⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-23 更新
DIFFA: Large Language Diffusion Models Can Listen and Understand
Authors:Jiaming Zhou, Hongjie Chen, Shiwan Zhao, Jian Kang, Jie Li, Enzhi Wang, Yujie Guo, Haoqin Sun, Hui Wang, Aobo Kong, Yong Qin, Xuelong Li
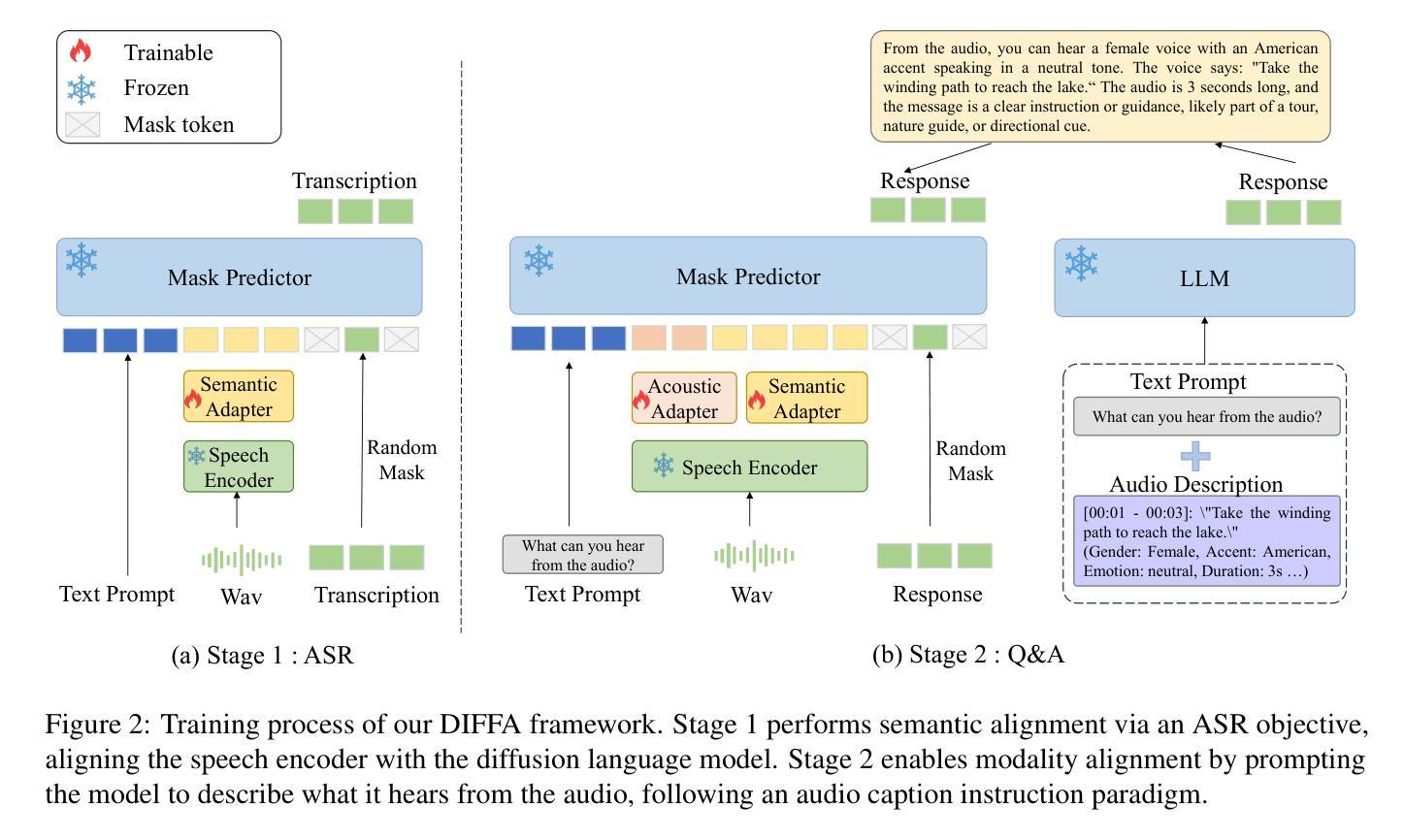
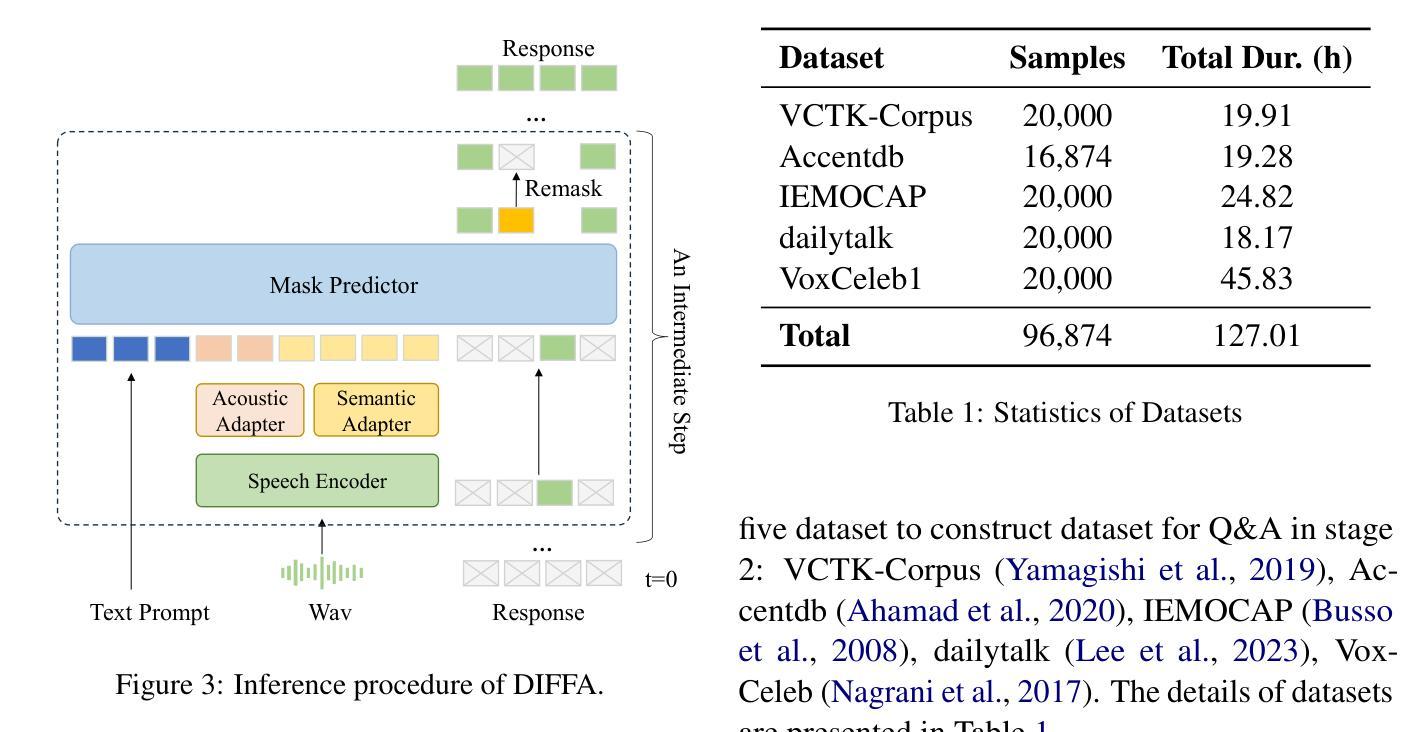
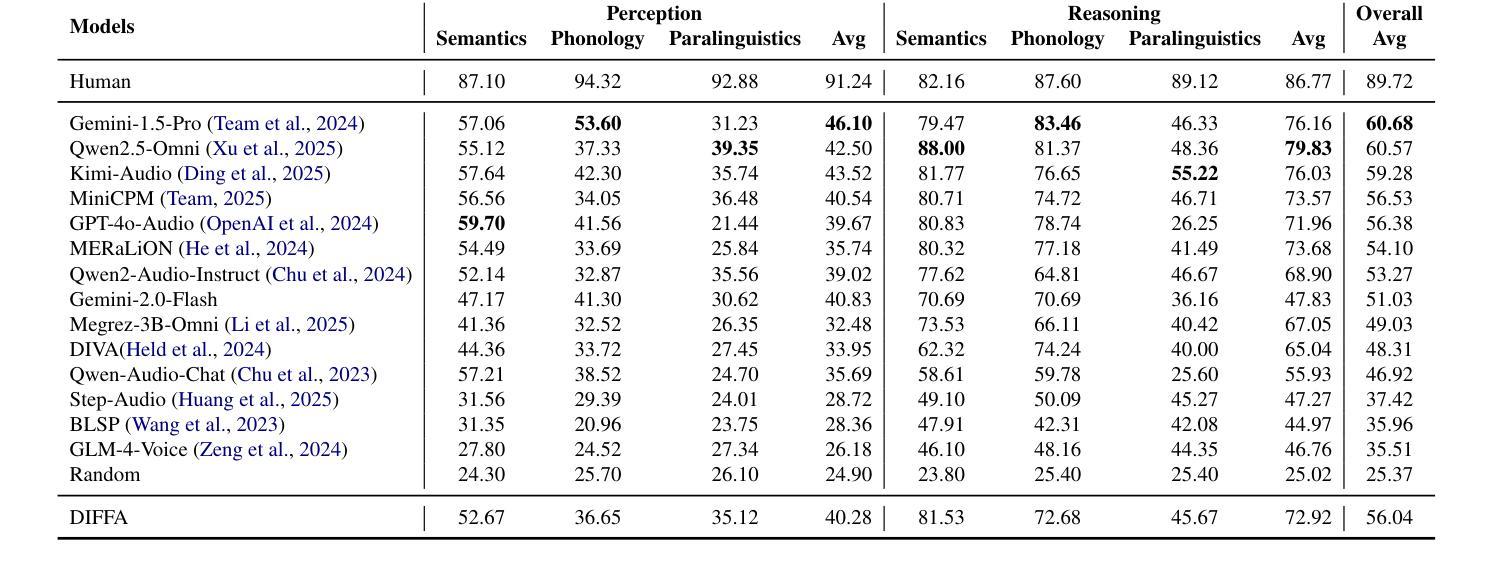
Recent advances in large language models (LLMs) have shown remarkable capabilities across textual and multimodal domains. In parallel, diffusion-based language models have emerged as a promising alternative to the autoregressive paradigm, offering improved controllability, bidirectional context modeling, and robust generation. However, their application to the audio modality remains underexplored. In this work, we introduce \textbf{DIFFA}, the first diffusion-based large audio-language model designed to perform spoken language understanding. DIFFA integrates a frozen diffusion language model with a lightweight dual-adapter architecture that bridges speech understanding and natural language reasoning. We employ a two-stage training pipeline: first, aligning semantic representations via an ASR objective; then, learning instruction-following abilities through synthetic audio-caption pairs automatically generated by prompting LLMs. Despite being trained on only 960 hours of ASR and 127 hours of synthetic instruction data, DIFFA demonstrates competitive performance on major benchmarks, including MMSU, MMAU, and VoiceBench, outperforming several autoregressive open-source baselines. Our results reveal the potential of diffusion-based language models for efficient and scalable audio understanding, opening a new direction for speech-driven AI. Our code will be available at https://github.com/NKU-HLT/DIFFA.git.
最近大型语言模型(LLM)的进步在文本和多模态领域展现了显著的能力。与此同时,基于扩散的语言模型作为自回归范式的有前途的替代品而出现,提供了更好的可控性、双向上下文建模和稳健生成。然而,它们在音频模态的应用仍然被较少探索。在这项工作中,我们介绍了基于扩散的大型音频语言模型DIFFA,用于进行口语理解。DIFFA将冻结的扩散语言模型与轻量级的双适配器架构相结合,该架构桥接了语音理解和自然语言推理。我们采用两阶段训练管道:首先,通过ASR目标对齐语义表示;然后,通过由LLMs自动生成的合成音频字幕对来学习指令执行能力。尽管仅在960小时的ASR和127小时的合成指令数据上进行训练,DIFFA在主要基准测试(包括MMSU、MMAU和VoiceBench)上的表现却颇具竞争力,超过了多个自回归开源基准。我们的结果揭示了基于扩散的语言模型在高效可扩展音频理解方面的潜力,为语音驱动的人工智能开启了新的方向。我们的代码将在https://github.com/NKU-HLT/DIFFA.git上提供。
论文及项目相关链接
Summary
扩散模型在自然语言处理领域展现出强大的潜力,特别是在文本和多模态领域。本研究推出首个基于扩散的大型音频语言模型DIFFA,用于进行口语理解。DIFFA结合冻结的扩散语言模型和轻量级双适配器架构,实现语音理解和自然语言推理的桥梁。通过两阶段训练流程,即使在有限的数据集上,DIFFA也在主要基准测试中表现出竞争力,揭示扩散模型在音频理解中的潜力和可扩展性。
Key Takeaways
- DIFFA是首个基于扩散的大型音频语言模型,旨在进行口语理解。
- DIFFA结合扩散语言模型和轻量级双适配器架构。
- 采用两阶段训练流程,包括通过ASR目标对齐语义表示和学习通过合成音频说明对指令的遵循能力。
- DIFFA在主要基准测试中表现出竞争力,包括MMSU、MMAU和VoiceBench。
- DIFFA优于多个开源的基于自回归的基线模型。
- 本研究证明扩散模型在音频理解中具有潜力和可扩展性。
点此查看论文截图