⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-08-26 更新
ANT: Adaptive Neural Temporal-Aware Text-to-Motion Model
Authors:Wenshuo Chen, Kuimou Yu, Haozhe Jia, Kaishen Yuan, Zexu Huang, Bowen Tian, Songning Lai, Hongru Xiao, Erhang Zhang, Lei Wang, Yutao Yue
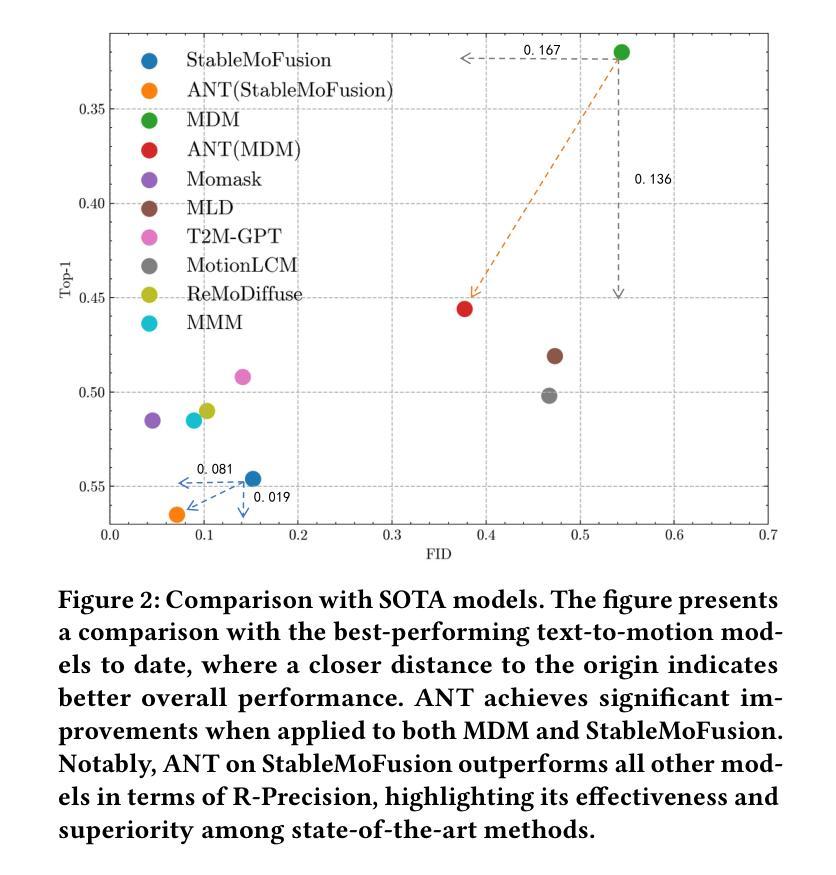
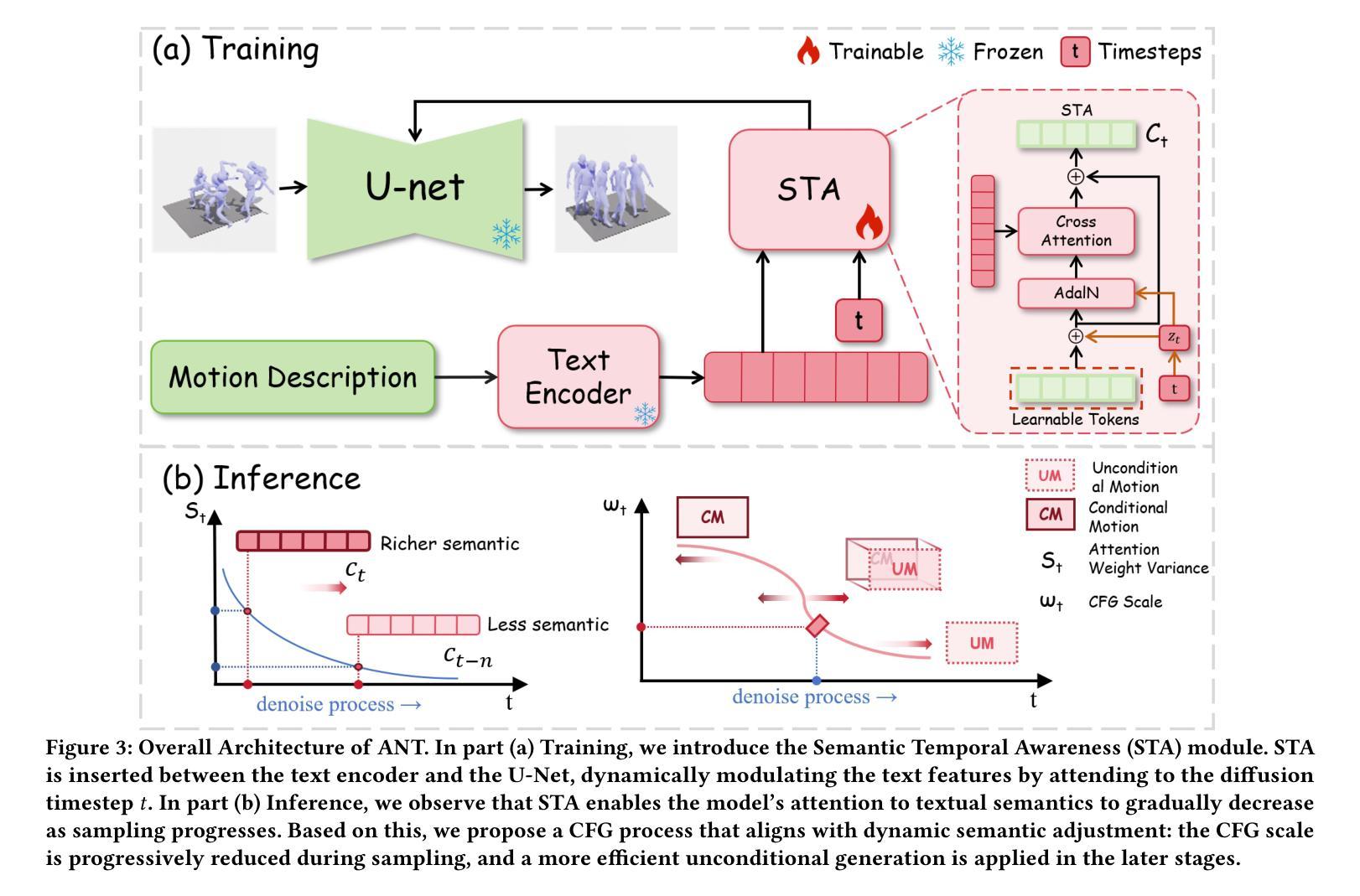
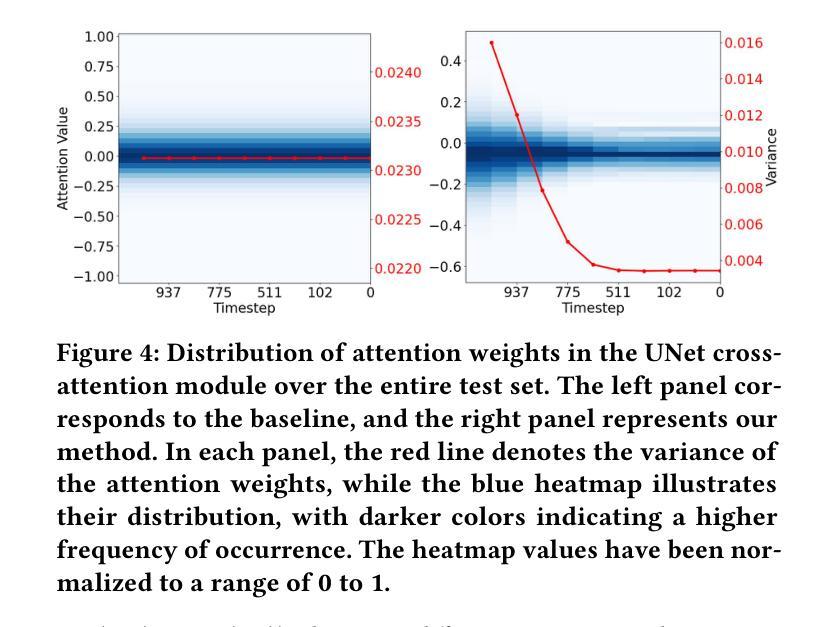
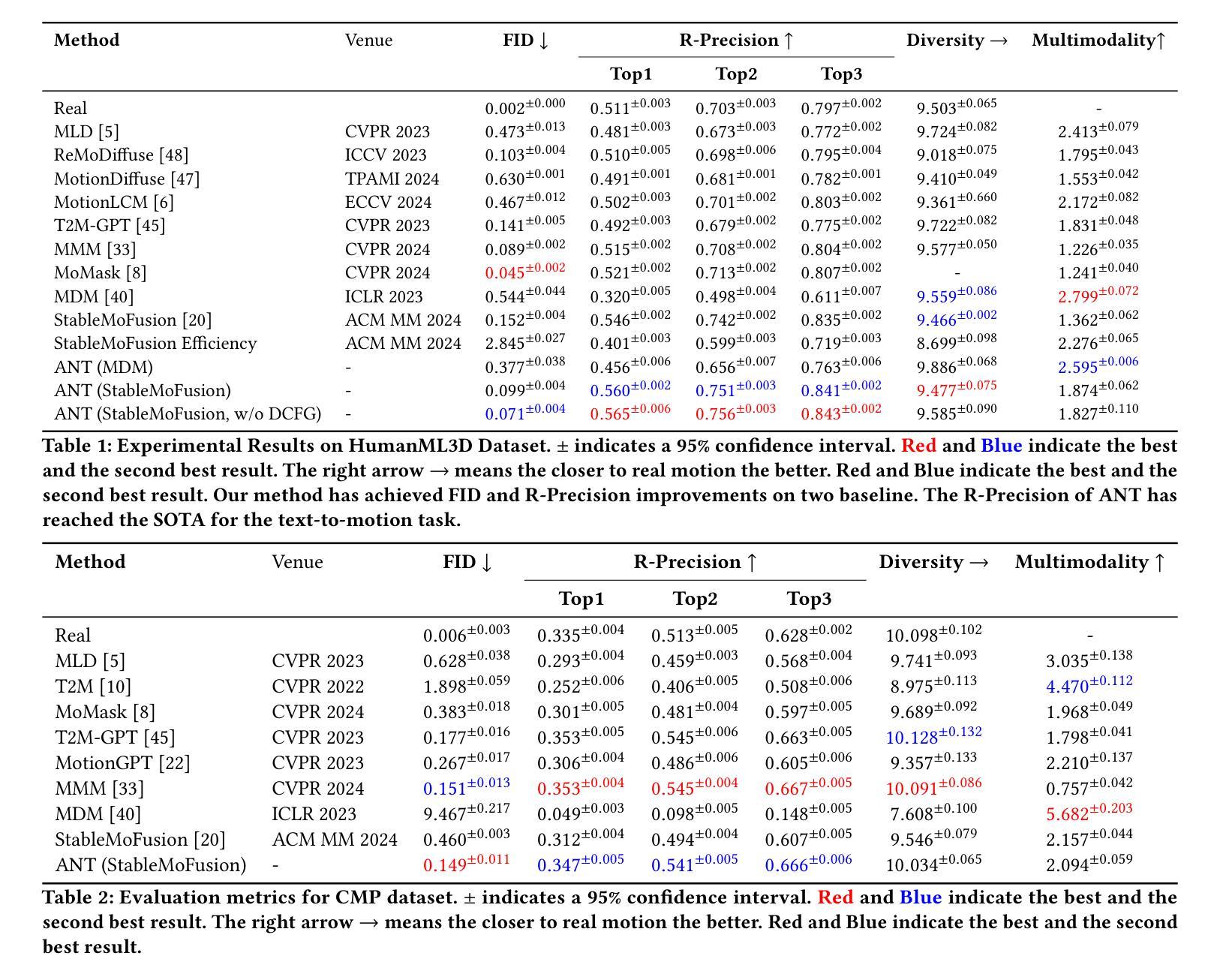
While diffusion models advance text-to-motion generation, their static semantic conditioning ignores temporal-frequency demands: early denoising requires structural semantics for motion foundations while later stages need localized details for text alignment. This mismatch mirrors biological morphogenesis where developmental phases demand distinct genetic programs. Inspired by epigenetic regulation governing morphological specialization, we propose (ANT), an Adaptive Neural Temporal-Aware architecture. ANT orchestrates semantic granularity through: (i) Semantic Temporally Adaptive (STA) Module: Automatically partitions denoising into low-frequency structural planning and high-frequency refinement via spectral analysis. (ii) Dynamic Classifier-Free Guidance scheduling (DCFG): Adaptively adjusts conditional to unconditional ratio enhancing efficiency while maintaining fidelity. Extensive experiments show that ANT can be applied to various baselines, significantly improving model performance, and achieving state-of-the-art semantic alignment on StableMoFusion.
随着扩散模型在文本到运动生成中的发展,其静态语义条件忽略了时间频率需求:早期降噪需要为运动基础提供结构语义,而后期则需要局部细节以实现文本对齐。这种不匹配反映了生物形态发生过程,发育阶段需要不同的遗传程序。受表观遗传调控支配形态特化的启发,我们提出了 **(ANT)**,一种自适应神经时序感知架构。ANT通过以下方式协调语义粒度:(i) 语义时间自适应(STA)模块:通过频谱分析自动将降噪划分为低频结构规划和高频细化。(ii) 动态无分类引导调度(DCFG):自适应调整条件与无条件比率,提高效率同时保持保真度。大量实验表明,ANT可应用于各种基准测试,显著提高模型性能,并在StableMoFusion上实现最先进的语义对齐。
论文及项目相关链接
Summary
随着扩散模型在文本到运动生成中的应用发展,其静态语义条件忽略了时间频率的需求。早期去噪需要结构语义为运动基础提供基础,而后期阶段则需要局部细节以实现文本对齐。受表观遗传调控形态特化的启发,我们提出了自适应神经时序感知架构(ANT)。ANT通过语义粒度调整来协调时序感知过程:首先通过光谱分析自动将去噪划分为低频结构规划和高频细节调整。其次动态调整有条件和无条件的比率来提高效率并维持保真度。经过大量实验证明,ANT可以应用于多种基准模型,显著提高了模型性能,并在StableMoFusion上实现了最先进的语义对齐。
Key Takeaways
- 扩散模型在文本到运动生成中的应用虽有所发展,但仍存在静态语义条件忽略时间频率需求的问题。
- 早期和后期去噪过程对语义的需求不同,早期需要结构语义为运动基础,后期则需要局部细节实现文本对齐。
- ANT架构通过自适应神经时序感知来调整语义粒度。
- ANT架构包括两个主要部分:语义时序自适应模块(STA)和动态无类别引导调度(DCFG)。
- STA模块通过光谱分析自动划分去噪过程为低频结构规划和高频细节调整。
- DCFG模块动态调整有条件和无条件的比率以提高效率和维持保真度。
- 经过实验验证,ANT架构可以应用于多种基准模型,显著提高模型性能。
点此查看论文截图

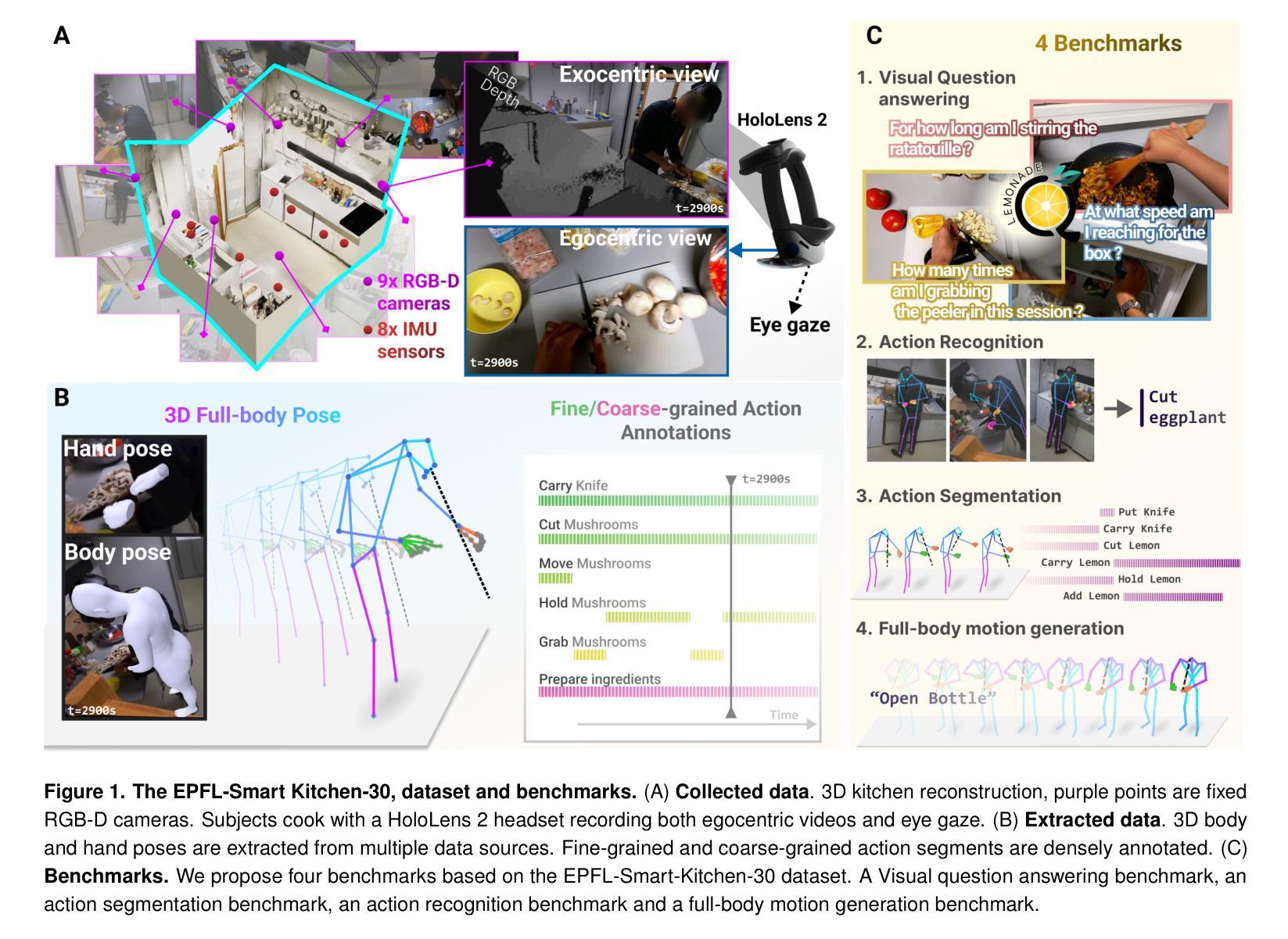
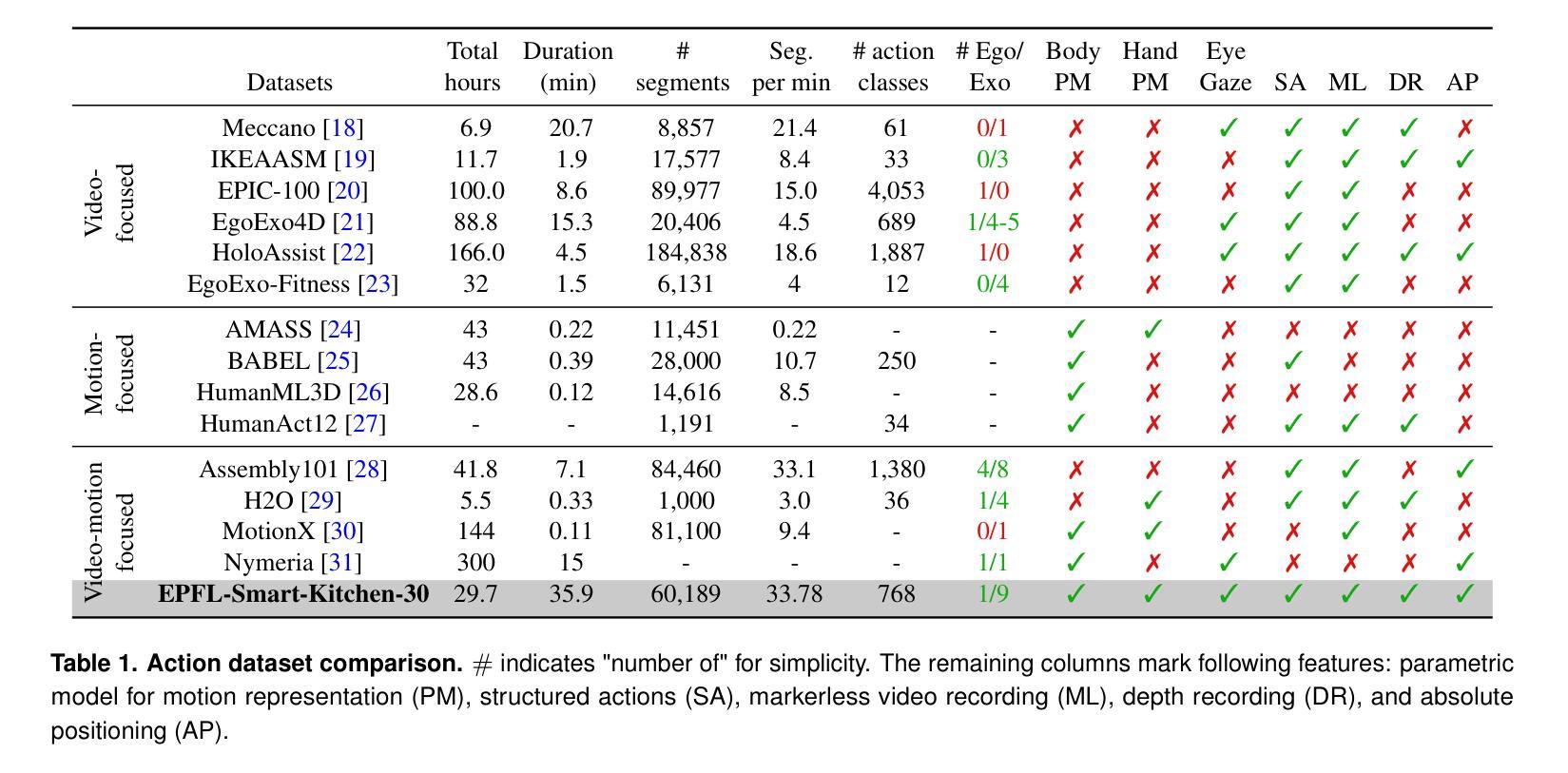
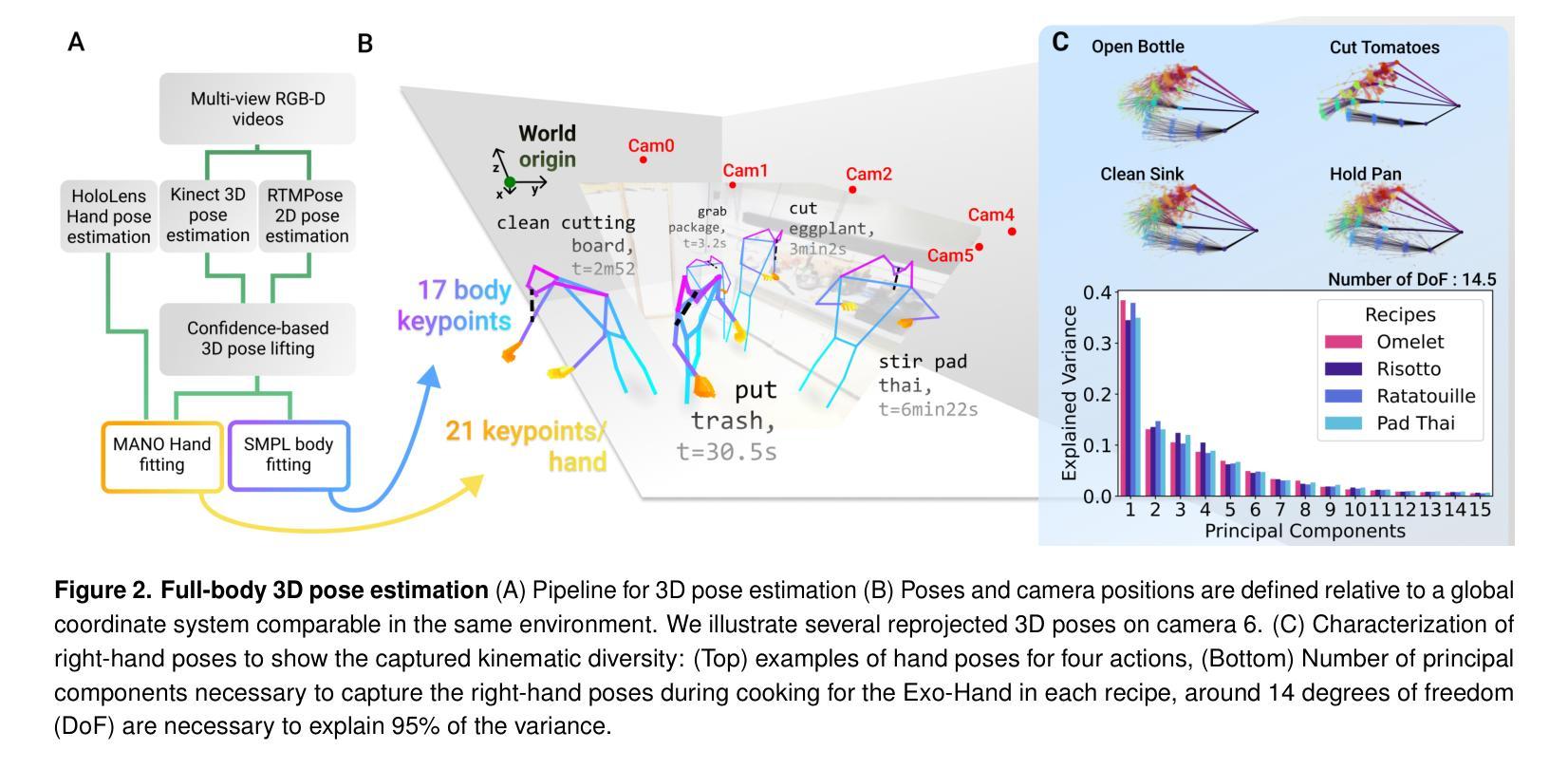
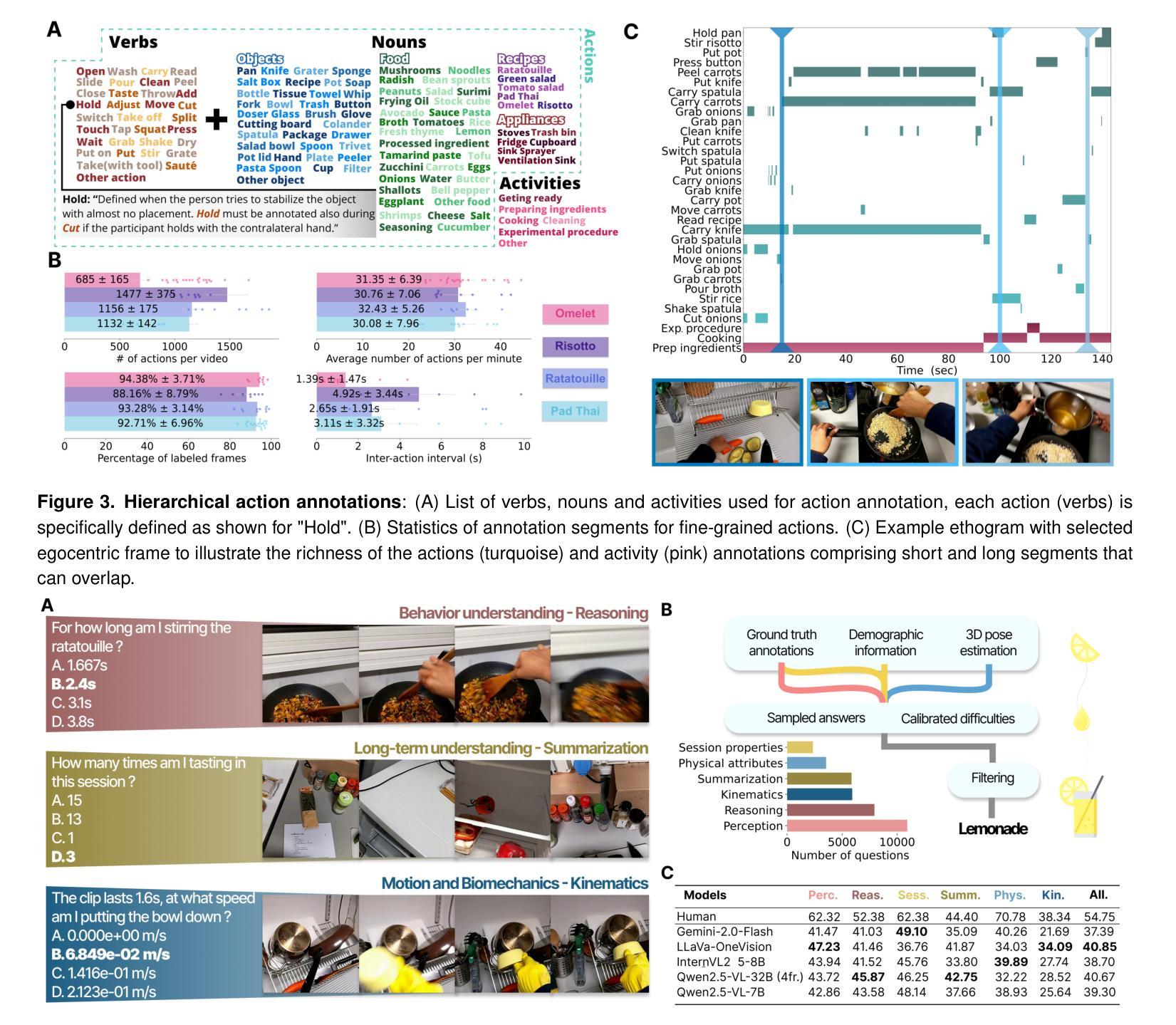
EPFL-Smart-Kitchen-30: Densely annotated cooking dataset with 3D kinematics to challenge video and language models
Authors:Andy Bonnetto, Haozhe Qi, Franklin Leong, Matea Tashkovska, Mahdi Rad, Solaiman Shokur, Friedhelm Hummel, Silvestro Micera, Marc Pollefeys, Alexander Mathis
Understanding behavior requires datasets that capture humans while carrying out complex tasks. The kitchen is an excellent environment for assessing human motor and cognitive function, as many complex actions are naturally exhibited in kitchens from chopping to cleaning. Here, we introduce the EPFL-Smart-Kitchen-30 dataset, collected in a noninvasive motion capture platform inside a kitchen environment. Nine static RGB-D cameras, inertial measurement units (IMUs) and one head-mounted HoloLens~2 headset were used to capture 3D hand, body, and eye movements. The EPFL-Smart-Kitchen-30 dataset is a multi-view action dataset with synchronized exocentric, egocentric, depth, IMUs, eye gaze, body and hand kinematics spanning 29.7 hours of 16 subjects cooking four different recipes. Action sequences were densely annotated with 33.78 action segments per minute. Leveraging this multi-modal dataset, we propose four benchmarks to advance behavior understanding and modeling through 1) a vision-language benchmark, 2) a semantic text-to-motion generation benchmark, 3) a multi-modal action recognition benchmark, 4) a pose-based action segmentation benchmark. We expect the EPFL-Smart-Kitchen-30 dataset to pave the way for better methods as well as insights to understand the nature of ecologically-valid human behavior. Code and data are available at https://github.com/amathislab/EPFL-Smart-Kitchen
为了理解人类行为,需要捕捉人类在执行复杂任务时的数据集。厨房是一个评估人类运动和认知功能的绝佳环境,因为在厨房从切割到清洁的过程中,许多复杂的行为都会自然展现。在这里,我们介绍了EPFL-Smart-Kitchen-30数据集,该数据集是在厨房环境内的非侵入式运动捕获平台上收集的。使用了九个静态RGB-D相机、惯性测量单元(IMU)和一个头戴式HoloLens 2耳机来捕捉手、身体和眼睛的三维运动。EPFL-Smart-Kitchen-30数据集是一个多视角动作数据集,同步了离身、近身、深度、IMU、眼动、身体和手的动力学,涵盖了16名受试者烹饪四种不同食谱的29.7小时。动作序列被密集地注释了,每分钟有33.78个动作片段。利用这个多模式数据集,我们提出了四个基准测试,以推动行为理解和建模的进步,包括1)视觉语言基准测试、2)语义文本到运动生成基准测试、3)多模式动作识别基准测试、4)基于姿势的动作分割基准测试。我们期望EPFL-Smart-Kitchen-30数据集能为更好地理解生态有效的人类行为的方法和见解铺平道路。代码和数据可在https://github.com/amathislab/EPFL-Smart-Kitchen找到。
论文及项目相关链接
PDF Code and data at: https://github.com/amathislab/EPFL-Smart-Kitchen
Summary:
本文介绍了EPFL-Smart-Kitchen-30数据集,该数据集是在厨房环境中采集的,用于评估人类运动和认知功能。通过使用RGB-D相机、惯性测量单元(IMU)和头戴式HoloLens 2头盔等设备,捕获了手、身体和眼睛的三维动作。该数据集包含多视角动作数据,涵盖外视角、内视角、深度、IMU、眼动追踪等多模态信息,可用于促进行为理解和建模的四个基准测试。数据集包含厨房环境下烹饪四种不同食谱的记录,涵盖了丰富多样的动作序列。该数据集预期能为更先进的方法和人类生态有效行为的洞察铺平道路。数据集和相关代码可通过链接访问:链接地址。
Key Takeaways:
- EPFL-Smart-Kitchen-30数据集用于评估人类运动和认知功能,特别适合研究厨房环境中的复杂动作。
- 数据集通过多模态采集设备捕获了丰富的动作信息,包括手、身体和眼睛的三维动作数据。
- 数据集涵盖了厨房环境下烹饪四种不同食谱的记录,动作序列被密集标注和分类。
- 数据集提供了四个基准测试用于行为理解和建模的研究,包括视觉语言基准测试、语义文本到动作的生成基准测试、多模态动作识别基准测试和基于姿态的动作分割基准测试。
- 数据集对理解和模拟生态有效的人类行为具有潜在价值。
- 数据集和相关代码可通过在线链接访问,便于研究者和开发者使用。
点此查看论文截图