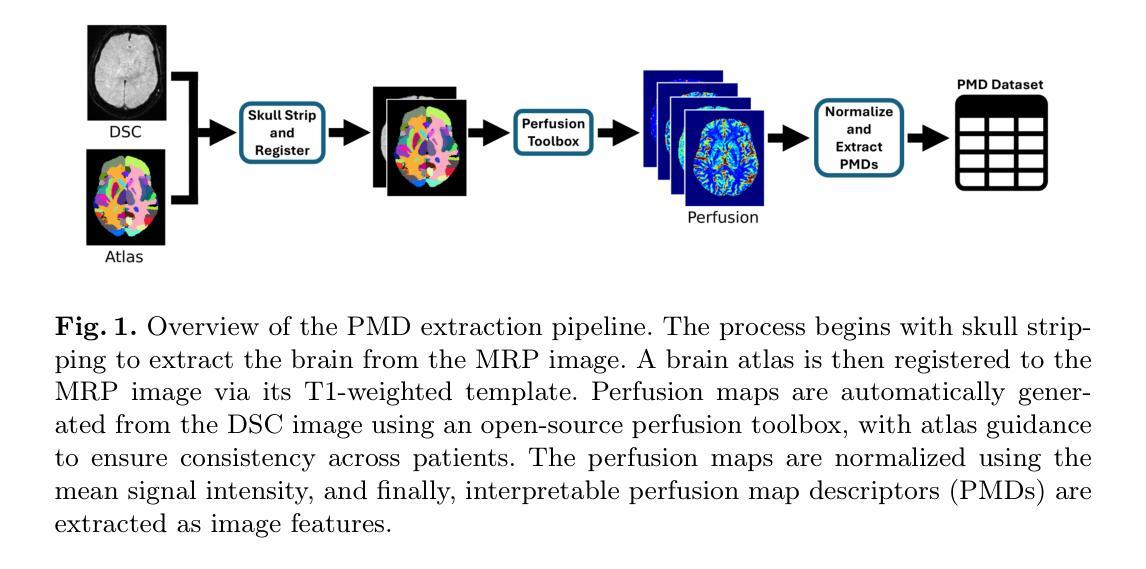
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-23 更新
You Only Pose Once: A Minimalist’s Detection Transformer for Monocular RGB Category-level 9D Multi-Object Pose Estimation
Authors:Hakjin Lee, Junghoon Seo, Jaehoon Sim
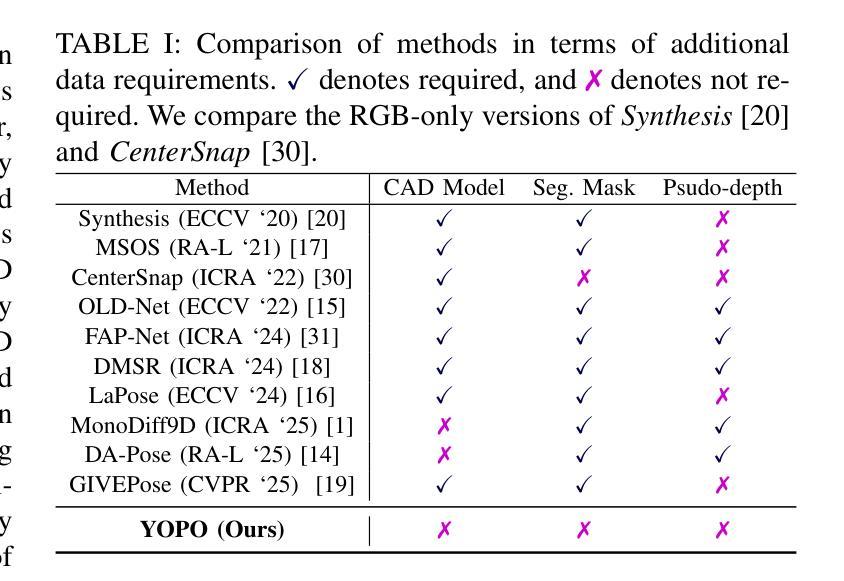
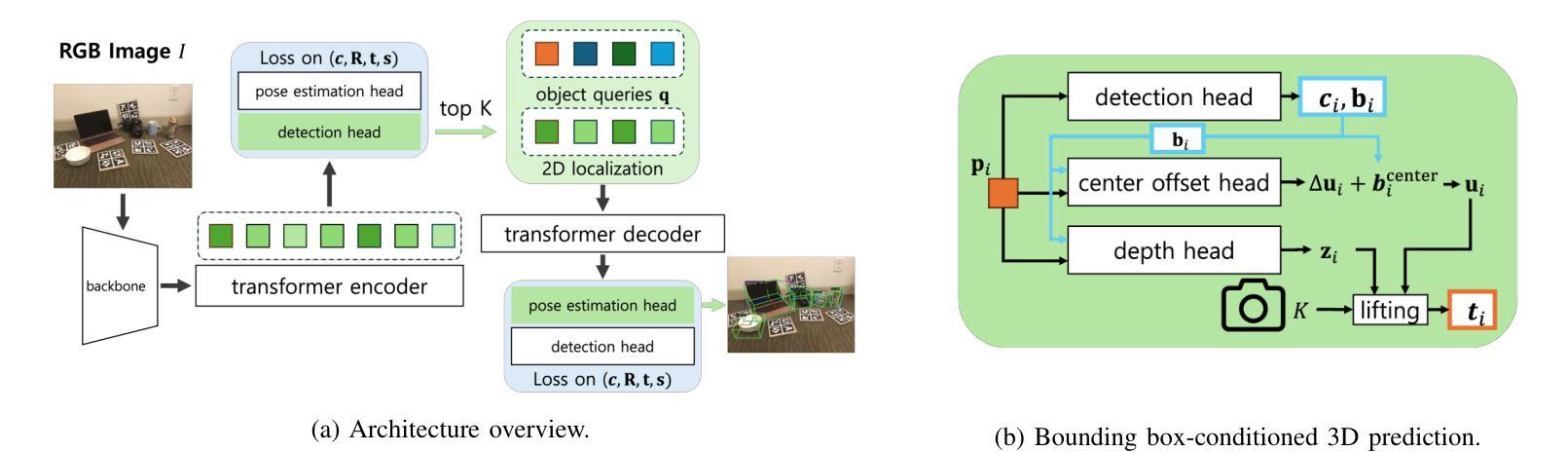
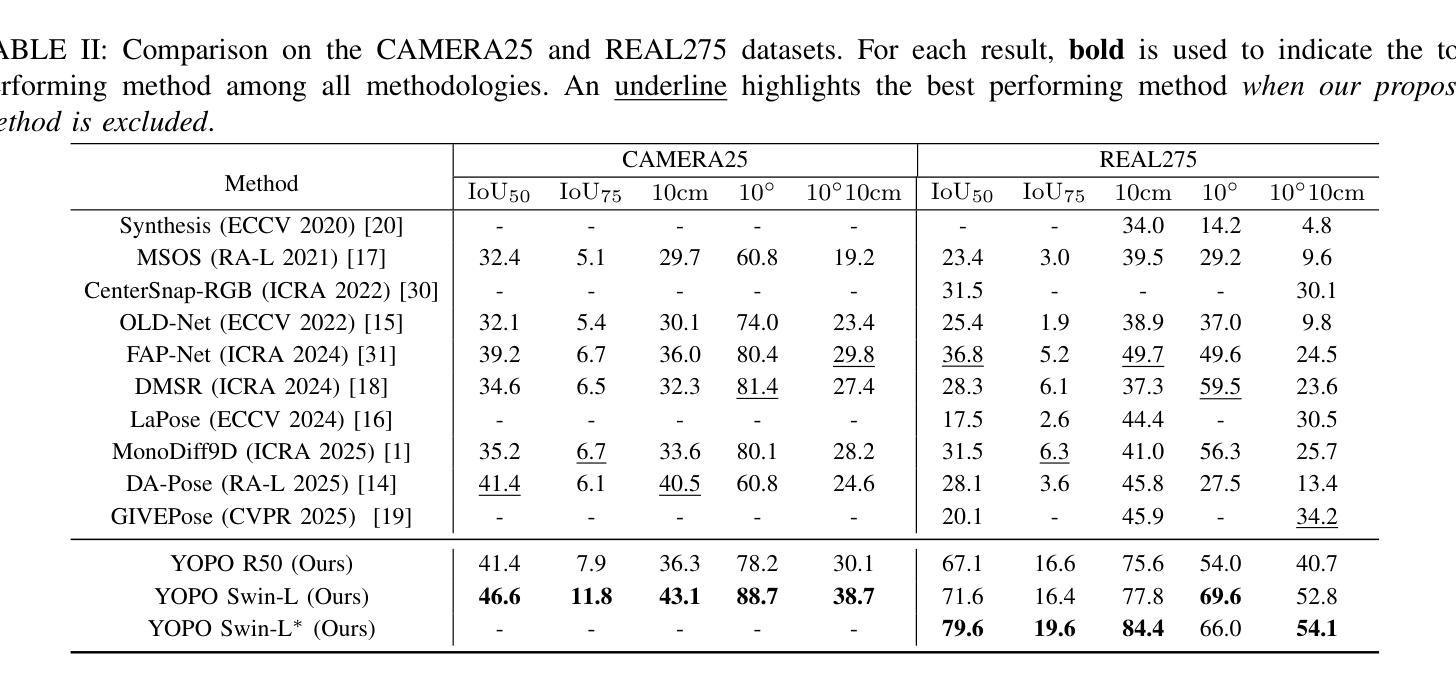
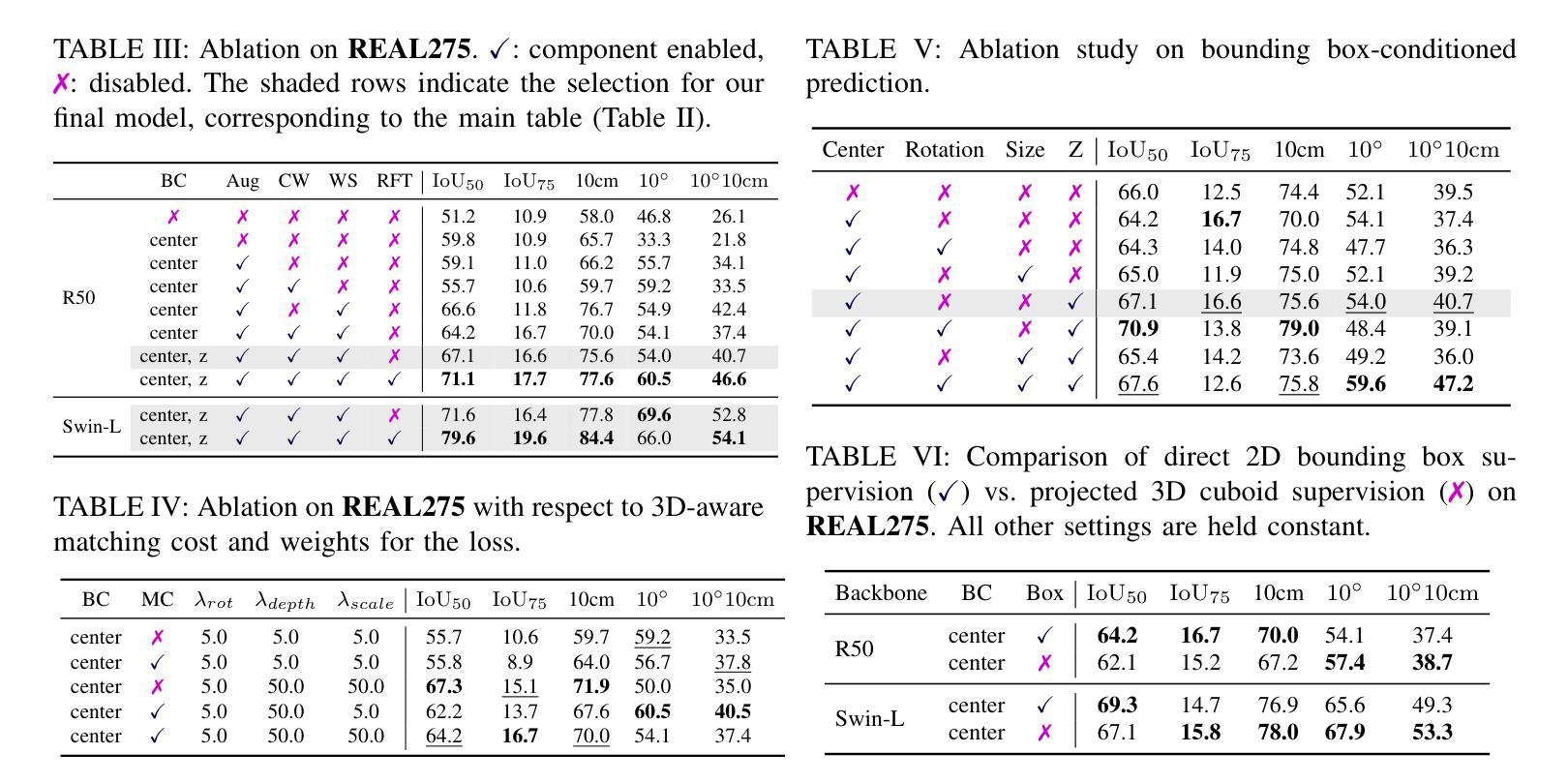
Accurately recovering the full 9-DoF pose of unseen instances within specific categories from a single RGB image remains a core challenge for robotics and automation. Most existing solutions still rely on pseudo-depth, CAD models, or multi-stage cascades that separate 2D detection from pose estimation. Motivated by the need for a simpler, RGB-only alternative that learns directly at the category level, we revisit a longstanding question: Can object detection and 9-DoF pose estimation be unified with high performance, without any additional data? We show that they can with our method, YOPO, a single-stage, query-based framework that treats category-level 9-DoF estimation as a natural extension of 2D detection. YOPO augments a transformer detector with a lightweight pose head, a bounding-box-conditioned translation module, and a 6D-aware Hungarian matching cost. The model is trained end-to-end only with RGB images and category-level pose labels. Despite its minimalist design, YOPO sets a new state of the art on three benchmarks. On the REAL275 dataset, it achieves 79.6% $\rm{IoU}_{50}$ and 54.1% under the $10^\circ$$10{\rm{cm}}$ metric, surpassing prior RGB-only methods and closing much of the gap to RGB-D systems. The code, models, and additional qualitative results can be found on our project.
从单一RGB图像中准确恢复特定类别中未见实例的完整9自由度姿态,仍然是机器人和自动化的核心挑战。现有的大多数解决方案仍然依赖于伪深度、CAD模型或分离2D检测和姿态估计的多阶段级联。受到需要更简单、仅使用RGB的替代方案(直接在类别级别学习)的驱动,我们重新审视了一个长期存在的问题:是否可以将对象检测和9自由度姿态估计统一起来,实现高性能,而无需任何额外数据?我们显示,使用我们的方法YOPO,这是基于查询的单阶段框架,将类别级别的9自由度估计视为2D检测的自然扩展,它们可以实现这一点。YOPO增强了一个带有轻量级姿态头的转换器检测器,一个带有边界框条件的翻译模块,以及一个6D感知匈牙利匹配成本。该模型仅通过RGB图像和类别级别的姿态标签进行端到端的训练。尽管其设计简洁,但YOPO在三个基准测试上创下了新的世界纪录。在REAL275数据集上,它实现了79.6%的IoU50和54.1%的10°10cm指标,超过了先前的仅RGB方法和大部分RGB-D系统。有关代码、模型和额外的定性结果,请参见我们的项目。
论文及项目相关链接
PDF https://mikigom.github.io/YOPO-project-page
Summary
本文提出了一种名为YOPO的新方法,用于从单一RGB图像中准确恢复特定类别未见过实例的完整9-DoF姿态。该方法将对象检测和9-DoF姿态估计统一为一个单阶段查询框架,将类别级别的9-DoF估计视为2D检测的自然扩展。YOPO通过增加一个轻量级的姿态头、一个受边界框条件约束的翻译模块和一个6D感知匈牙利匹配成本来增强变换检测器。该模型仅使用RGB图像和类别级别的姿态标签进行端到端的训练,尽管其设计简洁,但在三个基准测试上均达到了最新水平。
Key Takeaways
- 提出了一种新的方法YOPO,用于从单一RGB图像中恢复特定类别的未见过实例的完整9-DoF姿态。
- YOPO将对象检测和9-DoF姿态估计统一为一个查询框架,作为2D检测的自然扩展。
- YOPO采用单阶段、轻量级的设计,包括一个姿态头、一个受边界框条件约束的翻译模块和一个6D感知匈牙利匹配成本。
- 该模型仅使用RGB图像和类别级别的姿态标签进行端到端的训练。
- YOPO在三个基准测试上均达到了最新水平,包括REAL275数据集,实现了79.6%的IoU50和54.1%的10°10cm指标。
- YOPO超越了先前的RGB-only方法,并显著缩小了与RGB-D系统的差距。
点此查看论文截图