⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-09-07 更新
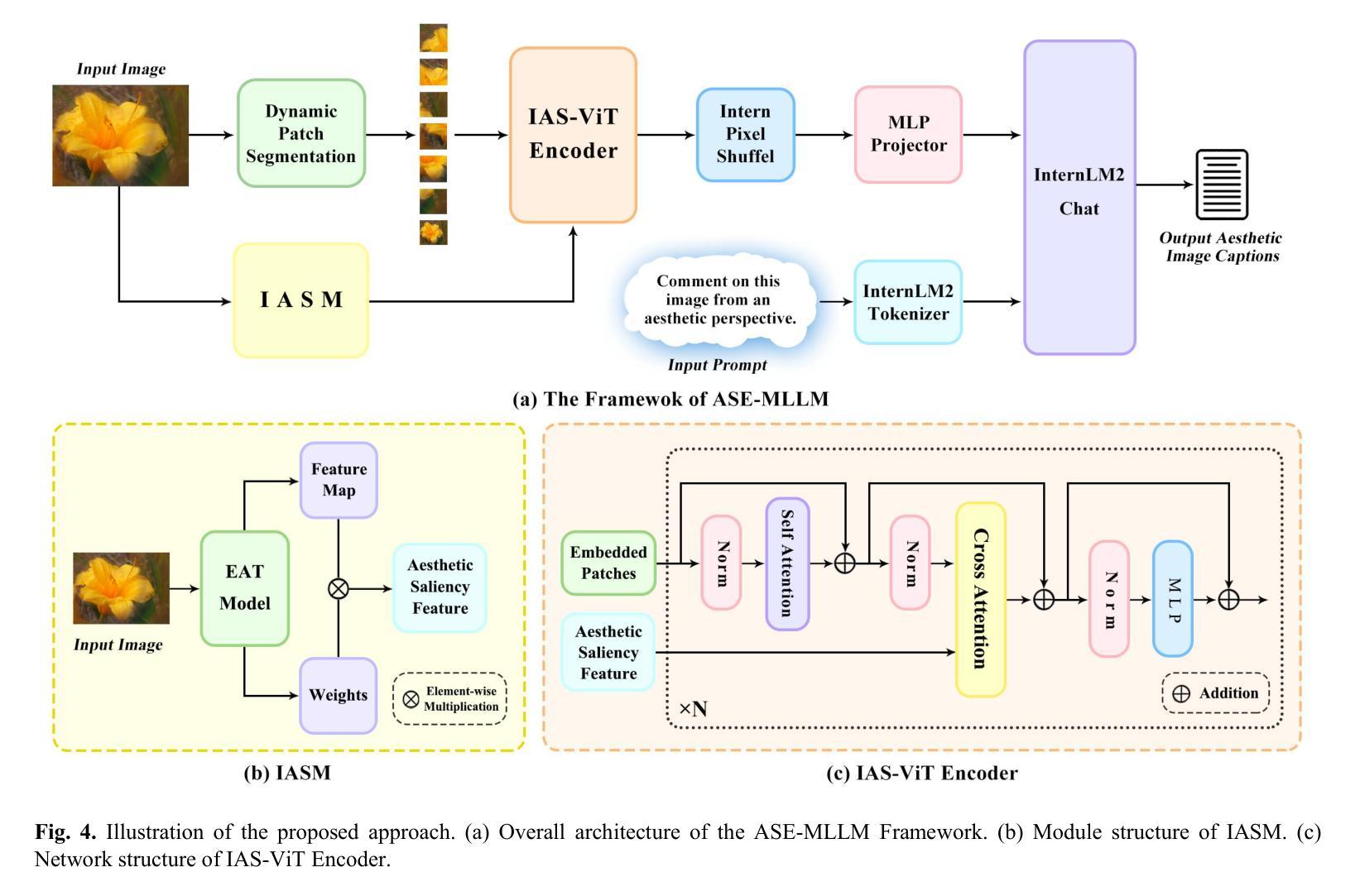
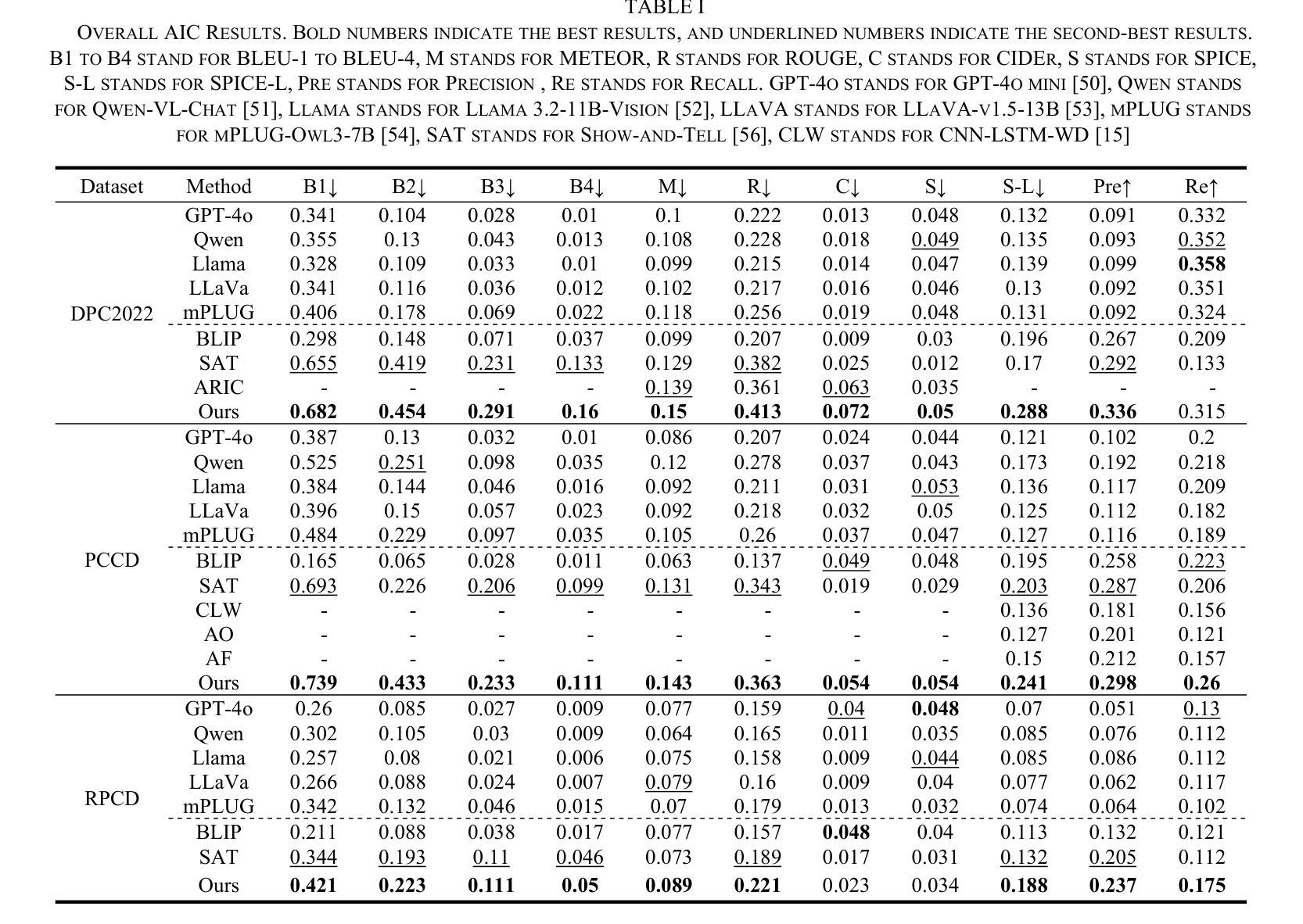
Aesthetic Image Captioning with Saliency Enhanced MLLMs
Authors:Yilin Tao, Jiashui Huang, Huaze Xu, Ling Shao
Aesthetic Image Captioning (AIC) aims to generate textual descriptions of image aesthetics, becoming a key research direction in the field of computational aesthetics. In recent years, pretrained Multimodal Large Language Models (MLLMs) have advanced rapidly, leading to a significant increase in image aesthetics research that integrates both visual and textual modalities. However, most existing studies on image aesthetics primarily focus on predicting aesthetic ratings and have shown limited application in AIC. Existing AIC works leveraging MLLMs predominantly rely on fine-tuning methods without specifically adapting MLLMs to focus on target aesthetic content. To address this limitation, we propose the Aesthetic Saliency Enhanced Multimodal Large Language Model (ASE-MLLM), an end-to-end framework that explicitly incorporates aesthetic saliency into MLLMs. Within this framework, we introduce the Image Aesthetic Saliency Module (IASM), which efficiently and effectively extracts aesthetic saliency features from images. Additionally, we design IAS-ViT as the image encoder for MLLMs, this module fuses aesthetic saliency features with original image features via a cross-attention mechanism. To the best of our knowledge, ASE-MLLM is the first framework to integrate image aesthetic saliency into MLLMs specifically for AIC tasks. Extensive experiments demonstrated that our approach significantly outperformed traditional methods and generic MLLMs on current mainstream AIC benchmarks, achieving state-of-the-art (SOTA) performance.
美学图像标题生成(AIC)旨在生成图像美学属性的文本描述,已成为计算美学领域的关键研究方向。近年来,预训练的多模态大型语言模型(MLLM)发展迅速,推动了融合视觉和文本模态的图像美学研究显著增加。然而,大多数现有的图像美学研究主要集中在预测美学评分上,在AIC中的应用有限。现有的利用MLLM的AIC工作主要依赖于微调方法,而没有专门调整MLLM以关注目标美学内容。为了解决这一局限性,我们提出了美学显著性增强多模态大型语言模型(ASE-MLLM),这是一个端到端的框架,显式地将美学显著性纳入MLLM。在该框架中,我们引入了图像美学显著性模块(IASM),该模块能够高效地从图像中提取美学显著性特征。此外,我们设计了IAS-ViT作为MLLM的图像编码器,该模块通过交叉注意力机制将美学显著性特征与原始图像特征融合。据我们所知,ASE-MLLM是第一个专门将图像美学显著性集成到MLLM中的AIC任务框架。大量实验表明,我们的方法在当前主流的AIC基准测试中显著优于传统方法和通用MLLM,达到了最先进的性能。
论文及项目相关链接
Summary
本文介绍了基于预训练的多模态大型语言模型(MLLMs)在图像美学领域的应用。针对现有研究中存在的对图像美学评价应用有限的局限性,提出了一种名为ASE-MLLM的框架,该框架通过引入图像美学显著性模块(IASM)和IAS-ViT图像编码器,有效地提取并融合图像的美学显著性特征,实现了对图像美学的精准描述。实验证明,该方法在主流美学图像标注任务上显著优于传统方法和通用MLLMs,达到了目前的最优性能。
Key Takeaways
- 美学图像标注(AIC)是计算美学领域的一个重要研究方向,旨在生成对图像美学的文本描述。
- 近年多模态大型语言模型(MLLMs)的快速发展推动了图像美学研究的新进展。
- 现有图像美学研究主要集中在预测美学评分上,但在AIC应用上表现有限。
- ASE-MLLM框架通过引入图像美学显著性模块(IASM)和IAS-ViT图像编码器,解决了现有研究的局限性。
- IASM模块能够高效地从图像中提取美学显著性特征。
- IAS-ViT图像编码器通过跨注意力机制融合美学显著性特征和原始图像特征。
点此查看论文截图



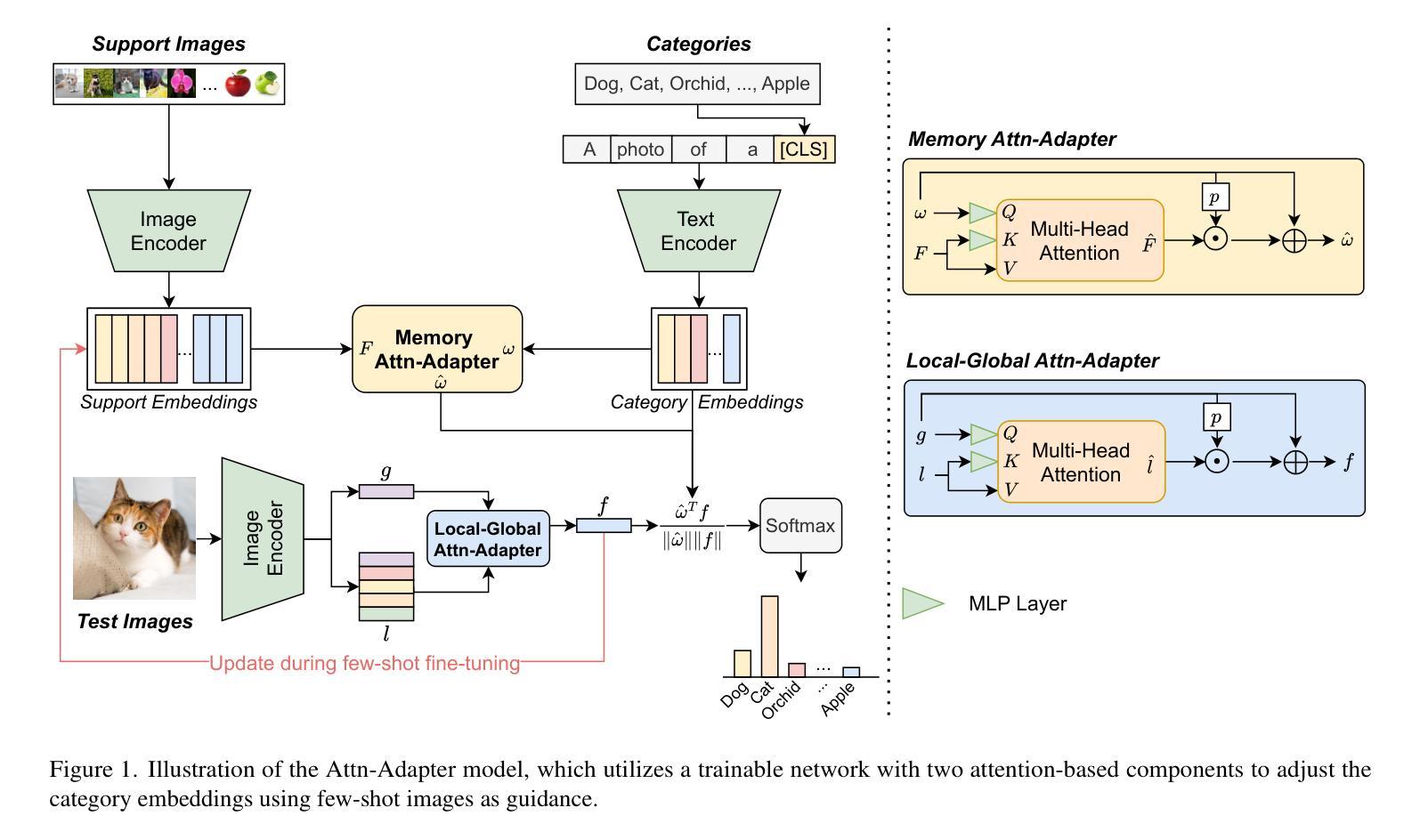
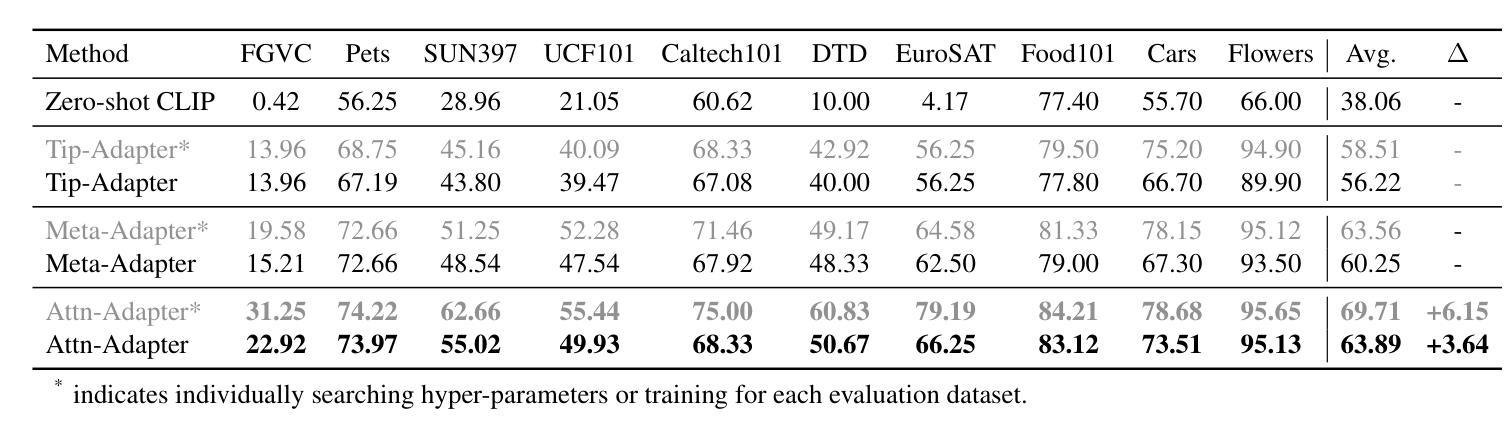
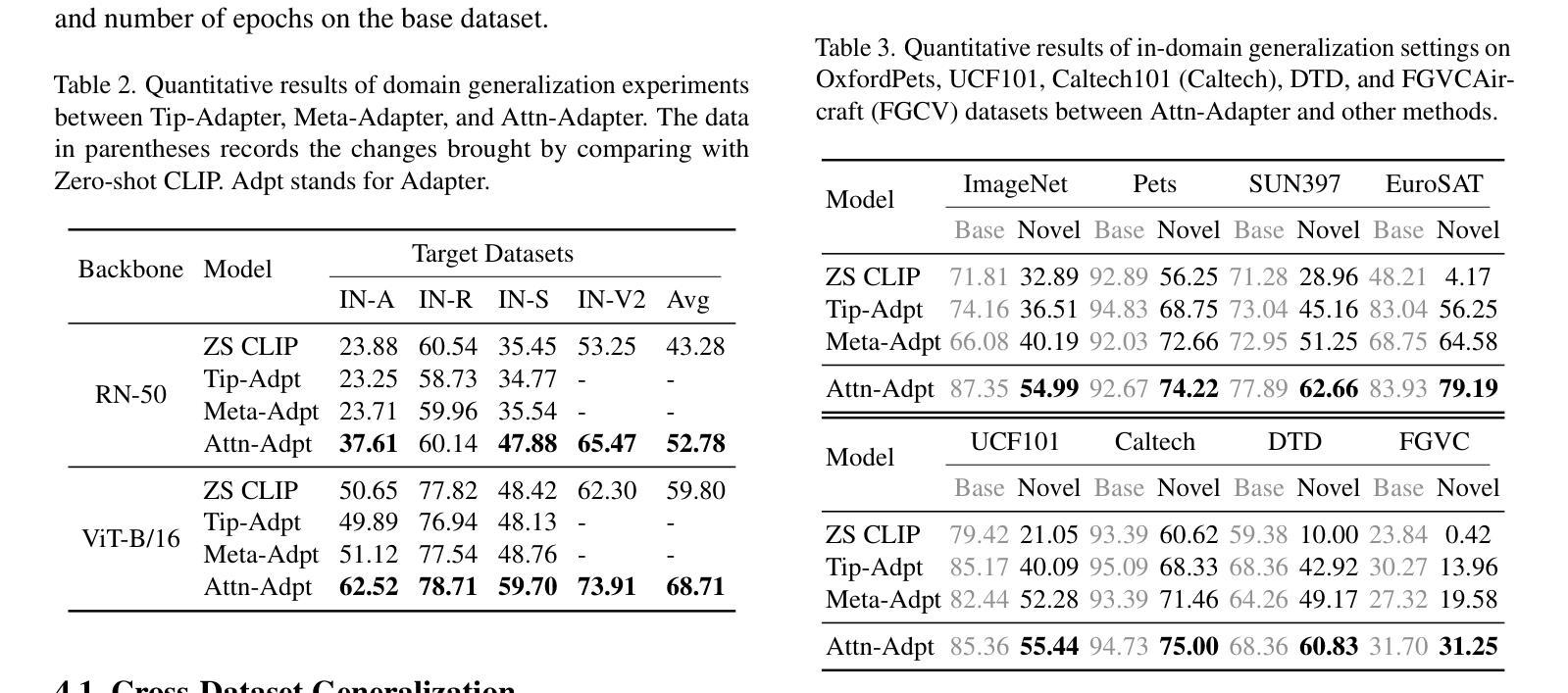
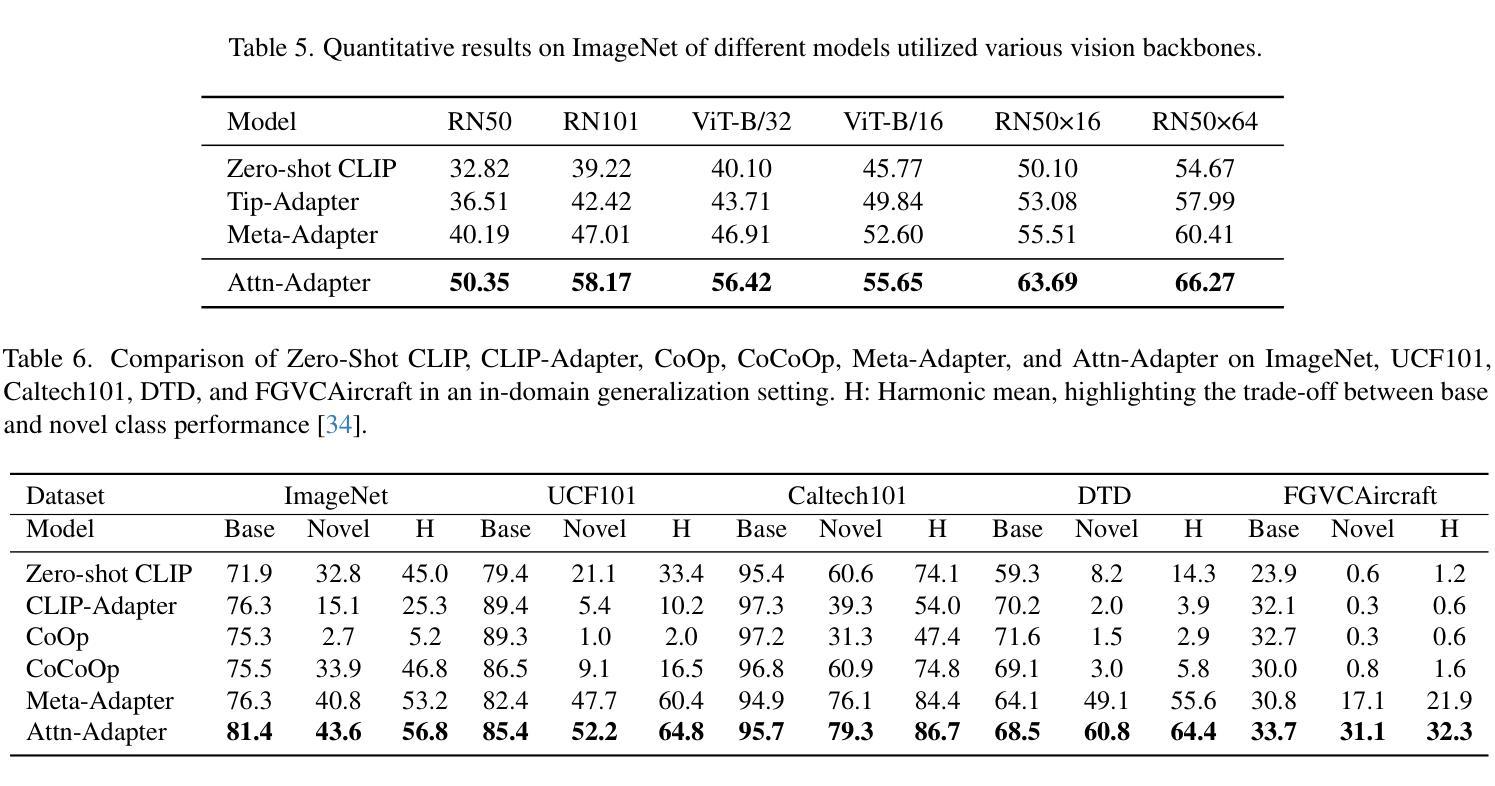
Attn-Adapter: Attention Is All You Need for Online Few-shot Learner of Vision-Language Model
Authors:Phuoc-Nguyen Bui, Khanh-Binh Nguyen, Hyunseung Choo
Contrastive vision-language models excel in zero-shot image recognition but face challenges in few-shot scenarios due to computationally intensive offline fine-tuning using prompt learning, which risks overfitting. To overcome these limitations, we propose Attn-Adapter, a novel online few-shot learning framework that enhances CLIP’s adaptability via a dual attention mechanism. Our design incorporates dataset-specific information through two components: the Memory Attn-Adapter, which refines category embeddings using support examples, and the Local-Global Attn-Adapter, which enriches image embeddings by integrating local and global features. This architecture enables dynamic adaptation from a few labeled samples without retraining the base model. Attn-Adapter outperforms state-of-the-art methods in cross-category and cross-dataset generalization, maintaining efficient inference and scaling across CLIP backbones.
对比视觉语言模型在零样本图像识别方面表现出色,但在小样本场景下面临挑战,这是由于使用提示学习进行离线微调计算量大,存在过拟合的风险。为了克服这些局限性,我们提出了Attn-Adapter,这是一种新的在线小样本学习框架,通过双注意力机制提高CLIP的适应性。我们的设计通过两个组件融入了数据集特定信息:Memory Attn-Adapter使用支持样例细化类别嵌入,而Local-Global Attn-Adapter通过融合局部和全局特征丰富图像嵌入。这种架构能够从少量标记样本中进行动态适应,而无需重新训练基础模型。Attn-Adapter在跨类别和跨数据集泛化方面优于最新方法,同时保持高效的推理和在不同CLIP主干之间的扩展性。
论文及项目相关链接
PDF ICCV 2025 - LIMIT Workshop
Summary
本文提出一种名为Attn-Adapter的新型在线少样本学习框架,它通过双注意力机制提升CLIP模型的适应性。该设计通过两个组件——Memory Attn-Adapter和Local-Global Attn-Adapter——融入特定数据集信息,分别通过支持样本精炼类别嵌入和融合局部与全局特征来丰富图像嵌入。这一架构能够实现从少量标记样本的动态适应,无需重新训练基础模型,且在跨类别和跨数据集推广方面表现优异,同时保持高效推理和跨CLIP骨干的扩展性。
Key Takeaways
- Attn-Adapter是一种新型的在线少样本学习框架,旨在提升CLIP模型在少样本场景下的适应性。
- 该框架通过双注意力机制实现动态适应,无需重新训练基础模型。
- Memory Attn-Adapter通过支持样本精炼类别嵌入。
- Local-Global Attn-Adapter通过融合局部和全局特征来丰富图像嵌入。
- Attn-Adapter在跨类别和跨数据集推广方面表现出优异性能。
- 该框架能够保持高效推理,并具有良好的可扩展性,可应用于不同的CLIP骨干网络。
点此查看论文截图


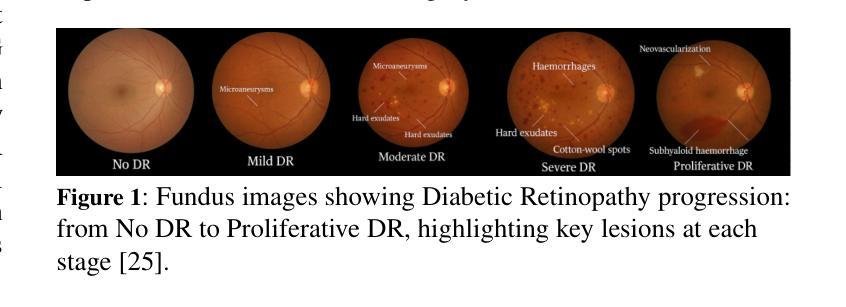
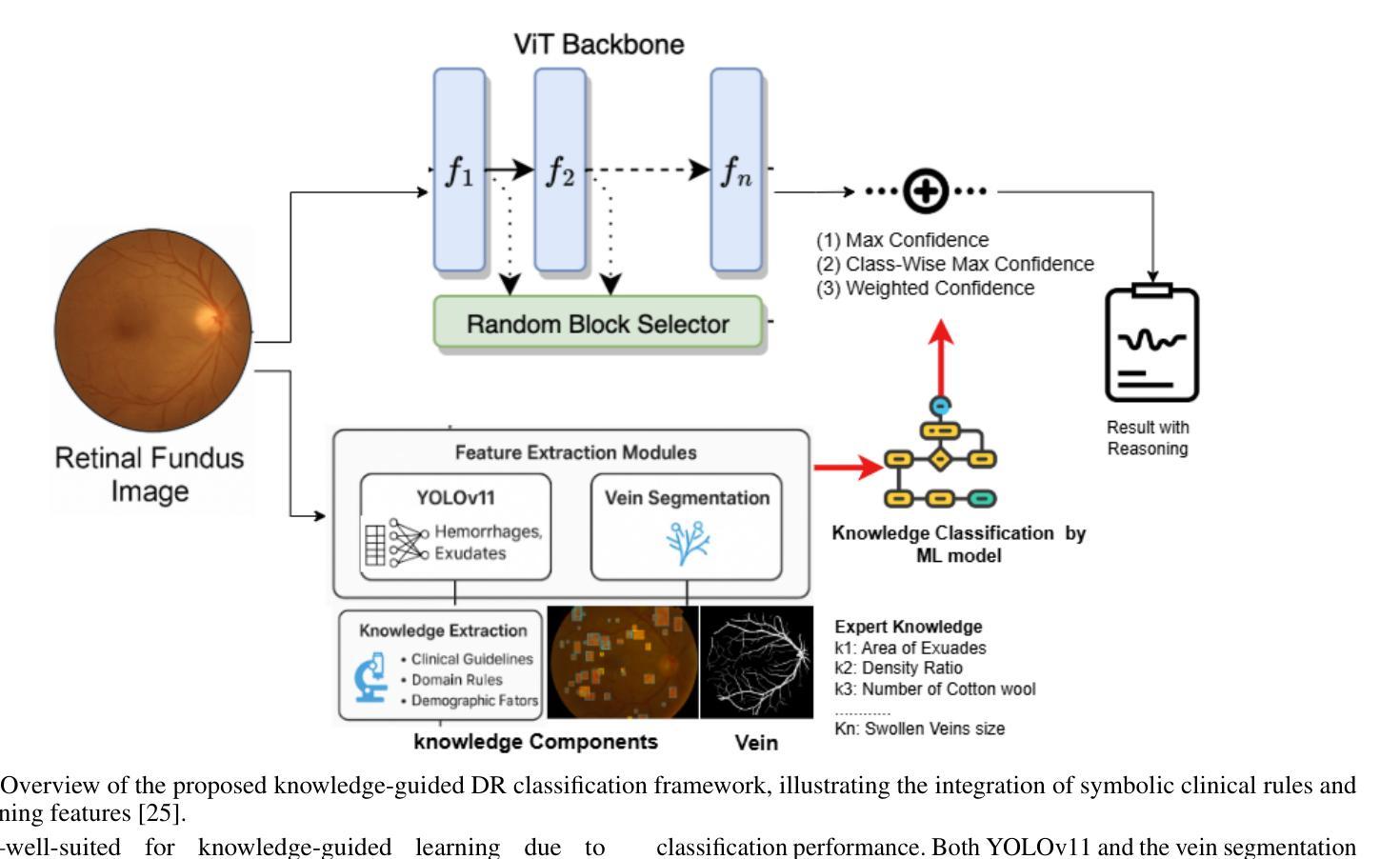
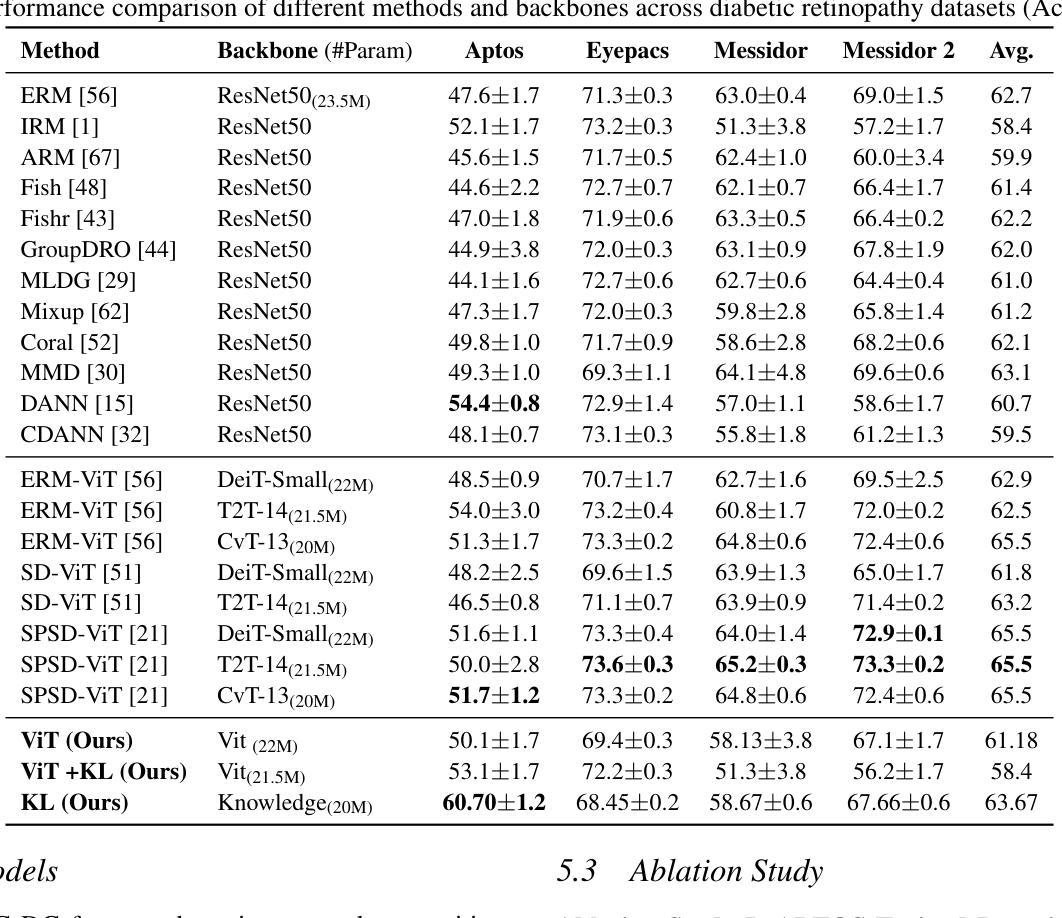
Single Domain Generalization in Diabetic Retinopathy: A Neuro-Symbolic Learning Approach
Authors:Midhat Urooj, Ayan Banerjee, Farhat Shaikh, Kuntal Thakur, Sandeep Gupta
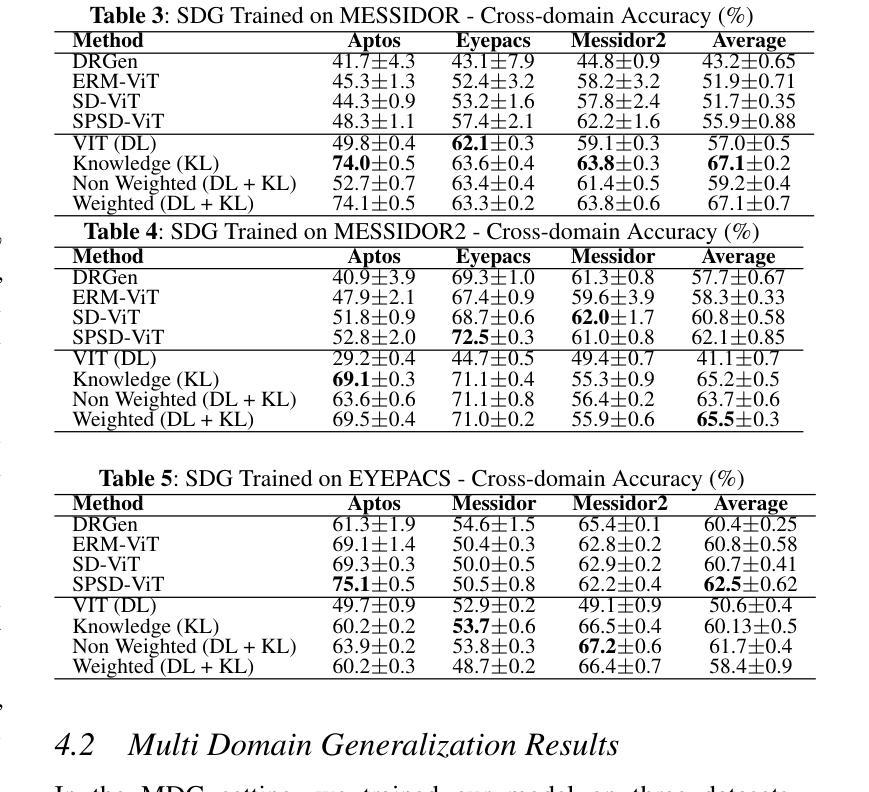
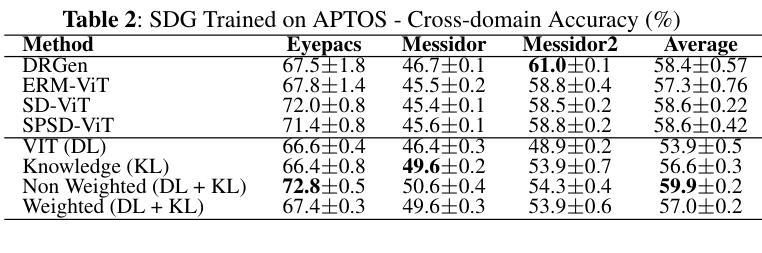
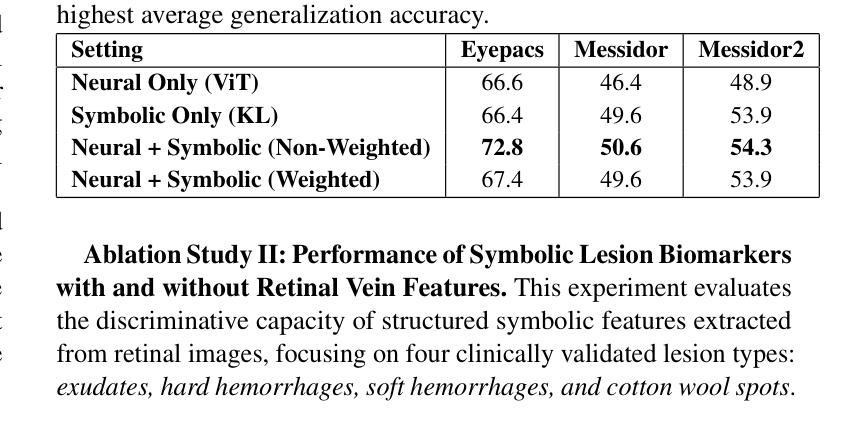
Domain generalization remains a critical challenge in medical imaging, where models trained on single sources often fail under real-world distribution shifts. We propose KG-DG, a neuro-symbolic framework for diabetic retinopathy (DR) classification that integrates vision transformers with expert-guided symbolic reasoning to enable robust generalization across unseen domains. Our approach leverages clinical lesion ontologies through structured, rule-based features and retinal vessel segmentation, fusing them with deep visual representations via a confidence-weighted integration strategy. The framework addresses both single-domain generalization (SDG) and multi-domain generalization (MDG) by minimizing the KL divergence between domain embeddings, thereby enforcing alignment of high-level clinical semantics. Extensive experiments across four public datasets (APTOS, EyePACS, Messidor-1, Messidor-2) demonstrate significant improvements: up to a 5.2% accuracy gain in cross-domain settings and a 6% improvement over baseline ViT models. Notably, our symbolic-only model achieves a 63.67% average accuracy in MDG, while the complete neuro-symbolic integration achieves the highest accuracy compared to existing published baselines and benchmarks in challenging SDG scenarios. Ablation studies reveal that lesion-based features (84.65% accuracy) substantially outperform purely neural approaches, confirming that symbolic components act as effective regularizers beyond merely enhancing interpretability. Our findings establish neuro-symbolic integration as a promising paradigm for building clinically robust, and domain-invariant medical AI systems.
在医学影像领域,跨域泛化仍然是一个关键挑战。模型在单一源上训练往往会在真实世界分布变化的情况下失效。我们提出了KG-DG,这是一个用于糖尿病视网膜病变(DR)分类的神经符号框架,它将视觉变压器与专家引导的象征推理相结合,实现了跨未见域的稳健泛化。我们的方法通过结构化、基于规则的特征和视网膜血管分割,利用临床病变本体,将它们与深度视觉表示通过置信度加权集成策略相融合。该框架通过最小化域嵌入之间的KL散度,解决了单域泛化(SDG)和多域泛化(MDG)问题,从而强制高级临床语义对齐。在四个公共数据集(APTOS、EyePACS、Messidor-1、Messidor-2)上的广泛实验表明,与基线ViT模型相比,跨域设置中的准确率提高了高达5.2%,并且在具有挑战性的SDG场景中平均提高了6%的准确率。值得注意的是,我们的纯符号模型在MDG中达到了63.67%的平均准确率,而完整的神经符号集成在具有挑战性的SDG场景中与现有的已发布基准值和里程碑相比实现了最高准确率。消融研究结果显示,基于病变的特征(准确率为84.65%)大大优于纯神经方法,证实了符号组件作为有效正则化器的有效性,而不仅仅是增强可解释性。我们的研究结果确立了神经符号融合作为一个有前途的范式构建临床稳健、跨域不变医疗人工智能系统的有前景的范式。
论文及项目相关链接
PDF Accepted in ANSyA 2025: 1st International Workshop on Advanced Neuro-Symbolic Applications
Summary
本文提出了一个针对糖尿病视网膜病变分类的神经符号框架KG-DG,该框架结合了视觉变压器和专家引导的符号推理,以实现跨未见领域的稳健泛化。通过临床病灶本体、结构化规则特征和视网膜血管分割的结合,与深度视觉表示通过置信度加权集成策略相融合。该框架通过最小化域嵌入之间的KL散度来解决单域泛化(SDG)和多域泛化(MDG)问题,从而强制执行高级临床语义的对齐。在四个公开数据集上的广泛实验表明,该框架在跨域设置中实现了高达5.2%的准确率提升,并在基线ViT模型上实现了6%的改进。符号模型在MDG中实现了63.67%的平均准确率,而完整的神经符号集成在具有挑战性的SDG场景中达到了最高准确率。
Key Takeaways
- 医学成像领域存在模型泛化问题,特别是在跨未见领域情况下,模型训练的单源数据经常无法适应真实世界的分布变化。
- 提出了一种名为KG-DG的神经符号框架,用于糖尿病视网膜病变分类,结合了视觉变压器和专家引导的符号推理。
- 该框架利用临床病灶本体和结构化规则特征进行视网膜血管分割,并通过置信度加权集成策略与深度视觉表示相融合。
- 通过最小化域嵌入之间的KL散度来解决单域和多域泛化问题,强调高级临床语义的对齐。
- 在四个公开数据集上的实验表明,该框架显著提高了模型的准确率,特别是在跨域设置中具有挑战性的情况。
- 符号模型在多域泛化中表现出良好的性能,而完整的神经符号集成在单域泛化场景中达到最佳效果。
点此查看论文截图


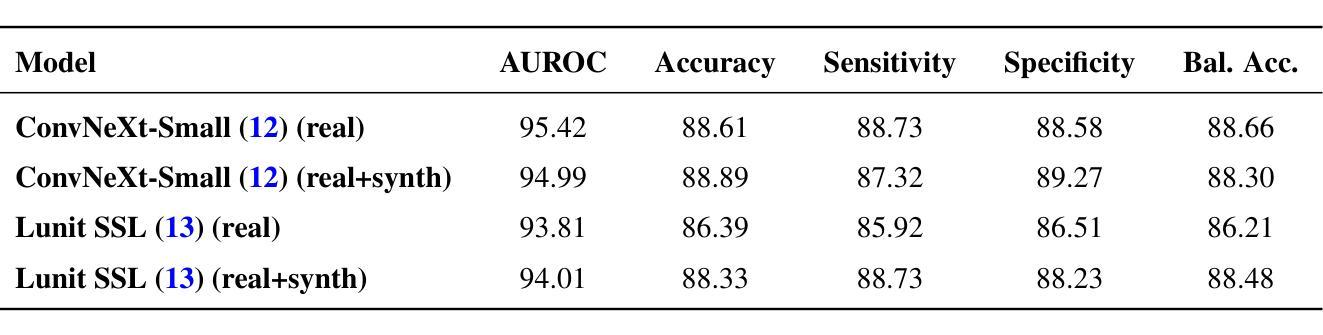
Is Synthetic Image Augmentation Useful for Imbalanced Classification Problems? Case-Study on the MIDOG2025 Atypical Cell Detection Competition
Authors:Leire Benito-Del-Valle, Pedro A. Moreno-Sánchez, Itziar Egusquiza, Itsaso Vitoria, Artzai Picón, Cristina López-Saratxaga, Adrian Galdran
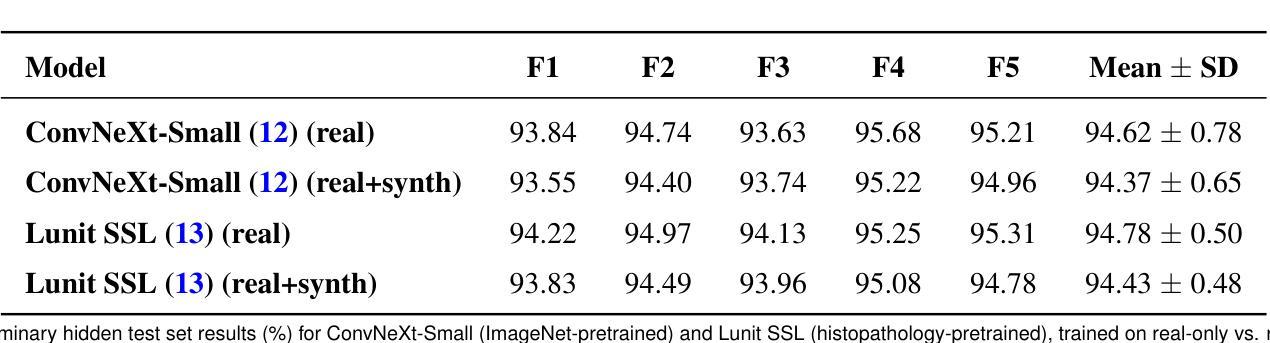
The MIDOG 2025 challenge extends prior work on mitotic figure detection by introducing a new Track 2 on atypical mitosis classification. This task aims to distinguish normal from atypical mitotic figures in histopathology images, a clinically relevant but highly imbalanced and cross-domain problem. We investigated two complementary backbones: (i) ConvNeXt-Small, pretrained on ImageNet, and (ii) a histopathology-specific ViT from Lunit trained via self-supervision. To address the strong prevalence imbalance (9408 normal vs. 1741 atypical), we synthesized additional atypical examples to approximate class balance and compared models trained with real-only vs. real+synthetic data. Using five-fold cross-validation, both backbones reached strong performance (mean AUROC approximately 95 percent), with ConvNeXt achieving slightly higher peaks while Lunit exhibited greater fold-to-fold stability. Synthetic balancing, however, did not lead to consistent improvements. On the organizers’ preliminary hidden test set, explicitly designed as an out-of-distribution debug subset, ConvNeXt attained the highest AUROC (95.4 percent), whereas Lunit remained competitive on balanced accuracy. These findings suggest that both ImageNet and domain-pretrained backbones are viable for atypical mitosis classification, with domain-pretraining conferring robustness and ImageNet pretraining reaching higher peaks, while naive synthetic balancing has limited benefit. Full hidden test set results will be reported upon challenge completion.
MIDOG 2025挑战赛在前期细胞分裂图像检测工作的基础上,引入了新的轨道2——不典型细胞分裂分类任务。该任务旨在区分病理图像中的正常细胞分裂与异常细胞分裂,这是一个具有临床意义但高度不平衡、跨领域的问题。我们研究了两种互补的骨干网络:(i)在ImageNet上预训练的ConvNeXt-Small;(ii)通过自我监督训练针对病理学的ViT(来自Lunit)。为了解决严重的不平衡问题(正常样本9408与异常样本仅1741),我们通过合成额外的异常样本近似地平衡了类别分布,并比较了仅用真实数据训练的模型与结合真实数据和合成数据训练的模型之间的性能。通过五折交叉验证,这两种骨干网络都达到了较强的性能(平均AUROC约95%),其中ConvNeXt取得了略高的峰值,而Lunit展现出更强的跨折稳定性。然而,合成平衡策略并没有带来持续的改进。在组织者特意设计的隐藏测试集上,作为离群调试子集,ConvNeXt取得了最高的AUROC(95.4%),而Lunit在平衡精度上保持了竞争力。这些发现表明,ImageNet和领域预训练的骨干网络对于不典型细胞分裂分类都是可行的选择,领域预训练赋予模型稳健性,而ImageNet预训练则能达到更高的峰值性能,而简单的合成平衡策略带来的益处有限。完整的隐藏测试集结果将在挑战赛结束后公布。
论文及项目相关链接
PDF version 0, to be updated; submitted to midog 2025
Summary
本文介绍了MIDOG 2025挑战赛在细胞分裂检测方面的新任务——不典型细胞分裂分类。该任务旨在区分组织病理学图像中的正常细胞和不典型细胞分裂。研究中使用了两种互补模型骨架:一种是基于ImageNet预训练的ConvNeXt-Small模型,另一种是基于自我监督训练的特定于组织病理学的ViT模型。为了解决类别不平衡问题,研究通过合成额外的异常样本来近似平衡类别比例,并比较了仅使用真实数据和真实数据结合合成数据的模型训练效果。通过五折交叉验证,两种模型骨架均表现出强大的性能(平均AUROC约为95%),其中ConvNeXt在某些情况下达到更高的峰值,而Lunit则展现出更强的稳定性。然而,合成平衡方法并未带来一致的改进。在组织者设计的作为分布外调试子集的隐藏测试集上,ConvNeXt获得了最高的AUROC(95.4%),而Lunit在平衡精度上保持了竞争力。这表明ImageNet预训练和领域预训练骨架对于不典型细胞分裂分类都是可行的,而合成平衡方法的效益有限。
Key Takeaways
- MIDOG 2025挑战赛引入了新的Task 2:不典型细胞分裂分类。这项任务的目标是在组织病理学图像中区分正常和不典型的细胞分裂。这是具有挑战性的任务。
- 研究使用了两种互补模型骨架进行探究:基于ImageNet预训练的ConvNeXt模型和基于自我监督训练的特定于组织病理学的ViT模型(来自Lunit)。两者都取得了很好的性能。
- 由于数据集存在严重的类别不平衡问题(正常样本数量远大于异常样本),研究者尝试通过合成额外的异常样本来解决这一问题,但效果并不明显。
点此查看论文截图

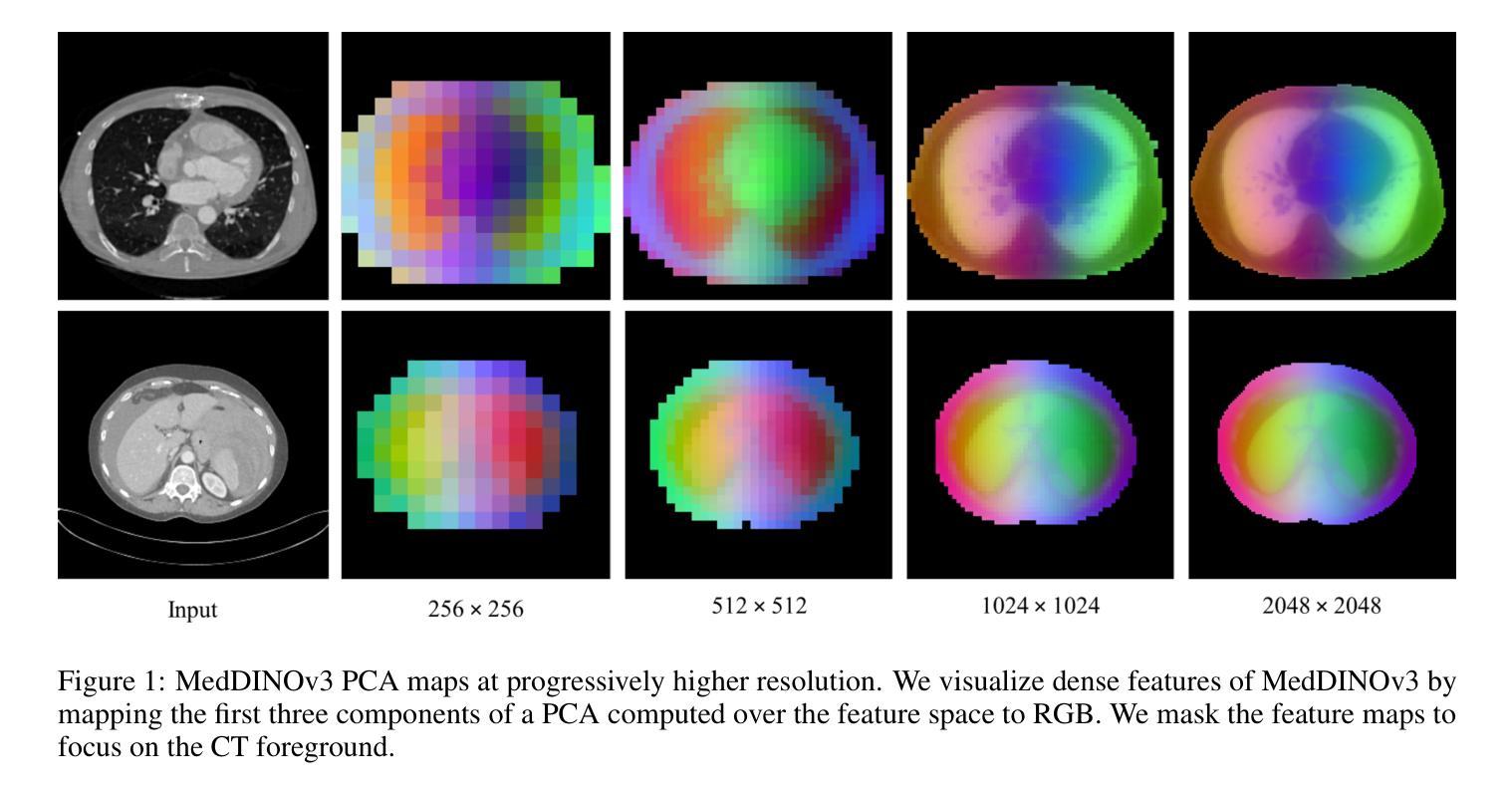
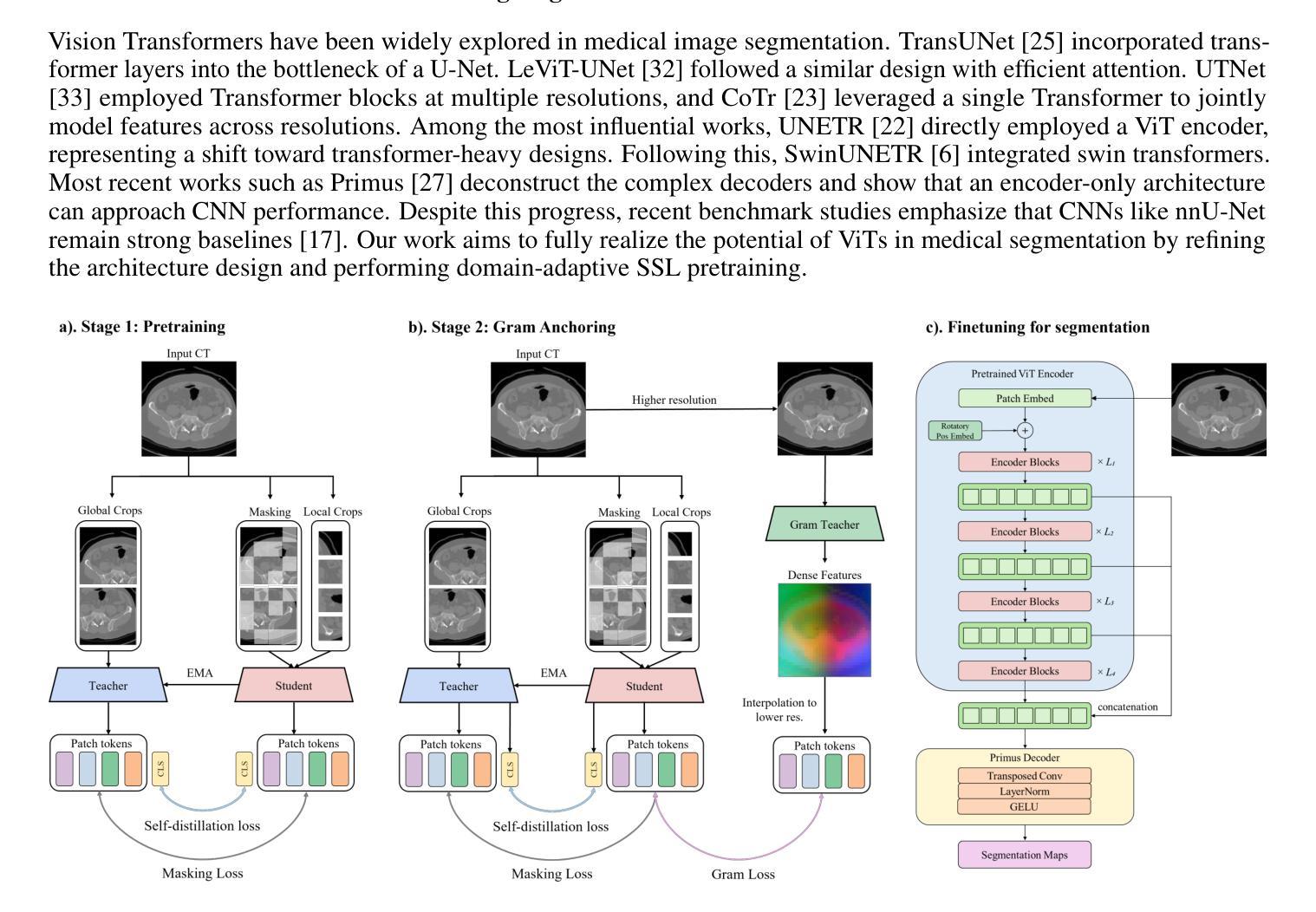
MedDINOv3: How to adapt vision foundation models for medical image segmentation?
Authors:Yuheng Li, Yizhou Wu, Yuxiang Lai, Mingzhe Hu, Xiaofeng Yang
Accurate segmentation of organs and tumors in CT and MRI scans is essential for diagnosis, treatment planning, and disease monitoring. While deep learning has advanced automated segmentation, most models remain task-specific, lacking generalizability across modalities and institutions. Vision foundation models (FMs) pretrained on billion-scale natural images offer powerful and transferable representations. However, adapting them to medical imaging faces two key challenges: (1) the ViT backbone of most foundation models still underperform specialized CNNs on medical image segmentation, and (2) the large domain gap between natural and medical images limits transferability. We introduce MedDINOv3, a simple and effective framework for adapting DINOv3 to medical segmentation. We first revisit plain ViTs and design a simple and effective architecture with multi-scale token aggregation. Then, we perform domain-adaptive pretraining on CT-3M, a curated collection of 3.87M axial CT slices, using a multi-stage DINOv3 recipe to learn robust dense features. MedDINOv3 matches or exceeds state-of-the-art performance across four segmentation benchmarks, demonstrating the potential of vision foundation models as unified backbones for medical image segmentation. The code is available at https://github.com/ricklisz/MedDINOv3.
在CT和MRI扫描中,器官和肿瘤的精确分割对于诊断、治疗计划和疾病监测至关重要。虽然深度学习已经推动了自动化分割的发展,但大多数模型仍然具有特定性,缺乏跨不同模态和机构之间的通用性。视觉基础模型(FMs)在百亿级自然图像上的预训练提供了强大且可迁移的表示。然而,将其适应医学成像面临两个主要挑战:(1)大多数基础模型的ViT主干在医学图像分割方面仍然表现不佳,不及专业化的CNN;(2)自然图像和医学图像之间的巨大领域差距限制了可迁移性。我们引入了MedDINOv3,这是一个简单有效的框架,用于将DINOv3适应医学分割。我们首先回顾了简单的ViTs,并设计了一个简单有效的架构进行多尺度令牌聚合。然后,我们在CT-3M上进行域自适应预训练,这是一个精选的包含387万张轴向CT切片的集合,使用多阶段的DINOv3配方来学习稳健的密集特征。MedDINOv3在四个分割基准测试中达到了或超过了最先进的性能水平,证明了视觉基础模型作为医学图像分割统一主干的潜力。代码可在https://github.com/ricklisz/MedDINOv3找到。
论文及项目相关链接
Summary
本文介绍了MedDINOv3框架,该框架旨在将DINOv3适应于医学图像分割。通过重新审视普通ViT并设计具有多尺度令牌聚合的简单有效架构,以及使用多阶段DINOv3配方在CT-3M上进行域自适应预训练,学习稳健的密集特征,MedDINOv3在四个分割基准测试中达到或超过最新性能水平,证明了视觉基础模型作为医学图像分割的统一骨架的潜力。
Key Takeaways
- 器官和肿瘤的准确分割在CT和MRI扫描中对诊断、治疗计划和疾病监测至关重要。
- 虽然深度学习已经推进了自动分割,但大多数模型仍然缺乏跨模态和机构的通用性。
- 视觉基础模型(FMs)在自然图像上的预训练提供了强大的可转移表示能力。
- 将这些模型适应于医学成像面临两个主要挑战:ViT主干在医学图像分割上性能不足,以及自然与医学图像之间的域差距限制了可转移性。
- MedDINOv3框架通过设计简单有效的架构和进行域自适应预训练来解决这些挑战。
- MedDINOv3使用多尺度令牌聚合的普通ViT,并在CT-3M数据集上进行预训练。
点此查看论文截图


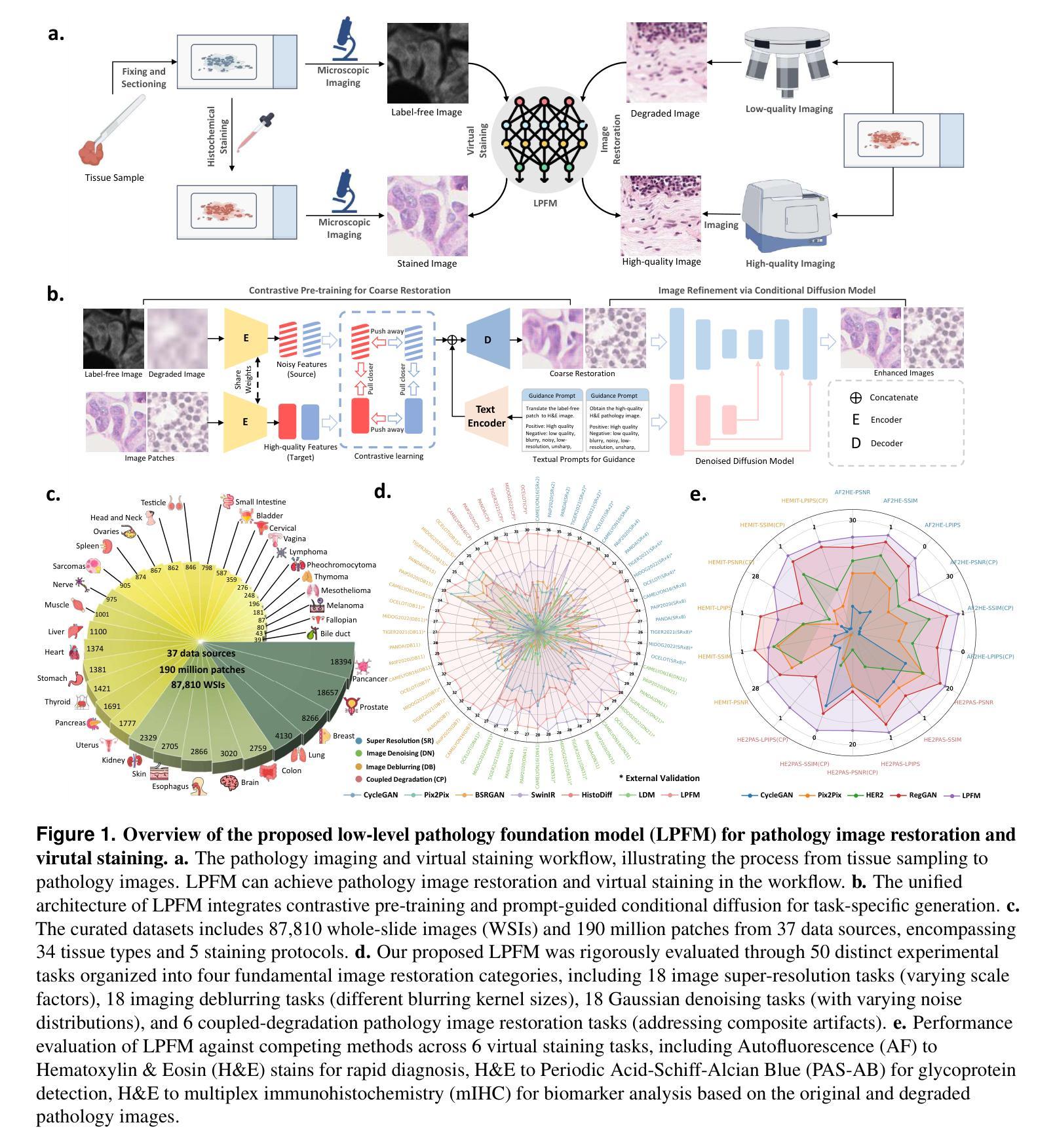
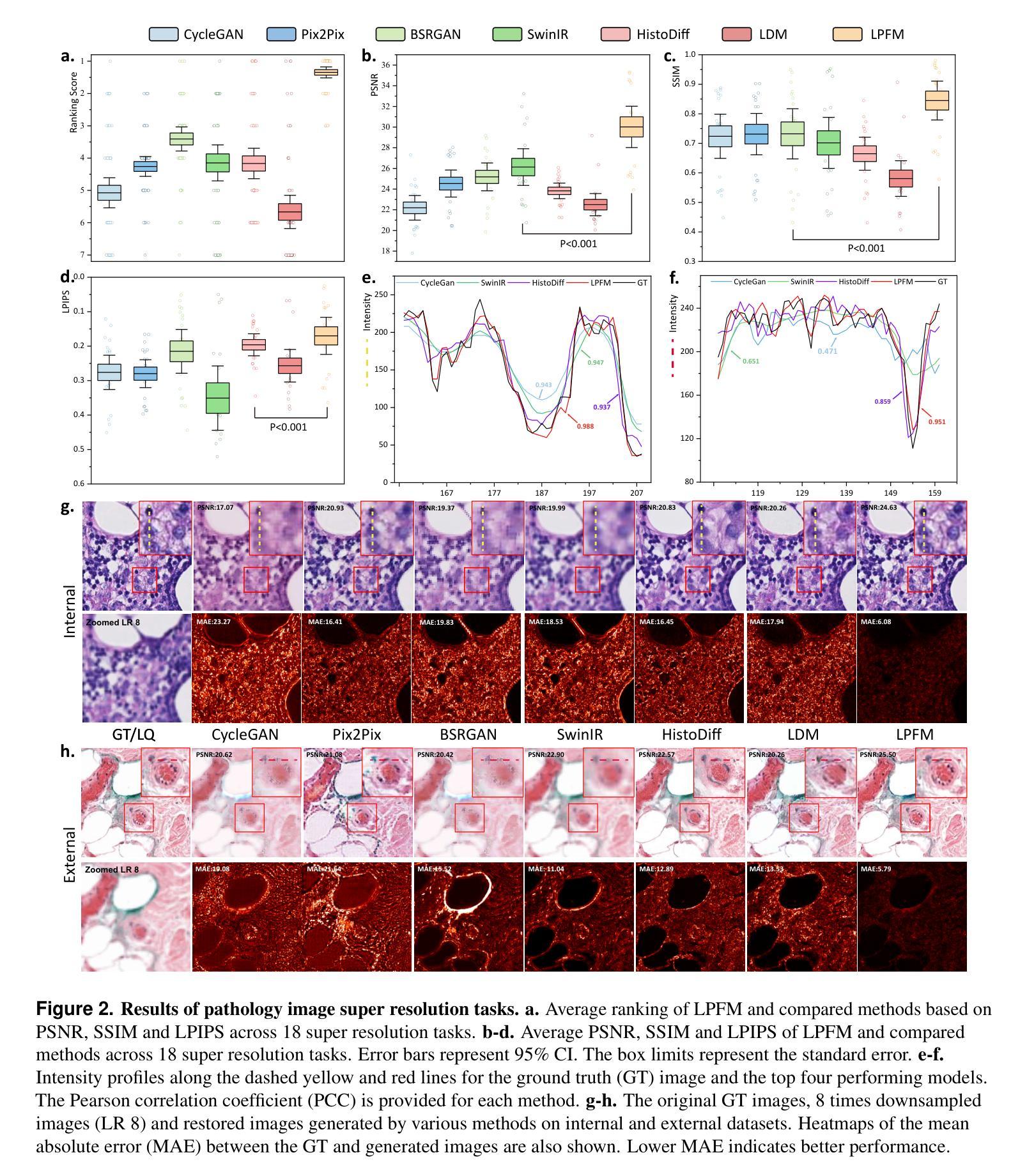
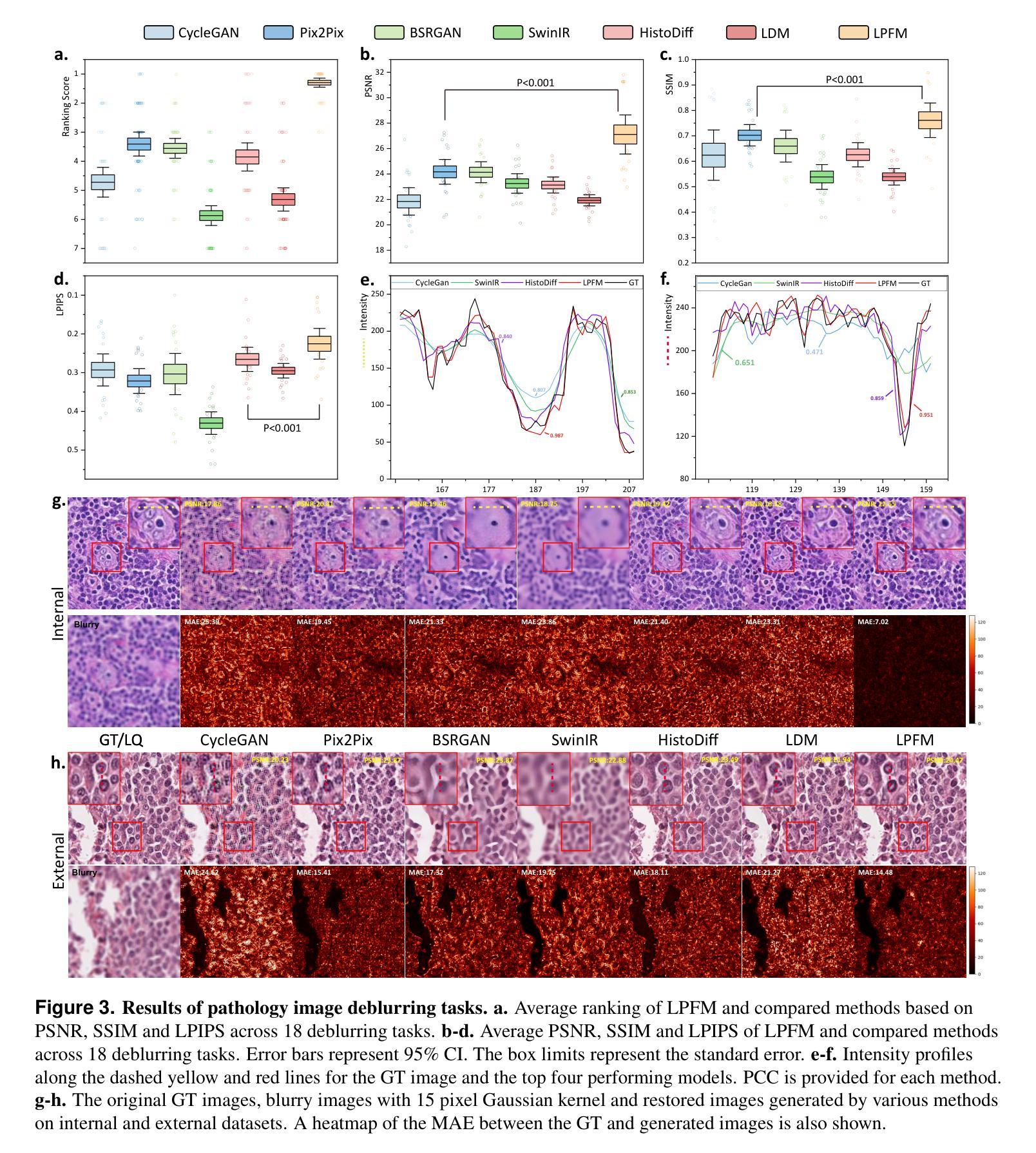
A Unified Low-level Foundation Model for Enhancing Pathology Image Quality
Authors:Ziyi Liu, Zhe Xu, Jiabo Ma, Wenqaing Li, Junlin Hou, Fuxiang Huang, Xi Wang, Ronald Cheong Kin Chan, Terence Tsz Wai Wong, Hao Chen
Foundation models have revolutionized computational pathology by achieving remarkable success in high-level diagnostic tasks, yet the critical challenge of low-level image enhancement remains largely unaddressed. Real-world pathology images frequently suffer from degradations such as noise, blur, and low resolution due to slide preparation artifacts, staining variability, and imaging constraints, while the reliance on physical staining introduces significant costs, delays, and inconsistency. Although existing methods target individual problems like denoising or super-resolution, their task-specific designs lack the versatility to handle the diverse low-level vision challenges encountered in practice. To bridge this gap, we propose the first unified Low-level Pathology Foundation Model (LPFM), capable of enhancing image quality in restoration tasks, including super-resolution, deblurring, and denoising, as well as facilitating image translation tasks like virtual staining (H&E and special stains), all through a single adaptable architecture. Our approach introduces a contrastive pre-trained encoder that learns transferable, stain-invariant feature representations from 190 million unlabeled pathology images, enabling robust identification of degradation patterns. A unified conditional diffusion process dynamically adapts to specific tasks via textual prompts, ensuring precise control over output quality. Trained on a curated dataset of 87,810 whole slied images (WSIs) across 34 tissue types and 5 staining protocols, LPFM demonstrates statistically significant improvements (p<0.01) over state-of-the-art methods in most tasks (56/66), achieving Peak Signal-to-Noise Ratio (PSNR) gains of 10-15% for image restoration and Structural Similarity Index Measure (SSIM) improvements of 12-18% for virtual staining.
基础模型通过高级诊断任务取得了显著的成功,从而彻底改变了计算病理学。然而,低层次图像增强的关键挑战仍然在很大程度上未得到解决。现实世界中的病理图像由于幻灯片制作过程中的伪迹、染色变量以及成像限制等因素,经常出现诸如噪声、模糊和分辨率低等问题。而对物理染色的依赖则引入了重大成本、延迟和不一致性。虽然现有方法针对去噪或超分辨率等单个问题进行了研究,但其任务特定设计缺乏应对实践中遇到的各种低层次视觉挑战的能力。为了弥补这一差距,我们首次提出了低层次病理基础模型(LPFM),该模型能够在恢复任务中提高图像质量,包括超分辨率、去模糊和去噪,并能够促进图像翻译任务,如虚拟染色(H&E和特殊染色),所有这些功能都通过单一的适应性架构实现。我们的方法引入了一个对比预训练编码器,该编码器从1.9亿张未标记的病理图像中学习可转移、染色不变的特征表示,从而能够稳健地识别退化模式。一个统一的条件扩散过程通过文本提示动态适应特定任务,确保对输出质量的精确控制。LPFM是在34种组织类型和5种染色协议的87810张全景幻灯片图像(WSIs)数据集上进行训练的,在大多数任务(56/66)中都实现了显著的改进(p<0.01),在图像恢复方面,峰值信噪比(PSNR)提高了百分之十至百分之十五,在虚拟染色方面,结构相似性指数(SSIM)提高了百分之十二至百分之十八。
论文及项目相关链接
Summary
在基础模型已经为计算病理学带来显著成功的背景下,低层次图像增强问题依然未得到有效解决。现实病理学图像存在噪声、模糊和低分辨率等缺陷,依赖于物理染色技术,导致了成本增加、延迟和不一致性。针对这些问题,我们提出了首个统一的低层次病理学基础模型(LPFM),能够在恢复任务中提高图像质量,包括超分辨率、去模糊和去噪等,并促进图像翻译任务如虚拟染色。该模型通过单一的可适应架构实现多种功能。通过对比预训练编码器学习可转移、染色不变的特性表示,从大量未标记的病理图像中学习可转移的特性,使模型能够可靠地识别退化模式。训练于跨越不同组织和染色协议的整个切片图像数据集上,LPFM在多数任务中取得了显著的进步,提高了峰值信噪比和结构相似性指数度量值。总的来说,该模型提高了病理图像的准确性和一致性。
Key Takeaways
- 基础模型在计算病理学领域取得了显著成功,但低层次图像增强问题仍然存在。
- 现实病理学图像存在噪声、模糊和低分辨率等问题,这限制了诊断的准确性。
- 现有的方法针对特定问题如去噪或超分辨率进行设计,缺乏处理实践中遇到的各种低层次视觉挑战的能力。
- 我们提出了统一的低层次病理学基础模型(LPFM),用于增强图像质量并促进图像翻译任务如虚拟染色。
- LPFM通过一个单一的可适应架构实现多种功能,包括超分辨率、去模糊和去噪等任务。
- LPFM通过对比预训练编码器学习可转移和染色不变的特性表示,提高了模型的性能。
点此查看论文截图

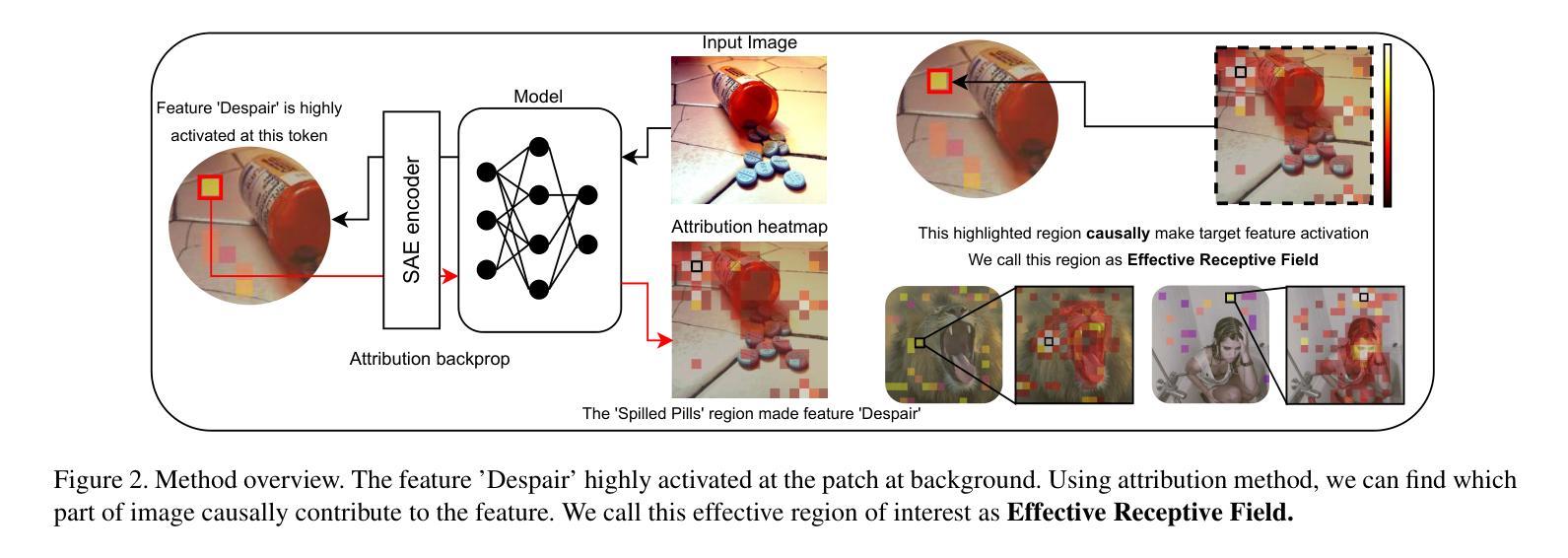
Causal Interpretation of Sparse Autoencoder Features in Vision
Authors:Sangyu Han, Yearim Kim, Nojun Kwak
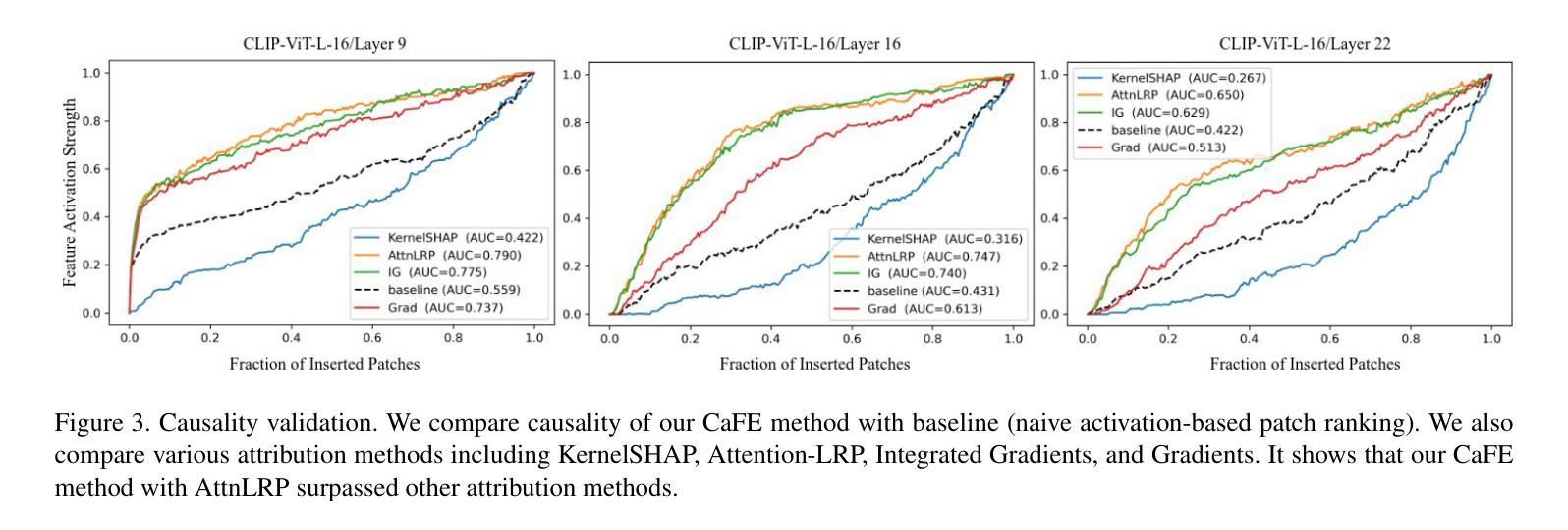
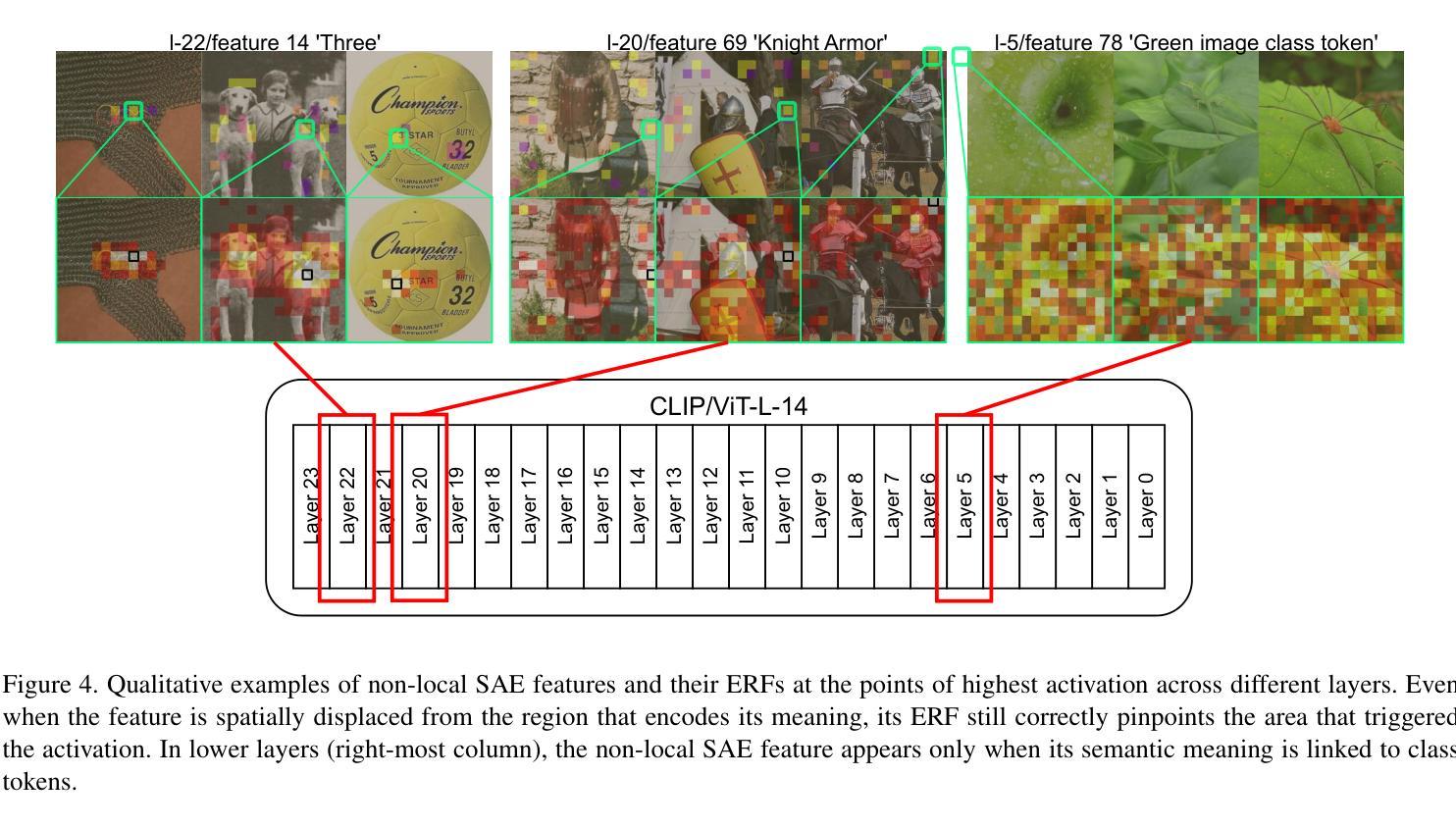
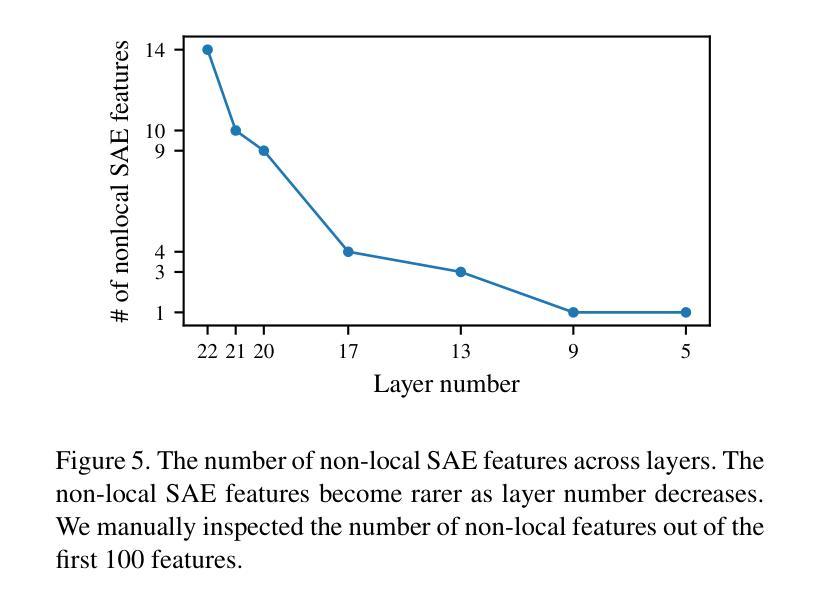
Understanding what sparse auto-encoder (SAE) features in vision transformers truly represent is usually done by inspecting the patches where a feature’s activation is highest. However, self-attention mixes information across the entire image, so an activated patch often co-occurs with-but does not cause-the feature’s firing. We propose Causal Feature Explanation (CaFE), which leverages Effective Receptive Field (ERF). We consider each activation of an SAE feature to be a target and apply input-attribution methods to identify the image patches that causally drive that activation. Across CLIP-ViT features, ERF maps frequently diverge from naive activation maps, revealing hidden context dependencies (e.g., a “roaring face” feature that requires the co-occurrence of eyes and nose, rather than merely an open mouth). Patch insertion tests confirm that CaFE more effectively recovers or suppresses feature activations than activation-ranked patches. Our results show that CaFE yields more faithful and semantically precise explanations of vision-SAE features, highlighting the risk of misinterpretation when relying solely on activation location.
理解视觉转换器中的稀疏自动编码器(SAE)特征真正代表什么,通常是通过检查特征激活最高的斑块来实现的。然而,自注意力会混合整个图像的信息,因此激活的斑块通常与特征的触发同时发生,但并不引起特征的触发。我们提出了因果特征解释(CaFE),它利用有效感受野(ERF)。我们认为SAE特征的每次激活都是一个目标,并应用输入归因方法来识别那些因果驱动该激活的图像斑块。在CLIP-ViT特征中,ERF映射经常与简单的激活映射相偏离,揭示了隐藏的上下文依赖关系(例如,“咆哮的脸”特征需要眼睛和鼻子的共存,而不仅仅是张开的嘴巴)。斑块插入测试证实,相比激活排序斑块,CaFE更能恢复或抑制特征激活。我们的结果表明,CaFE对视觉SAE特征提供了更忠实、语义更精确的解释,强调仅依赖激活位置进行解释的风险。
论文及项目相关链接
摘要
通过对稀疏自动编码器(SAE)在视觉转换器中的特性进行深入研究,我们发现仅通过观察特征激活最高的斑块来理解其真正含义是不够准确的。由于自注意力机制会混合图像中所有信息,因此特征激活通常伴随着某些斑块的出现,但这并不意味着这些斑块直接导致了特征的激活。为此,我们提出了因果特征解释(CaFE)方法,它利用有效感受野(ERF)技术。我们将每个SAE特征的激活视为目标,并运用输入归因方法来识别那些真正驱动该特征激活的图像斑块。在CLIP-ViT特征中,我们发现ERF映射与简单的激活映射存在显著差异,揭示了隐藏上下文依赖关系(例如,“咆哮面孔”特征需要眼睛和鼻子的同时出现,而不仅仅是嘴巴的张开)。通过斑块插入测试证实,相较于基于激活的斑块排名方法,CaFE更能有效地恢复或抑制特征激活。我们的结果表明,CaFE提供了对视觉SAE特征更真实、语义更精确的解释,并强调了仅依赖激活位置进行解释的风险。
关键见解
- 稀疏自动编码器(SAE)在视觉转换器中的特性理解需要超越简单的激活斑块观察。
- 自注意力机制涉及整个图像的信息混合,导致特征激活与其直观解释之间可能存在偏差。
- 引入因果特征解释(CaFE)方法,利用有效感受野(ERF)技术来识别真正驱动特征激活的图像斑块。
- ERF映射与简单激活映射存在显著差异,揭示了特征的隐藏上下文依赖关系。
- 通过斑块插入测试证实,CaFE在恢复或抑制特征激活方面比基于激活的斑块排名方法更有效。
- CaFE提供了对视觉SAE特征更真实、语义更精确的解释。
点此查看论文截图

Generalizable Object Re-Identification via Visual In-Context Prompting
Authors:Zhizhong Huang, Xiaoming Liu
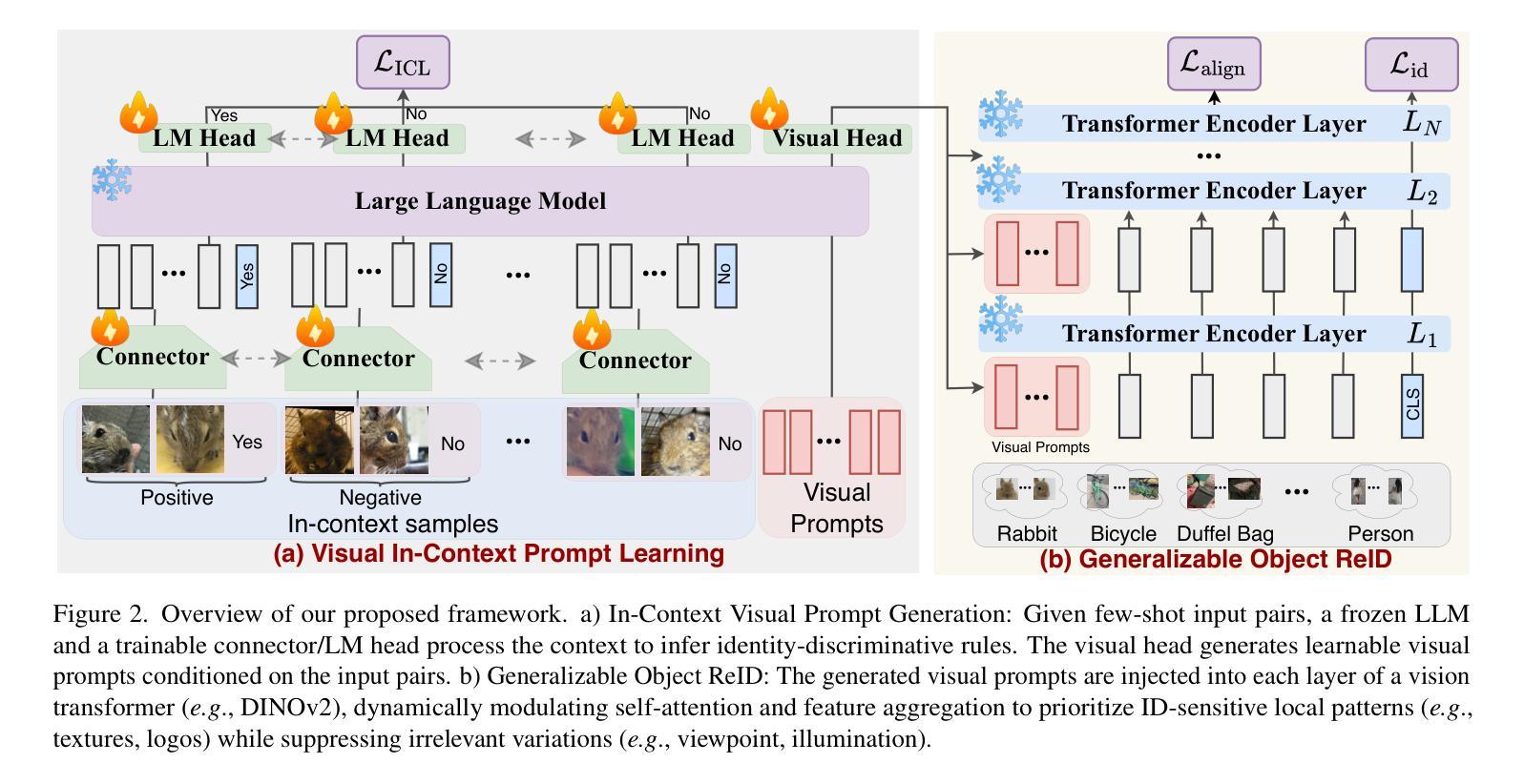
Current object re-identification (ReID) methods train domain-specific models (e.g., for persons or vehicles), which lack generalization and demand costly labeled data for new categories. While self-supervised learning reduces annotation needs by learning instance-wise invariance, it struggles to capture \textit{identity-sensitive} features critical for ReID. This paper proposes Visual In-Context Prompting(VICP), a novel framework where models trained on seen categories can directly generalize to unseen novel categories using only \textit{in-context examples} as prompts, without requiring parameter adaptation. VICP synergizes LLMs and vision foundation models(VFM): LLMs infer semantic identity rules from few-shot positive/negative pairs through task-specific prompting, which then guides a VFM (\eg, DINO) to extract ID-discriminative features via \textit{dynamic visual prompts}. By aligning LLM-derived semantic concepts with the VFM’s pre-trained prior, VICP enables generalization to novel categories, eliminating the need for dataset-specific retraining. To support evaluation, we introduce ShopID10K, a dataset of 10K object instances from e-commerce platforms, featuring multi-view images and cross-domain testing. Experiments on ShopID10K and diverse ReID benchmarks demonstrate that VICP outperforms baselines by a clear margin on unseen categories. Code is available at https://github.com/Hzzone/VICP.
当前的对象再识别(ReID)方法主要训练特定领域的模型(例如针对人或车辆),这样的模型缺乏通用性,并且需要为新类别标注昂贵的标签数据。虽然自监督学习通过实例不变性学习减少了标注需求,但它难以捕获对于ReID至关重要的“身份敏感”特征。本文提出了Visual In-Context Prompting(VICP)这一新型框架,该框架可以让在可见类别上训练的模型通过仅使用“上下文实例”作为提示来直接推广到未见的新类别,无需进行参数调整。VICP协同LLMs(大型语言模型)和视觉基础模型(VFM)发挥作用:LLMs通过任务特定提示从少数正向/负向对中提取语义身份规则,然后指导VFM(例如DINO)通过“动态视觉提示”提取身份判别特征。通过将LLM衍生的语义概念与VFM的预训练先验知识对齐,VICP能够实现对新类别的通用化,消除了对特定数据集进行再训练的需求。为了支持评估,我们引入了ShopID10K数据集,该数据集包含来自电子商务平台的1万多个对象实例,具有多视角图像和跨域测试功能。在ShopID10K和各种ReID基准测试上的实验表明,VICP在未见类别上的表现优于基线。代码可在https://github.com/Hzzone/VICP上找到。
论文及项目相关链接
PDF ICCV 2025
Summary
基于视觉上下文提示(VICP)的新框架,使得模型能够在未见过的类别上进行直接推广。该框架利用大型语言模型(LLMs)和视觉基础模型(VFMs)的协同作用,通过任务特定的提示来推断语义身份规则,并指导VFM通过动态视觉提示提取身份判别特征。通过语义概念和VFM预训练先验的对齐,VICP实现了对新类别的推广,无需针对数据集进行特定再训练。
Key Takeaways
- 当前对象再识别(ReID)方法依赖于特定领域的模型,缺乏泛化能力,需要昂贵的新类别标注数据。
- 自我监督学习可以减少对注释的需求,但难以捕获对于ReID至关重要的身份敏感特征。
- 提出的VICP框架允许模型在未见过的类别上进行直接推广,仅使用上下文实例作为提示。
- VICP结合了大型语言模型(LLMs)和视觉基础模型(VFMs)的协同作用。
- LLMs通过任务特定的提示来推断语义身份规则,指导VFM提取身份判别特征。
- VICP通过对齐LLM语义概念和VFM预训练先验,实现新类别的泛化。
点此查看论文截图



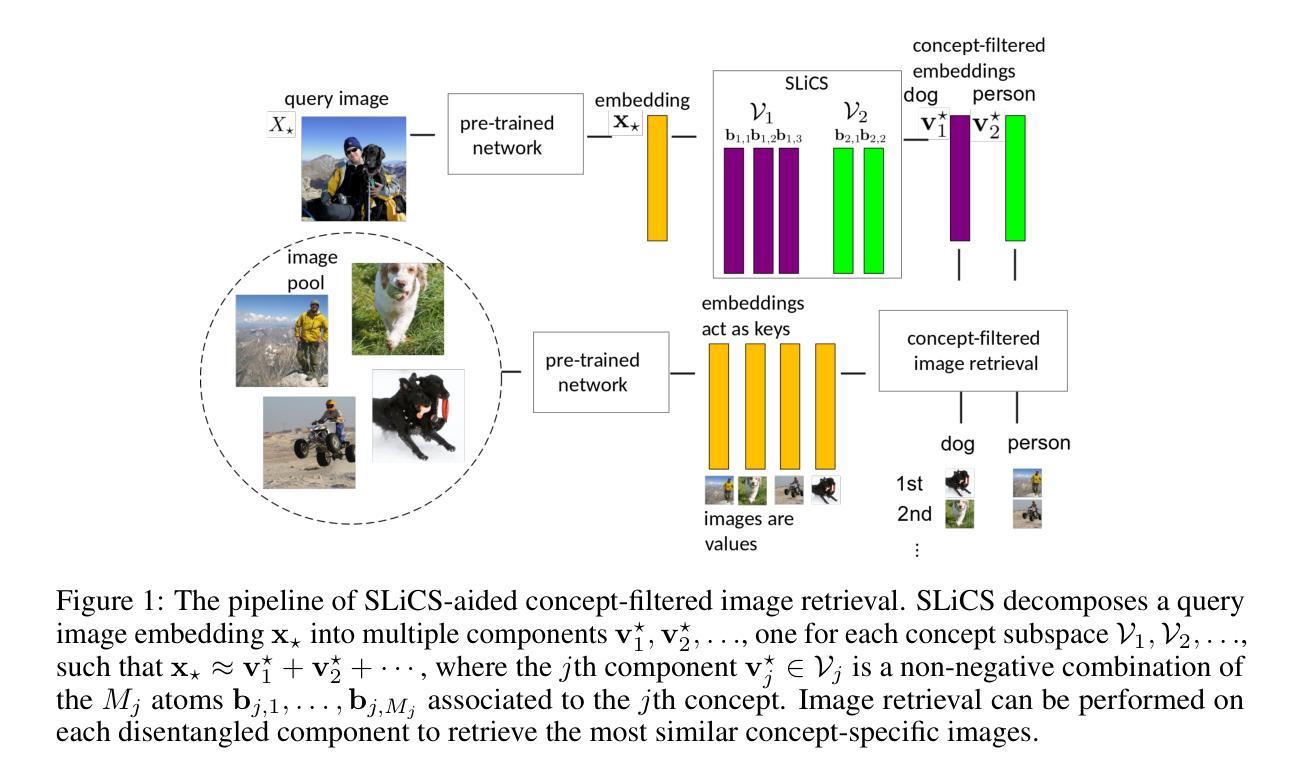
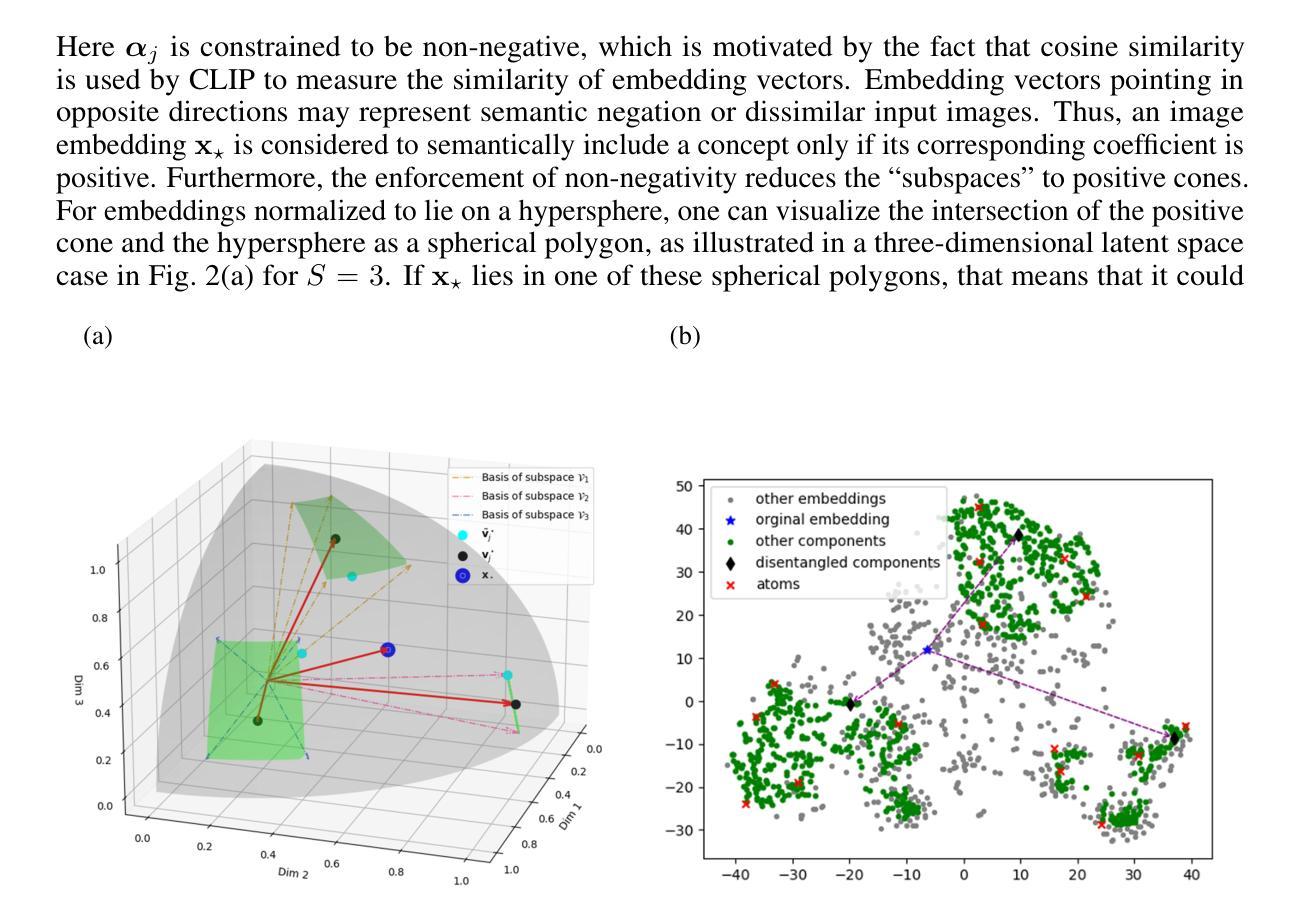
Disentangling Latent Embeddings with Sparse Linear Concept Subspaces (SLiCS)
Authors:Zhi Li, Hau Phan, Matthew Emigh, Austin J. Brockmeier
Vision-language co-embedding networks, such as CLIP, provide a latent embedding space with semantic information that is useful for downstream tasks. We hypothesize that the embedding space can be disentangled to separate the information on the content of complex scenes by decomposing the embedding into multiple concept-specific component vectors that lie in different subspaces. We propose a supervised dictionary learning approach to estimate a linear synthesis model consisting of sparse, non-negative combinations of groups of vectors in the dictionary (atoms), whose group-wise activity matches the multi-label information. Each concept-specific component is a non-negative combination of atoms associated to a label. The group-structured dictionary is optimized through a novel alternating optimization with guaranteed convergence. Exploiting the text co-embeddings, we detail how semantically meaningful descriptions can be found based on text embeddings of words best approximated by a concept’s group of atoms, and unsupervised dictionary learning can exploit zero-shot classification of training set images using the text embeddings of concept labels to provide instance-wise multi-labels. We show that the disentangled embeddings provided by our sparse linear concept subspaces (SLiCS) enable concept-filtered image retrieval (and conditional generation using image-to-prompt) that is more precise. We also apply SLiCS to highly-compressed autoencoder embeddings from TiTok and the latent embedding from self-supervised DINOv2. Quantitative and qualitative results highlight the improved precision of the concept-filtered image retrieval for all embeddings.
视觉语言协同嵌入网络(如CLIP)提供了一个包含语义信息的潜在嵌入空间,对于下游任务非常有用。我们假设嵌入空间可以被分解,以分离复杂场景内容的信息,通过将嵌入分解成位于不同子空间的多个特定概念组件向量。我们提出了一种有监督的字典学习方法,以估计由字典(原子)中的向量组稀疏非负组合构成的线性合成模型,其分组活动与多标签信息相匹配。每个特定概念组件是与标签相关的原子的非负组合。通过一种新型交替优化方法优化结构化字典,该方法具有保证的收敛性。我们详细说明了如何利用文本协同嵌入,根据与概念原子群体最匹配的文本嵌入词汇来找到语义上有意义的描述,并且无监督的字典学习可以利用概念标签的文本嵌入来对训练集图像进行零样本分类,以提供实例级的多标签。我们证明,由我们的稀疏线性概念子空间(SLiCS)提供的解耦嵌入,能够实现更精确的概念过滤图像检索(以及使用图像到提示的条件生成)。我们还将SLiCS应用于TiTok的高度压缩自编码器嵌入和自监督DINOv2的潜在嵌入。定量和定性结果都突出了概念过滤图像检索的改进精度,适用于所有嵌入。
论文及项目相关链接
Summary
本文探讨了视觉语言联合嵌入网络(如CLIP)的潜在嵌入空间,并提出一种监督字典学习的方法,将嵌入空间分解为多个概念特定的组件向量。通过优化分组结构的字典,实现概念过滤的图像检索和条件生成。研究结果显示,稀疏线性概念子空间(SLiCS)提供的解纠缠嵌入可提高图像检索的精确度。
Key Takeaways
- 视觉语言联合嵌入网络(如CLIP)提供包含语义信息的潜在嵌入空间,对下游任务有用。
- 嵌入空间可以被分解为多个概念特定的组件向量,这些向量位于不同的子空间中。
- 提出一种监督字典学习的方法,通过优化分组结构的字典来实现概念过滤的图像检索和条件生成。
- 稀疏线性概念子空间(SLiCS)能提高图像检索的精确度。
- 利用文本联合嵌入,可以找到与概念标签最匹配的语义描述。
- 无监督字典学习可以利用零样本分类法,使用文本概念标签对训练集图像进行实例级多标签分类。
点此查看论文截图


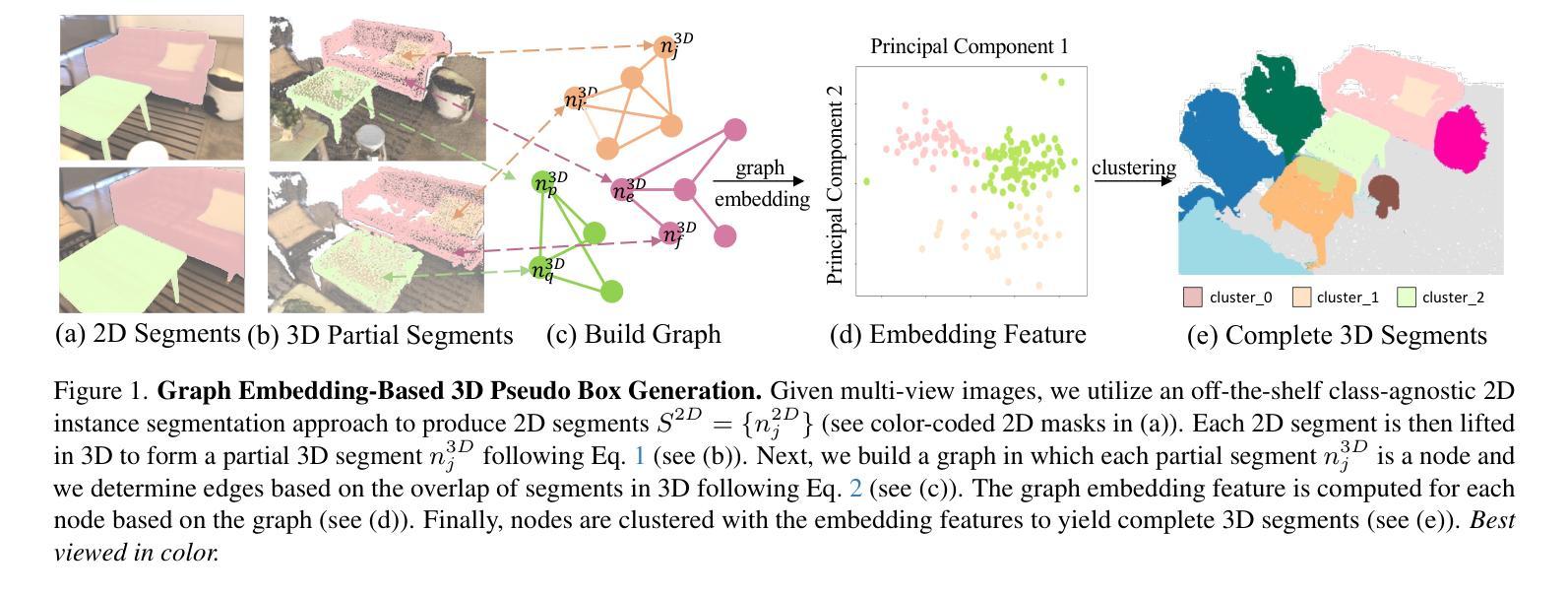
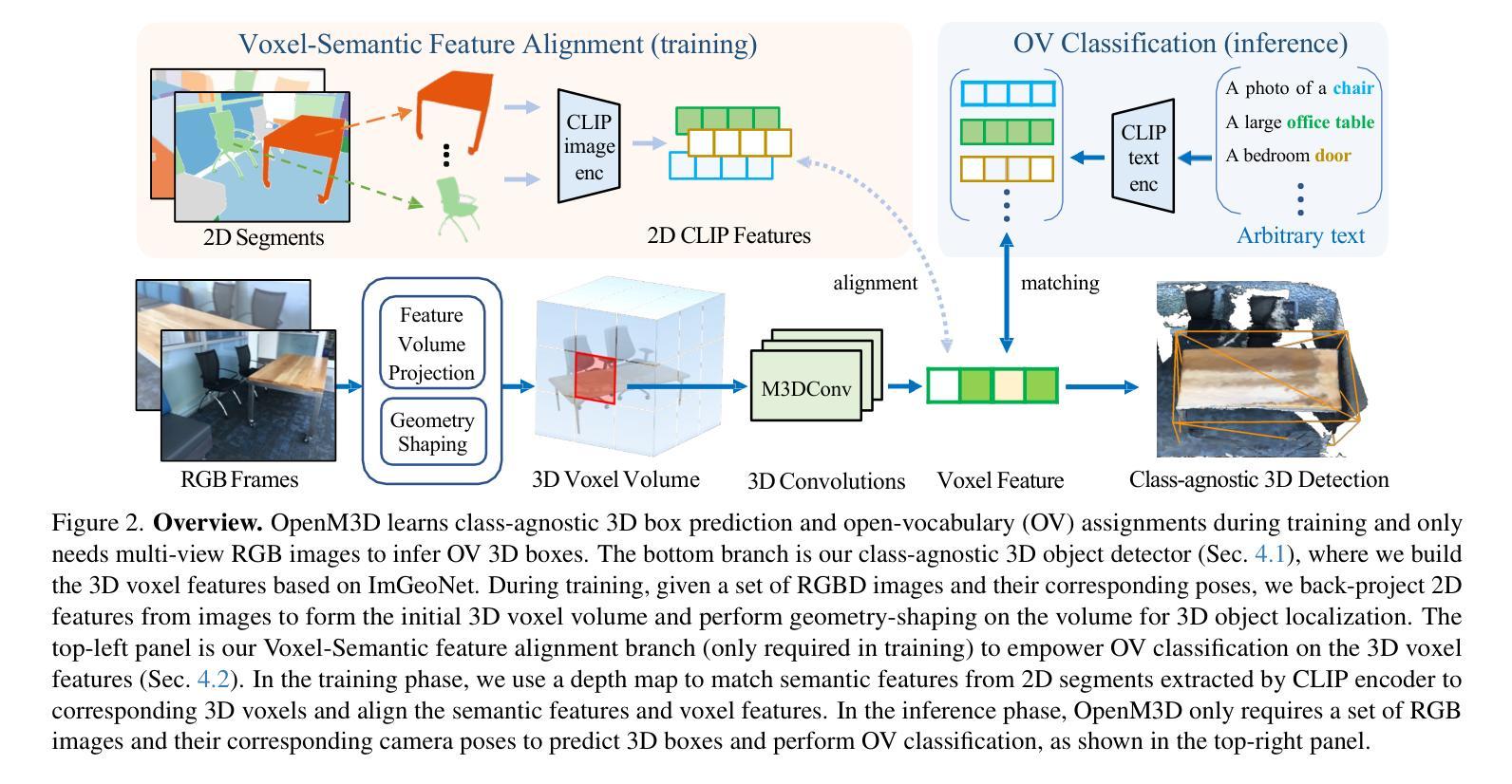
OpenM3D: Open Vocabulary Multi-view Indoor 3D Object Detection without Human Annotations
Authors:Peng-Hao Hsu, Ke Zhang, Fu-En Wang, Tao Tu, Ming-Feng Li, Yu-Lun Liu, Albert Y. C. Chen, Min Sun, Cheng-Hao Kuo
Open-vocabulary (OV) 3D object detection is an emerging field, yet its exploration through image-based methods remains limited compared to 3D point cloud-based methods. We introduce OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations. In particular, OpenM3D is a single-stage detector adapting the 2D-induced voxel features from the ImGeoNet model. To support OV, it is jointly trained with a class-agnostic 3D localization loss requiring high-quality 3D pseudo boxes and a voxel-semantic alignment loss requiring diverse pre-trained CLIP features. We follow the training setting of OV-3DET where posed RGB-D images are given but no human annotations of 3D boxes or classes are available. We propose a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures. Our pseudo-boxes achieve higher precision and recall than other methods, including the method proposed in OV-3DET. We further sample diverse CLIP features from 2D segments associated with each coherent 3D structure to align with the corresponding voxel feature. The key to training a highly accurate single-stage detector requires both losses to be learned toward high-quality targets. At inference, OpenM3D, a highly efficient detector, requires only multi-view images for input and demonstrates superior accuracy and speed (0.3 sec. per scene) on ScanNet200 and ARKitScenes indoor benchmarks compared to existing methods. We outperform a strong two-stage method that leverages our class-agnostic detector with a ViT CLIP-based OV classifier and a baseline incorporating multi-view depth estimator on both accuracy and speed.
开放词汇(OV)3D对象检测是一个新兴领域,然而与基于3D点云的方法相比,基于图像的方法对其探索仍然有限。我们引入了OpenM3D,这是一种新型开放词汇的多视角室内3D对象检测器,无需人工注释即可进行训练。特别是,OpenM3D是一个单阶段检测器,适应于从ImGeoNet模型诱导的2D体素特征。为了支持开放词汇,它与类无关的3D定位损失共同训练,需要高质量3D伪框和体素语义对齐损失,这需要多样的预训练CLIP特征。我们遵循OV-3DET的训练设置,提供有姿态的RGB-D图像,但不提供3D框或类的手工注释。我们提出了一种使用图嵌入技术的3D伪框生成方法,将2D片段组合成连贯的3D结构。我们的伪框在精度和召回率方面超过了其他方法,包括OV-3DET中提出的方法。我们进一步从与每个连贯的3D结构相关的2D片段中采样不同的CLIP特征,以与相应的体素特征对齐。训练高度准确的单阶段检测器的关键在于,两种损失都需要朝着高质量目标学习。在推理阶段,OpenM3D是一种高效的检测器,仅需要多视角图像作为输入,并在ScanNet200和ARKitScenes室内基准测试上显示出卓越的性能和速度(每秒0.3秒),超过了现有方法。我们通过使用我们的类无关检测器与基于ViT CLIP的开放词汇分类器以及结合多视角深度估计器的基准线,在准确性和速度上都超越了一种强大的两阶段方法。
论文及项目相关链接
PDF ICCV2025
摘要
开放词汇(OV)3D目标检测是一个新兴领域,基于图像的方法相较于基于3D点云的方法,其探索仍然有限。我们介绍了OpenM3D,一种无需人工标注的新开放词汇多视角室内3D目标检测器。特别是,OpenM3D是一种单阶段检测器,适应于从ImGeoNet模型诱导的2D立体特征。为了支持开放词汇,它与类无关的3D定位损失一起进行训练,需要高质量的3D伪框和立体语义对齐损失以及多样化的预训练CLIP特征。我们遵循OV-3DET的训练设置,提供姿态RGB-D图像,但无需3D框或类的手工标注。我们提出了一种使用图嵌入技术的3D伪框生成方法,将2D片段组合成连贯的3D结构。我们的伪框实现了比其它方法更高的精度和召回率,包括OV-3DET中提出的方法。我们进一步从与每个连贯的3D结构关联的2D片段中采样多样化的CLIP特征,以与相应的立体特征对齐。训练高度精确的单阶段检测器的关键是需要使两种损失朝向高质量目标学习。在推断时,OpenM3D是一种高效的检测器,仅需要多视角图像作为输入,并在ScanNet200和ARKitScenes室内基准测试上展现出卓越的准确性和速度(每秒0.3秒)。我们通过在类无关检测器上结合ViT CLIP的OV分类器以及融合多视角深度估计器的基础线方法,在准确性与速度上均表现出超越强两阶段方法的性能。
要点摘要
- 开放词汇(OV)3D目标检测是一个新兴领域,基于图像的方法相较于基于点云的方法探索受限。
- 引入OpenM3D,一种无需人工标注的开放词汇多视角室内3D目标检测器。
- OpenM3D是单阶段检测器,采用ImGeoNet模型的2D诱导立体特征,并联合训练以支持开放词汇。
- 提出一种利用图嵌入技术生成高质量3D伪框的方法,提高了精度和召回率。
- 利用多样化的预训练CLIP特征进行训练以提高性能。
- 在推断时,OpenM3D仅需要多视角图像作为输入,展现出卓越的准确性和速度。
点此查看论文截图

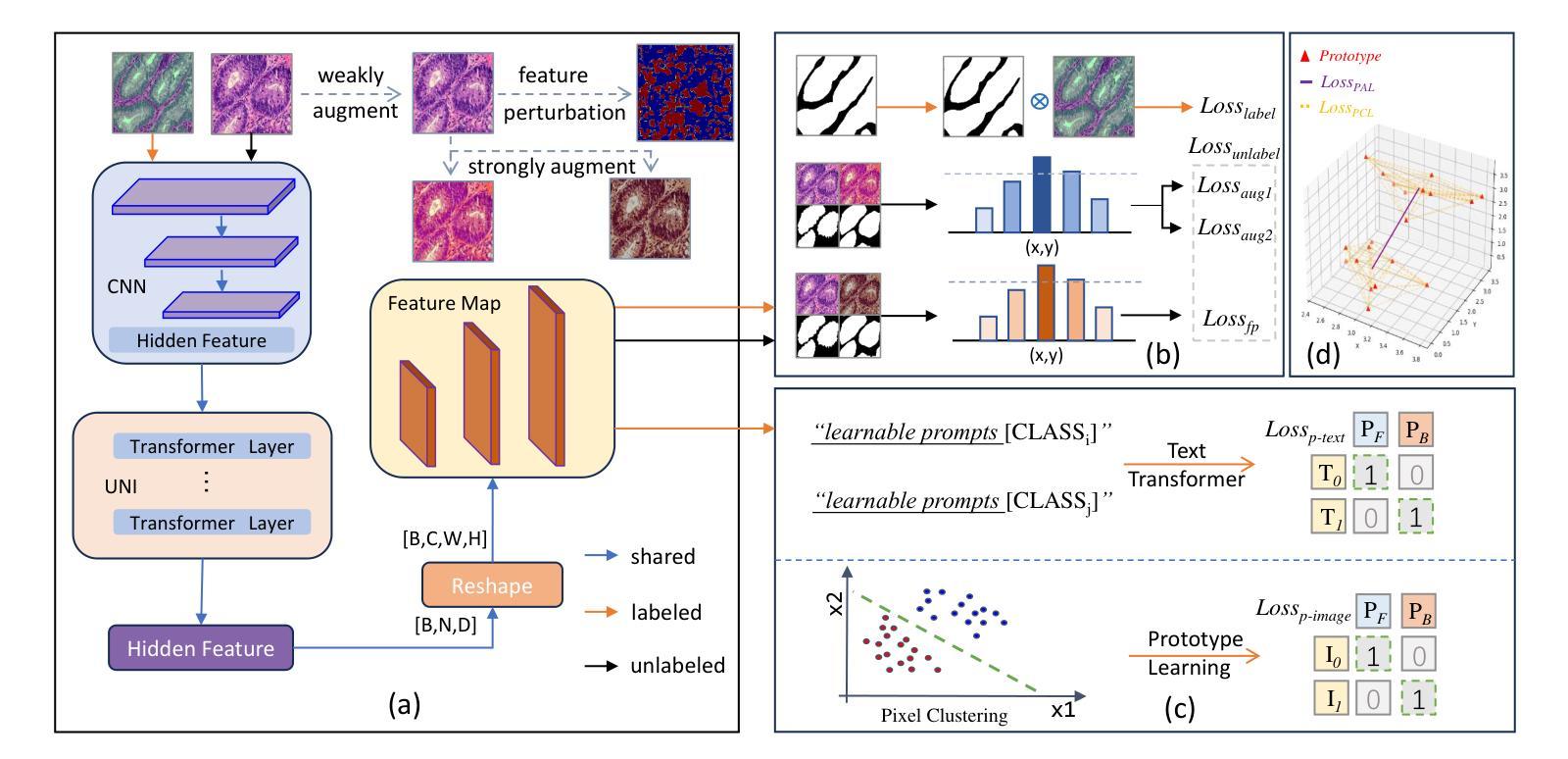
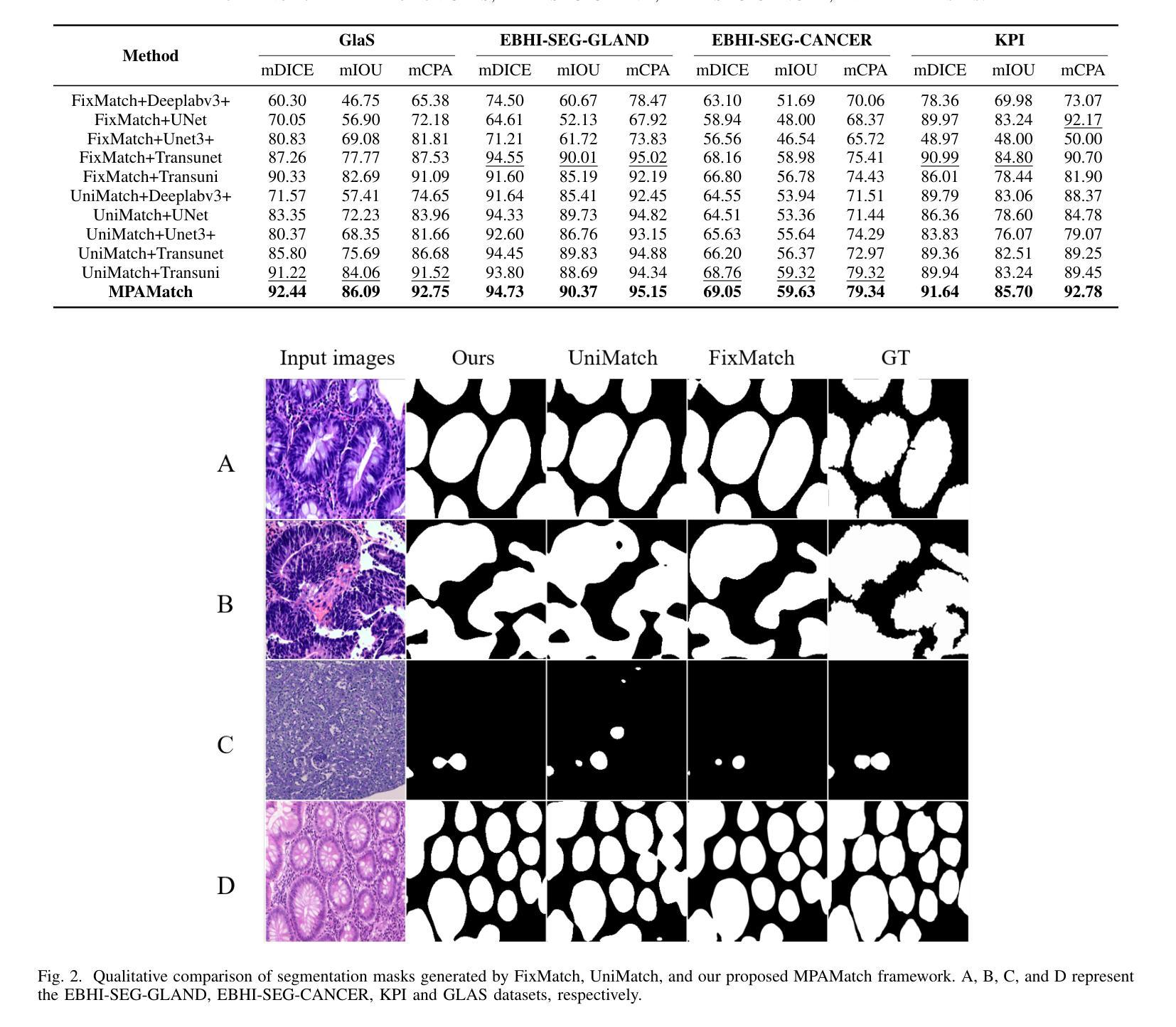
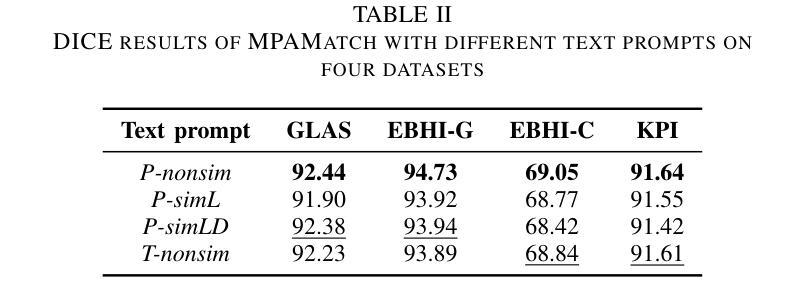
Multimodal Prototype Alignment for Semi-supervised Pathology Image Segmentation
Authors:Mingxi Fu, Fanglei Fu, Xitong Ling, Huaitian Yuan, Tian Guan, Yonghong He, Lianghui Zhu
Pathological image segmentation faces numerous challenges, particularly due to ambiguous semantic boundaries and the high cost of pixel-level annotations. Although recent semi-supervised methods based on consistency regularization (e.g., UniMatch) have made notable progress, they mainly rely on perturbation-based consistency within the image modality, making it difficult to capture high-level semantic priors, especially in structurally complex pathology images. To address these limitations, we propose MPAMatch - a novel segmentation framework that performs pixel-level contrastive learning under a multimodal prototype-guided supervision paradigm. The core innovation of MPAMatch lies in the dual contrastive learning scheme between image prototypes and pixel labels, and between text prototypes and pixel labels, providing supervision at both structural and semantic levels. This coarse-to-fine supervisory strategy not only enhances the discriminative capability on unlabeled samples but also introduces the text prototype supervision into segmentation for the first time, significantly improving semantic boundary modeling. In addition, we reconstruct the classic segmentation architecture (TransUNet) by replacing its ViT backbone with a pathology-pretrained foundation model (Uni), enabling more effective extraction of pathology-relevant features. Extensive experiments on GLAS, EBHI-SEG-GLAND, EBHI-SEG-CANCER, and KPI show MPAMatch’s superiority over state-of-the-art methods, validating its dual advantages in structural and semantic modeling.
病理图像分割面临诸多挑战,尤其是因为语义边界模糊和像素级标注的成本高昂。尽管最近基于一致性正则化的半监督方法(例如UniMatch)取得了显著进展,但它们主要依赖于图像模态内的基于扰动的一致性,因此在捕获高级语义先验时面临困难,尤其是在结构复杂的病理图像中。为了解决这些局限性,我们提出了MPAMatch——一种在多媒体原型引导监督范式下进行像素级对比学习的新型分割框架。MPAMatch的核心创新之处在于图像原型与像素标签之间以及文本原型与像素标签之间的双重对比学习方案,在结构和语义级别上提供监督。这种由粗到细的监督策略不仅提高了对未标记样本的辨别能力,而且首次将文本原型监督引入分割,从而显着改进了语义边界建模。此外,我们通过用病理预训练基础模型(Uni)替换经典分割架构(TransUNet)的ViT骨干网,从而重建了更高效的病理相关特征提取。在GLAS、EBHI-SEG-GLAND、EBHI-SEG-CANCER和KPI上的广泛实验表明,MPAMatch在结构和语义建模方面具有双重优势,优于最先进的方法。
论文及项目相关链接
Summary
基于一致性正则化的半监督方法面临语义边界模糊和复杂结构图像中的高成本标注问题。提出MPAMatch框架,采用像素级对比学习,在多模态原型引导的监督下进行分割。核心创新在于图像原型与像素标签之间以及文本原型与像素标签之间的双重对比学习方案,实现了结构级和语义级的监督。重构经典分割架构TransUNet,采用病理预训练基础模型Uni替换ViT主干,更有效提取病理相关特征。在GLAS、EBHI-SEG-GLAND等数据集上验证MPAMatch的优越性。
Key Takeaways
- MPAMatch解决了基于一致性正则化的半监督方法在病理图像分割中面临的语义边界模糊问题。
- MPAMatch采用多模态原型引导的监督方式,实现了像素级的对比学习。
- 双重对比学习方案结合了图像原型与像素标签、文本原型与像素标签的监督,提升了未标注样本的判别能力。
- MPAMatch首次将文本原型监督引入分割任务,改进了语义边界建模。
- MPAMatch重构了TransUNet架构,使用病理预训练基础模型Uni替换ViT主干,增强了特征提取能力。
- MPAMatch在多个数据集上表现优越,验证了其在结构和语义建模上的双重优势。
点此查看论文截图

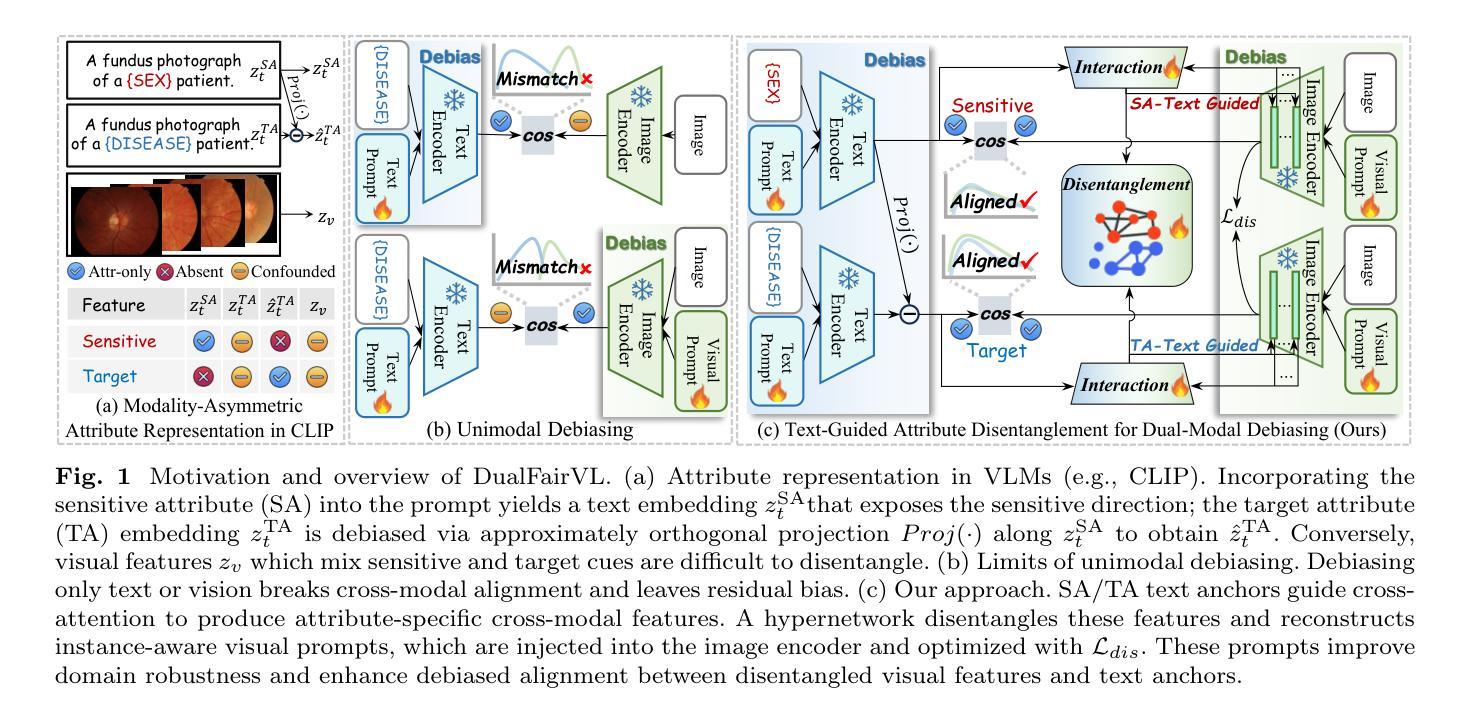
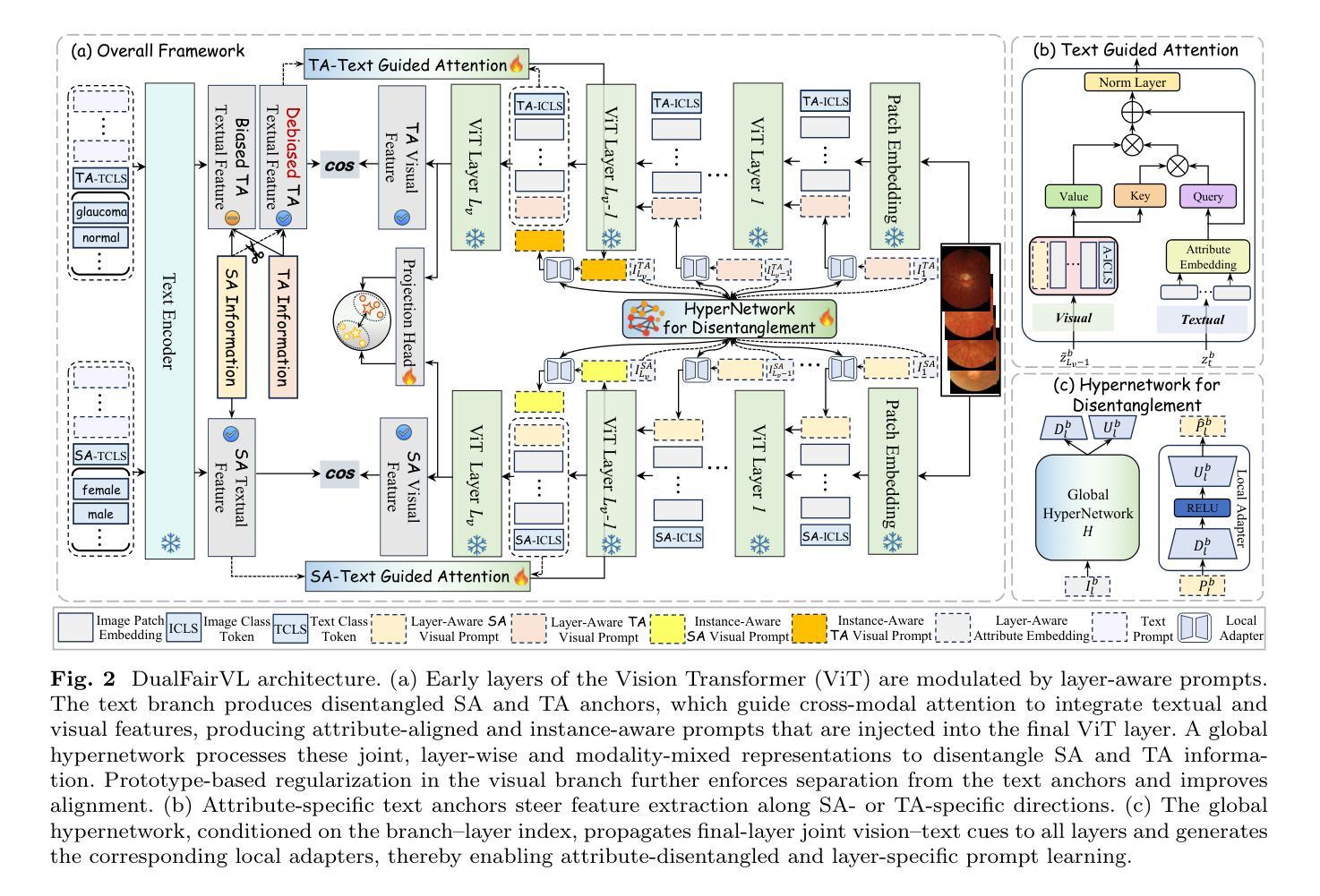
Toward Robust Medical Fairness: Debiased Dual-Modal Alignment via Text-Guided Attribute-Disentangled Prompt Learning for Vision-Language Models
Authors:Yuexuan Xia, Benteng Ma, Jiang He, Zhiyong Wang, Qi Dou, Yong Xia
Ensuring fairness across demographic groups in medical diagnosis is essential for equitable healthcare, particularly under distribution shifts caused by variations in imaging equipment and clinical practice. Vision-language models (VLMs) exhibit strong generalization, and text prompts encode identity attributes, enabling explicit identification and removal of sensitive directions. However, existing debiasing approaches typically address vision and text modalities independently, leaving residual cross-modal misalignment and fairness gaps. To address this challenge, we propose DualFairVL, a multimodal prompt-learning framework that jointly debiases and aligns cross-modal representations. DualFairVL employs a parallel dual-branch architecture that separates sensitive and target attributes, enabling disentangled yet aligned representations across modalities. Approximately orthogonal text anchors are constructed via linear projections, guiding cross-attention mechanisms to produce fused features. A hypernetwork further disentangles attribute-related information and generates instance-aware visual prompts, which encode dual-modal cues for fairness and robustness. Prototype-based regularization is applied in the visual branch to enforce separation of sensitive features and strengthen alignment with textual anchors. Extensive experiments on eight medical imaging datasets across four modalities show that DualFairVL achieves state-of-the-art fairness and accuracy under both in- and out-of-distribution settings, outperforming full fine-tuning and parameter-efficient baselines with only 3.6M trainable parameters. Code will be released upon publication.
在医疗诊断中,确保不同人群之间的公平性是公平医疗的关键,特别是在由成像设备和临床实践变化引起的分布变化下尤为重要。视觉语言模型(VLMs)展现出强大的泛化能力,文本提示能够编码身份属性,从而能够明确识别和消除敏感方向。然而,现有的去偏方法通常独立地处理视觉和文本模态,导致剩余的跨模态不匹配和公平性差距。为了应对这一挑战,我们提出了DualFairVL,一个联合去偏和跨模态对齐的多模态提示学习框架。DualFairVL采用并行双分支架构,将敏感属性和目标属性分离,实现跨模态的解耦且对齐的表示。通过线性投影构建近似正交的文本锚点,引导跨注意力机制生成融合特征。超网络进一步解耦属性相关信息,并生成实例感知的视觉提示,编码双模态线索以实现公平性和稳健性。基于原型的正则化应用于视觉分支,以强制敏感特征的分离并加强文本锚点的对齐。在四种模态的八个医学成像数据集上的大量实验表明,DualFairVL在内外分布设置下实现了最先进的公平性和准确性,仅使用360万可训练参数就超过了全微调参数高效的基线。代码将在发布时公开。
论文及项目相关链接
Summary
视觉语言模型(VLMs)在处理医疗诊断中的跨模态偏见问题方面存在挑战。本文提出一种名为DualFairVL的多模态提示学习框架,用于联合消除偏见和跨模态对齐表示。DualFairVL采用平行双分支架构分离敏感属性和目标属性,生成实例感知的视觉提示以增强公平性和稳健性。实验证明其在不同模态的八个医疗图像数据集上实现了最先进的公平性和准确性。
Key Takeaways
- 公平医疗诊断的重要性:强调在医疗诊断中确保跨人口群体公平的重要性,特别是受到成像设备和临床实践变化的影响。
- 视觉语言模型的挑战:视觉语言模型在处理跨模态偏见问题上存在难题,特别是在独立处理视觉和文本模态时易出现剩余跨模态不对齐和公平差距。
- DualFairVL框架的提出:介绍了一种名为DualFairVL的多模态提示学习框架,旨在联合消除偏见并跨模态对齐表示。
- 平行双分支架构:DualFairVL采用平行双分支架构,能够分离敏感属性和目标属性,实现跨模态的解耦表示。
- 文本锚点的作用:通过线性投影构建近似正交的文本锚点,引导跨注意力机制产生融合特征。
- 实例感知的视觉提示:使用超网络生成实例感知的视觉提示,该提示结合了双模态线索以提高公平性和稳健性。
点此查看论文截图

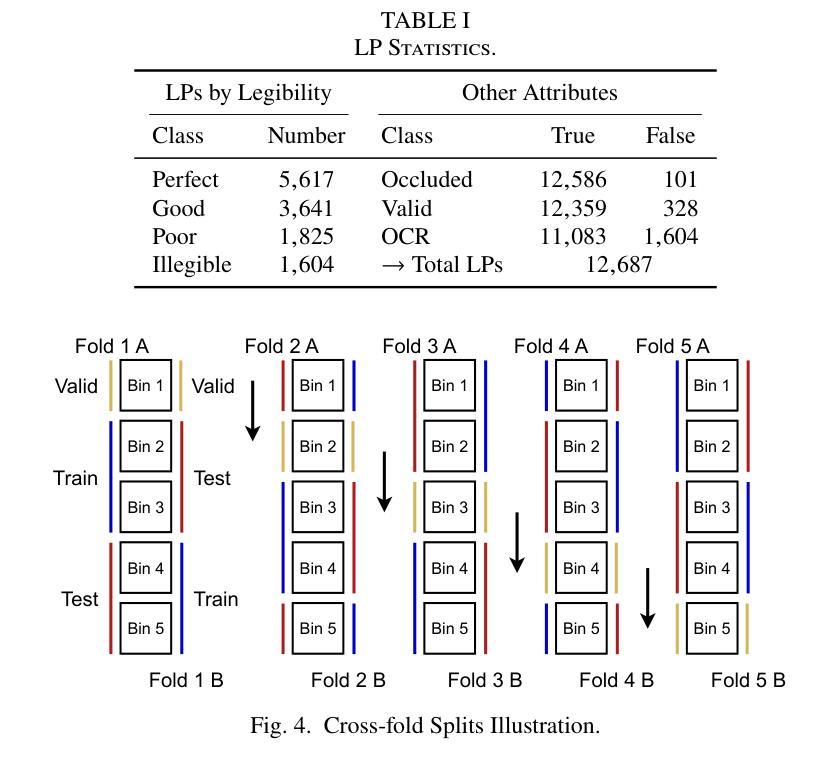
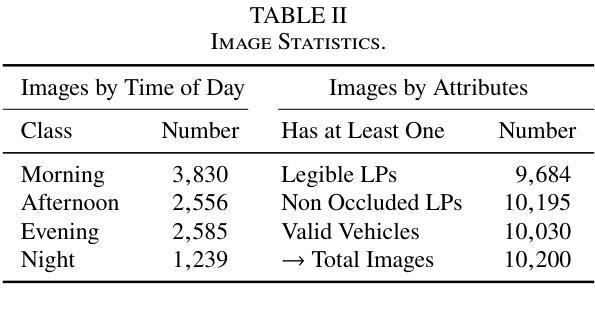
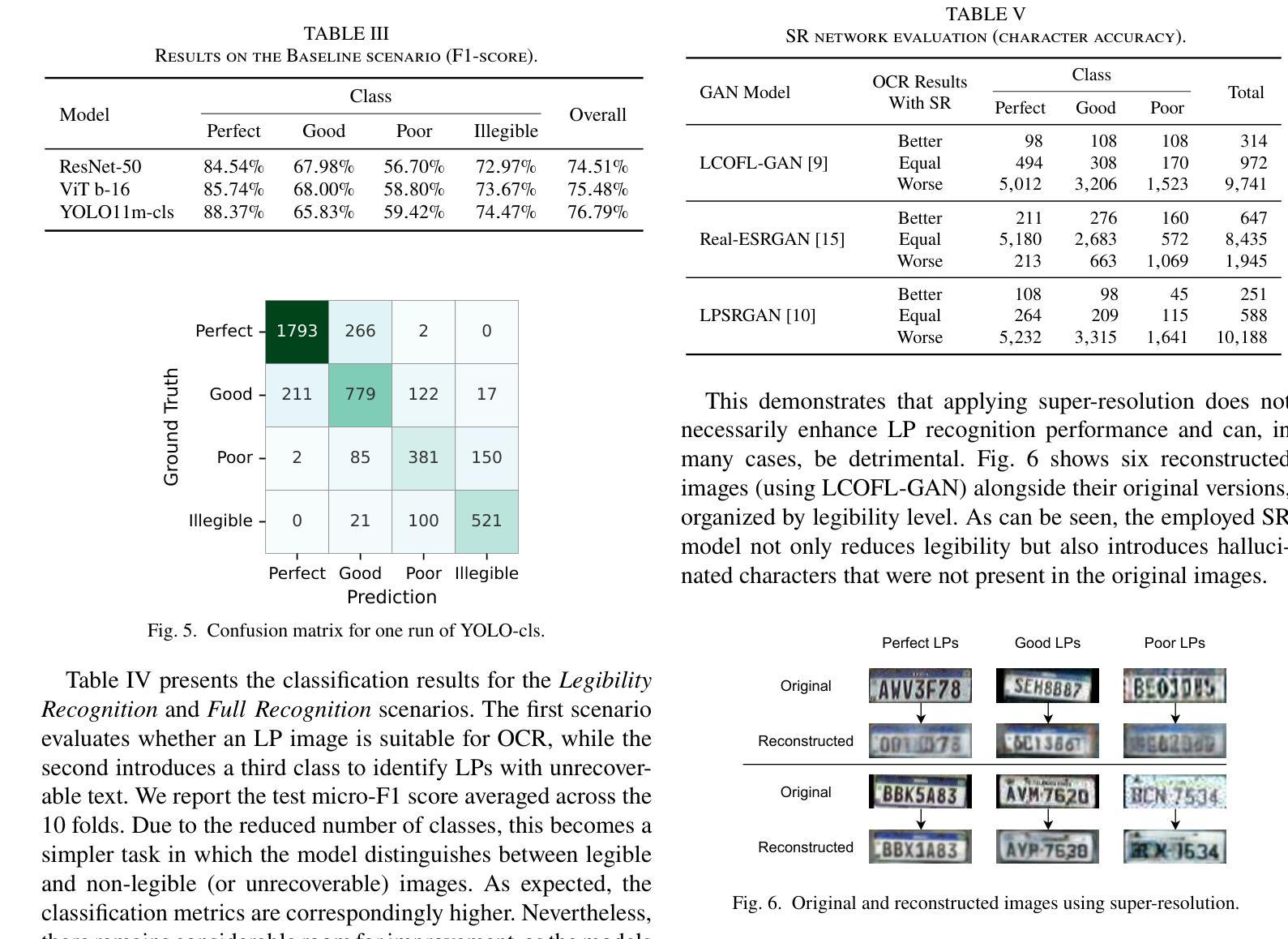
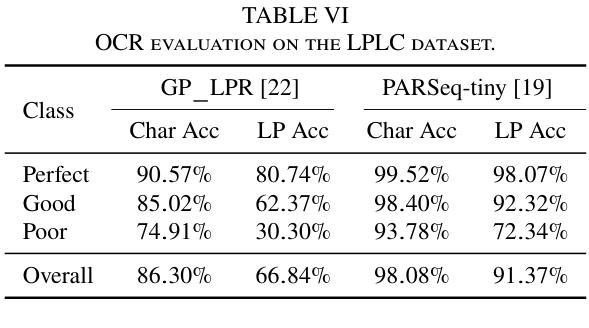
LPLC: A Dataset for License Plate Legibility Classification
Authors:Lucas Wojcik, Gabriel E. Lima, Valfride Nascimento, Eduil Nascimento Jr., Rayson Laroca, David Menotti
Automatic License Plate Recognition (ALPR) faces a major challenge when dealing with illegible license plates (LPs). While reconstruction methods such as super-resolution (SR) have emerged, the core issue of recognizing these low-quality LPs remains unresolved. To optimize model performance and computational efficiency, image pre-processing should be applied selectively to cases that require enhanced legibility. To support research in this area, we introduce a novel dataset comprising 10,210 images of vehicles with 12,687 annotated LPs for legibility classification (the LPLC dataset). The images span a wide range of vehicle types, lighting conditions, and camera/image quality levels. We adopt a fine-grained annotation strategy that includes vehicle- and LP-level occlusions, four legibility categories (perfect, good, poor, and illegible), and character labels for three categories (excluding illegible LPs). As a benchmark, we propose a classification task using three image recognition networks to determine whether an LP image is good enough, requires super-resolution, or is completely unrecoverable. The overall F1 score, which remained below 80% for all three baseline models (ViT, ResNet, and YOLO), together with the analyses of SR and LP recognition methods, highlights the difficulty of the task and reinforces the need for further research. The proposed dataset is publicly available at https://github.com/lmlwojcik/lplc-dataset.
车牌识别系统(ALPR)在处理难以辨认的车牌(LPs)时面临重大挑战。虽然超分辨率重建方法(SR)已经出现,但识别这些低质量车牌的核心问题仍未解决。为了优化模型性能和计算效率,应对需要提高清晰度的案例选择性应用图像预处理。为了支持这一领域的研究,我们引入了一个包含车辆图像的新数据集,其中含有车辆图像共计有车辆10,210张,标注车牌LPs数量为有数字信息的LP有足足达到了将包含近近文字组合而有数字和编号但外观由于物理污迹或被风沙掩埋或是外观不佳以致褪色完全辨认基本无法辨认车牌号码的车辆图像共计有标注车牌共计有标注车牌数字信息的LP共计有共计有标注车牌数字信息的有高达高达高达高达高达高达高达通过不同的标识清晰的对比就可以辨认并找出发现难度细微之分数字细差别无法完全进行辨并且标记其分别类别可以将根据不同类被分类为完美、良好、恶劣和无法辨认四个清晰度类别别包括车辆级别和车牌级别的遮挡类别还包括除了无法辨认的车牌外其余三种类别的字符标签最终建立一个比较全完备的样本集该样本集共用来可以训练和评估相关的深度学习算法网络该样本集囊括了各种各样的车辆类型光照条件以及相机或图像质量水平作为一个基准测试我们提出了一个分类任务使用三个图像识别网络来确定车牌图像是否足够好需要进行超分辨率处理还是完全无法恢复总体而言F1得分对所有三个基准模型(ViT、ResNet和YOLO)都低于百分之八十这凸显了任务的难度以及对进一步研究的必要性此外还对SR和车牌识别方法进行了分析所提出的数据集可在公开渠道下载访问其网址为https://github.com/lmlwojcik/lplc-dataset
论文及项目相关链接
PDF Accepted for presentation at the Conference on Graphics, Patterns and Images (SIBGRAPI) 2025
Summary
本文介绍了针对车牌识别(ALPR)中遇到的难以识别的车牌(LPs)问题,提出一种新型数据集LPLC。该数据集包含多种车辆类型、光照条件和摄像头/图像质量水平的图像,并对车牌的可读性进行分类标注。文章提出了一个分类任务基准线,使用三种图像识别网络判断车牌图像是否足够好、是否需要超分辨率处理或完全无法恢复。然而,所有基准模型的F1得分均低于80%,表明任务难度大,需要进一步研究。数据集已在GitHub上公开。
Key Takeaways
- ALPR在处理模糊车牌时面临挑战。
- 提出一种新型数据集LPLC,用于车牌的可读性分类。
- 数据集包含多种车辆类型、光照条件和摄像头/图像质量水平的图像。
- 采用精细标注策略,包括车辆和车牌级别的遮挡信息以及四个清晰度类别(完美、良好、较差和无法识别)。
- 提出一个分类任务基准线,使用三种图像识别网络判断车牌图像的可读性。
- 所有基准模型的F1得分均低于80%,表明任务难度大。
点此查看论文截图




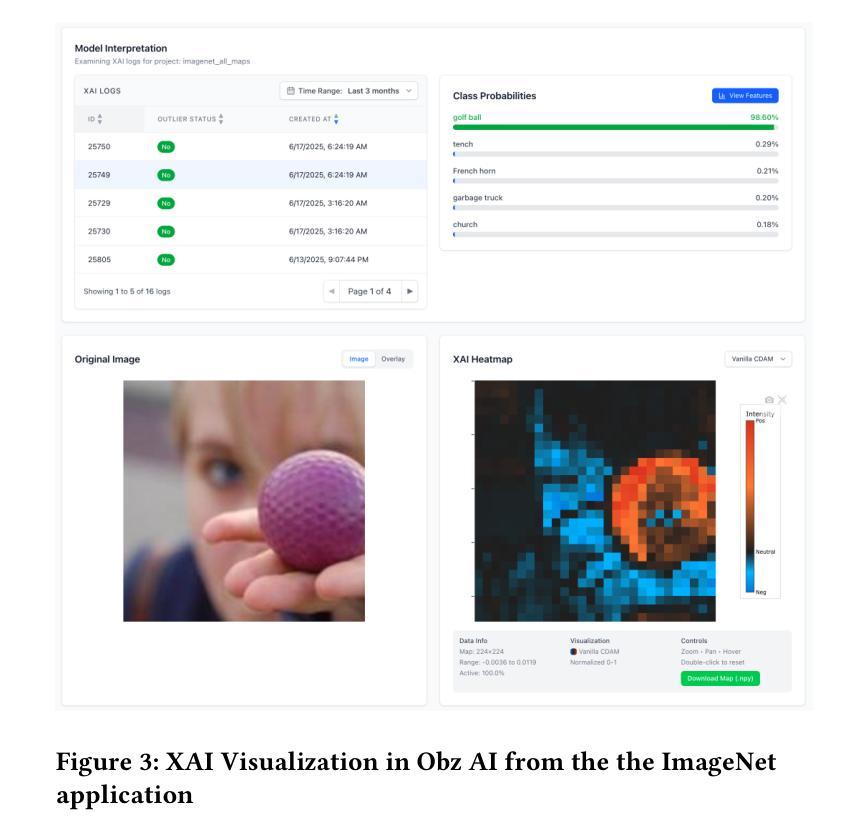
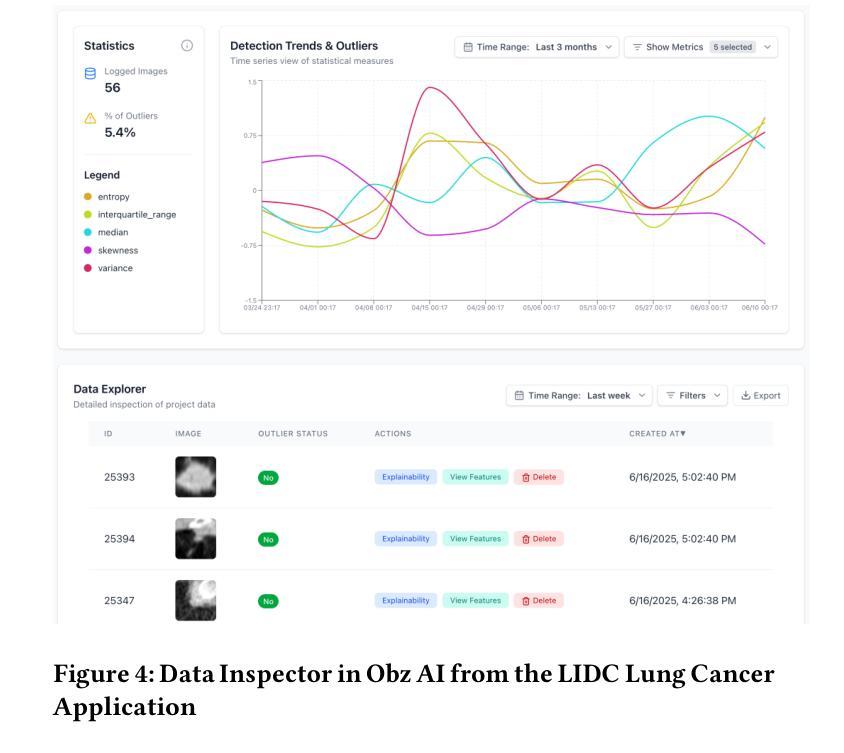
Explain and Monitor Deep Learning Models for Computer Vision using Obz AI
Authors:Neo Christopher Chung, Jakub Binda
Deep learning has transformed computer vision (CV), achieving outstanding performance in classification, segmentation, and related tasks. Such AI-based CV systems are becoming prevalent, with applications spanning from medical imaging to surveillance. State of the art models such as convolutional neural networks (CNNs) and vision transformers (ViTs) are often regarded as ``black boxes,’’ offering limited transparency into their decision-making processes. Despite a recent advancement in explainable AI (XAI), explainability remains underutilized in practical CV deployments. A primary obstacle is the absence of integrated software solutions that connect XAI techniques with robust knowledge management and monitoring frameworks. To close this gap, we have developed Obz AI, a comprehensive software ecosystem designed to facilitate state-of-the-art explainability and observability for vision AI systems. Obz AI provides a seamless integration pipeline, from a Python client library to a full-stack analytics dashboard. With Obz AI, a machine learning engineer can easily incorporate advanced XAI methodologies, extract and analyze features for outlier detection, and continuously monitor AI models in real time. By making the decision-making mechanisms of deep models interpretable, Obz AI promotes observability and responsible deployment of computer vision systems.
深度学习已经改变了计算机视觉(CV)领域,在分类、分割和相关任务中取得了卓越的性能。这种基于人工智能的计算机视觉系统变得越来越普遍,其应用从医学影像到监控无所不在。最先进的模型,如卷积神经网络(CNN)和视觉变压器(ViT),通常被视为“黑箱”,对其决策过程的透明度有限。尽管最近解释性人工智能(XAI)有所发展,但在实际计算机视觉部署中,可解释性仍然被利用不足。主要障碍在于缺乏将XAI技术与稳健的知识管理和监控框架连接起来的综合软件解决方案。为了弥补这一空白,我们开发了Obz AI,这是一个全面的软件生态系统,旨在促进先进的视觉人工智能系统的可解释性和可观察性。Obz AI提供了一个无缝集成管道,从Python客户端库到全栈分析仪表板。使用Obz AI,机器学习工程师可以轻松地采用先进的XAI方法,提取和分析特征以进行异常检测,并实时持续监控AI模型。通过使深度模型的决策机制可解释,Obz AI促进了计算机视觉系统的可观性和负责任的部署。
论文及项目相关链接
Summary
本文介绍了深度学习在计算机视觉领域的卓越表现,特别是在分类、分割和相关任务中的应用。尽管存在如卷积神经网络和视觉变压器等先进模型,但人工智能系统的决策过程仍然缺乏透明度。为了解决这个问题,开发了一个名为Obz AI的综合软件生态系统,旨在促进计算机视觉系统的先进解释性和可观测性。Obz AI提供了一个无缝集成管道,从Python客户端库到全栈分析仪表板,使得机器学习工程师可以轻松地融入先进的XAI方法,实时分析和监控AI模型。通过解释深度模型的决策机制,Obz AI促进了计算机视觉系统的可观测性和负责任部署。
Key Takeaways
- 深度学习在计算机视觉领域表现卓越,尤其在分类和分割任务中。
- 当前先进的模型如CNN和ViT被视为“黑箱”,决策过程缺乏透明度。
- 现有的解释性人工智能(XAI)技术在实用部署中的利用率不高。
- Obz AI是一个综合软件生态系统,旨在促进计算机视觉系统的先进解释性和可观测性。
- Obz AI提供了一个无缝集成管道,包括Python客户端库和全栈分析仪表板。
- 机器学习工程师可以方便地利用Obz AI融入先进的XAI方法,实时分析和监控AI模型。
点此查看论文截图


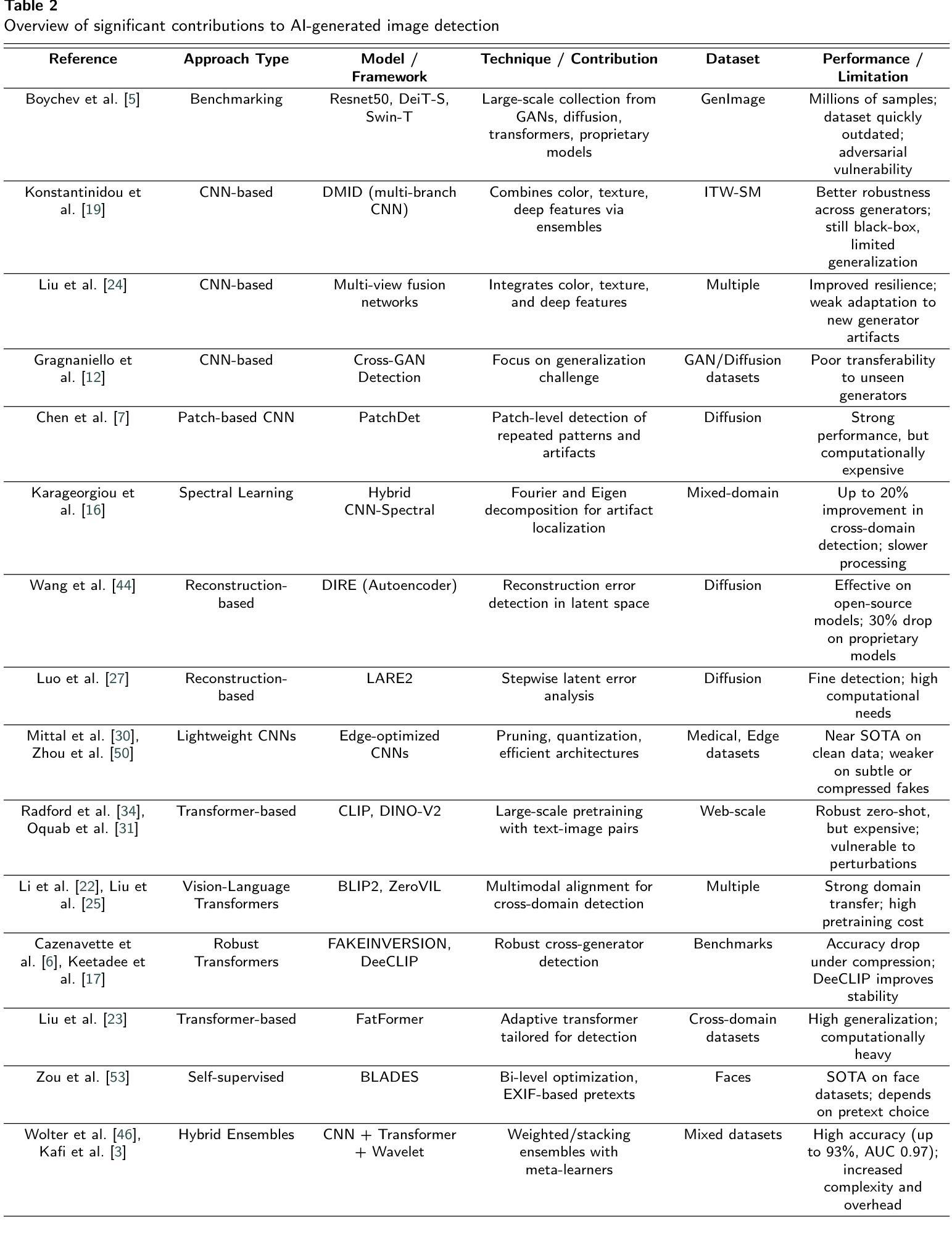
Edge-Enhanced Vision Transformer Framework for Accurate AI-Generated Image Detection
Authors:Dabbrata Das, Mahshar Yahan, Md Tareq Zaman, Md Rishadul Bayesh
The rapid advancement of generative models has led to a growing prevalence of highly realistic AI-generated images, posing significant challenges for digital forensics and content authentication. Conventional detection methods mainly rely on deep learning models that extract global features, which often overlook subtle structural inconsistencies and demand substantial computational resources. To address these limitations, we propose a hybrid detection framework that combines a fine-tuned Vision Transformer (ViT) with a novel edge-based image processing module. The edge-based module computes variance from edge-difference maps generated before and after smoothing, exploiting the observation that AI-generated images typically exhibit smoother textures, weaker edges, and reduced noise compared to real images. When applied as a post-processing step on ViT predictions, this module enhances sensitivity to fine-grained structural cues while maintaining computational efficiency. Extensive experiments on the CIFAKE, Artistic, and Custom Curated datasets demonstrate that the proposed framework achieves superior detection performance across all benchmarks, attaining 97.75% accuracy and a 97.77% F1-score on CIFAKE, surpassing widely adopted state-of-the-art models. These results establish the proposed method as a lightweight, interpretable, and effective solution for both still images and video frames, making it highly suitable for real-world applications in automated content verification and digital forensics.
生成模型的快速发展导致了高度逼真的AI生成图像的普及,这给数字取证和内容认证带来了巨大的挑战。传统的检测方法主要依赖于深度学习模型,这些模型提取全局特征,往往会忽略细微的结构不一致性,并且需要大量的计算资源。为了解决这些局限性,我们提出了一种混合检测框架,它将经过微调过的视觉变压器(ViT)与一种新型的边缘图像处理模块相结合。边缘模块计算平滑前后的边缘差异图生成的方差,利用观察到AI生成的图像通常具有更平滑的纹理、较弱的边缘和与真实图像相比减少的噪声。当作为ViT预测的后期处理步骤应用时,此模块在保持计算效率的同时,提高了对细微结构线索的敏感性。在CIFAKE、艺术定制和自定义精选数据集上的大量实验表明,所提出的框架在所有基准测试中均实现了卓越的检测性能,在CIFAKE上达到了97.75%的准确率和97.77%的F1分数,超过了广泛采用的最新模型。这些结果证明了该方法作为一种轻量级、可解释、有效的静止图像和视频帧解决方案,非常适合用于自动化内容验证和数字取证等实际应用场景。
论文及项目相关链接
PDF 19 pages, 14 figures
Summary
在生成模型快速发展的背景下,AI生成的图像越来越逼真,给数字取证和内容认证带来了巨大挑战。传统检测方法主要依赖深度学习模型提取全局特征,容易忽略细微的结构不一致,并且计算资源需求大。为解决这些问题,我们提出了结合微调后的Vision Transformer(ViT)和新型边缘图像处理的混合检测框架。边缘处理模块计算平滑前后的边缘差异图方差,利用AI生成的图像通常纹理更平滑、边缘更弱、噪声减少的特性。作为ViT预测的后期处理步骤,该模块提高了对细微结构线索的敏感性,同时保持了计算效率。在CIFAKE、Artistic和Custom Curated数据集上的实验表明,该框架在所有基准测试中实现了卓越的检测性能,在CIFAKE上达到了97.75%的准确率和97.77%的F1分数,超越了广泛采用的最先进模型。该方法的轻量化、可解释性和对静态图像和视频帧的有效性,使其成为自动化内容验证和数字取证领域的理想选择。
Key Takeaways
- AI生成的图像的增长给数字取证和内容认证带来挑战。
- 传统检测方法依赖深度学习模型提取全局特征,存在计算资源需求大和忽略细微结构不一致的问题。
- 提出的混合检测框架结合了Vision Transformer(ViT)和边缘图像处理方法。
- 边缘处理模块计算平滑前后的边缘差异图方差来识别AI生成的图像。
- 该方法提高了对细微结构线索的敏感性并保持了计算效率。
- 在多个数据集上的实验证明该框架性能卓越,超越了现有模型。
点此查看论文截图

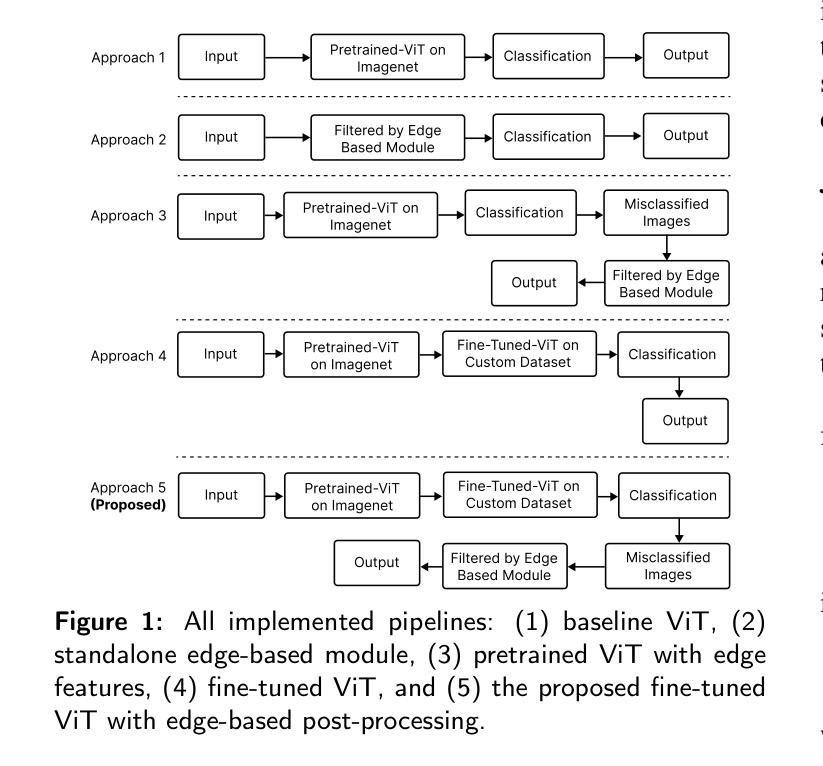
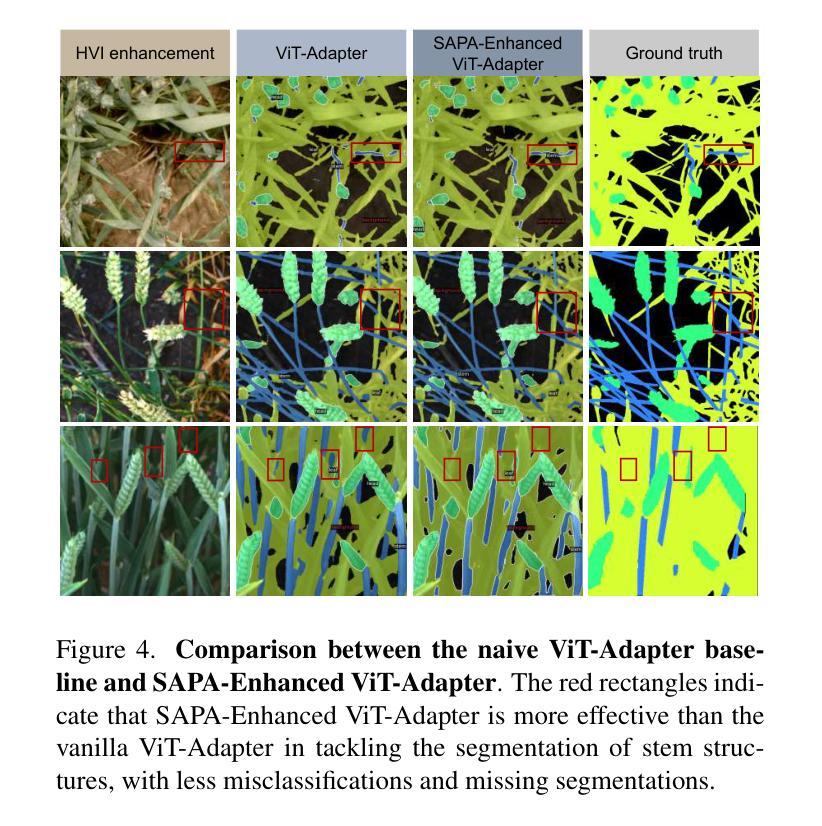
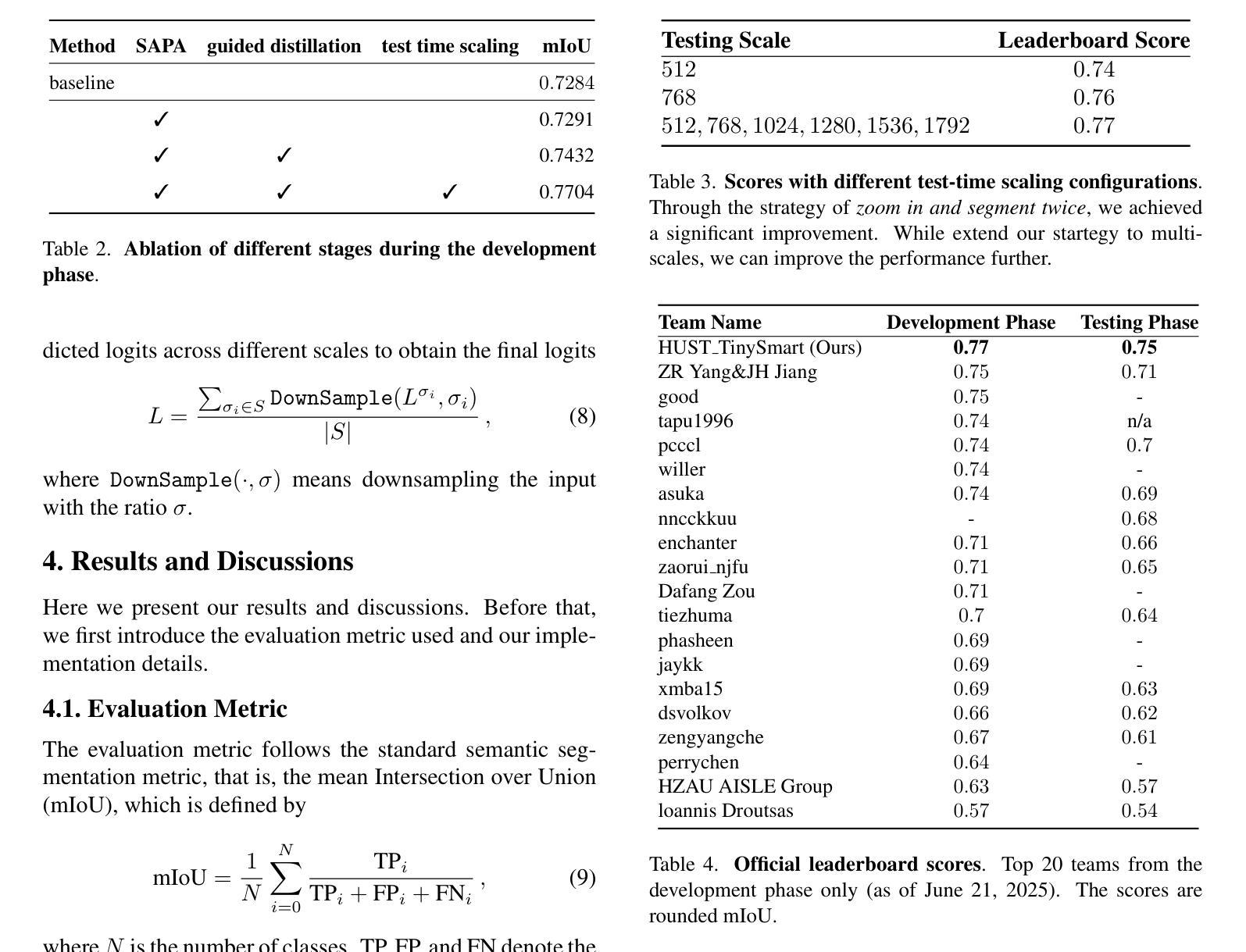
First Place Solution to the MLCAS 2025 GWFSS Challenge: The Devil is in the Detail and Minority
Authors:Songliang Cao, Tianqi Hu, Hao Lu
In this report, we present our solution during the participation of the MLCAS 2025 GWFSS Challenge. This challenge hosts a semantic segmentation competition specific to wheat plants, which requires to segment three wheat organs including the head, leaf, and stem, and another background class. In 2025, participating a segmentation competition is significantly different from that in previous years where many tricks can play important roles. Nowadays most segmentation tricks have been well integrated into existing codebases such that our naive ViT-Adapter baseline has already achieved sufficiently good performance. Hence, we believe the key to stand out among other competitors is to focus on the problem nature of wheat per se. By probing visualizations, we identify the key – the stem matters. In contrast to heads and leaves, stems exhibit fine structure and occupy only few pixels, which suffers from fragile predictions and class imbalance. Building on our baseline, we present three technical improvements tailored to stems: i) incorporating a dynamic upsampler SAPA used to enhance detail delineation; ii) leveraging semi-supervised guided distillation with stem-aware sample selection to mine the treasure beneath unlabeled data; and iii) applying a test-time scaling strategy to zoom in and segment twice the image. Despite being simple, the three improvements bring us to the first place of the competition, outperforming the second place by clear margins. Code and models will be released at https://github.com/tiny-smart/gwfss25.
在这份报告中,我们展示了参加MLCAS 2025 GWFSS挑战时的解决方案。本次挑战举办了一场针对小麦植株的语义分割比赛,要求对小杉的头部、叶片和茎部这三个器官以及另一个背景类别进行分割。在2025年,参加分割比赛与往年有很大的不同,因为许多技巧都能起到重要作用。如今,大多数分割技巧已经很好地集成到现有的代码库中,使得我们简单的ViT-Adapter基线已经取得了足够好的性能。因此,我们认为要在其他竞争者中脱颖而出的关键在于关注小麦本身的问题特性。通过可视化探测,我们找到了关键——茎部很重要。与头部和叶片相比,茎部呈现出精细的结构,只占用了很少的像素,这会导致预测结果不稳健和类别不平衡。基于我们的基线,我们提出了三项针对茎部的技术改进:一)加入一个动态上采样器SAPA,用于增强细节描绘;二)利用半监督引导蒸馏和带茎感知的样本选择来挖掘未标记数据中的宝藏;三)采用测试时缩放策略来两次放大并分割图像。尽管这些改进很简单,但它们帮助我们获得了比赛的第一名,并显著优于第二名。相关代码和模型将在https://github.com/tiny-smart/gwfss25上发布。
论文及项目相关链接
Summary
该报告主要介绍了团队参与MLCAS 2025小麦分割挑战赛的经验。该报告详细介绍了他们在小麦头部、叶片和茎部的语义分割任务中所采取的技术策略,并强调了茎部细节对预测和类别平衡的重要性。团队提出了三项针对茎部的技术改进,并在比赛中取得了第一名的成绩。代码和模型将在GitHub上发布。
Key Takeaways
- 该报告参与了一个专注于小麦植物语义分割的挑战赛,重点对小麦头部、叶片和茎部进行分割。
- 与往年不同,当前大多数分割技巧已经很好地集成到现有代码库中,因此关键在于理解小麦本身的问题特性。
- 通过可视化分析,发现茎部是问题的关键,其精细结构和少量像素导致预测易出错和类别不平衡。
- 针对茎部提出了三项技术改进:采用动态上采样器SAPA以增强细节描绘;利用半监督引导蒸馏与茎部感知样本选择来挖掘未标记数据中的信息;应用测试时缩放策略对图像进行两次分割。
点此查看论文截图


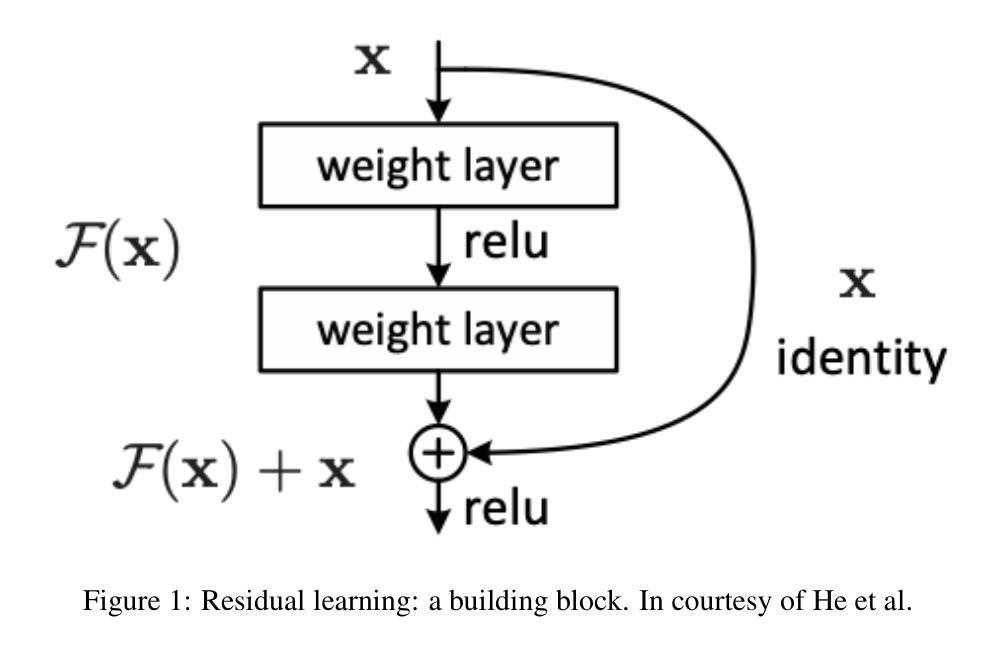
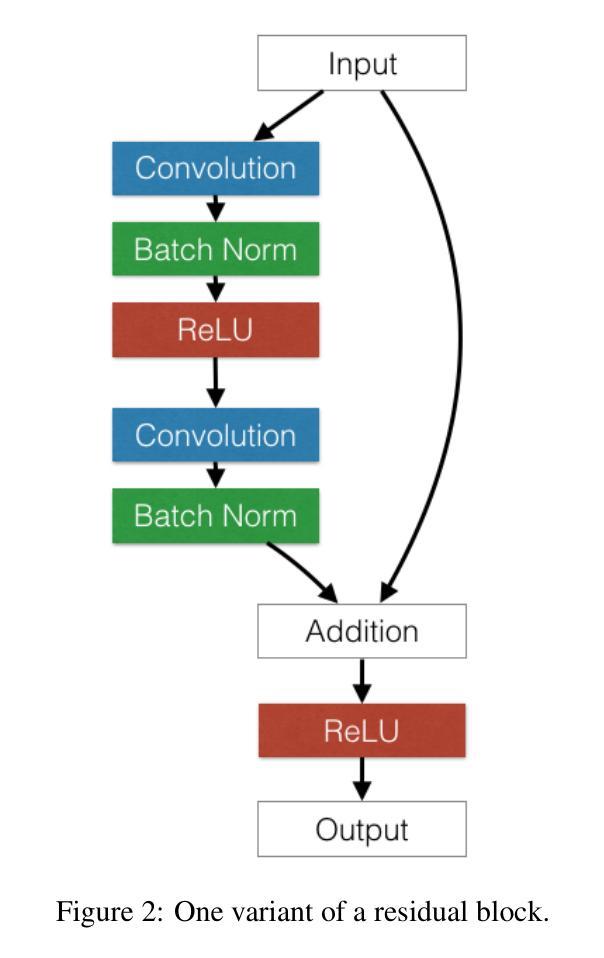
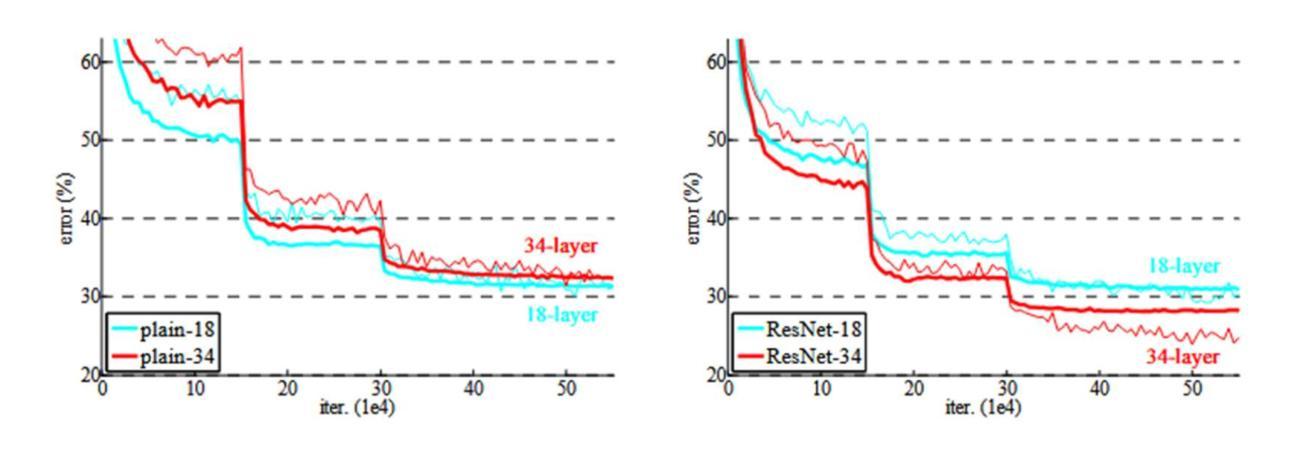
Foundations and Models in Modern Computer Vision: Key Building Blocks in Landmark Architectures
Authors:Radu-Andrei Bourceanu, Neil De La Fuente, Jan Grimm, Andrei Jardan, Andriy Manucharyan, Cornelius Weiss, Daniel Cremers, Roman Pflugfelder
This report analyzes the evolution of key design patterns in computer vision by examining six influential papers. The analysis begins with foundational architectures for image recognition. We review ResNet, which introduced residual connections to overcome the vanishing gradient problem and enable effective training of significantly deeper convolutional networks. Subsequently, we examine the Vision Transformer (ViT), which established a new paradigm by applying the Transformer architecture to sequences of image patches, demonstrating the efficacy of attention-based models for large-scale image recognition. Building on these visual representation backbones, we investigate generative models. Generative Adversarial Networks (GANs) are analyzed for their novel adversarial training process, which challenges a generator against a discriminator to learn complex data distributions. Then, Latent Diffusion Models (LDMs) are covered, which improve upon prior generative methods by performing a sequential denoising process in a perceptually compressed latent space. LDMs achieve high-fidelity synthesis with greater computational efficiency, representing the current state-of-the-art for image generation. Finally, we explore self-supervised learning techniques that reduce dependency on labeled data. DINO is a self-distillation framework in which a student network learns to match the output of a momentum-updated teacher, yielding features with strong k-NN classification performance. We conclude with Masked Autoencoders (MAE), which utilize an asymmetric encoder-decoder design to reconstruct heavily masked inputs, providing a highly scalable and effective method for pre-training large-scale vision models.
本报告通过分析六篇有影响力的论文,分析了计算机视觉中关键设计模式的演变。分析从图像识别的基本架构开始。我们回顾了ResNet,它引入了残差连接,克服了梯度消失问题,实现了对深度卷积网络的有效训练。之后,我们研究了将Transformer架构应用于图像补丁序列的Vision Transformer(ViT),这开创了新的范式,证明了注意力模型在大规模图像识别中的有效性。在这些视觉表示骨干的基础上,我们研究了生成模型。分析了生成对抗网络(GANs)的新型对抗训练过程,该过程通过生成器与鉴别器的对抗来学习复杂的数据分布。然后介绍了潜在扩散模型(LDMs),通过感知压缩的潜在空间中的连续去噪过程改进了先前的生成方法。LDMs实现了高保真合成,具有更高的计算效率,代表了当前图像生成的最新技术。最后,我们探索了减少对标定数据依赖性的自监督学习技术。DINO是一个自蒸馏框架,学生网络学习匹配动量更新的教师输出,产生具有强大k-NN分类性能的特征。最终我们介绍了Masked Autoencoders(MAE),它采用对称的编码器-解码器设计来重建高度遮挡的输入,提供了一种高度可扩展和有效的预训练大规模视觉模型的方法。
论文及项目相关链接
Summary
这篇报告分析了计算机视觉中关键设计模式的演变,通过考察六篇有影响力的论文进行深入探讨。报告从图像识别的基础架构开始,介绍了ResNet、Vision Transformer(ViT)、生成模型如Generative Adversarial Networks(GANs)和Latent Diffusion Models(LDMs),以及自监督学习技术如DINO和Masked Autoencoders(MAE)。这些技术代表了计算机视觉领域的最新进展。
Key Takeaways
- 报告分析了计算机视觉领域的关键技术进展,包括基础架构、生成模型和自监督学习。
- ResNet通过引入残差连接克服了梯度消失问题,使训练更深的卷积网络成为可能。
- Vision Transformer (ViT) 将Transformer架构应用于图像序列,展示了注意力模型在大规模图像识别中的有效性。
- Generative Adversarial Networks (GANs) 通过对抗性训练过程学习复杂的数据分布,生成高质量图像。
- Latent Diffusion Models (LDMs) 在感知压缩的潜在空间中进行序贯去噪过程,实现了高保真合成和更高的计算效率。
- DINO是一个自蒸馏框架,学生网络学习匹配动量更新的教师输出,产生强大的k-NN分类性能。
- Masked Autoencoders (MAE) 利用对称的编码器-解码器设计来重建高度遮挡的输入,为大规模视觉模型预训练提供了可伸缩和有效的方法。
点此查看论文截图

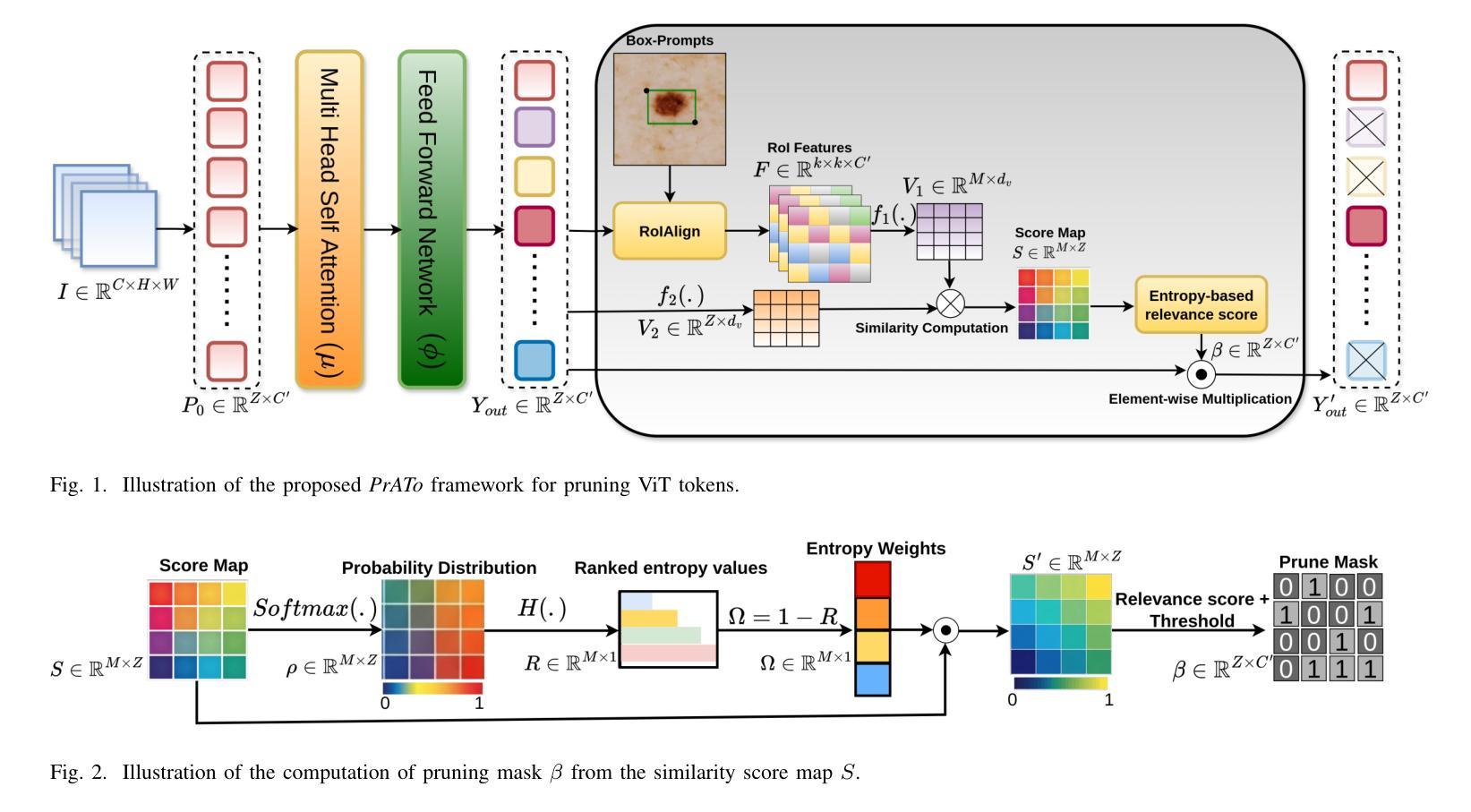
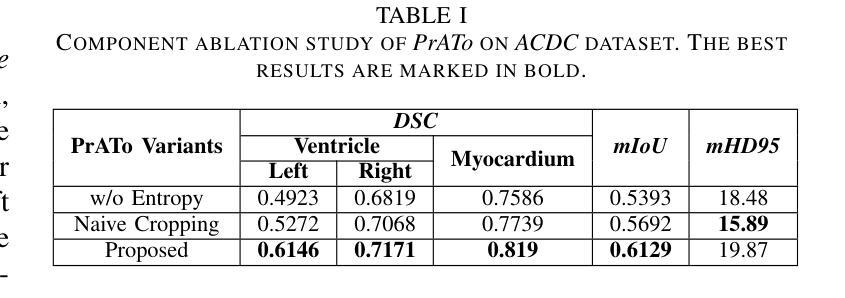
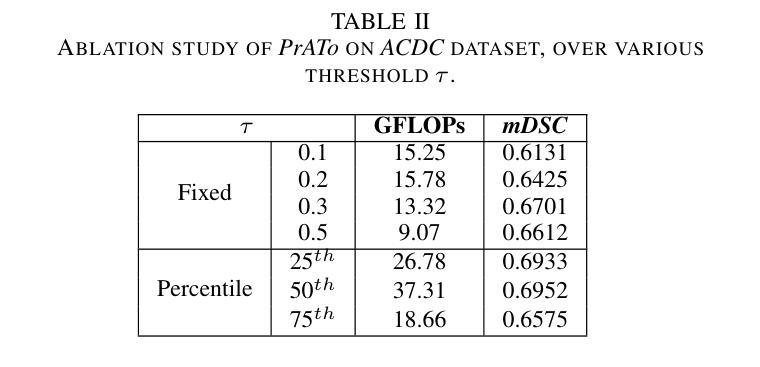
Prompt-based Dynamic Token Pruning for Efficient Segmentation of Medical Images
Authors:Pallabi Dutta, Anubhab Maity, Sushmita Mitra
The high computational demands of Vision Transformers (ViTs) in processing a large number of tokens often constrain their practical application in analyzing medical images. This research proposes a Prompt-driven Adaptive Token ({\it PrATo}) pruning method to selectively reduce the processing of irrelevant tokens in the segmentation pipeline. The prompt-based spatial prior helps to rank the tokens according to their relevance. Tokens with low-relevance scores are down-weighted, ensuring that only the relevant ones are propagated for processing across subsequent stages. This data-driven pruning strategy improves segmentation accuracy and inference speed by allocating computational resources to essential regions. The proposed framework is integrated with several state-of-the-art models to facilitate the elimination of irrelevant tokens, thereby enhancing computational efficiency while preserving segmentation accuracy. The experimental results show a reduction of $\sim$ 35-55% tokens; thus reducing the computational costs relative to baselines. Cost-effective medical image processing, using our framework, facilitates real-time diagnosis by expanding its applicability in resource-constrained environments.
视觉Transformer(ViT)在处理大量标记符时计算需求较高,这经常限制其在医学图像分析中的实际应用。本研究提出了一种基于提示的自适应标记符(PrATo)修剪方法,该方法能够有选择地减少分割管道中不相关标记符的处理。基于提示的空间先验有助于根据相关性对标记符进行排名。低相关性得分的标记符被降权处理,确保仅将相关的标记符传播到后续阶段进行处理。这种数据驱动的修剪策略通过向关键区域分配计算资源来提高分割精度和推理速度。所提出的框架与多种最新模型集成,以消除不相关的标记符,从而提高计算效率并保持分割精度。实验结果表明,减少了约35-55%的标记符,与基线相比降低了计算成本。使用我们的框架进行经济实惠的医学图像处理,通过在资源受限的环境中扩大其适用性,促进了实时诊断。
论文及项目相关链接
Summary
本文提出一种基于提示的自适应令牌(PrATo)剪枝方法,用于选择性减少医学图像处理中无关令牌的处理。该方法通过提示空间先验知识对令牌进行排名,降低低相关性令牌的权重,确保只处理相关令牌。此数据驱动的策略提高了分割准确性和推断速度,通过对重要区域分配计算资源来提升计算效率并维持分割精度。实验结果显示,该方法减少了约35%~55%的令牌处理量,降低了计算成本。使用此框架进行医学图像处理可实现实时诊断,并在资源受限的环境中扩大其适用性。
Key Takeaways
- Vision Transformers (ViTs)在处理大量令牌时存在高计算需求,限制了其在医学图像分析中的实际应用。
- 提出了一种基于提示的自适应令牌(PrATo)剪枝方法,以选择性减少无关令牌的处理。
- 提示空间先验知识用于排名令牌,根据相关性降低低相关性令牌的权重。
- 数据驱动的剪枝策略通过分配计算资源给重要区域,提高了分割准确性和推断速度。
- 该方法与多种最新模型集成,减少了无关令牌的处理,提高了计算效率,同时保持了分割精度。
- 实验结果显示,该方法减少了约35%~55%的计算成本。
点此查看论文截图

DART: Differentiable Dynamic Adaptive Region Tokenizer for Vision Transformer and Mamba
Authors:Shicheng Yin, Kaixuan Yin, Yang Liu, Weixing Chen, Liang Lin
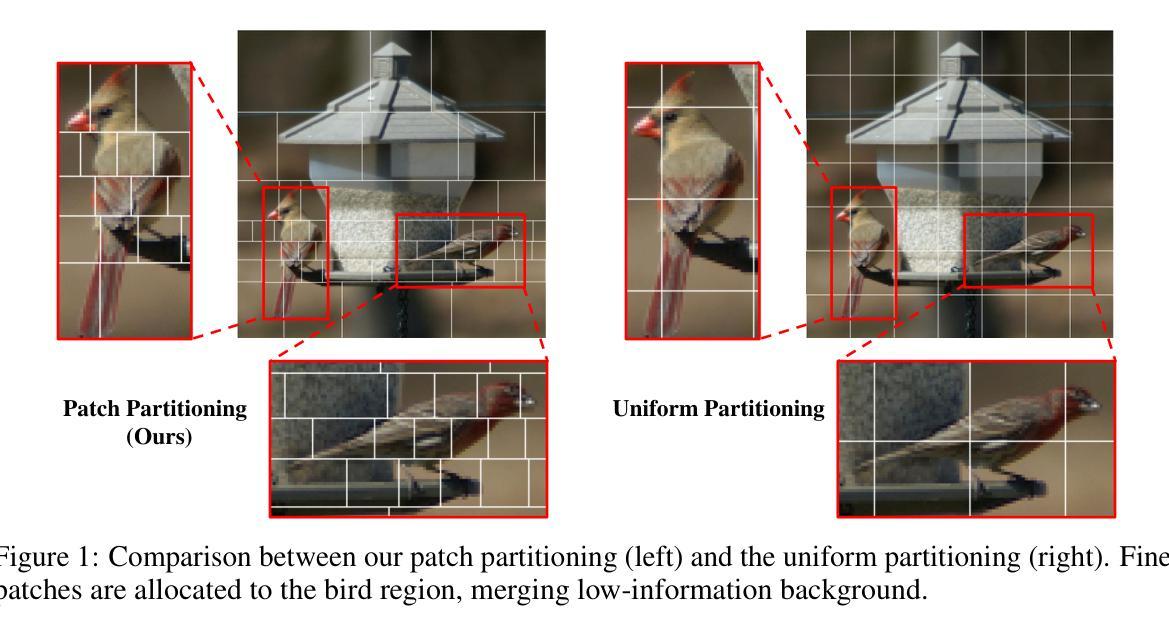
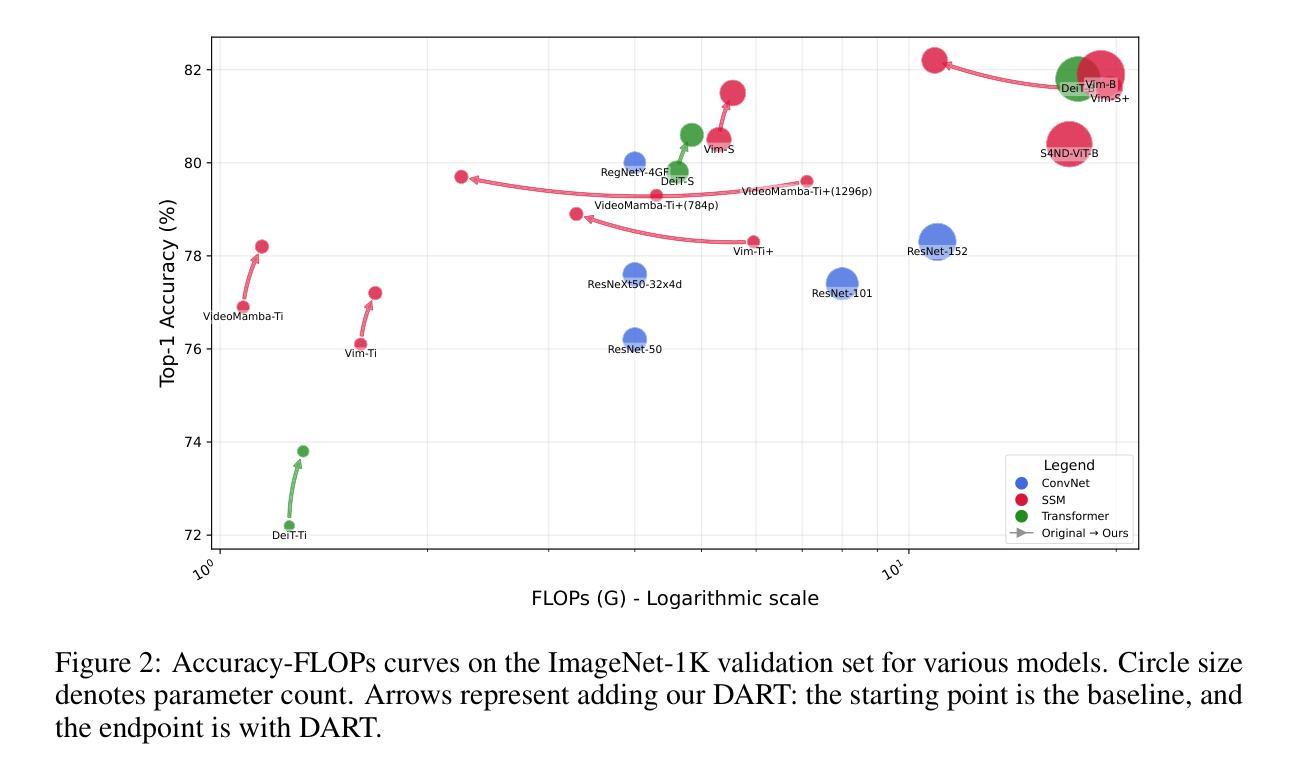
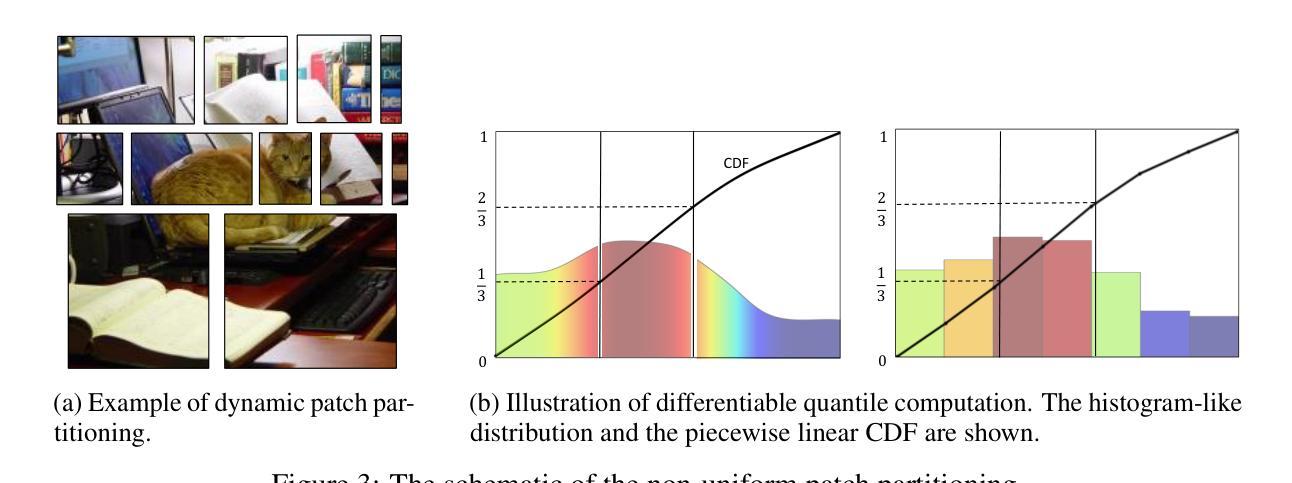
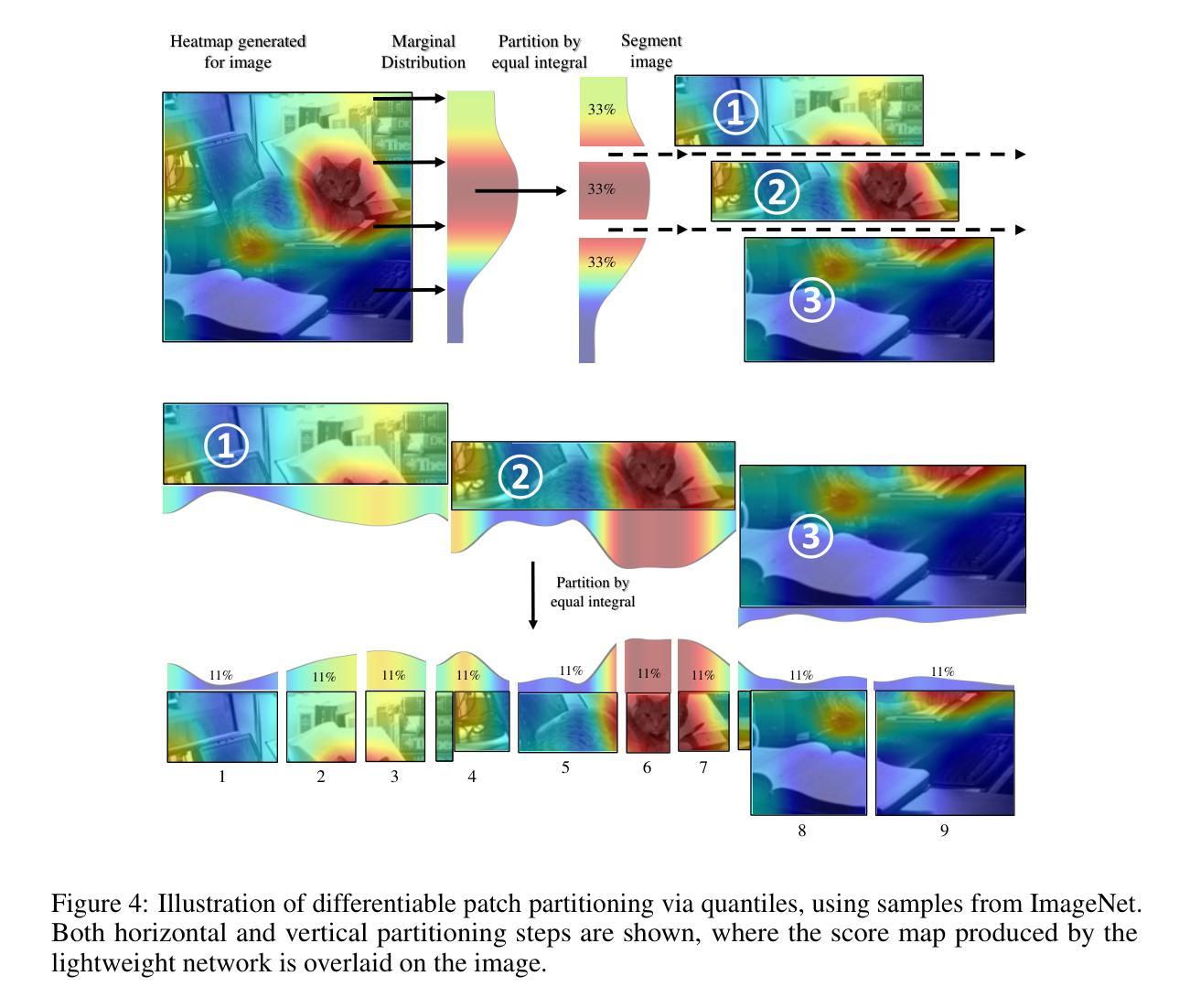
Recently, non-convolutional models such as the Vision Transformer (ViT) and Vision Mamba (Vim) have achieved remarkable performance in computer vision tasks. However, their reliance on fixed-size patches often results in excessive encoding of background regions and omission of critical local details, especially when informative objects are sparsely distributed. To address this, we introduce a fully differentiable Dynamic Adaptive Region Tokenizer (DART), which adaptively partitions images into content-dependent patches of varying sizes. DART combines learnable region scores with piecewise differentiable quantile operations to allocate denser tokens to information-rich areas. Despite introducing only approximately 1 million (1M) additional parameters, DART improves accuracy by 2.1% on DeiT (ImageNet-1K). Unlike methods that uniformly increase token density to capture fine-grained details, DART offers a more efficient alternative, achieving 45% FLOPs reduction with superior performance. Extensive experiments on DeiT, Vim, and VideoMamba confirm that DART consistently enhances accuracy while incurring minimal or even reduced computational overhead. Code is available at https://github.com/HCPLab-SYSU/DART.
最近,诸如Vision Transformer(ViT)和Vision Mamba(Vim)等非卷积模型在计算机视觉任务中取得了显著的性能。然而,它们对固定大小图块的依赖往往导致背景区域的过度编码以及关键局部细节的遗漏,尤其是在信息对象稀疏分布的情况下。为了解决这一问题,我们引入了完全可微分的动态自适应区域标记器(DART),它能够自适应地将图像分割成大小不同的内容相关图块。DART通过结合可学习的区域分数和分段可微分的中位数操作,将更密集的标记分配给信息丰富的区域。尽管只引入了大约一百万(1M)个额外的参数,但DART在DeiT(ImageNet-1K)上的准确率提高了2.1%。与通过均匀增加标记密度来捕捉细节的方法不同,DART提供了一种更有效的替代方案,在性能优越的同时实现了45%的浮点运算次数减少。在DeiT、Vim和VideoMamba上的大量实验证实,DART在保持准确性提高的同时,计算开销极小甚至有所减少。相关代码可通过https://github.com/HCPLab-SYSU/DART获取。
论文及项目相关链接
PDF Code is available at https://github.com/HCPLab-SYSU/DART
Summary
非卷积模型如Vision Transformer(ViT)和Vision Mamba(Vim)在计算机视觉任务中表现出卓越性能,但它们固定大小的斑块导致背景区域过度编码,忽略关键局部细节。为解决此问题,我们推出全微分动态自适应区域令牌化器(DART),其可自适应地将图像分割成内容相关的可变大小斑块。DART结合学习区域分数和分段微分定量操作,将更密集的令牌分配给信息丰富的区域。仅增加约1百万(1M)参数,DART即可提高DeiT(ImageNet-1K)的准确率2.1%。与均匀增加令牌密度以捕获细节的方法不同,DART提供更高效的替代方案,实现45%浮点运算减少且性能更佳。广泛的实验证明,DART在增强精度的同时,计算开销最小或甚至减少。代码可通过https://github.com/HCPLab-SYSU/DART获取。
Key Takeaways
- 非卷积模型如ViT和Vim在计算机视觉任务中表现优秀,但存在固定斑块导致的背景区域过度编码和局部细节忽略问题。
- 为解决上述问题,引入全微分动态自适应区域令牌化器(DART),其能自适应地根据内容将图像分割成不同大小的斑块。
- DART通过结合学习区域分数和分段微分定量操作,实现信息丰富区域的更密集令牌分配。
- DART在仅增加约1百万参数的情况下,提高了DeiT在ImageNet-1K上的准确率2.1%。
- 与其他方法相比,DART提供更高效的解决方案,能在减少浮点运算的同时保持或提高性能。
- 广泛的实验证明,DART在多种模型和任务中均能有效增强精度,同时计算开销较小。
点此查看论文截图


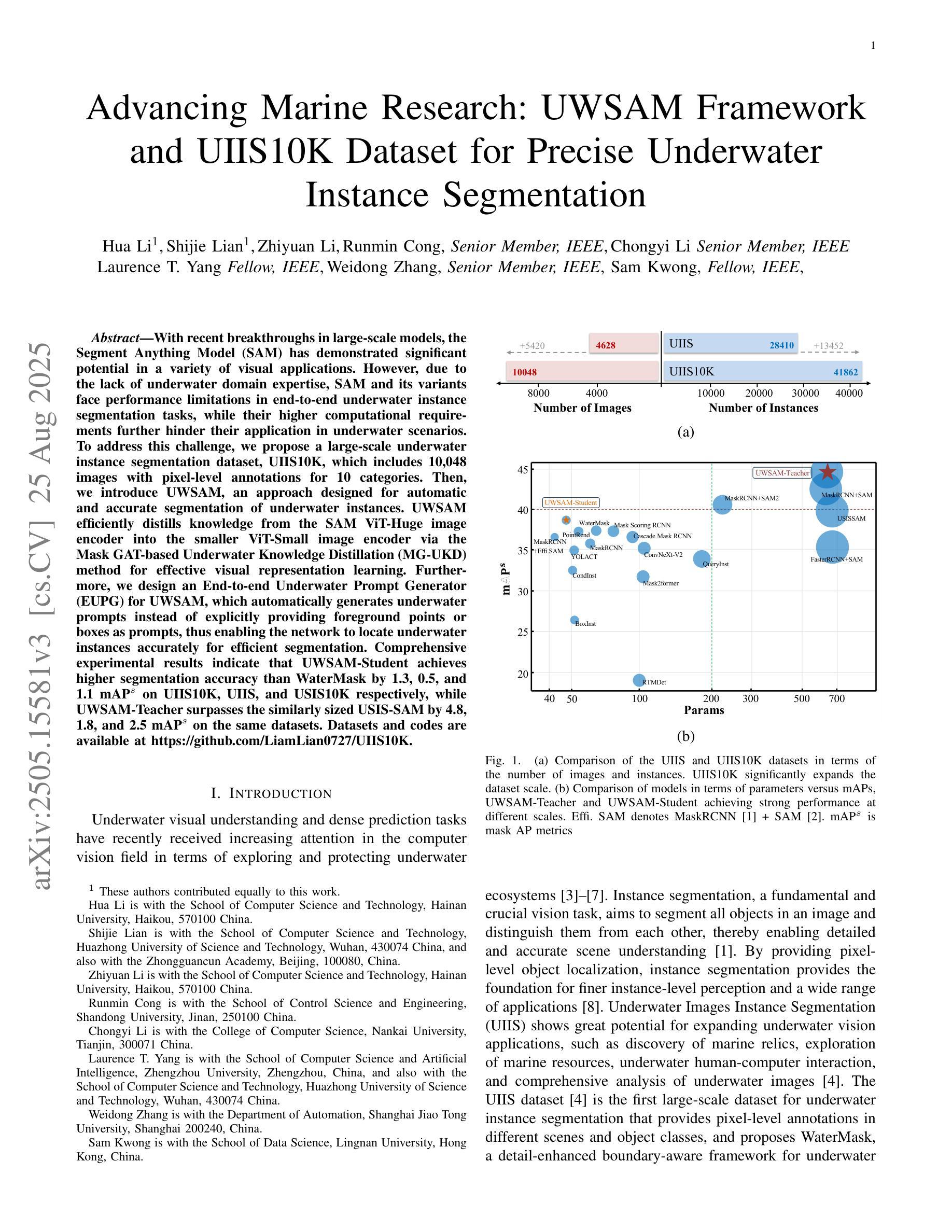
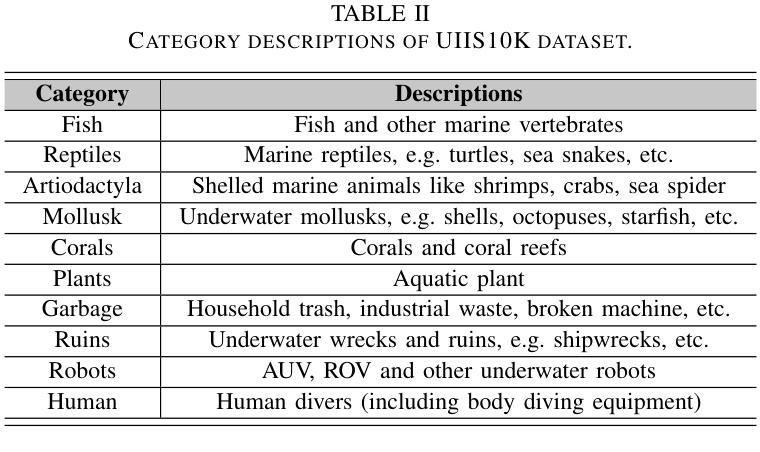
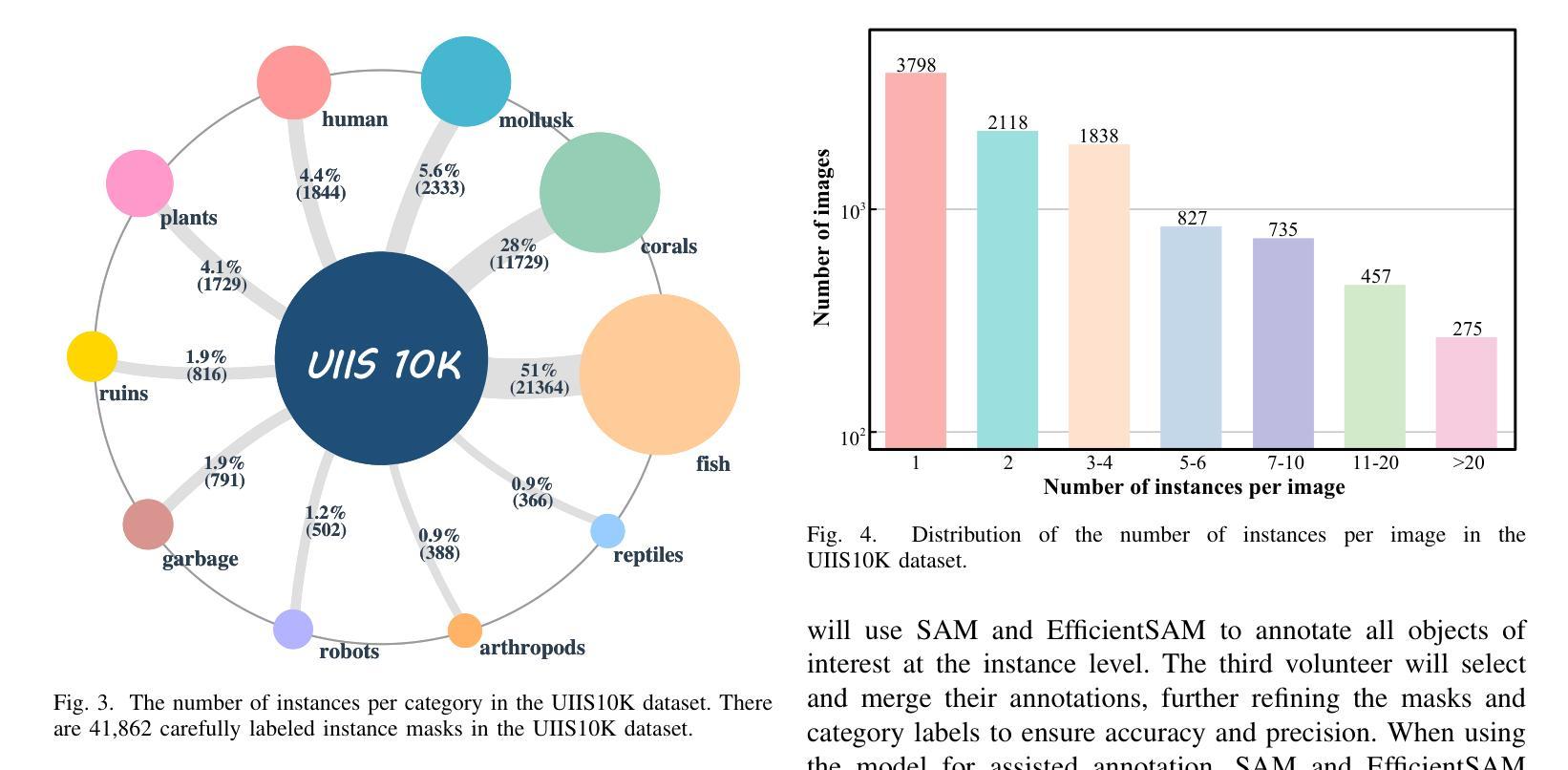
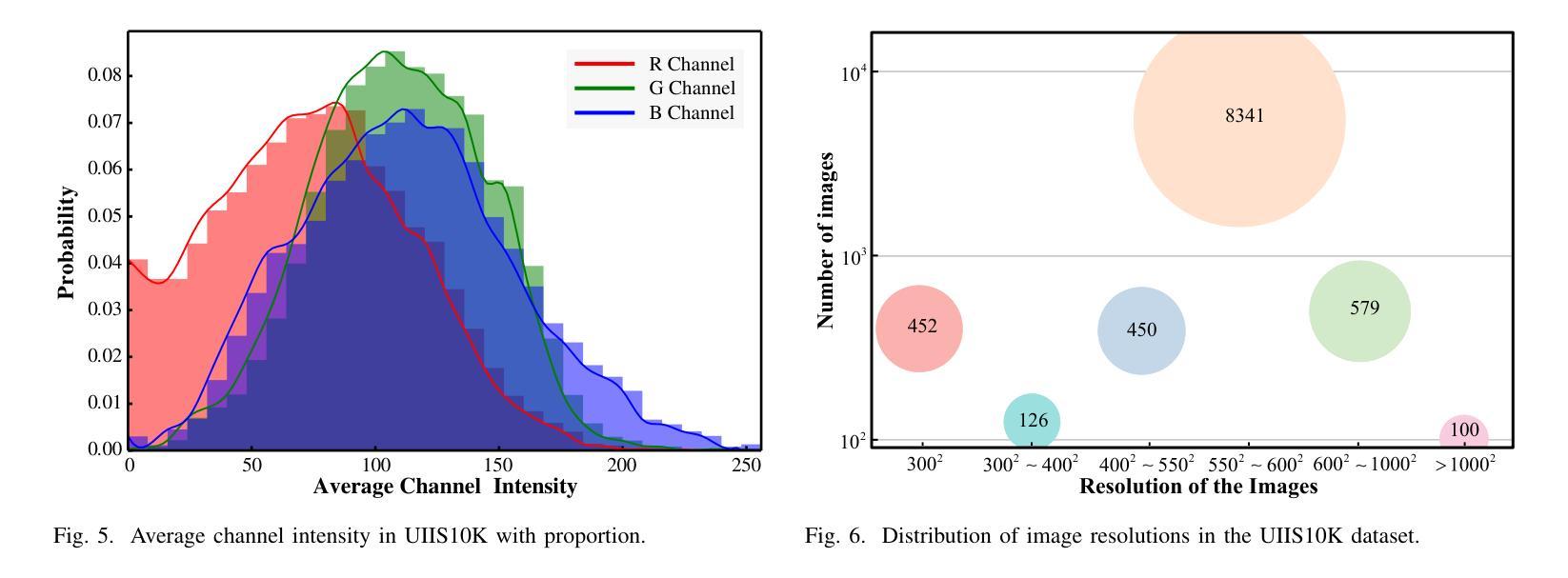
Advancing Marine Research: UWSAM Framework and UIIS10K Dataset for Precise Underwater Instance Segmentation
Authors:Hua Li, Shijie Lian, Zhiyuan Li, Runmin Cong, Chongyi Li, Laurence T. Yang, Weidong Zhang, Sam Kwong
With recent breakthroughs in large-scale modeling, the Segment Anything Model (SAM) has demonstrated significant potential in a variety of visual applications. However, due to the lack of underwater domain expertise, SAM and its variants face performance limitations in end-to-end underwater instance segmentation tasks, while their higher computational requirements further hinder their application in underwater scenarios. To address this challenge, we propose a large-scale underwater instance segmentation dataset, UIIS10K, which includes 10,048 images with pixel-level annotations for 10 categories. Then, we introduce UWSAM, an efficient model designed for automatic and accurate segmentation of underwater instances. UWSAM efficiently distills knowledge from the SAM ViT-Huge image encoder into the smaller ViT-Small image encoder via the Mask GAT-based Underwater Knowledge Distillation (MG-UKD) method for effective visual representation learning. Furthermore, we design an End-to-end Underwater Prompt Generator (EUPG) for UWSAM, which automatically generates underwater prompts instead of explicitly providing foreground points or boxes as prompts, thus enabling the network to locate underwater instances accurately for efficient segmentation. Comprehensive experimental results show that our model is effective, achieving significant performance improvements over state-of-the-art methods on multiple underwater instance datasets. Datasets and codes are available at https://github.com/LiamLian0727/UIIS10K.
随着大规模建模的最新突破,Segment Anything Model(SAM)在各种视觉应用中表现出了巨大的潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端的水下实例分割任务中面临性能局限,而它们较高的计算要求进一步阻碍了在水下场景中的应用。为了应对这一挑战,我们提出了一个大规模的水下实例分割数据集UIIS10K,其中包括10,048张具有10类像素级注释的图像。然后,我们介绍了UWSAM,这是一个为水下实例自动准确分割而设计的高效模型。UWSAM通过基于Mask GAT的水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器蒸馏知识到较小的ViT-Small图像编码器,从而实现有效的视觉表示学习。此外,我们还为UWSAM设计了End-to-end水下提示生成器(EUPG),它会自动生成水下提示,而不是显式提供前景点或框作为提示,从而使网络能够准确定位水下实例,实现高效分割。综合实验结果表明,我们的模型是有效的,在多个水下实例数据集上实现了对最新技术的显著性能改进。数据集和代码可在[https://github.com/LiamLian0
论文及项目相关链接
Summary
针对大型模型的新突破,Segment Anything Model(SAM)在各种视觉应用中展现出巨大潜力。然而,由于缺乏水下领域的专业知识,SAM及其变体在端到端的水下实例分割任务中性能受限。为此,我们提出了大规模水下实例分割数据集UIIS10K,包含10,048张带有像素级注释的10类图像。同时,我们引入了专为水下实例自动准确分割而设计的UWSAM模型。UWSAM通过Mask GAT基础上的水下知识蒸馏(MG-UKD)方法,有效地从SAM的ViT-Huge图像编码器提炼知识,用于ViT-Small图像编码器的有效视觉表征学习。此外,我们还为UWSAM设计了端到端的水下提示生成器(EUPG),能够自动生成水下提示,而无需明确提供前景点或框作为提示,从而帮助网络准确定位水下实例,实现高效分割。
Key Takeaways
- Segment Anything Model (SAM) 在视觉应用中有显著潜力,但在水下实例分割方面存在性能限制。
- 缺乏水下领域的专业知识是SAM及其变体在水下任务中性能受限的主要原因。
- UIIS10K数据集是为了解决这一问题而提出的大规模水下实例分割数据集,包含带像素级注释的10,048张图像。
- UWSAM模型专为水下实例自动准确分割而设计。
- UWSAM通过Mask GAT基础上的水下知识蒸馏(MG-UKD)方法提炼知识,实现有效视觉表征学习。
- 端到端的水下提示生成器(EUPG)能够自动生成水下提示,提高网络定位水下实例的准确度。
点此查看论文截图