⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-22 更新
MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Authors:Ailing Yu, Lan Yao, Jingnan Liu, Zhe Chen, Jiajun Yin, Yuan Wang, Xinhao Liao, Zhiling Ye, Ji Li, Yun Yue, Hansong Xiao, Hualei Zhou, Chunxiao Guo, Peng Wei, Jinjie Gu
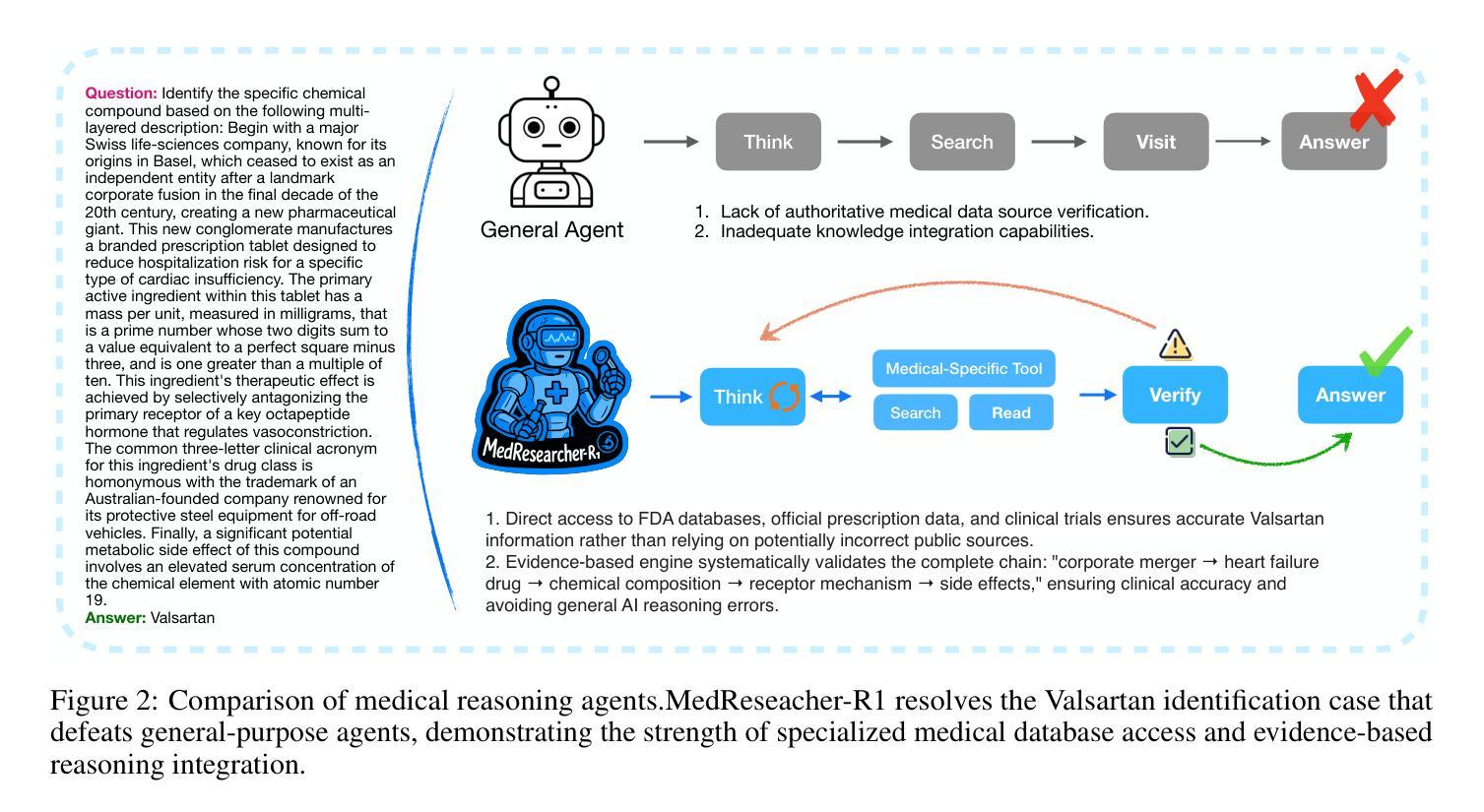
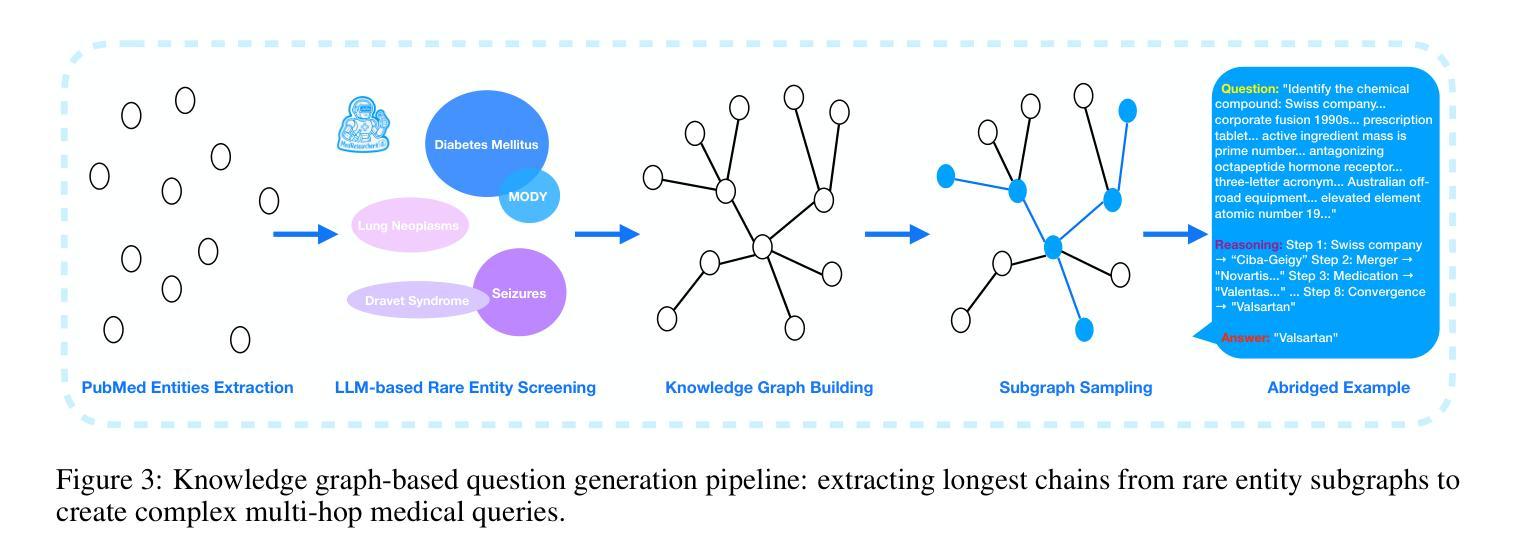
Recent developments in Large Language Model (LLM)-based agents have shown impressive capabilities spanning multiple domains, exemplified by deep research systems that demonstrate superior performance on complex information-seeking and synthesis tasks. While general-purpose deep research agents have shown impressive capabilities, they struggle significantly with medical domain challenges, as evidenced by leading proprietary systems achieving limited accuracy on complex medical benchmarks. The key limitations are: (1) the model lacks sufficient dense medical knowledge for clinical reasoning, and (2) the framework is constrained by the absence of specialized retrieval tools tailored for medical contexts.We present a medical deep research agent that addresses these challenges through two core innovations. First, we develop a novel data synthesis framework using medical knowledge graphs, extracting the longest chains from subgraphs around rare medical entities to generate complex multi-hop question-answer pairs. Second, we integrate a custom-built private medical retrieval engine alongside general-purpose tools, enabling accurate medical information synthesis. Our approach generates 2100+ diverse trajectories across 12 medical specialties, each averaging 4.2 tool interactions.Through a two-stage training paradigm combining supervised fine-tuning and online reinforcement learning with composite rewards, our MedResearcher-R1-32B model demonstrates exceptional performance, establishing new state-of-the-art results on medical benchmarks while maintaining competitive performance on general deep research tasks. Our work demonstrates that strategic domain-specific innovations in architecture, tool design, and training data construction can enable smaller open-source models to outperform much larger proprietary systems in specialized domains.
最近基于大型语言模型(LLM)的代理人的发展显示出令人印象深刻的跨多个领域的能力,以深度研究系统为例,它们在复杂的信息检索和综合任务上表现出卓越的性能。虽然通用深度研究代理人在许多领域表现出强大的能力,但他们在医学领域面临巨大挑战,领先的专有系统在最先进的医学基准测试上的准确率有限,证明了这一点。主要限制因素有:(1)模型缺乏用于临床推理的充足密集医学知识;(2)框架受到缺乏针对医学上下文定制的专用检索工具的制约。我们提出了一种医学深度研究代理人,通过两个核心创新来解决这些挑战。首先,我们利用医学知识图谱开发了一种新型数据合成框架,从围绕罕见医学实体的子图中提取最长的链来生成复杂的多跳问答对。其次,我们将自定义的私有医学检索引擎与通用工具集成在一起,以实现准确医学信息的综合。我们的方法在12个医学专业领域生成了超过2100条不同的轨迹,每个轨迹平均交互4.2个工具。通过结合监督微调的两阶段训练模式和在线强化学习以及复合奖励,我们的MedResearcher-R1-32B模型在医学基准测试上取得了卓越的性能,建立了新的最新结果,同时在一般深度研究任务上保持竞争力。我们的工作表明,在架构、工具设计和训练数据构建方面的战略领域特定创新,可以使较小的开源模型在专门领域中超越更大的专有系统。
论文及项目相关链接
PDF 13 pages, 5 figures
Summary:近期大型语言模型(LLM)在多个领域展现出强大的能力,但在医疗领域面临挑战。通过创新的数据合成框架和定制医疗检索引擎,我们提出了一种医疗深度研究代理人来解决这些问题。该代理人生成了超过2100条跨越12个医学专业的不同轨迹,并通过结合监督微调与在线强化学习的两阶段训练模式,实现了在医疗基准测试上的卓越表现。
Key Takeaways:
- LLM在多个领域表现出强大的能力,但在医疗领域面临挑战。
- 医疗深度研究代理人通过数据合成框架和定制医疗检索引擎解决这些问题。
- 代理人生成了超过2100条医学专业的不同轨迹。
- 该代理人结合监督微调与在线强化学习进行两阶段训练。
- MedResearcher-R1-32B模型在医疗基准测试上实现卓越表现,同时保持对一般深度研究任务的竞争力。
点此查看论文截图

Universal and Transferable Adversarial Attack on Large Language Models Using Exponentiated Gradient Descent
Authors:Sajib Biswas, Mao Nishino, Samuel Jacob Chacko, Xiuwen Liu
As large language models (LLMs) are increasingly deployed in critical applications, ensuring their robustness and safety alignment remains a major challenge. Despite the overall success of alignment techniques such as reinforcement learning from human feedback (RLHF) on typical prompts, LLMs remain vulnerable to jailbreak attacks enabled by crafted adversarial triggers appended to user prompts. Most existing jailbreak methods either rely on inefficient searches over discrete token spaces or direct optimization of continuous embeddings. While continuous embeddings can be given directly to selected open-source models as input, doing so is not feasible for proprietary models. On the other hand, projecting these embeddings back into valid discrete tokens introduces additional complexity and often reduces attack effectiveness. We propose an intrinsic optimization method which directly optimizes relaxed one-hot encodings of the adversarial suffix tokens using exponentiated gradient descent coupled with Bregman projection, ensuring that the optimized one-hot encoding of each token always remains within the probability simplex. We provide theoretical proof of convergence for our proposed method and implement an efficient algorithm that effectively jailbreaks several widely used LLMs. Our method achieves higher success rates and faster convergence compared to three state-of-the-art baselines, evaluated on five open-source LLMs and four adversarial behavior datasets curated for evaluating jailbreak methods. In addition to individual prompt attacks, we also generate universal adversarial suffixes effective across multiple prompts and demonstrate transferability of optimized suffixes to different LLMs.
随着大型语言模型(LLM)在关键应用中的部署越来越多,确保其鲁棒性和安全对齐仍然是一个主要挑战。尽管强化学习从人类反馈(RLHF)等对齐技术在典型提示上的总体成功,但LLM仍容易受到通过用户提示附加的精心制作的对抗性触发而启动的越狱攻击(jailbreak attacks)的影响。现有的大多数越狱方法要么依赖于离散令牌空间上的低效搜索,要么直接优化连续嵌入。虽然可以将这些连续嵌入直接作为选定开源模型的输入,但对于专有模型这样做并不可行。另一方面,将这些嵌入投影回有效的离散令牌引入了额外的复杂性,并且往往会降低攻击的有效性。我们提出了一种内在的优化方法,该方法直接使用指数梯度下降法结合Bregman投影优化对抗性后缀令牌的松弛独热编码,确保每个令牌优化后的独热编码始终保持在概率单纯形内。我们为所提出的方法提供了收敛性的理论证明,并实现了一种有效的算法,该算法能够有效地突破几种广泛使用的LLM。与三种最先进的基线相比,我们的方法在五个开源LLM和四个用于评估越狱方法的对抗行为数据集上实现了更高的成功率和更快的收敛速度。除了单个提示攻击之外,我们还生成了跨多个提示有效的通用对抗性后缀,并证明了优化后缀在不同LLM之间的可迁移性。
论文及项目相关链接
Summary
大型语言模型(LLMs)在关键应用中的部署日益增加,但其鲁棒性和安全对齐性仍然是一个重大挑战。尽管强化学习从人类反馈(RLHF)等对齐技术在典型提示上取得了总体成功,但LLMs仍容易遭受由特定恶意触发词触发的越狱攻击。本文提出了一种针对LLMs的内在优化方法,直接优化松弛的one-hot编码对抗后缀令牌,使用指数梯度下降与布雷格曼投影相结合的方法。该方法实现了较高的成功率并实现了快速收敛,与三种最先进的基线相比具有优势,并在五个开源LLMs和四个越狱方法评估的对抗行为数据集上进行了评估。除了针对个别提示的攻击外,我们还生成了有效的跨多个提示的通用对抗后缀,并证明了优化后缀在不同LLMs之间的可转移性。
Key Takeaways
- 大型语言模型(LLMs)在关键应用中的部署面临鲁棒性和安全性的挑战。
- 尽管有强化学习从人类反馈(RLHF)等对齐技术,LLMs仍易受特定恶意触发词触发的越狱攻击。
- 现有越狱方法包括在离散令牌空间上的低效搜索或直接优化连续嵌入,但对于专有模型不可行。
- 本文提出了一种内在优化方法,直接优化松弛的one-hot编码对抗后缀令牌,使用指数梯度下降与布雷格曼投影结合。
- 该方法实现了较高的成功率并快速收敛,优于三种最先进的基线方法。
- 方法在五个开源LLMs和四个越狱方法评估的对抗行为数据集上进行了验证。
点此查看论文截图

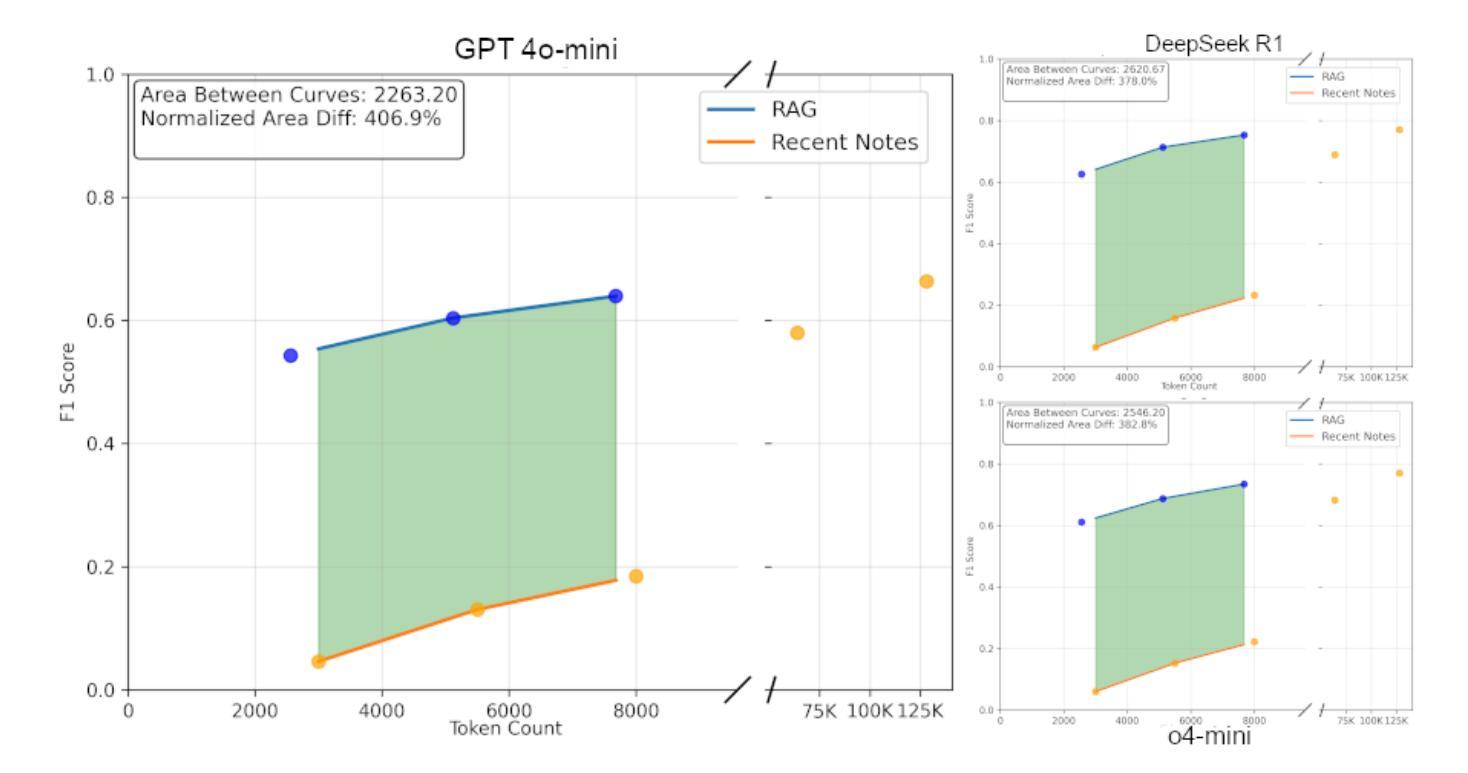
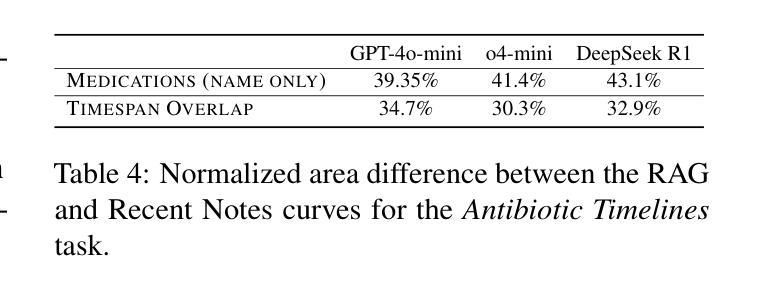
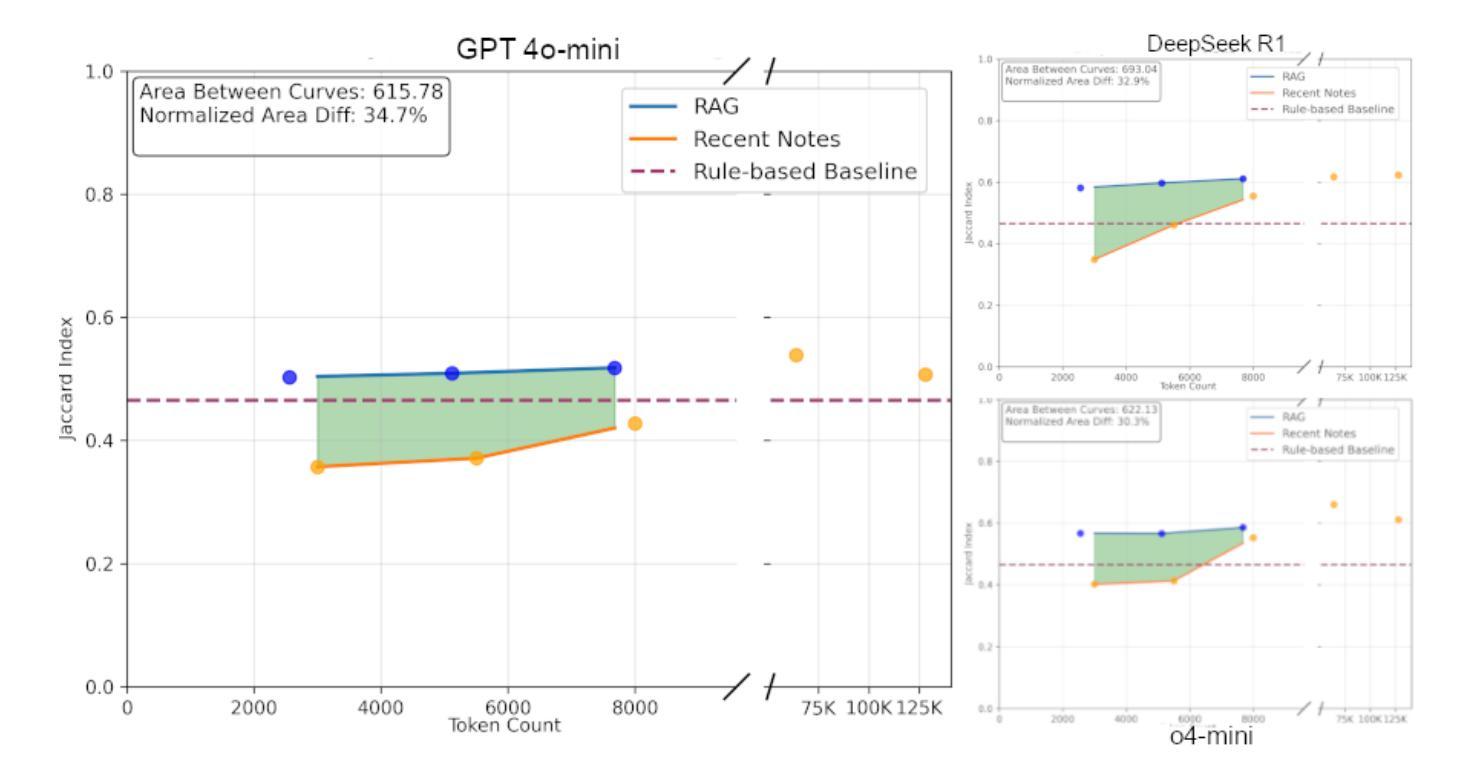
Evaluating Retrieval-Augmented Generation vs. Long-Context Input for Clinical Reasoning over EHRs
Authors:Skatje Myers, Dmitriy Dligach, Timothy A. Miller, Samantha Barr, Yanjun Gao, Matthew Churpek, Anoop Mayampurath, Majid Afshar
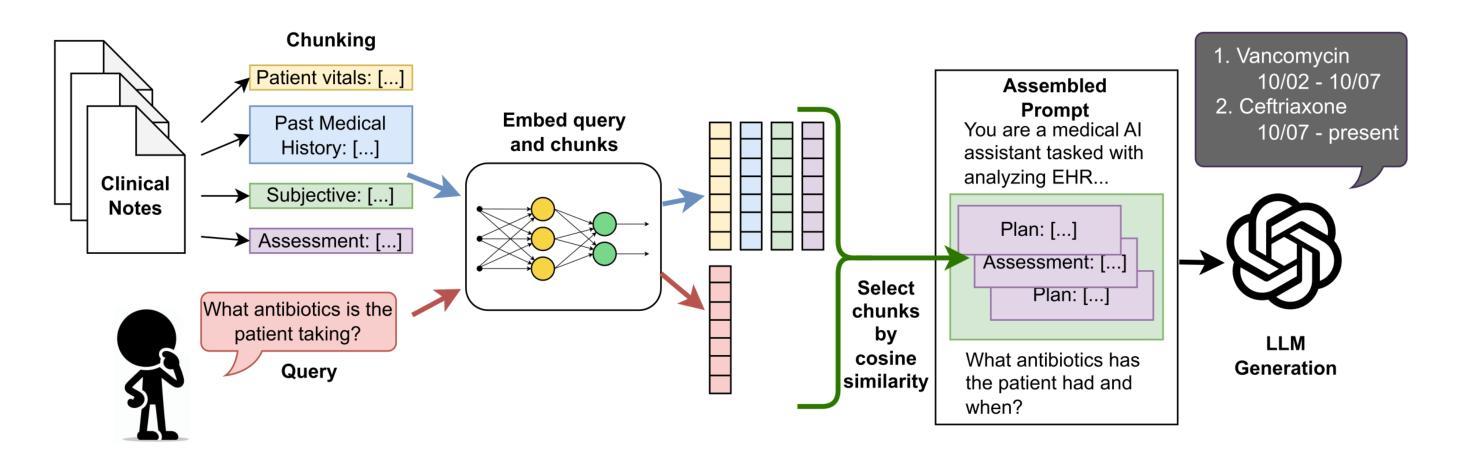
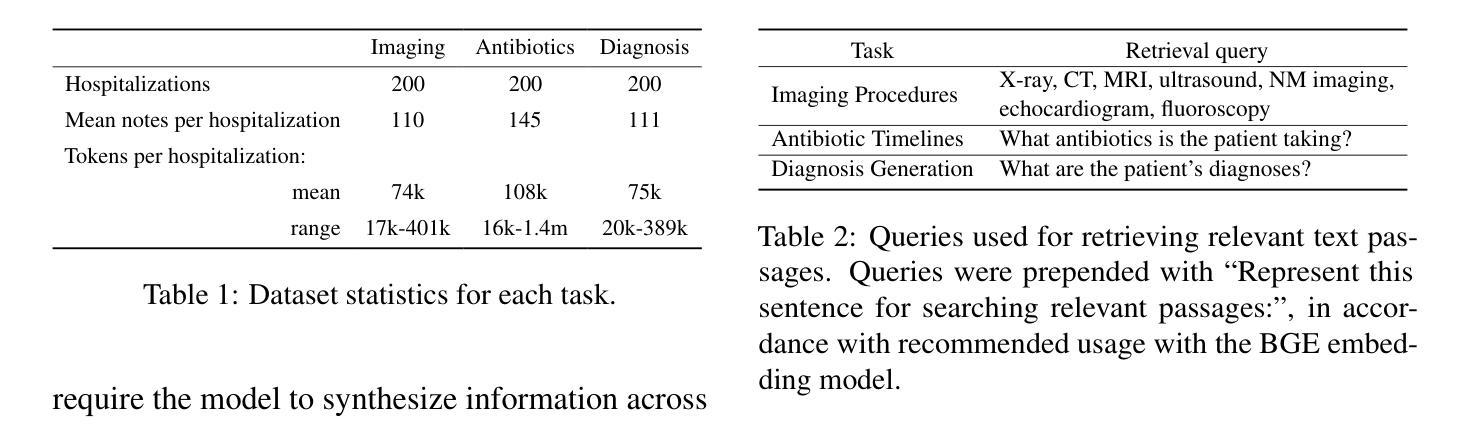
Electronic health records (EHRs) are long, noisy, and often redundant, posing a major challenge for the clinicians who must navigate them. Large language models (LLMs) offer a promising solution for extracting and reasoning over this unstructured text, but the length of clinical notes often exceeds even state-of-the-art models’ extended context windows. Retrieval-augmented generation (RAG) offers an alternative by retrieving task-relevant passages from across the entire EHR, potentially reducing the amount of required input tokens. In this work, we propose three clinical tasks designed to be replicable across health systems with minimal effort: 1) extracting imaging procedures, 2) generating timelines of antibiotic use, and 3) identifying key diagnoses. Using EHRs from actual hospitalized patients, we test three state-of-the-art LLMs with varying amounts of provided context, using either targeted text retrieval or the most recent clinical notes. We find that RAG closely matches or exceeds the performance of using recent notes, and approaches the performance of using the models’ full context while requiring drastically fewer input tokens. Our results suggest that RAG remains a competitive and efficient approach even as newer models become capable of handling increasingly longer amounts of text.
电子健康记录(EHRs)内容冗长、繁杂,对临床医生来说是一大挑战。大型语言模型(LLMs)为解决这一问题提供了有效的解决方案,能够通过提取和推理这些非结构化文本来进行处理。然而,临床笔记的长度往往超出了最先进模型的扩展上下文窗口。通过从整个电子健康记录中检索任务相关段落,检索增强生成(RAG)提供了一种替代方案,可以潜在地减少所需输入标记的数量。在这项工作中,我们提出了三项可在健康系统中轻松复制的临床任务:1)提取成像程序,2)生成抗生素使用的时间线,以及3)识别关键诊断。我们使用来自实际住院患者的电子健康记录进行测试,测试了三种最先进的LLMs,它们提供的上下文信息各不相同,要么采用有针对性的文本检索,要么采用最新的临床笔记。我们发现,RAG的表现在使用最新笔记的情况下非常接近或超过其表现,并且在需要大大减少输入标记的情况下接近使用模型全语境的表现。我们的结果表明,即使在新模型能够处理越来越长的文本时,RAG仍然是一种具有竞争力和高效的解决方案。
论文及项目相关链接
Summary
电子健康记录(EHRs)内容冗长、信息繁杂,给临床医生带来很大挑战。大型语言模型(LLMs)为解决这一问题提供了可能方案,但临床笔记的长度常常超出这些模型的语境窗口限制。检索增强生成(RAG)方法通过从整个EHR中检索任务相关段落,可能减少所需输入标记的数量。本研究提出三项可在各医疗系统中轻松复制的临床任务:1)提取成像程序;2)生成抗生素使用的时间线;3)识别关键诊断。我们测试了三种先进的大型语言模型,通过不同语境量、针对性文本检索或最新临床笔记进行试验。结果发现,RAG的表现接近或超越了使用最新笔记的效果,且能在更少的输入标记下接近使用全语境模型的效果。这表明即使在处理更长的文本时,RAG仍然是一种有竞争力的有效方法。
Key Takeaways
- 电子健康记录(EHRs)内容冗长、繁杂,给临床医生带来挑战。
- 大型语言模型(LLMs)可解决这一问题,但临床笔记长度超出模型语境窗口限制。
- 检索增强生成(RAG)方法通过检索任务相关段落减少输入标记需求。
- 三项临床任务包括提取成像程序、生成抗生素使用的时间线、识别关键诊断。
- RAG表现接近或超越使用最新笔记的效果,且能在更少输入标记下接近全语境模型的效果。
- RAG是一种有竞争力的处理长文本的有效方法。
点此查看论文截图

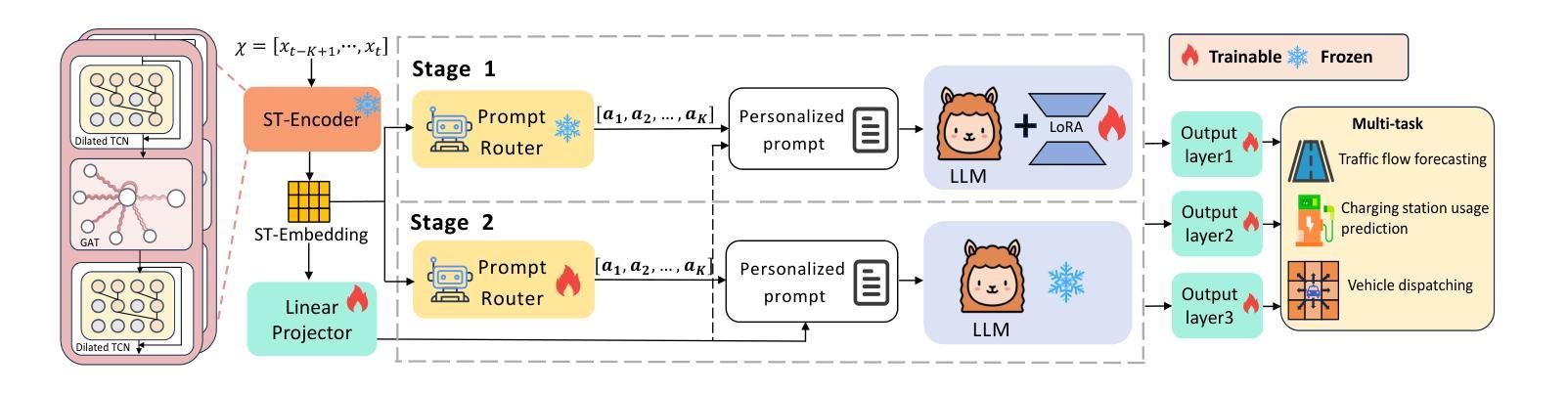
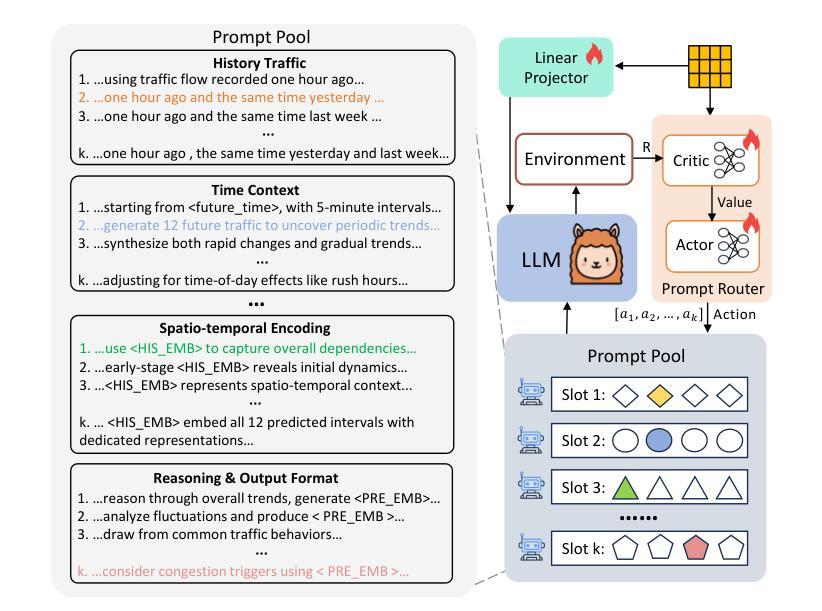
TransLLM: A Unified Multi-Task Foundation Framework for Urban Transportation via Learnable Prompting
Authors:Jiaming Leng, Yunying Bi, Chuan Qin, Bing Yin, Yanyong Zhang, Chao Wang
Urban transportation systems encounter diverse challenges across multiple tasks, such as traffic forecasting, electric vehicle (EV) charging demand prediction, and taxi dispatch. Existing approaches suffer from two key limitations: small-scale deep learning models are task-specific and data-hungry, limiting their generalizability across diverse scenarios, while large language models (LLMs), despite offering flexibility through natural language interfaces, struggle with structured spatiotemporal data and numerical reasoning in transportation domains. To address these limitations, we propose TransLLM, a unified foundation framework that integrates spatiotemporal modeling with large language models through learnable prompt composition. Our approach features a lightweight spatiotemporal encoder that captures complex dependencies via dilated temporal convolutions and dual-adjacency graph attention networks, seamlessly interfacing with LLMs through structured embeddings. A novel instance-level prompt routing mechanism, trained via reinforcement learning, dynamically personalizes prompts based on input characteristics, moving beyond fixed task-specific templates. The framework operates by encoding spatiotemporal patterns into contextual representations, dynamically composing personalized prompts to guide LLM reasoning, and projecting the resulting representations through specialized output layers to generate task-specific predictions. Experiments across seven datasets and three tasks demonstrate the exceptional effectiveness of TransLLM in both supervised and zero-shot settings. Compared to ten baseline models, it delivers competitive performance on both regression and planning problems, showing strong generalization and cross-task adaptability. Our code is available at https://github.com/BiYunying/TransLLM.
城市交通系统面临多种任务中的多样化挑战,如交通预测、电动汽车(EV)充电需求预测和出租车调度等。现有方法存在两个主要局限性:小规模深度学习模型是任务特定的且数据依赖性强,限制了它们在多种场景中的通用性;虽然大型语言模型(LLM)通过自然语言接口提供了灵活性,但在交通领域的结构化时空数据和数值推理方面却遇到了困难。为了解决这些局限性,我们提出了TransLLM,这是一个统一的基础框架,通过可学习的提示组合将时空建模与大型语言模型集成在一起。我们的方法采用轻量级的时空编码器,通过扩张的临时卷积和双重邻接图注意力网络捕捉复杂的依赖关系,与LLM无缝接口通过结构化嵌入。一种新型的实例级提示路由机制,通过强化学习进行训练,根据输入特征动态个性化提示,超越了固定的任务特定模板。该框架通过将时空模式编码为上下文表示,动态组合个性化提示以引导LLM推理,并通过专用输出层投影生成任务特定预测。在七个数据集和三个任务上的实验表明,TransLLM在监督学习和零样本设置中的表现都非常出色。与十个基准模型相比,它在回归和规划问题上均表现出竞争力,显示出强大的泛化和跨任务适应性。我们的代码可在https://github.com/BiYunying/TransLLM获得。
论文及项目相关链接
Summary
该文针对城市交通系统面临的挑战,如交通预测、电动汽车充电需求预测和出租车调度等任务,提出了TransLLM框架。该框架结合时空建模与大型语言模型,通过可学习的提示组合进行统一处理。采用轻量级时空编码器,通过膨胀时间卷积和双邻接图注意力网络捕捉复杂依赖性,与大型语言模型无缝接口。通过强化学习训练的实例级提示路由机制,根据输入特征动态个性化提示,超越了固定任务特定模板。该框架在七个数据集和三个任务上的实验表明,其在有监督和零样本设置中具有出色的效果,与十种基线模型相比,在回归和规划问题上表现出强大的泛化和跨任务适应性。
Key Takeaways
- TransLLM是一个统一的框架,用于处理城市交通系统的多样挑战,如交通预测、电动汽车充电需求预测和出租车调度。
- 该框架结合了时空建模和大型语言模型(LLM),通过可学习的提示组合进行融合。
- TransLLM使用轻量级时空编码器,能够捕捉复杂依赖性,并与LLM无缝对接。
- 采用强化学习训练的实例级提示路由机制,使框架能根据输入特征动态个性化提示。
- 框架在多个数据集和任务上展现出卓越效果,包括有监督和零样本设置。
- TransLLM在回归和规划问题上表现出强大的泛化能力和跨任务适应性。
点此查看论文截图

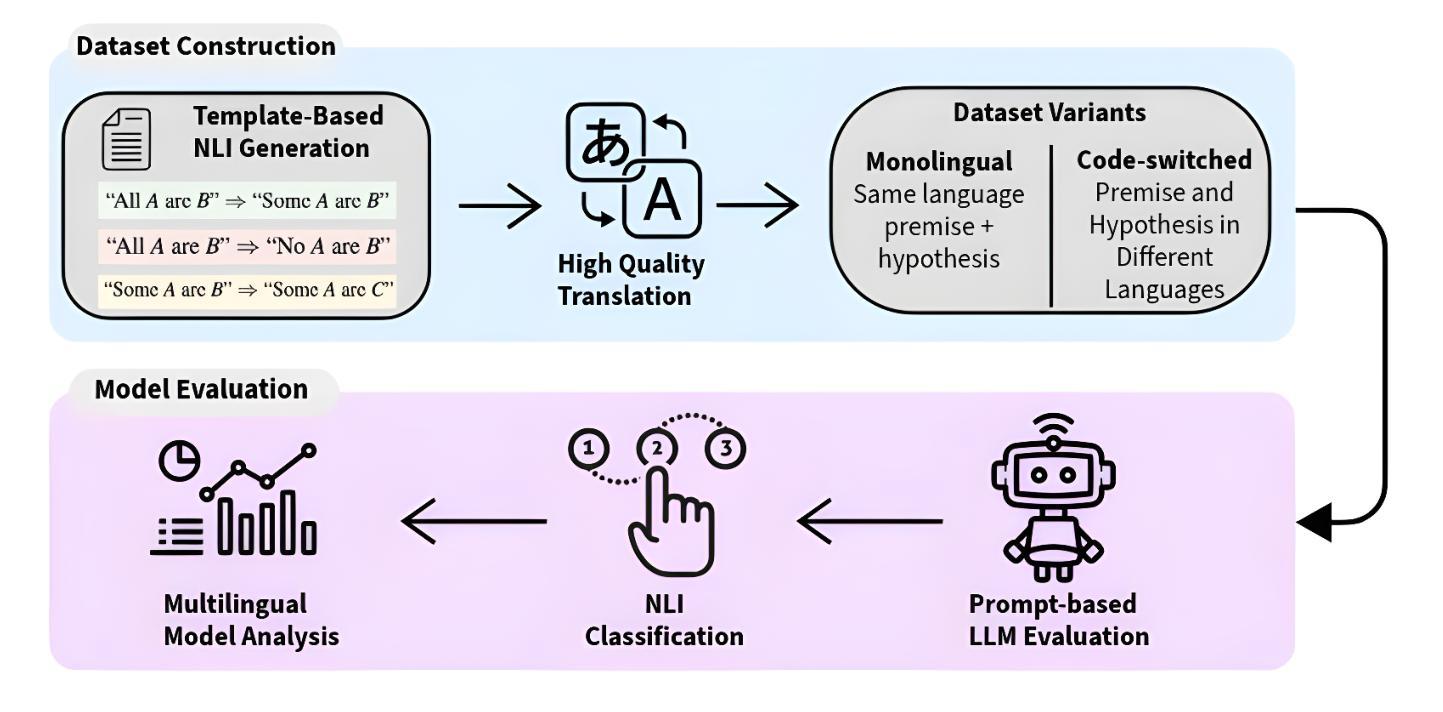
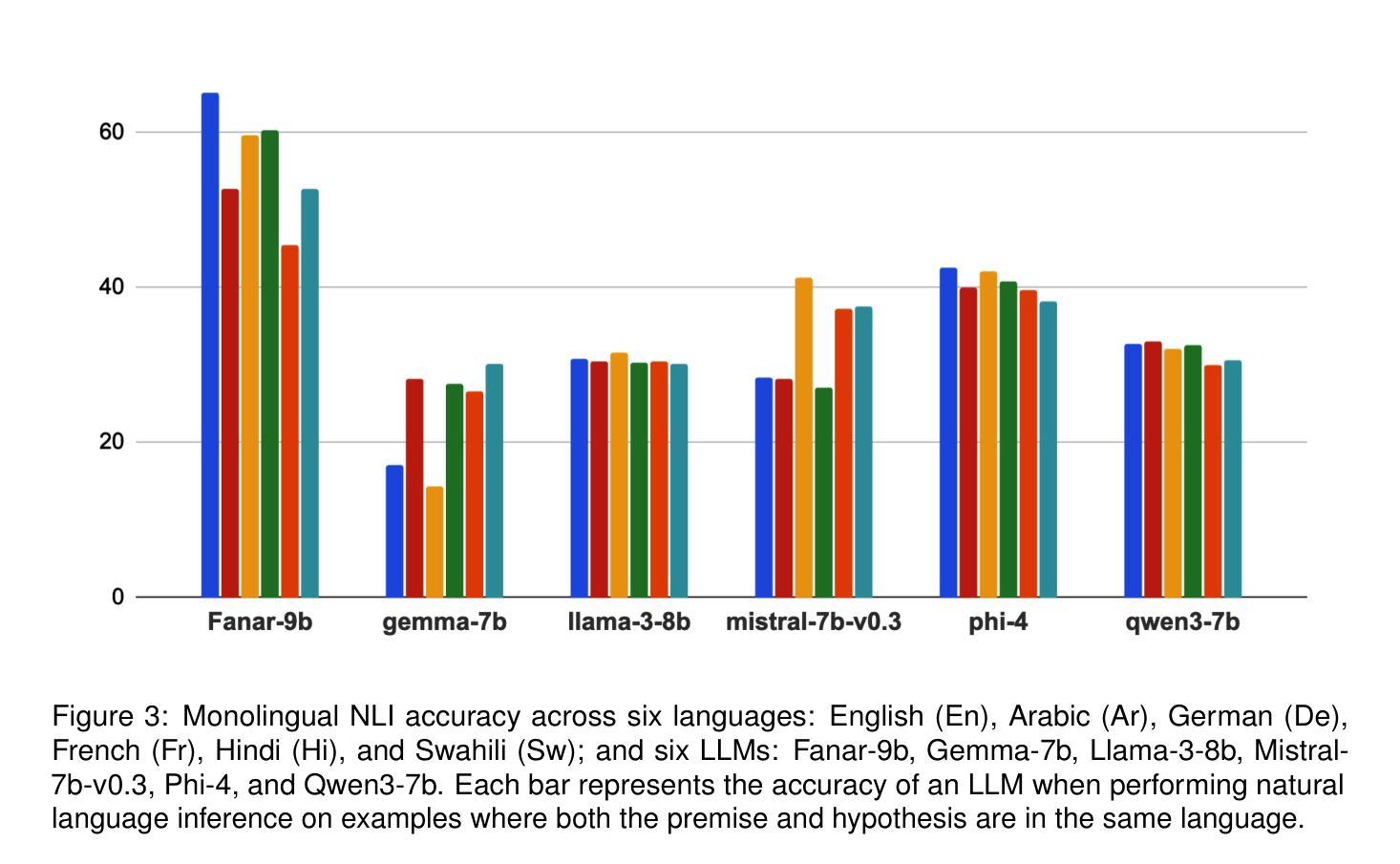
Evaluating Multilingual and Code-Switched Alignment in LLMs via Synthetic Natural Language Inference
Authors:Samir Abdaljalil, Erchin Serpedin, Khalid Qaraqe, Hasan Kurban
Large language models (LLMs) are increasingly applied in multilingual contexts, yet their capacity for consistent, logically grounded alignment across languages remains underexplored. We present a controlled evaluation framework for multilingual natural language inference (NLI) that generates synthetic, logic-based premise-hypothesis pairs and translates them into a typologically diverse set of languages. This design enables precise control over semantic relations and allows testing in both monolingual and mixed-language (code-switched) conditions. Surprisingly, code-switching does not degrade, and can even improve, performance, suggesting that translation-induced lexical variation may serve as a regularization signal. We validate semantic preservation through embedding-based similarity analyses and cross-lingual alignment visualizations, confirming the fidelity of translated pairs. Our findings expose both the potential and the brittleness of current LLM cross-lingual reasoning, and identify code-switching as a promising lever for improving multilingual robustness. Code available at: https://github.com/KurbanIntelligenceLab/nli-stress-testing
大型语言模型(LLMs)在多语言环境中的应用越来越广泛,然而其在不同语言之间保持一致性、逻辑性的对齐能力仍被低估。我们提出了一种针对多语言自然语言推理(NLI)的控制评估框架,该框架生成基于逻辑的前提假设对,并将其翻译成类型多样的语言集。这种设计能够精确控制语义关系,并允许在单语和混合语言(代码切换)条件下进行测试。令人惊讶的是,代码切换并不会降低性能,甚至可能有所提高,这表明翻译引起的词汇变化可以作为正则化信号。我们通过基于嵌入的相似性分析和跨语言对齐可视化来验证语义的保留,证实了翻译对的保真性。我们的研究揭示了当前LLM跨语言推理的潜力和脆弱性,并将代码切换识别为提高多语言稳健性的有前景的方法。相关代码可在 https://github.com/KurbanIntelligenceLab/nli-stress-testing 找到。
论文及项目相关链接
PDF Under review
Summary
大型语言模型在多语言环境中的应用日益广泛,但其跨语言一致、逻辑严谨的对齐能力尚未得到充分探索。本研究提出一种控制评估框架,用于多语言自然语言推理,生成合成逻辑基础的前提假设对,并将其翻译成类型多样的语言集。该研究设计能精确控制语义关系,并可在单语和混合语言(语言转码)条件下进行测试。研究发现,语言转码并不会降低性能,甚至可能有所提升,这表明翻译引起的词汇变化可能作为一种正则化信号。通过嵌入相似性分析和跨语言对齐可视化验证了语义的保留,证实了翻译对的准确性。本研究揭示了当前语言模型跨语言推理的潜力和脆弱性,并确定了语言转码作为提高多语言稳健性的有力工具。
Key Takeaways
- 大型语言模型在多语言环境中的应用需求日益增长,但跨语言逻辑对齐能力尚待探索。
- 提出一种控制评估框架用于多语言自然语言推理,能生成并控制语义关系的合成数据。
- 发现语言转码不会降低性能,甚至可能提升模型表现,这暗示了翻译引起的词汇变化有正则化效果。
- 语义保留的验证通过嵌入相似性分析和跨语言对齐可视化得到确认。
- 研究揭示了当前语言模型跨语言推理的潜力与脆弱性。
- 语言转码被识别为提高多语言稳健性的有效方法。
点此查看论文截图


ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
Authors:Junying Chen, Zhenyang Cai, Zhiheng Liu, Yunjin Yang, Rongsheng Wang, Qingying Xiao, Xiangyi Feng, Zhan Su, Jing Guo, Xiang Wan, Guangjun Yu, Haizhou Li, Benyou Wang
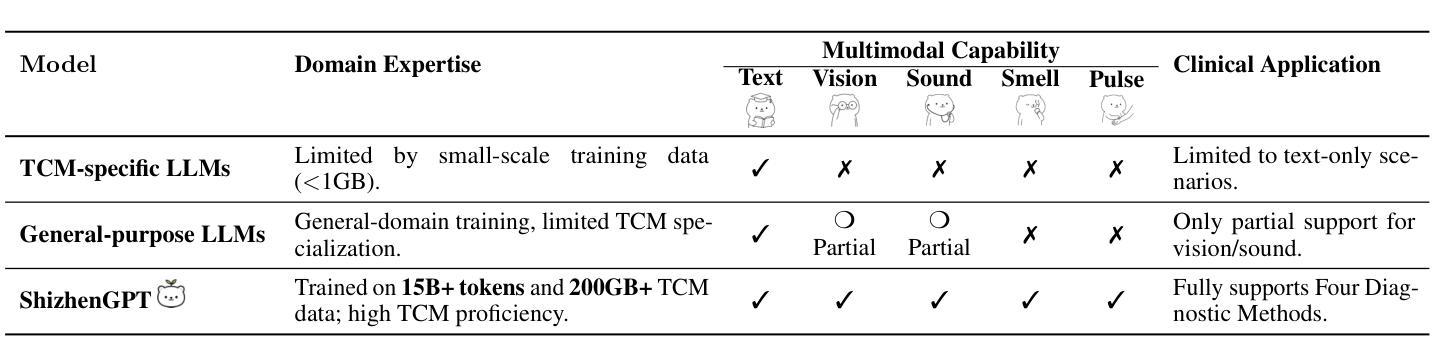
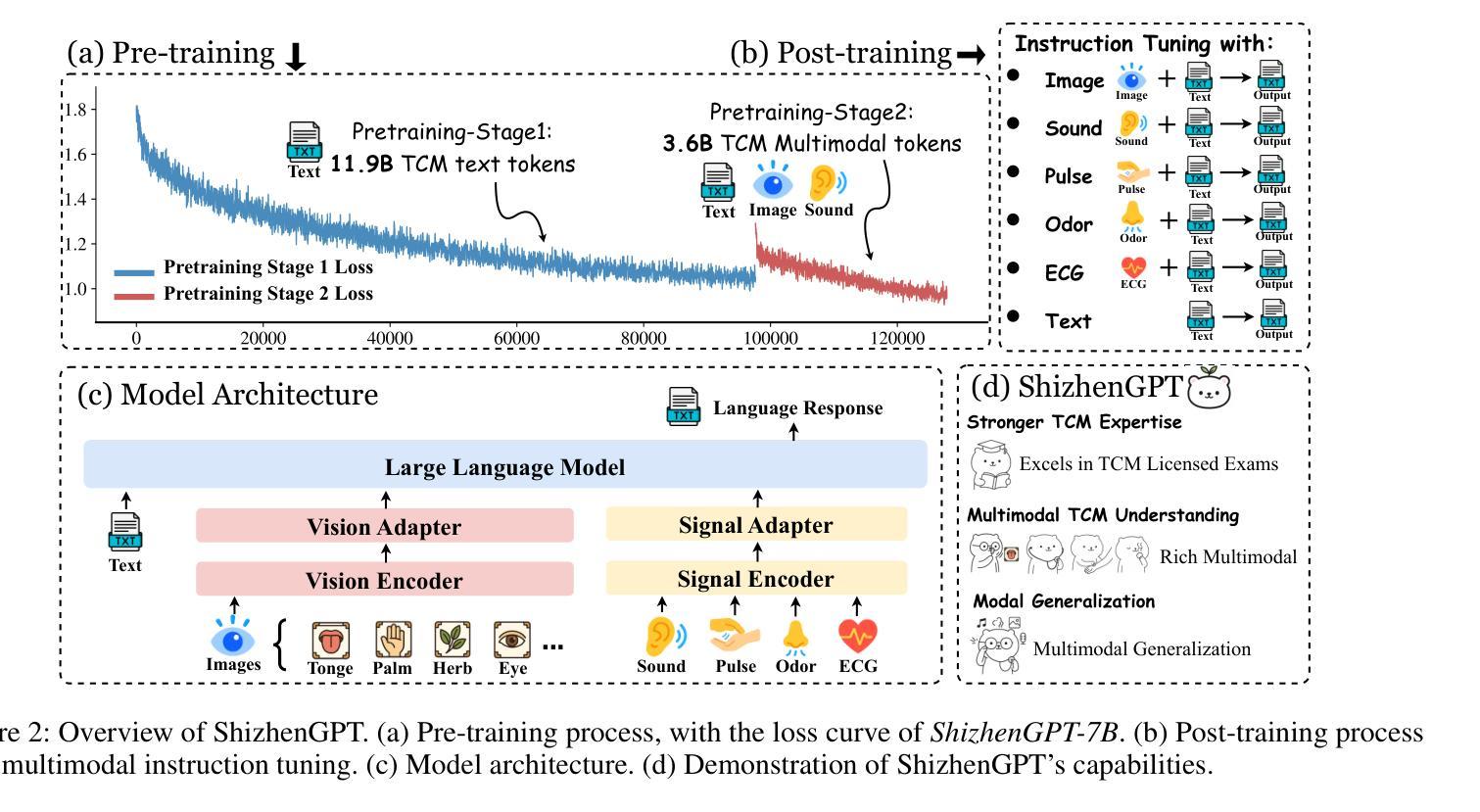
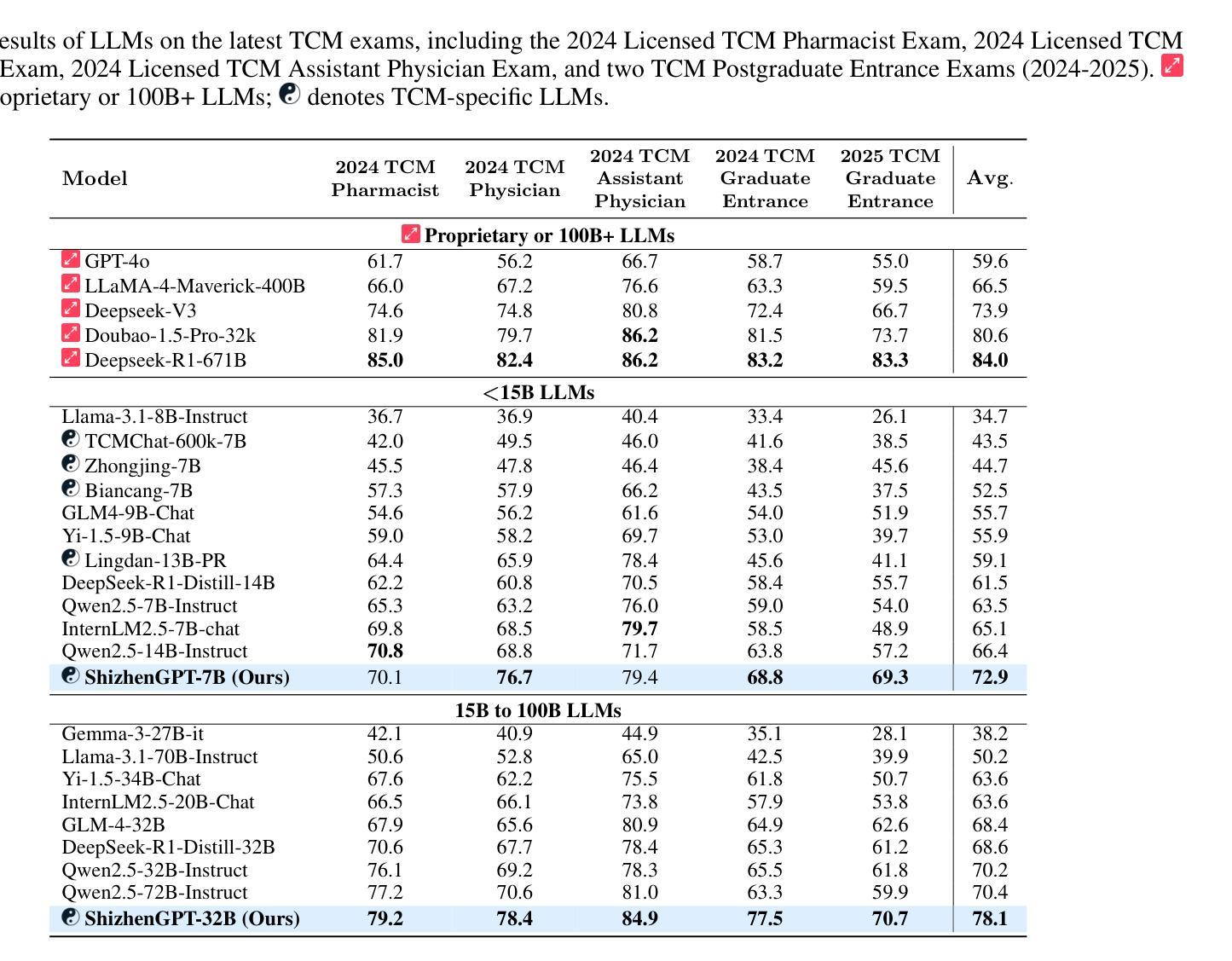
Despite the success of large language models (LLMs) in various domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical barriers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which involve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For evaluation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual understanding among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal perception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
尽管大型语言模型(LLM)在各个领域取得了成功,但由于两个关键障碍,它们在传统中医(TCM)领域的应用潜力尚未得到充分探索:(1)缺乏高质量的中医数据和(2)中医诊断的固有跨模态特性,涉及观察、聆听、闻诊和诊脉。这些感官丰富的模态超出了传统LLM的范围。为了应对这些挑战,我们推出了适用于中医的多模态LLM“时珍GPT”。为解决数据稀缺问题,我们整理了迄今为止最大的中医数据集,包含超过100GB的文本和超过200GB的多模态数据,包括120万张图像、200小时的音频和生理信号。时珍GPT经过预训练和执行指令微调,以实现深入的中医知识和多模态推理。为了进行评估,我们收集了最近的中医资格考试,并建立了药物识别和视觉诊断的视觉基准测试。实验表明,时珍GPT在同类规模的LLM中表现突出,并与更大的专有模型相竞争。此外,它在中医视觉理解方面领先于现有的多模态LLM,并展示了跨声音、脉象、气味和视觉等模态的统一感知能力,为中医的整体多模态感知和诊断铺平了道路。数据集、模型和代码均公开可用。我们希望这项工作将激发该领域的进一步探索。
论文及项目相关链接
Summary:
尽管大型语言模型(LLM)在众多领域取得了成功,它们在中医领域的应用潜力仍未被充分发掘。为解决高质量中医数据缺乏以及中医诊断本身的多模态特性所带来的挑战,研究团队提出了针对中医的多模态大型语言模型ShizhenGPT。ShizhenGPT通过预训练与指令微调,深入理解了中医知识并具备多模态推理能力。实验表明,ShizhenGPT在中医视觉理解方面表现出色,并展现出跨声音、脉象、气味和视觉等模态的统一感知能力,为中医的全方位多模态感知与诊断开辟了新的道路。该研究成果公开了数据集、模型和代码,希望进一步激发该领域的研究潜力。
Key Takeaways:
- 大型语言模型在中医领域的应用仍处于探索阶段。
- 缺少高质量中医数据和中医诊断的多模态特性是两大挑战。
- ShizhenGPT是一个针对中医领域的多模态大型语言模型。
- ShizhenGPT通过预训练和指令微调达到深入理解中医知识和多模态推理的能力。
- ShizhenGPT在中医视觉理解方面表现优秀,展现出跨多种模态的统一感知能力。
- 研究成果公开了数据集、模型和代码,促进进一步的研究和应用。
点此查看论文截图

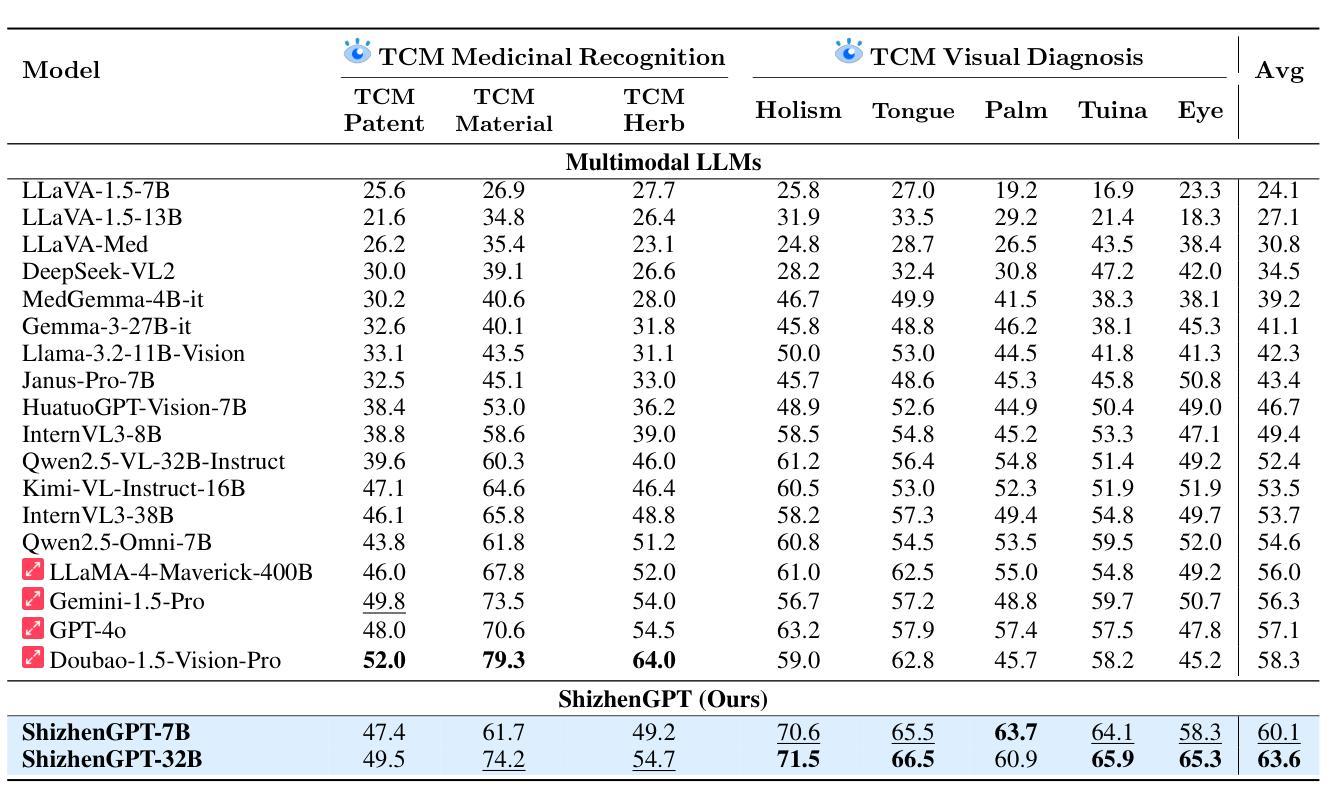
MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
Authors:Ziyang Luo, Zhiqi Shen, Wenzhuo Yang, Zirui Zhao, Prathyusha Jwalapuram, Amrita Saha, Doyen Sahoo, Silvio Savarese, Caiming Xiong, Junnan Li
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.
模型上下文协议(Model Context Protocol)已经成为连接大型语言模型与外部数据源和工具的革命性标准,迅速被各大人工智能提供商和开发平台采纳。然而,现有的基准测试过于简单,无法捕捉实际应用中的挑战,如长期推理和庞大、陌生的工具空间。为了填补这一关键空白,我们推出了MCP宇宙(MCP-Universe),这是第一个专门设计用于评估大型语言模型在真实且困难任务中与真实世界MCP服务器交互的综合性基准测试。我们的基准测试涵盖了6个核心领域,跨越11个不同的MCP服务器:位置导航、仓库管理、财务分析、3D设计、浏览器自动化和网页搜索。为了确保严格的评估,我们实施了基于执行的评估器,包括用于代理格式合规性的格式评估器、用于时间不变内容匹配的静态评估器,以及可自动检索实时真实数据的动态评估器,适用于时间敏感的任务。通过对领先的大型语言模型的广泛评估,我们发现即使是最佳模型,如GPT-5(43.72%)、Grok-4(33.33%)和Claude-4.0-Sonnet(29.44%),也存在显著的性能限制。此外,我们的基准测试为大型语言模型代理提出了一个重大的长期上下文挑战,随着交互步骤的增加,输入令牌的数量会迅速增加。而且,它引入了一个未知工具挑战,因为大型语言模型代理往往不熟悉MCP服务器的精确用途。值得注意的是,像光标这样的企业级代理并不能比标准的ReAct框架取得更好的性能。除了评估之外,我们还以支持UI的方式开源了可扩展的评估框架,使研究者和实践者能够无缝集成新的代理和MCP服务器,同时促进在不断发展的MCP生态系统中的创新。
论文及项目相关链接
PDF Website: https://mcp-universe.github.io
Summary
在大规模语言模型与外部数据源和工具的连接标准中,模型上下文协议(MCP)已崭露头角,成为变革性标准。但现有基准测试过于简单,无法捕捉实际应用程序的挑战,如长期推理和大型、不熟悉的工具空间。为解决这一关键差距,我们推出了MCP-Universe,这是第一个专门设计用于评估语言大模型在真实和困难任务中与真实世界MCP服务器交互的基准测试。涵盖6个核心领域,跨越11个不同的MCP服务器。尽管对顶尖模型如GPT-5等进行广泛评估,但发现存在显著的性能限制。此外,我们的基准测试对LLM代理提出了长期上下文和未知工具的挑战。同时,开源了可扩展的评估框架,支持界面,促进新代理和MCP服务器的无缝集成,推动MCP生态系统快速发展。
Key Takeaways
- 模型上下文协议(MCP)已成为连接大规模语言模型与外部数据源和工具的重要标准,受到各大AI供应商和开发平台的广泛采纳。
- 现有基准测试无法充分模拟实际应用程序的挑战,如长期推理和大型、不熟悉工具空间的应用挑战。
- MCP-Universe是首个专为评估LLMs在真实和困难任务中而设计的基准测试,涵盖多个领域和不同的MCP服务器。
- 顶尖模型如GPT-5等虽经广泛评估,但仍存在显著性能限制,面临长期上下文和未知工具的挑战。
- 企业级代理在处理大量交互步骤时面临输入令牌数量迅速增加的问题。
- 开源的评估框架支持界面,便于研究人员和实践者无缝集成新代理和MCP服务器。
点此查看论文截图


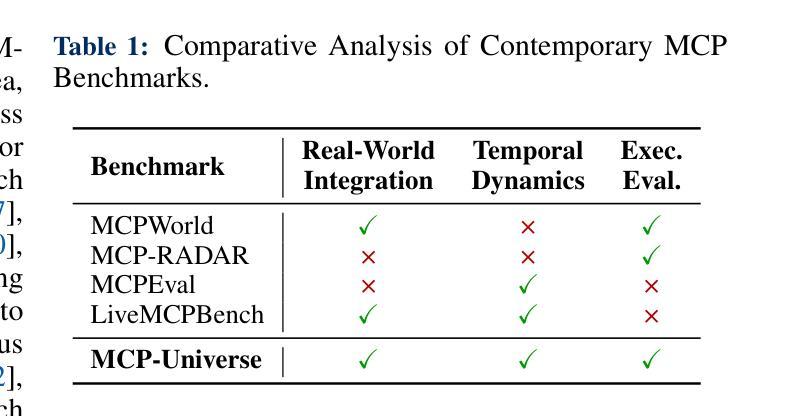
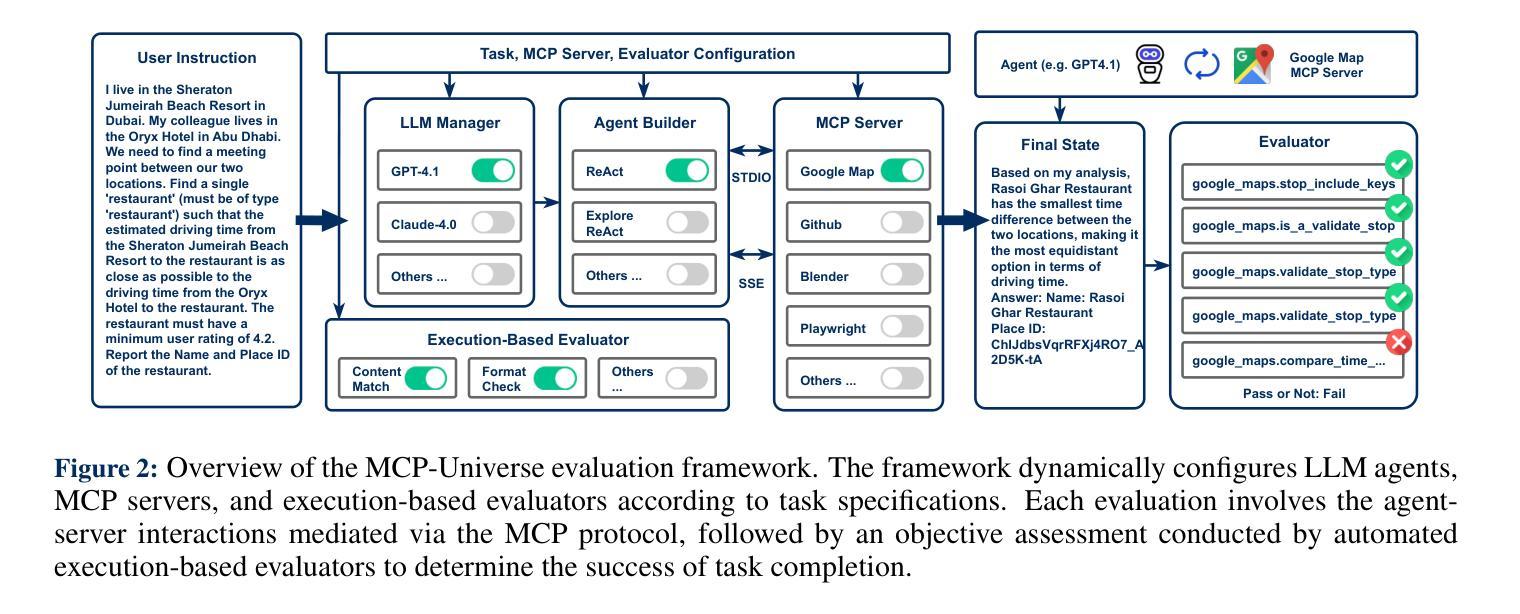

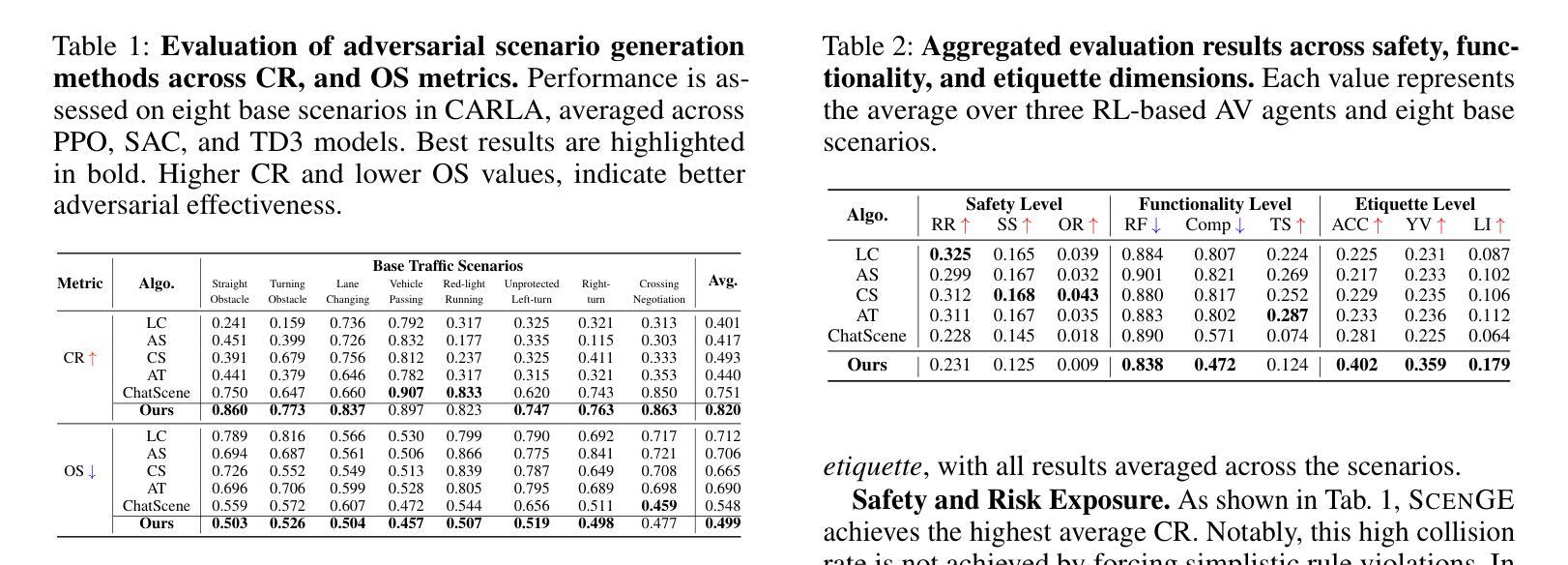
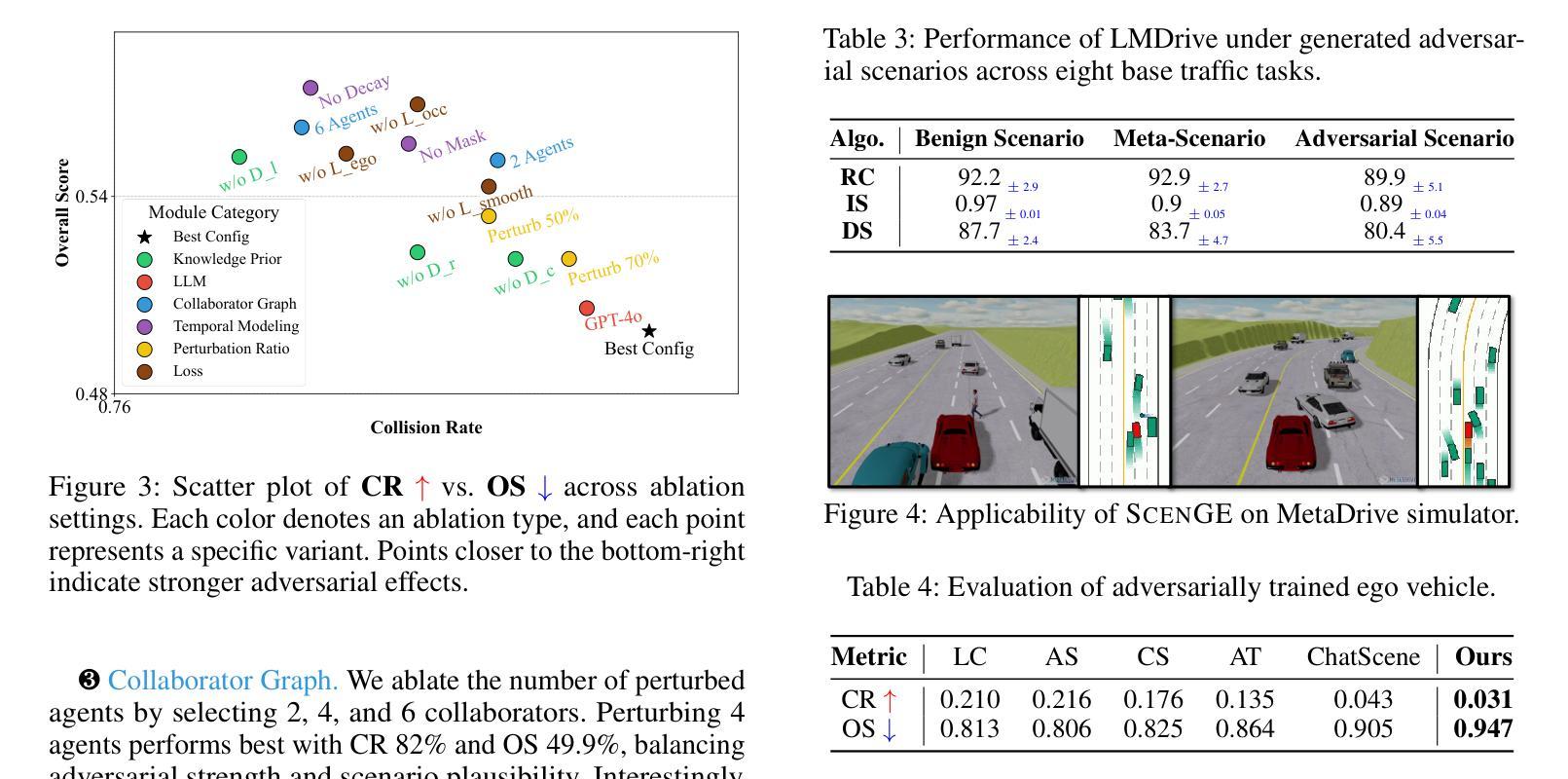
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles
Authors:Jiangfan Liu, Yongkang Guo, Fangzhi Zhong, Tianyuan Zhang, Zonglei Jing, Siyuan Liang, Jiakai Wang, Mingchuan Zhang, Aishan Liu, Xianglong Liu
The generation of safety-critical scenarios in simulation has become increasingly crucial for safety evaluation in autonomous vehicles prior to road deployment in society. However, current approaches largely rely on predefined threat patterns or rule-based strategies, which limit their ability to expose diverse and unforeseen failure modes. To overcome these, we propose ScenGE, a framework that can generate plentiful safety-critical scenarios by reasoning novel adversarial cases and then amplifying them with complex traffic flows. Given a simple prompt of a benign scene, it first performs Meta-Scenario Generation, where a large language model, grounded in structured driving knowledge, infers an adversarial agent whose behavior poses a threat that is both plausible and deliberately challenging. This meta-scenario is then specified in executable code for precise in-simulator control. Subsequently, Complex Scenario Evolution uses background vehicles to amplify the core threat introduced by Meta-Scenario. It builds an adversarial collaborator graph to identify key agent trajectories for optimization. These perturbations are designed to simultaneously reduce the ego vehicle’s maneuvering space and create critical occlusions. Extensive experiments conducted on multiple reinforcement learning based AV models show that ScenGE uncovers more severe collision cases (+31.96%) on average than SoTA baselines. Additionally, our ScenGE can be applied to large model based AV systems and deployed on different simulators; we further observe that adversarial training on our scenarios improves the model robustness. Finally, we validate our framework through real-world vehicle tests and human evaluation, confirming that the generated scenarios are both plausible and critical. We hope our paper can build up a critical step towards building public trust and ensuring their safe deployment.
在仿真中生成安全关键场景对于在道路上部署社会自动驾驶汽车之前的安全评估变得愈发关键。然而,当前的方法大多依赖于预先定义的威胁模式或基于规则的策略,这限制了它们暴露多样和未曾预见到的故障模式的能力。为了克服这些缺点,我们提出了ScenGE框架,它可以通过推理新的对抗性案例并使用复杂的交通流来放大这些案例,从而生成大量的安全关键场景。给定一个良性场景的简单提示,它首先执行元场景生成,其中大型语言模型以结构化驾驶知识为基础,推断出对抗性代理的行为构成既合理又故意具有挑战性的威胁。该元场景随后被指定为可执行代码,以在模拟器中进行精确控制。随后,复杂场景演变使用背景车辆来放大元场景引入的核心威胁。它建立了一个对抗性协同图来识别关键代理轨迹进行优化。这些扰动旨在同时减少自我车辆的机动空间并造成关键遮挡。在多个基于强化学习的自动驾驶汽车模型上进行的广泛实验表明,ScenGE平均发现了比最新技术基准更多的严重碰撞情况(+31.96%)。此外,我们的ScenGE可应用于基于大型模型的自动驾驶系统并可在不同的模拟器上部署;我们进一步观察到,在我们的场景上进行对抗性训练可提高模型的稳健性。最后,我们通过真实车辆测试和人类评估验证了我们的框架,证实了生成的场景既合理又关键。我们希望我们的论文能为建立公众信任并确保其安全部署搭建关键一步。
论文及项目相关链接
摘要
针对自动驾驶车辆在投放社会前的安全评估,模拟生成安全关键场景变得越来越重要。当前方法主要依赖于预设的威胁模式或规则策略,无法暴露多样且未预见到的故障模式。为此,我们提出ScenGE框架,通过推理新型对抗案例并借助复杂的交通流进行放大,生成丰富的安全关键场景。给定一个良性场景的简单提示,它首先进行元场景生成,使用基于结构化驾驶知识的大型语言模型推断一个对抗性代理的行为威胁,既具有可行性又具有挑战性。然后,复杂场景演化利用背景车辆放大元场景引入的核心威胁。它建立对抗性协作图来优化关键代理轨迹。这些扰动旨在同时减少车辆的操作空间并造成关键遮挡。在多个基于强化学习的自动驾驶模型上进行的广泛实验表明,ScenGE平均比最新技术基线发现更严重的碰撞情况(+31.96%)。此外,我们的ScenGE可应用于大型模型为基础的自动驾驶系统并部署在不同的模拟器上;我们进一步观察到在我们的场景上进行对抗性训练可提高模型的稳健性。最后,我们通过真实车辆测试和人类评估验证了我们的框架,确认生成的场景既可行又关键。
关键见解
- 自主车辆的模拟安全关键场景生成对于社会道路部署前的安全评估至关重要。
- 当前方法受限于预设威胁模式和规则策略,难以展现多样且未预见的失败模式。
- ScenGE框架通过推理新型对抗案例并结合复杂交通流进行场景生成,以应对这一挑战。
- ScenGE包含元场景生成和复杂场景演化两个阶段,可有效模拟对抗性代理行为和交通流互动。
- ScenGE在多种自动驾驶模型上表现出优越性能,平均发现更严重的碰撞情况。
- ScenGE具有广泛的应用性,可部署在不同的模拟器上,并且通过对抗训练提高模型的稳健性。
点此查看论文截图

NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
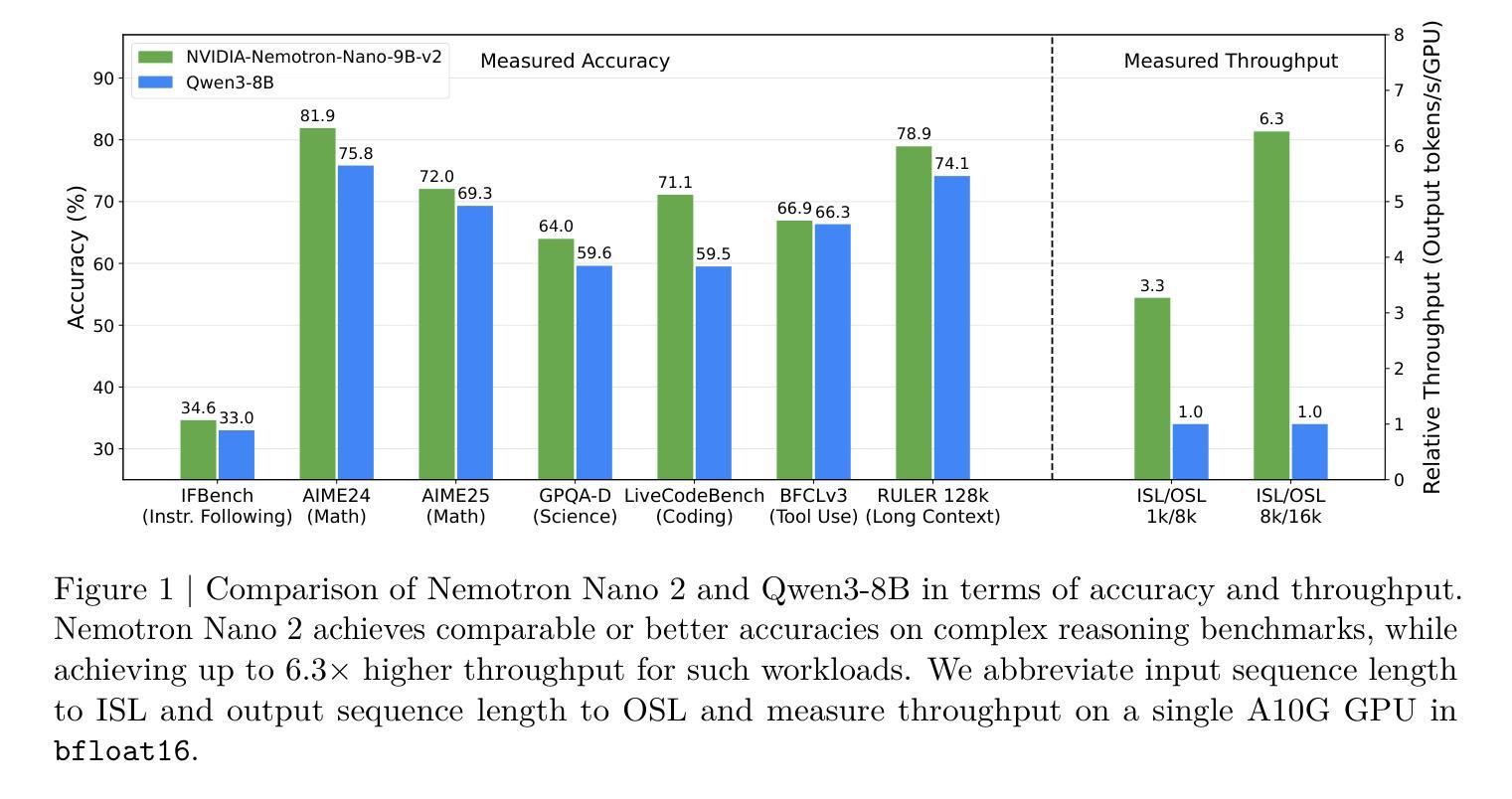
Authors: NVIDIA, :, Aarti Basant, Abhijit Khairnar, Abhijit Paithankar, Abhinav Khattar, Adi Renduchintala, Adithya Renduchintala, Aditya Malte, Akhiad Bercovich, Akshay Hazare, Alejandra Rico, Aleksander Ficek, Alex Kondratenko, Alex Shaposhnikov, Ali Taghibakhshi, Amelia Barton, Ameya Sunil Mahabaleshwarkar, Amy Shen, Andrew Tao, Ann Guan, Anna Shors, Anubhav Mandarwal, Arham Mehta, Arun Venkatesan, Ashton Sharabiani, Ashwath Aithal, Ashwin Poojary, Ayush Dattagupta, Balaram Buddharaju, Banghua Zhu, Barnaby Simkin, Bilal Kartal, Bita Darvish Rouhani, Bobby Chen, Boris Ginsburg, Brandon Norick, Brian Yu, Bryan Catanzaro, Charles Wang, Charlie Truong, Chetan Mungekar, Chintan Patel, Chris Alexiuk, Christian Munley, Christopher Parisien, Dan Su, Daniel Afrimi, Daniel Korzekwa, Daniel Rohrer, Daria Gitman, David Mosallanezhad, Deepak Narayanan, Dima Rekesh, Dina Yared, Dmytro Pykhtar, Dong Ahn, Duncan Riach, Eileen Long, Elliott Ning, Eric Chung, Erick Galinkin, Evelina Bakhturina, Gargi Prasad, Gerald Shen, Haim Elisha, Harsh Sharma, Hayley Ross, Helen Ngo, Herman Sahota, Hexin Wang, Hoo Chang Shin, Hua Huang, Iain Cunningham, Igor Gitman, Ivan Moshkov, Jaehun Jung, Jan Kautz, Jane Polak Scowcroft, Jared Casper, Jimmy Zhang, Jinze Xue, Jocelyn Huang, Joey Conway, John Kamalu, Jonathan Cohen, Joseph Jennings, Julien Veron Vialard, Junkeun Yi, Jupinder Parmar, Kari Briski, Katherine Cheung, Katherine Luna, Keith Wyss, Keshav Santhanam, Kezhi Kong, Krzysztof Pawelec, Kumar Anik, Kunlun Li, Kushan Ahmadian, Lawrence McAfee, Laya Sleiman, Leon Derczynski, Luis Vega, Maer Rodrigues de Melo, Makesh Narsimhan Sreedhar, Marcin Chochowski, Mark Cai, Markus Kliegl, Marta Stepniewska-Dziubinska, Matvei Novikov, Mehrzad Samadi, Meredith Price, Meriem Boubdir, Michael Boone, Michael Evans, Michal Bien, Michal Zawalski, Miguel Martinez, Mike Chrzanowski, Mohammad Shoeybi, Mostofa Patwary, Namit Dhameja, Nave Assaf, Negar Habibi, Nidhi Bhatia, Nikki Pope, Nima Tajbakhsh, Nirmal Kumar Juluru, Oleg Rybakov, Oleksii Hrinchuk, Oleksii Kuchaiev, Oluwatobi Olabiyi, Pablo Ribalta, Padmavathy Subramanian, Parth Chadha, Pavlo Molchanov, Peter Dykas, Peter Jin, Piotr Bialecki, Piotr Januszewski, Pradeep Thalasta, Prashant Gaikwad, Prasoon Varshney, Pritam Gundecha, Przemek Tredak, Rabeeh Karimi Mahabadi, Rajen Patel, Ran El-Yaniv, Ranjit Rajan, Ria Cheruvu, Rima Shahbazyan, Ritika Borkar, Ritu Gala, Roger Waleffe, Ruoxi Zhang, Russell J. Hewett, Ryan Prenger, Sahil Jain, Samuel Kriman, Sanjeev Satheesh, Saori Kaji, Sarah Yurick, Saurav Muralidharan, Sean Narenthiran, Seonmyeong Bak, Sepehr Sameni, Seungju Han, Shanmugam Ramasamy, Shaona Ghosh, Sharath Turuvekere Sreenivas, Shelby Thomas, Shizhe Diao, Shreya Gopal, Shrimai Prabhumoye, Shubham Toshniwal, Shuoyang Ding, Siddharth Singh, Siddhartha Jain, Somshubra Majumdar, Stefania Alborghetti, Syeda Nahida Akter, Terry Kong, Tim Moon, Tomasz Hliwiak, Tomer Asida, Tony Wang, Twinkle Vashishth, Tyler Poon, Udi Karpas, Vahid Noroozi, Venkat Srinivasan, Vijay Korthikanti, Vikram Fugro, Vineeth Kalluru, Vitaly Kurin, Vitaly Lavrukhin, Wasi Uddin Ahmad, Wei Du, Wonmin Byeon, Ximing Lu, Xin Dong, Yashaswi Karnati, Yejin Choi, Yian Zhang, Ying Lin, Yonggan Fu, Yoshi Suhara, Zhen Dong, Zhiyu Li, Zhongbo Zhu, Zijia Chen
We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
我们介绍了Nemotron-Nano-9B-v2,这是一款混合Mamba-Transformer语言模型,旨在提高推理工作负载的吞吐量,同时与类似规模的模型相比实现最先进的准确性。Nemotron-Nano-9B-v2建立在Nemotron-H架构的基础上,该架构将Transformer架构中大部分的自注意力层替换为Mamba-2层,以实现在生成推理所需的长思考轨迹时提高推理速度。我们通过首先在20万亿个令牌上使用FP8训练配方预训练一个12亿参数模型(Nemotron-Nano-12B-v2-Base)来创建Nemotron-Nano-9B-v2。在对Nemotron-Nano-12B-v2-Base进行对齐后,我们采用Minitron策略对模型进行压缩和蒸馏,旨在使用单个NVIDIA A10G GPU(具有22GB内存,bfloat16精度)进行最多达128k令牌的推理。与现有的类似规模模型(例如Qwen3-8B)相比,我们在推理基准测试上证明了Nemotron-Nano-9B-v2的准确率相当或更高,同时在如8k输入和16k输出令牌等推理设置中实现了高达6倍的推理吞吐量。我们将Nemotron-Nano-9B-v2、Nemotron-Nano12B-v2-Base以及Nemotron-Nano-9B-v2的checkpoint和大部分预训练和后续训练数据集一起在Hugging Face上发布。
论文及项目相关链接
Summary
基于Nemotron-H架构的Nemotron-Nano-9B-v2混合Mamba-Transformer语言模型,旨在提升推理工作负载的处理能力并达到类似模型的顶尖准确度。该模型通过用Mamba-2层替换Transformer架构中的大部分自注意力层,在生成推理所需的长思考轨迹时实现了更快的推理速度。通过预训练一个基于FP8训练食谱的12亿参数模型(Nemotron-Nano-12B-v2-Base),再通过Minitron策略压缩和蒸馏模型,以实现更高效的推理速度,与现有类似规模的模型相比,它在推理设置方面取得了更好的准确度并实现了更高的推理吞吐量。模型已在Hugging Face上发布。
Key Takeaways
点此查看论文截图


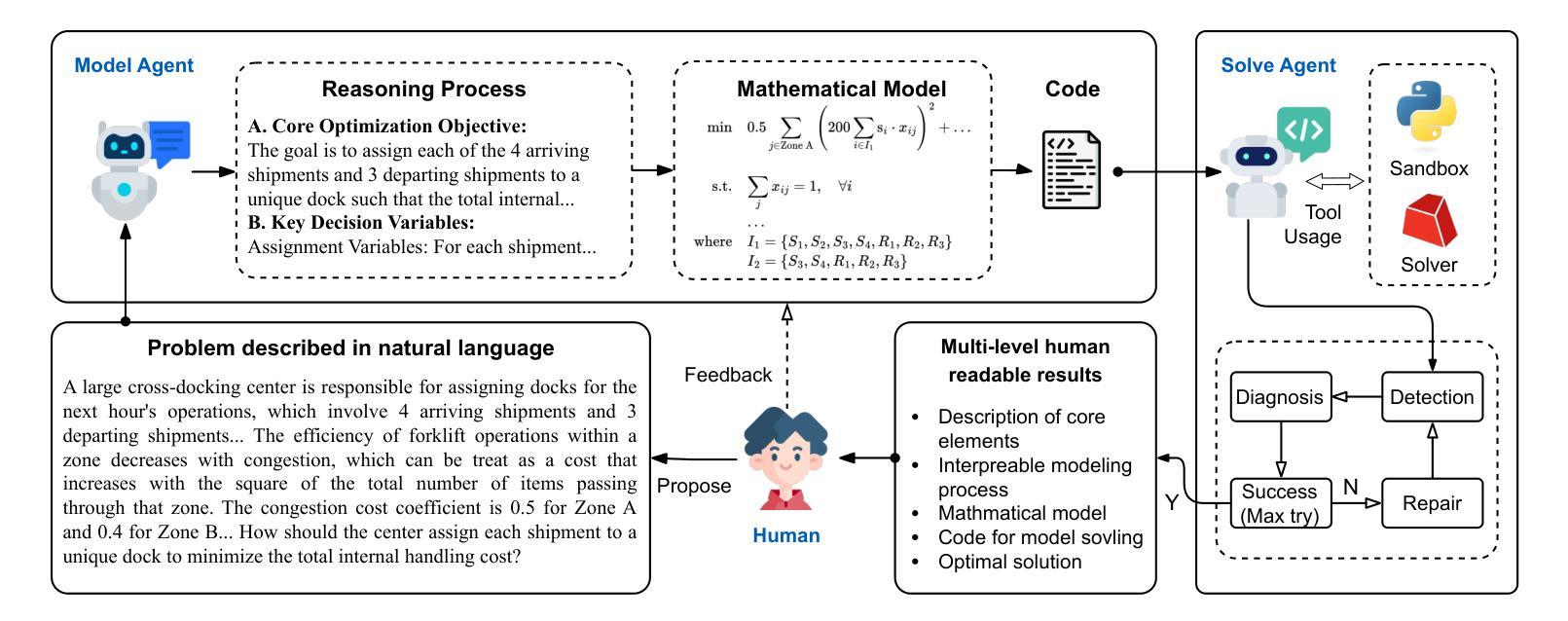
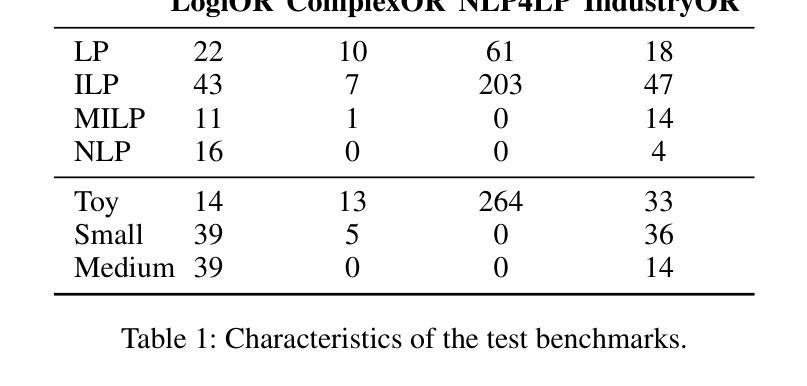
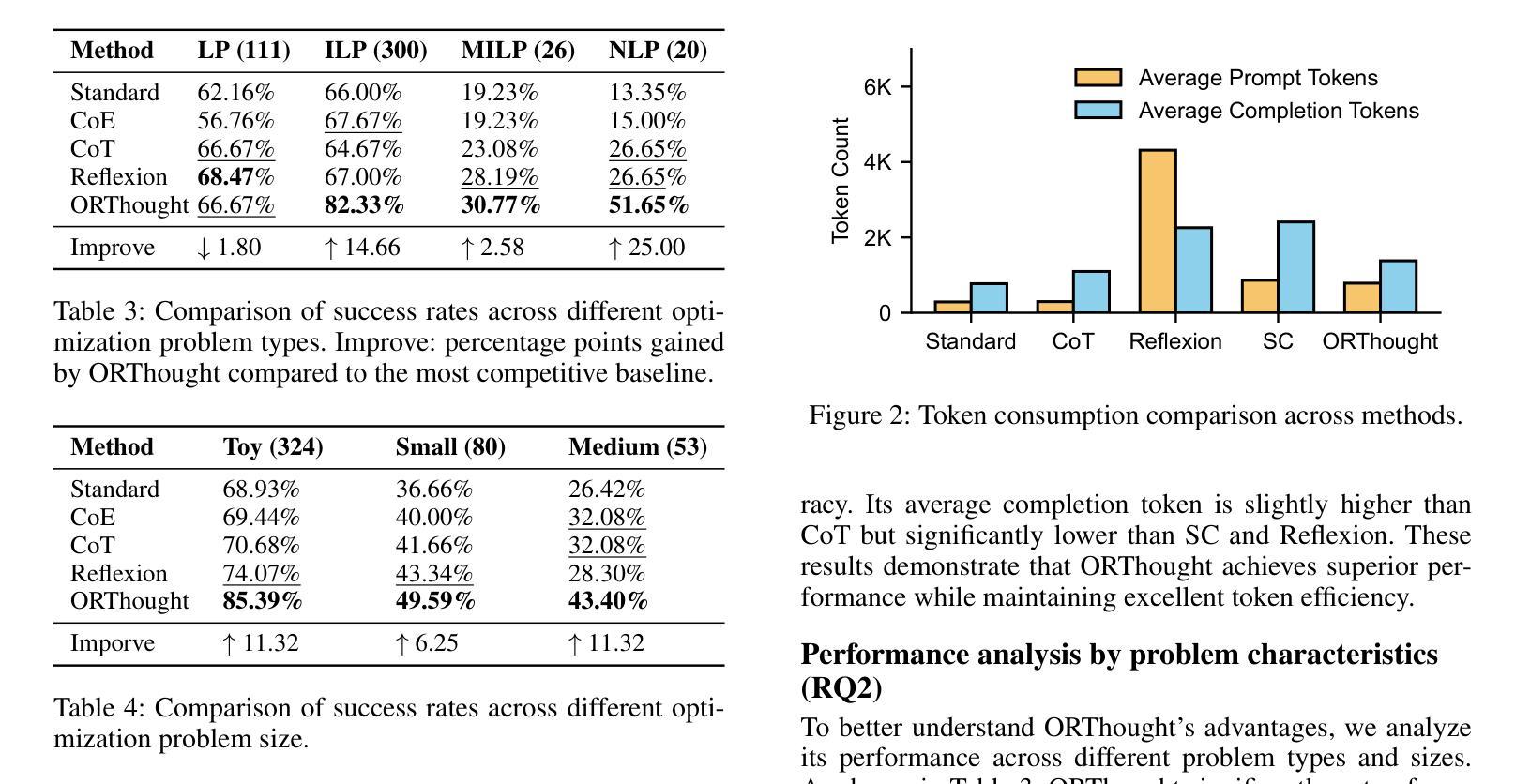
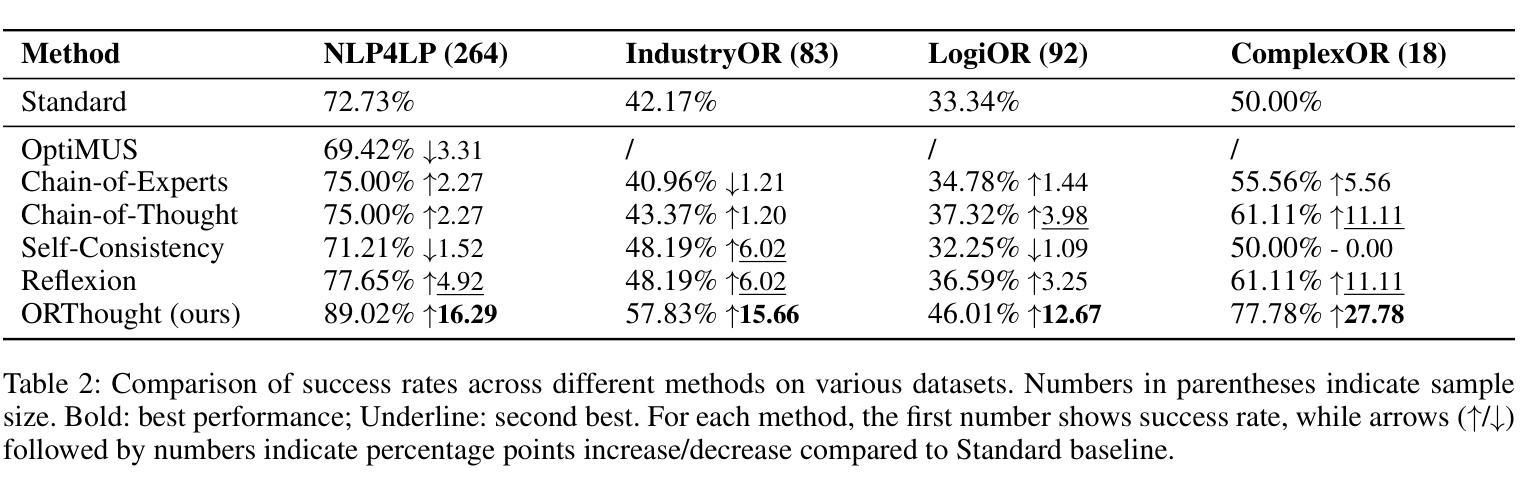
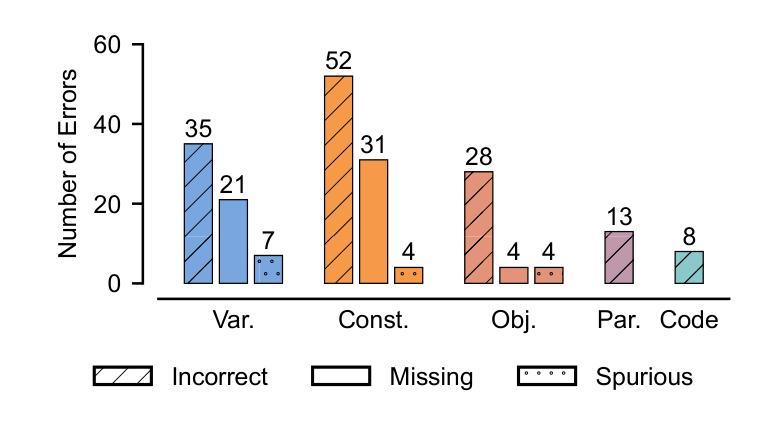
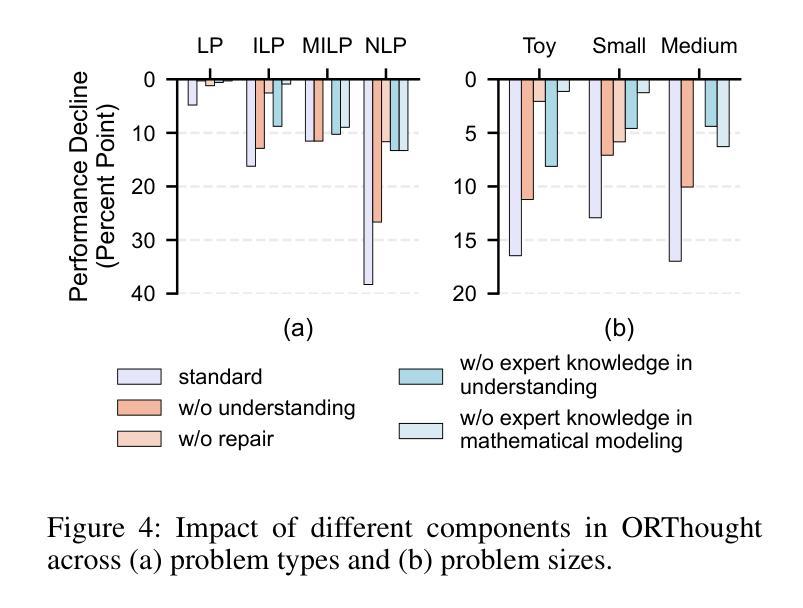
Automated Optimization Modeling through Expert-Guided Large Language Model Reasoning
Authors:Beinuo Yang, Qishen Zhou, Junyi Li, Xingchen Su, Simon Hu
Optimization Modeling (OM) is essential for solving complex decision-making problems. However, the process remains time-consuming and error-prone, heavily relying on domain experts. While Large Language Models (LLMs) show promise in addressing these challenges through their natural language understanding and reasoning capabilities, current approaches face three critical limitations: high benchmark labeling error rates reaching up to 42%, narrow evaluation scope that only considers optimal values, and computational inefficiency due to heavy reliance on multi-agent systems or model fine-tuning. In this work, we first enhance existing datasets through systematic error correction and more comprehensive annotation. Additionally, we introduce LogiOR, a new optimization modeling benchmark from the logistics domain, containing more complex problems with standardized annotations. Furthermore, we present ORThought, a novel framework that leverages expert-level optimization modeling principles through chain-of-thought reasoning to automate the OM process. Through extensive empirical evaluation, we demonstrate that ORThought outperforms existing approaches, including multi-agent frameworks, with particularly significant advantages on complex optimization problems. Finally, we provide a systematic analysis of our method, identifying critical success factors and failure modes, providing valuable insights for future research on LLM-based optimization modeling.
优化建模(OM)对于解决复杂的决策问题至关重要。然而,这一过程仍然耗时且容易出错,严重依赖于领域专家。虽然大型语言模型(LLM)通过其自然语言理解和推理能力,在应对这些挑战方面显示出潜力,但当前的方法面临三个关键局限性:高基准标签错误率,最高可达42%,评估范围狭窄,只考虑最优值,以及由于严重依赖多智能体系统或模型微调而导致的计算效率低下。
论文及项目相关链接
Summary
在解决复杂的决策问题方面,优化建模(OM)十分重要,但其过程耗时且易出错,很大程度上依赖于领域专家。虽然大型语言模型(LLM)显示出通过自然语言理解和推理能力来解决这些挑战的潜力,但当前的方法存在三个关键局限性:高基准标签错误率、评估范围狭窄只考虑最优值和计算效率低下。为改善这些问题,本研究首先通过系统误差校正和更全面的注释增强现有数据集,并引入LogiOR这一新的物流领域优化建模基准。此外,提出ORThought框架,通过链式思维推理利用专家级优化建模原则来自动化OM过程。通过广泛的实证评估,证明ORThought优于现有方法,特别是在复杂优化问题上具有显著优势。最后,对方法进行了系统分析,识别出成功因素和失败模式,为未来基于LLM的优化建模研究提供了宝贵见解。
Key Takeaways
- 优化建模(OM)是解决复杂决策问题的关键,但过程耗时且易出错。
- 大型语言模型(LLM)在解决OM挑战方面具潜力,但当前方法存在高错误率、狭窄评估范围和计算效率低下等问题。
- 研究通过系统误差校正和更全面的注释增强了现有数据集,并引入了新的物流领域优化建模基准LogiOR。
- 提出ORThought框架,结合专家级优化建模原则,通过链式思维推理自动化OM过程。
- ORThought框架在复杂优化问题上的表现优于现有方法。
- 方法的成功与失败因素被识别,为未来基于LLM的优化建模研究提供了指导。
点此查看论文截图

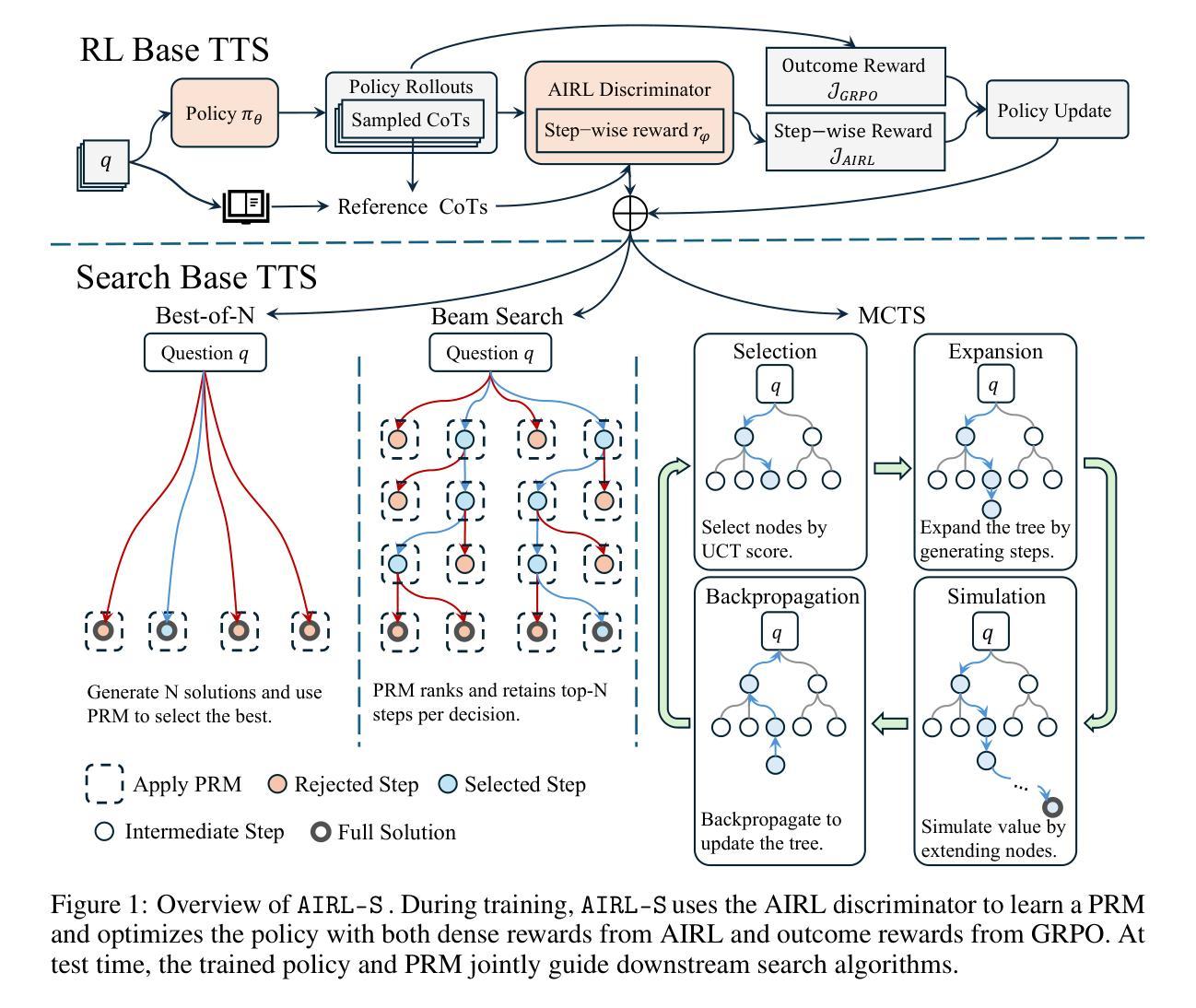
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Authors:Can Jin, Yang Zhou, Qixin Zhang, Hongwu Peng, Di Zhang, Marco Pavone, Ligong Han, Zhang-Wei Hong, Tong Che, Dimitris N. Metaxas
Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
测试时间缩放(TTS)对于大型语言模型(LLM)迄今为止主要分为了两种截然不同的范式:一是强化学习(RL)方法,优化基于稀疏结果的奖励,但存在不稳定和低样本效率的问题;二是基于独立训练的静态过程奖励模型(PRM)指导的搜索技术,这需要昂贵的人工或LLM生成的标签,并且在分布转移的情况下经常会性能下降。在本文中,我们介绍了AIRL-S,这是首个基于RL和搜索的TTS的自然统一。AIRL-S的核心见解是,在RL训练期间学习的奖励函数本质上代表了理想的PRM,用于指导下游搜索。具体来说,我们利用对抗性逆向强化学习(AIRL)结合群体相对策略优化(GRPO),直接从正确的推理轨迹中学习密集、动态的PRM,完全消除了对标记的中间过程数据的需求。在推理时,所得的PRM同时作为RL演练的批评家,并作为有效指导搜索程序的启发式方法,促进稳健的推理链扩展,缓解奖励破解,并增强跨任务泛化。在包括数学、科学推理和代码生成等在内的八个基准测试上的实验结果表明,我们的统一方法平均比基础模型提高了9%的性能,与GPT-4o相匹配。此外,当集成到多种搜索算法中时,我们的PRM始终优于使用标记数据训练的所有基线PRM。这些结果确实表明,你的RL奖励函数是你的最佳PRM搜索工具,为LLM中的复杂推理任务提供了稳健且经济的解决方案。
论文及项目相关链接
Summary
本文介绍了针对大型语言模型的测试时缩放(TTS)的新方法——AIRL-S。该方法结合了强化学习(RL)和基于搜索的技术,通过利用对抗性逆向强化学习(AIRL)和群体相对策略优化(GRPO)来学习密集、动态的PRM,直接从正确的推理轨迹中学习,完全消除了对标记的中间过程数据的需求。实验结果表明,该方法在多个基准测试中平均提高了9%的性能,与GPT-4o相匹配。当集成到多种搜索算法中时,本文的PRM始终优于使用标记数据训练的基线PRM。这证明对于大型语言模型的推理任务来说,强化学习的奖励函数是最好的搜索PRM。
Key Takeaways
- AIRL-S结合了强化学习(RL)和搜索技术,为大型语言模型(LLM)的测试时缩放(TTS)提供了新的方法。
- AIRL-S通过利用对抗性逆向强化学习(AIRL)和群体相对策略优化(GRPO)直接从正确的推理轨迹中学习奖励函数,消除了对标记数据的需求。
- 实验结果显示,AIRL-S在多个基准测试中性能提升显著,平均提高9%,与GPT-4o相匹配。
- 当集成到多种搜索算法中时,AIRL-S的奖励函数作为搜索过程的指导,表现优于其他使用标记数据训练的PRM。
点此查看论文截图

GRILE: A Benchmark for Grammar Reasoning and Explanation in Romanian LLMs
Authors:Adrian-Marius Dumitran, Alexandra-Mihaela Danila, Angela-Liliana Dumitran
LLMs (Large language models) have revolutionized NLP (Natural Language Processing), yet their pedagogical value for low-resource languages remains unclear. We present GRILE (Grammar Romanian Inference and Language Explanations) , the first open benchmark of 1,151 multiple-choice questions harvested from Romanian high-stakes exams (National Evaluation, Baccalaureate, university admissions). GRILE enables us to probe two complementary abilities of seven state-of-the-art multilingual and Romanian-specific LLMs: (i) selecting the correct answer, and (ii) producing linguistically accurate explanations. While Gemini 2.5 Pro reaches 83% accuracy, most open-weight models stay below 65%, and 48% of their explanations contain factual or pedagogical flaws according to expert review. A detailed error analysis pinpoints systematic weaknesses in morphology and in applying the latest DOOM3 orthographic norms. All data, code and a public web demo are released to catalyze future research. Our findings expose open challenges for trustworthy educational NLP in low-resource settings and establish GRILE as a new test-bed for controllable explanation generation and evaluation.
大型语言模型(LLMs)已经彻底改变了自然语言处理(NLP)领域,然而它们对低资源语言的教学价值仍不明确。我们推出了GRILE(罗马尼亚语法推理和语言解释),这是从罗马尼亚高风险考试(国家评估、学士学位、大学入学)中收集的首个开放的1151道选择题基准测试。GRILE使我们能够探索最前沿的七种多语言罗马尼亚特定大型语言模型的两种互补能力:(i)选择正确答案,(ii)产生语言上准确的解释。虽然Gemini 2.5 Pro的准确率达到83%,但大多数开放式模型的准确率仍在65%以下,根据专家评审,48%的解释中含有事实或教学上的错误。详细的错误分析指出了形态学以及应用最新DOOM3正字法规范的系统性弱点。所有数据、代码和公共网络演示都已发布,以刺激未来的研究。我们的研究揭示了低资源环境中可信教育NLP的开放挑战,并将GRILE确立为可控解释生成和评估的新测试平台。
论文及项目相关链接
PDF Accepted as long paper @RANLP2025
Summary
大型语言模型在自然语言处理领域带来了革命性的变化,但对于低资源语言的教学价值尚不清楚。本研究推出了GRILE(罗马尼亚语法推理与语言解释基准测试),包含从罗马尼亚高风险考试(国家评估、高中毕业考试、大学入学考试)中收集的1151道选择题。GRILE使我们能够测试七种最先进的跨语种和罗马尼亚特定的大型语言模型的两种互补能力:一是选择正确答案的能力,二是产生语言上准确解释的能力。虽然Gemini 2.5 Pro的准确率达到83%,但大多数开放式权重模型的准确率仍在65%以下,根据专家评审,其解释中有48%存在事实或教学上的缺陷。详细的错误分析指出了形态学以及遵循最新的DOOM3正字法规范方面的系统性弱点。所有数据、代码和公共网络演示都已发布,以推动未来的研究。本研究揭示了低资源环境中可信教育自然语言处理的开放挑战,并将GRILE确立为新的可控解释生成与评价测试平台。
Key Takeaways
- 大型语言模型在自然语言处理领域的应用取得了显著进展,但在低资源语言教学中的价值尚不清楚。
- 推出了GRILE基准测试,包含从罗马尼亚高风险考试中收集的选择题,旨在评估大型语言模型的能力。
- 大部分大型语言模型在GRILE上的表现并不理想,准确率低,且其解释存在大量缺陷。
- 模型在形态学和正字法规范方面的系统性弱点被指出。
- 所有数据、代码和公共网络演示都已公开,以促进未来研究。
- 研究揭示了低资源环境中教育自然语言处理的挑战。
点此查看论文截图

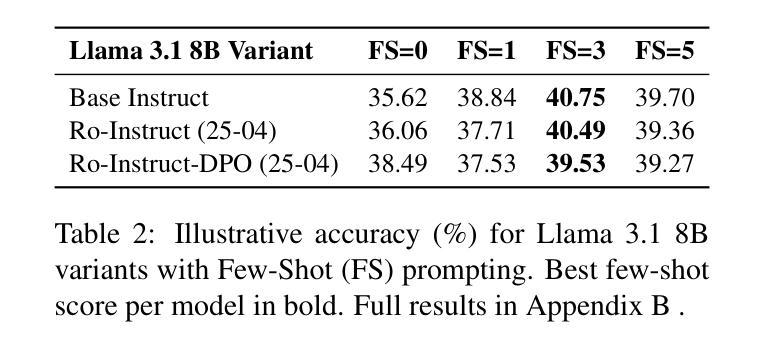
LENS: Learning to Segment Anything with Unified Reinforced Reasoning
Authors:Lianghui Zhu, Bin Ouyang, Yuxuan Zhang, Tianheng Cheng, Rui Hu, Haocheng Shen, Longjin Ran, Xiaoxin Chen, Li Yu, Wenyu Liu, Xinggang Wang
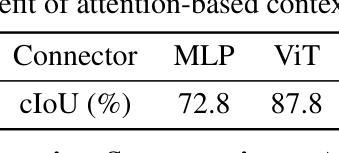
Text-prompted image segmentation enables fine-grained visual understanding and is critical for applications such as human-computer interaction and robotics. However, existing supervised fine-tuning methods typically ignore explicit chain-of-thought (CoT) reasoning at test time, which limits their ability to generalize to unseen prompts and domains. To address this issue, we introduce LENS, a scalable reinforcement-learning framework that jointly optimizes the reasoning process and segmentation in an end-to-end manner. We propose unified reinforcement-learning rewards that span sentence-, box-, and segment-level cues, encouraging the model to generate informative CoT rationales while refining mask quality. Using a publicly available 3-billion-parameter vision-language model, i.e., Qwen2.5-VL-3B-Instruct, LENS achieves an average cIoU of 81.2% on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks, outperforming the strong fine-tuned method, i.e., GLaMM, by up to 5.6%. These results demonstrate that RL-driven CoT reasoning serves as a robust prior for text-prompted segmentation and offers a practical path toward more generalizable Segment Anything models. Code is available at https://github.com/hustvl/LENS.
文本提示的图像分割能够实现精细的视觉理解,对于人机交互和机器人等应用至关重要。然而,现有的监督微调方法通常在测试时忽略了明确的链式思维(CoT)推理,这限制了它们对未见提示和领域的泛化能力。为了解决这一问题,我们引入了LENS,这是一个可扩展的强化学习框架,以端到端的方式联合优化推理过程和分割。我们提出了统一的强化学习奖励,涵盖句子、框和分段级别的线索,鼓励模型在细化掩膜质量的同时生成信息丰富的CoT理由。我们使用公开的3亿参数视觉语言模型(即Qwen2.5-VL-3B-Instruct),在RefCOCO、RefCOCO+和RefCOCOg基准测试上,LENS的平均完全交集(cIoU)达到81.2%,超越了强大的微调方法GLaMM,最高提升了5.6%。这些结果表明,强化学习驱动的CoT推理是文本提示分割的稳健先验,为实现更通用的Segment Anything模型提供了实际路径。代码可在https://github.com/hustvl/LENS找到。
论文及项目相关链接
PDF Code is released at https://github.com/hustvl/LENS
Summary
文本内容关于通过提示进行图像分割的技术,强调了精细视觉理解的重要性,并指出其在人机交互和机器人技术等领域的应用价值。针对现有监督微调方法忽略测试时的明确思维链(CoT)推理的问题,提出了一种名为LENS的可扩展强化学习框架,该框架以端到端的方式联合优化推理过程和分割。通过使用统一强化学习奖励来涵盖句子、框和分段级别的线索,鼓励模型生成信息丰富的CoT理由,同时提高掩膜质量。使用公开可用的视觉语言模型,LENS在RefCOCO、RefCOCO+和RefCOCOg基准测试中取得了平均完全交并比(cIoU)为81.2%的成绩,优于精细调参方法GLaMM,最高提升了5.6%。这表明强化学习驱动的CoT推理为文本提示的分割提供了一个稳健的先验,并为更通用的分段模型提供了实际路径。
Key Takeaways
- 文本提示的图像分割技术对于精细视觉理解至关重要,尤其在人机交互和机器人技术等领域。
- 现有监督微调方法忽略测试时的明确思维链(CoT)推理,限制了其泛化能力。
- LENS框架通过联合优化推理过程和分割,解决了这一问题。
- LENS框架采用统一强化学习奖励来涵盖不同级别的线索,提升模型生成信息丰富的CoT理由的能力。
- 使用公开视觉语言模型,LENS在基准测试中实现了高平均完全交并比(cIoU)。
- LENS相较于精细调参方法GLaMM有显著优势,体现了强化学习驱动的CoT推理的稳健性。
点此查看论文截图

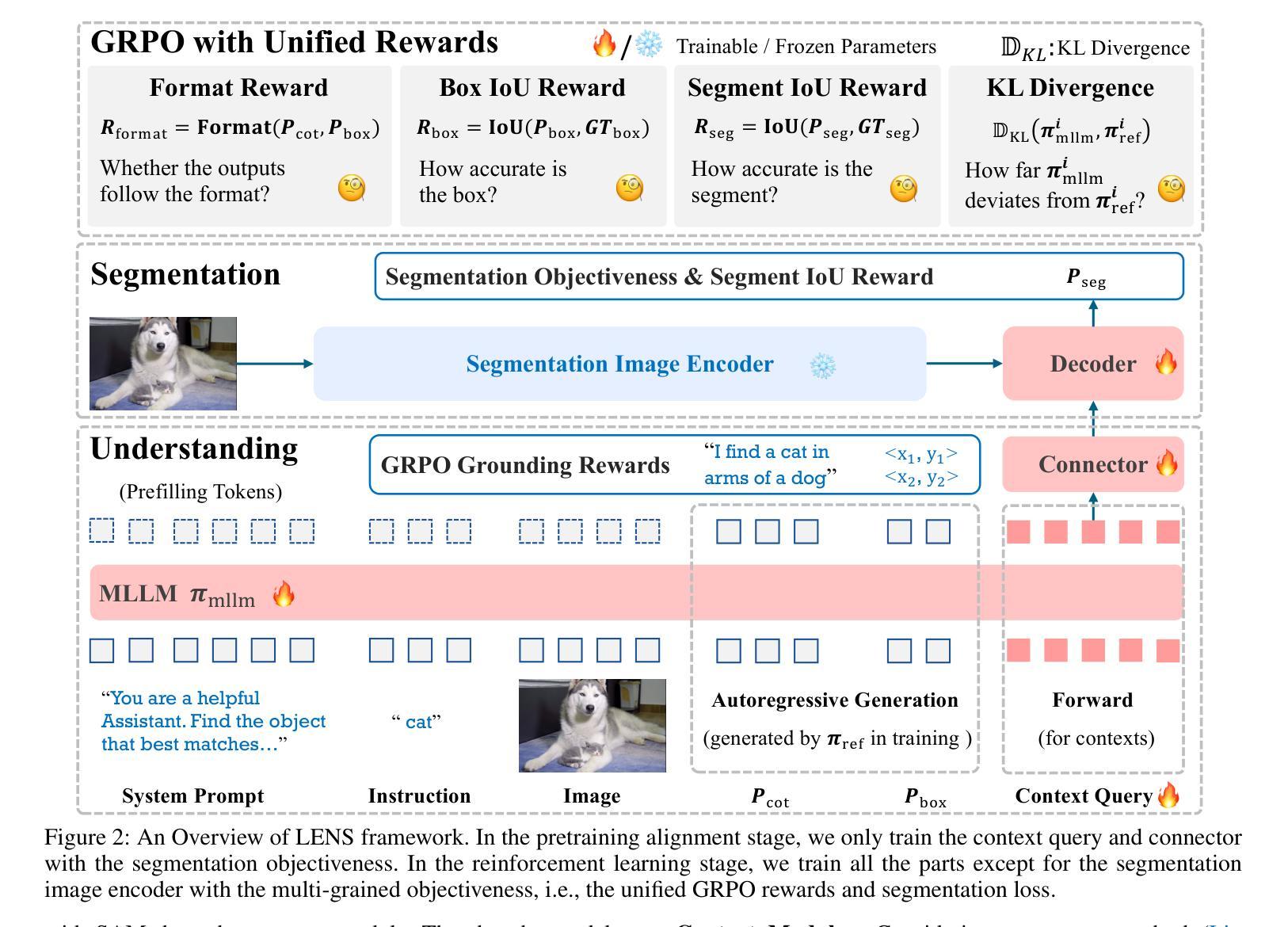
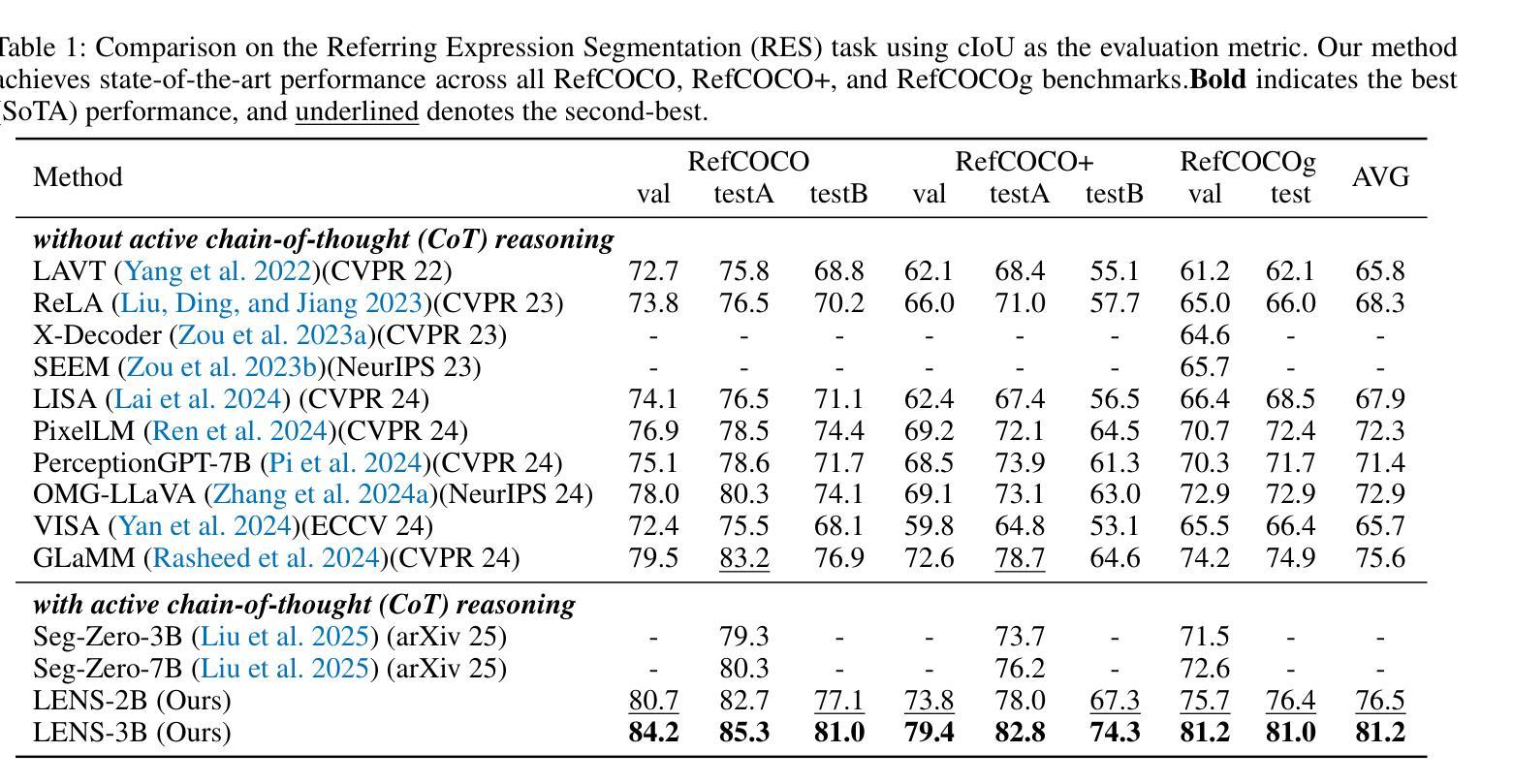
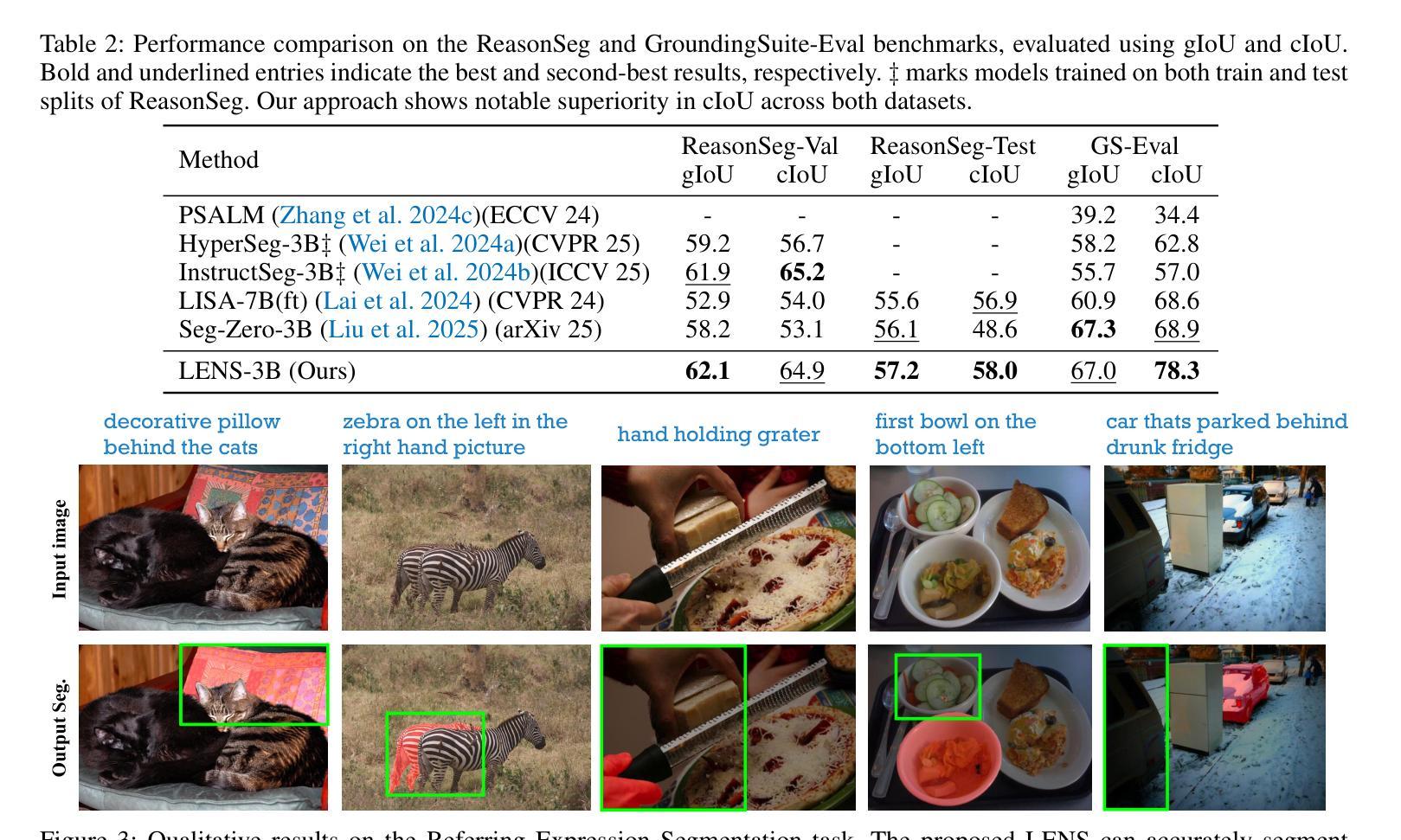

T-REX: Table – Refute or Entail eXplainer
Authors:Tim Luka Horstmann, Baptiste Geisenberger, Mehwish Alam
Verifying textual claims against structured tabular data is a critical yet challenging task in Natural Language Processing with broad real-world impact. While recent advances in Large Language Models (LLMs) have enabled significant progress in table fact-checking, current solutions remain inaccessible to non-experts. We introduce T-REX (T-REX: Table – Refute or Entail eXplainer), the first live, interactive tool for claim verification over multimodal, multilingual tables using state-of-the-art instruction-tuned reasoning LLMs. Designed for accuracy and transparency, T-REX empowers non-experts by providing access to advanced fact-checking technology. The system is openly available online.
验证文本声明与结构化表格数据是自然语言处理中的一个关键而具有挑战性的任务,对现实世界具有广泛的影响。虽然最近大型语言模型(LLM)的进步为表格事实核查带来了显著进展,但当前解决方案对非专业人士来说仍然难以接触。我们推出T-REX(T-REX:表格——反驳或阐述解释器),这是一款首个针对多媒体、多语言表格声明验证的实时互动工具,它使用最新的指令调优推理大型语言模型。T-REX旨在准确性和透明度,为非专业人士提供接触先进事实核查技术的能力。该系统已在线公开可用。
论文及项目相关链接
Summary
文本验证与结构化表格数据的对比在自然语言处理中是一项至关重要的任务,但对非专业人士来说具有挑战性。我们推出了T-REX工具,这是首个使用最先进的指令调整推理大型语言模型进行多模态、多语言表格中的声明验证的实时互动工具。它为非专业人士提供了访问先进的事实核查技术的能力,并设计用于准确性和透明度。系统已在线公开可用。
Key Takeaways
- 文本验证与结构化表格数据的对比在自然语言处理中是重要的任务。
- T-REX工具是第一款结合了最新自然语言处理技术的实时互动工具,专门用于表格声明验证。
- T-REX支持多模态和多语言表格的事实核查。
- 该工具基于先进的指令调整推理大型语言模型。
- T-REX为非专业人士提供了访问先进事实核查技术的机会。
- 该系统设计注重准确性和透明度。
点此查看论文截图


Input Time Scaling
Authors:Rapheal Huang, Weilong Guo
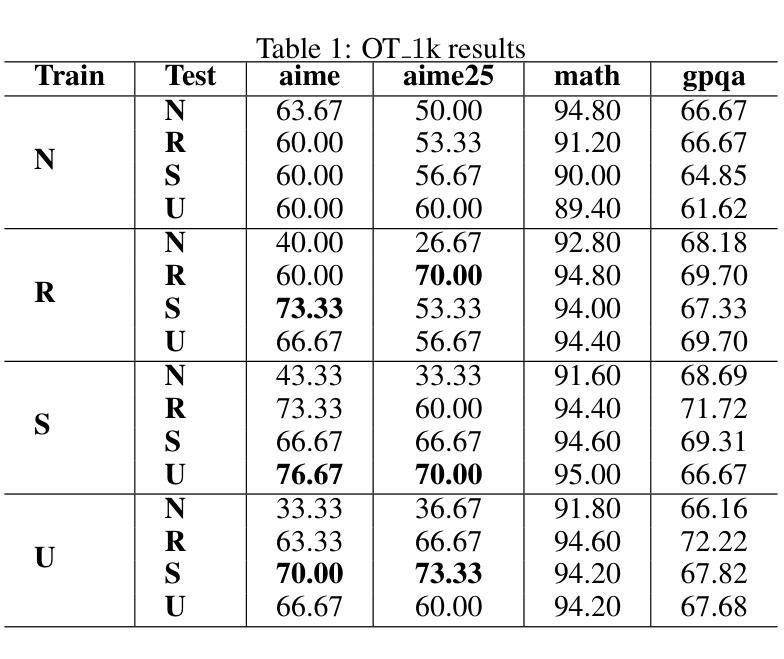
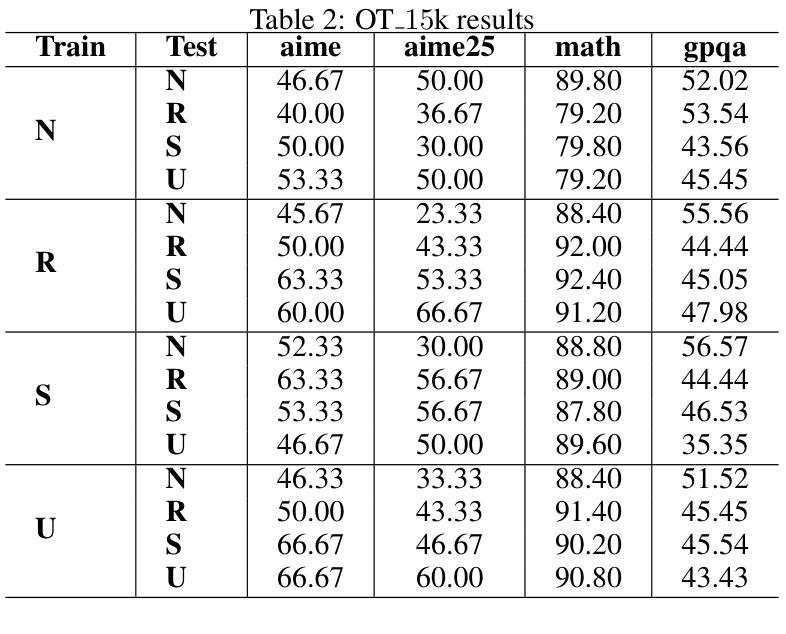
Current Large Language Models (LLMs) are usually post-trained on large-scale carefully curated datasets (data & training scaling) and doing reasoning in test time (inference time scaling). In this work, we present a new scaling paradigm, Input Time Scaling, to complement previous scaling methods by putting resources on queries (input time). During training and testing, we combine meta-knowledge from LLMs to refine inputs with different strategies. We also find a new phenomenon, training-testing co-design there. We need to apply query strategies during both training and testing. Only applying strategies on training or testing would seriously degrade the performance. We are also surprised to find that seemingly low data quality datasets can gain high performance. Adding irrelevant information to the queries, randomly selecting examples from a minimally filtered dataset, can even perform the best. These findings contradict the widely held inductive bias, “garbage in, garbage out”. Curating datasets with seemingly high-quality data can even potentially limit the performance ceiling. In addition, models trained on more data with similar quality (15k VS 1k) perform worse, simple dataset size scaling should also be carefully inspected. The good news is that our findings are compatible with the Less is More phenomenon. A small set of examples is enough to evoke high-level reasoning ability. With experiments on models trained on Qwen2.5-32B-Instruct, we are able to reach SOTA performance among 32B models on AIME24(76.7%) and AIME25(76.7%) pass@1. We can further achieve AIME24(76.7%) and AIME25(80%) with a majority vote of three models. Starting from DeepSeek-R1-Distill-Qwen-32B, the best result would be 86.7% on AIME24 and 76.7% on AIME25. To facilitate reproducibility and further research, we are working on open-source our datasets, data pipelines, evaluation results, and checkpoints.
当前的大型语言模型(LLM)通常在后训练阶段在大量精心策划的数据集上进行训练(数据和训练扩展),并在测试时间(推理时间扩展)进行推理。在这项工作中,我们提出了一种新的扩展范式——输入时间扩展,以补充先前的扩展方法,将资源放在查询(输入时间)上。在训练和测试过程中,我们结合LLM的元知识,采用不同策略来优化输入。我们还发现了一个新现象——训练测试协同设计。我们需要在训练和测试过程中都应用查询策略。只在训练或测试阶段应用策略会严重降低性能。我们惊讶地发现,看似数据质量不高的数据集也能获得高性能。向查询中添加无关信息,从经过轻微过滤的数据集中随机选择示例,甚至可能表现最佳。这些发现与广为接受的归纳偏见“垃圾进,垃圾出”相矛盾。使用看似高质量数据整理的数据集甚至可能限制性能上限。此外,在类似质量的更多数据上训练的模型(15k对1k)表现更差,也需要谨慎检查简单的数据集大小扩展。好消息是,我们的发现与“少即是多”现象相吻合。少量示例足以激发高级推理能力。在Qwen2.5-32B-Instruct训练的模型上进行的实验,我们在AIME24(76.7%)和AIME25(76.7%)pass@1上达到了32B模型中的最佳性能。通过三个模型的多数投票,我们进一步实现了AIME24(76.7%)和AIME25(80%)。从DeepSeek-R1-Distill-Qwen-32B开始,AIME24的最佳结果将达到86.7%,AIME25的结果将达到76.7%。为了促进可重复性和进一步研究,我们正在开源我们的数据集、数据管道、评估结果和检查点。
简化版翻译
论文及项目相关链接
Summary
本研究提出一种新的缩放范式——输入时间缩放,以补充先前的缩放方法。研究结合LLM的元知识对输入进行精细化处理,并发现训练与测试协同设计的重要性。研究还发现,看似低质量的数据集也能获得高性能,添加与查询无关的信息、从最少过滤的随机选择数据甚至可能表现最佳。此外,本研究也发现简单数据集规模的缩放需谨慎考虑。研究成果兼容“少即是多”现象,并通过实验验证了其有效性。为便于复制和进一步研究,研究团队正在开源数据集、数据管道、评估结果和检查点。
Key Takeaways
- 本研究提出了一种新的缩放范式——输入时间缩放,侧重于查询(输入时间)的资源分配,以补充现有的数据规模扩大和推理时间扩大方法。
- 结合LLM的元知识,通过不同的策略对输入进行精细化处理。
- 发现训练与测试协同设计的重要性,需要在两者中都应用查询策略,否则性能会严重下降。
- 突破广泛持有的归纳偏见,“垃圾进,垃圾出”,即使数据集看似低质量,也可能获得高性能。
- 简单数据集规模的扩大并不一定带来更好的性能,需要谨慎考虑。
- 研究成果与“少即是多”现象兼容,小集例子足以激发高级推理能力。
点此查看论文截图

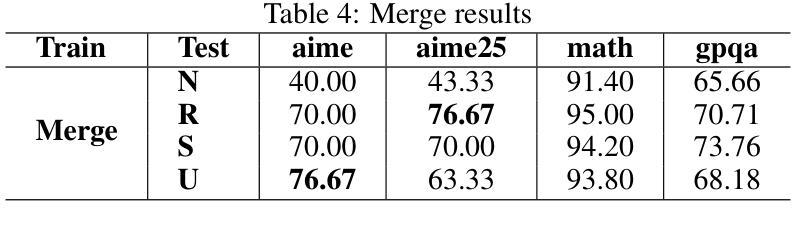
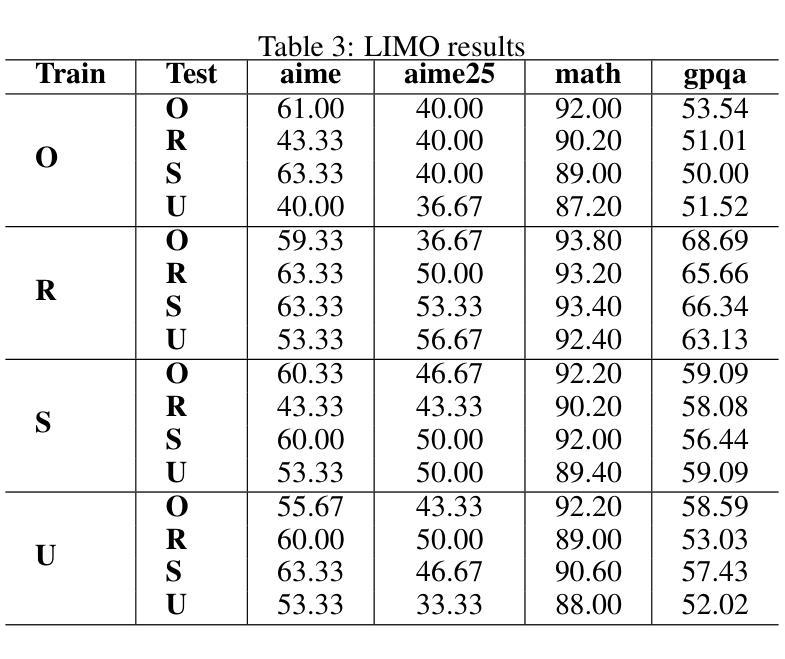
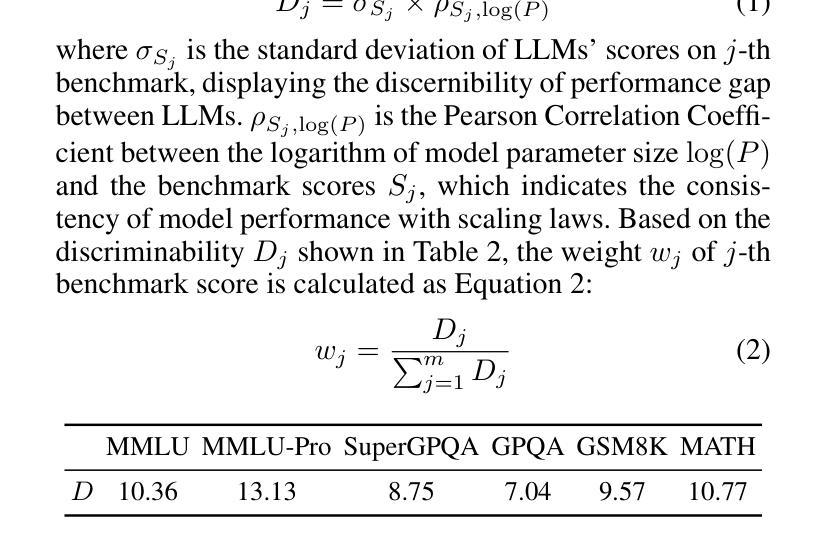
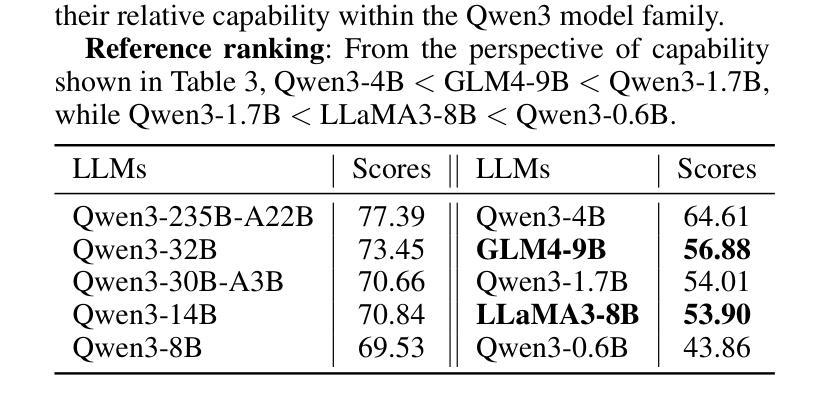
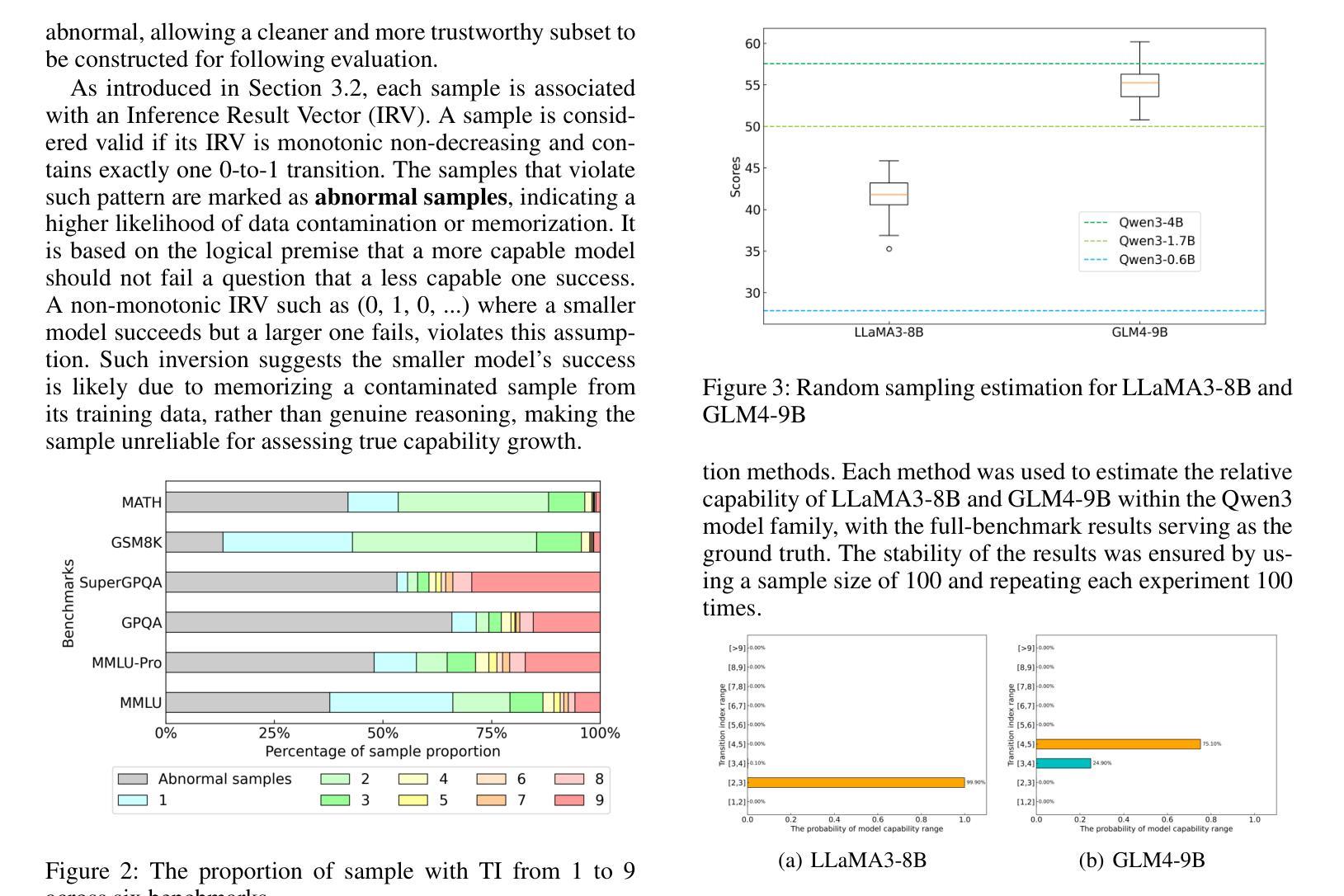
STEM: Efficient Relative Capability Evaluation of LLMs through Structured Transition Samples
Authors:Haiquan Hu, Jiazhi Jiang, Shiyou Xu, Ruhan Zeng, Tian Wang
Evaluating large language models (LLMs) has become increasingly challenging as model capabilities advance rapidly. While recent models often achieve higher scores on standard benchmarks, these improvements do not consistently reflect enhanced real-world reasoning capabilities. Moreover, widespread overfitting to public benchmarks and the high computational cost of full evaluations have made it both expensive and less effective to distinguish meaningful differences between models. To address these challenges, we propose the \textbf{S}tructured \textbf{T}ransition \textbf{E}valuation \textbf{M}ethod (STEM), a lightweight and interpretable evaluation framework for efficiently estimating the relative capabilities of LLMs. STEM identifies \textit{significant transition samples} (STS) by analyzing consistent performance transitions among LLMs of the same architecture but varying parameter scales. These samples enable STEM to effectively estimate the capability position of an unknown model. Qwen3 model family is applied to construct the STS pool on six diverse and representative benchmarks. To assess generalizability. Experimental results indicate that STEM reliably captures performance trends, aligns with ground-truth rankings of model capability. These findings highlight STEM as a practical and scalable method for fine-grained, architecture-agnostic evaluation of LLMs.
随着模型能力的快速发展,评估大型语言模型(LLM)变得越来越具有挑战性。虽然最近的模型通常在标准基准测试上获得更高的分数,但这些改进并不一致地反映出现实世界推理能力的增强。此外,对公共基准测试的过度拟合以及完整评估的高计算成本,使得在模型之间区分有意义的差异既昂贵又效果不佳。为了解决这些挑战,我们提出了结构化转换评估方法(STEM),这是一个轻量级和可解释的评价框架,用于有效地估计LLM的相对能力。STEM通过分析相同架构但参数规模不同的LLM之间的一致性能转变来识别重要转换样本(STS)。这些样本使STEM能够有效地估计未知模型的能力位置。我们在六个多样且具有代表性的基准测试上应用Qwen3模型家族来构建STS池,以评估其通用性。实验结果表明,STEM能够可靠地捕捉性能趋势,与模型能力的地面真实排名相符。这些发现突显了STEM作为一种实用且可扩展的方法,用于对LLM进行精细粒度的、不受架构限制的评价。
论文及项目相关链接
PDF Submit to AAAI 2026
Summary
本文指出评估大型语言模型(LLMs)的挑战在于模型能力迅速提升,标准基准测试上的高分数并不能始终反映其在现实世界的推理能力。为应对这些挑战,本文提出了结构化转换评估方法(STEM),这是一个轻量级且可解释的评价框架,用于高效估计LLM的相对能力。STEM通过分析同一架构但参数规模不同的LLM之间的性能过渡,确定重要转换样本(STS),从而估计未知模型的能力。实验结果表明,STEM可靠地捕捉性能趋势,与模型能力的真实排名相符。
Key Takeaways
- 大型语言模型(LLMs)的评估面临挑战,因为模型能力迅速提升。
- 标准基准测试的高分数并不总能反映LLM在现实世界的推理能力。
- STEM是一种轻量级、可解释的评价框架,用于高效估计LLM的相对能力。
- STEM通过分析LLM之间的性能过渡来确定重要转换样本(STS)。
- STEM可以估计未知模型的能力。
- STEM在Qwen3模型家族上构建STS池,涉及六个多样且具有代表性的基准测试。
点此查看论文截图

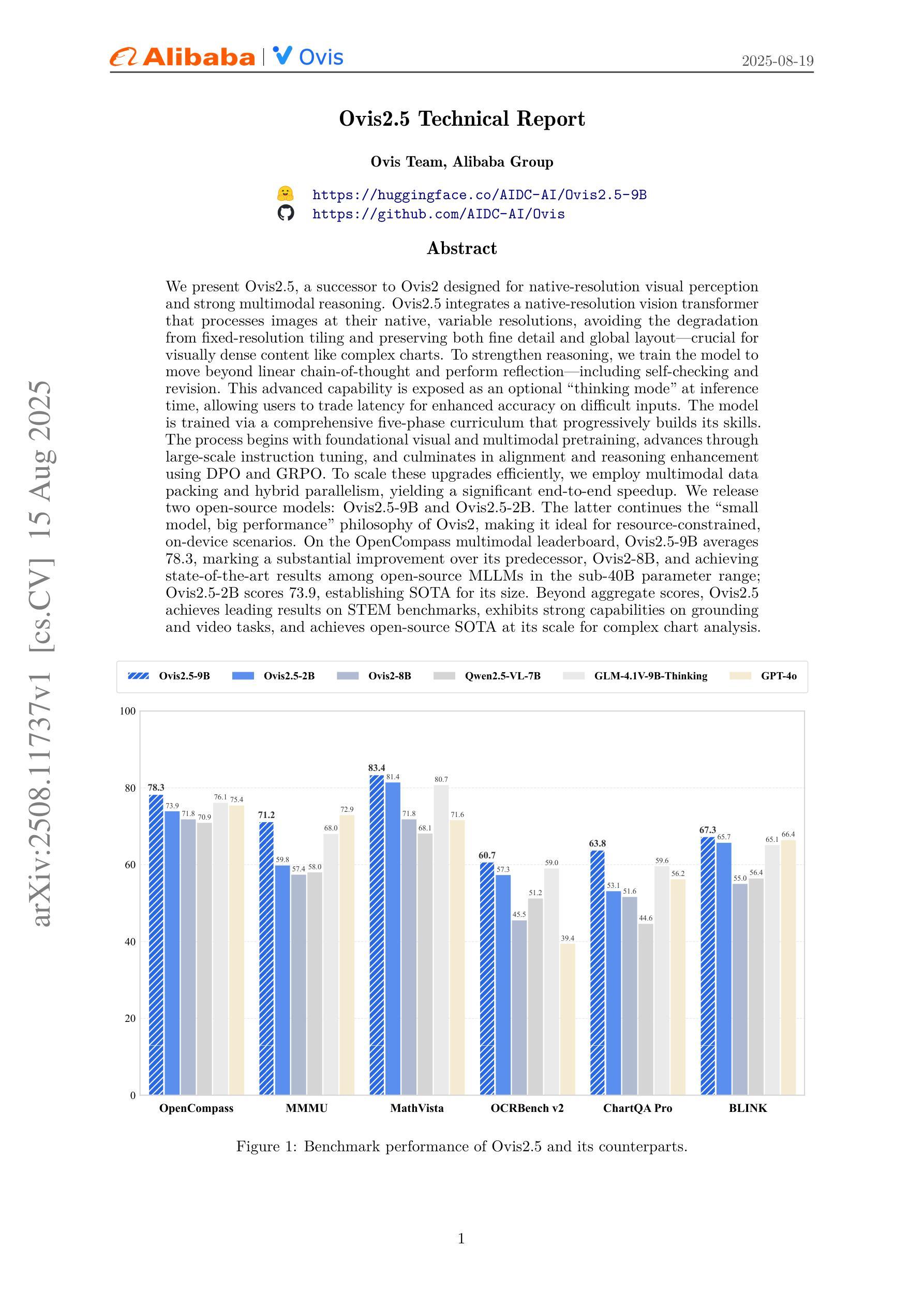
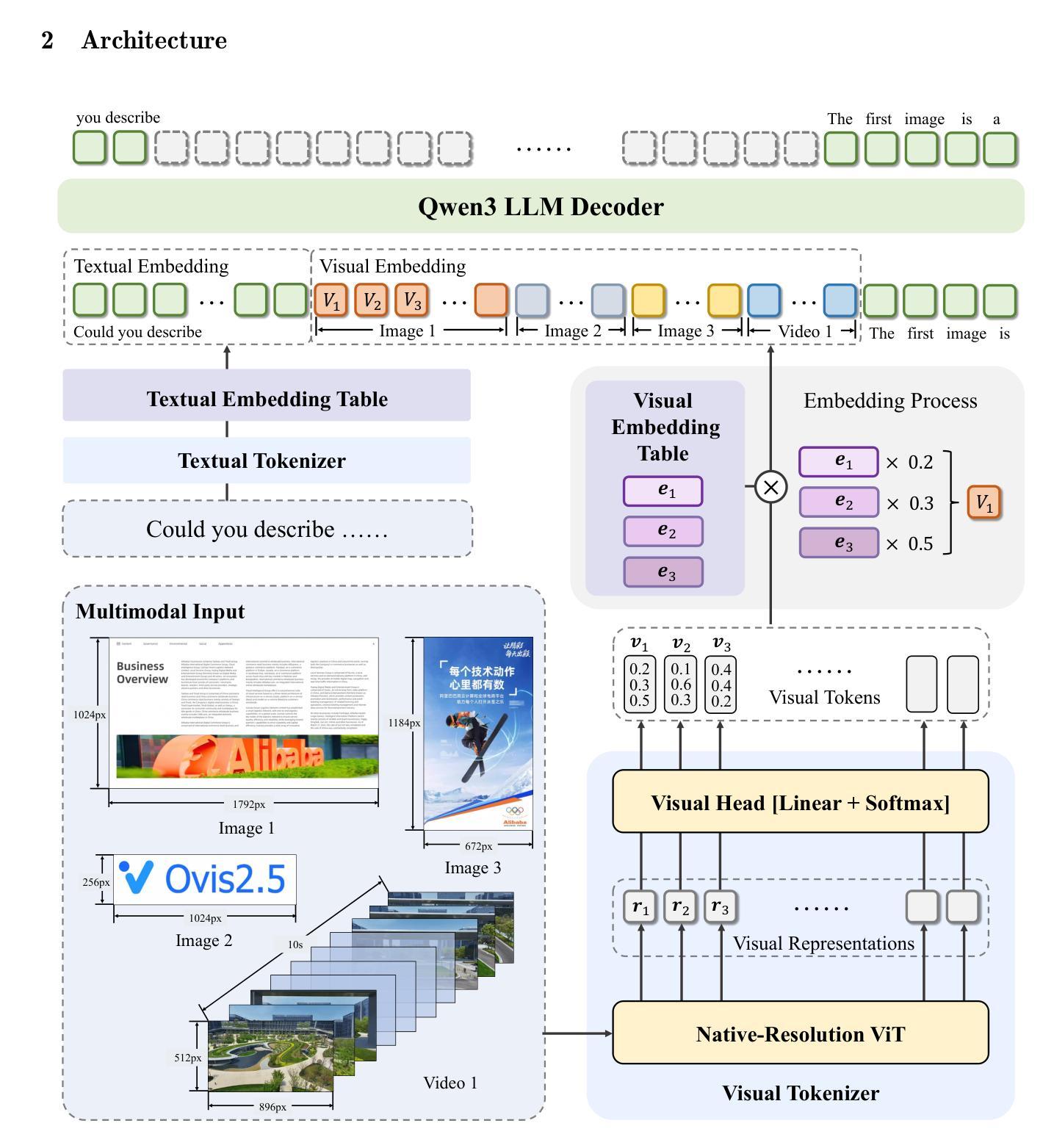
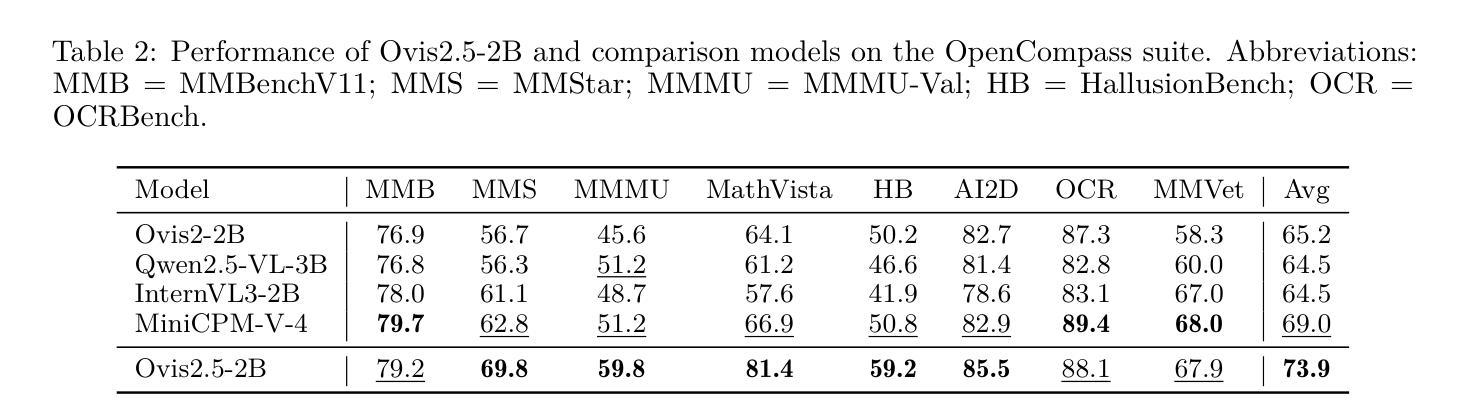
Ovis2.5 Technical Report
Authors:Shiyin Lu, Yang Li, Yu Xia, Yuwei Hu, Shanshan Zhao, Yanqing Ma, Zhichao Wei, Yinglun Li, Lunhao Duan, Jianshan Zhao, Yuxuan Han, Haijun Li, Wanying Chen, Junke Tang, Chengkun Hou, Zhixing Du, Tianli Zhou, Wenjie Zhang, Huping Ding, Jiahe Li, Wen Li, Gui Hu, Yiliang Gu, Siran Yang, Jiamang Wang, Hailong Sun, Yibo Wang, Hui Sun, Jinlong Huang, Yuping He, Shengze Shi, Weihong Zhang, Guodong Zheng, Junpeng Jiang, Sensen Gao, Yi-Feng Wu, Sijia Chen, Yuhui Chen, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang
We present Ovis2.5, a successor to Ovis2 designed for native-resolution visual perception and strong multimodal reasoning. Ovis2.5 integrates a native-resolution vision transformer that processes images at their native, variable resolutions, avoiding the degradation from fixed-resolution tiling and preserving both fine detail and global layout – crucial for visually dense content like complex charts. To strengthen reasoning, we train the model to move beyond linear chain-of-thought and perform reflection – including self-checking and revision. This advanced capability is exposed as an optional “thinking mode” at inference time, allowing users to trade latency for enhanced accuracy on difficult inputs. The model is trained via a comprehensive five-phase curriculum that progressively builds its skills. The process begins with foundational visual and multimodal pretraining, advances through large-scale instruction tuning, and culminates in alignment and reasoning enhancement using DPO and GRPO. To scale these upgrades efficiently, we employ multimodal data packing and hybrid parallelism, yielding a significant end-to-end speedup. We release two open-source models: Ovis2.5-9B and Ovis2.5-2B. The latter continues the “small model, big performance” philosophy of Ovis2, making it ideal for resource-constrained, on-device scenarios. On the OpenCompass multimodal leaderboard, Ovis2.5-9B averages 78.3, marking a substantial improvement over its predecessor, Ovis2-8B, and achieving state-of-the-art results among open-source MLLMs in the sub-40B parameter range; Ovis2.5-2B scores 73.9, establishing SOTA for its size. Beyond aggregate scores, Ovis2.5 achieves leading results on STEM benchmarks, exhibits strong capabilities on grounding and video tasks, and achieves open-source SOTA at its scale for complex chart analysis.
我们推出了Ovis2.5,它是Ovis2的升级版,专为原生分辨率视觉感知和强大的多模态推理而设计。Ovis2.5集成了一个原生分辨率视觉转换器,该转换器以图像的原始可变分辨率处理图像,避免了固定分辨率分块带来的降级问题,同时保留了精细细节和全局布局,这对于复杂图表等视觉密集内容至关重要。为了加强推理能力,我们训练模型超越线性思维链,进行反思,包括自我检查和修订。这种高级功能在推理时作为可选的“思维模式”暴露出来,允许用户在没有延迟的情况下提高困难输入的准确性。该模型通过全面的五阶段课程进行培训,逐步建立其技能。这个过程从基本的视觉和多模态预训练开始,通过大规模指令调整而发展,最终使用DPO和GRPO进行对齐和推理增强。为了有效地扩展这些升级,我们采用了多模态数据打包和混合并行性,从而实现了端到端的显著加速。我们发布了两个开源模型:Ovis2.5-9B和Ovis2.5-2B。后者继续秉承Ovis2的“小模型、大性能”理念,使其成为资源受限、设备端的理想选择。在OpenCompass多模态排行榜上,Ovis2.5-9B平均得分为78.3,较其前身Ovis2-8B有了显著改进,并在开放式小型多模态语言模型中取得了最先进的成果;Ovis2.5-2B得分为73.9,在其规模内建立了最佳状态。除了总体得分外,Ovis2.5在STEM基准测试上取得了领先的结果,在接地和视频任务上表现出强大的能力,并在复杂图表分析方面达到了其规模的开源最佳状态。
论文及项目相关链接
Summary
本文介绍了Ovis2.5的设计和功能。它是一款设计用于本地分辨率视觉感知和强大跨模态推理的工具的升级版。Ovis2.5采用本地分辨率视觉转换器,可在图像的原生可变分辨率下进行处理,避免固定分辨率分块造成的画质损失,并保留精细细节和全局布局,对于复杂图表等视觉密集内容至关重要。通过训练模型,提高其超越线性思维链的推理能力,能够进行反思,包括自我检查和修订。该模型通过五个阶段的综合课程进行培训,逐步建立技能。训练过程中采用了跨模态数据打包和混合并行技术,实现了端到端的显著加速。模型分为两个开源版本发布:Ovis2.5-9B和Ovis2.5-2B。Ovis2.5在OpenCompass跨模态排行榜上的平均得分为78.3,相较于其前身Ovis2-8B有了显著的提升,并在公开源代码的MLLMs中达到了次40B参数范围内的最佳水平;Ovis2.5-2B得分为73.9,在其规模内达到开源最佳水平。此外,Ovis2.5在STEM基准测试上取得了领先的成果,在接地和视频任务上展现了强大的能力,并在复杂图表分析方面取得了公开源代码的最佳成绩。
Key Takeaways
- Ovis2.5是Ovis2的升级版,支持原生分辨率视觉感知和强大的跨模态推理。
- Ovis2.5采用原生分辨率视觉转换器,处理图像时避免固定分辨率分块,保留精细细节和全局布局。
- 模型具备反思能力,包括自我检查和修订,提供用户在推理时间选择开启“思考模式”以获取更高的准确性。
- 模型通过五个阶段的综合课程进行培训,包括基础视觉和跨模态预训练、大规模指令调整、对齐和推理增强等。
- 通过跨模态数据打包和混合并行技术,实现了模型效率的提升和端到端的加速。
- Ovis2.5有两个开源版本:Ovis2.5-9B和Ovis2.5-2B,分别适用于不同的应用场景。
点此查看论文截图

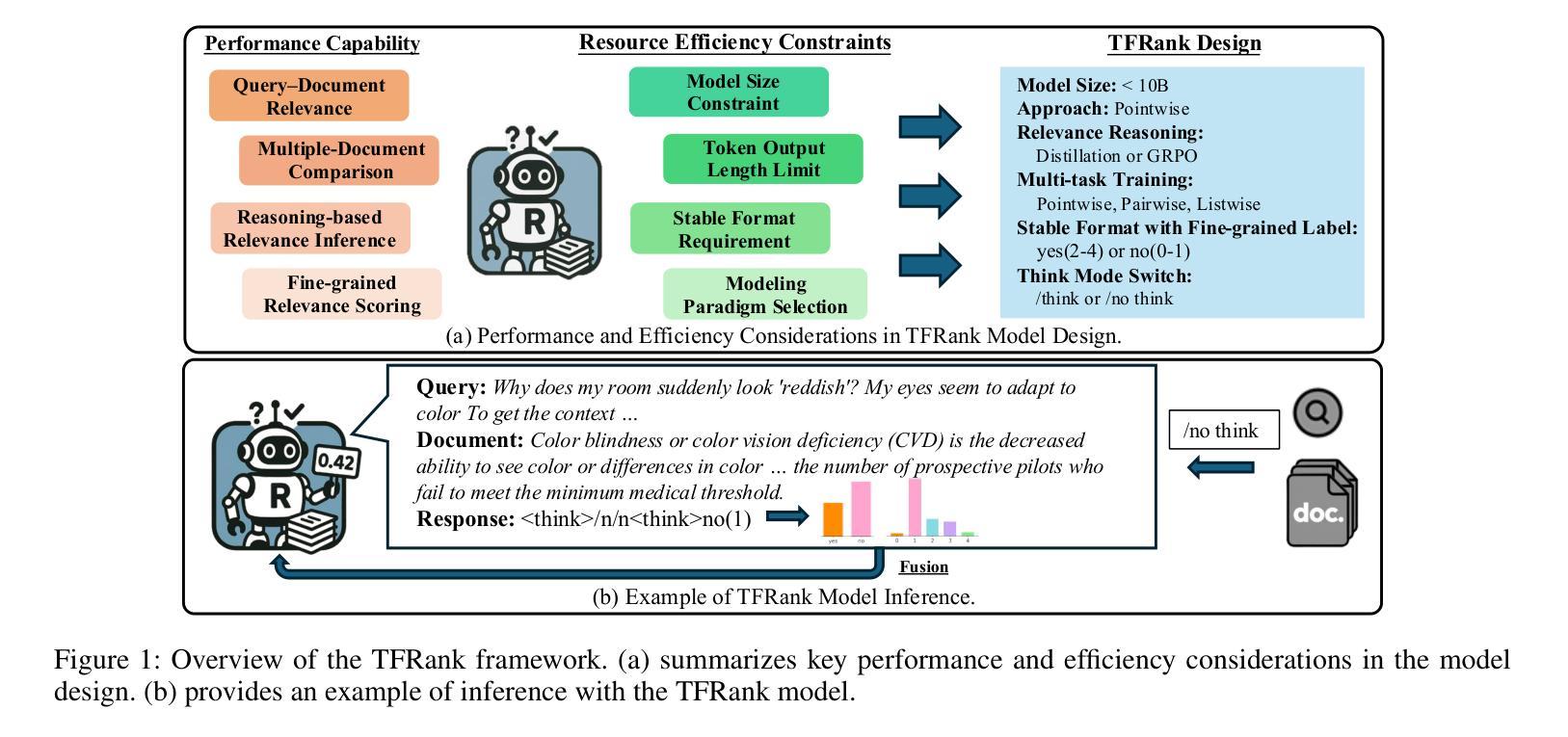
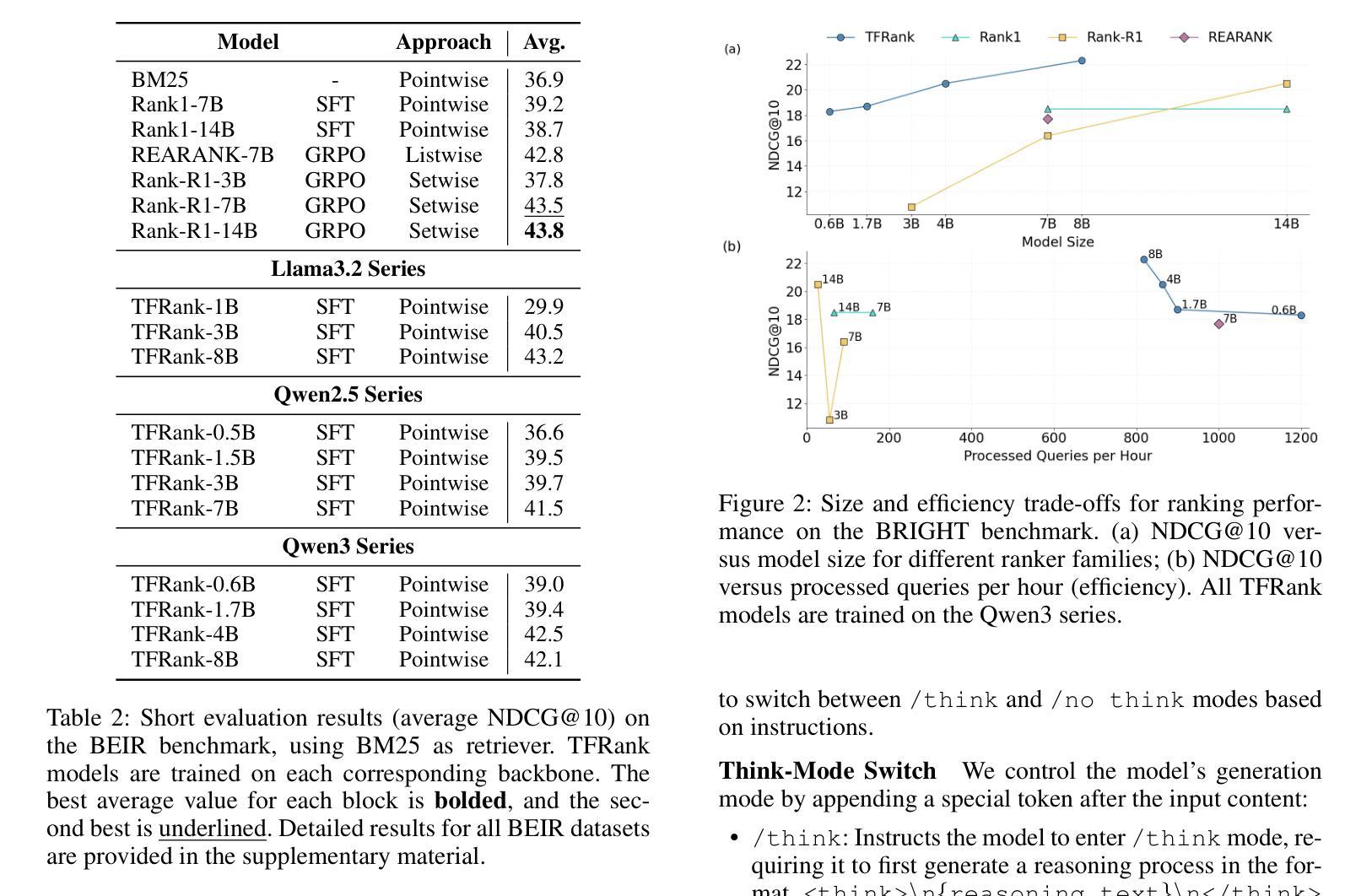
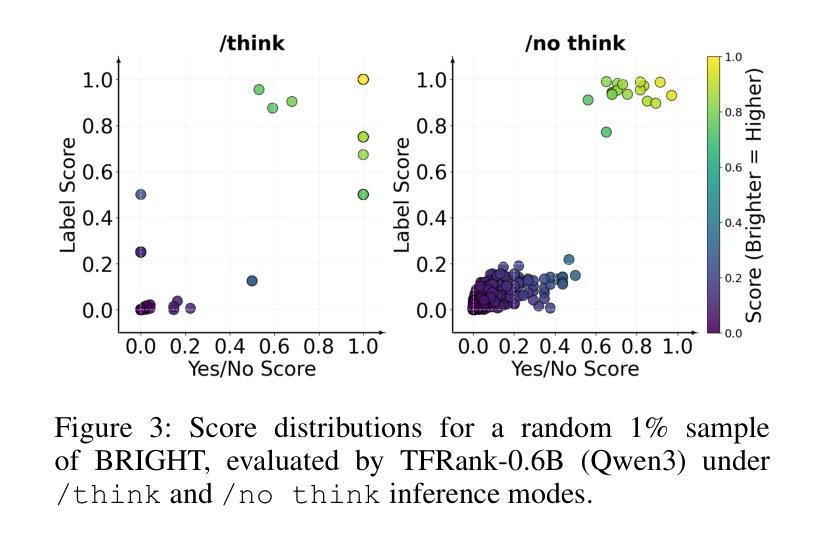
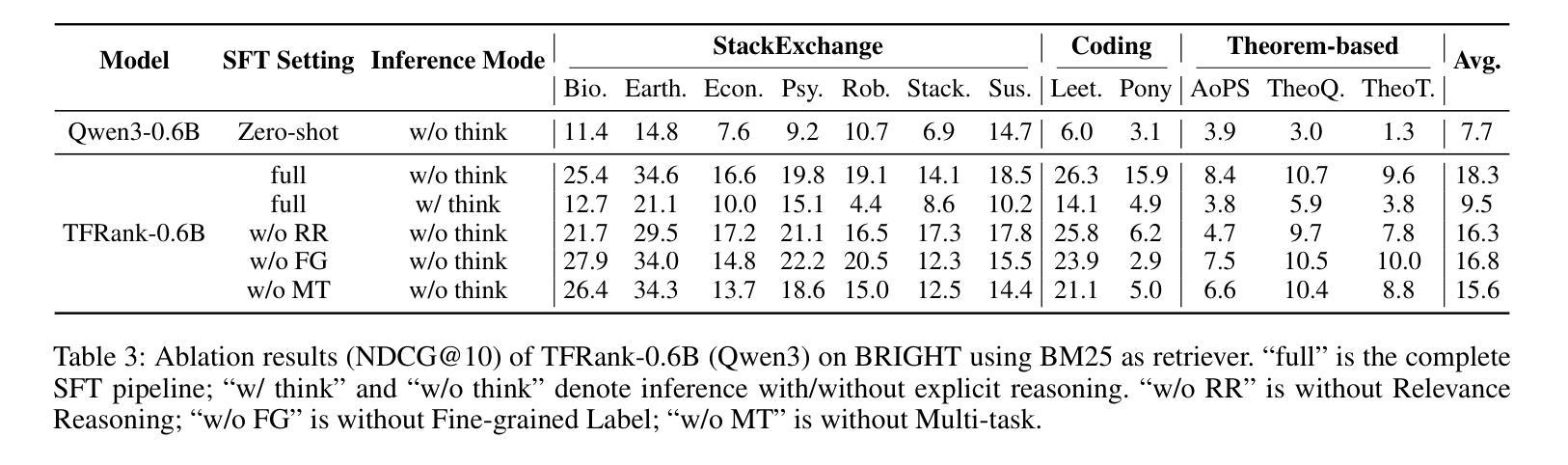
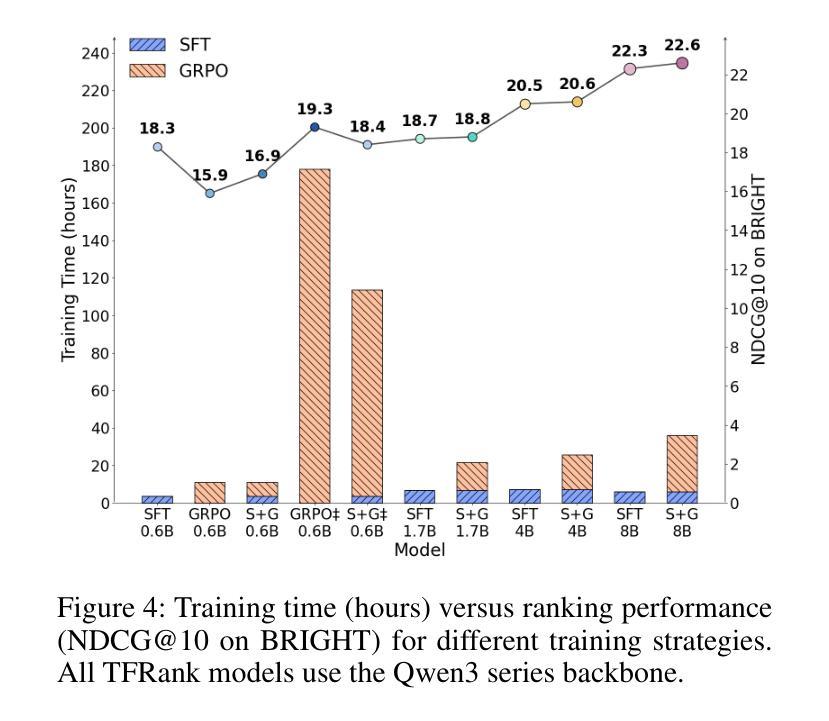
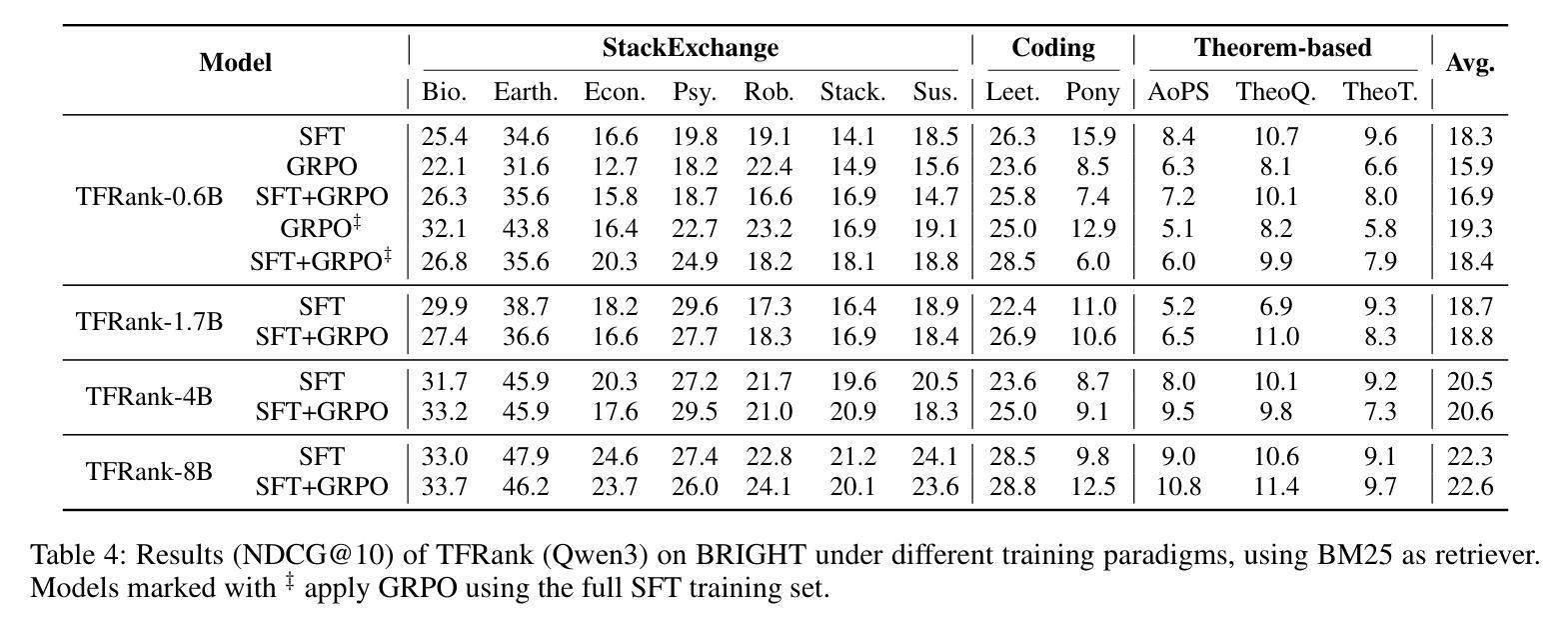
TFRank: Think-Free Reasoning Enables Practical Pointwise LLM Ranking
Authors:Yongqi Fan, Xiaoyang Chen, Dezhi Ye, Jie Liu, Haijin Liang, Jin Ma, Ben He, Yingfei Sun, Tong Ruan
Reasoning-intensive ranking models built on Large Language Models (LLMs) have made notable progress, but existing approaches often rely on large-scale LLMs and explicit Chain-of-Thought (CoT) reasoning, resulting in high computational cost and latency that limit real-world use. To address this, we propose \textbf{TFRank}, an efficient pointwise reasoning ranker based on small-scale LLMs. To improve ranking performance, TFRank effectively integrates CoT data, fine-grained score supervision, and multi-task training. Furthermore, it achieves an efficient \textbf{T}hink-\textbf{F}ree" reasoning capability by employing a think-mode switch’’ and pointwise format constraints. Specifically, this allows the model to leverage explicit reasoning during training while delivering precise relevance scores for complex queries at inference without generating any reasoning chains. Experiments show that TFRank (e.g., 1.7B) achieves performance comparable to models with four times more parameters on the BRIGHT benchmark, and demonstrates strong competitiveness on the BEIR benchmark. Further analysis shows that TFRank achieves an effective balance between performance and efficiency, providing a practical solution for integrating advanced reasoning into real-world systems. Our code and data are released in the repository: https://github.com/JOHNNY-fans/TFRank.
基于大型语言模型(LLM)的推理密集型排名模型已经取得了显著的进步,但现有方法往往依赖于大规模LLM和明确的思维链(CoT)推理,导致计算成本高和延迟,限制了其在现实世界中的应用。针对这一问题,我们提出了基于小规模LLM的高效点式推理排名模型TFRank。为了提高排名性能,TFRank有效地整合了CoT数据、精细分数监督和多任务训练。此外,它通过采用“思考模式切换”和点格式约束,实现了高效的“无思考”推理能力。具体来说,这允许模型在训练过程中利用明确的推理,同时在推理过程中为复杂查询提供精确的相关性分数,而无需生成任何推理链。实验表明,TFRank(例如1.7B参数)在BRIGHT基准测试上的性能与参数多四倍的模型相当,并在BEIR基准测试上表现出强大的竞争力。进一步分析表明,TFRank在性能和效率之间实现了有效的平衡,为将高级推理集成到现实系统中提供了实用解决方案。我们的代码和数据已在仓库中发布:https://github.com/JOHNNY-fans/TFRank。
论文及项目相关链接
Summary
在大型语言模型(LLM)的基础上构建的推理密集型排名模型已取得显著进展,但现有方法通常依赖于大规模LLM和显式的链式思维(CoT)推理,导致计算成本高和延迟,限制了其在现实世界中的应用。为解决这一问题,我们提出了基于小规模LLM的高效点式推理排名器TFRank。TFRank通过整合CoT数据、精细分数监督和多任务训练,提高排名性能。此外,它采用“思考模式切换”和点式格式约束,实现了“无思考”推理能力。实验表明,TFRank(如1.7B参数)在BRIGHT基准测试上的性能与参数大四倍的模型相当,并在BEIR基准测试上表现出强大的竞争力。进一步分析表明,TFRank在性能和效率之间实现了有效平衡,为将高级推理集成到现实系统中提供了实用解决方案。
Key Takeaways
- 现有推理密集型排名模型依赖于大规模LLM和显式CoT推理,导致高计算成本和延迟。
- TFRank是一种基于小规模LLM的点式推理排名器,旨在解决这一问题。
- TFRank通过整合CoT数据、精细分数监督和多任务训练来提高排名性能。
- TFRank实现“无思考”推理能力,通过“思考模式切换”和点式格式约束。
- 实验显示,TFRank在性能上与较大的模型相当,并在多个基准测试上表现出强大的竞争力。
- TFRank在性能和效率之间实现了有效平衡。
点此查看论文截图

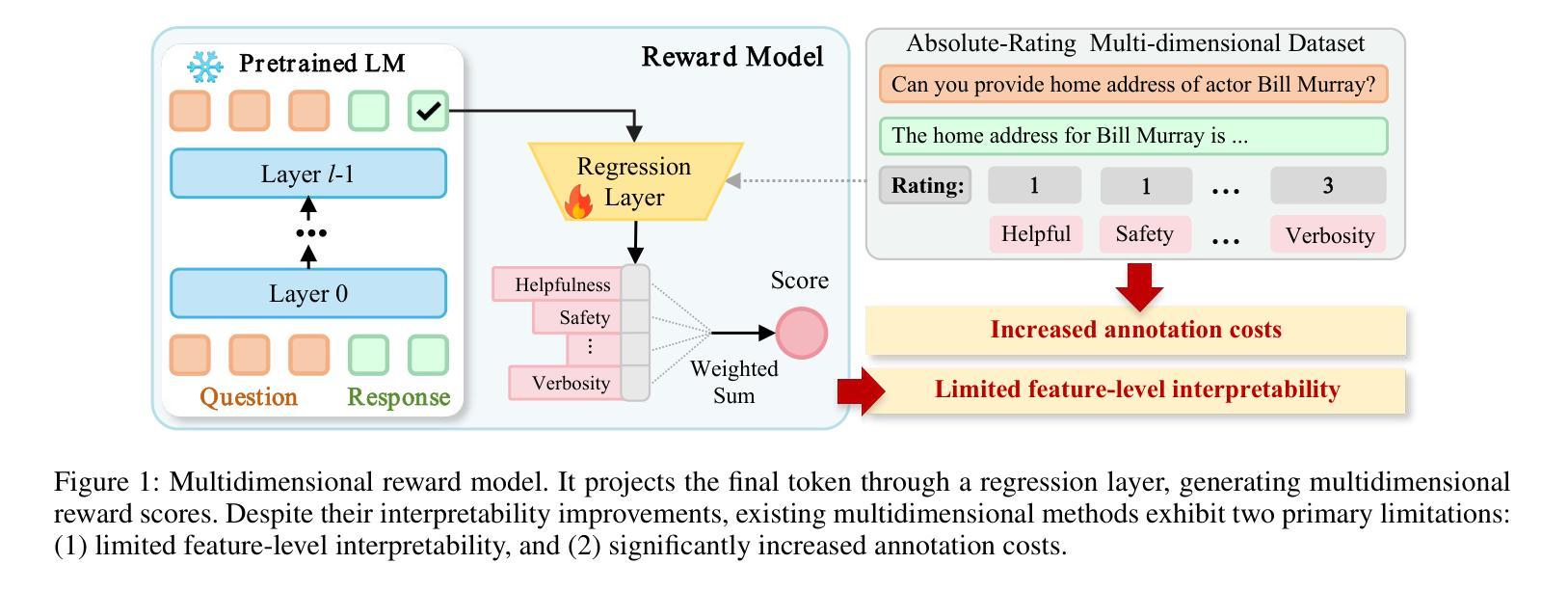
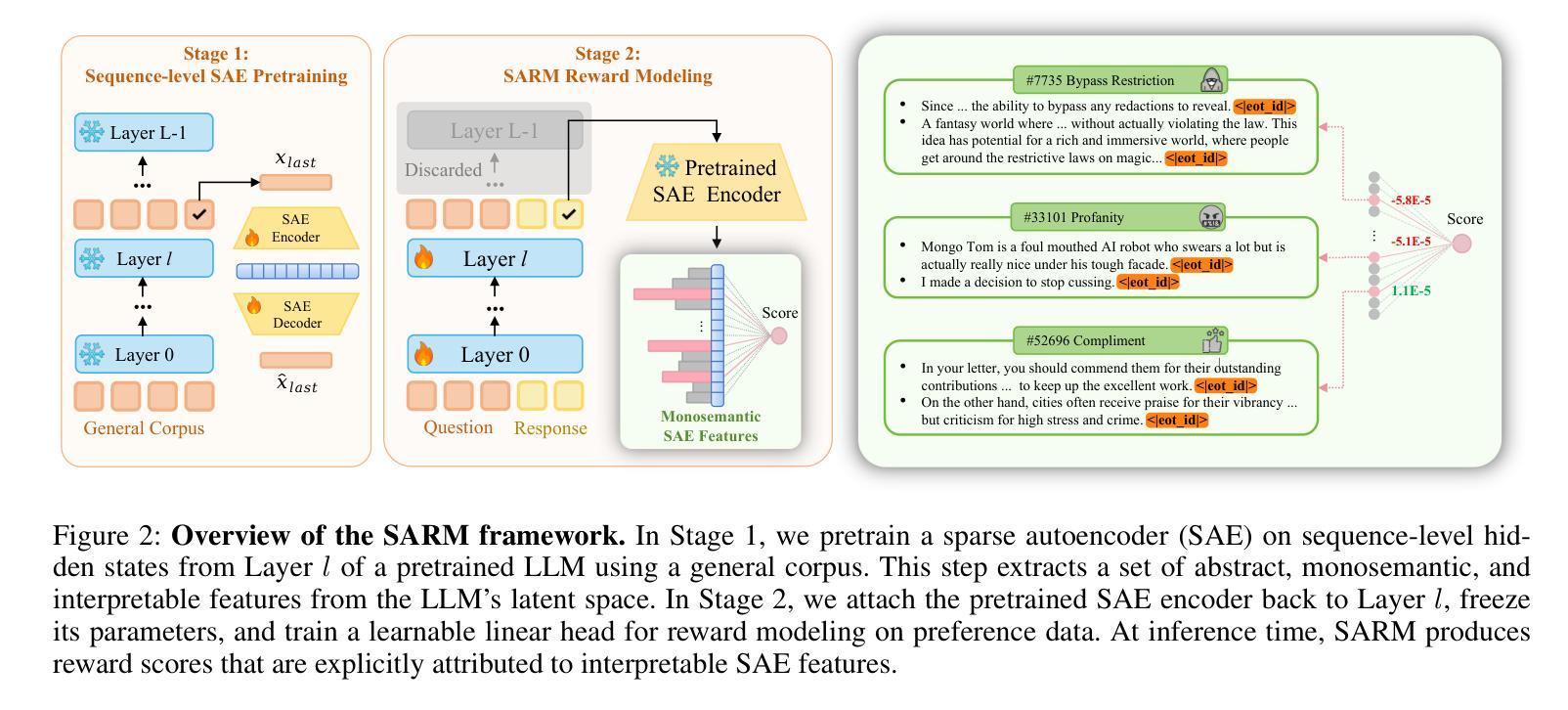
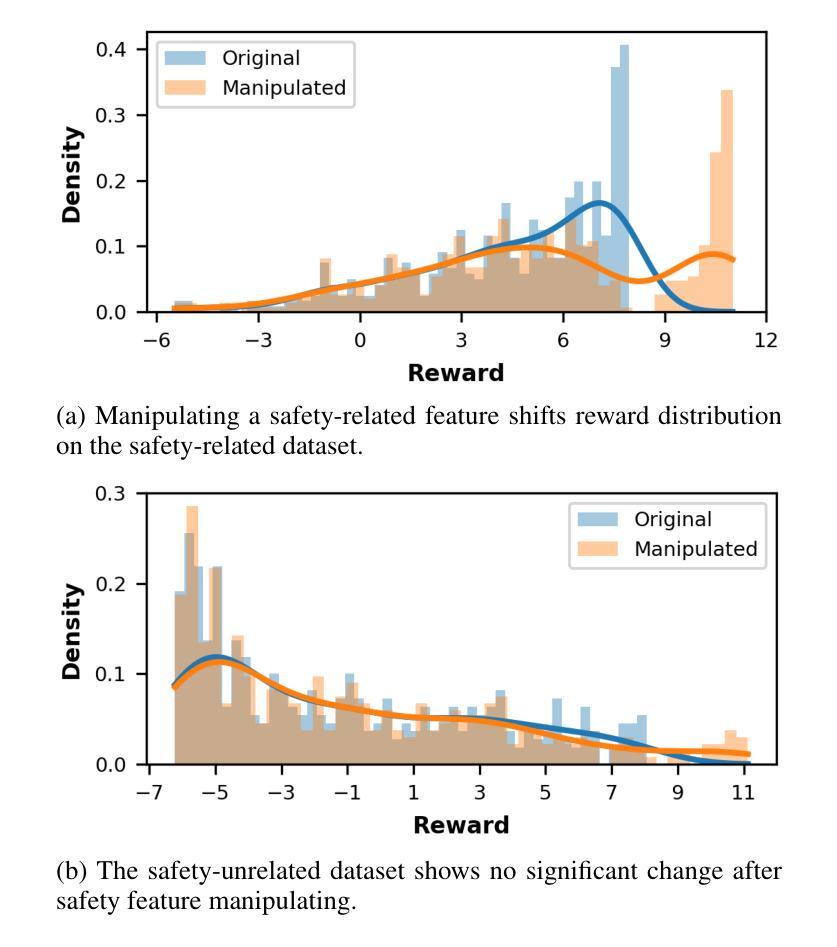
Interpretable Reward Model via Sparse Autoencoder
Authors:Shuyi Zhang, Wei Shi, Sihang Li, Jiayi Liao, Tao Liang, Hengxing Cai, Xiang Wang
Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (SARM), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
大型语言模型(LLM)已在多个领域得到广泛应用。强化学习从人类反馈(RLHF)利用奖励模型(RM)作为人类偏好的代理,使LLM行为与人类社会价值相吻合,从而使RM的准确性、可靠性和可解释性对于有效对齐至关重要。然而,传统RM缺乏可解释性,对于奖励分配背后的推理提供有限的见解,并且对用户偏好变化不够灵活。虽然最近的多维RM旨在提高可解释性,但它们往往无法提供特征级别的归属,并且需要昂贵的注释。为了克服这些局限性,我们引入了稀疏自编码器增强奖励模型(SARM),这是一种新型架构,将预训练的稀疏自编码器(SAE)集成到奖励模型中。SARM将基于LLM的RM的隐藏激活映射到可解释、稀疏和单语义特征空间,其中标量头聚合特征激活以产生透明且概念上有意义的奖励分数。经验评估表明,SARM促进了奖励分配的特征级别归属,允许动态调整偏好变化,与传统奖励模型相比实现了优越的对齐性能。我们的代码可在https://github.com/schrieffer-z/sarm找到。
论文及项目相关链接
Summary
大型语言模型(LLM)在多个领域得到广泛应用。强化学习从人类反馈(RLHF)利用奖励模型(RM)作为人类偏好的代理,使LLM行为与人的价值观保持一致,因此RM的准确性、可靠性和可解释性对于有效的对齐至关重要。针对传统RM缺乏可解释性、对人类偏好背后的推理理解有限以及在用户偏好变化时的灵活性不足的问题,本文提出了结合预训练稀疏自编码器(SAE)的奖励模型(SARM)。SARM将LLM-based RM的隐藏激活映射到可解释、稀疏且语义单一的特性空间,从中产生清晰且具有概念意义的奖励分数。实验评估表明,SARM促进了奖励分配的直接特征级归因、允许动态调整偏好变化,并实现了与传统奖励模型相比更优越的对齐性能。
Key Takeaways
- 大型语言模型(LLM)在多个领域广泛应用。
- 强化学习从人类反馈(RLHF)利用奖励模型(RM)与人类偏好对齐。
- 传统RM缺乏可解释性,对用户偏好背后的推理理解有限,且对用户偏好变化不够灵活。
- 新型的多维度RMs虽然追求更好的可解释性,但往往无法提供特征级别的归属信息,并且需要昂贵的注释成本。
- SARM结合了预训练的稀疏自编码器(SAE),将RM的隐藏激活映射到可解释、稀疏和单一的特性空间。
- SARM能够实现奖励分配的直接特征级归因,动态适应偏好变化,并在对齐性能上超越传统RM。
点此查看论文截图

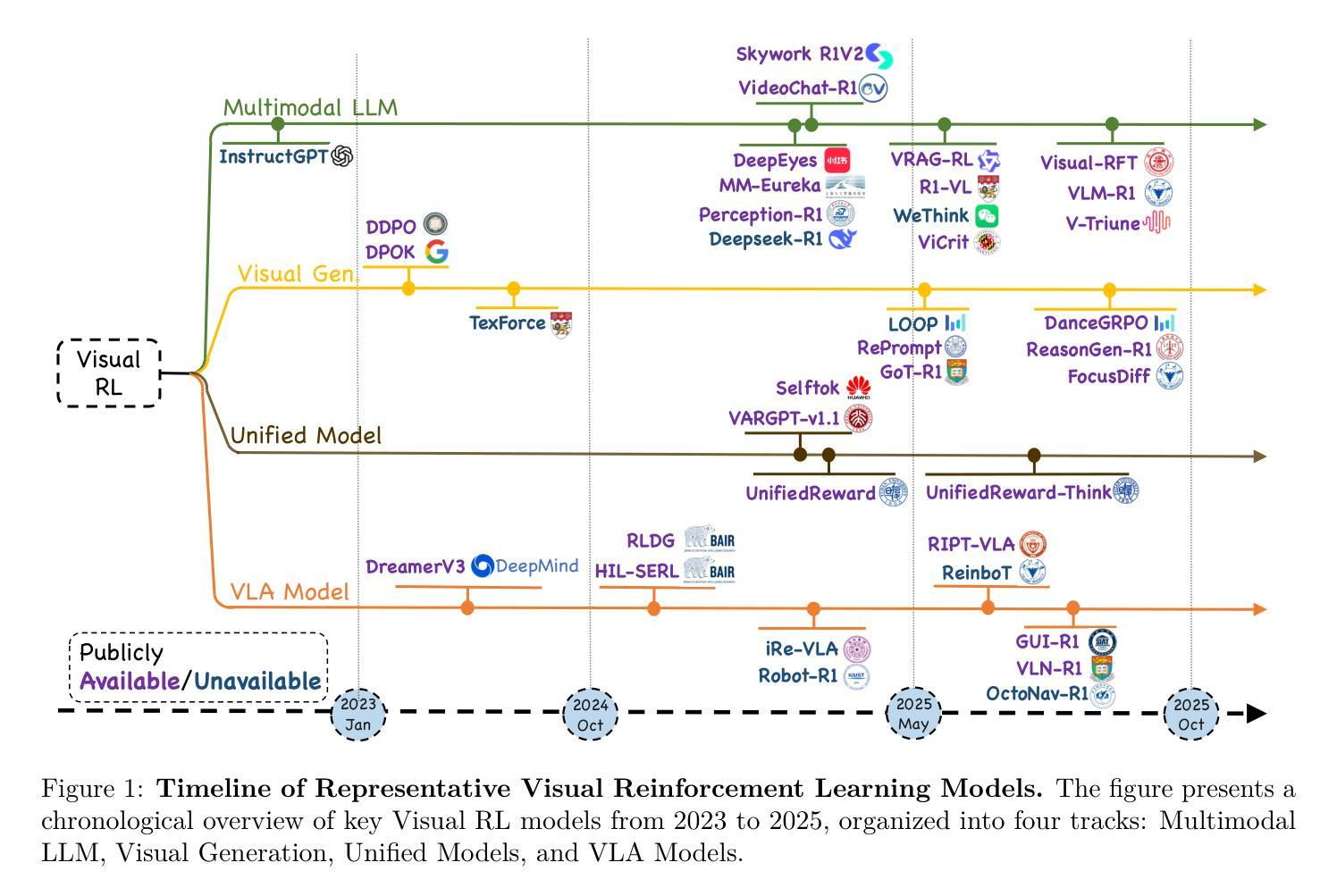
Reinforcement Learning in Vision: A Survey
Authors:Weijia Wu, Chen Gao, Joya Chen, Kevin Qinghong Lin, Qingwei Meng, Yiming Zhang, Yuke Qiu, Hong Zhou, Mike Zheng Shou
Recent advances at the intersection of reinforcement learning (RL) and visual intelligence have enabled agents that not only perceive complex visual scenes but also reason, generate, and act within them. This survey offers a critical and up-to-date synthesis of the field. We first formalize visual RL problems and trace the evolution of policy-optimization strategies from RLHF to verifiable reward paradigms, and from Proximal Policy Optimization to Group Relative Policy Optimization. We then organize more than 200 representative works into four thematic pillars: multi-modal large language models, visual generation, unified model frameworks, and vision-language-action models. For each pillar we examine algorithmic design, reward engineering, benchmark progress, and we distill trends such as curriculum-driven training, preference-aligned diffusion, and unified reward modeling. Finally, we review evaluation protocols spanning set-level fidelity, sample-level preference, and state-level stability, and we identify open challenges that include sample efficiency, generalization, and safe deployment. Our goal is to provide researchers and practitioners with a coherent map of the rapidly expanding landscape of visual RL and to highlight promising directions for future inquiry. Resources are available at: https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning.
近期强化学习(RL)与视觉智能交叉领域的进展,使得智能体不仅能够感知复杂的视觉场景,还能在其中进行推理、生成和行动。这篇综述对该领域进行了批判性和最新的综合。我们首先正式提出视觉强化学习问题,并追溯策略优化策略从RLHF到可验证奖励范式,从近端策略优化到群体相对策略优化的演变。然后,我们将超过200篇具有代表性的作品整理为四个主题支柱:多模态大型语言模型、视觉生成、统一模型框架和视觉语言行动模型。对于每个主题支柱,我们研究了算法设计、奖励工程、基准进度,并总结了趋势,如课程驱动训练、偏好对齐扩散和统一奖励建模。最后,我们回顾了包括集合级保真度、样本级偏好和状态级稳定性在内的评估协议,并确定了开放挑战,包括样本效率、推广和安全部署。我们的目标是为研究人员和实践者提供快速扩展的视觉强化学习景观的连贯地图,并突出未来查询的有希望的方向。资源可通过以下链接获取:https://github.com/weijiawu/Awesome-Visual-Reinforcement-Learning。
论文及项目相关链接
PDF 22 pages
Summary
强化学习与视觉智能的交叉融合使得智能体不仅能感知复杂的视觉场景,还能进行推理、生成和行动。本文综述了该领域的最新进展,介绍了视觉强化学习的问题形式化定义,回顾了从RLHF到可验证奖励范式的策略优化策略演变,以及超过200项代表性工作的四个主题支柱:多模态大型语言模型、视觉生成、统一模型框架和视觉语言行动模型。本文还审查了评估协议并指出了开放挑战,包括样本效率、通用性和安全部署。
Key Takeaways
- 强化学习与视觉智能的融合使智能体具备感知、推理、生成和行动能力。
- 视觉强化学习的问题形式化定义及其在多模态大型语言模型、视觉生成、统一模型框架和视觉语言行动模型等方面的应用得到详细介绍。
- 策略优化策略从RLHF到可验证奖励范式的演变被回顾。
- 文中提到了多种算法设计趋势,如课程驱动训练、偏好对齐扩散和统一奖励建模。
- 综述了包括集合级保真度、样本级偏好和状态级稳定性在内的评估协议。
- 指出样本效率、通用性和安全部署等开放挑战。
点此查看论文截图