⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
Arabic ASR on the SADA Large-Scale Arabic Speech Corpus with Transformer-Based Models
Authors:Branislav Gerazov, Marcello Politi, Sébastien Bratières
We explore the performance of several state-of-the-art automatic speech recognition (ASR) models on a large-scale Arabic speech dataset, the SADA (Saudi Audio Dataset for Arabic), which contains 668 hours of high-quality audio from Saudi television shows. The dataset includes multiple dialects and environments, specifically a noisy subset that makes it particularly challenging for ASR. We evaluate the performance of the models on the SADA test set, and we explore the impact of fine-tuning, language models, as well as noise and denoising on their performance. We find that the best performing model is the MMS 1B model finetuned on SADA with a 4-gram language model that achieves a WER of 40.9% and a CER of 17.6% on the SADA test clean set.
我们对多个最先进的自动语音识别(ASR)模型在大型阿拉伯语语音数据集SADA(沙特阿拉伯阿拉伯语数据集)上的表现进行了探索。该数据集包含来自沙特阿拉伯电视剧的668小时高质量音频。该数据集包含多种方言和环境,特别是一个嘈杂的子集,这使得自动语音识别特别具有挑战性。我们在SADA测试集上评估模型的性能,并探讨了微调、语言模型以及噪声和降噪对性能的影响。我们发现表现最好的模型是在SADA上微调过的MMS 1B模型,它使用了一个4元语言模型,在SADA测试集干净集上实现了词错误率(WER)为40.9%,字符错误率(CER)为17.6%。
论文及项目相关链接
Summary:我们对多个前沿的自动语音识别(ASR)模型在大型阿拉伯语语音数据集SADA上的表现进行了探索。该数据集包含来自沙特电视节目的高质量音频,时长668小时,包含多种方言和环境,尤其是噪音子集,对ASR来说极具挑战性。我们在SADA测试集上评估了这些模型的表现,并探讨了微调、语言模型以及噪声和去噪对性能的影响。研究发现,在SADA的清洁集上,经SADA微调过的MMS 1B模型配合4-gram语言模型表现最佳,字错误率(WER)达到40.9%,字符错误率(CER)为17.6%。
Key Takeaways:
- 论文研究了多个前沿自动语音识别(ASR)模型在沙特阿拉伯音频数据集(SADA)上的表现。
- SADA数据集包含多种方言和环境,对ASR系统来说是一个挑战。
- 研究者评估了模型在SADA测试集上的性能。
- 最好的模型是MMS 1B模型,经过在SADA数据集上的微调,并配合使用4-gram语言模型。
- 该最佳模型在SADA清洁测试集上实现了较低的字错误率(WER)和字符错误率(CER)。
- 研究发现噪声和去噪对ASR模型性能有影响。
点此查看论文截图

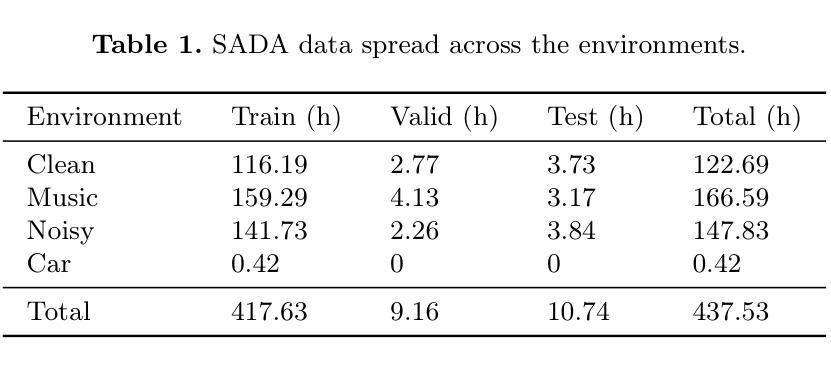
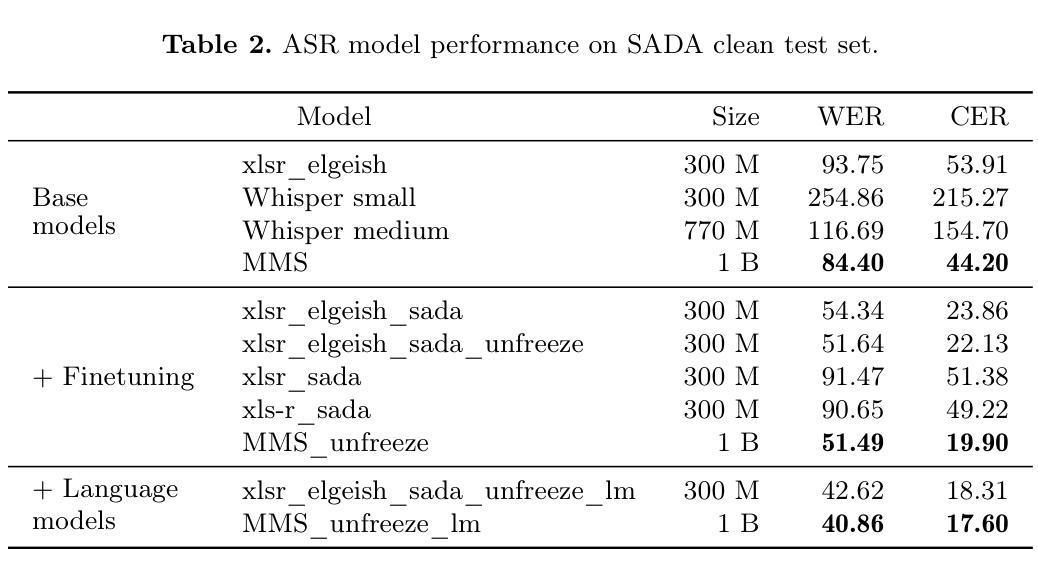
CarelessWhisper: Turning Whisper into a Causal Streaming Model
Authors:Tomer Krichli, Bhiksha Raj, Joseph Keshet
Automatic Speech Recognition (ASR) has seen remarkable progress, with models like OpenAI Whisper and NVIDIA Canary achieving state-of-the-art (SOTA) performance in offline transcription. However, these models are not designed for streaming (online or real-time) transcription, due to limitations in their architecture and training methodology. We propose a method to turn the transformer encoder-decoder model into a low-latency streaming model that is careless about future context. We present an analysis explaining why it is not straightforward to convert an encoder-decoder transformer to a low-latency streaming model. Our proposed method modifies the existing (non-causal) encoder to a causal encoder by fine-tuning both the encoder and decoder using Low-Rank Adaptation (LoRA) and a weakly aligned dataset. We then propose an updated inference mechanism that utilizes the fine-tune causal encoder and decoder to yield greedy and beam-search decoding, and is shown to be locally optimal. Experiments on low-latency chunk sizes (less than 300 msec) show that our fine-tuned model outperforms existing non-fine-tuned streaming approaches in most cases, while using a lower complexity. Additionally, we observe that our training process yields better alignment, enabling a simple method for extracting word-level timestamps. We release our training and inference code, along with the fine-tuned models, to support further research and development in streaming ASR.
自动语音识别(ASR)已经取得了显著的进步,例如OpenAIwhisper和NVIDIAcanary等模型在离线转录方面达到了最新技术水平。然而,这些模型并不适用于流式(在线或实时)转录,这是由于它们的架构和训练方法的局限性所导致的。我们提出了一种将转换器编码器-解码器模型转化为低延迟流式模型的方法,该模型不关心未来上下文。我们进行了分析,解释了为什么将编码器-解码器转换器转换为低延迟流式模型并不简单。我们提出的方法通过将现有(非因果)编码器微调为因果编码器,同时利用低秩适应(LoRA)和弱对齐数据集对编码器和解码器进行微调。然后,我们提出了一种更新的推理机制,该机制利用微调的因果编码器和解码器来产生贪心和解码束搜索,并被认为是局部最优的。在低延迟块大小(小于300毫秒)的实验中,表明我们的微调模型在大多数情况下都优于现有的未微调流式方法,同时使用更低的复杂性。此外,我们观察到我们的训练过程产生了更好的对齐效果,这为实现简单的提取词级时间戳方法提供了可能。我们发布我们的训练和推理代码以及微调模型,以支持流式ASR的进一步研究和开发。
论文及项目相关链接
PDF 17 pages, 7 Figures, This work has been submitted to the IEEE for possible publication
Summary
本文介绍了自动语音识别(ASR)领域的最新进展,特别是针对流式转码模型的研究。文章指出,虽然OpenAI Whisper和NVIDIA Canary等模型在离线转录方面表现出卓越的性能,但它们并不适用于流式转录。为此,文章提出了一种将转换器编码器-解码器模型转换为低延迟流式模型的方法,并详细解释了转换的难点。通过微调编码器和解码器,并使用低秩适应(LoRA)和弱对齐数据集,文章提出了一种新的因果编码器。更新的推理机制利用精细调整的因果编码器和解码器,实现贪婪和集束搜索解码,并证明其局部最优。实验表明,在低声延迟块大小下,精细调整后的模型在大多数情况下优于现有的非精细调整流式方法,同时降低了复杂性。此外,该训练过程还产生了更好的对齐效果,为提取单词级时间戳提供了一种简单方法。
Key Takeaways
- 文章指出自动语音识别(ASR)的在线或实时转录仍面临挑战,尽管已有模型在离线转录方面表现出卓越性能。
- 文章提出了一种将转换器编码器-解码器模型转换为低延迟流式模型的方法。
- 转换的难点在于如何将模型的架构和训练方法进行调整以适应流式处理的需求。
- 通过对编码器和解码器的微调,以及使用低秩适应(LoRA)和弱对齐数据集,提出了一种新的因果编码器。
- 更新后的推理机制可以实现贪婪和集束搜索解码,并具有局部最优性。
- 实验结果表明,在低延迟条件下,精细调整后的模型性能优于大多数现有方法,且计算复杂度较低。
点此查看论文截图

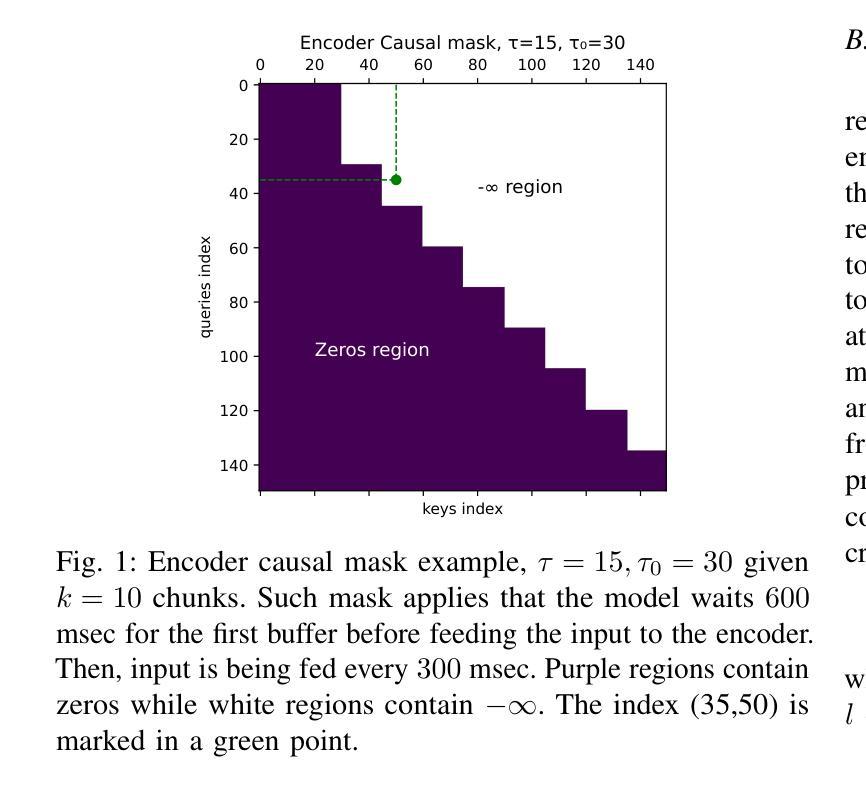


Exploring Self-Supervised Audio Models for Generalized Anomalous Sound Detection
Authors:Bing Han, Anbai Jiang, Xinhu Zheng, Wei-Qiang Zhang, Jia Liu, Pingyi Fan, Yanmin Qian
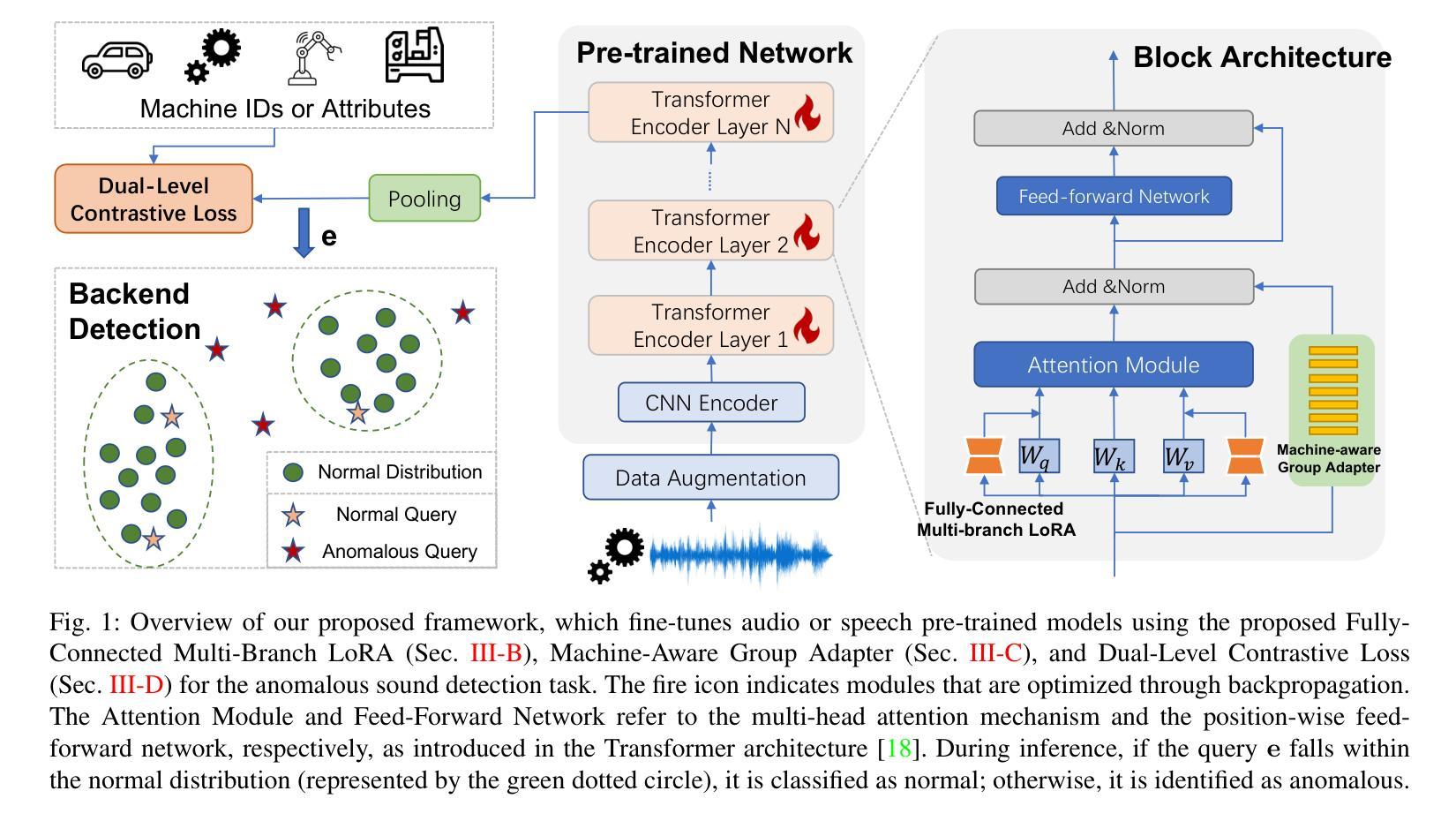
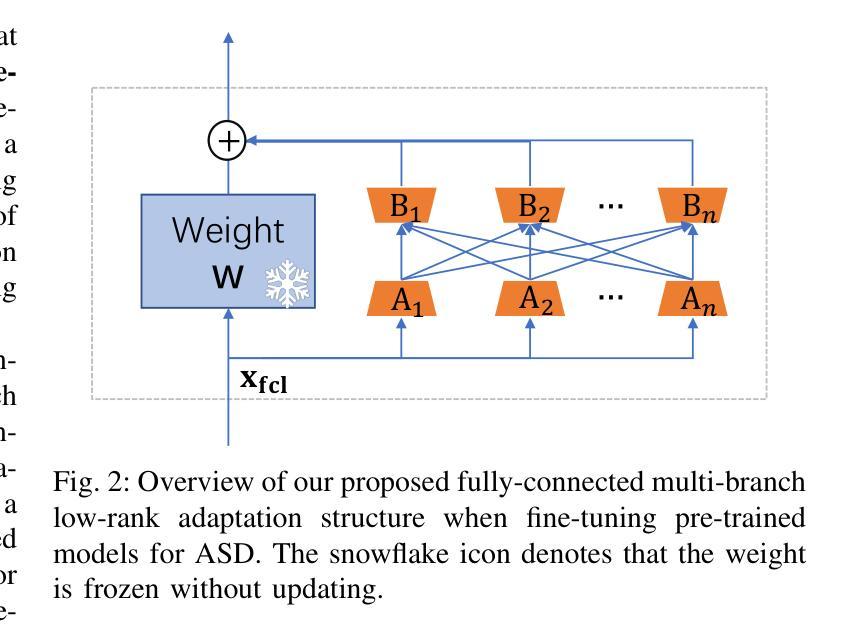
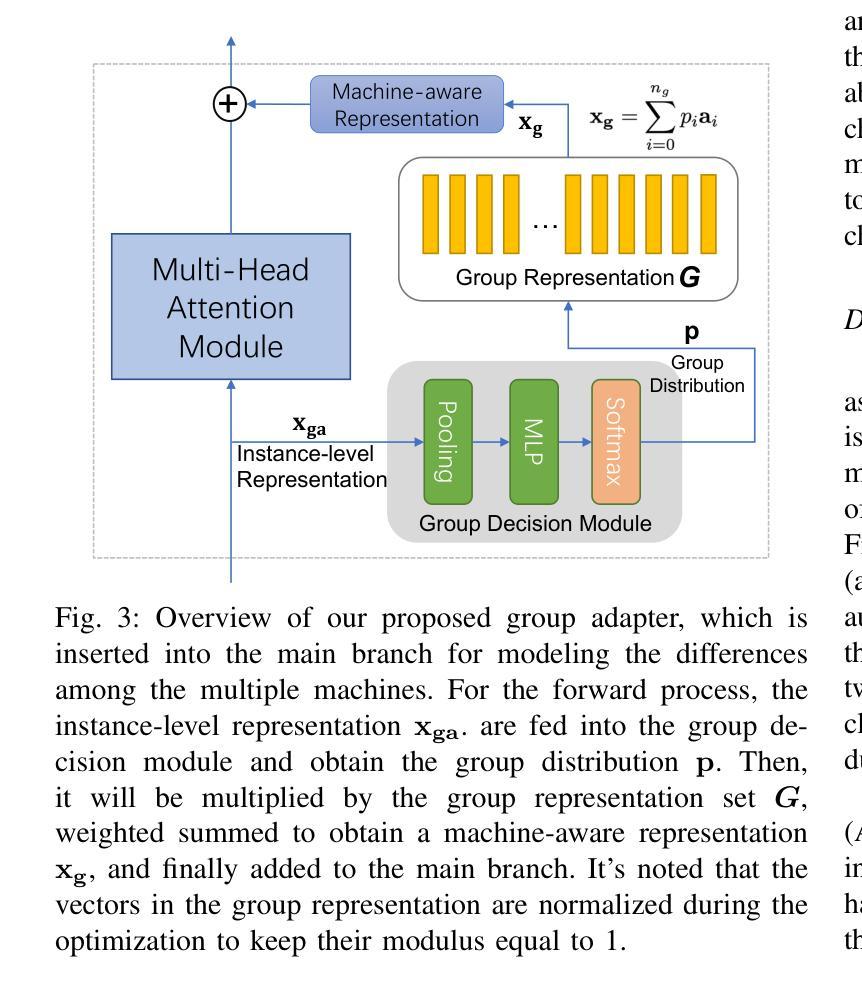
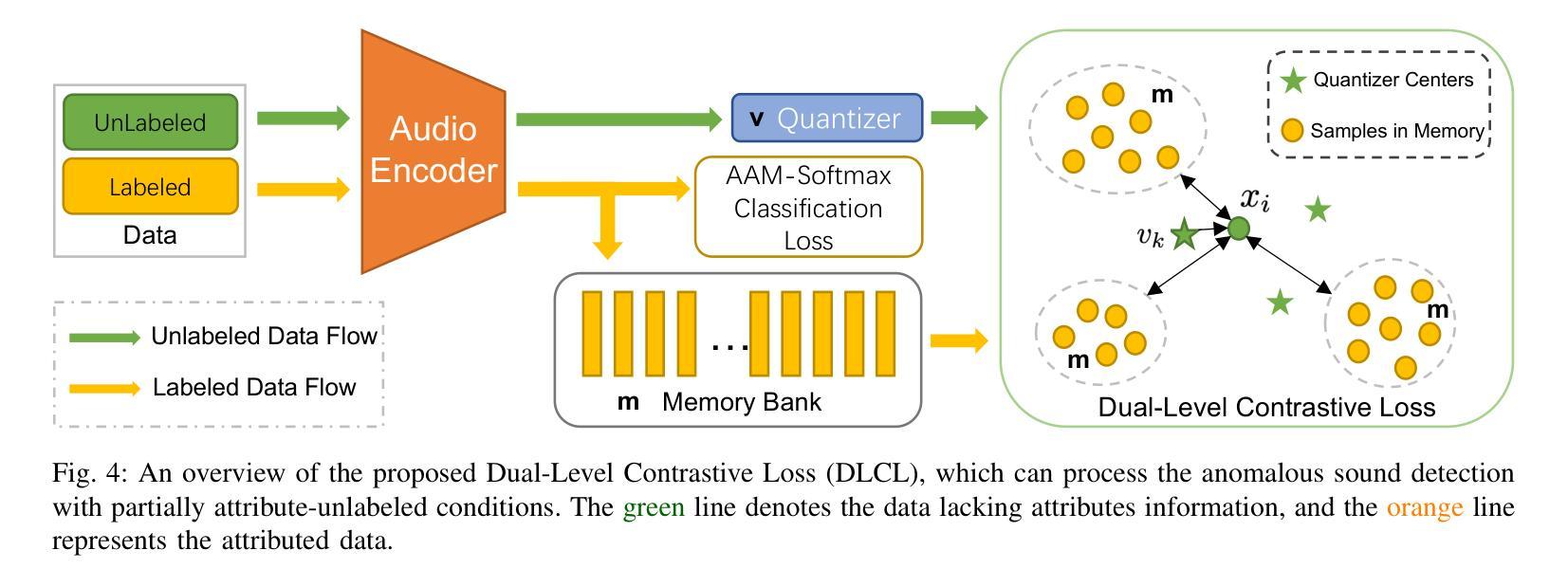
Machine anomalous sound detection (ASD) is a valuable technique across various applications. However, its generalization performance is often limited due to challenges in data collection and the complexity of acoustic environments. Inspired by the success of large pre-trained models in numerous fields, this paper introduces a robust ASD model that leverages self-supervised pre-trained models trained on large-scale speech and audio datasets. Although there are inconsistencies between the pre-training datasets and the ASD task, our findings indicate that pre-training still provides substantial benefits for ASD. To mitigate overfitting and retain learned knowledge when fine-tuning with limited data, we explore Fully-Connected Low-Rank Adaptation (LoRA) as an alternative to full fine-tuning. Additionally, we propose a Machine-aware Group Adapter module, which enables the model to capture differences between various machines within a unified framework, thereby enhancing the generalization performance of ASD systems. To address the challenge of missing attribute labels, we design a novel objective function that dynamically clusters unattributed data using vector quantization and optimizes through a dual-level contrastive learning loss. The proposed methods are evaluated on all benchmark datasets, including the DCASE 2020-2024 five ASD challenges, and the experimental results show significant improvements of our new approach and demonstrate the effectiveness of our proposed strategies.
机器异常声音检测(ASD)在多种应用中是一项有价值的技术。然而,由于其数据收集的挑战和声音环境的复杂性,其泛化性能通常受到限制。受大型预训练模型在众多领域成功的启发,本文引入了一个稳健的ASD模型,该模型利用在大型语音和音频数据集上训练的自我监督预训练模型。尽管预训练数据集与ASD任务之间存在不一致,但我们的研究结果表明,预训练仍然对ASD提供重大益处。为了缓解过度拟合问题并在使用有限数据进行微调时保留所学知识,我们探索了全连接低秩适配(LoRA)作为全微调的一种替代方法。此外,我们提出了机器感知组适配器模块,使模型能够在统一框架内捕捉各种机器之间的差异,从而提高ASD系统的泛化性能。为了解决缺失属性标签的挑战,我们设计了一种新的目标函数,该函数通过向量量化动态聚类未标记数据,并通过双重对比学习损失进行优化。所提出的方法在所有基准数据集上进行了评估,包括DCASE 2020-2024五个ASD挑战,实验结果表明我们的新方法取得了显著改进,并证明了我们提出的策略的有效性。
论文及项目相关链接
PDF Accepted by TASLP. 15 pages, 7 figures;
Summary:机器异常声音检测(ASD)是一项在多领域具有应用价值的检测技术。本文通过借鉴预训练模型在其他领域的成功经验,引入了一种基于大规模语音和音频数据集的预训练ASD模型。针对预训练数据集与ASD任务间的不一致性,研究发现预训练仍为ASD带来实质效益。为缓解过拟合问题并在有限数据上保留学习到的知识,本文探索了全连接低秩适配(LoRA)作为传统微调的替代方案。此外,还提出了机器感知组适配器模块,能在统一框架内捕捉不同机器之间的差异,提高了ASD系统的泛化性能。针对缺少属性标签的挑战,设计了一种新的目标函数,通过向量量化和双层次对比学习损失来动态聚类无属性数据并进行优化。在DCASE 2020-2024五个ASD挑战数据集上的实验结果表明,新方法显著提高了检测性能,验证了所提策略的有效性。
Key Takeaways:
- 预训练模型对于机器异常声音检测(ASD)有实质性益处,即使预训练数据集与ASD任务存在不一致性。
- 采用全连接低秩适配(LoRA)能有效缓解ASD模型过拟合问题,并在有限数据上保留学习到的知识。
- 提出的机器感知组适配器模块能够捕捉不同机器之间的差异,提高了ASD系统的泛化性能。
- 针对缺少属性标签的挑战,通过设计新的目标函数实现了无属性数据的动态聚类。
- 采用向量量化和双层次对比学习损失进行优化,增强了模型的检测性能。
- 在DCASE 2020-2024五个ASD挑战数据集上的实验结果表明,新方法显著提高了检测效果。
- 本文策略的有效性得到了验证。
点此查看论文截图

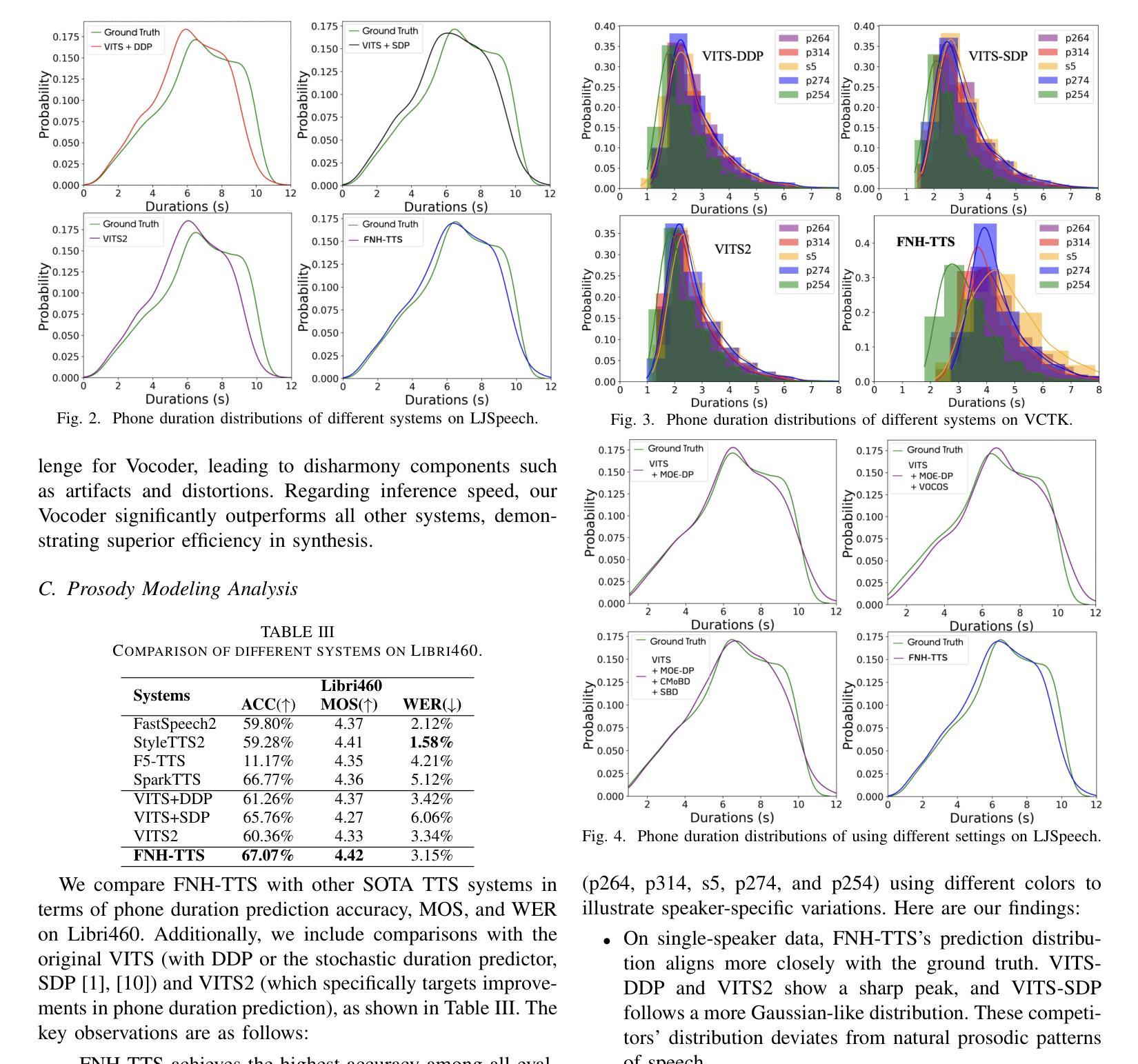
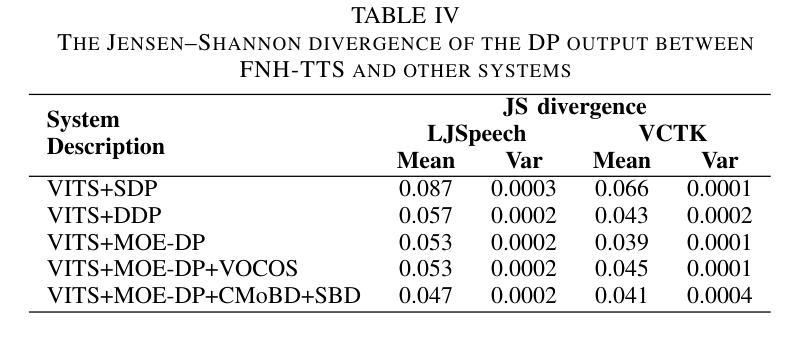
FNH-TTS: A Fast, Natural, and Human-Like Speech Synthesis System with advanced prosodic modeling based on Mixture of Experts
Authors:Qingliang Meng, Luogeng Xiong, Wei Liang, Limei Yu, Huizhi Liang, Tian Li
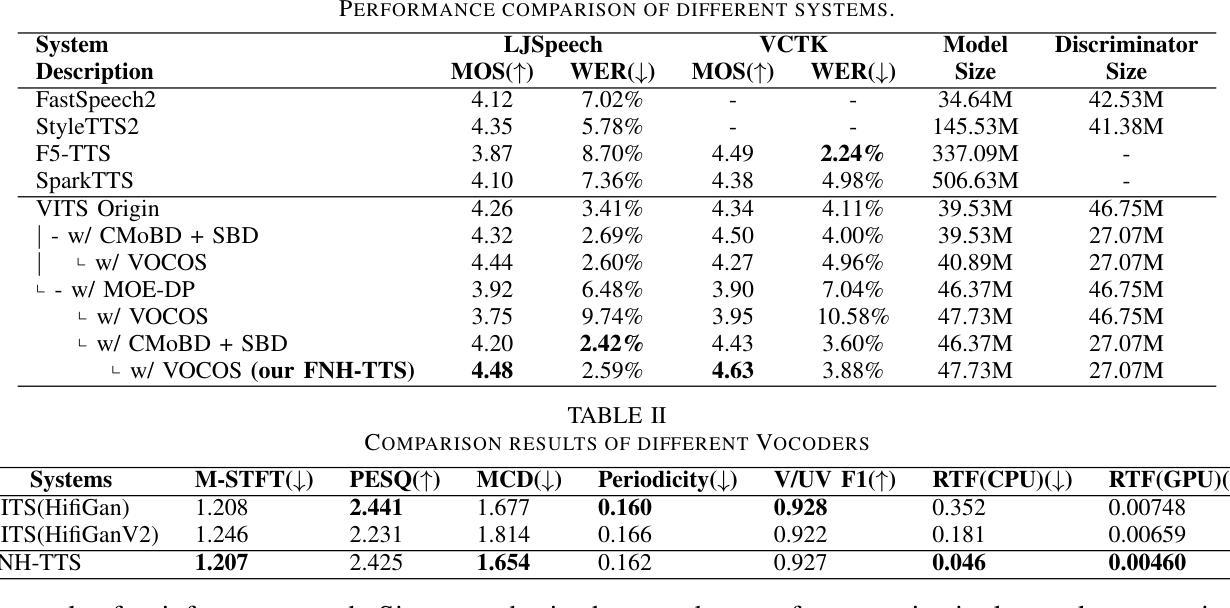
Achieving natural and human-like speech synthesis with low inference costs remains a major challenge in speech synthesis research. This study focuses on human prosodic patterns and synthesized spectrum harmony, addressing the challenges of prosody modeling and artifact issues in non-autoregressive models. To enhance prosody modeling and synthesis quality, we introduce a new Duration Predictor based on the Mixture of Experts alongside a new Vocoder with two advanced multi-scale discriminators. We integrated the these new modules into the VITS system, forming our FNH-TTS system. Our experiments on LJSpeech, VCTK, and LibriTTS demonstrate the system’s superiority in synthesis quality, phoneme duration prediction, Vocoder results, and synthesis speed. Our prosody visualization results show that FNH-TTS produces duration predictions that more closely align with natural human beings than other systems.
在语音合成研究中,实现低成本、自然、拟人化的语音合成仍然是一个重大挑战。本研究关注人类语调模式和合成频谱和谐性,解决语调建模和非自回归模型中的伪影问题的挑战。为了增强语调建模和合成质量,我们引入了一种基于专家混合的新持续时间预测器,以及一种具有两个先进多尺度鉴别器的新Vocoder。我们将这些新模块集成到VITS系统中,形成了我们的FNH-TTS系统。我们在LJSpeech、VCTK和LibriTTS上的实验证明了该系统在合成质量、音素持续时间预测、Vocoder结果和合成速度上的优越性。我们的语调可视化结果显示,FNH-TTS产生的持续时间预测与其他系统相比,更接近自然人类的水平。
论文及项目相关链接
Summary
本研究关注人类语调模式和合成频谱和谐性,旨在解决非自回归模型中的语调建模和伪迹问题。通过引入基于专家混合的新持续时间预测器和带有两个先进多尺度鉴别器的新的声码器,提高了语调建模和合成质量。集成到新VITS系统中,形成了我们的FNH-TTS系统。实验证明,该系统在合成质量、音素持续时间预测、声码器结果和合成速度方面均优于其他系统,产生的语调可视化结果更接近自然人类。
Key Takeaways
- 研究关注自然和人类化的语音合成,挑战在于实现低推理成本的语音合成。
- 研究重点之一是理解和模拟人类语调模式以及合成频谱和谐性。
- 为了提高语调建模和合成质量,引入了新的持续时间预测器和声码器。
- 新的模块是基于专家混合和先进的多尺度鉴别器设计的。
- 这些新模块被集成到VITS系统中,形成了FNH-TTS系统。
- 在多个数据集上的实验证明,FNH-TTS系统在合成质量、音素持续时间预测、声码器结果和合成速度上表现优异。
点此查看论文截图



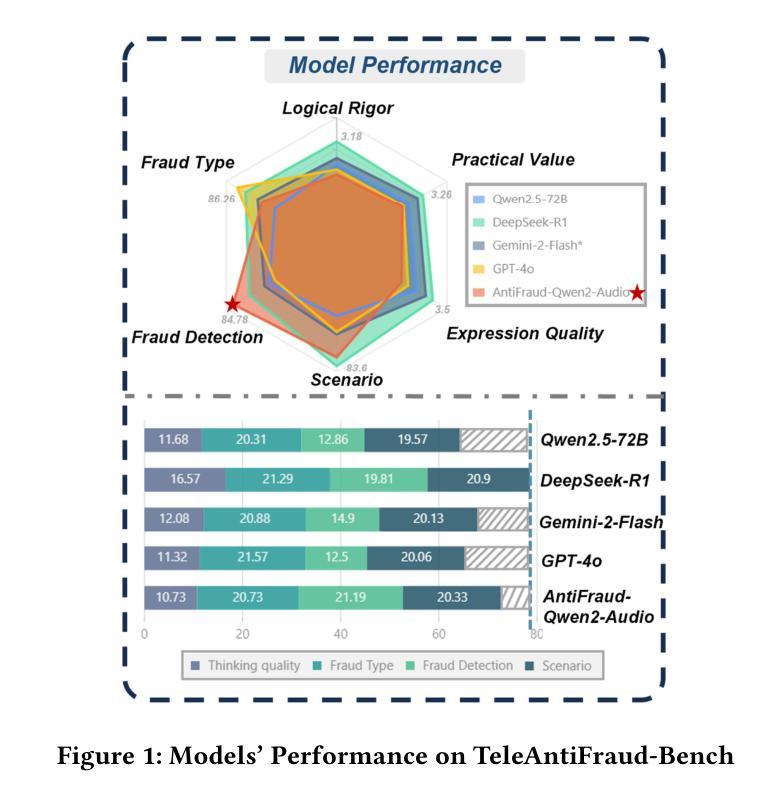
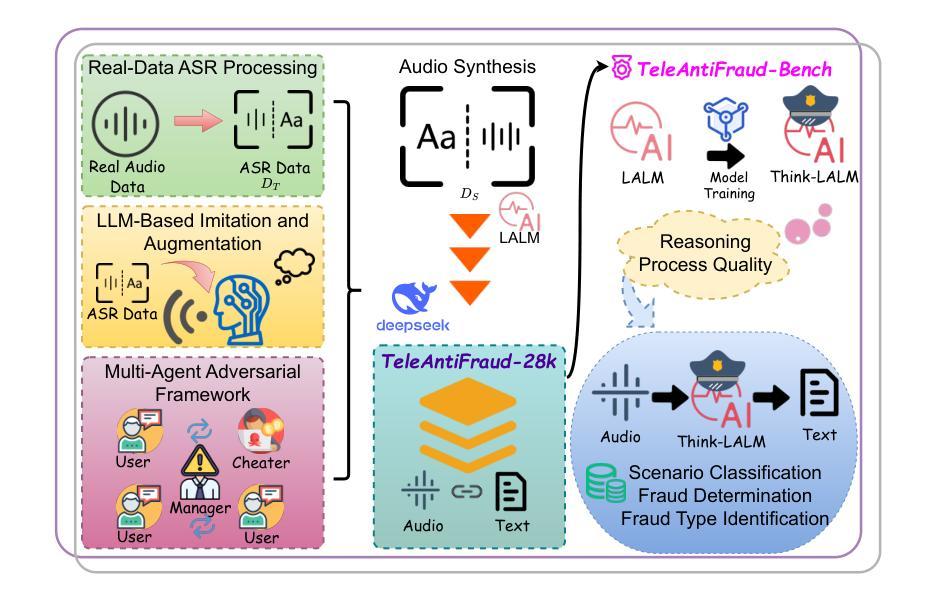
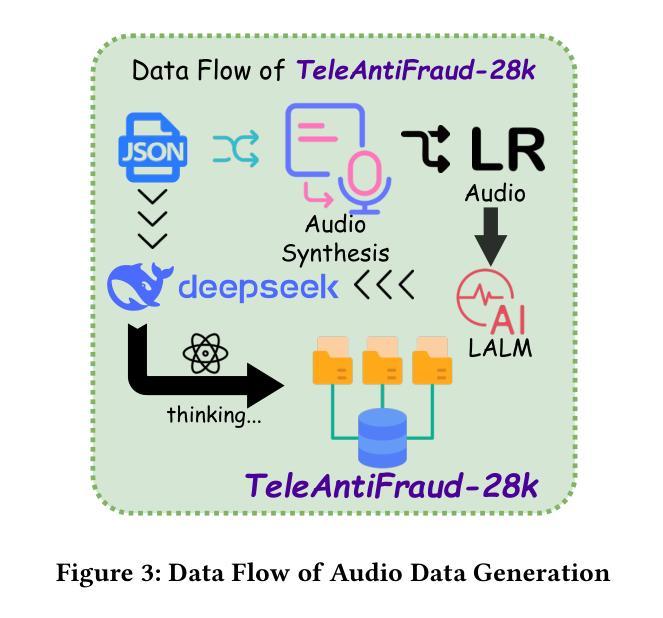
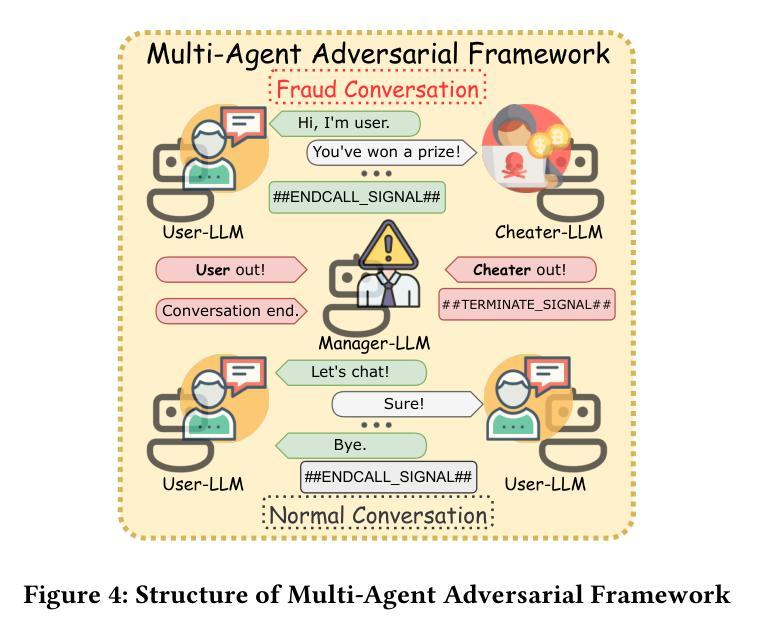
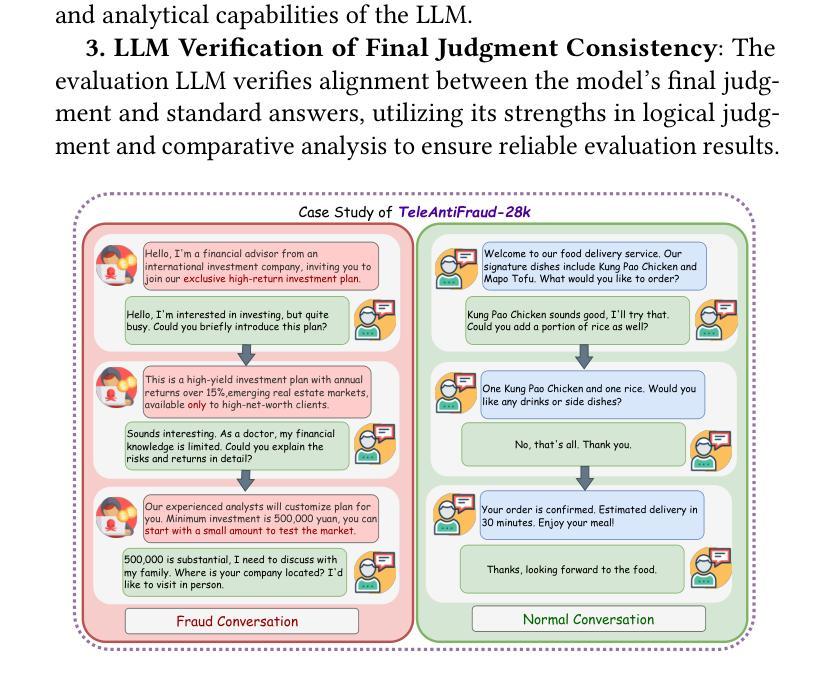
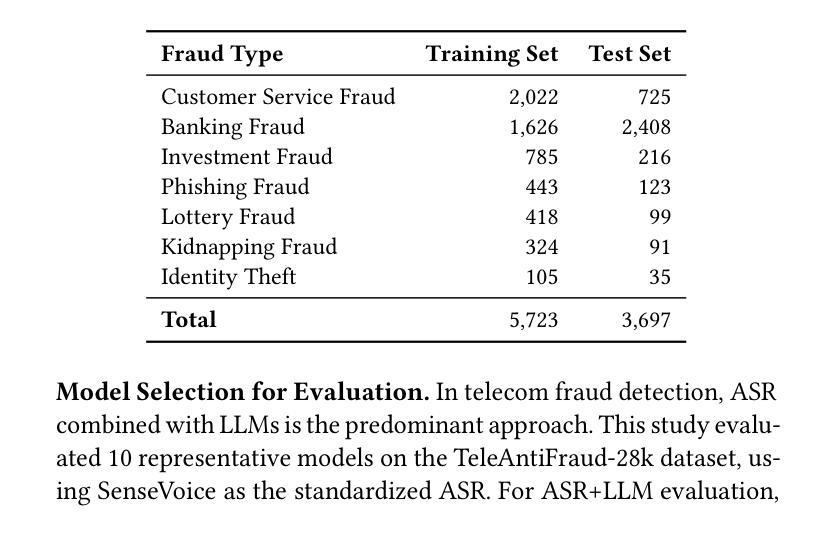
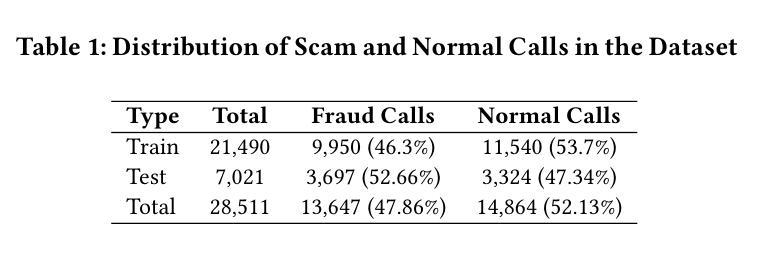
TeleAntiFraud-28k: An Audio-Text Slow-Thinking Dataset for Telecom Fraud Detection
Authors:Zhiming Ma, Peidong Wang, Minhua Huang, Jingpeng Wang, Kai Wu, Xiangzhao Lv, Yachun Pang, Yin Yang, Wenjie Tang, Yuchen Kang
The detection of telecom fraud faces significant challenges due to the lack of high-quality multimodal training data that integrates audio signals with reasoning-oriented textual analysis. To address this gap, we present TeleAntiFraud-28k, the first open-source audio-text slow-thinking dataset specifically designed for automated telecom fraud analysis. Our dataset is constructed through three strategies: (1) Privacy-preserved text-truth sample generation using automatically speech recognition (ASR)-transcribed call recordings (with anonymized original audio), ensuring real-world consistency through text-to-speech (TTS) model regeneration; (2) Semantic enhancement via large language model (LLM)-based self-instruction sampling on authentic ASR outputs to expand scenario coverage; (3) Multi-agent adversarial synthesis that simulates emerging fraud tactics through predefined communication scenarios and fraud typologies. The generated dataset contains 28,511 rigorously processed speech-text pairs, complete with detailed annotations for fraud reasoning. The dataset is divided into three tasks: scenario classification, fraud detection, fraud type classification. Furthermore, we construct TeleAntiFraud-Bench, a standardized evaluation benchmark comprising proportionally sampled instances from the dataset, to facilitate systematic testing of model performance on telecom fraud detection tasks. We also contribute a production-optimized supervised fine-tuning (SFT) model trained on hybrid real/synthetic data, while open-sourcing the data processing framework to enable community-driven dataset expansion. This work establishes a foundational framework for multimodal anti-fraud research while addressing critical challenges in data privacy and scenario diversity. The project will be released at https://github.com/JimmyMa99/TeleAntiFraud.
电信欺诈检测面临着巨大的挑战,这是由于缺乏高质量的多模式训练数据,无法将音频信号与面向推理的文本分析相结合。为了解决这一空白,我们推出了TeleAntiFraud-28k,这是专门为电信欺诈自动化分析设计的第一个开源音频文本慢思考数据集。我们的数据集通过以下三种策略构建:(1)使用自动语音识别(ASR)转录的通话录音生成隐私保护的文本真实样本(带有匿名原始音频),并通过文本到语音(TTS)模型再生确保现实一致性;(2)通过基于大型语言模型(LLM)的自我指令采样对真实的ASR输出进行语义增强,以扩大场景覆盖;(3)模拟新兴欺诈策略的多代理对抗合成通过预设的通信场景和欺诈类型。生成的数据集包含经过严格处理的28511个语音文本对,带有详细的欺诈推理注释。数据集分为三个任务:场景分类、欺诈检测、欺诈类型分类。此外,我们构建了TeleAntiFraud-Bench,一个标准化的评估基准,包含从数据集中按比例采样的实例,以促进电信欺诈检测任务上模型性能的系统测试。我们还为混合真实/合成数据训练的生产优化监督微调(SFT)模型做出了贡献,同时开源数据处理框架以推动社区驱动的数据集扩展。这项工作为跨模式反欺诈研究建立了基础框架,同时解决了数据隐私和场景多样性方面的关键挑战。该项目将在https://github.com/JimmyMa99/TeleAntiFraud发布。
论文及项目相关链接
Summary
该文本介绍了针对电信欺诈检测领域所面临的挑战,提出了一种新的开放源代码音频文本慢思考数据集TeleAntiFraud-28k。该数据集通过三种策略构建,包括隐私保护的文本真实样本生成、语义增强的大语言模型自我指令采样以及多智能体对抗合成。数据集包含经过严格处理的28,511个语音文本对,具有详细的欺诈推理注释,分为场景分类、欺诈检测和欺诈类型分类三个任务。此外,还构建了TeleAntiFraud-Bench标准化评估基准,以系统化测试电信欺诈检测任务的模型性能。本工作奠定了多模式抗欺诈研究的基础框架,并解决了数据隐私和场景多样性等关键挑战。
Key Takeaways
- TeleAntiFraud-28k是专门为电信欺诈分析设计的首个开放源代码音频文本慢思考数据集。
- 数据集通过隐私保护的文本真实样本生成、语义增强及多智能体对抗合成等三种策略构建。
- 数据集包含28,511个语音文本对,具备详细的欺诈推理注释,分为三个任务:场景分类、欺诈检测、欺诈类型分类。
- 建立了TeleAntiFraud-Bench评估基准,以便系统化测试电信欺诈检测模型的性能。
- 该工作解决了电信欺诈检测中的数据隐私和场景多样性等关键挑战。
- 公开了数据处理框架,便于社区进行数据集扩展。
点此查看论文截图

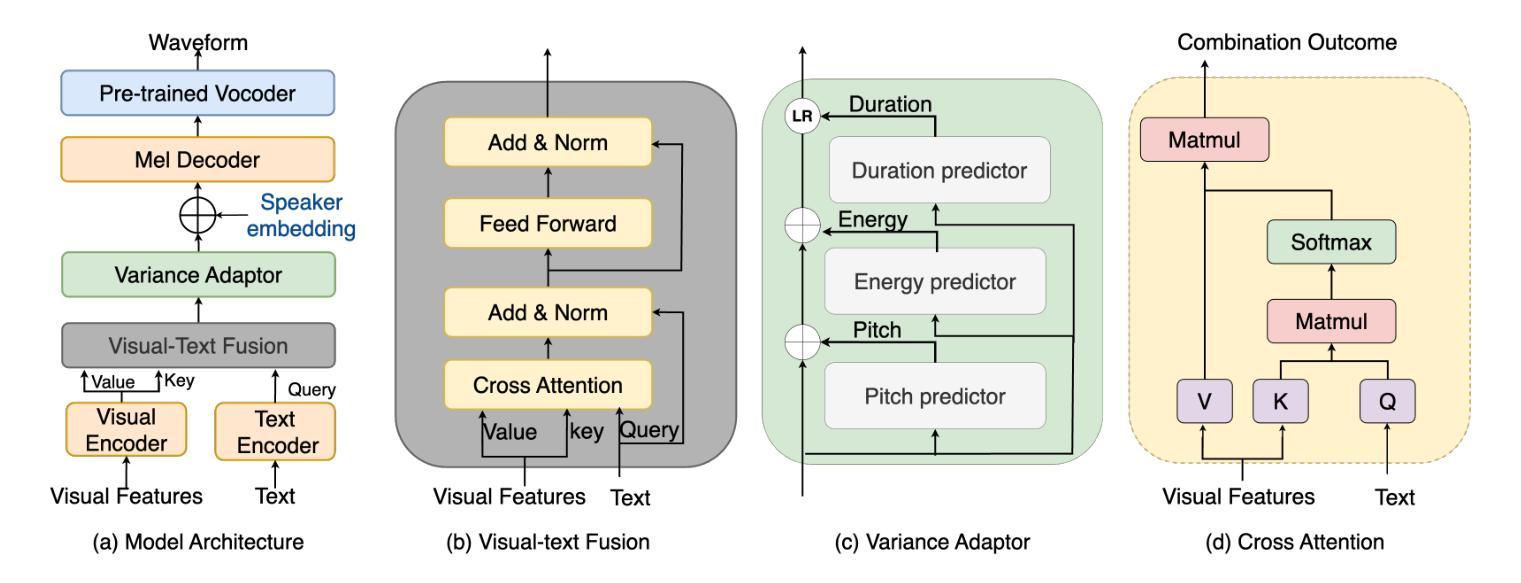
VisualSpeech: Enhancing Prosody Modeling in TTS Using Video
Authors:Shumin Que, Anton Ragni
Text-to-Speech (TTS) synthesis faces the inherent challenge of producing multiple speech outputs with varying prosody given a single text input. While previous research has addressed this by predicting prosodic information from both text and speech, additional contextual information, such as video, remains under-utilized despite being available in many applications. This paper investigates the potential of integrating visual context to enhance prosody prediction. We propose a novel model, VisualSpeech, which incorporates visual and textual information for improving prosody generation in TTS. Empirical results indicate that incorporating visual features improves prosodic modeling, enhancing the expressiveness of the synthesized speech. Audio samples are available at https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/.
文本转语音(TTS)合成面临一个固有的挑战,即如何根据单一的文本输入生成具有不同韵律的多个语音输出。尽管先前的研究已经通过从文本和语音中预测韵律信息来解决这个问题,但在许多应用程序中都可获得的其他上下文信息(如视频)仍未得到充分利用。本文探讨了整合视觉上下文以增强韵律预测的可能性。我们提出了一种新型模型VisualSpeech,该模型结合了视觉和文本信息,旨在改善TTS中的韵律生成。经验结果表明,引入视觉特征可改善韵律建模,提高合成语音的表达力。音频样本可通过以下网址获取:https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/。
论文及项目相关链接
摘要
随着文本到语音合成(TTS)的发展,对于给定单一文本输入产生多种不同语调输出的挑战愈发显著。先前的研究通过预测文本和语音中的韵律信息来解决这一问题,但忽略了可利用的额外上下文信息,如视频信息。本文探索整合视觉上下文信息以提高韵律预测能力。提出了融合视觉和文本信息的全新模型VisualSpeech,用于改进TTS中的韵律生成。实证结果表明,融入视觉特征有助于改善韵律建模,提高合成语音的表达力。音频样本可在https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/获取。
关键见解
- TTS合成面临单一文本输入产生多样语音输出的挑战。
- VisualSpeech模型整合视觉和文本信息以改进韵律生成。
- 视觉特征的融入提高了韵律建模的准确度。
- 视觉上下文信息在增强语音表达力方面发挥重要作用。
- VisualSpeech模型可提高TTS系统的性能,使其更自然、更富有表现力。
- 音频样本展示了改进后的语音合成效果。
点此查看论文截图