⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-22 更新
D^3-Talker: Dual-Branch Decoupled Deformation Fields for Few-Shot 3D Talking Head Synthesis
Authors:Yuhang Guo, Kaijun Deng, Siyang Song, Jindong Xie, Wenhui Ma, Linlin Shen
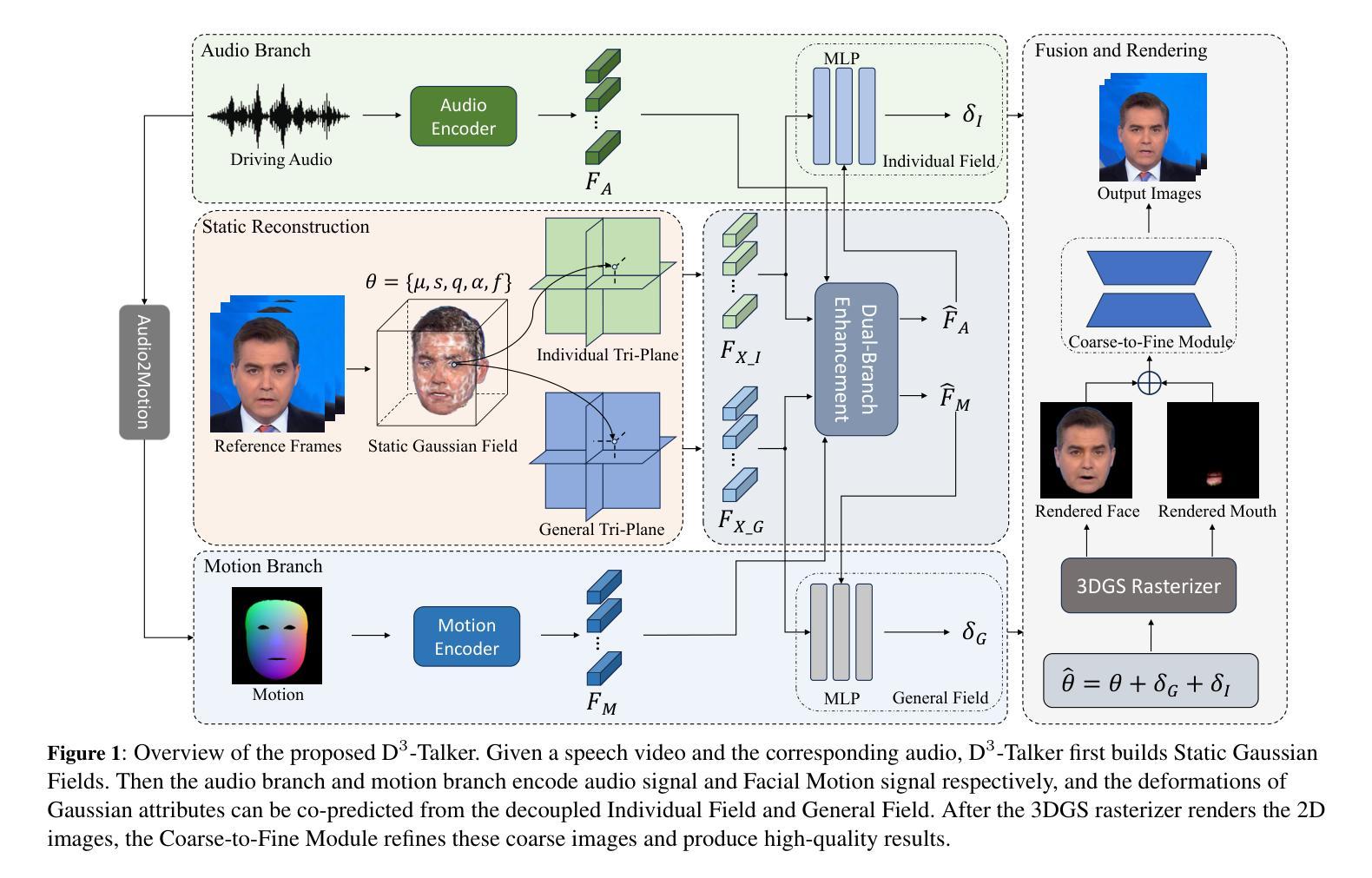
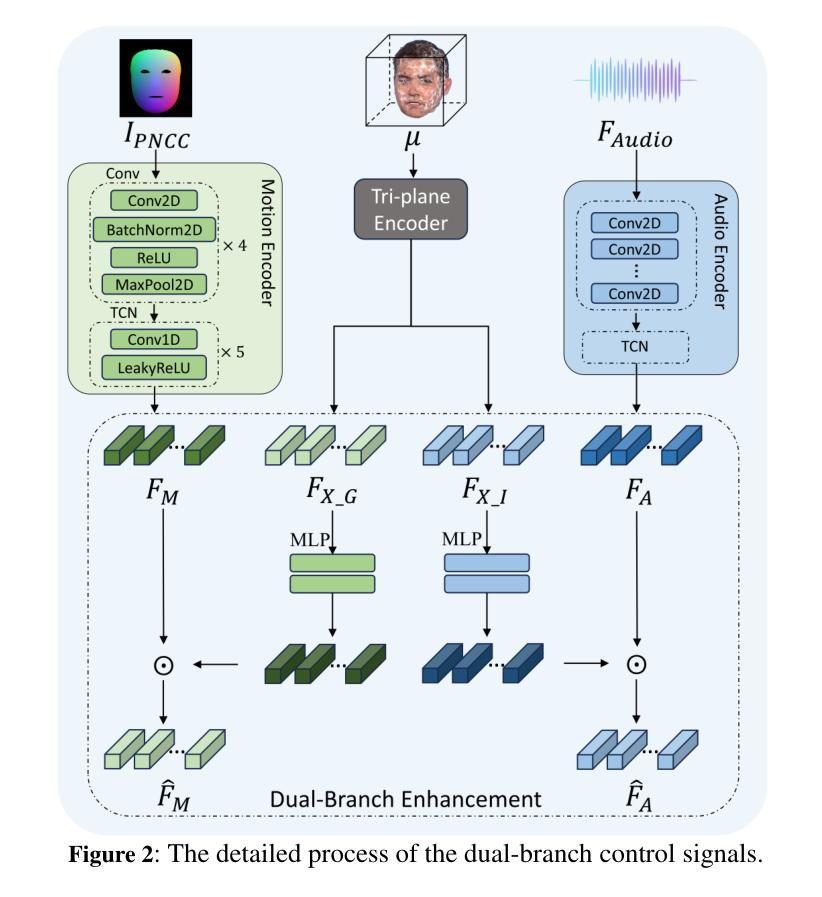
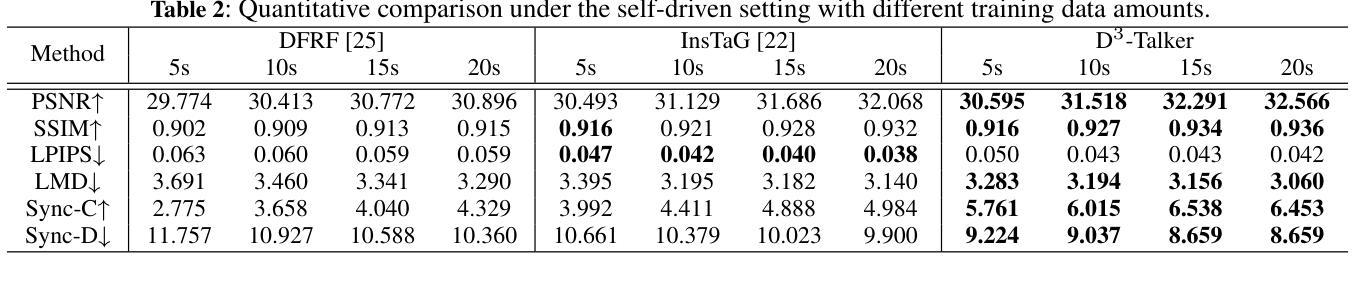
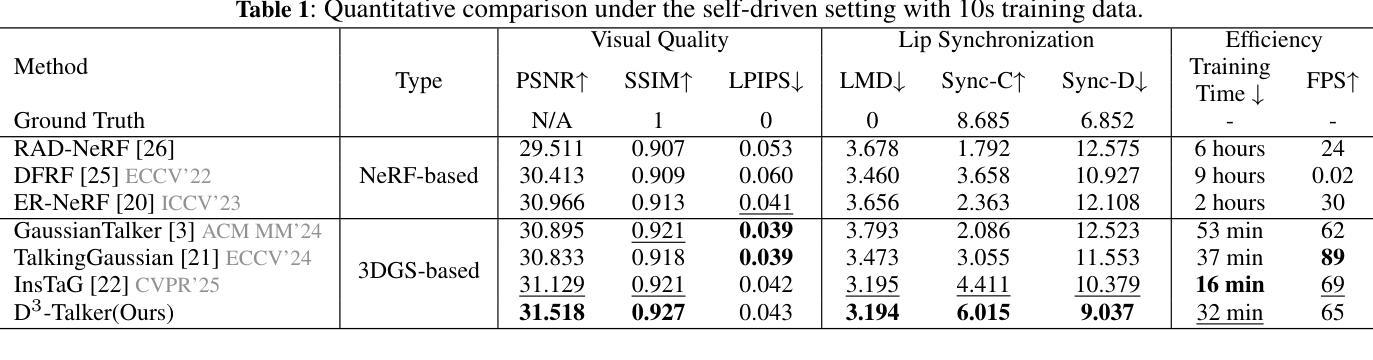
A key challenge in 3D talking head synthesis lies in the reliance on a long-duration talking head video to train a new model for each target identity from scratch. Recent methods have attempted to address this issue by extracting general features from audio through pre-training models. However, since audio contains information irrelevant to lip motion, existing approaches typically struggle to map the given audio to realistic lip behaviors in the target face when trained on only a few frames, causing poor lip synchronization and talking head image quality. This paper proposes D^3-Talker, a novel approach that constructs a static 3D Gaussian attribute field and employs audio and Facial Motion signals to independently control two distinct Gaussian attribute deformation fields, effectively decoupling the predictions of general and personalized deformations. We design a novel similarity contrastive loss function during pre-training to achieve more thorough decoupling. Furthermore, we integrate a Coarse-to-Fine module to refine the rendered images, alleviating blurriness caused by head movements and enhancing overall image quality. Extensive experiments demonstrate that D^3-Talker outperforms state-of-the-art methods in both high-fidelity rendering and accurate audio-lip synchronization with limited training data. Our code will be provided upon acceptance.
在3D对话头部合成中的关键挑战在于,依赖于长时间对话头部视频来从头开始为每一个目标身份训练一个新模型。近期的方法试图通过预训练模型从音频中提取通用特征来解决这个问题。然而,由于音频包含与唇部运动无关的信息,当仅在少数几帧上进行训练时,现有方法通常很难将给定的音频映射到目标脸部的真实唇部行为上,导致唇部同步和对话头部图像质量不佳。本文提出了D^3-Talker,这是一种构建静态3D高斯属性场的新方法,采用音频和面部运动信号独立控制两个不同的高斯属性变形场,有效地解耦了通用和个性化变形的预测。我们在预训练过程中设计了一种新型相似性对比损失函数,以实现更彻底的解耦。此外,我们集成了一个由粗到细的模块来优化渲染图像,减轻头部运动造成的模糊,提高整体图像质量。大量实验表明,在有限的训练数据下,D^3-Talker在高保真渲染和准确的音频-唇部同步方面都优于最先进的方法。代码在通过后将会提供。
论文及项目相关链接
Summary
该论文针对3D对话头合成中的关键挑战,提出了一种名为D^3-Talker的新方法。该方法构建了一个静态的3D高斯属性场,并利用音频和面部运动信号独立控制两个独特的高斯属性变形场,从而有效地解耦了一般和个性化变形的预测。通过设计预训练过程中的新型相似性对比损失函数,实现了更彻底的解耦。此外,集成了由粗到细的模块,以优化渲染图像,减轻头部移动造成的模糊,并提高整体图像质量。实验证明,D^3-Talker在有限训练数据的情况下,在高保真渲染和准确的音频-唇部同步方面优于现有方法。
Key Takeaways
- D^3-Talker解决了3D对话头合成中为每个目标身份从头开始训练模型所需的长时长视频的问题。
- 该方法通过构建静态的3D高斯属性场并利用音频和面部运动信号独立控制变形场,实现了预测解耦。
- 利用新型相似性对比损失函数在预训练阶段实现更彻底的解耦。
- D^3-Talker集成了由粗到细的模块,优化渲染图像,减少头部移动造成的模糊。
- 该方法在高保真渲染和音频与唇部同步方面具有出色的表现,尤其是在有限训练数据的情况下。
- D^3-Talker的源代码将在接受后提供。
- 该论文的方法为对话头合成提供了一个有效的解决方案,特别是在缺乏大量训练数据的情况下。
点此查看论文截图


Efficient Long-duration Talking Video Synthesis with Linear Diffusion Transformer under Multimodal Guidance
Authors:Haojie Zhang, Zhihao Liang, Ruibo Fu, Bingyan Liu, Zhengqi Wen, Xuefei Liu, Jianhua Tao, Yaling Liang
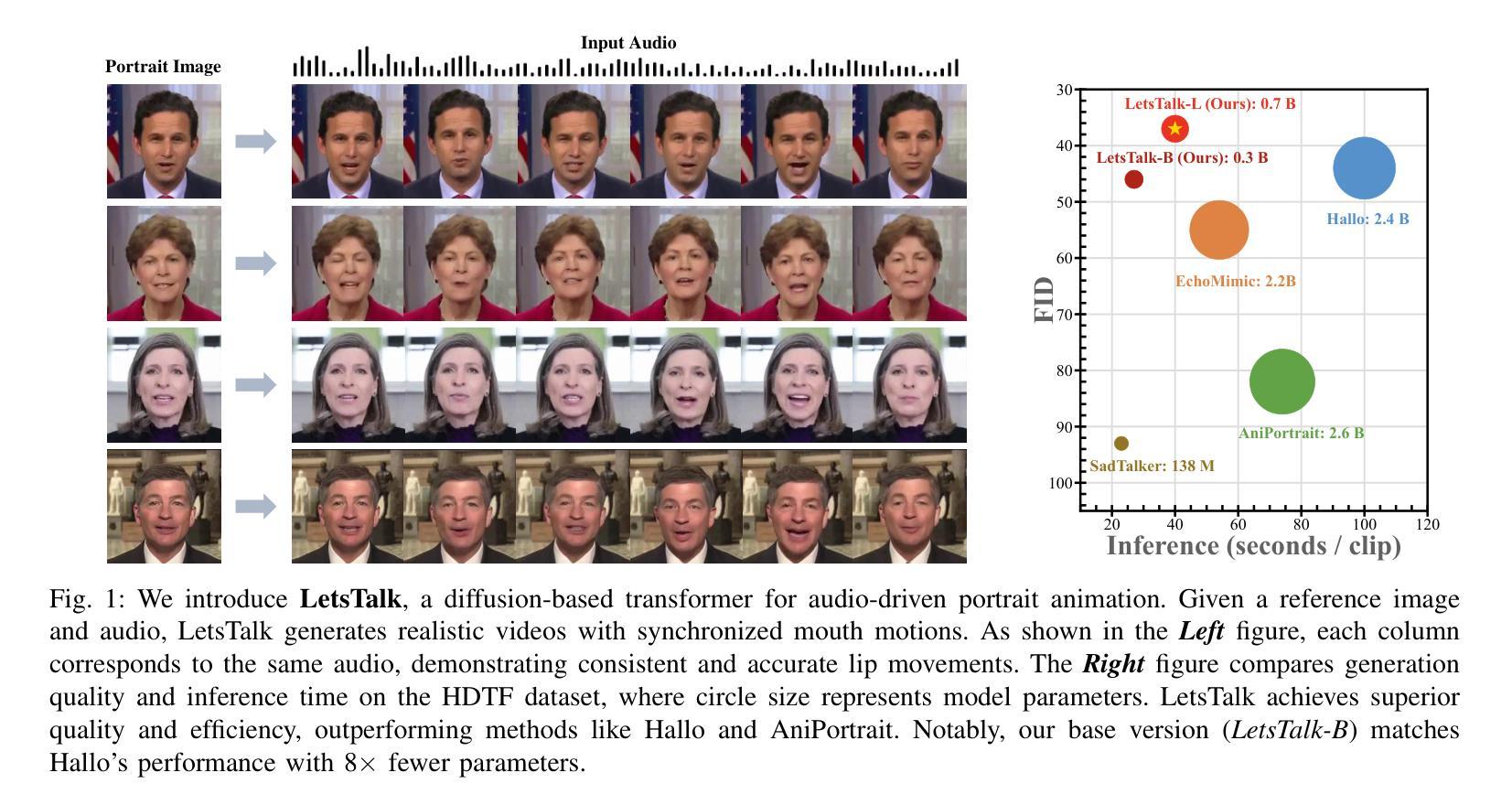
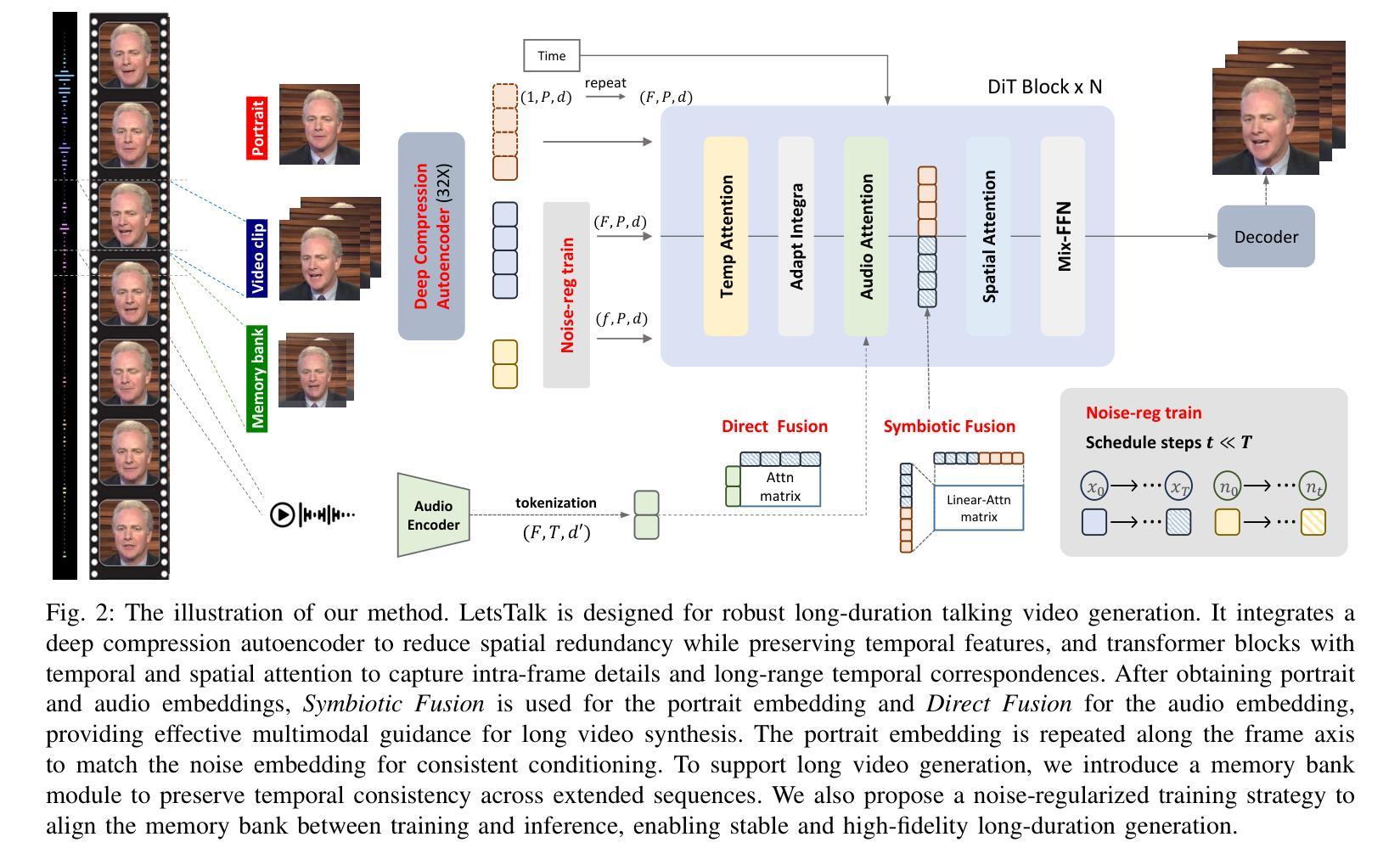
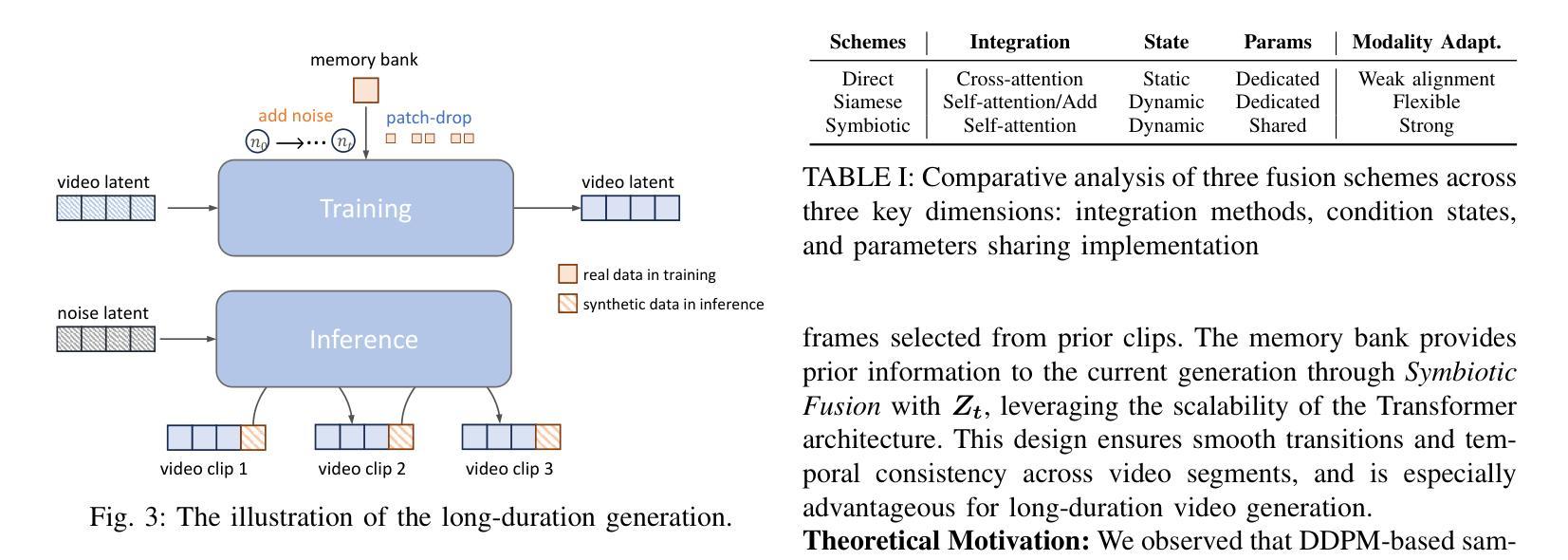
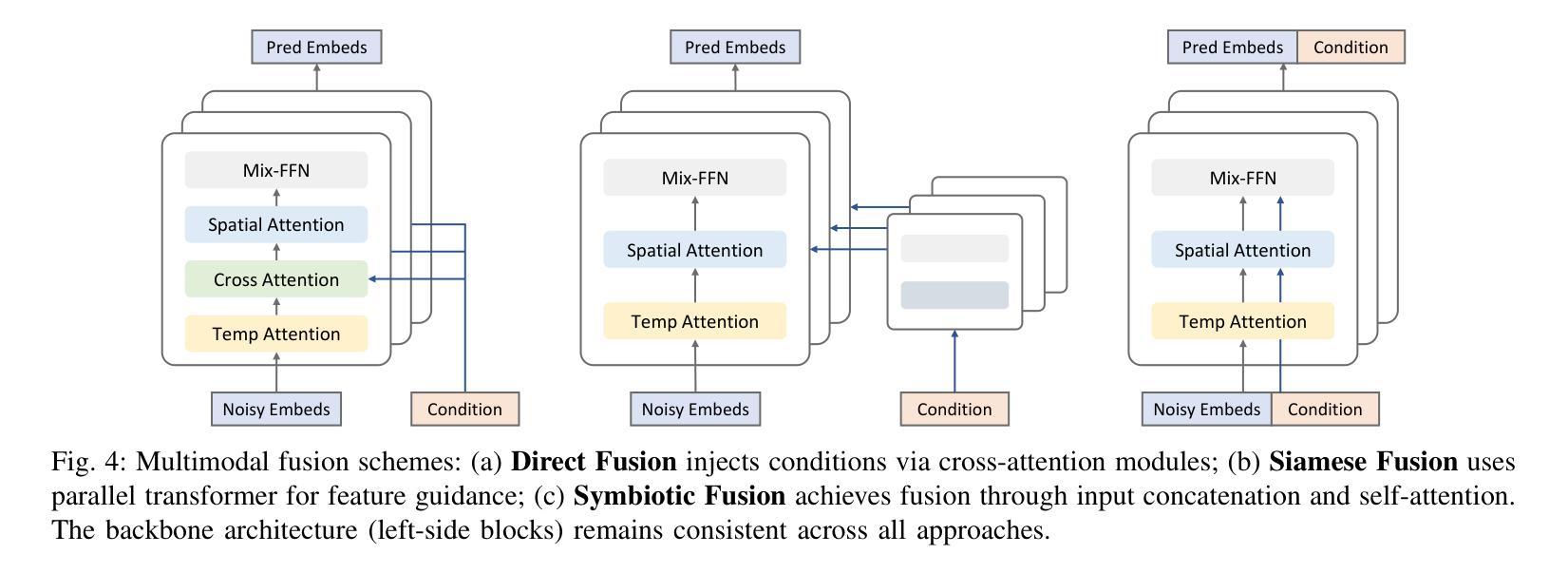
Long-duration talking video synthesis faces persistent challenges in simultaneously achieving high video quality, portrait and temporal consistency, and computational efficiency. As video length increases, issues such as visual degradation, loss of identity consistency, temporal incoherence, and error accumulation become increasingly prominent, severely impacting the realism and reliability of generated results. To address these issues, we present LetsTalk, a diffusion transformer framework that incorporates multimodal guidance and a novel memory bank mechanism, explicitly maintaining contextual continuity and enabling robust, high-quality, and efficient long-duration talking video generation. Specifically, LetsTalk introduces a memory bank combined with a noise-regularized training strategy to mitigate error accumulation and sampling artifacts during long video generation. To further enhance efficiency and spatiotemporal consistency, LetsTalk employs a deep compression autoencoder and a spatiotemporal-aware transformer with linear attention for effective multimodal fusion. Furthermore, we systematically analyze three multimodal fusion schemes, adopting deep (Symbiotic Fusion) for portrait features to ensure visual consistency, and shallow (Direct Fusion) for audio to synchronize animation with speech while preserving motion diversity. Extensive experiments demonstrate that LetsTalk achieves state-of-the-art generation quality, producing temporally coherent and realistic talking videos with enhanced diversity and liveliness, while maintaining remarkable efficiency with 8 fewer parameters than previous approaches.
长期对话视频合成的合成面临着同时实现高视频质量、肖像和时序一致性和计算效率的持续挑战。随着视频长度的增加,视觉退化、身份一致性丧失、时序不一致和误差累积等问题变得越来越突出,严重影响了生成结果的真实性和可靠性。为了解决这些问题,我们提出了LetsTalk,一个融合多模式指导的新型扩散变压器框架,并引入了一种新型记忆库机制,明确保持上下文连续性,实现稳健、高质量、高效的长期对话视频生成。具体来说,LetsTalk结合记忆库和噪声正则化训练策略,减轻长期视频生成过程中的误差累积和采样伪影。为了进一步提高效率和时空一致性,LetsTalk采用深度压缩自编码器和具有线性注意力的时空感知变压器,实现有效的多模式融合。此外,我们系统分析了三种多模式融合方案,采用深度(共生融合)进行肖像特征融合,以确保视觉一致性,以及浅层(直接融合)进行音频融合,以同步动画和语音同时保持运动多样性。大量实验表明,LetsTalk达到了最先进的生成质量,产生了时序一致且逼真的对话视频,增强了多样性和生动性,同时保持了显著的效率,比以前的方法减少了8个参数。
论文及项目相关链接
PDF 13 pages, 11 figures
Summary:
针对长时对话视频合成面临的挑战,如高视频质量、人像和时序一致性以及计算效率等问题,我们提出了LetsTalk扩散变换框架。该框架结合了多模式指导和新型记忆库机制,可显式地维持上下文连续性,并实现稳健、高质量和高效的长时间对话视频生成。实验证明,LetsTalk达到了最先进的生成质量,能够产生时序连贯和逼真的对话视频,同时保持了出色的效率。
Key Takeaways:
- LetsTalk框架采用扩散变换技术,有效应对长时对话视频合成中的挑战。
- 记忆库和多模式指导的结合,提高了视频生成的连贯性和质量。
- 噪声正则化训练策略减轻了长视频生成中的误差积累和采样伪影问题。
- 通过深度压缩自编码器和时空感知变换器,提高了效率和时空一致性。
- 系统分析了三种多模式融合方案,采用深度融合确保人像特征的一致性,采用浅融合同步动画和语音同时保持动作多样性。
- LetsTalk在生成高质量对话视频方面达到业界领先水平,同时具有增强多样性和逼真度。
点此查看论文截图