⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-21 更新
LongSplat: Robust Unposed 3D Gaussian Splatting for Casual Long Videos
Authors:Chin-Yang Lin, Cheng Sun, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, Yu-Lun Liu
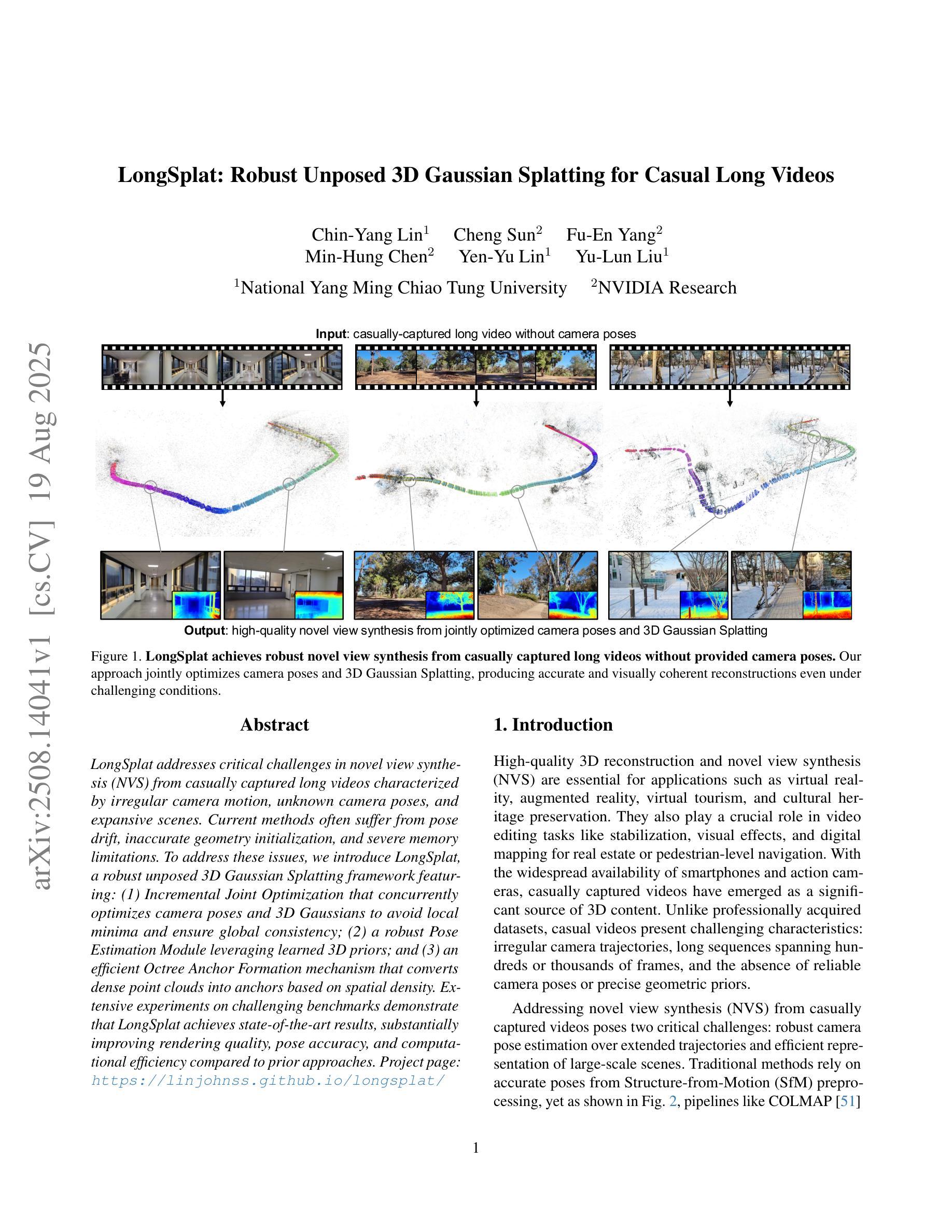
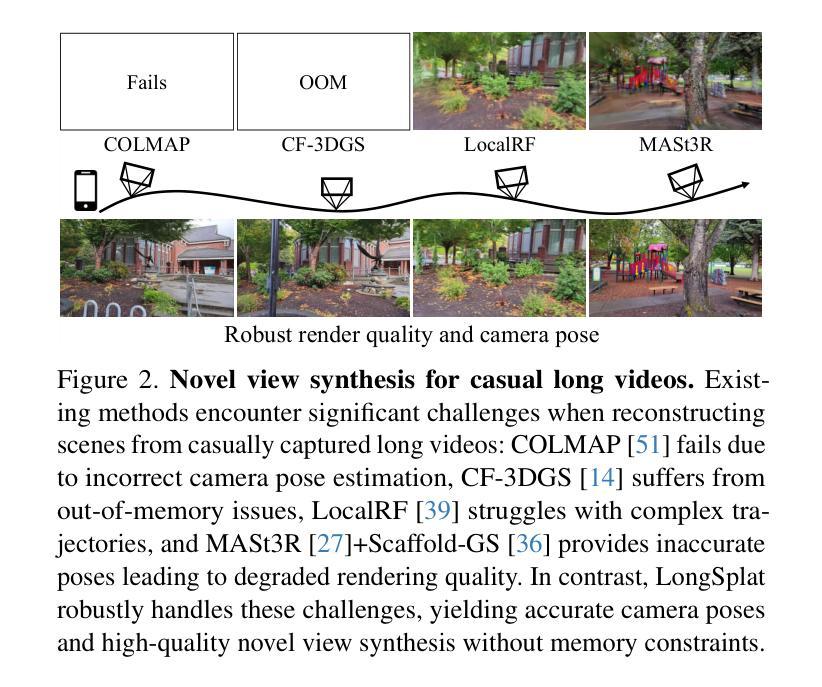
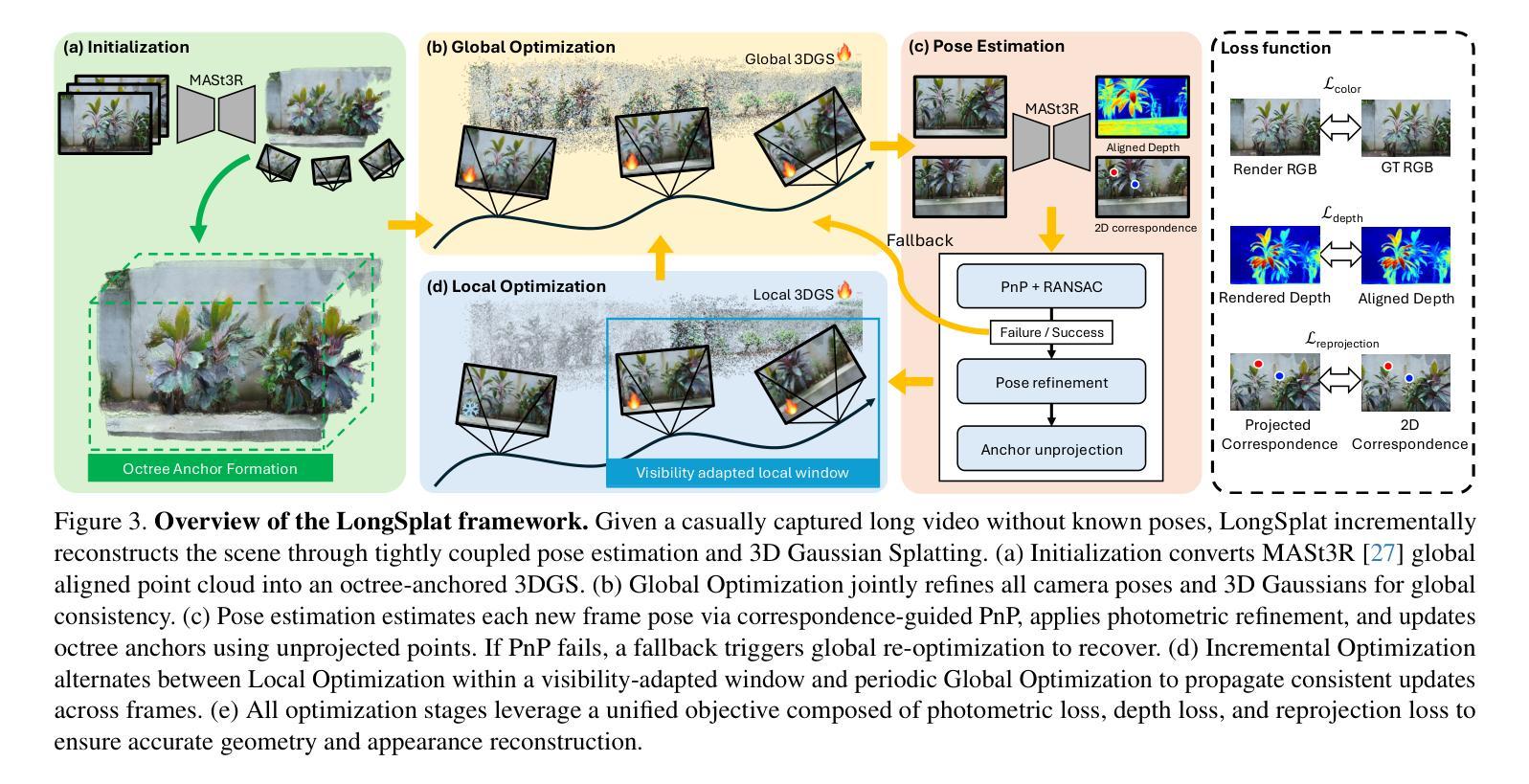
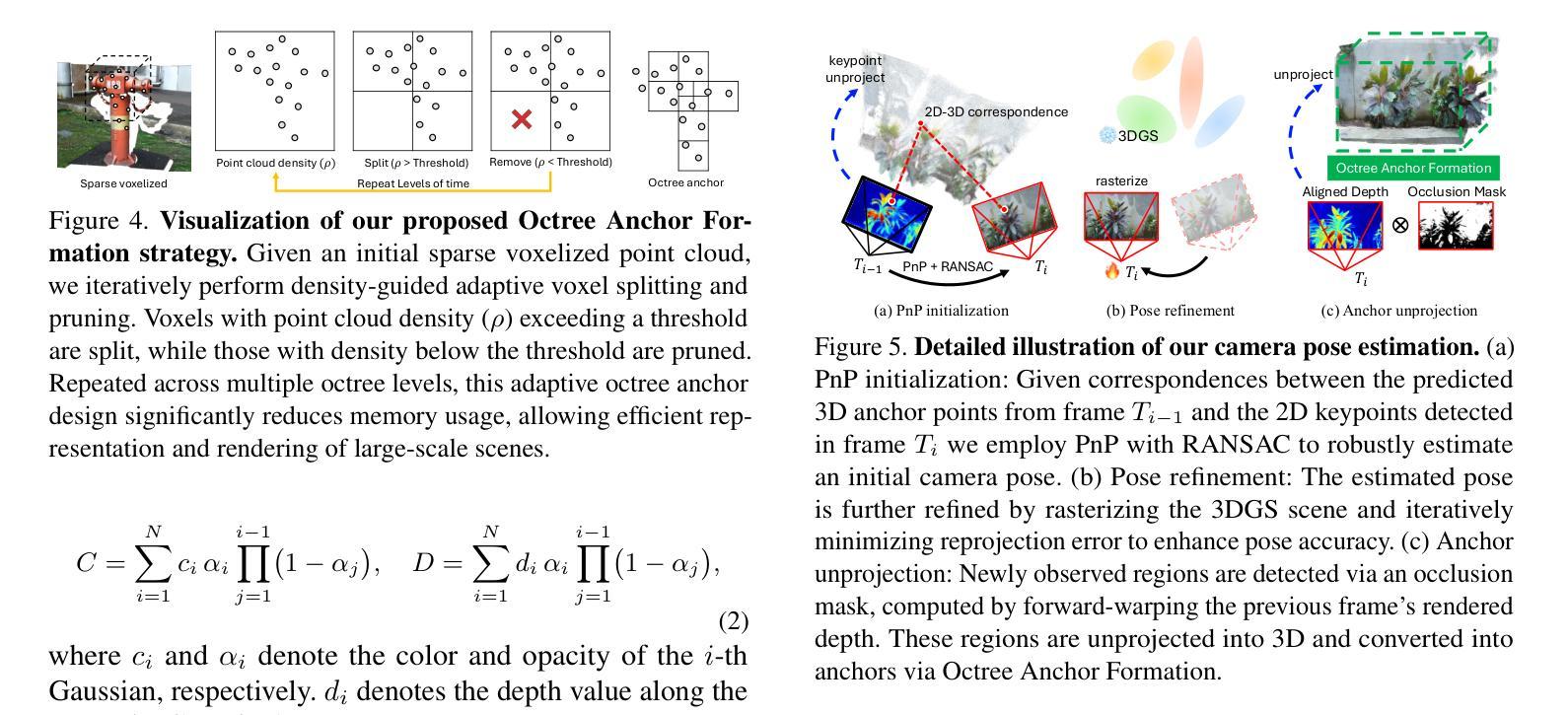
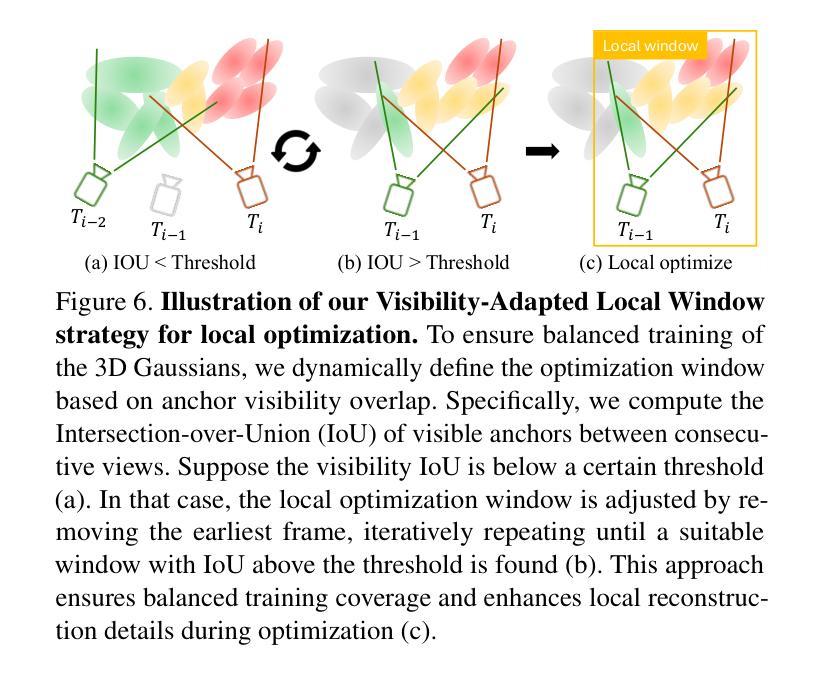
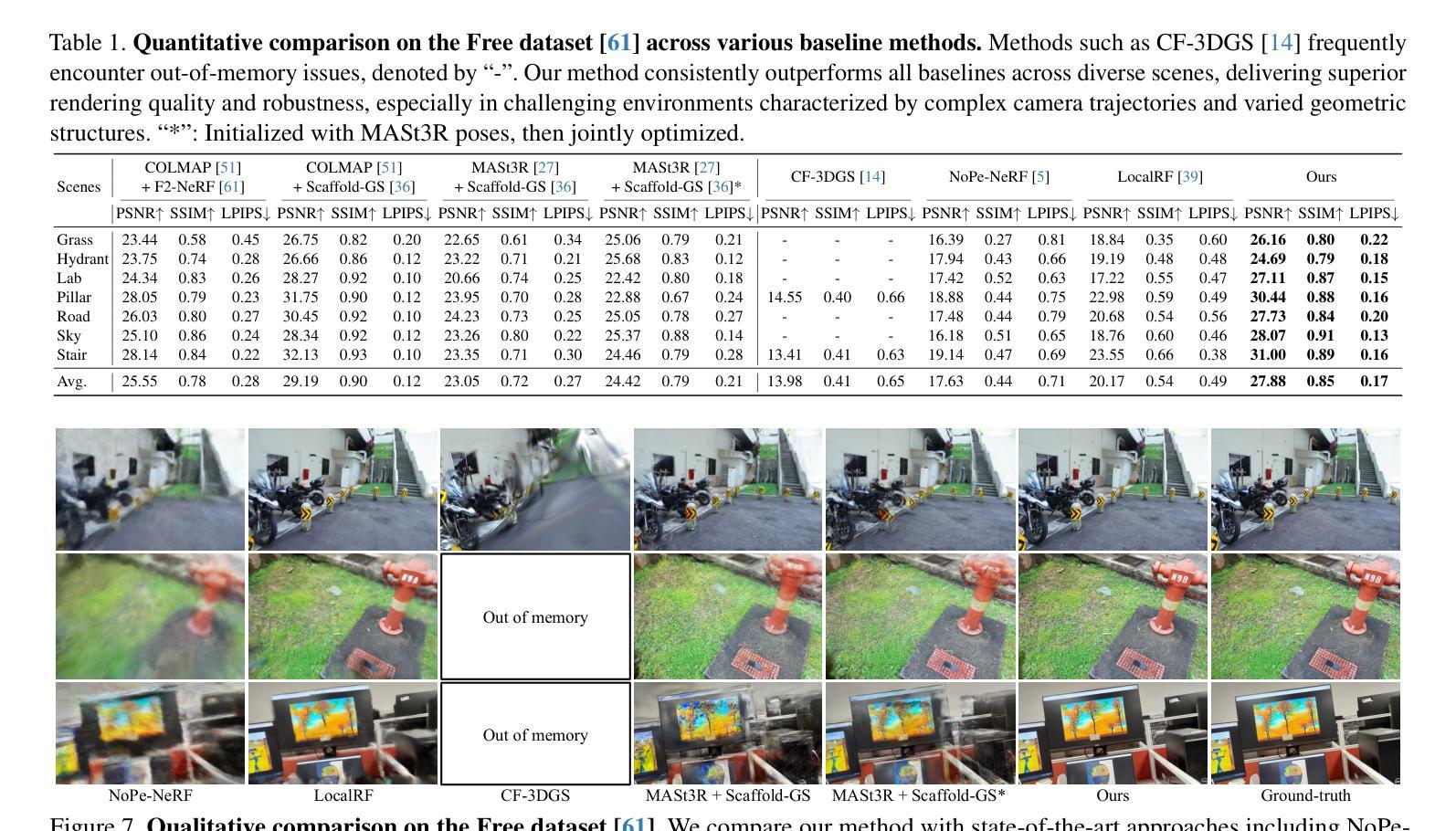
LongSplat addresses critical challenges in novel view synthesis (NVS) from casually captured long videos characterized by irregular camera motion, unknown camera poses, and expansive scenes. Current methods often suffer from pose drift, inaccurate geometry initialization, and severe memory limitations. To address these issues, we introduce LongSplat, a robust unposed 3D Gaussian Splatting framework featuring: (1) Incremental Joint Optimization that concurrently optimizes camera poses and 3D Gaussians to avoid local minima and ensure global consistency; (2) a robust Pose Estimation Module leveraging learned 3D priors; and (3) an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. Extensive experiments on challenging benchmarks demonstrate that LongSplat achieves state-of-the-art results, substantially improving rendering quality, pose accuracy, and computational efficiency compared to prior approaches. Project page: https://linjohnss.github.io/longsplat/
LongSplat解决了从偶然捕获的长视频中合成新视角(NVS)的关键挑战,这些视频的特点是相机运动不规则、相机姿态未知以及场景广阔。当前的方法经常遭受姿态漂移、几何初始化不准确和严重的内存限制等问题的影响。为了解决这些问题,我们引入了LongSplat,这是一个稳健的无姿态3D高斯拼贴框架,具有以下特点:(1)增量联合优化,同时优化相机姿态和3D高斯,以避免局部最小值并确保全局一致性;(2)利用学习到的3D先验的稳健姿态估计模块;(3)高效的八叉树锚点形成机制,将密集点云转换为基于空间密度的锚点。在具有挑战性的基准测试上的广泛实验表明,LongSplat达到了最先进的成果,与先前的方法相比,实质提高了渲染质量、姿态准确性和计算效率。项目页面:https://linjohnss.github.io/longsplat/
论文及项目相关链接
PDF ICCV 2025. Project page: https://linjohnss.github.io/longsplat/
Summary
LongSplat解决了从随意拍摄的长视频中合成新视角(NVS)所面临的挑战,包括不规则相机运动、未知相机姿态和广阔场景等问题。当前方法常常受到姿态漂移、几何初始化不准确和内存限制的影响。LongSplat采用无姿态的3D高斯拼贴框架,包括增量联合优化、利用学习到的3D先验的稳健姿态估计模块以及基于空间密度的高效八叉树锚点形成机制。在具有挑战性的基准测试上进行的广泛实验表明,LongSplat取得了最新技术成果,在渲染质量、姿态准确性和计算效率方面均优于先前的方法。
Key Takeaways
- LongSplat解决了从随意拍摄的长视频中进行新视角合成(NVS)的挑战。
- 当前方法面临姿态漂移、几何初始化不准确和内存限制的问题。
- LongSplat采用无姿态的3D高斯拼贴框架。
- 增量联合优化技术确保全局一致性,避免局部最小值。
- 利用学习到的3D先验的稳健姿态估计模块提升姿态估计的准确性。
- 通过高效的八叉树锚点形成机制,将密集点云转换为锚点。
点此查看论文截图
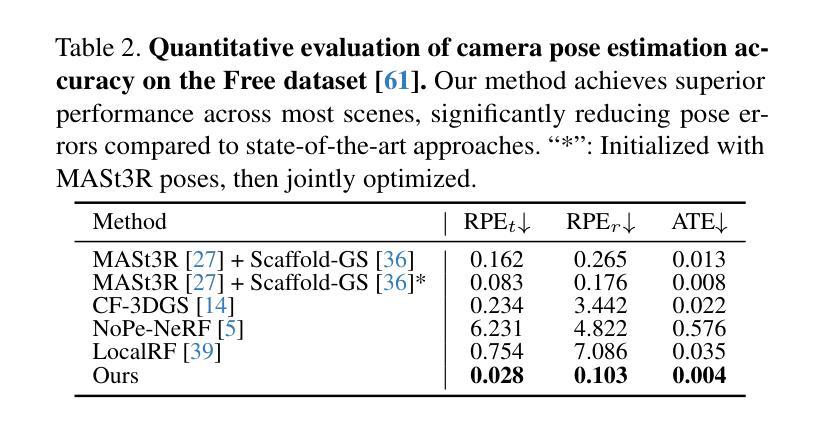
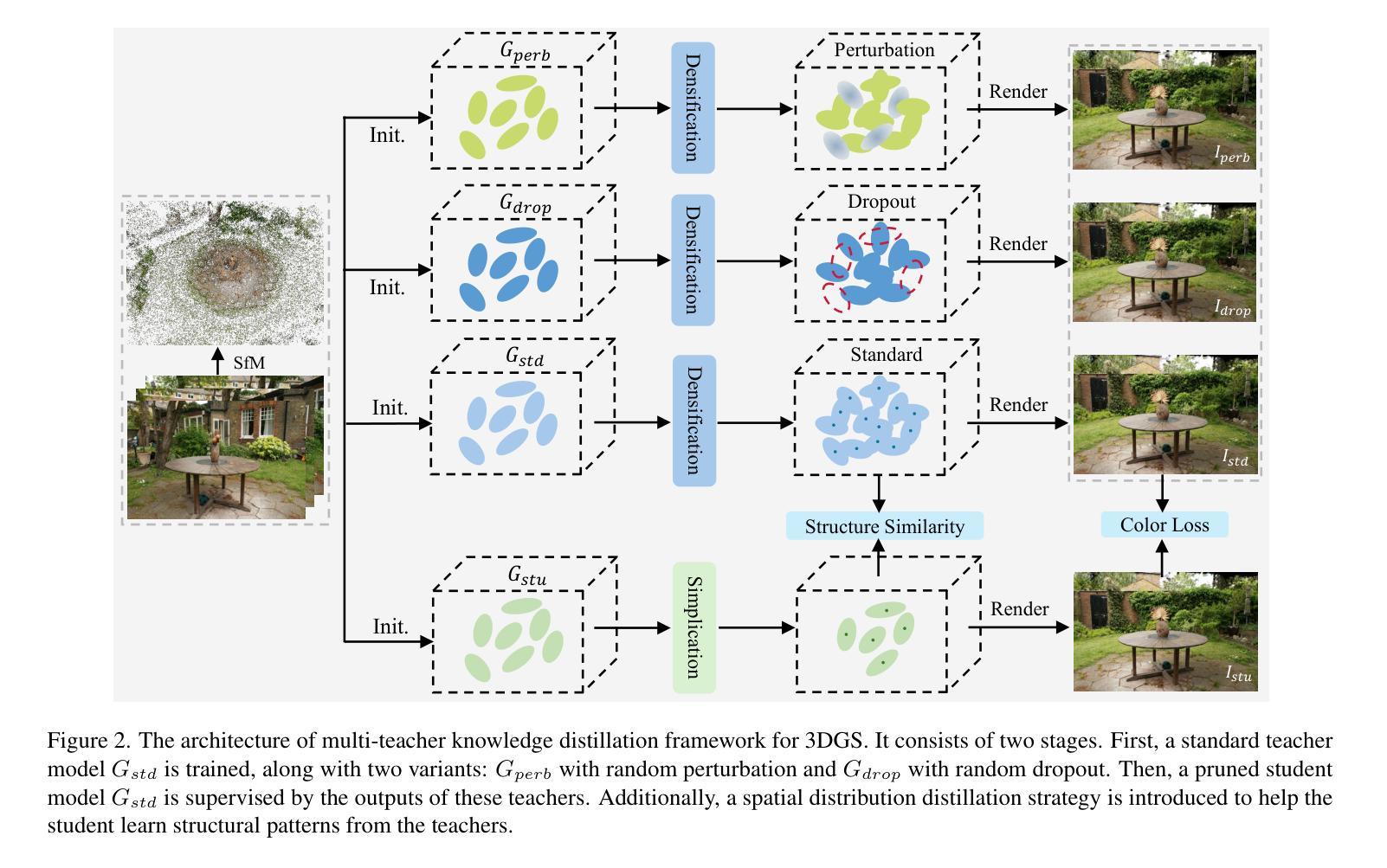
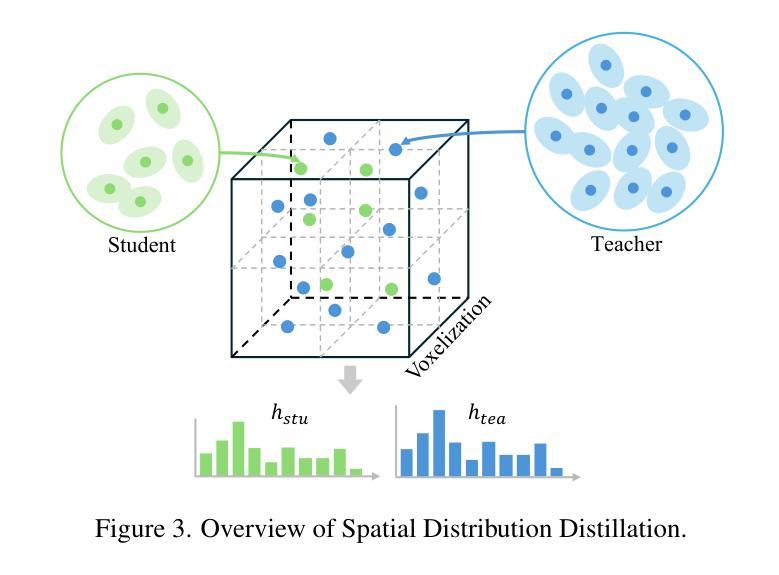
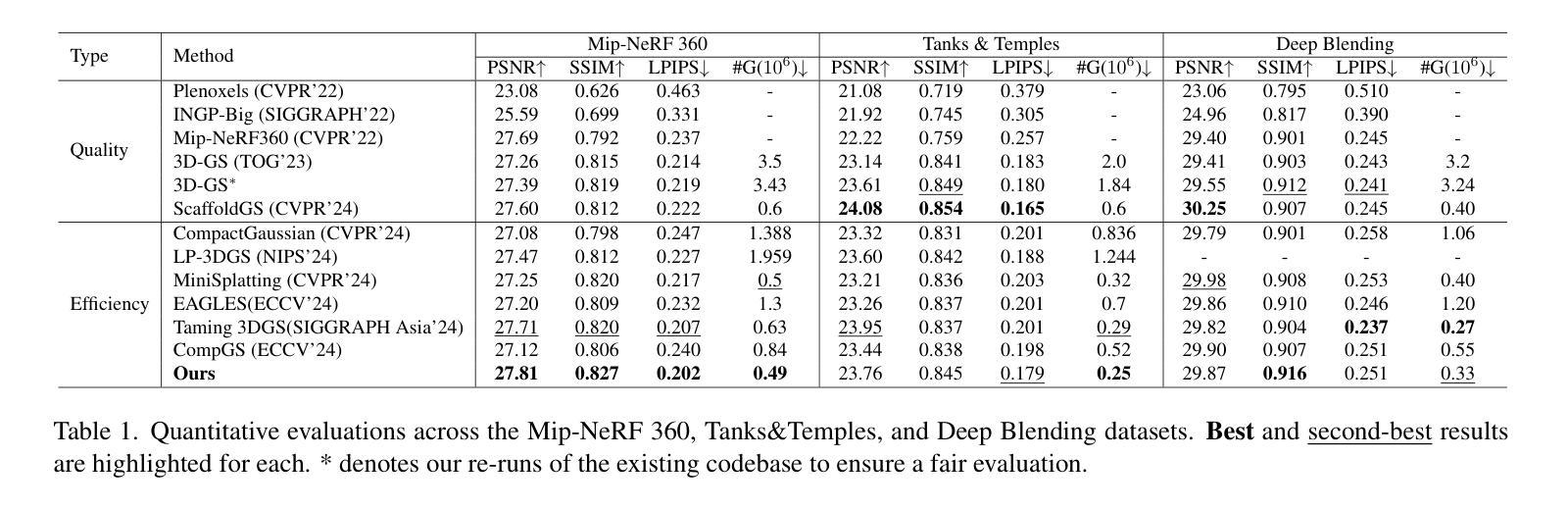
Distilled-3DGS:Distilled 3D Gaussian Splatting
Authors:Lintao Xiang, Xinkai Chen, Jianhuang Lai, Guangcong Wang
3D Gaussian Splatting (3DGS) has exhibited remarkable efficacy in novel view synthesis (NVS). However, it suffers from a significant drawback: achieving high-fidelity rendering typically necessitates a large number of 3D Gaussians, resulting in substantial memory consumption and storage requirements. To address this challenge, we propose the first knowledge distillation framework for 3DGS, featuring various teacher models, including vanilla 3DGS, noise-augmented variants, and dropout-regularized versions. The outputs of these teachers are aggregated to guide the optimization of a lightweight student model. To distill the hidden geometric structure, we propose a structural similarity loss to boost the consistency of spatial geometric distributions between the student and teacher model. Through comprehensive quantitative and qualitative evaluations across diverse datasets, the proposed Distilled-3DGS, a simple yet effective framework without bells and whistles, achieves promising rendering results in both rendering quality and storage efficiency compared to state-of-the-art methods. Project page: https://distilled3dgs.github.io . Code: https://github.com/lt-xiang/Distilled-3DGS .
3D高斯展平(3DGS)在新视角合成(NVS)中展现出显著的效果。然而,它存在一个重大缺陷:实现高保真渲染通常需要大量3D高斯,导致内存消耗和存储需求巨大。为了解决这一挑战,我们提出了首个针对3DGS的知识蒸馏框架,包含多种教师模型,包括普通3DGS、增强噪声的变种和丢弃正则化的版本。这些教师的输出被聚合起来,以指导轻量化学生的模型优化。为了提炼隐藏的几何结构,我们提出了一种结构相似性损失,以提高学生和教师模型之间空间几何分布的一致性。在多种数据集上进行了全面的定量和定性评估,所提出的Distilled-3DGS是一个简单有效的框架,在不使用任何花哨技巧的情况下,与最先进的方法相比,在渲染质量和存储效率方面都实现了有希望的渲染结果。项目页面:https://distilled3dgs.github.io。代码:https://github.com/lt-xiang/Distilled-3DGS。
论文及项目相关链接
PDF Project page: https://distilled3dgs.github.io Code: https://github.com/lt-xiang/Distilled-3DGS
Summary
3DGS在新型视图合成(NVS)中表现出显著效果,但存在高保真渲染需要大量3D高斯导致内存消耗大的问题。为解决此挑战,提出首个针对3DGS的知识蒸馏框架,包括多种教师模型,通过结构相似性损失提升学生和教师模型在空间几何分布上的一致性。经全面评估,蒸馏后的3DGS框架在渲染质量和存储效率方面表现优异。
Key Takeaways
- 3DGS在新型视图合成(NVS)中效果显著。
- 高保真渲染需要大量3D高斯,导致内存消耗大。
- 提出首个针对3DGS的知识蒸馏框架,包含多种教师模型。
- 通过结构相似性损失提升学生和教师模型在空间几何分布上的一致性。
- Distilled-3DGS框架在渲染质量和存储效率方面表现优异。
- 项目页面和代码已公开,方便研究者进一步了解和复现。
- 该方法简单有效,无需复杂的技术手段。
点此查看论文截图


Online 3D Gaussian Splatting Modeling with Novel View Selection
Authors:Byeonggwon Lee, Junkyu Park, Khang Truong Giang, Soohwan Song
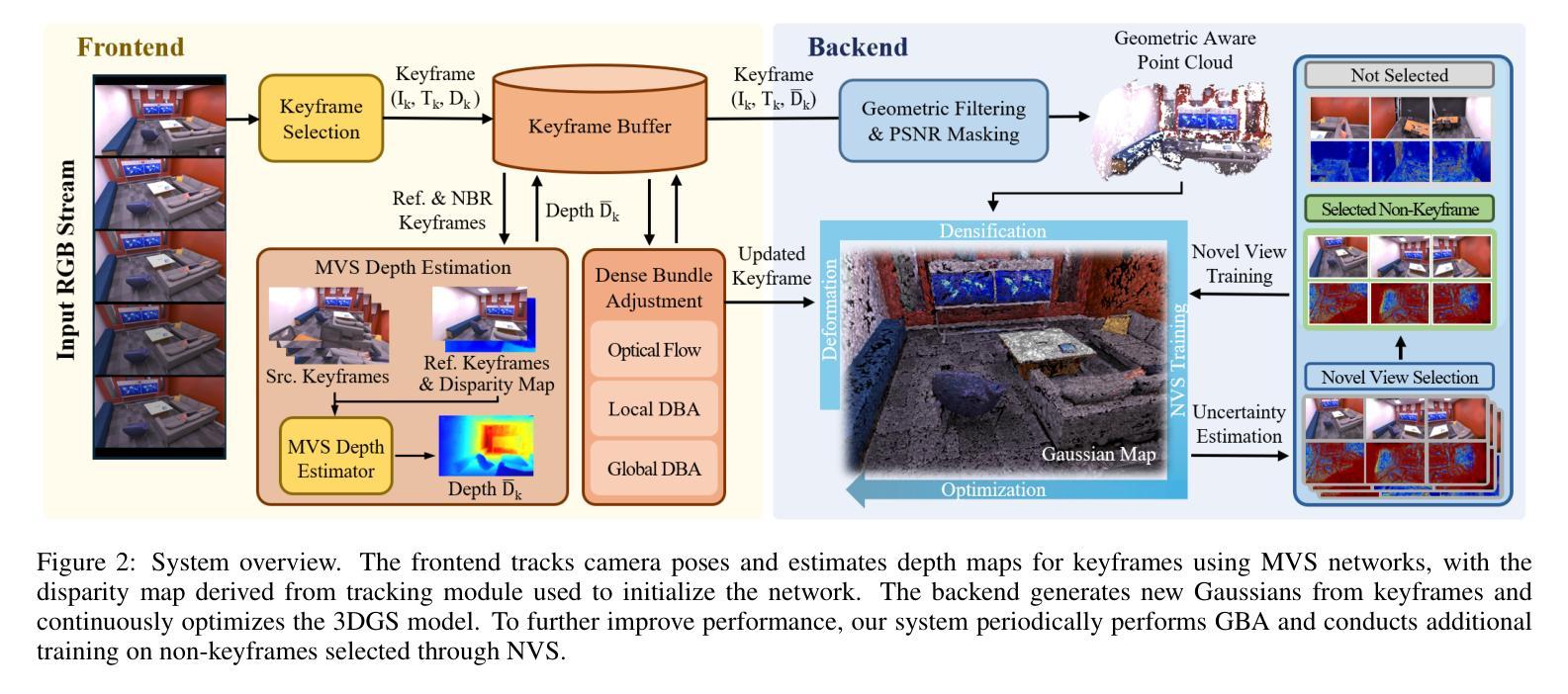
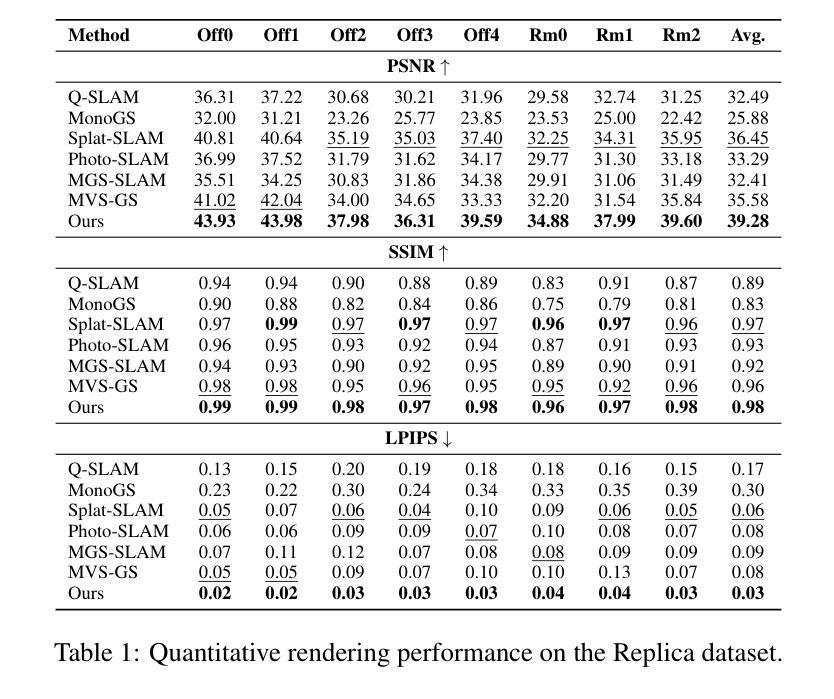
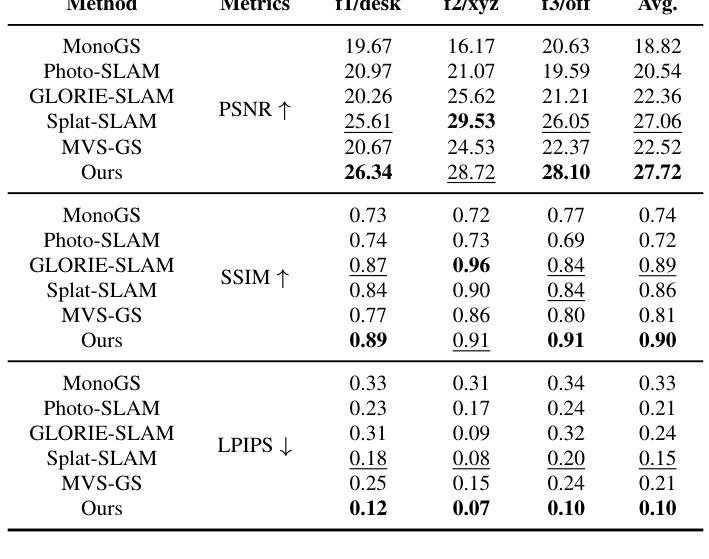
This study addresses the challenge of generating online 3D Gaussian Splatting (3DGS) models from RGB-only frames. Previous studies have employed dense SLAM techniques to estimate 3D scenes from keyframes for 3DGS model construction. However, these methods are limited by their reliance solely on keyframes, which are insufficient to capture an entire scene, resulting in incomplete reconstructions. Moreover, building a generalizable model requires incorporating frames from diverse viewpoints to achieve broader scene coverage. However, online processing restricts the use of many frames or extensive training iterations. Therefore, we propose a novel method for high-quality 3DGS modeling that improves model completeness through adaptive view selection. By analyzing reconstruction quality online, our approach selects optimal non-keyframes for additional training. By integrating both keyframes and selected non-keyframes, the method refines incomplete regions from diverse viewpoints, significantly enhancing completeness. We also present a framework that incorporates an online multi-view stereo approach, ensuring consistency in 3D information throughout the 3DGS modeling process. Experimental results demonstrate that our method outperforms state-of-the-art methods, delivering exceptional performance in complex outdoor scenes.
本研究致力于解决从仅包含RGB帧生成在线三维高斯Splatting(3DGS)模型这一挑战。以往研究已采用密集SLAM技术从关键帧估计三维场景用于构建三维GS模型。然而,这些方法仅依赖于关键帧,存在无法捕捉整个场景的局限性,导致重建不完整。此外,构建通用模型需要融入不同视角的帧来实现更广泛的场景覆盖。然而,在线处理限制了使用多个帧或大量训练迭代。因此,我们提出了一种新颖的在线高质量三维GS建模方法,通过自适应视角选择来提高模型的完整性。我们的方法通过在线分析重建质量来选择最佳的非关键帧进行额外训练。通过融合关键帧和所选的非关键帧,该方法从不同视角对不完整区域进行细化,显著提高了完整性。我们还提出了一个框架,融入在线多视角立体视觉方法,确保在整个三维GS建模过程中三维信息的一致性。实验结果表明,我们的方法优于最新技术,在复杂的户外场景中表现出卓越性能。
论文及项目相关链接
Summary
本文研究了从仅RGB帧生成在线3D高斯喷溅(3DGS)模型的挑战。先前的研究采用密集SLAM技术从关键帧估计3D场景以构建3DGS模型,但依赖关键帧导致场景覆盖不完整。本文提出一种高质量3DGS建模的新方法,通过自适应视角选择提高模型完整性。该方法在线分析重建质量,选择最佳非关键帧进行额外训练,从多种视角完善不完整区域。同时,引入在线多视角立体框架,确保3DGS建模过程中的3D信息一致性。实验结果证明,该方法优于现有技术,在复杂户外场景表现优异。
Key Takeaways
- 研究针对从仅RGB帧生成在线3D高斯喷溅(3DGS)模型的挑战。
- 先前方法依赖关键帧估计3D场景,导致场景覆盖不完整。
- 提出一种新方法来提高模型完整性,通过自适应视角选择最佳非关键帧。
- 新方法在线分析重建质量,选择最佳非关键帧进行额外训练,完善不完整区域。
- 引入在线多视角立体框架,确保3DGS建模过程中的信息一致性。
- 方法能够处理复杂户外场景的建模。
点此查看论文截图


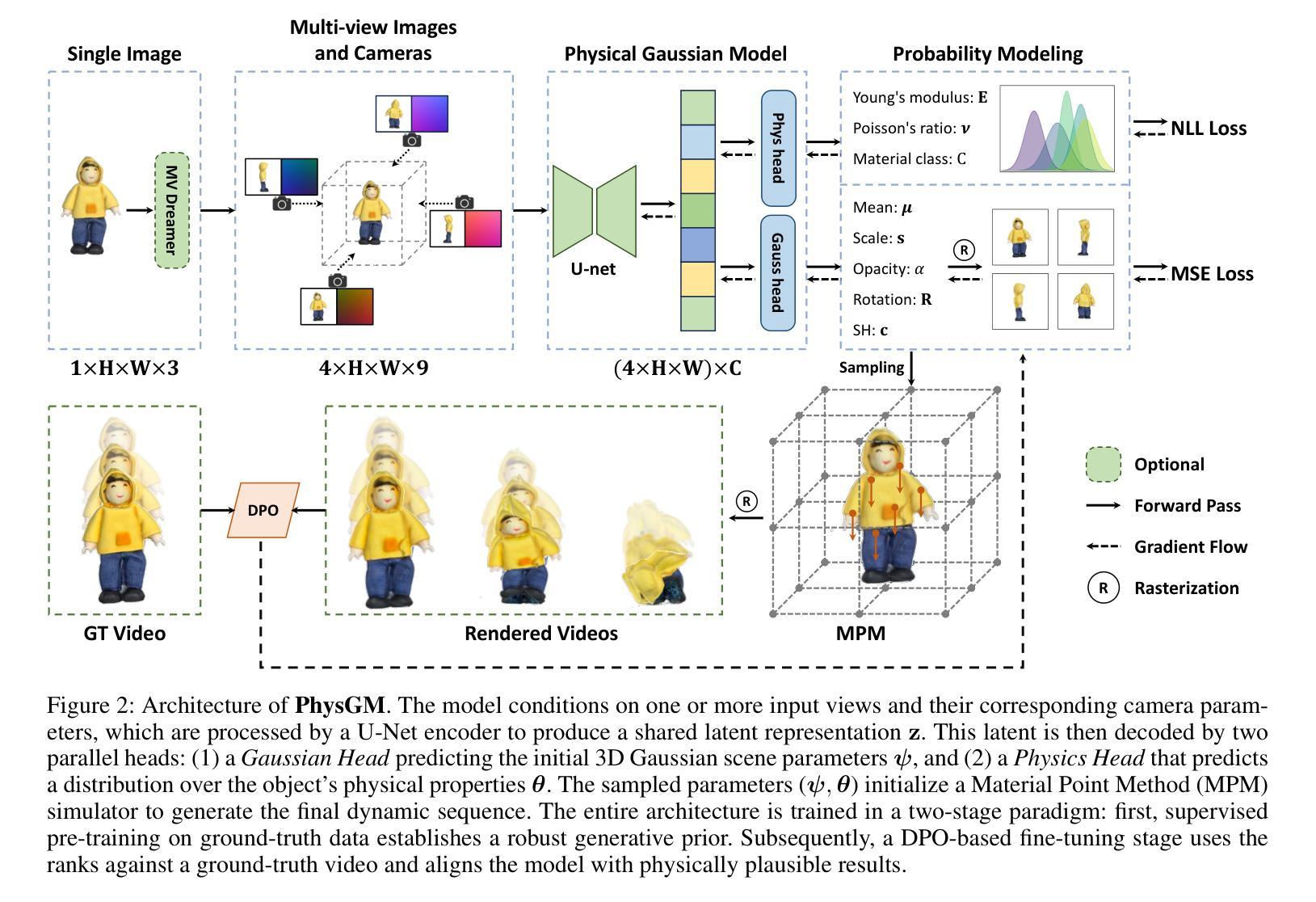
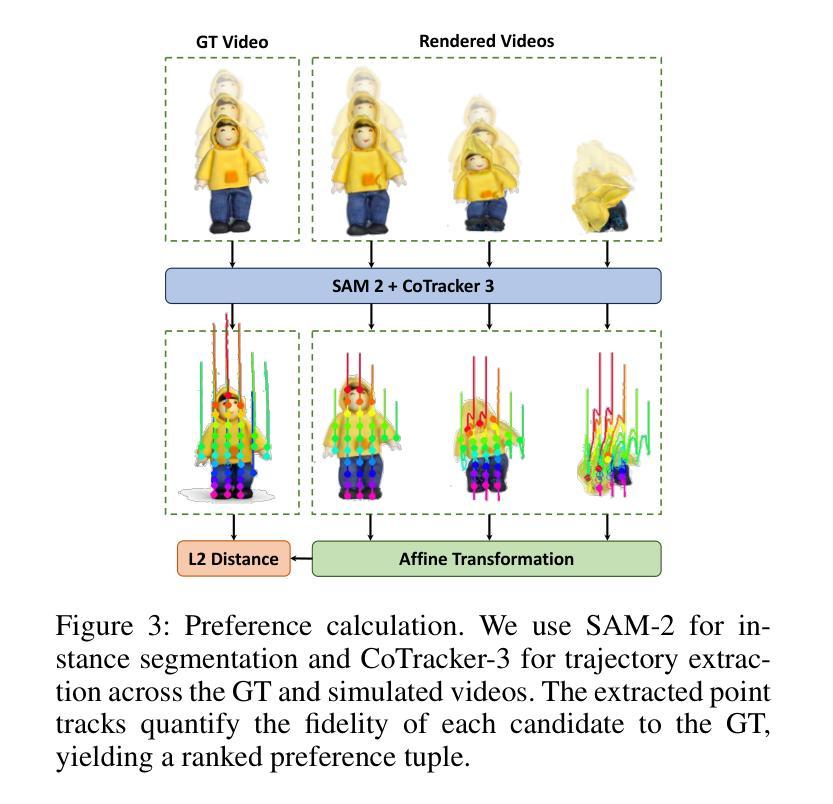
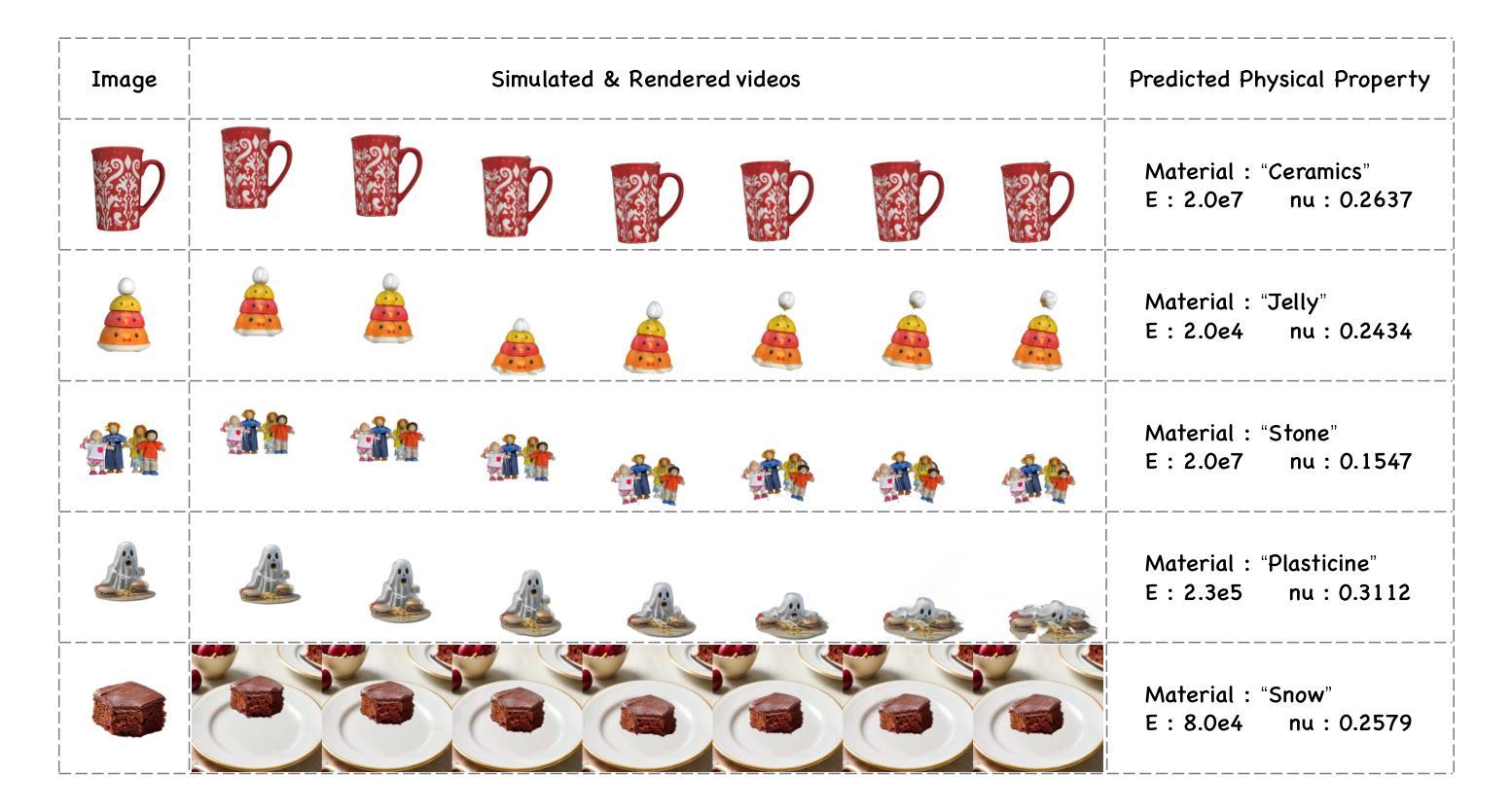
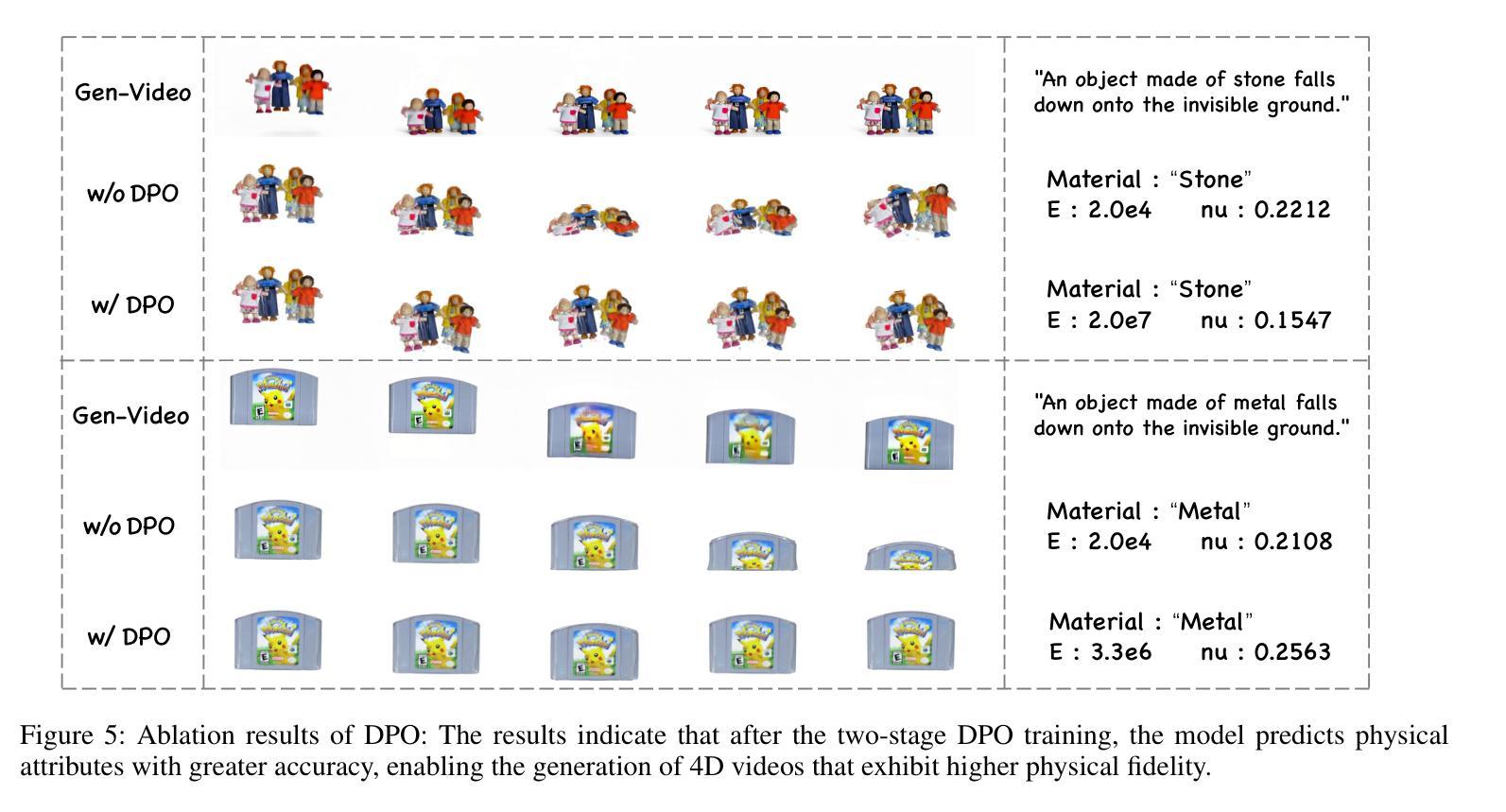
PhysGM: Large Physical Gaussian Model for Feed-Forward 4D Synthesis
Authors:Chunji Lv, Zequn Chen, Donglin Di, Weinan Zhang, Hao Li, Wei Chen, Changsheng Li
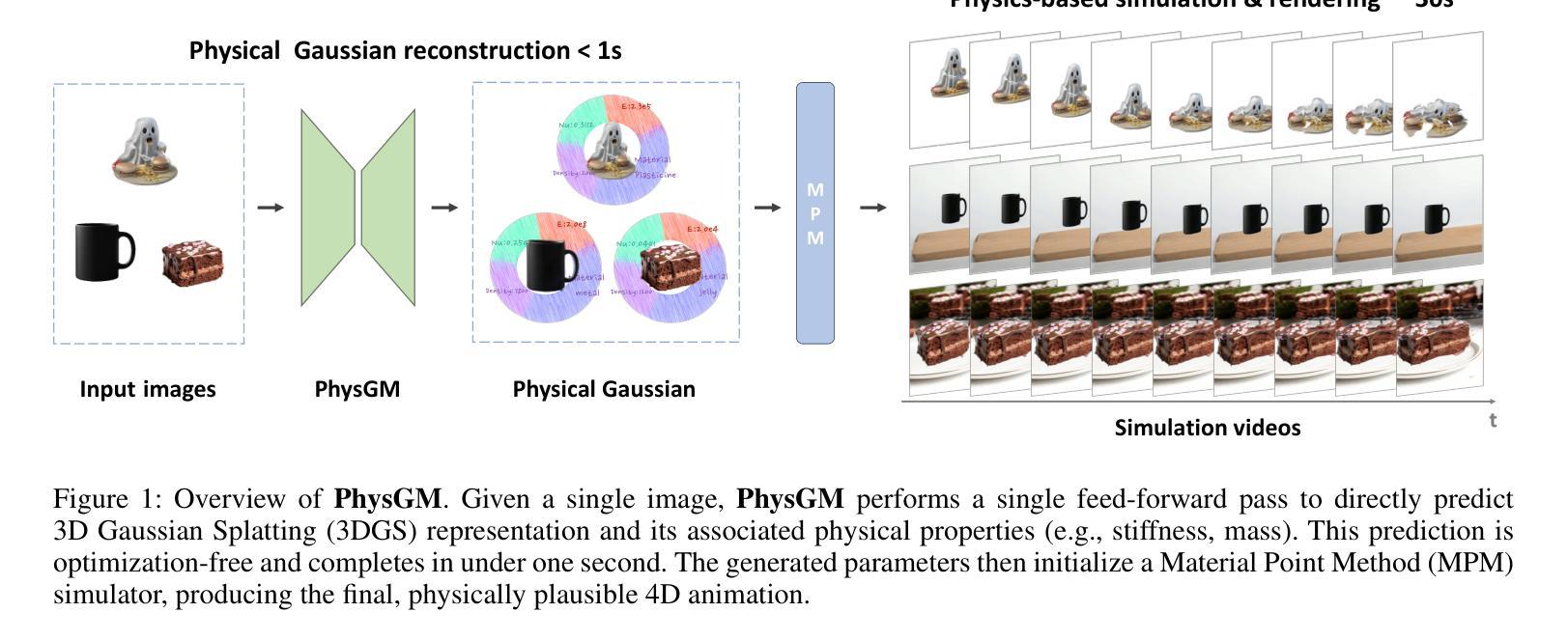
While physics-grounded 3D motion synthesis has seen significant progress, current methods face critical limitations. They typically rely on pre-reconstructed 3D Gaussian Splatting (3DGS) representations, while physics integration depends on either inflexible, manually defined physical attributes or unstable, optimization-heavy guidance from video models. To overcome these challenges, we introduce PhysGM, a feed-forward framework that jointly predicts a 3D Gaussian representation and its physical properties from a single image, enabling immediate, physical simulation and high-fidelity 4D rendering. We first establish a base model by jointly optimizing for Gaussian reconstruction and probabilistic physics prediction. The model is then refined with physically plausible reference videos to enhance both rendering fidelity and physics prediction accuracy. We adopt the Direct Preference Optimization (DPO) to align its simulations with reference videos, circumventing Score Distillation Sampling (SDS) optimization which needs back-propagating gradients through the complex differentiable simulation and rasterization. To facilitate the training, we introduce a new dataset PhysAssets of over 24,000 3D assets, annotated with physical properties and corresponding guiding videos. Experimental results demonstrate that our method effectively generates high-fidelity 4D simulations from a single image in one minute. This represents a significant speedup over prior works while delivering realistic rendering results. Our project page is at:https://hihixiaolv.github.io/PhysGM.github.io/
虽然基于物理的3D运动合成已经取得了重大进展,但当前的方法仍存在关键局限性。它们通常依赖于预先构建的3D高斯拼贴(3DGS)表示,而物理集成则依赖于僵硬的、手动定义的物理属性或来自视频模型的不稳定、以优化为重点的指导。为了克服这些挑战,我们引入了PhysGM,这是一个前馈框架,能够从单张图像中联合预测3D高斯表示及其物理属性,从而实现即时物理模拟和高保真4D渲染。我们首先通过联合优化高斯重建和概率物理预测来建立基础模型。然后,使用物理上合理的参考视频对模型进行精炼,以提高渲染保真度和物理预测精度。我们采用直接偏好优化(DPO)使模拟与参考视频对齐,避免了需要反向传播梯度通过复杂的可微分模拟和光线追踪的得分蒸馏采样(SDS)优化。为了促进训练,我们引入了一个新的数据集PhysAssets,包含超过24,000个3D资产,标注了物理属性和相应的指导视频。实验结果表明,我们的方法能够在1分钟内从单张图像生成高保真4D模拟。这相较于以前的工作代表了一个显著的速度提升,同时提供了逼真的渲染结果。我们的项目页面是:网站链接。
论文及项目相关链接
Summary
本文介绍了针对物理基础的三维运动合成所面临的挑战与一种名为PhysGM的新方法。该方法能从单张图像中预测出三维高斯表示及其物理特性,并实现即时物理模拟和高保真四维渲染。通过建立基础模型并优化高斯重建和概率物理预测,使用物理上合理的参考视频进行训练,以提高渲染保真度和物理预测精度。采用直接偏好优化(DPO)来使模拟与参考视频对齐,避免使用得分蒸馏采样(SDS)优化方法。同时,引入新的数据集PhysAssets来支持训练。实验结果显示,该方法在一分钟内就能从单张图像生成高保真的四维模拟,较之前的方法有显著提高。
Key Takeaways
- 当前物理基础的三维运动合成方法依赖于预构建的三维高斯模型,面临灵活性不足和稳定性问题。
- PhysGM是一种新的方法,能够从单张图像预测三维高斯表示及其物理特性,实现即时物理模拟和高保真四维渲染。
- 通过联合优化高斯重建和概率物理预测建立基础模型,并使用物理上合理的参考视频进行训练以提高性能。
- 采用直接偏好优化(DPO)对齐模拟与参考视频,避免复杂的优化过程。
- 引入新的数据集PhysAssets来支持训练和模拟验证。
- 实验结果显示,PhysGM在生成高保真的四维模拟方面具有显著优势,处理时间短。
点此查看论文截图

InnerGS: Internal Scenes Rendering via Factorized 3D Gaussian Splatting
Authors:Shuxin Liang, Yihan Xiao, Wenlu Tang
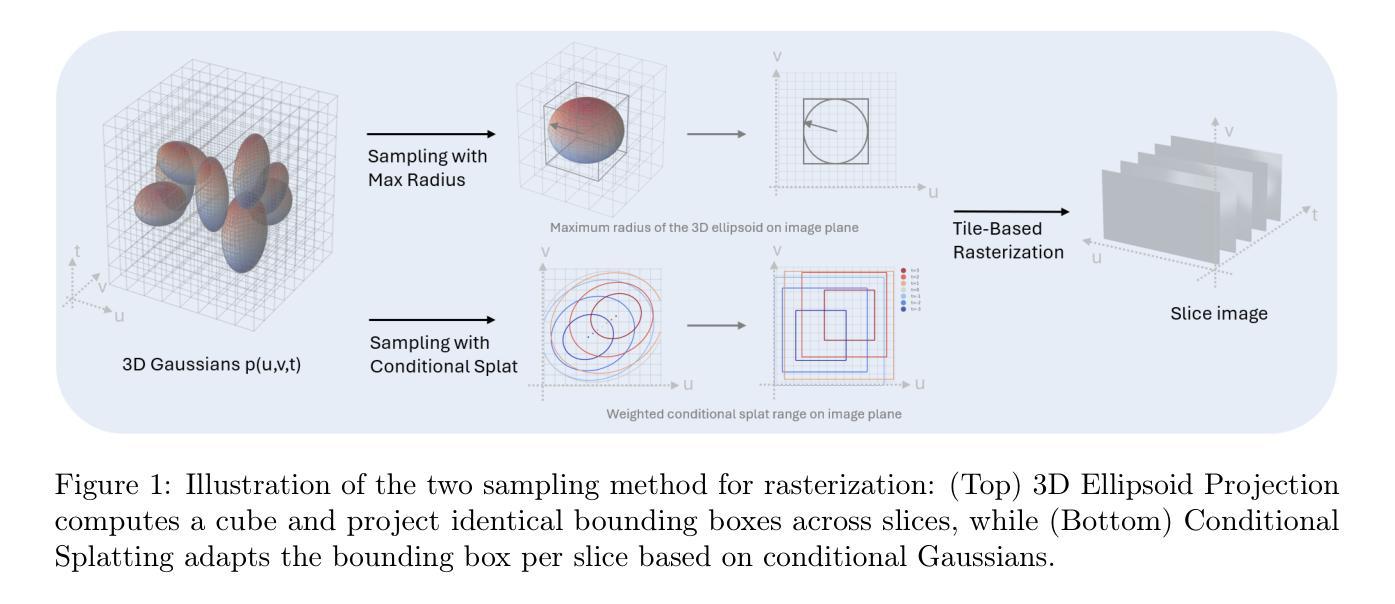
3D Gaussian Splatting (3DGS) has recently gained popularity for efficient scene rendering by representing scenes as explicit sets of anisotropic 3D Gaussians. However, most existing work focuses primarily on modeling external surfaces. In this work, we target the reconstruction of internal scenes, which is crucial for applications that require a deep understanding of an object’s interior. By directly modeling a continuous volumetric density through the inner 3D Gaussian distribution, our model effectively reconstructs smooth and detailed internal structures from sparse sliced data. Our approach eliminates the need for camera poses, is plug-and-play, and is inherently compatible with any data modalities. We provide cuda implementation at: https://github.com/Shuxin-Liang/InnerGS.
3D高斯拼贴(3DGS)最近因其将场景表示为各向异性的3D高斯集而进行高效场景渲染而广受欢迎。然而,现有的大多数工作主要集中在外部表面的建模上。在这项工作中,我们的目标是重建内部场景,这对于需要深入了解物体内部的应用至关重要。通过直接通过内部三维高斯分布对连续体积密度进行建模,我们的模型可以从稀疏切片数据中有效地重建平滑且详细的内部结构。我们的方法无需相机姿态,即插即用,并且与任何数据模式本质上兼容。我们提供的cuda实现地址为:https://github.com/Shuxin-Liang/InnerGS。
论文及项目相关链接
Summary
本文介绍了三维高斯描点法(3DGS)在内部场景重建方面的应用。通过直接对内部三维高斯分布进行建模,该方法能够从稀疏切片数据中重建出平滑且详细的内部结构,且无需相机姿态信息,可适用于各种数据模态。该方法已得到实现并在GitHub上提供cuda版本以供下载和应用。
Key Takeaways
- 三维高斯描点法(3DGS)在场景渲染中的应用日渐普及,但大部分工作聚焦于对外部表面的建模。本文将目标锁定在内部场景的重建上,这对需要深入理解物体内部的应用至关重要。
- 通过直接对连续体积密度进行建模,即使用内部三维高斯分布模型,可以从稀疏切片数据中重建出平滑且详细的内部结构。
- 该方法无需相机姿态信息,具有即插即用(plug-and-play)的特性,并天生兼容任何数据模态。这为在实际应用中提供了广泛的灵活性和便利性。
- 文章提供了相关实现的cuda版本下载地址,这有助于研究者和开发者进行学习和应用。
点此查看论文截图

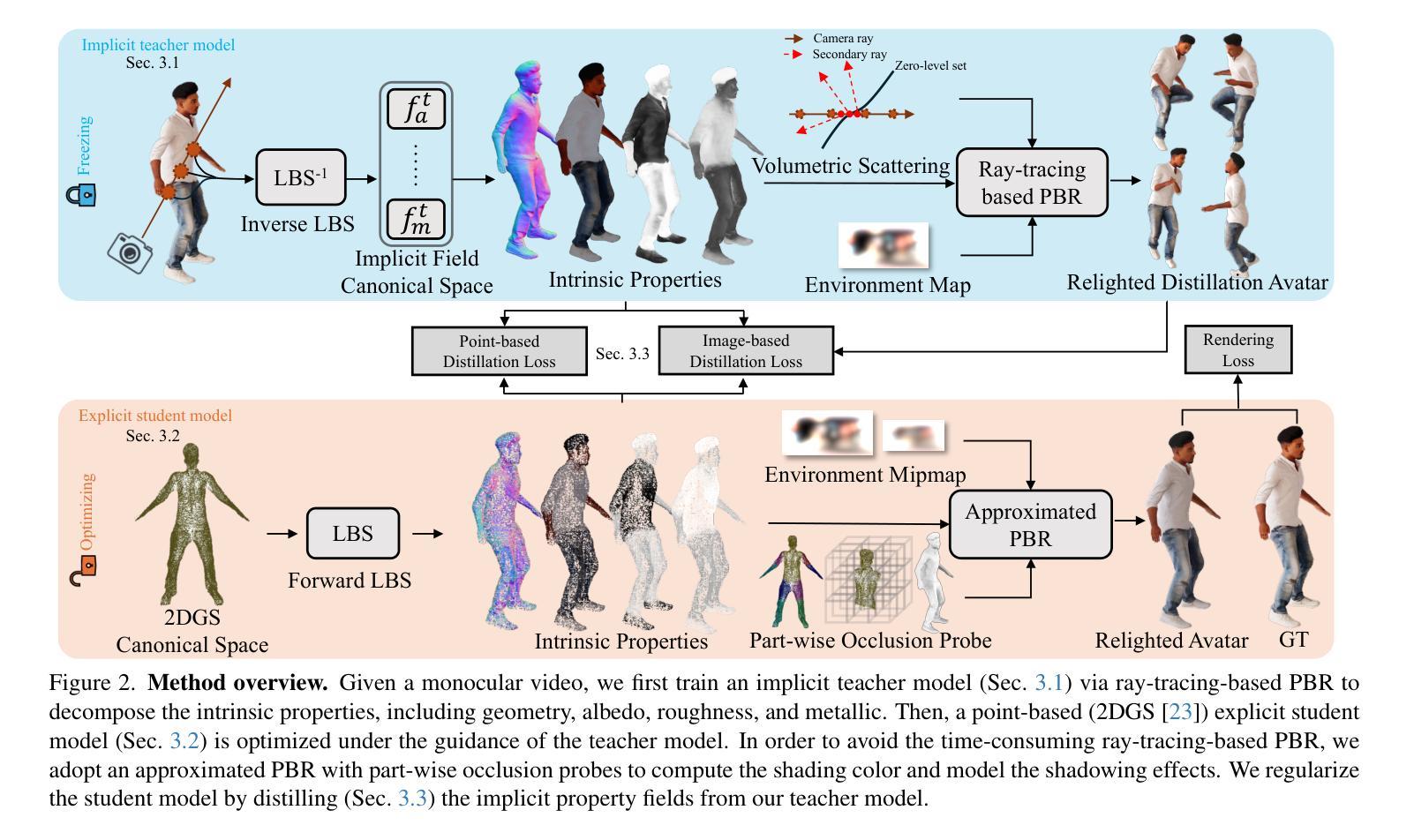
DNF-Avatar: Distilling Neural Fields for Real-time Animatable Avatar Relighting
Authors:Zeren Jiang, Shaofei Wang, Siyu Tang
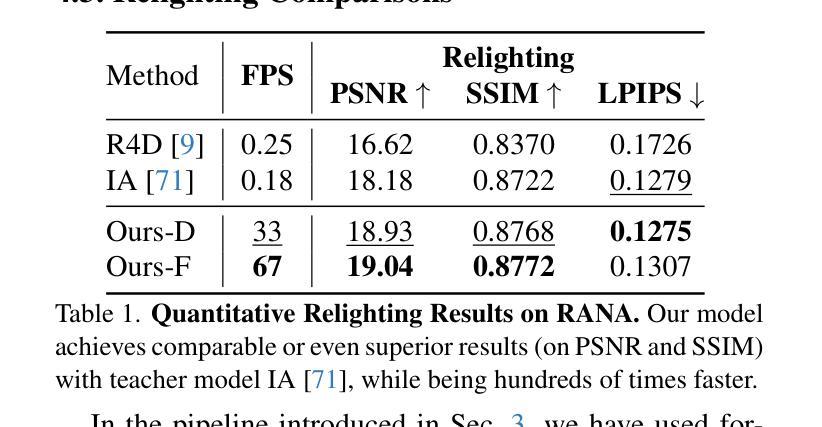
Creating relightable and animatable human avatars from monocular videos is a rising research topic with a range of applications, e.g. virtual reality, sports, and video games. Previous works utilize neural fields together with physically based rendering (PBR), to estimate geometry and disentangle appearance properties of human avatars. However, one drawback of these methods is the slow rendering speed due to the expensive Monte Carlo ray tracing. To tackle this problem, we proposed to distill the knowledge from implicit neural fields (teacher) to explicit 2D Gaussian splatting (student) representation to take advantage of the fast rasterization property of Gaussian splatting. To avoid ray-tracing, we employ the split-sum approximation for PBR appearance. We also propose novel part-wise ambient occlusion probes for shadow computation. Shadow prediction is achieved by querying these probes only once per pixel, which paves the way for real-time relighting of avatars. These techniques combined give high-quality relighting results with realistic shadow effects. Our experiments demonstrate that the proposed student model achieves comparable or even better relighting results with our teacher model while being 370 times faster at inference time, achieving a 67 FPS rendering speed.
创建从单目视频中可重新照明和可动画化的人类化身是一个新兴的研究课题,具有广泛的应用领域,例如虚拟现实、运动和电子游戏。之前的工作利用神经场与基于物理的渲染(PBR)相结合,来估计几何形状并解开人类化身的外观属性。然而,这些方法的一个缺点是渲染速度慢,因为昂贵的蒙特卡洛光线追踪。为了解决这一问题,我们提出将来自隐神经场(教师)的知识提炼到显式2D高斯喷涂(学生)表示中,以利用高斯喷涂的快速光栅化属性。为了避免光线追踪,我们采用分裂总和近似法来模拟基于物理的渲染外观。我们还提出了用于阴影计算的新型部分环境遮蔽探针。阴影预测是通过每个像素仅查询这些探针一次来实现的,这为实时重新照明化身铺平了道路。这些技术的结合实现了高质量的重新照明效果,带有逼真的阴影效果。我们的实验表明,所提出的学生模型在推理时间达到了370倍的加速,实现了每秒67帧的渲染速度,同时实现了与我们教师模型相当的甚至更好的重新照明效果。
论文及项目相关链接
PDF 17 pages, 9 figures, ICCV 2025 Findings Oral, Project pages: https://jzr99.github.io/DNF-Avatar/
Summary
该研究探讨从单目视频中创建可重新照明和可动画的人类角色的话题,涉及虚拟现实、体育、视频游戏等多个应用领域。为解决先前利用神经网络和物理渲染技术处理人类角色时出现的渲染速度慢的问题,该研究提出了一种将隐式神经网络(教师模型)的知识提炼到显式二维高斯斑点表示(学生模型)的方法,利用高斯斑点的快速栅格化特性。通过避免光线追踪,采用分割求和近似法模拟物理渲染外观。同时,提出了新型的部分环境遮蔽探针用于阴影计算,通过仅对每个像素进行一次探针查询来实现角色的实时重新照明。实验表明,学生模型在达到或超越教师模型的重新照明效果的同时,推理速度提高了370倍,实现了每秒渲染出帧率达67次。此技术的实施在促进角色动态光影调整的同时也大幅度提高了处理速度。
Key Takeaways
以下是七个关键要点:
- 研究利用单目视频创建可重新照明和可动画化的虚拟人类角色,具有广泛的应用前景。
- 提出了一种从隐式神经网络到显式二维高斯斑点表示的知识提炼方法,以提高渲染速度。
- 利用高斯斑点的快速栅格化特性,提高了渲染效率。
- 采用分割求和近似法模拟物理渲染外观,避免了昂贵的光线追踪过程。
- 提出新型部分环境遮蔽探针用于阴影计算,实现了角色的实时重新照明。
- 学生模型相较于教师模型具有更快的推理速度(提高370倍),且能取得相近或更好的重新照明效果。
点此查看论文截图