⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-08 更新
Embracing Aleatoric Uncertainty: Generating Diverse 3D Human Motion
Authors:Zheng Qin, Yabing Wang, Minghui Yang, Sanping Zhou, Ming Yang, Le Wang
Generating 3D human motions from text is a challenging yet valuable task. The key aspects of this task are ensuring text-motion consistency and achieving generation diversity. Although recent advancements have enabled the generation of precise and high-quality human motions from text, achieving diversity in the generated motions remains a significant challenge. In this paper, we aim to overcome the above challenge by designing a simple yet effective text-to-motion generation method, \textit{i.e.}, Diverse-T2M. Our method introduces uncertainty into the generation process, enabling the generation of highly diverse motions while preserving the semantic consistency of the text. Specifically, we propose a novel perspective that utilizes noise signals as carriers of diversity information in transformer-based methods, facilitating a explicit modeling of uncertainty. Moreover, we construct a latent space where text is projected into a continuous representation, instead of a rigid one-to-one mapping, and integrate a latent space sampler to introduce stochastic sampling into the generation process, thereby enhancing the diversity and uncertainty of the outputs. Our results on text-to-motion generation benchmark datasets~(HumanML3D and KIT-ML) demonstrate that our method significantly enhances diversity while maintaining state-of-the-art performance in text consistency.
从文本生成三维人体运动是一项具有挑战但价值极高的任务。该任务的关键方面在于确保文本与运动的一致性以及实现生成的多样性。尽管最近的技术进步使得从文本生成精确高质量的人体运动成为可能,但在生成运动的多样性方面仍存在重大挑战。在本文中,我们旨在通过设计一种简单有效的文本到运动生成方法,即Diverse-T2M,来克服上述挑战。我们的方法在生成过程中引入了不确定性,能够在保持文本语义一致性的同时,生成高度多样的运动。具体来说,我们提出了一种新的视角,利用噪声信号作为基于转换器方法中多样性信息的载体,实现对不确定性的显式建模。此外,我们构建了一个潜在空间,将文本投影到连续表示中,而不是僵化的一对一映射,并整合潜在空间采样器,将随机采样引入到生成过程中,从而提高了输出结果的多样性和不确定性。我们在文本到运动生成基准数据集(HumanML3D和KIT-ML)上的结果表明,我们的方法在保持文本一致性方面达到最新水平的同时,显著提高了多样性。
论文及项目相关链接
Summary
文本生成三维人体运动是一项具有挑战但价值极高的任务。本文旨在解决该任务中的多样性和文本一致性挑战。通过设计简单有效的文本到运动生成方法(即Diverse-T2M),本文引入不确定性到生成过程中,实现高度多样的运动生成,同时保持文本语义的一致性。利用噪声信号作为多样性信息的载体,在基于transformer的方法中明确建模不确定性。此外,构建一个将文本投影到连续表示的潜在空间,通过引入潜在空间采样器增强生成的多样性和不确定性。在文本到运动生成基准数据集上的实验结果表明,该方法在保持文本一致性的同时显著提高了多样性。
Key Takeaways
- 该研究关注从文本生成三维人体运动的任务,强调多样性和文本一致性的重要性。
- 提出了一种简单有效的文本到运动生成方法(Diverse-T2M),解决多样性和一致性挑战。
- 在Diverse-T2M方法中,引入不确定性到生成过程中,以实现高度多样的运动生成。
- 利用噪声信号作为多样性信息的载体,在基于transformer的方法中明确建模不确定性。
- 构建了一个潜在空间,将文本投影到连续表示中,而非刚性一对一映射,增强了方法的灵活性。
- 通过引入潜在空间采样器,进一步提高生成的多样性和不确定性。
点此查看论文截图


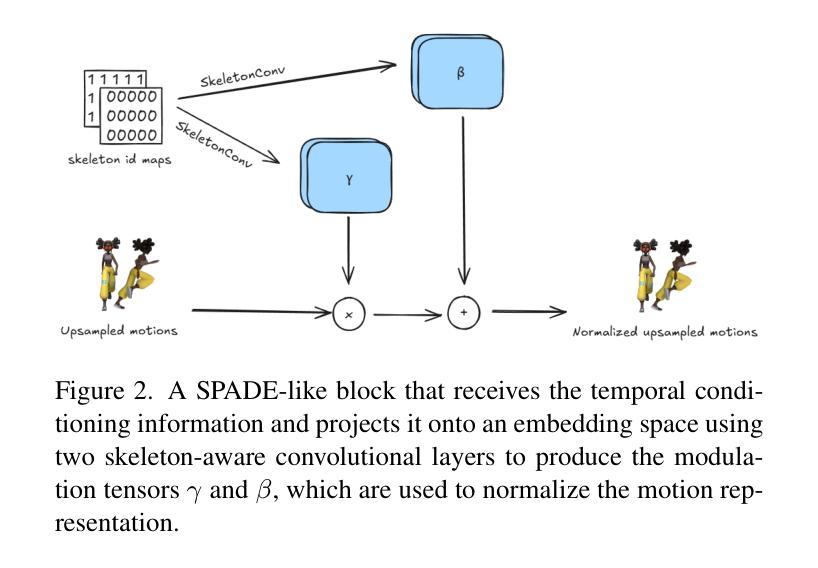
Controllable Single-shot Animation Blending with Temporal Conditioning
Authors:Eleni Tselepi, Spyridon Thermos, Gerasimos Potamianos
Training a generative model on a single human skeletal motion sequence without being bound to a specific kinematic tree has drawn significant attention from the animation community. Unlike text-to-motion generation, single-shot models allow animators to controllably generate variations of existing motion patterns without requiring additional data or extensive retraining. However, existing single-shot methods do not explicitly offer a controllable framework for blending two or more motions within a single generative pass. In this paper, we present the first single-shot motion blending framework that enables seamless blending by temporally conditioning the generation process. Our method introduces a skeleton-aware normalization mechanism to guide the transition between motions, allowing smooth, data-driven control over when and how motions blend. We perform extensive quantitative and qualitative evaluations across various animation styles and different kinematic skeletons, demonstrating that our approach produces plausible, smooth, and controllable motion blends in a unified and efficient manner.
在无需绑定到特定运动学树的情况下,对单一人类骨骼运动序列进行生成模型训练已经引起了动画界的广泛关注。不同于文本到运动的生成,单镜头模型允许动画师在不需要额外数据或大量重新训练的情况下,可控地生成现有运动模式的变体。然而,现有的单镜头方法并没有明确地提供一个可控框架,在一个单一生成过程中融合两种或多种运动。在本文中,我们首次提出了一个单镜头运动融合框架,它通过时间条件生成过程实现了无缝融合。我们的方法引入了一种骨架感知归一化机制来引导运动之间的过渡,从而允许在何时以及如何实现运动的融合上实现流畅、数据驱动的控制。我们在各种动画风格和不同的运动学骨架上进行了广泛的定量和定性评估,证明了我们的方法能够以统一高效的方式产生合理、流畅且可控的运动融合结果。
论文及项目相关链接
PDF Accepted to the AI for Visual Arts Workshop at ICCV 2025
Summary
本文介绍了基于单一人类骨骼运动序列训练的生成模型,无需特定骨骼动力学树,动画创作者可在不需要额外数据或大量再训练的情况下生成多种不同的动作。本文主要解决了单动作生成的融合问题,通过时序条件生成过程,实现流畅的动作融合框架。此外,该方法引入了一种骨架感知归一化机制,指导动作之间的过渡,使得动作的融合过程平滑可控。研究还表明该方法能在一套统一的框架中以高效的方式生成可信、平滑且可控的动作融合。
Key Takeaways
- 训练基于单一人类骨骼运动序列的生成模型在动画创作中具有重要地位。该模型允许动画创作者在无需额外数据或大量再训练的情况下生成多样的动作变化。
- 本文解决了单动作生成中的融合问题,通过引入动作融合框架实现流畅的动作过渡。
- 该方法引入了一种骨架感知归一化机制来指导动作间的过渡,确保动作融合的平滑和可控性。
点此查看论文截图