⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-21 更新
Hierarchical Vision-Language Retrieval of Educational Metaverse Content in Agriculture
Authors:Ali Abdari, Alex Falcon, Giuseppe Serra
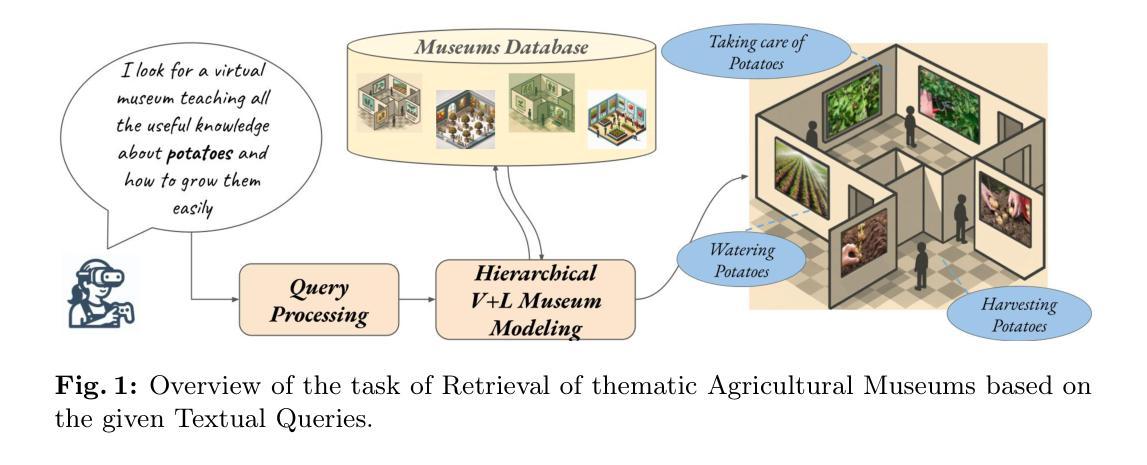
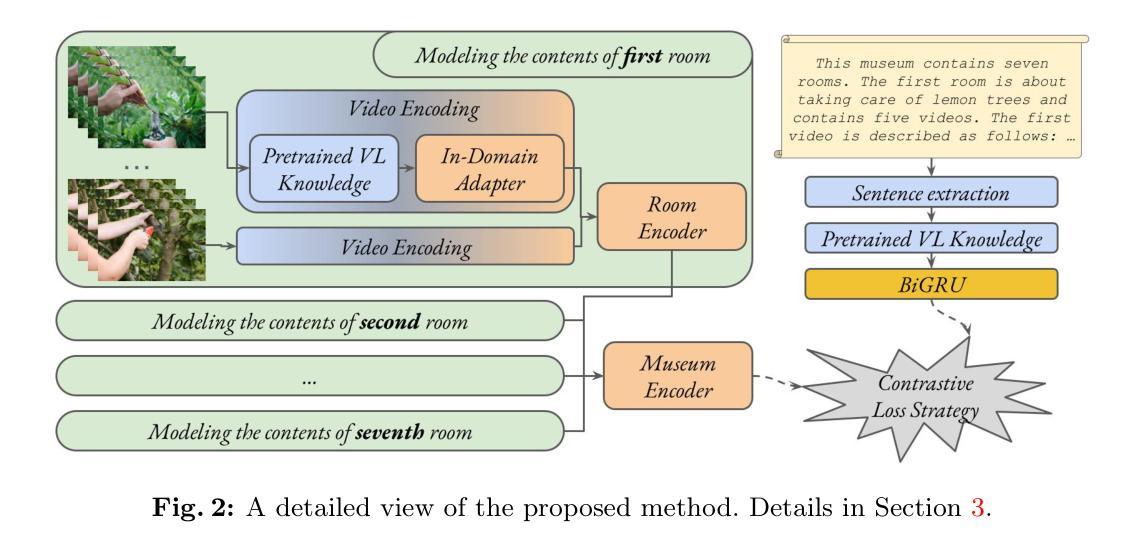
Every day, a large amount of educational content is uploaded online across different areas, including agriculture and gardening. When these videos or materials are grouped meaningfully, they can make learning easier and more effective. One promising way to organize and enrich such content is through the Metaverse, which allows users to explore educational experiences in an interactive and immersive environment. However, searching for relevant Metaverse scenarios and finding those matching users’ interests remains a challenging task. A first step in this direction has been done recently, but existing datasets are small and not sufficient for training advanced models. In this work, we make two main contributions: first, we introduce a new dataset containing 457 agricultural-themed virtual museums (AgriMuseums), each enriched with textual descriptions; and second, we propose a hierarchical vision-language model to represent and retrieve relevant AgriMuseums using natural language queries. In our experimental setting, the proposed method achieves up to about 62% R@1 and 78% MRR, confirming its effectiveness, and it also leads to improvements on existing benchmarks by up to 6% R@1 and 11% MRR. Moreover, an extensive evaluation validates our design choices. Code and dataset are available at https://github.com/aliabdari/Agricultural_Metaverse_Retrieval .
每天,大量教育内容被上传至网络,涵盖农业和园艺等多个领域。当这些视频或资料被有意义地分组时,它们可以使学习更加轻松有效。组织和完善此类内容的一种有前途的方式是通过元宇宙,它允许用户在互动和沉浸式环境中探索教育体验。然而,搜索相关的元宇宙场景并找到符合用户兴趣的场景仍然是一项具有挑战性的任务。最近已经迈出了第一步,但现有数据集较小,不足以训练高级模型。在这项工作中,我们做出了两个主要贡献:首先,我们引入了一个包含457个农业主题虚拟博物馆(AgriMuseums)的新数据集,每个博物馆都配备了丰富的文本描述;其次,我们提出了一种分层视觉语言模型,以使用自然语言查询来表示和检索相关的Agrimiuseums。在我们的实验设置中,所提出的方法达到了大约62%的R@1和78%的MRR,证实了其有效性,并且在现有基准测试上也有所改进,最高达到6%的R@1和11%的MRR。此外,一项全面的评估验证了我们设计选择的有效性。代码和数据集可通过https://github.com/aliabdari/Agricultural_Metaverse_Retrieval获取。
论文及项目相关链接
PDF Accepted for publication at the 23rd International Conference on Image Analysis and Processing (ICIAP 2025)
Summary:在农业和园艺等教育领域内,每天有大量的在线内容被上传。为让用户能更轻松有效地学习,研究人员通过元宇宙来组织丰富这些内容。但寻找相关的元宇宙场景和用户兴趣匹配仍是挑战。本文介绍了一项新数据集和一种分层视觉语言模型,旨在使用自然语言查询检索与农业相关的元宇宙博物馆。实验结果验证了该方法的有效性。数据集和代码可在指定网址下载。
Key Takeaways:
- 在线教育内容的组织和丰富通过元宇宙来实现更为有效和互动性强的学习体验。
- 寻找相关的元宇宙场景和用户兴趣匹配是一个挑战。
- 介绍了一个包含457个农业主题虚拟博物馆的新数据集,每个博物馆都附带有文本描述。
- 提出了一种分层视觉语言模型来代表和检索相关的农业虚拟博物馆。
- 该模型使用自然语言查询,并在实验环境中取得了良好的性能表现。
- 与现有基准测试相比,该模型在相关指标上有所提升。
点此查看论文截图

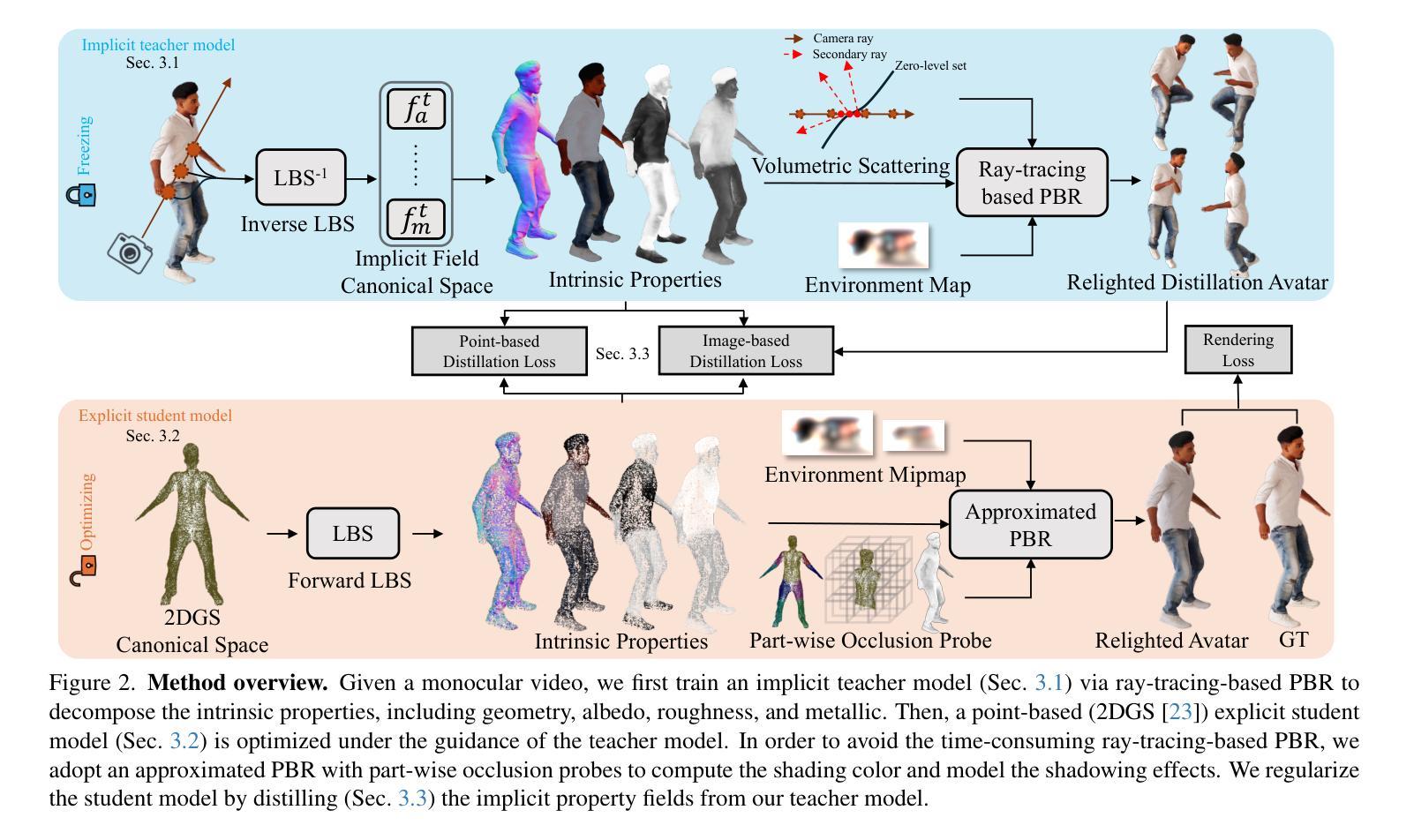
DNF-Avatar: Distilling Neural Fields for Real-time Animatable Avatar Relighting
Authors:Zeren Jiang, Shaofei Wang, Siyu Tang
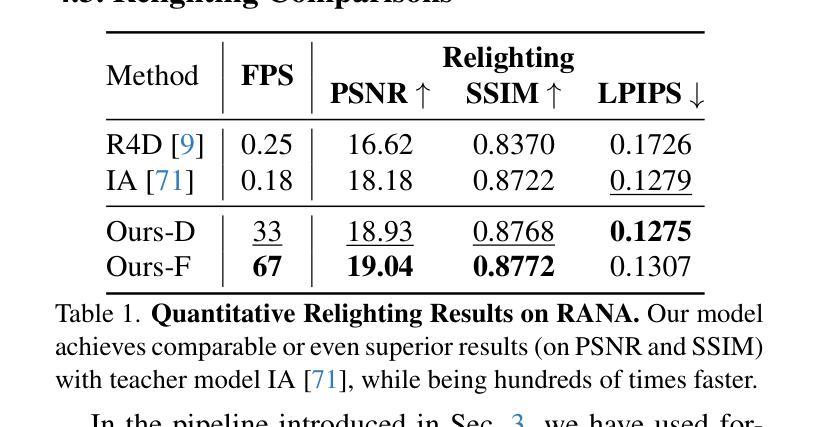
Creating relightable and animatable human avatars from monocular videos is a rising research topic with a range of applications, e.g. virtual reality, sports, and video games. Previous works utilize neural fields together with physically based rendering (PBR), to estimate geometry and disentangle appearance properties of human avatars. However, one drawback of these methods is the slow rendering speed due to the expensive Monte Carlo ray tracing. To tackle this problem, we proposed to distill the knowledge from implicit neural fields (teacher) to explicit 2D Gaussian splatting (student) representation to take advantage of the fast rasterization property of Gaussian splatting. To avoid ray-tracing, we employ the split-sum approximation for PBR appearance. We also propose novel part-wise ambient occlusion probes for shadow computation. Shadow prediction is achieved by querying these probes only once per pixel, which paves the way for real-time relighting of avatars. These techniques combined give high-quality relighting results with realistic shadow effects. Our experiments demonstrate that the proposed student model achieves comparable or even better relighting results with our teacher model while being 370 times faster at inference time, achieving a 67 FPS rendering speed.
创建从单目视频中可重新照明和可动画化的人类化身是一个新兴的研究课题,具有广泛的应用领域,例如虚拟现实、运动和电子游戏。以前的工作使用神经场与基于物理的渲染(PBR)相结合,来估计几何形状并解开人类化身的外观属性。然而,这些方法的一个缺点是渲染速度慢,因为昂贵的蒙特卡洛光线追踪。为了解决这一问题,我们提出将来自隐神经场(教师)的知识提炼到显式2D高斯喷涂(学生)表示中,以利用高斯喷涂的快速光栅化属性。为了避免光线追踪,我们采用分裂总和近似法来呈现PBR外观。我们还提出了用于阴影计算的新型部分环境遮蔽探针。阴影预测是通过每个像素仅查询这些探针一次来实现的,这为实时重新照明化身铺平了道路。这些技术的结合实现了高质量的重新照明结果和逼真的阴影效果。我们的实验表明,所提出的学生模型在推理时间达到了高达370倍的加速,渲染速度为每秒67帧的同时,可实现与我们教师模型相当甚至更好的重新照明效果。
论文及项目相关链接
PDF 17 pages, 9 figures, ICCV 2025 Findings Oral, Project pages: https://jzr99.github.io/DNF-Avatar/
Summary
该研究探讨了从单目视频中创建可重新照明和可动画的人类化身的技术。通过使用神经场和基于物理的渲染(PBR)来估计几何形状并分离化身外观属性。为解决因昂贵的蒙特卡洛光线追踪导致的渲染速度慢的问题,该研究提出了将隐神经场(教师模型)的知识蒸馏到显式二维高斯斑点表示(学生模型)的方法,利用高斯斑点的快速光线投射属性。研究还采用了分割求和近似来避免光线追踪,并提出新型的部分环境遮蔽探针以实现阴影计算。通过这些技术结合,实现了高质量的重照明结果和逼真的阴影效果。实验表明,学生模型在达到或超越教师模型的重照明结果的同时,推理速度是教师的370倍,渲染速度达到67帧每秒。
Key Takeaways
- 研究主题:从单目视频中创建可重新照明和可动画化的虚拟人类化身,应用领域广泛,如虚拟现实、体育和游戏。
- 技术方法:结合神经场和基于物理的渲染(PBR)来估计虚拟角色的几何形状和外观属性。
- 面临的问题:之前的蒙特卡洛光线追踪方法渲染速度较慢。
- 解决方案:将隐神经场(教师模型)的知识蒸馏到显式二维高斯斑点表示(学生模型),并利用高斯斑点的快速渲染特性以提高速度。
- 创新点:采用分割求和近似避免光线追踪,并提出新的部分环境遮蔽探针以实现高效的阴影计算。
- 实验结果:学生模型在重照明效果上与教师模型相当或更好,并且推理速度显著提高,达到67帧每秒的渲染速度。
点此查看论文截图