⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-22 更新
Towards PerSense++: Advancing Training-Free Personalized Instance Segmentation in Dense Images
Authors:Muhammad Ibraheem Siddiqui, Muhammad Umer Sheikh, Hassan Abid, Kevin Henry, Muhammad Haris Khan
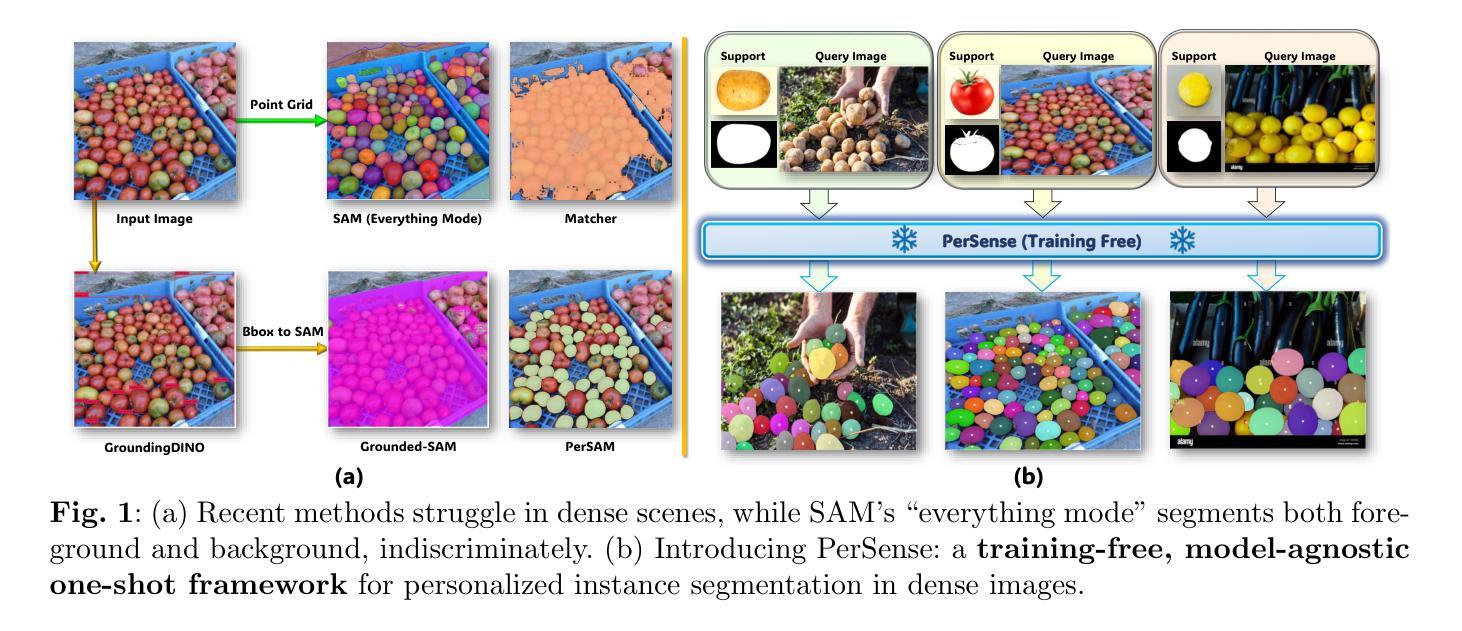
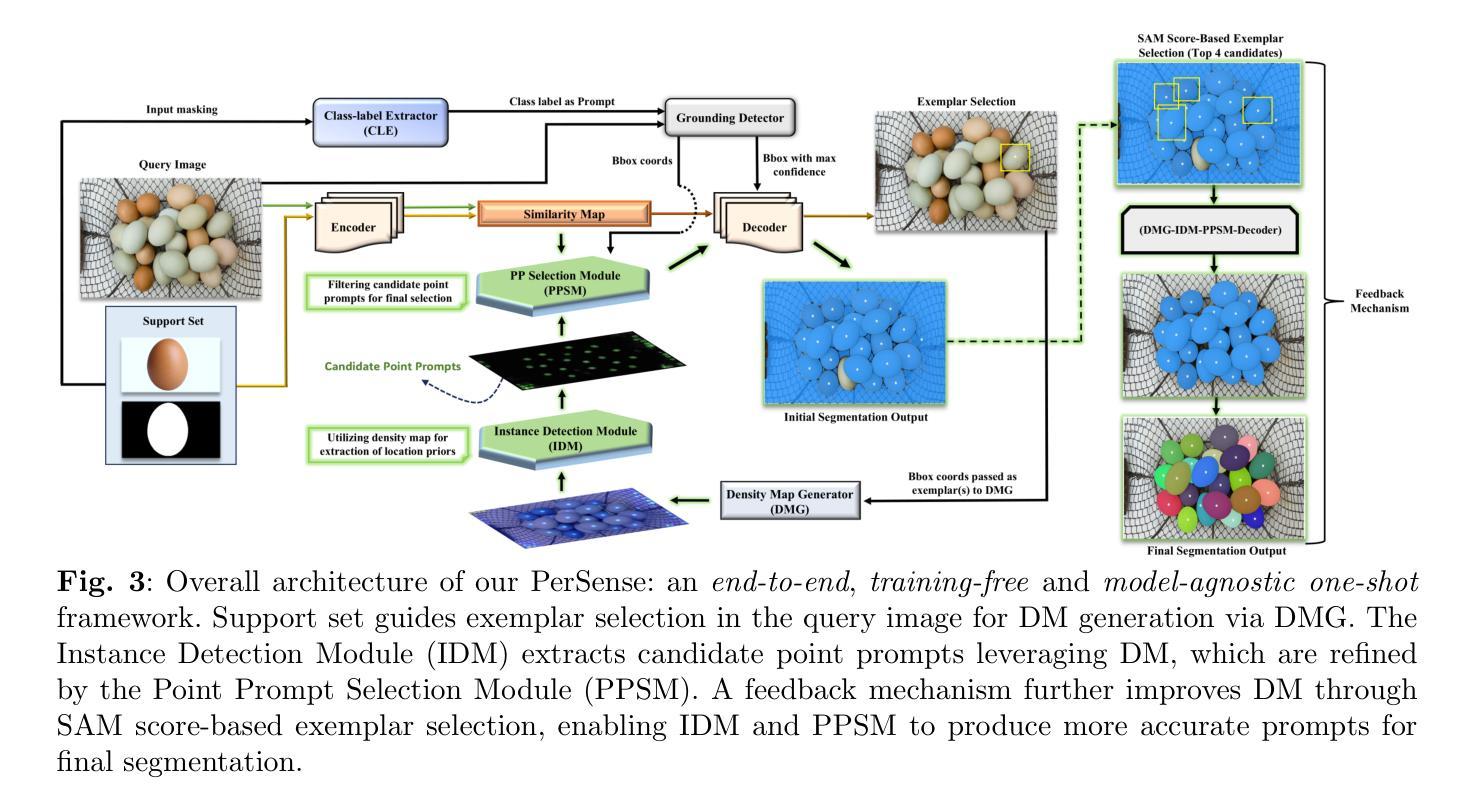
Segmentation in dense visual scenes poses significant challenges due to occlusions, background clutter, and scale variations. To address this, we introduce PerSense, an end-to-end, training-free, and model-agnostic one-shot framework for Personalized instance Segmentation in dense images. PerSense employs a novel Instance Detection Module (IDM) that leverages density maps (DMs) to generate instance-level candidate point prompts, followed by a Point Prompt Selection Module (PPSM) that filters false positives via adaptive thresholding and spatial gating. A feedback mechanism further enhances segmentation by automatically selecting effective exemplars to improve DM quality. We additionally present PerSense++, an enhanced variant that incorporates three additional components to improve robustness in cluttered scenes: (i) a diversity-aware exemplar selection strategy that leverages feature and scale diversity for better DM generation; (ii) a hybrid IDM combining contour and peak-based prompt generation for improved instance separation within complex density patterns; and (iii) an Irrelevant Mask Rejection Module (IMRM) that discards spatially inconsistent masks using outlier analysis. Finally, to support this underexplored task, we introduce PerSense-D, a dedicated benchmark for personalized segmentation in dense images. Extensive experiments across multiple benchmarks demonstrate that PerSense++ outperforms existing methods in dense settings.
在密集的视觉场景中,由于遮挡、背景杂乱和尺度变化,分割工作面临重大挑战。为解决这一问题,我们推出了PerSense,这是一个端到端、无需训练、模型无关的个性化实例分割密集图像的一次性框架。PerSense采用新型实例检测模块(IDM),利用密度图(DMs)生成实例级候选点提示,随后通过点提示选择模块(PPSM)通过自适应阈值和空间门控过滤误报。反馈机制通过自动选择有效的范例来增强分割,以提高密度图的质量。此外,我们还推出了PerSense++的增强版本,它结合了另外三个组件来提高杂乱场景中的稳健性:(i)一种利用特征和尺度多样性来更好地生成密度图的多样性感知范例选择策略;(ii)一种混合IDM,结合轮廓和基于峰值的提示生成,以在复杂的密度模式中实现更好的实例分离;(iii)一个无关掩膜拒绝模块(IMRM),它使用异常值分析丢弃空间不一致的掩膜。最后,为了支持这项尚未得到充分研究的任务,我们推出了PerSense-D,这是一个用于密集图像个性化分割的专用基准测试。在多个基准测试上的广泛实验表明,PerSense++在密集环境下的性能优于现有方法。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2405.13518
Summary
基于密度场景分割面临的挑战,如遮挡、背景杂波和尺度变化,我们提出了PerSense框架,这是一种端到端、无需训练、模型无关的个性化实例分割框架。它采用新型实例检测模块(IDM)和点提示选择模块(PPSM),通过密度图生成实例级候选点提示,并自适应阈值和空间门控过滤误报。此外,我们推出了PerSense++的增强版本,并引入三项附加组件以提升在复杂场景中的稳健性。最终,我们推出了专门用于密集图像个性化分割的PerSense-D基准测试集。实验证明,PerSense++在密集场景中的表现优于现有方法。
Key Takeaways
- PerSense框架是一种无需训练、模型无关的个性化实例分割框架,适用于密集图像的分割。
- PerSense采用新型实例检测模块(IDM)和点提示选择模块(PPSM),通过密度图生成实例级候选点提示,并过滤误报。
- PerSense++是PerSense的增强版本,引入三项附加组件以提升在复杂场景中的稳健性,包括多样性感知示例选择策略、混合IDM和无关掩膜拒绝模块。
- PerSense-D是一个专门用于个性化分割在密集图像的基准测试集。
- 实验证明,PerSense++在多个基准测试集上的表现优于现有方法,特别是在密集场景中的分割任务。
- 该框架可以自动选择有效的样本以提高密度图的质量,进一步优化分割效果。
点此查看论文截图



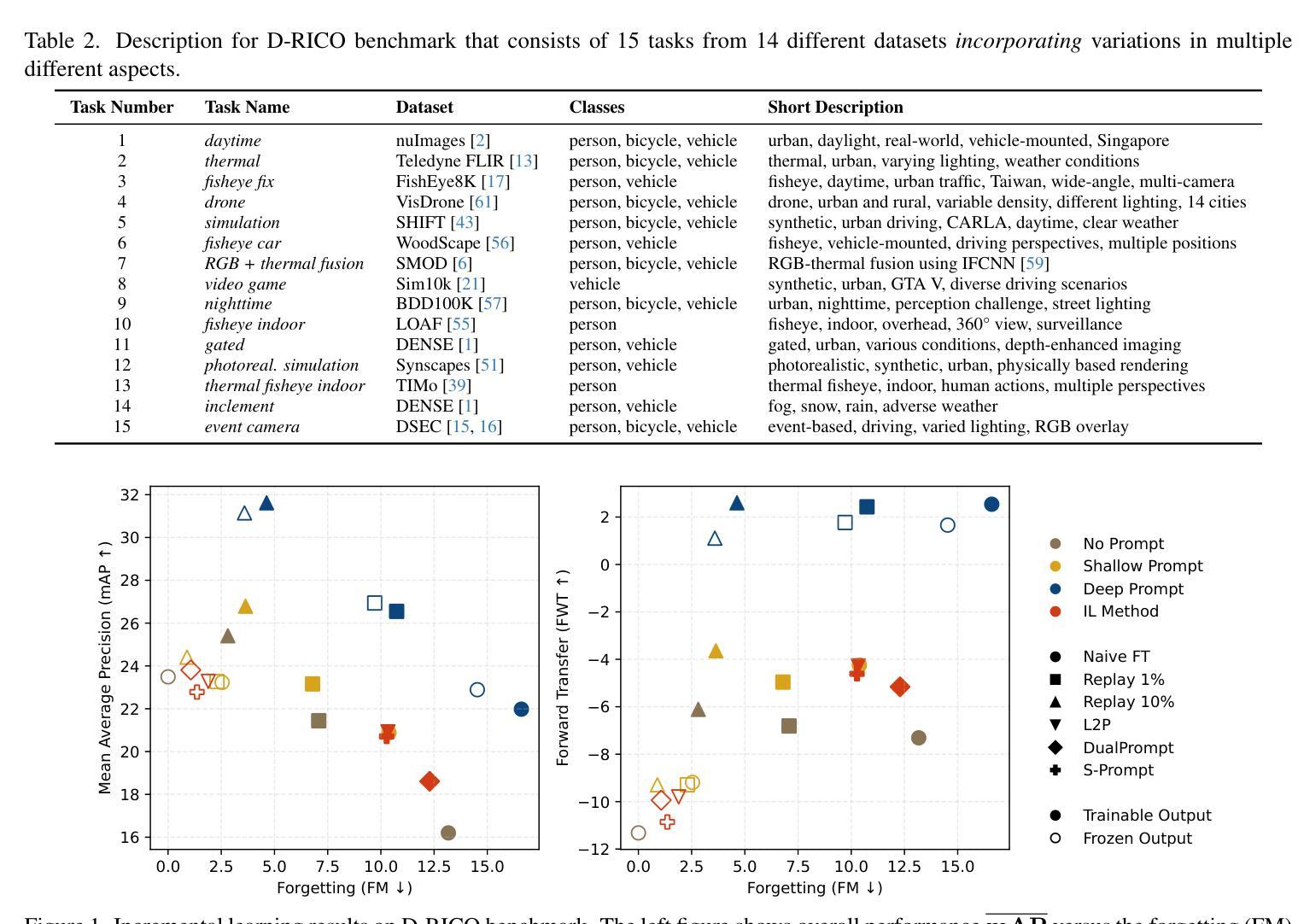
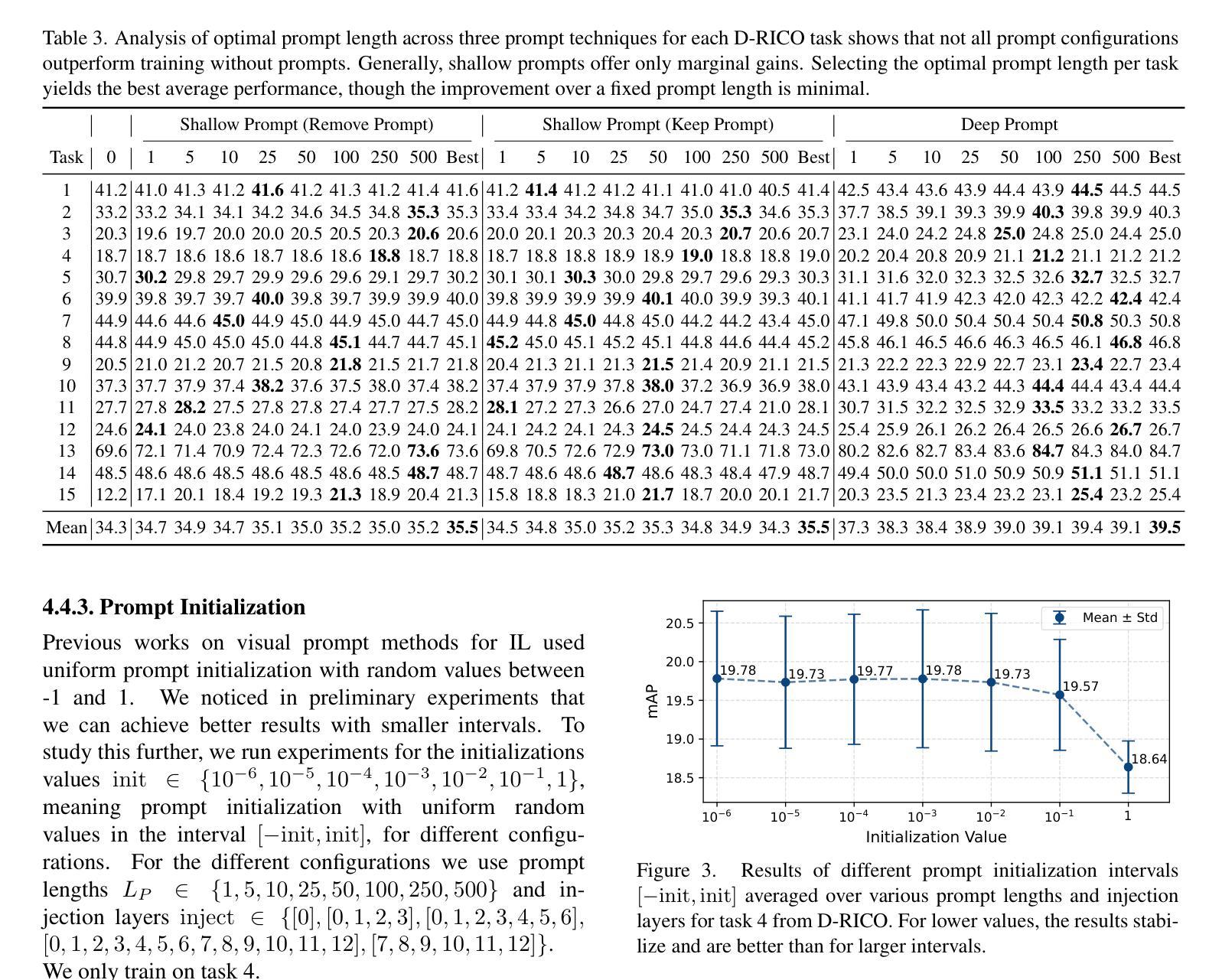
Incremental Object Detection with Prompt-based Methods
Authors:Matthias Neuwirth-Trapp, Maarten Bieshaar, Danda Pani Paudel, Luc Van Gool
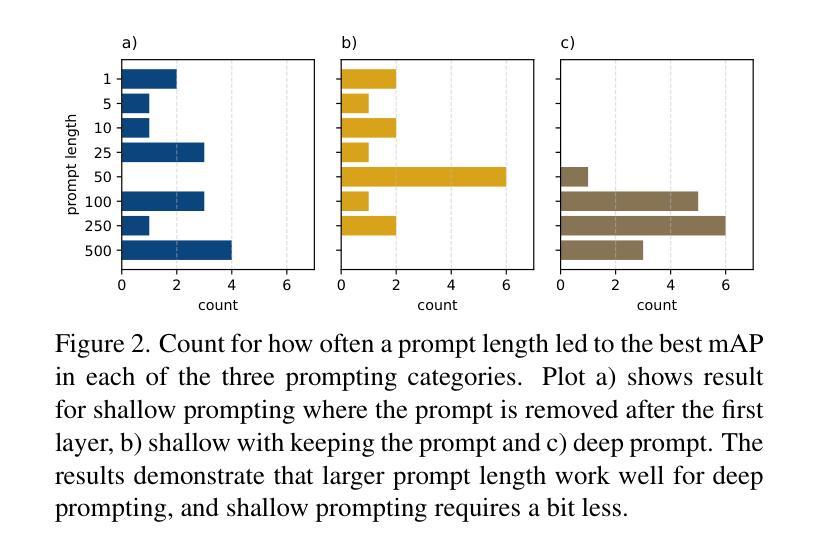
Visual prompt-based methods have seen growing interest in incremental learning (IL) for image classification. These approaches learn additional embedding vectors while keeping the model frozen, making them efficient to train. However, no prior work has applied such methods to incremental object detection (IOD), leaving their generalizability unclear. In this paper, we analyze three different prompt-based methods under a complex domain-incremental learning setting. We additionally provide a wide range of reference baselines for comparison. Empirically, we show that the prompt-based approaches we tested underperform in this setting. However, a strong yet practical method, combining visual prompts with replaying a small portion of previous data, achieves the best results. Together with additional experiments on prompt length and initialization, our findings offer valuable insights for advancing prompt-based IL in IOD.
基于视觉提示的方法在图像分类的增量学习(IL)中日益受到关注。这些方法在学习额外的嵌入向量时保持模型冻结,使它们训练效率很高。然而,之前的工作并未将此类方法应用于增量目标检测(IOD),使其泛化性尚不明确。在本文中,我们在复杂的域增量学习环境下分析了三种不同的基于提示的方法。我们还提供了一系列广泛的参考基线进行对比。从经验上看,我们在该环境下测试的基于提示的方法表现不佳。然而,一种强大而实用的方法,将视觉提示与回放一小部分之前的数据相结合,取得了最好的效果。此外,关于提示长度和初始化的附加实验,我们的研究为推进基于提示的IOD中的IL提供了宝贵的见解。
论文及项目相关链接
PDF Accepted to ICCV Workshops 2025
Summary
视觉提示方法对于图像分类的增量学习(IL)越来越受欢迎。这些方法在保持模型冻结的同时学习额外的嵌入向量,使得训练效率较高。然而,先前的工作尚未将这些方法应用于增量目标检测(IOD),其通用性尚不清楚。本文在一个复杂的域增量学习环境中分析了三种不同的基于提示的方法,并提供了广泛的参考基线进行对比。从经验上看,本文中测试的一些基于提示的方法在此设置中的表现不如预期,但通过结合视觉提示与回放部分之前的数据的有效方法仍能获得最佳结果。通过额外的关于提示长度和初始化的实验,本文的研究为推进基于提示的增量学习在增量目标检测中的发展提供了宝贵的见解。
Key Takeaways
- 基于视觉提示的方法在图像分类的增量学习中受到关注,但在增量目标检测中的应用尚不清楚。
- 在复杂的域增量学习环境中测试了三种基于提示的方法。
- 基于提示的方法在此设置中的表现不佳。
- 结合视觉提示与回放部分先前数据的实用方法表现最佳。
点此查看论文截图


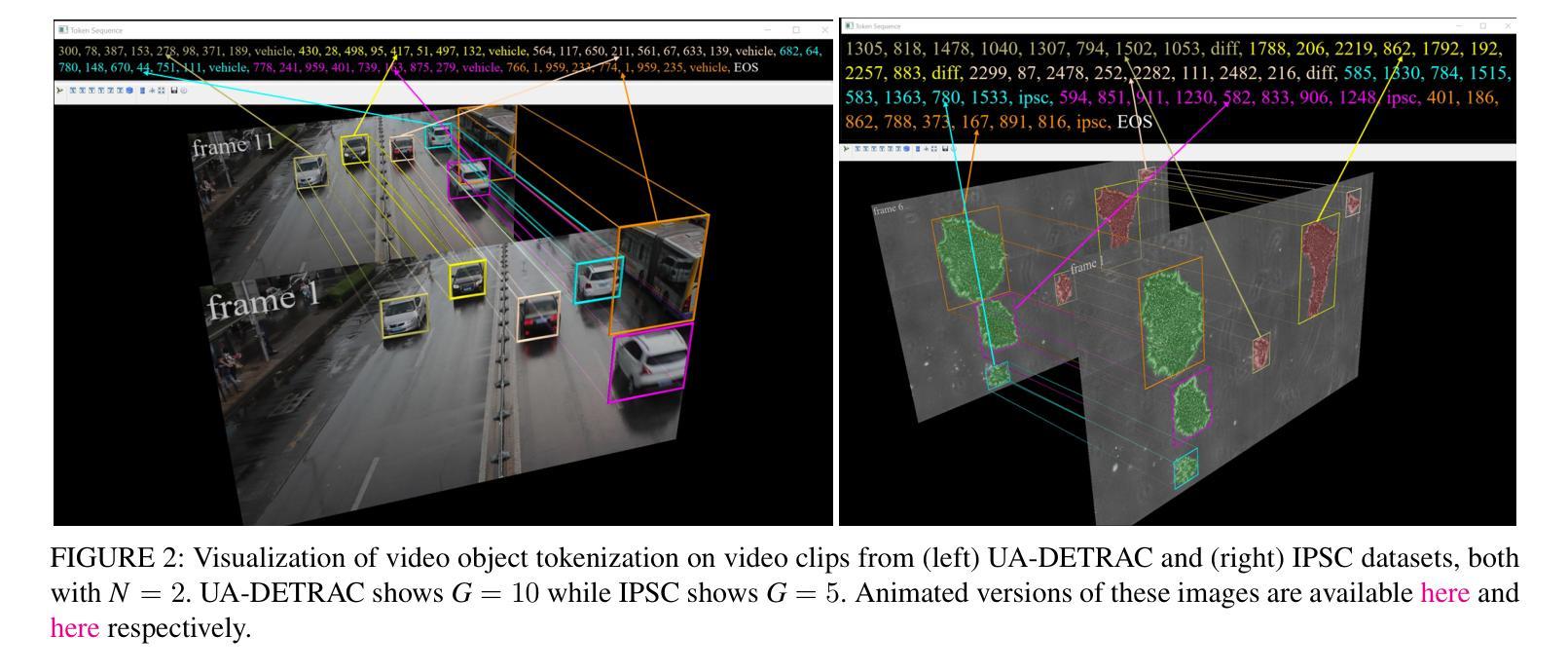
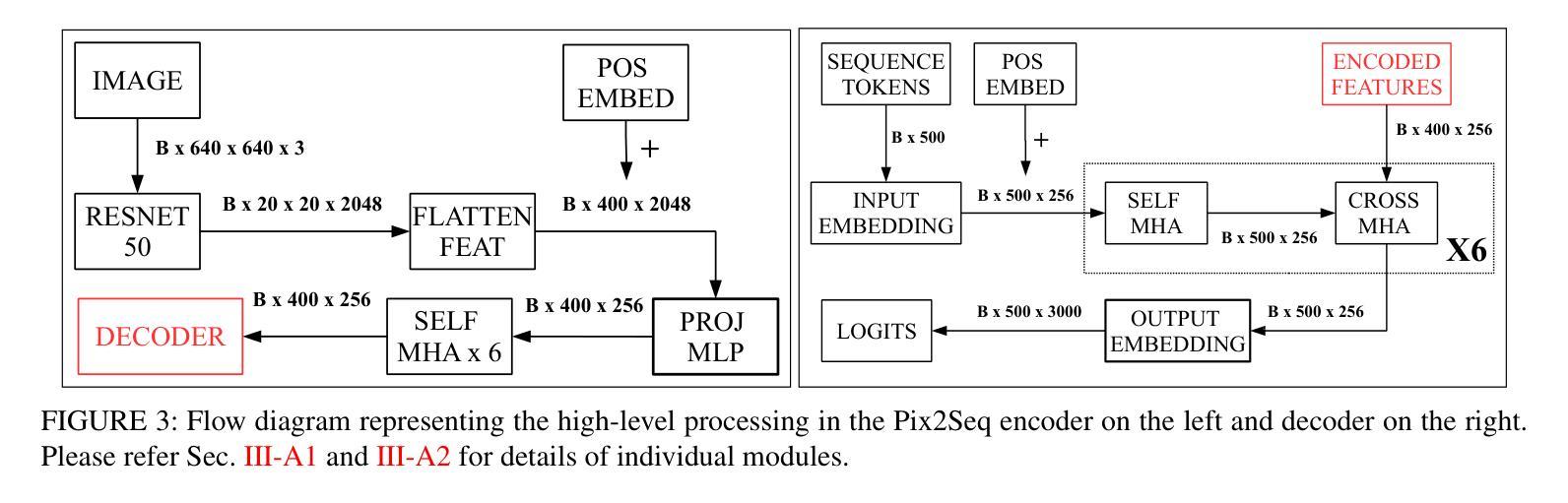
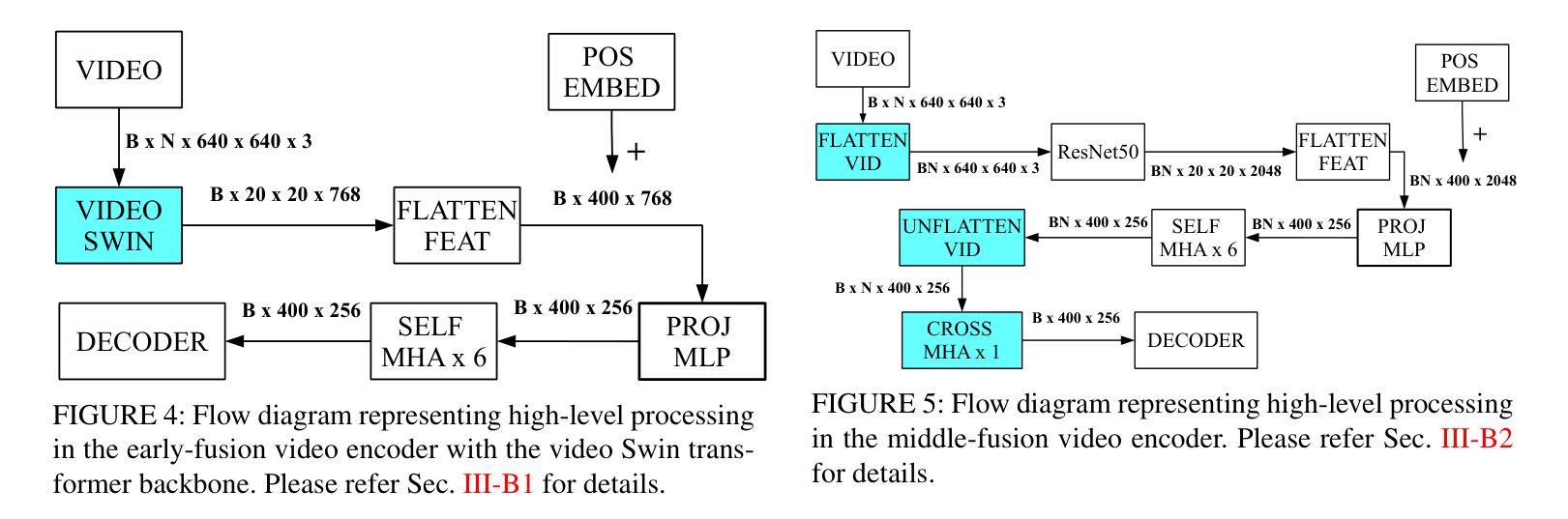
Improving Token-based Object Detection with Video
Authors:Abhineet Singh, Nilanjan Ray
This paper improves upon the Pix2Seq object detector by extending it for videos. In the process, it introduces a new way to perform end-to-end video object detection that improves upon existing video detectors in two key ways. First, by representing objects as variable-length sequences of discrete tokens, we can succinctly represent widely varying numbers of video objects, with diverse shapes and locations, without having to inject any localization cues in the training process. This eliminates the need to sample the space of all possible boxes that constrains conventional detectors and thus solves the dual problems of loss sparsity during training and heuristics-based postprocessing during inference. Second, it conceptualizes and outputs the video objects as fully integrated and indivisible 3D boxes or tracklets instead of generating image-specific 2D boxes and linking these boxes together to construct the video object, as done in most conventional detectors. This allows it to scale effortlessly with available computational resources by simply increasing the length of the video subsequence that the network takes as input, even generalizing to multi-object tracking if the subsequence can span the entire video. We compare our video detector with the baseline Pix2Seq static detector on several datasets and demonstrate consistent improvement, although with strong signs of being bottlenecked by our limited computational resources. We also compare it with several video detectors on UA-DETRAC to show that it is competitive with the current state of the art even with the computational bottleneck. We make our code and models publicly available.
本文改进了Pix2Seq目标检测器,将其扩展至视频领域。在此过程中,它引入了一种新的端到端视频目标检测方式,在两个关键方面改进了现有视频检测器。首先,通过将目标表示为离散标记的可变长度序列,我们可以简洁地表示数量众多、形状和位置各异的目标,而无需在训练过程中注入任何定位线索。这消除了需要对所有可能框的空间进行采样的需要,从而解决了传统检测器在训练过程中的损失稀疏问题和推理过程中的基于启发式规则的后处理问题。其次,它将视频目标概念化为完全集成和不可分的3D框或轨迹,而不是像大多数传统检测器那样生成特定的图像2D框,并将这些框连接起来构建视频目标。这使得它能够通过简单地增加网络作为输入的视频子序列的长度来轻松扩展计算资源,甚至在子序列可以跨越整个视频的情况下推广到多目标跟踪。我们在多个数据集上将我们的视频检测器与基线Pix2Seq静态检测器进行了比较,并展示了持续的改进,尽管受到我们有限的计算资源的限制。此外,我们在UA-DETRAC上与多种视频检测器进行了比较,以证明即使在计算瓶颈的情况下,它也是与当前最新技术相竞争的。我们的代码和模型是公开的。
论文及项目相关链接
PDF Published in IEEE Access
Summary
本文改进了Pix2Seq目标检测器,将其扩展至视频领域。文章引入了一种新的端到端视频目标检测方式,在两个方面超越了现有视频检测器。首先,通过把目标表示为离散代币的可变长度序列,能够简洁地表示数量众多、形状和位置各异的视频目标,而无需在训练过程中注入任何定位线索。这解决了传统检测器需要采样所有可能框的局限,并解决了训练过程中的损失稀疏性和推理过程中的基于启发式规则的后处理这两个问题。其次,它构思并输出视频目标为完整的、不可分割的3D框或轨迹,而不是生成特定的图像2D框,并将这些框连接起来构建视频目标(这是大多数传统检测器所做的)。这使得它能够轻松地随着可用的计算资源而扩展,通过简单地增加网络输入的视频子序列的长度,甚至可以推广到多目标跟踪,如果子序列能覆盖整个视频。我们在多个数据集上将我们的视频检测器与基线Pix2Seq静态检测器进行比较,表现出持续改进的迹象,尽管受到有限计算资源的限制。在与UA-DETRAC上的其他视频检测器的比较中,也显示出它即使受到计算瓶颈的限制,也处于当前技术的前沿。我们的代码和模型已公开可用。
Key Takeaways
- 文章改进了Pix2Seq目标检测器,使其适用于视频领域。
- 引入了一种新的端到端视频目标检测方式,能简洁表示不同数量和属性的视频目标。
- 通过将目标表示为离散代币序列,解决了训练过程中的损失稀疏问题和启发式后处理问题。
- 构思并输出视频目标为3D框或轨迹,不同于大多数传统检测器的2D框连接方式。
- 方法能够随着计算资源的增加轻松扩展,通过增加网络输入的视频子序列长度,甚至可以推广到多目标跟踪。
- 在多个数据集上与基线Pix2Seq静态检测器比较,表现出持续改进的趋势,尽管受限于计算资源。
- 与其他视频检测器相比,该方法具有竞争力,处于当前技术前沿,即使存在计算瓶颈。
点此查看论文截图