⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
Hyper Diffusion Avatars: Dynamic Human Avatar Generation using Network Weight Space Diffusion
Authors:Dongliang Cao, Guoxing Sun, Marc Habermann, Florian Bernard
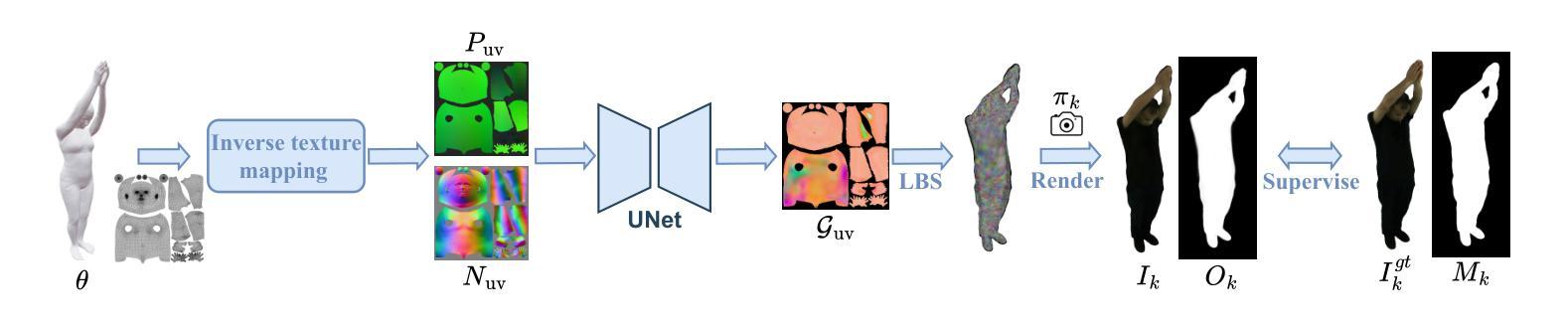
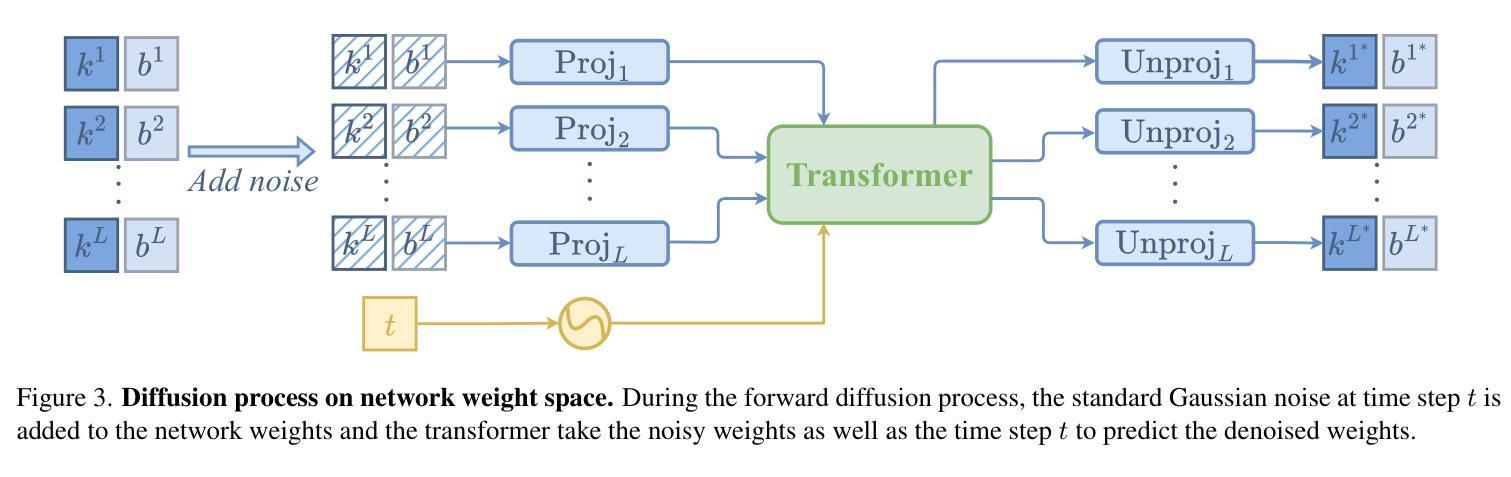
Creating human avatars is a highly desirable yet challenging task. Recent advancements in radiance field rendering have achieved unprecedented photorealism and real-time performance for personalized dynamic human avatars. However, these approaches are typically limited to person-specific rendering models trained on multi-view video data for a single individual, limiting their ability to generalize across different identities. On the other hand, generative approaches leveraging prior knowledge from pre-trained 2D diffusion models can produce cartoonish, static human avatars, which are animated through simple skeleton-based articulation. Therefore, the avatars generated by these methods suffer from lower rendering quality compared to person-specific rendering methods and fail to capture pose-dependent deformations such as cloth wrinkles. In this paper, we propose a novel approach that unites the strengths of person-specific rendering and diffusion-based generative modeling to enable dynamic human avatar generation with both high photorealism and realistic pose-dependent deformations. Our method follows a two-stage pipeline: first, we optimize a set of person-specific UNets, with each network representing a dynamic human avatar that captures intricate pose-dependent deformations. In the second stage, we train a hyper diffusion model over the optimized network weights. During inference, our method generates network weights for real-time, controllable rendering of dynamic human avatars. Using a large-scale, cross-identity, multi-view video dataset, we demonstrate that our approach outperforms state-of-the-art human avatar generation methods.
创建人类虚拟形象是一项非常理想但具有挑战性的任务。最近,辐射场渲染技术的进展为实现个性化动态人类虚拟形象的超真实感和实时性能提供了前所未有的能力。然而,这些方法通常仅限于针对单个个体的多视角视频数据训练的特定人物渲染模型,限制了它们在跨不同身份方面的泛化能力。另一方面,利用预训练的二维扩散模型的先验知识的生成方法,可以产生卡通式的静态人类虚拟形象,通过简单的基于骨骼的关节运动进行动画。因此,这些方法生成的虚拟形象与特定人物渲染方法相比,渲染质量较低,并且无法捕捉姿势相关的变形,如衣物褶皱等。在本文中,我们提出了一种结合特定人物渲染和基于扩散的生成建模优点的新方法,以实现具有高度真实感和现实姿势相关变形能力的动态人类虚拟形象生成。我们的方法遵循两阶段流程:首先,我们优化一组特定人物的U-Net网络,每个网络代表一个动态人类虚拟形象,捕捉复杂的姿势相关变形。在第二阶段,我们在优化后的网络权重上训练一个超扩散模型。在推理过程中,我们的方法生成网络权重以进行实时、可控的动态人类虚拟形象渲染。使用大规模跨身份多视角视频数据集,我们证明了我们的方法优于最先进的人类虚拟形象生成方法。
论文及项目相关链接
Summary
本论文提出了一种结合人物特定渲染和扩散生成模型的方法,实现了动态人类角色生成,具有高度的逼真性和真实的姿态依赖性变形。该方法采用两个阶段:首先优化人物特定的U-Net网络,捕捉复杂的姿态依赖性变形;然后训练超扩散模型以生成网络权重,实现实时可控的动态人类角色渲染。使用大规模跨身份多视角视频数据集,该方法表现出超越现有技术的人类角色生成方法的性能。
Key Takeaways
- 论文结合了人物特定渲染和扩散生成模型,实现了动态人类角色生成。
- 方法采用两个阶段:优化人物特定的U-Net网络和训练超扩散模型。
- U-Net网络捕捉复杂的姿态依赖性变形。
- 方法使用大规模跨身份多视角视频数据集进行验证。
- 该方法实现了动态人类角色的实时可控渲染。
- 论文提出的方法在性能上超越了现有的动态人类角色生成技术。
点此查看论文截图


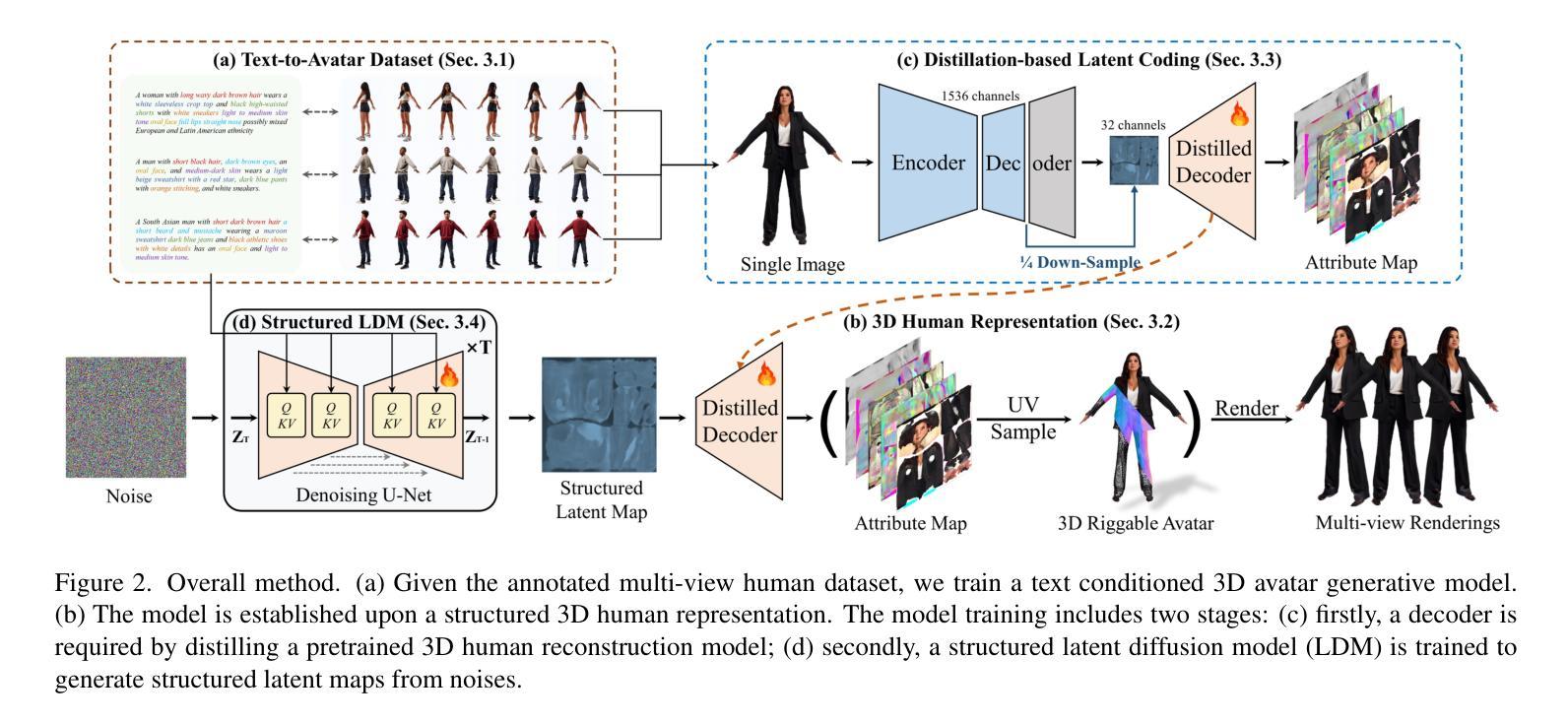
TeRA: Rethinking Text-guided Realistic 3D Avatar Generation
Authors:Yanwen Wang, Yiyu Zhuang, Jiawei Zhang, Li Wang, Yifei Zeng, Xun Cao, Xinxin Zuo, Hao Zhu
In this paper, we rethink text-to-avatar generative models by proposing TeRA, a more efficient and effective framework than the previous SDS-based models and general large 3D generative models. Our approach employs a two-stage training strategy for learning a native 3D avatar generative model. Initially, we distill a decoder to derive a structured latent space from a large human reconstruction model. Subsequently, a text-controlled latent diffusion model is trained to generate photorealistic 3D human avatars within this latent space. TeRA enhances the model performance by eliminating slow iterative optimization and enables text-based partial customization through a structured 3D human representation. Experiments have proven our approach’s superiority over previous text-to-avatar generative models in subjective and objective evaluation.
在这篇论文中,我们通过对TeRA的提出,重新思考了文本到虚拟角色的生成模型。TeRa是一个比之前的基于SDS的模型和一般的3D生成模型更加高效和有效的框架。我们的方法采用两阶段训练策略来学习一个原生的3D虚拟角色生成模型。首先,我们从大型人类重建模型中提炼出一个解码器,以获取结构化潜在空间。接着,我们在这一潜在空间内训练一个受文本控制的潜在扩散模型,以生成逼真的3D人类虚拟角色。TeRa通过消除缓慢的迭代优化过程提高了模型性能,并通过结构化3D人类表示实现了基于文本的局部定制。实验证明,我们的方法在主观和客观评价上都优于之前的文本到虚拟角色生成模型。
论文及项目相关链接
PDF Accepted by ICCV2025
Summary
文本提出一个更高效且有效的文本转化身像生成模型框架TeRA,改进了传统的SDS模型和一般的3D生成模型。采用两阶段训练策略来学习原生3D化身生成模型,首先通过大型人类重建模型蒸馏解码器得到结构化潜在空间,然后训练文本控制的潜在扩散模型在该潜在空间内生成逼真的3D人类化身。TeRA提高了模型性能,避免了缓慢的迭代优化,并通过结构化3D人类表现实现基于文本的个性化定制。实验证明,在主观和客观评估上,TeRA优于其他文本化身生成模型。
Key Takeaways
- TeRA是一个更高效和有效的文本转化身生成模型框架。
- 采用两阶段训练策略来学习原生3D化身生成模型。
- 通过大型人类重建模型蒸馏解码器得到结构化潜在空间。
- 文本控制的潜在扩散模型用于生成逼真的3D人类化身。
- TeRA避免了缓慢的迭代优化,并实现基于文本的个性化定制。
- 实验证明TeRA在主观和客观评估上优于其他文本化身生成模型。
点此查看论文截图

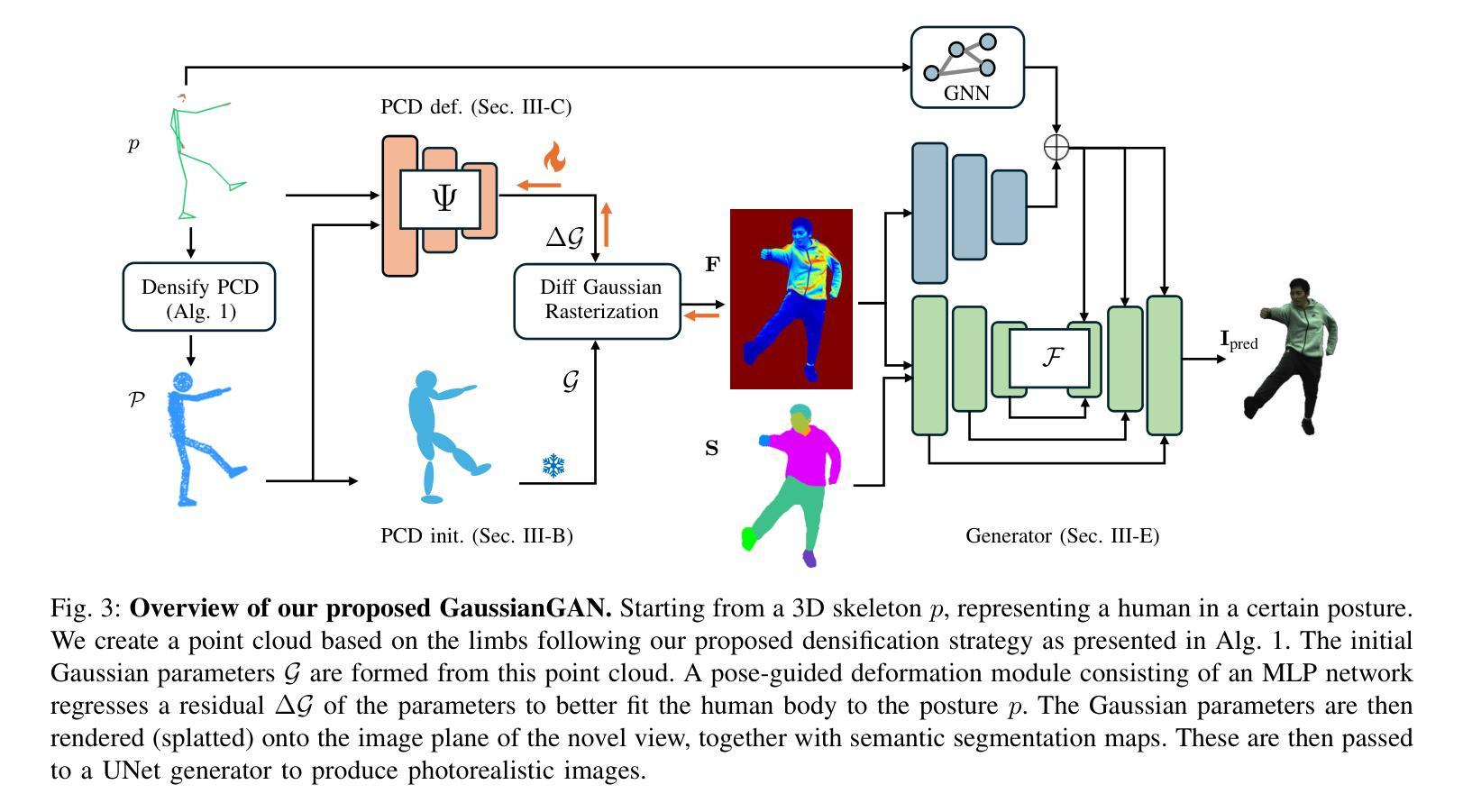
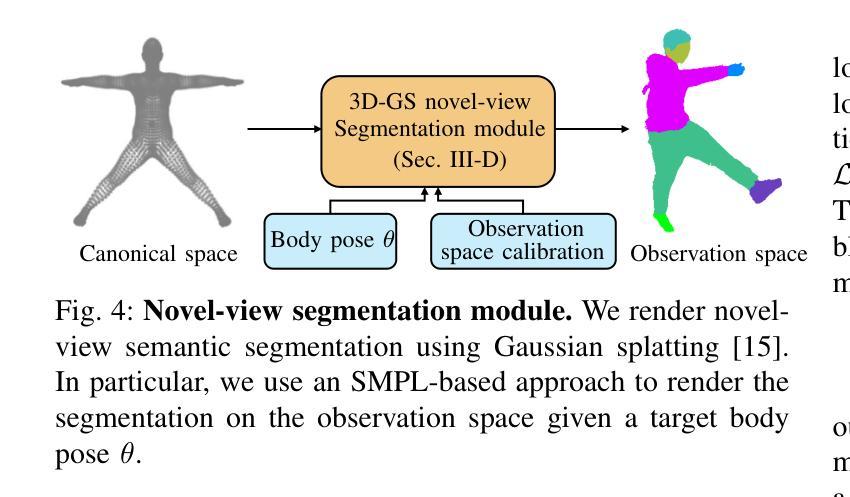
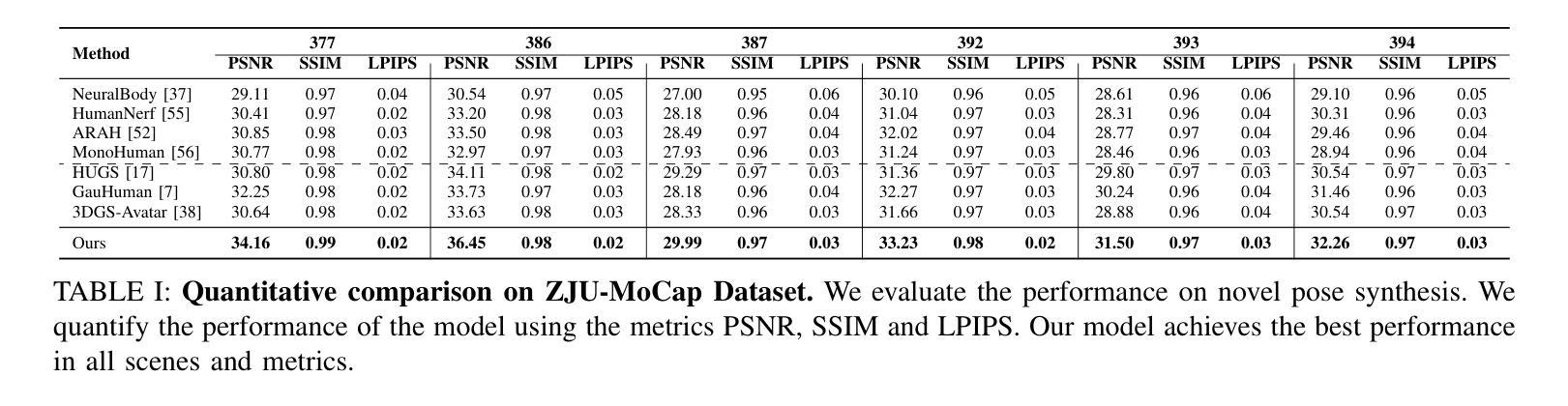
GaussianGAN: Real-Time Photorealistic controllable Human Avatars
Authors:Mohamed Ilyes Lakhal, Richard Bowden
Photorealistic and controllable human avatars have gained popularity in the research community thanks to rapid advances in neural rendering, providing fast and realistic synthesis tools. However, a limitation of current solutions is the presence of noticeable blurring. To solve this problem, we propose GaussianGAN, an animatable avatar approach developed for photorealistic rendering of people in real-time. We introduce a novel Gaussian splatting densification strategy to build Gaussian points from the surface of cylindrical structures around estimated skeletal limbs. Given the camera calibration, we render an accurate semantic segmentation with our novel view segmentation module. Finally, a UNet generator uses the rendered Gaussian splatting features and the segmentation maps to create photorealistic digital avatars. Our method runs in real-time with a rendering speed of 79 FPS. It outperforms previous methods regarding visual perception and quality, achieving a state-of-the-art results in terms of a pixel fidelity of 32.94db on the ZJU Mocap dataset and 33.39db on the Thuman4 dataset.
具有真实感和可控性的人类虚拟形象由于其快速发展的神经网络渲染技术所提供的快速且真实的合成工具,在学术界中受到了欢迎。然而,当前解决方案的一个局限性是存在明显的模糊。为了解决这个问题,我们提出了GaussianGAN,这是一种为实时渲染人的真实感而开发的可动态调整的虚拟形象方法。我们引入了一种新颖的Gaussian splatting densification策略,从估计的骨骼肢体的圆柱形结构表面构建Gaussian点。根据相机校准,我们使用全新的视图分割模块进行准确的语义分割。最后,UNet生成器使用渲染的Gaussian splatting特征和分割图来创建具有真实感的数字虚拟形象。我们的方法在实时运行,渲染速度为79 FPS。在视觉感知和质量方面,它优于以前的方法,在ZJU Mocap数据集上达到了每像素保真度32.94db的最新水平,并在Thuman4数据集上达到了33.39db。
论文及项目相关链接
PDF IEEE conference series on Automatic Face and Gesture Recognition 2025
Summary
当前神经网络渲染技术的快速发展推动了人类角色模型的流行。然而,现有解决方案存在模糊问题。为解决此问题,本文提出了GaussianGAN方法,采用高斯投射稠化策略构建高斯点,通过相机校准进行精确语义分割,并使用UNet生成器创建逼真的数字角色模型。该方法实时运行,渲染速度达到79 FPS,在ZJU Mocap和Thuman4数据集上的像素保真度达到业界领先水平。
Key Takeaways
一、神经网络渲染技术的快速发展推动了人类角色模型的流行。
二、现有解决方案存在模糊问题,需要新方法解决。
三、GaussianGAN方法采用高斯投射稠化策略构建高斯点。
四、通过相机校准进行精确语义分割。
五、使用UNet生成器创建逼真的数字角色模型。
六、该方法实时运行,渲染速度达到79 FPS。
点此查看论文截图




Im2Haircut: Single-view Strand-based Hair Reconstruction for Human Avatars
Authors:Vanessa Sklyarova, Egor Zakharov, Malte Prinzler, Giorgio Becherini, Michael J. Black, Justus Thies
We present a novel approach for 3D hair reconstruction from single photographs based on a global hair prior combined with local optimization. Capturing strand-based hair geometry from single photographs is challenging due to the variety and geometric complexity of hairstyles and the lack of ground truth training data. Classical reconstruction methods like multi-view stereo only reconstruct the visible hair strands, missing the inner structure of hairstyles and hampering realistic hair simulation. To address this, existing methods leverage hairstyle priors trained on synthetic data. Such data, however, is limited in both quantity and quality since it requires manual work from skilled artists to model the 3D hairstyles and create near-photorealistic renderings. To address this, we propose a novel approach that uses both, real and synthetic data to learn an effective hairstyle prior. Specifically, we train a transformer-based prior model on synthetic data to obtain knowledge of the internal hairstyle geometry and introduce real data in the learning process to model the outer structure. This training scheme is able to model the visible hair strands depicted in an input image, while preserving the general 3D structure of hairstyles. We exploit this prior to create a Gaussian-splatting-based reconstruction method that creates hairstyles from one or more images. Qualitative and quantitative comparisons with existing reconstruction pipelines demonstrate the effectiveness and superior performance of our method for capturing detailed hair orientation, overall silhouette, and backside consistency. For additional results and code, please refer to https://im2haircut.is.tue.mpg.de.
我们提出了一种从单张照片进行3D头发重建的新方法,该方法基于全局头发先验值结合局部优化。由于发型的多样性和几何复杂性,以及缺乏真实训练数据,从单张照片捕捉基于细线的头发几何结构是一个挑战。传统的重建方法(如多视角立体技术)只能重建可见的头发细线,忽略了发型的内部结构,阻碍了真实头发模拟。为了解决这个问题,现有方法利用基于合成数据的发型先验值。然而,此类数据在数量和质量上均受到限制,因为需要熟练艺术家的手工工作来建立3D发型并创建接近真实照片的渲染。为了解决这一问题,我们提出了一种新方法,同时使用真实和合成数据来学习有效的发型先验值。具体来说,我们在合成数据上训练了一个基于转换器的先验模型,以获得发型内部几何的知识,并在学习过程中引入真实数据来模拟外部结构。这种训练方案能够模拟输入图像中描绘的可见头发细线,同时保持发型的整体3D结构。我们利用这一先验值创建了一种基于高斯平铺的重建方法,可以从一张或多张照片创建发型。与现有重建管道的质量和数量比较表明,我们的方法在捕捉详细的头发方向、整体轮廓和背面一致性方面都非常有效且性能卓越。更多结果和代码请参见:https://im2haircut.is.tue.mpg.de。
论文及项目相关链接
PDF For more results please refer to the project page https://im2haircut.is.tue.mpg.de
Summary
基于合成和真实数据结合的方法,通过全球头发先验与局部优化相结合,实现了从单张照片中进行三维头发重建。该方法解决了因发型多样性和几何复杂性以及缺乏真实训练数据导致的头发重建难题。与传统重建方法相比,该方法不仅能重建可见的头发,还能保留发型内部结构,实现了更真实的头发模拟。
Key Takeaways
- 提出了一种结合真实和合成数据的新型头发重建方法。
- 利用基于合成数据的转换器模型学习发型先验,了解发型内部结构。
- 在学习过程中引入真实数据,以模拟外部结构。
- 通过高斯平铺技术重建发型,可从一张或多张图像创建发型。
- 方法能有效捕捉头发细节方向、整体轮廓和背面一致性。
- 与现有重建流程相比,该方法展现出优越的性能。
点此查看论文截图

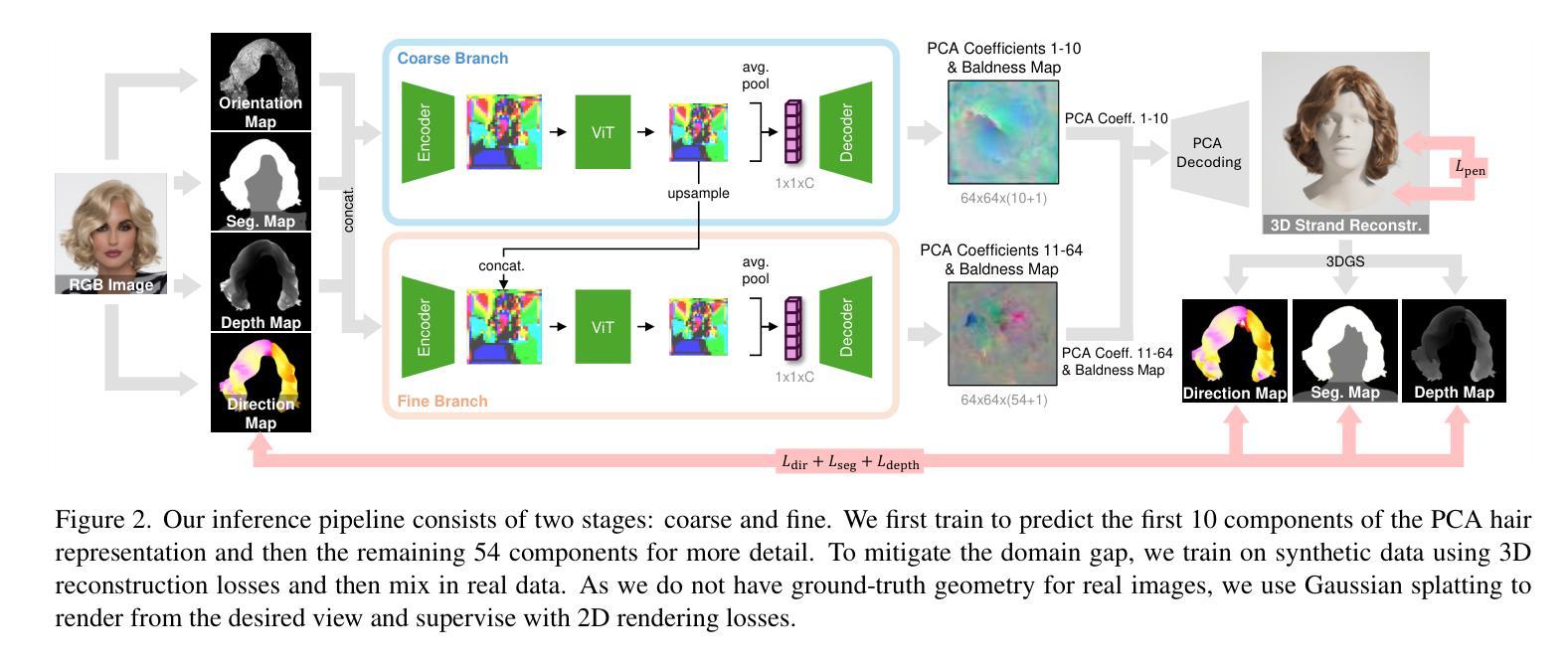
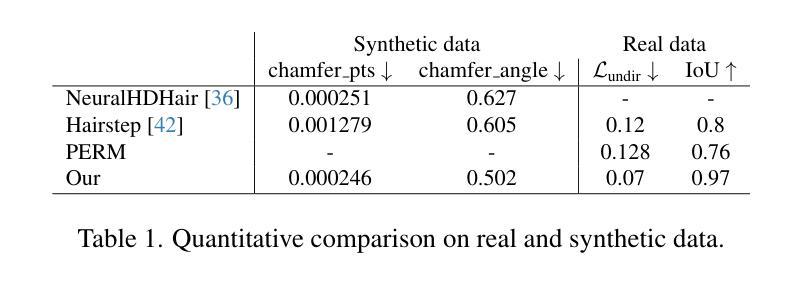

DevilSight: Augmenting Monocular Human Avatar Reconstruction through a Virtual Perspective
Authors:Yushuo Chen, Ruizhi Shao, Youxin Pang, Hongwen Zhang, Xinyi Wu, Rihui Wu, Yebin Liu
We present a novel framework to reconstruct human avatars from monocular videos. Recent approaches have struggled either to capture the fine-grained dynamic details from the input or to generate plausible details at novel viewpoints, which mainly stem from the limited representational capacity of the avatar model and insufficient observational data. To overcome these challenges, we propose to leverage the advanced video generative model, Human4DiT, to generate the human motions from alternative perspective as an additional supervision signal. This approach not only enriches the details in previously unseen regions but also effectively regularizes the avatar representation to mitigate artifacts. Furthermore, we introduce two complementary strategies to enhance video generation: To ensure consistent reproduction of human motion, we inject the physical identity into the model through video fine-tuning. For higher-resolution outputs with finer details, a patch-based denoising algorithm is employed. Experimental results demonstrate that our method outperforms recent state-of-the-art approaches and validate the effectiveness of our proposed strategies.
我们提出了一种新的框架,可以从单目视频中重建人类化身。最近的方法要么难以从输入中捕获精细的动态细节,要么难以在新视角生成合理的细节,这主要源于化身模型的有限表示能力和观察数据的不足。为了克服这些挑战,我们提议利用先进的视频生成模型Human4DiT,从替代视角生成人类运动作为额外的监督信号。这种方法不仅丰富了之前未见区域的细节,还有效地调整了化身表示,减轻了伪影。此外,我们介绍了两种互补的策略来提升视频生成:为确保人类运动的一致再现,我们通过视频微调将物理身份注入模型。对于更高分辨率的输出和更精细的细节,我们采用基于补丁的去噪算法。实验结果表明,我们的方法优于最近的最先进方法,并验证了我们所提出策略的有效性。
论文及项目相关链接
Summary
本文提出了一种新的框架,利用Human4DiT视频生成模型,从单目视频中重建人类角色(avatars)。该方法克服了现有方法在捕捉精细动态细节或生成新颖视角时的局限性,通过引入额外的监督信号生成人类运动,不仅丰富了之前未见区域的细节,还有效规范了角色表示,减轻了伪影。此外,还引入两种增强视频生成策略:通过视频微调将物理身份注入模型以确保人类运动的连贯再现;采用基于补丁的去噪算法,以获取更高分辨率的输出和更精细的细节。实验结果证明,该方法优于最新先进技术,验证了所提策略的有效性。
Key Takeaways
- 利用Human4DiT视频生成模型从单目视频中重建人类角色。
- 引入额外的监督信号生成人类运动,克服现有方法的局限性。
- 通过丰富细节和有效规范角色表示,提高视频质量。
- 引入两种增强视频生成策略:确保连贯的的运动再现和更高分辨率的输出。
- 通过视频微调将物理身份注入模型。
- 采用基于补丁的去噪算法以获取更精细的细节。
- 实验结果证明该方法优于最新先进技术。
点此查看论文截图

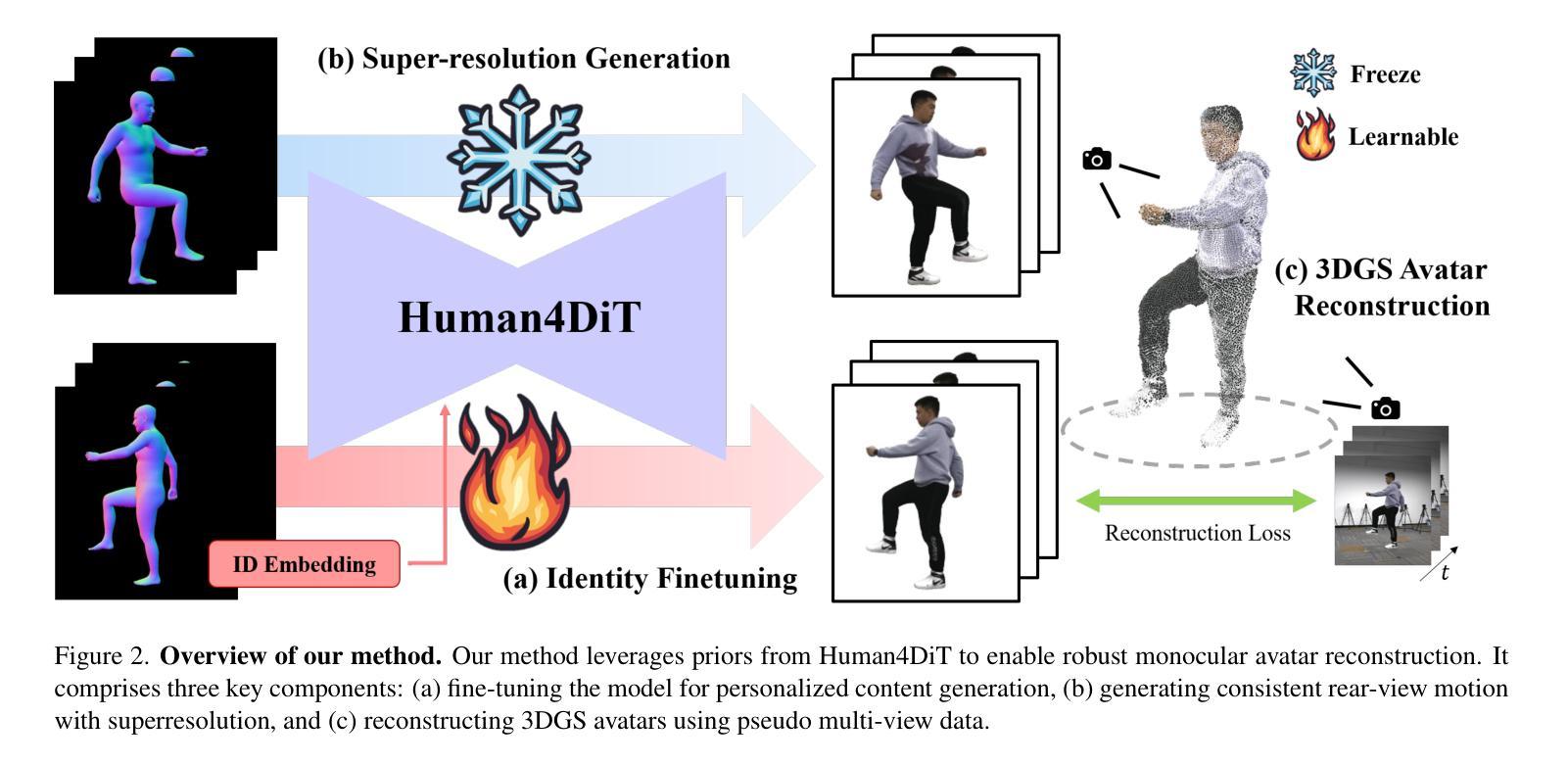

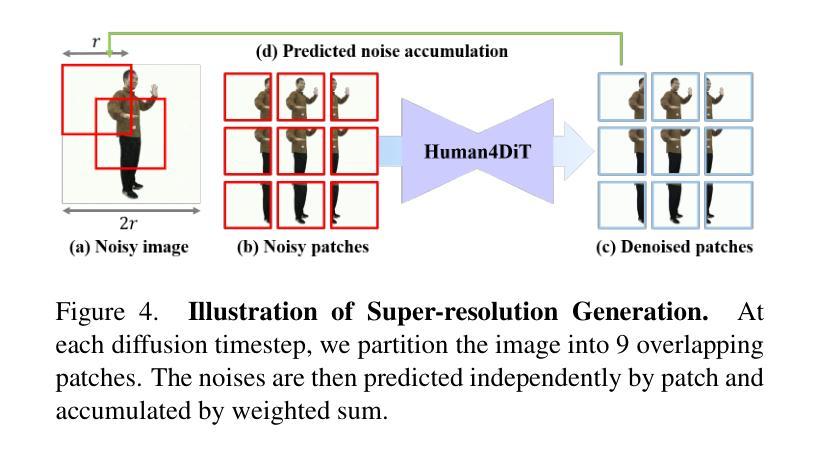
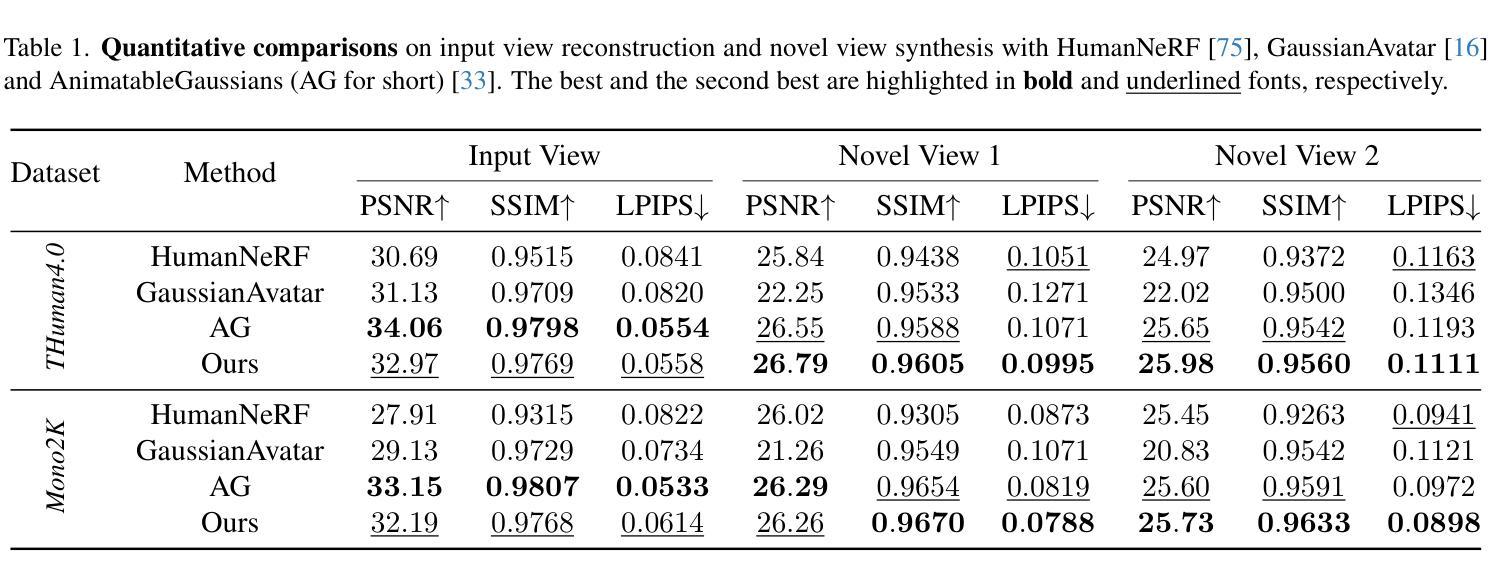
OmniHuman-1.5: Instilling an Active Mind in Avatars via Cognitive Simulation
Authors:Jianwen Jiang, Weihong Zeng, Zerong Zheng, Jiaqi Yang, Chao Liang, Wang Liao, Han Liang, Yuan Zhang, Mingyuan Gao
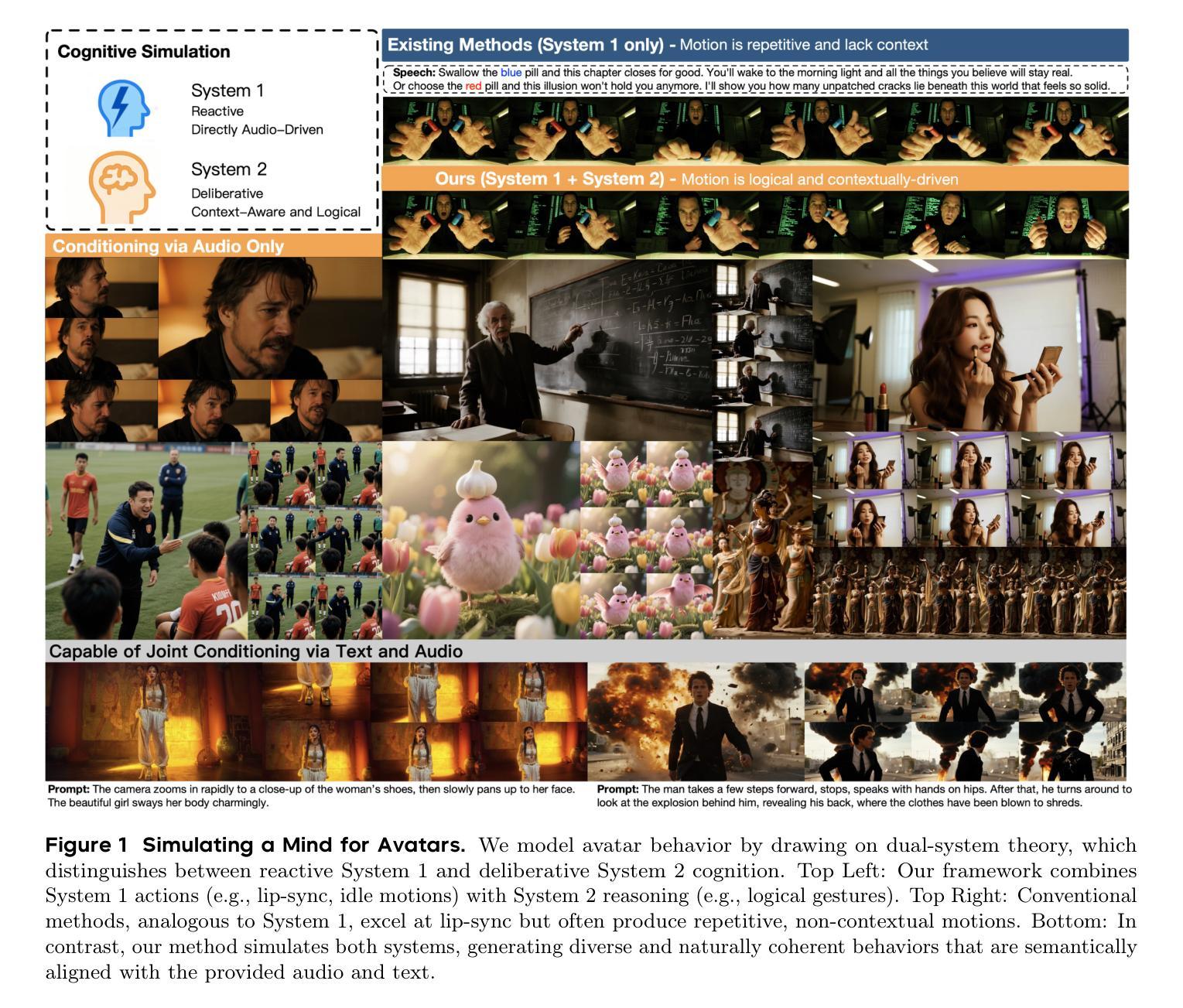
Existing video avatar models can produce fluid human animations, yet they struggle to move beyond mere physical likeness to capture a character’s authentic essence. Their motions typically synchronize with low-level cues like audio rhythm, lacking a deeper semantic understanding of emotion, intent, or context. To bridge this gap, \textbf{we propose a framework designed to generate character animations that are not only physically plausible but also semantically coherent and expressive.} Our model, \textbf{OmniHuman-1.5}, is built upon two key technical contributions. First, we leverage Multimodal Large Language Models to synthesize a structured textual representation of conditions that provides high-level semantic guidance. This guidance steers our motion generator beyond simplistic rhythmic synchronization, enabling the production of actions that are contextually and emotionally resonant. Second, to ensure the effective fusion of these multimodal inputs and mitigate inter-modality conflicts, we introduce a specialized Multimodal DiT architecture with a novel Pseudo Last Frame design. The synergy of these components allows our model to accurately interpret the joint semantics of audio, images, and text, thereby generating motions that are deeply coherent with the character, scene, and linguistic content. Extensive experiments demonstrate that our model achieves leading performance across a comprehensive set of metrics, including lip-sync accuracy, video quality, motion naturalness and semantic consistency with textual prompts. Furthermore, our approach shows remarkable extensibility to complex scenarios, such as those involving multi-person and non-human subjects. Homepage: \href{https://omnihuman-lab.github.io/v1_5/}
现有视频角色模型可以产生流畅的人物动画,但它们难以超越单纯的物理相似性,捕捉角色的真实本质。它们的动作通常与音频节奏等低级线索同步,缺乏情感、意图或上下文的深层语义理解。为了弥这一差距,我们提出了一种框架,旨在生成不仅在物理上合理,而且在语义上连贯且富有表现力的角色动画。我们的模型“OmniHuman-1.5”建立在两项关键技术贡献之上。首先,我们利用多模态大型语言模型合成结构化文本表示条件,为动作生成器提供高级语义指导。这种指导使动作生成器超越了简单的节奏同步,能够产生在上下文和情感上产生共鸣的动作。其次,为了确保这些多模态输入的有效融合并缓解跨模态冲突,我们引入了一种带有新颖Pseudo Last Frame设计的专用多模态DiT架构。这些组件的协同作用使我们的模型能够准确解释音频、图像和文本的共同语义,从而生成与角色、场景和语言内容深度一致的动作。大量实验表明,我们的模型在包括唇同步准确性、视频质量、动作自然性以及文本提示的语义一致性等全面指标上均达到领先水平。此外,我们的方法对于涉及多人以及非人类主题的复杂场景展现出惊人的可扩展性。官网链接:[https://omnihuman-lab.github.io/v1_5/]
论文及项目相关链接
PDF Homepage: https://omnihuman-lab.github.io/v1_5/
Summary
基于现有视频角色模型存在难以捕捉角色真实本质的问题,本文提出了一种生成角色动画的框架。该框架不仅物理上可行,而且语义上连贯且富有表现力。通过利用多模态大型语言模型,合成结构化文本表示条件,为运动生成器提供高级语义指导,实现了基于上下文和情感的动作生成。同时,引入多模态DiT架构和伪最后一帧设计,确保多模态输入的融合并缓解跨模态冲突。该模型准确解读音频、图像和文本的联合语义,生成与角色、场景和语言内容深度一致的动作。实验表明,该模型在多个指标上取得了领先水平。
Key Takeaways
- 当前视频角色模型存在难以捕捉角色真实本质的问题。
- 提出了一种新的框架,能够生成不仅物理可行而且语义连贯且富有表现力的角色动画。
- 利用多模态大型语言模型提供高级语义指导,实现基于上下文和情感的动作生成。
- 引入多模态DiT架构和伪最后一帧设计,确保多模态输入的融合并缓解跨模态冲突。
- 模型能准确解读音频、图像和文本的联合语义,生成与角色、场景和语言内容深度一致的动作。
- 该模型在多个指标上取得了领先水平,包括唇同步准确性、视频质量、运动自然性和与文本提示的语义一致性。
点此查看论文截图

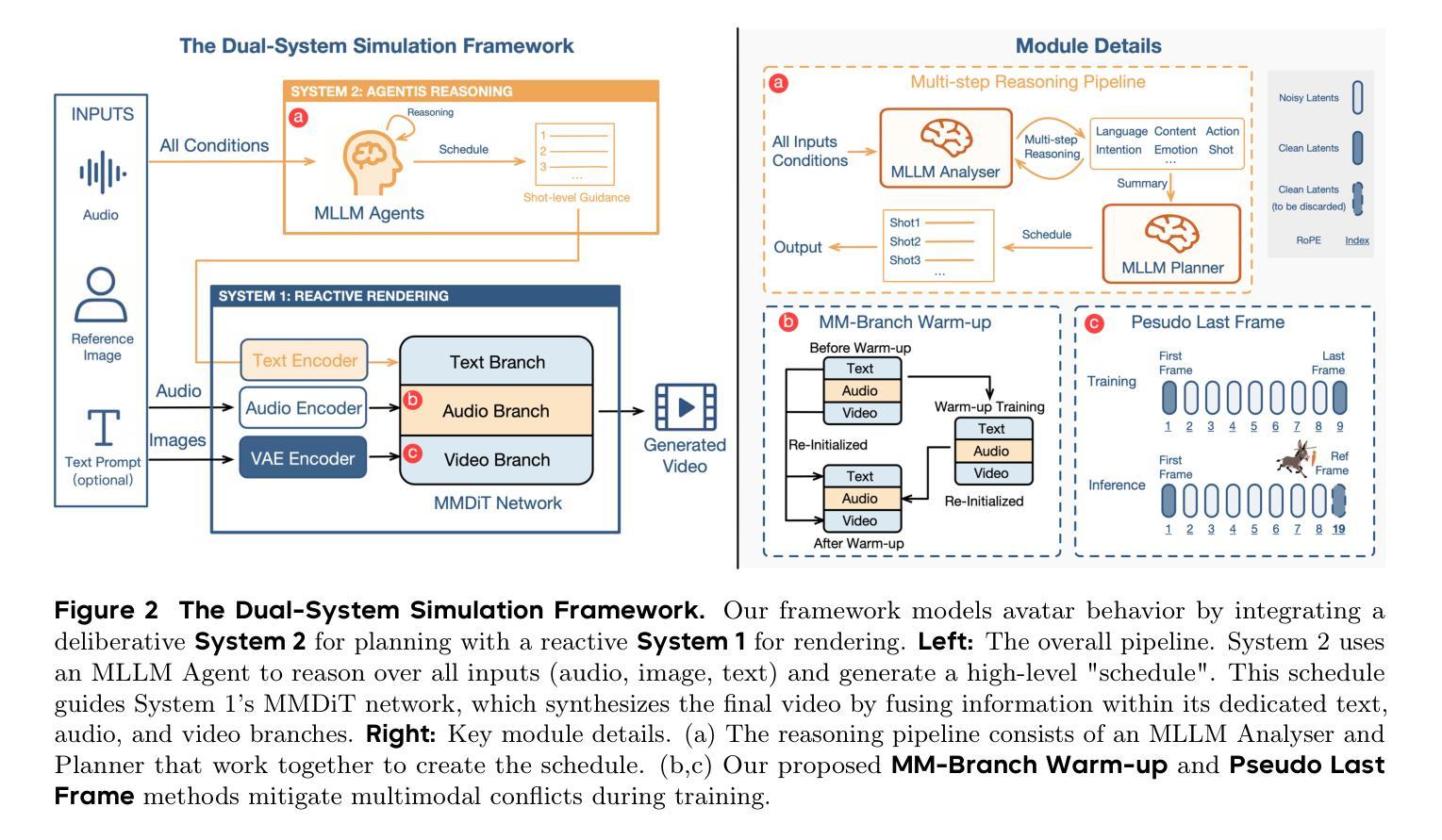
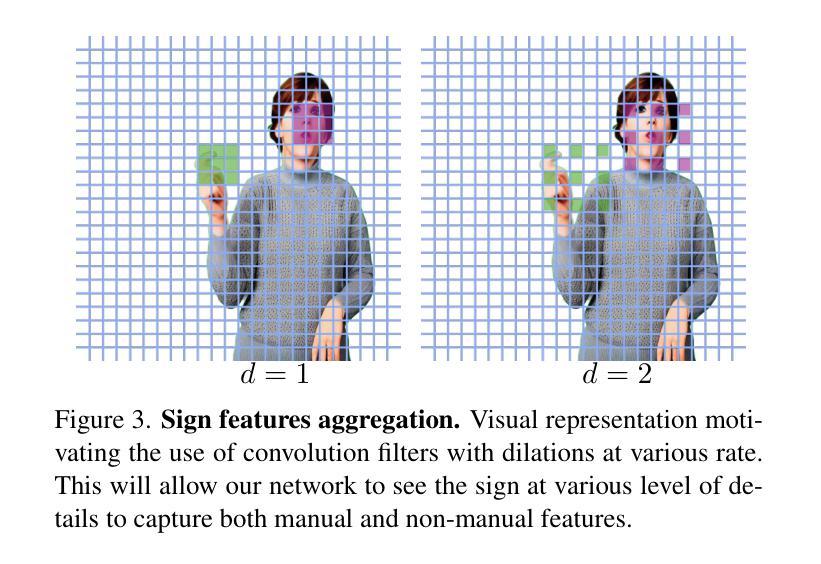
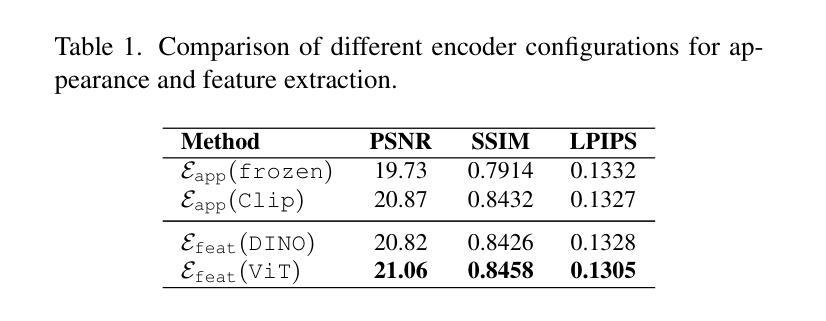
Diverse Signer Avatars with Manual and Non-Manual Feature Modelling for Sign Language Production
Authors:Mohamed Ilyes Lakhal, Richard Bowden
The diversity of sign representation is essential for Sign Language Production (SLP) as it captures variations in appearance, facial expressions, and hand movements. However, existing SLP models are often unable to capture diversity while preserving visual quality and modelling non-manual attributes such as emotions. To address this problem, we propose a novel approach that leverages Latent Diffusion Model (LDM) to synthesise photorealistic digital avatars from a generated reference image. We propose a novel sign feature aggregation module that explicitly models the non-manual features (\textit{e.g.}, the face) and the manual features (\textit{e.g.}, the hands). We show that our proposed module ensures the preservation of linguistic content while seamlessly using reference images with different ethnic backgrounds to ensure diversity. Experiments on the YouTube-SL-25 sign language dataset show that our pipeline achieves superior visual quality compared to state-of-the-art methods, with significant improvements on perceptual metrics.
手势表达的多样性对于手语生成(SLP)至关重要,因为它捕捉了外观、面部表情和手部动作的变化。然而,现有的SLP模型往往无法在手势多样性的同时保持视觉质量并建模非手动属性(如情绪)。为了解决这个问题,我们提出了一种利用潜在扩散模型(Latent Diffusion Model,LDM)从生成的参考图像中合成逼真的数字虚拟形象的新方法。我们提出了一种新的手势特征聚合模块,该模块明确地建模非手动特征(例如脸部)和手动特征(例如手部)。我们证明了我们的模块确保了语言内容的保留,同时无缝地使用具有不同种族背景的参考图像来确保多样性。在YouTube-SL-25手语数据集上的实验表明,我们的管道在视觉质量方面达到了优于现有技术的方法,并且在感知指标上取得了重大改进。
论文及项目相关链接
Summary
本文强调手势语言生成(SLP)中符号表示多样性的重要性,涵盖外观、面部表情和手部动作的变化。针对现有SLP模型在捕捉多样性时难以保持视觉质量及模拟非手动属性(如情绪)的问题,提出一种利用潜在扩散模型(LDM)合成基于参考图像的光照现实数字虚拟人的新方法。文章介绍了一种新的符号特征聚合模块,该模块显式地模拟非手动特征(如面部)和手动特征(如手部),确保语言内容的保留,同时使用具有不同种族背景的参考图像来确保多样性。在YouTube-SL-25手语数据集上的实验表明,与现有先进技术相比,该管道在视觉质量方面表现优越,感知指标上有显著提高。
Key Takeaways
- 多样性在手势语言生成中的重要性,包括外观、面部表情和手部动作的差异。
- 现有手势语言生成模型面临的挑战:难以捕捉多样性并保持视觉质量及模拟非手动属性。
- 提出一种利用潜在扩散模型(LDM)合成基于参考图像的光照现实数字虚拟人的新方法。
- 介绍了一种新的符号特征聚合模块,该模块显式模拟非手动和手动特征。
- 该模块能确保语言内容的保留及利用不同种族背景的参考图像来确保多样性。
- 在YouTube-SL-25手语数据集上的实验验证了该管道在视觉质量方面的优越性。
点此查看论文截图

Supervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Authors:Radek Daněček, Carolin Schmitt, Senya Polikovsky, Michael J. Black
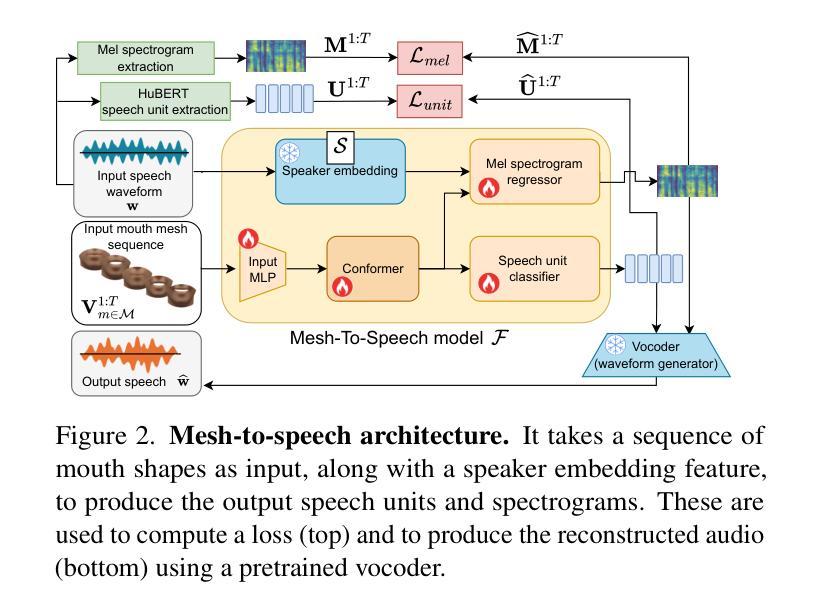
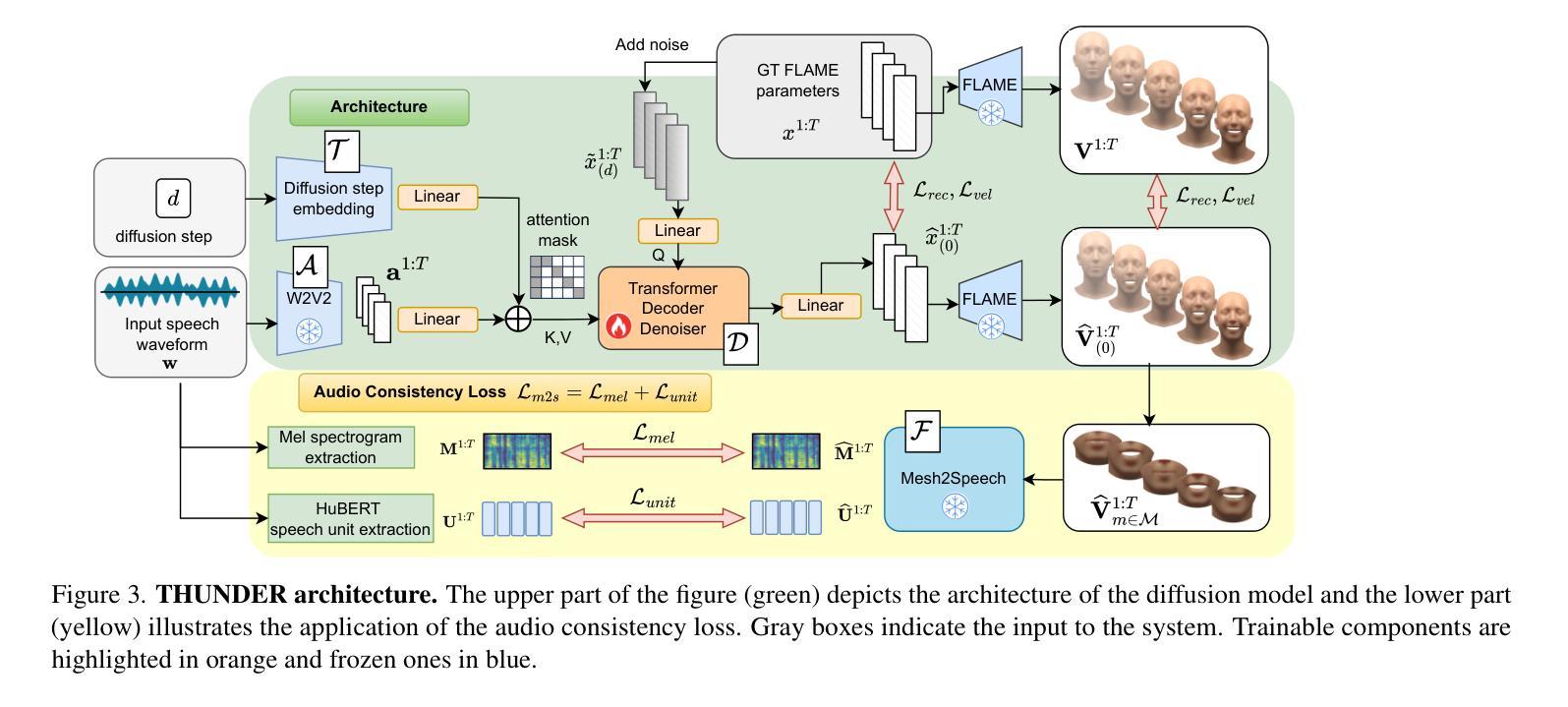
In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations. The code and models will be available at https://thunder.is.tue.mpg.de/
为了广泛应用于各个领域,语音驱动的3D头部化身必须根据语音进行唇部动作,同时借助动态变化的面部表情传达适当的情绪。关键问题在于,确定性模型虽然能产生高质量的唇部同步效果,但缺乏丰富的表情;而随机模型虽然能生成各种表情,但唇部同步质量较低。为了结合两者的优点,我们寻求具有精确唇部同步的随机模型。为此,我们基于以下观察结果开发了一种新方法:如果一种方法能够生成逼真的3D唇部运动,那么就应该可以从唇部运动中推断出语音。推断出的语音应与原始输入音频相匹配,错误的预测会创建一种新型监督信号,用于训练具有精确唇部同步的3D对话头部化身。为了展示这一效果,我们提出了THUNDER(神经可微语音重建下的对话头部,Talking Heads Under Neural Differentiable Elocution Reconstruction)项目,这是一个3D对话头部化身框架,通过可微声音产生引入了一种新型监督机制。首先,我们训练了一种新型网格语音模型,该模型从面部动画回归音频。然后,我们将该模型纳入基于扩散的对话化身框架。在训练过程中,网格语音模型会利用生成的动画产生声音,并与输入语音进行比较,从而创建一个可微音频合成分析监督循环。我们的广泛定性和定量实验表明,THUNDER项目在改善对话头部化身的唇部同步质量方面取得了显著成效,同时仍能够生成多样化、高质量、富有表现力的面部动画。相关代码和模型将公开在:[https://thunder.is.tue.mpg.de/]
论文及项目相关链接
Summary
本文探讨了在构建广泛适用的语音驱动的三维头部角色时面临的挑战,提出了一种基于神经网络可微声音生成技术的全新监督机制THUNDER框架。该框架结合了面部动画回归音频的模型,并在扩散式说话头像框架中引入此模型。训练过程中,通过比较生成的动画产生的声音与输入语音,创建一个可微的音频合成监督循环,从而在提高唇形同步质量的同时,允许生成多样化、高质量的表情动画。
Key Takeaways
- 语音驱动的三维头部角色需要实现唇音同步和表情传达。
- 现有确定性模型虽能实现高质量唇音同步,但表情表现不足;随机模型虽有多样化表情,但唇音同步质量较低。
- THUNDER框架结合面部动画回归音频的模型,旨在实现高质量唇音同步与多样化表情的完美结合。
- 引入可微声音产生技术,创建了一个通过比较生成动画与输入语音的声音来训练的监督机制。
- THUNDER框架在定性和定量实验中都表现出显著优势,显著提高了说话头像的唇形同步质量。
- 该框架将提供丰富的表情动画生成能力。
点此查看论文截图

Legacy Learning Strategy Based on Few-Shot Font Generation Models for Automatic Text Design in Metaverse Content
Authors:Younghwi Kim, Dohee Kim, Seok Chan Jeong, Sunghyun Sim
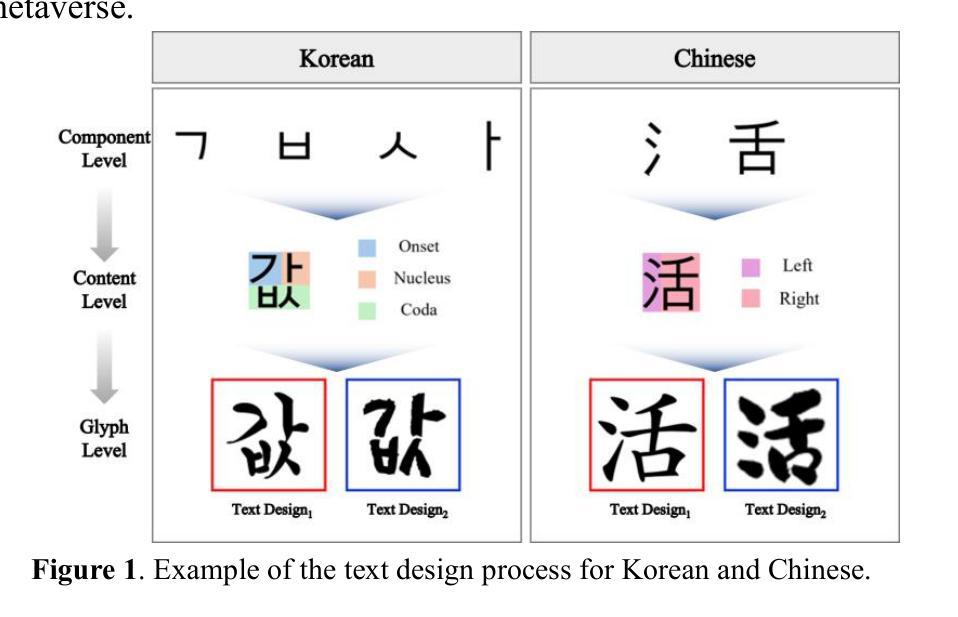
The metaverse consists of hardware, software, and content, among which text design plays a critical role in enhancing user immersion and usability as a content element. However, in languages such as Korean and Chinese that require thousands of unique glyphs, creating new text designs involves high costs and complexity. To address this, this study proposes a training strategy called Legacy Learning, which recombines and transforms structures based on existing text design models. This approach enables the generation of new text designs and improves quality without manual design processes. To evaluate Legacy Learning, it was applied to Korean and Chinese text designs. Additionally, we compared results before and after on seven state of the art text generation models. As a result, text designs generated using Legacy Learning showed over a 30% difference in Frechet Inception Distance (FID) and Learned Perceptual Image Patch Similarity (LPIPS) metrics compared to the originals, and also exhibited meaningful style variations in visual comparisons. Furthermore, the repeated learning process improved the structural consistency of the generated characters, and an OCR based evaluation showed increasing recognition accuracy across iterations, indicating improved legibility of the generated glyphs. In addition, a System Usability Scale (SUS) survey was conducted to evaluate usability among metaverse content designers and general users. The expert group recorded a score of 95.78 (“Best Imaginable”), while the non expert group scored 76.42 (“Excellent”), indicating an overall high level of usability. These results suggest that Legacy Learning can significantly improve both the production efficiency and quality of text design in the metaverse environment.
元宇宙由硬件、软件和内容构成,其中文本设计作为内容要素在提升用户沉浸感和可用性方面发挥着至关重要的作用。然而,在韩语和中文等需要成千上万独特字符的语言中,创建新的文本设计涉及高昂的成本和复杂性。为了解决这一问题,本研究提出了一种名为Legacy Learning的训练策略,该策略基于现有的文本设计模型重新组合和转换结构。这种方法能够生成新的文本设计,并在无需手动设计流程的情况下提高质量。为了评估Legacy Learning的效果,我们将其应用于韩语和中文的文本设计,并将结果与七款最先进的文本生成模型进行了比较。结果显告,使用Legacy Learning生成的文本设计在Frechet Inception Distance(FID)和Learned Perceptual Image Patch Similarity(LPIPS)指标上与原始设计相比有超过30%的差异,视觉比较中也呈现出有意义的设计风格变化。此外,重复学习过程提高了生成字符的结构一致性,基于OCR的评估显示迭代过程中的识别准确率不断提高,表明生成的字符可读性有所提高。此外,还进行了系统可用性量表(SUS)调查,以评估元宇宙内容设计师和普通用户的可用性。专家组得分为95.78分(“最佳想象”),而非专家组得分为76.42分(“优秀”),表明整体可用性较高。这些结果表明,Legacy Learning可以显著提高元宇宙环境中文本设计的生产效率和质量。
论文及项目相关链接
摘要
本研究的训练策略为Legacy Learning,通过重组和转换现有文本设计模型的结构,生成新的文本设计,提高了质量并降低了手动设计过程的成本。在韩语和中文文本设计中的应用以及七个最新文本生成模型的前后对比结果显示,Legacy Learning生成的文本设计在Frechet Inception Distance(FID)和Learned Perceptual Image Patch Similarity(LPIPS)指标上与原设计相比有超过30%的差异,并且在视觉比较中展现出有意义的风格变化。此外,重复学习过程提高了生成字符的结构一致性,OCR评估显示识别准确率随着迭代而提高,表明生成的字符可识别性提高。系统可用性量表调查显示专家和非专家用户的使用体验良好,证明Legacy Learning在改善虚拟元宇宙环境中文本设计的生产效率和质量方面有明显成效。该策略不仅提高了用户体验,还推动了元宇宙中文本设计的创新和发展。
关键见解
- Legacy Learning策略通过重组和转换现有文本设计模型的结构,实现了新文本设计的自动生成,提高了生产效率和质量。
- 在韩语和中文文本设计中的应用验证了Legacy Learning的有效性,与传统设计相比,新生成的文本设计在视觉风格和结构一致性方面有明显提升。
- 通过Frechet Inception Distance(FID)和Learned Perceptual Image Patch Similarity(LPIPS)等度量标准,证明了Legacy Learning生成的文本设计在质量上实现了显著提升。
- OCR评估结果显示字符的可识别性随着迭代的进行而提高,验证了Legacy Learning在提高字符质量方面的有效性。
- 系统可用性量表调查结果显示专家和非专家用户均对Legacy Learning生成的文本设计给出了高度评价,证明了其在提高用户体验方面的优势。
- Legacy Learning不仅提高了元宇宙中文本设计的生产效率和质量,而且推动了文本设计的创新和发展。
点此查看论文截图