⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
VideoRewardBench: Comprehensive Evaluation of Multimodal Reward Models for Video Understanding
Authors:Zhihong Zhang, Xiaojian Huang, Jin Xu, Zhuodong Luo, Xinzhi Wang, Jiansheng Wei, Xuejin Chen
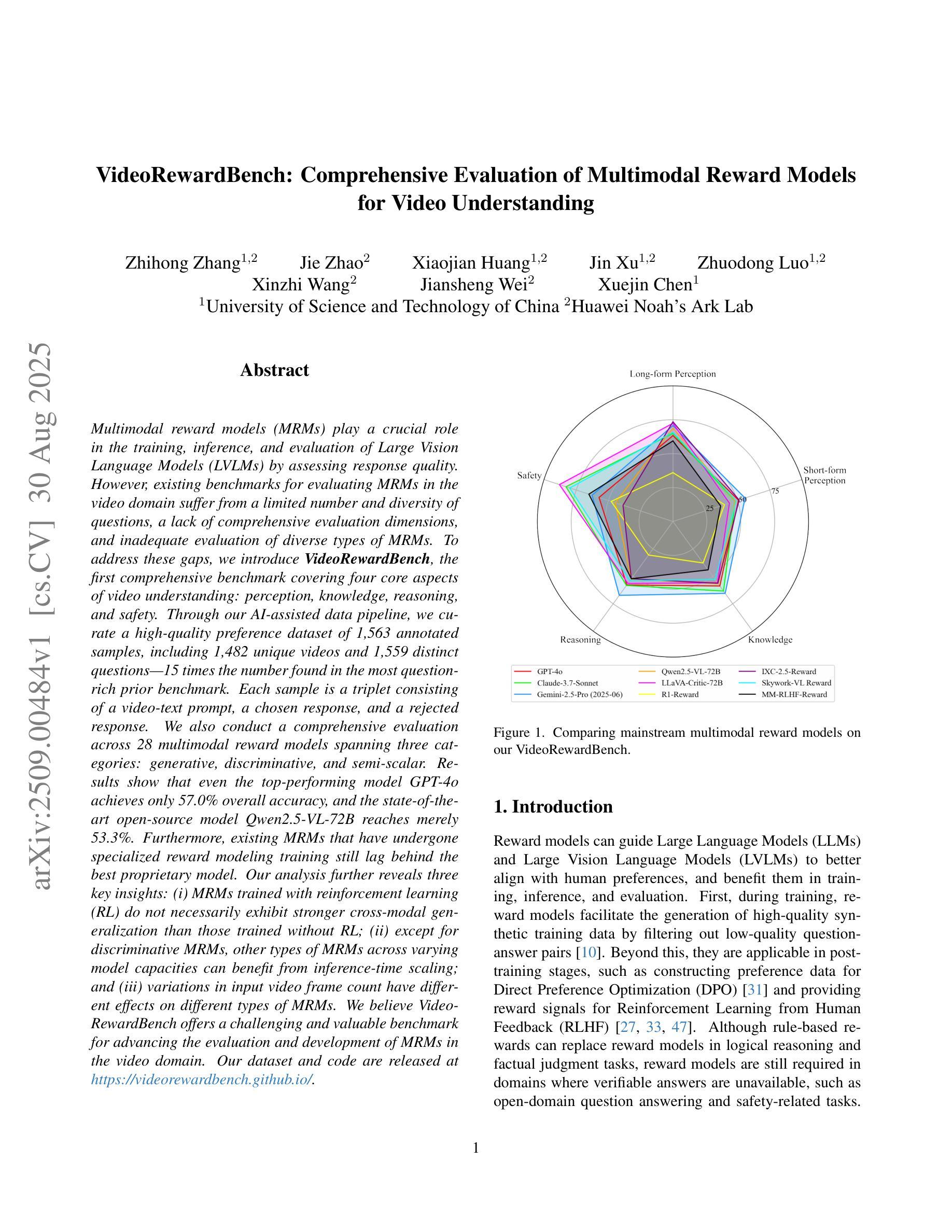
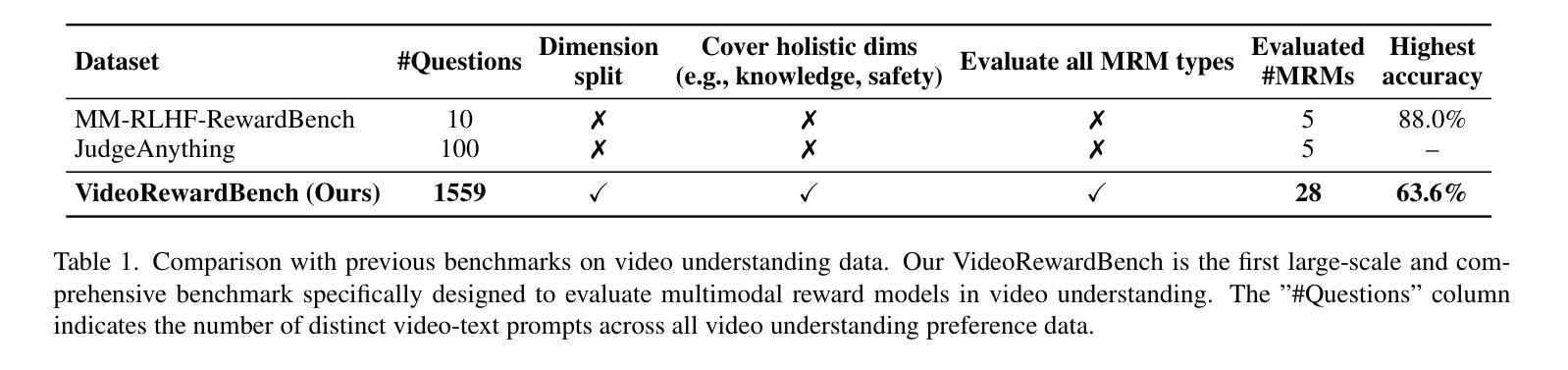
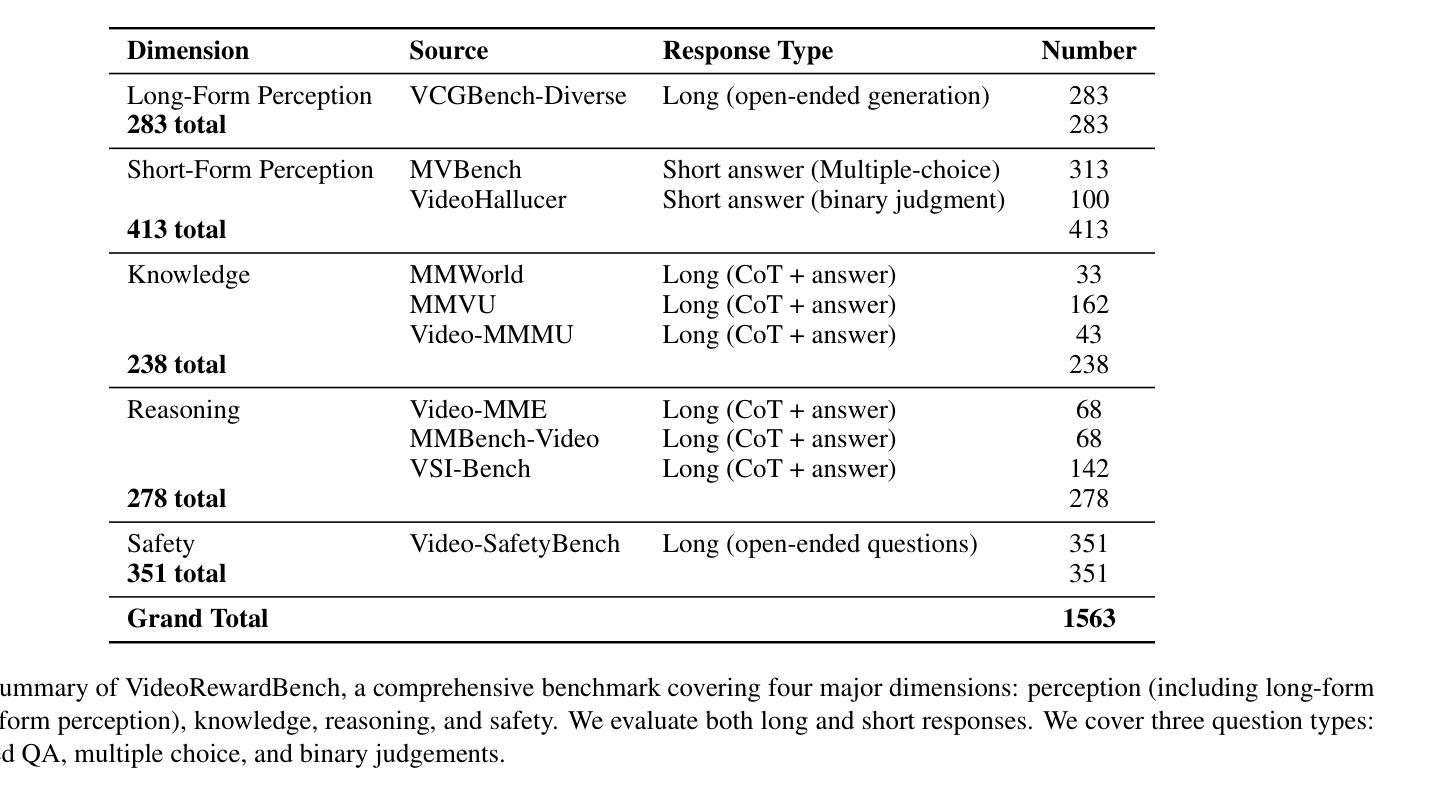
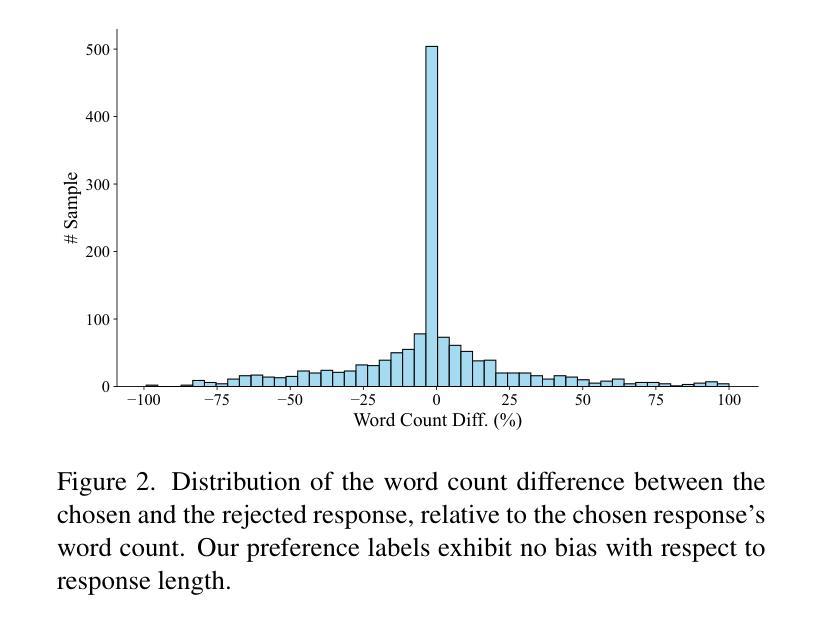
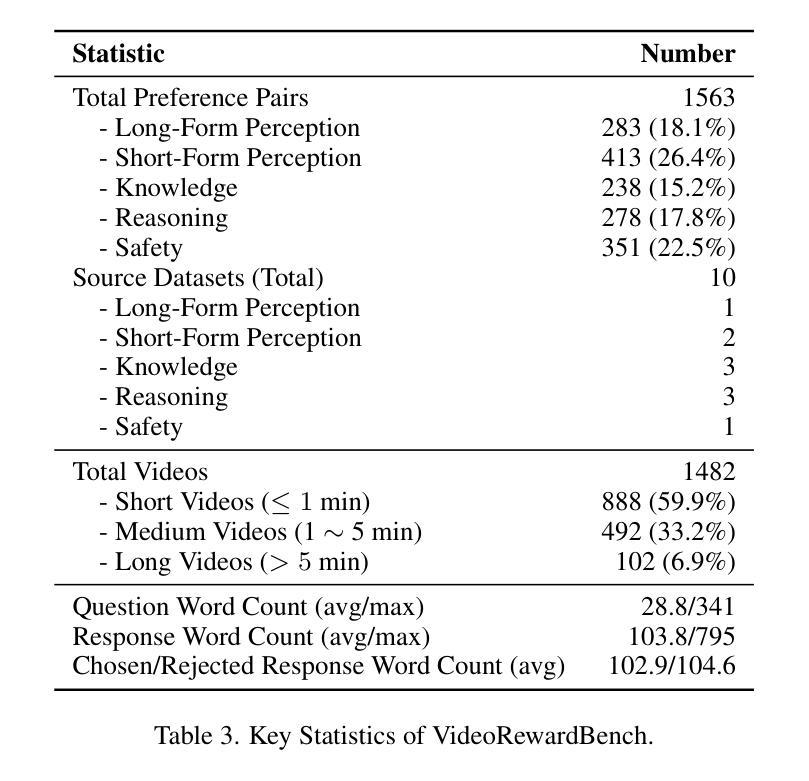
Multimodal reward models (MRMs) play a crucial role in the training, inference, and evaluation of Large Vision Language Models (LVLMs) by assessing response quality. However, existing benchmarks for evaluating MRMs in the video domain suffer from a limited number and diversity of questions, a lack of comprehensive evaluation dimensions, and inadequate evaluation of diverse types of MRMs. To address these gaps, we introduce VideoRewardBench, the first comprehensive benchmark covering four core aspects of video understanding: perception, knowledge, reasoning, and safety. Through our AI-assisted data pipeline, we curate a high-quality preference dataset of 1,563 annotated samples, including 1,482 unique videos and 1,559 distinct questions–15 times the number found in the most question-rich prior benchmark. Each sample is a triplet consisting of a video-text prompt, a chosen response, and a rejected response. We also conduct a comprehensive evaluation across 28 multimodal reward models spanning three categories: generative, discriminative, and semi-scalar. Results show that even the top-performing model GPT-4o achieves only 57.0% overall accuracy, and the state-of-the-art open-source model Qwen2.5-VL-72B reaches merely 53.3%. Our analysis further reveals three key insights: (i) MRMs trained with reinforcement learning (RL) do not necessarily exhibit stronger cross-modal generalization than those trained without RL; (ii) except for discriminative MRMs, other types of MRMs across varying model capacities can benefit from inference-time scaling; and (iii) variations in input video frame count have different effects on different types of MRMs. We believe VideoRewardBench offers a challenging and valuable benchmark for advancing the evaluation and development of MRMs in the video domain.
多模态奖励模型(MRMs)在大型视觉语言模型(LVLMs)的训练、推理和评估中起着至关重要的作用,通过对响应质量进行评估来实现这一点。然而,现有视频领域的MRM评估基准测试存在许多问题,如问题数量和多样性有限、评估维度不全面以及对多种MRM的评估不足。为了弥补这些差距,我们引入了VideoRewardBench,这是第一个全面涵盖视频理解的四个核心方面的基准测试:感知、知识、推理和安全。通过我们的人工智能辅助数据管道,我们整理了一个高质量的首选数据集,包含1563个注释样本,其中包括1482个唯一视频和1559个不同的问题,这是迄今为止问题最丰富的基准测试的15倍。每个样本都由一个视频文本提示、一个选定响应和一个被拒绝响应组成的三元组。我们还对28种跨三类别的多模态奖励模型进行了全面评估:生成式、判别式和半标量。结果表明,即使表现最佳的GPT-4o模型总体准确率也只有57.0%,而最先进的开源模型Qwen2.5-VL-72B仅达到53.3%。我们的进一步分析还揭示了三个关键见解:(i)用强化学习(RL)训练的多模态奖励模型并不一定比未用RL训练的模型表现出更强的跨模态泛化能力;(ii)除了判别式MRM外,其他类型的MRM在各种模型容量上都可以从推理时间缩放中受益;(iii)输入视频帧计数的变化对不同类型的MRM有不同的影响。我们相信VideoRewardBench为推进视频领域MRM的评估和开发提供了一个有挑战性和价值的基准测试。
论文及项目相关链接
PDF https://videorewardbench.github.io/
Summary
多模态奖励模型(MRMs)在大型视觉语言模型(LVLMs)的训练、推理和评估中起着重要作用。然而,现有的视频领域MRMs评估基准存在一些问题,如问题数量有限、缺乏全面评估维度以及对不同类型MRMs的评估不足。为解决这些问题,我们推出了VideoRewardBench,这是一个覆盖视频理解的四个核心方面的全面基准:感知、知识、推理和安全。通过人工智能辅助的数据管道,我们整理了一个高质量的首选数据集,包含1563个注释样本,包括1482个独特视频和1559个不同问题,数量是最富有的先前基准的十五倍。我们还对跨越三个类别的28个多模态奖励模型进行了全面评估:生成式、判别式和半标量式。研究结果表明,即使是表现最佳的GPT-4o模型也仅达到百分之五十七的整体准确率,最先进的开源模型Qwen2.5-VL-72B也仅达到百分之五十三点三。我们的分析揭示了三个关键见解。我们相信VideoRewardBench为推进视频领域MRMs的评估和发展提供了一个具有挑战性和价值的基准。
Key Takeaways
- 多模态奖励模型(MRMs)在评估大型视觉语言模型(LVLMs)的响应质量中起关键作用。
- 现有视频领域MRMs评估基准存在局限性,如问题数量少、缺乏全面评估维度以及对不同类型MRMs的评估不足。
- VideoRewardBench是首个覆盖视频理解的四个核心方面的全面基准,包括感知、知识、推理和安全。
- VideoRewardBench通过AI辅助的数据管道整理了一个高质量的首选数据集,样本包含视频文本提示、选定回应和拒绝回应的三元组。
- 现有顶尖模型如GPT-4o和Qwen2.5-VL-72B在VideoRewardBench上的表现并不理想,整体准确率有待提高。
- 研究发现,使用强化学习(RL)训练的MRMs并不一定能表现出更强的跨模态泛化能力。
点此查看论文截图
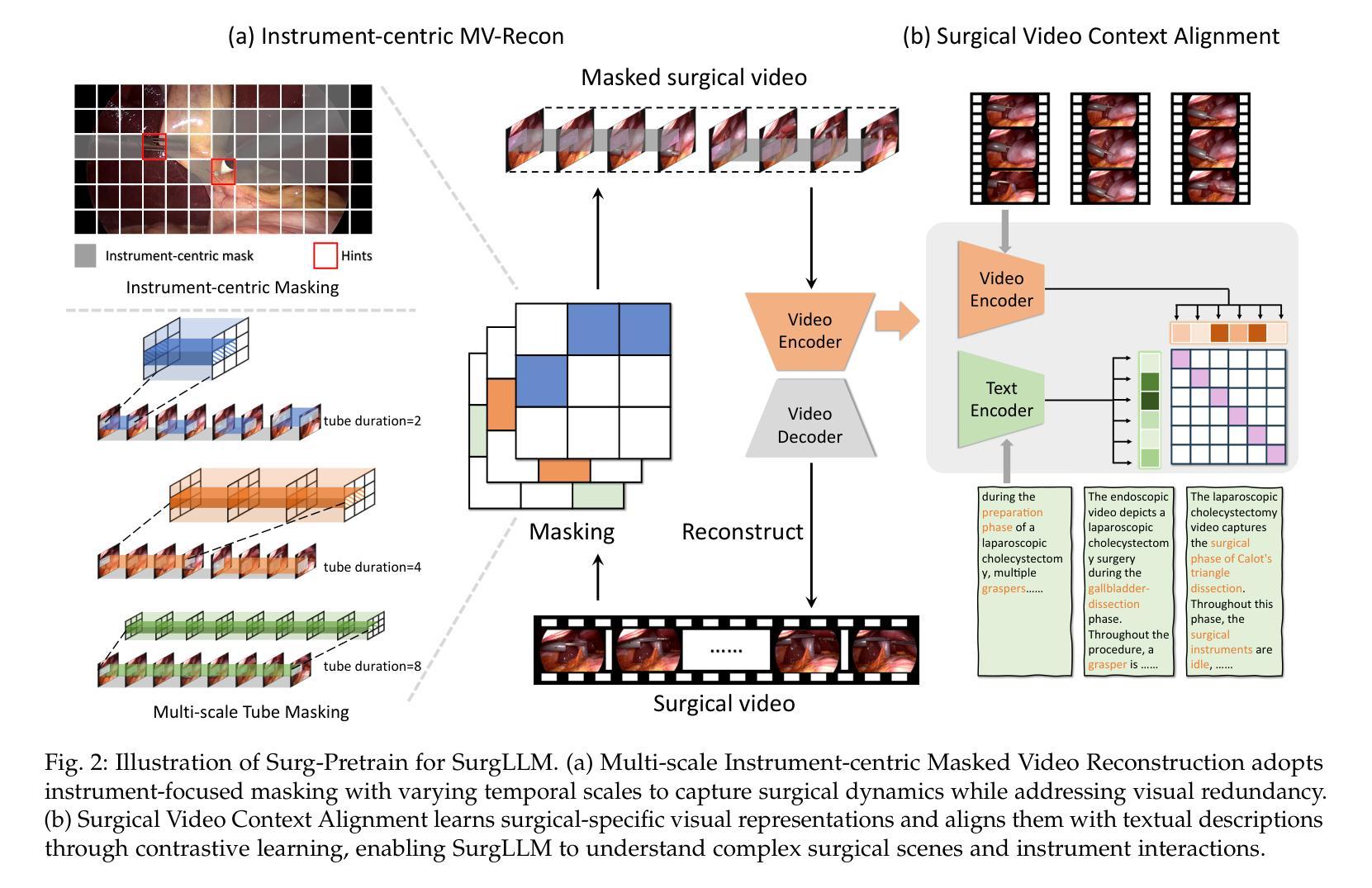
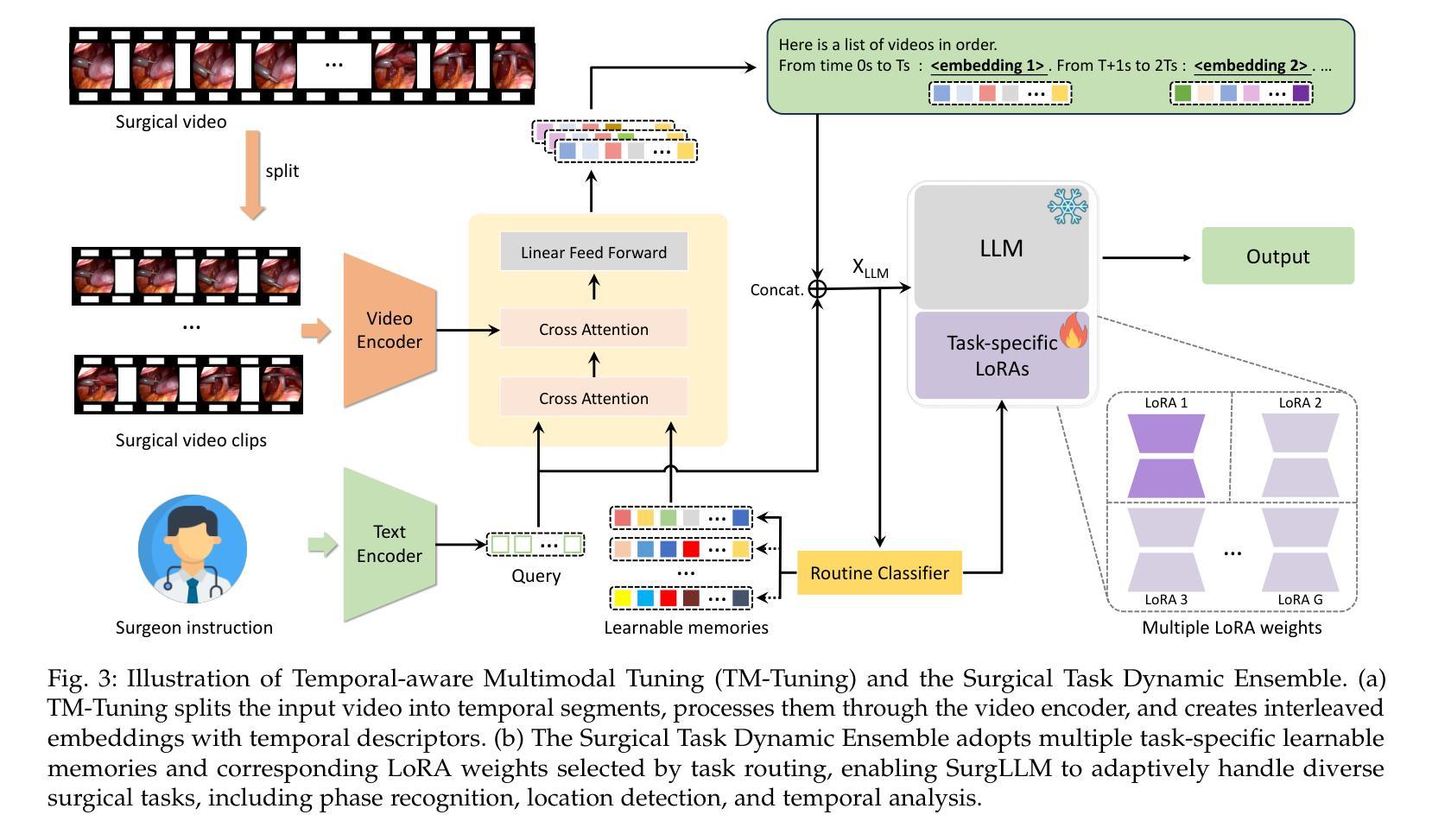
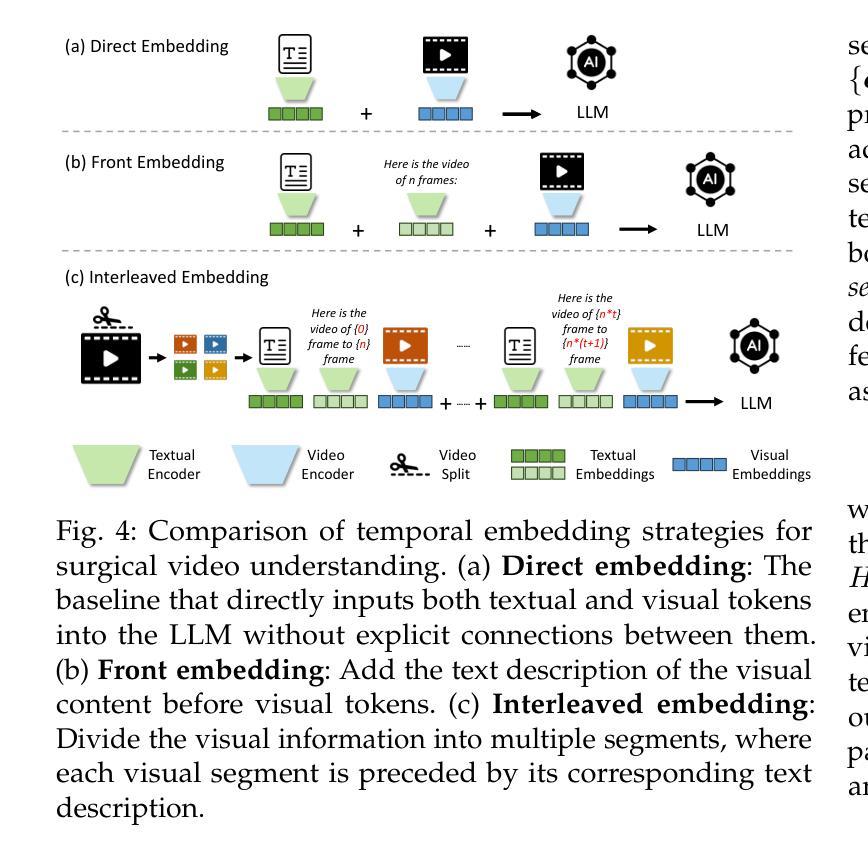
SurgLLM: A Versatile Large Multimodal Model with Spatial Focus and Temporal Awareness for Surgical Video Understanding
Authors:Zhen Chen, Xingjian Luo, Kun Yuan, Jinlin Wu, Danny T. M. Chan, Nassir Navab, Hongbin Liu, Zhen Lei, Jiebo Luo
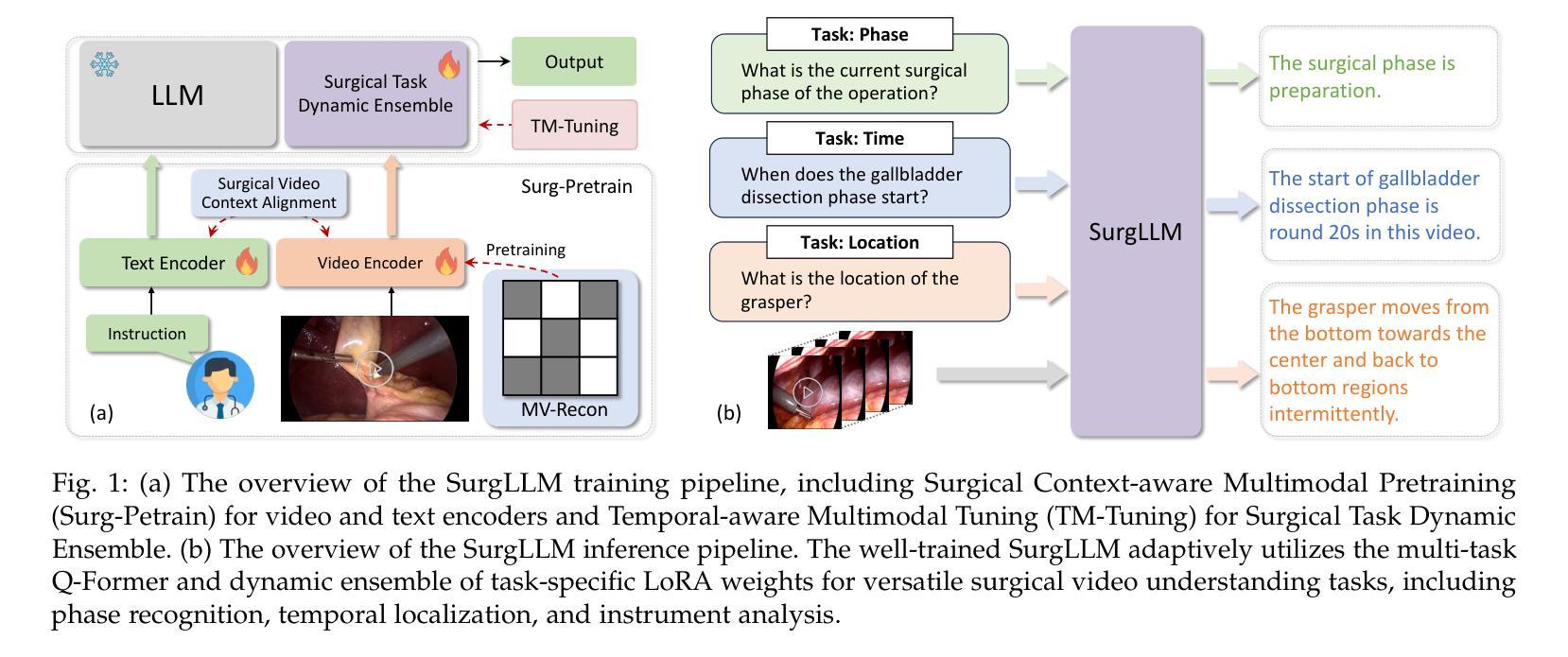
Surgical video understanding is crucial for facilitating Computer-Assisted Surgery (CAS) systems. Despite significant progress in existing studies, two major limitations persist, including inadequate visual content perception and insufficient temporal awareness in surgical videos, and hinder the development of versatile CAS solutions. In this work, we propose the SurgLLM framework, an effective large multimodal model tailored for versatile surgical video understanding tasks with enhanced spatial focus and temporal awareness. Specifically, to empower the spatial focus of surgical videos, we first devise Surgical Context-aware Multimodal Pretraining (Surg-Pretrain) for the video encoder of SurgLLM, by performing instrument-centric Masked Video Reconstruction (MV-Recon) and subsequent multimodal alignment. To incorporate surgical temporal knowledge into SurgLLM, we further propose Temporal-aware Multimodal Tuning (TM-Tuning) to enhance temporal reasoning with interleaved multimodal embeddings. Moreover, to accommodate various understanding tasks of surgical videos without conflicts, we devise a Surgical Task Dynamic Ensemble to efficiently triage a query with optimal learnable parameters in our SurgLLM. Extensive experiments performed on diverse surgical video understanding tasks, including captioning, general VQA, and temporal VQA, demonstrate significant improvements over the state-of-the-art approaches, validating the effectiveness of our SurgLLM in versatile surgical video understanding. The source code is available at https://github.com/franciszchen/SurgLLM.
手术视频理解对于促进计算机辅助手术(CAS)系统的发展至关重要。尽管现有研究取得了重大进展,但仍存在两大局限,包括手术视频中视觉内容感知不足和时间感知不足,这阻碍了多功能CAS解决方案的发展。在这项工作中,我们提出了SurgLLM框架,这是一个有效的大型多模态模型,针对通用的手术视频理解任务进行了优化,具有增强的空间焦点和时间感知。具体来说,为了增强手术视频的空间焦点,我们为SurgLLM的视频编码器设计了手术上下文感知多模态预训练(Surg-Pretrain),通过执行以仪器为中心的掩码视频重建(MV-Recon)和随后的多模态对齐。为了将手术时间知识融入SurgLLM,我们进一步提出了时间感知多模态调整(TM-Tuning),以增强具有交错多模态嵌入的时间推理。此外,为了容纳各种手术视频理解任务而不产生冲突,我们设计了一个手术任务动态集成,以在我们的SurgLLM中以最佳的可学习参数有效地处理查询。在多种手术视频理解任务上进行的广泛实验,包括描述、一般视频问答和时间视频问答,证明了我们的SurgLLM相较于最新方法有明显的改进,验证了其在通用手术视频理解中的有效性。源代码可在https://github.com/franciszchen/SurgLLM获得。
论文及项目相关链接
Summary
本研究针对计算机辅助手术系统中的手术视频理解问题,提出了SurgLLM框架,该框架具备增强的空间聚焦和时序感知能力,用于完成多样化的手术视频理解任务。通过Surgical Context-aware Multimodal Pretraining(Surg-Pretrain)和Temporal-aware Multimodal Tuning(TM-Tuning)技术,提高了视频的空间聚焦和时序推理能力。同时,通过Surgical Task Dynamic Ensemble策略,实现不同理解任务的灵活处理。实验结果显示,SurgLLM在手术视频理解任务上取得了显著进展。
Key Takeaways
- 手术视频理解在计算机辅助手术系统中至关重要,但存在视觉内容感知和时序感知不足两大挑战。
- SurgLLM框架被提出以解决这些问题,具备增强的空间聚焦和时序感知能力。
- SurgLLM通过Surgical Context-aware Multimodal Pretraining(Surg-Pretrain)提高视频的空间聚焦能力,通过MV-Recon和随后的多模式对齐实现。
- Temporal-aware Multimodal Tuning(TM-Tuning)被用于增强SurgLLM的时序推理能力,通过交替多模式嵌入实现。
- Surgical Task Dynamic Ensemble策略允许SurgLLM适应不同的手术视频理解任务,同时避免冲突。
- 在多个手术视频理解任务上的实验结果显示,SurgLLM显著优于现有方法,验证了其有效性。
点此查看论文截图

Looking Beyond the Obvious: A Survey on Abstract Concept Recognition for Video Understanding
Authors:Gowreesh Mago, Pascal Mettes, Stevan Rudinac
The automatic understanding of video content is advancing rapidly. Empowered by deeper neural networks and large datasets, machines are increasingly capable of understanding what is concretely visible in video frames, whether it be objects, actions, events, or scenes. In comparison, humans retain a unique ability to also look beyond concrete entities and recognize abstract concepts like justice, freedom, and togetherness. Abstract concept recognition forms a crucial open challenge in video understanding, where reasoning on multiple semantic levels based on contextual information is key. In this paper, we argue that the recent advances in foundation models make for an ideal setting to address abstract concept understanding in videos. Automated understanding of high-level abstract concepts is imperative as it enables models to be more aligned with human reasoning and values. In this survey, we study different tasks and datasets used to understand abstract concepts in video content. We observe that, periodically and over a long period, researchers have attempted to solve these tasks, making the best use of the tools available at their disposal. We advocate that drawing on decades of community experience will help us shed light on this important open grand challenge and avoid ``re-inventing the wheel’’ as we start revisiting it in the era of multi-modal foundation models.
视频内容的自动理解正在迅速发展。在更深的神经网络和大数据的支持下,机器越来越能理解视频帧中具体可见的内容,无论是物体、动作、事件还是场景。相比之下,人类还拥有超越具体实体的独特能力,能够识别正义、自由、团结等抽象概念。抽象概念识别是视频理解中的一个关键开放挑战,其中基于上下文信息在多语义层面进行推理是关键。在本文中,我们认为最近的进展基础模型为解决视频中的抽象概念理解提供了理想的平台。对高级抽象概念的自动理解至关重要,因为它可以使模型更符合人类推理和价值观。在这篇综述中,我们研究了用于理解视频内容中抽象概念的不同任务和数据集。我们发现,研究人员会定期并长期尝试解决这些任务,充分利用现有工具。我们主张借鉴社区几十年的经验,这将有助于我们解决这一重要的开放挑战,避免在多媒体基础模型的复兴时代“重蹈覆辙”。
论文及项目相关链接
PDF Under Review for IJCV
Summary
视频内容自动理解领域正迅速发展,得益于更深的神经网络和大数据集的支持,机器越来越能理解视频帧中具体可见的内容,如物体、动作、事件或场景。然而,人类独有的能力也能识别抽象概念,如正义、自由和团结。抽象概念识别是视频理解中的关键开放挑战,需要在多个语义层次上根据上下文信息进行推理。本文主张利用最新的基础模型来解决视频中的抽象概念理解问题。对高级抽象概念的自动理解至关重要,因为这能使模型更符合人类推理和价值观。本文调查了理解视频内容中抽象概念的不同任务和数据集,并发现研究者们已经尝试解决这些问题,如何利用现有的最佳工具尤为重要。我们相信借鉴社区多年的经验将有助于解决这一重要的开放挑战,避免在多媒体基础模型时代“重蹈覆辙”。
Key Takeaways
- 视频内容自动理解领域正在迅速发展,得益于技术进步如更深的神经网络和大数据集的应用。
- 机器能够理解视频帧中的具体可见内容(如物体、动作等),但人类还能识别抽象概念(如正义、自由等)。
- 抽象概念识别是视频理解领域的核心挑战之一,需要基于上下文信息在多个语义层次上进行推理。
- 基础模型的最新进展为解决视频中的抽象概念理解问题提供了理想工具。
- 高级抽象概念的自动理解至关重要,因为这有助于模型与人类推理和价值观的匹配。
- 视频理解领域的不同任务和数据集被广泛研究用于抽象概念的理解。
点此查看论文截图



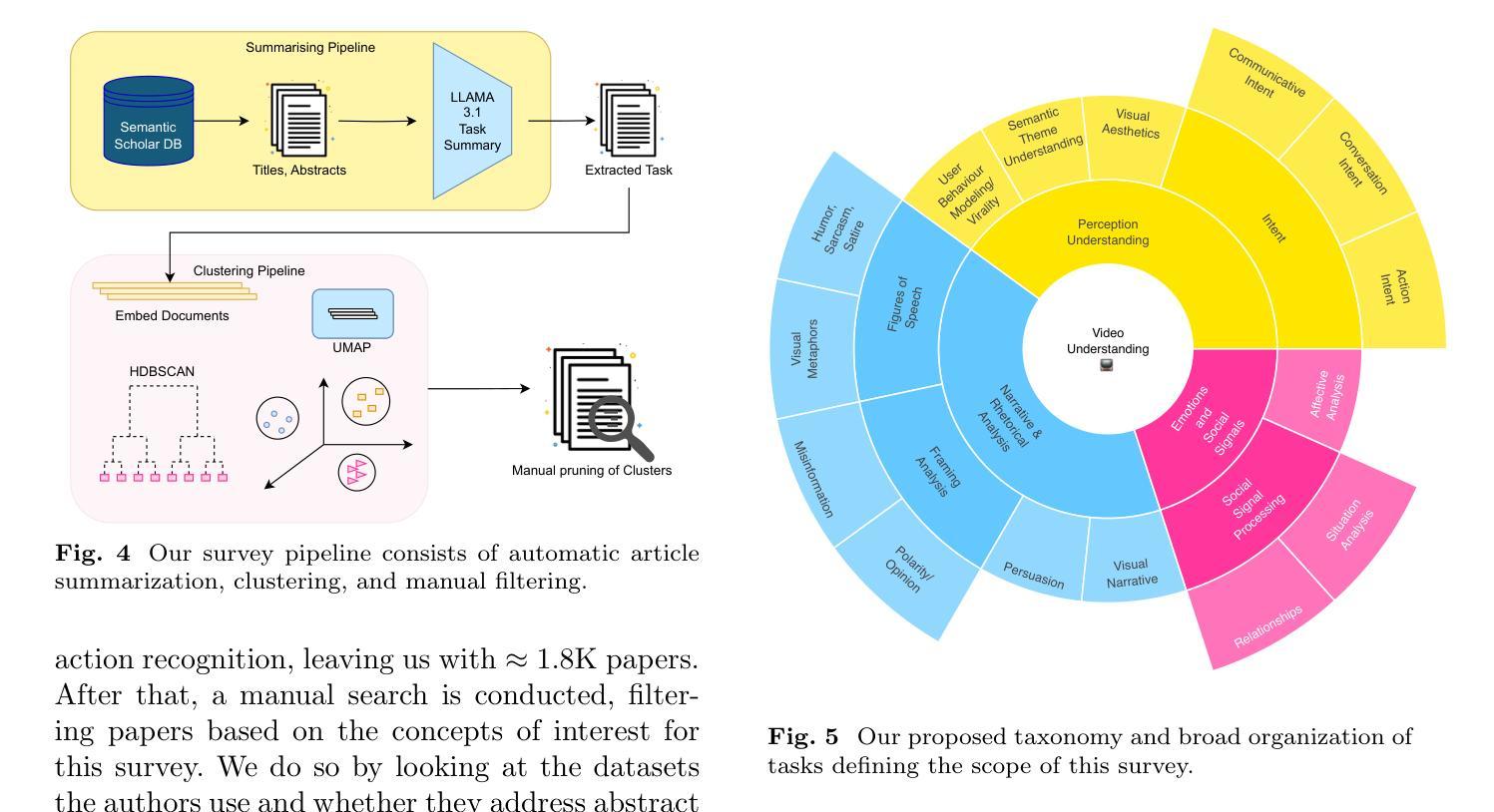

Video-MTR: Reinforced Multi-Turn Reasoning for Long Video Understanding
Authors:Yuan Xie, Tianshui Chen, Zheng Ge, Lionel Ni
Long-form video understanding, characterized by long-range temporal dependencies and multiple events, remains a challenge. Existing methods often rely on static reasoning or external visual-language models (VLMs), which face issues like complexity and sub-optimal performance due to the lack of end-to-end training. In this paper, we propose Video-MTR, a reinforced multi-turn reasoning framework designed to enable iterative key video segment selection and question comprehension. Unlike traditional video reasoning pipeline, which generate predictions in a single turn, Video-MTR performs reasoning in multiple turns, selecting video segments progressively based on the evolving understanding of previously processed segments and the current question. This iterative process allows for a more refined and contextually aware analysis of the video. To ensure intermediate reasoning process, we introduce a novel gated bi-level reward system, combining trajectory-level rewards based on answer correctness and turn-level rewards emphasizing frame-query relevance. This system optimizes both video segment selection and question comprehension, eliminating the need for external VLMs and allowing end-to-end training. Extensive experiments on benchmarks like VideoMME, MLVU, and EgoSchema demonstrate that Video-MTR outperforms existing methods in both accuracy and efficiency, advancing the state-of-the-art in long video understanding.
长视频理解仍然是一个挑战,其特点是具有长时依赖性,存在多个事件。现有的方法往往依赖于静态推理或外部视觉语言模型(VLMs),由于缺乏端到端的训练,这些方法面临复杂性和性能不佳的问题。在本文中,我们提出了Video-MTR,这是一个增强的多轮推理框架,旨在实现迭代的关键视频片段选择和问题理解。与传统的视频推理流程不同,Video-MTR在多轮中进行推理,根据已处理片段的演变理解和当前问题,逐步选择视频片段。这种迭代过程允许对视频进行更精细和上下文感知的分析。为确保中间推理过程,我们引入了一种新型的门控两级奖励系统,该系统结合基于答案正确性的轨迹级奖励和强调帧查询相关性的轮次级奖励。该系统优化了视频片段的选择和问题理解,无需外部VLMs,并实现了端到端的训练。在VideoMME、MLVU和EgoSchema等基准测试上的广泛实验表明,Video-MTR在准确性和效率方面超越了现有方法,推动了长视频理解的最新进展。
论文及项目相关链接
PDF 15 pages, 9 figures
Summary:
针对长视频理解中的长时间序列依赖和多事件问题,本文提出了Video-MTR框架,实现了迭代的关键视频片段选择和问题理解。与传统的视频推理流程不同,Video-MTR采用多轮推理,基于已处理片段的深入理解以及当前问题,逐步选择视频片段。为优化中间推理过程,引入了新型的门控双级奖励系统,结合了基于答案正确性的轨迹级奖励和强调帧查询相关性的回合级奖励。该框架无需外部视觉语言模型,实现了端到端的训练,并在VideoMME、MLVU和EgoSchema等基准测试中优于现有方法。
Key Takeaways:
- 长视频理解存在挑战,因涉及长时间序列依赖和多事件。
- 现有方法常依赖静态推理或外部视觉语言模型(VLMs),存在复杂性和性能不佳的问题。
- Video-MTR框架采用多轮推理,实现关键视频片段的迭代选择和问题理解。
- Video-MTR基于已处理片段的深入理解及当前问题逐步选择视频片段,实现更精细、更具上下文意识的分析。
- 引入新型的门控双级奖励系统,优化中间推理过程,结合轨迹级和回合级奖励。
- Video-MTR框架无需外部VLMs,实现端到端训练。
点此查看论文截图

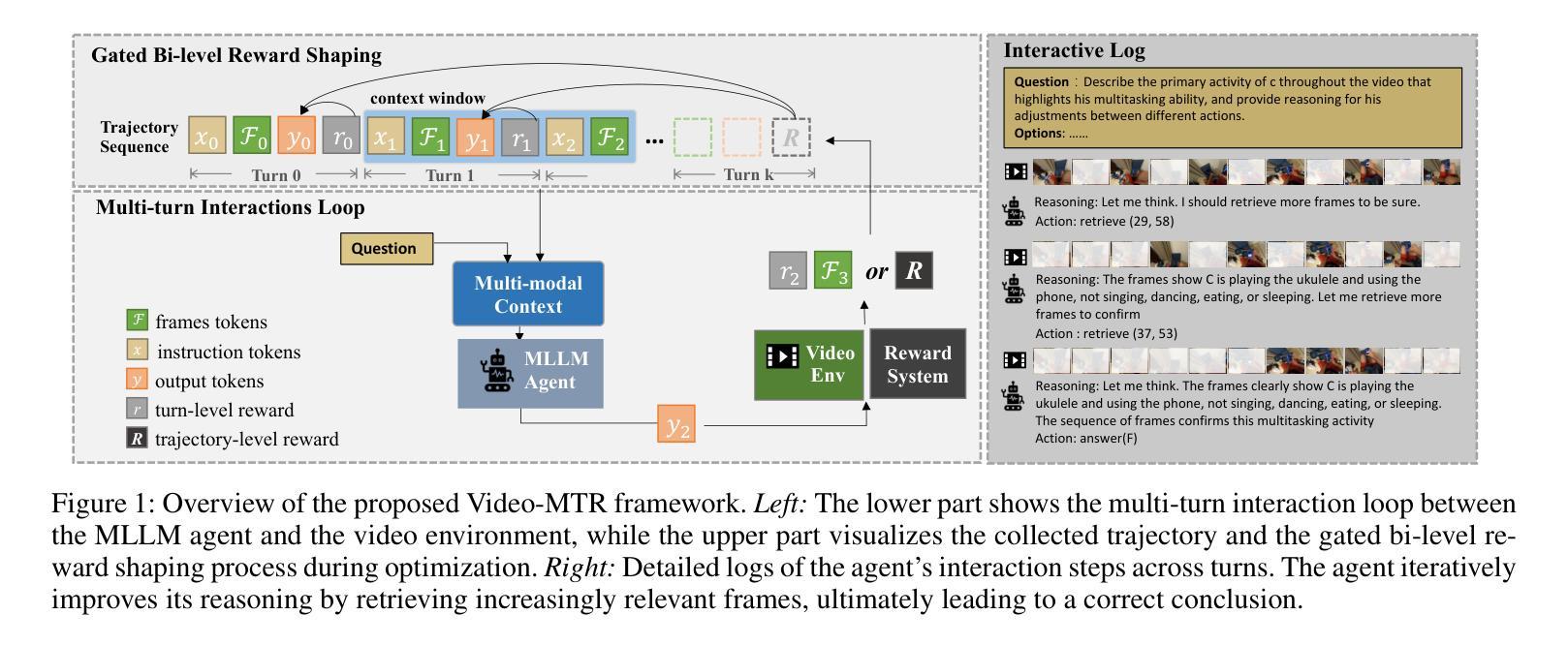

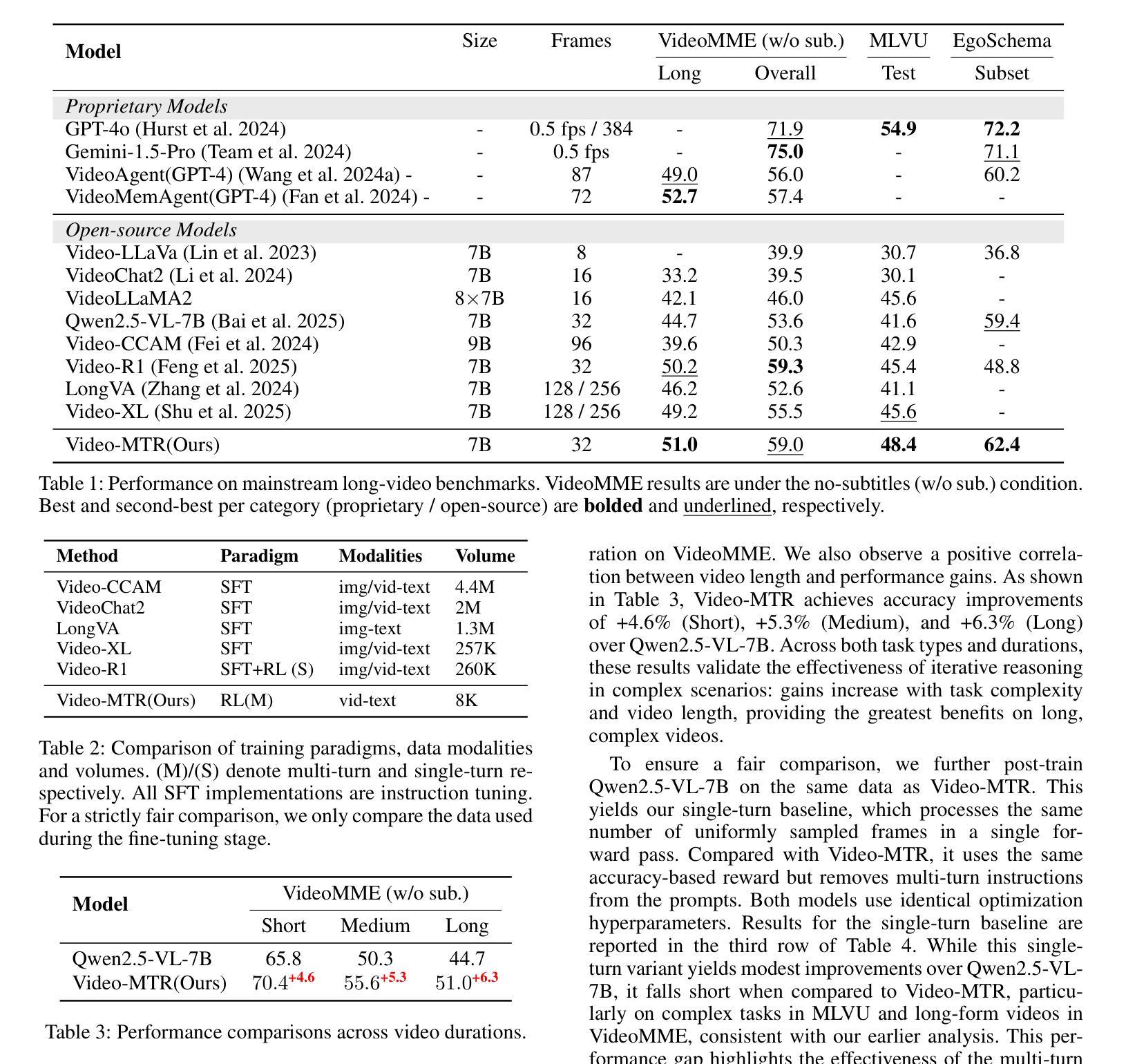
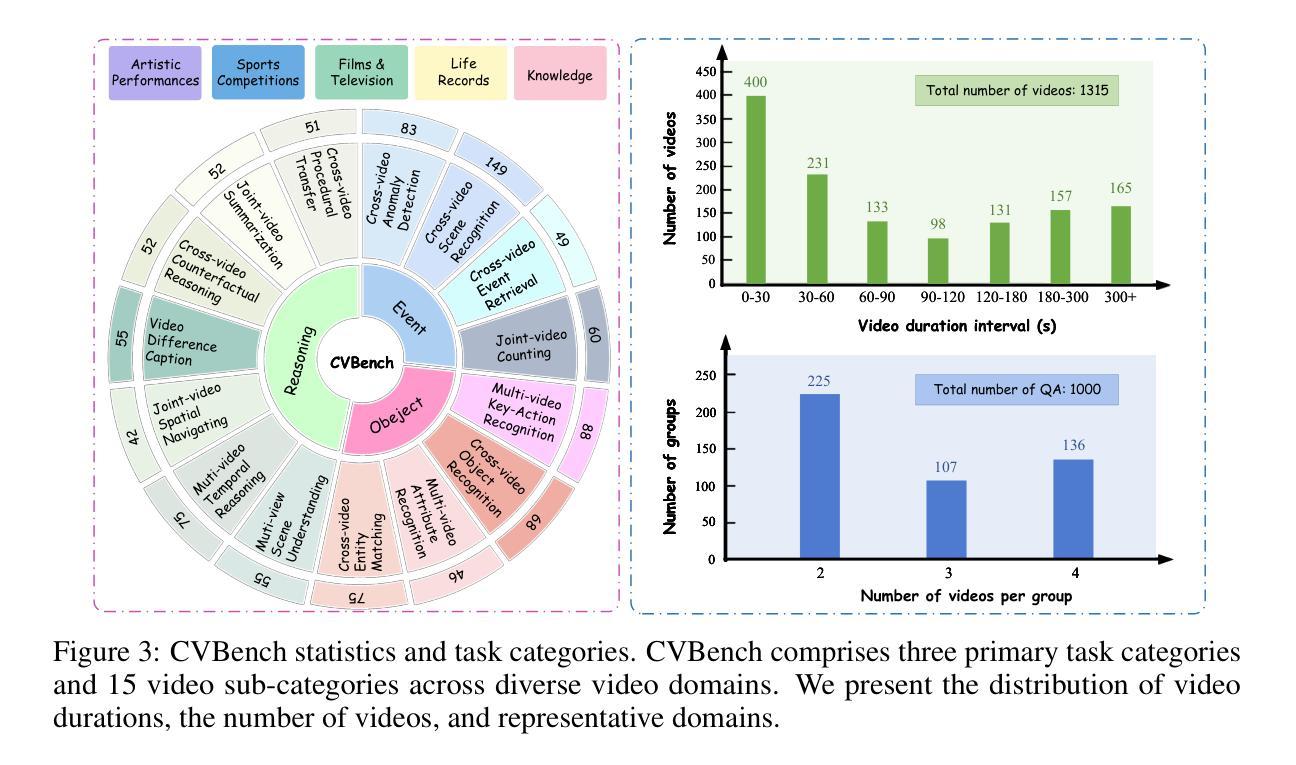
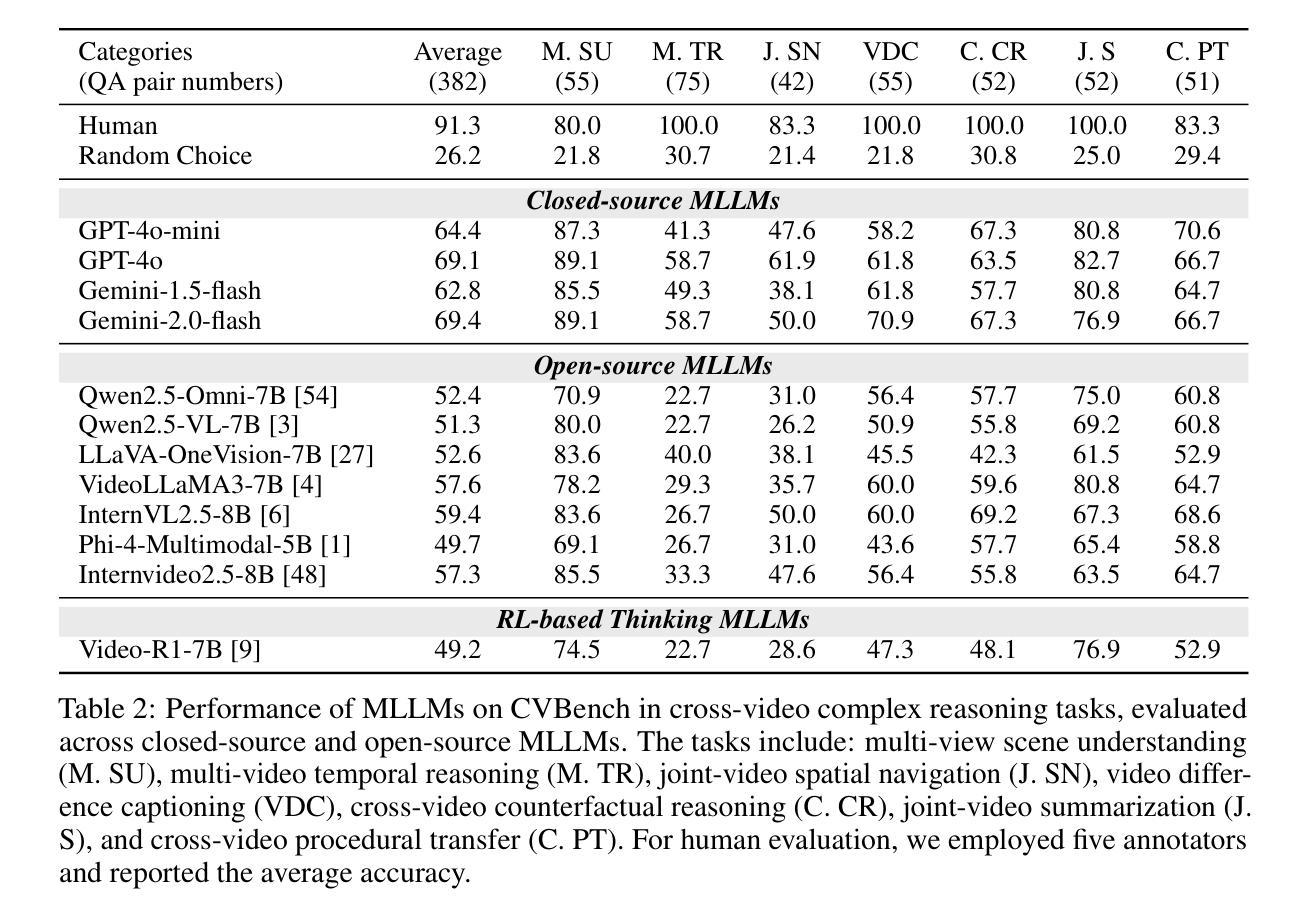
CVBench: Evaluating Cross-Video Synergies for Complex Multimodal Understanding and Reasoning
Authors:Nannan Zhu, Yonghao Dong, Teng Wang, Xueqian Li, Shengjun Deng, Yijia Wang, Zheng Hong, Tiantian Geng, Guo Niu, Hanyan Huang, Xiongfei Yao, Shuaiwei Jiao
While multimodal large language models (MLLMs) exhibit strong performance on single-video tasks (e.g., video question answering), their ability across multiple videos remains critically underexplored. However, this capability is essential for real-world applications, including multi-camera surveillance and cross-video procedural learning. To bridge this gap, we present CVBench, the first comprehensive benchmark designed to assess cross-video relational reasoning rigorously. CVBench comprises 1,000 question-answer pairs spanning three hierarchical tiers: cross-video object association (identifying shared entities), cross-video event association (linking temporal or causal event chains), and cross-video complex reasoning (integrating commonsense and domain knowledge). Built from five domain-diverse video clusters (e.g., sports, life records), the benchmark challenges models to synthesise information across dynamic visual contexts. Extensive evaluation of 10+ leading MLLMs (including GPT-4o, Gemini-2.0-flash, Qwen2.5-VL) under zero-shot or chain-of-thought prompting paradigms. Key findings reveal stark performance gaps: even top models, such as GPT-4o, achieve only 60% accuracy on causal reasoning tasks, compared to the 91% accuracy of human performance. Crucially, our analysis reveals fundamental bottlenecks inherent in current MLLM architectures, notably deficient inter-video context retention and poor disambiguation of overlapping entities. CVBench establishes a rigorous framework for diagnosing and advancing multi-video reasoning, offering architectural insights for next-generation MLLMs. The data and evaluation code are available at https://github.com/Hokhim2/CVBench.
多模态大型语言模型(MLLMs)在单视频任务(例如视频问答)上表现出强大的性能,但它们在多个视频上的能力仍然被严重忽视。然而,这种能力对于包括多摄像头监控和跨视频程序学习在内的实际应用至关重要。为了弥补这一差距,我们推出了CVBench,这是第一个旨在严格评估跨视频关系推理的综合基准测试。CVBench包含1000个问答对,涵盖三个层次:跨视频对象关联(识别共享实体)、跨视频事件关联(链接时间或因果事件链),以及跨视频复杂推理(整合常识和领域知识)。该基准测试由五个领域多样的视频集群(例如体育、生活记录)组成,挑战模型在动态视觉环境中的信息合成能力。对10多个领先的多模态大型语言模型(包括GPT-4o、Gemini-2.0-flash、Qwen2.5-VL)进行了广泛评估,采用零样本或思维链提示范式。关键研究发现,即使是顶级模型如GPT-4o,在因果推理任务上的准确率也只有60%,而人类的表现准确率为91%。我们的分析揭示了当前MLLM架构的内在根本瓶颈,尤其是缺乏跨视频上下文保留和重叠实体的辨别能力。CVBench为诊断和推进多视频推理提供了严格的框架,并为下一代MLLM提供了架构见解。数据和评估代码可在https://github.com/Hokhim2/CVBench获得。
论文及项目相关链接
Summary
多模态大型语言模型(MLLMs)在单视频任务上表现优秀,如在视频问答中,但它们在跨多个视频的能力方面仍待充分探索。这对现实世界应用至关重要,包括多摄像头监控和跨视频过程学习等领域。为填补这一空白,我们提出CVBench,它是首个旨在严格评估跨视频关系推理的综合性基准测试。CVBench包含跨越三个层次的1000个问答对:跨视频对象关联(识别共享实体)、跨视频事件关联(链接时间或因果事件链),以及跨视频复杂推理(整合常识和领域知识)。该基准测试由五个领域多样的视频集群构成(如体育、生活记录),挑战模型在动态视觉环境中的信息综合。对十余款领先MLLMs的广泛评估显示,存在显著性能差距:即使是顶尖模型如GPT-4o,在因果推理任务上的准确率也只有60%,而人类准确率高达91%。分析揭示了当前MLLM架构的内在瓶颈,特别是跨视频上下文保留不足和重叠实体辨析能力差。CVBench为诊断和改进多视频推理提供了严格框架,并为下一代MLLMs提供了架构见解。数据和评估代码可在https://github.com/Hokhim2/CVBench获得。
Key Takeaways
- 多模态大型语言模型(MLLMs)在跨多个视频的能力方面存在不足,尽管在单视频任务上表现良好。
- 跨视频关系推理能力对于现实世界应用至关重要,包括多摄像头监控和跨视频过程学习。
- CVBench是首个评估跨视频关系推理的综合性基准测试,包含三个层次的问答对:跨视频对象关联、跨视频事件关联和跨视频复杂推理。
- CVBench由五个领域多样的视频集群构成,挑战模型在动态视觉环境中的信息综合。
- 评估显示,当前MLLMs在跨视频推理任务上性能有限,特别是因果推理任务。
- 分析揭示了MLLM架构的内在瓶颈,如跨视频上下文保留不足和重叠实体辨析能力差。
点此查看论文截图


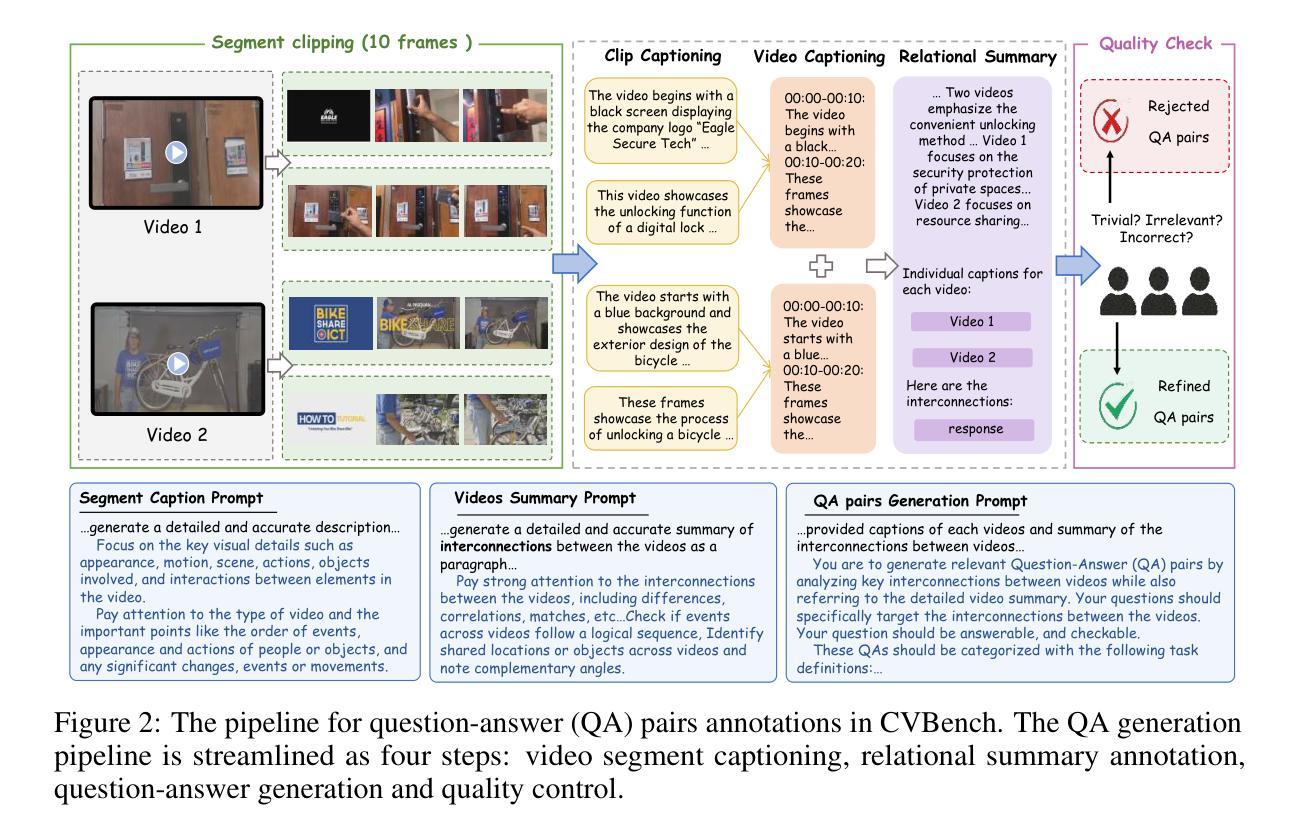
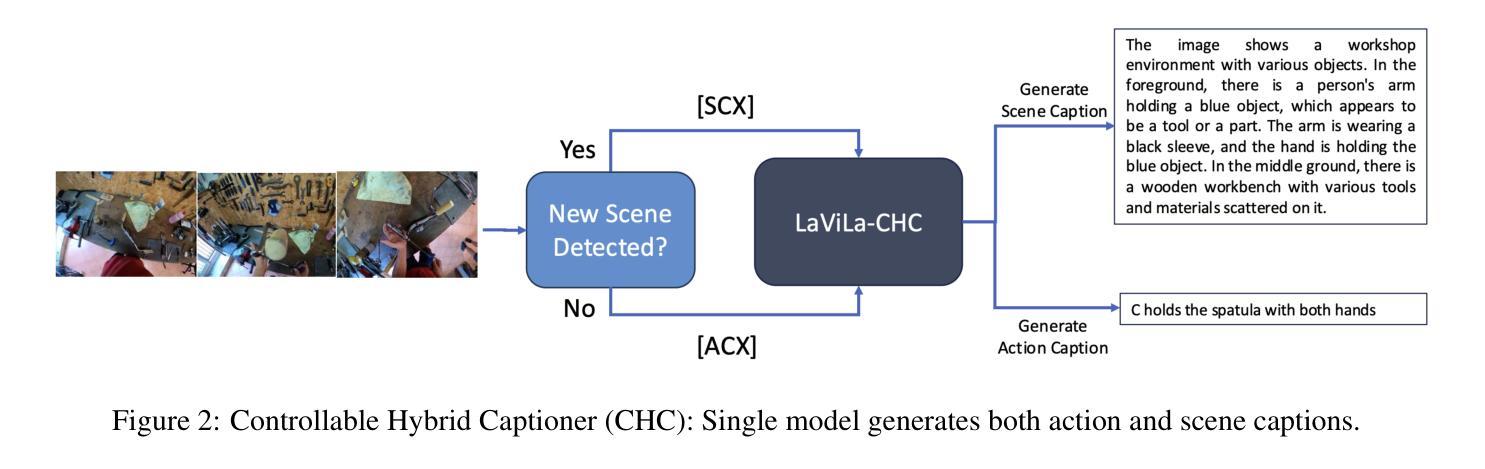
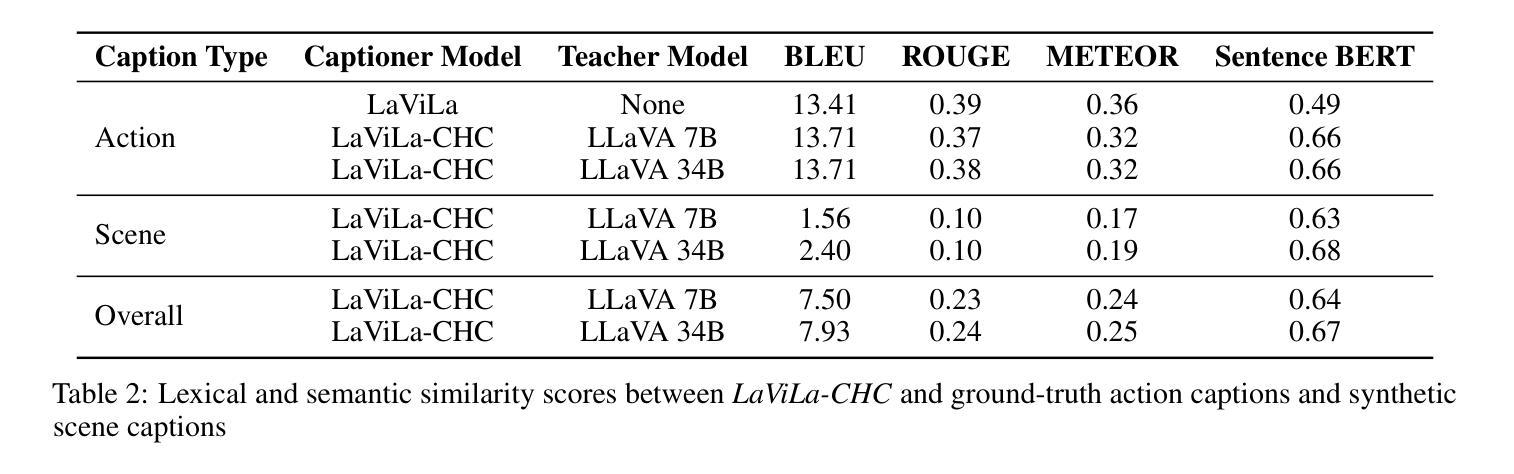
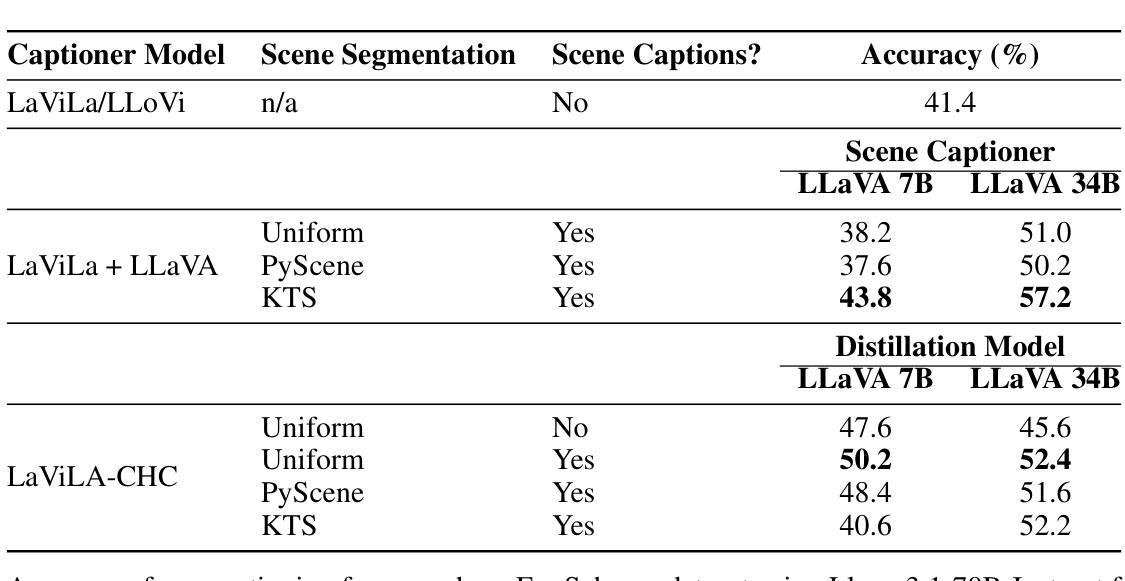
Controllable Hybrid Captioner for Improved Long-form Video Understanding
Authors:Kuleen Sasse, Efsun Sarioglu Kayi, Arun Reddy
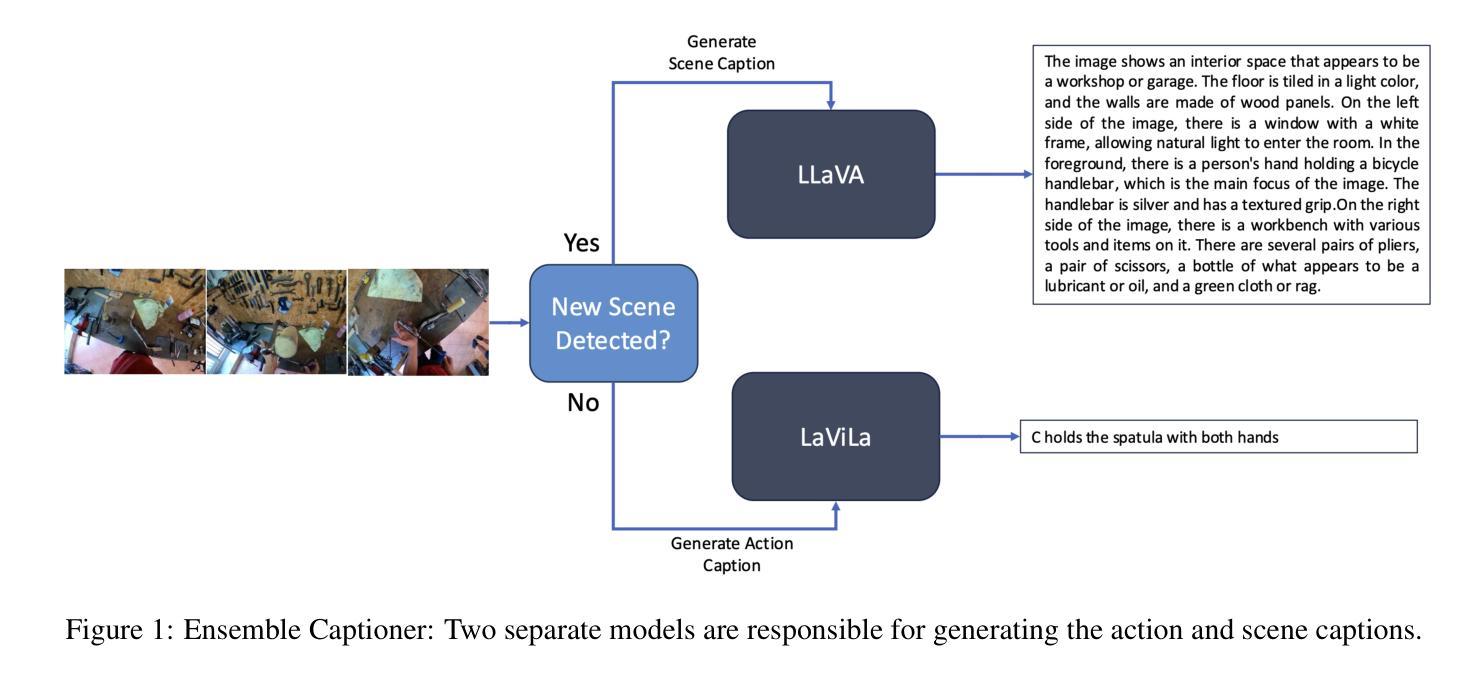
Video data, especially long-form video, is extremely dense and high-dimensional. Text-based summaries of video content offer a way to represent query-relevant content in a much more compact manner than raw video. In addition, textual representations are easily ingested by state-of-the-art large language models (LLMs), which enable reasoning over video content to answer complex natural language queries. To solve this issue, we rely on the progressive construction of a text-based memory by a video captioner operating on shorter chunks of the video, where spatio-temporal modeling is computationally feasible. We explore ways to improve the quality of the activity log comprised solely of short video captions. Because the video captions tend to be focused on human actions, and questions may pertain to other information in the scene, we seek to enrich the memory with static scene descriptions using Vision Language Models (VLMs). Our video understanding system relies on the LaViLa video captioner in combination with a LLM to answer questions about videos. We first explored different ways of partitioning the video into meaningful segments such that the textual descriptions more accurately reflect the structure of the video content. Furthermore, we incorporated static scene descriptions into the captioning pipeline using LLaVA VLM, resulting in a more detailed and complete caption log and expanding the space of questions that are answerable from the textual memory. Finally, we have successfully fine-tuned the LaViLa video captioner to produce both action and scene captions, significantly improving the efficiency of the captioning pipeline compared to using separate captioning models for the two tasks. Our model, controllable hybrid captioner, can alternate between different types of captions according to special input tokens that signals scene changes detected in the video.
视频数据,特别是长视频,极为密集且高维。基于文本的视频内容摘要提供了一种比原始视频更紧凑地表示查询相关内容的方式。此外,文本表示很容易被最新的大型语言模型(LLM)所接纳,这使得能够推理视频内容以回答复杂的自然语言查询。为解决此问题,我们依赖于由操作视频较短片段的视频字幕器逐步构建的基于文本的存储器,其中时空建模是计算可行的。我们探索了提高仅由短视频字幕构成的活动日志质量的方法。由于视频字幕往往侧重于人类行为,而问题可能与场景中的其他信息有关,我们寻求使用视觉语言模型(VLM)丰富存储器中的静态场景描述。我们的视频理解系统依赖于LaViLa视频字幕器结合LLM来回答视频问题。我们首先探索了将视频分割成有意义片段的不同方式,以便文本描述更准确地反映视频内容的结构。此外,我们利用LLaVA VLM将静态场景描述纳入字幕管道,从而得到更详细和完整的字幕日志,并扩大了可从文本存储器中回答的问题空间。最后,我们已经成功微调了LaViLa视频字幕器,以产生动作和场景字幕,与为两项任务使用单独的字幕模型相比,这大大提高了字幕管道的效率。我们的模型——可控混合字幕器,可以根据视频中的场景变化等特殊输入令牌在不同类型的字幕之间进行切换。
论文及项目相关链接
Summary
本文探讨了对视频内容进行文本摘要的方法。针对长视频数据的高密度和高维度特性,通过视频字幕员对视频较短片段的操作,逐步构建基于文本的记忆。为提高仅由短视频字幕构成的活动日志质量,结合使用视觉语言模型(VLMs)丰富记忆内容,包括静态场景描述。视频理解系统依赖LaViLa视频字幕员与大型语言模型(LLM),回答关于视频的问题。尝试不同方式划分视频片段,更准确反映视频内容结构。通过LLaVA VLM融入静态场景描述,生成更详细和完整的字幕日志,扩展可从文本记忆中提问的空间。成功调整LaViLa视频字幕员,可同时生成动作和场景字幕,相较于为两项任务分别使用单独的字幕模型,提高了字幕生成效率。提出的可控混合字幕员可根据视频中检测到的场景变化产生的特殊输入令牌,交替生成不同类型的字幕。
Key Takeaways
- 视频数据的高密度和高维度需要通过文本摘要进行简化表示。
- 通过短视频片段的逐步构建文本记忆来解决该问题。
- 为提高活动日志质量,结合使用视觉语言模型(VLMs)丰富文本记忆内容。
- LaViLa视频字幕员与大型语言模型(LLM)结合用于回答关于视频的问题。
- 通过划分视频片段以更准确反映视频内容结构的方式进行了探索。
- 成功调整LaViLa视频字幕员,可以同时生成动作和场景字幕,提高字幕生成效率。
点此查看论文截图

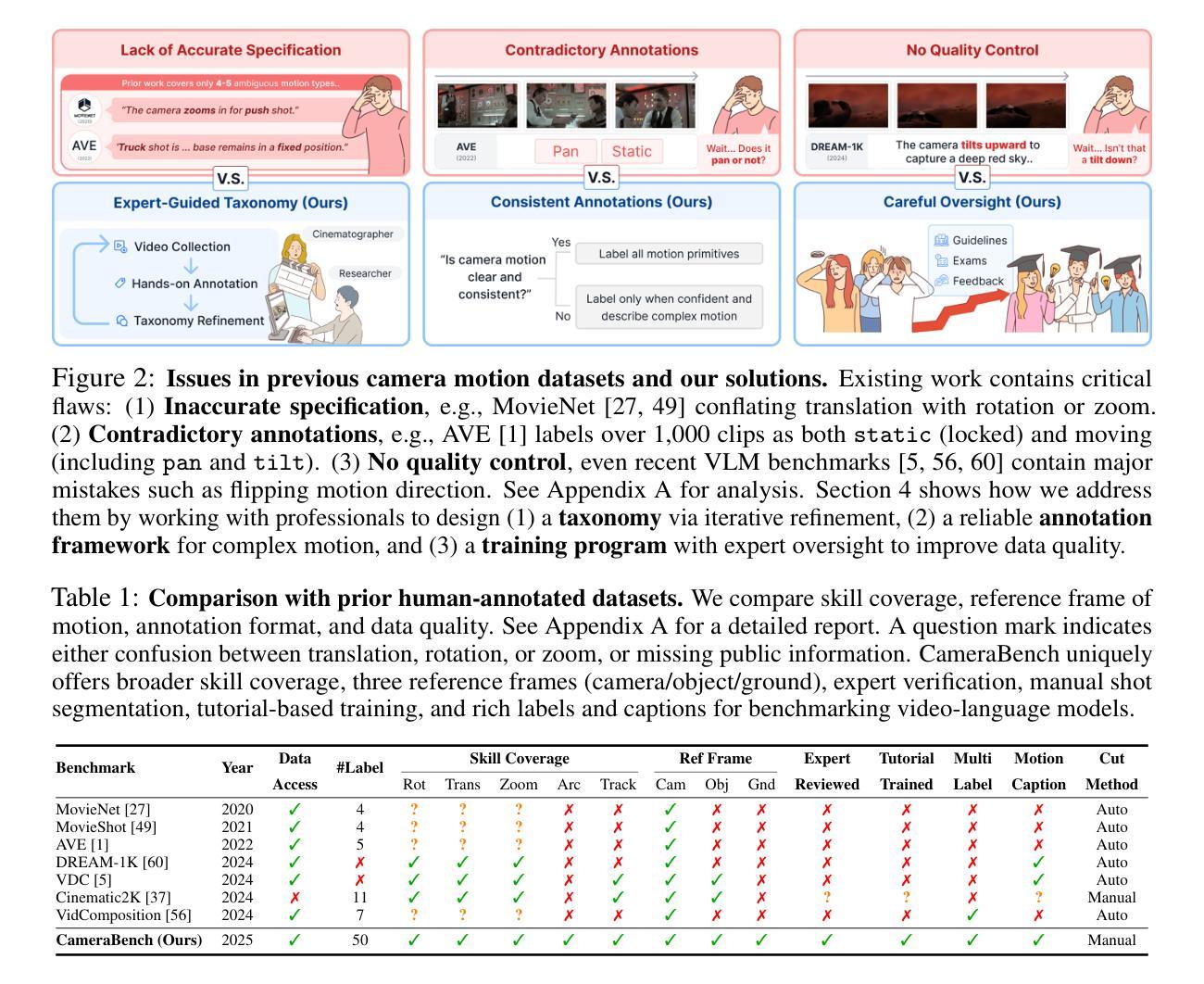
Towards Understanding Camera Motions in Any Video
Authors:Zhiqiu Lin, Siyuan Cen, Daniel Jiang, Jay Karhade, Hewei Wang, Chancharik Mitra, Tiffany Ling, Yuhan Huang, Sifan Liu, Mingyu Chen, Rushikesh Zawar, Xue Bai, Yilun Du, Chuang Gan, Deva Ramanan
We introduce CameraBench, a large-scale dataset and benchmark designed to assess and improve camera motion understanding. CameraBench consists of ~3,000 diverse internet videos, annotated by experts through a rigorous multi-stage quality control process. One of our contributions is a taxonomy of camera motion primitives, designed in collaboration with cinematographers. We find, for example, that some motions like “follow” (or tracking) require understanding scene content like moving subjects. We conduct a large-scale human study to quantify human annotation performance, revealing that domain expertise and tutorial-based training can significantly enhance accuracy. For example, a novice may confuse zoom-in (a change of intrinsics) with translating forward (a change of extrinsics), but can be trained to differentiate the two. Using CameraBench, we evaluate Structure-from-Motion (SfM) and Video-Language Models (VLMs), finding that SfM models struggle to capture semantic primitives that depend on scene content, while VLMs struggle to capture geometric primitives that require precise estimation of trajectories. We then fine-tune a generative VLM on CameraBench to achieve the best of both worlds and showcase its applications, including motion-augmented captioning, video question answering, and video-text retrieval. We hope our taxonomy, benchmark, and tutorials will drive future efforts towards the ultimate goal of understanding camera motions in any video.
我们介绍了CameraBench,这是一个旨在评估和提高摄像机运动理解的大型数据集和基准测试。CameraBench由大约3000个多样化的互联网视频组成,这些视频经过专家通过严格的多阶段质量控制过程进行标注。我们的贡献之一是与电影摄影师共同设计的摄像机运动原始分类。我们发现,例如,“跟随”(或跟踪)等动作需要理解场景内容,如移动主题。我们进行了一项大规模的人类研究,以衡量人类标注性能,发现领域专业知识和基于教程的培训可以显著提高准确性。例如,新手可能会混淆缩放(内在变化)和向前平移(外在变化),但可以通过训练来区分这两者。使用CameraBench,我们评估了结构从运动(SfM)和视频语言模型(VLMs),发现SfM模型在捕获依赖于场景内容的语义原始数据时遇到困难,而VLM在捕获需要精确估计轨迹的几何原始数据时则遇到困难。然后我们在CameraBench上对生成式VLM进行了微调,实现了两者的优点,并展示了其应用,包括运动增强描述、视频问答和视频文本检索。我们希望我们的分类、基准测试和教程将推动未来向着理解任何视频中的摄像机动作这一目标发展。
论文及项目相关链接
PDF Project site: https://linzhiqiu.github.io/papers/camerabench/
摘要
本文介绍了CameraBench,一个用于评估和改进摄像机动作理解的大型数据集和基准测试。CameraBench包含约3000个多样化的互联网视频,经过专家严格的多阶段质量控制过程进行标注。本文的贡献之一是与电影摄影师共同设计的摄像机动作原始分类法。我们发现,一些动作如“跟踪”需要理解场景内容如移动主体。我们进行了一项大规模的人机研究来量化人类标注性能,发现领域专业知识和基于教程的培训可以显著提高准确性。使用CameraBench,我们评估了结构从运动(SfM)和视频语言模型(VLMs),发现SfM模型在依赖于场景内容的语义原始动作上表现挣扎,而VLM在需要精确轨迹估计的几何原始动作上表现挣扎。我们对基准测试、分类法和教程的期望将推动未来向理解任何视频中的摄像机动作这一目标努力。
关键要点
- CameraBench是一个用于评估和改进摄像机动作理解的大型数据集和基准测试。
- 包含约3000个多样化互联网视频,经过专家严格标注。
- 与电影摄影师共同设计了一种摄像机动作原始分类法。
- 部分动作如“跟踪”需要理解场景内容。
- 领域专业知识和基于教程的培训可以显著提高人机标注性能。
- 结构从运动(SfM)和视频语言模型(VLMs)在特定领域存在挑战。
点此查看论文截图


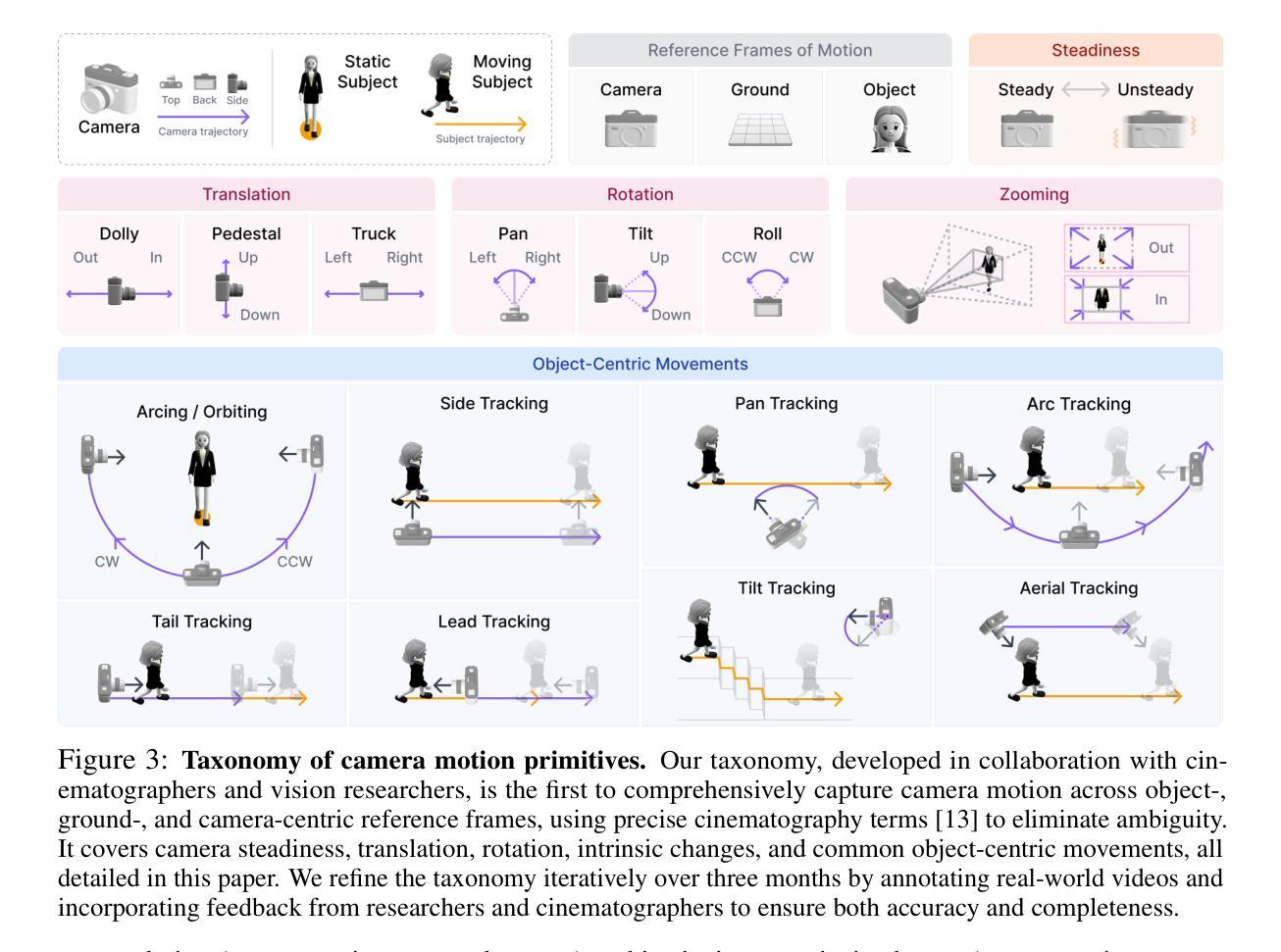
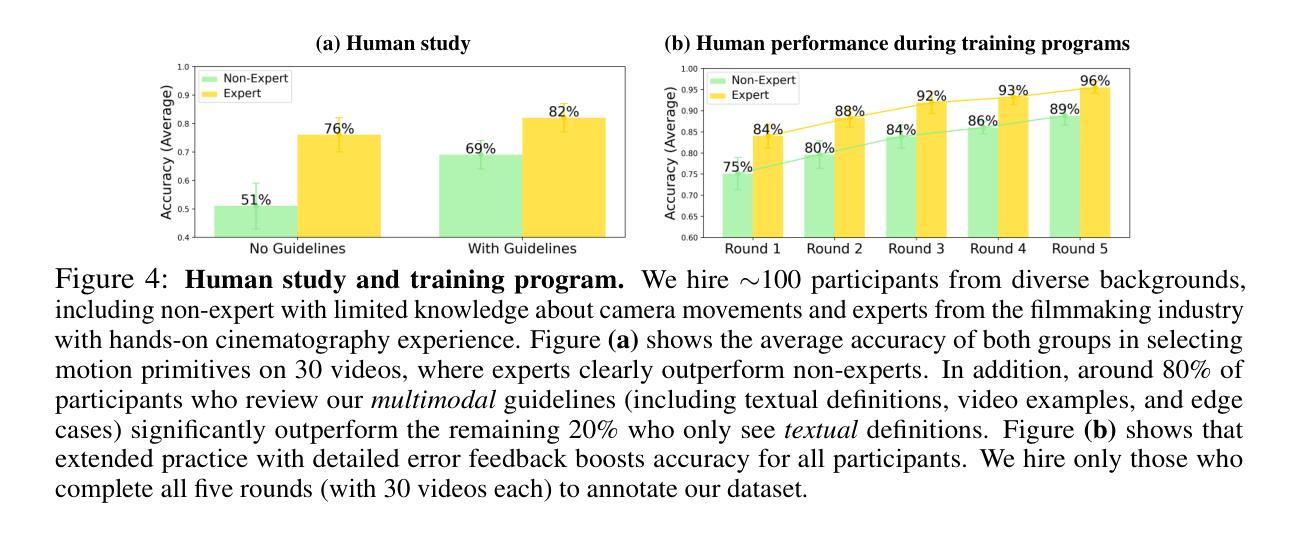
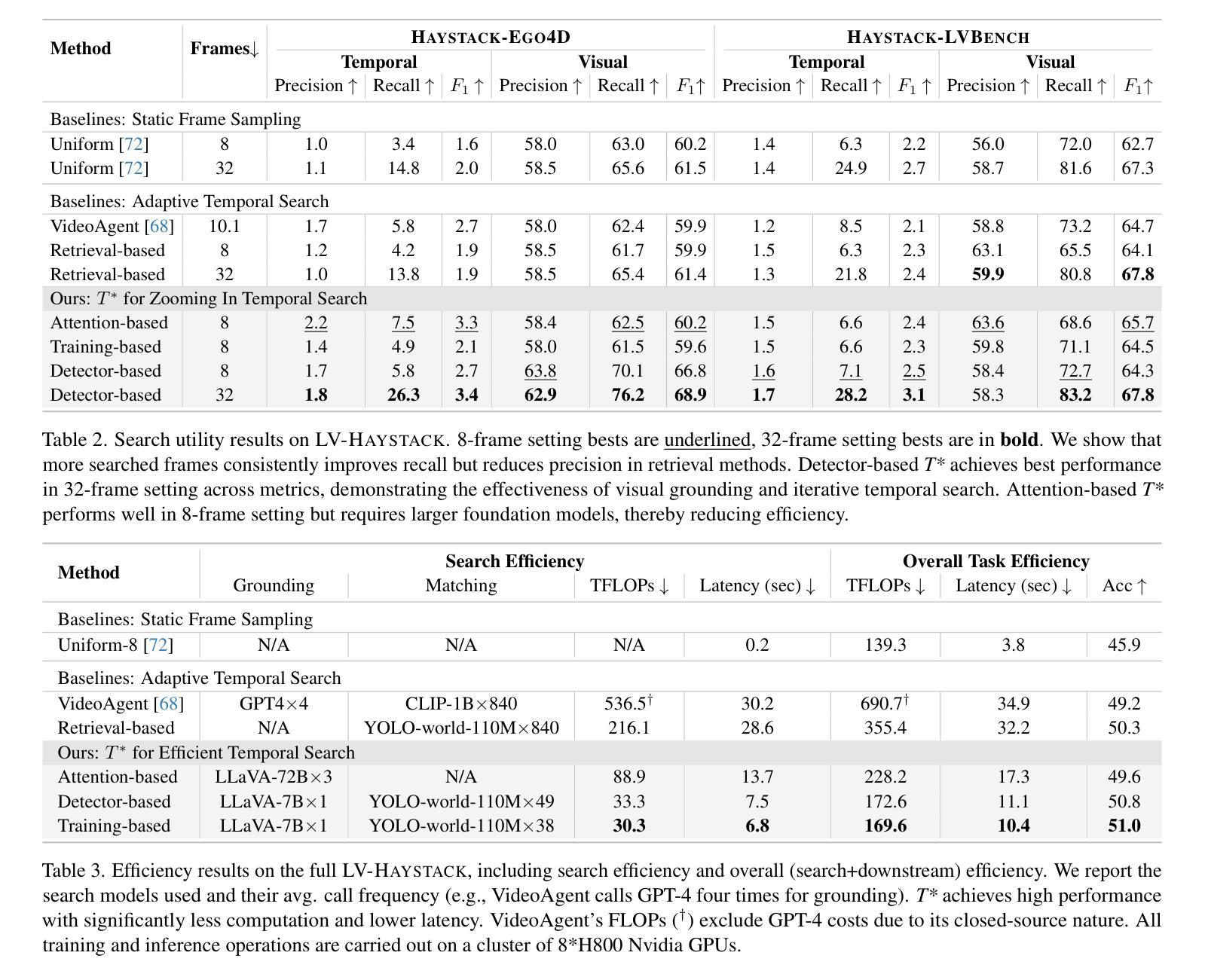
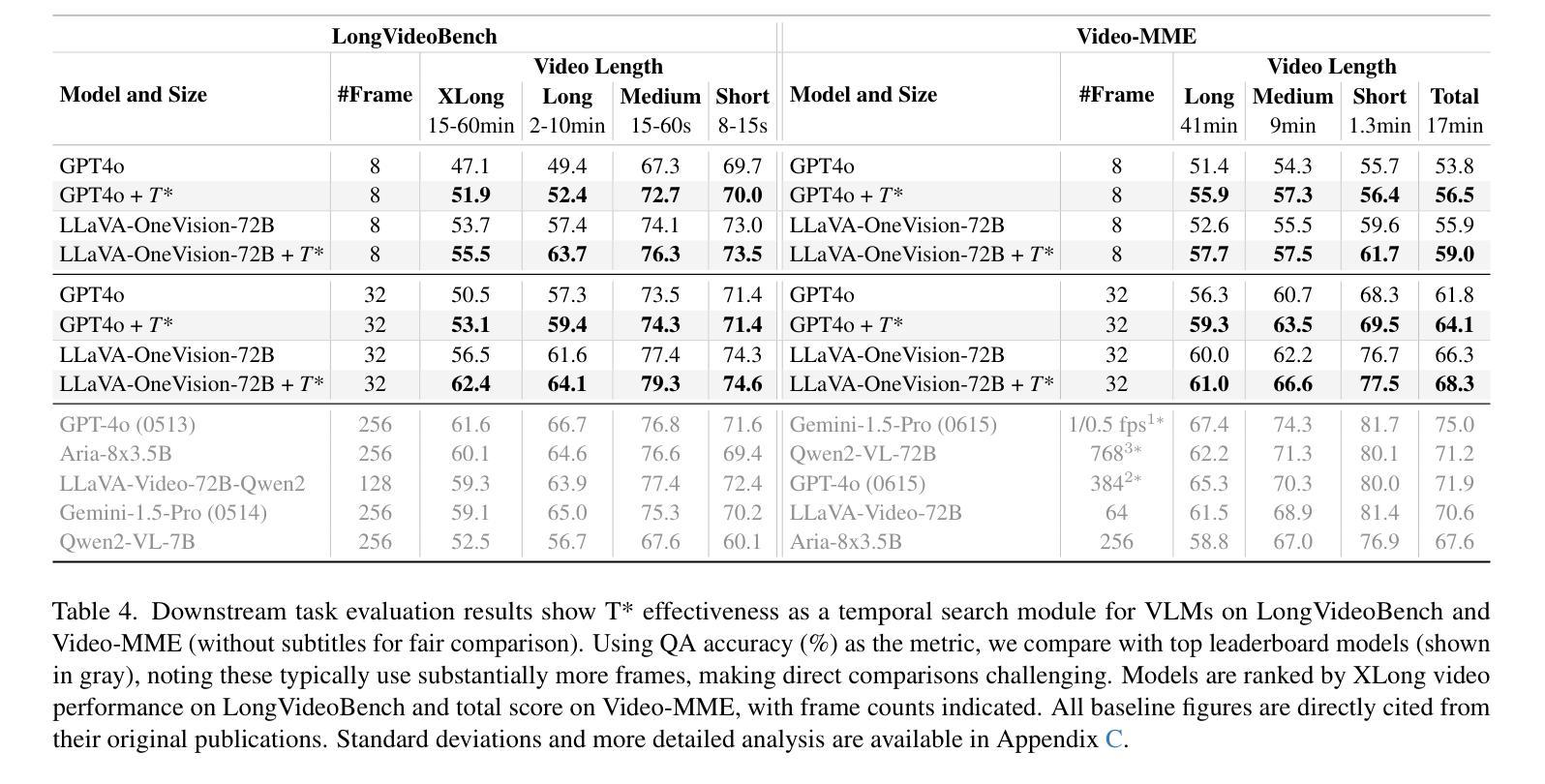
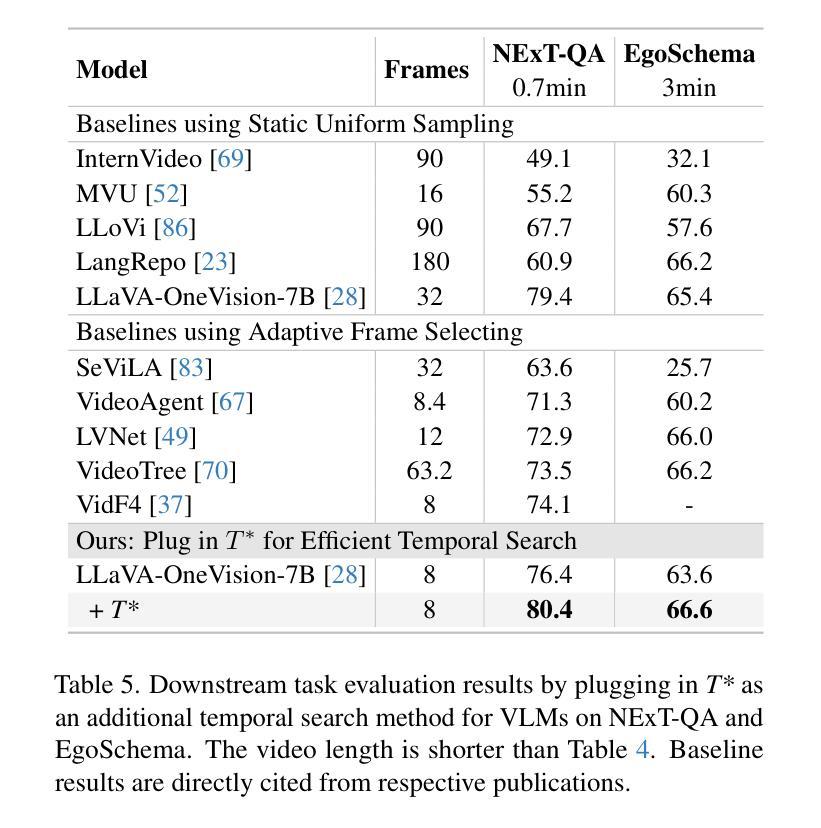
T*: Re-thinking Temporal Search for Long-Form Video Understanding
Authors:Jinhui Ye, Zihan Wang, Haosen Sun, Keshigeyan Chandrasegaran, Zane Durante, Cristobal Eyzaguirre, Yonatan Bisk, Juan Carlos Niebles, Ehsan Adeli, Li Fei-Fei, Jiajun Wu, Manling Li
Efficiently understanding long-form videos remains a significant challenge in computer vision. In this work, we revisit temporal search paradigms for long-form video understanding and address a fundamental issue pertaining to all state-of-the-art (SOTA) long-context vision-language models (VLMs). Our contributions are twofold: First, we frame temporal search as a Long Video Haystack problem: finding a minimal set of relevant frames (e.g., one to five) from tens of thousands based on specific queries. Upon this formulation, we introduce LV-Haystack, the first dataset with 480 hours of videos, 15,092 human-annotated instances for both training and evaluation aiming to improve temporal search quality and efficiency. Results on LV-Haystack highlight a significant research gap in temporal search capabilities, with current SOTA search methods only achieving 2.1% temporal F1 score on the Longvideobench subset. Next, inspired by visual search in images, we propose a lightweight temporal search framework, T* that reframes costly temporal search as spatial search. T* leverages powerful visual localization techniques commonly used in images and introduces an adaptive zooming-in mechanism that operates across both temporal and spatial dimensions. Extensive experiments show that integrating T* with existing methods significantly improves SOTA long-form video understanding. Under an inference budget of 32 frames, T* improves GPT-4o’s performance from 50.5% to 53.1% and LLaVA-OneVision-OV-72B’s performance from 56.5% to 62.4% on the Longvideobench XL subset. Our code, benchmark, and models are provided in the Supplementary material.
在计算机视觉领域,有效地理解长视频仍然是一个重大挑战。在这项工作中,我们重新思考了用于长视频理解的时序搜索范式,并解决了一个与所有最先进的长上下文视觉语言模型(VLMs)相关的基础问题。我们的贡献有两方面:首先,我们将时序搜索问题定位为长视频堆栈问题:从数万帧中找出与特定查询相关的最少帧数(例如一到五帧)。基于此构想,我们推出了LV-Haystack数据集,其中包含480小时的视频和针对训练和评估的15,092个人工注释实例,旨在提高时序搜索的质量和效率。在LV-Haystack上的结果显示出时序搜索能力存在显著的研究差距,当前最先进的方法在Longvideobench子集上仅实现了2.1%的时序F1分数。接下来,受到图像视觉搜索的启发,我们提出了一种轻量级的时序搜索框架T,它将昂贵的时序搜索重新定位为空间搜索。T利用图像中常用的强大视觉定位技术,并引入了一种自适应缩放机制,该机制在时空两个维度上运行。大量实验表明,将T与现有方法相结合,可以显著提高最先进的长视频理解能力。在推理预算为32帧的条件下,T将GPT-4o的性能从50.5%提高到53.1%,将LLaVA-OneVision-OV-72B的性能从56.5%提高到62.4%,这是在Longvideobench XL子集上的结果。我们的代码、基准测试和模型都已在补充材料中提供。
论文及项目相关链接
PDF Accepted by CVPR 2025; A real-world long video needle-in-haystack benchmark; long-video QA with human ref frames
摘要
本文重新审视了长视频理解的时序搜索范式,并针对当前主流的长上下文视觉语言模型(VLMs)存在的一个根本问题进行了研究。文章将时序搜索问题类比为长视频的“针尖搜寻”问题,即需要从数万帧中寻找极少量的关键帧。为此,文章推出了LV-Haystack数据集,包含480小时的视频和用于训练和评估的15,092个人类标注实例。当前最先进的方法在LV-Haystack的子集Longvideobench上的表现仍有显著差距,仅实现了2.1%的时间F1得分。文章受到图像视觉搜索的启发,提出了一个轻量级的时序搜索框架T,将昂贵的时序搜索重新定位为空间搜索。T利用图像中常用的视觉定位技术,并引入自适应缩放机制,该机制在时间和空版本上都有效。实验表明,将T与现有方法相结合,可显著提高长视频理解的最先进技术水平。在推理预算为32帧的条件下,T将GPT-4o的性能从50.5%提高到53.1%,将LLaVA-OneVision-OV-72B的性能从56.5%提高到62.4%。
关键见解
- 提出将时序搜索问题类比为长视频的“针尖搜寻”问题,并引入LV-Haystack数据集用于训练和评估时序搜索模型。
- 揭示了当前最先进方法在LV-Haystack上的性能差距,时间F1得分仅为2.1%。
- 提出了一个轻量级的时序搜索框架T*,将昂贵的时序搜索重新定位为空间搜索。
- T*利用视觉定位技术和自适应缩放机制,在时间和空间两个维度上操作。
- T*与现有方法的结合显著提高长视频理解性能,改善GPT-4o和LLaVA-OneVision-OV-72B的性能。
- 在推理预算为32帧的条件下,T*能显著提升性能表现。
- 提供了代码、基准测试和模型以供研究使用。
点此查看论文截图

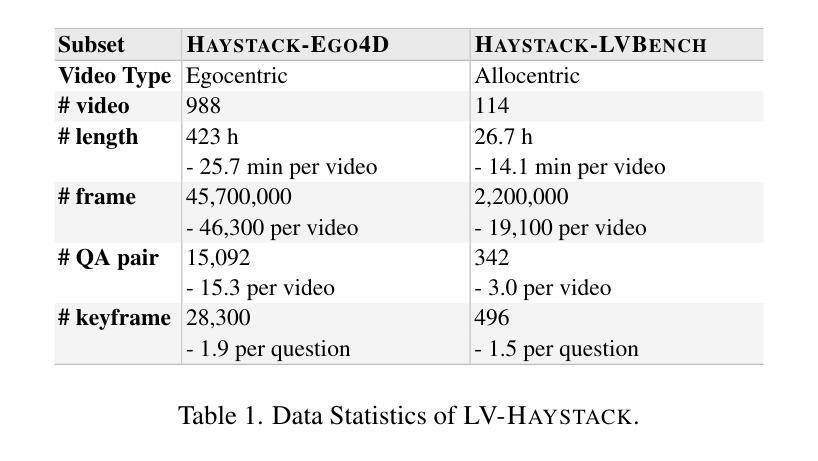
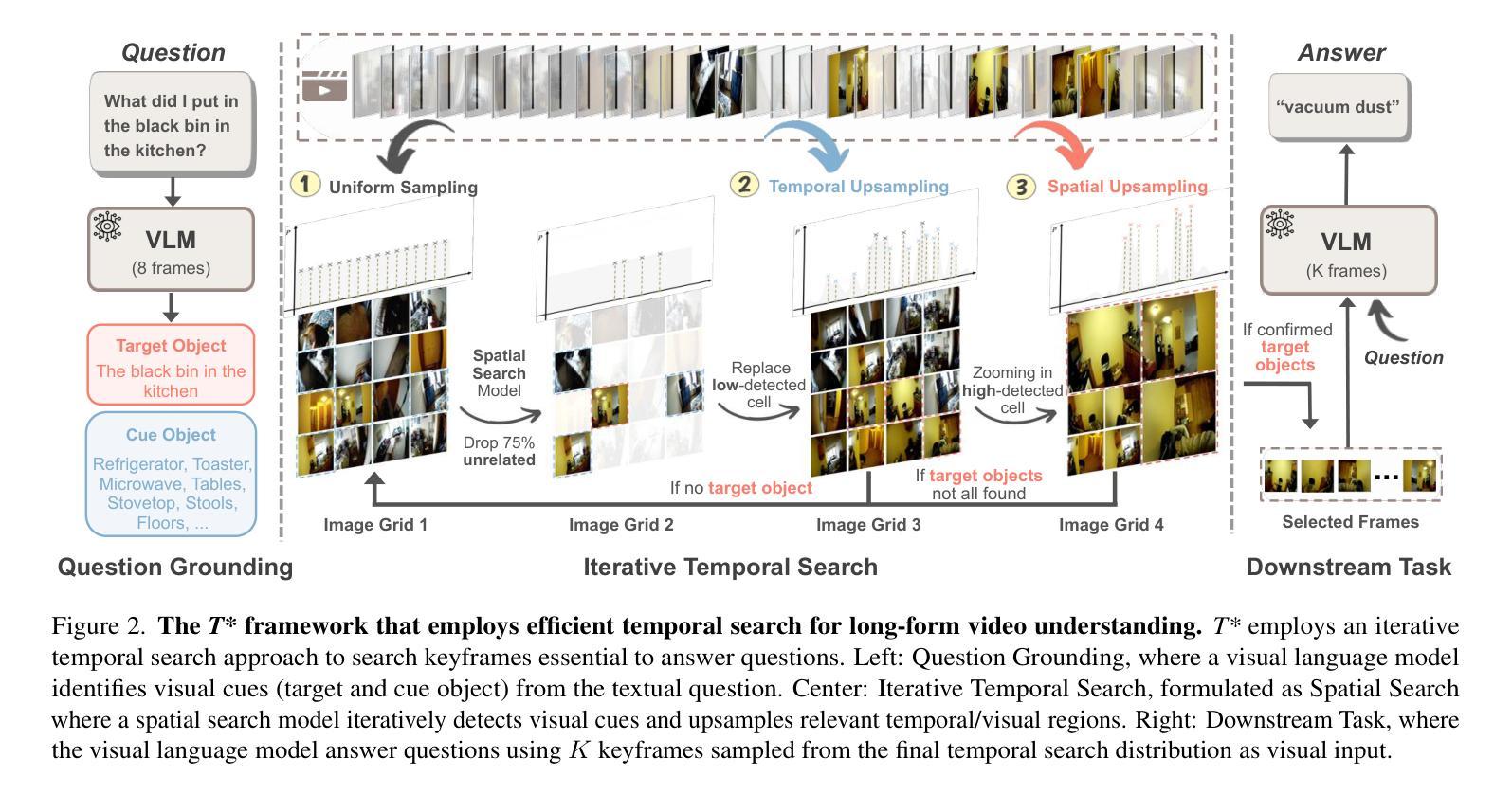

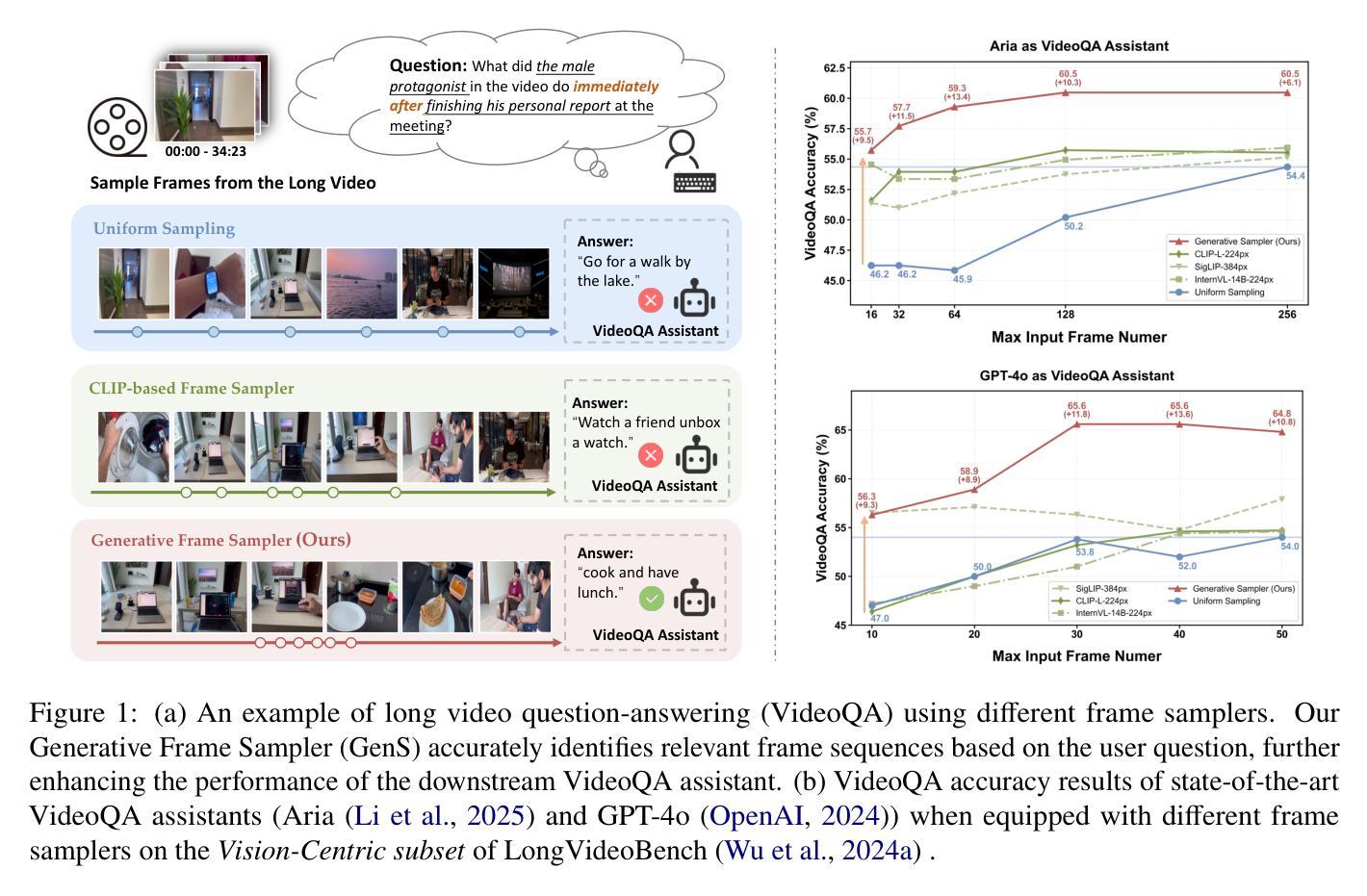
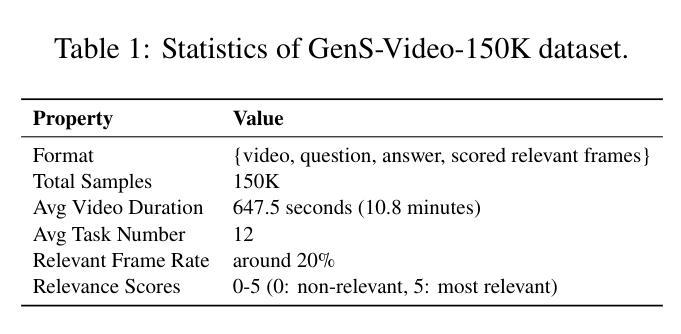
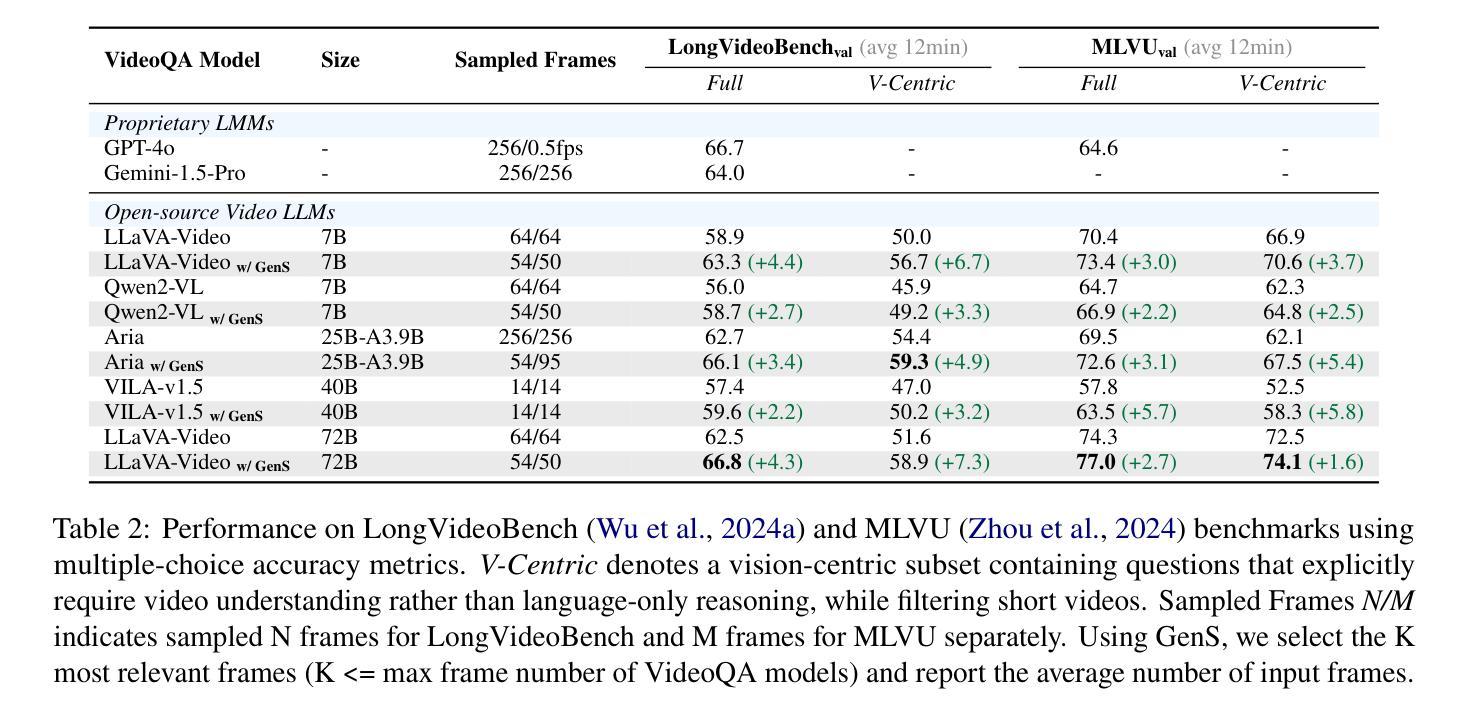
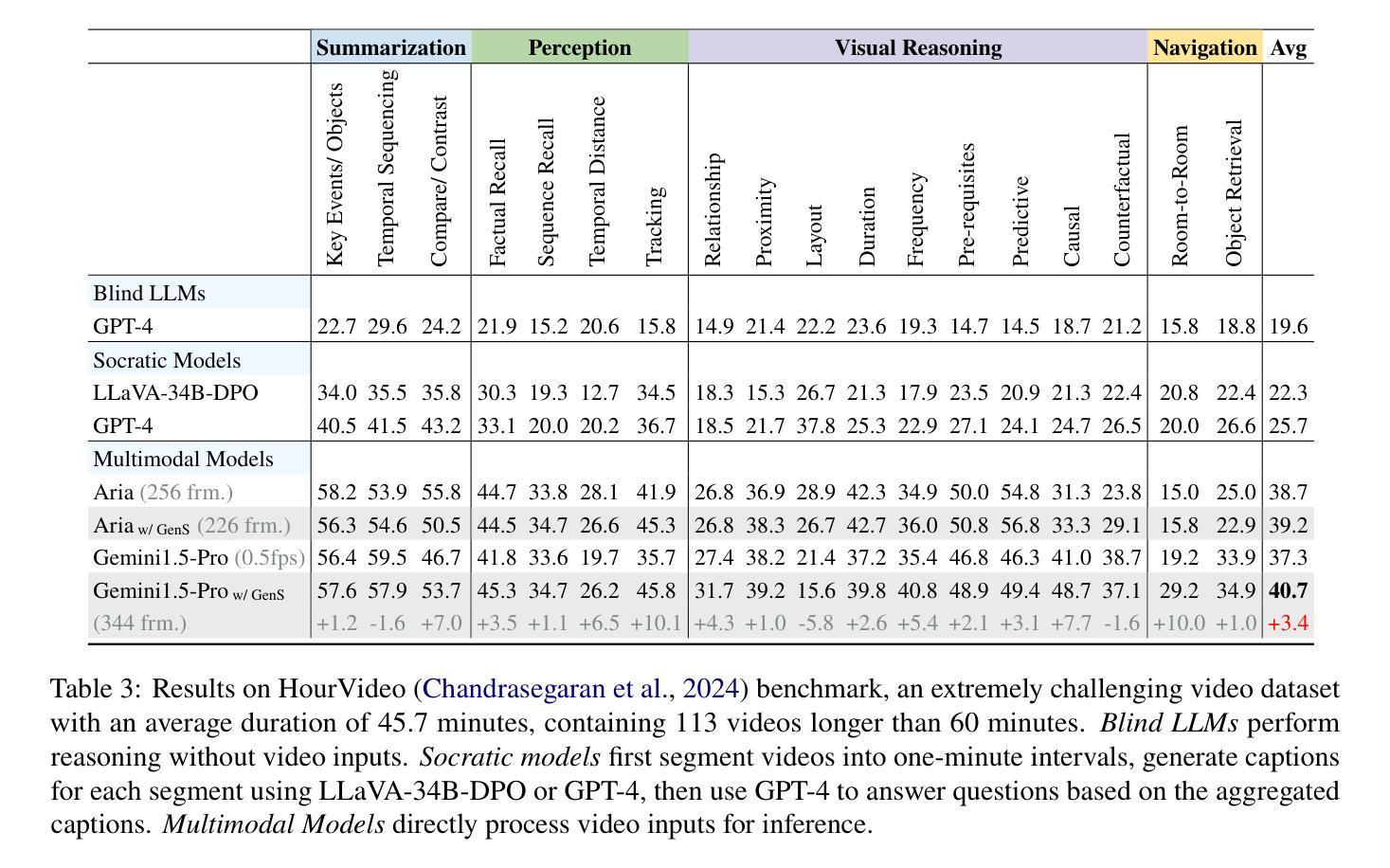
Generative Frame Sampler for Long Video Understanding
Authors:Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, Junnan Li
Despite recent advances in Video Large Language Models (VideoLLMs), effectively understanding long-form videos remains a significant challenge. Perceiving lengthy videos containing thousands of frames poses substantial computational burden. To mitigate this issue, this paper introduces Generative Frame Sampler (GenS), a plug-and-play module integrated with VideoLLMs to facilitate efficient lengthy video perception. Built upon a lightweight VideoLLM, GenS leverages its inherent vision-language capabilities to identify question-relevant frames. To facilitate effective retrieval, we construct GenS-Video-150K, a large-scale video instruction dataset with dense frame relevance annotations. Extensive experiments demonstrate that GenS consistently boosts the performance of various VideoLLMs, including open-source models (Qwen2-VL-7B, Aria-25B, VILA-40B, LLaVA-Video-7B/72B) and proprietary assistants (GPT-4o, Gemini). When equipped with GenS, open-source VideoLLMs achieve impressive state-of-the-art results on long-form video benchmarks: LLaVA-Video-72B reaches 66.8 (+4.3) on LongVideoBench and 77.0 (+2.7) on MLVU, while Aria obtains 39.2 on HourVideo surpassing the Gemini-1.5-pro by 1.9 points. We will release all datasets and models at https://generative-sampler.github.io.
尽管视频大语言模型(VideoLLMs)近期取得了进展,但有效理解长视频仍然是一项重大挑战。感知包含数千帧的冗长视频带来了巨大的计算负担。为了解决这一问题,本文介绍了生成帧采样器(GenS),这是一个与VideoLLMs集成的即插即用模块,可促进高效的长视频感知。基于轻量级的VideoLLM,GenS利用其固有的视觉语言功能来识别与问题相关的帧。为了促进有效检索,我们构建了GenS-Video-150K,这是一个大规模的视频指令数据集,具有密集的帧相关性注释。大量实验表明,GenS持续提升了各种VideoLLMs的性能,包括开源模型(Qwen2-VL-7B、Aria-25B、VILA-40B、LLaVA-Video-7B/72B)和专有助理(GPT-4o、Gemini)。配备GenS后,开源VideoLLMs在长视频基准测试上取得了令人印象深刻的最先进结果:LLaVA-Video-72B在LongVideoBench上达到66.8(+4.3),在MLVU上达到77.0(+2.7),而Aria在HourVideo上获得39.2分,超越了Gemini-1.5-pro 1.9分。我们将在https://generative-sampler.github.io发布所有数据集和模型。
论文及项目相关链接
PDF ACL 2025 Findings. Code: https://github.com/yaolinli/GenS
Summary
该文针对长视频理解的问题,提出了一个名为Generative Frame Sampler(GenS)的插件模块,它可以与VideoLLMs集成,以提高对长视频的高效感知。GenS利用轻量级的VideoLLM模型,通过识别与问题相关的帧来减少计算负担。同时,文章构建了一个大型视频指令数据集GenS-Video-150K,并进行了广泛的实验验证,结果显示GenS能够显著提高多种VideoLLMs的性能。
Key Takeaways
- Generative Frame Sampler(GenS)是一个插件模块,旨在解决长视频理解中的计算负担问题。
- GenS可以集成到现有的VideoLLMs中,提高长视频感知的效率。
- GenS利用轻量级的VideoLLM模型识别与问题相关的帧。
- 构建了大型视频指令数据集GenS-Video-150K,用于支持有效检索。
- 实验结果表明,GenS可以显著提高多种开源和专有VideoLLMs的性能。
- 配备GenS的开源VideoLLMs在长篇视频基准测试中取得了显著成绩。
点此查看论文截图

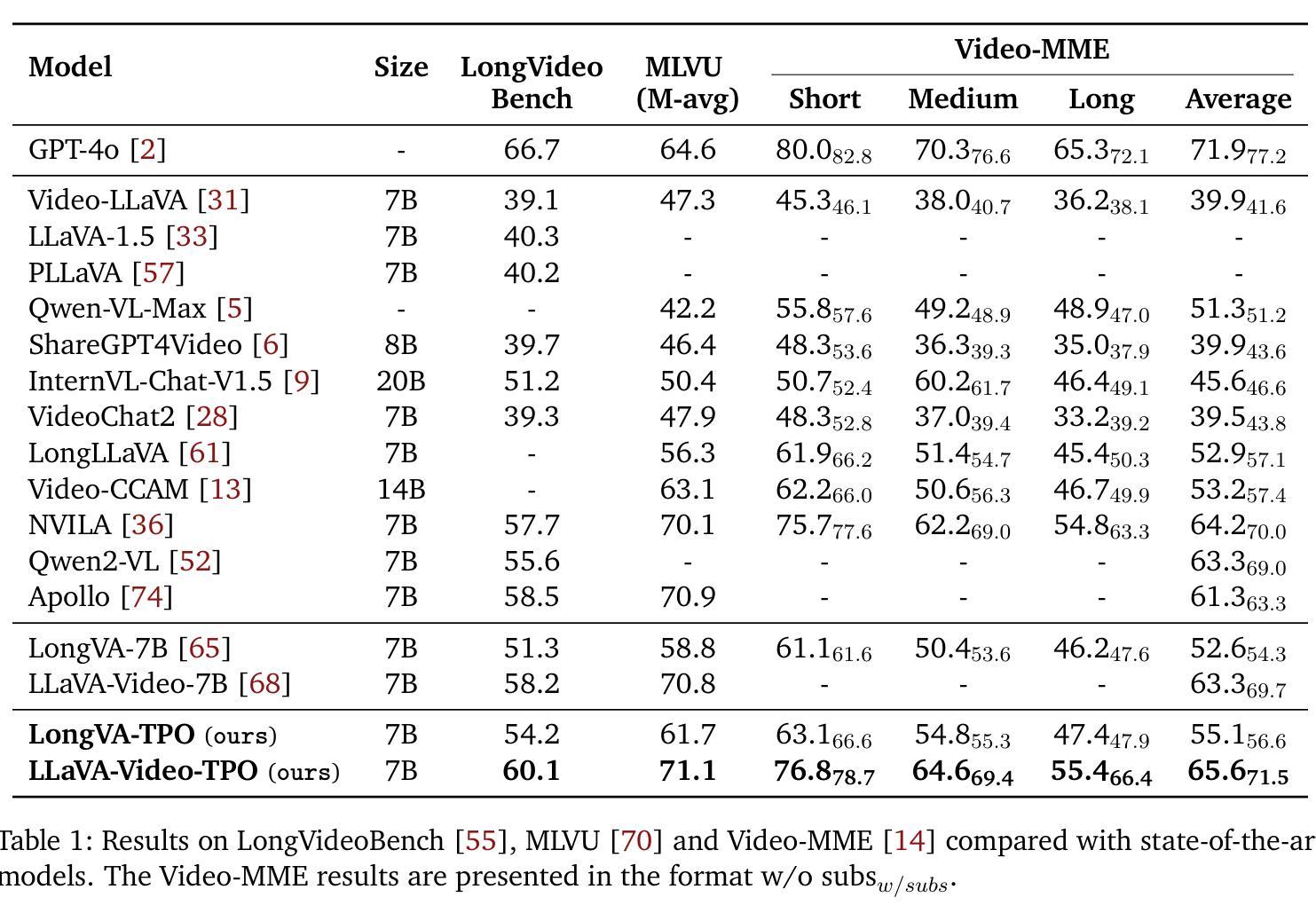
Temporal Preference Optimization for Long-Form Video Understanding
Authors:Rui Li, Xiaohan Wang, Yuhui Zhang, Orr Zohar, Zeyu Wang, Serena Yeung-Levy
Despite significant advancements in video large multimodal models (video-LMMs), achieving effective temporal grounding in long-form videos remains a challenge for existing models. To address this limitation, we propose Temporal Preference Optimization (TPO), a novel post-training framework designed to enhance the temporal grounding capabilities of video-LMMs through preference learning. TPO adopts a self-training approach that enables models to differentiate between well-grounded and less accurate temporal responses by leveraging curated preference datasets at two granularities: localized temporal grounding, which focuses on specific video segments, and comprehensive temporal grounding, which captures extended temporal dependencies across entire video sequences. By optimizing on these preference datasets, TPO significantly enhances temporal understanding while reducing reliance on manually annotated data. Extensive experiments on three long-form video understanding benchmarks–LongVideoBench, MLVU, and Video-MME–demonstrate the effectiveness of TPO across two state-of-the-art video-LMMs. Notably, LLaVA-Video-TPO establishes itself as the leading 7B model on the Video-MME benchmark, underscoring the potential of TPO as a scalable and efficient solution for advancing temporal reasoning in long-form video understanding. Project page: https://ruili33.github.io/tpo_website.
尽管视频大型多模态模型(video-LMMs)取得了显著进展,但在长视频中实现有效的时序定位仍然是现有模型的挑战。为了解决这一局限性,我们提出了时序偏好优化(TPO),这是一种新型的后训练框架,旨在通过偏好学习提高视频-LMMs的时序定位能力。TPO采用自我训练的方法,使模型能够在两个粒度上利用定制的偏好数据集来区分准确的时序响应和不那么准确的响应:局部时序定位,侧重于特定的视频片段;全面时序定位,捕捉整个视频序列中的扩展时间依赖关系。通过这些偏好数据集进行优化,TPO在提高时间理解的同时,减少了对手动注释数据的依赖。在LongVideoBench、MLVU和Video-MME三个长视频理解基准测试上的大量实验表明,TPO在两种最先进的视频-LMMs中都有效。值得注意的是,LLaVA-Video-TPO在Video-MME基准测试中成为领先的7B模型,突显了TPO作为推进长视频理解中时序推理的可扩展和高效解决方案的潜力。项目页面:https://ruili3.github.io/tpo_website。
论文及项目相关链接
Summary:尽管视频大模态模型(video-LMMs)取得了显著进展,但在长视频中实现有效的时序定位仍是现有模型的挑战。为解决这个问题,我们提出了时序偏好优化(TPO)这一新型后训练框架,旨在通过偏好学习提高视频模型的时序定位能力。TPO采用自训练方法,使模型能够在精细化的偏好数据集上区分准确的时序响应和不准确的响应,偏好数据集分为局部时序定位和全面时序定位两个粒度。通过优化这些数据集,TPO提高了时序理解能力,并降低了对人工标注数据的依赖。在三个长视频理解基准测试上的实验表明,TPO在两种最先进的视频大模态模型中都有效。特别是LLaVA-Video-TPO在Video-MME基准测试中成为领先的7B模型,突显了TPO在推进长视频理解中的时序推理的潜力和效率。
Key Takeaways:
- 视频大模态模型(video-LMMs)在长视频的时序定位上存在挑战。
- 提出了时序偏好优化(TPO)框架,旨在提高视频模型的时序定位能力。
- TPO采用自训练方法,利用精细化的偏好数据集来区分准确的时序响应和不准确的响应。
- 偏好数据集包括局部时序定位和全面时序定位两个粒度。
- TPO提高了模型的时序理解能力,并降低了对人工标注数据的依赖。
- 在多个长视频理解基准测试上,TPO显著提升了视频大模态模型的表现。
点此查看论文截图