⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-20 更新
Express4D: Expressive, Friendly, and Extensible 4D Facial Motion Generation Benchmark
Authors:Yaron Aloni, Rotem Shalev-Arkushin, Yonatan Shafir, Guy Tevet, Ohad Fried, Amit Haim Bermano
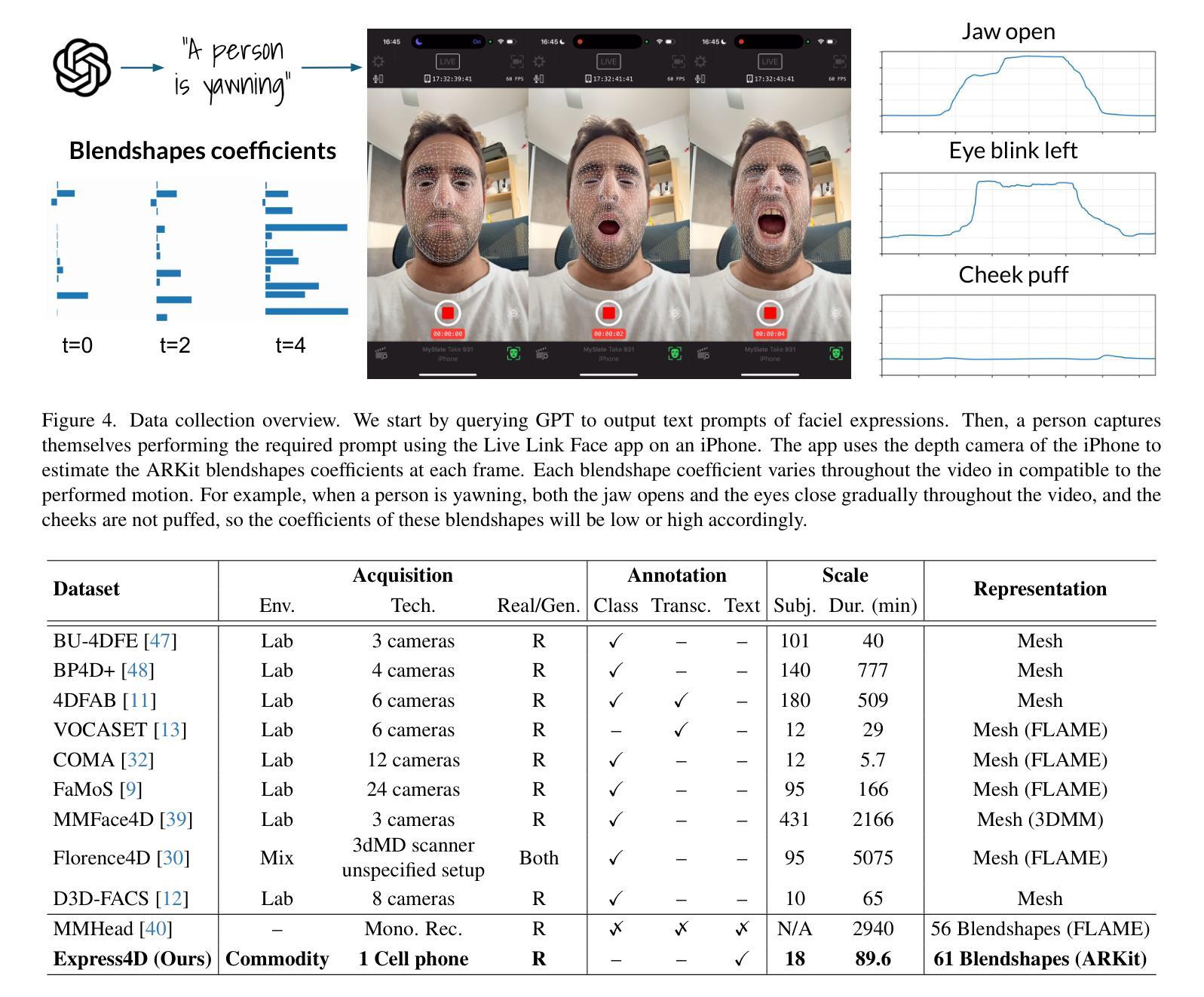
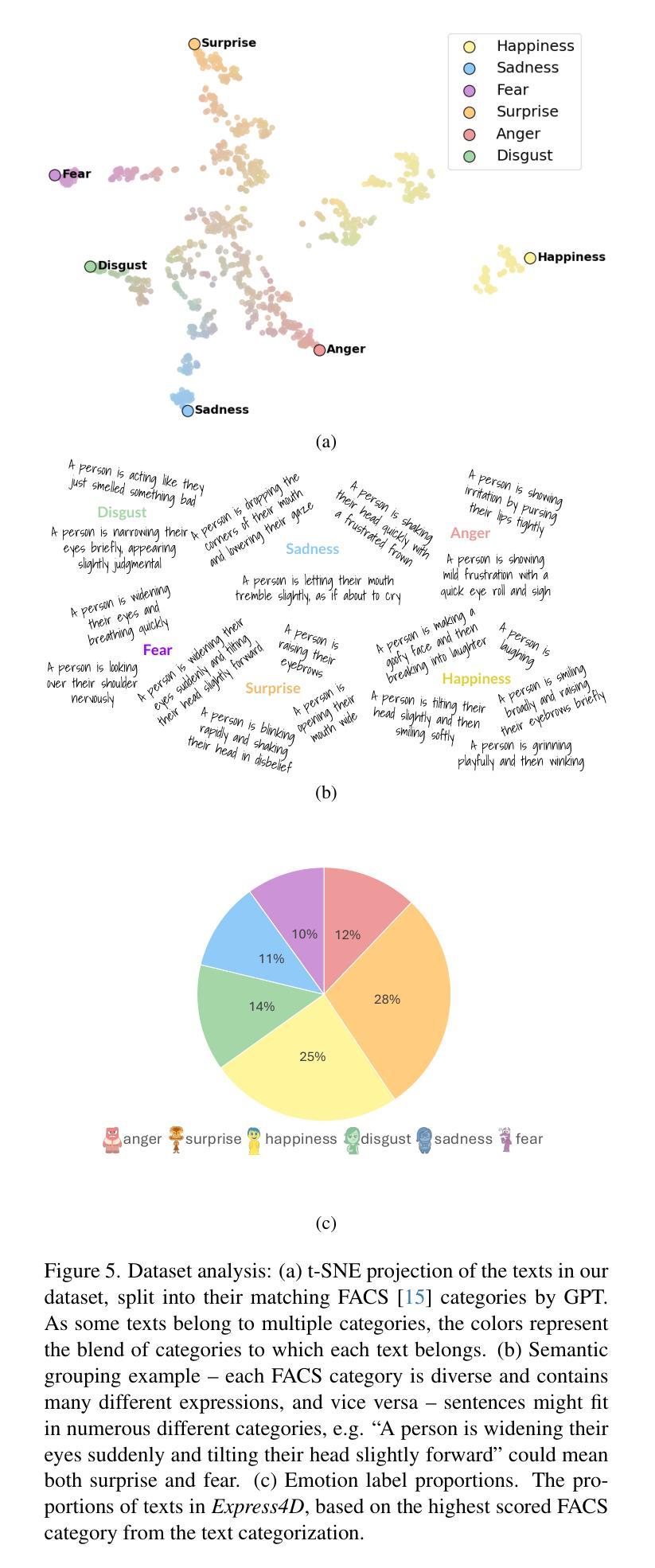
Dynamic facial expression generation from natural language is a crucial task in Computer Graphics, with applications in Animation, Virtual Avatars, and Human-Computer Interaction. However, current generative models suffer from datasets that are either speech-driven or limited to coarse emotion labels, lacking the nuanced, expressive descriptions needed for fine-grained control, and were captured using elaborate and expensive equipment. We hence present a new dataset of facial motion sequences featuring nuanced performances and semantic annotation. The data is easily collected using commodity equipment and LLM-generated natural language instructions, in the popular ARKit blendshape format. This provides riggable motion, rich with expressive performances and labels. We accordingly train two baseline models, and evaluate their performance for future benchmarking. Using our Express4D dataset, the trained models can learn meaningful text-to-expression motion generation and capture the many-to-many mapping of the two modalities. The dataset, code, and video examples are available on our webpage: https://jaron1990.github.io/Express4D/
动态面部表情从自然语言生成是计算机图形学中的一项重要任务,在动画、虚拟化身和人机交互等领域都有应用。然而,当前的生成模型存在缺陷,要么依赖于语音驱动的数据集,要么仅限于粗粒度的情感标签,缺乏精细控制所需的微妙、富有表现力的描述,并且是通过复杂昂贵的设备捕获的。因此,我们推出了一套新的面部运动序列数据集,具有微妙的表演和语义注释。这些数据使用普通设备和大型语言模型生成的自然语言指令轻松收集,采用流行的ARKit blendshape格式。这提供了可控制的运动,具有丰富的表现力和标签。据此,我们训练了两个基线模型,并评估了它们的性能以供未来基准测试。使用我们的Express4D数据集,训练后的模型可以学习有意义的文本到表情运动生成,并捕获两种模式的许多到许多映射。数据集、代码和视频示例可在我们的网页上找到:https://jaron1990.github.io/Express4D/。
论文及项目相关链接
Summary
动态面部表情从自然语言生成是计算机图形学中的一项重要任务,广泛应用于动画、虚拟化身和人机交互领域。然而,当前生成模型受限于数据集,存在表情驱动或仅使用粗略情感标签的问题,缺乏精细控制所需的微妙和表达性描述,且使用复杂昂贵的设备进行采集。因此,我们推出新的面部表情运动序列数据集Express4D,采用商品设备和大型语言模型生成的自然语言指令进行语义注释。数据易于收集,采用流行的ARKit blendshape格式,提供可控制的运动,具有丰富的表现力和标签。我们据此训练了两个基线模型,并评估其性能以供未来参考。使用Express4D数据集,训练模型能够学习有意义的文本到表情运动生成,捕捉两种模式的多元映射。数据集、代码和视频示例可在我们的网页上找到:https://jaron1990.github.io/Express4D/。
Key Takeaways
- 动态面部表情生成是计算机图形学中的重要任务,应用领域广泛。
- 当前生成模型受限于数据集,缺乏精细控制和微妙的表达性描述。
- 提出新的面部表情运动序列数据集Express4D,包含微妙的表演和语义注释。
- 数据集使用商品设备和自然语言指令进行采集,采用ARKit blendshape格式。
- Express4D数据集提供可控制的运动,丰富的表现力和标签。
- 训练了两个基线模型以评估性能,为未来提供参考。
点此查看论文截图



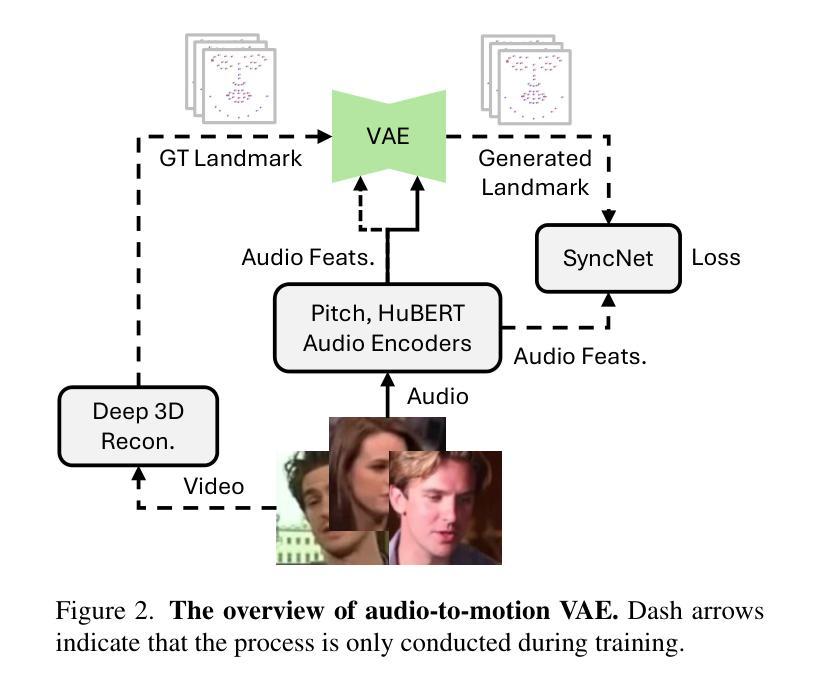
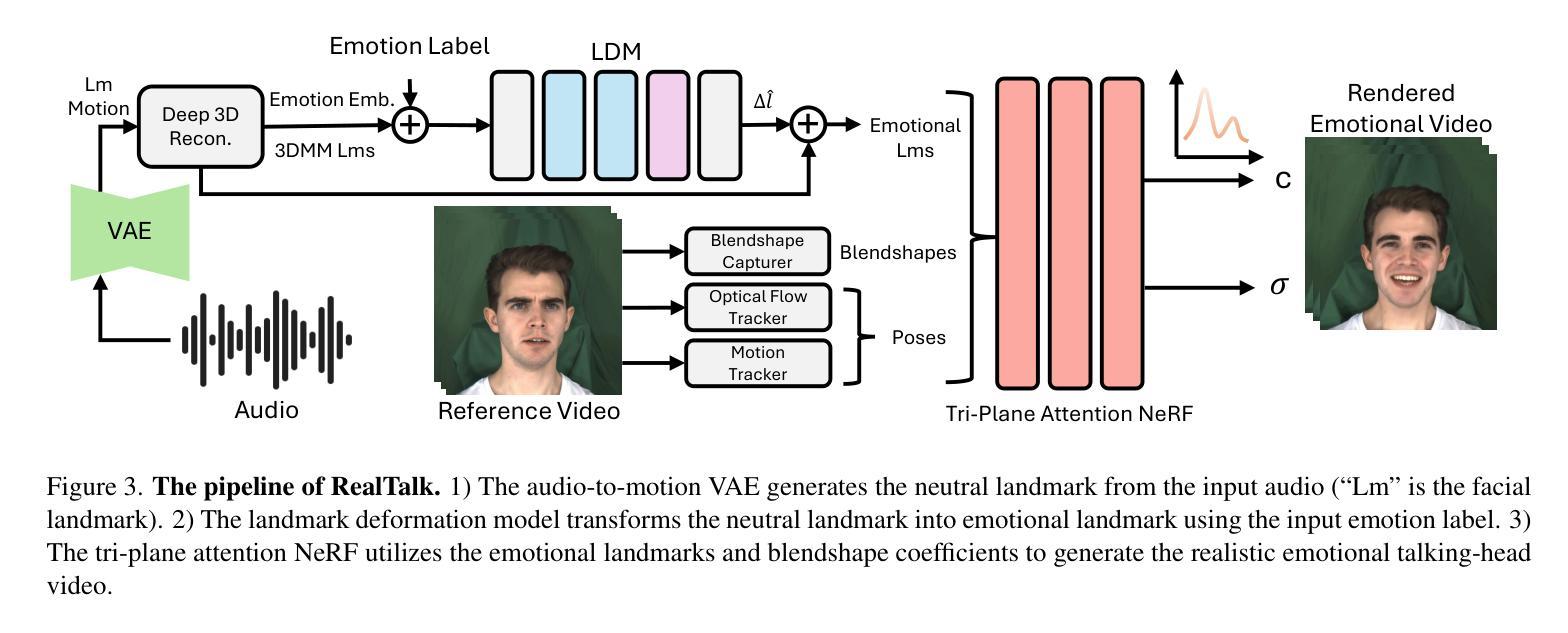
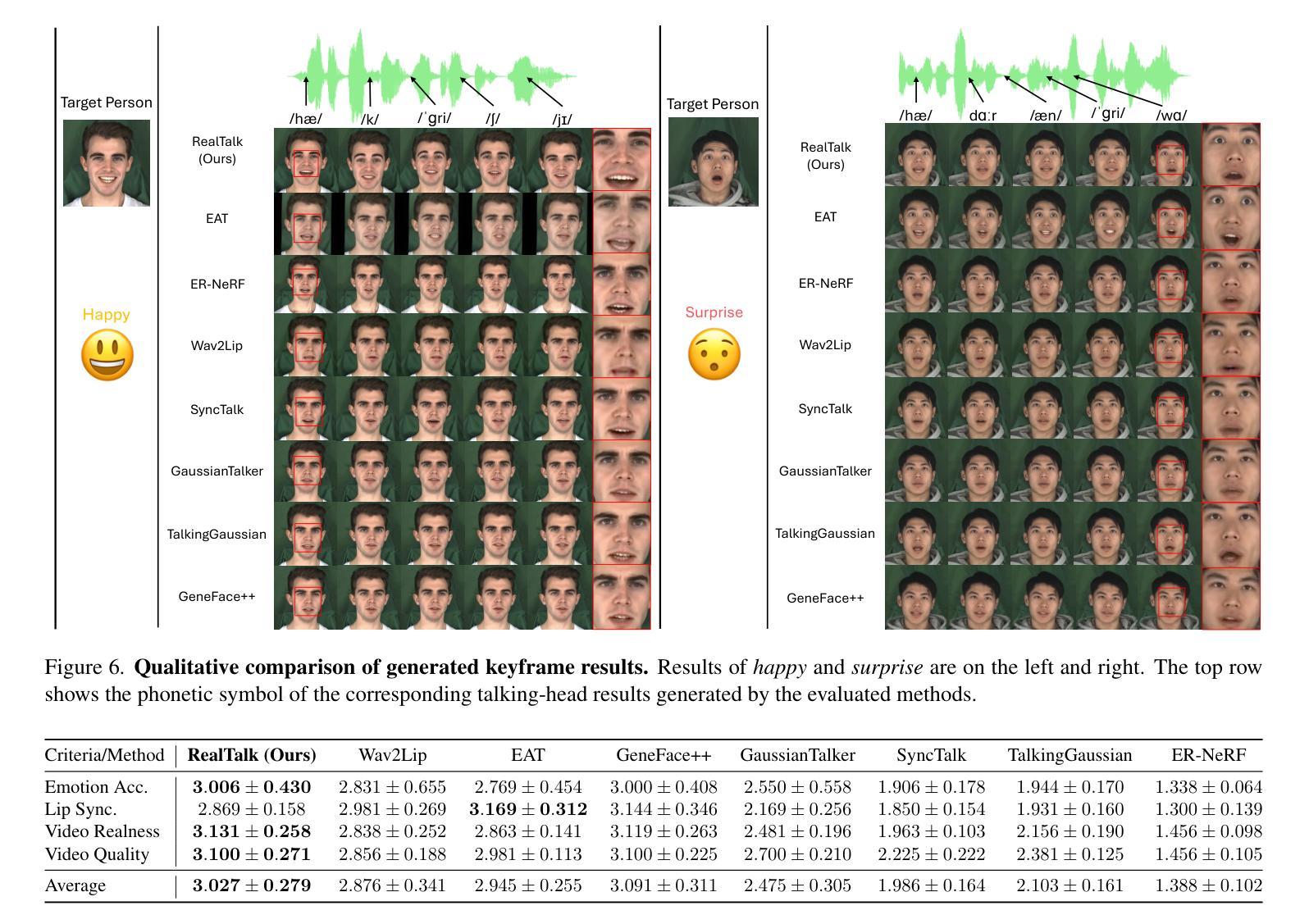
RealTalk: Realistic Emotion-Aware Lifelike Talking-Head Synthesis
Authors:Wenqing Wang, Yun Fu
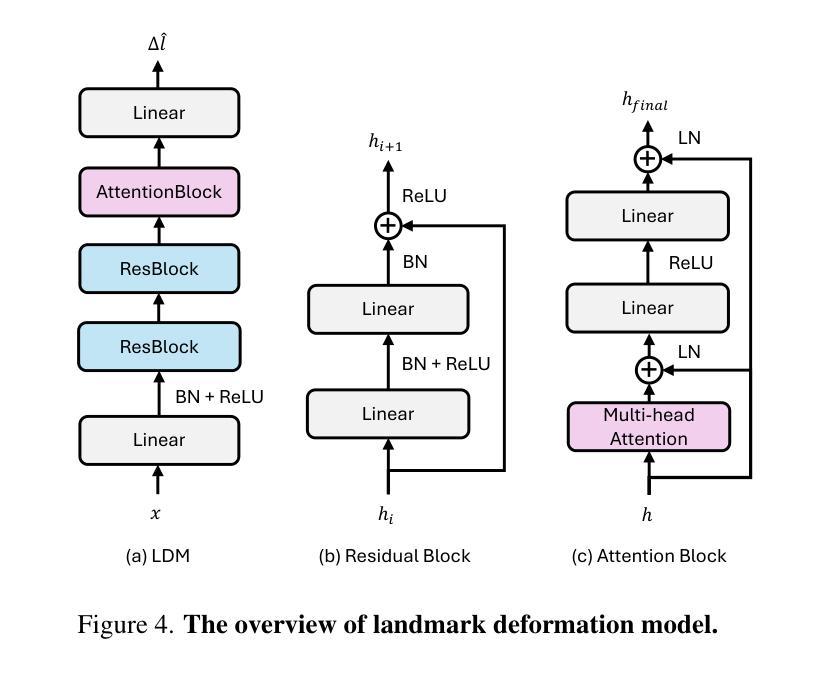
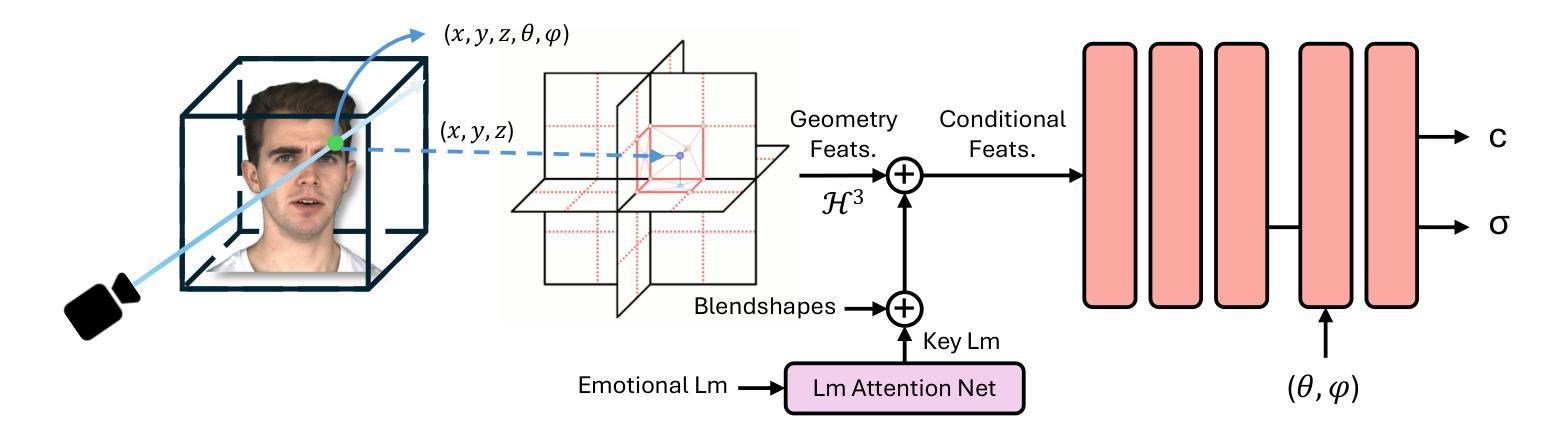
Emotion is a critical component of artificial social intelligence. However, while current methods excel in lip synchronization and image quality, they often fail to generate accurate and controllable emotional expressions while preserving the subject’s identity. To address this challenge, we introduce RealTalk, a novel framework for synthesizing emotional talking heads with high emotion accuracy, enhanced emotion controllability, and robust identity preservation. RealTalk employs a variational autoencoder (VAE) to generate 3D facial landmarks from driving audio, which are concatenated with emotion-label embeddings using a ResNet-based landmark deformation model (LDM) to produce emotional landmarks. These landmarks and facial blendshape coefficients jointly condition a novel tri-plane attention Neural Radiance Field (NeRF) to synthesize highly realistic emotional talking heads. Extensive experiments demonstrate that RealTalk outperforms existing methods in emotion accuracy, controllability, and identity preservation, advancing the development of socially intelligent AI systems.
情感是人工社交智能的关键组成部分。然而,虽然当前的方法在嘴唇同步和图像质量方面表现出色,但它们往往无法准确生成可控的情感表达,同时保留主体的身份。为了应对这一挑战,我们引入了RealTalk,这是一个用于合成情绪化的讲话头部的全新框架,具有高情绪精度、增强的情绪可控性和稳健的身份保留能力。RealTalk采用变分自编码器(VAE)从驱动音频生成3D面部地标,这些地标与基于ResNet的地标变形模型(LDM)结合使用情绪标签嵌入,以产生情绪化的地标。这些地标和面部混合形状系数共同调节新型的三平面注意力神经辐射场(NeRF),以合成高度逼真的情感化讲话头部。大量实验表明,RealTalk在情感准确性、可控性和身份保留方面优于现有方法,推动了社交智能AI系统的发展。
论文及项目相关链接
PDF Accepted to the ICCV 2025 Workshop on Artificial Social Intelligence
Summary
本文介绍了RealTalk框架,该框架能合成带有高情感准确性的情绪化说话人头部。通过结合变分自编码器(VAE)生成的三维面部地标、情感标签嵌入和基于ResNet的面部地标变形模型(LDM),RealTalk能够产生情绪化的地标,并与面部blendshape系数一起,共同调节新型的三平面注意力神经辐射场(NeRF),从而合成高度逼真的情绪化说话头部。RealTalk在情感准确性、可控性和身份保留方面表现出卓越性能,推动了社会智能AI系统的发展。
Key Takeaways
- RealTalk是一个用于合成情绪化说话头部的全新框架。
- 该框架采用变分自编码器(VAE)生成三维面部地标。
- RealTalk结合了情感标签嵌入和基于ResNet的面部地标变形模型(LDM)。
- 通过结合生成的地标和面部blendshape系数,RealTalk调节新型的三平面注意力神经辐射场(NeRF)。
- RealTalk能够合成高度逼真的情绪化说话头部。
- RealTalk在情感准确性、可控性和身份保留方面表现出卓越性能。
点此查看论文截图