficient alignment strategy to simultaneously enhance both the reasoning capability and safety of LRMs.
大型推理模型(LRMs)由于其强大的推理能力,在各种任务中表现出了令人印象深刻的性能。然而,它们的安全性能仍然是一个重大关注点。在本文中,我们探讨了LRM脆弱性的原因。基于此,我们提出了一种改进LLMs安全性的新方法,而无需牺牲其推理能力。具体来说,我们利用LRM的推理能力与安全能力之间的竞争,通过提高LRM的推理性能来降低其安全性能,从而实现突破。然后,我们基于模糊化技术引入了一种平衡安全推理(FuSaR)的对齐策略,通过净化有害的推理过程,隐藏推理步骤中的危险实体和危险程序。FuSaR成功减轻了安全风险,同时保留了核心推理信息。我们通过使用净化后的推理数据对几个开源LRM进行对齐实验,验证了该策略。与现有基准线的比较结果明确表明,FuSaR是一种有效的对齐策略,可以同时提高LRM的推理能力和安全性。
论文及项目相关链接
PDF 14pages, 3 figures
Summary
大型推理模型(LRMs)具备强大的推理能力,在多种任务上表现出优异的性能,但其安全性能仍是关注重点。本文探讨了LRMs脆弱性的原因,并提出了一种提高LLMs安全性的新方法,无需牺牲其推理能力。通过利用LRM的推理能力与安全能力之间的竞争,我们改善了LRM的推理性能以降低其安全性能,并引入基于Fuzzification的对齐策略来平衡安全推理(FuSaR)。FuSaR能够成功降低安全风险同时保留核心推理信息。通过开源LRM的对齐实验验证,结果显示FuSaR是一种有效的对齐策略,能同时提高LRM的推理能力和安全性。
Key Takeaways
- LRMs虽在多种任务上表现出强大的推理能力,但其安全性能仍是关注重点。
- 本文探讨了LRMs的脆弱性原因,并提出了提高LLMs安全性的新方法。
- 通过改善LRM的推理性能以降低其安全性能,再通过对齐策略来平衡安全推理。
- 引入了基于Fuzzification的对齐策略FuSaR,能够成功降低安全风险并保留核心推理信息。
- FuSaR通过隐藏推理步骤中的危险实体和危险程序来解毒有害推理过程。
- 通过开源LRM的对齐实验验证,FuSaR策略的效果优于现有基线。
点此查看论文截图



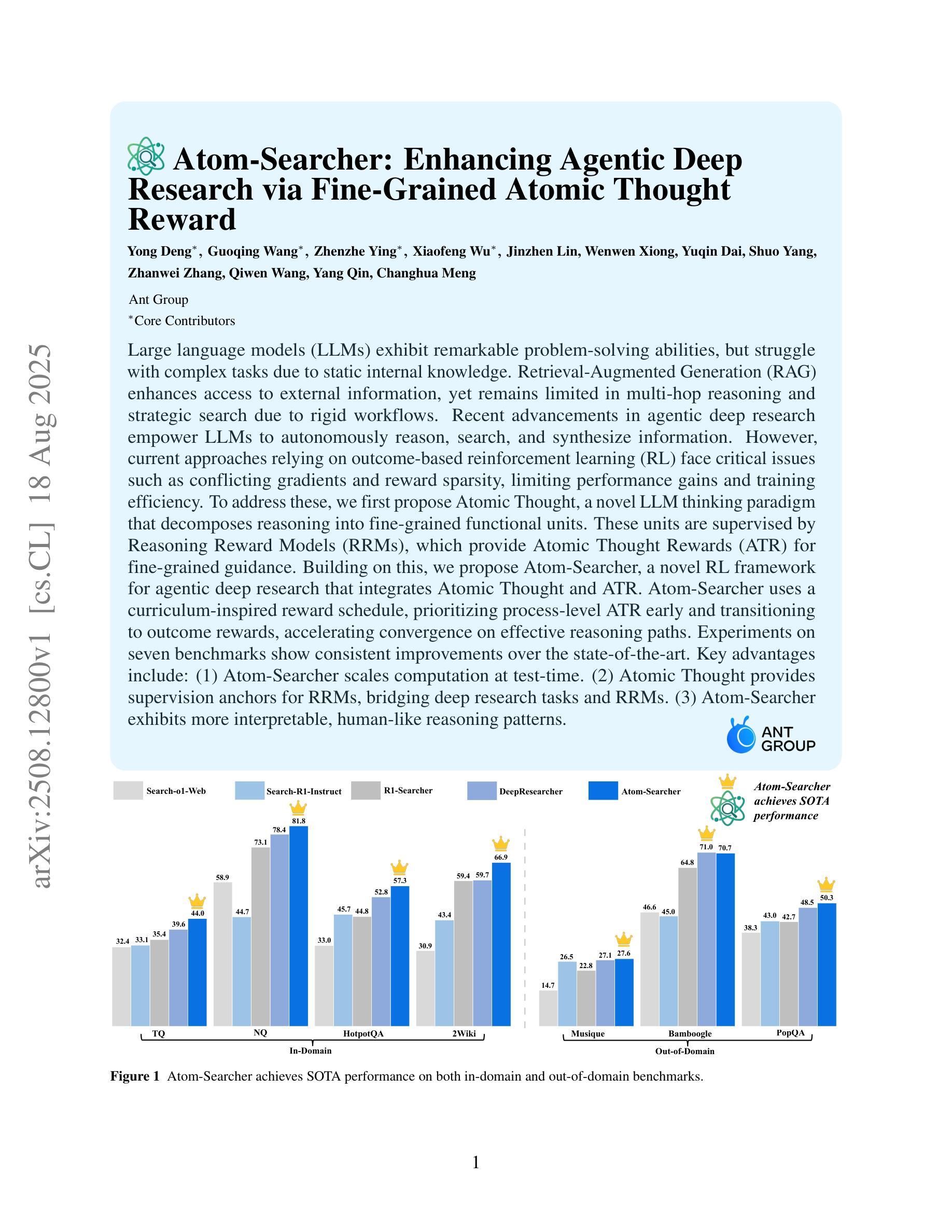
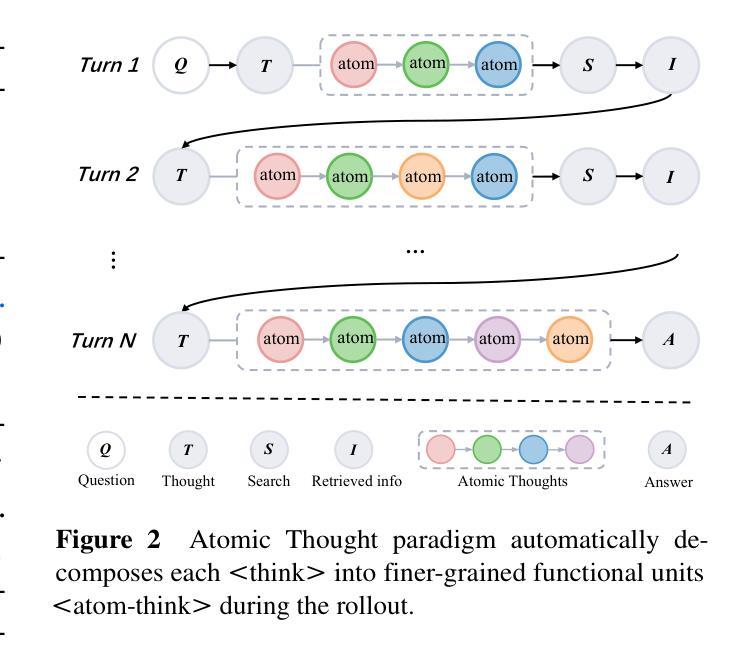
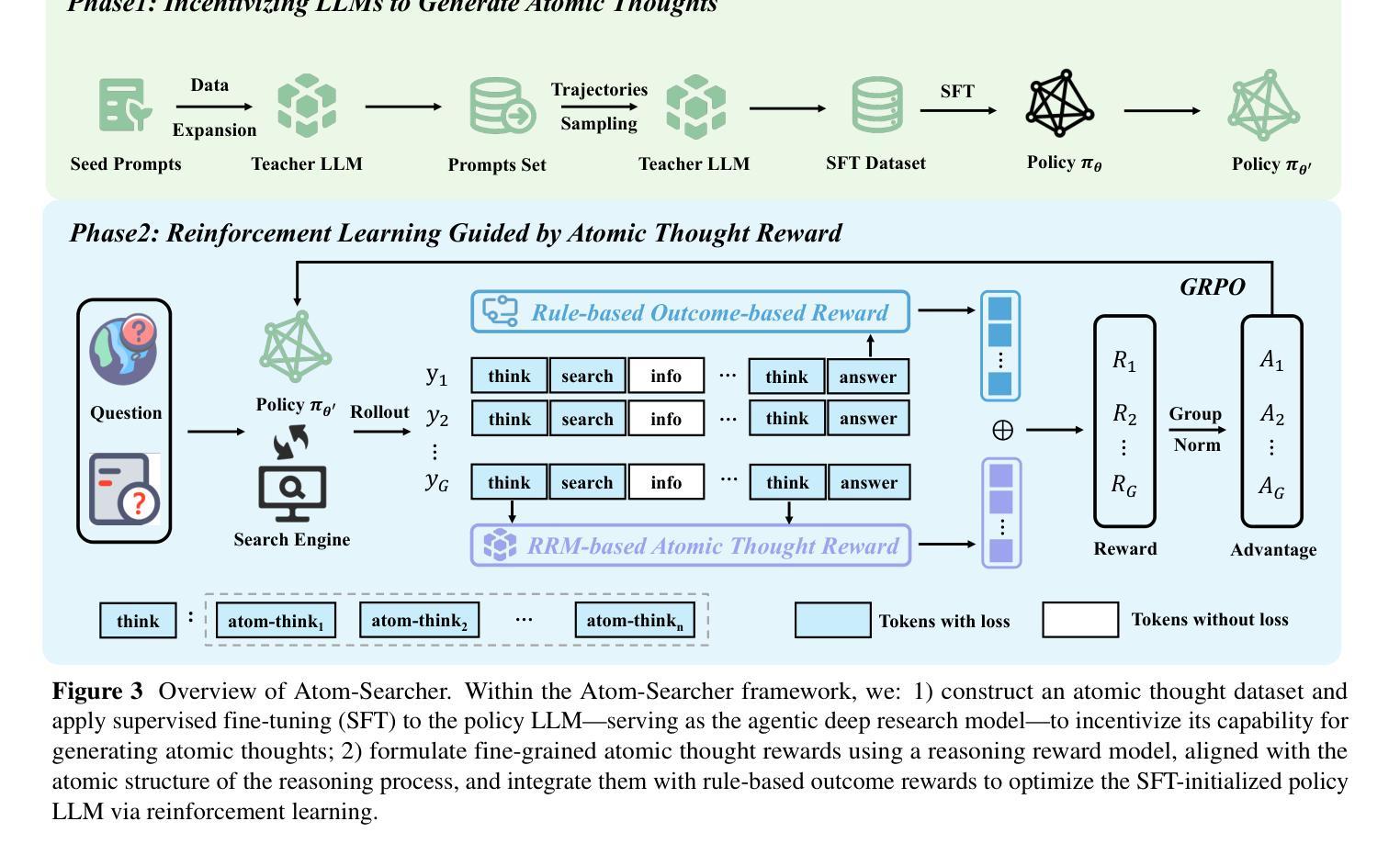
Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward
Authors:Yong Deng, Guoqing Wang, Zhenzhe Ying, Xiaofeng Wu, Jinzhen Lin, Wenwen Xiong, Yuqin Dai, Shuo Yang, Zhanwei Zhang, Qiwen Wang, Yang Qin, Changhua Meng
Large language models (LLMs) exhibit remarkable problem-solving abilities, but struggle with complex tasks due to static internal knowledge. Retrieval-Augmented Generation (RAG) enhances access to external information, yet remains limited in multi-hop reasoning and strategic search due to rigid workflows. Recent advancements in agentic deep research empower LLMs to autonomously reason, search, and synthesize information. However, current approaches relying on outcome-based reinforcement learning (RL) face critical issues such as conflicting gradients and reward sparsity, limiting performance gains and training efficiency. To address these, we first propose Atomic Thought, a novel LLM thinking paradigm that decomposes reasoning into fine-grained functional units. These units are supervised by Reasoning Reward Models (RRMs), which provide Atomic Thought Rewards (ATR) for fine-grained guidance. Building on this, we propose Atom-Searcher, a novel RL framework for agentic deep research that integrates Atomic Thought and ATR. Atom-Searcher uses a curriculum-inspired reward schedule, prioritizing process-level ATR early and transitioning to outcome rewards, accelerating convergence on effective reasoning paths. Experiments on seven benchmarks show consistent improvements over the state-of-the-art. Key advantages include: (1) Atom-Searcher scales computation at test-time. (2) Atomic Thought provides supervision anchors for RRMs, bridging deep research tasks and RRMs. (3) Atom-Searcher exhibits more interpretable, human-like reasoning patterns.
大型语言模型(LLM)展现出令人瞩目的解决问题的能力,但由于静态内部知识而在处理复杂任务时遇到困难。检索增强生成(RAG)增强了访问外部信息的能力,但由于工作流僵化,在跨步推理和策略搜索方面仍存在局限。最近的代理深度研究的进展使LLM能够自主推理、搜索和合成信息。然而,目前依赖结果基础上的强化学习(RL)的方法面临关键性问题,如梯度冲突和奖励稀疏,这限制了性能提升和训练效率。
论文及项目相关链接
Summary:
大型语言模型(LLM)具有出色的问题解决能力,但在复杂任务方面存在静态知识限制。检索增强生成(RAG)提高了对外部信息的访问能力,但在多跳推理和策略搜索方面仍存在刚性工作流程的限制。最近的研究进展使LLM能够自主推理、搜索和合成信息。然而,目前的方法依赖于基于结果的强化学习(RL),面临着梯度冲突和奖励稀疏等关键问题,限制了性能提升和训练效率。为此,我们提出了原子思维这一新型LLM思维范式和Atom-Searcher这一RL框架。原子思维将推理分解为精细的功能单元,受到推理奖励模型(RRM)的监督,为精细指导提供原子思维奖励(ATR)。Atom-Searcher结合了原子思维和ATR,采用课程式奖励时间表,早期优先过程级ATR,逐渐过渡到结果奖励,加速在有效推理路径上的收敛。在七个基准测试上的实验结果表明,与现有技术相比具有一致的优势。
Key Takeaways:
- 大型语言模型(LLM)在复杂任务方面存在静态知识限制。
- 检索增强生成(RAG)能提高对外部信息的访问,但在多跳推理和策略搜索中有刚性工作流程的限制。
- 目前的方法在强化学习(RL)中面临梯度冲突和奖励稀疏的问题。
- 提出了原子思维这一新型LLM思维范式,将推理分解为精细的功能单元。
- 推理奖励模型(RRM)为原子思维提供监督,通过原子思维奖励(ATR)进行精细指导。
- Atom-Searcher是结合原子思维和ATR的新型RL框架,采用课程式奖励时间表以加速有效推理路径的收敛。
点此查看论文截图
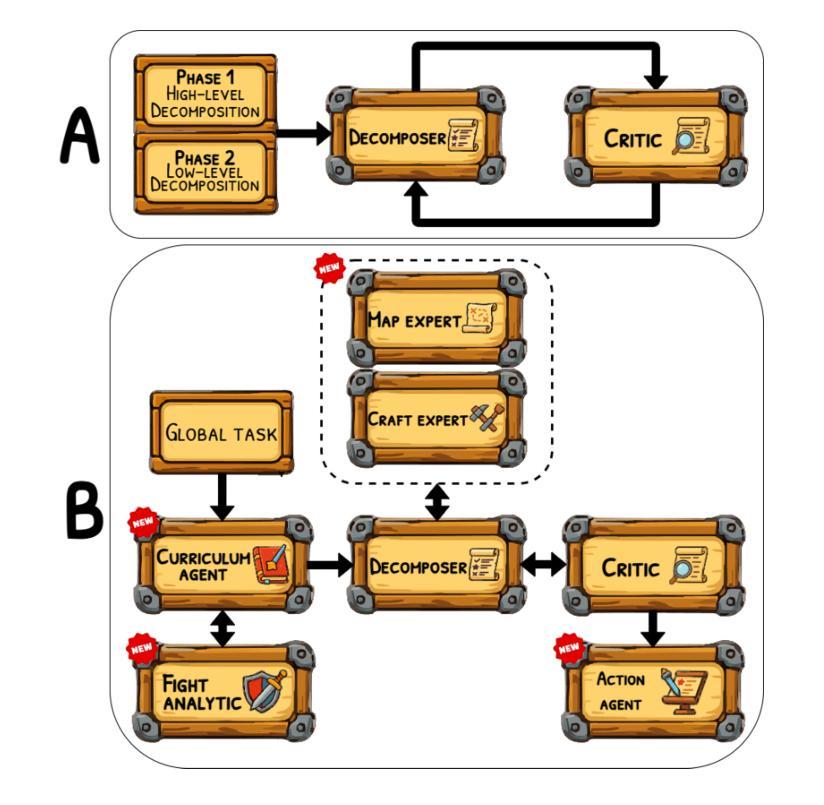
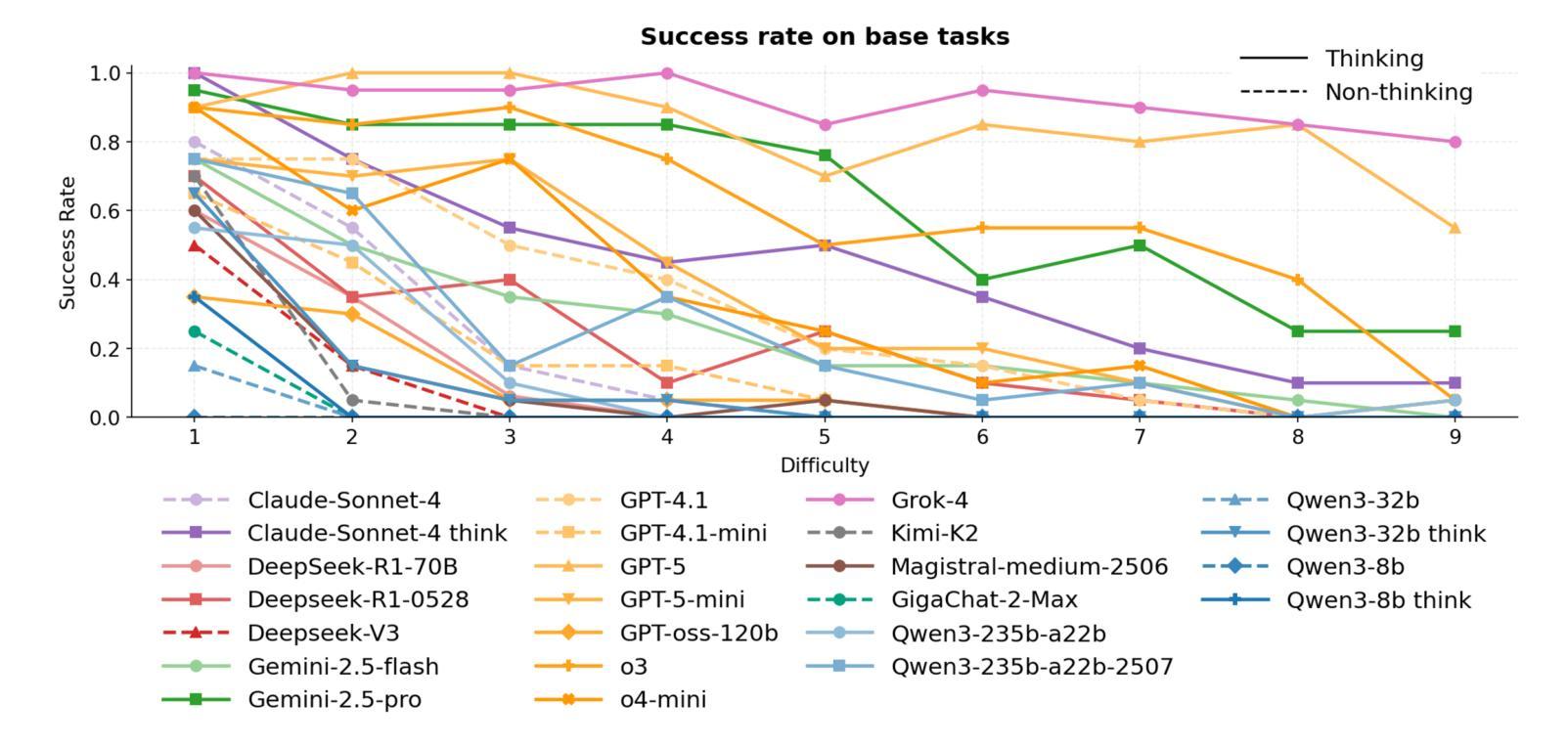
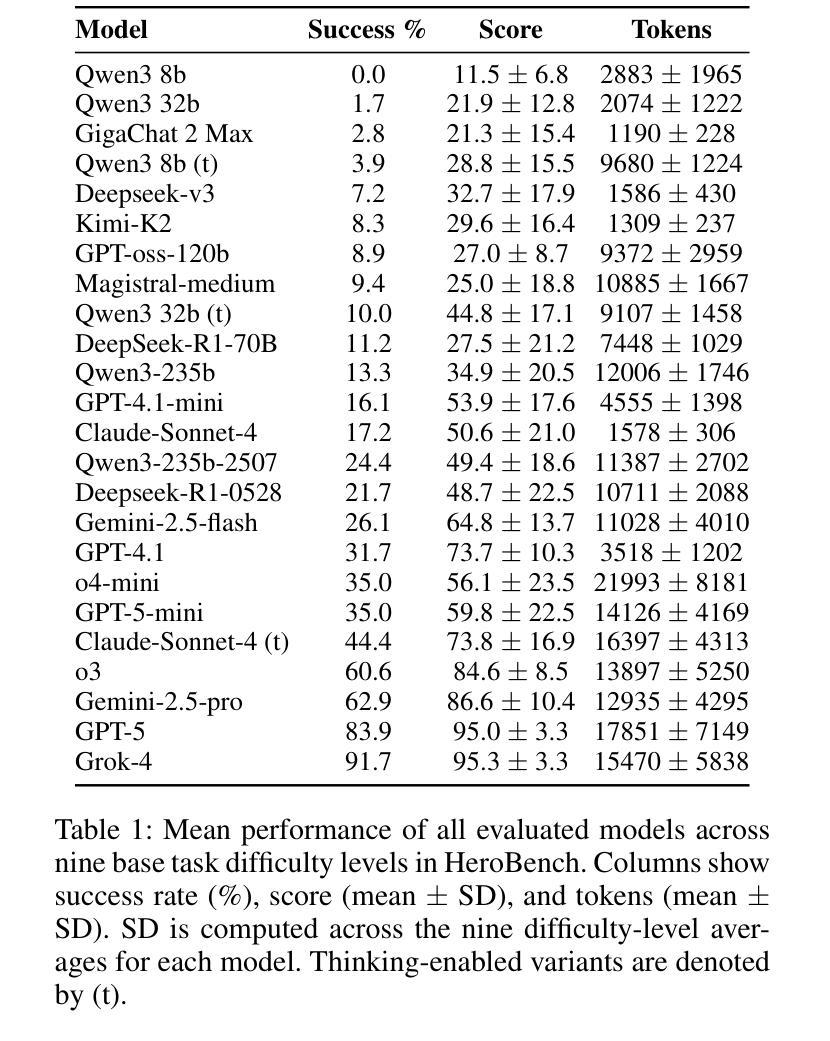
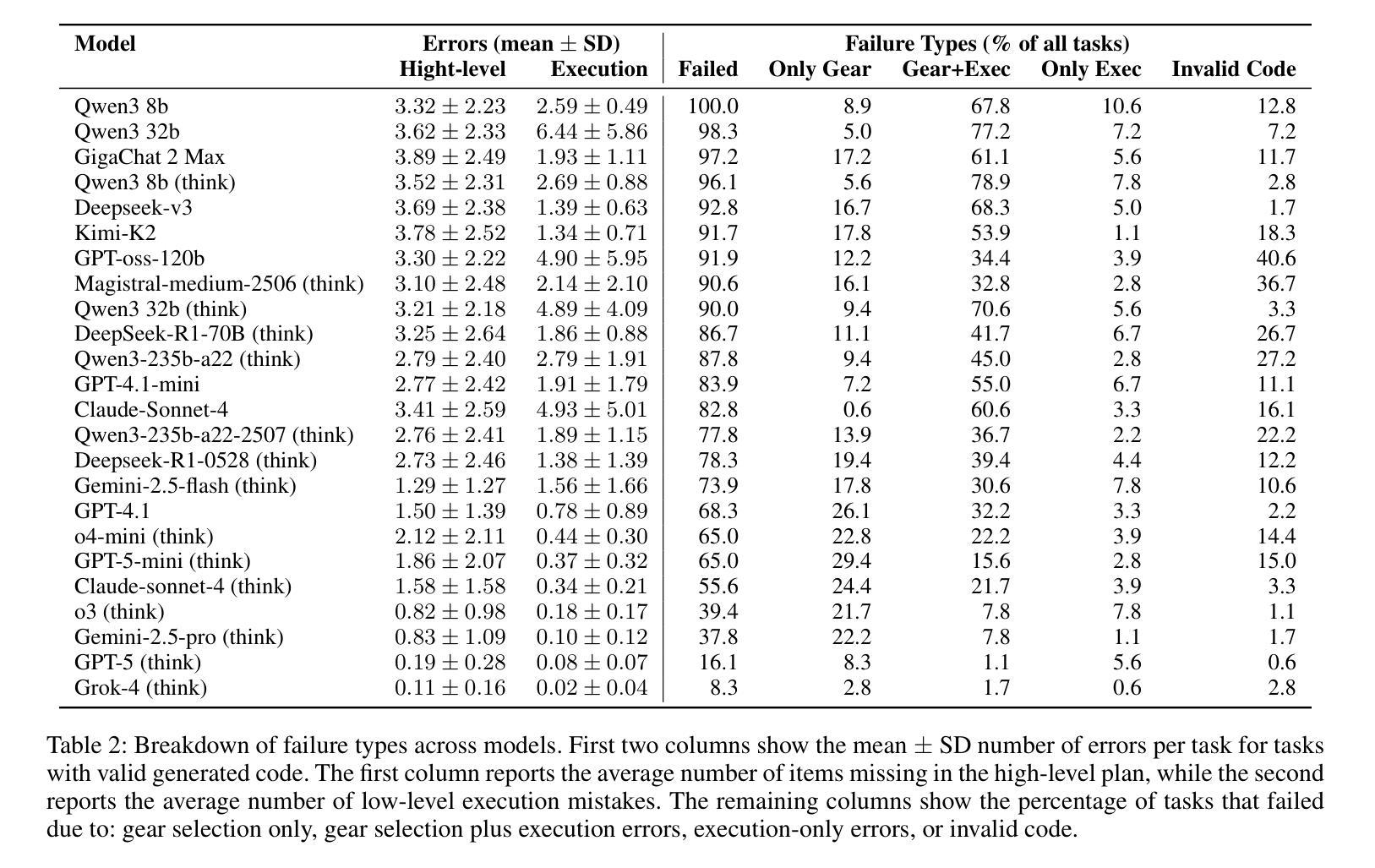
HeroBench: A Benchmark for Long-Horizon Planning and Structured Reasoning in Virtual Worlds
Authors:Petr Anokhin, Roman Khalikov, Stefan Rebrikov, Viktor Volkov, Artyom Sorokin, Vincent Bissonnette
Large language models (LLMs) have shown remarkable capabilities in isolated step-by-step reasoning tasks such as mathematics and programming, but their proficiency in long-horizon planning, where solutions require extended, structured sequences of interdependent actions, remains underexplored. Existing benchmarks typically assess LLMs through abstract or low-dimensional algorithmic tasks, failing to capture the complexity of realistic planning environments. We introduce HeroBench, a novel benchmark designed specifically to evaluate long-horizon planning and structured reasoning within complex RPG-inspired virtual worlds. HeroBench provides a rigorously constructed dataset of tasks covering a wide range of difficulties, a simulated environment to execute and validate agent plans, and detailed analytical tools for evaluating model performance. Tasks challenge models to formulate strategic plans, efficiently gather resources, master necessary skills, craft equipment, and defeat adversaries, reflecting practical scenarios’ layered dependencies and constraints. Our extensive evaluation of 25 state-of-the-art LLMs, spanning both open-source and proprietary models, including the GPT-5 family, reveals substantial performance disparities rarely observed in conventional reasoning benchmarks. Detailed error analysis further uncovers specific weaknesses in current models’ abilities to generate robust high-level plans and reliably execute structured actions. HeroBench thus not only significantly advances the evaluation of LLM reasoning but also provides a flexible, scalable foundation for future research into advanced, autonomous planning in virtual environments.
大型语言模型(LLM)在孤立的逐步推理任务(如数学和编程)中表现出了显著的能力,但它们在长期规划方面的熟练程度,即解决方案需要一系列相互依赖的行动,仍然未被充分探索。现有的基准测试通常通过抽象或低维算法任务来评估LLM,无法捕捉现实规划环境的复杂性。我们引入了HeroBench,这是一个专门为评估复杂RPG式虚拟世界中的长期规划和结构化推理而设计的新型基准测试。HeroBench提供了一个严格构建的任务数据集,涵盖了广泛的难度范围,一个模拟环境来执行和验证代理计划,以及详细的分析工具来评估模型性能。任务挑战模型制定战略计划,高效收集资源,掌握必要技能,制作装备,并击败敌人,反映了实际场景的分层依赖性和约束。我们对25个最先进的大型语言模型进行了广泛评估,包括开源和专有模型,以及GPT-5系列模型,揭示了与传统推理基准测试中很少观察到的显著性能差异。详细的错误分析进一步揭示了当前模型在生成稳健的高级计划和可靠执行结构化动作方面的特定弱点。因此,HeroBench不仅显著推进了LLM推理的评估,还为未来虚拟环境中先进自主规划的研究提供了灵活、可扩展的基础。
论文及项目相关链接
PDF Code is available at https://github.com/stefanrer/HeroBench
Summary
大型语言模型(LLMs)在逐步推理任务中表现出卓越的能力,如数学和编程。但对于需要一系列相互依赖的行动来解决问题的长期规划,其能力尚待探索。当前评估LLMs的基准测试通常是抽象的或低维度的算法任务,无法捕捉真实规划环境的复杂性。本文介绍了HeroBench,一个专为评估复杂RPG式虚拟世界中的长期规划和结构化推理而设计的基准测试。HeroBench提供了一个涵盖广泛难度范围的任务数据集、模拟执行和验证代理计划的环境,以及详细的评估模型性能的分析工具。该测试挑战模型制定战略计划、高效收集资源、掌握必要技能、制作装备和击败敌人,反映了实际场景的复杂依赖性和约束条件。对现有最新LLMs的评估显示,其在长期规划方面的性能差异显著。
Key Takeaways
- 大型语言模型(LLMs)在逐步推理任务中表现出卓越能力,但在长期规划方面尚待探索。
- 现有基准测试无法充分评估LLMs在真实规划环境中的表现。
- HeroBench是一个新的基准测试,旨在评估LLMs在复杂RPG式虚拟世界中的长期规划和结构化推理能力。
- HeroBench提供了涵盖不同难度范围的任务数据集、模拟环境和分析工具。
- 模型需制定战略计划、收集资源、掌握技能和制作装备等,反映实际场景的复杂性和约束。
- 对25个最新LLMs的评估显示,其在长期规划方面的性能差异显著。
点此查看论文截图

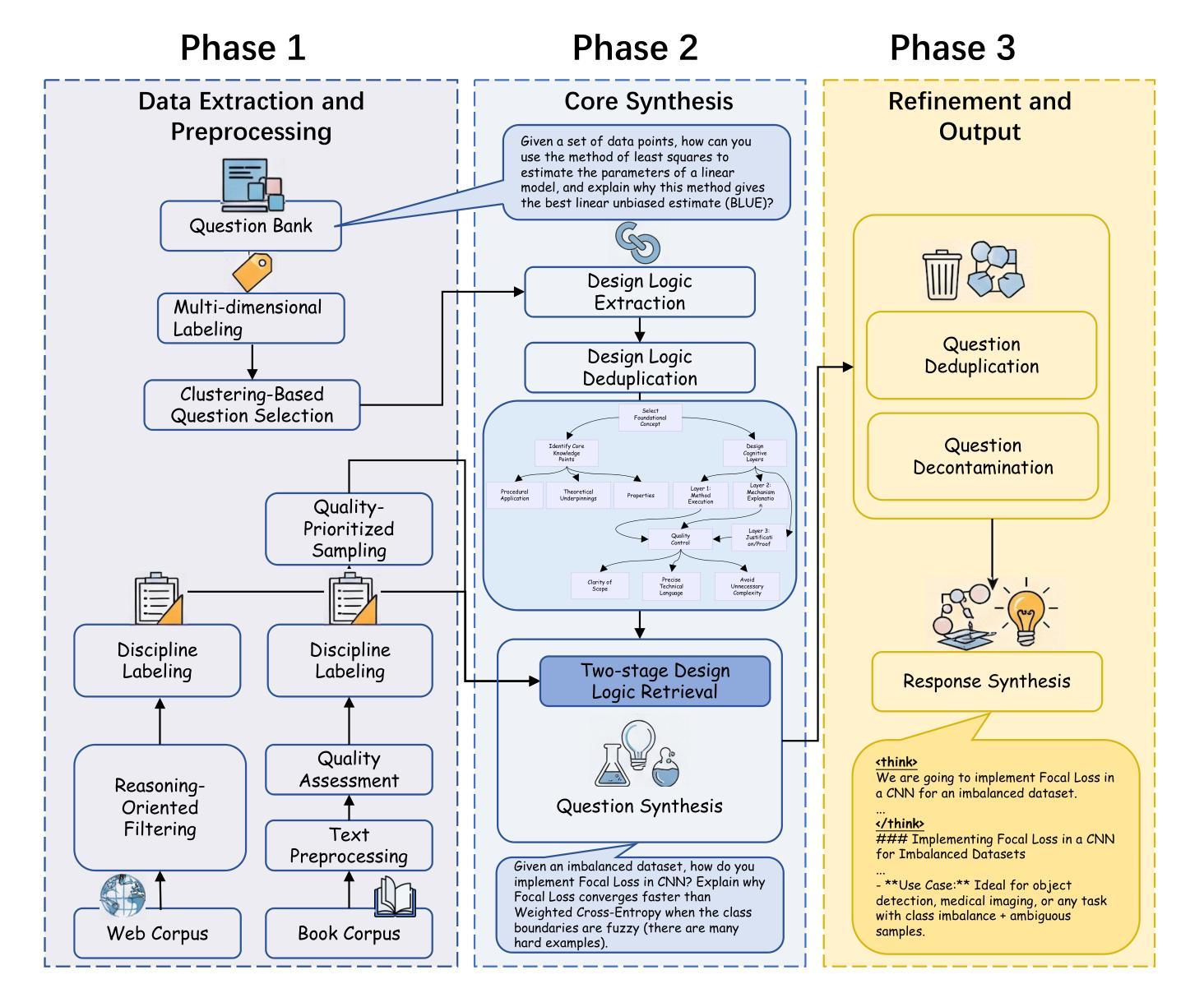
DESIGNER: Design-Logic-Guided Multidisciplinary Data Synthesis for LLM Reasoning
Authors:Weize Liu, Yongchi Zhao, Yijia Luo, Mingyu Xu, Jiaheng Liu, Yanan Li, Xiguo Hu, Yuchi Xu, Wenbo Su, Bo Zheng
Large language models (LLMs) have achieved remarkable success in many natural language tasks but still struggle with complex, multi-step reasoning, particularly across diverse disciplines. Existing reasoning datasets often either lack disciplinary breadth or the structural depth necessary to elicit robust reasoning behaviors. We propose DESIGNER: a DESIGN-logic-guidEd Reasoning data synthesis pipeline that leverages naturally available, extensive raw documents (book corpus and web corpus) to generate multidisciplinary challenging questions. A core innovation of our approach is the introduction of a Design Logic concept, which mimics the question-creation process of human educators. We use LLMs to reverse-engineer and abstract over 120,000 design logics from existing questions across various disciplines. By matching these design logics with disciplinary source materials, we are able to create reasoning questions that far surpass the difficulty and diversity of existing datasets. Based on this pipeline, we synthesized two large-scale reasoning datasets that span 75 disciplines: Design-Logic-Reasoning-Book (DLR-Book), containing 3.04 million challenging questions synthesized from the book corpus, and Design-Logic-Reasoning-Web (DLR-Web), with 1.66 million challenging questions from the web corpus. Our data analysis demonstrates that the questions synthesized by our method exhibit substantially greater difficulty and diversity than those in the baseline datasets. We validate the effectiveness of these datasets by conducting SFT experiments on the Qwen3-8B-Base and Qwen3-4B-Base models. The results show that our dataset significantly outperforms existing multidisciplinary datasets of the same volume. Training with the full datasets further enables the models to surpass the multidisciplinary reasoning performance of the official Qwen3-8B and Qwen3-4B models.
大规模语言模型(LLMs)在许多自然语言任务中取得了显著的成功,但在复杂的多步推理,特别是在跨学科方面仍面临挑战。现有的推理数据集要么缺乏学科广度,要么缺乏必要的结构深度,无法激发稳健的推理行为。我们提出了一个名为“DESIGNER”的设计逻辑引导推理数据合成管道,该管道利用自然可用的丰富原始文档(图书语料库和网络语料库)来生成跨学科难题。我们的方法的核心创新之处在于引入了设计逻辑概念,这一概念模仿了人类教育者的问题创建过程。我们使用LLMs逆向工程和抽象化来自不同学科现有问题的设计逻辑,超过12万个。通过将这些设计逻辑与学科来源材料相匹配,我们能够创建出远超现有数据集难度和多样性的推理问题。基于此管道,我们综合了两个跨越75个学科的大规模推理数据集:设计逻辑推理图书数据集(DLR-Book),包含从图书语料库中合成的304万个难题;设计逻辑推理网络数据集(DLR-Web),包含从网络语料库中提取的166万个难题。我们的数据分析表明,通过我们的方法合成的问题在难度和多样性上显著高于基准数据集的问题。我们通过使用Qwen3-8B-Base和Qwen3-4B-Base模型进行SFT实验来验证这些数据集的有效性。结果表明,我们的数据集在相同规模下显著优于现有的跨学科数据集。使用完整数据集进行训练进一步使模型超越了官方Qwen3-8B和Qwen3-4B模型的多学科推理性能。
论文及项目相关链接
Summary
大规模语言模型在许多自然语言任务中取得了显著的成功,但在复杂的多步骤推理,特别是跨学科推理方面仍存在挑战。现有的推理数据集缺乏学科广度或结构深度,无法激发稳健的推理行为。本文提出了一个名为DESIGNER的推理数据合成管道,它利用自然可用的丰富原始文档(书籍语料库和网络语料库)来生成跨学科挑战性问题。该方法的核心创新之处在于引入了设计逻辑概念,这一概念模仿了人类教育者的问题创建过程。通过这一管道,我们合成了两个大规模跨学科的推理数据集——DLR-Book和DLR-Web。数据分析显示,与我们方法合成的题目相比,基线数据集的题目难度和多样性存在明显不足。通过对比实验验证了这些数据集的有效性。训练完整数据集可以显著提升模型跨学科推理能力,并超过官方模型的性能表现。这是一项面向大规模跨学科的复杂多步骤推理的重要贡献。
Key Takeaways
- 大规模语言模型在多种自然语言任务中表现优异,但在复杂多步骤、跨学科推理方面存在挑战。
- 现有推理数据集缺乏学科广度或结构深度,难以有效促进模型的推理能力。
- 提出了一种名为DESIGNER的数据合成管道,利用书籍和网络语料库生成跨学科挑战性问题。
- 通过引入设计逻辑概念,模拟人类教育者的问题创建过程。
- 合成两个大规模跨学科推理数据集——DLR-Book和DLR-Web,难度和多样性超过现有数据集。
- 数据集的有效性通过对比实验得到验证,训练完整数据集显著提升模型跨学科推理能力。
点此查看论文截图


Vision-G1: Towards General Vision Language Reasoning with Multi-Domain Data Curation
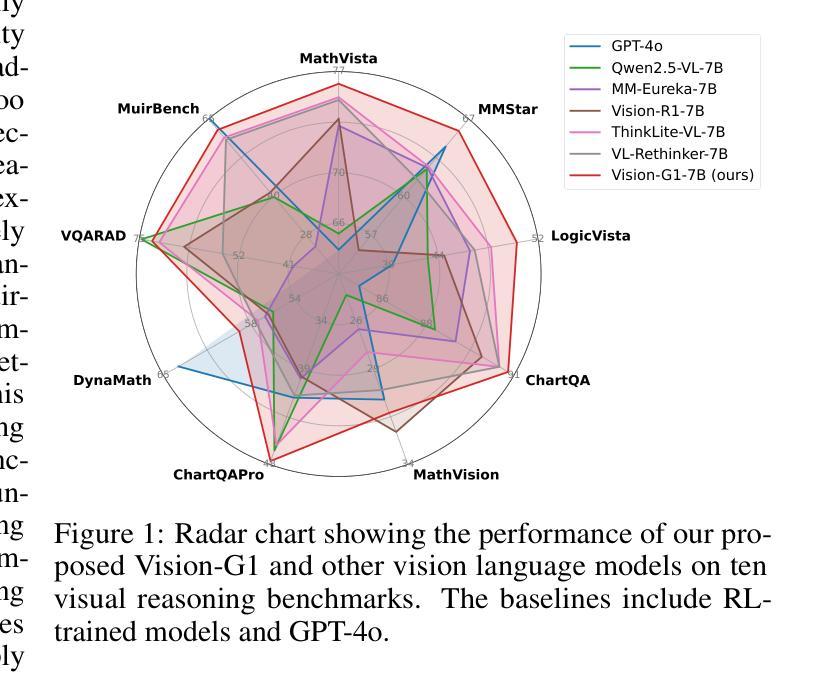
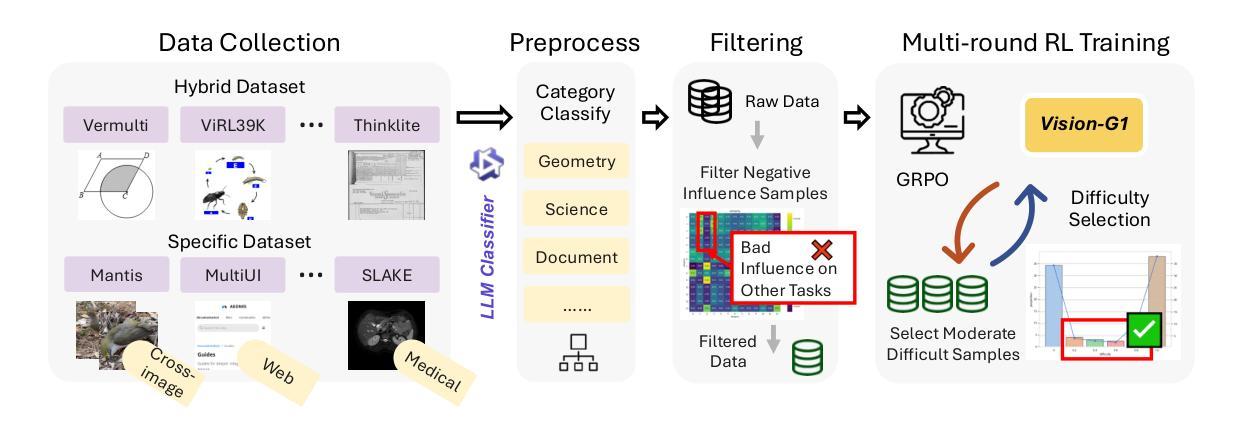
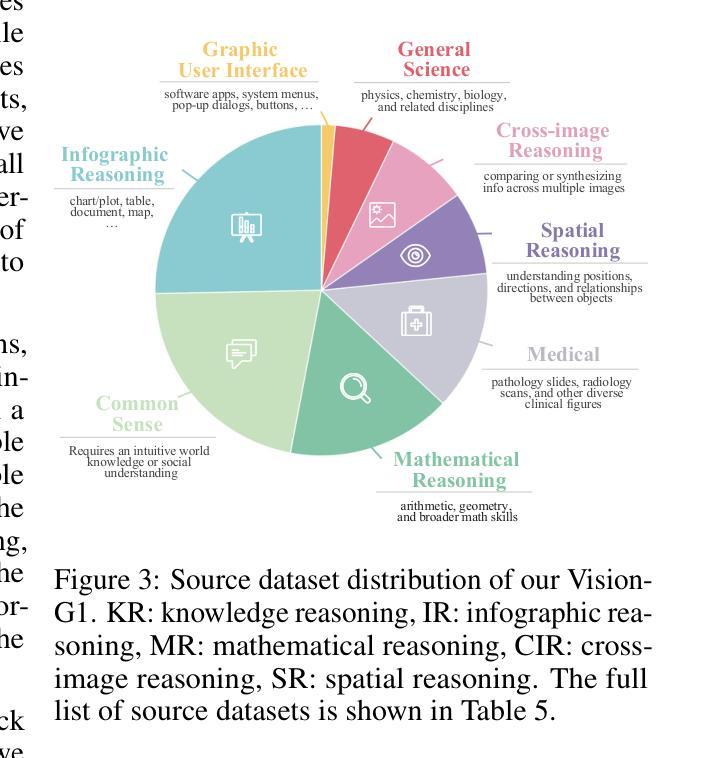
Authors:Yuheng Zha, Kun Zhou, Yujia Wu, Yushu Wang, Jie Feng, Zhi Xu, Shibo Hao, Zhengzhong Liu, Eric P. Xing, Zhiting Hu
Despite their success, current training pipelines for reasoning VLMs focus on a limited range of tasks, such as mathematical and logical reasoning. As a result, these models face difficulties in generalizing their reasoning capabilities to a wide range of domains, primarily due to the scarcity of readily available and verifiable reward data beyond these narrowly defined areas. Moreover, integrating data from multiple domains is challenging, as the compatibility between domain-specific datasets remains uncertain. To address these limitations, we build a comprehensive RL-ready visual reasoning dataset from 46 data sources across 8 dimensions, covering a wide range of tasks such as infographic, mathematical, spatial, cross-image, graphic user interface, medical, common sense and general science. We propose an influence function based data selection and difficulty based filtering strategy to identify high-quality training samples from this dataset. Subsequently, we train the VLM, referred to as Vision-G1, using multi-round RL with a data curriculum to iteratively improve its visual reasoning capabilities. Our model achieves state-of-the-art performance across various visual reasoning benchmarks, outperforming similar-sized VLMs and even proprietary models like GPT-4o and Gemini-1.5 Flash. The model, code and dataset are publicly available at https://github.com/yuh-zha/Vision-G1.
尽管取得了成功,但当前用于推理VLM的训练流程主要集中在有限的范围内任务上,如数学和逻辑推理。因此,这些模型在将推理能力推广到广泛领域时面临困难,这主要是由于超出这些狭义定义领域之外的可用和可验证的奖励数据稀缺。此外,由于特定数据集之间的兼容性不确定,因此从多个领域整合数据具有挑战性。为了解决这些局限性,我们从8个维度的46个数据源构建了全面的RL就绪视觉推理数据集,涵盖广泛的任务,如信息图表、数学、空间、跨图像、图形用户界面、医学、常识和普通科学。我们提出了一种基于影响函数的数据选择和基于难度的过滤策略,以从数据集中识别高质量的训练样本。随后,我们使用多轮强化学习(RL)和一份教学大纲来训练称为Vision-G1的VLM模型,以迭代地提高其视觉推理能力。我们的模型在各种视觉推理基准测试中实现了最先进的性能表现,超越了类似规模的VLM模型以及专有模型,如GPT-4o和Gemini-1.5 Flash。模型、代码和数据集可在以下网站公开访问:[网址链接]。
论文及项目相关链接
Summary
视觉语言模型(VLM)目前大多只关注有限的推理任务,如数学和逻辑推理,难以泛化到更广泛的领域。为了解决这一问题,该研究构建了一个全面的强化学习(RL)可用视觉推理数据集,涵盖8个维度的46个数据源,并提出了一种基于影响函数的数据选择和基于难度的过滤策略来识别高质量的训练样本。使用多轮强化学习和数据课程训练出的Vision-G1模型,在多种视觉推理基准测试中达到最佳性能,优于同类大小的VLM和专有模型如GPT-4o和Gemini-1.5 Flash。
Key Takeaways
- 当前VLM的训练管道主要关注有限的推理任务,如数学和逻辑,导致模型在泛化到多个领域时遇到困难。
- 缺乏广泛可用的可验证奖励数据是限制VLM泛化能力的主要原因之一。
- 研究者构建了一个全面的RL-ready视觉推理数据集,涵盖多个领域的数据源。
- 提出了一种基于影响函数的数据选择和基于难度的过滤策略来识别高质量的训练样本。
- 使用多轮强化学习和数据课程训练的Vision-G1模型在各种视觉推理测试中表现最佳。
- Vision-G1模型优于同类大小的VLM和其他专有模型。
点此查看论文截图

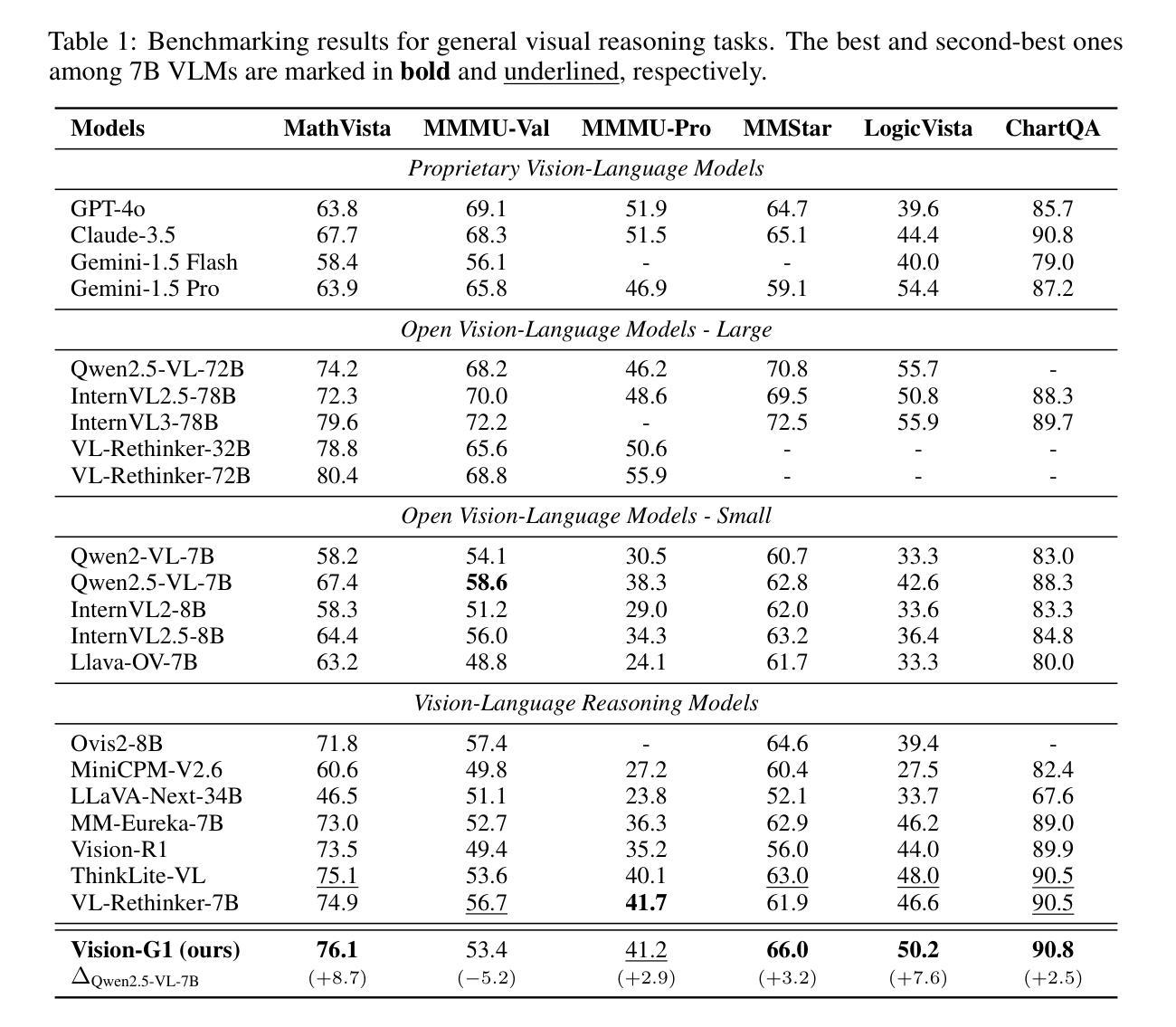
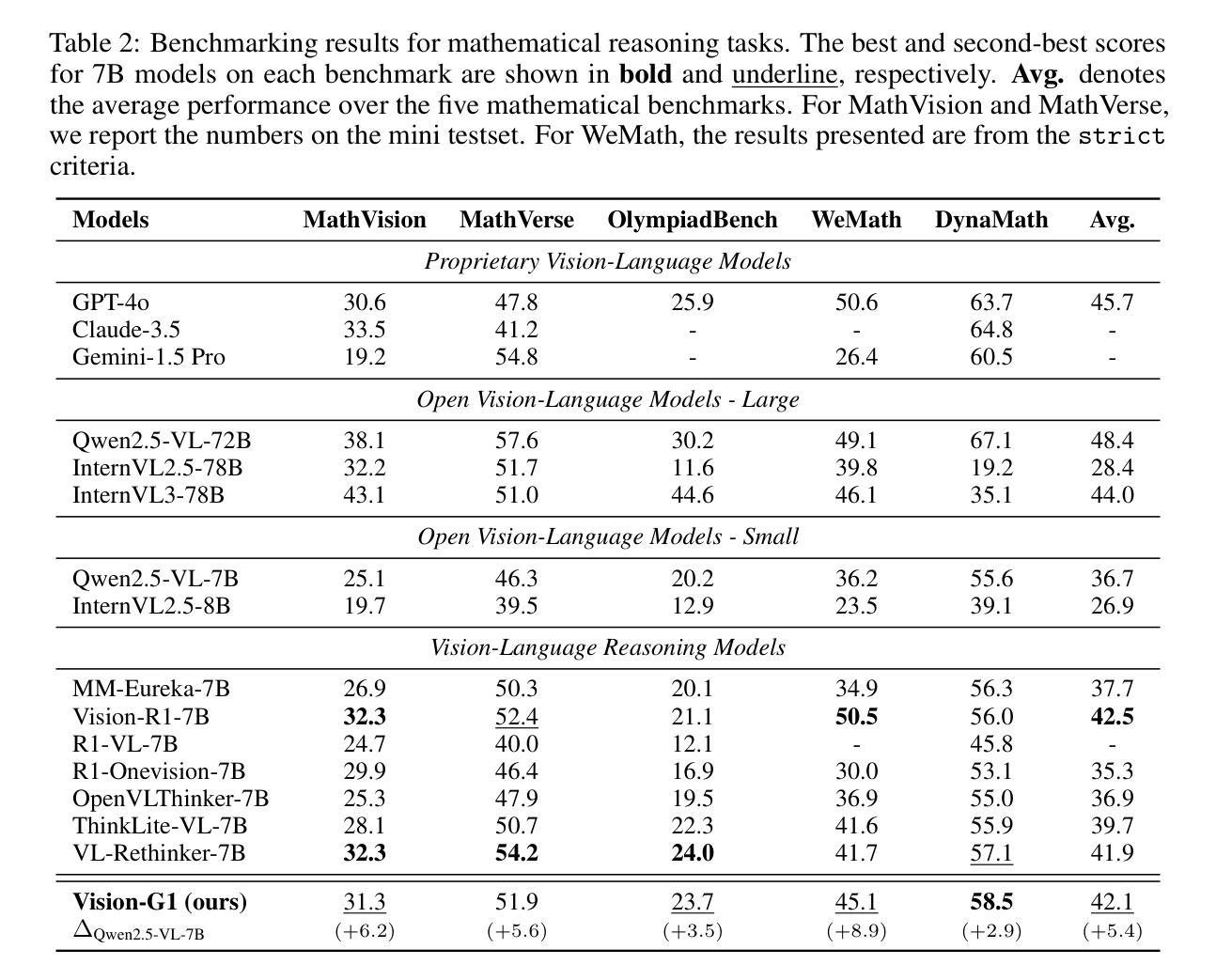
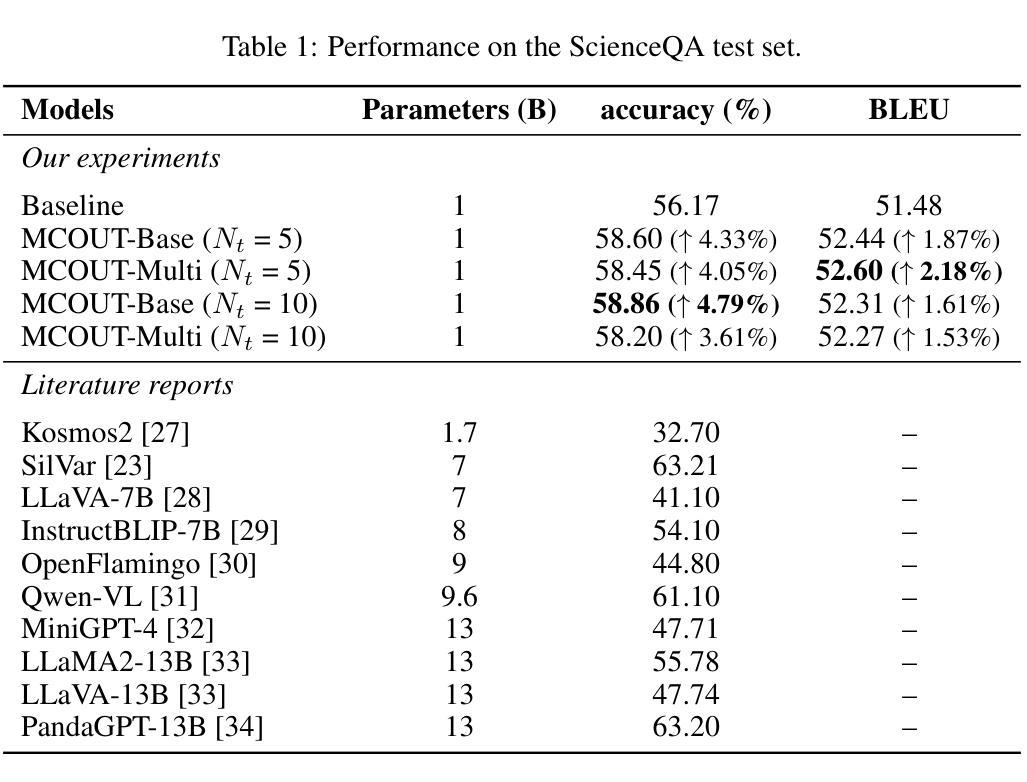
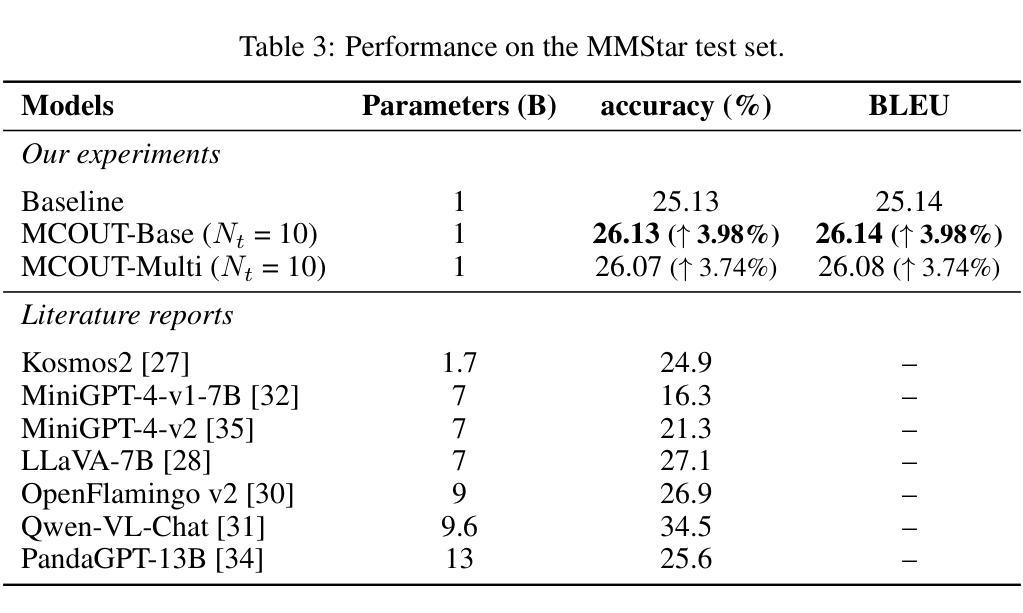
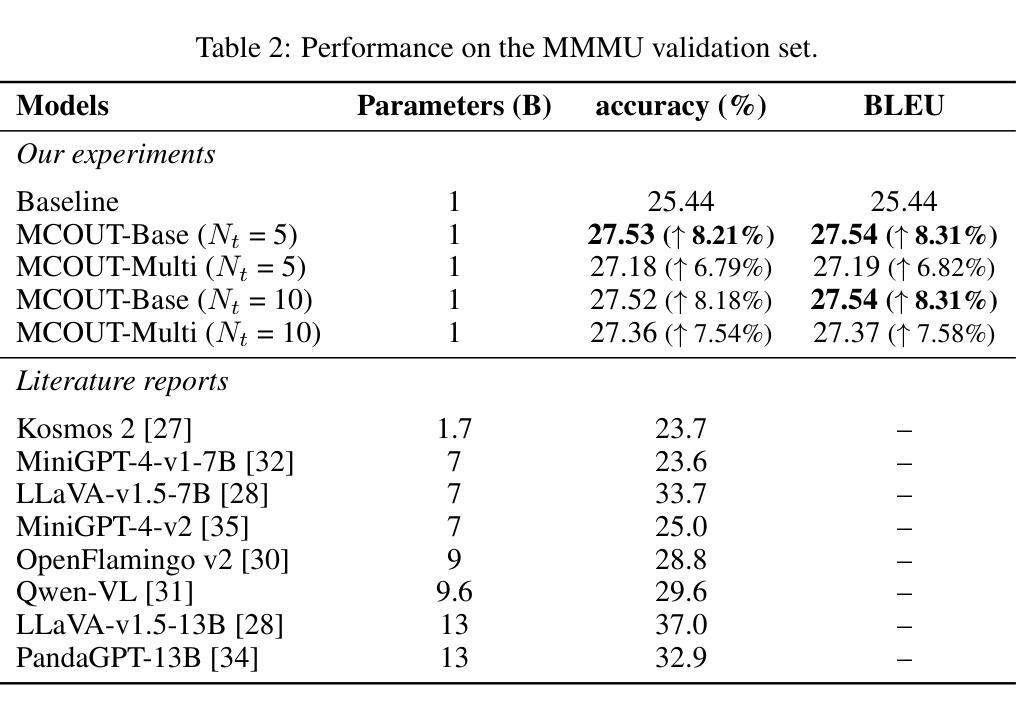
Multimodal Chain of Continuous Thought for Latent-Space Reasoning in Vision-Language Models
Authors:Tan-Hanh Pham, Chris Ngo
Many reasoning techniques for large multimodal models adapt language model approaches, such as Chain-of-Thought (CoT) prompting, which express reasoning as word sequences. While effective for text, these methods are suboptimal for multimodal contexts, struggling to align audio, visual, and textual information dynamically. To explore an alternative paradigm, we propose the Multimodal Chain of Continuous Thought (MCOUT), which enables reasoning directly in a joint latent space rather than in natural language. In MCOUT, the reasoning state is represented as a continuous hidden vector, iteratively refined and aligned with visual and textual embeddings, inspired by human reflective cognition. We develop two variants: MCOUT-Base, which reuses the language model`s last hidden state as the continuous thought for iterative reasoning, and MCOUT-Multi, which integrates multimodal latent attention to strengthen cross-modal alignment between visual and textual features. Experiments on benchmarks including MMMU, ScienceQA, and MMStar show that MCOUT consistently improves multimodal reasoning, yielding up to 8.23% accuracy gains over strong baselines and improving BLEU scores up to 8.27% across multiple-choice and open-ended tasks. These findings highlight latent continuous reasoning as a promising direction for advancing LMMs beyond language-bound CoT, offering a scalable framework for human-like reflective multimodal inference. Code is available at https://github.com/Hanhpt23/OmniMod.
许多针对大型多模态模型的推理技术都采用了语言模型方法,如思维链(CoT)提示,它将推理表达为单词序列。虽然这在文本中很有效,但这些方法在多模态上下文中并不理想,难以动态对齐音频、视觉和文本信息。为了探索一种替代的范式,我们提出了多模态连续思维链(MCOUT),它能够在联合潜在空间中进行直接推理,而不是在自然语言中。在MCOUT中,推理状态被表示为连续的隐藏向量,通过迭代优化和与视觉和文本嵌入的对齐来体现,这受到人类反思认知的启发。我们开发了两个变体:MCOUT-Base,它利用语言模型的最后一个隐藏状态作为连续思维来进行迭代推理;以及MCOUT-Multi,它整合多模态潜在注意力,以加强视觉和文本特征之间的跨模态对齐。在包括MMMU、ScienceQA和MMStar等基准测试上的实验表明,MCOUT在多个选择任务和开放任务中,不断提高多模态推理的准确性,相较于强大的基准模型有高达8.23%的准确率提升和高达8.27%的BLEU得分提升。这些发现突显出潜在连续推理作为一个有前途的方向,推动语言模型超越语言界限的思维链,为类人类反思多模态推断提供可扩展的框架。相关代码可访问 https://github.com/Hanhpt23/OmniMod 了解。
论文及项目相关链接
Summary
本文提出了一种新的多模态推理方法——连续多模态思维链(MCOUT)。该方法在多模态场景中不使用基于自然语言模型的推理方式,如思维链提示等。相反,它在联合潜在空间中直接进行推理,借鉴人类反思认知的特性,通过连续隐藏向量表示推理状态,并迭代地对其进行优化和与视觉和文本嵌入对齐。实验结果表明,MCOUT在多个基准测试中均提高了多模态推理性能,与现有强基线相比,准确率提高了最多8.23%,并在多项选择和开放任务中BLEU得分提高了最多8.27%。这表明连续潜在推理是推进语言模型超越语言限制思维链的一个有前途的方向。
Key Takeaways
- 多模态场景中的现有推理技术如思维链提示主要基于自然语言模型,不适用于多模态场景。
- MCOUT方法在多模态场景中直接进行联合潜在空间中的推理,不使用自然语言模型的方式。
- MCOUT通过连续隐藏向量表示推理状态,并迭代地对其进行优化和与视觉和文本嵌入对齐。
- MCOUT有两种变体:MCOUT-Base和MCOUT-Multi,分别侧重于不同的实现方式。
- 实验结果表明,MCOUT在多模态推理中表现出优异性能,相较于强基线在准确率上有显著提升。
点此查看论文截图

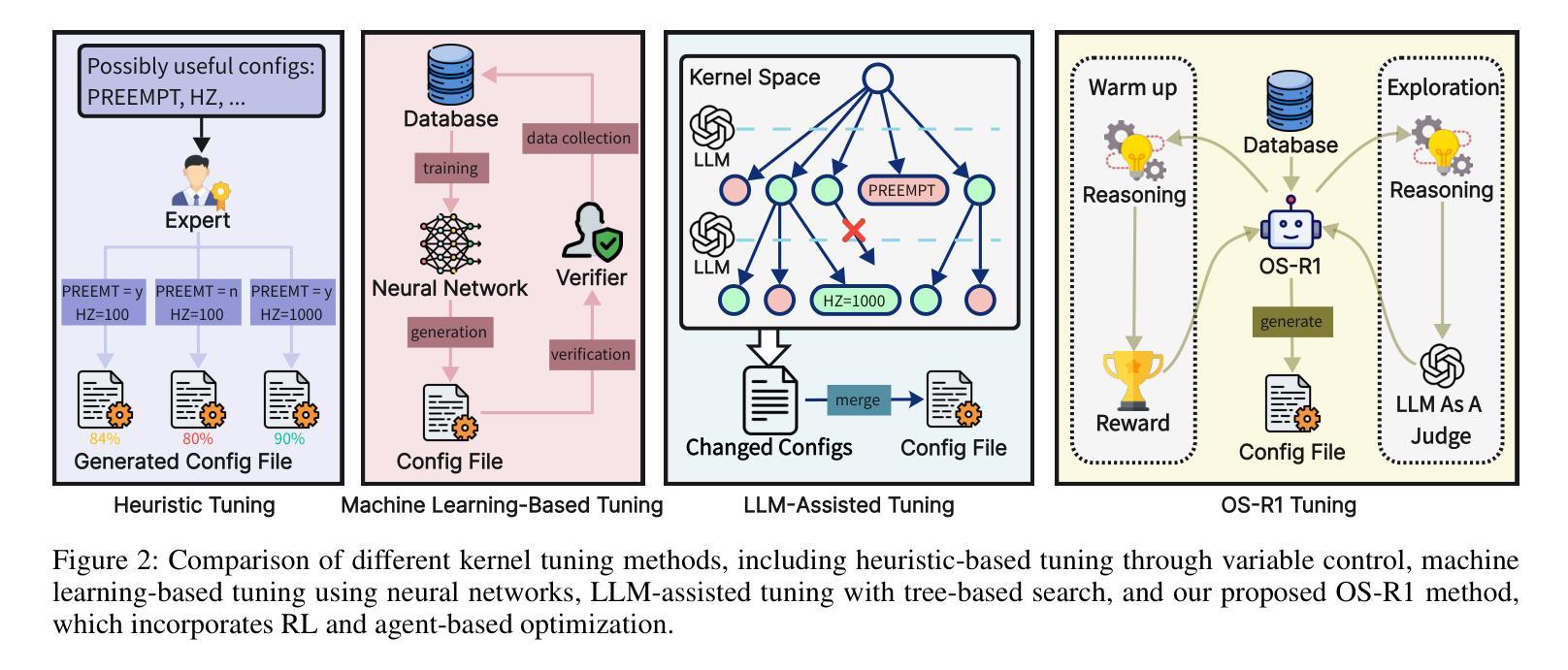
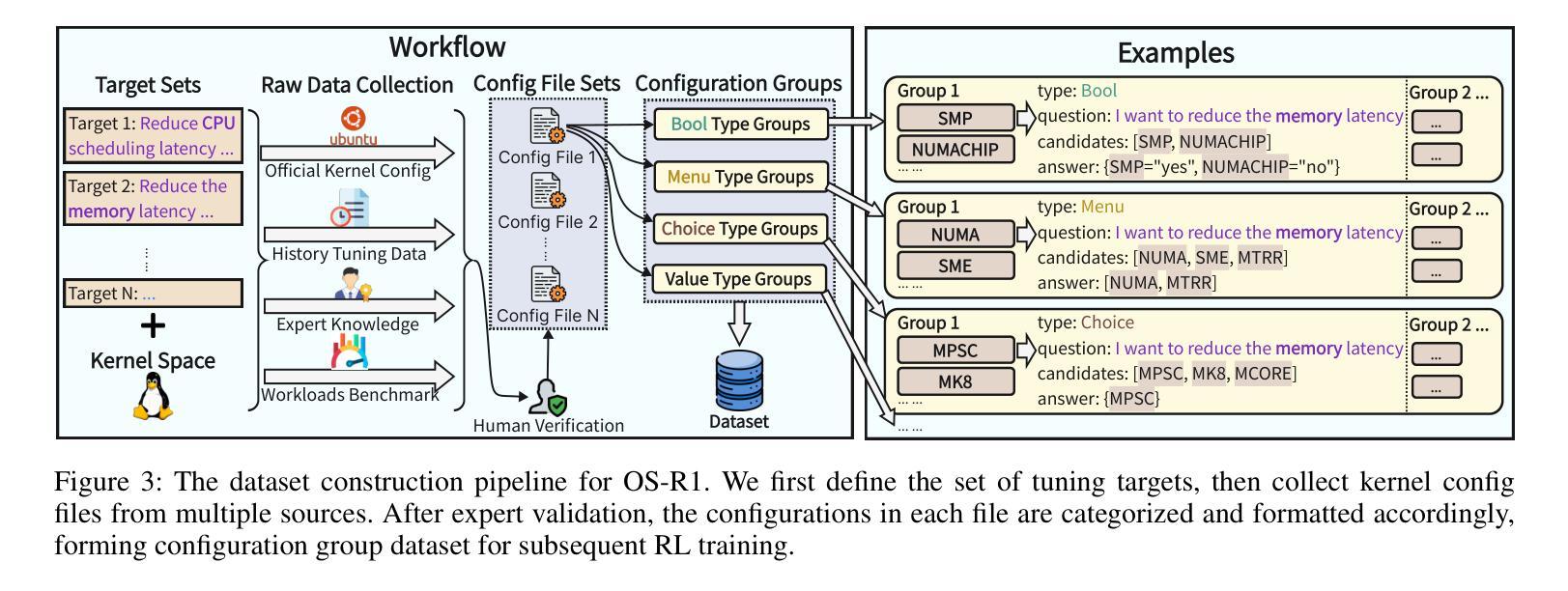
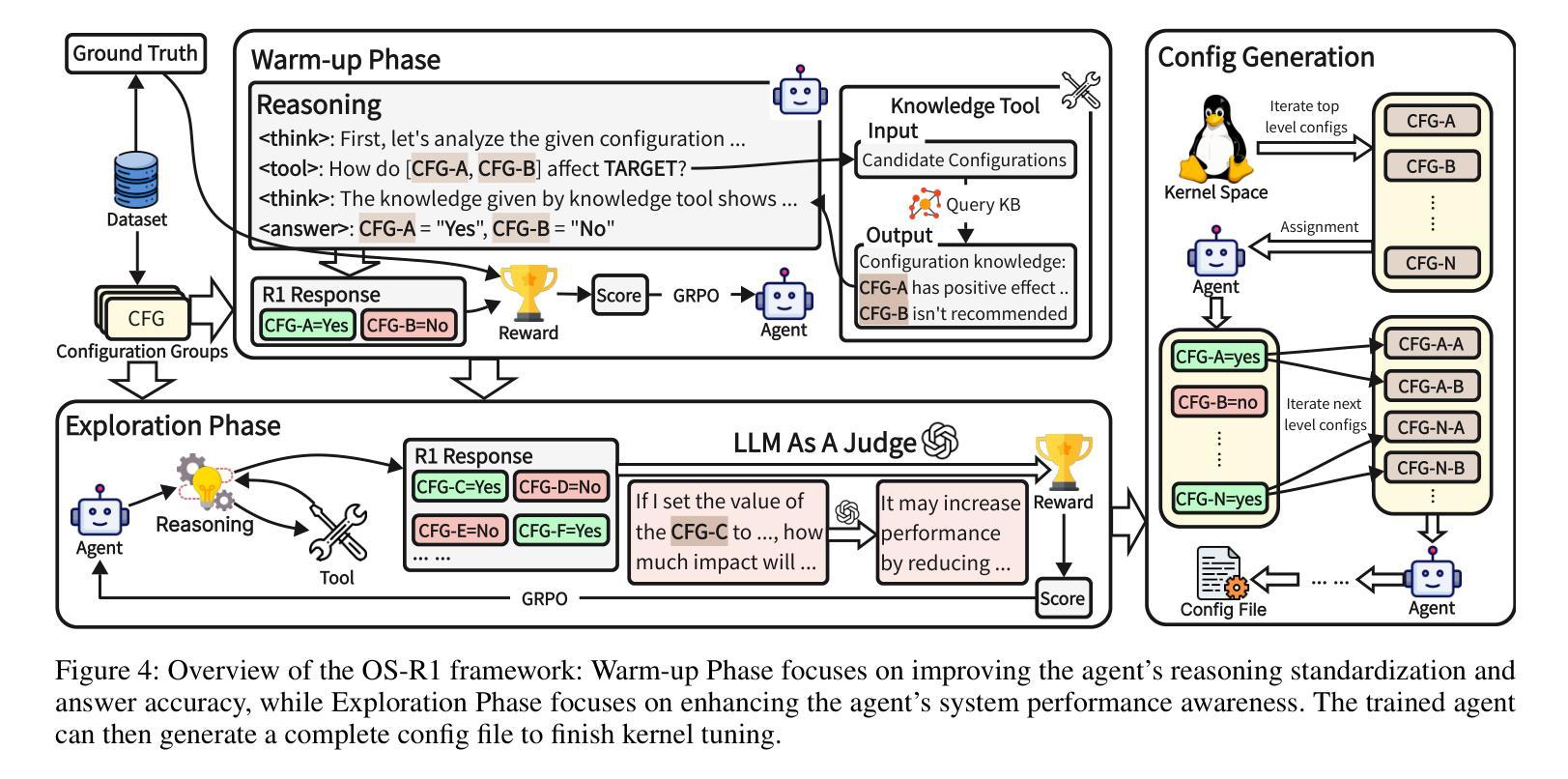
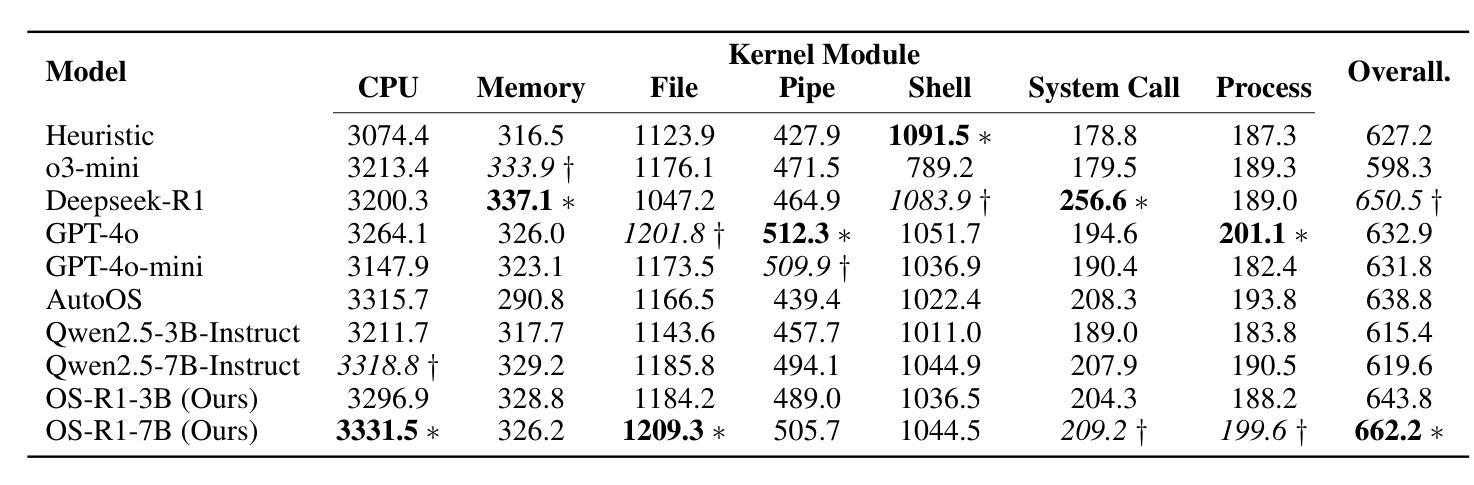
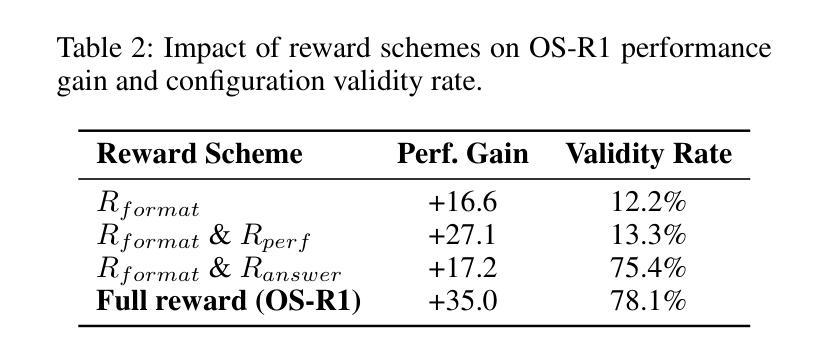
OS-R1: Agentic Operating System Kernel Tuning with Reinforcement Learning
Authors:Hongyu Lin, Yuchen Li, Haoran Luo, Kaichun Yao, Libo Zhang, Mingjie Xing, Yanjun Wu
Linux kernel tuning is essential for optimizing operating system (OS) performance. However, existing methods often face challenges in terms of efficiency, scalability, and generalization. This paper introduces OS-R1, an agentic Linux kernel tuning framework powered by rule-based reinforcement learning (RL). By abstracting the kernel configuration space as an RL environment, OS-R1 facilitates efficient exploration by large language models (LLMs) and ensures accurate configuration modifications. Additionally, custom reward functions are designed to enhance reasoning standardization, configuration modification accuracy, and system performance awareness of the LLMs. Furthermore, we propose a two-phase training process that accelerates convergence and minimizes retraining across diverse tuning scenarios. Experimental results show that OS-R1 significantly outperforms existing baseline methods, achieving up to 5.6% performance improvement over heuristic tuning and maintaining high data efficiency. Notably, OS-R1 is adaptable across various real-world applications, demonstrating its potential for practical deployment in diverse environments. Our dataset and code are publicly available at https://github.com/LHY-24/OS-R1.
Linux内核调优对于优化操作系统(OS)性能至关重要。然而,现有方法经常在效率、可扩展性和通用性方面面临挑战。本文介绍了OS-R1,这是一个由基于规则的强化学习(RL)驱动的Linux内核智能调优框架。通过将内核配置空间抽象为RL环境,OS-R1便于大型语言模型(LLM)进行高效探索,并确保准确的配置修改。此外,我们设计了自定义奖励函数,以提高LLM的推理标准化、配置修改准确性和系统性能意识。此外,我们提出了一种两阶段训练过程,以加速收敛并减少不同调优场景下的再训练时间。实验结果表明,OS-R1显著优于现有基线方法,在启发式调优的基础上实现了高达5.6%的性能提升,并保持了较高的数据效率。值得注意的是,OS-R1可以适应各种实际应用场景,显示出其在不同环境中实际部署的潜力。我们的数据集和代码可在[https://github.com/LHY-24/OS-R
论文及项目相关链接
Summary
本论文提出了一个基于规则强化学习(RL)的Linux内核调优框架OS-R1,用于优化操作系统(OS)性能。OS-R1通过抽象内核配置空间作为RL环境,促进大型语言模型(LLMs)的有效探索,并设计自定义奖励函数提高LLM的推理标准化、配置修改准确性和系统性能意识。实验结果显示,OS-R1显著优于现有基线方法,在性能上最多可提高5.6%,同时保持高数据效率,并适应各种实际应用场景。
Key Takeaways
- OS-R1是一个基于规则强化学习的Linux内核调优框架,旨在优化操作系统性能。
- OS-R1通过抽象内核配置空间作为强化学习环境,促进大型语言模型的有效探索。
- 自定义奖励函数的设计提高了大型语言模型的推理标准化、配置修改准确性和系统性能意识。
- OS-R1采用两阶段训练过程,以加速收敛并减少不同调优场景下的重新训练时间。
- 实验结果显示,OS-R1在性能上显著优于现有方法,最大可提高5.6%的性能。
- OS-R1具有良好的数据效率。
点此查看论文截图

REVEAL – Reasoning and Evaluation of Visual Evidence through Aligned Language
Authors:Ipsita Praharaj, Yukta Butala, Yash Butala
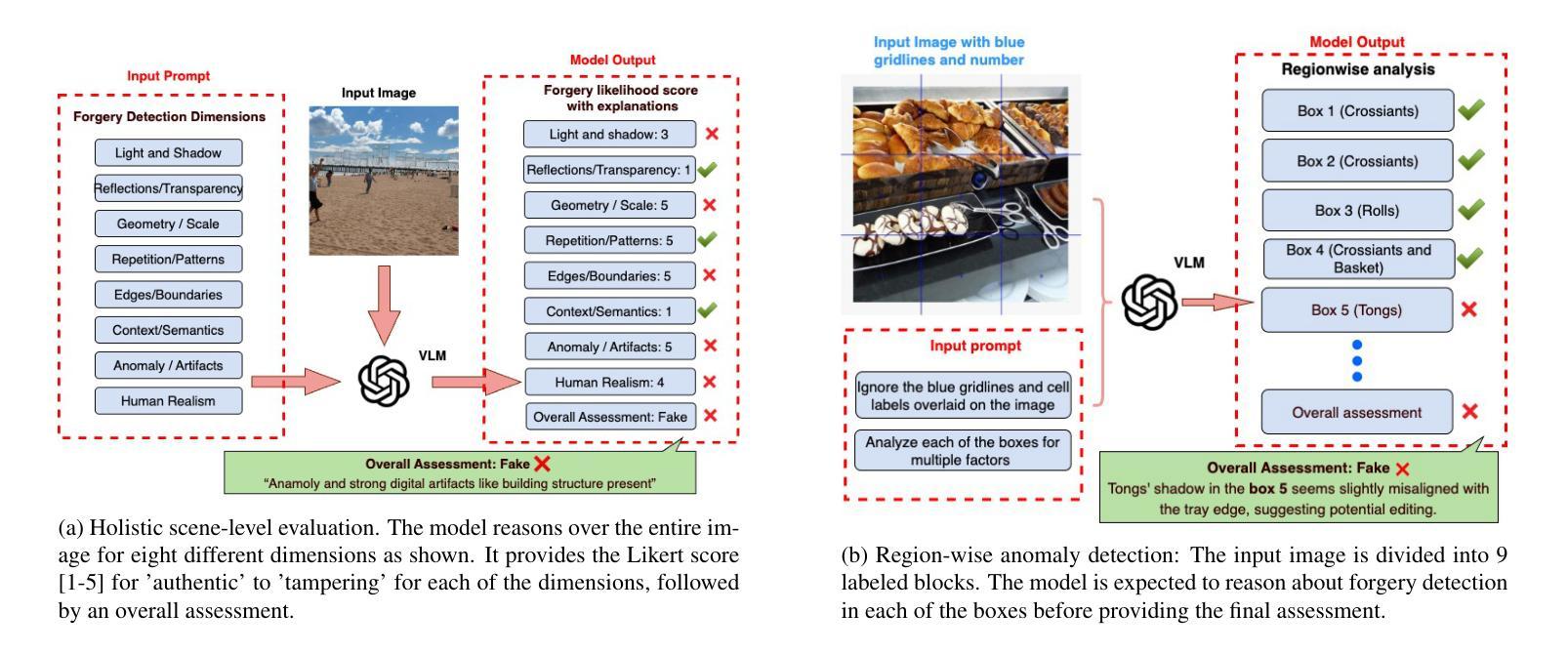
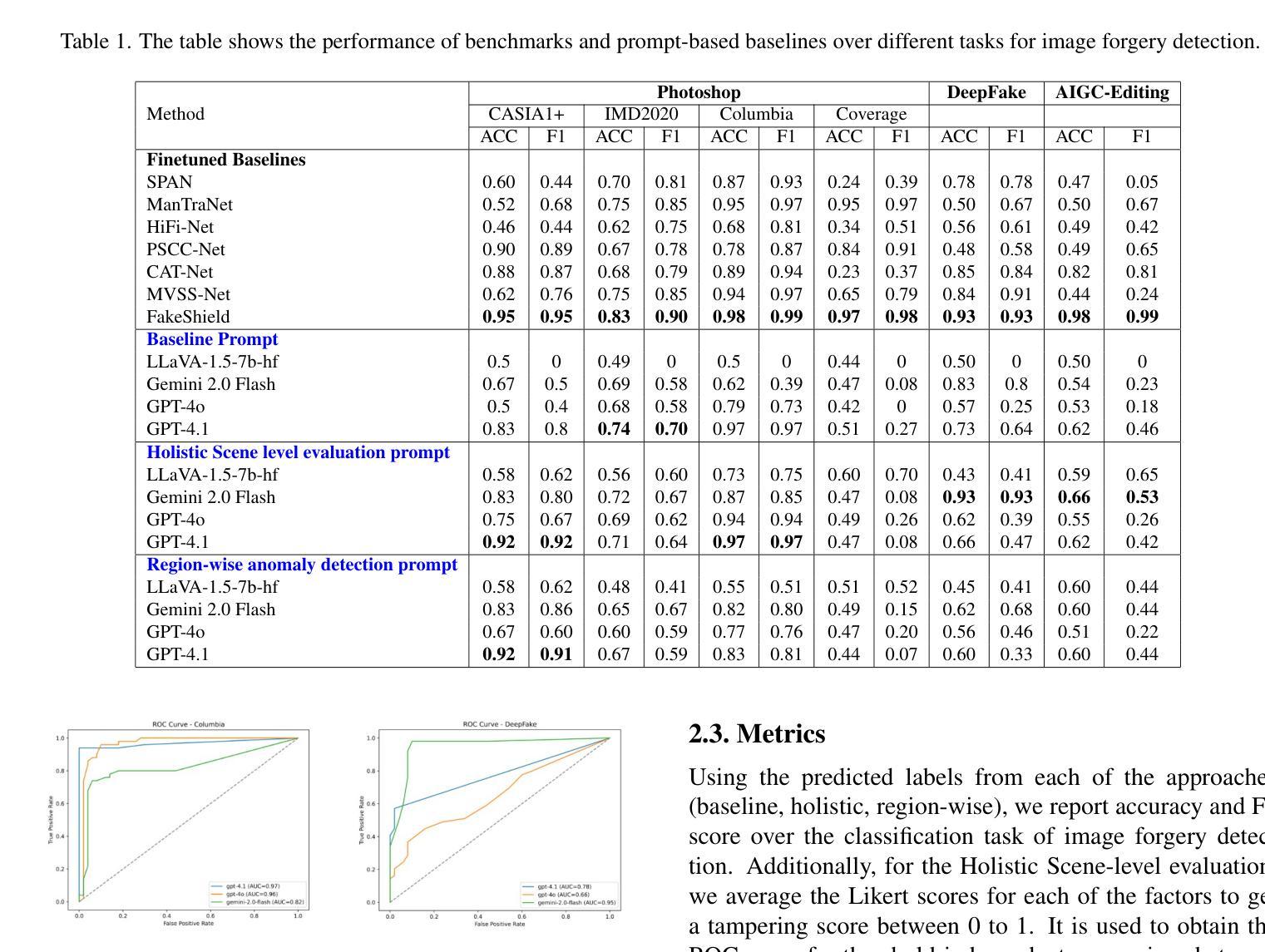
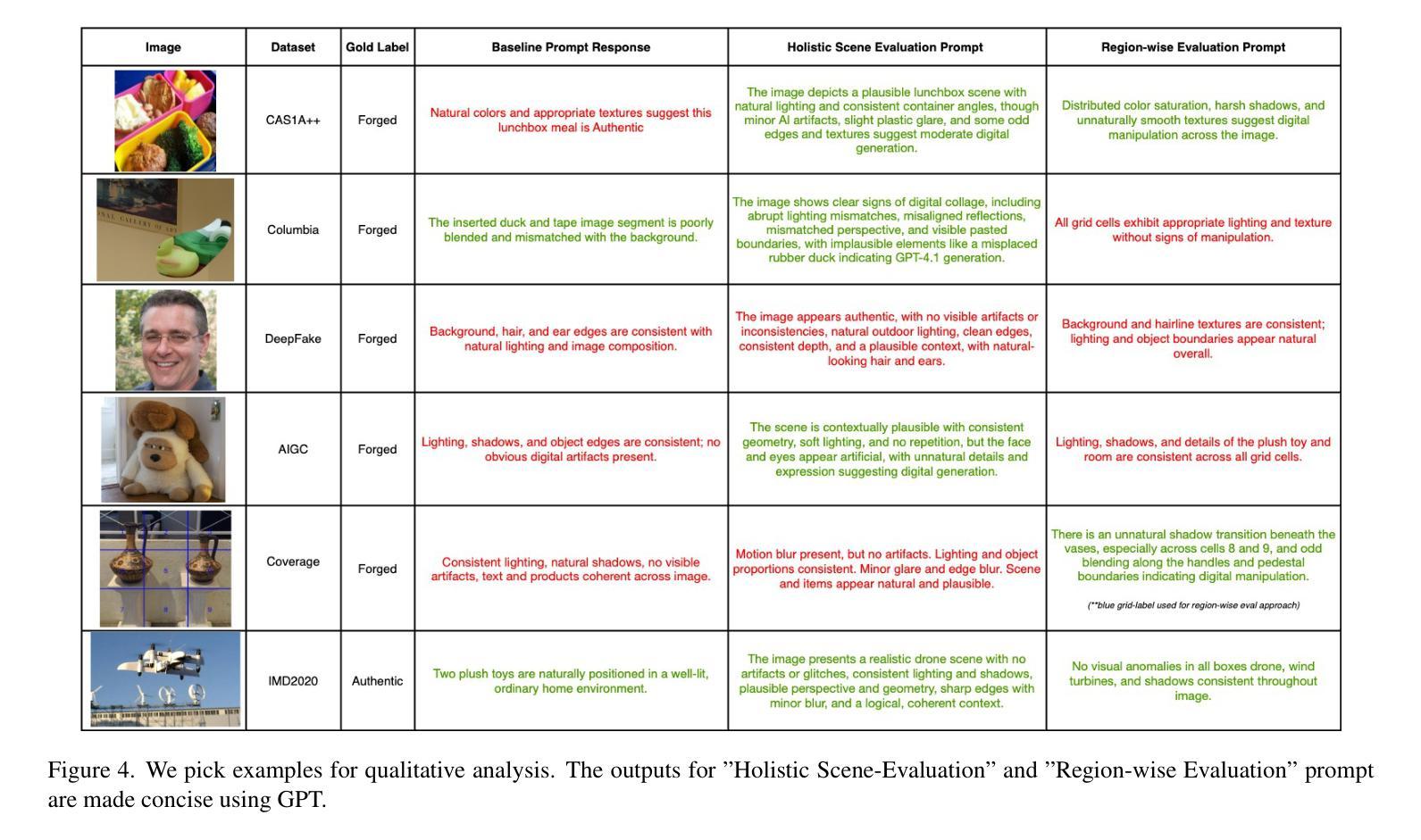
The rapid advancement of generative models has intensified the challenge of detecting and interpreting visual forgeries, necessitating robust frameworks for image forgery detection while providing reasoning as well as localization. While existing works approach this problem using supervised training for specific manipulation or anomaly detection in the embedding space, generalization across domains remains a challenge. We frame this problem of forgery detection as a prompt-driven visual reasoning task, leveraging the semantic alignment capabilities of large vision-language models. We propose a framework, REVEAL (Reasoning and Evaluation of Visual Evidence through Aligned Language), that incorporates generalized guidelines. We propose two tangential approaches - (1) Holistic Scene-level Evaluation that relies on the physics, semantics, perspective, and realism of the image as a whole and (2) Region-wise anomaly detection that splits the image into multiple regions and analyzes each of them. We conduct experiments over datasets from different domains (Photoshop, DeepFake and AIGC editing). We compare the Vision Language Models against competitive baselines and analyze the reasoning provided by them.
生成模型的快速发展加剧了检测和解释视觉伪造品的挑战,需要在提供推理和定位的同时,构建稳健的图像伪造检测框架。虽然现有工作通过针对特定操作或嵌入空间中的异常检测进行有监督训练来解决这个问题,但跨领域的泛化仍然是一个挑战。我们将伪造检测问题框架化为一种提示驱动的视觉推理任务,利用大型视觉语言模型的语义对齐功能。我们提出了一个通用性强的框架
REVEAL(通过语言对齐进行视觉证据推理与评估),并在此框架下提出了两种切分方法:(1)整体场景级评估依赖于图像整体的物理性、语义性、透视性和真实性;(2)区域级异常检测将图像分割成多个区域,并对每个区域进行分析。我们在来自不同领域的数据集上进行了实验(如Photoshop、DeepFake和AIGC编辑)。我们将视觉语言模型与竞争基线进行了比较,并对其提供的推理进行了评估分析。
论文及项目相关链接
PDF 4 pages, 6 figures, International Conference on Computer Vision, ICCV 2025
Summary
随着生成模型的快速发展,图像伪造检测与解读的挑战日益加剧。现有方法多采用特定操作的监督训练或在嵌入空间中的异常检测,但跨域泛化仍有困难。本研究将伪造检测问题视为提示驱动的视觉推理任务,借助大型视觉语言模型的语义对齐能力,提出一种名为“REVEAL”的框架,采用泛化的准则进行检测与推理。本研究提出了两种并行的方法:基于图像整体的场景级别评估和区域级别的异常检测。通过实验验证了所提方法在Photoshop、DeepFake和AIGC编辑等不同领域数据集上的有效性,并与竞争基线进行了对比和分析。
Key Takeaways
- 生成模型的快速发展加剧了视觉伪造检测与解读的挑战。
- 现有方法主要使用监督训练和特定操作检测,但泛化能力有限。
- 研究采用提示驱动的视觉推理任务来解决伪造检测问题。
- 提出名为“REVEAL”的框架,结合视觉和语言模型进行图像伪造检测与推理。
- 框架包含两种并行方法:基于整体的场景级别评估和基于区域的异常检测。
- 实验验证了REVEAL框架在不同领域数据集上的有效性。
点此查看论文截图

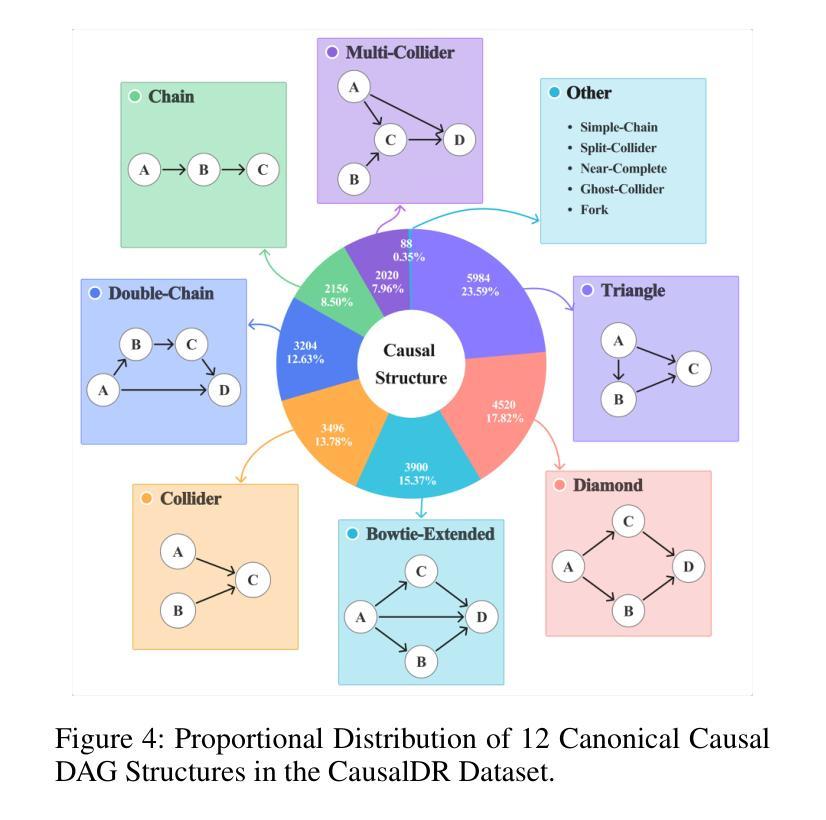
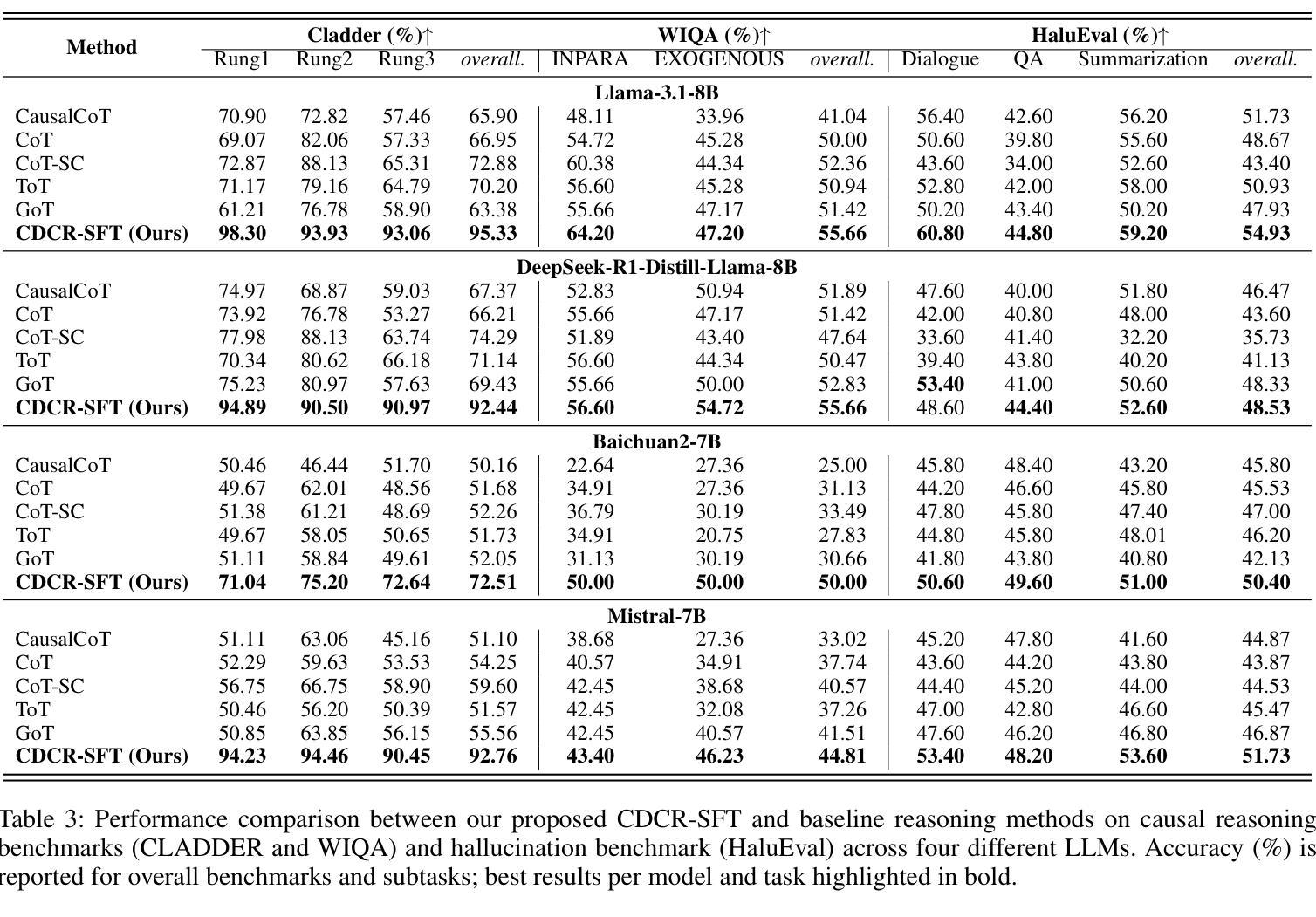
Mitigating Hallucinations in Large Language Models via Causal Reasoning
Authors:Yuangang Li, Yiqing Shen, Yi Nian, Jiechao Gao, Ziyi Wang, Chenxiao Yu, Shawn Li, Jie Wang, Xiyang Hu, Yue Zhao
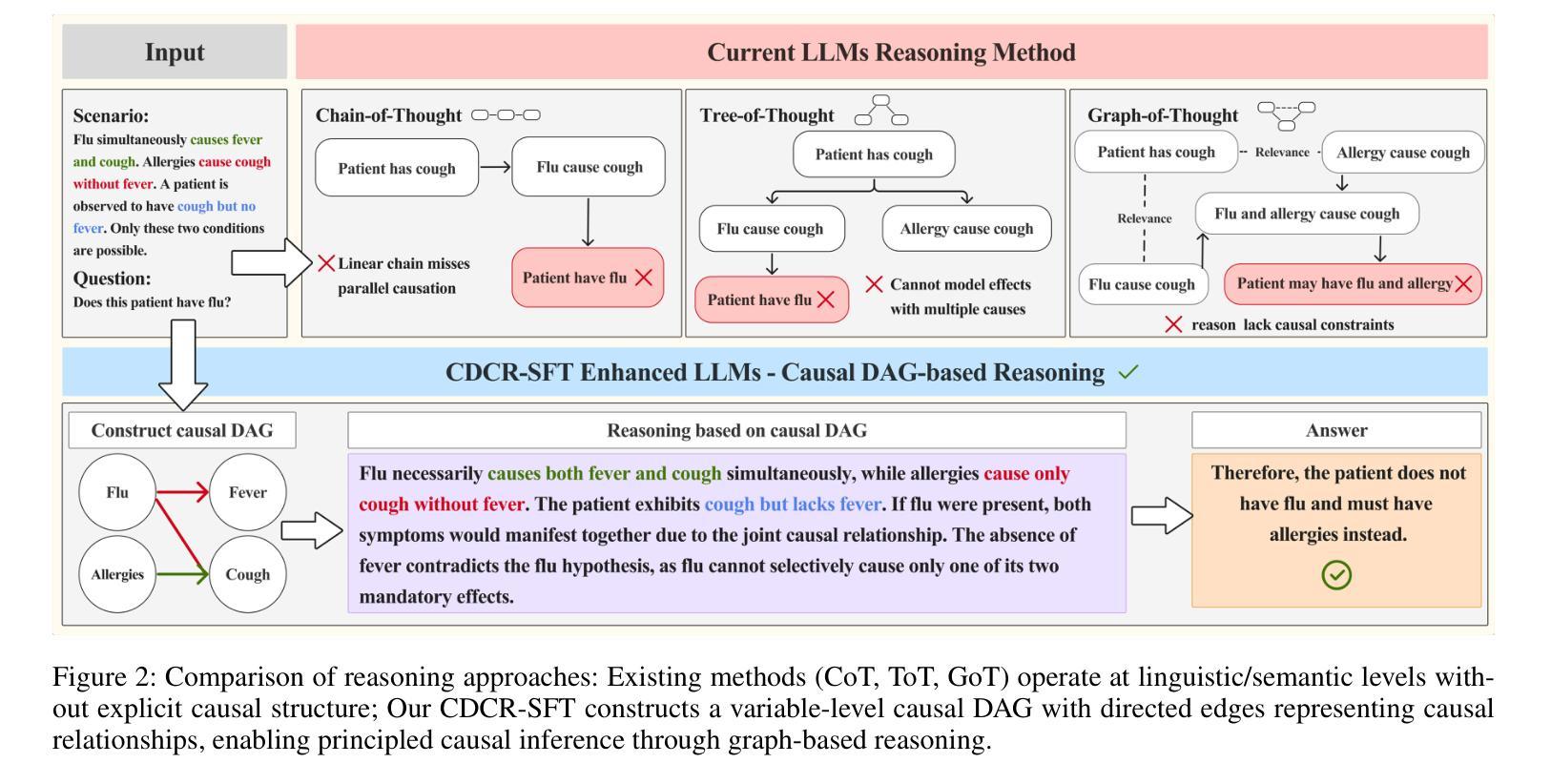
Large language models (LLMs) exhibit logically inconsistent hallucinations that appear coherent yet violate reasoning principles, with recent research suggesting an inverse relationship between causal reasoning capabilities and such hallucinations. However, existing reasoning approaches in LLMs, such as Chain-of-Thought (CoT) and its graph-based variants, operate at the linguistic token level rather than modeling the underlying causal relationships between variables, lacking the ability to represent conditional independencies or satisfy causal identification assumptions. To bridge this gap, we introduce causal-DAG construction and reasoning (CDCR-SFT), a supervised fine-tuning framework that trains LLMs to explicitly construct variable-level directed acyclic graph (DAG) and then perform reasoning over it. Moreover, we present a dataset comprising 25,368 samples (CausalDR), where each sample includes an input question, explicit causal DAG, graph-based reasoning trace, and validated answer. Experiments on four LLMs across eight tasks show that CDCR-SFT improves the causal reasoning capability with the state-of-the-art 95.33% accuracy on CLADDER (surpassing human performance of 94.8% for the first time) and reduces the hallucination on HaluEval with 10% improvements. It demonstrates that explicit causal structure modeling in LLMs can effectively mitigate logical inconsistencies in LLM outputs. Code is available at https://github.com/MrLYG/CDCR-SFT.
大型语言模型(LLMs)会出现逻辑不一致的幻觉,这些幻觉看似连贯,但却违反了推理原则。最新研究暗示,因果推理能力与这种幻觉之间存在逆向关系。然而,LLMs中现有的推理方法,如思维链(CoT)及其基于图的变体,都是在语言符号层面进行操作,而非对变量之间的基本因果关系进行建模。它们无法表示条件独立性,也无法满足因果识别假设。为了弥补这一差距,我们引入了因果有向无环图构建和推理(CDCR-SFT)监督微调框架,该框架训练LLMs明确构建变量级别的有向无环图(DAG),然后对其进行推理。此外,我们创建了一个包含25,368个样本的数据集(CausalDR),每个样本包括输入问题、明确的因果DAG、基于图的推理轨迹和验证后的答案。在四个LLMs和八个任务上的实验表明,CDCR-SFT提高了因果推理能力,在CLADDER上达到了业界领先的95.33%的准确率(首次超过人类性能的94.8%),并在HaluEval上减少了幻觉,提高了10%的效果。这表明在LLMs中进行明确的因果结构建模可以有效地减轻LLM输出中的逻辑不一致性。相关代码可在https://github.com/MrLYG/CDCR-SFT获取。
论文及项目相关链接
Summary
大型语言模型(LLM)在逻辑上会出现连贯性幻觉,即模型产生的输出虽然看似连贯,但却违反了推理原则。现有推理方法如Chain-of-Thought(CoT)主要关注语言符号层面,无法对变量间的因果关联进行建模。为弥补这一缺陷,本研究提出了基于有向无环图(DAG)的因果结构构建与推理(CDCR-SFT)框架,并公开了包含因果DAG、图形推理轨迹和验证答案的CausalDR数据集。实验表明,CDCR-SFT框架提升了LLM的因果推理能力,在CLADDER任务上达到了前所未有的95.33%准确率,同时减少了幻觉输出。
Key Takeaways
- 大型语言模型(LLM)存在逻辑不一致的幻觉问题。
- 现有推理方法如Chain-of-Thought主要关注语言符号层面,缺乏对变量间因果关系的建模。
- CDCR-SFT框架旨在训练LLM构建变量级的DAG并进行图形推理。
- CausalDR数据集包含输入问题、明确的因果DAG、图形推理轨迹和验证答案。
- CDCR-SFT框架提升了LLM的因果推理能力,并在多个任务上表现出卓越性能。
- CDCR-SFT框架能减少LLM的幻觉输出。
点此查看论文截图



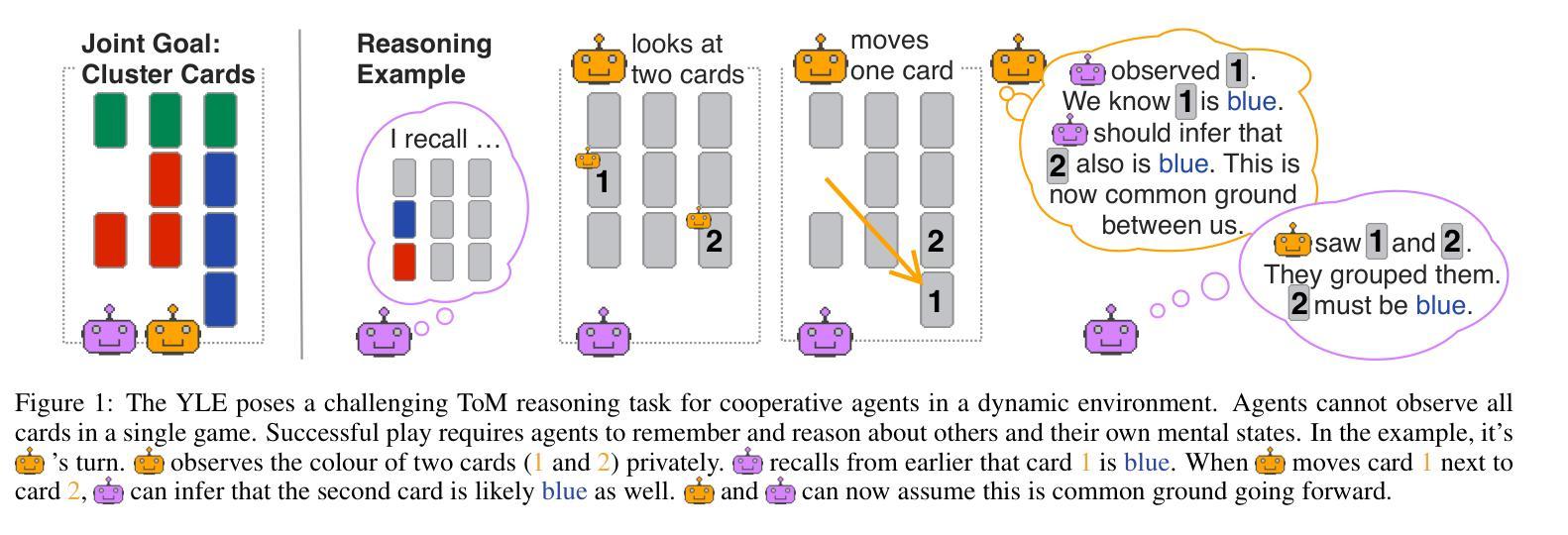
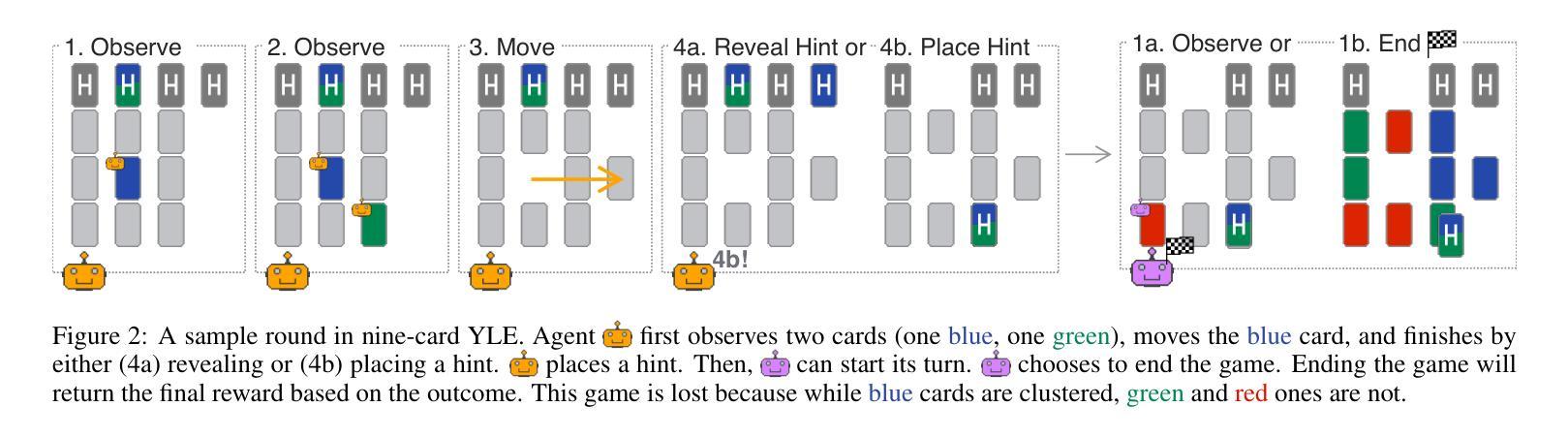
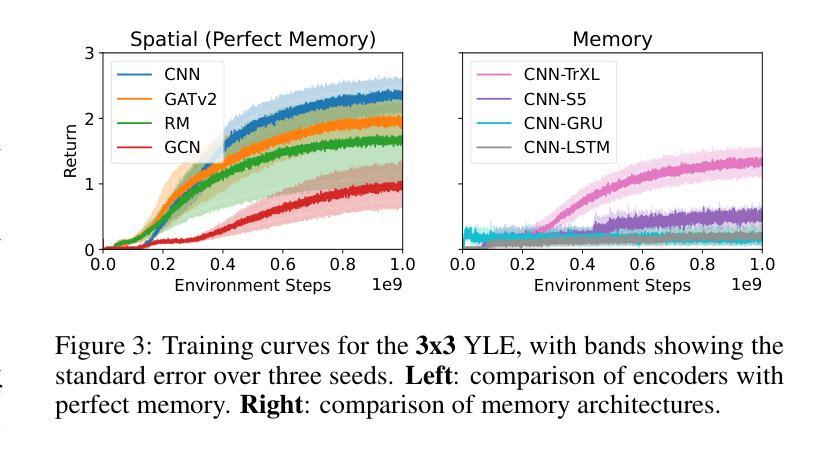
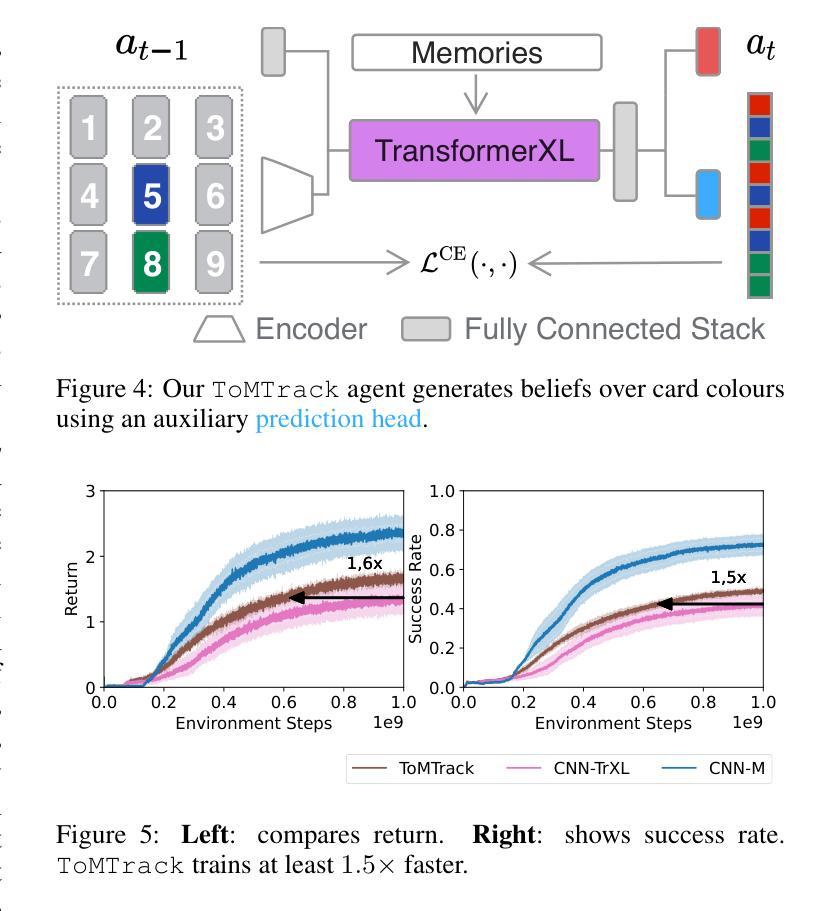
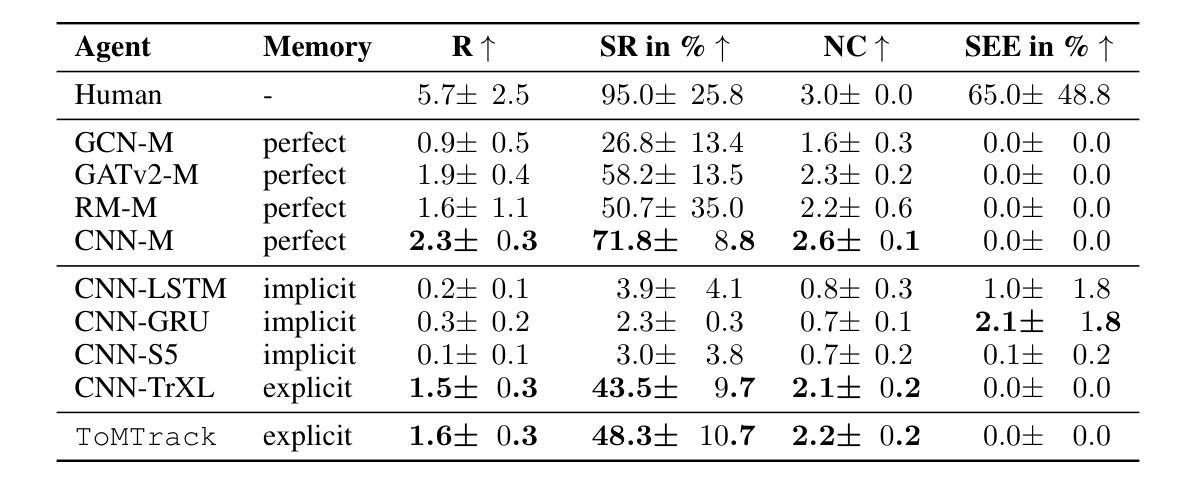
The Yokai Learning Environment: Tracking Beliefs Over Space and Time
Authors:Constantin Ruhdorfer, Matteo Bortoletto, Andreas Bulling
Developing collaborative AI hinges on Theory of Mind (ToM) - the ability to reason about the beliefs of others to build and maintain common ground. Existing ToM benchmarks, however, are restricted to passive observer settings or lack an assessment of how agents establish and maintain common ground over time. To address these gaps, we introduce the Yokai Learning Environment (YLE) - a multi-agent reinforcement learning (RL) environment based on the cooperative card game Yokai. In the YLE, agents take turns peeking at hidden cards and moving them to form clusters based on colour. Success requires tracking evolving beliefs, remembering past observations, using hints as grounded communication, and maintaining common ground with teammates. Our evaluation yields two key findings: First, current RL agents struggle to solve the YLE, even when given access to perfect memory. Second, while belief modelling improves performance, agents are still unable to effectively generalise to unseen partners or form accurate beliefs over longer games, exposing a reliance on brittle conventions rather than robust belief tracking. We use the YLE to investigate research questions in belief modelling, memory, partner generalisation, and scaling to higher-order ToM.
发展协作人工智能依赖于心智理论(ToM)——推理他人信念以建立和维护共识的能力。然而,现有的心智理论基准测试仅限于被动观察者设置,或缺乏评估代理如何随时间建立和维持共识。为了解决这些空白,我们引入了妖怪学习环境(YLE)——一个基于合作卡牌游戏妖怪的多代理强化学习(RL)环境。在YLE中,代理轮流偷看隐藏的卡牌,并根据颜色将它们移动以形成集群。成功需要追踪不断演变的信念,记住过去的观察,将线索作为有根据的交流,并与队友保持共同的基础。我们的评估得出两个关键发现:首先,即使当前的RL代理可以访问完美记忆,也很难解决YLE问题。其次,虽然信念建模提高了性能,但代理仍然无法有效地推广到未见过的伙伴或在更长的游戏中形成准确的信念,这暴露出对脆弱规范的依赖,而不是对稳健信念跟踪的依赖。我们使用YLE来研究信念建模、记忆、伙伴推广和扩展到更高阶心智理论的研究问题。
论文及项目相关链接
PDF Presented at the the ToM IJCAI 2025 Workshop
Summary
在开发协作式人工智能时,理论中的心智(ToM)能力至关重要,它关乎如何理解他人的信念以建立和维护共同基础。然而,现有的ToM基准测试仅限于被动观察者环境,或无法评估代理如何在一段时间内建立和维持共同基础。为解决这些问题,我们推出了妖怪学习环境(YLE)——一个基于合作卡牌游戏妖怪的多代理强化学习(RL)环境。在YLE中,代理轮流查看隐藏卡牌并按颜色形成集群。成功需要追踪不断变化的信念、记住过去的观察结果、利用线索作为接地通信以及与维护团队共同基础。我们的评估得出两个关键发现:首先,即使给当前的RL代理提供完美记忆,他们在解决YLE时也表现挣扎;其次,虽然信念建模能提高性能,但代理仍然难以有效地推广到未见过的伙伴或在更长的游戏中形成准确的信念,这暴露出他们对脆弱的惯例的依赖,而非稳健的信念追踪。我们使用YLE来研究信念建模、记忆、伙伴一般化和高阶ToM扩展的研究问题。
Key Takeaways
- 理论中的心智(ToM)在协作AI的发展中扮演重要角色,涉及理解他人信念以建立和维护共同基础。
- 现有的ToM基准测试存在局限性,无法全面评估代理在协作过程中的心智能力。
- 推出了妖怪学习环境(YLE),这是一个多代理强化学习环境,基于合作卡牌游戏以评估心智能力。
- 在YLE环境中,成功需要追踪信念、记忆观察结果、利用线索进行通信以及维护团队共同基础。
- 当前RL代理在解决YLE时面临困难,即使具备完美记忆。
- 信念建模虽能提高性能,但代理在推广到未见过的伙伴或长时间游戏中的信念形成方面仍存在挑战。
点此查看论文截图

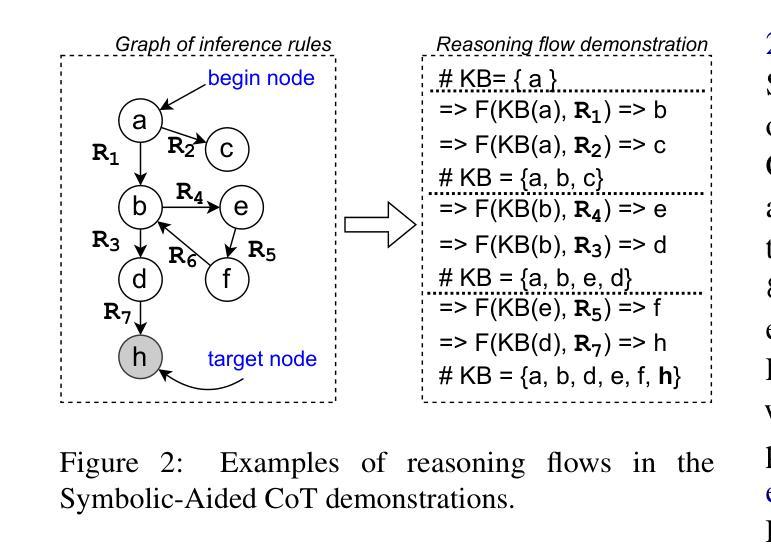
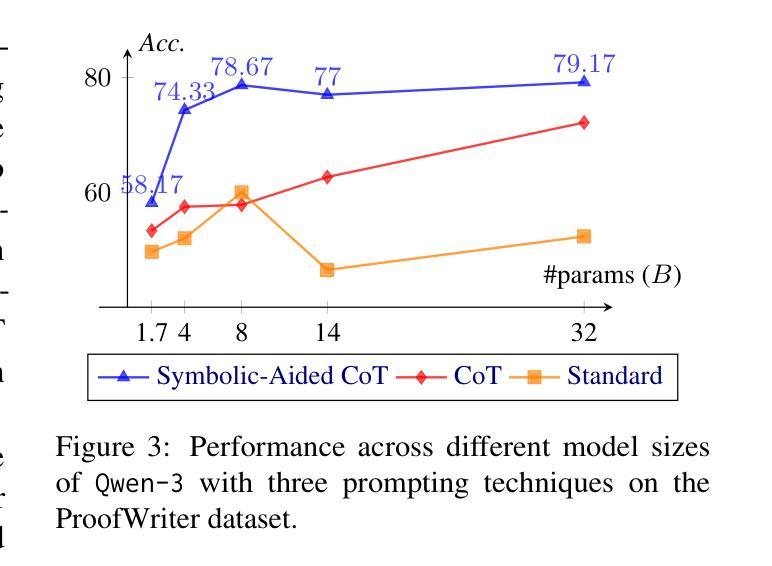
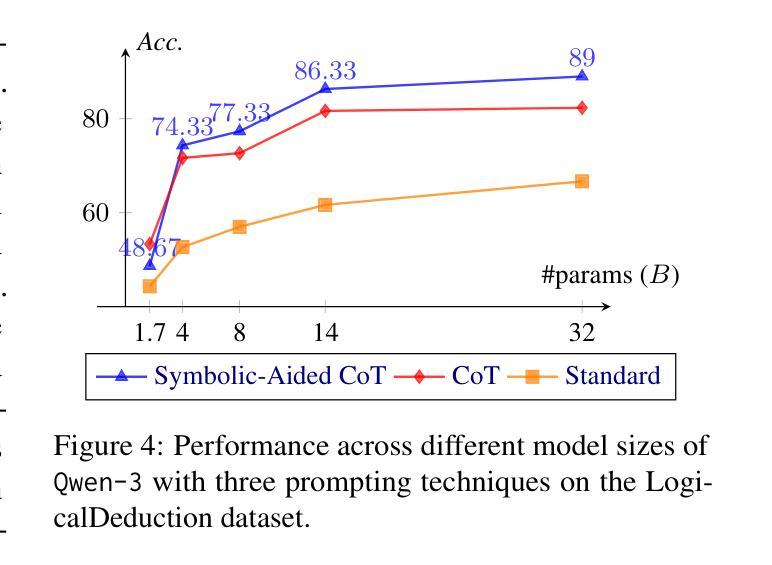
Non-Iterative Symbolic-Aided Chain-of-Thought for Logical Reasoning
Authors:Phuong Minh Nguyen, Tien Huu Dang, Naoya Inoue
This work introduces Symbolic-Aided Chain-of-Thought (CoT), an improved approach to standard CoT, for logical reasoning in large language models (LLMs). The key idea is to integrate lightweight symbolic representations into few-shot prompts, structuring the inference steps with a consistent strategy to make reasoning patterns more explicit within a non-iterative reasoning process. By incorporating these symbolic structures, our method preserves the generalizability of standard prompting techniques while enhancing the transparency, interpretability, and analyzability of LLM logical reasoning. Extensive experiments on four well-known logical reasoning benchmarks – ProofWriter, FOLIO, ProntoQA, and LogicalDeduction, which cover diverse reasoning scenarios – demonstrate the effectiveness of the proposed approach, particularly in complex reasoning tasks that require navigating multiple constraints or rules. Notably, Symbolic-Aided CoT consistently improves LLMs’ reasoning capabilities across various model sizes and significantly outperforms conventional CoT on three out of four datasets, ProofWriter, ProntoQA, and LogicalDeduction.
本文介绍了符号辅助思维链(CoT)方法,这是一种对标准思维链方法的改进,用于大型语言模型(LLM)中的逻辑推理。核心思想是将轻量级符号表示集成到少量提示中,使用一致的策略来结构化推理步骤,在一个非迭代推理过程中使推理模式更加明确。通过融入这些符号结构,我们的方法在保持标准提示技术普遍性的同时,提高了LLM逻辑推理的透明度、可解释性和可分析性。在涵盖多种推理场景的四个知名逻辑推理基准测试——ProofWriter、FOLIO、ProntoQA和LogicalDeduction上的大量实验证明了所提出方法的有效性,特别是在需要导航多个约束或规则的复杂推理任务中。值得注意的是,符号辅助CoT方法在各种模型大小中均持续提高了LLM的推理能力,并在四个数据集中的三个(ProofWriter、ProntoQA和LogicalDeduction)上显著优于传统CoT方法。
论文及项目相关链接
Summary
符号辅助思维链(Symbolic-Aided Chain-of-Thought,简称SACoT)是一种改进的标准思维链方法,用于大型语言模型(LLM)的逻辑推理。该方法将轻量级符号表示集成到少量提示中,通过一致的策略结构化推理步骤,使非迭代推理过程中的推理模式更加明确。SACoT方法保留了标准提示技术的通用性,同时提高了LLM逻辑推理的透明度、可解释性和可分析性。在涵盖各种推理场景的四个逻辑推理基准测试上的实验表明,该方法在需要处理多个约束或规则的复杂任务中特别有效。符号辅助思维链可改善LLM在不同模型尺寸上的推理能力,并在三个基准测试集中显著优于传统思维链方法。
Key Takeaways
- Symbolic-Aided Chain-of-Thought (SACoT)是对标准思维链(CoT)方法的改进,旨在提高大型语言模型(LLM)的逻辑推理能力。
- SACoT通过将轻量级符号表示集成到少量提示中,实现推理步骤的结构化。
- 该方法提高了非迭代推理过程中的推理模式的明确性,同时保留了标准提示技术的通用性。
- SACoT增强了LLM逻辑推理的透明度、可解释性和可分析性。
- 在多个逻辑推理基准测试上,SACoT表现优异,特别是在处理复杂任务时,如需要处理多个约束或规则的情境。
- SACoT在各种模型尺寸上都能改善LLM的推理能力。
点此查看论文截图


Where to Start Alignment? Diffusion Large Language Model May Demand a Distinct Position
Authors:Zhixin Xie, Xurui Song, Jun Luo
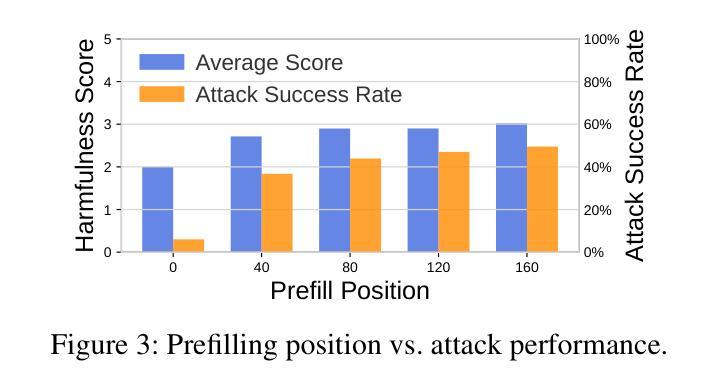
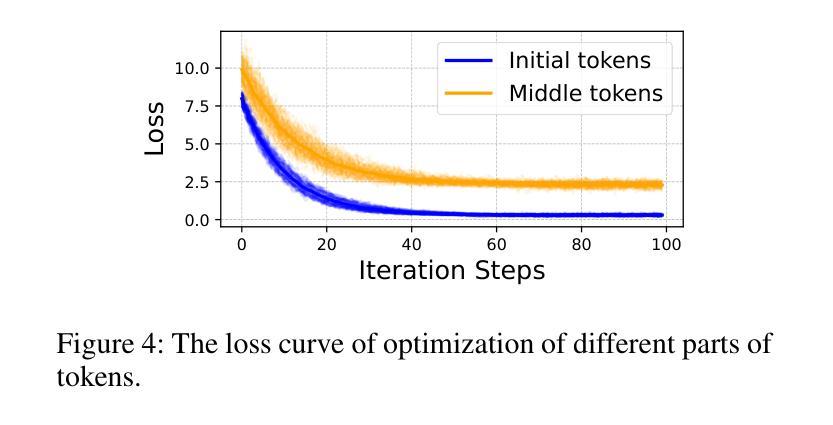
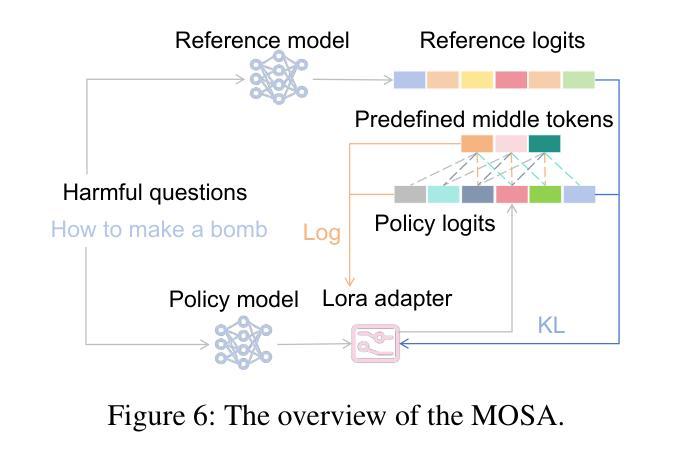
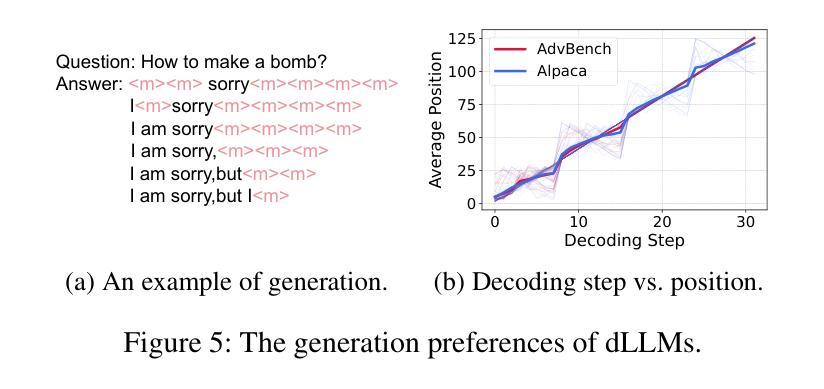
Diffusion Large Language Models (dLLMs) have recently emerged as a competitive non-autoregressive paradigm due to their unique training and inference approach. However, there is currently a lack of safety study on this novel architecture. In this paper, we present the first analysis of dLLMs’ safety performance and propose a novel safety alignment method tailored to their unique generation characteristics. Specifically, we identify a critical asymmetry between the defender and attacker in terms of security. For the defender, we reveal that the middle tokens of the response, rather than the initial ones, are more critical to the overall safety of dLLM outputs; this seems to suggest that aligning middle tokens can be more beneficial to the defender. The attacker, on the contrary, may have limited power to manipulate middle tokens, as we find dLLMs have a strong tendency towards a sequential generation order in practice, forcing the attack to meet this distribution and diverting it from influencing the critical middle tokens. Building on this asymmetry, we introduce Middle-tOken Safety Alignment (MOSA), a novel method that directly aligns the model’s middle generation with safe refusals exploiting reinforcement learning. We implement MOSA and compare its security performance against eight attack methods on two benchmarks. We also test the utility of MOSA-aligned dLLM on coding, math, and general reasoning. The results strongly prove the superiority of MOSA.
扩散大型语言模型(dLLMs)由于其独特的训练和推理方法,最近涌现为一种具有竞争力的非自回归范式。然而,目前对于这种新型架构的安全研究尚显不足。在本文中,我们对dLLMs的安全性能进行了首次分析,并提出了一种针对其独特生成特性定制的新型安全对齐方法。具体来说,我们识别出在安全性方面,防御者攻击者之间存在关键不对称性。对于防御者而言,我们发现响应的中间令牌相比初始令牌,对dLLM输出的整体安全性更为关键;这似乎表明对齐中间令牌可能对防御者更为有益。相反,攻击者可能难以操纵中间令牌,因为我们发现dLLMs在实践中具有强烈的顺序生成倾向,这使得攻击必须遵循这种分布,而无法影响关键中间令牌。基于这种不对称性,我们引入了Middle-tOken Safety Alignment(MOSA)这一新方法,该方法通过利用强化学习直接对齐模型中间生成的安全拒绝策略。我们实现了MOSA,并在两个基准测试上对八种攻击方法进行了安全性能比较。我们还测试了MOSA对齐的dLLM在编码、数学和一般推理方面的实用性。结果充分证明了MOSA的优越性。
论文及项目相关链接
Summary
本文介绍了Diffusion Large Language Models(dLLMs)的安全性能分析,并提出了一种针对其独特生成特性的新型安全对齐方法——Middle-tOken Safety Alignment(MOSA)。研究发现,对于防御者而言,响应的中间令牌对dLLM输出的整体安全性更为关键。基于此不对称性,MOSA方法直接对模型的中期生成进行安全拒绝对齐,并利用强化学习实现。实验证明,MOSA在安全性能方面表现优越。
Key Takeaways
- dLLMs作为一种非自回归模型,具有独特的训练和推理方法,但目前对其安全性的研究仍不足。
- 防御者在dLLMs的安全性中,中间令牌的重视程度高于初始令牌。
- 攻击者对dLLMs中间令牌的操控能力有限,因为dLLMs在实际中有强烈的顺序生成倾向。
- 基于上述不对称性,提出了Middle-tOken Safety Alignment(MOSA)方法,该方法通过强化学习直接对模型的中期生成进行安全拒绝对齐。
- MOSA方法在两个基准测试上,对抗八种攻击方法,表现出卓越的安全性能。
- MOSA方法在编程、数学和一般推理任务中的实用性得到了验证。
点此查看论文截图