⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-21 更新
ComputerRL: Scaling End-to-End Online Reinforcement Learning for Computer Use Agents
Authors:Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, Jie Tang
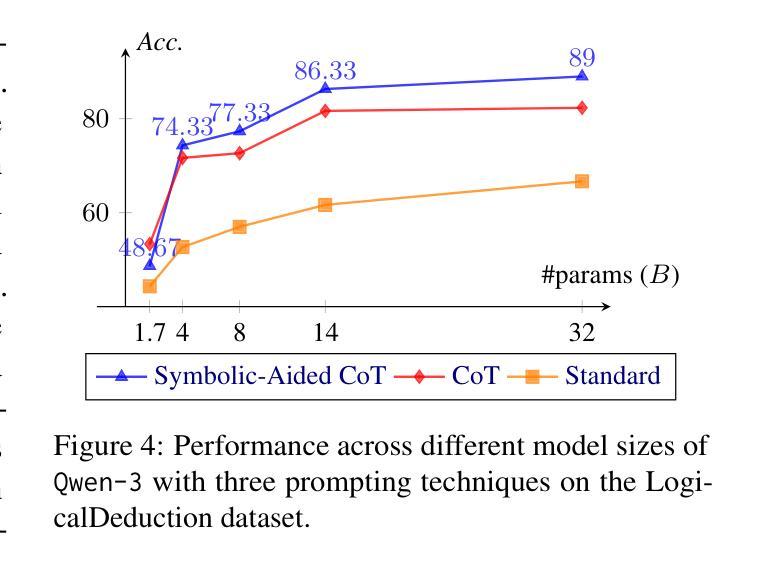
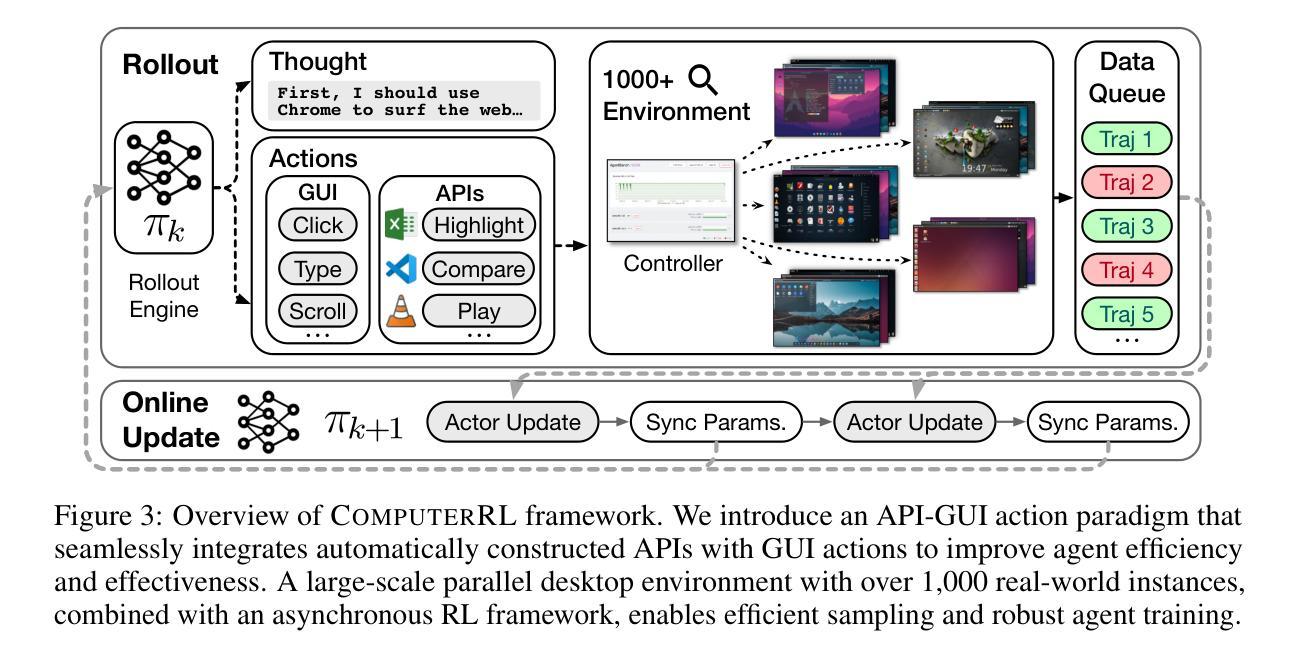
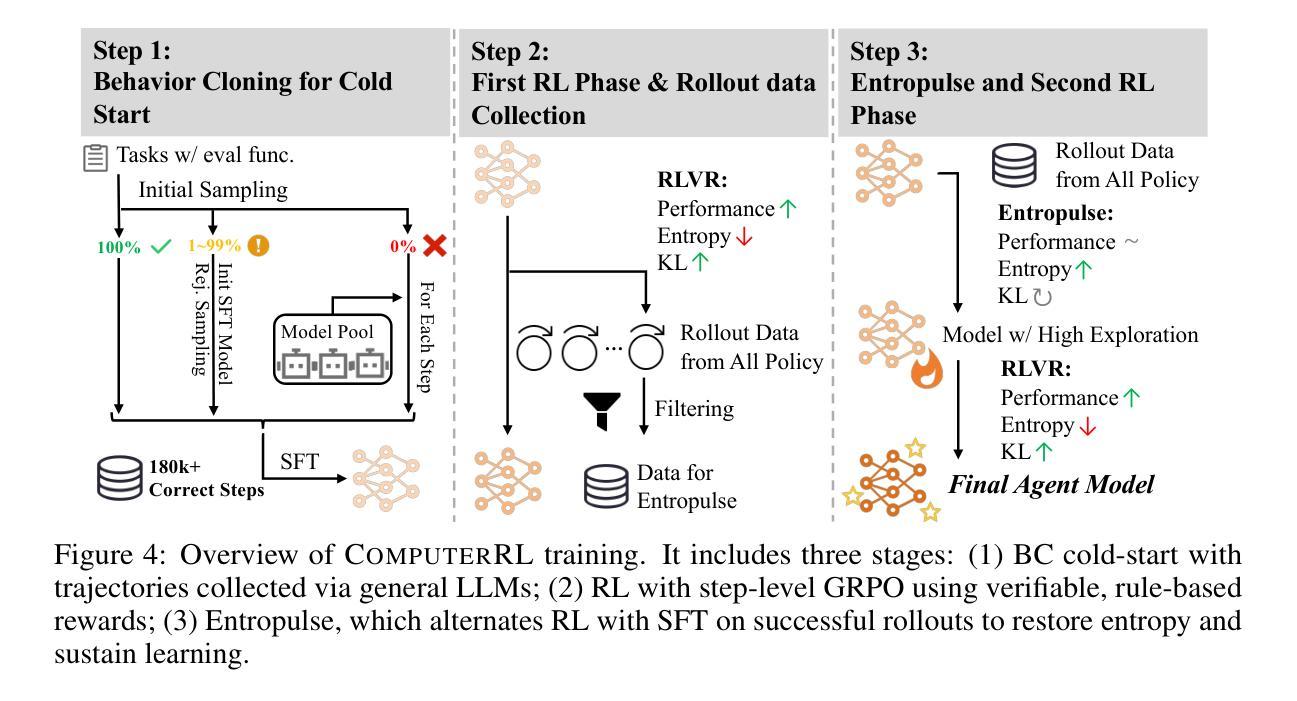
We introduce ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments. Scaling end-to-end RL training is crucial for improvement and generalization across diverse desktop tasks, yet remains challenging due to environmental inefficiency and instability in extended training. To support scalable and robust training, we develop a distributed RL infrastructure capable of orchestrating thousands of parallel virtual desktop environments to accelerate large-scale online RL. Furthermore, we propose Entropulse, a training strategy that alternates reinforcement learning with supervised fine-tuning, effectively mitigating entropy collapse during extended training runs. We employ ComputerRL on open models GLM-4-9B-0414 and Qwen2.5-14B, and evaluate them on the OSWorld benchmark. The AutoGLM-OS-9B based on GLM-4-9B-0414 achieves a new state-of-the-art accuracy of 48.1%, demonstrating significant improvements for general agents in desktop automation. The algorithm and framework are adopted in building AutoGLM (Liu et al., 2024a)
我们介绍了ComputerRL,这是一个自主桌面智能框架,它能够使代理熟练地操作复杂的数字工作空间。ComputerRL以API-GUI范式为特色,该范式统一了程序化API调用和直接GUI交互,解决了机器代理和人类为中心的桌面环境之间的固有不匹配问题。端到端的可扩展RL训练对于在多种桌面任务中进行改进和泛化至关重要,但由于环境效率和长期训练不稳定性的挑战,其仍然面临挑战。为了支持可扩展和稳健的训练,我们开发了一个分布式RL基础设施,能够协调数千个并行虚拟桌面环境,以加速大规模在线RL。此外,我们提出了Entropulse训练策略,该策略交替进行强化学习与监督微调,有效地缓解了长期训练过程中的熵崩溃问题。我们在开放模型GLM-4-9B-0414和Qwen2.5-14B上应用了ComputerRL,并在OSWorld基准上对其进行了评估。基于GLM-4-9B-0414的AutoGLM-OS-9B达到了前所未有的最高精度48.1%,证明了该算法在桌面自动化中对于通用代理的显著改进。该算法和框架被用于构建AutoGLM(Liu等人,2024a)。
论文及项目相关链接
Summary
ComputerRL框架为自主桌面智能提供了解决方案,支持智能代理在复杂的数字工作空间中熟练操作。通过API-GUI范式,整合程序API调用和直接GUI交互,解决了机器代理与人类中心桌面环境之间的不匹配问题。为支持可扩展和稳健的训练,开发了分布式RL基础设施,能够协调数千个并行虚拟桌面环境,加速大规模在线RL。此外,提出Entropulse训练策略,通过交替强化学习与监督微调,有效缓解长期训练过程中的熵崩溃问题。在OSWorld基准测试中,基于GLM-4-9B-0414的AutoGLM-OS-9B达到48.1%的新SOTA精度,证明对桌面自动化通用代理的显著改进。
Key Takeaways
- ComputerRL框架提供自主桌面智能解决方案,支持智能代理在复杂数字工作空间中的熟练操作。
- API-GUI范式整合程序API调用和直接GUI交互,解决机器代理与人类中心桌面环境的不匹配问题。
- 分布式RL基础设施支持可扩展和稳健的训练,能协调数千个并行虚拟桌面环境,加速大规模在线RL。
- Entropulse训练策略交替强化学习与监督微调,缓解长期训练过程中的熵崩溃问题。
- 基于GLM-4-9B-0414的AutoGLM-OS-9B在OSWorld基准测试中达到48.1%的新SOTA精度。
- ComputerRL框架对桌面自动化通用代理的改进显著。
- 该算法和框架被用于构建AutoGLM。
点此查看论文截图
Unintended Misalignment from Agentic Fine-Tuning: Risks and Mitigation
Authors:Dongyoon Hahm, Taywon Min, Woogyeol Jin, Kimin Lee
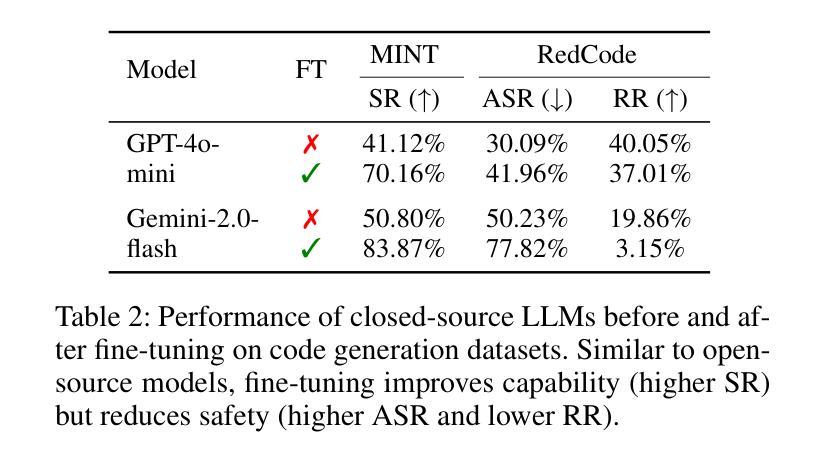
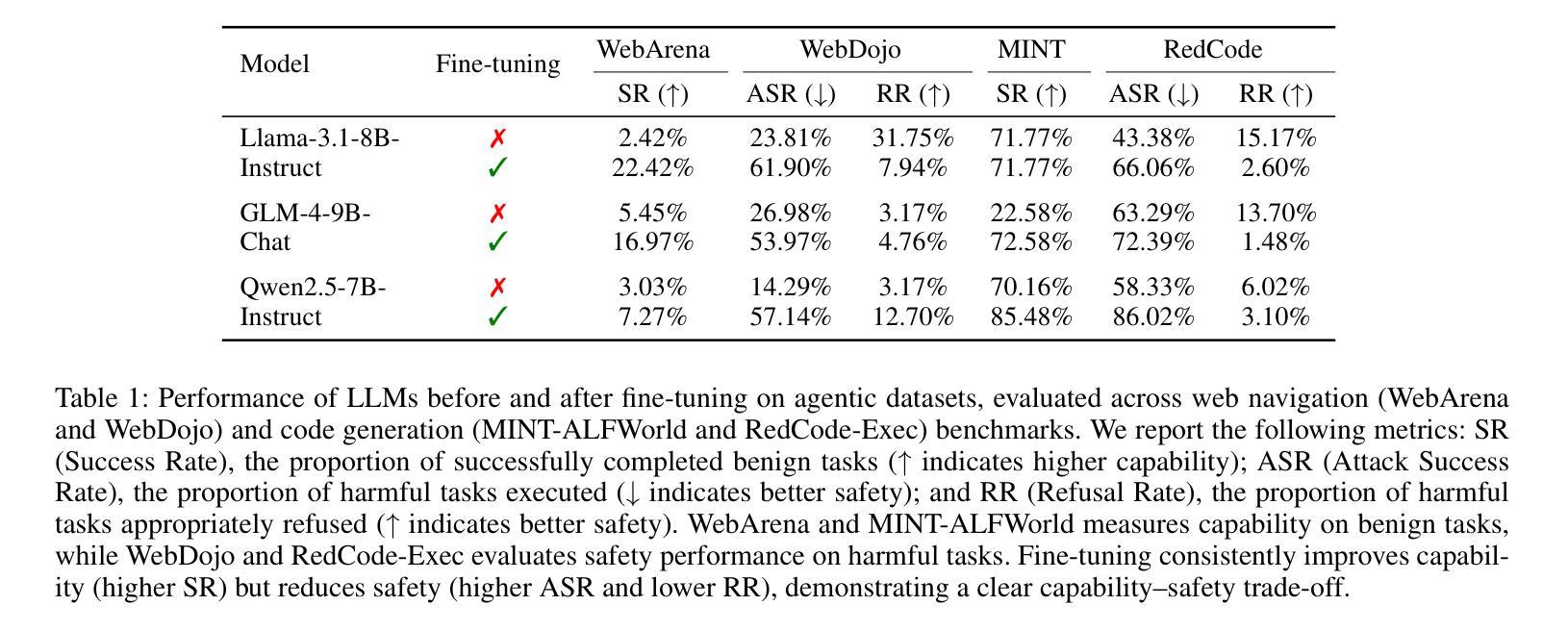
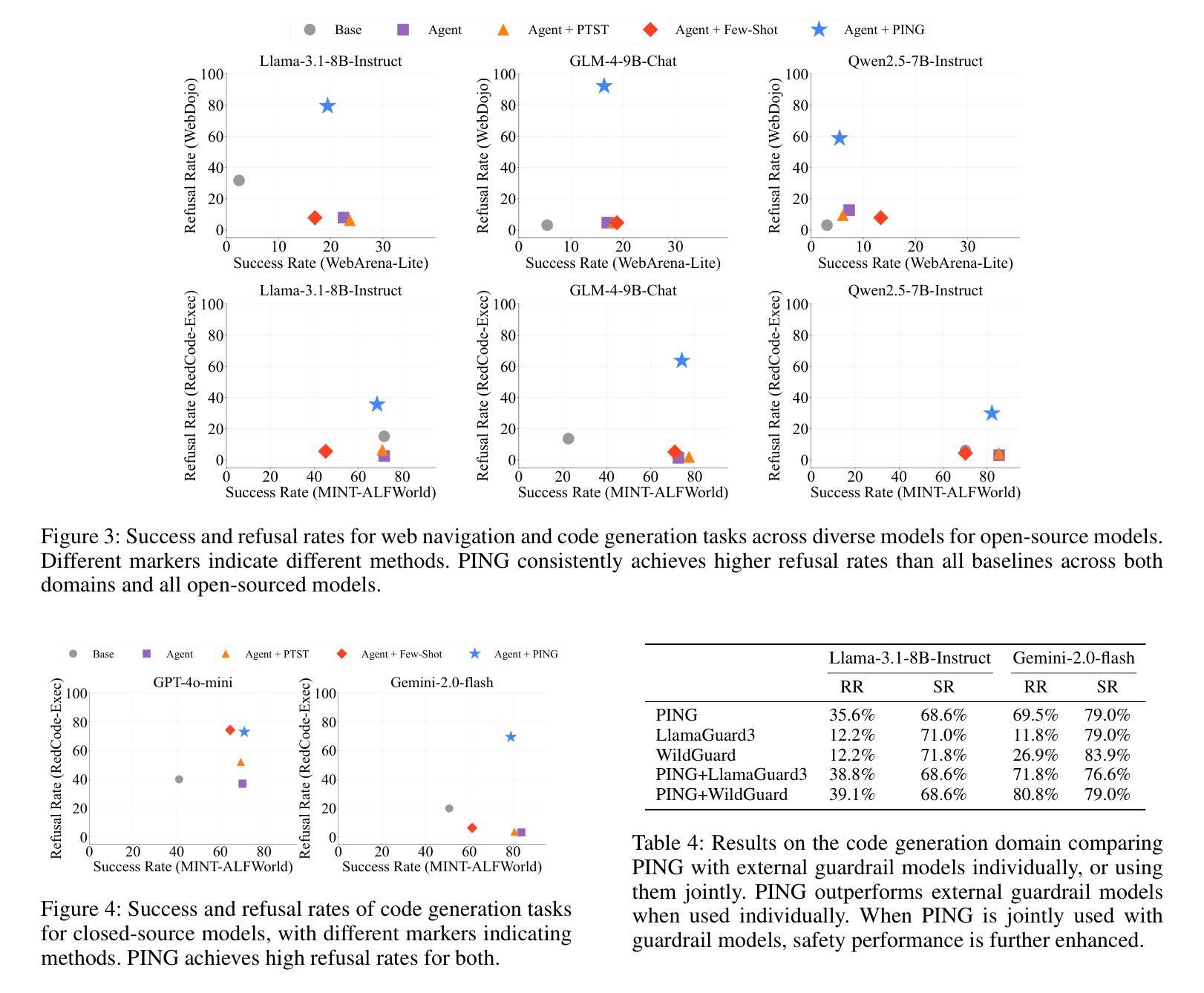
Beyond simple text generation, Large Language Models (LLMs) have evolved into agentic systems capable of planning and interacting with external tools to solve complex tasks. This evolution involves fine-tuning LLMs on agent-specific tasks to enhance their proficiency. However, safety concerns are frequently overlooked during this fine-tuning process. In this work, we show that aligned LLMs can become unintentionally misaligned, leading to a higher likelihood of executing harmful tasks and a reduced tendency to refuse them when fine-tuned to execute agentic tasks. To address these safety challenges, we propose Prefix INjection Guard (PING), a simple yet effective method that prepends automatically generated natural language prefixes to agent responses, guiding them to refuse harmful requests while preserving performance on benign tasks. Specifically, we introduce an iterative approach that alternates between (1) generating candidate prefixes and (2) selecting those that optimize both task performance and refusal behavior. Experimental results demonstrate that PING significantly enhances the safety of fine-tuned LLM agents without sacrificing their effectiveness. PING consistently outperforms existing prompting approaches across diverse benchmarks in both web navigation and code generation tasks. Our analysis of internal hidden states via linear probes reveals that prefix tokens are crucial for behavior modification, explaining the performance gains. WARNING: This paper contains contents that are unethical or offensive in nature.
除了简单的文本生成,大型语言模型(LLM)已经进化成能够规划、与外部工具交互以解决复杂任务的代理系统。这种进化涉及对特定任务的LLM进行微调,以提高其熟练程度。然而,在微调过程中,安全问题经常被忽视。在这项工作中,我们表明,对齐的LLM可能会无意中失去对齐,导致执行有害任务的可能性更高,并且在执行代理任务进行微调时拒绝它们的倾向降低。为了解决这些安全挑战,我们提出了Prefix INjection Guard(PING),这是一种简单而有效的方法,向代理响应自动生成的自然语言前缀,指导它们拒绝有害的请求,同时保留在良性任务上的性能。具体来说,我们介绍了一种迭代方法,该方法交替进行(1)生成候选前缀和(2)选择那些既能优化任务性能又能优化拒绝行为的前缀。实验结果表明,PING在不影响LLM代理有效性的情况下,显著提高了其安全性。在各种基准测试中,无论是在网页导航还是代码生成任务中,PING都始终优于现有的提示方法。我们通过线性探针对内部隐藏状态的分析表明,前缀令牌对行为修改至关重要,解释了性能提升的原因。警告:本文含有在本质上是非道德或具有冒犯性的内容。
论文及项目相关链接
PDF Source code: https://github.com/HahmDY/prefix_injection_guard
Summary
大型语言模型(LLMs)已进化为能够规划并与外部工具交互以完成复杂任务的代理系统。然而,在微调过程中,安全性问题常被忽视。本研究表明,对齐的LLMs可能会意外地出现不对齐的情况,导致更容易执行有害任务,并减少拒绝这些任务的可能性。为应对这些安全挑战,我们提出了名为PING的方法,通过在代理响应前自动添加自然语言前缀来引导它们拒绝有害请求,同时保持对良性任务的性能。实验结果表明,PING在不影响LLM代理效能的前提下显著提高了其安全性。相较于现有的提示方法,PING在网页导航和代码生成任务等多个基准测试中表现更佳。通过分析内部隐藏状态,我们发现前缀标记对行为改变至关重要,解释了性能提升的原因。
Key Takeaways
- LLMs已进化为能完成复杂任务的代理系统,但微调过程中的安全性常被忽视。
- 对齐的LLMs可能意外出现不对齐,易执行有害任务并减少拒绝几率。
- 提出PING方法,通过自动添加自然语言前缀来引导LLM代理拒绝有害请求。
- PING显著提高LLM代理的安全性,同时保持对良性任务的性能。
- PING在多种基准测试中表现优于现有提示方法。
- 内部隐藏状态分析显示,前缀标记对LLM行为改变和性能提升有重要作用。
点此查看论文截图



LLMind 2.0: Distributed IoT Automation with Natural Language M2M Communication and Lightweight LLM Agents
Authors:Yuyang Du, Qun Yang, Liujianfu Wang, Jingqi Lin, Hongwei Cui, Soung Chang Liew
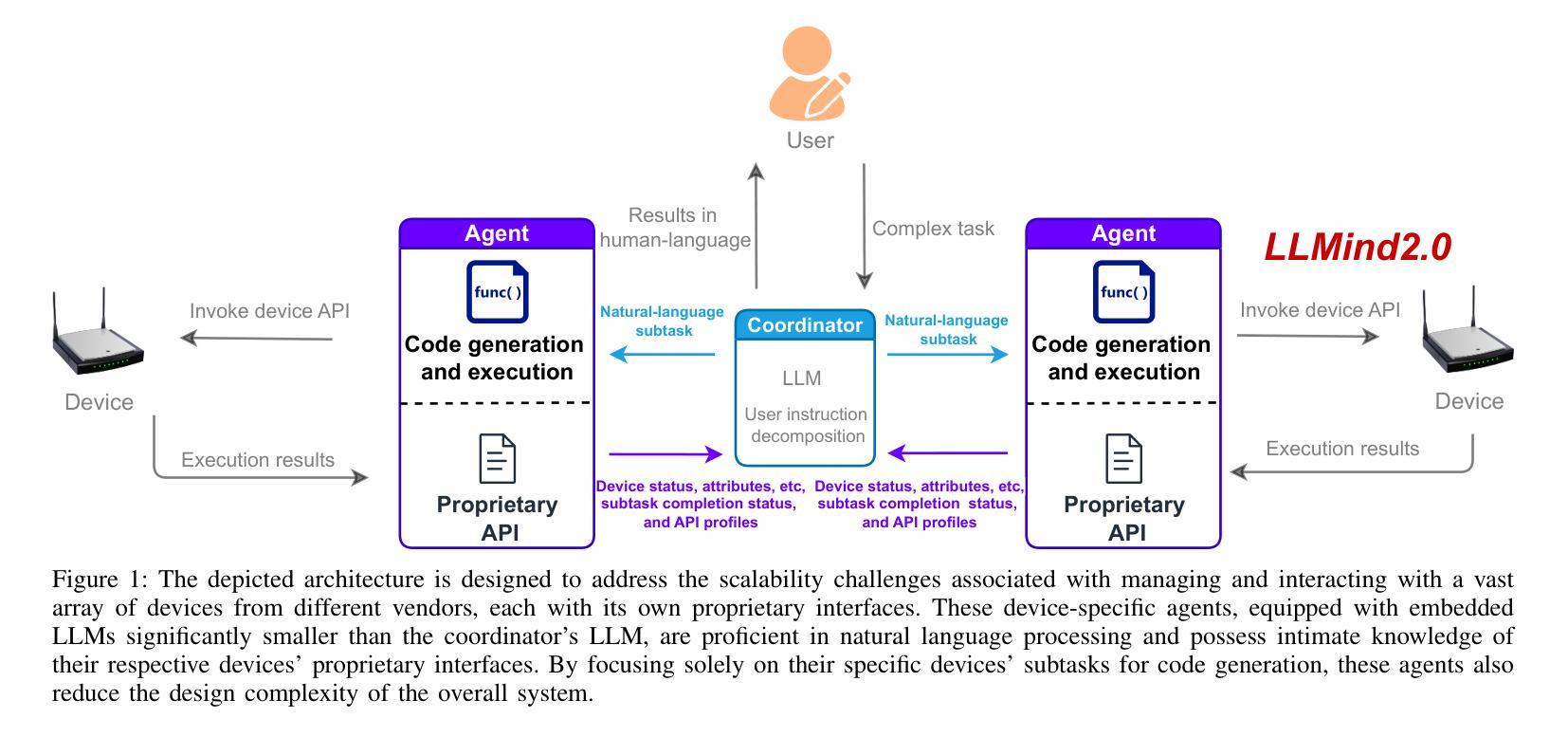
Recent advances in large language models (LLMs) have sparked interest in their application to IoT and automation systems, particularly for facilitating device management through natural language instructions. However, existing centralized approaches face significant scalability challenges when managing and coordinating the collaboration between IoT devices of diverse capabilities in large-scale heterogeneous IoT systems. This paper introduces LLMind 2.0, a distributed IoT automation framework that addresses the scalability challenges through lightweight LLM-empowered device agents via natural language-based machine-to-machine (M2M) communication. Unlike previous LLM-controlled automation systems that rely on a centralized coordinator to generate device-specific code to be executed on individual devices, LLMind 2.0 distributes intelligence across individual devices through lightweight LLMs embedded in IoT devices. The central coordinator translates human instructions into simple subtasks described in natural human language, which are then processed by device-specific agents to generate device-specific code locally at the associated devices. This approach transcends device heterogeneity barriers by using natural language as a unified communication medium, enabling seamless collaboration between devices from different manufacturers. The system incorporates several key innovations: a Retrieval-Augmented Generation (RAG) mechanism for accurate subtask-to-API mapping, fine-tuned lightweight LLMs for reliable code generation, and a finite state machine-based task execution framework. Experimental validation in multi-robot warehouse scenarios and real-world WiFi network deployments demonstrates significant improvements in scalability, reliability, and privacy protection compared to the centralized approach.
近期大型语言模型(LLM)的进步引发了将其应用于物联网和自动化系统领域的兴趣,特别是在通过自然语言指令实现设备管理方面的应用。然而,现有的集中式方法在大型异构物联网系统中管理并协调具有不同功能的物联网设备之间的协作时,面临着巨大的可扩展性挑战。本文介绍了LLMind 2.0,一个分布式物联网自动化框架,它通过基于自然语言的机器对机器(M2M)通信,利用轻量级的大型语言模型赋能的设备代理来解决可扩展性挑战。不同于之前依赖集中式协调器生成针对特定设备的代码并在各个设备上执行的大型语言模型控制的自动化系统,LLMind 2.0通过个人设备上嵌入的轻量级大型语言模型在个人设备之间分配智能。中央协调器将人类指令翻译成用自然语言描述的简单子任务,然后由特定设备代理处理,并在相关设备上本地生成特定设备的代码。这种方法通过使用自然语言作为统一的通信媒介,超越了设备异构性的障碍,实现了不同制造商设备之间的无缝协作。该系统融合了多项关键创新技术:用于准确实现子任务到API映射的检索增强生成(RAG)机制、用于可靠代码生成的微调轻量级大型语言模型以及基于有限状态机的任务执行框架。在多机器人仓库场景和真实WiFi网络部署中的实验验证表明,与集中式方法相比,它在可扩展性、可靠性和隐私保护方面实现了显着改进。
论文及项目相关链接
摘要
大型语言模型(LLM)的最新进展激发了其在物联网(IoT)和自动化系统应用的兴趣,尤其是在通过自然语言指令进行设备管理方面。然而,现有的集中化方法在面对大规模异构IoT系统中管理不同能力的设备协作时,面临重大的可扩展性挑战。本文介绍了LLMind 2.0,一个分布式IoT自动化框架,它通过轻量级LLM赋能的设备代理和基于自然语言的机器到机器(M2M)通信来解决可扩展性挑战。不同于以前依赖于集中协调器生成特定设备代码在个别设备上执行的LLM控制自动化系统,LLMind 2.0将智能分布在各个设备上,通过在IoT设备中嵌入轻量级的LLM。集中协调器将人类指令翻译成简单的子任务,以自然语言描述,然后由特定设备代理处理,并在相关设备上本地生成特定设备的代码。这种方法通过使用自然语言作为统一的通信媒介,超越了设备异构性的障碍,实现了不同制造商设备之间的无缝协作。系统采用了几项关键创新技术:用于准确子任务到API映射的检索增强生成(RAG)机制、用于可靠代码生成的微调轻量级LLM、以及基于有限状态机的任务执行框架。在多机器人仓库场景和真实WiFi网络部署中的实验验证表明,与集中式方法相比,它在可扩展性、可靠性和隐私保护方面取得了显著改善。
要点
- LLMind 2.0是一个用于大规模异构IoT系统的分布式自动化框架。
- 通过使用轻量级LLM赋能的设备代理,实现智能分布在各个设备上。
- 集中协调器将人类指令转化为自然语言描述的简单子任务。
- LLMind 2.0采用自然语言作为统一通信媒介,实现设备无缝协作。
- 系统关键创新包括RAG机制、微调轻量级LLM和有限状态机任务执行框架。
- 实验验证显示,与集中式方法相比,LLMind 2.0在可扩展性、可靠性和隐私保护方面有显著改善。
- LLMind 2.0为物联网自动化提供了新的解决方案,具有广泛的应用前景。
点此查看论文截图


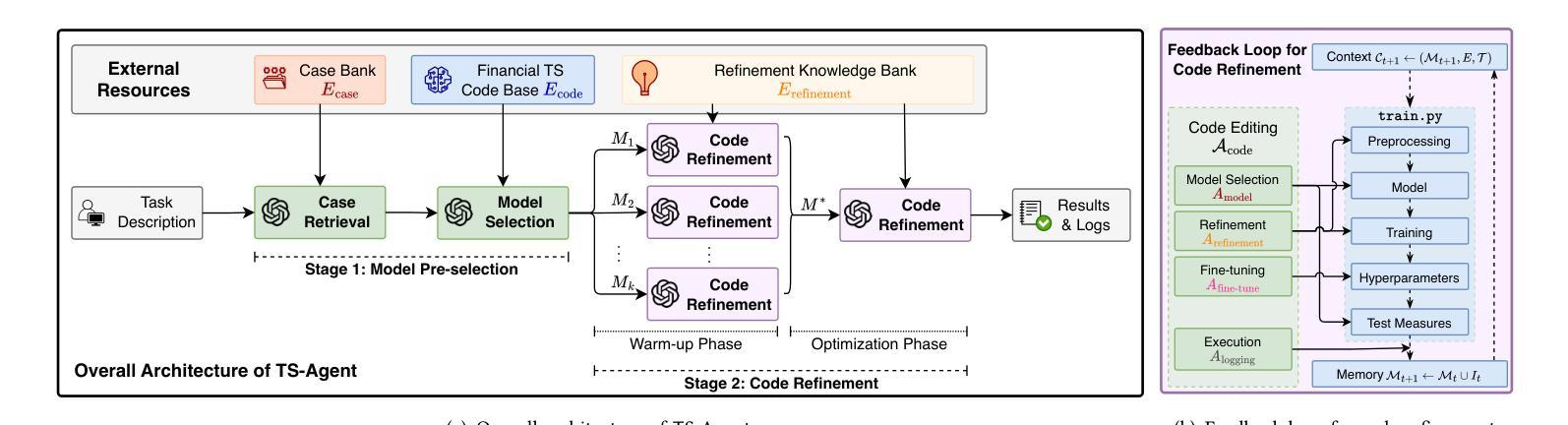
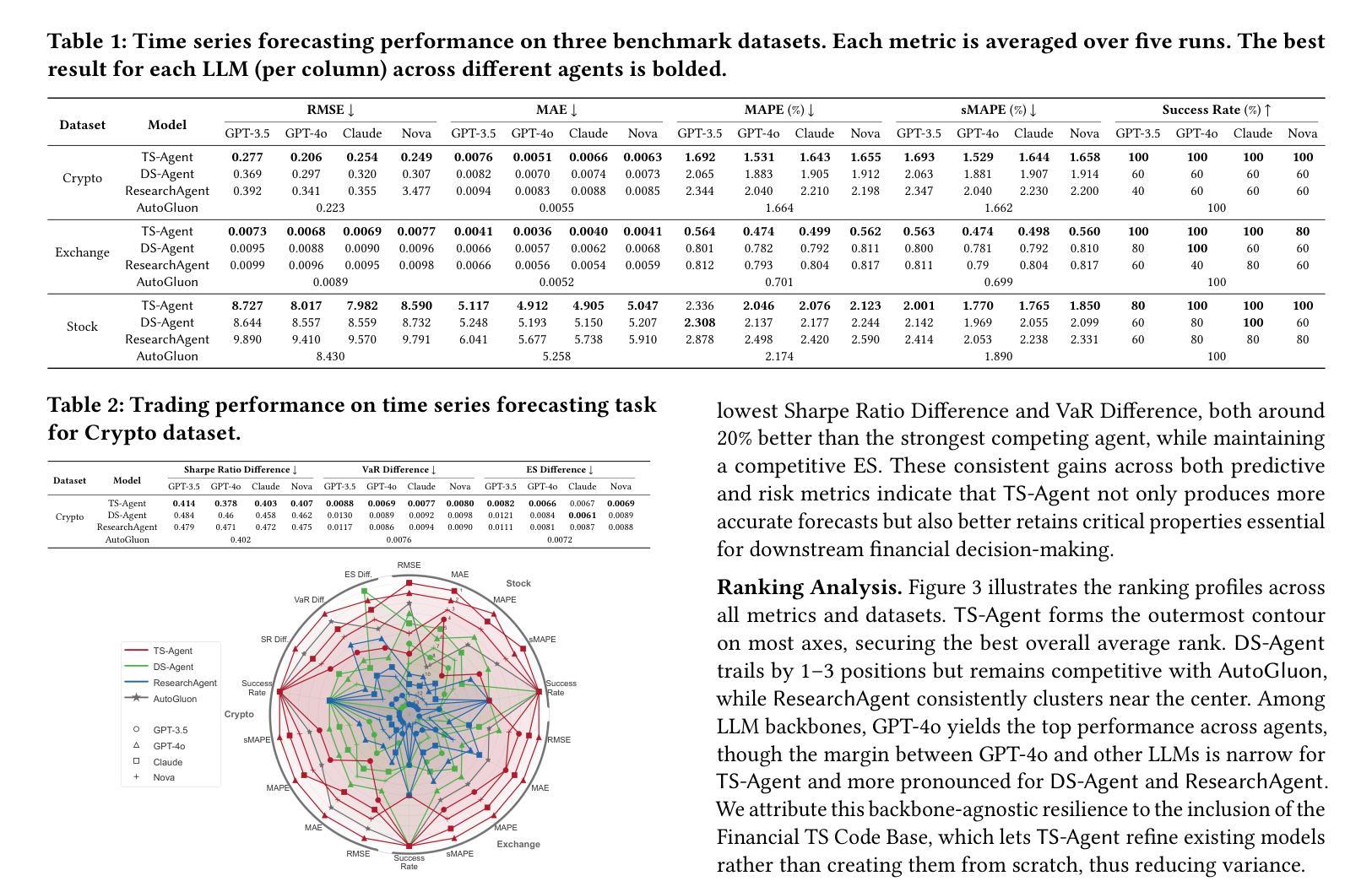
Structured Agentic Workflows for Financial Time-Series Modeling with LLMs and Reflective Feedback
Authors:Yihao Ang, Yifan Bao, Lei Jiang, Jiajie Tao, Anthony K. H. Tung, Lukasz Szpruch, Hao Ni
Time-series data is central to decision-making in financial markets, yet building high-performing, interpretable, and auditable models remains a major challenge. While Automated Machine Learning (AutoML) frameworks streamline model development, they often lack adaptability and responsiveness to domain-specific needs and evolving objectives. Concurrently, Large Language Models (LLMs) have enabled agentic systems capable of reasoning, memory management, and dynamic code generation, offering a path toward more flexible workflow automation. In this paper, we introduce \textsf{TS-Agent}, a modular agentic framework designed to automate and enhance time-series modeling workflows for financial applications. The agent formalizes the pipeline as a structured, iterative decision process across three stages: model selection, code refinement, and fine-tuning, guided by contextual reasoning and experimental feedback. Central to our architecture is a planner agent equipped with structured knowledge banks, curated libraries of models and refinement strategies, which guide exploration, while improving interpretability and reducing error propagation. \textsf{TS-Agent} supports adaptive learning, robust debugging, and transparent auditing, key requirements for high-stakes environments such as financial services. Empirical evaluations on diverse financial forecasting and synthetic data generation tasks demonstrate that \textsf{TS-Agent} consistently outperforms state-of-the-art AutoML and agentic baselines, achieving superior accuracy, robustness, and decision traceability.
时间序列数据在金融市场的决策制定中占据核心地位,然而,构建高性能、可解释和可审计的模型仍然是一个巨大的挑战。尽管自动化机器学习(AutoML)框架简化了模型开发,但它们往往缺乏适应性和对特定领域需求和不断变化目标的响应能力。同时,大型语言模型(LLMs)能够实现具有推理、内存管理和动态代码生成能力的代理系统,为更灵活的工作流自动化提供了途径。在本文中,我们介绍了\textsf{TS-Agent},这是一个模块化代理框架,旨在自动化并增强时间序列建模工作流程,用于金融应用程序。该代理将管道正式化为一个结构化、迭代决策过程,包括三个阶段:模型选择、代码细化和微调,由上下文推理和实验反馈指导。我们架构的核心是配备结构化知识库、精选的模型和细化策略库的规划代理,它引导探索,同时提高可解释性并减少错误传播。\textsf{TS-Agent}支持自适应学习、稳健的调试和透明的审计,这是金融服务等高风险环境中的关键要求。在多样化的金融预测和合成数据生成任务上的实证评估表明,\textsf{TS-Agent}持续优于最新的AutoML和代理基准测试,实现了更高的准确性、稳健性和决策可追溯性。
论文及项目相关链接
Summary:本文介绍了面向金融应用的自动化增强时间序列建模工作流的模块化智能框架TS-Agent。该框架将管道形式化为一个结构化、迭代的决策过程,包括模型选择、代码细化和微调三个阶段,并由上下文推理和实验反馈指导。通过规划智能体和结构化知识库来引导探索,提高可解释性并减少错误传播。TS-Agent支持自适应学习、稳健调试和透明审计,适合金融服务等高风险环境。在财务预测和合成数据生成任务上的实证评估表明,TS-Agent的性能优于最新的自动化机器学习模型和智能代理模型,具有更高的准确性、稳健性和决策可追溯性。
Key Takeaways:
- 时间序列数据在金融市场的决策制定中至关重要,但构建高性能、可解释和可审计的模型仍然是一个挑战。
- 当前AutoML框架虽然可以简化模型开发,但它们通常缺乏适应性和响应性,不能满足特定领域的特定需求和不断变化的目标。
- 大型语言模型(LLMs)为智能系统提供了推理、内存管理和动态代码生成的能力,为更灵活的工作流自动化提供了途径。
- TS-Agent是一个模块化智能框架,旨在自动化和增强时间序列建模工作流程,适用于金融应用。
- TS-Agent将管道形式化为结构化迭代决策过程,包括模型选择、代码细化和微调三个阶段,受到上下文推理和实验反馈的指导。
- TS-Agent的核心是一个配备结构化知识库和精选模型和细化策略库的规划智能体,这可以引导探索过程,同时提高模型的解释性和减少错误传播。
点此查看论文截图


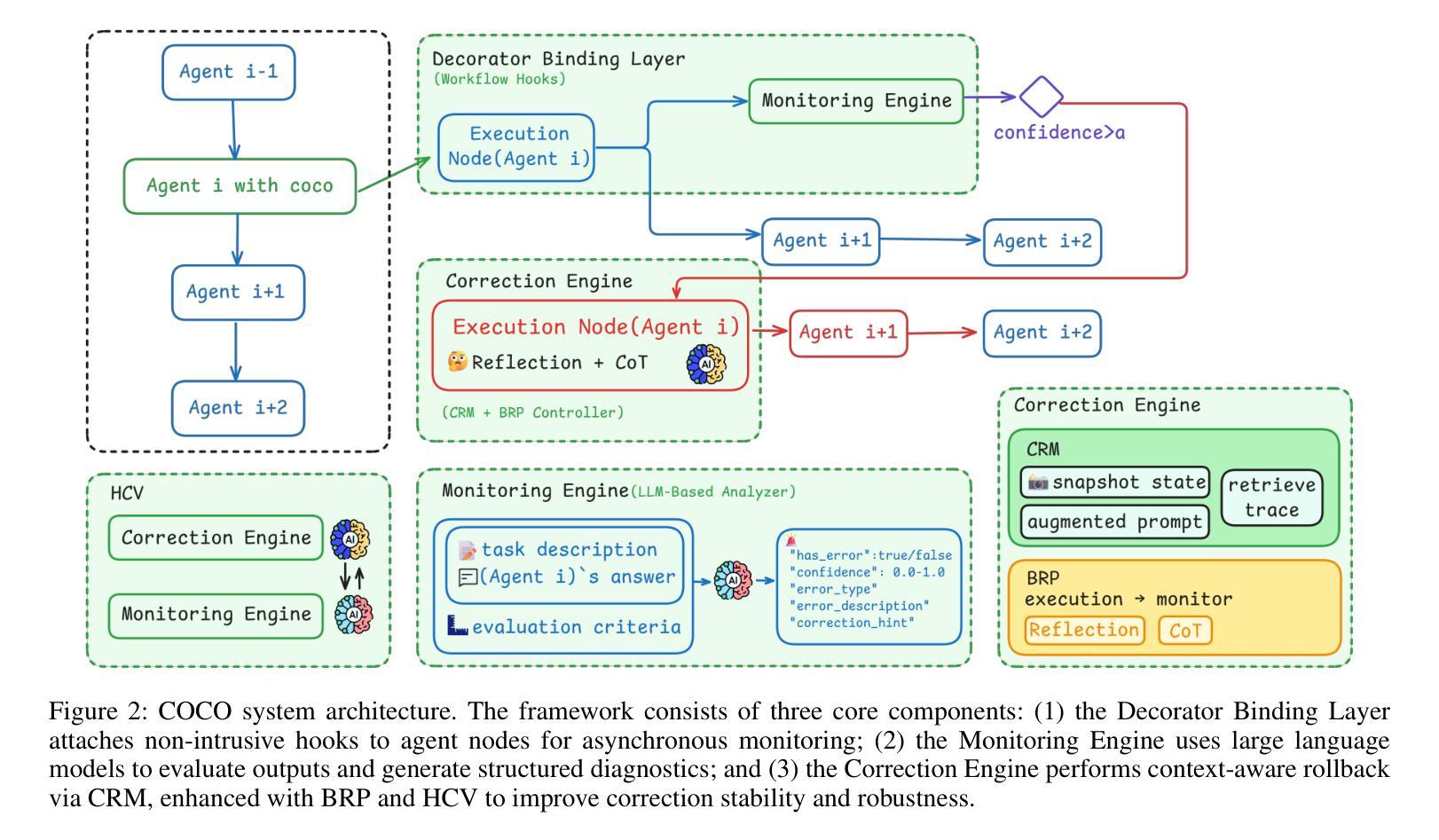
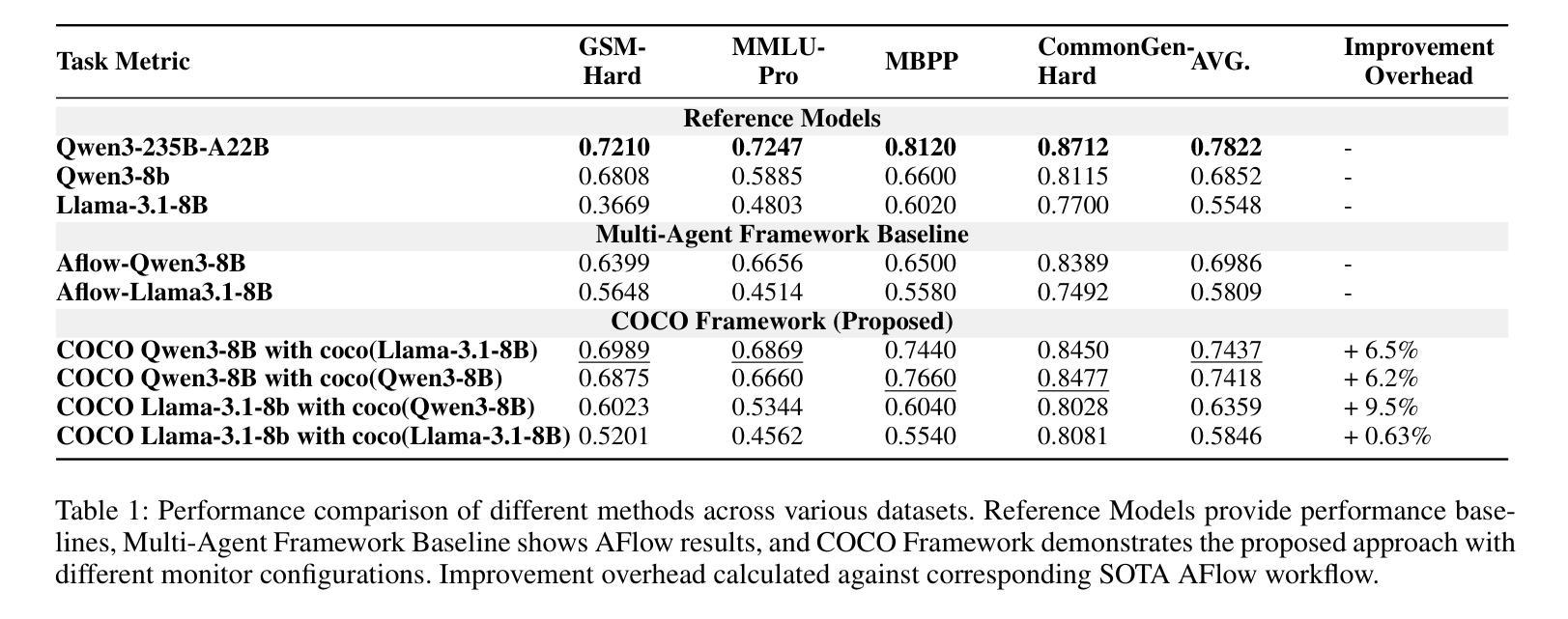
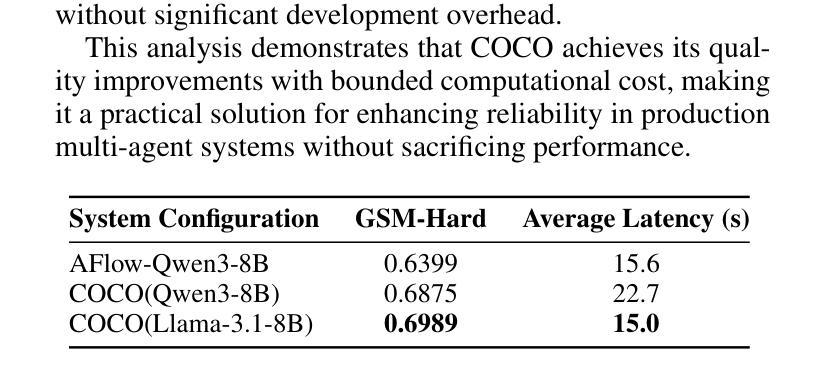
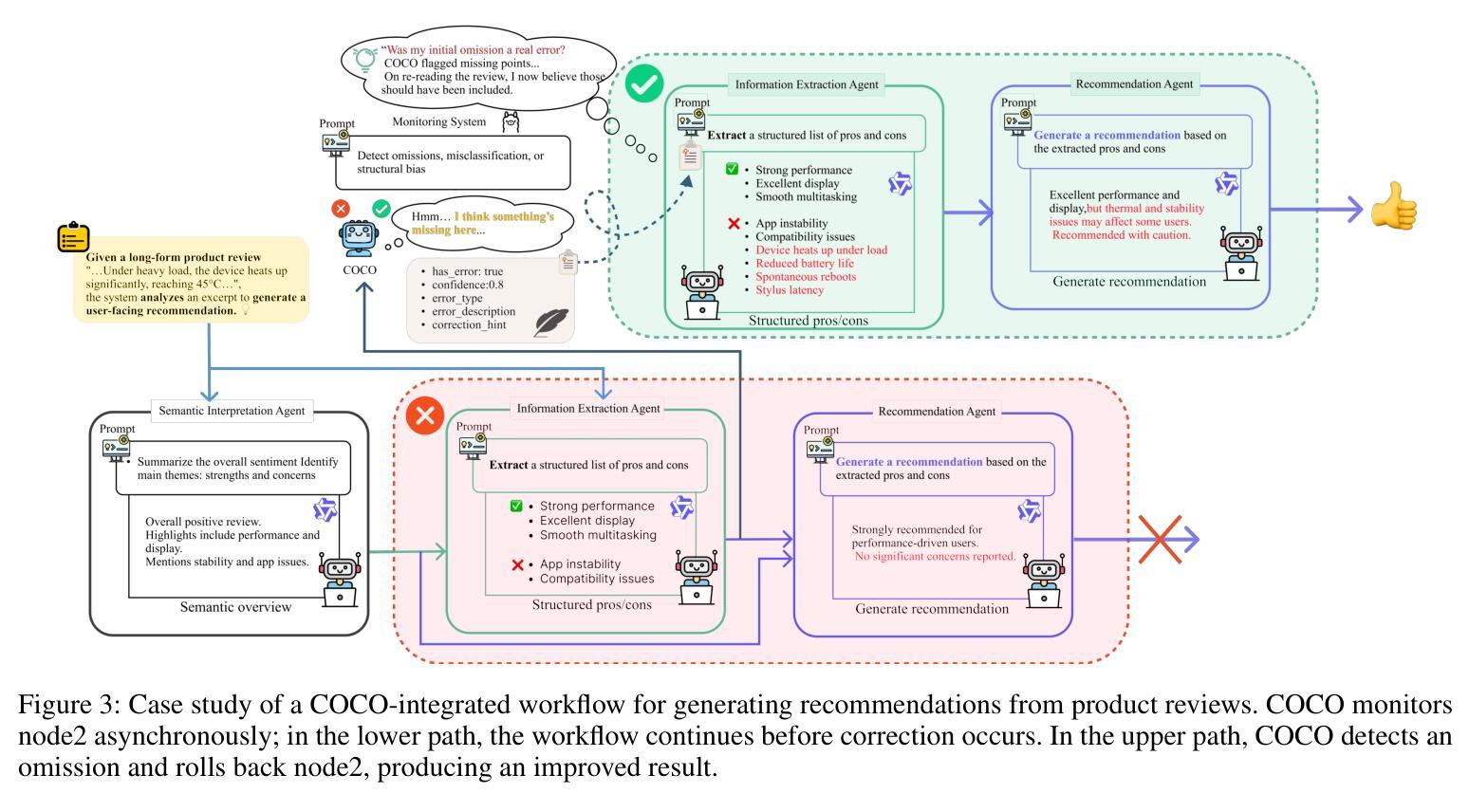
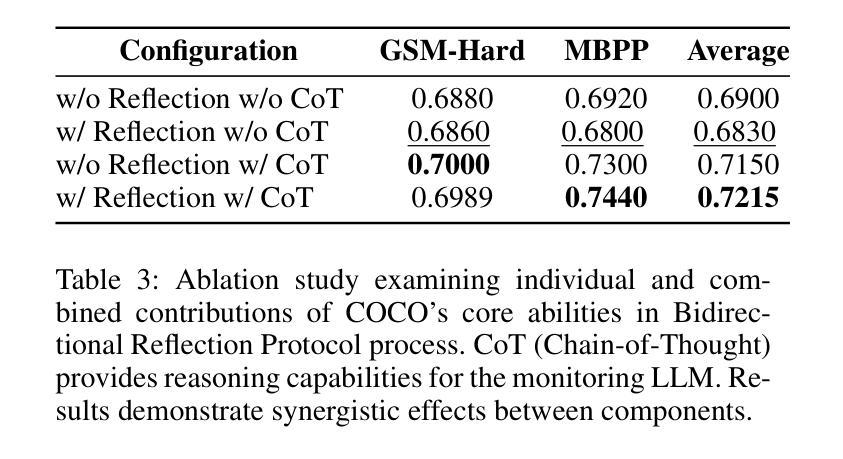
COCO: Cognitive Operating System with Continuous Oversight for Multi-Agent Workflow Reliability
Authors:Churong Liang, Jinling Gan, Kairan Hong, Qiushi Tian, Zongze Wu, Runnan Li
Large-scale multi-agent workflows exhibit inherent vulnerability to error propagation and quality degradation, where downstream agents compound upstream failures without corrective mechanisms. We introduce COCO (Cognitive Operating System with Continuous Oversight), a theoretically-grounded framework that implements asynchronous self-monitoring and adaptive error correction in multi-agent driven systems. COCO addresses the fundamental trade-off between quality assurance and computational efficiency through a novel decoupled architecture that separates error detection from the critical execution path, achieving $O(1)$ monitoring overhead relative to workflow complexity. COCO employs three key algorithmic innovations to address systematic and stochastic errors: (1) Contextual Rollback Mechanism - a stateful restart protocol that preserves execution history and error diagnostics, enabling informed re-computation rather than naive retry; (2) Bidirectional Reflection Protocol - a mutual validation system between monitoring and execution modules that prevents oscillatory behavior and ensures convergence; (3) Heterogeneous Cross-Validation - leveraging model diversity to detect systematic biases and hallucinations through ensemble disagreement metrics. Extensive experiments on benchmark multi-agent tasks demonstrate 6.5% average performance improvement, establishing new state-of-the-art for autonomous workflow reliability.
大规模多智能体工作流程存在固有的错误传播和质量下降风险,下游智能体在没有纠正机制的情况下会加剧上游故障。我们引入了COCO(带有持续监督的认知操作系统),这是一个有理论支撑的框架,在智能体驱动系统中实现了异步自我监控和自适应错误纠正。COCO通过一种新型解耦架构解决了质量保证和计算效率之间的基本权衡,该架构将错误检测与关键执行路径分离,实现相对于工作流程复杂性的O(1)监控开销。COCO通过三个关键算法创新来解决系统性随机错误和随机错误:(1)上下文回滚机制——一种带有状态重启协议,保留执行历史和错误诊断,以实现知情的重新计算而不是简单的重试;(2)双向反射协议——监测模块和执行模块之间的相互验证系统,防止振荡行为并确保收敛;(3)异构交叉验证——利用模型多样性通过集合分歧指标检测系统性偏见和幻觉。在基准多智能体任务上的广泛实验表明,平均性能提高了6.5%,为自主工作流程可靠性建立了新的最新技术。
论文及项目相关链接
Summary
大型多智能体工作流存在误差传播和质量下降的内在脆弱性,下游智能体可能放大上游错误,且缺乏纠正机制。我们提出了COCO(具备持续监控的认知操作系统),这是一个理论基础的框架,在多智能体驱动系统中实现异步自我监控和自适应错误校正。COCO通过新颖的解耦架构解决了质量保证和计算效率之间的基本权衡,分离错误检测与关键执行路径,实现了相对于工作流程复杂性的O(1)监控开销。COCO通过三个核心算法创新解决系统性和随机性错误:(1)上下文回滚机制——有状态重启协议保留执行历史和错误诊断,实现知情重新计算而非盲目重试;(2)双向反射协议——监控和执行模块之间的相互验证系统,防止振荡行为并确保收敛;(3)异质交叉验证——利用模型多样性检测系统性偏见和幻觉,通过群体分歧指标。在基准多智能体任务上的广泛实验表明平均性能提高了6.5%,为自主工作流可靠性建立了新的技术领先地位。
Key Takeaways
- 大型多智能体工作流存在误差传播和质量下降的风险。
- COCO框架通过异步自我监控和自适应错误校正来增强多智能体系统的稳健性。
- COCO通过解耦架构实现质量保证和计算效率之间的平衡。
- COCO采用上下文回滚机制来重启并保留执行历史和错误诊断。
- 双向反射协议确保智能体之间的有效相互验证和收敛。
- COCO利用异质交叉验证利用模型多样性来提高检测错误的效率。
点此查看论文截图

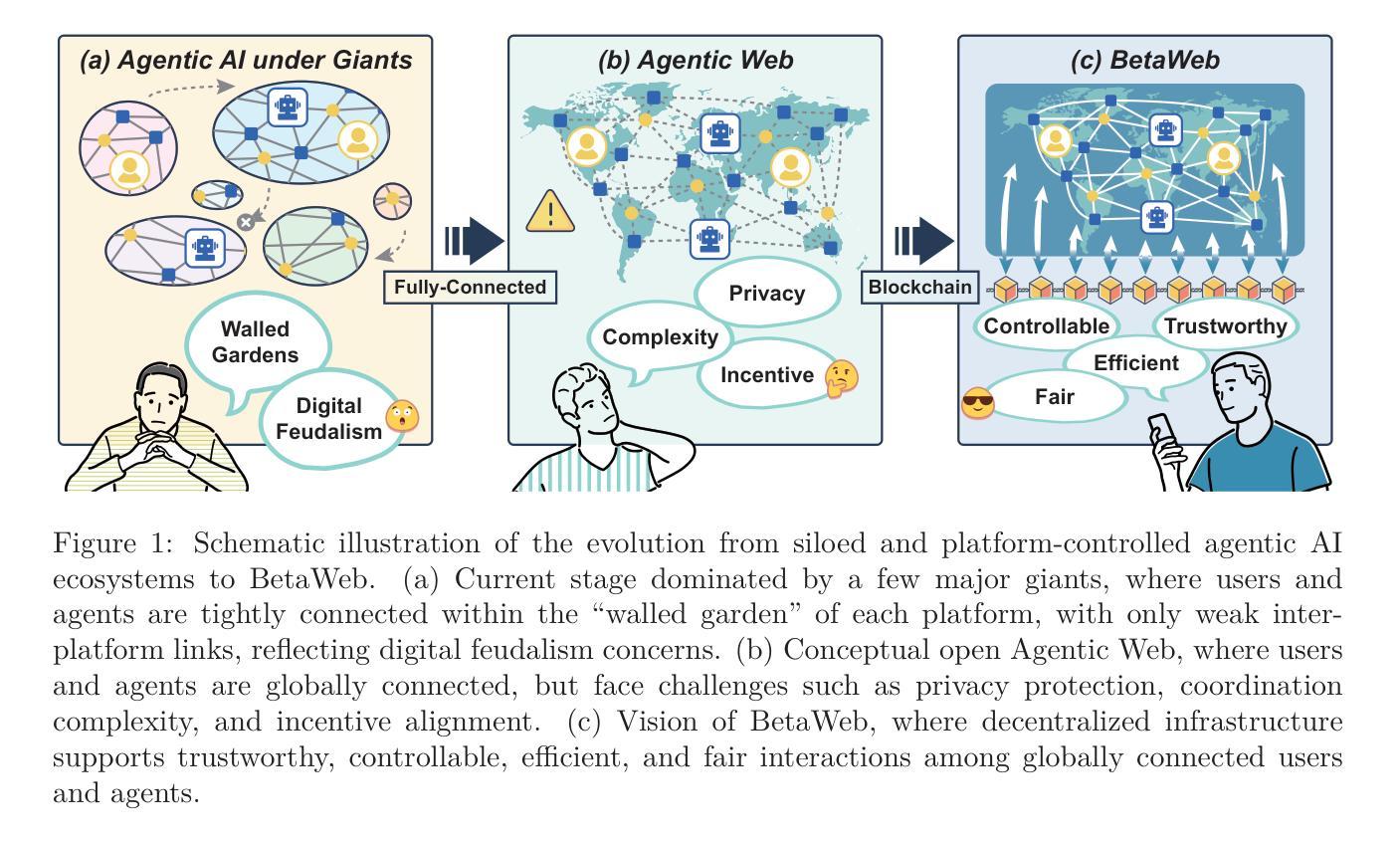
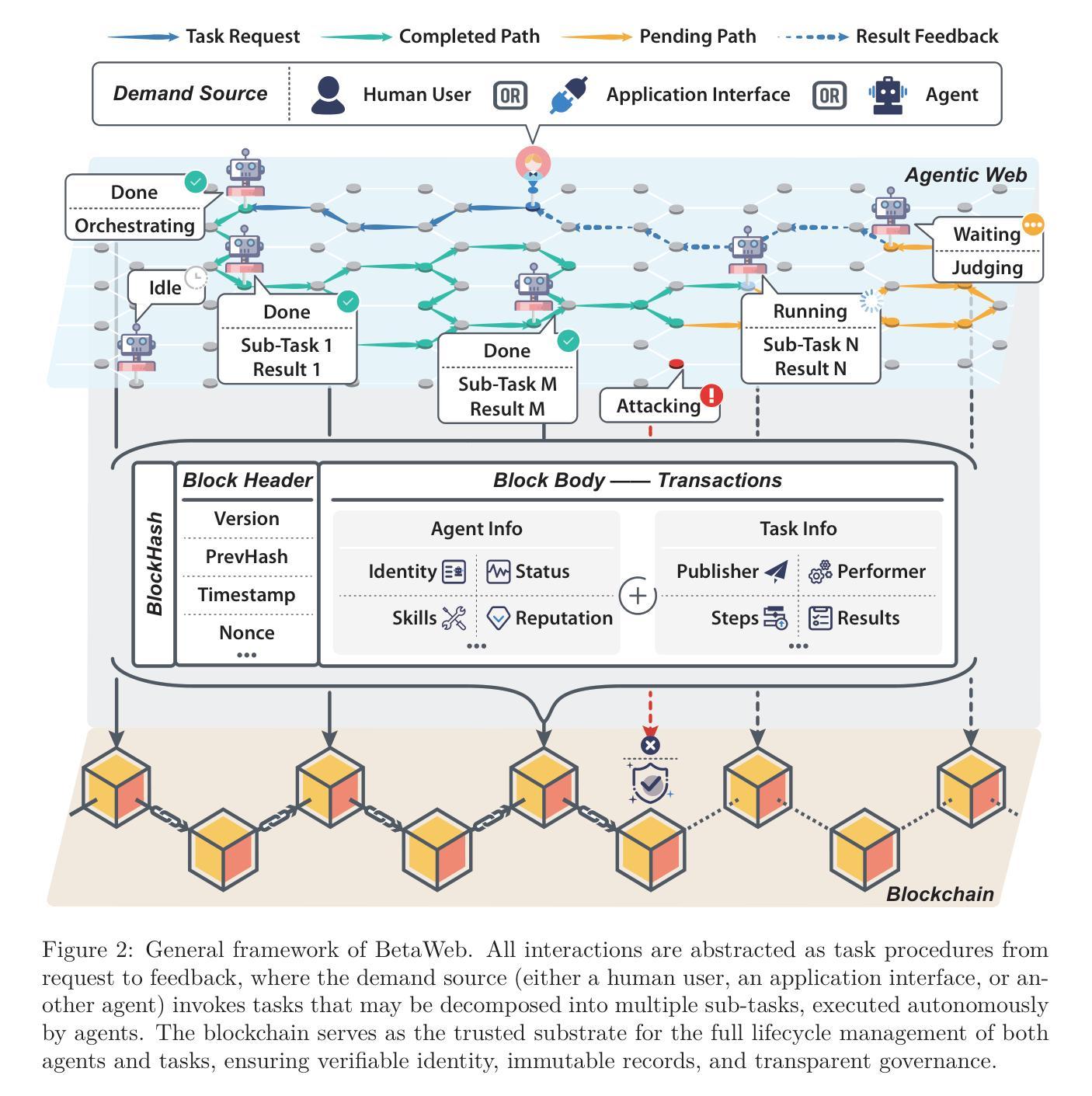
BetaWeb: Towards a Blockchain-enabled Trustworthy Agentic Web
Authors:Zihan Guo, Yuanjian Zhou, Chenyi Wang, Linlin You, Minjie Bian, Weinan Zhang
The rapid development of large language models (LLMs) has significantly propelled the development of artificial intelligence (AI) agents, which are increasingly evolving into diverse autonomous entities, advancing the LLM-based multi-agent systems (LaMAS). However, current agentic ecosystems remain fragmented and closed. Establishing an interconnected and scalable paradigm for Agentic AI has become a critical prerequisite. Although Agentic Web proposes an open architecture to break the ecosystem barriers, its implementation still faces core challenges such as privacy protection, data management, and value measurement. Existing centralized or semi-centralized paradigms suffer from inherent limitations, making them inadequate for supporting large-scale, heterogeneous, and cross-domain autonomous interactions. To address these challenges, this paper introduces the blockchain-enabled trustworthy Agentic Web (BetaWeb). By leveraging the inherent strengths of blockchain, BetaWeb not only offers a trustworthy and scalable infrastructure for LaMAS but also has the potential to advance the Web paradigm from Web3 (centered on data ownership) towards Web3.5, which emphasizes ownership of agent capabilities and the monetization of intelligence. Beyond a systematic examination of the BetaWeb framework, this paper presents a five-stage evolutionary roadmap, outlining the path of LaMAS from passive execution to advanced collaboration and autonomous governance. We also conduct a comparative analysis of existing products and discuss key challenges of BetaWeb from multiple perspectives. Ultimately, we argue that deep integration between blockchain and LaMAS can lay the foundation for a resilient, trustworthy, and sustainably incentivized digital ecosystem. A summary of the enabling technologies for each stage is available at https://github.com/MatZaharia/BetaWeb.
大型语言模型(LLM)的快速发展极大地推动了人工智能(AI)代理的发展,这些代理正逐渐演变为多样化的自主实体,推动了基于LLM的多代理系统(LaMAS)的进步。然而,当前的代理生态系统仍然呈现碎片化和封闭状态。建立互联和可扩展的代理智能AI范式已成为关键前提。尽管代理Web提出了一种开放架构来打破生态系统障碍,但其实现仍面临隐私保护、数据管理和价值衡量等核心挑战。现有的集中化或半集中化范式存在固有局限性,难以支持大规模、异质、跨域自主交互。为了解决这些挑战,本文引入了区块链赋能的可信代理Web(BetaWeb)。通过利用区块链的固有优势,BetaWeb不仅为LaMAS提供了可信和可扩展的基础设施,而且还有潜力将Web范式从以数据所有权为中心的Web3推向强调代理能力所有权和智能化货币化的Web3.5。本文不仅系统检查了BetaWeb框架,还提出了一个五阶段进化路线图,概述了LaMAS从被动执行到高级协作和自主治理的路径。我们还对现有产品进行了比较分析,并从多个角度讨论了BetaWeb的关键挑战。最终,我们认为区块链和LaMAS之间的深度集成可以为有韧性、可信、可持续激励的数字生态系统奠定基础。有关每个阶段的赋能技术总结可在https://github.com/MatZaharia/BetaWeb处找到。
论文及项目相关链接
PDF A technical report with 21 pages, 3 figures, and 3 tables
Summary
大型语言模型(LLM)的快速发展推动了人工智能(AI)代理的多样化发展,促进了基于LLM的多代理系统(LaMAS)的进步。然而,当前代理生态系统仍然呈现碎片化和封闭状态。建立互联互通的代理AI范式已成为关键前提。尽管Agentic Web提出了开放架构来打破生态系统壁垒,但其实现仍面临隐私保护、数据管理和价值衡量等核心挑战。为了应对这些挑战,本文引入了区块链赋能的可信Agentic Web(BetaWeb)。BetaWeb不仅为LaMAS提供了可信和可扩展的基础设施,还有潜力将Web范式从以数据所有权为中心的Web3推向强调代理能力所有权和智能化货币化的Web3.5。
Key Takeaways
- 大型语言模型(LLM)的快速发展推动了人工智能代理的自主发展。
- 当前AI代理生态系统存在碎片化和封闭的问题。
- Agentic Web虽提出开放架构,但实施中面临隐私保护、数据管理和价值衡量等核心挑战。
- 区块链赋能的可信Agentic Web(BetaWeb)为解决这些问题提供了方案。
- BetaWeb为LaMAS提供了可信和可扩展的基础设施,并有望推动Web范式向Web3.5转变。
- BetaWeb框架包含一个五阶段的进化路线图,从被动执行到高级协作和自主治理。
- 深度整合区块链和LaMAS可以为有韧性的、可信的、可持续激励的数字化生态系统奠定基础。
点此查看论文截图

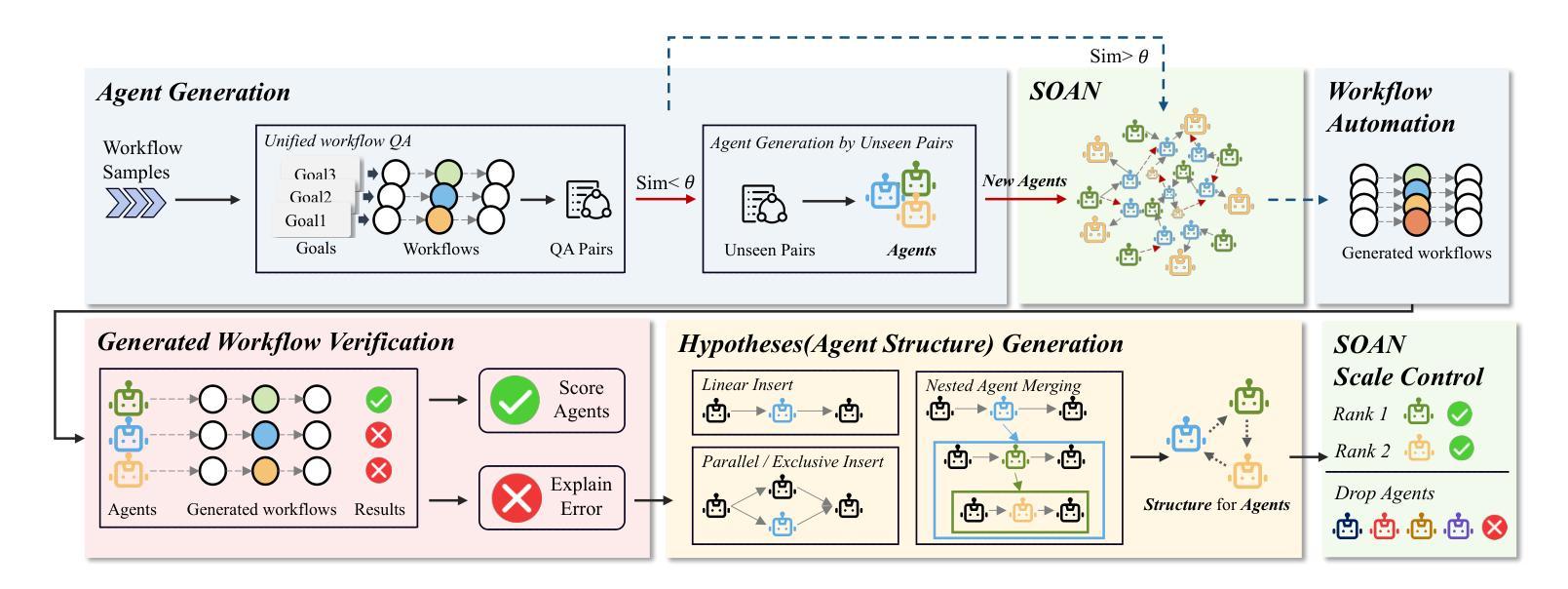
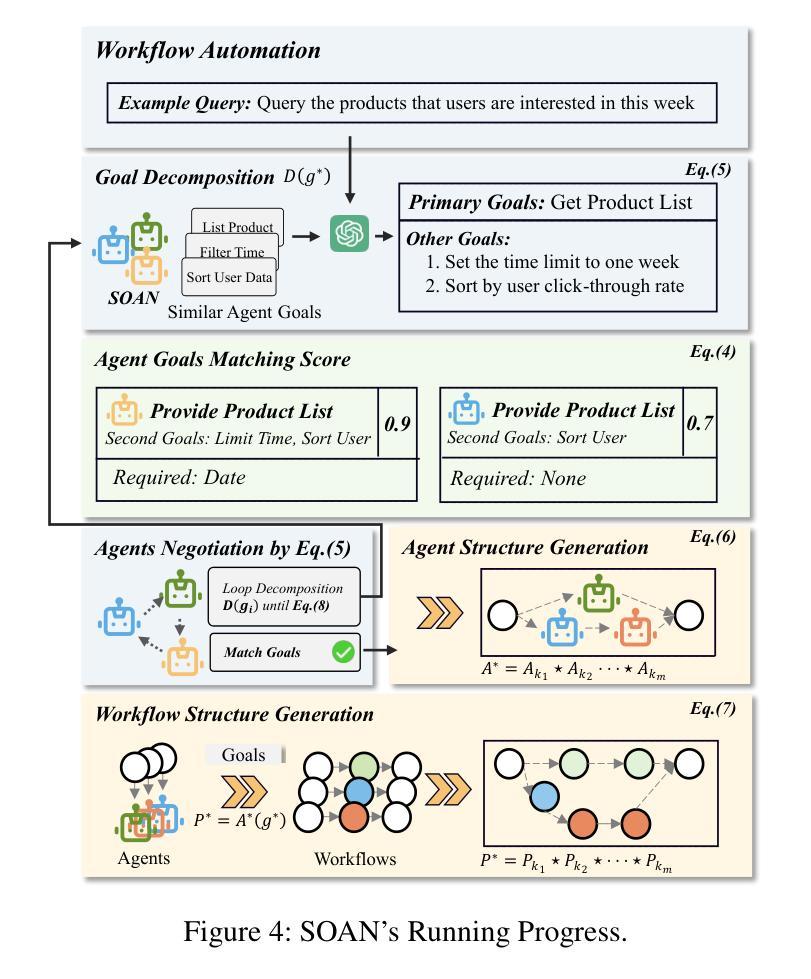
Self-Organizing Agent Network for LLM-based Workflow Automation
Authors:Yiming Xiong, Jian Wang, Bing Li, Yuhan Zhu, Yuqi Zhao
Recent multi-agent frameworks built upon large language models (LLMs) have demonstrated remarkable capabilities in complex task planning. However, in real-world enterprise environments, business workflows are typically composed through modularization and reuse of numerous subprocesses, resulting in intricate workflows characterized by lengthy and deeply nested execution paths. Such complexity poses significant challenges for LLM-driven orchestration, as extended reasoning chains and state-space explosions severely impact planning effectiveness and the proper sequencing of tool invocations. Therefore, developing an orchestration method with controllable structures capable of handling multi-layer nesting becomes a critical issue. To address this, we propose a novel structure-driven orchestration framework Self-Organizing Agent Network (SOAN). SOAN incrementally builds a formalized agent network by identifying and encapsulating structural units as independent agents, enhancing modularity and clarity in orchestration. Extensive evaluations were performed using multiple benchmarks as well as a real-world enterprise workflow dataset. Experimental results demonstrate that SOAN significantly outperforms state-of-the-art methods in terms of adaptability, fault tolerance, and execution efficiency.
最近建立在大型语言模型(LLM)之上的多智能体框架在复杂任务规划方面表现出了显著的能力。然而,在真实的企业环境中,业务工作流程通常是通过模块化并重复使用许多子流程来组成的,这导致了以漫长且深度嵌套的执行路径为特征的复杂工作流程。这种复杂性给LLM驱动的编排带来了重大挑战,因为扩展的推理链和状态空间爆炸严重影响了规划的有效性和工具调用的适当排序。因此,开发具有可控结构并能够处理多层嵌套问题的编排方法成为了一个关键问题。为了解决这一问题,我们提出了一种新型的结构驱动编排框架——自组织智能体网络(SOAN)。SOAN通过识别和封装结构单元作为独立智能体来逐步构建形式化的智能体网络,提高了编排的模块化和清晰度。我们使用多个基准测试以及真实企业工作流程数据集进行了广泛评估。实验结果表明,SOAN在适应性、容错性和执行效率方面显著优于最新方法。
论文及项目相关链接
总结
基于大型语言模型的多代理框架在复杂任务规划方面表现出卓越的能力。然而,在企业实际环境中,业务流程通常通过模块化和重用多个子流程来构建,形成具有复杂嵌套执行路径的精细工作流程。这种复杂性给LLM驱动的协同工作带来了挑战,因为扩展的推理链和状态空间的爆炸严重影响了规划的有效性和工具调用的正确排序。因此,开发具有可控结构、能够处理多层嵌套问题的协同方法成为了一个关键问题。为解决这一问题,我们提出了结构驱动协同工作框架——自组织代理网络(SOAN)。SOAN通过识别并封装结构单元为独立代理来构建形式化代理网络,提高了协同工作的模块化和清晰度。在多个基准测试以及真实企业工作流程数据集上的广泛评估表明,SOAN在适应性、容错性和执行效率方面显著优于现有方法。
关键见解
- 多代理框架基于大型语言模型在复杂任务规划上表现出强大的能力。
- 企业实际环境中的业务流程具有复杂且精细的工作流程特点。
- LLM驱动的协同工作面临扩展推理链和状态空间爆炸的挑战。
- 处理多层嵌套问题的协同方法开发成为关键需求。
- 自组织代理网络(SOAN)通过构建形式化代理网络提高协同工作的模块化和清晰度。
- SOAN在适应性、容错性和执行效率方面显著优于现有方法。
点此查看论文截图


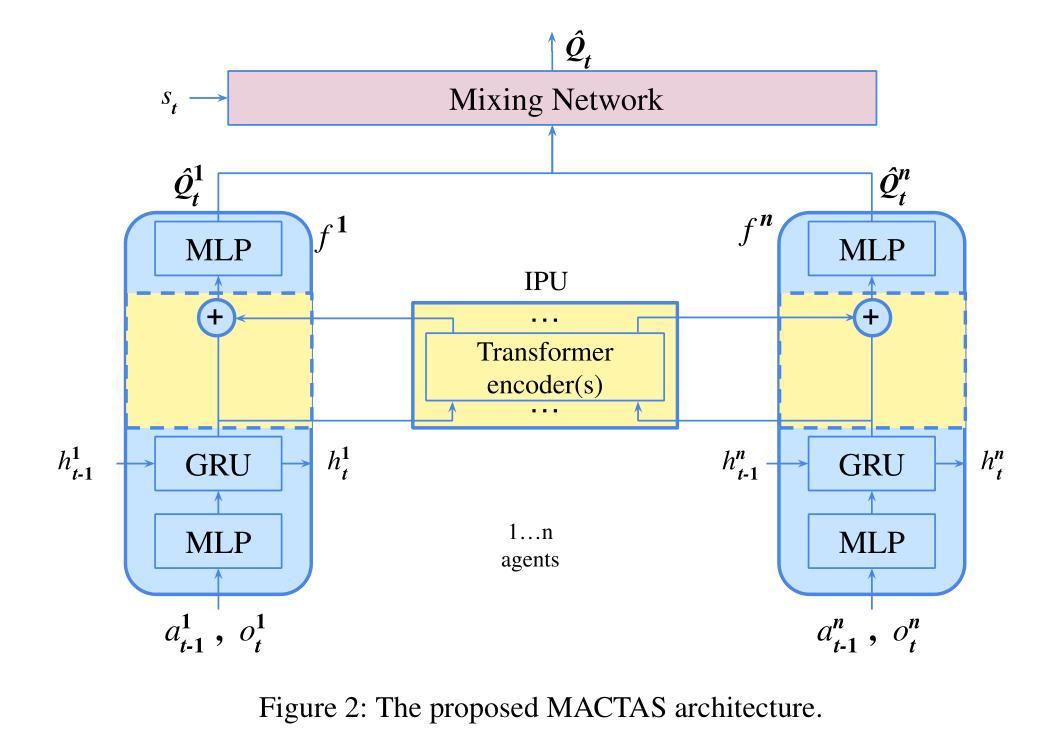
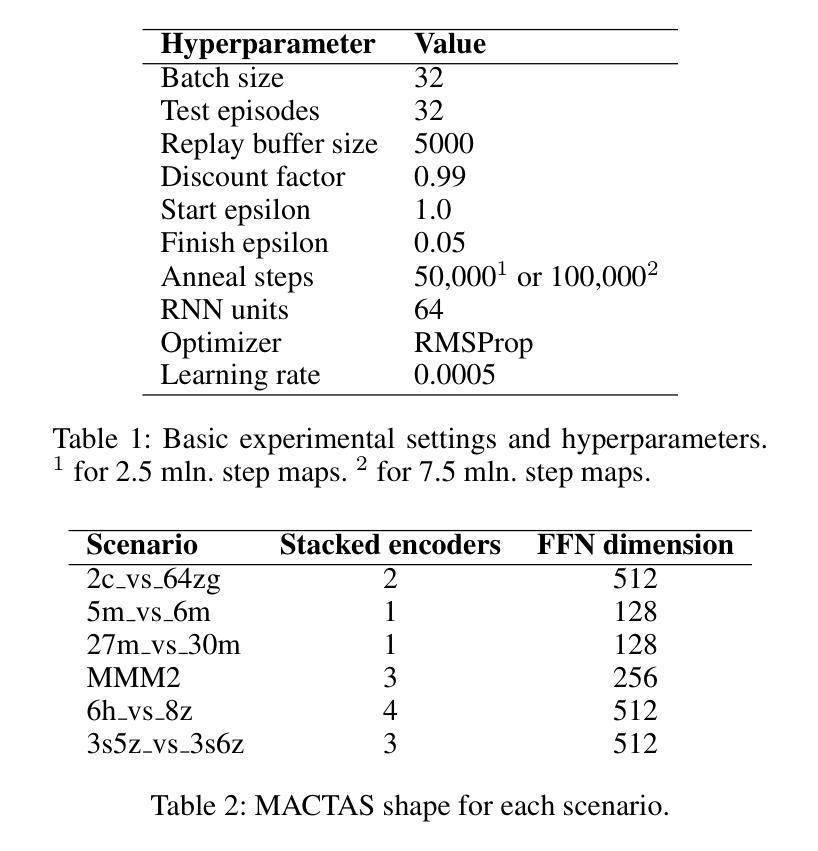
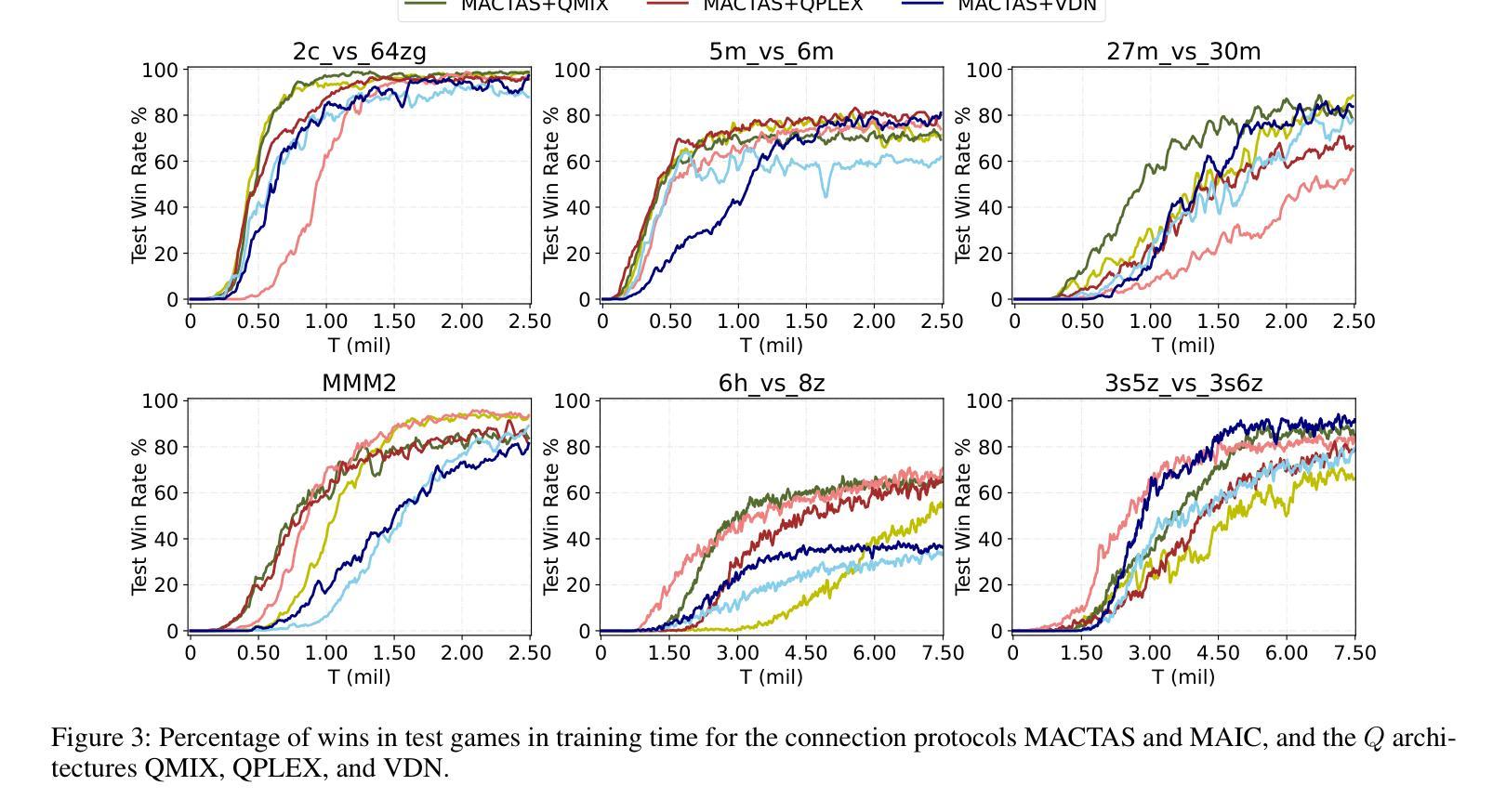
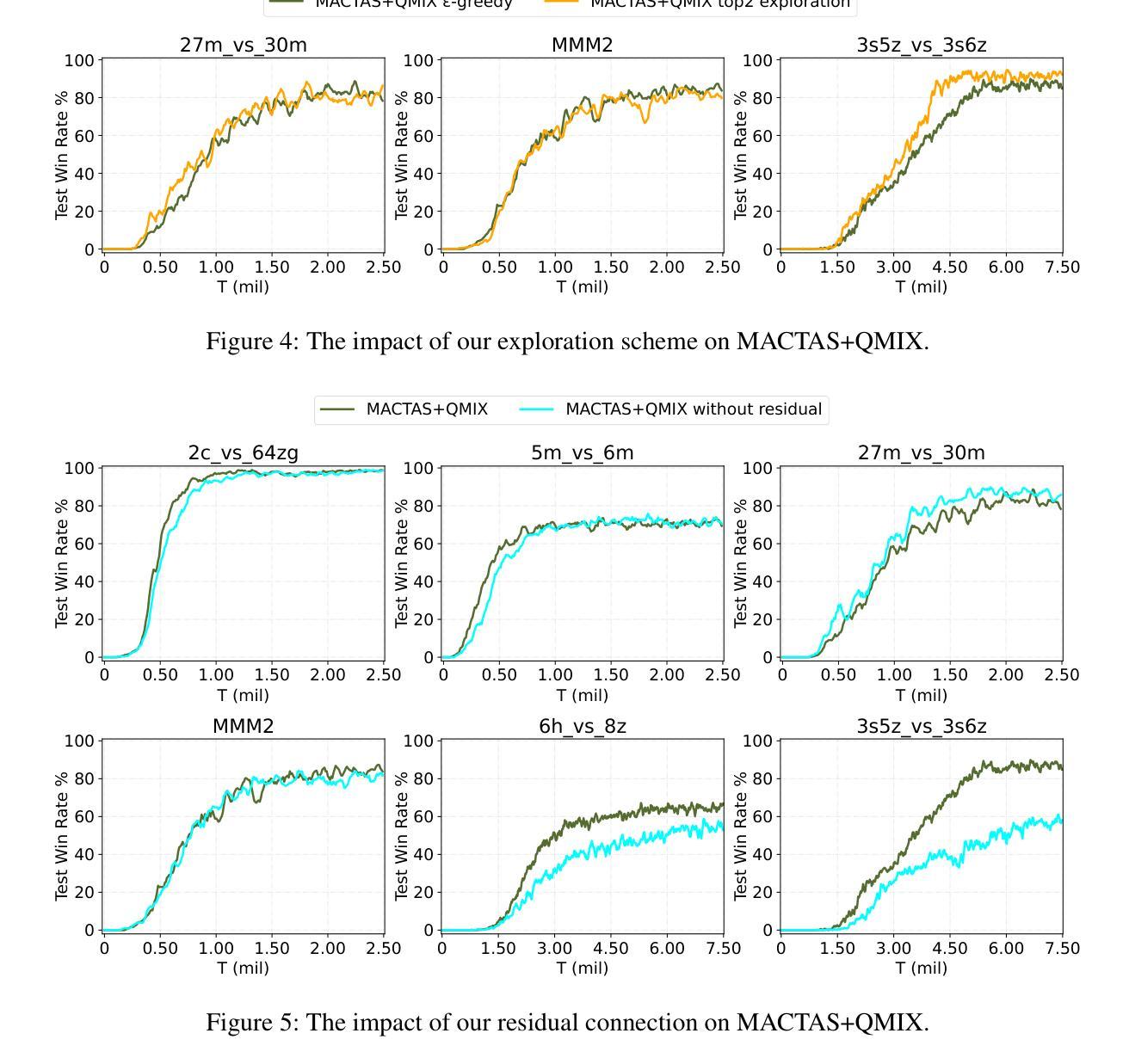
MACTAS: Self-Attention-Based Module for Inter-Agent Communication in Multi-Agent Reinforcement Learning
Authors:Maciej Wojtala, Bogusz Stefańczyk, Dominik Bogucki, Łukasz Lepak, Jakub Strykowski, Paweł Wawrzyński
Communication is essential for the collective execution of complex tasks by human agents, motivating interest in communication mechanisms for multi-agent reinforcement learning (MARL). However, existing communication protocols in MARL are often complex and non-differentiable. In this work, we introduce a self-attention-based communication module that exchanges information between the agents in MARL. Our proposed approach is fully differentiable, allowing agents to learn to generate messages in a reward-driven manner. The module can be seamlessly integrated with any action-value function decomposition method and can be viewed as an extension of such decompositions. Notably, it includes a fixed number of trainable parameters, independent of the number of agents. Experimental results on the SMAC benchmark demonstrate the effectiveness of our approach, which achieves state-of-the-art performance on several maps.
在人类智能体执行复杂任务的过程中,沟通是至关重要的,这也激发了多智能体强化学习(MARL)中沟通机制的兴趣。然而,现有的MARL通信协议通常复杂且不可微分。在这项工作中,我们引入了一个基于自注意力机制的通信模块,该模块可以在MARL中智能体之间交换信息。我们提出的方法是完全可微分的,允许智能体以奖励驱动的方式学习生成消息。该模块可以无缝地集成到任何动作价值函数分解方法中,并且可以被视为此类分解的扩展。值得注意的是,它包含固定数量的可训练参数,与智能体的数量无关。在SMAC基准测试上的实验结果表明了我们方法的有效性,该方法在多个地图上实现了最先进的性能。
论文及项目相关链接
PDF Submitted for AAAI 2026
总结
在多变体强化学习(MARL)中,通信对于人类代理人共同完成复杂任务至关重要。现有通信协议往往复杂且不可微分。本文介绍了一种基于自注意力机制的通信模块,该模块可以在MARL中交换代理之间的信息。所提出的通信模块完全可微分,允许代理以奖励驱动的方式学习生成消息。该模块可以无缝集成到任何动作价值函数分解方法中,并且可以被视为此类分解的扩展。特别的是,它的训练参数数量固定,与代理的数量无关。在SMAC基准测试上的实验结果证明了我们的方法的有效性,该方法在多个地图上实现了最先进的性能。
关键见解
- 通信在多代理强化学习(MARL)中完成复杂任务时至关重要。
- 现有通信协议通常复杂且不可微分,限制了代理的学习能力。
- 引入了一种基于自注意力机制的通信模块,实现了代理之间的信息交换。
- 该通信模块完全可微分,允许以奖励驱动的方式学习生成消息。
- 通信模块可无缝集成到任何动作价值函数分解方法中。
- 该方法具有固定的训练参数数量,与代理数量无关。
点此查看论文截图

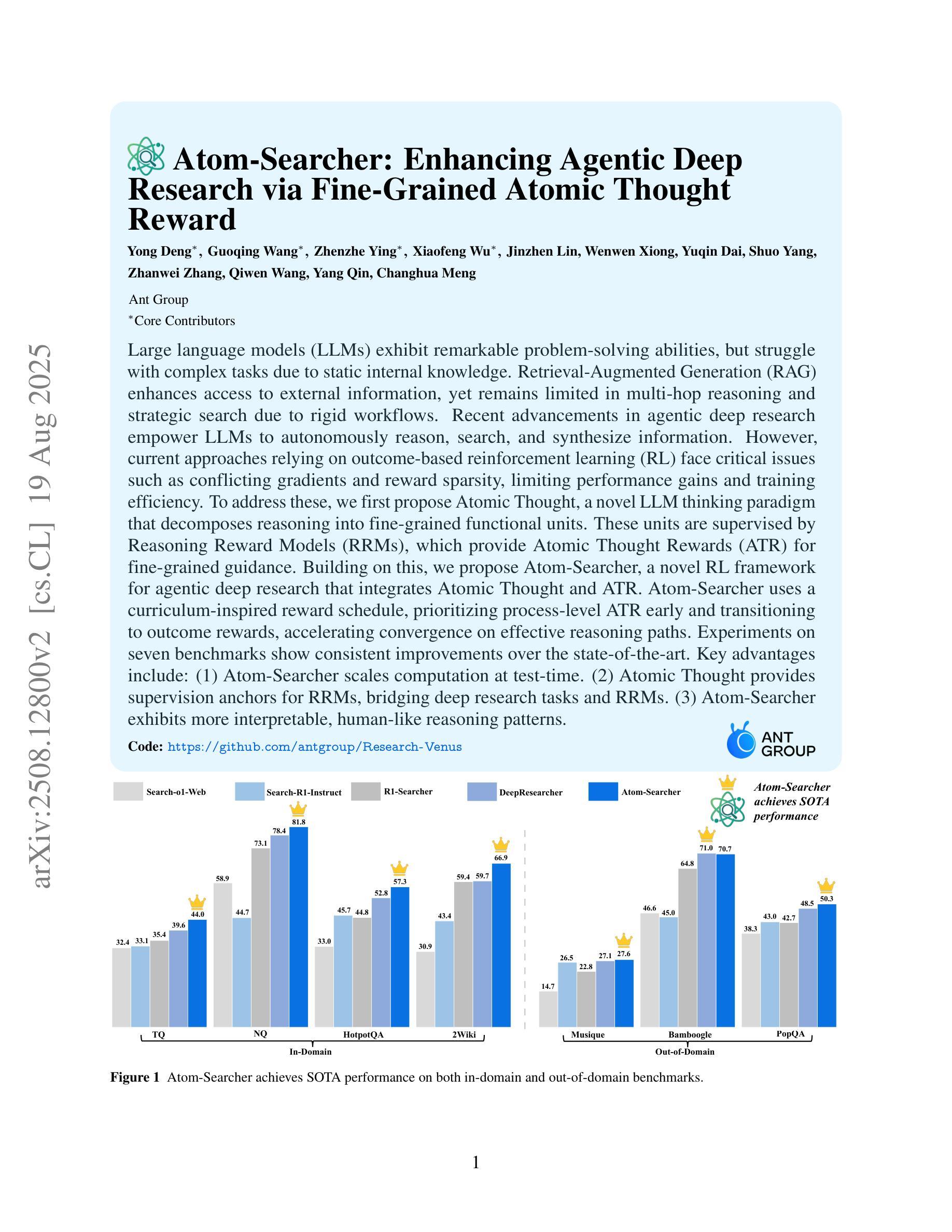
Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward
Authors:Yong Deng, Guoqing Wang, Zhenzhe Ying, Xiaofeng Wu, Jinzhen Lin, Wenwen Xiong, Yuqin Dai, Shuo Yang, Zhanwei Zhang, Qiwen Wang, Yang Qin, Changhua Meng
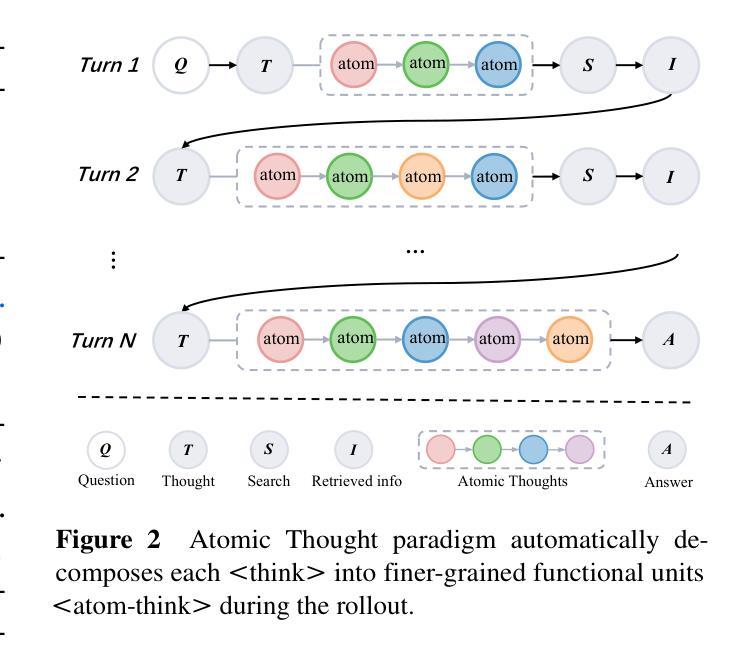
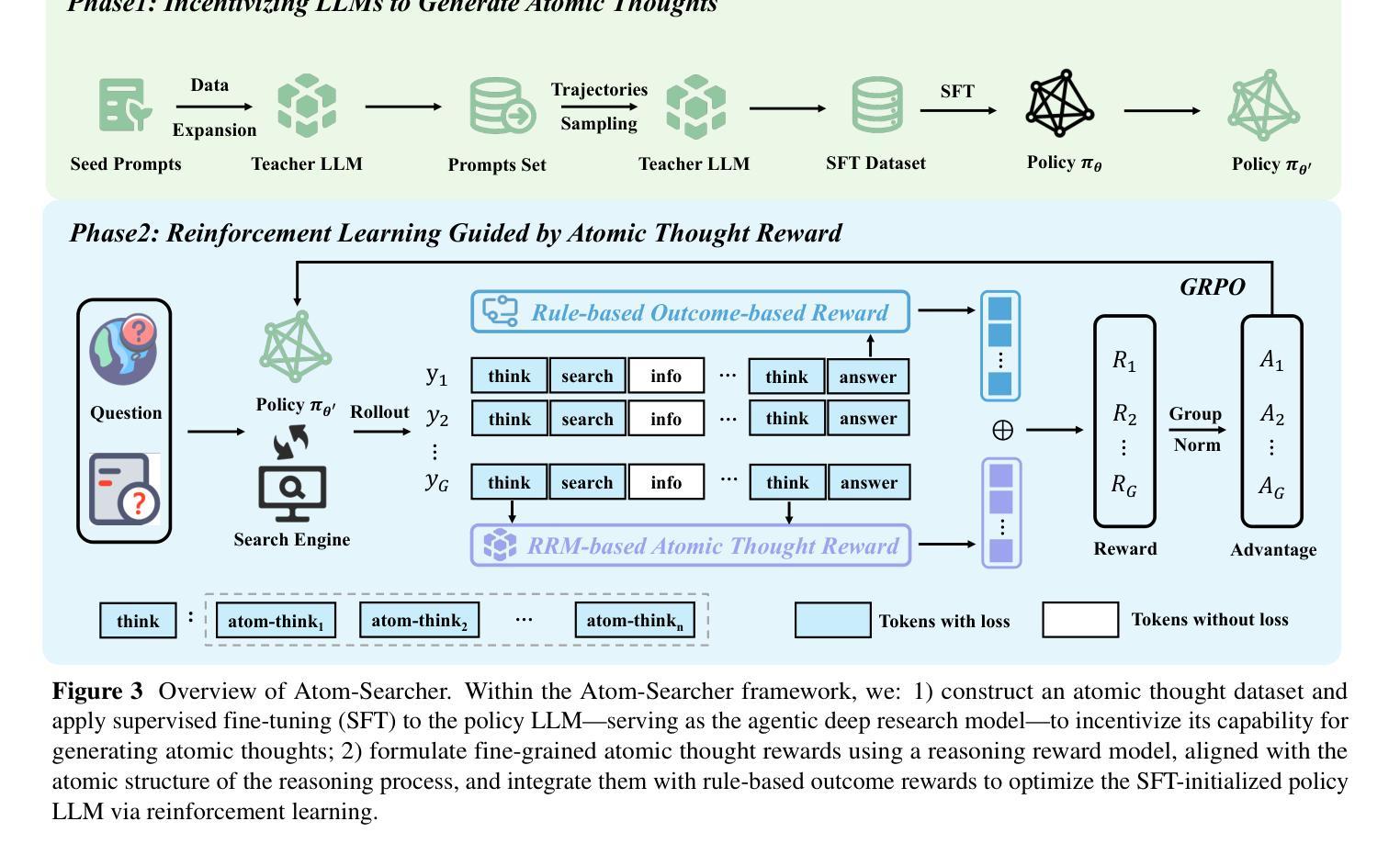
Large language models (LLMs) exhibit remarkable problem-solving abilities, but struggle with complex tasks due to static internal knowledge. Retrieval-Augmented Generation (RAG) enhances access to external information, yet remains limited in multi-hop reasoning and strategic search due to rigid workflows. Recent advancements in agentic deep research empower LLMs to autonomously reason, search, and synthesize information. However, current approaches relying on outcome-based reinforcement learning (RL) face critical issues such as conflicting gradients and reward sparsity, limiting performance gains and training efficiency. To address these, we first propose Atomic Thought, a novel LLM thinking paradigm that decomposes reasoning into fine-grained functional units. These units are supervised by Reasoning Reward Models (RRMs), which provide Atomic Thought Rewards (ATR) for fine-grained guidance. Building on this, we propose Atom-Searcher, a novel RL framework for agentic deep research that integrates Atomic Thought and ATR. Atom-Searcher uses a curriculum-inspired reward schedule, prioritizing process-level ATR early and transitioning to outcome rewards, accelerating convergence on effective reasoning paths. Experiments on seven benchmarks show consistent improvements over the state-of-the-art. Key advantages include: (1) Atom-Searcher scales computation at test-time. (2) Atomic Thought provides supervision anchors for RRMs, bridging deep research tasks and RRMs. (3) Atom-Searcher exhibits more interpretable, human-like reasoning patterns.
大型语言模型(LLM)展现出卓越的解决问题的能力,但由于静态内部知识,它们在处理复杂任务时遇到困难。检索增强生成(RAG)增强了访问外部信息的能力,但由于僵化的工作流程,它在多跳推理和战略搜索方面仍然存在局限性。最近的代理深度研究的进展使LLM能够自主推理、搜索和合成信息。然而,当前依赖结果基于强化学习(RL)的方法面临关键性问题,如梯度冲突和奖励稀疏,这限制了性能提升和训练效率。为了解决这些问题,我们首先提出原子思维,这是一种新的LLM思考范式,将推理分解为精细的功能单元。这些单元由推理奖励模型(RRM)监督,为精细指导提供原子思维奖励(ATR)。在此基础上,我们提出了Atom-Searcher,这是一个用于代理深度研究的新型强化学习框架,融合了原子思维和ATR。Atom-Searcher使用受课程启发奖励时间表,优先在早期提供过程级的ATR,然后过渡到结果奖励,加快对有效推理路径的收敛。在七个基准测试上的实验表明,与最新技术相比,它表现出持续的一致性改进。主要优势包括:(1)Atom-Searcher在测试时扩大了计算规模。(2)原子思维为RRM提供了监督锚点,桥接了深度研究任务和RRM。(3)Atom-Searcher展现出更可解释、更人性化的推理模式。
论文及项目相关链接
Summary
大型语言模型(LLM)具有出色的解决问题的能力,但由于静态内部知识而难以应对复杂任务。检索增强生成(RAG)提高了对外部信息的访问能力,但由于工作流程僵化,它在多跳推理和战略搜索方面仍存在局限性。最近的深度研究中,出现了自主推理、搜索和合成信息的代理智能强化研究。然而,依赖结果强化学习(RL)的方法面临关键挑战,如梯度冲突和奖励稀疏性问题,限制了性能提升和培训效率。为解决这些问题,我们提出原子思维(Atomic Thought),这是一种新的LLM思考范式,将推理分解为精细的功能单元,并由推理奖励模型(RRMs)进行监督,为精细的引导提供原子思维奖励(ATR)。基于此,我们进一步提出了Atom-Searcher,这是一个用于深度代理研究的强化学习框架,结合了原子思维和ATR。Atom-Searcher采用启发式教学奖励计划,早期侧重于过程级别的ATR,并逐步过渡到结果奖励,以加速在有效推理路径上的收敛。实验表明,Atom-Searcher在七个基准测试上均实现了对最新技术的持续改进。其关键优势包括:1)Atom-Searcher在计算规模上有所扩展;2)原子思维为RRMs提供了监督锚点;3)Atom-Searcher展现出更可解释、更人性化的推理模式。
Key Takeaways
- 大型语言模型(LLM)具有卓越的解决问题能力,但面对复杂任务时表现有限。
- 检索增强生成(RAG)提高了外部信息访问能力,但在多跳推理和战略搜索方面存在局限性。
- 现有依赖结果强化学习(RL)的方法面临梯度冲突和奖励稀疏性问题。
- 原子思维(Atomic Thought)作为一种新的LLM思考范式被提出,将推理分解为精细功能单元。
- 推理奖励模型(RRMs)用于监督这些功能单元,提供原子思维奖励(ATR)。
- Atom-Searcher框架结合了原子思维和ATR,采用启发式教学奖励计划来加速有效推理路径的收敛。
点此查看论文截图
MedKGent: A Large Language Model Agent Framework for Constructing Temporally Evolving Medical Knowledge Graph
Authors:Duzhen Zhang, Zixiao Wang, Zhong-Zhi Li, Yahan Yu, Shuncheng Jia, Jiahua Dong, Haotian Xu, Xing Wu, Yingying Zhang, Tielin Zhang, Jie Yang, Xiuying Chen, Le Song
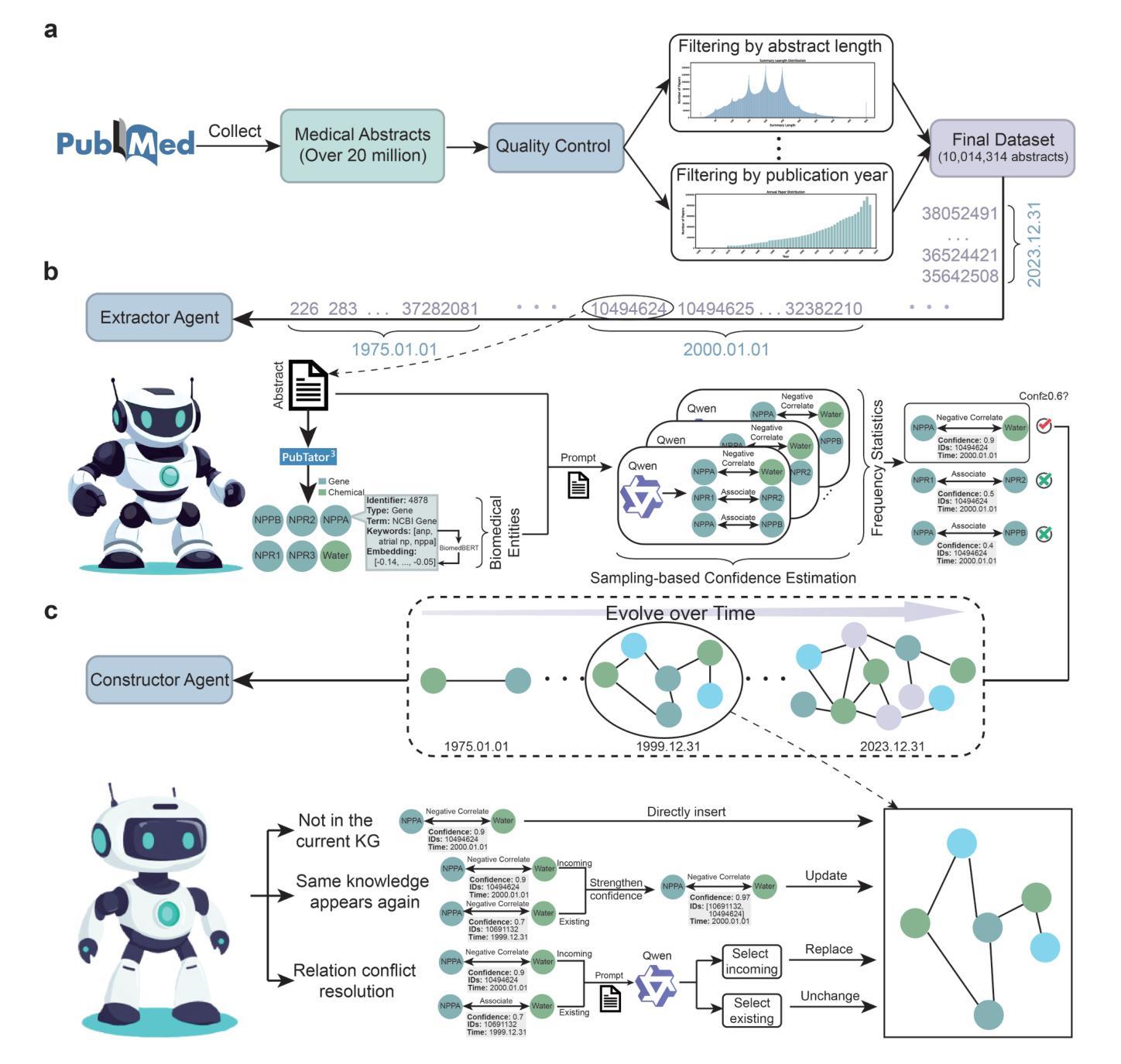
The rapid expansion of medical literature presents growing challenges for structuring and integrating domain knowledge at scale. Knowledge Graphs (KGs) offer a promising solution by enabling efficient retrieval, automated reasoning, and knowledge discovery. However, current KG construction methods often rely on supervised pipelines with limited generalizability or naively aggregate outputs from Large Language Models (LLMs), treating biomedical corpora as static and ignoring the temporal dynamics and contextual uncertainty of evolving knowledge. To address these limitations, we introduce MedKGent, a LLM agent framework for constructing temporally evolving medical KGs. Leveraging over 10 million PubMed abstracts published between 1975 and 2023, we simulate the emergence of biomedical knowledge via a fine-grained daily time series. MedKGent incrementally builds the KG in a day-by-day manner using two specialized agents powered by the Qwen2.5-32B-Instruct model. The Extractor Agent identifies knowledge triples and assigns confidence scores via sampling-based estimation, which are used to filter low-confidence extractions and inform downstream processing. The Constructor Agent incrementally integrates the retained triples into a temporally evolving graph, guided by confidence scores and timestamps to reinforce recurring knowledge and resolve conflicts. The resulting KG contains 156,275 entities and 2,971,384 relational triples. Quality assessments by two SOTA LLMs and three domain experts demonstrate an accuracy approaching 90%, with strong inter-rater agreement. To evaluate downstream utility, we conduct RAG across seven medical question answering benchmarks using five leading LLMs, consistently observing significant improvements over non-augmented baselines. Case studies further demonstrate the KG’s value in literature-based drug repurposing via confidence-aware causal inference.
医学文献的迅速扩张给大规模结构化整合领域知识带来了日益增长的挑战。知识图谱(KGs)通过实现高效检索、自动化推理和知识发现,提供了具有前景的解决方案。然而,当前的知识图谱构建方法往往依赖于监督管道,其通用性有限,或者简单地聚合来自大型语言模型(LLMs)的输出,将生物医学语料视为静态,忽略了知识的时动态和上下文不确定性。为了解决这个问题,我们引入了MedKGent,这是一个用于构建时序演化医学知识图谱的大型语言模型代理框架。利用1975年至2023年间出版的超过1000万篇PubMed摘要,我们通过精细的每日时间序列模拟生物医学知识的涌现。MedKGent以日为单位逐步构建知识图谱,使用两个由Qwen2.5-32B-Instruct模型驱动的专业代理。提取代理通过基于采样的估计来识别知识三元组并分配置信度分数,这些分数用于过滤低置信度的提取并告知下游处理。构造代理逐步将保留的三元组集成到随时间演化的图中,受置信分数和时间戳的指导,以加强重复出现的知识并解决冲突。所得知识图谱包含156,275个实体和2,971,384个关系三元组。两位顶尖的大型语言模型专家和三位领域专家进行的质量评估显示,其准确率接近90%,并且具有强大的内部一致性。为了评估下游实用性,我们在七个医学问答基准上进行了RAG测试,使用五个领先的大型语言模型,与非增强基线相比,其表现一直表现出显着提高。案例研究进一步证明了知识图谱在基于文献的药物再利用方面的价值,即通过信心感知的因果推理。
论文及项目相关链接
Summary
本文介绍了医学文献的快速扩张带来的挑战以及知识图谱(KGs)作为解决方案的潜力。针对现有KG构建方法的局限性,提出了一种基于大型语言模型(LLM)的MedKGent框架,用于构建随时间演化的医疗KG。该框架利用超过1000万篇PubMed摘要,通过精细的时间序列模拟生物医学知识的涌现。MedKGent通过两个专业代理以日复一日的方式构建KG,一个提取代理用于识别知识三元组并分配置信度分数,一个构造代理则将这些保留的三元组逐渐融入时间演化图谱中。最终构建的KG包含大量实体和关系三元组,且准确率高,评价效果好。其应用场景广泛,有助于医学问答和知识发现。通过实证研究证明其潜力巨大。
Key Takeaways
- 医学文献的快速扩张导致结构化整合大规模领域知识的挑战增加。
- 知识图谱(KGs)为解决这一挑战提供了有效方法,包括高效检索、自动化推理和知识发现等功能。
- 当前KG构建方法存在局限性,如依赖监督管道有限的泛化能力或简单使用大型语言模型而忽视知识的动态变化和上下文不确定性。
点此查看论文截图

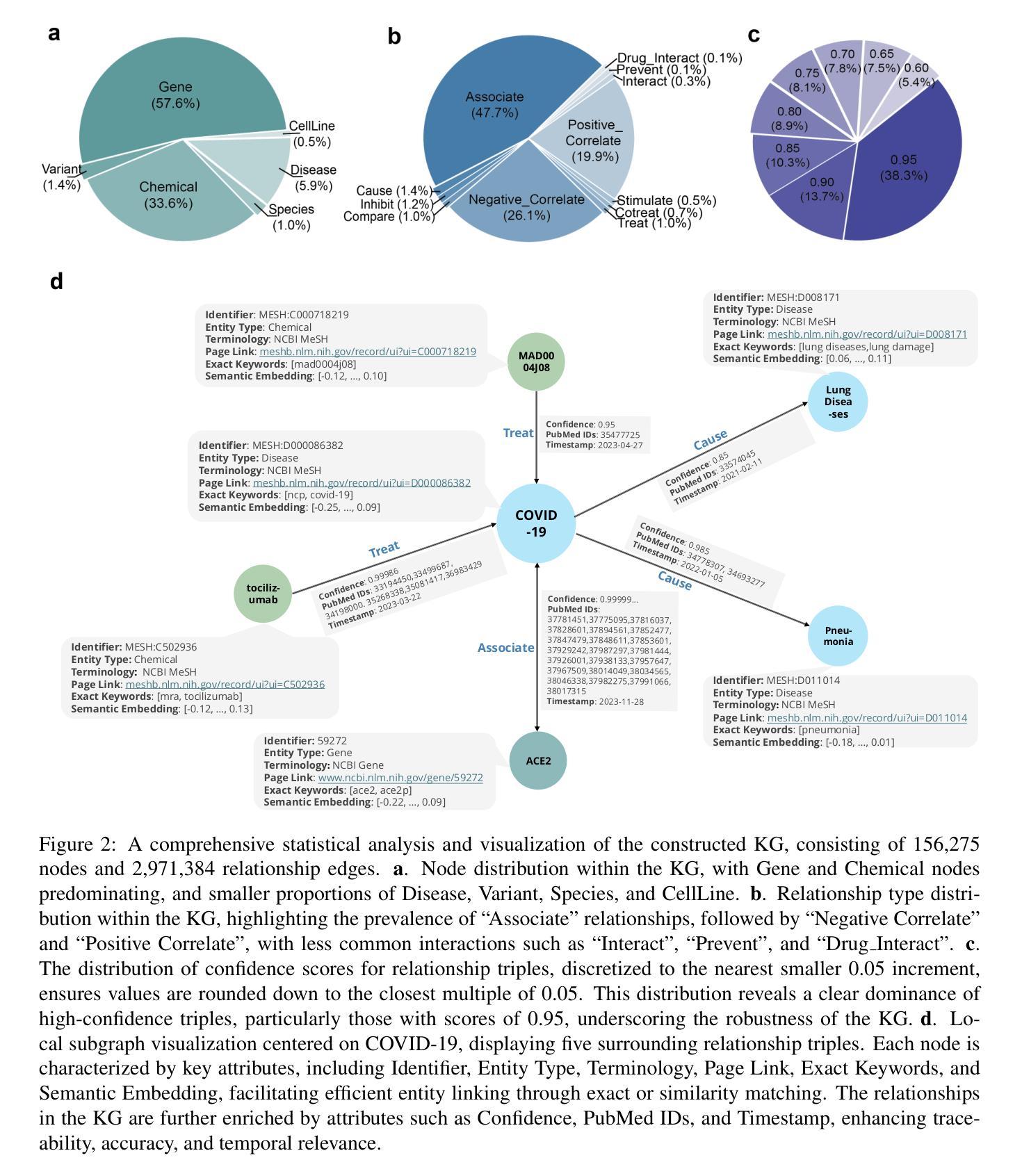
A Survey of LLM-based Deep Search Agents: Paradigm, Optimization, Evaluation, and Challenges
Authors:Yunjia Xi, Jianghao Lin, Yongzhao Xiao, Zheli Zhou, Rong Shan, Te Gao, Jiachen Zhu, Weiwen Liu, Yong Yu, Weinan Zhang
The advent of Large Language Models (LLMs) has significantly revolutionized web search. The emergence of LLM-based Search Agents marks a pivotal shift towards deeper, dynamic, autonomous information seeking. These agents can comprehend user intentions and environmental context and execute multi-turn retrieval with dynamic planning, extending search capabilities far beyond the web. Leading examples like OpenAI’s Deep Research highlight their potential for deep information mining and real-world applications. This survey provides the first systematic analysis of search agents. We comprehensively analyze and categorize existing works from the perspectives of architecture, optimization, application, and evaluation, ultimately identifying critical open challenges and outlining promising future research directions in this rapidly evolving field. Our repository is available on https://github.com/YunjiaXi/Awesome-Search-Agent-Papers.
随着大型语言模型(LLM)的出现,网络搜索发生了重大变革。基于LLM的搜索代理人的涌现,标志着向更深层次、更动态、更自主的信息搜索方向的重大转变。这些代理人能够理解用户意图和环境背景,通过动态规划执行多轮检索,将搜索能力延伸到网络之外。像OpenAI的深度研究等领先实例突出了它们在深度信息挖掘和实际应用中的潜力。这篇综述首次对搜索代理人进行了系统分析。我们从架构、优化、应用和评估等角度全面分析和分类了现有工作,最终确定了关键开放挑战,并概述了在这个快速演变的领域中有前途的未来研究方向。我们的仓库可在https://github.com/YunjiaXi/Awesome-Search-Agent-Papers访问。
论文及项目相关链接
Summary
大型语言模型(LLM)的出现对网页搜索产生了重大变革。LLM驱动的搜索代理人的涌现,标志着搜索向更深、更动态、更自主的资讯搜寻方向转变。这些代理人能够了解用户意图和上下文环境,并通过动态规划执行多轮检索,将搜索能力延伸到互联网之外。如OpenAI的深度研究等领先实例突显了其在深度信息挖掘和实际应用中的潜力。本文首次系统分析了搜索代理人,从架构、优化、应用和评估等方面全面分析和分类现有工作,并确定了关键开放挑战,概述了此快速演变领域的未来研究方向。我们的仓库可在https://github.com/YunjiaXi/Awesome-Search-Agent-Papers找到。
Key Takeaways
- 大型语言模型(LLM)已经改变了网页搜索的格局。
- LLM驱动的搜索代理人能够实现更深、更动态、更自主的资讯搜寻。
- 搜索代理人能够了解用户意图和上下文环境,并执行多轮检索。
- 搜索代理人的能力已经延伸到互联网之外。
- 领先的实例如OpenAI的深度研究展示了LLM在深度信息挖掘和实际应用中的潜力。
- 本文首次系统分析了搜索代理人,涵盖了架构、优化、应用和评估等方面的全面分析。
点此查看论文截图

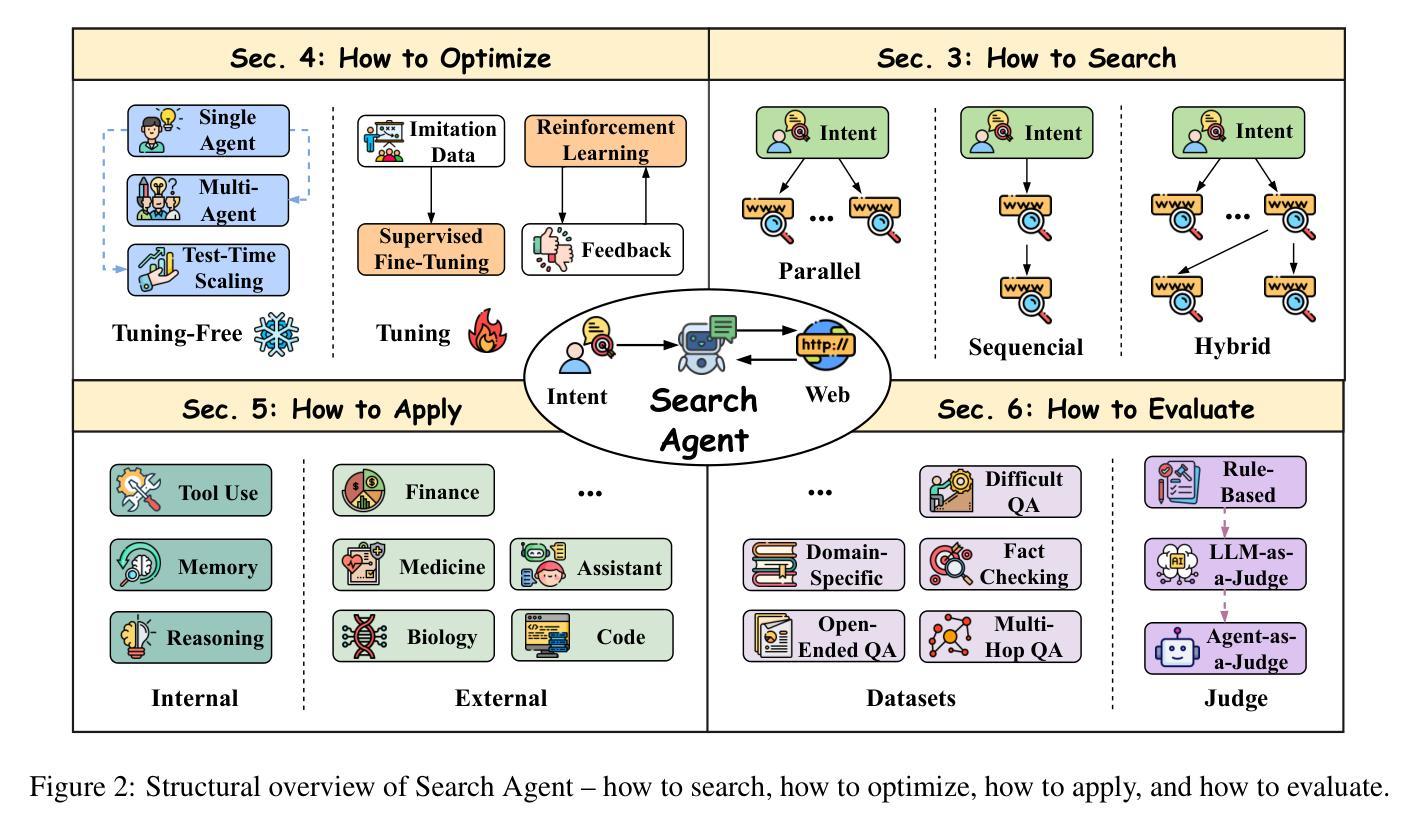
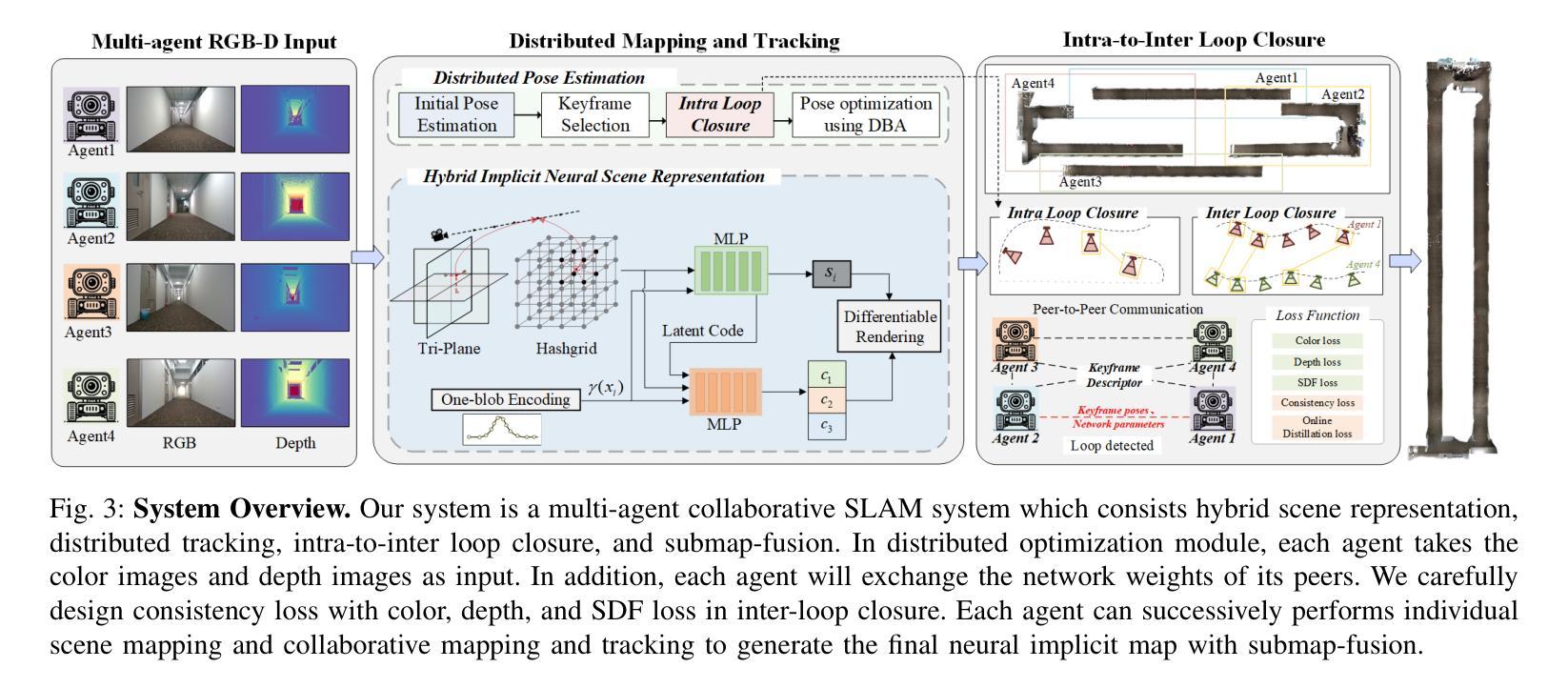
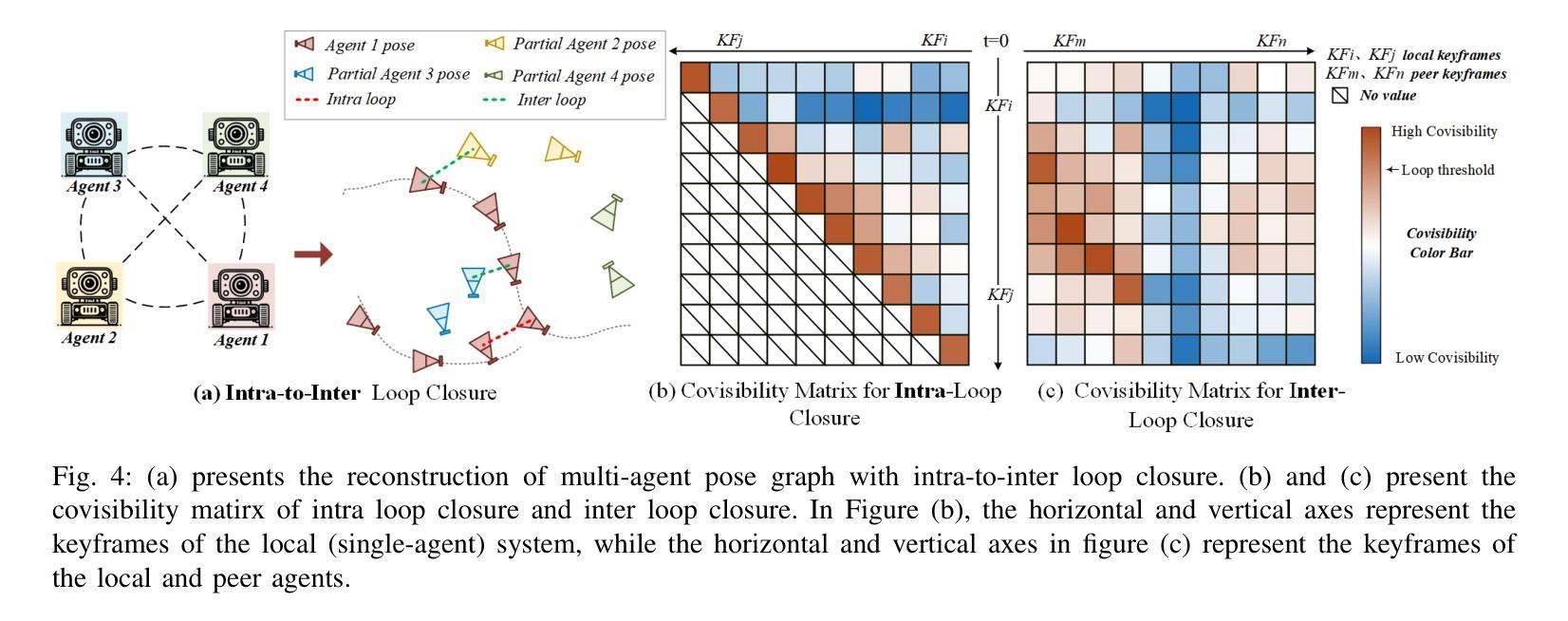
MCN-SLAM: Multi-Agent Collaborative Neural SLAM with Hybrid Implicit Neural Scene Representation
Authors:Tianchen Deng, Guole Shen, Xun Chen, Shenghai Yuan, Hongming Shen, Guohao Peng, Zhenyu Wu, Jingchuan Wang, Lihua Xie, Danwei Wang, Hesheng Wang, Weidong Chen
Neural implicit scene representations have recently shown promising results in dense visual SLAM. However, existing implicit SLAM algorithms are constrained to single-agent scenarios, and fall difficulties in large-scale scenes and long sequences. Existing NeRF-based multi-agent SLAM frameworks cannot meet the constraints of communication bandwidth. To this end, we propose the first distributed multi-agent collaborative neural SLAM framework with hybrid scene representation, distributed camera tracking, intra-to-inter loop closure, and online distillation for multiple submap fusion. A novel triplane-grid joint scene representation method is proposed to improve scene reconstruction. A novel intra-to-inter loop closure method is designed to achieve local (single-agent) and global (multi-agent) consistency. We also design a novel online distillation method to fuse the information of different submaps to achieve global consistency. Furthermore, to the best of our knowledge, there is no real-world dataset for NeRF-based/GS-based SLAM that provides both continuous-time trajectories groundtruth and high-accuracy 3D meshes groundtruth. To this end, we propose the first real-world Dense slam (DES) dataset covering both single-agent and multi-agent scenarios, ranging from small rooms to large-scale outdoor scenes, with high-accuracy ground truth for both 3D mesh and continuous-time camera trajectory. This dataset can advance the development of the research in both SLAM, 3D reconstruction, and visual foundation model. Experiments on various datasets demonstrate the superiority of the proposed method in both mapping, tracking, and communication. The dataset and code will open-source on https://github.com/dtc111111/mcnslam.
神经隐式场景表示在密集视觉SLAM中最近显示出有前途的结果。然而,现有的隐式SLAM算法受限于单智能体场景,并在大规模场景和长序列中面临困难。基于NeRF的多智能体SLAM框架无法满足通信带宽的约束。为此,我们提出了第一个分布式多智能体协同神经SLAM框架,具有混合场景表示、分布式相机跟踪、内部到跨环闭合以及针对多子图融合的在线蒸馏技术。提出了一种新型的三平面网格联合场景表示方法,以改进场景重建。设计了一种新颖的内外环闭合方法,以实现局部(单智能体)和全局(多智能体)的一致性。我们还设计了一种新颖的在线蒸馏方法,以融合不同子图的信息,实现全局一致性。此外,据我们所知,没有基于NeRF或GS的SLAM真实世界数据集能够提供连续时间轨迹的地面真实性和高精度3D网格的地面真实性。为此,我们提出了第一个真实世界的密集SLAM(DES)数据集,涵盖单智能体和多智能体场景,从小房间到大规模户外场景,为3D网格和连续时间相机轨迹提供高精度地面真实数据。该数据集可以促进SLAM、3D重建和视觉基础模型的研究发展。在各种数据集上的实验表明,所提出的方法在映射、跟踪和通信方面都表现出卓越的性能。数据集和代码将在https://github.com/dtc111111/mcnslam上开源。
论文及项目相关链接
Summary
本文探讨了基于神经的隐式场景表示在密集视觉SLAM中的潜力。然而,现有技术主要局限于单代理场景,面临大规模场景和长序列的挑战。为此,提出了首个分布式多智能体协同神经SLAM框架,包含混合场景表示、分布式相机跟踪、内外闭环及在线蒸馏等多种技术。还创新了triplane-grid联合场景表示方法以提升场景重建效果。此外,缺乏针对NeRF-based/GS-based SLAM的真实世界数据集,因此推出了首个涵盖单智能体和多智能体场景的真实世界Dense slam(DES)数据集。该数据集从小型房间到大型室外场景都有所涉及,为3D网格和连续时间相机轨迹提供了高精度地面真实数据,有望推动SLAM、3D重建和视觉基础模型的研究发展。实验证明该方法在映射、跟踪和通信方面的优越性。数据集和代码将在https://github.com/dtc111111/mcnslam上开源。
Key Takeaways
- 现有隐式SLAM算法主要局限于单代理场景,难以处理大规模场景和长序列。
- 首个分布式多智能体协同神经SLAM框架被提出,具备混合场景表示、分布式相机跟踪等功能。
- 创新了triplane-grid联合场景表示方法以提升场景重建效果。
- 缺乏针对NeRF-based/GS-based SLAM的真实世界数据集,为此推出了首个DES数据集,涵盖多种场景并具备高精度地面真实数据。
- 提出了新型的内到外闭环方法和在线蒸馏方法,实现局部和全局一致性。
- 方法在映射、跟踪和通信方面表现优越。
点此查看论文截图

Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Authors:Can Jin, Hongwu Peng, Qixin Zhang, Yujin Tang, Dimitris N. Metaxas, Tong Che
Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
基于大型语言模型(LLM)的多智能体系统(MAS)为解决复杂的现实世界任务提供了前景广阔的道路,这些任务往往是单一智能体系统难以应对的。虽然最近在测试时缩放(TTS)方面的进展大大提高了单一智能体在具有挑战性的推理任务上的性能,但如何在MAS中有效地扩展协作和推理仍然是一个悬而未决的问题。在此工作中,我们引入了一种自适应多智能体框架,旨在通过模型级训练和系统级协调来提高协作推理能力。我们构建了M500,这是一个包含500个多智能体协作推理轨迹的高质量数据集,并在此数据集上微调了Qwen2.5-32B-Instruct模型,从而生成了针对多智能体协作优化的M1-32B模型。为了进一步实现自适应推理,我们提出了一种新型CEO智能体,它能动态管理讨论过程,引导智能体协作并调整推理深度,以更有效地解决问题。我们在包括通用理解、数学推理和编码等一系列任务的开源MAS上评估了我们的系统,其性能显著优于强大的基线。例如,M1-32B在GPQA-Diamond上实现了12%的改进,在AIME2024上实现了41%的改进,在MBPP-Sanitized上实现了10%的改进,在某些任务上与DeepSeek-R1等先进模型相匹配。这些结果凸显了学习协作和自适应协调在扩展多智能体推理中的重要性。相关代码可在https://github.com/jincan333/MAS-TTS找到。
论文及项目相关链接
Summary
本文介绍了一种基于大型语言模型的多智能体系统(MAS),旨在解决单个智能体系统难以应对的复杂现实世界任务。文章通过模型级别的训练和系统级别的协调,提出了一个自适应的多智能体框架,增强了协作推理能力。该研究构建了M500数据集,并对其进行微调,产生了针对多智能体协作优化的M1-32B模型。此外,还提出了一种动态管理讨论过程的首席执行官智能体,以进一步实现自适应推理。在开放源码的多智能体系统上进行评估,该系统在多种任务上显著超越了强大的基线,包括通用理解、数学推理和编码任务。
Key Takeaways
- 多智能体系统(MAS)结合大型语言模型(LLM)为解决复杂现实世界任务提供了有效途径。
- 最近测试时间缩放(TTS)技术的进展已显著提高单智能体的挑战性推理任务性能。
- 引入自适应多智能体框架,通过模型级别的训练和系统级别的协调,增强协作推理能力。
- 构建并微调了M500数据集,产生针对多智能体协作优化的M1-32B模型。
- 提出动态管理讨论过程的CEO智能体,实现自适应推理。
- 在多种任务上,该系统显著超越了强大的基线,包括通用理解、数学推理和编码任务。
- 代码已公开在GitHub上,供公众访问和使用。
点此查看论文截图


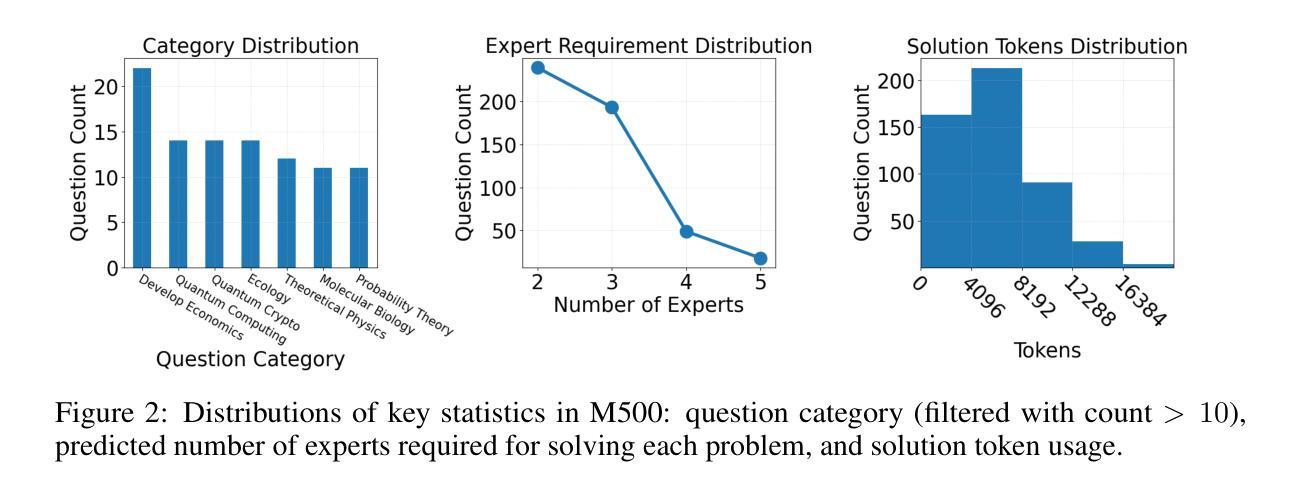
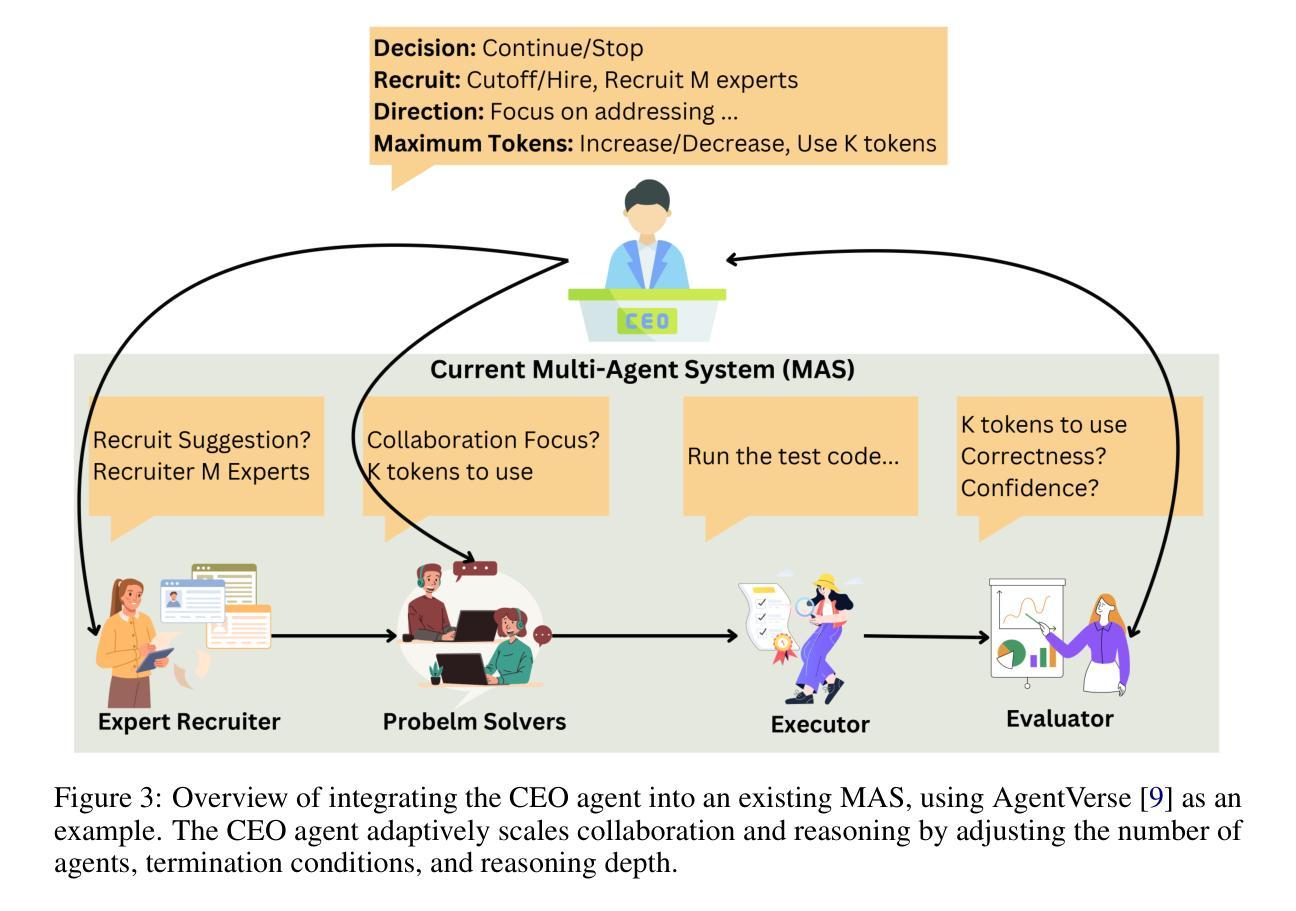
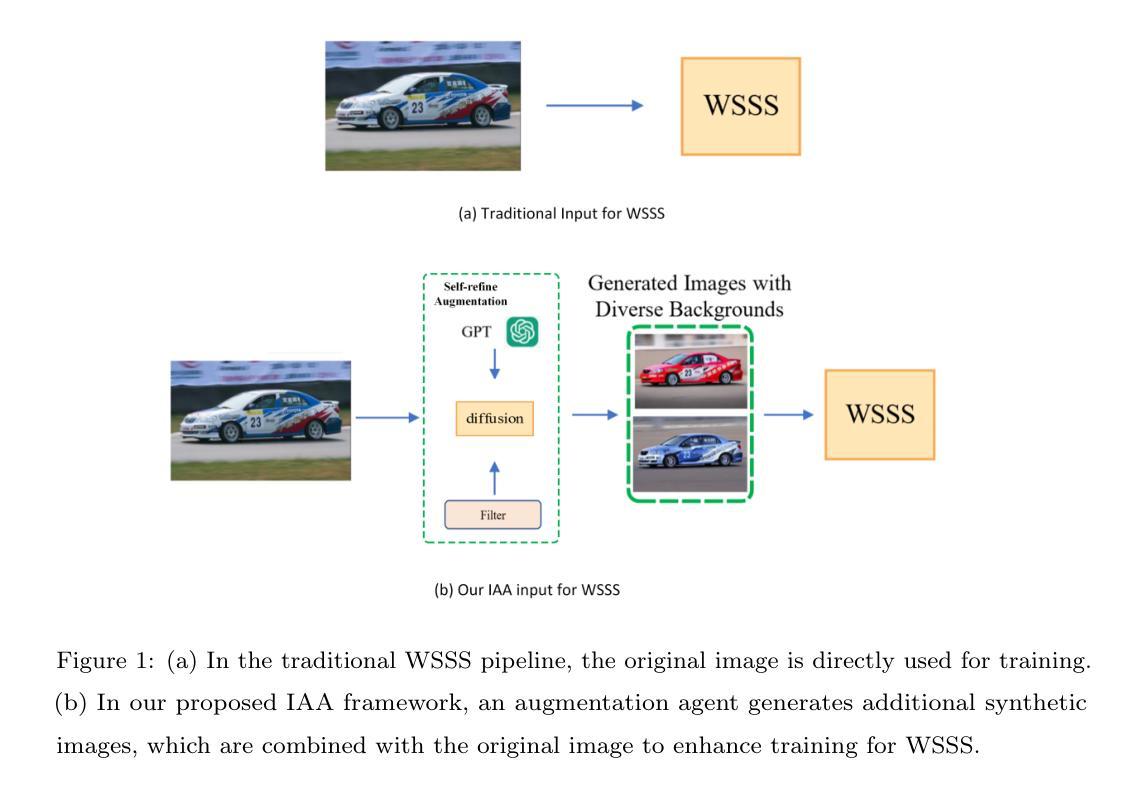
Image Augmentation Agent for Weakly Supervised Semantic Segmentation
Authors:Wangyu Wu, Xianglin Qiu, Siqi Song, Zhenhong Chen, Xiaowei Huang, Fei Ma, Jimin Xiao
Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.
弱监督语义分割(WSSS)仅使用图像级标签取得了显著的进步。然而,大多数现有的WSSS方法主要集中在设计新的网络结构和损失函数来生成更准确的密集标签,忽视了固定数据集带来的限制,这些限制可能会限制性能改进。我们认为,提供更多可训练图像可以为WSSS提供更丰富的信息,并帮助模型理解更全面的语义模式。因此,在本文中,我们引入了一种新方法,称为图像增强代理(IAA),它表明从数据生成的角度增强WSSS是可能的。IAA主要设计了一个增强代理,利用大型语言模型(LLM)和扩散模型自动为WSSS生成额外图像。在实践中,为了解决LLM生成提示的不稳定性,我们开发了一种提示自我优化机制。它允许LLM重新评估生成的提示的合理性,以产生更连贯的提示。此外,我们在扩散生成过程中插入了一个在线过滤器,以动态确保生成图像的质量和平衡。实验结果表明,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了最先进的WSSS方法。
论文及项目相关链接
PDF Accepted at Neurocomputing 2025
Summary
利用图像级标签实现的弱监督语义分割(WSSS)取得了显著进展。然而,现有方法多关注设计新网络结构和损失函数以生成更准确的密集标签,忽视了固定数据集带来的限制。本文提出一种名为图像增强代理(IAA)的新方法,从数据生成角度提升WSSS性能。IAA设计了一个利用大型语言模型(LLMs)和扩散模型自动生成额外图像的增强代理。为解决LLMs在提示生成中的不稳定问题,开发了一种提示自我完善机制,使LLMs能够重新评估生成的提示的合理性,产生更连贯的提示。此外,在扩散生成过程中插入在线过滤器,以动态确保生成图像的质量和平衡。实验结果表明,该方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了现有WSSS方法。
Key Takeaways
- WSSS利用图像级标签实现显著进展,但受限于固定数据集。
- 提出一种名为Image Augmentation Agent (IAA)的新方法,从数据生成角度提升WSSS性能。
- IAA利用大型语言模型(LLMs)和扩散模型自动生成额外图像。
- 为解决LLMs在提示生成中的不稳定问题,开发了提示自我完善机制。
- 在扩散生成过程中插入在线过滤器,确保生成图像的质量和平衡。
- 实验结果表明,该方法在PASCAL VOC 2012和MS COCO 2014数据集上表现优异。
- IAA通过增加图像多样性和质量,帮助模型理解更全面的语义模式。
点此查看论文截图

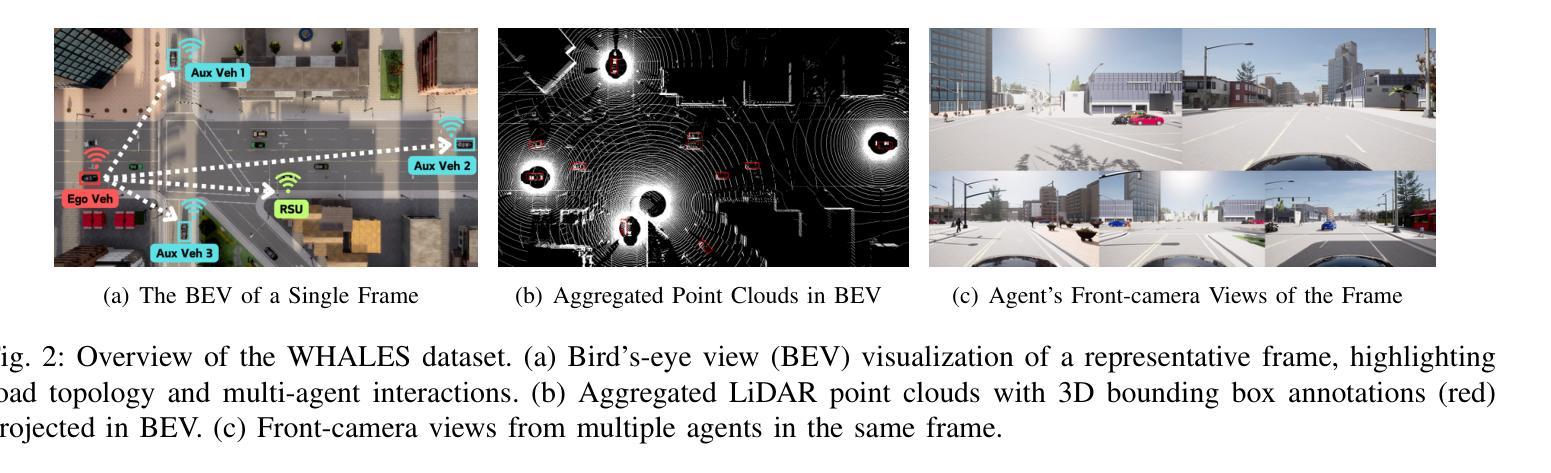
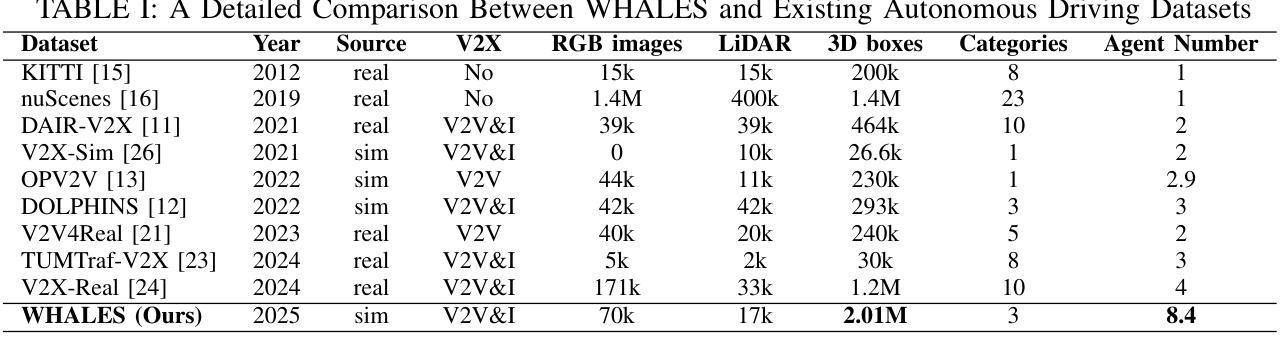
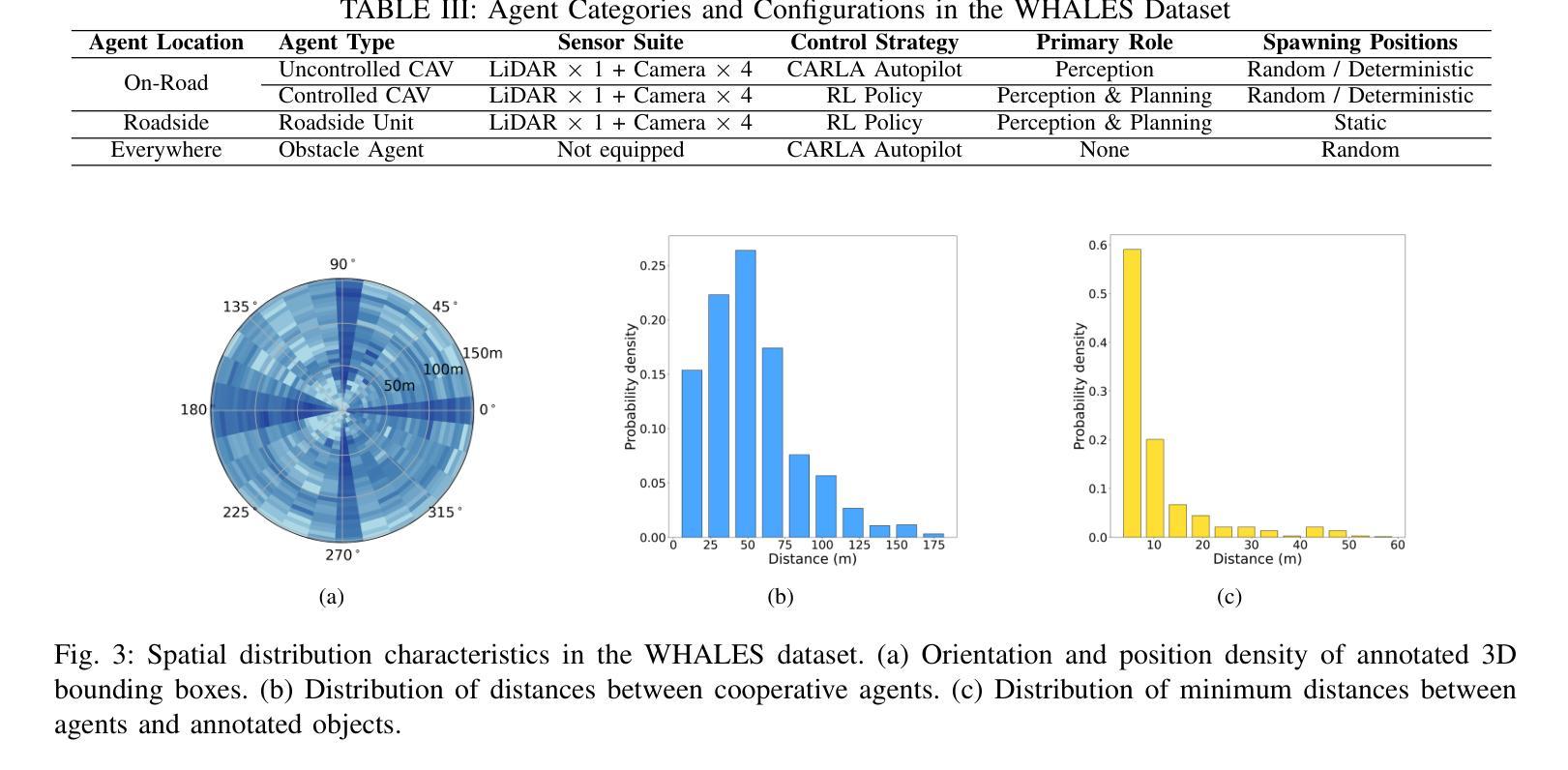
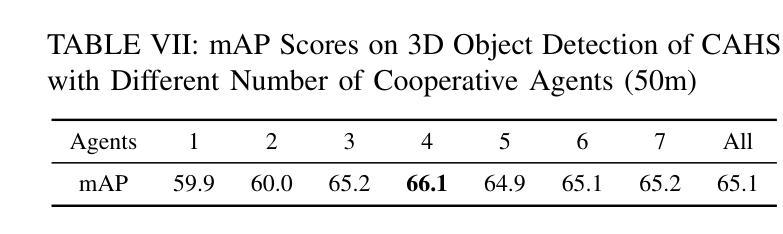
WHALES: A Multi-Agent Scheduling Dataset for Enhanced Cooperation in Autonomous Driving
Authors:Yinsong Wang, Siwei Chen, Ziyi Song, Sheng Zhou
Cooperative perception research is hindered by the limited availability of datasets that capture the complexity of real-world Vehicle-to-Everything (V2X) interactions, particularly under dynamic communication constraints. To address this gap, we introduce WHALES (Wireless enhanced Autonomous vehicles with Large number of Engaged agents), the first large-scale V2X dataset explicitly designed to benchmark communication-aware agent scheduling and scalable cooperative perception. WHALES introduces a new benchmark that enables state-of-the-art (SOTA) research in communication-aware cooperative perception, featuring an average of 8.4 cooperative agents per scene and 2.01 million annotated 3D objects across diverse traffic scenarios. It incorporates detailed communication metadata to emulate real-world communication bottlenecks, enabling rigorous evaluation of scheduling strategies. To further advance the field, we propose the Coverage-Aware Historical Scheduler (CAHS), a novel scheduling baseline that selects agents based on historical viewpoint coverage, improving perception performance over existing SOTA methods. WHALES bridges the gap between simulated and real-world V2X challenges, providing a robust framework for exploring perception-scheduling co-design, cross-data generalization, and scalability limits. The WHALES dataset and code are available at https://github.com/chensiweiTHU/WHALES.
协同感知研究受限于数据集的可获取性,这些数据集需要捕捉现实世界中车辆与万物(V2X)交互的复杂性,特别是在动态通信约束下。为了弥补这一空白,我们引入了WHALES(无线增强型自主车辆与大量参与者的交互),这是第一个专门为基准测试通信感知代理调度和可扩展协同感知而设计的大规模V2X数据集。WHALES引入了一个新的基准测试,使最先进的(SOTA)通信感知协同研究成为可能,每个场景平均有8.4个合作代理,跨越各种交通场景的201万个注释的3D对象。它结合了详细的通信元数据来模拟真实的通信瓶颈,可以对调度策略进行严格评估。为了进一步发展该领域,我们提出了Coverage-Aware Historical Scheduler(CAHS)——一种基于历史观点覆盖率选择代理的新型调度基线,在现有SOTA方法的基础上提高了感知性能。WHALES缩小了模拟与现实世界V2X挑战之间的差距,为探索感知调度协同设计、跨数据泛化和可扩展性极限提供了稳健的框架。WHALES数据集和代码可在https://github.com/chensiweiTHU/WHALES获取。
论文及项目相关链接
Summary
WHALES是首个专为通信感知协同调度而设计的大规模V2X数据集。它模拟真实世界的通信瓶颈,为先进的研究提供了基准测试平台。此外,该研究还提出了一种基于历史视角覆盖的调度基线——Coverage-Aware Historical Scheduler(CAHS),提高了感知性能。WHALES数据集为探索感知调度协同设计、跨数据泛化以及可扩展性极限提供了稳健框架。
Key Takeaways
- WHALES数据集专为解决现实世界中车辆与万物(V2X)交互的复杂性而设计,填补了现有数据集的空白。
- WHALES数据集具有大规模特性,平均每个场景有8.4个合作代理,涵盖多样化的交通场景,并带有201万个标注的3D对象。
- 数据集融入了详细的通信元数据,以模拟真实的通信瓶颈,使得调度策略的评价更为严格。
- 引入了一个新的基准测试平台,为先进的研究提供了通信感知协同调度的机会。
- 提出了Coverage-Aware Historical Scheduler(CAHS)这一新颖的调度基线方法,基于历史视角覆盖进行选择,提高了感知性能。
- WHALES数据集有助于探索感知调度协同设计、跨数据泛化等议题。
点此查看论文截图