⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-21 更新
EEG Blink Artifacts Can Identify Read Music in Listening and Imagery
Authors:Abhinav Uppal, Dillan Cellier, Min Suk Lee, Sean Bauersfeld, Yuchen Xu, Shihab A. Shamma, Gert Cauwenberghs, Virginia R. de Sa
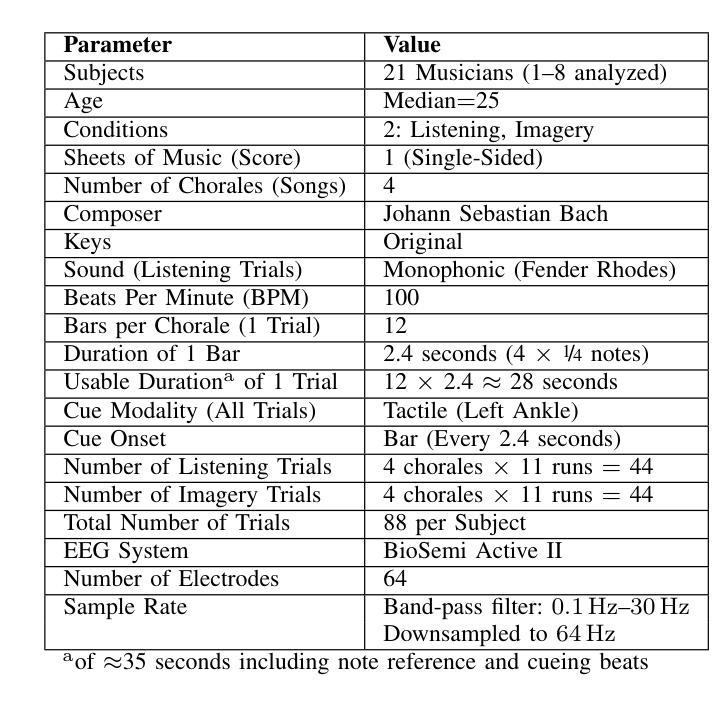
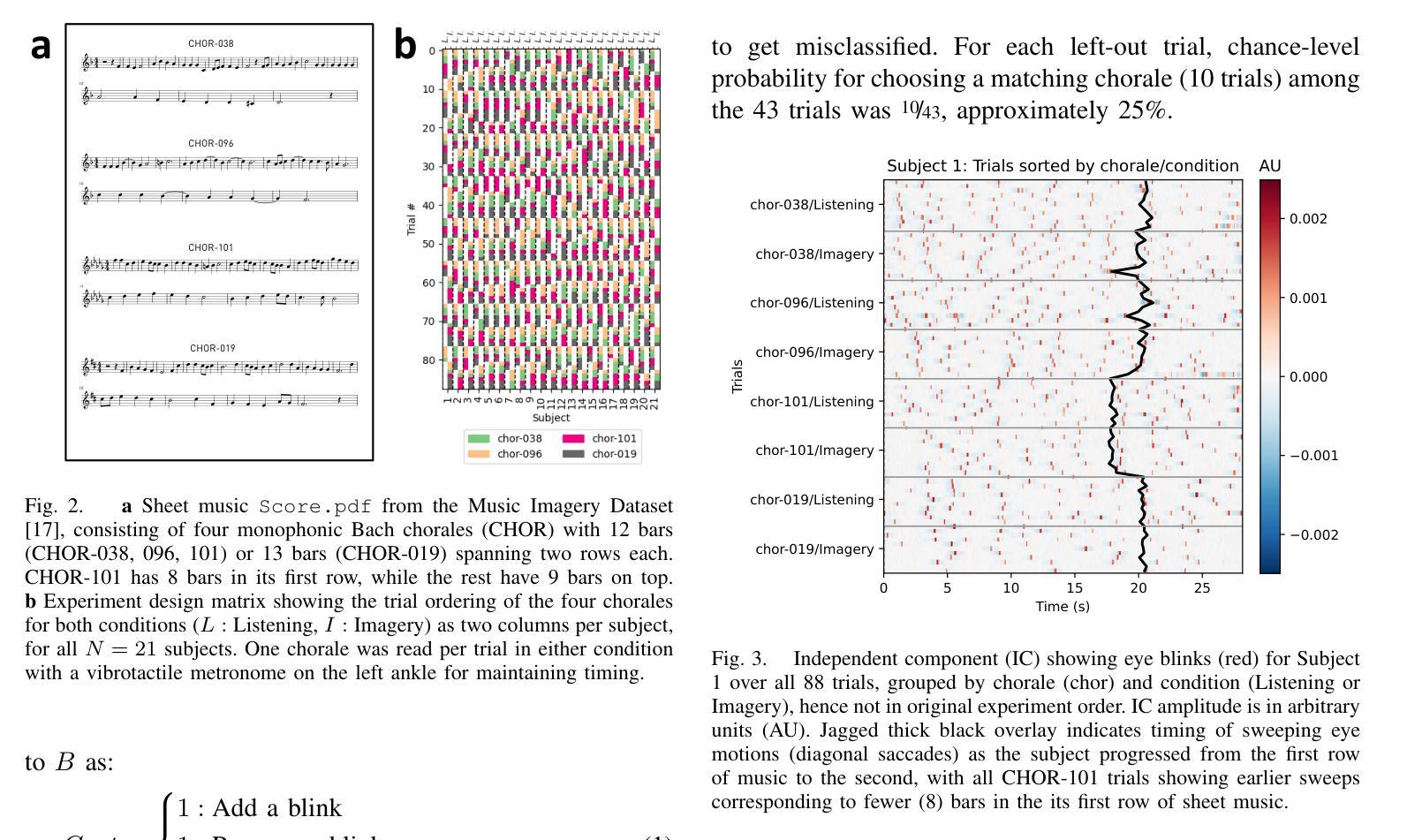
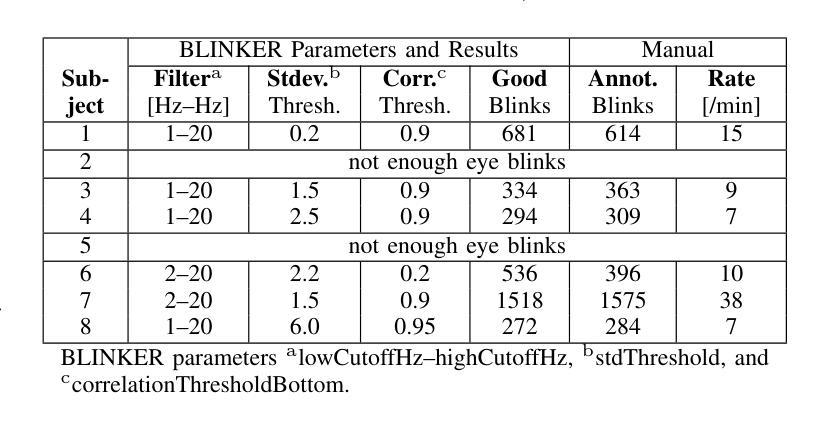
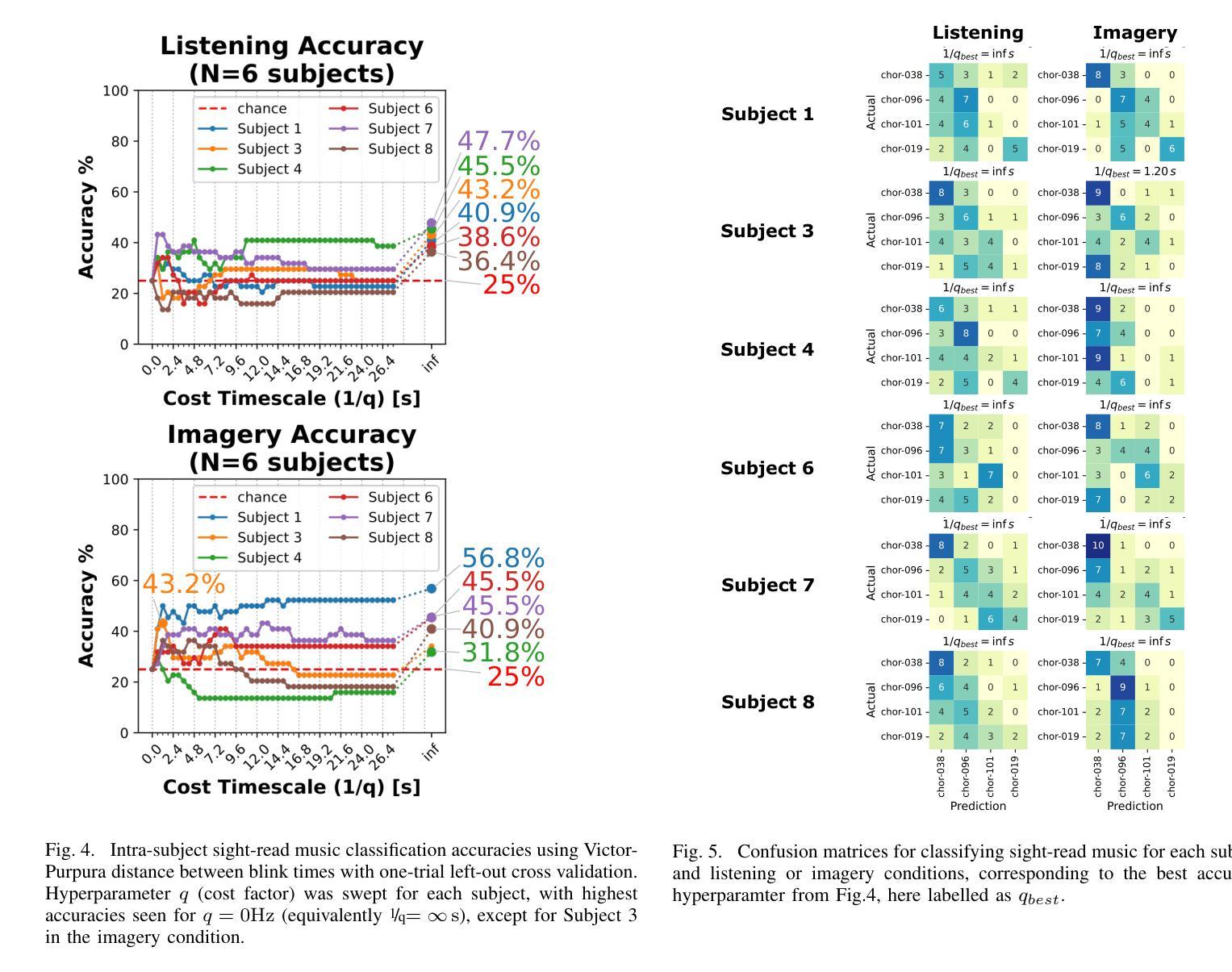
Eye-movement related artifacts including blinks and saccades are significantly larger in amplitude than cortical activity as recorded by scalp electroencephalography (EEG), but are typically discarded in EEG studies focusing on cognitive mechanisms as explained by cortical source activity. Accumulating evidence however indicates that spontaneous eye blinks are not necessarily random, and can be modulated by attention and cognition beyond just physiological necessities. In this exploratory analysis we reanalyze a public EEG dataset of musicians listening to or imagining music (Bach chorales) while simultaneously reading from a sheet of music. We ask whether blink timing in reading music, accompanied by listening or imagery, is sufficient to uniquely identify the music being read from a given score. Intra-subject blink counts and timing are compared across trials using a spike train distance metric (Victor and Purpura, 1997). One-trial-left-out cross-validation is used to identify the music being read with above chance level accuracy (best subject: 56%, chance: 25%), where accuracy is seen to vary with subject, condition, and a tunable cost factor for time shifts. Future studies may consider incorporating eye blink contributions to brain decoding, especially in wearables where eye blinks could be easier to record than EEG given their higher amplitudes.
眼动相关伪迹,包括眨眼和眼跳,其幅度明显大于通过头皮脑电图(EEG)记录的大脑皮层活动。然而,在专注于由皮层源活动解释的认知机制的EEG研究中,这些通常会被忽略。然而,越来越多的证据表明,自发性的眨眼并不一定是随机的,除了生理需求之外,还可能受到注意力和认知的调节。在这项探索性分析中,我们重新分析了一个公共的EEG数据集,音乐家们在听音乐(巴赫的众赞歌)或想象音乐的同时阅读乐谱。我们的问题是,在听音乐(伴随倾听或想象)过程中的眨眼时间是否能够足够独特地识别乐谱上播放的音乐。被试内的眨眼次数和时间通过SpikeTrain距离度量法(Victor和Purpura,1997)进行比较。使用单试次留一法交叉验证来识别正在阅读的音乐,准确率高于偶然水平(最佳受试者:56%,偶然水平:25%),其中准确率随受试者、条件和时间偏移的可调成本因素而变化。未来的研究可能会考虑将眼眨在脑解码中的贡献纳入考虑,特别是在可穿戴设备中,由于眼眨的幅度较高,可能更容易记录眼眨而非EEG信号。
论文及项目相关链接
PDF Accepted for publication in IEEE NER 2025
Summary
眼动相关信号(如眨眼和眼跳)的幅度显著大于头皮脑电图(EEG)记录的皮层活动,但在专注于皮层源活动的认知机制研究中通常会被舍弃。然而,有越来越多的证据表明,自发性眨眼并不一定是随机的,还可能受到注意力和认知的调节,而不仅仅是生理需求。本研究重新分析了一个公共EEG数据集,数据集涉及音乐家在听音乐(巴赫的众赞歌)同时阅读乐谱时的表现。本研究旨在探讨伴随阅读音乐的眨眼时机是否能够唯一地识别乐谱中的音乐。使用维克托和普普尔(Victor and Purpura, 1997)的距离度量方法比较受试者内部眨眼的次数和时机。通过单试次遗留交叉验证法识别出受试者的阅读音乐准确性超过偶然水平(最佳受试者准确率56%,偶然水平为25%),准确性因受试者、条件和时间偏移的可调成本因子而异。未来研究可考虑将眨眼对脑解码的贡献纳入其中,特别是在可穿戴设备领域,因为眨眼比EEG更容易记录,且其幅度更大。
Key Takeaways
- 眼动相关信号(眨眼和眼跳)在幅度上显著大于皮层活动,但在EEG研究中常被忽略。
- 自发性眨眼不仅仅是生理需求,还可能受到注意力和认知的调节。
- 研究者重新分析了一个涉及音乐家听音乐同时阅读乐谱的公共EEG数据集。
- 通过分析眨眼时机,能够识别出正在阅读的特定音乐。
- 使用了一种名为Victor和Purpura的距离度量方法来比较受试者内部眨眼的次数和时机。
- 通过单试次遗留交叉验证法发现阅读音乐的准确性超过偶然水平。
点此查看论文截图
Can Masked Autoencoders Also Listen to Birds?
Authors:Lukas Rauch, René Heinrich, Ilyass Moummad, Alexis Joly, Bernhard Sick, Christoph Scholz
Masked Autoencoders (MAEs) learn rich semantic representations in audio classification through an efficient self-supervised reconstruction task. However, general-purpose models fail to generalize well when applied directly to fine-grained audio domains. Specifically, bird-sound classification requires distinguishing subtle inter-species differences and managing high intra-species acoustic variability, revealing the performance limitations of general-domain Audio-MAEs. This work demonstrates that bridging this domain gap domain gap requires full-pipeline adaptation, not just domain-specific pretraining data. We systematically revisit and adapt the pretraining recipe, fine-tuning methods, and frozen feature utilization to bird sounds using BirdSet, a large-scale bioacoustic dataset comparable to AudioSet. Our resulting Bird-MAE achieves new state-of-the-art results in BirdSet’s multi-label classification benchmark. Additionally, we introduce the parameter-efficient prototypical probing, enhancing the utility of frozen MAE representations and closely approaching fine-tuning performance in low-resource settings. Bird-MAE’s prototypical probes outperform linear probing by up to 37 percentage points in mean average precision and narrow the gap to fine-tuning across BirdSet downstream tasks. Bird-MAE also demonstrates robust few-shot capabilities with prototypical probing in our newly established few-shot benchmark on BirdSet, highlighting the potential of tailored self-supervised learning pipelines for fine-grained audio domains.
基于掩码的自编码器(MAEs)通过高效的自监督重建任务在音频分类中学习到丰富的语义表示。然而,当直接应用于精细粒度的音频域时,通用模型往往无法很好地推广。具体来说,鸟类声音分类需要区分物种间的细微差异并处理高物种内的声学变化,揭示了通用领域Audio-MAE的性能局限性。这项工作表明,弥合这一领域差距需要全管道适应,而不仅仅是特定领域的预训练数据。我们系统地回顾并适应了预训练配方、微调方法和冻结特征的利用方法,以应对鸟类声音,使用了与AudioSet相当的大规模生物声学数据集BirdSet。我们得到的Bird-MAE在BirdSet的多标签分类基准测试中取得了最新 state-of-the-art 结果。此外,我们引入了参数高效的原型探针技术,提高了冻结MAE表示的实用性,并在低资源环境中接近微调性能。Bird-MAE的原型探针在平均精度均值方面比线性探针高出高达37个百分点,并缩小了在BirdSet下游任务的微调差距。Bird-MAE还展示了我们新建立的BirdSet少样本基准测试中少样本能力的稳健性,突显了针对精细粒度音频域量身定制的自监督学习管道的巨大潜力。
论文及项目相关链接
PDF accepted @TMLR: https://openreview.net/forum?id=GIBWR0Xo2J
摘要
通用音频MAE模型在精细粒度音频域上的泛化性能受限。本文探索了如何利用Masked Autoencoders(MAEs)在鸟声分类任务中构建丰富语义表示的方法,通过全管道适应性调整而非仅依赖特定领域预训练数据来缩小领域差距。通过系统回顾并适应预训练配方、微调方法和冻结特征利用方式,使用大规模生物声学数据集BirdSet,实现了对鸟声的多标签分类的新SOTA结果。此外,引入参数高效的原型探测技术,提高冻结MAE表示的实用性,并在低资源环境中接近微调性能。Bird-MAE的原型探针在平均精度上优于线性探针高达37个百分点,并在BirdSet下游任务中缩小了与精细调整的差距。同时,Bird-MAE展示了在新建立的BirdSet少样本基准测试中的稳健少样本能力,突显了针对精细粒度音频域量身定制的自监督学习管道的巨大潜力。
关键见解
- MAEs在音频分类中学习了丰富的语义表示,但在应用于精细粒度音频域时泛化性能受限。
- 鸟声分类需要区分物种间的细微差异并处理高物种内部的声音变化,暴露了通用领域Audio-MAEs的性能局限性。
- 全管道适应性调整而非仅依赖特定领域预训练数据是缩小领域差距的关键。
- 通过系统调整预训练配方、微调方法和冻结特征利用方式,使用大规模生物声学数据集BirdSet,实现了鸟声多标签分类的新SOTA结果。
- 引入参数高效的原型探测技术,提高冻结MAE表示的实用性,并接近低资源环境中的微调性能。
- Bird-MAE的原型探针在平均精度上有显著改进,缩小了与精细调整的差距。
点此查看论文截图