⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-08 更新
AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds
Authors:Qizhou Wang, Hanxun Huang, Guansong Pang, Sarah Erfani, Christopher Leckie
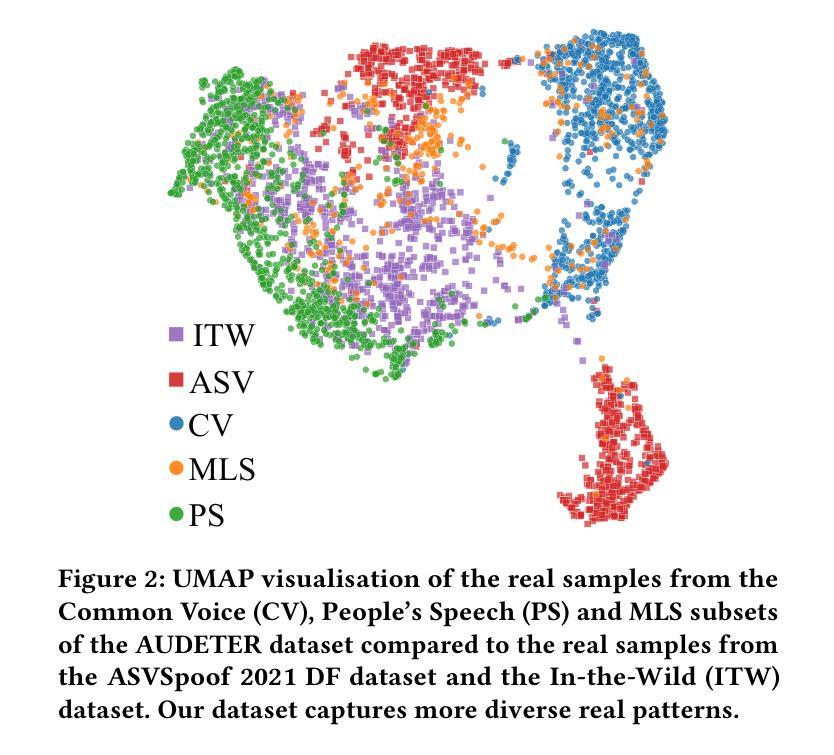
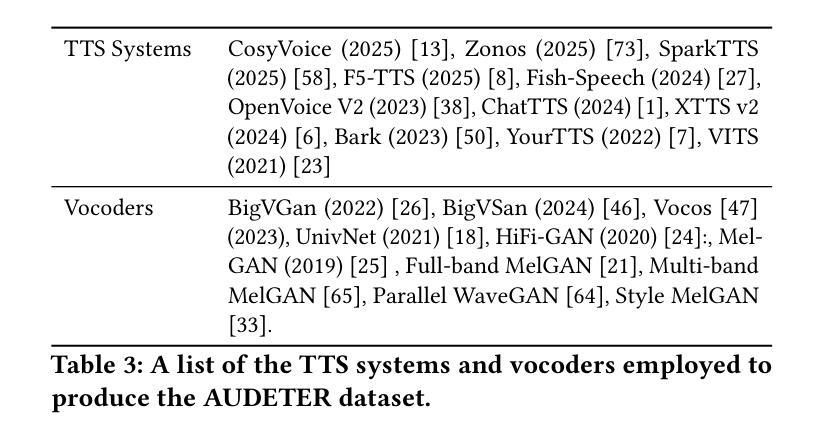
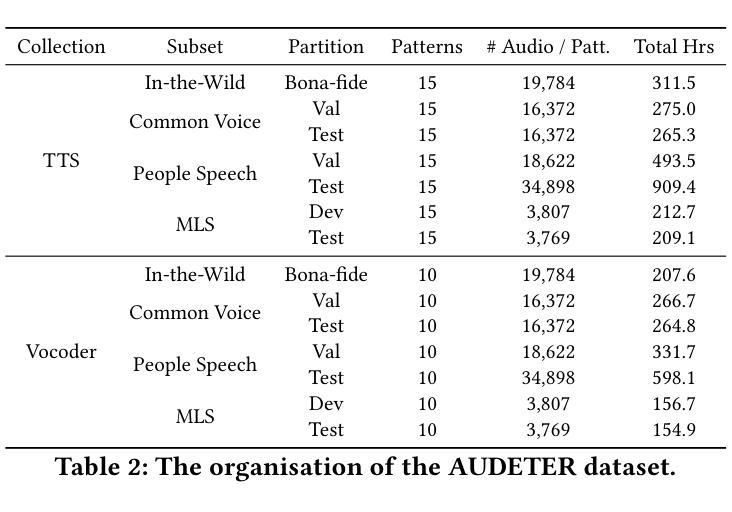
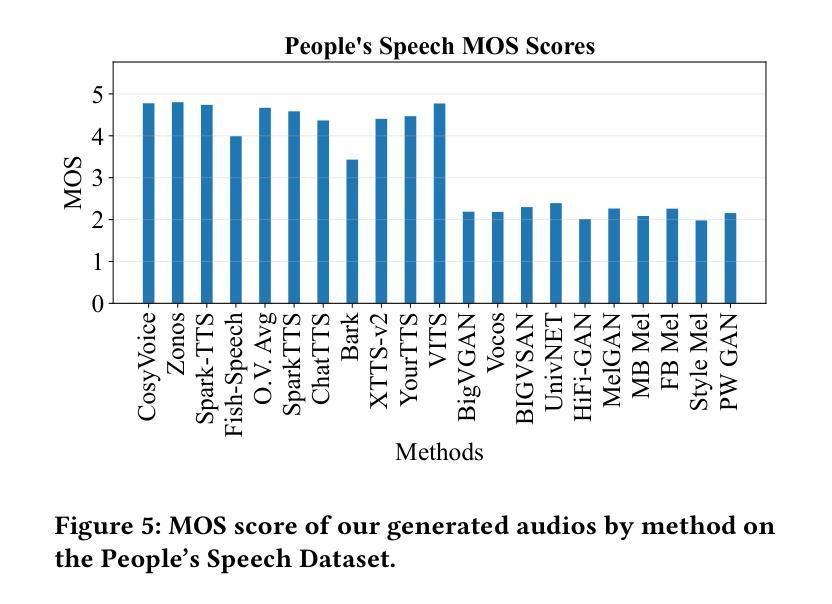
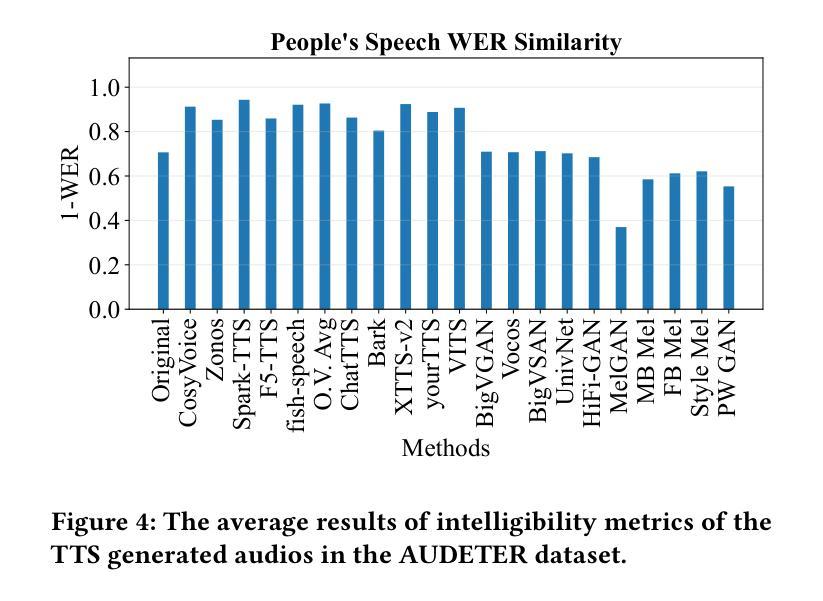
Speech generation systems can produce remarkably realistic vocalisations that are often indistinguishable from human speech, posing significant authenticity challenges. Although numerous deepfake detection methods have been developed, their effectiveness in real-world environments remains unrealiable due to the domain shift between training and test samples arising from diverse human speech and fast evolving speech synthesis systems. This is not adequately addressed by current datasets, which lack real-world application challenges with diverse and up-to-date audios in both real and deep-fake categories. To fill this gap, we introduce AUDETER (AUdio DEepfake TEst Range), a large-scale, highly diverse deepfake audio dataset for comprehensive evaluation and robust development of generalised models for deepfake audio detection. It consists of over 4,500 hours of synthetic audio generated by 11 recent TTS models and 10 vocoders with a broad range of TTS/vocoder patterns, totalling 3 million audio clips, making it the largest deepfake audio dataset by scale. Through extensive experiments with AUDETER, we reveal that i) state-of-the-art (SOTA) methods trained on existing datasets struggle to generalise to novel deepfake audio samples and suffer from high false positive rates on unseen human voice, underscoring the need for a comprehensive dataset; and ii) these methods trained on AUDETER achieve highly generalised detection performance and significantly reduce detection error rate by 44.1% to 51.6%, achieving an error rate of only 4.17% on diverse cross-domain samples in the popular In-the-Wild dataset, paving the way for training generalist deepfake audio detectors. AUDETER is available on GitHub.
语音生成系统能够产生非常逼真的语音,这些语音通常与人类语音无法区分,从而构成了重大的真实性挑战。尽管已经开发了许多深度伪造检测方法,但由于训练样本和测试样本之间存在的领域偏移以及人类语音的多样性和快速演变的语音合成系统,它们在现实环境中的有效性仍然不可靠。当前的数据集没有充分解决这一问题,它们缺乏真实世界的应用挑战,在真实和深度伪造类别中都缺乏多样性和最新的音频数据。为了填补这一空白,我们引入了AUDETER(音频深度伪造测试范围)数据集,这是一个大规模、高度多样化的深度伪造音频数据集,用于全面评估和稳健开发适用于深度伪造音频检测的通用模型。它由超过4500小时的人造音频组成,这些音频由11个最新的文本到语音转换模型和10个编码器生成,涵盖了广泛的TTS/编码器模式,总计300万个音频剪辑,使其成为规模最大的深度伪造音频数据集。通过对AUDETER进行的广泛实验,我们发现:i)在现有数据集上训练的最新方法很难推广到新的深度伪造音频样本上,并且在未见过的真人声音上出现了较高的误报率,这突显了全面数据集的需求;ii)在AUDETER上训练的方法实现了高度通用的检测性能,并将检测错误率降低了44.1%至51.6%,在流行的In-the-Wild数据集上的跨域样本的错误率仅为4.17%,这为训练通用的深度伪造音频检测器铺平了道路。AUDETER数据集已在GitHub上提供。
论文及项目相关链接
Summary
语音生成系统产生的语音非常逼真,给人类语音带来真实性的挑战。尽管已开发了许多深度伪造检测方法,但在现实世界环境中,它们的有效性仍不可靠。为了解决当前数据集在真实和深度伪造类别中都缺乏多样化和最新音频的问题,本文介绍了AUDETER数据集。它包含超过4,500小时由11种最新文本转语音模型和10种编码器生成的合成音频,共300万音频片段,是目前最大的深度伪造音频数据集。通过AUDETER的实验表明,现有数据集训练的先进方法难以推广到新的深度伪造音频样本上,并且在未见过的真人声音上假阳性率较高,凸显了需要全面的数据集;在AUDETER上训练的方法实现了高度通用的检测性能,检测错误率降低了44.1%至51.6%,在流行的In-the-Wild数据集上的跨域样本错误率仅为4.17%,为训练通用深度伪造音频检测器铺平了道路。AUDETER数据集已在GitHub上提供。
Key Takeaways
- 语音生成系统产生的语音与现实中的几乎无法区分,给真实性的鉴别带来挑战。
- 当前深度伪造检测方法的实际表现不够稳定,存在训练样本和测试样本领域偏移的问题。
- 当前数据集缺乏多样化和最新的音频样本,导致现有模型难以应对真实世界挑战。
- 介绍了AUDETER数据集,包含大量合成音频和真实音频样本,旨在解决上述问题。
- 先进的方法在AUDETER数据集上的训练表现出高度通用的检测性能。
- 与现有数据集相比,AUDETER显著降低了检测错误率。
点此查看论文截图

LibriQuote: A Speech Dataset of Fictional Character Utterances for Expressive Zero-Shot Speech Synthesis
Authors:Gaspard Michel, Elena V. Epure, Christophe Cerisara
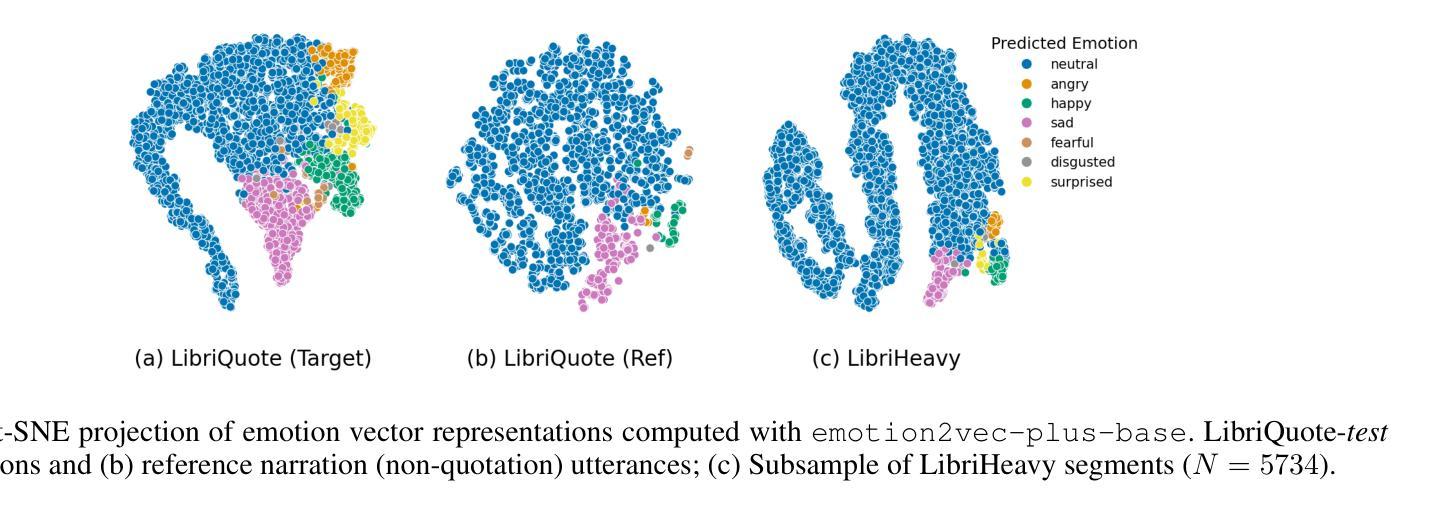
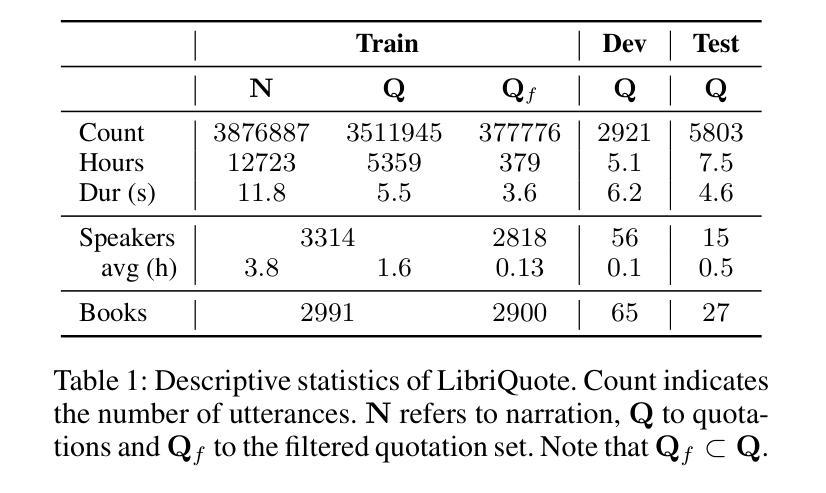
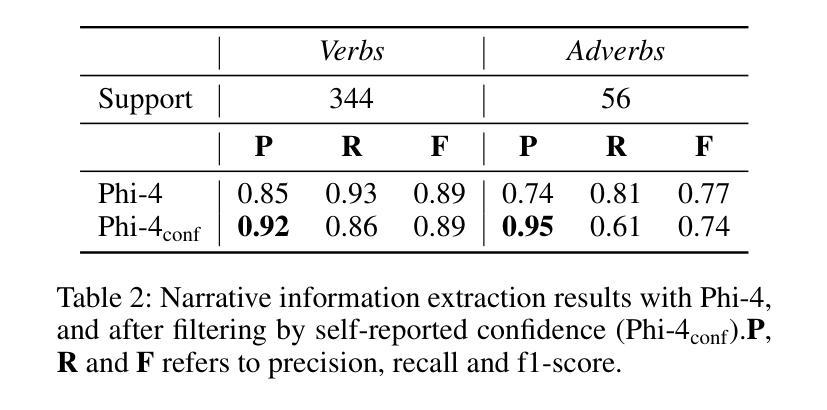
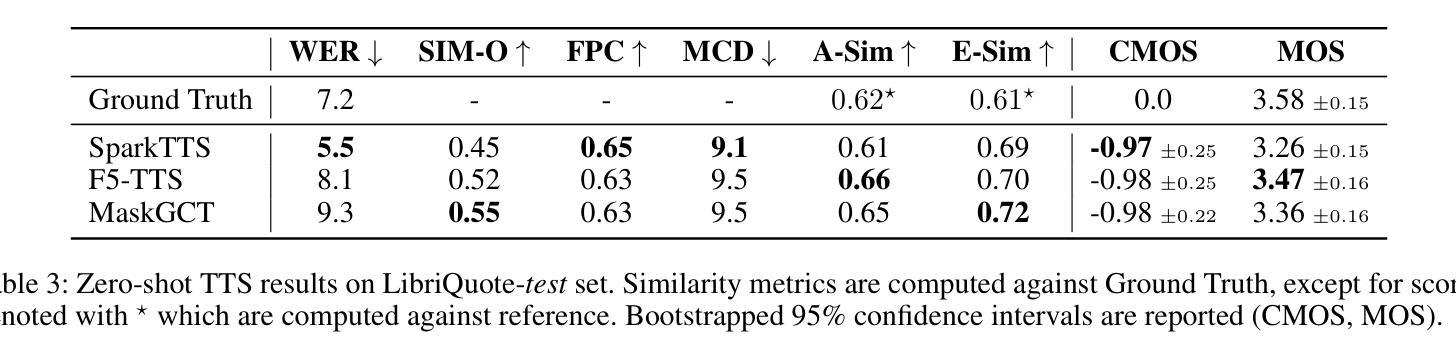
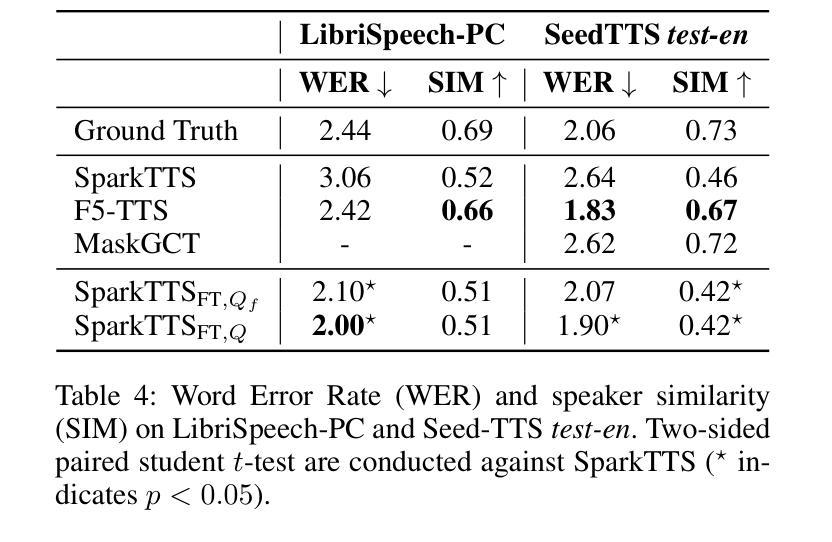
Text-to-speech (TTS) systems have recently achieved more expressive and natural speech synthesis by scaling to large speech datasets. However, the proportion of expressive speech in such large-scale corpora is often unclear. Besides, existing expressive speech corpora are typically smaller in scale and primarily used for benchmarking TTS systems. In this paper, we introduce the LibriQuote dataset, an English corpus derived from read audiobooks, designed for both fine-tuning and benchmarking expressive zero-shot TTS system. The training dataset includes 12.7K hours of read, non-expressive speech and 5.3K hours of mostly expressive speech drawn from character quotations. Each utterance in the expressive subset is supplemented with the context in which it was written, along with pseudo-labels of speech verbs and adverbs used to describe the quotation (\textit{e.g. ``he whispered softly’’}). Additionally, we provide a challenging 7.5 hour test set intended for benchmarking TTS systems: given a neutral reference speech as input, we evaluate system’s ability to synthesize an expressive utterance while preserving reference timbre. We validate qualitatively the test set by showing that it covers a wide range of emotions compared to non-expressive speech, along with various accents. Extensive subjective and objective evaluations show that fine-tuning a baseline TTS system on LibriQuote significantly improves its synthesized speech intelligibility, and that recent systems fail to synthesize speech as expressive and natural as the ground-truth utterances. The dataset and evaluation code are freely available. Audio samples can be found at https://libriquote.github.io/.
文本转语音(TTS)系统最近通过扩展到大规模语音数据集,实现了更具表现力和更自然的语音合成。然而,此类大规模语料库中表达性语音的比例通常是不明确的。此外,现有的表达性语音语料库规模通常较小,主要用于评估TTS系统的性能。在本文中,我们介绍了LibriQuote数据集,这是一个从朗读有声书籍中衍生出来的英语语料库,旨在用于微调以及评估表现性零样本TTS系统。训练数据集包含12.7K小时的朗读非表达性语音和5.3K小时的大部分表达性语音,这些语音来自角色引用。表达性子集中的每个语句都辅以书面上下文,以及与描述引用的动词和副词伪标签(例如“他轻声细语”)。此外,我们还提供了一个具有挑战性的7.5小时测试集,旨在评估TTS系统的性能:给定中性参考语音作为输入,我们评估系统合成表达性语句的同时保留参考音色的能力。我们通过定性验证测试集,表明其覆盖的情感范围与朗读非表达性语音相比广泛,且带有各种口音。大量主观和客观评估表明,在LibriQuote上微调基线TTS系统可显著提高合成语音的可懂度,而现有系统无法合成与真实话语一样有表现力和自然的语音。该数据集和评估代码可免费提供。音频样本可在https://libriquote.github.io/找到。
论文及项目相关链接
Summary
本文介绍了LibriQuote数据集,这是一个从有声读物中衍生的英语语料库,旨在用于微调与基准测试表达性零样本TTS系统。该训练数据集包含12.7K小时的朗读非表达性语音和5.3K小时的主要是表达性语音。表达性子集中的每个话语都附有书面上下文以及描述引用的伪标签(如“他轻声细语”)。此外,还提供了一个具有挑战性的7.5小时测试集,用于基准测试TTS系统:给定中性参考语音作为输入,我们评估系统合成表达性话语的能力,同时保留参考的音色。通过验证表明,测试集涵盖了与非表达性语音相比的广泛情绪以及各种口音。
Key Takeaways
- LibriQuote数据集是一个用于TTS研究的英语语料库,包含朗读的非表达性和表达性语音。
- 表达性子集中的每个话语都附有书面上下文和描述引用的伪标签。
- 提供了一个7.5小时的测试集,用于评估TTS系统在合成表达性语音方面的能力。
- 测试集涵盖了广泛的情绪和多种口音。
- 相比非表达性语音,表达性语音在数据集中的比例不明确。
- 通过在LibriQuote上微调基准TTS系统,可以显著提高合成语音的清晰度。
点此查看论文截图

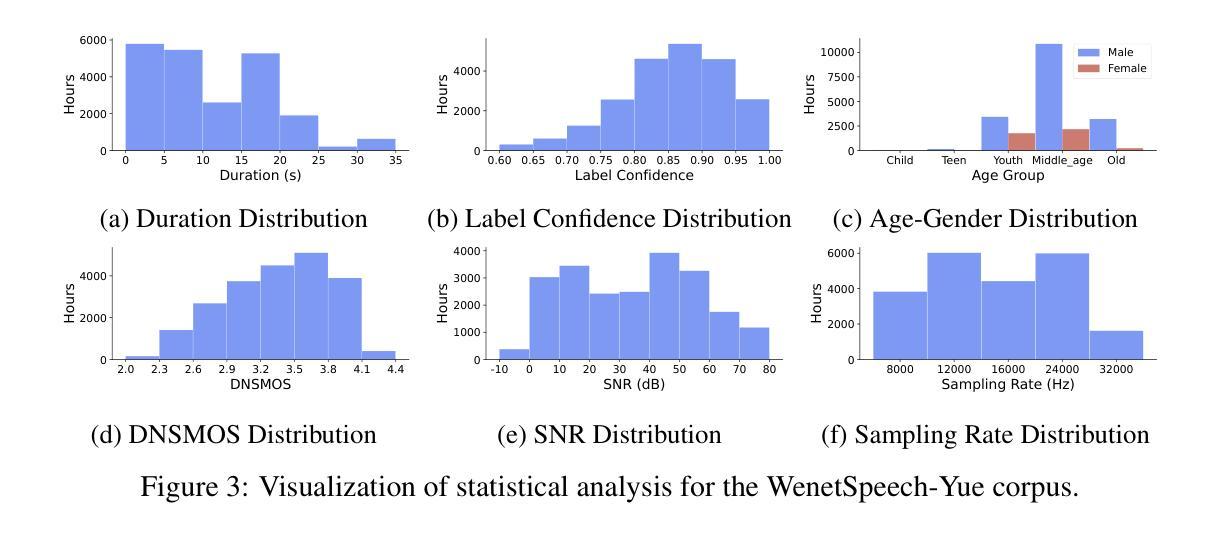
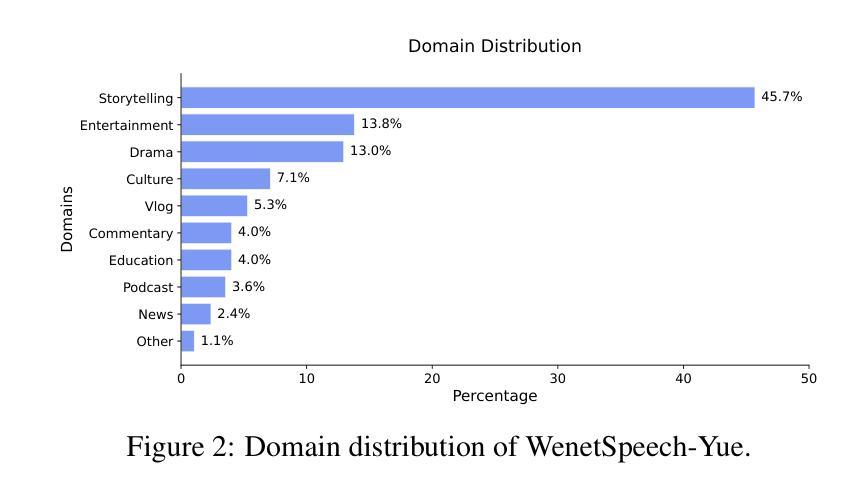
WenetSpeech-Yue: A Large-scale Cantonese Speech Corpus with Multi-dimensional Annotation
Authors:Longhao Li, Zhao Guo, Hongjie Chen, Yuhang Dai, Ziyu Zhang, Hongfei Xue, Tianlun Zuo, Chengyou Wang, Shuiyuan Wang, Jie Li, Xin Xu, Hui Bu, Binbin Zhang, Ruibin Yuan, Ziya Zhou, Wei Xue, Lei Xie
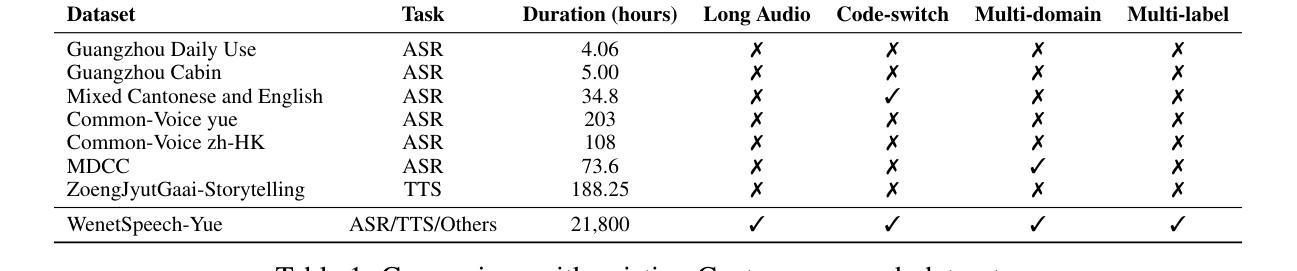
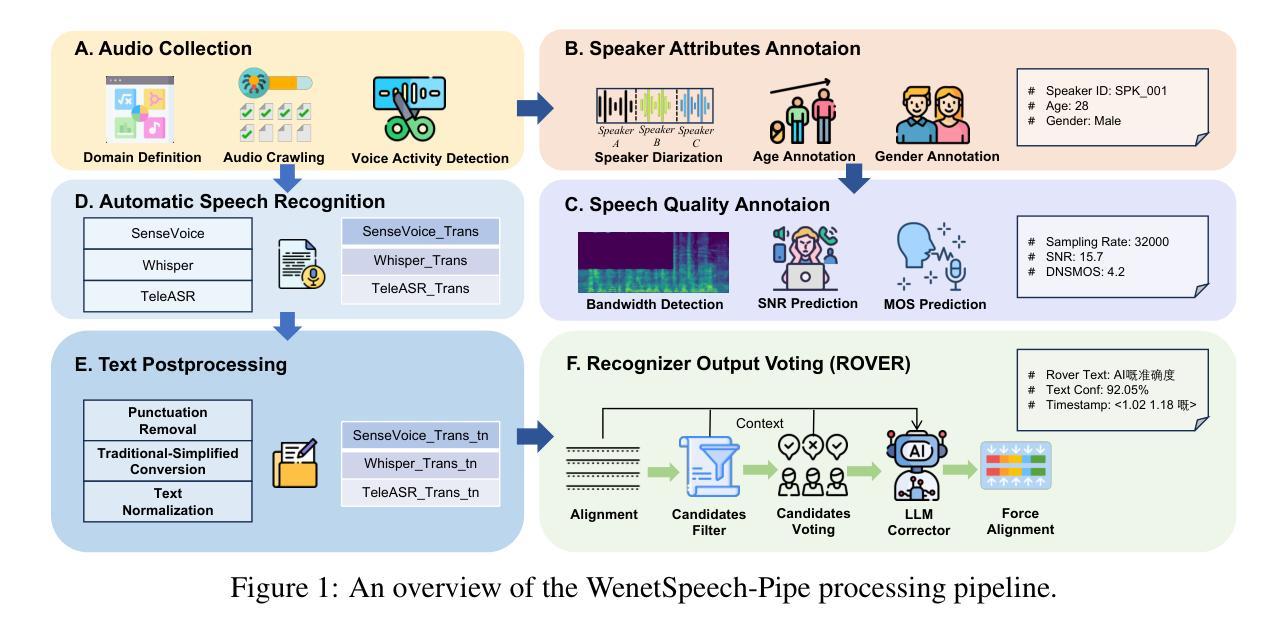
The development of speech understanding and generation has been significantly accelerated by the availability of large-scale, high-quality speech datasets. Among these, ASR and TTS are regarded as the most established and fundamental tasks. However, for Cantonese (Yue Chinese), spoken by approximately 84.9 million native speakers worldwide, limited annotated resources have hindered progress and resulted in suboptimal ASR and TTS performance. To address this challenge, we propose WenetSpeech-Pipe, an integrated pipeline for building large-scale speech corpus with multi-dimensional annotation tailored for speech understanding and generation. It comprises six modules: Audio Collection, Speaker Attributes Annotation, Speech Quality Annotation, Automatic Speech Recognition, Text Postprocessing and Recognizer Output Voting, enabling rich and high-quality annotations. Based on this pipeline, we release WenetSpeech-Yue, the first large-scale Cantonese speech corpus with multi-dimensional annotation for ASR and TTS, covering 21,800 hours across 10 domains with annotations including ASR transcription, text confidence, speaker identity, age, gender, speech quality scores, among other annotations. We also release WSYue-eval, a comprehensive Cantonese benchmark with two components: WSYue-ASR-eval, a manually annotated set for evaluating ASR on short and long utterances, code-switching, and diverse acoustic conditions, and WSYue-TTS-eval, with base and coverage subsets for standard and generalization testing. Experimental results show that models trained on WenetSpeech-Yue achieve competitive results against state-of-the-art (SOTA) Cantonese ASR and TTS systems, including commercial and LLM-based models, highlighting the value of our dataset and pipeline.
大规模高质量语音数据集的可用性极大地推动了语音识别和生成技术的发展。其中,自动语音识别(ASR)和文本转语音(TTS)被认为是最成熟、最基本的任务。然而,对于全球约有8490万使用者的粤语(又称广东话),有限的标注资源阻碍了其进展,导致ASR和TTS性能不佳。为了应对这一挑战,我们提出了WenetSpeech-Pipe,这是一个为语音理解和生成量身定制的大规模语音语料库构建的综合管道,具有多维度标注。它包含六个模块:音频收集、说话人属性标注、语音质量标注、自动语音识别、文本后处理和识别器输出投票,以实现丰富且高质量的标注。基于此管道,我们发布了WenetSpeech-Yue,这是首个具有多维度标注的粤语大规模语音语料库,用于ASR和TTS,覆盖10个领域的21800小时,标注包括ASR转录、文本置信度、说话人身份、年龄、性别、语音质量评分等其他标注。我们还发布了WSYue-eval,这是一个全面的粤语基准测试,包含两个组成部分:WSYue-ASR-eval,用于评估短句和长句、语言切换和各种声学条件下的ASR;以及WSYue-TTS-eval,包含用于标准和通用测试的基准和覆盖范围子集。实验结果表明,在WenetSpeech-Yue上训练的模型与最新的粤语ASR和TTS系统相比具有竞争力,包括商业和大型语言模型(LLM)基础模型,这凸显了我们数据集和管道的价值。
论文及项目相关链接
Summary
大规模、高质量的语音数据集极大地推动了语音识别和生成技术的发展。针对粤语(超过8千万粤语母语者),资源受限限制了语音识别和文本转语音的性能。为此,我们提出WenetSpeech-Pipe集成管道,用于构建大规模语音语料库,具有针对语音理解和生成的多维度注释。基于该管道,我们发布了WenetSpeech-Yue粤语大型语音语料库和多维度注释的ASR和TTS数据集,覆盖超过二十一万八千小时的音频数据。同时发布评估基准WSYue-eval,包含两个组件用于评估ASR和TTS性能。实验结果显示,基于WenetSpeech-Yue训练的模型在粤语ASR和TTS系统方面达到业界前沿水平。这突显了数据集的价值和意义。
Key Takeaways
- 大型高质量语音数据集推动语音识别和生成技术的发展。
- 针对粤语,资源受限导致语音识别和文本转语音性能不佳。
- WenetSpeech-Pipe是一个集成管道,用于构建大规模语音语料库并具有多维度注释功能。
- WenetSpeech-Yue是首个粤语大型语音语料库,用于ASR和TTS的评估和训练。它覆盖了超过二十一万八千小时的音频数据并包括多种注释类型。
点此查看论文截图

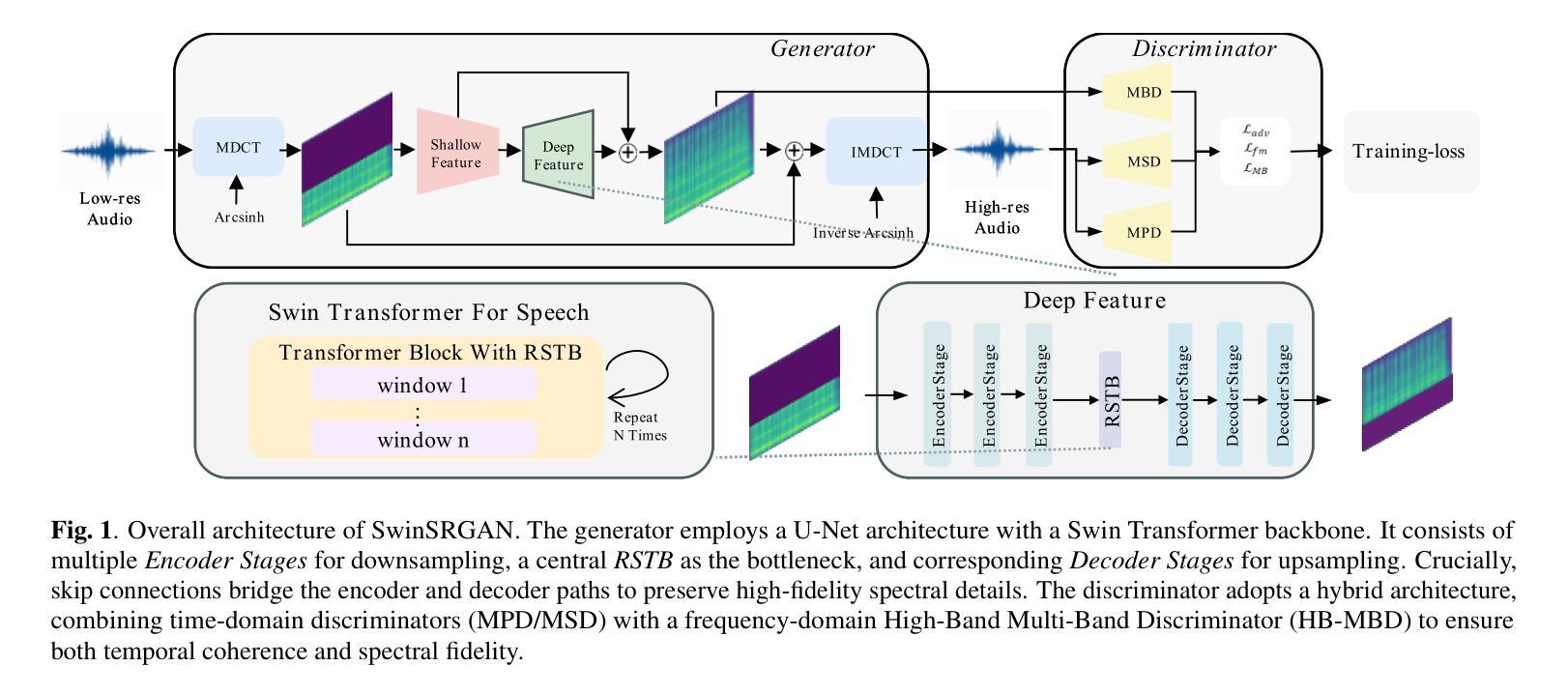
SwinSRGAN: Swin Transformer-based Generative Adversarial Network for High-Fidelity Speech Super-Resolution
Authors:Jiajun Yuan, Xiaochen Wang, Yuhang Xiao, Yulin Wu, Chenhao Hu, Xueyang Lv
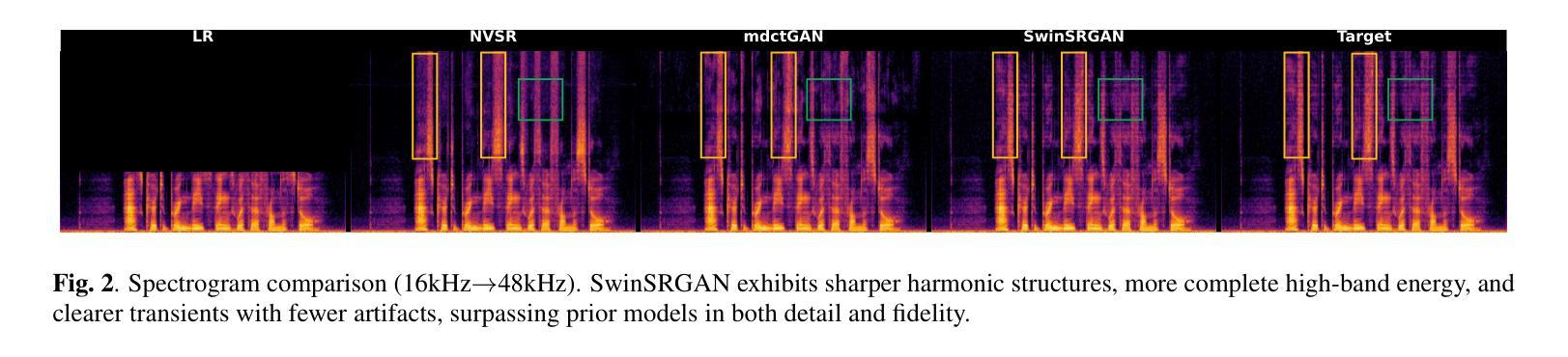
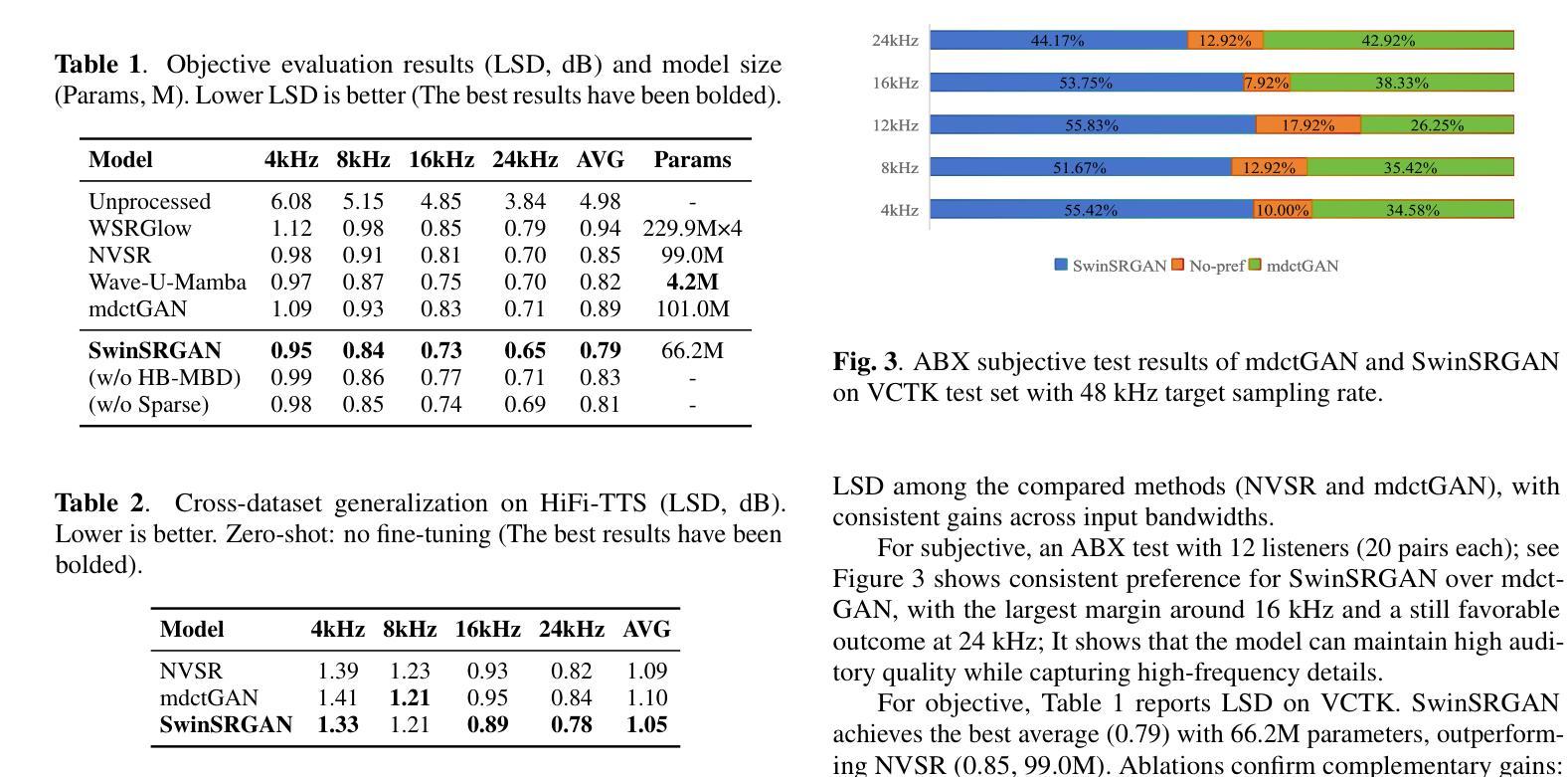
Speech super-resolution (SR) reconstructs high-frequency content from low-resolution speech signals. Existing systems often suffer from representation mismatch in two-stage mel-vocoder pipelines and from over-smoothing of hallucinated high-band content by CNN-only generators. Diffusion and flow models are computationally expensive, and their robustness across domains and sampling rates remains limited. We propose SwinSRGAN, an end-to-end framework operating on Modified Discrete Cosine Transform (MDCT) magnitudes. It is a Swin Transformer-based U-Net that captures long-range spectro-temporal dependencies with a hybrid adversarial scheme combines time-domain MPD/MSD discriminators with a multi-band MDCT discriminator specialized for the high-frequency band. We employs a sparse-aware regularizer on arcsinh-compressed MDCT to better preserve transient components. The system upsamples inputs at various sampling rates to 48 kHz in a single pass and operates in real time. On standard benchmarks, SwinSRGAN reduces objective error and improves ABX preference scores. In zero-shot tests on HiFi-TTS without fine-tuning, it outperforms NVSR and mdctGAN, demonstrating strong generalization across datasets
语音超分辨率(SR)技术从低分辨率语音信号中重建高频内容。现有系统常常在两级梅尔频谱解码器管道中存在表示不匹配的问题,并且仅由CNN生成器生成的假高频内容会出现过度平滑的情况。扩散和流模型计算开销大,其在不同领域和采样率之间的鲁棒性仍然有限。我们提出了SwinSRGAN,这是一个基于修改后的离散余弦变换(MDCT)幅度的端到端框架。它是一种基于Swin Transformer的U-Net,能够捕捉长期光谱时间依赖关系,并采用了混合对抗方案,将时域MPD/MSD鉴别器与专门针对高频频带的多频带MDCT鉴别器相结合。我们在亚辛压缩的MDCT上采用了稀疏感知正则化器,以更好地保留瞬态分量。该系统在一次传递中可将各种采样率的上采样至48 kHz,并实时运行。在标准基准测试中,SwinSRGAN降低了客观误差并提高了ABX偏好分数。在未经微调的高保真度文本到语音(HiFi-TTS)的零样本测试中,它的性能优于NVSR和mdctGAN,显示出强大的跨数据集泛化能力。
论文及项目相关链接
PDF 5 pages
Summary
本文介绍了基于Swin Transformer的端到端语音超分辨率框架SwinSRGAN。它通过结合MDCT幅度上的长时间谱时空依赖性和混合对抗方案,解决了现有系统存在的表示不匹配和过平滑问题。该框架能在单个通道中以实时方式将输入采样率提高到48kHz,同时在标准基准测试中减少了客观误差并提高了ABX偏好分数。在无需微调的情况下,SwinSRGAN在HiFi-TTS上的零样本测试表现优异,优于NVSR和mdctGAN,显示出强大的跨数据集泛化能力。
Key Takeaways
- SwinSRGAN是一个基于Swin Transformer的端到端语音超分辨率框架,用于从低分辨率语音信号重建高频内容。
- 该框架解决了现有系统存在的表示不匹配和过平滑问题,通过结合长时间谱时空依赖性和混合对抗方案,提高了语音超分辨率的效果。
- SwinSRGAN能够实时地将输入采样率提高到48kHz,满足了实时处理的需求。
- 在标准基准测试中,SwinSRGAN减少了客观误差,提高了ABX偏好分数,显示出其优异的性能。
- SwinSRGAN通过稀疏感知正则化器对arcsinh压缩的MDCT进行处理,更好地保留了瞬态成分。
- 该框架在无需微调的情况下,能够在零样本测试中获得良好的性能,显示出强大的跨数据集泛化能力。
点此查看论文截图

Multi-level SSL Feature Gating for Audio Deepfake Detection
Authors:Hoan My Tran, Damien Lolive, Aghilas Sini, Arnaud Delhay, Pierre-François Marteau, David Guennec
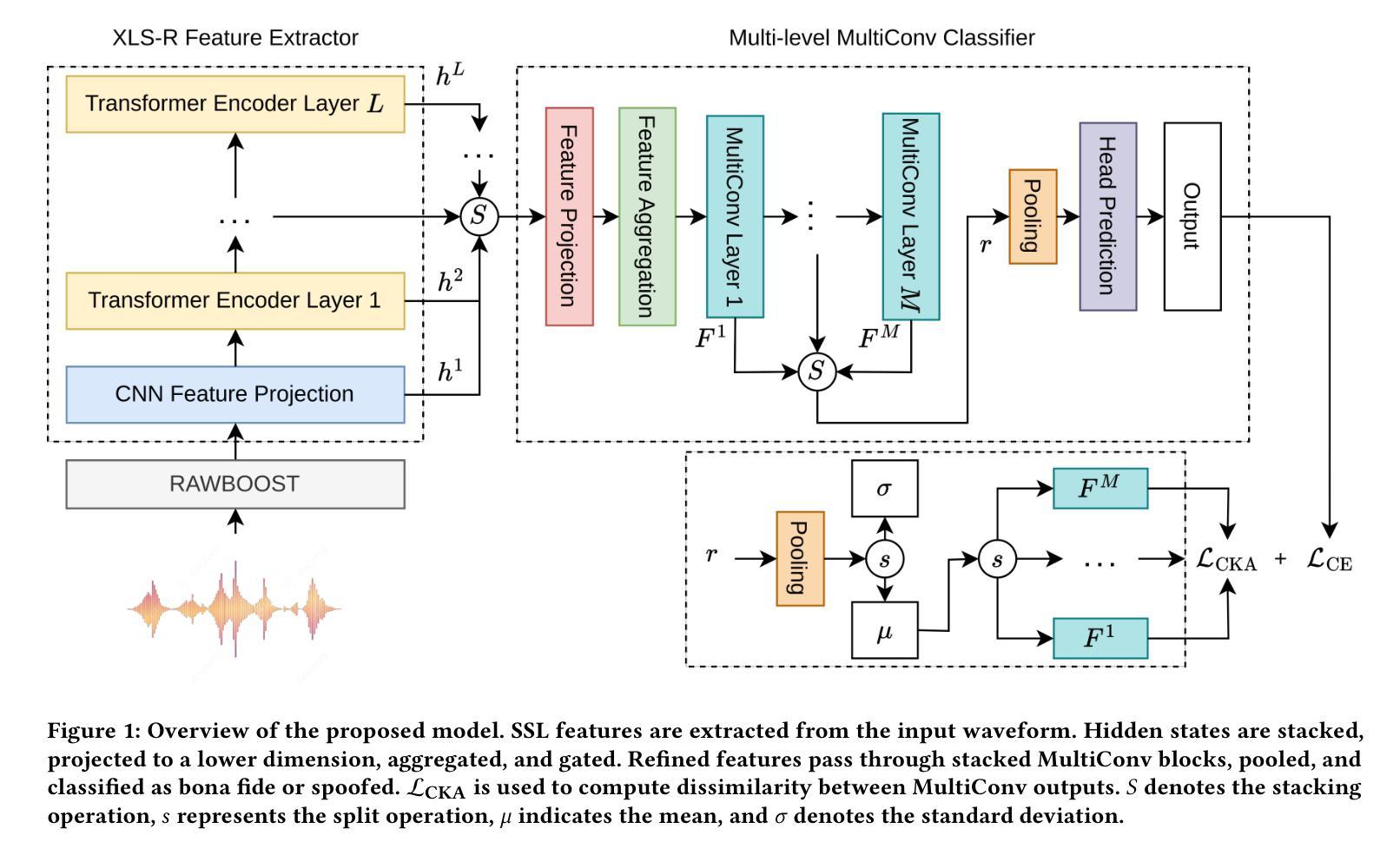
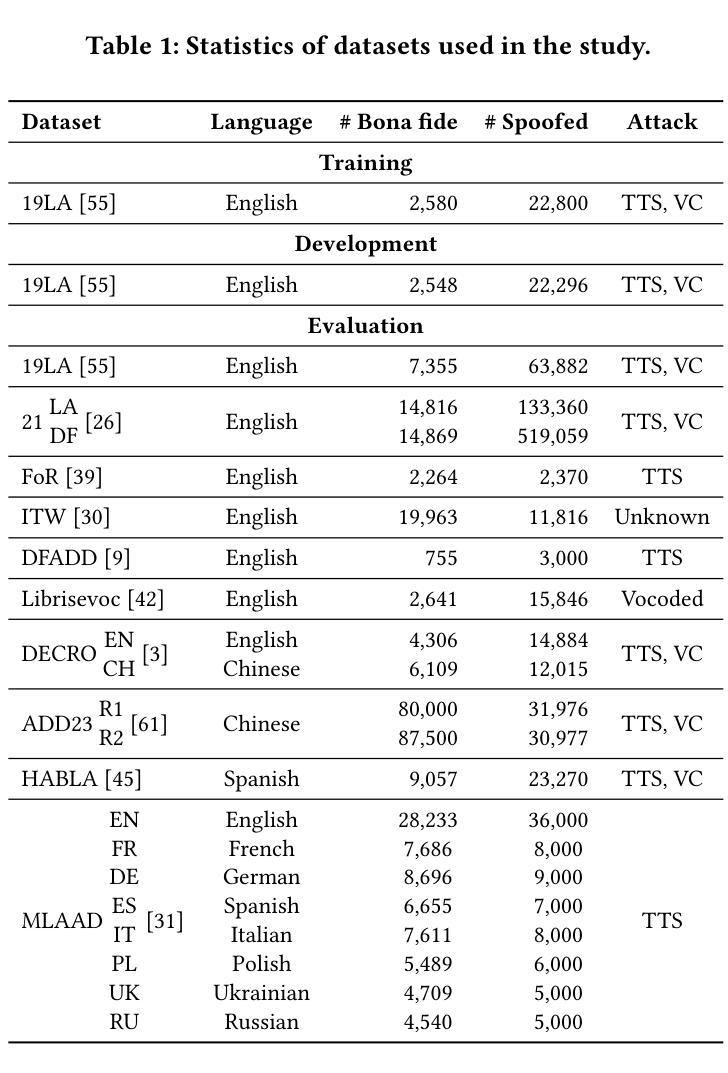
Recent advancements in generative AI, particularly in speech synthesis, have enabled the generation of highly natural-sounding synthetic speech that closely mimics human voices. While these innovations hold promise for applications like assistive technologies, they also pose significant risks, including misuse for fraudulent activities, identity theft, and security threats. Current research on spoofing detection countermeasures remains limited by generalization to unseen deepfake attacks and languages. To address this, we propose a gating mechanism extracting relevant feature from the speech foundation XLS-R model as a front-end feature extractor. For downstream back-end classifier, we employ Multi-kernel gated Convolution (MultiConv) to capture both local and global speech artifacts. Additionally, we introduce Centered Kernel Alignment (CKA) as a similarity metric to enforce diversity in learned features across different MultiConv layers. By integrating CKA with our gating mechanism, we hypothesize that each component helps improving the learning of distinct synthetic speech patterns. Experimental results demonstrate that our approach achieves state-of-the-art performance on in-domain benchmarks while generalizing robustly to out-of-domain datasets, including multilingual speech samples. This underscores its potential as a versatile solution for detecting evolving speech deepfake threats.
近期生成式人工智能领域的进展,特别是在语音合成方面,已经能够实现生成高度自然逼真、紧密模仿人声的合成语音。虽然这些创新技术辅助技术等领域的应用前景广阔,但它们也带来了重大风险,包括被误用于欺诈活动、身份盗窃和安全威胁等。目前关于欺骗检测对策的研究仍受限于对未见过的深度伪造攻击和语言的泛化能力。为解决这一问题,我们提出了一种门控机制,从语音基础XLS-R模型中提取相关特征作为前端特征提取器。对于下游后端分类器,我们采用多核门控卷积(MultiConv)来捕捉局部和全局语音特征。此外,我们还引入了中心核对齐(CKA)作为相似度度量,以强制不同MultiConv层之间学习特征的多样性。通过将CKA与我们的门控机制相结合,我们假设每个组件有助于改进对不同合成语音模式的识别。实验结果表明,我们的方法在实现域内基准测试的最先进性能的同时,也能稳健地推广到域外数据集,包括多语种语音样本。这凸显了其在检测不断发展的语音深度伪造威胁方面的通用潜力。
论文及项目相关链接
PDF This paper has been accepted by ACM MM 2025
Summary
生成式AI在语音合成领域的最新进展能够生成高度自然、逼真模仿人类声音的合成语音。尽管这些创新在辅助技术等领域具有应用前景,但它们也带来欺诈活动、身份盗用和安全威胁等风险。针对当前欺骗检测对策在应对未见过的深度伪造攻击和语言方面的局限性,我们提出一种提取语音基础XLS-R模型相关特征的门控机制作为前端特征提取器。对于下游后端分类器,我们采用多核门控卷积(MultiConv)捕捉局部和全局语音特征。此外,我们还引入中心核对齐(CKA)作为相似度度量,以强化不同MultiConv层学习特征的多样性。通过整合CKA与我们的门控机制,我们假设每个组件有助于改善对不同合成语音模式的识别。实验结果表明,我们的方法在实现领域内的基准测试时达到了最新技术水平,并且在多元化数据集上表现出强大的泛化能力,包括多语种语音样本。这突显了其作为检测不断发展的语音深度伪造威胁的通用解决方案的潜力。
Key Takeaways
- 生成式AI可以生成高度自然的合成语音,具有广泛的应用前景,但也存在被用于欺诈和身份盗用的风险。
- 当前欺骗检测对策在应对深度伪造攻击和语言方面的局限性需要新的解决方案。
- 提出的门控机制利用XLS-R模型提取相关特征,作为前端特征提取器。
- 采用多核门控卷积(MultiConv)捕捉语音的局部和全局特征。
- 引入中心核对齐(CKA)以增强不同层学习特征的多样性。
- CKA与门控机制的结合有助于提高对不同合成语音模式的识别能力。
- 实验结果表明,该方法在领域内达到最新技术水平,并具有良好的泛化能力,包括在多语种语音样本上的表现。
点此查看论文截图

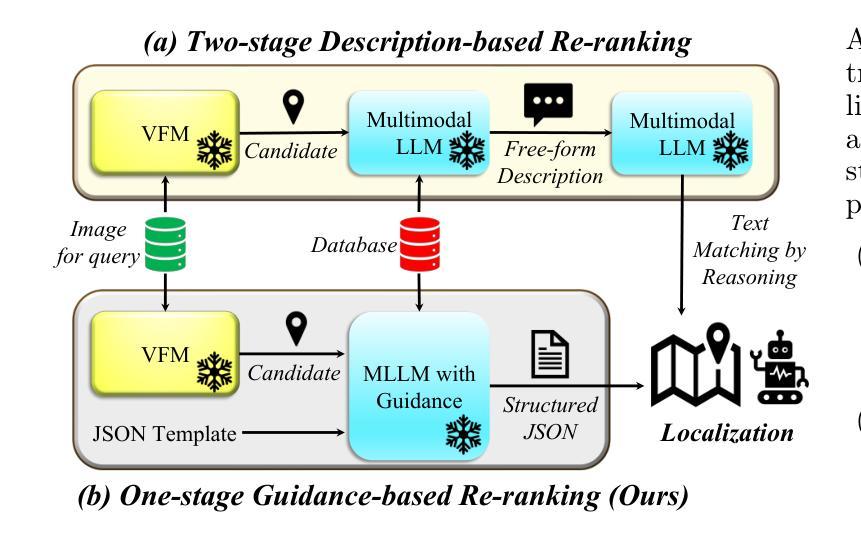
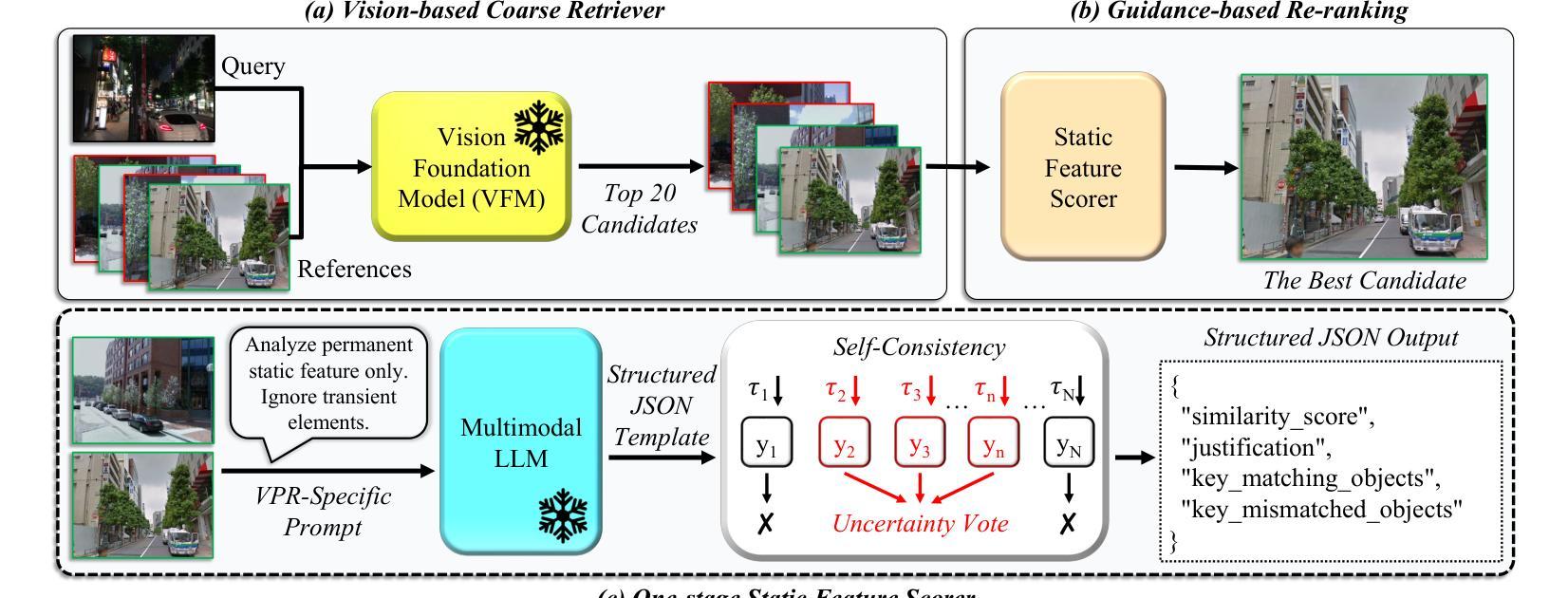
Scale, Don’t Fine-tune: Guiding Multimodal LLMs for Efficient Visual Place Recognition at Test-Time
Authors:Jintao Cheng, Weibin Li, Jiehao Luo, Xiaoyu Tang, Zhijian He, Jin Wu, Yao Zou, Wei Zhang
Visual Place Recognition (VPR) has evolved from handcrafted descriptors to deep learning approaches, yet significant challenges remain. Current approaches, including Vision Foundation Models (VFMs) and Multimodal Large Language Models (MLLMs), enhance semantic understanding but suffer from high computational overhead and limited cross-domain transferability when fine-tuned. To address these limitations, we propose a novel zero-shot framework employing Test-Time Scaling (TTS) that leverages MLLMs’ vision-language alignment capabilities through Guidance-based methods for direct similarity scoring. Our approach eliminates two-stage processing by employing structured prompts that generate length-controllable JSON outputs. The TTS framework with Uncertainty-Aware Self-Consistency (UASC) enables real-time adaptation without additional training costs, achieving superior generalization across diverse environments. Experimental results demonstrate significant improvements in cross-domain VPR performance with up to 210$\times$ computational efficiency gains.
视觉场所识别(VPR)已经从手工描述符进化到深度学习方法,但仍存在重大挑战。当前的方法,包括视觉基础模型(VFMs)和多模态大型语言模型(MLLMs),提高了语义理解,但在微调时存在计算开销大、跨域迁移能力有限的问题。为了解决这些局限性,我们提出了一种新的零样本框架,采用测试时缩放(TTS)策略,利用MLLMs的视觉语言对齐能力,通过基于指导的方法直接进行相似性评分。我们的方法通过采用结构化的提示来生成长度可控的JSON输出,消除了两阶段处理。具有不确定性感知自我一致性(UASC)的TTS框架可实现实时适应,无需额外的训练成本,在多种环境中实现了优越的泛化能力。实验结果表明,在跨域VPR性能方面实现了显著改进,计算效率提高了高达210倍。
论文及项目相关链接
摘要
本研究提出了一种新型的零样本框架,利用测试时间缩放(TTS)技术和基于引导的方法实现视觉和语言的直接相似性评分,利用多模态大型语言模型(MLLMs)的视觉语言对齐能力,以解决当前视觉定位(VPR)所面临的计算量大、跨域转移能力不足等问题。该方法使用结构化提示生成可控长度的JSON输出,并引入不确定性感知自一致性(UASC),无需额外的训练成本即可实现实时适应,显著提高了跨域环境下的VPR性能。
关键见解
- 当前视觉定位(VPR)方法虽然已从手工描述符发展到深度学习方法,但仍面临计算量大和跨域转移能力有限的挑战。
- 现有方法如视觉基础模型(VFMs)和多模态大型语言模型(MLLMs)提高了语义理解,但在精细调整时仍存在高计算开销和跨域适应性问题。
- 提出了新型的零样本框架,采用测试时间缩放(TTS)技术,利用MLLMs的视觉语言对齐能力进行直接相似性评分,解决了上述问题。
- 通过结构化提示生成长度可控的JSON输出,简化了处理流程。
- 引入的不确定性感知自一致性(UASC)使模型能够在无需额外训练成本的情况下实现实时适应。
- 实验结果表明,该框架在跨域视觉定位性能上有显著提高,计算效率提高了高达210倍。
- 该框架为未来的视觉定位研究提供了新的方向,有望推动该领域的进一步发展。
点此查看论文截图


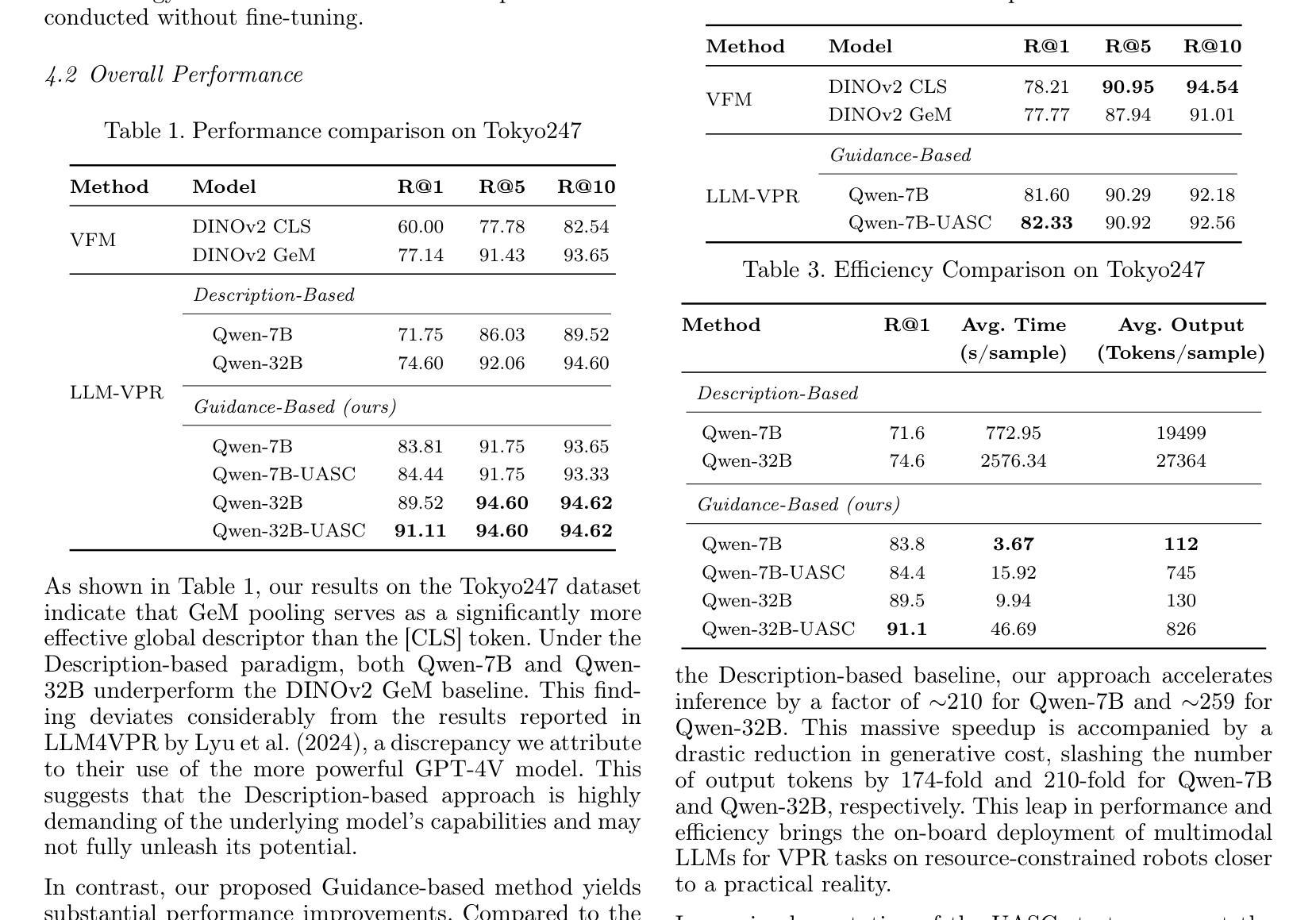
FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot
Authors:Kun Xie, Feiyu Shen, Junjie Li, Fenglong Xie, Xu Tang, Yao Hu
Current dialogue generation approaches typically require the complete dialogue text before synthesis and produce a single, inseparable speech containing all voices, making them unsuitable for interactive chat; moreover, they suffer from unstable synthesis, inaccurate speaker transitions, and incoherent prosody. In this work, we present FireRedTTS-2, a long-form streaming TTS system for multi-speaker dialogue generation, delivering stable, natural speech with reliable speaker switching and context-aware prosody. A new 12.5Hz streaming speech tokenizer accelerates training and inference, extends maximum dialogue length, encodes richer semantics to stabilize text-to-token modeling and supports high-fidelity streaming generation for real-time applications. We adopt a text-speech interleaved format, concatenating speaker-labeled text with aligned speech tokens in chronological order, and model it with a dual-transformer: a large decoder-only transformer predicts tokens at the first layer, and a smaller one completes subsequent layers. Experimental results show that FireRedTTS-2 integrates seamlessly with chat frameworks and, with minimal fine-tuning, produces emotionally expressive speech guided by implicit contextual cues. In podcast generation, it surpasses existing systems including MoonCast, Zipvoice-Dialogue, and MOSS-TTSD in objective intelligibility, speaker-turn reliability, and perceived naturalness with context-consistent prosody. Our demos are available at https://fireredteam.github.io/demos/firered_tts_2.
当前对话生成方法通常需要在合成之前拥有完整的对话文本,并生成包含所有声音的一个不可分割的语音,这使得它们不适合进行交互式聊天。此外,它们还存在合成不稳定、发言人转换不准确、语调不连贯等问题。在这项工作中,我们推出了FireRedTTS-2,这是一款用于多发言人对话生成的长形式流式TTS系统,能够生成稳定、自然的语音,具备可靠的发声人切换和语境感知的语调。一款新的12.5Hz流式语音标记器加速了训练和推理,延长了最大对话长度,丰富了语义编码,稳定了文本到标记的建模,并支持实时应用的高保真流式生成。我们采用文本语音交错格式,按时间顺序将带标签的发言者文本与对齐的语音标记连接起来,并用双变压器对其进行建模:一个大型仅解码器变压器在第一层预测标记,另一个较小的变压器完成后续层。实验结果表明,FireRedTTS-2无缝集成聊天框架,在微调最少的情况下,可以根据隐式上下文线索产生富有情感的语音。在播客生成方面,它在客观清晰度、发言人轮替可靠性和具有语境连贯性的语调感知自然度等方面超越了现有的系统,包括MoonCast、Zipvoice-Dialogue和MOSS-TTSD。我们的演示视频可在网站链接观看。
论文及项目相关链接
摘要
本文介绍了FireRedTTS-2,一个用于多说话者对话生成的长形式流式TTS系统。相较于传统对话生成方法,该系统能够稳定、自然地合成语音,支持可靠的说话者切换和上下文感知的语调。采用12.5Hz流式语音标记器加速训练和推理,扩展最大对话长度,编码丰富的语义以稳定文本到标记的建模,并支持高保真流式生成用于实时应用。通过文本语音交织格式,按时间顺序连接说话者标记的文本与对齐的语音标记,并用双变压器模型进行建模。实验结果显示,FireRedTTS-2无缝集成聊天框架,经过最小微调即可产生受隐性上下文线索引导的情感表达语音。在播客生成方面,它在客观清晰度、说话者切换可靠性和上下文一致性的语调感知自然性等方面超过了MoonCast、Zipvoice-Dialogue和MOSS-TTSD等现有系统。我们的演示视频可在 https://fireredteam.github.io/demos/firered_tts_2 查看。
关键见解
- FireRedTTS-2是一个长形式流式TTS系统,用于多说话者对话生成。
- 系统能稳定、自然地合成语音,支持可靠说话者切换和上下文感知的语调。
- 采用12.5Hz流式语音标记器加速训练、扩展对话长度并编码丰富的语义。
- 通过文本语音交织格式与双变压器模型进行建模,提高性能。
- FireRedTTS-2可无缝集成聊天框架,并产生受上下文引导的情感表达语音。
- 在播客生成方面,该系统在清晰度、说话者切换和语调自然性等方面超越了现有系统。
点此查看论文截图

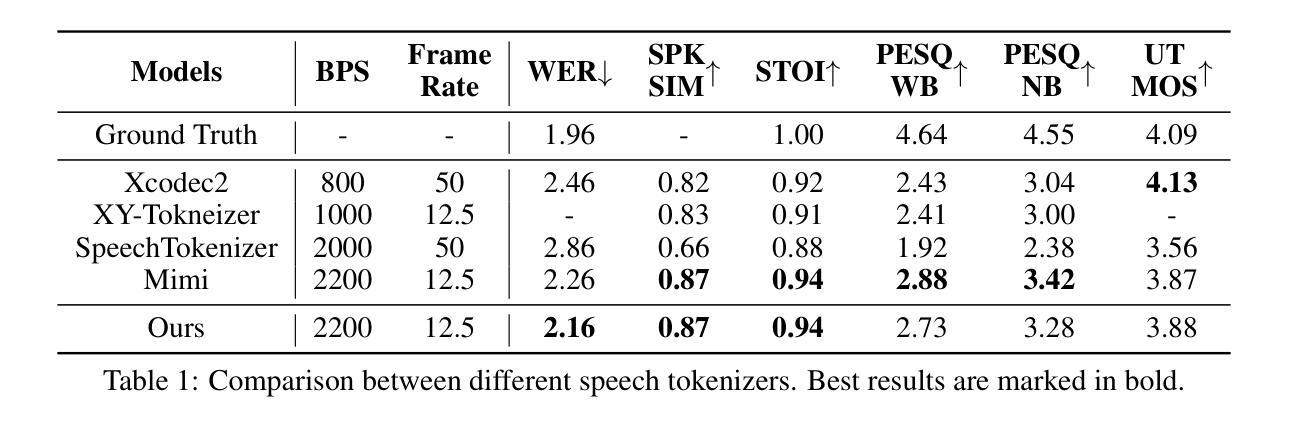
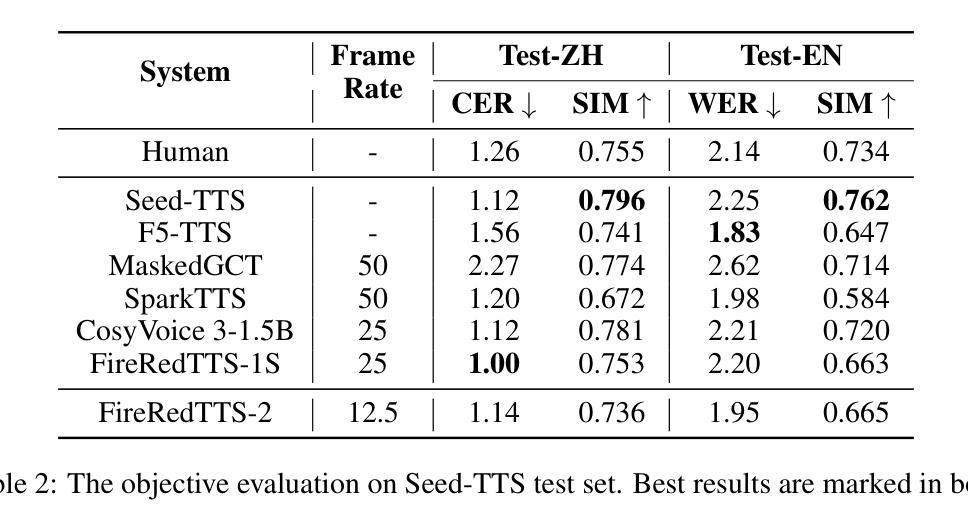

SimulMEGA: MoE Routers are Advanced Policy Makers for Simultaneous Speech Translation
Authors:Chenyang Le, Bing Han, Jinshun Li, Songyong Chen, Yanmin Qian
Simultaneous Speech Translation (SimulST) enables real-time cross-lingual communication by jointly optimizing speech recognition and machine translation under strict latency constraints. Existing systems struggle to balance translation quality, latency, and semantic coherence, particularly in multilingual many-to-many scenarios where divergent read and write policies hinder unified strategy learning. In this paper, we present SimulMEGA (Simultaneous Generation by Mixture-of-Experts Gating), an unsupervised policy learning framework that combines prefix-based training with a Mixture-of-Experts refiner to learn effective read and write decisions in an implicit manner, without adding inference-time overhead. Our design requires only minimal modifications to standard transformer architectures and generalizes across both speech-to-text and text-to-speech streaming tasks. Through comprehensive evaluation on six language pairs, our 500M parameter speech-to-text model outperforms the Seamless baseline, achieving under 7 percent BLEU degradation at 1.5 seconds average lag and under 3 percent at 3 seconds. We further demonstrate the versatility of SimulMEGA by extending it to streaming TTS with a unidirectional backbone, yielding superior latency quality tradeoffs.
同时语音翻译(SimulST)通过联合优化语音识别和机器翻译,在严格的延迟限制下实现实时跨语言交流。现有系统在平衡翻译质量、延迟和语义连贯性方面存在困难,特别是在多语言多对多的场景中,不同的读取和写入策略阻碍了统一策略学习。在本文中,我们提出了SimulMEGA(基于专家混合门控的实时生成),这是一种无监督的策略学习框架,它将基于前缀的训练与专家混合精炼器相结合,以隐式的方式学习有效的读取和写入决策,而不会增加推理时间开销。我们的设计只需要对标准变压器架构进行最小限度的修改,就可以推广到语音到文本和文本到语音的流式处理任务。通过对六种语言对的全面评估,我们的5亿参数语音到文本模型的性能超过了无缝基线,在平均延迟1.5秒的情况下,BLEU得分降低不到7%,在3秒延迟的情况下,降低不到3%。我们通过在具有单向骨干的流式TTS中扩展SimulMEGA,进一步证明了其通用性,获得了更好的延迟质量权衡。
论文及项目相关链接
Summary
本文介绍了SimulMEGA(基于专家门控的实时生成方法),这是一种用于解决多语言同时翻译问题的新方法。SimulMEGA结合了前缀训练与专家混合精炼器,在无需额外推理时间开销的情况下,可以隐式学习读写决策策略。通过对标准转换器架构进行少量修改,该模型可在语音到文本和文本到语音的流媒体任务中通用化。在六种语言对的综合评估中,我们的语音到文本模型在平均延迟仅为几秒的情况下实现了出色的性能表现。此外,我们还展示了SimulMEGA在具有单向骨干的流式文本到语音合成中的通用性。
Key Takeaways
- SimulMEGA解决了同时翻译中存在的问题,包括平衡翻译质量、延迟和语义连贯性。
- 该方法结合了前缀训练与专家混合精炼器,能隐式学习读写决策策略。
- SimulMEGA仅需对标准转换器架构进行最小修改,即可应用于语音到文本和文本到语音的流媒体任务。
- 在六种语言对的测试中,SimulMEGA的语音到文本模型在较短延迟下实现了高翻译质量。
- SimulMEGA通过利用单向骨干,展示了在流式文本到语音合成中的优异表现。
- 该方法在未增加推理时间开销的前提下提高了翻译性能。
点此查看论文截图

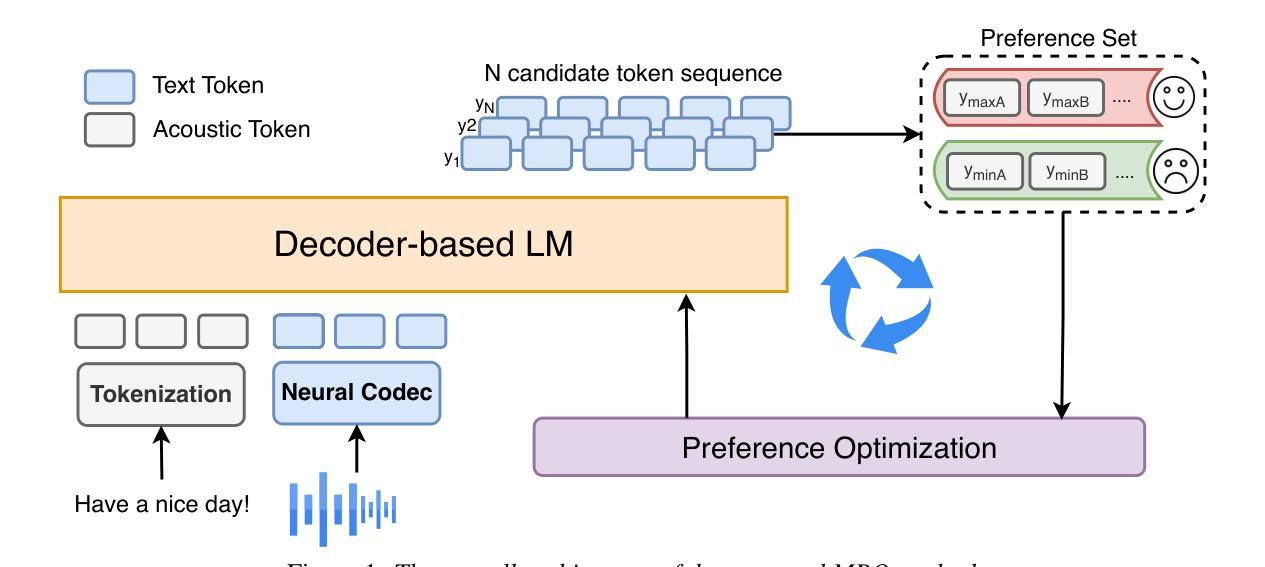
MPO: Multidimensional Preference Optimization for Language Model-based Text-to-Speech
Authors:Kangxiang Xia, Xinfa Zhu, Jixun Yao, Lei Xie
In recent years, text-to-speech (TTS) has seen impressive advancements through large-scale language models, achieving human-level speech quality. Integrating human feedback has proven effective for enhancing robustness in these systems. However, current approaches face challenges in optimizing TTS with preference data across multiple dimensions and often suffer from performance degradation due to overconfidence in rewards. We propose Multidimensional Preference Optimization (MPO) to better align TTS systems with human preferences. MPO introduces a preference set that streamlines the construction of data for multidimensional preference optimization, enabling alignment with multiple dimensions. Additionally, we incorporate regularization during training to address the typical degradation issues in DPO-based approaches. Our experiments demonstrate MPO’s effectiveness, showing significant improvements in intelligibility, speaker similarity, and prosody compared to baseline systems.
近年来,文本到语音(TTS)技术通过大规模语言模型取得了令人印象深刻的进步,实现了人类级别的语音质量。集成人类反馈已经证明可以提高这些系统的稳健性。然而,当前的方法在优化具有多个维度的偏好数据时面临挑战,并且由于过于依赖奖励而导致性能下降。我们提出多维度偏好优化(MPO)来更好地将TTS系统与人类偏好对齐。MPO引入了一个偏好集,简化了用于多维度偏好优化的数据构建,实现了与多个维度的对齐。此外,我们在训练过程中引入了正则化,以解决DPO方法常见的退化问题。我们的实验证明了MPO的有效性,与基线系统相比,在清晰度、说话人相似度和语调方面都有显著提高。
论文及项目相关链接
PDF Accepted by NCMMSC2025
Summary
近年来,文本转语音(TTS)技术通过大规模语言模型取得了显著进展,实现了人类水平的语音质量。通过整合人类反馈提高了系统的稳健性。然而,当前的方法在优化具有多维度偏好数据的TTS时面临挑战,并常因过度自信于奖励而出现性能下降。为此,我们提出多维度偏好优化(MPO)以更好地使TTS系统与人类偏好对齐。MPO引入偏好集,简化了用于多维度偏好优化的数据构建,实现了与多个维度的对齐。此外,我们在训练过程中加入了正则化,以解决DPO方法常见的退化问题。实验证明MPO的有效性,在可懂度、说话人相似性和语调方面相比基线系统有明显提升。
Key Takeaways
- 文本转语音(TTS)技术近年通过大规模语言模型取得显著进展。
- 整合人类反馈能提高TTS系统的稳健性。
- 当前TTS优化面临多维度偏好数据优化挑战及性能下降问题。
- 提出多维度偏好优化(MPO)方法以更好地使TTS系统与人类偏好对齐。
- MPO引入偏好集,简化数据构建,实现与多个维度的对齐。
- 在训练过程中加入正则化,解决DPO方法常见的退化问题。
点此查看论文截图



Towards Improved Speech Recognition through Optimized Synthetic Data Generation
Authors:Yanis Perrin, Gilles Boulianne
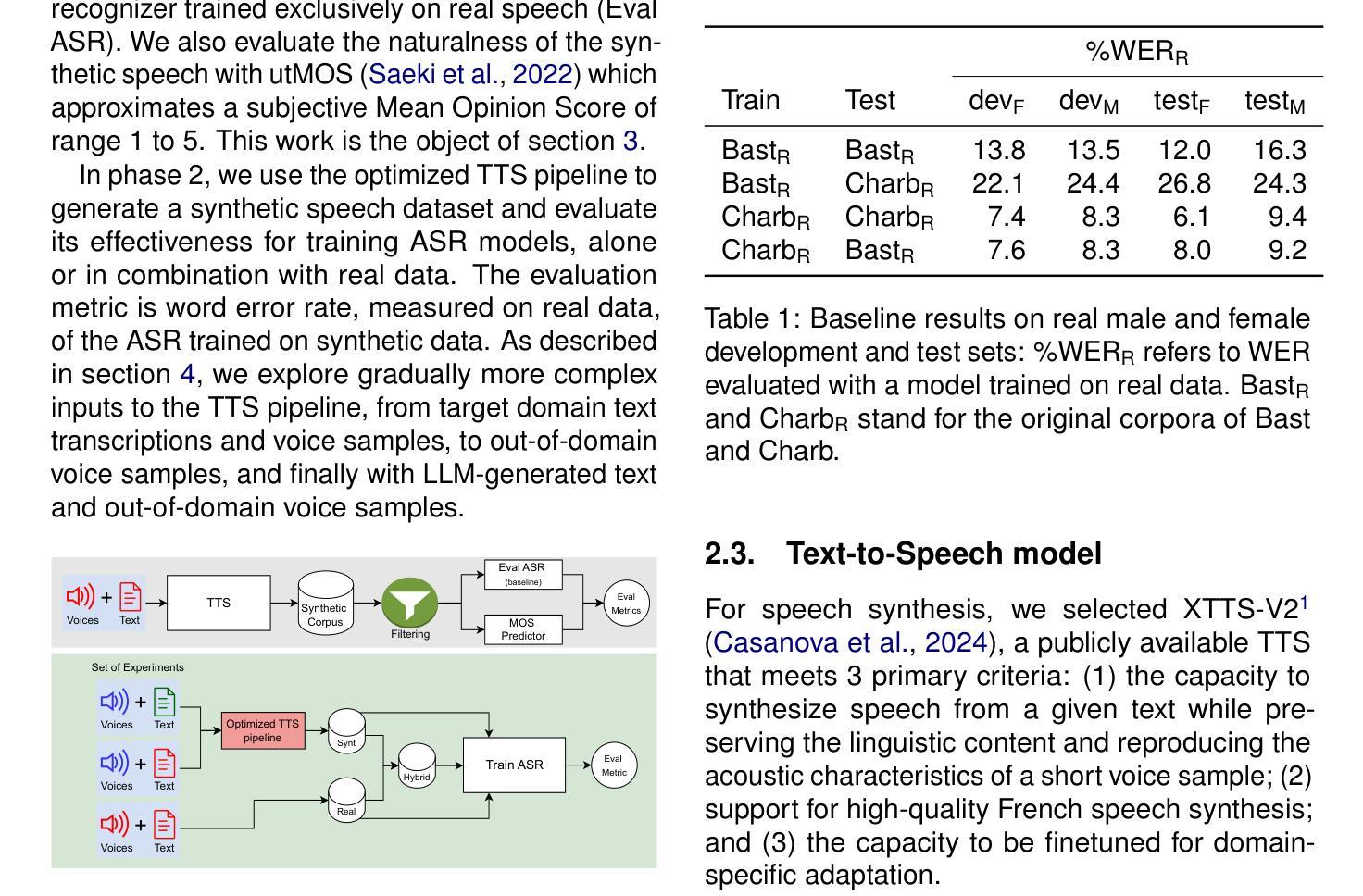
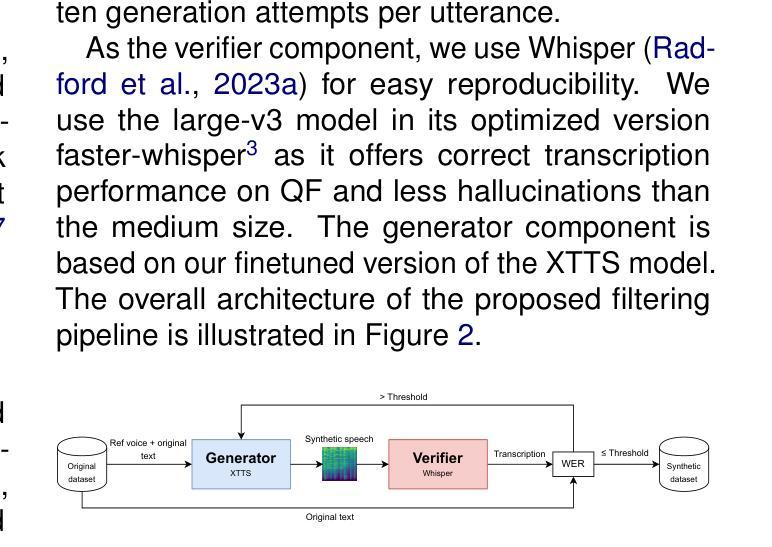
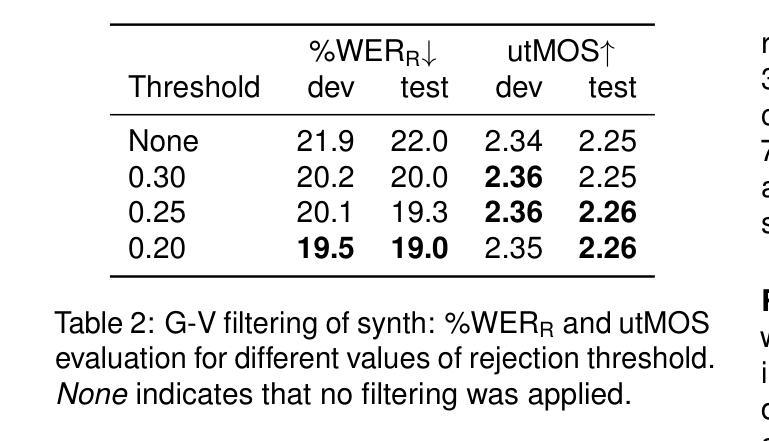
Supervised training of speech recognition models requires access to transcribed audio data, which often is not possible due to confidentiality issues. Our approach to this problem is to generate synthetic audio from a text-only corpus using a state-of-the-art text-to-speech model with voice cloning capabilities. Our goal is to achieve automatic speech recognition (ASR) performance comparable to models trained on real data. We explore ways to optimize synthetic data generation through finetuning, filtering and evaluation, and its use for training an end-to-end encoder-decoder ASR model. Experiments were conducted using two datasets of spontaneous, conversational speech in Qu'ebec French. We show that improving data generation leads to large improvements in the final ASR system trained on synthetic data.
语音识别的监督训练模型需要访问转录的音频数据,但由于保密问题,这通常是不可能的。我们解决此问题的方法是利用具有语音克隆功能的最新文本到语音模型,从仅包含文本的语料库中生成合成音频。我们的目标是实现与在真实数据上训练的模型相当的自动语音识别(ASR)性能。我们探索了通过微调、过滤和评估优化合成数据生成的方法,以及其用于训练端到端编码器-解码器ASR模型的应用。实验使用了魁北克法语的两套自然对话语音数据集。我们证明了改进数据生成可以大大提高在合成数据上训练的最终ASR系统的性能。
论文及项目相关链接
PDF 12 pages, 3 figures
Summary
本文探讨了由于保密问题,语音识别模型无法获取转录音频数据的问题。研究团队通过采用最新语音克隆技术,生成基于纯文本语料库的合成音频数据。目标是实现与真实数据训练的模型相当的自动语音识别(ASR)性能。研究团队通过微调、过滤和评估优化合成数据的生成,并利用这些合成数据训练端到端的编码器解码器ASR模型。实验采用魁北克法语的两份自然对话语音数据集,证明了改进数据生成对基于合成数据的最终ASR系统性能有显著提升。
Key Takeaways
- 研究团队解决了因保密问题无法获取转录音频数据的问题。
- 研究采用了最新语音克隆技术,生成基于纯文本语料库的合成音频数据。
- 研究目标是实现与真实数据训练的模型相当的自动语音识别(ASR)性能。
- 通过微调、过滤和评估优化了合成数据的生成过程。
- 利用合成数据训练了端到端的编码器解码器ASR模型。
- 实验采用了魁北克法语的两份自然对话语音数据集。
点此查看论文截图


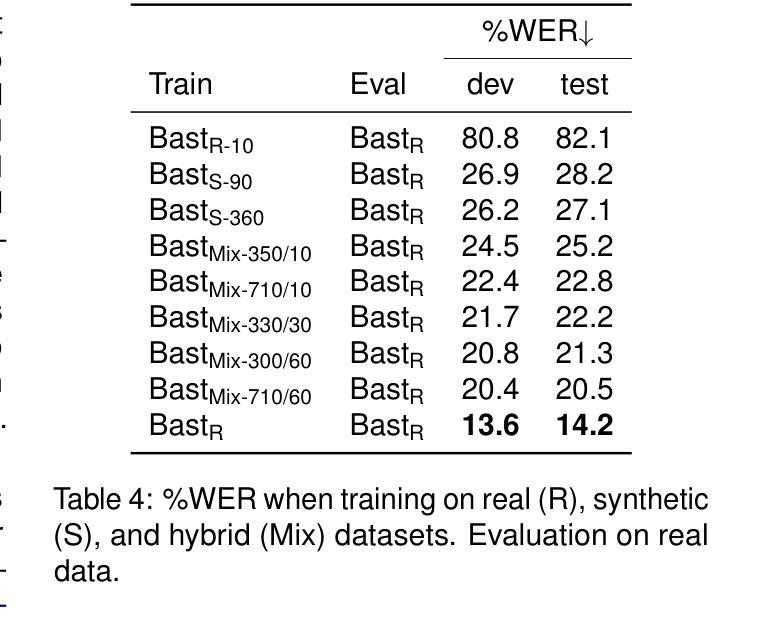


CLEAR: Continuous Latent Autoregressive Modeling for High-quality and Low-latency Speech Synthesis
Authors:Chun Yat Wu, Jiajun Deng, Guinan Li, Qiuqiang Kong, Simon Lui
Autoregressive (AR) language models have emerged as powerful solutions for zero-shot text-to-speech (TTS) synthesis, capable of generating natural speech from a few seconds of audio prompts. However, conventional AR-based TTS systems relying on discrete audio tokens face the challenge of lossy compression during tokenization, requiring longer discrete token sequences to capture the same information as continuous ones, which adds inference latency and complicates AR modeling. To address this challenge, this paper proposes the Continuous Latent Autoregressive model (CLEAR), a unified zero-shot TTS framework that directly models continuous audio representations. More specifically, CLEAR introduces an enhanced variational autoencoder with shortcut connections, which achieves a high compression ratio to map waveforms into compact continuous latents. A lightweight MLP-based rectified flow head that operates independently for each hidden state is presented to model the continuous latent probability distribution, and trained jointly with the AR model within a single-stage framework. Experiments show that the proposed zero-shot CLEAR TTS can synthesize high-quality speech with low latency. Compared to state-of-the-art (SOTA) TTS models, CLEAR delivers competitive performance in robustness, speaker similarity and naturalness, while offering a lower real-time factor (RTF). In particular, CLEAR achieves SOTA results on the LibriSpeech test-clean dataset, with a word error rate of 1.88% and an RTF of 0.29. Moreover, CLEAR facilitates streaming speech synthesis with a first-frame delay of 96ms, while maintaining high-quality speech synthesis.
自回归(AR)语言模型已作为零样本文本到语音(TTS)合成的强大解决方案而出现,它能够根据几秒钟的音频提示生成自然语音。然而,传统的基于AR的TTS系统依赖于离散音频令牌面临着令牌化过程中的有损压缩挑战,需要更长的离散令牌序列来捕获与连续令牌相同的信息,这增加了推理延迟并复杂化了AR建模。为了解决这一挑战,本文提出了连续潜在自回归模型(CLEAR),这是一个统一的零样本TTS框架,直接对连续音频表示进行建模。更具体地说,CLEAR引入了一个带有快捷方式连接的高级变分自动编码器,实现了高压缩比,将波形映射到紧凑的连续潜在空间。还提出了一种基于MLP的校正流头,它针对每个隐藏状态独立运行,用于对连续潜在概率分布进行建模,并与AR模型在同一个单一阶段框架内联合训练。实验表明,所提出的零样本CLEAR TTS可以合成高质量语音,并具有低延迟。与最先进的(SOTA)TTS模型相比,CLEAR在稳健性、说话人相似性和自然性方面表现出竞争力,同时提供了更低的实时因子(RTF)。特别是在LibriSpeech测试清洁数据集上,CLEAR取得了最先进的成果,词错误率为1.88%,RTF为0.29%。此外,CLEAR可实现流式语音合成,首帧延迟为96毫秒,同时保持高质量语音合成。
论文及项目相关链接
PDF Preprint
Summary
连续潜在自回归模型(CLEAR)是一种零样本文本-语音(TTS)合成的新解决方案,它直接对连续音频表示进行建模。通过使用增强型变分自编码器与快捷连接,以及基于MLP的校正流头,CLEAR实现了波形到紧凑连续潜在空间的映射,并在单阶段框架中与AR模型联合训练。实验表明,CLEAR能合成高质量语音,具有低延迟。在LibriSpeech测试集上,CLEAR表现卓越,词错误率为1.88%,实时因子为0.29。此外,CLEAR支持流式语音合成,首帧延迟仅为96毫秒,同时保持高质量语音合成。
Key Takeaways
- 自回归(AR)语言模型已成为零样本TTS合成的强大解决方案。
- 传统AR-based TTS系统面临离散音频令牌损失压缩的挑战。
- CLEAR模型直接对连续音频表示进行建模,解决了令牌化过程中的损失压缩问题。
- CLEAR使用增强型变分自编码器和基于MLP的校正流头进行音频表示。
- CLEAR实现了波形到紧凑连续潜在空间的映射,提高了压缩比。
- CLEAR在LibriSpeech测试集上表现卓越,具有较低的词错误率和实时因子。
- CLEAR支持流式语音合成,具有较低的首帧延迟,同时保持高质量语音合成。
点此查看论文截图


Unseen Speaker and Language Adaptation for Lightweight Text-To-Speech with Adapters
Authors:Alessio Falai, Ziyao Zhang, Akos Gangoly
In this paper we investigate cross-lingual Text-To-Speech (TTS) synthesis through the lens of adapters, in the context of lightweight TTS systems. In particular, we compare the tasks of unseen speaker and language adaptation with the goal of synthesising a target voice in a target language, in which the target voice has no recordings therein. Results from objective evaluations demonstrate the effectiveness of adapters in learning language-specific and speaker-specific information, allowing pre-trained models to learn unseen speaker identities or languages, while avoiding catastrophic forgetting of the original model’s speaker or language information. Additionally, to measure how native the generated voices are in terms of accent, we propose and validate an objective metric inspired by mispronunciation detection techniques in second-language (L2) learners. The paper also provides insights into the impact of adapter placement, configuration and the number of speakers used.
在这篇论文中,我们从适配器的角度探讨了轻量级TTS系统中的跨语言文本到语音(TTS)合成。特别是,我们比较了未见说话人和语言适配的任务,目标是合成目标语言中的目标语音,其中目标语音没有相应的录音。客观评估的结果证明了适配器在学习特定语言和特定说话人信息方面的有效性,使得预训练模型能够学习未知的说话人或语言,同时避免对原始模型的说话人或语言信息的灾难性遗忘。此外,为了衡量生成语音的口音有多地道,我们提出并验证了一种受第二语言学习者发音错误检测技术启发的客观指标。本文还提供了关于适配器位置、配置以及使用说话人数量等方面的见解。
论文及项目相关链接
PDF Accepted at IEEE MLSP 2025
Summary
本文探讨了基于适配器的跨语言文本转语音(TTS)合成,在轻量级TTS系统的背景下,对比了未见说话人和语言适配的任务,旨在合成目标语言的目标声音,其中目标声音没有相应的录音。研究结果证明了适配器在学习语言特性和说话人特性信息方面的有效性,能够让预训练模型学习未知的说话人或语言,同时避免对原始模型的说话人或语言信息遗忘。此外,为评估生成声音的口音本地化程度,本文受二语学习者发音错误检测技术的启发,提出并验证了一项客观指标。本文还深入探讨了适配器的位置、配置以及使用说话人的数量所产生的影响。
Key Takeaways
- 适配器在跨语言TTS合成中展现有效性,能学习语言特性和说话人特性。
- 适配器能让预训练模型适应未见过的说话人或语言,同时保留原有知识。
- 提出了一项基于二语学习者发音错误检测技术的口音评估客观指标。
- 适配器的位置、配置以及使用说话人的数量对TTS性能有重要影响。
- 适配器有助于避免灾难性遗忘,即原有模型的说话人或语言信息不会丢失。
- 在跨语言TTS合成中,适配器的应用有助于提高语音合成的质量和效率。
- 研究结果对TTS系统的进一步优化和改进具有指导意义。
点此查看论文截图




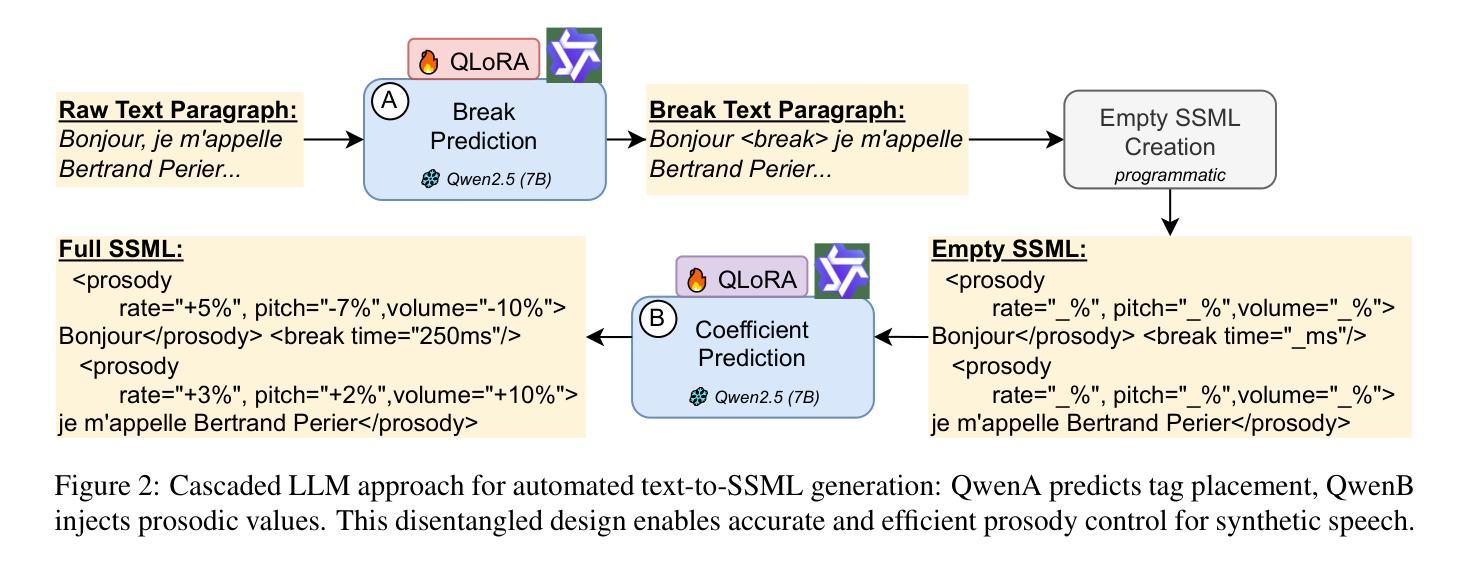
Improving French Synthetic Speech Quality via SSML Prosody Control
Authors:Nassima Ould Ouali, Awais Hussain Sani, Ruben Bueno, Jonah Dauvet, Tim Luka Horstmann, Eric Moulines
Despite recent advances, synthetic voices often lack expressiveness due to limited prosody control in commercial text-to-speech (TTS) systems. We introduce the first end-to-end pipeline that inserts Speech Synthesis Markup Language (SSML) tags into French text to control pitch, speaking rate, volume, and pause duration. We employ a cascaded architecture with two QLoRA-fine-tuned Qwen 2.5-7B models: one predicts phrase-break positions and the other performs regression on prosodic targets, generating commercial TTS-compatible SSML markup. Evaluated on a 14-hour French podcast corpus, our method achieves 99.2% F1 for break placement and reduces mean absolute error on pitch, rate, and volume by 25-40% compared with prompting-only large language models (LLMs) and a BiLSTM baseline. In perceptual evaluation involving 18 participants across over 9 hours of synthesized audio, SSML-enhanced speech generated by our pipeline significantly improves naturalness, with the mean opinion score increasing from 3.20 to 3.87 (p < 0.005). Additionally, 15 of 18 listeners preferred our enhanced synthesis. These results demonstrate substantial progress in bridging the expressiveness gap between synthetic and natural French speech. Our code is publicly available at https://github.com/hi-paris/Prosody-Control-French-TTS.
尽管近期有所进展,但由于商业文本到语音(TTS)系统中韵律控制有限,合成语音往往缺乏表现力。我们引入了首个端到端的管道,通过向法语文本插入语音合成标记语言(SSML)标签来控制音调、语速、音量和暂停持续时间。我们采用级联架构,使用两个微调过的QLoRA Qwen 2.5-7B模型:一个用于预测短语断点位置,另一个则对韵律目标进行回归,生成与商业TTS兼容的SSML标记。在14小时的法语播客语料库上进行评估,我们的方法在断点放置方面达到了99.2%的F1分数,与仅使用提示的大型语言模型(LLM)和BiLSTM基线相比,在音调、速度和音量方面的平均绝对误差降低了25-40%。在涉及18名参与者、超过9小时合成音频的感知评估中,通过我们的管道生成的SSML增强语音的自然度显著提高,平均意见分数从3.20提高到3.87(p < 0.005)。此外,18名听众中有15人更喜欢我们增强的合成语音。这些结果表明,在缩小合成法语和自然法语之间表现力差距方面取得了实质性进展。我们的代码可在https://github.com/hi-paris/Prosody-Control-French-TTS上公开访问。
论文及项目相关链接
PDF 13 pages, 9 figures, 6 tables. Accepted for presentation at ICNLSP 2025 (Odense, Denmark). Code and demo: https://github.com/hi-paris/Prosody-Control-French-TTS. ACM Class: I.2.7; H.5.5
摘要
文本引入了一种端到端的管道,通过插入语音合成标记语言(SSML)标签来控制法语文本的音调、语速、音量和停顿时间,从而弥补了商业文本转语音(TTS)系统中表达能力的有限性。采用级联架构,通过两个微调过的Qwen 2.5-7B模型,一个预测语句断点位置,另一个对语调目标进行回归,生成与商业TTS兼容的SSML标记。在14小时法语播客语料库上进行评估,该方法在断点放置方面达到99.2%的F1分数,与仅使用提示的大型语言模型(LLM)和BiLSTM基线相比,在音调、语速和音量方面的平均绝对误差降低了25-40%。在涉及18名参与者、超过9小时合成音频的感知评估中,通过我们的管道生成的SSML增强语音的自然度显著提高,平均意见分数从3.20提高到3.87(p<0.005)。此外,有15名听众更喜欢我们增强的合成效果。该研究显著缩小了合成法语和自然法语在表达力方面的差距。相关代码已公开提供。
要点掌握
- 商业TTS系统存在表达能力的局限性,缺乏语调控制。
- 引入了一种新的端到端管道,使用SSML标签增强法语的语调控制。
- 采用级联架构和QLoRA微调模型,实现精准地预测语句断点位置和语调目标回归。
- 在法语播客语料库上的评估显示,该方法在断点放置、语调控制方面表现出色。
- 与其他模型相比,该方法在音调、语速和音量方面有明显改进。
- 感知评估显示,通过该管道生成的语音自然度显著提高,获得大部分听众的偏好。
点此查看论文截图



RephraseTTS: Dynamic Length Text based Speech Insertion with Speaker Style Transfer
Authors:Neeraj Matiyali, Siddharth Srivastava, Gaurav Sharma
We propose a method for the task of text-conditioned speech insertion, i.e. inserting a speech sample in an input speech sample, conditioned on the corresponding complete text transcript. An example use case of the task would be to update the speech audio when corrections are done on the corresponding text transcript. The proposed method follows a transformer-based non-autoregressive approach that allows speech insertions of variable lengths, which are dynamically determined during inference, based on the text transcript and tempo of the available partial input. It is capable of maintaining the speaker’s voice characteristics, prosody and other spectral properties of the available speech input. Results from our experiments and user study on LibriTTS show that our method outperforms baselines based on an existing adaptive text to speech method. We also provide numerous qualitative results to appreciate the quality of the output from the proposed method.
我们提出了一种针对文本条件语音插入任务的方法,即在输入语音样本中插入一个语音样本,该插入受相应完整文本转录的制约。该任务的一个示例用例是在相应文本转录进行更正时更新语音音频。所提出的方法采用基于转换器的非自回归方法,允许在推理过程中根据文本转录和现有部分输入的语速动态确定可变长度的语音插入。它能够保持说话人的声音特征、语调和其他现有语音输入的频谱特性。在LibriTTS上进行的实验和用户研究的结果表明,我们的方法优于基于现有自适应文本到语音方法的基线。我们还提供了许多定性结果,以评估所提出方法的输出质量。
论文及项目相关链接
总结
提出一种用于文本条件语音插入任务的方法,即根据相应的完整文本转录在输入语音样本中插入语音样本。该方法的用例是当对相应的文本转录进行更正时,更新语音音频。该方法采用基于转换器的非自回归方法,允许在推理过程中根据文本转录和现有部分输入的语速动态确定可变长度的语音插入。它能够保持说话人的语音特征、语调和其他光谱属性。在LibriTTS上的实验和用户研究结果证明,该方法优于基于现有自适应文本到语音方法的基线。还提供许多定性结果来展示所提出方法的输出质量。
要点
- 提出了文本条件语音插入的新方法,适用于插入与文本转录相对应的语音样本。
- 方法采用基于转换器的非自回归方式,允许动态确定语音插入的长度。
- 方法能基于现有部分输入和文本转录保持语音的说话人特征、语调和其他光谱属性。
- 在LibriTTS数据集上的实验和用户研究证明该方法性能优于现有基线方法。
- 通过提供的定性结果展示了该方法的良好输出质量。
- 这种技术可以应用于语音编辑和语音替换等场景,具有广泛的应用前景。
点此查看论文截图



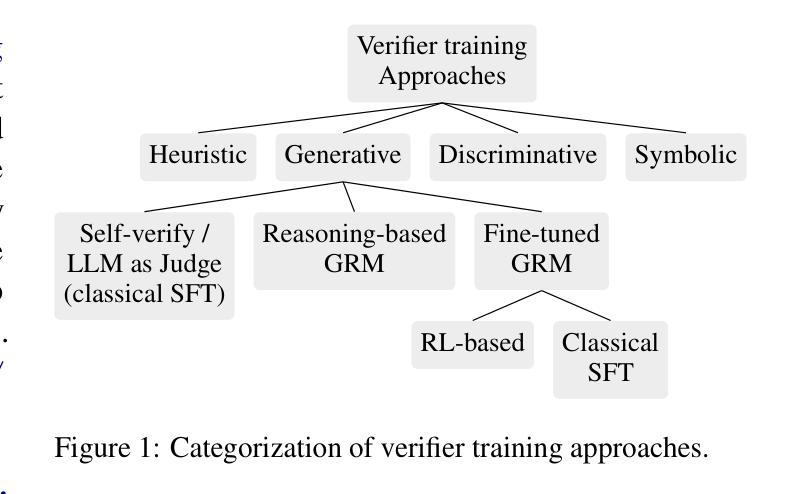
Trust but Verify! A Survey on Verification Design for Test-time Scaling
Authors:V Venktesh, Mandeep Rathee, Avishek Anand
Test-time scaling (TTS) has emerged as a new frontier for scaling the performance of Large Language Models. In test-time scaling, by using more computational resources during inference, LLMs can improve their reasoning process and task performance. Several approaches have emerged for TTS such as distilling reasoning traces from another model or exploring the vast decoding search space by employing a verifier. The verifiers serve as reward models that help score the candidate outputs from the decoding process to diligently explore the vast solution space and select the best outcome. This paradigm commonly termed has emerged as a superior approach owing to parameter free scaling at inference time and high performance gains. The verifiers could be prompt-based, fine-tuned as a discriminative or generative model to verify process paths, outcomes or both. Despite their widespread adoption, there is no detailed collection, clear categorization and discussion of diverse verification approaches and their training mechanisms. In this survey, we cover the diverse approaches in the literature and present a unified view of verifier training, types and their utility in test-time scaling. Our repository can be found at https://github.com/elixir-research-group/Verifierstesttimescaling.github.io.
测试时缩放(TTS)已成为提高大型语言模型性能的新前沿。在测试时缩放中,通过推理过程中的更多计算资源的使用,LLM可以改善其推理过程和任务性能。多种TTS方法已经出现,例如从另一个模型中提取推理痕迹,或者通过采用验证器来探索庞大的解码搜索空间。验证器作为奖励模型,帮助对解码过程中的候选输出进行评分,从而仔细探索巨大的解决方案空间并选择最佳结果。这一范式通常被认为是优于其他方法,因为它具有推理时间参数自由缩放和性能增益高的优点。验证器可以是基于提示的,也可以作为判别模型或生成模型进行微调,以验证过程路径、结果或两者。尽管它们得到了广泛的应用,但关于各种验证方法和其训练机制的详细收集、明确分类和讨论仍然缺乏。在本文中,我们涵盖了文献中的不同方法,并对验证器的训练、类型及其在测试时缩放中的实用性进行了统一的阐述。我们的仓库可以在https://github.com/elixir-research-group/Verifierstesttimescaling.github.io找到。
论文及项目相关链接
PDF 18 pages
Summary
测试时缩放(TTS)已成为扩展大型语言模型性能的新前沿。在测试时缩放中,通过在推理过程中使用更多的计算资源,LLM可以改善其推理过程并提升任务性能。本文介绍了多种TTS方法,如通过另一种模型提炼推理痕迹和利用验证器扩展庞大的解码搜索空间等。验证器作为一种奖励模型,能够在解码过程中评估候选输出,认真探索庞大的解空间并选择最佳结果。尽管验证器已得到广泛应用,但关于各种验证方法和其训练机制的详细收集和分类讨论仍不足。本文综述了文献中的不同方法,并对验证器的训练、类型及其在测试时缩放中的应用提供了统一视角。
Key Takeaways
- 测试时缩放(TTS)是扩展大型语言模型性能的新领域。
- 通过在推理过程中使用更多计算资源,LLM可以提高其推理能力和任务性能。
- TTS的方法包括通过另一种模型提炼推理痕迹和利用验证器扩展解码搜索空间。
- 验证器作为奖励模型,能够评估候选输出并选择最佳结果。
- 验证器可以基于提示进行训练,也可以作为判别或生成模型进行微调以验证过程路径、结果或两者。
- 当前对于验证器和其训练机制的详细收集和分类讨论仍不足。
点此查看论文截图



Parallel GPT: Harmonizing the Independence and Interdependence of Acoustic and Semantic Information for Zero-Shot Text-to-Speech
Authors:Jingyuan Xing, Zhipeng Li, Jialong Mai, Xiaofen Xing, Xiangmin Xu
Advances in speech representation and large language models have enhanced zero-shot text-to-speech (TTS) performance. However, existing zero-shot TTS models face challenges in capturing the complex correlations between acoustic and semantic features, resulting in a lack of expressiveness and similarity. The primary reason lies in the complex relationship between semantic and acoustic features, which manifests independent and interdependent aspects.This paper introduces a TTS framework that combines both autoregressive (AR) and non-autoregressive (NAR) modules to harmonize the independence and interdependence of acoustic and semantic information. The AR model leverages the proposed Parallel Tokenizer to synthesize the top semantic and acoustic tokens simultaneously. In contrast, considering the interdependence, the Coupled NAR model predicts detailed tokens based on the general AR model’s output. Parallel GPT, built on this architecture, is designed to improve zero-shot text-to-speech synthesis through its parallel structure. Experiments on English and Chinese datasets demonstrate that the proposed model significantly outperforms the quality and efficiency of the synthesis of existing zero-shot TTS models. Speech demos are available at https://t1235-ch.github.io/pgpt/.
随着语音表示和大型语言模型的进步,零样本文本到语音(TTS)的性能得到了提升。然而,现有的零样本TTS模型在捕捉声音和语义特征之间的复杂关联方面面临挑战,导致表现力不足和相似性不足。主要原因在于语义和声音特征之间的复杂关系,表现为独立和相互依存的方面。
论文及项目相关链接
PDF Submitted to IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
摘要
基于先进的语音表示和大型语言模型,零样本文本到语音(TTS)性能得到了提升。然而,现有零样本TTS模型在捕捉声学特征与语义特征之间的复杂关联方面面临挑战,导致表现力不足和相似性不足。本文引入了一种结合自回归(AR)和非自回归(NAR)模块的TTS框架,以协调声学特征和语义信息的独立性和相互依赖性。AR模型利用提出的并行分词器同时合成顶级语义和声音标记。考虑到相互依赖性,耦合的NAR模型基于AR模型的输出预测详细的标记。基于这种架构构建的并行GPT旨在通过其并行结构提高零样本文本到语音的合成质量。在英语和中文数据集上的实验表明,该模型在合成质量和效率上显著优于现有零样本TTS模型。语音演示请访问:链接地址。
要点
- 先进的语音表示和大型语言模型提升了零样本文本到语音(TTS)的性能。
- 现有TTS模型在捕捉声学特征与语义特征的复杂关联方面存在挑战。
- 本文提出的TTS框架结合AR和NAR模块,以协调声学语义的独立性和相互依赖性。
- AR模型利用并行分词器同时合成语义和声音标记。
- NAR模型基于AR模型的输出进行详细的预测。
- 构建的并行GPT架构提高了零样本文本到语音的合成质量。
点此查看论文截图



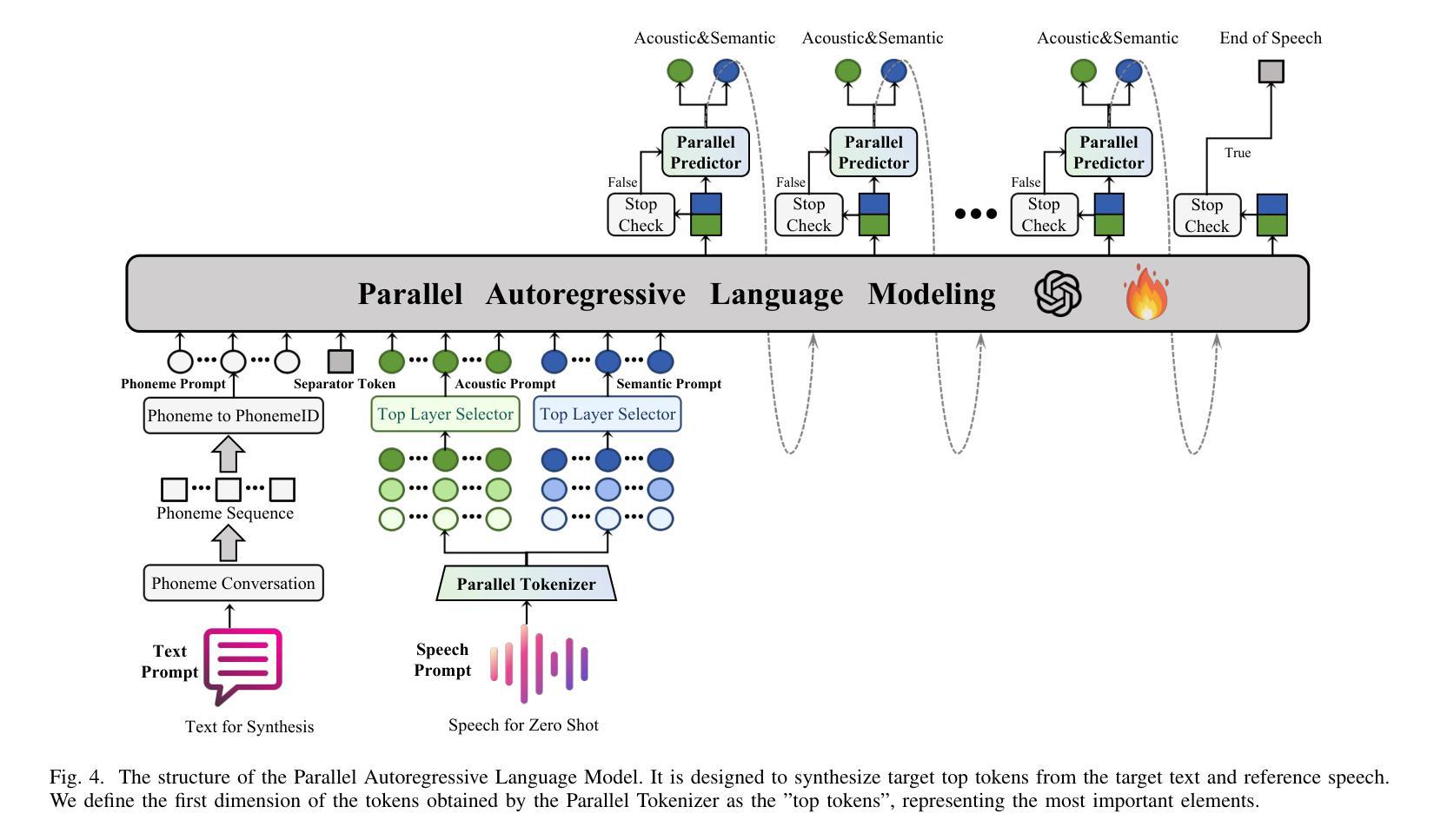
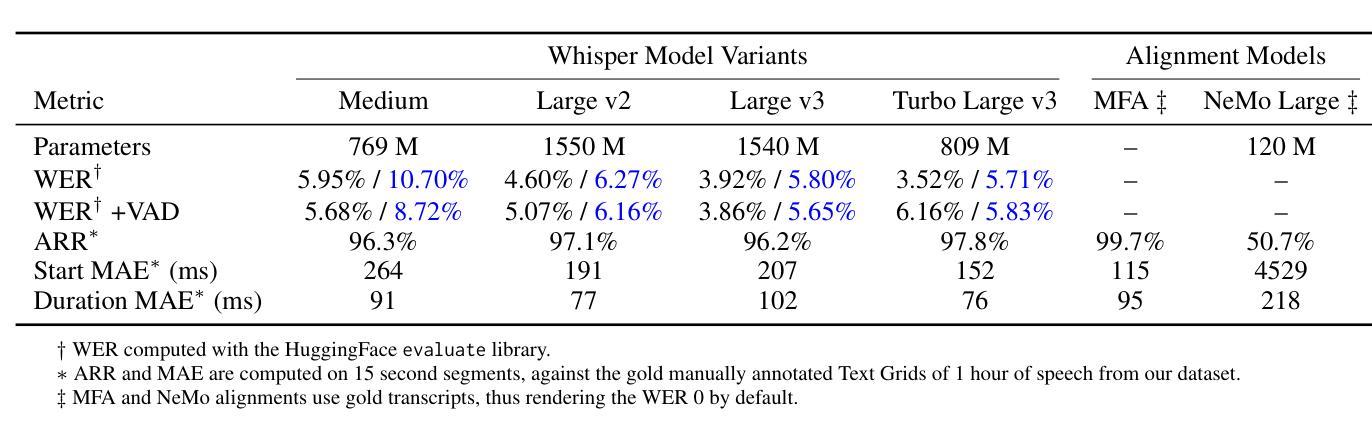
IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech
Authors:Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu
Existing autoregressive large-scale text-to-speech (TTS) models have advantages in speech naturalness, but their token-by-token generation mechanism makes it difficult to precisely control the duration of synthesized speech. This becomes a significant limitation in applications requiring strict audio-visual synchronization, such as video dubbing. This paper introduces IndexTTS2, which proposes a novel, general, and autoregressive model-friendly method for speech duration control. The method supports two generation modes: one explicitly specifies the number of generated tokens to precisely control speech duration; the other freely generates speech in an autoregressive manner without specifying the number of tokens, while faithfully reproducing the prosodic features of the input prompt. Furthermore, IndexTTS2 achieves disentanglement between emotional expression and speaker identity, enabling independent control over timbre and emotion. In the zero-shot setting, the model can accurately reconstruct the target timbre (from the timbre prompt) while perfectly reproducing the specified emotional tone (from the style prompt). To enhance speech clarity in highly emotional expressions, we incorporate GPT latent representations and design a novel three-stage training paradigm to improve the stability of the generated speech. Additionally, to lower the barrier for emotional control, we designed a soft instruction mechanism based on text descriptions by fine-tuning Qwen3, effectively guiding the generation of speech with the desired emotional orientation. Finally, experimental results on multiple datasets show that IndexTTS2 outperforms state-of-the-art zero-shot TTS models in terms of word error rate, speaker similarity, and emotional fidelity. Audio samples are available at: https://index-tts.github.io/index-tts2.github.io/
现有的大型自回归文本到语音(TTS)模型在语音自然性方面具有优势,但其逐个标记的生成机制使得难以精确控制合成语音的持续时间。这在需要严格音视频同步的应用中成为一个重要限制,例如在视频配音中。本文介绍了IndexTTS2,它提出了一种新颖、通用、适用于自回归模型的语音持续时间控制方法。该方法支持两种生成模式:一种明确指定生成的标记数量以精确控制语音持续时间;另一种以自回归的方式自由生成语音,无需指定标记数量,同时忠实再现输入提示的韵律特征。此外,IndexTTS2实现了情感表达和说话人身份的解耦,实现了对音色和情感的独立控制。在零样本设置中,该模型可以准确重建目标音色(来自音色提示),同时完美再现指定的情感基调(来自风格提示)。为了提高高度情感表达中的语音清晰度,我们引入了GPT潜在表示,并设计了一种新型的三阶段训练范式,以提高生成语音的稳定性。此外,为了降低情感控制的障碍,我们基于文本描述设计了一种柔和的指令机制,通过微调Qwen3,有效地引导生成具有所需情感倾向的语音。最后,在多个数据集上的实验结果表明,IndexTTS2在词错误率、说话人相似度和情感保真度方面优于最先进的零样本TTS模型。音频样本可在:https://index-tts.github.io/index-tts2.github.io/。
论文及项目相关链接
摘要
本文介绍了一种名为IndexTTS2的文本转语音(TTS)模型,该模型解决了现有自回归大规模TTS模型在语音合成时长控制上的困难。IndexTTS2提出了一种新颖、通用且与自回归模型兼容的语音时长控制方法,支持两种生成模式:一种是通过明确指定生成的令牌数量来控制语音时长;另一种是以自回归方式自由生成语音,同时忠实保留输入提示的韵律特征。此外,IndexTTS2实现了情感表达和说话人身份的解耦,能够独立控制音色和情感。通过结合GPT潜在表征并设计新颖的三阶段训练范式,提高了生成语音的清晰度和稳定性。同时,为降低情感控制的障碍,通过微调Qwen3并设计基于文本描述的软指令机制,有效引导生成具有所需情感倾向的语音。实验结果表明,IndexTTS2在多个数据集上的零样本设置中,相较于先进TTS模型,其在单词错误率、说话人相似度和情感保真度方面表现更优。
关键见解
- IndexTTS2模型解决了自回归大规模文本转语音(TTS)模型在语音时长控制上的难题。
- 模型支持两种生成模式,一种可精确控制语音时长,另一种可自回归方式生成语音并保留输入韵律。
- IndexTTS2实现了情感表达和说话人身份的解耦,允许独立控制。
- 融入GPT潜在表征和三阶段训练范式,提高语音清晰度和稳定性。
- 通过软指令机制引导生成具有所需情感倾向的语音。
- IndexTTS2在多个数据集上的零样本设置中表现出优异的性能,优于其他先进TTS模型。
- 提供音频样本以供听众体验:https://index-tts.github.io/index-tts2.github.io/。
点此查看论文截图




FELLE: Autoregressive Speech Synthesis with Token-Wise Coarse-to-Fine Flow Matching
Authors:Hui Wang, Shujie Liu, Lingwei Meng, Jinyu Li, Yifan Yang, Shiwan Zhao, Haiyang Sun, Yanqing Liu, Haoqin Sun, Jiaming Zhou, Yan Lu, Yong Qin
To advance continuous-valued token modeling and temporal-coherence enforcement, we propose FELLE, an autoregressive model that integrates language modeling with token-wise flow matching. By leveraging the autoregressive nature of language models and the generative efficacy of flow matching, FELLE effectively predicts continuous-valued tokens (mel-spectrograms). For each continuous-valued token, FELLE modifies the general prior distribution in flow matching by incorporating information from the previous step, improving coherence and stability. Furthermore, to enhance synthesis quality, FELLE introduces a coarse-to-fine flow-matching mechanism, generating continuous-valued tokens hierarchically, conditioned on the language model’s output. Experimental results demonstrate the potential of incorporating flow-matching techniques in autoregressive mel-spectrogram modeling, leading to significant improvements in TTS generation quality, as shown in https://aka.ms/felle.
为推动连续值令牌建模和时间连贯性执行的发展,我们提出了FELLE,这是一种将语言建模与令牌级流匹配相结合的自动生成模型。通过利用语言模型的自动递归特性和流匹配的生成效能,FELLE可以有效地预测连续值令牌(梅尔频谱图)。对于每个连续值令牌,FELLE通过结合上一步的信息来修改流匹配中的一般先验分布,提高了连贯性和稳定性。此外,为了提高合成质量,FELLE引入了一种从粗到细的流匹配机制,以层次结构生成连续值令牌,依赖于语言模型的输出。实验结果表明,在自动回归梅尔频谱图建模中融入流匹配技术具有潜力,能够显著提高TTS生成质量,详情参见https://aka.ms/felle。
论文及项目相关链接
PDF Accepted by ACM Multimedia 2025
Summary
本文提出了一个名为FELLE的自回归模型,该模型结合了语言建模和基于token的流匹配技术,用于推进连续值token建模和时序一致性强化。通过利用语言模型的自回归特性和流匹配的生成效能,FELLE能够有效地预测连续值token(mel频谱图)。该模型通过结合前一步的信息,改进了流匹配中的一般先验分布,提高了连贯性和稳定性。此外,为了提升合成质量,FELLE引入了从粗到细的流匹配机制,根据语言模型的输出,层次性地生成连续值token。实验结果表明,在自回归mel频谱图建模中融入流匹配技术具有潜力,能够显著提升文本到语音生成的质量。
Key Takeaways
- FELLE是一个自回归模型,结合了语言建模和基于token的流匹配技术。
- 通过利用语言模型的自回归特性和流匹配的生成效能,有效地预测连续值token(mel频谱图)。
- 模型通过结合前一步的信息改进了一般先验分布,增强了时序连贯性和稳定性。
- 引入了从粗到细的流匹配机制来提升语音合成质量。
- 语言模型的输出作为条件用于层次性地生成连续值token。
- 实验证明了融入流匹配技术在自回归mel频谱图建模中的潜力。
点此查看论文截图





Towards Controllable Speech Synthesis in the Era of Large Language Models: A Systematic Survey
Authors:Tianxin Xie, Yan Rong, Pengfei Zhang, Wenwu Wang, Li Liu
Text-to-speech (TTS) has advanced from generating natural-sounding speech to enabling fine-grained control over attributes like emotion, timbre, and style. Driven by rising industrial demand and breakthroughs in deep learning, e.g., diffusion and large language models (LLMs), controllable TTS has become a rapidly growing research area. This survey provides the first comprehensive review of controllable TTS methods, from traditional control techniques to emerging approaches using natural language prompts. We categorize model architectures, control strategies, and feature representations, while also summarizing challenges, datasets, and evaluations in controllable TTS. This survey aims to guide researchers and practitioners by offering a clear taxonomy and highlighting future directions in this fast-evolving field. One can visit https://github.com/imxtx/awesome-controllabe-speech-synthesis for a comprehensive paper list and updates.
文本转语音(TTS)已从生成自然声音的语音发展到实现对情感、音质和风格等属性的精细控制。随着工业需求的增长和深度学习等领域的突破,如扩散模型的大型语言模型(LLM)的推动,可控TTS已成为一个快速发展的研究领域。这篇综述提供了从传统的控制技巧到使用自然语言提示的新兴方法之间可控TTS方法的首次全面回顾。我们对模型架构、控制策略和特征表示进行分类,同时总结了可控TTS中的挑战、数据集和评估方法。本综述旨在通过提供清晰的分类学和高亮快速进化领域的未来方向,为研究人员和实践者提供指导。可以通过访问 https://github.com/imxtx/awesome-controllabe-speech-synthesis 来获取全面的论文列表和最新更新。
论文及项目相关链接
PDF The first comprehensive survey on controllable TTS. Accepted to the EMNLP 2025 main conference
Summary
文本转语音(TTS)已从生成自然语音发展到实现对情感、音色和风格等属性的精细控制。受日益增长的需求和深度学习技术突破的推动,如扩散技术和大型语言模型(LLM),可控TTS已成为一个快速增长的研究领域。这篇综述首次全面回顾了可控TTS方法,包括传统控制技术和新兴的自然语言提示方法。本文分类了模型架构、控制策略和特征表示,并总结了可控TTS中的挑战、数据集和评估方法。本综述旨在为研究人员和实践者提供清晰的分类和在这个快速演变的领域的未来方向的指南。有关完整的论文列表和更新,请访问:[链接地址]。
Key Takeaways
- TTS技术已从基础语音合成发展至精细控制情感、音色和风格等属性。
- 深度学习和大型语言模型在可控TTS领域起到了关键作用。
- 本文提供了可控TTS方法的首次全面综述,涵盖传统控制技术和新兴的自然语言提示方法。
- 模型架构、控制策略和特征表示在TTS中起到重要作用,同时面临诸多挑战。
- 综述总结了相关的数据集和评估方法,为研究人员和实践者提供了指南。
- 可以通过特定链接获取更全面的论文列表和最新更新。
点此查看论文截图





I2TTS: Image-indicated Immersive Text-to-speech Synthesis with Spatial Perception
Authors:Jiawei Zhang, Tian-Hao Zhang, Jun Wang, Jiaran Gao, Xinyuan Qian, Xu-Cheng Yin
Controlling the style and characteristics of speech synthesis is crucial for adapting the output to specific contexts and user requirements. Previous Text-to-speech (TTS) works have focused primarily on the technical aspects of producing natural-sounding speech, such as intonation, rhythm, and clarity. However, they overlook the fact that there is a growing emphasis on spatial perception of synthesized speech, which may provide immersive experience in gaming and virtual reality. To solve this issue, in this paper, we present a novel multi-modal TTS approach, namely Image-indicated Immersive Text-to-speech Synthesis (I2TTS). Specifically, we introduce a scene prompt encoder that integrates visual scene prompts directly into the synthesis pipeline to control the speech generation process. Additionally, we propose a reverberation classification and refinement technique that adjusts the synthesized mel-spectrogram to enhance the immersive experience, ensuring that the involved reverberation condition matches the scene accurately. Experimental results demonstrate that our model achieves high-quality scene and spatial matching without compromising speech naturalness, marking a significant advancement in the field of context-aware speech synthesis. Project demo page: https://spatialTTS.github.io/ Index Terms-Speech synthesis, scene prompt, spatial perception
控制语音合成的风格和特性对于适应特定的上下文和用户要求至关重要。之前的文本到语音(TTS)工作主要集中在产生自然语音的技术方面,如语调、节奏和清晰度。然而,他们忽略了这样一个事实,即对合成语音的空间感知的重视程度正在不断增长,这可能会在游戏和虚拟现实等领域提供沉浸式体验。为了解决这一问题,本文提出了一种新型的多模式TTS方法,即图像指示沉浸式文本到语音合成(I2TTS)。具体来说,我们引入了一个场景提示编码器,它将视觉场景提示直接集成到合成管道中,以控制语音生成过程。此外,我们还提出了一种混响分类和细化技术,该技术可以对合成的梅尔频谱进行调整,以增强沉浸式体验,并确保所涉及的混响条件与场景准确匹配。实验结果表明,我们的模型在保持语音自然性的同时实现了高质量的场景和空间匹配,标志着上下文感知语音合成领域取得了重大进展。项目演示页面:https://spatialTTS.github.io/ 索引术语-语音合成、场景提示、空间感知。
论文及项目相关链接
PDF Accepted by APSIPA ASC2025
Summary
文本重点介绍了一种名为I2TTS的多模态TTS方法,该方法通过引入场景提示编码器,将视觉场景提示直接融入合成管道,控制语音生成过程。同时提出一种混响分类和细化技术,调整合成mel频谱图,增强沉浸式体验,确保涉及的混响条件与场景准确匹配。此方法在上下文感知语音合成领域实现了显著进展。
Key Takeaways
- 文本合成需要适应特定上下文和用户要求,控制风格和特性至关重要。
- 以往TTS研究主要关注自然语音的技术方面,如语调、节奏和清晰度。
- 文本强调了合成语音的空间感知的日益增长重要性,尤其在游戏和虚拟现实中的沉浸式体验。
- 提出了一种新型多模态TTS方法I2TTS,引入场景提示编码器直接融入视觉场景提示到合成管道中。
- I2TTS方法通过调整合成mel频谱图,使用混响分类和细化技术,增强了沉浸式体验。
- 实验结果证明,I2TTS模型实现了高质量的场景和空间匹配,且不牺牲语音的自然性。
点此查看论文截图