⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-24 更新
Label Anything: Multi-Class Few-Shot Semantic Segmentation with Visual Prompts
Authors:Pasquale De Marinis, Nicola Fanelli, Raffaele Scaringi, Emanuele Colonna, Giuseppe Fiameni, Gennaro Vessio, Giovanna Castellano
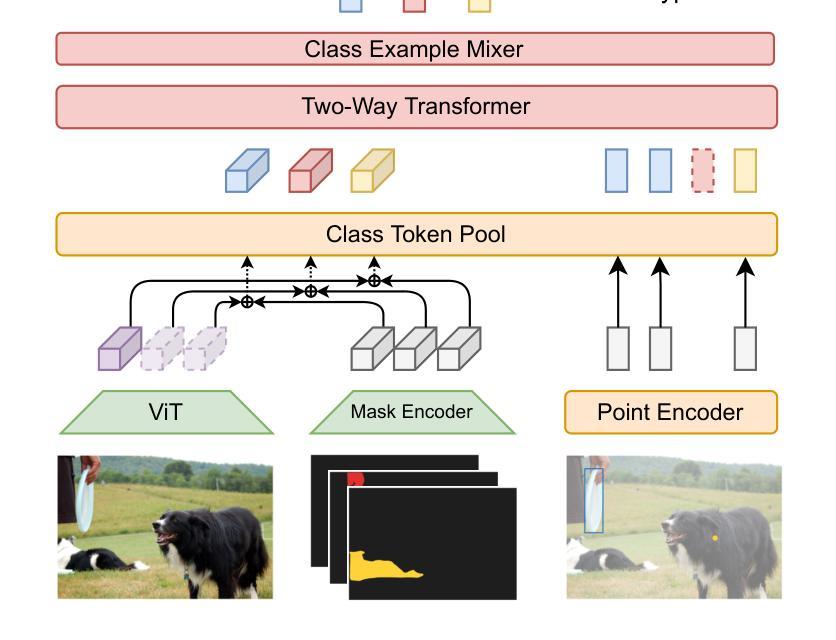
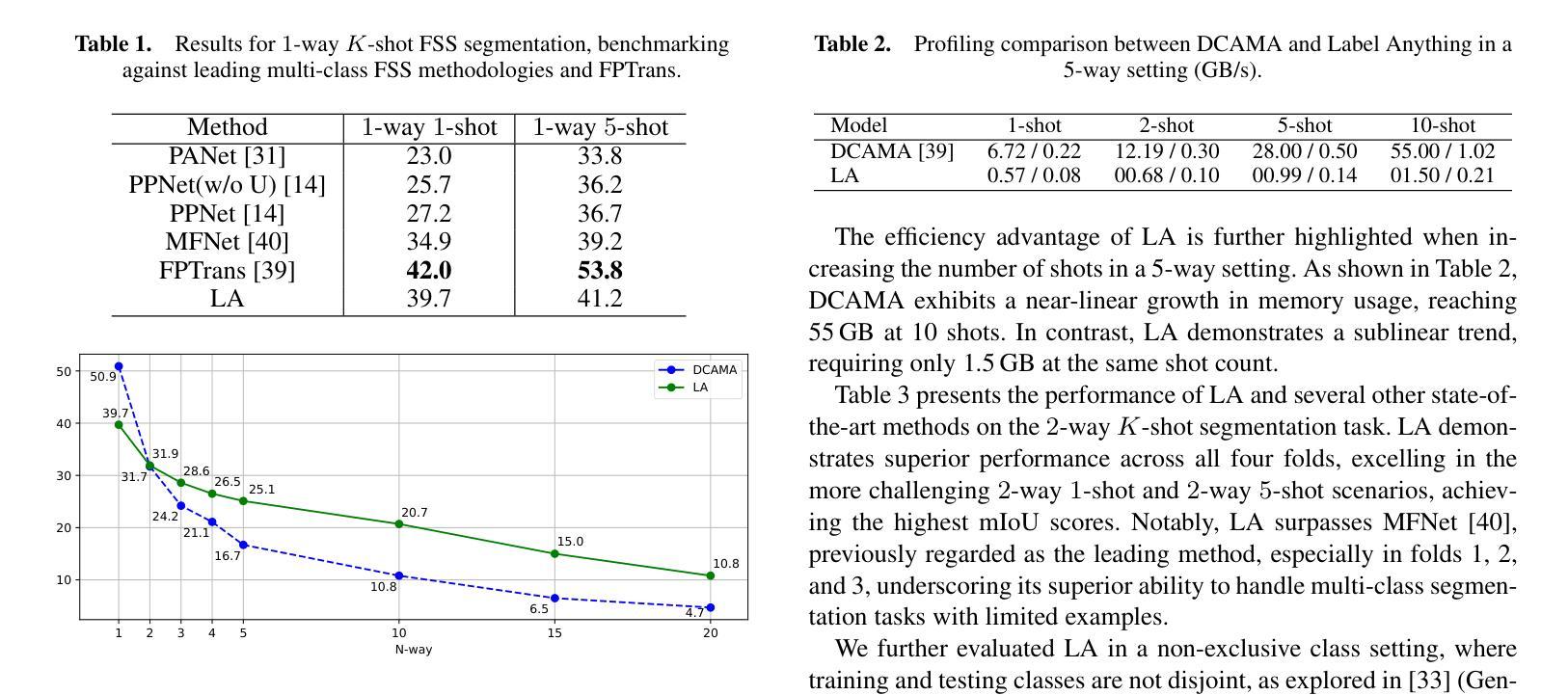
Few-shot semantic segmentation aims to segment objects from previously unseen classes using only a limited number of labeled examples. In this paper, we introduce Label Anything, a novel transformer-based architecture designed for multi-prompt, multi-way few-shot semantic segmentation. Our approach leverages diverse visual prompts – points, bounding boxes, and masks – to create a highly flexible and generalizable framework that significantly reduces annotation burden while maintaining high accuracy. Label Anything makes three key contributions: ($\textit{i}$) we introduce a new task formulation that relaxes conventional few-shot segmentation constraints by supporting various types of prompts, multi-class classification, and enabling multiple prompts within a single image; ($\textit{ii}$) we propose a novel architecture based on transformers and attention mechanisms; and ($\textit{iii}$) we design a versatile training procedure allowing our model to operate seamlessly across different $N$-way $K$-shot and prompt-type configurations with a single trained model. Our extensive experimental evaluation on the widely used COCO-$20^i$ benchmark demonstrates that Label Anything achieves state-of-the-art performance among existing multi-way few-shot segmentation methods, while significantly outperforming leading single-class models when evaluated in multi-class settings. Code and trained models are available at https://github.com/pasqualedem/LabelAnything.
少样本语义分割旨在使用有限的标记样本对之前未见过的类别进行对象分割。在本文中,我们介绍了Label Anything,这是一种基于transformer的新型架构,旨在用于多提示、多类别的少样本语义分割。我们的方法利用各种视觉提示——点、边界框和蒙版,创建一个高度灵活和可推广的框架,在保持高准确性的同时,大大降低了注释负担。Label Anything做出了三项重要贡献:(i)我们引入了一种新的任务公式,通过支持各种提示类型、多类分类,并在单个图像内启用多个提示,放松了传统的少样本分割约束;(ii)我们提出了一种基于transformer和注意力机制的新型架构;(iii)我们设计了一种通用训练程序,使我们的模型能够在不同的N路K样本和提示类型配置中使用单个训练模型无缝运行。我们在广泛使用的COCO-20i基准测试上的大量实验评估表明,Label Anything在现有的多类别少样本分割方法中实现了最先进的性能,同时在多类别设置中显著优于领先的单类别模型。代码和训练好的模型可在https://github.com/pasqualedem/LabelAnything找到。
论文及项目相关链接
PDF ECAI 2025 - 28th European Conference on Artificial Intelligence
Summary
基于Transformer架构的Label Anything模型实现了多提示、多类别的小样本语义分割。通过利用点、边界框和遮罩等多种视觉提示,创建了一个灵活且通用的框架,显著减少了标注负担,同时保持了高准确性。Label Anything在COCO-20i基准测试中实现了最佳性能。
Key Takeaways
- Label Anything模型是一个基于Transformer架构的小样本语义分割模型。
- 通过使用多样化的视觉提示(点、边界框和遮罩等),显著减少了标注工作量,同时维持了高精度。
- Label Anything模型引入了新的任务表述方式,支持多种类型的提示、多类别分类,并在单个图像内支持多个提示。
- 模型提出了基于Transformer和注意力机制的新型架构。
- 模型设计了一种通用的训练程序,使得单个模型能在不同的N-way K-shot和提示类型配置下无缝操作。
- 在广泛使用的COCO-20i基准测试中,Label Anything模型实现了最佳性能。
点此查看论文截图