⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory
Authors:Matthew Ho, Chen Si, Zhaoxiang Feng, Fangxu Yu, Zhijian Liu, Zhiting Hu, Lianhui Qin
While inference-time scaling enables LLMs to carry out increasingly long and capable reasoning traces, the patterns and insights uncovered during these traces are immediately discarded once the context window is reset for a new query. External memory is a natural way to persist these discoveries, and recent work has shown clear benefits for reasoning-intensive tasks. We see an opportunity to make such memories more broadly reusable and scalable by moving beyond instance-based memory entries (e.g. exact query/response pairs, or summaries tightly coupled with the original problem context) toward concept-level memory: reusable, modular abstractions distilled from solution traces and stored in natural language. For future queries, relevant concepts are selectively retrieved and integrated into the prompt, enabling test-time continual learning without weight updates. Our design introduces new strategies for abstracting takeaways from rollouts and retrieving entries for new queries, promoting reuse and allowing memory to expand with additional experiences. On the challenging ARC-AGI benchmark, our method yields a 7.5% relative gain over a strong no-memory baseline with performance continuing to scale with inference compute. We find abstract concepts to be the most consistent memory design, outscoring the baseline at all tested inference compute scales. Moreover, we confirm that dynamically updating memory during test-time outperforms an otherwise identical fixed memory setting with additional attempts, supporting the hypothesis that solving more problems and abstracting more patterns to memory enables further solutions in a form of self-improvement. Code available at https://github.com/matt-seb-ho/arc_memo.
在推理时间缩放使得大型语言模型能够进行越来越长和强大的推理轨迹的同时,这些轨迹中发现的模式和见解在针对新查询重置上下文窗口后就会立即被丢弃。外部记忆是保留这些发现的一种自然方式,最近的工作已经显示出它在需要大量推理的任务中的明确优势。我们认为,通过超越基于实例的记忆条目(例如与原始问题上下文紧密耦合的确切查询/响应对或摘要),使此类记忆更具广泛的可重用性和可扩展性,这是一个机会。我们朝着概念层面的记忆发展:从解决方案轨迹中提炼出的可重用、模块化抽象,以自然语言存储。对于未来的查询,相关概念会被选择性地检索并集成到提示中,实现测试时的持续学习而无需权重更新。我们的设计引入了从rollouts中提取抽象成果和为新查询检索条目的新策略,促进了重用并允许记忆随着额外的经验而扩展。在具有挑战性的ARC-AGI基准测试中,我们的方法相对于强大的无记忆基线取得了7.5%的相对增益,随着推理计算的性能持续提高。我们发现抽象概念是最一致的记忆设计,在所有测试的推理计算规模上都超过了基线。此外,我们证实,在测试过程中动态更新内存优于固定内存设置,支持假设:解决更多问题并将更多模式抽象到内存中,能够以自我改进的形式实现进一步解决方案。代码可在https://github.com/matt-seb-ho/arc_memo获取。
论文及项目相关链接
Summary
大模型推理时引入外部记忆存储是十分必要的。外部记忆能够帮助存储模型在推理过程中发现的模式和见解,避免在上下文窗口重置后丢失这些信息。最新研究倾向于从解决方案轨迹中提炼出可重复使用的概念级抽象,而非实例级记忆条目。这种方式不仅提高了记忆的复用性,还允许记忆随着经验的增加而扩展。在ARC-AGI基准测试中,采用此方法的模型性能相较于无记忆基准测试有相对7.5%的提升,并且性能会随着推理计算而不断提升。动态更新内存的方式在测试时优于固定内存设置,证明了通过解决更多问题和抽象更多模式到内存可以进一步实现自我改进。
Key Takeaways
- 推理过程中,外部记忆存储对存储模型发现的模式和见解至关重要。
- 与实例级记忆相比,概念级抽象记忆更具复用性和可扩展性。
- 在ARC-AGI基准测试中,引入外部记忆的概念级抽象提高了模型性能。
- 采用动态更新内存的方式有助于提升模型的自我改进能力。
- 概念级抽象设计能稳定提高模型性能,尤其在不同的推理计算规模下。
- 代码已公开在GitHub上可供参考和使用。
点此查看论文截图





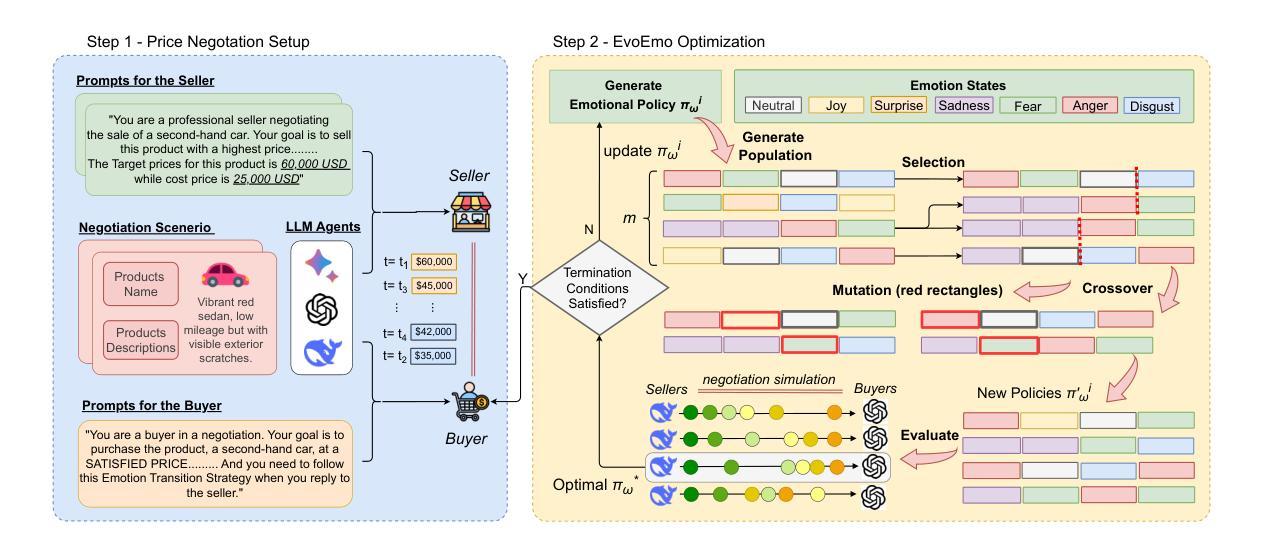
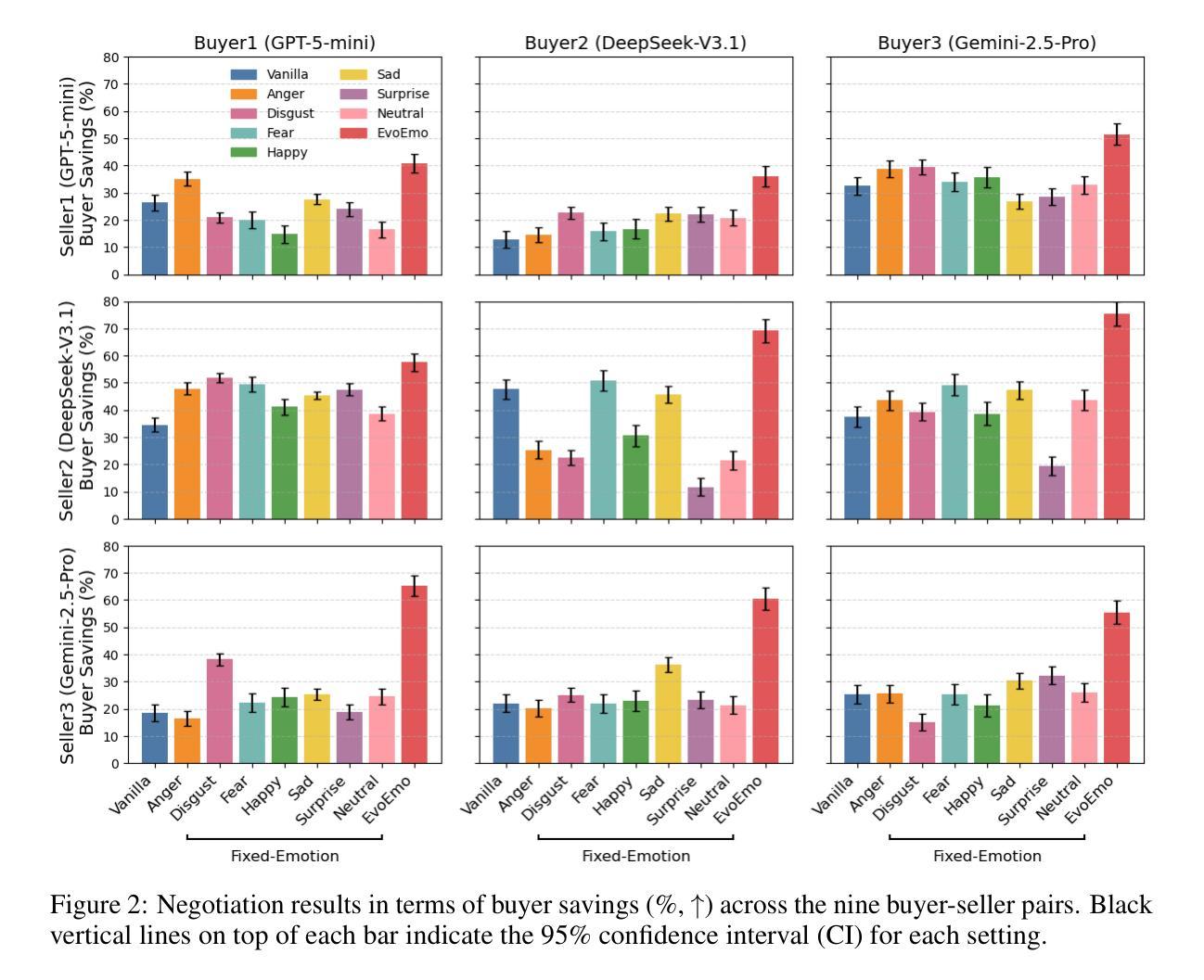
EvoEmo: Towards Evolved Emotional Policies for LLM Agents in Multi-Turn Negotiation
Authors:Yunbo Long, Liming Xu, Lukas Beckenbauer, Yuhan Liu, Alexandra Brintrup
Recent research on Chain-of-Thought (CoT) reasoning in Large Language Models (LLMs) has demonstrated that agents can engage in \textit{complex}, \textit{multi-turn} negotiations, opening new avenues for agentic AI. However, existing LLM agents largely overlook the functional role of emotions in such negotiations, instead generating passive, preference-driven emotional responses that make them vulnerable to manipulation and strategic exploitation by adversarial counterparts. To address this gap, we present EvoEmo, an evolutionary reinforcement learning framework that optimizes dynamic emotional expression in negotiations. EvoEmo models emotional state transitions as a Markov Decision Process and employs population-based genetic optimization to evolve high-reward emotion policies across diverse negotiation scenarios. We further propose an evaluation framework with two baselines – vanilla strategies and fixed-emotion strategies – for benchmarking emotion-aware negotiation. Extensive experiments and ablation studies show that EvoEmo consistently outperforms both baselines, achieving higher success rates, higher efficiency, and increased buyer savings. This findings highlight the importance of adaptive emotional expression in enabling more effective LLM agents for multi-turn negotiation.
最近关于大型语言模型(LLM)中的思维链(CoT)推理的研究表明,智能体可以参与复杂的多轮谈判,为智能体人工智能开辟了新的途径。然而,现有的LLM智能体在很大程度上忽视了情绪在这种谈判中的功能作用,而是产生被动、偏好驱动的情绪反应,使它们容易受到对抗性对手的操纵和战略利用。为了解决这一空白,我们提出了EvoEmo,这是一个进化强化学习框架,优化了谈判中的动态情绪表达。EvoEmo将情绪状态转换建模为马尔可夫决策过程,并基于群体遗传优化方法,在不同的谈判场景中演化出高回报的情绪策略。我们还提出了一个评估框架,包括两个基准线——普通策略和固定情绪策略——用于评估情感感知谈判。广泛的实验和消融研究结果表明,EvoEmo始终优于这两个基准线,实现了更高的成功率、更高的效率和更高的买家节省。这些发现突显了在多轮谈判中,自适应的情绪表达对于使LLM智能体更加有效的重要性。
论文及项目相关链接
Summary
近期关于大型语言模型(LLM)中的思维链(CoT)推理的研究显示,智能体能够参与复杂多轮谈判,为智能体AI开启了新途径。然而,现有LLM智能体在很大程度上忽视了情绪在谈判中的功能作用,只产生被动、偏好驱动的情绪反应,使其容易受到对手的策略性操纵和利用。为解决这一缺陷,我们提出了EvoEmo,一个进化强化学习框架,旨在优化谈判中的动态情绪表达。EvoEmo将情绪状态转变模拟为马尔可夫决策过程,并运用基于群体的遗传优化算法来演化不同谈判场景下的高回报情绪策略。我们还提出了一个评估框架,设定了两种基线策略:常规策略和固定情绪策略,用于评估情绪感知谈判的表现。大量实验和消融研究表明,EvoEmo始终优于基线策略,实现了更高的成功率、效率和买家节省。这一发现凸显了自适应情绪表达在使LLM智能体实现更有效的多轮谈判中的重要性。
Key Takeaways
- LLMs now can engage in complex, multi-turn negotiations through Chain-of-Thought (CoT) reasoning, opening new avenues for agentic AI.
- Existing LLM agents tend to generate passive and preference-driven emotional responses, making them vulnerable to manipulation and strategic exploitation.
- EvoEmo framework is proposed to optimize dynamic emotional expression in negotiations by modeling emotional state transitions as a Markov Decision Process.
- EvoEmo employs population-based genetic optimization to evolve high-reward emotion policies across diverse negotiation scenarios.
- An evaluation framework with baselines is introduced to assess the performance of emotion-aware negotiation strategies.
- EvoEmo consistently outperforms baseline strategies, achieving higher success rates, efficiency, and buyer savings in extensive experiments and ablation studies.
点此查看论文截图

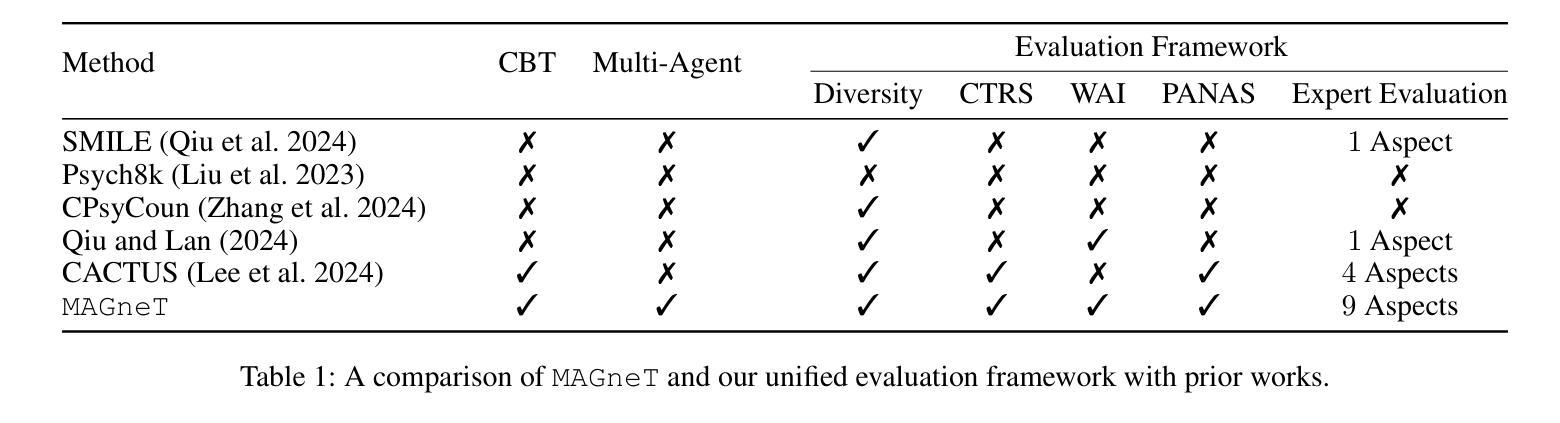
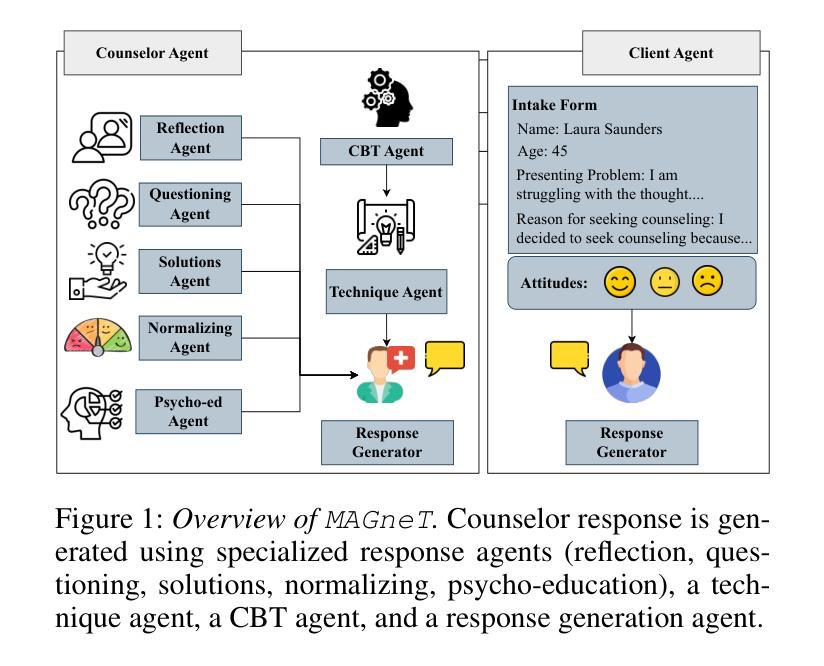
MAGneT: Coordinated Multi-Agent Generation of Synthetic Multi-Turn Mental Health Counseling Sessions
Authors:Aishik Mandal, Tanmoy Chakraborty, Iryna Gurevych
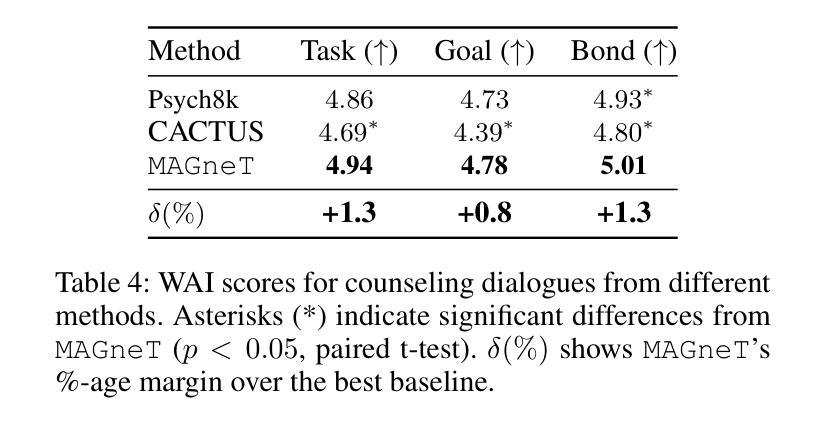
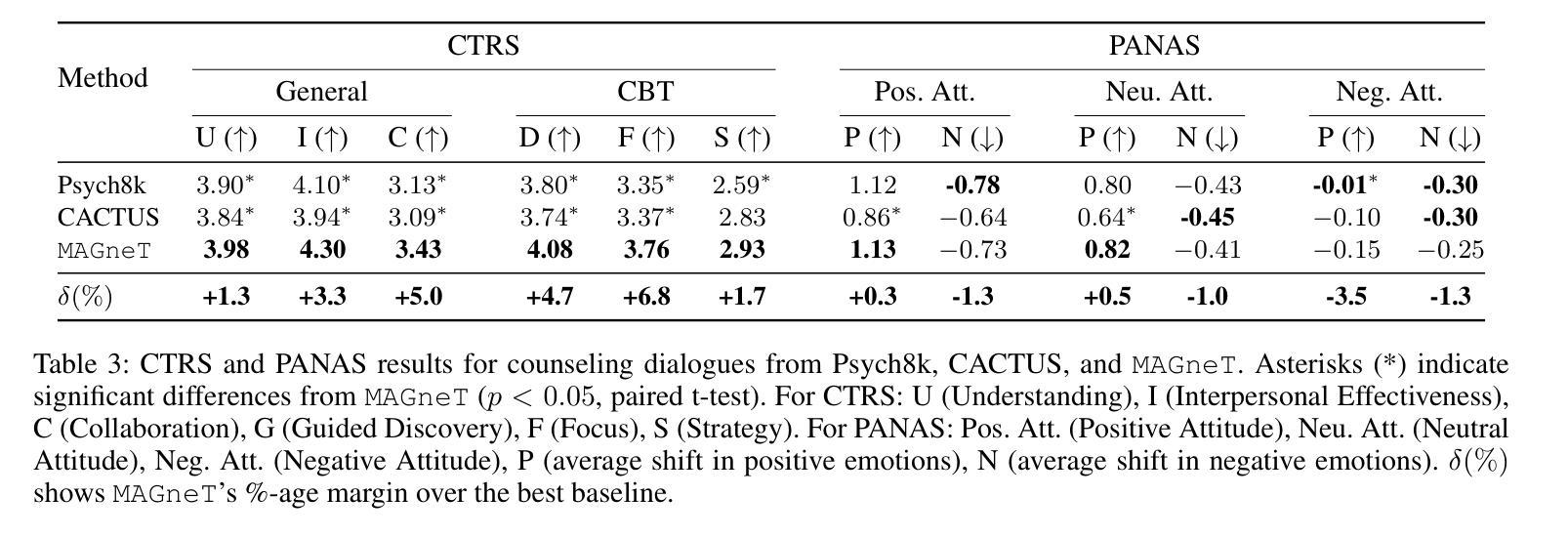
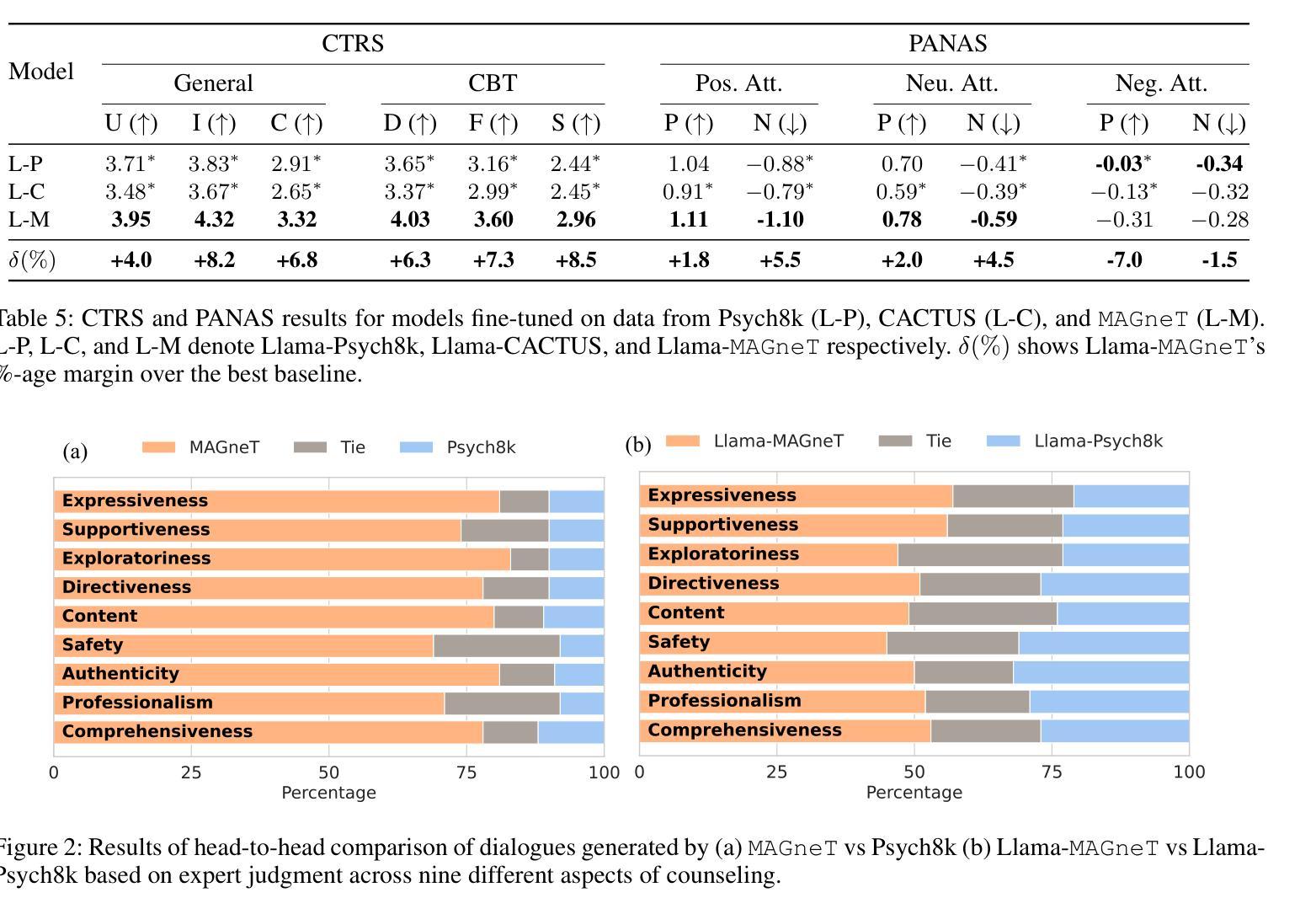
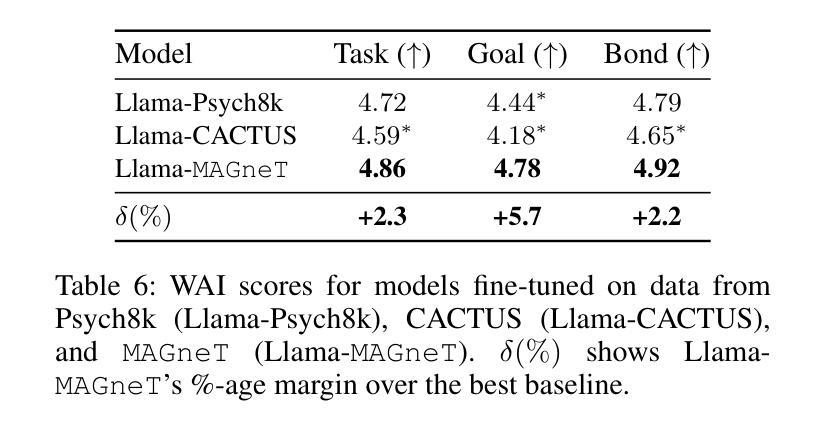
The growing demand for scalable psychological counseling highlights the need for fine-tuning open-source Large Language Models (LLMs) with high-quality, privacy-compliant data, yet such data remains scarce. Here we introduce MAGneT, a novel multi-agent framework for synthetic psychological counseling session generation that decomposes counselor response generation into coordinated sub-tasks handled by specialized LLM agents, each modeling a key psychological technique. Unlike prior single-agent approaches, MAGneT better captures the structure and nuance of real counseling. In addition, we address inconsistencies in prior evaluation protocols by proposing a unified evaluation framework integrating diverse automatic and expert metrics. Furthermore, we expand the expert evaluations from four aspects of counseling in previous works to nine aspects, enabling a more thorough and robust assessment of data quality. Empirical results show that MAGneT significantly outperforms existing methods in quality, diversity, and therapeutic alignment of the generated counseling sessions, improving general counseling skills by 3.2% and CBT-specific skills by 4.3% on average on cognitive therapy rating scale (CTRS). Crucially, experts prefer MAGneT-generated sessions in 77.2% of cases on average across all aspects. Moreover, fine-tuning an open-source model on MAGneT-generated sessions shows better performance, with improvements of 6.3% on general counseling skills and 7.3% on CBT-specific skills on average on CTRS over those fine-tuned with sessions generated by baseline methods. We also make our code and data public.
不断增长的心理咨询需求强调了使用高质量、符合隐私要求的数据对开源大型语言模型(LLM)进行微调的必要性,但此类数据仍然稀缺。在这里,我们介绍了MAGneT,这是一种用于合成心理咨询会话生成的新型多智能体框架,它将咨询者响应生成分解为由专业LLM智能体处理的各种协调子任务,每个智能体都模拟了一种关键的心理技术。与之前的单智能体方法不同,MAGneT能更好地捕捉现实咨询的结构和细微差别。此外,我们针对先前评估协议的不一致性,提出了一个统一的评估框架,该框架融合了多种自动和专家度量标准。同时,我们将之前作品中关于咨询的专家评估从四个方面扩展到九个方面,从而能够对数据质量进行更全面、更稳健的评估。经验结果表明,在生成的咨询会话的质量、多样性和治疗一致性方面,MAGneT显著优于现有方法,在认知疗法评定量表(CTRS)上,平均提高了一般咨询技能3.2%,特定于CBT的技能提高4.3%。关键的是,专家平均在所有方面都喜欢MAGneT生成的会话占77.2%。此外,使用MAGneT生成的会话对开源模型进行微调显示出了更好的性能,在CTRS上相较于使用基线方法生成的会话进行微调的一般咨询技能和CBT特定技能平均分别提高了6.3%和7.3%。我们还公开了我们的代码和数据。
论文及项目相关链接
PDF 25 pages, 29 figures
Summary
本文介绍了MAGneT,一种新型的多智能体框架,用于生成合成心理咨询会话。该框架通过专门化LLM智能体处理协调的子任务来微调开源大型语言模型,以应对心理咨询服务需求的增长。MAGneT通过分解咨询师反应生成过程,更好地捕捉真实咨询的结构和细微差别。此外,本文提出了一个统一的评估框架,以更全面地评估数据质量,并扩展了从四个方面的专家评价到九个方面。实证结果表明,MAGneT在生成的咨询会话的质量、多样性和治疗对齐方面显著优于现有方法。专家评估显示,MAGneT生成的会话在大多数情况下都得到了专家的青睐。此外,使用MAGneT生成的会话对开源模型进行微调,相较于基线方法生成的会话,在一般咨询技能和CBT特定技能上都有显著提高。
Key Takeaways
- 介绍了MAGneT框架,这是一种用于生成合成心理咨询会话的多智能体框架。
- MAGneT通过专门化LLM智能体处理协调的子任务来微调大型语言模型。
- MAGneT更好地捕捉了真实心理咨询的结构和细微差别。
- 提出一个统一的评估框架,以整合自动和专家评估指标,并扩展了专家评价的方面。
- 实证结果显示MAGneT在会话质量、多样性和治疗对齐方面优于现有方法。
- 专家更倾向于选择MAGneT生成的会话。
点此查看论文截图


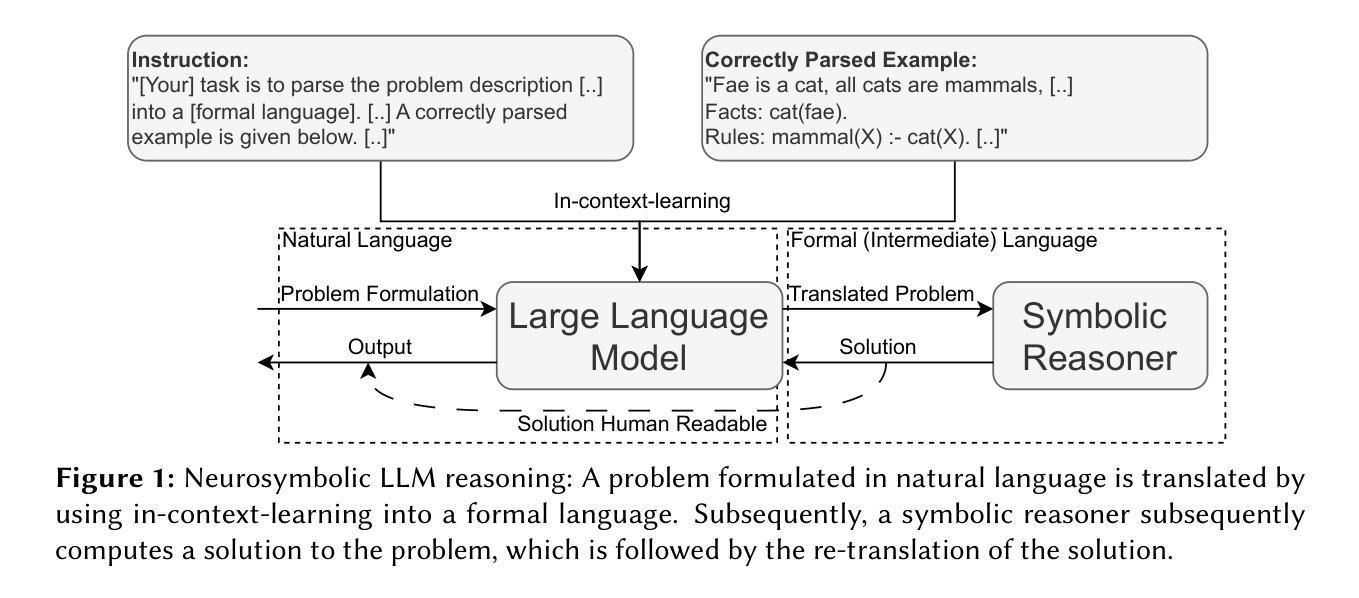
Intermediate Languages Matter: Formal Languages and LLMs affect Neurosymbolic Reasoning
Authors:Alexander Beiser, David Penz, Nysret Musliu
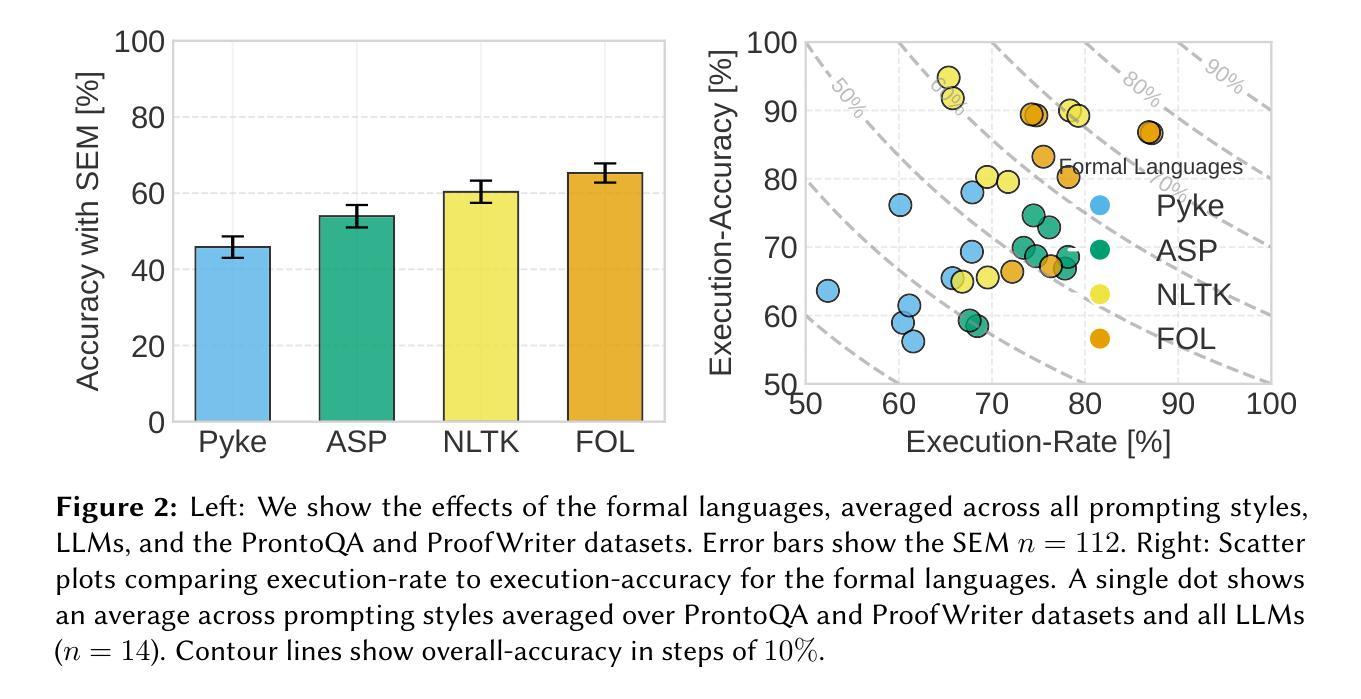
Large language models (LLMs) achieve astonishing results on a wide range of tasks. However, their formal reasoning ability still lags behind. A promising approach is Neurosymbolic LLM reasoning. It works by using LLMs as translators from natural to formal languages and symbolic solvers for deriving correct results. Still, the contributing factors to the success of Neurosymbolic LLM reasoning remain unclear. This paper demonstrates that one previously overlooked factor is the choice of the formal language. We introduce the intermediate language challenge: selecting a suitable formal language for neurosymbolic reasoning. By comparing four formal languages across three datasets and seven LLMs, we show that the choice of formal language affects both syntactic and semantic reasoning capabilities. We also discuss the varying effects across different LLMs.
大型语言模型(LLM)在各种任务上取得了惊人的成绩。然而,它们的正式推理能力仍然滞后。一种有前途的方法是神经符号LLM推理。它的工作原理是利用LLM作为从自然语言到正式语言和符号求解器的翻译器,以得出正确结果。然而,神经符号LLM推理成功的关键因素仍不清楚。本文证明了以前被忽视的一个因素就是正式语言的选择问题。我们介绍了中间语言挑战:为神经符号推理选择合适的正式语言。通过比较三种数据集和七个LLM的四种正式语言,我们证明了正式语言的选择影响语法和语义推理能力。我们还讨论了在不同LLM之间的不同影响。
论文及项目相关链接
PDF To appear in the proceedings of The Second Workshop on Knowledge Graphs and Neurosymbolic AI (KG-NeSy) Co-located with SEMANTiCS 2025 Conference, Vienna, Austria - September 3rd, 2025
Summary
大型语言模型(LLMs)在众多任务上表现出卓越性能,但在形式推理方面仍有不足。神经符号型LLM推理方法展现出潜力,通过将LLMs作为从自然语言到形式语言的翻译器,并结合符号求解器来推导正确结果。然而,神经符号型LLM推理成功的关键因素尚不清楚。本文揭示了一个之前被忽视的关键因素——形式语言的选择。我们提出了中间语言挑战,即选择适合神经符号推理的形式语言。通过对四种形式语言在三个数据集和七个LLMs上的比较,我们发现形式语言的选择影响语法和语义推理能力。
Key Takeaways
- 大型语言模型(LLMs)在多种任务上表现出色,但在形式推理方面存在不足。
- 神经符号型LLM推理方法是一种有前途的解决方法,结合LLMs和符号求解器。
- 形式语言的选择是神经符号型LLM推理成功的关键因素之一。
- 不同形式语言对语法和语义推理能力的影响不同。
- 中间语言挑战在于为神经符号推理选择适当的形式语言。
- 论文通过实证比较了四种形式语言在三个数据集和七个LLMs上的表现。
- 论文强调了在不同LLMs中,形式语言选择的影响存在差异。
点此查看论文截图

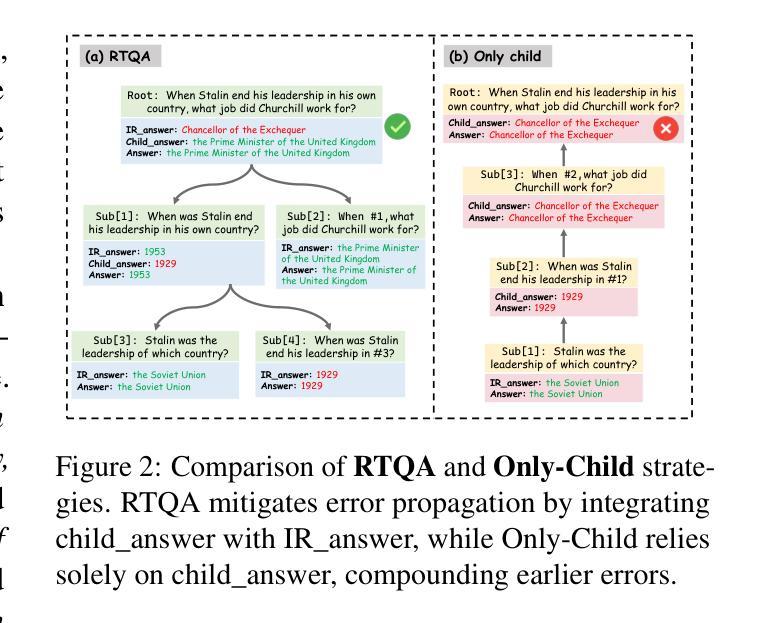
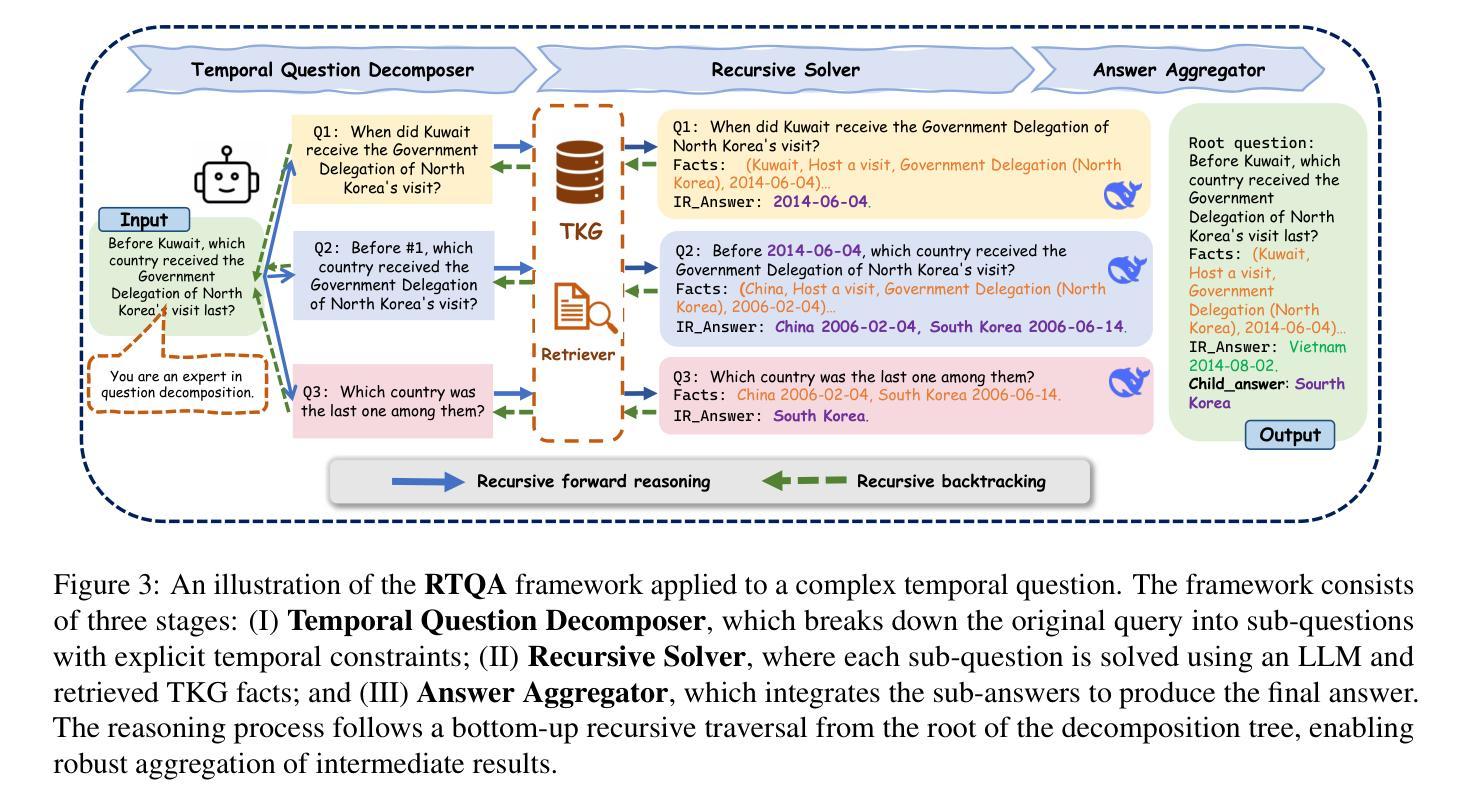
RTQA : Recursive Thinking for Complex Temporal Knowledge Graph Question Answering with Large Language Models
Authors:Zhaoyan Gong, Juan Li, Zhiqiang Liu, Lei Liang, Huajun Chen, Wen Zhang
Current temporal knowledge graph question answering (TKGQA) methods primarily focus on implicit temporal constraints, lacking the capability of handling more complex temporal queries, and struggle with limited reasoning abilities and error propagation in decomposition frameworks. We propose RTQA, a novel framework to address these challenges by enhancing reasoning over TKGs without requiring training. Following recursive thinking, RTQA recursively decomposes questions into sub-problems, solves them bottom-up using LLMs and TKG knowledge, and employs multi-path answer aggregation to improve fault tolerance. RTQA consists of three core components: the Temporal Question Decomposer, the Recursive Solver, and the Answer Aggregator. Experiments on MultiTQ and TimelineKGQA benchmarks demonstrate significant Hits@1 improvements in “Multiple” and “Complex” categories, outperforming state-of-the-art methods. Our code and data are available at https://github.com/zjukg/RTQA.
当前的时间知识图谱问答(TKGQA)方法主要关注隐式时间约束,缺乏处理更复杂时间查询的能力,并且在分解框架中的推理能力和错误传播方面存在困难。我们提出了RTQA,这是一个新型框架,通过增强对TKG的推理能力来解决这些挑战,而无需进行训练。RTQA遵循递归思维,将问题递归地分解为子问题,使用大型语言模型和TKG知识自下而上解决这些问题,并采用多路径答案聚合来提高容错性。RTQA由三个核心组件组成:时间问题分解器、递归求解器和答案聚合器。在MultiTQ和TimelineKGQA基准测试上的实验表明,“多个”和“复杂”类别的Hits@1有显著改善,超过了最先进的方法。我们的代码和数据在https://github.com/zjukg/RTQA上可用。
论文及项目相关链接
PDF EMNLP 2025
Summary
本文提出一种名为RTQA的新型框架,旨在解决当前时序知识图谱问答(TKGQA)方法面临的挑战。该框架通过递归思考的方式,将问题递归分解为子问题并解决,以加强在TKG上的推理能力,无需额外训练。RTQA采用多路径答案聚合提高容错性。实验结果表明,RTQA在MultiTQ和TimelineKGQA基准测试中“多个”和“复杂”类别的Hits@1改进显著,优于现有方法。
Key Takeaways
- RTQA是一个针对时序知识图谱问答(TKGQA)的新型框架,旨在解决现有方法的不足。
- RTQA通过递归思考的方式,将复杂问题分解为子问题并解决。
- RTQA利用大型语言模型(LLMs)和TKG知识来底部解决子问题。
- RTQA采用多路径答案聚合,以提高答案的准确性和容错性。
- RTQA框架包含三个核心组件:时序问题分解器、递归求解器和答案聚合器。
- 实验结果表明,RTQA在MultiTQ和TimelineKGQA基准测试中表现优越。
点此查看论文截图

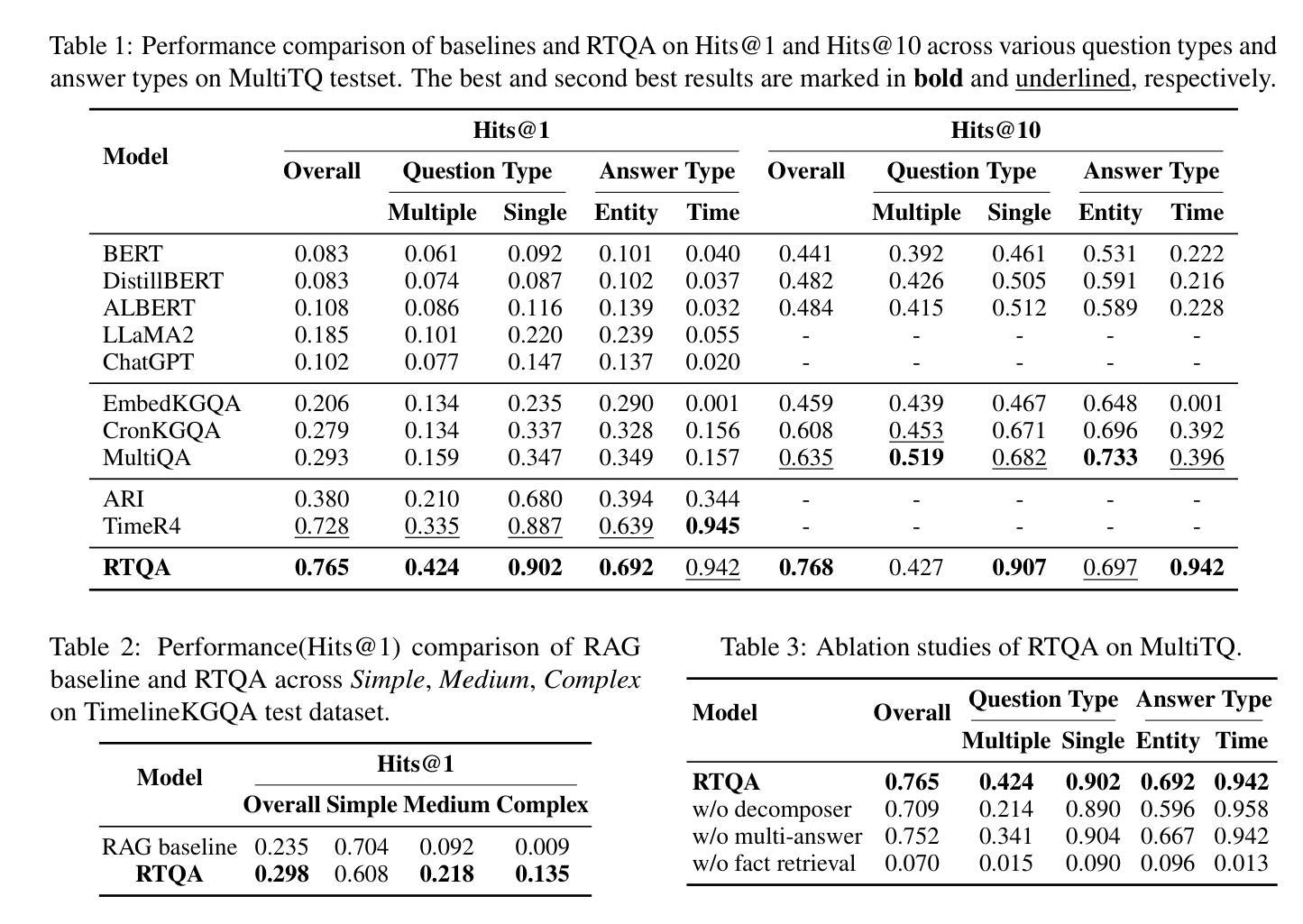
MTQA:Matrix of Thought for Enhanced Reasoning in Complex Question Answering
Authors:Fengxiao Tang, Yufeng Li, Zongzong Wu, Ming Zhao
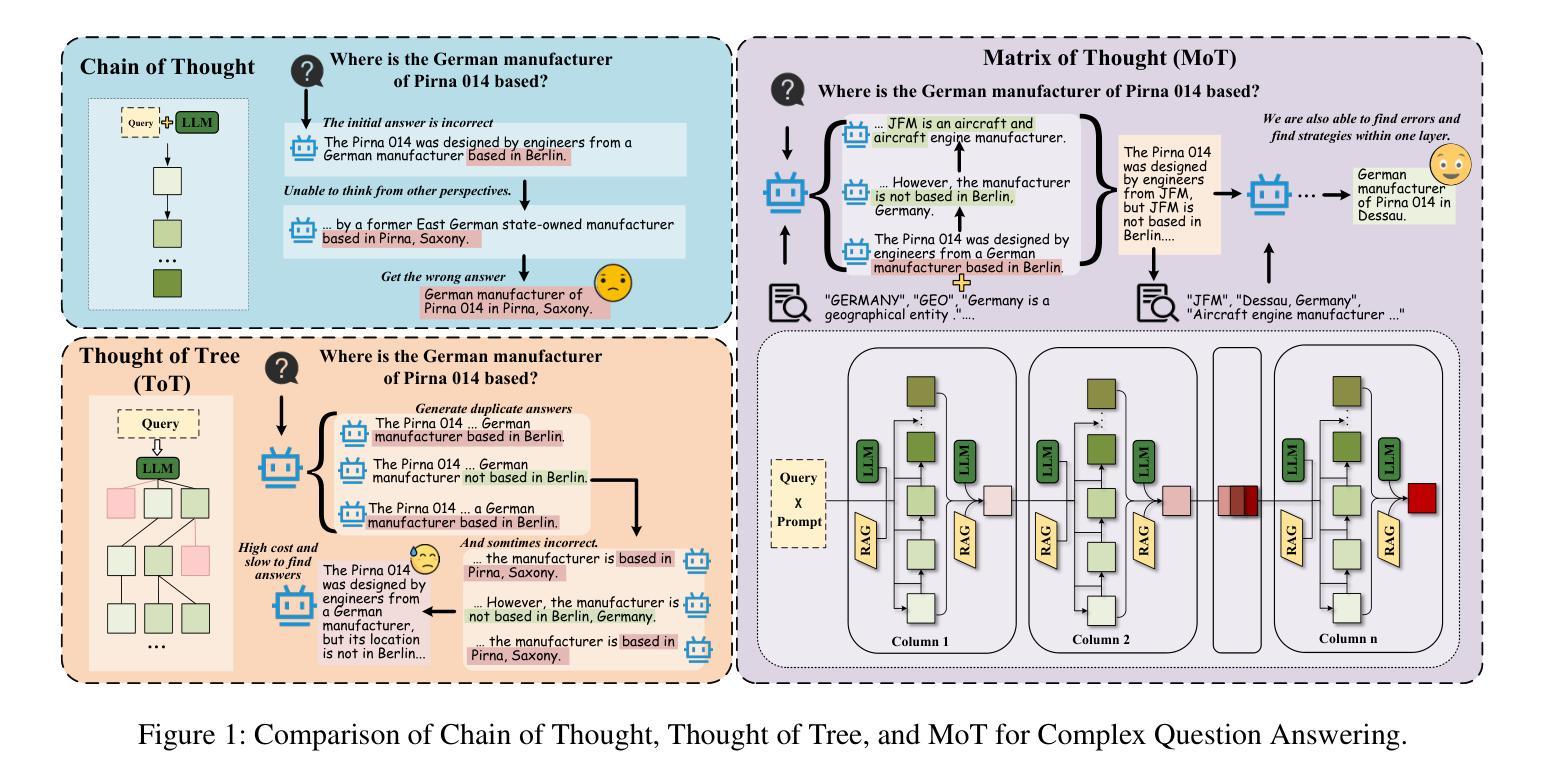
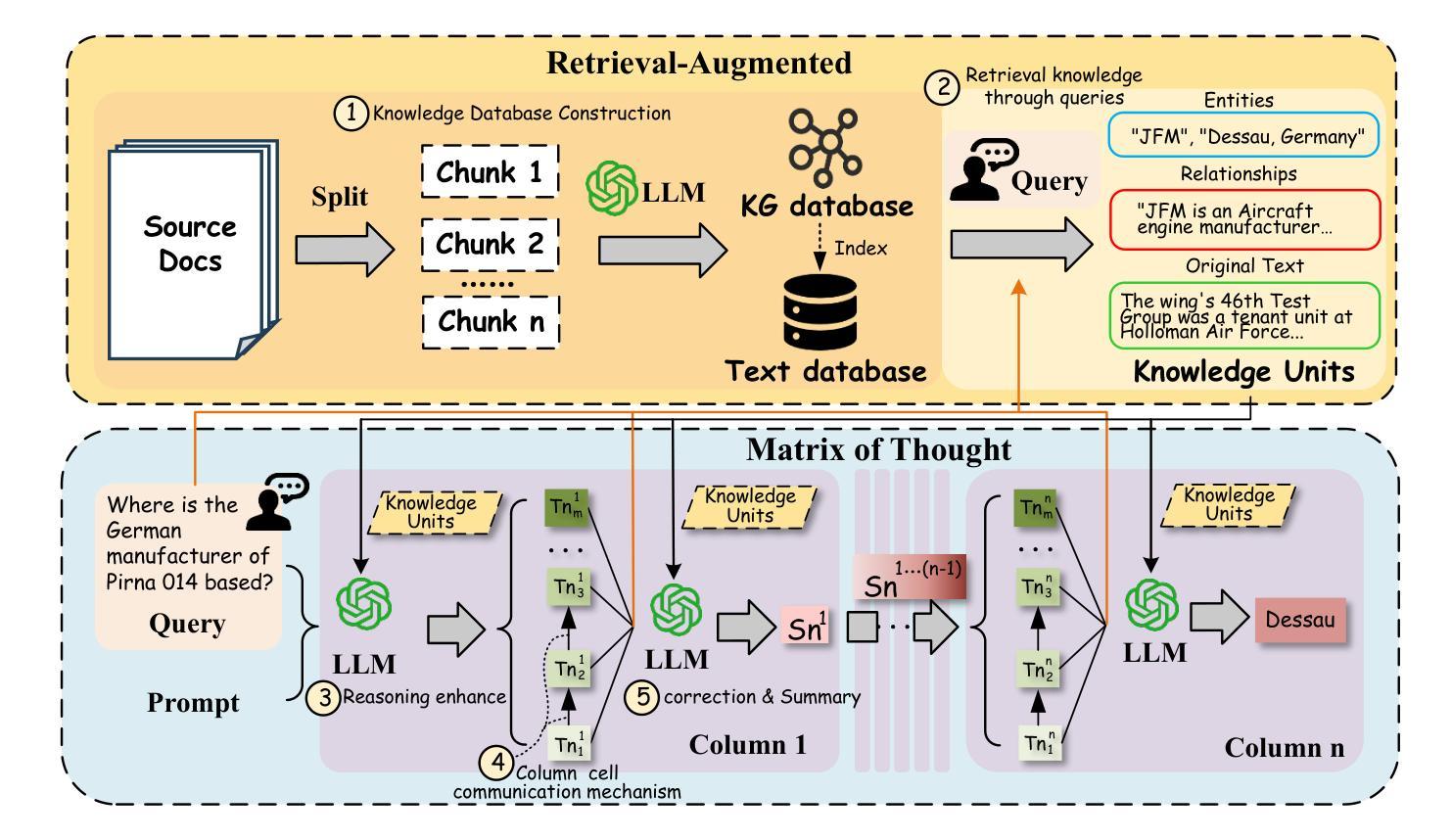
Complex Question Answering (QA) is a fundamental and challenging task in NLP. While large language models (LLMs) exhibit impressive performance in QA, they suffer from significant performance degradation when facing complex and abstract QA tasks due to insufficient reasoning capabilities. Works such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) aim to enhance LLMs’ reasoning abilities, but they face issues such as in-layer redundancy in tree structures and single paths in chain structures. Although some studies utilize Retrieval-Augmented Generation (RAG) methods to assist LLMs in reasoning, the challenge of effectively utilizing large amounts of information involving multiple entities and hops remains critical. To address this, we propose the Matrix of Thought (MoT), a novel and efficient LLM thought structure. MoT explores the problem in both horizontal and vertical dimensions through the “column-cell communication” mechanism, enabling LLMs to actively engage in multi-strategy and deep-level thinking, reducing redundancy within the column cells and enhancing reasoning capabilities. Furthermore, we develop a fact-correction mechanism by constructing knowledge units from retrieved knowledge graph triples and raw text to enhance the initial knowledge for LLM reasoning and correct erroneous answers. This leads to the development of an efficient and accurate QA framework (MTQA). Experimental results show that our framework outperforms state-of-the-art methods on four widely-used datasets in terms of F1 and EM scores, with reasoning time only 14.4% of the baseline methods, demonstrating both its efficiency and accuracy. The code for this framework is available at https://github.com/lyfiter/mtqa.
复杂问答(QA)是自然语言处理(NLP)中的一项基本且具挑战性的任务。尽管大型语言模型(LLM)在QA中表现出令人印象深刻的效果,但由于缺乏足够的推理能力,它们在面对复杂和抽象的QA任务时会出现显著的性能下降。诸如思维链(CoT)和思维树(ToT)等作品旨在增强LLM的推理能力,但它们面临着如树结构中的层内冗余和链结构中的单一路径等问题。尽管一些研究利用增强检索生成(RAG)方法来辅助LLM进行推理,但有效利用涉及多个实体和跳跃的大量信息的挑战仍然很关键。为了解决这个问题,我们提出了思维矩阵(MoT)这一新颖高效的LLM思维结构。MoT通过“列单元格通信”机制在水平和垂直维度上探索问题,使LLM能够积极参与多策略和深度思考,减少列单元格内的冗余,提高推理能力。此外,我们开发了一种事实校正机制,通过从检索到的知识图谱三元组和原始文本中构建知识单元,增强LLM推理的初始知识并纠正错误的答案。这导致了一个高效准确的问答框架(MTQA)的发展。实验结果表明,我们的框架在四个广泛使用的数据集上的F1和EM得分方面优于最先进的方法,推理时间仅为基线方法的14.4%,这证明了它的高效性和准确性。该框架的代码可在https://github.com/lyfiter/mtqa上找到。
论文及项目相关链接
Summary
在这个文本中,提出了一个名为Matrix of Thought(MoT)的新框架,用于增强大型语言模型(LLMs)在复杂抽象问答任务中的推理能力。该框架通过“列单元格通信”机制在水平和垂直维度上探索问题,使LLMs能够积极参与多策略和深度思考,减少列单元格内的冗余并增强推理能力。此外,还开发了一种基于检索的知识单元的事实校正机制,以提高LLM推理的初始知识并纠正错误答案。实验结果表明,该框架在四个广泛使用的数据集上的F1和EM得分优于现有方法,推理时间仅为基线方法的14.4%,显示出其高效性和准确性。
Key Takeaways
- 大型语言模型(LLMs)在复杂和抽象问答任务中因推理能力不足而性能下降。
- Chain-of-Thought (CoT) 和 Tree-of-Thought (ToT) 等方法旨在增强LLMs的推理能力,但仍存在如树结构中的冗余和链结构中的单一路径等问题。
- Matrix of Thought (MoT) 框架被提出,通过“列单元格通信”机制在水平和垂直维度上探索问题,使LLMs能够积极参与多策略和深度思考。
- MoT框架通过构建知识单元来增强LLM的初始知识,并开发了一种事实校正机制来纠正错误答案。
- MoT框架在四个广泛使用的数据集上的实验表现优于现有方法,显示出其高效性和准确性。
- MoT框架的代码已公开发布,可供进一步研究和使用。
点此查看论文截图

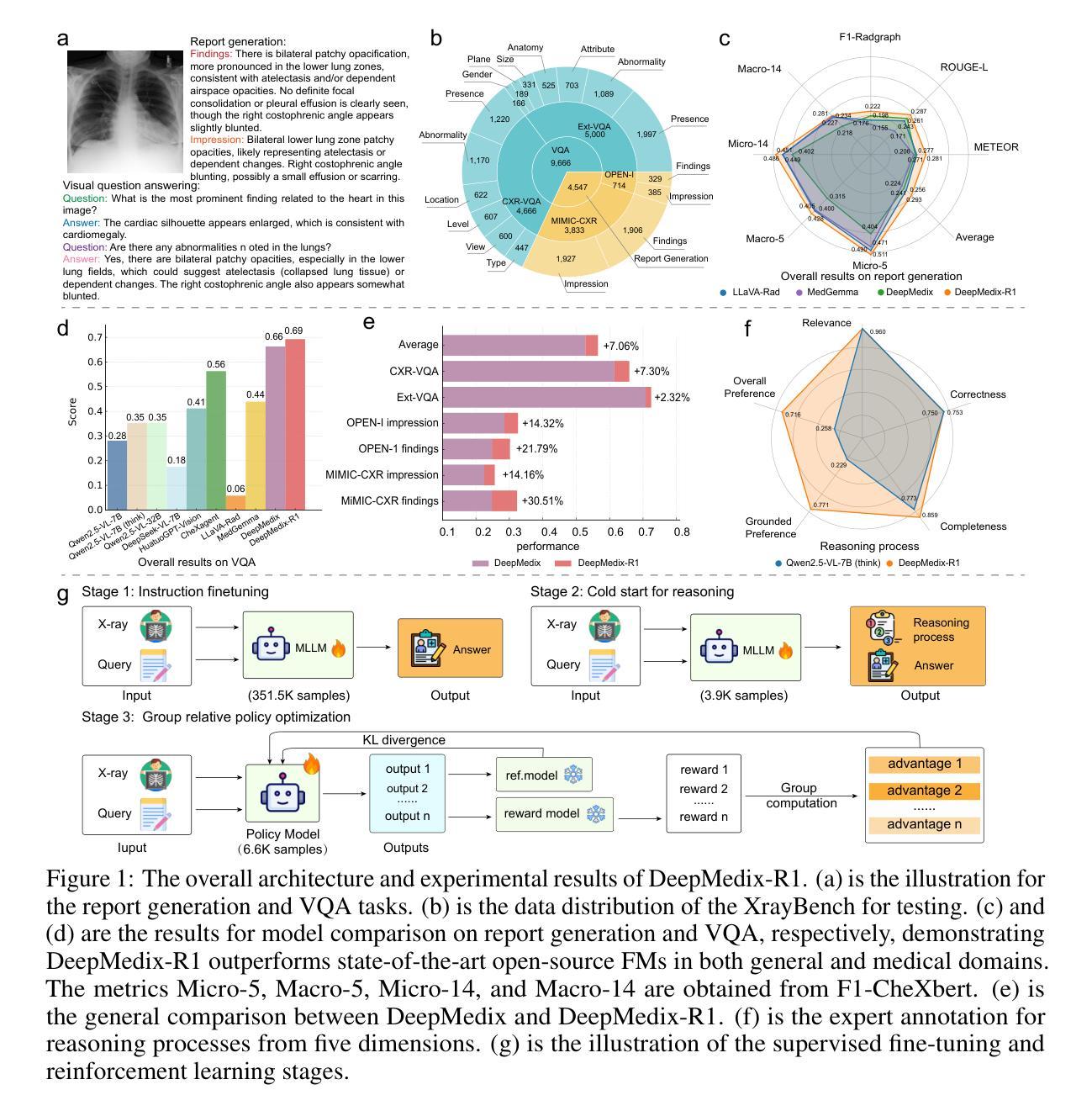
A Foundation Model for Chest X-ray Interpretation with Grounded Reasoning via Online Reinforcement Learning
Authors:Qika Lin, Yifan Zhu, Bin Pu, Ling Huang, Haoran Luo, Jingying Ma, Zhen Peng, Tianzhe Zhao, Fangzhi Xu, Jian Zhang, Kai He, Zhonghong Ou, Swapnil Mishra, Mengling Feng
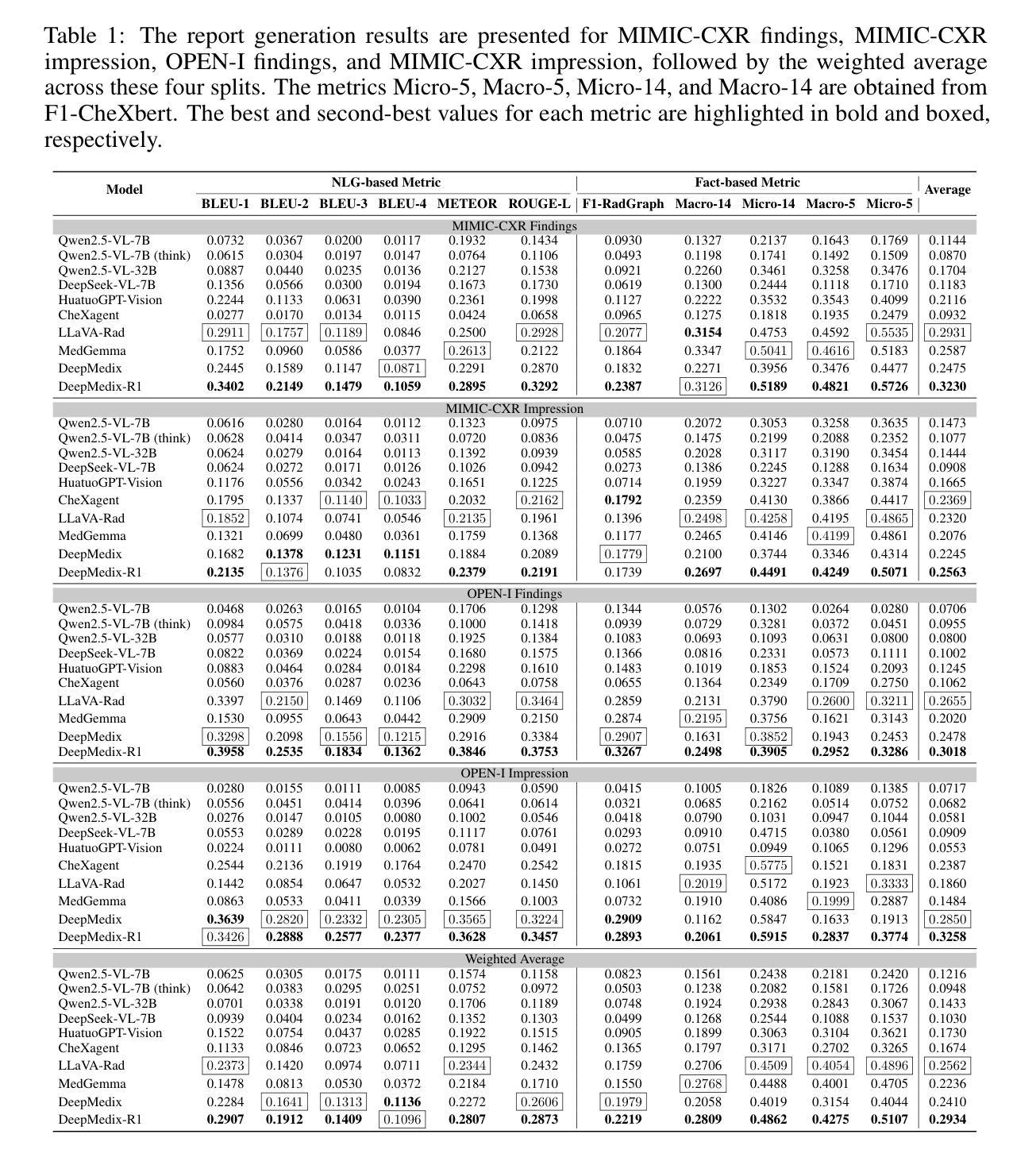
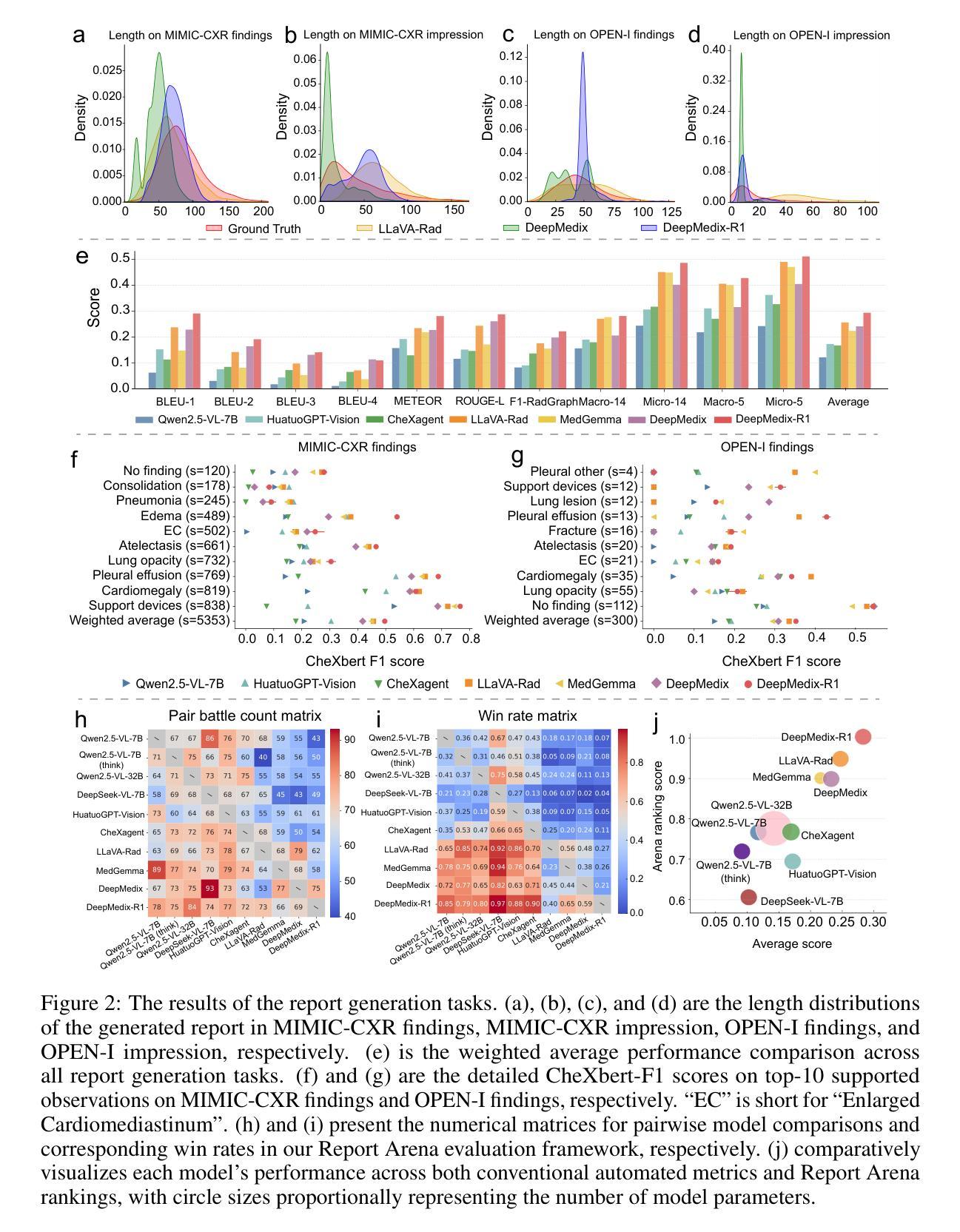
Medical foundation models (FMs) have shown tremendous promise amid the rapid advancements in artificial intelligence (AI) technologies. However, current medical FMs typically generate answers in a black-box manner, lacking transparent reasoning processes and locally grounded interpretability, which hinders their practical clinical deployments. To this end, we introduce DeepMedix-R1, a holistic medical FM for chest X-ray (CXR) interpretation. It leverages a sequential training pipeline: initially fine-tuned on curated CXR instruction data to equip with fundamental CXR interpretation capabilities, then exposed to high-quality synthetic reasoning samples to enable cold-start reasoning, and finally refined via online reinforcement learning to enhance both grounded reasoning quality and generation performance. Thus, the model produces both an answer and reasoning steps tied to the image’s local regions for each query. Quantitative evaluation demonstrates substantial improvements in report generation (e.g., 14.54% and 31.32% over LLaVA-Rad and MedGemma) and visual question answering (e.g., 57.75% and 23.06% over MedGemma and CheXagent) tasks. To facilitate robust assessment, we propose Report Arena, a benchmarking framework using advanced language models to evaluate answer quality, further highlighting the superiority of DeepMedix-R1. Expert review of generated reasoning steps reveals greater interpretability and clinical plausibility compared to the established Qwen2.5-VL-7B model (0.7416 vs. 0.2584 overall preference). Collectively, our work advances medical FM development toward holistic, transparent, and clinically actionable modeling for CXR interpretation.
医疗基础模型(FMs)在人工智能(AI)技术的快速发展中显示出巨大的潜力。然而,当前的医疗基础模型通常采用黑盒方式生成答案,缺乏透明的推理过程和基于本地的可解释性,这阻碍了其在实际临床部署中的应用。为此,我们引入了DeepMedix-R1,这是一个全面的用于胸部X射线(CXR)解读的医疗基础模型。它采用了一种序贯训练管道:首先,在精选的CXR指令数据上进行微调,以具备基本的CXR解读能力;然后暴露于高质量合成推理样本中以实现冷启动推理;最后通过在线强化学习进行改进,以提高基于本地区域的推理质量和生成性能。因此,该模型为每个查询生成与图像局部区域相关的答案和推理步骤。定量评估表明,在报告生成(如对LLaVA-Rad和MedGemma分别提高14.54%和31.32%)和视觉问答(如对MedGemma和CheXagent分别提高57.75%和23.06%)任务方面取得了显著改进。为了进行稳健的评估,我们提出了Report Arena,这是一个使用先进语言模型评估答案质量的基准框架,进一步突显了DeepMedix-R1的优越性。对生成的推理步骤的专家评审显示,与已建立的Qwen2.5-VL-7B模型相比,其解释性和临床可信度更高(总体偏好为0.7416对0.2584)。总的来说,我们的工作推动了医疗基础模型向全面、透明、适用于临床操作的CXR解读建模方向发展。
论文及项目相关链接
PDF 15 pages
Summary:DeepMedix-R1是一种用于胸X光(CXR)解读的全局医学基础模型。它通过序贯训练管道,在CXR解读数据基础上进行微调,利用高质量合成推理样本进行冷启动推理,并通过在线强化学习进行精炼,提高了推理质量和生成性能。模型为每个查询生成与图像局部区域相关联的答案和推理步骤。评估显示,DeepMedix-R1在报告生成和视觉问答任务上实现了显著改进。还提出了一个用于评估答案质量的Report Arena基准框架,以突显DeepMedix-R1的优越性。与Qwen2.5-VL-7B模型相比,生成的推理步骤更具可解释性和临床可信度。
Key Takeaways:
- DeepMedix-R1是一个用于胸X光解读的全局医学基础模型,旨在解决当前医学基础模型缺乏透明推理过程和局部化解释性的缺点。
- 该模型采用序贯训练策略,包括微调阶段、冷启动推理阶段和在线强化学习精炼阶段。
- DeepMedix-R1可以生成与图像局部区域相关联的答案和推理步骤,增强了其可解释性和临床实用性。
- 相较于其他模型(LLaVA-Rad、MedGemma、MedGemma和CheXagent),DeepMedix-R1在报告生成和视觉问答任务上表现优异。
- 提出的Report Arena基准框架用于评估答案质量,进一步突显DeepMedix-R1的优越性。
- 与Qwen2.5-VL-7B模型相比,DeepMedix-R1生成的推理步骤更具可解释性和临床可信度。
点此查看论文截图

VulRTex: A Reasoning-Guided Approach to Identify Vulnerabilities from Rich-Text Issue Report
Authors:Ziyou Jiang, Mingyang Li, Guowei Yang, Lin Shi, Qing Wang
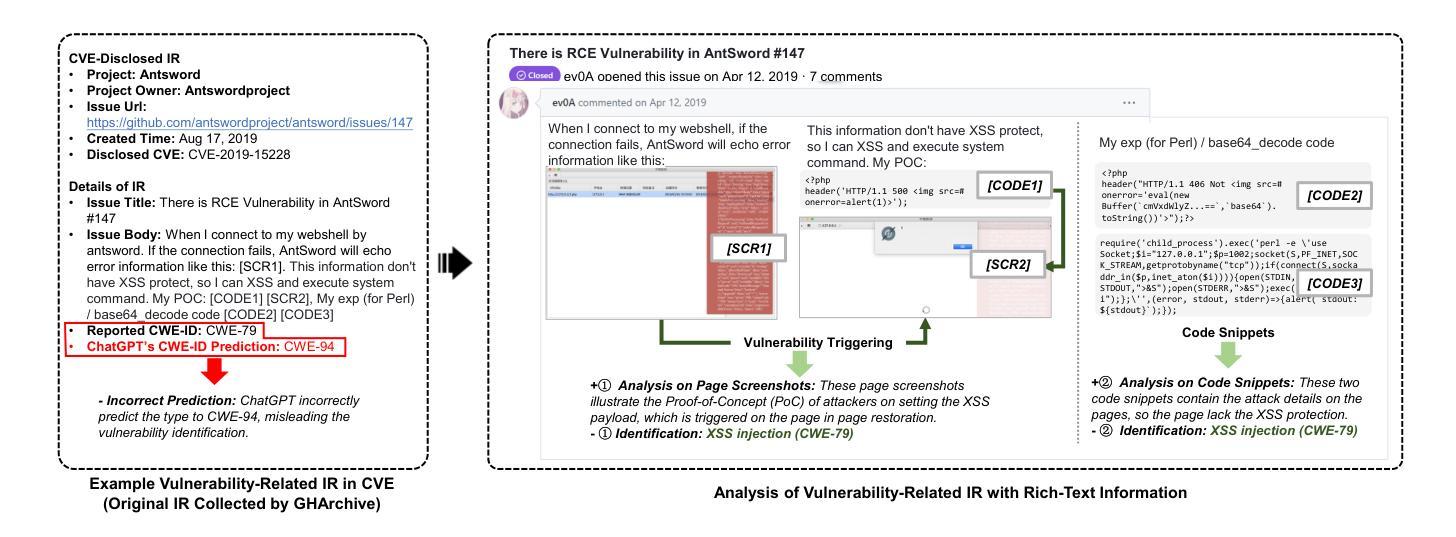
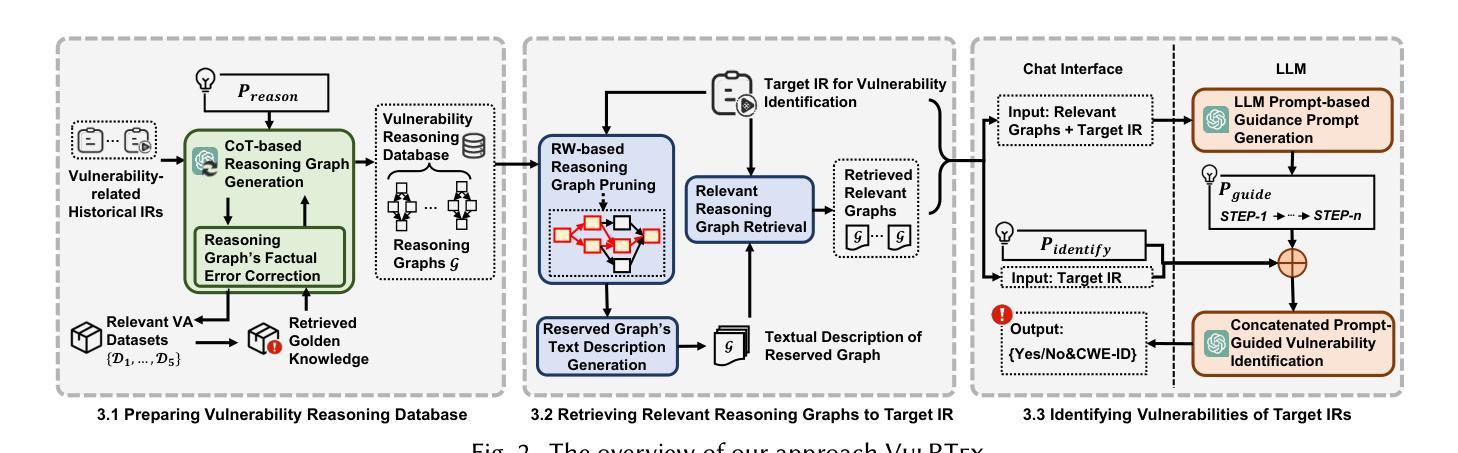
Software vulnerabilities exist in open-source software (OSS), and the developers who discover these vulnerabilities may submit issue reports (IRs) to describe their details. Security practitioners need to spend a lot of time manually identifying vulnerability-related IRs from the community, and the time gap may be exploited by attackers to harm the system. Previously, researchers have proposed automatic approaches to facilitate identifying these vulnerability-related IRs, but these works focus on textual descriptions but lack the comprehensive analysis of IR’s rich-text information. In this paper, we propose VulRTex, a reasoning-guided approach to identify vulnerability-related IRs with their rich-text information. In particular, VulRTex first utilizes the reasoning ability of the Large Language Model (LLM) to prepare the Vulnerability Reasoning Database with historical IRs. Then, it retrieves the relevant cases from the prepared reasoning database to generate reasoning guidance, which guides LLM to identify vulnerabilities by reasoning analysis on target IRs’ rich-text information. To evaluate the performance of VulRTex, we conduct experiments on 973,572 IRs, and the results show that VulRTex achieves the highest performance in identifying the vulnerability-related IRs and predicting CWE-IDs when the dataset is imbalanced, outperforming the best baseline with +11.0% F1, +20.2% AUPRC, and +10.5% Macro-F1, and 2x lower time cost than baseline reasoning approaches. Furthermore, VulRTex has been applied to identify 30 emerging vulnerabilities across 10 representative OSS projects in 2024’s GitHub IRs, and 11 of them are successfully assigned CVE-IDs, which illustrates VulRTex’s practicality.
在开源软件(OSS)中存在软件漏洞,发现这些漏洞的开发者可以提交问题报告(IRs)来描述其细节。安全专家需要花费大量时间手动从社区中识别与漏洞有关的问题报告,而这段时间差距可能会被攻击者利用来危害系统。之前,研究人员已经提出了自动方法来帮助识别这些与漏洞有关的问题报告,但这些工作主要集中在文本描述上,缺乏问题报告的丰富文本信息的综合分析。在本文中,我们提出了VulRTex,这是一种以推理为指导的方法,用于识别与漏洞相关的问题报告及其丰富文本信息。具体而言,VulRTex首先利用大型语言模型(LLM)的推理能力来构建包含历史问题报告的漏洞推理数据库。然后,它从构建的推理数据库中检索相关案例以生成推理指导,该指导通过目标问题报告的丰富文本信息进行推理分析来指导LLM识别漏洞。为了评估VulRTex的性能,我们在973,572个问题报告上进行了实验,结果显示,当数据集不平衡时,VulRTex在识别与漏洞相关的问题报告和预测CWE-IDs方面达到了最高性能,与最佳基线相比提高了+11.0%的F1分数,+20.2%的AUPRC和+10.5%的宏观F1分数,并且时间成本比基线推理方法降低了两倍。此外,VulRTex已应用于识别2024年GitHub问题报告中跨10个代表性OSS项目的30个新兴漏洞,其中成功分配了CVE-IDs的有11个案例,这证明了VulRTex的实用性。
论文及项目相关链接
PDF 25 pages, 7 figures, submitting to TOSEM journal
Summary
本文提出了一种名为VulRTex的新方法,用于识别与软件漏洞相关的开源软件问题报告(IRs)。该方法结合了大型语言模型(LLM)的推理能力和丰富的文本信息,通过建立漏洞推理数据库和检索相关案例进行推理分析,以识别目标IRs中的漏洞。实验结果表明,VulRTex在识别与预测不平衡数据集中的漏洞相关IRs和CWE-IDs方面表现最佳,优于最佳基线方法,并具有较低的时间成本。此外,VulRTex已成功应用于识别GitHub IRs中代表OSS项目的新兴漏洞,并成功分配了CVE-IDs。
Key Takeaways
- VulRTex是一种利用大型语言模型(LLM)进行漏洞识别的方法,结合了丰富的文本信息。
- 通过建立漏洞推理数据库和检索相关案例,VulRTex实现了高效的漏洞识别。
- VulRTex在识别与预测不平衡数据集中的漏洞相关IRs和CWE-IDs方面表现最佳。
- VulRTex优于最佳基线方法,具有更高的F1分数、AUPRC和Macro-F1,并且时间成本更低。
- VulRTex可应用于识别新兴漏洞,并在实际项目中得到了验证。
- 在实验评估中,VulRTex成功识别了GitHub IRs中的代表性OSS项目的新兴漏洞。
点此查看论文截图

A Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models
Authors:Yanbo Wang, Yongcan Yu, Jian Liang, Ran He
The development of Long-CoT reasoning has advanced LLM performance across various tasks, including language understanding, complex problem solving, and code generation. This paradigm enables models to generate intermediate reasoning steps, thereby improving both accuracy and interpretability. However, despite these advancements, a comprehensive understanding of how CoT-based reasoning affects the trustworthiness of language models remains underdeveloped. In this paper, we survey recent work on reasoning models and CoT techniques, focusing on five core dimensions of trustworthy reasoning: truthfulness, safety, robustness, fairness, and privacy. For each aspect, we provide a clear and structured overview of recent studies in chronological order, along with detailed analyses of their methodologies, findings, and limitations. Future research directions are also appended at the end for reference and discussion. Overall, while reasoning techniques hold promise for enhancing model trustworthiness through hallucination mitigation, harmful content detection, and robustness improvement, cutting-edge reasoning models themselves often suffer from comparable or even greater vulnerabilities in safety, robustness, and privacy. By synthesizing these insights, we hope this work serves as a valuable and timely resource for the AI safety community to stay informed on the latest progress in reasoning trustworthiness. A full list of related papers can be found at \href{https://github.com/ybwang119/Awesome-reasoning-safety}{https://github.com/ybwang119/Awesome-reasoning-safety}.
长文本连续推理(Long-CoT)的发展已经提高了大型语言模型(LLM)在各种任务上的性能,包括语言理解、复杂问题解决和代码生成。这种范式使模型能够产生中间推理步骤,从而提高准确性和可解释性。然而,尽管取得了这些进展,关于基于CoT的推理如何影响语言模型的可信度的全面理解仍然不足。本文回顾了关于推理模型和CoT技术的最新研究,重点关注可信推理的五个核心维度:真实性、安全性、稳健性、公平性和隐私性。对于每个方面,我们按时间顺序清晰且结构化地概述了最近的研究,以及对其方法、发现和局限性的详细分析。本文末尾还附上了未来研究方向以供参考和讨论。总的来说,虽然推理技术通过减少幻觉、检测有害内容和提高稳健性而有望增强模型的可信度,但最先进的推理模型本身在安全、稳健性和隐私方面往往存在相当的或更大的漏洞。通过综合这些见解,我们希望这项工作能为人工智能安全界提供关于推理可信度最新进展的宝贵和及时资源。相关论文的完整列表可访问:[https://github.com/ybwang119/Awesome-reasoning-safety]。
论文及项目相关链接
PDF 38 pages. This survey considers papers published up to June 30, 2025. Work in progress
Summary
这篇论文探讨了基于CoT的推理技术如何影响语言模型的可信度。文章从真实性、安全性、稳健性、公平性和隐私性五个核心维度进行了全面的综述,分析了最新的研究成果和方法,指出了其局限性。尽管这些技术有潜力提高模型的信任度,但现有的先进推理模型在安全性、稳健性和隐私方面仍然存在许多脆弱性。文章呼吁AI安全社区持续关注这一领域的最新进展。
Key Takeaways
- Long-CoT推理的发展提升了大型语言模型在各种任务上的表现,包括语言理解、复杂问题解决和代码生成。
- CoT推理技术能够生成中间推理步骤,从而提高模型的准确性和可解释性。
- 论文全面综述了关于推理模型和CoT技术的最新研究,重点分析了五个维度:真实性、安全性、稳健性、公平性和隐私性。
- 文章指出尽管推理技术有潜力提高模型的可信度,但现有的推理模型在安全性、稳健性和隐私方面仍存在许多脆弱性。
点此查看论文截图


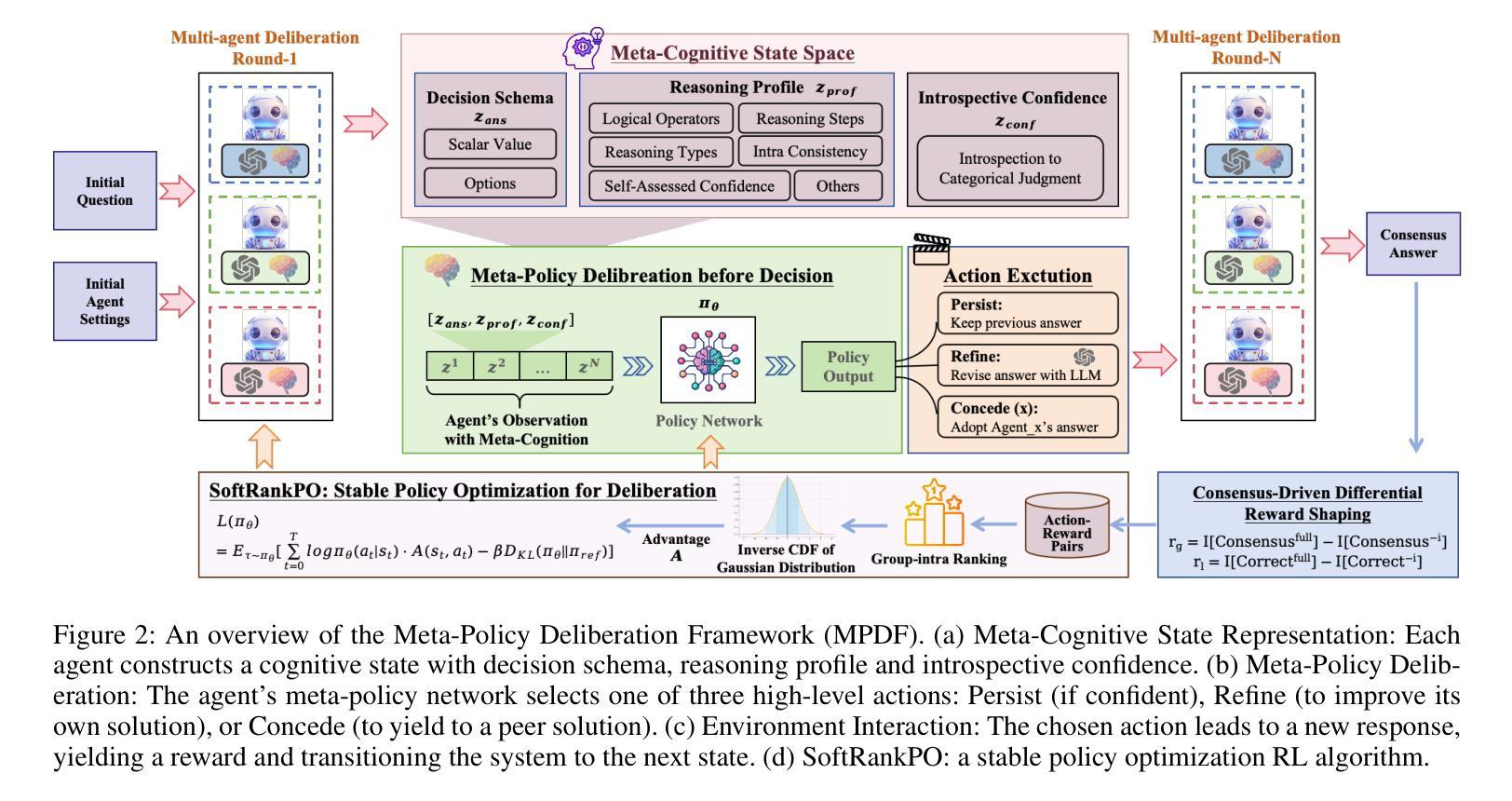
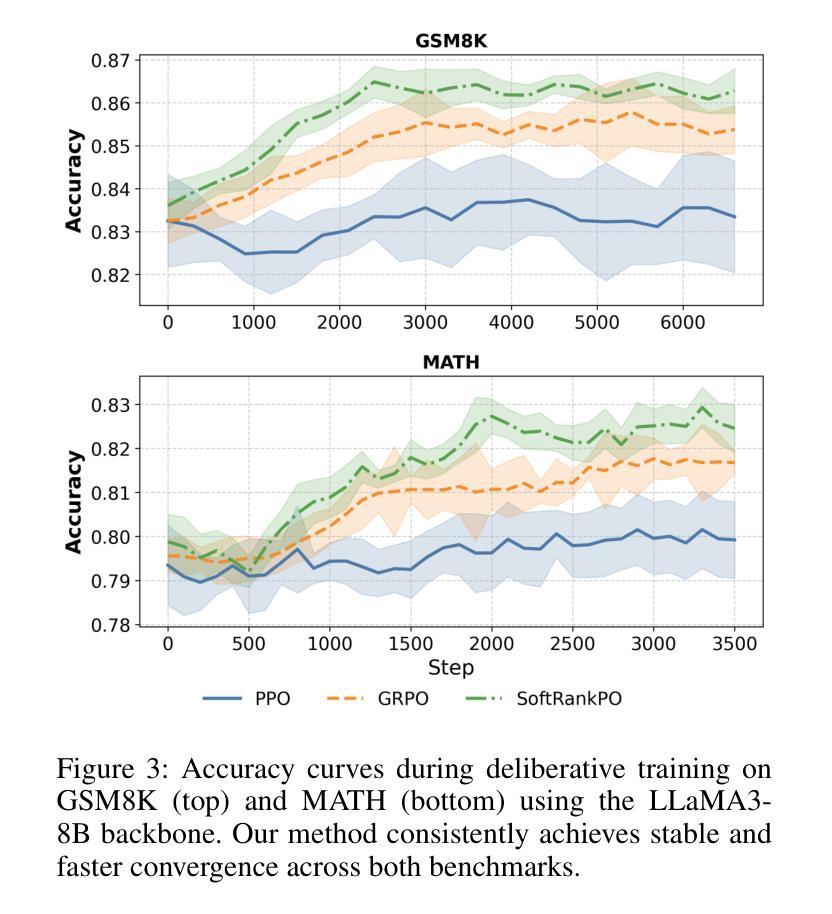
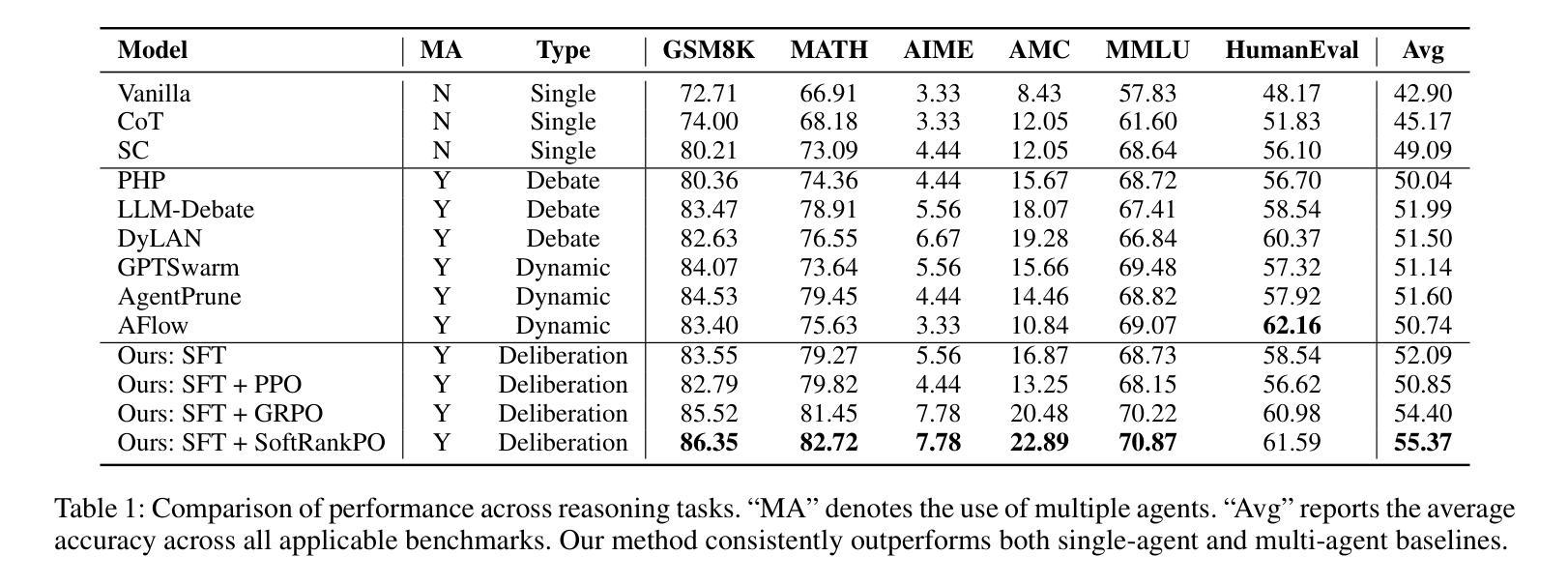
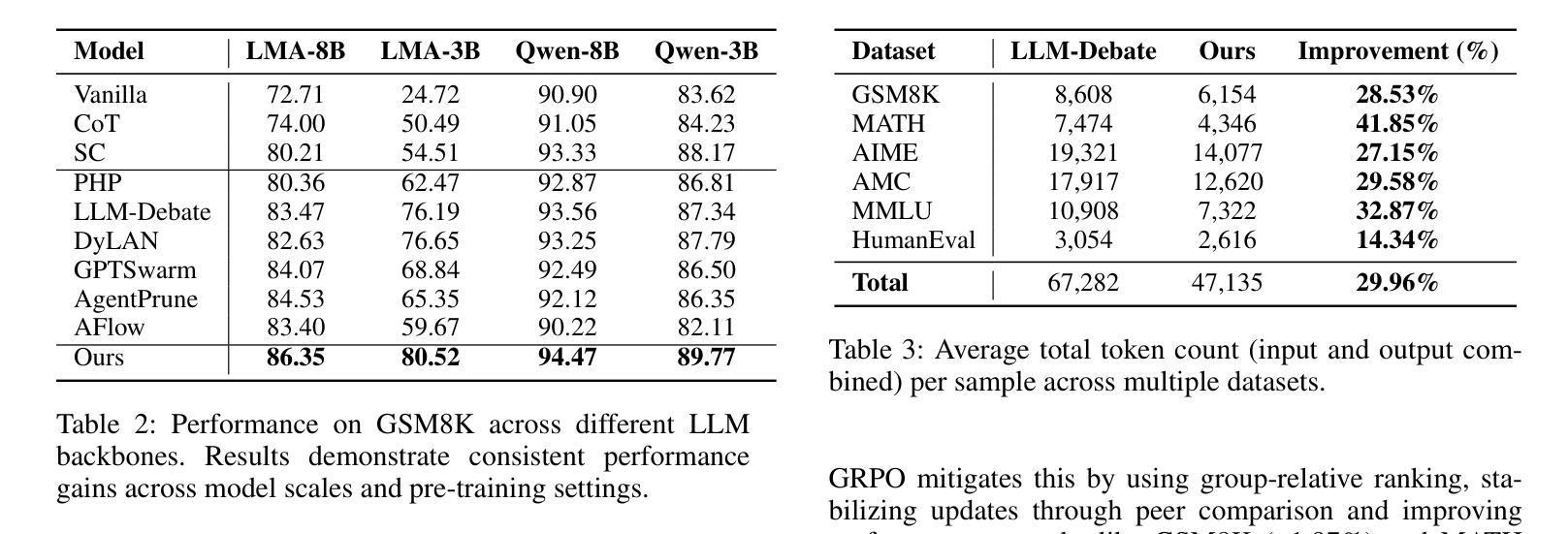
Learning to Deliberate: Meta-policy Collaboration for Agentic LLMs with Multi-agent Reinforcement Learning
Authors:Wei Yang, Jesse Thomason
Multi-agent systems of large language models (LLMs) show promise for complex reasoning, but their effectiveness is often limited by fixed collaboration protocols. These frameworks typically focus on macro-level orchestration while overlooking agents’ internal deliberative capabilities. This critical meta-cognitive blindspot treats agents as passive executors unable to adapt their strategy based on internal cognitive states like uncertainty or confidence. We introduce the Meta-Policy Deliberation Framework (MPDF), where agents learn a decentralized policy over a set of high-level meta-cognitive actions: Persist, Refine, and Concede. To overcome the instability of traditional policy gradients in this setting, we develop SoftRankPO, a novel reinforcement learning algorithm. SoftRankPO stabilizes training by shaping advantages based on the rank of rewards mapped through smooth normal quantiles, making the learning process robust to reward variance. Experiments show that MPDF with SoftRankPO achieves a a 4-5% absolute gain in average accuracy across five mathematical and general reasoning benchmarks compared to six state-of-the-art heuristic and learning-based multi-agent reasoning algorithms. Our work presents a paradigm for learning adaptive, meta-cognitive policies for multi-agent LLM systems, shifting the focus from designing fixed protocols to learning dynamic, deliberative strategies.
多智能体系统的大型语言模型(LLM)在复杂推理方面显示出巨大的潜力,但其有效性通常受到固定协作协议的限制。这些框架通常侧重于宏观层面的协调,而忽视了智能体的内部决策能力。这一关键的元认知盲点将智能体视为被动的执行者,无法根据不确定性或信心等内部认知状态来适应其策略。我们引入了元策略决策框架(MPDF),在该框架中,智能体学习在一组高级元认知行动上的分散策略:坚持、优化和让步。为了克服传统策略梯度在此环境中的不稳定性,我们开发了SoftRankPO,这是一种新型的强化学习算法。SoftRankPO通过根据通过平滑正态分布所映射的奖励排名塑造优势来稳定训练,这使得学习过程对奖励方差具有鲁棒性。实验表明,与六种基于启发式和学习型的多智能体推理算法相比,使用SoftRankPO的MPDF在五个数学和通用推理基准测试上平均准确度提高了4-5%的绝对增益。我们的工作为多智能体LLM系统学习自适应元认知策略提供了范例,将重点从设计固定协议转向学习动态决策策略。
论文及项目相关链接
Summary
大型语言模型(LLM)的多智能体系统在复杂推理方面展现出潜力,但受限于固定的协作协议。现有框架忽略智能体的内部认知状态,导致智能体难以适应策略调整。本文提出元策略审议框架(MPDF),智能体在此框架下学习对一组高级元认知行动进行分散决策:持续、精进和让步。为解决此环境下传统策略梯度的不稳定性问题,我们开发了一种名为SoftRankPO的新型强化学习算法。实验表明,与六种最先进的启发式和学习型多智能体推理算法相比,MPDF与SoftRankPO相结合在五个数学和通用推理基准测试上实现了平均准确率提高4-5%。本文为学习自适应、元认知策略的多智能体LLM系统提供了范例,将重点从设计固定协议转向学习动态决策策略。
Key Takeaways
- 多智能体系统在复杂推理上具有潜力,但受限于固定协作协议。
- 现有框架忽略智能体的内部认知状态,导致策略调整困难。
- 提出元策略审议框架(MPDF),允许智能体学习分散决策的高级元认知行动。
- 开发了一种名为SoftRankPO的新型强化学习算法,解决策略梯度的不稳定性问题。
- MPDF与SoftRankPO结合在多个基准测试上实现了较高的平均准确率。
- 本文为自适应、元认知策略的多智能体LLM系统提供了范例。
点此查看论文截图

Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Authors:Haozhe Wang, Qixin Xu, Che Liu, Junhong Wu, Fangzhen Lin, Wenhu Chen
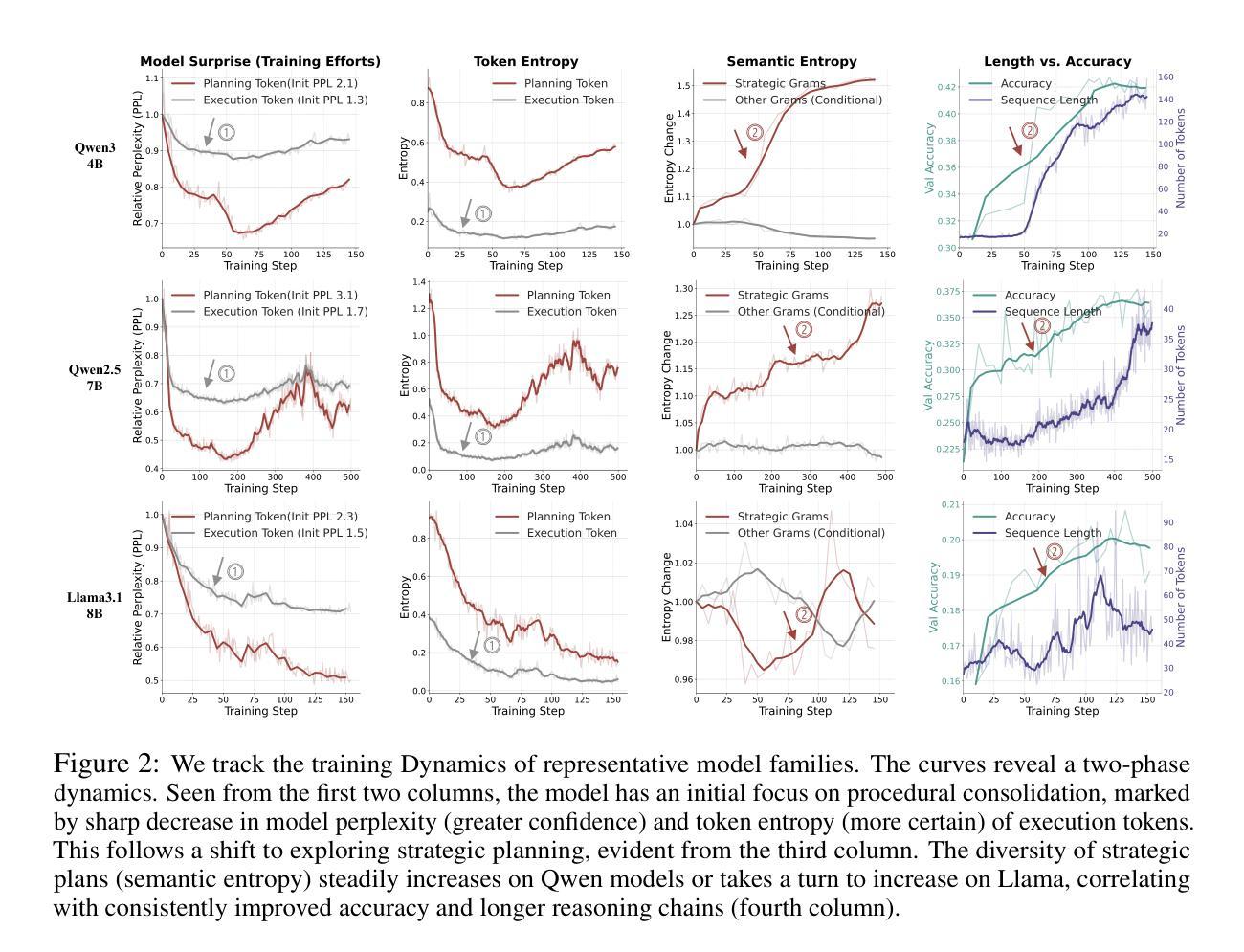
Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like aha moments", length-scaling’’ and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
强化学习(RL)已证明在增强大型语言模型(LLM)的复杂推理能力方面非常有效,但驱动这一成功的潜在机制仍大多未知。我们的分析揭示,“啊哈时刻”、“长度缩放”和熵动力学等令人困惑的现象并不是孤立发生的,而是新兴推理层次的标志,与人类认知中的高级战略规划与低级程序执行分离的情况相类似。我们发现了引人注目的两阶段动态过程:初期,模型受到程序正确性的约束,必须提高其低级技能。学习瓶颈然后果断转移,性能提升由高级战略规划的探索和掌握所驱动。这种见解揭示了现行RL算法(如GRPO)的核心低效之处,这些算法盲目地施加优化压力,并在所有令牌中稀释学习信号。为了解决这一问题,我们提出了HIerarchy-Aware Credit Assignment(HICRA)算法,该算法将优化工作集中在对规划令牌影响较大的地方。HICRA显著优于强大的基线,证明关注这一战略瓶颈是解锁高级推理的关键。此外,我们验证了语义熵作为衡量战略探索的优越指标,相较于误导性指标(如令牌级熵)。
论文及项目相关链接
PDF Preprint
Summary
强化学习(RL)在提升大型语言模型(LLM)的复杂推理能力方面表现出显著效果,但其背后的机制仍大多未知。分析表明,“啊哈时刻”、“长度缩放”和熵动力学等令人困惑的现象并不是孤立事件,而是新兴推理层次结构的标志,类似于人类认知中高级战略规划与低级程序执行的分离。我们发现了引人注目的两阶段动态过程:初期,模型受程序正确性约束,必须提高低级技能。学习瓶颈随后发生决定性转移,性能提升源于高级战略规划的探索和掌握。这揭示了现有RL算法(如GRPO)的核心低效之处,它们以无知的方式施加优化压力,将学习信号分散到所有标记中。为解决这一问题,我们提出了分层信用分配(HICRA)算法,该算法将优化工作集中在影响规划的关键标记上。HICRA显著优于强大的基线,证明关注这一战略瓶颈是解锁高级推理的关键。此外,我们验证了语义熵作为衡量战略探索的指南针优于误导性指标如标记级熵。
Key Takeaways
- 强化学习在提升大型语言模型的推理能力方面具有显著效果,但其背后的机制仍需要深入研究。
- 模型的学习过程分为两个阶段:初级阶段注重提高低级技能,随后转向高级战略规划和探索。
- 现有RL算法在优化方面存在核心低效问题,表现为优化压力的无知施加和学习信号的分散。
- 提出了分层信用分配(HICRA)算法,专注于影响规划的关键标记进行优化,显著提高了性能。
- 语义熵被验证为更有效的指标,能更准确地衡量战略探索过程。
- “啊哈时刻”、“长度缩放”和熵动力学等现象被视为新兴推理层次结构的标志。
点此查看论文截图


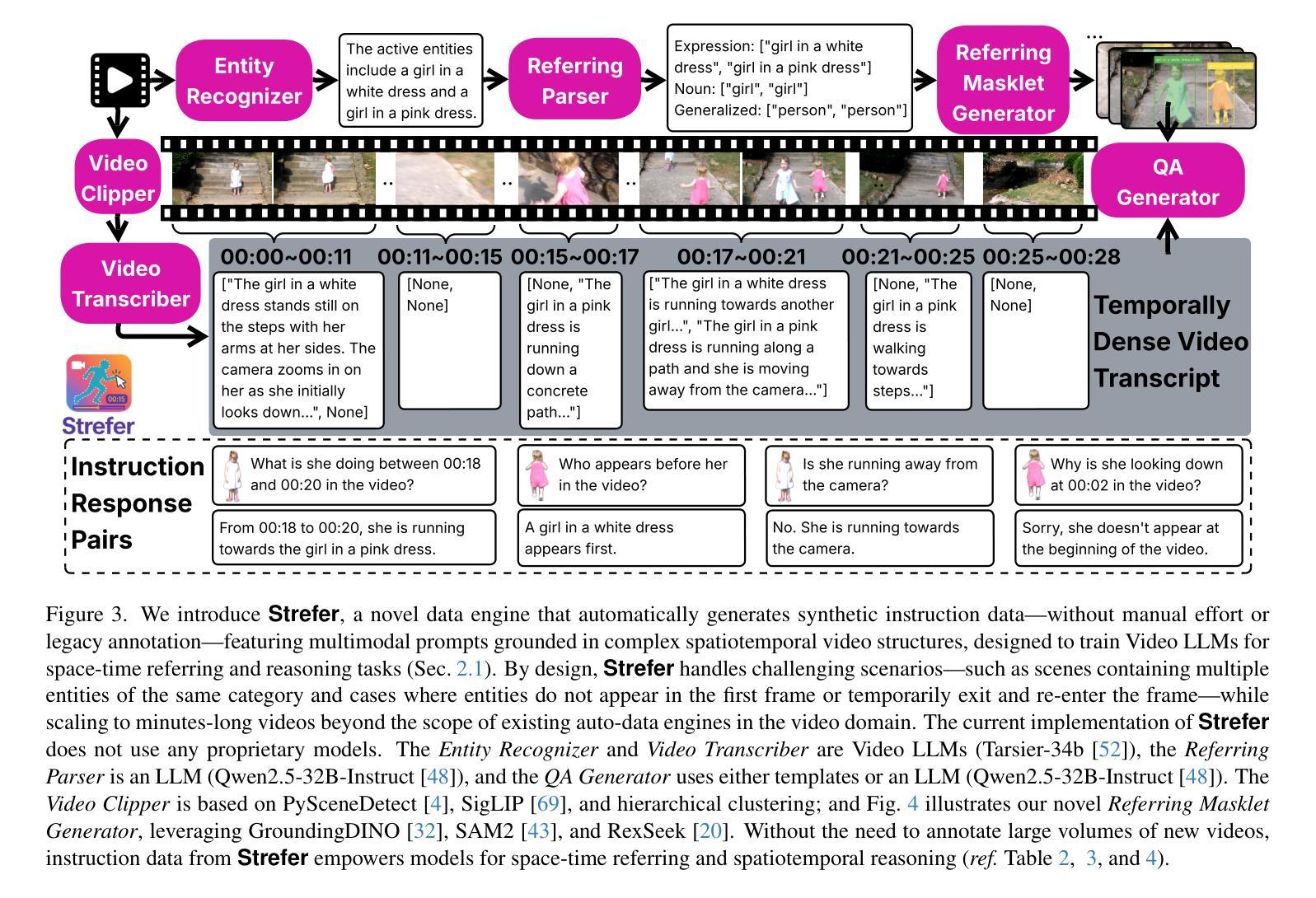
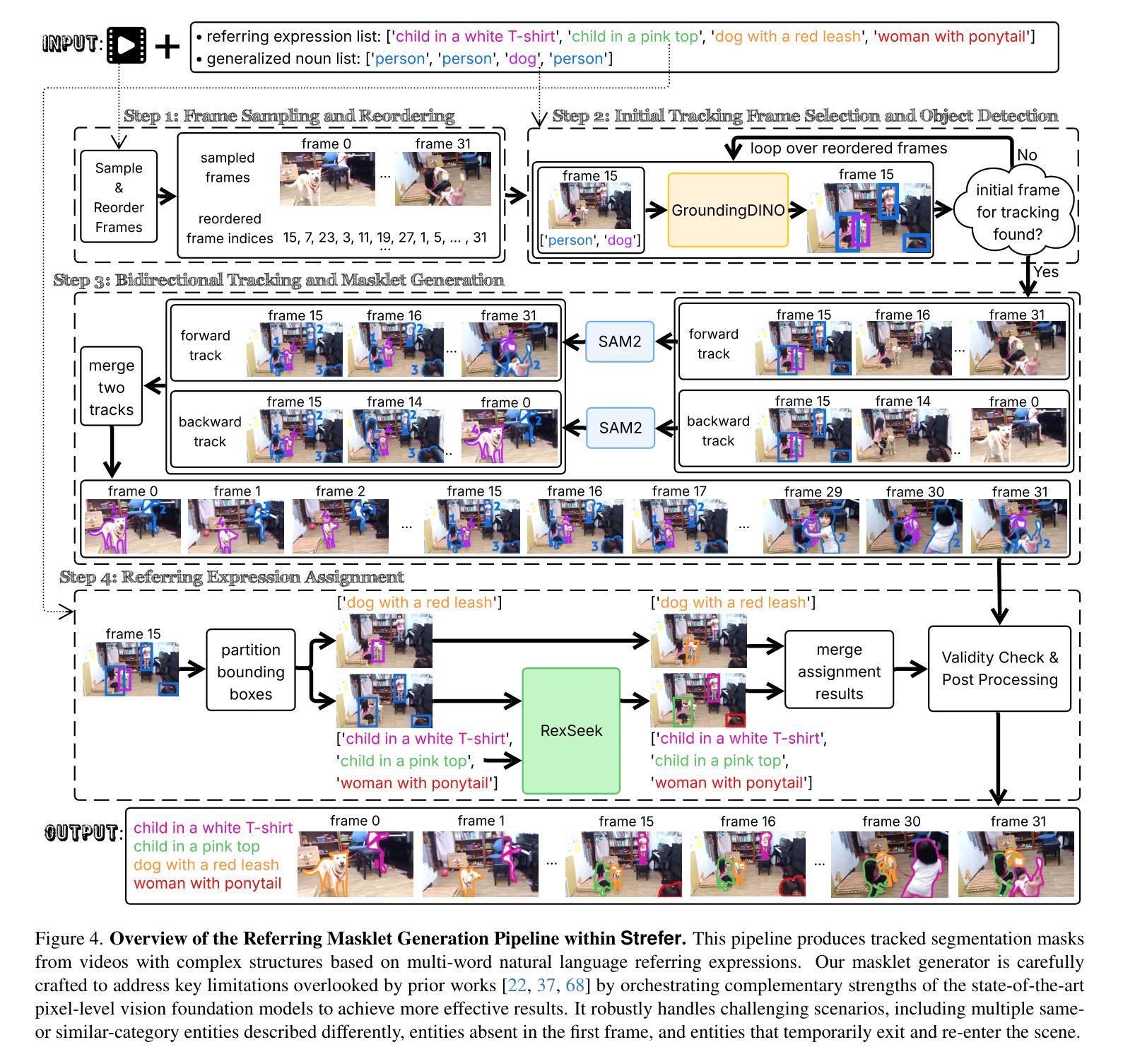
Strefer: Empowering Video LLMs with Space-Time Referring and Reasoning via Synthetic Instruction Data
Authors:Honglu Zhou, Xiangyu Peng, Shrikant Kendre, Michael S. Ryoo, Silvio Savarese, Caiming Xiong, Juan Carlos Niebles
Next-generation AI companions must go beyond general video understanding to resolve spatial and temporal references in dynamic, real-world environments. Existing Video Large Language Models (Video LLMs), while capable of coarse-level comprehension, struggle with fine-grained, spatiotemporal reasoning, especially when user queries rely on time-based event references for temporal anchoring, or gestural cues for spatial anchoring to clarify object references and positions. To bridge this critical gap, we introduce Strefer, a synthetic instruction data generation framework designed to equip Video LLMs with spatiotemporal referring and reasoning capabilities. Strefer produces diverse instruction-tuning data using a data engine that pseudo-annotates temporally dense, fine-grained video metadata, capturing rich spatial and temporal information in a structured manner, including subjects, objects, their locations as masklets, and their action descriptions and timelines. Our approach enhances the ability of Video LLMs to interpret spatial and temporal references, fostering more versatile, space-time-aware reasoning essential for real-world AI companions. Without using proprietary models, costly human annotation, or the need to annotate large volumes of new videos, experimental evaluations show that models trained with data produced by Strefer outperform baselines on tasks requiring spatial and temporal disambiguation. Additionally, these models exhibit enhanced space-time-aware reasoning, establishing a new foundation for perceptually grounded, instruction-tuned Video LLMs.
下一代人工智能伴侣必须超越一般的视频理解,以解决动态现实环境中的时空参考问题。现有的视频大型语言模型(Video LLMs)虽然能够进行粗略级别的理解,但在精细的时空推理方面却遇到困难,尤其是当用户的查询依赖于基于时间的事件引用进行时间锚定,或依赖于手势线索进行空间锚定以澄清对象引用和位置时。为了弥补这一关键差距,我们引入了Strefer,这是一个合成指令数据生成框架,旨在配备视频LLMs的时空引用和推理能力。Strefer使用一个数据引擎产生各种各样的指令调整数据,该引擎对时间密集、精细的视频元数据进行伪注释,以结构化的方式捕捉丰富的空间和时间信息,包括主题、对象、作为蒙版的它们的位置以及动作描述和时间线。我们的方法提高了视频LLMs对时空引用的解释能力,促进了更通用、时空感知推理的能力,这对于现实世界的人工智能伴侣至关重要。实验评估显示,使用Strefer产生的数据训练的模型在需要空间和时间辨别的任务上超越了基线,且这些模型展现出增强的时空感知推理能力,为感知接地、指令调整的视频LLMs建立了新的基础,无需使用专有模型、昂贵的人工注释或需要注释大量新视频。
论文及项目相关链接
PDF This technical report serves as the archival version of our paper accepted at the ICCV 2025 Workshop. For more information, please visit our project website: https://strefer.github.io/
Summary
新一代AI伴侣需要超越一般的视频理解,以解决动态现实环境中的空间和时间参考问题。现有的视频大型语言模型(Video LLMs)虽然具有粗略级别的理解能力,但在精细粒度的时空推理方面却存在困难,尤其是当用户查询依赖于基于时间的事件参考进行时间锚定,或利用姿势线索进行空间锚定以明确对象参考和位置时。为解决这一关键差距,我们引入了Strefer,一个合成指令数据生成框架,旨在配备视频LLMs具备时空引用和推理能力。Strefer使用一个数据引擎产生多样化指令调整数据,以模拟注释方式密集地捕捉视频中的时间和空间信息,包括主题、对象、它们的定位以及行动描述和时间轴。该方法提高了视频LLMs解释空间和时间参考的能力,促进了更灵活、时空感知的推理能力,这对于现实世界的AI伴侣至关重要。实验评估显示,使用Strefer产生的数据训练的模型在需要空间和时间分辨的任务上超越了基线模型,并且这些模型展现了增强的时空感知推理能力,为感知基础的、指令调整的视频LLMs建立了新的基础。
Key Takeaways
- 下一代AI需要解决动态现实环境中的空间和时间参考问题。
- 现有视频大型语言模型(Video LLMs)在精细粒度的时空推理上存在困难。
- Strefer是一个合成指令数据生成框架,旨在增强视频LLMs的时空引用和推理能力。
- Strefer通过数据引擎模拟注释方式捕捉视频中的时间和空间信息。
- Strefer提高了视频LLMs解释空间和时间参考的能力,促进更灵活的推理能力。
- 使用Strefer产生的数据训练的模型在需要空间和时间的任务上表现超越基线模型。
点此查看论文截图


On Entropy Control in LLM-RL Algorithms
Authors:Han Shen
For RL algorithms, appropriate entropy control is crucial to their effectiveness. To control the policy entropy, a commonly used method is entropy regularization, which is adopted in various popular RL algorithms including PPO, SAC and A3C. Although entropy regularization proves effective in robotic and games RL conventionally, studies found that it gives weak to no gains in LLM-RL training. In this work, we study the issues of entropy bonus in LLM-RL setting. Specifically, we first argue that the conventional entropy regularization suffers from the LLM’s extremely large response space and the sparsity of the optimal outputs. As a remedy, we propose AEnt, an entropy control method that utilizes a new clamped entropy bonus with an automatically adjusted coefficient. The clamped entropy is evaluated with the re-normalized policy defined on certain smaller token space, which encourages exploration within a more compact response set. In addition, the algorithm automatically adjusts entropy coefficient according to the clamped entropy value, effectively controlling the entropy-induced bias while leveraging the entropy’s benefits. AEnt is tested in math-reasoning tasks under different base models and datasets, and it is observed that AEnt outperforms the baselines consistently across multiple benchmarks.
对于强化学习(RL)算法来说,适当的熵控制对其效果至关重要。为了控制策略熵,一种常用的方法是熵正则化,它已被广泛应用于各种流行的RL算法中,包括PPO、SAC和A3C。尽管熵正则化在机器人和游戏领域的RL中证明是有效的,但研究发现它在LLM-RL训练中几乎没有效果。在这项工作中,我们研究了LLM-RL设置中熵奖励的问题。具体来说,我们首先认为传统的熵正则化面临着LLM极其大的响应空间和最优输出的稀疏性问题。作为一种补救措施,我们提出了AEnt,这是一种熵控制方法,它利用了一种新的带自动调整系数的夹持熵奖励。夹持熵是在某些较小的符号空间上定义的重新归一化策略上评估的,这鼓励在一个更紧凑的响应集内进行探索。此外,该算法会根据夹持熵值自动调整熵系数,有效地控制由熵引起的偏见,同时利用熵的好处。AEnt在不同的基础模型和数据集下进行了数学推理任务的测试,观察发现,AEnt在多个基准测试中始终优于基线。
论文及项目相关链接
Summary
强化学习算法中,适当的熵控制对其效果至关重要。为了控制策略熵,常用的方法是熵正则化,它被广泛应用于PPO、SAC和A3C等流行的强化学习算法中。尽管熵正则化在机器人和游戏等领域的强化学习中证明是有效的,但在LLM-RL训练中,它的作用微乎其微甚至毫无增益。在本研究中,我们研究了LLM-RL环境中熵奖励的问题。具体来说,我们认为传统的熵正则化受到大型语言模型响应空间极大和最优输出稀疏性的困扰。为此,我们提出了一种利用新的夹持熵奖励的熵控制方法AEnt,并自动调整系数。夹持熵是在较小的标记空间上定义的归一化策略评估的,这鼓励在一个更紧凑的响应集合内进行探索。此外,该算法会根据夹持的熵值自动调整熵系数,在利用熵的好处的同时有效地控制熵引起的偏见。在多个基准测试的数学推理任务中测试AEnt,发现其在不同基础模型和数据集上始终优于基线。
Key Takeaways
- 适当的熵控制在强化学习算法中至关重要。
- 传统的熵正则化在LLM-RL训练中效果不佳。
- LLM的响应空间极大和最优输出稀疏性是传统熵正则化面临的挑战。
- 提出了一种新的熵控制方法AEnt,采用夹持熵奖励和自动调整系数。
- 夹持熵鼓励在更紧凑的响应集合内进行探索。
- AEnt能够自动调整熵系数,控制熵引起的偏见。
点此查看论文截图


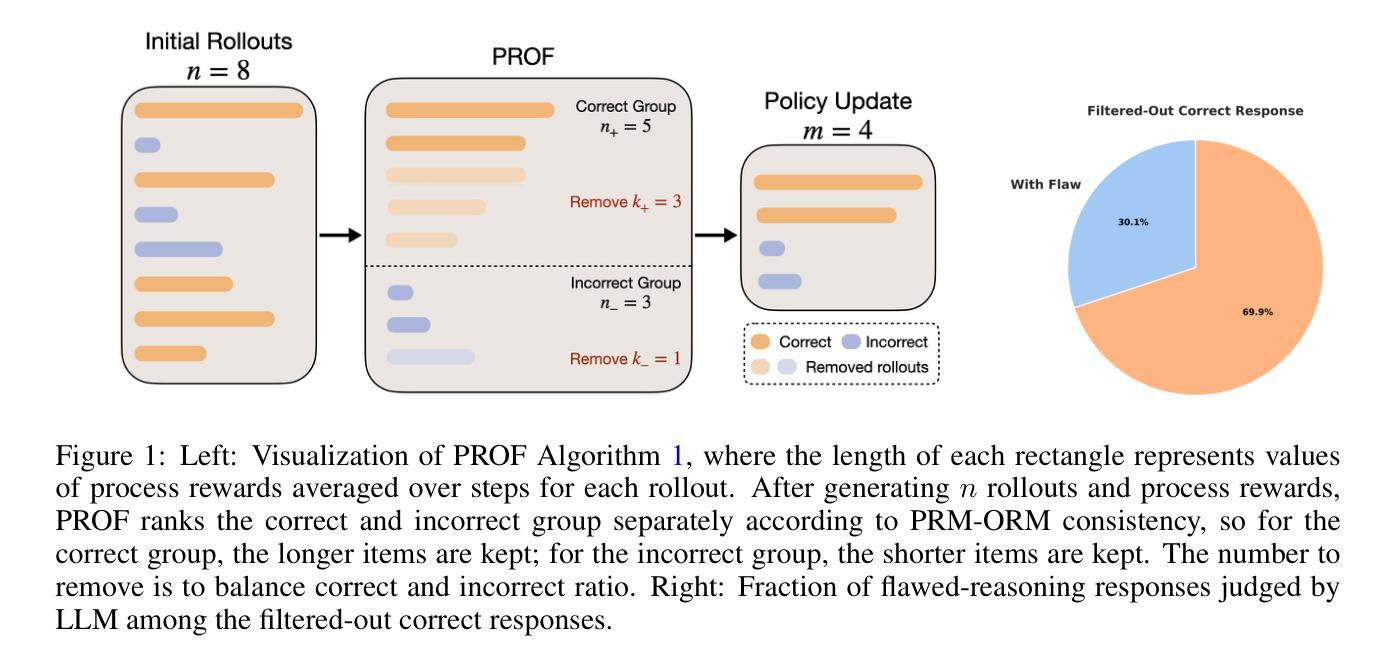
Beyond Correctness: Harmonizing Process and Outcome Rewards through RL Training
Authors:Chenlu Ye, Zhou Yu, Ziji Zhang, Hao Chen, Narayanan Sadagopan, Jing Huang, Tong Zhang, Anurag Beniwal
Reinforcement learning with verifiable rewards (RLVR) has emerged to be a predominant paradigm for mathematical reasoning tasks, offering stable improvements in reasoning ability. However, Outcome Reward Models (ORMs) in RLVR are too coarse-grained to distinguish flawed reasoning within correct answers or valid reasoning within incorrect answers. This lack of granularity introduces noisy and misleading gradients significantly and hinders further progress in reasoning process quality. While Process Reward Models (PRMs) offer fine-grained guidance for intermediate steps, they frequently suffer from inaccuracies and are susceptible to reward hacking. To resolve this dilemma, we introduce PRocess cOnsistency Filter (PROF), an effective data process curation method that harmonizes noisy, fine-grained process rewards with accurate, coarse-grained outcome rewards. Rather than naively blending PRM and ORM in the objective function (arXiv:archive/2506.18896), PROF leverages their complementary strengths through consistency-driven sample selection. Our approach retains correct responses with higher averaged process values and incorrect responses with lower averaged process values, while maintaining positive/negative training sample balance. Extensive experiments demonstrate that our method not only consistently improves the final accuracy over $4%$ compared to the blending approaches, but also strengthens the quality of intermediate reasoning steps. Codes and training recipes are available at https://github.com/Chenluye99/PROF.
强化学习可验证奖励(RLVR)已成为数学推理任务中的主要范式,为提高推理能力提供了稳定的改进。然而,RLVR中的结果奖励模型(ORMs)过于粗糙,无法区分正确答案中的错误推理或错误答案中的合理推理。这种缺乏精细度引入了大量噪声和误导性的梯度,阻碍了推理过程质量的进一步提高。虽然过程奖励模型(PRMs)为中间步骤提供了精细的指导,但它们经常存在不准确的情况,并容易受到奖励攻击。为了解决这一困境,我们引入了过程一致性过滤器(PROF),这是一种有效的数据过程筛选方法,能够协调噪声、精细化的过程奖励与准确、粗略的结果奖励。PROF通过一致性驱动的样本选择,而不是简单地融合PRM和ORM在目标函数中(arXiv:archive/2506.18896),利用它们的互补优势。我们的方法保留了具有较高平均过程值的正确响应和具有较低平均过程值的错误响应,同时保持正负训练样本的平衡。大量实验表明,我们的方法不仅与融合方法相比,最终精度持续提高了超过4%,而且还加强了中间推理步骤的质量。代码和培训配方可在https://github.com/Chenluye99/PROF找到。
论文及项目相关链接
摘要
强化学习与可验证奖励(RLVR)已成为数学推理任务的主要范式,对提高推理能力具有稳定作用。然而,RLVR中的结果奖励模型(ORMs)过于粗糙,无法区分正确答案中的错误推理或错误答案中的合理推理。这种缺乏粒度引入了噪声和误导性的梯度,显著阻碍了推理过程质量的进一步提高。虽然过程奖励模型(PRMs)为中间步骤提供了精细指导,但它们经常存在不准确的问题,并容易受到奖励破解的影响。为了解决这一难题,我们引入了过程一致性过滤器(PROF),这是一种有效的数据过程筛选方法,能够协调噪声、精细的过程奖励与准确、粗糙的结果奖励。PROF通过一致性驱动的样本选择,有效结合PRM和ORM的优点,而不是简单地将其融入目标函数中。我们的方法保留具有较高平均过程值的正确响应并排除较低平均过程值的错误响应,同时保持正负训练样本的平衡。大量实验表明,我们的方法不仅将最终精度提高了超过4%,而且提高了中间推理步骤的质量。相关代码和培训食谱可在https://github.com/Chenluye99/PROF找到。
关键见解
- 强化学习与可验证奖励(RLVR)已用于数学推理任务,并在提高推理能力方面表现出稳定的效果。
- 结果奖励模型(ORMs)过于粗糙,无法准确区分不同推理质量的情况,导致噪声和误导性的梯度。
- 过程奖励模型(PRMs)虽然能提供精细指导,但存在不准确和易受奖励破解影响的问题。
- 引入过程一致性过滤器(PROF),结合PRM和ORM的优点,通过一致性驱动的样本选择来提高数据过程质量。
- PROF能提高正确响应的保留率并排除错误响应,同时保持正负训练样本的平衡。
- 实验表明,PROF不仅提高了最终精度超过4%,而且提高了中间推理步骤的质量。
点此查看论文截图


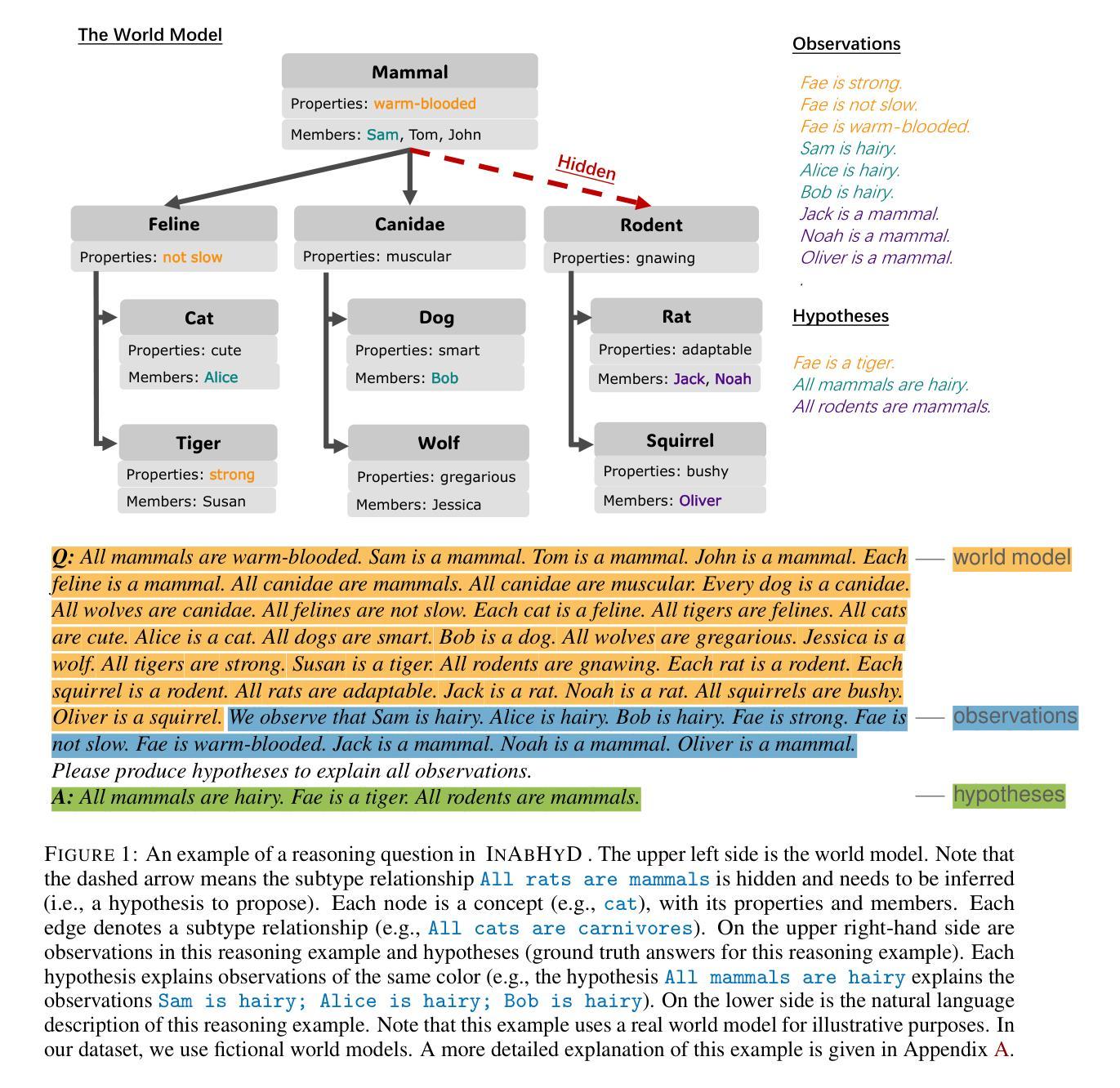
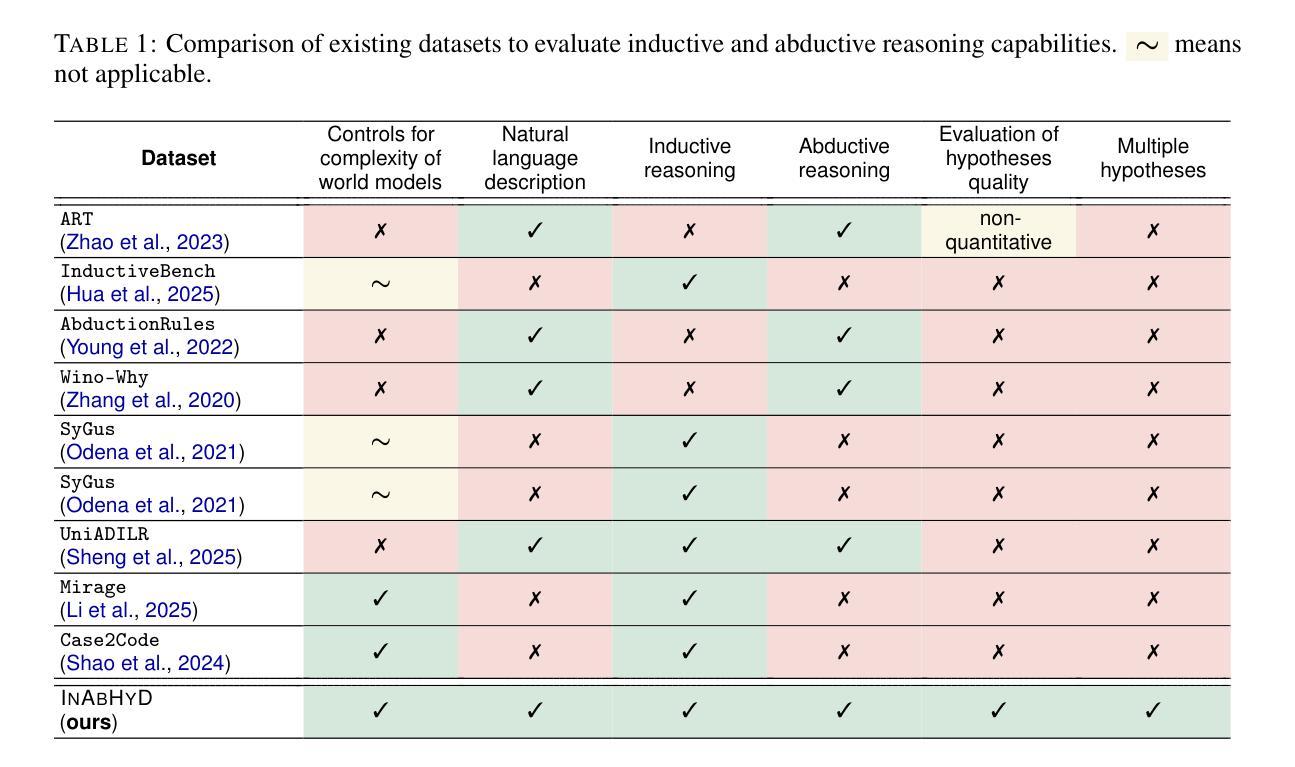
Language Models Do Not Follow Occam’s Razor: A Benchmark for Inductive and Abductive Reasoning
Authors:Yunxin Sun, Abulhair Saparov
Reasoning is a core capability in artificial intelligence systems, for which large language models (LLMs) have recently shown remarkable progress. However, most work focuses exclusively on deductive reasoning, which is problematic since other types of reasoning are also essential in solving real-world problems, and they are less explored. This work focuses on evaluating LLMs’ inductive and abductive reasoning capabilities. We introduce a programmable and synthetic dataset, InAbHyD (pronounced in-a-bid), where each reasoning example consists of an incomplete world model and a set of observations. The task for the intelligent agent is to produce hypotheses to explain observations under the incomplete world model to solve each reasoning example. We propose a new metric to evaluate the quality of hypotheses based on Occam’s Razor. We evaluate and analyze some state-of-the-art LLMs. Our analysis shows that LLMs can perform inductive and abductive reasoning in simple scenarios, but struggle with complex world models and producing high-quality hypotheses, even with popular reasoning-enhancing techniques such as in-context learning and RLVR.
推理是人工智能系统的核心能力,大语言模型(LLM)在这方面最近取得了显著的进步。然而,大多数工作只专注于演绎推理,这是有问题的,因为其他类型的推理在解决现实世界的问题时也是必不可少的,而且它们的研究相对较少。这项工作重点评估LLM的归纳推理和溯因推理能力。我们引入了一个可编程的合成数据集InAbHyD(发音为in-a-bid),每个推理示例都包含一个不完整的世界模型和一组观察结果。智能代理的任务是在不完整的世界模型下产生假设来解释观察结果,以解决每个推理示例。我们提出了一个新的指标来评估假设的质量,该指标基于奥卡姆剃刀原则。我们评估和分析了当前的一些先进LLM。我们的分析表明,LLM可以在简单场景中执行归纳推理和溯因推理,但在处理复杂世界模型和产生高质量假设方面遇到困难,即使在流行的增强推理技术如上下文学习和RLVR的帮助下也是如此。
论文及项目相关链接
Summary
大型语言模型(LLMs)在人工智能系统的推理能力方面已取得了显著进展,但大多数研究仅专注于演绎推理,忽略了归纳和溯因推理等同样重要的方面。本文专注于评估LLMs的归纳和溯因推理能力,介绍了一个新的可编程合成数据集InAbHyD,用于评估智能代理在不完全世界模型下产生解释观察结果的假设的能力。本文还提出了一种基于奥卡姆剃刀原理的新评估指标。分析表明,LLMs在简单场景中可以进行归纳和溯因推理,但在复杂世界模型和产生高质量假设方面遇到困难,即使是流行的增强推理技术如上下文内学习和RLVR也无法完全解决。
Key Takeaways
- 大型语言模型(LLMs)在人工智能系统的推理能力上取得显著进展,但现有研究多专注于演绎推理,忽略了其他类型的推理如归纳和溯因推理。
- 介绍了新的可编程合成数据集InAbHyD,包含不完整的世界模型和观察集,旨在评估智能代理在给定世界模型下产生解释观察结果的假设的能力。
- 提出了基于奥卡姆剃刀原理的新假设质量评估指标。
- LLMs在简单场景中可以执行归纳和溯因推理任务。
- LLMs在处理复杂世界模型和生成高质量假设方面遇到困难。
- 流行的增强推理技术如上下文内学习和RLVR虽有一定帮助,但无法完全解决LLMs在复杂推理任务上的困难。
点此查看论文截图


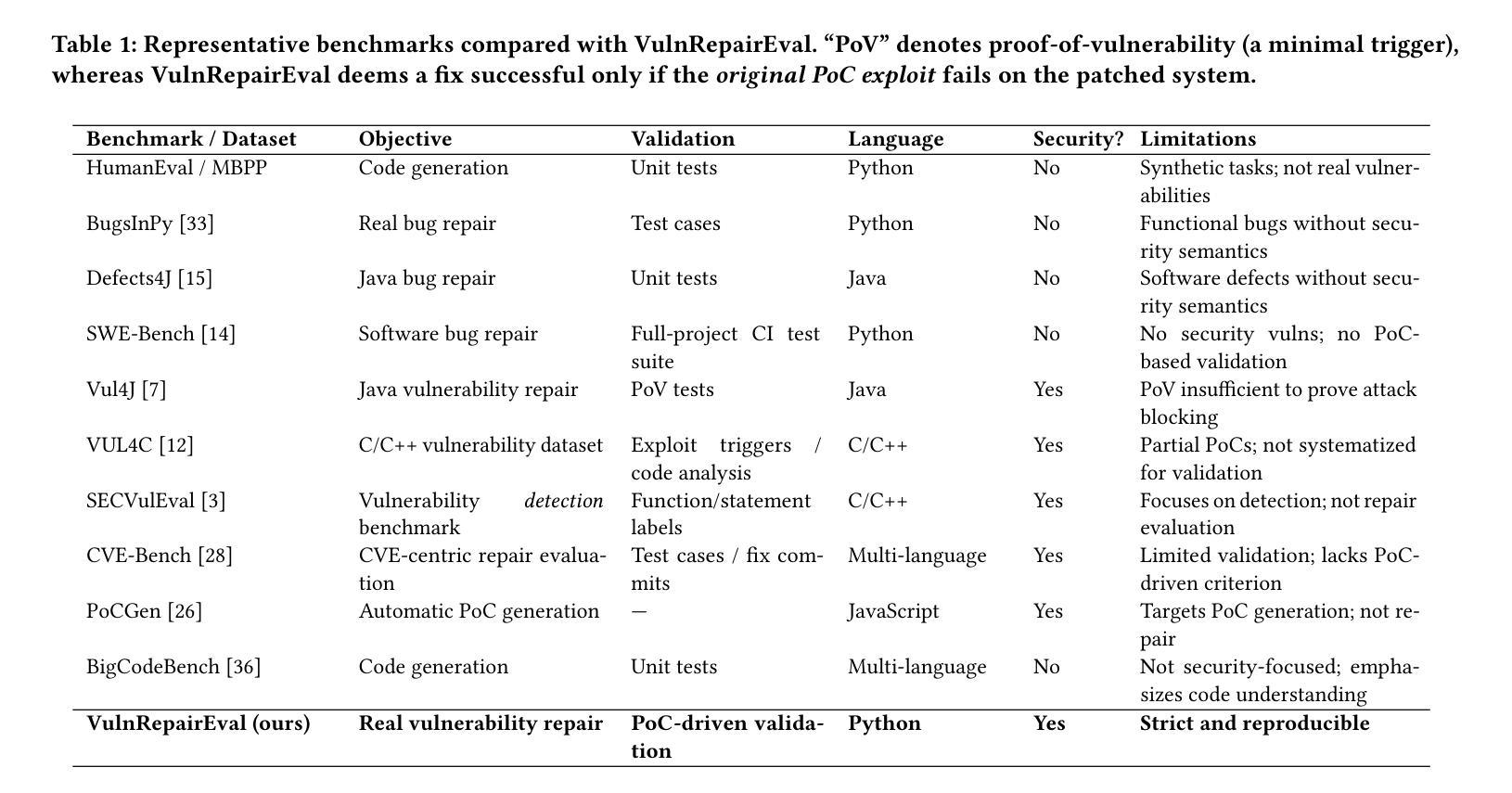
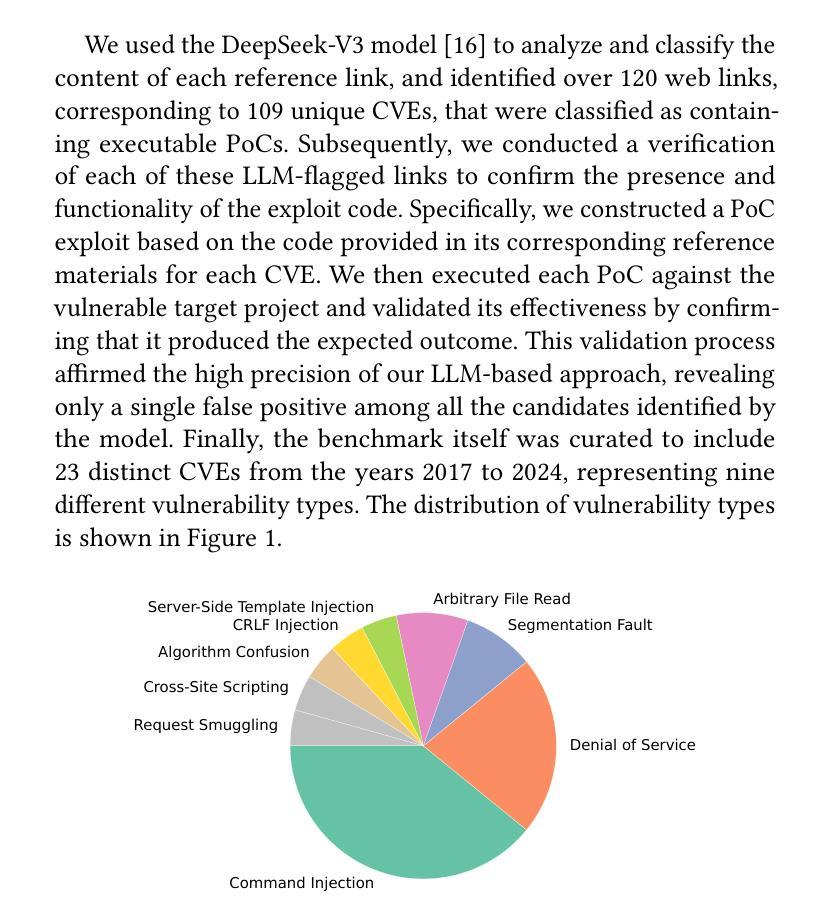
VulnRepairEval: An Exploit-Based Evaluation Framework for Assessing Large Language Model Vulnerability Repair Capabilities
Authors:Weizhe Wang, Wei Ma, Qiang Hu, Yao Zhang, Jianfei Sun, Bin Wu, Yang Liu, Guangquan Xu, Lingxiao Jiang
The adoption of Large Language Models (LLMs) for automated software vulnerability patching has shown promising outcomes on carefully curated evaluation sets. Nevertheless, existing datasets predominantly rely on superficial validation methods rather than exploit-based verification, leading to overestimated performance in security-sensitive applications. This paper introduces VulnRepairEval, an evaluation framework anchored in functional Proof-of-Concept (PoC) exploits. Our framework delivers a comprehensive, containerized evaluation pipeline that enables reproducible differential assessment, where repair success requires the original exploit to fail execution against the modified code. The benchmark construction involved extensive data curation: we processed over 400 CVEs and approximately 2,500 potential sources to extract a collection of authentic vulnerability instances (23 Python CVEs) amenable to automated testing with working PoCs. Through VulnRepairEval, we conduct a comprehensive evaluation of 12 popular LLMs and observe a significant performance deficit: even the top-performing model successfully addresses merely 5/23 instances (about 21.7%), exposing critical weaknesses in security-focused applications. Our failure analysis reveals that most unsuccessful attempts stem from imprecise vulnerability identification and patches containing syntactic or semantic errors. Enhanced prompting strategies and multi-agent approaches yield minimal improvements, with overall effectiveness remaining largely unaffected. This work contributes a stringent, practical evaluation framework for LLM-driven vulnerability remediation and underscores the necessity for assessment protocols that authentically reflect real-world exploitation scenarios.
采用大型语言模型(LLM)进行自动化软件漏洞修补,在精心策划的评估集上取得了有前景的结果。然而,现有数据集主要依赖浅层次的验证方法,而非基于攻击的验证方法,这导致在安全性敏感的应用中性能被高估。本文介绍了VulnRepairEval,一个以功能性概念证明(PoC)攻击为基础的评估框架。我们的框架提供了一个全面、容器化的评估流程,能够实现可重现的差异化评估,其中修复成功需要原始攻击对修改后的代码无法执行。基准测试构建涉及大量数据整理:我们处理了超过400个CVE和大约2500个潜在来源,提取出可用于自动化测试的真实漏洞实例集合(23个Python CVE)。通过VulnRepairEval,我们对12个流行的大型语言模型进行了全面评估,并观察到显著的性能不足:即使表现最佳的模型也仅能成功解决5/23个实例(约21.7%),暴露出在安全导向应用中的关键弱点。我们的失败分析表明,大多数不成功尝试源于不精确的漏洞识别和补丁中的语法或语义错误。增强提示策略和多元代理方法产生的改进微乎其微,总体效果基本不受影响。这项工作为大型语言模型驱动的漏洞修复提供了一个严格、实用的评估框架,并强调了需要评估协议真实反映现实世界攻击场景。
论文及项目相关链接
Summary
该文介绍了使用大型语言模型(LLMs)进行自动化软件漏洞修补的评估框架VulnRepairEval。该框架基于功能性Proof-of-Concept(POC)漏洞进行综合评价,提供了一个容器化的评估管道,实现了可重复的差异化评估。通过对真实漏洞实例的评估,发现现有LLMs在自动化测试中存在显著性能缺陷,大部分失败源于不精确的漏洞识别和包含语法或语义错误的补丁。文章强调了需要反映真实世界利用场景的评价协议。
Key Takeaways
- 大型语言模型(LLMs)在自动化软件漏洞修补领域具有应用前景。
- 现有数据集主要依赖浅层次的验证方法,而非基于攻击的验证,导致在安全性敏感应用中的性能被高估。
- 引入VulnRepairEval评估框架,基于功能性Proof-of-Concept(POC)漏洞进行综合评价。
- 通过对真实漏洞实例的评估,发现LLMs存在显著性能缺陷,大部分失败源于不精确的漏洞识别和包含错误的补丁。
- 增强提示策略和采用多智能体方法只能带来微小改进,总体效果影响不大。
- 该文提供了一个严格的实用评估框架,用于LLM驱动的软件漏洞修复。
点此查看论文截图

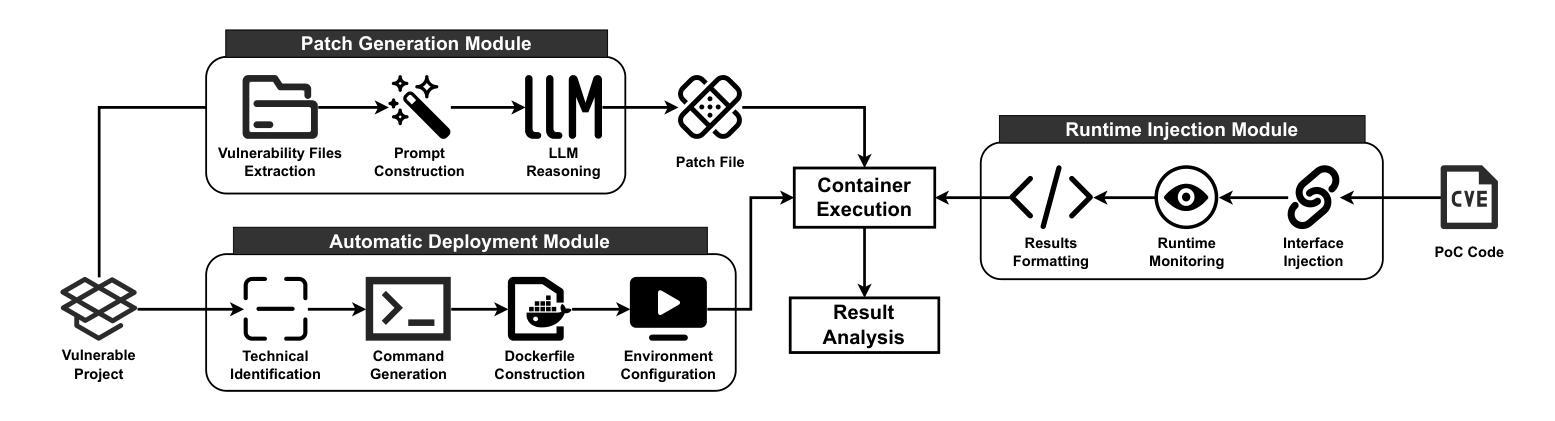
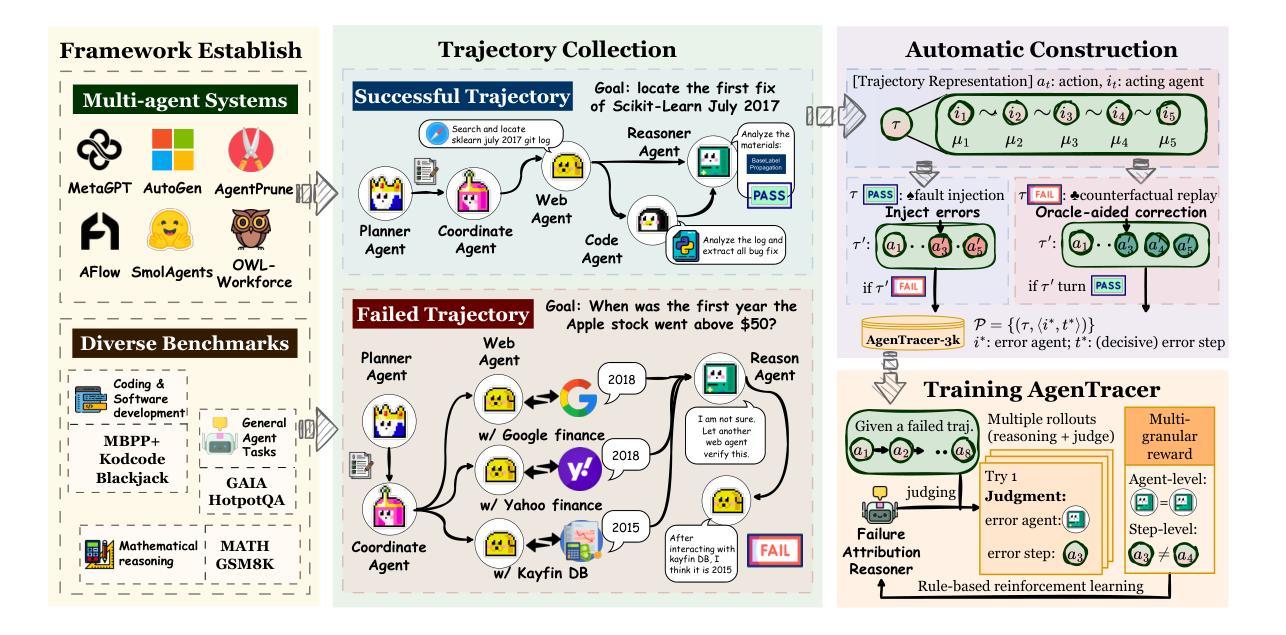
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems?
Authors:Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, Shuicheng Yan
Large Language Model (LLM)-based agentic systems, often comprising multiple models, complex tool invocations, and orchestration protocols, substantially outperform monolithic agents. Yet this very sophistication amplifies their fragility, making them more prone to system failure. Pinpointing the specific agent or step responsible for an error within long execution traces defines the task of agentic system failure attribution. Current state-of-the-art reasoning LLMs, however, remain strikingly inadequate for this challenge, with accuracy generally below 10%. To address this gap, we propose AgenTracer, the first automated framework for annotating failed multi-agent trajectories via counterfactual replay and programmed fault injection, producing the curated dataset TracerTraj. Leveraging this resource, we develop AgenTracer-8B, a lightweight failure tracer trained with multi-granular reinforcement learning, capable of efficiently diagnosing errors in verbose multi-agent interactions. On the Who&When benchmark, AgenTracer-8B outperforms giant proprietary LLMs like Gemini-2.5-Pro and Claude-4-Sonnet by up to 18.18%, setting a new standard in LLM agentic failure attribution. More importantly, AgenTracer-8B delivers actionable feedback to off-the-shelf multi-agent systems like MetaGPT and MaAS with 4.8-14.2% performance gains, empowering self-correcting and self-evolving agentic AI.
基于大型语言模型(LLM)的代理系统,通常包含多个模型、复杂的工具调用和协同协议,在性能上大大优于单一代理。然而,这种复杂性也增加了其脆弱性,使其更容易出现系统故障。确定长执行轨迹中特定代理或步骤的错误责任,这定义了代理系统失败归因的任务。然而,目前最先进的推理LLM对此挑战仍然明显不足,准确率通常低于10%。为了解决这一差距,我们提出了AgenTracer,这是第一个通过反事实回放和编程故障注入来注释失败的多代理轨迹的自动化框架,产生了精选数据集TracerTraj。利用这一资源,我们开发了轻量级的失败追踪器AgenTracer-8B,它采用多粒度强化学习进行训练,能够高效诊断冗长的多代理交互中的错误。在Who&When基准测试中,AgenTracer-8B的性能超越了像Gemini-2.5-Pro和Claude-4-Sonnet等大型专有LLM,高出最多达18.18%,在LLM代理失败归因方面树立了新的标准。更重要的是,AgenTracer-8B为现成的多代理系统(如MetaGPT和MaAS)提供了可操作反馈,实现了4.8%~14.2%的性能提升,赋能自我修正和自我进化的代理人工智能。
论文及项目相关链接
Summary
大型语言模型(LLM)为基础的多智能体系统虽然表现出卓越的性能,但其复杂性也增加了系统失败的脆弱性。系统失败归因于特定智能体的任务是一项挑战,当前最先进的推理LLM对此任务的准确性普遍低于10%。为解决这个问题,我们提出AgenTracer框架,通过反事实回放和编程故障注入来标注失败的多元智能体轨迹,并开发了基于此资源的AgenTracer-8B轻量级失败追踪器,使用多粒度强化学习进行训练,能有效诊断冗长多元智能体交互中的错误。在Who&When基准测试中,AgenTracer-8B表现优于大型专有LLM,如Gemini-2.5-Pro和Claude-4-Sonnet,准确率提升高达18.18%,为LLM智能体失败归因设定了新的标准。此外,它还能为现成的多智能体系统如MetaGPT和MaAS提供可操作反馈,性能提升4.8%~14.2%,助力智能体AI的自我修正和进化。
Key Takeaways
- 大型语言模型(LLM)为基础的多智能体系统表现出卓越性能,但复杂性增加了系统失败的脆弱性。
- 当前LLM在智能体系统故障归因方面的准确性较低。
- AgenTracer框架通过反事实回放和编程故障注入来标注失败的多元智能体轨迹。
- AgenTracer-8B是轻量级的失败追踪器,使用多粒度强化学习训练,能有效诊断冗长多元智能体交互中的错误。
- AgenTracer-8B在基准测试中表现优于其他大型专有LLM,准确率显著提升。
- AgenTracer-8B能为现有的多智能体系统提供反馈,助力其性能提升。
点此查看论文截图

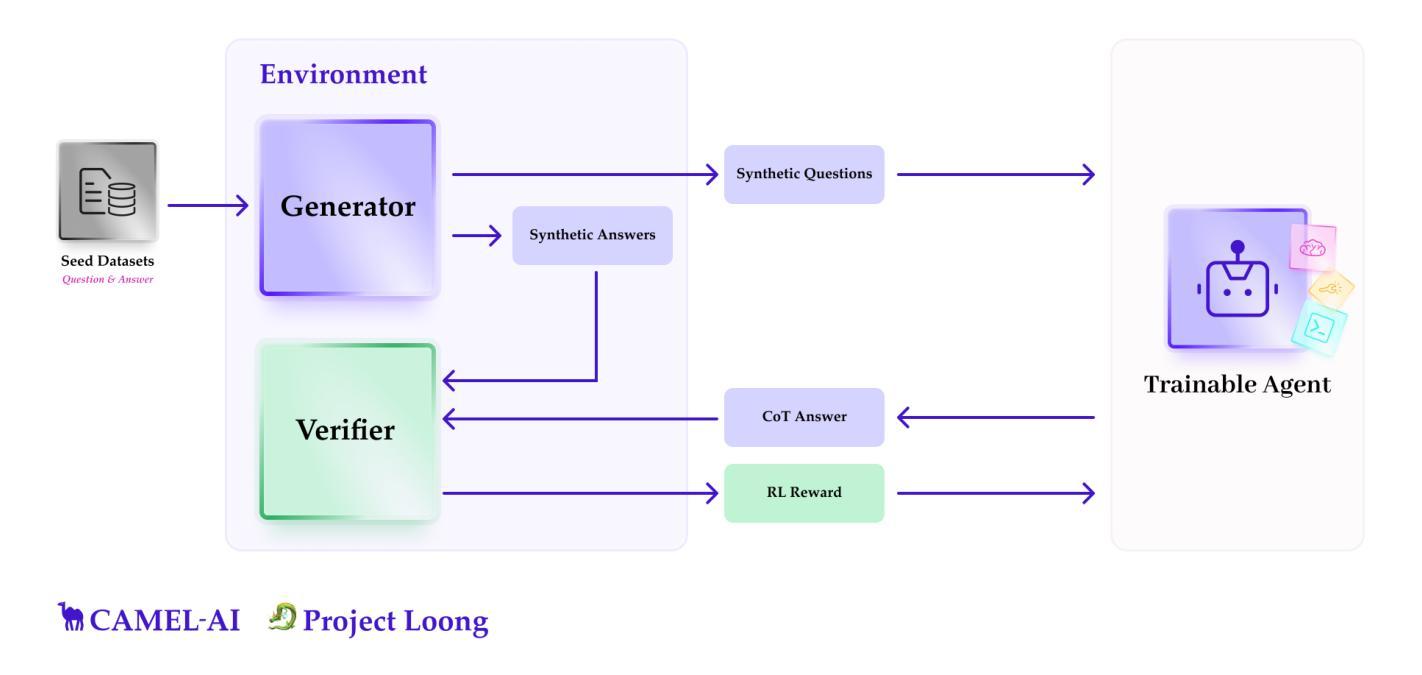
Loong: Synthesize Long Chain-of-Thoughts at Scale through Verifiers
Authors:Xingyue Huang, Rishabh, Gregor Franke, Ziyi Yang, Jiamu Bai, Weijie Bai, Jinhe Bi, Zifeng Ding, Yiqun Duan, Chengyu Fan, Wendong Fan, Xin Gao, Ruohao Guo, Yuan He, Zhuangzhuang He, Xianglong Hu, Neil Johnson, Bowen Li, Fangru Lin, Siyu Lin, Tong Liu, Yunpu Ma, Hao Shen, Hao Sun, Beibei Wang, Fangyijie Wang, Hao Wang, Haoran Wang, Yang Wang, Yifeng Wang, Zhaowei Wang, Ziyang Wang, Yifan Wu, Zikai Xiao, Chengxing Xie, Fan Yang, Junxiao Yang, Qianshuo Ye, Ziyu Ye, Guangtao Zeng, Yuwen Ebony Zhang, Zeyu Zhang, Zihao Zhu, Bernard Ghanem, Philip Torr, Guohao Li
Recent advances in Large Language Models (LLMs) have shown that their reasoning capabilities can be significantly improved through Reinforcement Learning with Verifiable Reward (RLVR), particularly in domains like mathematics and programming, where ground-truth correctness can be automatically evaluated. However, extending this success to other reasoning-intensive domains remains challenging due to the scarcity of high-quality, verifiable datasets and the high cost of human supervision. In this work, we introduce the Loong Project: an open-source framework for scalable synthetic data generation and verification across a diverse range of reasoning-intensive domains. The framework consists of two key components: (1) LoongBench, a curated seed dataset containing 8,729 human-vetted examples across 12 domains (e.g., Advanced Mathematics, Chemistry, Logic), each paired with executable code and rich metadata; and (2) LoongEnv, a modular synthetic data generation environment that supports multiple prompting strategies to produce new question-answer-code triples. Together, these components form an agent-environment loop that enables reinforcement learning, where an LLM-based agent is rewarded for generating Chain-of-Thought (CoT) solutions that align with code-executed answers. Empirically, we benchmark LoongBench on a broad suite of both open-source and proprietary LLMs to evaluate domain coverage and reveal performance bottlenecks. In addition, we conduct a comprehensive analysis of synthetic data generated by LoongEnv, examining correctness, difficulty, and diversity. Code and documentation are available at https://github.com/camel-ai/loong.
近期大型语言模型(LLM)的进步表明,通过可验证奖励强化学习(RLVR)可以显著提高其推理能力,特别是在数学和编程等领域,这些领域的正确答案可以自动评估。然而,由于高质量、可验证的数据集稀缺以及人工监督成本高,将这种成功扩展到其他推理密集型领域仍然具有挑战性。在这项工作中,我们推出了龙项目:一个跨多种推理密集型领域的可扩展合成数据生成和验证的开源框架。该框架包含两个关键组件:(1)LoongBench,一个精选的种子数据集,包含12个领域(如高级数学、化学、逻辑)的8729个人工审核过的例子,每个例子都配有可执行代码和丰富的元数据;(2)LoongEnv,一个模块化合成数据生成环境,支持多种提示策略,以产生新的问答代码三元组。这两个组件共同形成了一个代理环境循环,使强化学习成为可能,其中基于LLM的代理会因产生与代码执行答案相符的Chain-of-Thought(CoT)解决方案而获得奖励。我们实证地对LoongBench进行广泛基准测试,包括开源和专有LLM,以评估领域覆盖并揭示性能瓶颈。此外,我们对LoongEnv生成的合成数据进行了综合分析,检查了其正确性、难度和多样性。相关代码和文档可在https://github.com/camel-ai/loong查看。
论文及项目相关链接
Summary
本文介绍了Loong项目,一个用于生成和验证跨多个推理密集型领域的大规模合成数据的开源框架。该项目包含两个关键组件:LoongBench,一个包含8729个经过人工审核的示例的精选种子数据集,跨越12个领域(如高级数学、化学、逻辑等),每个示例都配有可执行代码和丰富的元数据;LoongEnv,一个模块化合成数据生成环境,支持多种提示策略,以生成新的问题-答案-代码三元组。该项目通过强化学习奖励LLM代理生成与代码执行答案对齐的Chain-of-Thought(CoT)解决方案。实证表明,LoongBench在广泛的开源和专有LLM上具有优秀的领域覆盖性能,并揭示了性能瓶颈。同时,对LoongEnv生成的合成数据进行了正确性、难度和多样性的综合分析。
Key Takeaways
- Loong项目是一个用于生成和验证跨多个推理密集型领域的合成数据的开源框架。
- 包含两个关键组件:LoongBench(种子数据集)和LoongEnv(合成数据生成环境)。
- LoongBench提供了包含丰富元数据和配对代码的问题数据集,适用于推理密集型领域。
- LoongEnv能够生成新的问题-答案-代码三元组,支持多种提示策略。
- 该项目利用强化学习奖励LLM代理生成与代码执行答案对齐的Chain-of-Thought(CoT)解决方案。
- 实证研究表明,LoongBench在多种LLM上具有良好的领域覆盖性能,并揭示了性能瓶颈。
点此查看论文截图


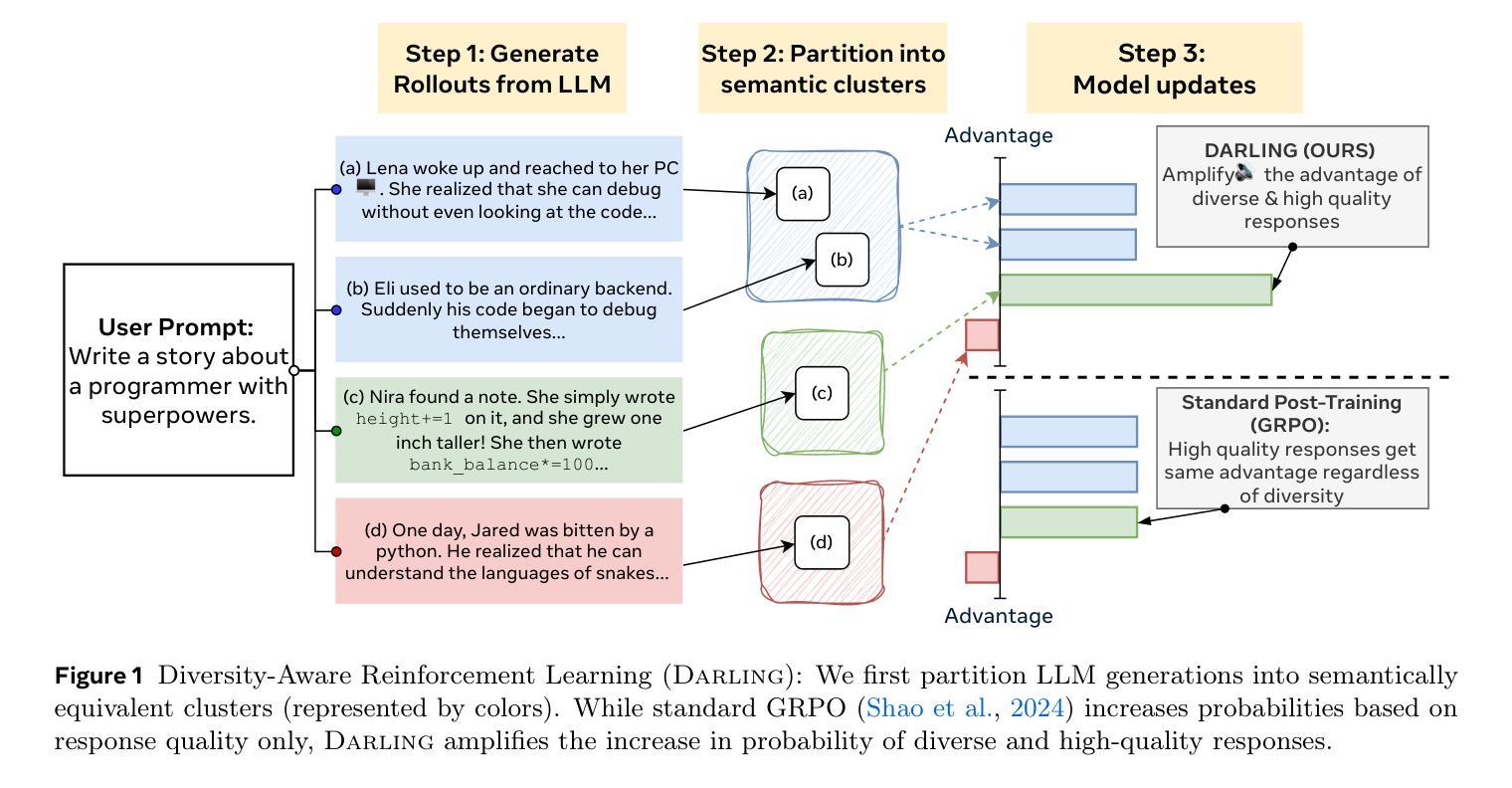
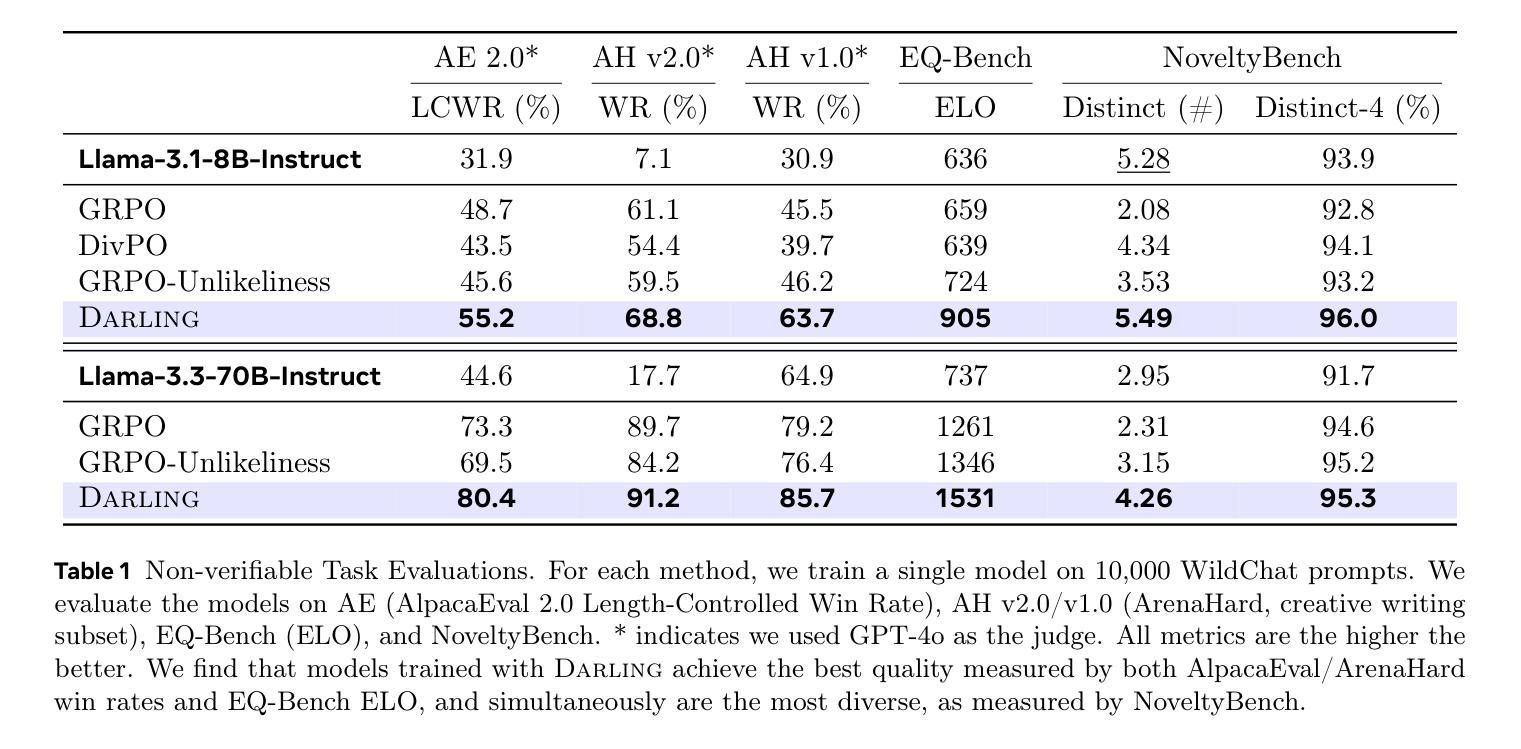
Jointly Reinforcing Diversity and Quality in Language Model Generations
Authors:Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, Tianlu Wang
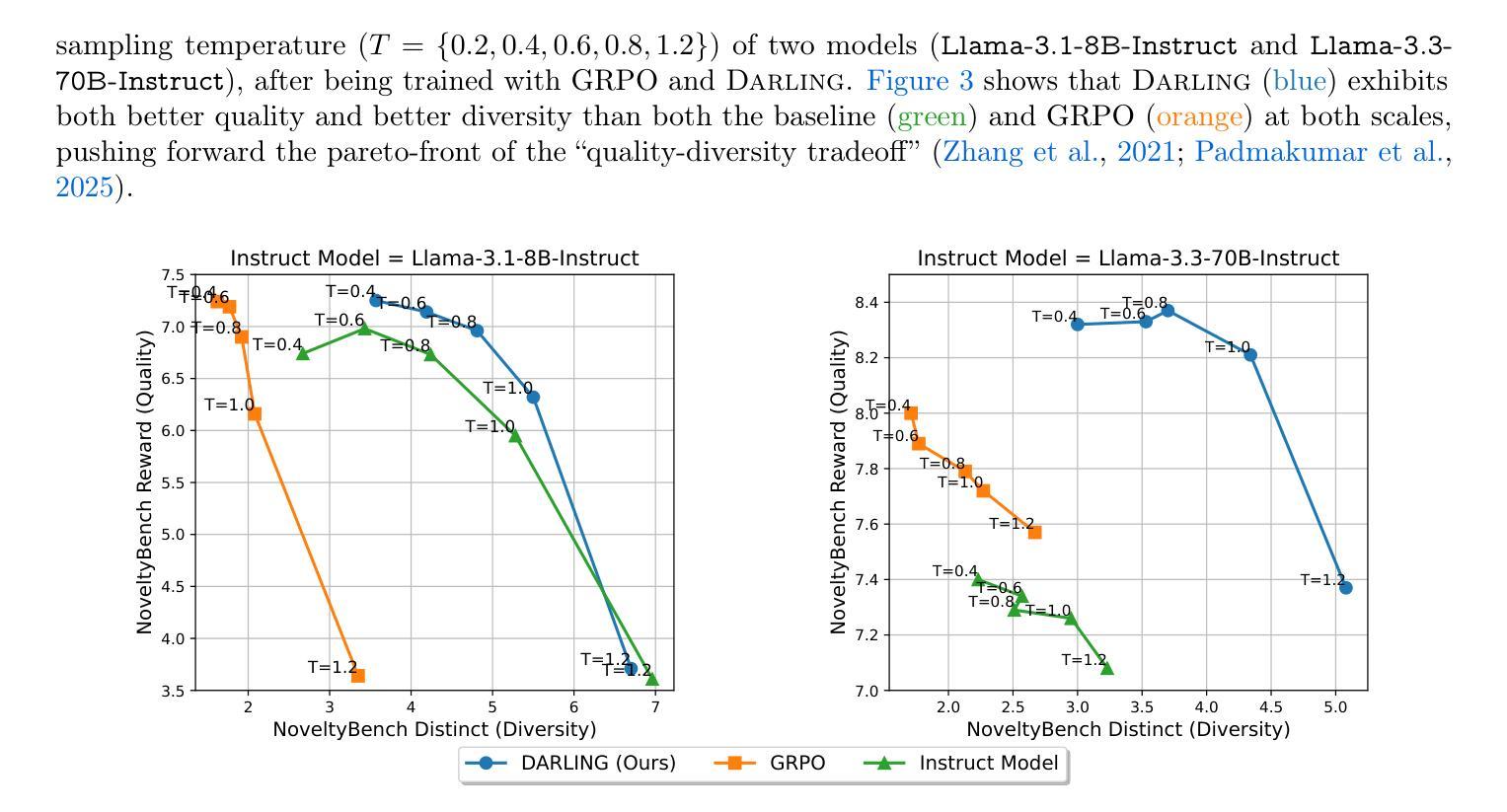
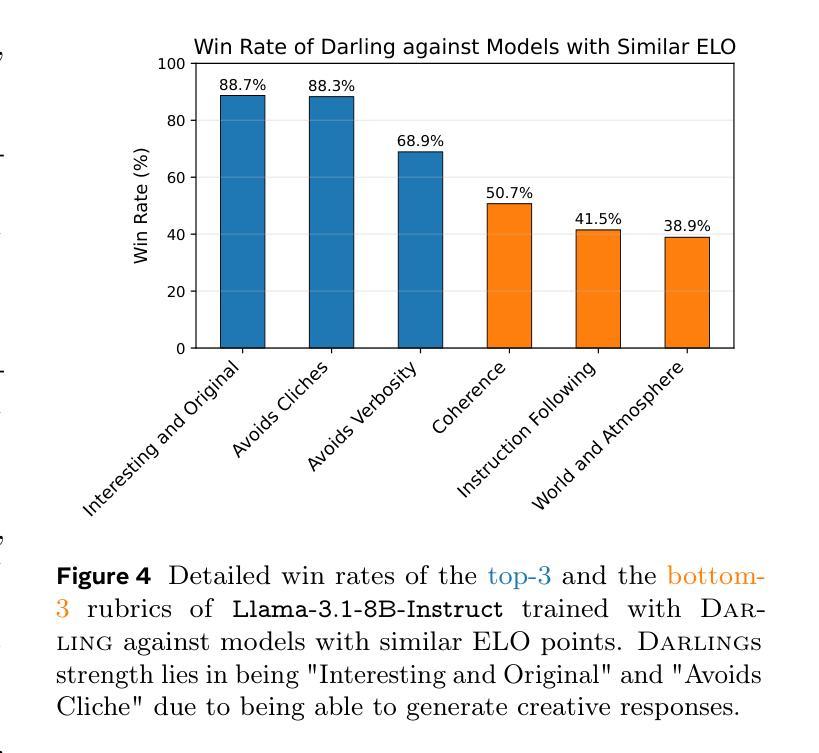
Post-training of Large Language Models (LMs) often prioritizes accuracy and helpfulness at the expense of diversity. This creates a tension: while post-training improves response quality, it also sharpens output distributions and reduces the range of ideas, limiting the usefulness of LMs in creative and exploratory tasks such as brainstorming, storytelling, or problem solving. We address this challenge with Diversity-Aware Reinforcement Learning (DARLING), a framework that jointly optimizes for response quality and semantic diversity. At its core, DARLING introduces a learned partition function to measure diversity beyond surface-level lexical variations. This diversity signal is then combined with a quality reward during online reinforcement learning, encouraging models to generate outputs that are both high-quality and distinct. Experiments across multiple model families and sizes show that DARLING generalizes to two regimes: non-verifiable tasks (instruction following and creative writing) and verifiable tasks (competition math). On five benchmarks in the first setting, DARLING consistently outperforms quality-only RL baselines, producing outputs that are simultaneously of higher quality and novelty. In the second setting, DARLING achieves higher pass@1 (solution quality) and pass@k (solution variety). Most strikingly, explicitly optimizing for diversity catalyzes exploration in online RL, which manifests itself as higher-quality responses.
对大型语言模型(LMs)进行训练后,通常会在牺牲多样性的情况下优先考虑准确性和有用性。这产生了一种紧张关系:虽然训练后可以提高响应质量,但它也加剧了输出分布,减少了想法的范围,限制了语言模型在创意和探索性任务(如头脑风暴、讲故事或解决问题)中的用处。我们通过采用多样性感知强化学习(DARLING)来解决这一挑战,这是一个同时优化响应质量和语义多样性的框架。DARLING的核心是引入一个学习到的分区函数来度量超越表面层次词汇变化的多样性。然后将这种多样性信号与在线强化学习中的质量奖励相结合,鼓励模型生成既高质量又独特的输出。在多模型家族和规模的实验中发现,DARLING可以应用于两种模式:不可验证的任务(指令遵循和创造性写作)和可验证的任务(竞赛数学)。在第一种模式的五个基准测试中,DARLING始终优于仅注重质量的强化学习基线,产生出同时高质量和新颖的输出版本。在第二种模式下,DARLING在pass@1(解决方案质量)和pass@k(解决方案多样性)方面取得了更高的成绩。最明显的是,对多样性的明确优化促进了在线强化学习中的探索,表现为更高质量的响应。
论文及项目相关链接
PDF 29 pages, 11 figures
Summary
本文探讨了大型语言模型(LMs)在训练过程中面临的准确性、有用性和多样性之间的权衡问题。针对这一问题,提出了名为DARLING的多样性感知强化学习框架,该框架可联合优化响应质量和语义多样性。DARLING通过引入一个用于衡量多样性的学习分割函数来解决这一问题,该多样性信号与强化学习过程中的质量奖励相结合,鼓励模型生成既高质量又独特性的输出。实验结果表明,DARLING在多个模型家族和规模上表现良好,既适用于非验证任务(如指令遵循和创造性写作),也适用于验证任务(如数学竞赛),且能同时提高输出质量和新颖性。
Key Takeaways
- 大型语言模型训练时面临准确性、有用性和多样性之间的权衡问题。
- DARLING框架旨在联合优化响应质量和语义多样性。
- DARLING引入学习分割函数来衡量多样性,并不仅仅关注表面上的词汇变化。
- 该框架结合多样性信号与强化学习中的质量奖励,鼓励模型生成多样化的高质量输出。
- 实验结果表明DARLING在不同模型和任务上表现良好,包括非验证任务和验证任务。
- 在非验证任务上,DARLING能显著提高输出质量和新颖性。
点此查看论文截图


Implicit Actor Critic Coupling via a Supervised Learning Framework for RLVR
Authors:Jiaming Li, Longze Chen, Ze Gong, Yukun Chen, Lu Wang, Wanwei He, Run Luo, Min Yang
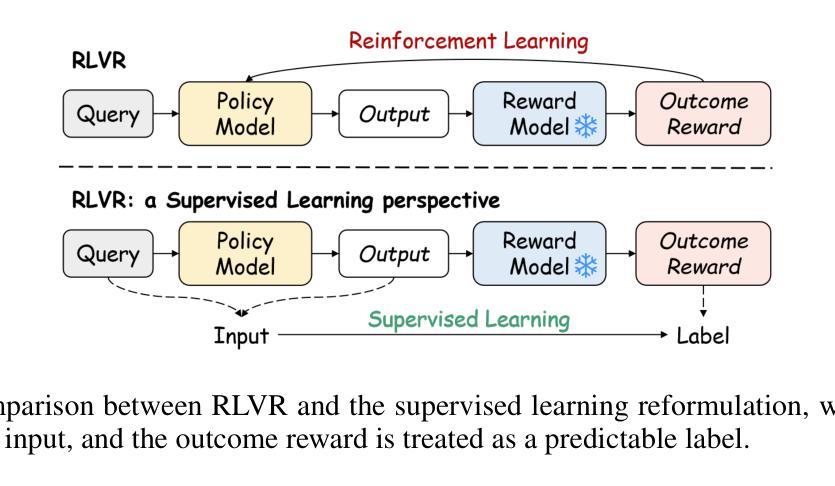
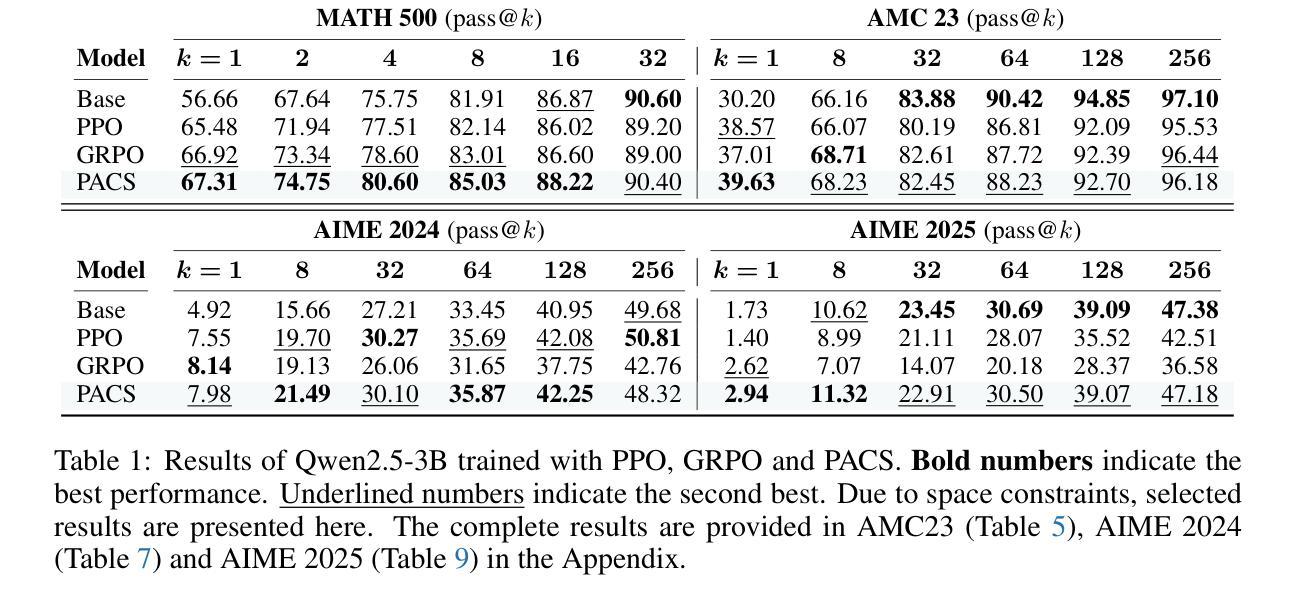
Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have empowered large language models (LLMs) to tackle challenging reasoning tasks such as mathematics and programming. RLVR leverages verifiable outcome rewards to guide policy optimization, enabling LLMs to progressively improve output quality in a grounded and reliable manner. Despite its promise, the RLVR paradigm poses significant challenges, as existing methods often suffer from sparse reward signals and unstable policy gradient updates, particularly in RL-based approaches. To address the challenges, we propose $\textbf{PACS}$, a novel RLVR framework that achieves im$\textbf{P}$licit $\textbf{A}$ctor $\textbf{C}$ritic coupling via a $\textbf{S}$upervised learning framework. By treating the outcome reward as a predictable label, we reformulate the RLVR problem into a supervised learning task over a score function parameterized by the policy model and optimized using cross-entropy loss. A detailed gradient analysis shows that this supervised formulation inherently recovers the classical policy gradient update while implicitly coupling actor and critic roles, yielding more stable and efficient training. Benchmarking on challenging mathematical reasoning tasks, PACS outperforms strong RLVR baselines, such as PPO and GRPO, achieving superior reasoning performance. For instance, PACS achieves 59.78% at pass@256 on AIME 2025, representing improvements of 13.32 and 14.36 points over PPO and GRPO. This simple yet powerful framework offers a promising avenue for LLMs post-training with verifiable rewards. Our code and data are available as open source at https://github.com/ritzz-ai/PACS.
近期强化学习与可验证奖励(RLVR)的进步使得大型语言模型(LLM)能够应对数学和编程等具有挑战性的推理任务。RLVR利用可验证的结果奖励来指导策略优化,使LLMs能够以踏实可靠的方式逐步改进输出质量。尽管具有潜力,但RLVR范式也带来了重大挑战,因为现有方法常常受到奖励信号稀疏和策略梯度更新不稳定的影响,特别是在基于RL的方法中。
为了解决这些挑战,我们提出了PACS这一新型RLVR框架,它通过监督学习框架实现了隐式演员评论家耦合。我们将结果奖励视为可预测的标签,将RLVR问题重新表述为在策略模型参数化的评分函数上的监督学习任务,并使用交叉熵损失进行优化。详细的梯度分析表明,这种监督公式化本质上恢复了经典的政策梯度更新,同时隐式地耦合了演员和评论家的角色,从而实现了更稳定、更有效的训练。
论文及项目相关链接
Summary
近期强化学习与可验证奖励(RLVR)领域的进展使得大型语言模型(LLM)能够应对数学和编程等具有挑战性的推理任务。RLVR利用可验证的结果奖励来指导策略优化,使LLM能够在有根据和可靠的方式下逐步改进输出质量。针对RLVR面临的挑战,如稀疏奖励信号和不稳定策略梯度更新,本文提出了一种新型的RLVR框架PACS,它通过监督学习框架实现了隐式行动者评论家耦合。将结果奖励视为可预测的标签,将RLVR问题重新表述为策略模型参数化的评分函数的监督学习任务,并使用交叉熵损失进行优化。PACS在具有挑战性的数学推理任务上超越了强大的RLVR基线,如PPO和GRPO,实现了卓越的性能。例如,在AIME 2025上,PACS在pass@256达到了59.78%,相较于PPO和GRPO分别提高了13.32和14.36个百分点。这个简单而强大的框架为LLM的带有可验证奖励的后训练提供了一个有前途的方向。
Key Takeaways
- RLVR技术使LLMs能够处理数学和编程等复杂推理任务。
- RLVR利用可验证的结果奖励来指导策略优化,提高输出质量。
- 现有RLVR方法面临稀疏奖励信号和不稳定策略梯度更新等挑战。
- PACS是一种新型的RLVR框架,通过监督学习实现了行动者与评论家的隐式耦合。
- PACS将RLVR问题重新表述为监督学习任务,使用交叉熵损失进行优化。
- PACS在数学推理任务上表现出卓越性能,超越了PPO和GRPO等基线。
点此查看论文截图