⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
Think2Sing: Orchestrating Structured Motion Subtitles for Singing-Driven 3D Head Animation
Authors:Zikai Huang, Yihan Zhou, Xuemiao Xu, Cheng Xu, Xiaofen Xing, Jing Qin, Shengfeng He
Singing-driven 3D head animation is a challenging yet promising task with applications in virtual avatars, entertainment, and education. Unlike speech, singing involves richer emotional nuance, dynamic prosody, and lyric-based semantics, requiring the synthesis of fine-grained, temporally coherent facial motion. Existing speech-driven approaches often produce oversimplified, emotionally flat, and semantically inconsistent results, which are insufficient for singing animation. To address this, we propose Think2Sing, a diffusion-based framework that leverages pretrained large language models to generate semantically coherent and temporally consistent 3D head animations, conditioned on both lyrics and acoustics. A key innovation is the introduction of motion subtitles, an auxiliary semantic representation derived through a novel Singing Chain-of-Thought reasoning process combined with acoustic-guided retrieval. These subtitles contain precise timestamps and region-specific motion descriptions, serving as interpretable motion priors. We frame the task as a motion intensity prediction problem, enabling finer control over facial regions and improving the modeling of expressive motion. To support this, we create a multimodal singing dataset with synchronized video, acoustic descriptors, and motion subtitles, enabling diverse and expressive motion learning. Extensive experiments show that Think2Sing outperforms state-of-the-art methods in realism, expressiveness, and emotional fidelity, while also offering flexible, user-controllable animation editing.
唱歌驱动的3D头部动画是一项充满挑战但前景光明的任务,在虚拟角色、娱乐和教育等领域具有广泛的应用。不同于语音,唱歌包含了更丰富的情感细微差别、动态韵律和基于歌词的语义,要求合成精细、时间连贯的面部运动。现有的语音驱动方法往往产生过于简化、情感平淡、语义不一致的结果,对于唱歌动画来说远远不够。为了解决这一问题,我们提出了Think2Sing,这是一个基于扩散的框架,利用预训练的大型语言模型来生成语义一致、时间连贯的3D头部动画,根据歌词和声学条件进行驱动。一个关键的创新点在于引入了运动字幕,这是一种辅助语义表示,通过新颖的歌声思维链推理过程与声学引导检索相结合得出。这些字幕包含精确的时间戳和区域特定的运动描述,作为可解释的运动先验。我们将任务框架设定为运动强度预测问题,实现对面部区域的更精细控制,并改进了表达性运动的建模。为了支持这一点,我们创建了一个多模态歌唱数据集,包含同步视频、声学描述符和运动字幕,实现了多样化和表达性的运动学习。大量实验表明,Think2Sing在真实性、表达力和情感保真度方面超越了最先进的方法,同时提供了灵活、用户可控制的动画编辑功能。
论文及项目相关链接
Summary
本文介绍了唱歌驱动的3D头部动画技术,并指出其在虚拟角色、娱乐和教育等领域的应用前景。现有语音驱动的方法在处理唱歌动画时存在简化、情感平淡和语义不一致的问题。为此,本文提出了一种基于扩散的框架Think2Sing,利用预训练的大型语言模型,根据歌词和声学条件生成语义连贯、时间一致的3D头部动画。关键创新点包括运动字幕的引入,这是一种通过新颖的唱歌思维链过程结合声学引导检索得到的辅助语义表示。运动字幕包含精确的时间戳和区域特定的运动描述,作为可解释的运动先验。文章将任务框架定义为运动强度预测问题,实现对面部区域的精细控制,并改进了表达性运动的建模。
Key Takeaways
- 唱歌驱动的3D头部动画在虚拟角色、娱乐和教育领域有广泛应用。
- 现有语音驱动方法在唱歌动画处理上表现不足,存在简化、情感平淡和语义不一致的问题。
- Think2Sing框架利用预训练的大型语言模型,根据歌词和声学条件生成更逼真的3D头部动画。
- 引入运动字幕作为辅助语义表示,结合新颖的唱歌思维链过程和声学引导检索得到。
- 运动字幕包含精确时间戳和区域特定运动描述,作为可解释的运动先验。
- 将任务框架定义为运动强度预测问题,实现对面部区域的精细控制,改进表达性运动的建模。
- 创建了多模态唱歌数据集,支持多样化和表达性的运动学习。
点此查看论文截图

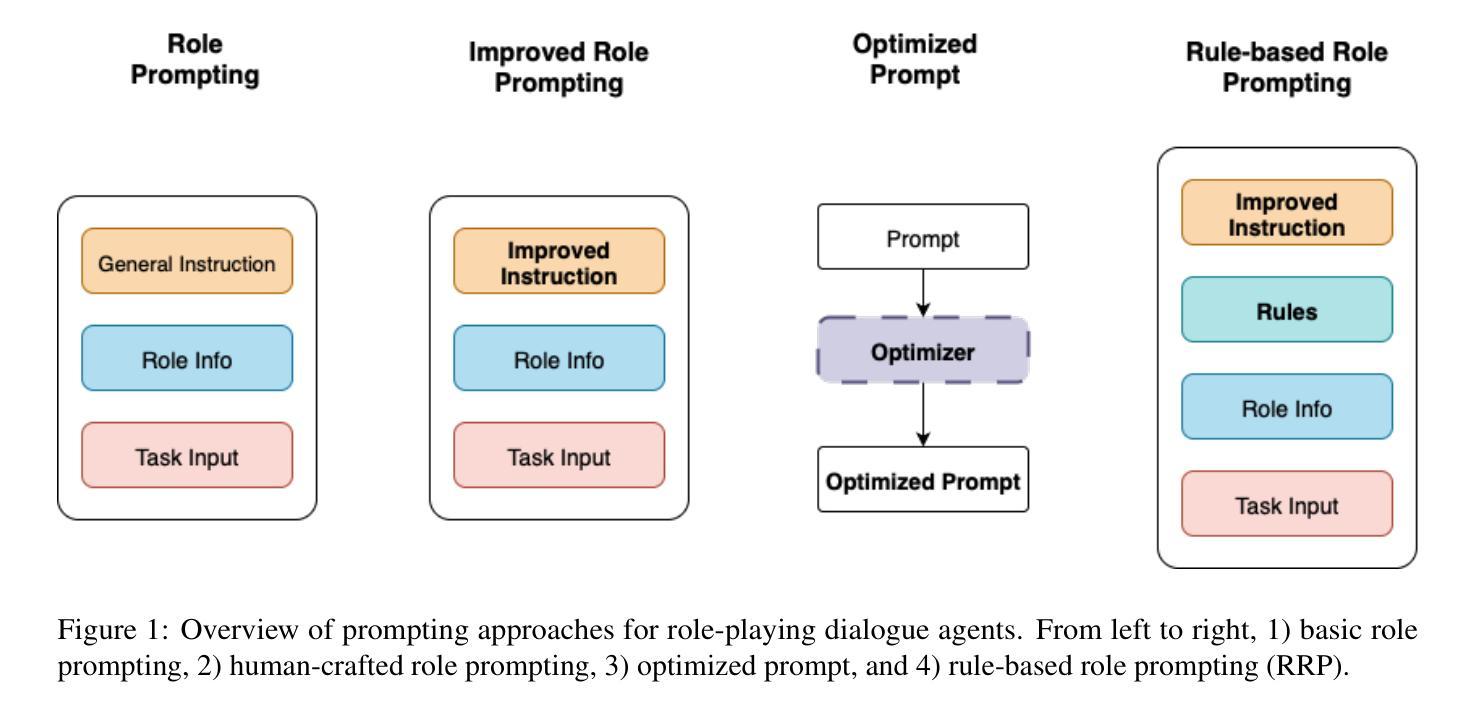
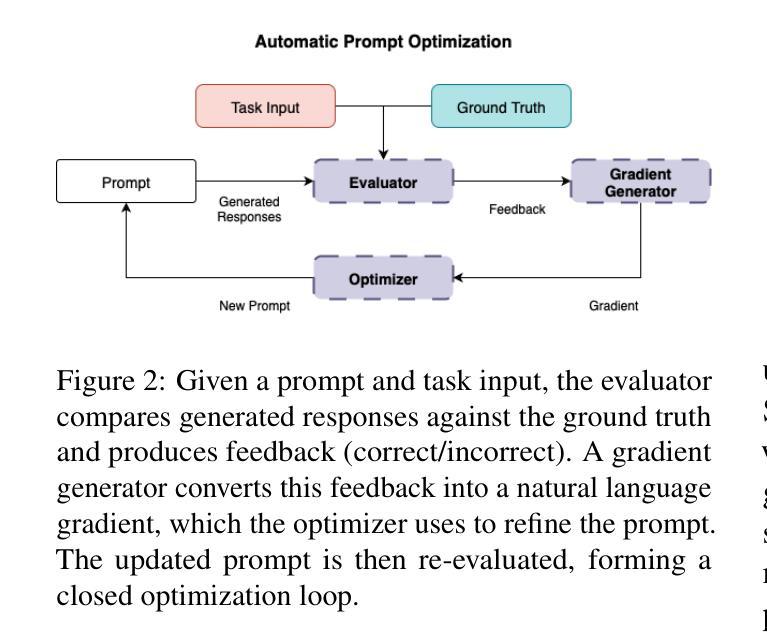
Talk Less, Call Right: Enhancing Role-Play LLM Agents with Automatic Prompt Optimization and Role Prompting
Authors:Saksorn Ruangtanusak, Pittawat Taveekitworachai, Kunat Pipatanakul
This report investigates approaches for prompting a tool-augmented large language model (LLM) to act as a role-playing dialogue agent in the API track of the Commonsense Persona-grounded Dialogue Challenge (CPDC) 2025. In this setting, dialogue agents often produce overly long in-character responses (over-speaking) while failing to use tools effectively according to the persona (under-acting), such as generating function calls that do not exist or making unnecessary tool calls before answering. We explore four prompting approaches to address these issues: 1) basic role prompting, 2) human-crafted role prompting, 3) automatic prompt optimization (APO), and 4) rule-based role prompting. The rule-based role prompting (RRP) approach achieved the best performance through two novel techniques–character-card/scene-contract design and strict enforcement of function calling–which led to an overall score of 0.571, improving on the zero-shot baseline score of 0.519. These findings demonstrate that RRP design can substantially improve the effectiveness and reliability of role-playing dialogue agents compared with more elaborate methods such as APO. To support future efforts in developing persona prompts, we are open-sourcing all of our best-performing prompts and the APO tool. Source code is available at https://github.com/scb-10x/apo.
本报告调查了在Commonsense Persona-grounded Dialogue Challenge(CPDC)2025的API赛道中,如何提示工具增强的大型语言模型(LLM)扮演角色对话代理的方法。在这个场景中,对话代理往往产生过长的角色内响应(说得太多),同时未能根据角色有效地使用工具(表现不足),例如生成不存在的函数调用或在回答问题之前进行不必要的工具调用。我们探索了四种提示方法来解决这些问题:1)基本角色提示,2)人工制作的角色提示,3)自动提示优化(APO),以及4)基于规则的角色提示。基于规则的角色提示(RRP)方法表现最佳,它通过两种新技术——角色卡/场景合约设计和严格的函数调用执行——实现了整体得分0.571,提高了零样本基线得分0.519。这些发现表明,与更精细的方法(如APO)相比,RRP设计可以显著提高角色扮演对话代理的有效性和可靠性。为了支持未来在开发个性化提示方面的努力,我们公开了所有表现最佳的提示和APO工具。源代码可在https://github.com/scb-10x/apo获取。
论文及项目相关链接
PDF 17 pages, 2 figures
摘要
本报告探讨了如何引导工具增强型大型语言模型(LLM)在Commonsense Persona-grounded Dialogue Challenge(CPDC)的API赛道中扮演角色对话代理的方法。在此场景中,对话代理常常产生过长的角色内响应(说话过多),同时未能根据角色有效地使用工具(表现不足),例如生成不存在的函数调用或在回答之前进行不必要的工具调用。本文探索了四种提示方法来解决这些问题:基本角色提示、人工构建角色提示、自动提示优化(APO)和基于规则的角色提示。通过两种新技术——角色卡/场景合约设计和严格的功能调用强制执行,规则基础的角色提示(RRP)方法取得了最佳性能,总体得分为0.571,相较于零基准线的0.519有所提升。这些发现表明,相较于更为复杂的方法(如APO),RRP设计能大幅增强角色扮演对话代理的有效性和可靠性。为了支持未来在开发个性提示方面的努力,我们公开了所有表现最佳的提示和APO工具。源代码可在https://github.com/scb-10x/apo获取。
关键见解
- 报告探讨了如何引导大型语言模型在特定对话挑战中扮演角色对话代理的问题。
- 对话代理在面对任务时常常出现过度响应和表现不足的问题。
- 四种提示方法被用于解决上述问题,其中规则基础的角色提示方法表现最佳。
- 通过角色卡和场景合约设计以及严格的功能调用强制执行,规则基础的角色提示方法实现了显著的性能提升。
- 该方法相较于自动提示优化等更复杂的方法更为有效和可靠。
- 报告公开了所有表现最佳的提示和自动提示优化工具以支持未来的研究。
点此查看论文截图


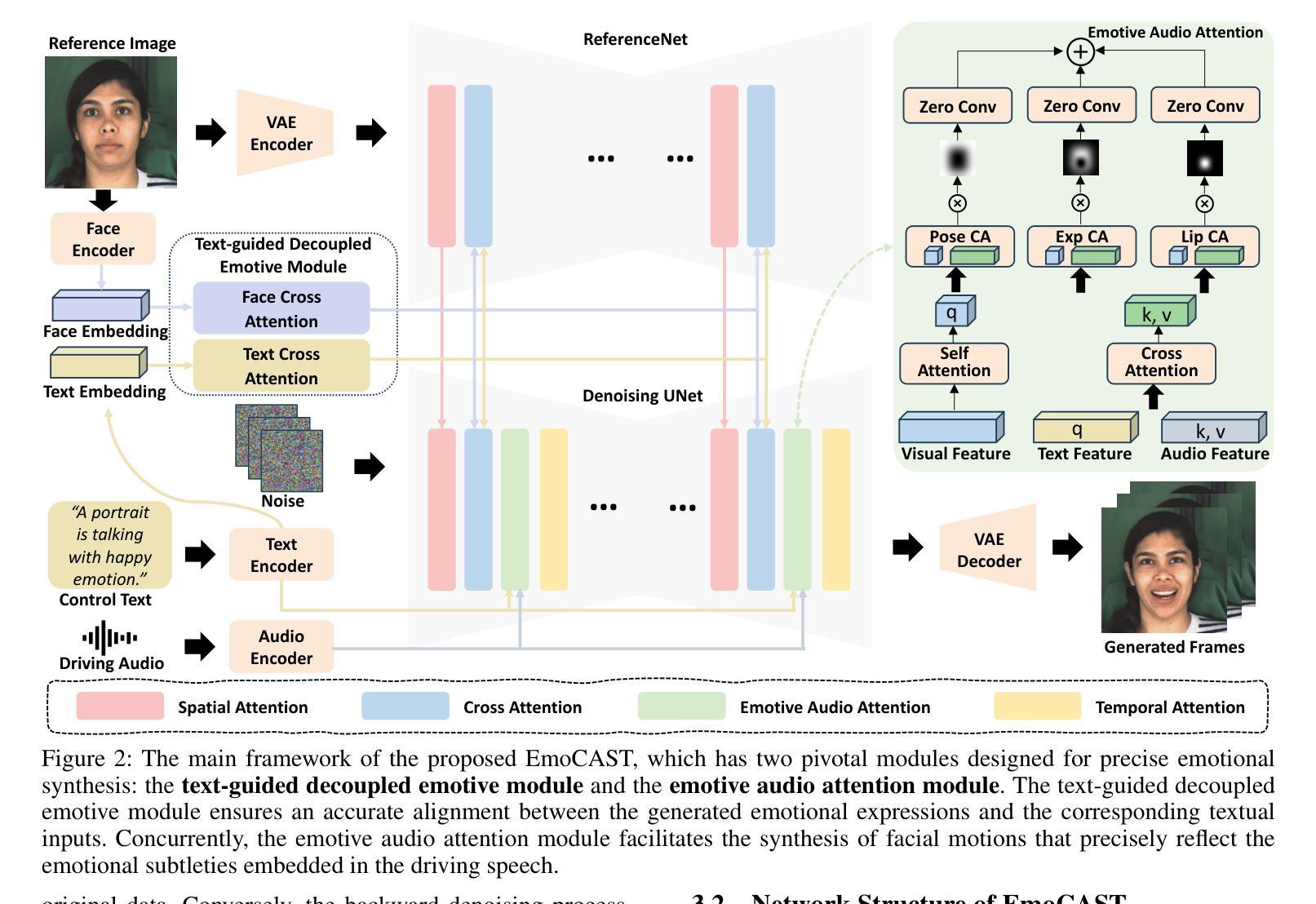
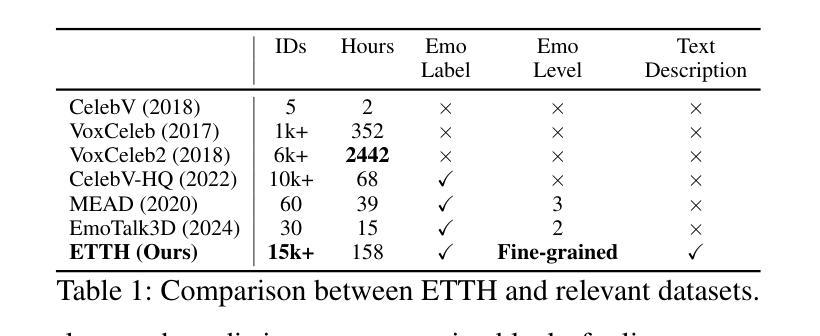
EmoCAST: Emotional Talking Portrait via Emotive Text Description
Authors:Yiguo Jiang, Xiaodong Cun, Yong Zhang, Yudian Zheng, Fan Tang, Chi-Man Pun
Emotional talking head synthesis aims to generate talking portrait videos with vivid expressions. Existing methods still exhibit limitations in control flexibility, motion naturalness, and expression quality. Moreover, currently available datasets are primarily collected in lab settings, further exacerbating these shortcomings. Consequently, these limitations substantially hinder practical applications in real-world scenarios. To address these challenges, we propose EmoCAST, a diffusion-based framework with two key modules for precise text-driven emotional synthesis. In appearance modeling, emotional prompts are integrated through a text-guided decoupled emotive module, enhancing the spatial knowledge to improve emotion comprehension. To improve the relationship between audio and emotion, we introduce an emotive audio attention module to capture the interplay between controlled emotion and driving audio, generating emotion-aware features to guide more precise facial motion synthesis. Additionally, we construct an emotional talking head dataset with comprehensive emotive text descriptions to optimize the framework’s performance. Based on the proposed dataset, we propose an emotion-aware sampling training strategy and a progressive functional training strategy that further improve the model’s ability to capture nuanced expressive features and achieve accurate lip-synchronization. Overall, EmoCAST achieves state-of-the-art performance in generating realistic, emotionally expressive, and audio-synchronized talking-head videos. Project Page: https://github.com/GVCLab/EmoCAST
情绪化说话人头部合成旨在生成具有生动表情的肖像视频。现有方法仍存在于控制灵活性、动作自然性和表情质量方面的局限性。此外,目前可用的数据集主要在实验室环境中收集,进一步加剧了这些不足。因此,这些局限在实际应用场景中的实用受到了很大的阻碍。为了应对这些挑战,我们提出了EmoCAST,这是一个基于扩散的框架,具有两个精确文本驱动的情感合成的关键模块。在外观建模中,我们通过文本指导的解耦情感模块整合情感提示,增强空间知识以提高情感理解。为了改善音频和情感之间的关系,我们引入了一个情感音频注意力模块,以捕捉受控情感与驱动音频之间的相互作用,生成情感感知特征,以引导更精确的面部动作合成。此外,我们构建了一个情感说话人头部数据集,其中包含全面的情感文本描述,以优化框架的性能。基于所提出的数据集,我们提出了一种情感感知采样训练策略和一种渐进功能训练策略,进一步提高模型捕捉细微表情特征的能力,实现准确的唇同步。总体而言,EmoCAST在生成逼真、情感丰富、音频同步的说话人头视频方面达到了最先进的性能。项目页面:https://github.com/GVCLab/EmoCAST
论文及项目相关链接
Summary:
情感说话人头部合成旨在生成具有生动表情的说话人像视频。针对现有方法在控制灵活性、动作自然性和表情质量方面的局限性,以及数据集主要在实验室环境下收集的不足,我们提出了EmoCAST,一个基于扩散的框架,具有两个关键模块,用于精确的文字驱动情感合成。通过外观建模中的情感提示集成,以及音频与情感关系的强化,生成了更具情感感知特征的脸部运动。此外,我们构建了一个情感说话人头数据集,包含全面的情感文本描述,以优化框架性能。总体来说,EmoCAST在生成真实、情感丰富、音频同步的谈话视频方面达到了最先进的性能。
Key Takeaways:
- 情感说话人头部合成旨在生成具有生动表情的谈话人像视频。
- 现有方法在控制灵活性、动作自然性和表情质量方面存在局限。
- 现有数据集主要在实验室环境下收集,加剧了现有方法的不足。
- EmoCAST是一个基于扩散的框架,具有两个关键模块用于精确的文字驱动情感合成。
- 通过外观建模和情感提示集成,提高了空间知识,改善了情感理解。
- 引入情感音频注意力模块,捕捉控制情感和驱动音频之间的相互作用,生成情感感知特征。
点此查看论文截图



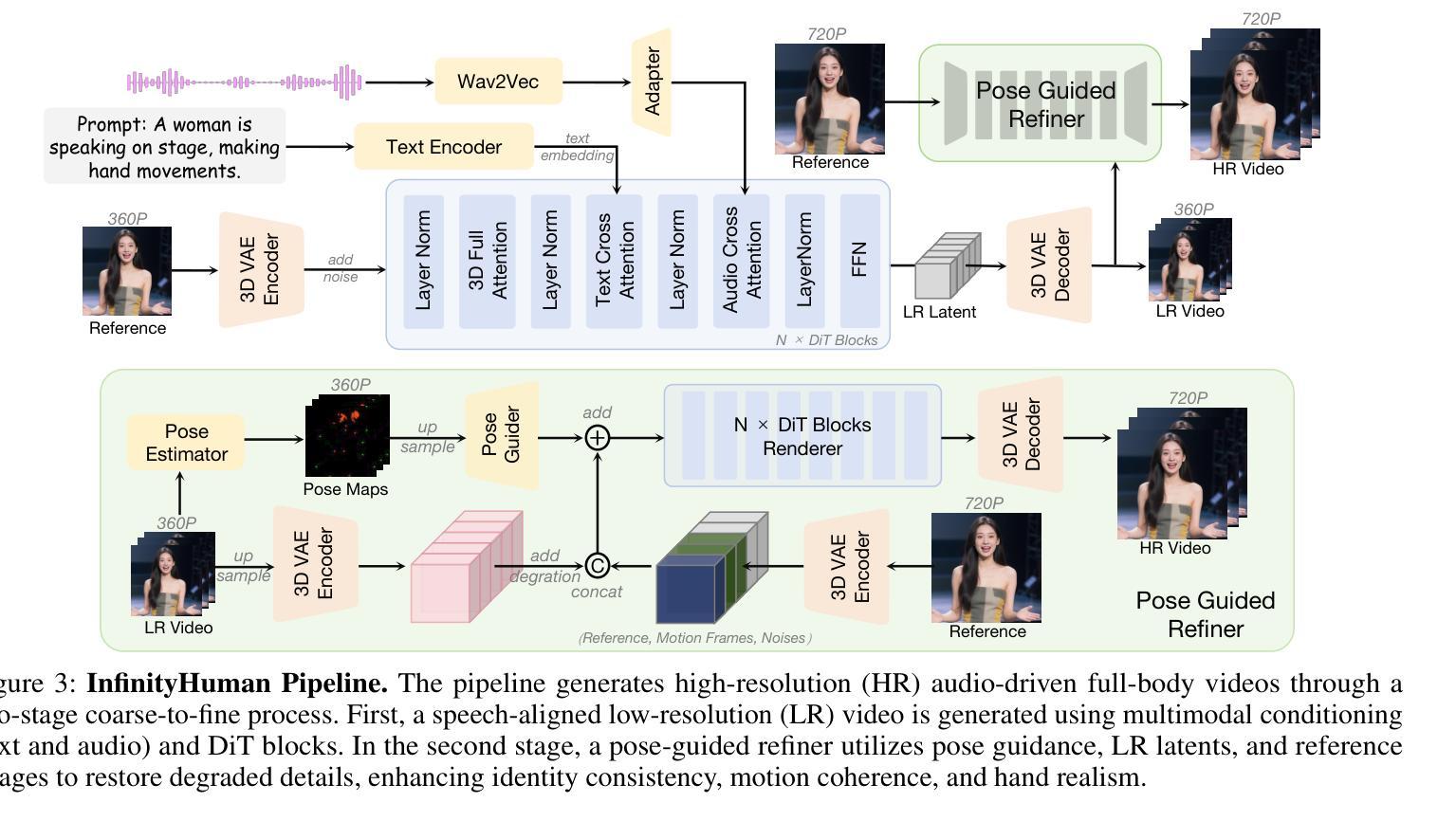
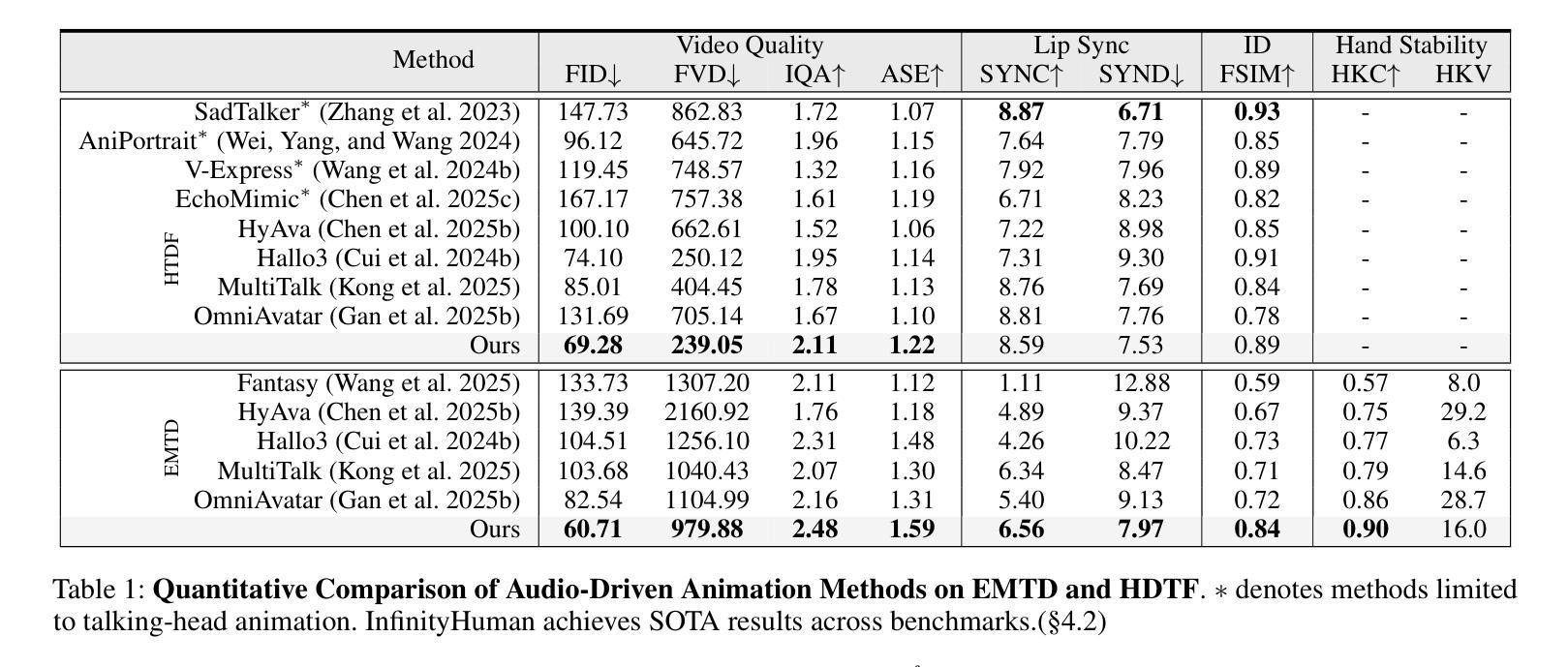
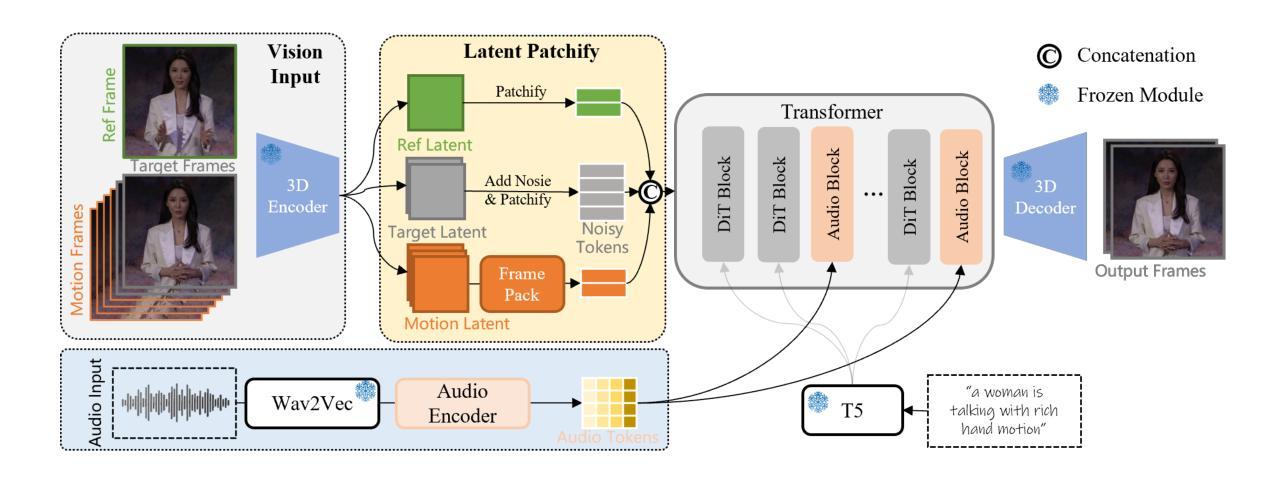
InfinityHuman: Towards Long-Term Audio-Driven Human
Authors:Xiaodi Li, Pan Xie, Yi Ren, Qijun Gan, Chen Zhang, Fangyuan Kong, Xiang Yin, Bingyue Peng, Zehuan Yuan
Audio-driven human animation has attracted wide attention thanks to its practical applications. However, critical challenges remain in generating high-resolution, long-duration videos with consistent appearance and natural hand motions. Existing methods extend videos using overlapping motion frames but suffer from error accumulation, leading to identity drift, color shifts, and scene instability. Additionally, hand movements are poorly modeled, resulting in noticeable distortions and misalignment with the audio. In this work, we propose InfinityHuman, a coarse-to-fine framework that first generates audio-synchronized representations, then progressively refines them into high-resolution, long-duration videos using a pose-guided refiner. Since pose sequences are decoupled from appearance and resist temporal degradation, our pose-guided refiner employs stable poses and the initial frame as a visual anchor to reduce drift and improve lip synchronization. Moreover, to enhance semantic accuracy and gesture realism, we introduce a hand-specific reward mechanism trained with high-quality hand motion data. Experiments on the EMTD and HDTF datasets show that InfinityHuman achieves state-of-the-art performance in video quality, identity preservation, hand accuracy, and lip-sync. Ablation studies further confirm the effectiveness of each module. Code will be made public.
音频驱动的人物动画因其实际应用而备受关注。然而,在生成高分辨率、长时长的视频时,仍然存在一致性外观和自然手部动作方面的重大挑战。现有方法通过使用重叠的运动帧来扩展视频,但存在误差累积的问题,从而导致身份漂移、色彩偏移和场景不稳定。此外,手部动作建模较差,导致明显的失真和与音频的不对齐。在这项工作中,我们提出了InfinityHuman,这是一个从粗到细的框架,首先生成与音频同步的表示,然后使用姿态引导精炼器逐步将其精细化为高分辨率、长时长的视频。由于姿态序列与外观解耦并抵抗时间退化,我们的姿态引导精炼器采用稳定的姿态和初始帧作为视觉锚点,以减少漂移并改善唇部同步。此外,为了提高语义准确性和手势现实感,我们引入了一种手特定的奖励机制,该机制使用高质量的手部运动数据进行训练。在EMTD和HDTF数据集上的实验表明,InfinityHuman在视频质量、身份保留、手部准确性和唇同步方面达到了最新技术水平。消融研究进一步证实了每个模块的有效性。代码将公开。
论文及项目相关链接
PDF Project Page: https://infinityhuman.github.io/
Summary
音频驱动的人脸动画因其实际应用而受到广泛关注,但仍存在生成高分辨率、长时长视频的挑战,如身份漂移、色彩移位、场景不稳定以及手部动作建模不良等问题。此工作提出InfinityHuman,一个由粗到细的框架,先生成音频同步的表示,然后使用姿态引导的细化器逐步细化成高分辨率、长时长的视频。该细化器利用稳定的姿态和初始帧作为视觉锚点,减少漂移并提高唇部同步。此外,为提高语义准确性和手势真实感,引入基于高质量手部运动数据的手部特定奖励机制。在EMTD和HDTF数据集上的实验显示,InfinityHuman在视频质量、身份保留、手部准确性和唇部同步方面达到最佳性能。
Key Takeaways
- 音频驱动的人脸动画具有广泛的应用前景,但生成高质量视频仍存在挑战。
- 现存方法通过重叠运动帧延长视频,但会导致误差累积,出现身份漂移、色彩移位和场景不稳定等问题。
- InfinityHuman框架采用由粗到细的生成方式,首先生成音频同步的表示,然后逐步细化。
- 姿态引导细化器利用稳定姿态和初始帧作为视觉锚点,提高视频质量,减少身份漂移。
- 引入手部特定奖励机制,基于高质量手部运动数据,提高语义准确性和手势真实感。
- 在EMTD和HDTF数据集上的实验表明,InfinityHuman在多个指标上达到最佳性能。
- 该研究的代码将公开。
点此查看论文截图



Wan-S2V: Audio-Driven Cinematic Video Generation
Authors:Xin Gao, Li Hu, Siqi Hu, Mingyang Huang, Chaonan Ji, Dechao Meng, Jinwei Qi, Penchong Qiao, Zhen Shen, Yafei Song, Ke Sun, Linrui Tian, Guangyuan Wang, Qi Wang, Zhongjian Wang, Jiayu Xiao, Sheng Xu, Bang Zhang, Peng Zhang, Xindi Zhang, Zhe Zhang, Jingren Zhou, Lian Zhuo
Current state-of-the-art (SOTA) methods for audio-driven character animation demonstrate promising performance for scenarios primarily involving speech and singing. However, they often fall short in more complex film and television productions, which demand sophisticated elements such as nuanced character interactions, realistic body movements, and dynamic camera work. To address this long-standing challenge of achieving film-level character animation, we propose an audio-driven model, which we refere to as Wan-S2V, built upon Wan. Our model achieves significantly enhanced expressiveness and fidelity in cinematic contexts compared to existing approaches. We conducted extensive experiments, benchmarking our method against cutting-edge models such as Hunyuan-Avatar and Omnihuman. The experimental results consistently demonstrate that our approach significantly outperforms these existing solutions. Additionally, we explore the versatility of our method through its applications in long-form video generation and precise video lip-sync editing.
当前最先进的音频驱动角色动画方法主要应用在演讲和歌唱场景中,表现出良好的性能。然而,它们在更复杂的电影和电视制作中常常表现不足,无法满足细微的角色互动、逼真的身体动作和动态的摄影等高级元素的需求。为了解决长期存在的电影级角色动画挑战,我们提出了一种音频驱动模型,我们将其称为Wan-S2V,基于Wan构建。我们的模型相较于现有方法,在电影语境下实现了显著增强的表现力和保真度。我们进行了广泛实验,将我们的方法与顶尖模型(如Hunyuan-Avatar和Omnihuman)进行了比较。实验结果一致表明,我们的方法显著优于这些现有解决方案。此外,我们还通过其在长视频生成和精确视频唇同步编辑中的应用,探索了我们的方法的通用性。
论文及项目相关链接
摘要
当前主流音频驱动角色动画方法在语音和歌唱场景表现良好,但在更复杂影视制作中表现欠佳,难以满足影视级角色动画的需求。为此,我们提出了一种名为Wan-S2V的音频驱动模型,该模型在Wan基础上构建,实现了电影级语境下更高的表达力和逼真度。我们进行了大量实验,将Wan-S2V与顶尖模型如Hunyuan-Avatar和Omnihuman进行对比。实验结果显示,我们的方法显著优于现有解决方案。此外,我们还探讨了该方法在长视频生成和精确视频唇同步编辑中的应用。
关键见解
- 当前音频驱动角色动画方法在复杂影视制作中存在局限,难以满足电影级角色动画的需求。
- Wan-S2V模型在Wan基础上构建,旨在解决这一难题。
- Wan-S2V模型在表达力和逼真度上较现有方法有明显提升。
- 实验结果显示,Wan-S2V显著优于其他顶尖模型。
- Wan-S2V模型可应用于长视频生成和精确视频唇同步编辑等多个领域。
- 该模型的提出推动了音频驱动角色动画领域的发展。
- Wan-S2V模型为影视制作带来了更高效、更真实的角色动画解决方案。
点此查看论文截图

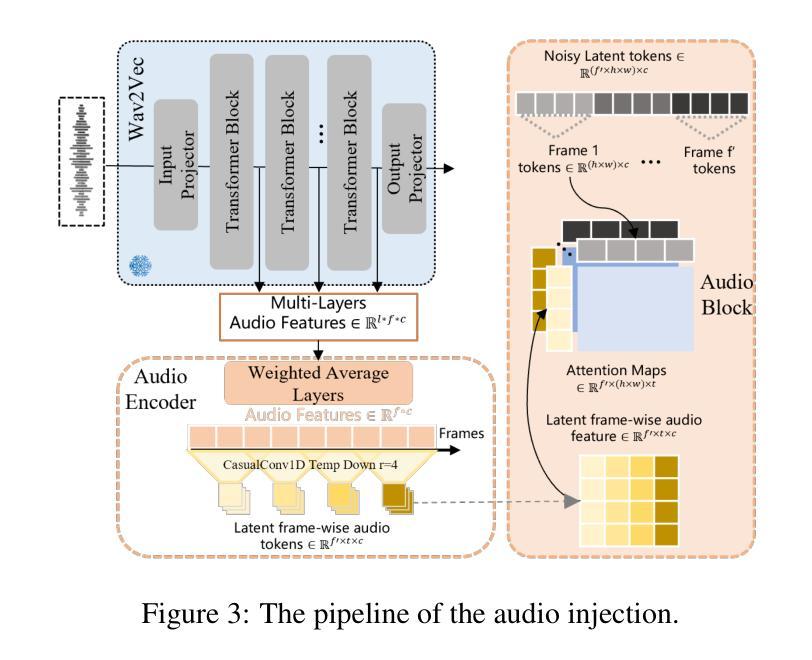
Talking to Robots: A Practical Examination of Speech Foundation Models for HRI Applications
Authors:Theresa Pekarek Rosin, Julia Gachot, Henri-Leon Kordt, Matthias Kerzel, Stefan Wermter
Automatic Speech Recognition (ASR) systems in real-world settings need to handle imperfect audio, often degraded by hardware limitations or environmental noise, while accommodating diverse user groups. In human-robot interaction (HRI), these challenges intersect to create a uniquely challenging recognition environment. We evaluate four state-of-the-art ASR systems on eight publicly available datasets that capture six dimensions of difficulty: domain-specific, accented, noisy, age-variant, impaired, and spontaneous speech. Our analysis demonstrates significant variations in performance, hallucination tendencies, and inherent biases, despite similar scores on standard benchmarks. These limitations have serious implications for HRI, where recognition errors can interfere with task performance, user trust, and safety.
在现实世界的设置中,自动语音识别(ASR)系统需要处理不完美的音频,这些音频经常因硬件限制或环境噪声而退化,同时还要适应不同的用户群体。在人机交互(HRI)中,这些挑战交织在一起,创造了一个独特且具有挑战性的识别环境。我们在八个公开数据集上评估了四种最新前沿的ASR系统,这些数据集捕捉到了六个维度的难度:特定领域的、带口音的、嘈杂的、年龄变化的、受损的以及即兴的语音。我们的分析表明,尽管在标准基准测试上的得分相似,但在性能、幻觉倾向和内在偏见方面仍存在显著差异。这些限制对HRI有严重的影响,识别错误可能会干扰任务性能、用户信任和安全。
论文及项目相关链接
PDF Accepted at the workshop on Foundation Models for Social Robotics (FoMoSR) at ICSR 2025
Summary
随着自动语音识别(ASR)系统在现实场景中的应用越来越广泛,它们需要应对硬件限制和环境噪声所带来的音频失真问题,同时还需要满足不同用户群体的需求。在人机互动(HRI)领域,这些挑战相互交织,形成了一个独特的识别环境。本文对四种前沿的ASR系统进行了评估,涉及八个公开数据集,涵盖了领域特定、口音、噪声、年龄差异、受损以及自发性的六个难度维度。分析显示,虽然这些系统在标准测试上得分相近,但在实际环境下表现显著不一,存在误解倾向和固有偏见。这些限制对人机互动产生了严重影响,识别错误可能干扰任务执行、用户信任和安全。
Key Takeaways
- ASR系统在现实场景下面临多种挑战,包括硬件限制和环境噪声导致的音频失真。
- ASR系统在HRI领域的应用面临独特挑战,因为需要处理多种不同的用户群体和环境因素。
- 对四种前沿ASR系统的评估表明,在多个公开数据集上的表现存在显著差异。
- ASR系统在处理不同维度(如领域特定、口音、噪声等)的困难时,表现出不同的性能。
- ASR系统在实际环境下存在误解倾向和固有偏见。
- ASR系统的识别错误可能对HRI的任务执行、用户信任和安全产生严重影响。
点此查看论文截图

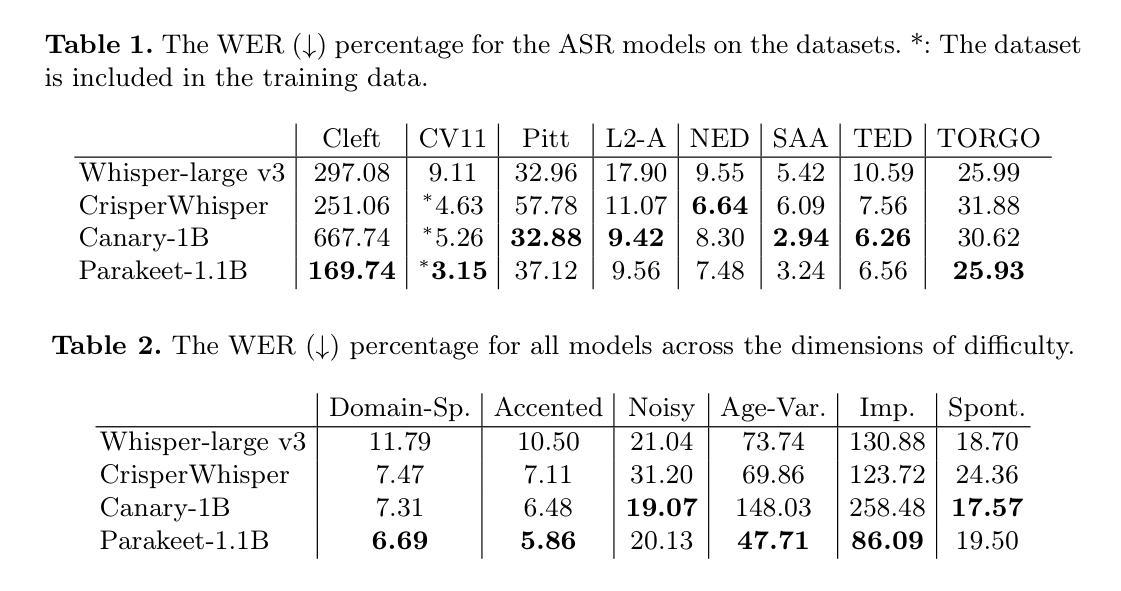
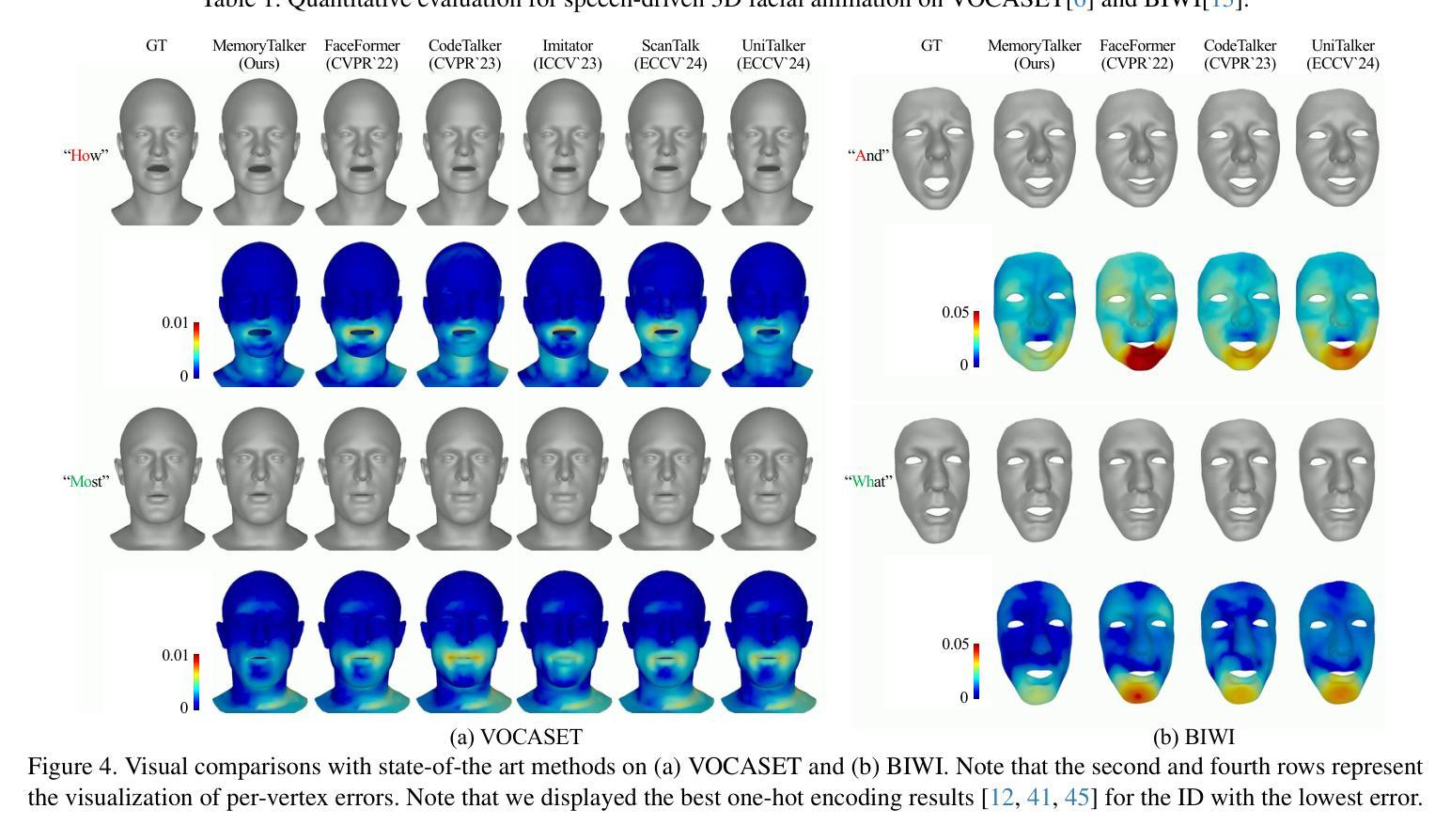
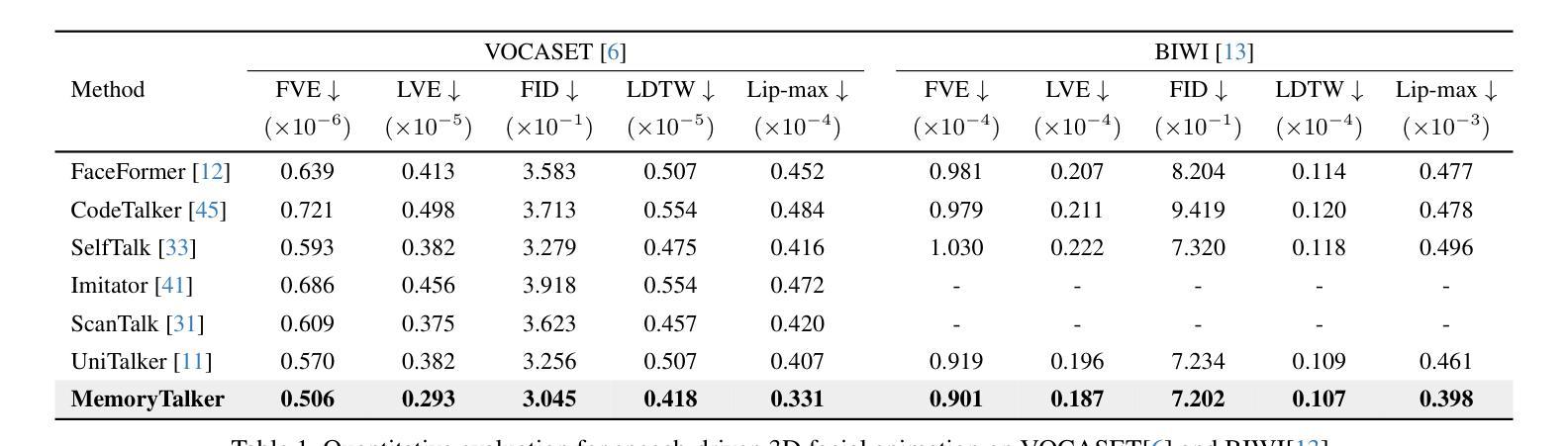
MemoryTalker: Personalized Speech-Driven 3D Facial Animation via Audio-Guided Stylization
Authors:Hyung Kyu Kim, Sangmin Lee, Hak Gu Kim
Speech-driven 3D facial animation aims to synthesize realistic facial motion sequences from given audio, matching the speaker’s speaking style. However, previous works often require priors such as class labels of a speaker or additional 3D facial meshes at inference, which makes them fail to reflect the speaking style and limits their practical use. To address these issues, we propose MemoryTalker which enables realistic and accurate 3D facial motion synthesis by reflecting speaking style only with audio input to maximize usability in applications. Our framework consists of two training stages: 1-stage is storing and retrieving general motion (i.e., Memorizing), and 2-stage is to perform the personalized facial motion synthesis (i.e., Animating) with the motion memory stylized by the audio-driven speaking style feature. In this second stage, our model learns about which facial motion types should be emphasized for a particular piece of audio. As a result, our MemoryTalker can generate a reliable personalized facial animation without additional prior information. With quantitative and qualitative evaluations, as well as user study, we show the effectiveness of our model and its performance enhancement for personalized facial animation over state-of-the-art methods.
语音驱动的3D面部动画旨在根据给定的音频合成逼真的面部运动序列,以匹配说话者的说话风格。然而,之前的工作通常需要先验信息,如说话者的类别标签或推理时的额外3D面部网格,这使得它们无法反映说话风格,并限制了其实际应用。为了解决这些问题,我们提出了MemoryTalker,它通过仅使用音频输入来反映说话风格,实现了逼真且准确的3D面部运动合成,以最大化其在应用程序中的可用性。我们的框架由两个训练阶段组成:第一阶段是存储和检索一般运动(即记忆),第二阶段是执行个性化的面部运动合成(即动画)与由音频驱动的说话风格特征进行运动记忆的风格化。在第二阶段,我们的模型学习哪类面部运动应该为特定的音频片段而强调。因此,我们的MemoryTalker可以在没有额外先验信息的情况下生成可靠的个人面部动画。通过定量和定性评估以及用户研究,我们展示了我们的模型的有效性及其在个性化面部动画方面的性能提升,超过了最先进的方法。
论文及项目相关链接
PDF Accepted in ICCV 2025; Project Page: https://cau-irislab.github.io/ICCV25-MemoryTalker/
Summary
语音驱动的3D面部动画旨在根据给定的音频合成逼真的面部运动序列,匹配说话者的说话风格。然而,之前的方法通常需要先验信息,如说话者的类别标签或额外的3D面部网格进行推断,这使得它们无法反映说话风格并限制了实际应用。为解决这些问题,我们提出了MemoryTalker,通过仅使用音频输入反映说话风格,实现逼真且准确的3D面部运动合成,以在应用程序中最大化可用性。我们的框架包括两个阶段:第一阶段是存储和检索通用运动(即记忆),第二阶段是利用音频驱动的说话风格特征进行个性化面部运动合成(即动画)。在第二阶段,我们的模型学习如何强调针对特定音频的面部运动类型。因此,我们的MemoryTalker无需额外的先验信息即可生成可靠的个性化面部动画。
Key Takeaways
- MemoryTalker旨在解决语音驱动的3D面部动画中反映说话风格的问题,并提高其在实际应用中的可用性。
- 该方法通过仅使用音频输入实现逼真且准确的3D面部运动合成。
- MemoryTalker采用两阶段框架:存储和检索通用运动(记忆阶段)以及个性化面部运动合成(动画阶段)。
- 在动画阶段,模型学习如何根据特定音频强调面部运动类型。
- MemoryTalker无需额外的先验信息即可生成个性化的面部动画。
- 通过定量和定性评估以及用户研究,验证了MemoryTalker模型的有效性及其在个性化面部动画方面的性能提升。
点此查看论文截图

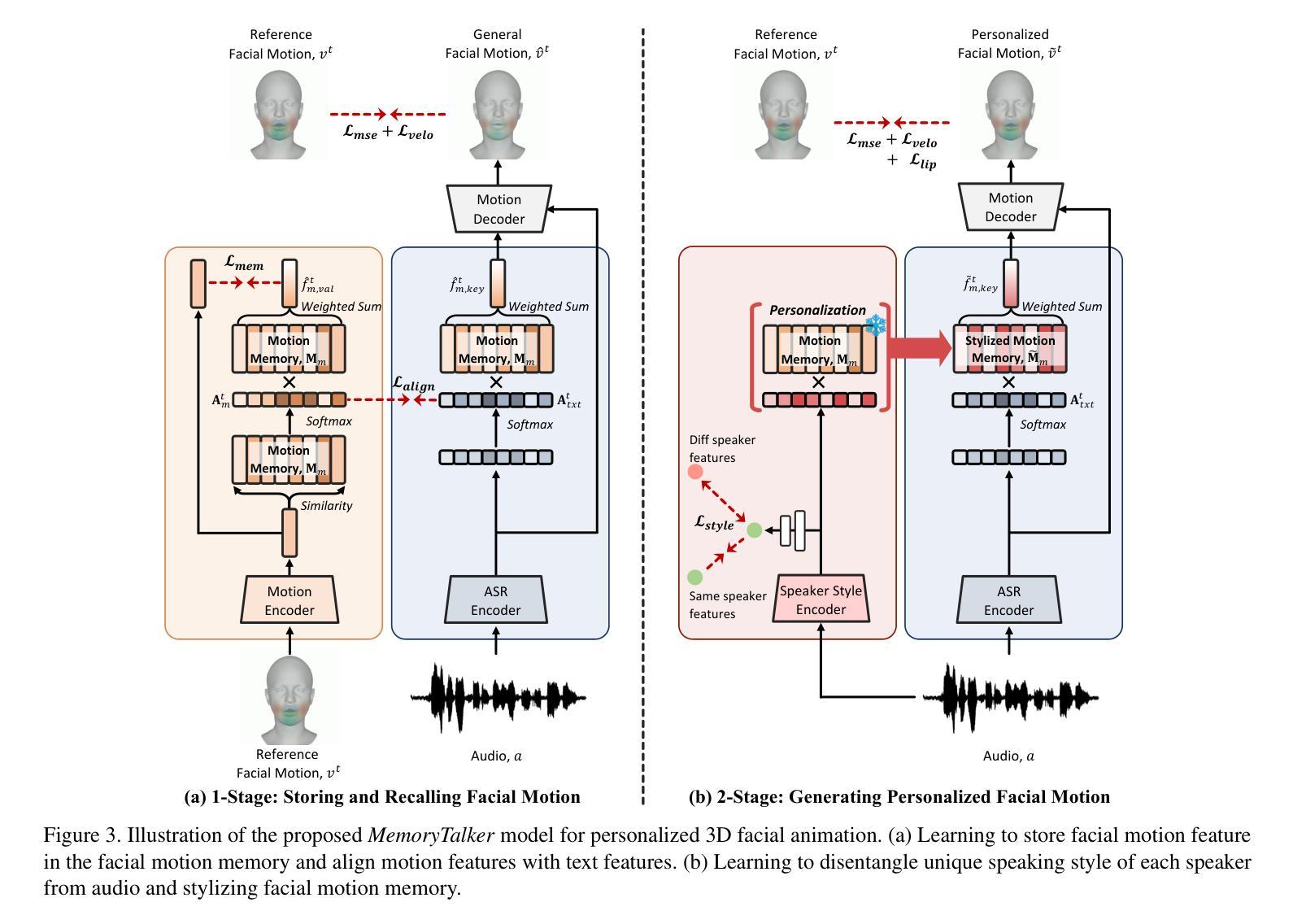
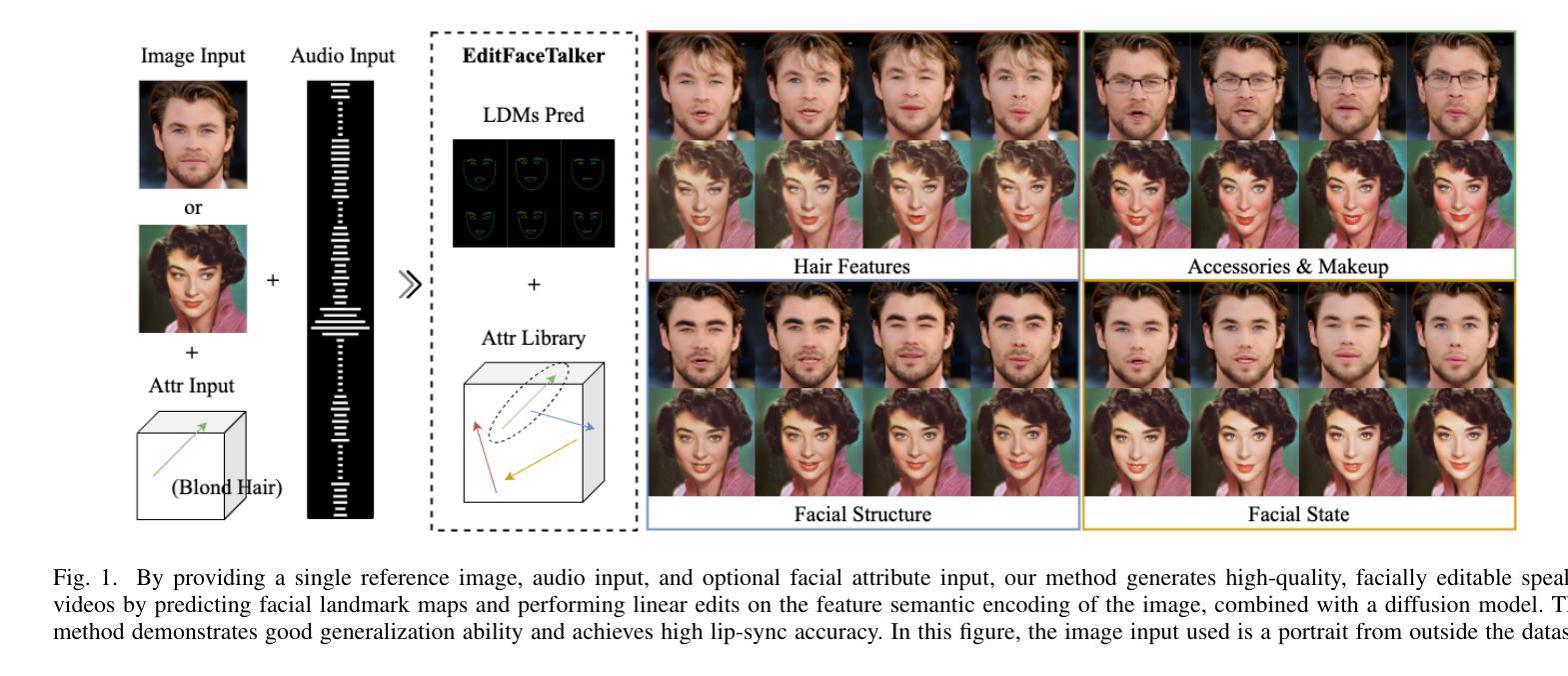
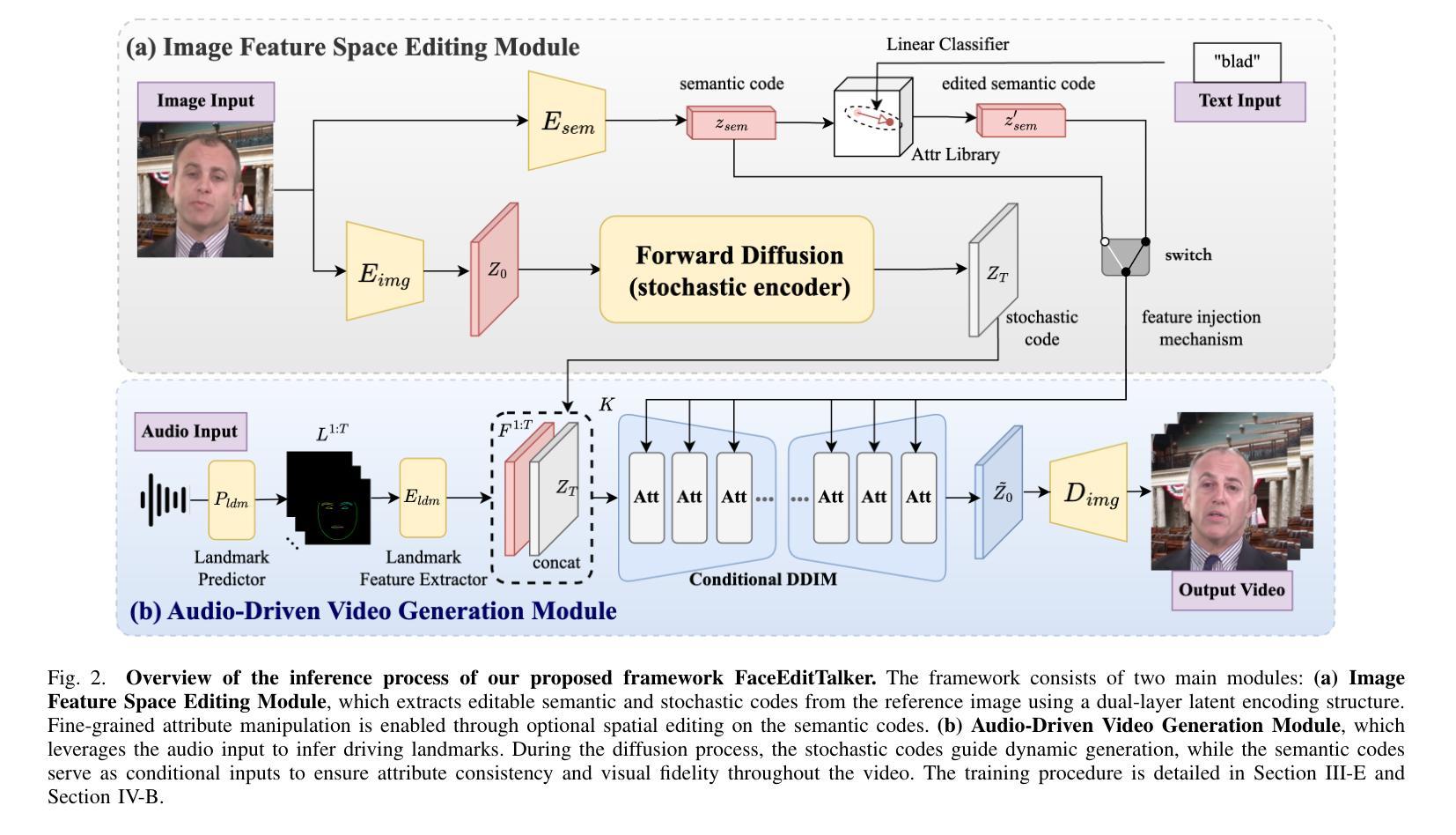
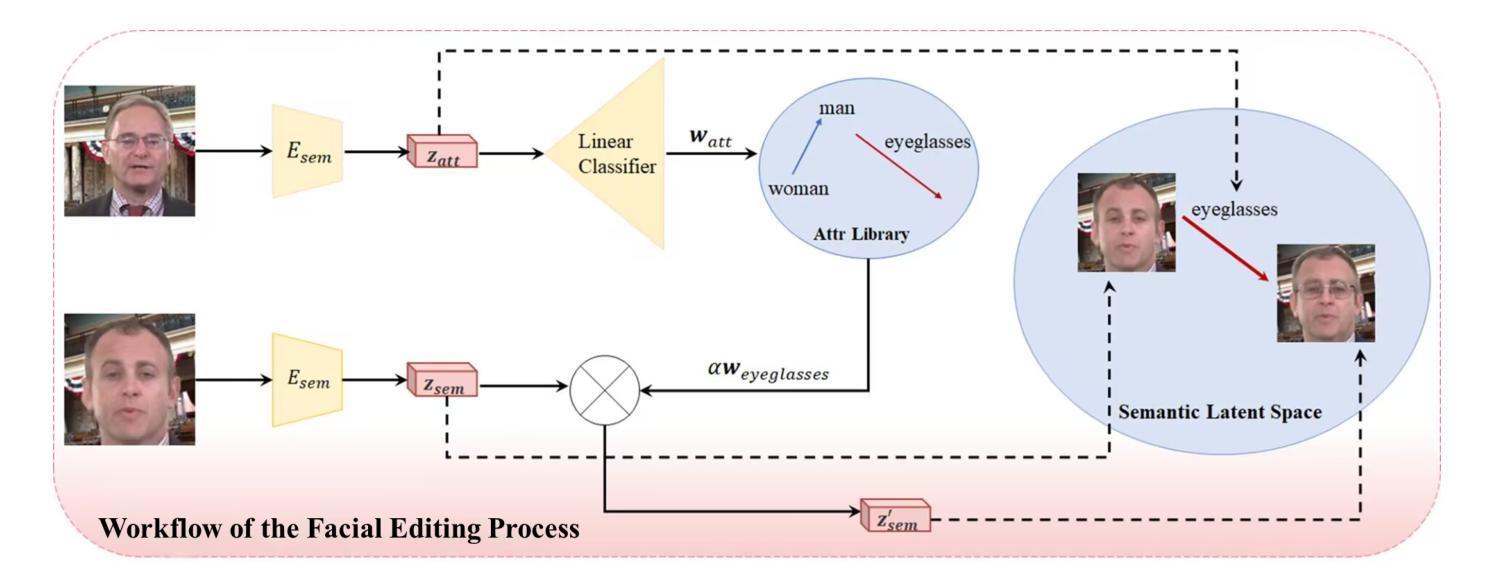
FaceEditTalker: Controllable Talking Head Generation with Facial Attribute Editing
Authors:Guanwen Feng, Zhiyuan Ma, Yunan Li, Jiahao Yang, Junwei Jing, Qiguang Miao
Recent advances in audio-driven talking head generation have achieved impressive results in lip synchronization and emotional expression. However, they largely overlook the crucial task of facial attribute editing. This capability is indispensable for achieving deep personalization and expanding the range of practical applications, including user-tailored digital avatars, engaging online education content, and brand-specific digital customer service. In these key domains, flexible adjustment of visual attributes, such as hairstyle, accessories, and subtle facial features, is essential for aligning with user preferences, reflecting diverse brand identities and adapting to varying contextual demands. In this paper, we present FaceEditTalker, a unified framework that enables controllable facial attribute manipulation while generating high-quality, audio-synchronized talking head videos. Our method consists of two key components: an image feature space editing module, which extracts semantic and detail features and allows flexible control over attributes like expression, hairstyle, and accessories; and an audio-driven video generation module, which fuses these edited features with audio-guided facial landmarks to drive a diffusion-based generator. This design ensures temporal coherence, visual fidelity, and identity preservation across frames. Extensive experiments on public datasets demonstrate that our method achieves comparable or superior performance to representative baseline methods in lip-sync accuracy, video quality, and attribute controllability. Project page: https://peterfanfan.github.io/FaceEditTalker/
音频驱动谈话头部生成领域的最新进展在唇部同步和情感表达方面取得了令人印象深刻的结果。然而,他们很大程度上忽视了面部属性编辑这一关键任务。这种能力对于实现深度个性化以及拓展实际应用范围(包括用户定制的数字化身、引人入胜的在线教育内容和特定品牌的数字客户服务)是必不可少的。在这些关键领域中,视觉属性的灵活调整(如发型、配饰和微妙的面部特征)对于符合用户偏好、反映多样化的品牌身份以及适应各种上下文需求至关重要。在本文中,我们提出了FaceEditTalker,这是一个统一框架,能够在生成高质量、与音频同步的谈话头部视频的同时,实现面部属性的可控操作。我们的方法由两个关键组件组成:图像特征空间编辑模块,该模块提取语义和细节特征,并允许对表情、发型和配饰等属性进行灵活控制;音频驱动视频生成模块,该模块将这些编辑后的特征与音频引导的面部地标相融合,以驱动基于扩散的生成器。这种设计确保了时间连贯性、视觉保真度和跨帧的身份保留。在公共数据集上的广泛实验表明,我们的方法在唇同步准确性、视频质量和属性可控性方面达到了或超越了代表性基准方法的性能。项目页面:https://peterfanfan.github.io/FaceEditTalker/
论文及项目相关链接
Summary
随着音频驱动的说话人头部生成技术的最新进展,唇同步和情绪表达方面取得了令人印象深刻的结果。然而,面部属性编辑这一关键任务却被忽视了。为实现深度个性化并扩展实际应用范围,如用户定制的数字化身、引人入胜的在线教育内容以及特定品牌的数字客户服务,灵活的面部属性调整至关重要。本文提出了FaceEditTalker框架,能够在生成高质量、与音频同步的说话人头视频的同时,实现可控的面部属性操作。该框架包括两个关键组件:图像特征空间编辑模块和音频驱动的视频生成模块。前者提取语义和细节特征,并允许灵活控制表情、发型和配饰等属性;后者融合这些编辑后的特征与音频引导的面部地标,驱动基于扩散的生成器。该设计确保了跨帧的时间连贯性、视觉保真度和身份保留。在公共数据集上的广泛实验表明,该方法在唇同步准确性、视频质量和属性可控性方面达到了或超越了代表性基准方法。
Key Takeaways
- 最近音频驱动的说话人头部生成技术在唇同步和情绪表达上取得了显著进展,但忽视了面部属性编辑的重要性。
- 面部属性编辑对于实现深度个性化以及扩展实际应用范围至关重要,包括用户定制的数字化身、在线教育和品牌客户服务等。
- FaceEditTalker框架结合了图像特征空间编辑和音频驱动的视频生成,实现了高质量且可控的说话人头视频生成。
- 该框架包含两个关键组件:图像特征空间编辑模块允许灵活控制表情、发型和配饰等属性;音频驱动的视频生成模块确保了时间连贯性、视觉保真度和身份保留。
- FaceEditTalker在公共数据集上的实验表现优异,达到了或超越了现有方法在唇同步、视频质量和属性控制方面的标准。
- 该项目提供了一个统一的框架,解决了面部属性编辑和音频驱动的说话人头视频生成之间的融合问题。
点此查看论文截图



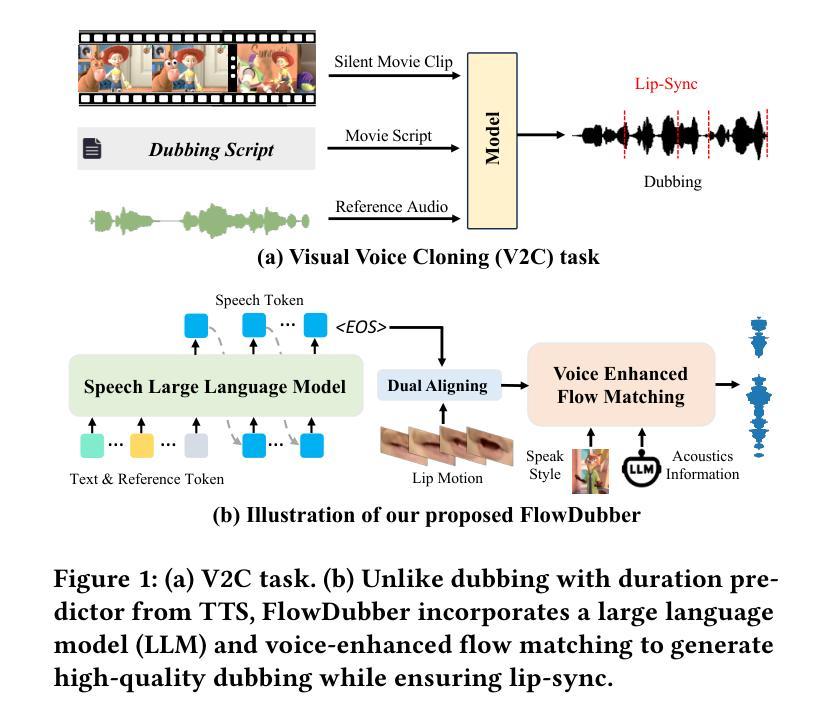
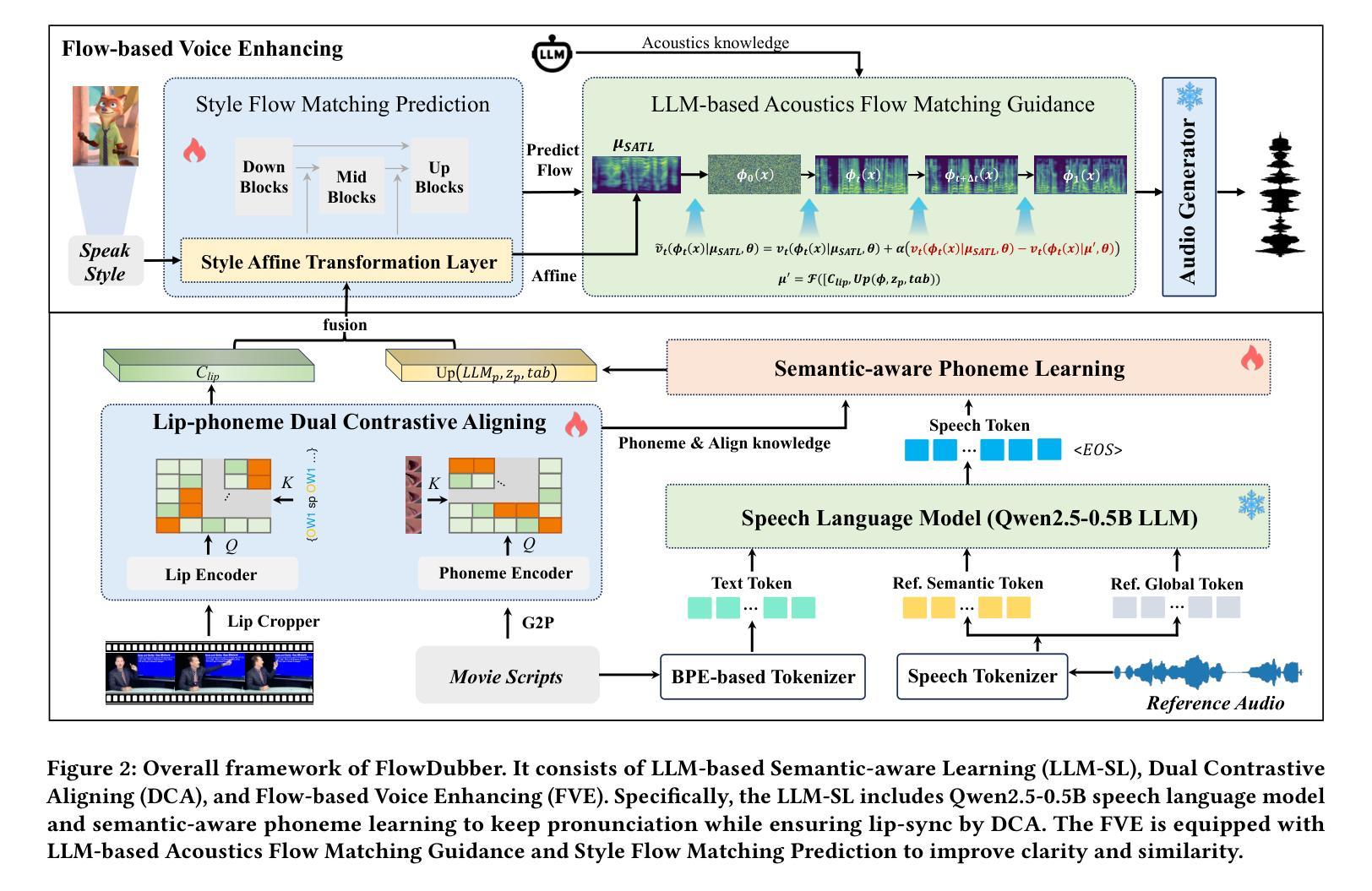
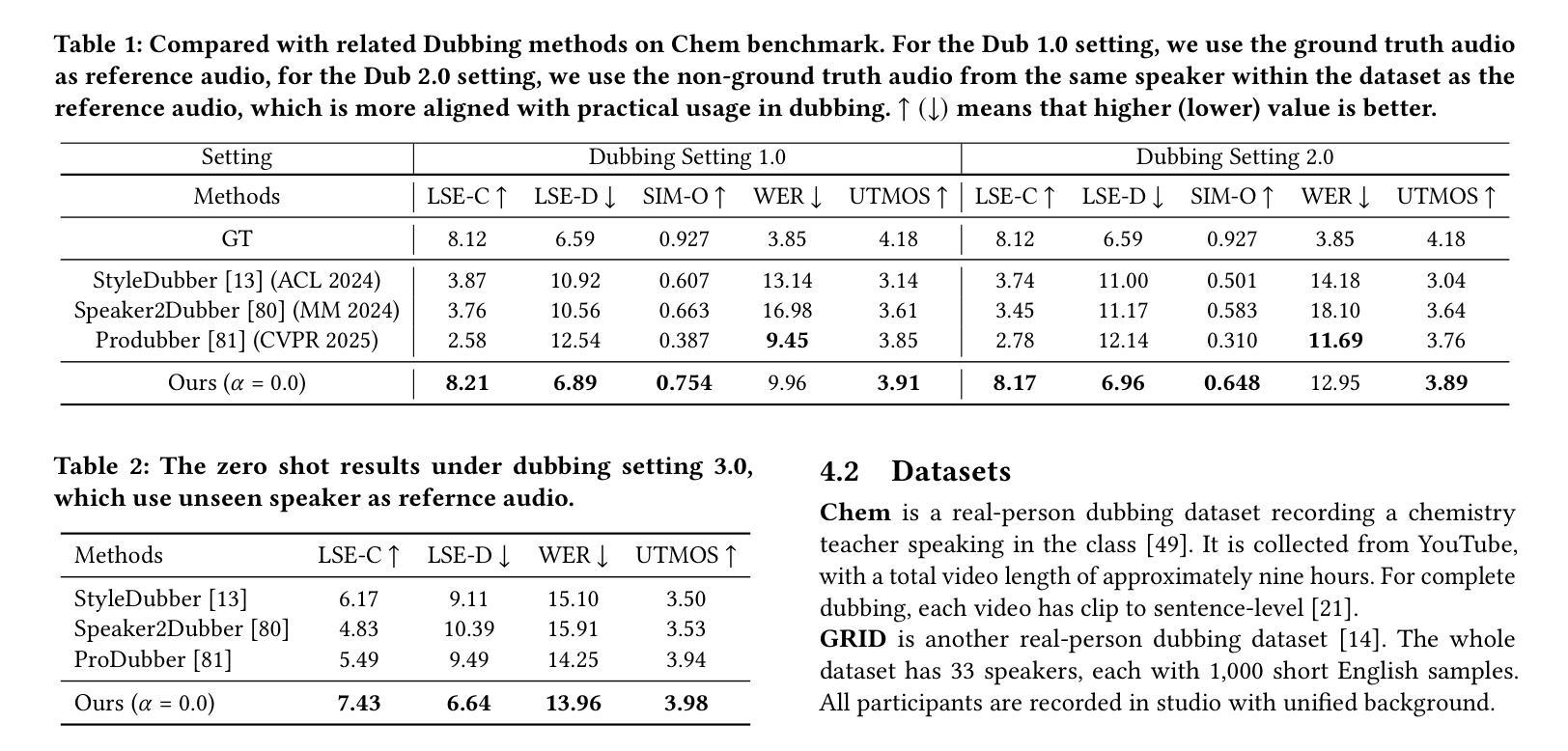
FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing
Authors:Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton van den Hengel, Yuankai Qi, Qingming Huang
Movie Dubbing aims to convert scripts into speeches that align with the given movie clip in both temporal and emotional aspects while preserving the vocal timbre of a given brief reference audio. Existing methods focus primarily on reducing the word error rate while ignoring the importance of lip-sync and acoustic quality. To address these issues, we propose a large language model (LLM) based flow matching architecture for dubbing, named FlowDubber, which achieves high-quality audio-visual sync and pronunciation by incorporating a large speech language model and dual contrastive aligning while achieving better acoustic quality via the proposed voice-enhanced flow matching than previous works. First, we introduce Qwen2.5 as the backbone of LLM to learn the in-context sequence from movie scripts and reference audio. Then, the proposed semantic-aware learning focuses on capturing LLM semantic knowledge at the phoneme level. Next, dual contrastive aligning (DCA) boosts mutual alignment with lip movement, reducing ambiguities where similar phonemes might be confused. Finally, the proposed Flow-based Voice Enhancing (FVE) improves acoustic quality in two aspects, which introduces an LLM-based acoustics flow matching guidance to strengthen clarity and uses affine style prior to enhance identity when recovering noise into mel-spectrograms via gradient vector field prediction. Extensive experiments demonstrate that our method outperforms several state-of-the-art methods on two primary benchmarks.
电影配音旨在将剧本转换为与给定电影片段在时间和情感方面都对齐的语音,同时保留给定简短参考音频的音色。现有方法主要关注降低词错误率,而忽视唇同步和音质的重要性。为了解决这些问题,我们提出了一种基于大型语言模型(LLM)的配音流匹配架构,名为FlowDubber。它通过结合大型语音语言模型和双对比对齐,以及通过提出的语音增强流匹配,实现了高质量的声音视觉同步和发音。首先,我们引入Qwen2.5作为LLM的后端,学习电影剧本和参考音频的上下文序列。然后,提出的语义感知学习侧重于在音素级别捕获LLM语义知识。接下来,双对比对齐(DCA)通过唇动增强相互对齐,减少相似音素的混淆。最后,提出的基于流的语音增强(FVE)从两个方面提高了音质:它引入了一种基于LLM的声学流匹配指导,以提高清晰度,并在通过梯度矢量场预测恢复噪声时,采用仿射风格增强身份特征。大量实验表明,我们的方法在两个主要基准测试上优于几种最新方法。
论文及项目相关链接
Summary
本文介绍了电影配音的任务,旨在将剧本转换为与给定电影片段在时间和情感方面对齐的演讲,同时保留简短参考音频的音色。针对现有方法主要关注降低词错误率而忽视唇同步和音质的问题,提出了基于大型语言模型的FlowDubber架构。通过引入LLM作为骨干、语义感知学习、双重对比对齐和基于流的语音增强,实现了高质量的电影配音。
Key Takeaways
- 电影配音任务旨在将剧本转换为与电影片段对齐的演讲,需考虑时间和情感因素,同时保留参考音频的音色。
- 现有方法主要关注词错误率,而忽视唇同步和音质。
- 提出的FlowDubber架构基于大型语言模型,实现了高质量的电影配音。
- Qwen2.5作为LLM的骨干,学习电影剧本和参考音频的上下文序列。
- 语义感知学习专注于捕捉LLM在音素级别的语义知识。
- 双重对比对齐(DCA)通过加强唇动与语音的相互对齐,减少相似音素的混淆。
- 基于流的语音增强(FVE)在两个方面提高了音质,通过引入LLM的声学流匹配指导增强清晰度,并使用仿射风格先验在通过梯度矢量场预测恢复噪声时增强身份识别。
点此查看论文截图

Supervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Authors:Radek Daněček, Carolin Schmitt, Senya Polikovsky, Michael J. Black
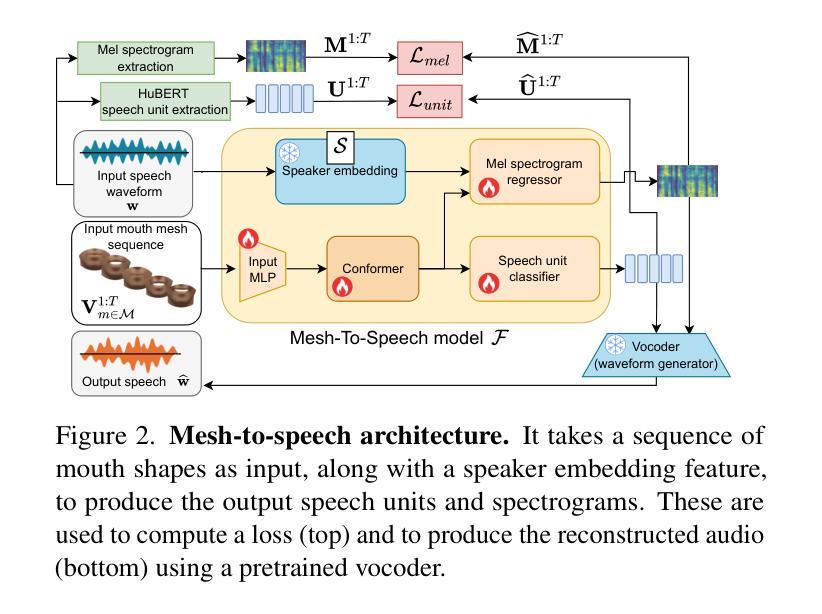
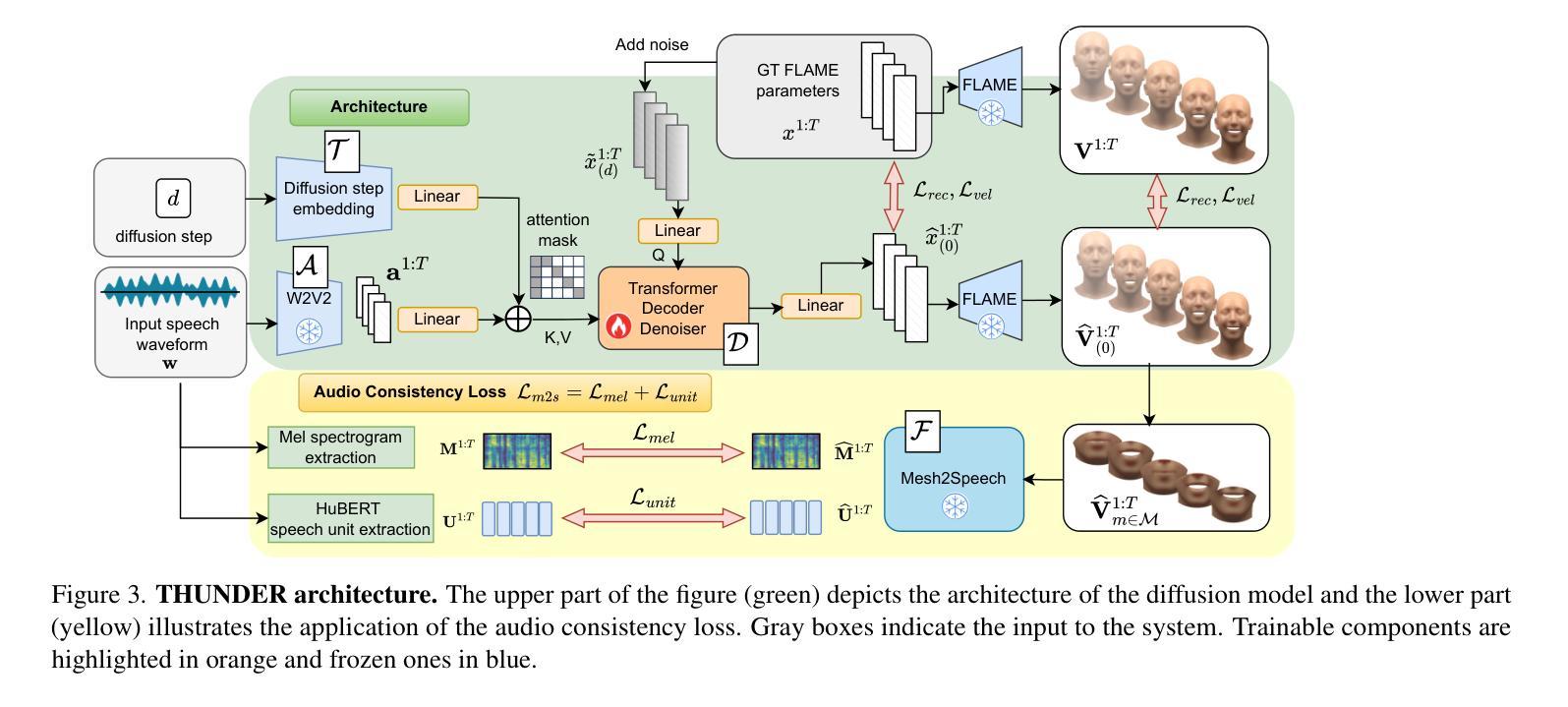
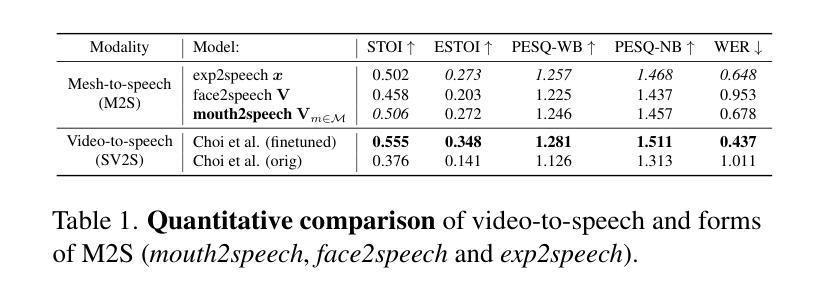
In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations. The code and models will be available at https://thunder.is.tue.mpg.de/
为了具有广泛的应用性,语音驱动的三维头部化身必须根据语音进行唇部动作的表达,同时借助动态变化的面部表情来传达适当的情绪。关键问题在于确定性模型虽然能产生高质量的唇部同步效果,但缺乏丰富的表情;而随机模型虽然能生成多样化的表情,但唇部同步质量较低。为了兼顾两者之优点,我们寻求具有精确唇部同步的随机模型。为此,我们基于以下观察结果开发了一种新方法:如果一个方法能够生成逼真的三维唇部运动,那么就应该能够从唇部运动中推断出语音。推断出的语音应与原始输入音频相匹配,错误的预测会创建一个新的监督信号,用于训练具有精确唇部同步的三维说话头部化身。为了展示这一效果,我们提出了THUNDER(神经可微语音重建下的说话头),这是一个三维说话头部化身框架,通过可微分的声音产生引入了一种新型监督机制。首先,我们训练了一种新型网格到语音模型,该模型可以从面部动画回归音频。然后,我们将该模型纳入基于扩散的说话化身框架。在训练过程中,网格到语音模型会接受生成的动画并产生声音,该声音会与输入语音进行比较,从而创建一个可微分的分析-由音频合成监督循环。我们的广泛定性和定量实验表明,THUNDER显著提高了说话头部化身的唇部同步质量,同时仍能够生成多样化、高质量、富有表现力的面部动画。相关代码和模型将在https://thunder.is.tue.mpg.de/ 上发布。
论文及项目相关链接
Summary
本文介绍了创建具有实时语音驱动的面部表情和口型同步的3D头像的挑战。确定性模型可以产生高质量的口型同步,但缺乏丰富的表情,而随机模型则能生成多样化的表情,但口型同步质量较低。为了结合两者的优点,研究者们开发了一种基于生成真实3D唇部运动可以从其运动中推断语音的新方法,并据此构建了THUNDER框架。该框架引入了一种新型监督机制,通过可微声音产生来实现对说话人头部的精准控制,进而实现了口型同步的改进和表情动画的多样化生成。
Key Takeaways
- 语音驱动的3D头像需要同步口型以传达语音和动态变化的面部表情。
- 确定性模型提供高质量的口型同步但缺乏丰富表情,而随机模型则产生多样化的表情但口型同步质量较低。
- 新方法通过生成真实的3D唇部运动并据此推断语音,为训练具有精准口型同步的说话人头模提供了基础。
- THUNDER框架引入了一种新型监督机制,通过可微声音产生来实现对说话人头部的精准控制。
- THUNDER显著提高了头像的口型同步质量,并允许生成多样化、高质量的表情动画。
点此查看论文截图

Removing Averaging: Personalized Lip-Sync Driven Characters Based on Identity Adapter
Authors:Yanyu Zhu, Lichen Bai, Jintao Xu, Hai-tao Zheng
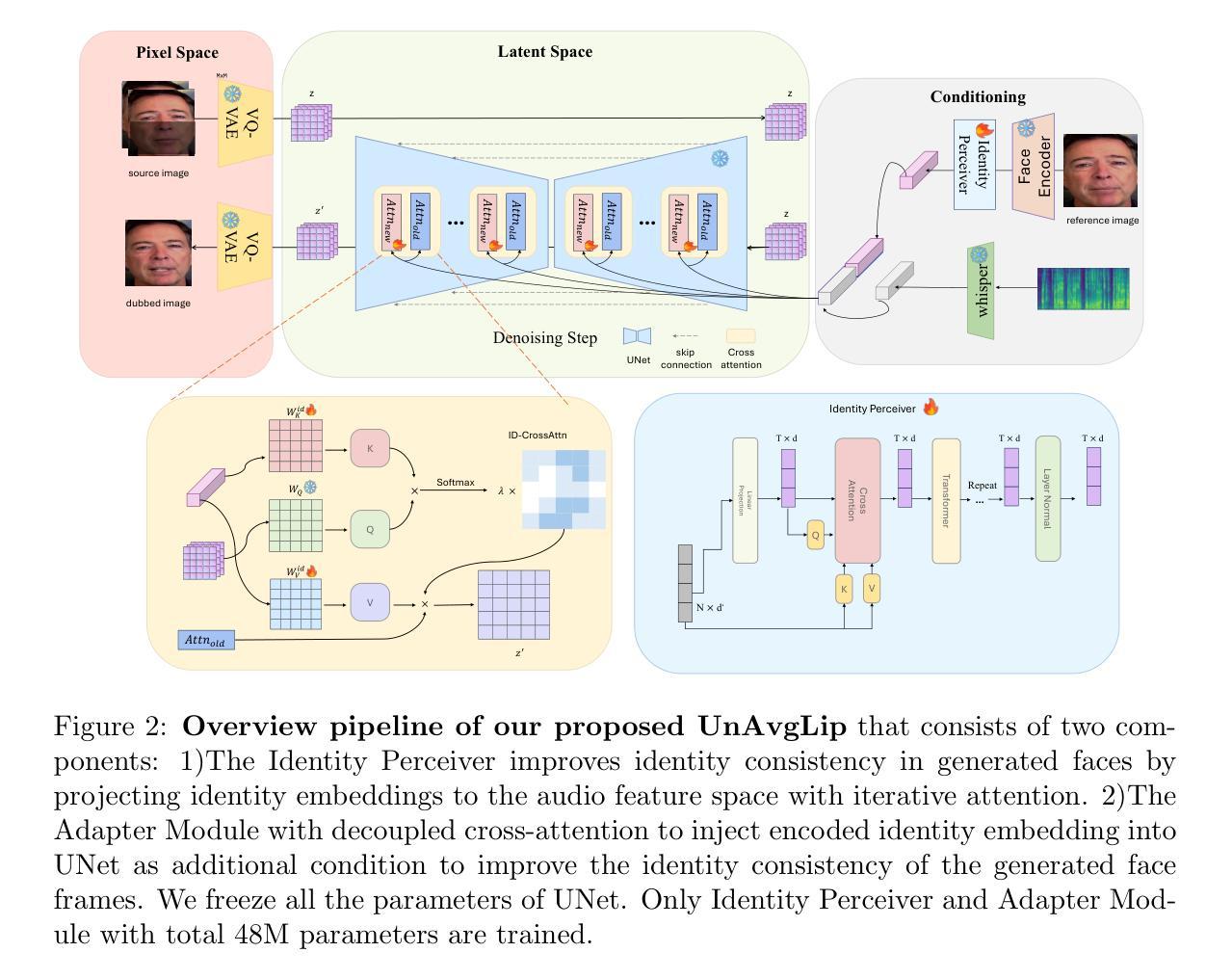
Recent advances in diffusion-based lip-syncing generative models have demonstrated their ability to produce highly synchronized talking face videos for visual dubbing. Although these models excel at lip synchronization, they often struggle to maintain fine-grained control over facial details in generated images. In this work, we identify “lip averaging” phenomenon where the model fails to preserve subtle facial details when dubbing unseen in-the-wild videos. This issue arises because the commonly used UNet backbone primarily integrates audio features into visual representations in the latent space via cross-attention mechanisms and multi-scale fusion, but it struggles to retain fine-grained lip details in the generated faces. To address this issue, we propose UnAvgLip, which extracts identity embeddings from reference videos to generate highly faithful facial sequences while maintaining accurate lip synchronization. Specifically, our method comprises two primary components: (1) an Identity Perceiver module that encodes facial embeddings to align with conditioned audio features; and (2) an ID-CrossAttn module that injects facial embeddings into the generation process, enhancing model’s capability of identity retention. Extensive experiments demonstrate that, at a modest training and inference cost, UnAvgLip effectively mitigates the “averaging” phenomenon in lip inpainting, significantly preserving unique facial characteristics while maintaining precise lip synchronization. Compared with the original approach, our method demonstrates significant improvements of 5% on the identity consistency metric and 2% on the SSIM metric across two benchmark datasets (HDTF and LRW).
基于扩散的唇同步生成模型的最新进展已经证明它们在视觉配音中生成高度同步的说话面部视频的能力。尽管这些模型在唇同步方面表现出色,但它们在保持生成图像的面部细节方面往往面临困难。在这项工作中,我们发现了“唇部平均化”现象,即模型在配音未见过的野外视频时,无法保留微妙的面部细节。这个问题出现的原因是,常用的UNet主干网络主要通过跨注意机制和多尺度融合将音频特征集成到视觉表示中,但在生成的面部中难以保留精细的唇部细节。为了解决这一问题,我们提出了UnAvgLip,它从参考视频中提取身份嵌入,以生成高度忠实的面部序列,同时保持准确的唇部同步。具体来说,我们的方法包括两个主要组成部分:(1)身份感知器模块,它编码面部嵌入以与条件音频特征对齐;(2)ID-CrossAttn模块,它将面部嵌入注入生成过程,增强模型保留身份的能力。大量实验表明,在适度的训练和推理成本下,UnAvgLip有效地缓解了唇部补全中的“平均化”现象,在保持精确唇部同步的同时,显著保留了独特的面部特征。与原始方法相比,我们的方法在HDTF和LRW两个基准数据集上身份一致性指标提高了5%,SSIM指标提高了2%。
论文及项目相关链接
Summary
基于扩散的唇同步生成模型能够在视觉配音中生成高度同步的说话面部视频。然而,这些模型在保持面部细节方面存在缺陷。本文中,我们发现了“唇部平均化”现象,即模型在为未见过的野生视频配音时,无法保持微妙的面部细节。为解决这一问题,我们提出了UnAvgLip方法,它通过提取参考视频的身份嵌入来生成高度真实的面部序列,同时保持准确的唇部同步。
Key Takeaways
- 扩散基于的唇同步生成模型能制作高度同步的说话面部视频,但维持面部细节有难度。
- 出现“唇部平均化”现象,即在为未见视频配音时,模型无法保留微妙的面部细节。
- UnAvgLip方法通过提取参考视频的身份嵌入来解决这个问题。
- UnAvgLip包含两个主要组件:Identity Perceiver模块和ID-CrossAttn模块。
- Identity Perceiver模块编码面部嵌入,与条件音频特征对齐。
- ID-CrossAttn模块将面部嵌入注入生成过程,增强了模型保留身份的能力。
点此查看论文截图


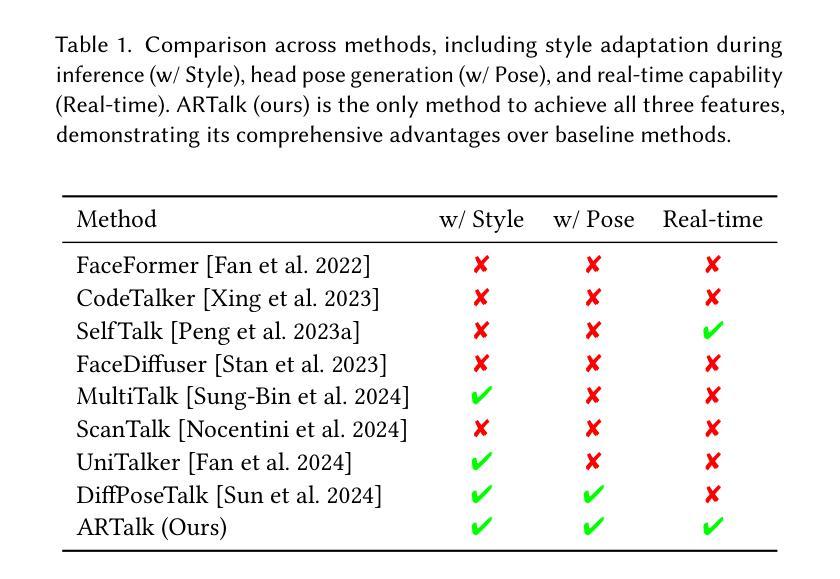
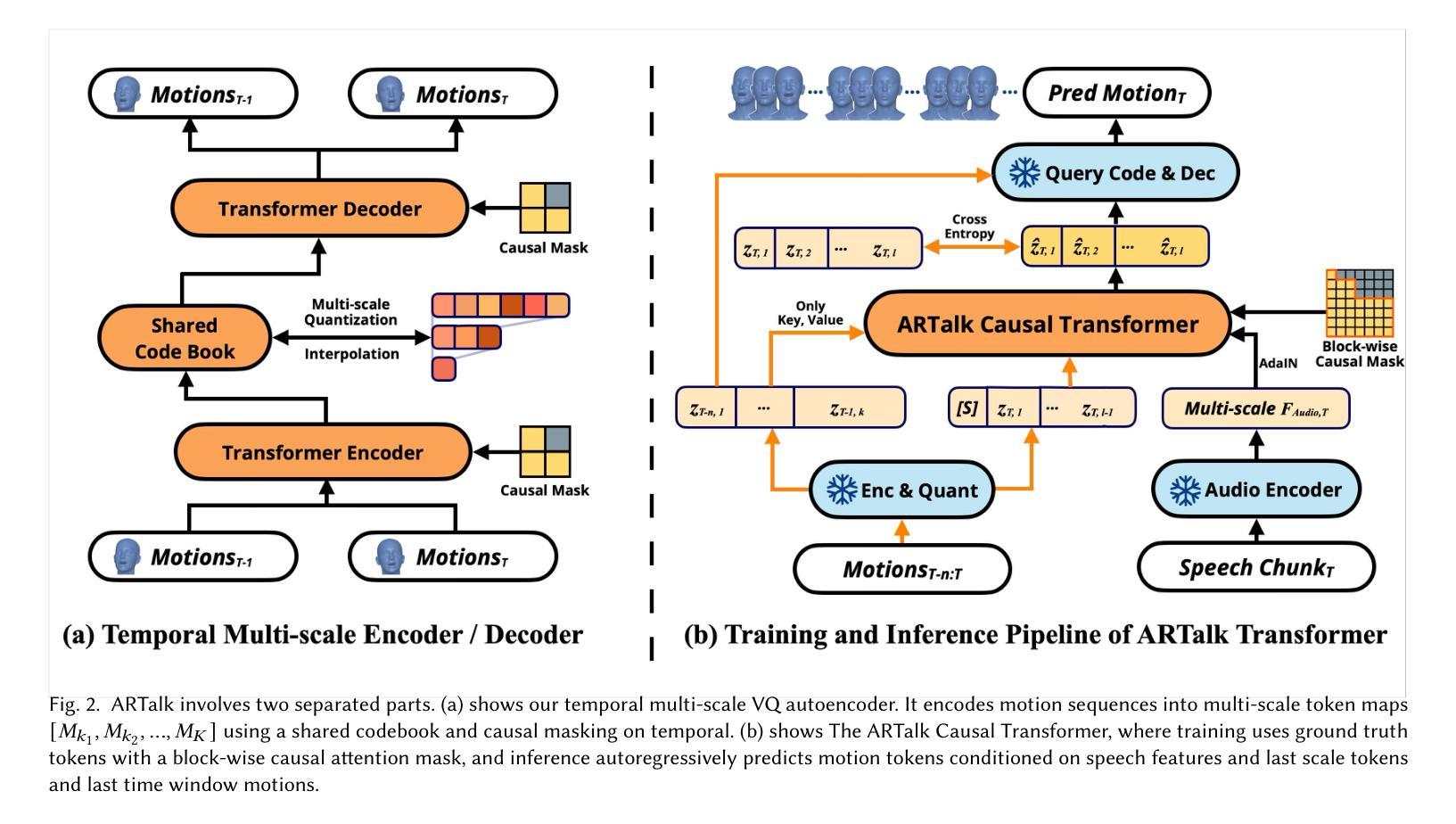
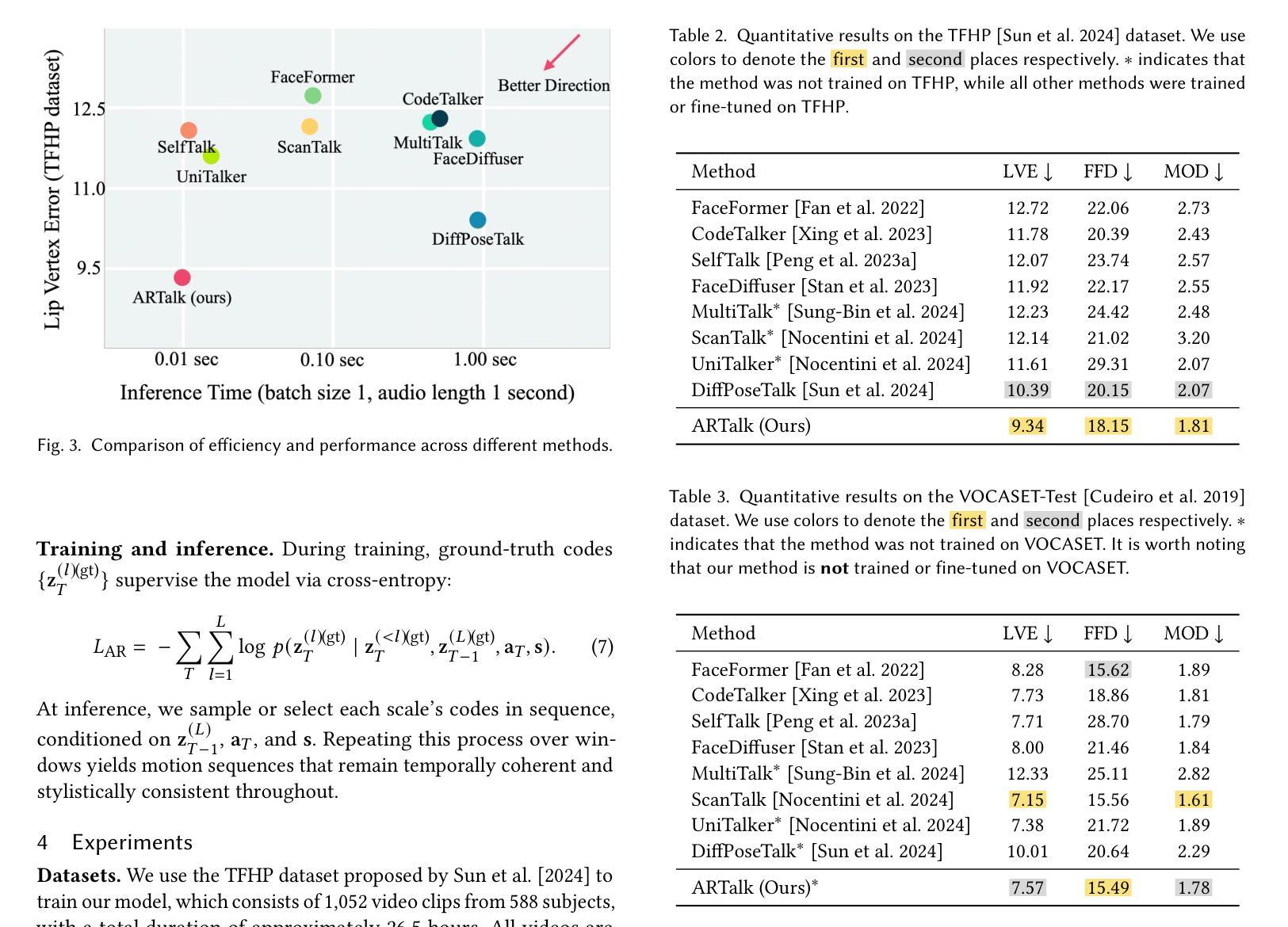
ARTalk: Speech-Driven 3D Head Animation via Autoregressive Model
Authors:Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, Tatsuya Harada
Speech-driven 3D facial animation aims to generate realistic lip movements and facial expressions for 3D head models from arbitrary audio clips. Although existing diffusion-based methods are capable of producing natural motions, their slow generation speed limits their application potential. In this paper, we introduce a novel autoregressive model that achieves real-time generation of highly synchronized lip movements and realistic head poses and eye blinks by learning a mapping from speech to a multi-scale motion codebook. Furthermore, our model can adapt to unseen speaking styles, enabling the creation of 3D talking avatars with unique personal styles beyond the identities seen during training. Extensive evaluations and user studies demonstrate that our method outperforms existing approaches in lip synchronization accuracy and perceived quality.
语音驱动的3D面部动画旨在从任意音频片段中为3D头部模型生成逼真的嘴唇动作和面部表情。尽管现有的基于扩散的方法能够产生自然运动,但其缓慢的生成速度限制了其应用潜力。在本文中,我们引入了一种新型自回归模型,通过学习与多尺度运动字典之间的映射关系,实现高度同步的嘴唇动作和逼真的头部姿势以及眨眼等动作的实时生成。此外,我们的模型能够适应未见过的说话风格,使能够创建具有独特个人风格的3D对话角色,而不仅仅是训练期间见过的身份。全面的评估和用户研究证明,我们的方法在嘴唇同步精度和感知质量方面优于现有方法。
论文及项目相关链接
PDF SIGGRAPH Asia 2025, More video demonstrations, code, models and data can be found on our project website: http://xg-chu.site/project_artalk/
Summary
本文提出了一种基于自回归模型的实时语音驱动3D面部动画技术。该技术利用多尺度运动代码本实现高度同步的唇动和逼真的头部姿态以及眨眼动作,并能适应未见过的说话风格,创建具有独特个性的3D头像。此方法在唇同步准确性和感知质量方面优于现有方法。
Key Takeaways
- 该技术实现了基于自回归模型的实时语音驱动3D面部动画。
- 通过学习从语音到多尺度运动代码本的映射,生成高度同步的唇动。
- 技术能够产生逼真的头部姿态和眨眼动作。
- 模型能够适应不同的说话风格,创建具有独特个性的3D头像。
- 该技术在唇同步准确性方面表现出优越性能。
- 与现有方法相比,该技术提供了更高的感知质量。
点此查看论文截图


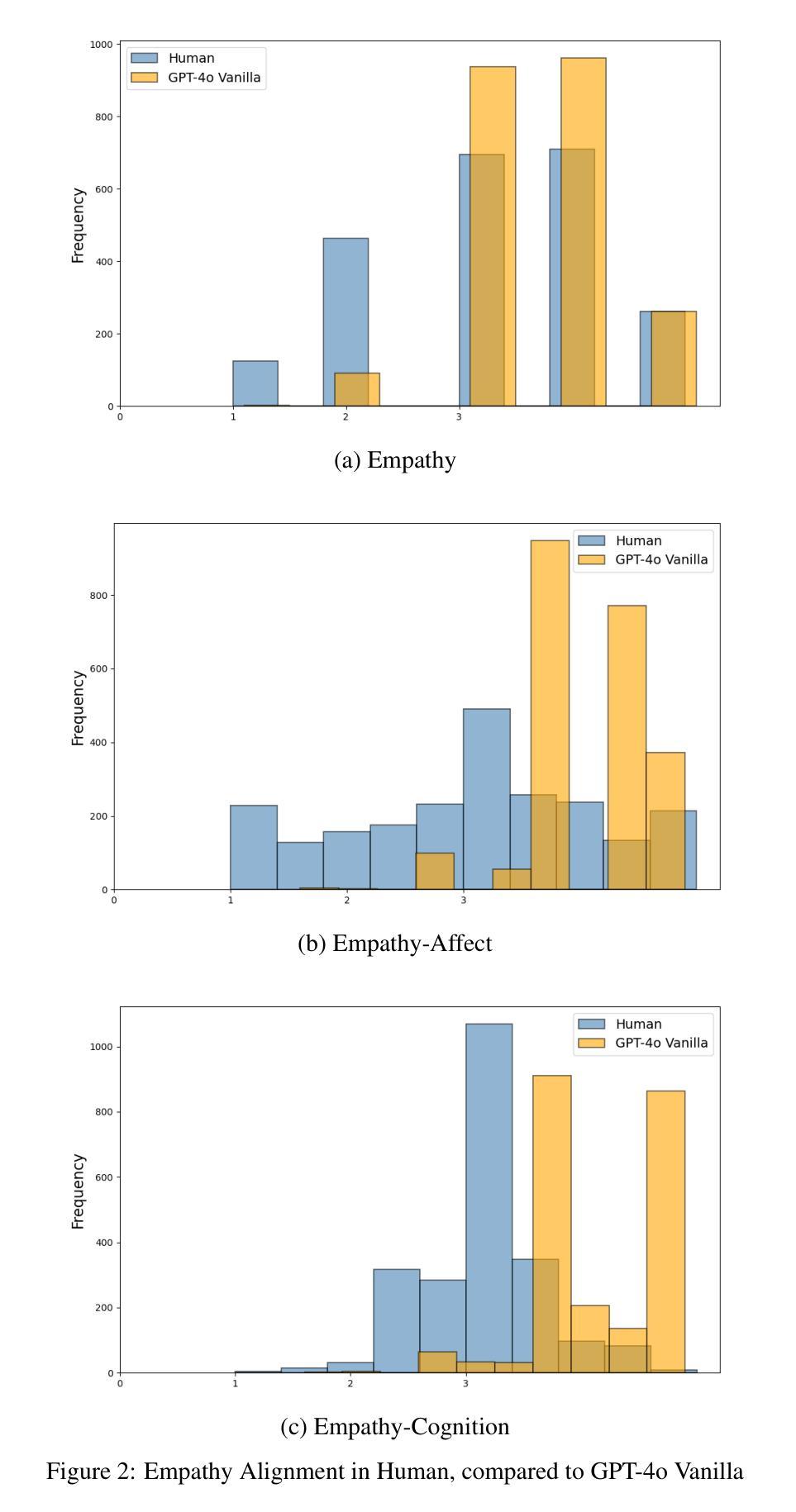
Talk, Listen, Connect: How Humans and AI Evaluate Empathy in Responses to Emotionally Charged Narratives
Authors:Mahnaz Roshanaei, Rezvaneh Rezapour, Magy Seif El-Nasr
Social interactions promote well-being, yet barriers like geographic distance, time limitations, and mental health conditions can limit face-to-face interactions. Emotionally responsive AI systems, such as chatbots, offer new opportunities for social and emotional support, but raise critical questions about how empathy is perceived and experienced in human-AI interactions. This study examines how empathy is evaluated in AI-generated versus human responses. Using personal narratives, we explored how persona attributes (e.g., gender, empathic traits, shared experiences) and story qualities affect empathy ratings. We compared responses from standard and fine-tuned AI models with human judgments. Results show that while humans are highly sensitive to emotional vividness and shared experience, AI-responses are less influenced by these cues, often lack nuance in empathic expression. These findings highlight challenges in designing emotionally intelligent systems that respond meaningfully across diverse users and contexts, and informs the design of ethically aware tools to support social connection and well-being.
社会互动有助于促进福祉,然而,地理距离、时间限制和心理健康状况等障碍限制了面对面的互动。情感响应的AI系统,如聊天机器人,为社会和情感支持提供了新的机会,但也引发了关于人类与AI互动中如何感知和体验共情的关键问题。本研究考察了AI生成响应与人类响应中的共情评估方式。通过个人叙事,我们探讨了人格属性(如性别、共情特质、共享经验)和故事质量如何影响共情评级。我们将标准AI模型和经过微调后的AI模型的响应与人类判断进行了比较。结果表明,虽然人类对情绪生动性和共享经验高度敏感,但AI的响应受这些线索的影响较小,往往缺乏微妙的共情表达。这些发现突显了在设计和情感智能系统时面临的挑战,这些系统需要在不同的用户和背景下做出有意义的响应,并为支持社会联系和福祉的伦理意识工具的设计提供了信息。
论文及项目相关链接
PDF 21 pages, 4 figures, 6 tables. Title updated from “Talk, Listen, Connect: Navigating Empathy in Human-AI Interactions” to “Talk, Listen, Connect: How Humans and AI Evaluate Empathy in Responses to Emotionally Charged Narratives” in this version. This is version 2 (v2) of the paper. All previous citations of arXiv:2409.15550 with the old title still refer to the same paper
Summary
人工智能聊天机器人等情感响应系统为社会互动提供了新的机会,但人们对其中的共情体验感知存在质疑。本研究通过个人叙事,探讨了人格属性(如性别、共情特质、共同经历)和故事质量如何影响共情评价。对比人工智能模型的标准响应和精细调整响应与人的判断,发现人类对于情感的生动性和共同经历高度敏感,而人工智能的响应则较少受到这些线索的影响,往往缺乏微妙的共情表达。这为设计能够跨不同用户和情境做出有意义响应的情感智能系统带来了挑战,也为支持社会联系和福祉的道德工具的设计提供了启示。
Key Takeaways
- 社会互动对福祉有积极影响,但地理距离、时间限制和精神健康等障碍限制了面对面的交流。
- 情感响应的AI系统如聊天机器人为社会和情感支持提供了新的机会。
- 人类对于情感的生动性和共同经历高度敏感,而AI响应受其影响较小。
- AI在表达共情时常常缺乏细微差别。
- 设计情感智能系统时需要考虑跨不同用户和情境的有意义响应。
- 需要设计道德工具以支持社会联系和福祉。
点此查看论文截图


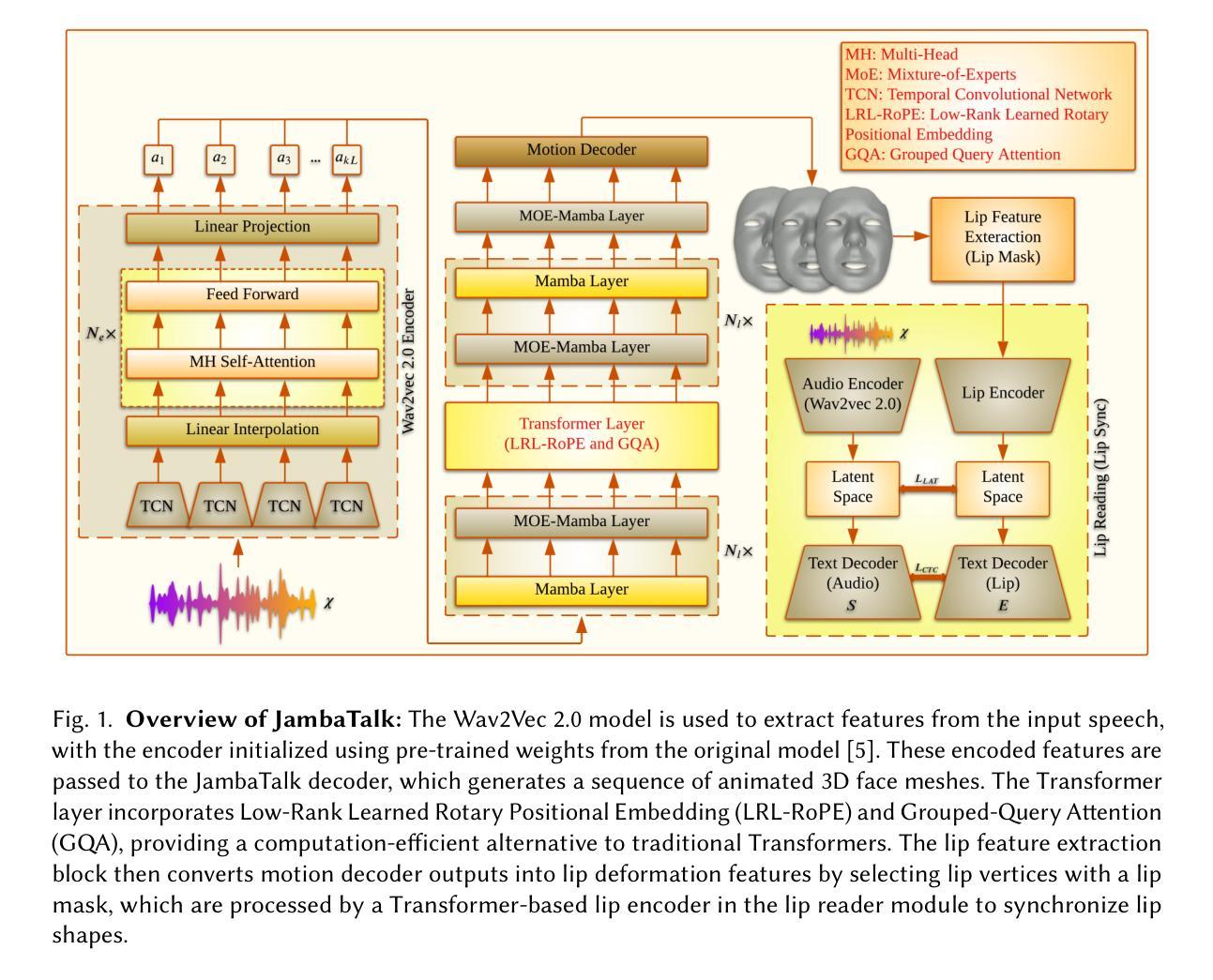
JambaTalk: Speech-Driven 3D Talking Head Generation Based on Hybrid Transformer-Mamba Model
Authors:Farzaneh Jafari, Stefano Berretti, Anup Basu
In recent years, the talking head generation has become a focal point for researchers. Considerable effort is being made to refine lip-sync motion, capture expressive facial expressions, generate natural head poses, and achieve high-quality video. However, no single model has yet achieved equivalence across all quantitative and qualitative metrics. We introduce Jamba, a hybrid Transformer-Mamba model, to animate a 3D face. Mamba, a pioneering Structured State Space Model (SSM) architecture, was developed to overcome the limitations of conventional Transformer architectures, particularly in handling long sequences. This challenge has constrained traditional models. Jamba combines the advantages of both the Transformer and Mamba approaches, offering a comprehensive solution. Based on the foundational Jamba block, we present JambaTalk to enhance motion variety and lip sync through multimodal integration. Extensive experiments reveal that our method achieves performance comparable or superior to state-of-the-art models.
近年来,说话人头部生成已成为研究人员的关注点。人们正在付出相当大的努力来改进唇部同步动作,捕捉面部表情,生成自然头部姿势,并实现高质量视频。然而,目前还没有任何单一模型能够在所有定量和定性指标上实现等效。我们引入了Jamba,这是一个混合的Transformer-Mamba模型,用于驱动3D面部动画。Mamba是一种开创性的结构化状态空间模型(SSM)架构,旨在克服传统Transformer架构的局限性,特别是在处理长序列方面的挑战。Jamba结合了Transformer和Mamba方法的优点,提供了一个全面的解决方案。基于基本的Jamba模块,我们推出了JambaTalk,通过多模式融合增强运动多样性和唇部同步性。大量实验表明,我们的方法与最先进的模型性能相当或更优。
论文及项目相关链接
PDF 23 pages with 8 figures
Summary
本文介绍了针对说话人头部生成的研究进展,并引入了名为Jamba的混合模型。该模型结合了Transformer和Mamba两种方法的优点,用于动画化3D面部。Mamba是一种新型的SSM架构,旨在克服传统Transformer在处理长序列时的局限性。JambaTalk的提出增强了运动多样性和唇同步效果。实验表明,该方法性能与现有先进技术相当或更优。
Key Takeaways
- 说话人头部生成已成为研究焦点,集中于改进唇同步运动、面部表情捕捉、自然头部姿态生成及高质量视频。
- 当前尚未有单一模型在所有定量和定性指标上实现等效性。
- 引入Jamba模型,结合了Transformer和Mamba两种方法,以动画化3D面部。
- Mamba是一种新型的SSM架构,旨在解决传统Transformer处理长序列时的局限性。
- JambaTalk增强了运动多样性和唇同步效果。
- 实验结果显示Jamba模型性能优越,与现有先进技术相当。
点此查看论文截图