⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-26 更新
Vevo2: Bridging Controllable Speech and Singing Voice Generation via Unified Prosody Learning
Authors:Xueyao Zhang, Junan Zhang, Yuancheng Wang, Chaoren Wang, Yuanzhe Chen, Dongya Jia, Zhuo Chen, Zhizheng Wu
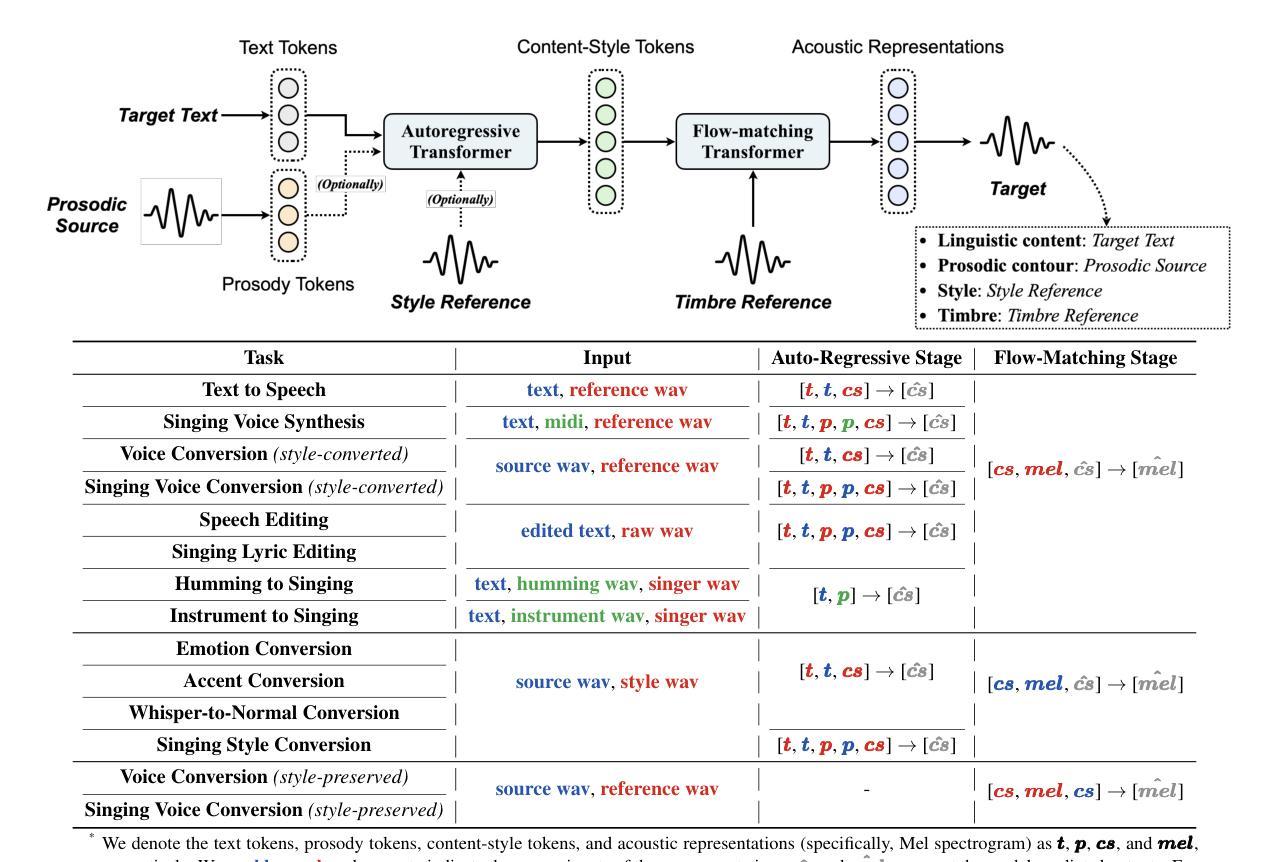
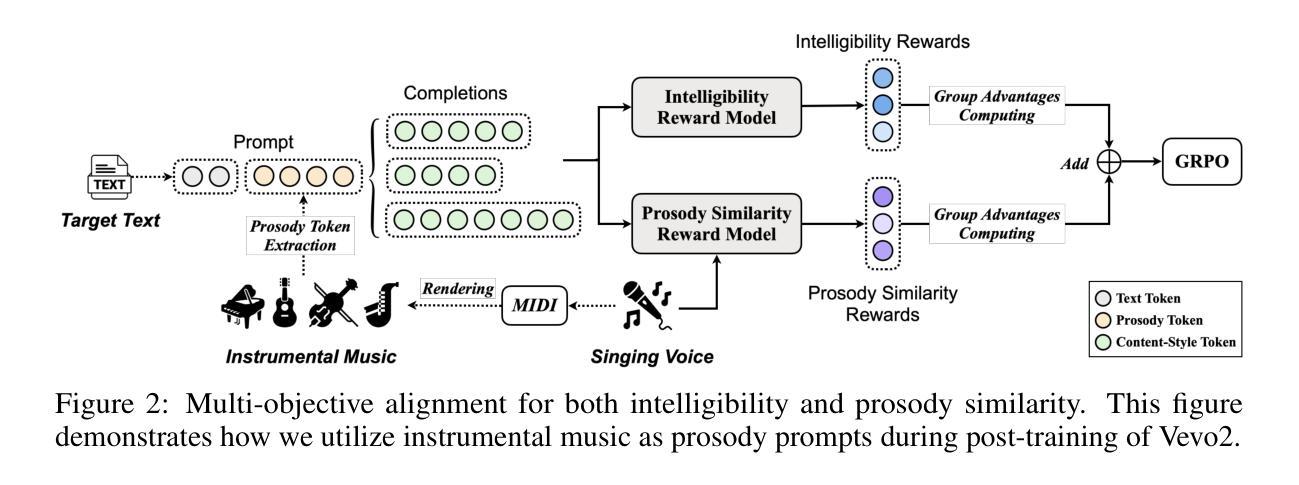
Controllable human voice generation, particularly for expressive domains like singing, remains a significant challenge. This paper introduces Vevo2, a unified framework for controllable speech and singing voice generation. To tackle issues like the scarcity of annotated singing data and to enable flexible controllability, Vevo2 introduces two audio tokenizers: (1) a music-notation-free prosody tokenizer that captures prosody and melody from speech, singing, and even instrumental sounds, and (2) a low-frame-rate (12.5 Hz) content-style tokenizer that encodes linguistic content, prosody, and style for both speech and singing, while enabling timbre disentanglement. Vevo2 consists of an auto-regressive (AR) content-style modeling stage, which aims to enable controllability over text, prosody, and style, as well as a flow-matching acoustic modeling stage that allows for timbre control. Particularly, during pre-training of the AR model, we propose both explicit and implicit prosody learning strategies to bridge speech and singing voice. Moreover, to further enhance the AR model’s ability to follow text and prosody, we design a multi-objective post-training task that integrates both intelligibility and prosody similarity alignment. Experimental results show that the unified modeling in Vevo2 brings mutual benefits to both speech and singing voice generation. Additionally, Vevo2’s effectiveness across a wide range of synthesis, conversion, and editing tasks for both speech and singing further demonstrates its strong generalization ability and versatility. Audio samples are are available at https://versasinger.github.io/.
可控的人声生成,特别是在歌唱等表达领域,仍然是一个巨大的挑战。本文介绍了Vevo2,一个用于可控语音和歌唱声音生成的统一框架。为了解决标注歌唱数据稀缺的问题并实现灵活的可控性,Vevo2引入了两种音频标记器:(1)一种无需音乐符号的语调标记器,可以从语音、歌唱甚至乐器声音中捕捉语调和旋律;(2)一种低帧率(12.5 Hz)的内容风格标记器,编码语音和歌唱的语言内容、语调和风格,同时实现音色分离。Vevo2包括一个自回归(AR)的内容风格建模阶段,旨在实现对文本、语调和风格的控制,以及一个流匹配声学建模阶段,允许音色控制。特别是在AR模型的预训练过程中,我们提出了显性和隐性的语调学习策略,以弥合语音和歌唱声音之间的差距。此外,为了进一步提高AR模型对文本和语调的跟随能力,我们设计了一个多目标后训练任务,融合了可理解性和语调相似性对齐。实验结果表明,Vevo2的统一建模对语音和歌唱声音生成都带来了互惠互利的效果。此外,Vevo2在语音和歌唱的广泛合成、转换和编辑任务中的有效性进一步证明了其强大的通用性和多功能性。音频样本可在https://versasinger.github.io/中找到。
论文及项目相关链接
PDF We will release code and model checkpoints at https://github.com/open-mmlab/Amphion
摘要
该论文提出了一种统一的框架Vevo2,用于可控的人声生成,特别是适用于唱歌等表达领域。Vevo2通过引入两种音频标记器来解决标注歌唱数据稀缺和灵活性控制问题。其一是无需音乐符号的语调标记器,能够捕捉语音、歌唱甚至器乐声音中的语调和旋律;其二是低帧率(12.5Hz)的内容风格标记器,能够对语音和歌唱进行文本、语调和风格的控制,同时实现音色分离。Vevo2包括一个自回归内容风格建模阶段,旨在实现对文本、语调和风格的控制,以及一个流程匹配声学建模阶段,可实现音色控制。论文还介绍了自回归模型预训练和基于文本与语调跟踪的多目标后训练任务的设计。实验结果表明,Vevo2的统一建模为语音和歌唱声音生成带来了互利效益,其在合成、转换和编辑任务上的广泛适用性进一步证明了其强大的通用性和灵活性。相关音频样本可在https://versasinger.github.io/获取。
关键见解
- Vevo2是一个统一的框架,用于可控的人声生成,包括语音和歌唱。
- 引入两种音频标记器:无需音乐符号的语调标记器和低帧率内容风格标记器。
- 自回归内容风格建模阶段实现对文本、语调和风格的控制。
- 流程匹配声学建模阶段允许音色控制。
- 提出预训练中的明确和隐含语调学习策略,以缩小语音和歌唱之间的差距。
- 设计多目标后训练任务,以提高自回归模型对文本和语调的跟踪能力。
- 实验结果表明Vevo2在语音和歌唱生成上的优越性,及其在多种任务上的广泛适用性。
点此查看论文截图

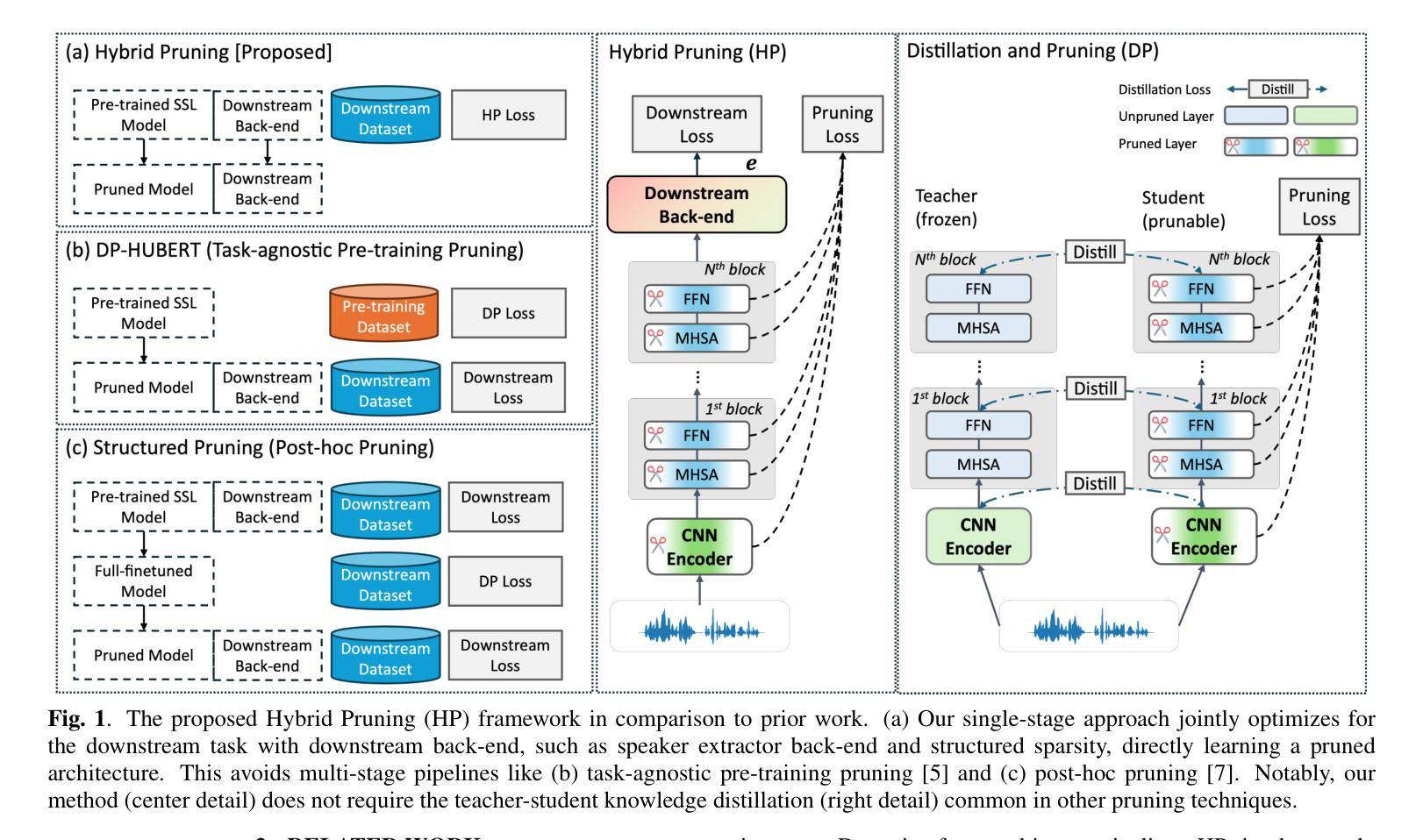
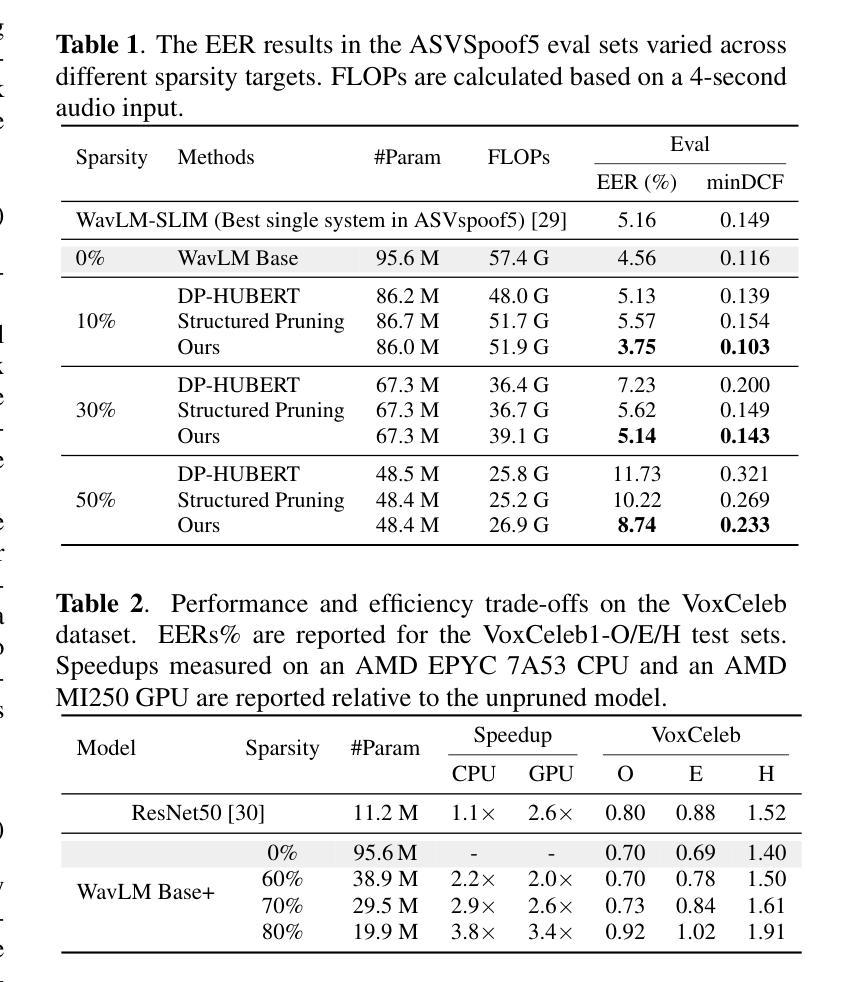
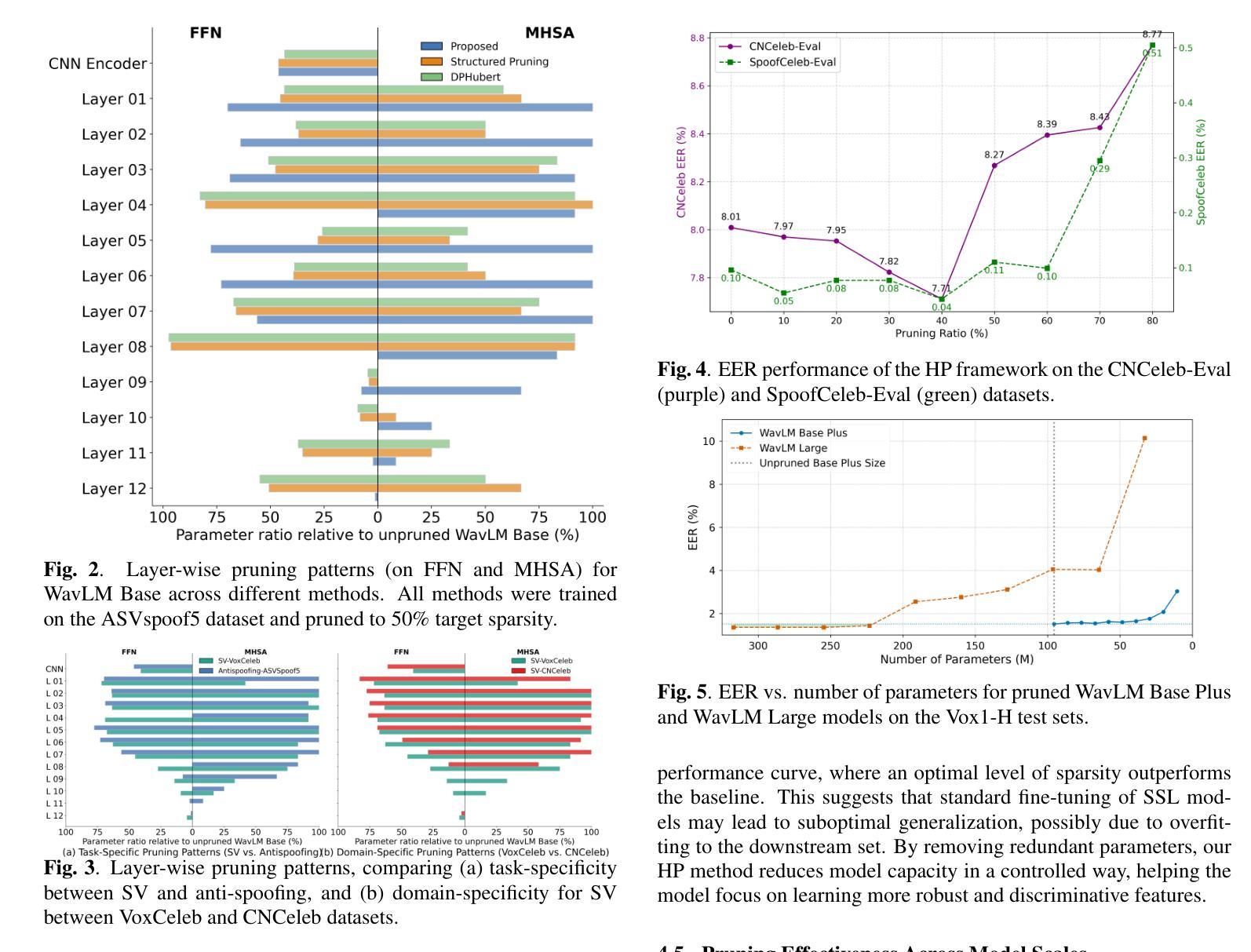
Hybrid Pruning: In-Situ Compression of Self-Supervised Speech Models for Speaker Verification and Anti-Spoofing
Authors:Junyi Peng, Lin Zhang, Jiangyu Han, Oldřich Plchot, Johan Rohdin, Themos Stafylakis, Shuai Wang, Jan Černocký
Although large-scale self-supervised learning (SSL) models like WavLM have achieved state-of-the-art performance in speech processing, their significant size impedes deployment on resource-constrained devices. While structured pruning is a key technique for model compression, existing methods typically separate it from task-specific fine-tuning. This multi-stage approach struggles to create optimal architectures tailored for diverse downstream tasks. In this work, we introduce a unified framework that integrates structured pruning into the downstream fine-tuning process. Our framework unifies these steps, jointly optimizing for task performance and model sparsity in a single stage. This allows the model to learn a compressed architecture specifically for the end task, eliminating the need for complex multi-stage pipelines and knowledge distillation. Our pruned models achieve up to a 70% parameter reduction with negligible performance degradation on large-scale datasets, achieving equal error rates of 0.7%, 0.8%, and 1.6% on Vox1-O, -E, and -H, respectively. Furthermore, our approach demonstrates improved generalization in low-resource scenarios, reducing overfitting and achieving a state-of-the-art 3.7% EER on ASVspoof5.
尽管像WavLM这样的大规模自监督学习(SSL)模型在语音处理方面已经达到了最前沿的性能,但它们的大规模阻碍了其在资源受限设备上的部署。虽然结构化剪枝是模型压缩的关键技术,但现有方法通常将其与特定任务的微调分开。这种多阶段的方法很难为各种下游任务创建最佳架构。在这项工作中,我们介绍了一个统一的框架,该框架将结构化剪枝集成到下游微调过程中。我们的框架统一了这些步骤,在一个阶段中联合优化任务性能和模型稀疏性。这允许模型为终端任务学习一个压缩架构,从而无需复杂的多阶段管道和蒸馏。我们的剪枝模型实现了高达70%的参数减少,在大规模数据集上的性能下降可以忽略不计,在Vox1-O、-E和-H上的错误率分别为0.7%、0.8%和1.6%。此外,我们的方法在资源稀缺场景中表现出更好的泛化能力,减少了过拟合现象,并在ASVspoof5上达到了最先进的3.7%的拒真率。
论文及项目相关链接
Summary
大规模自监督学习模型如WavLM在语音处理方面达到了先进的技术水平,但其庞大的规模阻碍了其在资源受限设备上的部署。本研究引入了一个统一的框架,将结构化剪枝集成到下游微调过程中,以优化任务性能和模型稀疏性。该框架消除了复杂的多阶段管道和知识蒸馏的需求,使模型能够学习专门针对终端任务的压缩架构。经过修剪的模型在大型数据集上实现了高达70%的参数减少,同时性能下降微乎其微,在Vox1-O、-E和-H上分别达到了0.7%、0.8%和1.6%的错误率。此外,该方法在低资源场景中的泛化性能有所提升,减少了过拟合现象,并在ASVspoof5上达到了最先进的3.7%的EER。
Key Takeaways
- 大型自监督学习模型如WavLM在语音处理上表现卓越,但难以在资源受限设备上部署。
- 结构化剪枝是模型压缩的关键技术,但现有方法通常将其与任务特定微调分开。
- 本研究提出一个统一框架,将结构化剪枝与下游微调过程相结合,优化任务性能和模型稀疏性。
- 该框架实现了高达70%的参数减少,同时保持或略微提高了性能。
- 在大型数据集上,经过修剪的模型性能下降微乎其微。
- 该方法在低资源场景中的泛化性能有所提升,减少了过拟合现象。
点此查看论文截图

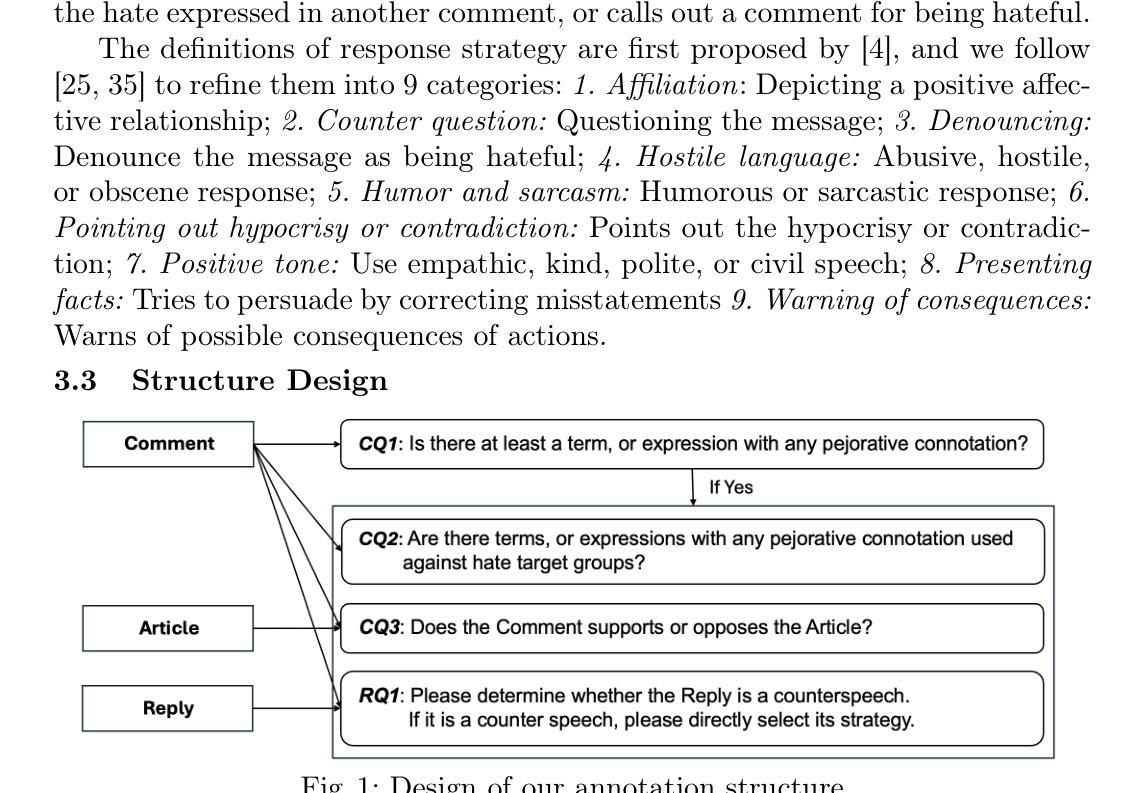
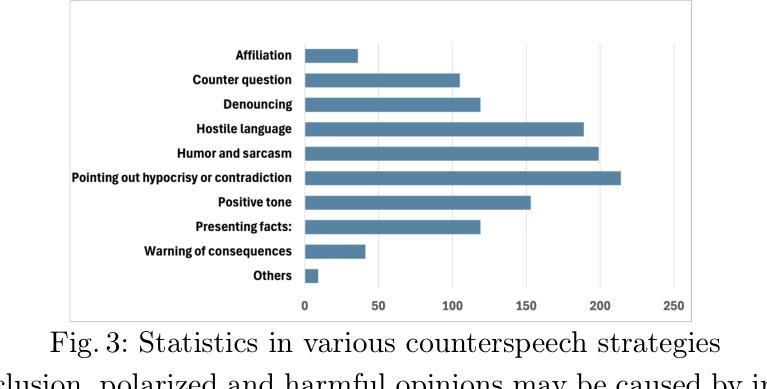
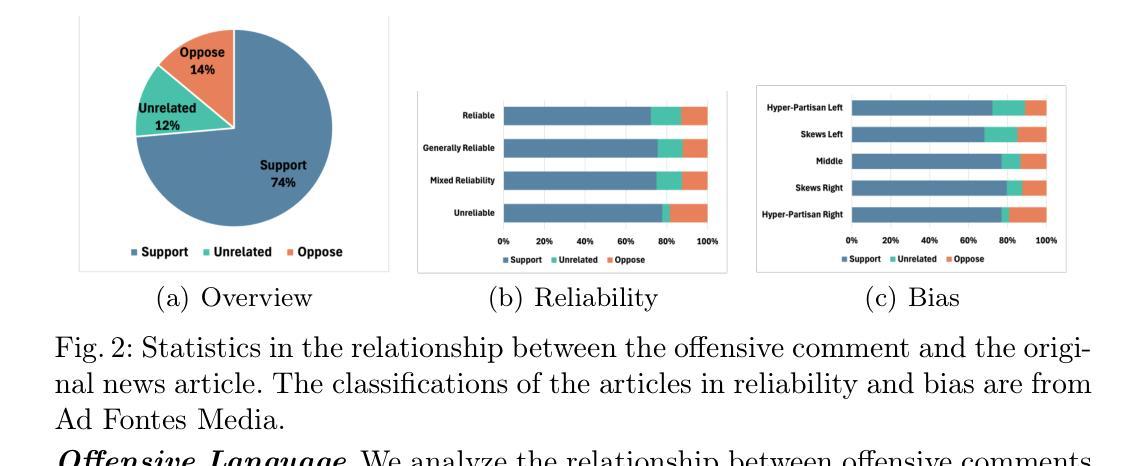
Counterspeech for Mitigating the Influence of Media Bias: Comparing Human and LLM-Generated Responses
Authors:Luyang Lin, Zijin Feng, Lingzhi Wang, Kam-Fai Wong
Biased news contributes to societal polarization and is often reinforced by hostile reader comments, constituting a vital yet often overlooked aspect of news dissemination. Our study reveals that offensive comments support biased content, amplifying bias and causing harm to targeted groups or individuals. Counterspeech is an effective approach to counter such harmful speech without violating freedom of speech, helping to limit the spread of bias. To the best of our knowledge, this is the first study to explore counterspeech generation in the context of news articles. We introduce a manually annotated dataset linking media bias, offensive comments, and counterspeech. We conduct a detailed analysis showing that over 70% offensive comments support biased articles, amplifying bias and thus highlighting the importance of counterspeech generation. Comparing counterspeech generated by humans and large language models, we find model-generated responses are more polite but lack the novelty and diversity. Finally, we improve generated counterspeech through few-shot learning and integration of news background information, enhancing both diversity and relevance.
有偏见的新闻会导致社会两极化,往往还会得到敌对读者评论的强化,这是新闻传播的一个重要但常被忽视的方面。我们的研究表明,攻击性评论支持有偏见的内容,放大偏见,对目标群体或个人造成伤害。反语是一种在不侵犯言论自由的情况下对抗这种有害言论的有效方法,有助于限制偏见的传播。据我们所知,这是第一项探索新闻文章背景下反语生成的研究。我们引入了一个手动注释的数据集,将媒体偏见、攻击性评论和反语联系起来。我们进行了详细的分析,发现超过70%的攻击性评论支持有偏见的文章,放大偏见,从而凸显反语生成的重要性。通过对比人类和反语生成的大型语言模型生成的回应,我们发现模型生成的回应更加礼貌,但缺乏新颖性和多样性。最后,我们通过小样本学习和新闻背景信息的整合,改进了生成的反语,增强了其多样性和相关性。
论文及项目相关链接
Summary
本文研究了偏见新闻如何导致社会两极化,并指出攻击性读者评论强化了这种偏见。研究发现,攻击性评论支持有偏见的内容,放大了偏见,对目标群体或个人造成伤害。文章提出了用反语作为一种有效的应对方式,这种方式可以在不侵犯言论自由的前提下对抗有害言论。这是首个探索新闻文章中反语生成的研究。研究介绍了一个手动标注的数据集,涉及媒体偏见、攻击性评论和反语。分析显示,超过70%的攻击性评论支持有偏见的文章,凸显了生成反语的重要性。比较了人类和大型语言模型生成的反语,发现模型生成的反语更为礼貌,但缺乏新颖性和多样性。通过少量样本学习和整合新闻背景信息,提高了生成反语的质量和相关性。
Key Takeaways
- 偏见新闻加剧社会两极化,受攻击性读者评论强化。
- 攻击性评论支持偏见内容,放大偏见,对目标造成损害。
- 反语是一种有效应对有害言论的方式,不侵犯言论自由。
- 首次探索新闻文章中的反语生成。
- 研究介绍了一个涉及媒体偏见、攻击性评论和反语的手动标注数据集。
- 超过70%的攻击性评论支持有偏见的文章,凸显反语生成的重要性。
点此查看论文截图


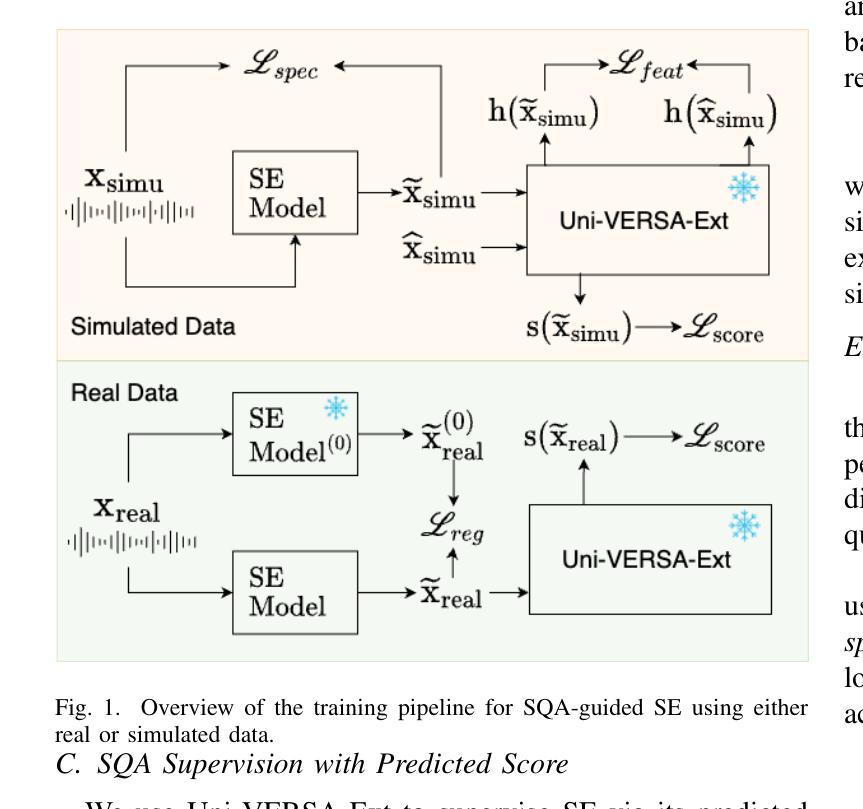
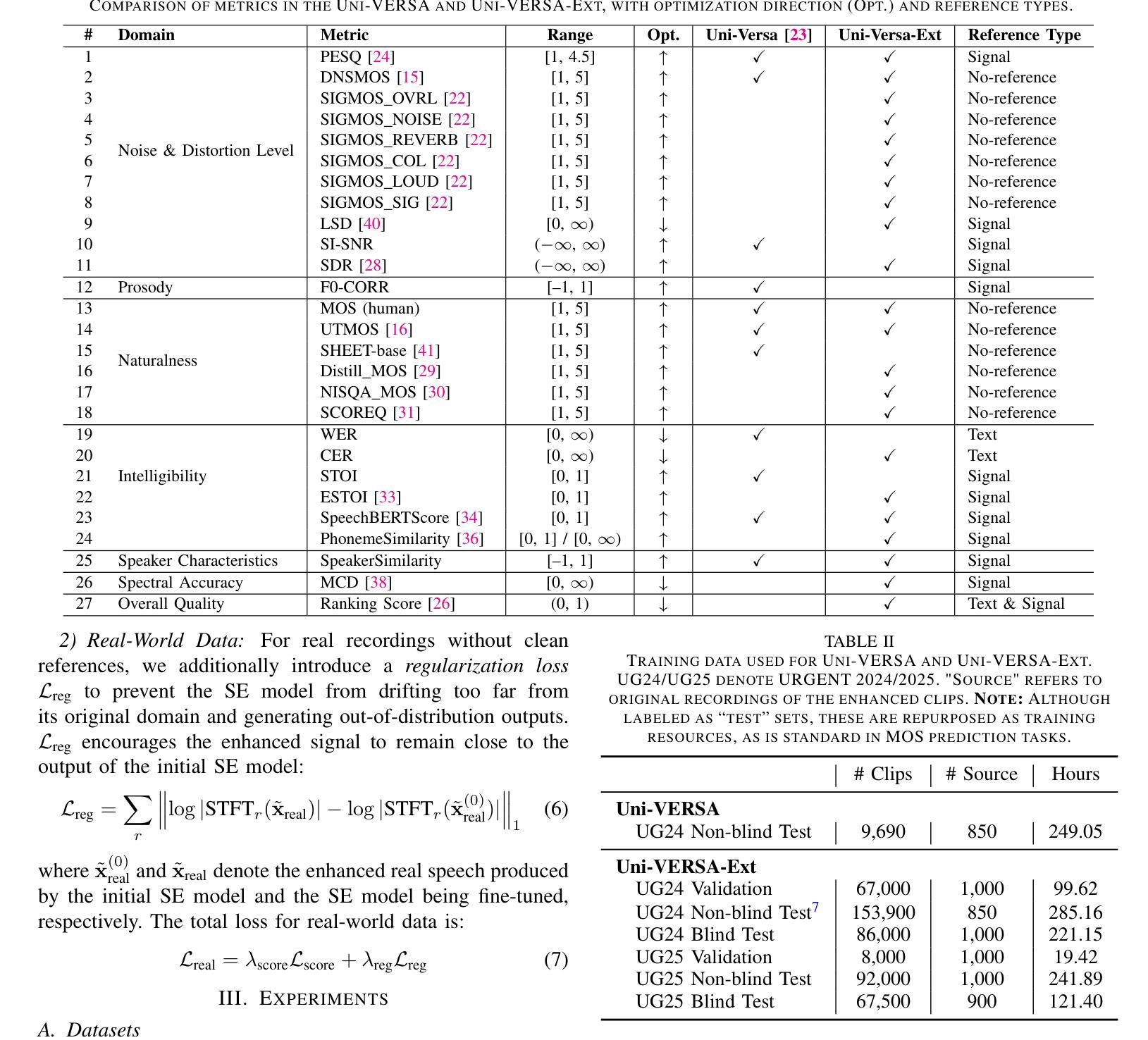
Improving Speech Enhancement with Multi-Metric Supervision from Learned Quality Assessment
Authors:Wei Wang, Wangyou Zhang, Chenda Li, Jiatong Shi, Shinji Watanabe, Yanmin Qian
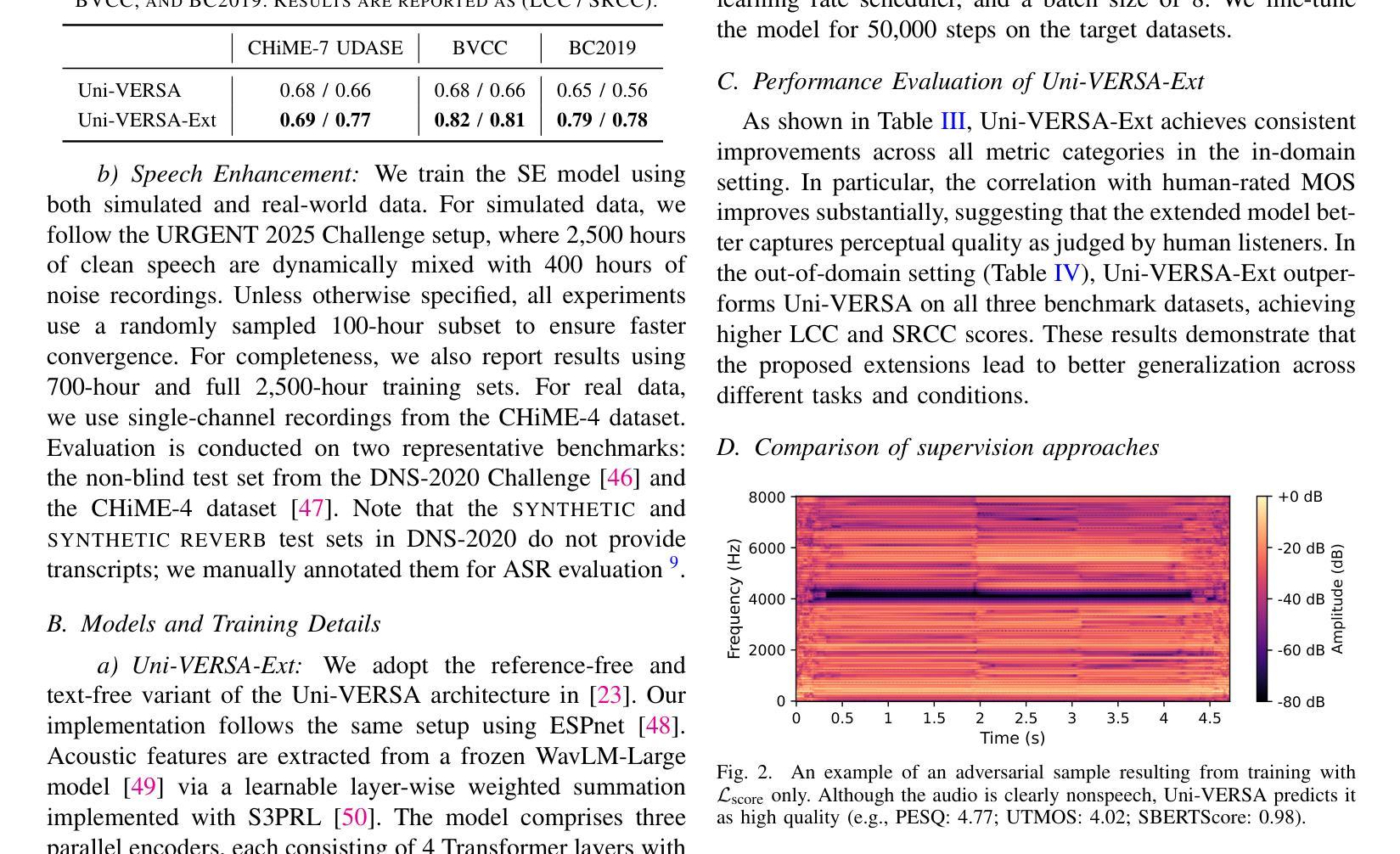
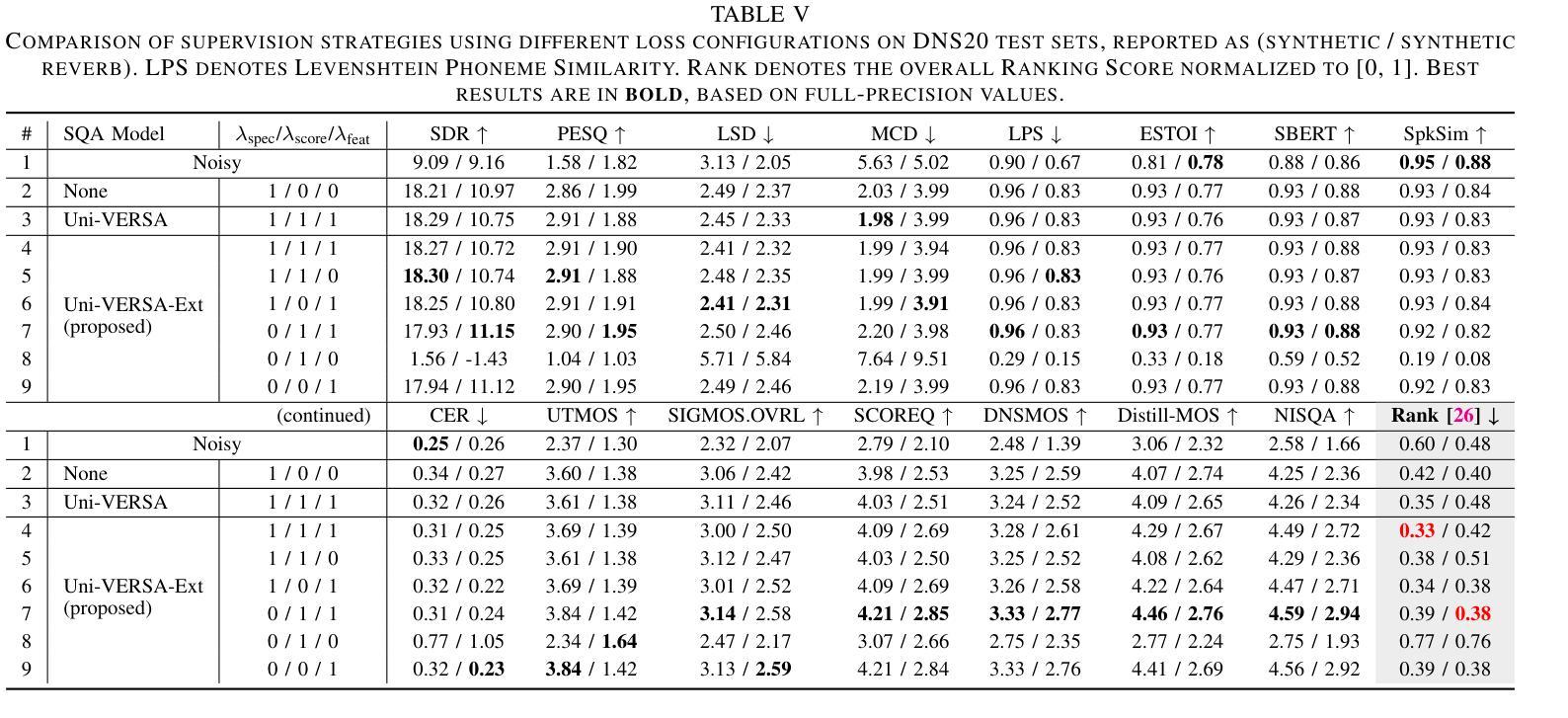
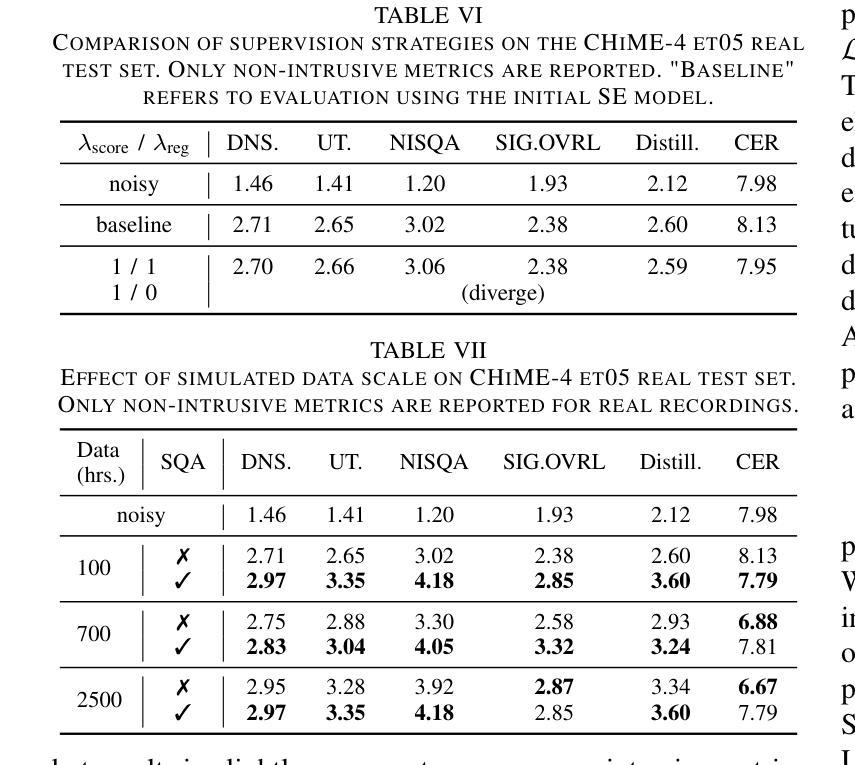
Speech quality assessment (SQA) aims to predict the perceived quality of speech signals under a wide range of distortions. It is inherently connected to speech enhancement (SE), which seeks to improve speech quality by removing unwanted signal components. While SQA models are widely used to evaluate SE performance, their potential to guide SE training remains underexplored. In this work, we investigate a training framework that leverages a SQA model, trained to predict multiple evaluation metrics from a public SE leaderboard, as a supervisory signal for SE. This approach addresses a key limitation of conventional SE objectives, such as SI-SNR, which often fail to align with perceptual quality and generalize poorly across evaluation metrics. Moreover, it enables training on real-world data where clean references are unavailable. Experiments on both simulated and real-world test sets show that SQA-guided training consistently improves performance across a range of quality metrics. Code and checkpoints are available at https://github.com/urgent-challenge/urgent2026_challenge_track2
语音质量评估(SQA)旨在预测大范围失真情况下的语音信号感知质量。它与语音增强(SE)紧密相连,旨在通过消除不需要的信号成分来提高语音质量。虽然SQA模型广泛用于评估SE性能,但其指导SE训练方面的潜力尚未得到充分探索。在这项工作中,我们研究了一个训练框架,该框架利用SQA模型,通过训练以预测来自公共SE排行榜的多个评价指标,作为SE的监督信号。这种方法解决了传统SE目标的一个关键局限性,如SI-SNR常常无法与感知质量保持一致,并且在评价指标上的泛化能力较差。此外,它可以在没有干净参考的情况下进行真实世界数据的训练。在模拟和真实世界测试集上的实验表明,SQA引导的训练在各种质量指标上的表现持续得到改善。代码和检查点可通过https://github.com/urgent-challenge/urgent2026_challenge_track2获得。
论文及项目相关链接
PDF Accepted by ASRU 2025
Summary
本文介绍了语音质量评估(SQA)在预测各种失真情况下的语音感知质量方面的应用。文章还探讨了将SQA模型作为监督信号应用于语音增强(SE)训练的可能性。该模型经过训练,能够预测公开SE排行榜中的多个评估指标,解决了传统SE目标(如SI-SNR)与感知质量不一致以及在跨评估指标上表现不佳的问题。此外,该模型能够在无清洁参考数据的情况下进行现实数据的训练。实验表明,在模拟和真实测试集上,SQA引导的训练在多种质量指标上的表现都有所提高。
Key Takeaways
- 语音质量评估(SQA)旨在预测各种失真情况下的语音感知质量。
- SQA模型作为监督信号应用于语音增强(SE)训练是可能的。
- SQA模型能够预测公开SE排行榜中的多个评估指标,解决了传统SE目标的问题。
- 传统语音增强目标(如SI-SNR)存在与感知质量不一致的问题。
- SQA引导的训练在多种质量指标上的表现均有所提高。
- 该模型能够在无清洁参考数据的情况下进行现实数据的训练。
点此查看论文截图


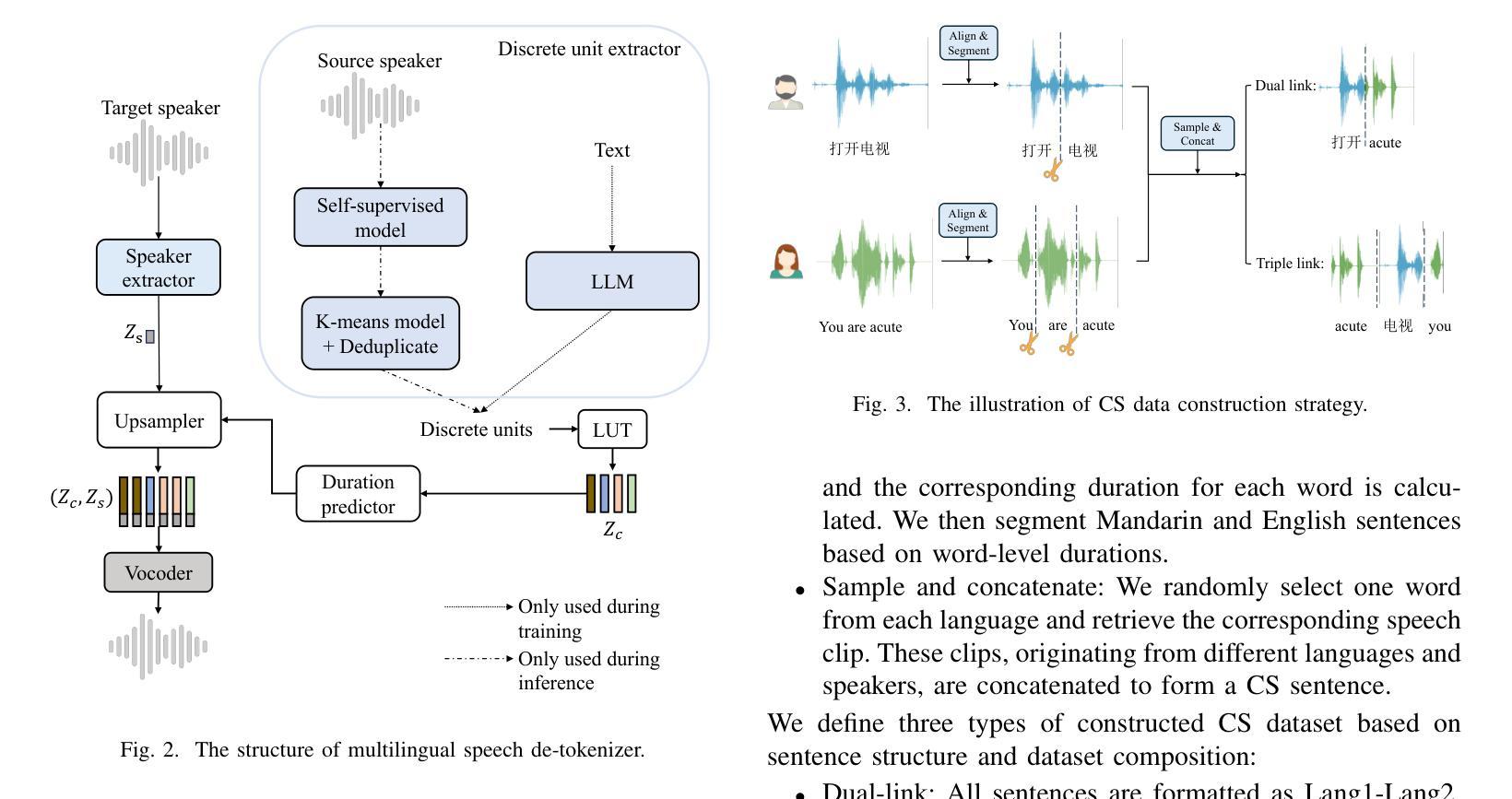
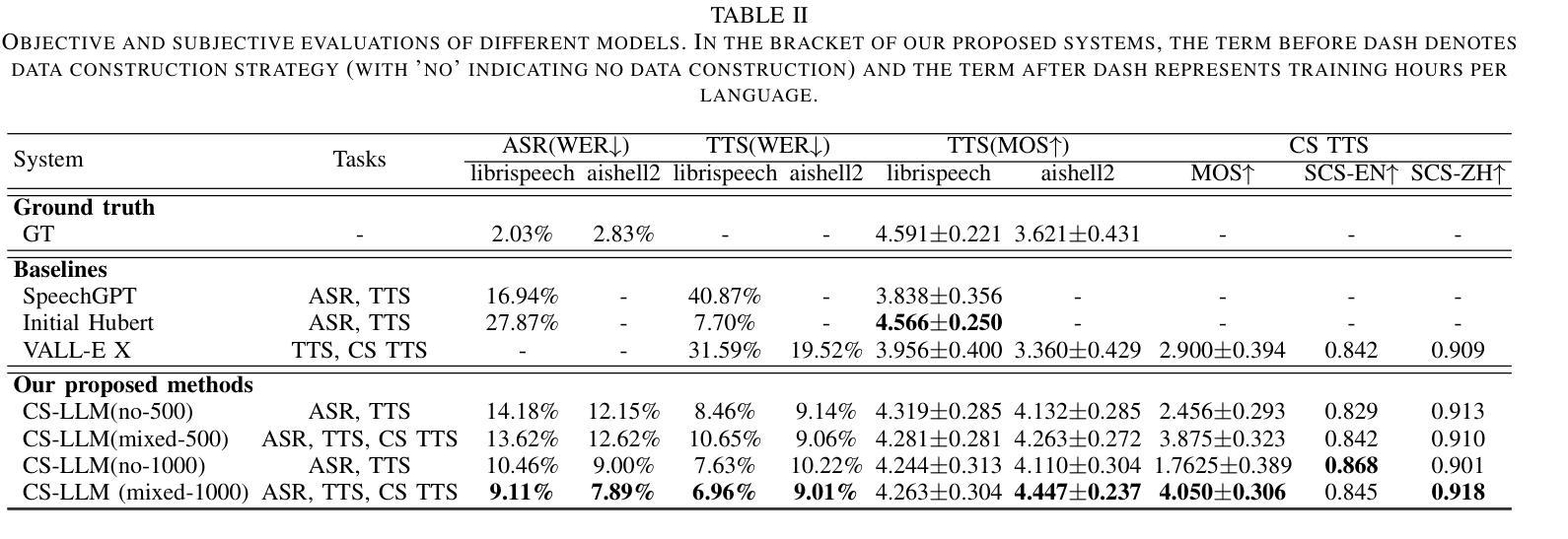
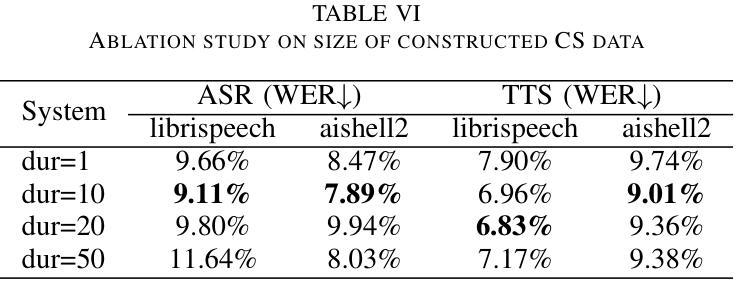
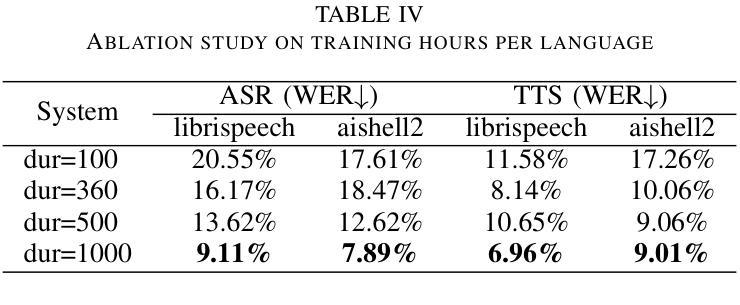
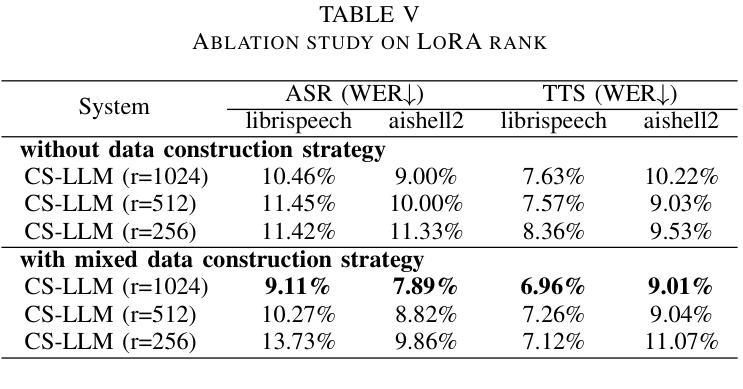
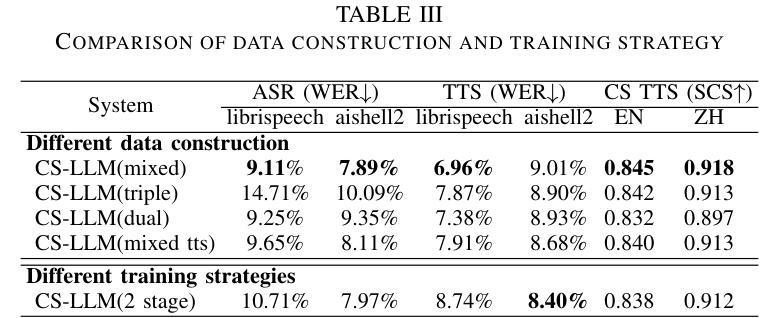
Enhancing Code-switched Text-to-Speech Synthesis Capability in Large Language Models with only Monolingual Corpora
Authors:Jing Xu, Daxin Tan, Jiaqi Wang, Xiao Chen
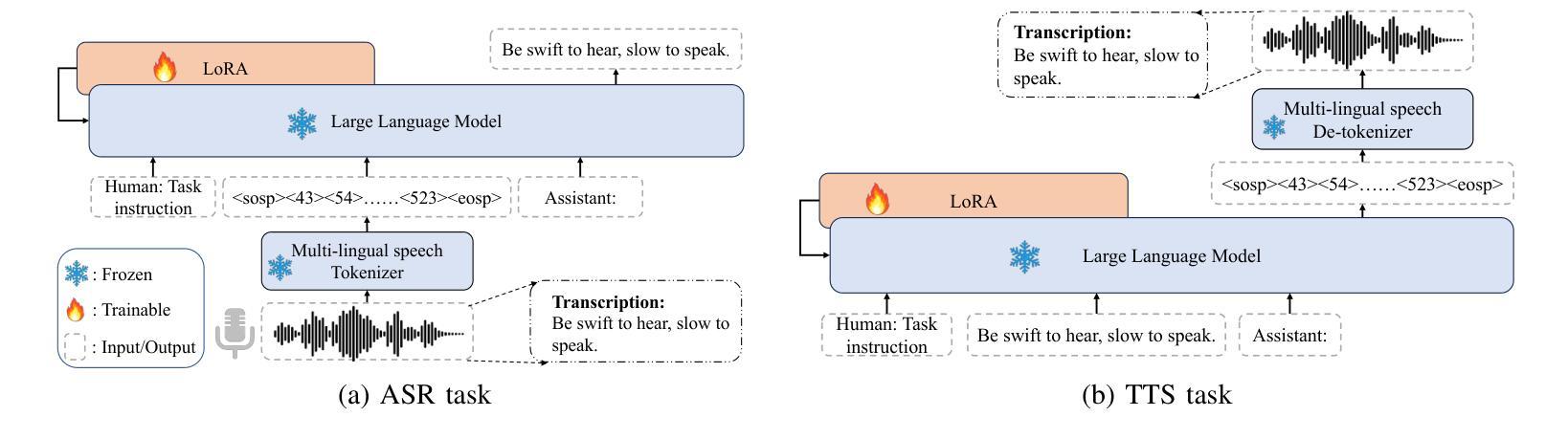
While Large Language Models (LLMs) have shown potential in speech generation and recognition, their applications are mainly confined to monolingual scenarios, with limited explorations in code-switched (CS) contexts. In this paper, we propose a Code-Switched Large Language Model (CS-LLM) to enhance the code-switched text-to-speech synthesis (CS TTS) capability in LLMs with only monolingual corpora. Specifically, we begin by enhancing the multilingual speech processing ability of LLMs through multilingual speech recognition and synthesis tasks. Then, we develop an effective code-switched (CS) data construction strategy that splits and concatenates words from different monolingual speech corpora to equip LLMs with improved CS TTS ability. Experiments show that our approach outperforms baselines in CS TTS in terms of naturalness, speaker consistency and similarity even with limited data. Additionally, the constructed CS data further improves multilingual speech synthesis and recognition.
虽然大型语言模型(LLM)在语音生成和识别方面显示出潜力,但它们的应用主要局限于单语场景,对混合语言(CS)环境的探索有限。在本文中,我们提出了一种混合语言大型语言模型(CS-LLM),旨在利用单语语料库增强大型语言模型在混合文本到语音合成(CS TTS)方面的能力。具体来说,我们首先通过多语言语音识别和合成任务增强LLM的多语言语音处理能力。然后,我们开发了一种有效的混合(CS)数据构建策略,该策略可以拆分和合并来自不同单语语音语料库的单词,以赋予LLM改进的CSTTS能力。实验表明,即使在有限数据的情况下,我们的方法在CSTTS方面的表现也优于基准线,体现在自然度、说话人一致性和相似性等方面。此外,构建的CS数据进一步提高了多语言语音合成和识别。
论文及项目相关链接
PDF Accepted to ASRU2025
Summary
多语言模型在语音生成和识别方面显示出潜力,但其应用主要集中在单语场景上,对混合语言环境下的应用探索有限。本文提出了一种混合大型语言模型(CS-LLM),旨在通过仅使用单语语料库提高大型语言模型在混合文本到语音合成(CS TTS)中的能力。具体来说,我们首先通过多语言语音识别与合成任务来增强大型语言模型的多语言语音处理能力。然后,我们开发了一种有效的混合(CS)数据构建策略,该策略可以拆分和合并来自不同单语语音语料库的单词,以赋予大型语言模型改进后的CSTTS能力。实验表明,即使在有限的数据下,我们的方法在自然度、说话人一致性和相似性方面也比基线在CSTTS中的表现要好。此外,构建的CS数据进一步提高了多语言语音合成和识别的性能。
Key Takeaways
- 大型语言模型在语音生成和识别方面具有潜力,但其在混合语言环境下的应用仍然有限。
- 论文提出了一种混合大型语言模型(CS-LLM),旨在提高大型语言模型在混合文本到语音合成(CS TTS)中的性能。
- 通过多语言语音识别与合成任务增强大型语言模型的多语言语音处理能力。
- 开发了一种有效的混合数据构建策略,通过拆分和合并不同单语语音语料库的单词,提高模型的CSTTS能力。
- 实验结果显示,CS-LLM在自然度、说话人一致性和相似性方面优于基线方法。
- 构建的CS数据不仅提高了CSTTS性能,还进一步提高了多语言语音合成和识别的性能。
点此查看论文截图

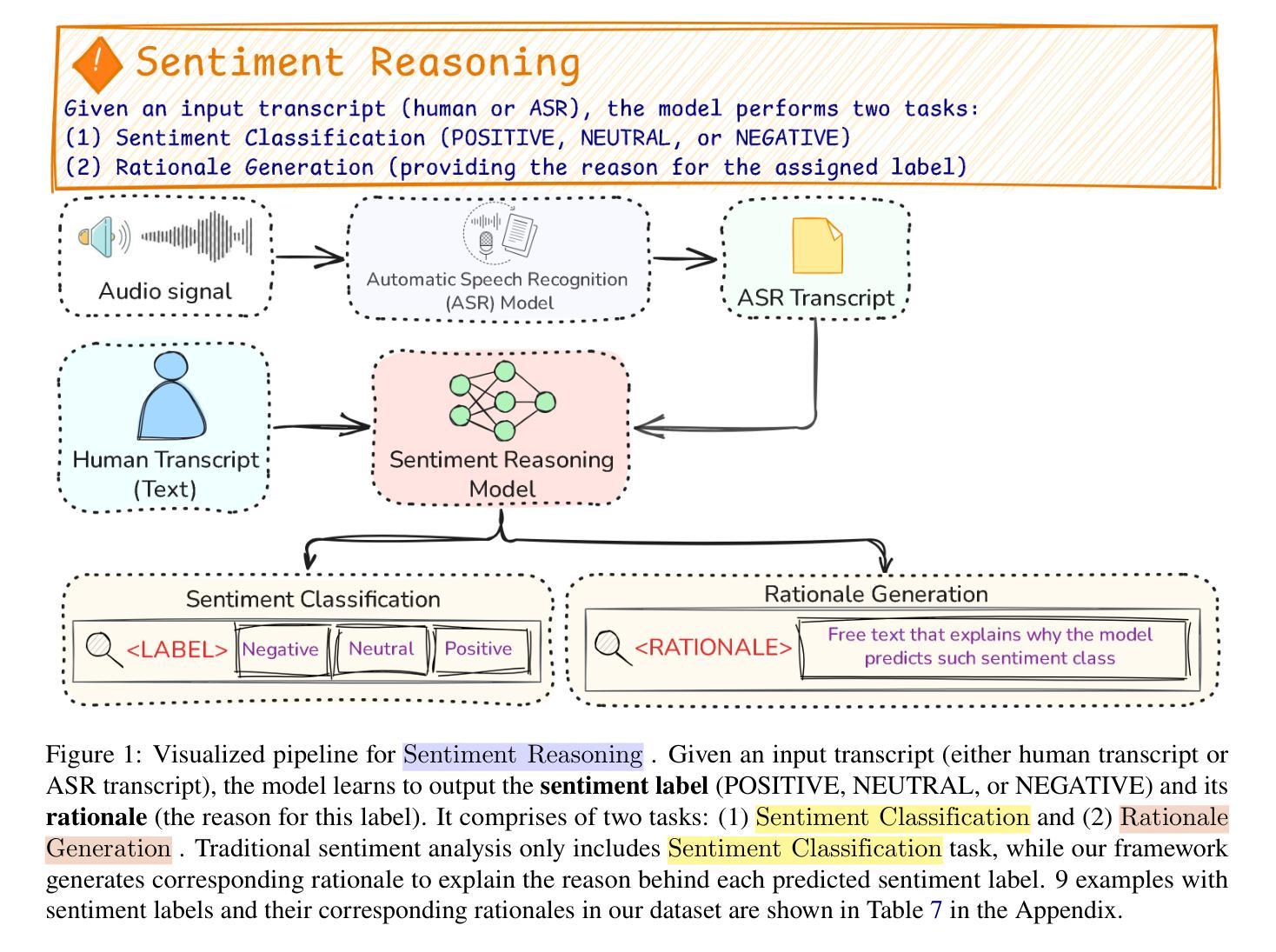
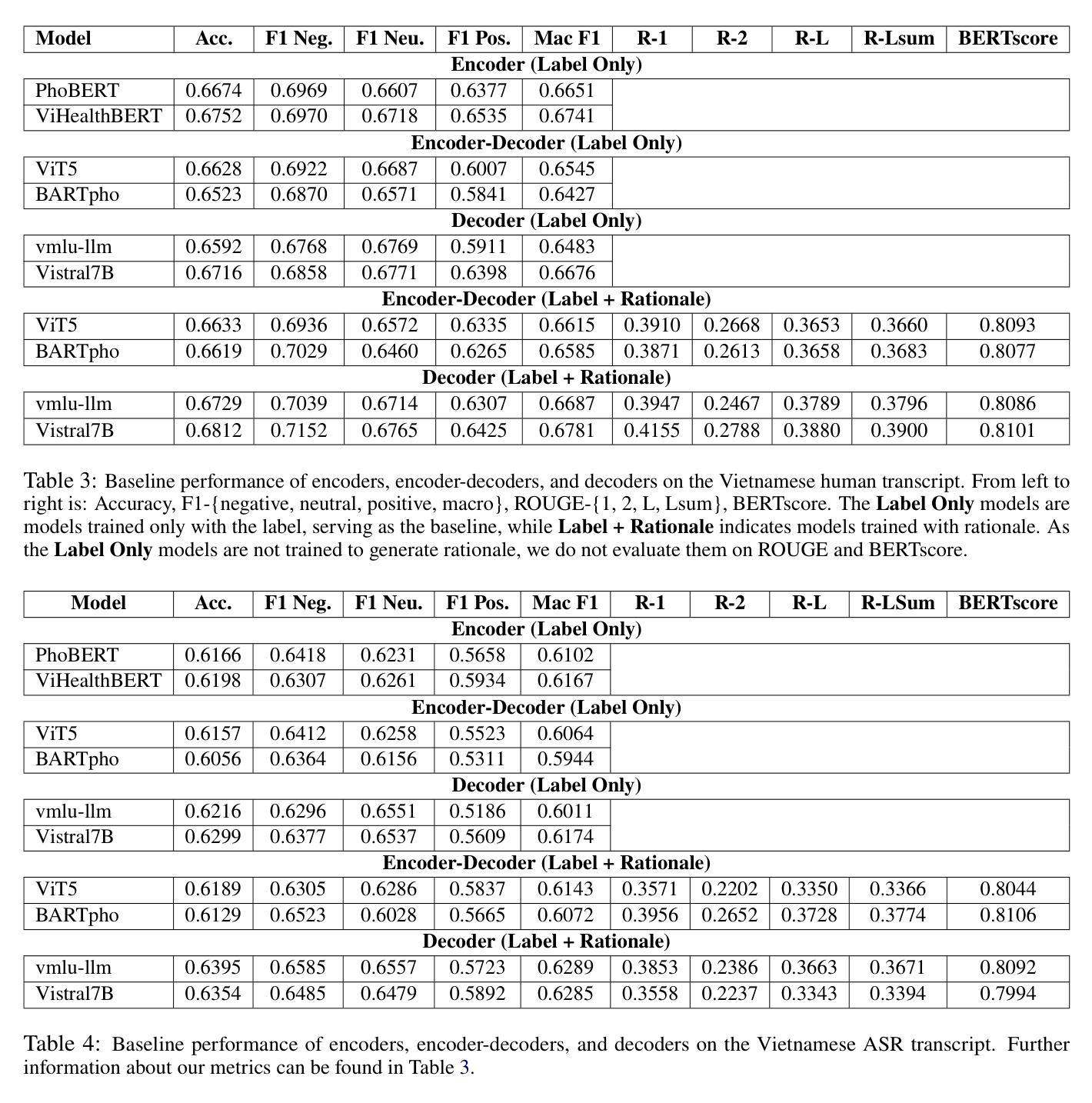
Sentiment Reasoning for Healthcare
Authors:Khai-Nguyen Nguyen, Khai Le-Duc, Bach Phan Tat, Duy Le, Long Vo-Dang, Truong-Son Hy
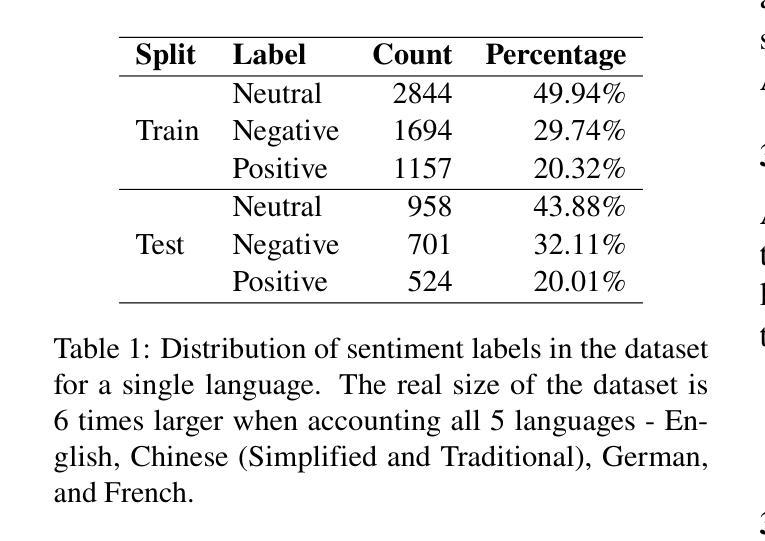
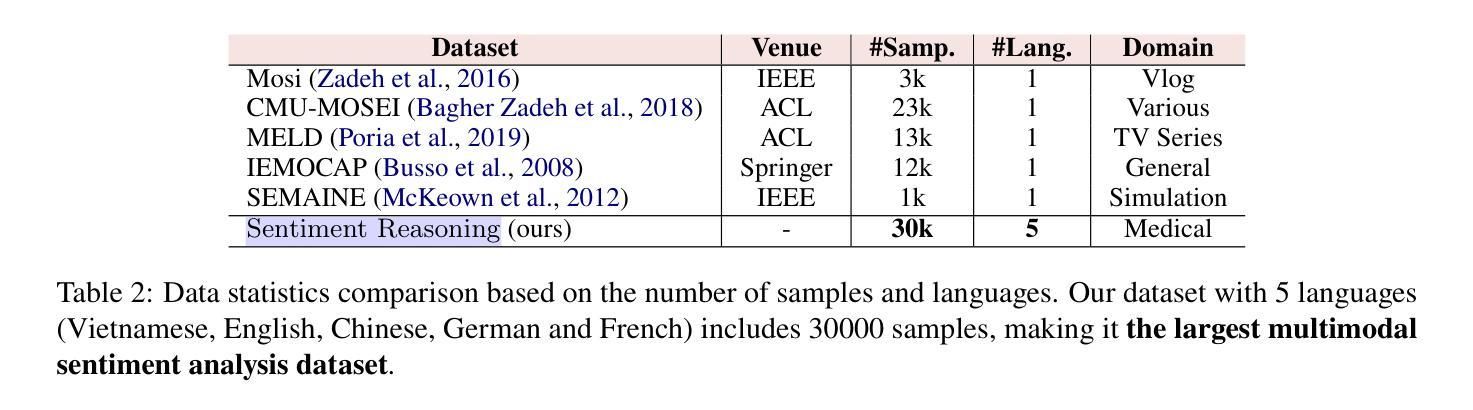
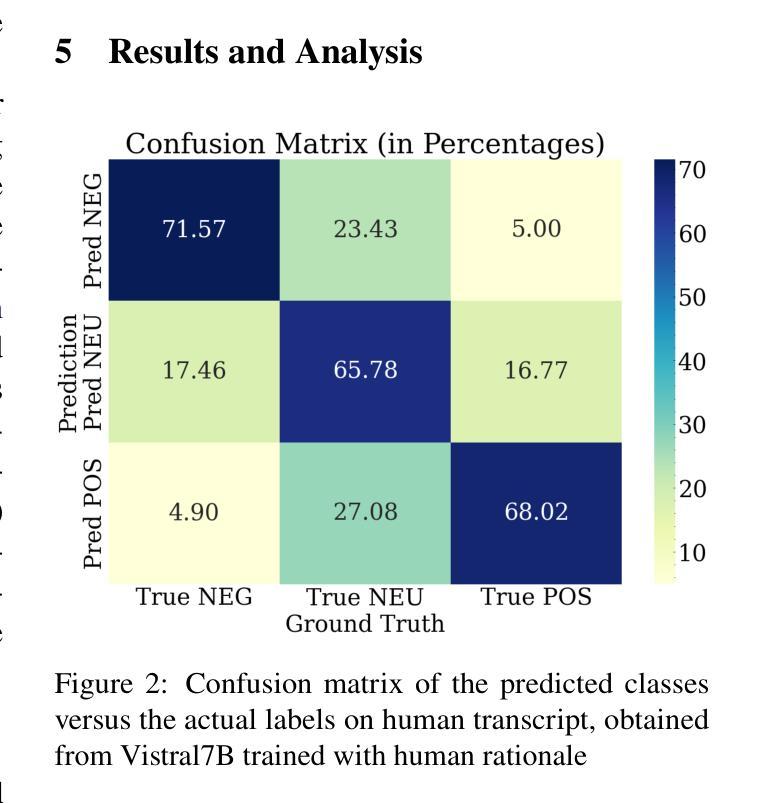
Transparency in AI healthcare decision-making is crucial. By incorporating rationales to explain reason for each predicted label, users could understand Large Language Models (LLMs)’s reasoning to make better decision. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, and our proposed multimodal multitask framework and the world’s largest multimodal sentiment analysis dataset. Sentiment Reasoning is an auxiliary task in sentiment analysis where the model predicts both the sentiment label and generates the rationale behind it based on the input transcript. Our study conducted on both human transcripts and Automatic Speech Recognition (ASR) transcripts shows that Sentiment Reasoning helps improve model transparency by providing rationale for model prediction with quality semantically comparable to humans while also improving model’s classification performance (+2% increase in both accuracy and macro-F1) via rationale-augmented fine-tuning. Also, no significant difference in the semantic quality of generated rationales between human and ASR transcripts. All code, data (five languages - Vietnamese, English, Chinese, German, and French) and models are published online: https://github.com/leduckhai/Sentiment-Reasoning
人工智能医疗决策中的透明度至关重要。通过将每个预测标签的理由融入其中,用户可以理解大型语言模型(LLM)的推理,以做出更好的决策。在这项工作中,我们为语音和文本模态引入了一项新任务——情感推理,以及我们提出的多模态多任务框架和世界上最大的多模态情感分析数据集。情感推理是情感分析中的辅助任务,模型根据输入内容预测情感标签并生成其背后的理由。我们的研究对人类转录和自动语音识别(ASR)转录的文本进行了实验,结果表明,情感推理通过为模型预测提供理由,提高了模型的透明度,其语义质量与人类相当,同时还通过增加理由的微调提高了模型的分类性能(+2%准确度和宏观F1分数提高)。此外,人类和ASR转录文本在生成理由的语义质量上没有显著差异。所有代码、数据(五种语言:越南语、英语、中文、德语和法语)和模型均在线发布:https://github.com/leduckhai/Sentiment-Reasoning
论文及项目相关链接
PDF ACL 2025 Industry Track (Oral)
Summary
本文强调人工智能健康决策中的透明度至关重要。通过融入解释预测标签的理由,用户能更好地理解大型语言模型(LLMs)的推理过程以做出更好的决策。本文介绍了一项新的任务——情感推理,涉及语音和文本两种模式,并提出了一个多模态多任务框架和全球最大的多模态情感分析数据集。情感推理是情感分析中的辅助任务,模型根据输入内容预测情感标签并生成背后的理由。研究表明,情感推理有助于提高模型的透明度,并为模型预测提供理由,其语义质量与人类相似。此外,通过基于理由的微调,情感推理还可提高模型的分类性能(+2%的提升)。人类和自动语音识别(ASR)转录生成的文本在语义质量上没有显著差异。所有代码、数据和模型均已在线发布。
Key Takeaways
- 人工智能健康决策需要更高的透明度。
- 通过融入预测标签的理由,用户能更好地理解大型语言模型的推理过程。
- 介绍了一项新的任务——情感推理,适用于语音和文本两种模式。
- 提出了多模态多任务框架和全球最大多模态情感分析数据集。
- 情感推理有助于提升模型的透明度并提高其分类性能。
- 对比研究表明,情感推理模型在语义质量上与人类表现相似。
点此查看论文截图