⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
FNH-TTS: A Fast, Natural, and Human-Like Speech Synthesis System with advanced prosodic modeling based on Mixture of Experts
Authors:Qingliang Meng, Luogeng Xiong, Wei Liang, Limei Yu, Huizhi Liang, Tian Li
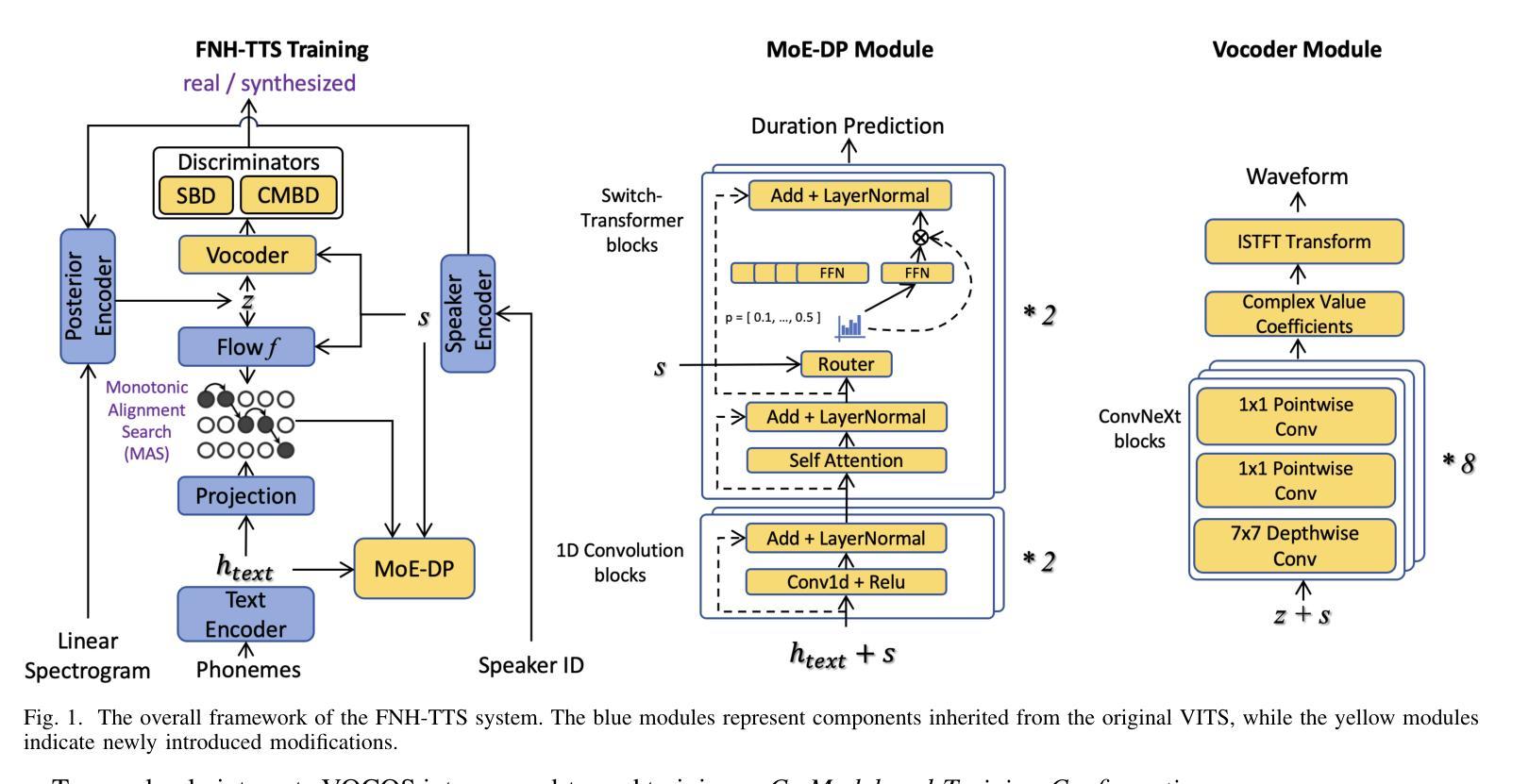
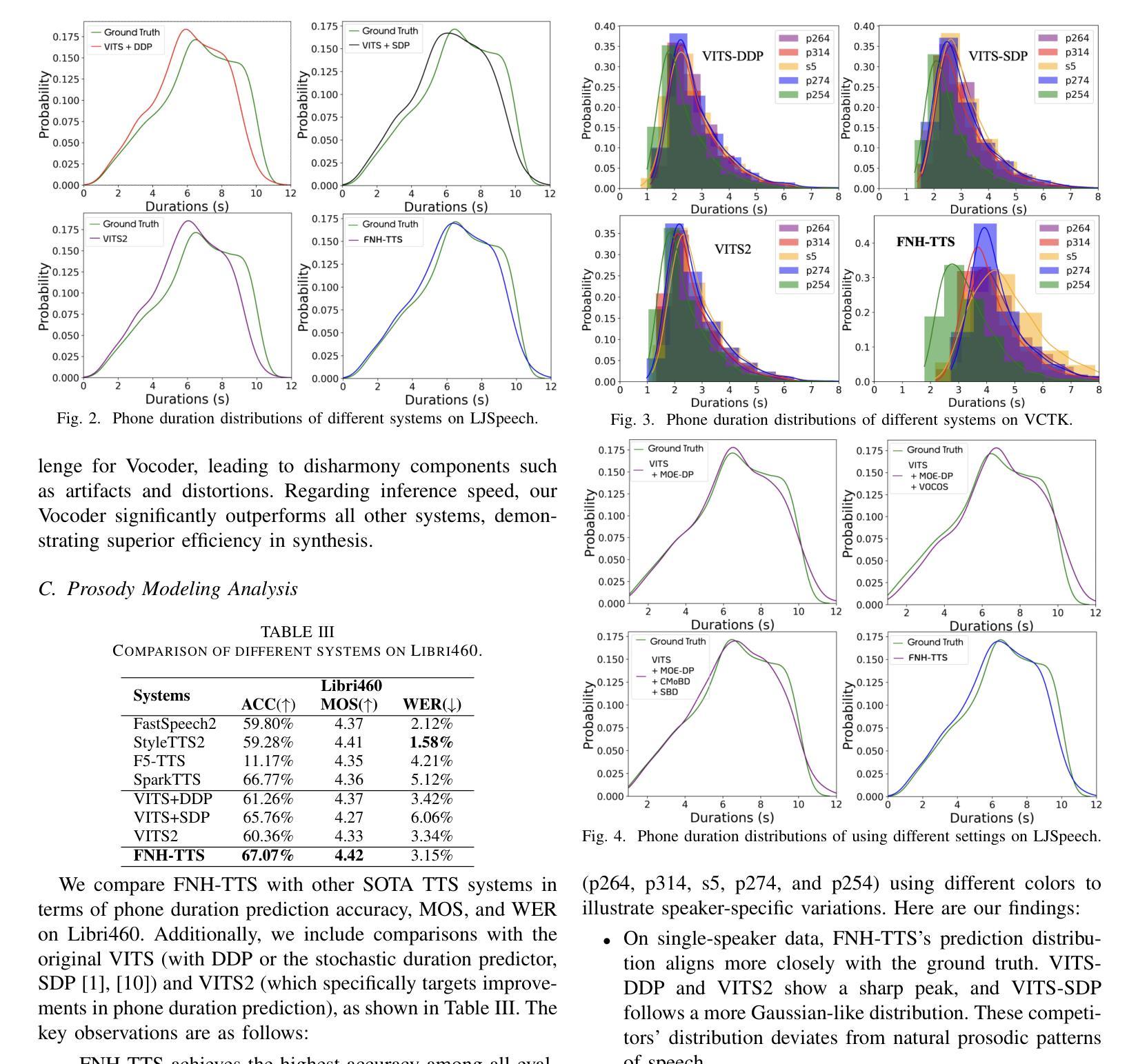
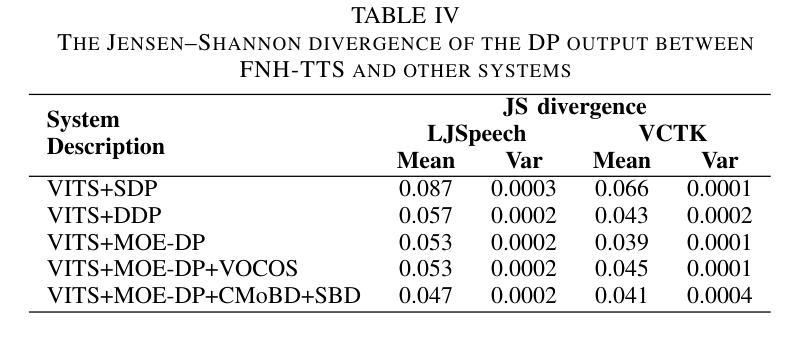
Achieving natural and human-like speech synthesis with low inference costs remains a major challenge in speech synthesis research. This study focuses on human prosodic patterns and synthesized spectrum harmony, addressing the challenges of prosody modeling and artifact issues in non-autoregressive models. To enhance prosody modeling and synthesis quality, we introduce a new Duration Predictor based on the Mixture of Experts alongside a new Vocoder with two advanced multi-scale discriminators. We integrated the these new modules into the VITS system, forming our FNH-TTS system. Our experiments on LJSpeech, VCTK, and LibriTTS demonstrate the system’s superiority in synthesis quality, phoneme duration prediction, Vocoder results, and synthesis speed. Our prosody visualization results show that FNH-TTS produces duration predictions that more closely align with natural human beings than other systems.
在语音合成研究中,实现低成本且听起来自然、人性化的语音合成仍然是主要挑战。本研究聚焦于人类韵律模式和合成频谱和谐性,旨在解决非自回归模型中的韵律建模和人工制品问题。为了增强韵律建模和合成质量,我们引入了基于专家混合体的新时长预测器以及具有两个先进多尺度鉴别器的新Vocoder。我们将这些新模块集成到VITS系统中,形成了我们的FNH-TTS系统。我们在LJSpeech、VCTK和LibriTTS上的实验证明了该系统在合成质量、音素时长预测、Vocoder结果和合成速度方面的优越性。我们的韵律可视化结果表明,FNH-TTS产生的时长预测与其他系统相比更接近自然人类。
论文及项目相关链接
Summary
文本聚焦于实现自然且类似人类发音的合成语音,旨在解决语音合成中的重大挑战,包括韵律建模和非自回归模型中的伪影问题。研究引入了基于混合专家算法的新持续时间预测器,并配有新型vocoder和两个先进的多尺度鉴别器。新模块集成到VITS系统中形成了FNH-TTS系统。实验证明其在语音合成质量、音素持续时间预测、vocoder结果和合成速度上的优越性。FNH-TTS产生的持续时间预测与自然人类更相符。
Key Takeaways
- 实现自然和类似人类的语音合成是一大挑战。
- 研究集中在韵律模式和非自回归模型的合成频谱和谐上。
- 引入基于混合专家算法的持续时间预测器增强韵律建模和合成质量。
- 新Vocoder与两个先进的多尺度鉴别器结合使用。
- 新模块集成到VITS系统中形成FNH-TTS系统。
- 实验证明FNH-TTS在多个方面的优越性,包括合成质量、持续时间预测和自然度。
点此查看论文截图



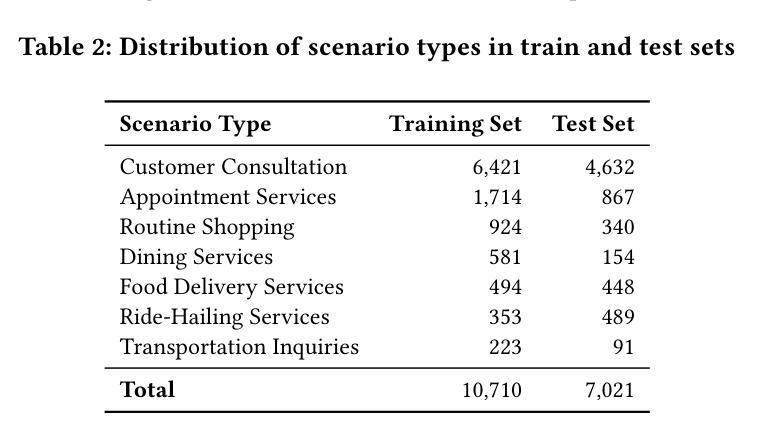
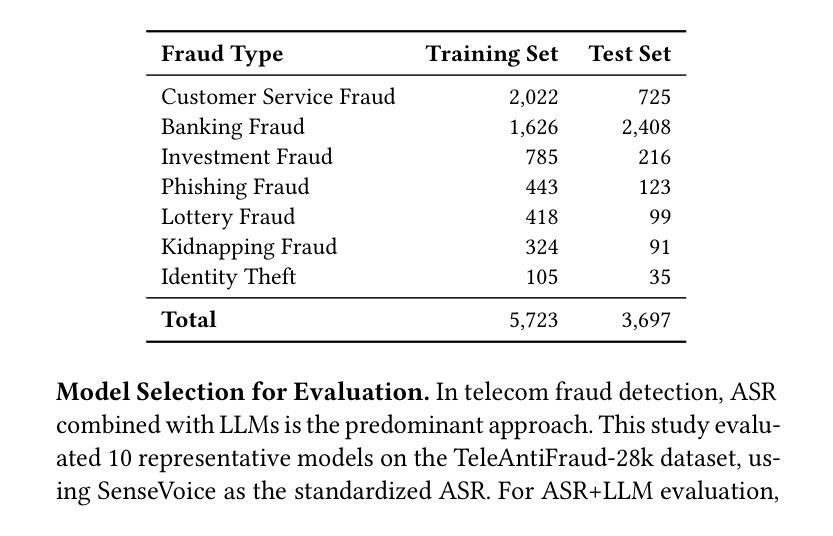
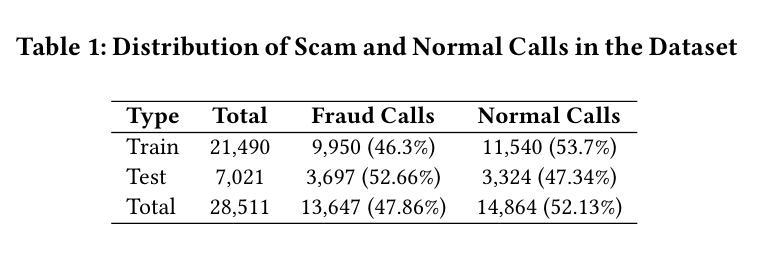
TeleAntiFraud-28k: An Audio-Text Slow-Thinking Dataset for Telecom Fraud Detection
Authors:Zhiming Ma, Peidong Wang, Minhua Huang, Jingpeng Wang, Kai Wu, Xiangzhao Lv, Yachun Pang, Yin Yang, Wenjie Tang, Yuchen Kang
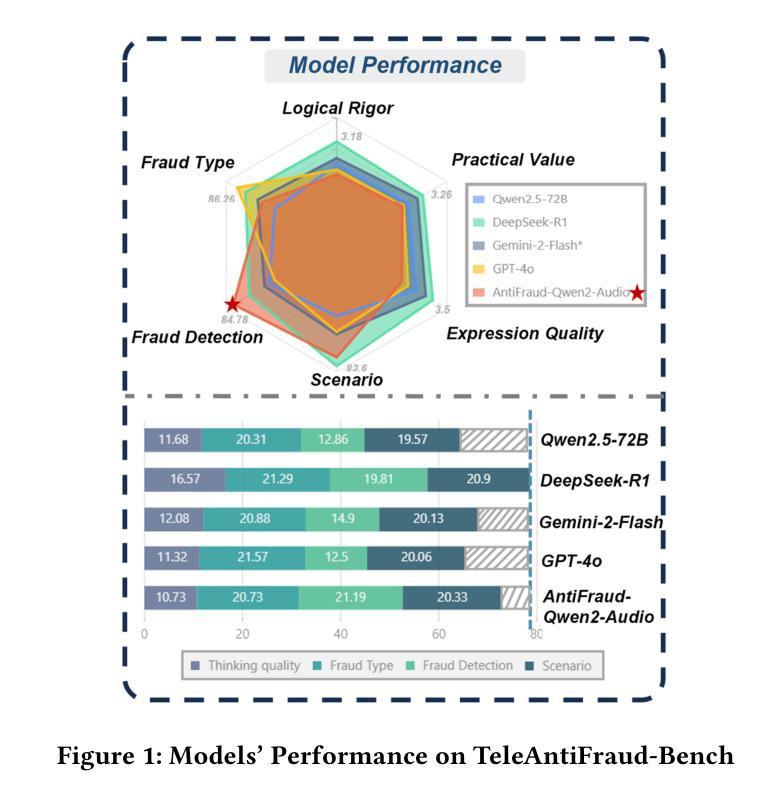
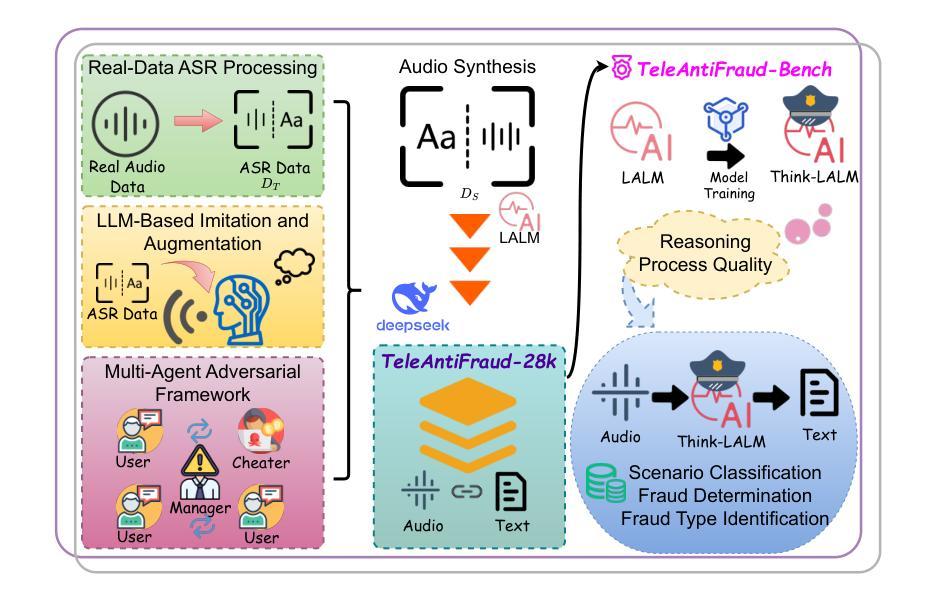
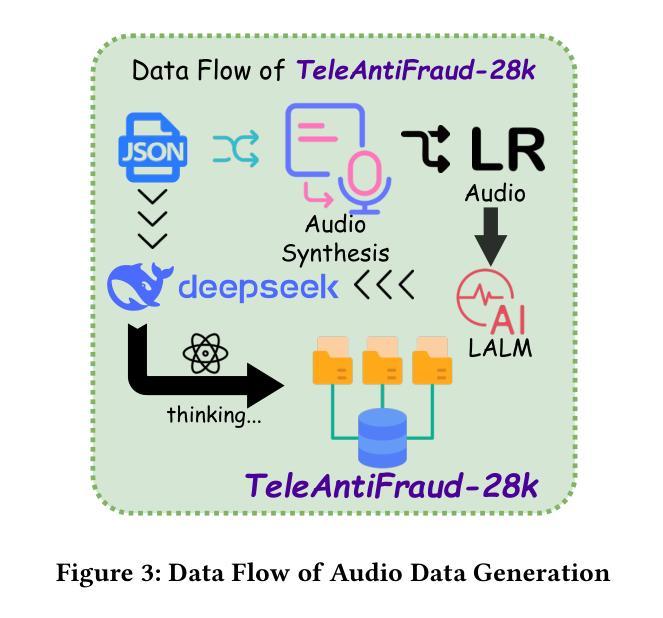
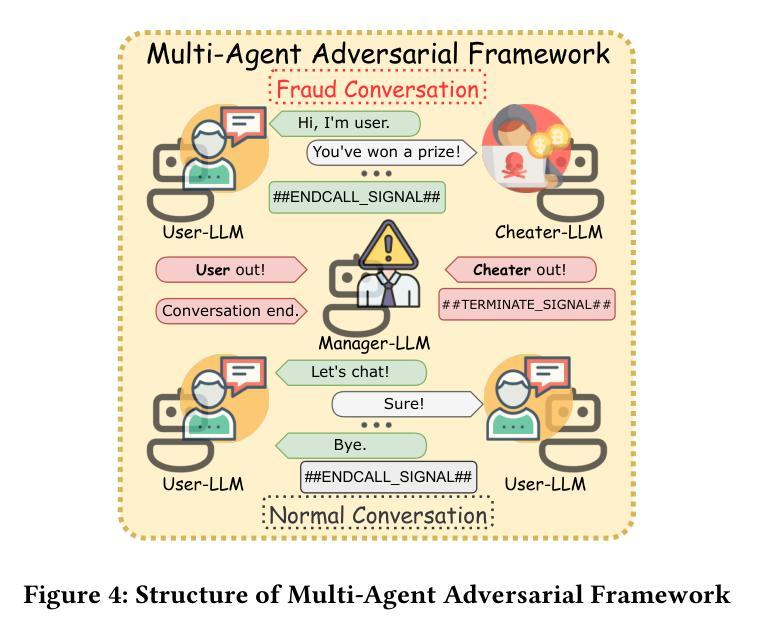
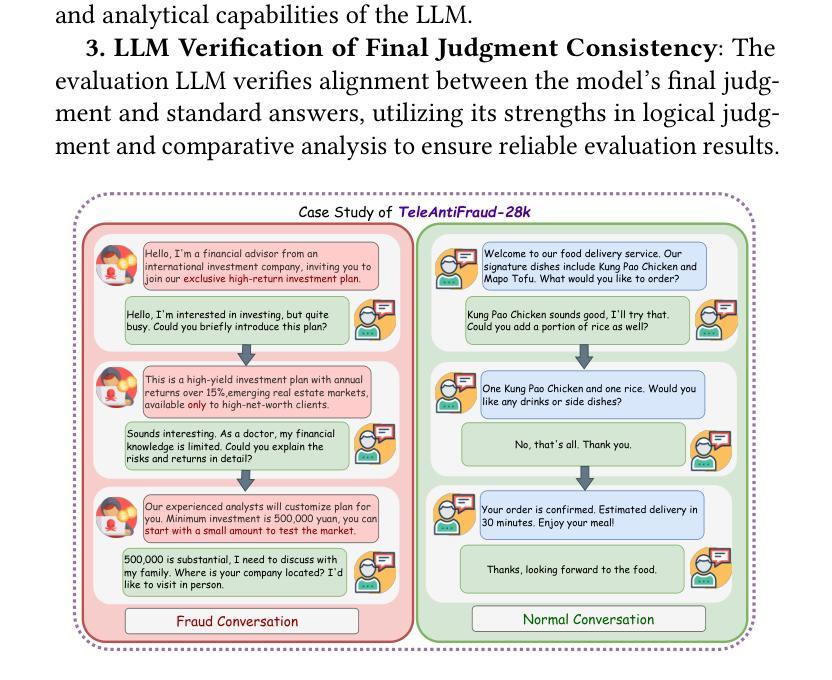
The detection of telecom fraud faces significant challenges due to the lack of high-quality multimodal training data that integrates audio signals with reasoning-oriented textual analysis. To address this gap, we present TeleAntiFraud-28k, the first open-source audio-text slow-thinking dataset specifically designed for automated telecom fraud analysis. Our dataset is constructed through three strategies: (1) Privacy-preserved text-truth sample generation using automatically speech recognition (ASR)-transcribed call recordings (with anonymized original audio), ensuring real-world consistency through text-to-speech (TTS) model regeneration; (2) Semantic enhancement via large language model (LLM)-based self-instruction sampling on authentic ASR outputs to expand scenario coverage; (3) Multi-agent adversarial synthesis that simulates emerging fraud tactics through predefined communication scenarios and fraud typologies. The generated dataset contains 28,511 rigorously processed speech-text pairs, complete with detailed annotations for fraud reasoning. The dataset is divided into three tasks: scenario classification, fraud detection, fraud type classification. Furthermore, we construct TeleAntiFraud-Bench, a standardized evaluation benchmark comprising proportionally sampled instances from the dataset, to facilitate systematic testing of model performance on telecom fraud detection tasks. We also contribute a production-optimized supervised fine-tuning (SFT) model trained on hybrid real/synthetic data, while open-sourcing the data processing framework to enable community-driven dataset expansion. This work establishes a foundational framework for multimodal anti-fraud research while addressing critical challenges in data privacy and scenario diversity. The project will be released at https://github.com/JimmyMa99/TeleAntiFraud.
电信欺诈检测面临着巨大的挑战,主要是由于缺乏高质量的多模式训练数据,无法将音频信号与面向推理的文本分析相结合。为了解决这一空白,我们推出了TeleAntiFraud-28k,这是专门为电信欺诈自动化分析设计的首个开源音频文本慢思考数据集。我们的数据集通过三种策略构建:(1)使用自动语音识别(ASR)转录的录音生成隐私保护的文本真实样本(带有匿名原始音频),并通过文本到语音(TTS)模型的再生确保现实世界的一致性;(2)通过基于大型语言模型(LLM)的自我指令采样对真实的ASR输出进行语义增强,以扩大场景覆盖范围;(3)模拟新兴欺诈策略的多代理对抗性合成通过预设的通信场景和欺诈类型。生成的数据集包含经过严格处理的28,511个语音文本对,以及详细的欺诈推理注释。数据集分为三个任务:场景分类、欺诈检测、欺诈类型分类。此外,我们构建了TeleAntiFraud-Bench,一个标准化的评估基准,由数据集中按比例采样的实例组成,以促进电信欺诈检测任务上模型性能的系统测试。我们还为混合真实/合成数据训练的生产优化监督微调(SFT)模型做出了贡献,同时开源数据处理框架,以促进社区驱动的数据集扩展。这项工作为多媒体抗欺诈研究提供了基础框架,并解决了数据隐私和场景多样性方面的关键挑战。该项目将在https://github.com/JimmyMa99/TeleAntiFraud发布。
论文及项目相关链接
摘要
针对电信欺诈检测面临的挑战,如缺乏高质量的多模式训练数据,我们推出了TeleAntiFraud-28k数据集。该数据集融合音频信号与面向推理的文本分析,专为电信欺诈自动分析设计。通过三种策略构建:隐私保护文本样本生成、语义增强和大模型自我指导采样、多智能体对抗合成。包含28,511个严格处理的语音-文本对,带详细欺诈推理注释。分为场景分类、欺诈检测和欺诈类型分类三个任务。同时构建评估基准TeleAntiFraud-Bench,开放数据处理框架,促进数据集扩展。为跨模态反欺诈研究提供基础框架,解决数据隐私和场景多样性挑战。
要点
- 面临电信欺诈检测的挑戁:缺乏高质量的多模式训练数据。
- 提出TeleAntiFraud-28k数据集:融合音频与文本分析,专用于电信欺诈自动分析。
- 数据集构建策略:隐私保护文本样本生成、语义增强、多智能体对抗合成。
- 详细注释的语音-文本对:包含场景分类、欺诈检测和欺诈类型分类三个任务。
- 构建评估基准TeleAntiFraud-Bench:便于模型性能的系统测试。
- 开放数据处理框架:促进数据集社区扩展。
- 为跨模态反欺诈研究提供基础框架。
点此查看论文截图

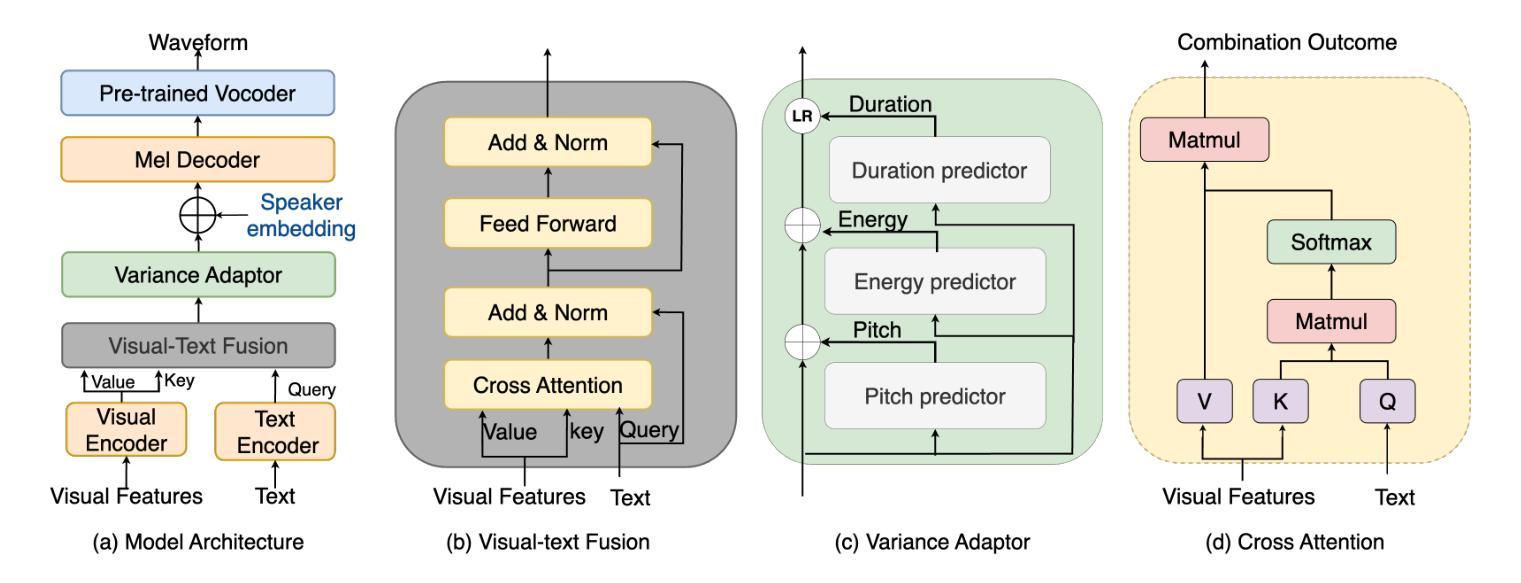
VisualSpeech: Enhancing Prosody Modeling in TTS Using Video
Authors:Shumin Que, Anton Ragni
Text-to-Speech (TTS) synthesis faces the inherent challenge of producing multiple speech outputs with varying prosody given a single text input. While previous research has addressed this by predicting prosodic information from both text and speech, additional contextual information, such as video, remains under-utilized despite being available in many applications. This paper investigates the potential of integrating visual context to enhance prosody prediction. We propose a novel model, VisualSpeech, which incorporates visual and textual information for improving prosody generation in TTS. Empirical results indicate that incorporating visual features improves prosodic modeling, enhancing the expressiveness of the synthesized speech. Audio samples are available at https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/.
文本转语音(TTS)合成面临一个固有挑战,即如何根据单一文本输入生成具有不同韵律的多个语音输出。尽管之前的研究已经通过从文本和语音预测韵律信息来解决这个问题,但在许多应用中,额外的上下文信息(如视频)仍未得到充分利用。本文探讨了整合视觉上下文以增强韵律预测的可能性。我们提出了一种新型模型VisualSpeech,该模型结合了视觉和文本信息,旨在提高TTS中的韵律生成。经验结果表明,引入视觉特征改善了韵律建模,提高了合成语音的表达力。音频样本可通过以下网址获取:[https://ariameetgit.github.io/VISUALSPEECH-SAMPLES/。]
论文及项目相关链接
Summary
本文探讨了文本转语音(TTS)合成面临的挑战,即如何根据单一文本输入生成具有不同语调的多种语音输出。针对这一问题,文章提出了一种全新的模型VisualSpeech,它融合了视觉和文本信息以提高TTS中的语调生成能力。实验结果表明,融入视觉特征能够改善语调建模,增强合成语音的表达力。
Key Takeaways
- TTS合成面临单一文本输入生成多种语音输出的挑战。
- 视觉信息在许多应用中是可用的,但在TTS中尚未得到充分利用。
- 本文提出了一个名为VisualSpeech的新模型,融合了视觉和文本信息。
- 融入视觉特征可以改善语调建模,提高合成语音的表达力。
- VisualSpeech模型通过结合视觉和文本信息增强了TTS的语调生成能力。
- 实证结果表明,VisualSpeech模型在改善语调建模方面表现出积极的效果。
点此查看论文截图