⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-23 更新
Any-to-any Speaker Attribute Perturbation for Asynchronous Voice Anonymization
Authors:Liping Chen, Chenyang Guo, Rui Wang, Kong Aik Lee, Zhenhua Ling
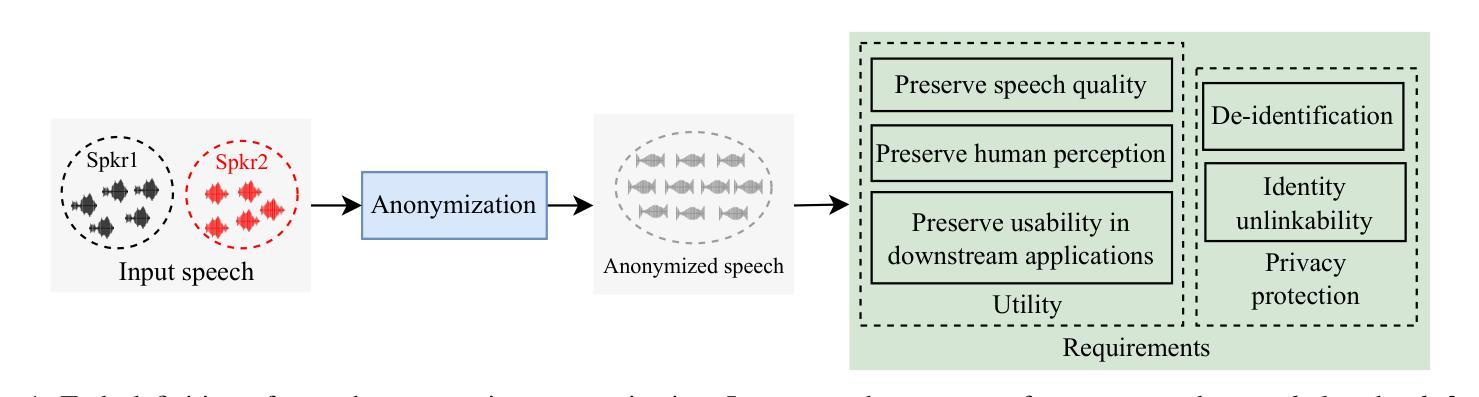
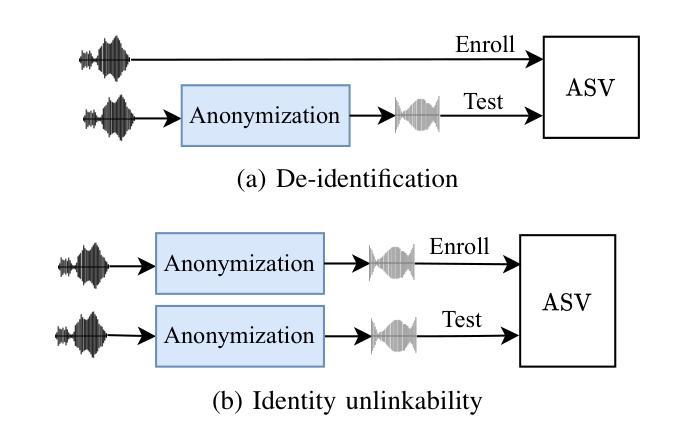
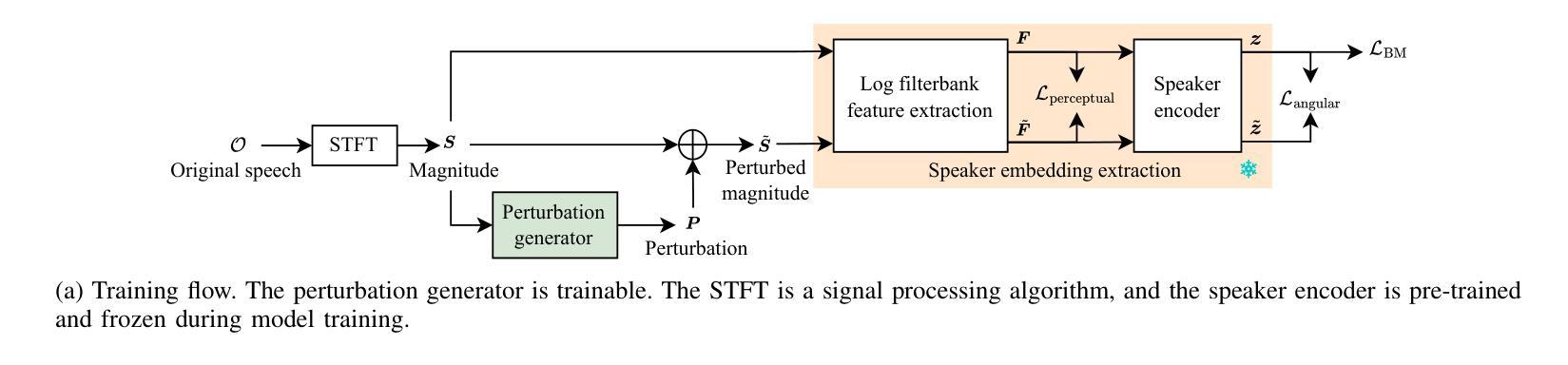
Speaker attribute perturbation offers a feasible approach to asynchronous voice anonymization by employing adversarially perturbed speech as anonymized output. In order to enhance the identity unlinkability among anonymized utterances from the same original speaker, the targeted attack training strategy is usually applied to anonymize the utterances to a common designated speaker. However, this strategy may violate the privacy of the designated speaker who is an actual speaker. To mitigate this risk, this paper proposes an any-to-any training strategy. It is accomplished by defining a batch mean loss to anonymize the utterances from various speakers within a training mini-batch to a common pseudo-speaker, which is approximated as the average speaker in the mini-batch. Based on this, a speaker-adversarial speech generation model is proposed, incorporating the supervision from both the untargeted attack and the any-to-any strategies. The speaker attribute perturbations are generated and incorporated into the original speech to produce its anonymized version. The effectiveness of the proposed model was justified in asynchronous voice anonymization through experiments conducted on the VoxCeleb datasets. Additional experiments were carried out to explore the potential limitations of speaker-adversarial speech in voice privacy protection. With them, we aim to provide insights for future research on its protective efficacy against black-box speaker extractors \textcolor{black}{and adaptive attacks, as well as} generalization to out-of-domain datasets \textcolor{black}{and stability}. Audio samples and open-source code are published in https://github.com/VoicePrivacy/any-to-any-speaker-attribute-perturbation.
说话人属性扰动(Speaker Attribute Perturbation)提供了一种可行的异步语音匿名化方法,它通过利用对抗扰动语音作为匿名化输出。为了提高来自同一原始说话者的匿名发言身份难以建立联系性,通常采用有针对性的攻击训练策略将发言匿名化为一个通用的指定说话者。然而,这种策略可能会侵犯实际说话者的隐私。为了降低这种风险,本文提出了一种“任意到任意”(any-to-any)的训练策略。它通过定义批量平均损失来实现,将一个训练小批次中不同说话者的发言匿名化为一个通用的伪说话者,近似为批次中的平均说话者。在此基础上,提出了一种说话人对抗性语音生成模型,该模型结合了非目标攻击和任意到任意策略的监督。说话人属性扰动被生成并融入原始语音中,以产生其匿名版本。该模型的有效性已通过VoxCeleb数据集上的实验在异步语音匿名化中得到证实。此外,还进行了其他实验来探索说话人对抗性语音在语音隐私保护中的潜在局限性。通过这些实验,我们旨在为针对黑箱说话人提取器和自适应攻击的防护有效性研究提供未来研究的见解,并探讨其在跨域数据集上的通用性和稳定性。音频样本和开源代码已发布在https://github.com/VoicePrivacy/any-to-any-speaker-attribute-perturbation。
论文及项目相关链接
摘要
这篇论文研究了说话人属性扰动在异步语音匿名化中的应用。针对同一原始说话人的匿名化语音身份难以断开链接的问题,论文提出了“any-to-any”训练策略。该策略通过将训练批次中的不同说话人的语音匿名化为一个共同的伪说话人(即批次中的平均说话人)来解决此问题。此外,论文还提出了一种结合非目标攻击和any-to-any策略的说话人对抗性语音生成模型。通过实验验证了该模型在异步语音匿名化中的有效性,并探讨了该技术在语音隐私保护方面的潜在局限性。该研究旨在为未来的研究提供对抗黑箱说话人提取器和自适应攻击的防护效能的见解,并探索其在跨领域数据集上的通用性和稳定性。相关音频样本和开源代码已发布在GitHub上。
关键见解
- 说话人属性扰动可用于异步语音匿名化。
- “any-to-any”训练策略提高了匿名化语音的身份不可链接性,降低了对指定说话人隐私的侵犯风险。
- 说话人对抗性语音生成模型结合了非目标攻击和any-to-any训练策略的监督。
- 实验验证了模型在异步语音匿名化中的有效性。
- 研究探讨了语音隐私保护的潜在局限性,并为未来的研究提供了关于对抗黑箱说话人提取器和自适应攻击的防护效能的见解。
- 该方法具有一定的跨领域数据集通用性和稳定性。
- 音频样本和开源代码已发布在GitHub上,便于公众访问和进一步研究。
点此查看论文截图

LLaSO: A Foundational Framework for Reproducible Research in Large Language and Speech Model
Authors:Yirong Sun, Yizhong Geng, Peidong Wei, Yanjun Chen, Jinghan Yang, Rongfei Chen, Wei Zhang, Xiaoyu Shen
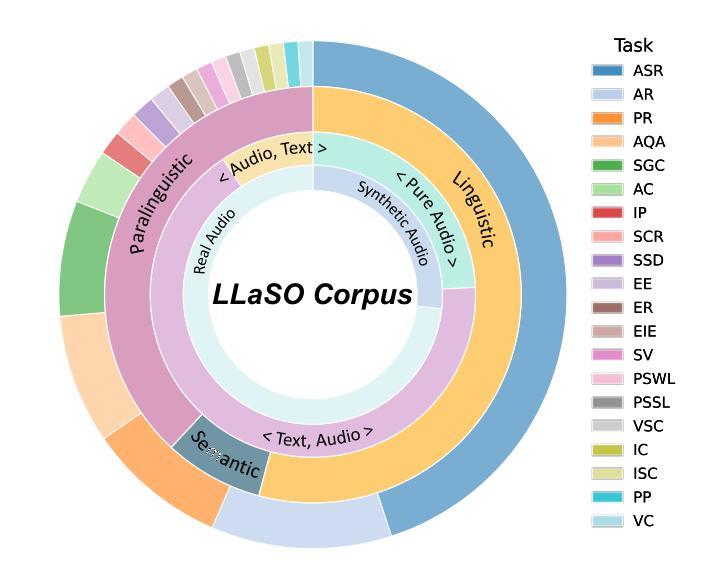
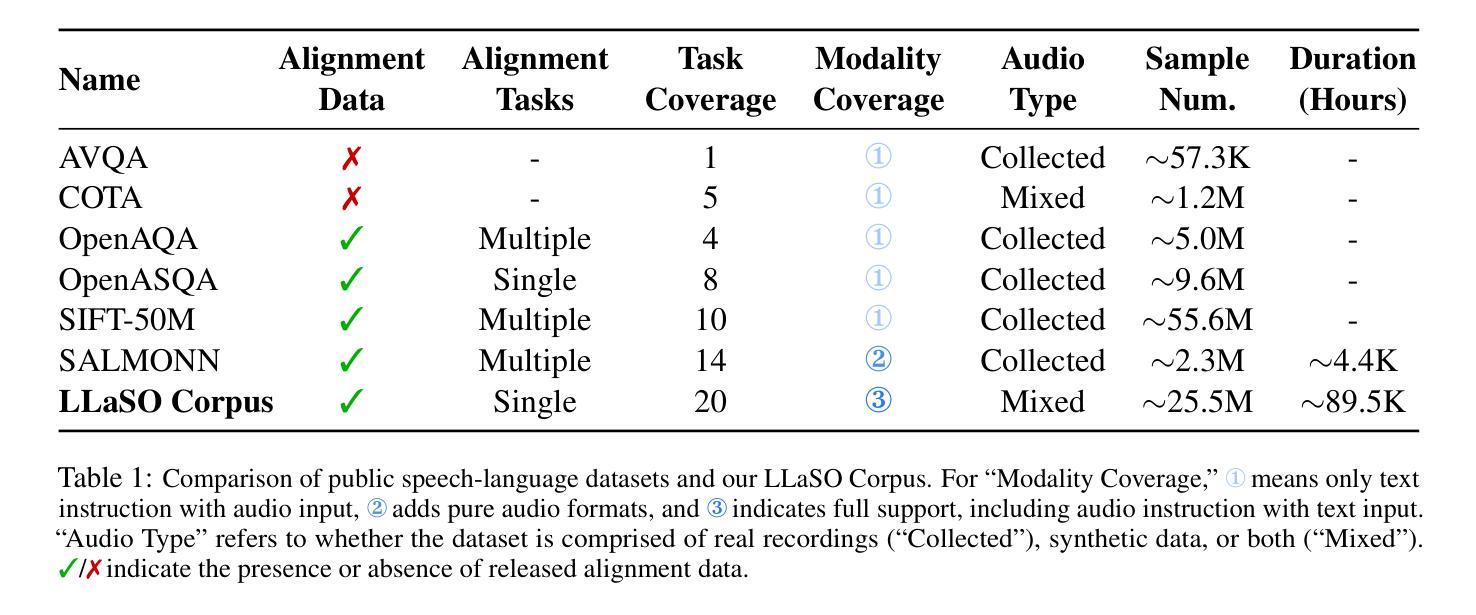
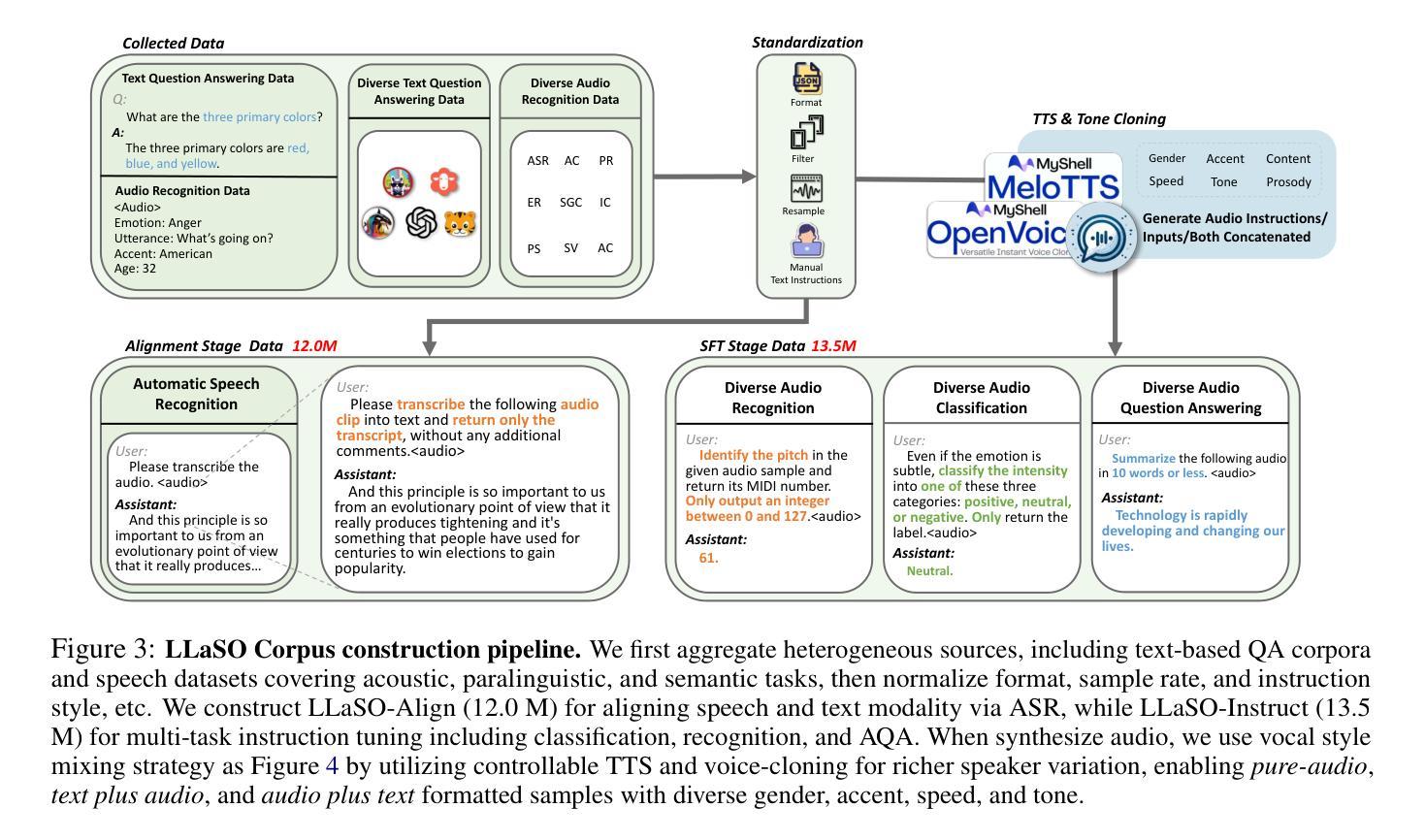
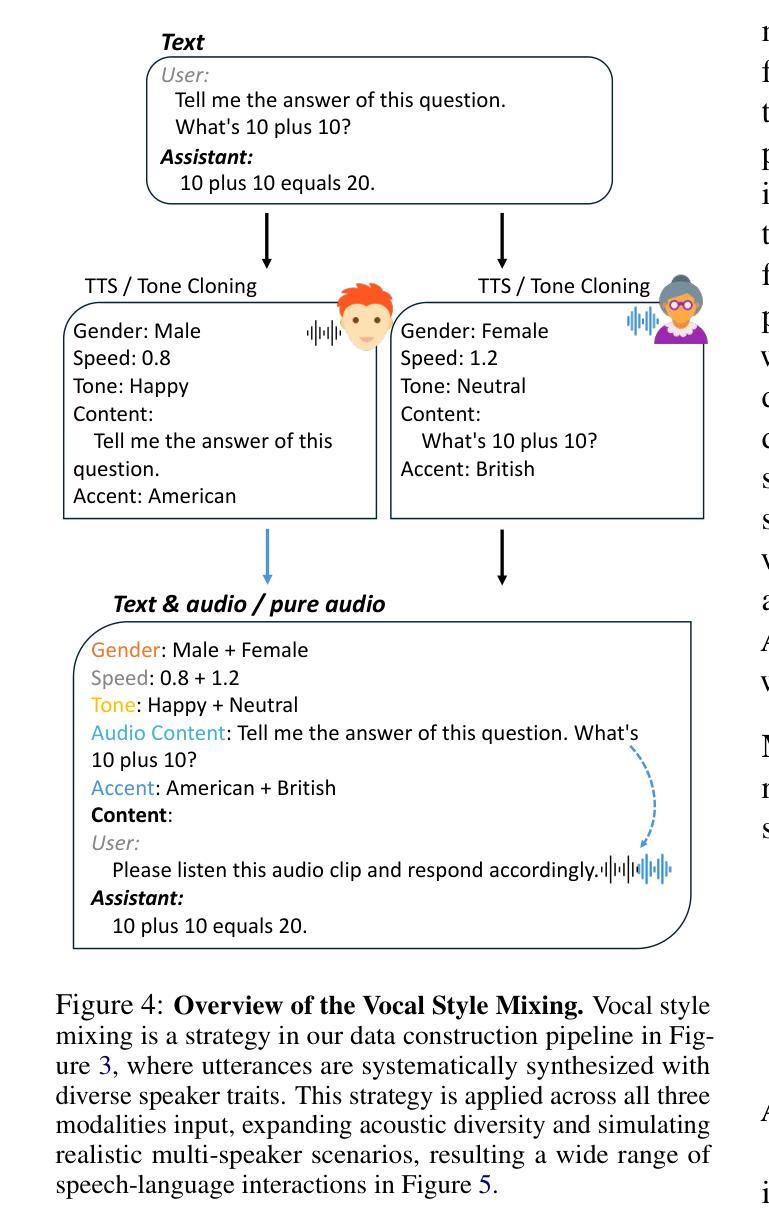
The development of Large Speech-Language Models (LSLMs) has been slowed by fragmented architectures and a lack of transparency, hindering the systematic comparison and reproducibility of research. Unlike in the vision-language domain, the LSLM field suffers from the common practice of releasing model weights without their corresponding training data and configurations. To address these critical gaps, we introduce LLaSO, the first fully open, end-to-end framework for large-scale speech-language modeling. LLaSO provides the community with three essential resources: (1) LLaSO-Align, a 12M-instance speech-text alignment corpus; (2) LLaSO-Instruct, a 13.5M-instance multi-task instruction-tuning dataset; and (3) LLaSO-Eval, a reproducible benchmark for standardized evaluation. To validate our framework, we build and release LLaSO-Base, a 3.8B-parameter reference model trained exclusively on our public data. It achieves a normalized score of 0.72, establishing a strong, reproducible baseline that surpasses comparable models. Our analysis reveals that while broader training coverage enhances performance, significant generalization gaps persist on unseen tasks, particularly in pure audio scenarios. By releasing the complete stack of data, benchmarks, and models, LLaSO establishes a foundational open standard to unify research efforts and accelerate community-driven progress in LSLMs. We release the code, dataset, pretrained models, and results in https://github.com/EIT-NLP/LLaSO.
大规模语言模型(LSLM)的发展受到了碎片化架构和缺乏透明度的阻碍,这阻碍了研究的系统比较和可重复性。与视觉语言领域不同,LSLM领域普遍存在一种做法,即仅发布模型权重,而没有相应的训练数据和配置。为了解决这些关键差距,我们引入了LLaSO,这是第一个完全开放的大规模语音语言建模端到端框架。LLaSO为社区提供了三种重要资源:(1)LLaSO-Align,一个包含1200万实例的语音文本对齐语料库;(2)LLaSO-Instruct,一个包含1350万实例的多任务指令调整数据集;(3)LLaSO-Eval,一个可复现的标准化评估基准。为了验证我们的框架,我们构建并发布了LLaSO-Base,这是一个仅在公共数据上训练的38亿参数参考模型。它达到了归一化得分为0.72,建立了一个强大的可复现基线,超越了同类模型。我们的分析表明,虽然更广泛的训练覆盖面可以增强性能,但在未见过的任务上仍然存在重大的泛化差距,特别是在纯音频场景中。通过发布完整的数据堆栈、基准测试和模型,LLaSO建立了一个基本的开放标准,以统一研究努力并加速LSLM的社区驱动进展。我们在https://github.com/EIT-NLP/LLaSO上发布代码、数据集、预训练模型和结果。
论文及项目相关链接
摘要
本文介绍了大型语言模型(LSLMs)领域存在的挑战和问题,包括模型架构的碎片化以及透明度的缺失。为了解决这些问题,文章提出了一种全新的、端到端的框架LLaSO,用于大规模的语言建模。LLaSO提供了三个核心资源:LLaSO-Align对齐语料库、LLaSO-Instruct多任务指令调整数据集和LLaSO-Eval可重复的基准测试集。基于该框架,文章建立并发布了一个名为LLaSO-Base的参考模型,该模型在公开数据上进行训练,实现了标准化的评估分数,并超过了同类模型。文章还指出,尽管更广泛的训练覆盖可以提高性能,但在未见任务上仍存在显著的泛化差距。通过发布完整的数据集、基准测试和模型,LLaSO建立了一个统一的开放标准,以加速LSLMs领域的社区驱动进展。
关键见解
- LSLMs领域存在模型架构的碎片化和透明度缺失的问题,影响研究的系统比较和可重复性。
- LLaSO是第一个完全开放、端到端的大型语言建模框架,提供了三个核心资源:对齐语料库、多任务指令调整数据集和可重复的基准测试集。
- LLaSO-Base模型的发布验证了LLaSO框架的有效性,建立了可复制的基线,超越了同类模型。
- 更广泛的训练覆盖可以提高性能,但未见任务上的泛化差距仍然存在。
- LLaSO通过发布数据集、基准测试和模型,建立了统一的开放标准,以加速LSLMs领域的社区进展。
- LLaSO框架及其资源对于解决LSLMs领域的问题和挑战具有重要意义。
点此查看论文截图