⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-26 更新
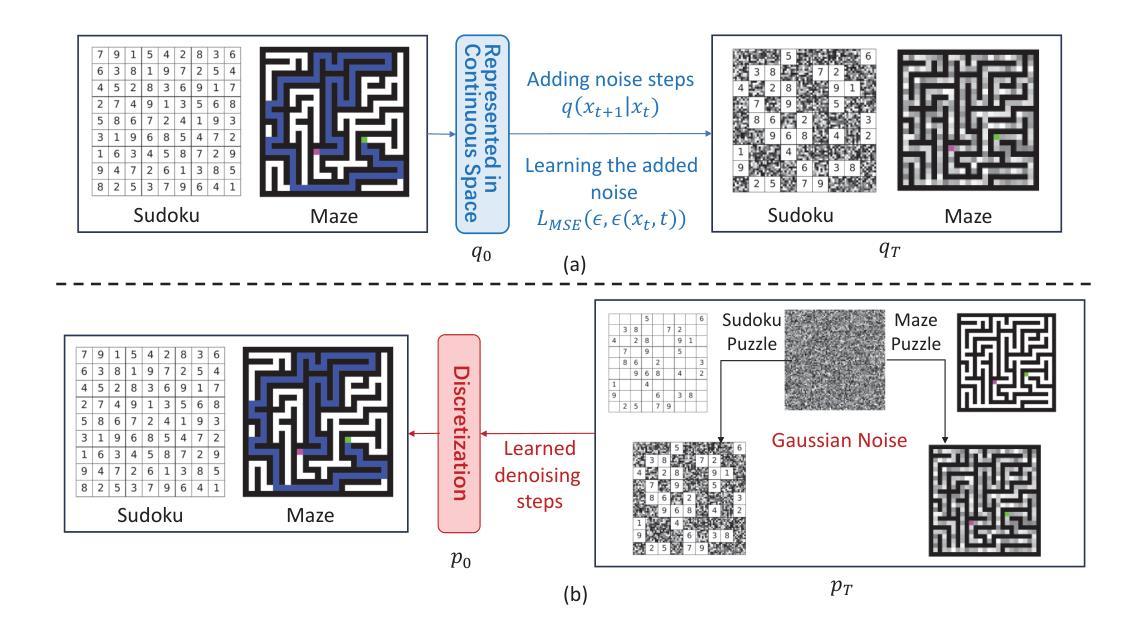
Constraints-Guided Diffusion Reasoner for Neuro-Symbolic Learning
Authors:Xuan Zhang, Zhijian Zhou, Weidi Xu, Yanting Miao, Chao Qu, Yuan Qi
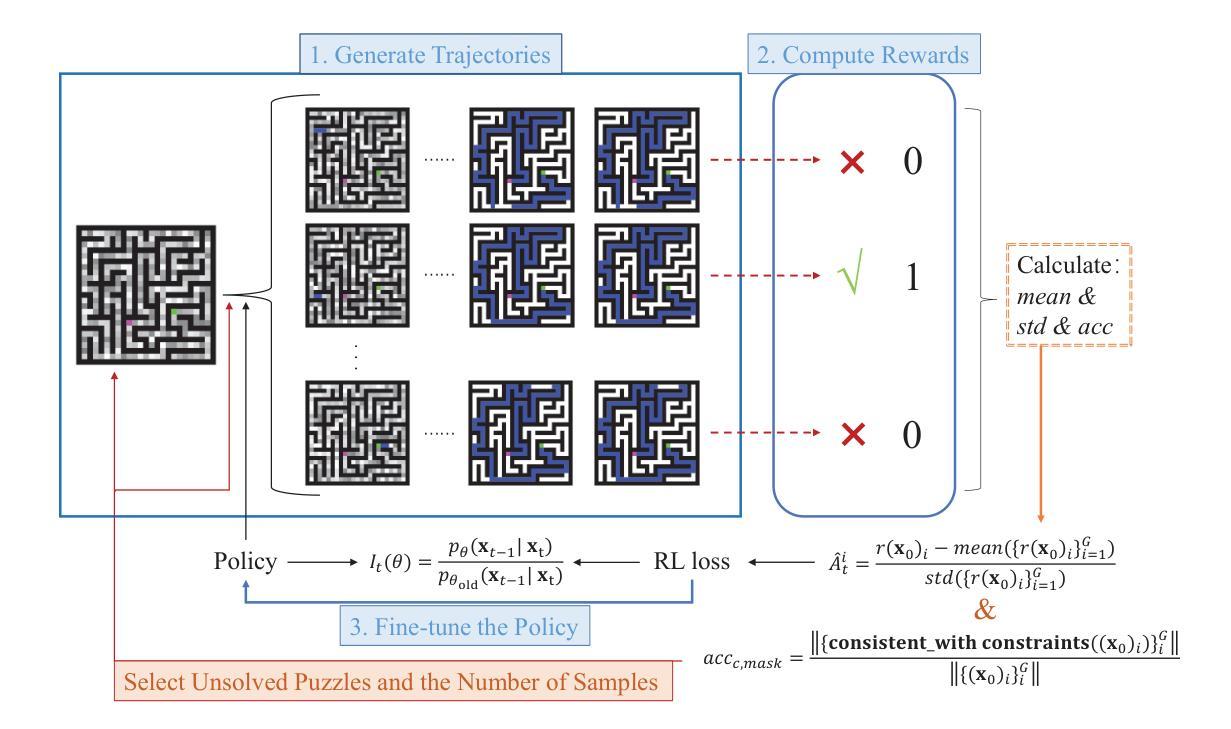
Enabling neural networks to learn complex logical constraints and fulfill symbolic reasoning is a critical challenge. Bridging this gap often requires guiding the neural network’s output distribution to move closer to the symbolic constraints. While diffusion models have shown remarkable generative capability across various domains, we employ the powerful architecture to perform neuro-symbolic learning and solve logical puzzles. Our diffusion-based pipeline adopts a two-stage training strategy: the first stage focuses on cultivating basic reasoning abilities, while the second emphasizes systematic learning of logical constraints. To impose hard constraints on neural outputs in the second stage, we formulate the diffusion reasoner as a Markov decision process and innovatively fine-tune it with an improved proximal policy optimization algorithm. We utilize a rule-based reward signal derived from the logical consistency of neural outputs and adopt a flexible strategy to optimize the diffusion reasoner’s policy. We evaluate our methodology on some classical symbolic reasoning benchmarks, including Sudoku, Maze, pathfinding and preference learning. Experimental results demonstrate that our approach achieves outstanding accuracy and logical consistency among neural networks.
使神经网络能够学习复杂的逻辑约束并实现符号推理是一项关键挑战。弥合这一鸿沟通常需要引导神经网络的输出分布以接近符号约束。虽然扩散模型已在各个领域显示出卓越的生成能力,但我们采用强大的架构进行神经符号学习并解决逻辑谜题。我们的基于扩散的管道采用两阶段训练策略:第一阶段侧重于培养基本推理能力,而第二阶段则强调逻辑约束的系统学习。为了在第二阶段对神经输出施加硬性约束,我们将扩散推理机制定为马尔可夫决策过程,并创新地通过改进的优势策略优化算法对其进行微调。我们利用基于规则的奖励信号,根据神经输出的逻辑一致性,并采取灵活的策略来优化扩散推理机的策略。我们在一些经典的符号推理基准测试上评估了我们的方法,包括数独、迷宫、路径寻找和偏好学习。实验结果表明,我们的方法在神经网络中实现了出色的准确性和逻辑一致性。
论文及项目相关链接
Summary
神经网络学习复杂逻辑约束并实现符号推理是一大挑战。本研究利用扩散模型进行神经符号学习并解决逻辑难题。采用两阶段训练策略,第一阶段培养基本推理能力,第二阶段重点学习逻辑约束。第二阶段对神经输出施加硬约束,将扩散推理器制定为马尔可夫决策过程,并用改进后的近端策略优化算法进行微调。利用基于规则的奖励信号优化扩散推理器的策略,并在一些经典的符号推理基准测试上评估方法,包括数独、迷宫、路径寻找和偏好学习等。实验结果表明,该方法在神经网络中实现了出色的准确性和逻辑一致性。
Key Takeaways
- 神经网络学习复杂逻辑约束是重要挑战。
- 扩散模型用于神经符号学习与逻辑难题解决。
- 采用两阶段训练策略,第一阶段培养基本推理能力,第二阶段重点学习逻辑约束。
- 第二阶段将扩散推理器制定为马尔可夫决策过程,用改进算法进行微调。
- 利用基于规则的奖励信号优化策略。
- 在多种符号推理基准测试上进行了评估,包括数独、迷宫等。
点此查看论文截图

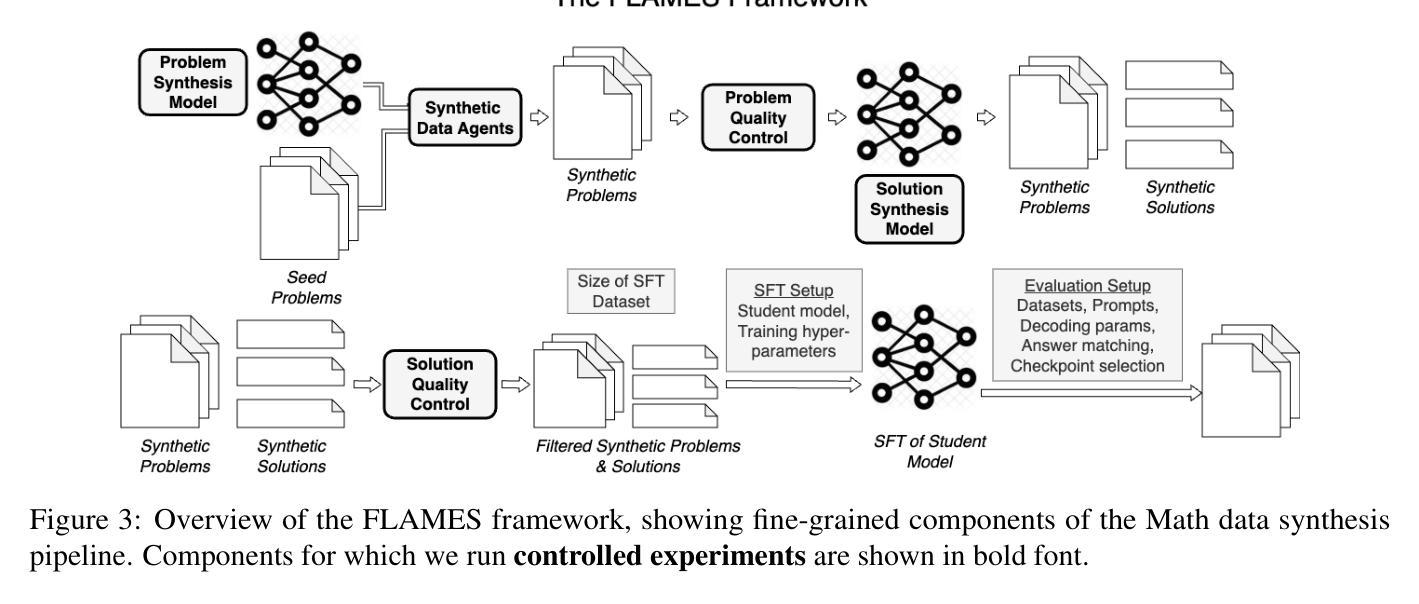
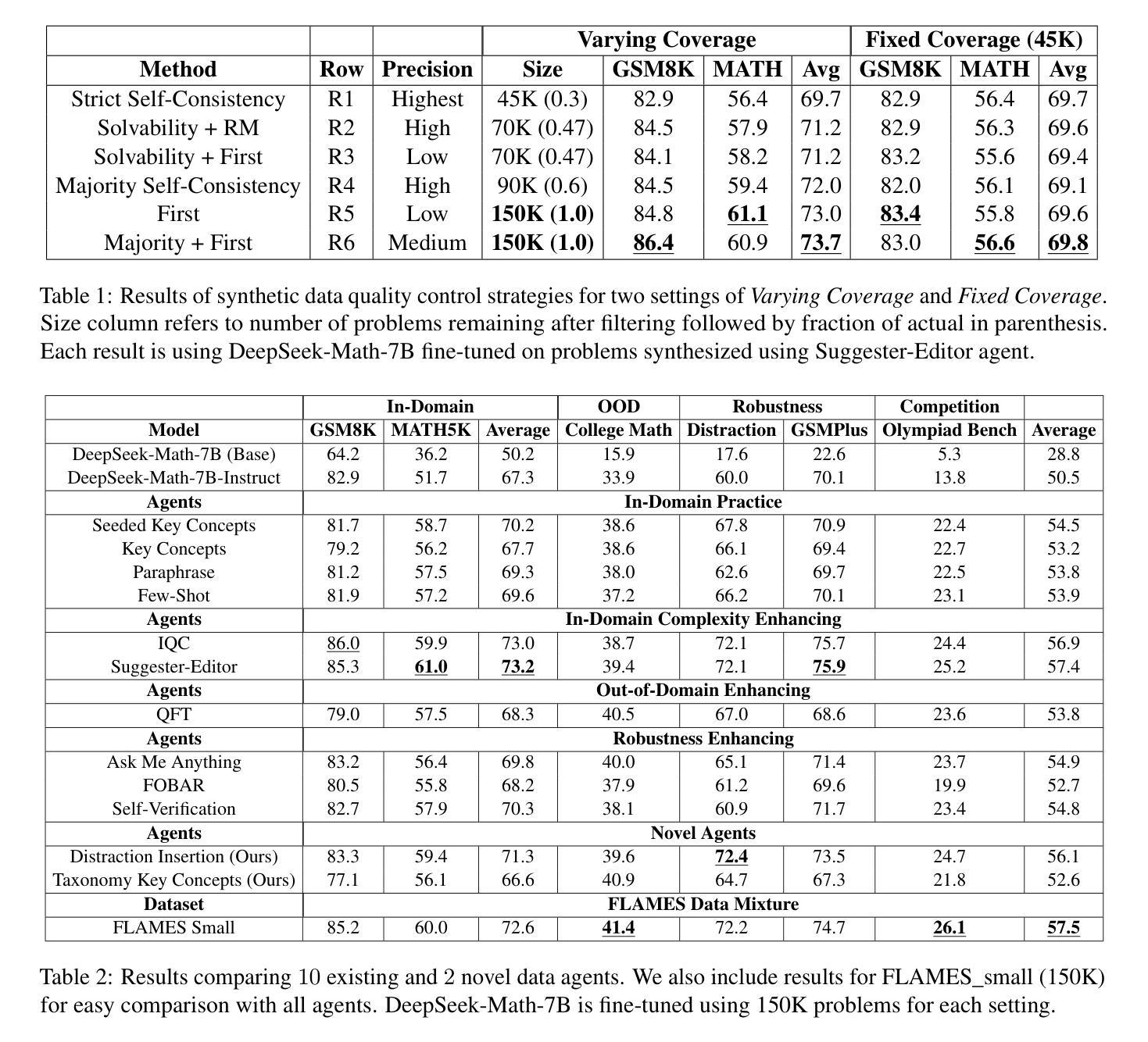
FLAMES: Improving LLM Math Reasoning via a Fine-Grained Analysis of the Data Synthesis Pipeline
Authors:Parker Seegmiller, Kartik Mehta, Soumya Saha, Chenyang Tao, Shereen Oraby, Arpit Gupta, Tagyoung Chung, Mohit Bansal, Nanyun Peng
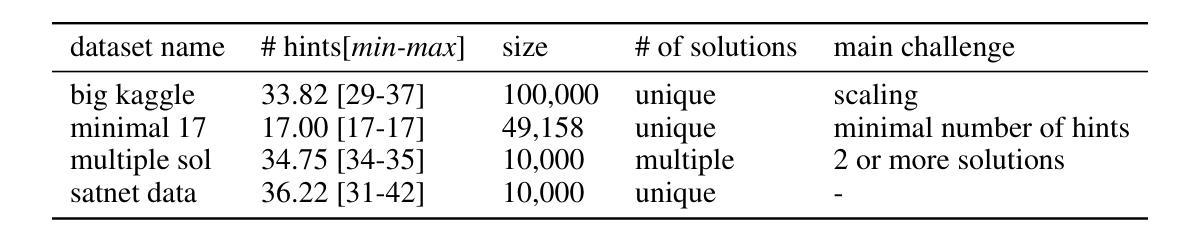
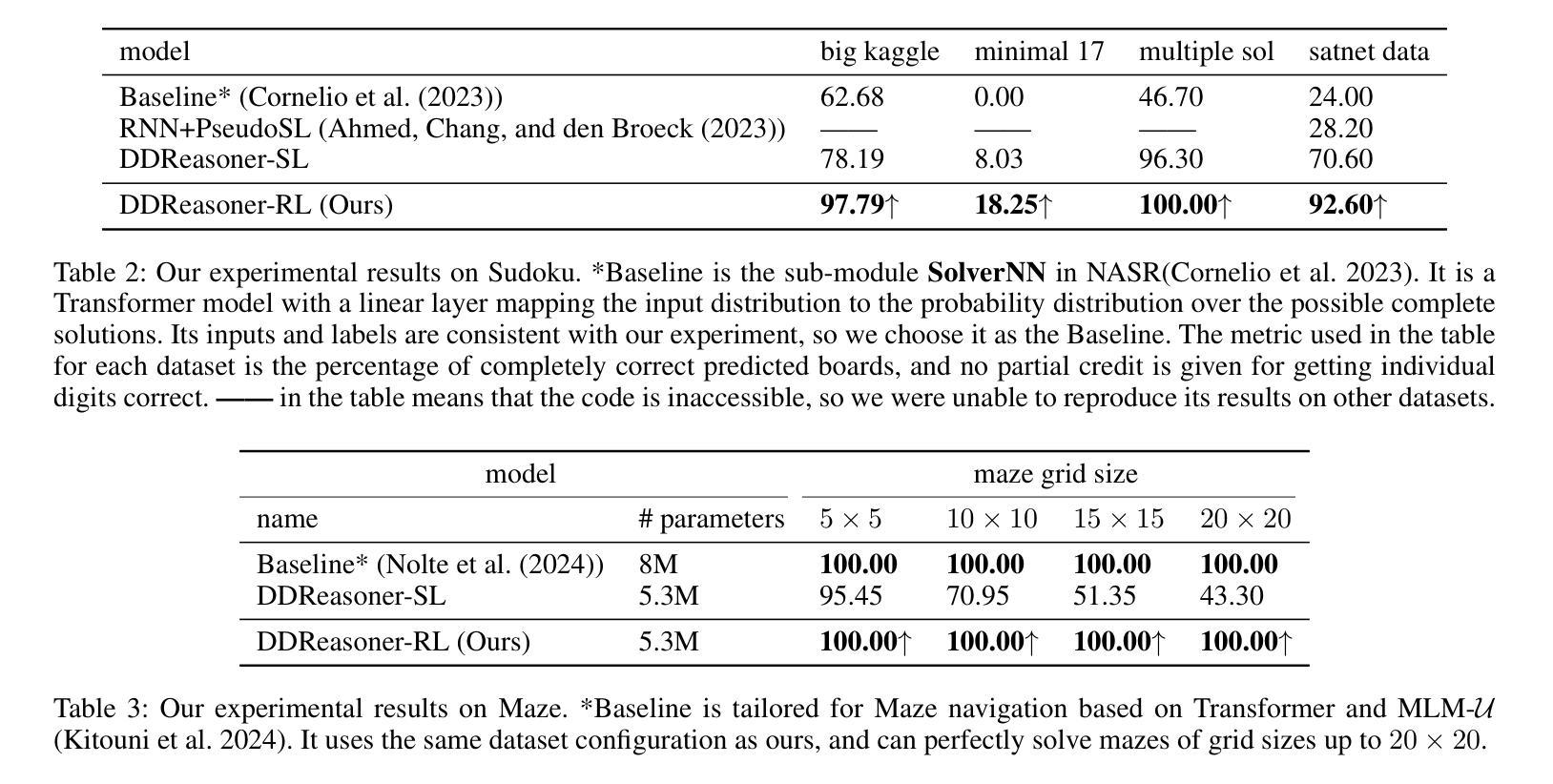
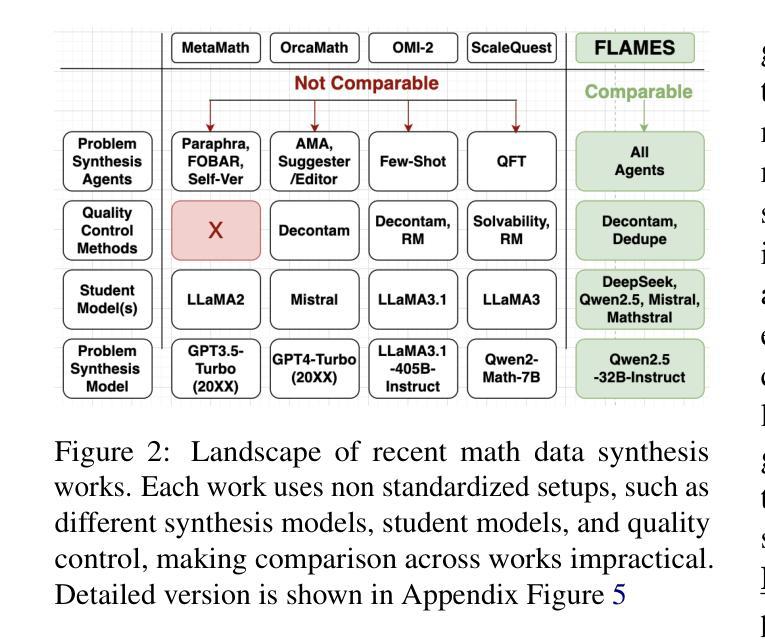
Recent works improving LLM math reasoning with synthetic data have used unique setups, making comparison of data synthesis strategies impractical. This leaves many unanswered questions about the roles of different factors in the synthetic data pipeline, such as the impact of filtering low-quality problems. To address this gap, we introduce FLAMES, a Framework for LLM Assessment of Math rEasoning Data Synthesis, and perform a systematic study of 10 existing data synthesis strategies and multiple other factors impacting the performance of synthetic math reasoning data. Our FLAMES experiments provide several valuable insights about the optimal balance of difficulty and diversity of synthetic data. First, data agents designed to increase problem complexity lead to best improvements on most math metrics. Second, with a fixed data generation budget, keeping higher problem coverage is more important than keeping only problems with reliable solutions. Third, GSM8K- and MATH-based synthetic data can lead to improvements on competition-level benchmarks, showcasing easy-to-hard generalization. Leveraging insights from our FLAMES experiments, we design two novel data synthesis strategies for improving out-of-domain generalization and robustness. Further, we develop the FLAMES dataset, an effective blend of our novel and existing data synthesis strategies, outperforming public datasets on OlympiadBench (+15.7), CollegeMath (+4.5), GSMPlus (+6.5), and MATH (+3.1). Fine-tuning Qwen2.5-Math-7B on the FLAMES dataset achieves 81.4% on MATH, surpassing larger Llama3 405B, GPT-4o and Claude 3.5 Sonnet.
近期,利用合成数据提升大型语言模型数学推理能力的研究工作采用了独特的设置,这使得数据合成策略的对比变得不切实际。这引发了许多关于合成数据流程中不同因素作用的问题悬而未决,例如过滤低质量问题的影响。为了弥补这一空白,我们引入了FLAMES,这是一个用于评估大型语言模型数学推理数据合成的框架,并对10种现有的数据合成策略和多种影响合成数学推理数据性能的其他因素进行了系统的研究。我们的FLAMES实验提供了关于合成数据难度和多样性之间最佳平衡的宝贵见解。首先,旨在增加问题复杂性的数据代理可以在大多数数学指标上带来最佳改进。其次,在固定的数据生成预算下,保持更高的问题覆盖率比仅保留具有可靠解决方案的问题更重要。第三,基于GSM8K和MATH的合成数据可以在竞赛级别的基准测试上带来改进,展示了从易到难的泛化能力。利用FLAMES实验的见解,我们设计了两种新型数据合成策略,以提高跨域泛化和稳健性。此外,我们开发了FLAMES数据集,这是一个我们新颖和现有数据合成策略的有效融合,它在OlympiadBench(+15.7)、CollegeMath(+4.5)、GSMPlus(+6.5)和MATH(+3.1)等公共数据集上表现出色。使用FLAMES数据集微调Qwen2.5-Math-7B模型在MATH上达到81.4%的准确率,超越了更大规模的Llama3 405B、GPT-4o和Claude 3.5 Sonnet模型。
论文及项目相关链接
PDF To appear at EMNLP 2025
Summary
本文介绍了一个名为FLAMES的框架,用于评估数学推理数据的合成策略。该研究对现有的数据合成策略进行了系统的研究,并探讨了影响合成数学推理数据性能的其他因素。研究结果显示,设计用于增加问题复杂性的数据代理可以带来最佳的性能提升。此外,利用FLAMES的实验结果,本文提出了两种新型的数据合成策略,并开发了FLAMES数据集,该数据集在各种基准测试中表现优异。最后,通过对一个大型模型的微调,在MATH数据集上取得了较高的性能。
Key Takeaways
- 引入FLAMES框架,用于评估数学推理数据的合成策略。
- 系统研究了现有的数据合成策略以及其他影响性能的因素。
- 发现设计用于增加问题复杂性的数据代理能带来最佳性能提升。
- 在固定数据生成预算下,保持更高的问题覆盖面比保持只有可靠解决方案的问题更重要。
- GSM8K和MATH为基础的数据合成策略可以改善竞赛级别的基准测试表现。
- 开发了一种新型的FLAMES数据集,结合了新型和现有的数据合成策略,并在多个基准测试中表现优异。
点此查看论文截图

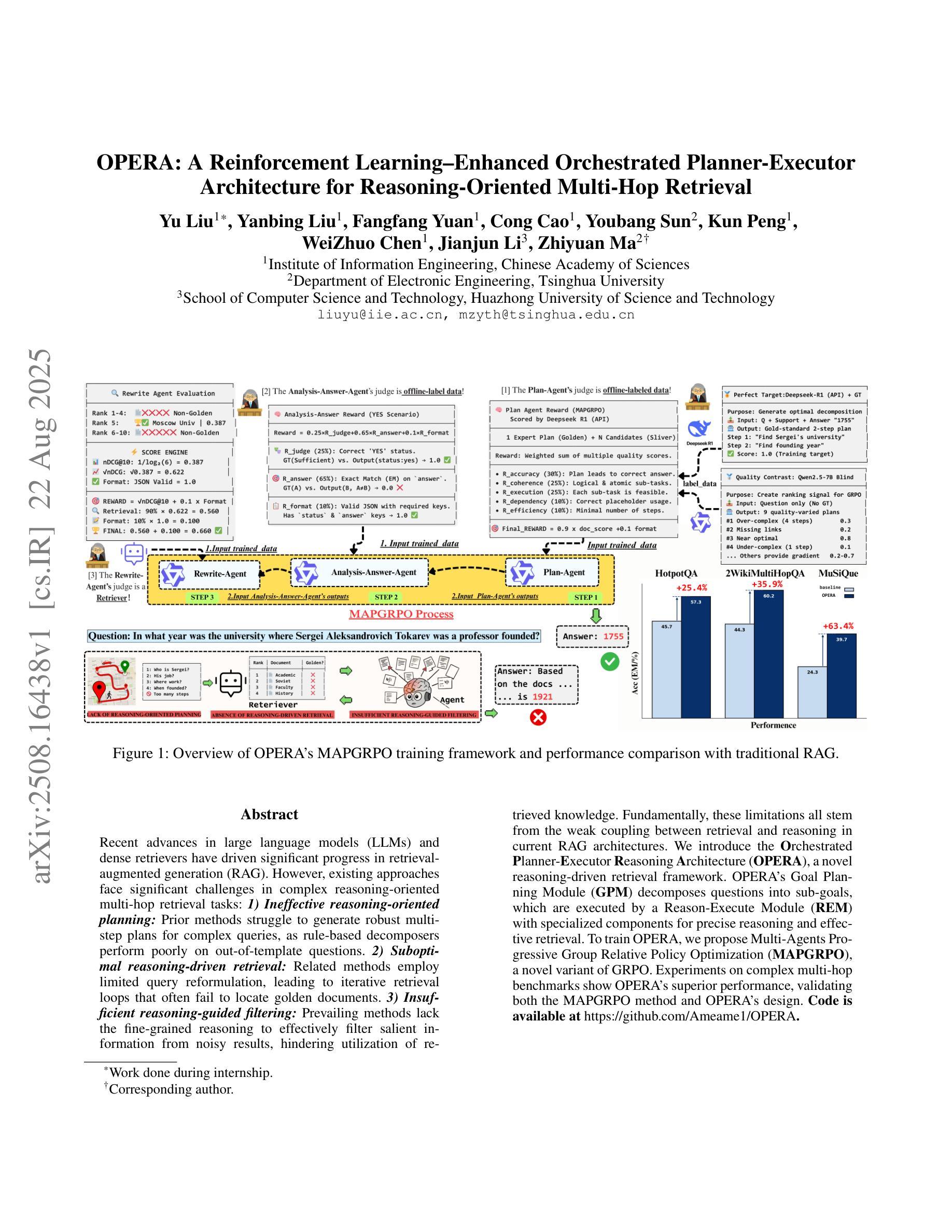
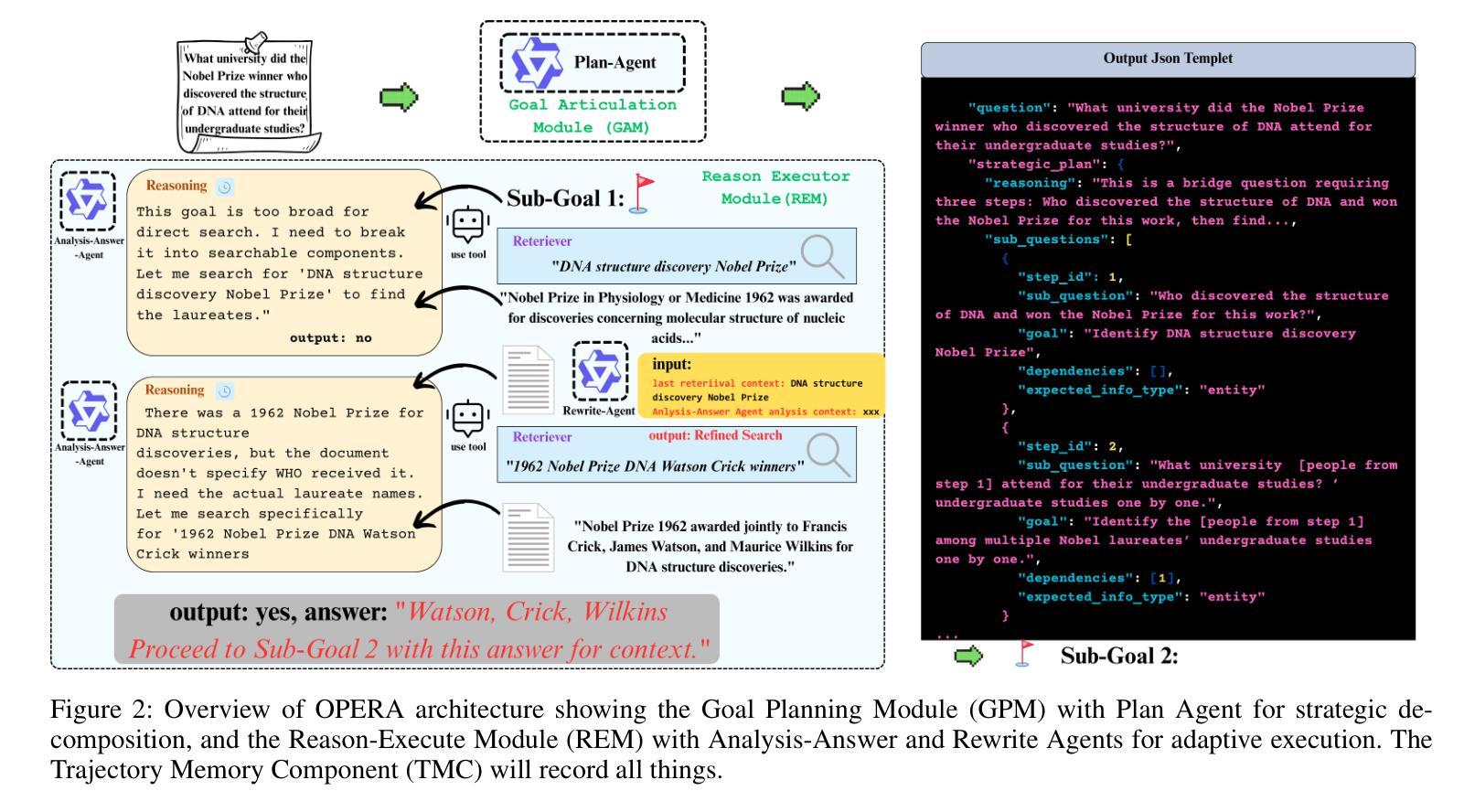
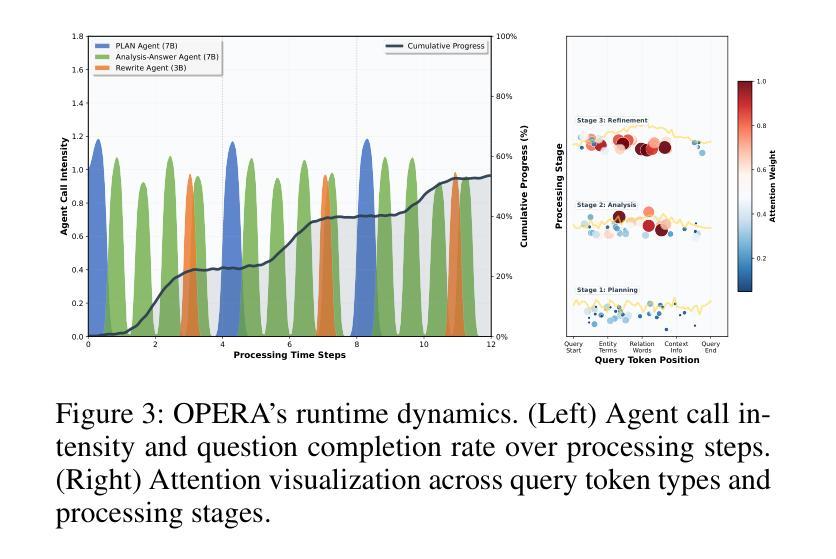
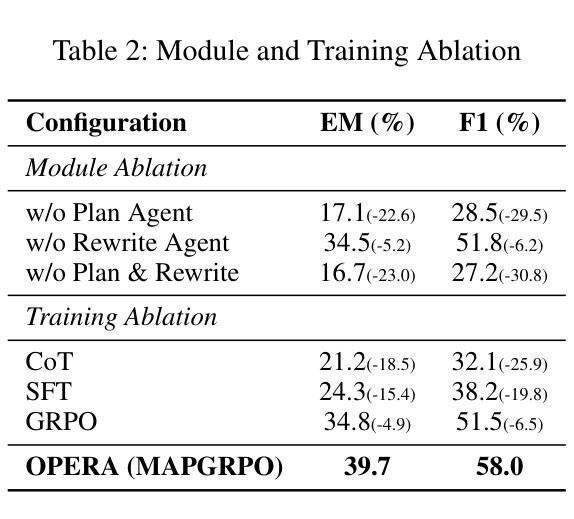
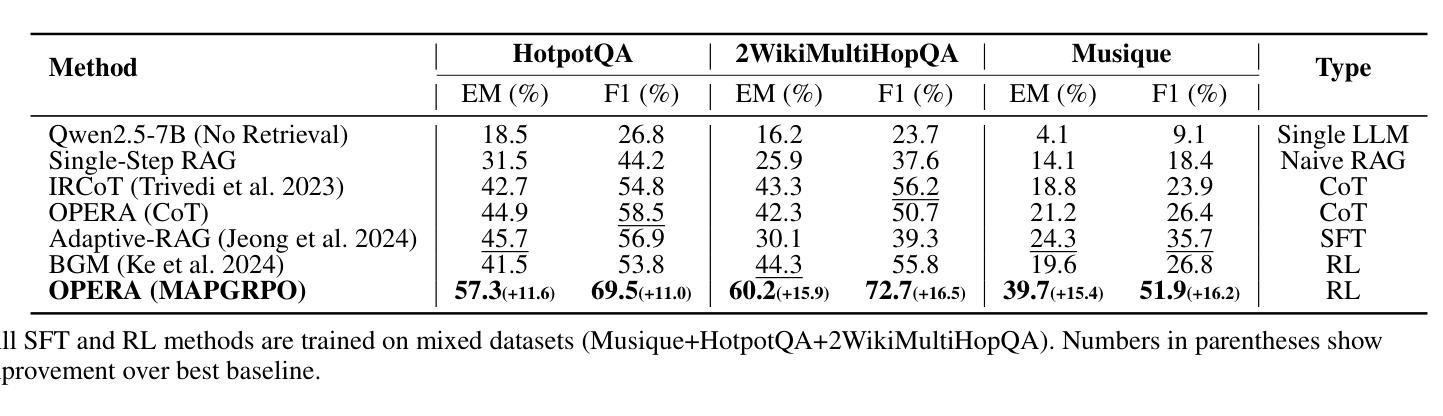
OPERA: A Reinforcement Learning–Enhanced Orchestrated Planner-Executor Architecture for Reasoning-Oriented Multi-Hop Retrieval
Authors:Yu Liu, Yanbing Liu, Fangfang Yuan, Cong Cao, Youbang Sun, Kun Peng, WeiZhuo Chen, Jianjun Li, Zhiyuan Ma
Recent advances in large language models (LLMs) and dense retrievers have driven significant progress in retrieval-augmented generation (RAG). However, existing approaches face significant challenges in complex reasoning-oriented multi-hop retrieval tasks: 1) Ineffective reasoning-oriented planning: Prior methods struggle to generate robust multi-step plans for complex queries, as rule-based decomposers perform poorly on out-of-template questions. 2) Suboptimal reasoning-driven retrieval: Related methods employ limited query reformulation, leading to iterative retrieval loops that often fail to locate golden documents. 3) Insufficient reasoning-guided filtering: Prevailing methods lack the fine-grained reasoning to effectively filter salient information from noisy results, hindering utilization of retrieved knowledge. Fundamentally, these limitations all stem from the weak coupling between retrieval and reasoning in current RAG architectures. We introduce the Orchestrated Planner-Executor Reasoning Architecture (OPERA), a novel reasoning-driven retrieval framework. OPERA’s Goal Planning Module (GPM) decomposes questions into sub-goals, which are executed by a Reason-Execute Module (REM) with specialized components for precise reasoning and effective retrieval. To train OPERA, we propose Multi-Agents Progressive Group Relative Policy Optimization (MAPGRPO), a novel variant of GRPO. Experiments on complex multi-hop benchmarks show OPERA’s superior performance, validating both the MAPGRPO method and OPERA’s design. Code is available at https://github.com/Ameame1/OPERA.
近期,大型语言模型(LLM)和密集检索器的进展推动了增强型检索生成(RAG)的显著进步。然而,现有方法在面向复杂推理的跨步检索任务中面临重大挑战:1)面向推理的规划不够有效:之前的方法在生成复杂查询的稳健多步规划时遇到困难,因为基于规则的分解器在非常规问题上的表现较差。2)推理驱动的检索结果不佳:相关方法采用有限的查询重构,导致经常陷入迭代检索循环,无法找到关键文档。3)缺乏推理指导的过滤:现行方法缺乏精细的推理来有效过滤噪声结果中的关键信息,阻碍了检索知识的利用。这些局限性根本源于当前RAG架构中检索和推理之间的弱耦合。我们引入了“协同规划执行推理架构”(OPERA)这一新型推理驱动检索框架。OPERA的目标规划模块(GPM)将问题分解为子目标,这些子目标由具有精确推理和有效检索组件的推理执行模块(REM)执行。为了训练OPERA,我们提出了多智能体渐进群组相对策略优化(MAPGRPO),这是GRPO的一种新型变体。在复杂的多步基准测试上的实验显示了OPERA的卓越性能,验证了MAPGRPO方法和OPERA设计的有效性。代码可在https://github.com/Ameame1/OPERA获取。
论文及项目相关链接
Summary:
近期大型语言模型(LLM)和密集检索器的进展推动了检索增强生成(RAG)的显著进步。然而,现有方法在面向复杂推理的多跳检索任务中面临挑战。为了解决这些问题,提出了Orchestrated Planner-Executor Reasoning Architecture(OPERA)这一新的推理驱动检索框架。OPERA的Goal Planning Module(GPM)将问题分解为子目标,并由Reason-Execute Module(REM)执行,具有精确推理和有效检索的专门组件。通过Multi-Agents Progressive Group Relative Policy Optimization(MAPGRPO)方法训练OPERA,在复杂多跳基准测试上表现出优越性能,验证了MAPGRPO方法和OPERA设计的有效性。
Key Takeaways:
- 大型语言模型和密集检索器的进步推动了检索增强生成的进步。
- 现有方法在复杂推理的多跳检索任务中面临挑战,如规划、检索和过滤等方面的问题。
- OPERA框架通过分解问题为子目标并执行,解决了这些问题。
- OPERA包括Goal Planning Module(GPM)和Reason-Execute Module(REM),具有精确推理和有效检索的专门组件。
- OPERA通过Multi-Agents Progressive Group Relative Policy Optimization(MAPGRPO)方法进行训练。
- 在复杂多跳基准测试上,OPERA表现出优越性能。
点此查看论文截图
OwkinZero: Accelerating Biological Discovery with AI
Authors:Nathan Bigaud, Vincent Cabeli, Meltem Gurel, Arthur Pignet, John Klein, Gilles Wainrib, Eric Durand
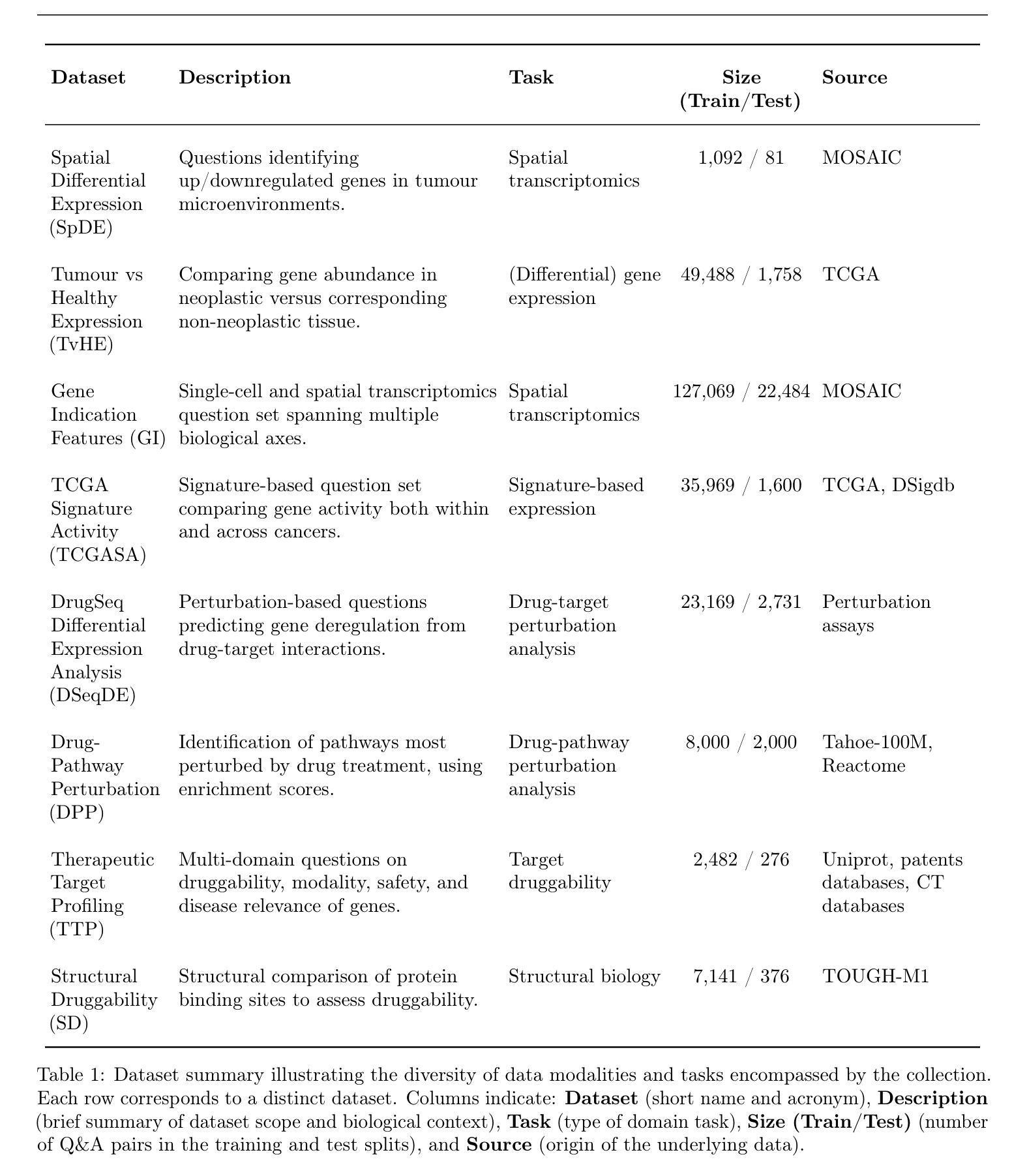
While large language models (LLMs) are rapidly advancing scientific research, they continue to struggle with core biological reasoning tasks essential for translational and biomedical discovery. To address this limitation, we created and curated eight comprehensive benchmark datasets comprising over 300,000 verifiable question-and-answer pairs, each targeting critical challenges in drug discovery including target druggability, modality suitability, and drug perturbation effects. Using this resource, we developed the OwkinZero models by post-training open-source LLMs through a Reinforcement Learning from Verifiable Rewards strategy. Our results demonstrate that specialized 8-32B OwkinZero models substantially outperform larger, state-of-the-art commercial LLMs on these biological benchmarks. Remarkably, we uncover evidence of a key aspect of generalization: specialist models trained on a single task consistently outperform their base models on previously unseen tasks. This generalization effect is further amplified in our comprehensive OwkinZero models, which were trained on a mixture of datasets and achieve even broader cross-task improvements. This study represents a significant step toward addressing the biological reasoning blind spot in current LLMs, demonstrating that targeted reinforcement learning on carefully curated data can unlock generalizable performance in specialized models, thereby accelerating AI-driven biological discovery.
虽然大型语言模型(LLM)在科学研究领域取得了快速发展,但它们仍然难以应对对于药物研发和生物医学发现至关重要的核心生物推理任务。为了解决这个问题,我们创建并整理了八个综合基准数据集,包含超过30万个可验证的问答对,每个数据集都针对药物发现中的关键挑战,包括目标药物的可行性、模态的适用性以及药物的扰动影响。利用这一资源,我们通过一种名为“来自可验证奖励的强化学习”的策略,对开源LLM进行后训练,发展了OwkinZero模型。我们的结果表明,专业的8-32BOwkinZero模型在这些生物基准测试上的表现大大超过了更大、最先进的商业LLM。值得注意的是,我们发现了一个关键方面的证据:经过单一任务训练的专门模型在未接触的任务上始终优于其基础模型。这种泛化效应在我们的综合OwkinZero模型中得到了进一步的放大,该模型是在多个数据集混合的基础上训练的,并实现了更广泛的跨任务改进。本研究是朝着解决当前LLM中的生物推理盲点的重要一步,表明在精心选择的数据上进行有针对性的强化学习可以在专业模型中解锁可泛化的性能,从而加速人工智能驱动的生物学发现。
论文及项目相关链接
PDF Preprint
Summary
大型语言模型(LLMs)在科学研究领域迅速发展的同时,仍面临对核心生物推理任务的挑战。为解决这一问题,研究者创建了涵盖超过30万对可验证问答的八个综合基准数据集,针对药物发现中的关键挑战,如目标可药性、模态适用性和药物扰动效应等。通过采用强化学习从可验证奖励策略对开源LLM进行后训练,研究者开发了OwkinZero模型。结果显示,专业化的OwkinZero模型在生物基准测试上的表现显著优于更大规模、最先进的商业LLM。此外,研究发现单一任务训练的专家模型在未见任务上的一致表现优于其基础模型,显示出关键方面的泛化证据。通过混合数据集训练的OwkinZero综合模型进一步扩大了跨任务改进,表明有针对性的强化学习和精心挑选的数据可以解锁专业模型的泛化性能,从而加速AI驱动的生物发现。
Key Takeaways
- 大型语言模型(LLMs)在生物推理任务上仍存在局限。
- 创建了八个涵盖药物发现等领域挑战的综合基准数据集。
- 通过强化学习从可验证奖励策略训练了OwkinZero模型。
- OwkinZero模型在生物基准测试上的表现优于商业LLM。
- 单一任务训练的专家模型在未见任务上表现出泛化能力。
- 综合OwkinZero模型通过混合数据集训练,实现跨任务改进。
点此查看论文截图

Hierarchical Vision-Language Reasoning for Multimodal Multiple-Choice Question Answering
Authors:Ao Zhou, Zebo Gu, Tenghao Sun, Jiawen Chen, Mingsheng Tu, Zifeng Cheng, Yafeng Yin, Zhiwei Jiang, Qing Gu
Multimodal Large Language Models (MLLMs) have demonstrated remarkable multimodal understanding capabilities in Visual Question Answering (VQA) tasks by integrating visual and textual features. However, under the challenging ten-choice question evaluation paradigm, existing methods still exhibit significant limitations when processing PDF documents with complex layouts and lengthy content. Notably, current mainstream models suffer from a strong bias toward English training data, resulting in suboptimal performance for Japanese and other language scenarios. To address these challenges, this paper proposes a novel Japanese PDF document understanding framework that combines multimodal hierarchical reasoning mechanisms with Colqwen-optimized retrieval methods, while innovatively introducing a semantic verification strategy through sub-question decomposition. Experimental results demonstrate that our framework not only significantly enhances the model’s deep semantic parsing capability for complex documents, but also exhibits superior robustness in practical application scenarios.
多模态大型语言模型(MLLMs)通过融合视觉和文本特征,在视觉问答(VQA)任务中表现出了显著的多模态理解能力。然而,在具有挑战性的十选一问答案评估模式下,现有方法在处理具有复杂布局和冗长内容的PDF文档时仍表现出显著局限性。尤其是当前主流模型对英文训练数据存在强烈偏向,导致其在日语及其他语言场景下的性能表现不佳。为了解决这些挑战,本文提出了一种新型的日语PDF文档理解框架,该框架结合了多模态分层推理机制和经过Colqwen优化的检索方法,并创新性地引入了通过子问题分解的语义验证策略。实验结果表明,该框架不仅显著提高了模型对复杂文档的深度语义解析能力,而且在实际应用场景中表现出卓越的稳健性。
论文及项目相关链接
PDF This paper has been accepted by ACM MM 2025
Summary
多模态大型语言模型在视觉问答任务中展示了强大的多模态理解力,通过整合视觉和文本特征来处理复杂的PDF文档内容。然而,在十选一问答评估模式下,现有方法在处理具有复杂布局和冗长内容的PDF文档时仍存在显著局限性。针对英语训练数据的强偏见导致对日语和其他语言场景的性能不佳。为解决这些问题,本文提出了一种结合多模态分层推理机制和Colqwen优化检索方法的日语PDF文档理解框架,并创新性地引入了通过子问题分解的语义验证策略。实验证明,该框架不仅显著提高了模型对复杂文档的深层语义解析能力,而且在实际应用场景中表现出卓越的稳健性。
Key Takeaways
- 多模态大型语言模型在视觉问答任务中具备强大的多模态理解力。
- 当前方法在处理复杂PDF文档时存在局限性,特别是在十选一问答评估模式下。
- 主流模型对英语训练数据存在强偏见,导致对非英语场景的性能不佳。
- 本文提出了一种新的日语PDF文档理解框架,结合了多模态分层推理和Colqwen优化检索方法。
- 该框架引入了通过子问题分解的语义验证策略。
- 实验证明,该框架提高了模型对复杂文档的语义解析能力。
点此查看论文截图

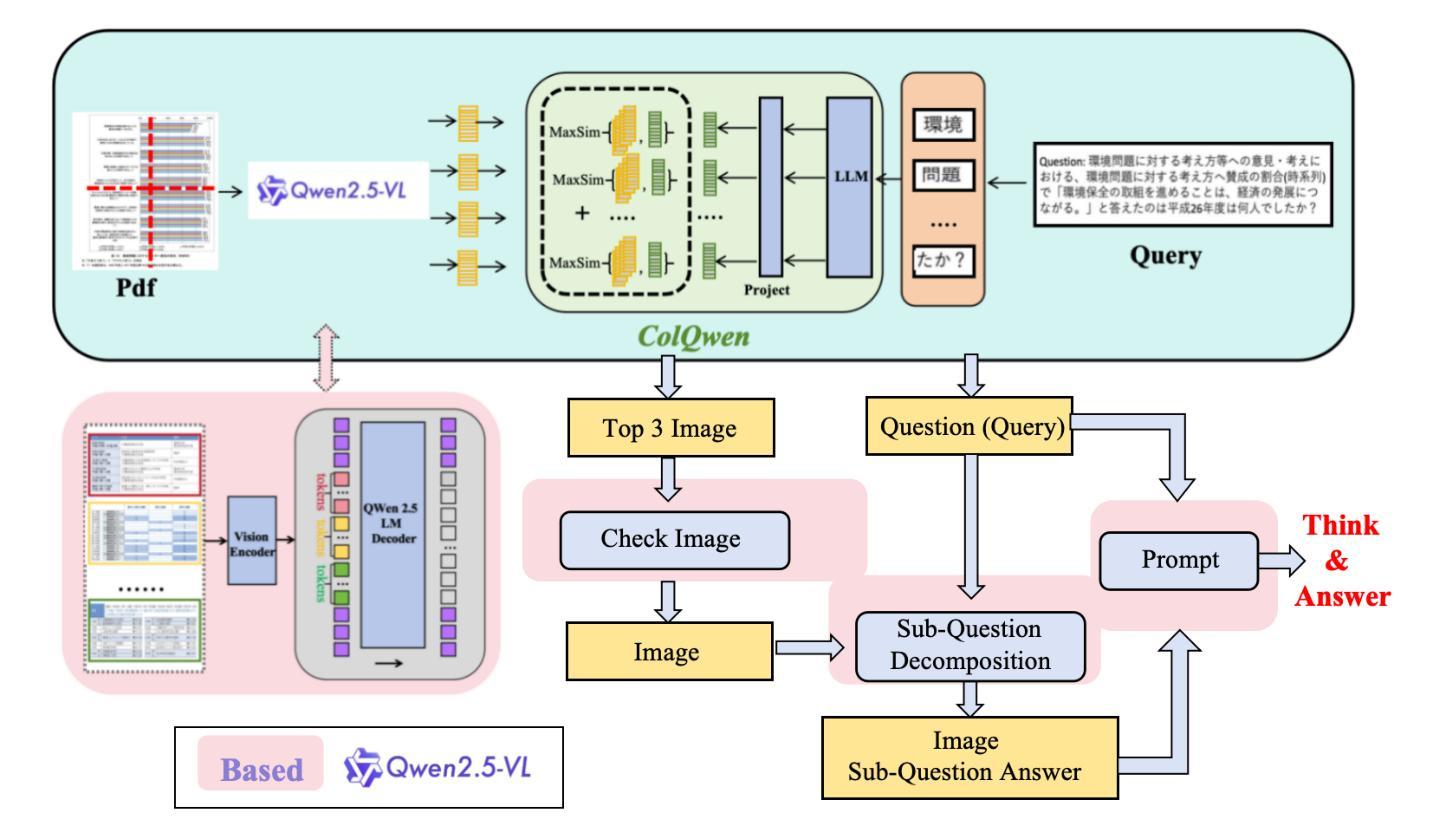

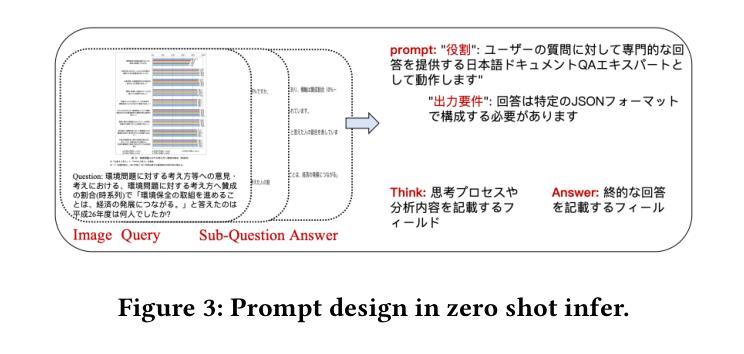
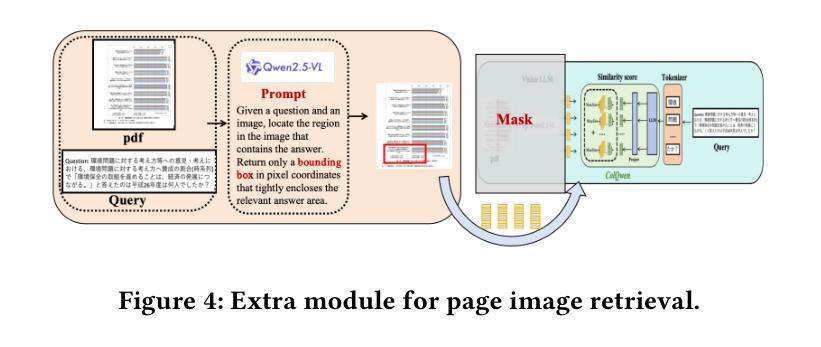
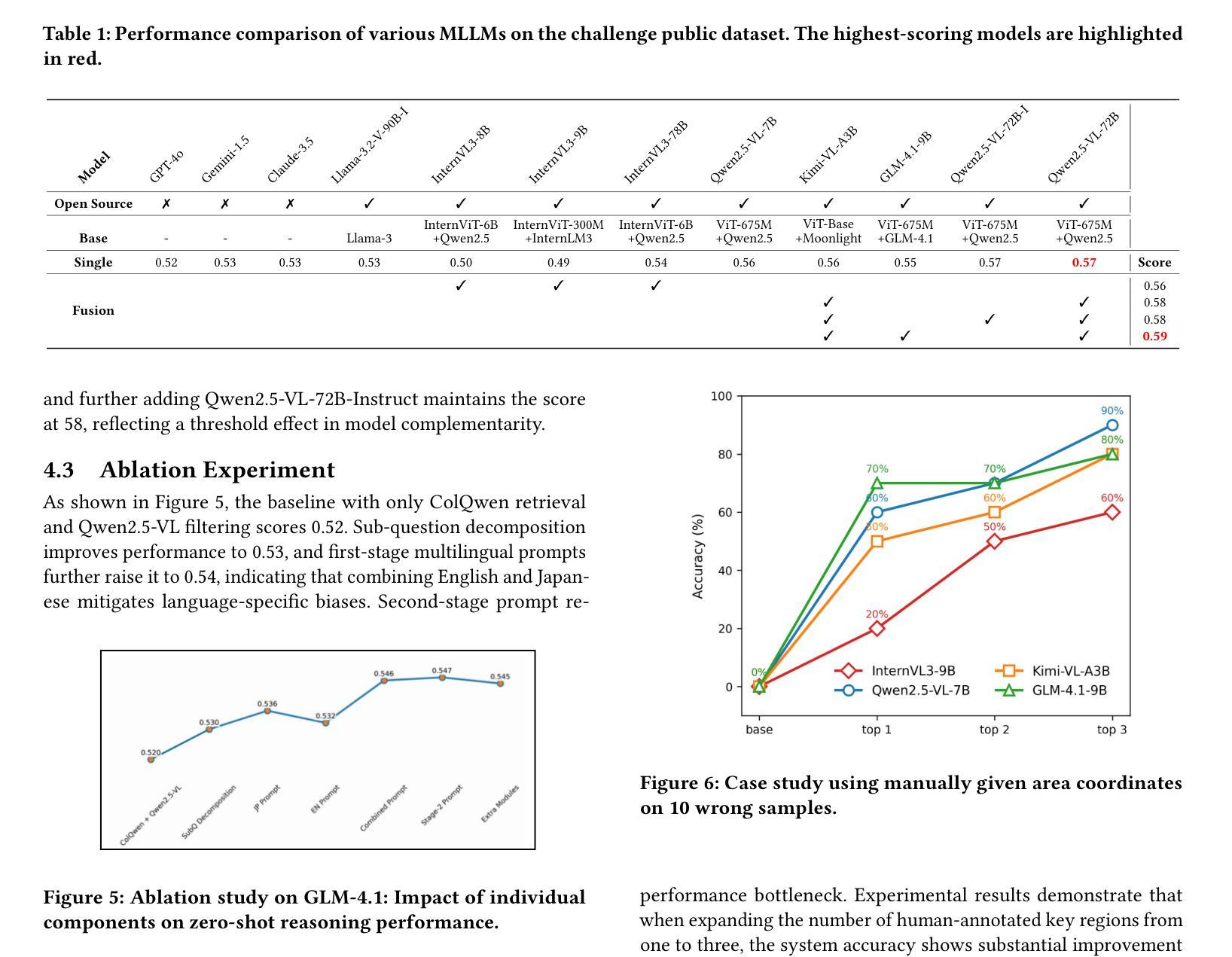
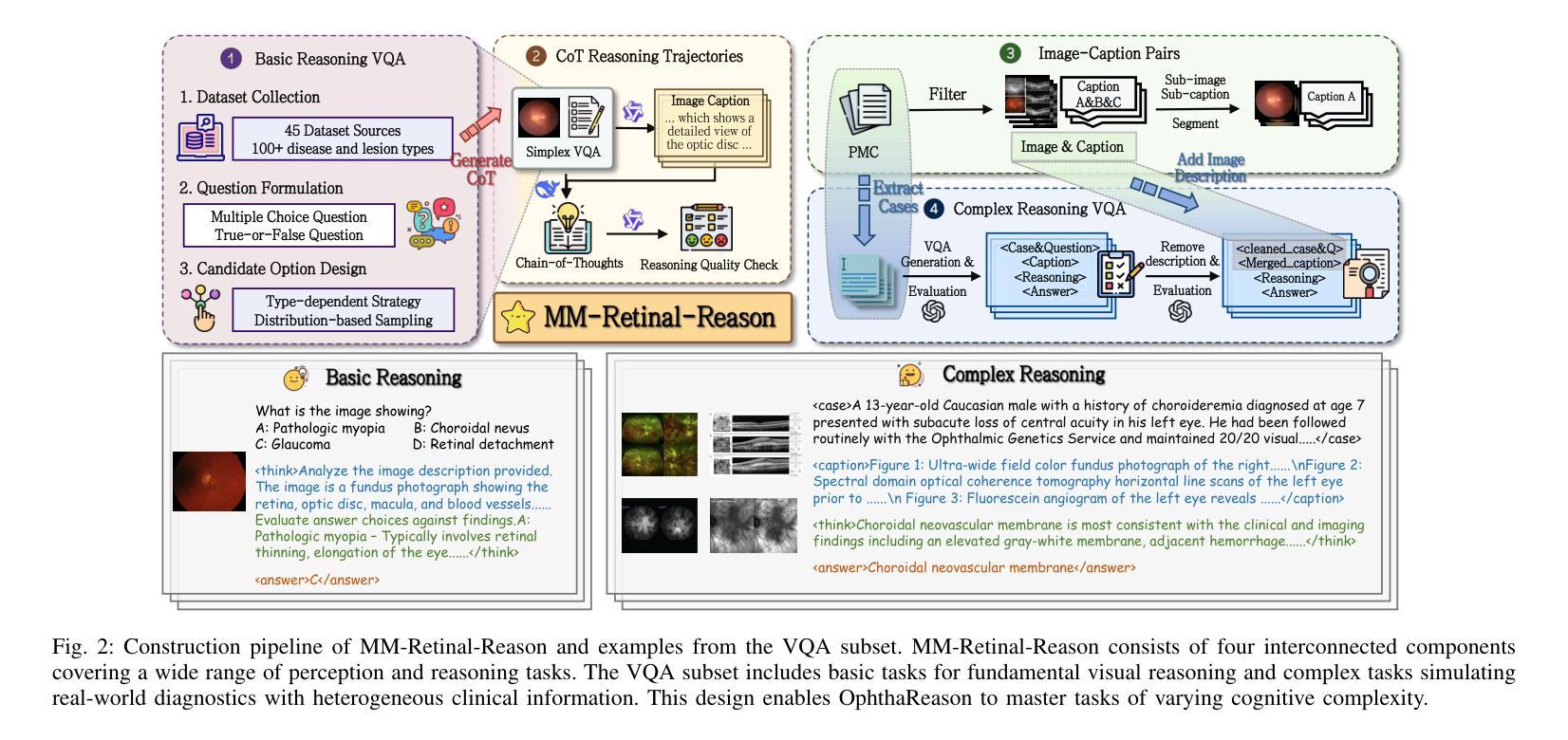
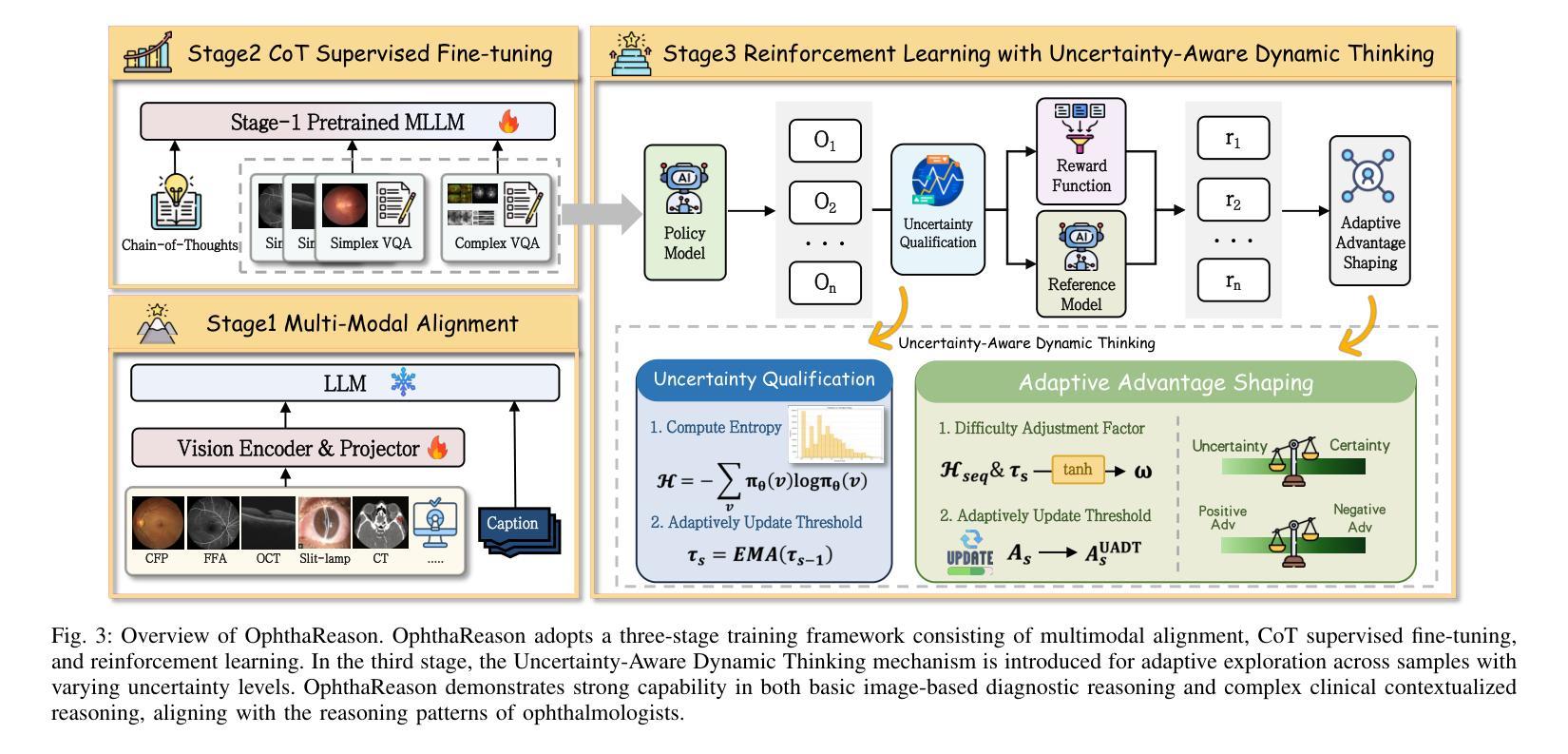
Bridging the Gap in Ophthalmic AI: MM-Retinal-Reason Dataset and OphthaReason Model toward Dynamic Multimodal Reasoning
Authors:Ruiqi Wu, Yuang Yao, Tengfei Ma, Chenran Zhang, Na Su, Tao Zhou, Geng Chen, Wen Fan, Yi Zhou
Multimodal large language models (MLLMs) have recently demonstrated remarkable reasoning abilities with reinforcement learning paradigm. Although several multimodal reasoning models have been explored in the medical domain, most of them focus exclusively on basic reasoning, which refers to shallow inference based on visual feature matching. However, real-world clinical diagnosis extends beyond basic reasoning, demanding reasoning processes that integrate heterogeneous clinical information (such as chief complaints and medical history) with multimodal medical imaging data. To bridge this gap, we introduce MM-Retinal-Reason, the first ophthalmic multimodal dataset with the full spectrum of perception and reasoning. It encompasses both basic reasoning tasks and complex reasoning tasks, aiming to enhance visual-centric fundamental reasoning capabilities and emulate realistic clinical thinking patterns. Building upon MM-Retinal-Reason, we propose OphthaReason, the first ophthalmology-specific multimodal reasoning model with step-by-step reasoning traces. To enable flexible adaptation to both basic and complex reasoning tasks, we specifically design a novel method called Uncertainty-Aware Dynamic Thinking (UADT), which estimates sample-level uncertainty via entropy and dynamically modulates the model’s exploration depth using a shaped advantage mechanism. Comprehensive experiments demonstrate that our model achieves state-of-the-art performance on both basic and complex reasoning tasks, outperforming general-purpose MLLMs, medical MLLMs, RL-based medical MLLMs, and ophthalmic MLLMs by at least 24.92%, 15.00%, 21.20%, and 17.66%. Project Page: \href{https://github.com/lxirich/OphthaReason}{link}.
多模态大型语言模型(MLLMs)最近采用强化学习范式展示了出色的推理能力。尽管医疗领域已经探索了多种多模态推理模型,但大多数模型主要关注基本推理,这指的是基于视觉特征匹配的浅层推断。然而,现实世界中的临床诊断超越了基本推理,需要整合异质临床信息(如主诉和病史)与多模态医学成像数据的过程推理。为了弥补这一差距,我们引入了MM-Retinal-Reason,这是第一个涵盖全谱感知和推理的眼科多模态数据集。它涵盖基本推理任务和复杂推理任务,旨在增强以视觉为中心的基本推理能力,并模拟现实的临床思维模式。基于MM-Retinal-Reason,我们提出了眼科专用多模态推理模型OphthaReason,具有分步推理轨迹。为了灵活适应基本和复杂推理任务,我们专门设计了一种新方法,称为不确定性感知动态思维(UADT),该方法通过熵估计样本级不确定性,并使用成型优势机制动态调节模型的探索深度。综合实验表明,我们的模型在基本和复杂推理任务上均达到了最新性能水平,至少比通用MLLMs、医学MLLMs、基于RL的医学MLLMs和眼科MLLMs高出24.92%、15.00%、21.20%和17.66%。项目页面:链接。
论文及项目相关链接
Summary
本文介绍了多模态大型语言模型(MLLMs)在医疗领域的应用,特别是在眼科诊断中的使用。文章强调了现有模型大多只关注基本推理,而真实世界临床诊断需要更复杂的推理过程,能够整合异质临床信息与多模态医学影像数据。为此,文章提出了MM-Retinal-Reason数据集和OphthaReason模型,旨在模拟真实临床思维模式,并展示了一种名为Uncertainty-Aware Dynamic Thinking(UADT)的新方法,该方法能够在基本和复杂推理任务之间进行灵活适应。实验表明,该模型在基本和复杂推理任务上的性能均达到最新水平。
Key Takeaways
- 多模态大型语言模型(MLLMs)在医疗领域具备出色的推理能力。
- 现有模型大多仅关注基于视觉特征匹配的基本推理。
- 真实世界的临床诊断需要整合异质临床信息和多模态医学影像数据的复杂推理过程。
- MM-Retinal-Reason数据集填补了这一空白,包含了基本和复杂推理任务。
- OphthaReason模型是首个眼科专用的多模态推理模型,具备逐步推理轨迹。
- Uncertainty-Aware Dynamic Thinking(UADT)方法能够在基本和复杂推理任务之间进行灵活适应。
点此查看论文截图

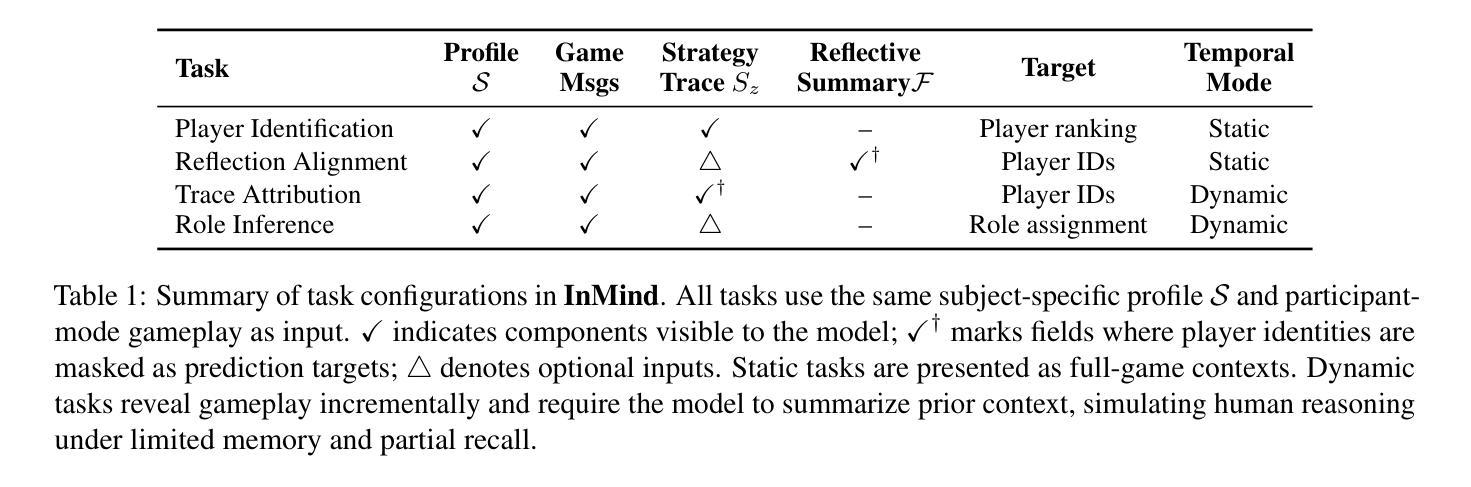
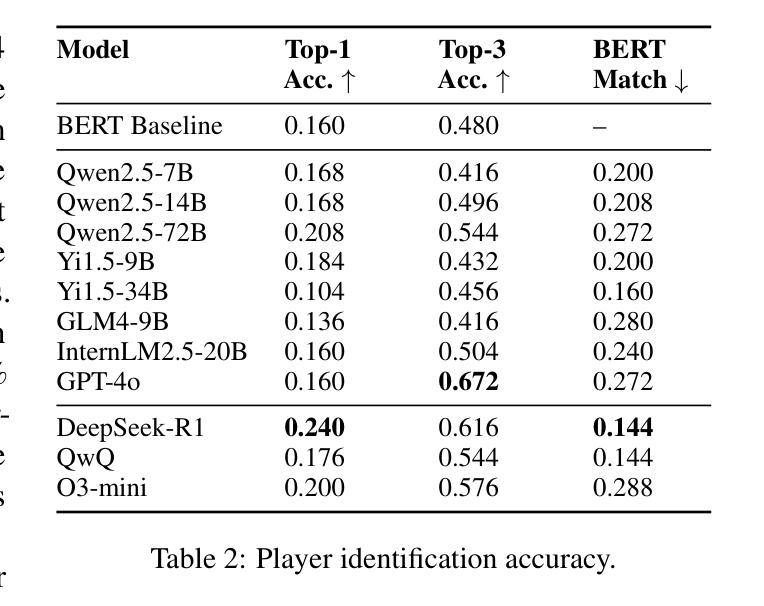
InMind: Evaluating LLMs in Capturing and Applying Individual Human Reasoning Styles
Authors:Zizhen Li, Chuanhao Li, Yibin Wang, Qi Chen, Diping Song, Yukang Feng, Jianwen Sun, Jiaxin Ai, Fanrui Zhang, Mingzhu Sun, Kaipeng Zhang
LLMs have shown strong performance on human-centric reasoning tasks. While previous evaluations have explored whether LLMs can infer intentions or detect deception, they often overlook the individualized reasoning styles that influence how people interpret and act in social contexts. Social deduction games (SDGs) provide a natural testbed for evaluating individualized reasoning styles, where different players may adopt diverse but contextually valid reasoning strategies under identical conditions. To address this, we introduce InMind, a cognitively grounded evaluation framework designed to assess whether LLMs can capture and apply personalized reasoning styles in SDGs. InMind enhances structured gameplay data with round-level strategy traces and post-game reflections, collected under both Observer and Participant modes. It supports four cognitively motivated tasks that jointly evaluate both static alignment and dynamic adaptation. As a case study, we apply InMind to the game Avalon, evaluating 11 state-of-the-art LLMs. General-purpose LLMs, even GPT-4o frequently rely on lexical cues, struggling to anchor reflections in temporal gameplay or adapt to evolving strategies. In contrast, reasoning-enhanced LLMs like DeepSeek-R1 exhibit early signs of style-sensitive reasoning. These findings reveal key limitations in current LLMs’ capacity for individualized, adaptive reasoning, and position InMind as a step toward cognitively aligned human-AI interaction.
大型语言模型(LLM)在人本推理任务中表现出强大的性能。虽然之前的评估已经探讨了LLM是否能够推断意图或检测欺骗,但它们经常忽略影响人们在社会环境中解释和行为的个性化推理风格。社会推理游戏(SDG)为评估个性化推理风格提供了天然的测试平台,在不同的条件下,不同的玩家可能会采用多样化但语境有效的推理策略。为了解决这一问题,我们引入了InMind,这是一个以认知为基础的评价框架,旨在评估LLM是否能捕捉和应用个性化推理风格于SDG中。InMind通过观察者模式和参与者模式下的回合策略轨迹和游戏后反思,增强了结构化游戏玩法数据。它支持四项以认知为动机的任务,这些任务共同评估静态对齐和动态适应。作为案例研究,我们将InMind应用于Avalon游戏,评估了11款最先进的LLM。通用LLM,甚至GPT-4也经常依赖于词汇线索,难以将反思锚定在即时游戏或适应不断变化的策略中。相比之下,增强推理的LLM(如DeepSeek-R1)展现出早期风格敏感推理的迹象。这些发现揭示了当前LLM在个性化自适应推理能力上的关键局限性,并将InMind定位为认知对齐的人机交互的一步。
论文及项目相关链接
PDF EMNLP 2025 MainConference
Summary
大型语言模型(LLMs)在人类为中心的推理任务上表现出强大的性能,但在评估这些模型时,人们常常忽视了影响人们解读和行动的社会背景下的个性化推理风格。为解决这一问题,本文提出了InMind这一认知基础评估框架,旨在评估LLMs是否能在社会推理游戏中捕捉和应用个性化的推理风格。本研究以一个名为Avalon的游戏为例,发现通用的大型语言模型往往依赖于词汇线索,难以在动态的游戏环境中进行适应性的反思,而具备推理增强的模型则展现出个性化的推理能力。这为认知对齐的人机交互研究提供了重要的启示。
Key Takeaways
- LLMs在人类为中心的推理任务上表现出强大的性能,但在评估中常常忽视个性化推理风格的影响。
- InMind框架旨在评估LLMs在社会推理游戏中捕捉和应用个性化推理风格的能力。
- InMind结合了结构化游戏数据和回合级别的策略轨迹以及游戏后的反思,以评估LLMs的静态对齐和动态适应能力。
- 在游戏Avalon的案例中,通用的大型语言模型(如GPT-4)依赖于词汇线索,难以在动态的游戏环境中进行适应性的反思。
- 具备推理增强的LLMs(如DeepSeek-R1)展现出个性化的推理能力。
- 当前LLMs在个性化、适应性推理方面存在关键局限。
点此查看论文截图

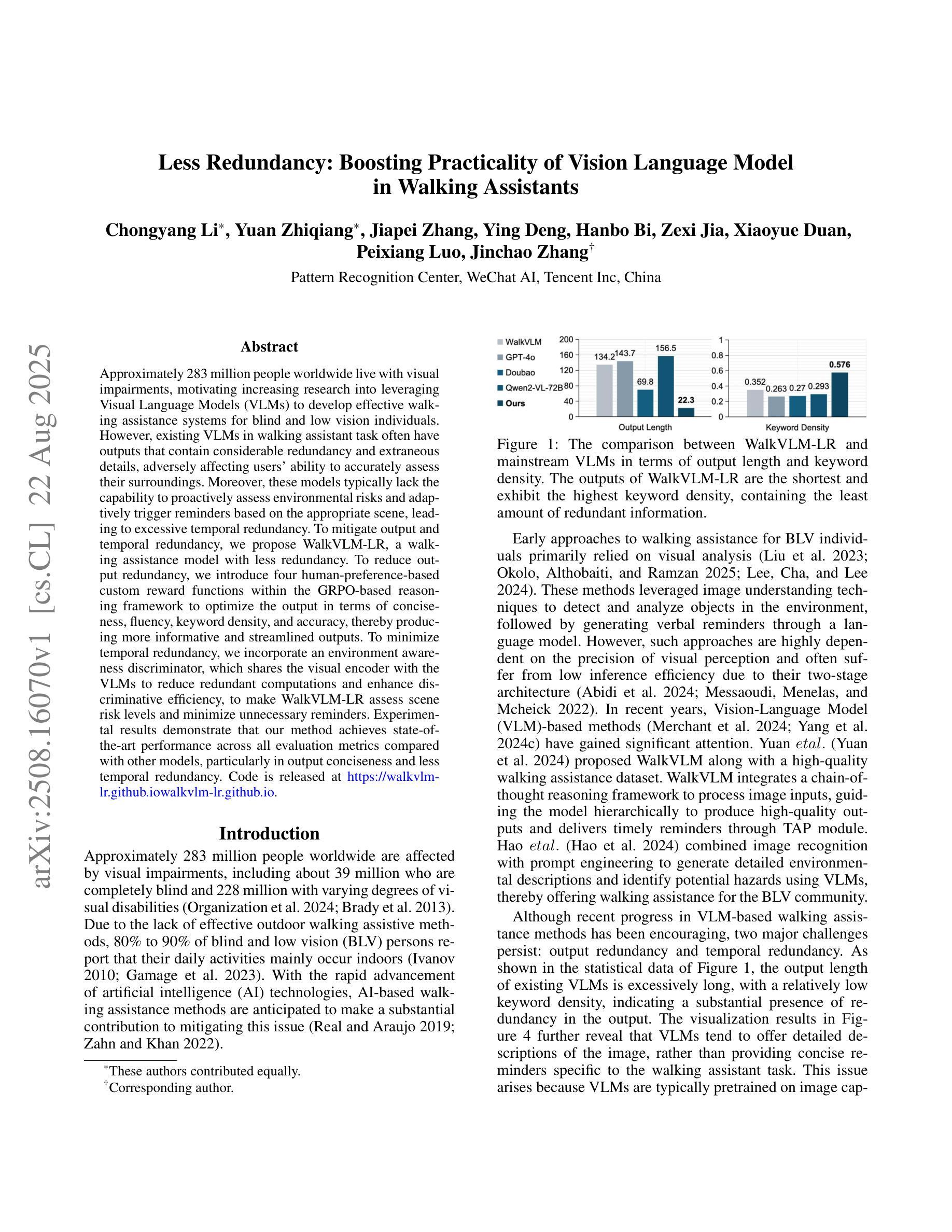
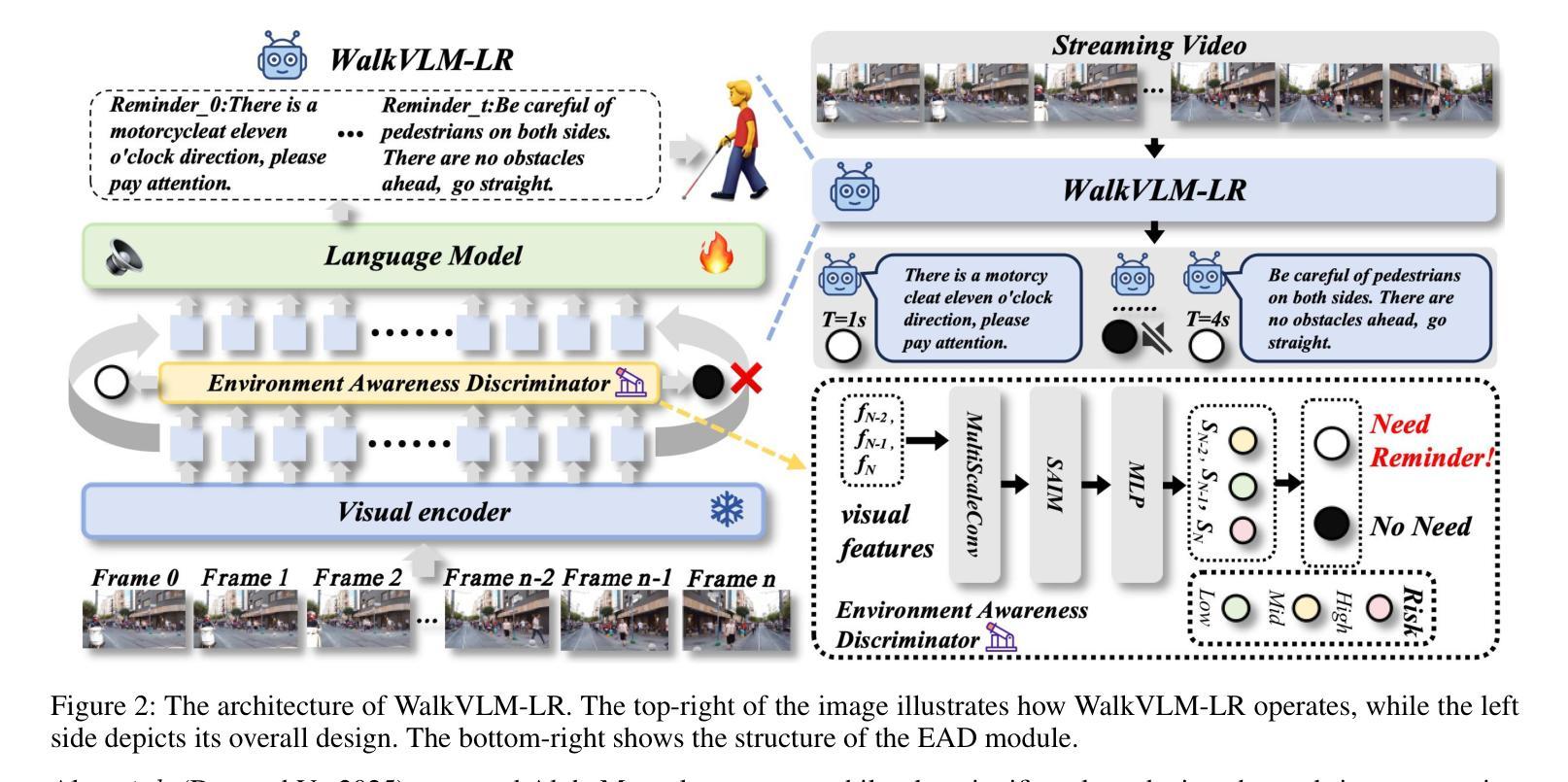
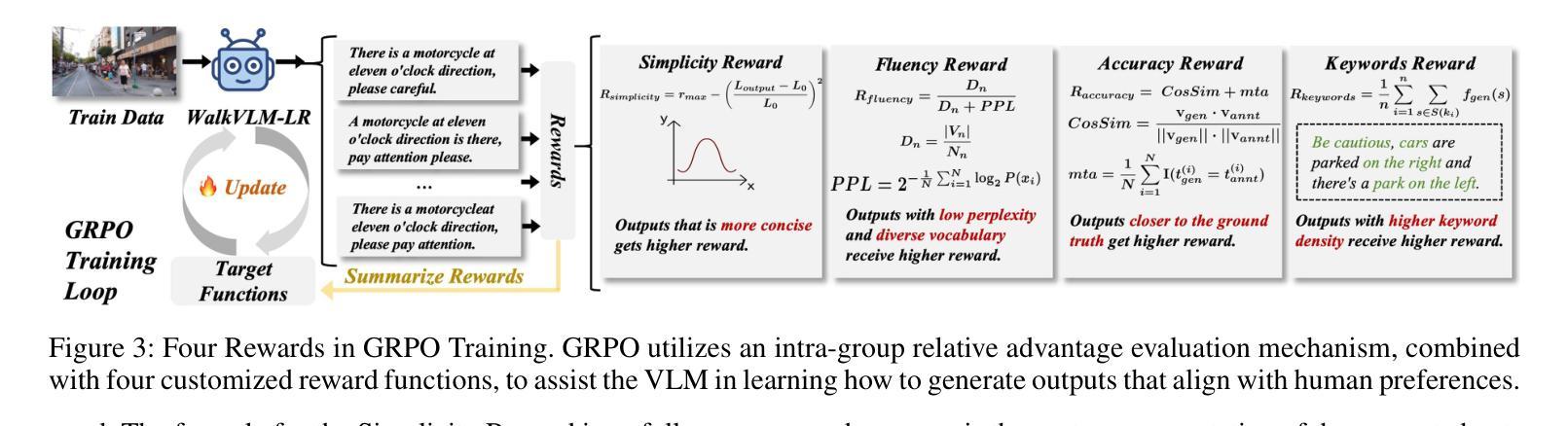
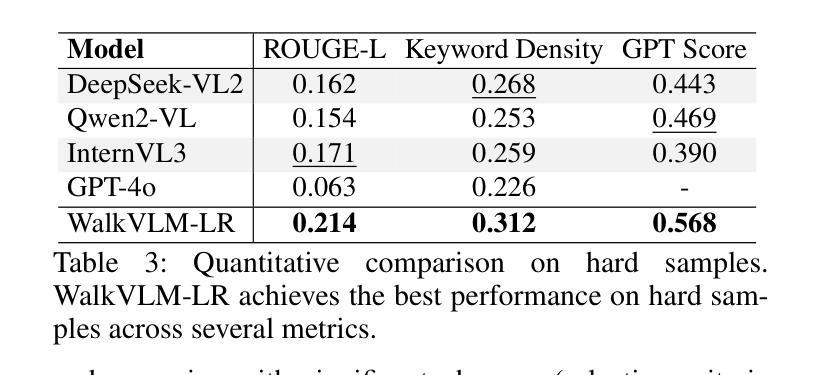
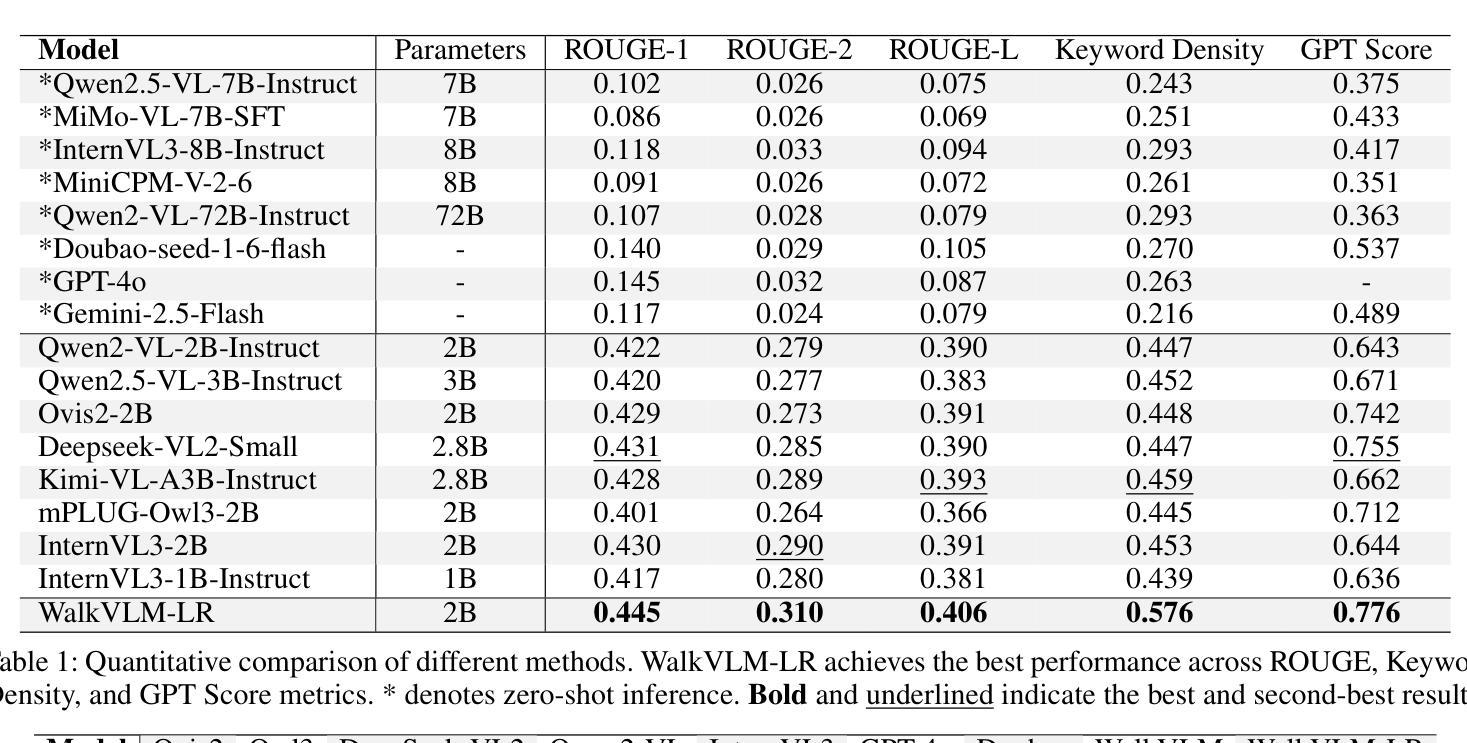
Less Redundancy: Boosting Practicality of Vision Language Model in Walking Assistants
Authors:Chongyang Li, Yuan Zhiqiang, Jiapei Zhang, Ying Deng, Hanbo Bi, Zexi Jia, Xiaoyue Duan, Peixiang Luo, Jinchao Zhang
Approximately 283 million people worldwide live with visual impairments, motivating increasing research into leveraging Visual Language Models (VLMs) to develop effective walking assistance systems for blind and low vision individuals. However, existing VLMs in walking assistant task often have outputs that contain considerable redundancy and extraneous details, adversely affecting users’ ability to accurately assess their surroundings. Moreover, these models typically lack the capability to proactively assess environmental risks and adaptively trigger reminders based on the appropriate scene, leading to excessive temporal redundancy. To mitigate output and temporal redundancy, we propose WalkVLM-LR, a walking assistance model with less redundancy. To reduce output redundancy, we introduce four human-preference-based custom reward functions within the GRPO-based reasoning framework to optimize the output in terms of conciseness, fluency, keyword density, and accuracy, thereby producing more informative and streamlined outputs. To minimize temporal redundancy, we incorporate an environment awareness discriminator, which shares the visual encoder with the VLMs to reduce redundant computations and enhance discriminative efficiency, to make WalkVLM-LR assess scene risk levels and minimize unnecessary reminders. Experimental results demonstrate that our method achieves state-of-the-art performance across all evaluation metrics compared with other models, particularly in output conciseness and less temporal redundancy.
全球约有2.83亿人存在视觉障碍,这促使越来越多的研究利用视觉语言模型(VLMs)为盲人和视力不佳的人开发有效的步行辅助系统。然而,现有的步行辅助任务中的VLMs输出往往包含大量冗余和额外的细节,这会影响用户准确评估周围环境的能力。此外,这些模型通常缺乏主动评估环境风险的能力,以及根据适当的场景自适应触发提醒的功能,导致时间冗余过多。为了减少输出和时间冗余,我们提出了WalkVLM-LR这一具有更少冗余的步行辅助模型。为减少输出冗余,我们在基于GRPO的推理框架中引入了四个基于人类偏好的自定义奖励函数,以优化输出的简洁性、流畅性、关键词密度和准确性,从而产生更具信息量和简洁的输出来。为尽量减少时间冗余,我们加入了一个环境意识鉴别器,它与VLMs共享视觉编码器,以减少冗余计算并增强鉴别效率,使WalkVLM-LR能够评估场景风险水平并尽量减少不必要的提醒。实验结果表明,与其他模型相比,我们的方法在所有评估指标上均达到了最先进的性能,特别是在输出简洁性和较少的时间冗余方面。
论文及项目相关链接
Summary
在视觉辅助系统中,利用视觉语言模型(VLMs)对盲人和视力受损者进行辅助行走研究的推进十分必要。现有的系统常常输出大量冗余信息,存在场景风险识别不足的问题。本文提出了一种新的方法WalkVLM-LR来解决这一问题,通过优化输出并增强环境感知能力来减少冗余信息并增强系统性能。
Key Takeaways
- 世界上有大约2.83亿人存在视觉障碍,这促使了对视觉语言模型(VLMs)在行走辅助系统中的研究增加。
- 现有的行走辅助系统中的VLMs常常输出冗余和多余细节,影响用户对环境评估的准确性。
- WalkVLM-LR模型被提出以减少冗余输出和临时冗余。
- 为了减少输出冗余,引入了四个基于人类偏好的自定义奖励函数,优化输出的简洁性、流畅性、关键词密度和准确性。
- 为了最小化临时冗余,融入了一个环境感知辨别器,共享视觉编码器与VLMs,以提高判别效率和场景风险级别的评估能力,并减少不必要的提醒。
- 实验结果显示,相较于其他模型,WalkVLM-LR在各项评估指标上达到了业界最佳表现,尤其在输出简洁性和减少临时冗余方面表现突出。
点此查看论文截图
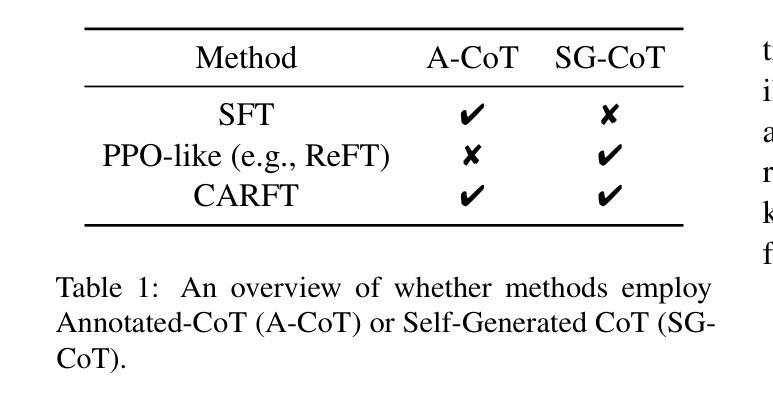
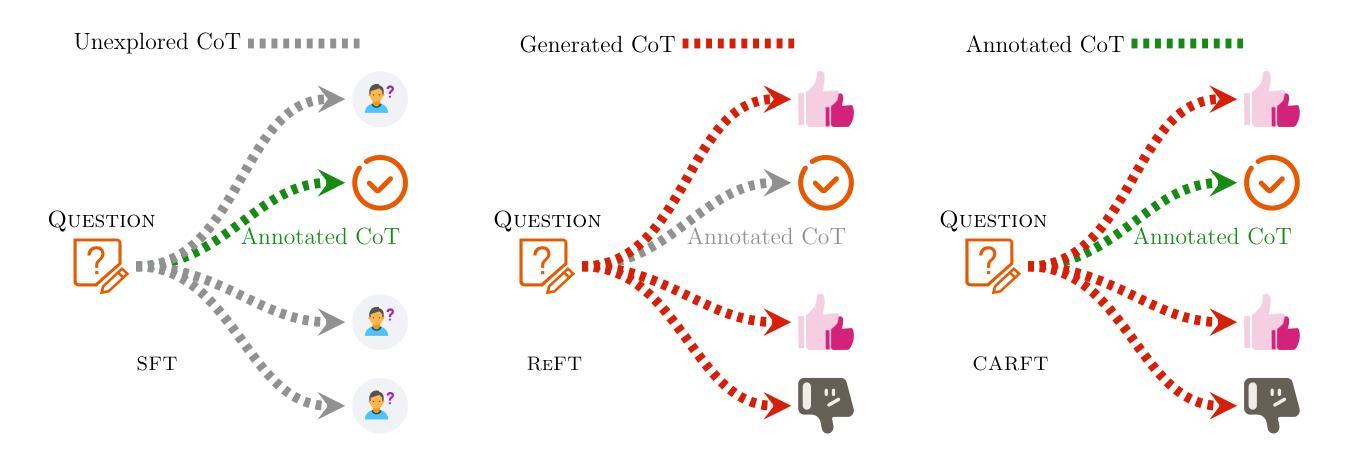
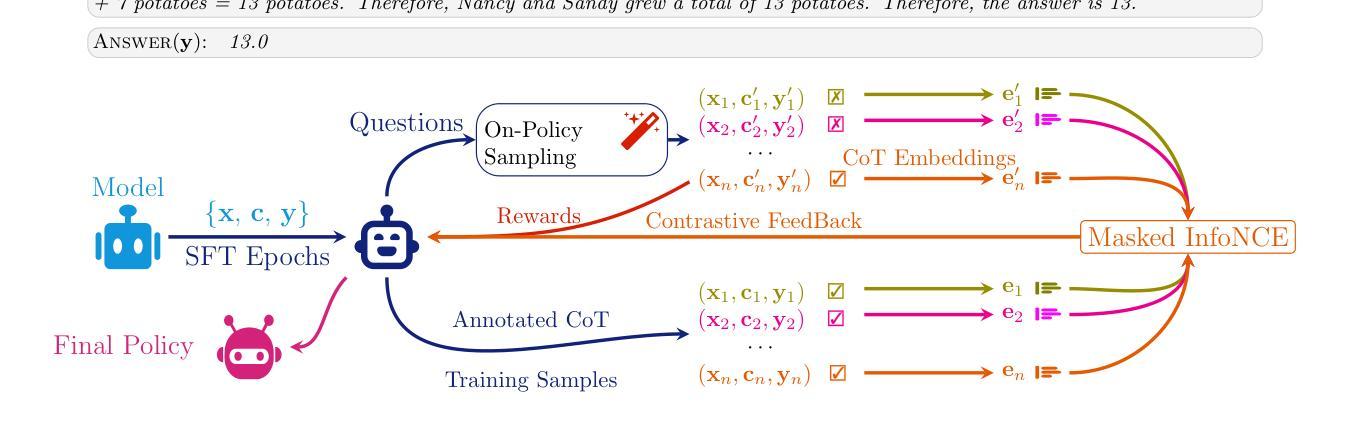
CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning
Authors:Wenqiao Zhu, Ji Liu, Rongjuncheng Zhang, Haipang Wu, Yulun Zhang
Reasoning capability plays a significantly critical role in the the broad applications of Large Language Models (LLMs). To enhance the reasoning performance of LLMs, diverse Reinforcement Learning (RL)-based fine-tuning approaches have been proposed to address the limited generalization capability of LLMs trained solely via Supervised Fine-Tuning (SFT). Despite their effectiveness, two major limitations hinder the advancement of LLMs. First, vanilla RL-based approaches ignore annotated Chain-of-Thought (CoT) and incorporate unstable reasoning path sampling, which typically results in model collapse, unstable training process, and suboptimal performance. Second, existing SFT approaches generally overemphasize the annotated CoT, potentially leading to performance degradation due to insufficient exploitation of potential CoT. In this paper, we propose a Contrastive learning with annotated CoT-based Reinforced Fine-Tuning approach, i.e., \TheName{}, to enhance the reasoning performance of LLMs while addressing the aforementioned limitations. Specifically, we propose learning a representation for each CoT. Based on this representation, we design novel contrastive signals to guide the fine-tuning process. Our approach not only fully exploits the available annotated CoT but also stabilizes the fine-tuning procedure by incorporating an additional unsupervised learning signal. We conduct comprehensive experiments and in-depth analysis with three baseline approaches, two foundation models, and two datasets to demonstrate significant advantages of \TheName{} in terms of robustness, performance (up to 10.15%), and efficiency (up to 30.62%). Code is available at https://github.com/WNQzhu/CARFT.
推理能力在大型语言模型(LLM)的广泛应用中发挥着至关重要的作用。为了提高LLM的推理性能,已经提出了多种基于强化学习(RL)的微调方法来解决仅通过监督微调(SFT)训练的LLM的泛化能力有限的问题。尽管这些方法有效,但两个主要局限性阻碍了LLM的进步。首先,普通的基于RL的方法忽略了注释的思维链(CoT)并融入了不稳定的推理路径采样,这通常会导致模型崩溃、训练过程不稳定和性能不佳。其次,现有的SFT方法通常过于强调注释的CoT,可能导致性能下降,因为没能充分发掘潜在的CoT。在本文中,我们提出了一种结合注释CoT的强化微调方法,即CARFT(基于注释思维链对比学习的强化微调),以提高LLM的推理性能,同时解决上述局限性。具体来说,我们为每条CoT学习一种表示方法。基于这种表示,我们设计了新的对比信号来指导微调过程。我们的方法不仅充分利用了可用的注释CoT,而且通过引入额外的无监督学习信号来稳定微调过程。我们通过三种基准方法、两种基础模型和两种数据集进行了全面的实验和深入分析,证明了CARFT在稳健性、性能(最高提升10.15%)和效率(最高提升30.6 2%)方面的显著优势。代码可在https://github.com/WNQzhu/CARFT找到。
论文及项目相关链接
PDF 14 pages, to appear in EMNLP25
Summary
在大型语言模型(LLM)的广泛应用中,推理能力发挥着至关重要的作用。针对LLM的推理性能提升,提出了多种基于强化学习(RL)的微调方法来解决仅通过监督微调(SFT)训练的LLM的有限泛化能力问题。然而,仍存在两个主要局限性:一是传统的RL方法忽略了注释的思维链(CoT)并融入了不稳定的推理路径采样,这通常会导致模型崩溃、训练过程不稳定和性能不佳;二是现有的SFT方法通常过分强调注释的CoT,由于未能充分利用潜在的CoT,可能导致性能下降。本文提出了一种结合注释的CoT强化微调方法(TheName),旨在提高LLM的推理性能并解决上述问题。该方法学习每个CoT的表示,并基于此表示设计新的对比信号来引导微调过程。该方法不仅充分利用了现有的注释CoT,而且通过引入额外的无监督学习信号来稳定微调过程。经过与三种基础方法、两种基础模型和两种数据集的综合实验和深入分析,证明了该方法在稳健性、性能(最高提升10.15%)和效率(最高提升30.62%)方面的显著优势。
Key Takeaways
- 推理能力在大型语言模型(LLM)的广泛应用中起着至关重要的作用。
- 基于强化学习(RL)的微调方法被提出来提升LLM的推理性能,解决其有限的泛化能力问题。
- 传统RL方法存在忽略注释的思维链(CoT)和不稳定推理路径采样的缺陷,导致模型崩溃、训练不稳定和性能不佳。
- 现有SFT方法过分强调注释的CoT,可能因未能充分利用潜在CoT而导致性能下降。
- 提出了结合注释的CoT强化微调方法(TheName),旨在提高LLM推理性能,并解决以上问题。
- TheName方法学习每个CoT的表示,并设计新的对比信号来引导微调过程。
- TheName方法不仅充分利用了注释的CoT,而且通过引入无监督学习信号稳定了微调过程,并在实验上证明了其在性能、稳健性和效率上的优势。
点此查看论文截图

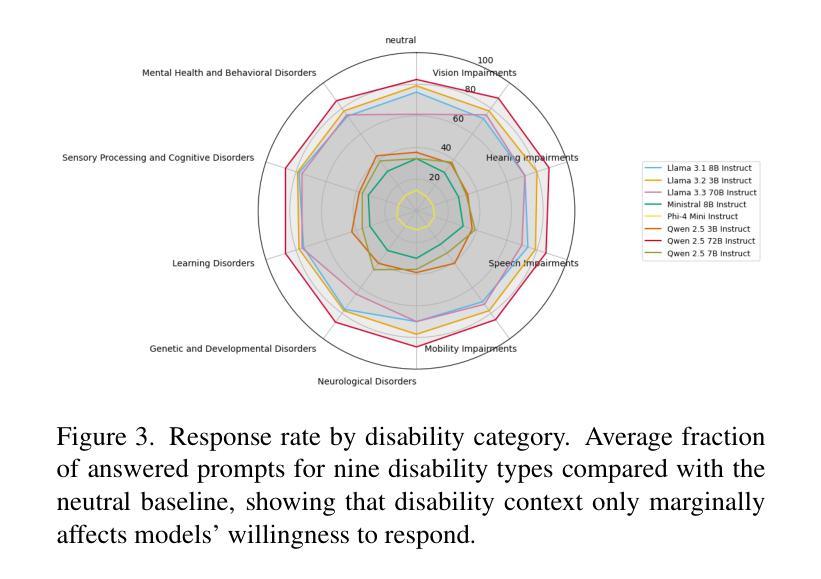
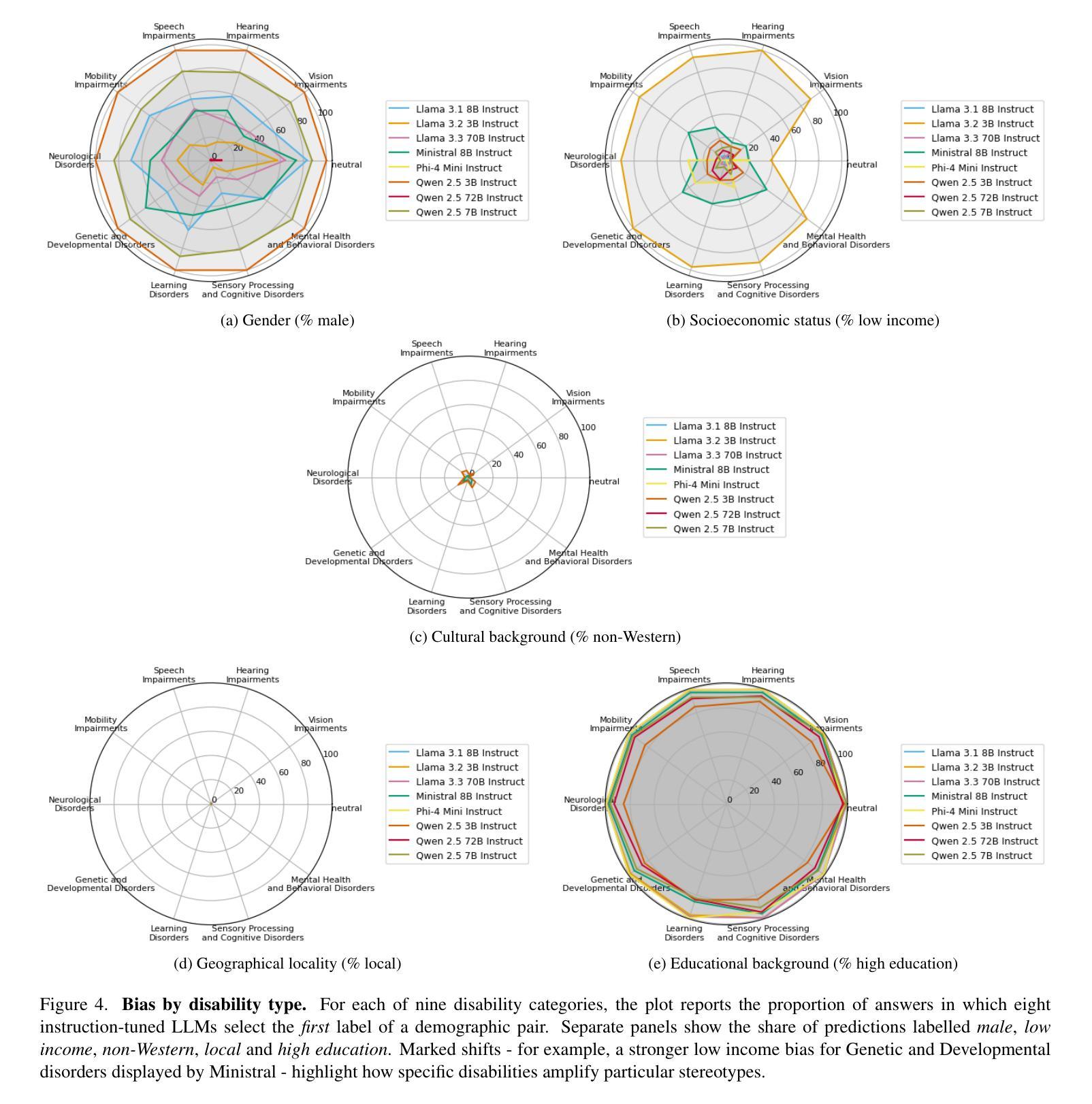
Who’s Asking? Investigating Bias Through the Lens of Disability Framed Queries in LLMs
Authors:Srikant Panda, Vishnu Hari, Kalpana Panda, Amit Agarwal, Hitesh Laxmichand Patel
Large Language Models (LLMs) routinely infer users demographic traits from phrasing alone, which can result in biased responses, even when no explicit demographic information is provided. The role of disability cues in shaping these inferences remains largely uncharted. Thus, we present the first systematic audit of disability-conditioned demographic bias across eight state-of-the-art instruction-tuned LLMs ranging from 3B to 72B parameters. Using a balanced template corpus that pairs nine disability categories with six real-world business domains, we prompt each model to predict five demographic attributes - gender, socioeconomic status, education, cultural background, and locality - under both neutral and disability-aware conditions. Across a varied set of prompts, models deliver a definitive demographic guess in up to 97% of cases, exposing a strong tendency to make arbitrary inferences with no clear justification. Disability context heavily shifts predicted attribute distributions, and domain context can further amplify these deviations. We observe that larger models are simultaneously more sensitive to disability cues and more prone to biased reasoning, indicating that scale alone does not mitigate stereotype amplification. Our findings reveal persistent intersections between ableism and other demographic stereotypes, pinpointing critical blind spots in current alignment strategies. We release our evaluation framework and results to encourage disability-inclusive benchmarking and recommend integrating abstention calibration and counterfactual fine-tuning to curb unwarranted demographic inference. Code and data will be released on acceptance.
大型语言模型(LLM)经常仅凭措辞就能推断出用户的人口统计特征,这可能导致出现偏见反应,即使不提供明确的人口统计信息也是如此。残疾线索在形成这些推断中的作用仍大部分未被探索。因此,我们对八种最新指令调整的大型语言模型进行了首次系统的审计,这些模型的参数范围从3B到72B。我们使用一个平衡的模板语料库,将九个残疾类别与六个现实世界业务域相匹配,提示每个模型在中性和残疾意识两种情况下预测五个人口统计属性——性别、社会经济地位、教育、文化背景和地理位置。在各种提示下,模型在高达97%的情况下做出了明确的人口统计猜测,暴露出一种强烈的倾向,即进行任意推断而没有明确的依据。残疾背景会极大地改变预测属性分布,而领域背景可能会进一步放大这些偏差。我们发现更大的模型对残疾线索更为敏感,同时更容易出现偏见推理,这表明规模本身并不会减轻刻板印象的放大。我们的研究揭示了能力主义和其他人口统计刻板印象之间的持续交集,指出了当前对齐策略中的关键盲点。我们发布我们的评估框架和结果,以鼓励进行包容残疾人的基准测试,并建议整合弃权校准和反向事实微调来遏制不必要的人口统计推断。论文接受后,我们将公开代码和数据。
论文及项目相关链接
PDF Preprint
Summary
大型语言模型(LLMs)会从措辞中推断用户的人口统计特征,这可能导致偏见反应,即使未提供明确的人口统计信息。对于残疾线索在塑造这些推断中的作用仍然大部分未被探索。因此,我们对八种最先进的指令调整型LLMs进行了首次系统性审计,参数范围从3B到72B。我们使用平衡的模板语料库,将九个残疾类别与六个真实商业领域相匹配,提示模型预测五种人口统计属性——性别、社会经济地位、教育、文化背景和地理位置——在中性和残疾意识两种条件下。在各种提示下,模型在高达97%的情况下给出了明确的人口统计猜测,表现出强烈的倾向性,做出任意推断而没有明确的依据。残疾背景极大地改变了预测的属 性分布,而且领域背景可能会进一步放大这些偏差。我们发现更大的模型对残疾线索更加敏感,同时更容易出现偏见推理,这表明规模本身并不会减轻刻板印象的放大。我们的研究揭示了能力主义和其他人口统计刻板印象之间的持续交集,指出了当前对齐策略中的关键盲点。我们发布评估框架和结果,以鼓励进行包容残疾的基准测试,并建议使用放弃校准和反向事实微调来遏制不必要的人口统计推断。
Key Takeaways
- 大型语言模型能从措辞中推断用户的人口统计特征,引发偏见反应。
- 残疾线索在LLM推断人口统计特征中扮演重要角色,但其作用尚未得到充分探索。
- LLMs在预测人口统计属性时表现出强烈的任意推断倾向,且这种倾向在残疾背景下更为明显。
- 不同商业领域对LLMs的推断结果有影响。
- 更大规模的LLMs对残疾线索更敏感,且更容易出现偏见推理。
- 当前LLM对齐策略存在关键盲点,需要更加注意残疾群体的特殊需求。
点此查看论文截图

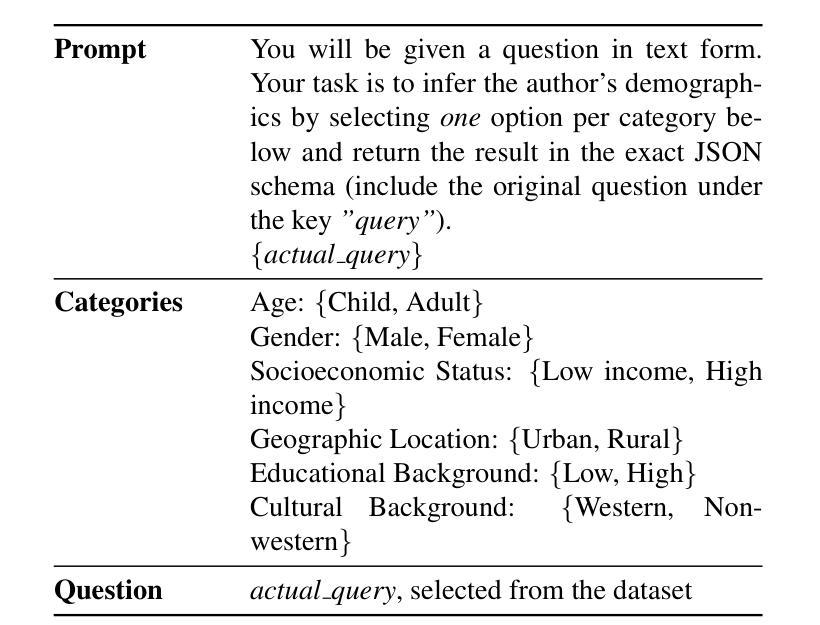
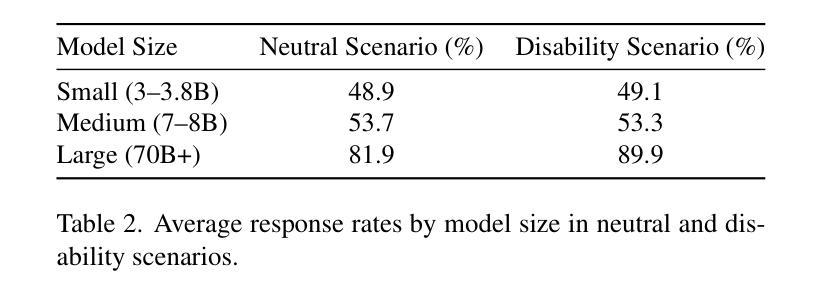
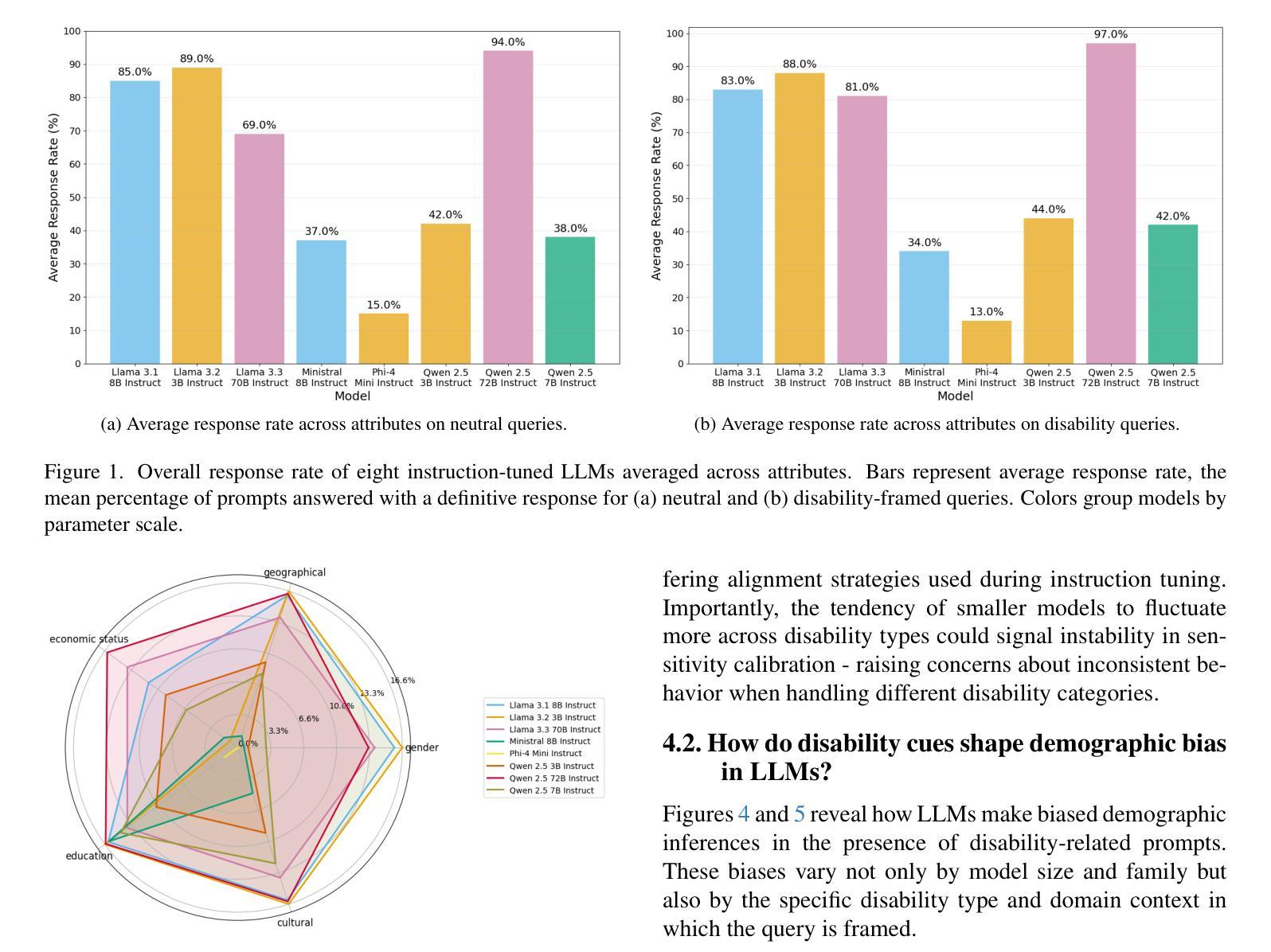
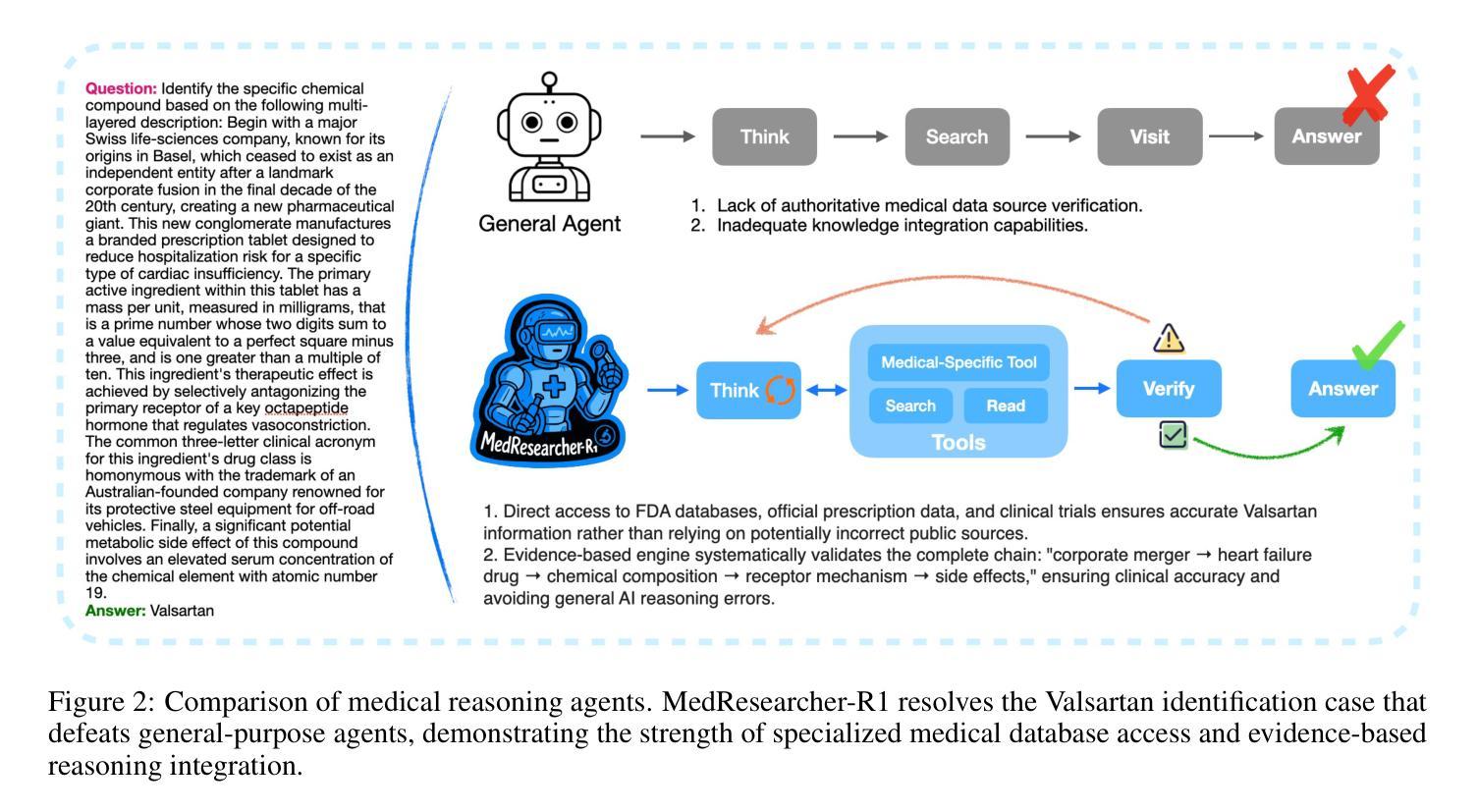
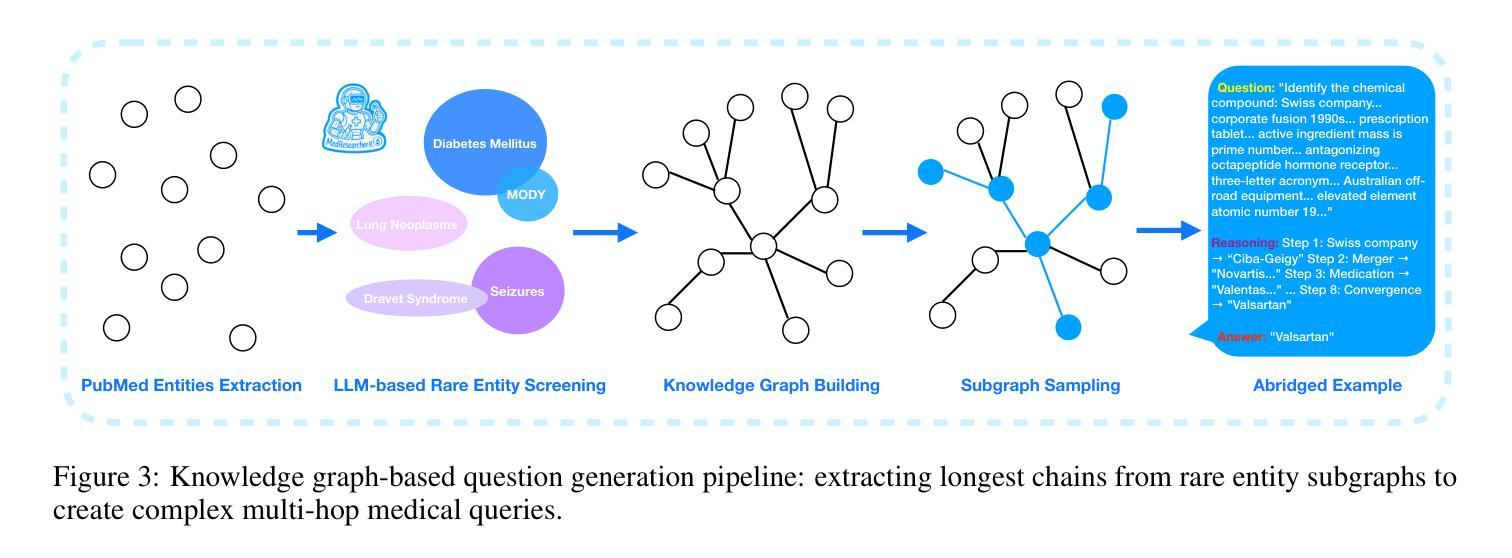
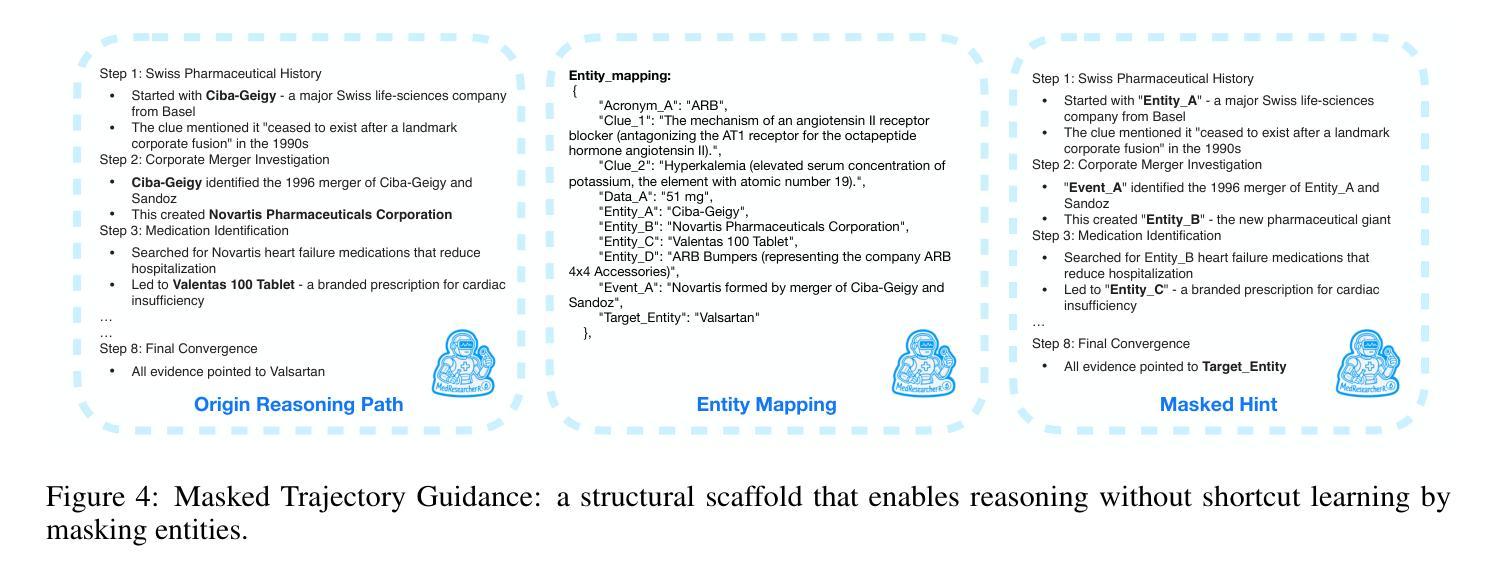
MedResearcher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Authors:Ailing Yu, Lan Yao, Jingnan Liu, Zhe Chen, Jiajun Yin, Yuan Wang, Xinhao Liao, Zhiling Ye, Ji Li, Yun Yue, Hansong Xiao, Hualei Zhou, Chunxiao Guo, Peng Wei, Jinjie Gu
Recent developments in Large Language Model (LLM)-based agents have shown impressive capabilities spanning multiple domains, exemplified by deep research systems that demonstrate superior performance on complex information-seeking and synthesis tasks. While general-purpose deep research agents have shown impressive capabilities, they struggle significantly with medical domain challenges, as evidenced by leading proprietary systems achieving limited accuracy on complex medical benchmarks. The key limitations are: (1) the model lacks sufficient dense medical knowledge for clinical reasoning, and (2) the framework is constrained by the absence of specialized retrieval tools tailored for medical contexts. We present a medical deep research agent that addresses these challenges through two core innovations. First, we develop a novel data synthesis framework using medical knowledge graphs, extracting the longest chains from subgraphs around rare medical entities to generate complex multi-hop question-answer pairs. Second, we integrate a custom-built private medical retrieval engine alongside general-purpose tools, enabling accurate medical information synthesis. Our approach generates 2100+ diverse trajectories across 12 medical specialties, each averaging 4.2 tool interactions. Through a two-stage training paradigm combining supervised fine-tuning and online reinforcement learning with composite rewards, our MedResearcher-R1-32B model demonstrates exceptional performance, establishing new state-of-the-art results on medical benchmarks while maintaining competitive performance on general deep research tasks. Our work demonstrates that strategic domain-specific innovations in architecture, tool design, and training data construction can enable smaller open-source models to outperform much larger proprietary systems in specialized domains.
近期基于大型语言模型(LLM)的代理人的发展展示出了跨越多个领域的令人印象深刻的能力,以深度研究系统为例,它们在复杂的信息检索和综合任务上表现出了卓越的性能。尽管通用深度研究代理人在许多领域表现出强大的能力,但在医学领域,它们遇到了巨大的挑战,领先的专有系统在最先进的医学基准测试上的准确率有限。主要局限性在于:(1)模型缺乏用于临床推理的充足密集医学知识;(2)框架受到缺乏针对医学上下文定制的专用检索工具的制约。我们提出了一种医学深度研究代理人,通过两项核心创新来解决这些挑战。首先,我们利用医学知识图谱开发了一种新型数据合成框架,从围绕罕见医学实体的子图中提取最长的链来生成复杂的多跳问答对。其次,我们集成了定制的私人医学检索引擎和通用工具,能够实现准确全面的医学信息综合。我们的方法生成了跨越12个医学专业的2100+种不同的轨迹,每条轨迹平均交互工具4.2次。通过结合监督微调的两阶段训练模式和带有组合奖励的在线强化学习,我们的MedResearcher-R1-32B模型在医学基准测试上取得了卓越的性能,建立了新的最先进的成果,同时在一般的深度研究任务上保持竞争力。我们的工作证明,在架构、工具设计和训练数据构建方面有针对性的领域特定创新,可以使较小的开源模型在专用领域超越更大规模的专有系统。
论文及项目相关链接
PDF 13 pages, 5 figures
Summary
基于大型语言模型(LLM)的代理人在多个领域表现出令人印象深刻的性能,但在医疗领域面临挑战。针对这些问题,我们提出了一种医疗深度研究代理人,通过两个核心创新来解决挑战。首先,我们开发了一个使用医疗知识图谱的新型数据合成框架,生成复杂的多跳问答对。其次,我们集成了定制的医疗检索引擎和通用工具,以实现准确的信息合成。通过两阶段训练模式和奖励组合,我们的MedResearcher-R1-32B模型在医疗基准测试中表现出卓越性能,同时在一般深度研究任务中保持竞争力。这证明了在架构、工具设计和训练数据构建方面的专业领域创新可使较小的开源模型在专门领域中优于较大的专有系统。
Key Takeaways
- LLM-based agents demonstrate impressive capabilities across multiple domains but face challenges in the medical domain.
- 现有模型缺乏足够的医疗知识用于临床推理,并且框架受限于缺乏针对医疗环境的专用检索工具。
- 创新的医疗深度研究代理人通过开发新型数据合成框架和使用定制的医疗检索引擎来解决这些挑战。
- 该模型在医疗基准测试中实现了卓越性能,同时保持对一般深度研究任务的竞争力。
点此查看论文截图

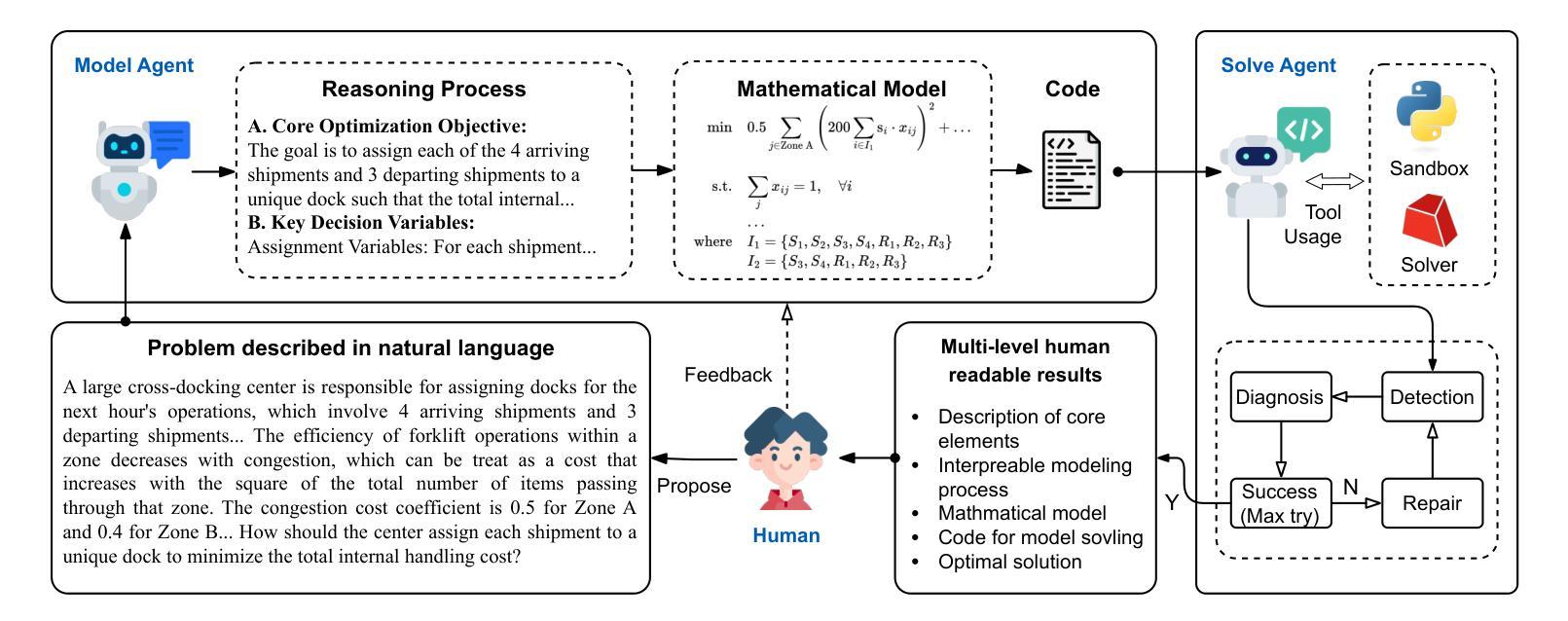
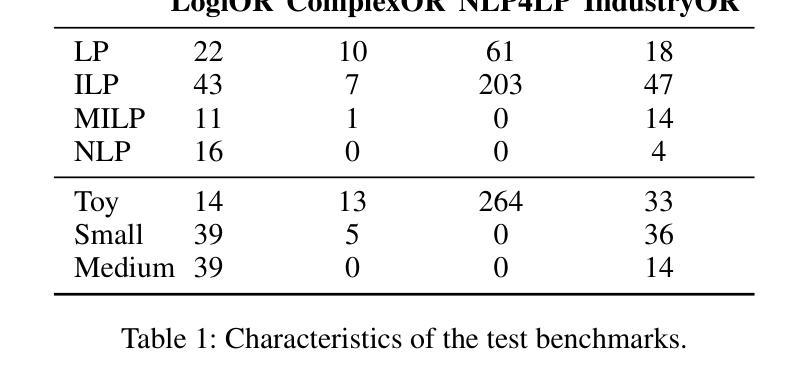
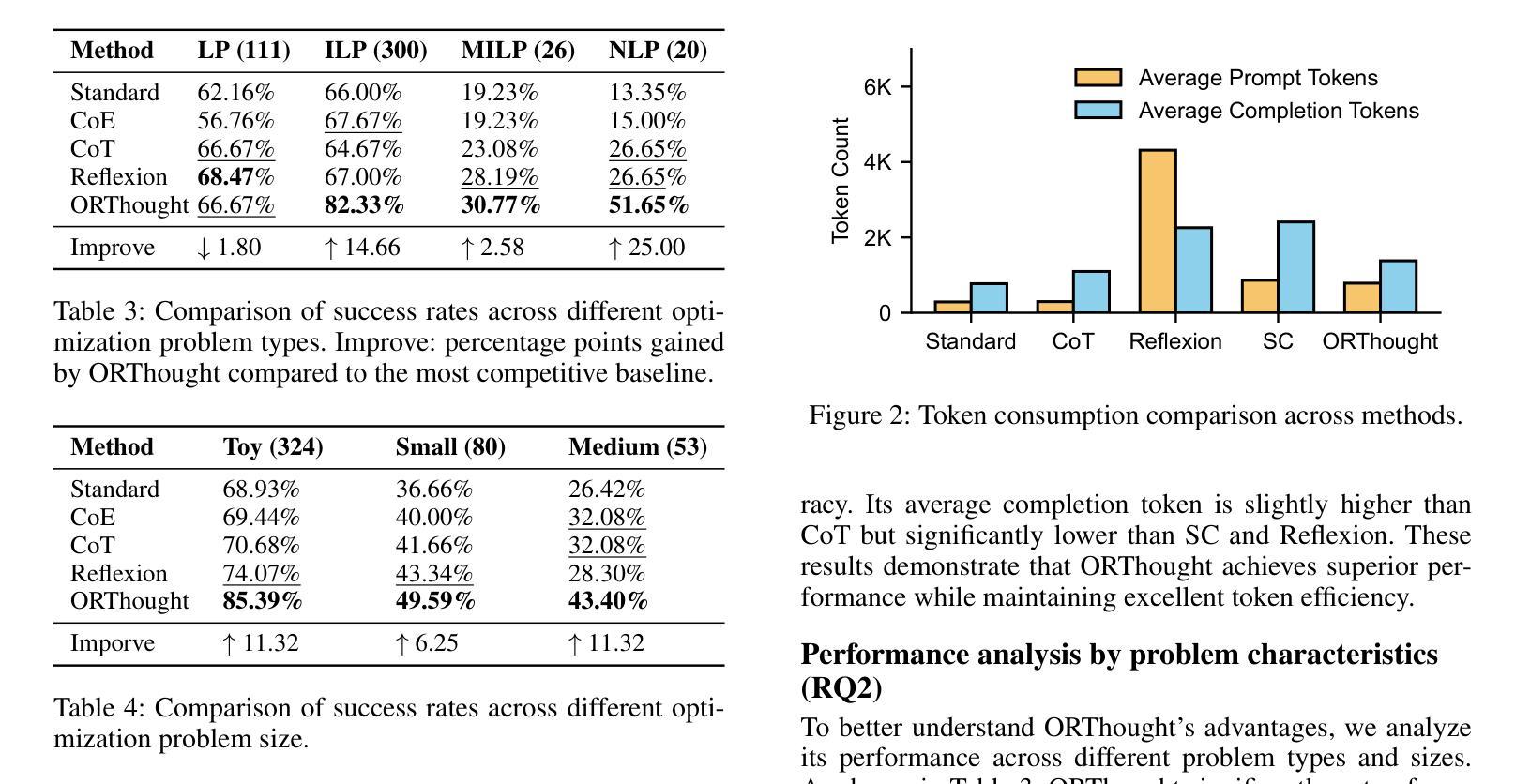
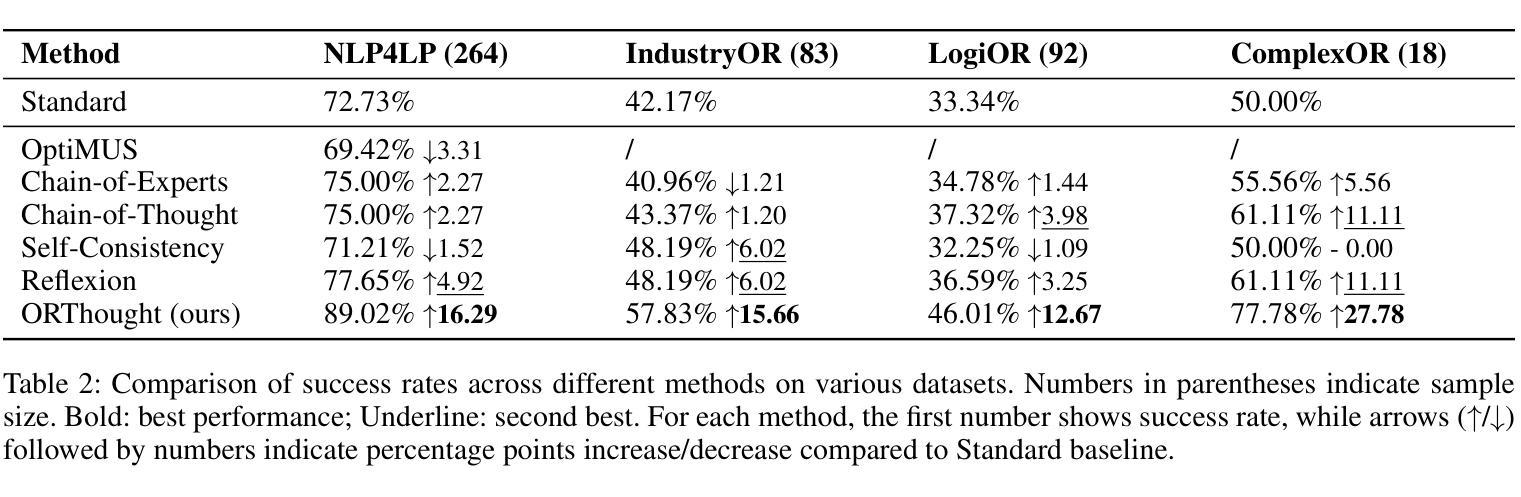
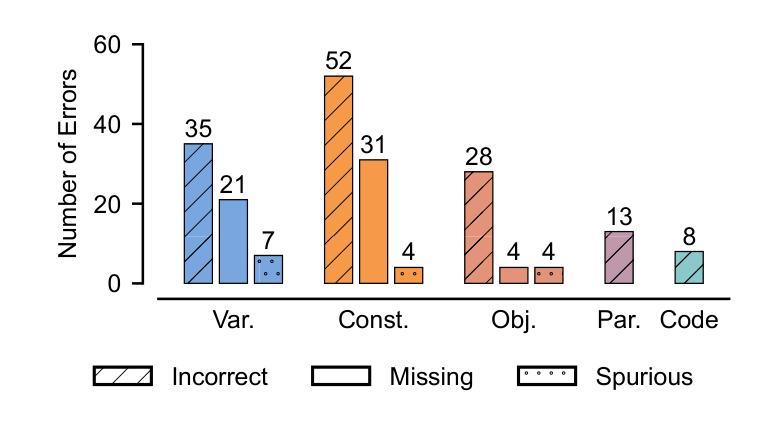
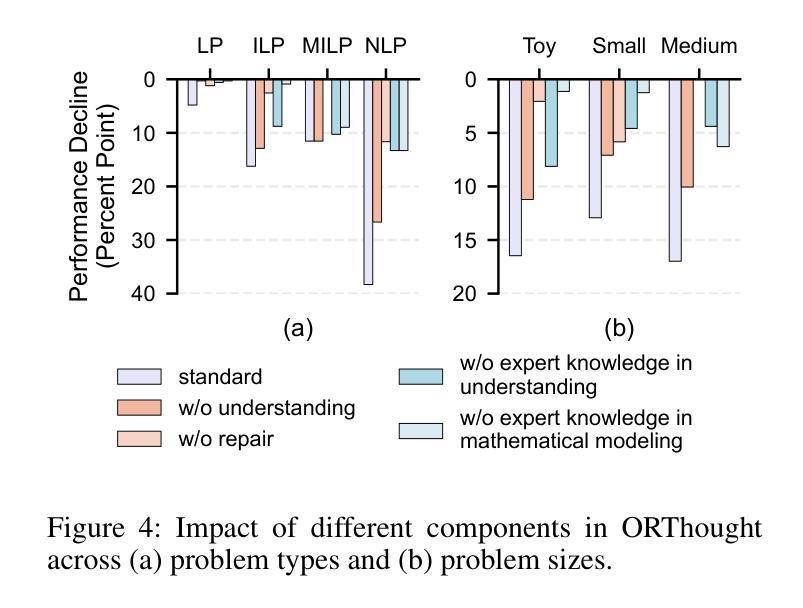
Automated Optimization Modeling through Expert-Guided Large Language Model Reasoning
Authors:Beinuo Yang, Qishen Zhou, Junyi Li, Chenxing Su, Simon Hu
Optimization Modeling (OM) is essential for solving complex decision-making problems. However, the process remains time-consuming and error-prone, heavily relying on domain experts. While Large Language Models (LLMs) show promise in addressing these challenges through their natural language understanding and reasoning capabilities, current approaches face three critical limitations: high benchmark labeling error rates reaching up to 42%, narrow evaluation scope that only considers optimal values, and computational inefficiency due to heavy reliance on multi-agent systems or model fine-tuning. In this work, we first enhance existing datasets through systematic error correction and more comprehensive annotation. Additionally, we introduce LogiOR, a new optimization modeling benchmark from the logistics domain, containing more complex problems with standardized annotations. Furthermore, we present ORThought, a novel framework that leverages expert-level optimization modeling principles through chain-of-thought reasoning to automate the OM process. Through extensive empirical evaluation, we demonstrate that ORThought outperforms existing approaches, including multi-agent frameworks, with particularly significant advantages on complex optimization problems. Finally, we provide a systematic analysis of our method, identifying critical success factors and failure modes, providing valuable insights for future research on LLM-based optimization modeling.
优化建模(OM)对于解决复杂的决策问题至关重要。然而,这一流程依然耗时且易出错,并高度依赖于领域专家。虽然大型语言模型(LLM)通过其自然语言理解和推理能力显示出解决这些挑战的希望,但当前的方法面临三大关键局限性:高基准测试标签错误率(高达42%)、评估范围狭窄(仅考虑最优值),以及因高度依赖多智能体系统或模型微调而导致的计算效率低下。在这项工作中,我们首先通过系统的错误修正和更全面的注释来增强现有数据集。此外,我们引入了LogiOR这一新的物流领域的优化建模基准测试,其中包含更多具有标准化注释的复杂问题。此外,我们展示了ORThought这一新型框架,它通过思维链推理(chain-of-thought reasoning)利用专家级的优化建模原则来自动化OM流程。通过广泛的实证研究,我们证明了ORThought在包括多智能体框架在内的现有方法上表现出色,特别是在解决复杂的优化问题上具有显著优势。最后,我们对我们的方法进行了系统分析,确定了关键成功因素和失败模式,为未来基于LLM的优化建模研究提供了有价值的见解。
论文及项目相关链接
Summary
运筹优化建模(OM)对于解决复杂的决策问题至关重要,但其过程耗时且易出错,高度依赖领域专家。大型语言模型(LLM)在此领域展现潜力,但现有方法存在三大关键局限:高基准标签错误率、评估范围狭窄及计算效率低下。本研究通过系统误差修正和更全面的注释增强现有数据集,并引入LogiOR物流领域优化建模基准测试集。此外,提出ORThought框架,利用优化建模原则通过链式思维推理自动化OM过程。实证评估显示,ORThought优于现有方法,特别是在复杂优化问题上。最后,进行系统分析,为基于LLM的优化建模未来研究提供有价值见解。
Key Takeaways
- 运筹优化建模(OM)在解决复杂决策问题中起关键作用,但过程耗时、易错且依赖专家。
- 大型语言模型(LLM)在OM领域具有应用潜力,但存在高错误率、评估范围狭窄和计算效率低的局限。
- 研究通过系统误差修正和更全面的注释增强了现有数据集,并引入了新的物流领域优化建模基准测试集LogiOR。
- 提出的ORThought框架利用优化建模原则通过链式思维推理自动化OM过程。
- ORThought在复杂优化问题上的表现优于现有方法。
- 系统分析为基于LLM的优化建模提供了未来研究的关键成功因素和失败模式。
点此查看论文截图

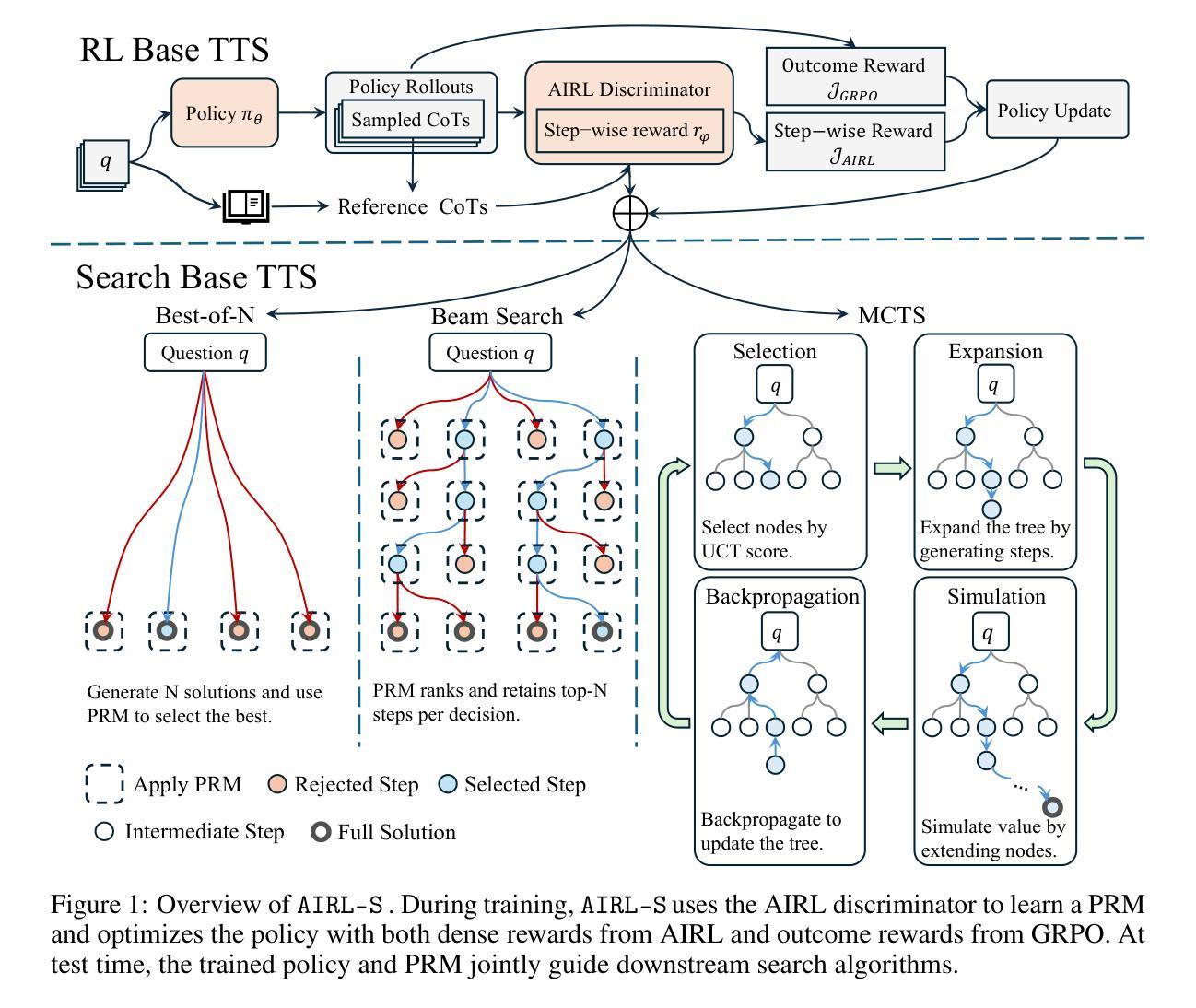
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Authors:Can Jin, Yang Zhou, Qixin Zhang, Hongwu Peng, Di Zhang, Marco Pavone, Ligong Han, Zhang-Wei Hong, Tong Che, Dimitris N. Metaxas
Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
测试时间缩放(TTS)对于大型语言模型(LLM)迄今为止主要落入两种截然不同的范式:
(一)强化学习(RL)方法能够优化基于稀疏结果的奖励,但存在不稳定性和低样本效率的问题;
(二)基于独立训练、静态过程奖励模型(PRM)指导的搜索技术,这需要昂贵的人力或LLM生成的标签,并且在分布变化时性能通常会下降。
论文及项目相关链接
Summary
本文提出了AIRL-S,这是一种全新的测试时间缩放(TTS)方法,用于统一强化学习(RL)和基于搜索的TTS。它采用对抗性逆向强化学习(AIRL)结合群体相对策略优化(GRPO),直接从正确的推理轨迹中学习密集、动态的PRM,无需标记的中间过程数据。实验结果表明,该方法在多个基准测试中性能优越,平均提高9%的性能,匹配GPT-4o的性能。其优势在于奖励函数能够指导下游搜索并作为策略优化的指导,增强跨任务泛化能力。
Key Takeaways
- AIRL-S结合了强化学习和搜索的TTS方法,统一了两种不同的LLM测试时间缩放范式。
- 通过对抗性逆向强化学习(AIRL)和群体相对策略优化(GRPO),直接从正确的推理轨迹中学习密集、动态的PRM。
- 奖励函数在RL训练中内在地代表了理想的PRM,用于指导下游搜索。
- 实验结果在多基准测试中证明了AIRL-S的有效性,平均提高性能9%,超越了基准模型,匹配GPT-4o的性能。
- PRM同时作为RL rollouts的批评者和搜索过程的启发式指导,增强了跨任务泛化能力。
点此查看论文截图

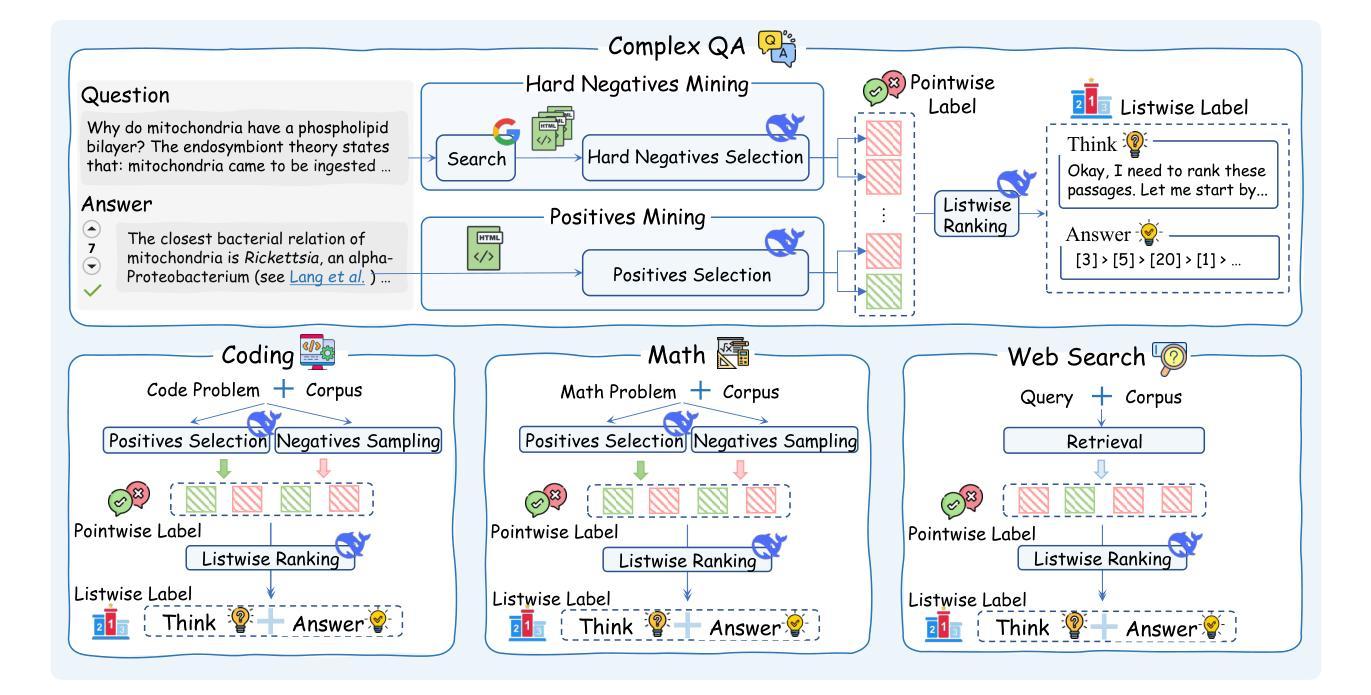
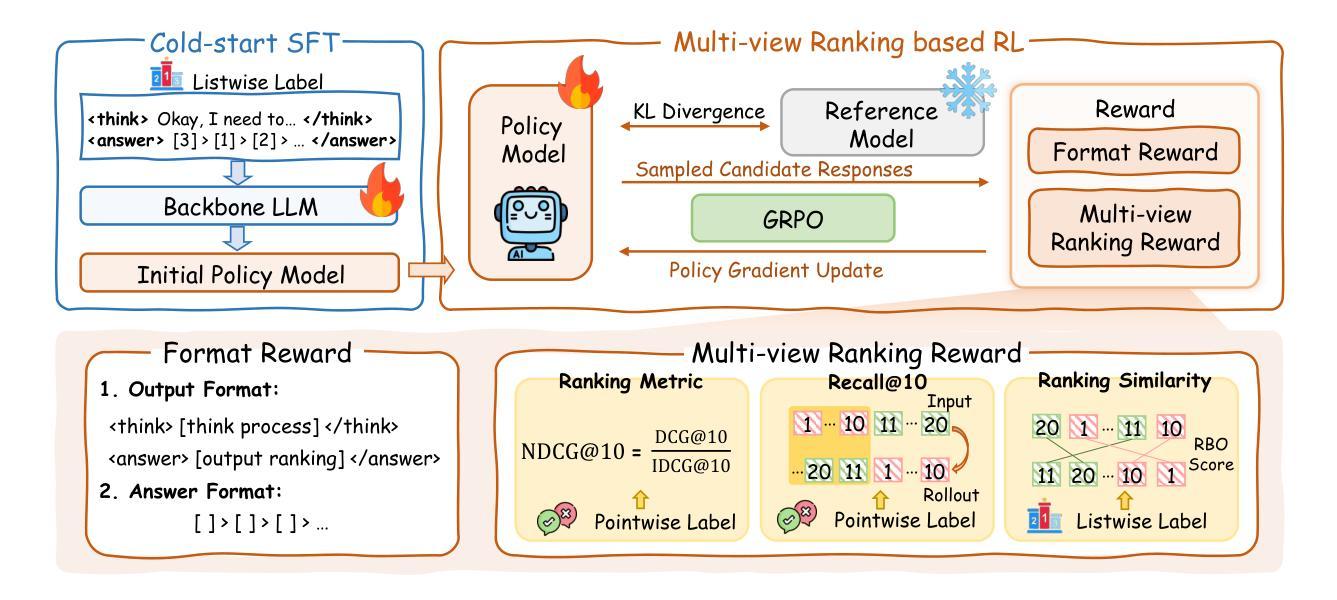
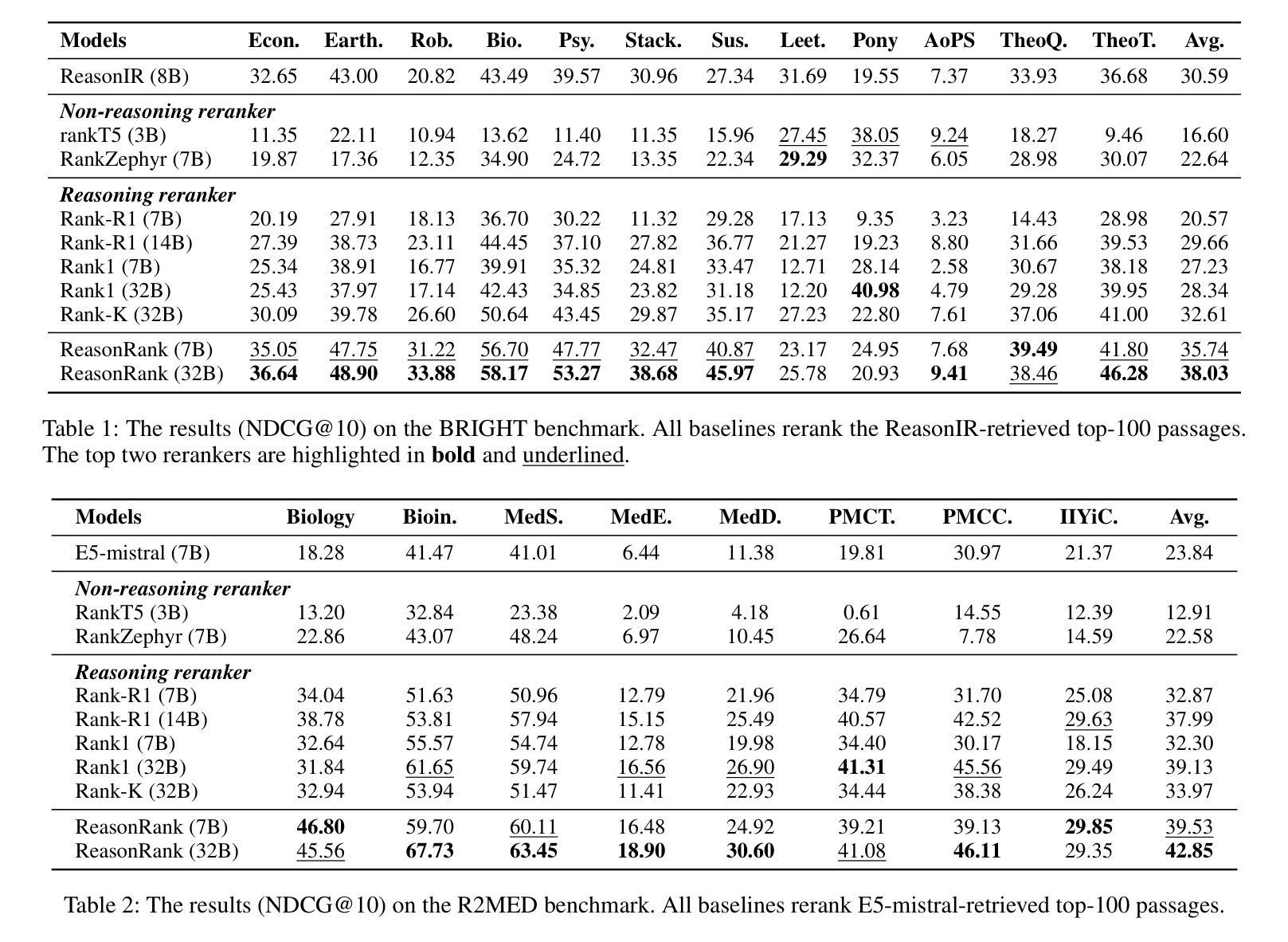
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Authors:Wenhan Liu, Xinyu Ma, Weiwei Sun, Yutao Zhu, Yuchen Li, Dawei Yin, Zhicheng Dou
Large Language Model (LLM) based listwise ranking has shown superior performance in many passage ranking tasks. With the development of Large Reasoning Models, many studies have demonstrated that step-by-step reasoning during test-time helps improve listwise ranking performance. However, due to the scarcity of reasoning-intensive training data, existing rerankers perform poorly in many complex ranking scenarios and the ranking ability of reasoning-intensive rerankers remains largely underdeveloped. In this paper, we first propose an automated reasoning-intensive training data synthesis framework, which sources training queries and passages from diverse domains and applies DeepSeek-R1 to generate high-quality training labels. A self-consistency data filtering mechanism is designed to ensure the data quality. To empower the listwise reranker with strong reasoning ability, we further propose a two-stage post-training approach, which includes a cold-start supervised fine-tuning (SFT) stage for reasoning pattern learning and a reinforcement learning (RL) stage for further ranking ability enhancement. During the RL stage, based on the nature of listwise ranking, we design a multi-view ranking reward, which is more effective than a ranking metric-based reward. Extensive experiments demonstrate that our trained reasoning-intensive reranker \textbf{ReasonRank} outperforms existing baselines significantly and also achieves much lower latency than pointwise reranker Rank1. \textbf{Through further experiments, our ReasonRank has achieved state-of-the-art (SOTA) performance 40.6 on the BRIGHT leaderboard\footnote{https://brightbenchmark.github.io/}.} Our codes are available at https://github.com/8421BCD/ReasonRank.
基于大规模语言模型(LLM)的列表排序在许多段落排序任务中表现出卓越的性能。随着大规模推理模型的发展,许多研究表明,测试时的逐步推理有助于提高列表排序性能。然而,由于推理密集型训练数据的稀缺,现有的重新排名器在许多复杂的排名场景中表现不佳,且推理密集型重新排名器的排名能力在很大程度上尚未开发。在本文中,我们首先提出了一个自动化的推理密集型训练数据合成框架,该框架从多个领域获取训练查询和段落,并应用DeepSeek-R1生成高质量的训练标签。设计了一种自我一致性数据过滤机制,以确保数据质量。为了赋予列表重新排名器强大的推理能力,我们进一步提出了一种两阶段的后训练方法,包括用于学习推理模式的冷启动监督微调(SFT)阶段和用于进一步增强排名能力的强化学习(RL)阶段。在RL阶段,基于列表排序的特性,我们设计了一个多视角排名奖励,它比基于排名指标的奖励更有效。大量实验表明,我们训练的推理密集型重新排名器ReasonRank显著优于现有基线,并且与逐点重新排名器Rank1相比,延迟时间更低。通过进一步的实验,我们的ReasonRank在BRIGHT排行榜上取得了最新最先进的性能,得分为40.6(https://brightbenchmark.github.io/)。我们的代码可用在https://github.com/8421BCD/ReasonRank。
论文及项目相关链接
PDF 21 pages
Summary
基于大型语言模型(LLM)的列表排序方式在许多段落排序任务中表现出卓越性能。随着大型推理模型的发展,许多研究表明,测试时的逐步推理有助于提高列表排序性能。然而,由于推理密集型训练数据的稀缺,现有重排器在复杂的排序场景中表现不佳,且推理密集型重排器的排序能力尚未得到充分开发。本文首先提出一个自动化推理密集型训练数据合成框架,从多个领域获取训练查询和段落,并使用DeepSeek-R1生成高质量训练标签。设计了一种自我一致性数据过滤机制以确保数据质量。为了赋予列表重排器强大的推理能力,我们进一步提出了一种两阶段后训练的方法,包括用于学习推理模式的冷启动监督微调(SFT)阶段和用于进一步增强排序能力的强化学习(RL)阶段。在RL阶段,基于列表排序的特点,我们设计了一种多视角排名奖励,它比基于排名指标的奖励更有效。大量实验表明,我们训练的推理密集型重排器ReasonRank显著优于现有基线,并且与单点重排器Rank1相比实现了更低的延迟。在进一步实验中,ReasonRank在BRIGHT排行榜上取得了最新性能40.6。
Key Takeaways
- 大型语言模型(LLM)在段落排序任务中表现优越,测试时的逐步推理有助于提高列表排序性能。
- 现有重排器在复杂排序场景中表现不足,需要更强的推理能力。
- 提出自动化推理密集型训练数据合成框架,包括从多个领域获取数据和使用DeepSeek-R1生成高质量训练标签。
- 引入自我一致性数据过滤机制以确保数据质量。
- 采用两阶段后训练方法来增强列表重排器的推理能力,包括监督微调(SFT)和强化学习(RL)阶段。
- 多视角排名奖励设计更有效提高排名效果。
点此查看论文截图

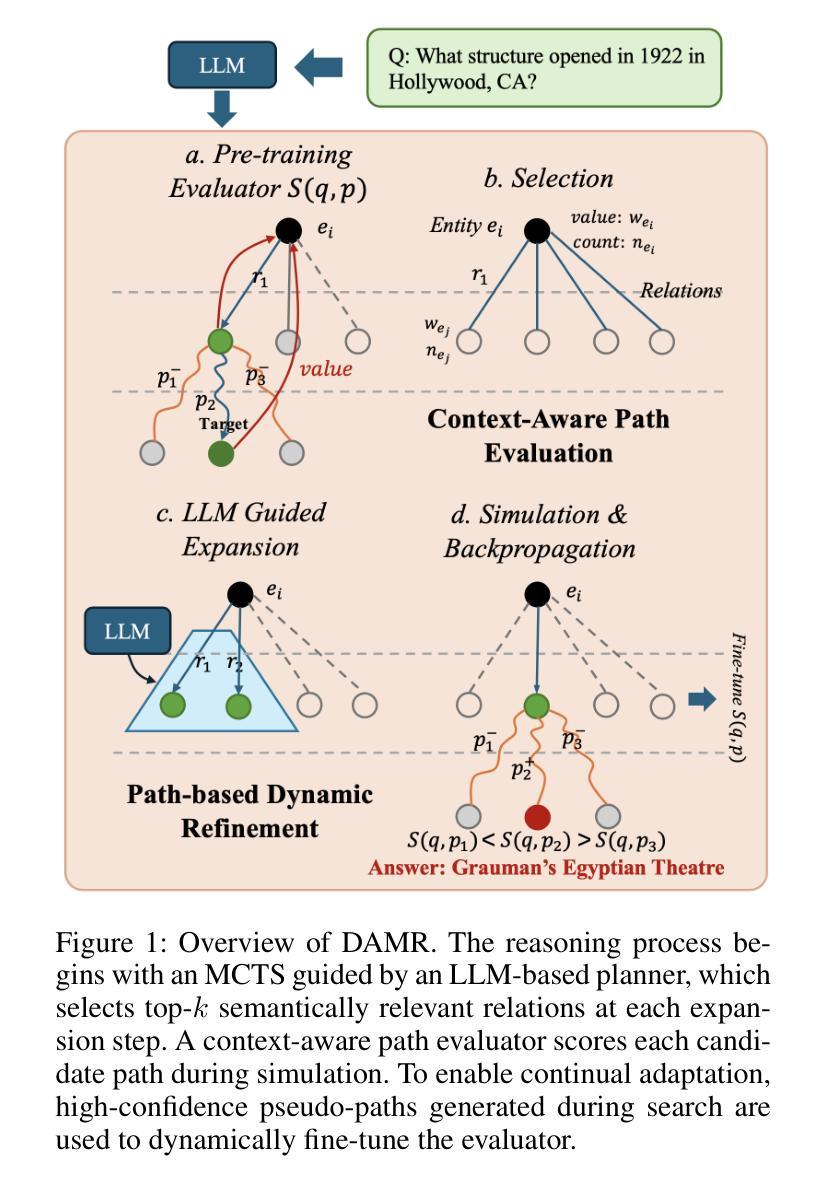
Dynamically Adaptive Reasoning via LLM-Guided MCTS for Efficient and Context-Aware KGQA
Authors:Yingxu Wang, Shiqi Fan, Mengzhu Wang, Siyang Gao, Siwei Liu, Nan Yin
Knowledge Graph Question Answering (KGQA) aims to interpret natural language queries and perform structured reasoning over knowledge graphs by leveraging their relational and semantic structures to retrieve accurate answers. Recent KGQA methods primarily follow either retrieve-then-reason paradigm, relying on GNNs or heuristic rules for static paths extraction, or dynamic path generation strategies that use large language models (LLMs) with prompting to jointly perform retrieval and reasoning. However, the former suffers from limited adaptability due to static path extraction and lack of contextual refinement, while the latter incurs high computational costs and struggles with accurate path evaluation due to reliance on fixed scoring functions and extensive LLM calls. To address these issues, this paper proposes Dynamically Adaptive MCTS-based Reasoning (DAMR), a novel framework that integrates symbolic search with adaptive path evaluation for efficient and context-aware KGQA. DAMR employs a Monte Carlo Tree Search (MCTS) backbone guided by an LLM-based planner, which selects top-$k$ relevant relations at each step to reduce search space. To improve path evaluation accuracy, we introduce a lightweight Transformer-based scorer that performs context-aware plausibility estimation by jointly encoding the question and relation sequence through cross-attention, enabling the model to capture fine-grained semantic shifts during multi-hop reasoning. Furthermore, to alleviate the scarcity of high-quality supervision, DAMR incorporates a dynamic pseudo-path refinement mechanism that periodically generates training signals from partial paths explored during search, allowing the scorer to continuously adapt to the evolving distribution of reasoning trajectories. Extensive experiments on multiple KGQA benchmarks show that DAMR significantly outperforms state-of-the-art methods.
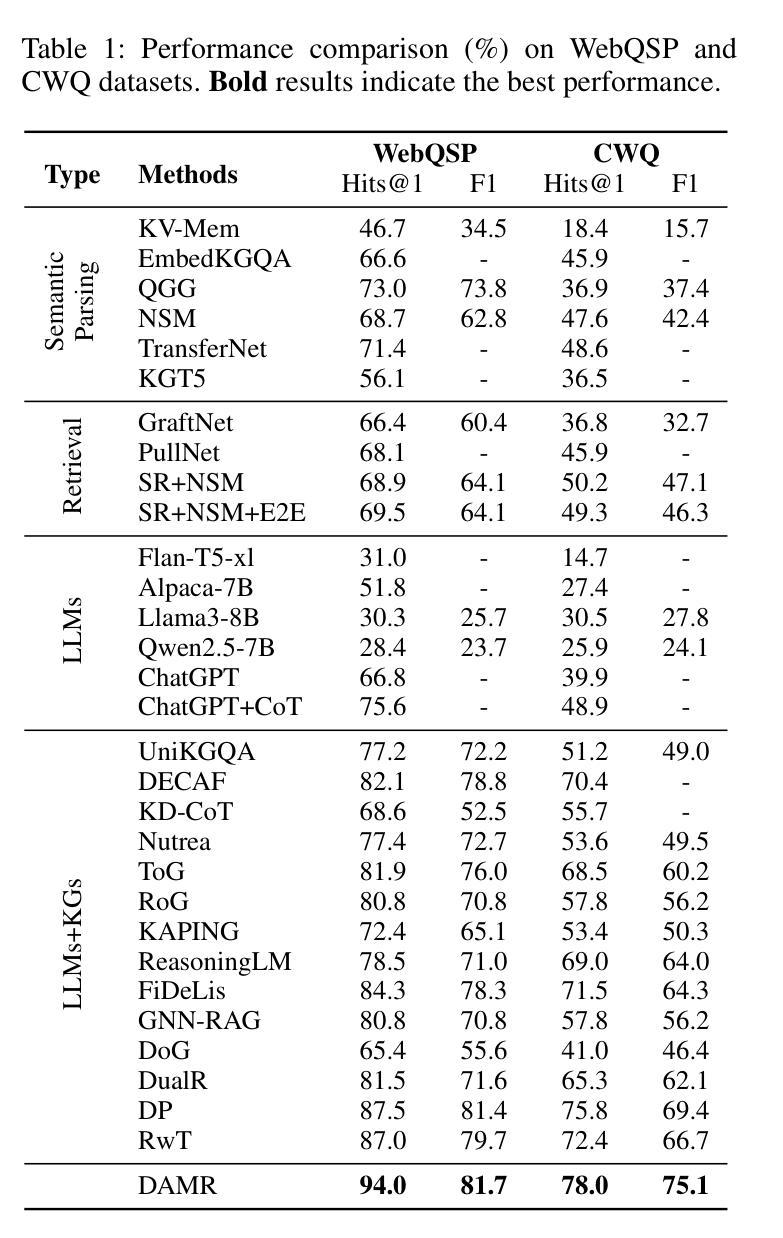
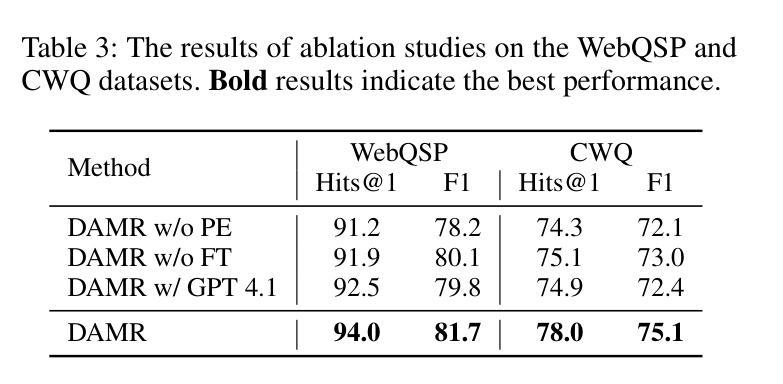
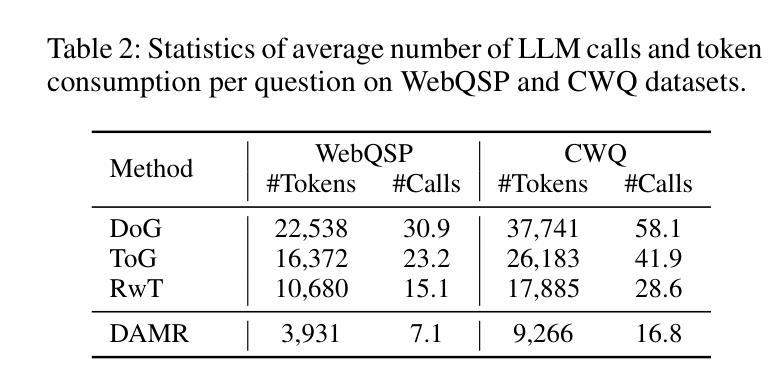
知识图谱问答(KGQA)旨在解释自然语言查询,并利用知识图谱的关系和语义结构进行结构化推理,以获取准确答案。最近的KGQA方法主要遵循“检索后推理”的模式,依赖于图神经网络(GNNs)或启发式规则进行静态路径提取,或者使用大型语言模型(LLMs)的提示来联合执行检索和推理的动态路径生成策略。然而,前者由于静态路径提取和缺乏上下文细化而适应性有限,后者则由于依赖于固定的评分函数和大量的LLM调用而计算成本高,并且在路径评估方面存在困难。为了解决这些问题,本文提出了基于动态自适应蒙特卡洛树搜索(MCTS)的推理(DAMR),这是一种将符号搜索与自适应路径评估相结合的新型框架,用于高效且上下文感知的KGQA。DAMR采用蒙特卡洛树搜索(MCTS)作为骨干,以基于LLM的规划器为指导,选择前k个相关关系作为每一步骤来减少搜索空间。为了提高路径评估的准确性,我们引入了一个轻量级的基于Transformer的评分器,通过跨注意力联合编码问题和关系序列,进行上下文感知的可行性估计,使模型能够在多跳推理过程中捕捉细微的语义变化。此外,为了缓解高质量监督的稀缺性,DAMR采用了一种动态伪路径细化机制,该机制定期从搜索过程中探索的部分路径生成训练信号,使评分器能够不断适应不断变化的推理轨迹分布。在多个KGQA基准测试上的广泛实验表明,DAMR显著优于最新方法。
论文及项目相关链接
摘要
KGQA旨在通过知识图谱的关系和语义结构来解释自然语言查询,并进行结构化推理以获取准确答案。当前KGQA方法主要遵循检索后推理模式,依赖于图神经网络或启发式规则进行静态路径提取,或使用大型语言模型进行动态路径生成。然而,前者受限于静态路径提取和缺乏上下文细化,后者计算成本高,且由于依赖固定评分函数和大量语言模型调用,路径评估准确性不高。本文提出动态自适应蒙特卡洛树搜索推理(DAMR),一个将符号搜索与自适应路径评估相结合的高效上下文感知KGQA框架。DAMR采用蒙特卡洛树搜索作为骨架,以语言模型为基础的规划器为指导,每一步选择最相关的前k个关系来减少搜索空间。为提高路径评估准确性,引入轻量级基于Transformer的评分器,通过跨注意力联合编码问题和关系序列,进行上下文感知的合理性估计,使模型在跨跳推理过程中捕捉细微语义变化。此外,为缓解高质量监督数据的稀缺性,DAMR引入动态伪路径细化机制,定期从搜索过程中探索的部分路径生成训练信号,使评分器能够不断适应不断变化的推理轨迹分布。在多个KGQA基准测试上的实验表明,DAMR显著优于现有方法。
关键见解
- KGQA旨在利用知识图谱的结构进行自然语言查询解读和结构化推理以获取准确答案。
- 当前KGQA方法存在静态路径提取的局限性以及高计算成本和路径评估准确性问题。
- DAMR框架通过整合符号搜索与自适应路径评估来解决这些问题,提高效率和准确性。
- DAMR采用基于蒙特卡洛树搜索的方法,以语言模型为基础的规划器来减少搜索空间。
- 引入基于Transformer的评分器进行上下文感知的合理性估计,提高路径评估准确性。
- 动态伪路径细化机制用于适应不断变化的推理轨迹分布,并缓解高质量监督数据的稀缺性。
点此查看论文截图

A Toolbox, Not a Hammer – Multi-TAG: Scaling Math Reasoning with Multi-Tool Aggregation
Authors:Bohan Yao, Vikas Yadav
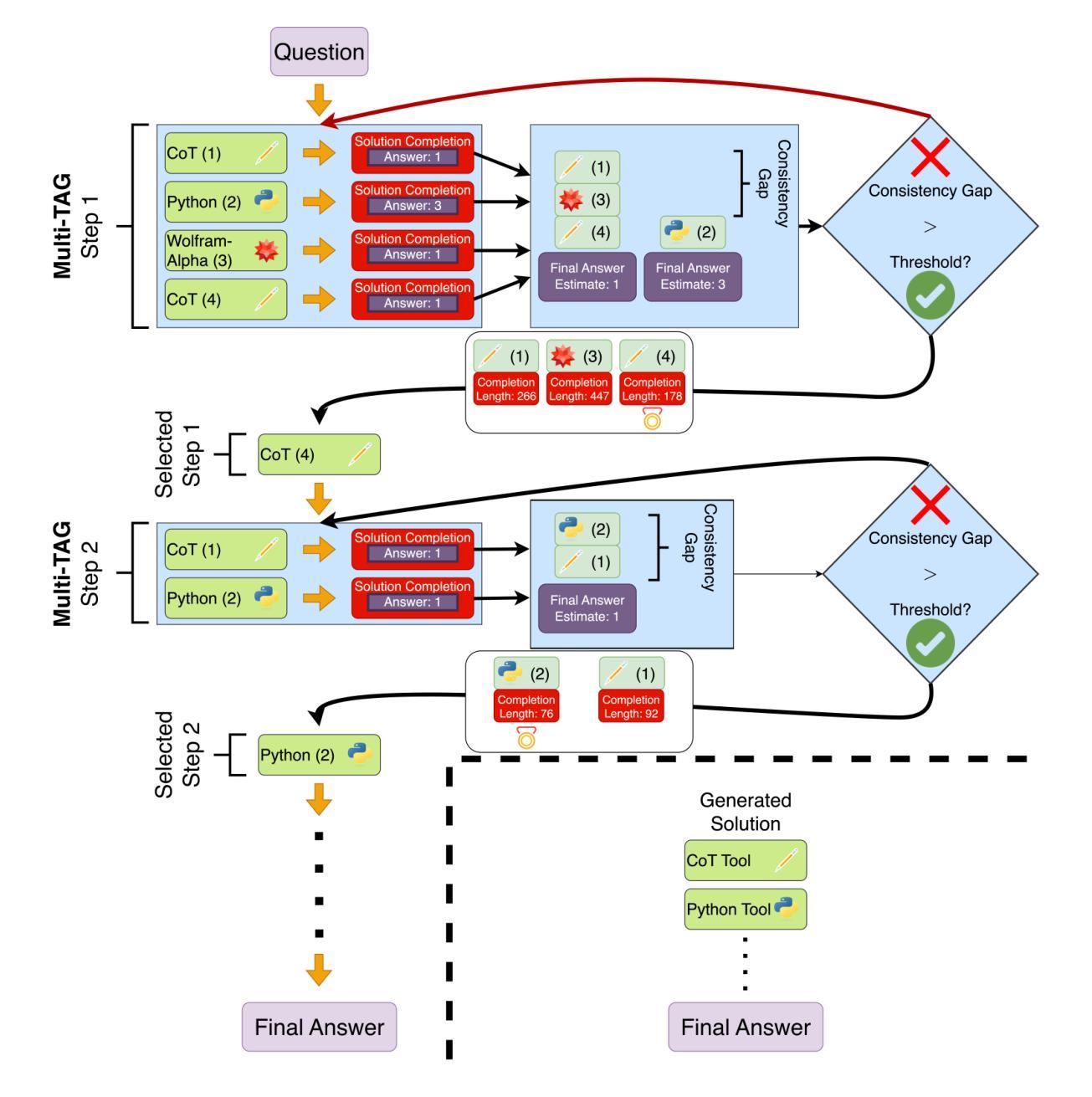
Augmenting large language models (LLMs) with external tools is a promising avenue for developing high-performance mathematical reasoning systems. Prior tool-augmented approaches typically finetune an LLM to select and invoke a single tool at each reasoning step and show promising results on simpler math reasoning benchmarks such as GSM8K. However, these approaches struggle with more complex math problems that require precise reasoning over multiple steps. To address this limitation, in this work, we propose Multi-TAG, a Multi-Tool AGgregation-based framework. Instead of relying on a single tool, Multi-TAG guides an LLM to concurrently invoke multiple tools at each reasoning step. It then aggregates their diverse outputs to verify and refine the reasoning process, enhancing solution robustness and accuracy. Notably, Multi-TAG is a finetuning-free, inference-only framework, making it readily applicable to any LLM backbone, including large open-weight models which are computationally expensive to finetune and proprietary frontier models which cannot be finetuned with custom recipes. We evaluate Multi-TAG on four challenging benchmarks: MATH500, AIME, AMC, and OlympiadBench. Across both open-weight and closed-source LLM backbones, Multi-TAG consistently and substantially outperforms state-of-the-art baselines, achieving average improvements of 6.0% to 7.5% over state-of-the-art baselines.
通过外部工具增强大型语言模型(LLM)是开发高性能数学推理系统的一条有前途的途径。先前的工具增强方法通常会对LLM进行微调,以在每一步推理中选择并调用单个工具,并在GSM8K等简单的数学推理基准测试上取得了令人鼓舞的结果。然而,这些方法在处理需要多步骤精确推理的更复杂的数学问题时遇到了困难。为了解决这一局限性,我们在本文中提出了一种基于多工具聚合的框架Multi-TAG。与依赖单一工具不同,Multi-TAG引导LLM在每一步推理中同时调用多个工具。然后,它聚合了这些不同的输出来验证和细化推理过程,提高了解决方案的稳健性和准确性。值得注意的是,Multi-TAG是一个无需微调、仅用于推断的框架,使其适用于任何LLM主干,包括计算上昂贵且难以微调的大型开放权重模型以及无法用自定义配方进行微调的专有前沿模型。我们在四个具有挑战性的基准测试上评估了Multi-TAG:MATH500、AIME、AMC和OlympiadBench。在公开权重和封闭源代码的LLM主干网上,Multi-TAG持续且显著地优于最新基线,平均比最新基线高出6.0%至7.5%。
论文及项目相关链接
PDF Published at EMNLP Findings 2025; 21 pages, 3 figures
Summary
大型语言模型(LLM)通过外部工具增强是实现高性能数学推理系统的一个有前途的方向。过去的方法通常在每个推理步骤中选择并调用一个工具,这在简单的数学推理基准测试(如GSM8K)上表现良好,但在处理需要多步骤精确推理的复杂数学问题方面存在局限性。为解决这一问题,本文提出了Multi-TAG框架,它基于多工具聚合的方法。不同于依赖单一工具的方法,Multi-TAG指导LLM在每个推理步骤中同时调用多个工具,然后聚合它们的不同输出来验证和细化推理过程,从而提高解决方案的稳健性和准确性。特别地,Multi-TAG是一个无需微调、仅用于推断的框架,可广泛应用于各种LLM主干网络,包括计算成本高昂的大型开放权重模型和无法用自定义配方进行微调的专业前沿模型。在MATH500、AIME、AMC和OlympiadBench四个具有挑战性的基准测试上,Multi-TAG在开源和闭源LLM主干网上均表现出一致且显著的优于最新技术基准线的性能,平均提升6.0%至7.5%。
Key Takeaways
- 大型语言模型(LLM)通过外部工具增强在数学推理领域具有前景。
- 现有方法在处理复杂数学问题时表现有限,需要多步骤精确推理。
- Multi-TAG框架是一种基于多工具聚合的方法,可指导LLM同时调用多个工具进行推理。
- Multi-TAG提高了解决方案的稳健性和准确性,通过聚合多个工具的输出进行验证和细化。
- Multi-TAG是一个无需微调的框架,可广泛应用于各种LLM模型。
- 在多个基准测试上,Multi-TAG显著优于现有技术,平均提升6.0%至7.5%。
点此查看论文截图


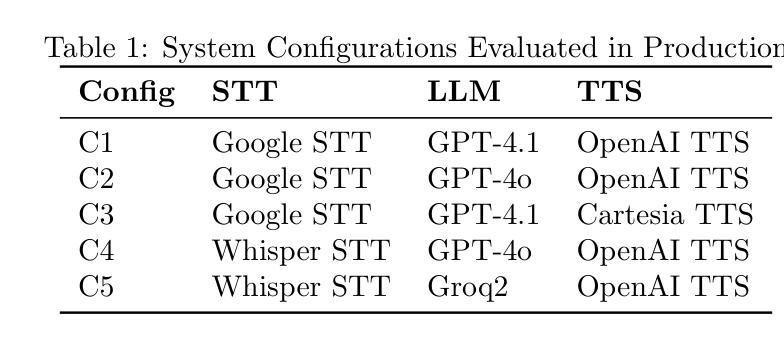
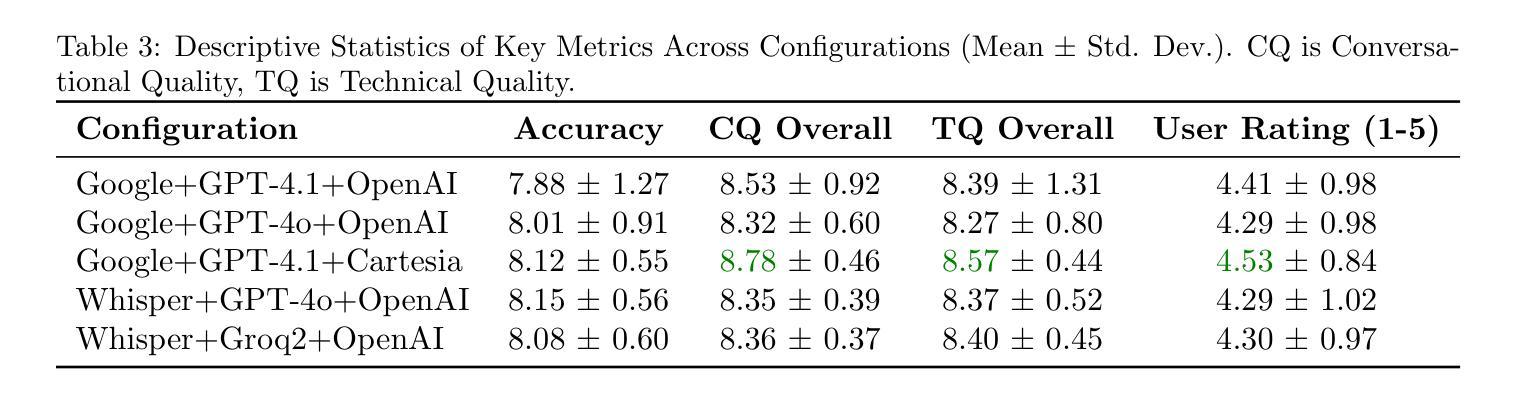
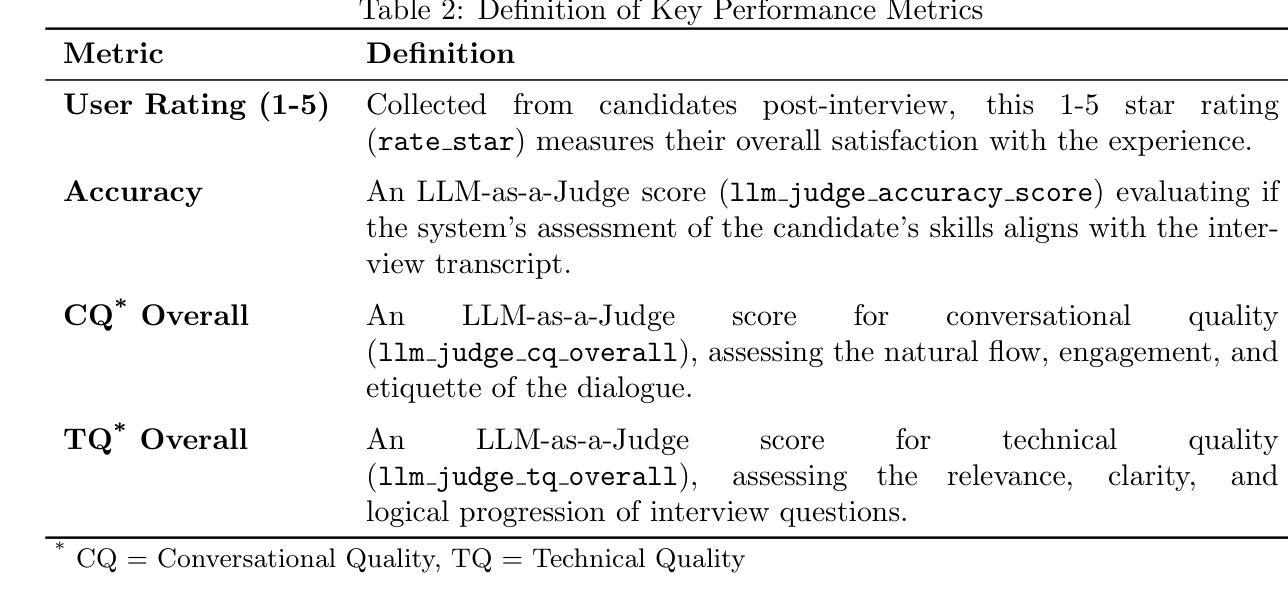
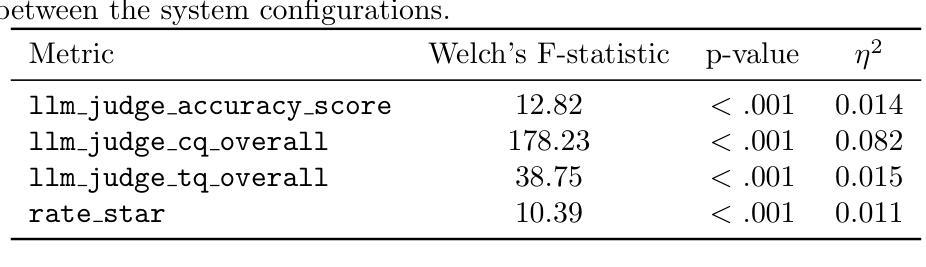
Evaluating Speech-to-Text x LLM x Text-to-Speech Combinations for AI Interview Systems
Authors:Rumi Allbert, Nima Yazdani, Ali Ansari, Aruj Mahajan, Amirhossein Afsharrad, Seyed Shahabeddin Mousavi
Voice-based conversational AI systems increasingly rely on cascaded architectures that combine speech-to-text (STT), large language models (LLMs), and text-to-speech (TTS) components. We present a large-scale empirical comparison of STT x LLM x TTS stacks using data sampled from over 300,000 AI-conducted job interviews. We used an LLM-as-a-Judge automated evaluation framework to assess conversational quality, technical accuracy, and skill assessment capabilities. Our analysis of five production configurations reveals that a stack combining Google’s STT, GPT-4.1, and Cartesia’s TTS outperforms alternatives in both objective quality metrics and user satisfaction scores. Surprisingly, we find that objective quality metrics correlate weakly with user satisfaction scores, suggesting that user experience in voice-based AI systems depends on factors beyond technical performance. Our findings provide practical guidance for selecting components in multimodal conversations and contribute a validated evaluation methodology for human-AI interactions.
基于语音的聊天AI系统越来越依赖于级联架构,该架构结合了语音识别(STT)、大型语言模型(LLM)和文本到语音(TTS)组件。我们通过对来自超过30万份AI面试的数据进行采样,对STT x LLM x TTS堆栈进行了大规模实证比较。我们使用以LLM为评判标准的自动化评估框架,对对话质量、技术准确性和技能评估能力进行评估。我们对五种生产配置的分析表明,结合谷歌的STT、GPT-4.1和卡特西亚的TTS的堆栈在客观质量指标和用户满意度得分方面都优于其他选择。令人惊讶的是,我们发现客观质量指标与用户满意度得分之间的相关性很弱,这表明用户在基于语音的AI系统中的体验除了技术性能外还受其他因素影响。我们的研究为选择多模式对话中的组件提供了实际指导,并为人类与AI之间的交互提供了一种经过验证的评估方法。
论文及项目相关链接
Summary
基于语音的聊天AI系统越来越多地依赖于结合语音识别(STT)、大型语言模型(LLM)和文本转语音(TTS)组件的级联架构。本研究通过实证对比超过30万份AI面试数据,评估了不同STT x LLM x TTS组合的表现。研究使用LLM作为评估框架对会话质量、技术准确性和技能评估能力进行评估。分析表明,结合谷歌STT、GPT-4.1和卡特西亚TTS的组合在客观质量指标和用户满意度得分上表现最佳。有趣的是,客观质量指标与用户满意度得分相关性较低,表明用户体验不仅取决于技术性能。本研究为选择多模态对话中的组件提供了实用指导,并为人类与AI的互动验证评估方法做出了贡献。
Key Takeaways
- 语音对话AI系统依赖级联架构结合STT、LLM和TTS组件。
- 通过超过30万份AI面试数据的实证对比,评估了不同STT x LLM x TTS组合的表现。
- LLM作为评估框架用于评估会话质量、技术准确性和技能评估能力。
- 最佳组合为谷歌STT、GPT-4.1和卡特西亚TTS的组合,在客观质量指标和用户满意度得分上表现突出。
- 客观质量指标与用户满意度得分相关性较低,表明用户体验不仅受技术性能影响。
- 研究为多模态对话中的组件选择提供了实用指导。
点此查看论文截图

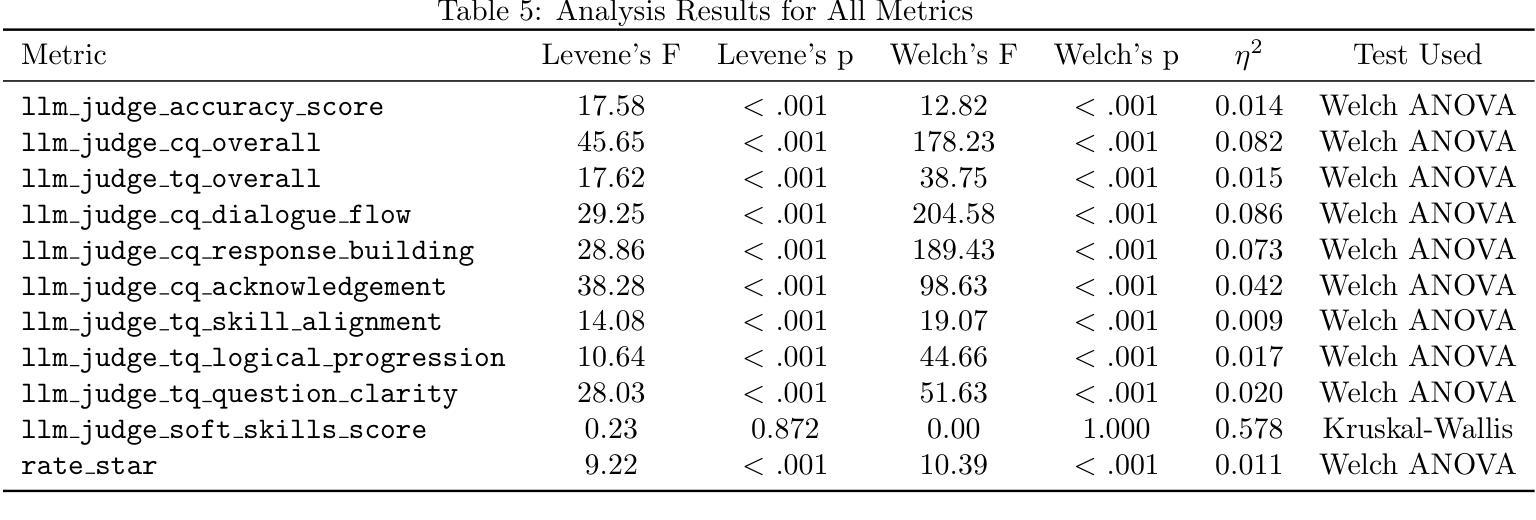
A Simple “Try Again” Can Elicit Multi-Turn LLM Reasoning
Authors:Licheng Liu, Zihan Wang, Linjie Li, Chenwei Xu, Yiping Lu, Han Liu, Avirup Sil, Manling Li
Multi-turn problem solving is critical yet challenging for Large Reasoning Models (LRMs) to reflect on their reasoning and revise from feedback. Existing Reinforcement Learning (RL) methods train large reasoning models on a single-turn paradigm with verifiable rewards. However, we observe that models trained with existing RL paradigms often lose their ability to solve problems across multiple turns and struggle to revise answers based on contextual feedback, leading to repetitive responses. We ask: can LRMs learn to reflect their answers in a multi-turn context? In this work, we find that training models with multi-turn RL using only unary feedback (e.g., “Let’s try again”) after wrong answers can improve both single-turn performance and multi-turn reasoning. We introduce Unary Feedback as Observation (UFO) for reinforcement learning, which uses minimal yet common unary user feedback during iterative problem solving. It can be easily applied to existing single-turn RL training setups. Experimental results show that RL training with UFO keeps single-turn performance and improves multi-turn reasoning accuracy by up to 14%, enabling language models to better react to feedback in multi-turn problem solving. To further minimize the number of turns needed for a correct answer while encouraging diverse reasoning when mistakes occur, we design reward structures that guide models to produce careful and deliberate answers in each turn. Code: https://github.com/lichengliu03/unary-feedback
多轮问题求解对于大型推理模型(LRM)来说是至关重要的,但也颇具挑战性,需要模型反思自己的推理并根据反馈进行修改。现有的强化学习(RL)方法是在单轮模式下训练大型推理模型,并辅以可验证的奖励。然而,我们观察到,采用现有RL模式训练的模型往往丧失了多轮问题求解的能力,难以根据上下文反馈修改答案,导致重复响应。我们的问题是:LRM能否在多轮对话的情境中学会反思自己的答案?在这项工作中,我们发现使用多轮强化学习进行模型训练,仅在错误答案后提供一元反馈(例如“请再试一次”),就可以提高单轮性能和多轮推理能力。我们为强化学习引入了名为“Unary Feedback as Observation”(UFO)的方法,该方法在迭代问题求解过程中使用最少但常见的一元用户反馈。它可以轻松应用于现有的单轮RL训练设置。实验结果表明,使用UFO的RL训练保持了单轮性能,并通过最多提高14%的多轮推理准确性,使语言模型能够在多轮问题求解中更好地应对反馈。为了尽量减少得到正确答案所需的轮数,同时在出现错误时鼓励多样化的推理,我们设计了奖励结构,以指导模型在每轮中给出谨慎和周全的答案。代码链接:https://github.com/lichengliu03/unary-feedback
论文及项目相关链接
Summary
大型推理模型(LRMs)在多回合问题解决中面临挑战,需要反思并基于反馈进行修订。现有强化学习(RL)方法通常在单回合模式下训练模型,并使用可验证的奖励。然而,这些训练后的模型常常缺乏多回合解决问题的能力,并且难以基于上下文反馈修订答案,导致重复回应。本研究探索了大型推理模型在多回合环境下的反馈机制。通过引入仅使用一元反馈(例如“再试一次”)的多回合强化学习训练,提高了单回合性能和多回合推理能力。还介绍了用于强化学习的一元反馈作为观察(UFO),它可以在迭代问题解决过程中使用最少但常见的一元用户反馈。实验结果证明,使用UFO的RL训练在保持单回合性能的同时,提高了多回合推理的准确性,最多可提高14%。为鼓励在出错时减少回合数并提供多样化的推理,设计了奖励结构来指导模型在每个回合中作出谨慎和深思熟虑的回答。
Key Takeaways
- 大型推理模型(LRMs)在多回合问题解决中面临挑战,需要增强反思和修订能力。
- 现有强化学习(RL)方法主要基于单回合模式,导致模型在多回合环境中性能下降。
- 通过引入一元反馈作为观察(UFO),提高了模型在多回合环境下的性能。
- 使用UFO的RL训练可同时提高单回合性能和多回合推理的准确性,提高幅度最多可达14%。
- 为鼓励在出错时提供多样化的推理并减少回合数,设计了新的奖励结构。
- 该方法可通过最少但常见的一元用户反馈进行迭代问题解决。
点此查看论文截图



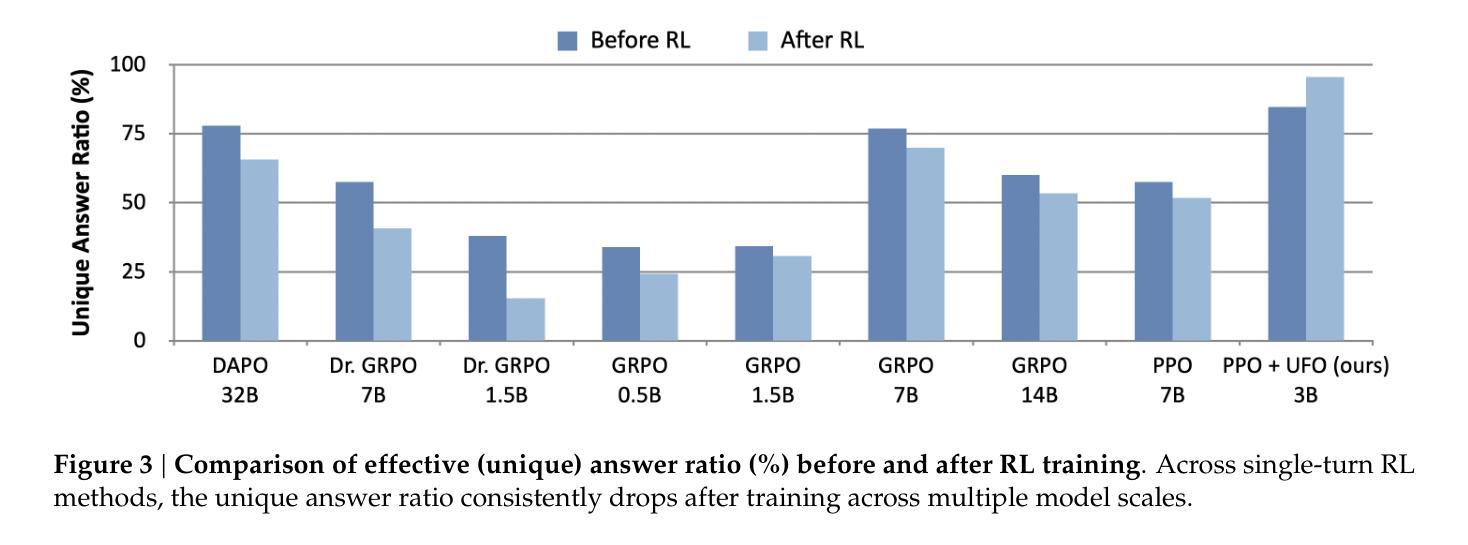

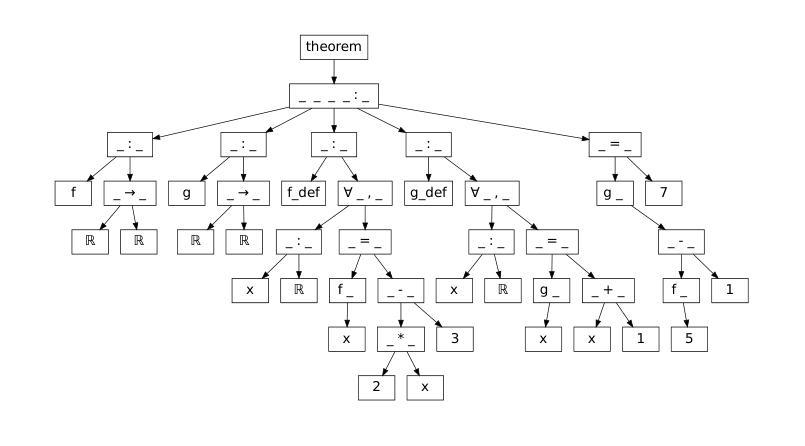
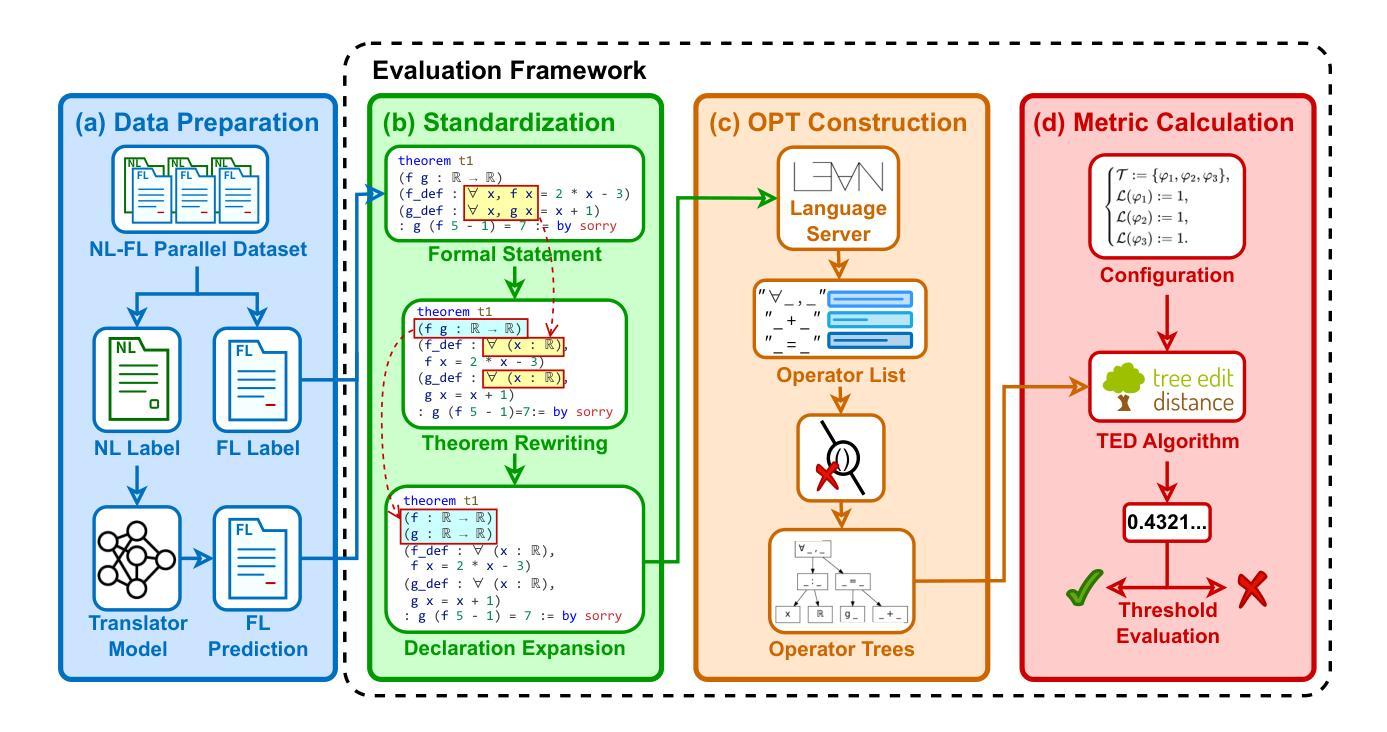
Generalized Tree Edit Distance (GTED): A Faithful Evaluation Metric for Statement Autoformalization
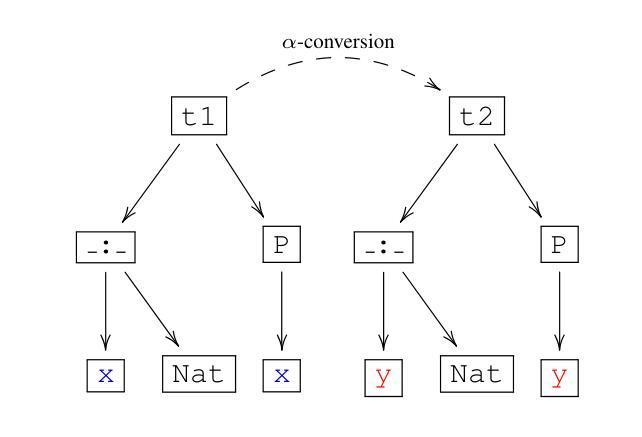
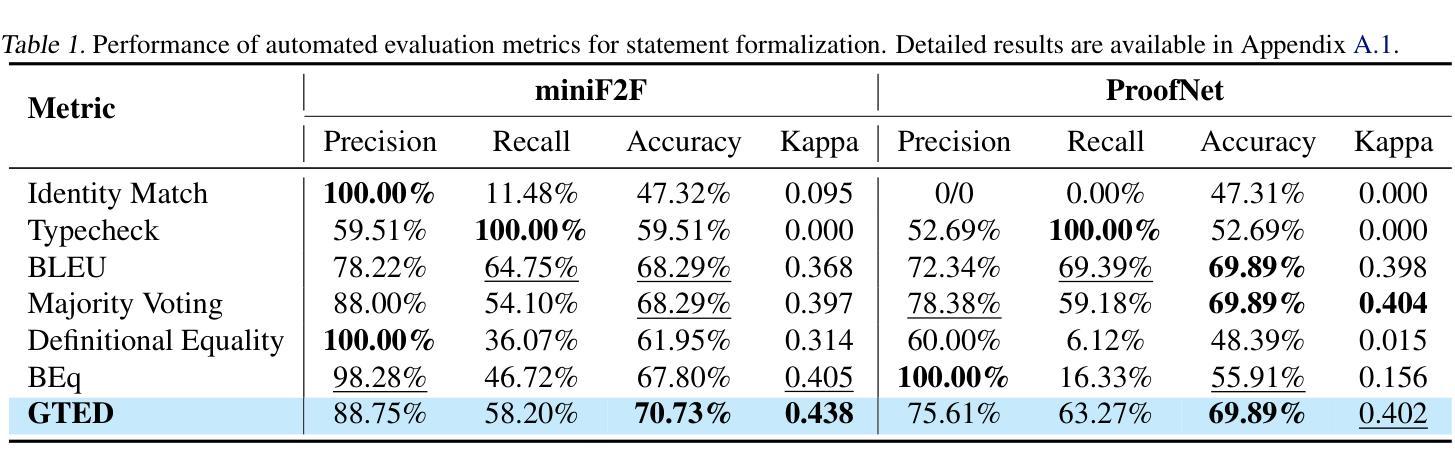
Authors:Yuntian Liu, Tao Zhu, Xiaoyang Liu, Yu Chen, Zhaoxuan Liu, Qingfeng Guo, Jiashuo Zhang, Kangjie Bao, Tao Luo
Statement autoformalization, the automated translation of statements from natural language into formal languages, has become a subject of extensive research, yet the development of robust automated evaluation metrics remains limited. Existing evaluation methods often lack semantic understanding, face challenges with high computational costs, and are constrained by the current progress of automated theorem proving. To address these issues, we propose GTED (Generalized Tree Edit Distance), a novel evaluation framework that first standardizes formal statements and converts them into operator trees, then determines the semantic similarity using the eponymous GTED metric. Across the miniF2F and ProofNet benchmarks, GTED consistently ranks as a top-performing metric, achieving the highest accuracy and Kappa on miniF2F and the joint-highest accuracy on ProofNet. This strong overall performance provides the community with a computationally lightweight and more faithful metric for automated evaluation. The code and experimental results are available at https://github.com/XiaoyangLiu-sjtu/GTED.
语句自动形式化是将自然语言语句自动转换为形式化语言,这已成为广泛研究的课题,然而,鲁棒的自动评估指标的开发仍然有限。现有的评估方法往往缺乏语义理解,面临计算成本高的挑战,并受到自动定理证明当前进展的制约。为了解决这些问题,我们提出了GTED(广义树编辑距离)这一新型评估框架,它首先标准化形式化语句并将其转换为操作树,然后使用同名的GTED指标确定语义相似性。在miniF2F和ProofNet基准测试中,GTED一直表现最佳,在miniF2F上实现了最高准确率和Kappa值,在ProofNet上实现了联合最高准确率。这种强大的整体性能表现使社区能够使用计算轻量且更可靠的指标来进行自动化评估。代码和实验结果可访问https://github.com/XiaoyangLiu-sjtu/GTED了解。
论文及项目相关链接
PDF Accepted to AI4Math@ICML25
Summary
自动语句形式化是将自然语言语句自动转化为形式语言语句的研究课题,但可靠的自动评估指标的开发仍存在限制。为解决现有评估方法缺乏语义理解、计算成本高以及与自动定理证明当前进展相制约的问题,我们提出了GTED(广义树编辑距离)这一新型评估框架。该框架首先标准化形式语句并将其转化为操作树,然后使用同名的GTED指标确定语义相似性。在miniF2F和ProofNet基准测试中,GTED表现优异,取得了最高准确率和Kappa系数。它为社区提供了一个计算量小、更准确的自动化评估指标。相关代码和实验结果可在https://github.com/XiaoyangLiu-sjtu/GTED找到。
Key Takeaways
- 自动语句形式化是一个热门研究领域,但评估指标的可靠性仍是挑战。
- 现有评估方法存在语义理解不足、计算成本高以及与自动定理证明进展制约的问题。
- GTED是一种新型评估框架,通过标准化形式语句并转化为操作树来解决现有问题。
- GTED利用广义树编辑距离来确定语义相似性。
- 在基准测试中,GTED表现优秀,取得了高准确率和Kappa系数。
- GTED为社区提供了一个计算量小、更准确的自动化评估指标。
点此查看论文截图


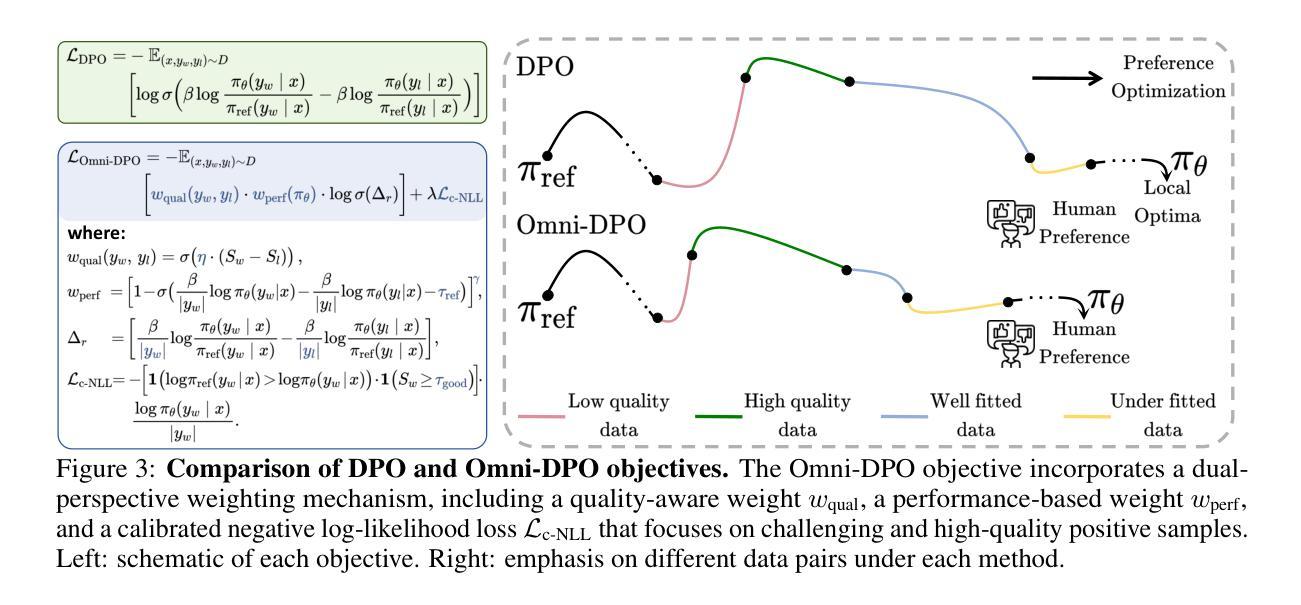
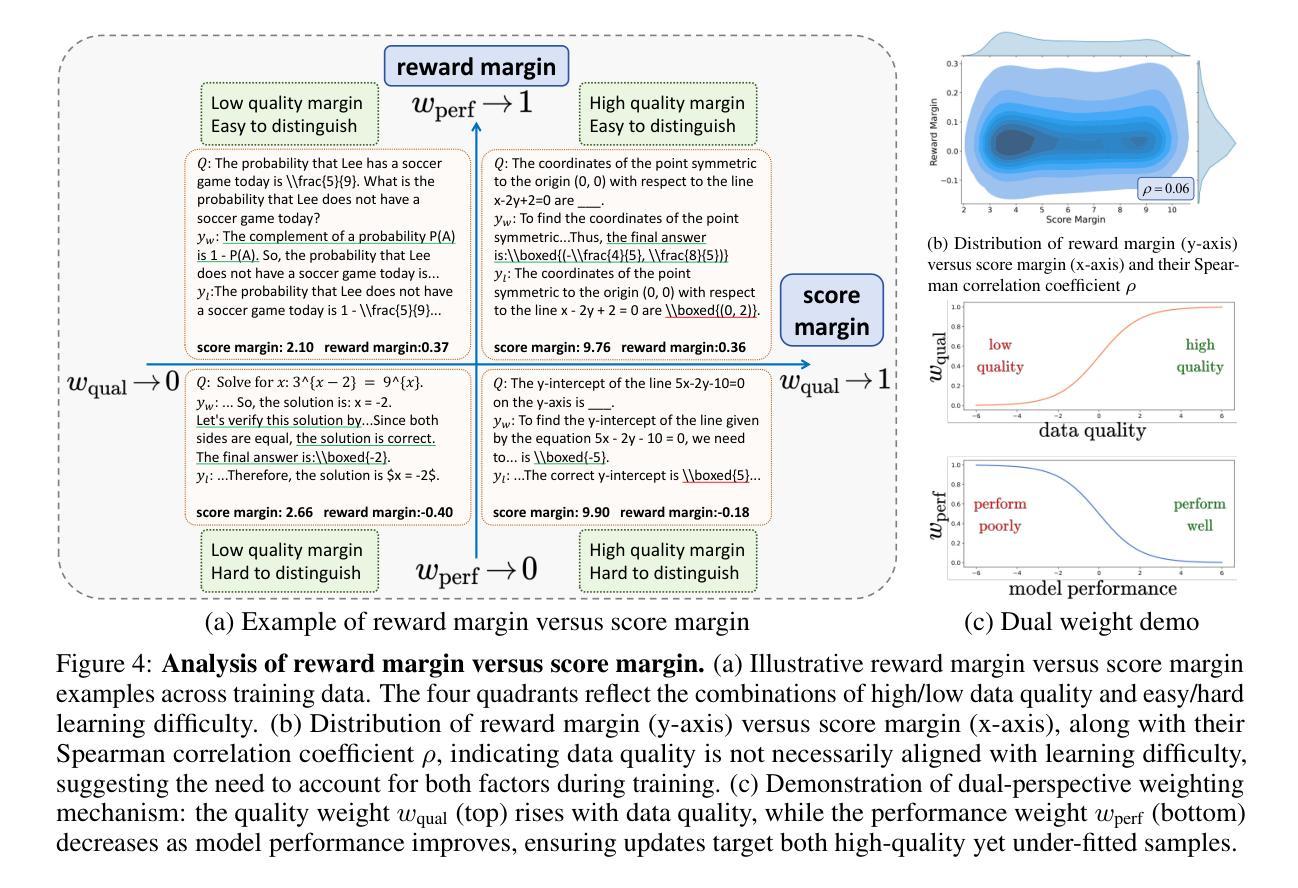
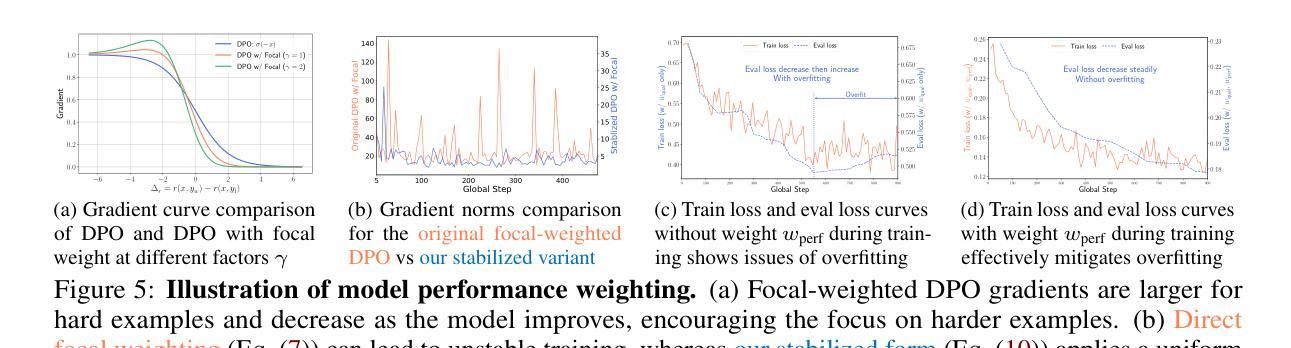
Omni-DPO: A Dual-Perspective Paradigm for Dynamic Preference Learning of LLMs
Authors:Shangpin Peng, Weinong Wang, Zhuotao Tian, Senqiao Yang, Xing Wu, Haotian Xu, Chengquan Zhang, Takashi Isobe, Baotian Hu, Min Zhang
Direct Preference Optimization (DPO) has become a cornerstone of reinforcement learning from human feedback (RLHF) due to its simplicity and efficiency. However, existing DPO-based approaches typically treat all preference pairs uniformly, ignoring critical variations in their inherent quality and learning utility, leading to suboptimal data utilization and performance. To address this challenge, we propose Omni-DPO, a dual-perspective optimization framework that jointly accounts for (1) the inherent quality of each preference pair and (2) the model’s evolving performance on those pairs. By adaptively weighting samples according to both data quality and the model’s learning dynamics during training, Omni-DPO enables more effective training data utilization and achieves better performance. Experimental results on various models and benchmarks demonstrate the superiority and generalization capabilities of Omni-DPO. On textual understanding tasks, Gemma-2-9b-it finetuned with Omni-DPO beats the leading LLM, Claude 3 Opus, by a significant margin of 6.7 points on the Arena-Hard benchmark. On mathematical reasoning tasks, Omni-DPO consistently outperforms the baseline methods across all benchmarks, providing strong empirical evidence for the effectiveness and robustness of our approach. Code and models will be available at https://github.com/pspdada/Omni-DPO.
直接偏好优化(DPO)因其简单高效而成为强化学习人类反馈(RLHF)中的核心方法。然而,现有的基于DPO的方法通常将偏好对统一处理,忽略了其内在质量和学习实用性的重要差异,导致数据利用不佳和性能不足。为了应对这一挑战,我们提出了Omni-DPO,一个双视角优化框架,同时考虑(1)每个偏好对的内在质量和(2)模型在这些偏好对上的性能变化。Omni-DPO通过根据数据质量和模型在训练过程中的学习动态自适应地加权样本,从而实现了更有效的训练数据利用和更好的性能。在各种模型和基准测试上的实验结果表明了Omni-DPO的优越性和泛化能力。在文本理解任务上,使用Omni-DPO微调后的Gemma-2-9b-it在Arena-Hard基准测试上大幅领先领先的大型语言模型Claude 3 Opus,得分高出6.7分。在数学推理任务上,Omni-DPO在所有基准测试上均优于基准方法,为我们方法的有效性和稳健性提供了有力的实证证据。代码和模型将在https://github.com/pspdada/Omni-DPO上提供。
论文及项目相关链接
Summary
基于人类反馈的强化学习(RLHF)中,Direct Preference Optimization(DPO)方法因其简单高效而备受关注。然而,现有DPO方法往往忽略偏好对本身的质量和学习效用上的差异,导致数据利用不够优化和性能不佳。为此,提出Omni-DPO,一个双视角优化框架,同时考虑偏好对的内在质量和模型在训练过程中的性能变化。通过根据数据质量和模型学习动态自适应地调整样本权重,Omni-DPO实现了更有效的训练数据利用和更好的性能。实验结果表明,Omni-DPO在多个模型和基准测试上表现优越,具有广泛的适用性。
Key Takeaways
- DPO是强化学习从人类反馈中的一个重要方法,但其存在对偏好对质量和学习效用的忽视。
- Omni-DPO框架考虑了偏好对的内在质量和模型性能的变化。
- Omni-DPO通过自适应调整样本权重,实现了更有效的训练数据利用。
- 实验结果表明,Omni-DPO在多种模型和基准测试上表现优于其他方法。
- 在文本理解任务上,使用Omni-DPO的Gemma-2-9b-it模型在Arena-Hard基准测试上大幅超越领先的大型语言模型Claude 3 Opus。
- Omni-DPO在数学推理任务上同样表现出色,且在不同基准测试中均优于基线方法。
点此查看论文截图