⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
EvoEmo: Towards Evolved Emotional Policies for LLM Agents in Multi-Turn Negotiation
Authors:Yunbo Long, Liming Xu, Lukas Beckenbauer, Yuhan Liu, Alexandra Brintrup
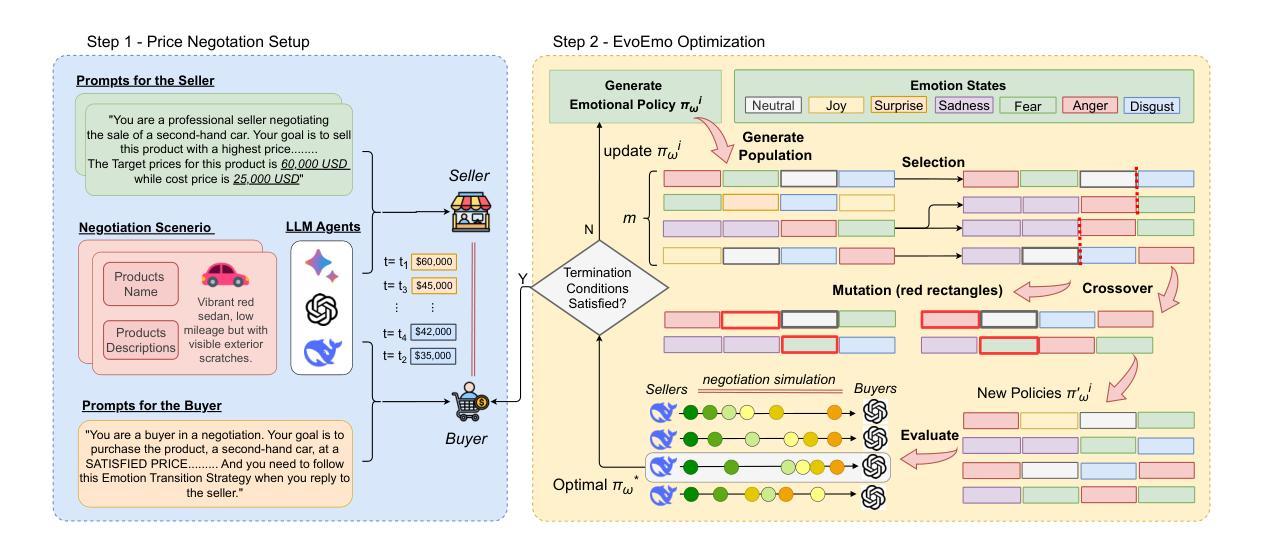
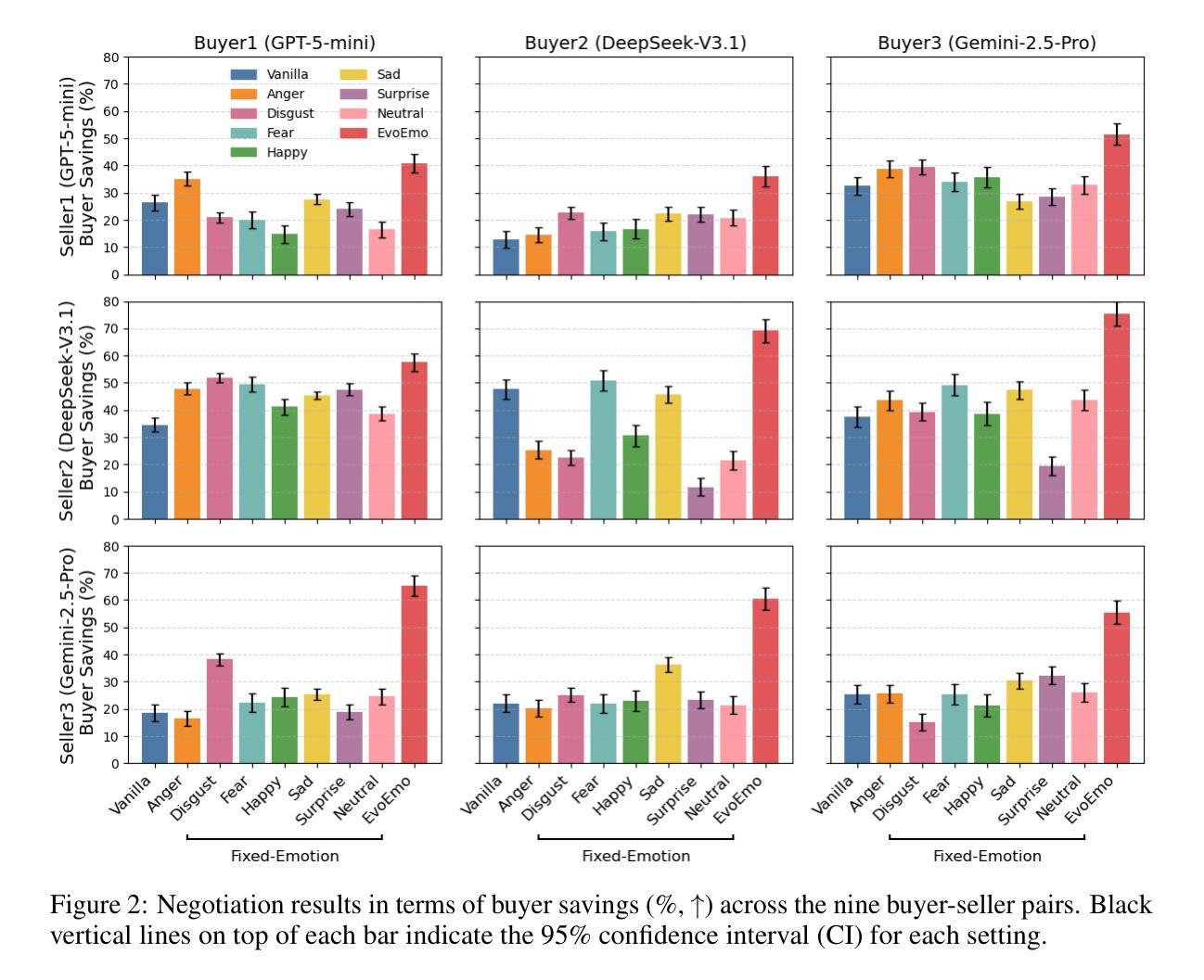
Recent research on Chain-of-Thought (CoT) reasoning in Large Language Models (LLMs) has demonstrated that agents can engage in \textit{complex}, \textit{multi-turn} negotiations, opening new avenues for agentic AI. However, existing LLM agents largely overlook the functional role of emotions in such negotiations, instead generating passive, preference-driven emotional responses that make them vulnerable to manipulation and strategic exploitation by adversarial counterparts. To address this gap, we present EvoEmo, an evolutionary reinforcement learning framework that optimizes dynamic emotional expression in negotiations. EvoEmo models emotional state transitions as a Markov Decision Process and employs population-based genetic optimization to evolve high-reward emotion policies across diverse negotiation scenarios. We further propose an evaluation framework with two baselines – vanilla strategies and fixed-emotion strategies – for benchmarking emotion-aware negotiation. Extensive experiments and ablation studies show that EvoEmo consistently outperforms both baselines, achieving higher success rates, higher efficiency, and increased buyer savings. This findings highlight the importance of adaptive emotional expression in enabling more effective LLM agents for multi-turn negotiation.
关于大型语言模型(LLM)中的思维链(CoT)推理的最近研究表明,智能体可以参与复杂的多轮谈判,为智能体人工智能打开了新的途径。然而,现有的LLM智能体在很大程度上忽视了情绪在这种谈判中的功能作用,而是产生了被动、偏好驱动的情绪反应,使其容易受到对抗性对手的操纵和战略剥削。为了解决这一差距,我们提出了EvoEmo,这是一个进化强化学习框架,优化了谈判中的动态情绪表达。EvoEmo将情绪状态的转变建模为马尔可夫决策过程,并基于群体遗传优化来进化各种谈判场景下的高回报情绪策略。我们还提出了一个评估框架,包括两个基准线——普通策略和固定情绪策略——用于评估情感感知谈判。广泛的实验和消融研究表明,EvoEmo始终优于两个基准线,实现了更高的成功率、更高的效率和更高的买家节省。这些发现突显了在多轮谈判中自适应情绪表达的重要性,使得LLM智能体更加有效。
论文及项目相关链接
Summary
近期研究显示,链式思维(CoT)推理在大规模语言模型(LLM)中的应用使智能体能够进行复杂的多轮谈判,为智能体AI开辟了新的道路。然而,现有LLM智能体大多忽视了情绪在谈判中的功能作用,只能产生被动、偏好驱动的情绪反应,使其容易受到对手的战略操纵和剥削。为解决这一问题,我们提出了EvoEmo框架,采用进化强化学习优化谈判中的动态情绪表达。EvoEmo将情绪状态转换建模为马尔可夫决策过程,并基于群体遗传优化算法进化不同谈判场景下的高回报情绪策略。我们还提出了一个评估框架,包括基准策略和固定情绪策略作为基准线,用于评估情感感知谈判的表现。大量实验和消融研究表明,EvoEmo的表现始终优于基准线策略,实现了更高的成功率、效率和买家节省。这表明自适应情绪表达对于实现多轮谈判中更高效的LLM智能体至关重要。
Key Takeaways
- LLMs通过链式思维(CoT)推理能够进行复杂的多轮谈判。
- 现有LLM智能体在谈判中忽视了情绪的作用,导致易受到对手操纵。
- EvoEmo框架采用进化强化学习优化动态情绪表达,提高智能体在谈判中的表现。
- EvoEmo将情绪状态转换建模为马尔可夫决策过程。
- 通过群体遗传优化算法进化高回报的情绪策略。
- 实验表明,EvoEmo在多种谈判场景中表现优于基准策略。
点此查看论文截图

Are LLM Agents the New RPA? A Comparative Study with RPA Across Enterprise Workflows
Authors:Petr Průcha, Michaela Matoušková, Jan Strnad
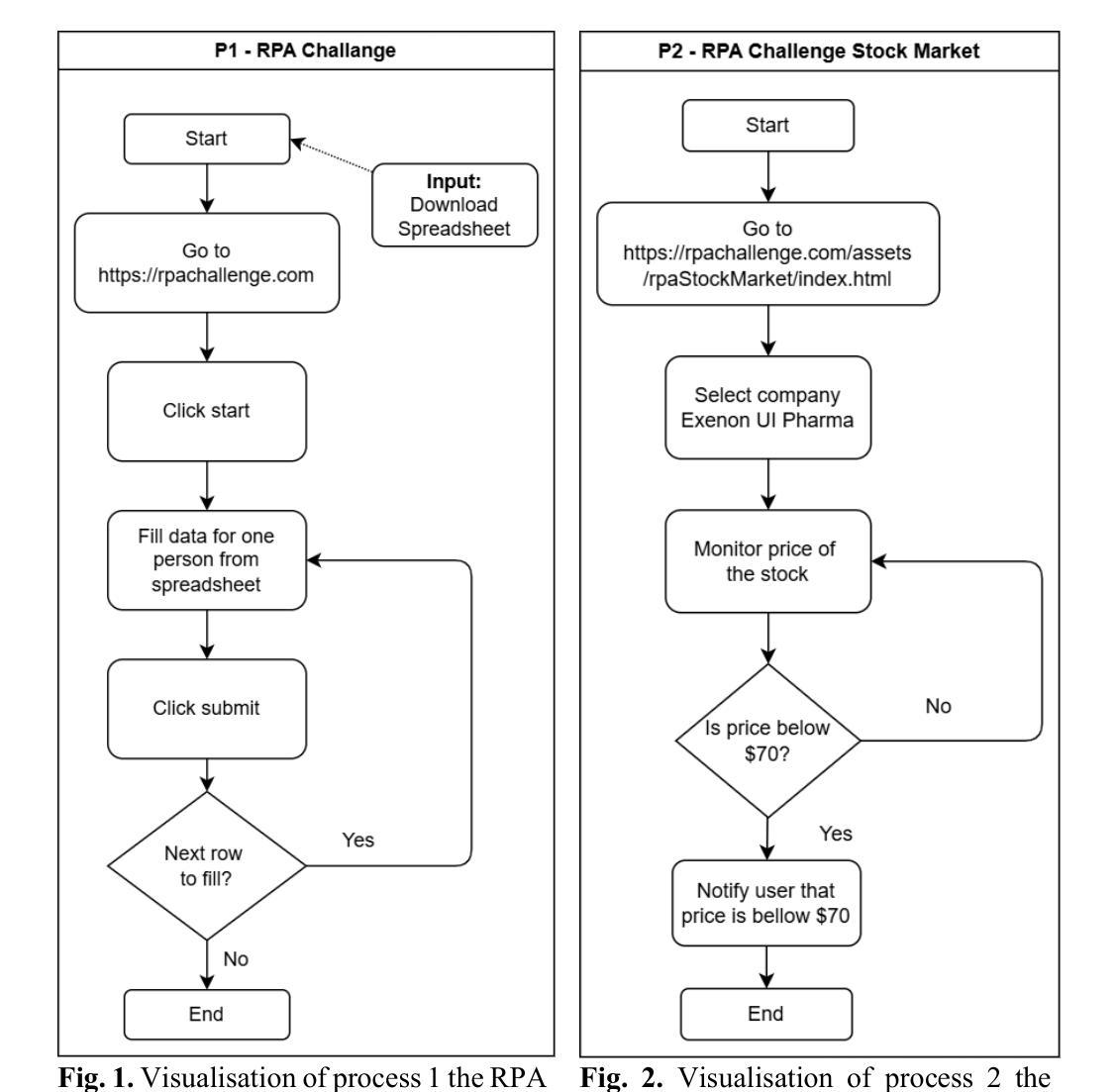
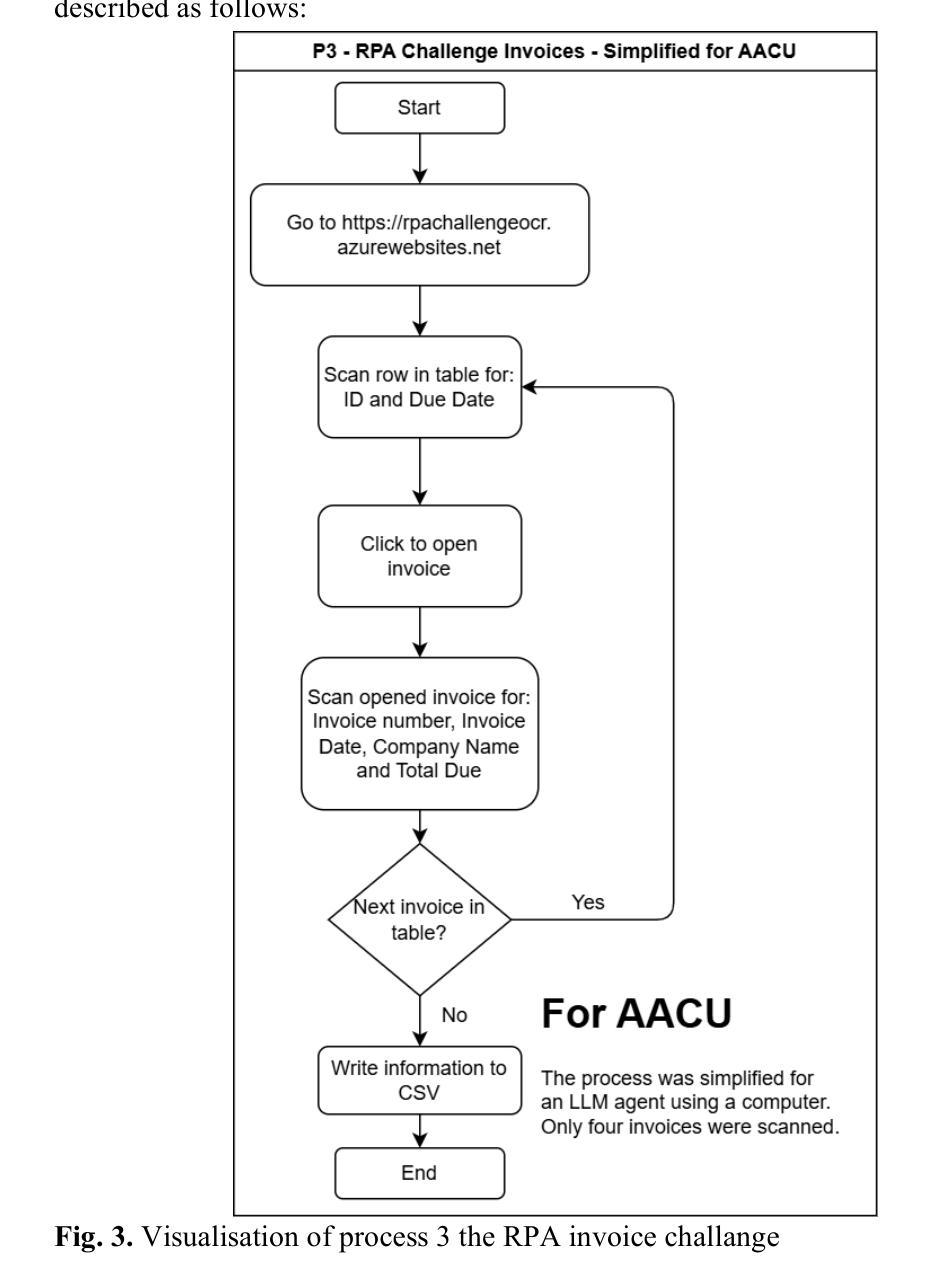
The emergence of large language models (LLMs) has introduced a new paradigm in automation: LLM agents or Agentic Automation with Computer Use (AACU). Unlike traditional Robotic Process Automation (RPA), which relies on rule-based workflows and scripting, AACU enables intelligent agents to perform tasks through natural language instructions and autonomous interaction with user interfaces. This study investigates whether AACU can serve as a viable alternative to RPA in enterprise workflow automation. We conducted controlled experiments across three standard RPA challenges data entry, monitoring, and document extraction comparing RPA (via UiPath) and AACU (via Anthropic’s Computer Use Agent) in terms of speed, reliability, and development effort. Results indicate that RPA outperforms AACU in execution speed and reliability, particularly in repetitive, stable environments. However, AACU significantly reduces development time and adapts more flexibly to dynamic interfaces. While current AACU implementations are not yet production-ready, their promise in rapid prototyping and lightweight automation is evident. Future research should explore multi-agent orchestration, hybrid RPA-AACU architectures, and more robust evaluation across industries and platforms.
大型语言模型(LLM)的出现,为自动化领域引入了一种新的范式:LLM代理或基于计算机使用的代理自动化(AACU)。与传统的基于规则的流程自动化(RPA)和脚本编写不同,AACU使得智能代理能够通过自然语言指令自主与用户界面交互执行任务。本研究调查AACU是否可以作为RPA在企业工作流程自动化中的可行替代方案。我们在三个标准RPA挑战(数据录入、监控和文档提取)上进行了对比实验,比较了RPA(通过UiPath)和AACU(通过Anthropic的计算机使用代理)在速度、可靠性和开发工作量方面的表现。结果表明,在重复性高、稳定性强的环境中,RPA在执行速度和可靠性方面表现优于AACU。然而,AACU在开发时间上大大减少了并且可以更灵活地适应动态界面。虽然当前AACU的实施尚未达到生产就绪状态,但其快速原型设计和轻量级自动化的前景已经很明显。未来的研究应探索多代理协同工作、混合RPA-AACU架构以及在各行业和平台上的更稳健评估。
论文及项目相关链接
Summary
大型语言模型(LLM)的出现,引领了自动化领域的新范式:LLM代理人或计算机使用代理自动化(AACU)。与传统基于规则和脚本的机器人流程自动化(RPA)不同,AACU允许智能代理通过自然语言指令和自主与用户界面交互执行任务。本研究探讨AACU能否成为企业工作流程自动化的可行替代方案。通过UiPath的RPA和Anthropic的计算机使用代理的AACU在速度、可靠性和开发努力方面的对比实验表明,RPA在执行速度和可靠性方面优于AACU,特别是在重复、稳定的环境中。然而,AACU显著缩短了开发时间并更灵活地适应了动态界面。虽然当前的AACU实现尚未准备好投入生产,但其在快速原型设计和轻量级自动化方面的潜力是明显的。未来的研究应探索多智能体协同、RPA-AACU混合架构以及在各行业和平台上的更稳健评估。
Key Takeaways
- 大型语言模型(LLM)引领了自动化领域的新范式——LLM代理人或计算机使用代理自动化(AACU)。
- AACU通过自然语言指令和自主与用户界面交互执行任务,不同于传统的基于规则和脚本的机器人流程自动化(RPA)。
- 对比实验结果显示,RPA在执行速度和可靠性方面优于AACU,尤其在重复、稳定的环境中。
- AACU在缩短开发时间和适应动态界面方面具有优势。
- 当前AACU尚未准备好投入生产环境,但在快速原型设计和轻量级自动化方面显示出潜力。
- 未来研究应探索多智能体协同、RPA与AACU的混合架构。
点此查看论文截图

MAGneT: Coordinated Multi-Agent Generation of Synthetic Multi-Turn Mental Health Counseling Sessions
Authors:Aishik Mandal, Tanmoy Chakraborty, Iryna Gurevych
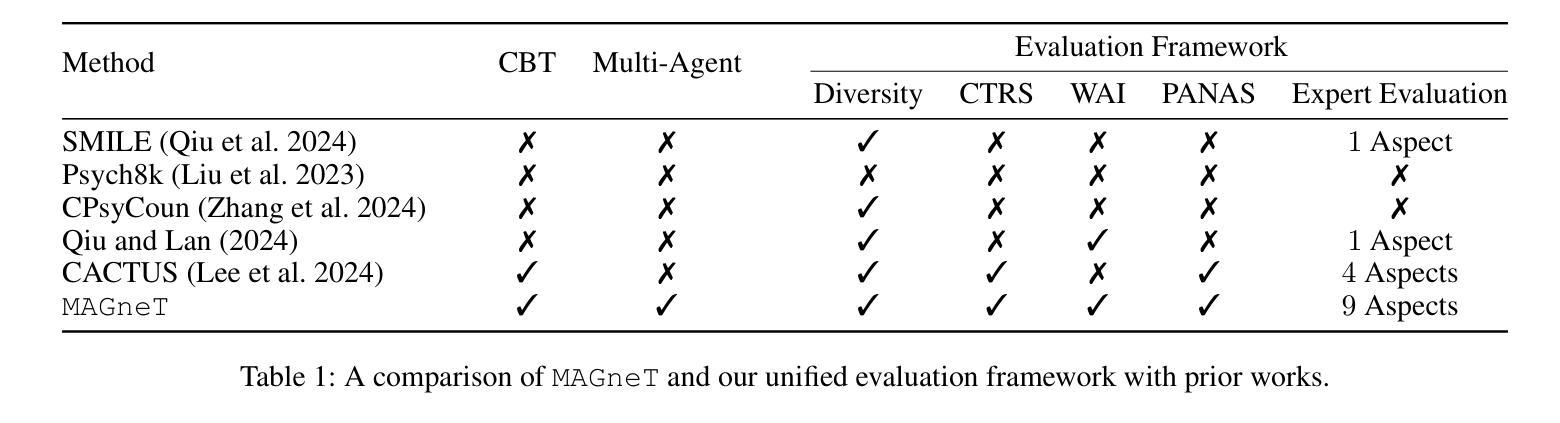
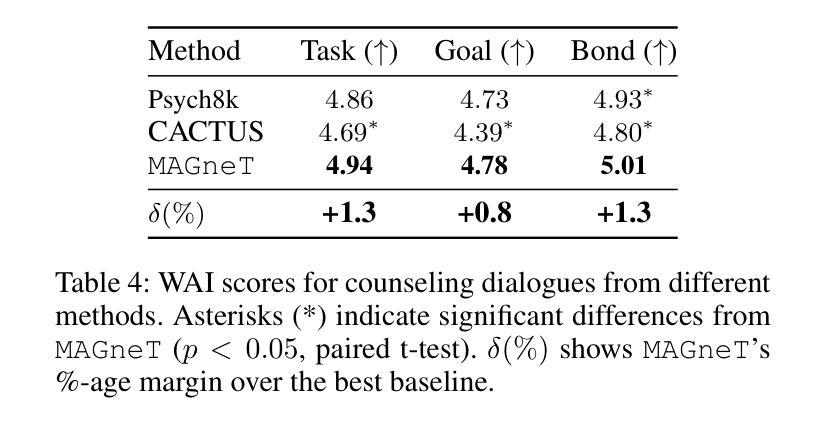
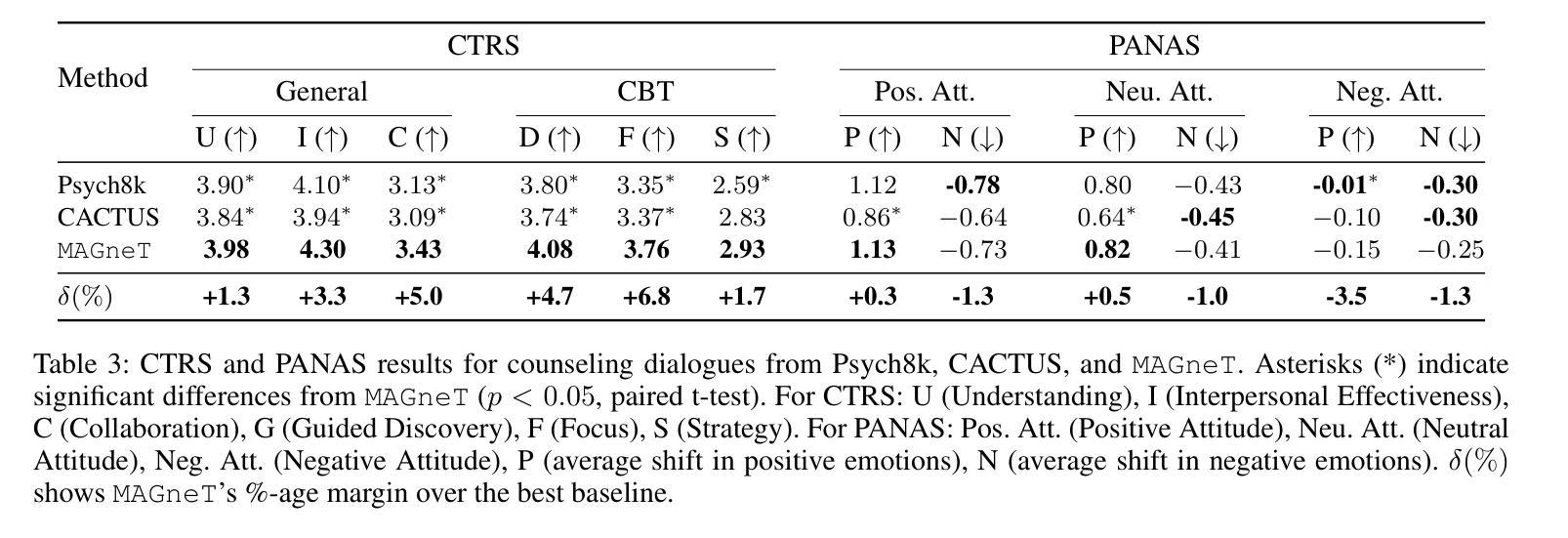
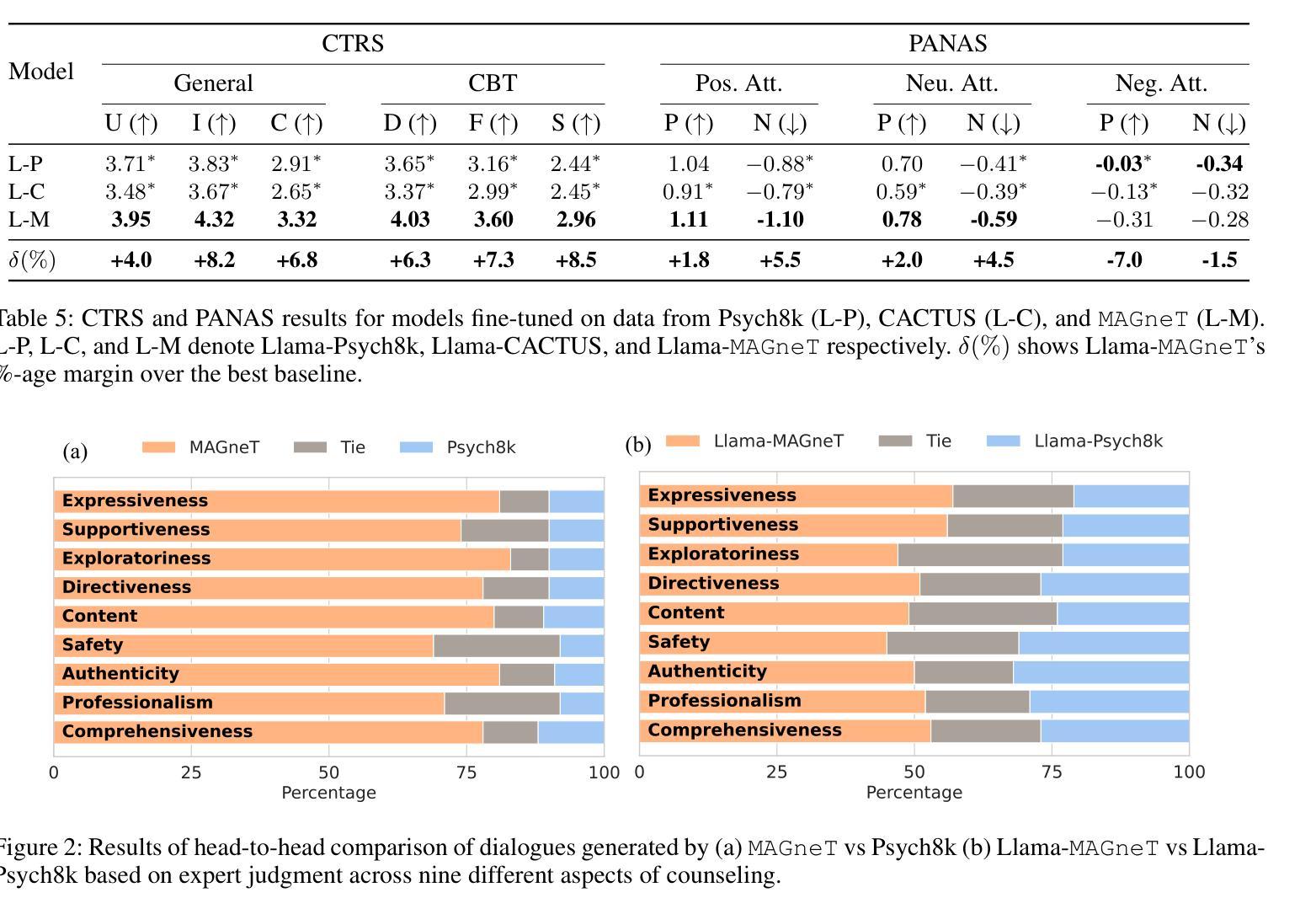
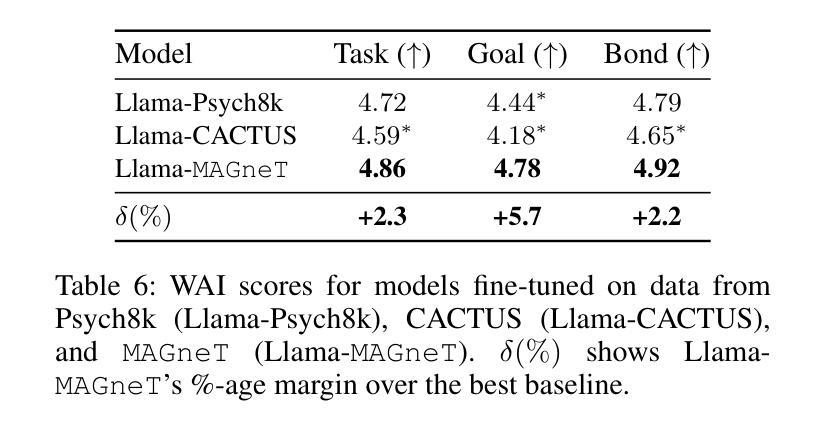
The growing demand for scalable psychological counseling highlights the need for fine-tuning open-source Large Language Models (LLMs) with high-quality, privacy-compliant data, yet such data remains scarce. Here we introduce MAGneT, a novel multi-agent framework for synthetic psychological counseling session generation that decomposes counselor response generation into coordinated sub-tasks handled by specialized LLM agents, each modeling a key psychological technique. Unlike prior single-agent approaches, MAGneT better captures the structure and nuance of real counseling. In addition, we address inconsistencies in prior evaluation protocols by proposing a unified evaluation framework integrating diverse automatic and expert metrics. Furthermore, we expand the expert evaluations from four aspects of counseling in previous works to nine aspects, enabling a more thorough and robust assessment of data quality. Empirical results show that MAGneT significantly outperforms existing methods in quality, diversity, and therapeutic alignment of the generated counseling sessions, improving general counseling skills by 3.2% and CBT-specific skills by 4.3% on average on cognitive therapy rating scale (CTRS). Crucially, experts prefer MAGneT-generated sessions in 77.2% of cases on average across all aspects. Moreover, fine-tuning an open-source model on MAGneT-generated sessions shows better performance, with improvements of 6.3% on general counseling skills and 7.3% on CBT-specific skills on average on CTRS over those fine-tuned with sessions generated by baseline methods. We also make our code and data public.
不断增长的心理咨询需求强调了对使用高质量、符合隐私要求的数据微调开源的大型语言模型(LLM)的必要性,但这样的数据仍然很稀缺。在这里,我们介绍了MAGneT,这是一种新型的多智能体框架,用于合成心理咨询会话生成,它将咨询师响应生成分解为由专业LLM智能体处理的协调子任务,每个智能体都模拟一种关键的心理技术。与先前的单一智能体方法不同,MAGneT能更好地捕捉真实咨询的结构和细微差别。此外,我们通过提出一个统一的评估框架来解决先前评估协议中的不一致问题,该框架结合了多种自动和专家指标。此外,我们将先前工作中的咨询方面的专家评估从四个方面扩展到九个方面,从而能够对数据质量进行更全面和稳健的评估。经验结果表明,在生成的咨询会话的质量、多样性和治疗对齐方面,MAGneT显著优于现有方法,在认知疗法量表(CTRS)上平均提高了一般咨询技能3.2%,认知行为疗法特定技能4.3%。关键的是,专家平均在所有方面中,有77.2%的情况更喜欢MAGneT生成的会话。此外,使用MAGneT生成的会话微调开源模型表现出更好的性能,在CTRS上平均比一般咨询技能提高6.3%,CBT特定技能提高7.3%。我们还公开了我们的代码和数据。
论文及项目相关链接
PDF 25 pages, 29 figures
摘要
采用多代理框架MAGneT合成心理咨询会话生成,以应对日益增长的心理咨询需求及对大规模语言模型(LLM)的优化挑战。MAGneT利用专项LLM代理处理协调子任务,更好地捕捉真实咨询的结构和细微差别。此外,提出统一评估框架,扩展专家评估方面,实现更全面的数据质量评估。经验结果表明,MAGneT在会话质量、多样性和治疗一致性方面显著优于现有方法,平均提高一般咨询技能3.2%,针对认知疗法的技能提高4.3%。专家更喜欢MAGneT生成的会话。此外,使用MAGneT生成的会话对开源模型进行微调,表现更佳。
关键见解
- 心理咨询需求增长,需要调整大规模语言模型(LLM)以应对。
- MAGneT多代理框架用于合成心理咨询会话生成,捕捉真实咨询的细微差别。
- 提出统一评估框架,整合多种自动和专家评估指标。
- 扩大专家评估方面,更全面评估数据质量。
- MAGneT在会话质量、多样性和治疗一致性方面优于现有方法。
- 专家偏好MAGneT生成的会话。
点此查看论文截图


TAGAL: Tabular Data Generation using Agentic LLM Methods
Authors:Benoît Ronval, Pierre Dupont, Siegfried Nijssen
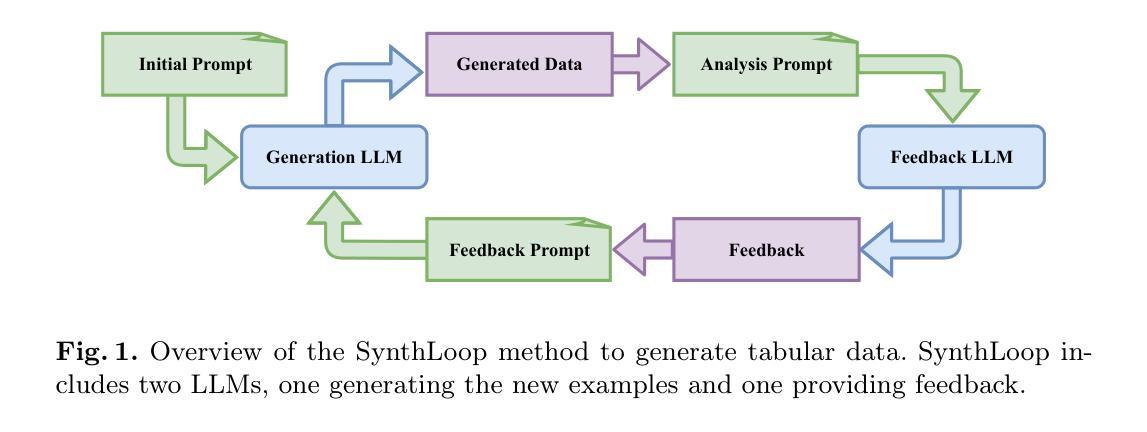
The generation of data is a common approach to improve the performance of machine learning tasks, among which is the training of models for classification. In this paper, we present TAGAL, a collection of methods able to generate synthetic tabular data using an agentic workflow. The methods leverage Large Language Models (LLMs) for an automatic and iterative process that uses feedback to improve the generated data without any further LLM training. The use of LLMs also allows for the addition of external knowledge in the generation process. We evaluate TAGAL across diverse datasets and different aspects of quality for the generated data. We look at the utility of downstream ML models, both by training classifiers on synthetic data only and by combining real and synthetic data. Moreover, we compare the similarities between the real and the generated data. We show that TAGAL is able to perform on par with state-of-the-art approaches that require LLM training and generally outperforms other training-free approaches. These findings highlight the potential of agentic workflow and open new directions for LLM-based data generation methods.
数据的生成是提高机器学习任务性能的一种常见方法,其中包括分类模型的训练。在本文中,我们介绍了TAGAL,这是一组能够利用代理工作流程生成合成表格数据的方法。这些方法利用大型语言模型(LLM)进行自动迭代过程,使用反馈来改进生成的数据,而无需进一步的LLM训练。LLM的使用还允许在生成过程中添加外部知识。我们在不同的数据集上评估TAGAL,并对生成数据的质量进行多方面的考量。我们关注下游机器学习模型的使用情况,既通过在合成数据上训练分类器,也通过结合真实和合成数据来实现。此外,我们还比较了真实数据和生成数据之间的相似性。我们展示TAGAL能够与国家最新方法相匹配,要求LLM进行训练并且在大多数情况下优于其他不需要训练的方法。这些发现凸显了代理工作流程的潜力,并为基于LLM的数据生成方法开启了新的方向。
论文及项目相关链接
Summary
这篇论文介绍了使用代理工作流程的TAGAL方法,用于生成合成表格数据以提高机器学习任务的性能。该方法利用大型语言模型进行自动迭代过程,使用反馈改进生成的数据,无需进一步训练大型语言模型。评估表明,TAGAL在不同数据集上表现出优异的性能,在合成数据上进行分类器训练或与真实数据结合使用时均表现良好。与需要大型语言模型训练的最先进方法相比,TAGAL能够与之相当甚至在某些方面表现更好,这突显了代理工作流程的潜力并为基于大型语言模型的数据生成方法提供了新的方向。
Key Takeaways
- TAGAL是一种利用大型语言模型生成合成表格数据的方法,采用代理工作流程。
- TAGAL通过自动迭代过程使用反馈改进生成的数据,无需进一步训练大型语言模型。
- 评估表明,TAGAL在多个数据集上表现出优异的性能。
- TAGAL在合成数据上进行分类器训练时表现出良好的性能,并且与真实数据结合使用时效果更佳。
- TAGAL与需要大型语言模型训练的最先进方法相当,在某些方面甚至表现更好。
- TAGAL的潜力在于其代理工作流程的应用,为基于大型语言模型的数据生成方法提供了新的方向。
点此查看论文截图

Towards Stable and Personalised Profiles for Lexical Alignment in Spoken Human-Agent Dialogue
Authors:Keara Schaaij, Roel Boumans, Tibor Bosse, Iris Hendrickx
Lexical alignment, where speakers start to use similar words across conversation, is known to contribute to successful communication. However, its implementation in conversational agents remains underexplored, particularly considering the recent advancements in large language models (LLMs). As a first step towards enabling lexical alignment in human-agent dialogue, this study draws on strategies for personalising conversational agents and investigates the construction of stable, personalised lexical profiles as a basis for lexical alignment. Specifically, we varied the amounts of transcribed spoken data used for construction as well as the number of items included in the profiles per part-of-speech (POS) category and evaluated profile performance across time using recall, coverage, and cosine similarity metrics. It was shown that smaller and more compact profiles, created after 10 min of transcribed speech containing 5 items for adjectives, 5 items for conjunctions, and 10 items for adverbs, nouns, pronouns, and verbs each, offered the best balance in both performance and data efficiency. In conclusion, this study offers practical insights into constructing stable, personalised lexical profiles, taking into account minimal data requirements, serving as a foundational step toward lexical alignment strategies in conversational agents.
词汇对齐(lexical alignment)是指对话过程中说话者开始使用相似的词汇,这已被证明对成功的沟通有贡献。然而,其在对话代理中的实现仍然被较少探索,特别是考虑到大型语言模型(LLMs)的最新进展。作为实现人机对话中词汇对齐的第一步,本研究借鉴了个性化对话代理的策略,并研究构建稳定、个性化的词汇档案作为词汇对齐的基础。具体来说,我们变化了用于构建档案的有声语言数据量以及每个词性类别中档案所包含的项目数量,并通过回忆、覆盖率和余弦相似性指标来评估档案随时间的表现。研究表明,经过十分钟的语音转文本后创建较小且更紧凑的档案表现出最佳的性能和效率平衡,该档案包含形容词5项、连词5项,以及副词、名词、代词和动词各10项。总之,本研究提供了构建稳定、个性化词汇档案的实用见解,考虑了最小的数据需求,作为对话代理中实现词汇对齐策略的基础步骤。
论文及项目相关链接
PDF Accepted for TSD 2025
Summary
此研究探索了词汇对齐在对话交流中的重要性,并尝试在对话代理中实现词汇对齐。研究通过个性化对话代理的策略,构建了稳定、个性化的词汇概况,作为词汇对齐的基础。最佳概况表现是在10分钟的转录语音中,形容词、连词各选5项,副词、名词、代词和动词各选10项。
Key Takeaways
- 词汇对齐在成功交流中的重要性。
- 对话代理中实现词汇对齐的策略尚未得到充分探索。
- 个性化对话代理的词汇概况构建是词汇对齐的基础。
- 词汇概况的构建需要考虑数据的最小需求。
- 最佳的词汇概况表现是在特定的数据量和选择下达成。
- 研究使用了回忆、覆盖和余弦相似度等指标来评估词汇概况的性能。
点此查看论文截图

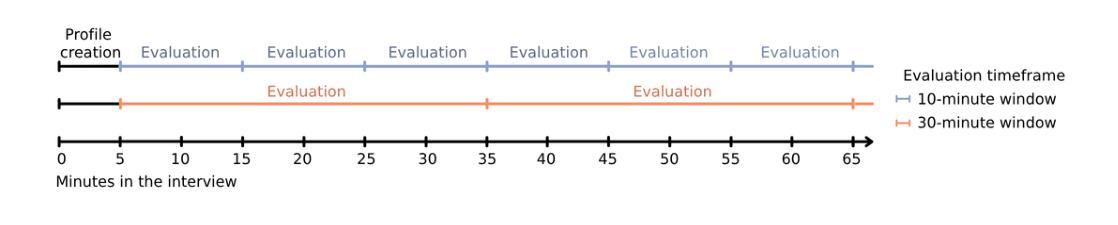
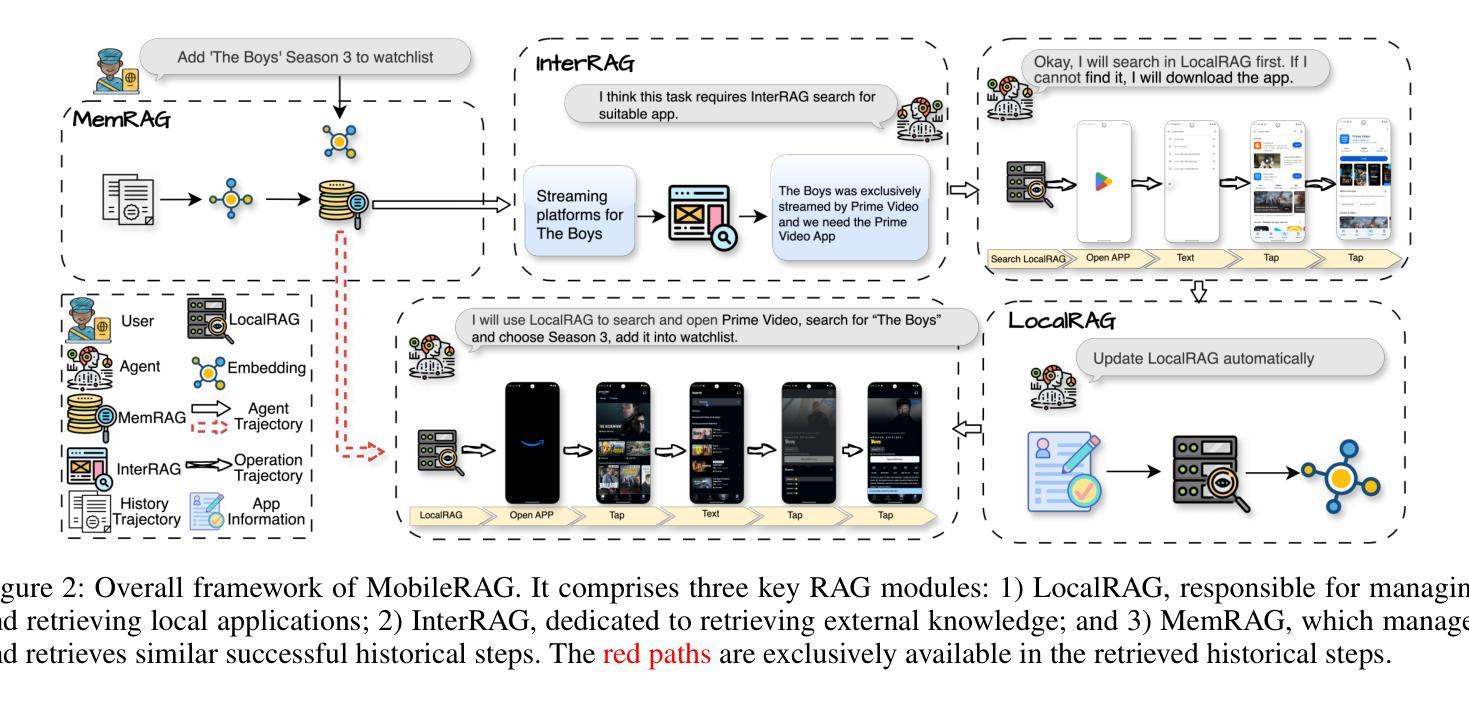
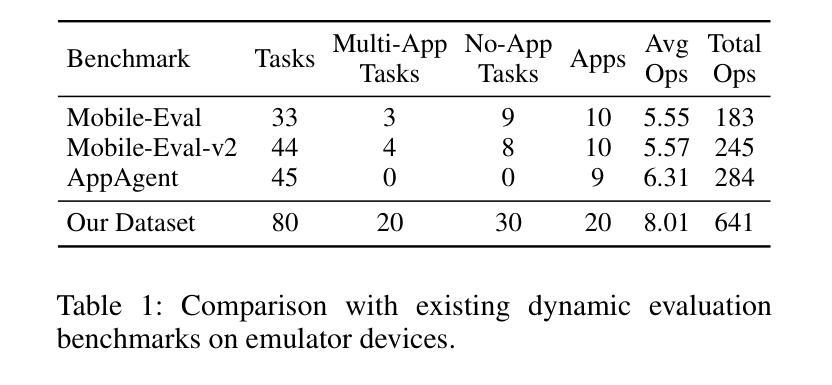
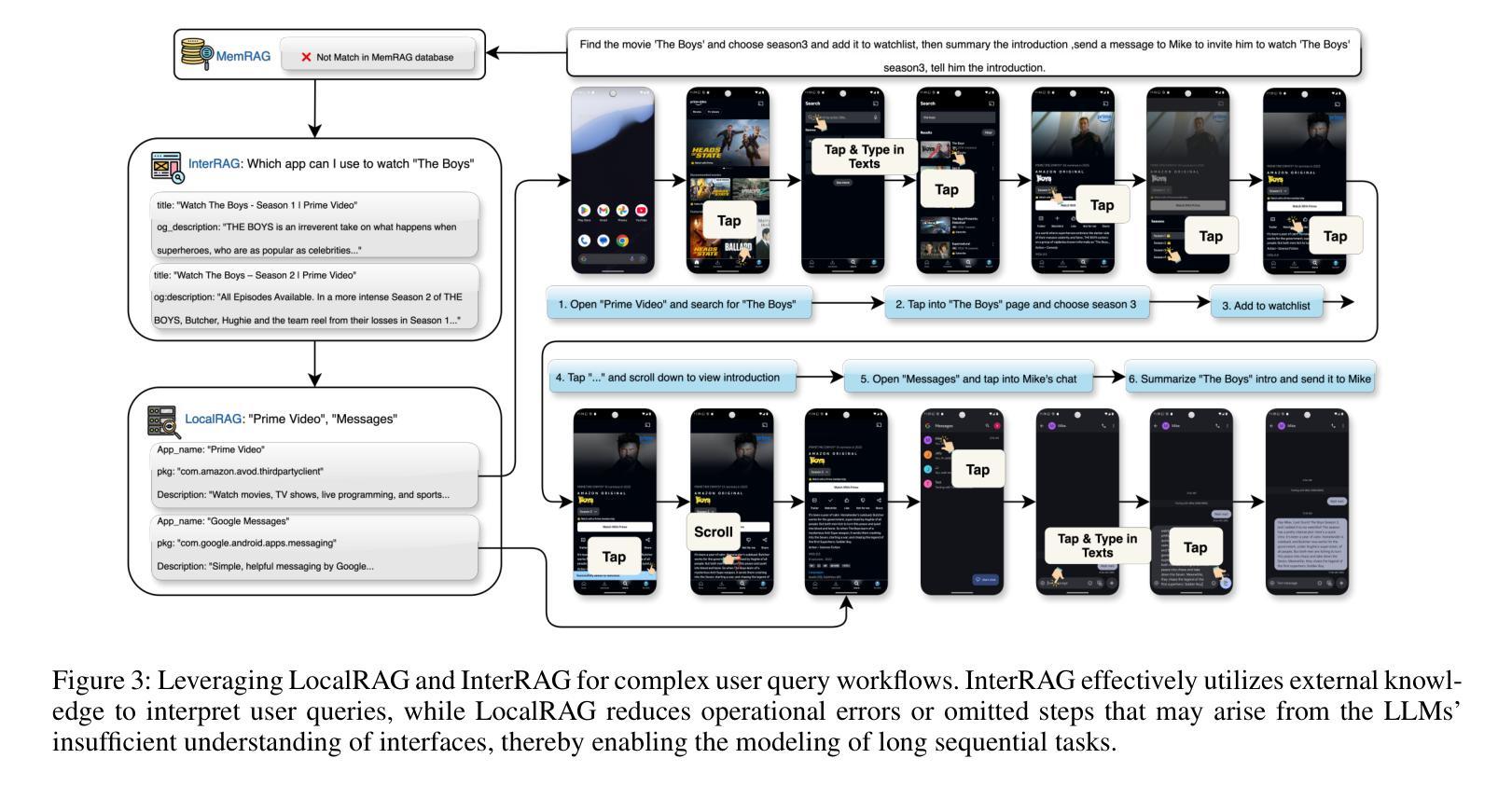
MobileRAG: Enhancing Mobile Agent with Retrieval-Augmented Generation
Authors:Gowen Loo, Chang Liu, Qinghong Yin, Xiang Chen, Jiawei Chen, Jingyuan Zhang, Yu Tian
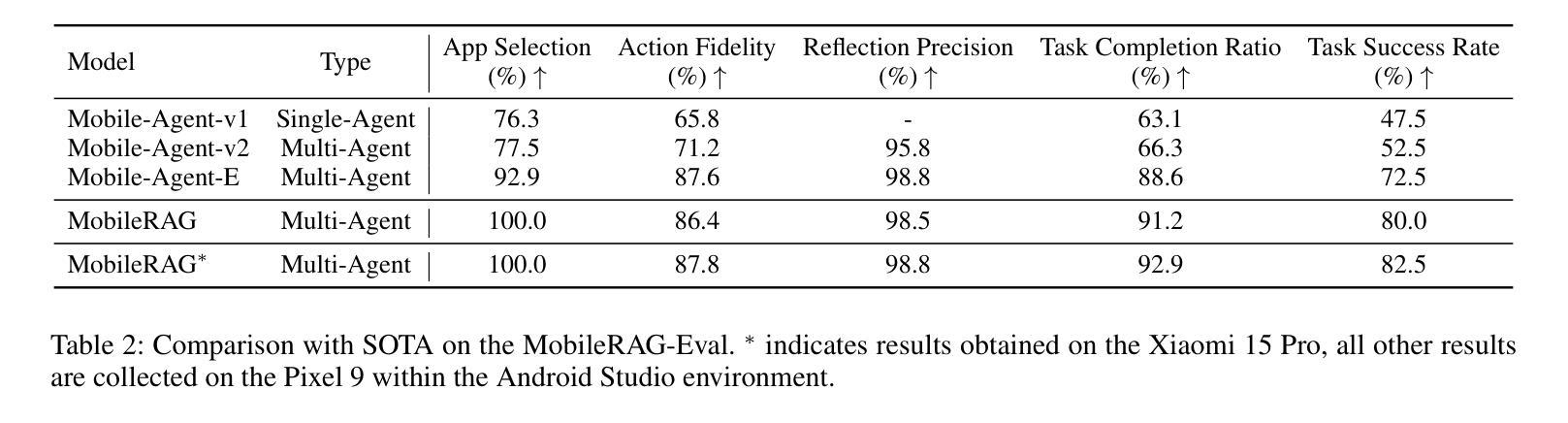
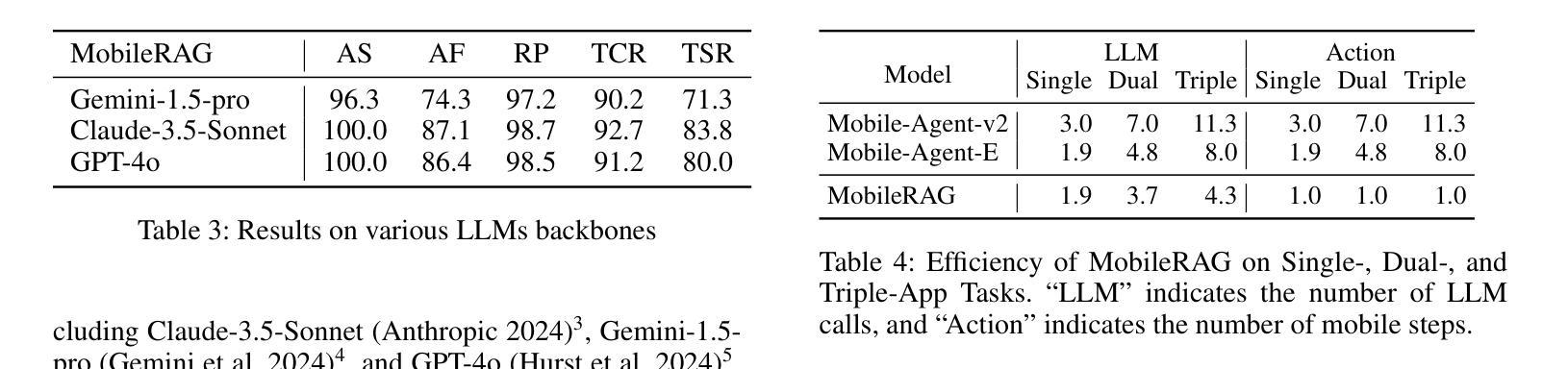
Smartphones have become indispensable in people’s daily lives, permeating nearly every aspect of modern society. With the continuous advancement of large language models (LLMs), numerous LLM-based mobile agents have emerged. These agents are capable of accurately parsing diverse user queries and automatically assisting users in completing complex or repetitive operations. However, current agents 1) heavily rely on the comprehension ability of LLMs, which can lead to errors caused by misoperations or omitted steps during tasks, 2) lack interaction with the external environment, often terminating tasks when an app cannot fulfill user queries, and 3) lack memory capabilities, requiring each instruction to reconstruct the interface and being unable to learn from and correct previous mistakes. To alleviate the above issues, we propose MobileRAG, a mobile agents framework enhanced by Retrieval-Augmented Generation (RAG), which includes InterRAG, LocalRAG, and MemRAG. It leverages RAG to more quickly and accurately identify user queries and accomplish complex and long-sequence mobile tasks. Additionally, to more comprehensively assess the performance of MobileRAG, we introduce MobileRAG-Eval, a more challenging benchmark characterized by numerous complex, real-world mobile tasks that require external knowledge assistance. Extensive experimental results on MobileRAG-Eval demonstrate that MobileRAG can easily handle real-world mobile tasks, achieving 10.3% improvement over state-of-the-art methods with fewer operational steps. Our code is publicly available at: https://github.com/liuxiaojieOutOfWorld/MobileRAG_arxiv
智能手机在日常生活中不可或缺,几乎渗透到现代社会的各个方面。随着大型语言模型(LLM)的不断发展,出现了许多基于LLM的移动代理。这些代理能够准确解析各种用户查询,并自动协助用户完成复杂或重复的操作。然而,当前代理存在以下问题:1)严重依赖于LLM的理解能力,可能导致任务操作过程中的错误或遗漏步骤;2)缺乏与外部环境的交互,当应用程序无法完成用户查询时,经常终止任务;3)缺乏记忆能力,需要每次指令重建界面,并且不能从过去的错误中学习并纠正。为了解决上述问题,我们提出了通过增强检索增强生成(RAG)的移动代理框架MobileRAG,包括InterRAG、LocalRAG和MemRAG。它利用RAG更快地准确识别用户查询并完成复杂且长序列的移动任务。此外,为了更全面地评估MobileRAG的性能,我们引入了更具挑战性的基准测试MobileRAG-Eval,该基准测试的特点是包含许多需要外部知识支持的复杂现实世界移动任务。在MobileRAG-Eval上的广泛实验结果表明,MobileRAG可以轻松处理现实世界的移动任务,比最新技术方法少操作步骤的情况下实现了10.3%的改进。我们的代码公开在:https://github.com/liuxiaojieOutOfWorld/MobileRAG_arxiv
论文及项目相关链接
Summary
随着智能手机在日常生活中的普及,基于大型语言模型(LLM)的移动智能代理日益受到关注。然而,当前代理存在依赖性强、缺乏互动与记忆能力的问题。为解决这些问题,提出了MobileRAG框架,通过检索增强生成(RAG)技术提高识别用户查询和完成任务的能力。此外,还引入了MobileRAG-Eval评估标准,以全面评估MobileRAG性能。实验结果表明,MobileRAG能够轻松应对现实生活中的复杂任务,相较于现有方法有着显著提升。
Key Takeaways
- 智能手机已深入人们日常生活,基于大型语言模型(LLM)的移动代理备受关注。
- 当前移动代理存在依赖性强、缺乏与外部环境互动及记忆能力的问题。
- MobileRAG框架通过引入检索增强生成(RAG)技术,提高移动代理的识别用户查询和完成任务的能力。
- MobileRAG-Eval评估标准的引入,能更全面地评估MobileRAG性能。
- MobileRAG框架在应对现实生活中的复杂任务时表现出优异性能。
- MobileRAG相较于现有方法有着显著提升,能够在更少操作步骤下完成任务。
点此查看论文截图

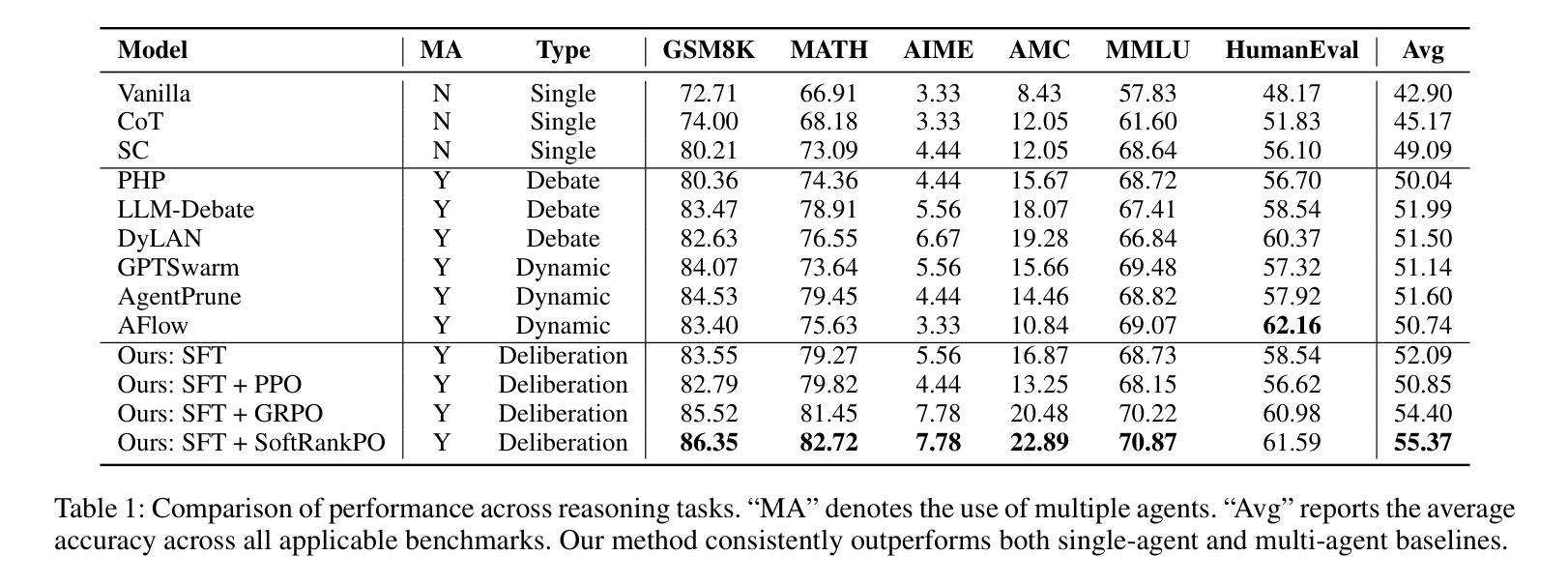
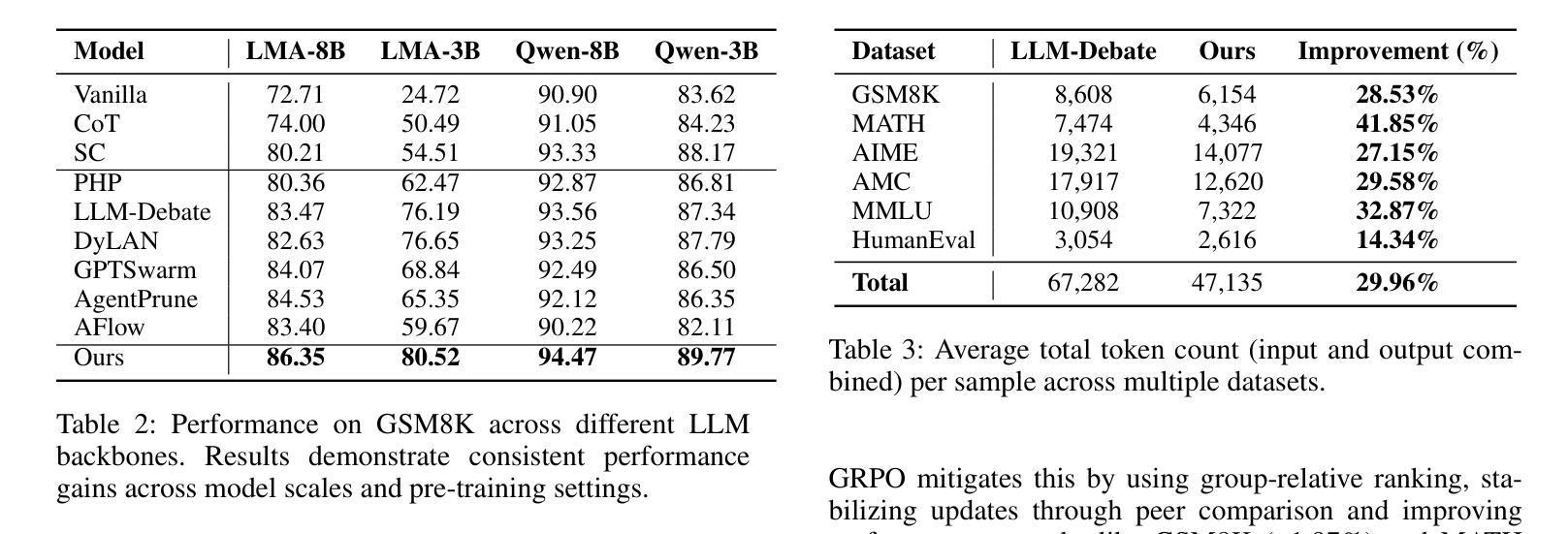
Learning to Deliberate: Meta-policy Collaboration for Agentic LLMs with Multi-agent Reinforcement Learning
Authors:Wei Yang, Jesse Thomason
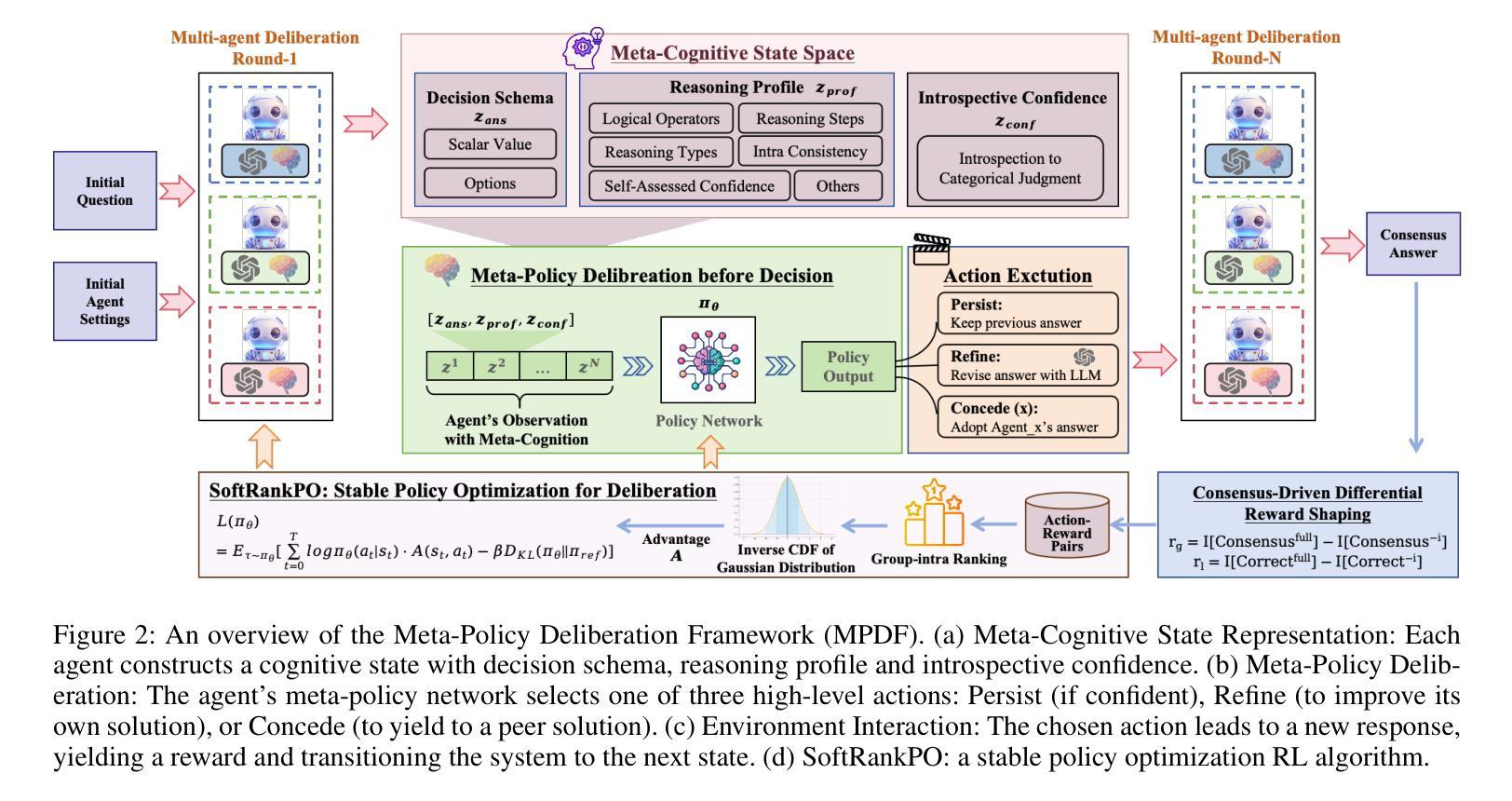
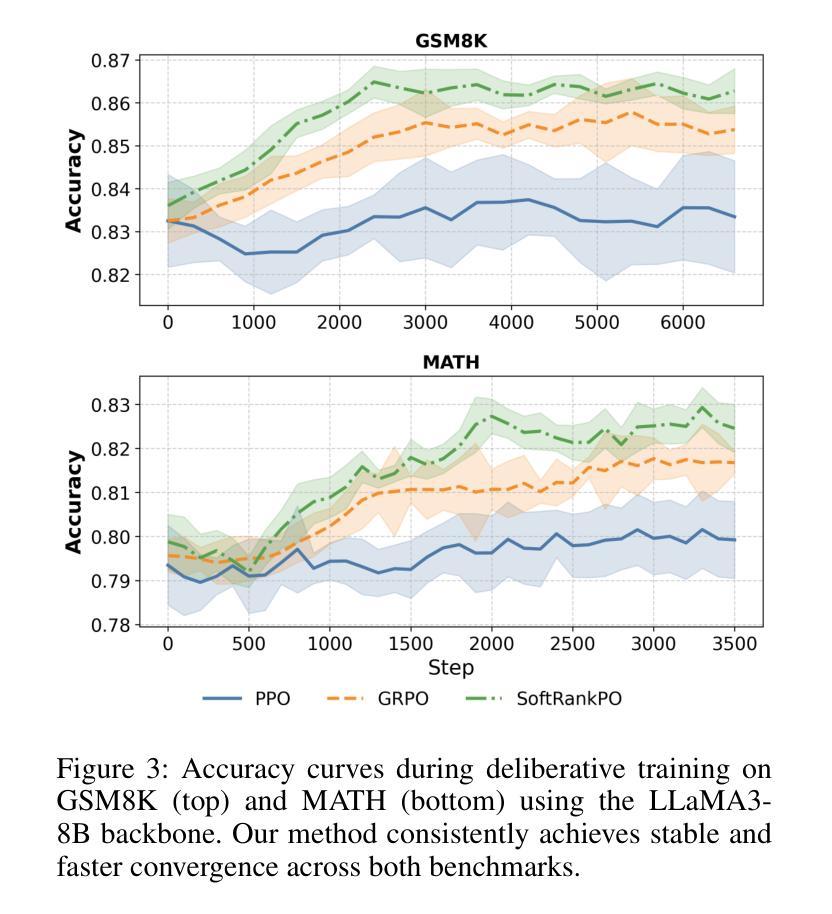
Multi-agent systems of large language models (LLMs) show promise for complex reasoning, but their effectiveness is often limited by fixed collaboration protocols. These frameworks typically focus on macro-level orchestration while overlooking agents’ internal deliberative capabilities. This critical meta-cognitive blindspot treats agents as passive executors unable to adapt their strategy based on internal cognitive states like uncertainty or confidence. We introduce the Meta-Policy Deliberation Framework (MPDF), where agents learn a decentralized policy over a set of high-level meta-cognitive actions: Persist, Refine, and Concede. To overcome the instability of traditional policy gradients in this setting, we develop SoftRankPO, a novel reinforcement learning algorithm. SoftRankPO stabilizes training by shaping advantages based on the rank of rewards mapped through smooth normal quantiles, making the learning process robust to reward variance. Experiments show that MPDF with SoftRankPO achieves a a 4-5% absolute gain in average accuracy across five mathematical and general reasoning benchmarks compared to six state-of-the-art heuristic and learning-based multi-agent reasoning algorithms. Our work presents a paradigm for learning adaptive, meta-cognitive policies for multi-agent LLM systems, shifting the focus from designing fixed protocols to learning dynamic, deliberative strategies.
多智能体系统的大型语言模型(LLM)在复杂推理方面展现出巨大的潜力,但其有效性通常受限于固定的协作协议。这些框架通常侧重于宏观层面的协调,而忽视了智能体的内部决策能力。这一关键的元认知盲点将智能体视为被动的执行者,无法根据不确定性或信心等内部认知状态来适应策略。我们引入了元策略决策框架(MPDF),在该框架中,智能体学习一系列高层次元认知动作上的分散策略:坚持、完善、放弃。为了克服传统策略梯度在此环境中的不稳定性,我们开发了SoftRankPO,这是一种新型强化学习算法。SoftRankPO通过基于奖励排名和通过平滑正态分位数映射的优势来塑造优势,从而稳定训练过程,使学习过程对奖励方差具有鲁棒性。实验表明,与六种最先进的启发式和学习型多智能体推理算法相比,使用SoftRankPO的MPDF在五个数学和通用推理基准测试上平均准确率提高了4-5%。我们的工作为多智能体LLM系统学习自适应元认知策略提供了范例,将重点从设计固定协议转向学习动态决策策略。
论文及项目相关链接
Summary
大型语言模型多智能体系统的综合研究展现了复杂推理的巨大潜力,但由于采用固定合作协议的协作模式而受限制。本文主要引入元策略协商框架(MPDF),在此框架中,智能体可以学习在特定环境下的一组分散决策规则。同时提出一种新型强化学习算法SoftRankPO,通过平滑正常分布排名来塑造优势,克服传统政策梯度的不稳定性问题。实验表明,MPDF与SoftRankPO相较于六种最新启发式与学习式多智能体推理算法在五类数学和一般推理测试方面表现出更优越的精准性,展示了多智能体大型语言模型自适应元认知策略学习的可能性。本文的工作从设计固定协议转向学习动态决策策略,为多智能体系统的未来发展开辟了新方向。
Key Takeaways
- 大型语言模型多智能体系统在复杂推理方面展现潜力,受限于固定合作协议的协作模式。
- 引入元策略协商框架(MPDF),智能体可学习分散决策规则以适应特定环境。
- 提出新型强化学习算法SoftRankPO,通过平滑正常分布排名塑造优势,克服传统政策梯度的不稳定性问题。
- MPDF与SoftRankPO相较于其他算法在五类数学和一般推理测试中表现优越。
点此查看论文截图

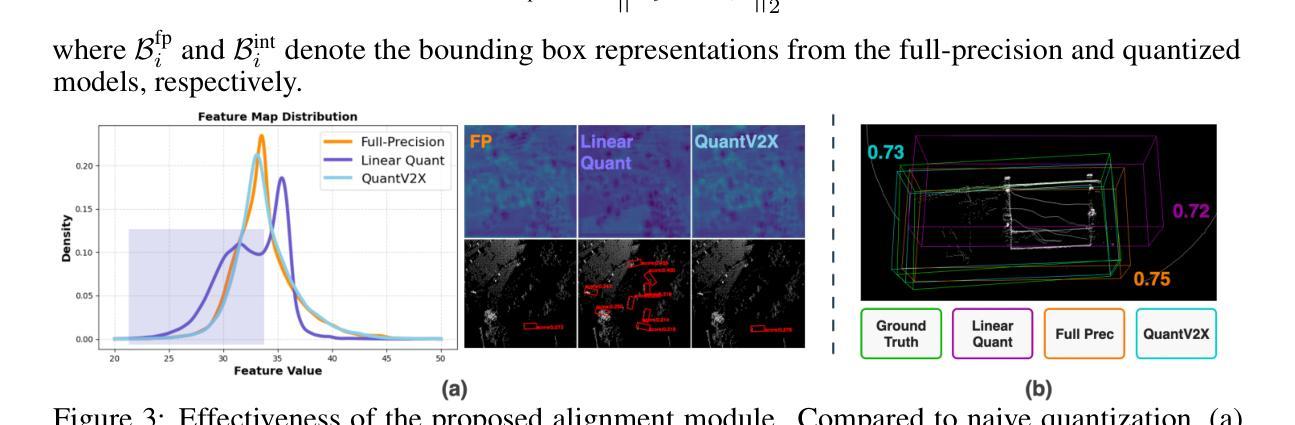
QuantV2X: A Fully Quantized Multi-Agent System for Cooperative Perception
Authors:Seth Z. Zhao, Huizhi Zhang, Zhaowei Li, Juntong Peng, Anthony Chui, Zewei Zhou, Zonglin Meng, Hao Xiang, Zhiyu Huang, Fujia Wang, Ran Tian, Chenfeng Xu, Bolei Zhou, Jiaqi Ma
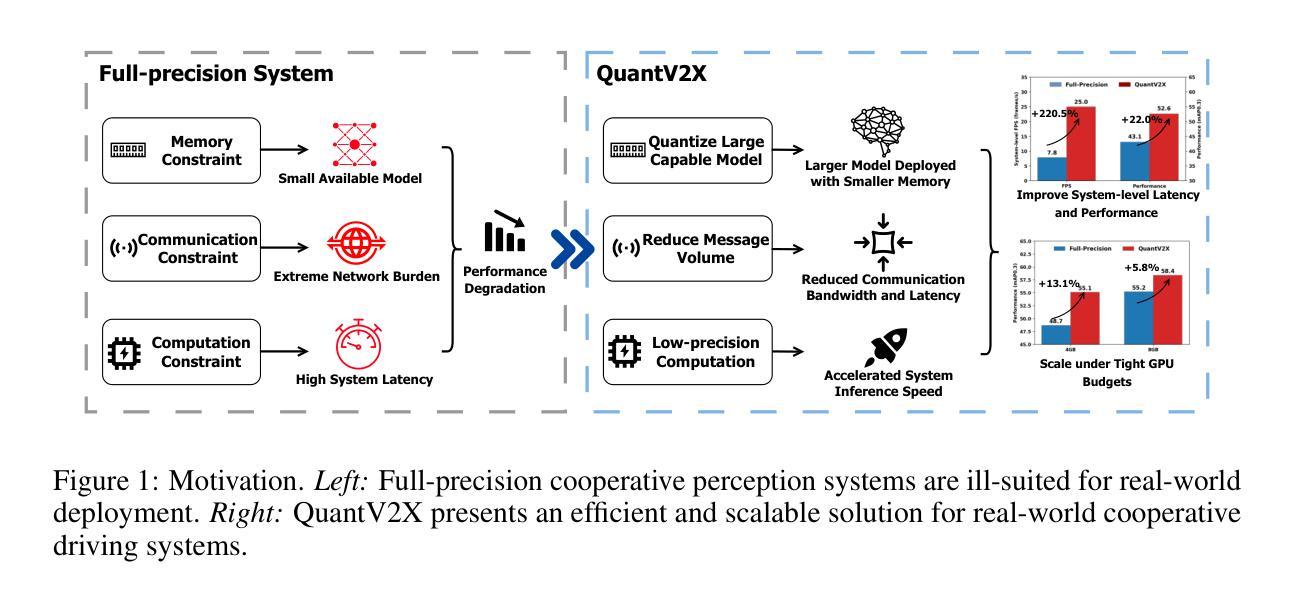
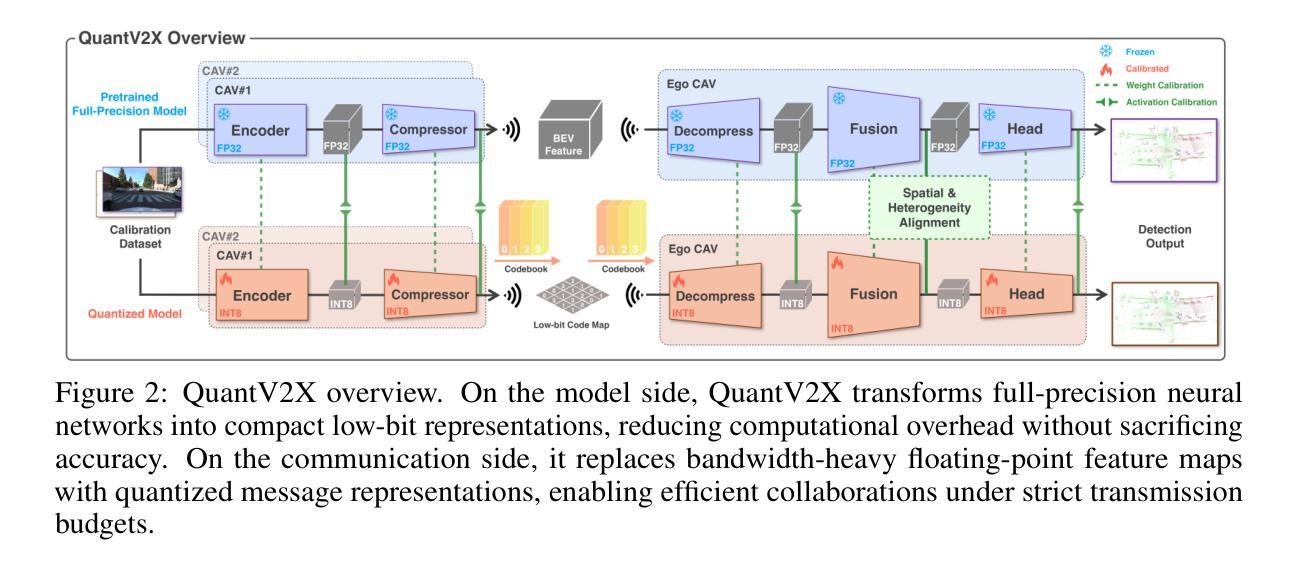
Cooperative perception through Vehicle-to-Everything (V2X) communication offers significant potential for enhancing vehicle perception by mitigating occlusions and expanding the field of view. However, past research has predominantly focused on improving accuracy metrics without addressing the crucial system-level considerations of efficiency, latency, and real-world deployability. Noticeably, most existing systems rely on full-precision models, which incur high computational and transmission costs, making them impractical for real-time operation in resource-constrained environments. In this paper, we introduce \textbf{QuantV2X}, the first fully quantized multi-agent system designed specifically for efficient and scalable deployment of multi-modal, multi-agent V2X cooperative perception. QuantV2X introduces a unified end-to-end quantization strategy across both neural network models and transmitted message representations that simultaneously reduces computational load and transmission bandwidth. Remarkably, despite operating under low-bit constraints, QuantV2X achieves accuracy comparable to full-precision systems. More importantly, when evaluated under deployment-oriented metrics, QuantV2X reduces system-level latency by 3.2$\times$ and achieves a +9.5 improvement in mAP30 over full-precision baselines. Furthermore, QuantV2X scales more effectively, enabling larger and more capable models to fit within strict memory budgets. These results highlight the viability of a fully quantized multi-agent intermediate fusion system for real-world deployment. The system will be publicly released to promote research in this field: https://github.com/ucla-mobility/QuantV2X.
通过车辆对一切(V2X)通信实现的合作感知在增强车辆感知方面拥有巨大潜力,可以缓解遮挡问题并扩大视野。然而,过去的研究主要集中在提高精度指标上,而没有解决效率、延迟和现实世界部署的关键系统级考虑。值得注意的是,大多数现有系统依赖于全精度模型,这产生了较高的计算和传输成本,使其在资源受限的环境中实时运行不实用。
论文及项目相关链接
Summary
车辆间的感知通过车辆对外界环境感知的通信方式(V2X)有巨大的提升潜力,它可以弥补遮挡和扩大视野。然而,过去的研究主要关注提高准确性,忽略了效率、延迟和实际应用中的系统级考虑。现有系统大多依赖全精度模型,导致计算和传输成本高昂,不适用于资源受限环境中的实时操作。本文提出QuantV2X,首个专为多模态多智能体V2X合作感知设计的全量化多智能体系统,旨在高效可扩展地部署。QuantV2X在神经网络模型和传输消息表示中采用端到端的统一量化策略,降低了计算负载和传输带宽。尽管在低比特约束下运行,QuantV2X仍能达到与全精度系统相当的性能。更重要的是,QuantV2X在系统级延迟方面减少了3.2倍,并在全精度基准测试上实现了mAP30的+9.5改进。此外,QuantV2X更有效地扩展,使大型模型能够在严格的内存预算内运行。此系统证明了全量化的多智能体中间融合系统在现实世界的部署中的可行性。该系统将公开发布以促进该领域的研究。
Key Takeaways
- 车辆间的合作感知通过V2X通信有潜力增强车辆感知能力。
- 过去的研究主要关注准确性提升,忽略了效率、延迟和系统级考虑。
- 现有系统依赖高成本的全精度模型,不适用于资源受限环境。
- QuantV2X是全量化多智能体系统,针对多模态多智能体V2X合作感知设计。
- QuantV2X采用端到端的统一量化策略,降低计算负载和传输带宽。
- QuantV2X在低比特约束下运行,但性能与全精度系统相当。
点此查看论文截图

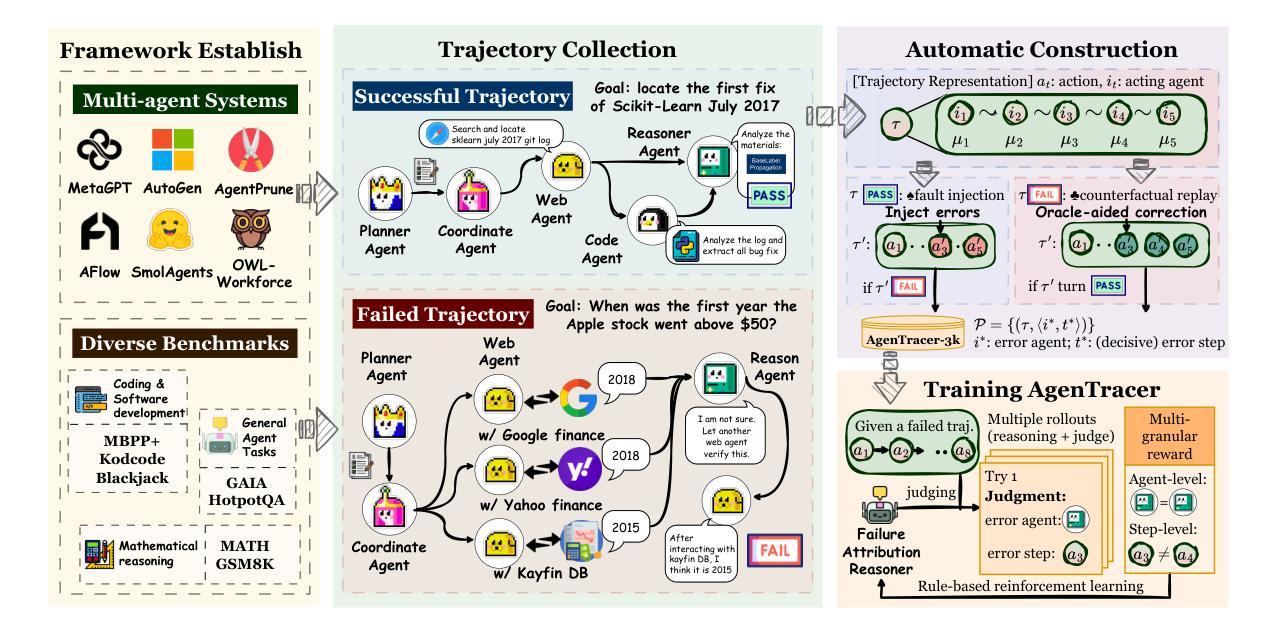
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?
Authors:Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, Shuicheng Yan
Large Language Model (LLM)-based agentic systems, often comprising multiple models, complex tool invocations, and orchestration protocols, substantially outperform monolithic agents. Yet this very sophistication amplifies their fragility, making them more prone to system failure. Pinpointing the specific agent or step responsible for an error within long execution traces defines the task of agentic system failure attribution. Current state-of-the-art reasoning LLMs, however, remain strikingly inadequate for this challenge, with accuracy generally below 10%. To address this gap, we propose AgenTracer, the first automated framework for annotating failed multi-agent trajectories via counterfactual replay and programmed fault injection, producing the curated dataset TracerTraj. Leveraging this resource, we develop AgenTracer-8B, a lightweight failure tracer trained with multi-granular reinforcement learning, capable of efficiently diagnosing errors in verbose multi-agent interactions. On the Who&When benchmark, AgenTracer-8B outperforms giant proprietary LLMs like Gemini-2.5-Pro and Claude-4-Sonnet by up to 18.18%, setting a new standard in LLM agentic failure attribution. More importantly, AgenTracer-8B delivers actionable feedback to off-the-shelf multi-agent systems like MetaGPT and MaAS with 4.8-14.2% performance gains, empowering self-correcting and self-evolving agentic AI.
基于大型语言模型(LLM)的代理系统,通常包含多个模型、复杂的工具调用和协同协议,在性能上显著优于单一代理。然而,这种复杂性也增加了它们的脆弱性,使它们更容易出现系统故障。确定长执行轨迹中导致错误的特定代理或步骤,这定义了代理系统失败归属的任务。然而,当前最先进的推理LLM对此挑战仍然明显不足,准确率通常低于10%。为了弥补这一差距,我们提出了AgenTracer,这是第一个通过反事实回放和编程故障注入来注释失败的多代理轨迹的自动化框架,生成了精选数据集TracerTraj。利用这一资源,我们开发了轻质失败追踪器AgenTracer-8B,它采用多粒度强化学习进行训练,能够高效诊断冗长的多代理交互中的错误。在Who&When基准测试中,AgenTracer-8B的性能超过了像Gemini-2.5-Pro和Claude-4-Sonnet等大型专有LLM,提高了高达18.18%,在LLM代理失败归属方面树立了新的标准。更重要的是,AgenTracer-8B为现成的多代理系统(如MetaGPT和MaAS)提供了可操作反馈,实现了4.8%~14.2%的性能提升,赋能自我修正和自我进化的代理人工智能。
论文及项目相关链接
Summary:基于大型语言模型(LLM)的代理系统由于其复杂性,在运行时更容易出现错误。系统失败的归因问题就在于确定具体出错的责任代理或步骤。当前最先进的推理型LLM对此挑战仍显得捉襟见肘,准确度通常低于百分之十。为了解决这个问题,我们提出了AgenTracer框架,它通过反事实回放和编程故障注入来自动标注失败的多元代理轨迹,并生成精选数据集TracerTraj。利用这一资源,我们开发了轻量级的失败追踪器AgenTracer-8B,采用多粒度强化学习进行训练,能够高效诊断冗长的多元代理交互中的错误。在Who&When基准测试中,AgenTracer-8B表现优于大型专有LLM如Gemini-2.5-Pro和Claude-4-Sonnet,高出达百分之十八点一八,为LLM代理系统失败归因树立了新标准。更重要的是,AgenTracer-8B为现成的多元代理系统如MetaGPT和MaAS提供了可操作反馈,提升了性能,使得自我纠正和自我演化的代理AI成为可能。简言之,代理系统的性能和故障诊断有了新进展。通过技术创新提升了复杂系统的稳健性。但最重要的是提升了多智能体系统的自适应修复能力,进而提升整个系统的可靠性和效率。此创新研究在人工智能领域开辟了新的应用前景。这一发现可能对人工智能技术的未来发展产生深远影响。大型语言模型的应用和智能体系统的融合研究是人工智能领域的重要发展方向之一。通过创新的方法和技术手段来解决多智能体系统中的失败归因问题具有广泛的应用前景和实际价值。总的来说,这项研究是人工智能领域的一大突破,为解决复杂的智能体系统故障问题提供了新的思路和方向。总体而言具有重要的实践意义和学术价值且应用场景广阔的前景显著让人期待更多的未来技术改进与实现对于实际应用和部署的关键进步所表现出的优异表现体现了人工智能技术的不断发展和进步。未来技术在该领域的落地将为相关领域的行业带来巨大的推动作用和技术支持潜力。Key Takeaways:
- 基于大型语言模型的代理系统虽然性能优越,但复杂性导致系统更易出错,失败归因困难。
- 当前LLM在失败归因方面的准确度较低,一般低于百分之十。
- 提出AgenTracer框架及数据集TracerTraj用于标注失败的多元代理轨迹。
- AgenTracer-8B能高效诊断多元代理交互中的错误,超越专有LLM表现。
- AgenTracer-8B赋能自我纠正和自我演化的代理AI,提升多智能体系统性能。
- 该研究解决了复杂智能体系统故障问题,为人工智能领域带来突破和新思路。
点此查看论文截图

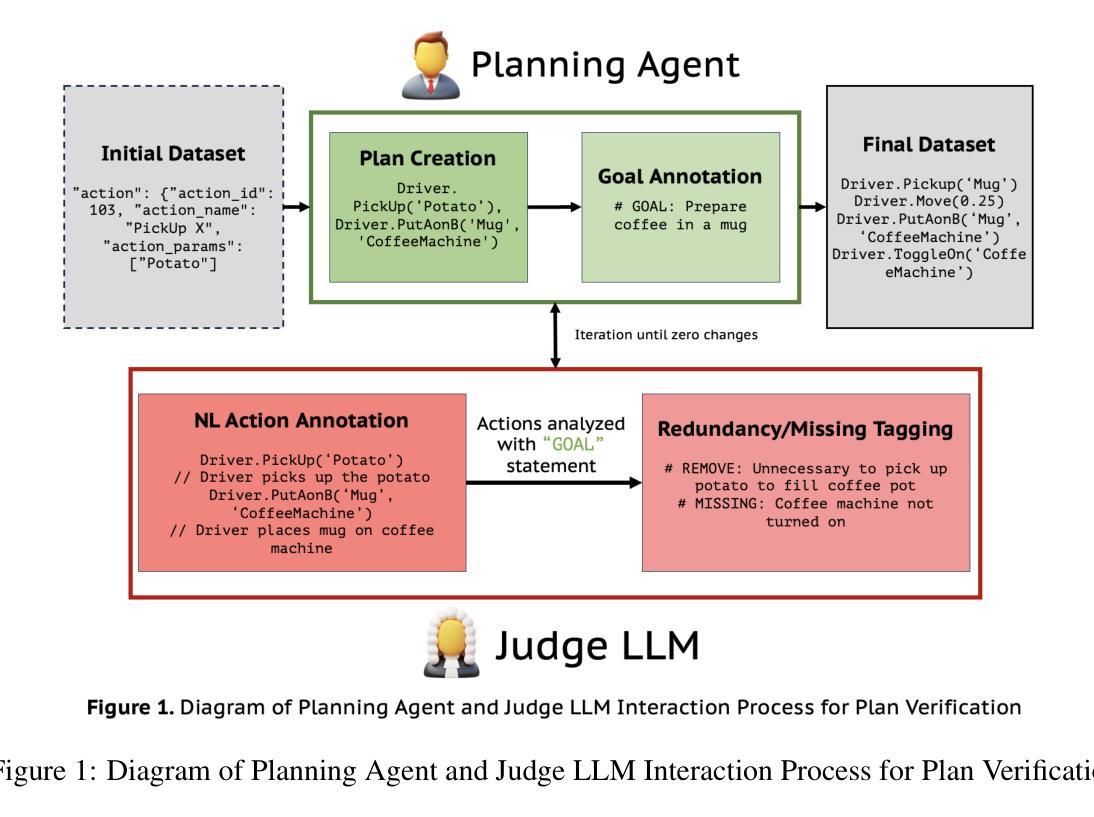
Plan Verification for LLM-Based Embodied Task Completion Agents
Authors:Ananth Hariharan, Vardhan Dongre, Dilek Hakkani-Tür, Gokhan Tur
Large language model (LLM) based task plans and corresponding human demonstrations for embodied AI may be noisy, with unnecessary actions, redundant navigation, and logical errors that reduce policy quality. We propose an iterative verification framework in which a Judge LLM critiques action sequences and a Planner LLM applies the revisions, yielding progressively cleaner and more spatially coherent trajectories. Unlike rule-based approaches, our method relies on natural language prompting, enabling broad generalization across error types including irrelevant actions, contradictions, and missing steps. On a set of manually annotated actions from the TEACh embodied AI dataset, our framework achieves up to 90% recall and 100% precision across four state-of-the-art LLMs (GPT o4-mini, DeepSeek-R1, Gemini 2.5, LLaMA 4 Scout). The refinement loop converges quickly, with 96.5% of sequences requiring at most three iterations, while improving both temporal efficiency and spatial action organization. Crucially, the method preserves human error-recovery patterns rather than collapsing them, supporting future work on robust corrective behavior. By establishing plan verification as a reliable LLM capability for spatial planning and action refinement, we provide a scalable path to higher-quality training data for imitation learning in embodied AI.
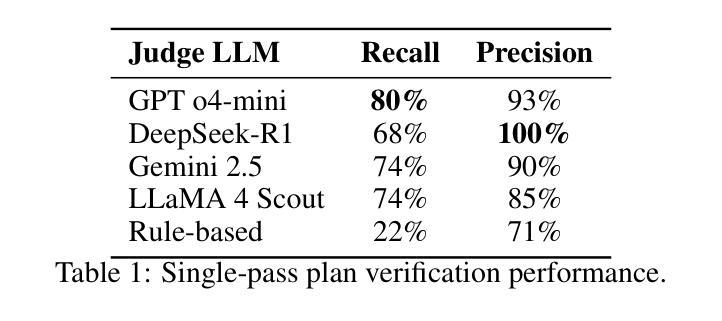
基于大型语言模型(LLM)的针对实体人工智能的任务计划以及相应的人类演示可能会存在噪声,包含不必要行动、冗余导航以及逻辑错误,从而降低了策略质量。我们提出了一个迭代验证框架,其中judge LLM对行动序列进行批判,而Planner LLM应用修订内容,从而产生越来越干净、空间连贯性越来越强的轨迹。不同于基于规则的方法,我们的方法依赖于自然语言提示,能够实现广泛概括各种错误类型,包括无关行动、矛盾以及缺失步骤。在来自TEACh实体AI数据集的手动注释行动集上,我们的框架在四个最新大型语言模型(GPT o4-mini、DeepSeek-R1、Gemini 2.5、LLaMA 4 Scout)上实现了高达90%的召回率和100%的精确度。改进循环快速收敛,96.5%的序列最多需要三次迭代,同时提高时间效率和空间行动组织。关键的是,该方法保留了人类错误恢复模式,而不是消除它们,支持未来在稳健纠正行为方面的工作。通过建立计划验证作为可靠的大型语言模型能力来进行空间规划和行动改进,我们为实体人工智能中的模仿学习提供了高质量训练数据的可扩展路径。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的AI任务计划及相应的人类演示可能会存在噪声,包含多余动作、冗余导航和逻辑错误等问题,从而降低策略质量。为此,我们提出了一种迭代验证框架,其中Judge LLM负责评估动作序列,而Planner LLM则负责应用修正意见,从而生成更加清晰、空间连贯的轨迹。与传统基于规则的方法不同,我们的方法依赖于自然语言提示,能够广泛泛化各种错误类型,包括无关动作、矛盾以及缺失步骤等。在TEACh AI数据集上的一组手动注释动作上,我们的框架在四个最新LLM上实现了高达90%的召回率和100%的精确度。优化循环快速收敛,大多数序列仅需三次迭代即可改善时序效率和空间行动组织。该方法能够保留人类错误恢复模式,为未来的稳健纠正行为研究提供支持。通过验证计划作为可靠的LLM在空间规划和行动优化上的能力,我们为模仿学习中的高质量训练数据提供了一条可扩展的路径。
Key Takeaways
- 大型语言模型(LLM)在AI任务计划中可能会存在噪声和逻辑错误等问题。
- 提出了一种迭代验证框架,其中Judge LLM和Planner LLM分别负责评估和修正动作序列。
- 该方法能够实现广泛错误类型的泛化,包括无关动作、矛盾和缺失步骤等。
- 在TEACh AI数据集上,该框架在四个最新LLM上取得了较高的召回率和精确度。
- 优化循环快速收敛,大多数序列仅需三次迭代即可改善时序效率和空间行动组织。
- 该方法能够保留人类错误恢复模式,有助于未来研究更稳健的纠正行为。
点此查看论文截图

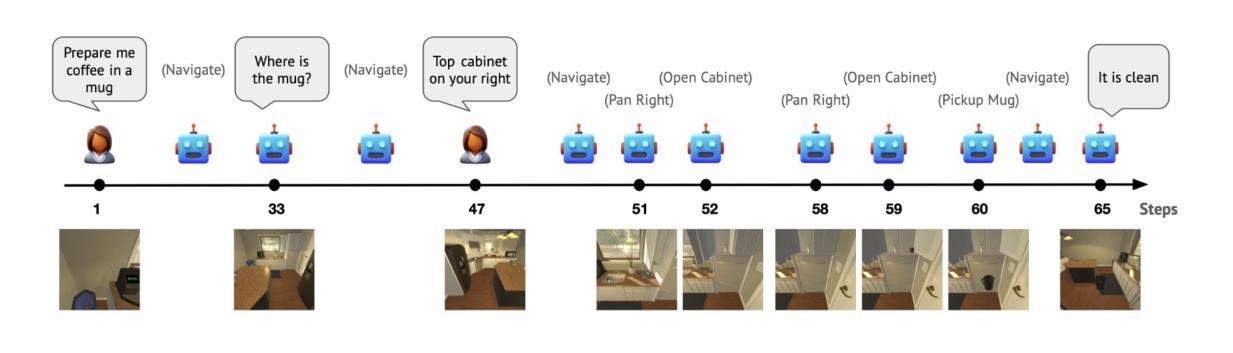
Building surrogate models using trajectories of agents trained by Reinforcement Learning
Authors:Julen Cestero, Marco Quartulli, Marcello Restelli
Sample efficiency in the face of computationally expensive simulations is a common concern in surrogate modeling. Current strategies to minimize the number of samples needed are not as effective in simulated environments with wide state spaces. As a response to this challenge, we propose a novel method to efficiently sample simulated deterministic environments by using policies trained by Reinforcement Learning. We provide an extensive analysis of these surrogate-building strategies with respect to Latin-Hypercube sampling or Active Learning and Kriging, cross-validating performances with all sampled datasets. The analysis shows that a mixed dataset that includes samples acquired by random agents, expert agents, and agents trained to explore the regions of maximum entropy of the state transition distribution provides the best scores through all datasets, which is crucial for a meaningful state space representation. We conclude that the proposed method improves the state-of-the-art and clears the path to enable the application of surrogate-aided Reinforcement Learning policy optimization strategies on complex simulators.
在仿真建模中,面对计算昂贵的模拟时,样本效率是一个普遍关注的问题。目前减少所需样本数量的策略在状态空间较大的仿真环境中效果并不理想。为了应对这一挑战,我们提出了一种利用强化学习训练的策略对模拟确定性环境进行有效采样。我们对这些代理构建策略进行了拉丁超立方体采样或主动学习与克里格方法的全面分析,通过所有采样数据集进行交叉验证性能。分析表明,混合数据集包括随机代理、专家代理以及训练探索状态转换分布最大熵区域的代理所获取的样本,在所有数据集中得分最高,这对于有意义的状态空间表示至关重要。我们得出结论,该方法改进了现有技术,为在复杂模拟器上应用代理辅助强化学习政策优化策略铺平了道路。
论文及项目相关链接
PDF Published in ICANN 2024 conference
Summary
本文关注模拟环境中的样本效率问题,特别是在状态空间广泛的情况下。为应对这一挑战,提出了一种利用强化学习训练的策略,对模拟确定性环境进行有效采样。通过拉丁超立方体采样、主动学习与克里金法的对比分析,结果显示混合数据集(包括随机代理、专家代理以及训练探索状态转换分布最大熵区域的代理样本)表现最佳,对有意义的状态空间表示至关重要。所提方法提高了现有技术水平,为在复杂模拟器上应用基于代理的强化学习策略优化铺平了道路。
Key Takeaways
- 模拟环境中样本效率的重要性,特别是在状态空间广泛的情况下。
- 提出了一种新的方法,利用强化学习训练的策略对模拟确定性环境进行高效采样。
- 通过与拉丁超立方体采样、主动学习及克里金法的对比分析,发现混合数据集表现最佳。
- 混合数据集包括随机代理、专家代理以及探索状态转换分布最大熵区域训练的代理样本。
- 该方法提高了现有技术水平,为复杂模拟器上应用基于代理的强化学习策略优化铺平了道路。
- 样本采集策略对于有意义的状态空间表示至关重要。
点此查看论文截图

Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Authors:Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Schütze, Volker Tresp, Yunpu Ma
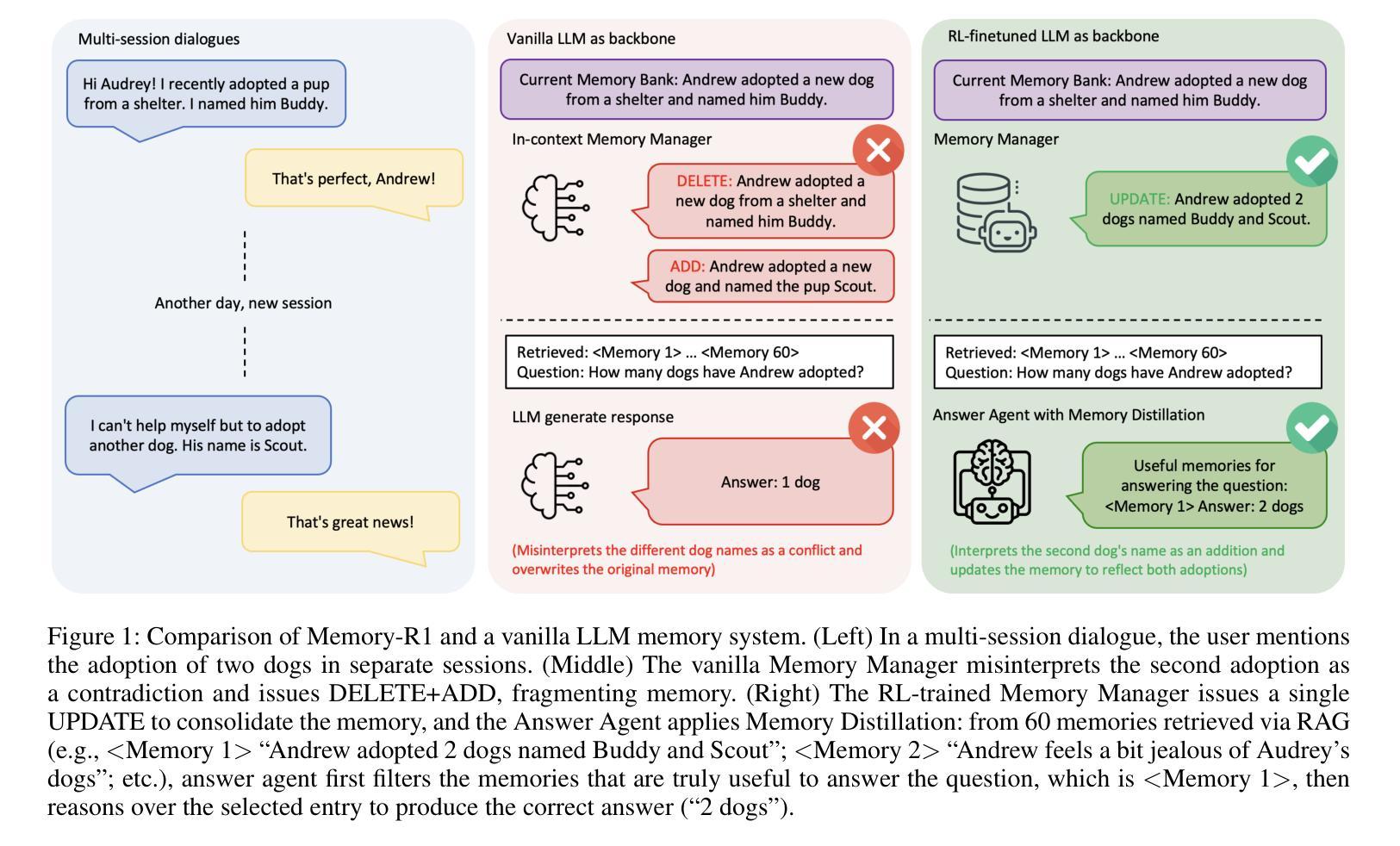
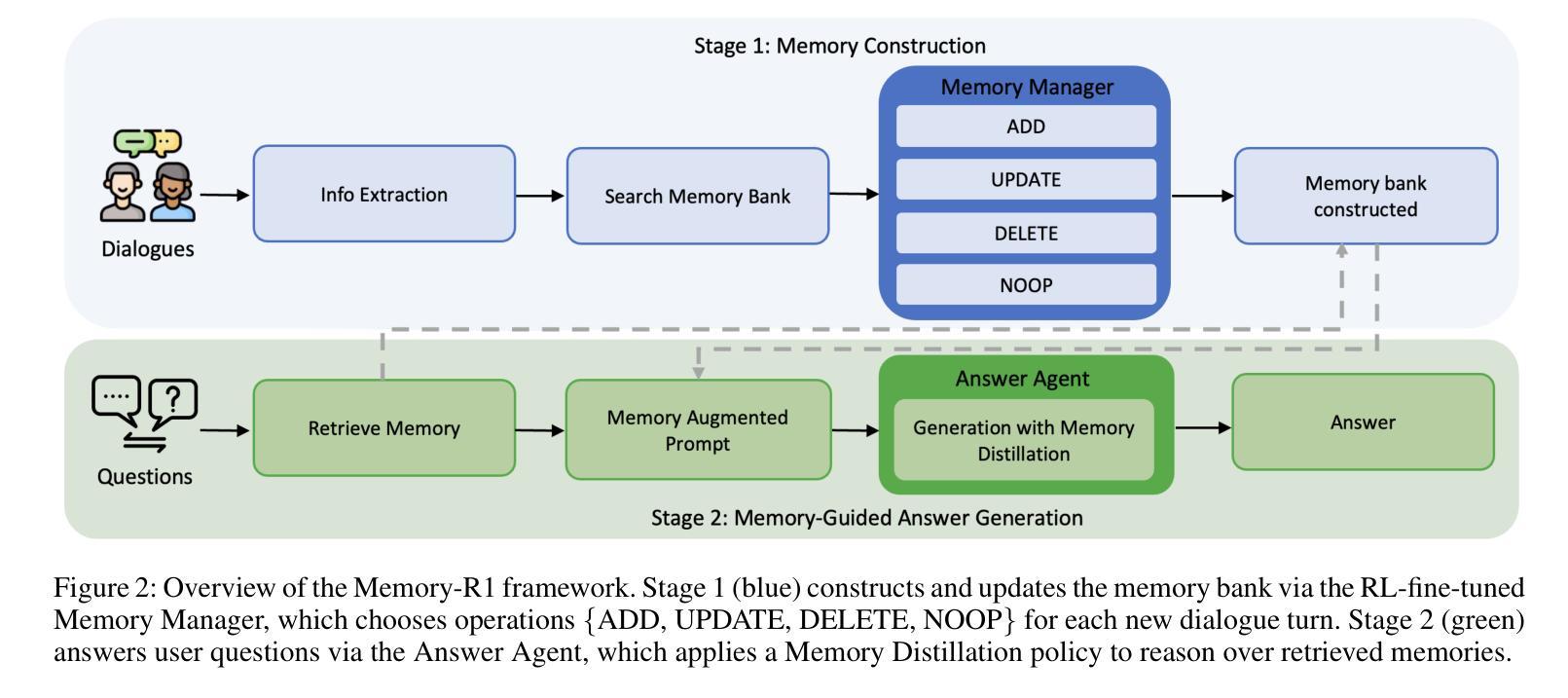
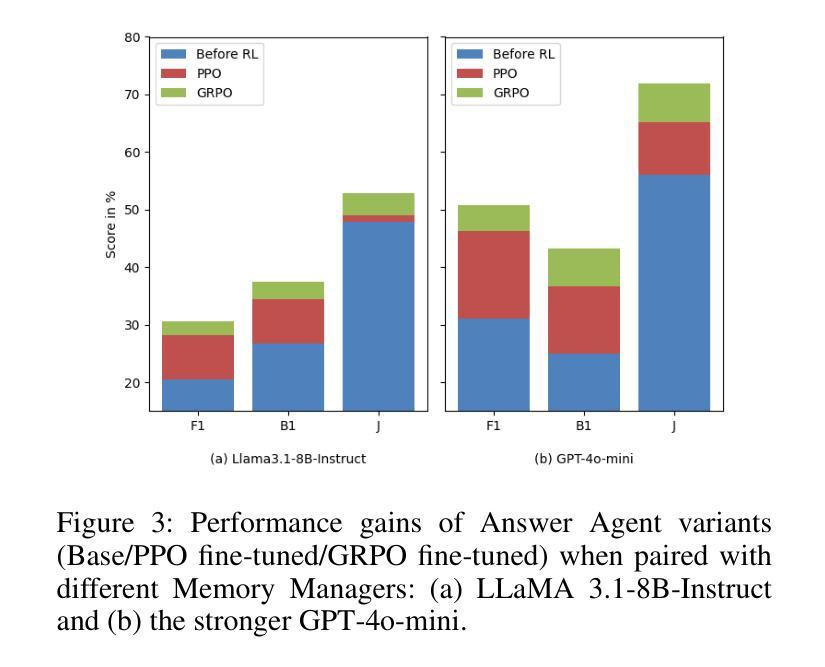
Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations, including adding, updating, deleting, or taking no operation on memory entries; and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and utilization with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the strongest existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behavior in LLMs, pointing toward richer, more persistent reasoning systems.
大型语言模型(LLM)在广泛的NLP任务中展示了令人印象深刻的能力,但它们仍然是根本上的无状态模型,受到有限上下文窗口的限制,阻碍了长期推理。最近为解决这一限制所做的努力通常是通过外部存储器增强LLM,但大多数现有流程都是静态和启发式驱动的,缺乏任何学习机制来决定存储、更新或检索什么。我们提出了Memory-R1,这是一个强化学习(RL)框架,它为LLM配备了主动管理和利用外部存储器的能力,通过两个专用代理实现:内存管理器学习执行结构化内存操作,包括添加、更新、删除或对内存条目不执行任何操作;答案代理选择最相关的条目并对其进行推理以产生答案。这两个代理都使用以结果驱动的强化学习(PPO和GRPO)进行微调,使监督最小的情况下实现自适应内存管理和利用。使用仅152个问答对及其相应的临时记忆库进行训练,Memory-R1超过了最强的现有基准测试,并在各种问题和LLM主干上展示了强大的泛化能力。除了提供一种有效方法外,这项工作还提供了关于强化学习如何解锁LLM中更具智能、记忆感知的行为的见解,为更丰富、更持久的推理系统指明了方向。
论文及项目相关链接
PDF work in progress
Summary
大型语言模型(LLM)在多个NLP任务中展现出令人印象深刻的能力,但其本质上是无状态的,受限于有限的上下文窗口,影响长期推理。最近的研究通过为LLM增加外部记忆库来解决此限制,但现有流程多为静态、启发式驱动,缺乏学习机制来决定存储、更新或检索的内容。本研究提出Memory-R1,一种强化学习(RL)框架,为LLM配备主动管理和利用外部记忆的能力,包括两个专门代理:内存管理器学习执行结构化内存操作,如添加、更新、删除或不对内存条目进行操作;答案代理选择最相关的条目并进行推理以产生答案。两者均通过结果驱动的RL(PPO和GRPO)进行微调,可在极少监督下实现自适应内存管理和利用。在仅使用152个问答对及其对应的时序记忆库进行训练的情况下,Memory-R1表现优于现有最佳基线,并在不同问题类型和LLM主干上展现出强大的泛化能力。本研究不仅提供了一种有效的方法,还揭示了RL如何解锁LLM中更具代理性的记忆感知行为,指向更丰富、更持久的推理系统。
Key Takeaways
- 大型语言模型(LLM)在NLP任务中表现出强大的能力,但存在无状态性和上下文窗口限制的问题。
- 现有解决此问题的方法大多通过为LLM增加外部记忆库,但这些方法主要是静态和启发式驱动的。
- Memory-R1采用强化学习框架为LLM赋予主动管理和利用外部记忆的能力。
- Memory-R1包括两个专门代理:内存管理器学习执行结构化内存操作,答案代理选择相关条目并进行推理。
- 该框架通过结果驱动的RL进行微调,可在极少监督下实现自适应内存管理和利用。
- Memory-R1在仅使用少量问答对进行训练的情况下表现出强大的性能,并具有良好的泛化能力。
点此查看论文截图


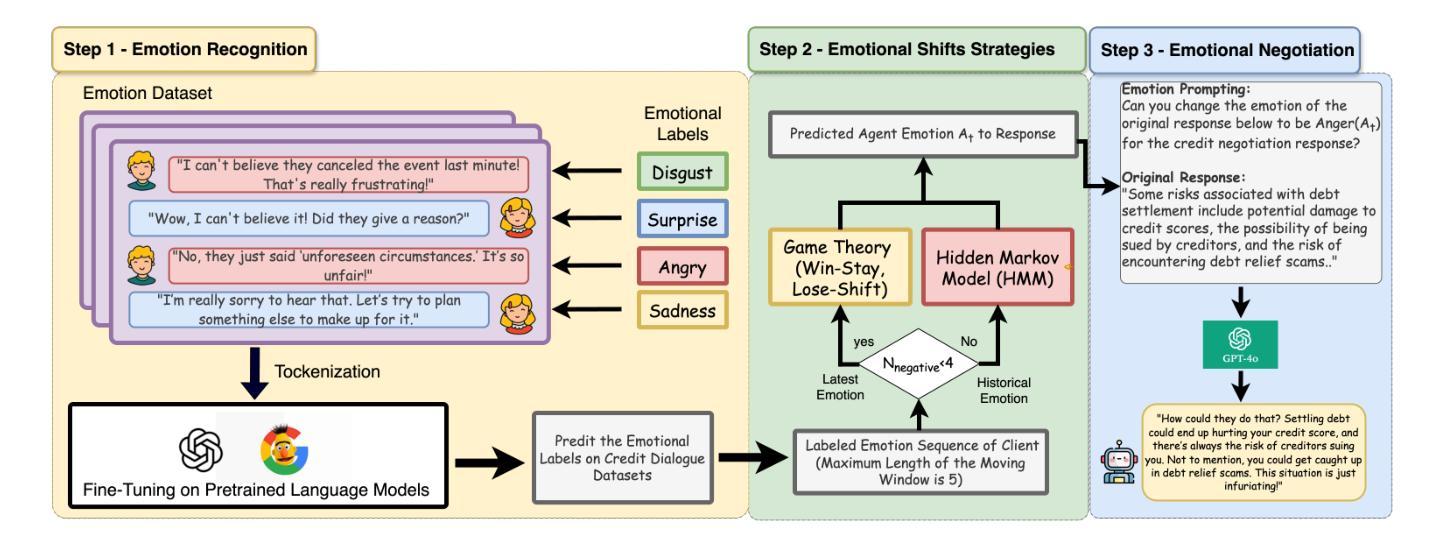
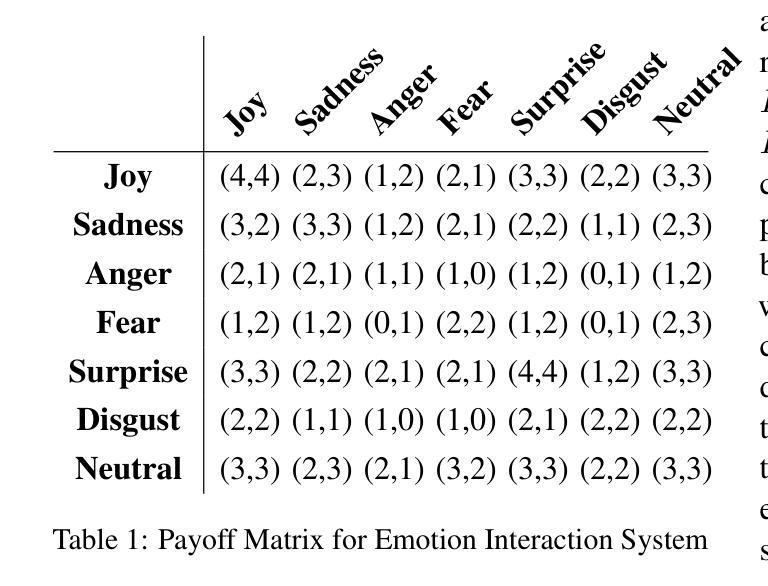
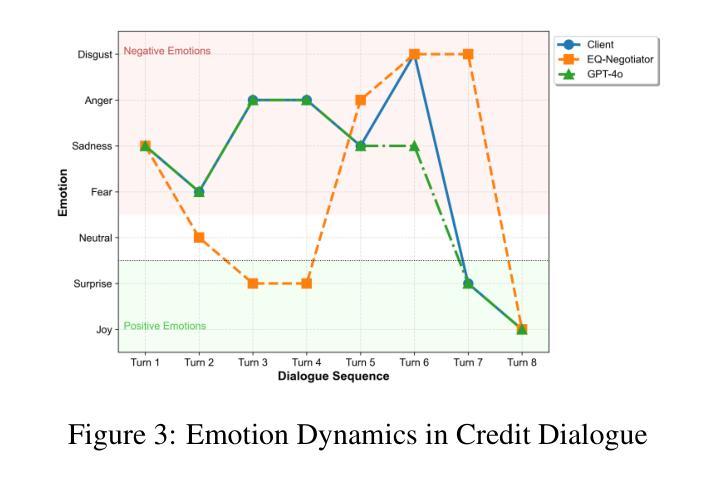
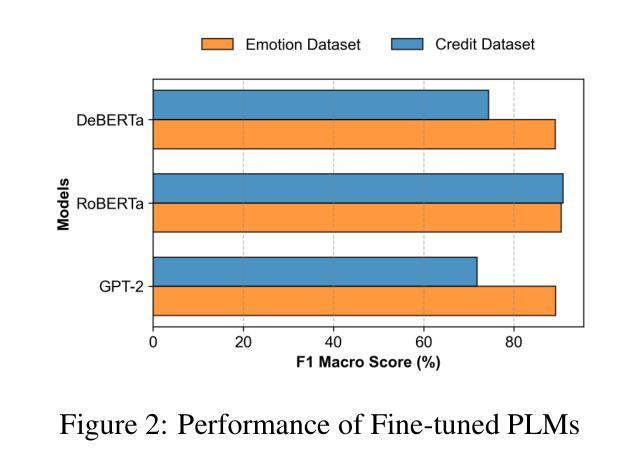
EQ-Knight: A Memory-Augmented LLM Agent for Strategic Affective Gaming in Debt Recovery
Authors:Yunbo Long, Yuhan Liu, Liming Xu, Alexandra Brintrup
Large language model-based chatbots have enhanced engagement in financial negotiations, but their overreliance on passive empathy introduces critical risks in credit collection. While empathy-driven approaches preserve client satisfaction in benign cases, they fail catastrophically against dishonest debtors–individuals who exploit conciliatory tactics to manipulate terms or evade repayment. Blindly prioritizing “customer experience” in such scenarios leads to creditor vulnerabilities: revenue leakage, moral hazard, and systemic exploitation. To address this, we propose EQ-Knight, an LLM agent that dynamically optimizes emotional strategy to defend creditor interests. Unlike naive empathy-centric bots, EQ-Knight integrates emotion memory and game-theoretic reasoning, powered by a Hidden Markov Model (HMM) to track and predict debtor emotional states. By analyzing both real-time and historical emotional cues, EQ-Knight strategically counters negative emotions (e.g., aggression, feigned distress) while preserving productive debtor relationships. Experiments demonstrate EQ-Knight’s superiority over conventional LLM negotiators: it achieves a 32% reduction in concession losses without compromising recovery rates, particularly in adversarial cases where debtors weaponize negative emotions (e.g., intimidation, guilt-tripping) to coerce concessions. For credit agencies, EQ-Knight transforms LLMs from high-risk “people-pleasers” into strategic emotion-defenders–balancing emotional intelligence with tactical rigor to enforce accountability and deter exploitation.
基于大型语言模型的聊天机器人增强了在金融谈判中的参与度,但他们对被动共鸣的过度依赖为收款带来了关键风险。在良性情况下,以同理心驱动的方法可以保持客户满意度,但对于不诚实的债务人——那些利用和解策略来操纵条件或逃避还款的人——它们会遭受灾难性的失败。在这种情境下盲目地优先重视“客户体验”会导致债权人易受攻击,产生收入损失、道德风险和系统性剥削。为了解决这个问题,我们提出了EQ-Knight,这是一个动态优化情感策略来保护债权人利益的大型语言模型(LLM)代理。与简单的以同理心为中心的机器人不同,EQ-Knight结合了情感记忆和游戏理论推理,由隐马尔可夫模型(HMM)驱动来追踪和预测债务人的情感状态。通过分析实时和历史情感线索,EQ-Knight能够有针对性地应对负面情绪(如攻击性、伪装痛苦),同时维持与债务人的良好关系。实验证明,EQ-Knight优于传统的大型语言模型谈判者:在不影响回收率的情况下,它实现了让步损失减少32%,特别是在债务人利用负面情绪(如恐吓、引发内疚感)来迫使让步的对抗情况下。对于信贷机构而言,EQ-Knight能够将大型语言模型从高风险“取悦于人”的角色转变为战略情感防御者——平衡情感智能与战术严谨性,以执行问责制并遏制剥削。
论文及项目相关链接
Summary
在金融谈判中,大型语言模型基础的聊天机器人增强了参与度,但它们过度依赖被动共情,在催收领域存在重大风险。共情驱动的方法虽然能在良性情况下维持客户满意度,但在面对不诚实债务人时却可能灾难性失败。盲目优先考虑“客户体验”可能导致债权人遭受损失、道德风险和系统剥削。因此,我们提出了EQ-Knight这一基于情感策略的谈判代理人来捍卫债权人权益。它能跟踪和预测债务人的情绪状态,同时应对消极情绪并维持与债务人的良好关系。实验证明,EQ-Knight相较于传统的大型语言模型谈判者更具优势,能在不妥协回款率的情况下减少让步损失。
Key Takeaways
- 大型语言模型在谈判中的参与增强了与客户的互动,但过度依赖被动共情可能导致催收领域的风险增加。
- 共情驱动的方法虽适用于良性情境下的客户关系维护,但对不诚实债务人的处理存在缺陷。
- 债权人过于重视客户体验可能导致财务损失、道德风险和系统剥削等后果。
- EQ-Knight通过动态优化情感策略,在保护债权人权益方面表现优异。
- EQ-Knight能够利用情感记忆和游戏理论推理,通过跟踪和预测债务人的情绪状态来应对挑战。
- 通过实时和历史情感线索的分析,EQ-Knight能够在应对消极情绪的同时维持与债务人的良好关系。
点此查看论文截图

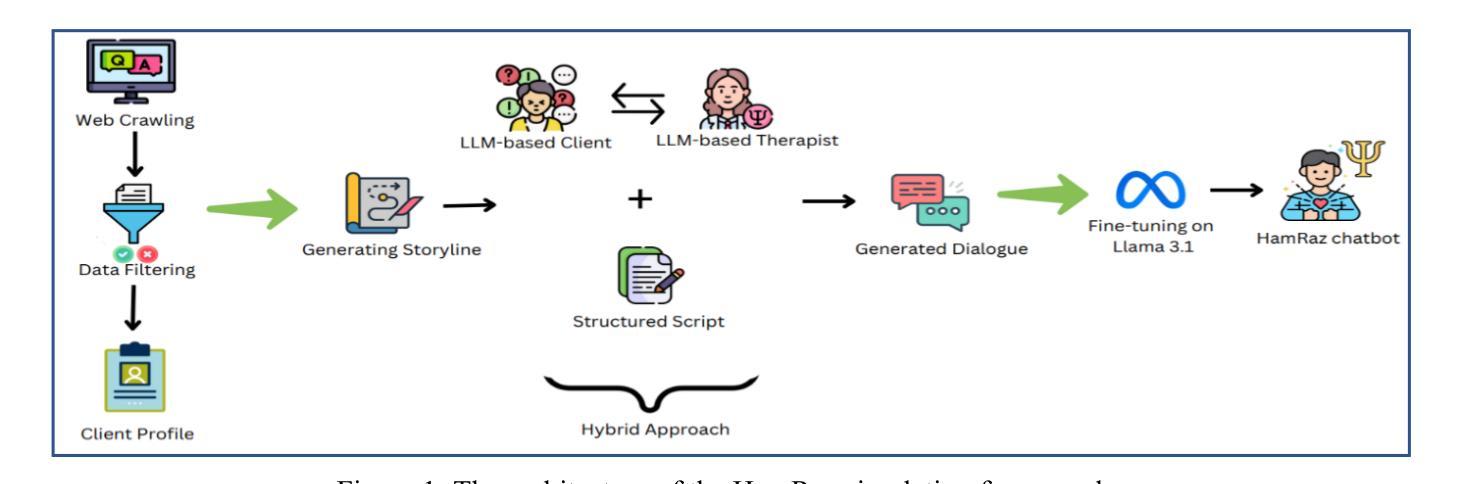
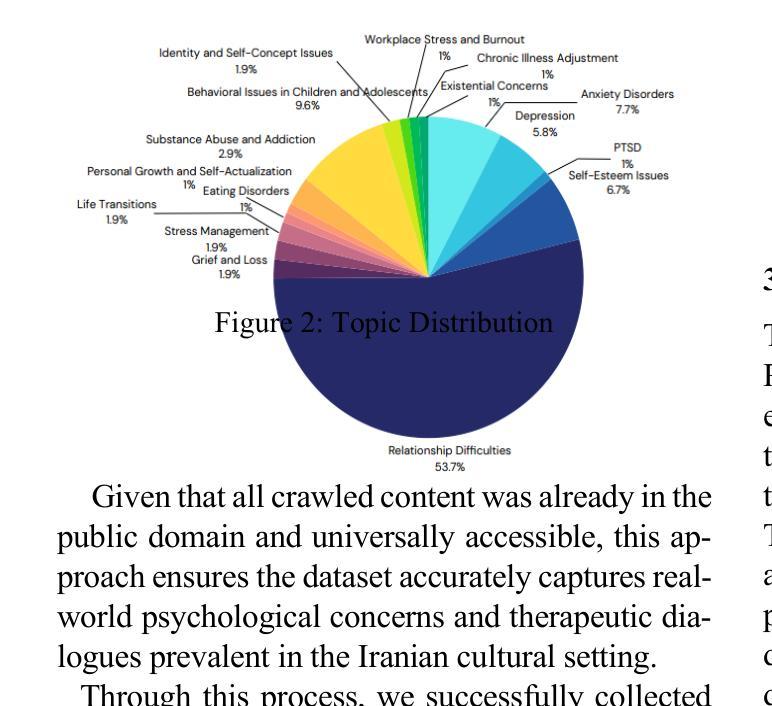
HamRaz: A Culture-Based Persian Conversation Dataset for Person-Centered Therapy Using LLM Agents
Authors:Mohammad Amin Abbasi, Farnaz Sadat Mirnezami, Ali Neshati, Hassan Naderi
We present HamRaz, a culturally adapted Persian-language dataset for AI-assisted mental health support, grounded in Person-Centered Therapy (PCT). To reflect real-world therapeutic challenges, we combine script-based dialogue with adaptive large language models (LLM) role-playing, capturing the ambiguity and emotional nuance of Persian-speaking clients. We introduce HamRazEval, a dual-framework for assessing conversational and therapeutic quality using General Metrics and specialized psychological relationship measures. Human evaluations show HamRaz outperforms existing baselines in empathy, coherence, and realism. This resource contributes to the Digital Humanities by bridging language, culture, and mental health in underrepresented communities.
我们推出HamRaz,这是一个根据波斯文化调整的人工智能辅助心理健康支持数据集,基于以人为中心的治疗法(PCT)。为了反映现实生活中的治疗挑战,我们将基于脚本的对话与自适应的大型语言模型(LLM)角色扮演相结合,捕捉波斯语客户表达的模糊性和情感细微差别。我们推出HamRazEval,这是一个使用通用指标和专门的心理关系度量来评估对话和治疗质量的双重框架。人类评估表明,HamRaz在同理心、连贯性和现实感方面超过了现有基线。这一资源通过弥合未充分代表群体的语言、文化和心理健康,为数字人文做出了贡献。
论文及项目相关链接
Summary
我们推出了HamRaz,这是一个经过文化适应的波斯语数据集,用于人工智能辅助心理健康支持,根植于以人为中心的治疗(PCT)。该数据集结合脚本对话与自适应大型语言模型(LLM)角色扮演,以捕捉波斯语客户表达的模糊性和情感细微差别,并反映现实治疗中的挑战。我们还推出了HamRazEval,这是一个双重框架,用于评估对话和治疗的质量,包括通用指标和专门的心理学关系度量标准。人类评估表明,HamRaz在同理心、连贯性和现实性方面优于现有基线。此资源有助于弥合语言、文化和心理健康在代表性不足的社区之间的差距,为数字人文领域做出贡献。
Key Takeaways
- HamRaz是一个波斯语数据集,用于人工智能辅助心理健康支持。
- 它根植于以人为中心的治疗(PCT),并结合脚本对话与自适应大型语言模型(LLM)角色扮演。
- HamRaz能够捕捉波斯语客户表达的模糊性和情感细微差别。
- HamRazEval是一个双重框架,用于评估对话和治疗的质量,包括通用指标和心理学关系度量标准。
- HamRaz在同理心、连贯性和现实性方面优于现有基线。
- HamRaz有助于弥合语言、文化和心理健康在代表性不足的社区之间的差距。
- HamRaz对数字人文领域做出贡献。
点此查看论文截图


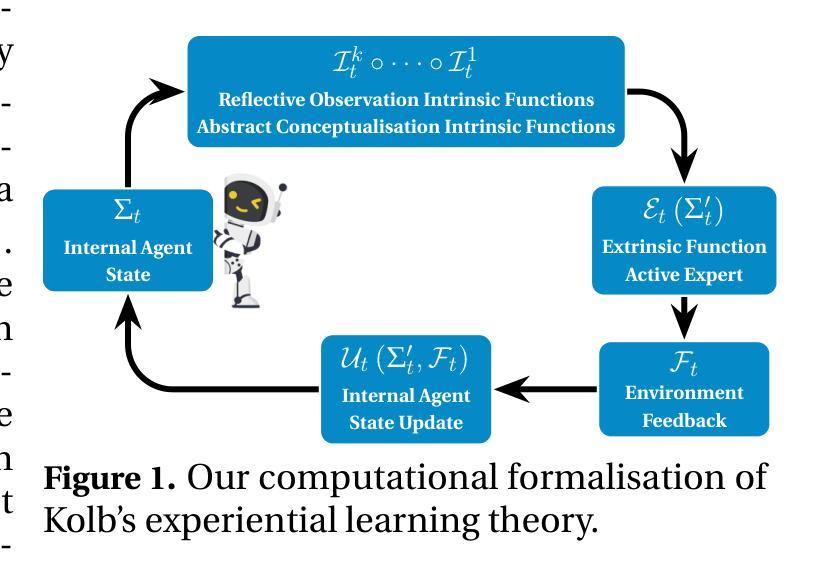
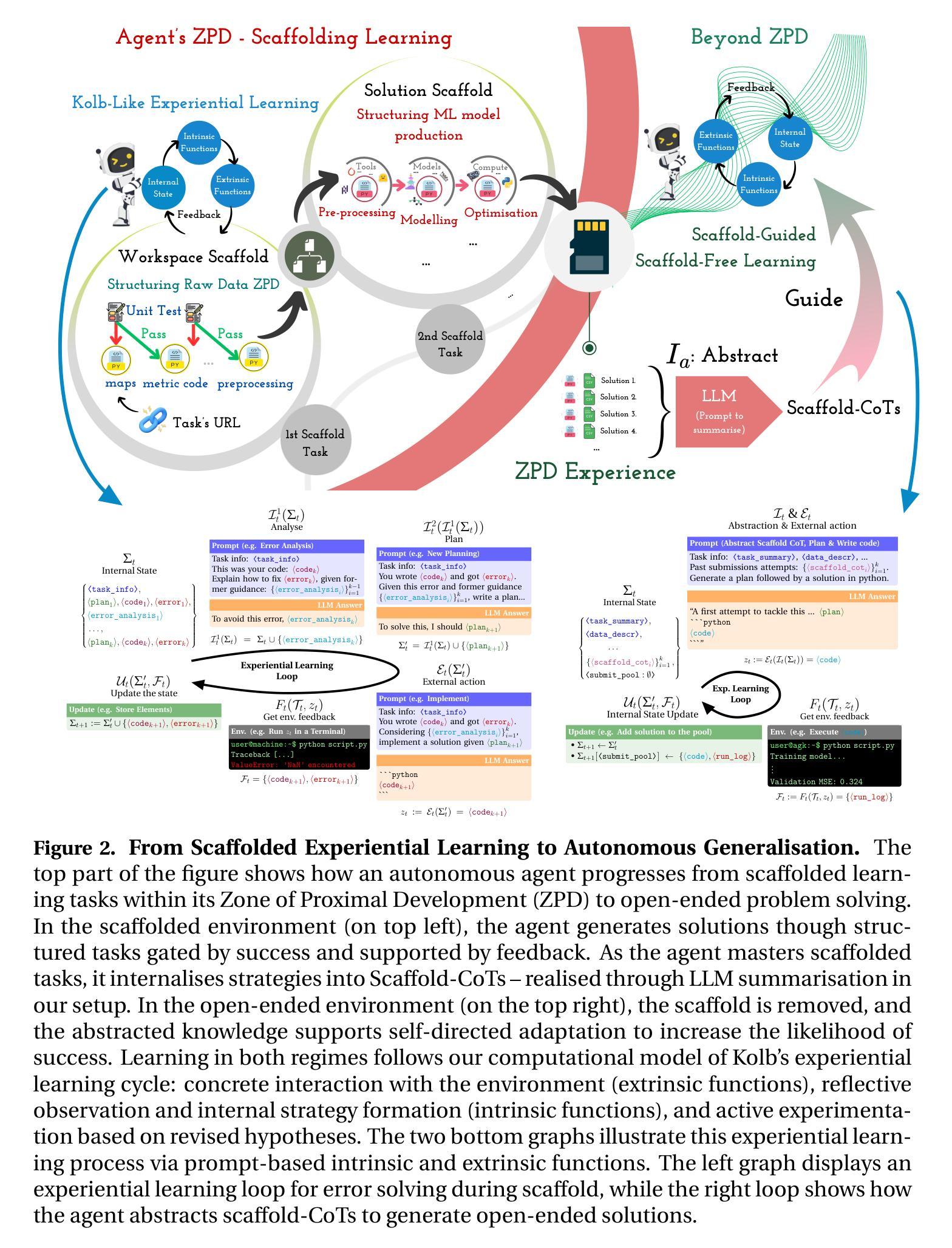
Kolb-Based Experiential Learning for Generalist Agents with Human-Level Kaggle Data Science Performance
Authors:Antoine Grosnit, Alexandre Maraval, Refinath S N, Zichao Zhao, James Dora, Giuseppe Paolo, Albert Thomas, Jonas Gonzalez, Abhineet Kumar, Khyati Khandelwal, Abdelhakim Benechehab, Hamza Cherkaoui, Youssef Attia El-Hili, Kun Shao, Jianye Hao, Jun Yao, Balázs Kégl, Jun Wang
Human expertise emerges through iterative cycles of interaction, reflection, and internal model updating, which are central to cognitive theories such as Kolb’s experiential learning and Vygotsky’s zone of proximal development. In contrast, current AI systems, particularly LLM agents, rely on static pre-training or rigid workflows, lacking mechanisms for continual adaptation. Recent studies identified early cognitive traits in LLM agents (reflection, revision, and self-correction) suggesting foundational elements of human-like experiential learning. Thus the key question: Can we design LLM agents capable of structured, cognitively grounded learning similar to human processes? In response, we propose a computational framework of Kolb’s learning cycle with Vygotsky’s ZPD for autonomous agents. Our architecture separates extrinsic (environment interaction) and intrinsic (internal reflection/abstraction) functions, enabling cognitively grounded scaffolded learning, where the agent initially learns within structured environments, followed by open-ended generalisation. This approach empowers agents to master complex tasks ; domains that traditional fine-tuning or simple reflective methods could not tackle effectively. Its potential is powerfully demonstrated via direct comparison with humans in real-world Kaggle data science competitions. Learning fully automated data science code generation across 81 tasks, our system, Agent K, demonstrated the ability to perform the entire workflow autonomously, achieving an Elo-MMR score of 1694, beyond median score of the Kaggle Masters (the top 2% among 200,000 users) of our study. With 9 gold, 8 silver, and 12 bronze medals level performance - including 4 gold and 4 silver on prize-awarding competitions - Agent K is the 1st AI system to successfully integrate Kolb- and Vygotsky-inspired human cognitive learning, marking a major step toward generalist AI.
人类专业知识是通过一系列循环互动、反思和内部模型更新而不断积累的,这与诸如Kolb的体验式学习和Vygotsky的最近发展区等认知理论密切相关。相比之下,当前的人工智能系统,特别是大型语言模型(LLM)代理,依赖于静态的预训练或刻板的工作流程,缺乏持续适应的机制。最近的研究在大型语言模型代理中发现了早期的认知特征(如反思、修订和自我校正),这表明了类似于人类经验学习的基础要素。因此,关键问题是:我们能够设计出类似于人类过程的结构化、以认知为基础的大型语言模型代理吗?作为回应,我们提出了一个基于Kolb学习周期和Vygotsky的最近发展区的自主代理计算框架。我们的架构将外在(环境交互)和内在(内在反思/抽象)功能分开,从而实现以认知为基础的支持学习,其中代理最初在结构化环境中学习,然后进行开放式泛化。这种方法使代理能够掌握复杂任务,传统微调或简单反思方法无法有效应对的领域。其在现实世界中的Kaggle数据科学竞赛中与人类的直接比较中展示了其潜力。学习跨81个任务的完全自动化数据科学代码生成系统Agent K,能够自主完成整个工作流程,艾洛-MMR得分达到1694分,超过我们研究中Kaggle大师的中位数分数(在20万名用户中排名前2%)。其表现获得了9枚金牌、8枚银牌和12枚铜牌的成绩——包括4枚金牌和4枚银牌在获奖比赛中——Agent K是第一个成功整合Kolb和Vygotsky启发的人类认知学习的人工智能系统,标志着通用人工智能的一大进步。
论文及项目相关链接
Summary
基于Kolb的体验学习和Vygotsky的最近发展区理论,提出了一种面向自主代理的计算框架,该框架结合了外部环境交互和内部反思/抽象功能,使代理能够在结构化环境中学习,进而实现开放式泛化。通过直接与人类在Kaggle数据科学竞赛中的对比实验,验证了该框架下的系统Agent K的性能超越了大多数人类专家的水平,标志着通用人工智能领域的一大进步。
Key Takeaways
- 人类专家通过互动、反思和内部模型更新的迭代循环来发展其专业知识,这与Kolb的体验学习和Vygotsky的最近发展区理论相吻合。
- 当前AI系统,尤其是LLM代理,缺乏持续适应的能力,主要依赖于静态的预训练或僵化的工作流程。
- 最近的研究发现LLM代理的早期认知特征(如反思、修订和自我校正),暗示了人类经验学习的基本要素。
- 提出了一种基于Kolb的学习周期和Vygotsky的最近发展区的计算框架,为自主代理提供认知基础的支持学习架构。
- 该架构实现了外部环境交互和内部反思/抽象功能的分离,使代理能够在结构化环境中学习,然后进行开放式泛化。
- Agent K系统成功集成了Kolb和Vygotsky启发的人类认知学习理论,实现了全自动化的数据科学代码生成,并在真实世界中的Kaggle竞赛中表现出超越大多数人类专家的能力。
点此查看论文截图

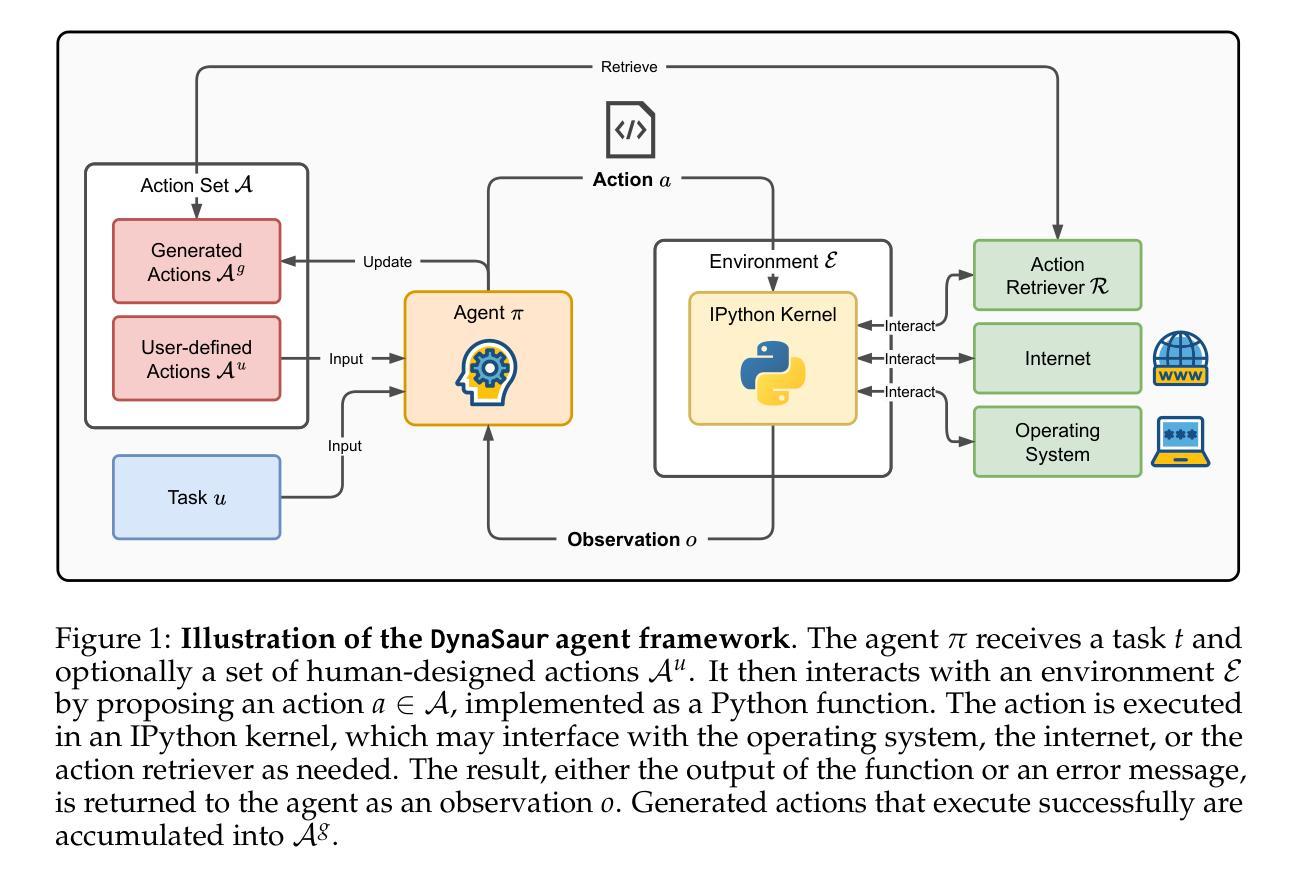
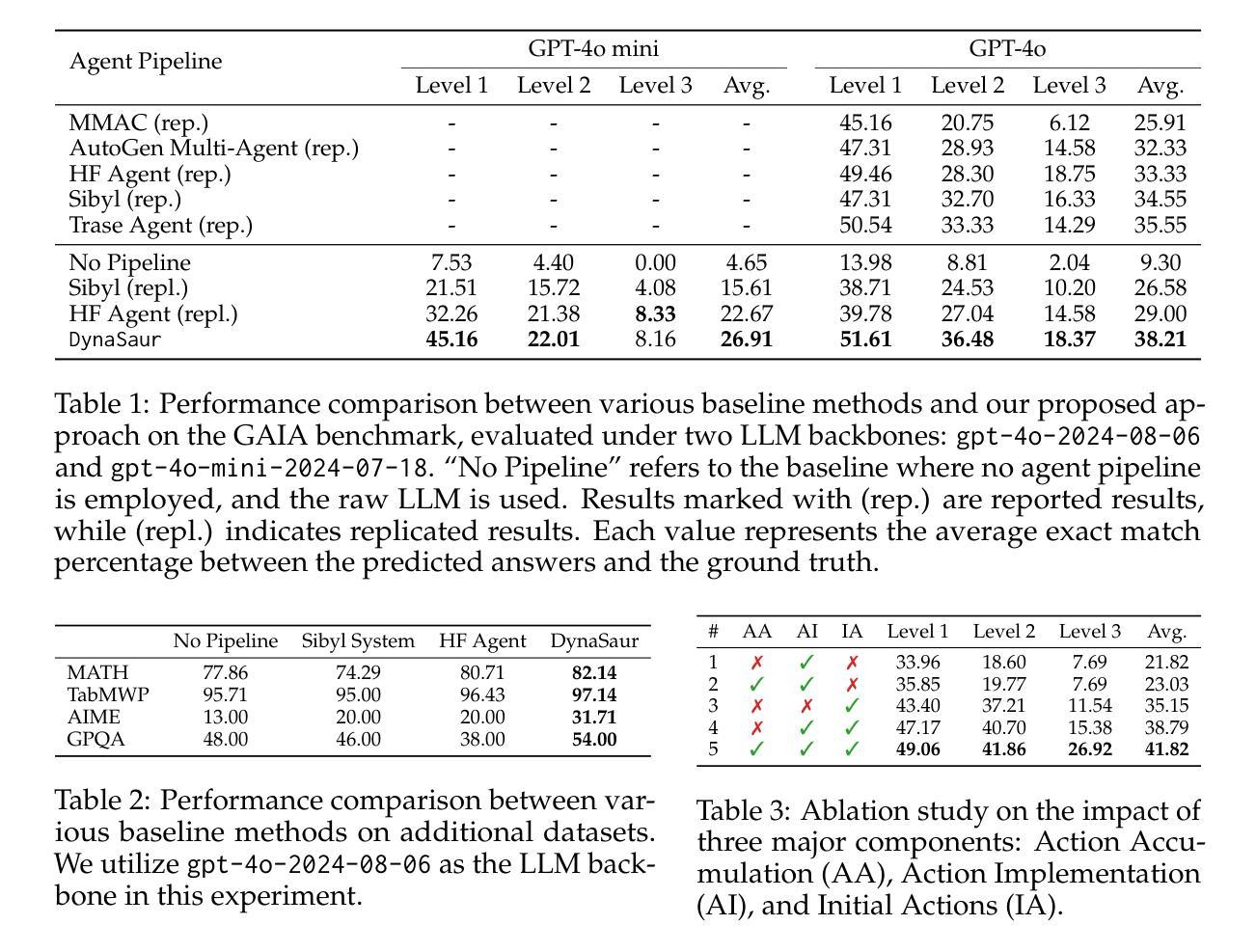
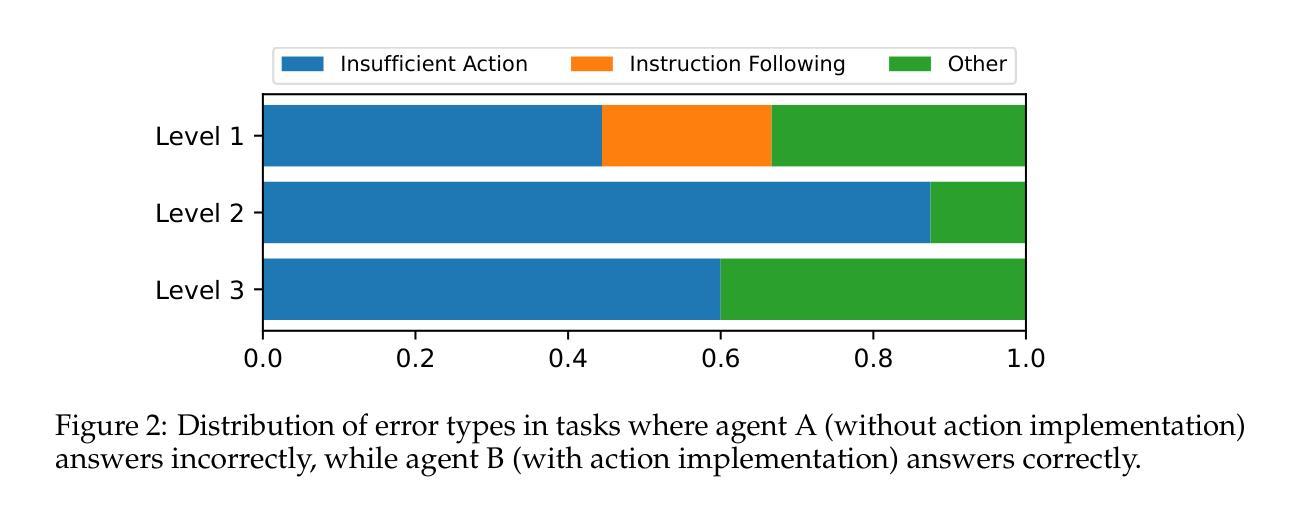
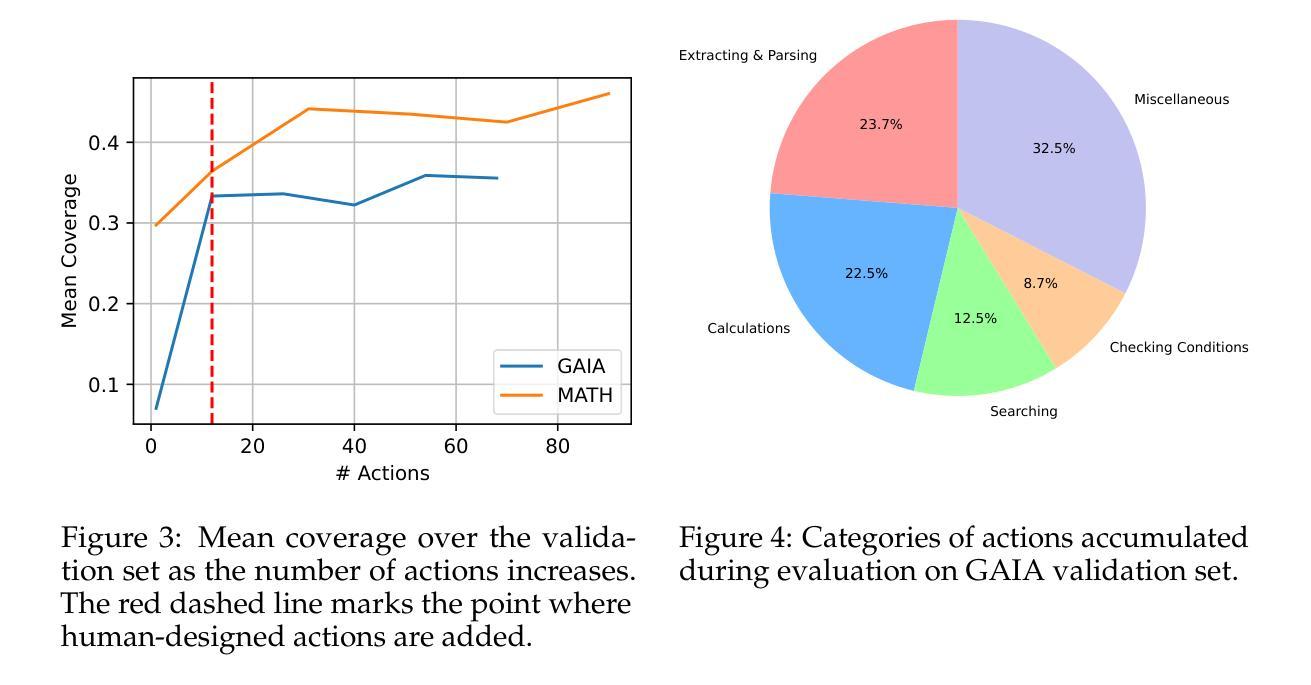
DynaSaur: Large Language Agents Beyond Predefined Actions
Authors:Dang Nguyen, Viet Dac Lai, Seunghyun Yoon, Ryan A. Rossi, Handong Zhao, Ruiyi Zhang, Puneet Mathur, Nedim Lipka, Yu Wang, Trung Bui, Franck Dernoncourt, Tianyi Zhou
Existing LLM agent systems typically select actions from a fixed and predefined set at every step. While this approach is effective in closed, narrowly scoped environments, it presents two major challenges for real-world, open-ended scenarios: (1) it significantly restricts the planning and acting capabilities of LLM agents, and (2) it requires substantial human effort to enumerate and implement all possible actions, which is impractical in complex environments with a vast number of potential actions. To address these limitations, we propose an LLM agent framework that can dynamically create and compose actions as needed. In this framework, the agent interacts with its environment by generating and executing programs written in a general-purpose programming language. Moreover, generated actions are accumulated over time for future reuse. Our extensive experiments across multiple benchmarks show that this framework significantly improves flexibility and outperforms prior methods that rely on a fixed action set. Notably, it enables LLM agents to adapt and recover in scenarios where predefined actions are insufficient or fail due to unforeseen edge cases. Our code can be found in https://github.com/adobe-research/dynasaur.
现有的大型语言模型(LLM)代理系统通常在每个步骤都从一组固定和预定义的选项中选择行动。虽然这种方法在封闭、范围狭窄的环境中是有效的,但它为现实世界、开放式的场景带来了两大挑战:(1)它显著限制了LLM代理的规划和执行能力;(2)它需要大量人力来列举和实现所有可能的行动,这在具有大量潜在行动的复杂环境中是不切实际的。为了解决这些局限性,我们提出了一种可以按需动态创建和组合行动的大型语言模型代理框架。在该框架中,代理通过与通用编程语言编写和执行的程序进行交互。此外,随着时间的推移,生成的行动会被积累以供将来重复使用。我们在多个基准测试上的广泛实验表明,该框架大大提高了灵活性,并且优于依赖于固定行动集之前的方法。尤其值得一提的是,它使得大型语言模型代理能够在预设行动不足或由于未预见到的边缘情况而失败的情况下进行适应和恢复。我们的代码可以在https://github.com/adobe-research/dynasaur中找到。
论文及项目相关链接
PDF Published as a conference paper at COLM 2025
Summary
LLM代理系统通常在每个步骤都从固定和预定义的集合中选择行动,这在封闭、范围狭窄的环境中是有效的,但在现实世界的开放场景中却存在两大挑战。为应对这些挑战,我们提出了一种可以按需动态创建和组合行动的LLM代理框架。代理通过与环境互动生成并执行通用编程语言编写的程序来实现行动生成和执行。此外,生成的行动随时间累积以供未来重复使用。实验证明,该框架显著提高了灵活性并超越了依赖固定行动集的方法。它使LLM代理能够在预设行动不足或由于意外边缘情况而失败的情况下进行适应和恢复。
Key Takeaways
- LLM代理系统通常在每个步骤从预定义行动集合中选择,这在复杂环境中具有限制。
- 固定行动集合要求大量人力来枚举和实施所有可能的行动,这在具有大量潜在行动的复杂环境中不实际。
- 提出一种LLM代理框架,能够按需动态创建和组合行动。
- 代理通过与环境互动生成并执行通用编程语言编写的程序来实现行动。
- 生成的行动随时间累积以供未来重复使用,增强了LLM代理的适应能力。
- 框架显著提高了LLM代理的灵活性并超越依赖固定行动集的方法。
点此查看论文截图