⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-22 更新
SATURN: Autoregressive Image Generation Guided by Scene Graphs
Authors:Thanh-Nhan Vo, Trong-Thuan Nguyen, Tam V. Nguyen, Minh-Triet Tran
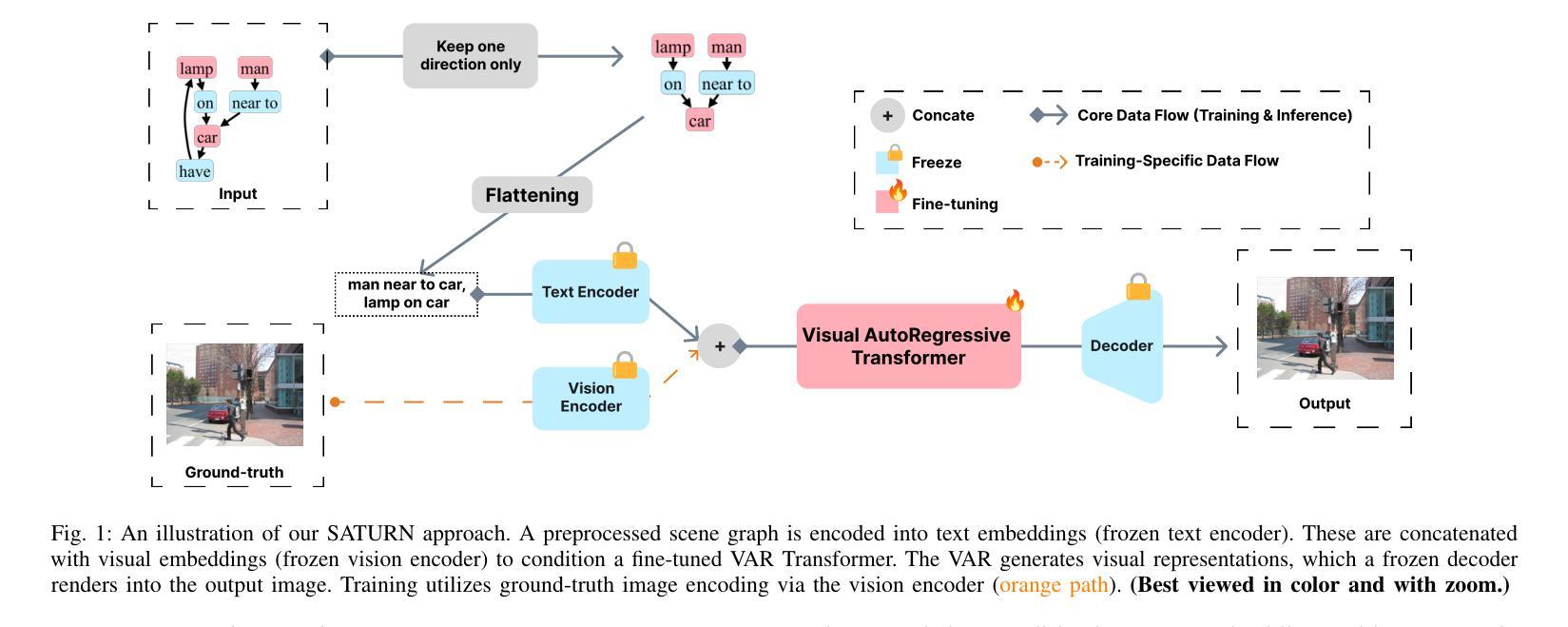
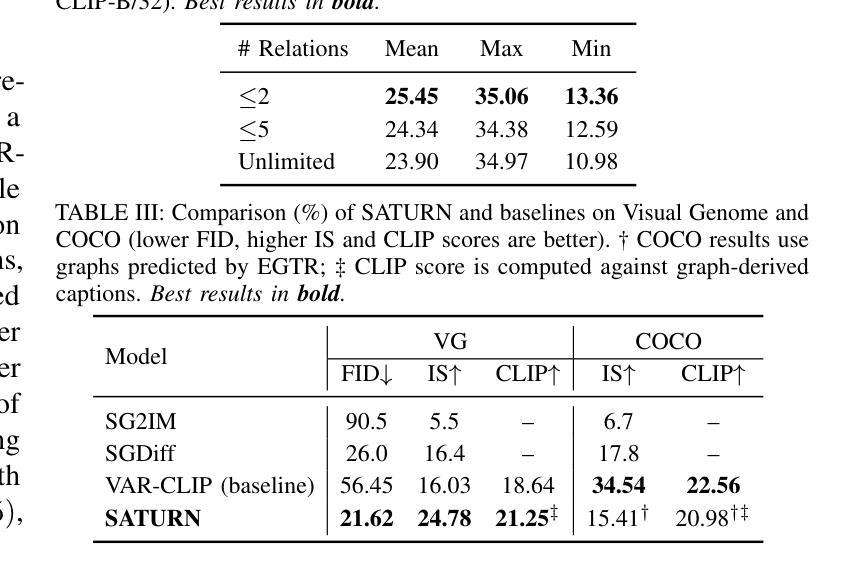
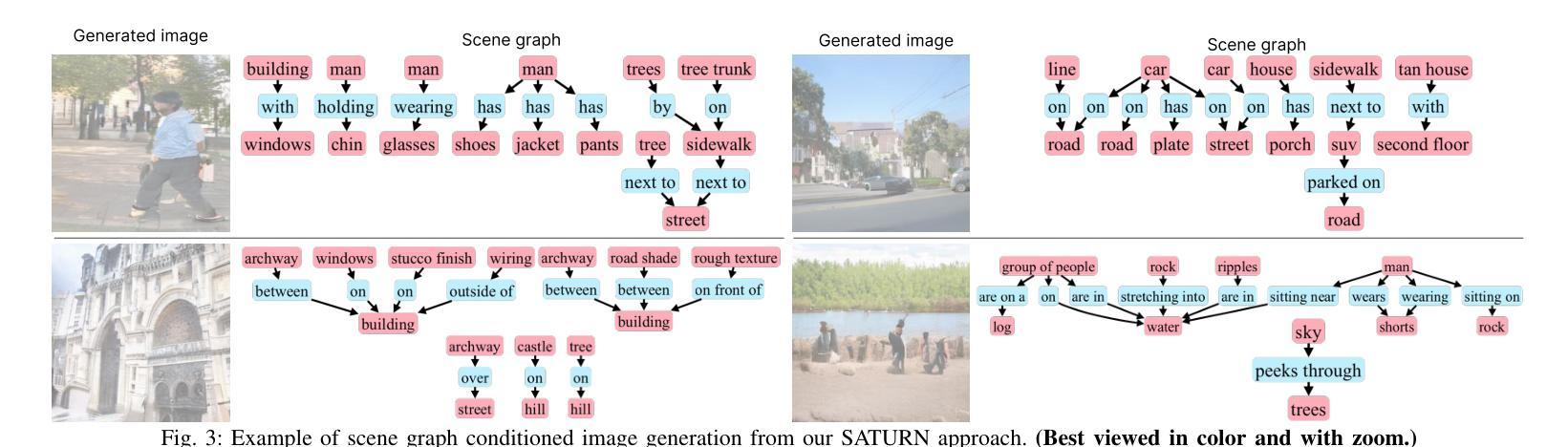
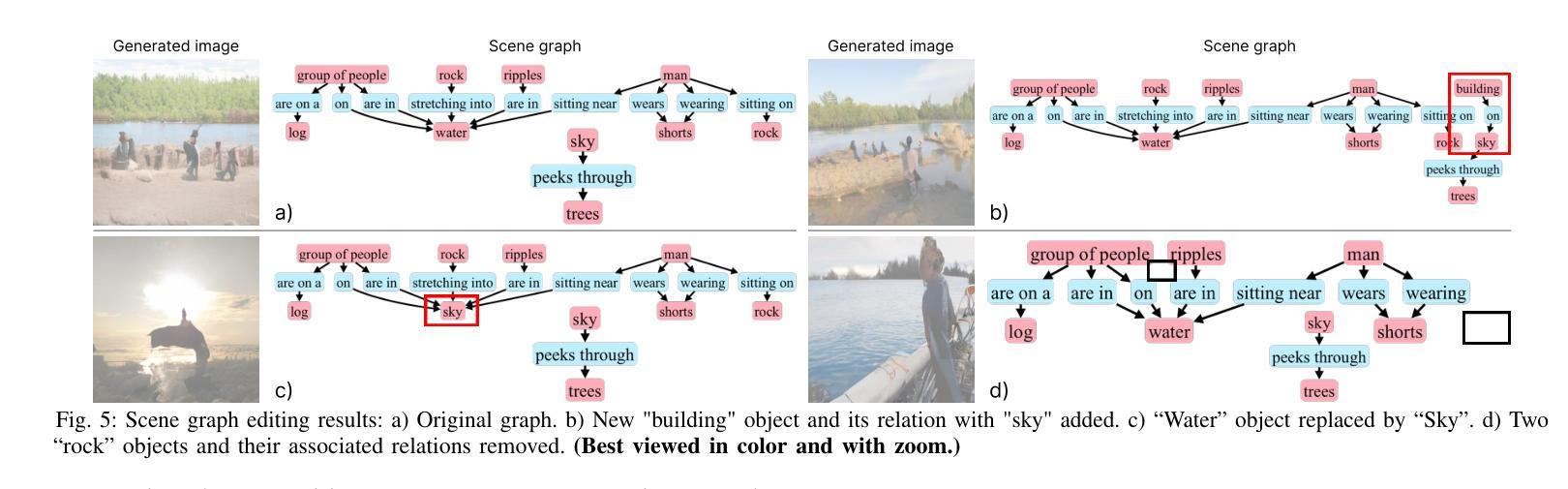
State-of-the-art text-to-image models excel at photorealistic rendering but often struggle to capture the layout and object relationships implied by complex prompts. Scene graphs provide a natural structural prior, yet previous graph-guided approaches have typically relied on heavy GAN or diffusion pipelines, which lag behind modern autoregressive architectures in both speed and fidelity. We introduce SATURN (Structured Arrangement of Triplets for Unified Rendering Networks), a lightweight extension to VAR-CLIP that translates a scene graph into a salience-ordered token sequence, enabling a frozen CLIP-VQ-VAE backbone to interpret graph structure while fine-tuning only the VAR transformer. On the Visual Genome dataset, SATURN reduces FID from 56.45% to 21.62% and increases the Inception Score from 16.03 to 24.78, outperforming prior methods such as SG2IM and SGDiff without requiring extra modules or multi-stage training. Qualitative results further confirm improvements in object count fidelity and spatial relation accuracy, showing that SATURN effectively combines structural awareness with state-of-the-art autoregressive fidelity.
当前先进的文本到图像模型在逼真渲染方面表现出色,但往往难以捕捉复杂提示所隐含的布局和对象关系。场景图提供了一种自然的结构先验,但以前的图引导方法通常依赖于沉重的GAN或扩散管道,这在速度和保真度方面都落后于现代的自回归架构。我们介绍了SATURN(用于统一渲染网络的三元组结构排列),这是VAR-CLIP的一个轻量级扩展,它将场景图翻译成显著性排序的令牌序列,使得冻结的CLIP-VQ-VAE主干能够解释图形结构,同时只需要微调VAR变压器。在视觉基因组数据集上,SATURN将FID从56.45%降低到21.62%,并将Inception Score从16.03提高到24.78,优于不需要额外模块或多阶段训练的SG2IM和SGDiff等先前方法。定性结果进一步证实了对象计数保真度和空间关系准确性的提高,表明SATURN有效地结合了结构意识和最先进的自回归保真度。
论文及项目相关链接
PDF Accepted to MAPR 2025
Summary
本文介绍了SATURN(用于统一渲染网络的三元组结构排列)技术,该技术是对VAR-CLIP的轻量级扩展,可将场景图翻译为重要性排序的令牌序列。SATURN使冻结的CLIP-VQ-VAE后端能够解释图形结构,同时只微调VAR变压器。在视觉基因组数据集上,SATURN降低了FID(从56.45%降至21.62%),提高了Inception Score(从16.03增至24.78),在不需要额外模块或多阶段训练的情况下,优于SG2IM和SGDiff等先前方法。定性结果进一步证实了其在对象计数保真度和空间关系准确性方面的改进,表明SATURN有效地结合了结构意识和最先进的自回归保真度。
Key Takeaways
- SATURN技术是对VAR-CLIP模型的改进,能够翻译场景图为令牌序列。
- SATURN提高了模型对图形结构的解释能力。
- 通过轻量级扩展,SATURN实现了在视觉基因组数据集上的高性能表现,降低了FID并提高了Inception Score。
- SATURN在对象计数保真度和空间关系准确性方面有所改进。
- SATURN技术不需要额外的模块或多阶段训练。
- SATURN与其他先前的方法如SG2IM和SGDiff相比具有优越性。
点此查看论文截图



2D Gaussians Meet Visual Tokenizer
Authors:Yiang Shi, Xiaoyang Guo, Wei Yin, Mingkai Jia, Qian Zhang, Xiaolin Hu, Wenyu Liu, Xinggang Wang
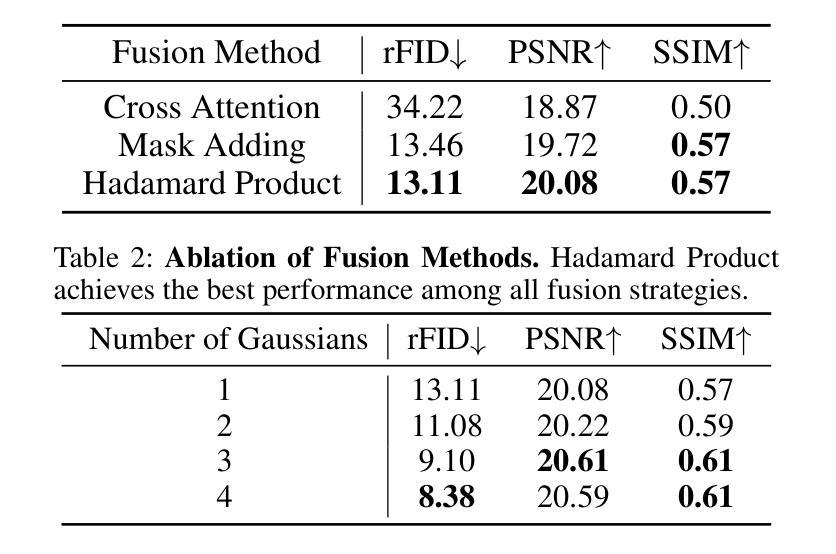
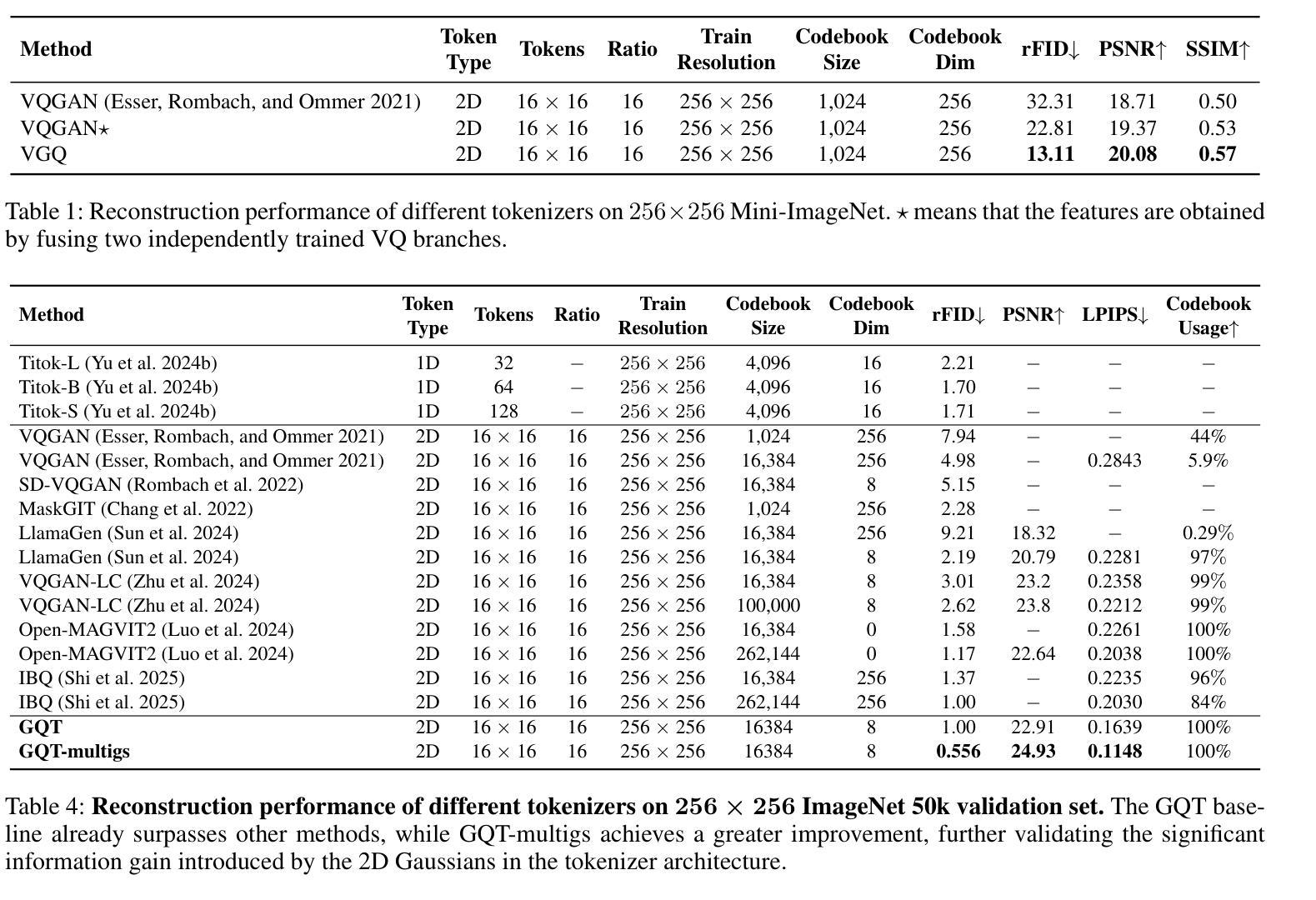
The image tokenizer is a critical component in AR image generation, as it determines how rich and structured visual content is encoded into compact representations. Existing quantization-based tokenizers such as VQ-GAN primarily focus on appearance features like texture and color, often neglecting geometric structures due to their patch-based design. In this work, we explored how to incorporate more visual information into the tokenizer and proposed a new framework named Visual Gaussian Quantization (VGQ), a novel tokenizer paradigm that explicitly enhances structural modeling by integrating 2D Gaussians into traditional visual codebook quantization frameworks. Our approach addresses the inherent limitations of naive quantization methods such as VQ-GAN, which struggle to model structured visual information due to their patch-based design and emphasis on texture and color. In contrast, VGQ encodes image latents as 2D Gaussian distributions, effectively capturing geometric and spatial structures by directly modeling structure-related parameters such as position, rotation and scale. We further demonstrate that increasing the density of 2D Gaussians within the tokens leads to significant gains in reconstruction fidelity, providing a flexible trade-off between token efficiency and visual richness. On the ImageNet 256x256 benchmark, VGQ achieves strong reconstruction quality with an rFID score of 1.00. Furthermore, by increasing the density of 2D Gaussians within the tokens, VGQ gains a significant boost in reconstruction capability and achieves a state-of-the-art reconstruction rFID score of 0.556 and a PSNR of 24.93, substantially outperforming existing methods. Codes will be released soon.
图像标记器是AR图像生成中的关键组件,因为它决定了丰富的结构化视觉内容如何被编码成紧凑的表示形式。现有的基于量化的标记器(如VQ-GAN)主要关注纹理和颜色等外观特征,但由于其基于补丁的设计,往往忽略了几何结构。在这项工作中,我们探讨了如何将更多的视觉信息融入标记器,并提出了一种新的框架——视觉高斯量化(VGQ),这是一种新型的标记器范式,通过在传统视觉代码本量化框架中融入二维高斯值来显式增强结构建模。我们的方法解决了诸如VQ-GAN等简单量化方法的固有局限性,由于它们基于补丁的设计和强调纹理和颜色,因此在建模结构化视觉信息方面存在困难。相比之下,VGQ将图像潜在变量编码为二维高斯分布,通过直接建模与结构相关的参数(如位置、旋转和尺度)来有效地捕获几何和空间结构。我们进一步证明,通过在标记内增加二维高斯值的密度,可以在重建保真度方面实现显著的提升,在标记效率和视觉丰富性之间提供了灵活的权衡。在ImageNet 256x256基准测试中,VGQ以rFID得分1.00实现了强大的重建质量。此外,通过增加标记内二维高斯值的密度,VGQ在重建能力上获得了重大提升,并实现了最先进的重建rFID得分0.556和PSNR 24.93,大大优于现有方法。代码将很快发布。
论文及项目相关链接
Summary
本文介绍了图像分词器在AR图像生成中的重要性,并探讨了如何在传统视觉代码本量化框架中融入更多的视觉信息。提出了一种名为视觉高斯量化(VGQ)的新方法,该方法通过整合二维高斯分布来强化结构建模,有效捕捉图像中的几何和空间结构信息。在ImageNet 256x256基准测试中,VGQ取得了强大的重建质量,并通过增加令牌内二维高斯分布的密度,实现了显著的重建能力提升。
Key Takeaways
- 图像分词器是AR图像生成中的关键组件,负责将丰富的视觉内容编码成紧凑的表示形式。
- 现有基于量化的分词器如VQ-GAN主要关注外观特征(如纹理和颜色),而忽视几何结构。
- VGQ是一种新型分词器范式,通过整合二维高斯分布来增强结构建模,有效捕捉图像中的几何和空间结构信息。
- VGQ解决了传统量化方法(如VQ-GAN)在建模结构化视觉信息方面的固有局限性。
- VGQ通过编码图像潜在值作为二维高斯分布,直接建模结构相关参数(如位置、旋转和尺度)。
- 增加令牌内二维高斯分布的密度可以显著提高重建保真度,实现令牌效率和视觉丰富性之间的灵活权衡。
点此查看论文截图


Identity Preserving 3D Head Stylization with Multiview Score Distillation
Authors:Bahri Batuhan Bilecen, Ahmet Berke Gokmen, Furkan Guzelant, Aysegul Dundar
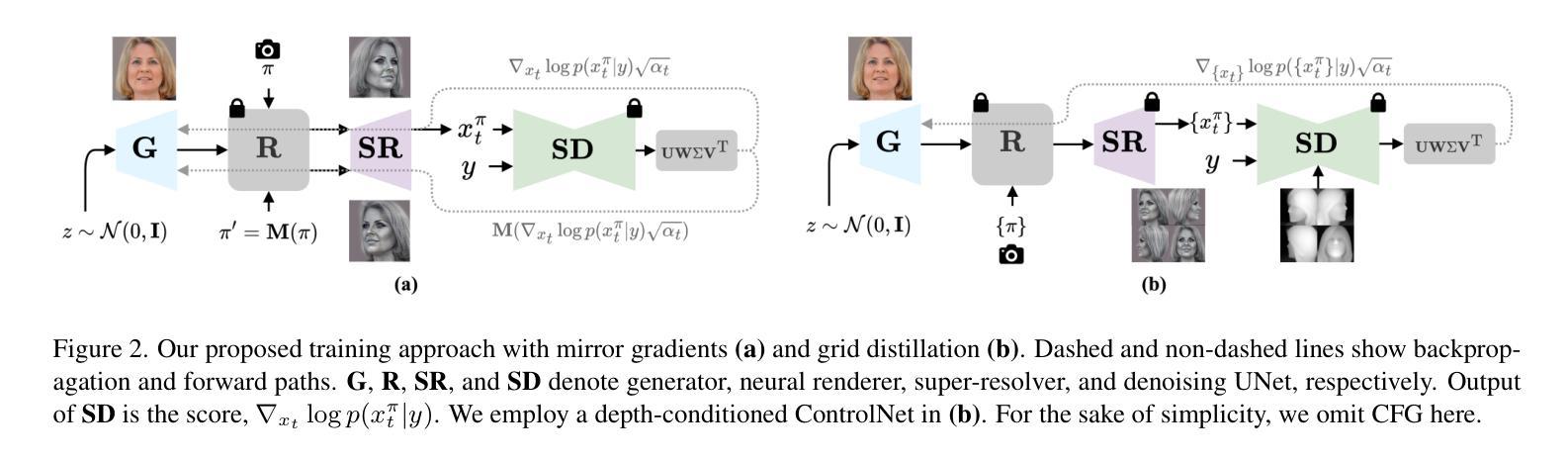
3D head stylization transforms realistic facial features into artistic representations, enhancing user engagement across gaming and virtual reality applications. While 3D-aware generators have made significant advancements, many 3D stylization methods primarily provide near-frontal views and struggle to preserve the unique identities of original subjects, often resulting in outputs that lack diversity and individuality. This paper addresses these challenges by leveraging the PanoHead model, synthesizing images from a comprehensive 360-degree perspective. We propose a novel framework that employs negative log-likelihood distillation (LD) to enhance identity preservation and improve stylization quality. By integrating multi-view grid score and mirror gradients within the 3D GAN architecture and introducing a score rank weighing technique, our approach achieves substantial qualitative and quantitative improvements. Our findings not only advance the state of 3D head stylization but also provide valuable insights into effective distillation processes between diffusion models and GANs, focusing on the critical issue of identity preservation. Please visit the https://three-bee.github.io/head_stylization for more visuals.
3D头部风格化转换能将真实的面部特征转化为艺术表现形式,增强游戏和虚拟现实应用中的用户参与度。虽然3D感知生成器已经取得了重大进展,但许多3D风格化方法主要提供近正面视图,并且在保持原始主体的独特身份方面存在困难,往往导致输出结果缺乏多样性和个性化。本文利用PanoHead模型,从全面的360度视角合成图像,应对这些挑战。我们提出了一种采用负对数似然蒸馏(LD)的新型框架,以提高身份保留和提高风格化质量。通过在3D GAN架构中整合多视图网格评分和镜像梯度,并引入评分排名加权技术,我们的方法在定性和定量方面都取得了显著改进。我们的研究不仅推动了3D头部风格化的现状,而且为扩散模型和GAN之间的有效蒸馏过程提供了有价值的见解,重点关注身份保留的关键问题。想了解更多视觉效果,请访问https://three-bee.github.io/head_stylization。
论文及项目相关链接
PDF https://three-bee.github.io/head_stylization
Summary
本文介绍了基于PanoHead模型的3D头部风格化技术,该技术可以从全方位的视角合成图像,解决了现有方法在头部风格化时主要提供近正面视角的问题。文章提出了一种新的框架,采用负对数似然蒸馏(LD)技术增强身份保留并提高风格化质量。通过整合多视角网格评分和镜像梯度在3D GAN架构中,并引入评分排名加权技术,该方法在质量和数量上都取得了显著的改进,不仅推动了3D头部风格化的状态,也为扩散模型和GAN之间的有效蒸馏过程提供了有价值的见解。
Key Takeaways
- 3D头部风格化技术能够增强用户在游戏和虚拟现实应用中的参与度,将现实面部特征转化为艺术表现形式。
- 当前3D风格化方法主要提供近正面视角,缺乏多样性和个性化。
- PanoHead模型可以从全方位的视角合成图像,解决了上述限制。
- 新型框架采用负对数似然蒸馏技术来提升身份保留和风格化质量。
- 通过整合多视角网格评分和镜像梯度在3D GAN架构中,实现了显著的性能提升。
- 引入的评分排名加权技术有助于提高风格化的质量。
点此查看论文截图




Parallelly Tempered Generative Adversarial Nets: Toward Stabilized Gradients
Authors:Jinwon Sohn, Qifan Song
A generative adversarial network (GAN) has been a representative backbone model in generative artificial intelligence (AI) because of its powerful performance in capturing intricate data-generating processes. However, the GAN training is well-known for its notorious training instability, usually characterized by the occurrence of mode collapse. Through the lens of gradients’ variance, this work particularly analyzes the training instability and inefficiency in the presence of mode collapse by linking it to multimodality in the target distribution. To ease the raised training issues from severe multimodality, we introduce a novel GAN training framework that leverages a series of tempered distributions produced via convex interpolation. With our newly developed GAN objective function, the generator can learn all the tempered distributions simultaneously, conceptually resonating with the parallel tempering in statistics. Our simulation studies demonstrate the superiority of our approach over existing popular training strategies in both image and tabular data synthesis. We theoretically analyze that such significant improvement can arise from reducing the variance of gradient estimates by using the tempered distributions. Finally, we further develop a variant of the proposed framework aimed at generating fair synthetic data which is one of the growing interests in the field of trustworthy AI.
生成对抗网络(GAN)因其捕捉复杂数据生成过程方面的强大性能,已成为生成式人工智能(AI)中的代表性骨干模型。然而,GAN训练因其众所周知的训练不稳定而备受关注,通常表现为模式崩溃的出现。本文从梯度的方差角度,特别分析了模式崩溃下的训练不稳定性和低效率,并将其与目标分布的多元性联系起来。为了解决由严重多元性引起的训练问题,我们引入了一种新型的GAN训练框架,该框架利用通过凸插值产生的一系列温和分布。通过我们新开发的GAN目标函数,生成器可以同时学习所有的温和分布,这在概念上与统计中的并行模拟相契合。我们的模拟研究表明,我们的方法在图像和表格数据合成方面优于现有的流行训练策略。我们从理论上分析了这种显著改进可能是由于使用温和分布减少梯度估计的方差而产生的。最后,我们进一步开发了一种所提出的框架的变体,旨在生成公平的合成数据,这是可信人工智能领域日益关注的重点之一。
论文及项目相关链接
Summary
生成对抗网络(GAN)在生成人工智能中是一种具有代表性的骨干模型,其捕捉复杂数据生成过程的能力强大。然而,GAN训练存在众所周知的训练不稳定问题,通常表现为模式崩溃。本文通过梯度的方差来分析模式崩溃下的训练不稳定性和低效率,并将其与目标分布中的多模态性联系起来。为了解决由严重多模态性引发的训练问题,我们引入了一种新型GAN训练框架,该框架利用通过凸插值产生的系列温和分布。使用我们新开发的GAN目标函数,生成器可以同时学习所有温和分布,这与统计中的并行回火在概念上相呼应。仿真研究表明,我们的方法在图像和表格数据合成方面优于现有的流行训练策略。我们从使用温和分布减少梯度估计的方差方面进行了理论分析,认为这种显著改进是可能的。最后,我们进一步开发了一种针对生成公平合成数据的提议框架的变体,这是可信人工智能领域日益关注的一个话题。
Key Takeaways
- GAN作为生成人工智能的代表模型,具有捕捉复杂数据生成过程的能力。
- GAN训练存在训练不稳定和模式崩溃的问题。
- 本文通过梯度的方差分析训练不稳定性和低效率,将其与多模态目标分布相联系。
- 引入新型GAN训练框架,利用温和分布解决多模态导致的训练问题。
- 新GAN目标函数使生成器能同时学习所有温和分布。
- 仿真研究证明该方法在图像和表格数据合成方面优于现有策略。
点此查看论文截图