⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-21 更新
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Authors:Shaoshu Yang, Zhe Kong, Feng Gao, Meng Cheng, Xiangyu Liu, Yong Zhang, Zhuoliang Kang, Wenhan Luo, Xunliang Cai, Ran He, Xiaoming Wei
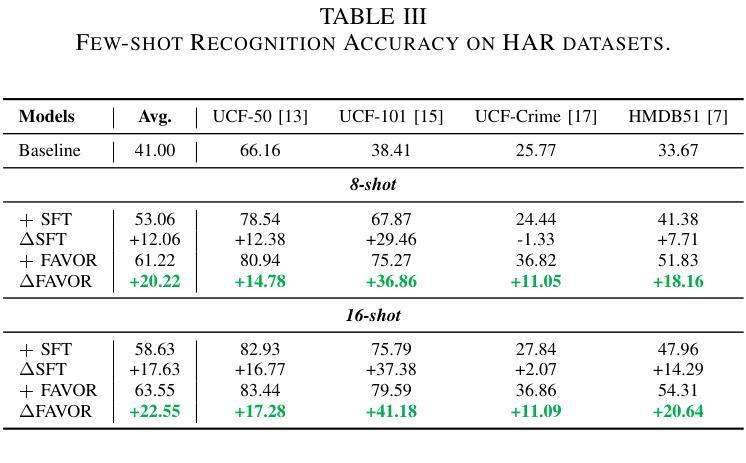
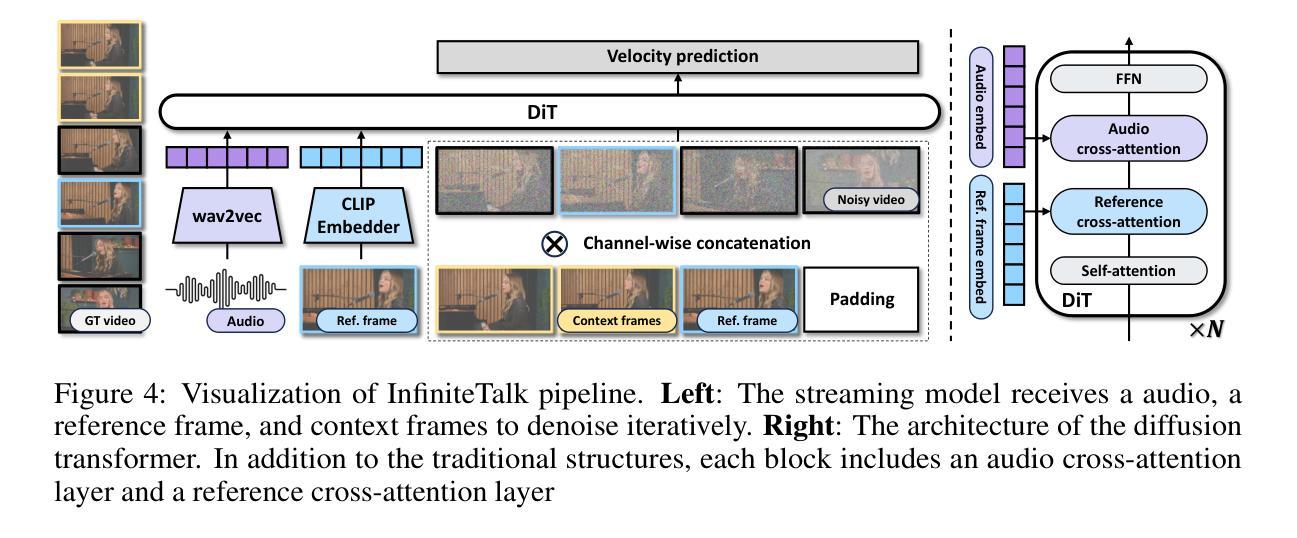
Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
近期视频人工智能生成内容(AIGC)的突破为音频驱动的人脸动画带来了一个变革时代。然而,传统的视频配音技术仍然局限于口型区域的编辑,导致面部表情和体态不一致,影响观众的沉浸感。为了克服这一局限性,我们引入了稀疏帧视频配音,这是一种新型范式,通过战略性保留参考关键帧来保持身份、标志性手势和摄像机轨迹,同时实现全面、与音频同步的全身动作编辑。通过批判性分析,我们确定了为什么简单的图像到视频模型无法完成此任务,尤其是它们无法实现自适应条件。为了解决这一问题,我们提出了InfiniteTalk,这是一个为无限长度长序列配音设计的音频驱动生成器。该架构利用时间上下文帧实现无缝跨块过渡,并采用了简单有效的采样策略,通过精细的参考帧定位优化控制力度。在HDTF、CelebV-HQ和EMTD数据集上的综合评估证明了其卓越性能。定量指标证实了其在视觉逼真度、情感连贯性和全身动作同步方面的优势。
论文及项目相关链接
PDF 11 pages, 7 figures
Summary
近期视频AIGC的突破为音频驱动的人形动画带来了变革性时代。传统的视频配音技术受限于口型区域编辑,导致面部表情和体态不协调,影响观众沉浸感。为克服此局限,本文提出稀疏帧视频配音范式,通过保留关键帧维持人物身份、标志性动作及摄像轨迹,实现音频同步的全身动作编辑。本文分析了现有图像转视频模型在此任务中的失败原因,特别是其无法实现自适应调节的问题。为解决此问题,本文提出了适用于无限长序列配音的流式音频驱动生成器——InfiniteTalk。该架构利用临时上下文帧实现无缝跨块过渡,并采用简单有效的采样策略,通过精细参考帧定位优化控制力度。在HDTF、CelebV-HQ和EMTD数据集上的综合评估证明了其卓越性能,定量指标证实了其在视觉逼真度、情感连贯性和全身动作同步方面的优势。
Key Takeaways
- 音频驱动人形动画的突破:近期视频AIGC的发展推动了音频驱动人形动画的进步,带来变革性时代。
- 传统视频配音技术的局限:传统技术主要关注口型区域编辑,导致面部表情和体态的不协调。
- 稀疏帧视频配音范式的引入:通过保留关键帧来实现更真实的全身动作编辑,提高观众沉浸感。
- 现有图像转视频模型的不足:分析指出图像转视频模型在音频驱动配音任务中的失败原因,特别是自适应调节能力的问题。
- InfiniteTalk架构的提出:适用于无限长序列配音的流式音频驱动生成器,实现无缝跨块过渡和精细的参考帧定位。
- 卓越性能的综合评估:在多个数据集上的评估证明了该架构的卓越性能。
点此查看论文截图




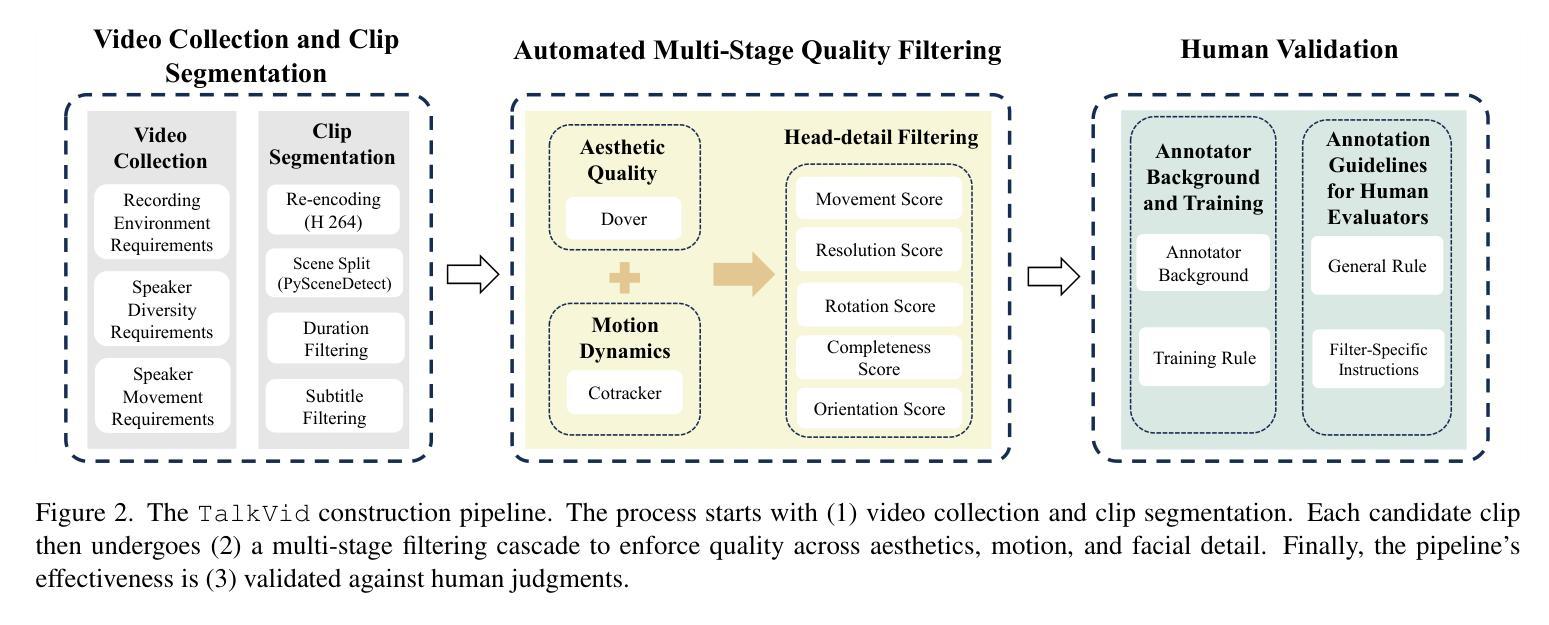
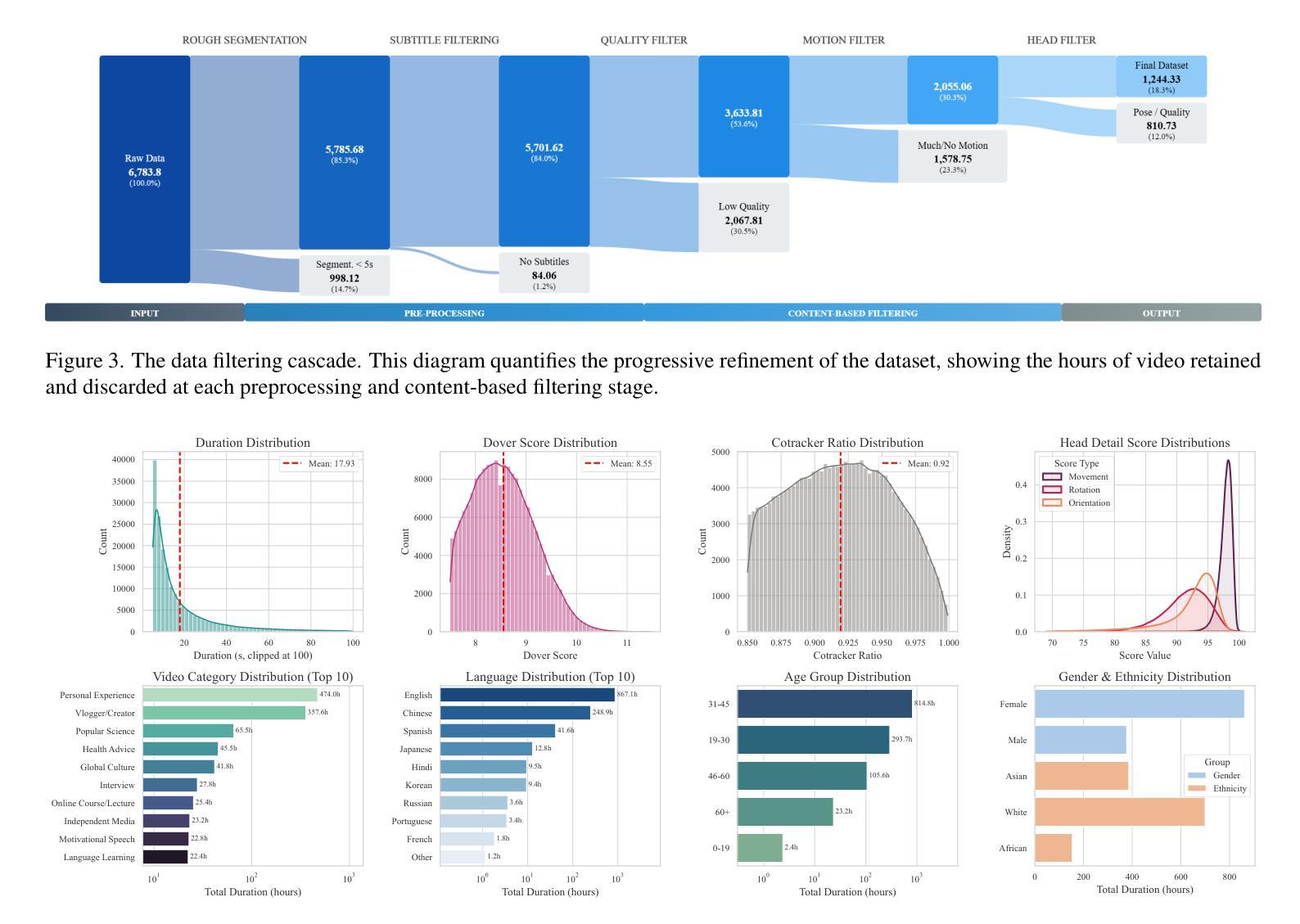
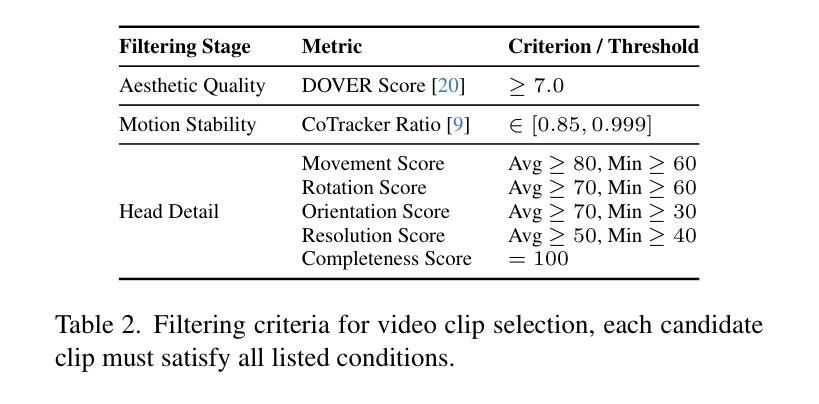
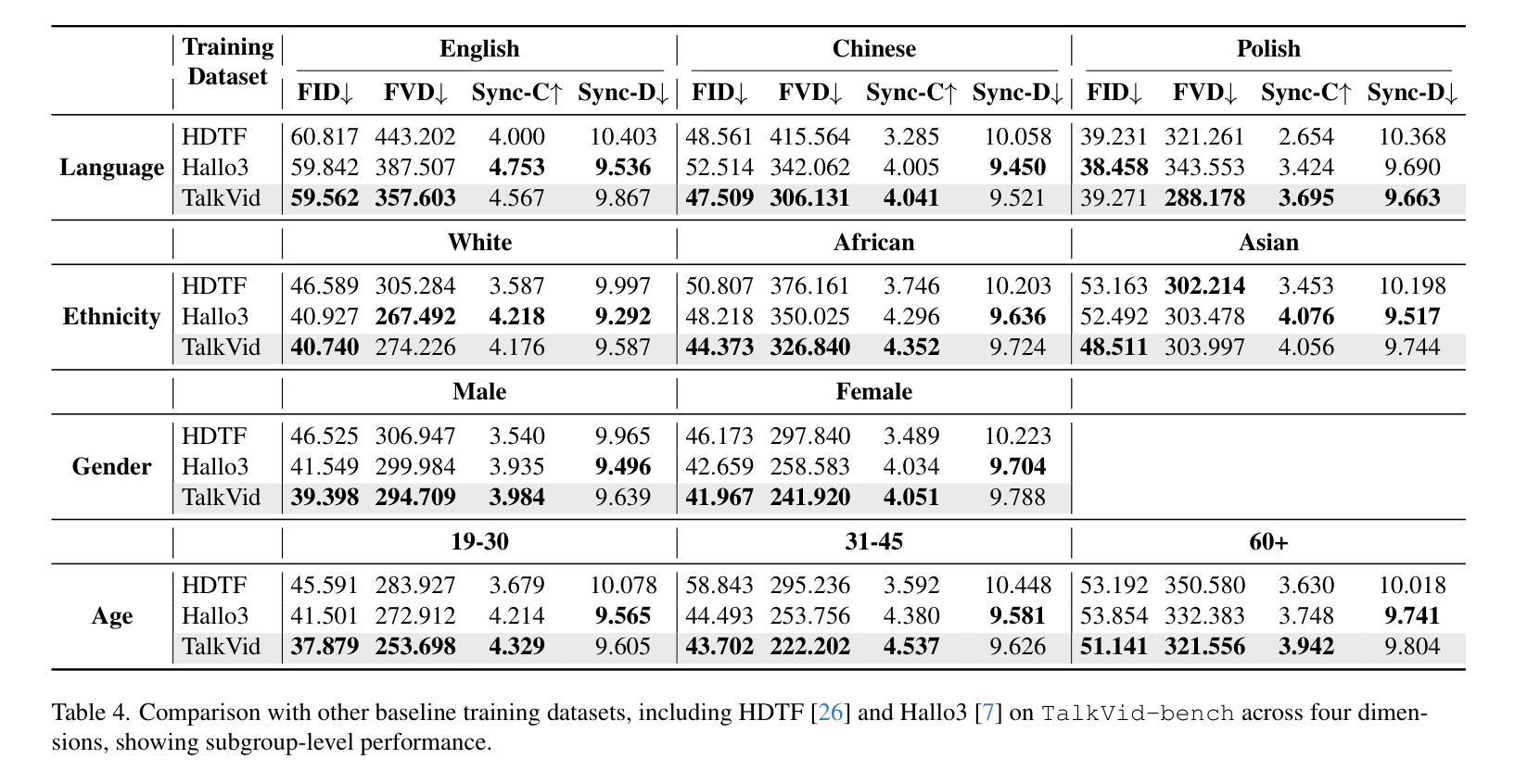
TalkVid: A Large-Scale Diversified Dataset for Audio-Driven Talking Head Synthesis
Authors:Shunian Chen, Hejin Huang, Yexin Liu, Zihan Ye, Pengcheng Chen, Chenghao Zhu, Michael Guan, Rongsheng Wang, Junying Chen, Guanbin Li, Ser-Nam Lim, Harry Yang, Benyou Wang
Audio-driven talking head synthesis has achieved remarkable photorealism, yet state-of-the-art (SOTA) models exhibit a critical failure: they lack generalization to the full spectrum of human diversity in ethnicity, language, and age groups. We argue that this generalization gap is a direct symptom of limitations in existing training data, which lack the necessary scale, quality, and diversity. To address this challenge, we introduce TalkVid, a new large-scale, high-quality, and diverse dataset containing 1244 hours of video from 7729 unique speakers. TalkVid is curated through a principled, multi-stage automated pipeline that rigorously filters for motion stability, aesthetic quality, and facial detail, and is validated against human judgments to ensure its reliability. Furthermore, we construct and release TalkVid-Bench, a stratified evaluation set of 500 clips meticulously balanced across key demographic and linguistic axes. Our experiments demonstrate that a model trained on TalkVid outperforms counterparts trained on previous datasets, exhibiting superior cross-dataset generalization. Crucially, our analysis on TalkVid-Bench reveals performance disparities across subgroups that are obscured by traditional aggregate metrics, underscoring its necessity for future research. Code and data can be found in https://github.com/FreedomIntelligence/TalkVid
音频驱动的说话人头部合成已经实现了惊人的逼真度,但最新技术(SOTA)模型存在一个重大缺陷:它们缺乏对种族、语言和年龄群体等方面人类多样性的全面概括。我们认为,这种泛化差距是现有训练数据存在局限性的直接表现,这些局限性缺乏必要的规模、质量和多样性。为了应对这一挑战,我们推出了TalkVid,这是一个新的大规模、高质量、多样化的数据集,包含来自7729名独特说话者的1244小时视频。TalkVid是通过一项有原则的、多阶段的自动化管道进行策划的,该管道严格筛选运动稳定性、美学质量和面部细节,并通过人类判断进行验证,以确保其可靠性。此外,我们构建并发布了TalkVid-Bench,这是一套精心平衡的500个剪辑的分层评估集,关键的人口统计和语言学轴都有涵盖。我们的实验表明,在TalkVid上训练的模型优于在以前的数据集上训练的模型,表现出优异的跨数据集泛化能力。重要的是,我们在TalkVid-Bench上的分析揭示了各子组之间的性能差异,这些差异被传统的总体指标所掩盖,从而凸显出其对未来研究的必要性。代码和数据可在https://github.com/FreedomIntelligence/TalkVid找到。
论文及项目相关链接
Summary
本文介绍了音频驱动的说话人头部合成技术面临的挑战及新数据集TalkVid的解决方法。现有技术难以实现全面的人群泛化能力,而新的数据集TalkVid能够提供大规模、高质量和多元化的视频资源来提高模型的泛化能力。TalkVid通过多阶段自动化管道进行筛选和验证,确保数据的可靠性和质量。同时,引入TalkVid-Bench作为分层评估集来平衡关键人口和语言学轴线数据,助力更精准的性能分析。训练在TalkVid上的模型表现优于以往数据集,显示出更好的跨数据集泛化能力。
Key Takeaways
- 音频驱动的说话人头部合成技术面临泛化问题,特别是在人种、语言和年龄群体方面。
- 现有训练数据存在规模、质量和多样性方面的局限性。
- TalkVid数据集旨在解决上述问题,包含大规模、高质量和多元化的视频资源。
- TalkVid通过多阶段自动化管道进行筛选和验证数据可靠性。
- TalkVid-Bench作为分层评估集,平衡关键人口和语言学轴线数据,助力性能分析。
- 在TalkVid上训练的模型表现出更好的跨数据集泛化能力。
点此查看论文截图